Embed Size (px)
Citation preview

8
Réseaux de neurones sans apprentissage
pour l’optimisation
Dans les chapitres précédents, nous avons montré que les réseaux de neurones constituent des outils puis-sants pour la modélisation, la commande, la discrimination et la classification automatique. Dans tous cesdomaines, ce sont les propriétés de non-linéarité et d’apprentissage qui sont mises à profit : on réalise unefonction statique ou dynamique, paramétrée, et l’on a recours à un apprentissage pour estimer les para-mètres. Dans ce chapitre, nous décrivons un autre mode de mise en œuvre des réseaux de neurones : lespropriétés de non-linéarité et de dynamique sont également mises à profit, mais les paramètres desréseaux sont dictés « naturellement » par l’application, sans qu’il soit nécessaire d’avoir recours à unapprentissage. C’est dans le cadre des
problèmes d’optimisation
que cette approche se révèle particuliè-rement intéressante.
Quelle décision prendre ? Comment minimiser les coûts de production par une planification des tâches etune gestion des flux et des ressources qui soient aussi efficaces que possible ? Comment augmenter laproductivité ? Comment utiliser au mieux les ressources disponibles pour satisfaire une demande, aumoindre coût ? Au cœur de ces préoccupations se trouve un
problème d’optimisation
. En effet, la tâched’optimisation consiste à choisir entre plusieurs termes d’une alternative. Ce choix est gouverné par ledésir de prendre
la meilleure
décision, qui se résume souvent à une solution satisfaisant les exigences d’unproblème et dont le coût de mise en œuvre est le plus faible possible. La théorie et les méthodes d’optimi-sation, qui font l’objet de ce chapitre, traitent de la sélection de la meilleure solution.
Modélisation d’un problème d’optimisation
Face à un problème réel dont on pense qu’il s’agit d’un problème d’optimisation, la première étapeconsiste à reformuler le problème sous la forme mathématique d’un problème d’optimisation. Cettemodélisation est cruciale et parfois délicate, car quantifier la qualité d’une solution n’est pas toujourssimple, et la formulation mathématique (appelée aussi « codage ») d’un problème influe sur le choix de latechnique de résolution à mettre en œuvre. Cette étape requiert donc une collaboration étroite entre lesspécialistes d’optimisation et ceux de l’application source du problème à résoudre. Le résultat de cetteétape est un modèle mathématique, généralement défini par :• des variables ;• un objectif, fonction des variables, exprimé en général comme la minimisation d’un coût, ou d’un
ensemble de coûts, de mise en œuvre de la solution ;• des contraintes à satisfaire par la solution. Certaines sont impératives ; on les appelle alors des
contraintes strictes
. D’autres expriment des préférences ; on les nomme
contraintes relaxables
.
Le problème tient alors en ceci qu’il faut trouver, dans un temps limité, un ensemble de valeurs des varia-bles qui permettent d’atteindre l’objectif tout en satisfaisant les contraintes. Suivant les applications, le

Les réseaux de neurones
338
nombre de variables d’optimisation va de quelques unités à plusieurs centaines de milliers, et les tempsde réponse attendus vont de quelques microsecondes, par exemple dans des applications de télécommu-nications, à quelques heures. De plus, il est parfois souhaitable de disposer de plusieurs solutions, parmilesquelles l’utilisateur fera son choix.
Les variables des problèmes d’optimisation peuvent être :• à valeurs continues,• à valeurs discrètes, par exemple binaires (il s’agit alors de problèmes d’optimisation « combinatoire »,• ou à valeurs continues et discrètes (ces problèmes sont qualifiés de « mixtes »).
En outre, le problème peut ne pas contenir de contraintes, ou bien de fonction de coût à optimiser. Dansce dernier cas, on ne se pose alors que la question de l’existence d’une solution qui satisfasse l’ensembledes contraintes ; le problème est appelé « problème de satisfaction de contraintes ». Quand toutes lescontraintes ne peuvent être satisfaites, et donc que le problème n’admet pas de solutions, il est parfoispossible de chercher un bon compromis qui viole certaines contraintes relaxables.
Les fonctions de coût à optimiser peuvent avoir des formes plus ou moins complexes : c’est le cas parexemple des fonctions linéaires, ou quadratiques, des variables.
Parfois, les données nécessaires pour résoudre le problème d’optimisation ne sont pas toutes disponiblesimmédiatement, mais peuvent le devenir progressivement : les méthodes doivent alors produire des solu-tions dynamiquement, au rythme de la variation des données d’entrée du problème.
Enfin, certains problèmes sont distribués : des centres de décisions, localement connectés entre eux, pren-nent des décisions partielles en fonction des données locales dont ils disposent, mais c’est l’ensemble deces décisions qui doit bien résoudre le problème global.
Exemples
Il existe une très grande variété de problèmes d’optimisation combinatoire. On les rencontre communé-ment dans de nombreuses applications industrielles. Pour n’en citer que quelques-unes, dans lesquellesl’auteur est intervenu, on peut mentionner les domaines suivants :• Militaire : problèmes d’affectations de ressources (affectation d’armes sur des cibles [H
ÉRAULT
1995a],[H
ÉRAULT
1995b], [H
ÉRAULT
1995c]), de suivi de cibles [H
ÉRAULT
1997a], d’optimisation de surfaceéquivalente radar (SER).
• Conception assistée par ordinateur (CAO) : synthèse de matériaux complexes, par exemple de filtres opti-ques ou de matériaux composites [B
OUDET
et al.
1996] ; optimisation de formes, de structures, de pièces.• Télécommunications : routage par déflexion de paquets dans les réseaux à très haut débit [H
ÉRAULT
1997b]; optimisation du codage de l’information ; optimisation des diagrammes de rayonnement deréseaux d’antennes.
• Nucléaire : optimisation de la gestion d’un stock de matières périssables [P
RIVAULT
et al.
1998a],[P
RIVAULT
et al.
1998b].• Spatial : ordonnancement ; planification de mission ; affectation de fréquences ; optimisation de la
redondance des équipements embarqués dans les satellites ; optimisation des antennes.• Ressources humaines : optimisation de la gestion du personnel ; affectation de personnes sur des
postes ; réalisation d’emploi du temps.• Traitement du signal et des images : trajectographie de particules [D
ÉROU
et al.
1996], reconnaissancede formes [H
ÉRAULT
et al.
1993].• Industrie : ordonnancement d’ateliers ; placement de pièces ; optimisation de tournées de véhicules.
De nombreuses autres applications sont présentées dans [T
AKEFUJI
1992], [C
ICHOCKI
et al.
1993], [D
AGLI
1994], [T
AKEFUJI
et al.
1996].

Réseaux de neurones sans apprentissage pour l’optimisation
C
HAPITRE
8
339
Ces problèmes se codent souvent de manière générique sous la forme mathématique de problèmes dethéorie des graphes, qu’il s’agisse par exemple des problèmes de coloriage, de découpage, de morphismesde graphes, ou encore d’extraction de sous-graphes particuliers comme des cliques, des chemins, descycles, etc. [G
ONDRAN
et al.
1995]. Il est donc intéressant d’étudier, parallèlement aux applications, larésolution de ces familles de problèmes génériques. Le problème du « voyageur de commerce » fait partiede ces problèmes difficiles, archétypiques ; nous le présentons en détail dans le paragraphe suivant.
Problème du voyageur de commerce
Tout au long de ce chapitre, afin de comparer les différentes approches présentées, nous utiliserons à titred’exemple en forme de « fil rouge » un problème de théorie des graphes, dit « problème du voyageur decommerce », qui est une référence parmi les problèmes d’optimisation combinatoire.
Rappel du problème
C’est un problème d’optimisation de tournée : un voyageur de commerce doit visiter des villes, dont on connaît les coordonnées géogra-phiques. Afin de réduire ses coûts, il cherche une tournée aussi courte que possible en termes de distance parcourue, et qui passe exac-tement une fois par chaque ville.
Nombre d’algorithmes ont été proposés dans la littérature [R
EINELT
1994], [G
ONDRAN
et al.
1995], pourrésoudre ce problème.
Un exemple de problème à 101 villes est illustré par les figures 8-1 et 8-2. Beaucoup d’applications seramènent à ce type de problème, même en dehors des problèmes de « distributique » : c’est ainsi le caspour la recherche du plus court trajet d’un outil industriel qui doit usiner un certain nombre de parties d’unobjet (par exemple, percer des trous dans une plaque de circuit imprimé).
Complexité d’un problème d’optimisation
Les problèmes d’optimisation peuvent être classés en fonction de leur complexité intrinsèque.
Il est fréquent, dans des applications industrielles, qu’un problème d’optimisation puisse être modélisépar une fonction de coût, et un ensemble de contraintes, qui sont linéaires par rapport aux variables d’opti-misation (nombres réels). Il s’agit alors d’un problème de « programmation linéaire », dont on peuttrouver une solution exacte en un temps raisonnable : la solution optimale peut être trouvée en un nombred’itérations qui varie d’une manière polynomiale avec le nombre de variables. Bien des méthodes permet-tent de résoudre très efficacement ce type de problèmes [S
CHRIJVER
1986] ; la plus connue est le
simplexe
0
10
20
30
40
50
60
70
80
0 10 20 30 40 50 60 70
Problème de voyageur de commerce 101 villes
0
10
20
30
40
50
60
70
80
0 10 20 30 40 50 60 70
Problème de voyageur de commerce de la figure 8-1 : tour optimumFigure 8-1. Exemple
de problème du voyageur de commerce à 101 villes
Figure 8-2. Solutionoptimale du problème
du voyageur de commercede la figure 8-1

Les réseaux de neurones
340
(dont nous avons mentionné l’utilisation, dans les compléments théoriques et algorithmiques duchapitre 2, pour la mise sous forme canonique de modèles dynamiques). Néanmoins, lorsque le nombrede variables devient très grand, le simplexe est excessivement lent ; des approches plus rapides existent,telles que
les méthodes de points intérieurs
[G
ONZAGA
1992].
Pratiquement, il est parfois nécessaire de linéariser des problèmes qui sont non linéaires. L’erreur demodélisation qui en résulte peut néanmoins coûter cher : il faut alors avoir recours à d’autres méthodes, àmême de manipuler directement des entités non linéaires. Nous avons vu dans les chapitres précédentsque c’est précisément une des propriétés caractéristiques des réseaux de neurones.
Nombre de problèmes d’optimisation sous contraintes associés à des applications industrielles sont desproblèmes d’optimisation combinatoire. Les problèmes de théorie des graphes sous-jacents sont souventNP-complets [G
AREY
et al.
1979] : en d’autres termes, le nombre de solutions potentielles subit une« explosion combinatoire », c’est-à-dire qu’il croît exponentiellement avec le nombre de variables. Onpeut alors avoir recours à des « heuristiques », techniques
ad hoc
qui, à défaut de trouver des solutionsexactes, permettent de proposer de bonnes solutions, dont le caractère optimal ne peut être garanti, dansun temps de calcul raisonnable.
Exemple
Le problème du voyageur de commerce, présenté ci-dessus, est combinatoire, et l’on peut montrer, plusprécisément, qu’il appartient à la classe des problèmes dits « NP-complets » [R
EINELT
1994]. Le nombrede solutions potentielles, c’est-à-dire de tournées possibles, pour le problème du voyageur de commerceà
N
villes, est
N
! (factorielle de N). Ainsi, dans l’exemple donné sur la figure 8-1, le nombre de solutionspotentielles est supérieur à 10
159
. Il va sans dire qu’une énumération exhaustive de l’ensemble des tour-nées possibles n’est pas envisageable. Même le fait de tester aléatoirement un grand nombre de tournéespossibles pour n’en garder que la meilleure ne donnerait pas de bons résultats : les solutions évaluées nereprésenteraient qu’une partie infime de l’ensemble des solutions possibles. Le recours à une techniqued’optimisation plus élaborée est donc indispensable pour proposer de « bonnes » solutions dans un tempsde recherche raisonnable.
Approches classiques des problèmes combinatoires
Pour les problèmes combinatoires dit
de programmation linéaire en nombres entiers
, qui sont extrême-ment fréquents dans les applications, des heuristiques consistent à réduire le volume de l’enveloppeconvexe des solutions en ajoutant des contraintes. C’est par exemple le cas de la méthode des
coupes deGomory
[S
CHRIJVER
1986].
Les
méthodes arborescentes
sont des méthodes exactes, qui essaient d’énumérer
intelligemment
les solu-tions réalisables de manière à trouver rapidement de bonnes solutions [P
RINS
1994]. Elles partagentl’espace des solutions en sous-ensembles de plus en plus petits, la plupart étant éliminés par des calculsde bornes avant d’être construits explicitement : voilà pourquoi on les appelle méthodes d’énumérationimplicites. Appliquées aux problèmes combinatoires, ces approches nécessitent des temps de calcul quicroissent exponentiellement avec le nombre de variables, mais leur complexité est cependant moindrequ’une énumération exhaustive. En général, ces approches s’avèrent inefficaces pour les problèmes degrandes tailles comportant des centaines de variables, car les temps de résolution sont prohibitifs.
Les
méthodes de programmation dynamique
sont des techniques énumératives fondées sur l’idée que dessolutions à des sous-problèmes du problème peuvent aider à guider la recherche de la solution optimaledu problème global. Là encore, cette approche atteint ses limites pour les problèmes de grandes tailles.

Réseaux de neurones sans apprentissage pour l’optimisation
C
HAPITRE
8
341
Les
méthodes de recherche locale
, utilisées dès les années 1970, sont en général mises en œuvre quandles techniques précédentes prennent trop de temps. Elles consistent, à partir d’une solution réalisable, àessayer d’améliorer cette solution en en explorant un petit voisinage. Si une meilleure solution esttrouvée, elle devient la solution courante et la recherche est itérée à partir de celle-ci. L’algorithme s’arrêtequand aucune solution voisine n’améliore la solution courante. Les métaheuristiques, telles que le recuitsimulé et la recherche tabou, que nous présenterons ultérieurement, constituent des raffinements de cestechniques, destinées à éviter les minima locaux des fonctions de coût. À cet effet, à partir d’une solutionréalisable, on explore comme précédemment un petit voisinage, mais on s’autorise à « bouger » demanière
ad
hoc
, dans l’espace des solutions possibles, vers des solutions éventuellement moins bonnesque la solution courante, de manière à sortir des minima locaux.
Les
méthodes de programmation par contraintes
sont des techniques qui couplent une réduction del’espace de recherche des solutions et des méthodes efficaces de parcours d’arbres. Leur efficacité a étéconstatée sur certains problèmes de grandes tailles, où la satisfaction de contraintes est plus importanteque la minimisation du coût.
Introduction aux métaheuristiques
Depuis le début des années 1980, des techniques très génériques de résolution des problèmes combina-toires, regroupées sous le nom de « métaheuristiques », ont été proposées pour traiter les problèmes detrès grande complexité ([R
EEVES
1995], [O
SMAN
et al.
1996], [A
ARTS
et al.
1997], [T
EGHEM
et al.
2001]).Ces méthodes d’optimisation sont itératives : elles convergent vers des « attracteurs » qui codent de« bonnes » solutions du problème. La théorie de ces méthodes relève donc de l’étude des systèmes dyna-miques, discrets ou continus, multidimensionnels et en général non linéaires, qui ont été abordés dans leschapitres 2 et 4. Ces méthodes sont issues de la modélisation mathématique de processus naturels :• La modélisation de processus physiques, notamment par les approches de la physique statistique, a
permis le développement de méthodes telles que le « recuit simulé ».• La modélisation de processus à mémoires a été à l’origine de la méthode appelée « recherche tabou ».
La particularité de cette méthode est de mémoriser, au cours de la recherche de la solution, le passéproche (et éventuellement des bribes du passé lointain) du déroulement de cette recherche.
• La modélisation de systèmes nerveux a donné naissance aux algorithmes neuronaux. Le fait que cesalgorithmes sont massivement parallèles et peuvent donner lieu à des implantations matérielles analogi-ques, numériques, voire optiques, les rend particulièrement attrayants pour les applications où les tempsde résolution doivent être très brefs.
• La modélisation de processus génétiques a initié le développement des « algorithmes génétiques » ou« évolutionnistes », dans lesquels des solutions potentielles sont considérées comme des individus quiévoluent dans une population.
• La modélisation de processus d’apprentissage a donné naissance aux méthodes d’apprentissage parrenforcement. Les algorithmes associés peuvent être distribués sur un réseau de calculateurs, chacund’eux apprenant à agir de manière optimale (dans un environnement stationnaire) par la seule connais-sance d’une évaluation de ses décisions par ses voisins. Ces techniques sont particulièrement adaptéesaux problèmes d’optimisation dynamique dans des environnements non stationnaires.
Enfin, il faut signaler l’existence de méthodes hybrides, qui couplent des métaheuristiques entre elles oudes métaheuristiques et des méthodes plus conventionnelles.
Avant d’aborder la mise en œuvre des réseaux de neurones pour l’optimisation, nous allons présenter lamétaheuristique qui en est la plus proche : le recuit simulé.

