Embed Size (px)
Citation preview

Chapitre 3
Analyse
1. Introduction
1.1 Objectifs de l’analyse
Rappelons que l’analyse a pour objectif de réaliser des spécifications qui facilitent et orientent la conception de la solution. Elle consiste essentiellement à rechercher les objets du domaine, leurs propriétés et leurs relations. Elle focalise sur la production d’un modèle appelé modèle d’analyse. Il faut bien distinguer entre analyse objet et analyse des besoins dans laquelle les développeurs expriment et restructurent les besoins du point de vue des utilisateurs et du client en établissant un modèle de cas d’utilisation.
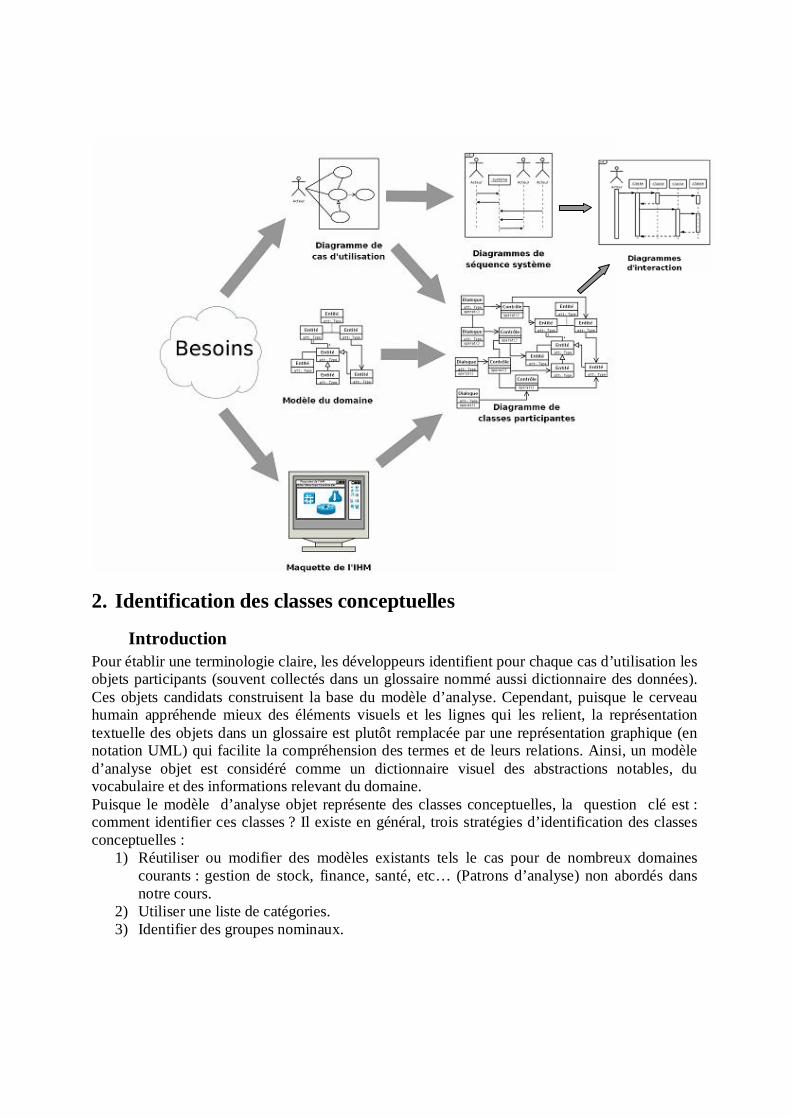
1.2 Modèle d’analyse En fait, le modèle d’analyse se compose de trois modèles individuels :
- Modèle fonctionnel (représenté par les cas d’utilisation et les scénarios) modèle des cas d’utilisation (voir chapitre 2). Ce modèle peut éventuellement contenir une maquette d’IHM (Interface Homme-Machine) qui est en fait un produit jetable permettant aux
Analyse orientée objet

