Embed Size (px)
Citation preview

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 1/415
Laboratoire d’Analyse et Modélisation de Systèmes pour l’Aide à la Décision
UMR CNRS 7024
ANNALES DU LAMSADE N°8Mai 2007
Modèles formels de l’interactionMFI’07Actes des Quatrièmes Journées Francophones
Numéro publié grâce au Bonus Qualité Recherche
accordé par l’Université Paris IX - Dauphine
Responsables de la collection : Vangelis PASCHOS, Bernard ROY
Comité de Rédaction : Cristina BAZGAN, Marie-José BLIN, Denis BOUYSSOU,Albert DAVID, Marie-Hélène HUGONNARD-ROCHE, Eric JACQUET-LAGRÈZE, Patrice MOREAUX, Pierre TOLLA, Alexis TSOUKIÁS.
Pour se procurer l’ouvrage, contactez Mme D. François (secrétariat de rédaction)tél. 01 44 05 42 87 e-mail : [email protected]

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 2/415

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 3/415
I
COLLECTION « CAHIERS, DOCUMENTS ET NOTES » DU LAMSADE
La collection « Cahiers, Documents et Notes » du LAMSADE publie, en anglais ou
en français, des travaux effectués par les chercheurs du laboratoire éventuellement
en collaboration avec des chercheurs externes. Ces textes peuvent ensuite êtresoumis pour publication dans des revues internationales. Si un texte publié dans la
collection a fait l'objet d'une communication à un congrès, ceci doit être alors
mentionné. La collection est animée par un comité de rédaction.
Toute proposition de cahier de recherche est soumise au comité de rédaction qui la
transmet à des relecteurs anonymes. Les documents et notes de recherche sontégalement transmis au comité de rédaction, mais ils sont publiés sans relecture. Pour
toute publication dans la collection, les opinions émises n'engagent que les auteurs
de la publication.
Depuis mars 2002, les cahiers, documents et notes de recherche sont en ligne. Les
numéros antérieurs à mars 2002 peuvent être consultés à la Bibliothèque du
LAMSADE ou être demandés directement à leurs auteurs.
Deux éditions « papier » par an, intitulées « Annales du LAMSADE » sont prévues.
Elles peuvent être thématiques ou représentatives de travaux récents effectués au
laboratoire.
COLLECTION "CAHIERS, DOCUMENTS ET NOTES" OF LAMSADE
The collection “Cahiers, Documents et Notes” of LAMSADE publishes, in Englishor in French, research works performed by the Laboratory research staff, possibly in
collaboration with external researchers. Such papers can (and we encourage to) besubmitted for publication in international scientific journals. In the case one of thetexts submitted to the collection has already been presented in a conference, it has to
be mentioned. The collection is coordinated by an editorial board.
Any submission to be published as “cahier” of LAMSADE, is sent to the editorial
board and is refereed by one or two anonymous referees. The “notes” and“documents” are also submitted to the editorial board, but they are published without
refereeing process. For any publication in the collection, the authors are the unique
responsible for the opinions expressed.
Since March 2002, the collection is on-line. Old volumes (before March 2002) can be found at the LAMSADE library or can be asked directly to the authors.
Two paper volumes, called “Annals of LAMSADE” are planned per year. They can
be thematic or representative of the research recently performed in the laboratory.

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 4/415

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 5/415
III
Préface
L’interactivité est une tendance majeure des systèmes informatiques actuels et unchamp de recherche important. Elle se décline sous plusieurs aspects :
– interaction entre un système et son environnement ;
– interaction entre utilisateurs et systèmes informatiques ; – interaction entre entités informatiques autonomes (agents) interconnectées sur
un réseau local ou sur «la toile», en vue de coopérer, de concourir ou tout
simplement de coexister ; – sans oublier l’intégration de ces deux aspects dans les divers agents conver-
sationnels, agents de recherche, assistants personnels, etc.
Ces tendances sont à l’origine d’un besoin croissant de modèles formels de
l’interaction, intégrant les règles, normes et protocoles divers, ainsi que lesconnaissances spécifiques des agents (en particulier sur les autres agents - humains
ou artificiels - et leurs comportements). Ces modèles doivent permettre deconcevoir, spécifier, valider et contrôler de tels agents coopératifs et commu-
nicationnels.
Le but des Journées Francophones sur les Modèles Formels de l’Interaction(MFI) est de rassembler des chercheurs de différentes communautés scientifiques
(informatique, économie, psychologie cognitive, linguistique, sociologie, etc.) ayanten commun la volonté de formaliser tel ou tel aspect de l’interaction entre agents
artificiels et/ou humains. Plus que jamais, les journées se veulent un point derencontre entre les chercheurs de toutes les disciplines oeuvrant dans le domaine.
MFI’07 est la quatrième édition des Journées. Après Toulouse (2001), Lille(2003) et Caen (2005), l’édition de 2007 a lieu à Paris. Les actes sont publiés dans la
série des «Annales du LAMSADE».
Le programme de MFI’07 est composé de quatre exposés invités et de 39 pré-
sentations (20 longues et 19 courtes) sélectionnées parmi 50 soumissions. Chaquearticle a été évalué par trois relecteurs (voire quatre). Les communications acceptées
proviennent en majorité de laboratoires français, mais aussi de laboratoires
britanniques, canadiens, chypriotes, italiens, néerlandais et néo-zélandais. Lesaffiliations des auteurs reflètent l’aspect pluridisciplinaire des Journées : on y trouve
des chercheurs en informatique (en particulier en intelligence artificielle, systèmesmulti-agents et interaction homme-machine), en économie mathématique, en
psychologie cognitive, en logique et en linguistique.

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 6/415
Préface
IV
Nous avons la chance cette année d’accueillir quatre conférenciers invités de
renommée internationale : Jean-Pierre Benoît, Professeur d’Economie à la LondonBusiness School ; Robert Demolombe, Chercheur associé à l’Institut de Recherche
en Informatique de Toulouse ; Boi Faltings, Professeur à 1’Ecole PolytechniqueFédérale de Lausanne ; et Wiebe van der Hoek, Professeur à l’Université de
Liverpool.
Enfin, nous tenons à remercier toutes les personnes qui ont contribué au succès
de MFI’07 : le comité de programme, ainsi que les relecteurs supplémentaires, quiont fait un excellent travail d’évaluation des articles; le comité d’organisation, qui
s’est non seulement chargé de mettre en place les Journées à l’Université de Paris-Dauphine, mais aussi de mettre en page et de produire les Actes ; le LAMSADE, pour son soutien financier et logistique ; France Telecom et l’Université de Paris-
Dauphine, pour leur soutien financier.
Jérôme Lang, Yves Lespérance et David Sadek,
présidents du comité de programme
Nicolas Maudet, président du comité d’organisation

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 7/415
Annales du LAMSADE N°8
V
Comité de Programme
PrésidentsJ. Lang IRIT, Univ. Paul Sabatier Toulouse (France)
Y. Lespérance York University Toronto (Canada)D. Sadek France Télécom RD Lannion (France)
MembresE. Aimeur S. KoniecznyL. Amgoud P. Lamarre
N. Asher D. Longin
P. Baibiani V. Louis
M. Batt P. MathieuB. Beaufils P. MarquisJ.-F. Bonnefon N. Maudet
B. Chaib-draa A.-I. MouaddibJ. Caelen P. Muller
F. Charpillet M. PaulyR. Demolombe O. Papini
J.-L. Dessalles P. PernyH. van Ditmarsch E. Raufaste
P. Egré N. Sabouret
A. El-Fallah Seghrouchni P.-Y. SchobbensJ. Euzenat S. ShapiroF. Evrard J.-C. Vergnaud
C. Garion B. Walliser
A. Herzig E. WeydertM.-P. Huget
Relecteurs additionnelsM. Bouzid L. Laera
L. Cholvy C. PiraB. Gaudou N. Troquard
Comité d’Organisation
F. Badeig S. KornmanM.-J. Bellosta A. Machado
G. Bourgne N. MaudetY. Chevaieyre W. Ouerdane
S. Estivie J. Saunier

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 8/415

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 9/415
Sommaire/Contents Annales du LAMSADE N°8
Collection Cahiers et Documents I Préface I II
MFI’07 – Actes des Quatrièmes Journées Francophones
- Articles longs -
L. Amgoud, Y. Dimopoulos, P. Moraïtis An abstract framework for argumentation- based negotiation 3
L. Amgoud, H. Prade Practical reasoning as a generalized decision making problem 15
R. Ben Larbi, S. Konieczny, P. Marquis Planification multi-agent et diagnostic stratégique 25
A. Boularias, B. Chaib-draa
Les représentations prédictives des états et des politiques 37
S. Bouveret, M. Lemaître Fonctions d’utilité collective avec droits exogènes inégaux 49
C. Dégremont, J. A. Zvesper Logique dynamique pour le raisonnement stratégique dans
les jeux extensifs 61
V. Demeure, J. F. Bonnefon, E. Raufaste
Rôle de la face et de l’utilité dans l’interprétation d’énoncés ambigusquestion/requête incompréhension/désaccord 75
R. Demolombe, V. Louis Actes communicatifs à effets institutionnels 89
J. Derveeuw, B. Beaufils, P. Mathieu, O. BrandouyUn modèle d’interaction réaliste pour la simulation
de marchés financiers 103
J. -L. Dessalles Le rôle de l’impact émotionnel dans la communication des événements 113
H. van Ditmarsch, A. Herzig, T. de Lima Raisonnement sur les actions : de Toronto à Amsterdam 127

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 10/415
H. van Ditmarsch, J. Ruan Model checking logic puzzles 139
A. Goultiaeva, Y. Lespérance
Incremental plan recognition in an agent programming framework 151
N. Houy, L. Ménager Communication, consensus et ordre de parole.
Qui veut parler en premier ? 163
J. Hue, E. Wurbel, O. Papini Fusion de bases propositionnelles : une méthode basée
sur les R-ensembles 175
S. KoniecznySBGM: concialiation et mesures de conflits 189
J. Lieber Application de la théorie de la révision à l’adaptation en raisonnement
à partir de cas : l’adaptation conservatrice 201
M. Morge, J. -C. Routier Debating over heterogeneous descriptions 215
M. Ochs, D. Sadek, C. PelachaudVers un modèle formel des émotions d’un agent rationnel dialoguant
empathique 227
S. Saget, M. Guyomard Doit-on dire la vérité pour se comprendre ? Principes d’un modèlecollaboratif du dialogue basé sur la notion d’acceptation 239
- Articles courts -
G. Aucher, A. Herzig De DEL à EDL ou comment illustrer la puissance
des événements inverses. 253
Ph. Balbiani, F. Cheikh, G. FeuilladeConsidérations relatives à la décidabilité et à la complexité
du problème de la composition de services 261
F. Bouchet, J.-P. Sansonnet
Caractérisation de requêtes d’assistance à partir de corpus 269
M. Boussard, M. Bouzid, A. Mouaddib La décision multi-critère pour la coordination localedans les systèmes multi- agents 277

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 11/415
L. Chauvin, D. Genest, S. Loiseau Le modèle des cartes cognitives contextuelles 285
Y. Chevaleyre, N. Maudet
Règles naturelles optimales pour l’argumentation 293
L. Cholvy, Ch. Garion, C. Saurel Modélisation de réglementations pour le partaged’information dans un SMA 301
S. Estivie Influence du protocole sur l’issue des négociations 309
N. Hameurlain An optimistic approach for the specification of more flexible
roles behavioural compatibility relations in MAS 317
N. Laverny Logique doxastique graduelle 325
Ph. Mathieu, S. Picault, J.-C. Routier Donner corps aux interactions (l’interaction enfin concrétisée) 333
L. Mazuel, N. Sabouret Interprétation de commandes en langage naturel pour les agents
conversationnels à base d’ontologie 341
B. Menoni, J.-Ch. Vergnaud Représentations syntaxique et sémantique d’un acte 349
M. Morge, P. MancarellaThe hedgehog and the fox : an argumentation-based decision support system 357
A. Pauchet et al. Interactions collaboratives en situations co-localisée et distante 365
L. Perrussel, S. Doutre, J.-M. Thévenin, P. McBurneyUn dialogue de persuasion pour l’accès et l’obtention d’informations 373
C. Pira, A. El Fallah Seghrouchni Autour du problème du consensus 379
J. A. Quiané-Ruiz, Ph. Lamarre, P. ValduriezUn modèle pour caractériser des participants autonomes dansun processus de médiation 389
J. Saunier, F. BalboVers un support des communications multi-parties pour les systèmes multi-agents 397

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 12/415

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 13/415
ARTICLES LONGS

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 14/415

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 15/415
An Abstract Framework for Argumentation-based Negotiation
Leila Amgoud
Yannis Dimopoulos
Pavlos Moraitis
IRIT–CNRS118, Route de Narbonne
31062 Toulouse cedex 09, FRANCE
Univ. of Cyprus75 Kallipoleos Str.
PO Box 20537, Cyprus
Paris Descartes Univ.45 rue des Saints-Pères
75270 Paris, France
Résumé :Le papier propose un cadre abstrait pour la négo-ciation à base d’argumentation, dans lequel le rôlede l’argumentation est formellement analysé, et lesrésultats d’une telle négociation sont étudiés. Il for-malise la notion d’un accord dans une négociation.Le papier montre aussi comment cet accord est liéaux théories des agents et quand il peut être atteint.Il définit aussi la notion de concession et montredans quelle situation un agent en fera une.
Mots-clés : Négociation, ArgumentationAbstract:
This paper proposes an abstract framework forargumentation-based negotiation, in which the roleof argumentation is formally analyzed. The frame-work makes it possible to study the outcomes of an argumentation-based negotiation. It shows whatan agreement is, how it is related to the theories of the agents, when it is possible, and how this can beattained by the negotiating agents in this case. Itdefines also the notion of concession, and shows inwhich situation an agent will make one, as well as
how it influences the evolution of the dialogue.Keywords: Negotiation, Argumentation
1 Introduction
Roughly speaking, negotiation is a processaiming at finding some compromise orconsensus between two or several agentsabout some matters of collective agree-ment, such as pricing products, allocatingresources, or choosing candidates.
Integrating argumentation theory in nego-tiation provides a good means for supply-ing additional information and also helps
agents to convince each other by adequatearguments during a negotiation dialogue.Indeed, an offer supported by a good ar-gument has a better chance to be acceptedby an agent, and can also make him revealhis goals or give up some of them. The ba-sic idea is that by exchanging arguments,the theories of the agents (i.e. their mentalstates) may evolve, and consequently, the
status of offers may change. For instance,an agent may reject an offer because it isnot acceptable for it. However, the agentmay change its mind if it receives a strongargument in favor of this offer.
Several proposals have been made in theliterature for modeling such an approach[1, 2, 6, 7, 11]. However, the work isstill preliminary. Some researchers have
mainly focused on relating argumentationwith protocols. They have shown how andwhen arguments in favor of offers can becomputed and exchanged. Others haveemphasized on the decision making prob-lem. In [2, 6], the authors argued thatselecting an offer to propose at a givenstep of the dialogue is a decision mak-ing problem. They have thus proposed anargumentation-based decision model, andhave shown how such a model can be re-lated to the dialogue protocol.
In existing works, there is no formal anal-ysis on the role of argumentation in nego-tiation dialogues. It is not clear how ar-
3

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 16/415
gumentation can influence the outcome of the dialogue. Moreover, basic concepts innegotiation such as concession and agree-ment (i.e. optimal solutions, or compro-mise) are neither defined nor studied.This paper aims at proposing an abstract framework for argumentation-based nego-tiation, in which the role of argumentationis formally analyzed, and where the exist-ing systems can be restated. In this frame-work, a negotiation dialogue takes placebetween two agents on a set O of offers,whose structure is not known. The goal of a negotiation is to find among elements of
O, an offer that satisfies more or less thepreferences of both agents. Each agent issupposed to have a theory represented inan abstract way. A theory consists of a setA of arguments whose structure and ori-gin are not known, a function specifyingfor each possible offer in O, the argumentsof A that support it, a non specified con-flict relation among the arguments, and fi-nally a preference relation between the ar-
guments. The status of each argument isdefined using Dung’s acceptability seman-tics. Consequently, the set of offers is par-titioned into four subsets: acceptable, re-
jected , negotiable and non-supported of-fers. We show how an agent’s theory mayevolve during a negotiation dialogue. Wedefine formally the notions of concession,compromise, and optimal solution. Then,we propose a protocol that allows agents i)to exchange offers and arguments, and ii)to make concessions when necessary. Weshow that dialogues generated under sucha protocol terminate, and even reach opti-mal solutions when they exist.
2 The logical language
In what follows, L will denote a logicallanguage, and ≡ is an equivalence relation
associated with it.
From L, a set O = o1, . . . , on of n offersis identified, such that oi, o j ∈ O suchthat oi ≡ o j . This means that the offers are
different. Offers correspond to the differ-ent alternatives that can be exchanged dur-ing a negotiation dialogue. For instance, if the agents try to decide the place of theirnext meeting, then the set O will containdifferent towns.
Different arguments can be built from L.The set Args(L) will contain all those ar-guments. By argument, we mean a rea-son in believing or of doing something.In [2], it has been argued that the selec-tion of the best offer to propose at a givenstep of the dialogue is a decision prob-
lem. In [3], it has been shown that inan argumentation-based approach for de-cision making, two kinds of argumentsare distinguished: arguments supportingchoices (or decisions), and arguments sup-porting beliefs. Moreover, it has been ac-knowledged that the two categories of ar-guments are formally defined in differentways, and they play different roles. In-deed, an argument in favor of a decision,built both on an agent’s beliefs and goals,tries to justify the choice; whereas an ar-gument in favor of a belief, built only frombeliefs, tries to destroy the decision ar-guments, in particular the beliefs part of those decision arguments. Consequently,in a negotiation dialogue, those two kindsof arguments are generally exchanged be-tween agents. In what follows, the setArgs(L) is then divided into two subsets:a subset Argso(L) of arguments support-
ing offers, and a subset Argsb(L) of argu-ments supporting beliefs. Thus, Args(L)= Argso(L) ∪ Argsb(L). As in [4], in whatfollows, we consider that the structure of the arguments is not known.Since the knowledge bases from which ar-guments are built may be inconsistent, thearguments may be conflicting too. In whatfollows, those conflicts will be captured bythe relation RL, thus RL ⊆ Args(L) ×Args(L). Three assumptions are made onthis relation: First the arguments support-ing different offers are conflicting. Theidea behind this assumption is that sinceoffers are exclusive, an agent has to choose
An abstract framework for argumentation-based negotiation ____________________________________________________________________________
4

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 17/415
only one at a given step of the dialogue.Note that, the relation RL is not neces-sarily symmetric between the argumentsof Argsb(L). The second hypothesis saysthat arguments supporting the same offerare also conflicting. The idea here is to re-turn the strongest argument among thesearguments. The third condition does notallow an argument in favor of an offerto attack an argument supporting a belief.This avoids wishful thinking. Formally:
Definition 1 RL ⊆ Args(L) × Args(L)is a conflict relation among arguments s.t:- ∀a, a ∈ Argso(L) , s.t. a = a , a RL a
- a ∈ Argso(L) and a ∈ Argsb(L) s.t aRL a
Note that the relation RL is not symmetric.This is due to the fact that arguments of Argsb(L) may be conflicting but not nec-essarily in a symmetric way. In what fol-lows, we assume that the set Args(L) of
arguments is finite, and each argument isattacked by a finite number of arguments.
3 Negotiating agents theoriesand reasoning models
In this section we define formally the ne-gotiating agents, i.e. their theories, aswell as the reasoning model used by those
agents in a negotiation dialogue.
3.1 Negotiating agents theories
Agents involved in a negotiation dialogue,called negotiating agents, are supposed tohave theories. In this paper, the theory of an agent will not refer, as usual, to its men-tal states (i.e. its beliefs, desires and in-tentions). However, it will be encoded in
a more abstract way in terms of the argu-ments owned by the agent, a conflict re-lation among those arguments, a prefer-ence relation between the arguments, anda function that specifies which arguments
support offers of the set O. We assumethat an agent is aware of all the argumentsof the set Args(L). The agent is evenable to express a preference between anypair of arguments. This does not meanthat the agent will use all the arguments of Args(L), but it encodes the fact that whenan agent receives an argument from an-other agent, it can interpret it correctly, andit can also compare it with its own argu-ments. Similarly, each agent is supposedto be aware of the conflicts between argu-ments. This also allows us to encode thefact that an agent can recognize whether
the received argument is in conflict or notwith its arguments. However, in its the-ory, only the conflicts between its own ar-guments are considered.
Definition 2 (Negotiating agent theory) Let O be a set of n offers. A negotiatingagent theory is a tuple A , F , , R , Def:
• A ⊆ Args(L).
• F : O → 2A s.t ∀i, j with i = j , F (oi)∩ F (o j) = ∅. Let AO = ∪F (oi) withi = 1, . . . , n.
• ⊆ Args(L) × Args(L) is a partial preorder denoting a preference rela-tion between arguments.
• R ⊆ RL s.t R ⊆ A × A
• Def ⊆ A × A s.t ∀ a, b ∈ A , a defeatsb , denoted a Def b iff a R b , and not (b a).
The function F returns the arguments sup-porting offers in O. We assume that an ar-gument cannot support two distinct offers.However, F (oi) may be empty.
Example 1 Let O = o1, o2, o3.
• A = a1, a2, a3, a4
• F (o1) = a1 , F (o2) = a2 ,F (o3) = ∅. Thus, Ao = a1, a2
___________________________________________________________________________ Annales du LAMSADE N°8
5