Les réseaux de neurones
342
Les techniques dérivées de la physique statistique
Il est possible d’établir une analogie entre les problèmes d’optimisation combinatoire et la modélisationde systèmes complexes à l’aide des méthodes de la physique statistique. En effet, un système physiquecomplexe possède une multitude d’états possibles ; parmi ceux-ci, un état
d’équilibre
est un état pourlequel une grandeur, dépendant de l’état du système (l’énergie libre, par exemple), est minimale. Chercherun état d’équilibre d’un système simulé sur ordinateur revient donc à chercher le minimum d’une fonctionde l’état du système, ce dernier pouvant être défini par un très grand nombre de variables (les positionsrelatives des particules qui constituent le système, par exemple). Ainsi, la simulation des propriétésmacroscopiques d’un système physique à l’équilibre thermodynamique se ramène fréquemment à larecherche d’un minimum de grandeurs thermodynamiques telles que l’énergie libre. En établissant uneanalogie entre grandeurs thermodynamiques et les fonctions de coût d’un problème d’optimisation, ildevient possible de trouver un minimum de cette dernière, et donc une solution au problème d’optimisa-tion, en mettant en œuvre les méthodes de simulation de la physique statistique.
Remarque
À cet effet, on assimile le problème d’optimisation à un problème de simulation d’un système physique de particules en interaction dont lesétats codent les valeurs des variables du problème. La solution optimale est alors considérée comme un état fondamental (état d’énergieminimale) de ce système physique. Pour s’approcher de ces états fondamentaux, des résultats de la physique statistique sont utilisés.
Deux hypothèses sur le système physique sont à l’origine de deux familles de méthodes d’optimisation :l’
analyse canonique
et l’
analyse micro-canonique
.
Analyse canonique
L’analyse canonique suppose que le système physique n’est pas isolé : il peut échanger de la chaleur avecson environnement. On introduira donc dans les méthodes un paramètre « température », noté
T
.
À une température donnée, l’équilibre thermodynamique d’un tel système se caractérise par le fait queson énergie libre est minimale. Cette énergie libre est définie comme la différence entre l’énergie interneet le produit de la température par l’entropie. On sait par ailleurs que, à température nulle, l’entropie dusystème est nulle. Afin d’exploiter ces résultats pour résoudre un problème d’optimisation, on fait corres-pondre à l’énergie interne du système la fonction de coût du problème.
Durant la recherche de l’optimum, il est important d’explorer un grand territoire dans l’espace dessolutions : on utilise à cette fin un « bruit thermique ».
Enfin, la physique statistique nous apprend que, lors de l’équilibre thermodynamique, les états du systèmesont distribués suivant une loi de Boltzmann, selon laquelle la probabilité que le système soit dans l’étatd’énergie
E
0
est donnée par :
Remarque
Les états possibles sont en nombre
fini
puisque l’on traite d’optimisation combinatoire : les états d’énergie sont donc
discrets
. Par consé-quent, on a le droit d’utiliser la notion de probabilité ; pour un problème en variables continues, où les énergies ont elles-mêmes des valeurscontinues, il faudrait utiliser la notion de
densité de probabilité
, introduite dans le chapitre 2.
Dans cette équation,
k
est la
constante de Boltzmann
et
Z
(
T
) est une fonction de normalisation assurantque la somme des probabilités de toutes les énergies accessibles vaut 1. Il résulte de cette propriété que
P E0( )
E0
kT------–
exp
Z T( )-------------------------=

Réseaux de neurones sans apprentissage pour l’optimisation
C
HAPITRE
8
343
les états les plus probables à l’équilibre thermodynamique et à la température
T
sont ceux d’énergie mini-male. Cette propriété a un grand intérêt pour résoudre les problèmes d’optimisation.
Recuit simulé
La métallurgie nous apprend par ailleurs qu’un bon moyen pour atteindre des états de basse énergie d’unsolide consiste à placer ce système à une température élevée, puis à le laisser refroidir lentement. Ceprocessus, appelé « recuit », a pour effet de forcer l’évolution du système vers des états de basse énergie ;le fait que le refroidissement soit lent (par opposition à un refroidissement rapide ou « trempe ») évite quele système soit piégé dans des états métastables correspondant à des minima locaux de son énergie.
Le principe de l’algorithme de recuit simulé, établi indépendamment les uns des autres par Kirkpatrick en1983 [K
IRKPATRICK
et al.
1983], Siarry en 1984 [S
IARRY
et al.
1984] et Cerny en 1985 [C
ERNY
1985],consiste à exprimer ces concepts sous la forme d’un algorithme numérique. L’idée est la suivante : à despaliers de températures décroissantes, l’algorithme utilise une procédure itérative, développée par Metro-polis en 1953, pour atteindre un état de quasi-équilibre thermodynamique. Cette procédure permet desortir des minima locaux avec une probabilité d’autant plus grande que la température est élevée. Quandl’algorithme atteint les très basses températures, les états les plus probables constituent d’excellentessolutions du problème d’optimisation.
■ Algorithme de Metropolis
Metropolis, en 1953, a proposé un algorithme itératif qui permet de trouver l’état d’équilibre thermody-namique d’un système simulé à une température T [METROPOLIS et al. 1953]. Il consiste à itérer un grandnombre de fois les deux étapes suivantes :• Évaluation de la variation d’énergie associée à une transition élémentaire aléatoire de l’état courant i,
d’énergie Ei, vers un nouvel état j, d’énergie Ej : ∆Eij = Ej - Ei.• Acceptation de cette transition vers ce nouvel état avec une probabilité :
Aij(T) = 1 si ∆Eij ≤ 0,
sinon.
■ Algorithme du recuit simulé
L’algorithme du recuit simulé consiste à réduire d’une manière contrôlée la température, à partir d’unetempérature initiale élevée, au sein de l’algorithme de Metropolis. Plusieurs lois de décroissance de latempérature peuvent être utilisées en pratique. L’une d’entre elles est une décroissance géométrique, danslaquelle la température au palier k est donnée par :T(k) = α T(k-1), où α est une constante strictement inférieure à 1, mais proche de 1.
On distingue deux types de recuit simulé suivant la manière dont la température décroît :• dans le recuit simulé homogène, le paramètre de température n’est diminué que lorsque l’équilibre ther-
modynamique a été atteint à la température en cours ; cet algorithme suppose que la procédure deMetropolis est itérée un nombre infini de fois et n’a donc qu’un intérêt purement théorique ;
• en pratique, le paramètre de température est diminué après un nombre fini d’évaluations de transitionsà une température donnée : l’algorithme est alors dit inhomogène.
■ Codage des problèmes d’optimisation
Les performances pratiques du recuit simulé sont très liées au codage du problème, et en particulier auxchoix :• des variables ;
Aij T( )∆Eij
T----------–
exp=

Les réseaux de neurones344
• des transitions élémentaires, qui définissent la topologie de l’espace des solutions : en effet, dans cetespace, la distance entre deux solutions est le nombre de transitions élémentaires nécessaires pour allerde l’une à l’autre ;
• des fonctions codant les coûts et les contraintes. Les contraintes relaxables peuvent être combinées avecla fonction de coût ; les contraintes strictes peuvent, par exemple, être satisfaites par un choix ad hoc destransitions élémentaires.
■ Quelques résultats théoriques
Le comportement du recuit simulé a été étudié très en détail sur le plan théorique, en le modélisant commeune chaîne de Markov. Une bonne synthèse de ces résultats est donnée dans [AARST et al. 1989]. Nousrésumons ci-après les résultats les plus importants.
L’algorithme de Metropolis à une température T converge asymptotiquement vers l’équilibre thermody-namique à cette température, qui est caractérisé par une distribution stationnaire des états.
Le recuit simulé homogène, qui suppose qu’une distribution stationnaire a été atteinte par l’algorithme deMetropolis à chaque palier de température, converge vers les solutions optimales du problème, quelle quesoit la loi de décroissance de T.
Relativement au recuit simulé inhomogène, qui est le seul utilisé en pratique, Hajek a établi une conditionnécessaire et suffisante sur la loi de décroissance de la température entre deux transitions élémentaires (ouun plus grand nombre d’entre elles) [HAJEK 1988]. Ainsi, la température à la k-ième transition, ou encoreau k-ième palier de température, doit vérifier :
où C est une constante égale à la profondeur maximale des minima locaux.
■ Avantages et inconvénients
Cette technique connaît un grand succès pour deux raisons principales. Tout d’abord, la détermination desvaleurs des paramètres internes à la méthode ne présente pas de difficultés majeures et un comportementde type boîte noire est souvent possible pour des applications réelles. Ensuite, les résultats théoriquesétablissent que le recuit simulé a la capacité de s’approcher d’aussi près que l’on souhaite des solutionsoptimales à une vitesse plus rapide qu’une exploration exhaustive de l’espace des solutions ; mais c’est auprix de la patience de l’utilisateur. En pratique, il est généralement possible, en fonction du temps dispo-nible pour résoudre un problème, d’ajuster automatiquement les paramètres internes de la méthode pourexploiter au mieux ce temps et proposer une solution qui présente un très bon rapport « qualité de solu-tion/ temps de résolution ». Enfin, cet algorithme est généralisable aux problèmes à variables continues.
Le principal défaut du recuit simulé réside dans sa réputation de lenteur. En fonction des exigences quel’on peut avoir sur la qualité de solution, il peut nécessiter beaucoup de calculs, associés aux évaluationsde transitions, ce qui peut être rédhibitoire dans certaines applications nécessitant des temps de réponsetrès brefs. En outre, la parallélisation de cet algorithme est difficile, surtout si l’on souhaite conserver despropriétés de convergence théorique vers les solutions optimales. Enfin, l’algorithme de Metropolis, ausein du recuit simulé, peut paraître coûteux : il nécessite en effet une bonne précision numérique dans lescalculs. Par ailleurs, le critère d’acceptation d’une transition élémentaire nécessite un tirage aléatoire d’unnombre réel et un calcul d’une fonction exponentielle.
De nombreuses variantes plus rapides ont été proposées [DOWSLAND 1995]. Certaines exploitent uneconnaissance a priori de l’espace des solutions, quand elle est disponible. D’autres utilisent diverses loisde décroissance de la température. Enfin, de nombreuses études ont été conduites pour paralléliser l’algo-
T k( ) C1 k+( )log
-------------------------≥

Réseaux de neurones sans apprentissage pour l’optimisation
CHAPITRE 8345
rithme. Mais souvent le gain en vitesse de convergence se traduit par la perte des propriétés théoriques deconvergence asymptotique sur les solutions optimales.
Il faut cependant souligner l’existence d’approches rapides qui sont simples à mettre en œuvre et quiconservent ces propriétés. La première consiste en une parallélisation astucieuse du recuit simulé surplusieurs calculateurs en parallèle [ROUSSEL-RAGOT et al. 1990]. L’autre consiste à utiliser le recuitsimulé avec changement d’échelle ou le recuit microcanonique, présentés ci-après.
Recuit simulé avec changement d’échelle
Cet algorithme permet dans bien des cas pratiques d’accélérer la convergence du recuit simulé, tout enfaisant en sorte qu’il conserve des propriétés théoriques de convergence asymptotique sur les solutionsoptimales [HÉRAULT 2000].
Il est issu d’un constat : le recuit simulé est « impatient » et cela lui fait perdre du temps. En effet, dès quepossible, le critère de Metropolis le fait plonger dans des minima locaux de l’espace des solutions, et enressortir. Chaque visite de minimum peut ainsi nécessiter plusieurs transitions élémentaires. Toutefois,aux paliers de température élevée, tous les minima locaux visités sont mauvais. Il gaspille donc des tran-sitions élémentaires et perd du temps.
Pour corriger ce défaut, l’algorithme n’autorise que des transitions dans une bande d’énergie centréeautour d’une énergie « cible » Ecible, fonction décroissante de la température. Pour imposer cela aux tran-sitions élémentaires dans l’algorithme de Metropolis, il suffit de modifier les énergies des états au sein decet algorithme. Le calcul de la variation d’énergie associée à une transition élémentaire de l’état i à l’étatj devient :
Cette modification est une généralisation de l’algorithme de Metropolis : on retrouve ce dernier en impo-sant Ecible = 0.
On peut montrer qu’une loi de décroissance de l’énergie cible, qui garantit de bonnes propriétés deconvergence asymptotique sur les solutions optimales, est la suivante :Ecible = α T2 où α est un réel positif.
Tout se passe comme si cette généralisation du recuit simulémodifiait le paysage énergétique pendant la convergence del’algorithme. L’algorithme du recuit simulé avec changementd’échelle démarre à partir d’un paysage des solutions« aplati », qui est ensuite « déplié » progressivement, à chaquepalier de température, de manière appropriée. Il est importantde noter que ce repliement se fait sans aucun déplacement desextrema de la fonction d’origine. Pour illustrer cet effet, consi-dérons l’exemple d’une fonction mono-dimensionnelle àminimiser, donné sur la figure 8-3. La figure 8-4 montre ladéformation de cette fonction en fonction de l’énergie cible.Quand cette dernière est nulle, la fonction recalculée est celled’origine. Quand l’énergie cible est élevée, les minima de lafonction recalculée correspondent aux maxima de la fonctiond’origine. Ainsi, si l’énergie cible est grande au début de larecherche, les états les plus probables issus de l’algorithme deMetropolis seront les crêtes de la fonction d’origine. Une fois l’énergie cible inférieure au minimumabsolu de la fonction, la fonction recalculée et la fonction d’origine ont leurs minima aux mêmes endroits,
∆Eij E j Ecible–( )2Ei Ecible–( )2
–=
0
5
10
15
20
0.5 1 1.5 2 2.5 3
Ené
rgie
des
sol
utio
ns
Solutions
Exemple de fonction énergiemonodimensionnelle
Figure 8-3. Exemple de fonction 1D à minimiser

