Embed Size (px)
Citation preview

Atelier JDEV 2017
Marseille 04 – 07 Juillet 2017
Parallélisme synchrone et asynchrone en calcul scientifique
Thierry Garcia & Pierre Spiteri
(1) IRIT – ENSEEIHT, UMR CNRS 5505, Toulouse – France (2) Li-PaRAD, Univ. Paris-Saclay-UVSQ, Versailles, France
2
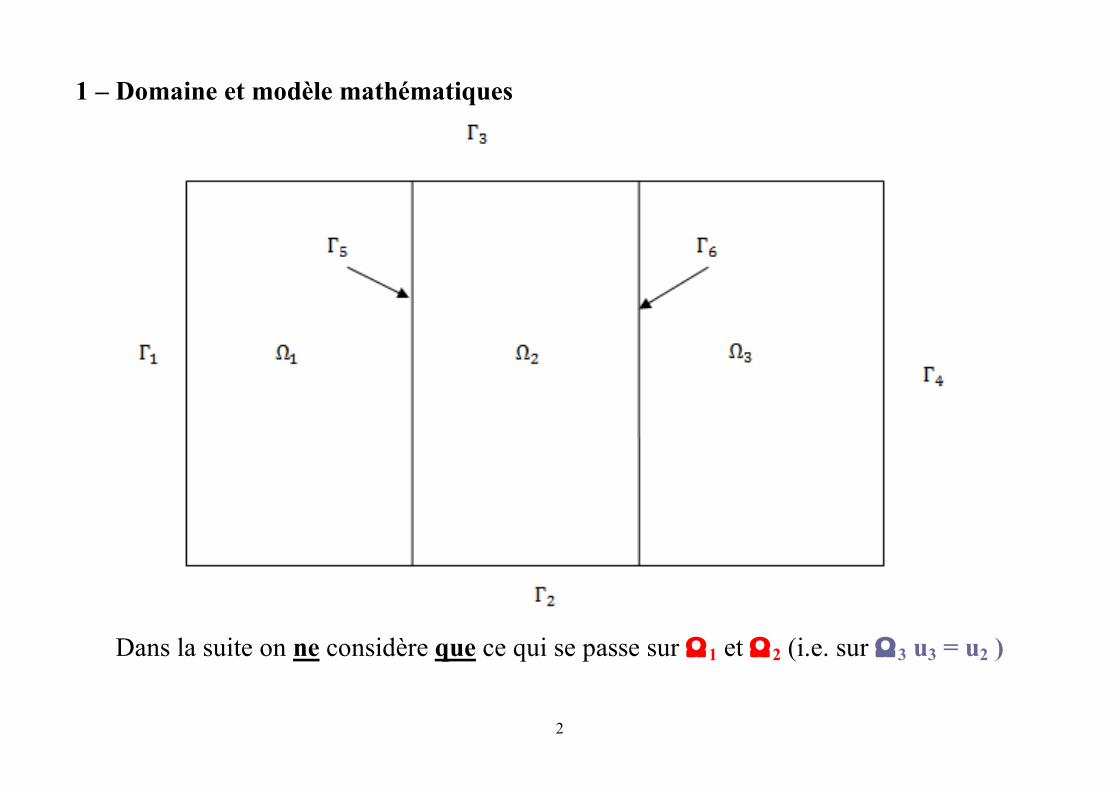
1 – Domaine et modèle mathématiques
Dans la suite on ne considère que ce qui se passe sur Ω1 et Ω2 (i.e. sur Ω3 u3 = u2 )

3
- Pose Γ1,2 = Γ2∩ Ω1 & Γ1,3 = Γ3∩ Ω1 (frontières haut & bas) -
-
!
c1"u1
"t# div($1%u1) = f1(x, t), 0, tfinal] ]x&1
u1(x, y,t = 0) = u1,0 (x, y) C.I.u1 = 'imp , sur (1
u1 = g1, sur (1,2 (1,3U
#$1"u1
"n=
1R
(u1 # u1,cst ), sur (5
)
*
+ + + +
,
+ + + +
-
- Pose Γ2,2 = Γ2∩ Ω2 & Γ2,3 = Γ3∩ Ω2 (frontières haut & bas) -
!
!
c2"u2
"t# div($2%u2 ) = f2 (x,t), 0, tfinal] ]x&2
u2 (x, y,t = 0) = u2,0 (x, y) C.I.u2 = u1,'5
, sur '5 (condition transmission)
u2 = g2 , sur '2,2 U '2,3 u2 = g3, sur '6
(
)
* * * *
+
* * * *