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 18/415
• = (a1, a2), (a2, a1), (a3, a2), (a4, a3)
• R = a1, a2), (a2, a1), (a3, a2), (a4, a3)
• Def = (a4, a3), (a3, a2)
3.2 The reasoning model
From the theory of an agent, one can de-fine the argumentation system used by thatagent for reasoning about the offers andthe arguments, i.e. for computing the sta-tus of the different offers and arguments.
Definition 3 (Argumentation system) Let A , F , , R , Def be the theory of anagent. The argumentation system of that agent is the pair A, Def.
In [4], different acceptability semanticshave been introduced for computing thestatus of arguments. These are based on
two basic concepts, defence and conflict- free, defined as follows:
Definition 4 (Defence/conflict-free) Let S ⊆ A.
• S defends an argument a iff each argu-ment that defeats a is defeated by someargument in S .
• S is conflict-free iff there exist no a , ain S such that a Def a.
Definition 5 (Acceptability semantics) Let S be a conflict-free set of arguments,and let T : 2A → 2A be a function suchthat T (S ) = a | a is defended by S .
• S is a complete extension iff S =
T (S ).
• S is a preferred extension iff S is amaximal (w.r.t set ⊆) complete exten-sion.
• S is a grounded extension iff it is thesmallest (w.r.t set ⊆) complete exten-sion.
Let E 1, . . . , E x denote the different exten-sions under a given semantics.
Note that there is only one grounded ex-tension. It contains all the arguments thatare not defeated, and those arguments thatare defended directly or indirectly by non-defeated arguments.
Theorem 1 Let A , Def the argumenta-tion system defined as shown above.
1. It may have x ≥ 1 preferred exten-sions.
2. The grounded extensions is S =i≥1 T (∅).
Note that when the grounded extension(or the preferred extension) is empty, thismeans that there is no acceptable offer forthe negotiating agent.
Example 2 In example 1, there is one pre- ferred extension, E = a1 , a2 , a4.
Now that the acceptability semantics is de-fined, we are ready to define the status of any argument.
Definition 6 (Argument status) Let A, Def be an argumentation system, and E 1, . . . , E x its extensions under a givensemantics. Let a ∈ A.
1. a is accepted iff a ∈ E i , ∀E i with i =1, . . . , x.
2. a is rejected iff E i such that a ∈ E i.
3. a is undecided iff a is neither accepted nor rejected. This means that a is insome extensions and not in others.
An abstract framework for argumentation-based negotiation ____________________________________________________________________________
6

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 19/415
Note that A = a|a is accepted ∪ a|a isrejected ∪ a|a is undecided.
Example 3 In example 1, the argumentsa1 , a2 and a4 are accepted, whereas theargument a3 is rejected.
As said before, agents use argumentationsystems for reasoning about offers. In anegotiation dialogue, agents propose andaccept offers that are acceptable for them,and reject bad ones. In what follows, wewill define the status of an offer. Accord-
ing to the status of arguments, one can de-fine four statuses of the offers as follows:
Definition 7 (Offers status) Let o ∈ O.
• The offer o is acceptable for the ne-gotiating agent iff ∃ a ∈ F (o) s.t ais accepted. Oa = oi ∈ O , s.t oi isacceptable.
• The offer o is rejected for the negotiat-ing agent iff ∀ a ∈ F (o) , a is rejected.Or = oi ∈ O , s.t oi is rejected .
• The offer o is negotiable iff ∀ a ∈F (o) , a is undecided. On = oi ∈ O ,s.t oi is negotiable.
• The offer o is non-supported iff it isneither acceptable, nor rejected or ne-
gotiable. Ons = oi ∈ O , s.t oi is non-supported offers.
Example 4 In example 1, the two offers o1and o2 are acceptable since they are sup-
ported by accepted arguments, whereasthe offer o3 is non-supported since it hasno argument in its favor.
From the above definitions, the followingresults hold:
Property 1 Let o ∈ O.
• O = Oa ∪ Or ∪ On ∪ Ons.
• The set Oa may contain more than oneoffer.
From the above partition of the set O of offers, a preference relation between offersis defined. Let Ox and Oy be two subsetsof O. Ox Oy means that any offer in Ox
is preferred to any offer in the set Oy. Wecan write also for two offers oi, o j , oi o jiff oi ∈ Ox, o j ∈ Oy and Ox Oy.
Definition 8 (Preference between offers)
Let O be a set of offers, and Oa , Or , On ,Ons its partition. Oa On Ons Or.
Example 5 In example 1, we have o1 o3 ,and o2 o3. However, o1 and o2 are indif-
ferent.
4 Argumentation-based Negoti-ation
In this section, we define formally a pro-tocol that generates argumentation-basednegotiation dialogues between two nego-tiating agents P and C . The two agentsnegotiate about an object whose possiblevalues belong to a set O. This set O issupposed to be known and the same forboth agents. For simplicity reasons, we as-sume that this set does not change duringthe dialogue. The agents are equipped withtheories denoted respectively AP , F P ,P , RP , DefP , and AC , F C , C , RC ,
DefC . Note that the two theories may bedifferent in the sense that the agents mayhave different sets of arguments, and dif-ferent preference relations. Worst yet, theymay have different arguments in favor of the same offers. Moreover, these theoriesmay evolve during the dialogue.
4.1 Evolution of the theories
Before defining formally the evolution of an agent’s theory, let us first introduce the
___________________________________________________________________________ Annales du LAMSADE N°8
7

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 20/415
notion of moves.
Definition 9 (Move) A move is a tuple mi
= pi , ai , oi, ti such that:
• pi ∈ P, C
• ai ∈ Args(L) ∪ θ1
• oi ∈ O ∪ θ
• ti ∈ N ∗ is the target of the move, suchthat ti < i
The function Player (resp. Argument ,Offer , Target) returns the player of themove (i.e. pi) (resp. the argument of amove, i.e ai , the offer oi , and the target of the move, ti). Let M denote the set of all the moves that can be built fromP, C , Arg(L), O.
Note that the set M is finite since Arg(L)
and O are assumed to be finite. Let usnow see how an agent’s theory evolves andwhy. The idea is that if an agent receivesan argument from another agent, it willadd the new argument to its theory. More-over, since an argument may bring newinformation for the agent, thus new argu-ments can emerge.
Example 6 Suppose that an agent P has
the following propositional knowledgebase: ΣP = x, y → z. From this baseone cannot deduce z. Let’s assume that this agent receives the following argument a, a → y that justifies y. It is clear that now P can build an argument, saya, a → y, y → z in favor of z.
In a similar way, if a received argument isin conflict with the arguments of the agent
i, then those conflicts are also added toits relation Ri. Note that new conflictsmay arise between the original arguments
1In what follows θ denotes the fact that no argument, or no
offer is given
of the agent and the ones that emerge afteradding the received arguments to its the-ory. Those new conflicts should also beconsidered. As a direct consequence of theevolution of the sets Ai and Ri, the defeatrelation Defi is also updated.The initial theory of an agent i, (i.e. itstheory before the dialogue starts), is de-noted by Ai
0, F i0, i0, Ri
0, Defi0, withi ∈ P, C . Besides, in this paper, we sup-
pose that the preference relation i of anagent does not change during the dialogue.
Definition 10 (Theory evolution) Let m1 , . . . , mt , . . . , m j be a sequence of moves. The theory of an agent i at a stept > 0 is: Ai
t , F it , it , Ri
t , Defit such that:
• Ait = Ai
0 ∪ ai , i = 1, . . . , t , ai
= Argument(mi) ∪ A with A ⊆Args(L)
• F it = O → 2Ai
t
• it = i
0
• Rit = Ri
0 ∪ (ai, a j) | ai =Argument(mi) ,a j = Argument(m j) , i, j ≤ t , and ai
RL a j ∪ R with R ⊆ RL
• Defit ⊆ Ait × Ai
t
The above definition captures the mono-
tonic aspect of an argument. Indeed, anargument cannot be removed. However, itsstatus may change. An argument that is ac-cepted at step t of the dialogue by an agentmay become rejected at step t + i. Con-sequently, the status of offers also change.Thus, the sets Oa, Or, On, and Ons maychange from one step of the dialogue to an-other. That means for example that someoffers could move from the set Oa to the
set Or and vice-versa. Note that in thedefinition of Rt, the relation RL is usedto denote a conflict between exchanged ar-guments. The reason is that, such a con-flict may not be in the set Ri of the agent
An abstract framework for argumentation-based negotiation ____________________________________________________________________________
8

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 21/415
i. Thus, in order to recognize such con-flicts, we have supposed that the set RL
is known to the agents. This allows us tocapture the situation where an agent is ableto prove an argument that it was unable toprove before, by incorporating in its be-liefs some information conveyed throughthe exchange of arguments with anotheragent. This, unknown at the beginning of the dialogue argument, could give to thisagent the possibility to defeat an argumentthat it could not by using its initial argu-ments. This could even lead to a changeof the status of these initial arguments and
this change would lead to the one of theassociated offers’ status.
In what follows, Oit,x denotes the set of of-
fers of type x, where x ∈ a,n,r,ns, of the agent i at step t of the dialogue. Insome places, we can use for short the no-tation Oi
t to denote the partition of the setO at step t for agent i. Note that we have:not(Oi
t,x ⊆ Oit+1,x).
4.2 The notion of agreement
As said in the introduction, negotiationis a process aiming at finding an agree-ment about some matters. By agreement,one means a solution that satisfies to thelargest possible extent the preferences of both agents. In case there is no such solu-
tion, we say that the negotiation fails. Inwhat follows, we will discuss the differentkinds of solutions that may be reached ina negotiation. The first one is the optimalsolution. An optimal solution is the bestoffer for both agents. Formally:
Definition 11 (Optimal solution) Let Obe a set of offers, and o ∈ O. The offer o is an optimal solution at a step t ≥ 0 iff
o ∈ OP t,a ∩ OC
t,a
Such a solution does not always exist sinceagents may have conflicting preferences.
Thus, agents make concessions by propos-ing/accepting less preferred offers.
Definition 12 (Concession) Let o ∈ O.The offer o is a concession for an agent iiff o ∈ Oi
x such that ∃Oiy = ∅ , and Oi
y
Oix.
During a negotiation dialogue, agents ex-change first their most preferred offers,and if these last are rejected, they makeconcessions. In this case, we say that theirbest offers are no longer defendable. In
an argumentation setting, this means thatthe agent has already presented all its ar-guments supporting its best offers, and ithas no counter argument against the onespresented by the other agent. Formally:
Definition 13 (Defendable offer) Let Ai
t , F it , it , Ri
t , Defit be the theoryof agent i at a step t > 0 of the dia-logue. Let o ∈ O such that ∃ j ≤ t with
Player(m j) = i and offer(m j) = o.The offer o is defendable by the agent i iff:
• ∃a ∈ F it (o) , and k ≤ t s.t.Argument(mk) = a , or
• ∃a ∈ At\F it (o) s.t. a Defit b with
– Argument(mk) = b , k ≤ t , and Player(mk) = i
– l ≤ t , Argument(ml) = a
The offer o is said non-defendable other-wise and N Di
t is the set of non-defendableoffers of agent i at a step t.
4.3 Negotiation dialogue
Now that we have shown how the the-
ories of the agents evolve during a dia-logue, we are ready to define formally anargumentation-based negotiation dialogue.For that purpose, we need to define first thenotion of a legal continuation.
___________________________________________________________________________ Annales du LAMSADE N°8
9

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 22/415
Definition 14 (Legal move) A move m isa legal continuation of a sequence of moves m1, . . . , ml iff j, k < l , such that:
• Offer(m j) = Offer(mk) , and
• Player(m j) = Player(mk)
The idea here is that if the two agentspresent the same offer, then the dialogueshould terminate, and there is no longerpossible continuation of the dialogue.
Definition 15 (Negotiation) A negotia-tion dialogue d between two agents P and C is a non-empty sequence of movesm1, . . . , ml s.t:
• pi = P iff i is even, and pi = C iff i isodd
• Player(m1) = P , Argument(m1) =θ , Offer(m
1) = θ , and Target(m
1)
= 02
• ∀ mi , if Offer(mi) = θ ,then Offer(mi) o j , ∀ o j ∈
O\(OPlayer(mi)i,r ∪ ND
Player(mi)i )
• ∀i = 1, . . . , l , mi is a legal continua-tion of m1, . . . , mi−1
• Target(mi) = m j such that j < i and
Player(mi) = Player(m j)
• If Argument(mi) = θ , then:
– if Offer(mi) = θ thenArgument(mi) ∈ F (Offer(mi))
– if Offer(mi) = θ then
Argument(mi) DefPlayer(mi)i
Argument(Target(mi))
• i, j ≤ l such that mi = m j
• m ∈ M such that m is a legal con-tinuation of m1, . . . , ml
2The first move has no target.
Let D be the set of all possible dialogues.
The first condition says that the two agents
take turn. The second condition says thatagent P starts the negotiation dialogue bypresenting an offer. Note that, in the firstturn, we suppose that the agent does notpresent an argument. This assumption ismade for strategical purposes. Indeed, ar-guments are exchanged as soon as a con-flict appears. The third condition ensuresthat agents exchange their best offers, butnever the rejected ones. This condition
takes also into account the concessionsthat an agent will have to make if it wasestablished that a concession is the onlyoption for it at the current state of the di-alogue. Of course, as we have shown in aprevious section, an agent may have sev-eral good or acceptable offers. In thiscase, the agent chooses one of them ran-domly. The fourth condition ensures thatthe moves are legal. This condition al-
lows to terminate the dialogue as soon asan offer is presented by both agents. Thefifth condition allows agents to backtrack.The sixth condition says that an agent maysend arguments in favor of offers, and inthis case the offer should be stated in thesame move. An agent can also send argu-ments in order to defeat arguments of theother agent. The next condition preventsrepeating the same move. This is usefulfor avoiding loops. The last condition en-sures that all the possible legal moves havebeen presented.
The outcome of a negotiation dialogue iscomputed as follows:
Definition 16 (Dialogue outcome) Let d= m1 , . . . , ml be a argumentation-based negotiation dialogue. The out-
come of this dialogue, denoted Outcome ,is Outcome(d) = Offer(ml) iff ∃ j <l s.t. Offer(ml) = Offer(m j) , and Player(ml) = Player(m j). Otherwise,Outcome(d) = θ.
An abstract framework for argumentation-based negotiation ____________________________________________________________________________
10

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 23/415
Note that when Outcome(d) = θ, thenegotiation fails, and no agreement isreached by the two agents. However, if Outcome(d) = θ, the negotiation succeeds,and a solution that is either optimal or acompromise is found.
Theorem 2 ∀di ∈ D , the argumentation-based negotiation di terminates.
The above result is of great importance,since it shows that the proposed protocolavoids loops, and dialogues terminate. An-
other important result shows that the pro-posed protocol ensures to reach an optimalsolution if it exists. Formally:
Theorem 3 (Completeness) Let d =m1, . . . , ml be a argumentation-based negotiation dialogue. If ∃t ≤ l such that OP
t,a ∩ OC t,a = ∅ , then Outcome(d) ∈ OP
t,a
∩ OC t,a.
We show also that the proposed dialogueprotocol is sound in the sense that, if a dia-logue returns a solution, then that solutionis for sure a compromise. In other words,that solution is a “common agreement” ata given step of the dialogue. We show alsothat if the negotiation fails, then there is nopossible solution.
Theorem 4 (Soundness) Let d =m1, . . . , ml be a argumentation-based negotiation dialogue.
1. If Outcome(d) = o , (o = θ), then ∃t ≤l such that o ∈ OP
t,x ∩ OC t,y , with x, y ∈
a,n,ns.
2. If Outcome(d) = θ , then ∀t ≤ l , OP t,x
∩ OC t,y = ∅ , ∀ x, y ∈ a,n,ns.
A direct consequence of the above theoremis the following:
Property 2 Let d = m1, . . . , ml be aargumentation-based negotiation dia-logue. If Outcome(d) = θ , then ∀t ≤ l ,
• OP t,r = OC
t,a ∪ OC t,n ∪ OC
t,ns , and
• OC t,r = OP
t,a ∪ OP t,n ∪ OP
t,ns.
5 Illustrative examples
In this section we will present some exam-ples that illustrate the framework.
Example 7 (No argumentation) Let O =o1, o2 , P and C are two agents equipped with the same theory: A , F , , R , Defs.t. A = ∅ , F (o1) = F (o2) = ∅ , = ∅ , R =∅ , Def = ∅. It is clear that the two offers o1and o2 are non-supported. The proposed
protocol (see Definition 15) will generateone of the following dialogues:
P: m1 = P,θ,o1, 0
C: m2 = C,θ,o1, 1
This dialogue ends with o1 as a compro-mise. This solution is optimal since it isnot an acceptable offer for the agents.
P: m1 = P,θ,o1, 0
C: m2 = C,θ,o2, 1
P: m3 = P,θ,o2, 2
This dialogue ends with o2 as a compro-mise.
P: m1 = P,θ,o2, 0
C: m2 = C,θ,o2, 1
This dialogue also ends with o2 as a com- promise. The last possible dialgue endswith o1 as a compromise.
___________________________________________________________________________ Annales du LAMSADE N°8
11

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 24/415
P: m1 = P,θ,o2, 0
C: m2 = C,θ,o1, 1
P: m3 = P,θ,o1, 2
In the above example, the theories of bothagents do not change since there is no ex-change of arguments. Let us now considerthe following example.
Example 8 (Static theories) Let O =o1, o2 be the set of all possible offers.
The theory of agent P is AP , F P , P ,
RP , DefP such that: AP = a1, a2 ,F P (o1) = a1 , F P (o2) = a2 , P
= (a1, a2) , RP = (a1, a2), (a2, a1) ,DefP = a1, a2. The argumentation sys-
tem AP , DefP of this agent will returna1 as an accepted argument, and a2 as arejected one. Consequently, the offer o1 isacceptable and o2 is rejected.
The theory of agent C is AC
, F C
, C
,RC , DefC such that: AC = a1, a2 ,F C (o1) = a1 , F C (o2) = a2 , C
= (a2, a1) , RC = (a1, a2), (a2, a1) ,DefC = a2, a1. The argumentation sys-
tem AC , DefC of this agent will returna2 as an accepted argument, and a1 as arejected one. Consequently, the offer o2is acceptable and o1 is rejected. The first
possible dialogue is:
P: m1 = P,θ,o1, 0
C: m2 = C,θ,o2, 1
P: m3 = P, a1, o1, 2
C: m4 = C, a2, o2, 3
The second possible dialogue is:
P: m1 = P,θ,o1, 0
C: m2 = C, a2, o2, 1
P: m3 = P, a1, o1, 2
C: m4 = C,θ,o2, 3
Both dialogues end with failure. Note
that in both dialogues, the theories of both agents do not change. The reasonis that the exchanged arguments are al-ready known to both agents. The negotia-tion fails because the agents have conflict-ing preferences.
Let us now consider an example in whichargumentation will allow agents to reachan agreement.
Example 9 (Dynamic theories) Let O =o1, o2 be the set of all possible of-
fers. The theory of agent P is AP ,
F P , P , RP , DefP such that: AP
= a1, a2 , F P (o1) = a1 , F P (o2) =
a2 , P = (a1, a2), (a3, a1) , RP =
(a1, a2), (a2, a1) , DefP = (a1, a2).
The argumentation system AP , DefP of
this agent will return a1 as an accepted ar-gument, and a2 as a rejected one. Conse-quently, the offer o1 is acceptable and o2 isrejected.
The theory of agent C is AC , F C ,C , RC , DefC such that: AC =
a1, a2, a3 , F C (o1) = a1 , F C (o2)= a2 , C = (a1, a2), (a3, a1) , RC
= (a1, a2), (a2, a1), (a3, a1) , DefC =
(a1, a2), (a3, a1). The argumentationsystem AC , DefC of this agent will returna3 and a2 as accepted arguments, and a1
as a rejected one. Consequently, the offer o2 is acceptable and o1 is rejected.
The following dialogue may take place be-tween the two agents:
P: m1 = P,θ,o1, 0
C: m2 = C,θ,o2, 1
P: m3 = P, a1, o1, 2
C: m4 = C, a3, θ, 3
An abstract framework for argumentation-based negotiation ____________________________________________________________________________
12

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 25/415
C: m5 = P ,θ ,o2, 4
At step 4 of the dialogue, the agent P receives the argument a3 fromP . Thus, its theory evolves as fol-lows: AP = a1, a2, a3 , RP =
(a1, a2), (a2, a1), (a3, a1) , DefP =(a1, a2), (a3, a1). At this step, the argu-ment a1 which was accepted will becomerejected, and the argument a2 which wasat the beginning of the dialogue rejected will become accepted. Thus, the offer o2will be acceptable for the agent, whereaso1 will become rejected. At this step 4, theoffer o2 is acceptable for both agents, thusit is an optimal solution. The dialogueends by returning this offer as an outcome.
6 Related work
Argumentation has been integrated in ne-gotiation dialogues at the early nineties bySycara [11]. In that work, the author has
emphasized the advantages of using argu-mentation in negotiation dialogues, and aspecific framework has been introduced.In [7], the different types of arguments thatare used in a negotiation dialogue, such asthreats and rewards, have been discussed.Moreover, a particular framework for ne-gotiation have been proposed. In [8], dif-ferent other frameworks have been pro-posed. Even if all these frameworks arebased on different logics, and use differ-ent definitions of arguments, they all haveat their heart an exchange of offers and ar-guments. However, none of those propos-als explain when arguments can be usedwithin a negotiation, and how they shouldbe dealt with by the agent that receivesthem. Thus the protocol for handling ar-guments was missing. Another limitationof the above frameworks is the fact thatthe argumentation frameworks they use are
quite poor, since they use a very simple ac-ceptability semantics. In [1] a negotiationframework that fills the gap has been sug-gested. A protocol that handles the argu-ments was proposed. However, the notion
of concession is not modeled in that frame-work, and it is not clear what is the statusof the outcome of the dialogue. Moreover,it is not clear how an agent chooses the of-fer to propose at a given step of the dia-logue. In [2, 6], the authors have focusedmainly on this decision problem. Theyhave proposed an argumentation-based de-cision framework that is used by agents inorder to choose the offer to propose or toaccept during the dialogue. In that work,agents are supposed to have a beliefs baseand a goals base.
Our framework is more general since itdoes not impose any specific structure forthe arguments, the offers, or the beliefs.The negotiation protocol is general as well.Thus this framework can be instantiated indifferent ways by creating, in such man-ner, different specific argumentation-basednegotiation frameworks, all of them re-specting the same properties. Our frame-work is also a unified one because frame-
works like the ones presented above canbe represented within this framework. Forexample the decision making mechanismproposed in [6] for the evaluation of ar-guments and therefore of offers, whichis based on a priority relation betweenmutually attacked arguments, can be cap-tured by the relation defeat proposed in ourframework. This relation takes simultane-ously into account the attacking and pref-erence relations that may exist between
two arguments.
7 Conclusions and FutureWork
In this paper we have presented a unifiedand general framework for argumentation-based negotiation. Like any otherargumentation-based negotiation frame-
work, as it is evoked in (e.g. [9]),our framework has all the advantagesthat argumentation-based negotiation ap-proaches present when related to the ne-gotiation approaches based either on game
___________________________________________________________________________ Annales du LAMSADE N°8
13