Les réseaux de neurones346
avec les mêmes profondeurs relatives. De plus, au fur et à mesure de la décroissance de l’énergie cible, lesminima de la fonction recalculée se creusent et convergent vers ceux de la fonction d’origine.
Comme en recuit simulé, on peutconsidérer l’algorithme homo-gène et l’algorithme inhomo-gène. En termes de codage,aucune modification par rapportau recuit simulé n’est nécessaire.
Les propriétés de convergenceasymptotique vers les solutionsoptimales ont été établies et secomparent favorablement àcelles du recuit simulé.
L’algorithme de Metropolisminimise l’énergie libre du sys-tème avec les énergies corrigées.Par ailleurs, on montre que laconvergence asymptotique versun équilibre thermodynamique(distribution stationnaire desétats) est estimée plus rapidequ’avec l’algorithme de Metro-polis standard. Ainsi, à chaque palier de température, la distance à la stationnarité après un nombre fini detransitions élémentaires est réduite.
Comme en recuit simulé, on montre que l’algorithme homogène converge asymptotiquement vers lessolutions optimales.
Concernant l’algorithme inhomogène, une condition suffisante sur la loi de décroissance de la tempéra-ture entre deux transitions élémentaires est la suivante :
où C1et C2 sont des réels positifs.
Cette loi de décroissance est plus rapide que les lois données par Mitra et al. en 1986 pour le recuit simulé[MITRA et al. 1986].
■ Avantages et inconvénients
En pratique, les qualités du recuit simulé sont conservées par le changement d’échelle. Qui plus est, quandle temps de résolution du problème est limité, cet algorithme fournit de meilleures solutions que le recuitsimulé car il sélectionne mieux les transitions élémentaires à effectuer lors de la convergence. Ce gain parrapport au recuit simulé est d’autant plus significatif que le temps alloué à la résolution est bref.
Analyse microcanoniqueL’analyse microcanonique en physique statistique suppose que le système physique étudié est isolé : il nepeut échanger de la chaleur avec son environnement. En conséquence, l’énergie totale du système estconstante. Cette énergie totale est la somme de l’énergie cinétique et de l’énergie potentielle. Pour
Exemple de fonction énergie monodimensionnelle
0.5 1 1.5 2 2.5 3
0
5
10
15
20
5
10
15
Solutions
Énergie cible
Énergierecalculée
Figure 8-4. Déformation de la fonction de la figure 8-3 en fonction de Ecible
T k( )C1
1 k+( )log C2+-------------------------------------≥

Réseaux de neurones sans apprentissage pour l’optimisation
CHAPITRE 8347
résoudre un problème d’optimisation, on fait correspondre à l’énergie potentielle du système la fonctionde coût du problème d’optimisation combinatoire.
L’équilibre thermodynamique d’un tel système se caractérise par le fait que son entropie est maximale.Cette dernière représente la quantité d’information manquante pour déterminer de manière exacte l’étatdu système. La conséquence de ce résultat est que les états à l’équilibre thermodynamique sont uniformé-ment distribués sur une surface d’énergie constante (hypersphère), et sont donc équiprobables.
De même que l’on utilise un bruit thermique, en analyse canonique, afin d’explorer un grand territoiredans l’espace des solutions lors de cette recherche, de même on se servira en analyse microcanonique du« bruit cinétique ».
Quand le nombre de particules en interaction est très grand, c’est-à-dire à la limite thermodynamique, laphysique statistique montre que l’analyse canonique et l’analyse microcanonique sont équivalentes.Cependant, appliquée à l’optimisation, l’analyse microcanonique présente des avantages en termes desimplicité de mise en œuvre et de vitesse de convergence.
Le recuit microcanonique
Le recuit microcanonique exploite des principes proches de ceux du recuit simulé. La différence essen-tielle réside dans le fait que le recuit microcanonique effectue des paliers d’énergie totale décroissante endiminuant l’énergie cinétique entre deux paliers, alors que le recuit simulé effectue des paliers de tempé-rature décroissante. Ainsi, l’algorithme converge par réduction des énergies d’un ensemble de solutionsautour de celles qui sont optimales.
En termes de codage d’un problème d’optimisation, le codage peut être strictement identique à celui d’unrecuit simulé.
À la place de l’algorithme de Metropolis, le recuit microcanonique utilise l’algorithme de Creutz, quipermet de maximiser l’entropie pour une énergie totale constante, fixée [CREUTZ 1983]. Cet algorithmeest, lui aussi, fondé sur l’évaluation d’une succession de transitions élémentaires.
■ Algorithme de Creutz
Pour une énergie totale Et, un algorithme itératif permet de converger vers l’équilibre thermodynamique.Il consiste à itérer un grand nombre de fois les deux étapes suivantes :• Évaluation de la variation d’énergie associée à une transition élémentaire aléatoire de l’état courant i,
d’énergie potentielle Ei, vers un nouvel état j, d’énergie Ej : ∆Eij = Ej – Ei.• Acceptation de cette transition vers ce nouvel état si ∆Eij ≤ Et – Ei.
Dans cet algorithme, Et - Ei représente l’énergie cinétique du système quand il est dans l’état i. On cons-tate que des transitions vers des états d’énergie potentielle plus élevée sont autorisées, à condition qu’il yait suffisamment d’énergie cinétique pour compenser l’augmentation de l’énergie potentielle, et doncpour rester à énergie totale constante.
■ Recuit microcanonique
L’algorithme du recuit microcanonique consiste à réduire l’énergie totale, à partir d’une énergie totaleélevée, au sein de l’algorithme de Creutz. Plusieurs lois de décroissance de l’énergie totale peuvent êtreutilisées en pratique, comme pour la température dans le cas du recuit simulé.
■ Avantages et inconvénients
L’algorithme de Creutz est beaucoup plus simple que la procédure de Metropolis, et nécessite bien moinsde calculs. De plus, il ne nécessite pas une bonne précision numérique dans les calculs. Si le problème se

Les réseaux de neurones348
code en nombres entiers, il n’est pas nécessaire de faire des calculs en nombres flottants. Par ailleurs, iln’est pas nécessaire de calculer une exponentielle, ni de tirer un nombre aléatoire pour le comparer à cetteexponentielle. Les calculs mis en œuvre sont donc extrêmement simples.
Le recuit microcanonique fournit des solutions de qualité comparable à celles que fournit le recuit simulépour les problèmes de grande taille, tout en étant particulièrement économique en termes de calculs.Enfin, une parallélisation de cette approche est possible.
On peut noter que le recuit microcanonique permet de créer des familles de solutions de qualités compa-rables, car toutes les solutions d’un même niveau d’énergie totale sont équiprobables. Quand l’énergietotale est faible, les états accessibles sont tous d’énergie inférieure (car l’énergie cinétique est une quantitépositive) et constituent une famille de bonnes solutions.
En revanche, il n’existe pas aujourd’hui de théorèmes de convergence comme pour le recuit simulé. L’unedes raisons en est l’existence de barrières énergétiques que cet algorithme, contrairement au recuit simulé,ne permet pas de franchir : dans le critère de Creutz, la probabilité de transition d’un état i à un état j peutêtre nulle quand Et devient petite. Des travaux de recherche sont encore nécessaires pour établir lespropriétés de convergence.
Exemple : problème du voyageur de commerceNous allons considérer le codage suivant pour le problème du voyageur de commerce. C’est un descodages parmi les plus simples possibles [REINELT 1994].
On part initialement d’une tournée aléatoire acceptable. On représente une tournée par un vecteur denombres entiers dont la composante i indique le numéro de passage du voyageur de commerce dans laville i.
On opte pour une transition d’un état à un autre, comme l’échange des positions respectives de deuxvilles, choisies aléatoirement, dans la tournée. Ce type de transition a deux avantages. Tout d’abord, elleest simple à mettre en œuvre, et donc peu coûteuse, et elle permet de rester dans l’espace des tournéesacceptables. Une transition entre deux états est constituée de deux étapes :• choix aléatoire de deux villes,• échange de leurs positions dans la tournée.
Exemples d’algorithmes de recuit
Dans ce qui suit, nous donnons des exemples pratiques d’algorithmes du recuit simulé, du recuit simuléavec changement d’échelle et du recuit microcanonique. En particulier, nous présentons des algorithmes« quasi homogènes », c’est-à-dire qui effectuent à chaque palier un grand nombre de transitions permet-tant de s’approcher de l’équilibre thermodynamique.
RemarquesOn peut noter, en comparant ces algorithmes, les points suivants :— On passe d’un algorithme de recuit simulé « standard » à un algorithme de recuit simulé avec changement d’échelle avec très peu demodifications dans le logiciel correspondant ; seules quelques lignes de codes supplémentaires sont nécessaires. En pratique, on peutdonc comparer, à peu de frais, les performances de ces deux approches. En un temps de résolution fixé, le recuit simulé avec changementd’échelle doit effectuer moins de transitions que le recuit simulé ; elles sont légèrement plus complexes à évaluer, mais plus efficaces. Cegain en efficacité est d’autant plus net que le nombre de transitions autorisé dans le temps imparti est bref.— Le recuit microcanonique est plus simple à développer que le recuit simulé, et peut fournir des résultats aussi bons. Mais, dans des casoù l’utilisateur a peu de temps pour résoudre le problème, il peut s’avérer moins performant, car il construit, au cours de sa recherche, desbarrières d’énergies infranchissables qui peuvent le piéger dans des parties de l’espace des solutions qui ne contiennent pas d’excellentessolutions.

Réseaux de neurones sans apprentissage pour l’optimisation
CHAPITRE 8349
Recuit simulé
■ Initialisation de l’algorithme• Définir le pourcentage minimal p de transitions acceptées sur le premier palier.• Déterminer la température initiale T = T0 telle que p% des transformations testées sont acceptées.• Engendrer aléatoirement une solution acceptable et calculer son énergie E.• Choisir le nombre maximal de transitions testées à chaque palier : Nbmaxtest.• Choisir le paramètre de décroissance de la température entre deux paliers : dec.
■ Algorithme du recuit simulé
Recuit simulé avec changement d’échelle
■ Initialisation de l’algorithme• Définir le pourcentage minimal p de transitions acceptées sur le premier palier.• Déterminer la température initiale T = T0 telle que p% des transformations testées sont acceptées.• Initialiser α, par exemple avec une valeur proche de , où Ê est l’énergie moyenne des solutions.• Engendrer aléatoirement une solution acceptable et calculer son énergie E.• Choisir le nombre maximal de transitions testées à chaque palier : Nbmaxtest.• Choisir le paramètre de décroissance de la température entre deux paliers : dec.
■ Algorithme du recuit simulé avec changement d’échelle
• Fixer Nbacceptées = 1• Tant que Nbacceptées est non nul
o Nbtestés = Nbacceptées = 0o Tant que Nbtestés < Nbmaxtest /* Algorithme de Metropolis */o Incrémenter Nbtestés.o Tirer une transition possible.o Calculer la variation d’énergie ∆E.o Si ∆E<0 alors /* Transition acceptée */
1. Effectuer la transition.2. Mettre à jour E : E := E + ∆E.3. Incrémenter Nbacceptées.4. Comparer le nouvel état au meilleur état trouvé depuis le début de la recherche et
le mémoriser s’il est meilleur.o Sinon
1. Tirer un nombre aléatoire rand dans [0,1].2. Si rand<exp(-∆E/T) alors /* Transition acceptée */
Effectuer la transition. Mettre à jour E : E := E + ∆E. Incrémenter Nbacceptées.
o Décroître la température : T := dec T /* Recuit */• Retourner le meilleur état rencontré au cours de la recherche.
• Fixer Nbacceptées=1.• Tant que Nbacceptées est non nul.
o Nbtestés = Nbacceptées = 0o Tant que Nbtestés < Nbmaxtest /* Algorithme de Metropolis généralisé*/
o Incrémenter Nbtestés.o Tirer une transition possible.o Calculer la variation d’énergie ∆E.
o Corriger la variation d’énergie en lui retranchant .
E T 0⁄
2αT E ∆E+ E–( )–

