Embed Size (px)
Citation preview

Une introduction �a la notion de robustesse
Bernard Rapacchi
Centre Interuniversitaire de Calcul de Grenoble
19 aout 1994

\La Statistique est une science immuable mais
elle �evolue sans cesse."
Jules Verne: L'�etrange voyage de la mission
Barzach.
Dans cette note, nous vous proposons une introduction de la notion de robustesse. Apr�es
quelques d�e�nitions, nous faisons une approche pratique des qualit�es de la robustesse en utilisant
le logiciel EDA.
i

Table des mati�eres
1 QUELQUES D�EFINITIONS 1
1.1 R�esistance : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 1
1.2 Robustesse : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 1
1.3 Point d'e�ondrement : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 2
1.4 Parametre de localisation : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 2
1.5 Distribution sym�etrique : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 2
1.6 Quelques remarques : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 3
2 DES ESTIMATEURS DE PARAM�ETRE DE LOCALISATION 4
2.1 D�e�nitions : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 4
2.1.1 Le probl�eme : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 4
2.1.2 Statistiques d'ordre : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 4
2.2 Les L-estimateurs : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 5
2.3 Les M-estimateurs : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 6
2.3.1 �Equivariance : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 7
2.3.2 Exemples de M-estimateurs : : : : : : : : : : : : : : : : : : : : : : : : : : 8
2.3.3 L'estimateur biweight : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 9
2.3.4 L'estimateur de Huber : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 9
2.3.5 L'estimateur de Andrew : : : : : : : : : : : : : : : : : : : : : : : : : : : : 9
2.4 Les W-estimateurs : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 10
2.4.1 Calcul des M-estimateurs et des W-estimateurs : : : : : : : : : : : : : : : 11
2.5 Choisir un estimateur robuste : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 11
3 UNE SIMULATION AVEC EDA 12
3.1 M�ethode : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 12
3.2 Une macro EDA : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 12
3.3 La loi Gaussienne : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 14
3.4 La loi Double-Exponentielle : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 15
3.5 La loi Double Gaussienne : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 17
3.6 La loi Cauchy : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 18
4 UNE SIMULATION AVEC XLISPSTAT 21
4.1 Les fonctions XlispStat : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 21
4.2 La loi Gaussienne : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 24
4.3 La loi Double-Exponentielle : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 24
4.4 La loi Double Gaussienne : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 24
4.5 La loi Cauchy : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 25
ii

5 UNE SIMULATION AVEC SPLUS 26
5.1 Les fonctions SPlus : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 26
5.2 La loi Gaussienne : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 27
5.3 La loi Double Exponentielle : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 28
5.4 La loi Double Exponentielle : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 28
5.5 La loi Cauchy : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 28
6 R�EGRESSIONS R�ESISTANTES ET ROBUSTES 29
6.1 La droite \R�esistante" : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 29
6.2 Les R�egressions lin�eaires robustes : : : : : : : : : : : : : : : : : : : : : : : : : : : 30
6.2.1 Principe : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 30
6.2.2 R�egression Biweight : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 31
6.2.3 R�egression des moindres valeurs absolues : : : : : : : : : : : : : : : : : : 31
7 INTRODUCTION AU \CYRANO" 32
7.1 L'id�ee : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 32
7.2 Principe : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 33
7.3 Distributions Cyraniesques et Intervalles de con�ance : : : : : : : : : : : : : : : 34
7.4 A-t-on refait l'univers? : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 34
7.5 Quelques trucs : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 34
7.6 Le couteau suisse : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 34
7.7 Un exemple: l'Analyse de Variance : : : : : : : : : : : : : : : : : : : : : : : : : : 35
7.8 Un autre exemple: les r�egressions : : : : : : : : : : : : : : : : : : : : : : : : : : : 37
8 D'AUTRES M�ETHODES DE R�E-�ECHANTILLONNAGES 40
8.1 Les permutations : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 40
8.2 Tests d'hypoth�eses : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : : 41
iii

Chapitre 1
QUELQUES D�EFINITIONS
\Batir une th�eorie avant d'avoir des donn�ees
est une erreur monumentale: insensiblement
on se met �a torturer les faits pour qu'ils
collent avec la th�eorie alors que ce sont les
th�eories qui doivent coller avec les faits."
Conan Doyle: Les Aventures de Sherlock
Holmes, un scandale en Boheme.
1.1 R�esistance
La \R�esistance" permet d'avoir une certaine insensibilit�e aux quelques erreurs localis�ees qu'il
peut y avoir dans les donn�ees. Une m�ethode r�esistante doit produire un r�esultat qui ne changera
que l�eg�erement si une petite partie des donn�ees est remplac�ee par de nouvelles valeurs qui peuvent
etre tr�es di��erentes des originales. Les m�ethodes r�esistantes doivent accorder une importance
assez grande �a la partie principale des donn�ees et laisser une part tr�es faible aux possibles
\lointains". Par exemple, la m�ediane est une statistique r�esistante tandis que la moyenne ne
l'est pas.
1.2 Robustesse
La \robustesse" implique une insensibilit�e aux �ecarts dus �a une non-conformit�e aux hy-
poth�eses sous-jacentes �a un mod�ele probabiliste. Le plus souvent, nous voulons obtenir des
m�ethodes dont les hypoth�eses d'application ne soient pas trop restrictives. Les m�ethodes clas-
siques d'Analyse Statistique n�ecessitent tr�es souvent une distribution Gaussienne des donn�ees.
Les m�ethodes robustes garantiront que le r�esultat est bon pour une tr�es grande collection de
distributions sans pour autant etre les meilleures pour une en particulier. L'Analyse de Va-
riance classique, par exemple, n�ecessite que les r�esidus suivent une loi Gaussienne avec un meme
�ecart-type pour chacun des groupes �etudi�es; ce n'est pas une m�ethode robuste.
1

1.3 Point d'e�ondrement
D�e�nition 1 (Point d'e�ondrement) Le point d'e�ondrement [4] d'un estimateur est le maxi-
mum de la proportion d'observations pour laquelle il existe une borne dans le changement du
r�esultat de l'estimateur quand cette partie de l'�echantillon est modif�ee sans restriction.
Un estimateur est r�esistant seulement si son point d'e�ondrement est sup�erieur �a 0. Il n'existe
pas de borne dans le changement de la moyenne en modi�ant une seule donn�ee: il su�t de prendre
une seule valeur et de lui donner une valeur arbitrairement tr�es grande pour changer l'estimation
de la moyenne de fa�con signi�cative. Le point d'e�ondrement de la moyenne est donc nul, elle
n'est pas r�esistante. Le point d'e�ondrement de la m�ediane est:(12� 1
nsi n est pair
12� 1
2nsi n est impair
Le point d'e�ondrement d'un estimateur qui traite les observations uniform�ement ne peut pas
d�epasser 0.5, mais il existe des estimateurs dont le point d'e�ondrement est sup�erieur �a 0.5.
1.4 Parametre de localisation
Un parametre de localisation indice une famille de distribution de forme �x�ee dans le sens
suivant: quand les fonctions de densit�e de probabilit�e ont toutes la meme forme et meme �etendue
mais sont d�ecal�ees les unes des autres, un parametre qui sp�eci�e le d�ecalage est un parametre
de localisation ou parametre de positionnement. Prenons comme exemple la densit�e de la dist-
ribution Gaussienne de moyenne � et de variance �2:
f(x;�; �) =1
p2��
e�(x��)2=(2�2) (1.1)
Quand nous �xons l'�ecart-type � et que nous faisons varier la moyenne � les graphes de
densit�e seront d�ecal�es par rapport �a l'origine de cette valeur � mais ils auront exactement la
meme forme. La moyenne d'une Gaussienne est un parametre de localisation.
Dans l'�equation 1.1, la densit�e peut s'�ecrire comme une fonction h(y; �) o�u le parametre �
n'intervient plus en prenant y = x� �:
h(y; �) =1
p2��
e�y
2=(2�2) (1.2)
De cette remarque on peut en d�eduire une d�e�nition formelle d'un parametre de localisation.
D�e�nition 2 (Parametre de localisation) Soit f(x;�; �) la fonction de densit�e d'une va-
riable al�eatoire X. Le parametre � est un parametre de localisation si cette densit�e peut etre
�ecrite comme une fonction h(�; �) de x� � qui ne d�epend pas de �.
1.5 Distribution sym�etrique
D�e�nition 3 (Distribution sym�etrique) La distribution d'une variable al�eatoireX est sym�etrique
autour d'un centre de sym�etrie c si les variables al�eatoires X � c et �(X � c) ont meme distri-
bution.
2

Visuellement, le graphe de la densit�e d'une distribution sym�etrique est sym�etrique par rap-
port �a la droite verticale d'�equation x = c.
Th�eor�eme 1 Soit X une variable al�eatoire avec une distribution sym�etrique autour de c, de
moyenne �x et de m�ediane x0:5 alors c = x0:5 et si �x est �ni alors c = x0:5 = �x.
Dans le cas de distributions sym�etriques, le parametre de localisation prend souvent le nom
de \tendance centrale" qui exprime mieux ce �a quoi il correspond.
1.6 Quelques remarques
Le th�eor�eme pr�ec�edent donne une bonne indication du parametre de localisation d'une dist-
ribution sym�etrique comme �etant sa moyenne, sa m�ediane, et son centre de sym�etrie.
Les distributions asym�etriques n'ont pas la meme d�e�nition naturelle de parametre de loca-
lisation. Ce peut etre une borne inf�erieure comme pour une distribution exponentielle, ou une
valeur centrale mais qui ne sera pas forc�ement la moyenne ou la m�ediane qui sont d'ailleurs
di��erentes dans ce cas.
3

Chapitre 2
DES ESTIMATEURS DE
PARAM�ETRE DE
LOCALISATION
2.1 D�e�nitions
2.1.1 Le probl�eme
Un des travaux essentiels d'un Analyseur de Donn�ees est, �a partir d'un �echantillon de n
observations, de conna�tre la localisation de ces valeurs. L'aspect sympathique des distributions
sym�etriques l'am�enera �a transformer ces donn�ees pour rendre leur distribution sym�etrique. Dans
la suite, nous supposerons donc que nous n'avons que des �echantillons relevant d'une distribution
sym�etrique. Le probl�eme de l'Analyseur de Donn�ees reviendra alors �a trouver un bon estimateur
de la localisation des valeurs. S'il a la chance de savoir que les donn�ees suivent une loi Gaussienne
(cas extr�emement rare), il utilisera la moyenne comme estimateur. En e�et, nous savons que la
moyenne, dans ce cas pr�ecis, est le meilleur estimateur au sens de plusieurs crit�eres. Mais, a
priori, il ne conna�t pas la distribution exacte de ces donn�ees. Il lui faudra alors utiliser des
estimateurs robustes.
2.1.2 Statistiques d'ordre
D�e�nition 4 (Statistiques d'ordre) Soit x1; x2; : : : ; xn un �echantillon de taille n, les obser-
vations r�earrang�ees dans un ordre de magnitudes croissantes, not�ees x(1); x(2); : : : ; x(n) sont
appel�ees statistiques d'ordre de l'�echantillon et x(i) est appel�ee la i-i�eme statistique d'ordre.
Quand nous voudrons etre plus explicite sur la taille de l'�echantillon, nous noterons xijn la
i-i�eme statistique d'ordre.
Il faut remarquer que, dans le cas d'une distribution sym�etrique autour de �, les distributions
des statistiques d'ordre de meme profondeur depuis les extr�emes, x(i) et x(n+1�i) sont des images
comme dans un miroir par rapport �a �.
La moyenne a, tout de meme, quelques aspects int�eressants; en particulier d'etre le meil-
leur estimateur du centre de sym�etrie d'une distribution Gaussienne. Mais la m�ediane, qui est
bas�ee sur les statistiques d'ordre, a l'avantage d'etre robuste. C'est pourquoi, nous allons d�e�nir
des estimateurs qui feront intervenir ces statistiques d'ordre, mais en y incluant un aspect de
moyenne.
4