4
2 – Discrétisation du problème 2 – 1 - Discrétisation spatiale
!
"2u"x2
#1.0$x(u(x +$x, y, z)% u(x, y, z)
$x%u(x, y, z)% u(x %$x, y, z)
$x)+O($x2 )
!
"2u"x2
#u(x +$x, y, z)% 2.u(x, y, z)+ u(x %$x, y, z)
$x2+O($x2 )
schémas différences finies
Remarque : même type de schéma pour les autres coordonnées spatiales Remarque : même type de schéma par discrétisation volumes finis ou éléments finis 2 – 1 - Discrétisation temporelle
!
"u(xi,t
n)
"t#u(x
i,t
n+1)$ u(x
i,t
n)
%t+ o(%t)
!
"t = TN
⇒ plusieurs choix possibles (explicites; implicite)
Schéma explicite : écriture du problème à l’instant t ⇒ équation de récurrence ⇒ peut être instable
⇒ Un+1 = δt Fn + (I - α A) Un
!
" = #$th2
(h = δx)
5
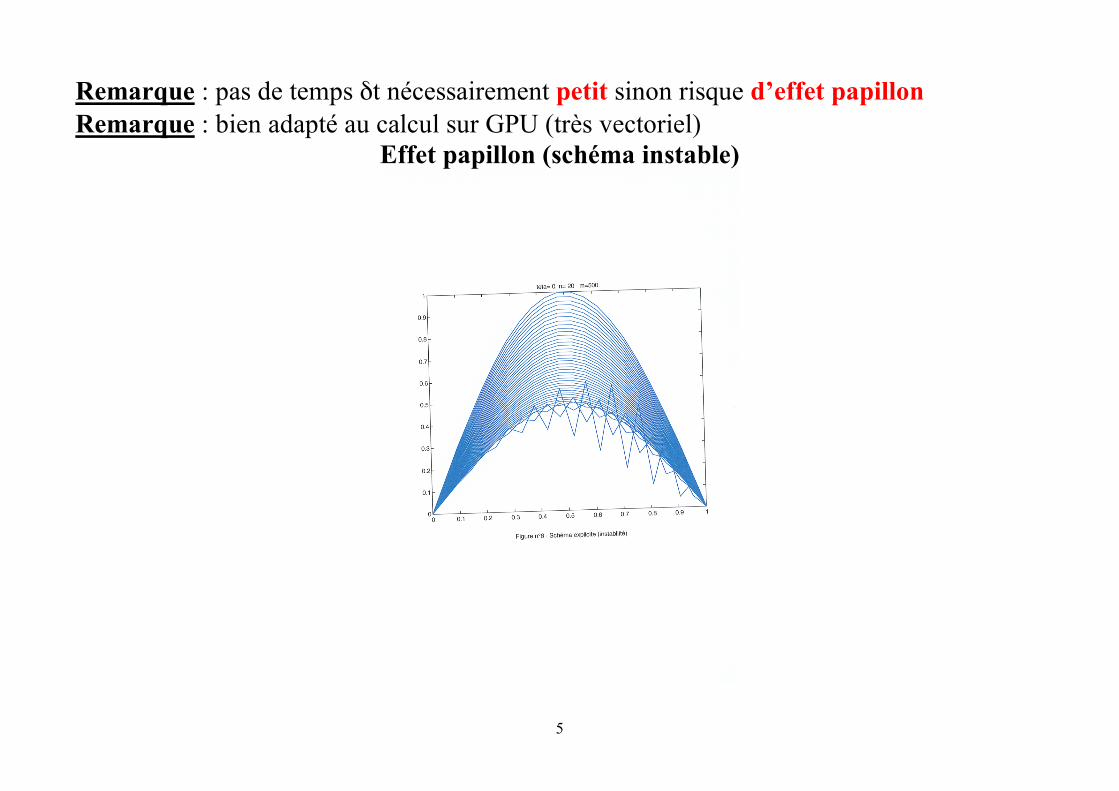
Remarque : pas de temps δt nécessairement petit sinon risque d’effet papillon Remarque : bien adapté au calcul sur GPU (très vectoriel)
Effet papillon (schéma instable)

6
Schéma implicite : écriture du problème à l’instant t+1 ⇒ résolution de systèmes linéaires ⇒ stable
⇒ (I + α A) Un+1 = δt Fn+1 + Un
!
" = #$th2
(h = δx)
Remarque : pas de temps δt quelconque et pas d’effet papillon Remarque : il existe une solution intermédiaire : schéma semi – implicite, en principe stable

7
Exemple : Discrétisation implicite de l’équation 1D exemple : discrétisation par différences finies de problèmes d’évolution (équation de la chaleur)
!
"u(x,t)"t
- a " 2u(x,t)"x 2
= f(x, t), p.p. sur 0,1[ ] x 0,T[ ], a > 0,
u(x,0) = u0(x), p.p. sur 0,1[ ]
u(0, t) = u(1, t) = 0, p.p. sur 0,T[ ]
#
$
% %
&
% %
exemple : schéma implicite : écriture de l’équation de la chaleur au point (xi,tn+1) qui conduit à la résolution d’une séquence de systèmes algébriques à chaque pas de temps
!
ui
n+1 " ui
n
#t " a ui+1
n+1 " 2ui
n+1 + ui"1
n+1
h 2= f
i
n+1 , 1$ i $ m, n % 0,
u0
n+1 = um+1
n+1 = 0, n % 0,u
i
0 = u0(ih),
&
'
( (
)
( (
⇒ (I + α A) Un+1 = δt Fn+1 + Un
!
" = a #th2
(h = δx)

8
Matrice de discrétisation 1 D : matrice tridiagonale
!
A =
2 "1"1 2 "1
. . .. . .. . .
. . .. 2 "1
"1 2
#
$
% % % % % % % % %
&
'
( ( ( ( ( ( ( ( (
et
!
F =
h 2 f1+ u
0
h 2 f2
.
.
.
.h 2 f
m"1
h 2 fm
+ um+1
#
$
% % % % % % % % %
&
'
( ( ( ( ( ( ( ( (

