Embed Size (px)
Citation preview

Simulation Aléatoire et Méthode de
Monte Carlo
Charles-Abner DADI
31 décembre 2012

SOMMAIRE
I Générer de l'aléatoire 3
1 Générer de l'aléatoire : une nécessité en simulation 4
1.1 Générateurs à Congruence Linéaire GCL . . . . . . . . . . . . . . . . . . . . . . . . . . 4
1.1.1 Du bon choix des paramètres . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
1.1.2 Détermination de la période optimale . . . . . . . . . . . . . . . . . . . . . . . 5
1.1.3 Généralisation des générateurs congruents : Générateurs récursifs multiples . . 7
1.1.4 Utilisation d'un générateur pseudo aléatoire . . . . . . . . . . . . . . . . . . . . 7
1.2 Test sur l'ecacité des générateurs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
1.2.1 Test d'uniformité . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
1.2.2 Test d'indépendance . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
1.3 Le générateur de Mersenne Twister . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
2 Générer des variables aléatoires 14
2.1 Méthode de la transformation inverse . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.1.1 Cas de variables continues . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.1.2 Cas des variables Gaussiennes . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.2 Méthode du rejet . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
2.3 Loi conditionnelle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
2.3.1 Couple de variables corrélées . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
II Méthodes de Monte Carlo et réduction de la variance 28
3 Calcul d'intégrale 29
3.1 Premiers exemples . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
4 Vitesse de convergence et temps de calcul 32
4.1 Evaluation de la vitesse de convergence . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
4.2 Evaluation de la variation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
4.2.1 Construction d'un intervalle de conance . . . . . . . . . . . . . . . . . . . . . 32
5 Méthodes de Réduction de la variance 35
5.1 Échantillonnage préférentiel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
5.2 Méthode de variables de contrôle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
5.3 Méthode des variables antithétiques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
5.4 Technique de conditionnement . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
1

III Simulation de Chaînes de Markov et algorithme de Metropolis Hastings 42
6 Rappels sur les chaines de Markov 43
6.1 Théorème ergodique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
7 Algorithme de Metropolis Hasting 45
7.0.1 Simulation d'une loi Bêta via Metropolis Hasting . . . . . . . . . . . . . . . . . 46
8 Contrôle de convergence des algorithmes MCMC 48
8.1 Convergence vers la loi stationnaire. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48
8.1.1 Approche par les séries temporelles . . . . . . . . . . . . . . . . . . . . . . . . . 49
8.1.2 Test de Gelman Rubin . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
8.2 Autres types de convergence . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
IV Exercices 52
8.3 Exercice 2.10 : Algorithme de Jönk . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
8.4 exercices 2.07 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
8.5 Exercice 2.10 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
8.6 Exercice 3.7 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
8.7 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
Introduction
La modélisation mathématique est bien à des égards essentielle. Une analyse et une anticipation
aussi ne que possible permettent de comprendre, et par conséquent d'agir, pour améliorer le fonction-
nement des systèmes et ainsi mieux les contrôler. Ce type de démarche qui reposent sur des techniques
de modélisation et de simulation se retrouvent dans tous les domaines scientiques. En nance par
exemple, il est important de déterminer quand lever une option sur un actif ; en assurance il faut
déterminer les risques pour évaluer le montant optimal de la prime de risque. Le niveau de détail du
modèle est donc essentiel pour rendre compte au mieux du niveau de complexité d'un système, tout
en maintenant des coûts de calcul raisonnable.
Les méthode de Monte Carlo contrairement aux autres méthodes numériques reposent sur l'utilisa-
tion des nombres aléatoires. Cette méthode est intéressante puisqu'elle peut s'appliquer à des problèmes
de grande dimension, comme par exemple pour calculer l'espérance de rendement sur l'ensemble d'un
marché boursier.
Toutefois, il est à noter que le champs théorique autour des méthodes de Monte Carlo est étendu.
Nous nous concentrerons uniquement sur certains points selon l'enchainement suivant :
Générer des nombres aléatoires qui seront à la base de nos simulations
Réduire la variance empirique an de pouvoir réduire la taille de nos échantillons sans perdre
en ecacité.
Simuler des chaines de Markov, et utiliser les propriétés de stationnarité
Soulignons enn que nous nous eorcerons de rendre ce mémoire aussi concret que possible, en orant
un exemple traité de façon informatique après chaque point de théorie.
2

Première partie
Générer de l'aléatoire
3

CHAPITRE 1
GÉNÉRER DE L'ALÉATOIRE : UNE NÉCESSITÉ EN SIMULATION
Pour réaliser des simulations probabilistes, c'est-à-dire mettre en ÷uvre un modèle contenant une
part d'aléatoire, on souhaite pouvoir générer des suites (xn)n, de nombres dans [0,1] qui représentent
une suite (Un)n de variables aléatoires (Ω, A, P)→ [0,1] ∀n ≥ 0 où Un sont indépendantes et uniformé-
ment distribuées sur [0,1]. Bien que nous ne pouvons pas atteindre informatiquement toutes les valeurs
réelles sur [0,1], au moins peut-on considérer un grand nombre de valeurs espacées de façon régulière
en considérant l'ensemble : 0, 1k ,
2k ,
3k ...
k−1k où k est un entier assez grand. Ainsi on ne s'intéresse plus
aux suites dans [0,1] mais dans 0, 1...m− 1.De plus pour rendre compte de l'indépendance, nous avons besoin d'une certaine "`imprédictibilité"'
lors du passage d'un terme à l'autre, ce qui en théorie demeure relatif puisque la suite choisie est bien
une suite déterministe.
Ainsi nous pouvons parler d'ecacité pour un générateur qui répond avec succès à ces diérents cri-
tères d'uniformité, d'indépendance. Le coût de l'incrémentation informatique sera également un critère
à retenir.
Nous étudierons dans une section de ce chapitre, diérents tests qui nous permettent de juger de l'ef-
cacité d'un générateur .
1.1 Générateurs à Congruence Linéaire GCL
Un générateur congruent est une des méthodes les plus usitées et les plus utile pour générer des
nombres pseudo-aléatoires. Son fonctionnement repose sur la programmation d'une suite récurrente qui
prend la forme d'une fonction linéaire. La particularité de cette fonction linéaire est qu'elle est basée
sur des congruences .
On dénit la suite récurrente suivante : ∀n ∈ N∗, xn+1 = axn + c modm , où a est appelé le
multiplicateur, c l'incrément et m est le module. De plus, comme toute suite dénie par récurrence il
est nécessaire de dénir le premier terme x0 qu'on appelle : la graine. C'est en eet à partir de cette
graine que la suite de nombres aléatoires sera générée. Toute modication de cette graine modiera
la suite de nombres générés. C'est pour cette raison que nous disons que la suite est déterministe.
Nous devrons s'intéresser aux méthodes qui permettent de modier la graine à chaque simulation, an
d'augmenter le caractère aléatoires des séries produites.
Notons que du fait de la présence du modulo (qui est le reste de la division euclidienne axn + c
par m), xn+1 est compris entre 0 et m− 1. Il en ressort que puisque la suite prend ses valeurs dans un
4

ensemble de card <∞, elle est amenée à se répéter au bout d'un certain temps.
1.1.1 Du bon choix des paramètres
La qualité du générateur semble totalement dépendre du choix de a, c et m. En eet, on cherche à
obtenir un générateur qui produise le plus "aléatoirement" possible une suite de nombres . De ce fait,
nous cherchons donc à maximiser la période - qui se déni comme la plus petite valeur l tel qu'il existe
n avec xn+l = xn, an que l'utilisateur ne s'aperçoive pas, ou très peu de l'existence de cette période .
1.1.2 Détermination de la période optimale
Un générateur aléatoire est souvent répéter plusieurs fois au cours d'un programme ; ainsi la présence
d'une division euclidienne risque d'entrainer des coûts de calcul assez importants. Or, les ordinateurs
calculent naturellement en base binaire, ainsi en choisissant une période de la forme : 2e, le processeur
eectuera donc ce calcul de façon transparente. C'est pourquoi pour un processeur de 32-bits (ie. un
processeur dont la largeur des registres est de 32-bits) la période maximale est pour e = 31 soit 231 .
Toutefois, nous devons souligner que dans la représentation binaire, un mot de k bits avec k < e on
aura alors les k bits faibles ( ie. ceux qui sont le plus vers la droite) qui sont beaucoup moins aléatoires
( période 2k) que les bits dits forts, les plus à gauche.
Considérons deux générateurs : G1 et G2 tels que :
G1 dénit par a = 25, c = 16, et m = 256 avec X0 = 12 : xn+1 := 25xn + 16[256]
G2 dénit par a = 65539, c = 0, et m = 231 avec X0 = 7 : xn+1 := 65539xn + 0[231]
On programme sur R ces deux suites de la façon suivante :
1 #Nombre d ' obse rvat i on N
2 N=500
3 par (mfrow=c ( 3 , 1 ) )
4 h=runif (N)
5 plot (h)
6 u=rep (0 ,N)
7 u [1]=12
8 # fonc t i on modulo %%
9 for ( i in 1 :N) u [ i +1]=(25∗u [ i ]+16)%%256
10 plot (u , main = "a=25 c=16 m=256" , col . main= "blue " )
11 v=rep (0 ,N)
12 #I n i t i a l i s a t i o n par un nombre impaire
13 v [1 ]=7
14 # fonc t i on modulo %%
15 for ( i in 1 :N) v [ i +1]=(65539∗v [ i ] )%%2^3116 v2=v/2^31
17 v2
18 plot (v , main="RANDU a=65539 c=0 m=2^31" , col . main= "blue " )
On obtient les graphiques suivants :
5
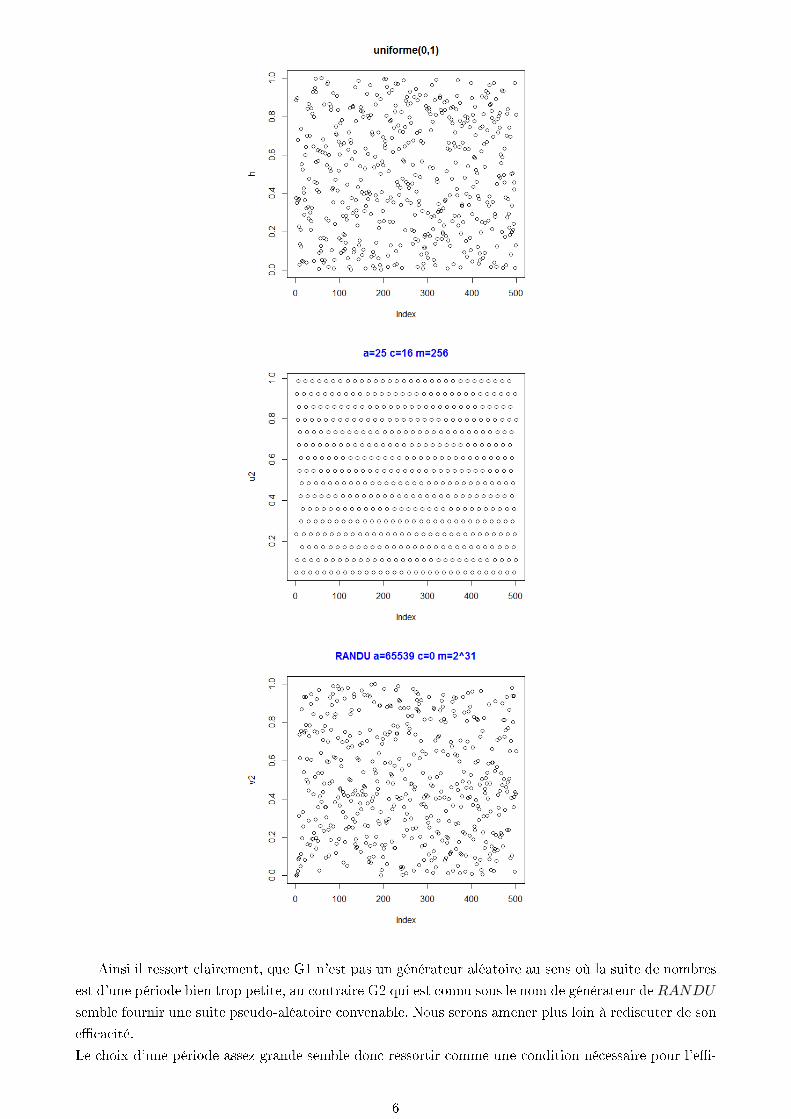
Ainsi il ressort clairement, que G1 n'est pas un générateur aléatoire au sens où la suite de nombres
est d'une période bien trop petite, au contraire G2 qui est connu sous le nom de générateur de RANDU
semble fournir une suite pseudo-aléatoire convenable. Nous serons amener plus loin à rediscuter de son
ecacité.
Le choix d'une période assez grande semble donc ressortir comme une condition nécessaire pour l'e-
6

cacité d'un générateur .
1.1.3 Généralisation des générateurs congruents : Générateurs récursifs multiples
Il existe une généralisation des générateurs congruents qui permet de donner une apparence encore
plus chaotique au comportement des éléments successifs de la suite. Cette généralisation consiste à
générer une suite récurrente d'ordre k. Cette suite prend donc la forme suivante :
xn = (a1xn−1 + a2xn−2 + ...+ akxn−k) mod m,
Il faut alors fournir non plus une graine mais k graines x0....xk−1. Grâce à cette méthode la période
est de l'ordre de mk. Car la suite utiliser k nombres précédents au lieu d'un seul.
1.1.4 Utilisation d'un générateur pseudo aléatoire
Nous pouvons nous interroger comment utiliser un générateur sur un logiciel tel que R, C++ ou
autre . En eet, après avoir écrit notre suite récurrente congruente, nous souhaitons pouvoir utiliser
cette fonction an de tirer un seul nombre aléatoire dans [0, 1]. Pour cela il sut de créer une fonction
qui utilise la suite récurrente congruente avec la graine qui vaut "time(0)". On obtient donc une
réalisation de dimension souhaitée, et nous divisons chaque terme par la période m , selon le modèle
rédiger en C++ suivant :
1
2
3 #inc lude <iostream> // i o s t ream l i b r a r y f i l e needed f o r input/output
4 #inc lude <c s td l i b > // c s t d l i b ( standard l i b r a r y ) needed f o r rand ( )
5 #inc lude <ctime>
6
7 us ing namespace std ;
8
9
10 double getRand ( )
11 long x [ 1 0 0 ] ;
12 x [0 ]= time (0 ) ;
13
14 for ( i n t i =1; i <100; i++)
15 x [ i ]=(66539∗x [ i −1])%(2^31);
16 return x [ i ] /2^31;
17
18
19 i n t main ( )
20 cout << time (0 ) << endl ;
21 cout << getRand ( ) <<endl ;
22 return 0 ;
Notons que sur R, la fonction est system.time(0) qui fonctionne de la même manière. En outre il est
nécessaire de s'interroger sur la graine ("seed") qui est appelée à chaque fois que faisons appel au
générateur aléatoire. En eet, tout générateur congruent est sous forme de suite déterministe ; ainsi si
nous modions pas la graine à chaque implémentation les séries de nombres simulées seront identiques.
Il existe deux techniques classiques qui permettent d'éviter ce problème :
1/ Implémenter la graine avec l'horloge interne du processeur . Ainsi par exemple, en C++, il s'agit
de la fonction time(0) qui permet de poser la graine égale au temps de l'horloge interne, à chaque im-
7

plémentation .
2/ La seconde solution est d'incrémenter la graine avec la dernière valeur calculer. Concrètement, il
s'agit de générer une suite x0...xn à partir de la suite congruente puis de stocker la valeur de xn. Ensuite
lors de la simulation d'une seconde suite on pose x′0 := xn. Ceci nous permet d'être sûr d'obtenir deux
suites de n nombres diérents.
1.2 Test sur l'ecacité des générateurs
1.2.1 Test d'uniformité
Le test nous permet de rejeter l'hypothèse d'uniformité de la suite de nombres pseudo-aléatoire
obtenue. Le principe est le suivant : On Subdivise l'intervalle [0, 1] en un nombre k d'intervalles de
longueur égales. On compte ensuite le nombre de points dans chacun des intervalles.
Si le résultat est trop régulier alors on conclut que la suite de nombres est ordonnée, on rejette alors
l'uniformité. Si à l'opposé,on obtient une concentration des points dans un nombre restreint d'inter-
valles alors on peut conclure à une absence d'uniformité.
A partir des résultats obtenus on peut construire la statistique du test de χ2, qui permet de tester
l'adéquation entre une loi empirique et une loi discrète donnée. Dans notre cas nous testerons que la
loi empirique correspond à une loi uniforme discrète sur le nombre de subdivision de l'intervalle [0,1],
an de tester l'uniformité de notre générateur :
ZN=k∑i=1
(ni −Npi)2
Npi, où pi= 1
30 qui est la probabilité d'une loi uniforme sur l'intervalle 0, .., k, sous
l'hypothèse H0. Si l'hypothèse de distribution est vériée, la statistique suit pour N assez grand
(env. N > 50)- une loi χ2(k-1) sinon, si sur au moins une subdivision de [0, 1] la distribution n'est pas
uniforme alors ZN tend vers +∞ presque sûrement. Ainsi on calcule ZN et si ZN > χ95%2 (k − 1) on
rejette l'hypothèse nulle (uniformité).
Pour un test sur une loi uniforme il nous faut séparer l'intervalle [0, 1] en 30 subdivisions et
considérer un échantillon d'au moins 105 points.
Dans R, nous avons testé G1 et G2 (cf Supra), de la façon suivante :
1
2 #Nombre d ' obse rvat i on N
3 N=10^5
4 par (mfrow=c ( 3 , 1 ) )
5 h=runif (N)
6 plot (h , main = "uniforme (0 , 1 ) " )
7
8 # generateur congruent l i n e a i r e a=25 c=16 m=256
9
10 u=rep (0 ,N)
11 u [1]=12
12 # fonc t i on modulo %%
13 for ( i in 1 :N) u [ i +1]=(25∗u [ i ]+16)%%256
14 y=c ( 1 : 3 00 )
15
16
17
18 u2=u/256
8

19 u2
20 plot ( u2 , main ="a=25 c=16 m=256" , col . main= "blue " , )
21
22
23
24 # generateur RANDU a=65539 c= 0 m=2^31,
25
26 v=rep (0 ,N)
27 #I n i t i a l i s a t i o n par un nombre impaire
28 v [1 ]=7
29 # fonc t i on modulo %%
30 for ( i in 1 :N) v [ i +1]=(65539∗v [ i ] )%%2^3131
32 v2=v/2^31
33 v2
34
35 plot ( v2 , main = "RANDU a=65539 c=0 m=2^31" , col . main= "blue " )
36
37 # Test un i f o rmi t e
38
39 #on sub i d i v i s e l ' i n t e r v a l l e en 30 pa r t i e de meme longueur
40
41
42 #Test sur u2 ( per i ode 256)
43
44 w=rep (0 , 31 ) #on subd i v i s e en 30 sous i n t e r v a l l e s [ i−1/30 , i \30 ]
45 n=rep (0 , 30 ) # vecteur qui cont i endra l e nombre de po in t s dans chaque sous i n t e r v a l l e
46
47 for ( i in 1 : 29 )
48 w[ i+1]= i /30
49 w[31]=1
50 n [ i ]=0
51
52 # pour chaque po int on cherche dans que l i n t e r v a l l e i l s e s i t u e
53 for ( i in 1 :N)
54
55 for ( j in 1 : 30 )
56
57 i f ( ( u2 [ i ]>w[ j ] ) & ( u2 [ i ]<w[ j +1])) n [ j ]=n [ j ]+1
58
59
60
61 Z_n=0
62 for ( i in 1 : 30 )Z_n=Z_n+(n [ i ]−N∗1/30)^2/ (N∗1/30)63
64 Z_n
65 q=qchisq ( 0 . 9 5 , df=29)
66 q
67 i f (Z_n>q)FALSE else TRUE
68
69 #te s t sur v2 (RANDU)
70
71 w=rep (0 , 31 ) #on subd i v i s e [ 0 , 1 ] en 30 sous i n t e r v a l l e s [ i−1/30 , i \30 ]
72 n=rep (0 , 30 ) # vecteur qui cont i endra l e nombre de po in t s dans chaque sous i n t e r v a l l e
73
74 for ( i in 1 : 29 )
75 w[ i+1]= i /30
76 w[31]=1
77 n [ i ]=0
9