2.2 Les L-estimateurs
D�e�nition 5 (L-estimateurs) Soit x(1) � x(2) � : : : � x(n) les statistiques d'ordre d'un
�echantillon de taille n. Soit a1; a2; : : : ; an des nombres r�eels v�eri�ant 0 � ai � 1; i = 1; : : : ; n etPn
i=1 ai = 1; un L-estimateur T de poids a1; a2; : : : ; an est:
T =nXi=1
aix(i) (2.1)
Du fait de la sym�etrie des statistiques d'ordre, nous ne choisirons que des L-estimateurs
qui ont des poids sym�etriques, c'est-�a-dire ai = an+1�i; i = 1; : : : ; n=2. Nous aurons �a notre
disposition des estimateurs non-biais�es du centre de sym�etrie.
D�e�nition 6 (Moyenne) La moyenne est le L-estimateur dont tous les poids sont �egaux.
ai = 1=n; i = 1; : : : ; n
La moyenne donne la meme importance �a toutes les statistiques d'ordre.
D�e�nition 7 (M�ediane) La m�ediane est le L-estimateur qui ne fait intervenir que la statis-
tique d'ordre centrale si n est impair et qui donne la moyenne des deux statistiques d'ordre
centrales si n est pair.
Si n = 2p+ 1 alors ai =
(1 si i = p
0 si i 6= p
Si n = 2p alors ai =
(1=2 si i = p ou i = p+ 1
0 sinon
D�e�nition 8 (Moyenne �-censur�ee) Soit � un r�eel v�eri�ant 0 � � < 0:5, la moyenne �-
censur�ee, not�ee T (�), est un L-estimateur avec des poids ai tels que:
ai =
8><>:
0 si i � g ou i � n� g + 11�r
n(1�2�)si i = g + 1 ou i = n� g
1n(1�2�)
si g + 2 � i � n� g � 1
o�u g = [�n] et r = �n� g
Cette d�e�nition math�ematique est peut-etre un peu indigeste. Le principe g�en�eral de cet
estimateur est d'omettre une proportion � des plus petites valeurs et une autre proportion � des
plus grandes valeurs, puis de calculer la moyenne de l'ensemble des valeurs restantes. Prenons
comme exemple d'�echantillon de taille 16: xi; i = 1; : : : ; 16. En choisissant � = 0:25, nous
enlevons la moiti�e de cet �echantillon. En e�et �n = 0:25� 16 = 4, et:
T (0:25) =1
8
12Xi=5
x(i)
Choisissons � = 0:2, nous obtenons alors �n = 0:20 � 16 = 3:2. Nous enl�everons donc les
3 premi�eres et les 3 derni�eres observations, mais les quatri�eme et treizi�eme observations vont
intervenir dans le calcul de la moyenne.
T (0:20) =0:8
9:6x(4) +
1
9:6
12Xi=5
x(i) +0:8
9:6x(13)
5

Vous pourrez constater que la somme des poids est bien �egale �a 1.
D�e�nition 9 (Mimoyenne) La mimoyenne est d�e�nie comme �etant la moyenne �-censur�ee
pour � = 0:25.
Dans ce calcul, on ne fait intervenir que la moiti�e centrale des observations tri�ees.
D�e�nition 10 (M�ediane G�en�eralis�ee) Pour n impair, la m�ediane g�en�eralis�ee est la moyenne
des trois statistiques d'ordre centrales pour 5 � n � 12 ou des cinq statistiques d'ordre cent-
rales pour n � 13. Pour n pair, la m�ediane g�en�eralis�ee est une moyenne pond�er�ee des quatre
statistiques d'ordre centrales pour 5 � n � 12 avec des poids 16;13;13;16; pour n � 13 c'est une
moyenne pond�er�ee des six statistiques d'ordre centrales avec des poids 110 ;
15 ;
15 ;
15 ;
15 ;
110.
Cette m�ediane g�en�eralis�ee, que nous noterons BMED, essaye de pr�eserver la r�esistance de
la m�ediane en conservant une insensibilit�e aux e�ets dus aux arrondis et aux aggr�egations dans
les observations. Prenons un exemple, cit�e dans [5], o�u les mesures des observations ont �et�e
arrondies �a 5 pr�es:
110; 115; 120; 120; 125; 130; 130; 135; 140
la m�ediane de 125. Une seule nouvelle valeur inf�erieure �a 125 ferait chuter la m�ediane �a 120.
La m�ediane g�en�eralis�ee permet de donner une certaine importance relative �a plusieurs valeurs
centrales.
Un peu de calcul �el�ementaire vous permettra de constater que la m�ediane g�en�eralis�ee est une
moyenne censur�ee avec une proportion de censure de:
(0:5�1:5
n
) pour 5 � n � 12
et
(0:5�2:5
n
) pour n � 13
D�e�nition 11 (Trimoyenne) Soit Qb et Qh les quatri�emes bas et haut de l'�echantillon, M la
m�ediane; la trimoyenne, not�ee TRI, est:
TRI =1
4(Qb + 2M +Qh)
Cette moyenne est un exemple typique de ce qui a �et�e d�evelopp�e dans le cadre de l'Analyse
Exploratoire. En e�et, il faut remarquer que Tukey a d�e�ni les quatri�emes, qui ne sont qu'�a peu
pr�es les quartiles, par le fait de prendre une partie de l'�echantillon jusqu'�a la m�ediane, ajouter
une observation, et prendre la statistique d'ordre centrale de ce nouvel �echantillon.
Cet estimateur est le seul, ici, qui ne peut pas etre d�e�ni comme un L-estimateur.
2.3 Les M-estimateurs
Les M-estimateurs minimisent des fonctions objectives plus g�en�erales que l'habituelle somme
des carr�es des r�esidus associ�ee �a la moyenne d'un �echantillon. Plutot que de prendre le carr�e de
l'�ecart entre chaque observation xi et l'estimateur t, nous allons utiliser une fonction �(x; t) et
former la fonction objective en faisant la somme sur tout l'�echantillon:P
n
i=1 �(xi; t). Souvent
cette fonction �(x; t) ne d�ependra de x et de t qu'�a travers x� t.
D�e�nition 12 (M-estimateurs) Le M-estimateur Tn(x1; : : : ; xn) pour la fonction � et l'�echantillon
fxi; i = 1; : : : ; ng est la valeur de t qui minimise la fonction objectiveP
n
i=1 �(xi; t).
6

Nous prendrons soin de ne prendre que des fonctions � ayant une d�eriv�ee par rapport �a t
sauf en un nombre �ni de points pour nous �eviter de gros probl�emes. Ainsi pour trouver notre
estimateur, il su�ra de trouver la valeur de t qui v�eri�e:
nXi=1
(xi; t) = 0
D�e�nition 13 (Moyenne) La moyenne est un M-estimateur pour la fonction � d�e�nie par:
�(x; t) = (x� t)2
Nous vous proposons de v�eri�er ceci en exercice si cela ne vous para�t pas �evident.
D�e�nition 14 (M�ediane) La m�ediane est un M-estimateur pour la fonction � d�e�nie par:
�(x; t) =j x� t j
Dans le cas de la m�ediane, le probl�eme est un peu plus ardu. Tout d'abord, la fonction j u jn'a pas de d�eriv�ee en 0, mais il est raisonnable de prendre comme fonction :
(x; t) = sgn(x; t)
avec
sgn(u) =
8><>:
+1 si u > 0
0 si u = 0
�1 si u < 0
Ensuite, il y a plusieurs solutions au probl�eme de minimisation dans le cas d'un nombre pair
d'observations. L'expression
nXi=1
(xi; t) =nXi=1
sgn(xi � t)
compte les observations sup�erieures �a t moins les observations inf�erieures �a t. Dans le cas o�u n
est impair, la m�ediane d�e�nie habituellement annule cette expression; si n est pair, toute valeur
comprise entre les deux statistiques d'ordre centrales annule cette expression.
2.3.1 �Equivariance
Si nous d�ecalons tout l'�echantillon d'une valeur a, un bon estimateur de localisation devrait
�egalement etre d�ecal�e de la meme valeur; c'est-�a-dire:
Tn(x1 + a; : : : ; xn + a) = Tn(x1; : : : ; xn) + a
De tels estimateurs seront \�equivariants en localisation". Il est facile de voir que si la fonction
peut s'�ecrire (x; t) = (x� t) alors Tn v�eri�e cette condition. Si Tn est la valeur qui v�eri�e:
nXi=1
(xi � t) = 0
alors Tn + a est celle qui v�eri�e
7

nXi=1
(xi + a � t) = 0
De meme, si nous multiplions les valeurs de nos observations par b et les d�ecalons d'une
valeur a, nous voudrions qu'il en soit de meme pour l'estimateur:
Tn(bx1 + a; : : : ; bxn + a) = bTn(x1; : : : ; xn) + a
Equation que nous pouvons �ecrire �egalement
Tn(x1; : : : ; xn) = BTn(x1 �A
B
; : : : ;
xn �A
B
) + A
De tels estimateurs seront \�equivariants en localisation et en �echelle".
2.3.2 Exemples de M-estimateurs
Nous pouvons pr�esenter une classe de M-estimateurs dans lesquels nous introduisons une
grandeur Sn qui mesure la dispersion de l'�echantillon. On prendra des fonctions Sn qui v�eri�ent:
Sn(x1 + a; : : : ; xn + a) = Sn(x1; : : : ; xn)
et
Sn(bx1; : : : ; bxn) =j b j Sn(x1; : : : ; xn)
Ensuite, nous allons centrer et r�eduire les observations en introduisant les valeurs:
ui =xi � t
cSn
Un M-estimateur Tn sera la valeur qui minimiseP
n
i=1 �(ui). Si Sn v�eri�ent les conditions
cit�ees plus haut, alors Tn est �equivariant en localisation et en �echelle.
En g�en�eral, un M-estimateur de localisation implique une mesure �xe de l'�echelle. La constante
c dans la d�e�nition de ui existe pour ajuster les fonctions � et �a l'�echelle des donn�ees compt�ee
en unit�es de Sn. Cette constante c est appel�ee le \potentiometre" car c'est celui qui peut-etre
\r�egl�e" pour ajuster un M-estimateur a�n de lui donner une bonne e�cacit�e asymptotique pour
une distribution choisie. Pour l'unit�e d'�echelle, les valeurs Sn les plus commun�ement utilis�ees
sont:
{ la m�ediane des valeurs absolues des �ecarts, MAD = medifj xi �medjfxjg jg
{ L'�ecart entre les quatri�emes (la di��erence entre le quatri�eme haut et la quatri�eme bas [10])
ou une valeur approch�ee, l'interquartile.
{ l'�ecart-type.
8

2.3.3 L'estimateur biweight
L'estimateur \biweight", souvent surnomm�e \biweight de Tukey", est d�e�ni par la solution
Tn deP
n
i=1 (ui) = 0, o�u:
(u) =
(u(1� u
2)2 j u j� 1
0 j u j> 1
et
ui =xi � Tn
cSn
La fonction � correspondante est:
�(u) =
(16
�1� (1� u
2)3�
j u j� 116
j u j> 1
L'estimateur Sn couramment utilis�e est soit la m�ediane des �ecarts absolus, soit la moiti�e de
l'�ecart entre les quatri�emes. La valeur du potentiom�etre varie entre 3 et 12.
C'est un M-estimateur dont on peut facilement trouver le calcul en utilisant le logiciel
EDA [6].
2.3.4 L'estimateur de Huber
L'estimateur \de Huber" est d�e�ni par la solution Tn deP
n
i=1 (ui) = 0, o�u:
(u) =
(u j u j� k
ksgn(u) j u j> k
avec
ui =xi � Tn
Sn
et k est strictement positif.
La fonction � correspondante est:
�(u) =
(12u2 j u j� k
k j u j �12k2 j u j> k
L'estimateur Sn couramment utilis�e est la m�ediane des �ecarts absolus.
2.3.5 L'estimateur de Andrew
L'estimateur \de Andrew", souvent surnomm�e \vague de Andrew", est d�e�ni par la solution
Tn deP
n
i=1 (ui) = 0, o�u:
(u) =
(1�sin �u j u j� 1
0 j u j> 1
et
ui =xi � Tn
cSn
La fonction � correspondante est:
9