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 26/415
theoretic models (see e.g. [10]) or heuris-tics ([5]). This work is a first attempt toformally define the role of argumentationin the negotiation process. More precisely,for the first time, it formally establishes thelink that exists between the status of the ar-guments and the offers they support, it de-fines the notion of concession and showshow it influences the evolution of the ne-gotiation, it determines how the theories of agents evolve during the dialogue and per-forms an analysis of the negotiation out-comes. It is also the first time where astudy of the formal properties of the ne-
gotiation theories of the agents as well asof an argumentative negotiation dialogueis presented.
Our future work concerns several points.A first point is to relax the assumption thatthe set of possible offers is the same toboth agents. Indeed, it is more natural toassume that agents may have different setsof offers. During a negotiation dialogue,these sets will evolve. Arguments in fa-vor of the new offers may be built from theagent theory. Thus, the set of offers will bepart of the agent theory. Another possibleextension of this work would be to allowagents to handle both arguments PRO andCONS offers. This is more akin to the wayhuman take decisions. Considering bothtypes of arguments will refine the evalua-
tion of the offers status. In the proposedmodel, a preference relation between of-fers is defined on the basis of the partitionof the set of offers. This preference rela-tion can be refined. For instance, amongthe acceptable offers, one may prefer theoffer that is supported by the strongest ar-gument. In [3], different criteria have beenproposed for comparing decisions. Ourframework can thus be extended by inte-grating those criteria. Another interest-
ing point to investigate is that of consid-ering negotiation dialogues between twoagents with different profiles. By profile,we mean the criterion used by an agent tocompare its offers.
References
[1] L. Amgoud, S. Parsons, and N. Maudet. Ar-guments, dialogue, and negotiation. In Proc.
of the 14th ECAI , 2000.[2] L. Amgoud and H. Prade. Reaching agree-
ment through argumentation: A possibilisticapproach. In Proc. of the 9 th KR, 2004.
[3] L. Amgoud and H. Prade. Explaining qualita-tive decision under uncertainty by argumenta-tion. In Proc. of the 21st AAAI , pages 16–20,2006.
[4] P. M. Dung. On the acceptability of argu-ments and its fundamental role in nonmono-
tonic reasoning, logic programming andn
-person games. Artificial Intelligence, 77:321–357, 1995.
[5] N. R. Jennings, P. Faratin, A. R. Lumuscio,S. Parsons, and C. Sierra. Automated nego-tiation: Prospects, methods and challenges.International Journal of Group Decision andNegotiation, 2001.
[6] A. Kakas and P. Moraitis. Adaptive agent ne-gotiation via argumentation. In Proc. of the5th AAMAS , pages 384–391, 2006.
[7] S. Kraus, K. Sycara, and A. Evenchik. Reach-ing agreements through argumentation: a log-ical model and implementation. Artificial In-telligence, 104:1–69, 1998.
[8] S. Parsons and N. R. Jennings. Negoti-ation through argumentation—a preliminaryreport. In Proc. of the 2nd ICMAS , pages 267–274, 1996.
[9] I. Rahwan, S. D. Ramchurn, N. R. Jennings,P. McBurney, S. Parsons, and E. Sonenberg.
Argumentation-based negotiation. Knowl-edge Engineering Review, 18 (4):343–375,2003.
[10] J. Rosenschein and G. Zlotkin. Rules of En-counter: Designing Conventions for Auto-mated Negotiation Among Computers,. MITPress, Cambridge, Massachusetts, 1994.
[11] K. Sycara. Persuasive argumentation in ne-gotiation. Theory and Decision, 28:203–242,1990.
An abstract framework for argumentation-based negotiation ____________________________________________________________________________
14

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 27/415
Practical reasoning as a generalized decision making problem
Leila Amgoud
Henri Prade
IRIT–CNRS118, Route de Narbonne
31062 Toulouse cedex 09, FRANCE
Résumé :
La prise de décision, souvent vue comme uneforme de raisonnement sur les actions, a étéconsidérée de différents points de vue. La théorieclassique de la décision, développée principale-
ment par des économistes, s’est concentrée surl’identification et la justification de critères, telsque l’utilité espérée, pour comparer différentesalternatives. Cette approche prend en entrée unensemble d’actions qui sont atomiques faisables,et une fonction qui évalue les conséquences dechaque action. Un trait remarquable mais aussiune limitation de cette approche est la réductiondu problème de décision à la disponibilité dedeux fonctions : une fonction de distribution deprobabilité et une fonction d’utilité. C’est pourquoicertains chercheurs en IA ont préconisé le besoin
d’une approche dans laquelle tous les aspectsqui interviennent dans un problème de décision(tels que les désirs d’un agent, la faisabilité desactions, etc..) sont explicitement représentés.Dans cette perspective, des architectures BDI(Beliefs, Desires, Intentions) ont été proposées.Elles prennent leur inspiration dans le travail dephilosophes sur ce que les anglo-saxons nommentpractical reasoning ou le "raisonnement pratique".Le raisonnement pratique traite principalementde la pertinence au contexte, de la faisabilité etfinalement des intentions retenues et exécutables.Cependant, ces approches souffrent d’un manquede formulation claire de règles de décision quicombinent les considérations ci-dessus pour dé-cider quelle action exécuter.
Dans cet article, nous montrons que le raison-nement pratique est un problème de la prise dedécision généralisé. L’idée fondamentale estqu’au lieu de comparer des actions atomiques, oncompare des ensembles d’actions. L’ensemblepréféré d’actions devient les intentions retenuespar l’un agent.Le papier présente un cadre unifié qui bénéfi-
cie des avantages des trois approches (décisionclassique, architectures BDI, l’idée générales duraisonnement pratique). Plus précisément, nousproposons un cadre formel qui prend en entréeun ensemble de croyances, un ensemble de désirsconditionnels, et un ensemble de règles présisant
comment des désirs peuvent être réalisés, etrenvoie en sortie un sous-ensemble cohérent dedésirs ainsi que les actions pour les réaliser. Detelles actions s’appellent les intentions. En effet,nous montrons que ces intentions sont choisiespar l’intermédiaire de quelques règles de décision.Ainsi, selon que l’agent ait une attitude optimisteou pessimiste, l’ensemble des intentions peut nepas être le même.
Mots-clés : Raisonnement pratique, Théorie de ladécision, Argumentation
Abstract:Decision making, often viewed as a form of reasoning toward action, has been considered fromdifferent points of view. Classical decision theory,as developed by economists, has focused mainlyon identifying criteria such as expected utility for
comparing different alternatives. The inputs of this approach are a set of feasible atomic actions,and a function that assesses the value of theirconsequences when the actions are performed ina given state. One of the main practical limitationof this approach is the fact that it reduces thewhole decision problem to the availability of twofunctions: a probability distribution and a utilityfunction. This is why some researchers in AIhave advocated the need for a different approachin which all the aspects that may be involvedin a decision problem (such as the desires of anagent, the feasibility of actions, etc) are explicitlyrepresented. Hence, BDI architectures have beendeveloped. They take their inspiration in the workof philosophers who have advocated practicalreasoning. Practical reasoning mainly deals withthe adoption, filling in, and reconsideration of intentions. However, these approaches suffer froma lack of a clear formulation of decision rules thatcombine the above qualitative concepts to decidewhich action to perform.
In this paper, we argue that practical reason-ing is a generalized decision making problem.
The basic idea is that instead of comparing atomicactions, one has to compare sets of actions. Thepreferred set of actions becomes the intentions of the agent. The paper presents a unified settingthat benefits from the advantages of the threeabove-mentioned approaches (classical decision,
15

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 28/415
BDI, practical reasoning). More precisely, wepropose a formal framework that takes as input aset of beliefs, a set of conditional desires, and aset of rules stating how desires can be achieved,
and returns a consistent subset of desires as wellas ways/actions for achieving them. Such actionsare called intentions. Indeed, we show that theseintentions are generated via some decision rules.Thus, depending on whether the agent has anoptimistic or a pessimistic attitude, the set of intentions may not be the same.
Keywords: Practical reasoning, Decision making,Argumentation theory
1 Introduction
Decision making, often viewed as a formof reasoning toward action, has raisedthe interest of many scholars includingphilosophers, economists, psychologists,and computer scientists for a long time.Any decision problem amounts to selectthe best option(s) among different alterna-tives.
The decision problem has been consid-ered from different points of view. Clas-sical decision theory, as developed byeconomists, has focused mainly on iden-tifying criteria for comparing different al-ternatives. The inputs of this approachare a set of feasible actions, and a func-tion that assesses the value of their conse-quences when the actions are performed ina given state. The output is a preference
relation between actions. A decision cri-terion, such as the classical expected util-ity [11], should then be justified on thebasis of a set of postulates to which thepreference relation between action shouldobey. Note that such an approach consid-ers a group of candidate actions as a wholerather than focusing on a candidate actionindividually. Moreover, the candidate ac-tions are supposed to be feasible.
More recently, some researchers in AIhave advocated the need for a new ap-proach in which the different aspects thatmay be involved in a decision problem(such as the goals of the agent, the feasi-
bility of an action, its consequences, theconflicts between goals, the alternativeplans for achieving the same goal, etc) canbe handled. In [5, 6], it has been arguedthat this can be done by representing thecognitive states, namely agent’s beliefs,desires and intentions (thus the so-called
BDI architecture). The decision problemis then to select among the conflictingdesires a consistent and feasible subsetthat will constitute the intentions. Theabove line of research takes its inspirationin the work of philosophers who have ad-vocated practical reasoning [10]. Practical
reasoning mainly deals with the adoption,filling in, and reconsideration of intentionsand plans. It follows two main steps: 1)deliberation, in which an agent decideswhat state of affairs it wants to achieve–that is, its desires; and (2) means-endsreasoning, in which an agent devises plansfor achieving these desires.
In this paper, we argue that practical
reasoning is a generalized decision mak-ing problem. The basic idea is that insteadof comparing atomic actions, one hasto compare sets of coherent plans (i.e.plans that can be achieved together) thatwill achieve the desires computed at thedeliberation step. The preferred set of plans becomes the intentions of the agent.The paper presents a formal frameworkfor practical reasoning that works in threesteps: at the first step one computes,from a set of conditional desires, a setof arguments supporting them, and aconflict relation among these arguments,a set of what is called justified desires.These desires can be pursued providedthat they have plans for achieving them.The second step computes sets of plansthat can are achievable together. The inputis the set of conditional desires, a set of plans (whose structure and origin are not
discussed here), a function specifyingfor each conditional desire the plans forachieving it, and finally a set of conflictingplans. The framework returns extensions
Practical reasoning as a generalized decision making problem ___________________________________________________________________________
16

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 29/415
of plans. An extension is a set of plans thatcan be achieved together. Once, these setsidentified, one applies decision makingtechniques for ordering these extensions.The idea is to prefer the set that achievesthe most important desires returned at thedeliberation level.
The paper is organized as follows: we startby presenting our abstract framework of practical reasoning, then we illustrate it onan example. Then we compare our workwith existing works in the literature. Thelast section is devoted to some concluding
remarks and perspectives.
2 General framework for prac-tical reasoning
Practical reasoning is the reasoning towardaction. It follows three main steps:
1. Generating desires to be achieved,
called also deliberation
2. Generating plans for achieving thosedesires, called means-end reasoning
3. Selecting the intentions to be pursuedby the agent. The intentions are theplans that will be performed for reach-ing the generated desires.
In what follows, L will denote a logicallanguage. From L, we distinguish a finiteset D of potential conditional desires.Desires will be denotes by d1, . . . , dn.Some desires may be more importantthan others. This is captured by a partialpreordering d on D, thus d ⊆ D × D.
Similarly, from L, different argumentscan be built. An argument may provide a
reason of generating or adopting a givendesire. Let A denote the set of thesearguments whose structure and origin arenot known.
Since knowledge bases may be inconsis-tent, arguments may be conflicting too.These conflicts are captured by a binaryrelation Ra ⊆ A × A.
Let us define a function F d that returns foreach desire di in D the set of argumentssupporting it. Thus,
F d : D → 2A
for instance, F d(d1) = a1, . . . , an witha1, . . . , an ⊆ A. Note that some desires
may not be supported by arguments. Suchdesires will not be considered as inten-tions. We assume that an argument cannotsupport two or more desires at the sametime. Formally: ∀di, d j, F d(di) ∩ F d(d j)= ∅.
We assume that we have a set P = p1, . . . , pm of plans. A plan is a way of
achieving a desire. The structure and theorigin of the plans are left unknown.
Plans are related to the desires they achieveby the following function
F p : D → 2P .
Each plan is assumed to achieve at leastone desire, i.e. ∀di, d j ∈ D, F p(d)∩F p(d)
= ∅.
It is very common that a given plan maynot be achievable because, for instance, ithas a consequence that contradicts the de-sire it wants to achieve. It is also possiblethat two or more plans cannot be achiev-able at the same time since, for instancethey yield to conflicting situations. Such
conflicts among elements of P are givenby a set R p ⊆ 2P . We assume that onlyminimal conflicts are given in R p, thismeans that S, S ∈ RP such that S ⊆ S .Let us consider the following example.
____________________________________________________________________________ Annales du LAMSADE N°8
17

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 30/415
Example 1 Let D = d1, d2, d3 , A =a1, a2, a3, a4 , Ra = (a1, a2), (a2, a3) ,F d(d1) = a3 , F d(d2) = a4 , F d(d3)= ∅ , P = p1, p2, p3 , F p(d1) = p1 ,F p(d2) = p2 , F p(d3) = p3 , and R p = p2, p1, p3.
2.1 A general framework for delibera-
tion
This section aims at generating the desiresthat can be pursued by the agent (in casethey are feasible, i.e. they have plans). As
shown in the above illustrative example,one may have conditional desires that de-pend on some beliefs. The idea is to checkwhether the conditions of these desireshold in the current state of the world. Inthe above example, both desires d1 and d2are generated since their conditions hold.
In our general framework, we suppose thatan argument is built for supporting a desireas soon as the conditions on which it de-pends hold. However, since a knowledgebase may be inconsistent, i.e. the conditionmay hold but, at the same time there is aninformation which contradicts it, counter-arguments can be built. Thus, the gener-ated desires, or the outcome of the delib-eration step, is the result of a simple argu-mentation system defined as follows.
Definition 1 (Argumentation system)
An argumentation system for generatingdesires to be pursued in a pair A,Ra.
In [7], different acceptability semanticshave been introduced for computing thestatus of arguments. These are based ontwo basic concepts, defence and conflict-
free, defined as follows:
Definition 2 (Defence/conflict-free) Let
S ⊆ A.
• S defends an argument a iff each ar-gument that defeats a is defeated in thesense of Ra by some argument in S .
• S is conflict-free iff there exist no a , a
in S such that a Ra a.
Definition 3 (Acceptability semantics) Let S be a conflict-free set of arguments,and let T : 2A → 2A be a function suchthat T (S ) = a | S defends a.
• S is a complete extension iff S =T (S ).
• S is a preferred extension iff S is amaximal (w.r.t set ⊆) complete exten-
sion.• S is a grounded extension iff it is the
smallest (w.r.t set ⊆) complete exten-sion.
Let E 1, . . . , E x denote the different exten-sions under a given semantics.
Note that there is only one grounded ex-
tension. It contains all the arguments thatare not defeated, and those arguments thatare defended directly or indirectly by non-defeated arguments.
Now that the acceptability semantics de-fined, we are ready to define the status of any argument.
Definition 4 (Argument status) Let
A,Ra be an argumentation system, and E 1, . . . , E x its extensions under a givensemantics. Let a ∈ A.
1. a is accepted iff a ∈ E i , ∀E i with i =1, . . . , x.
2. a is rejected iff E i such that a ∈ E i.
3. a is undecided iff a is neither accepted
nor rejected. This means that a is insome extensions and not in others.
On the basis of the status of each argu-ment, it is now possible to compute the set
Practical reasoning as a generalized decision making problem ___________________________________________________________________________
18

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 31/415
of desires that are supposed to be justifiedin the current state of the world. As saidbefore, this will represent the outcome of the deliberation step.
Definition 5 (Justified desires) Let D bea set of potential desires. The justifieddesires are gathered in the set Output =di ∈ D such that ∃a ∈ A , a is accepted,and a ∈ F d(di).
Example 2 (Example 1 continued) Let
D = d1, d2, d3 , A = a1, a2, a3, a4 ,Ra = (a1, a2), (a2, a3) , F d(d1) = a3 ,F d(d2) = a4 , F d(d3) = ∅. In this ex-ample, the argumentation system A,Rareturns only one grounded extensiona1, a3, a4. Thus, the output of the delib-eration is d1, d2. The desire d3 is not supported by arguments, thus there is noreason to generate this desire.
Note that the generated desires will notnecessarily be pursued by an agent. Theyshould also be feasible.
2.2 A general framework for means-
end reasoning
The second step of practical reasoning
consists of looking for plans to achieve de-sires. Since an agent may have severaldesires at the same time, then it needs toknow not only which desire is achievable,but also which subsets of desires can beachieved together. In what follows, wepropose an abstract framework that returnsextensions of plans, i.e. sets of coher-ent plans, and thus subsets of desires thatcan be pursued at the same time. Thisframework takes as input the following el-ements: D, P , F p, and R p.
Definition 6 A framework for generating feasible plans is a pair P ,R p.
Here again, we are looking for groups of plans that are achievable together. Thismeans that the plans should not be con-flicting. Thus, the extensions should beconflict-free:
Definition 7 (Conflict-free) Let S ⊆ P . S is conflict-free iff S ⊆ S , such that S ∈R p.
Definition 8 (Extension of plans) Let S ⊆ P . S is an extension iff:
• S is conflict-free
• S is maximal for set inclusion amongsubsets of P that satisfies the first con-dition.
S 1, . . . ,S n will denote the different exten-sions of plans.
As for arguments, it also possible to definethe status of each plan as follows:
Definition 9 (Status of plans) Let p ⊆ P .
• p is feasible iff ∃S i such that p ∈ S i
• p is unachievable iff S i such that p ∈S i
• p is universally feasible iff ∀S i , p ∈ S i.This means that such a plan is feasiblewith other plans.
On the basis of the status of plans, one candefine the status of each desire. Four casesare distinguished:
Definition 10 (Status of desires) Let d ⊆D.
• d is achievable iff ∃ p ∈ F p(d) suchthat p is feasible
____________________________________________________________________________ Annales du LAMSADE N°8
19

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 32/415
• d is unachievable iff ∀ p ∈ F p(d) , p isunachievable
• d is universally feasible iff ∃ p ∈ F p(d)
such that p is universally feasible
• d is universally accepted iff ∀ p ∈F p(d) , p is universally feasible
The desires achieved by each extension arereturned by a function defined as follows:
Definition 11 Let S i be an extension of the framework P ,R p.
Desires(S i) = d j ∈ D s.t. ∃ p ∈ S i and F p(d j) = p.
Example 3 (Example 1 continued) P = p1, p2, p3 , F p(d1) = p1 , F p(d2)= p2 , F p(d3) = p3 , and R p = p2, p1, p3.
The set R p means that the plan p2 is not
achievable, and that the two plans p1 , and p3 cannot be achieved together. Thus,the system P ,R p will return two exten-sions: S 1 = p1 , and S 2 = p3 , withDesires(S 1) = d1 and Desires(S 2) =d3.
It is clear that the desire d2 is unachiev-able, and the two desires d1, d3 cannot be pursued at the same time. The agent should select only one of them.
2.3 Selecting intentions
In the previous section, we have proposeda framework that returns extensions of plans, i.e. plans that may co-exist together.However, as shown before, several exten-sions may exist at the same time. Oneneeds to select the one that will constitute
the intentions of the agent. A preordering on the set S 1, . . . , S n is then needed.This is a decision making problem. Thislatter amounts to defining a pre-ordering,usually a complete one, on a set of possible
alternatives, on the basis of the differentconsequences of each alternative. In [1],it has been shown that argumentation canbe used for defining such a pre-ordering.The idea is to construct arguments infavor of and against each alternative,to evaluate such arguments, and finallyto apply some principle for comparingpairs of alternatives on the basis of thequality or strength of their arguments.In that framework, atomic actions areordered. In what follows, we will extendthe framework to the case of sets of plans,i.e. instead of ordering atomic actions, we
will define a preordering on the set E =S 1, . . . , S n.
The main ingredients that are involved inthe definition of an argumentation-baseddecision framework are the following:
Definition 12 (Decision framework) Anargumentation-based decision frameworkis a tuple
E ,
Ae ,
ewhere:
• E is the set of possible alternatives.
• Ae is a set of arguments support-ing/attacking elements of E .
• e is a (partial or complete) pre-ordering on Ae.
The output is a preordering on E . S i S jmeans that the extension S i is preferred tothe extension S j.
Once the relation is identified, one cancompute the intentions of an agent. Theintentions are the set of plans belonging tothe most preferred extension w.r.t. , andwhich achieve generated desires.
Definition 13 (The intentions) The set of intentions is pi ∈ S j| pi ∈ F p(d) , d ∈Output , and ∀S k , S j S k.
Practical reasoning as a generalized decision making problem ___________________________________________________________________________
20