Les réseaux de neurones350
Recuit microcanonique
■ Initialisation de l’algorithme
• Définir le pourcentage minimal p de transitions acceptées sur le premier palier.• Fixer Et initiale telle que p% des transformations testées soient acceptées.• Engendrer aléatoirement une solution acceptable et calculer son énergie E.• Choisir le nombre maximal de transitions testées à chaque palier de d’énergie totale : Nbmaxtest.• Choisir le paramètre de décroissance de la température entre deux paliers : dec.
■ Algorithme du recuit microcanonique
Pour approcher les solutions optimales du problème illustré sur la figure 8-1, on peut utiliser par exemplele paramétrage suivant :• p = 90 %• dec = 0,99• Nbmaxtest = 500000
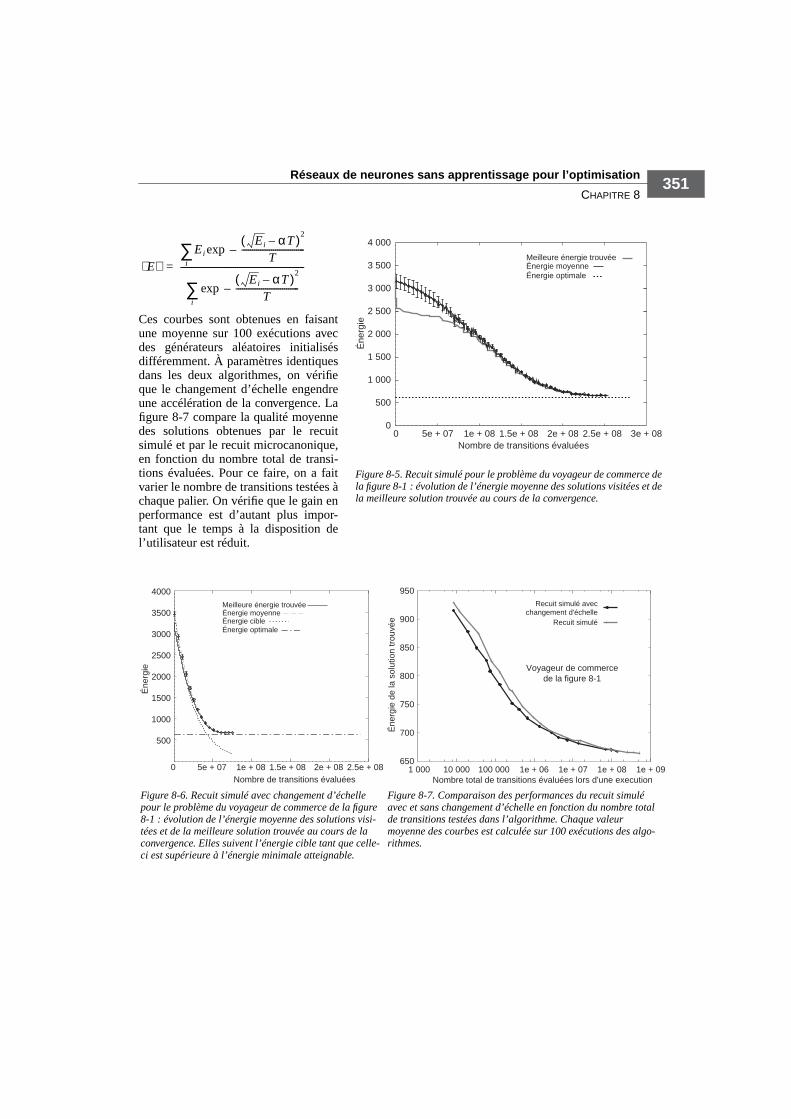
Avec ces valeurs de paramètres, les figures 8-5 et 8-6 montrent, pour le recuit simulé et le recuit simuléavec changement d’échelle, la décroissance de l’énergie moyenne des états visités au cours de la conver-gence, ainsi que la longueur de la meilleure tournée, trouvée au fur et à mesure de la convergence.L’énergie moyenne des solutions est calculée par la formule :
o Si ∆E < 0 alors /* Transition acceptée */1. Effectuer la transition.2. Mettre à jour E : E := E + ∆E.3. Incrémenter Nbacceptées.4. Comparer le nouvel état au meilleur état trouvé depuis le début de la recherche
et le mémoriser s’il est meilleur.o Sinon
1. Tirer un nombre aléatoire rand dans [0,1].2. Si rand < exp(-∆E/T) alors /* Transition acceptée */
Effectuer la transition. Mettre à jour E : E := E + ∆E. Incrémenter Nbacceptées.
o Décroître la température : T := dec T /* Recuit */• Retourner le meilleur état rencontré au cours de la recherche.
• Fixer Nbacceptées = 1.• Tant que Nbacceptées est non nul.
o Nbtestés = Nbacceptées = 0o Tant que Nbtestés < Nbmaxtest /* Algorithme de Creutz */
o Incrémenter Nbtestés.o Tirer aléatoirement une transition.o Calculer la variation d’énergie ∆E associée à la transition.o Si ∆E ≤ Et - E alors /* Transition acceptée */
1. Effectuer la transition.2. Mettre à jour E : E := E + ∆E.3. Incrémenter Nbacceptées.4. Si ∆E < 0, comparer le nouvel état au meilleur état trouvé depuis le début de la
recherche et le mémoriser s’il est meilleur.o Décroître l’énergie totale : Et := dec Et /* Recuit */
• Retourner le meilleur état rencontré au cours de la recherche.
Réseaux de neurones sans apprentissage pour l’optimisation
CHAPITRE 8351
Ces courbes sont obtenues en faisantune moyenne sur 100 exécutions avecdes générateurs aléatoires initialisésdifféremment. À paramètres identiquesdans les deux algorithmes, on vérifieque le changement d’échelle engendreune accélération de la convergence. Lafigure 8-7 compare la qualité moyennedes solutions obtenues par le recuitsimulé et par le recuit microcanonique,en fonction du nombre total de transi-tions évaluées. Pour ce faire, on a faitvarier le nombre de transitions testées àchaque palier. On vérifie que le gain enperformance est d’autant plus impor-tant que le temps à la disposition del’utilisateur est réduit.
0
500
1 000
1 500
2 000
2 500
3 000
3 500
4 000
0 5e + 07 1e + 08 1.5e + 08 2e + 08 2.5e + 08 3e + 08
Éne
rgie
Nombre de transitions évaluées
Meilleure énergie trouvéeÉnergie moyenneÉnergie optimale
Figure 8-5. Recuit simulé pour le problème du voyageur de commerce de la figure 8-1 : évolution de l’énergie moyenne des solutions visitées et de la meilleure solution trouvée au cours de la convergence.
E⟨ ⟩Ei
i∑
E
i α
T
– ( )
2
T
------------------------------–exp
E
i α
T
– ( )
2
T
------------------------------–exp
i
∑
-----------------------------------------------------------=
500
1000
1500
2000
2500
3000
3500
4000
0 5e + 07 1e + 08 1.5e + 08 2e + 08 2.5e + 08
Éne
rgie
Nombre de transitions évaluées
Meilleure énergie trouvéeÉnergie moyenneÉnergie cibleÉnergie optimale
650
700
750
800
850
900
950
1 000 10 000 100 000 1e + 06 1e + 07 1e + 08 1e + 09
Éne
rgie
de
la s
olut
ion
trou
vée
Nombre total de transitions évaluées lors d'une execution
Voyageur de commercede la figure 8-1
Recuit simulé avecchangement d'échelle
Recuit simulé
Figure 8-6. Recuit simulé avec changement d’échelle pour le problème du voyageur de commerce de la figure 8-1 : évolution de l’énergie moyenne des solutions visi-tées et de la meilleure solution trouvée au cours de la convergence. Elles suivent l’énergie cible tant que celle-ci est supérieure à l’énergie minimale atteignable.
Figure 8-7. Comparaison des performances du recuit simulé avec et sans changement d’échelle en fonction du nombre total de transitions testées dans l’algorithme. Chaque valeur moyenne des courbes est calculée sur 100 exécutions des algo-rithmes.

Les réseaux de neurones
352
Les approches neuronales
Depuis le début des années 1980, les réseaux de neurones bouclés (définis dans les chapitres 2 et 4) ontmontré des potentialités intéressantes pour la résolution des problèmes d’optimisation. Ils présentent,dans ce domaine, deux atouts majeurs : le premier réside dans le fait que les algorithmes neuronaux résol-vent souvent très bien des problèmes d’optimisation ; le second vient de ce que ces algorithmes peuventdonner lieu à des réalisations électroniques numériques, analogiques, et même optiques, qui peuventbénéficier des avantages du parallélisme.
Par comparaison avec les autres métaheuristiques, les réseaux de neurones bouclés sont particulièrementadaptés aux problèmes qui requièrent des temps de réponse extrêmement brefs, et qui justifient éventuel-lement la réalisation de circuits.
Les neurones formels utilisés pour l’optimisation
Dans les réseaux de neurones bouclés utilisés pour l’optimisation, les neurones sont soit binaires (leurfonction d’activation est un échelon entre –1 et +1), soit à fonction d’activation sigmoïde : dans ce derniercas, la sortie
y
i
du neurone
i
est donnée par :
y
i
= th(
γ
v
i
), où
γ
est la pente à l’origine de la sigmoïde, et où
v
i
est le potentiel du neurone
i
, défini comme dans les chapitres précédents, pour un réseau de
N
neuronesmutuellement connectés :
où
I
i
est l’entrée constante (biais) du neurone
i
.
Remarque
Contrairement à ce que nous avons fait dans les chapitres précédents, nous serons amenés, pour les réseaux utilisés en optimisationcombinatoire, à distinguer explicitement le biais des autres entrées du neurone.
La seule différence avec les neurones utilisésdans les chapitres 2 à 4 réside donc en cecique la pente
γ
peut être différente de 1. Onnote que la sigmoïde se rapproche del’échelon lorsque
γ
augmente (figure 8-8) ;pour cette raison, l’inverse de la pente peutêtre considéré comme une température, paranalogie avec les algorithmes présentés dansles paragraphes précédents.
Il est parfois préférable d’utiliser desneurones à sortie continue entre 0 et 1. Ilss’obtiennent directement à partir de laformule précédente par le changement devariable (
v
i
+ 1)/2.
Quand les sorties doivent être binaires à laconvergence du réseau, au lieu d’utiliser lafonction sigmoïde précédente pour laquelle 0(ou –1) et 1 sont des valeurs asymptotiques,on peut aussi se servir de la fonction d’acti-vation suivante qui est continue sur [0,1] :
vi wijy j I i+j 1=
N
∑=
– 1
– 0.5
0
0.5
1
– 4 – 2 0 2 4
Sor
tie
Potentiel d'activation
Exemples de fonction de transfert d'un neurone analogique
Figure 8-8. Fonction sigmoïde pour différentes valeurs de γ (γ = 50, 10, 5, 3, 2, 1, 0.5, 0.2)

Réseaux de neurones sans apprentissage pour l’optimisation
C
HAPITRE
8
353
y
i
= 0 si
v
i
≤
0
si 0 <
v
i
<
ρ
y i = 1 si v i ≥ ρ La figure 8-9 montre l’allure de cette fonc-tion d’activation pour
ρ
= 1.
Dans cette fonction d’activation,
ρ
est unréel strictement positif qui contrôle la pentemaximale de cette fonction ; cette dernièreest continue, différentiable et monotonecroissante. Quand
ρ
tend vers 0, la fonctiond’activation tend vers un échelon.
Architectures de réseaux de neurones pour l’optimisation
Les
réseaux de neurones bouclés (ou récurrents)
constituent les techniques neuronales les plus fréquem-ment utilisées pour résoudre des problèmes d’optimisation. Comme nous l’avons indiqué dans le chapitre2, ces réseaux sont caractérisés par le fait que le graphe de leurs connexions contient au moins un cycle.Pour l’optimisation, on utilise ces réseaux sans entrées de commande : sous leur dynamique propre, ilsévoluent, à partir d’un état initial (souvent aléatoire), vers un
attracteur
qui code une solution du problèmed’optimisation. Nous verrons par la suite que le recuit simulé et ses variantes peuvent être modélisés aumoyen de ce type de réseaux de neurones, que l’on appelle alors « machines de Boltzmann ».
Une bonne introduction aux réseaux de neurones appliqués à l’optimisation est fournie dans [C
ICHOKI
etal.
1993]. Les travaux de Takefuji donnent de nombreux exemples de problèmes combinatoires résolus aumoyen de réseaux de neurones récursifs [T
AKEFUJI
1992], [T
AKEFUJI
et al.
1996].
Fonctions d’énergie pour l’optimisation combinatoire
La manière courante de traiter un problème d’optimisation combinatoire avec un réseau de neurones consiste,dans un premier temps, à associer au problème des
fonctions d’énergie
convenablement construites, puis àtransformer le problème de leur minimisation en la résolution d’un système d’équations différentielles oud’équations aux différences. En général, une telle fonction d’énergie s’écrit sous la forme de la somme d’unterme de coût et d’un terme qui exprime les contraintes :
E
= «
Coût
» + «
Contraintes
»
Dans cette équation, les deux termes sont en concurrence ; cela se traduit par l’existence de nombreux
minima locaux
. On cherche donc à minimiser la fonction de coût tout en maximisant simultanément lenombre de contraintes satisfaites. Mathématiquement, la minimisation de la fonction d’énergie se ramènefréquemment à la minimisation d’une fonction
E
(
x
) sur un ensemble
fini
de points
X
, généralement choisicomme un
hypercube
dans un espace de dimension
N
, {-1,1}
N
ou {0,1}
N
. Le vecteur
x
regroupe les varia-bles du problème d’optimisation :
x
= [
x
1
,
x
2
, …,
x
N
]
T
. La fonction
E
(x) est définie de la manière suivante :
où Ec(x) est la fonction de coût, les Ek(x) sont les termes de pénalités associés à des violations decontraintes, et les ak sont des coefficients de pondération qui doivent assurer un bon équilibre entre laminimisation du coût et la satisfaction des contraintes.
0
0.2
0.4
0.6
0.8
1
0 0.2 0.4 0.6 0.8 1
Sor
tie
Potentiel d'activation
Exemple de fonction de transfert d'un neurone analogique
Figure 8-9. Fonction d’activation pour ρ = 1.
yi12--- 1 π
vi
ρ--- 1
2---–
sin+=
E x( ) EC x( ) akEk x( )k∑+=

Les réseaux de neurones354
Pour nombre de problèmes d’optimisation, la fonction E peut être exprimée par une forme quadratique dutype :
Dans cette expression, les coefficients Tij et Ii sont complètement déterminés par la fonction énergie àminimiser. Pour une fonction énergie E(x) donnée, les coefficients Tij expriment une courbure locale :
et le coefficient Ii est donné par la dérivée première de l’énergie :
Nous verrons par la suite que la fonction énergie peut être minimisée par un réseau de neurones bouclés,tel celui qui a été proposé par Hopfield.
Les réseaux de neurones récurrents de HopfieldUn réseau de Hopfield ([HOPFIELD 1982], [HOPFIELD 1984]), défini dans le chapitre 4, est constitué d’unecouche de neurones complètement connectés ; à chaque connexion est associé un retard d’une unité detemps ; le vecteur d’état étant le vecteur des sorties des neurones, l’ordre du réseau est égal au nombre deneurones.
Réseaux de Hopfield binaires
Le réseau de neurones proposé initialement par Hopfield est un réseau de neurones récurrent à tempsdiscret, dont la matrice des connexions wij est symétrique et à diagonale nulle [HOPFIELD 1982]. Nousl’avons présenté dans le chapitre 4.
Principes de fonctionnement du réseau de Hopfield pour l’optimisation
Pour l’optimisation, on utilise le réseau de la manière suivante : à partir d’un état initial, on laisse leréseau évoluer librement jusqu’à un attracteur, qui est généralement, pour les problèmes d’optimisa-tion, un état indépendant du temps (un « point fixe » de la dynamique). On dit alors que le réseau aconvergé : la convergencea est atteinte lorsque les sorties des neurones n’évoluent plus.Pour plus de détails sur les propriétés de convergence, on se référera aux travaux de Goles [GOLES
1995]. La dynamique du réseau est généralement asynchrone : entre deux instants de temps, un seulneurone, choisi aléatoirement, est mis à jour ; autrement dit, son potentiel est calculé, et sa sortieréévaluée en conséquence.Quand ces réseaux sont utilisés pour résoudre des problèmes d’optimisation, les poids des connexionssont déterminés analytiquement à partir de la formulation du problème ; en général, cela est fait direc-tement à partir de la fonction énergie associée au problème, comme nous le verrons dans les exemplesque nous présenterons. De plus, les sorties des neurones, dans l’attracteur vers lequel converge leréseau, codent une solution au problème d’optimisation.
a. Cette convergence n’a rien à voir avec la convergence des algorithmes d’apprentissage mentionnés dans les chapitresprécédents.
E x( ) 12--- T ij x i x j I i x i
i
1=
N
∑ –
j
1=
N
∑
i
1=
N
∑ –=
T ij∂2E
∂xi∂x j
---------------–=
I i∂E∂xi
-------x 0=
–=

Réseaux de neurones sans apprentissage pour l’optimisation
C
HAPITRE
8
355
Chaque connexion ayant un retard unité, le potentiel du neurone
i
au temps
k
est la somme pondérée del’activité des autres neurones du réseau au temps
k
-1 :
où
y
i
(
k
) est la sortie du neurone
i
à l’instant
k
,
w
ij
est le poids relatif à la connexion entre le neurone
j
et leneurone
i
, et
I
i
est le biais (entrée constante) du neurone
i
.
Les attracteurs vers lesquels converge un tel réseau correspondent aux minima d’une fonction, appeléeénergie du réseau, définie par :
,
où
y
est le vecteur des sorties des neurones du réseau, c’est-à-dire le vecteur d’état du système :
y
= [
y
1
,
y
2
, ...,
y
N
]
T
.
Cette fonction est une fonction de
N
variables qui comporte généralement un très grand nombre deminima locaux.
On établit naturellement un lien entre une telle énergie et la fonction d’énergie d’un problème d’optimi-sation combinatoire, décrite précédemment. On comprend dès lors aisément l’attrait des réseaux deneurones récursifs pour traiter des problèmes d’optimisation.
Réseaux de Hopfield analogiques
Hopfield a proposé une version continue (dite « analogique ») des réseaux de neurones récursifs binaires,présentés dans le paragraphe précédent [H
OPFIELD
1984]. Dans ce cas, la fonction d’énergie correspon-dante est de la forme :
,
où
α
est un réel positif, et
Ψ
est la fonction d’activation des neurones.
En général, le dernier terme de cette énergie est négligeable comparé aux précédents dès lors que la pente
γ
à l’origine des neurones est grande, ou encore que
α
est petit.
Hopfield et Tank ont appliqué ce type de réseaux de neurones à l’optimisation combinatoire [
HOPFIELD
etal.
1985].
Un intérêt potentiel de ce type de réseaux réside en ceci qu’ils peuvent permettre de réaliser des circuitsspécialisés analogiques en interconnectant un ensemble de résistances, des amplificateurs non linéaires àsorties symétriques, des sources de courant externes et des condensateurs [N
EWCOMB
et al.
1995].
L’équation d’évolution d’un neurone continu
i
est donnée par l’équation différentielle suivante :
et la sortie est .
Dans ces équations,
µ
i
= 1/
τ
i
est un réel positif paramétrant la vitesse de convergence,
α
i
est un réel positif,
T
est la
température
(inverse de la pente à l’origine de la fonction d’activation du neurone) et
E
(
y
) est lafonction d’énergie du problème, qui n’est pas nécessairement quadratique.
La dérivée de la fonction énergie
E
par rapport au temps peut s’écrire, d’après les équations de mouve-ment des neurones que l’on vient de présenter :
vi k( ) wijy j k 1–( ) I i+j 1≠∑=
E y( ) 12--- w ij y i y j I i y i
i
1=
N
∑ –
j
1=
N
∑
i
1=
N
∑ –=
E y( ) 12--- w ij y i y j I i x i α
γ --- Ψ 1– y ( ) yd 0
y
i ∫
i
1=
N
∑ +
i
1=
N
∑ –
j
1=
N
∑
i
1=
N
∑ –=
dvi
dt------- µi α ivi– ∂E y( )
∂yi
---------------–= yi thµi
T----
=