78
79 # pour chaque po int on cherche dans que l i n t e r v a l l e i l s e s i t u e
80 for ( i in 1 :N)
81
82 for ( j in 1 : 30 )
83
84 i f ( ( v2 [ i ]>w[ j ] ) & ( v2 [ i ]<w[ j +1])) n [ j ]=n [ j ]+1
85
86
87
88 Z_n=0
89 for ( i in 1 : 30 )Z_n=Z_n+(n [ i ]−N∗1/30)^2/ (N∗1/30)90
91 Z_n
92 q=qchisq ( 0 . 9 5 , df=29)
93 q
94 i f (Z_n>q)FALSE else TRUE
Les résultats pour le test du χ2 sont clairs : On obtient pour le générateur G1 (période 256) :
- le vecteur n=3357 9664 3360 9615 3341 9629 3357 9633 9642 3298 9592 3343 9480 3347 9614 3196
9540 3253 9509 3296 9674 3349 9657 9590 3307 9588 3370 9511 3354 9534
-ZN = 188046.6
Alors que pour G2 (RANDU) :
- le vecteur n=3357 3414 3360 3365 3341 3379 3357 3383 3392 3298 3342 3343 3230 3347 3364 3196
3290 3253 3259 3296 3424 3349 3407 3340 3307 3338 3370 3261 3354 3284
-ZN = 26.645
Or, χ229 = 42.55697, on est donc amener à rejeter l'hypothèse d'uniformité pour G1 et à l'accepter
pour G2 pour un seuil de conance de 95%.
1.2.2 Test d'indépendance
L'indépendance des variables est également un critère qui permet de dénir l'aléatoire. En eet,
il est évident par exemple que pour un système de cryptologie qui utiliserait un générateur pseudo-
aléatoire, l'absence d'indépendance permettrait de deviner un terme en étudiant les termes précédents.
A l'inverse une suite de valeur croissante , ie 1 seul run) serait tout aussi suspecte .
De nombreux tests existent pour tester l'indépendance. Nous retenons ici, le test ACF( auto corrélation
function) ainsi que le test du signe de la diérence.
Test ACF
On dénit la fonction :
ρ 1...n → [-1,1] telle que ∀ i ∈ 1...n, ρ(i)=cov(xt,xt+i).
On pose :
H0 : ρ(i)=0 ∀ i ∈ 1...n
H1 : ∃ i ∈ 1...n tel que ρ(i) 6=0
Sous R, la fonction ACF calcule et représente les auto covariances.
10
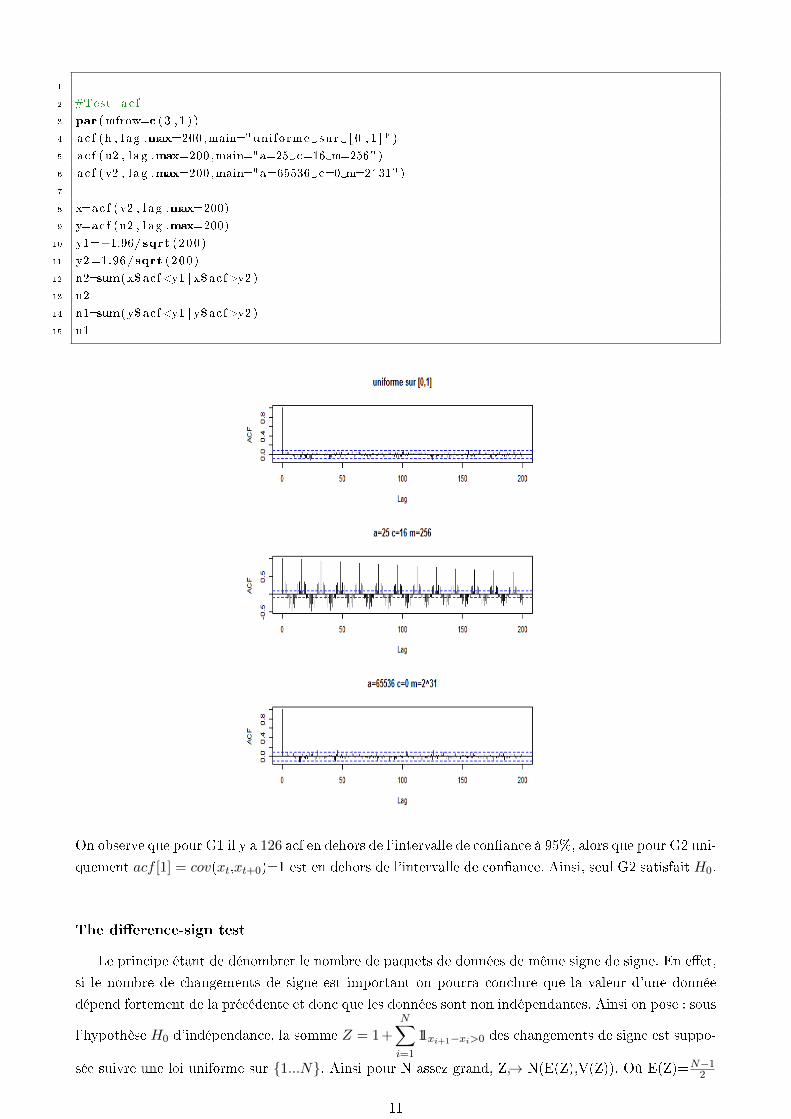
1
2 #Test ac f
3 par (mfrow=c ( 3 , 1 ) )
4 ac f (h , l ag .max=200 ,main="uniforme sur [ 0 , 1 ] " )
5 ac f ( u2 , l ag .max=200 ,main="a=25 c=16 m=256" )
6 ac f ( v2 , l ag .max=200 ,main="a=65536 c=0 m=2^31" )
7
8 x=ac f ( v2 , l ag .max=200)
9 y=ac f (u2 , l ag .max=200)
10 y1=−1.96/sqrt (200)
11 y2=1.96/sqrt (200)
12 n2=sum( x$acf<y1 | x$acf>y2 )
13 n2
14 n1=sum( y$acf<y1 | y$acf>y2 )
15 n1
On observe que pour G1 il y a 126 acf en dehors de l'intervalle de conance à 95%, alors que pour G2 uni-
quement acf [1] = cov(xt,xt+0)=1 est en dehors de l'intervalle de conance. Ainsi, seul G2 satisfait H0.
The dierence-sign test
Le principe étant de dénombrer le nombre de paquets de données de même signe de signe. En eet,
si le nombre de changements de signe est important on pourra conclure que la valeur d'une donnée
dépend fortement de la précédente et donc que les données sont non indépendantes. Ainsi on pose : sous
l'hypothèse H0 d'indépendance, la somme Z = 1 +N∑i=1
11xi+1−xi>0 des changements de signe est suppo-
sée suivre une loi uniforme sur 1...N. Ainsi pour N assez grand, Z→ N(E(Z),V(Z)). Où E(Z)=N−12
11

et V(Z)=N+112 .
Ainsi on peut chercher la P − value et rejeter où pas l'hypothèse H0. On réalise ce test sur G1 et G2 :
1 #The d i f f e r e n c e−s i gn t e s t
2 X=rep (0 ,500)
3 X=u2
4 r=0
5 for ( i in 2 :500)
6 i f (X[ i−1]<X[ i ] ) r=r+1
7
8
9 mu=(500−1)/2
10 s2=(500+1)/12
11
12 t=abs ( r−mu)/sqrt ( s2 )
13 p=1−pnorm( t )
14 p
15
16 idem pour v2
On obtient pour G1 une P − value égale à 5.438043.10−7 < 0.05 le test est donc très signicatif, on
rejette donc H0 alors que pour G2 la P − value obtenue est égale à 0.24307 > 0.05, on ne peut donc
pas rejeter H0 dans ce cas .
1.3 Le générateur de Mersenne Twister
Le Mersenne Twister, est particulièrement réputé pour sa qualité. Sa période est de 219937 − 1 et
réussit le test spectral pour une dimension égale à 623. De plus la graine initiale est un vecteur de
dimension 624 composée d'entiers naturels codés en 32− bits
Logiciel R
Dans la suite de notre mémoire sauf mention contraire, nous utiliserons le générateur uniforme
fondamental fourni par le logiciel R. La fonction runif sur R se base sur le générateur Mersenne
-Twister, ce qui assure une relative ecacité.
1 runif (100 , min , max)
On peut rapidement vérier les propriétés élémentaires de ce générateur en examinant comme suit
le graph des auto corrélations estimées, ainsi qu'un histogramme des Xi.Ces graphiques indiquent que
runif est (relativement) acceptable comme générateur uniforme.
12
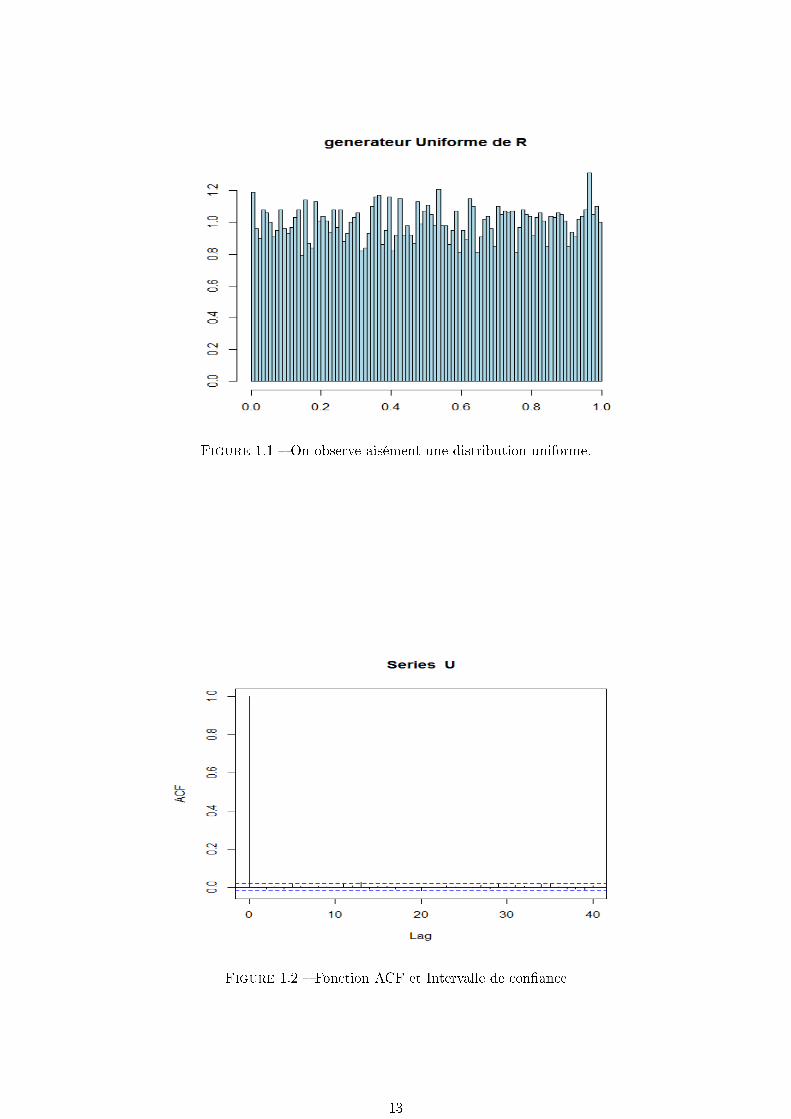
Figure 1.1 On observe aisément une distribution uniforme.
Figure 1.2 Fonction ACF et Intervalle de conance
13

CHAPITRE 2
GÉNÉRER DES VARIABLES ALÉATOIRES
2.1 Méthode de la transformation inverse
2.1.1 Cas de variables continues
Nous souhaitons à présent parvenir à simuler des réalisations de variables aléatoires indépendantes
de même loi. Une méthode simple et souvent susante s'appelle la transformation de la fonction
de répartition . Le principe étant de transformer n'importe quelle variable continue en une variable
uniforme et inversement.
Par exemple, si X a une loi de densité f et une fonction de répartition associée F , il est possible dans
le cas ou F est inversible de poser U = F (X), où U est une variable aléatoire de loi U (0, 1). En eet,
P(U ≤ u) = P[F (X) ≤ u] = P[F−1((F (X)) ≤ F−1((F (x))] = P(X ≤ x)
Traitons un exemple sur une loi E(λ) avec λ >0 :
Soit X → E(λ). Sa fonction de répartition est F (x) = 1 − e−λx 11x>0. On résout alors l'équation
t = F (x) et on obtient après calcul : x=- ln 1−tλ . Donc, si U→ U([0, 1]) alors
X = − ln 1−Uλ =- lnU
λ suit une loi E(λ)
Nous pouvons comparer le résultat d'une exponentielle obtenue par cette méthode et celle générée
par la fonction de R :rexp(λ)
1 #l o i e xpon en t i e l l e ( lambda ,N) par i nv e r s i o n f onc t i on r e p a r t i t i o n
2
3 t1=proc . time ( ) # permet de c a l c u l e r l e temps d ' execut ion : t1 depart , t2 f i n
4
5 f<−function (x ,N)−log ( runif (N) )/x
6 exp1=f (1 ,10^7)
7
8 t2=proc . time ( )
9 t2−t1
10
11 par (mfrow=c ( 1 , 2 ) )
12 hist ( exp1 , p r obab i l i t y=TRUE, main="Exp( lambda ) par i nv e r s i o n F . r " , col=" l i g h t b l u e " )
13 curve (dexp( x ) ,add=T, lwd=2,col="red " )
14 mean1=mean( exp1 )
15 mean1
16 sd ( exp1 )^2
17
18
14

19 #l o i e xpon en t i e l l e ( lambda ) par f on c t i on Rexp
20 t1=proc . time ( )
21
22 N=10^7
23 exp2=rexp (N, 1 )
24
25 t2=proc . time ( )
26 t2−t1
27
28 hist ( exp2 , p r obab i l i t y=TRUE, main="Exp( lambda ) par f onc t i on R" , col=" l i g h t b l u e " )
29 curve (dexp( x ) ,add=T, lwd=2,col="red " )
30 mean2=mean( exp2 )
31 mean2
32 sd ( exp2 )^2
On obtient les densités suivantes qui montrent une grande ressemblance entre la fonction R rexp et
l'inversion de la fonction de répartition comme nous pouvons l'observer dans les tableaux suivants :
Exponentielle par inversion de fonction de répartition
N Temps Moy. Var
103 0.03 0.9775 0.8836
104 0.04 0.9810 0.9370
105 0.04 0.9982 1.015
106 0.04 0.9959 0.9993
107 0.16 0.9997 0.9995
Exponentielle par rexp(1) (fonction R)
N Temps Moy. Var
103 0.03 0.9963 0.9747
104 0.02 0.9985 1.004
105 0.02 0.9985 1.003
106 0.01 0.9999 1.001
107 0.04 0.9999 1.000
Nous avons réaliser la même procédure C++, an de pouvoir comparer le temps de calcul.
1 #inc lude<iostream>
2 #inc lude<c s td l i b >
3 #inc lude<math . h>
4 us ing namespace std ;
5
6 main ( )
7
8 f l o a t u , x ;
9 i n t i ;
10 f l o a t tab [ 1 0 000 ] , esperance , var ;
11
12 for ( i =0; i <=999; i++)
13 u=rand ( ) ;
14 u=u/ (double ) RAND_MAX;
15 x=−log(1−u ) ;
16 cout <<endl ;
17
18 return 0 ;
19
On remarque que le temps de calcul est sensiblement le même pour N = 103, N = 104 et N = 105 ,
mais pour N = 106 en C++ le temps est de 0.450 contre 0.800s en R, et pour 107 de 1.2 contre 3sec
en R.
15
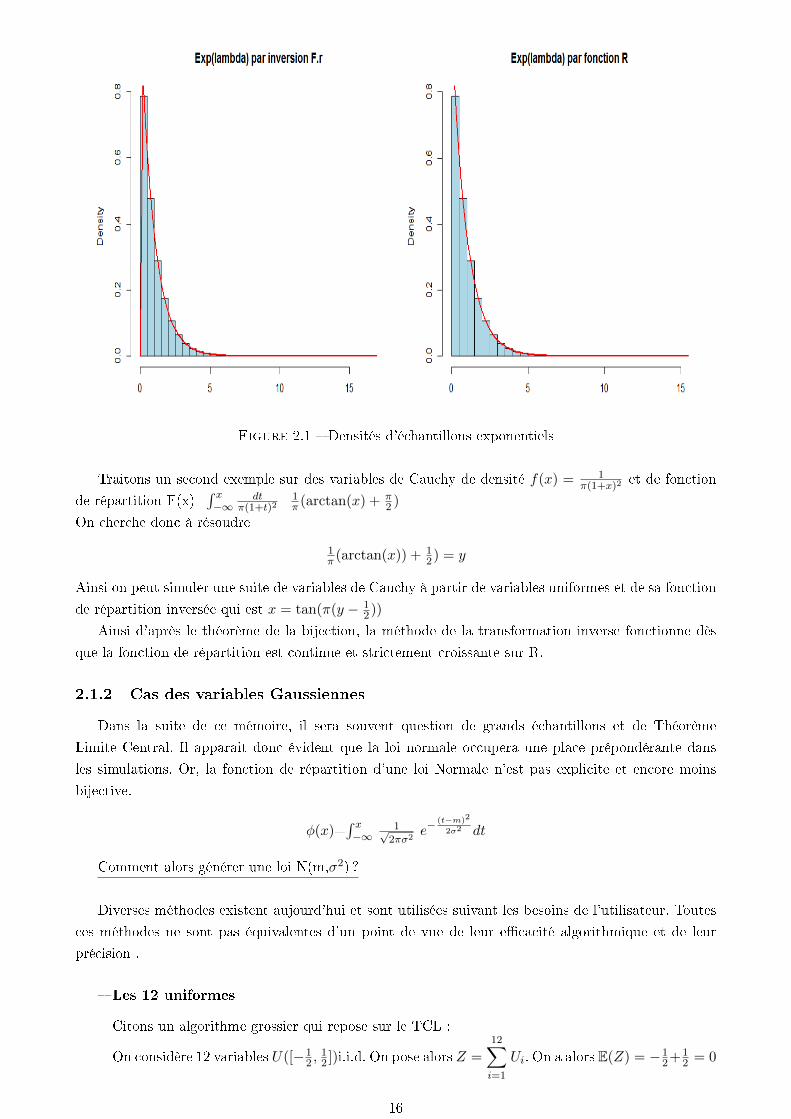
Figure 2.1 Densités d'échantillons exponentiels
Traitons un second exemple sur des variables de Cauchy de densité f(x) = 1π(1+x)2
et de fonction
de répartition F(x)=∫ x−∞
dtπ(1+t)2
= 1π (arctan(x) + π
2 )
On cherche donc à résoudre
1π (arctan(x)) + 1
2) = y
Ainsi on peut simuler une suite de variables de Cauchy à partir de variables uniformes et de sa fonction
de répartition inversée qui est x = tan(π(y − 12))
Ainsi d'après le théorème de la bijection, la méthode de la transformation inverse fonctionne dès
que la fonction de répartition est continue et strictement croissante sur R.
2.1.2 Cas des variables Gaussiennes
Dans la suite de ce mémoire, il sera souvent question de grands échantillons et de Théorème
Limite Central. Il apparait donc évident que la loi normale occupera une place prépondérante dans
les simulations. Or, la fonction de répartition d'une loi Normale n'est pas explicite et encore moins
bijective.
φ(x)=∫ x−∞
1√2πσ2
e−(t−m)2
2σ2 dt
Comment alors générer une loi N(m,σ2) ?
Diverses méthodes existent aujourd'hui et sont utilisées suivant les besoins de l'utilisateur. Toutes
ces méthodes ne sont pas équivalentes d'un point de vue de leur ecacité algorithmique et de leur
précision .
Les 12 uniformes
Citons un algorithme grossier qui repose sur le TCL :
On considère 12 variables U([−12 ,
12 ])i.i.d. On pose alors Z =
12∑i=1
Ui. On a alors E(Z) = −12+ 1
2 = 0
16
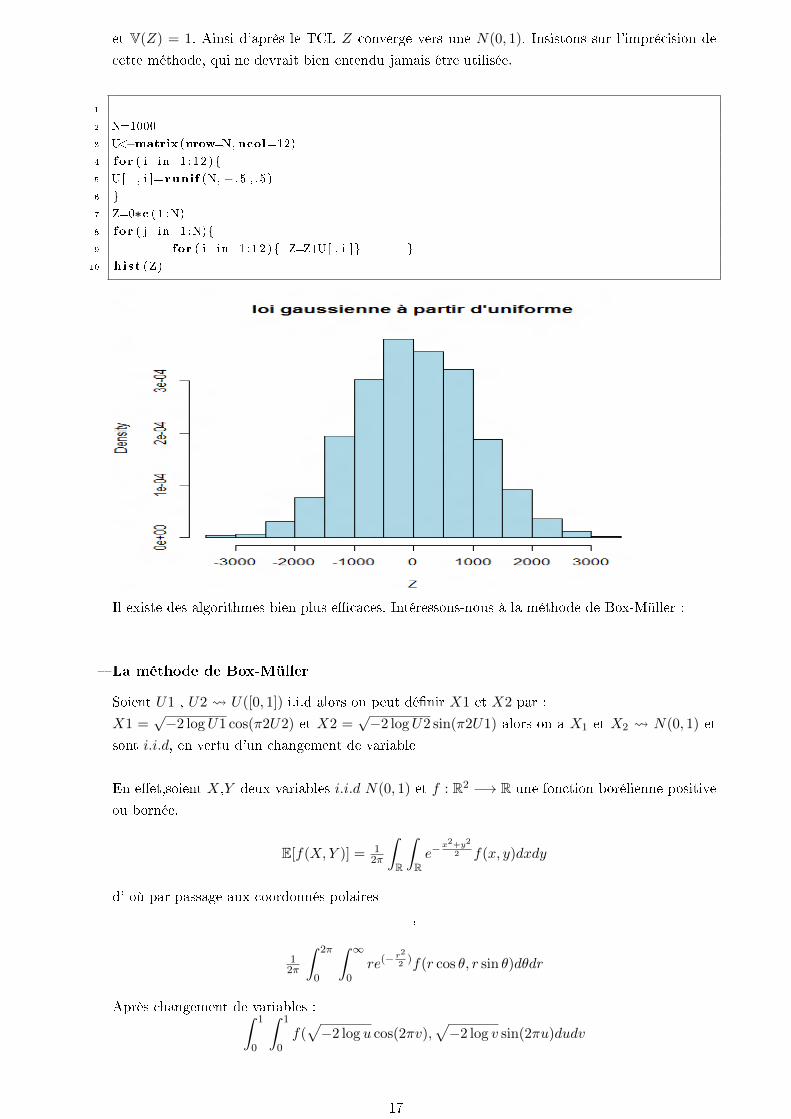
et V(Z) = 1. Ainsi d'après le TCL Z converge vers une N(0, 1). Insistons sur l'imprécision de
cette méthode, qui ne devrait bien entendu jamais être utilisée.
1
2 N=1000
3 U<−matrix (nrow=N, ncol=12)
4 for ( i in 1 : 12 )
5 U[ , i ]= runif (N, − . 5 , . 5 )
6
7 Z=0∗c ( 1 :N)
8 for ( j in 1 :N)
9 for ( i in 1 : 12 ) Z=Z+U[ , i ]
10 hist (Z)
Il existe des algorithmes bien plus ecaces. Intéressons-nous à la méthode de Box-Müller :
La méthode de Box-Müller
Soient U1 , U2 U([0, 1]) i.i.d alors on peut dénir X1 et X2 par :
X1 =√−2 logU1 cos(π2U2) et X2 =
√−2 logU2 sin(π2U1) alors on a X1 et X2 N(0, 1) et
sont i.i.d, en vertu d'un changement de variable
En eet,soient X,Y deux variables i.i.d N(0, 1) et f : R2 −→ R une fonction borélienne positive
ou bornée.
E[f(X,Y )] = 12π
∫R
∫Re−
x2+y2
2 f(x, y)dxdy
d' où par passage aux coordonnés polaires
,
12π
∫ 2π
0
∫ ∞0
re(− r2
2)f(r cos θ, r sin θ)dθdr
Après changement de variables :∫ 1
0
∫ 1
0f(√−2 log u cos(2πv),
√−2 log v sin(2πu)dudv
17