�(u) =
(1�2
[1� cos�u] j u j� 12�2
j u j> 1
L'estimateur Sn couramment utilis�e est soit la m�ediane des �ecarts absolus, soit la moiti�e de
l'�ecart entre les quatri�emes. La valeur du potentiom�etre varie entre 3 et 12.
2.4 Les W-estimateurs
Une autre forme des M-estimateurs est appel�e W-estimateurs. Prenons Tn un estimateur
d�e�ni par:
nXi=1
(xi � Tn
cSn
) = 0
Nous introduisons une fonction w telle que uw(u) = (u), nous obtenons:
nXi=1
(xi � Tn
cSn
)w(xi � Tn
cSn
) = 0
et apr�es modi�cation:
Tn =
Pn
i=1 xiw[(xi � Tn)=cSn]Pn
i=1 w[(xi � Tn)=cSn](2.2)
Ainsi, Tn est une moyenne pond�er�ee des xi. Nous dirons que Tn est d�e�ni it�erativement par
l'�equation 2.2 comme le W-estimateur bas�e sur la fonction de poids w.
D�e�nition 15 (Moyenne) La moyenne est un W-estimateur d�e�ni pour la fonction de poids
w
w(u) = 1 pour tout u
D�e�nition 16 (Biweight) L'estimateur Biweight est un W-estimateur d�e�ni pour la fonction
de poids w
w(u) =
((1� u
2)2 j u j� 1
0 j u j> 1
Par cette formulation, on comprend mieux le nom de Biweight que Tukey a donn�e �a cet
estimateur.
D�e�nition 17 (Huber) L'estimateur de Huber est un W-estimateur d�e�ni pour la fonction de
poids w
w(u) =
(1 j u j� k
ksgn(u)u
j u j> k
D�e�nition 18 (Andrew) L'estimateur de Andrew est un W-estimateur d�e�ni pour la fonction
de poids w
w(u) =
(1�u
sin �u j u j� 1
0 j u j> 1
10

2.4.1 Calcul des M-estimateurs et des W-estimateurs
La solution alg�ebrique directe de l'�equation 2.2 obtenue pour la moyenne est rarement pos-
sible. Mais la formulation meme de cette �equation sugg�ere une m�ethode de calcul it�erative. Soit
T
(k)n l'estimateur de la k-i�eme it�eration, et
u
(k)i
=xi � T
(k)n
cSn
alors, nous calculerons T(k+1)n par
T(k+1)n
=
Pn
i=1 xiw[u(k)i]P
n
i=1 w[u(k)i]
Algorithme de Newton-Raphson
L'algorithme de Newton-Raphson cherche un z�ero de la fonction h(t) en �evaluant h et sa
d�eriv�ee h0 en un point t(k) approchant du z�ero. La valeur approch�ee suivante t(k+1) est le point
o�u la tangente �a h au point t(k) rencontre l'axe des t.
Soit Tn un M-estimateur solution de
nXi=1
(xi � Tn
cSn
) = 0
alors, l'algorithme se d�e�ni par:
T(k+1)n = T
(k)n �
h[T(k)n ]
h0[T
(k)n ]
= T(k)n � cSn
Pn
i=1 [u(k)i]P
n
i=1 0[u
(k)i]
Une bonne valeur de d�epart T(0)n est la m�ediane. La valeur limite des T
(k)n est le M-estimateur
Tn, mais dans la pratique on fait tourner cet algorithme jusqu'�a ce que deux valeurs cons�ecutives
T
(k)n est T
(k+1)n soient su�samment pr�es l'une de l'autre.
C'est cet algorithme qui est utilis�e dans le logiciel EDA [6].
2.5 Choisir un estimateur robuste
A partir de cet ensemble d'estimateurs de localisation, il nous faudrait d�e�nir lequel prendre
parmi les meilleurs pour telle forme de distribution. Malheureusement, au vu de notre �echantillon,
il est plus que di�cile de conna�tre sa distribution r�eelle. L'id�ee de l'Explorateur de Donn�ees
sera justement de ne pas se �er �a un seul estimateur mais d'en regarder plusieurs.
Un travail essentiel d'ordre math�ematique a �et�e d�ecrit dans [5]. Il y d�ecrit les meilleurs
estimateurs pour plusieurs familles de distributions et di��erentes tailles d'�echantillon. Notre
sujet ici n'est pas de revenir sur cette �etude mais plutot de vous faire prendre conscience des
di��erentes qualit�es des estimateurs.
11

Chapitre 3
UNE SIMULATION AVEC EDA
Nous allons utiliser le logiciel EDA [6] d'Eug�ene Horber pour vous faire appr�ehender l'aspect
curieux de ces estimateurs. Nous supposerons donc que vous connaissez un peu ce logiciel, mais
meme si ce n'est pas le cas, il vous est possible de regarder simplement les r�esultats sans vous
soucier des commandes de EDA que nous utilisons pour les obtenir.
3.1 M�ethode
Avec EDA, nous allons tirer au hasard 300 �echantillons de taille 100 d'une certaine dist-
ribution th�eorique. Pour chacun de ces �echantillons, nous calculerons di��erents estimateurs de
localisation. Nous aurons ainsi pour chacun de ces estimateurs un �echantillon de la population
de l'ensemble de ces estimateurs et nous pourrons alors avoir une id�ee de la vraie distribution
de chacun de ces estimateurs, et comparer ensuite ces distributions.
Nous utiliserons �a chaque fois des distributions qui soient sym�etriques. Ainsi, nous d�e�nirons
le meilleur estimateur de localisation comme �etant celui qui a la plus petite variance. Ce crit�ere a
plusieurs vertus; en particulier dans le cas d'une distribution Gaussienne on sait que la moyenne
est parmi tous les estimateurs celui qui a la plus faible variance. Cette qualit�e de la moyenne
d'un �echantillon d'une loi Gaussienne est utilis�ee dans l'Analyse de Variance classique: en gros,
dans cette m�ethode o�u on veut regarder l'e�et de groupe sur une variable, on calcule la moyenne
de chacun des groupes et connaissant les variances de ces moyennes on teste si ces moyennes sont
statistiquement di��erentes. Ca marche bien car on sait que les variances des moyennes sont les
plus petites parmi tous les estimateurs, si on a au d�epart des distributions Gaussiennes.
3.2 Une macro EDA
Nous d�ecrivons ici une \macro" EDA qui calculera plusieurs estimateurs de localisation sur
un �echantillon.
Nous supposons que la variable de l'�echantillon est rang�ee dans la premi�ere variable de la
Zone de Travail (WA) de EDA. A chaque loi de distribution, cette macro sera modi��ee dans ces
premi�eres lignes pour permettre l'obtention de la premi�ere variable. La variable 2 contiendra
l'�echantillon tri�e en ordre croissant. Les i-i�emes observations des variables 3 �a 10 contiendront
les estimateurs du i-i�eme �echantillon tir�e. Il faudra cr�eer arti�ciellement ces variables avant
d'ex�ecuter cette macro par la commande:
generate 3-10 n=300
12

La macro compl�ete est la suivante:
set message off
calc #2=ugrd(#1)
set message on
calc [3,i]=mean(#2)
calc [9,i]=medi(#2)
calc [8,i]=0.25*(lhi(#2)+2*medi(#2)+uhi(#2))
calc a=$noc.2/2
calc b=a-2
calc c=a-1
calc d=a+1
calc e=a+2
calc f=a+3
calc D[7,i]=0.1*(D[2,b]+D[2,f])+0.2*(D[2,c]+D[2,a]+D[2,d]+D[2,e])
calc a=0.10*$noc.2
calc b=0.90*$noc.2
calc [4,i]=mean(sub(#2,a,b))
calc a=0.20*$noc.2
calc b=0.80*$noc.2
calc [5,i]=mean(sub(#2,a,b))
calc a=0.25*$noc.2
calc b=0.75*$noc.2
calc [6,i]=mean(sub(#2,a,b))
display 2 biweight /d
calc [10,i]=$5
Commentons un peu celle-ci. La commande set message off permet de ne pas faire im-
primer le message d'avertissement comme quoi nous allons r�e�ecrire une variable existante. La
fonction urgd permet de trier la variable 1, et de la ranger dans la variable num�ero 2. La
quatri�eme ligne permet de ranger la moyenne de la variable 2 dans la i-i�eme observation de la
variable 3. Remarquons que si on n'avait qu'un seul estimateur �a calculer �a partir d'une variable
d�ecrivant une population totale, nous aurions pu �ecrire:
calc [3,i]=mean(roll(100,#1)) \ for i start=1 end=300
Nous rangeons ensuite la m�ediane dans la variable 9. Les fonctions lhi et uhi permettent
de calculer les quatri�emes (Lower Hinge et Upper Hinge) et nous rangeons la Trimoyenne dans
la variable 8. La constante $noc.2 donne le nombre de cas de la variable 2. Nous avons pris la
pr�ecaution de trier l'�echantillon, ainsi il est facile de calculer la M�ediane G�en�eralis�ee et de la
ranger dans la variable 7.
Dans le cas actuel o�u on a 100 observations, nous aurons la chance que dans le calcul de
moyennes censur�ees, nous ne prendrons que des proportions � telles que �n soit entier. Ainsi,
les scalaires a et b indiqueront les indices de d�epart et de �n pour les calculs des moyennes
censur�ees. La fonction sub(#2,a,b) permet de ne prendre de la variable 2 que les observations
allant de l'indice a �a l'indice b. Nous rangeons la moyenne 0.10-censur�ee dans la variable 4, la
moyenne 0.20-censur�ee dans la variable 5 et la Mimoyenne dans la variable 6.
L'avant-derni�ere ligne permet de calculer la \Biweight" pour la variable 2 et ne pas l'a�cher
( /d ). La derni�ere ligne permet de ranger ce r�esultat sauvegard�e temporairement dans la Z-
variable num�ero 5, dans la variable 10.
13

3.3 La loi Gaussienne
Commen�cons par le cas le plus simple mais peut-etre pas le plus r�epandu. La densit�e de la
distribution Gaussienne G de moyenne � et de variance �2 est:
G(x;�; �) =1
p2��
e�(x��)2=(2�2)
C'est le cas sympathique de distribution sym�etrique.
Une commande simple d'EDA permet de g�en�erer automatiquement un �echantillon suivant
cette loi de distribution: nous prenons une loi centr�ee r�eduite, il nous faudra alors estimer la
valeur 0 centre de la distribution. Nous ins�ererons la ligne suivante comme deuxi�eme ligne de
notre macro:
generate 1 random normal n=100 /d
Apr�es avoir g�en�erer les 8 variables n�ecessaires, nous lan�cons l'ex�ecution de la macro.
execute for i start=1 end=300
Pour comparer les estimateurs nous regardons les \Bo�tes �a Pattes" et nous pr�esentons leur
moyenne et �ecart-type.
14

Parallel Boxplots300 cases
-.38532 .35019-------------------------------------------------------------------------
+----------+Moyenne : @@@ oo ooo----------| * |---------x oo o@@ @ :
2 +----------+ 2 2+-----------+
T(0.10) : @ ooooox----------| * |----------xoooo @ @@ :2 2 +-----------+ 32 2
+-----------+T(0.20) : @ o o ox-----------| * |-----------xo ooo @ @ :
2 2 2 +-----------+ 3 2 2+------------+
Mimoyenn: @ oo ooo------------| * |-----------xooooo @ @ :2 +------------+ 3 2
+-------------+MediGene:@ o o oo------------| * |------------xo o o @@ @:
4 +-------------+ 2 2+------------+
Trimoyen: @ oooox-----------| * |-----------xoo o @@:2222 +------------+ 3 2
+-------------+Mediane :@ o ooox------------| * |-------------o o o @ @ :
3 +-------------+ 2 2+------------+
Biweight: @ oo oo x----------| * |-----------xooooo @@ :3 2 +------------+ 3 2 2>>>boxplot 3-10 para
300 cases# 3 Moyenne :Mean -.00520,SD .10023
300 cases# 4 T(0.10) :Mean -.03617,SD .10553
300 cases# 5 T(0.20) :Mean -.01796,SD .11046
300 cases# 6 Mimoyenn:Mean -.01692,SD .11285
300 cases# 7 MediGene:Mean -.00280,SD .12273
300 cases# 8 Trimoyen:Mean -.00339,SD .11102
300 cases# 9 Mediane :Mean -.00314,SD .12354
300 cases# 10 Biweight:Mean -.00317,SD .11343
>>>display 3-10 mean
3.4 La loi Double-Exponentielle
Cette loi est la juxtaposition de 2 lois exponentielles. Sa fonction de densit�e D est:
DE(x;�; �) =1
2�e�jx��j=�
Nous prendrons pour simpli�er les calculs les valeurs � = 0 et � = 1. La fonction de densit�e
devient:
DE(x) =1
2e�jxj
15

