Embed Size (px)
Citation preview

Bernard Clement Travail d'etude 2002/2003El Mahrati Hassan Licence
Informatique
La compression de données et Internet …

Sommaire :1. La compression de données
1.1. Pourquoi compresser?
1.2. Comment compresser ?
1.3. Les différent types de compressions
1.4. Les différent types d'encodages
2. Traitement de l'image
2.1. Introduction
2.1.1. Définition d'une image numérique ?
2.1.2. Les différentes Caractéristiques d'une image numérique :
2.1.2.1. La taille d'une image
2.1.2.2. La résolution
2.1.2.3. La couleur
2.1.2.4. Les modes
2.2. Etudes des différents formats d'images
2.2.1. Le format JPEG
2.2.1.1. Principales caractéristiques
2.2.1.2. Principes de la compression au format JPEG
2.2.1.3. Principes de la décompression du format JPEG
2.2.1.4. Etude performance / Qualité
2.2.2. Format GIF
2.2.3. Le format PNG
3. Traitement du son
3.1. Introduction :
3.1.1. D’où vient le son?
3.1.2. L'échantillonnage du son
3.1.3. La représentation informatique du son

3.1.4. Calcul de la mémoire requise pour stocker un son
3.2. Etude des différents formats de compressions
3.2.1. Le WAV
3.2.2. Le MP3
3.2.2.1. Historique
3.2.2.2. Caractéristiques
3.2.2.3. les algorithmes
3.2.2.3.1. L’effet de masque
3.2.2.3.2. La courbe de Fletcher-Munsen
3.2.2.3.3. La stéréo combinée
3.2.2.3.4. La mémoire tampon
3.2.2.3.5. L’algorithme de Huffman
3.2.2.4. Les résultats
3.2.2.5. les successeurs du MP3
3.2.2.5.1. AC-3 (Audio Code Number 3)
3.2.2.5.2.AAC (Advanced Audio Coding)
3.2.2.5.3.TwinVQ (Transform-domain Weighted Interleave Vector Quantization)
3.2.2.5.4.Comparatif AAC/VQF/MP3
4. Traitement de la vidéo :
4.1. Introduction
4.1.1. Qu'est-ce qu'une vidéo
4.1.2. La Vidéo numérique et analogique
4.1.3. Les normes Vidéo
4.1.4. La vidéo numérique
4.2. Etude de la compression des vidéos numériques
4.2.1. Le M-JPEG
4.2.2. Le MPEG

4.2.3. Le MPEG-1
4.2.3.1. Principes de la compression MPEG1
4.2.3.1.1. Compression temporelle
4.2.3.1.2. Compression spatiale
4.2.3.2. Hiérarchie des données
4.2.3.2.1. Hiérarchie des données vidéo
4.2.3.2.2. Hiérarchie des données audio
4.2.3.3. Application de la compression temporelle
4.2.3.4. Composition du flux vidéo
4.2.3.4.1. Compensation du mouvement
4.2.3.4.2. L'encodage des images clés
4.2.3.4.3. Méthode de synchronisation
4.3. Conclusion
4.3.1. L'avenir de la vidéo numérique : Le MPEG 4.
4.3.1.1. Description et objectif du MPEG 4.
4.3.1.2. La notion d'objet media
5. Le streaming
5.1. Introduction
5.1.1. La diffusion en Broadcast
5.1.2. La diffusion en Multicast
5.1.3. La diffusion en unicast
5.2. Les techniques et protocoles
5.2.1. La gestion des applications temps réel
5.2.2. Le protocole RTP
5.2.3. Le protocole RTCP
5.2.4. Le protocole RSVP
5.2.5. Le protocole RTSP

5.2.6. Le protocole SMIL
5.2.7. Comparaison de RTP/RSH dans http
5.3. La compression des media
5.3.1. Présentation
5.3.2. Les formats de compression audio
5.3.3. Les formats de compression vidéo
5.4. Les 3 technologie du Streaming
5.4.1. Quicktime
5.4.1.1. Le lecteur Quicktime
5.4.1.2. Encodage et préparation des fichiers
5.4.1.3. Le serveur de Streaming Quicktime
5.4.2. Windows Media
5.4.2.1. Le lecteur Windows media player
5.4.2.2. Encodage et préparation des fichiers
5.4.2.3. Le serveur de Streaming Windows media
5.4.3. Real Networks
5.4.3.1. Le lecteur Real Player
5.4.3.2. Encodage et préparation des fichiers
5.4.3.3. Le serveur de Streaming Real
5.5. Conclusion
5.5.1. Corona, L'avenir du Streaming
5.5.1.1. Plus besoin de Buffering
5.5.1.2. De quoi faire démarrer le marché de la vidéo en ligne ?

1. La compression de donnée :
Pourquoi compresser ? De nos jours, l'augmentation de la puissance des processeurs devient plus rapide que celle des capacités de stockage, surpassant ainsi la rapidité de la bande passante des réseaux, En effet cela demande beaucoup de changements dans les infrastructures de télécommunication. Pour palier à ce problème, on préconise la réduction de la taille des données en utilisant la puissance des processeurs plutôt que l'augmentation des capacités de stockage et de transmission des données.
Comment compresser ?La compression a pour objectif de réduire la taille physique de blocs d'informations. Un compresseur optimise les données en utilisant des considérations propres au type de données à compresser à l'aide d'algorithme ; un décompresseur est donc nécessaire pour reconstruire grâce à l'algorithme inverse de celui utilisé pour la compression les données premières. La méthode de compression dépend du type de données à compresser : par exemple on ne compressera pas de la même façon une image qu'un fichier audio...
Les différents types de compressions :
Compression physique : La compression physique agit directement sur les données; il s'agit ainsi de regarder les données redondantes d'un train de bits à un autre.
Compression logique : La compression logique est effectuée par un raisonnement logique en substituant une information par une information équivalente.
Compression symétrique: La compression symétrique utilise la même méthode pour compresser et décompresser l'information, pour chacune de ces opérations il est donc demandé la même quantité de travail. Ce type de compression est généralement utilisé dans les transmissions de données.
Compression asymétrique : La compression asymétrique utilise plus de travail pour l'une des deux opérations, le plus souvent on trouve des algorithmes pour lesquels la compression est plus lente que la décompression. Des algorithmes plus rapides en compression qu'en décompression peuvent être utilisés lorsque l'on archive des données auxquelles on n'accède peu souvent (pour des raisons de sécurité par exemple), ce type de compression rée des fichiers compacts.
Compression avec pertes : Un programme a besoin de conserver son intégrité pour fonctionner, aussi il n'est pas concevable de reconstruire un programme en omettant de ci de là des bits et en en ajoutant là où il n'en faut pas. La compression avec pertes se permet d'éliminer quelques informations pour avoir une compression optimisée le plus possible, tout en gardant un résultat qui soit le plus proche possible des données originales. Ces le cas par exemple de certaines compressions d'images ou de sons. Pour une image de zèbre par exemple, l'algorithme n'effacera pas les rayures mais les modifiera éventuellement légèrement pour pouvoir appliquer l'algorithme de façon optimale.
Les différents Type d'encodage :

Certains algorithmes de compression sont basés sur des dictionnaires spécifiques à un type de données: ce sont des encodeurs non adaptifs. Les occurrences de lettres dans un fichier texte par exemple dépendent de la langue dans laquelle celui-ci est écrit.
Un encodeur adaptif s'adapte aux données qu'il va devoir compresser, il ne part pas avec un dictionnaire déjà préparé pour un type de données.
Enfin un encodeur semi adaptif construira celui-ci en fonction des données à compresser : il construit le dictionnaire en parcourant le fichier, puis compresse ce dernier
2. Traitement de l'image :
Introduction :
Parallèlement au développement rapide des applications informatiques on a observé un fort accroissement de l’utilisation des images numériques, notamment dans le domaine des multimédias, des jeux, des transmissions satellites ou de l’imagerie médicale. Les images numérisées, posent, cependant par leur taille importante, de nombreux problèmes de transmission et de stockage. Il est donc nécessaire de " compresser " l’image. L’utilisation d’algorithmes de compression d’image dont l'évolution est en perpétuel mouvement permet de réduire la taille de mémoire utilisée par une image en perdant un minimum de qualité.
Définitions d’une image numérique :
On distingue deux familles d'images numériques : les images numérisées d’origine extérieure et les images de synthèse (produites sur un ordinateur). Les images sont décomposées géométriquement en petites surfaces élémentaires, les pixels (contraction des mots anglais picture et element). Chaque pixel est alors défini par ses abscisses et ordonnées. Le stockage de l’image en mémoire est réalisé en conservant les données attachées à chaque pixel dans un tableau ou matrice (à chaque pixel correspondra une case de la matrice).
Une image en noir et blanc ne nécessitera que l’intervention de deux types de pixels différents pour être décrite. Un seul bit suffira pour coder la valeur d’un pixel. Les images à plusieurs niveaux de gris sont définies avec 256 niveaux de gris, mais seuls 128 sont reconnaissables par l’œil. La quantité d’information est de 8 bit par point.
Une image colorée est toujours le mélange de trois images de couleurs données, donc le mélange de trois images monochromes. Ces couleurs dites primaires sont indépendantes entre elles. Les terminaux des systèmes multimédia (caméras, récepteurs) utilisent les couleurs primaires : rouge, vert et bleu. L’imprimerie utilise le jaune, magenta et cyan. Ces trois couleurs sont nécessaires pour restituer l’ensemble des couleurs observables par le système visuel humain (elles forment un espace vectoriel de dimension trois).
Une représentation classique est celle qui consiste à matérialiser les trois couleurs selon trois axes dont les directions matérialisent leurs teintes (R, V, B dans notre cas) et de représenter la couleur d’un point p d’une image par un vecteur Cp, obtenu par combinaison linéaire (mélange) des quantités de couleur.
Représentation vectorielle de la couleur d’un point
L’écriture algébrique équivalente est :

Pour les images couleurs, la valeur d’un pixel est codée par des informations sur la chrominance (paramètres I et Q) et sur la luminance (paramètre Y). Chacun des paramètres Y, I, Q est codé sur 8 bits ce qui fait un total de 24 bits nécessaire au codage d’un pixel d’une image en couleur. Dans de nombreuses applications le nombre de teintes possibles pour chaque primaire est de 256. Par combinaison linéaire on peut alors réaliser environ 16 millions de couleurs différentes.
Les différentes caractéristiques d'une image numérique :
Plusieurs paramètres définissent une image : sa taille, son format, sa résolution, son mode couleur... Maîtriser les caractéristiques de cette image permette d'obtenir un poids convenable tout en lui conservant une bonne qualité.
La taille d'une image :
Il existe deux sortes d'images numériques : Les images vectorielles : Ce sont des descriptions mathématiques qui peuvent s'exprimer par une
formule, ce qui les rend indépendantes de toute question de résolution. Elles présentent l'avantage d'être peu volumineuses. On ne les trouve que depuis peu de temps sur Internet et elles restent inaccessibles à certains navigateurs.
Les images bitmap : Elle se mesurent en pixels. Chaque pixel possède une unique valeur RVB (cf. plus loin) et est insécable. Augmenter ou diminuer la taille d'une image revient à faire une interpolation mais dans les deux cas on a une perte de qualité. Les images bitmap sont utilisées sur le net avec des formats différents.
La résolution :
La résolution d'une image est le rapport entre le nombre de pixels qui la composent et sa taille (en centimètres ou en pouces). Pour l'impression, une image pourra avoir une résolution de 500 dpi (dot per inch = point par pouce). Pour une publication sur écran, une résolution supérieure à 72 dpi ne changera pas sa qualité d'affichage. En revanche, son poids en octets sera beaucoup plus important. Ceci ne veut pas dire qu'une image issue d'Internet n'est pas imprimable à une résolution supérieure. Il suffit d'ouvrir l'image (enregistrée sur le disque dur) dans un logiciel de traitement d'image (Adobe photoshop, Jasc Paintshop pro …) et d'augmenter sa résolution à 200 dpi. Le document reste malgré tout de basse qualité.
La couleur :
Une image numérique est composée d'un nombre maximum de couleurs appelé profondeur. Cette profondeur détermine le poids de l'image. Le codage numérique s'exprime en bit. Une image à 1 bit est une image où à chaque pixel ne sera attribué que deux états possibles (2x1) : couleur ou sans couleur, noir ou blanc (codage numérique 1 ou 0).
Une image en 2 bits permet quatre combinaisons de couleurs (00, 01, 10, 11) pour chaque pixel (2x2). Une image en 4 bits permet seize combinaisons (0001, 0010, 0011, etc...), soit 2x2x2x2 possibilités.Une image d'une profondeur de 256 couleurs est une image en 8 bits (2^8). Ce niveau de codage est utilisé pour des images en niveaux de gris.
A 24 bits, le nombre maximum de couleurs possible est de 16 777 216, soit 256^3 pour une image à 3 couches de 8 bits ou encore 2 puissance 24. Tous les écrans ne possèdent pas un affichage en 24 bits. Les moniteurs grands publics sont généralement dotés de couleurs 8 bits et ne peuvent donc afficher plus de 256 couleurs. On trouve aussi des images à 32 bits qui, dans le cas précis d'une utilisation sur Internet, sont en fait des images 24 bits auxquelles on attribue une couche dite alpha (voir la définition au chapitre 62.2.4 sur le format PNG) codée en 8 bits. Cette couche gère habituellement les zones de transparence dans l'image.
On parle en général de bits par couleur : par exemple, en mode RVB, pour une image en 24 bits sont attribués à chaque couleur (rouge, vert, bleu) 8 bits. Il y a donc 8 bits de nuance par couleur.

Image GIF indexée en 8 bits Image GIF indexée en 5 bits Image GIF indexée en 5 bits
Les modes :
Les modes utilisés sur Internet :
Le mode RVB : Il s'agit du mode colorimétrique additif basé sur la lumière. Il est utilisé par exemple par les écrans d'ordinateur. Les initiales RVB (ou RGB en anglais) signifient rouge, vert, bleu; C'est à partir de l'addition ou non de ces couleurs de bases que sont créés toutes les nuances de couleurs utilisées par l'ordinateur. Si le moniteur affiche en 24 bits (True Color), chaque couleur a une valeur en rouge, vert, bleu allant de 0 à 255 (codée en 8 bits respectivement pour le rouge le vert et le bleu). Une carte vidéo limitée à 8 bits ne permettra donc au maximum qu'un affichage en 256 couleurs.
Les couleurs indexées : Les images définies à partir d'une palette de couleurs sont dites indexées. Elles ne sont pas codées en RVB mais ont une valeur fixe pour chaque pixel. La palette suit les fichiers indexés et sert de référent pour la distribution des couleurs aux pixels des images. L'indexation d'une image permet ainsi un gain de place puisque l'image comprend au final moins de données. Il est cependant déconseillé d'indexer une image que l'on n'a pas fini de travailler, tout comme il est préférable de conserver une copie en RVB.
Les autres modes :
Le mode CMJN (ou CMYK en anglais) : Couramment utilisé pour l'impression en quadrichromie, il s'agit d'un mode colorimétrique soustractif. On parle aussi de couleur de procédé (process color). Ce système s'appuie sur le mélange de trois couleurs (jaune, cyan et magenta) et du noir. Un affichage à l'écran en CMJN limite la qualité de l'image, lui fait perdre de sa luminosité et de son dynamisme.
Le mode TSL (ou HSV en anglais) : Pour ce mode ,les trois paramètres régissant l'affichage de l'image sont les Teinte, la saturation et la luminosité (intensité) .
Etudes des différents formats d'images :
Il existe différents types de formats. Actuellement, Internet n'en utilise pratiquement que trois : JPEG, GIF, PNG. D'autres formats sont lisibles par les navigateurs après l'ajout de plug-ins.
Le format JPEG :
Les principales caractéristiques de la norme JPEG sont les suivantes :
o Une qualité paramétrable de l’image : Les données sont d’autant moins compressées que la qualité exigée est bonne.
o La norme JPEG n’impose pas de format de fichier. en principe Le processus de compression est applicable à toutes les sources d’images numérisées. Les spécifications n’indiquent pas la dimension de l’image et le nombre de pixels, ni le type de codage des données représentant la couleur. La norme définit des plans mémoires correspondant aux différents plans de la couleur.
o Le choix pour les utilisateurs entre une implémentation matérielle ou logicielle.
En fait le JPEG est le plus adapté à la compression d'images photographiques possédant de nombreux niveaux de gris ou de couleurs. Il n'est pas recommandé pour les images de petite taille ou les dessins au trait.