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 33/415
Arguments. A decision may have argu-ments in its favor (called PROS), and ar-guments against it (called CONS). Argu-ments PROS point out the existence of good consequences for a given decision. Inour application, an argument PRO an ex-tension S i points out the fact it achieves agenerated desire, i.e. an element of the setOutput. Formally:
Definition 14 (Arguments PROS) Let S i ∈ E . An argument in favor of , or PRO,the extension S i is a triple A = p j,S i, dk
such that p j ∈ S i , p j ∈ F p(dk) , and dk ∈Output. Let ArgP be the set of all such argumentsthat can built.
Note that there are as many arguments asplans to carry out the same desire. Ar-guments CONS highlight the existence of bad consequences for a given decision, orthe absence of good ones. Arguments
CONS are defined by exhibiting a gener-ated desire that is not achieved by the ex-tension. Formally:
Definition 15 (Arguments CONS) Let S i ∈ E . An argument against , or CONS,the extension S i is a pair A = S i, dksuch that p j ∈ S i , p j ∈ F p(dk) , and dk ∈Output.
Let ArgC be the set of all such arguments
that can built.
Note that some arguments may be strongerthan others. For instance, an argumentA = p j,S i, dk in favor of the extensionS i may be preferred to an argument B = p j,S i, dl if the desire dk is preferred to
the desire dl. In this case, the preferencerelation e is based on a preference rela-tion d between the potential desires of
D. The relation e can also be definedon the basis of the plans themselves. Forinstance, one may prefer the argument Aover the argument B if the cost of p j islower than the cost of the plan p j .
Some decision criteria. Different criteriafor defining the preordering on E can bedefined. In what follows, we will presentsome examples borrowed from [1], andadapted to our application, i.e. orderingsets of plans.
In what follows, GoalsX (S i) be a functionthat returns for a given decision or exten-sion S i, all the desires for which there ex-ists an argument of type X (i.e. PROS orCONS) with conclusion S i.Let S i, S j ∈ E .
S i 1 S j iff GoalsP (S i) = ∅, andGoalsP (S j) = ∅ (1)
The above criterion prefers the extensionthat achieves generated desires. This canbe refined as follows:
S i 2 S j iff GoalsP (S i) ⊃ GoalsP (S j) (2)
The above criterion prefers the extensionthat achieves more generated desires. Thispartial preorder can be further refined intoa complete preorder as follows:
S i 3 S j iff |GoalsP (S i)| > |GoalsP (S j)|(3)
3 Illustrative exampleLet us consider an agent who has the twofollowing conditional desires:
1. To go on a journey to central Africa if he is in holidays. (hol → jca)
2. To finish a publication if there is adeadline of a conference. (conf →
fp)
In addition to the desires, the agent issupposed to have beliefs on the way of achieving a given desire:
____________________________________________________________________________ Annales du LAMSADE N°8
21

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 34/415
t ∧ vac → jcaw → fpag → t
fr → thop → vacdr → vac
with: t = “to get the tickets”, vac =“to be vaccinated”, w = “to work”, ag= “to go to the agency”, fr = “to have afriend who may bring the tickets”, hop =“to go to the hospital”, dr = “to go to adoctor”.
For example, the rule t ∧ vac → jcameans that the agent believes that if hegets tickets and he is vaccinated then hewill be able to go on a journey in centralAfrica. The rule w → fp expresses thatthe agent believes that if he works thenhe will be able to finish his paper. Toget tickets, the agent can either visit anagency or ask a friend of him to get them.
Similarly, to be vaccinated, the agent hasthe choice between going to a doctor orgoing to the hospital. In these two lastcases, the agent has two ways to achievethe same desire.An agent may have also another kind of beliefs representing integrity constraintsand facts. In our example, we have:
hol
conf w → ¬agw → ¬hop
The two latter rules mean that the agentbelieves that if he works, he can neithervisit an agency nor go to a doctor. In thisexample, the two conditional desires jcaand fp are justified in the current state of the world since the they depend on beliefs
(respectively hol and conf ) that are true.Moreover, both desires have at least a planfor achieving them. However, some waysof achieving the desires are conflicting.
<t, vac, jca> <t, vac, jca>
< a g , t> < d r , v ac >
<, dr><, ag>
<ag, t> <hop, vac>
g3
<, hop>
<hop, vac>
<, hop>
<fr, t>
<, fr>
<fr, t>
<, fr>
<dr, vac>
<, dr>
g2
g4
<t, vac, jca><t, vac, jca>
<, ag>
g1
<w, fp>
<, w>
g5
Figure 1: Complete plans
Of course, it would be ideal if all the de-sires can become intentions. As our exam-ple illustrates, this may not always be thecase. We will answer the following ques-tions: which desires will be pursued by theagent and with which plans?
In this example, we have two arguments infavor of the conditional desires jca and fp.
Let A = hol,hol → jca,jca and B= conf, conf → fp, fp. These argu-ments are not defeated at all, thus they be-long to the grounded extension of the argu-mentation system. Consequently, Output= jca, fp.
there are four complete plans (g1, g2, g3,g4) for the desire ‘going on a journey tocentral africa’ and exactly one complete
plan g5 for the desire ‘finishing the paper’.These are given in figure 1. Moreover, g5attacks g1, g2 and g3. Thus, there are ex-actly two extensions:
• S 1 = g1, g2, g3, g4
• S 2 = g4, g5
The extension S 1 is supported by four ar-
guments:
• A1 = g1,S 1,jca
• A2 = g2,S 1,jca
Practical reasoning as a generalized decision making problem ___________________________________________________________________________
22

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 35/415
• A3 = g3,S 1,jca
• A4 = g4,S 1,jca
The four arguments exhibits the same de-sire jca. However, the extension S 2 is sup-ported by only two arguments:
• B1 = g4,S 1,jca
• B2 = g5,S 1, fp
However, the two arguments refer to twodifferent desires. According to crite-
rion (2), it is clear that S 2 is preferredto S 1 since GoalsP (S 2) ⊃ GoalsP (S 1),knowing that GoalsP (S 1) = jca, andGoalsP (S 1) = jca, fp. The inten-sions to be pursued by the agent are theng4, g5.
4 Related works
Recently, a number of attempts have been
made to use formal models of argumen-tation as a basis for practical reasoning.Some of these models (e.g. [2, 3, 8]) areinstantiations of the abstract argumenta-tion framework of Dung [7]. Others (e.g.[9, 12]) are based on an encoding of argu-mentative reasoning in logic programs. Fi-nally, there are frameworks based on em-pirical approaches to practical reasoningand persuasion (e.g. [4, 13]). Our frame-
work builds on the former, and is thereforea contribution towards formalising practi-cal reasoning using abstract argumentationsystems.
Amgoud [2] presented an argumentationframework for generating consistent plansfrom a given set of desires and planningrules. This was later extended with ar-gumentation frameworks that generate thedesires themselves (see below).
Amgoud and Kaci [3] have a notion of “conditional rule”, which is meant to gen-erate desires from beliefs. Our frame-work is more general in the sense that we
don’t specify how arguments are built frombases. Indeed, the structure and the originof the arguments are left unknown and canbe instantiated with any logic. Moreover,in that work it is not clear how intentionsare chosen.
Hulstijn and van der Torre [8], on the otherhand, have a notion of “desire rule”, whichcontains only desires in the consequent.But their approach is still problematic. Itrequires that the selected goals are sup-ported by goal trees which contain both de-sire rules and belief rules that are deduc-
tively consistent. This consistent deduc-tive closure again does not distinguish be-tween desire literals and belief literals (seeProposition 2 in [8]). This means that onecannot both believe ¬ p and desire p. Hereagain, the selection of intention is left un-solved.
5 Conclusion
This paper has presented the first generaland abstract framework for practical rea-soning. It shows that this latter generalizesthe decision making problem.
We presented a formal model for reason-ing about desires (generating desires andplans for achieving them) based on argu-mentation theory. We adapted the notionsof attack and preference among argumentsin order to capture the differences in argu-ing about desires and plans.
One of the main advantages of our frame-work is that, being grounded in argumen-tation, it lends itself naturally to facili-tating dialogues about desires and plans.Indeed, we are currently extending ourframework with dialogue game protocols
in order to facilitate negotiation and per-suasion among agents. Another interestingarea of future work is investigating the re-lationship between our framework and ax-iomatic approaches to BDI agents.
____________________________________________________________________________ Annales du LAMSADE N°8
23

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 36/415
References
[1] L. Amgoud and H. Prade. Explainingqualitative decision under uncertainty
by argumentation. In Proc. of the 21st National Conference on Artificial In-telligence, AAAI’06 , pages 219–224,2006.
[2] Leila Amgoud. A formal frame-work for handling conflicting de-sires. In Thomas D. Nielsen andNevin Lianwen Zhang, editors, Proc.
ECSQARU , volume 2711 of LNCS ,
pages 552–563. Springer, Germany,2003.
[3] Leila Amgoud and Souhila Kaci. Onthe generation of bipolar goals inargumentation-based negotiation. InIyad Rahwan et al, editor, Proc. 1st
Int. Workshop on Argumentation in Multi-Agent Systems (ArgMAS), vol-ume 3366 of LNCS . Springer, Ger-many, 2005.
[4] Katie Atkinson, Trevor Bench-Capon, and Peter McBurney.Justifying practical reasoning. InC. Reed F. Grasso and G. Carenini,editors, Proc. Workshop on Compu-tational Models of Natural Argument (CMNA), pages 87–90, 2004.
[5] M. Bratman. Intentions, plans, and practical reason. Harvard University
Press, Massachusetts., 1987.
[6] M. Bratman, D. Israel, and M. Pol-lack. Plans and resource bounded reasoning., volume 4. ComputationalIntelligence., 1988.
[7] Phan Minh Dung. On the accept-ability of arguments and its funda-mental role in nonmonotonic rea-soning, logic programming and n-person games. Artificial Intelligence,77(2):321–358, 1995.
[8] Joris Hulstijn and Leendert van derTorre. Combining goal generation
and planning in an argumentationframework. In Anthony Hunter andJerome Lang, editors, Proc. Work-shop on Argument, Dialogue and De-cision, at NMR, Whistler, Canada,June 2004.
[9] Antonis Kakas and Pavlos Moraitis.Argumentation based decision mak-ing for autonomous agents. In Proc.2nd International Joint Conferenceon Autonomous Agents and Multia-gent Systems (AAMAS), pages 883–890, Melbourne, Australia, 2003.
[10] J. Raz. Practical reasoning. Oxford,Oxford University Press, 1978.
[11] L. J. Savage. The Foundations of Statistics. Dover, New York, 1954.Reprinted by Dover, 1972.
[12] Guillermo R. Simari, Alejandro J.Garcia, and Marcela Capobianco.Actions, planning and defeasible rea-soning. In Proc. 10th InternationalWorkshop on Non-Monotonic Rea-soning, pages 377–384, 2004.
[13] Yuqing Tang and Simon Parsons.Argumentation-based dialogues fordeliberation. In Frank Dignum et al,editor, Proc. AAMAS, Utrecht, The
Netherlands, pages 552–559, NewYork NY, USA, 2005. ACM Press.
Practical reasoning as a generalized decision making problem ___________________________________________________________________________
24

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 37/415
Planification multi-agent et diagnostic stratégique
Ramzi Ben Larbi
Sébastien Konieczny
Pierre Marquis
CRIL - CNRS, Université d’Artois, Lens
Résumé :Quand plusieurs agents opèrent dans un environ-nement commun, leurs plans peuvent interférer.Le résultat de chaque plan peut être altéré parcette interaction et la notion de plan valide de laplanification classique (mono-agent) ne convientplus. Dans cet article, nous étendons ce cadre àun cadre multi-agent. Nous montrons comment les"meilleurs" plans pour un agent rationnel peuventêtre caractérisés en utilisant des notions de théoriedes jeux, en particulier celle d’équilibre de Nash.Nous identifions par ailleurs les scénarios pour les-quels une coopération entre agents devrait s’effec-tuer et montrons que nombre d’informations straté-giques peuvent être dérivées du jeu.
Mots-clés : Planification, interaction, systèmesmulti-agents
Abstract:When several agents act in a common environmenttheir plans may interfere. The predicted outcomeof each plan may be altered and the usual notion of valid plan of classical (monoagent) planning is notadequate. In this paper we extend this framework tothe multi-agent case. We show how the “best” plansof rational agents can be characterized using game-theoretic notions, especially Nash equilibrium. Wealso identify the scenarios for which a cooperationbetween agents is likely to occur and show thatmany strategic information can be derived from thegame.
Keywords: Planning, interaction, multiagent sys-tems
1 Introduction
La modélisation de l’interaction entreagents est un domaine de recherche qui aété exploré depuis des années en écono-mie, psychologie mais aussi intelligence
artificielle. En planification classique, oncalcule des plans qui, une fois exécutés,permettent à l’agent qui les a formés d’at-teindre son but. Parmi les hypothèses stan-dard de planification classique figurent le
fait que l’agent connaît l’état initial dumonde, chaque action possible est déter-ministe et son résulat peut être parfaite-ment prédit quel que soit l’état où elle estexécutée, les buts sont binaires (i.e. un étatdu monde est soit complètement satisfai-
sant soit complètement insatisfaisant), etle monde est statique dans le sens où laseule manière de le modifier est d’exécu-ter l’une des actions de l’agent (ainsi, nonseulement il n’y a pas d’évènement exo-gène mais aussi le monde n’a pas de dyna-mique intrinsèque).
Dans cet article, nous étendons le cadrede la planification classique à un cadre de
planification multi-agent, i.e., nous consi-dérons un groupe d’agents. Chaque agentpossède ses propres actions et buts. Lesagents agissent dans un environnementcommun. Dans ce cadre, les hypothèsesstandard de planification classique sontfaites (excepté le fait que les buts ne sontpas forcément binaires). Quand plus d’unagent est considéré, de telles hypothèsesde planification (en particulier, le mondestatique et les actions déterministes) nesont pas suffisantes pour permettre de pré-dire comment le monde va évoluer aprèsl’exécution du plan. En effet, même siles actions restent déterministes, l’inter-action entre les plans des agents intro-duit un surplus de complexité. Chaqueagent ignore généralement quels plans lesautres agents vont finalement choisir etcomment ses propres actions s’intercale-ront avec les leurs. Nous suggérons de
pallier cela en utilisant des concepts dethéorie des jeux qui permettront à l’agentde construire un diagnostic stratégique ex-primant ses chances d’atteindre ses butsétant données les interactions possibles
25

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 38/415
avec les autres agents. Nous supposonsque l’agent connaît les buts de chaqueagent du groupe, ainsi que les plans quechaque agent peut proposer. Par ailleurs,les agents peuvent aussi se coordonner, cequi veut dire qu’ils peuvent décider de bâ-tir un plan commun. Dans ce cas l’incer-titude causée par l’interaction est dissipée.Mais il n’est pas toujours dans l’intérêt del’agent de se coordonner.
Exemple 1 Deux agents, un peintre et unélectricien, agissent dans une même pièce.
L’ampoule doit être changée (ce qui est le but de l’électricien) et le plafond doit être peint (ce qui est le but du peintre).
L’électricien a une nouvelle ampoule et le peintre a le matériel nécessaire à la
peinture. Il y a une seule échelle dans la pièce (l’échelle est donc une ressourcecritique). De plus, le peintre a besoinde lumière pour peindre. L’électricien
possède trois actions Prendre-Echelle-
Electricien (PEE), Changer-Ampoule(CA), Reposer-Echelle-Electricien (REE),et le peintre trois actions : Prendre-
Echelle-Peintre (PEP), Peindre (P), Reposer-Echelle-Peintre (REP). Peindreréussit seulement si Changer-Ampoule adéjà été exécuté. Prendre-Echelle-Peindreréussit seulement si l’échelle est dispo-nible (i.e., elle a été reposée auparavant).
Les interactions suivantes peuvent être
facilement envisagées : – si le peintre prend l’échelle en premier, il
ne sera pas capable d’atteindre son but (l’ampoule doit être changée avant) ;s’il ne repose pas l’échelle, l’électricienne sera pas capable d’atteindre son but.
– si l’électricien prend l’échelle en pre-mier, il sera capable d’atteindre sonbut ; alors, le peintre sera capabled’atteindre son but si et seulement si
l’éléctricien repose l’échelle. En consé-quence, si les deux agents peuvent se coordonner pour exécuter le plan
joint PEE.CA.REE.PEP.P, alors les deuxagents seront satisfaits.
L’idée de se concentrer sur des plans li-néaires peut être justifiée dans ce cadrelorsque l’agent en charge de l’exécution(qui peut être différent de l’agent quiconstruit le plan) ne peut observer l’envi-ronnement et ainsi ne peut adapter son planaux événements extérieurs (i.e. actions desautres agents), ou lorsqu’il peut observerl’environnement mais ne peut replanifierdynamiquement à cause d’un manque deressources calculatoires ou la présence decontraintes temps réel (c’est le cas parexemple d’agents autonomes et mobilescomme des drones volant à grande vitesse,
ou des infobots - agents logiciels - devantagir sur des marchés hautement volatiles).
Les questions clés que nous posons dansce papier sont les deux suivantes : pourchaque agent du groupe, quels sont ses"meilleurs" plans ? Est-ce qu’un plandonné requiert une coordination afin d’êtreexécuté d’une manière satisfaisante pourles deux agents ? En nous concentrant
principalement sur le cas de deux agentset en considérant seulement des buts bi-naires, nous montrons comment un jeupeut être associé à n’importe quel pro-blème de planification multi-agent ; enconséquence, les "meilleurs" plans pour unagent rationnel peuvent être caractérisés enutilisant des notions de théorie des jeux,spécialement l’équilibre de Nash. Nousidentifions aussi les scénarios pour les-quels une coopération entre agents est op-
portune et montrons comment plusieurs in-formations stratégiques peuvent être déri-vées du jeu sous forme stratégique. Finale-ment, nous montrons que plusieurs cadresformels dans lesquels on considère l’inter-action entre agents peuvent être intégrés aunôtre, incluant ceux de la planification ro-buste et des jeux booléens.
2 Un cadre formel pour la pla-nification multi-agent
On considère un groupe d’agents N=1, 2, · · · , k, où chaque agent est identi-
Planification multi-agent et diagnostic stratégique ___________________________________________________________________________
26

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 39/415
fié par un entier. Soit S un ensemble fininon vide d’états abstraits. Notons s0 l’étatinitial, supposé être l’état actuel du monde.s0 est connu par chacun des agents de N.Chaque agent est associé à un ensembled’actions :
Définition 1 (action) Une action α est une application de S dans S. L’ensembledes actions de l’agent i est noté Ai.
Dans la suite, une action sera notée par
une lettre grecque (α,β, · · · ). La défini-tion précédente impose que les actionssoient déterministes et toujours exécu-tables. Cette dernière hypothèse n’est pasexcessive. En effet, si l’on veut modéliserle fait qu’une action n’est pas exécutablesi l’état du monde est s, on peut typique-ment la représenter par une action qui nechange pas l’état du monde dans cet état,i.e. α(s) = s, ou qui conduit à un état"puits", i.e., α(s) = s⊥, avec s⊥ un état
qui a la pire évaluation par rapport auxbuts de l’agent et tel que β (s⊥) = s⊥ pourtoute action β . A partir de son ensembled’actions, chaque agent peut construire desplans :
Définition 2 (plan) Soit A un ensembled’actions. Un plan p sur A est une suite(possiblement vide) d’actions de A, i.e.
p = α1.α2. · · · .αn , où chaque αi ∈ A.Sémantiquement, c’est une application deS dans S, définie à partir de la composi-tion de ses actions, i.e., pour toute actionα ∈ S , p(s) = s si p = (la séquence vide),et p(s) = αn(· · · (α1(s)) · · · ) autrement.
L’ensemble des plans sur A est noté A∗.
Soit un plan p = α1.α2. · · · .αn. Un sous-plan de p est une sous-suite de ses ac-
tions, i.e., p = α1. · · · .αm est un sous-plan de p si et seulement si il existeune application strictement croissante tde 1, · · · , m dans 1, · · · , n telle que∀q ∈ 1, · · · , m, αa
= αt(q). Soit
un autre plan p = β 1. · · · .β k, p.p dé-note la concaténation de p et p, i.e., p.p=α1. · · · .αn.β 1. · · · .β k. Enfin, si p est unplan sur A, A( p) dénote le sous-ensemblede A formé par les actions de p.
Les buts d’un agent sont exprimés d’unemanière qualitative au moyen d’une rela-tion de préférence (un pré-ordre) sur l’en-semble des états : G
i ⊆ S × S . Ainsi,pour s, s ∈ S, sG
is signifie que pourchaque agent i, l’état s est au moins aussipréféré que s. Quand S est fini, chaquepréordre G
i sur S peut être représenté
par une fonction réelle Gi telle que pourtout s, s ∈ S , sG
is si et seulement siGi(s) ≤ Gi(s). Dans la suite, nous allonssouvent nous concentrer sur le cas binairedans lequel les états sont divisés entre étatsbuts et états non-buts :
Définition 3 (but binaire) On dit qu’unagent i a des buts binaires Gi ⊆ S si
et seulement si sa relation de préférenceG
i est telle que sGis si et seulement si
s ∈ Gi ou s, s /∈ Gi. Nous utiliserons lanotation Gi(s) = 1 si s ∈ Gi et Gi(s) = 0si s /∈ Gi.
Assez naturellement, toute relation de pré-férence sur les états induit une relation depréférence sur les plans :
Définition 4 (préférence sur les plans)Soit i un agent, A∗ un ensemble de plans,s0 un état et G
i une relation de préfé-rence sur les états. La relation de préfé-rence ≤i sur A∗ est définie comme suit :
pour tout p, p ∈ A∗ , p ≤i p si et seule-ment si p(s0)G
i p(s0).
La qualité d’un plan est donnée par la qua-lité de l’état atteint; comme en planifi-cation classique, des critères additionnels(e.g., le coût du plan) peuvent être uti-lisés pour discriminer les meilleurs plans
____________________________________________________________________________ Annales du LAMSADE N°8
27