D'où,
=E(√−2 logU cos(2πV ),
√−2 log V sin(2πU)]
A noter que la fonction pré-programmée sous R : rnorm(N, mean, sd) repose sur l'algorithme de
Box-Muller.
Ce qui donne sur R la forme suivante :
1 N=1000
2 m=0
3 sigma=1
4 U1=runif (N)
5 U2=runif (N)
6 X3=rnorm(N,mean=m, sd=sigma )
7 X1=m+sigma∗sqrt(−2∗log (U1) )∗cos (2∗pi∗U2)8 X2=m+sigma∗sqrt(−2∗log (U2) )∗cos (2∗pi∗U1)9
10 par (mfrow=c ( 1 , 3 ) )
11
12 hist (X1 , col=" l i g h t b l u e " , xlim=c (−10 ,10) , yl im=c ( 0 , 0 . 5 ) , p r obab i l i t y=TRUE, main="X1" )
13 par (new=TRUE)
14 curve ( yl im=c ( 0 , 0 . 5 ) , xl im=c (−10 ,10) ,dnorm( x ) , lwd=2,col="red " ,main="" )
15 mean(X1)
16 sd (X1)^2
17
18 hist (X2 , col=" l i g h t b l u e " , xlim=c (−10 ,10) , yl im=c ( 0 , 0 . 5 ) , p r obab i l i t y=TRUE, main="X2" )
19 par (new=TRUE)
20 curve ( yl im=c ( 0 , 0 . 5 ) , xl im=c (−10 ,10) ,dnorm( x ) , lwd=2,col="red " ,main="" )
21 mean(X2)
22 sd (X2)^2
23
24 hist (X3 , col=" l i g h t b l u e " , xlim=c (−10 ,10) , yl im=c ( 0 , 0 . 5 ) , p r obab i l i t y=TRUE, main="rnorm" )
25 par (new=TRUE)
26 curve ( yl im=c ( 0 , 0 . 5 ) , xl im=c (−10 ,10) ,dnorm( x ) , lwd=2,col="red " ,main="" )
27 mean(X3)
28 sd (X3)^2
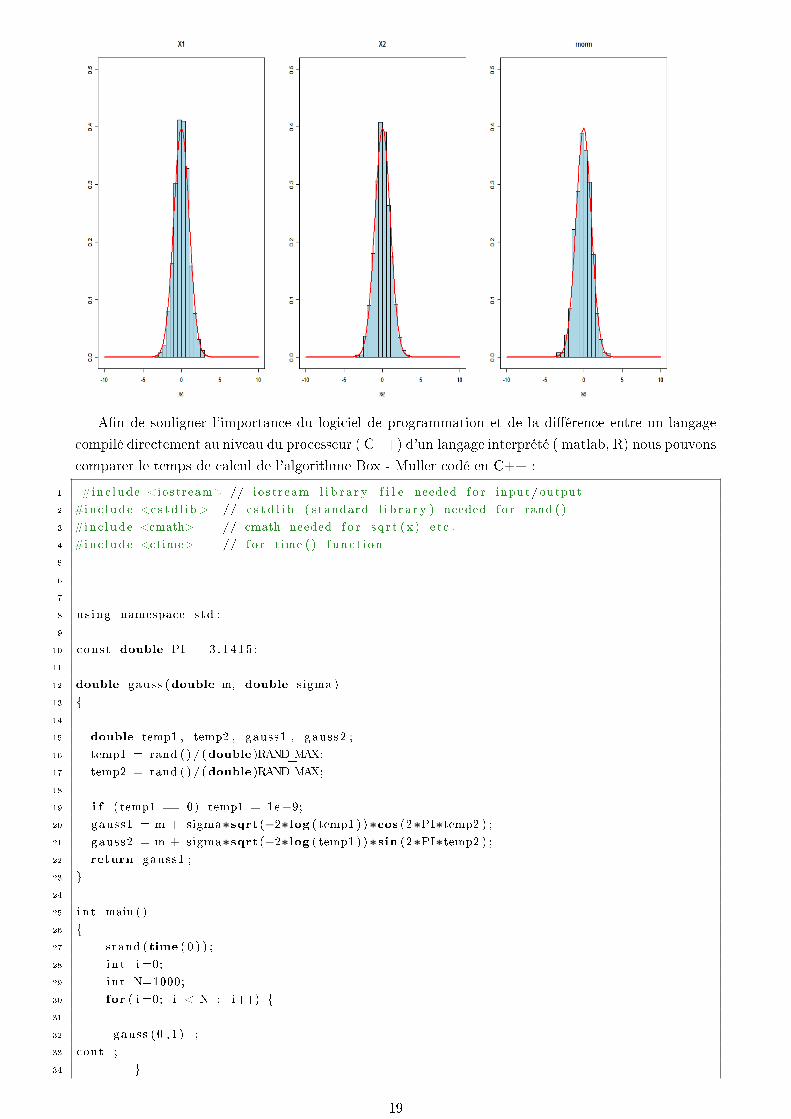
On obtient pour X1,X2 des valeurs correctes pour les moyennes et variances empiriques. Toutefois,
pour gagner en temps de calcul il peut etre utile de ne garder que X1 ou que X2 car sinon le temps de
calcul est dédoublé comme le montre les tableaux suivants :
Loi Normale ( première composante de Box-Muller)
N Temps Moy. Var
103 0.1 −0.0704 1.026
104 0.3 0.00329258 1.014077
105 0.4 −0.003076994 1.010051
106 0.8 −0.0004220485 1.000203
107 3.0 1.406661e− 05 1.000023
Loi Normale parrnorm(N,0,1) (fonction R)
N Temps Moy. Var
103 0.1 −0.012 1.044108
104 0.1 0.00356185 0.9846939
105 0.2 0.0009078085 0.9951027
106 0.3 −0.00156899 1.000683
107 0.6 0.0004878232 1.000295
18
An de souligner l'importance du logiciel de programmation et de la diérence entre un langage
compilé directement au niveau du processeur ( C++) d'un langage interprété ( matlab, R) nous pouvons
comparer le temps de calcul de l'algorithme Box - Muller codé en C++ :
1 #inc lude <iostream> // i o s t ream l i b r a r y f i l e needed f o r input/output
2 #inc lude <c s td l i b > // c s t d l i b ( standard l i b r a r y ) needed f o r rand ( )
3 #inc lude <cmath> // cmath needed f o r sq r t ( x ) e t c .
4 #inc lude <ctime> // f o r time ( ) func t i on
5
6
7
8 us ing namespace std ;
9
10 const double PI = 3 . 1415 ;
11
12 double gauss (double m, double sigma )
13
14
15 double temp1 , temp2 , gauss1 , gauss2 ;
16 temp1 = rand ( )/ (double )RAND_MAX;
17 temp2 = rand ( )/ (double )RAND_MAX;
18
19 i f ( temp1 == 0) temp1 = 1e−9;
20 gauss1 = m + sigma∗sqrt(−2∗log ( temp1 ) )∗cos (2∗PI∗temp2 ) ;
21 gauss2 = m + sigma∗sqrt(−2∗log ( temp1 ) )∗sin (2∗PI∗temp2 ) ;
22 return gauss1 ;
23
24
25 i n t main ( )
26
27 srand ( time ( 0 ) ) ;
28 i n t i =0;
29 i n t N=1000;
30 for ( i =0; i < N ; i++)
31
32 gauss (0 , 1 ) ;
33 cout ;
34
19

35
36
Pour un temps de 0.144s contre 0.3s sur R , ce qui souligne le gain en rapidité pour des langage tel
que C++.
Intéressons-nous à la généralisation en dimension n :
-Méthode de Choleski
Soient X=X1....Xn un vecteur gaussien non dégénéré d'espérance m=(m1...mn), et de matrice
de covariance Γ . Considérons mi = 0 ∀i ∈ 1, ..., n. Sinon, il surait de poser Xi=Yi+mi pour s'y
ramener.
Supposons que Γ ne soit pas diagonale, car dans ce cas il surait de simuler n variables gaussiennes
centrées/réduites.On sait de plus que Γ est dénie positive car X est non dégénérée.
Ainsi on peut appliquer la décomposition de Choleski qui consiste à écrire Γ=AA' où A est une
matrice triangulaire inférieure et est unique car ai,i>0 ∀i .Ainsi en écrivant Y = AZ où Z est un vecteur gaussien centré réduit de dimension n, on a bien :
1. X transformation linéaire d'un vecteur gaussien donc X vecteur gaussien
2. E[X] = AE[Z] = 0
3. Cov(Xi, Xj) = Γi,j
Cette méthode nous sera utile an de simuler des mouvements browniens notamment dans le cadre
du pricing d'option en nance. Nous n'expliciterons pas davantage la factorisation de Choleski, on se
contentera de mentionner l'existence d'une fonction sous R qui calcule la matrice de Choleski :
1 chol \ .\
Réalisons deux exemples pour illustrer cette méthode :
Nous considérons un vecteur gaussien de matrice de variance/covariance Σ =
(1116
7√
316
7√
316
2516
).
1
2 N=10^4
3
4 sigma = matrix (c (11/16 , (7∗sqrt ( 3 ) )/16 , (7∗sqrt ( 3 ) )/16 ,25/16) , ncol=2, byrow=T)
5 A=chol ( sigma )
6
7 Z1=rnorm(N)
8 Z2=rnorm(N)
9 Z<−matrix (c (Z1 , Z2 ) ,nrow=2,byrow=T)
10
11 X<−matrix (ncol=N,nrow=2)
12 for ( i in 1 :N)X[ , i ]=A%∗%Z [ , i ]
13
14 X1=X[ 1 , ]
15 X2=X[ 2 , ]
16
17 plot (X1 ,X2 , xlim=c (−6 ,6) , yl im=c (−5 ,5) , pch=46,main="Simulat ion de coup l e s gau s s i en s c o r r e l e s " )
20
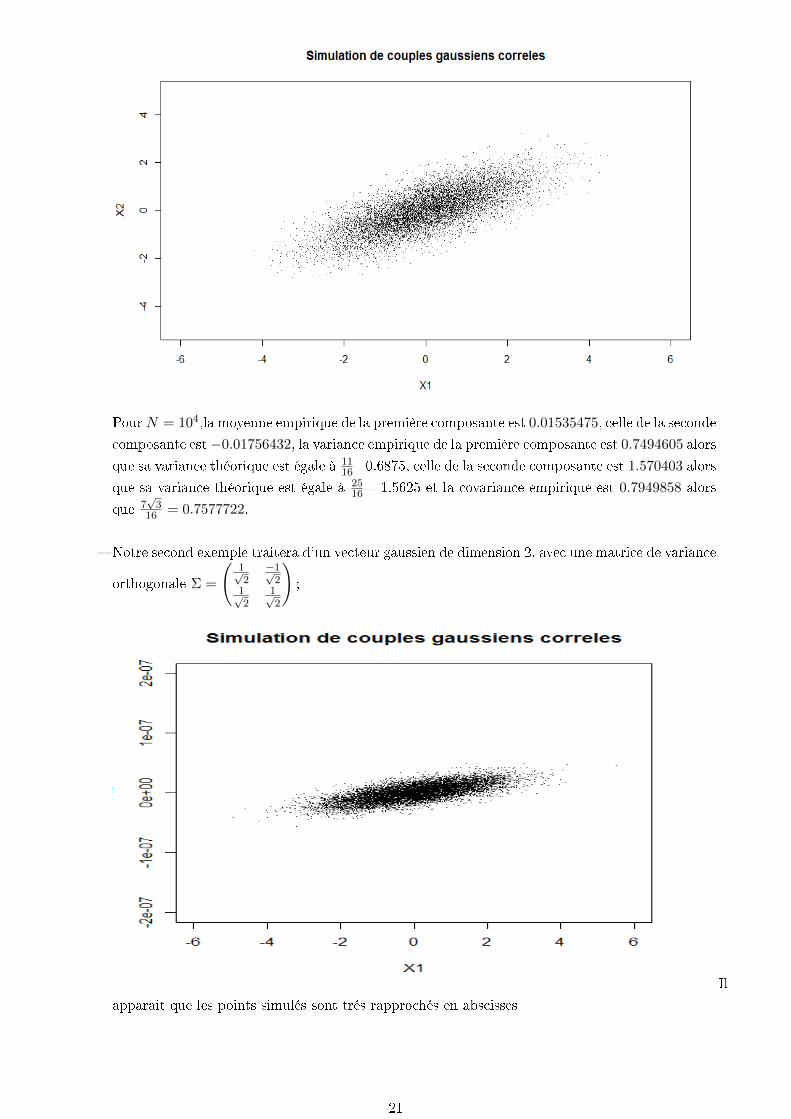
PourN = 104,la moyenne empirique de la première composante est 0.01535475, celle de la seconde
composante est−0.01756432, la variance empirique de la première composante est 0.7494605 alors
que sa variance théorique est égale à 1116=0.6875, celle de la seconde composante est 1.570403 alors
que sa variance théorique est égale à 2516= 1.5625 et la covariance empirique est 0.7949858 alors
que 7√
316 = 0.7577722.
Notre second exemple traitera d'un vecteur gaussien de dimension 2, avec une matrice de variance
orthogonale Σ =
(1√2−1√
21√2
1√2
);
Il
apparait que les points simulés sont trés rapprochés en abscisses
21

2.2 Méthode du rejet
Il nous faut souligner que pour beaucoup de variables aléatoires, ni la méthode de transformation
inverse ni celle des transformations plus générales ne permettent de fournir une simulation de ces dis-
tributions. Pour ces cas là, nous devons nous orienter vers d'autres méthodes, souvent moins naturelles.
Le principe général de ces méthodes est de générer une variable aléatoire dite "candidate" puis de la
soumettre à un test .L'acceptation de ce test conduit à conserver la valeur simulée, son rejet, à répéter
la simulation.
Construction du test :
Soit X une variable aléatoire de fonction de densité f . On suppose qu'il existe une densité de
probabilité g plus facile à simuler (exemple une gaussienne..) telle que
∃ K > 0 ,∀ x ∈ R, h(x) := f(x)Kg(x) .
La méthode consiste ensuite à :
-tirer au hasard une réalisation d'une variable Y de densité g
-tirer au hasard une réalisation d'une variable U U([0, 1]), et indépendante de Y
-On pose X = Y à condition que U ≤ h(Y ), sinon on recommence le tirage.
Notons que le nombre de tirages que l'on est amené à rejeter dépend de la densité g choisie , il sera
donc important de choisir g "très" proche de f .
Les deux critères qui conditionnent le choix de g sont :
Simplicité : Le temps de calcul du quotient fKg doit être le rapide
Majorer f : On souhaite majorer la densité f à une constant K prés.
Montrons dans un premier lieu que L(Y |U≤ f(Y )
Kg(Y ))
= LX :
Soit x ∈ Y (Ω), P[Y ≤ x|U ≤ f(Y )Kg(Y ) ] =
P[Y ≤ x⋂U ≤ f(Y )
g(Y ) ]
P[ f(Y )Kg(Y ) ]
=
∫ x−∞
∫ f(y)Kg(y)
−∞ dP(Y,U)(y, u)∫R∫ f(y)Kg(y)
−∞ dP(Y,U)(y, u)
=
∫ x−∞
∫ f(y)Kg(y)
−∞ g(y)dydu∫R∫ f(yKg(y)
−∞ g(y)dydu
=
∫ x−∞[ f(y)
Kg(y) ]g(y)dy∫R[ f(y)Kg(y) ]g(y)dy
=
∫ x−∞[f(y)
K ]dy
1=P[X ≤ x]
Déterminons à présent la probabilité d'acception :
Nous pouvons de plus déterminer la probabilité d'acceptation, ie la probabilité avec laquelle
on ne rejette pas une valeur. En eet,P (U ≤ h(Y )) = E[11U≤h(Y )] =
∫R
∫R
11(U≤h(Y ))dPUdPY =∫R
∫R
11(u≤h(Y ))11[0,1](u)dudPY =
∫Rh(Y )dPY = E[h(Y )] =
∫f(y)
Kg(y)g(y)dy= 1
K
Il en ressort que pour maximiser cette probabilité, il nous faut trouver la constante K maximale ie
qui vérie K = supf(y)
g(y), y ∈ Y (Ω)
1er exemple : la loi Gamma
Concentrons nous sur la simulation de loi Γ(a, b) de densité f(x) = ba
Γ(a)xa−1e−bx11x>0 par la
méthode de rejet. Nous savons :
Si X1....Xn sont indépendantes telles que Xi Γ(αi, β) alors X1 + .....Xn Γ(α1 + ....αn, β)
22
Si α = 1 alors X E(β)
Si α ∈ N alors la loi Γ(α, β) peut se voir comme la somme de α variables i.i.d de loi Eβ).
Si Y Γ(α, 1) alors Z = Yβ Γ(α, β)
Dans la suite de l'exemple, nous poserons β = 1 sans perte de généralité.
1er Cas : α ∈ N Il nous sut alors de simuler α variables i.i.d de loi E(1). On choisira arbitrairement
α = 6.
1 N=100000
2 alpha=6
3
4 t1=proc . time ( )
5 M<−matrix (data = NA, nrow =N , ncol =alpha , byrow = FALSE)
6
7 Z=rep (0 ,N)
8 I=rep (1 , alpha )
9 I<−matrix (data=I , byrow=FALSE)
10
11 for ( i in 1 : alpha )M[ , i ]=−log ( runif (N) )
12
13 for ( j in 1 :N)Z [ j ]=sum(M[ j , ] )
14
15 t2=proc . time ( )
16 t2−t1
17
18 hist (Z , p r obab i l i t y=TRUE, col=" l i g h t b l u e " ,main=" l o i gamma(6 , 1 ) " )
19
20 x <− rgamma(N, 6 , 1 )
21 l ines (density (x ,bw=1) , col=' red ' , lwd=3)
Après simulation, la moyenne empirique est 6.002241 (espérance théorique =α∗β=6) et la varianceempirique est de 5.973638(variance théorique = α ∗ β2 = 6).De plus, temps de calcul est de 0.21
23

secondes. Nous pouvons comparer ces résultats avec la méthode de rejet pour une densité candidate,
une loi uniforme sur [0, 1] et une constante K qui est
K = sup(xa−1e−x11x>0
11[0,1](x)), en dérivant on obtient K∗ = α− 1 = 5.
On pose donc h(x) =xα−1e−x11(x>0)
5∗Γ(a)11]0,1[
2nd Cas : 0<α<1
Le reste de l'exemple d'une simulation Γ(α, 1) traitera du cas particulier où 0< α <1, en explicitant
l'algorithme mis au point par Ahrens & Dieter (1974) qui se fonde sur la méthode de rejet :
K(α) = (α+e)αe , g(x) = K(α)[11]1,∞[e
−x + xα−111]0,1[], ∀x > 0.
D'où h(x) =f(x)
K(α)g(x)=
xα−1e−x11x>0Γ(α) ∗ 1
K(α)11]1,∞[(e−x) + 11]0,1[x
α
Pour appliquer la méthode de rejet il nous faut simuler une variable Y de densité g, pour cela on
détermine l'inverse de la fonction de répartition :
Si x ∈]1,∞[, ∀t ∈]0,∞[, G(t) =∫ t
1αeα+ee
−xdx = αeα+e [
1e − e
−t]11]1,∞[(t),
d'où G−1(t) = −log[(1− t)α+eαe ]11] e
α+e,1[(t)
Si x ∈]0, 1[, ∀t ∈]0, 1[, G(t) =∫ t
0αeα+ex
α−1dx= eα+e t
α11]0,1[(t),
d'où G−1(t) = [(α+eαe )t]
1α 11]0, e
α+e[(t) car a>0 et e>0.
1 N=10^4
2
3 W=rep (NaN,N)
4 Z=rep (NaN,N)
5
6 U=runif (N)
7
8 K<−function ( alpha ) ( alpha+exp ( 1 ) )/exp (1 )
9 Y=runif (N,max=K( . 5 ) )
10 for ( i in 1 :N)
11 i f (Y[ i ]<1)Z [ i ]=Y[ i ]^(1/ . 5 )
12 W=−log ( runif (N) )
13 X=Y[W>Z]
14
15 else Z [ i ]=−log ( (K(.5)−Y[ i ] ) / . 5 )
16 W=(runif (N))^(1/ ( .5−1))
17 X=Y[W<Z]
18
19
20
21
22 hist (X)
2nd exemple : la loi Beta(a,b)
Nous traiterons ici du cas des variables X β(a, b), de densité fX(x) = xa−1(1−x)b−1
β(a,b) 11]0,1[(x).
1er Cas : a > 0 et b > 0
Pour un premier exemple, intéressons-nous à simuler une loi β(a, b), où a = 4.5 > 1 et b = 8.5 > 1.Pour
cela il nous faut déterminer une densité "candidate" ecace :
24