9
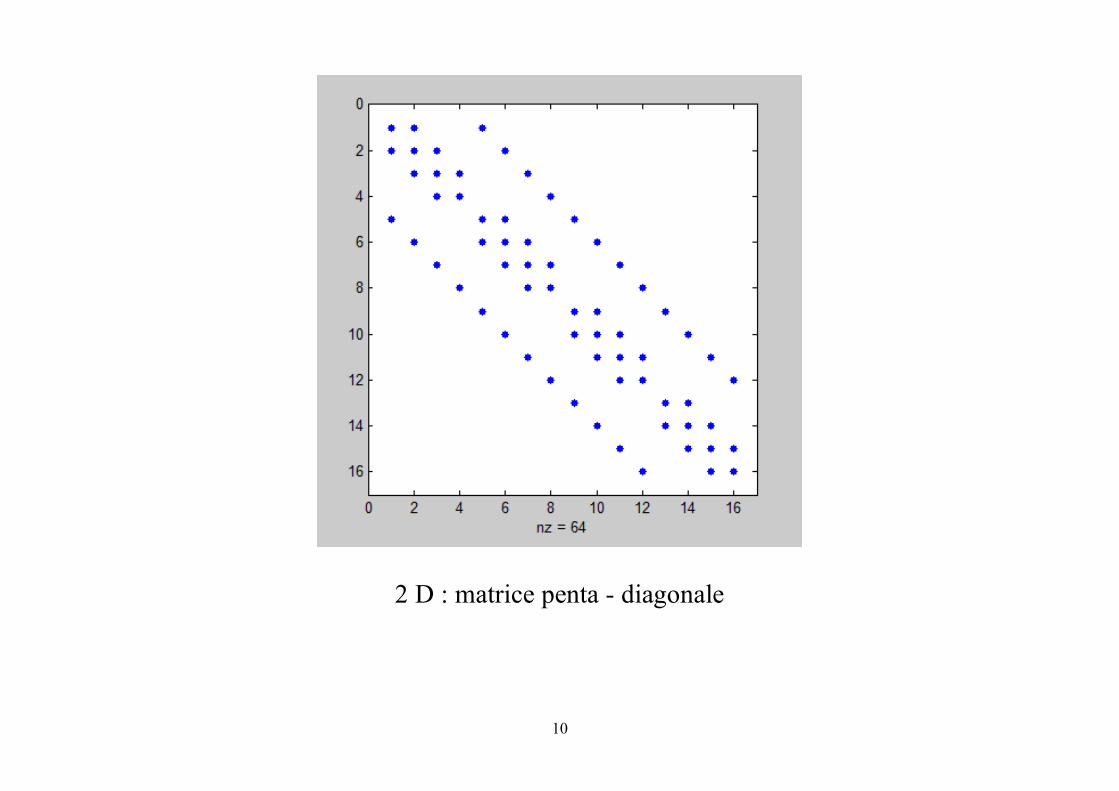
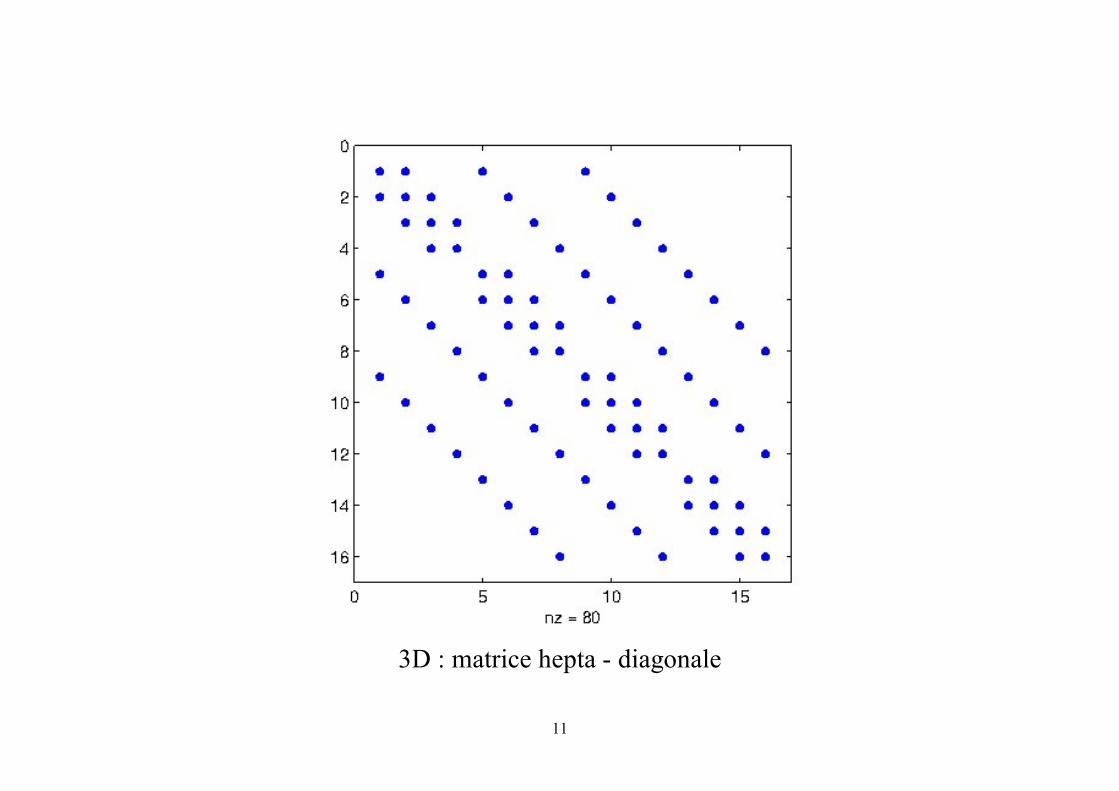
Matrice de discrétisation 2D & 3D : structure par blocs des matrices
10
2 D : matrice penta - diagonale
11
3D : matrice hepta - diagonale