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 40/415
ainsi définis. Dans plusieurs cas, il est rai-sonnable de supposer que seulement un
sous-ensemble Πi de Ai∗ est envisagé parl’agent i ; en particulier, à cause de capa-cités de calcul limitées, les plans dont lalongueur excède un seuil donné peuventêtre éliminés. Toutefois, cela a du sens deconsidérer que Πi est clos pour les sous-plans, i.e., quand un plan p appartient à Πi,alors tout sous-plan de p appartient aussià Πi. En particulier, le plan vide appar-tient toujours à Πi. Nous sommes mainte-nant prêts à définir la notion de représen-tation d’un agent et celle de problème deplanification multi-agent :
Définition 5 (représentation d’un agent)Chaque agent i ∈ N est caractérisé par un triplet A
i = Ai, Πi, Gi formé par
un ensemble d’actions Ai , un ensemble de plans Πi ⊆ Ai et une relation de préfé-rence G
i.
Définition 6 (problème de planification multi-agent) Un problème de planificationmulti-agent (MAPP) pour un ensemble N d’agents est un triplet S, s0, A i|i ∈ N
formé par un ensemble d’états S, un état initial s0 ∈ S et un ensemble de représen-tations d’agents A i. Un MAPP avec butsbinaires est tel que chacun des agents pos-sède une structure de buts binaire.
Lorsque chaque agent a choisi un plan, lasuite d’évènements correspondant à leurexécution jointe est l’un de leurs mélanges,sauf si une coordination est réalisée. Nousnotons ⊕ l’application de A∗×A∗ dans 2A
∗
qui associe à chaque paire de plans pi et p j,l’ensemble contenant leurs mélanges :
Définition 7 (mélange, ensemble de mé-langes) Soit pi = αi1. . . . . αi
n ∈ Ai, p j =
α j1. . . . . α j p ∈ A j. Alors pi ⊕ p j est l’en-
semble de plans p qui sont des permuta-tions de pi.p j pour lesquel pi et p j sont des
sous-plans. Chaque p est appelé un mé-lange de pi et p j et pi ⊕ p j est appelé l’ensemble de mélanges de pi et p j.
Exemple 2 Reprenons l’exemple 1 avec p1 le plan de l’éléctricien : PEe.CAet p2 le plan du peintre : PEp.P.
Alors p1 ⊕ p2 = PEe.CA.PEp.P,PEe.PEp.CA.P, PEe.PEp.P.CA, PEp.PEe.P.CA, PEp.P.PEe.CA, PEp.PEe.CA.P.
Observons que ⊕ est une fonction permu-
tative (i.e., commutative et associative). Ils’en suit que les définitions précédentesde mélange et d’ensemble de mélangespeuvent être facilement étendues au cas oùn > 2. Observons aussi que (la suitevide) est un élément neutre pour ⊕. Dansle cas déterministe avec un seul agent, éva-luer un plan est une tâche facile. L’état pré-dit est le résultat de l’exécution du plan.Caractériser un meilleur plan est aussi fa-
cile pour l’agent considéré : le plan estd’autant meilleur que l’état atteint l’est.Dans le cas non déterministe, l’agent doitconsidérer tous les états possiblement at-teints et agréger leurs scores afin d’évaluerle plan (plusieurs fonctions d’agrégationpeuvent être utilisées, e.g. min (critère deWald) pour traduire le comportement d’unagent pessimiste, ou un critère d’utilité es-pérée quand les scores sont quantitatifs et
les actions non déterministes sont donnéespar des ensembles de distributions de pro-babilité).
Dans le cas multi-agent (quoique détermi-niste), qui est le cas étudié dans cet ar-ticle, la situation est similaire à celle ducas non-déterministe à un agent dans lesens où chaque agent doit considérer tousles états possiblement atteints pour évaluerses plans. La différence principale vient
de la nature de l’incertitude : dans notrecadre, l’incertitude vient de l’interactionavec les plans fournis par les autres agents.En conséquence, chaque agent doit ex-ploiter le fait qu’il connaît les représen-
Planification multi-agent et diagnostic stratégique ___________________________________________________________________________
28

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 41/415
tations des autres agents (il connaît lesbuts des agents ainsi que leurs plans) afinde déduire quel est son "meilleur" plan.Il diffère en cela du cas non déterministeoù l’incertitude vient de l’impossibilité deprédire précisement le résultat de certainesactions, comme "tirer à pile ou face". Dansplusieurs cas, une telle impossibilité ré-sulte d’évènements extérieurs (sur lesquelsnotre connaissance est imparfaite), qui nepeuvent être totalement observés ou pré-dits et qui ont un certain effet sur le monde.Par exemple, dans le cas de planificationdes mouvements d’un robot, l’effet nor-
mal de l’action "avancer(1m)" est d’avan-cer le robot d’un mètre ; toutefois, il sepeut que cet effet normal ne se produisepas : si le sol est mouillé (et que cela nepuisse pas être observé), un effet excep-tionnel de "avancer(1m) sera d’avancer lerobot de 0.5 mètre, seulement. Toutefois,dans la section 5, nous expliquerons com-ment la planification robuste, qui traite leproblème de trouver un plan robuste dans
un cadre non déterministe, peut être expri-mée dans notre cadre.
Exemple 3 Si le peintre dans l’exemple 1 propose le plan p = PEp.P.REp , il est seulement assuré que les actions de p se-ront exécutés dans l’ordre désiré. Alorsqu’il connaît la représentation de l’électri-cien, il ne sait pas quel plan l’électricienva proposer (en effet, l’ensemble des plans
possibles n’est en général pas un single-ton). Même si cet ensemble est un single-ton, le peintre ignore encore l’ordre d’exé-cution, i.e., comment son plan va s’inter-caler avec celui de l’électricien. Suppo-sons que l’électricien propose le plan p =PEe.CA.REe , le plan joint qui va être fi-nalement exécuté peut être n’importe quel
plan de p⊕ p. L’incertitude résultante dis- parait dès que les deux agents se coor-
donnent pour exécuter un plan communcomme p= PEp.P.REp.PEe.CA.PEe.
Dans notre approche, une tâche capitalepour chaque agent est celle d’évaluer l’in-
teraction de ses plans avec ceux des autresagents. Formellement, cela requiert l’éva-luation de chaque ensemble de mélanges.A cette fin, nous associons à chaque en-semble de mélanges son profil de satis-faction (SP), qui est une vue résuméeet abstraite de l’évaluation des mélangespour tous les agents du groupe. Expliquonscomment construire un profil de satisfac-tion pour un groupe de deux agents ayantdes buts binaires. Etant donnée un couplede plans, pi ∈ Πi et p j ∈ Π j, chaque mé-lange de l’ensemble de mélanges pi ⊕ p jest un plan construit à partir des actions
des deux agents ; l’exécution d’un tel planconduit à un état spécifique qui est plusou moins satisfaisant pour chaque agent.L’évaluation d’un plan dépend de l’état ré-sultant de son exécution. On peut repré-senter l’évaluation d’un ensemble de mé-langes par les agents en utilisant une re-présentation sur 2 axes (chaque axe ex-prime la satisfaction de l’agent correspon-dant) qui associe un point de coordonnées
(x,y) à un mélange p ssi Gi
( p(s0)) = x etG j( p(s0)) = y. Notons qu’une telle repré-sentation peut être facilement généraliséeau cas de n agents.
Définition 8 (profil de satisfaction) Soit un MAPP avec buts binaires pour un en-semble N = 1, . . . , m d’agents, avec unétat intial s0. Un profil de satisfaction (SP)
pour l’ensemble de mélanges p1⊕ p2⊕. . .⊕ pk ( pi ∈ Πi pour i ∈ 1, . . . k) est unensemble SP ( p1 ⊕ p2 ⊕ . . . ⊕ pk) de vec-teurs (x1, . . . , xk) vérifiant (x1, . . . , xk) ∈SP ( p1 ⊕ p2 ⊕ . . . ⊕ pk) si et seulement si ∃ p ∈ p1 ⊕ p2 ⊕ . . . ⊕ pk tel que ∀i ∈1, . . . k , Gi( p(s0)) = xi.
Quand nous considérons seulement deuxagents ayant des buts binaires, les profils
de satisfaction possibles est décrit dans lafigure 1.
De nombreuses conclusions peuvent êtretirées à partir de tels SPs. Ainsi, quelques
____________________________________________________________________________ Annales du LAMSADE N°8
29

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 42/415
6•
10
1
i
j
-
1 6•
•10
1
i
j
-
2 6•
•
•
10
1
i
j
-
3
6•
•
•
• 10
1
i
j
-
4 6
•10
1
i
j
-
5 6•
10
1
i
j
-
6
6
• 10
1
i
j
-
7 6••
10
1
i
j
-
8 6•
• 10
1
i
j
-
9
6•
• 10
1
i
j
-
10 6
•• 10
1
i
j
-
11 6
•
•
10
1
i
j
-
12
6••
• 10
1
i
j
-
13 6•
•• 10
1
i
j
-
14 6
•
•
• 10
1
i
j
-
15
FIG . 1 – SPs possibles dans le cas binaire
avec deux agents
SPs sont clairement meilleurs pour unagent donné que d’autres. Clairement, SP2 dans lequel les mélanges conduisentseulement à des états que l’agent i évalueà 1, est plus intéressant pour lui que SP 10,dans lequel les mélanges conduisent tou-
jours à des états non buts pour cet agent.De plus, considérons SP 3 : pour chacun
des deux agents, au moins l’un des mé-langes conduit à un mauvais état (i.e., unétat non but), et au moins l’un des mé-langes conduit à un état but. Cet SP montreaussi l’exsistence d’au moins un mélangegagnant-gagnant (évalué comme le vecteur(1,1)). Dans un tel cas, si les deux agentssont rationnels (i.e., ils agissent pour chan-ger le monde vers un état but), alors il de-vraient se coordonner pour exécuter un tel
mélange. En effet, la coordination est unmoyen d’éliminer l’incertitude. Si les deuxagents i et j proposent deux plans pi ∈ Ai∗
et p j ∈ A j∗ de manière indépendante, ilscourent le risque que l’exécution jointe de
pi ⊕ p j conduise à un état évalué à (0,1) ou(1,0), auquel cas, l’un des agents sera in-satisfait. A l’inverse, s’ils se coordonnentet proposent conjointement un plan corres-pondant à un mélange gagnant-gagnant, ilsauront la garantie d’être tous deux satis-faits. Dans une situation correspondant auSP 3, les deux agents ont intérêt à offrir (etaccepter) une coordination. En l’absencede plus d’information (comme une distri-bution de probabilité sur l’ensemble desmélanges), cela a un sens de classer les SPssur une échelle ordinale. Prenons pour celale point de vue de l’agent i et montrons
comment les SPs peuvent être rassembléset ordonnés :– Toujours Satisfait SP 1,2,5. Pour ces
SPs, l’agent i est assuré d’atteindre sesbuts même si l’agent j n’accepte aucunecoordination. C’est le cas le plus favo-rable pour i.
– Intérêt Mutuel SP 3,4,9,13,14. Pourchacun de ces SPs, une certaine exé-cution jointe est bénéfique et d’autres
non (pour les deux agents), mais ils par-tagent tous le vecteur (1,1), ce qui si-gnifie que si les deux agents se coor-donnent, il peuvent tous deux atteindreleurs buts.
– Dépendance SP 8,11. Pour ces SPs,l’évaluation des mélanges par l’autreagent est constante. Cela signifie que, apriori, il n’y a aucune raison pour l’autreagent d’accepter une coordination afind’aider l’agent i à atteindre son but.
– Antagonisme SP 12,15. Ces SPs re-flètent des situations plus probléma-tiques étant donné que les intérêts desdeux agents sont clairement distincts.Cela signifie que si l’un est satisfait,alors l’autre ne l’est pas ( i.e. la coordi-nation (1,1) n’est pas une option). Dansde tels cas, l’agent i peut juste espérerque l’exécution jointe lui sera favorable.
– Toujours Insatisfait SP 6,7,10. Quelle
que soit la suite des évènements, l’agenti sera insatisfait (aucune exécution jointene permet à l’agent d’atteindre son but).De tels SPs sont clairement les pirespour l’agent i.
Planification multi-agent et diagnostic stratégique ___________________________________________________________________________
30

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 43/415
Notre thèse est que, en l’absence d’infor-mation supplémentaire, une telle classifi-cation est la plus rationnelle. Par consé-quent, nous considérons que chaque agentpossède les préférences suivantes sur lesévaluations des ensembles de mélanges :
Toujours Satisfait> Intérêt Mutuel >Dépendance > Antagonisme> ToujoursInsatisfait
X>Y signifie que les SPs de la classeX sont strictement préférés à ceux de laclasse Y. Tous les SPs d’une même classesont indifférents. On peut facilement en-coder un tel préordre total en utilisantdes nombres. Ainsi, nous écrivons ei( pi ⊕
p j) = 4 si et seulement si SP ( pi ⊕ p j) ∈Toujours Satisfait(i), · · · , ei( pi ⊕ p j) = 0si et seulement si SP ( pi ⊕ p j) ∈ ToujoursInsatisfait(i) (voir table1).
Classe EvaluationToujours Satisfait 4
Intérêt Mutuel 3Dépendance 2Antagonisme 1
Toujours Insatisfait 0
TAB . 1 – Evaluation des SPs
De telles évaluations ei( pi ⊕ p j) peuventgrossièrement être vues comme des utili-tés, mais elles ne dépendent pas seulementdes buts de l’agent i. Notons aussi queles nombres utilisés importent peu, seull’ordre compte (notre cadre n’est pas quan-titatif). Notons finalement que, alors queles définitions à venir vont utiliser des éva-luations ei( pi ⊕ p j) et e j( pi ⊕ p j), ellesont encore du sens quand d’autres évalua-tions sont utilisées. Ainsi, si quelqu’un est
en désaccord avec l’échelle proposée, lesdéfinitons suivantes s’appliquent toujours(tant que l’on utilise une évaluation quipermet de comparer tous les couples deplans).
3 Résolution du jeu et généra-tion de diagnostic stratégique
A partir de la construction précédente,nous sommes maintenant capables d’asso-cier à chaque mélange une évaluation pourchaque agent. Ceci nous permet de modé-liser l’interaction entre les plans des agentscomme un jeu (non-coopératif) sous formestratégique. En faisant cela, on peut uti-liser deux concepts de solutions pour ces
jeux : ceux de niveau de sécurité et d’équi-libre de Nash. En effet, à chaque MAPP
à buts binaires pour un ensemble de deuxagents N=i, j, on peut associer un jeusous forme stratégique, défini par l’en-semble N de joueurs, l’ensemble de straté-gies pour chaque joueur (les ensembles Πi
et Π j de plans dans notre cas), et par unefonction d’évaluation pour chaque joueurqui associe une évaluation à chaque profilde stratégies (les évaluations ei( pi ⊕ p j) ete j( pi ⊕ p j) pour chaque ensemble de mé-
langes pi ⊕ p j dans notre cas).
Exemple 4 Considérons le MAPP sui-vant : S, s0, A
i | i ∈ 1, 2. A 1 =
A1, Π1 = p1, p1, 1G. A
2 = A2, Π2 = p2, p2, 2
G. Supposons qu’il en résultele SP de la figure 2 :
6•
•
•
• 10
1
1
2
-
p1 ⊕ p2 6•
10
1
1
2
-
p1 ⊕ p2
6
•10
1
1
2
-
p1 ⊕ p2 6
•
•
10
1
1
2
-
p1 ⊕ p2
FIG . 2 – Exemple de SPs
On peut maintenant associer un MAPP
avec le jeu suivant sous forme stratégiquede la table 2
Une première analyse qu’un agent peutfaire est basée sur la notion de niveau de
____________________________________________________________________________ Annales du LAMSADE N°8
31

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 44/415
p2 p2 p1 (3,3) (0,4) p1 (4,0) (1,1)
TAB . 2 – Jeu associé
sécurité de ses plans.
Définition 9 (niveau de sécurité d’un plan) Etant donné un MAPP avec buts bi-naires pour N = 1, 2 , le niveau de sé-curité d’un plan pi d’un agent i (i ∈ N )
face à un ensemble Π j
de plan de l’agent j ( j = i) est défini comme l’évaluation mi-nimum de l’ensemble de mélanges entre le
plan pi et un plan du joueur j , i.e.,
S Πj ( pi) = min pj∈Πj
ei( pi ⊕ p j).
A partir des niveaux de sécurité des plansd’un agent on peut définir le niveau de sé-
curité de l’agent :
Définition 10 (niveau de sécurité d’un agent) Etant donné un MAPP avec buts bi-naires N = 1, 2 , le niveau de sécurité de
l’agent i face à l’ensemble Π j de plans del’agent j est le plus grand niveau de sécu-rité des plans de l’agent i , i.e.,
S Πj(i) = max pi∈Πi
S Πj( pi).
Une solution au jeu associé à un MAPPdonné peut être définie comme un couplede plans p1 ∈ Π1, p2 ∈ Π2 telle que
p1 (resp. p2) maximise le niveau de sé-curité de l’agent 1 ( resp 2) face à Π2
(resp. Π1). Une telle solution a du sensdans notre cadre étant donné qu’elle peutêtre vue comme une analyse au pire cas de
l’interaction stratégique. En effet, les SPssont des ensembles de vecteurs de satis-faction possibles, et comme la classifica-tion des SPs que nous avons fournie re-pose sur une analyse au pire cas, il semble
raisonnable d’utiliser les niveaux de sécu-rité pour comparer des mélanges. Toute-fois, les niveaux de sécurité ne prennentpas en compte toutes les opportunités of-fertes aux agents. Une notion de solutionbeaucoup plus largement acceptée est ba-sée sur la notion d’équilibre de Nash.
Définition 11 (équilibre de Nash) Etant donné un MAPP avec buts binaires pour N = i, j , un couple de plans pi ∈Πi, p j ∈ Π j est un équilibre de Nashsi aucun des agents ne peut avoir unemeilleure évaluation en choisissant unautre plan, i.e., pi, p j est un équilibre
de Nash si et seulement si p ∈ Πi s.t ei( p ⊕ p j) > ei( pi ⊕ p j) et p ∈ Π j s.t.e j( pi ⊕ p) > e j( pi ⊕ p j).
Exemple 5 Revenons au jeu donné à latable 2. Considérons le couple p1, p2.
L’agent 1 n’a aucun intérêt à dévier seulde ce couple. En effet, p1, p2 le conduit
à une situation moins favorable (e1( p1 ⊕ p2) < e1( p1 ⊕ p2)). De même, p1, p2est clairement moins favorable à l’agent 2que p1, p2. Ainsi, on peut conclure que p1, p2 est un équilibre de Nash. Il est fa-cile de vérifier que c’est le seul du jeu.
Comme dans le cas général en théorie des jeux, il se peut dans notre cadre qu’un jeu n’ait pas d’équilibre de Nash en stra-
tégie pure [?], ou qu’il y en ait plusieurs.Quand il y a plusieurs équilibres de Nash,d’autres critères, comme la Pareto optima-lité 1, sont souvent utilisés pour les diffé-rentier. Les propositions suivantes donnentdeux conditions suffisantes à l’existenced’un équilibre de Nash.
Proposition 1 Considérons un MAPPavec buts binaires et deux agents 1 et 2 tel
que G1 = G2. Alors le jeu associé exhibeun équilibre de Nash.
1Un vecteur Pareto domine un autre si chacune des compo-
santes du premier est supérieure ou égale à la composante cor-
respondante du second
Planification multi-agent et diagnostic stratégique ___________________________________________________________________________
32

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 45/415
Autrement dit, si les deux agents partagentles mêmes buts et s’il existe un plan formésur l’ensemble de leurs actions qui per-mette d’y parvenir, alors le modèle pré-senté retient ce plan comme solution.
Proposition 2 Considérons un MAPPavec buts binaires pour deux agents 1 et 2.
Notons G1,+ (resp. G2,+) le sous-ensembleG1 (resp. G2) des états atteignables enutilisant des plans sur A1 (resp. A2) et G1,2,+ (resp. G2,1,+) le sous-ensemblede G1 (resp. G2) des états atteignablesen utilisant des plans sur A1 ∪ A2. Si
G1,+ = G2,+ = ∅ et G1,2,+ = G2,1,+ = ∅ ,alors le jeu associé au MAPP exhibe unéquilibre de Nash.
Notons que, dans notre cadre, le dilemnedes prisonniers, un jeu particulier large-ment étudié[?, ?], peut aussi être atteint.
Exemple 6 Considérons encore une fois l’exemple 4. Le jeu associé (table 2) exhibeune situation de “dilemne du prisonnier” . p1, p2 est un équilibre de Nash. Le couple p1, p2 qui est plus profitable que p1, p2
pour les deux agents n’est pas un équilibrede Nash (chaque agent est tenté d’utiliser un autre plan).
Au delà de la notion de solution, cha-cun des deux agents i et j considérésdans le MAPP peut dériver beaucoup d’in-formations stratégiques à partir du jeusous forme stratégique associé. Concen-trons nous sur les notions de plans ro-bustes, d’effets de synergie, et d’indépen-dance. Un plan pi pour l’agent i est ro-buste par rapport à l’agent j si et seule-ment si son exécution jointe avec n’im-porte quel plan de l’agent j lui assure d’at-teindre son but. Dans le jeu sous formestratégique, un tel plan correspond à une
ligne (ou colonne) pour laquelle toutes lesévaluations pour cet agent sont égales à 4 :∀ p j ∈ Π j, ei( pi ⊕ p j) = 4 . Assez claire-ment, un tel plan maximise le niveau de sé-curité de l’agent i. Si un plan robuste existe
pour un agent i, alors aucune coordinationn’est nécéssaire avec l’agent j. L’existenced’une synergie entre deux agents peut as-sez facilement être déduite du jeu sousforme stratégique. En effet, un effet syner-gétique pour les agents i et j est possible siet seulement si il existe pi ∈ Πi et p j ∈ Π j
tel que ei( pi ⊕ p j) > max p∈Πiei( p) ete j( pi ⊕ p j) > max p∈Πje j( p). Assez claire-ment, aucun effet synergétique n’est pos-sible quand au moins l’un des agents pos-sède un plan robuste. La proposition sui-vante donne une condition suffisante pourassurer qu’un couple de plans p1, p2 ex-hibant un effet synergétique pour les deuxagents 1 et 2 soit aussi une solution du jeu :
Proposition 3 Considérons un MAPPavec buts binaires et deux agents 1 et 2. Supposons que ∃ p ∈ (A1 ∪ A2)∗
satisfaisant G1( p(s0)) = 1 et
G2( p(s0) ) = 1 et ∀ p ∈ (A1 ∪ A2)∗ , p = p ⇒ (G1( p(s0)) = 0 et
G2( p
(s0)) = 0). Soient p1 ∈ Π1, p2 ∈ Π2.Si p ∈ p1 ⊕ p2 alors p1, p2 est unéquilibre de Nash du jeu associé.
Une notion d’indépendance entre agents,reflétant le fait qu’il n’y a pas d’interactionentre leurs plans, peut aussi être facilementdérivée du jeu sous forme stratégique. Eneffet, les deux agents sont indépendants siet seulement si ∀ pi ∈ Πi, ∀ p j ∈ Π j, ei( pi⊕
p j) = ei( pi⊕) et e j( pi⊕ p j) = e j(⊕ p j).
4 Exemple : le pont
On considère deux agents 1 et 2. L’agent1 est en position a et l’agent 2 est en posi-tion b. Afin d’aller de a à c, l’agent 1 doittraverser le pont, qui doit être ouvert aupa-ravant (action B1). Il en va de même pour
2 (action B2
). Si le pont est ouvert pour 1,il est fermé pour 2 et inversement. Chaqueagent a une action C i lui permettant de tra-verser le pont (mais requiert que le pontsoit ouvert pour réussir), i.e., C 1 change la
____________________________________________________________________________ Annales du LAMSADE N°8
33