Supposons que nous choisissons Y U([0, 1]), donc g(y)=11[0,1](y)
Ainsi nous pouvons déterminer K telle que K = supf(y), y ∈ R+∗, on obtient numériquement
K = 3.015621 grâce à la fonction prédé nie Optimize, soit une probabilité d'acceptation égale
à 34%.
Une autre façon de calculer la constante K aurait été de maximiser "à la main" la fonction
q(x) = xa(1−x)1−b
11[0,1](x). On dérive la fonction et on cherche là où elle s'annule : on obtient (a − 1) +
(1− a+ b− 1)x = 0 ⇒ x = a−1b−a d'où ici une constante égale à 0.875.
Une troisième méthode encore pour déterminer K, sans doute la plus ne serait de poser K =Γ(a+b)
Γ(a)Γ(b) , facilement calculable et qui nous permet d'avoir une simplication du quotient h(x) =f(x)K.g(x) = xa(1− x)1−b.
On fera donc l'arbitrage entre temps de calcul et précision voulue pour la probabilité d'acceptation.
Ainsi avec le choix de K = 1β(a,b) = Γ(a+b)
Γ(a)Γ(b) . La densité candidate g étant égale à 1 car on se
restreint à une loi U([0, 1]) et que le support de f est aussi [0, 1].
Ainsi la valeur proposée Y est acceptée si K ∗ U < f(Y ). Autrement dit, si K*U est située en des-
sous de la densité f(Y). A noter que simuler K ∗U où U U([0, 1]) revient à simuler U ′ U([0,K]).
Cette procédure ce traduit par l'algorithme suivant, que nous déclinons pour deux constantes
diérentes , nous illustrons les deux cas par leurs graphiques respectifs ainsi que par leur moyennes /
variances empiriques :
1 N=10^4
2 x = runif (10^4 ,0 ,1)
3
4 a=4.5
5 b=8.5
6 f<−function ( x )dbeta (x , a , b )
7
8 K1=(a−1)/ (b−a )9 K2=optimise ( f , i n t e r v a l=c ( 0 , 1 ) ,maximum=TRUE)$ ob j e c t i v e
10
11 va l eur_acceptee = c ( )
12
13 for ( i in 1 : length ( x ) )
14 U = runif (1 )
15 i f (dunif ( x [ i ] ) ∗K2∗U <= dbeta ( x [ i ] , a , b ) )
16 va l eur_acceptee [ i ] = 'Oui '
17
18 else i f (dunif ( x [ i ] ) ∗K2∗U > dbeta ( x [ i ] , a , b ) )
19 va l eur_acceptee [ i ] = 'Non '
20
21
22
23 T = data . frame (x , va l eur_acceptee= factor ( va l eur_acceptee , levels= c ( 'Oui ' , 'Non ' ) ) )
24 par (mfrow=c ( 1 , 2 ) )
25 hist (T [ , 1 ] [T$ va l eur_acceptee=='Oui ' ] , breaks = seq ( 0 , 1 , 0 . 0 1 ) , p r obab i l i t y=TRUE, main = ' Loi Beta ( 4 . 5 , 8 . 5 ) ' , x lab = 'X ' , col=' l i g h t b l u e ' ,main=' beta ( 4 . 5 , 8 . 5 ) avec K1=(a−1)/ (b−a ) ' )26 par (new=TRUE)
27 curve ( f ( x ) , col=' red ' , lwd=3)
28 print ( qp lo t (x , data = T, geom = ' histogram ' , f i l l = va l eur_acceptee , binwidth =0.01 ,main=' beta ( 4 . 5 , 8 . 5 ) avec K1=(a−1)/ (b−a ) ' ) )
25
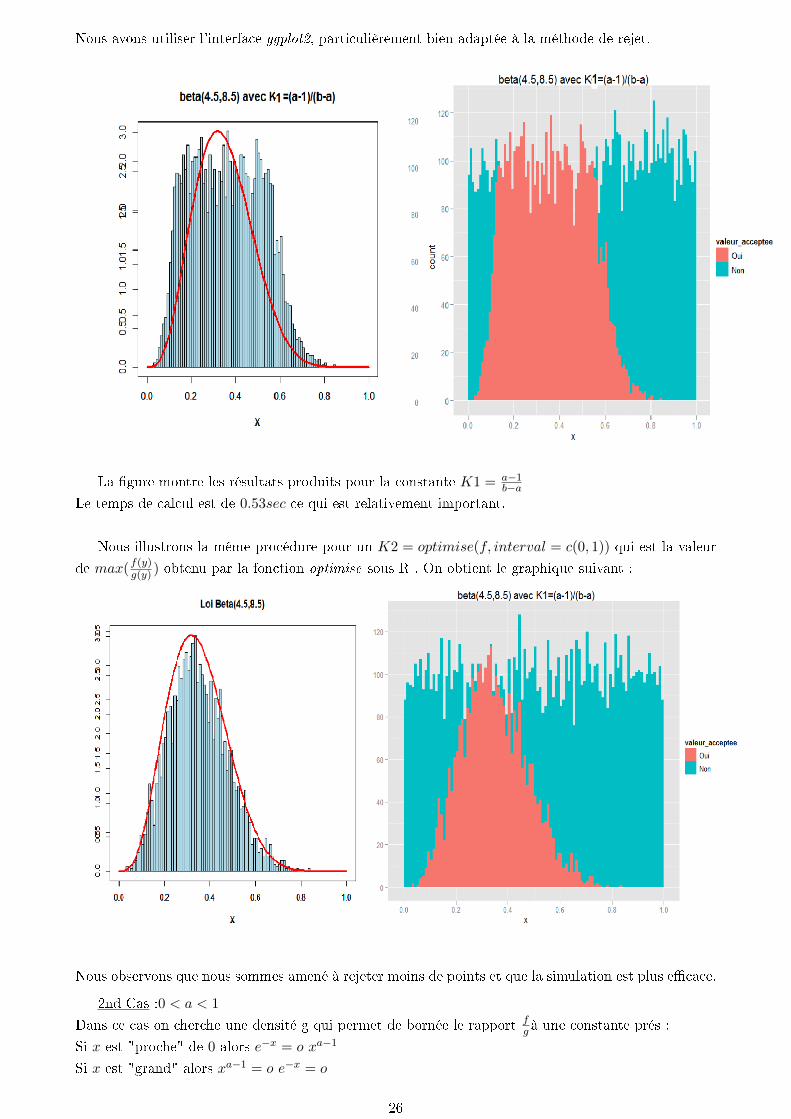
Nous avons utiliser l'interface ggplot2, particulièrement bien adaptée à la méthode de rejet.
La gure montre les résultats produits pour la constante K1 = a−1b−a
Le temps de calcul est de 0.53sec ce qui est relativement important.
Nous illustrons la même procédure pour un K2 = optimise(f, interval = c(0, 1)) qui est la valeur
de max(f(y)g(y) ) obtenu par la fonction optimise sous R . On obtient le graphique suivant :
Nous observons que nous sommes amené à rejeter moins de points et que la simulation est plus ecace.
2nd Cas :0 < a < 1
Dans ce cas on cherche une densité g qui permet de bornée le rapport fg à une constante prés :
Si x est "proche" de 0 alors e−x = o xa−1
Si x est "grand" alors xa−1 = o e−x = o
26

On pose donc g(x) = xa−111]0,1[ + e−x11x>1
De plus une des critiques de l'algorithme de rejet est qu'il génère des simulations "inutiles" car
rejetées lors du test. Nous verrons plus loin, lors de l'étude de la réduction de variance, qu'il existe des
méthodes plus ecientes tel que l'échantillonnage préférentiel .
2.3 Loi conditionnelle
2.3.1 Couple de variables corrélées
Nous souhaitons pouvoir simuler un couple de variables (X,Y ) telle que Y dépendent de X. Pour
cela, il est nécessaire de simuler loi de X de densité f puis de pouvoir simuler la loi de Y |(X = x),
∀x ∈ X(Ω).
Pour simuler X de densité fX nous pouvons utiliser les méthodes vues précédemment (inversion f.R,
méthode rejet ..), ensuite nous simulons Y |X = x∀x ∈ X(Ω) de densité fY |X=x, nous pouvons enn
obtenir la densité f(x, y) = fX(x) ∗ fY |(X=x)(y).
Considérons l'exemple suivant :
Soit X U([0, 1]) et Y E(x). On cherche la loi de (X,Y ) de densité f(X,Y )(x, y).
On a fX(x) = 11[0,1](x) d'où fY |X=x(y) = xe−xy11[0,1](y), ∀x ∈ [0, 1]
1 #methode de melange
2 N=100
3
4 X=runif (N)
5
6 Y=rexp (N,X)
7
8 U=X∗Y9
10 hist (U, col=" l i g h t b l u e " , p r obab i l i t y=TRUE)
Ainsi nous pouvons généraliser cette méthode par simple récurrence :
Pour simuler un vecteur aléatoireX = (X1....Xn) de densité fX(x1.....xn) = f(xn|x1..xn−1)∗f(x1..xn−1) =
f(xn|x1....xn−1) ∗ f(x1....xn−1)......f(x2|x1) ∗ f(x1)
Conclusion
Au terme de cette première partie nous avons étudier le fonctionnement d'un générateur de nombres
pseudo aléatoires et nous nous sommes intéressés aux tests qui valident ou non l'ecacité de ces géné-
rateurs. Nous avons souligner que l'ecacité correspond aux propriétés d'indépendance, d'uniformité ..
mais aussi au coût de calcul algorithmique. Puis nous avons explicité les diérentes méthodes qui nous
permettent de simuler des variables de diérentes lois de probabilité. A présent, nous sommes aptes à
pouvoir appliquer ces méthodes an de résoudre des calculs d'intégrales, d'espérances .
27

Deuxième partie
Méthodes de Monte Carlo et réduction de
la variance
28

CHAPITRE 3
CALCUL D'INTÉGRALE
Dans ce chapitre, sauf mention du contraire on se place dans l'ensemble probabilisé (R,B(R),P).Nous
allons étudier la méthode de Monte Carlo qui vise à estimer la valeur d'une intégrale en la réécrivant
sous forme d'espérance. Posons le problème suivant :
Soit g une fonction borélienne positive ou bornée de Rd→ R et I=∫Rd g(x)f(x)dx où
∫mathbbRd
f(x)dx =
1 et f(x) ≥ 0.Nous pouvons alors écrire I=E[g(X)] où X a pour densité f par rapport à la mesure de
Lebesgue que Rd.
Rappel :
Loi forte des grands nombres :
Soit(Xi)i∈N, une suite de variables de carré intégrable, non corrélées et de même loi alors
1n
n∑i=1
g(Xi) −→ ps E[g(X1)]
Ainsi si (x1....xn) est une réalisation de (X1...Xn) alors 1n
n∑i=1
g(Xi) est une approximation de I.
Un autre théorème qui a toute son importance dans les méthodes de Monte Carlo est le Théo-
rème Central Limite. Nous en donnerons pas d'énoncé, seulement une illustration qui souligne sont
ecacité. Nous représentons sous forme d'histogramme les valeurs obtenues pour des échantillons de
loi U([0, 1]) de tailles diérentes que nous centrons et réduisons. Nous superposons la densité de la loi
normale centrée réduites . Il apparait concrètement qu'au dessus du seuil de N = 30 la convergence est
eective.(Le code sous R de la loi des grands nombres ne comporte pas d'élément intéressant, il n'est
donc pas explicité)
29
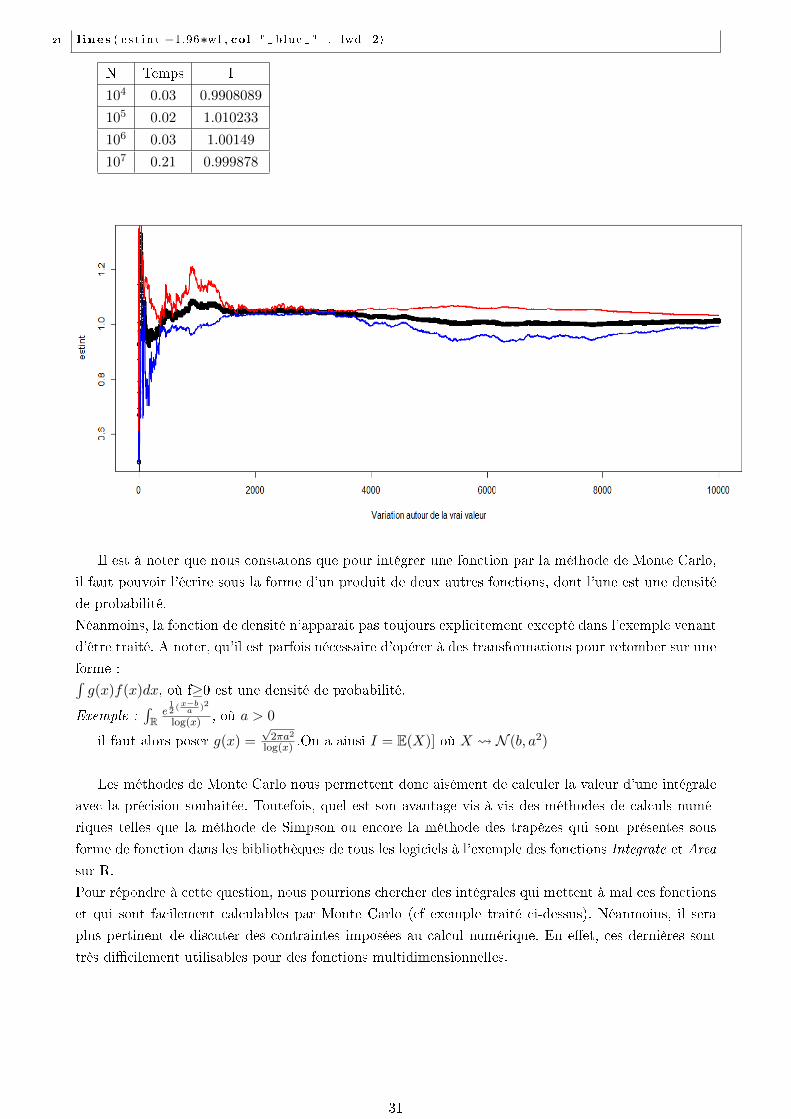
3.1 Premiers exemples
Considérons immédiatement un exemple simple :
Estimons par la méthode de Monte Carlo l'intégrale suivante : I=∫ ∞
0λx e−λxdx, λ > 0
Cette intégrale doit être résolue par intégration par partie mais nous reconnaissons une densité
de loi E (λ) par rapport à la mesure de Lebesque sur R avec λ > 0. Ainsi nous pouvons appliquer la
méthode de Monte Carlo :
-Soit (U1.....UN ), une suite i.i.d U([0, 1])
-Nous appliquons à ce vecteur la transformation −log(Ui)λ
-On calcule ensuite 1N
N∑i=1
xi (ici g≡ Id). Il nous sut ensuite d'augmenter la taille de l'échantillon N,
pour aner nettement le résultat.
1 #Monte Carlo pour une i n t e g r a l e expo
2
3 t1=proc . time ( )
4
5 I<−function (N, lambda )sum(−log ( runif (N) )/lambda )/N
6 I (10^4 ,1)
7
8 t2=proc . time ( )
9 t2−t1
10
11 #fonc t i on cumsum retourne un vecteur dont l e s e lements sont l e s sommes cumumlatives
12
13 e s t i n t
14 e s t i n t=cumsum(U)/ ( 1 :N)
15 plot ( e s t i n t , x lab="Var ia t ion autour de l a v ra i va l eur " , lwd=2)
16
17 # on dete rmine l e s borne d ' e l ' i n t e r v a l l e de con f i anc e
18 w1=sqrt (cumsum( I (10^4)− e s t i n t )^2)/ ( 1 :N)
19
20 l ines ( e s t i n t +1.96∗w1 , col="red " , lwd=2)
30
21 l ines ( e s t i n t −1.96∗w1 , col=" blue " , lwd=2)
N Temps I
104 0.03 0.9908089
105 0.02 1.010233
106 0.03 1.00149
107 0.21 0.999878
Il est à noter que nous constatons que pour intégrer une fonction par la méthode de Monte Carlo,
il faut pouvoir l'écrire sous la forme d'un produit de deux autres fonctions, dont l'une est une densité
de probabilité.
Néanmoins, la fonction de densité n'apparait pas toujours explicitement excepté dans l'exemple venant
d'être traité. A noter, qu'il est parfois nécessaire d'opérer à des transformations pour retomber sur une
forme :∫g(x)f(x)dx, où f≥0 est une densité de probabilité.
Exemple :∫Re12 (x−ba )2
log(x) , où a > 0
il faut alors poser g(x) =√
2πa2
log(x) .On a ainsi I = E(X)] où X N (b, a2)
Les méthodes de Monte Carlo nous permettent donc aisément de calculer la valeur d'une intégrale
avec la précision souhaitée. Toutefois, quel est son avantage vis-à-vis des méthodes de calculs numé-
riques telles que la méthode de Simpson ou encore la méthode des trapèzes qui sont présentes sous
forme de fonction dans les bibliothèques de tous les logiciels à l'exemple des fonctions Integrate et Area
sur R.
Pour répondre à cette question, nous pourrions chercher des intégrales qui mettent à mal ces fonctions
et qui sont facilement calculables par Monte Carlo (cf exemple traité ci-dessus). Néanmoins, il sera
plus pertinent de discuter des contraintes imposées au calcul numérique. En eet, ces dernières sont
très dicilement utilisables pour des fonctions multidimensionnelles.
31

