Embed Size (px)
Citation preview

Partie 2 : l’estimation bayésienne des DSGE
F. Karamé
TEPP (EPEE et CEE) & CEPREMAP (Dynare team)
Contribution à l’école ETEPP

Introduction : l’économétrie bayésienne des DSGE
1. Il est souvent difficile d’exprimer analytiquement la vraisemblance d’un DSGE mais l’évaluer numériquement est possible.
Il est difficile d’estimer un modèle DSGE par maximum de vraisemblance
car les données sont peu informatives : limitées dans le temps, en nombre, …
La vraisemblance peut se révéler plate dans certaines directions et cela peut
poser des problèmes d’identification.
Il faut donc trouver d’autres sources d’information : l’utilisation de priorsde l’approche bayésienne.
2. Les DSGE sont des modèles mal spécifiés.
Estimer un modèle mal spécifié de façon bayésienne avec des priors non informatifs (uniformes par exemple) peut souvent conduire à des résultats
peu crédibles.
L’utilisation des priors peut donc modifier notre vision de la vraisemblance et conduire à des résultats plus interprétables en manipulant la distribution
a posteriori des paramètres.
3. L’utilisation de priors informatifs permet de réduire l’incertitude a posteriori (en termes de variance).
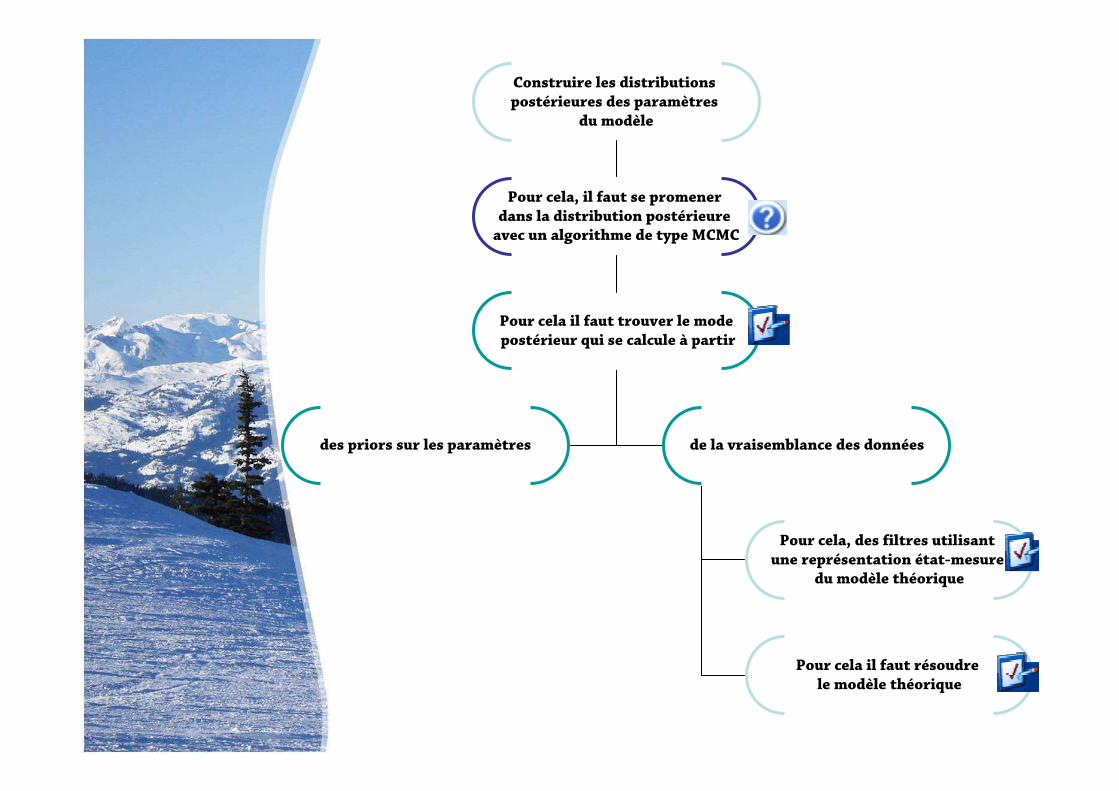
Construire les distributions postérieures des paramètres
du modèle
Pour cela, il faut se promener dans la distribution postérieure avec un algorithme de type MCMC
Pour cela il faut trouver le modepostérieur qui se calcule à partir
des priors sur les paramètres de la vraisemblance des données
Pour cela, des filtres utilisant une représentation état-mesure
du modèle théorique
Pour cela il faut résoudre le modèle théorique

Trouver le mode postérieur
)(p)y(L)y(p
)(p)y(L)y(p T:
T:
T:T: θθ
θθθ ⋅∝
⋅= 1
1
11
On s’intéresse à la distribution a posteriori des paramètres du modèle selon la traditionnelleformule de Bayes :
à une constante multiplicative près indépendante des paramètres ∫ ⋅=i
iiiT:T: d)(p)y(L)y(pθ
θθθ11
)y(LmaxargˆT:
MLT θθ
θ1=
{ }{ })(pln)y(Llnmaxarg
)(p)y(Lmaxarg
)y(pmaxargˆ
T:
T:
T:modT
θθ
θθ
θθ
θ
θ
θ
+=
⋅=
=
1
1
1
L’estimation dite classique ou fréquentiste consiste à trouver les paramètres associés au maximum
de vraisemblance :
Une première estimation bayésienne consiste à déterminer le mode de la distribution postérieure des paramètres :
Construire les distributions postérieures des paramètres
du modèle
Pour cela, il faut se promener dans la distribution postérieure avec un algorithme de type MCMC
Pour cela il faut trouver le modepostérieur qui se calcule à partir
des priors sur les paramètres de la vraisemblance des données
Pour cela, des filtres utilisant une représentation état-mesure
du modèle théorique
Pour cela il faut résoudre le modèle théorique