12
3 – Méthode de relaxation par blocs Prise en compte de la structure bloc de la matrice ⇔ nécessaire en calcul parallèle
!
Ai,iVi + Ai, jVjj"i
#
$ = Bi , i =1,..,# % Vi = Ai,i&1(Bi & Ai, jVj
j"i
#
$ )
α nombre de blocs méthode de Jacobi par blocs
!
Vi(p+1) = Ai,i
"1(Bi " Ai, jVj( p)
j#i
$
% ) = Fi,BJ (V ), i =1,..,$ méthode de Gauss – Seidel par blocs
!
Vi(p+1) = Ai,i
"1(Bi " Ai, jVj( p+1) " Ai, jVj
( p)
j=i+1
#
$j=1
i"1$ ) = Fi,GS (V ), i =1,..,#
Remarque : on n’inverse pas les matrices blocs diagonales Ai,i ; on résout plutôt les sous – systèmes linéaires Ai,i.Vi = Gi en utilisant des algorithmes efficaces (par exemple gradient conjugué et ses variantes ou bien des méthodes de relaxation ou encore des méthodes directes lorsque les sous – matrices sont creuses (triple diagonales))

13
Programme structuré : résolution séquentielle par blocs de AV = B (problème stationnaire)
V0 approximation initiale de V* norme ← bidon ; tantque norme > ε faire pour i = 1 à α faire norme ← 0 ; calcul de
!
Gi = Bi " Ai, jV jj#i
$
% ; résoudre
!
Ai,iVinew =Gi ;
calcul
!
Vinew "Vi
old ;
!
norme " Max(norme, Vinew #Vi
old ) ; ranger
!
Vinew
; finpouri ; fintantque. α nombre de blocs

