Embed Size (px)
Citation preview

1
BATTAGLIA GIAMPAOLO
DATA MINING
Projet sous Sodas
Etude d’une Clinique Vétérinaire Base : Clinique.mdb
Enseignant : E. DIDAY

2
SOMMAIRE
Introduction 3 I- Etat de l’art du Data Mining et Description du Logiciel SODAS 4
a) Objectifs généraux du DATAMINING 4 b) Présentation du logiciel SODAS 5
c) Schéma illustratif des étapes du logiciel SODAS 6
II- Description de la Base de données choisie 7
a) Présentation des tables 8
b) Schéma relationnel 8
c) Description des relations 8
III- Justifications de l’étude, description des individus et concepts 9
a) Justification de l’étude 9
b) Description des individus et des concepts 9
c) Les Variables Descriptives 9
IV- Description des requêtes réalisées 11 a) Requêtes initiales pour l’extraction DB2SO 12
b) Requêtes relatives à l’exécution de la méthode TREE de Sodas 12
V - Evolution du Programme 13
a) Importation de base de données 14
b) Modification des concepts : le Menu AddSingle 15
VI - La méthode SOE 16
a) Introduction à la méthode 16
b) Description de concepts illustratifs 17
c) Description des autres concepts 19
VII- Analyse en composantes Principales 20 a) Introduction à la méthode PCM 20
b) Description des résultats de l’application 20
VIII- La méthode STAT 24 a) Introduction à la méthode STAT 24
b) Description des résultats de l’application 24
IX- La méthode PYR 31 a) Introduction à la méthode PYR 31
b) Description des résultats de l’application 31
X- La méthode TREE 34 a) Introduction à la méthode TREE 34
b) Description des résultats de l’application 34
XI- La méthode DIV 37 a) Introduction à la méthode DIV 37
b) Description des résultats de l’application 37
XII – La méthode SCLUST (avec Sodas 2.0) 39 a) Description de la méthode 39
b) Description des résultats de l’application 39 XIII – Conclusions et Perspectives 41
Annexes 42

3
Introduction
Depuis plusieurs décennies, le développement considérable des moyens informatiques de
stockage et de calcul a permis de traiter et analyser une quantité de données particulièrement
importante.
En outre, dans un contexte étroitement lié à la gestion et l’optimisation de bases de données,
la constante amélioration des outils statistiques - autant du point de vue de leur efficacité en
terme de vitesse et de précision, que de leur interface utilisateur - , a permis d’intégrer au
mieux l’ensemble de méthodes algorithmiques au sein de logiciels performants.
C’est au sein de ce contexte de « fouilles de données » que le Data Mining a vu le jour. Cette
approche qui provenait initialement de l’analyse Marketing spécialisée dans la gestion des
relations auprès de la clientèle, se manifeste également au sein d’applications industrielles en
contrôle de qualité ou même dans certaines disciplines scientifiques à partir du moment où les
ingénieurs et chercheurs se retrouvent face à un volume de données particulièrement
important.
En effet, le traitement de toutes ces informations par l’intermédiaire d’une série d’outils
statistiques - comme la régression linéaire et logistique, de l’analyse multi-variée, de l’analyse
des composantes principales, des arbres décisionnels etc.. – permet de dresser des « profils-
type » particulièrement utiles au sein de toute Direction Décisionnelle.
Le développement de programmes étroitement liés à l’analyse de données symboliques,
témoigne de l’intérêt grandissant pour cette discipline.
Le logiciel SODAS en est l’exemple type : particulièrement performant, ce logiciel permet
d’extraire des informations issues d’une base de données relationnelle de type ACCES et
surtout de générer une série de traitements statistiques très poussés.
Le projet, qui prend comme support la gestion d’une clinique vétérinaire, va dévoiler l’état
actuel du Data Mining, puis va décrire le Logiciel SODAS, en s’attardant sur un éventail de
méthodes d’analyse statistique qu’il présente, appliqué aux données sur les animaux soignés.

4
I- Etat de l’art du Data Mining et Description du Logiciel SODAS
a) Objectifs généraux du DATAMINING
Les progrès de la technologie informatique au sein du recueil et du transport des informations
ont permis à toutes les dimensions de l’activité humaine de transmettre des données selon le
type d’expression privilégié (numérique, textuelle, graphique etc…). En outre, cette masse de
codes informatique peut sans problème, être stockée en quantité très importante.
Alors que les anciennes machines traitaient les informations codées en suivant un langage
tellement complexe qu’une poignée d’individus seulement pouvaient les comprendre, les
systèmes d’aujourd’hui sont criant de simplicité d’accès et d’utilisation pour celui qui prend la
peine de s’y intéresser.
Résumer ces données à l’aide de concepts sous-jacents (une ville, un type de chômeur, un
produit industriel, une catégorie de panne …), afin de mieux les appréhender et d’en extraire
de nouvelles connaissances constitue une question cruciale. Ces concepts sont décrits par des
données plus complexes que celles habituellement rencontrées en statistique. Ces données
sont dites « symboliques », car elles expriment la variation interne inéluctable des concepts et
sont structurées.
Dans ce contexte, l’extension des méthodes de l’Analyse des Données Exploratoires et plus
généralement, de la statistique multidimensionnelle à de telles données, pour en extraire des
connaissances d’interprétation aisée, devient d’une importance grandissante.
Le marché que génère le Data Mining est majoritairement développé autour de solutions pour
les entreprises, qui ne cessent de chercher des outils de plus en plus performants afin de leur
permettre de gagner des parts de marché.
On peut considérer, dans un premier temps, les TPE et PME, qui peuvent se baser sur
l’emploi d’outils en pleine expansion, comme AliceVersion TS (Isoft) ou Scenario (Cognos)
qui permettent d’extraire des arbres de décision.
Des entreprises à plus grand moyens peuvent s’offrir le luxe de progiciels plus développés,
comme Clémentine version 8.0 (SPSS) et SPAD version 5.6 (DECISIA), outils offrant une
gamme d’applications plus larges (AFC, ACP par exemple).
En dernier lieu, de grands comptes comme IBM et SAS proposent des produits
(respectivement Intelligent Miner & SAS Entreprise Miner)

5
b) Présentation du logiciel SODAS (Symbolic Official Data Analysis System) Le logiciel SODAS a été réalisé par le groupe EUROSTAT afin de proposer un ensemble
d’outils statistiques faciles d’usage, et pourvu d’une grande flexibilité.
A partir d’une base de données relationnelle, le logiciel SODAS élabore un répertoire de
données symboliques, pouvant comporter un ensemble de règles de taxonomies.
L’objectif du programme réside dans l’identification et la description de concepts relatifs à la
masse, particulièrement importante, de données entrantes, afin d’y extraire des connaissances
utiles et pertinentes.
Afin de réaliser une analyse de données, le logiciel SODAS nécessite une base de données
relationnelle de type ACCESS.
Par la suite, l’utilisateur doit définir :
- les unités statistiques dites, de premier niveau – les individus pouvant être des animaux,
habitants, articles de magasin …
- les variables qui sont amenées à les décrire,
- finalement, les concepts qui en découlent (races ou types d’animaux, agrégat de personnes,
pouvant former des catégories socio-professionnelles, rayon de magasin etc…)
Il est important de noter la très forte connexion entre les individus d’un côté, et les concepts
qui les lie. Ce contexte est défini par une requête sur la base de données relationnelle.
Après avoir défini toutes ces catégories, il est alors possible de concevoir un tableau de
données symboliques, de façon à prendre en compte chaque concept, lui même défini par des
variables dont les valeurs peuvent prendre la forme d’histogrammes, intervalles, ou même des
valeurs uniques.
Par la suite, on peut alors créer un fichier d’objets symboliques sur lequel une pléthore de
méthodes d’analyse de données symboliques peuvent s’appliquer (analyse factorielle,
classification hiérarchique, histogrammes des variables symboliques, classification
automatique, analyse discriminante, visualisation d’objet symbolique sous forme d’étoiles en
3 dimensions…).
Il est important de noter qu’une nouvelle version du logiciel SODAS (version 2.0 qui
remplace la version 1.2) a vu le jour : en plus d’une plus grande convivialité – que ce soit au
niveau des requêtes d’importations jusqu’au niveau de l’ergonomie- les méthodes de
traitement des données symboliques on vu leur nombre augmenter, notamment au niveau des
classification automatiques comme la méthode SCLUST (décrite dans le projet).
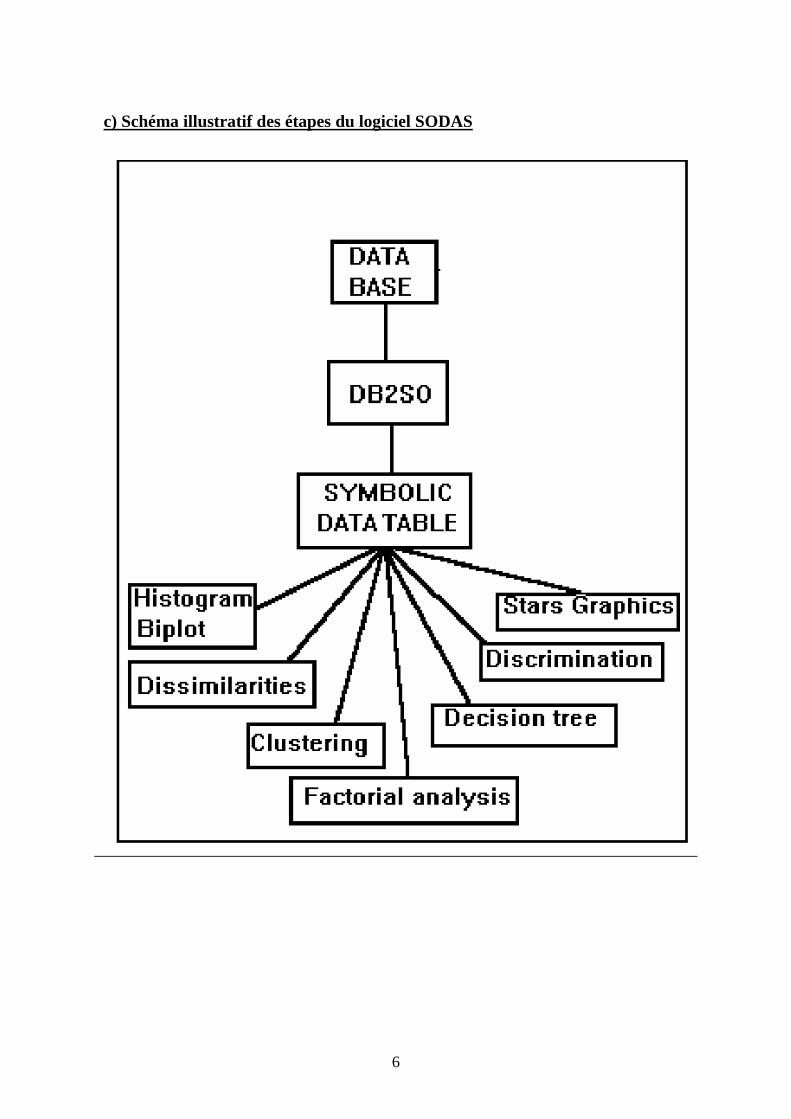
6
c) Schéma illustratif des étapes du logiciel SODAS

7
II- Description de la Base de données choisie
Mon projet de Data Mining se base sur les données issues de la gestion d’une clinique
vétérinaire qui devrait se trouver entre le Languedoc Roussillon et le Midi-Pyrénées.
L’ensemble des données est présenté sous forme d’un fichier .mdb MS Access (provenant de
l’adresse web : http://www.ceremade.dauphine.fr/%7Etouati/cliniquevet.htm) dans lequel
figurent un ensemble de tables qui retracent l’activité de la clinique (des clients se présentent
avec leurs animaux qui peuvent suivre une visite médicale avec peut être des traitements).
a) Présentation des tables
Dans un premier temps, la présence de la base de données seule- sans un rapport explicatif-
m’amène à décrire un peu plus en profondeur les tables qui vont entrer en jeu dans l’analyse
de données.
La table Animal représente toutes les données concernant l’animal enregistré: un numéro
d’identification (unique par animal, qui est la clé primaire de la table), un numéro client du
propriétaire de l’animal (on note que le numéro client forme les trois premiers chiffres du
numéro ID de l’animal), le nom de l’animal, le type auquel l’animal appartient, la race (plus
précise que le type, qui est générique), la date de naissance, le sexe, la couleur, le statut de
stérilisation (booléen), la taille, le poids, la date de la dernière visite, le statut de
vaccination (booléen), le statut de décès (booléen), une photo potentielle (lien OLE), et un
champ de commentaires.
La table Client représente les informations des maîtres ou dresseurs des animaux. On peut
remarquer que tout client possède au moins un animal. Les différents champs présents portent
sur le numéro d’identifiant du client –qui est la clé primaire de la table-, le type de client-
sous la forme d’un chiffre codifiant le statut de personne privée, d’établissement public ou
commercial-, le nom du client ou de son enseigne, la rue, la localité, le département
(numérique), le code postal, le numéro de téléphone, la date depuis sa première visite, la
date de la dernière visite, la remise sur ce qu’il paie, et la balance des paiements.
La table Département indique les données de la région d’origine du client. Les champs
présents sont : le numéro du département – qui représente la clé primaire de la table-, le
nom du département, et le taux de taxation relatif à celui-ci (on peut être amené à payer
plus en fonction de son appartenance à telle ou telle zone de France).
La table Visite représente les informations relatives aux visites qui ont pu être effectuées sur
les animaux. Elle contient les champs numéro de visite – qui est la clé primaire de la table-
qui est attribué à chaque fois qu’une visite est réalisée ; le numéro ID de l’animal, la date de
la visite, le type de suivi (si l’animal a dû effectuer des examens supplémentaires etc..), le
montant total de la visite, celui qui est déjà payé, le statut de taxation (booléen) , la taxe
relative au département du client et le statut d’envoi de la facture chez le client (booléen)
La table Détail Visite donne toutes les informations relatives à chacune des visites qui est
enregistrée. Elle comporte le numéro de la visite et le numéro de ligne de la facture (les
deux champs sont clés primaires), le type de visite (la raison pour laquelle la visite a lieu), le
code numérique du traitement préconisé, le code du médicament prescrit ainsi que les prix
de ceux-ci.

8
Les détails des Traitements et Médicaments sont dans deux tables respectives dans
lesquelles figurent leur cote numérique, de leurs noms complets et des prix fixés.
Dans cet ensemble figure également la table Liste Animaux dans laquelle sont répertoriés
tous les types d’animaux présents (clé primaire).
b) Schéma relationnel Les relations entre les différentes tables sont présentées à travers le Schéma Conceptuel de
Données :
c) Description des relations On note qu’un animal possède un et un seul maître alors que celui-ci peut détenir plusieurs
animaux.
Le client habite dans un seul département, zone qui peut abriter plusieurs clients.
Une visite est réalisée pour un seul animal à chaque fois;l’animal, quant à lui, peut effectuer
plusieurs visites.
Chaque visite peut être précisée par plusieurs détails, alors qu’un détail de visite ne fait
référence qu’à une seule visite.
En outre, notons que chaque détail de visite ne fait référence au maximum qu’à un seul
médicament et traitement ; cependant, un même traitement ou médicament peut faire
référence à plusieurs détails de visite.
9
III- Justifications de l’étude, description des individus et concepts
a) Justification de l’étude Face aux différentes données présentes au sein de cette base, il est intéressant de pouvoir faire
émerger des tendances et des axes d’analyse. On pourrait ainsi orienter une stratégie de
gestion de la clinique .
On recoupant certaines informations qui, à première vue, peuvent sembler sans rapport, nous
pourrions établir des « profils » intéressants d’animaux et de clients.
Par exemple, peut-on mettre en corrélation des facteurs comme l’âge, la taille ou le poids et le
caractère de la visite dans la clinique ? Y a t’il plus d’animaux d’une certaine espèce chez une
catégorie bien précise de clients ? La localité joue t’elle sur une infection ? Y a t’il certaines
espèces d’animaux prédisposées à des soins onéreux ?
Pour tenter d’approcher toutes ces caractéristiques, nous allons identifier les variables qui
vont intervenir dans l’étude.
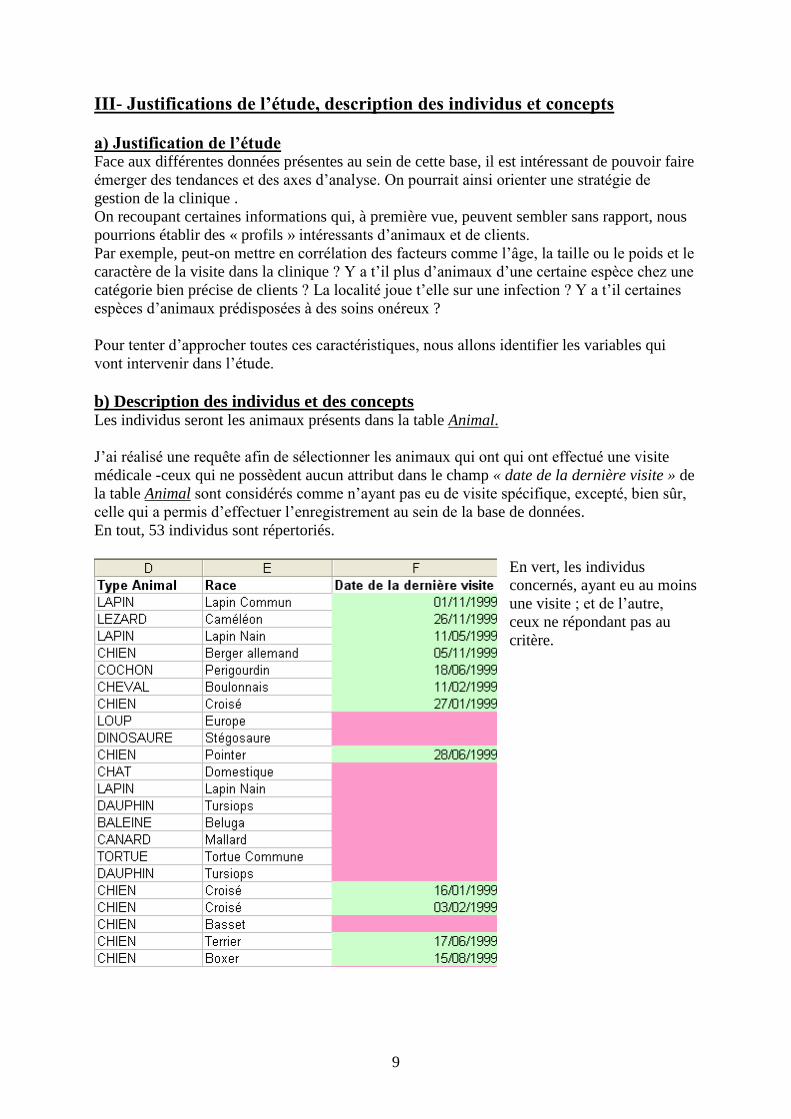
b) Description des individus et des concepts Les individus seront les animaux présents dans la table Animal.
J’ai réalisé une requête afin de sélectionner les animaux qui ont qui ont effectué une visite
médicale -ceux qui ne possèdent aucun attribut dans le champ « date de la dernière visite » de
la table Animal sont considérés comme n’ayant pas eu de visite spécifique, excepté, bien sûr,
celle qui a permis d’effectuer l’enregistrement au sein de la base de données.
En tout, 53 individus sont répertoriés.
En vert, les individus
concernés, ayant eu au moins
une visite ; et de l’autre,
ceux ne répondant pas au
critère.