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 46/415
position de l’agent 1 de a à c. L’agent 1a une action supplémentaire J 1 qui lui pe-met de sauter par dessus le pont. En utili-sant cette action, l’agent 1 n’a pas besoind’ouvrir le pont. Cette action conduit di-rectement l’agent 1 à la position c.
c
d
b 2
1a
FIG . 3 – Traverser le pont
Clairement, l’agent 1 doit exécuter le planB1.C 1 ou le plan J 1 afin d’atteindre laposition désirée ; l’agent 2 doit exécuterB2.C 2. Etant donné qu’un agent ne peutouvrir le pont pour un autre, les plansqui ne contiennent pas l’un de ces sous-plans ne peuvent conduire à un état but.Si chaque agent était tout seul dans cetenvironnement, le problème de planifica-tion serait facilement résolu étant donné
qu’un agent serait alors sûr d’atteindre sonbut (Bi.C i permet d’atteindre le but dei). Ce n’est plus la même histoire lorsqueles deux agents agissent conjointement.En effet, dans ce cas, une coordinationest nécessaire : si l’exécution jointe estB1.B2.C 1.C 2 l’agent 1 ne pourra pas tra-verser le pont et ne pourra pas atteindre sonbut. Représentons le jeu sous forme straté-gique associé à ce problème de planifica-
tion multi-agent. Nous restreignons la lon-gueur des plans examinés à deux actions(observons que les plans de longueur su-périeure à 2 sont inutiles). Ce jeu peut êtresimplifié en supprimant les plans nuls (unplan nul est un plan qui conduit à une satis-faction de 0 quel que soit le mélange danslequel il est impliqué). Toutefois, nous gar-dons le plan dans la version simplifiée,même lorsque c’est un plan nul (voir Table
3).
Avec n’importe lequel des plans J 1.B1,J 1.C 1, J 1, B1.J 1 ou C 1.J 1, l’agent 1 aun niveau de sécurité de 4. Comme J 1 est
B2C 2
0, 0 0, 4J 1 4, 0 4, 4
B1
C 1
4, 0 3, 3B1J 1 4, 0 4, 2C 1J 1 4, 0 4, 4J 1B1 4, 0 4, 2J 1C 1 4, 0 4, 4
TAB . 3 – Jeu sous forme stratégique (sim-plifié)
un sous-plan de tous ces plans, les autresplans incluent des actions inutiles. L’agent1 va probablement choisir le plan J 1. Pourl’agent 2, le seul plan dont le niveau de sé-curité est non nul est B2.C 2 (tous les autresplans sont des plans nuls, ils ne peuventdonc conduire à un état but). Ainsi, danscette situation, le résultat probable du jeusera le couple de plans J 1, B2.C 2 qui estévaluée à 4 par chaque agent, ce qui si-gnifie que les deux agents vont sûrementatteindre leurs buts et que cette situationstratégique ne requiert aucune coordina-tion. L’agent 1 peut aussi choisir B1.J 1 aulieu de J 1. Ces deux plans sont pareille-ment évalués par l’agent 1. Cependant,avec B1.J 1 l’agent 1 peut s’assurer que leplan de l’agent 2 obtiendra une plus faibleévaluation (2 au lieu de 4) face à J 1. Sil’agent 1 choisit B1.J 1, il exhibe un com-portement agressif par rapport à l’agent 2.On ne développera pas ce point dans lasuite, mais il est intéressant d’observer quede telles attitudes peuvent être modéliséesdans notre cadre. Les équilibres de Nashde ce MAPP correspondent ici exactementaux solutions obtenues en utilisant la no-tion de niveau de sécurité.
5 Généralité du cadre
Nous allons voir dans ce paragraphe queplusieurs cadres formels dans lesquelson considère l’interaction entre agents
Planification multi-agent et diagnostic stratégique ___________________________________________________________________________
34

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 47/415
peuvent être facilement vus comme des casparticuliers du nôtre. Il s’agit de la planifi-cation robuste et des jeux booléens.
5.1 Planification robuste
En planification robuste (see e.g. [?]), lebut est de déterminer si une suite d’actions(i.e., un plan) est robuste, i.e., s’il permetd’atteindre le but pour toutes les contin-gences possibles.
Définition 12 (planification robuste) – Une action non déterministe α sur unensemble fini et non vide S d’états est une application de S dans 2S \∅.
– Un plan non déterministe π sur un en-semble A d’actions non déterministesest une suite finie d’éléments de A.
– Une trajectoire pour un plan non déter-ministe π = α1. · · · . αn étant donné un état initial s0 ∈ S est une suite
d’états sO, . . . , sn+1 telle que pour tout i ∈ 0 . . . n , si+1 ∈ αi(si). – Un plan non déterministe π = α1. · · · .
αn sur A est robuste pour un but G ⊆S étant donné un état initial s0 ∈ S siet seulement si pour chaque trajectoiresO, . . . , sn+1 pour π , sn+1 ∈ G.
Le problème de la planification robustepeut être facilement exprimé dans notre
cadre. Le codage est assez technique,donnons-en simplement le principe : l’idéeest de considérer chaque trajectoire duplan non déterministe considéré π commele résultat d’un mélange avec le plan d’unsecond agent qui joue le rôle de la nature ;considérons la première action α de π etsupposons qu’elle possède au plus k ef-fets ; dans ce cas, le plan du second agentva débuter par le sous-plan α
1,...,αk, où
α
j est l’action vide si α n’a pas été exécu-tée lorsque α
j est rencontrée (information
que l’on mémorise dans les états via unfluent supplémentaire), et produit le kèmeeffet de α sinon ; il reste essentiellement à
répéter ce traitement pour les actions sui-vantes de π en mettant à jour le plan dusecond agent par concaténation avec lessous-plans produits à chaque étape.
5.2 Jeux booléens
Les jeux booléens (see e.g. [?, ?]) traitentle cas d’agents contrôlant un ensemble devariables (binaires) propositionnelles. Plusprécisement, ce sont des jeux où les uti-lités des agents sont binaires et les butssont spécifiés par des formules proposi-
tionnelles.
Définition 13 (jeu booléen) Un jeu boo-léen est un quadruplet A,V, Π, Φ oùA = 1 · · · n est un ensemble d’agents,V est un ensemble de variables propo-sitionnelles (variables de décision), Π :A → 2V une fonction d’assignation qui in-duit une partition π1, · · · , πn de V où πi
est l’ensemble de variables contrôlées par
l’agent i , Φ = φ1 · · · φn un ensemble de formules propositionnelles.
Pour un joueur i ∈ A, une stratégie est uneinstanciation des variables qu’il contrôle(i.e., une application de Π(i) = πi dans0, 1). Un profil de stratégies P consisteen l’instanciation de toutes les variablesconsidérées et peut être vu comme une ap-plication de V dans 0, 1). Un agent i est
satisfait par un profil de stratégies P si etseulement si P est un modèle de Φi. Onpeut exprimer ce cadre dans le nôtre en as-sociant à chaque variable v ∈ V une actionv+ qui affecte la variable v à 1. A chaque
jeu booléen G = A,V, Π, Φ nous asso-cions un MAPP S, s0, A
i | i ∈ 1 · · · noù P est l’ensemble de toutes les affec-tations de V , s0 est l’affectation telle ques0(v) = 0 pour tout v ∈ V . Pour chaque
agent i, Ai
= v+
| v ∈ πi, Πi
est le sous-ensemble de plans de Ai∗ tels que chaqueaction possède au plus une seule occurencedans chaque plan et Gi est l’ensemble desmodèles de φi.
____________________________________________________________________________ Annales du LAMSADE N°8
35

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 48/415
6 Conclusion
Dans ce travail, nous avons proposé un
cadre pour modéliser des problèmes deplanification multi-agents. Ce cadre nouspermet de former diverses conclusionsstratégiques à propos d’interactions spé-cifiques et nous permet de "résoudre" denombreuses situations. Ce travail ouvrede nombreuses perspectives. L’une d’ellesconsiste à ajouter des coûts aux actions,comme dans certains problèmes de planifi-cation. Dans ce cas, l’objectif principal dechaque agent est d’atteindre un état but etun objectif auxiliaire est de dériver un plande coût minimal. Une autre extension estde considérer plus en profondeur le cas den agents (n>2), et de rechercher les coali-tions possibles dans ce cadre.
Si de nombreux travaux ont été consacrésà la planification multi-agent, on y supposesouvent que les agents partagent un certainnombre de buts. Relâcher cette hypothèse
a un impact majeur sur les approches pos-sibles du problème et appelle à des notionsprovenant de la théorie des jeux.
Une approche comparable à la nôtre estdécrite dans [?]. Dans ce papier, lespolitiques sont évaluées au niveau dugroupe par rapport à chaque agent et les"meilleures" sont caractérisés comme deséquilibres de Nash, comme c’est le casdans notre travail. Cette approche est néan-moins différente de la nôtre par de nom-breux aspects :– le cadre formel considéré est celui de la
planification sous incertitude et observa-bilité totale et non celui de la planifica-tion classique. Des actions non détermi-nistes sont considérées et un ensembled’états initiaux possibles (et non un seulétat) est connu par chaque agent. Les po-litiques sont des applications associant
des actions à des états et non des planslinéaires (suites d’actions), et la qualitéd’un plan n’est pas binaire par essence(à l’inverse de ce qui se passe dans lecadre classique).
– les politiques au niveau du groupe fontpartie de l’entrée du problème mais lespolitiques au niveau des agents ne lesont pas (alors que les plans possiblesau niveau du groupe sont caractériséscomme des mélanges de plans au niveaudes agents dans notre travail).
– enfin, aucune notion de diagnostic stra-tégique n’est abordée (en particulier, lebesoin de coordination ne peut être dé-duit de l’entrée considérée).
Remerciements
Merci aux relecteurs pour leurs remarquesavisées. Les auteurs ont bénéficié du sou-tien de la Région Nord/Pas-de-Calais, del’IRCICA et du programme FEDER de laCommunauté Européenne.
Références
[1] R. Axelrod. The Evolution of Coope-
ration. Basic Books, New York, USA,1984.
[2] B. Beaufils, J.-P. Delahaye, and Ph.Mathieu. Complete classes of strate-gies for the classical iterated prisoner’sdilemma. In Proc. of EP’98 , pages 33–41, 1998.
[3] E. Bonzon, M.-C. Lagasquie-Schiex,J. Lang, and B. Zanuttini. Booleangames revisited. In Proc. of ECAI’06 ,
pages 265–269, 2006.[4] M.H. Bowling, R.M. Jensen, and
M.M. Veloso. A formalization of equi-libria for multiagent planning. In Proc.of IJCAI’03, pages 1460–1462, 2003.
[5] A. Cimatti and M. Roveri. Conformantplanning via model checking. In Proc.of ECP’99, pages 21–34, 1999.
[6] P. Harrenstein. Logic in Conflict . PhDthesis, Utrecht University, 2004.
[7] J.F Nash. Equilibrium points in n-person games. Proc. of the Natio-nal Academy of Sciences of the USA,36(1) :48–49, 1950.
Planification multi-agent et diagnostic stratégique ___________________________________________________________________________
36

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 49/415
Les représentations prédictives des états et des politiques
A. Boularias
B. Chaib-draa
Laboratoire DAMASDépartement d’informatique et génie logiciel, Université Laval
G1K7P4, Québec – Canada
Résumé :Nous proposons dans cet article une nouvelle ap-proche pour représenter les politiques (stratégies)dans les environnements stochastiques et partiel-lement observables. Nous nous intéressons plusparticulièrement aux systèmes multi-agents, oùchaque agent connaît uniquement ses propres poli-tiques, et doit choisir la meilleure parmi elles selonson état de croyance sur les politiques du reste desagents. Notre modèle utilise moins de paramètresque les méthodes de représentation usuelles, tellesque les arbres de décision ou les contrôleurs d’étatsfinis stochastiques, permettant ainsi une accéléra-tion des algorithmes de planification. Nous mon-trons aussi comment ce modèle peut être utiliséefficacement dans le cas de la planification multi-agents coopérative et sans communication, les ré-sultats empiriques sont comparés avec le modèle
DEC-POMDP (Decentralized Partially ObservableMarkov Decision Process).
Mots-clés : Incertitude, PSRs, POMDPs, DEC-POMDPs.
Abstract:We discuss the problem of policy representation instochastic and partially observable systems, and ad-dress the case where the policy is a hidden parame-ter of the planning problem. We present a new mo-del that generalizes the predictive state representa-
tions (PSRs) by introducing tests about the policy.Our approach uses less parameters than the usualpolicy representation methods, such as the decisiontrees or the stochastic finite-state controllers. Weshow how this model can be used efficiently in thecooperative multi-agent planning, and compare itempirically with the Decentralized Partially Obser-vable Markov Decision Process (DEC-POMDP).
Keywords: Uncertainty, PSRs, POMDPs, DEC-POMDPs.
1 Introduction
La planification est certainement l’une destâches les plus importantes pour n’importe
quel agent évoluant dans un environne-ment dynamique. Un environnement dyna-mique est un système qui réagit aux ac-tions de l’agent en changeant son état, eten produisant en même temps des obser-vations qui permettent à l’agent de déduirele nouveau état. L’objectif de la planifi-cation est d’atteindre certains états dési-rables du système en choisissant l’actionappropriée dans chacun des états intermé-diaires. Cependant, dans la plupart des en-vironnements du monde réel, l’état du sys-tème est partiellement observable, et l’ef-fet des actions sur l’évolution du systèmeest non déterministe. Les processus déci-
sionnels de Markov partiellement obser-vables (POMDPs : Partially ObservableMarkov Decision Processes) est un modèletrès populaire utilisé pour résoudre ce typede problèmes, et plusieurs algorithmes ef-ficaces pour résoudre les POMDPs ont étédéveloppés auparavant. Les POMDPs uti-lisent une représentation explicite de l’étatsous-jacent (caché) sous la forme d’unedistribution de probabilité sur tous les états
du système. Ce vecteur de probabilité, ap-pelé l’état de croyance, dépend directe-ment du nombre d’états spécifiés dans lemodèle, ce qui rend les algorithmes de pla-nification extrêmement lents pour les pro-blèmes à très large espace des états. Les re-présentations prédictives des états (PSRs :Predictive State Representations) [1, 2] estune méthode alternative, récente et pro-metteuse, permettant de résoudre efficace-ment ce même type de problèmes. Contrai-rement aux POMDPs, l’état de croyancedans les PSRs est représenté par un vec-teur de probabilités sur des entités com-plètement observables appelées tests. Les
37

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 50/415
tests sont des séquences finies d’actions etd’observations. De ce fait, l’un des avan-tages immédiats des PSRs est que l’agentpeut apprendre plus facilement le modèlestochastique de transition et d’observation juste en interagissant avec son environne-ment [3]. De plus, l’agent doit garder uni-quement la quantité d’information (reflé-tée par le nombre de paramètres) suffisantepour prédire l’évolution future du système.Il a été aussi prouvé que dans un typeparticulier des PSRs, appelés les PSRs li-néaires, on peut réutiliser tous les algo-rithmes de planifications développés origi-
nalement pour les POMDPs, sans faire unegrande modification [4].
Dans plusieurs situations, l’état du sys-tème n’est pas le seul paramètre cachédu problème, la politique de l’agent peutl’être aussi. En effet, d’un point de vueexterne, l’agent est lui même considérécomme un système dynamique qui réagitaux observations qu’il reçoit en produi-
sant des actions, selon une politique quipeut y aller d’une simple fonction réac-tive : observation→action, à un contrôleurd’états finis stochastique. Les méthodes derecherche de la politique optimale (PolicySearch) maintiennent des probabilités surles différentes politiques, représentant lacroyance de l’agent à propos de la poli-tique optimale. Dans les systèmes multi-agents, la politique d’un agent ne peut pasconnue des autres, sauf si la communica-tion est possible, et que les agents sontdans un contexte de coopération. La figure1 montre un problème classique de navi-gation de robots dans une grille 3 × 3. Lesdeux agents, agent 1 and agent 2, choi-sissent leurs actions de l’ensemble sui-vant : Right, Left, Up, Down, et reçoiventcomme observation W : L’agent vient detoucher un mur , ou N : Pas de mur touché .Si l’objectif de l’agent 1 est de rencontrer
l’agent 2, on comprend alors facilementque l’agent 1 doit connaître la politique del’agent 2 pour pouvoir trouver la meilleurepolitique qui mène vers un point de ren-contre. Mais l’agent 1 ne peut connaître
qu’un état de croyance sur les politiquesde l’agent 2, représenté par des paramètresprobabilistes. La figure 2 montre un en-semble de politiques possibles pour l’agent2. Intuitivement, l’agent 1 doit maintenirune distribution de probabilité sur toutesces politiques, et résoudre le problème dela planification en utilisant cette représen-tation. Malheureusement, cette représenta-tion utilise un nombre de paramètres (pro-babilités) qui est égal au nombre de poli-tiques, et donc doublement exponentiel enlongueur de l’horizon, et en nombre d’ob-servations. Par conséquence, le coût de la
solution est très élevé en termes du tempsd’exécution et de l’espace mémoire.
D’une manière générale, l’agent fait face àdeux types d’incertitudes : d’un coté, l’in-certitude sur l’état du système, et de l’autrecoté, l’incertitude sur la politique (qui peutêtre la politique d’un autre agent, ou lapolitique optimale que l’agent cherche).Le modèle des représentations prédictives
des états et des politiques (PSPR : Pre-dictive State and Policy Representations)que nous proposons dans cet article, estune tentative d’unifier ces deux problèmes.En effet, on utilise le même principe, quiest les prédictions, pour représenter lescroyances sur les états et sur les politiques.Lorsque la politique n’est pas cachée, cemodèle permet plutôt de représenter la po-litique d’une manière potentiellement pluscompacte que les autres méthodes, tellesque les arbres de décision par exemple.
Dans la prochaine section, nous présen-tons une description étendue des représen-tations prédictives des états. Dans la sec-tion 3, on décrit le modèle PSPR en intro-duisant la notion des tests sur la politique,nous présentons aussi quelques résultatsthéoriques sur la puissance des PSPRs. Onmontre par la suite comment ce modèle
peut être utilisé dans un contexte de pla-nification multi-agent coopérative et sanscommunication. On compare alors les ré-sultats empiriques d’un algorithme de pla-nification (Programmation Dynamique en
Les représentations prédictives des états et des problèmes ___________________________________________________________________________
38

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 51/415

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 52/415
h
o
= Ø
h
1
h
2
.
.
.
h
i
.
s t
0
s t
1 . . .
s t
i …
s t
j …
s t
k . .
p ( s t
i
)
p ( s t
i
| h
1
)
p ( s t
i
| h
2
)
.
.
.
p ( s t
i
| h
i
)
.
D
Q s
FIG . 3 – La matrice de la dynamique dusystème.
de la dynamique du système D (Figure3) est constituée de l’ensemble infini detous les tests d’état possibles sti et detous les historiques hi possibles. Cette ma-trice forme un modèle adéquat du système,puisque elle peut être utilisée à toute étapedu temps pour prédire le comportement fu-
tur du système. Une entrée D(sti, h j) de lamatrice de la dynamique est la probabilitéde réussir le test sti lorsqu’on commenceavec un historique h j, i.e. P r(sti|h j).
Une caractéristique intéressante de la plu-part des systèmes réels est que la proba-bilité de n’importe quel test sti dépenduniquement des probabilités d’un certainnombre de tests, appelés les tests de base.En d’autres termes, les probabilités destests de base constituent une statistiquesuffisante pour le système. Notant que cestests ne doivent pas être nécessairement ef-fectués pour connaître l’état du système,on a juste besoin de connaître leur proba-bilités de réussite sans pour autant essayerde les effectuer pour voir s’il réussissentou pas.
Pour mieux comprendre la notion des tests
de base, considérons l’environnement del’agent 1 dans la figure 1 (et ignorantl’agent 2). Afin de simplifier l’exemple,nous supposons que les actions et les ob-servations sont déterministes. L’agent 1
observe W lorsqu’il à coté d’un mur etil essaie d’avancer dans sa direction, etil observe N dans toutes les autres situa-tions. Ce système contient 9 états (posi-tions possibles de l’agent), mais il peutêtre représenté uniquement avec 4 testsde base Left Wall, Right Wall, Up Wallet Down Wall. En effet, si l’agent connaîtlesquels de ces tests vont réussir s’il se-ront effectués et lesquels vont échouer, ilpourra alors déterminer exactement dansquelle case de la grille il se trouve. Si ona par exemple P r( Left Wall)=1, P r( Right Wall)=0, P r(Up Wall)=1 et P r( Down
Wall)=0, alors on conclue que l’agent setrouve dans la case (0,0) (la première ligneet la première colonne), par conséquenceon pourra prédire la réussite ou l’échec den’importe quel autre test.
On dénote les tests de base parqs1, qs2, . . . q sN , Qs désigne l’en-semble de ces tests. P r(Qs|h j) =(P r(qs1|h j), P r(qs2|h j), . . . , P r(qsN |h j))
est le vecteur de probabilité des tests debase, c’est l’équivalent de l’état decroyance pour les POMDPs, on a alors :
P r(sti|hj) = f sti(P r(Qs|hj)) (1)
où f sti est une fonction propre au test sti.Donc chaque test qui ne fait pas partie dela base, a une fonction associée, indépen-dante de l’historique, qui permet de pré-dire sa probabilité de réussite en utilisantuniquement les probabilités de la base Qs.
Après avoir fait l’action a et observer l’ob-servation o, le vecteur p(Qs|h j) est mis à jours selon la formule :
P r(qsi|hjao) =P r(aoqsi|hj)
P r(ao|hj)
=f aoqsi(Qs|hj)
f ao(Qs|hj)(2)
Si la fonction f sti est linéaire pour tout sti,alors le modèle PSR utilisé est dit linéaire,et l’équation (1) peut être simplifiée ainsi :
P r(sti|h) = P r(Qs|h)mT sti
(3)
Les représentations prédictives des états et des problèmes ___________________________________________________________________________
40