Son intérêt devient croissant à partir d'images de taille 100x100 pixels. Il est capable de supprimer la plupart des nuances de couleurs que l'oeil ne distingue pas. La méthode de formatage du JPEG consiste en une découpe de l'image en zones.
Ce format supporte la compression de toute profondeur de couleurs, y compris en 24 bits. Le format JPEG est un mode de compression à perte. Il est donc recommandé de travailler l'image sous un autre format et de l'enregistrer une unique fois en JPEG pour éviter la perte inutile de données.
Il est intéressant d'essayer plusieurs niveaux pour le taux de compression sur une même image pour comparer les résultats obtenus. Il existe aussi trois options de compression : standard, optimisé et progressif. L'option optimisée améliore la qualité des couleurs et produit une image de poids plus petit. Le JPEG progressif optimisé se traduit par un affichage graduel de l'image, ce qui présente l'avantage de faire patienter le lecteur en attente de l'affichage complet de la page. Les fichiers JPEG progressifs sont toutefois des fichiers plus volumineux. Ils mobilisent aussi plus de RAM pour le décodage des données. Il est intéressant de les utiliser lorsque l'image dépasse 30 Ko
Principes de la compression au format JPEG :
Le principe de l’algorithme JPEG pour une image à niveaux de gris (étant donné qu’une image couleur est la somme de 3 images de ce même type, dans la suite du TIPE nous ne considérerons plus que ce genre d’images) est le suivant :
La matrice des pixels de l’image numérique est décomposée en blocs de 8x8 pixels qui vont tous subir le même traitement. Une transformation linéaire, le plus souvent du type FFT (Fast Fourier Transform) ou DCT (Discret consine Transform) est réalisée sur chaque bloc. Ces transformations complexes concentrent l’information sur l’image en haut et à gauche de la matrice.
Les coefficients de la matrice après avoir été transformée sont ensuite quantifiés à l’aide d‘une table de 64 éléments définissant les pas de quantification. Cette table permet de choisir un pas de quantification important pour certaines composantes jugées peu significatives visuellement. On introduit ainsi un critère perceptif qui peut être rendu dépendant des caractéristiques de l’image et de l’application (taille du document).
Des codages (prédictif, entropique, l’algorithme de Huffmann ou arithmétique), sans distorsion, sont ensuite réalisés en utilisant les propriétés statistiques des images.
Ces compressions seront suivies d’une transformation inverse de la transformation initiale, conduisant à la restitution de l’image.
Plan d'application de l'algorithme JPEG
Pour mieux comprendre ce principe, prenons comme exemple la matrice suivante représentant la composante rouge d'une image codée en 16 millions de couleurs (soit 256 rouges) :
255 255 255 0 0 0 0 036 255 100 100 36 36 36 36
73 255 100 73 100 73 73 73
image originale :

109 255 100 100 100 100 100 109
146 146 100 146 100 146 146 146182 182 100 182 100 100 100 182
218 218 218 218 100 218 218 218255 255 255 255 100 100 100 255
Etape 1 : La transformation linéaire
Cette première étape consiste à soustraire à chaque valeur de la matrice 128 (ce numéro correspond au nombre de rouges divisé par 2) puis à appliquer la DCT donnée par :
. Nous obtenons le résultat suivant :
50 258 135 -120 -73 -76 -57 -103
-319 148 -9 28 -124 -101 -55 6368 170 52 -89 -15 31 80 35
-21 25 40 44 16 68 60 3022 81 46 -9 14 14 55 47
66 33 39 33 -54 4 29 38-31 68 30 -10 54 -29 13 33
41 -30 0 34 -31 37 36 29
On remarquera que les coefficients possédantsLes valeurs absolues les plus fortes se trouvent en haut à gauche de la matrice.
Etape 2 : La quantification
Elle consiste à donner des valeurs approximatives de la matrice précédente. Pour cela, on remplace chaque valeur par le quotient de la division euclidienne de cette valeur par le pas de quantification. Ainsi, si l'on choisit un pas de quantification de 4, on remplacera les valeurs 0, 1, 2 et 3 par 0 ; les valeurs 4, 5, 6 et 7 par 1 et ainsi de suite. C'est ici que nous allons perdre des données, mais d'une manière astucieuse. En effet, on va choisir un petit pas pour les valeurs en haut à gauche et un pas de plus en plus grand au fur et à mesure que l'on descend vers le bas droit de la matrice.
La matrice de quantification Q nous est donnée par la relation suivante :
Q(i,j) = 1 + F(1 + µ (in + jn)) , où F est le facteur de qualité.
Dans notre exemple, nous prendrons µ = n = 1 et F = 5. Ce qui nous donne, après simplification :
Q(i,j) = 1 + 5(1 + i + j)
Nous obtenons la matrice de quantification suivante :
6 11 16 21 26 31 36 41

11 16 21 26 31 36 41 4616 21 26 31 36 41 46 51
21 26 31 36 41 46 51 5626 31 36 41 46 51 56 61
31 36 41 46 51 56 61 6636 41 46 51 56 61 66 71
41 46 51 56 61 66 71 76
Divisons maintenant la matrice de données par notre matrice de quantification. Le résultat est le suivant :
8 23 8 -5 -2 -2 -1 -2-29 9 0 1 -4 -2 -1 1
4 8 2 -2 0 0 1 0-1 0 1 1 0 1 1 0
0 2 1 0 0 0 0 02 0 0 0 -1 0 0 0
0 1 0 0 0 0 0 01 0 0 0 0 0 0 0
Vous serez sans doute étonné par le nombre de zéros.
Etape 3 : La compression
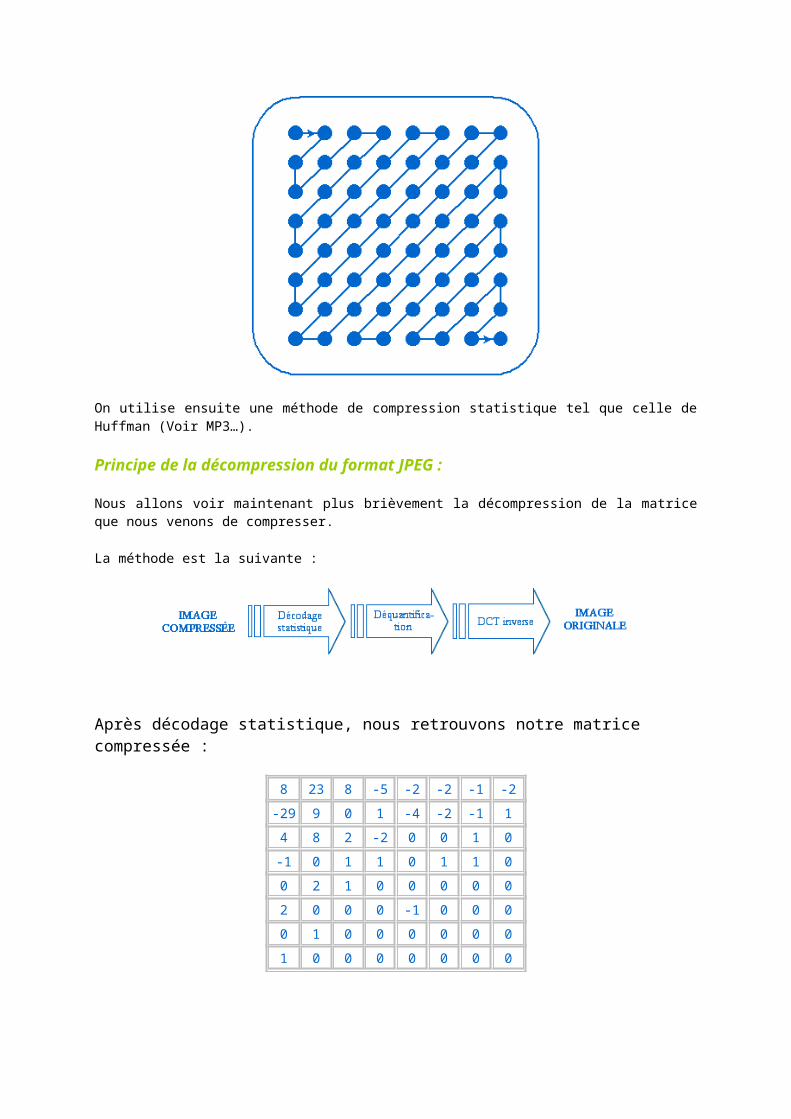
La dernière étape consiste à compresser (sans perte) la matrice obtenue. La norme JPEG traite les 0, en raison de leur nombre important, d'une manière particulière. On va d'abord balayer la matrice d'une façon particulière pour obtenir les suites de 0 les plus importantes possibles :
On utilise ensuite une méthode de compression statistique tel que celle de Huffman (Voir MP3…).
Principe de la décompression du format JPEG :

Nous allons voir maintenant plus brièvement la décompression de la matrice que nous venons de compresser.
La méthode est la suivante :
Après décodage statistique, nous retrouvons notre matrice compressée :
8 23 8 -5 -2 -2 -1 -2
-29 9 0 1 -4 -2 -1 14 8 2 -2 0 0 1 0
-1 0 1 1 0 1 1 00 2 1 0 0 0 0 0
2 0 0 0 -1 0 0 00 1 0 0 0 0 0 0
1 0 0 0 0 0 0 0
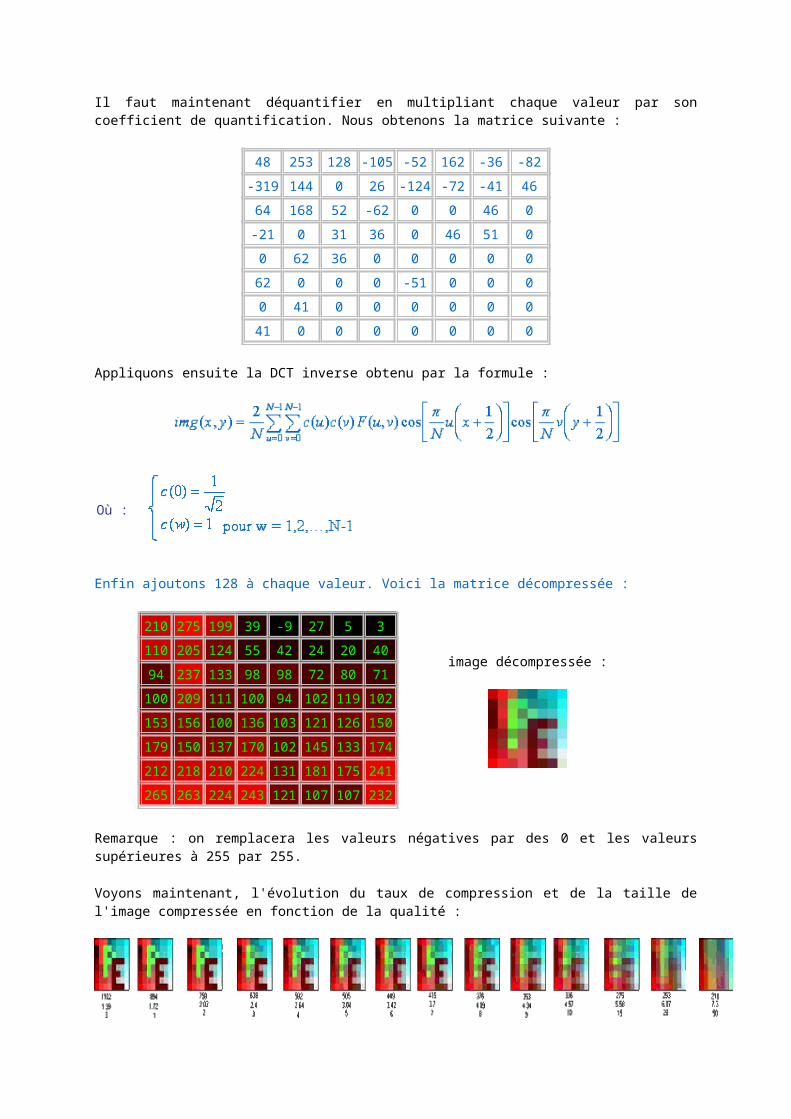
Il faut maintenant déquantifier en multipliant chaque valeur par son coefficient de quantification. Nous obtenons la matrice suivante :
48 253 128 -105 -52 162 -36 -82
-319 144 0 26 -124 -72 -41 4664 168 52 -62 0 0 46 0
-21 0 31 36 0 46 51 00 62 36 0 0 0 0 0
62 0 0 0 -51 0 0 00 41 0 0 0 0 0 0
41 0 0 0 0 0 0 0
Appliquons ensuite la DCT inverse obtenu par la formule :
Où :
Enfin ajoutons 128 à chaque valeur. Voici la matrice décompressée :
210 275 199 39 -9 27 5 3 image décompressée :

110 205 124 55 42 24 20 40
94 237 133 98 98 72 80 71100 209 111 100 94 102 119 102
153 156 100 136 103 121 126 150179 150 137 170 102 145 133 174
212 218 210 224 131 181 175 241265 263 224 243 121 107 107 232
Remarque : on remplacera les valeurs négatives par des 0 et les valeurs supérieures à 255 par 255.
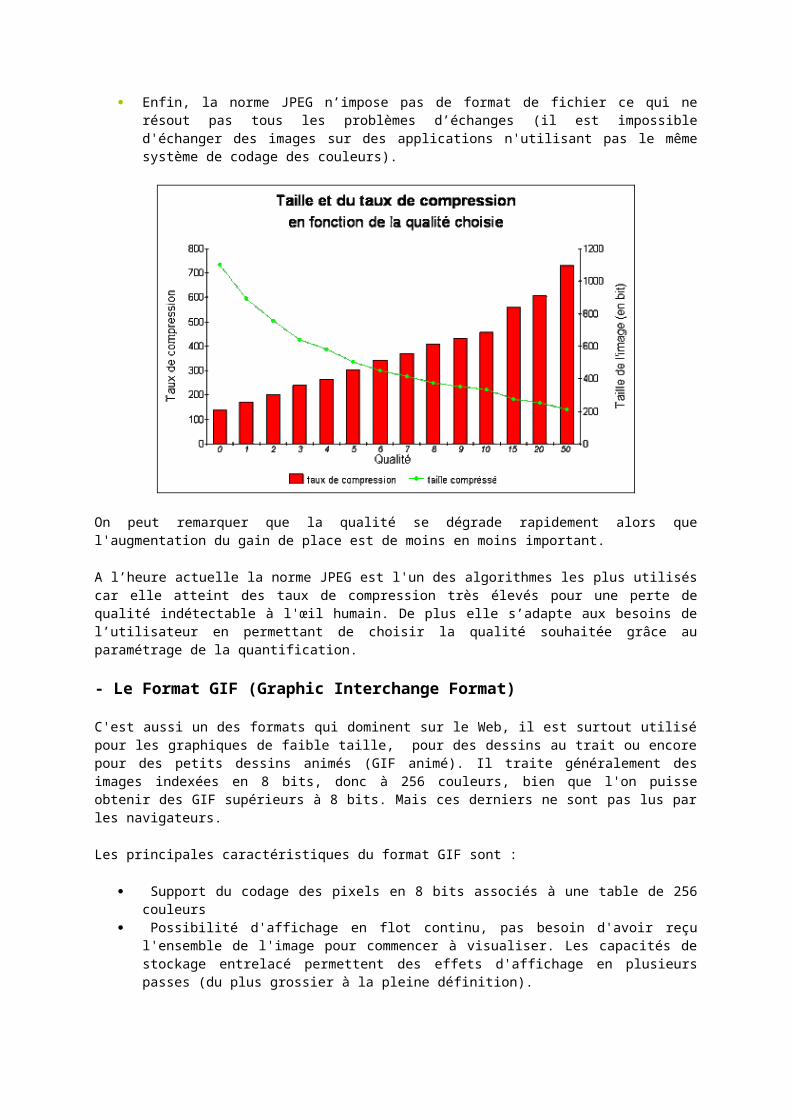
Voyons maintenant, l'évolution du taux de compression et de la taille de l'image compressée en fonction de la qualité :
Le premier nombre est le nombre de bits de l'image compressée, le second est le taux de compression obtenu et le dernier indique la qualité choisie.
Etude performance / Qualité :
8794 octets (niveau de qualité de 100) 2407 octets (niveau de qualité de 60) 1164 octets (niveau de qualité de 10)
On remarque qu’à partir d’un certain taux de compression l’image devient méconnaissable, et semble être composée de blocs de 8x8 pixels d’une couleur unique.
Lorsque l’image est agrandie cet effet est amplifié. Baptisé sous le nom d’effet mosaïque, bien connu par son utilisation dans les medias.
Les taux de compression obtenus sont impressionnants mais restent difficiles à interpréter car ils dépendent souvent de la nature de l’image.
Mais on peut définir les niveaux de qualité d’image selon le taux de compression en indiquant le nombre de bits nécessaire au codage d’un pixel. On dit alors que :
entre 1,5 et 2 bits par pixel, l’image est visuellement in différentiable de l’originale entre 0,75 et 1,5 bits par pixel, l’image est d’excellente qualité et répond à tous les besoins entre 0,5 et 0,75 bits par pixel, l’image est de bonne qualité entre 0,25 et 0,5 bits par pixel, l’image est de qualité moyenne.
La caractéristique principale de la norme JPEG est le paramétrage de la qualité de l’image effectué lors du choix de la matrice de quantification. Cela donne une très grande flexibilité sur le choix de la qualité de l’image en fonction de la capacité de stockage et des contraintes de rendu.