utilisateurs d’avoir une vue concrète mais non définitive de la future interface de l’application.
- Modèle d’analyse objet (exprimé généralement par des diagrammes de classes et d’objets)
- Modèle dynamique (décrit souvent par des diagrammes d’interaction, d’état :transition ou encore d’activité).
Nous nous intéressons dans ce chapitre donc au raffinement du modèle des cas d’utilisation pour dériver les deux derniers modèles.
1.2.1 Modèle d’analyse objet
Le modèle d’analyse objet appelé aussi modèle du domaine est le modèle le plus important. Son élaboration est effectuée lors de la première itération de la phase Elaboration du processus unifié. Il est une représentation visuelle des classes conceptuelles ou des objets manipulés par le système. Pour le processus UP, ce modèle est constitué d’un ensemble de diagrammes de classes dans lequel aucune opération (méthode, signature) n’est définie. Il fournit une perspective conceptuelle et peut représenter les éléments suivants :
- Les classes conceptuelles ou les objets du domaine ; - Les associations entre classes conceptuelles ; - Les attributs des classes conceptuelles.
1.2.2 Modèle dynamique
Le modèle dynamique focalise sur le comportement du système (toujours lors de la première itération de la phase Elaboration de UP). Des diagrammes d’interaction (souvent de séquence) sont construits pour chaque cas d’utilisation. Ce modèle permet d’assigner des responsabilités à chaque classe individuelle dans le processus afin d’identifier de nouvelles classes, associations et attributs à ajouter au modèle d’analyse objet. Il faut noter qu’avec ces modèles, nous ne sommes pas encore au niveau classes ou composants logiciels.
1.3 Activités d’analyse Pour transformer les UC et les scénarios produits lors de la phase Analyse des besoins en un modèle d’analyse, il faut :
- Identifier les objets ou classes conceptuelles (candidates, participantes). Chaque UC via ses scénarios fournit son lot d’objets.
- Construire les diagrammes d’interaction (séquence ou collaboration) pour étudier la distribution de comportement de chaque cas d’utilisation entre ses objets et identifier des objets éventuellement oubliés.
- Identifier les attributs et les associations. - Représenter sous forme de classes dans un diagramme UML. - Identifier les relations d’héritage. - Déterminer les responsabilités principales de chacune des classes conceptuelles.
2. Identification des classes conceptuelles
Introduction Pour établir une terminologie claire, les développeurs identifient pour chaque cas d’utilisation les objets participants (souvent collectés dans un glossaire nommé aussi dictionnaire des données). Ces objets candidats construisent la base du modèle d’analyse. Cependant, puisque le cerveau humain appréhende mieux des éléments visuels et les lignes qui les relient, la représentation textuelle des objets dans un glossaire est plutôt remplacée par une représentation graphique (en notation UML) qui facilite la compréhension des termes et de leurs relations. Ainsi, un modèle d’analyse objet est considéré comme un dictionnaire visuel des abstractions notables, du vocabulaire et des informations relevant du domaine. Puisque le modèle d’analyse objet représente des classes conceptuelles, la question clé est : comment identifier ces classes ? Il existe en général, trois stratégies d’identification des classes conceptuelles :
1) Réutiliser ou modifier des modèles existants tels le cas pour de nombreux domaines courants : gestion de stock, finance, santé, etc… (Patrons d’analyse) non abordés dans notre cours.
2) Utiliser une liste de catégories. 3) Identifier des groupes nominaux.

2.1 Identification d’une liste de catégories de classes
Le tableau suivant présente un certain nombre de catégories de classes conceptuelles courantes qui peuvent être prise en compte avec une insistance particulière sur les informations métier dont le système a besoin.
2.2 Identification des groupes nominaux
En 1983, Abbot R. a proposé une technique basée sur une « analyse linguistique » connue aussi sous le nom de « modélisation du langage naturel », qui consiste à repérer les noms et les groupes nominaux dans la description textuelle d’un domaine et à les considérer comme des classes conceptuelles ou des attributs possibles. L’un des points faibles de cette méthode est l’imprécision du langage naturel : différentes classes conceptuelles peuvent représenter la même classe ou le même attribut.
Les cas d’utilisation détaillés fournissent une excellente description qui sert de base à cette analyse.
- Examiner la description de chaque cas d’utilisation, notamment les différents scénarios (nominal, alternatifs, exceptions).
- Extraire des noms ou des groupes nominaux et en faire des classes conceptuelles candidates.
- Eliminer les noms qui : Sont redondants Sont vagues ou trop généraux. Ne sont pas des classes conceptuelles par expérience et connaissance dans le
contexte de l’application.