14
Remarques : - pour la résolution des sous-systèmes on pourra utiliser n’importe quel algorithme, en particulier le plus efficace, - ici on a considéré la norme uniforme (du maximum) pour stopper les itérations ; on peut prendre d’autres normes car en dimension finie elles sont toutes équivalents, mais certaines sont plus fines que d’autres, - en séquentiel : pour le rangement des sous vecteurs Vi dans le vecteur global V on utilise un système de pointage définis en fonction du découpage en sous problèmes, - en calcul parallèle chaque processeur aura à sa charge une partie de la gestion de la boucle pour associée à son bloc ; les sous-matrices Ai,i sont donc découpées en sous blocs et les portions de chaque vecteur traitées par un processeur sont repérées par un autre système de pointeurs. Pour avoir une meilleure granularité, plusieurs blocs sont affectés à un processeur. - en calcul parallèle il y aura des communications entre processeurs pour la transmission des données d’interaction
!
V i ; on pourra effectuer des communications synchrones (on suit donc la méthode séquentielle) ou asynchrones (on utilise les données d’interaction disponibles les plus « fraîchement » calculées par les autres processeurs) et on résoudra de façon synchrone ou asynchrone les sous-systèmes.
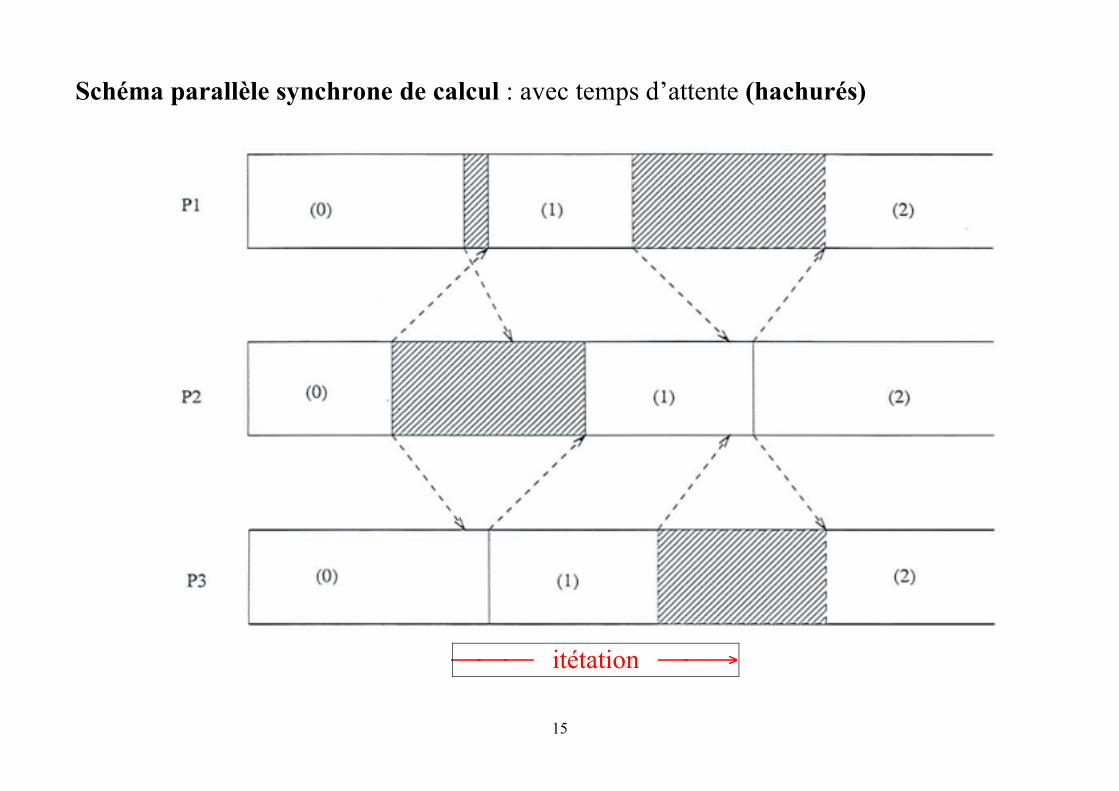
15
Schéma parallèle synchrone de calcul : avec temps d’attente (hachurés)
⎯⎯⎯ itétation ⎯⎯→
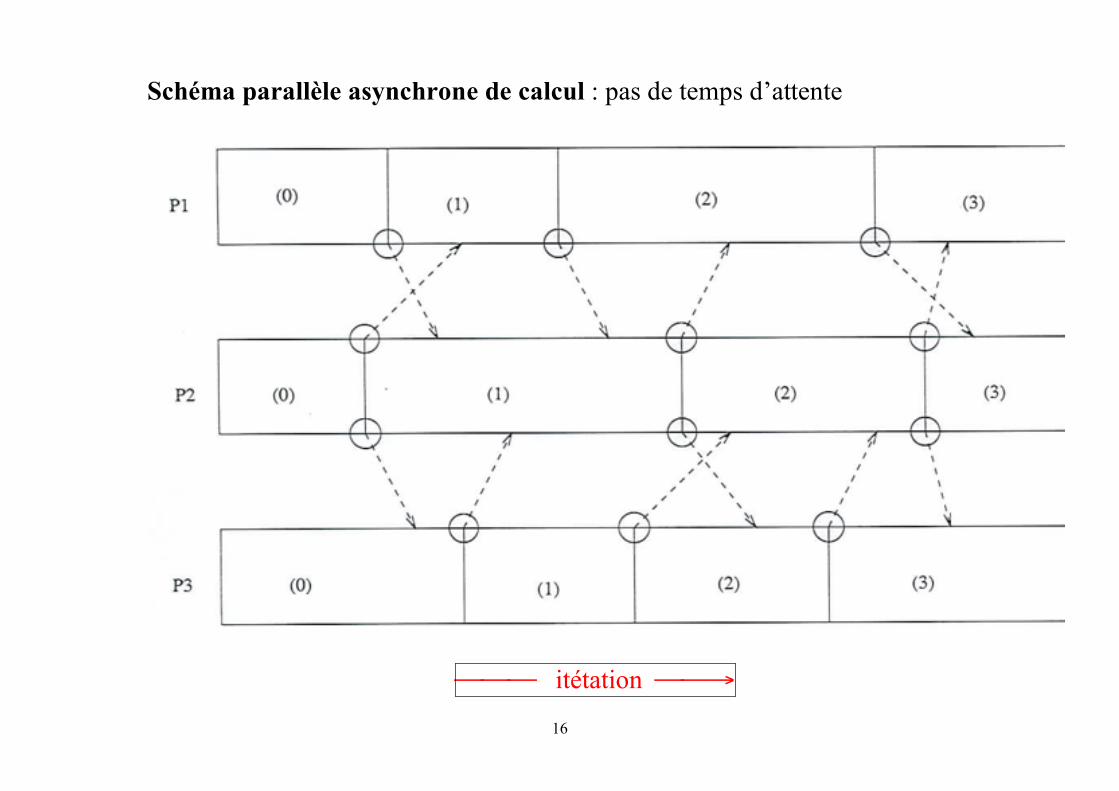
16
Schéma parallèle asynchrone de calcul : pas de temps d’attente
⎯⎯⎯ itétation ⎯⎯→
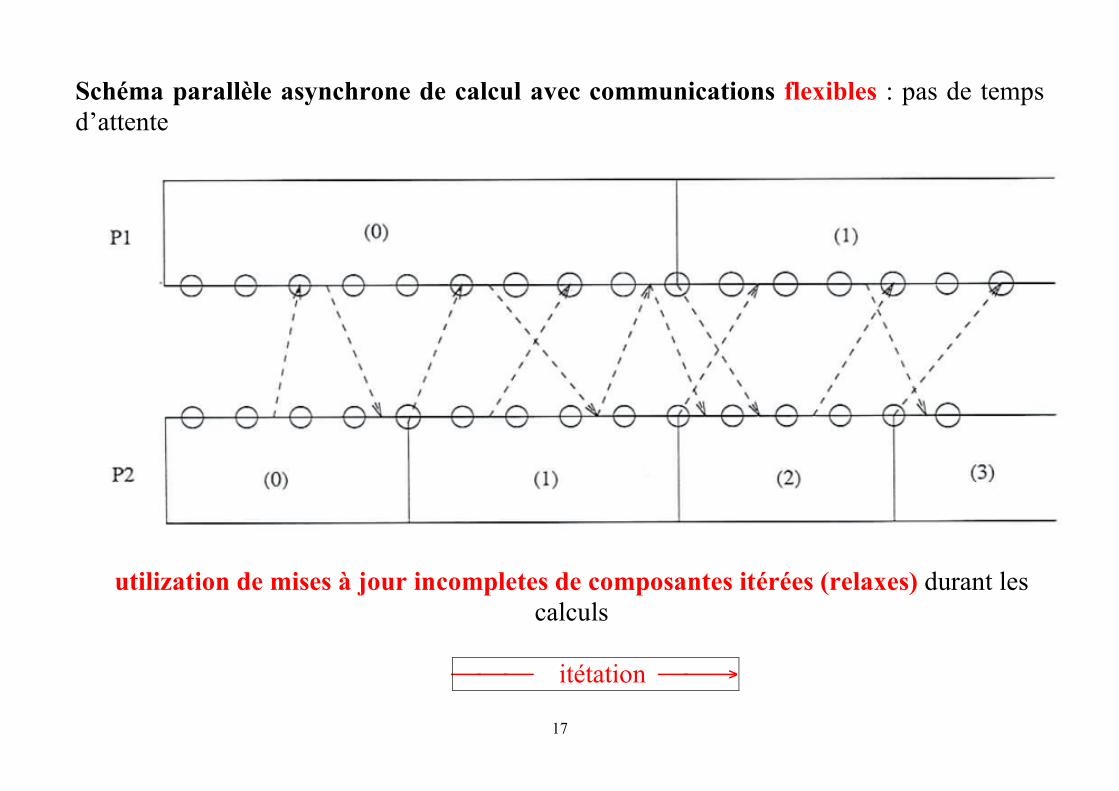
17
Schéma parallèle asynchrone de calcul avec communications flexibles : pas de temps d’attente
utilization de mises à jour incompletes de composantes itérées (relaxes) durant les calculs
⎯⎯⎯ itétation ⎯⎯→