10
Les concepts sont les types d’animaux ayant réalisé au moins une visite. Notons que le champ
Type permet de catégoriser tout animal, sans pour autant aller dans le détail – à l’instar de
Race qui multiplie les catégories, un même type correspondant à plusieurs races différentes-.
Nous obtenons alors 11 concepts.
c) Les Variables Descriptives Les variables qui ont été choisies pour l’étude ont été déterminées par la nécessité d’analyser
le profil des animaux en fonction de leurs caractéristiques de base (taille, poids..) mais aussi
en fonction de leur maîtres, de l’endroit où ils vivent, et de ce qu’ils coûtent en terme de soins.
Les Variables quantitatives choisies sont donc :
- La Taille de l’animal
- Le Poids de l’animal
- L’âge de l’animal, obtenu à partir de la donnée relative à sa date de naissance
- Le Montant Total de Soins qu’il entraîne
Les Variables nominales sont :
- Le Nom de l’animal
- La Race de l’animal
- Le Nom du Client
- La Catégorie du Client (bien que les données soient numériques elles ne sont
qu’arbitraires, on aurait pu tout aussi bien mettre des chaînes de caractères)
- Le Département du Client
Notons que lors du Traitement par Sodas, la Catégorie du Client est interprétée comme une
variable quantitative, due à la présence des Catégories 1 pour Personne Privée, 2 pour
Etablissement Commercial, et 3 pour Etablissement Public.
J’ai donc été amené à changer ce champs de manière à ce qu’il soit sous forme de texte.

11
IV- Description des requêtes réalisées
a) Requêtes initiales pour l’extraction DB2SO
Les requêtes réalisées permettent d’extraire les informations relatives aux animaux ayant eu
au moins une visite.
La première requête, appelée Jointure de base, établit une jointure entre les tables Visite,
Animal, Client et Département, en affichant certains champs de chacune d’elles :
SELECT [Animal].[ID ANIMAL], [Animal].[Nom Animal], [Animal].[Type Animal], [Animal].[Race],
ROUND((Date()-[Animal].[Date de Naissance])/365, 2) AS Age, [Animal].[Sexe], [Animal].[Taille],
[Animal].[Poids], [Animal].[Décédé], [Visite].[Montant Total], [Visite].[Taux de Taxation], [Client].[Nom
Client], [Client].[Type de Client], [Client].[Localité], [Département].[Département]
FROM Animal, Visite, Client, Département
WHERE [Visite].[ID Animal]=[Animal].[ID Animal] And [Animal].[Numéro Client]=[Client].[Numéro Client]
And [Client].[Département]=[Département].[Code Département];
L’exécution de cette requête nous a permis de constater deux « complications »:
- les données qui résultent possèdent des champs doublons pour les individus ; en effet,
chaque visite du même animal apparaît sur deux lignes différentes. Cet affichage
risque de nous poser problème dans le sens qu’il serait préférable de posséder des
individus dédoublonnés. Pour palier ce défaut, nous avons incorporé dans la requête
suivante un regroupement pour chaque individu de façon a obtenir des informations
sur le montant total à payer pour chaque animal – et non plus une succession de
montants intermédiaires.
- Alors que 53 individus étaient répertoriés précédemment, la jointure ne nous en donne
que 43 : une recherche plus approfondie nous a indiqué que les 10 animaux
n’apparaissant pas ont subi une visite mais n’ont généré aucun coût (et ne sont donc
pas présents dans la table Visite). On peut supposer que les maîtres avaient souscrit à
une mutuelle tous risques et ne payaient donc rien. Cependant, ces animaux possèdent
des profils qui doivent être pris en compte. J’ai donc rajouté manuellement dans la
table Visite ces 10 animaux manquants, en leur affectant un montant à payer de 0
Euros.
Par la suite, j’ai donc réalisé la requête REQUETE EXTRACTION afin d’obtenir les
informations non doubles, par l’utilisation du GROUP BY : SELECT [JOINTURE DE BASE].[ID Animal], [JOINTURE DE BASE].[Type Animal], [JOINTURE DE
BASE].[Nom Animal], [JOINTURE DE BASE].[Race], [JOINTURE DE BASE].[Age], [JOINTURE DE
BASE].[Taille], [JOINTURE DE BASE].[Poids], [JOINTURE DE BASE].[Nom Client], [JOINTURE DE
BASE].[Type de Client], [JOINTURE DE BASE].[Département], Sum([JOINTURE DE BASE].[Montant Total])
AS [MONTANT TOTAL]
FROM [JOINTURE DE BASE]
GROUP BY [JOINTURE DE BASE].[ID Animal], [JOINTURE DE BASE].[Type Animal], [JOINTURE DE
BASE].[Nom Animal], [JOINTURE DE BASE].[Race], [JOINTURE DE BASE].[Age], [JOINTURE DE
BASE].[Taille], [JOINTURE DE BASE].[Poids], [JOINTURE DE BASE].[Nom Client], [JOINTURE DE
BASE].[Type de Client], [JOINTURE DE BASE].[Département];

12
b) Requêtes relatives à l’execution de la méthode TREE de Sodas Afin de réaliser la méthode TREE, il a également été nécessaire de préparer une suite de
requêtes permettant de donner la liste des concepts, suivis de leurs variables descriptives.
Afin d’obtenir des données cohérentes, un attribut supplémentaire à la table Animal a été crée.
Unité permet de donner une caractérisation de chaque type d’animal d’un point de vue global.
Ainsi, l’ensemble du règne animal sera partagé entre les mammifères, les poissons, les
reptiles, les batraciens et les volatiles.
Cependant, pour obtenir des résultats un peu plus pertinents, la catégorie mammifère a été
affinée en la subdivisant entre:
- ceux étant typiques de l’élevage Fermier comme le Lapin, le Cochon, le Cheval,
l’Agneau, la Chèvre etc..
- ceux « domestiqués » comme animaux de compagnie comme le Chien, le Chat…
- les Rongeurs moyennement domesticables , comme l’Ecureuil la Gerboise, le Rat (on
peut remarquer que le Lapin fait partie des Rongeurs, mais on admettra son
appartenance à l’Elevage comme prédominante sur le reste)…
- les sauvages ou peu domestiqués, comme le loup, l’ours, la baleine, le singe etc..
Les autres catégories d’animaux n’ont pas besoin d’être affinées.
J’ai alors crée la requête JOINTURE DE BASE TREE qui reprend les commandes précédentes
avec la simple adjonction de la table Animal.Unite.
Ensuite, j’ai conçu la requête REQUETE ADDSINGLE afin d’obtenir la liste des concepts et
les variables du champs Unité : SELECT [JOINTURE DE BASE TREE].[Type Animal], [JOINTURE DE BASE TREE].[Unite]
FROM [JOINTURE DE BASE TREE]
GROUP BY [JOINTURE DE BASE TREE].[Type Animal], [JOINTURE DE BASE TREE].[Unite];
13
V - Evolution du Programme
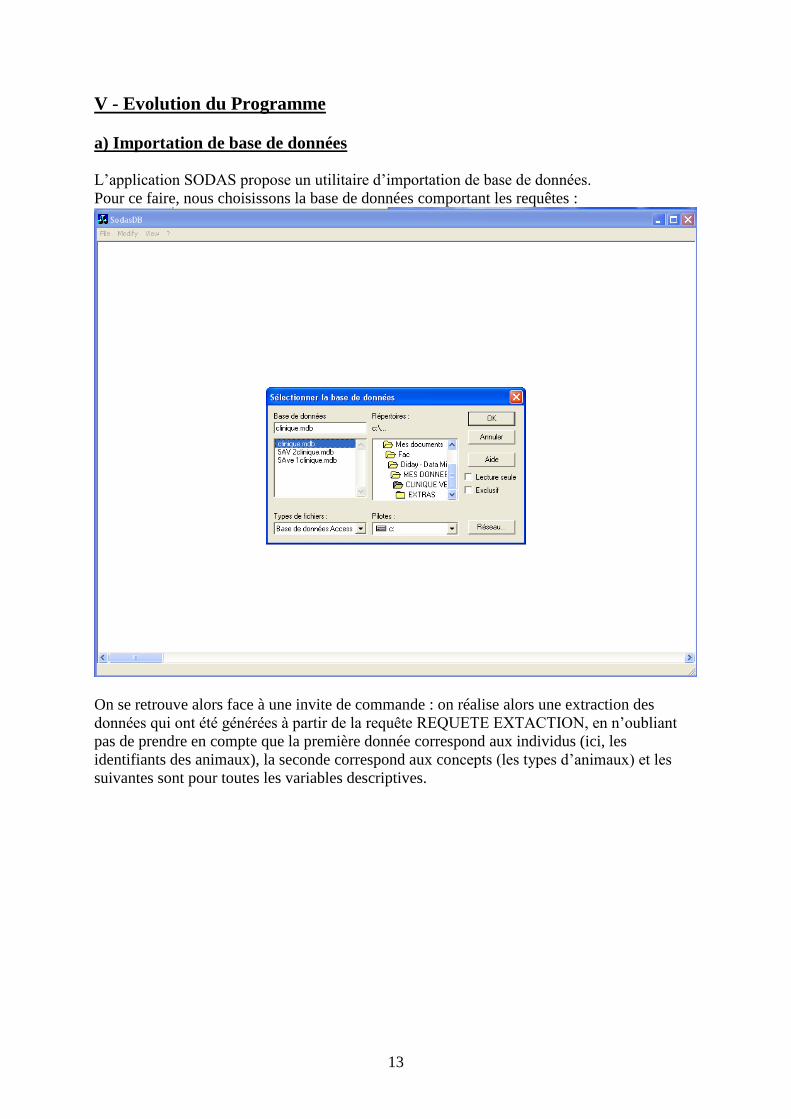
a) Importation de base de données
L’application SODAS propose un utilitaire d’importation de base de données.
Pour ce faire, nous choisissons la base de données comportant les requêtes :
On se retrouve alors face à une invite de commande : on réalise alors une extraction des
données qui ont été générées à partir de la requête REQUETE EXTACTION, en n’oubliant
pas de prendre en compte que la première donnée correspond aux individus (ici, les
identifiants des animaux), la seconde correspond aux concepts (les types d’animaux) et les
suivantes sont pour toutes les variables descriptives.
14
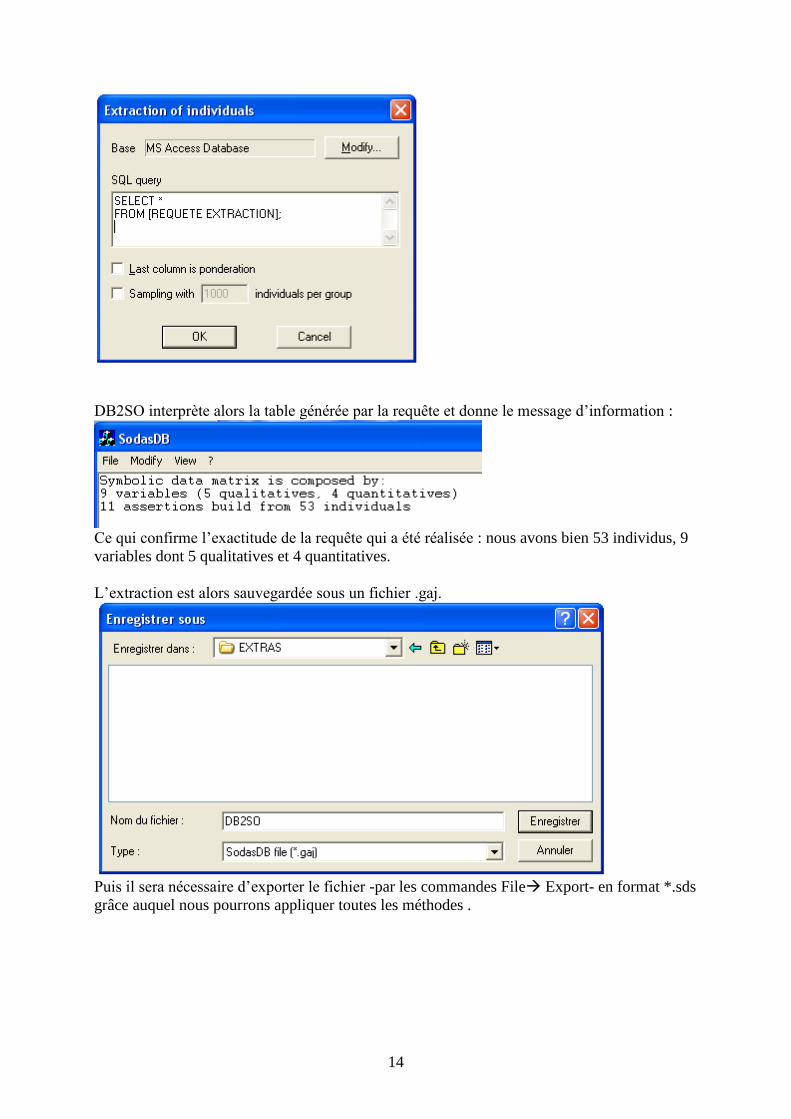
DB2SO interprète alors la table générée par la requête et donne le message d’information :
Ce qui confirme l’exactitude de la requête qui a été réalisée : nous avons bien 53 individus, 9
variables dont 5 qualitatives et 4 quantitatives.
L’extraction est alors sauvegardée sous un fichier .gaj.
Puis il sera nécessaire d’exporter le fichier -par les commandes File Export- en format *.sds
grâce auquel nous pourrons appliquer toutes les méthodes .
15
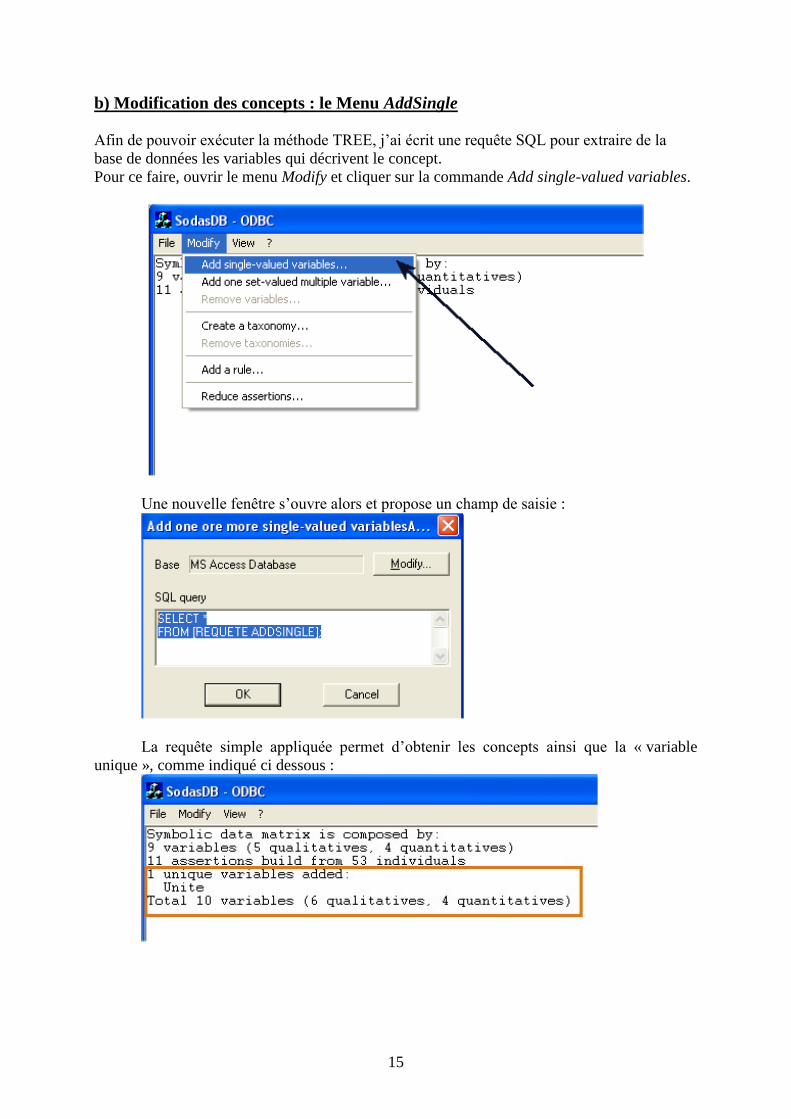
b) Modification des concepts : le Menu AddSingle
Afin de pouvoir exécuter la méthode TREE, j’ai écrit une requête SQL pour extraire de la
base de données les variables qui décrivent le concept.
Pour ce faire, ouvrir le menu Modify et cliquer sur la commande Add single-valued variables.
Une nouvelle fenêtre s’ouvre alors et propose un champ de saisie :
La requête simple appliquée permet d’obtenir les concepts ainsi que la « variable
unique », comme indiqué ci dessous :

