Embed Size (px)
Citation preview

REX sur Pentaho Data Integration - ce que PDI nous a apporté
29 Mai 2013

PRÉSENTATION DE SMILE

Une expertise multi technologies
CMS GED Portail
Décisionnel
E-commerce
ERP Système
NOTRE OFFRE – LA MATURITÉ OPEN SOURCE

CONTEXTE LE CLIENT
• Pur player du web – Site de petites annonces
• 22 Millions d’annonces actives
• 500 000 nouvelles annonces par jour
• 8ème site le plus visité en France

CONTEXTE LE PROJET (1/2)
• Développement et alimentation d’un entrepôt de donnée – Sources multiples
• Site, Site-mobile, applications
• CRM
• Référentiel produit
• Fichiers de logs (Site, Transaction, …)
– SGBD standard utilisé
• PostgreSQL
• Evolution vers les technologies Big Data à l’étude
• Mise en place d’une solution BI complète – Solution retenue : Pentaho BI Suite
CONTEXTE LE PROJET (2/2)
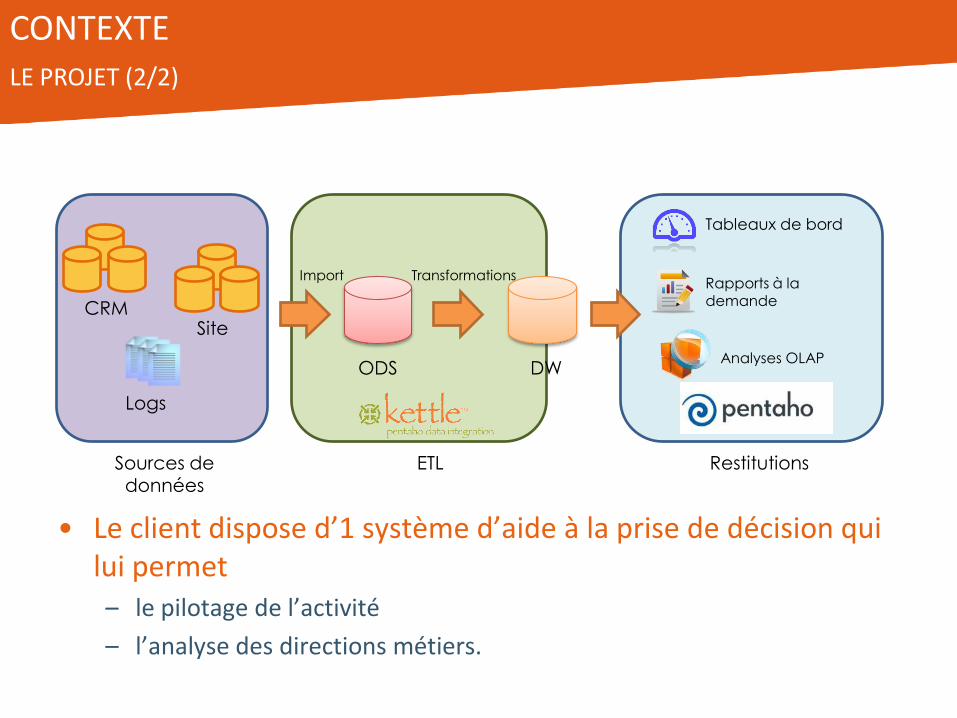
• Le client dispose d’1 système d’aide à la prise de décision qui lui permet – le pilotage de l’activité
– l’analyse des directions métiers.
CRM Site
Logs
Sources de données
ETL
DW
Restitutions
ODS
Transformations Import
Tableaux de bord
Rapports à la demande
Analyses OLAP

CONTEXTE LES PRINCIPAUX CHALLENGES
• Premier projet BI réalisé par le client – Phase de spécification complexe
– De nombreuses sources
• Forte volumétrie (log du site, transactions)
• Fichiers complexes
• De nombreux indicateurs à calculer
• Problématique de déboulonnage / qualité de donnée importantes
– Fenêtre de tire réduite
– Choix du SGBD imposé par le client : PostgreSQL

LA SOLUTION L’ETL - PENTAHO DATA INTEGRATION
• Présentation de PDI – Projet Open Source existant : Kettle, aujourd’hui intégré à la suite
Pentaho
– Licence Apache 2.0
– Dernière version : 4.4.1 datant du 29/11/2012
– E.T.L. (Extract Transform Load)
– Lit et écrit dans n’importe quelle source de données
• Principales bases de données (Open Source ou propriétaire)
• Fichiers Excel, CSV, XML
• AS400 …
– Intégration à la plateforme WEB
• Contrôle à distance des jobs (traitements)
• Suivi des performances
• Gestion des alertes
– Nombreuses fonctions de load/balancing, partitionnement, cluster