La norme JPEG présente cependant trois défauts majeurs :
Sur la plupart des images, une matrice de quantification avec une taille de pas de 5 produit une perte de définition se ressentant sur la qualité de l’image. De plus, si on dépasse ce facteur, l’image a tendance à apparaître comme une composition de blocs de 8x8 pixels.
L’algorithme de compression nécessite une puissance de traitement égale pour la compression et la décompression ce qui oblige une importante implémentation matérielle. Les applications multimédia de diffusion d’images numériques nécessitent de moyens de décompression peu coûteux quitte à augmenter le temps de compression.
Enfin, la norme JPEG n’impose pas de format de fichier ce qui ne résout pas tous les problèmes d’échanges (il est impossible d'échanger des images sur des applications n'utilisant pas le même système de codage des couleurs).
On peut remarquer que la qualité se dégrade rapidement alors que l'augmentation du gain de place est de moins en moins important.
A l’heure actuelle la norme JPEG est l'un des algorithmes les plus utilisés car elle atteint des taux de compression très élevés pour une perte de qualité indétectable à l'œil humain. De plus elle s’adapte aux besoins de l’utilisateur en permettant de choisir la qualité souhaitée grâce au paramétrage de la quantification.
- Le Format GIF (Graphic Interchange Format)
C'est aussi un des formats qui dominent sur le Web, il est surtout utilisé pour les graphiques de faible taille, pour des dessins au trait ou encore pour des petits dessins animés (GIF animé). Il traite généralement des images indexées en 8 bits, donc à 256 couleurs, bien que l'on puisse obtenir des GIF supérieurs à 8 bits. Mais ces derniers ne sont pas lus par les navigateurs.
Les principales caractéristiques du format GIF sont :
Support du codage des pixels en 8 bits associés à une table de 256 couleurs Possibilité d'affichage en flot continu, pas besoin d'avoir reçu l'ensemble de l'image pour commencer à
visualiser. Les capacités de stockage entrelacé permettent des effets d'affichage en plusieurs passes (du plus grossier à la pleine définition).
La définition de zones transparentes peut faire apparaître l'image comme n'étant pas de forme rectangulaire.
Les données sont compressées par un algorithme réversible. Après décompression l'image initiale sera intégralement restituée. Cet algorithme est efficace sur une image constituée de plages de couleurs, mais il l'est moins si l'image est composée de dégradés de couleur.
Le mode de compression utilisé par le format GIF est appelé LZW (Lempel-Ziv-Welch), aussi utilisé par les fichiers zip. Ce procédé n'entraîne aucune perte : l'image décompressée est identique à l'image d'origine. Dans le fichier à compresser, l'encodage de schémas réguliers est systématique. Il s'agit d'un encodage en longueur de ligne et c'est de la gauche vers la droite que s'effectue le stockage des pixels. Ansi la compression est aisé pour toute régularité horizontale.
Un dégradé allant du haut vers le bas prendra beaucoup moins de place que le même dégradé allant de la gauche vers la droite (voir exemple ci-dessous)
7719 octets 8926 octets
Les images GIF 89a, basé sur le format d'origine GIF 87a, gèrent les zones de transparence simple: On attribue à l'un des éléments de la palette des couleurs une fonction de transparence.L'option entrelacement permet le stockage non linéaire des pixels. Le téléchargement d'une image entrelacée est effectuée de façon progressive : des blocs également espacés arrivent sur le navigateur qui va les afficher. On a ainsi rapidement une idée de l'image finale grâce aux premiers blocs. Cette option augmente la taille du fichier tout comme le JPEG progressif. De même que pour le JPEG progressif, l'utilisation de l'option entrelacé est intéressante à partir d'une image supérieure à 30 Ko.
Avec ce format, il est possible de créer de petites animations. Le principe, assez simple, consiste en la succession de petites images comprise sur un même document GIF.
256 couleurs, 4511 octets. 64 couleurs, 2752 octets. 8 couleurs, 1166 octets
- Le format PNG (Portable Network Graphic - ou png's not GIF) :
A l'avenir, le PNG devrait remplacer JPEG et GIF en raison de sa méthode de compression plus efficace, de la présence d'une couche alpha et de ses fonctions de colorisation. On estime qu'un fichier en PNG est 15% à 35% plus léger qu'un fichier GIF et plus de 40% plus léger qu'un fichier JPEG.
Ce format peut être utilisé pour des images en 24 bits (voire 48 bits), pour les graphiques en 256 couleurs ou en niveau de gris (allant jusqu'à 16 bits). Seul défaut, il n'est actuellement lisible que par les versions ressentes des navigateurs internet.
En effet grâce à la présence d'une couche alpha, la gestion de plusieurs degrés de transparence devient possible. On peut définir simplement une couche alpha comme une "couleur" supplémentaire attribuée à chaque pixel. Sur une image en RVB, chacune des couches bénéficie de 8 bits auxquelles s'ajoute une autre couche en niveau de gris de 8 bits. Cette va gérer les niveaux de transparence à la manière d'un pochoir.
Aux pixels noirs correspondent les zones d'opacité; aux pixels blancs correspond la transparence absolue. Les zones de gris gèrent les niveaux de transparence et d'opacité.
La compression de fichier en PNG est basée sur une version publique de LZW. Par ailleurs, ce format effectue un lissage automatique des images.
24 bits + couche alpha, 9731 octets 24 bits, 9005 octets 8 bits, 1173 octets

3. Traitement du son :Introduction :
D’où vient le son?
A la base, le son est une vibration de l'air, une suite de dépressions et de surpressions de l'air par rapport à une moyenne, la pression atmosphérique. La façon la plus simple de reproduire un son est de faire vibrer un objet. Par exemple, une guitare émet une note lorsque l'on frappe une corde, la faisant ainsi vibrer.
On utilise généralement des haut-parleurs pour reproduire le son. Il s'agit d'une membrane reliée à un électro-aimant, qui, suivant les sollicitations d'un courant électrique va vibrer , effectuant un mouvement en avant et en arrière très rapidement, ce qui provoque une perturbation de l'air situé devant lui, c'est-à-dire du son!
De cette façon on produit des ondes sonores qui peuvent être représentées sur un graphique comme les variations de la pression de l'air (ou bien de l'électricité dans l'électro-aimant) en fonction du temps. On obtient alors une représentation de la forme suivante:
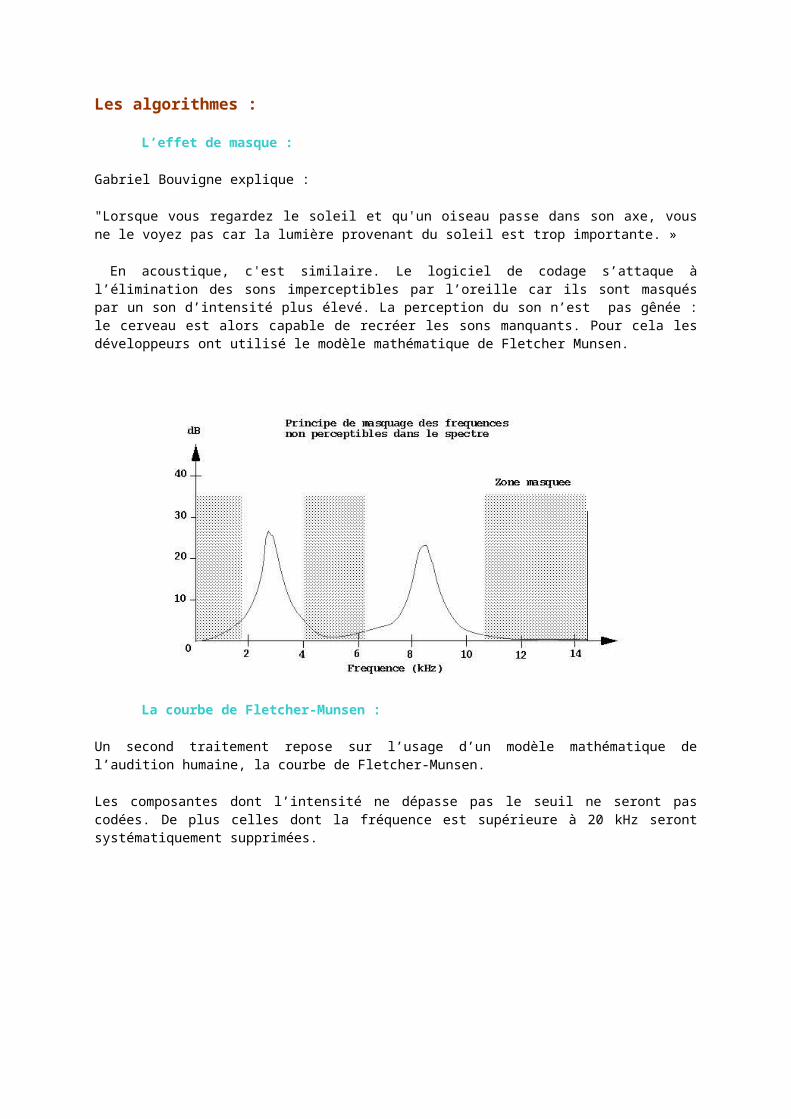
Cette représentation d'un son est appelée spectre de modulation d'amplitude (il représente la modulation de l'amplitude d'un son en fonction du temps). Le sonogramme représente lui la variation des fréquences sonores en fonction du temps. On peut remarquer qu'un sonogramme présente une fréquence fondamentale, à laquelle se superposent des fréquences plus élevées, appelées harmoniques.
C'est ce qui permet d'arriver à distinguer plusieurs sources sonores: les sons aigus auront des fréquences élevées , et les fréquences graves des fréquences basses.
L'échantillonnage du son :
Pour représenter un son sur un ordinateur, il faut le convertir en valeurs numériques. Il s'agit donc de relever des petits échantillons de son (des différences de pression) à des intervalles de temps précis : on appelle cette action l'échantillonnage ou la numérisation du son. L'intervalle de temps entre deux échantillons est appelé taux d'échantillonnage. Pour que le son paraisse continu à l’oreille, il faut établir des échantillons tous les 100000ème de seconde. Pour cela il est plus commode de raisonner sur le nombre d’échantillons par seconde, exprimés en Hertz (Hz). Voici quelques exemples de taux d'échantillonnage et de qualités de sons associés:
Taux d'échantillonnage Qualité du son44000 Hz qualité CD22000 Hz qualité radio8000 Hz qualité téléphone
La valeur du taux d'échantillonnage, pour un CD audio est déterminé à partir du théorème de Shannon, qui stipule que pour numériser fidèlement une valeur ayant une fréquence donnée, il faut numériser au double de cette fréquence. En effet l'oreille humaine n'arrive pas à distinguer des sons dont la fréquence dépasse 22 kHz, c’est pourquoi il faut numériser à 44 kHz!
La représentation informatique du son :
A chaque échantillon (correspondant à un intervalle de temps) est associé une valeur qui détermine la valeur de la pression de l'air à ce moment, le son n'est donc plus représenté comme une courbe continue présentant des variations mais comme une suite de valeurs pour chaque intervalle de temps:

L'ordinateur travaille avec des bits, il faut donc déterminer le nombre de valeurs que l'échantillons peut prendre, cela revient à fixer le nombre de bits sur lequel on code les valeurs des échantillons.
Avec un codage sur 8 bits, on a 28 possibilités de valeurs, c'est-à-dire 256 valeurs possibles Avec un codage sur 16 bits, on a 216 possibilités de valeurs, c'est-à-dire 65536 valeurs possibles
Avec la seconde représentation, on aura bien évidemment une qualité de son bien meilleure, mais aussi un besoin en mémoire beaucoup plus important. Enfin, la stéréophonie nécessite deux canaux sur lesquels on enregistre individuellement un son qui sera fourni au haut-parleur de gauche, ainsi qu'un son qui sera diffusé sur celui de droite.
Un son est donc représenté (informatiquement) par plusieurs paramètres:
la fréquence d'échantillonnage le nombre de bits d'un échantillon le nombre de voies (un seul correspond à du mono, deux à de la stéréo, et quatre à de la quadriphonie)
Calcul de la mémoire requise pour stocker un son :
Il est simple de calculer la taille d'une séquence sonore non compressée. En effet, en connaissant le nombre de bits sur lequel est codé un échantillon, on connaît la taille de celui-ci (la taille d'un échantillon est le nombre de bits...).
Pour connaître la taille d'une voie, il suffit de connaître le taux d'échantillonnage, qui va nous permettre de savoir le nombre d'échantillons par seconde, donc la taille qu'occupe une seconde de musique. Celle-ci vaut: Taux d'échantillonnage x Nombre de bits
Ainsi, pour savoir l'espace mémoire que consomme un extrait sonore de plusieurs secondes, il suffit de multiplier la valeur précédente par le nombre de seconde: Taux d'échantillonnage x Nombre de bits x nombre de secondes
Enfin, la taille finale de l'extrait est à multiplier par le nombre de voies (elle sera alors deux fois plus importante en stéréo qu'en mono... ) . La taille en bits d'un extrait sonore est ainsi égale à :
Taux d'échantillonnage x Nombre de bits x nombre de secondes x nombre de voie .
Etude des différents formats de compressions :
Comme pour les images, on peut ensuite comprimer l'information numérique selon divers formats, tels que le WAV, MP3… . Les divers formats de compression permettent de réduire la taille des fichiers avec des pertes plus ou moins grandes de qualité sonore.
Le WAV :
Le format WAV est en fait dérivé du RIFF.Le format RIFF qui signifie "Ressource Interchange File Format" à été créé par Microsoft.Il existe actuellement cinq types de fichiers RIFF différents :
Nom du Riff SignificationPAL_ Fichier palette
RDIB Bitmap indépendant du type d'appareilRMID Fichier format MIDI