Il nous faut calculer la fonction de probabilit�e cumul�ee F (x) qui est:
F (x) =
Zx
�1
DE(t)dt
Nous avons:
F (x) =
(12ex
x � 0
1� 12e�x
x > 0
Pour g�en�erer arti�ciellement cette variable, il faudra g�en�erer une variable de loi uniforme
entre [0; 1] et prendre la fonction inverse F�1(y) de F qui est:
F�1(y) =
(ln 2y y � 0:5
� ln[2(1� y)] y > 0:5
Le d�ebut de la macro sera modi��e ainsi:
generate 11 random uniform n=100 /d
if #11>0.5 then #1=-log(2*(1-#11)) else #1=log(2*#11)
Le r�esultat des estimateurs est le suivant:
16

Parallel Boxplots300 cases
-.15179 .16658-------------------------------------------------------------------------
+---------------+Moyenne : o oo ooox---------------| * |---------------xooooo o:
2 +---------------++--------------+
T(0.10) :o oo ox-------------| * |-------------x ooo :2 +--------------+ 2
+------------+T(0.20) : o ooox------------| * |------------x ooooooo :
+------------+ 2+-----------+
Mimoyenn: o o o------------| * |------------oo oo o@@@ :+-----------+ 2 2
+---------+MediGene: @oooo x----------| * |----------oooo o@ @ @ @ :
2 +---------+ 534 2+------------+
Trimoyen: o ooo------------| * |------------xo o o @ :2 +------------+ 2 2
+---------+Mediane : @oo x----------| * |---------xooooo @@ @@ @ :
3 2 +---------+ 36 23+------------+
Biweight: @ o oox----------| * |-----------oo ooo@@ @@ :2 +------------+ 2 2>>>boxplot 3-10 para
300 cases# 3 Moyenne :Mean .00913,SD .05943
300 cases# 4 T(0.10) :Mean -.00935,SD .05101
300 cases# 5 T(0.20) :Mean -.00045,SD .04833
300 cases# 6 Mimoyenn:Mean -.00021,SD .04766
300 cases# 7 MediGene:Mean .00529,SD .04504
300 cases# 8 Trimoyen:Mean .00598,SD .04797
300 cases# 9 Mediane :Mean .00543,SD .04538
300 cases# 10 Biweight:Mean .00642,SD .04698
>>>display 3-10 mean
3.5 La loi Double Gaussienne
Cette loi est construite par la juxtaposition de 2 Gaussiennes de variances tr�es di��erentes.
On peut d�e�nir sa fonction de densit�e DG par:
DG(x;�; �) = �G(x;�; �) + (1� �)G(x;�; �=K) avec 0 < � < 1
Dans notre cas, nous prendrons une variable Gaussienne centr�ee r�eduite et une autre centr�ee
d'�ecart-type 10; la valeur � sera choisie �egale �a 0:99 ce qui correspond �a prendre une valeur sur
100 qui suivra la deuxi�eme loi pertubatrice. La macro sera donc modi��ee en son d�ebut par:
17

gene 11 random normal n=100 /d
gene 12 random normal n=100 s=10 /d
gene 13 index n=100 /d
if #13<99 then #1=#11 else #1=#12
Parallel Boxplots300 cases
-.95672 1.10465-------------------------------------------------------------------------
+-----------------+Moyenne :o ox----------------| * |-----------------xo oo o:
2 2 +-----------------+ 3+-----+
T(0.10) : @ o x-----| * |------ooo @ @ :+-----++-----+
T(0.20) : @@ x----| * |----oo o @@ :+-----+ 2+----+
Mimoyenn: @ @ x-----| * |----xooo @@ :+----++-----+
MediGene: ooox-----| * |-----oooo@ :22 +-----+ 4
+-----+Trimoyen: @ oox----| * |----oo o@ @ :
22 +-----+ 2+------+
Mediane : oooox----| * |-----xoo @ :2 +------+ 2
+----+Biweight: @@oox----| * |----xo @ @@ :
2 +----+ 2 2>>>boxplot 3-10 para
300 cases# 3 Moyenne :Mean .00227,SD .41793
300 cases# 4 T(0.10) :Mean -.05088,SD .15090
300 cases# 5 T(0.20) :Mean -.01428,SD .13291
300 cases# 6 Mimoyenn:Mean -.01337,SD .13283
300 cases# 7 MediGene:Mean .00639,SD .14524
300 cases# 8 Trimoyen:Mean .00623,SD .13534
300 cases# 9 Mediane :Mean .00634,SD .14819
300 cases# 10 Biweight:Mean .00390,SD .13259
>>>display 3-10 mean
3.6 La loi Cauchy
La densit�e C de la loi de distribution de Cauchy de parametres � et � est:
C(x;�; �) =1
�
�
�2 + (x� �)2
18

Dans notre �etude, nous prendrons � = 0 et � = 1. Il est vrai que, dans cet exemple, nous
poussons le probl�eme �a son maximum: cette loi de distribution n'a pas d'esp�erance �nie: donc,
pas de moyenne. La moyenne d'un �echantillon sera donc surement un tr�es mauvais estimateur
du centre de sym�etrie.
La fonction de densit�e, pour notre exemple est:
f(x) =1
�
1
1 + x2
Sa fonction de probabilit�e cumul�ee H devient:
H(x) =1
�
arctanx+1
2
et la fonction inverse H�1 est:
H�1(y) = tan[�(y �
1
2)]
La macro sera modi��ee ainsi:
calc p=3.141592
gene 11 random n=100 /d
calc #1=tan(p*(#11-0.5))
Les r�esultats sont les suivants:
19
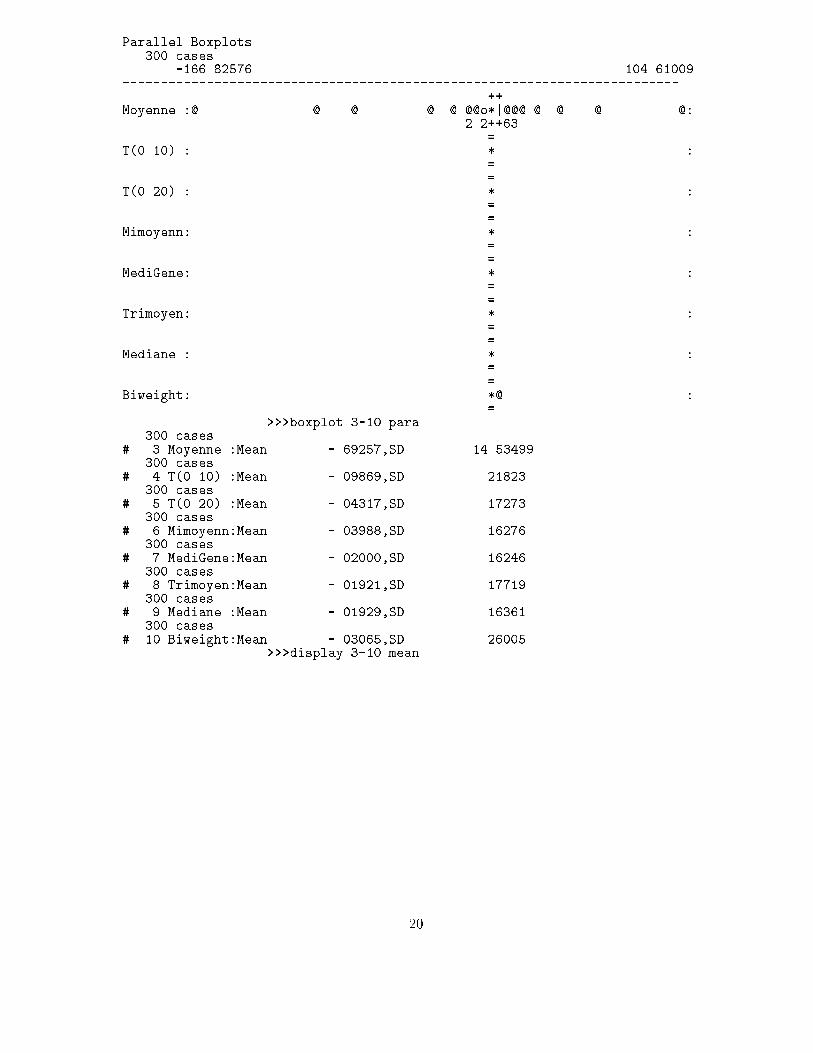
Parallel Boxplots300 cases
-166.82576 104.61009-------------------------------------------------------------------------
++Moyenne :@ @ @ @ @ @@o*|@@@ @ @ @ @:
2 2++63=
T(0.10) : * :==
T(0.20) : * :==
Mimoyenn: * :==
MediGene: * :==
Trimoyen: * :==
Mediane : * :==
Biweight: *@ :=
>>>boxplot 3-10 para300 cases
# 3 Moyenne :Mean -.69257,SD 14.53499300 cases
# 4 T(0.10) :Mean -.09869,SD .21823300 cases
# 5 T(0.20) :Mean -.04317,SD .17273300 cases
# 6 Mimoyenn:Mean -.03988,SD .16276300 cases
# 7 MediGene:Mean -.02000,SD .16246300 cases
# 8 Trimoyen:Mean -.01921,SD .17719300 cases
# 9 Mediane :Mean -.01929,SD .16361300 cases
# 10 Biweight:Mean -.03065,SD .26005>>>display 3-10 mean
20

Chapitre 4
UNE SIMULATION AVEC
XLISPSTAT
Nous allons maintenant regarder la meme �etude qu'au chapitre pr�ec�edent en utilisant cette
fois le logiciel XlispStat de Luke Tierney [9]. Le principe sera exactement le meme, nous allons
produire, par une simulation de type Monte Carlo, 300 �echantillons de taille 100 d'une certaine
distribution th�eorique. L'essentiel de ce chapitre sera de montrer les principes de programmation
du langage statistique XlispStat.
4.1 Les fonctions XlispStat
Il nous faut tout d'abord d�e�nir les fonctions qui vont nous permettre de calculer les di��erents
M-estimateurs. Pour la moyenne et la m�ediane nous utliserons les fonctions standards \mean"
et \median". La fonction qui permet de calculer la tri-moyenne est la suivante:
(defun tri-moyenne (x)
(let* ((fiv (fivnum x))
(lhi (select fiv 1))
(uhi (select fiv 3))
(med (select fiv 2))
)
(* 0.25 (+ lhi (* 2 med) uhi))
))
La m�ediane g�en�eralis�ee peut etre calcul�ee par la fonction:
(defun mediane-generalisee (x)
(let* ((nx (length x))
(pair (= (mod nx 2) 0))
(grand (> nx 12))
(trie (sort-data x))
(nxs2 (+ (truncate (/ nx 2)) 1))
)
(if pair
(if grand (* (+ (select trie (- nxs2 3))
(* (select trie (- nxs2 2)) 2)
21