Exemple :
Glossaire des classes conceptuelles identifiées : Clent Produit achat Caisse Description Ticket Caissier Exemplaire Représentation graphique : Client Produit

2.3 Types de classes d’analyse
La réalisation des cas d’utilisation, en d’autres termes des collaborations, fait intervenir d’autres objets supplémentaires qui n’appartiennent pas au domaine de l’application mais qui sont nécessaires à son fonctionnement. La nature de ces objets peut être signifiée au moyen de stéréotypes (stéréotypes de Jacobson).
Trois types de classes d’analyse sont généralement identifiés (Principe fondamental du découpage en couches d’une application) :
- Classes entités (stéréotype : «entité »): appelée aussi classes métier résultent de l’analyse initiale et apparaissent souvent dans plusieurs UC. Elles sont les classes données du système et leur durée de vie est plus longue que celle des UC. Elles sont généralement persistantes (permettent à des données ou des relations d’être stockées dans des fichiers ou des bases de données).
- Classes frontière (stéréotype : «interface»): appelées aussi classes interface ou classes de dialogue, servent comme interface entre acteurs et système en convertissant les entrées des acteurs en évènement ou en messages internes et en transformant les messages de sorties pour qu’ils puissent être compris par les acteurs.
- Classes Contrôle (stéréotype : «contrôle»): servent comme liaison entre interface et objets entité et encapsulent donc le comportement d’un UC. Leur durée de vie est égale à celle des UC. Les UC simples n’ont pas besoins de classe contrôle.
Exp : Pour un distributeur automatique on peut identifier les classes :
Client : entité Guichet automatique : frontière Vérificateur du code secret : contrôle
Remarques : Les classes frontière et contrôle sont souvent identifiées en analysant les diagrammes d’interaction.
Les comportements des UC sont placés dans les classes contrôle et frontière.
2.4 Paquetages
Il est aussi possible de procéder à un découpage logique indépendant de la réalisation et identifier ainsi des paquetages d’analyse à partir des UC et du domaine. Cela constitue un point

de départ du découpage du système en sous systèmes. Il est alors nécessaire de définir des relations de dépendance entre ces paquetages.
3. Analyse des interactions entre objets Pour analyser les interactions entre objets d’un UC et compléter la définition des objets d’analyse, il est nécessaire de construire pour chaque UC (ou scénario) un diagramme d’interaction (DI). Le choix entre diagramme de séquence et diagramme de collaboration est subjectif puisqu’ils représentent souvent les mêmes éléments. Les diagrammes de collaboration mettent l’accent sur « l’organisation spéciale » des objets (numérotation des messages introduit une dimension temporelle). Les diagrammes de séquence mettent l’accent sur « l’organisation temporelle ». Les diagrammes de séquence sont généralement plus faciles à obtenir (la séquentialité des interactions découle de la description textuelles des UC). Dans l’analyse, ces diagrammes sont utiles pour préciser la réalisation des cas d’utilisation). Un diagramme de séquence met en œuvre des instances (instances de classes, instances d’acteurs). La durée de vie des instances est définie sur l’axe vertical du diagramme. A travers des diagrammes de séquences :
- Les relations entre objets peuvent être identifiées.