Les réseaux de neurones
356
On voit clairement que le premier terme de cette équation est toujours négatif ou nul car
τ
i
> 0 et d
y
i
/d
v
i
> 0.En revanche, le second terme peut être positif, négatif ou nul ; en conséquence, la dérivée temporelle dela fonction d’énergie peut être positive [T
AKEFUJI
1992]. Pour éviter cela, on utilise fréquemment uneversion différente des équations de mouvement, qui est la suivante :
i
= 1,…,
N
Du point de vue des sorties des neurones, on obtient, à partir de ces équations de mouvement, les équa-tions suivantes :
i
= 1, …,
N
Les propriétés dynamiques d’un réseau de Hopfield analogique sont donc régies par un système d’équa-tions différentielles non linéaires.
Avec cette modification, on peut montrer facilement que tout changement d’état (de sortie) d’un neuronese traduit sur l’énergie du réseau par une diminution ou un maintien à sa valeur. En effet :
En d’autres termes, le système d’équations d’évolution contraint la fonction d’énergie
E
à décroître d’unemanière monotone vers un minimum local. Plus précisément, ce système a la propriété suivante : à partir d’unpoint initial
x
à l’intérieur de l’hypercube {-1, 1}
N
, le système dynamique converge vers un minimum local de
la fonction d’énergie
E
(
y
), situé soit sur un sommet, soit sur la surface de l’hypercube. Quand l’attracteur estsur la surface, on peut choisir comme solution tout sommet de la surface car l’énergie est constante sur cettesurface. Ainsi, chaque solution vers laquelle converge le réseau de neurones est localement optimale.
En pratique, avec une réalisation électronique d’un tel réseau, les temps de convergence sont de l’ordre dequelques nanosecondes ou microsecondes. Cela autorise en général plusieurs résolutions du problème enpartant de différents points initiaux. Cette stratégie peut parfois se montrer efficace, mais en général lesminima attracteurs ne sont pas de qualité suffisante.
Pour traiter des problèmes d’optimisation combinatoire avec plus d’efficacité, on a souvent intérêt àutiliser des neurones continus avec une pente variable. En effet, en évoluant à l’intérieur de l’hypercubedes solutions, et non uniquement sur les sommets comme le ferait un réseau de neurones binaires, lesminima locaux sous-optimaux de haute énergie sont mieux évités au cours de la convergence. En outre,on peut montrer qu’un réseau continu est bien plus rapide et fiable qu’un réseau de neurones binaires avecune mise à jour asynchrone des neurones [A
YER
et al.
1990], [L
EE
et al.
1991a]. Minimiser la fonction
E
(
y
) avec
y
continu réduit considérablement la probabilité d’être piégé dans un minimum local, car lesvallées de l’espace des solutions sont plus larges que dans le cas binaire. Hélas, il est rare que les neuronesanalogiques, en évoluant à l’intérieur de l’hypercube, convergent finalement vers un sommet de cedernier. Pour forcer les neurones analogiques à prendre finalement des valeurs binaires, codant une solu-tion du problème, il existe plusieurs solutions. L’une d’entre elles consiste à faire croître les pentes àl’origine des fonctions de transfert des neurones analogiques au cours du processus d’optimisation. Une
dEdt-------
∂E∂yi
-------dyi
dt-------
i 1=
N
∑ τ i
dyi
dvi
------- du
i
dt -------
2
α i v i dy
i
dt -------
i
1=
N
∑ –
i
1=
N
∑ –= =
dyi
dt------- µi
∂E y( )∂yi
---------------–=
dyi
dt-------
µi
T---- 1 yi
2–( )∂E y( )∂yi
---------------–=
dEdt-------
∂E∂yi
-------dyi
dt-------
i 1=
N
∑ τ– i
dvi
dt-------
dyi
dt-------
i 1=
N
∑ τ i
dyi
dvi
-------dvi
dt-------
2
i 1=
N
∑–= = =
dEdt------- 0≤

Réseaux de neurones sans apprentissage pour l’optimisation
C
HAPITRE
8
357
autre solution, qu’il est possible de mettre en œuvre conjointement à la solution précédente, est d’ajouterà la fonction d’énergie un terme de pénalité de la forme :
Ce terme est nul si les sorties des neurones sont discrètes à valeurs dans {– 1,1}.
Application des réseaux de Hopfield à l’optimisation
Ce sont des propriétés de convergence des réseaux de Hopfield, décrites ci-avant, qu’a découlé l’applica-tion de ce type de réseaux à la résolution de problèmes d’optimisation. Celle-ci comprend quatre étapes :1. Déterminer un codage du problème. Il s’agit, dans un premier temps, de trouver une représentation du
problème d’optimisation telle qu’une solution, c’est-à-dire une instanciation des variables duproblème, soit représentée par l’état des sorties des neurones à la convergence.
2. Exprimer la fonction de coût et les contraintes sous la forme d’une énergie d’un réseau de Hopfield.On cherchera à exprimer la fonction de coût comme une fonction quadratique. Quant aux contraintesà satisfaire, elles sont de deux types : celles qui sont définies par le problème d’optimisation, et cellesqui résultent du codage du problème choisi à l’étape précédente. Parfois, il n’est pas possible de trou-ver une énergie quadratique. Il faut alors essayer d’exprimer le problème comme celui de la minimi-sation d’une fonction
F
, dérivable par rapport aux sorties des neurones.3. Déterminer les équations d’évolution de chaque neurone.4. Démarrer l’exécution du réseau de neurones. Généralement, quand on ne dispose d’aucune connais-
sance
a priori
sur la localisation de la solution recherchée, les états des neurones sont initialisés aléatoi-rement. La dynamique du réseau de neurones les fera converger vers un minimum local de l’énergie.
Ce type de méthodologie a été appliqué pour résoudre une grande variété de problèmes combinatoires, quise ramènent en général à des problèmes de théorie des graphes.
Exemple de réseau de Hopfield pour le problème du voyageur de commerce
Pour illustrer les propos qui précèdent à l’aide d’un exemple concret, nous allons détailler la résolutiond’un problème de voyageur de commerce, proposée par Hopfield et Tank en 1985 [H
OPFIELD
et al.
1985].Cette résolution n’est pas la plus efficace possible, comme nous le verrons par la suite, mais elle a unintérêt didactique.
■
Étape 1 : Codage du problème
La première étape consiste à reformuler le problème d’un point de vue mathé-matique, afin qu’il soit possible de le résoudre par un réseau de neurones.
Une solution au problème, c’est-à-dire une tournée entre les différentesvilles, peut être codée comme une matrice de permutation, c’est-à-direune matrice carrée à éléments binaires contenant exactement un 1 parligne et par colonne. Autrement dit, étant donné
N
villes, une tournée estreprésentée par une matrice
N
×
N
de
N
2
éléments. Dans cette matrice, uneligne représente une ville, et une colonne un numéro de passage au coursd’une tournée. Une tournée acceptable est représentée par une matrice depermutation, ayant donc exactement N « 1 » et N
2
– N « 0 ». Le tableau 8-1présente un exemple de matrice qui code une solution acceptable d’unproblème à 5 villes :
Ey 1 y j2–( )
j 1=
N
∑=
Tableau 8-1. Solution acceptabledu problème du voyageur de
commerce pour cinq villes.
1 2 3 4 5
Ville A 0 0 1 0 0
Ville B 1 0 0 0 0
Ville C 0 1 0 0 0
Ville D 0 0 0 1 0
Ville E 0 0 0 0 1

Les réseaux de neurones358
La solution ainsi codée correspond à une tournée où les villes A, B, C, D et E sont visitées dans l’ordresuivant : B-C-A-D-E-B.
À chaque coefficient de la matrice est associé un neurone. Ce codage nécessite donc N2 neurones et N4
connexions entre les neurones. On notera yi,j la sortie du neurone (i, j) correspondant à la i-ème ligne et àla j-ème colonne, et vi,j son potentiel. Par ailleurs, on connaît a priori les distances deux à deux entre lesvilles : dij représente ainsi la distance entre la ville i et la ville j.
■ Étape 2 : Détermination de l’énergie du réseau
Fonction de coût
La fonction de coût à minimiser s’exprime comme une mesure de la longueur du trajet parcouru lors dela tournée. Elle peut s’exprimer en fonction des sorties des N neurones qui valent 1 dans la matrice depermutation, de la manière suivante :
où, par définition, yk,0 = yk,N et yk,N+1 = yk,1.
Elle peut s’écrire d’une manière simplifiée de la manière suivante :
Dans cette équation, di,k est la distance entre les villes i et k. L’opérateur ⊕ est défini de la manièresuivante :
Pour j < N, = j + 1, et = 1
Le terme dans les sommes multiples est non nul quand la ville i est en position j, et ce terme est égal à ladistance du trajet entre cette ville et celle qui la suit. La sortie du neurone en position (i, j) est ainsi multi-pliée par les sorties des neurones de la colonne j ⊕ 1. Ainsi, chaque neurone est connecté à 2N neuronesdans le réseau. Le codage de cette fonction de coût ne nécessite donc pas N4 connexions, mais N3.
Contraintes
Pour garantir que, à la convergence, la matrice des sorties des neurones est bien une matrice de permuta-tion, ce qui assure la validité de la solution, des contraintes supplémentaires sont définies. On associe àleur éventuelle violation une fonction de pénalité.
Pour que le tour soit acceptable, chaque ville doit être visitée exactement une fois. Cela impose que, danschaque ligne, il n’existe pas deux neurones dont la sortie est à 1. Pour cela, on définit la fonction énergiesuivante, qui est non nulle si au moins deux neurones ont une sortie à 1 dans une ligne :
De même, à chaque étape, le voyageur de commerce ne peut pas être dans plus d’une ville. En consé-quence, dans chaque colonne, il n’existe pas deux neurones dont la sortie vaut 1 à la convergence duréseau. On définit donc la fonction de pénalisation suivante, qui est non nulle si au moins deux neuronesont une sortie à 1 dans une colonne :
FC12--- d i k , y i j , y k j 1– , y k j 1+ , ( )
k
1=
k i
≠
N
∑
j
0=
N
∑
i
1=
N
∑ =
FC12--- d i k , y i j 1 ⊕,
k
1=
k i
≠
N
∑
j
0=
N
∑
i
1=
N
∑ =
j 1⊕ N 1⊕
F112--- y i j , y i l ,
l
1=
l j
≠
N
∑
j
0=
N
∑
i
1=
N
∑ =

Réseaux de neurones sans apprentissage pour l’optimisation
C
HAPITRE
8
359
Les deux contraintes définies ci-avant ne sont pas encore suffisantes pour garantir la validité d’une solu-tion. En effet, sans nouvelle contrainte, le processus de minimisation ferait naturellement converger toutesles sorties des neurones vers 0, ce qui n’aurait aucun sens. La validité d’une solution lui impose qu’il y aitexactement N neurones dont la sortie soit égale à 1. Une troisième fonction de contraintes est doncdéfinie :
Énergie du réseau de neurone
L’énergie totale du réseau de Hopfield est la somme pondérée des fonctions définies ci-avant :
E
=
F
c
+
a
1
F
1
+
a
2
F
2
+
a
3
F
3
Les constantes
a
1
,
a
2
et
a
3
doivent être ajustées en fonction des poids relatifs des différentes contraintes.
■
Étape 3 : Détermination des équations d’évolution des neurones
On peut mettre la fonction d’énergie du problème sous la forme d’une fonction quadratique du typesuivant, qui est l’énergie d’un réseau de Hopfield :
Dans cette équation, on détermine les poids
w
ij
,
kl
à partir de la forme analytique du coût et des contraintes.Ainsi, si l’on considère la première contrainte
F
1
, sa contribution aux coefficients synaptiques s’écrit : où
δ
x,y
= 1 si et seulement si
x
=
y
.
De même, la contribution de la contrainte
F
2
aux coefficients synaptiques est :.
La contribution de la contrainte
F
3
est – 1.
Enfin, la contribution de la fonction de coût est :–
d
i
,
k
La forme finale des poids est donc :
L’entrée externe sur le neurone ( i , j ) vaut : I i , j = a 3 N .
L’équation d’évolution d’un neurone (
i
,
j
) s’en déduit aisément, par exemple dans le cas de neuronesbinaires. Ainsi, au temps
t
+ 1, on a :
F212--- y i j , y i k ,
k
1=
k i
≠
N
∑
j
0=
N
∑
i
1=
N
∑ =
F312--- y i j , N –
j
0=
N
∑
i
1=
N
∑
2
=
E y( ) 12--- wij kl, yi j, yk l,
l 1=
N
∑k 1=
N
∑j 1=
N
∑ I i j, yi j,j 1=
N
∑i 1=
N
∑–i 1=
N
∑–=
δi k, 1 δ j l,–( )–
δ j l, 1 δi k,–( )–
δl j, 1+ δl j 1–,+( )
wi j kl, 2di k, δl j 1⊕,– a1δi k, 1 δ j l,–( )– a2δ j l, 1 δi k,–( )– a3–=
∆vi j, t 1+( ) wij kl, yk l, t( ) I i j,+l 1=l j≠
N
∑k 1=k i≠
N
∑=