Résoudre le modèle
Méthodes de projections Méthodes de perturbations

Illustration : le modèle de base
�

Idée : on approxime numériquement le modèle en faisant un développement de Taylor localement autour de l’état stationnaire déterministe.
Ecrivons le modèle sous la forme suivante (connue) :
et posons la solution (inconnue) :
Le modèle et sa solution respectent l’état stationnaire :
En substituant, on peut définir :
et donc réécrire le problème comme :
Plusieurs ordres d’approximation existent.
Les méthodes de perturbations (ou locales)
011 =−+ )]u,y,y,y(f[E ttttt
)u,y,),u,y(g,),u),,u,y(g(g(f),u,u,y(F tt
y
tt
y
ttttttg
tt
111111
1
−−+−+−
+
=44844764444 84444 76σσσσ
),,y(gy
),y,y,y(f
00
00
==
),u,y(gy ttt σ1−=
011 =+− )],u,u,y(F[E tttgt σ

Le développement de Taylor à l’ordre 1 :
avec :
En prenant l’espérance conditionnelle et en regroupant, il vient :
On est en présence d’un système de trois blocs d’équations à trois blocs d’inconnus qui est satisfait si :
σσ ∂∂=
∂∂=
∂∂=
∂∂=
∂∂=
∂∂=
∂∂=
==−=
−−
++
++−
gg
u
gg
y
gg
u
ff
y
ff
y
ff
y
ff
uuuuyyy
tu
ty
tu
ty
ty
ty
ttt
11
11
ufyf)gugyg(f
)gug)gugyg(g(f),u,u,y(F
uyuyy
uuyyy)(
g
+++++
++++=≈
−
+++−
σσσσ
σ
σσ10
σσσσ ⋅+++
⋅+++⋅++≈
++
+−+
)gfgfggf(
u)fgfggf(y)fgfggf(
yyyy
uuyuyyyyyyyy0
=
→⇒
=++=++
⇔
=++=++
=++
+
−+
++
+
−+
0
et egénéraliséSchur
de iondécomposit
0
0
0
0
0
σσσσ
θθ
g
)(g)(gfgfggf
fgfggf
gfgfggf
fgfggf
fgfggfuy
uuyuyy
yyyyyy
yyyy
uuyuyy
yyyyyy
tutyt u)(gy)(gyy ⋅+⋅+= − θθ 1

A l’ordre 2 :
avec F.. des matrices de dérivées du vecteur de fonctions. En prenant l’espérance conditionnelle et en réorganisant, il vient :
satisfait si
Ces matrices dépendent des dérivées simples et secondes de f (connues) et de g (inconnues) et de la solution à l’ordre 1. Elles définissent 6 blocs d’équations à résoudre numériquement.
La solution à l’ordre 2 est alors de la forme :
σσ
σσ
σσ
σ
σ
σ
σσ
+
+
+
++
+−+−
+
+
−+−−
++−−
+
+⊗+
+⊗+⊗+
+⊗+⊗+⊗⋅+
=
uF
uF)uu(F
yF)uy(F)uy(F
]F)uu(F)uu(F)yy(F[,
),u,u,y(F),u,u,y(F
u
uuu
yuyuy
uuuuyy
)(g
)(g
2
12
50
σσσσ
σσ
σσε
uFyF)uy(F
])FF()uu(F)yy(F[,)],u,u,y(F[E
uyuy
uuuuyy)(
gt
++⊗+
+Σ+⊗+⊗⋅+≈
−−
++−−+−21 500
)uy()(g,)uu()(g,)yy()(g,
u)(gy)(g)(g,yy
ttyuttuuttyy
tutyt
⊗⋅⋅+⊗⋅⋅+⊗⋅⋅+
⋅+⋅+⋅⋅+=
−−−
−
111
12
505050
50
θθθθθσθσσ
0 et00000 ====+Σ==−−++−− σσσσε uyuyuuuuyy FF,F,)FF(,F,F