18
Programme structuré : résolution séquentielle par blocs de AV = B (problème d’évolution) ⇒ on ajoute une boucle en temps
!
V 0 donnée initiale du problème d’évolution
pour chaque pas de temps faire V0 approximation initiale de V* (valeur au pas de temps précédent) norme ← bidon ;
V0 ←
!
V 0
tantque norme > ε faire pour i = 1 à α faire norme ← 0 ;
calcul de
!
Gi = Bi " Ai, jV jj#i
$
% ;
résoudre
!
Ai,iVinew =Gi ;
calcul
!
Vinew "Vi
old ;
!
norme " Max(norme, Vinew #Vi
old ) ; ranger
!
Vinew dans
!
V 0;
finpouri fintantque.; finpour.

19
Parallélisation en temps : rendre cohérent l’algorithme en temps !!
!
V 0 donnée initiale du problème d’évolution
pour chaque pas de temps faire V0 approximation initiale de V* (valeur au pas de temps précédent)
norme ← bidon ; V0 ←
!
V 0
pour i = 1 à α faire tantque norme > ε faire norme ← 0 ;
calcul de
!
Gi = Bi " Ai, jV jj#i
$
% ;
résoudre
!
Ai,iVinew =Gi ;
calcul
!
Vinew "Vi
old ;
!
norme " Max(norme, Vinew #Vi
old ) ; ranger
!
Vinew dans
!
V 0;
fintantque. finpouri ; Barrière de synchronisation ⇐ finpour.

20
Retour au problème défini sur deux sous-domaines Ω1 et Ω2 - Pose Γ1,2 = Γ2∩ Ω1 & Γ1,3 = Γ3∩ Ω1 (frontières haut & bas) -
-
!
c1"u1
"t# div($1%u1) = f1(x, t), 0, tfinal] ]x&1
u1(x, y,t = 0) = u1,0 (x, y) C.I.u1 = 'imp , sur (1
u1 = g1, sur (1,2 (1,3U
#$1"u1
"n=
1R
(u1 # u1,cst ), sur (5
)
*
+ + + +
,
+ + + +
- Pose Γ2,2 = Γ2∩ Ω2 & Γ2,3 = Γ3∩ Ω2 (frontières haut & bas)
!
!
c2"u2
"t# div($2%u2 ) = f2 (x,t), 0, tfinal] ]x&2
u2 (x, y,t = 0) = u2,0 (x, y) C.I.u2 = u1,'5
, sur '5 (condition transmission)
u2 = g2 , sur '2,2 U '2,3 u2 = g3, sur '6
(
)
* * * *
+
* * * *

21
Programme séquentiel et sous programmes en Fortran iterG1=0 iterG2=0 do it=1,Nbtemp ! Boucle en temps ! Dans omega1 ! Calcul du second membre dans OMEGA 1 CALL SCDMB1(f,u,A1,nn,n,m) ! Boucle de calcul dans OMEGA 1 normmax1=10. iter1=0 ! Boucle de calcul dans OMEGA 1 (points interieurs) CALL PTSINT1(f,u,diag1,codiag1,nn,n,m,normmax1,iter1,epsi) iterG1=iterG1+iter1 ! Dans omega 2 ! Calcul du second membre dans OMEGA 2 CALL SCDMB2(f,u,A2,nn,n,m,p) ! Boucle de calcul dans OMEGA 2 (points interieurs) normmax2=10. iter2=0 CALL PTSINT2(f,u,diag2,codiag2,nn,n,m,p,normmax2,iter2,epsi) iterG2=iterG2+iter2 enddo ! Fin boucle en temps

22
CALCUL DES SECONDS MEMBRE ! SECOND MEMBRE 1 DANS OMEGA 1
SUBROUTINE SCDMB1(f,u,A1,nn,n,m) integer nn,n,m real*8 ,dimension (141,141,141):: u real*8, dimension (141,141,141):: f real*8 A1 do k=1,nn+2 do j=1,n+2 do i=2,m f(i,j,k)=A1*u(i,j,k) enddo enddo enddo return end Note : dans le problème le terme source est nul ; s’il était égal à g, g différent de zero, on mettrait
f(i,j,k)=g(i,j,k)+ A1*u(i,j,k)

23
! SECOND MEMBRE 2 DANS OMEGA 2 SUBROUTINE SCDMB2(f,u,A2,nn,n,m,p) integer nn,n,m,p real*8 ,dimension (141,141,141):: u real*8, dimension (141,141,141):: f real*8 A2 do k=1,nn+2 do j=1,n+2 do i=m+2,m+p f(i,j,k)=A2*u(i,j,k) enddo enddo enddo return end

24
INTERFACE ! INTERFACE OMEGA 1 OMEGA 2 SUBROUTINE LINTERFACE(u,epsi,nn,n,m,iter1,normmax1,ct11,ct2,ct31prim) integer nn,n,m, iter1 real*8 ,dimension (141,141,141):: u real*8 epsi, normmax1,ct11,ct2,ct31prim, SS, RR ! VERTICAL INTERFACE omega1 omega2 indice I=m+1 do k=1,nn+2 do j=1,n+2 SS=(ct11*u(m,j,k)+ct2)/ct31prim ! %norme RR=dabs(SS-u(m+1,j,k)) if ( RR .gt. normmax1) then normmax1=RR endif u(m+1,j,k)=SS enddo enddo return end