- A chaque objet (instance) sont assignées des responsabilités (responsabilité = union des rôles dans tous les cas où l’objet intervient).
- De nouveaux objets ou ceux oubliés peuvent être identifiés. - Un diagramme de classe peut être généré pour chaque UC.
Exemple : Cas d’utilisation « payer en espèce »
Diagramme de collaboration :
Diagramme de séquence :
Le système des diagrammes de séquences système, vu comme une boîte noire, est remplacé par un ensemble d’objets en collaboration.

Remarque : Lorsque les scénarios alternatifs d’un cas d’utilisation sont nombreux et importants, l’utilisation d’un diagramme d’états/transitions ou d’activités peut s’avérer préférable à une multitude de diagrammes de séquence.
4. Identification des attributs et des associations Commencer avec les classes considérées centrales dans le système. Eviter d’ajouter trop d’associations et d’attributs à une classe afin de la mieux maîtriser.
4.1 Identification des associations
Pour juger quelles associations entre objets d’analyse représenter, il faut généralement identifier les relations qui nécessitent d’être conservées un certain temps (critère de mémorabilité).
Identifier les groupes verbaux dénotant un état dans la description textuelle des UC.
Le plus souvent, une association devrait exister entre une classe A et une classe B si : - A est un service ou un produit de B - A est une partie de B - A est une description pour B - A est connecté à B - A possède B ou A utilise B ou A gère B - A contrôle B - A est un rôle relatif à B
Observer les liaisons dans les DI :
- Chaque liaison peut être une instance d’une association. - Dans certains cas, elle peut impliquer une agrégation ou une généralisation.

Les associations sont représentées suivant la notation UML relative aux diagrammes de classes (nom, multiplicité, sens de lecture).
4.2 Identification des attributs
Les attributs (et éventuellement leurs types) sont souvent trouvés lors de l’identification des classes. Il faut lister et décrire chaque attribut à partir de chaque réalisation de UC. Exp : Le caissier encode l’identificateur de chaque produit. La caisse calcule et affiche le montant total à régler . Les attributs des classes qui s’interfacent à des humains sont souvent des champs de données comme ceux des boîtes de dialogue. Les attributs de classes qui s ’interfacent à des équipements sont souvent des valeurs ou les états de capteurs, ou les paramètres d’un protocole de communication. Les attributs des classes contrôle sont des données temporaires de UC. Remarques : Si un ensemble d’attributs forme un groupe cohérent, une nouvelle classe peut être introduite. Exp :
La syntaxe de tout attribut doit respecter la notation UML associée. A travers une analyse linguistique de la description textuelle détaillée de UC, les attributs sont identifiées en examinant les noms et les adjectifs exprimant des propriétés d’objets. Il est recommandé d’identifier le maximum d’associations possibles avant d’identifier les attributs afin d’éviter la confusion entre attributs et objets.
4.3 Identification des relations d’héritage L’identification de relation d’héritage aide à éliminer des redondances du modèle d’analyse. Les héritages peuvent être identifiés de deux façons :

- De bas en haut : généralisation. Si deux ou plusieurs classes partagent des attributs ou un comportement, les similarités sont consolidées dans une super classe.
- De haut en bas : Spécialisation. Construire des sous classes à partir de classes existantes. Exp :
5. Révision et validation du modèle d’analyse Le modèle d’analyse est construit de manière incrémentale et itérative. Il n’existe pas en fait de modèle d’analyse correct. Tous les modèles sont des approximations du domaine que nous essayons de comprendre pour appréhender ainsi ses concepts, sa terminologie et ses relations. Plusieurs itérations avec le client et les utilisateurs sont nécessaires avant que le modèle d’analyse ne converge vers une spécification utilisable pour la conception de l’implémentation. Une fois le modèle devenu stable, il doit être révisé par les développeurs en premier lieu puis conjointement par les développeurs et le client. Le but de cette révision est de s’assurer que la spécification des besoins est correcte, complète, consistante et non ambiguë.
6. Etude de cas : Modélisation d’un site web marchand, en l’occurrence une librairie : La librairie en ligne constitue en effet un exemple facile à comprendre et suffisamment représentatif des projets d’applications web. L’objectif fondamental de tels sites est de permettre aux internautes de rechercher des ouvrages par thème, auteur, mot-clé, etc., de se constituer un panier virtuel, puis de pouvoir les commander et les payer directement sur le Web. Dans notre cas, nous nous restreindrons à la fonctionnalité de gestion du panier virtuel. Dans un véritable magasin, le client choisit ses articles les uns à la suite des autres, les dépose dans son panier, puis se rend à la caisse pour régler le tout. Les sites marchands tentent de reproduire ces habitudes d'achat le plus fidèlement. Ainsi, lorsque l'internaute est intéressé par un ouvrage, il peut l'enregistrer dans un panier virtuel, comme indiqué sur l’exemple de la figure suivante. Il doit pouvoir ensuite à tout moment en ajouter, en supprimer ou encore en modifier les quantités avant de passer sa commande.
LivreAdulte Auteur Editeur Titre Discipline Niveau
LivreEnfant Auteur Editeur Titre FourchetteAge
Livre Auteur Editeur Titre
LivreEnfant FourchetteAge
LivreAdulte Discipline Niveau GENERALISATION
SPECIALISATION