IMPLEMENTATION GESTION DE LA FORTE VOLUMETRIE (1/2)
• Quelques chiffres – 500 000 nouvelles annonces chaque jour
– 22 000 000 d’annonces actives (vivantes)
– 350 000 000 de lignes / 100Go dans le fichier de log principal
– 3 500 000 visiteur unique / jour
• Suivi du cycle de vie des annonces – Modèle de données adapté à la production
• pas aux requêtes analytiques
• Indexes non-adaptés : ajout d’un indexe peu représenter plusieurs jours de calculs
– Problématique dès lors qu’il faut effectuer des requêtes sur la table des « actions »

IMPLEMENTATION GESTION DE LA FORTE VOLUMETRIE (2/2)
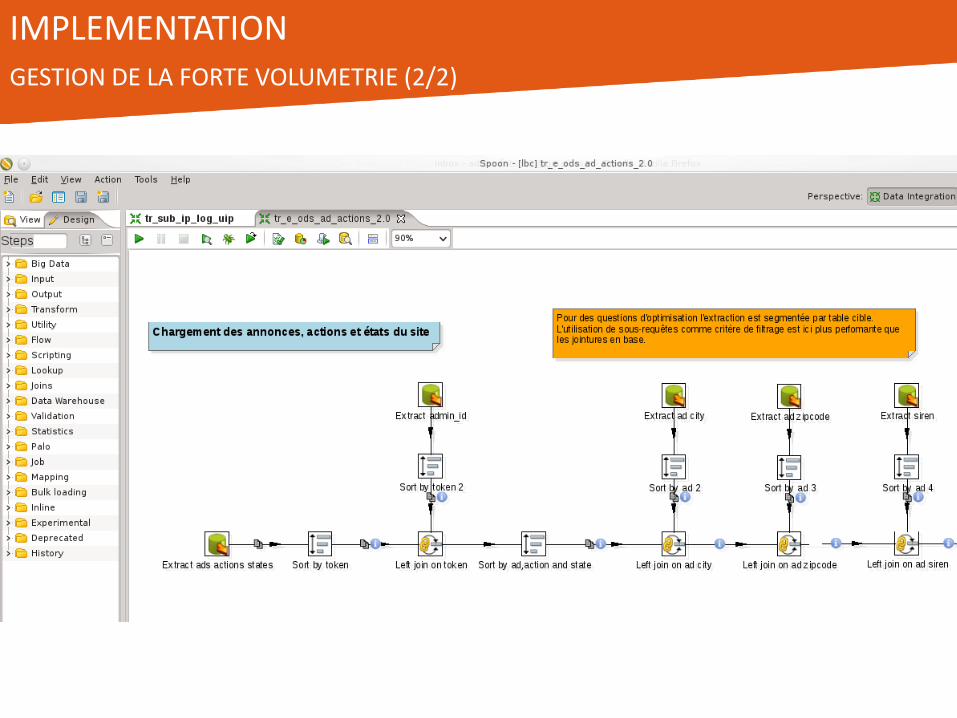
• PDI à la rescousse – Les jointures sur plusieurs tables de millions de lignes non
performantes
– Déport des calculs dans l’ETL
• Exploitation de la puissance de la machine de calcul de l’ETL
• Remplacement jointures SQL par des composants « Merge Join » de PDI – Découpage en plusieurs requêtes