Les réseaux de neurones
360
Dans le cas de neurones analogiques, les équations d’évolution s’écrivent :
où
µ
i,j
et
α
i,j
sont des réels positifs.
■
Étape 4 : Lancement de la dynamique
À partir d’une solution aléatoire acceptable, on peut définir les valeurs initiales des entrées et des sortiesde chaque neurone. Ensuite, une dynamique asynchrone aléatoire, fondée sur les équations d’évolutiondes neurones, fait converger le réseau vers un minimum local de l’énergie, dans lequel les entrées et lessorties des neurones ne varient plus. À la convergence, en lisant les valeurs de sorties des neurones, onobtient un codage d’une solution potentielle au problème. La validité de cette solution doit cependant êtrevérifiée. Si elle n’est pas acceptable (c’est-à-dire si elle viole une ou plusieurs contraintes), on peut redé-marrer le réseau à partir d’un autre état initial aléatoire, et/ou ajuster les constantes de pondération descontraintes, par exemple en augmentant celle qui est associée à une contrainte violée.
Limitations des réseaux de Hopfield
L’utilisation des réseaux de Hopfield pour résoudre des problèmes d’optimisation pose un certain nombrede problèmes.
La principale difficulté, pour l’optimisation d’une fonction d’énergie, vient du fait que la dynamique duréseau conduit fréquemment vers un minimum local de l’énergie, qui n’est pas nécessairement proche del’optimum, ou bien qui ne correspond pas à une solution acceptable. Et ce, parce que les contraintes sontcombinées à la fonction de coût dans l’énergie du réseau.
De plus, le réseau de Hopfield ne fait aucune distinction entre les contraintes strictes et les contraintes depréférence, autrement que par des pondérations différentes dans la fonction d’énergie.
Enfin, les valeurs des paramètres qui pondèrent les divers termes de l’énergie du réseau influent sur lenombre d’itérations nécessaires pour que le réseau converge.
Ces difficultés ont été à l’origine de nombreux travaux qui ont cherché à en limiter les effets.
Améliorations des réseaux de Hopfield
De nombreux travaux de recherche sont en cours pour limiter les défauts des réseaux récurrents sansapprentissage, utilisés pour l’optimisation. Nous ne les citerons pas tous ici, mais nous donnons quelquespistes qui ont été récemment explorées.
Améliorations du codage et des énergies à minimiser
Pour éviter d’être piégé dans des minima locaux de haute énergie correspondant à des solutions non accep-tables, il est souvent fructueux de réfléchir aux différents types de codage possibles du problème, et auxdifférentes énergies envisageables. Pour un même problème, des énergies différentes peuvent être utilisées,chacune d’elles caractérisant un espace des solutions plus ou moins complexe à explorer. Ainsi, dans le casdu problème du voyageur de commerce, Brandt a suggéré, afin d’éviter d’être piégé dans un mauvaisminimum local au cours de la convergence, de minimiser l’énergie suivante [B
RANDT
et al.
1988] :
dvi j,
dt---------- µi j, – α i j , v i j , w ij kl , y k l , I i j , +
l
1=
l j
≠
N
∑
k
1=
k i
≠
N
∑ +
=
E FCγ2--- 1 yi j,
j 1=
N
∑–
2
1 yi j,i 1=
N
∑–
2
j 1=
N
∑+i 1=
N
∑+=

Réseaux de neurones sans apprentissage pour l’optimisation
C
HAPITRE
8
361
Dans le même but, Szu, en 1988 [S
ZU
1988], a proposé encore une autre énergie :
Réseaux de Hopfield analogiques avec recuit
Comme nous l’avons expliqué sommairement plus haut, une première solution consiste à faire varier latempérature
τ
i
(l’inverse de la pente à l’origine de la fonction d’activation du neurone
i
) dans les réseauxde Hopfield analogiques. Comme en recuit simulé, initialement, elle est choisie élevée, puis décroissanteau cours de la convergence. Pour les températures élevées, le système dynamique se comporte comme unsystème presque linéaire, car les fonctions d’activation sont quasi linéaires sur de grandes plages devaleurs des potentiels. Ainsi, les sorties des neurones varient entre –1 et +1. En faisant décroître la tempé-rature, les sorties des neurones tendent vers les valeurs +1 ou –1, qui codent une solution. Au cours de laconvergence, on constate l’existence d’une température critique
T
c
en dessous de laquelle le systèmecommence à se
geler
, c’est-à-dire que les sorties des neurones évoluent d’une manière significative vers+1 ou –1 [H
ÉRAULT
et al.
1989]. Cette température peut être estimée théoriquement pour certainsproblèmes d’optimisation [P
ETERSON
et al.
1989]. Quand c’est le cas, il n’est pas nécessaire de fairedécroître la température régulièrement, mais il suffit de laisser le système converger vers un équilibre à latempérature critique, puis d’effectuer une
trempe
en se plaçant à une température proche de 0. À l’issuede cette deuxième étape, les neurones sont pratiquement binaires.
Réseaux probabilistes
Pour éviter d’être piégé trop facilement dans des minima locaux, une autre approche consiste à définir deséquations d’évolution probabilistes, en ajoutant un terme de bruit dans les équations d’évolution desneurones analogiques, l’influence de ce terme diminuant au fur et à mesure que le réseau converge [A
SAI
1995]. L’équation d’évolution est ainsi modifiée de la manière suivante :
i
= 1, …,
N
où les
N
i
sont des sources de bruit blanc de moyenne nulle non corrélées, et
c
(
t
) impose la loi de décrois-sance du bruit. Typiquement,
c
(
t
) peut s’exprimer de la manière suivante :
D’un point de vue matériel, il est nécessaire d’ajouter une source de bruit non corrélée sur chaque neuroneet d’en réduire graduellement la puissance au cours de la convergence. Cela a pour effet, comme en recuitsimulé, de donner au système la capacité de s’extraire des minima locaux de haute énergie, et ainsi deconverger vers des solutions bien meilleures. C’est pour cette raison que cette technique d’optimisationest parfois appelée
recuit simulé hardware
.
La machine de Boltzmann
La machine de Boltzmann a été proposée en 1984 et 1985 ([H
INTON
et al.
1984], [A
CKLEY
et al.
1985]).Elle peut être considérée comme une combinaison des principes du recuit simulé avec des réseaux deHopfield binaires. Son architecture est semblable à celle d’un réseau de Hopfield binaire.
L’énergie d’un réseau de Boltzmann s’exprime sous la même forme que l’énergie d’un réseau de Hopfieldbinaire :
E FC a1F1 a2F2 a3 1 yi j,j 1=
N
∑–
2
1 yi j,i 1=
N
∑–
2
j 1=
N
∑+i 1=
N
∑+ + +=
dyi
dt------- µi 1 yi
2–( )∂E y( )∂yi
--------------- c t( )Ni+–=
c t( ) c0 t τ --–
exp=

Les réseaux de neurones
362
La mise à jour d’un neurone
i
consiste tout d’abord à calculer la variation d’énergie induite par son chan-gement d’état. Ainsi, la variation d’énergie associée au passage de 0 à 1 de la sortie d’un neurone estdonnée par :
Le neurone change alors d’état avec la probabilité donnée par le critère de Metropolis utilisé en recuitsimulé. Au cours de la convergence du réseau, comme en recuit simulé, le paramètre de température estdiminué progressivement.
Si l’on considère par exemple le problème du voyageur de commerce, on peut utiliser le même codage quecelui qui est utilisé pour les réseaux de Hopfield, fondé sur une matrice de permutation. Les sortiesbinaires du réseau codent une solution au problème. Les énergies associées à la fonction de coût à mini-miser et aux contraintes sont exactement les mêmes que celles utilisées dans un réseau de Hopfieldbinaire. Les sorties des neurones sont initialisées aléatoirement avec les valeurs 0 ou 1. L’état initial necode donc pas nécessairement une solution acceptable au problème.
Dans tout ce qui précède, on a opéré exactement de la même manière qu’avec un réseau de Hopfield. Lamise à jour des neurones est cependant différente. Pour faire évoluer le réseau, on sélectionne aléatoire-ment un neurone
i
. Indépendamment de la valeur de sa sortie, on détermine la probabilité de mettre lasortie de ce neurone à 1. Pour cela, on calcule la différence
∆
Ε
ι
entre valeur de l’énergie du réseau quand
p
i
vaut 0 et sa valeur quand
p
i
vaut 1. Ces valeurs dépendent de l’état courant des autres neurones duréseau. La probabilité de mettre la sortie du neurone
i
à 1 est calculée à partir de
∆
E
i
et de la températureselon la formule utilisée en recuit simulé :1 si
∆
E
i
≤
0,
sinon.
Si la probabilité vaut 1, la sortie du neurone
i
est mise à 1. Sinon, on tire un nombre aléatoire entre 0 et 1.Si celui-ci est inférieur à la probabilité calculée, alors la sortie du neurone i est mise à 1 ; dans le cascontraire, elle est mise à 0. Cette procédure de mise à jour des neurones est itérée un grand nombre de fois,de manière à s’approcher de l’équilibre thermodynamique à la température
T
.
La procédure que l’on vient de spécifier est appliquée sur des paliers de températures décroissantes,comme en recuit simulé.
Le réseau a convergé quand le nombre de changements d’état de neurones est réduit au minimum.
Ce qui vient d’être énoncé établit donc un lien étroit entre le recuit simulé, les réseaux de neurones récur-rents de Hopfield et les machines de Boltzmann. C’est la raison pour laquelle les algorithmes dérivés dela physique statistique sont souvent considérés comme des techniques neuronales. Les propriétés deconvergence des machines de Boltzmann sont détaillées dans [A
ARTS
et al.
1989].
Recuit en champ moyen
Une autre approche, comparable dans ses objectifs à la technique précédente, est la
théorie du champmoyen
ou le
recuit en champ moyen
. Le principe en est de manipuler des moyennes statistiques des états
E y( ) 12--- wijyiy j
j 1=
N
∑i 1=
N
∑–=
∆Ei Eyi 1= Eyi 0=– wijv j
j 1=j i≠
N
∑–= =
∆Ei
T---------–
exp

Réseaux de neurones sans apprentissage pour l’optimisation
C
HAPITRE
8
363
visités dans la procédure de Metropolis utilisée en recuit simulé. Hélas, il est nécessaire de faire l’approxi-mation dite du
champ moyen
pour manipuler mathématiquement ces moyennes. Cette approximationconsiste à remplacer des fonctions très complexes par leur développement de Taylor tronqué autour d’unpoint selle (voir plus bas) : c’est la différence majeure entre le recuit simulé et le recuit en champ moyen.Les performances du recuit en champ moyen sont parfois améliorées par l’utilisation de normalisation surdes groupes de neurones ([H
ÉRAULT
et al.
1989], [P
ETERSON
et al.
1989]). Des contraintes du type « unesortie à 1 parmi N » sont alors prises en considération naturellement, sans avoir recours, dans la définitionde l’énergie du réseau, à des termes pénalisant leur violation. Par analogie avec le recuit microcanonique[H
ÉRAULT
et al.
1993], il est possible d’établir un algorithme de recuit en champ moyen microcanonique[L
EE
et al.
1991b].
Les équations de l’approximation du champ moyen, exprimant les sorties des neurones entre –1 et 1, sontdéfinies de la manière suivante :
i
= 1, …,
N
Dans la théorie du champ moyen, la température est fixée, et elle est choisie autour de la températurecritique
T
c
, qu’il est en général très difficile d’estimer. Voilà pourquoi on préfère utiliser le recuit en champmoyen, dans lequel la température est décroissante selon une loi prédéterminée ([V
AN
DEN
B
OUT
et al.
1989], [V
AN
DEN
B
OUT
et al.
1990], [P
ETERSON
et al.
1988], [P
ETERSON
et al.
1989], [P
ETERSON
1990],[H
ÉRAULT
et al.
1991], [H
ÉRAULT
et al.
1989]). Contrairement au recuit simulé, le recuit en champ moyenest une méthode parfaitement déterministe et intrinsèquement parallèle, décrite par le système d’équa-tions différentielles suivant :
i
= 1, …,
N
Réseaux de neurones pulsés
Les réseaux de neurones
pulsés
[H
ÉRAULT
1995c] ne présentent pas les limitations des réseaux deHopfield en termes de violation de contraintes. Ils sont définis avec des modèles de neurones binaires plusgénéraux que ceux qui sont utilisés dans les réseaux de Hopfield. La non-linéarité d’un neurone d’unréseau de Hopfield se situe uniquement dans sa fonction d’activation : son potentiel est une fonctionlinéaire de la sortie des neurones auxquels il est connecté, et sa sortie est une fonction non linéaire de sonpotentiel. Dans un réseau de neurones pulsés, le potentiel d’un neurone est une fonction éventuellementnon linéaire de la sortie des neurones auxquels il est connecté, et l’équation d’évolution a une forme plusgénérale :
y
i
=
Φ
[
v
i
(k – 1), y1(k – 1), ..., yN(k – 1)]
La dynamique associée à ce type de réseau alterne successivement des phases de satisfaction decontraintes, au cours desquelles le réseau converge vers des solutions réalisables, et des phases de pulsa-tion, au cours desquelles le réseau essaie de sortir des minima locaux en direction de meilleurs minima.D’un point de vue opérationnel, le réseau propose donc très régulièrement des solutions réalisables (s’ilen existe) de bonne qualité. La solution retenue sera alors choisie parmi l’ensemble des solutions propo-sées. Ce type de réseau a été utilisé avec succès pour résoudre des problèmes où les solutions sont atten-dues dans des temps de réponse très brefs tels que des problèmes d’allocation de ressources (par exemple,d’affectation d’armes sur des cibles ; on se reportera à [HÉRAULT 1995a], [HÉRAULT 1995b], [HÉRAULT
1995c]), des problèmes d’extraction de cliques maximum rencontrés en mécanique des fluides [DÉROU etal. 1996].
yi th1T---∂E y( )
∂yi
---------------– =
dyi
dt------- µi yi th
1T---∂E y( )
∂yi
---------------– ––=

Les réseaux de neurones364
Réseaux de neurones d’ordre supérieur
Afin d’essayer de satisfaire au mieux les contraintes au cours de la convergence, des auteurs ont proposédes réseaux de neurones à sortie continue utilisant des termes de pénalisation d’ordre supérieur à 2 [SUN
1993]. Cela permet ainsi d’avoir des équations d’évolution des neurones fondées sur des méthodes deNewton dont la vitesse de convergence est d’ordre 2, par exemple :
Ce type de réseau a été appliqué avec succès à la résolution de problèmes combinatoires, en utilisant unedynamique un peu particulière, qui consiste à choisir le neurone à mettre à jour de la manière suivante :• calculer en parallèle tous les ∆vi associés à l’énergie de pénalisation des contraintes, et sélectionner ceux
qui ont les ∆vi les plus petits ;• calculer le gradient de la fonction coût pour les neurones sélectionnés à l’étape précédente, et retenir le
neurone qui dégrade le moins la valeur du coût.
■ Exemple du problème du voyageur de commerce
Reprenons le problème du voyageur de commerce, avec le même codage que celui qui est utilisé par unréseau de Hopfield (matrice de permutation codée par les sorties des neurones) ; pour utiliser les équationsde mouvement que l’on vient de présenter, les termes de pénalisation associés à la violation descontraintes doivent être d’ordre supérieur. On les déduit des conditions suivantes pour qu’une tournée soitacceptable :
• pour toute ville i : et ∀ j, l yi, jyi, l = 0 ;
• pour toute position j sur la tournée : et ∀ i, l yi, jyk, j = 0.
On en déduit une énergie associée à la violation des contraintes :
Réseaux de neurones lagrangiens
Kuhn et Tucker ont montré que les solutions d’un problème d’optimisation continue sous contraintes sontles points selle d’une fonction associée, nommée un « lagrangien » [KUHN et al. 1951]. Les problèmesd’optimisation continue sous contraintes peuvent donc être résolus au moyen de méthodes de gradientappliquées au lagrangien du problème.
Les réseaux de neurones lagrangiens sont des réseaux de neurones récurrents à sortie continue, qui ont laparticularité de converger vers les points selle d’une fonction de Lyapunov et non vers les minima locaux.Ils peuvent être utilisés pour résoudre des problèmes d’optimisation combinatoire ([MAA et al. 1992],[MJOLSNESS et al. 1990], [MJOLSNESS et al. 1991], [ZANG 1992], [RANGARAJAN et al. 1996]).
dvi
dt-------
∂E∂yi
-------
∂2E
∂yi2
------------------–=
1 yi j,–( )j 1=
N
∏ 0=
1 yi j,–( )i 1=
N
∏ 0=
EC 1 yi j,–( )2 1 yi j,–( )2 yi j,2 yi l,
2 yi2 jyk j,
2,k 1=
k i≠
N
∑i 1=
N
∑j 1=
N
∑+l 1=
l j≠
N
∑j 1=
N
∑i 1=
N
∑+i 1=
N
∑j 1=
N
∑+j 1=
N
∑i 1=
N
∑=