25
SOUS PROGRAMMES RESOLUTION : POINTS INTERIEURS OMEGA 1 ! SOUS PROGRAMMES RESOLUTION ! POINTS INTERIEURS OMEGA 1 SUBROUTINE PTSINT1(f,u,diag1,codiag1,nn,n,m,normmax1,iter1,epsi) integer :: nn,n,m integer,intent(inout) :: iter1 real*8,dimension (141,141,141):: u real*8,dimension (141,141,141):: f real*8 :: diag1,codiag1, epsi, SS, RR real*8,intent(inout) :: normmax1 ! POINTS INTERIEURS do while( normmax1.gt.epsi) normmax1=0. do k=2,nn+1 do j=2,n+1 do i=2,m SS=(1.0/diag1)*(f(i,j,k)& -codiag1*u(i+1,j,k)-codiag1*u(i,j+1,k)-codiag1*u(i-1,j,k)& -codiag1*u(i,j-1,k)-codiag1*u(i,j,k+1)-codiag1*u(i,j,k-1)) !%norme RR=dabs(SS-u(i,j,k)) if (RR .gt. normmax1)then normmax1=RR endif u(i,j,k)=SS enddo enddo enddo ! Verticale interface entre omega1 et omega2 CALL LINTERFACE(u,epsi,nn,n,m,iter1,normmax1,ct11,ct2,ct31prim) iter1=iter1+1 enddo return end

26
C POINTS INTERIEURS OMEGA 2 ! POINTS INTERIEURS OMEGA 2 SUBROUTINE PTSINT2(f,u,diag2,codiag2,nn,n,m,p,normmax2,iter2,epsi) integer :: nn,n,m,p integer,intent(inout) :: iter2 real*8,dimension (141,141,141):: u real*8,dimension (141,141,141):: f real*8 :: diag2,codiag2, epsi, SS, RR real*8,intent(inout) :: normmax2 ! POINTS INTERIEURS do while(normmax2.gt.epsi) normmax2=0 do k=2,nn+1 do j=2,n+1 do i=m+2,m+p SS=(1.0/diag2)*(f(i,j,k)& -codiag2*u(i+1,j,k)-codiag2*u(i,j+1,k)-codiag2*u(i-1,j,k)& -codiag2*u(i,j-1,k)-codiag2*u(i,j,k+1)-codiag2*u(i,j,k-1)) !%norme RR=dabs(SS-u(i,j,k)) if (RR .gt. normmax2) then normmax2=RR endif u(i,j,k)=SS enddo enddo enddo iter2 =iter2+1 enddo return end

27
PROGRAMME COMPLET SEQUENTIEL !===================================================================== ! Resolution du probleme a coefficients constants par la methode ! des differences finies !===================================================================== ! Declaration des variables !===================================================================== real*8,dimension (141,141,141):: u real*8,dimension (141,141,141):: f real*8,dimension (141):: x,y,z integer :: Nbtemp,m,p,n,nn,i,j,k,t,tt,num,iter1,iter2,it integer :: iterG1,iterG2 real*8 :: Temps,lamda1,Rij,Uconst,cmv1,ct2 real*8 :: lamda2,cmv2,longx real*8 :: epsi,h,kk,A1,codiag1, diag1,ct11,ct31prim real*8 :: A2,codiag2, diag2 real*8 :: start,normmax1,normmax2, stop_time,start_time !=================================================================== ! Initialisation ! Temps : horizon - longx : dimension - Nbtemp : nb de pas de temps ! - m - p - nombre de pts !=================================================================== Temps=1. longx=1. Nbtemp=100 m=70 p=70 n=m+p-1 nn=m+p-1 !=================================================================== ! Definition constantes physiques !=================================================================== Rij=15. Uconst=30. epsi=1.0e-03 ! précision !===================================================================

28
! Pas de discretisation h : espace - kk : temps !=================================================================== h= longx/(m+p) kk=Temps/Nbtemp !=================================================================== ! Initialisation second membre !=================================================================== do k=1,nn+2 do j=1,n+2 do i=1,m+p+1 f(i,j,k)=0. end do end do enddo !================================================================ ! Appel horloge (mesure du temps d execution) !================================================================ call cpu_time(start_time) !================================================================ ! Coefficients physiques concernant la zone Omega 1 !================================================================ lamda1=32. cmv1=7340. * 688. A1=cmv1/kk codiag1=-lamda1/(h*h) diag1=(-6*codiag1+A1) ct11=(lamda1/h) ct31prim=(ct11+(1.0/Rij)) ct2=(Uconst/Rij) !================================================================= ! Coefficients physiques concernant la zone Omega 2 !================================================================= lamda2=35.6 cmv2=7659. * 745. A2=cmv2/kk

29
codiag2=-lamda2/(h*h) diag2=(-6*codiag2+A2) !============================================================== ! C.L DIRICHLET PARTOUT SAUF A L'INTERFACE !============================================================= !============================================================== ! Conditions initiales !============================================================== do k=1,nn+2 do j=1,n+2 do i=1,m+1 u(i,j,k)= 1500 end do do i= m+2,m+p+1 u(i,j,k)=900 enddo enddo enddo !============================================================= ! Phase de calcul !============================================================= iterG1=0 iterG2=0 do it=1,Nbtemp ! Boucle en temps ! Dans omega1 ! Calcul du second membre dans OMEGA 1 CALL SCDMB1(f,u,A1,nn,n,m) ! Boucle de calcul dans OMEGA 1 normmax1=10. iter1=0 ! Boucle de calcul dans OMEGA 1 (points interieurs) CALL PTSINT1(f,u,diag1,codiag1,nn,n,m,normmax1,iter1,epsi) iterG1=iterG1+iter1 ! Dans omega 2