16
VI - La méthode SOE
a) Introduction à la méthode La méthode SOE, pour Symbolic Objects Editor, est une application qui permet d’observer les
objets symboliques –les concepts- , à partir d’une interface graphique, notamment par
l’affichage en étoile Zoom 2D ou 3D.
Cette représentation est fort utile dans la mesure où elle permet de visualiser en une fois tout
le « profil » du concept, par rapport à toutes les variables sélectionnées.
En outre, il est possible d’effectuer des modifications sur les variables observées telles que le
changement de libellé, du nom de la variable etc...
Après chargement du fichier .sds, création d’une méthode « vide » puis insertion de la
procédure SOE, et enregistrement, nous pouvons exécuter la méthode et obtenir l’affichage
suivant :
En cliquant sur l’icône graphique, nous obtenons un tableau croisé avec les concepts en ligne
et l’ensemble des variables en colonne.
On peut remarquer que les variables qualitatives sont exprimées en fréquence d’apparition :
ainsi, on notera ainsi que pour le concept CHAT, 38% des propriétaires sont des
établissements commerciaux (des magasins, animaleries etc…) et 63% sont des Personnes
Privées ; il n’y a pas d’établissement public.
17
Bien que l’on puisse réaliser un grand nombre d’analyses grâce à ce tableau, il est
visuellement plus intéressant d’éditer ces données sous forme de graphiques.
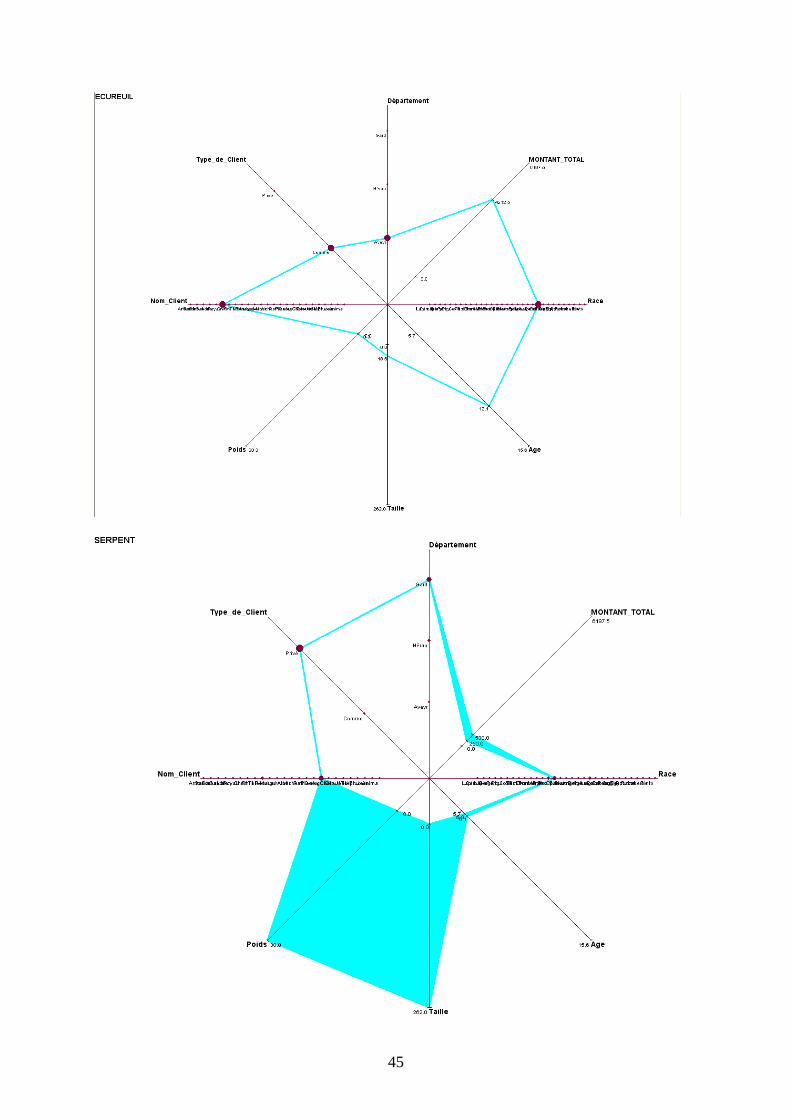
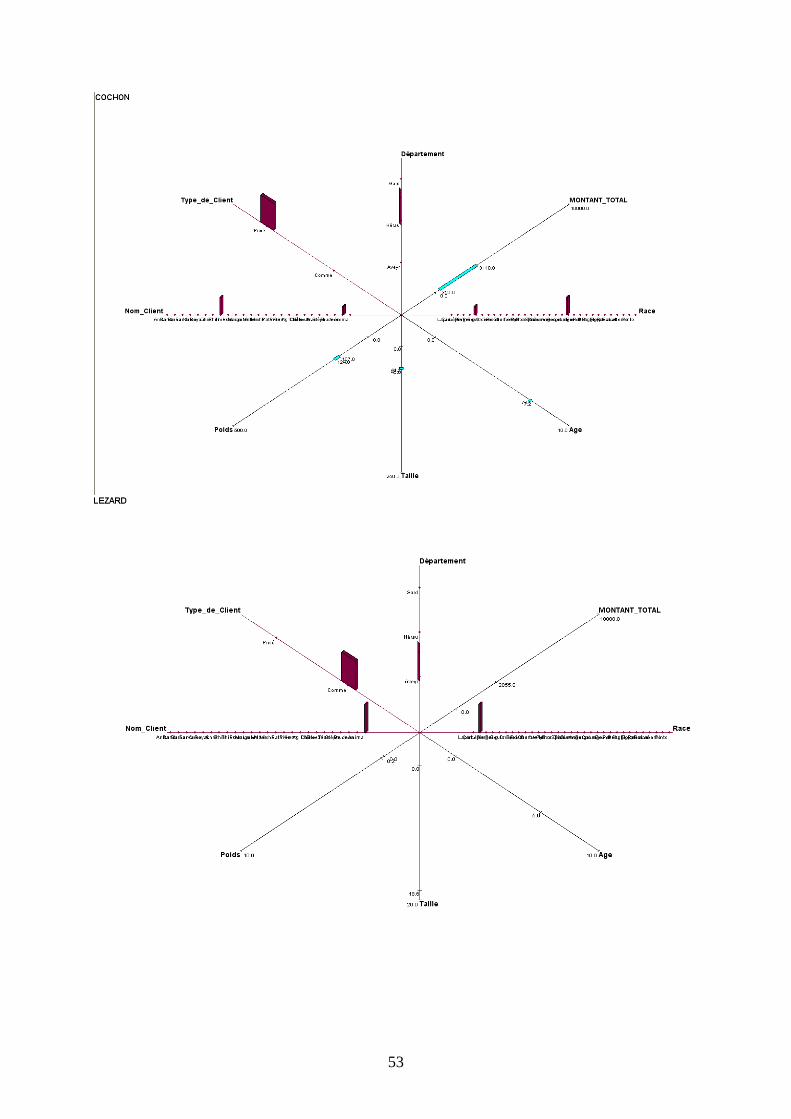
b) Description de concepts illustratifs
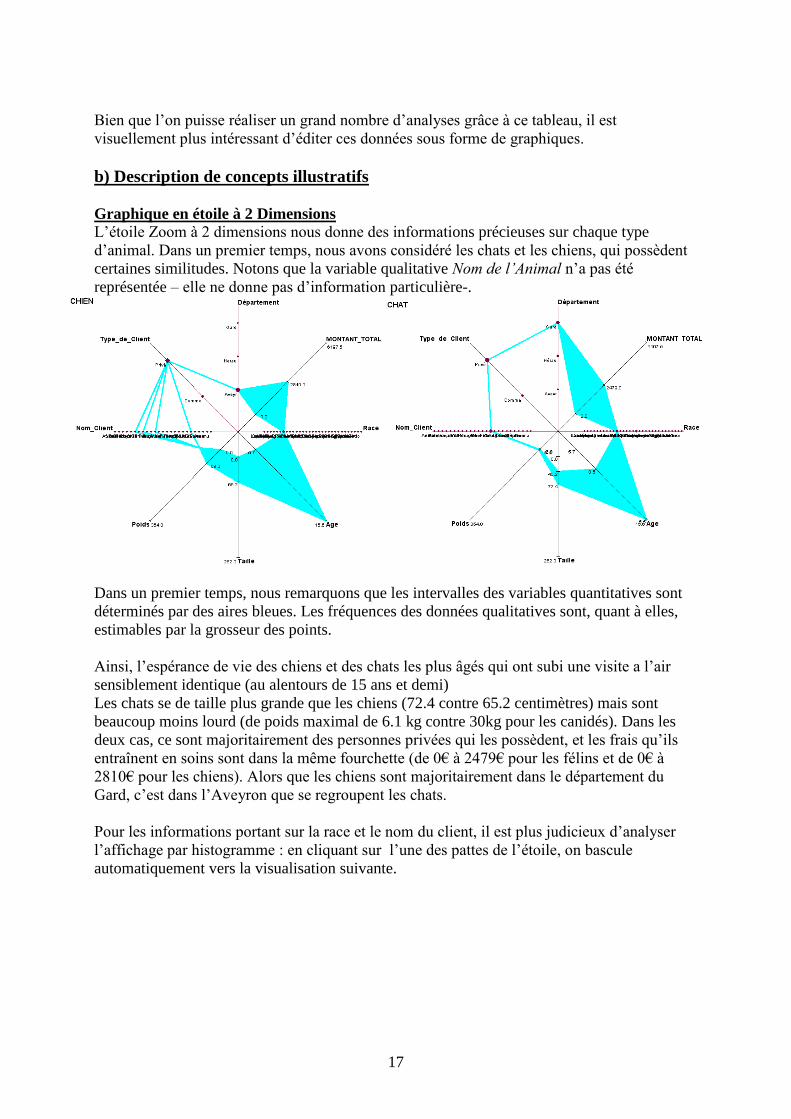
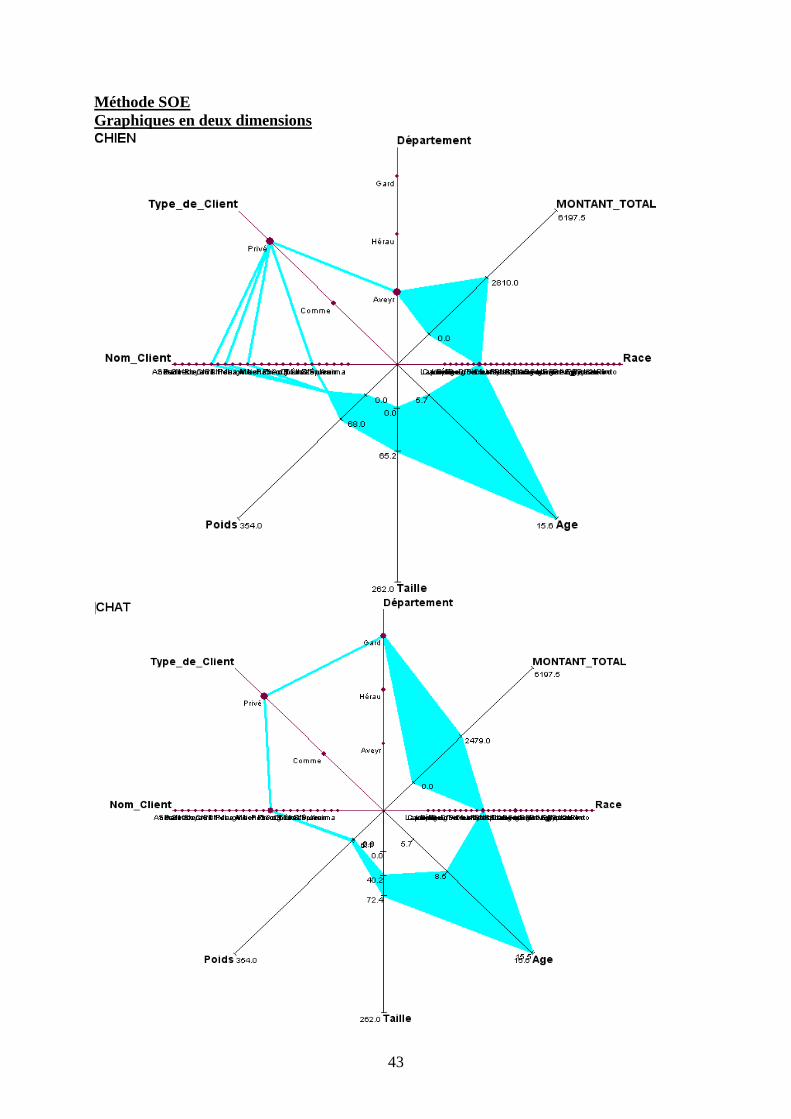
Graphique en étoile à 2 Dimensions
L’étoile Zoom à 2 dimensions nous donne des informations précieuses sur chaque type
d’animal. Dans un premier temps, nous avons considéré les chats et les chiens, qui possèdent
certaines similitudes. Notons que la variable qualitative Nom de l’Animal n’a pas été
représentée – elle ne donne pas d’information particulière-.
Dans un premier temps, nous remarquons que les intervalles des variables quantitatives sont
déterminés par des aires bleues. Les fréquences des données qualitatives sont, quant à elles,
estimables par la grosseur des points.
Ainsi, l’espérance de vie des chiens et des chats les plus âgés qui ont subi une visite a l’air
sensiblement identique (au alentours de 15 ans et demi)
Les chats se de taille plus grande que les chiens (72.4 contre 65.2 centimètres) mais sont
beaucoup moins lourd (de poids maximal de 6.1 kg contre 30kg pour les canidés). Dans les
deux cas, ce sont majoritairement des personnes privées qui les possèdent, et les frais qu’ils
entraînent en soins sont dans la même fourchette (de 0€ à 2479€ pour les félins et de 0€ à
2810€ pour les chiens). Alors que les chiens sont majoritairement dans le département du
Gard, c’est dans l’Aveyron que se regroupent les chats.
Pour les informations portant sur la race et le nom du client, il est plus judicieux d’analyser
l’affichage par histogramme : en cliquant sur l’une des pattes de l’étoile, on bascule
automatiquement vers la visualisation suivante.