CHAPITRE 4
VITESSE DE CONVERGENCE ET TEMPS DE CALCUL
4.1 Evaluation de la vitesse de convergence
Dénition
On se place dans un modèle statistique ((Ω′), ξ′,P′θ, θ ∈ Θ), et soit (θn)n une suite d'estimateurs
de θ. Si il existe (an)n une suite de réels positifs telle que an(θn − θ) converge en loi vers N(0, 1) alors
on dit que (θn) converge vers θ à la vitesse an. La vitesse de convergence dépend donc de la taille de
l'échantillon ainsi qu'à la régularité ou la stationnarité des lois considérées. Pour débuter nous nous
intéresserons au Théorème Central Limite qui fournit une convergence pour une vitesse de l'ordre de1√n. Ainsi il en ressort que plus la vitesse de convergence est grande moins notre échantillon a besoin
d'être grand pour estimer ecacement le paramètre.
4.2 Evaluation de la variation
La méthode de Monte Carlo se fonde sur la loi forte des grands nombres, ainsi nous pouvons dénir
l'erreur de cet estimateur, pour un N donné de la façon suivante :
εN = E[h(X)]− 1n
N∑i=1
h(Xi) .
Cette variation tend vers 0 pour N susamment grand.
4.2.1 Construction d'un intervalle de conance
On considère l'intégrale suivante :
I =∫ π
20 cos2(x) ∗ sin4(x)dx
Le choix de cette fonction est arbitraire, à titre purement expérimental . On a I =
∫Rh(x)dPU (x)
où h R → Rx 7→ cos2(x) ∗ sin4(x) et U U([0, π2 ), nous pouvons alors calculer cette intégrale en
appliquant la méthode de Monte Carlo. On considère (U1......UN ) un échantillon de N variables i.i.d
U([0, π2 ]) et en supposant h continue, sur [0,π2 ] (compact) donc h(U) intégrable, on a d'après la loi
Forte des Grands Nombres :
1N
N∑i=1
h(Ui) cv P-ps vers I
32
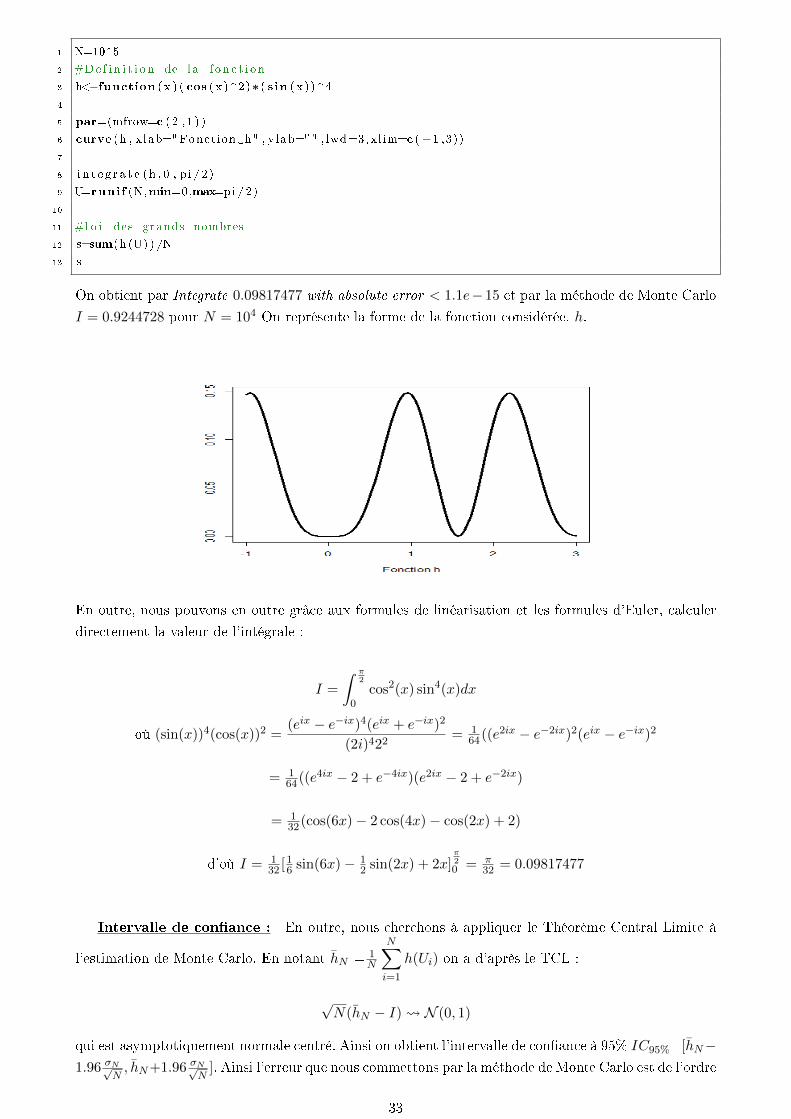
1 N=10^5
2 #De f i n i t i o n de l a f on c t i on
3 h<−function ( x ) ( cos ( x )^2)∗ ( sin ( x ))^4
4
5 par=(mfrow=c ( 2 , 1 ) )
6 curve (h , xlab="Fonction h" , ylab="" , lwd=3, xlim=c (−1 ,3))
7
8 i n t e g r a t e (h , 0 , p i/2)
9 U=runif (N,min=0,max=pi/2)
10
11 #l o i des grands nombres
12 s=sum(h(U) )/N
13 s
On obtient par Integrate 0.09817477 with absolute error < 1.1e−15 et par la méthode de Monte Carlo
I = 0.9244728 pour N = 104 On représente la forme de la fonction considérée. h.
En outre, nous pouvons en outre grâce aux formules de linéarisation et les formules d'Euler, calculer
directement la valeur de l'intégrale :
I =
∫ π2
0cos2(x) sin4(x)dx
où (sin(x))4(cos(x))2 =(eix − e−ix)4(eix + e−ix)2
(2i)422= 1
64((e2ix − e−2ix)2(eix − e−ix)2
= 164((e4ix − 2 + e−4ix)(e2ix − 2 + e−2ix)
= 132(cos(6x)− 2 cos(4x)− cos(2x) + 2)
d'où I = 132 [1
6 sin(6x)− 12 sin(2x) + 2x]
π20 = π
32 = 0.09817477
Intervalle de conance : En outre, nous cherchons à appliquer le Théorème Central Limite à
l'estimation de Monte Carlo. En notant hN = 1N
N∑i=1
h(Ui) on a d'après le TCL :
√N(hN − I) N (0, 1)
qui est asymptotiquement normale centré. Ainsi on obtient l'intervalle de conance à 95% IC95%=[hN−1.96 σN√
N, hN+1.96 σN√
N]. Ainsi l'erreur que nous commettons par la méthode de Monte Carlo est de l'ordre
33
de 1.96 σ√N. Toutefois, σ nous reste inconnu, il nous faut donc utiliser d'estimateur de l'écart type.
D'après un résultat de L3, nous savons que pour estimer σ2 on a σN 2= 1N−1
∑Ni=1[h(Ui)− hN ]2.Notons
que de plus σN 2 est un estimateur sans biais et consistant. A présent nous possédons tous les éléments
pour pouvoir expliciter et calculer un Intervalle de Conance :
IC95% = [hN − 1.96 σN√N, hN + 1.96 σN√
N]
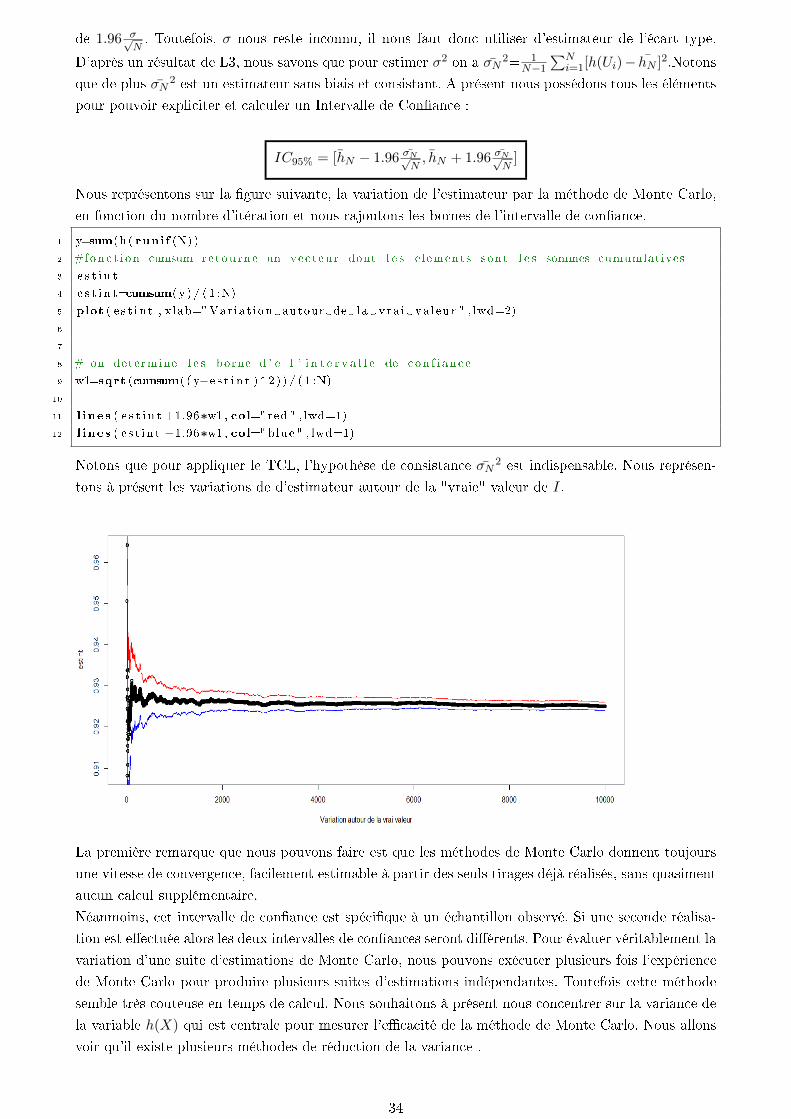
Nous représentons sur la gure suivante, la variation de l'estimateur par la méthode de Monte Carlo,
en fonction du nombre d'itération et nous rajoutons les bornes de l'intervalle de conance.
1 y=sum(h( runif (N) )
2 #fonc t i on cumsum retourne un vecteur dont l e s e lements sont l e s sommes cumumlatives
3 e s t i n t
4 e s t i n t=cumsum( y )/ ( 1 :N)
5 plot ( e s t i n t , x lab="Var ia t ion autour de l a v ra i va l eur " , lwd=2)
6
7
8 # on determine l e s borne d ' e l ' i n t e r v a l l e de con f i anc e
9 w1=sqrt (cumsum( ( y−e s t i n t )^2))/ ( 1 :N)
10
11 l ines ( e s t i n t +1.96∗w1 , col="red " , lwd=1)
12 l ines ( e s t i n t −1.96∗w1 , col="blue " , lwd=1)
Notons que pour appliquer le TCL, l'hypothèse de consistance σN 2 est indispensable. Nous représen-
tons à présent les variations de d'estimateur autour de la "vraie" valeur de I.
La première remarque que nous pouvons faire est que les méthodes de Monte Carlo donnent toujours
une vitesse de convergence, facilement estimable à partir des seuls tirages déjà réalisés, sans quasiment
aucun calcul supplémentaire.
Néanmoins, cet intervalle de conance est spécique à un échantillon observé. Si une seconde réalisa-
tion est eectuée alors les deux intervalles de conances seront diérents. Pour évaluer véritablement la
variation d'une suite d'estimations de Monte Carlo, nous pouvons exécuter plusieurs fois l'expérience
de Monte Carlo pour produire plusieurs suites d'estimations indépendantes. Toutefois cette méthode
semble très couteuse en temps de calcul. Nous souhaitons à présent nous concentrer sur la variance de
la variable h(X) qui est centrale pour mesurer l'ecacité de la méthode de Monte Carlo. Nous allons
voir qu'il existe plusieurs méthodes de réduction de la variance .
34

CHAPITRE 5
MÉTHODES DE RÉDUCTION DE LA VARIANCE
Une évaluation fondée sur des simulations suivant une densité f n'est presque jamais optimale.
Au sens où nous pouvons utiliser des méthodes alternatives qui réduisent la variance empirique. La
méthode de l'échantillonnage préférentiel est la première que nous pouvons étudier .
5.1 Échantillonnage préférentiel
La méthode de l'échantillonnage préférentiel relie une fonction "instrumentale", à une fonction
"d'intérêt" qui est une densité de probabilité. Partons à nouveau du problème qui nous anime à savoir
calculer :
I =
∫Rh(x)f(x)dx
où f une densité de probabilité et h une fonction borélienne positive ou bornée.
La méthode d'échantillonnage préférentiel nous permet d'introduire une fonction de densité g telle que :
I = Ef [h(X)] =
∫Rh(x)f(x)dx =
∫Rh(x)
f(x)
g(x)g(x)dx = Eg[h(x)
f(x)
g(x)].
Nous pouvons alors comme dans une méthode de Monte Carlo de base, appliquer la loi forte des grands
nombres :
1n
N∑i=1
f(Xi)
g(Xi)h(Xi)→ P− psEf [h(X)],
avec (X1...XN ) un échantillon de var i.i.d de densité g.
Quel peut-être l'intérêt d'introduire une telle procédure ?
Cette méthode n'aura d'intérêt que si elle permet de réduire la variance, c'est-à-dire si :
V[h(Y )f(Y )
g(Y )] < V[h(X)], où Y suit la loi de densité g et X la loi de densité f .
Posons Z = h(Y )f(Y )
g(Y )et vérions alors que V[Z]− V[h(X)] < 0 :
Or, E[Z2]− E[Z]2 < E[h(X)2]− E[h(X)]2
⇔ E[Z2]− E[g(X)]2 < E[h(X)2]− E[g(X)]2 car E[Z]2 = E[h(X)]2
⇔ E[Z2] < E[h(X)2]
35
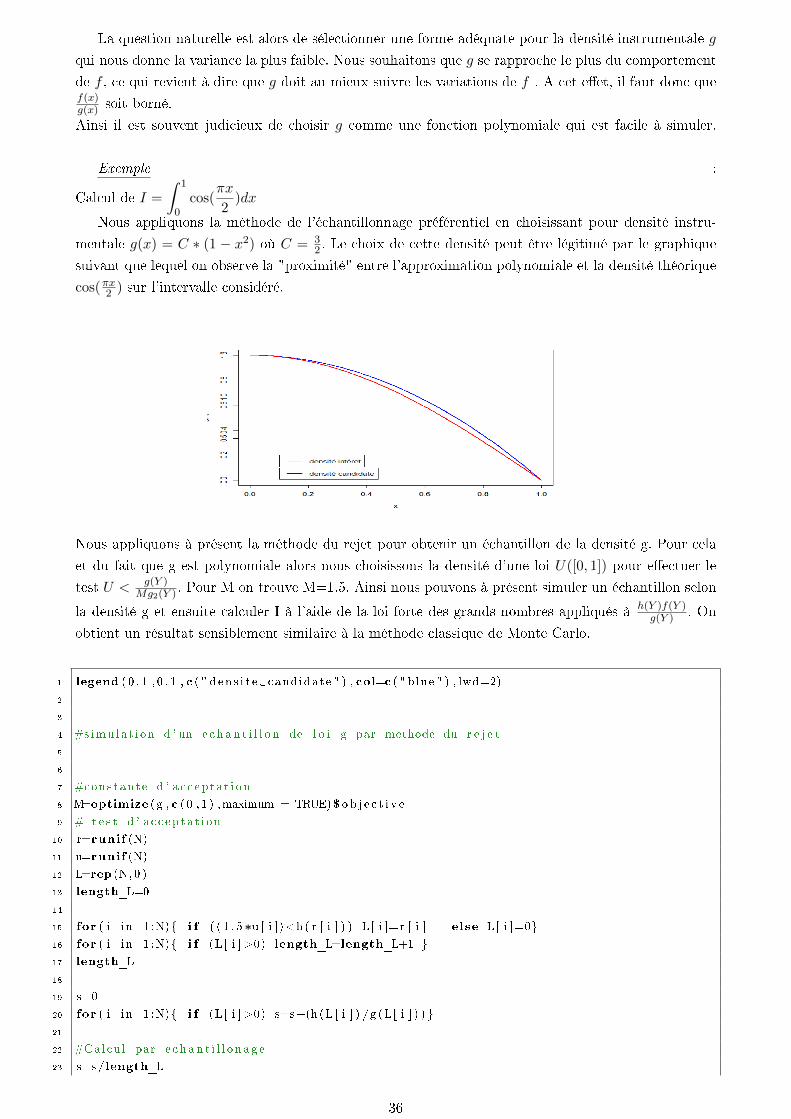
La question naturelle est alors de sélectionner une forme adéquate pour la densité instrumentale g
qui nous donne la variance la plus faible. Nous souhaitons que g se rapproche le plus du comportement
de f , ce qui revient à dire que g doit au mieux suivre les variations de f . A cet eet, il faut donc quef(x)g(x) soit borné.
Ainsi il est souvent judicieux de choisir g comme une fonction polynomiale qui est facile à simuler.
Exemple :
Calcul de I =
∫ 1
0cos(
πx
2)dx
Nous appliquons la méthode de l'échantillonnage préférentiel en choisissant pour densité instru-
mentale g(x) = C ∗ (1 − x2) où C = 32 . Le choix de cette densité peut être légitimé par le graphique
suivant que lequel on observe la "proximité" entre l'approximation polynomiale et la densité théorique
cos(πx2 ) sur l'intervalle considéré.
Nous appliquons à présent la méthode du rejet pour obtenir un échantillon de la densité g. Pour cela
et du fait que g est polynomiale alors nous choisissons la densité d'une loi U([0, 1]) pour eectuer le
test U < g(Y )Mg2(Y ) . Pour M on trouve M=1.5. Ainsi nous pouvons à présent simuler un échantillon selon
la densité g et ensuite calculer I à l'aide de la loi forte des grands nombres appliqués à h(Y )f(Y )g(Y ) . On
obtient un résultat sensiblement similaire à la méthode classique de Monte Carlo.
1 legend ( 0 . 1 , 0 . 1 , c ( " d en s i t e candidate " ) , col=c ( " blue " ) , lwd=2)
2
3
4 #simula t i on d ' un e ch an t i l l o n de l o i g par methode du r e j e t
5
6
7 #constante d ' accepta t i on
8 M=optimize ( g , c ( 0 , 1 ) ,maximum = TRUE)$ ob j e c t i v e
9 # te s t d ' a c c ep ta t i on
10 r=runif (N)
11 u=runif (N)
12 L=rep (N, 0 )
13 length_L=0
14
15 for ( i in 1 :N) i f ( ( 1 . 5∗u [ i ])<h( r [ i ] ) ) L [ i ]= r [ i ] else L [ i ]=0
16 for ( i in 1 :N) i f (L [ i ]>0) length_L=length_L+1
17 length_L
18
19 s=0
20 for ( i in 1 :N) i f (L [ i ]>0) s=s+(h(L [ i ] ) /g (L [ i ] ) )
21
22 #Calcul par e chan t i l l o nag e
23 s=s/length_L
36

24 s
25
26 #Calcul d i r e c t par f on c t i on i n t e g r a t e
27 I=in t e g r a t e (h , 0 , 1 )
28 I
29
30 #ca l c u l par MMC directement sur h
31 S=sum(h(u ) )/N
32 S
33
34 h_2<−f u n c t i c h an t i l l o n a g e
35 V_2=in t e g r a t e ( f ,0 ,1)−(2/pi )^2
36 V_2
Toutefois l'avantage provient d'une réduction de la variance . En eet, après calcul on obtient
V(h(X))=0.5-( 2π )2=0.9471527 et V(h(Y )f(Y )
g(Y ) ) = 0.0009908654 d'où une réduction d'environ 10 fois de
la variance. Quel utilité majeure pour l'échantillonnage préférentiel ?
Une application majeure est la simulation d'événement rares . Nous souhaitons par exemple simu-
ler un événement A ∈ B(R) telle que P(A) << 10−3 . Dans ce cas la méthode de Monte Carlo
classique ne fonctionne plus. En eet, supposons P(A) = 10−9. On dénit X B(1,P(A)) alors
E[X] = P(A) = 10−9. Ainsi un estimateur de la forme 1N
∑Xi est bien trop grossier. En eet, l'espé-
rance du nombre de passage avant l'obtention du première apparition de A est égale à l'espérance d'une
loi géométrique G(P(A)) soit 110−9 . Il faut donc un échantillon de taille minimale 10−9 pour observer
une seule fois l'événement A. Sinon, l'estimateur ainsi que la variance sont nuls.
L'échantillonnage préférentiel nous permet de changer la mesure de probabilité, ainsi nous pouvons
choisir une mesure de probabilité qui augmente l'occurrence de l'événement A, de rendre A "moins
rare".C'est notamment le cas pour le calcul de la VaR en nance, qui est la probabilité de perte maxi-
male potentielle à horizon et niveau de conance donnés.
5.2 Méthode de variables de contrôle
Une méthode de réduction de la variance assez utilisée en statistique est celle des variables de
contrôles. Le principe étant de calculer une espérance E[h(X)] où X est une variable aléatoire de de
densité f , grâce à l'information apportée par E[h0(X)] qui est facilement calculable. En eet, sous
la condition d'intégralité de h0(X), nous pouvons grâce à la loi forte des grands nombres trouver un
estimateur φ0 de E[h0(X)]. Nous rajoutons la contrainte supplémentaire que cet estimateur d'être sans
biais pour E[h0(X)]. En outre on note φ1 l'estimateur de E[h(X)].
On a donc φ0= 1N
N∑i=1
h0(Xi) et φ1= 1N
N∑i=1
h(Xi). Ainsi on considére à présent "l'estimateur pondéré"
φ2=φ1+β(φ0 − E[h0(X)]).
On a E[φ2] = E[φ1] + βE[φ0 − E[h0(X)]] = E[φ1] qui converge bien vers E[h(X)] .
Cette méthode sera donc intéressante à la condition que :
V[φ2] < V[φ1]⇔ V[φ1] + β2V[φ0] + 2βcov(φ1, φ0) < V[φ1]
Il sut donc de minimiser ce polynôme dépendant de β. On trouve alors
β=− cov(φ1,φ0)V [φ0] .
Ainsi pour cette valeur optimale de β on a V[φ2] = V [φ1] + cov(φ1,φ0)V[φ0]
2V [h0(X)]− 2 cov(φ1,φ0)
V[φ0] cov(φ1, φ0)
37