– Gain obtenu : 45 minutes -> 5 minutes (90% plus rapide dans l’ETL)
– En grande partie lié à la puissance du serveur
IMPLEMENTATION GESTION DE LA FORTE VOLUMETRIE (2/2)
IMPLEMENTATION EXPLOITATION DES FICHIERS DE LOG (1/4)
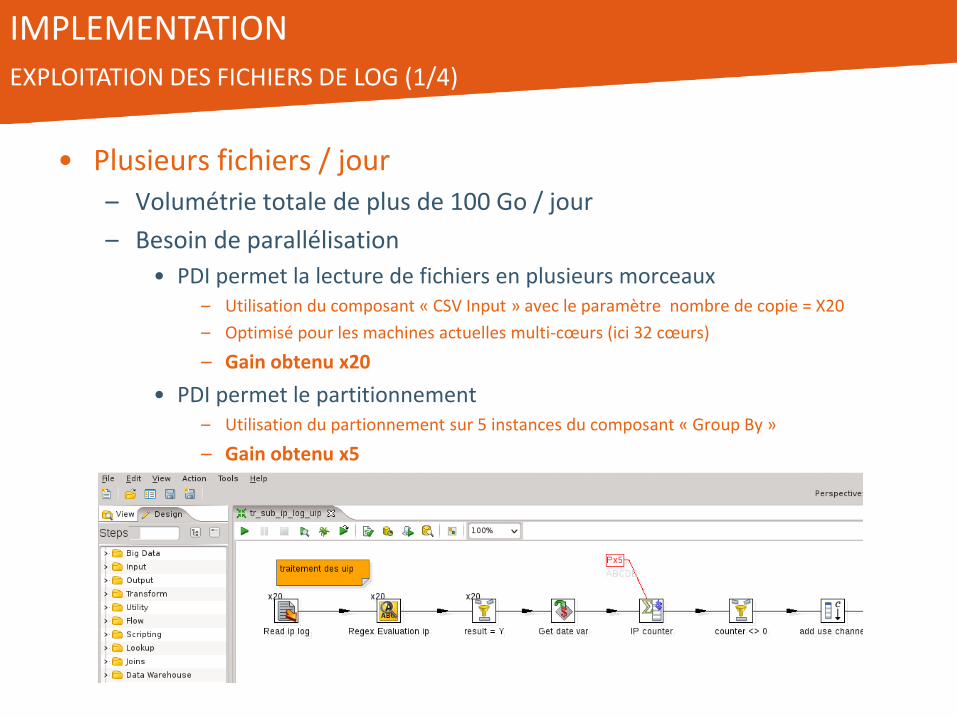
• Plusieurs fichiers / jour – Volumétrie totale de plus de 100 Go / jour
– Besoin de parallélisation
• PDI permet la lecture de fichiers en plusieurs morceaux – Utilisation du composant « CSV Input » avec le paramètre nombre de copie = X20
– Optimisé pour les machines actuelles multi-cœurs (ici 32 cœurs)
– Gain obtenu x20
• PDI permet le partitionnement – Utilisation du partionnement sur 5 instances du composant « Group By »
– Gain obtenu x5
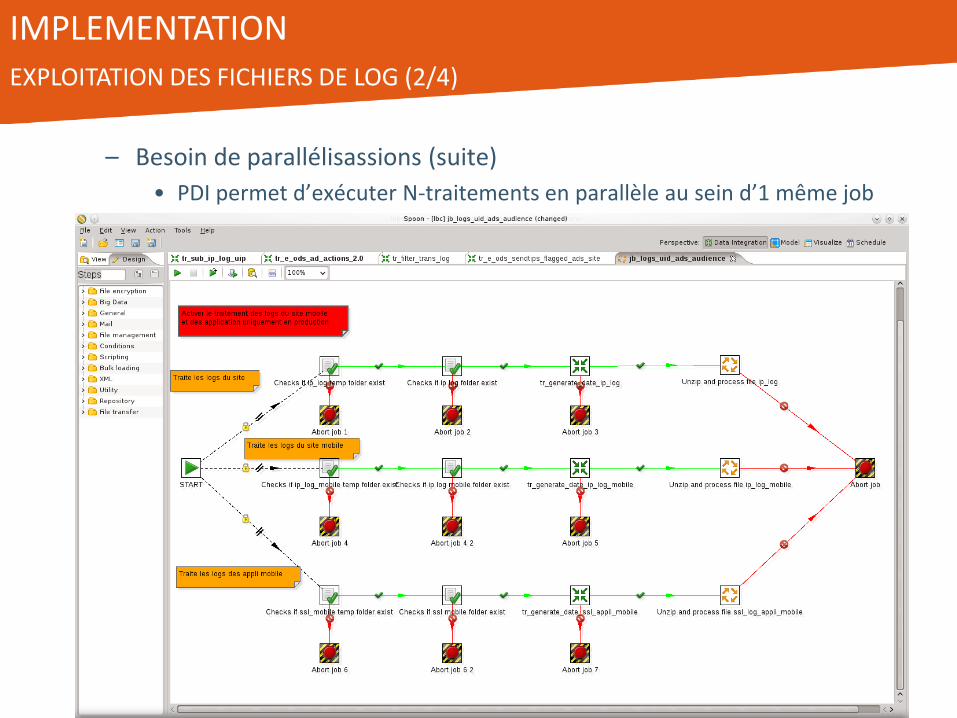
IMPLEMENTATION EXPLOITATION DES FICHIERS DE LOG (2/4)
– Besoin de parallélisassions (suite)
• PDI permet d’exécuter N-traitements en parallèle au sein d’1 même job