18
Pour ce qui est de la distribution des chats et chiens aux clients, on note que presque la moitié
des chats appartiennent à un client « Patri », et l’analyse précédente du type de client nous
amène à penser que Patri est un particulier. Cette analyse est confirmée, puisque le client
Patricia Irribarado est Particulier et possède plusieurs chats. Pour les chiens, la possession
est équilibrée entre les clients.
Pour ce qui est des races, les chiens sont plutôt des croisé ou boxers, alors que les chats sont
plutôt Domestiques, Chartreux ou Siamois.
19
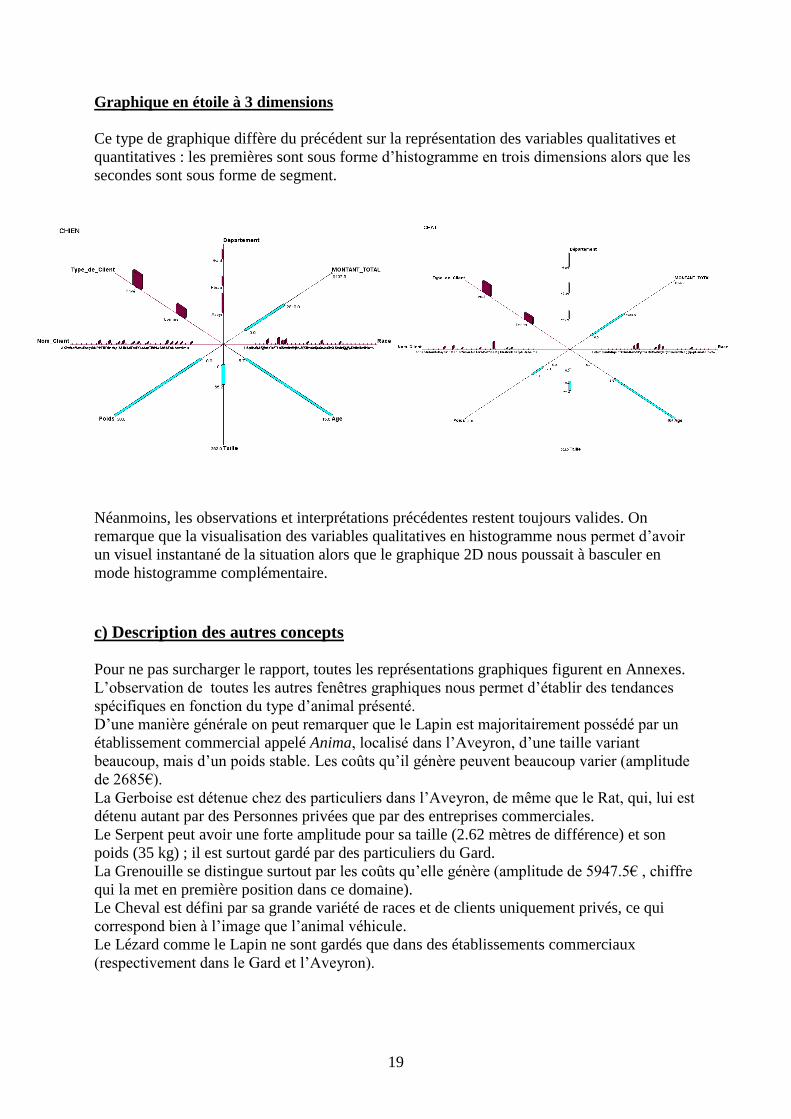
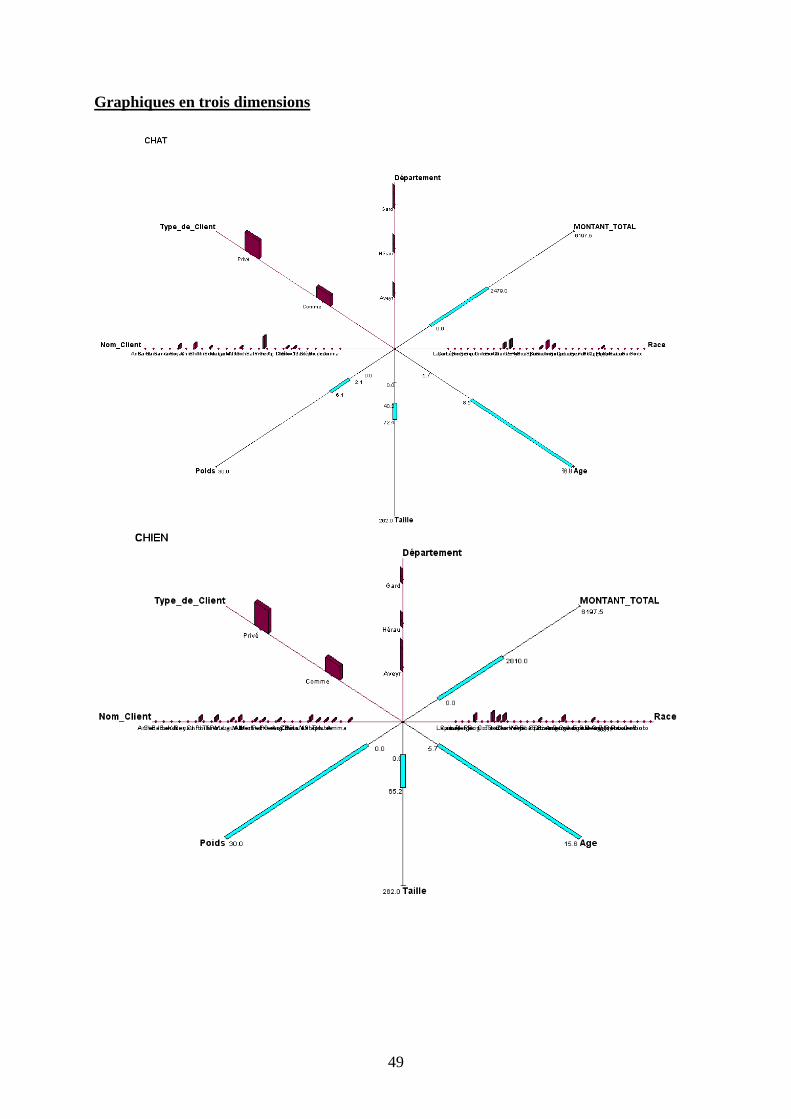
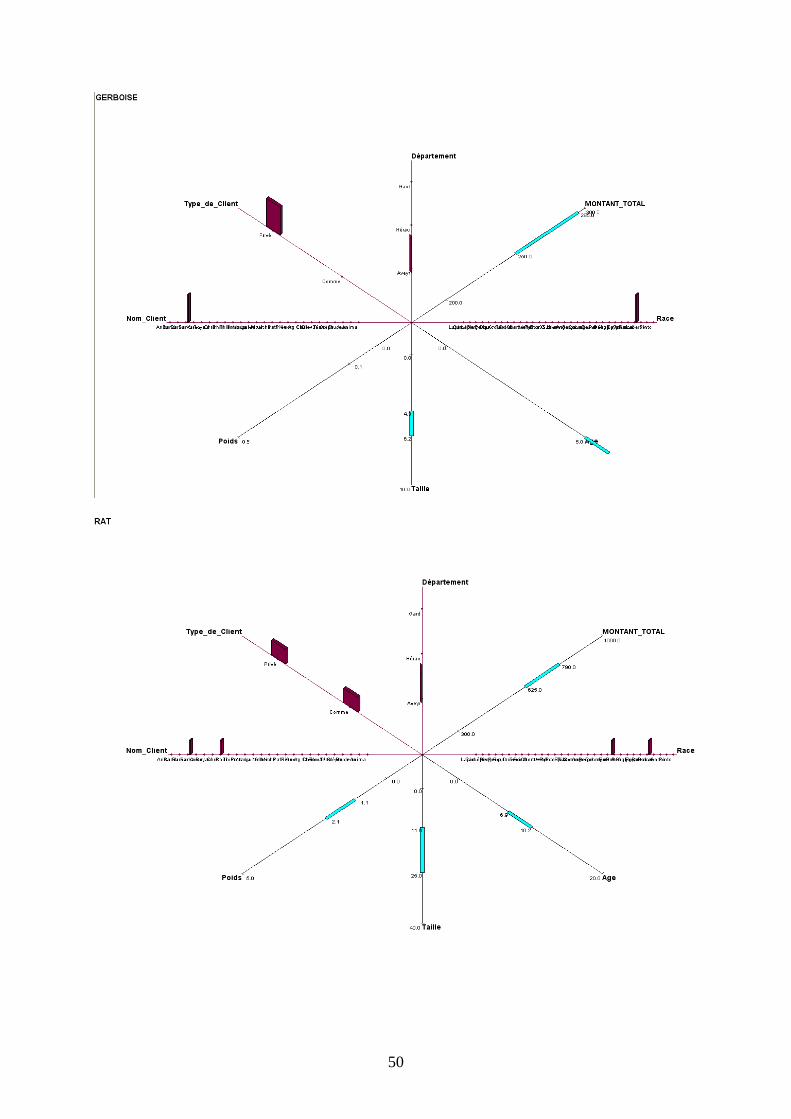
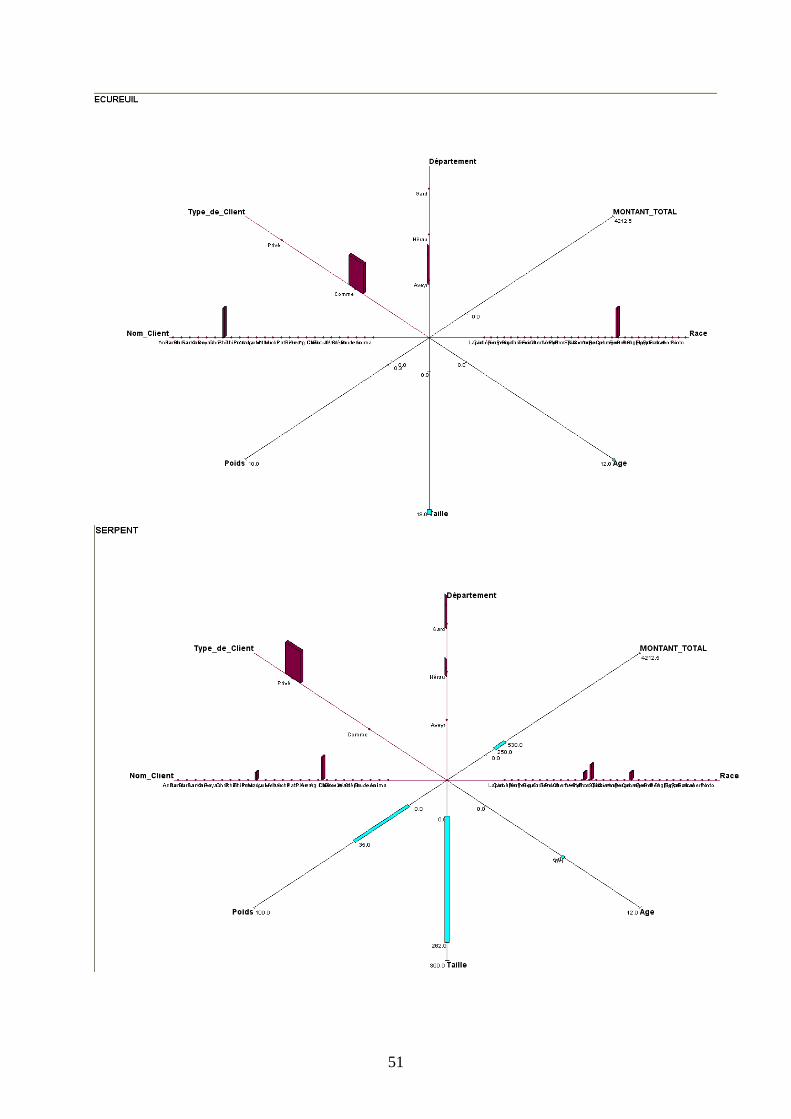
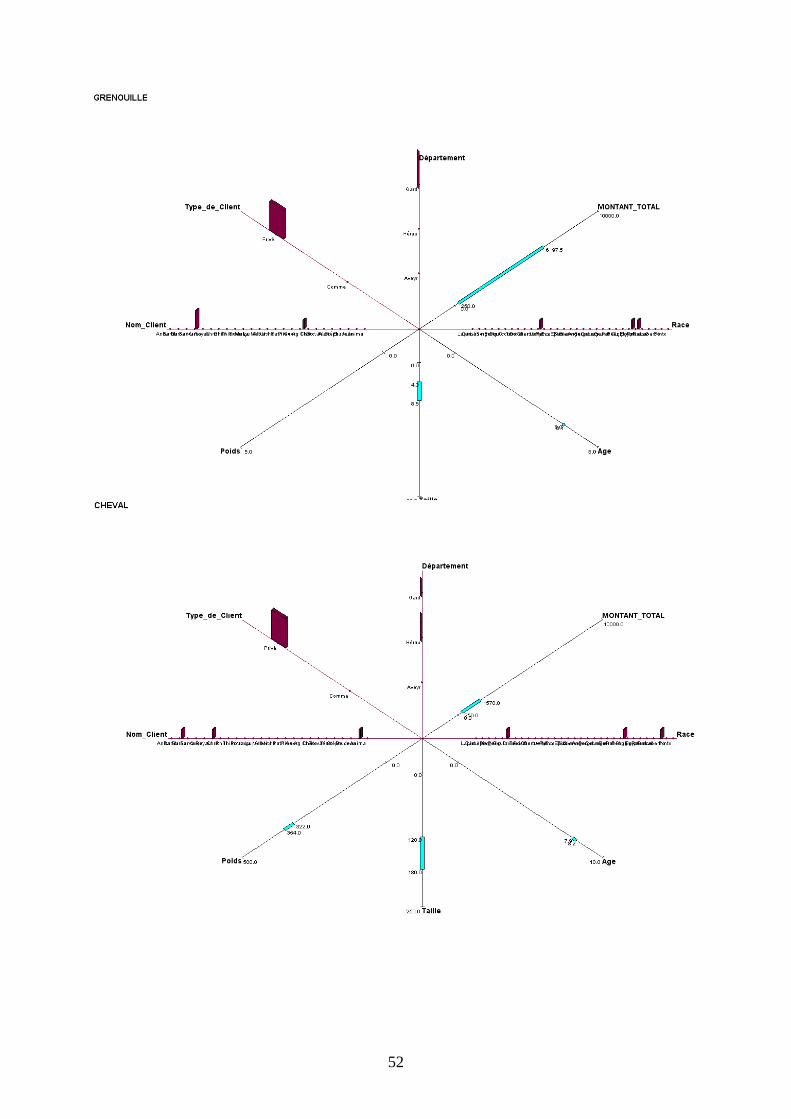
Graphique en étoile à 3 dimensions
Ce type de graphique diffère du précédent sur la représentation des variables qualitatives et
quantitatives : les premières sont sous forme d’histogramme en trois dimensions alors que les
secondes sont sous forme de segment.
Néanmoins, les observations et interprétations précédentes restent toujours valides. On
remarque que la visualisation des variables qualitatives en histogramme nous permet d’avoir
un visuel instantané de la situation alors que le graphique 2D nous poussait à basculer en
mode histogramme complémentaire.
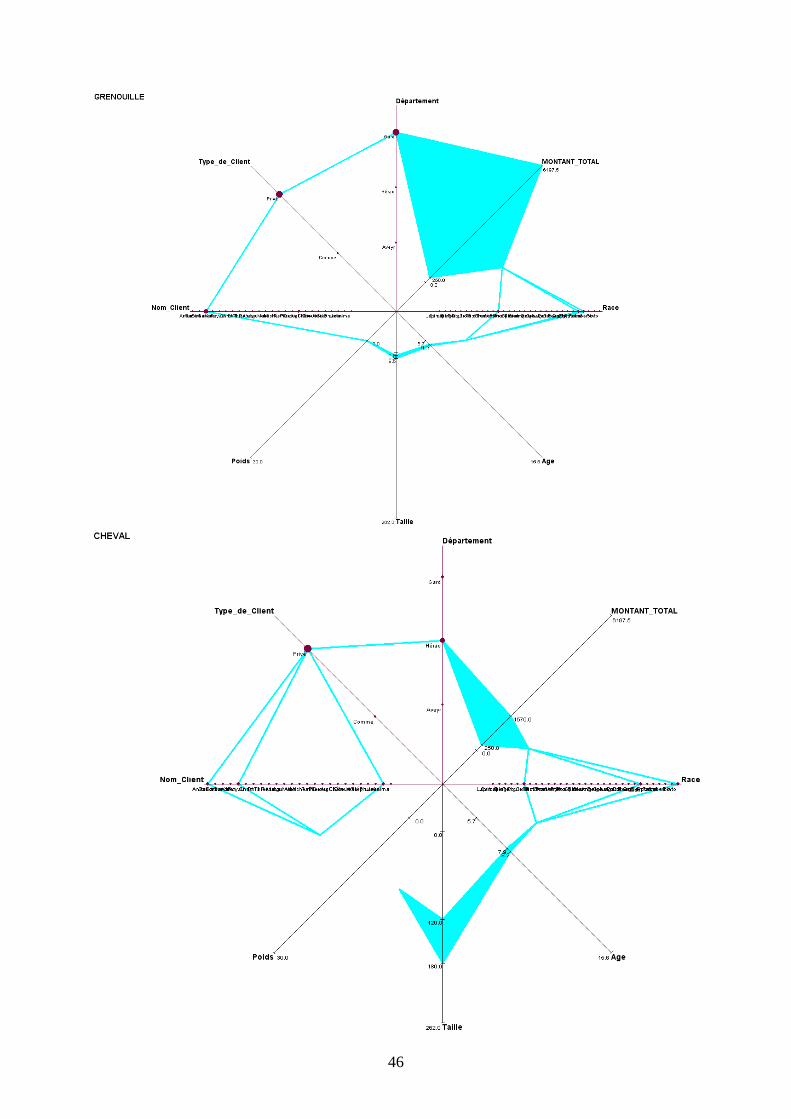
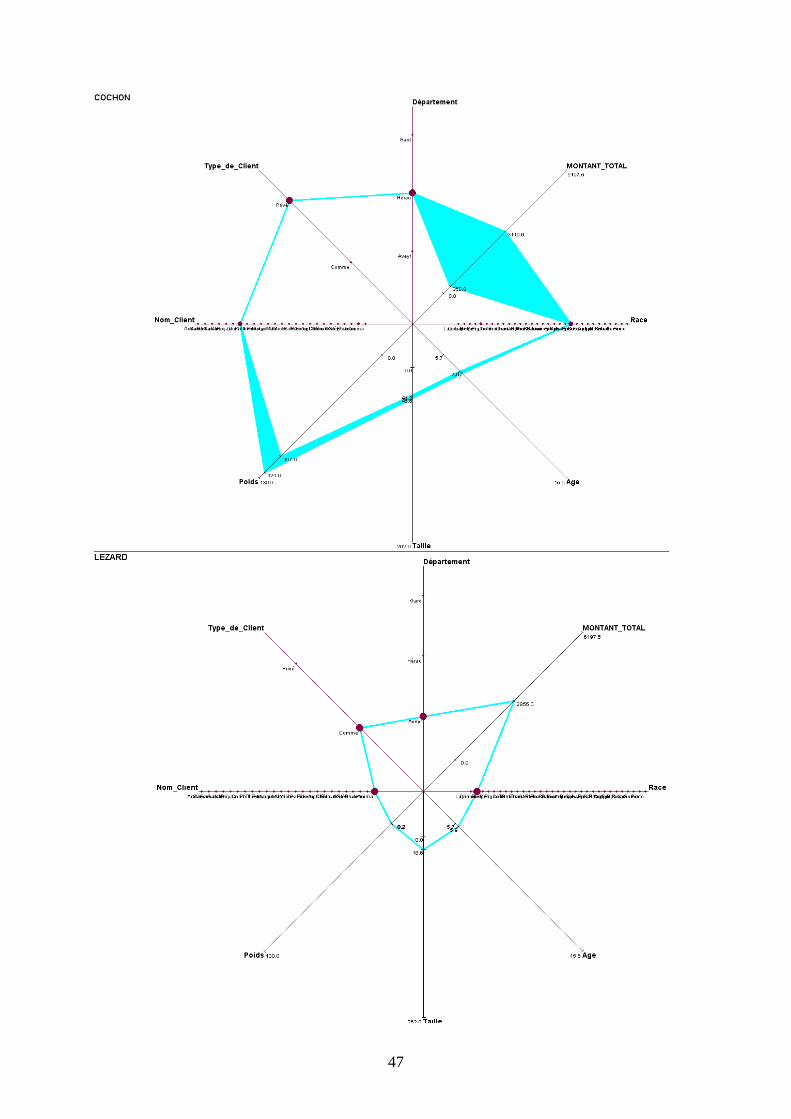
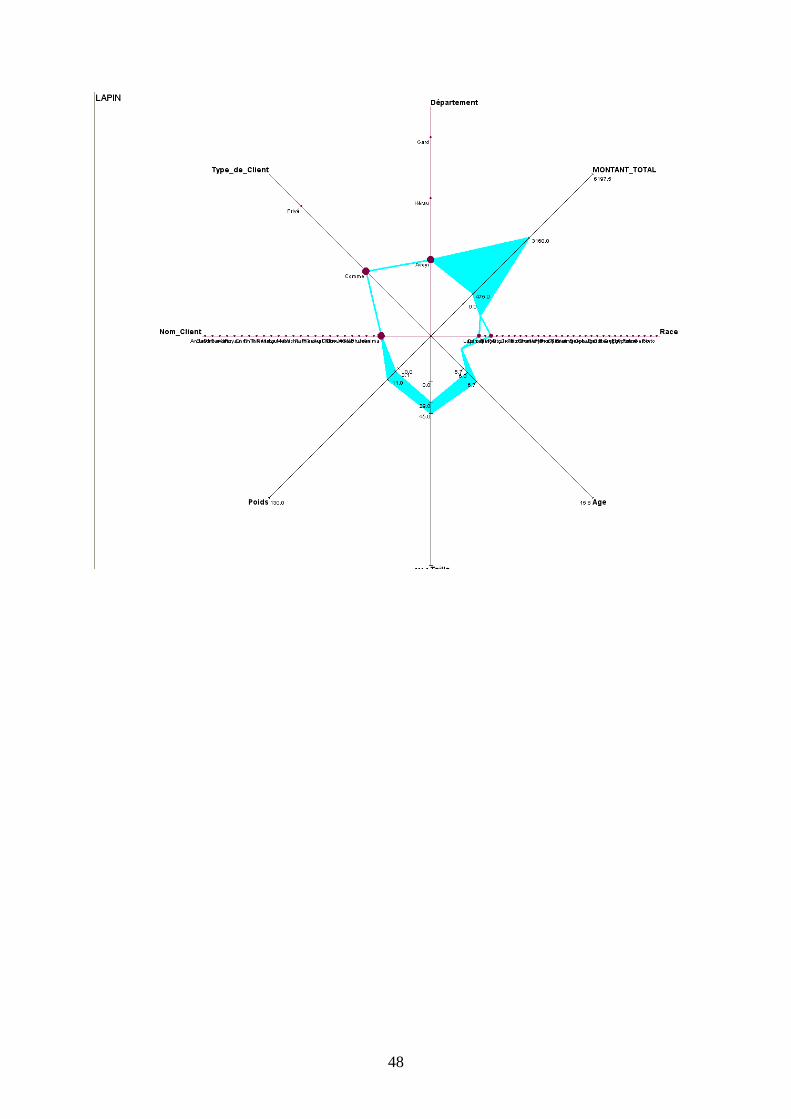
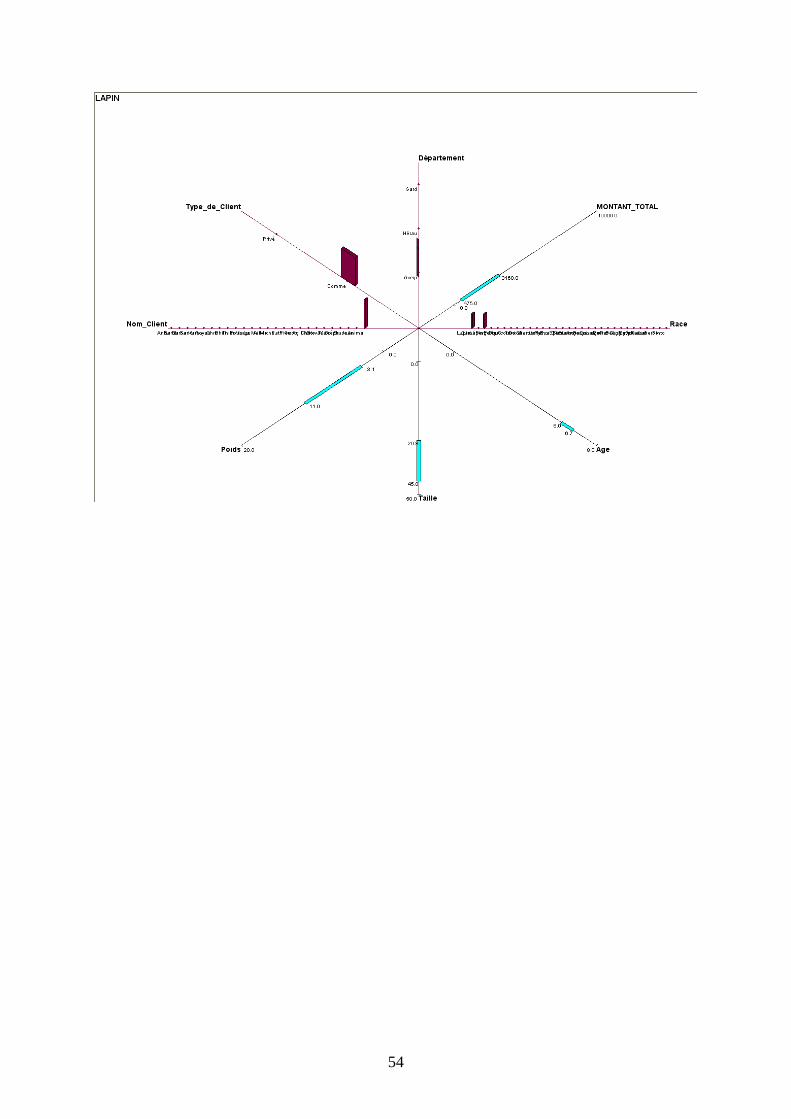
c) Description des autres concepts
Pour ne pas surcharger le rapport, toutes les représentations graphiques figurent en Annexes.
L’observation de toutes les autres fenêtres graphiques nous permet d’établir des tendances
spécifiques en fonction du type d’animal présenté.
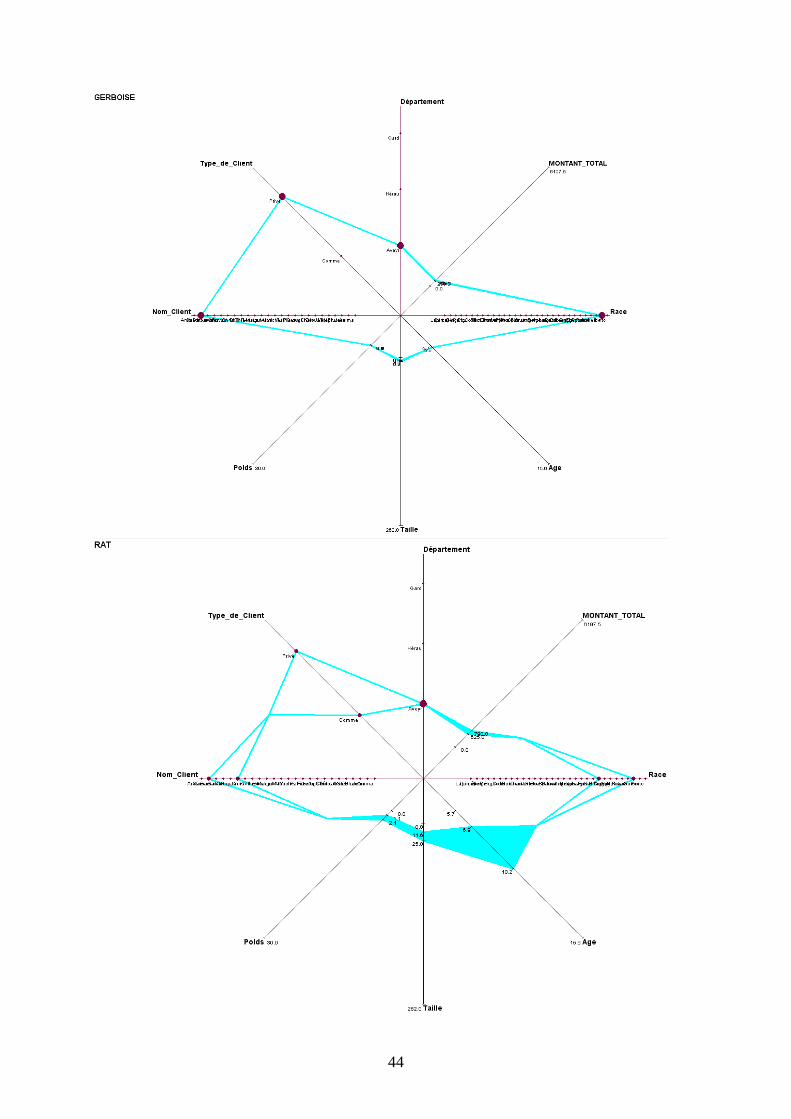
D’une manière générale on peut remarquer que le Lapin est majoritairement possédé par un
établissement commercial appelé Anima, localisé dans l’Aveyron, d’une taille variant
beaucoup, mais d’un poids stable. Les coûts qu’il génère peuvent beaucoup varier (amplitude
de 2685€).
La Gerboise est détenue chez des particuliers dans l’Aveyron, de même que le Rat, qui, lui est
détenu autant par des Personnes privées que par des entreprises commerciales.
Le Serpent peut avoir une forte amplitude pour sa taille (2.62 mètres de différence) et son
poids (35 kg) ; il est surtout gardé par des particuliers du Gard.
La Grenouille se distingue surtout par les coûts qu’elle génère (amplitude de 5947.5€ , chiffre
qui la met en première position dans ce domaine).
Le Cheval est défini par sa grande variété de races et de clients uniquement privés, ce qui
correspond bien à l’image que l’animal véhicule.
Le Lézard comme le Lapin ne sont gardés que dans des établissements commerciaux
(respectivement dans le Gard et l’Aveyron).
20
VII- Analyse en composantes Principales
a) Introduction à la méthode PCM
L’Analyse en Composantes Principales – ou Principal Component Analysis – permet
d’apporter un nouvel axe de vision des concepts en les disposant non plus en simples points
transposés sur les axes factoriels, mais en tant que structures rectangulaires.
Cette nouvelle disposition permet de mettre plus facilement en corrélation les différents
concepts et ainsi trouver des aspects voisins.
b) Description des résultats de l’application
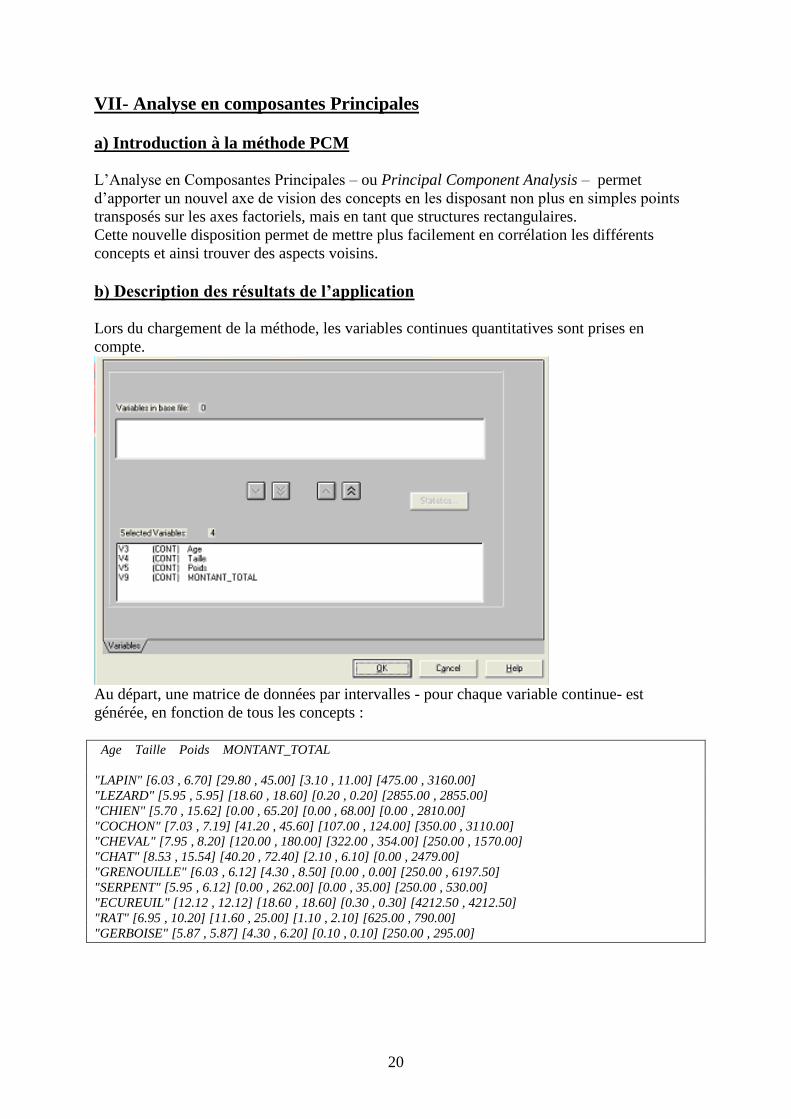
Lors du chargement de la méthode, les variables continues quantitatives sont prises en
compte.
Au départ, une matrice de données par intervalles - pour chaque variable continue- est
générée, en fonction de tous les concepts :
Age Taille Poids MONTANT_TOTAL
"LAPIN" [6.03 , 6.70] [29.80 , 45.00] [3.10 , 11.00] [475.00 , 3160.00]
"LEZARD" [5.95 , 5.95] [18.60 , 18.60] [0.20 , 0.20] [2855.00 , 2855.00]
"CHIEN" [5.70 , 15.62] [0.00 , 65.20] [0.00 , 68.00] [0.00 , 2810.00]
"COCHON" [7.03 , 7.19] [41.20 , 45.60] [107.00 , 124.00] [350.00 , 3110.00]
"CHEVAL" [7.95 , 8.20] [120.00 , 180.00] [322.00 , 354.00] [250.00 , 1570.00]
"CHAT" [8.53 , 15.54] [40.20 , 72.40] [2.10 , 6.10] [0.00 , 2479.00]
"GRENOUILLE" [6.03 , 6.12] [4.30 , 8.50] [0.00 , 0.00] [250.00 , 6197.50]
"SERPENT" [5.95 , 6.12] [0.00 , 262.00] [0.00 , 35.00] [250.00 , 530.00]
"ECUREUIL" [12.12 , 12.12] [18.60 , 18.60] [0.30 , 0.30] [4212.50 , 4212.50]
"RAT" [6.95 , 10.20] [11.60 , 25.00] [1.10 , 2.10] [625.00 , 790.00]
"GERBOISE" [5.87 , 5.87] [4.30 , 6.20] [0.10 , 0.10] [250.00 , 295.00]
21
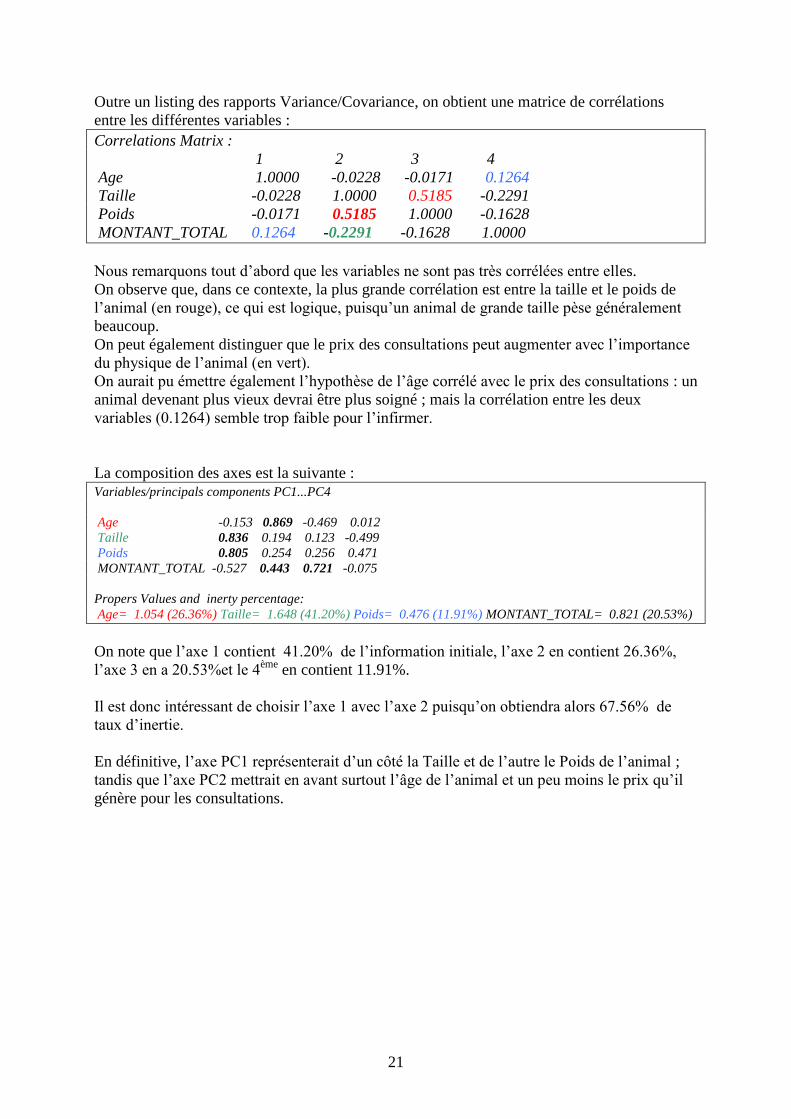
Outre un listing des rapports Variance/Covariance, on obtient une matrice de corrélations
entre les différentes variables :
Correlations Matrix :
1 2 3 4
Age 1.0000 -0.0228 -0.0171 0.1264
Taille -0.0228 1.0000 0.5185 -0.2291
Poids -0.0171 0.5185 1.0000 -0.1628
MONTANT_TOTAL 0.1264 -0.2291 -0.1628 1.0000
Nous remarquons tout d’abord que les variables ne sont pas très corrélées entre elles.
On observe que, dans ce contexte, la plus grande corrélation est entre la taille et le poids de
l’animal (en rouge), ce qui est logique, puisqu’un animal de grande taille pèse généralement
beaucoup.
On peut également distinguer que le prix des consultations peut augmenter avec l’importance
du physique de l’animal (en vert).
On aurait pu émettre également l’hypothèse de l’âge corrélé avec le prix des consultations : un
animal devenant plus vieux devrai être plus soigné ; mais la corrélation entre les deux
variables (0.1264) semble trop faible pour l’infirmer.
La composition des axes est la suivante : Variables/principals components PC1...PC4
Age -0.153 0.869 -0.469 0.012
Taille 0.836 0.194 0.123 -0.499
Poids 0.805 0.254 0.256 0.471
MONTANT_TOTAL -0.527 0.443 0.721 -0.075
Propers Values and inerty percentage:
Age= 1.054 (26.36%) Taille= 1.648 (41.20%) Poids= 0.476 (11.91%) MONTANT_TOTAL= 0.821 (20.53%)
On note que l’axe 1 contient 41.20% de l’information initiale, l’axe 2 en contient 26.36%,
l’axe 3 en a 20.53%et le 4ème
en contient 11.91%.
Il est donc intéressant de choisir l’axe 1 avec l’axe 2 puisqu’on obtiendra alors 67.56% de
taux d’inertie.
En définitive, l’axe PC1 représenterait d’un côté la Taille et de l’autre le Poids de l’animal ;
tandis que l’axe PC2 mettrait en avant surtout l’âge de l’animal et un peu moins le prix qu’il
génère pour les consultations.