⇔ V [φ2] = V (φ1) + cov(φ1,φ0)V[φ0]
2− 2 cov(φ1,φ0)2
V(φ0
⇔ V[φ2] = V[φ1]− cov(φ1,φ0)2
V [φ0] = V(φ1)[1− cov(φ1,φ0)2
V(φ0)V (φ1) ] = V(φ1)[1− ρ2φ0φ1
]
On a donc toujours V[φ2] < V[φ1], pour cette valeur optimale de β.
Ainsi en pratique nous estimerons le paramètre β = − cov(h0(X),h(X))V(h0(X) , par une simple régression
linéaire entre le vecteur h(Xi) et h0(Xi).
Exemple : Calcul de I =∫ 1
0 exdx :
On peut poser h0 = 1 +X car pour une loi X U([0, 1]), E[1 +X]=32 ( facilement calculable) et
de plus on retrouve le développement limité à l'ordre 1 en O de h(x) = ex.
Ainsi on note φ0 = 1N
N∑i=1
1 +Xi et φ1 = 1N
N∑i=1
eXi On pose φ2 = 1N
N∑i=1
h(Xi) + β[h0(Xi − E[h0(X)]]
d'où φ2 = 1N
N∑i=1
eXi + β∗[1 +Xi −3
2]
Ainsi d'après la méthode de Monte Carlo directe on obtient la valeur de I = 1.719675 Toutefois un
simple calcule de la variance nous permet d'observer une variance d'environ 0.2408044.
1 N=10^4
2 X=runif (N)
3 h<−function ( x )exp( x )
4 h_0<−function ( x)1+x
5
6 #MMC d i r e c t e :
7 s=sum(h(X) )/N
8 s
9
10 #Methode par va r i ab l e de c on t r o l e
11
12 #Calcul de beta
13 reg=lm(h(X)~h_0(X) )
14 summary( reg )
15 beta=reg$coef [ 2 ]
16 beta
17
18 s_0=sum(h(X)−beta∗ (h_0(X)−(3/ 2 ) ) )/N
19 s_0
20
21 plot (cumsum(h(X)−beta∗ (h_0(X)−(3/ 2 ) ) )/ ( 1 :N) , col="red " , axes=yast , lwd=1)
22 abline (h=1.716 , col="gold " , lwd=2)
23 par (new=TRUE)
24 plot (cumsum(h(X) )/ ( 1 :N) , col="blue " , lwd=1)
25
26 legend ( 1000 , 1 . 4 , c ( " va r i ab l e de con t r o l e " ) , col=c ( " red " ) , lwd=1)
27 legend ( 1000 , 1 . 5 , c ( "MMC d i r e c t e " ) , col=c ( " blue " ) , lwd=1)
28
29 # ca l c u l de l a var iance
30 sd (h(X))^2
31
32 sd (h(X)−beta∗ (h_0(X)−(3/2)))^2
38
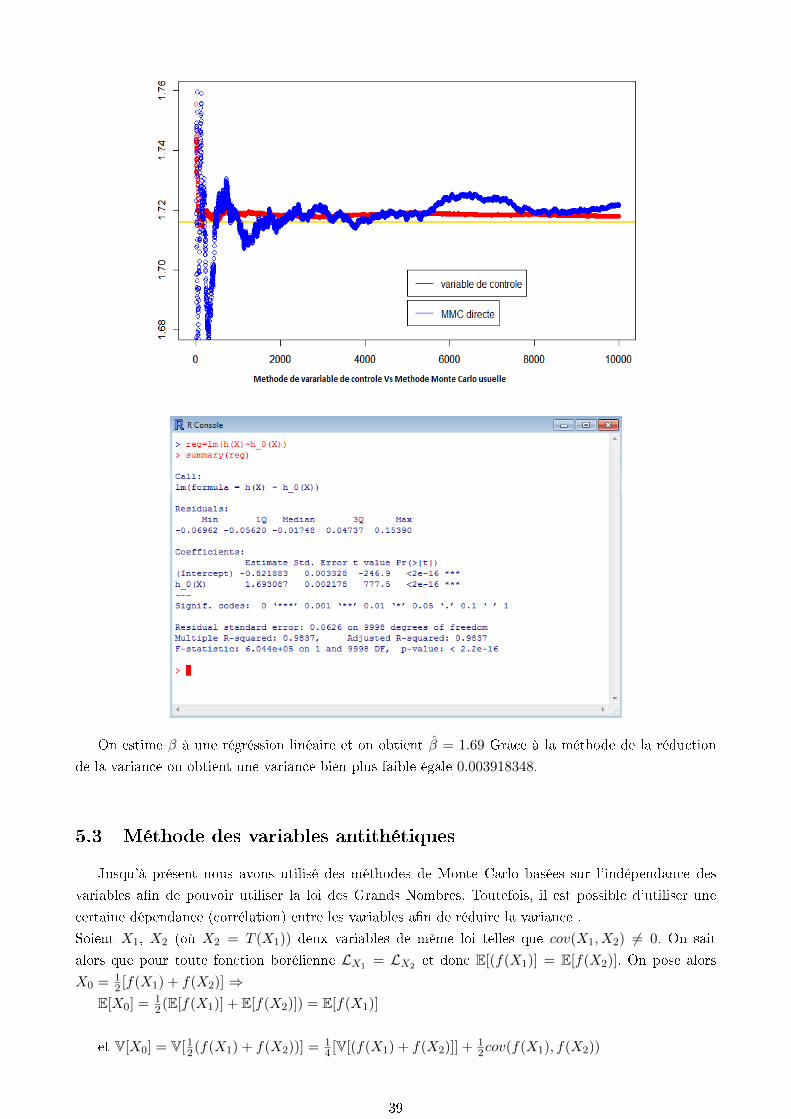
On estime β à une régréssion linéaire et on obtient β = 1.69 Grâce à la méthode de la réduction
de la variance on obtient une variance bien plus faible égale 0.003918348.
5.3 Méthode des variables antithétiques
Jusqu'à présent nous avons utilisé des méthodes de Monte Carlo basées sur l'indépendance des
variables an de pouvoir utiliser la loi des Grands Nombres. Toutefois, il est possible d'utiliser une
certaine dépendance (corrélation) entre les variables an de réduire la variance .
Soient X1, X2 (où X2 = T (X1)) deux variables de même loi telles que cov(X1, X2) 6= 0. On sait
alors que pour toute fonction borélienne LX1 = LX2 et donc E[(f(X1)] = E[f(X2)]. On pose alors
X0 = 12 [f(X1) + f(X2)] ⇒
E[X0] = 12(E[f(X1)] + E[f(X2)]) = E[f(X1)]
et V[X0] = V[12(f(X1) + f(X2))] = 1
4 [V[(f(X1) + f(X2)]] + 12cov(f(X1), f(X2))
39

= 12 [V[(f(X1) + cov(f(X1), f(X2))]
Ainsi la méthode "classique" de Monte Carlo avec f(X1) indépendante de f(X2) nous permettrait
d'obtenir une variance : V[12(f(X1) + f(X2))] = 1
2V [f(X1)]. Alors que la méthode des variables anti-
thétique nous fournit une variance égale à 12(V[f(X1)]+cov(f(X1), f(X2)). Il en ressort que la variance
est réduite à la condition que cov(f(X1), f(X2)) < 0.
A quelle condition sur f et sur T peut-on armer que les variables f(X1) et f(X2) sont négative-
ment corrélées ?
D'après un théorème (dont la démonstration sort du cadre de ce mémoire), nous avons des condi-
tions susantes, à savoir : Si f : R → R est une fonction monotone, et si T : R → R est décroissante,
si de plus T (X) et X on la même loi alors les variables T (X) et X sont négativement corrélées.
On peut alors appliquer la méthode de Monte Carlo avec l'estimateur : 1N
N∑i=1
X0,i.
Ainsi si on veut calculer I =
∫ 1
0e−xdx
I =
∫ 1
0e−xdPU (x) U U([0, 1]) or U = 1− U
donc I =
∫ 1
0e−xdP1−U (x). Ainsi on construit la méthode des variables antithétiques en posant
X0 = 12(eU + e1−U ) où x 7→ e−x est monotone et u 7→ 1− u est décroissante. Ainsi cov(eU + e1−U ) < 0
1 N=10^4
2 h<−function ( x )exp(−x )
3 U1=runif (N)
4
5 #Calcul d i r e c t
6 I=0
7 I=in t e g r a t e (h , 0 , 1 )
8 I
9
10 #Methode monte c a r l o d i r e c t e
11 s=sum(h(U1) )/N
12 s
13
14 var1=(sd (h(U1))^2
15 var1
16
17 e s t i n t=0
18 e s t i n t=cumsum(h(U) )/ ( 1 :N)
19 plot ( yl im=c ( 0 . 6 1 , 0 . 6 5 ) , e s t i n t , col="red " , lwd=2)
20
21 #Methode des v a r i a b l e s an t i t h e t i q u e s
22 X0=0.5∗ (h(U)+h(1−U))
23 s0=sum(X0)/N
24 s0
25
26 var0=(sd (X0))^2
27 var0
28
29 par (new=TRUE)
30 e s t i n t 0=0
40
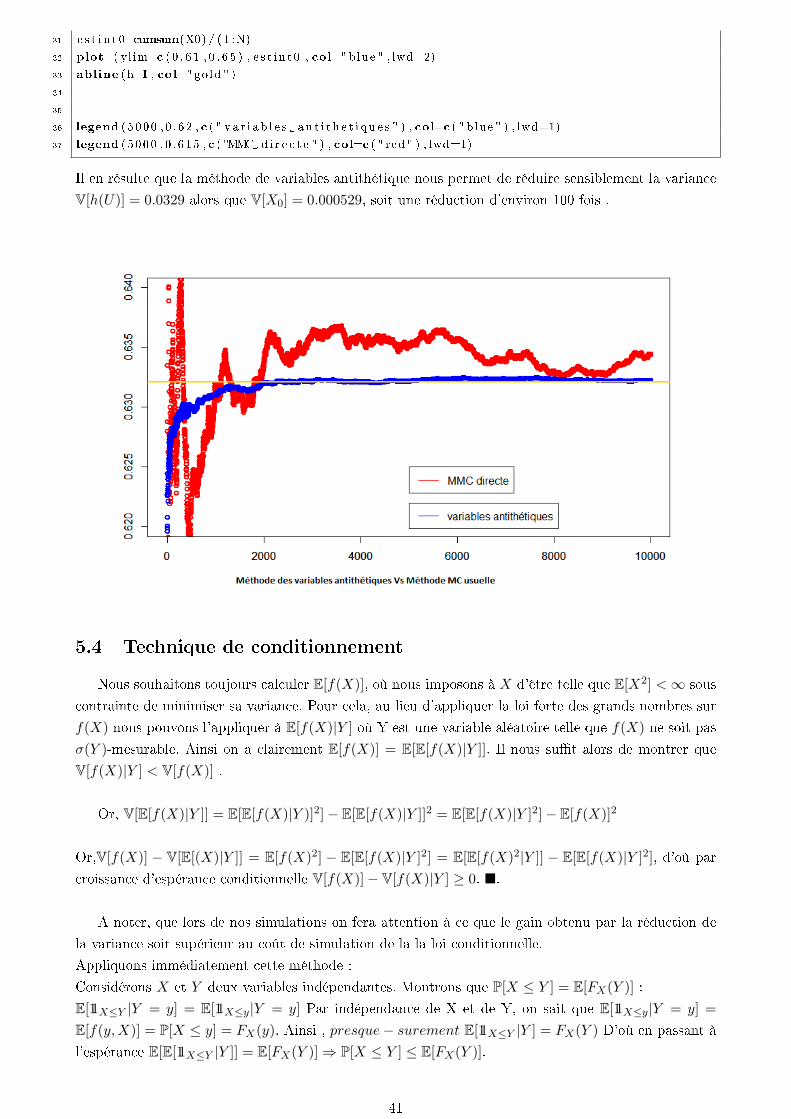
31 e s t i n t 0=cumsum(X0)/ ( 1 :N)
32 plot ( yl im=c ( 0 . 6 1 , 0 . 6 5 ) , e s t i n t 0 , col="blue " , lwd=2)
33 abline (h=I , col="gold " )
34
35
36 legend ( 5000 , 0 . 62 , c ( " v a r i a b l e s an t i t h e t i q u e s " ) , col=c ( " blue " ) , lwd=1)
37 legend (5000 ,0 . 615 , c ( "MMC d i r e c t e " ) , col=c ( " red " ) , lwd=1)
Il en résulte que la méthode de variables antithétique nous permet de réduire sensiblement la variance
V[h(U)] = 0.0329 alors que V[X0] = 0.000529, soit une réduction d'environ 100 fois .
5.4 Technique de conditionnement
Nous souhaitons toujours calculer E[f(X)], où nous imposons à X d'être telle que E[X2] <∞ sous
contrainte de minimiser sa variance. Pour cela, au lieu d'appliquer la loi forte des grands nombres sur
f(X) nous pouvons l'appliquer à E[f(X)|Y ] où Y est une variable aléatoire telle que f(X) ne soit pas
σ(Y )-mesurable. Ainsi on a clairement E[f(X)] = E[E[f(X)|Y ]]. Il nous sut alors de montrer que
V[f(X)|Y ] < V[f(X)] .
Or, V[E[f(X)|Y ]] = E[E[f(X)|Y )]2]− E[E[f(X)|Y ]]2 = E[E[f(X)|Y ]2]− E[f(X)]2
Or,V[f(X)] − V[E[(X)|Y ]] = E[f(X)2] − E[E[f(X)|Y ]2] = E[E[f(X)2|Y ]] − E[E[f(X)|Y ]2], d'où par
croissance d'espérance conditionnelle V[f(X)]− V[f(X)|Y ] ≥ 0. .
A noter, que lors de nos simulations on fera attention à ce que le gain obtenu par la réduction de
la variance soit supérieur au coût de simulation de la la loi conditionnelle.
Appliquons immédiatement cette méthode :
Considérons X et Y deux variables indépendantes. Montrons que P[X ≤ Y ] = E[FX(Y )] :
E[11X≤Y |Y = y] = E[11X≤y|Y = y] Par indépendance de X et de Y, on sait que E[11X≤y|Y = y] =
E[f(y,X)] = P[X ≤ y] = FX(y). Ainsi , presque− surement E[11X≤Y |Y ] = FX(Y ) D'où en passant à
l'espérance E[E[11X≤Y |Y ]] = E[FX(Y )]⇒ P[X ≤ Y ] ≤ E[FX(Y )].
41

Troisième partie
Simulation de Chaînes de Markov et
algorithme de Metropolis Hastings
42

CHAPITRE 6
RAPPELS SUR LES CHAINES DE MARKOV
Jusqu'à présent nous avons mis en évidence diérentes méthodes pour simuler une variable aléatoire
de loi π donnée. Toutefois, il existe des lois qui sont plus diciles à expliciter, comme par exemple des
loi discrète de Card très grand .Ce qui ralentirait considérablement les méthodes de rejet ou d'inversion
de fonction de répartition. Ainsi pour rester ecace en temps de calcul nous introduisons les méthodes
de Monte Carlo par chaine de Markov. Le principe général qui sera exposé dans la suite est de parve-
nir à simuler une variable de loi π en considérant une chaine de Markov de loi stationnaire π. Ainsi
asymptotiquement, on obtient une simulation de la loi π.
Ainsi la diculté sera de pouvoir déterminer des matrices de transition de loi stationnaire π.
Dénition :Un processus X := (Xn)n∈N est dit Markovien "discret" si Xn+1 dépend de (X0....Xn)
que par Xn.
On note dans la suite E l'ensemble des états de la chaine, et on suppose E ⊂ N, on note de plus Q sa
matrice de transition qui est une matrice stochastique telle que :
P(Xn+1 = x|X0....Xn) = Q(xn, x)
∑
y∈E Q(x, y) = 1, ∀x ∈ E
P(X0....Xn) = π(x0)Q(x0, x)....Q(xn−1, xn)
où π0 est la loi initiale. On a alors π0Qn pour loi de Xn
En Outre,
On dit qu'une chaine de Markov X est invariante si π0 = Qπ0
On dit de même qu'une chaine est irréductible si ∀x, y ∈ E,∃n ∈ N / P(X0 = x|Xn = y) =
Qn(x, y) > 0, ce qui signie qu'on peut atteindre tous les états à partir de n'importe quel état
avec un probabilité strictement positive.
6.1 Théorème ergodique
Le caractère récurrent de la chaine est assez fort puisqu'il permet d'armer que la loi stationnaire
est aussi la loi limite.D'où le théorème ergodique suivant :
Théorème :Supposons que Q est irréductible et qu'il existe une probabilité π telle que πQ = π.Alors
π est l'unique probabilité invariante,
43

tous les états sont récurrents
Si X := (Xn)n≥1 désigne la chaine de Markov stationnaire au sens strict de loi π,alors, pour
toute fonction f telle que∫|f(x)|dπ(x) <∞ :
limn→+∞
1
n
n∑p=1
f(Xp) =
∫f(x)dπ(x) p.s
Ce théorème nous permet donc de généraliser la loi forte des grands nombres aux Chaines de Markov.
Ainsi pour obtenir une simulation suivant une densité cible f il sut donc de générer une chaine
de Markov de telle sorte que la loi limite soit f. On peut alors appliquer le théorème ergodique pour
calculer les intégrales qui dépendent de f . Il nous faut à présent déterminer une démarche pour générer
une chaine de Markov de loi stationnaire f . C'est le but de l'algorithme de Metropolis Hasting.
44

CHAPITRE 7
ALGORITHME DE METROPOLIS HASTING
Le principe est le suivant :
Soit f une densité cible donnée , on choisit une densité instrumentale q(y|x) arbitraire pour laquelle on
souhaite qu'elle soit simple à simuler et qu'elle ait une dispersion assez importante pour que la chaine
explore tout le support de f . Insistons sur le fait que q(y|x) est arbitraire et qu'il est ainsi possible de
choisir q(y|x) = q(y) indépendante de l'état de X.
Ainsi l'algorithme est le suivant :
On initialise la chaine X0 = x0 avec x0 ∈ E puis on construit Xn de façon itérative
Supposons Xn = xn, on génère alors deux variables indépendantes Un, Yn telle que :
Yn suit la loi Q(xn, .)
Un U([0, 1])
On pose alors ρ(x, y) = min[1,π(y)Q(y, x)
π(x)Q(x, y)]
et on dénit
Xn+1 = Yn si Un ≤ ρ(Xn, Yn)
Xn+1 = Xn, sinon
Nous pouvons généraliser cet algorithme. En eet la loi instrumentale est choisie arbitrairement,
ainsi nous n'avons pas de raison de choisir une loi instrumentale dépendant de la chaine xt. Il existe
donc une version de Metropolis Hasting indépendant qui se présente de la façon suivant :
On initialise la chaine X0 = x0
Yn suit la loi q(y) indépendante de x
Un U([0, 1])
On pose alors ρ(x, y) = min[1,π(y)q(x))
π(x)q(y)]
et on dénit :
Xn+1 = Yn si Un ≤ ρ(Xn, Yn)
Xn+1 = Xn, sinon
45