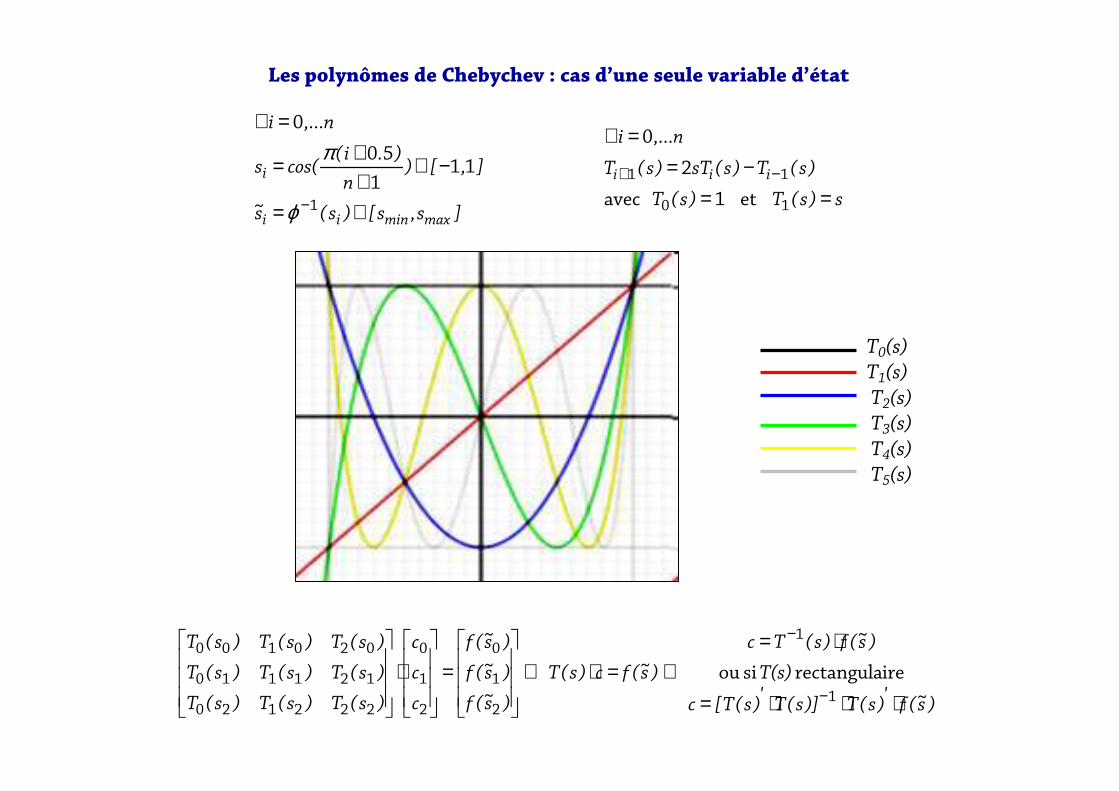
On veut approximer les règles de décision f(.) en fonction des variables d’état s.
On suppose la forme de la fonction permettant d’ajuster les règles de décision :
Idée : on construit une grille multidimensionnelle sur un intervalle de valeurs des états et on cherche le vecteur c permettant d’ajuster les valeurs des règles en les points de la grille. Cela permettra ensuite d’avoir une fonction paramétrée pour extrapoler les règles de décision pour toute valeur des états.
Problème : on se donne des valeurs pour les états mais on n’a rien sur les règles. On sait seulement que lorsque les valeurs prises par les règles sont cohérentes avec celles des états, les CPO sont nulles.
La méthode de la collocation orthogonale :
avec r(.,.) le système des CPO du modèle calculé pour le point i de la grille (donc au total la dimension du problème est le nombre des CPO multiplié par le nombre de nœuds).
Critère : le vecteur solution fournit la valeur des règles qui annule les CPO du modèle en chaque point de la grille multidimensionnelle sur les états.
Les méthodes de projections (ou globales)
)s~(st],[s
]s,s[s~c)s(T)s~(f
maxmin ϕ=−∈
∈⋅= e
11avec
n,...i)c;s(r i 00 ==
Les polynômes de Chebychev : cas d’une seule variable d’état
)s~(f')s(T)]s(T')s(T[c
T(s)
)s~(f)s(Tc
)s~(fc)s(T
)s~(f
)s~(f
)s~(f
c
c
c
)s(T)s(T)s(T
)s(T)s(T)s(T
)s(T)s(T)s(T
⋅⋅⋅=
⋅=⇔=⋅⇔
=
⋅
−
−
1
1
2
1
0
2
1
0
222120
121110
020100
irerectangula si ou
]s,s[)s(s~
],[)n
).i(cos(s
n,...i
maxminii
i
∈=
−∈++=
=∀
−1
111
50
0
ϕ
π
s)s(T)s(T
)s(T)s(sT)s(T
n,...i
iii
==−=
=∀
−+
10
11
et1 avec
2
0
T0(s) T1(s) T2(s) T3(s) T4(s) T5(s)

Cela revient à choisir un opérateur de combinaison des nœuds et des polynômes de Chebychev.
Le plus général : le produit tensoriel :
Mais ‘curse of dimensionality’ : la taille du problème à résoudre croît très vite.
Une alternative : l’opérateur Smolyak pour le choix des nœuds (->grille creuse) et des puissances (-> polynômes complets). Par exemple, pour les nœuds :
Comment passer au cas multidimensionnel ?
{ } { } { }nik,i
ni,i
ni,i
j,i
s...sss
)n
).i(cos(s
k,...j,n,...i
00201
1
50
10
=== ×××=++=
=∀=∀π
)s(T)...s(T)s(T)s(T
s)s(T)s(T
)s(T)s(Ts)s(T
k,...jn,...i
k,ik,i,ii
jjj,jj,
jj,ijj,ijjj,i
2211
10
11
et1 avec
2
10
=
==
−==∀=∀
−+
Construire les distributions postérieures des paramètres
du modèle
Pour cela, il faut se promener dans la distribution postérieure avec un algorithme de type MCMC
Pour cela il faut trouver le modepostérieur qui se calcule à partir
des priors sur les paramètres de la vraisemblance des données
Pour cela, des filtres utilisant une représentation état-mesure
du modèle théorique
Pour cela il faut résoudre le modèle théorique
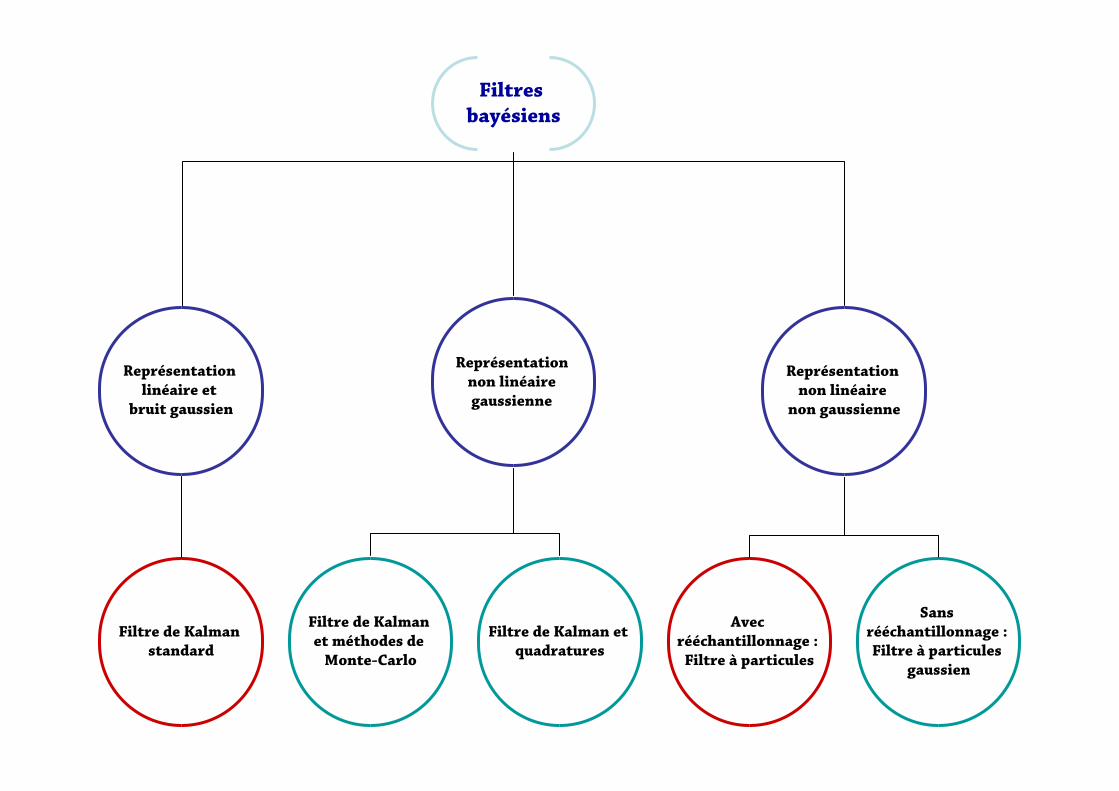
Filtres bayésiens
Représentation linéaire et
bruit gaussien
Représentation non linéaire gaussienne
Filtre de Kalmanstandard
Représentation non linéaire
non gaussienne
Filtre de Kalmanet méthodes de Monte-Carlo
Filtre de Kalman et quadratures
Avec rééchantillonnage : Filtre à particules
Sans rééchantillonnage : Filtre à particules
gaussien