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 53/415
ou msti est le vecteur de poids spécifiqueau test d’état sti. Les paramètres d’un PSRlinéaire sont :
– Qs, l’ensemble des tests d’état de base.– p(Qs|∅), les probabilités initiales des
tests d’état de base.– ∀a ∈ A, ∀o ∈ O : mao, le vecteur de
poids du test d’état ao.– ∀a ∈ A, ∀o ∈ O, ∀qsi ∈ Qs : maoqsi , le
vecteur de poids du test d’état aoqsi quiest composé du test ao suivi par le testqsi.
Le cardinal du plus petit ensemble Qs, telque f sti est une fonction linéaire, est ap-pelé la dimension linéaire du système, quiest aussi le rang linéaire de la matrice D.
Les auteurs de [2] ont prouvé que tout sys-tème qui peut être représenté (modélisé)par un POMDP, ou un modèle basé surl’historique, peut aussi être représenté parun PSR avec un certain nombre de tests
de base au plus égal au nombre d’étatsdans le POMDP. Dans [8], on peut trou-ver quelque exemples de systèmes qui nepeuvent pas être représentés par aucunPOMDP, mais qui peuvent être représen-tés par des PSRs, et d’autres où le nombrede tests de base est exponentiellement in-férieur au nombre d’états dans le POMDPéquivalant. Le modèle PSR est alors plusgénéral que les POMDPs, et plus com-pact. Une autre propriété intéressante estque les paramètres d’un PSR peuvent plusfacilement être apprises que les probabili-tés de transition des POMDPs [3], car onpeut toujours connaître si le test réussit ouéchoue après quelques étapes du temps,par contre, on ne peut pas vérifier direc-tement l’état sous-jacent du système. Cespropriétés intéressantes sont derrière notremotivation pour généraliser les PSRs detelle sorte que les politique aussi peuvent
être représentées par des prédictions surla réussite ou l’échec de certains tests.Comme on verra dans la section suivante,le problème de la représentation de la poli-tique n’est pas très différents du problème
de la représentation des états.
3 Représentation prédictive des
politiques
Dans le modèle PSPR que nous propo-sons ici, on utilise deux types de tests :les tests d’état usuels qu’on a vu dansla section précédente, et les tests de po-litique. Un test de politique pt peut êtrevu comme le duel du test de l’état, où lesactions et les observations sont interchan-gés. La probabilité qu’un test de politique
pt = o0, a1, o1, a2, o2 . . . ok−1, ak réussisseest donnée par P r( pt) = prob(a1 =a1, a2 = a2, . . . ak = ak|o0 = o0, o1 =o1, o2 = o2, . . . ok−1 = ok−1). Pour biencomprendre cette notion, imaginons quel’environnement E d’un agent A est lui-même un agent. Donc pour E , A est consi-déré comme un environnement dont oncherche à connaître la dynamique, et pré-dire ses comportements futurs. E choisit
des actions qu’il applique sur A, qui nesont rien d’autre que les observations deO, et il reçoit comme observations les ac-tions de A.
La probabilité qu’un test de politique ptréussisse lorsqu’on commence à l’étape iest P r( pt|hi) = P r(ai+1 = a1, ai+2 =a2, . . . , ai+k = ak|hi, oi = o0, oi+1 =o1, oi+2 = o2, . . . , oi+k−1 = ok−1). L’his-
torique hi ici se termine par une actionet pas par une observation, et l’étape detemps i désigne l’étape après avoir fait aiet avant d’observer oi, on considère aussique tous les historiques commencent parl’observation fictive o∗. La politique del’agent peut être représentée par une ma-trice P (figure 4), construite en considé-rant l’ensemble infini de tous les histo-riques possibles (lignes), et tous les testsde politique possibles. Cette matrice est
équivalente à la politique de l’agent, mêmesi cette dernière n’est pas stationnaire.Une entrée P ( pti|h j) définit la probabi-lité que l’agent choisisse les actions dutest pti, sachant que l’historique actuel
____________________________________________________________________________ Annales du LAMSADE N°8
41

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 54/415
h
o
= Ø
h
1
h
2
.
.
.
h
i
.
p t
0
p t
1 . . .
p t
i …
p t
j …
p t
k . .
p ( p t
i
)
p ( p t
i
| h
1
)
p ( p t
i
| h
2
)
.
.
.
p ( p t
i
| h
i
)
.
P
Q p
FIG . 4 – La matrice de la politique.
est h j , et que les observations futures se-ront celles de pti. On définit aussi l’en-semble des tests de politique de base Qp =qp1, qp2, . . . q pM , ces tests sont suffi-sants pour déterminer la probabilité den’importe quel autre test de politique pti :
P r( pti|hj) = f pti( p(Qp|hj)) (4)
Tel que f pti est la fonction as-sociée à pti, et P r(Qp|h j) =(P r(qp1|h j), P r(qp2|h j), . . . , P r(qpM |h j)).
La fonction de mise à jours des tests de po-litique de base est donnée par :
P r(qpi|hjoa) =P r(oaqpi|hj)
P r(oa|hj)
= f oaqpi(Qp|hj)f oa(Qp|hj) (5)
Les paramètres des repésentations prédic-tives des politiques sont :– Qp, les tests de politique de base.– (Qp|∅), les probabilités initiales des
tests de base.– ∀a ∈ A, ∀o ∈ O : f oa, la fonction asso-
ciée au test de politique oa.– ∀a ∈ A, ∀o ∈ O, ∀qpi ∈ Qp : f oaqpi ,
la fonction associée au test de politiqueoaqpi composé du test oa suiviparletestqpi.
Si la fonction f pti est linéaire, les para-mètres devient alors :
– Qp, les tests de politique de base.– (Qp|∅), les probabilités initiales des
tests de base.– ∀a ∈ A, ∀o ∈ O : moa, le vecteur des
poids du test de politique ao.– ∀a ∈ A, ∀o ∈ O, ∀qpi ∈ Qp : moaqpi ,
le vecteur des poids du test de politiqueaoqpi.
En utilisant ces paramètres, on peut mettreà jours la probabilité du test qpi après avoirobservé l’évènement oa par :
p(qpi|hjoa) = p(Qp|hj)mT
oaqpi
p(Qp|hj)mT
oa
(6)
L’ensemble des paramètres des tests d’étatet des tests de politique forment les para-mètres du modèle PSPR. Notant que cesdeux ensembles sont séparés et utilisés in-dépendamment l’un de l’autre, car on peutbien représenter les états avec les testsd’état et les politique avec des arbre de dé-cision par exemple, comme on peut bien
représenter les politiques avec des tests depolitique et les états avec un POMDP parexemple. La relation qui peut potentielle-ment exister entre ces deux types de testfera l’objet d’une futur investigation.
Les théorèmes suivants permettent decomparer les PSPRs avec quelques autresmodèles.
Theorem 1. Une politique d’un MDP
(Markov Decision Process) peut être re- présentée par un PSPR utilisant au plus lemême nombre de paramètres.
Démonstration. Dans les MDPs, les étatssont complètement observables, On a doncO = S . Une politique π est une fonctionde S vers une distribution de probabilitésur les actions de A, tel que π(s, a) est laprobabilité que l’agent choisisse l’actiona dans l’état s. La politique du MDP estdonc représentée avec |S||A| paramètres.Dans le modèle PSPR, les tests de po-litique sa, au nombre |S||A|, sont suffi-sants pour décrire π si on considère que
Les représentations prédictives des états et des problèmes ___________________________________________________________________________
42

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 55/415
p(sa|h) = π(s, a). On peut voire faci-lement que ces deux représentations sontéquivalantes.
Theorem 2. Une politique d’horizon fini pour un POMDP peut être représentée par un PSPR utilisant au plus le même nombrede paramètres.
Démonstration. Une politique d’horizonfini t pour un POMDP est un arbre de déci-sion déterministe (à condition de connaîtrel’état de croyance initial). Cet arbre de
décision contient exactement(|A||O|)t+1−1(|A||O|)−1
noeuds. La matrice P correspondante àcette politique a (|A||O|)t+1−1
(|A||O|)−1lignes et
(|A||O|)t+1−1(|A||O|)−1
colonnes, donc le rang de P
ne peut pas être supérieur à ce nombre,un PSPR peut utiliser les tests de politiqueformant les colonnes linéairement indé-pendantes pour décrire cette politique.
Theorem 3. Une politique décrite par uncontrôleur d’états finis stochastique peut être représentée par un PSPR utilisant au
plus le même nombre de paramètres.
Démonstration. (sketch) Un contrôleurd’états finis stochastique est un tupleQ, ψ , η, tel que Q est un ensemble finid’états du contrôleur, ψ est une fonctiondéfinie de Q vers une distribution deprobabilité sur A, tel que ψ(q, a) est laprobabilité de choisir l’action a dans l’étatq du contrôleur. η est une fonction detransition, η(q,a,o,q ) est la probabilitéque le prochain état du contrôleur soit q
lorsque le dernier état a été q , et la der-nière action effectuée est a et la dernièreobservation est o. Si on remplace Q parS et on échange A avec O, on obtientexactement une description d’un POMDP,
donc on peut utiliser la même preuve de[2] pour prouver que le rang linéaire de P ne peut pas être supérieur à |Q|. Donc lenombre de tests de politique de base donton a besoin est au plus |Q| tests.
a 1 a 2
a 4 a 3
o 1
o 1
o 1
o 1
o 2
o 2
o 2
o 2
FIG . 5 – Un contrôleur d’états finis déter-ministe à 4 états qui peut être complète-ment décrit avec 2 tests de politique seule-ment.
Les fonction ψ et η dans le contrôleurreprésenté dans la figure 5 sont détermi-nistes, chaque état est étiqueté par une ac-tion. Ce contrôleur contient 4 états, mais ilpeut être exactement décrit avec les deuxtests de politique : pt1 = o1a1 et pt2 =o2a2. On peut vérifier que les réponses àces deux tests sont suffisantes pour dé-
terminer l’état du contrôleur. Si on a parexemple P r( pt1) = 1 et P r( pt2) = 1 ondéduit alors qu’on est dans l’état étiquetépar a4.
Afin de pouvoir comparer empiriquementles performances du modèle PSPR avec lesautres modèles, nous avons choisi le pro-blème de la planification multi-agent co-opérative pour être la première applicationdes PSPRs, ce choix est motivé par le fait
que la représentation des politiques sousl’incertain est une difficulté inhérente à cegenre de problèmes.
4 PSPR versus DEC-POMDPs
Les DEC-POMDPs (Decentralized Mar-kov Decision Processes), proposés récem-ment par Daniel S. Bernstein et al. [5],
sont une généralisation des POMDPs auxsystèmes multiagent. À chaque étape detemps, chaque agent i fait une action aiet reçoit une observation oi et une récom-pense immédiate r, qui est la même pour
____________________________________________________________________________ Annales du LAMSADE N°8
43

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 56/415
tous les agents bien qu’ils peuvent choisirdes actions différentes, ceci les incitent àchoisir des politiques individuelles coopé-ratives. Les agents ne peuvent pas commu-niquer entre eux des informations à pro-pos des actions qu’ils choisissent ou desobservations qu’ils reçoivent. L’objectif dela planification dans les DEC-POMDPsconsiste donc à trouver la politique jointeoptimale, qui est composée de plusieurspolitiques individuelles, une pour chacundes agents.
Un DEC-POMDP pour n agents est un
tuple S ,A,T ,R,O,t, p0, tel que :– S est un ensemble fini d’états.– A est un ensemble fini d’actions pour
chaque agent, les agents partagent lemême ensemble A d’actions indivi-duelles. An est l’ensemble des actions jointes.
– R(s, a1, a2, . . . , an) est la fonction de larécompense immédiate.
– O est un ensemble fini d’observationspour chaque agent, les agents partagentle même ensemble O d’observations in-dividuelles.
– T (s, a1, a2, . . . , an, o1, o2, . . . , on, s)est une fonction de transition et d’obser-vation.
– t est l’horizon de la planification.– γ est le facteur d’escompte.– b0 est l’état de croyance initial.On désigne par q ti une politique à horizon tpour l’agent i, et par q t = (q 1, . . . , q n) unepolitique jointe à horizon t pour tous lesagents. q t−i = (q 1, . . . , q i−1, q i+1, . . . , q n)est une politique d’horizon t pour tousles agents sauf l’agent i. on a donc q t =q t−i, q ti. On utilise Qt
i pour désigner l’en-semble des politiques q ti et Qt
−i pour lespolitiques q t−i
Les états et les politiques dans les DEC-POMDPs sont représentés par un état
de croyance bi pour chaque agent i, quicontient une distribution de probabilité surles états, et une autre distribution sur lespolitiques jointes q −i des autres agents,car l’agent i ne connaît pas exactement
quelles sont les politiques suivi par lesautres agents.
Dans les DEC-POMDPs, on a deux fonc-
tions de valeur. La première est la valeurd’une politique jointe q dans un état s :
V (s, q ) = R(s, A(q ))
+γ
o∈On
s∈S
T (s, A(q ), o , s)V (s, q (o)) (7)
tel que A(q ) la première action jointe quise trouve à la racine de l’arbre q , o estune observation jointe, et q (o) la politique
jointe qui reste dans l’arbre q après l’ob-servation o. On définie aussi la fonction devaleur d’une politique individuelle q i selonl’état de croyance bi par :
V (bi, q i) =
s∈S
q−i∈P −i
bi(s, q −i)V (s, q −i, q i)
(8)Pour trouver la politique jointe optimale
à partir de ces formules, les auteurs de [6]ont proposé l’opérateur de la programma-tion dynamique pour les DEC-POMDPs :1. Étant donnés les ensembles Qt−1
i despolitiques d’horizon t − 1 pour chaqueagent i.
2. Pour chaque agent i, générer à partirde Qt−1
i , l’ensemble Qti de toutes les
politiques d’horizon t.3. Pour chaque agent i, élaguer les po-
litiques complètement dominées. Unepolitique q i est dite complètement do-minée si et seulement si :
∀bi, ∃q i ∈ Qti : V (bi, q i) > V (bi, q i) (9)
4. Retourner l’ensemble Qti des poli-
tiques optimales pour chaque agent i.Le problème le plus important dans l’opé-rateur de la programmation dynamique estl’élagage des politiques dominées, car on
doit considérer tous les états de croyancebi possibles pour chaque agent, ceci peutêtre fait avec un programme linéaire, maisl’exécution de tels programmes est rela-tivement importante dans ce cas, car le
Les représentations prédictives des états et des problèmes ___________________________________________________________________________
44

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 57/415
nombre de variables (états, et politiques)évolue exponentiellement en la taille del’horizon et en nombre d’observations. Lesauteurs de [7] avaient proposé d’utiliserune méthode approximative pour détermi-ner les politiques dominées. Au lieu de vé-rifier l’équation 9 pour tous les états decroyance, on peut se limiter à un petit en-semble de points de croyances. Cependant,le nombre de paramètres utilisés pour re-présenter les probabilités sur les politiques jointes dans chaque état de croyance esttoujours important, car on a une probabi-lité par politique jointe. Dans nos expé-
rimentations, nous avons implémenté uneversion modifiée de l’algorithme PBDP[7], la seule différence est que nous sé-lectionnons aléatoirement les points decroyances utilisés pour l’élagage, sans te-nir en considération le fait que ces pointssoient accessibles ou pas.
Nous proposons ici une solution à ce pro-blème qui est basée sur les représenta-
tions prédictives. On verra que les étatsde croyance sur les politiques jointes sontplus compactes lorsqu’on utilise des testsau lieu d’énumérer explicitement toutes lespolitiques.
Les actions et les observations dans lestests d’état tels qu’on les a vu jusqu’àmaintenant sont remplacées par des ac-tions et des observations jointes. Donc, untest st devient st = a1o1a2o2 . . . akok,avecai ∈ An et oi ∈ On.
Puisque on a dans ce cas deux types depolitiques, à savoir les politiques indivi-duelles et les politiques jointes (qui nesont qu’une collection de politiques indi-viduelles, une par agent), on doit alors uti-liser deux types de tests de politique, lestests de politique individuels, et les tests depolitique joints, qui sont de la forme pt =
o0a1o1 . . . ak, avec ai ∈ An et oi ∈ On.L’état de croyance bi pour un agent i estconstitué des trois vecteurs :– Qs : les probabilités des tests d’état.
R
U
R
N
N
p(pt 0 )=0.5
R
U
L
N
N
p(pt 1 )=0.5
R
U
R
N
W
p(pt 2 )=0.5
R
U
L
N
W
p(pt 3 )=0.5
R
U
R
W
N
p(pt 4 )=0.5
R
U
L
W
N
p(pt 5 )=0.5
R
U
R
W
W
p(pt 6 )=0.5
R
U
L
W
W
p(pt 7 )=0.5
FIG . 6 – La représentation d’un état de
croyance sur les politiques dans les PSPRs.
– Qp : les probabilités des tests depolitique joints, elles représentent lacroyance de l’agent i sur les politiquesdes autres agents.
– Qpi : les probabilité des tests de poli-tique individuels, elle déterminent unepolitique pour l’agent i.
Puisqu’on utilise des politiques détermi-
nistes (des arbres de décision), les proba-bilités de Qpi sont toutes des 1 ou des 0.On a donc un arbre de décision par vecteurQpi, et un vecteur Qpi par arbre.
Si on considère que les récompenses im-médiates font partie des observations, alorson peut utiliser l’équation de Bellman sui-vante pour résoudre ce problème, avecn’importe quelle technique de programma-tion dynamique utilisée pour les POMDPs
(ou les DEC-POMDP)[4] :V (bi, q ) =
r∈R
P r(A(q )r|bi)r
+γ
o∈On
P r(A(q )o|bi)V (ζ (bi, A(q ), o), q (o))
(10)tel que R est l’ensemble des récompenses,ζ estlafonctiondemiseàjours(équation1en utilisant les paramètres mao et maoqsi),A(q )r est un test d’état composé de la pre-mière action jointe de q et de l’observation(récompense) r.
Pour bien montrer l’apport de l’utilisation
____________________________________________________________________________ Annales du LAMSADE N°8
45