RMMP Fichier "Movie" MultimédiaWAVE Fichier d'échantillons Son
Le fichier RIFF de type WAVE porte l'extension .WAV. La structure d'un échantillon wav ou d'un morceau comporte les informations suivantes : La fréquence d'échantillonnage, le nombre de bits sous lequel est codé l'échantillon (8 ou 16), le type de signal (Monophonique ou Stereophonique) et des données donnant des informations sur l'existence de boucle (ou Loop).
En fait, même si le wav permet d'obtenir une très bonne restitution sonore, son utilisation pour Internet est très limitée car le poids des fichiers est trop important. Nous nous pencherons donc plus en détail sur le principal format son sur Internet, le MP3.
Le MP3 :
Le mp3 (MPEG Audio layer 3) est un format de compression audio qui permet de réduire la taille d’un fichier audio. Après le MPEG Audio Layer 1 et le MPEG Audio Layer 2, le MP3 est le format actuellement le plus évolué et utilisé pour le codage audio des données MPEG-1 ( utilisé par le CDI Phillips) ou MPEG-2(utilisé pour le DVD).
Historique :
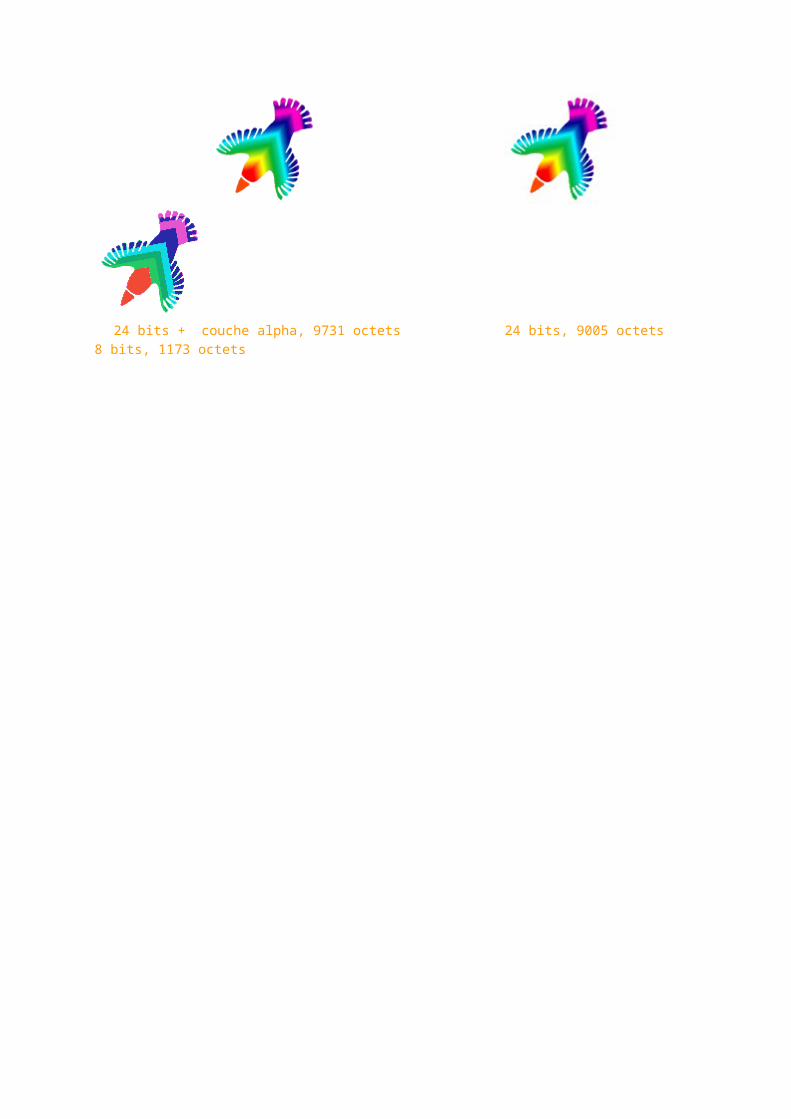
Dans les années 80, l’International Organization for Standardization(ISO) demande au groupe MPEG (Moving Expert Group) de travailler sur une norme internationale de codage des images. Puis en décembre 1988, le codage du son est mis à l’ordre du jour lors d’une réunion au bureau de Hanovre de la filiale allemande de Thomson Brandt : le MPEG l’inclut dans ses documents de référence. Les algorithmes de compression ne sont pas définis par MPEG. MPEG décrit des méthodes pour tester les données compressées et les décodeurs associée au standard. MPEG publie aussi tous les rapports techniques. MPEG-1 est un standard comprenant 5 parties :
Partie 1: SystèmesTout d’abord la combinaison d’un ou plusieurs flux de données provenant des parties vidéo ou audio avec les informations temporelles. De ce fait cela ne forme plus qu’un seul flux ce qui facilite la transmission des données. La figure ci-dessous illustre cette première partie :
Partie 2: Vidéo La spécification de la représentation codée pouvant être utilisée pour compresser des séquences vidéo à des taux de 1,5 Mbps environ.
Partie 3 : Audio Cette partie concerne la compression audio et sera développée plus loin.
Partie 4: TestLa spécification de la manière dont les tests peuvent être conçus pour vérifier si les flux de données et les décodeurs sont conformes aux spécificités mentionnées dans les parties 1, 2 et 3.
Partie 5: Simulation du softwareCette partie est un rapport comprenant l’implémentation complète des 3 premières parties du MPEG-1.
En 1986, Karlheinz Brandenburg et son équipe, travaillant à l’institut Franhofer de Hanovre, sont chargés du projet Eurêka qui est la création d’une radio numérique(du nom de DAB (Digital Audio Broadcasting).
Le problème auquel ce chercheur et son équipe ont été confrontés était que le son ne pouvait être transmis intégralement. Il fallait donc trouver un moyen de le transformer et de le compresser pour le transmettre. En 1992, le travail de Brandenburg aboutit : le MPEG audio layer 3 est reconnu comme standard de compression et en 94ee et son concepteur Brandenburg opte pour une diffusion libre. Rapidement, du fait de sa diffusion, le MPEG audio layer 3 est renommé MP3.
Caractéristiques :
Le mp3 est fondé sur le principe du « Codage perceptuel ». Cela consiste à retirer des données audio les fréquences inaudibles par l'oreille humaine. Pour cela il suffit d'analyser les composantes spectrométriques d'un signal audio, et de leur appliquer un modèle psycho-accoustique pour ne conserver que les sons audibles. La compression consiste à déterminer les sons que nous n'entendons pas et à les supprimer, il s'agit donc d'une

compression destructive, c'est-à-dire avec une perte d'information. Cependant l’innovation consiste dans le fait que cette perte est quasiment imperceptible car elle est fondée sur les limites connues du système auditif. L'oreille humaine est capable de discerner des sons entre 0.02kHz et 20kHz, sachant que sa sensibilité est maximale pour des fréquences entre 2 et 5kHz (la voix humaine est entre 0.5 et 2kHz), suivant une courbe donnée par la loi de Fletcher et Munsen.
Le principal intérêt du système de codage est qu’il permet de réduire la taille occupée par des données audio d’un facteur voisin de 12, sans dégradation sensible de la qualité du son. Par exemple, sur un CD, le son est numérisé en stéréo à 44,1 kHz, sur 16 bits : le débit nécessaire à un tel flux de données est proche de 180 kilooctets (Ko) par seconde, et une minute de musique stockée sur un CD représente plus de 10 mégaoctets (Mo) de données. Avec un taux de compression de 12, le débit est réduit à 15 Ko par seconde, et une minute de musique représente moins d’un mégaoctet de données. C’est le format de choix utilisé pour les fichiers audio sur Internet, la réduction de la taille des données permettant celle des temps de téléchargement.
Ce codage ne s’applique pas au signal audio lui même. Il faut le transformer. Le son à la sortie du micro se présente sous la forme d’une variation périodique de tension, évoluant au cours du temps. Ce signal est découpé en blocs de 24 millisecondes que l’on traite successivement. Le signal de chaque bloc est transformé à l’aide d’une décomposition en série de Fourier en 32 composantes nommées sous-bandes.Après avoir codé les sous bandes, on les assemble pour obtenir le fichier codé.Les algorithmes interviennent seulement sur les sous-bandes.
Les algorithmes :
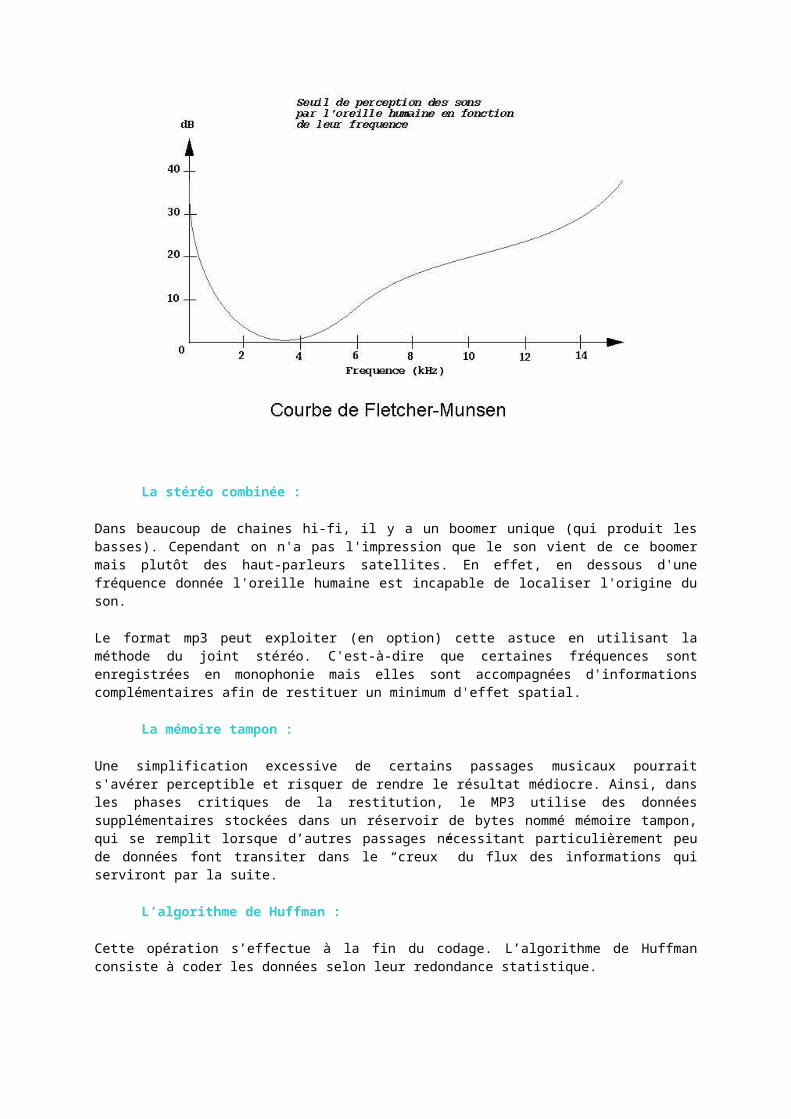
L’effet de masque :
Gabriel Bouvigne explique :
"Lorsque vous regardez le soleil et qu'un oiseau passe dans son axe, vous ne le voyez pas car la lumière provenant du soleil est trop importante. »
En acoustique, c'est similaire. Le logiciel de codage s’attaque à l’élimination des sons imperceptibles par l’oreille car ils sont masqués par un son d’intensité plus élevé. La perception du son n’est pas gênée : le cerveau est alors capable de recréer les sons manquants. Pour cela les développeurs ont utilisé le modèle mathématique de Fletcher Munsen.
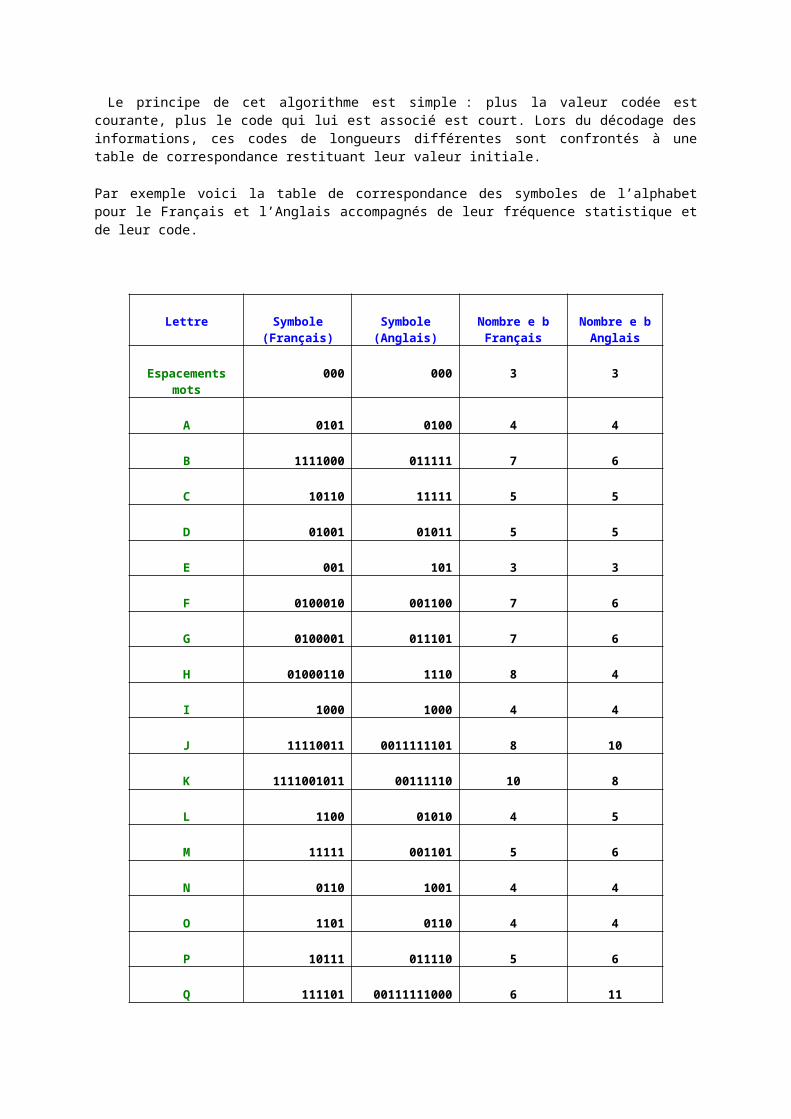
La courbe de Fletcher-Munsen :
Un second traitement repose sur l’usage d’un modèle mathématique de l’audition humaine, la courbe de Fletcher-Munsen.
Les composantes dont l’intensité ne dépasse pas le seuil ne seront pas codées. De plus celles dont la fréquence est supérieure à 20 kHz seront systématiquement supprimées.
La stéréo combinée :
Dans beaucoup de chaines hi-fi, il y a un boomer unique (qui produit les basses). Cependant on n'a pas l'impression que le son vient de ce boomer mais plutôt des haut-parleurs satellites. En effet, en dessous d'une fréquence donnée l'oreille humaine est incapable de localiser l'origine du son.
Le format mp3 peut exploiter (en option) cette astuce en utilisant la méthode du joint stéréo. C'est-à-dire que certaines fréquences sont enregistrées en monophonie mais elles sont accompagnées d'informations complémentaires afin de restituer un minimum d'effet spatial.
La mémoire tampon :
Une simplification excessive de certains passages musicaux pourrait s'avérer perceptible et risquer de rendre le résultat médiocre. Ainsi, dans les phases critiques de la restitution, le MP3 utilise des données supplémentaires stockées dans un réservoir de bytes nommé mémoire tampon, qui se remplit lorsque d’autres passages nécessitant particulièrement peu de données font transiter dans le “creux” du flux des informations qui serviront par la suite.
L’algorithme de Huffman :
Cette opération s’effectue à la fin du codage. L’algorithme de Huffman consiste à coder les données selon leur redondance statistique.