(* (select trie (- nxs2 1)) 2)
(* (select trie nxs2 ) 2)
(* (select trie (+ nxs2 1)) 2)
(select trie (+ nxs2 2))
) 0.1)
(/ (+ (select trie (- nxs2 2))
(* (select trie (- nxs2 1)) 2)
(* (select trie nxs2 ) 2)
(select trie (+ nxs2 1))
) 6)
)
(if grand (* (+ (select trie (- nxs2 2))
(select trie (- nxs2 1))
(select trie nxs2 )
(select trie (+ nxs2 1))
(select trie (+ nxs2 2))
) 0.2)
(/ (+ (select trie (- nxs2 1))
(select trie nxs2 )
(select trie (+ nxs2 1))
) 3)
))))
Comme on peut le constater, cette fonction n'est pas tr�es compliqu�ee en soi, mais il faut
rester tr�es rigoureux dans l'�ecriture de ses fonctions quand on utilise le langage XlispStat (\lisp
= Lots of Insipid and Stupid Parentheses"). Nous n'insistons pas sur cette fonction qui n'est
qu'un suite de test et de calculs.
Pour le calcul d'une moyenne censur�ee, un deuxi�eme parametre est pr�esent en plus du vecteur
des valeurs, c'est la valeur � de la portion censur�ee.
(defun moyenne-censuree (x a)
(let* ((nx (length x))
(g (truncate (* a nx)))
(r (- (* a nx) g))
(w1 (/ (- 1 r) (* nx (- 1 (* 2 a)))))
(w2 (/ 1 (* nx (- 1 (* 2 a)))))
(l1 (repeat 0 g))
(l2 (repeat w2 (- nx (* 2 g) 2)))
(w (append l1 (list w1) l2 (list w1) l1))
)
(sum (* (sort-data x) w))))
Dans cette fonction, le vecteur w est le vecteur des poids des observations dans le calcul de la
moyenne. On peut ainsi d�e�nir facilement la mi-moyenne.
(defun mi-moyenne (x)
(moyenne-censuree x 0.25))
22

La calcul de l'estimateur biweight est l�eg�erement plus compliqu�e.
(defun biweight (x &key (c 6) (epsi 0.001))
(let* ((tt (median x))
(nx (length x))
(cs (* c (interquartile-range x) 0.5))
(tp (+ tt 1))
(u (repeat 0 nx))
(iw (repeat 0 nx))
(w (repeat 0 nx))
)
(do* ()
((< (abs (- tp tt)) epsi) tt)
(setf u (/ (- x tt) cs) )
(setf iw (which (< 1 (abs u))))
(setf w (^ (- 1 (* u u)) 2))
(setf (select w iw) (repeat 0 (length iw)))
(setf tp tt)
(setf tt (/ (sum (* x w)) (sum w)))
)))
La variable tt est la valeur courante de l'estimateur, la variable tp la valeur pr�ec�edente. La
boucle s'arrete quand les deux valeurs sont di��erentes de moins de epsi. Le vecteur iw contient
les indices pour lesquels la valeur absolue de u est plus grande que 1. Le vecteur w contient les
poids utilis�es pour le calcul de l'estimateur. On les calcule en oubliant le probl�eme de valeur
absolue trop grande puis on met �a 0 les poids n�ecessaires.
Il nous faut en�n une fonction pour la g�en�eration �nale des valeurs. On suppose qu'on veut
obtenir nb valeurs des estimateurs �a partir d'�echantillons de nx valeurs qui sont donn�ees par une
fonction fun de g�en�eration.
(defun estimation (nx nb fun)
(let* ((x nil)
(moy-l nil)
(med-l nil)
(tri-m-l nil)
(med-g-l nil)
(moy-c1-l nil)
(moy-c2-l nil)
(mi-m-l nil)
(biw-l nil)
)
(dotimes (i nb)
(setf x (select (mapcar fun (list nx)) 0))
(setf moy-l (append moy-l (list (mean x))))
(setf med-l (append med-l (list (median x))))
(setf tri-m-l (append tri-m-l (list (tri-moyenne x))))
(setf med-g-l (append med-g-l (list (mediane-generalisee x))))
(setf moy-c1-l (append moy-c1-l (list (moyenne-censuree x 0.1))))
(setf moy-c2-l (append moy-c2-l (list (moyenne-censuree x 0.2))))
23

(setf mi-m-l (append mi-m-l (list (mi-moyenne x))))
(setf biw-l (append mi-m-l (list (biweight x))))
)
(list moy-l moy-c1-l moy-c2-l mi-m-l med-g-l tri-m-l med-l biw-l)
))
Le seul probl�eme dans cette fonction est l'utilisation de la fonction mapcar dont il faut se
souvenir qu'elle rend une liste de listes et qu'on en selectionne donc que la premi�ere pour nos
besoins dans cette fonction.
4.2 La loi Gaussienne
La fonction utilis�ee dans la g�en�eration sera la fonction \normal-rand". Pour avoir le r�esultat
chercher il su�t donc de faire:
(def rob-gauss (estimation 100 300 #'normal-rand))
4.3 La loi Double-Exponentielle
La fonction utilis�ee est la suivante:
(defun d-exp-rand (n)
(let* ( (uni (uniform-rand n))
(iun (which (> uni 0.5)))
(d-exp (log (* 2 uni)))
)
(setf (select d-exp iun) (- (log (* 2 (- 1 (select uni iun))))))
d-exp))
4.4 La loi Double Gaussienne
Nous d�e�nissons d'abord une fonction g�en�erale pour une loi Double Gaussienne:
(defun d-normal-rand (n s1 s2 alpha)
(let* ( (gs1 (* s1 (normal-rand n)))
(gs2 (* s2 (normal-rand n)))
(im1 (truncate (* alpha n)))
(ind (iseq (- n im1) (- n 1)))
)
(setf (select gs1 ind) (select gs2 ind))
gs1))
Du fait de la mani�ere choisie pour faire nos tests, il nous faut d�e�nir une fonction qui ne
d�epende que du nombre de valeurs �a g�en�erer. Nous utiliserons donc la fonction:
(defun double-normal (n)
(d-normal-rand n 1 10 0.01))
24

4.5 La loi Cauchy
La fonction utilis�ee dans la g�en�eration sera la fonction \cauchy-rand".
25

Chapitre 5
UNE SIMULATION AVEC SPLUS
Naturellement, ce logiciel dispose en lui-meme de plusieurs fonctions ayant un rapport avec
la robustesse ; beaucoup sont disponibles avec le logiciel lui-meme mais de nombreuses autres
sont disponibles par le r�eseau InterNet, soit par la biblioth�eque �electronique STATLIB.
5.1 Les fonctions SPlus
Pour calculer la moyenne et la m�ediane, nous pourrons utiliser les fonctions standards \mean"
et \median". De plus, comme Splus est bien pr�epar�e, la fonction mean permet de calculer les
moyennes censur�ees. Par exemple, la moyenne censur�ee de coe�cient 0.25 se calcule par :
mean(x, trim=0.25)
Pour calculer la m�ediane g�en�eralis�ee on peut utiliser la remarque comme quoi elle se calcule
comme une moyenne censur�ee :
bmed <-function(x)
{
nx <- length(x)
alpha <- 0.5 - ifelse(nx > 12, 2.5/nx, 1.5/nx)
mean(x, trim = alpha)
}
La tri-moyenne peut etre �egalement d�e�nie tr�es simplement :
tri.mean <-function(x)
{
med <- median(x)
uplow <- quantile(x, c(0.25, 0.75))
t <- 0.25 * (uplow[1] + 2 * med + uplow[2])
t
}
Curieusement, l'estimateur biweight n'est pas d�e�ni dans SPlus. Celui de Hubert est d�e�ni, le
biweight est utilis�e pour la r�egression (cf plus loin), mais on ne trouve l'estimateur directement.
Pourtant la fonction le d�e�nissant n'est pas d'une compl�exit�e �enorme :
26

biweight <-
function(x, cut = 6, epsi = 0.001)
{
tt <- median(x)
nx <- length(x)
uplow <- quantile(x, c(0.25, 0.75))
cs <- 0.5 * cut * (uplow[2] - uplow[1])
repeat {
u <- (x - tt)/cs
les <- (1:length(x))[abs(u) > 1]
w <- (1 - u^2)^2
w[les] <- rep(0, length(les))
tp <- tt
tt <- weighted.mean(x, w)
if(abs(tt - tp) > epsi)
break
}
tp
}
5.2 La loi Gaussienne
Beaucoup de fonctions g�en�eratrices de nombres al�eatoires sont disponibles dans SPlus. On
peut citer les lois B�eta, Binomiale, Cauchy, Chi-2, Exponentielle, Gamma, : : :Bien entendu la
loi Gaussienne existe et on peut g�en�erer N nombres suivant cette loi par la fonction :
x <- rnorm(100)
Pour g�en�erer 300 �echantillons de 100 nombres al�eatoires suivant une loi Gaussienne on peut
�ecrire en SPlus :
gauss <- sapply(rep(100, 300), rnorm)
Les fonctions sapply, lapply sont pratiques pour l'�ecriture des fonctions SPlus mais elles
ont deux inconv�enients, le premier est qu'elles sont tr�es lentes, le deuxi�eme est qu'il semblerait
qu'elles soient bogg�ees. On pourra donc utiliser la mani�ere suivante :
gauss <- array(dim=c(300,100))
for (i in 1:300) {
gauss[i,] <- rnorm(100)
}
Comme vous l'avez remarqu�e, il faut d'abord cr�ee l'objet avant de lancer la boucle.
Pour calculer les 300 moyennes, on peut utiliser encore la fonction sapply, et meme d'une
seule phrase.
gauss.mean <- sapply (sapply(rep(100, 300), rnorm), mean)
27

Mais il faut dire que nous ne sommes jamais arriv�e �a la faire marcher. Donc il faut utiliser
encore la boucle :
gauss.mean <- 1
for (i in 1:100) {
gauss.mean[i] <- mean(rgauss[,i])
}
5.3 La loi Double Exponentielle
Elle n'est pas d�e�nie dans SPlus, la fontion qui permet de g�en�erer la loi de parametres � = 0
et � = 1 peut s'�ecrire :
rdexp <- function(n)
{
texp <- runif(n)
sele <- texp
sele[texp > 0.5] <- log(2 * texp[texp > 0.5])
sele[texp <= 0.5] <- - log(2 * (1 - texp[texp <= 0.5]))
sele
}
5.4 La loi Double Exponentielle
Il faut �ecrire une fonction qui g�en�ere cett distribution :
rdblnorm <- function (n, sd1=1, sd2=10, alpha=0.01)
{
gs1 <- rnorm(n, sd=sd1)
im1 <- trunc(alpha*n)
gs2 <- rnorm(im1, sd=sd2)
ind <- sample(n,im1)
gs1[ind] <- gs2
gs1
}
Cette fonction est un peu plus �elabor�ee que celle de XLispStat car les indices des valeurs
d�ependant de la deuxi�eme gaussienne sont choisis au hasard en utilisant la fonction sample.
5.5 La loi Cauchy
Ici la fonction rcauchy permet de g�en�erer notre fonction.
28