7.0.1 Simulation d'une loi Bêta via Metropolis Hasting
Bien que l'algorithme permette de simuler des chaines de Markov en temps discret
nous pouvons toutefois générer un échantillon de Metropolis dont la distribution suit une
loi continue. Dans le cas continu il faut donc raisonner sur les densités. Pour cela il nous
faut choisir la loi cible de densité f par rapport à la mesure de Lebesgue sur R , et la loi
instrumentale de densité q.
Nous allons appliquer l'algorithme précédent pour une densité f d'une loi β(4.5, 8.5) que nous avions
déja réaliser par méthode de rejet. Le support d'une loi bêta étant [0,1],il nous sura alors de choisir
pour densité instrumentale une loi U([0, 1]) qui ne dépend par de la valeur de la chaine, ce qui facilitera
la réalisation de l'algorithme.
1 a=4.5
2 b=8.5
3
4 N=10^5
5
6 x=rep ( runif ( 1 ) ,N) # i n i t i a l i s a t i o n de l a cha ine
7
8 for ( i in 2 :N)
9 can <− runif (1 ) # l o i de p ropo s i t i on uniforme , depend pas de l a cha ine
10 prob <− min(1 , (dgamma( can , a , b )/dgamma( x [ i −1] , a , b ) ) )
11
12 u <− runif (1 )
13 i f (u < prob )
14 x [ i ] <− can
15 else x [ i ]=x [ i −1]
16
17
18 # So r t i e s graphiques
19 par (mfrow=c ( 1 , 2 ) )
20 hist ( vec , col=" l i g h t b l u e " ,main="beta ( 4 . 5 , 8 . 5 ) " , p r obab i l i t y=TRUE, , ylim=c ( 0 , 4 ) )
21 x=rbeta (N, 4 . 5 , 8 . 5 )
22 l ines (density ( x ) , col=' red ' , lwd=3, ylim=c ( 0 , 4 ) )
23 ac f ( v )
46
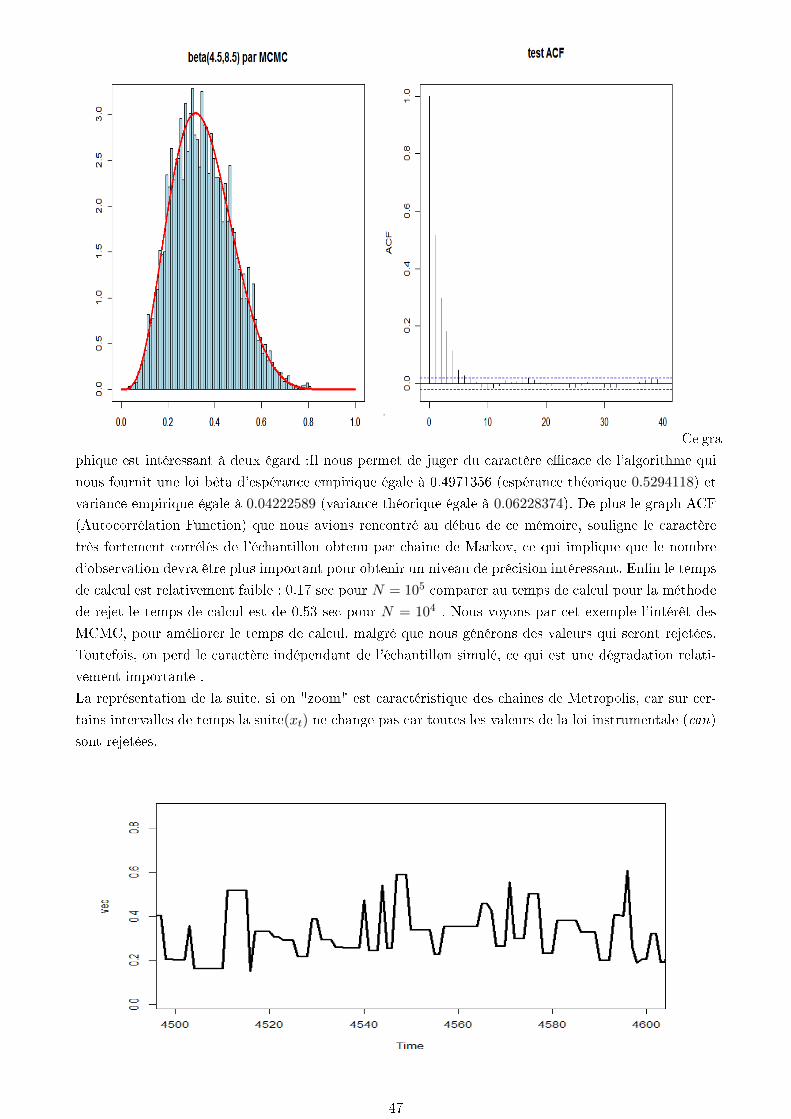
Ce gra-
phique est intéressant à deux égard :Il nous permet de juger du caractère ecace de l'algorithme qui
nous fournit une loi bêta d'espérance empirique égale à 0.4971356 (espérance théorique 0.5294118) et
variance empirique égale à 0.04222589 (variance théorique égale à 0.06228374). De plus le graph ACF
(Autocorrélation Function) que nous avions rencontré au début de ce mémoire, souligne le caractère
très fortement corrélés de l'échantillon obtenu par chaine de Markov, ce qui implique que le nombre
d'observation devra être plus important pour obtenir un niveau de précision intéressant. Enn le temps
de calcul est relativement faible : 0.17 sec pour N = 105 comparer au temps de calcul pour la méthode
de rejet le temps de calcul est de 0.53 sec pour N = 104 . Nous voyons par cet exemple l'intérêt des
MCMC, pour améliorer le temps de calcul, malgré que nous générons des valeurs qui seront rejetées.
Toutefois, on perd le caractère indépendant de l'échantillon simulé, ce qui est une dégradation relati-
vement importante .
La représentation de la suite, si on "zoom" est caractéristique des chaines de Metropolis, car sur cer-
tains intervalles de temps la suite(xt) ne change pas car toutes les valeurs de la loi instrumentale (can)
sont rejetées.
47
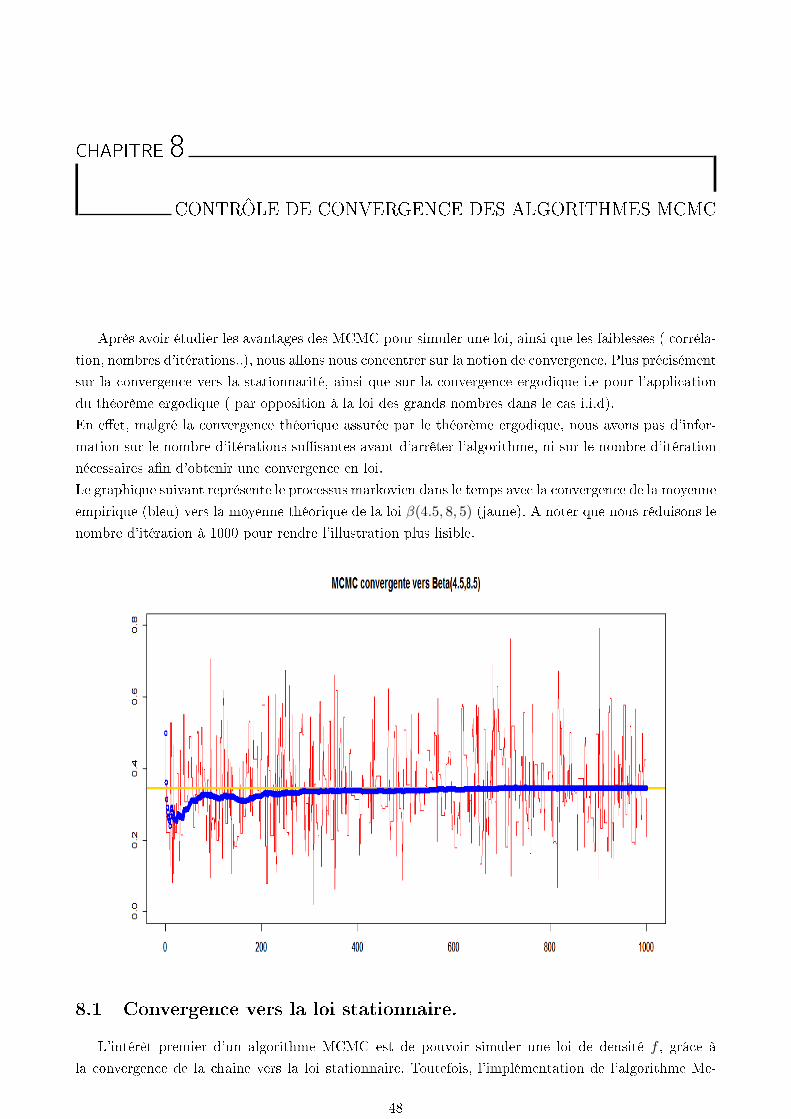
CHAPITRE 8
CONTRÔLE DE CONVERGENCE DES ALGORITHMES MCMC
Après avoir étudier les avantages des MCMC pour simuler une loi, ainsi que les faiblesses ( corréla-
tion, nombres d'itérations..), nous allons nous concentrer sur la notion de convergence. Plus précisément
sur la convergence vers la stationnarité, ainsi que sur la convergence ergodique i.e pour l'application
du théorème ergodique ( par opposition à la loi des grands nombres dans le cas i.i.d).
En eet, malgré la convergence théorique assurée par le théorème ergodique, nous avons pas d'infor-
mation sur le nombre d'itérations susantes avant d'arrêter l'algorithme, ni sur le nombre d'itération
nécessaires an d'obtenir une convergence en loi.
Le graphique suivant représente le processus markovien dans le temps avec la convergence de la moyenne
empirique (bleu) vers la moyenne théorique de la loi β(4.5, 8, 5) (jaune). A noter que nous réduisons le
nombre d'itération à 1000 pour rendre l'illustration plus lisible.
8.1 Convergence vers la loi stationnaire.
L'intérêt premier d'un algorithme MCMC est de pouvoir simuler une loi de densité f , grâce à
la convergence de la chaine vers la loi stationnaire. Toutefois, l'implémentation de l'algorithme Me-
48
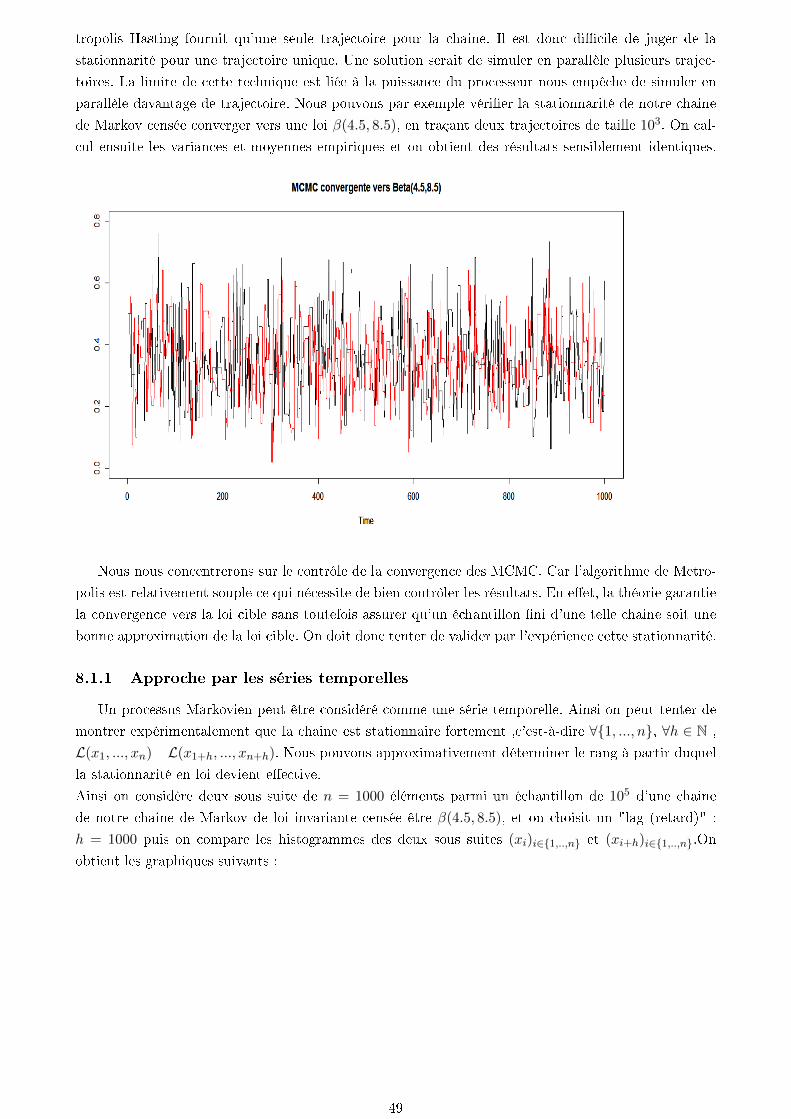
tropolis Hasting fournit qu'une seule trajectoire pour la chaine. Il est donc dicile de juger de la
stationnarité pour une trajectoire unique. Une solution serait de simuler en parallèle plusieurs trajec-
toires. La limite de cette technique est liée à la puissance du processeur nous empêche de simuler en
parallèle davantage de trajectoire. Nous pouvons par exemple vérier la stationnarité de notre chaine
de Markov censée converger vers une loi β(4.5, 8.5), en traçant deux trajectoires de taille 103. On cal-
cul ensuite les variances et moyennes empiriques et on obtient des résultats sensiblement identiques.
Nous nous concentrerons sur le contrôle de la convergence des MCMC. Car l'algorithme de Metro-
polis est relativement souple ce qui nécessite de bien contrôler les résultats. En eet, la théorie garantie
la convergence vers la loi cible sans toutefois assurer qu'un échantillon ni d'une telle chaine soit une
bonne approximation de la loi cible. On doit donc tenter de valider par l'expérience cette stationnarité.
8.1.1 Approche par les séries temporelles
Un processus Markovien peut être considéré comme une série temporelle. Ainsi on peut tenter de
montrer expérimentalement que la chaine est stationnaire fortement ,c'est-à-dire ∀1, ..., n, ∀h ∈ N ,
L(x1, ..., xn)= L(x1+h, ..., xn+h). Nous pouvons approximativement déterminer le rang à partir duquel
la stationnarité en loi devient eective.
Ainsi on considère deux sous suite de n = 1000 éléments parmi un échantillon de 105 d'une chaine
de notre chaine de Markov de loi invariante censée être β(4.5, 8.5), et on choisit un "lag (retard)" :
h = 1000 puis on compare les histogrammes des deux sous suites (xi)i∈1,..,n et (xi+h)i∈1,..,n.On
obtient les graphiques suivants :
49
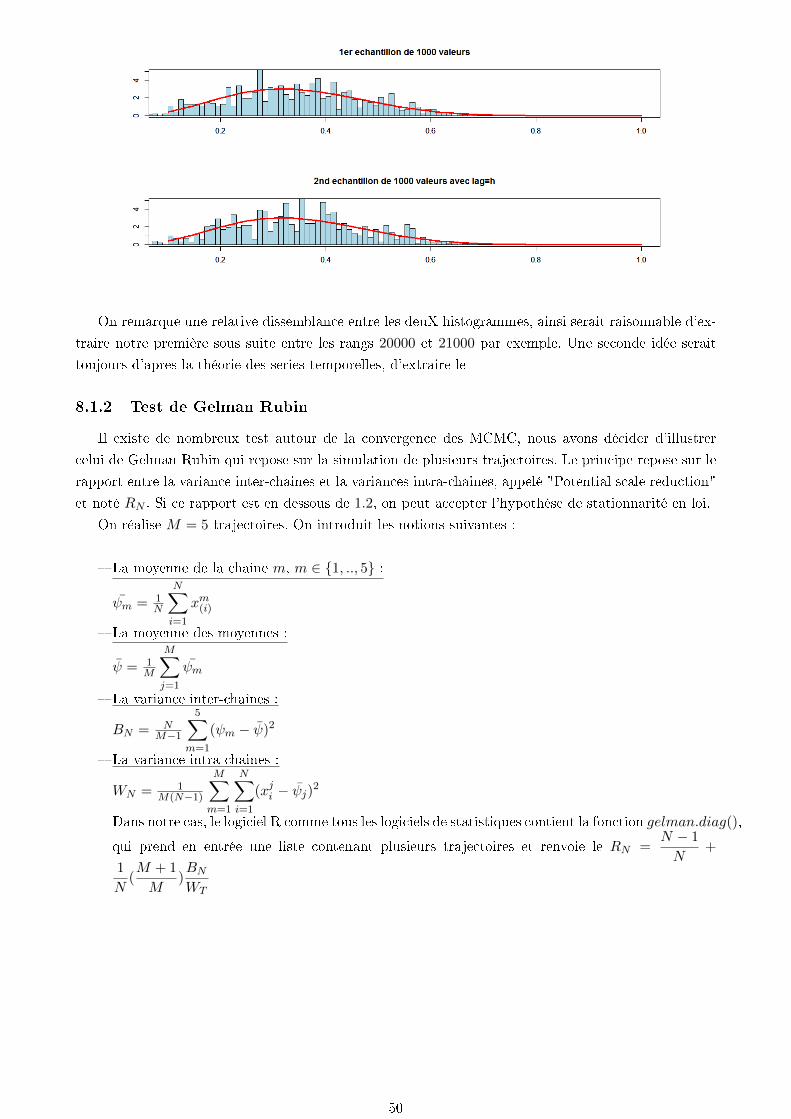
On remarque une relative dissemblance entre les deuX histogrammes, ainsi serait raisonnable d'ex-
traire notre première sous suite entre les rangs 20000 et 21000 par exemple. Une seconde idée serait
toujours d'apres la théorie des series temporelles, d'extraire le
8.1.2 Test de Gelman Rubin
Il existe de nombreux test autour de la convergence des MCMC, nous avons décider d'illustrer
celui de Gelman Rubin qui repose sur la simulation de plusieurs trajectoires. Le principe repose sur le
rapport entre la variance inter-chaines et la variances intra-chaines, appelé "Potential scale reduction"
et noté RN . Si ce rapport est en dessous de 1.2, on peut accepter l'hypothèse de stationnarité en loi.
On réalise M = 5 trajectoires. On introduit les notions suivantes :
La moyenne de la chaine m, m ∈ 1, .., 5 :
ψm = 1N
N∑i=1
xm(i)
La moyenne des moyennes :
ψ = 1M
M∑j=1
ψm
La variance inter-chaînes :
BN = NM−1
5∑m=1
(ψm − ψ)2
La variance intra-chaines :
WN = 1M(N−1)
M∑m=1
N∑i=1
(xji − ψj)2
Dans notre cas, le logiciel R comme tous les logiciels de statistiques contient la fonction gelman.diag(),
qui prend en entrée une liste contenant plusieurs trajectoires et renvoie le RN =N − 1
N+
1
N(M + 1
M)BNWT
50
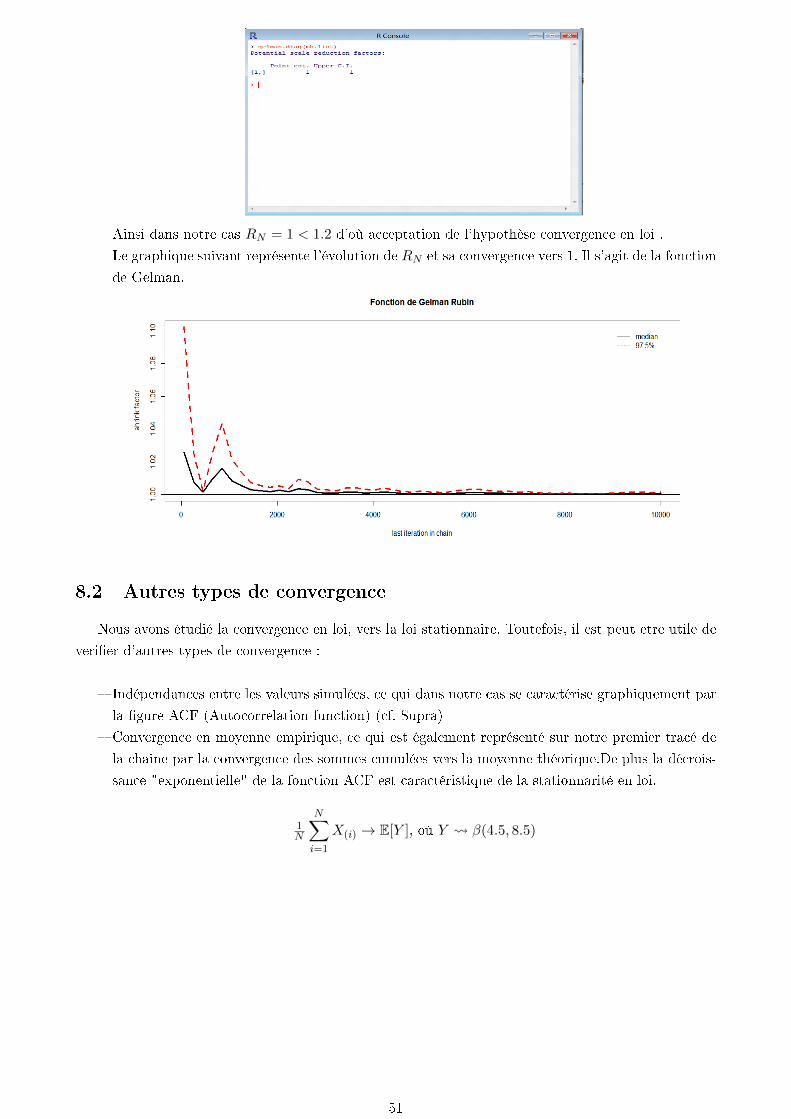
Ainsi dans notre cas RN = 1 < 1.2 d'où acceptation de l'hypothèse convergence en loi .
Le graphique suivant représente l'évolution de RN et sa convergence vers 1. Il s'agit de la fonction
de Gelman.
8.2 Autres types de convergence
Nous avons étudié la convergence en loi, vers la loi stationnaire. Toutefois, il est peut etre utile de
verier d'autres types de convergence :
Indépendances entre les valeurs simulées, ce qui dans notre cas se caractérise graphiquement par
la gure ACF (Autocorrelation function) (cf. Supra)
Convergence en moyenne empirique, ce qui est également représenté sur notre premier tracé de
la chaine par la convergence des sommes cumulées vers la moyenne théorique.De plus la décrois-
sance "exponentielle" de la fonction ACF est caractéristique de la stationnarité en loi.
1N
N∑i=1
X(i) → E[Y ], où Y β(4.5, 8.5)
51