La formule des probabilités totales (Chapman & Kolmogorov)
∫ −−− ⋅⋅= 111 ttttt dx)x(p)xx(p)x(p

∏∫∫
∏
∏
=−
=−
=−
⋅⋅⋅⋅=
=
=
T
t
tt:ttt
T
t
t:t
T
t
t:tT:
ds);y|s(p);s|y(pds)s(p);s|y(p
);y|y(p)|y(p
);y|y(p)|y(p
2
110001
2
111
1
111
θθθ
θθ
θθ
Comment calculer la vraisemblance ?
Hypothèse : on connaît la distribution initiale des états s0.
Constat : on peut calculer la vraisemblance si on connaît la distribution a priori des états à la date t.

∫∫∫
−−−−
−−−−−
−−−−
⋅⋅=
⋅⋅=
⋅=
11111
1111111
111111
tt:ttt
tt:tt:tt
tt:ttt:t
ds)y|s(p)s|s(p
ds)y|s(p)y,s|s(p
ds)y|s,s(p)y|s(p
);e,s(gs tt*
t θ1−= les équations d’état du modèle résolu+ des tirages dans la loi supposée des chocs
La distribution a priori des états

∫ ⋅⋅
⋅=
⋅=
⋅=
=
−
−
−
−
−
−−
−
tt:ttt
t:ttt
t:t
t:ttt
t:t
t:tt:tt
t:ttt:t
ds)y|s(p)s|y(p
)y|s(p)s|y(p
)y|y(p
)y|s(p)s|y(p
)y|y(p
)y|s(p)y,s|y(p
)y,y|s(p)y|s(p
11
11
11
11
11
1111
111
);,s(my ttt θε= les équations de mesure du modèle+ une hypothèse sur la loi des erreurspour écrire la vraisemblance
La distribution a posteriori des états

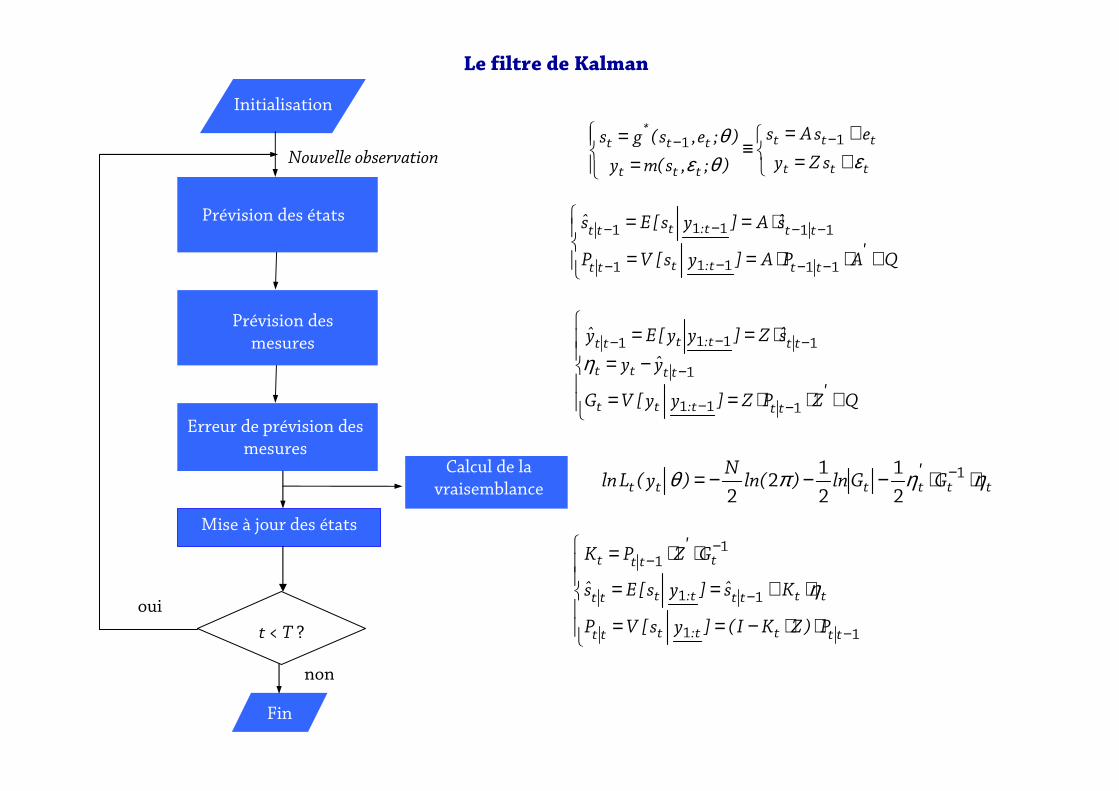
Sous l’hypothèse de linéarité du modèle et de normalité des chocs, tout se simplifie et donne le filtre de Kalman.
Implication sympathiques :
- Comme le modèle est linéaire, toutes les distributions sont gaussiennes. On
manipule uniquement les résumés de la distribution des états et des
mesures : l’espérance et la variance.
- Comme le modèle est linéaire, il suffit de dire que l’espérance des chocs est
nulle.
⋅⋅−==
⋅+==
⋅⋅=
−
−
−−
11
11
11
tttt:ttt
ttttt:ttt
tttt
P)ZKI(]ys[VP
Ks]ys[Es
G'ZPK
η
Calcul de la vraisemblance
Initialisation
Prévision des états
Nouvelle observation
Fin
Prévision des
mesures
Mise à jour des états
t < T ?
oui
non
Erreur de prévision des mesures
tttttt G'Gln)ln(N
)y(Lln ηηπθ ⋅⋅−−−= −12
1
2
12
2
+⋅⋅==
−=⋅==
−−
−
−−−
Q'ZPZ]yy[VG
yy
sZ]yy[Ey
ttt:tt
tttt
ttt:ttt
111
1
1111
η
+⋅⋅==
⋅==
−−−−
−−−−
Q'APA]ys[VP
sA]ys[Es
ttt:ttt
ttt:ttt
11111
11111
+=+=
≡
== −−
ttt
ttt
ttt
tt*
t
sZy
esAs
);,s(my
);e,s(gs
εθεθ 11
Le filtre de Kalman