Le principe de cet algorithme est simple : plus la valeur codée est courante, plus le code qui lui est associé est court. Lors du décodage des informations, ces codes de longueurs différentes sont confrontés à une table de correspondance restituant leur valeur initiale.
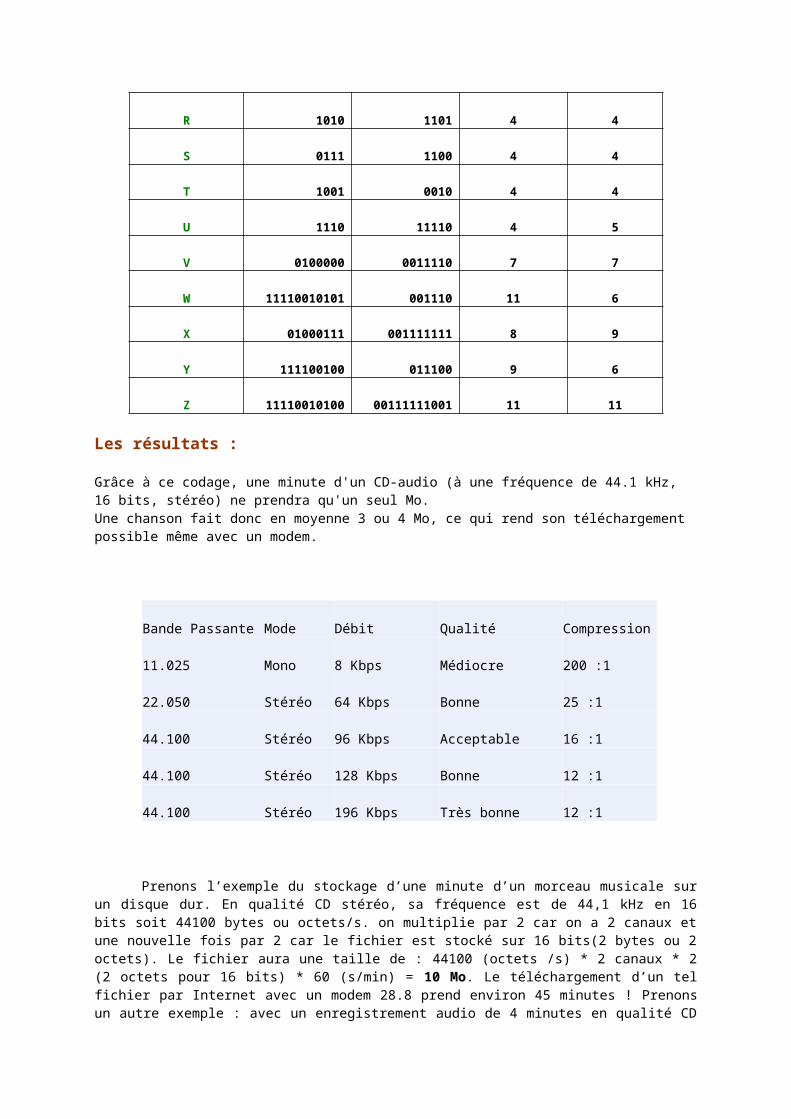
Par exemple voici la table de correspondance des symboles de l’alphabet pour le Français et l’Anglais accompagnés de leur fréquence statistique et de leur code.
Lettre Symbole (Français)
Symbole (Anglais)
Nombre e b Français
Nombre e b Anglais
Espacements mots 000 000 3 3
A 0101 0100 4 4
B 1111000 011111 7 6
C 10110 11111 5 5
D 01001 01011 5 5
E 001 101 3 3
F 0100010 001100 7 6
G 0100001 011101 7 6
H 01000110 1110 8 4
I 1000 1000 4 4
J 11110011 0011111101 8 10
K 1111001011 00111110 10 8
L 1100 01010 4 5
M 11111 001101 5 6
N 0110 1001 4 4
O 1101 0110 4 4
P 10111 011110 5 6
Q 111101 00111111000 6 11
R 1010 1101 4 4
S 0111 1100 4 4
T 1001 0010 4 4
U 1110 11110 4 5

V 0100000 0011110 7 7
W 11110010101 001110 11 6
X 01000111 001111111 8 9
Y 111100100 011100 9 6
Z 11110010100 00111111001 11 11
Les résultats :
Grâce à ce codage, une minute d'un CD-audio (à une fréquence de 44.1 kHz, 16 bits, stéréo) ne prendra qu'un seul Mo. Une chanson fait donc en moyenne 3 ou 4 Mo, ce qui rend son téléchargement possible même avec un modem.
Bande Passante Mode Débit Qualité Compression
11.025 Mono 8 Kbps Médiocre 200 :1
22.050 Stéréo 64 Kbps Bonne 25 :1
44.100 Stéréo 96 Kbps Acceptable 16 :1
44.100 Stéréo 128 Kbps Bonne 12 :1
44.100 Stéréo 196 Kbps Très bonne 12 :1
Prenons l’exemple du stockage d’une minute d’un morceau musicale sur un disque dur. En qualité CD stéréo, sa fréquence est de 44,1 kHz en 16 bits soit 44100 bytes ou octets/s. on multiplie par 2 car on a 2 canaux et une nouvelle fois par 2 car le fichier est stocké sur 16 bits(2 bytes ou 2 octets). Le fichier aura une taille de : 44100 (octets /s) * 2 canaux * 2 (2 octets pour 16 bits) * 60 (s/min) = 10 Mo. Le téléchargement d’un tel fichier par Internet avec un modem 28.8 prend environ 45 minutes ! Prenons un autre exemple : avec un enregistrement audio de 4 minutes en qualité CD (Stéréo, 44.1 KHz, 16 bits), on atteint facilement les 50 Mo pour le fichier Wave. Après compression MP3, le fichier ne dépassera pas les 4 Mo sans dégradation sonore. La compression digitale audio permet donc de minimiser la taille de stockage de tels fichiers.
Les successeurs du MP3 :
D’autres formats ont fait leur apparition pour compresser et coder le format audio :
AC-3 (Audio Code Number 3)
Ce format de compression audio a été mis au point par les laboratoires DOLBY. Cette technique produit une représentation digitale d’un signal audio qui, lorsqu’elle est décodée est identique à la source, tout en utilisant le moins de données (bitrate) possible. Comme le mp3, l’AC-3 utilise le masquage de certaines fréquences par l’oreille humaine. L’avantage de l’AC-3 par rapport au mp3 est qu’il gère les multi-canaux ainsi que le SURROUND. Au départ le terme DOLBY DIGITAL était consacré pour le cinéma en salle alors que le terme DOLBY SURROUND AC-3 concernait plutôt le cinéma à domicile. Ces deux techniques ne se différenciant que par le taux de compression, on a décidé de réunir pour plus de clarté ces deux appellations sous

le terme de DOLBY DIGITAL. L’AC-3 peut contenir jusqu’à cinq canaux audio complets (3Hz à 20000Hz), 3 à l’avant et deux à l’arrière (surround). Il contient aussi 6 canaux pour les effets de basses (3Hz à 120Hz) et des données sur la géométrie de la pièce et le point entre les différents canaux. Le Dolby AC-3 est beaucoup utilisé au cinéma avec un flux de 640 Kbps. De plus le THX, utilisé pour les DVD et les LaserDiscs(324 Kbps) utilise aussi ce format.
AAC (Advanced Audio Coding)
Aussi appelé NBC (Non Backward Compatible).Ce format est intégré au MPEG-2. L’AAC se rapproche de la norme AC3 (multi-canaux…) mais beaucoup plus flexible car il supporte une large gamme de fréquences d’échantillonnage et de débits. Il gère jusqu’à 48 canaux audio et le multi-langage. A qualité sonore identique, l’AAC réduit la taille des fichiers d’un facteur 2 par rapport au MP3.
TwinVQ (Transform-domain Weighted Interleave Vector Quantization)
Aussi appelé format VQF, ce format est une nouvelle technologie de compression audio développée par NTT Human Interface laboratories. TwinVQ est une méthode de codage comme MP3, AAC et AC3, elle utilise des outils de AAC mais elle est totalement différente. Avec TwinVQ, les bits de musique ne sont pas codés directement mais assemblés en segments puis ces segments sont envoyés à l’algorithme de codage. Cela permet de minimiser les distorsions pour des bitrates assez faibles. La norme TwinVQ sera intégrée au standard MPEG-4. TwinVQ a été développé pour des processeurs très puissants car le codage demande énormément de puissance de processeur et prend beaucoup de temps (trois fois plus que le codage MP3 en qualité maximale).La qualité du son d’un fichier TwinVQ 96 Kbps est meilleure qu’un fichier MP3 128 Kbps. On peut donc atteindre un ratio de 1:15 pour un codage haute qualité et en plus, le résultat sera meilleur que le codage MP3 avec un ratio de 1:12. Il est donc possible de stocker plus de 15 heures de sons haute qualité sur un CD-ROM. Pour des taux de compression plus élevés, TwinVQ est préférable au format MP3.De plus grâce à sa taille inférieure aux fichiers MP3, ce format peut être diffusé en temps réel sur Internet.
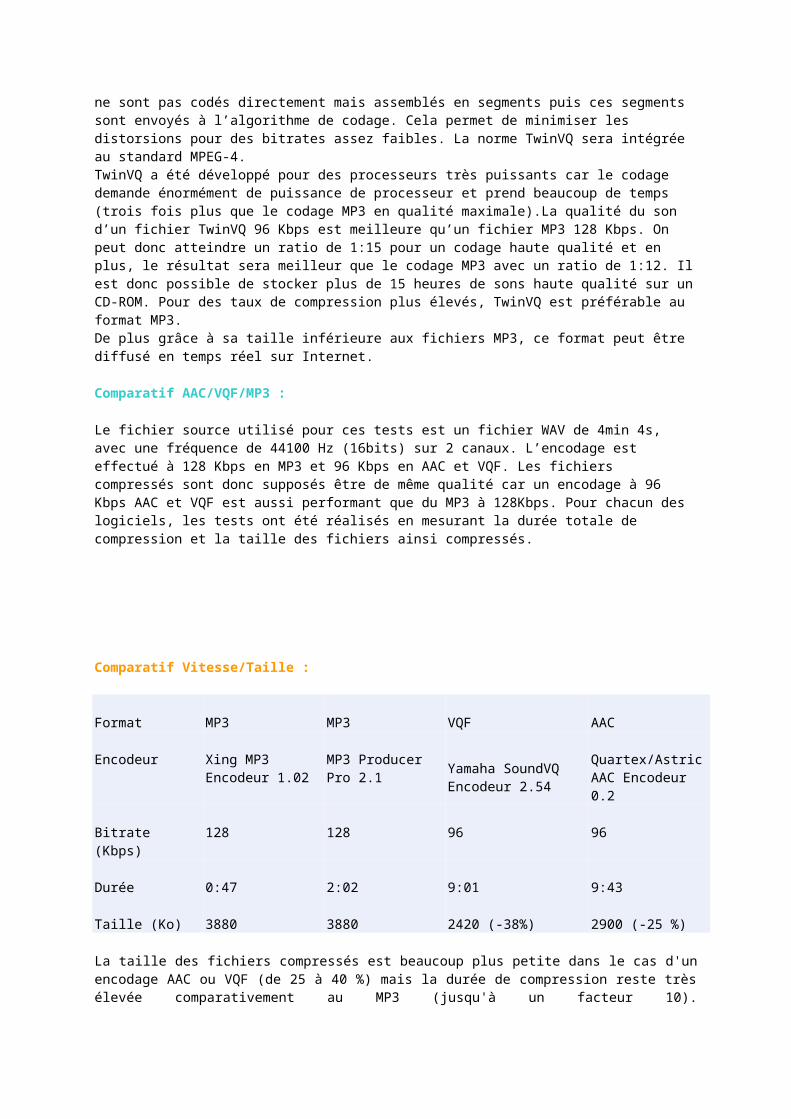
Comparatif AAC/VQF/MP3 :
Le fichier source utilisé pour ces tests est un fichier WAV de 4min 4s, avec une fréquence de 44100 Hz (16bits) sur 2 canaux. L’encodage est effectué à 128 Kbps en MP3 et 96 Kbps en AAC et VQF. Les fichiers compressés sont donc supposés être de même qualité car un encodage à 96 Kbps AAC et VQF est aussi performant que du MP3 à 128Kbps. Pour chacun des logiciels, les tests ont été réalisés en mesurant la durée totale de compression et la taille des fichiers ainsi compressés.
Comparatif Vitesse/Taille :
Format MP3 MP3 VQF AAC
Encodeur Xing MP3 Encodeur 1.02
MP3 Producer Pro 2.1
Yamaha SoundVQ Encodeur 2.54
Quartex/Astric AAC Encodeur 0.2
Bitrate (Kbps) 128 128 96 96

Durée 0:47 2:02 9:01 9:43
Taille (Ko) 3880 3880 2420 (-38%) 2900 (-25 %)
La taille des fichiers compressés est beaucoup plus petite dans le cas d'un encodage AAC ou VQF (de 25 à 40 %) mais la durée de compression reste très élevée comparativement au MP3 (jusqu'à un facteur 10).En ce qui concerne le codage AAC, sa qualité de compression est équivalente au format VQF. Les formats AAC et VQF permettent d’obtenir une qualité de compression supérieure au format MP3 et avec un taux de compression plus élevé (fichiers 25 à 35 % plus petits). Cependant la compression est trop lente (8 à 10 fois plus lente que les encodeurs MP3) et nécessite des PC assez puissants (idem pour la lecture).
4. Traitement de la vidéo : Introduction :
Définition d'une vidéo ?