Quatrième partie
Exercices
52
Cette partie sera réservée à la résolution d'exercices tirés de la brochure :Méthodes de Monte Carlo
de Mme Annie MILLET 1 :
8.3 Exercice 2.10 : Algorithme de Jönk
Commençons par déterminer la loi de U1(k)1a et U2(k)
1b ∀k ≥ 1 a, b ∈]0, 1[
Soit u, v ∈]0, 1[, P[U1(k)1a ≤ u] = P[U1(k) ≤ ua] d'où on obtient fU1(k)(u) = aua−111]0,1[,∀k ≥ 1, a ∈
]0, 1[ On obtient de façon analogue fU2(k)(u) = bub−111]0,1[,∀k ≥ 1, b ∈]0, 1[
A présent on cherche à déterminer la loi de : X := VτSτ
X =∞∑k=1
VkSk
11τ=k =∞∑k=1
VkVk +Wk
11τ=k
Déterminons grâce à un changement de variable la loi de ( VkVk+Wk
, Vk +Wk) :
On a φ qui est une bijection de D dans ∆ où D =]0, 1[ ouvert de R2 et ∆ =]0, 1[ ouvert de R2 tel
que ∀(x, y) ∈ D, φ(x, y) = ( xx+y , x+ y) et ∀(u, v) ∈ ∆ φ−1(u, v) = (uv, v(1− u)).
En eet, xx+y = u
x+ y = v
⇔
x = u(x+ y)
x+ y = v
⇔
uv = x
v(1− u) = y
Or,(x, y) ∈]0, 1[2 d'où
⇔
uv ∈]0, 1[
v(1− u) ∈]0, 1[
⇔
v ∈]0, 1
u [
v ∈]0, 11−u [
En notant ∀u ∈ R∗ \ 1, Au = v ∈ R|0 < v < 1u et Bu = v ∈ R|0 < v < 1
1−u : Si u ∈]0, 1[, Au ∩Bu = v ∈ R|0 < v < min( 1
u ,1
1−u) si u ∈ R+ \ [0, 1], Au ∩Bu = ∅
1. http ://www.proba.jussieu.fr/pageperso/millet/montecarlo.pdf page 30-36
53

Ainsi ∀(u, v) ∈ ∆ ∃!(x, y) ∈ D | φ−1(u, v) = (x, y). Donc φ est bijective.De plus on montrer facile-
ment que φ est C1 De plus, ∀(u, v) ∈ ∆|Jφ−1(u, v)| =
∣∣∣∣∣ v u
−v (1− u)
∣∣∣∣∣ = |v| 6= 0
Ainsi on peut conclure que φ est un C1-diéomorphisme .On peut alors appliquer le théorème de la bi-
jection et armer qu'il existe une densité pour la loi de (VkSk , Sk) égale à g(VkSk,Sk)
(u, v) = fU,V (uv, v(1−
u))11∆(uv, v(1− u))|Jφ−1(u, v)|, ∀(u, v) ∈ ∆. Or d'après le calcul des lois de U1a et V
1b fait précédem-
ment, et par indépendance de U et V comme fonctions boréliennes positives de U1a (resp.) V
1b , on ob-
tient g(VkSk,Sk)
(u, v) = abua−1(1−u)b−1va+b−111(u,v)∈]0,1[2 . D'où gU (u) =∫
]0,1[ g(U,V )(u, v)dv = aba+bu
a(1−
u)b−111u∈]0,1[.
Ainsi, nous pouvons à présent déterminer loi de X := VτSτ
: Pour toute fonction borélienne positive g,∞∑k=1
E[g(VkSk
)11(τ=k)]=
∞∑k=1
E[g(VkSk
)11(∩k−1i=1 Si > 1)
11(Sk>1)]
=∞∑k=1
E[g(VkSk
)11(∩k−1i=1 Si > 1)
11(Sk>1)]=ind.
∞∑k=1
E[g(VkSk
)11(Sk<1)P[(∩k−1i=1 Si > 1)].
Or,par indépendance P[(∩k−1i=1 Si > 1)] =
k−1∏i=1
P[U1(i)1a + U2(i)
1b > 1]=id.P[U1(i)
1a + U2(i)
1b > 1]k−1.
D'après le produit de convolution, E[11U1(i)
1a+U2(i)
1b>1
] =
∫R2
11U1(i)
1a+U2(i)
1b>1
baua−1vb−111(u,v)∈]0,1[2dudv =∫ 1
0
∫ 1
1−vabua−1vb−1dudv =
∫ 1
0bvb−1(1− (1−v)a)dv =
∫ 1
0bvb−1dv− b
∫ 1
0vb−1(1−v)adv = 1− bβ(a+
1, b) = 1− bΓ(a+ 1)Γ(b)
Γ(a+ b+ 1).
Donc∞∑k=0
(1− bΓ(a+ 1)Γ(b)
Γ(a+ b+ 1))k=serie−go =
Γ(a+ b+ 1)
bΓ(a+ 1)Γ(b)
Ainsi, E[g(VkSk )11(Sk<1)P[(∩k−1i=1 Si > 1)] =
∫Rg(x)
ab
a+ bxa−1(1 − x)b− 111x∈]0,1[dx ∗
Γ(a+ b+ 1)
bΓ(a+ 1)Γ(b).
Or, aba+b ∗Γ(a+ b+ 1)
bΓ(a+ 1)Γ(b)=a(a+ b)Γ(a+ b)
(a+ b)aΓ(a)Γ(b)= 1
β(a,b)
Ainsi, X a pour densité : 1β(a,b)x(1 − x)a−111b−1x ∈]0, 1[ qui est la densité d'une β(a, b)
Nous pouvons donc simuler une loi bêta de paramètre (a, b) = (0.5, 0.5) :
1 #Jonk
2
3 N=10000
4 a=.5
5 b=.5
6
7 t1=proc . time ( )
8
9 for ( i in 1 :N)
10 U1=runif (N)
11 U2=runif (N)
12
13 V=U1^(1/a )
14 W=U2^(1/b)
15 S=V+W
16
17 X[ i ]=V[ 1 ] /S [ 1 ]
18 k=1
19 i f (S [ k ]<1)X[ i ]=V[ k ] /S [ k ]
20
21 k=k+1
22
54
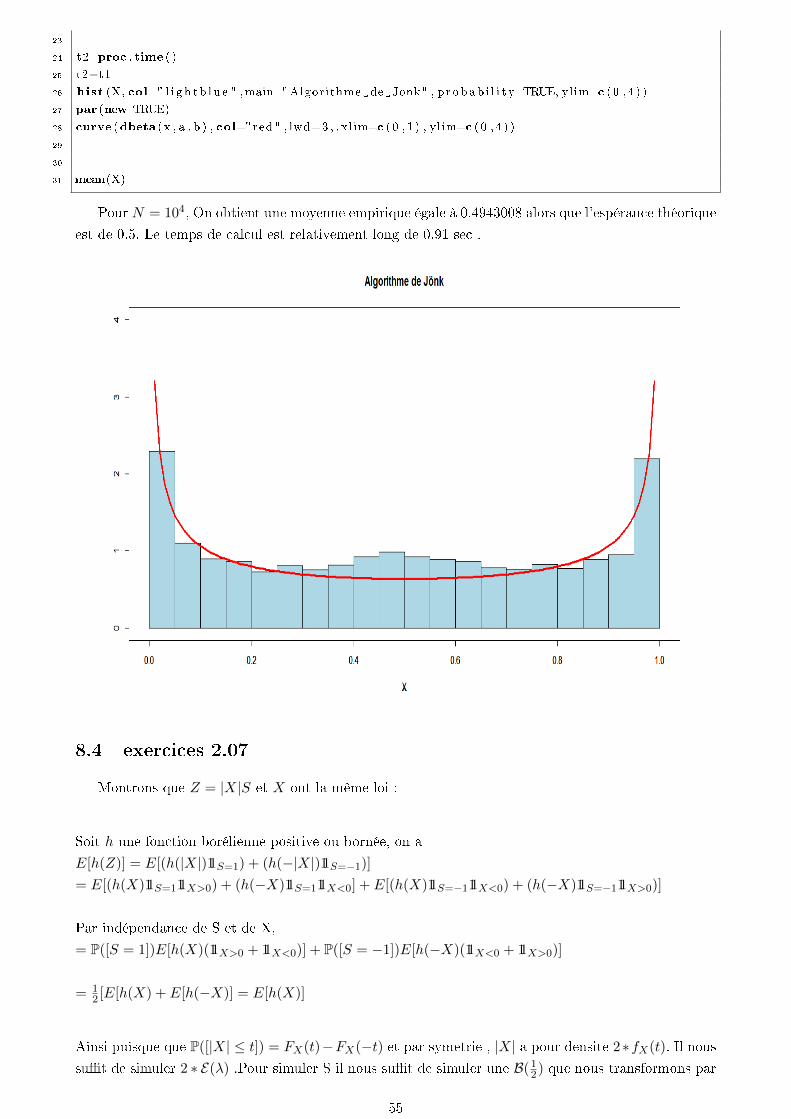
23
24 t2=proc . time ( )
25 t2−t1
26 hist (X, col=" l i g h t b l u e " ,main="Algorithme de Jonk" , p r obab i l i t y=TRUE, ylim=c ( 0 , 4 ) )
27 par (new=TRUE)
28 curve (dbeta (x , a , b ) , col="red " , lwd=3 , , xl im=c ( 0 , 1 ) , yl im=c ( 0 , 4 ) )
29
30
31 mean(X)
Pour N = 104, On obtient une moyenne empirique égale à 0.4943008 alors que l'espérance théorique
est de 0.5. Le temps de calcul est relativement long de 0.91 sec .
8.4 exercices 2.07
Montrons que Z = |X|S et X ont la même loi :
Soit h une fonction borélienne positive ou bornée, on a
E[h(Z)] = E[(h(|X|)11S=1) + (h(−|X|)11S=−1)]
= E[(h(X)11S=111X>0) + (h(−X)11S=111X<0] + E[(h(X)11S=−111X<0) + (h(−X)11S=−111X>0)]
Par indépendance de S et de X,
= P([S = 1])E[h(X)(11X>0 + 11X<0)] + P([S = −1])E[h(−X)(11X<0 + 11X>0)]
= 12 [E[h(X) + E[h(−X)] = E[h(X)]
Ainsi puisque que P([|X| ≤ t]) = FX(t)−FX(−t) et par symetrie , |X| a pour densite 2∗fX(t). Il nous
sut de simuler 2 ∗ E(λ) .Pour simuler S il nous sut de simuler une B(12) que nous transformons par
55

la fonction x → 2x − 1 pour se ramener sur −1, 1. Nous construisons ainsi Z qui est de même loi
que X.
1
2 f<−function (x ,N)−log ( runif (N) )/x
3 exp1=f (1 ,10^7)
4
5 b=rbinom ( 10^4 ,1 , . 5 )
6 S=(2∗b)−1
7
8 Z=2∗exp1∗S9 hist (Z , col=" l i g h t b l u e " ,main="exo3 . 7 " )
8.5 Exercice 2.10
1 # Exo 2 .10
2
3
4 #1 er
5
6 N=rep (0 , n )
7 X=rep (0 , n )
8
9 for ( i in 1 : n)
10 N[ i ]=PARTIE ENTIERE( runif (1 )∗5)11 X[ i ]= pa r t i e_e n t i e r e ( runif (1 )∗N[ i ] )
12
13 plot (X)
14
15
16
17 #2nd :
18 n=10^2
19
20 x=rep (0 , n )
21 Y=rep (1 , n )
22 for ( i in 1 : n)
23 while ( runif (1)<Y[ i ] ) x [ i ]=x [ i ]+1
24 Y[ i ]=Y[ i ] /2
25 hist (x , col=" l i g h t b l u e " , p r obab i l i t y=T)
26 par=(new=TRUE)
27 curve (dgeom(x , . 5 ) , col=' blue ' , xl im=c (−5 ,5) , lwd=3, l t y =3, add=T)
28
29
30 #3eme :
31 p1=.5
32 p2=.5
33 N=0
34 for ( i in 1 : n) i f ( runif (1)>p1 )N=N+1
35 N
36 X=rep (0 , n )
37
38 for ( i in 1 :N) i f ( runif (1)>p2 )X[ i ]=X[ i ]+1
39 hist (X, p r obab i l i t y=T, col=" l i g h t b l u e " )
40
41 #4eme :
42
43 p=.5
56

44 P=p
45 F=P
46 X=1
47 while ( runif (1)>F)P=P∗(1−P)
48 F=F+P
49 X=X+1
50
51 P
52 F
53 X
Il nous faut reconnaitre la loi pour chacun des cas . Pour cela nous pouvons nous y prendre de dié-
rentes manières.
1/ Tracer des histogramme et tenter de repérer une loi usuelle. Vérier en traçant la fonction de densité
supposée par dessus pour vérier graphiquement.
2/Une seconde méthode consisterait a calculer la loi conditionnelle.
1. Pour le premier exemple on peut déterminer " à la main" la loi de X.
On sait que N U0, 1, 2, 3, 4 donc X U0, 1, 2, 3, car X = [U ∗ N ] où "[ ]" désigne la
partie entière et N = [5 ∗ U ] avec U U([0, 1]) d'où
P([X = 0]) =
4∑0
P([X = 0|N = k])P[[N = k]] =15(
4∑0
P([X = 0|N = k])) =1
5(1
4+
1
3+
1
2+
1 + 1) =37
60Explicitons le premier calcul : On a P([X = 0|N = 0]) = 1,P([X = 0|N = 1]) = 1,P([X =
0|N = 2]) = 12 ,P([X = 0|N = 3]) = 1
3 ,P([X = 0|N = 4]) = 14 .
P([X = 1]) =
4∑k=0
P([X = 0|N = k])P[[N = k]] =15(
4∑0
P([X = 0|N = k])) =1
5(1
4+
1
3+
1
2) =
13
60
P([X = 2]) =4∑
k=0
P([X = 0|N = k])P[[N = k]] =15(
4∑0
P([X = 0|N = k])) =1
5(1
4+
1
3) =
7
60
P([X = 3]) =4∑
k=0
P([X = 0|N = k])P[[N = k]] =15(
4∑0
P([X = 0|N = k])) =1
5(1
4) =
3
60
On vérie bien que3∑i=0
P([X = i]) = 1 On a donc obtenu la loi de N.
2. Pour le cas 3/, on cherche la loi de X : On note que N(Ω) = 0...n et X(Ω) = 0...N(ω),∀ω ∈ N−1(0..n)
P([X = 0|N = 0]) =P([X = 0, N = 0])
P(N = 0)= 1 ; P([X = k|N = 0]) =
P([X = k,N = 0])
P(N = 0)= 0
∀k > 0
P([X = 0|N = 1]) =P([X = 0, N = 1])
P(N = 1)=
(1− p2)
pn−11 (1− p1)
, P([X = 1|N = 1]) =P([X = 1, N = 1])
P(N = 1)=
(p2)
pn−11 (1− p1)
et P([X = k|N = 1]) =P([X = k,N = 1])
P(N = 1)= 0 ∀k ≥ 1
ainsi on obtient P([X = k|N = j]) =P([X = k,N = j])
P(N = j)=
(1− p2)j−kpk2
pn−j1 (1− p1)jsi j ≥ k 0 Sinon.
57

Ainsi d'aprés la formule des probabilité totale on obtient :
P(X = k) =n∑j=0
P([X = k|N = j])P(N = j) =n∑j=0
(1 − p2)j−kpk2 ..( il nous manque les
combinaisons pour obtenir la fonction de répartition pour une B(N(ω), p2)
3.
4. Quatriéme exemple :
Il s'agit d'un cas classique d'algorithme inverse pour simuler une variable X de loi discrète.
P([X = x]) = px où x ∈ X(Ω)
Alors F−1(u) = x011u≤p0 +∑
xi∈X(Ω)
xi11p0+p1...+pi−1≤u≤p0+p1...+pi .
Ainsi pour simuler X il sura de tirer u dans [0, 1], puis de poser X = xi si
p0 + p1 + ...pi−1 < u ≤ p0 + p1 + ....+ pi.
Revenons à l'exemple 4/, X(Ω) = N∗,Soit U [0, 1], Nous avons :
[X = 1] = [U < p] d'où P([X = 1]) = p
([X = 2] = [p < U ≤ p+ p(1− p)] d'où P([X = 2]) = P([U ≤ p+ p(1− p)])−P([U ≤]) = p(1− p)
par itération on obtient ∀k ∈ N∗, [X = k] = [
k−1∑i=0
< U ≤k∑i=0
] d'où P([X = k]) = p(1− p)k
On retrouve donc une loi G G(p)
8.6 Exercice 3.7
(i) ∀n ≥ 0, ∀(x0, ...xn) ∈ En+1 :
P(Xn = xn, ...X0 = x0) = P(Xn = xn|Xn−1...X0 = x0)P(Xn−1...X0 = x0)
d'après la propriété de Markov P(Xn = xn, ...X0 = x0) = P(Xn = xn|Xn−1)P(Xn−1...X0 = x0)
Par itération on obtient, P(Xn = xn, ...X0 = x0) =n∏i=1
P(Xi = xi|Xi−1 = xi−1)P(X0 = x0).
Or ∀i ∈ 1...n, P(Xi = xi|Xi−1 = xi−1) = Q(xi−1, xi) et P(X0 = x0) = µ(x0) d'où
P(Xn = xn, ...X0 = x0) =
n∏i=1
Q(xi−1, xi)µ(x0)
(ii) P(Xn = y|X0 = x) =∑
(x1...xn−1)∈E
P(Xn = y,Xn−1 = xn−1...X1 = x1|X0 = x0)
=∑
(x1...xn−1)∈E
P(Xn = y,Xn−1 = xn−1...X1 = x1, X0 = x0)
µ(x0)
(d'après (i)) on obtient
µ(x0)
n∏i=1
Q(xi−1, xi)
µ(x0)=
n∏i=1
Q(xi−1, xi) = (Qn(x, y)
En outre,P(Xn = y) =∑
x∈E P(Xn = y,X0 = x) =∑x∈E
P(Xn = y|X0 = x)µ(x) =∑x∈E
(Qn(x, y))µ(x)
or on somme sur toutes les valeurs possibles pour X0 d'où P(Xn = y) = (µQn)(y)
(iii) Soit f : E→ R qui vérie les hypothèses de l'énoncé, à savoir une fonction harmonique (f =
Q.f) . E[f(Xn+1)|F0n] = E[E[f(Xn+1|F0
n−1]|F0n] = E[Q(f(Xn))|F0
n] Or Q(f(Xn)) est F0n −mesurable
d'où E[f(Xn+1|F0n] = Q(f(Xn))
58

8.7 Conclusion
Avant de démarrer ce T.E.R, je n'avais qu'une vague idée du fonctionnement des méthodes de
Monte Carlo ainsi que du champs d'application de ces méthodes. Toutefois, je souhaitais travailler sur
un sujet qui ferait le lien entre les diérentes matières étudiées en licence (informatique, probabilité,
statistique..) et c'est à ce titre que je me suis naturellement orienté vers la simulation informatique.
.Au terme de ce mémoire je suis particulièrement heureux d'avoir choisi ce sujet et d'avoir découvert
tant de choses. La simulation informatique nous oblige à penser les probabilités d'une façon nouvelle
et pas toujours aisée. J'ai pris plaisir à réaliser chacun des codes sous R, ainsi que de progresser dans
ce domaine très étendu que constitue les méthodes de Monte Carlo. Je souhaite à présent poursuivre
ce travail en l'appliquant à des domaines concrets tels que la nance ou encore les télécoms.
Avant de conclure je souhaite remercier Mme Annie Millet qui a dirigé ce T.E.R et qui a pris le temps
de répondre à toutes mes questions.
59

BIBLIOGRAPHIE
[1] Annie Millet,Méthodes de Monte-Carlo :"http ://www.proba.jussieu.fr/pageperso/millet/montecarlo.pdf"
[2] Christian P.Roberts & George Cassela, Introducing Monte Carlo Methods
[3] Bernard Lapeyre, Méthodes de Monte Carlo
[4] Brooks, S. and Roberts,(1998). Assessing convergence of Markov chain Monte Carlo
algorithms.
[5] Murrell, P. (2005). R Graphics. Lecture Notes in Statistics. Chapman and Hall, New
York.
[6] Robert, C. (1995a). Convergence control techniques for MCMC algorithms.Statistical
Science, 10(3) :231253.
[7] Dalgaard, P. (2002). Introductory Statistics with R. SpringerVerlag, New York.
[8] The Monte Carlo Framework, Examples from Finance and Generating Correlated Ran-
dom Variables - Martin Haugh
"http : :/www.stat.columbia.edu/ gelman/research/published/brooksgelman.pdf"
[9] "http ://theoreticalecology.wordpress.com/2011/12/09/mcmc-chain-analysis-and-
convergence-diagnostics-with-coda-in-r/" Test et optimisation d'un générateur pseudo-
aléatoire - Philippe GAMBETTE - ENS
60





![3ULQFLSHV GH O·RUJDQLVDWLRQ IXWXUH GHV … · j exv k vhqv k k k k k k exv k vhqv 3,67(6' $&7,216$'(9(/233(5 $ppolrudwlrqghviuptxhqfhv qrwdpphqwdx[khxuhv ghsrlqwhyhuvohv]rqhvg dfwlylwpv](https://img.pdfslide.fr/doc/110x75/5beb183d09d3f22d248be34b/3ulqflshv-gh-orujdqlvdwlrq-ixwxuh-ghv-j-exv-k-vhqv-k-k-k-k-k-k-exv-k-vhqv.jpg)





![K hD EdK EKZD d/sK ^K Z > d ZD/EK>K'1 z sK h> Z/K > ^ dKZ ...€¦ · K hD EdK EKZD d/sK ^K Z > d ZD/EK>K'1 z sK h> Z/K > ^ dKZ ,Kd > ZK E >K^ W 1^ ^ í d u ] v } o } P _ Ç s } µ](https://img.pdfslide.fr/doc/110x75/5fed60cb5fdaf7798e74da39/k-hd-edk-ekzd-dsk-k-z-d-zdekk1-z-sk-h-zk-dkz-k-hd-edk.jpg)
