Sans l’hypothèse de linéarité du modèle et de normalité des chocs, on doit utiliser un filtre à particules
Implications beaucoup moins sympathiques :
- on manipule toute la distribution des états et des mesures : revient àappliquer le modèle état-mesure à chaque particule qui constitue
l’approximation de ces distributions pour les faire évoluer au cours du
temps.
- on doit aussi tirer les chocs des équations d’état car dans un modèle non linéaire, il ne suffit plus de dire que l’espérance des chocs est nulle, il
faut faire des tirages aléatoires…

Comment calculer des intégrales du type ?
On approxime p(.) par unemesure aléatoire, c’est-à-dire on la discrétise par un plus ou moins grand nombre de noeuds xi et de poids wi :
Dans le cas d’une quadrature, les noeuds et les poids sont optimaux.
Dans le cas de tirages de Monte-Carlo, on tire N noeuds xi avec des poidséquiprobables wi = 1/N.
∫ ⋅⋅= dx)x(p)x(g)]x(g[Ep
∑=
⋅≈N
i
iip )x(gw)]x(g[E
1
∑=
−⋅=N
i
ii )xx(w)x(p
1
δ)

Que faire quand la loi p(.) n’est pas connue et/ou qu’on ne peut pas tirer dedans mais
qu’on peut quand même l’évaluer ?
On suppose une distribution d’importance q(.) dans laquelle il est facile d’effectuer des tiragesaléatoires.
Dès lors, l’intégrale peut s’écrire :
Si on peut approximer q(.) par quadrature ou par Monte-Carlo (wi = 1/N)
Alors il vient :
L’échantillonnage d’importance
])x(q
)x(p)x(g[E
dx)x(q)x(q
)x(p)x(g
dx)x(p)x(g)]x(g[E
q
p
⋅=
⋅⋅⋅=
⋅⋅=
∫
∫
∑=
⋅⋅≈N
i i
iiip
)x(q
)x(p)x(gw)]x(g[E
1
∑=
−⋅=N
i
ii )xx(w)x(q
1
δ

∑
∑∑
∑
∫
∫
∫∫
=
=
=
=
=
⋅=
⋅
≈
⋅⋅
⋅⋅⋅=
⋅
⋅⋅=
N
i i
i
i
i
i
N
i
iiN
i i
i
N
i i
ii
p
)x(q~)x(p~
)x(q~)x(p~
w~
w~)x(g
)x(q~)x(p~
N
)x(q~)x(p~
)x(gN
dx)x(q~)x(q~)x(p~
dx)x(q~)x(q~)x(p~
)x(g
dx)x(p~
dx)x(p~)x(g)]x(g[E
1
1
1
1
1
1
Si p(.) et q(.) ne somment pas à 1, on introduit une normalisation :

A la date t, on approxime les distributions a priori et a posteriori des états conditionnellement à l’information présente et passée par une mesure aléatoire
La distribution d’importance nous permettra de tirer les particules :
Sequential Importance Sampling (SIS) Particle Filter
)y,s|s(q~s t)i(
t)i(
t)i(
t 1−
Ni
)i(t
)i(t }w,s{ 1=

)y,s|s(q
)s|s(p)s|y(pw
)y,s|s(q
)s|s(p)s,y|y(pw
)y|s(q
)y|s(p
)y,s|s(q
)s|s(p)s,y|y(p
)y|s(q
)y|s(pw
t:)i(
t)i(
t
)i(t
)i(t)i(
tt)i(
t
t:)i(t:
)i(t
)i(t:
)i(t)i(
tt:t)i(
t
t:)i(t:
t:)i(t:
t:)i(t:
)i(t
)i(t:
)i(t)i(
tt:t
t:)i(t:
t:)i(t:)i(
t
11
11
110
10111
1110
1110
110
1011
10
10
−
−−
−
−−−
−−
−−
−
−−
⋅⋅=
⋅⋅=
⋅⋅=
=
Comment obtient-on les poids ?
Le choix usuel pour la densité d’importance
)s|y(pww)s|s(p)y,s|s(q )i(tt
)i(t
)i(tttt:tt ⋅=⇒= −−− 1111