L'oeil humain a comme caractéristique d'être capable de distinguer environ 20 images par seconde. Ainsi, en affichant plus de 20 images par seconde, il est possible de tromper l'oeil et de lui faire croire à une image animée. Une vidéo est donc une succession d'images à une certaine cadence. D'autre part la vidéo au sens multimédia du terme est généralement accompagnée de son, c'est-à-dire de données audio.
La Vidéo numérique et analogique
On distingue généralement plusieurs grandes familles d'"images animées"
Le cinéma, consistant à stocker sur une pellicule la succession d'images en négatif. La restitution du film se fait alors grâce à une source lumineuse projetant les images successives sur un écran
La vidéo analogique, représentant l'information comme un flux continu de données analogiques, destiné à être affichées sur un écran de télévision (basé sur le principe du balayage. Il existe plusieurs normes pour la vidéo analogique.
La vidéo numérique consistant à coder la vidéo en une succession d'images numériques.
Les normes Vidéo :
PAL :
Le format PAL/SECAM (Phase Alternating Line/Séquentiel Couleur avec Mémoire), utilisé en Europe pour la télévision, permet de coder les vidéos sur 625 lignes (576 seulement sont affichées car 8% des lignes servent à la synchronisation). A raison de 25 images par seconde a un format 4:3 (c'est-à-dire que le rapport largeur sur hauteur vaut 4/3). Or a 25 images par seconde, de nombreuses personnes perçoivent un battement dans l'image. Ainsi, étant donné qu'il n'était pas possible d'envoyer plus d'information en raison de la limitation de bande passante, il a été décidé d'entrelacer les images, c'est-à-dire d'envoyer en premier lieu les lignes paires, puis les lignes impaires. Le terme "champ" désigne ainsi la "demi-image" formée soit par les lignes paires, soit par les lignes impaires.
Grâce à ce procédé appelé "entrelacement", le téléviseur PAL/SECAM affiche 50 champs par seconde (à une fréquence de 50 Hz), soit 2x25 images en deux secondes.
NTSC :
Le norme NTSC (National Télévision Standards Committee), utilisée aux Etats-Unis et au Japon, utilise un système de 525 lignes entrelacées à 30 images/sec (donc à une fréquence de 60Hz). Comme dans le cas du PAL/SECAM, 8% des lignes servent à synchroniser le récepteur. Ainsi, étant donné que le SECAM affiche un format d'image 4:3, la résolution réellement affichée est de 640x480.
La vidéo numérique :
La vidéo numérique consiste à afficher une succession d'images numériques. Puisqu'il s'agit d'images numériques affichées à une certaine cadence, il est possible de connaître le débit nécessaire pour l'affichage d'une vidéo, c'est-à-dire le nombre d'octets affichés (ou transférés) par unité de temps.
Ainsi le débit nécessaire pour afficher une vidéo (en octets par seconde) est égal à la taille d'une image que multiplie le nombre d'images par seconde.
Soit une image true color (24 bits) ayant une définition de 640 pixels par 480. Pour afficher correctement une vidéo possédant cette définition il est nécessaire d'afficher au moins 30 images par seconde, c'est-à-dire un débit égal à :
900 Ko * 30 = 27 Mo/s
Etude de la compression des vidéos numériques :
Le M-JPEG :
La première idée qui vient à l'esprit après s'être intéressé à la compression d'images est d'appliquer l'algorithme de compression JPEG à une séquence vidéo (qui n'est finalement qu'une suite d'images). C'est notamment le cas du M-JPEG (qui n'est pas vraiment ce que l'on appelle le MPEG) qui autorise un débit de 8 à 10 Mbps, ce qui le rend utilisable dans les studios de montage numérique, d'autant plus que chaque image étant codée séparément, on peut y accéder aléatoirement.
Le MPEG :
Dans de nombreuses séquences vidéos, de nombreuses scènes sont fixes, cela se nomme la redondance temporelle.
Lorsque seules les mains de l'actrices bougent, presque seuls les pixels des mains vont être modifiés d'une image à l'autre, il suffit donc de ne décrire seulement le changement d'une image à l'autre. C'est là la différence majeure entre le MPEG et le M-JPEG.
Cependant cette méthode aura beaucoup moins d'impact sur une scène de mouvement.
Il existe donc 4 façons d'encoder une image avec le MPEG-1:
Intra coded frames (Frames I, correspondant à un codage interne): les images sont codées séparément sans faire référence aux images précédentes
Predictive coded frames (frames P ou codage prédictif): les images sont décrites par différence avec les images précédentes
Bidirectionally predictive coded frames (Frames B): les images sont décrites par différence avec l'image précédente et l'image suivante
DC Coded frames: les images sont décodées en faisant des moyennes par bloc
Les frames I :
Ces images sont codées uniquement en utilisant le codage JPEG, sans se soucier des images qui l'entourent. De telles images sont nécessaires dans une vidéo MPEG car ce sont elles qui assurent la cohésion de l'image (puisque les autres sont décrites par rapport aux images qui les entourent), elles sont utiles notamment pour les flux vidéo qui peuvent être pris en cours de route (télévision), et sont indispensables en cas d'erreur dans la réception. Il y en a donc une ou deux par seconde dans une vidéo MPEG.
Les frames P :
Ces images sont définies par différence par rapport à l'image précédente. L'encodeur recherche les différences de l'image par rapport à la précédente et définit des blocs, appelés macroblocs (16x16 pixels) qui se superposeront à l'image précédente.
L'algorithme compare les deux images bloc par bloc et à partir d'un certain seuil de différence, il considère le bloc de l'image précédente différent de celui de l'image en cours et lui applique une compression JPEG.
C'est la recherche des macroblocs qui déterminera la vitesse de l'encodage, car plus l'algorithme cherche des "bons" blocs, plus il perd de temps... Par rapport aux frames-I (compressant directement), les frames-P demandent d'avoir toujours en mémoire l'image précédente.
Les frames B :
De la même façon que les frames P, les frames B sont travaillée par différence par rapport à une image de référence, sauf que dans le cas des frames B cette différence peut s'effectuer soit sur la précédente (comme dans les cas des frames P) soit sur la suivante, ce qui donne une meilleure compression, mais induit un retard (puisqu'il faut connaître l'image suivante) et oblige à garder en mémoire trois images (la précédente, l'actuelle et la suivante).
Les frames D :
Ces images donnent une résolution de très basse qualité mais permettent une décompression très rapide, cela sert notamment lors de la visualisation en avance rapide car le décodage "normal" demanderait trop de ressources processeur.
Dans la pratique...
Afin d'optimiser le codage MPEG, les séquences d'images sont dans la pratique codées suivant une suite d'images I, B, et P (D étant comme on l'a dit réservé à l'avance rapide) dont l'ordre a été déterminé expérimentalement. La séquence type appelée GOP (Group Of Pictures ou en français groupes d'images) est la suivante:
IBBPBBPBBPBBI
Une image I est donc insérée toutes les 12 frames.
Le MPEG-1 :
La norme MPEG-1 représente chaque image comme un ensemble de blocs 16 x 16. Il permet d'obtenir une résolution de:
352x240 à 30 images par seconde en NTSC 352x288 à 25 images par seconde en PAL/SECAM
Le MPEG-1 permet d'obtenir des débits de l'ordre de 1.2 Mbps (exploitable sur un lecteur de Cd-rom).
MPEG convertit les signaux vidéos analogiques en paquets de données numériques (digitales, en franglais) qui seront plus faciles à transporter sur un réseau. Les données digitales ont plusieurs avantages dont, en premier
lieu, la non dégradation du signal. Le principe de la compression est de réduire autant que possible les redondances d'information sans que cela ne modifie l'aspect visuel du fichier ainsi traité.MPEG est constitué de deux couches :la couche système, qui stocke l'information temporelle nécessaire à la synchronisation vidéo et audio.
la couche compression, qui inclue les flux audio et vidéo.
Principe de la compression vidéo MPEG1:
Il faut ajouter 2 types de compressions pour la vidéo :
Compression temporelle :
Son objet est de ne stocker que ce qui est modifié lors du passage d'une image à une autre dans une séquence vidéo. Les images ainsi compressées peuvent être de deux types : image clé ou image delta. Les images clés sont des images de références, qui contiennent en elle-même, toute l'information. Les images delta ne contiennent que les pixels modifiés vis à vis de l'image précédente, qui peut être elle-même une image clé ou une image delta. La première image est nécessairement une image clé. Des techniques particulières, dont la compensation de mouvement, permettent d'optimiser la génération et la compression des images delta.
Compression spatiale :
Cette compression s'applique exclusivement à une image donnée (clé ou delta), sans tenir compte des images environnantes. Il y a là différentes techniques : null suppression, RLE (Run Length Encoding), JPEG (Join Pictures Expert Group), Vector Quantization. MPEG utilise la compression JPEG.
Schématisation du système général de décompression MPEG
Hiérarchie des données :
Hiérarchie des données Vidéo :
Schématisation la hiérarchie des données dans le flux vidéo
Les données sont hiérarchisées de la façon suivante :
Séquence vidéo:Elle commence par une en-tête de séquence, contient un ou plusieurs groupe d'images et s'achève par un code de fin de séquence.
Groupe d'images :Il regroupe une en-tête et une série d'une ou plusieurs images permettant d'y accéder de façon alléatoire.
Images : C'est l'unité élémentaire pour le codage de la séquence vidéo. Une image est un groupe de trois matrices rectangulaires qui représentent la luminance (Y) et la chrominance (Cb et Cr), un élément de la matrice représentant un pixel. Cette représentation YCbCr est équivalente à celle RGB. Elle lui est préférable, car l'oeil étant plus sensible à la luminosité qu'à la chrominance, il n'est pas nécessaire de stocker autant d'informations dans les matrices Cb et Cr que dans la matrice Y, alors qu'en RGB, les trois matrices sont de même taille. Les matrices Cb et Cr sont ainsi de dimension deux fois plus petites que la matrice Y.
Tranche Les tranches sont un ou plusieurs macro blocs adjacents ordonnées de gauche à droite puis de haut en bas. Ce sont des éléments importants pour la gestion des erreurs. Si le flux de données contient une erreur, le décodeur peut sauter la tranche et passer au début de la suivante directement. Plus il y a de tranches, meilleur est letraitement des erreurs mais fait perdre de la place.
Macro blocs :C'est une matrice rectangulaire de dimension 2 et constituée de blocs.
Blocs : C'est un ensemble des valeurs de luminance et chrominance de 8 lignes de 8 pixels.

Hiérarchie des données Audio:
Le standard MPEG définit une hiérarchie de structures de données qui code le signal audio. Ce flux audio est composé de paquets selon le schéma suivant :
Application de la Compression temporelle :
Le standard MPEG spécifie trois types d'images :
Images clés :Ces images sont comprimées indépendamment de leur contexte, c'est à dire qu'on ne tiend compte que du contenu de l'image elle-même et non des images environnantes. Elles autorisent l'accès aléatoire, soit l'accès à la séquence vidéo depuis n'importe lequel de ses points. Elles ont un taux de compression moderé, typiquement 2 bits par pixel codé.
Images prédites : Ces images sont codées par rapport à l'image précédente. Elles utilisent la compensation de mouvement pour un meilleur taux de compression. Par ailleurs, elles ont l'inconvénient de propager les erreurs, du fait qu'elles réutilisent les informations de l'image précédente.
Images bidirectionnelles :
Ces images utilisent à la fois l'image précédente et l'image suivante comme références. Ceci a le grand avantage d'offrir le meilleur taux de compression, sans pour autant propager les erreurs puisqu'elles ne sont jamais utilisées comme références.
Composition du flux vidéo:
L'algorithme MPEG autorise à l'encodage le choix de la fréquence et de la position des images clés. ceci permet à l'application un accès aléatoire aux plages enregistrées.
Pour les applications où l'accès aléatoire est important, les images clés sont positionnées typiquement toutes les demies secondes. à l'encodage on peut choisir le nombre d'images prédites entre n'importe quelle paire d'images de référence.
Ce choix est basé sur des facteurs liés au décodeur (comme par exemple la quantité de mémoire) ainsi qu'aux caractéristiques de la séquence vidéo.
Les codeurs MPEG réordonnent les images dans le flux vidéo pour optimiser le travail du décodeur.
Ainsi, les images de référence nécessaires à la reconstruction d'images prédites sont envoyés avant les images prédites.
Compensation du mouvement :
La compensation de mouvement est une technique pour optimiser le compression des images intermédiaires et des images clés en éliminant la redondance temporelle. Typiquement, la méthode de compensation de mouvement optimise la compression par un facteur d'ordre trois comparé au codage interne à l'image.
Les algorithmes de compensation de mouvement travaillent au niveau des macro blocs. Quand un macro bloc est compressé par la technique de compensation de mouvement, le fichier compressé contient les informations suivantes :
le vecteur spatial entre le macro bloc de référence et le macro bloc qui va être codé (vecteur déplacement)
la différence entre le contenu du macro bloc de référence et du macro bloc qui va être codé (terme d'erreurs)
Toutes les informations d'une image ne peuvent pas être prédites de l'image précédente. Considérons une scène dans laquelle une porte s'ouvre : les détails visuels de la chambre derrière la porte ne peuvent pas être prédits de l'image précédente quand la porte était fermée.

Quand un cas comme celui-ci arrive, c'est-à-dire lorsqu'un macro bloc ne peut pas être codé de manière efficace dans une image prédite par la technique de la compensation de mouvement, il est codé de la même façon qu'un macro bloc dans son image clé.
La différence, au niveau de la compensation de mouvement, entre une image prédite et une image bidirectionnelle est la suivante : les macro blocs d'une image prédite n'utilisent que des références à l'image antérieure, alors que les images bidirectionnelles utilisent toute combinaison d'images futures et/ou passées.
Il y a ainsi quatre types d'encodage d'un macro bloc d'une image prédite :
codage interne : pas de compensation de mouvement prédiction avant : l'image de référence précédente est utilisée comme référence prédiction arrière : l'image suivante est utilisée comme référence prédiction bidirectionnelle : deux images de référence sont utilisées, la précédente image de référence et
la prochaine image de référence.
L'encodage des images clés :
La compression MPEG compressé s'est d'images avec un algorithme prend trois étapes
transformation en cosinus discrète (DCT) quantisation Run-length encoding
Les blocs d'erreur ainsi que les blocs image possède une grande redondance spatiale. Pour réduire cette redondance, l'algorithme MPEG transforme les blocs de huit pixels par huit pixels du domaine spatial vers le domaine fréquentiel en utilisant une transformation en cosinus discrète. Ensuite, l'algorithme quantise les coefficients fréquentiels. La quantisation consiste à approximer chaque coefficient fréquentiel par un nombre dans une nombre limité de valeurs. Le codeur choisit une matrice de quantisation qui détermine comment chaque coefficient de la matrice 8 x 8 est quantisé.
La perception humaine de l'erreur de quantisation est plus faible pour les hautes fréquences spatiales, ces fréquences seront alors quantisées plus sévèrement (c'est-à-dire avec moins de valeurs) que les basses fréquences. la combinaison de la transformée en cosinus discrète et de la quantisation permet de transformer beaucoup de coefficients fréquentiels à zéro, notamment les coefficients correspondant à une grande fréquence spatiale. Les coefficients non nuls étant regroupés en haut et à gauche de la matrice, la matrice n'est pas lue par ligne et colonne mais en zigzag pour optimiser la compression. Ceci permet de mettre tous les zéros de la matrice les uns à la suite des autres.
Certains blocs, par exemple les blocs qui ont un léger gradient intensité, ont besoin d'être codés de manière plus précise pour éviter que leurs frontières deviennes visible.

Pour gérer ces différences entre les blocs, l'algorithme MPEG autorise la modification du niveau de quantisation pour chaque macro bloc. Ce mécanisme peut être utilisé pour permettre une adaptation souple à débit particulier.
Méthodes de synchronisation :
Le standard MPEG définit un mécanisme qui assure la synchronisation entre audio et vidéo. Le système inclus deux paramètres : l'horloge de référence du système (SCR) et le marquage temporel (PTS).
Horloge système de référence : L'horloge système de référence est une photo du système d'encodage placée dans la couche système du flux. Durant le décodage, ces valeurs sont utilisées pour mettre à jour l'horloge du décodeur.
Marquage temporel : Le marquage temporel est une valeur associée à chaque image vidéo décodée qui indique au système à quel moment il doit afficher celle-ci. Le décodeur peut sauter ou répéter certaines images pour s'assurer que le marquage temporel d'une image est respecté.
CONCLUSION :
L'avenir de la vidéo numérique : Le MPEG4.
MPEG4, dont la désignation ISO/IEC sera ISO/IEC 14496, est le plus récent travail du groupe MPEG. La version 1 a été finalisée en octobre 1998 et la version 2 est en cours de complétude. Description et objectifs du MPEG4 :
MPEG4 est plus qu’une simple amélioration des générations précédentes, il définit une véritable philosophie de la vidéo en dépassant les concepts de codage et de compression. Le MPEG4, en effet, définit à la fois une syntaxe du flux vidéo codé et un ensemble d’outils permettant la diffusion de cette vidéo sur des réseaux hétérogènes. Nous allons décrire cette norme en parlant de ce qu’elle définit et également de ce qu’elle ne définit pas.
La notion d’objets médias :
L’aspect le plus visible du MPEG4 est l’introduction de la notion d’objets médias. La scène vidéo est décomposée en objets visuels indépendants, une personne, un meuble, une carte,... et en objets audio comme la voix d’une personne, le bruit de moteur d’une voiture … En plus de définir des objets, MPEG4 définit une arborescence structurant ces objets en les décomposant en d’autres objets. Une personne pourra être décomposée en sa voix, son visage, ses mains, et le reste du corps. La scène vidéo sera donc ainsi décomposée selon une hiérarchie de ces médias objets et selon leur disposition spatiale.
MPEG4 permet également de les manipuler de différentes façons et ainsi de rendre interactif la scène vidéo transmise. On pourra par exemple :
Démarrer une séquence vidéo en cliquant sur le bouton d’un téléviseur. Changer de place un élément. Changer les propriétés d’un objet (dimension, couleur,…) Etc…
Les objets média pourront être identifiés et recevoir un code qui leur permettra de ne pas être réutilisé à outrance. On pourra ainsi protéger les droits d’un auteur sur son objet média.
5. Le Streaming

Introduction :
Le streaming est utilisé pour rendre accessible un flux audio ou vidéo à des utilisateurs distants. Ce terme vient de l’anglais « stream » qui signifie « flot ». Cette technique permet la diffusion de son et de vidéo en continu (sans interruption) et en temps réel (au moment où se passe l’événement). Le streaming est utilisé sur les réseaux de télécommunications : Internet, câble, télévision numérique,… Cela permet de diffuser le même flot de données à plusieurs utilisateurs en même temps. Pour cela, plusieurs techniques existent :
La diffusion en broadcast (ex : télévision satellite) :
Lors d’une diffusion en broadcast, un seul flux est émis pour tous les utilisateurs. Cette technique a l’avantage de diminuer la bande passante nécessaire et de diminuer la charge au niveau du serveur car il n’a plus à gérer N connexions distinctes.
La diffusion en multicast :
Ce principe de diffusion fonctionne un peu comme le broadcast. En effet un seul flux est émis à partir du serveur. Ce flux est reçu par tous les clients. Cependant, les clients doivent s’abonner au groupe pour recevoir le flux contrairement au broadcast. Cette technique est utilisée dans le streaming sur Internet mais pose quelques problèmes d’implémentation au niveau des routeurs (les routeurs doivent gérer le multicast).
La diffusion en unicast :
Cette technique consiste à accorder un flux à chaque utilisateur. Le serveur est évidemment plus sollicité mais cela permet une plus grande souplesse vis-à-vis des clients qui peuvent choisir le débit qui convient à leur infrastructure.
Ce procédé est le plus utilisé sur Internet car il fonctionne bien sur le réseau actuel et n’a pas les problèmes d’implémentation rencontrés avec le multicast.
Diffusion multicast Diffusion unicast
Le streaming est surtout utilisé sur Internet pour la diffusion de radios ou de vidéo. Une nouvelles génération de services apparaît sur Internet. En effet on constate le développement de sites qui se spécialise dans la diffusion de programmes de télévision ou de radios.
Cependant le streaming doit se confronter à un problème : la limitation de la bande passante. En effet même si le haut-débit devient plus accessible, il n’est pas encore assez diffusé pour permettre un fonctionnement de serveur

de streaming. D’ailleurs la plupart des sites possèdent d’ailleurs deux types de flux : bas débit (56Kb/s) et haut débit (quelques centaines de Kb/s voire Mb/s).
Le but d’un serveur de streaming est de diffuser un flux de données avec la meilleure qualité sonore et visuelle tout en évitant les interruptions de diffusion. Pour résoudre ce problème on utilise la technique du buffering : on mémorise dans un buffer une partie du flux afin de pouvoir continuer la transmission même si le trafic est perturbé. Il est donc nécessaire de remplir le buffer au de chaque connexion ce qui occasionne une fenêtre de temps.
La taille du buffer est un paramètre très important. En effet si sa capacité est trop petite il n’empêchera pas les interruptions de diffusion et si elle est trop importante, le temps de remplissage du tampon sera trop long et se répercutera sur le temps au démarrage.
Les techniques et protocoles :
La gestion des applications temps réel :
Protocoles de streaming
Le protocole RTP :
Ce protocole se base sur la couche TCP ou UDP de la pile TCP/IP. Il permet la diffusion de manière synchrone des flux de données en temps réel.
Ce protocole ne gère pas la qualité de service au sein du transport des données mais son implémentation est fortement recommandée afin d'assurer le bon séquencement des données sur le poste client. De plus, le protocole RTP intègre un mode connecté équivalent à celui employé avec TCP.
Le protocole RTCP :