22
L’axe PC2 nous indique que le chien et le chat – et aussi le cheval- sont proches quant à leur
espérance de vie ; d’un autre côté, nous trouvons les animaux d’espérance de vie recensée
plus réduite comme le Lézard, le Rat, le Lapin, la Gerboise.
Le long de l’axe PC1, nous trouvons l’animal de plus volumineux, le cheval en tête, puis un
groupe relativement diffus chien, chat, cochon ; et enfin le Lézard, Lapin, Rat, Grenouille,
Gerboise.
La structure rectangulaire du chat et du chien n’est pas aisée à décrire parce qu’elle est très
large et empêche une catégorisation définitive. Cet état est du aux mesures initiales, qui
comprennent une proportion jusqu’à plus de 10 fois supérieure en nombre, des chats et chiens
par rapport aux autres animaux.
23
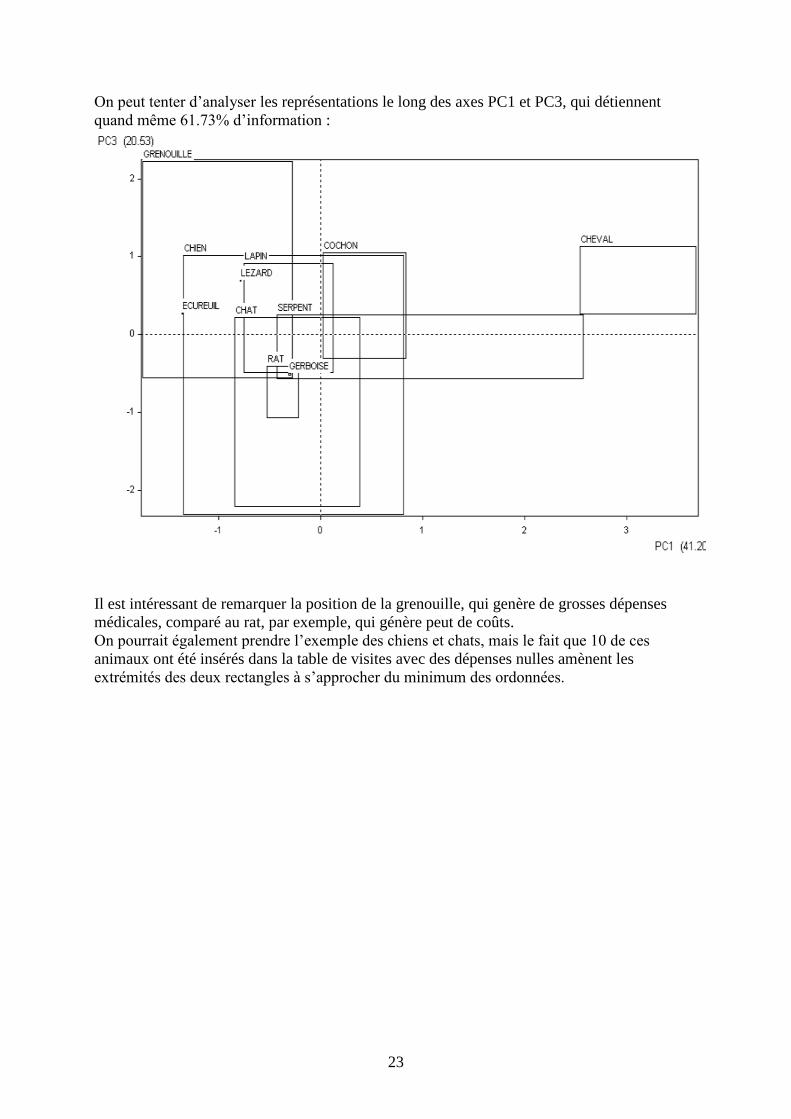
On peut tenter d’analyser les représentations le long des axes PC1 et PC3, qui détiennent
quand même 61.73% d’information :
Il est intéressant de remarquer la position de la grenouille, qui genère de grosses dépenses
médicales, comparé au rat, par exemple, qui génère peut de coûts.
On pourrait également prendre l’exemple des chiens et chats, mais le fait que 10 de ces
animaux ont été insérés dans la table de visites avec des dépenses nulles amènent les
extrémités des deux rectangles à s’approcher du minimum des ordonnées.