la contrepartie empirique
∫ −−−−− ⋅⋅= 1111111 tt:tttt:t ds)y|s(p)s|s(p)y|s(p );e,s(gs)s|s(p~s t)i(
t*)i(
ttt)i(
t θ11 −− =↔
1 );,s(my)s|y(pww t)i(
t)i(
t)i(
tt)i(
t)i(
t θε=↔⋅= −
{ }Ni
)i(t
)i(tt:t w,s)ys(p
111111 =−−−− ↔
la théorie
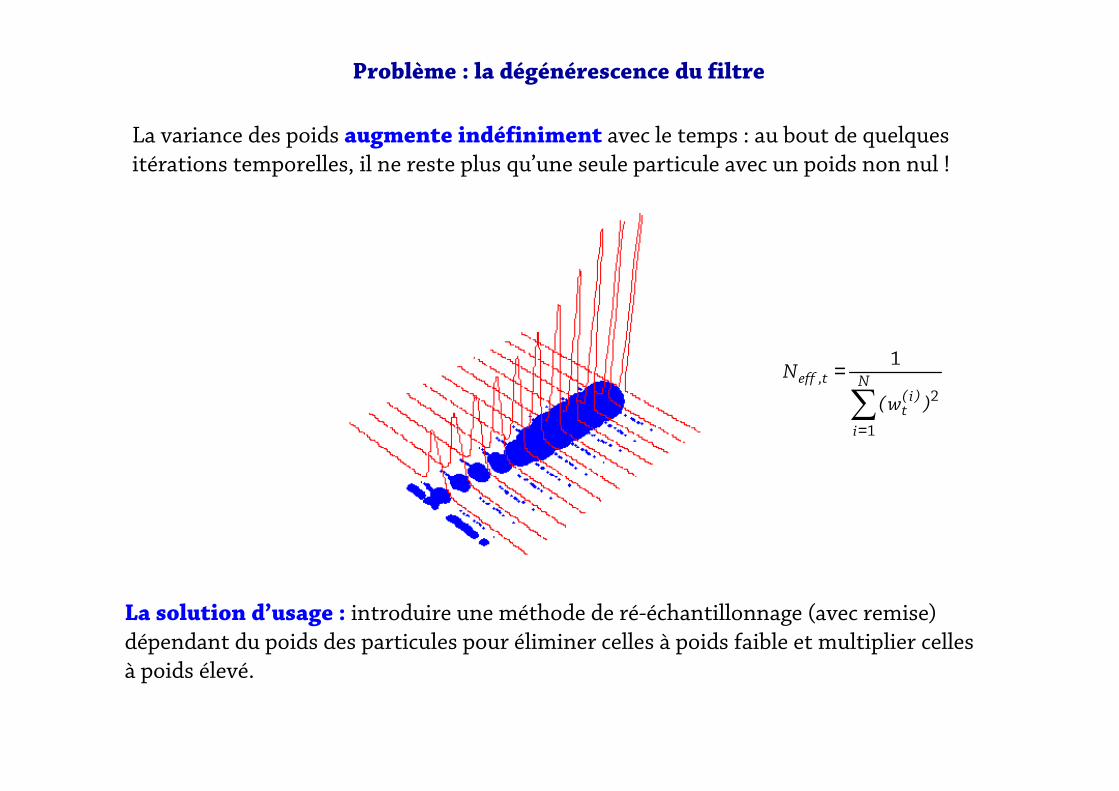
Problème : la dégénérescence du filtre
La variance des poids augmente indéfiniment avec le temps : au bout de quelquesitérations temporelles, il ne reste plus qu’une seule particule avec un poids non nul !
La solution d’usage : introduire une méthode de ré-échantillonnage (avec remise) dépendant du poids des particules pour éliminer celles à poids faible et multiplier celles
à poids élevé.
∑=
=N
i
)i(t
t,eff
)w(
N
1
2
1