Chapitre 6
R�EGRESSIONS R�ESISTANTES
ET ROBUSTES
On part d'une s�erie d'observations f(xi; yi); i = 1; : : : ; ng. On veut faire une r�egression
lin�eaire:
y = a+ bx
Si on a des estimations des valeurs a et b, on posera:
ri = yi � (a+ bxi) pour i = 1; : : : ; n
ri repr�esente le r�esidu de la r�egression pour l'indice i.
6.1 La droite \R�esistante"
Cette droite, appel�ee \Resistant Line" dans la litt�erature anglo-saxone, est obtenue de la
mani�ere suivante.
On commence par diviser l'ensemble des donn�ees en 3 groupes d'importance �egale en fonction
des valeurs des xi. On aura ainsi les points avec des faibles valeurs des xi (sur la gauche du
graphique), les points des valeurs \m�edianes" des xi, et les points des fortes valeurs des xi (sur
la droite du graphique). Si n = 3k + 1, on prendra les portions de points de fa�con (k; k + 1; k);
si n = 3k + 2 on prendra (k + 1; k; k+ 1) comme r�epartition des points de fa�con �a �equilibrer le
d�ecoupage.
Pour chacune des trois parties, on prend les m�edianes des valeurs en x et des valeurs en y
des points obtenus. Si on �etiquette les trois parties comme Gauche (G), Milieu (M) et Droite
(D), on obtient 3 points \r�esum�es" du d�ecoupage en trois classes: (xG; yG); (xM ; yM); (xD; yD).
Comme premi�ere estimation de la droite, on va prendre une droite parall�ele �a la droite
passant par les deux points de Gauche et de Droite. On aura comme premi�ere estimation de la
pente b:
b1 =yD � yG
xD � xG
Comme valeur de a, on prendra une \moyenne" des droites passant par les 3 points r�esum�es.
a1 = (1=3)[(yG + yM + yD)� b1(xG + xM = xD)]
Toutes les techniques exploratoires sont bas�ees sur l'examen des r�esidus: ici, encore ce principe
est v�eri��e. Une fois, l'estimation de la droite faite comme expliqu�e ci-dessus, on applique la meme
29

proc�edure aux points:
(xi; ri) = (xi; yi � (a1 + b1xi))
On obtient une estimation b0
1 de la pente pour les r�esidus. Si cette valeur est nulle (ou tr�es
petite) on arrete le processus. Sinon, on obtient une nouvelle estimation pour la pente de la
droite qui est:
b2 = b1 + b0
1
Mais il peut arriver que la pente uctue ainsi autour de 2 valeurs. Pour �eviter ce probl�eme, on
refait la r�egression sur les r�esidus obtenus par l'estimation b2, on obtient ainsi, une estimation
b0
2 pour la pente des r�esidus. On choisit comme nouvelle valeur de la pente de la droite:
b3 = b2 � b0
2
b2 � b1
b02 � b
01
On it�ere ce processus autant de fois que n�ecessaire.
Pour avoir une id�ee de la qualit�e de l'ajustement lin�eaire, on utilise un coe�cient appel�e
\rapport des demies-pentes". Pour cela, on calcule les pentes des droites passant l'une par les
points Gauche et Milieu, l'autre par les points Droit et Milieu puis on en fait le rapport, et on
\ram�ene" ce rapport entre 0 et 1.
bG =yM � yG
xM � xG
bD =yD � yM
xD � xM
r = bG=bD
r1 = minfr; 1=rg
Plus ce coe�cient sera proche de 1, meilleur sera l'ajustement lin�eaire.
6.2 Les R�egressions lin�eaires robustes
6.2.1 Principe
Le principe des r�egressions lin�eaires robustes est relativement simple:
{ On commence par faire une r�egression des moindres carr�es.
{ On calcule des poids �a partir des r�esidus obtenus par la r�egression.
{ On fait une r�egression pond�er�ee des moindres carr�es. C'est-�a-dire qu'on cherche les valeurs
de a et b qui minimisent:
�wir2i
{ On change les poids en fonction des r�esidus obtenus et on recommence les r�egressions
pond�er�ees.
Les W-estimateurs pr�esent�es plus haut serviront dans le calcul des poids �a chaque it�eration.
Pour plus de clart�e, il nous faut pr�esenter des exemples.
30

6.2.2 R�egression Biweight
L'algorithme est le suivant:
1. On pose k = 1 et wi = 1 pour i = 1; : : : ; n.
2. On fait une r�egression lin�eaire pond�er�ee des moindres carr�es des valeurs yi sur les xi avec
les poids wi. On obtient ainsi des estimations ak et bk des parametres.
3. On calcule les r�esidus:
ri = yi � (ak + bkxi) pour i = 1; : : : ; n
et les valeurs:
ui =ri
cSk
4. On calcule les poids wi par:
wi =
((1� u
2i)2 j ui j� 1
0 j ui j> 1
5. On pose k = k + 1 et on retourne au pas 2.
On arrete cet algorithme quand les valeurs des parametres ne di��erent pas trop d'une
it�eration sur l'autre.
On utilise souvent:
Sk = m�ediane des j ri jc = 6 �a 9
Sk mesure la variation des r�esidus autour de z�ero qui peut etre consid�er�e comme la \m�ediane"
de ces r�esidus. Les valeurs ui mesurent la d�eviation de chacun des r�esidus en termes de mesure
de cette variation. Le potentiometre c permet d'�eliminer plus ou moins facilement les r�esidus
trop grands en valeur absolue.
6.2.3 R�egression des moindres valeurs absolues
Au lieu de minimiser la somme des carr�es des r�esidus comme dans le cas de la r�egression des
moindres carr�es, il est louable de vouloir minimiser la somme des valeurs absolues des r�esidus.
On minimise donc:
� j ri j= �1
j ri jr2i
Cette option, en termes de robustesse est meilleure que les moindres carr�es car elle donne
moins d'importance au r�esidus tr�es grands en valeur absolue.
Si dans le processus it�eratif d�ecrit au d�ebut de ce chapitre, on choisit comme poids:
wi =
(1jrij
ri 6= 0
0 ri = 0
en supposant qu'on converge vers une solution yi; �a la �n, nous aurons minimis�e:
�wir2i = �
1
j ri jr2i
Ainsi, on peut comprendre qu'un processus it�eratif de moindre carr�es pond�er�es peut aboutir
�a une solution des moindres valeurs absolues.
31

Chapitre 7
INTRODUCTION AU \CYRANO"
\: : :En�n, me pla�cant sur un plateau
de fer,
Prendre un morceau d'aimant et le
lancer en l'air!
C�a, c'est un bon moyen: le fer se
pr�ecipite,
Aussitot que l'aimant s'envole, �a sa
poursuite;
On relance l'aimant bien vite, et
cad�edis!
On peut monter ainsi ind�e�niment.
: : :
E. Rostand: Cyrano de Bergerac (Acte III, Sc.
XIII).
7.1 L'id�ee
Le \Bootstrap" est essentiellement une approche pour estimer des variances ou des intervalles
de con�ance des statistiques, sans vouloir parler uniquement de variances \unidimensionnelles".
L'id�ee principale r�eside dans le fait que l'ensemble des donn�ees observ�ees va servir comme popu-
lation sous-jacente. Les variances, distributions, intervalles de con�ance obtenus par le bootstrap
le seront en tirant des �echantillons �a partir de l'�echantillon observ�e.
Le fait de ne se servir uniquement de ce qu'on a sous la main, a amen�e certaines personnes �a
traduire le terme bootstrap par \m�ethode �a la Cyrano", ou \m�ethode Cyrano"; pour conserver
le meme parall�ele avec la litt�erature anglo-saxone, nous appellerons celui-ci le \Cyrano".
Ces m�ethodes Cyrano donnent des erreurs-types qui sont naturellement meilleures que celles
qui reposent sur des hypoth�eses qui, la plupart du temps, ne sont meme pas test�ees par l'analyste
de donn�ees. La souplesse et la �exibilit�e de ces m�ethodes donnent �a l'analyste une grande libert�e
dans le choix de statistiques dont les erreurs-types seraient autrement di�cilement calculables.
32

L'apparition de ces m�ethodes a permis d'oter un frein th�eorique �a beaucoup de probl�emes.
Les m�ethodes Cyrano impliquent des demandes de calculs tr�es gourmandes en moyens infor-
matiques. Elles remplacent les di�cult�es math�ematiques par des demandes de calculs intensifs.
Par exemple, elles remplacent le calcul d'un ensemble de coe�cients de r�egression par un millier.
Elles n'auraient pas �et�e immaginables sans la mont�ee en puissance des ordinateurs actuels.
7.2 Principe
On a comme donn�ee un �echantillon de taille n: (x1; x2; : : : ; xn). On veut calculer une statis-
tique quelconque �a partir de cet �echantillon, par exemple, la moyenne. Mais surtout ce qui nous
int�eresse, c'est la variance de cette statistique. Dans le cas de la moyenne, on conna�t celle-ci mais
la plupart du temps on ne la conna�t pas. On va tirer avec remise B �echantillons de meme taille n
�a partir de l'�echantillon de d�epart. On va calculer pour chacun des B �echantillons, la statistique
choisie et on calculera l'estimation de la variance �a partir des statistiques calcul�ees. Chacun des
�echantillons \cyraniesques" aura certaines observations retir�ees alors que d'autres appara�tront
plusieurs fois. Par exemple, dans le cas o�u n vaut 5, on pourra avoir comme �echantillon cyra-
niesque (x3; x2; x2; x4; x4) ou (x1; x5; x5; x5; x5).
Dans l'exemple de la moyenne, l'algorithme cyraniesque sera le suivant:
1. Utiliser un g�en�erateur de nombres al�eatoires pour cr�eer les �echantillons cyraniesques de
taille n, avec remise �a partir des observations donn�ees. Pour l'�echantillon b, l'observation
num�ero j not�ee xbjsera ainsi:
i = int(random() � n) + 1
xb
j = xi
2. Pour chaque b de 1 �a B, calculer la moyenne xb par:
xb = �n
j=1xb
j=n
3. Utiliser les moyennes ainsi calcul�ees pour avoir une estimation de la variance de la moyenne:
var(x) = �B
b=1[xb �moy(x)]2=(B � 1)
o�u
moy(x) = �B
b=1xb=B
Dans le principe de g�en�eration des �echantillons cyraniesques, il est souvent pr�ef�erable que
chaque observation se retrouve au total le meme nombre de fois. Pour cela, il su�t de dupliquer
B fois le tableaux des donn�ees, le trier dans un ordre al�eatoire, et prendre les �echantillons de n
observations les uns apr�es les autres.
33

7.3 Distributions Cyraniesques et Intervalles de con�ance
Souvent pour calculer un intervalle de con�ance, on utilise l'intervalle donn�e par l'estimateur
plus ou moins 2 fois son erreur-type. Sous certaines conditions, celui-ci est approximativement
l'intervalle de con�ance �a 95%, quelque soit la m�ethode employ�ee pour le calcul de l'erreur-type,
th�eorique ou cyraniesque.
Mais dans le cas des m�ethodes Cyrano, on obtient une distribution de la statistique utilis�ee.
On utilisera donc comme intervalle de con�ance, les percentiles empiriques calcul�es �a partir de
la distribution empirique de la statistique, obtenue par le Cyrano.
7.4 A-t-on refait l'univers?
Il faut faire toutefois tr�es attention �a ce qui est dans l'utilisation du Cyrano. Il est paradoxal
de penser qu'on puisse trouver toute l'information li�ee �a une population enti�ere �a partir d'un
seul �echantillon tir�e dans cette population. En fait, ce qui a �et�e d�emontr�e c'est: en moyenne, les
m�ethodes Cyrano donnent une bonne pr�ecision statistique de l'estimation, mais il existe des cas
o�u ces m�ethodes ne donneront pas de bons r�esultats et on ne peut pas le savoir �a l'avance.
7.5 Quelques trucs
Il faut surtout avoir �a l'esprit que les m�ethodes cyraniesques sont des m�ethodes empiriques:
on essaye et on regarde malgr�e le cout prohibitif du calcul informatique que cela peut entrainer.
Il a �et�e montr�e que parfois il est de bon sens de faire des estimations de statistiques non
born�ees. Par exemple, il est parfois pr�ef�erable de ne pas faire une m�ethode cyraniesque sur un
coe�cient de corr�elation r mais sur une transform�ee (arctan(r); : : :).
7.6 Le couteau suisse
Il est ici utile de rappeler l'utilisation de l'ancetre des m�ethodes cyraniesques: le couteau
suisse ou \Jacknife" en anglais. Celui-ci demande moins de calculs que les premi�eres. Le principe
est le suivant: on \coupe" l'�echantillon des observations en S sous-ensembles disjoints, chacun
ayant le meme nombre d'observations. La statistique qui nous int�eresse est ensuite calcul�e S fois,
o�u �a chaque fois on retire un des ces sous-ensembles. La plupart du temps, on prendra comme
sous-ensemble chaque observation, on fera ainsi n calculs, si n est la taille de l'�echantillon.
Pour illustrer nos propos, prenons l'exemple du calcul d'une statistique quelconque not�ee y.
On commence par calculer l'estimation ytous de tout l'�echantillon. On calcule ensuite l'estimation
yj de l'�echantillon auquel on a enlev�e le j-i�eme sous-ensemble, et ceci pour les k sous-ensemble
choisi. Ensuite, on calcule les \pseudo-valeurs" y�jpar
y�
j = kytous � (k � 1)yj
.
L'estimateur du couteau suisse est donn�e par la moyenne des pseudos-valeurs.
y� =
1
k
�y�j
34