30
! Calcul du second membre dans OMEGA 2 CALL SCDMB2(f,u,A2,nn,n,m,p) ! Boucle de calcul dans OMEGA 2 (points interieurs) normmax2=10. iter2=0 CALL PTSINT2(f,u,diag2,codiag2,nn,n,m,p,normmax2,iter2,epsi) iterG2=iterG2+iter2 enddo ! Fin boucle en temps call cpu_time(stop_time) start=stop_time-start_time write (*,*) 'temps=', start write (*,*) 'normmax1=',normmax1 write (*,*) 'normmax2=',normmax2 write (*,*) 'iter1=',iterG1 write (*,*) 'iter2=',iterG2 stop end ! SOUS - PROGRAMMES ! SECOND MEMBRE 1 DANS OMEGA 1 SUBROUTINE SCDMB1(f,u,A1,nn,n,m) integer nn,n,m real*8 ,dimension (141,141,141):: u real*8, dimension (141,141,141):: f real*8 A1 do k=1,nn+2 do j=1,n+2 do i=2,m f(i,j,k)=A1*u(i,j,k) enddo enddo enddo return end

31
! SECOND MEMBRE 2 DANS OMEGA 2 SUBROUTINE SCDMB2(f,u,A2,nn,n,m,p) integer nn,n,m,p real*8 ,dimension (141,141,141):: u real*8, dimension (141,141,141):: f real*8 A2 do k=1,nn+2 do j=1,n+2 do i=m+2,m+p f(i,j,k)=A2*u(i,j,k) enddo enddo enddo return end ! INTERFACE OMEGA 1 OMEGA 2 SUBROUTINE LINTERFACE(u,epsi,nn,n,m,iter1,normmax1,ct11,ct2,ct31prim) integer nn,n,m, iter1 real*8 ,dimension (141,141,141):: u real*8 epsi, normmax1,ct11,ct2,ct31prim, SS, RR ! VERTICAL INTERFACE omega1 omega2 I=m+1 do k=1,nn+2 do j=1,n+2 SS=(ct11*u(m,j,k)+ct2)/ct31prim ! %norme RR=dabs(SS-u(m+1,j,k)) if ( RR .gt. normmax1) then normmax1=RR endif u(m+1,j,k)=SS enddo enddo return end

32
! SOUS PROGRAMMES RESOLUTION ! POINTS INTERIEURS OMEGA 1 SUBROUTINE PTSINT1(f,u,diag1,codiag1,nn,n,m,normmax1,iter1,epsi) integer :: nn,n,m integer,intent(inout) :: iter1 real*8,dimension (141,141,141):: u real*8,dimension (141,141,141):: f real*8 :: diag1,codiag1, epsi, SS, RR real*8,intent(inout) :: normmax1 ! POINTS INTERIEURS do while( normmax1.gt.epsi) normmax1=0. do k=2,nn+1 do j=2,n+1 do i=2,m SS=(1.0/diag1)*(f(i,j,k)& -codiag1*u(i+1,j,k)-codiag1*u(i,j+1,k)-codiag1*u(i-1,j,k)& -codiag1*u(i,j-1,k)-codiag1*u(i,j,k+1)-codiag1*u(i,j,k-1)) !%norme RR=dabs(SS-u(i,j,k)) if (RR .gt. normmax1)then normmax1=RR endif u(i,j,k)=SS enddo enddo enddo ! Verticale interface entre omega1 et omega2 CALL LINTERFACE(u,epsi,nn,n,m,iter1,normmax1,ct11,ct2,ct31prim) iter1=iter1+1 enddo return end ! POINTS INTERIEURS OMEGA 2 SUBROUTINE PTSINT2(f,u,diag2,codiag2,nn,n,m,p,normmax2,iter2,epsi)

33
integer :: nn,n,m,p integer,intent(inout) :: iter2 real*8,dimension (141,141,141):: u real*8,dimension (141,141,141):: f real*8 :: diag2,codiag2, epsi, SS, RR real*8,intent(inout) :: normmax2 ! POINTS INTERIEURS do while(normmax2.gt.epsi) normmax2=0 do k=2,nn+1 do j=2,n+1 do i=m+2,m+p SS=(1.0/diag2)*(f(i,j,k)& -codiag2*u(i+1,j,k)-codiag2*u(i,j+1,k)-codiag2*u(i-1,j,k)& -codiag2*u(i,j-1,k)-codiag2*u(i,j,k+1)-codiag2*u(i,j,k-1)) !%norme RR=dabs(SS-u(i,j,k)) if (RR .gt. normmax2) then normmax2=RR endif u(i,j,k)=SS enddo enddo enddo iter2 =iter2+1 enddo return end
!

34
Note d’utilisation
Paramètres influant sur les performances : cmv1, cmv2, lamda1, lamda2
Dans le source : cmv1=7340*688, cmv2=7659*745, lamda1=32, lamda2=35.6
Forte diagonal dominance ⇒ grande vitesse de convergence
Faire des essais avec : cmv1=1, cmv2=1.2, lamda1=1, lamda2=1.5
Comportement différent ⇒ vitesse de convergence faible
Pour chaque jeu de données : influence sur performances parallèles

35
En parallèle dans la boucle en temps on va traiter - d’abord le premier domaine Ω1 jusqu’à convergence - on inclut une barrière de synchronisation lorsque Ω1 est traité - puis on traite le second sous domaine Ω2 jusqu’à convergence - on inclut une barrière de synchronisation lorsque Ω2 est traité pour chaque pas de temps faire Traitement du problème dans Ω1 jusqu’à convergence Barrière de synchronisation Traitement du problème dans Ω2 jusqu’à convergence Barrière de synchronisation Finpour. il y aura des communications entre processeurs pour la transmission des données d’interaction
!
V i ; on pourra effectuer des communications synchrones ou asynchrones et on résoudra de façon synchrone ou asynchrone les sous-systèmes.
⇒ Relais à Thierry Garcia





