24
VIII- La méthode STAT
a) Introduction à la méthode STAT
La méthode STAT (également appelée Elementary Statistics On Symbolic Objects) est
constituée d’une série de traitements statistiques qui, habituellement réservés aux données
ordinaires, s’appliquent sur nos données symboliques représentées par leurs descriptions.
Ainsi, il est possible d’obtenir une visualisation claire, sous forme de sortie texte ou de
graphique, de ces statistiques.
A l’insertion de la méthode, le logiciel SODAS nous invite à vérifier et sélectionner nos
variables en fonction de leur type :
- des variables multimodales probabilistes (Mult-Nominal-Modif dans le logiciel) qui
vont être triées selon les capacités et min/max/mean.
- des variables multimodales (appelées Mult_Nominal dans le logiciel) simples
analysées selon les fréquences relatives
- des variables d’intervalles (nommées Inter_cont dans le logiciel) qui vont être traitées
selon les fréquences relatives ou selon le Biplot
b) Description des résultats de l’application
1) Analyse de la méthode Capacités – Min/Max/Mean appliquée aux variables
multimodales Probabilistes
Ici, les variables considérées comme Multimodales Probabilistes sont le Département, le Type
de Client, la Race de l’Animal, le Nom de l’Animal et le Nom du Client ( ce qui est tout à fait
logique puisque ce sont les variables nominales).
L’exécution de la méthode STAT permet l’élaboration de plusieurs listings en format texte,
des capacités de l’étendue et de la moyenne des différentes modalités de chaque variable
considérée , du même type que ci dessous :
--------------------------------------------------------------------------- SODAS - STAT
CAPACITIES Dec 01 File: EXPORT~1.SDS
Title: Clinique
---------------------------------------------------------------------------
capa mini maxi mean
Nom_Animal
[…] Race
AC06 Boulonnais 0.3333 0.0000 0.3333 0.0303
[…] Nom_Client
AG01 Animaux Câlins 1.0000 0.0000 1.0000 0.1875
AG02 Jean Adams 0.5556 0.0000 0.3333 0.0606
[…] AG06 Bow Wow House 0.1250 0.0000 0.1250 0.0114
0.0625 0.0000 0.0625 0.0057
AG11 Patricia Irribarado 0.4375 0.0000 0.4375 0.0398
[…] AG24 Sandra Young 1.0000 0.0000 1.0000 0.1364
0.3333 0.0000 0.3333 0.0303
Type_de_Client
25
AH01 Commercial 1.0000 0.0000 1.0000 0.3864
AH02 Privé 1.0000 0.0000 1.0000 0.6136
Département
AI01 Aveyron 1.0000 0.0000 1.0000 0.5284
AI02 Hérault 1.0000 0.0000 1.0000 0.2197
AI03 Gard 1.0000 0.0000 1.0000 0.2519
Pour comprendre ce listing, prenons l’exemple, dans Nom_Client, la donnée AG11 (qui est
l’indice visible sur le graphique suivant) relative à Patricia Irribarado.
La valeur de capa – pour capacité- et de max égale à 0.4375 correspond au nombre d’animaux
possédés en fonction du type.
Pour étayer ce fait, nous faisons référence au listing initial des animaux recensés. Nous
pouvons remarquer que Patricia Irribarado ne possède qu’exclusivement des animaux de
type CHAT : un proportion de 7 sur les 13 animaux de cette catégorie.
Animaux possédés par Patricia Irribarado
Nous avons donc une proportion de 7/13=0.4375
La visualisation sous forme de graphique est plus agréable et permet tout aussi bien de mettre
en avant certaines « tendances » de nos données.
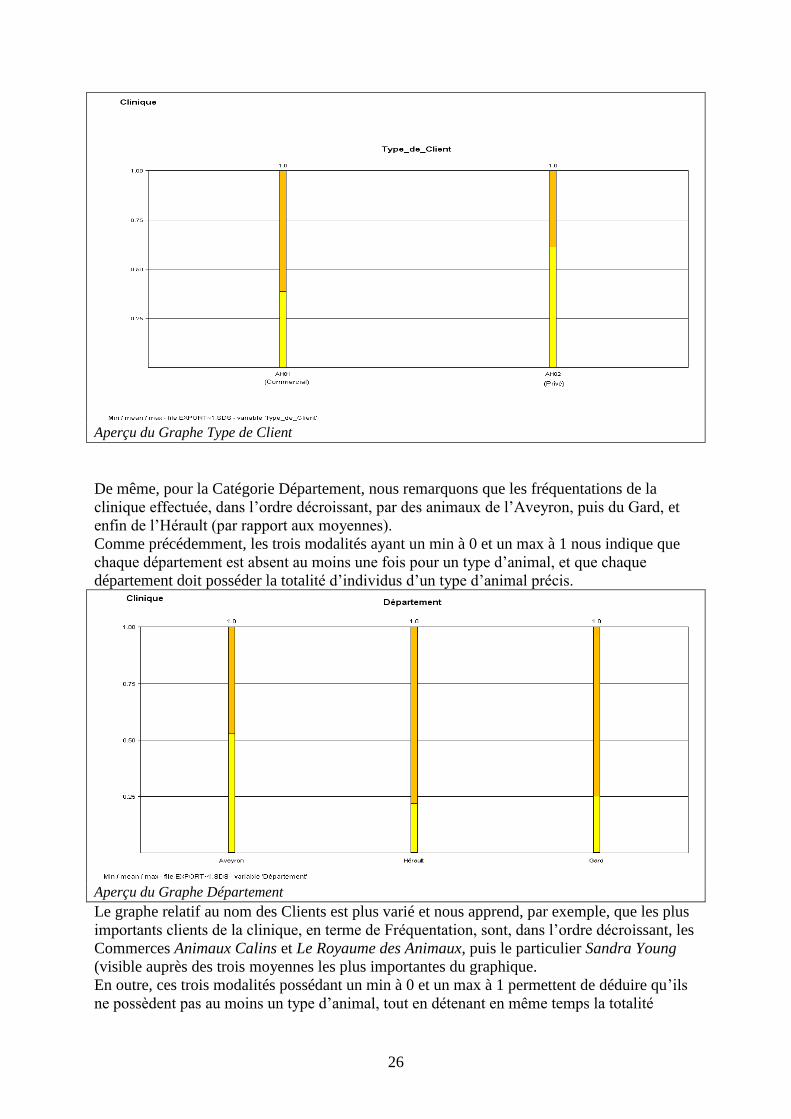
Par exemple, pour la Catégorie Type de Client, nous remarquons que les personnes Privées
ont un taux de fréquentation de notre clinique plus élevé (moyenne Privé supérieure à
moyenne Commercial) ; en outre, on remarque :
- d’une part, que ces deux types sont absents un moment ou un autre dans un ou
plusieurs des concepts (ceci est dû à leur minimum égal à 0)
- d’autre part, que pour certains objets symboliques, le type de client est le seul
demandeur (ceci est dû aux modalités ayant un max égal à 1).
26
Aperçu du Graphe Type de Client
De même, pour la Catégorie Département, nous remarquons que les fréquentations de la
clinique effectuée, dans l’ordre décroissant, par des animaux de l’Aveyron, puis du Gard, et
enfin de l’Hérault (par rapport aux moyennes).
Comme précédemment, les trois modalités ayant un min à 0 et un max à 1 nous indique que
chaque département est absent au moins une fois pour un type d’animal, et que chaque
département doit posséder la totalité d’individus d’un type d’animal précis.
Aperçu du Graphe Département
Le graphe relatif au nom des Clients est plus varié et nous apprend, par exemple, que les plus
importants clients de la clinique, en terme de Fréquentation, sont, dans l’ordre décroissant, les
Commerces Animaux Calins et Le Royaume des Animaux, puis le particulier Sandra Young
(visible auprès des trois moyennes les plus importantes du graphique.
En outre, ces trois modalités possédant un min à 0 et un max à 1 permettent de déduire qu’ils
ne possèdent pas au moins un type d’animal, tout en détenant en même temps la totalité
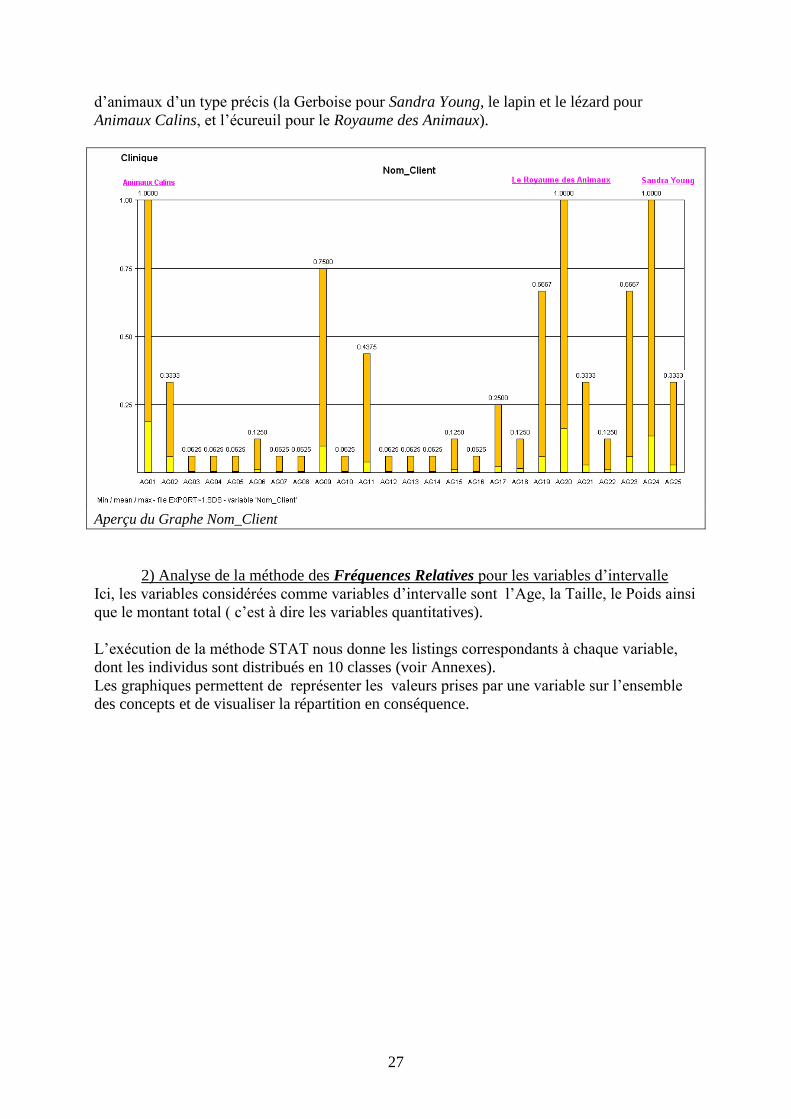
27
d’animaux d’un type précis (la Gerboise pour Sandra Young, le lapin et le lézard pour
Animaux Calins, et l’écureuil pour le Royaume des Animaux).
Aperçu du Graphe Nom_Client
2) Analyse de la méthode des Fréquences Relatives pour les variables d’intervalle
Ici, les variables considérées comme variables d’intervalle sont l’Age, la Taille, le Poids ainsi
que le montant total ( c’est à dire les variables quantitatives).
L’exécution de la méthode STAT nous donne les listings correspondants à chaque variable,
dont les individus sont distribués en 10 classes (voir Annexes).
Les graphiques permettent de représenter les valeurs prises par une variable sur l’ensemble
des concepts et de visualiser la répartition en conséquence.
28
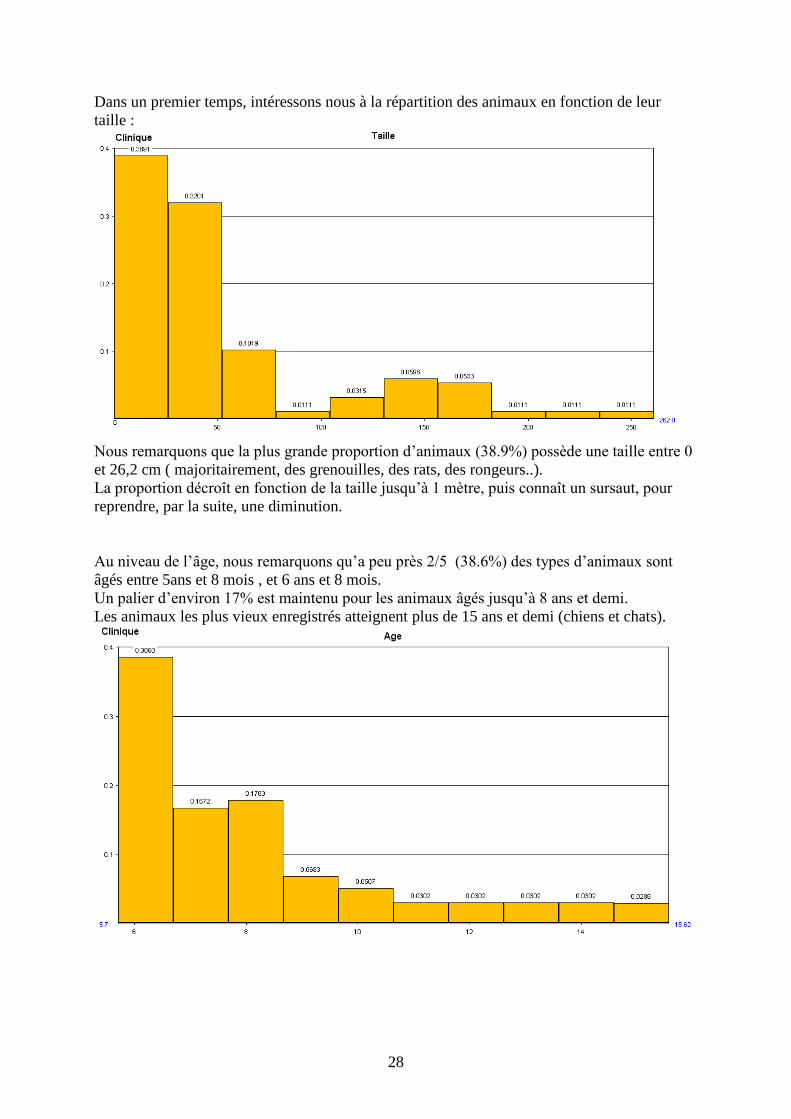
Dans un premier temps, intéressons nous à la répartition des animaux en fonction de leur
taille :
Nous remarquons que la plus grande proportion d’animaux (38.9%) possède une taille entre 0
et 26,2 cm ( majoritairement, des grenouilles, des rats, des rongeurs..).
La proportion décroît en fonction de la taille jusqu’à 1 mètre, puis connaît un sursaut, pour
reprendre, par la suite, une diminution.
Au niveau de l’âge, nous remarquons qu’a peu près 2/5 (38.6%) des types d’animaux sont
âgés entre 5ans et 8 mois , et 6 ans et 8 mois.
Un palier d’environ 17% est maintenu pour les animaux âgés jusqu’à 8 ans et demi.
Les animaux les plus vieux enregistrés atteignent plus de 15 ans et demi (chiens et chats).
29
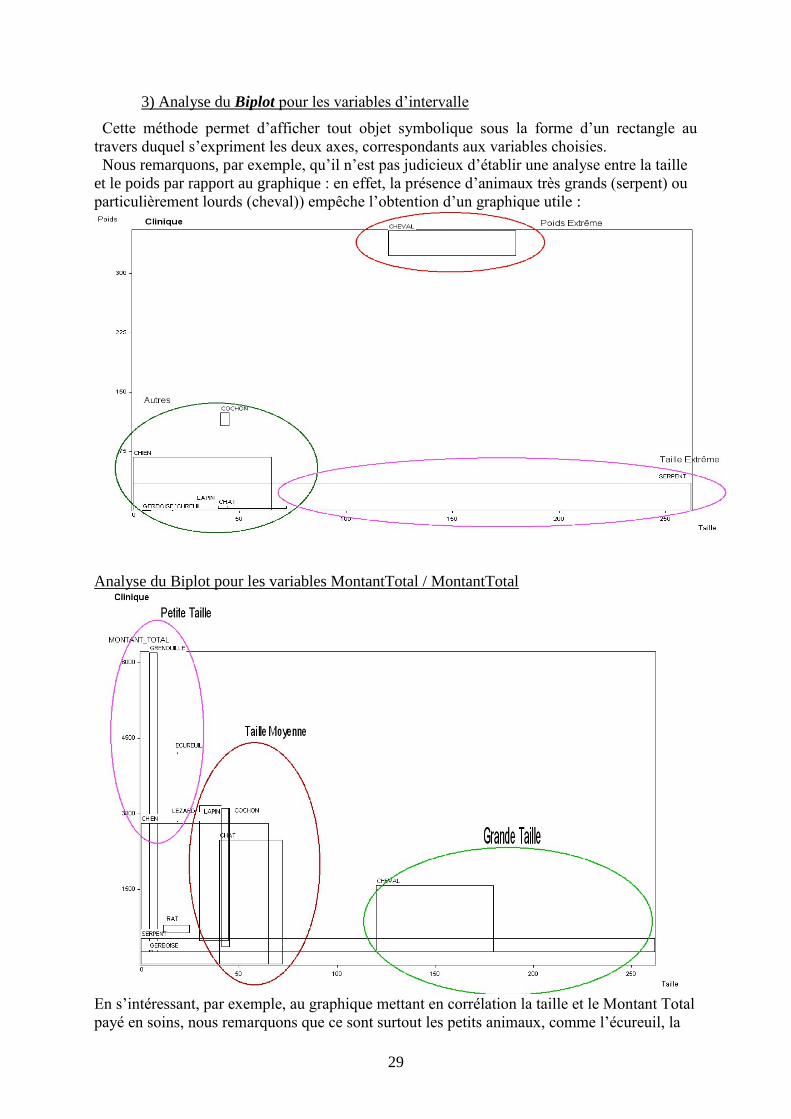
3) Analyse du Biplot pour les variables d’intervalle
Cette méthode permet d’afficher tout objet symbolique sous la forme d’un rectangle au
travers duquel s’expriment les deux axes, correspondants aux variables choisies.
Nous remarquons, par exemple, qu’il n’est pas judicieux d’établir une analyse entre la taille
et le poids par rapport au graphique : en effet, la présence d’animaux très grands (serpent) ou
particulièrement lourds (cheval)) empêche l’obtention d’un graphique utile :
Analyse du Biplot pour les variables MontantTotal / MontantTotal
En s’intéressant, par exemple, au graphique mettant en corrélation la taille et le Montant Total
payé en soins, nous remarquons que ce sont surtout les petits animaux, comme l’écureuil, la

30
grenouille, et le lézard qui coûtent le plus cher. Apparaissent ensuite des animaux de taille
intermédiaire, comme le chien, le chat, le cochon ou le lapin, qui coûtent une somme
intermédiaire, et enfin, des animaux plus grands (cheval) ou longs (serpent), qui, selon les
données, valent le moins cher.
Il est cependant important d’émettre une réserve sur cette classification à travers la présence
d’exceptions, comme le rat ou la gerboise, qui coûtent peu en dépit de leur taille réduite.