IMPLEMENTATION EXPLOITATION DES FICHIERS DE LOG (3/4)
• Fichiers complexes – Besoin : exploiter le logs des serveur de transaction
• Structure – Transaction sur plusieurs lignes
– Transaction avec statuts différents
– Transactions se chevauchent (Il est impératif de trier les transactions avec traitement)
• Très forte volumétrie – Pré-traitement (tri du fichier et filtre sur les transactions valides)
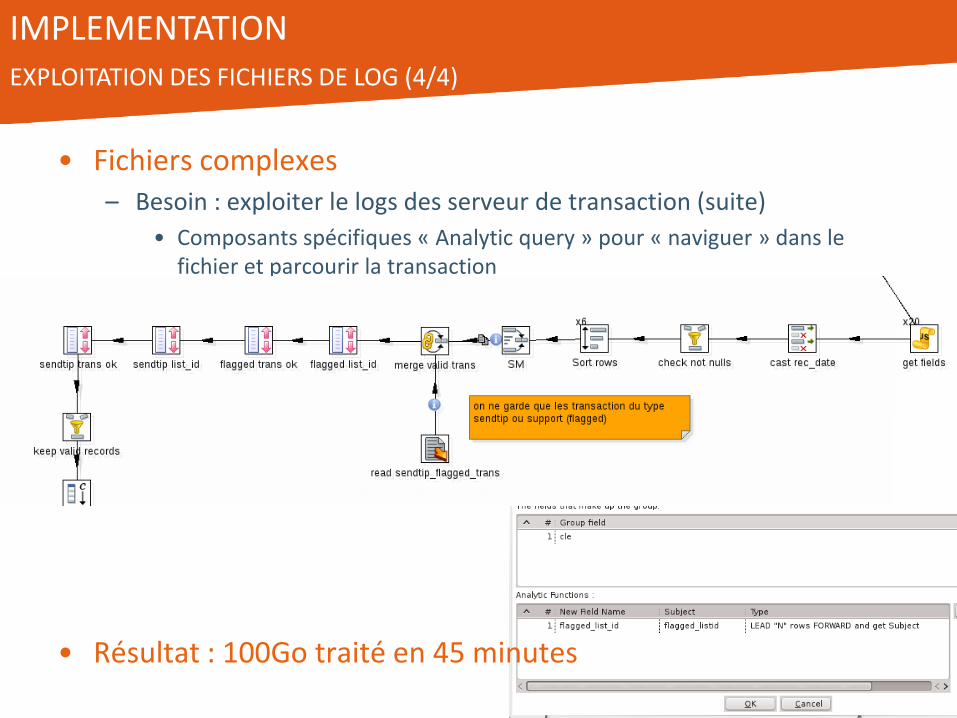
IMPLEMENTATION EXPLOITATION DES FICHIERS DE LOG (4/4)
• Fichiers complexes – Besoin : exploiter le logs des serveur de transaction (suite)
• Composants spécifiques « Analytic query » pour « naviguer » dans le fichier et parcourir la transaction
• Résultat : 100Go traité en 45 minutes
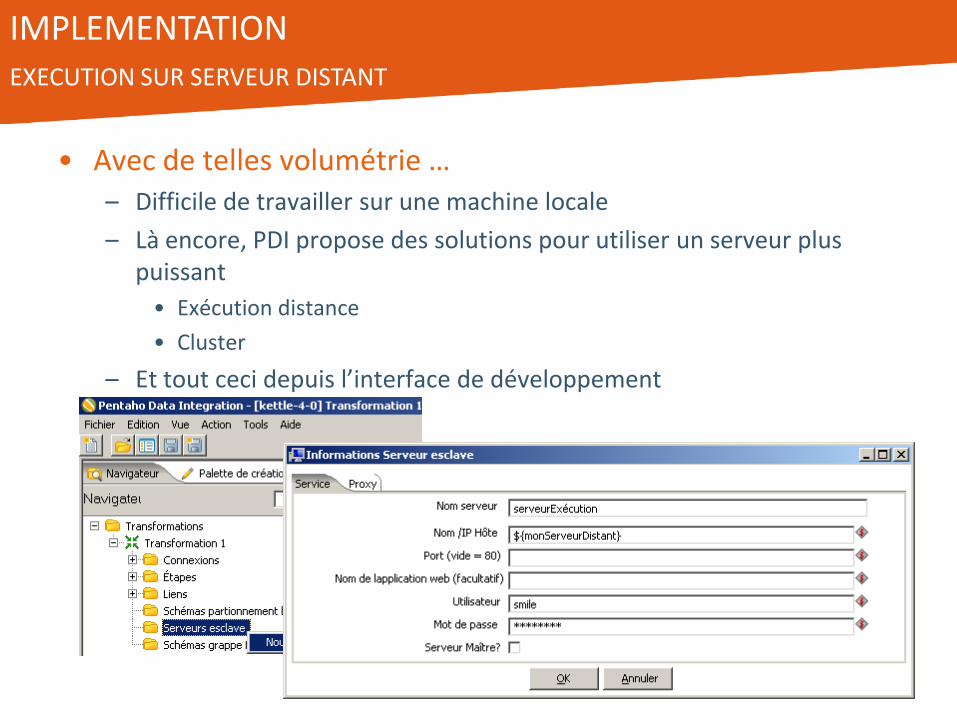
IMPLEMENTATION EXECUTION SUR SERVEUR DISTANT
• Avec de telles volumétrie … – Difficile de travailler sur une machine locale
– Là encore, PDI propose des solutions pour utiliser un serveur plus puissant