Ce protocole est chargé de la partie contrôle du flux de la connexion temps réel avec le client. Il est souvent associé à l'utilisation du protocole RTP pour éviter les problèmes d’encombrement éventuel. Le contrôle s'effectue sur la base de rapports (messages RTCP) produits et envoyés périodiquement par chacun des acteurs. Ces rapports contiennent des statistiques sur le nombre de paquets émis, le nombre de paquets perdus et le délai moyen d'envoi. Ce rapport est utilisé dans le but d'optimiser la qualité de la communication en augmentant ou en diminuant le débit employé pour la communication. Dans le cas de dialogues avec plusieurs clients, la charge introduite par l'envoi de messages RTCP peut être importante. C'est pourquoi on doit prendre soin d’ajuster l'intervalle de temps entre chaque création de rapport. Celle-ci devra être choisie de manière à ce que les messages RTCP n'occupe que 5% de la bande passante à disposition (25% pour l'émetteur et 75% pour les récepteurs).
Le protocole RSVP :
Le protocole RSVP est une proposition de standard faite par l'IETF pour répondre aux besoins de qualité de service sur les réseaux IP tel qu'Internet. Ce protocole a été conçu de manière à donner une priorité à chaque application de « streaming », que ce soit du son ou de la vidéo, à la condition qu'elle génère un trafic continu. RSVP fonctionne en permettant à une application qui transmet ses données à travers une certaine route, de réserver un certain niveau de bande passante sur cette route. Cette réservation de ressource est appelée réservation "soft" car pour qu'elle persiste, il est nécessaire au client de réémettre des demandes de réservation.
Le protocole RTSP :
RTSP est un protocole de niveau applicatif, qui propose de fournir un protocole solide pour délivrer en Unicast ou en Multicast du contenu multimédia. Il propose également des fonctions de télécommande du précédent permettant une intéraction entre le client et le serveur. L'idée principale derrière l'utilisation de RTSP est de proposer au client une sorte de « télécommande réseau » pour commander le serveur de diffusion. Ainsi, par l'intermédiaire du protocole RTSP, le client est libre d'arrêter le flux provenant du serveur (mode pause) ou de manière plus intéressante, d'accéder directement une partie avancée du média sans avoir à télécharger la partie passée (mode avance rapide). Il propose également au client la possibilité de négocier certaines options avec le serveur comme par exemple le type de protocole de transport à utiliser (UDP ou TCP). De la même manière le serveur peut être amener à envoyer des requêtes au client comme la demande d'émission de compte rendu sur la qualité de la connexion pour adapter, s’il est nécessaire, la nature du flux.
Voici les principaux points forts du protocole RTSP :
Extensible (de nouveaux paramètres et de nouvelles méthodes peuvent être aisément implémentés) Facile à lire (les parseurs standard HTML ou MIME peuvent être utilisés)
Sécurisé (méthode d'authentification HTTP, mécanisme de sécurité applicable sur les couches transports ou réseaux)
Indépendant de la méthode de transport (les protocoles tels que UDP, RDP et TCP sont supportés)
Capacité à gérer plusieurs serveur de diffusion (il peut y avoir plusieurs flux de différents serveurs de diffusion à l'intérieur d'une même présentation)
Commande de contrôle de l'enregistrement (les deux fonctions de lecture et d'enregistrement peuvent être utilisées par le client)
Séparation du contrôle du flux multimédia et de la commande d'ouverture du média
Description des données neutre (pas de format particulier imposé, le format des descriptions doit nécessairement contenir au minimum l'URI RTSP du média)
Fonctionne avec proxy ou firewall
Fonctionne avec HTTP (RTSP réutilise les concepts HTTP)

Control du serveur distant
Type du transport négociable (la méthode de transport peut être négociée avant la diffusion du média)
Capacité de négociation (le client doit avoir le moyen de savoir si certains services de base ont été retirés du serveur)
Le protocole SMIL (Synchronized Multimedia Integration Language) :
SMIL, Synchronized Multimedia Integration Language (prononcé "smile"), a été approuvé par le World Wide Web Consortium en 1998 en tant que marqueur standard pour les applications de streaming. Ce protocole est principalement utilisé pour les services de streaming vidéo à la demande pour introduire au sein de la présentation une interactivité plus forte avec l'utilisateur. Il a été conçu par le consortium W3C. Son implémentation permet d'introduire du texte, des animations ou des liens hypertextes à une vidéo de manière synchrone. Ainsi, les vidéos peuvent être enrichies de textes explicatifs, de liens hypertextes, ou bien d'animations faisant ressortir les points essentiels. Ces exemples sont très employés dans le cadre de vidéos sur demande, de e-learning, de présentations commerciales ou bien encore rendre les utilisateurs plus captif aux informations diffusées. SMIL permet donc de rendre cohérent un ensemble de d’informations multimédia riches.
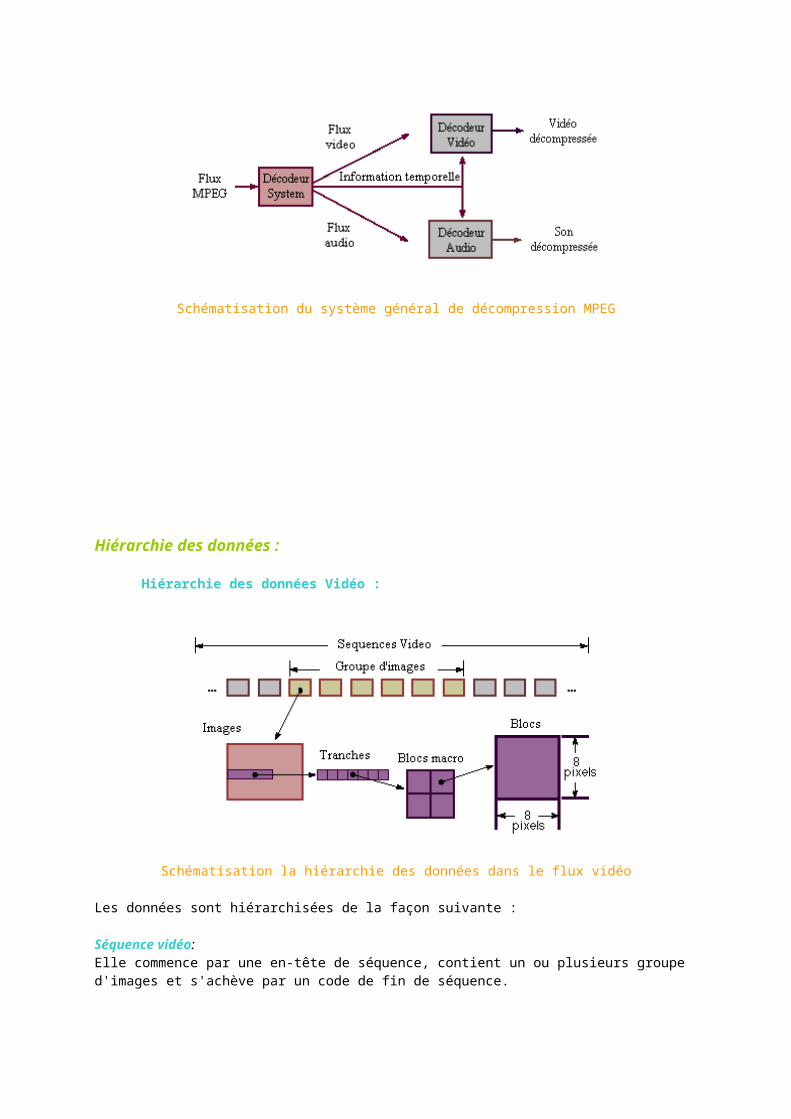
Protocole RTSP sur RTP
Messages échangés lors d’une connexion RTSP
Comparaison de RTP / RTSP dans HTTP :
Nous avons jugé important d’aborder cet aspect du fonctionnement de la diffusion de contenu multimédia sur Internet parce que cette situation peut être rencontrée dans de nombreux cas. En effet, nous savons bien aujourd’hui qu’une faible minorité des stations personnelles connectées disposent d'une adresse IP publique et donc que la majeur partie des utilisateurs d'Internet se trouve placés derrière des firewalls ou des proxys.
Pour les flots temps réel, l'encapsulation des données par HTTP n'est pas envisageable. Par contre, pour tout autre type de diffusion vidéo cette solution a de bonnes raisons d'être employée.
Les pour et les contre sur l'usage de RTP / RTSP :
Pour Contre
Seule solution pour transmettre du contenu temps réel Nécessite un serveur de streaming et un broadcaster
Support des modes broadcast et multicast (un seul flux pour de plusieurs clients)
La vidéo est coupée si le flux de données est supérieur à la bande passante disponible
Accès aléatoire pour les vidéos préenregistrées Les transmissions sont plus sensibles à la perte de données
N'utilise la bande passante que si nécessaire Peut être bloqué par certains NAT ou FireWall
Ne laisse pas de copie de la vidéo sur le disque dur du client
Les pour et les contre sur l'usage du protocole HTTP :

Pour Contre
Pas de serveur particulier nécessaire Ne peut pas utiliser les modes de fonctionnement en broadcast ou multicast
Les vidéos transitent du serveur au client sans besoin particulier de qualité de services
Ne peut pas transmettre de flot temps réel
Dans ce mode de fonctionnement la vidéo est lue au fur et à mesure qu'elle est téléchargée ce qui donne un aspect de
streaming au client
Ne peut pas sauter un passage de la vidéo sans télécharger tout le début
Permet de délivrer tout type de médias Dépose une copie du média sur le disque dur du client
Les paquets perdus sont retransmis jusqu'à ce qu'ils soient reçus
Pas de problèmes particuliers avec les FireWall ou les NAT
La compression des médias :
Présentation :
Comme nous l'avons vu précédemment,le principal problème auquel est confronté le développement des applications multimédia provient de la faible bande passante dont jouisse chacun des clients. Le format de la vidéo transmise au client et sa qualité dépend donc essentiellement de la bande passante dont les principaux clients vont disposer. C'est pourquoi la qualité des algorithmes de compression utilisés est un point primordial lors de la sélection du serveur de streaming.
Les formats de compression audio :
Dans l'industrie du streaming audio il existe trois principaux concurrents en matière de format de compression :
Le format MPEG Layer III, comme vous l’avez deviné le format MP3 Le format OGG Vorbis, assez similaire au format MP3 mais il reste moins répandu malgré toutes ses
qualités
Le format RealAudio est un format propriétaire développé par Sony sous le sigle : ATRAC3
Windows Média Server propose également le format de fichier propriétaire WMA
Support RealAudio ICE-Cast Shout-Cast Windows Media Darwin (QuickTime)
Codec MP3 / Sony MP3 / OGG MP3 MP3 / WMA MOV / MP3

Support RealAudio ICE-Cast Shout-Cast Windows Media Darwin (QuickTime)
ATRAC3
Les formats de compression vidéo :
Aujourd’hui, la qualité des codecs de compression est telle qu’il est possible de diffuser via Internet un film en qualité VHS à des clients équipés de connexion Cable ou DSL. Cependant les majors de diffusion vidéo(Microsoft et RealNetworks) constatant que la majeure partie des clients possèdent un bas débit ont décidé de développer leurs serveurs respectifs de façon à ce que la qualité de la diffusion soit en rapport avec la qualité de la connexion. Cette qualité prend en compte par exemple la bande passante ou le taux de charge. De plus le troisième acteur de ce marché QuickTime Media étend son marché en se concentrant aussi sur la diffusion d’applications intéractives sur des supports de grande capacité de stockage comme les cdroms ou bien possédant un fort taux de transfert.
Les codecs actuels de compression vidéo :
H 261 : flux constant P*64 kbit/s privilégie la fluidité de l'animation à la qualité H 263 : identique à H 261 mais supporte les hautes qualités
MJPEG : compression des frames une à une au format JPEG sans corrélation entre elles utilisé pour les softs de montage vidéo pour minimiser les traitements
MPEG-1: faible bit/rate 1-1,5 Mbit/s introduit des infos de prédiction -> léger retard de N frames pour la vidéo conférence ! Ce format a une haute sensibilité à la perte de paquet ! De plus, il segmente le flux vidéo par suppression des frames d'information B et P -> dégradation de la qualité d'image
MPEG-2 : amélioration du MPEG-1 pour autoriser le support des hautes résolutions -> augmentation de la BP nécessaire : 4-15 Mbit/s. Il est utilisé pour la diffusion TV Sat et DVD. 5 chaînes TV MPEG-2 passé sur un canal radio satellite autrefois réservé à un chaîne analogique
MPEG-4 : Ce format n'est pas un format de compression classique comme les précédents puisqu'il intègre dans ses fondements la notion de couches (layer en anglais) ce qui permet de diffuser un contenu multimédia riche. Plus généralement il permet la description standard d'une scène. D'autre part il introduit de puissants algorithmes de compression pour la vidéo basés sur la compression spatiale et temporelle.
Les 3 technologies du streaming :
Quicktime :
Dés 1990, grâce à la technologie QuickTime, Apple a introduit l'audiovisuel sur les micro-ordinateurs. Mais les applications multimédias ont été cantonnées à des utilisations en mode local (documents audiovisuels interactifs, montage vidéo, consultation de CD-ROM).
La diffusion audiovisuelle sur Internet se limitait pour Apple à des téléchargements longs et fastidieux de films QuickTime volumineux. Ce n'est qu'en 1999, avec la version 4.0 de QuickTime qu'Apple a réellement abordé la technologie du streaming.
Le lecteur QuickTime :

Pour consulter des sites Internet diffusant des émissions en streaming QuickTime, il faut installer le logiciel de lecture (en version 4.0 minimum pour une lecture en vrai streaming) ou les plug-ins correspondant dans un navigateur Internet.Le poste de consultation devra posséder au minimum les caractéristiques suivantes :
Pour PC, processeur Pentium avec 16 Mo de Ram, Windows 95 et sup. avec une carte audio et directX 3.0.
Pour Mac, processeur PowerPC avec 16 Mo de Ram, MacOS 7.5.5 et sup. Le flux de streaming vidéo est diffusé en format QuickTime ou AVI. Pour la partie audio, les formats Audio AIFF, SoundDesigner 7, Wave…, sont reconnus avec divers algorithmes de compression.
Interface graphique du lecteur Quiktime
Dans la présentation de la technologie QuickTime, Apple continue de distinguer les services de faux streaming, mode Fast Start, avec hébergement des films vidéo sur un serveur HTTP, des fonctionnalités du vrai streaming avec diffusion depuis un serveur RTP/RTSP. En vrai streaming, certaines données ne sont pas diffusables, entre autres les sprites (éléments graphiques mobiles indépendants de l'image de fond), le QuickTime VR et les animations Flash.
Apple vient de présenter la nouvelle version de QuickTime 5 qui gère les animations Flash 4, le MP3 et le Mpeg 1 (tous deux en mode streaming), possède un codec DV plus rapide, améliore la sécurisation des documents et permet du QuickTime VR en mode 360°.
Encodage et préparation des fichiers :
Pour être diffusé depuis un serveur de streaming, un film QuickTime doit être pourvu de pistes " hint " qui contiennent des paramètres sur le fonctionnement du serveur (taille des paquets, protocole employé, période de rafraîchissement des données) et facilitent l'envoi des données sur le réseau, ce qui simplifie la gestion d'un serveur RTP qui n'a pas besoin de connaître tous les réglages et fonctions internes de QuickTime.
Puis, il faut convertir le document vidéo dans un format QuickTime avec les réglages appropriés. C'est ensuite qu'il sera pourvu de ses pistes "hint" (une pour chaque piste spécifique audio, vidéo, etc.) avec la fonction export de Lecture QuickTime Pro.
Le problème qui se pose par rapport aux autres technologies est que QuickTime enregistre le même film dans des fichiers distincts correspondant à chaque débit de transmission. Cela rend cette opération de préparation rapidement fastidieuse et donc beaucoup plus simple de l'effectuer avec Media Cleaner Pro, qui réalise toutes ces étapes en une seule passe.