Nous donnons ci-dessous la description textuelle détaillée des scénarios du cas d’utilisation "Gérer son panier", que nous analyserons.
Scénario nominal : 1. L’Internaute enregistre les ouvrages qui l’intéressent dans un panier virtuel (voir le cas
d’utilisation Rechercher des ouvrages). 2. Le Système lui affiche l’état de son panier. Chaque ouvrage qui a été préalablement
sélectionné est présenté sur une ligne, avec son titre, son auteur et son numéro ISBN. Son prix unitaire est affiché, la quantité est positionnée à « 1 » par défaut, et le prix total de la ligne est calculé. Le total général est calculé par le Système et affiché en bas du panier avec le nombre d’articles.
3. L’Internaute continue ses achats (voir le cas d’utilisation Rechercher des ouvrages). Extensions : 2.a : Le panier est vide
1. Le système affiche un message d’erreur à l’Internaute (« Votre panier est vide ») et lui propose de revenir à une recherche d’ouvrage (voir le cas d’utilisation Chercher des ouvrages).
4.a : L’Internaute modifie les quantités des lignes du panier, ou en supprime. 1. L’Internaute revalide le panier en demandant la mise à jour du panier 2. Le cas d’utilisation reprend à l’étape 2 du scénario nominal.
4.b : L’Internaute demande un devis pour commander par courrier. 1. Le Système fournit un devis imprimable à joindre au règlement récapitulant la
commande et le total à payer. 4.c : L’Internaute souhaite commander en ligne.
1. Le Système l’amène sur la page d’identification 2a. L’Internaute s’identifie en tant que client (voir le cas d’utilisation S’authentifier) 2b. L’Internaute visiteur demande à créer un (voir le cas d’utilisation Créer un compte
client)