31
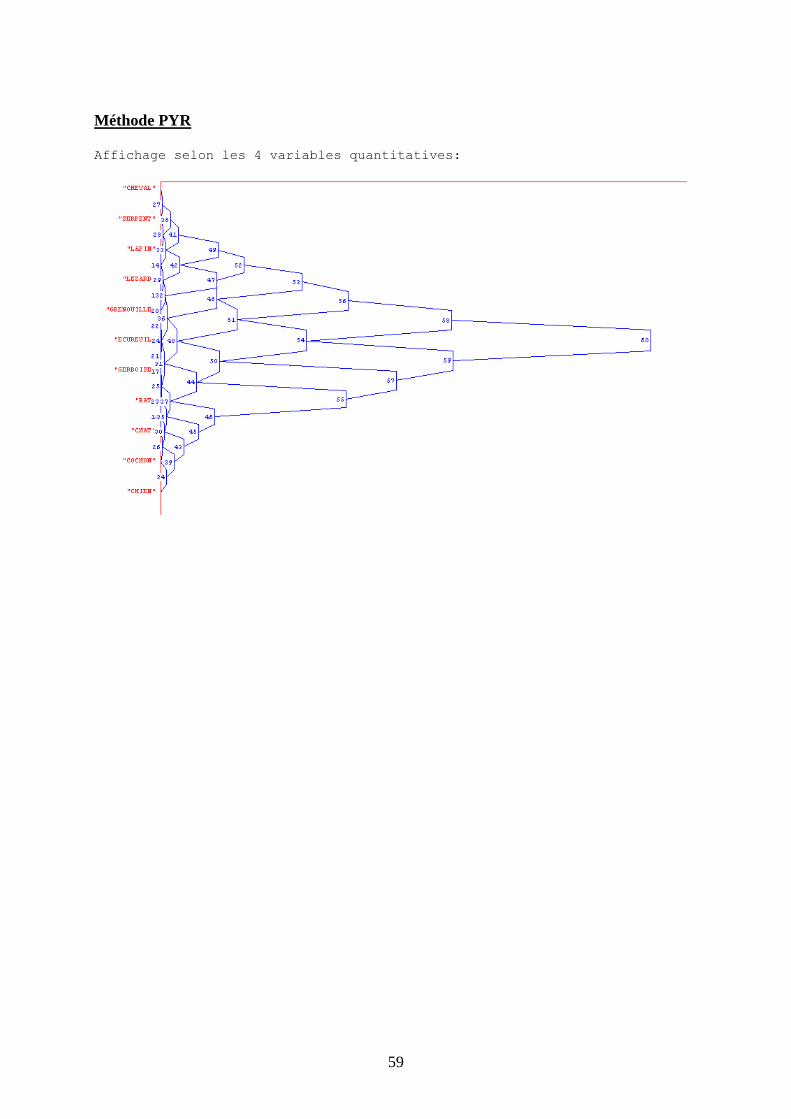
IX - La méthode PYR
a) Introduction à la méthode PYR La méthode PYR(pour Pyramidal Clustering) est conçue afin d’offrir une représentation
issue d’une classification pyramidale. Pour se faire, la hiérarchisation habituelle est
généralisée par l’autorisation de classes non disjointes à un niveau donné.
Cette représentation pyramidale prend en compte toute variation de valeur des variables, et
réalise un rapprochement des objets symboliques situés à la base, afin de réaliser à chaque
niveau, une jointure supplémentaire des classes.
Pour débuter, il est nécessaire de sélectionner les variables qui seront utilisées pour construire
la pyramide. Elles peuvent être de tous types confondus - continues, intervalles ou même
histogrammes. On doit faire un choix entre des variables qualitatives et continues, ou bien
même les deux.
b) Description des résultats de l’application L’exécution de cette méthode va nous permettre, dans un premier temps, de regrouper nos
types d’animaux en fonction de variables quantitatives comme l’âge, la taille, le poids et le
montant total des soins.
Ce choix précis de variables va nous permettre de renforcer l’analyse réalisée par la méthode
STAT.
Nous obtenons alors un listing qui recense toutes les classes empiétantes et qui met donc en
valeur des liens entre les concepts, vis à vis des variables sélectionnées (le listing est présent
en en fichier joint PYR VariablesQuantitatives.txt). DESCRIPTION-OF-THE-NODES
Where_the_labels_are_of_the_individuals_are:
1.="LAPIN"
2.="LEZARD"
3.="CHIEN"
4.="COCHON"
5.="CHEVAL"
6.="CHAT"
7.="GRENOUILLE"
8.="SERPENT"
9.="ECUREUIL"
10.="RAT"
11.="GERBOISE"
Where_the_labels_are_of_the_variables_are:
y3.=Age
y4.=Taille
y5.=Poids
y9.=MONTANT_TOTAL
[…] Ext(P12)={"LEZARD","GRENOUILLE"}
[…] Ext(P13)={"GRENOUILLE","ECUREUIL"}
32
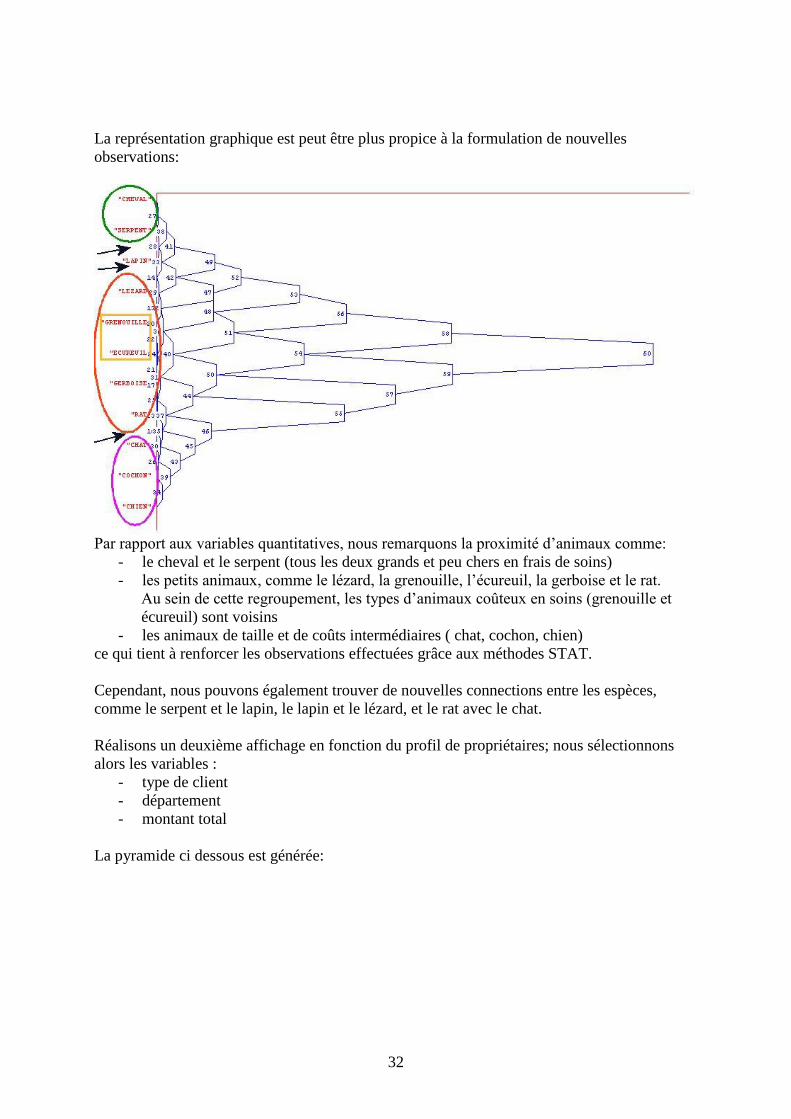
La représentation graphique est peut être plus propice à la formulation de nouvelles
observations:
Par rapport aux variables quantitatives, nous remarquons la proximité d’animaux comme:
- le cheval et le serpent (tous les deux grands et peu chers en frais de soins)
- les petits animaux, comme le lézard, la grenouille, l’écureuil, la gerboise et le rat.
Au sein de cette regroupement, les types d’animaux coûteux en soins (grenouille et
écureuil) sont voisins
- les animaux de taille et de coûts intermédiaires ( chat, cochon, chien)
ce qui tient à renforcer les observations effectuées grâce aux méthodes STAT.
Cependant, nous pouvons également trouver de nouvelles connections entre les espèces,
comme le serpent et le lapin, le lapin et le lézard, et le rat avec le chat.
Réalisons un deuxième affichage en fonction du profil de propriétaires; nous sélectionnons
alors les variables :
- type de client
- département
- montant total
La pyramide ci dessous est générée:

33
Ici, on remarque alors que certains animaux ont le même profil de propriétaire et provenance
au niveau du département. On pourrait même étayer des hypothèses en fonction des liens
inter-espèces :
- on pourrait assimiler le lien chien-chat-cheval à des éleveurs spécialisés ou privés dans
des régions de campagne par exemple;
- le lien rat – gerboise – écureuil - grenouille pour des individus en appartements;
- le lien rat-serpent pour des éleveurs spécialisés
- la proximité cochon-lapin pour des habitants de zones rurales
Ces simples hypothèses servent surtout à rendre compte de l’agencement presque « naturel »
des animaux selon ces variables (comme si les éleveurs avaient choisi des espèces ayant des
affinités entre elles).

34
X- La méthode TREE
a) Introduction à la méthode TREE
La méthode TREE est conçue afin de trouver l’organisation des objets symboliques la plus
efficiente, compte tenu des données initiales. Pour se faire, le programme exécute un
agrandissement d’arbre par le biais d’une recherche itérative de l’agglomération de concepts
qui correspond le mieux aux données.
L’objectif de cet arbre de décision réside dans l’agencement des concepts en classes, et ce
faisant, de trouver les variables qui traduisent le mieux cette opération.
A chaque étape, le découpage optimal est obtenu en utilisant une mesure générale, donnée en
paramètre.
En sortie, nous obtenons une nouvelle liste d’objets symboliques qui permet éventuellement
d’assigner de nouveaux objets à une classe.
b) Description des résultats de l’application Après avoir réalisé la procédure initiale AddSingle qui porte sur les Types Généraux
d’animaux (Mammifère, Reptiles, Batraciens, Volatiles, Poissons), il est désormais possible
d’exécuter la méthode TREE.
La fenêtre de sélection des variables classe (Variable Class Identifier) m’amène à choisir la
modalité Unité
En choisissant des variables qualitatives Département et Type de Client dans la catégorie
Predictors Variables, nous obtenons le listing suivant : -------------------------------------------------------
BASE= C:\DOCUME~1\GIAMPI\BUREAU\DATAMI~1\SODASN~1\PAOLO.SDS
Number of OS = 11
Number of variables = 10
METHOD=SODAS_TREE Version 1.3 01:03:01 INRIA 1998
--------------------------------------------------------
Learning Set : 11
Number of variables : 2
Max. number of nodes: 19
Soft Assign : ( 1 ) FUZZY
Criterion coding : ( 3 ) LOG-LIKELIHOOD
Min. number of object by node : 5
Min. size of no-majority classes : 2
Min. size of descendant nodes : 2.00
Frequency of test set : 0.00
GROUP OF PREDICATE VARIABLES :
( 7 ) Type_de_Client 2 MODALITIES
( 8 ) Département 3 MODALITIES
CLASSIFICATION VARIABLE :
( 10 ) Unite
NUMBER OF A PRIORI CLASSES : 5
ID_CLASS NAME_CLASS
1 Mammifere Domestique
2 Mammifere Elevage
3 Mammifere Rongeur
4 Batracien

35
5 Reptile
==================================
| EDITION OF DECISION TREE |
==================================
PARAMETERS :
Learning Set : 11
Number of variables : 2
Max. number of nodes: 7
Soft Assign : ( 1 ) FUZZY
Criterion coding : ( 3 ) LOG-LIKELIHOOD
Min. number of object by node : 5
Min. size of no-majority classes : 2
Min. size of descendant nodes : 2.00
Frequency of test set : 0.00
+ --- IF ASSERTION IS TRUE (up)
!
--- x [ ASSERTION ]
!
+ --- IF ASSERTION IS FALSE (down)
+---- [ 4 ]Mammifere Rongeur ( 0.30 1.00 1.50
0.00 1.00 )
!
!----2[ Type_de_Client = 10 ]
! !
! +---- [ 5 ]Mammifere Rongeur ( 0.51 0.00 1.50
0.00 0.00 )
!
!----1[ Département = 100 ]
!
! +---- [ 6 ]Mammifere Elevage ( 0.32 1.67 0.00
0.00 0.25 )
! !
!----3[ Département = 010 ]
!
+---- [ 7 ]Batracien ( 0.86 0.33 0.00 1.00
0.75 )
On remarque alors que ce qui peut distinguer deux rongeurs est le type de client qui les
possède. En outre, deux sous catégories de mammifères (Elevage et Rongeur) sont
différentiables par leur Département.
De même, le critère de distinction entre tout mammifère et tout batracien est le Département.
En choisissant des variables quantitatives Poids, Taille et Age dans la catégorie Predictors
Variables, nous obtenons le listing suivant :
==================================
| EDITION OF DECISION TREE |
==================================
PARAMETERS :

36
Learning Set : 11
Number of variables : 3
Max. number of nodes: 7
Soft Assign : ( 1 ) FUZZY
Criterion coding : ( 3 ) LOG-LIKELIHOOD
Min. number of object by node : 5
Min. size of no-majority classes : 2
Min. size of descendant nodes : 1.00
Frequency of test set : 0.00
+ --- IF ASSERTION IS TRUE (up)
!
--- x [ ASSERTION ]
!
+ --- IF ASSERTION IS FALSE (down)
+---- [ 4 ]Reptile ( 0.00 0.00 1.00 1.00 1.06
)
!
!----2[ Age <= 6.120000]
! !
! +---- [ 5 ]Mammifere Rongeur ( 0.03 0.00 2.00 0.00
0.00 )
!
!----1[ Poids <= 2.100000]
!
! +---- [ 6 ]Mammifere Elevage ( 0.24 3.00 0.00 0.00
0.94 )
! !
!----3[ Age <= 8.200000]
!
+---- [ 7 ]Mammifere Domestique ( 1.72 0.00 0.00
0.00 0.00 )
On observe que ce qui distingue les mammifères d’Elevage et ceux domestiqués des Rongeurs
et Reptiles est le Critère de Poids.
D’un autre côté, l’âge est le critère qui différencie :
- les Mammifères d’Elevage avec ceux Domestiqués,
- les Mammifères Rongeurs avec des Reptiles

37
XI – La méthode DIV
a) Introduction à la méthode DIV La méthode DIV (pour Divisive Clustering) permet d’obtenir le classement sous forme de
hiérarchie des objets symboliques de la même classe. Pour ce faire, le programme prend la
totalité des objets symboliques pour les placer dans un même échantillon.
Il est important de noter que les variables d’échantillonnage ne peuvent être à la fois
qualitatives et quantitatives. Ici encore, l’utilisateur doit pouvoir prendre la décision la plus
judicieuse.
Par la suite, l’échantillon formé est divisé à chaque itération en deux sous échantillons, en
fonction de questions binaires, de façon à obtenir les variances interclasse maximale, et
intraclasse minimale.
b) Description des résultats de l’application Dans un premier temps, la méthode est exécutée avec les variables qualitatives :
- Département
- Type de Client
Nous obtenons le listing suivant : THE CLUSTERING TREE :
---------------------
- the number noted at each node indicates
the order of the divisions
- Ng <-> yes and Nd <-> no
+---- Classe 1 (Ng=4)
!
!----3- [Type_de_Client = Commercial]
! !
! +---- Classe 4 (Nd=2)
!
!----1- [Département <= Aveyron]
!
! +---- Classe 2 (Ng=3)
! !
!----2- [Département <= Hérault]
!
+---- Classe 3 (Nd=2)
Nous remarquons, comme nous pouvions le supposer, des types d’animaux différents en
fonction du département.
Dans un second temps, les variables quantitatives - Age, Taille, Poids et Montant Total-
permettent d’obtenir le listing suivant :
THE CLUSTERING TREE :
---------------------
- the number noted at each node indicates
the order of the divisions
- Ng <-> yes and Nd <-> no
+---- Classe 1 (Ng=3)
!

38
!----5- [Poids <= 177.750000]
! !
! +---- Classe 6 (Nd=1)
!
!----2- [MONTANT_TOTAL <= 1074.750000]
! !
! ! +---- Classe 3 (Ng=2)
! ! !
! !----6- [Age <= 8.885000]
! !
! +---- Classe 7 (Nd=2)
!
!----1- [MONTANT_TOTAL <= 2336.250000]
!
! +---- Classe 2 (Ng=1)
! !
!----3- [Taille <= 12.500000]
!
! +---- Classe 4 (Ng=1)
! !
!----4- [Age <= 9.035000]
!
+---- Classe 5 (Nd=1)
Nous remarquons que le premier critère de partage joue sur le Montant Total en soins
prodigués à l’animal. On pourra donc considérer les animaux en fonction de la catégorie de
prix qu’ils coûtent en médicaments, analyses et visites.
39
XII – La méthode SCLUST (avec Sodas 2.0)
a) Description de la méthode
La méthode SCLUST (pour Symbolic Dynamic Clustering) a pour objectif d’ordonner un
ensemble d’objet symboliques au sein d’un ensemble prédéfini de k classes distinctes.
Dans cette méthode, il est possible d’activer un module spécifique permettant d’atteindre le
nombre optimal de classes. L’approche proposée est issue de l’extension du de l’algorithme
du Traitement des Nuées Dynamiques (Diday, 1971).
Ce procédé de Classification Dynamique insiste sur la détermination de partitions dont la
succession d’itérations améliore le critère d’optimalité.
Un des critères de classification est optimisé en fonction des distances calculées entre les
objets symboliques.
b) Description des résultats de l’application
Afin de pouvoir exécuter cette méthode SCLUST, il a été nécessaire d’installer la nouvelle
version de SODAS.
Afin de ne pas perdre les affichages et méthodes déjà archivées, je vais créer un nouveau
fichier sds dans lequel la même base de données clinique.mdb sera importée, mais avec lequel
je n’exécuterai que la méthode SCLUST.
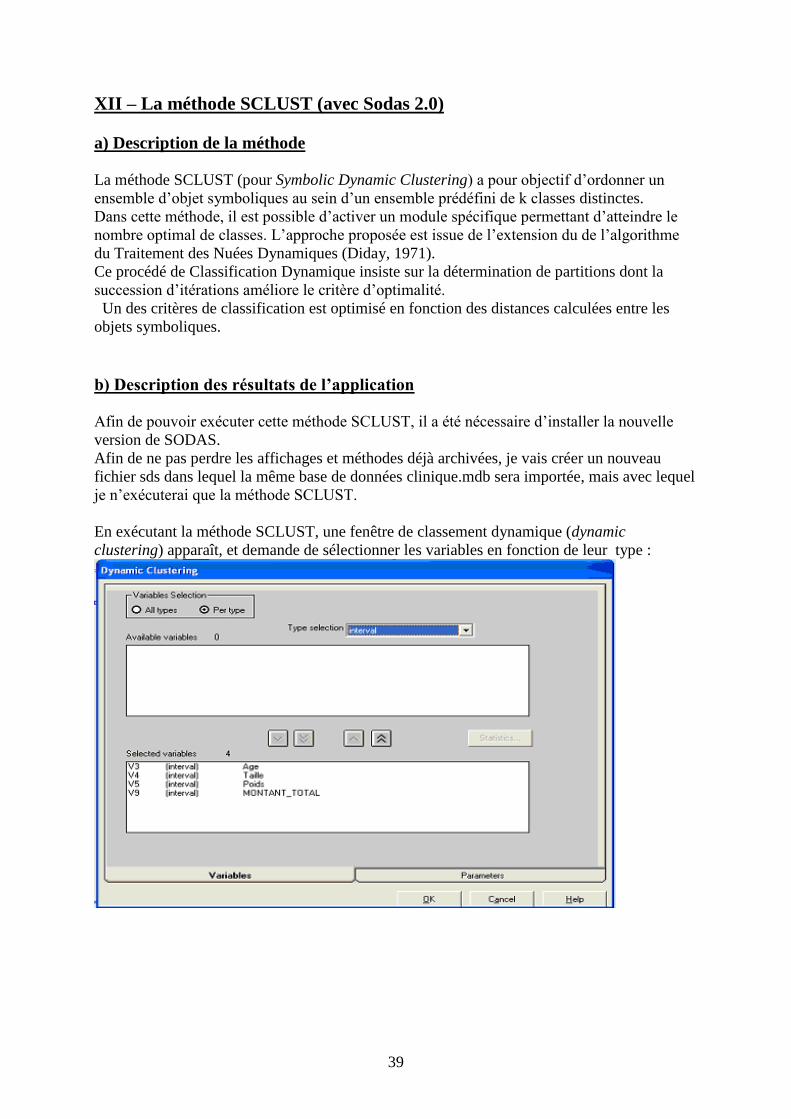
En exécutant la méthode SCLUST, une fenêtre de classement dynamique (dynamic
clustering) apparaît, et demande de sélectionner les variables en fonction de leur type :
40
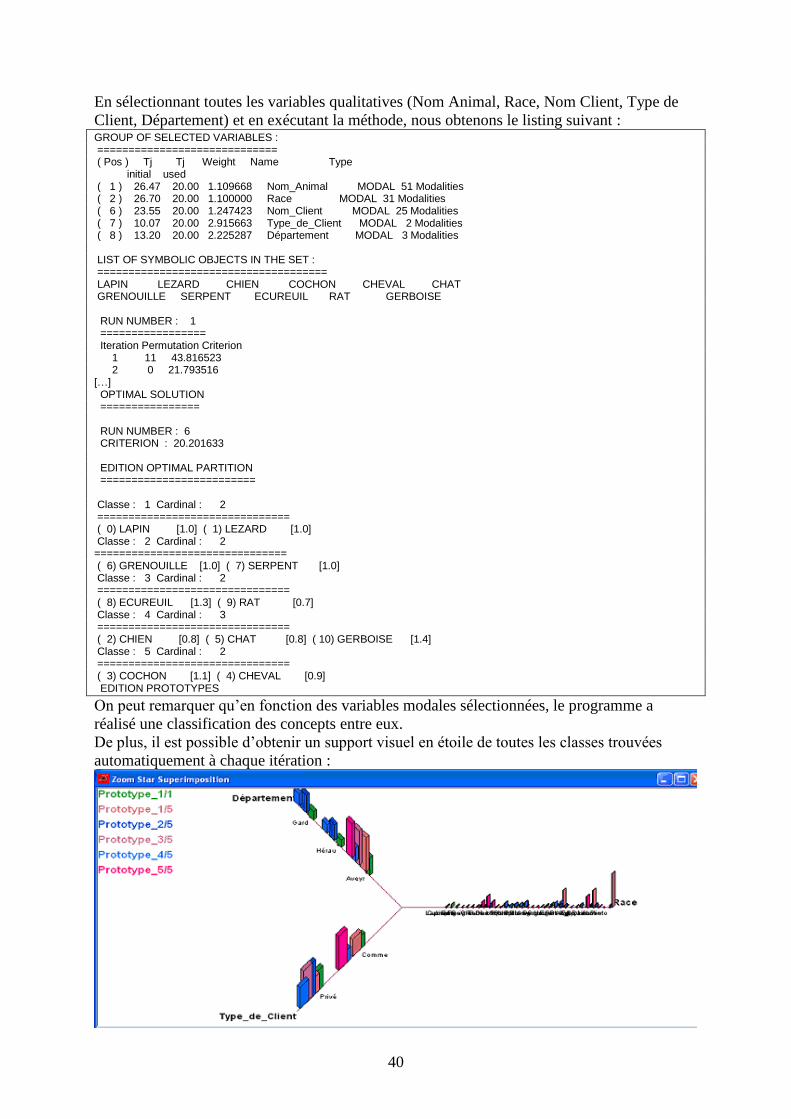
En sélectionnant toutes les variables qualitatives (Nom Animal, Race, Nom Client, Type de
Client, Département) et en exécutant la méthode, nous obtenons le listing suivant : GROUP OF SELECTED VARIABLES : ============================= ( Pos ) Tj Tj Weight Name Type initial used ( 1 ) 26.47 20.00 1.109668 Nom_Animal MODAL 51 Modalities ( 2 ) 26.70 20.00 1.100000 Race MODAL 31 Modalities ( 6 ) 23.55 20.00 1.247423 Nom_Client MODAL 25 Modalities ( 7 ) 10.07 20.00 2.915663 Type_de_Client MODAL 2 Modalities ( 8 ) 13.20 20.00 2.225287 Département MODAL 3 Modalities LIST OF SYMBOLIC OBJECTS IN THE SET : ===================================== LAPIN LEZARD CHIEN COCHON CHEVAL CHAT GRENOUILLE SERPENT ECUREUIL RAT GERBOISE RUN NUMBER : 1 ================= Iteration Permutation Criterion 1 11 43.816523 2 0 21.793516 […] OPTIMAL SOLUTION ================ RUN NUMBER : 6 CRITERION : 20.201633 EDITION OPTIMAL PARTITION ========================= Classe : 1 Cardinal : 2 =============================== ( 0) LAPIN [1.0] ( 1) LEZARD [1.0] Classe : 2 Cardinal : 2 =============================== ( 6) GRENOUILLE [1.0] ( 7) SERPENT [1.0] Classe : 3 Cardinal : 2 =============================== ( 8) ECUREUIL [1.3] ( 9) RAT [0.7] Classe : 4 Cardinal : 3 =============================== ( 2) CHIEN [0.8] ( 5) CHAT [0.8] ( 10) GERBOISE [1.4] Classe : 5 Cardinal : 2 =============================== ( 3) COCHON [1.1] ( 4) CHEVAL [0.9] EDITION PROTOTYPES
On peut remarquer qu’en fonction des variables modales sélectionnées, le programme a
réalisé une classification des concepts entre eux.
De plus, il est possible d’obtenir un support visuel en étoile de toutes les classes trouvées
automatiquement à chaque itération :