7.7 Un exemple: l'Analyse de Variance
Nous voulons vous pr�esenter un petit exemple de ce qui peut etre fait par une m�ethode
Cyrano en utilisant le logiciel EDA.
Principalement en Marketing, les chercheurs utilisent dans leurs questionnaires des �echelles
de \Likert" qui repr�esentent des �echelles de valeurs enti�eres dans lesquelles les r�epondants se
situent par rapport �a une question: par exemple:L'Analyse Exploratoire des Donn�ees devrait etre enseign�ee au Lyc�ee:
1. Tout �a fait d'accord
2. D'accord
3. Un peu d'accord
4. Pas d'accord
5. Pas du tout d'accord
Ensuite, ces caract�eres sont utilis�es comme des caract�eres quantitatifs.
On nous a soumis un questionnaire de ce type o�u on �evaluait certaines propositions par
une �echelle de ce type. Ce questionnaire �etait soumis dans 2 r�egions di��erentes et on voulait
conna�tre si la premi�ere r�egion �etait plus sensible �a ces propositions.
En utilisant la proc�edure \BREAKDOWN" de SPSSx, on obtient le r�esultat suivant:
CRITERION VARIABLE Q23 Evaluations propositions
BROKEN DOWN BY Q51 Region
VALUE LABEL SUM MEAN STD DEV SUM OF SQ CASES
Region 1 311.0000 3.0194 1.5465 243.9612 103
Region 2 216.0000 2.6667 1.2145 118.0000 81
WITHIN GROUPS TOTAL
527.0000 2.8641 1.4102 361.9612 184
A N A L Y S I S O F V A R I A N C E
SOURCE SUM OF MEAN
SQUARES D.F. SQUARE F SIG.
BETWEEN GROUPS
5.6421 1 5.6421 2.8369 .0938
WITHIN GROUPS
361.9612 182 1.9888
Au seuil de 5% on ne peut pas rejeter l'hypoth�ese nulle et conclure que les deux moyennes sont
di��erentes. Or, les hypoth�eses concernant ce type de probl�eme sont tr�es restrictives: distributions
gaussiennes pour chacun des groupes, �egalit�e des variances de chaque groupe : : :Pourtant il existe
des r�ef�erences qui disent que l'ANOVA est une m�ethode robuste.
35

Pour prouver la relative robustesse de cette m�ethode prenons deux exemples d'utilisation de
celle-ci.
Dans le premier, le groupe 1 est constitu�e de n individus (autant que vous voulez mais assez
grand) qui ont une mesure �egale �a 1 et 4 autres qui ont une mesure �egale �a 0. Le deuxi�eme
groupe est constitu�e de n individus qui ont aussi 1 comme mesure et de 4 autres individus qui
ont une mesure de 2. En utilisant l'Analyse de la Variance et au risque de 5% vous conclurez
qu'il y a un e�et de groupe alors que n peut valoir 100 000, et que ces 8 individus atypiques
peuvent tr�es bien s'etre tromp�es en cochant le questionnaire.
Dans le sens contraire, prenons un deuxi�eme exemple o�u le premier groupe est constitu�e
de 99 individus ayant un caract�ere mesur�e �a 0.9995 un seul individu �a 0; le deuxi�eme groupe
est constitu�e de 99 individus dont la caract�ere est mesur�e �a 1.0005 et un seul �a 2. En utilisant
l'ANOVA et au risque de premi�ere esp�ece de 5%, vous ne pourrez pas conclure qu'il y a un e�et
de groupe alors que toutes les valeurs du premier groupe sont inf�erieures �a toutes les valeurs du
deuxi�eme groupe.
Revenons �a notre exemple des �echelles de Likert. Nous allons utiliser le Cyrano pour �evaluer
les \intervalles de con�ance" de chacun des centres des distributions des 2 groupes form�es par
les r�egions: nous choisirons le biweight.
Par des manipulations que nous ne d�ecrirons pas ici, nous avons �a notre disposition une Zone
de Travail EDA qui contient une premi�ere variable des 103 valeurs du caract�ere Q23 pour la
premi�ere r�egion et une deuxi�eme variable des 81 valeurs pour la deuxi�eme r�egion.
Nous allons utiliser une macro EDA pour g�en�erer des �echantillons cyraniesques �a partir
de chacune des 2 variables. Nous utiliserons la commande INCLUDE avec l'option ROLL qui
permet de tirer un �echantillon avec remise.
include n=n roll /d
display #a biweight c=2 /d
end
calc [b,i]=$5
On voit ansi l'utilisation de la commande SKIP dans les macros EDA. Le parametre n
contient le nombre de cas de la variable a sur laquelle on fait le Cyrano. On suppose que la
variable 101 a �et�e g�en�er�ee au moins une fois avec n cas pour pouvoir y mettre le Cyrano. La
variable 100 contient les valeurs tir�ees au hasard entre 0 et 1, puis les indices des cas qui vont
entrer dans le Cyrano. La variable b doit etre initialis�ee et elle contiendra les estimations de la
statistique par le Cyrano. Le calcul da la statistique du Cyrano est faite en derni�ere ligne; nous
avons choisi de calculer la moyenne pour l'exemple qui nous int�eresse, mais nous pourrions y
mettre un autre calcul.
Dans notre exemple, il faut donc faire l'ensemble des commandes suivantes:
calc a=1
calc b=3
calc n=$noc.a
generate 3 n=500
execute for i start=1 end=500
On a ainsi dans la variable 3 une estimation de la distribution du biweight pour la r�egion 1.
On fait de meme pour la r�egion 2.
calc a=2
36

calc b=4
calc n=$noc.a
generate 4 n=500
execute for i start=1 end=500
On peut faire les Bo�tes �a Pattes des deux distributions.
Parallel Boxplots
2.36 3.63
-------------------------------------------------------------------------
+---------+
moyreg01: @ oooo x--------| * |-------x ooo @:
2 +---------+ 524
+--------+
moyreg02:oooo--------| * |------xo :
23 +--------+
>>>boxp 3 4 parallele
On peut aussi avoir une estimation des intervalles de con�ance de chaque parametre de
localisation.
# 3 moyreg01: 5th percentile 3.05
>>>disp 3 p=5
# 3 moyreg01: 95th percentile 3.54
>>>disp 3 p=95
# 4 moyreg02: 5th percentile 2.43
>>> 4 p=5
# 4 moyreg02: 95th percentile 2.88
>>> 4 p=95
# 3 moyreg01:Mean 3.21,SD .15
# 4 moyreg02:Mean 2.69,SD .13
>>> display 3 4 mean
On a des \intervalles de con�ance" �a 90% pour les centres de distribution qui sont [3:05; 3:54]
pour la r�egion 1 et [2:43; 2:88] pour la r�egion 2. On peut ainsi conclure qu'il y a bien un e�et du
�a la r�egion.
7.8 Un autre exemple: les r�egressions
Dans la pr�esentation des r�egressions r�esistantes et robustes, nous n'avons pas parl�e d'erreurs-
type, ou d'intervalles de con�ance pour les parametres de la r�egression. Nous voulons vous
montrer comment r�esoudre ce prob�eme grace au Cyrano.
Prenons un exemple simple: les �elections europ�ennes de 1989 par d�epartement, et int�eressons
nous aux listes pr�esent�ees par le Parti Socialiste et le Front National. Nous avons transform�e
ces deux mesures en prenant le logarithme pour une sym�etrisation de celles-ci. Le graphique
correspondant est le suivant:
37

1.40 One tick on x = .01 units, on y = .04
|6
| 83
| 13
| 66
| 93 84
F| $7 34
N| 9294$057
| 68 7$ 676091 90
|2A $0 1 2$
| 74 $$47$$2182 31
| 55$2 81
| $5 56 39 $$570 76 11
| 80 61 $ $1 58
| 43 2$36
| 48 503 24 654432 9
| 86 $6 40
| 4$ 35 72 $46
| 53 1222 23
| 19
| 15 79
+----------------------------------------
1.23 PS 1.57
.69
>>>plot 10 11 casi
Chaque point est repr�esent�e par son num�ero de d�epartement. Nous allons e�ectuer un Cyrano
sur la Droite R�esistante. Pour cela, la macro est:
include n=96 roll /d
line 10 11 /d
end
calc [12,i]=$5
calc [13,i]=$6
Le r�esultat de la Droite R�esistante est:
96 cases
Independant: ( 10)PS #10=log(#2) *t*
Dependant : ( 11)FN #11=log(#6) *t*
Resistant line (Velleman&Hoaglin)
Slope -1.63 intercept 3.27
Half-slope-ratio 1.10(HSR1 .91)
>>> Linear fit is appropriate
Fit .17 Resistant correlation= -.47
>>>line 10 11
Apr�es ex�ecution de la macro 200 fois, on peut avoir un \intervalle de con�ance" des coe�cients.
38

200 cases
Boxplot :gene0012( 12) gen. variable:gene 12 13 n=200 *c*
-2.16 -.49
+------------+
@ooooo x-----------| * |-----------oo o @@ @ @ @ @ @ @
2 +------------+ 25 2 3
Extreme values (LO,HI): 193 167 adjacent(LO,HI): 162 97
Lo outliers:193 123 158 114 31 23 16
Hi outliers:163 135 171 48 177 131 6 140 87 54 72 4 64
71 144 195 47 127 167
200 cases
Boxplot :gene0013( 13) gen. variable:gene 12 13 n=200 *c*
1.69 3.97
+-----------+
@ @ @ @ @ @@@ o o o------------| * |-----------x ooooo
2 2 2 +-----------+ 2 2
Extreme values (LO,HI): 167 193 adjacent(LO,HI): 131 133
Lo outliers:167 127 47 195 144 71 64 4 72 87 54 140 48
177
Hi outliers:16 23 31 114 158 123 193
>>>boxp 12 13
200 cases
# 12 gene0012:Mean -1.56,SD .28
200 cases
# 13 gene0013:Mean 3.18,SD .39
>>>disp mean
200 cases
# 12 gene0012: 5th percentile -1.98
200 cases
5th percentile 2.43
>>> p=5
200 cases
# 12 gene0012: 95th percentile -1.02
200 cases
95th percentile 3.72
>>> p=95
On peut donner comme \intervalles de con�ance" �a 90%.
pente 2 [�1:98;�1:02]abscisse �a l'origine 2 [2:43; 3:72]
39