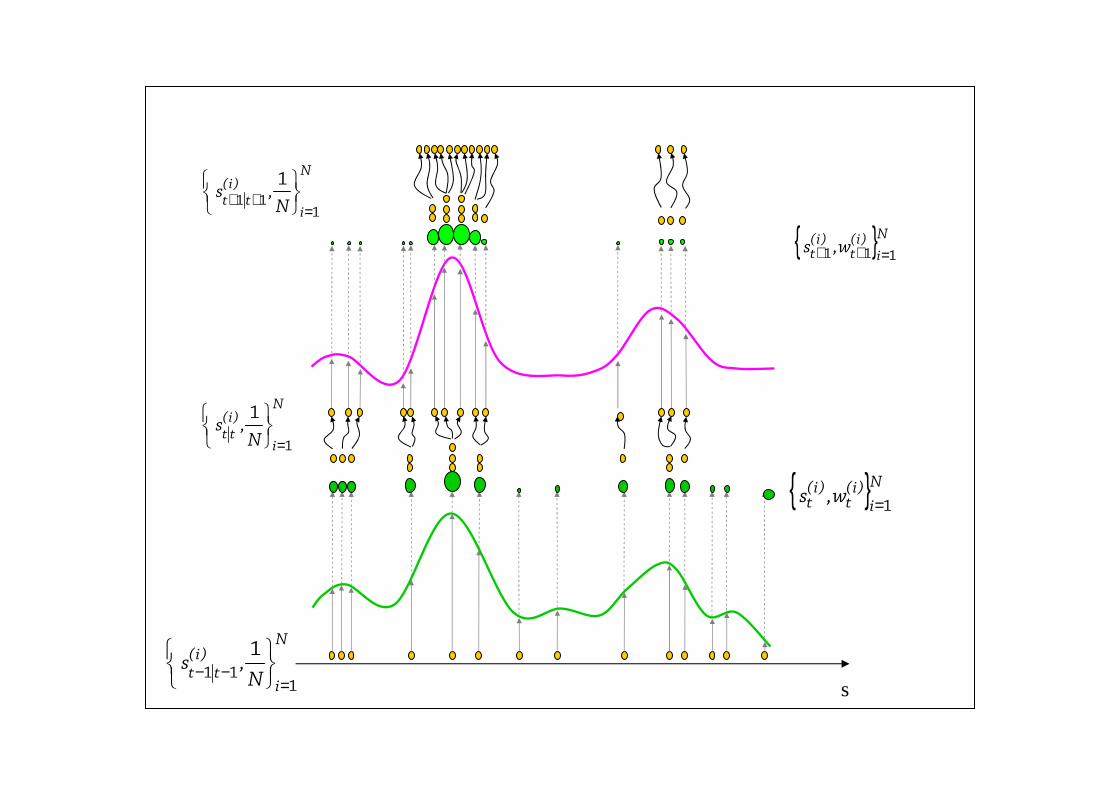
Soit u suit une loi uniforme U[0,1].
Soit F-1(.) l’inverse de la fonction de répartition F(.).
F-1(u) suit la loi de F.
Rééchantillonnage par la méthode inverse
distribution cumuléedes particules { }N
i)i(
t)i(
t w~,s1=
Particules rééchantillonnées avec remiseN
i
)i(tt N,s
1
1
=
∑=
=N
i
)i(t
)i(t)i(
t
w
ww~
1
Tirage aléatoire de
{ }Ni
)i(tu 1=
N
i
)i(tt N
,s1
11
1
=−−
s
{ }Ni
)i(t
)i(t w,s
1=
N
i
)i(tt N,s
1
1
=
{ }Ni
)i(t
)i(t w,s
111 =++
N
i
)i(tt N
,s1
11
1
=++
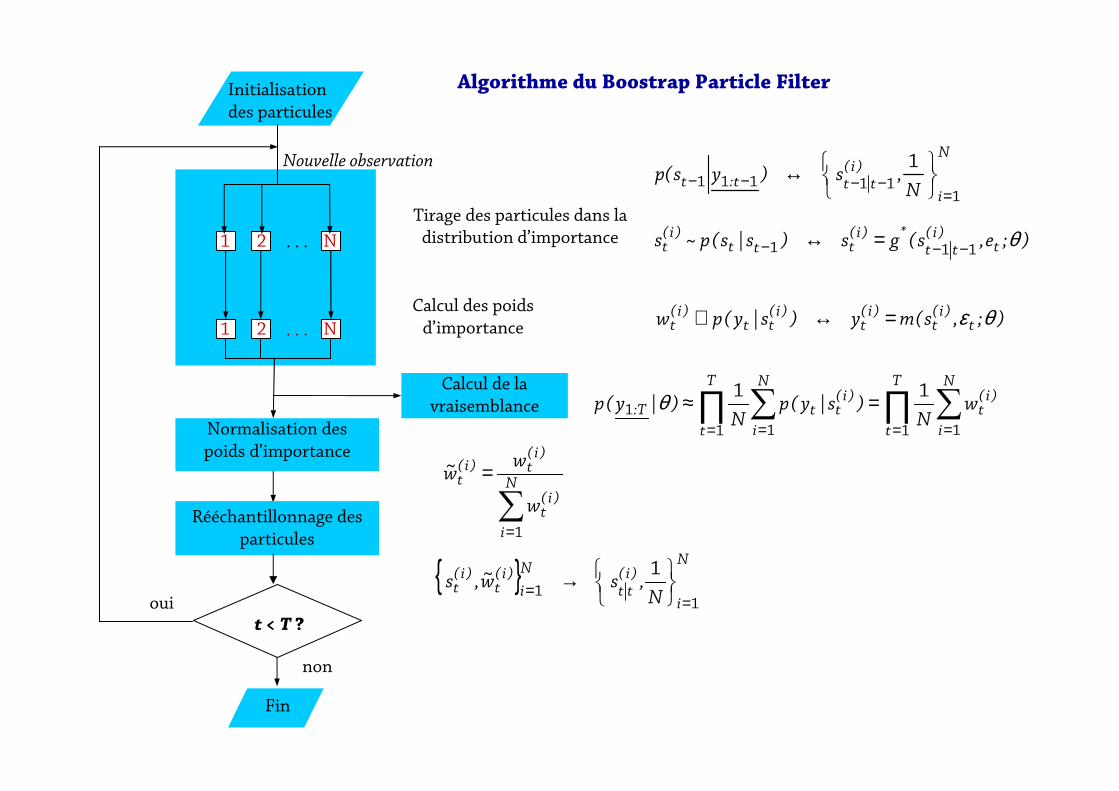
Algorithme du Boostrap Particle FilterInitialisation
des particules
Calcul de la
vraisemblance
1 2 N. . .
Tirage des particules dans la distribution d’importance
Nouvelle observation
Fin
Normalisation des
poids d’importance
1 2 N. . .
Calcul des poids
d’importance
Rééchantillonnage des
particules
t < T ?oui
non
);e,s(gs)s|s(p~s t)i(tt
*)i(ttt
)i(t θ
111 −−− =↔
∑=
=N
i
)i(t
)i(t)i(
t
w
ww~
1
);,s(my)s|y(pw t)i(
t)i(
t)i(
tt)i(
t θε=↔∝
N
i
)i(ttt:t N
,s)ys(p1
11111
1
=−−−−
↔
{ } N
i
)i(tt
N
i)i(
t)i(
tN,sw~,s
11
1
==
→
∏ ∑∏ ∑= == =
=≈T
t
N
i
)i(t
T
t
N
i
)i(ttT: w
N)s|y(p
N)|y(p
1 11 1
111θ
Construire les distributions postérieures des paramètres
du modèle
Pour cela, il faut se promener dans la distribution postérieure avec un algorithme de type MCMC
Pour cela il faut trouver le modepostérieur qui se calcule à partir
des priors sur les paramètres de la vraisemblance des données
Pour cela, des filtres utilisant une représentation état-mesure
du modèle théorique
Pour cela il faut résoudre le modèle théorique