41
XIII – Conclusions et Perspectives
En définitive, l’emploi du logiciel SODAS m’a permis de mieux comprendre la thématique et
les enjeux de l’analyse de données symboliques.
L’incroyable flexibilité du programme, et la pléthore de méthodes (en augmentation avec la
nouvelle version) m’a permis de mettre en évidence un certain nombre de profils liés à ma
base de départ, comme par exemple le fait que:
- la clinique vétérinaire étudiée réalise la plus grande plus value sur de petits animaux
(comme l’écureuil, la grenouille ou le lézard), ce qui, au départ, ne semblait pas du
tout évident
- le type des propriétaires d’animaux (privé ou commercial) joue beaucoup sur le type
d’animal possédé
- certains animaux possèdent des affinités entre eux, et se retrouvent en compagnie l’un
l’autre chez les mêmes propriétaires
Il ne faut pas non plus oublier que toute conclusion -établie à la suite de l’exécution et
l’analyse de méthodes de SODAS- est induite par la base initiale.
Je ne pourrai donc pas émettre l’hypothèse que TOUTES les cliniques vétérinaires possèdent
des clients adoptant les profils établis. En plus de l’exactitude des données, il est
particulièrement important de réfléchir sur l’écart, nécessairement induit, entre les valeurs de
ma base et la réalité.
En d’autres termes, toute description d’un objet, aussi profonde et précise qu’elle soit, ne
pourra jamais totalement définir l’objet de la réalité.
Malgré ce dilemme qui, je le crains, ne pourra jamais être contourné, je me dois d’insister sur
le fait que l’extraction de connaissances à partir de toute base de données relationnelle m’a
permis de faire la différence entre l’image de l’entreprise basique, orientée vers le stockage
d’informations simple, et la cellule d’intelligence décisionnelle qui peut mettre à profit toute
la masse de données qu’elle possède, afin d’extraire des profils, et d’orienter toute démarche
stratégique vers un avenir sûr et florissant.

42
ANNEXES
43
Méthode SOE
Graphiques en deux dimensions
44
45
46
47
48
49
Graphiques en trois dimensions
50
51
52
53
54
55
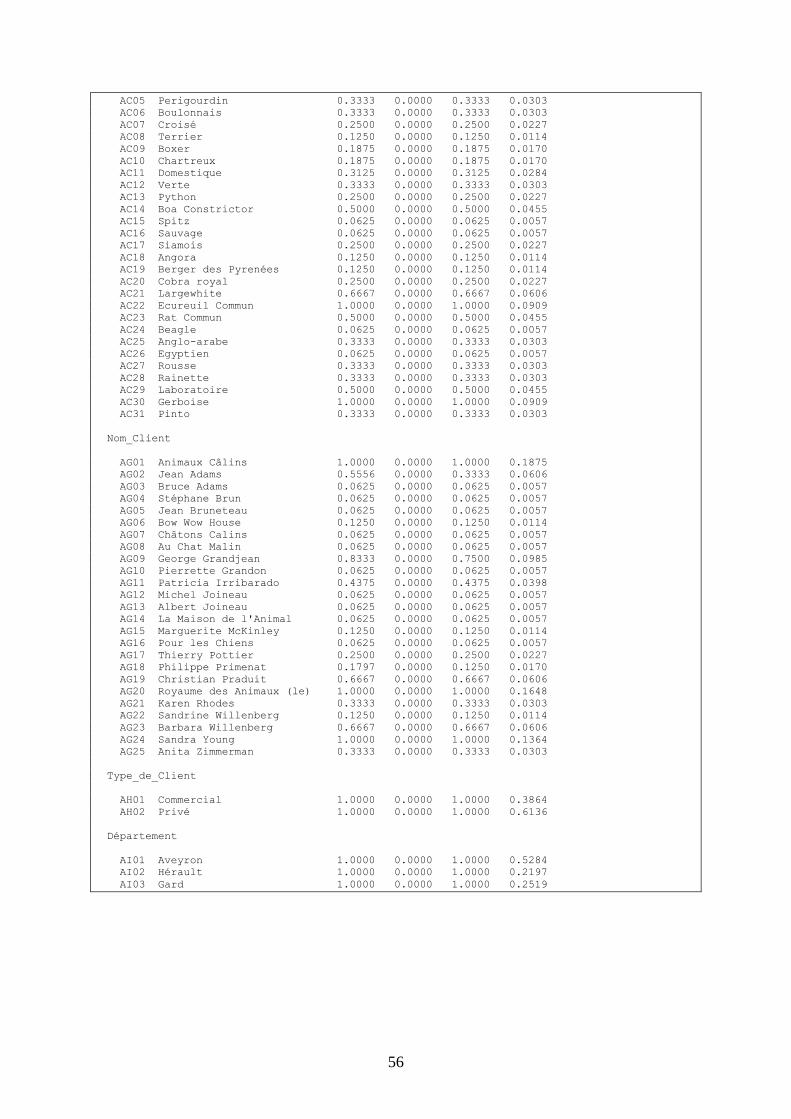
Méthode STAT
Sortie Listing Capacités Min/Max/Mean
--------------------------------------------------------------------------------
SODAS - STAT CAPACITIES Dec 08 àSUÕ?2004 21:43
File: EXPORT~1.SDS
Title: Clinique
--------------------------------------------------------------------------------
capa mini maxi mean
Nom_Animal
AB01 Bobo 0.5000 0.0000 0.5000 0.0455
AB02 Presto Chango 1.0000 0.0000 1.0000 0.0909
AB03 Aquilon 0.5000 0.0000 0.5000 0.0455
AB04 Fido 0.0625 0.0000 0.0625 0.0057
AB05 Porky 0.3333 0.0000 0.3333 0.0303
AB06 Rising Sun 0.3333 0.0000 0.3333 0.0303
AB07 Désirée 0.0625 0.0000 0.0625 0.0057
AB08 Janvier 0.0625 0.0000 0.0625 0.0057
AB09 John Boy 0.0625 0.0000 0.0625 0.0057
AB10 Douce 0.0625 0.0000 0.0625 0.0057
AB11 Quintin 0.0625 0.0000 0.0625 0.0057
AB12 Stupide 0.0625 0.0000 0.0625 0.0057
AB13 Cracmouche 0.0625 0.0000 0.0625 0.0057
AB14 Adam 0.3333 0.0000 0.3333 0.0303
AB15 Tueur 0.2500 0.0000 0.2500 0.0227
AB16 Fuyant 0.2500 0.0000 0.2500 0.0227
AB17 Sammie 0.2500 0.0000 0.2500 0.0227
AB18 Sammie Girl 0.0625 0.0000 0.0625 0.0057
AB19 C.C. 0.0625 0.0000 0.0625 0.0057
AB20 Gizmo 0.0625 0.0000 0.0625 0.0057
AB21 Doudoune 0.0625 0.0000 0.0625 0.0057
AB22 Roméo 0.0625 0.0000 0.0625 0.0057
AB23 César 0.1211 0.0000 0.0625 0.0114
AB24 Juliette 0.0625 0.0000 0.0625 0.0057
AB25 Tigre 0.0625 0.0000 0.0625 0.0057
AB26 Rôdeur 0.0625 0.0000 0.0625 0.0057
AB27 Fi Fi 0.0625 0.0000 0.0625 0.0057
AB28 Micro 0.0625 0.0000 0.0625 0.0057
AB29 Rex 0.0625 0.0000 0.0625 0.0057
AB30 Sylvester 0.0625 0.0000 0.0625 0.0057
AB31 Kaa 0.2500 0.0000 0.2500 0.0227
AB32 Brutus 0.0625 0.0000 0.0625 0.0057
AB33 Cleo 0.0625 0.0000 0.0625 0.0057
AB34 P'tit bout 0.0625 0.0000 0.0625 0.0057
AB35 Rosie 0.3333 0.0000 0.3333 0.0303
AB36 Bouton d'or 0.3333 0.0000 0.3333 0.0303
AB37 Margo 1.0000 0.0000 1.0000 0.0909
AB38 Tom 0.0625 0.0000 0.0625 0.0057
AB39 Jerry 0.5000 0.0000 0.5000 0.0455
AB40 Marcus 0.0625 0.0000 0.0625 0.0057
AB41 Pookie 0.0625 0.0000 0.0625 0.0057
AB42 Mario 0.0625 0.0000 0.0625 0.0057
AB43 Luigi 0.0625 0.0000 0.0625 0.0057
AB44 Oren Girl 0.3333 0.0000 0.3333 0.0303
AB45 Fleur 0.0625 0.0000 0.0625 0.0057
AB46 Ombre 0.0625 0.0000 0.0625 0.0057
AB47 Hop 0.3333 0.0000 0.3333 0.0303
AB48 Benjamin 0.6667 0.0000 0.5000 0.0758
AB49 Frileuse 0.5000 0.0000 0.5000 0.0455
AB50 Princesse 0.5000 0.0000 0.5000 0.0455
AB51 Minuit 0.3333 0.0000 0.3333 0.0303
Race
AC01 Lapin Commun 0.5000 0.0000 0.5000 0.0455
AC02 Caméléon 1.0000 0.0000 1.0000 0.0909
AC03 Lapin Nain 0.5000 0.0000 0.5000 0.0455
AC04 Berger allemand 0.1875 0.0000 0.1875 0.0170
56
AC05 Perigourdin 0.3333 0.0000 0.3333 0.0303
AC06 Boulonnais 0.3333 0.0000 0.3333 0.0303
AC07 Croisé 0.2500 0.0000 0.2500 0.0227
AC08 Terrier 0.1250 0.0000 0.1250 0.0114
AC09 Boxer 0.1875 0.0000 0.1875 0.0170
AC10 Chartreux 0.1875 0.0000 0.1875 0.0170
AC11 Domestique 0.3125 0.0000 0.3125 0.0284
AC12 Verte 0.3333 0.0000 0.3333 0.0303
AC13 Python 0.2500 0.0000 0.2500 0.0227
AC14 Boa Constrictor 0.5000 0.0000 0.5000 0.0455
AC15 Spitz 0.0625 0.0000 0.0625 0.0057
AC16 Sauvage 0.0625 0.0000 0.0625 0.0057
AC17 Siamois 0.2500 0.0000 0.2500 0.0227
AC18 Angora 0.1250 0.0000 0.1250 0.0114
AC19 Berger des Pyrenées 0.1250 0.0000 0.1250 0.0114
AC20 Cobra royal 0.2500 0.0000 0.2500 0.0227
AC21 Largewhite 0.6667 0.0000 0.6667 0.0606
AC22 Ecureuil Commun 1.0000 0.0000 1.0000 0.0909
AC23 Rat Commun 0.5000 0.0000 0.5000 0.0455
AC24 Beagle 0.0625 0.0000 0.0625 0.0057
AC25 Anglo-arabe 0.3333 0.0000 0.3333 0.0303
AC26 Egyptien 0.0625 0.0000 0.0625 0.0057
AC27 Rousse 0.3333 0.0000 0.3333 0.0303
AC28 Rainette 0.3333 0.0000 0.3333 0.0303
AC29 Laboratoire 0.5000 0.0000 0.5000 0.0455
AC30 Gerboise 1.0000 0.0000 1.0000 0.0909
AC31 Pinto 0.3333 0.0000 0.3333 0.0303
Nom_Client
AG01 Animaux Câlins 1.0000 0.0000 1.0000 0.1875
AG02 Jean Adams 0.5556 0.0000 0.3333 0.0606
AG03 Bruce Adams 0.0625 0.0000 0.0625 0.0057
AG04 Stéphane Brun 0.0625 0.0000 0.0625 0.0057
AG05 Jean Bruneteau 0.0625 0.0000 0.0625 0.0057
AG06 Bow Wow House 0.1250 0.0000 0.1250 0.0114
AG07 Châtons Calins 0.0625 0.0000 0.0625 0.0057
AG08 Au Chat Malin 0.0625 0.0000 0.0625 0.0057
AG09 George Grandjean 0.8333 0.0000 0.7500 0.0985
AG10 Pierrette Grandon 0.0625 0.0000 0.0625 0.0057
AG11 Patricia Irribarado 0.4375 0.0000 0.4375 0.0398
AG12 Michel Joineau 0.0625 0.0000 0.0625 0.0057
AG13 Albert Joineau 0.0625 0.0000 0.0625 0.0057
AG14 La Maison de l'Animal 0.0625 0.0000 0.0625 0.0057
AG15 Marguerite McKinley 0.1250 0.0000 0.1250 0.0114
AG16 Pour les Chiens 0.0625 0.0000 0.0625 0.0057
AG17 Thierry Pottier 0.2500 0.0000 0.2500 0.0227
AG18 Philippe Primenat 0.1797 0.0000 0.1250 0.0170
AG19 Christian Praduit 0.6667 0.0000 0.6667 0.0606
AG20 Royaume des Animaux (le) 1.0000 0.0000 1.0000 0.1648
AG21 Karen Rhodes 0.3333 0.0000 0.3333 0.0303
AG22 Sandrine Willenberg 0.1250 0.0000 0.1250 0.0114
AG23 Barbara Willenberg 0.6667 0.0000 0.6667 0.0606
AG24 Sandra Young 1.0000 0.0000 1.0000 0.1364
AG25 Anita Zimmerman 0.3333 0.0000 0.3333 0.0303
Type_de_Client
AH01 Commercial 1.0000 0.0000 1.0000 0.3864
AH02 Privé 1.0000 0.0000 1.0000 0.6136
Département
AI01 Aveyron 1.0000 0.0000 1.0000 0.5284
AI02 Hérault 1.0000 0.0000 1.0000 0.2197
AI03 Gard 1.0000 0.0000 1.0000 0.2519

57
Sortie Listing Fréquences relatives pour les variables intervalles :
--------------------------------------------------------------------------------
SODAS - STAT RELATIVE FREQUENCIES (INTERVAL) Dec 08 2004 21:45
File: EXPORT~1.SDS
Title: Clinique
--------------------------------------------------------------------------------
Age
limits: 5.7 - 15.62 class width: 0.992
class 1 0.3860
class 2 0.1672
class 3 0.1783
class 4 0.0683
class 5 0.0507
class 6 0.0302
class 7 0.0302
class 8 0.0302
class 9 0.0302
class 10 0.0288
Central tendancy: 8.1553
Dispersion: 2.4273
Taille
limits: 0.0 - 262.0 class width: 26.2
class 1 0.3891
class 2 0.3201
class 3 0.1019
class 4 0.0111
class 5 0.0315
class 6 0.0596
class 7 0.0533
class 8 0.0111
class 9 0.0111
class 10 0.0111
Central tendancy: 54.1824
Dispersion: 55.2013
Poids
limits: 0.0 - 354.0 class width: 35.4
class 1 0.6458
class 2 0.0685
class 3 0.0000
class 4 0.1429
class 5 0.0000
class 6 0.0000
class 7 0.0000
class 8 0.0000
class 9 0.0000
class 10 0.1429
Central tendancy: 80.8102
Dispersion: 110.5214
MONTANT_TOTAL
limits: 0.0 - 6197.5 class width: 619.75
class 1 0.3294
class 2 0.2777
class 3 0.1423
class 4 0.1145
class 5 0.0753
class 6 0.0146
class 7 0.0116
58
class 8 0.0116
class 9 0.0116
class 10 0.0116
Central tendancy: 1318.1400
Dispersion: 1153.0549
59
Méthode PYR
Affichage selon les 4 variables quantitatives:





