Nous identifions facilement les concepts métier « Panier » et « Livre » nommé aussi ouvrage. Nous allons modéliser ces concepts sous forme de diagrammes de classes contenant uniquement des attributs et des associations. Le concept de panier est un concept du domaine, car dans les librairies réelles le client remplit également un panier avant de passer à la caisse. Le panier est simplement un conteneur des livres sélectionnés par le client. Pour exprimer le fait que le panier peut contenir plusieurs exemplaires du même livre, nous allons ajouter un concept intermédiaire qui correspond à une ligne du panier et qui concerne donc un seul livre, mais avec un attribut quantité, initialisé à « 1 » par défaut.
Nous allons maintenant identifier les classes d’analyse qui vont participer à la réalisation du cas d’utilisation. NB. Il faut tout d’abord, élaborer un (ou plusieurs) diagrammes de séquence (à faire
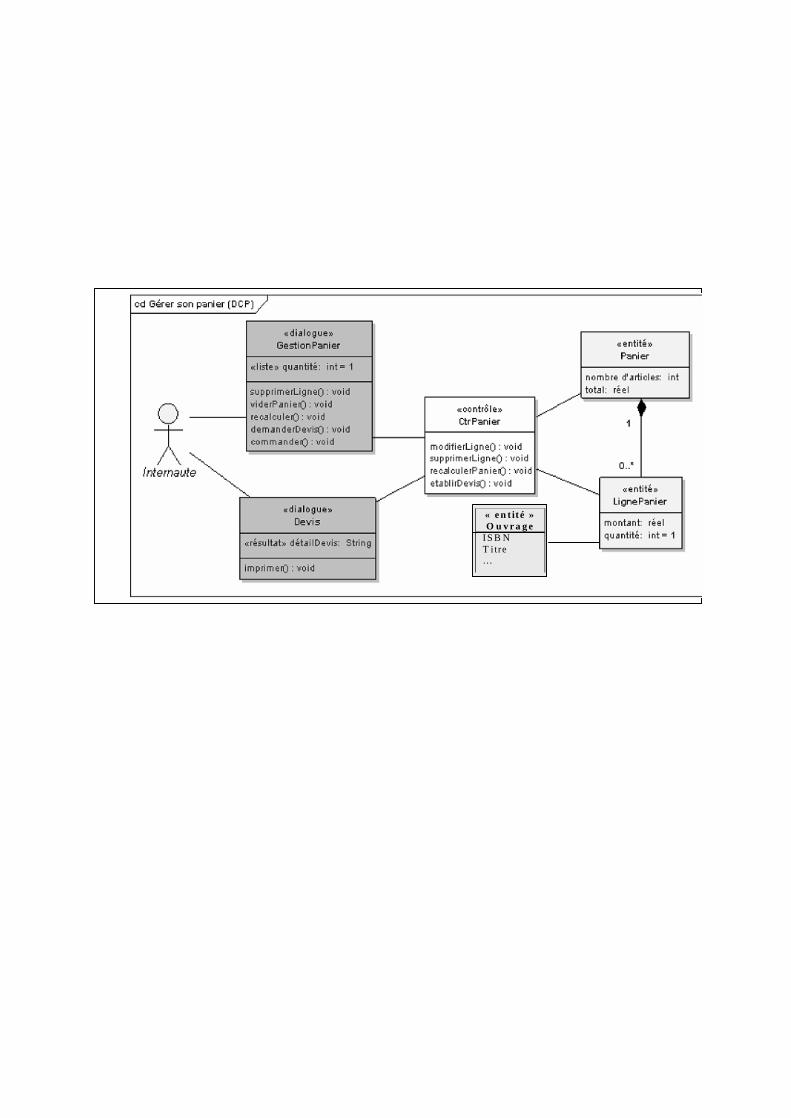
comme exercice). Nous distinguerons trois types de classes d’analyse (comme proposé par I. Jacobson) :
- les « dialogues » qui représentent les moyens d’interaction avec le système, - les « contrôles » qui contiennent la logique applicative - et les « entités » qui sont les objets métier manipulés.
Pour compléter ce travail d’identification, nous allons ajouter aussi des attributs dans les classes d’analyse ainsi que des associations entre elles.
- Les «entités» vont seulement posséder des attributs. Ces attributs représentent en général des informations persistantes de l’application.
- Les «contrôles» vont seulement posséder « des opérations ». Ces opérations montrent la logique de l’application, les règles métier, les comportements du système informatique.
- Les «dialogues » vont posséder des attributs et « des opérations ». Les attributs vont représenter des champs de saisie ou des résultats. Les résultats seront distingués en utilisant la notation de l’attribut dérivé. Les opérations représenteront des actions de l’utilisateur sur l’IHM.
Le diagramme de classes participantes du cas d’utilisation « Gérer son panier » est donné ci-après (l’acteur est relié au dialogue qui est relié au contrôle, lui-même relié aux entités). NB. Les opérations ne peuvent être rajoutées qu’après une analyse plus approfondie des diagrammes d’interaction (séquence) et au début de la conception.
ou plutôt Ouvrage
« e n t it é » O u v r a g e
IS B N T i tre …





