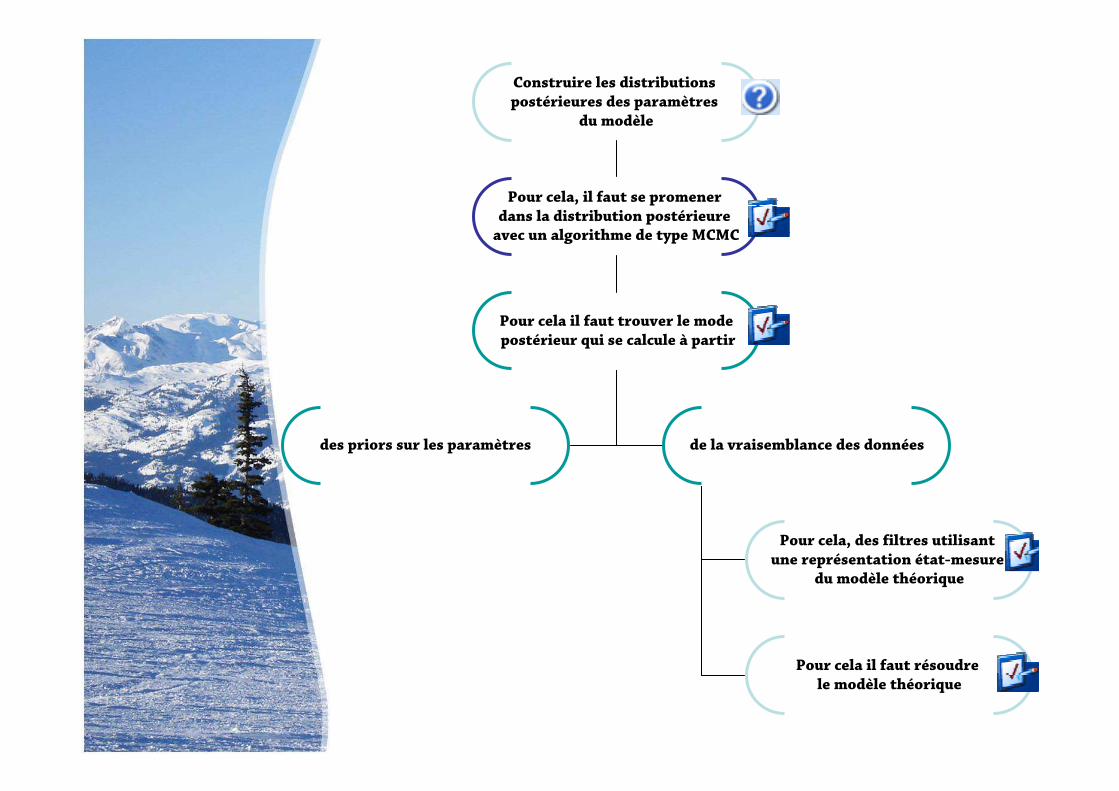
Explorer la densité postérieure : l’algorithme de Métropolis
- L’algorithme à pas aléatoire peut être mono-chaîne ou multi-chaînes indépendantes.
- L’approche multi-chaînes permet de calculer des indicateurs de convergence vers la
distribution stationnaire.
- La marche aléatoire s’interprète comme une distribution d’importance pour tirer les
candidats.
- γRW est déterminé de façon à avoir 30% d’acceptation environ.
- Le stockage (après convergence) des candidats acceptés permet d’obtenir une
approximation de la densité postérieure des paramètres du modèle.
- Les tirages des chocs exogènes et les probabilités uniformes du ré-échantillonnage sont
conservés identiques pendant les itérations de l’algorithme de Métropolis.
≤=
=≈+=
−
−
−
(rejet)sinon
on)(acceptati110si
0
1
11
1
01
n
:Tn
:T*n*
nn
modT
modT
RWn
*n
θ
)yθp(
)yθp(,min),U(θ
θ
θθ))θ(V,N(θθ γυυ
Construire les distributions postérieures des paramètres
du modèle
Pour cela, il faut se promener dans la distribution postérieure avec un algorithme de type MCMC
Pour cela il faut trouver le modepostérieur qui se calcule à partir
des priors sur les paramètres de la vraisemblance des données
Pour cela, des filtres utilisant une représentation état-mesure
du modèle théorique
Pour cela il faut résoudre le modèle théorique

Présentation construite en partie à partir de :
Adjemian S., 2007, Estimation of DSGE models, université du Mans (Gains) & CEPREMAP.
Miodrag B., University of Ottawa, Canada.
Références bibliographiques :
An S. & F. Schorfheide, 2006, Bayesian Analysis of DSGE Models, Econometric Reviews 26, 113-172.
Arulampalam A.S., S. Maskell, N. Gordon & T. Clapp, 2002, A Tutorial on Particle Filters for Online Nonlinear/Non-Gaussian Bayesian Tracking, IEEE Transactions on Signal Processing 50, 174-188.
Doucet A., N. de Freitas & N. Gordon, 2001, Sequential Monte Carlo Methods in Practice, Springer Verlag.
Durbin J. & S.J. Koopman, 2002, Time Series Analysis by State-Space Methods, Oxford University Press.
Fernández-Villaverde J. & J.F. Rubio-Ramírez, 2008, How Structural are Structural Parameters?, NBER Macroeconomics Annual 2007, 83-137.
Fernandez-Villaverde J., 2009, The Econometrics of DSGE Models, Working paper, n°14677, NBER.
Harvey A.C., 1989, Forecasting, Structural Time Series Models and the Kalman Filter, Cambridge University Press.
Haug A.J., 2005, A Tutorial on Bayesian Estimation and Tracking Techniques Applicable to Nonlinear and Non-Gaussian Processes, MITRE Technical Report #W400.
Judd K., 1992, Projection Methods for Solving Aggregate Growth Models, Journal of Economic Theory 58, 410-452.
Schmitt-Grohé S. & M. Uribe, 2004, Solving Dynamic General Equilibrium Models Using a Second-Order Approximation to the Policy Function, Journal of Economic Dynamics and Control 28, 755-775.
Winschel V. & M. Krätzig, 2008, Solving, Estimating and Selecting Nonlinear Dynamic Models without the Curse of Dimensionality, forthcoming Econometrica.



![[tel-00585727, v1] Approche bayésienne de l'évaluation de ... · Lisa Hauswaldt de la PTB (Physikalisch-Technischen Bundesanstalt), pour la richesse d'une première expérience](https://img.pdfslide.fr/doc/110x75/5ed04614e14d1766ba59ece5/tel-00585727-v1-approche-baysienne-de-lvaluation-de-lisa-hauswaldt-de.jpg)

