Réseaux de neurones sans apprentissage pour l’optimisation
CHAPITRE 8365
■ Exemple du problème du voyageur de commerce
Ainsi, on peut définir un lagrangien augmenté pour le problème du voyageur de commerce, codé commedans un réseau de Hopfield :
Dans cette équation, les coefficients {λi0}, {λi
1} sont les multiplicateurs de Lagrange, tandis que les coef-ficients {µi
0}, {µi1}sont les coefficients de pénalisation.
On définit ensuite les équations d’évolution continues suivantes des sorties des neurones et des multipli-cateurs de Lagrange :
Dans ces équations, les coefficients µ et ρ règlent la vitesse de convergence du réseau.
Cette approche est beaucoup moins sensible aux paramètres de pénalités des violations de contraintes queles réseaux de Hopfield. En revanche, les temps de convergence peuvent s’avérer beaucoup plus longs.
Réseaux de neurones de Potts
Dans nombre de problèmes d’optimisation combinatoire, on a intérêt à coder les neurones sous formevectorielle, en généralisant la structure d’un neurone par l’utilisation de K potentiels d’activation et de Ksorties couplées, dont la somme est constante. Par analogie avec les « verres de spins de Potts » enphysique statistique, ces neurones sont appelés neurones de Potts.
Ce codage permet de coder naturellement des contraintes du type « 1-parmi-K » ou « n-parmi-K ». Autre-ment dit, parmi les K sorties d’un neurone vectoriel, exactement n doivent valoir +1 dans une solution, toutesles autres valant –1. Ce type de contrainte pourrait s’exprimer sous la forme d’une énergie à minimiser. Maiscette contrainte stricte risquerait de ne pas être satisfaite à la convergence sur un minimum local.
L’utilisation de neurones de Potts consiste à remplacer la fonction d’activation sigmoïde des neurones pardes fonctions d’activation multidimensionnelles. Pour une contrainte de type « 1-parmi-K », cela revientà définir des neurones binaires (i, a), de potentiel via et de sortie yia définie par :
L y λ µ, ,( ) Coût= λ i0 yi j, 1–
j 1=
N
∑i 1=
N
∑ λ j1 yi j, 1–
i 1=
N
∑ 12--- µi
0 yi j, 1–j 1=
N
∑2
i 1=
N
∑+j 1=
N
∑+ +
+ 12--- µ i
1 y i j , 1–
i
1=
N
∑
2
j
1=
N
∑
dyi j,
dt----------- µ di k, yk j, λ i
0 λ j1 µi
0 yi j, 1–j 1=
N
∑ µ j1 yi j, 1–
i 1=
N
∑++ + +k 1=
k i≠
N
∑–=
dλ i0
dt-------- ρ yi j, 1–
j 1=
N
∑–=
dλ j1
dt-------- ρ yi j, 1–
i 1=
N
∑–=

Les réseaux de neurones
366
i
= 1, …,
N
a
= 1, …,
K
On vérifie immédiatement que, pour tout neurone de Potts
i
, on a : .
Autrement dit, à la fin du processus de convergence, la contrainte est automatiquement satisfaite.
Les équations du champ moyen présentées précédemment peuvent aussi s’écrire avec des neurones analo-giques de Potts ([P
ETERSON et al. 1989], [P
ETERSON 1990], [H
ÉRAULT et al. 1989], [H
ÉRAULT et al.
1991]).
Utiliser ce modèle de neurones présente les avantages suivants :• la fonction d’énergie contient moins de termes en compétition les uns avec les autres,• il n’est pas nécessaire de régler un paramètre qui pondère l’énergie de violation de ce type de contrainte,• les résultats sont en général bien meilleurs que ceux fournis avec des neurones scalaires.
Ce type de réseau de neurones a été appliqué à de nombreux problèmes tels que ceux de partitionnementde graphes [H
ÉRAULT
et al.
1989], des problèmes de type
sac à dos
[O
HLSSON
et al.
1993], ou encored’ordonnancement [L
AGERHOLM
et al.
1997].
Réseaux de neurones de Rangarajan
Quand les solutions d’un problème s’expriment sous la forme d’une matrice de permutation, on peututiliser le réseau de neurones proposé par Rangarajan, qui a l’avantage de ne pas nécessiter l’addition determes de pénalisation dans la fonction énergie à minimiser pour coder cette contrainte ([R
ANGARAJAN
etal.
1995], [R
ANGARAJAN
et al.
1999]). Il combine les réseaux de Hopfield avec un algorithme de projec-tion sur l’espace des matrices doublement stochastiques, dérivé des deux théorèmes suivants [S
INKHORN
1964] :
Rappel
Une matrice doublement stochastique est une matrice dont la somme des coefficients de chaque ligne et de chaque colonne est égale à 1.
Théorème 1
: À une matrice
N
x
N
strictement
positive correspond exactement une matrice
T
A
doublementstochastique qui peut être exprimée sous la forme
T
A
=
D
1
AD
2
, où
D
1
et
D
2
sont des matrices diagonalespositives. Les matrices
D
1
et
D
2
sont elles-mêmes uniques, à un facteur scalaire près.
Théorème 2
: La normalisation alternative itérative des lignes et des colonnes d’une matrice
strictement
positive
N
x
N
converge vers une matrice doublement stochastique strictement positive.
Remarque
Cette normalisation consiste, quand on considère un élément de la matrice, à le diviser successivement par la somme des coefficients dela ligne, puis de la colonne, auxquelles il appartient.
Le théorème 2 est donc un algorithme de projection sur l’espace des matrices doublement stochastiques.Combiné avec un réseau bouclé analogique avec recuit, il donne un algorithme particulièrement efficacequi assure la convergence du réseau sur une solution acceptable (codée par une matrice de permutation),de bonne qualité.
■ Exemple du problème du voyageur de commerce
Considérons le problème du voyageur de commerce. On utilise le même codage que pour les réseaux deHopfield : une tournée acceptable est codée par une matrice de permutation.
yia
via( )exp
vib( )expb 1=
K
∑-----------------------------=
yia
a 1=
K
∑ 1=

Réseaux de neurones sans apprentissage pour l’optimisation
CHAPITRE 8367
La fonction énergie à minimiser est définie de la manière suivante :
où γ est un réel strictement positif.
Le deuxième terme de cette équation est appelé terme d’auto-amplification ; il est utile pour éviter deconverger vers une matrice nulle.
L’équation de mouvement d’un neurone analogique (i, j) est définie par :
Pour assurer la stricte positivité des sorties des neurones, les auteurs utilisent une fonction de transfertexponentielle au lieu d’une fonction sigmoïde.
où β est un réel positif.
La dynamique de ce réseau de neurones analogiques peut être soit synchrone, soit asynchrone aléatoire.Après une mise à jour des neurones, les sorties du réseau sont projetées sur une matrice doublementstochastique proche au moyen d’une normalisation alternative itérative des lignes et des colonnes :
• Normalisation de la colonne j :
• Normalisation de la ligne i :
Durant la convergence du réseau, on effectue un recuit pour forcer les sorties des neurones à convergervers des valeurs binaires en augmentant le paramètre β. Ce type d’approche est très efficace quand les sorties des neurones doivent être sous la forme d’unematrice de permutation. D’excellents résultats ont été obtenus sur d’autres problèmes combinatoires[RANGARAJAN et al. 1999].
Réseaux de neurones à pénalités mixtes
Des réseaux de neurones bouclés à pénalités mixtes peuvent être utilisés pour la résolution des problèmesde programmation linéaire en nombres entiers. On peut voir schématiquement ces réseaux comme desréseaux de Hopfield analogiques avec recuit, pour lesquels la fonction d’énergie à minimiser a étécomplétée de termes énergétiques qui aident la convergence. Ces termes sont directement inspirés desfonctions énergies utilisées dans les méthodes de points intérieurs pour résoudre des problèmes deprogrammation linéaire [GONZAGA 1992].
Considérons le problème de satisfaction de contraintes qui consiste à rechercher Q variables binaires quisatisfont simultanément M inégalités linéaires. Ce problème est NP-complet. Il s’exprime de la manièresuivante :
gk(y) ≤ 0 k = 1, ..., M
E di k, yi j, yk j 1⊕,γ2--- yi j,
2
j 1=
N
∑i 1=
N
∑–k 1=
k i≠
N
∑j 1=
N
∑i 1=
N
∑=
dvi j,
dt---------- dE
dyi j,-----------– di k, yk j 1⊕, γyi j,+
k 1=
k i≠
N
∑–= =
yi j, βvi j,( )exp=
yi j,yi j,
yi j,i 1=
N
∑---------------=
yi j,yi j,
yi j,j 1=
N
∑----------------=

Les réseaux de neurones368
y ∈ {0, 1}Q
On associe à ces variables la sortie de neurones analogiques yi.
L’énergie du réseau de neurones est de la forme [PRIVAULT et al. 1998a] :
où γ et α sont des réels positifs, et où δk vaut 1 si la contrainte k est violée, et vaut 0 dans le cas contraire.
Dans cette énergie, le premier terme pénalise le fait que les sorties des neurones ne soient pas des entiers.
Le deuxième terme est associé aux contraintes. Pour le k-ième terme :• la première partie pénalise la violation de la contrainte k : c’est un terme de pénalité extérieure.• la deuxième partie est un terme de pénalité intérieure qui a pour but d’empêcher le réseau de se laisser
attirer dans de mauvais minima locaux. Il n’est pas associé à une violation de contrainte. Au contraire,il n’est appliqué à la contrainte k que lorsque celle-ci est satisfaite ; cependant, il a pour objet de forcerl’état courant du réseau à rester le plus loin possible des frontières de contraintes d’équations gk(y) = 0,et donc à rester proche du centre analytique du problème, défini par :
.
Au cours de la convergence du réseau, un recuit est effectué en augmentant le coefficient α de manière àpouvoir visiter des états proches des frontières de contraintes.
Ce réseau a été évalué sur de nombreuses instances d’un problème industriel contenant jusqu’à 30 000variables binaires et 1500 inégalités. Dans chaque cas, une solution a été trouvée en moins de 500 misesà jour complètes du réseau.
La recherche tabouLes algorithmes de recherche tabou sont des algorithmes itératifs de recherche de solutions, dont la prin-cipale caractéristique est qu’ils mémorisent le passé proche (et éventuellement des bribes du passé loin-tain) de la recherche, afin d’interdire de revenir sur ses pas. Par ailleurs, des mécanismes permettentd’intensifier la recherche dans une zone de l’espace où des solutions semblent intéressantes. A contrario,d’autres mécanismes permettent de diversifier la recherche, autrement dit de partir dans de nouvellesparties de l’espace des solutions quand la zone en cours d’exploration ne semble pas contenir de solutionsintéressantes.
L’initiateur de cette approche a été F. Glover, en 1986, mais des idées similaires ont été proposées à lamême époque par P. Hansen. Aujourd’hui, les publications relatives à la recherche tabou augmentent trèsrapidement. Cette approche a été évaluée sur un très grand nombre d’applications et a fourni, comme lesalgorithmes dérivés de la physique statistique, d’excellents résultats [GLOVER et al. 1997]. Parmi cesapplications, on trouve de nombreux problèmes combinatoires tels que les problèmes d’ordonnancement,de routage de véhicules, d’affectation de ressources, de coloriage de graphes, de partitionnement, etc.
Comme le recuit simulé et ses améliorations, ce type d’algorithme nécessite un temps de calcul parfoisimportant. Une différence notable avec les techniques dérivées de la physique statistique réside cependantdans la pauvreté actuelle des résultats théoriques. Une des conséquences en est que leur mise au point estsouvent plus empirique, donc plus délicate. Néanmoins, d’un point de vue pratique, quand le temps de
E yi 1 yi–( ) γ2---δk gk y( )( )2 1
α--- 1 δk–( )Log gk y( )–
k 1=
Q
∑+i 1=
Q
∑=
arg miny Log gk y( )–k 1=
M
∏–

Réseaux de neurones sans apprentissage pour l’optimisation
CHAPITRE 8369
résolution d’un problème est borné par l’application, il est difficile de prévoir quelle méthode, du recuitsimulé ou de la recherche tabou, fournira les meilleures solutions.
Les algorithmes génétiquesLes algorithmes génétiques sont issus des travaux de Holland, en 1975. Initialement, ils n’étaient pasconçus pour faire de l’optimisation de fonctions, mais pour modéliser des comportements adaptatifs. Eneffet, les algorithmes génétiques modélisent un processus d’évolution des espèces. Ils sont inspirés de lathéorie de l’évolution de Darwin.
Dans un algorithme génétique adapté à l’optimisation, une solution potentielle est considérée comme unindividu dans une population [GOLDBERG 1989]. La valeur de la fonction de coût associée à une solutionmesure « l’adaptation » de l’individu associé à son environnement. Un algorithme génétique simulel’évolution, sur plusieurs générations, d’une population initiale dont les individus sont mal adaptés, aumoyen d’opérateurs génétiques de reproduction et de mutation. Après un certain nombre de générations,la population est constituée d’individus bien adaptés, autrement dit de solutions supposées « bonnes » auproblème d’optimisation. La principale différence avec le recuit simulé ou la recherche tabou est que lesalgorithmes génétiques manipulent des populations de solutions, au lieu de manipuler une seule solutionque l’on améliore statistiquement de manière itérative. Ils peuvent être vus comme des algorithmes derecherche locale généralisés.
Actuellement, les algorithmes génétiques souffrent de limitations majeures, principalement dues à leurmise au point très délicate. Des choix structurels cruciaux doivent être faits pour leur mise au point(codage des solutions, type d’opérateurs de reproduction, taille de la population initiale, nombre de géné-rations nécessaires, pourcentage de mutations, de croisements, etc.). De plus, ces algorithmes sont lentset peuvent nécessiter des capacités de mémoire importantes pour stocker les individus de plusieurs géné-rations. En termes de résultats théoriques, il n’existe pas, à l’heure actuelle, de résultats théoriquessolides, comparables à ceux du recuit simulé.
Vers des approches hybridesDans la recherche des meilleurs algorithmes capables de résoudre une classe donnée de problèmes, unetendance actuelle veut que l’on bâtisse des méthodes complexes incorporant des connaissances et destechniques issues de plusieurs horizons (programmation linéaire, séparation et évaluation, recuit simulé,recherche tabou, etc.).
Par exemple, pour résoudre un problème de programmation linéaire en nombres entiers de plusieursdizaines de milliers de variables et de contraintes, associé à un problème de gestion de stock, une méta-heuristique a été développée autour d’un cœur de recuit simulé, avec les particularités suivantes[PRIVAULT et al. 1998b] :• la solution initiale est issue d’une binarisation d’une solution du problème continu, obtenue par l’algo-
rithme du simplexe ;• au cours de la recherche, on utilise des mécanismes d’intensification et de diversification dérivés de la
recherche Tabou ;• comme il est difficile de trouver des solutions acceptables, dès qu’une nouvelle contrainte linéaire est
satisfaite, cette contrainte n’est plus violée par la suite.
Une autre manière de combiner efficacement différents concepts rencontrés dans les métaheuristiques estprésentée sur le problème du voyageur de commerce, dans [CHARON et al. 1996].