Chapitre 8
D'AUTRES M�ETHODES DE
R�E-�ECHANTILLONNAGES
Le Cyrano est une m�ethode o�u on reprend plusieurs �echantillons g�en�er�es �a partir de l'�echantillon
qu'on a \sous la main". D'autres m�ethodes de ce type sont disponibles, permettant de se passer de
th�eor�emes compliqu�es, n�ecessitant des hypoth�eses sur les donn�ees tr�es souvent inv�eri�ables.Si
le Cyrano permet d'avoir une estimation de la variabilit�e d'un param�etre d'autres m�ethodes
permettent d'avoir une estimation de la distribution d'une statistique, et ainsi de conna�tre la
signi�cation de la valeur d'un param�etre.
8.1 Les permutations
Prenons un exemple de donn�ees bien connu, les concentrations en ozone dans le Nord-
Est des �Etats-Unis pendant l'�et�e 1974 (ces donn�ees sont disponibles avec Splus sous le nom
\ozone.data"). 111 mesures ont �et�e faites, le coe�cient de correlation entre le vent et la concent-
ration d'ozone est de -0.613. Le nuage de points de ces deux variables est :
••
••
• •
••
• • ••
•
•
•
••
••
••
•
•
••
•
•
• •
•
•••
•
•
•
•
•
•
••
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
•
••
•
••
•
•
•
•
•
•
•
•
••
•
•
•
•
•
• •
•
••
•
••
•
•
•
•• ••
•
••
• •
•
••
•• •
•
•
••
•
•• •
wind
ozon
e
5 10 15 20
050
100
150
40
Le probl�eme est de savoir si cette valeur est \statistiquement" di��erente de 0. Si on fait
l'hypoth�ese que nos variables suivent des lois gaussiennes, bien sympathiques, on peut conna�tre
la distribution th�eorique du coe�cient de corr�elation lin�eaire. Mais si on veut se passer de ce
genre d'hypoth�eses contraignantes, on peut g�en�erer une distribution empirique de ce coe�cient
de corr�elation en faisant des permutations sur les valeurs d'une des variables et en calculant �a
chaque fois, la corr�elation des 2 nouvelles variables.
Une mani�ere de faire ceci en langage S est la suivante :
correl <- 1:500
for (i in 1:500) {
correl[i] <- cor(wind,ozone[sample(length(ozone))]))
}
correl[1] <- cor(wind,ozone)
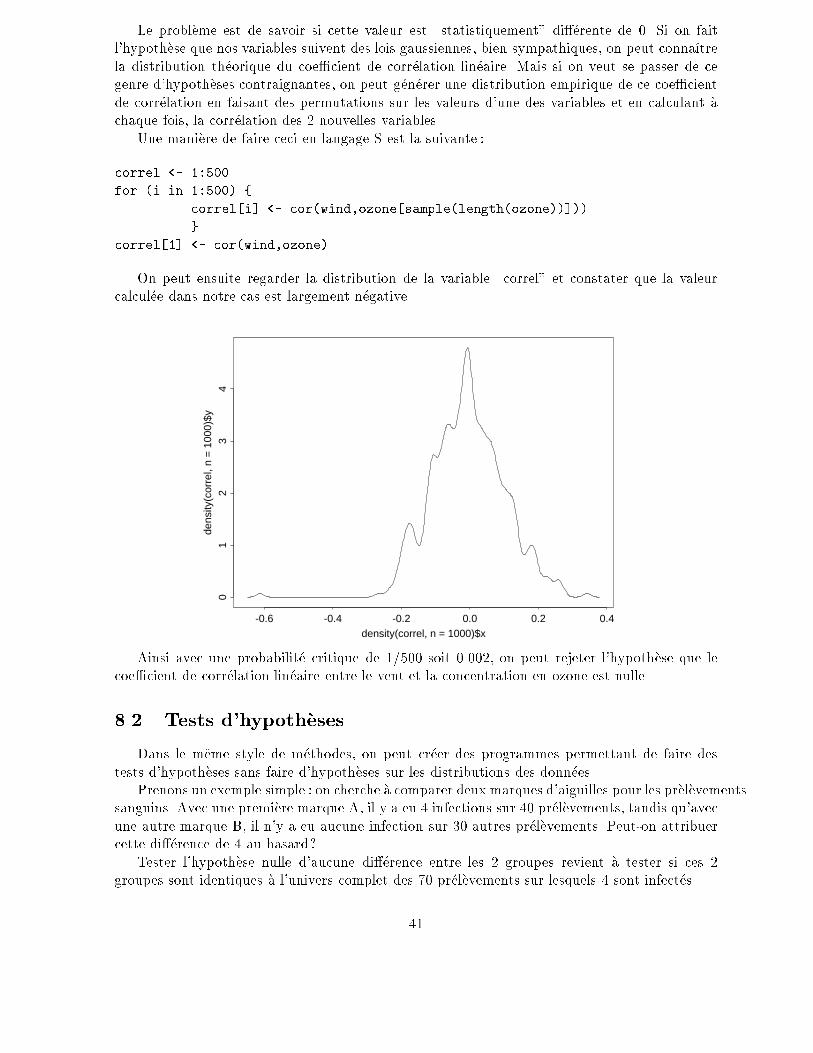
On peut ensuite regarder la distribution de la variable \correl" et constater que la valeur
calcul�ee dans notre cas est largement n�egative.
density(correl, n = 1000)$x
dens
ity(c
orre
l, n
= 1
000)
$y
-0.6 -0.4 -0.2 0.0 0.2 0.4
01
23
4
Ainsi avec une probabilit�e critique de 1/500 soit 0.002, on peut rejeter l'hypoth�ese que le
coe�cient de corr�elation lin�eaire entre le vent et la concentration en ozone est nulle.
8.2 Tests d'hypoth�eses
Dans le meme style de m�ethodes, on peut cr�eer des programmes permettant de faire des
tests d'hypoth�eses sans faire d'hypoth�eses sur les distributions des donn�ees.
Prenons un exemple simple : on cherche �a comparer deux marques d'aiguilles pour les pr�el�evements
sanguins. Avec une premi�ere marque A, il y a eu 4 infections sur 40 pr�el�evements, tandis qu'avec
une autre marque B, il n'y a eu aucune infection sur 30 autres pr�el�evements. Peut-on attribuer
cette di��erence de 4 au hasard?
Tester l'hypoth�ese nulle d'aucune di��erence entre les 2 groupes revient �a tester si ces 2
groupes sont identiques �a l'univers complet des 70 pr�el�evements sur lesquels 4 sont infect�es.
41

Pour cela on va r�ep�eter plusieurs fois le processus suivant :
1. G�en�erer 40 pr�el�evements par des nombres au hasard entre 1 et 70.
2. Regarder combien de fois apparaissent les pr�el�evements num�erot�es de 1 �a 4, cens�es etre les
pr�el�evements infect�es.
3. G�en�erer 30 pr�el�evements par des nombres au hasard entre 1 et 70.
4. Regarder combien de fois apparaissent les pr�el�evements num�erot�es de 1 �a 4.
5. Calculer la di��erence entre les 2 groupes.
Ensuite il su�t de calculer la probabilit�e de l'�ev�enement \la di��erence entre les 2 groupes
est au moins �egale �a 4" en calculant le nombre de fois o�u la di��erence g�en�er�ee est sup�erieure �a
4, divis�e par le nombre total de g�en�erations.
En langage SPlus, on �ecrira :
gene <- function(n)
{
diffe <- 1:n
for (i in 1:length(diffe)) {
groupe1 <- sample(70, 40, replace = T)
nb.infectes1 <- length(groupe1[groupe1<=4])
groupe2 <- sample(70, 30, replace = T)
nb.infectes2 <- length(groupe2[groupe2<=4])
diffe[i] <- nb.infectes1-nb.infectes2
}
return(diffe)
}
diffe <- gene(3000)
length(diffe[diffe>=4])/length(diffe)
Dans notre cas, nous avons trouv�e une probabilit�e de 0.043, ce qui fait qu'au seuil de 5%, on
peut rejeter l'hypoth�ese nulle que les 2 groupes sont identiques.
Dans ce genre de probl�eme, un statisticien � calculerait ce qu'on appelle commun�ement le
\chi-2", qui suivrait th�eoriquement (mais surtout asymptotiquement) une loi du chi-deux �a un
degr�e de libert�e. De la meme fa�con que pr�ec�edement, on peut g�en�erer plusieurs �echantillons
pour conna�tre une estimation de la distribution de ce \chi-2" dont il faut rappeler que celui est
calcul�e ainsi:
�2 =
X(observ�e� esp�er�e)2=esp�er�e
On peut �ecrire une fonction SPlus :
chi2.s <- function(n){
diffe <- 1:n
exp <- c(66*40/70,4*40/70,66*30/70,4*30/70)
for (i in 1:length(diffe)) {
g1 <- sample(70, 40, replace = T)
i1 <- length(g1[g1<=4])
42
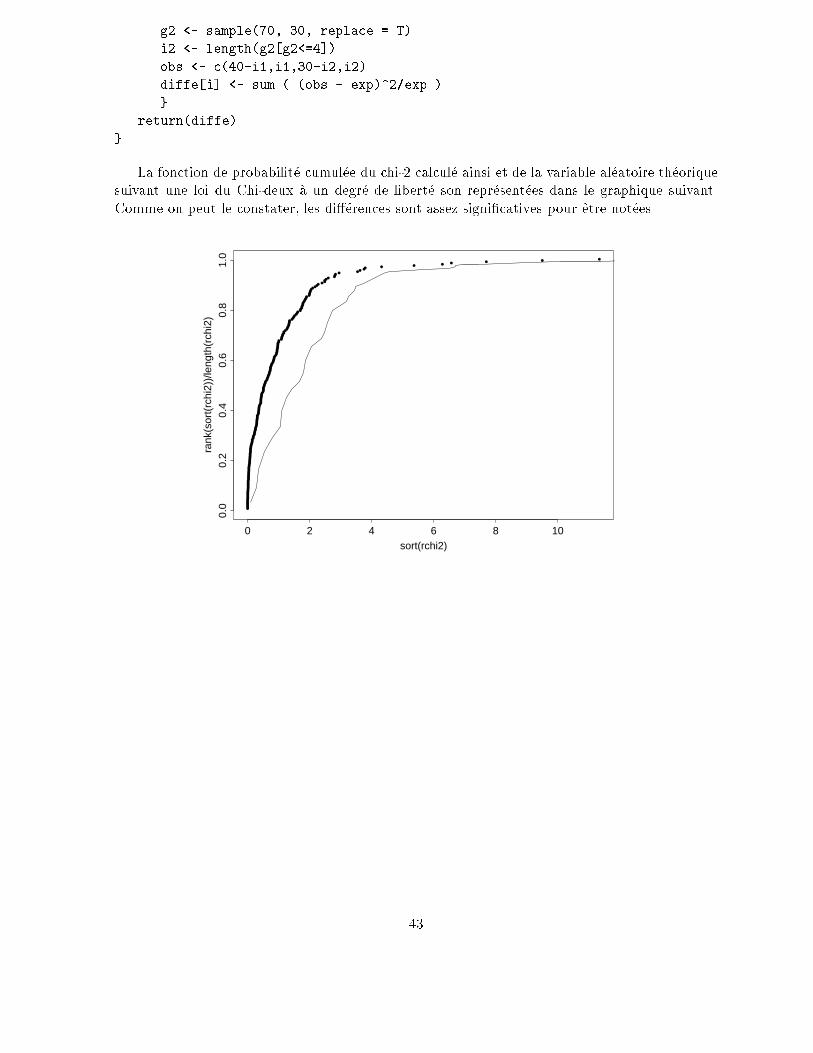
g2 <- sample(70, 30, replace = T)
i2 <- length(g2[g2<=4])
obs <- c(40-i1,i1,30-i2,i2)
diffe[i] <- sum ( (obs - exp)^2/exp )
}
return(diffe)
}
La fonction de probabilit�e cumul�ee du chi-2 calcul�e ainsi et de la variable al�eatoire th�eorique
suivant une loi du Chi-deux �a un degr�e de libert�e son repr�esent�ees dans le graphique suivant.
Comme on peut le constater, les di��erences sont assez signi�catives pour etre not�ees.
•••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••••
•••••••••••••••••••••••••
••••••••• •••• • • • • • • •
sort(rchi2)
rank
(sor
t(rc
hi2)
)/le
ngth
(rch
i2)
0 2 4 6 8 10
0.0
0.2
0.4
0.6
0.8
1.0
43

Bibliographie
[1] R.A. Becker, J.M. Chambers, A.R. Wilks. The New S Language.Wadsworth & Brooks/Cole
(1988).
[2] P. Diaconis et B. Efron. M�ethodes de calculs statistiques intensifs sur ordinateurs. dans Le
calcul intensif. Biblioth�eque Pour La Science. (1989).
[3] J. Fox et J. Scott Long (Eds). Modern Methods of Data Analysis. Sage (1990).
[4] F.R. Hampel, E. M. Ronchetti, P. J. Rousseeuw et W. A. Stahel. Robust statistics. John
Wiley (1986).
[5] D. C. Hoaglin, F. Mosteller et J. W. Tukey (Eds). Understanding Robust and Exploratory
Data Analysis. John Wiley (1983).
[6] E. Horber. Exploratory Data Analysis: User's Manual. Version 2.1/1. Universit�e de Gen�eve.
(1989).
[7] F. Mosteller et J. W. Tukey. Data Analysis and Regression. Addison-Wesley (1977).
[8] P.F. Velleman et D.C. Hoaglin. Applications, Basics, and Computing of Exploratory Data
Analysis. Duxbury Press (1981).
[9] L. Tierney. Xlisp-Stat: A Statistical Environment Based on the XLISP Language. University
of Minnesota. (1991).
[10] J.W. Tukey. Exploratory Data Analysis. Addison-Wesley (1977).
44