• Exécution distance
• Cluster
– Et tout ceci depuis l’interface de développement
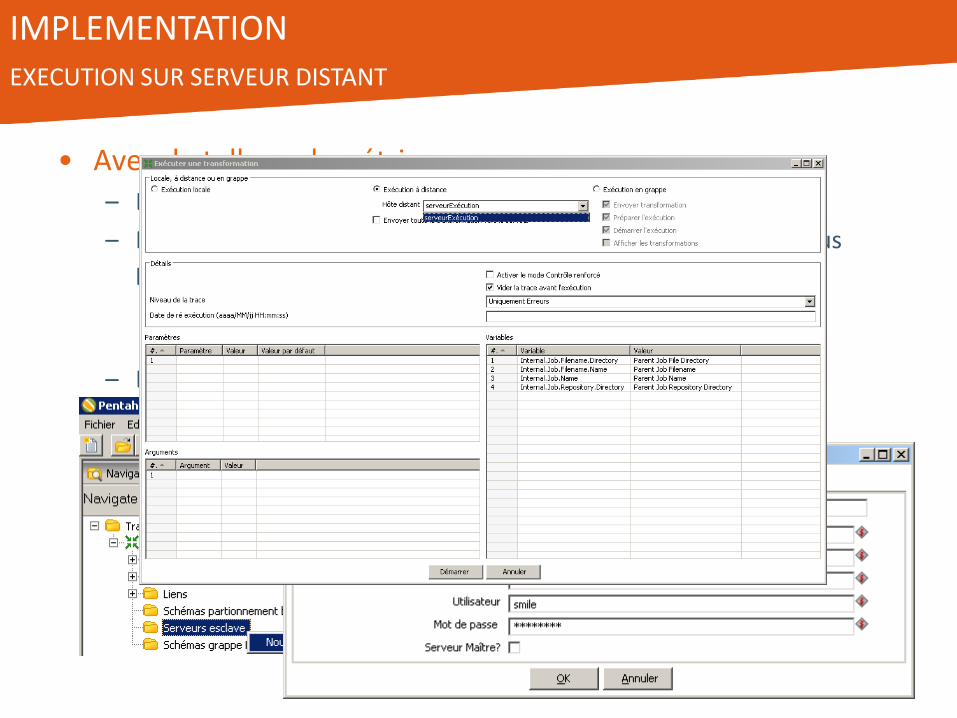
IMPLEMENTATION EXECUTION SUR SERVEUR DISTANT
• Avec de telles volumétrie … – Difficile de travailler sur une machine locale
– Là encore, PDI propose des solutions pour utiliser un serveur plus puissant
• Exécution distance
• Cluster
– Et tout ceci depuis l’interface de développement

BILAN PDI – PUISSANT ET FLEXIBLE
• Travail collaboratif – Projet de 6 mois
– Jusqu’à 5 développeurs en //
– Prise en main facile
• Outil très adapté au traitement de fortes volumétries – Composants simples pour paralléliser les traitements
– G ain de temps non-négligeables vs jointures SQL
• Très flexible – Exploitation efficace de fichiers complexes
– Evolution vers l’utilisation de technologies Big Data type Hadoop ou NoSQL

Pour aller plus loin : www.smile.fr
Merci de votre attention
@GroupeSmile_BI on Twitter