Les réseaux de neurones370
Conclusion
Le choix d’une techniqueLes considérations développées dans les sections précédentes permettent d’effectuer des choix en fonc-tion du problème posé :• analyser la complexité du problème :
– complexité théorique, afin de voir si une approche classique peut suffire : complexité intrinsèque,nombre de variables, nombre de contraintes, type de coûts à minimiser ;
– complexité pratique : temps de calcul pour évaluer une solution potentielle, contraintes sur lestemps de résolution globale, exigences sur la qualité de la solution ;
• préciser le type d’utilisation de la méthode (automatique, semi-automatique avec des paramètres ajusta-bles par l’opérateur, etc.) et le degré de compétence des utilisateurs ;
• préciser les exigences sur la qualité de la solution ; si, par exemple, les données du problème à résoudresont entachées de bruit, il n’est pas nécessaire de chercher à s’approcher d’aussi près que possible del’optimum ;
• préciser le temps de développement disponible.
Si l’on est exigeant sur la qualité de la solution, et que l’on souhaite un fonctionnement « automatique »,les algorithmes de recuit sont très performants. La recherche tabou demande un temps de développementgénéralement plus long, mais peut donner, au cas par cas, de meilleurs résultats que le recuit simulé. Lesalgorithmes génétiques demandent un temps de développement très long et des réajustements des para-mètres internes en fonction des données du problème. Les réseaux de neurones récurrents sont davantageadaptés aux problèmes de taille moyenne, où le temps de résolution l’emporte sur les exigences en termesde qualité de solution.
Pour réduire les temps de résolution tout en produisant d’excellentes solutions, une approche hybride estsouvent le meilleur choix, mais au prix d’un temps de développement qui peut être important.
Pour conclure, face à un problème d’optimisation, la comparaison des performances des différentes méta-heuristiques entre elles est délicate et doit être conduite avec beaucoup de soin. Une présentation desécueils fréquemment rencontrés et une bonne méthodologie d’évaluation est donnée dans [BARR et al.1995], [HOOKER 1995], [RARDIN et al. 2001].
BibliographieAARTS E., KORST J. [1989], Simulated Annealing and Boltzmann Machines – a Stochastic Approach toCombinatorial Optimization and Neural Computing, John Wiley & Sons Ed., 1989.
AARTS E., LENSTRA J. K. [1997], Local Search in Combinatorial Optimization, John Wiley & Sons Ed.,1997.
ACKLEY D. H., HINTON G. E., SEJNOWSKI T. J. [1985], A learning algorithm for Boltzmann machines,Cognitive Science, 9, p. 147-169, 1985.
ASAI H., ONODERA K., KAMIO T., NINOMIYA H. [1995], A study of Hopfield neural networks with externalnoise, 1995 IEEE International Conference on Neural Networks Proceedings, New York, États-Unis, vol.4, p. 1584-1589.
AYER S. V. B. et al. [1990], A theoretical investigation into the performance of the Hopfield model, IEEETransactions on Neural Networks, vol.1, p. 204-215, juin 1990.

Réseaux de neurones sans apprentissage pour l’optimisation
CHAPITRE 8371
BARR R. S., GOLDEN B. L., KELLY J. P., RESENDE M. G. C., STEWART W. R. [1995], Designing and repor-ting on computational experiments with heuristic methods, Journal of Heuristics, vol. 1, no 1, p. 9-32,1995.
BOUDET T., CHATON P., HÉRAULT L., GONON G., JOUANET L., KELLER P. [1996], Thin film designs bysimulated annealing, Applied Optics, vol. 35, no 31, p. 6219-6226, nov. 1996.
BRANDT R. D., WANG Y., LAUB A. J., MITRA S. K. [1988], Alternative networks for solving the TSP andthe list-matching problem, Proceedings of the International Joint Conference on Neural Networks, SanDiego, II, p. 333-340, 1988.
CERNY V. [1985], A thermodynamical approach to the travelling salesman problem: an efficient simulatedalgorithm, Journal of Optimization Theory and Applications, no 45, p. 41-51, 1985.
CHARON I., HUDRY O. [1996], Mixing different components of metaheuristics, chapitre 35 de [OSMAN
1996].
CICHOCKI A., UNBEHAUEN R. [1993], Neural Networks for Optimization and Signal Processing, JohnWiley & Sons Ed., 1993.
CREUTZ M. [1983], Microcanonical Monte Carlo simulations, Physic Review Letters, vol. 50, no 19,p. 411-1414, 1983.
DAGLI C. [1994], Artificial Neural Networks for Intelligent Manufacturing, Chapman & Hall, 1994.
DÉROU D., HÉRAULT L. [1996], A new paradigm for particle tracking velocimetry, based on graph-theoryand pulsed neural networks, Developments in Laser Techniques and Applications to Fluid Mechanics,p. 438-462, Springer-Verlag Ed., 1996.
DOWSLAND K. A. [1995], Simulated annealing, chapitre 2 de [REEVES 1995].
GAREY M. R., JOHNSON D. S. [1979], Computers and intractability. A guide to the theory of NP-comple-teness, W. H. Freeman and company Ed., 1979.
GLOVER F., LAGUNA M. [1997], Tabu search, Kluwer Academic Publishers, 1997.
GOLDBERG D. E. [1989], Genetic Algorithms in Search, Optimization and Machine Learning, AddisonWesley, 1989.
GOLES E. [1995], Energy functions for neural networks, The Handbook of Brain Theory and NeuralNetworks, The MIT Press, p. 363-367, 1995.
GONDRAN M., MINOUX M. [1995], Graphes et al.gorithmes, Éditions Eyrolles, 1995.
GONZAGA C. C. [1992], Path-following methods for linear programming, SIAM Review 34(2), p. 167-224,1992.
HAJEK B. [1988], Cooling schedules for optimal annealing, Mathematics of operations research, vol. 13,no 2, p. 311-329, 1988.
HÉRAULT L., NIEZ J. J. [1989], Neural networks & graph K-partitioning, Complex Systems, vol. 3, no 6,p. 531-576, 1989.
HÉRAULT L., NIEZ J. J. [1991], Neural networks & combinatorial optimization: a study of NP-completegraph problems, Neural Networks: Advances and Applications, p. 165-213, Elsevier Science PublishersB.V. (North-Holland), 1991.
HÉRAULT L., HORAUD R. [1993], Figure-ground discrimination: a combinatorial optimization approach,I.E.E.E. Transactions on Pattern Analysis and Machine Intelligence, vol. 15, no 9, p. 899-914, 1993.

Les réseaux de neurones372
HÉRAULT L. [1995a], Pulsed recursive neural networks & resource allocation – Part 1: static allocation,Proceedings of the 1995 SPIE's International Symposium on Aerospace/Defense Sensing and Dual-UsePhotonics, Orlando, Florida, États-Unis, p. 229-240, avril 1995.
HÉRAULT L. [1995b], Pulsed recursive neural networks & resource allocation – Part 2: static allocation,Proceedings of the 1995 SPIE's International Symposium on Aerospace/Defense Sensing and Dual-UsePhotonics, Orlando, Florida, États-Unis, p. 241-252, avril 1995.
HÉRAULT L. [1995c], Réseaux de neurones récursifs pulsés pour l’allocation de ressources, Revue Auto-matique – Productique – Informatique industrielle (APII), vol. 29, nos 4-5, p. 471-506, 1995.
HÉRAULT L. [1997a], A new multitarget tracking algorithm based on cinematic grouping, Proceedings ofthe 11th SPIE's International Symposium on Aerospace/Defense Sensing, Simulation and Controls, vol.3086, p. 296-307, Orlando, Florida, États-Unis, avril 1997.
HÉRAULT L., DÉROU D., GORDON M. [1997b], New Q-routing approaches to adaptive traffic control,Proceedings of the International Workshop on Applications of Neural Networks to Telecommunications 3,p. 274-281, Lawrence Erlbaum Associates Ed., 1997.
HÉRAULT L. [2000], Rescaled Simulated Annealing – Accelerating convergence of Simulated Annealingby rescaling the states energies, Journal of Heuristics, p. 215-252, vol. 6, Kluwer Academic Publishers,2000.
HINTON G. E., SEJNOWSKI T. J., ACKLEY D. H. [1984], Boltzmann machines: constraint satisfactionnetwork that learn, Carnegie Mellon Uuniversity technical report, CMU-CS-84-119, États-Unis, 1984.
HOOKER J. N. [1995], Testing heuristics: we have it all wrong, Journal of Heuristics, vol. 1, no 1, p. 33-42,1995.
HOPFIELD J. [1982], Neural Networks and Physical Systems with emergent collective computational abili-ties, Proceedings of National Academy of Sciences of USA, vol. 79, p. 2554-2558, 1982.
HOPFIELD J. [1984], Neurons with graded response have collective computational properties like those oftwo-state neurons, Proceedings of National Academy of Sciences of USA, vol. 81, p. 3088-3092, 1984.
HOPFIELD J., TANK D. [1985], Neural computation of decisions in optimization problems, BiologicalCybernetics, vol. 52, p. 141-152, 1985.
KIRKPATRICK S., GELATT C. D., VECCHI M. P.[1983], Optimization by simulated annealing, Science, vol.220, p. 671-680, 1983.
KUHN H. W., TUCKER A. W. [1951], Nonlinear programming, Proceedings of the Second Berkeley Sympo-sium on Mathematical Statistics and Probability, p. 481-492, University of California Press, 1951.
LAGERHOLM M., PETERSON C., SÖDERBERG B. [1997], Airline crew scheduling with Potts neurons, NeuralComputation, vol. 9, no 7, p. 1589-1599, 1997.
LEE B. W., SHEN B. J. [1991a], Hardware annealing in electronic neural networks, IEEE Transactions onCircuits and Systems, vol. 38, p. 134-137, 1991.
LEE H. J., LOURI A. [1991b], Microcanonical mean field annealing: a new algorithm for increasing theconvergence speed of mean field annealing, Proceedings of the International Joint Conference on NeuralNetworks, Singapour, p. 943-946, 1991.
MAA C. Y., SHANBLATT M. A. [1992], A two-phase optimization neural netwok, IEEE Transactions onNeural Networks, vol. 3, no 6, p. 1003-1009, 1992.
METROPOLIS N., ROSENBLUTH A., ROSENBLUTH M., TELLER A., TELLER E. [1953], Equation of statecalculations by fast computing machines, Journal of Chemical Physics, vol. 21, p. 1087-1092, 1953.

Réseaux de neurones sans apprentissage pour l’optimisation
CHAPITRE 8373
MITRA D., ROMEO F., SANGIOVANNI-VINCENTELLI A. [1986], Convergence and finite-time behavior ofsimulated annealing, Adv. Appl. Prob., vol. 18, p. 747-771, 1986.
MJOLSNESS E., GARRETT C. [1990], Algebraic transformations of objective functions, Neural Networks,no 3, p. 651-669, 1990.
MJOLSNESS E., MIRANKER W. L. [1991], A lagrangian approach to fixed points, Advances in Neural Infor-mation Processing Systems 3, p. 77-83, Morgan Kaufman Pub., 1991.
NEWCOMB R. W., LOHN J. D. [1995], Analog VLSI for neural networks, The Handbook of Brain Theoryand Neural Networks, The MIT Press, p. 86-90, 1995.
OHLSSON M., PETERSON C., SÖDERBERG B. [1993], Neural networks for optimization problems withinequality constraints – the knapsack problem, Neural Computation, vol. 5, no 2, p. 331-339, 1993.
OSMAN I, KELLY J. P.[1996], Meta-heuristics: theory and applications, Kluwer Academic Publishers,1996.
PETERSON C., ANDERSON J. R. [1988], Neural networks and NP-complete optimization problems: aperformance study on the graph bisection problem, Complex Systems, vol. 2, p. 59-89, 1988.
PETERSON C., SÖDERBERG B. [1989], A new method for mapping optimization problems onto neuralnetworks, International Journal on Neural Systems, vol. 1, p. 3-22, 1989.
PETERSON C. [1990], Parallel distributed approaches to combinatorial optimization: benchmark studies ontravelling salesman problem, Neural Computation, vol. 2, p. 261-269, 1990.
PRINS C. [1994], Algorithmes de graphes, Éditions Eyrolles, 1994.
PRIVAULT C., HÉRAULT L. [1998a], Constraints satisfaction through recursive neural networks with mixedpenalties: a case study, Neural Processing Letters, Kluwer Academic Publishers, vol. 8, no 1, p. 15-26,1998.
PRIVAULT C., HÉRAULT L. [1998b], Solving a real world assignment problem with a metaheuristic,Journal of Heuristics, vol. 4, p. 383-398, Kluwer Academic Publishers, 1998.
RANGARAJAN A., GOLD S. [1995], Softmax to softassign: neural network algorithms for combinatorialoptimization, Journal of Artificial Neural Networks, vol. 2, no 4, p. 381-399, 1995.
RANGARAJAN A., MJOLSNESS E. D. [1996], A Lagrangian relaxation network for graph matching, IEEETransactions on Neural Networks, vol. 7, no 6, p. 1365-81, 1996.
RANGARAJAN A., YUILLE A., MJOLSNESS E. D. [1999], Convergence properties of the softassign quadraticassignment algorithm, Neural Computation, vol. 11, no 6, p. 1455-1474, 1999.
RARDIN R. L., UZSOY R. [2001], Experimental evaluation of heuristic optimisation algorithms: a tutorial,Journal of Heuristics, vol. 7, no 3, p. 261-304, 2001.
REEVES C. R. [1995], Modern Heuristic Techniques for Combinatorial Problems, McGraw-Hill, 1995.
REINELT G. [1994], The travelling salesman. Computational solutions for TSP applications, note delecture in Computer Science 840, Springer Verlag, 1994.
ROUSSEL-RAGOT P., DREYFUS G. [1990], A Problem-Independent Parallel Implementation of SimulatedAnnealing: Models and Experiments, IEEE Transactions on Computer-Aided Design, vol. 9, p. 827,1990.
SCHRIJVER A. [1986], Theory of Linear and Integer Programming, John Wiley & Sons, 1986.
SIARRY P., DREYFUS G. [1984], Application of Physical Methods to the Computer-Aided Design of Elec-tronic Circuits, J. Phys. Lett. 45, L 39, 1984.

Les réseaux de neurones374
SINKHORN R. [1964], A relationship between arbitrary positive matrices and doubly stochastic matrices,The annals of mathematical statistics, vol. 35, no 1, p. 141-152, 1964.
SZU H. [1988], Fast TSP algorithm based on binary neuron output and analog neuron input using the zero-diagonal interconnect matrix and necessary and sufficient constraints on the permutation matrix, Procee-dings of the International Joint Conference on Neural Networks, San Diego, II, p. 259-266, 1988.
SUN K. T., FU H. C. [1993], A hybrid neural network model for solving optimisation problems, IEEETransactions on Computers, vol. 42, no 2, 1993.
TAKEFUJI Y. [1992], Neural Network Parallel Computing, Kluwer Academic Publishers, 1992.
TAKEFUJI Y., WANG J. [1996], Neural Computing for Optimization and Combinatorics, World Scientific,1996.
TEGHEM J., PIRLOT M. [2001], Métaheuristiques et outils nouveaux en recherche opérationnelle. Tome I :Méthodes. Tome II : Implémentations et Applications, Éditions Hermès, 2001, à paraître.
VAN DEN BOUT D. E., MILLER T. K. [1989], Improving the performance of the Hopfield-Tank neuralnetwork through normalization and annealing, Biological Cybernetics, vol. 62, p. 129-139, 1989.
VAN DEN BOUT D. E., MILLER T. K. [1990], Graph partitioning using annealing neural networks, IEEETransactions on Neural Networks, vol. 1, p. 192-203, 1990.
ZHANG S., CONSTANTINIDES A. G. [1992], Lagrange programming neural networks, IEEE Transactionson Circuits and Systems II: Analog and Digital Processing, vol. 39, no 7, p. 441-452, 1992.





