Dans le cas d'une diffusion en direct, les équipements de prise de vues et de prise de sons sont raccordés à un micro-ordinateur équipé d'interfaces de numérisation qui fait office de station d'encodage (prévoir une station par débit). Le seul logiciel disponible pour cette opération est Sorenson Broadcaster. Avant de démarrer l'émission, il faut préparer sur le poste d'encodage un fichier SDP (Session Desciption File) qui sera transféré sur le serveur dans le dossier Media. Les postes de consultation pointent sur ce fichier pour connaître les paramètres de diffusion. Le codec vidéo Sorenson fournit les meilleurs résultats pour la diffusion vidéo en streaming.
Le codec H.263 a été conçu pour des applications de visioconférence à bas débit et pour des séquences rapides. Il donne parfois des meilleurs résultats pour les accès par modem.
Pour l'audio, le codec Qualcom Purevoice (issu des technologies de compression employées sur les téléphones portables) est réservé uniquement au codage de la voix. Avec QuickTime 4.1, il fonctionne à débit variable (mode VBR).
Pour des documents musicaux, le codec le mieux adapté est le Qdesign Music 2. Il est actuellement le seul codec audio capable de transmettre un signal stéréo numérisé à 44,1 kHz dans un débit de 8 kbits.
Le serveur de streaming QuickTime :
Le logiciel serveur s'appelle QuickTime Streaming Server (QTSS).La version 2.0.1 fonctionne sur :
PowerMac G4 Mac Serveur G4 PowerMac G3
Sous le système d'exploitation Mac OS X Serveur 1.0.2, avec 62 Mo de Ram et 1 Go d'espace Disque Dur minimum.
Pour dimensionner les capacités d'un serveur, il est nécessaire d'évaluer le débit maximal des flux vidéo diffusés. Dans le cas de programmes diffusés à une seule valeur de débit, il suffit de multiplier ce chiffre par le nombre d'utilisateurs connectés simultanément. Si les films sont diffusés avec plusieurs valeurs de débit, cela se complique car la répartition des spectateurs pour chaque valeur de flux varie. Le serveur ne sait pas le nombre d'accès par débit et il y a risque de dépassement de débit total dans certains cas. En même temps que l'annonce de QuickTime 5, Apple a présenté la version 3 de QTTS, qui est aussi disponible sur son site en version preview.
Windows Media :
Cette solution a été mise au point avec une architecture totalement centrée sur son système d'exploitation Windows. Avant de s'appeler Windows Media, les premiers pas de Microsoft dans le domaine du streaming se sont déroulés sous le sigle NetShow.
Le lecteur Windows Media player :
Le lecteur de streaming de Microsoft s'appelle Windows Media Player 7. Cette version a été lancé au printemps 2000 et marque une étape importante dans l'évolution du logiciel Player car Microsoft le transforme en véritable plaque tournante de toutes les activités multimédias du micro-ordinateur.
Outre la réception de programmes radio et télé diffusés en streaming, cette application gère la lecture des CD audio, leur transfert sur disque dur en mode compressé, l'établissement de play-lists personnalisées pour écouter la musique, quelle que soit son format.

Interface graphique de Windows media player
A terme, Windows Media Player saura gérer les cartes de numérisation vidéo et manipuler toutes formes de séquences d'images entre tous les périphériques gérant des films vidéo.
Encodage et préparation des fichiers :
La préparation des séquences de streaming au format Windows Media est effectuée grâce au logiciel Windows Media Encoder 7, mais ce logiciel ne fonctionne que sous Windows 95, 98, 2000 et NT 4. Il sert aussi bien à l'encodage de fichiers enregistrés qu'à la transmission de programmes filmés en direct. Il existe un second logiciel d'encodage uniquement pour les documents enregistrés, On Demand Producer, qui possède des fonctions simples de montage.
Microsoft diffuse un plug-in compatible avec Première qui permet l'export de séquences vidéo en format Windows Media depuis ce logiciel.Le logiciel d'encodage travaille uniquement en mode CBR (Constant Bit Rate) et ne fournit pas de streaming en mode VBR (Variable Bit Rate). Il dispose, comme les produits concurrents, d'outils d'assistance pour effectuer tous les réglages d'encodage.
Le format de fichiers de streaming vidéo/audio est dénommé ASF (Advanced Streaming Format). Il compte jusqu'à six pistes vidéo encodées à des débits variables et une piste audio. Dans la version 7, le codec de compression utilisé est le Mpeg-4 v.3, alors que la compression audio est un développement spécifique de Microsoft, ce qui rend les fichiers de streaming Windows Media incompatibles avec la vraie norme Mpeg-4. Le codec audio conduit à des débits inférieurs de moitié à ceux du MP3 à qualité équivalente. Le système d'encodage traite des images de 320x240 pixels au rythme de 60 images par seconde ou de 620x480 à 30 images par seconde.
Dans le cas d'une conférence diffusée à distance, il est prévu un dispositif qui mélange des séquences filmées en direct (images et sons) avec les diapos d'une présentation PowerPoint. Ces dernières sont transmises sous forme d'images fixes avec préservation de la qualité initiale.
Le serveur de streaming Windows Media :
Il n'y a pas de logiciel serveur indépendant dans l'architecture Windows Media. Ce sont des services qui sont ajoutés à l'architecture interne de serveurs Windows NT ou 2000. Les Windows Media Services sont fournis gratuitement avec Windows 2000 Server.Même pour de petites applications, Microsoft conseille de réserver une machine pour le serveur Web et une pour le serveur de streaming. Microsoft a prévu dans son architecture de serveur des interfaces qui associent le fonctionnement des outils de streaming avec des applications d'e-commerce. L'éditeur annonce également qu'un serveur tournant sur un Pentium 2 peut desservir 2000 connections simultanées pour modem 28 800 bits/s. .
RealNetworks :
RealNetworks a été créé en 1995 et a depuis fortement contribué au développement des techniques de streaming sur Internet. Cette solution combine des codecs de compression à bas débit avec une architecture innovante pour tenir compte des contraintes du réseau. RealNetworks propose une gamme complète d'outils performants. Grâce à son dynamisme, elle maintient son leadership malgré la concurrence d'Apple et de Microsoft.

Le lecteur RealPlayer :
Malgré une interface un peu brouillonne et un look fade par rapport à ses concurrents, le lecteur RealPlayer évolue rapidement et s'enrichit régulièrement de nouvelles technologies et de nouveaux services. Dans un premier temps, Real ne faisait que du streaming audio, la vidéo à été ajoutée à la version 4.C'est la version G2 publiée en 1999, qui a marqué une étape dans l'histoire du streaming avec l'introduction de la technologie SureStream. Elle autorise l'enregistrement d'un même film à plusieurs débits dans un seul fichier. En fonction des aléas de transmission, le serveur modifie en temps réel le débit lu et facilite ainsi la continuité de la diffusion en adaptant la qualité de l'image et du son. La version 8 utilise un codec vidéo encore plus performant que la version G2 et 7, son traitement est plus complexe et donc l'encodage est plus lent.
Interface graphique du lecteur real "one" player
Real traite d'autres formats de données et transmet en streaming des fichiers d'images fixes codées en Jpeg, le format RealPix ainsi que du texte en RealText. Pour la partie audio, le codec gère 21 combinaisons de formats en laissant le libre choix entre débit et fréquence d'échantillonnage combiné avec le choix mono/stéréo et voix/musique.
Pour faire face au renouvellement rapide des versions et pour garantir l'évolution du parc de lecteurs, RealNetworks a équipé son logiciel de consultation d'une procédure de mise à jour automatique.
Encodage et préparation des fichiers :
L'encodage au format Real se fait grâce au logiciel Real Producer. Il sert à la fois pour le traitement de fichiers enregistrés pour la diffusion à la demande depuis un serveur et aussi pour l'encodage d'émissions diffusées en direct.
Il dispose d'assistants facilitant le choix des options selon les situations de consultation. Un fichier Real contient jusqu'à 7 débits différents de diffusion. Les valeurs vont de 14 kbits/s à 300 kbits/s avec une qualité VHS dans format demi-écran. En général, on réalise deux fichiers, l'un pour les bas débits (modem 56 k ) et l'autre pour les accès à haut débit.
La version 8 offre des fonctions de montage simplifiées, un simulateur de bande passante indiquant les débits et le niveau de qualité selon les configurations de diffusion.
Pour faciliter la mise en place de configurations simples d'encodage, RealNetworks a conçu différents packages regroupant cartes de numérisation et logiciels de montage et d'encodage.
L serveur de Streaming Real :

Les logiciels serveurs de streaming Real fonctionnent sous de nombreux systèmes d'exploitation :
Windows NT et 2000, Linux, FreeBSD, Solaris (Sun), IRIX (SGI), AIX (IBM) et HP-Unix.Il y a trois gammes :
Basic, 25 connexions : gratuit Plus, 60 connexions : 2 000 $ par unité centrale Professionnal, 100 à 400 connexions : 6 000 à 21 600 $
Les versions Professionnal reçoivent diverses options combinables parmi lesquelles une gestion des publicités, un système d'authentification et une architecture de réplication.
RealNetworks vient de signer un accord avec Apple pour que la future version 8 des serveurs soit compatible avec la diffusion des films au format QuickTime.
Conclusion :
Corona, l’avenir du Streaming ?
Microsoft a présenté en avant-première lors du salon Streaming Media 2001, la plate-forme Corona qui sera incorporée dans la future version de Microsoft Windows Media Technologies. Cette nouvelle solution d’encodage et de diffusions audiovisuels permet une qualité d’image équivalente à la télévision haute définition grâce à de nouveaux codecs audio et vidéo.et prend en charge la diffusion en streaming sans buffer et le son numérique 5.1.
A priori, la diffusion de tels fichiers nécessitera l'usage d'un nouveau lecteur. On ignore s'il s'agit du Windows Media Player 8 actuellement réservé à Windows XP ou d'un nouveau player. On ignore également si ce lecteur prendra en charge le format MP3 tant en écriture qu'en lecture
Plus besoin de buffering :
Outre une qualité optimale, si l'on veut bien en croire l'éditeur de Redmond, Corona offrira un serveur de streaming dotée d'une nouvelle fonction baptisée Fast Stream. Ce mode de diffusion "maison" supprimerait le besoin de mise en mémoire tampon (buffering) avant de commencer la diffusion. Microsoft ne précise pas encore les taux de transfert nécessaires pour ce type de service mais tout laisse à croire que seuls les clients possédant un haut débit pourront en jouir.
De quoi faire démarrer le marché de la vidéo en ligne ?
La présentation de Corona, qui a été commercialisé dans le courant de l'année 2002, intervient quelques jours après le lancement officiel de RealOne, la plate-forme commerciale de distribution de contenus multimédia de RealNetworks et, à ce jour, seul vrai concurrent de Microsoft dans les solutions de diffusion vidéo. Avec l'augmentation du nombre de lignes haut débit, tant aux Etats-Unis qu'en Europe et en Asie, le marché de la distribution de contenus numériques via Internet semble se dessiner. Du moins dans l'esprit des éditeurs. Et, comme à son habitude, Microsoft ne compte pas le laisser entre les seules mains d'un concurrent. Après la disponibilité du son et de la vidéo, puis une amélioration du format de la vidéo et la prise en compte de la gestion des droits d'auteur/producteur, cette nouvelle génération de services permettra-t-elle pour autant au marché de la distribution de contenu audiovisuel sur Internet de décoller ?

Notre Webographie :
Images :
http://www.megapixel.net/html/articles/article-compressionf.html http://www.chez.com/algorithmejpeg/reli.htm
http://iphilgood.chez.tiscali.fr/Codage/Compressionjpeg.htm
http://www.chez.com/jpeg/general.htm
http://membres.lycos.fr/compressions/jpeg.html
http://stim-imagerie.tripod.com/GifOuJpg.htm
http://www.nlc-bnc.ca/9/1/p1-232-f.html
http://eduweb.brandonu.ca/~internet/class/jpeg.htm
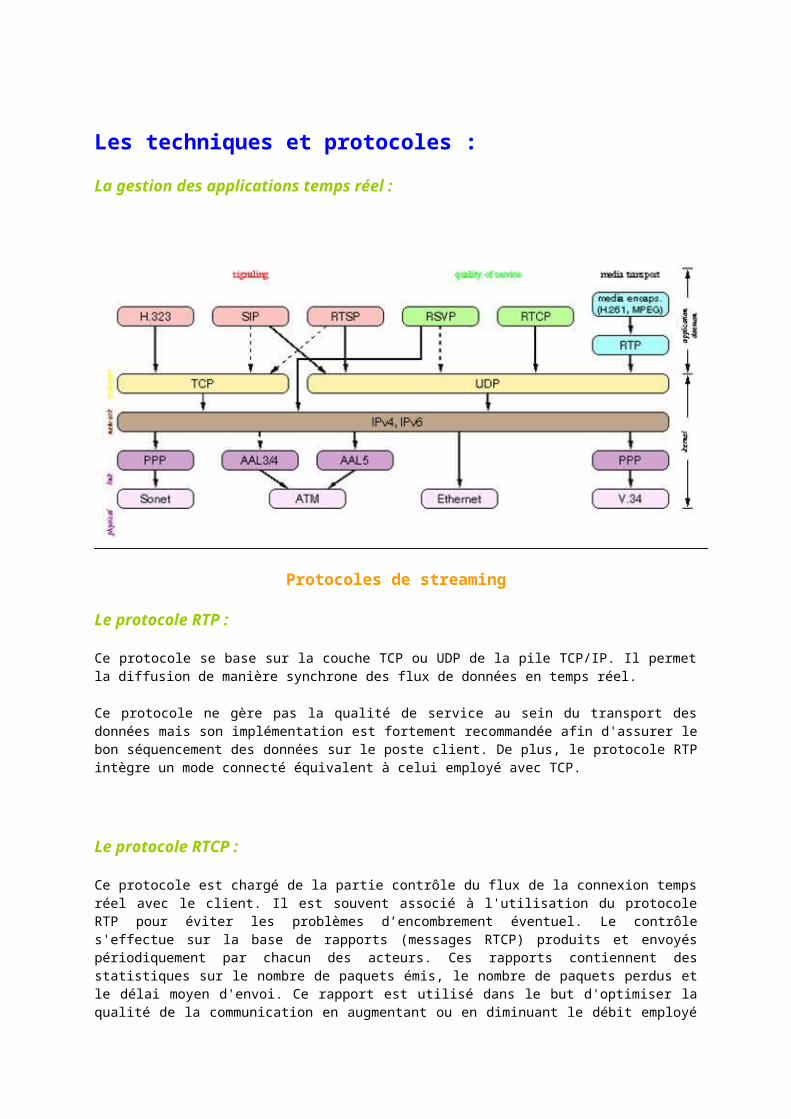
Video :
http://www.mpeg.org/MPEG/ http://multimania.com/mpeg4/word
http://www.musicrun.com/dossiers/mpeg_2/mpeg_2.php3
http://rtsq.grics.qc.ca/video_en_classe/numerique_compression.htm
http://www.evariste.org/100tc/1996/f036.html
http://www.apacabar.fr/news_detail.asp?Idnews=60
http://mpeg.telecomitalialab.com/faq/mp4-vid/mp4-vid.htm
…
Sons :
http://www.mp3mag.net/?r=decouvrir&p=encodeurs http://perso.wanadoo.fr/gilles.gomez/digital/digital_fr_1.htm
http://www.the-asw.com/affiche_article.php?art=52
http://www.mp3.com/
http://www.technosphere.tm.fr/chaine_multimedia/audio/02_mp3_p1.cfm
http://01audiovideo.free.fr/mp3_tech2.htm
http://manulepro.free.fr/mp3.htm
…
Streaming :
http://solutions.journaldunet.com/dossiers/streaming/sommaire.shtml http://perso.wanadoo.fr/psychomad/rapports/streaming/evolution.html
http://www.ac-grenoble.fr/crt/national/tic2002/webstrea.htm
http://www.novocom.asso.fr/webtv/streaming/techno.htm
http://solutions.journaldunet.com/0201/020104_corona.shtml
…













![pour-poly.ppt [Mode de compatibilité] - deptinfo.unice.frdeptinfo.unice.fr/~lahire/enseignement/SYSL3/miage/annee-2013-2014/... · élémentaires Un système de fichiers « hiérarchique](https://img.pdfslide.fr/doc/110x75/5b9c73bc09d3f221608d3ae9/pour-polyppt-mode-de-compatibilite-lahireenseignementsysl3miageannee-2013-2014.jpg)