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 58/415
des représentations prédictives des poli-tiques, on a choisit des environnementsde test où la représentation prédictive desétats est équivalente à la représentationPOMDP, i.e. les tests d’état sont linéaireset leur nombre est égal au nombre d’étatsde l’environnement, donc le fait d’utiliserles PSRs ici n’apporte aucun gain en tempsde calcul, puisque ils ne permettent pas decompresser l’espace des états. On va foca-liser notre discussion dans ce qui suit uni-quement sur les représentations prédictivesdes politiques.
Initialement, à l’étape d’horizon 1, l’en-semble des politiques Q1i pour un agent i,
est représenté par :– Qp1i = A : L’ensemble des tests de base,
qui est formé de toutes les actions indi-viduelles possibles.
– P r(Qp1i ) : Le vecteur des probabilitésinitiales des tests de base.
– Les paramètres moa et moaqp ne sont pasutilisés ici car l’horizon est 1,donconne
fait pas de mise à jours des probabilitésP r(Qp1i ).Chaque politique de Q1
i correspond à uneinstance de P r(Qp1i ). Les paramètres dela politique qui consiste à faire l’actionai sont donc P r(ai) = 1 et P r(a j) =0, ∀a j = ai.
L’ensemble Q1 de toutes les politiques jointes d’horizon 1 est représenté de la
même manière que les ensembles Q1i , ilsuffit de remplacer les actions de A par des
actions de An.
À l’étape d’horizon t > 1, on génère Qti,
l’ensemble de toutes les politiques d’hori-zon t pour l’agent i, à partir de l’ensembleQt−1
i . Les paramètres de Qti sont :
– Qpti = Qpt−1i
a∈A,o∈O,q
t−1
i∈Qp
t−1
i
aoq t−1i .
– P r(Qpti).
– ma(a jo jq t−1i ) = 1 pour a = a j ,ma(a jo jq t−1i ) = 0 pour a = a j .
– maoqt−1
i
(a jo jq t−1i ) = 1 pour ao = a jo j ,
maoqt−1
i
(a jo jq t−1i ) = 0 pour ao = a jo j.
Les tests de politique de base qu’on aconsidéré ici sont des séquences qui se ter-minent avec une action ou une politique.On a choisi d’utiliser des tests de la formeaoq t−1i (de profondeur 2) plutôt que de laforme conventionnelle aoao.. .a (de pro-fondeur t) car ça nous permet de réduire lenombre de tests de base utilisés. En effet,si le nombre de politiques par horizon estborné (par le nombre de points de croyancedans notre algorithme) et l’horizon t estsuffisament grand, alors on aura besoinsde plus de tests de base de profondeur tque de politiques. Par contre, on a besoins
de seulement |A||O||Qt−1i | de tests de basedelaforme aoq t−1i générés exhaustivementà partir de Qt−1
i , au lieu des |A||O||Qt−1
i|
politiques (arbre) générées dans le modèleDEC-POMDP.
La prochaine étape consiste à élaguer lespolitiques individuelles qui sont complè-tement dominées dans tous les points decroyance. On génère d’abord l’ensemble
de toutes les politiques jointes Qt−1, cetensemble est décrit de la même façonque Qt−1
i , avec a ∈ An, o ∈ On, etq t−1 ∈ Qt−1. Les états de croyance pourl’agent i sont donc des vecteurs bi =(P r(Qpt), P r(Qs)). P r(Qpt) est une dis-tribution de probabilité sur les tests de po-litique aoq t−1 (c’est une distribution carces tests sont évènements disjoints), etP r(Qs) est un vecteur de probabilités surles tests d’état qs. Pour chaque politiqueq ti , on redistribue les probabilités unique-ment sur les tests joints qui sont compa-tibles avec q ti . Un test aoq t−1 est dit com-patible avec q ti si et seulement si l’actionde l’agent i dans l’action jointe a estlapre-mière action (la racine de l’arbre) de q ti , etla politique de l’agent i dans q t−1 est la po-litique qui reste dans q ti après l’observationo.On définie aussi la fonction de valeur deq ti , dans un état de croyance bi, par :
V (bi, q ti) =
aoqt−1∈Qpt
P r(aoq t−1|bi)V (bi,aoq t−1)
Les représentations prédictives des états et des problèmes ___________________________________________________________________________
46
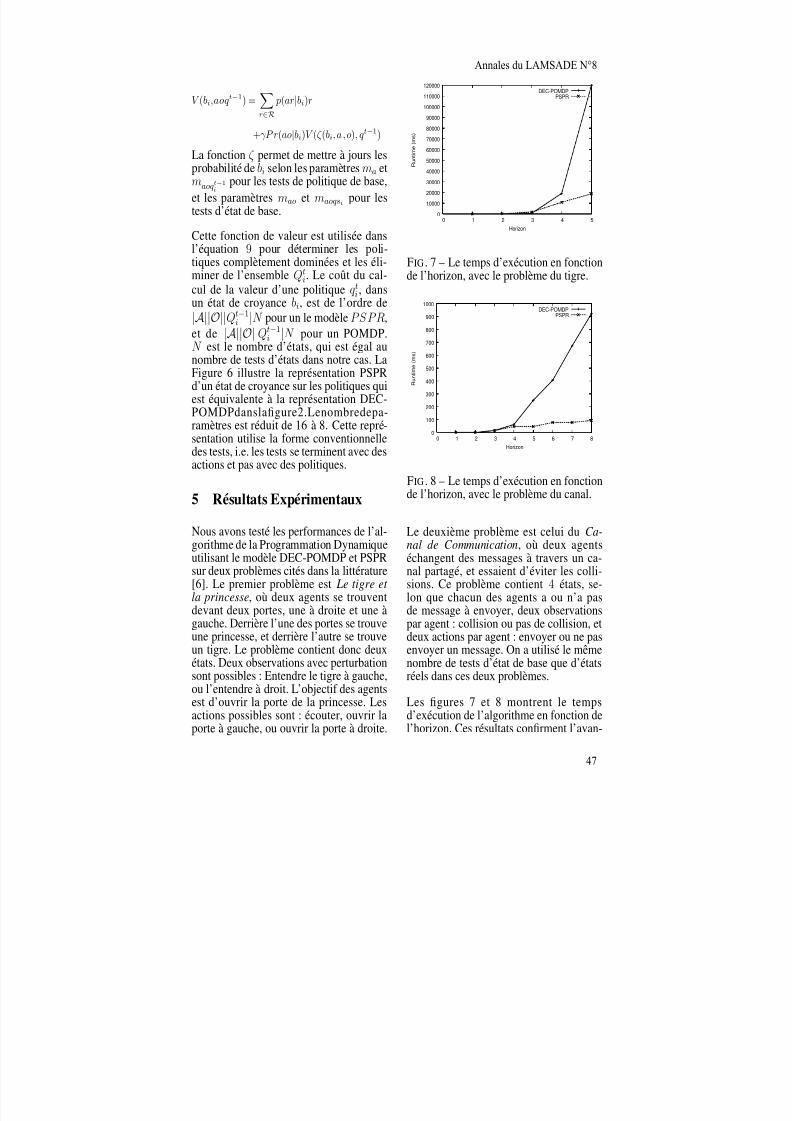
7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 59/415
V (bi,aoq t−1) =
r∈R
p(ar|bi)r
+γP r(ao|bi)V (ζ (bi, a , o), q t−1
)
La fonction ζ permet de mettre à jours lesprobabilité de bi selon les paramètres ma etmaoq
t−1i
pour les tests de politique de base,et les paramètres mao et maoqsi pour lestests d’état de base.
Cette fonction de valeur est utilisée dansl’équation 9 pour déterminer les poli-tiques complètement dominées et les éli-miner de l’ensemble Qt
i. Le coût du cal-cul de la valeur d’une politique q ti , dansun état de croyance bi, est de l’ordre de|A||O||Qt−1
i |N pour un le modèle P S P R,et de |A||O||Qt−1
i |N pour un POMDP.N est le nombre d’états, qui est égal aunombre de tests d’états dans notre cas. LaFigure 6 illustre la représentation PSPRd’un état de croyance sur les politiques qui
est équivalente à la représentation DEC-POMDPdanslafigure2.Lenombredepa-ramètres est réduit de 16 à 8. Cette repré-sentation utilise la forme conventionnelledes tests, i.e. les tests se terminent avec desactions et pas avec des politiques.
5 Résultats Expérimentaux
Nous avons testé les performances de l’al-gorithme de la Programmation Dynamiqueutilisant le modèle DEC-POMDP et PSPRsur deux problèmes cités dans la littérature[6]. Le premier problème est Le tigre et la princesse, où deux agents se trouventdevant deux portes, une à droite et une àgauche. Derrière l’une des portes se trouveune princesse, et derrière l’autre se trouveun tigre. Le problème contient donc deuxétats. Deux observations avec perturbation
sont possibles : Entendre le tigre à gauche,ou l’entendre à droit. L’objectif des agentsest d’ouvrir la porte de la princesse. Lesactions possibles sont : écouter, ouvrir laporte à gauche, ou ouvrir la porte à droite.
0
10000
20000
30000
40000
50000
60000
70000
80000
90000
100000
110000
120000
0 1 2 3 4 5
R u n t i m e ( m s )
Horizon
DEC-POMDP
PSPR
FIG . 7 – Le temps d’exécution en fonctionde l’horizon, avec le problème du tigre.
0
100
200
300
400
500
600
700
800
900
1000
0 1 2 3 4 5 6 7 8
R u n t i m e ( m s )
Horizon
DEC-POMDP
PSPR
FIG . 8 – Le temps d’exécution en fonctionde l’horizon, avec le problème du canal.
Le deuxième problème est celui du Ca-nal de Communication, où deux agentséchangent des messages à travers un ca-nal partagé, et essaient d’éviter les colli-sions. Ce problème contient 4 états, se-lon que chacun des agents a ou n’a pasde message à envoyer, deux observationspar agent : collision ou pas de collision, etdeux actions par agent : envoyer ou ne pasenvoyer un message. On a utilisé le mêmenombre de tests d’état de base que d’états
réels dans ces deux problèmes.
Les figures 7 et 8 montrent le tempsd’exécution de l’algorithme en fonction del’horizon. Ces résultats confirment l’avan-
____________________________________________________________________________ Annales du LAMSADE N°8
47

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 60/415
Le tigre t=1 t=2 t=3 t=4
DEC-POMDP -2 -4 5.19 4.80PSPR -2 -4 5.19 4.80
Le canal t=1 t=2 t=3 t=4 t=5 t=6 t=7 t=8
DEC-POMDP 1 2 2.90 3.89 4.79 5.69 6.59 7.49
PSPR 1 2 2.99 3.80 4.79 5.60 6.50 7.49
TAB . 1 – Les valeurs retournées dans lesmodèles DEC-POMDP et PSPR avec leproblème du tigre et le problème du canal.
tage d’utiliser les représentations prédic-tives des politiques par rapport aux repré-sentations nominales. On remarque que le
temps d’exécution avec le modèle PSPRest polynomial, quasiment linéaire, alorsque le temps d’exécution avec le modèleDEC-POMDP est exponentiel. L’étape quiconsomme le plus du temps dans cet algo-rithme est celle de l’élagage des politiquesdominées, et c’est précisement cette étapequi a été améliorée significativement dansle modèle PSPR.
6 Conclusion et Travaux futurs
Dans la plupart des systèmes du monderéel, l’incertitude de l’agent ne porte pasuniquement sur l’état du système, maisbien aussi sur les politiques. Ce problèmedevient plus crucial dans le cas des sys-tèmes multi-agents. Dans cet article, nousavons proposé une méthode originale quipermet de représenter les politiques et lesétats en utilisant le même principe, quiest la prédiction. L’avantage de ce mo-dèle, appelé PSPR, est que l’agent uti-lise uniquement la quantité d’informationminimale et suffisante pour représentersa croyance. Comme première applicationdes PSPRs, on a implémenté un algo-rithme de programmation dynamique pro-posé pour résoudre le problème de la pla-nification multi-agent coopérative, et com-
paré les résultats obtenu de cet algorithmelorsqu’il utilise la représentation standardDEC-POMDP pour modéliser les poli-tiques, et lorsqu’il utilise la représentationprédictive. Ces résultats nous permettent
de confirmer que les PSPRs sont un mo-dèle prometteur. Dans les travaux futurs,on essayera de trouver d’autres applica-tions de ce modèle, telles que l’apprentis-sage par renforcement , qui peut être vucomme une recherche dans l’espace despolitiques, ou bien les algorithmes de pla-nification pour le cas mono-agent. On étu-diera aussi plus profondement les proprié-tés théoriques de ce modèle, et commenton peut exploiter efficacement les liens quiexistent entre les tests d’état et les tests depolitique.
Références
[1] M. Littman, R. Sutton, S. Singh, Predictive re-presentations of state. Advances in Neural In- formation Processing Systems 14 (NIPS’02).pp. 1555-1561, 2002.
[2] S. Singh, M. James, M.R. Rudary, Predictivestate representations : A new theory for mo-deling dynamical systems. Uncertainty in Ar-tificial Intelligence : Proceedings of the 20thconference (UAI’04). pp. 512-519, 2004.
[3] S. Singh, M. Littman, N. Jong, D. Pardoe andP. Stone, Learning Predictive State Represen-tations, Proceedings of the 20th InternationalConference on Machine Learning (ICML’03).pp. 712-719, 2003.
[4] M. James, S. Singh and M. Littman, Planningwith Predictive State Representations, Procee-dings of the International Conference on Ma-chine Learning and Applications (ICMLA’04),pp. 304-311, 2004.
[5] D. Bernstein, N. Immerman and S. Zilberstein,The complexity of decentralized control of
markov decision processes, Journal of Mathe-matics of Operations Research, Vol. 27, Num.4, pp. 819-840, 2002.
[6] E. A. Hansen, D. S. Bernstein and S. Zilber-stein, Dynamic programming for partially ob-servable stochastic games, Proceedings of the19th National Conference on Artificial Intelli-gence (AAAI’04), pp. 709-715, 2004.
[7] D. Szer and F. Charpillet, Point-based Dy-namic Programming for DEC-POMDPs, Pro-ceedings of the 21th National Conference on Artificial Intelligence (AAAI’06), pp. 304-311,2006.
[8] M. James, Using Predictions for Planning andModeling in Stochastic Environments, Thèse
de doctorat , Université de Michigan, 2005.
Les représentations prédictives des états et des problèmes ___________________________________________________________________________
48

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 61/415
Fonctions d’utilité collective avec droits exogènes inégaux
Sylvain Bouveret†
Michel Lemaître
Office National d’Études et de Recherches Aérospatiales–DCSD.2, avenue Edouard Belin. BP 4025.
31055 TOULOUSE Cedex 4 – FRANCE.†Institut de Recherche en Informatique de Toulouse.
118, route de Narbonne.31062 TOULOUSE Cedex – FRANCE.
Résumé :On s’intéresse à la prise de décision collective et
coopérative dans un groupe d’agents ayant des pré-férences individuelles s’exprimant par des utilitésnumériques. Dans ce modèle, les préférences desagents sont agrégées en une préférence communeà l’aide d’une fonction d’utilité collective, tradui-sant ainsi de manière formelle le critère «éthique»choisi par la collectivité. La plupart des travaux is-sus du choix social supposent que les agents sontégaux a priori vis-à-vis de la prise de décision,mais ce n’est pas toujours le cas pour des pro-blèmes réels. Nous nous intéressons à la construc-tion et à l’étude de fonctions d’utilité collective pre-
nant en compte ces droits inégaux.Mots-clés : Modèles économiques de la décision,choix social, allocation centralisée de tâches et deressources, résolution coopérative de problèmes
Abstract:We study the collective and cooperative decisionmaking in a group of agents having unequal rightsexpressed by numerical utilities. In that framework,the agents’ preferences are aggregated into a com-mon decision using a collective utility function thatencompasses the “ethical” criterion choosen by thesociety of agents. Most social choice works assumethat the agents are equal a priori as regards the col-lective decision making, but this is not always thecase in real-world problems. In this paper, we focuson the construction and the study of collective uti-lity functions that take unequal rights into account.
Keywords: Economical models of decision ma-king, social choice, centralized tasks and resourceallocation, cooperative problem solving
1 IntroductionOn s’intéresse aux problèmes dans les-quels un groupe d’agent doit s’accorderde manière collective et coopérative sur
une décision commune choisie parmi unensemble de décisions admissibles. Dansla littérature, ce type de problèmes estclassiquement décrit par le modèle utili-tariste1. Dans ce modèle, on admet quel’on est capable de mesurer le « bien-être» de chaque agent sous la forme d’unefonction d’utilité individuelle qui associechaque décision potentielle à un indicenumérique, l’utilité individuelle. Le pro-blème de choix de la bonne décision pourle groupe d’agents se ramène donc à la
donnée de l’ensemble des utilités indivi-duelles pour chaque décision admissible.On supposera ici que toutes les utilités in-dividuelles sont exprimées de manière sin-cère par les agents sur une échelle com-mune, et on ne s’intéressera pas au pro-blème de l’élicitation de ces préférences.
Le choix entre les décisions admissiblesse fait à l’aide d’une fonction d’utilité col-
lective (CUF pour Collective Utility Func-tion) dont le rôle est d’agréger l’ensembledes utilités individuelles en une utilité col-lective, représentant le « bien-être » dugroupe vis-à-vis de chaque décision po-tentielle. Cette CUF est supposée choisiede manière consensuelle, ou émane d’uneinstance de décision supérieure (un ar-bitre). Le processus de prise de décisionse ramène alors à déterminer la décisionqui maximise la CUF. Si l’application decette approche à des problèmes macroé-conomiques est très criticable (et critiquée
1À ne pas confondre avec l’utilitarisme classique qui est unemanière particulière d’agréger les utilités individuelles.
49

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 62/415
[10]), elle reste utile à l’échelle microéco-nomique pour étudier et formaliser les pro-blèmes de décision collective en contextelimité et à enjeux restreints. C’est dans cecadre que nous nous plaçons.
La CUF la plus fréquemment proposée estla somme des utilités individuelles (uti-litarisme classique). Avec cette fonction,chaque agent est considéré comme pro-ducteur d’utilité collective, et plus chacunproduit, plus le groupe est satisfait. Unpeu moins classique, la CUF égalitaristeconsiste à prendre, pour utilité collective,
le minimum des utilités individuelles (lasatisfaction du groupe est celle du moinssatisfait des membres du groupe), ce quicorrespond à une vision radicalement dif-férente de la justice sociale [9]. Entreces deux extrêmes, il y a place pour denombreuses CUF intermédiaires (voir parexemple [7, chapitre 2] ou [1, chapitre12]).
S’il existe de nombreux travaux sur lesCUF, la plupart de ces travaux considèrentimplicitement le cas d’agents situés au dé-part sur un pied d’égalité, nous dironsayant des droits exogènes égaux. Cettesupposition, qui se traduit par exempleen théorie du vote par le principe «une
personne, une voix», s’exprime dans lemodèle utilitariste par la symétrie desCUF. Pourtant, dans beaucoup de situa-tions concrètes, ce n’est pas le cas, carles agents ne doivent pas avoir le mêmepoids dans la décision collective, pour desraisons aussi diverses que celles exposéesdans les exemples présentés ci-après. Danscet article, nous traduirons cette différenced’importance entre agents par la notion dedroits des agents, ces droits étant représen-tés par des indices numériques : plus ledroit est élevé, plus l’agent est censé bé-néficier de la décision, d’une manière que
nous cherchons à capturer précisément. Ceproblème est lié avec celui des indices de pouvoir [4] en théorie du vote, dans uncontexte cependant légèrement différent,puisque dans ce contexte la procédure de
vote est en général fixée, et l’on cherchesoit à attribuer les droits aux votants demanière à ce qu’ils aient un certain pou-voir de vote, soit, les droits étant fixés, oncherche à analyser le pouvoir de vote dechaque votant.
Voici quelques exemples de problèmesd’allocation de ressources, qui seront re-pris en section 6 :– un bien de consommation (ressource)
à répartir entre plusieurs populations(agents) de tailles (droits) différentes ;
– un ensemble de représentants (res-
source) de circonscriptions (agents) detailles (droits) différentes à désignerpour un comité de taille fixée ;
– l’actif (ressource) – inférieur aux dettes– d’une société en faillite à répartir entreses créanciers (agents), auquels l’entre-prise doit des montants (droits) diffé-rents;
– une ressource industrielle commune ex-ploitée par plusieurs agents ayant par-
ticipé de manière inégale à son finan-cement, chacun attendant un retour surinvestissement (droits) proportionnel àcelui-ci (voir le problème de partage deressources satellitaires [5]) ;
– une ressource à partager entre plusieursagents qui la transforment en biens re-vendus au bénéfice du groupe, les agentsayant des productivités différentes2.
Dans cet article, nous nous intéressons àla prise en compte de droits inégaux dansle modèle utilitariste. Après avoir définiformellement la notion de droits inégauxen section 2 nous introduisons quelquesexemples de CUF à droits égaux ou in-égaux, qui illustreront l’ensemble de l’ar-ticle. Les sections 4 et 5, qui constituentles principales contributions de cet article,concernent respectivement le principe deduplication, au cœur du schéma proposé,et l’extension des propriétés classiques des
CUF aux droits inégaux ainsi que l’in-2Cet exemple est à la limite du cadre des droits exogènes,
car la «productivité» d’un agent constitue plutôt une propriétéintrinsèque de sa fonction d’utilité. Cependant, son traitement(section 6) apporte une solution tout-à-fait plausible.
Fonctions d'utilité collective avec droits exogènes inégaux ___________________________________________________________________________
50

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 63/415
troduction de nouvelles propriétés liées àces droits. La suite de l’article traite deCUF réalisant des compromis entre l’éga-litarisme et l’utilitarisme classique (sec-tion 7), et enfin quelques idées sont in-troduites sur la prise en compte de droitsinégaux dans un contexte pour lequel cesdroits sont ordinaux (section 8).
2 Formalisation et notations
L’ensemble de n agents est noté N =1, . . . , n. La décision collective est à
prendre dans un ensemble A de dé-cisions admissibles. La décision admis-sible a apporte à chaque agent i l’uti-lité ui(a). À chaque décision admis-sible a correspond un profil d’utilité −→u (a)
def = u1(a), · · · , un(a), écrit sim-
plement −→udef = u1, · · · , un lorsque a est
sous-entendue. L’ensemble des agents doits’accorder sur une CUF à maximiser, ou
s’en remettre pour ce choix à un arbitre im-partial. Cette CUF est notée W : Rn → R.
Les droits inégaux des agents sont don-
nés par un vecteur −→edef = e1, · · · , en (e
pour entitlement ), et on notera m =
i ei.Nous considérons sans perte de généra-lité que les ei sont des entiers naturels(ei ∈ N) : si, pour les besoins d’une ap-plication quelconque, les droits sont dans
Q, nous pouvons raisonner sur des droitsentiers proportionnels au vecteur −→e grâceà la propriété d’Indépendance à l’ÉchelleCommune de Droits introduite en section 5(nous excluons les droits non rationnels).Une CUF à droits inégaux sera notée W −→e .
3 Exemples repères
Nous allons montrer comment, dans unmême contexte initial, plusieurs CUFpeuvent se justifier, lorsque les droitspeuvent être égaux ou inégaux. Le pro-blème est le suivant : une collectivité de
fermiers utilise un système commun dedistribution d’eau captée. Ils doivent dé-cider ensemble de la quantité d’eau ai al-louée annuellement à chaque fermier i,toutes les distributions n’étant pas admis-sibles (quantité limitée, tuyaux plus oumoins gros...). De sa quantité d’eau ai,le fermier i retire une utilité individuelleui(ai). Même si les fermiers ont une capa-cité de travail identique, cette fonction estpropre à chaque fermier (par exemple ilsne cultivent pas tous les mêmes plantes, lessols n’ont pas le même rendement...), eton admettra qu’il existe une échelle com-
mune des utilités (par exemple des euros).
3.1 Avec des droits égaux
Utilitarisme classique : La collectivité s’inté-resse à l’utilité globale produite. La CUFnaturelle est W (−→u ) =
i ui. Noter l’in-
terchangeabilité des utilités individuelles :pour atteindre un haut niveau d’utilité col-lective, un bas niveau d’utilité produite parune ferme devra être compensé par un bonniveau d’une autre. Un litre d’eau sup-plémentaire ira au fermier ayant la plusgrande utilité individuelle marginale3. Sil’utilité individuelle représente ou est liéeausalairedufermier,lechoixdecetteCUFimplique qu’un fermier sera amené à se sa-crifier pour la communauté.Égalitarisme : L’utilité individuelle repré-sente le revenu du fermier. La collecti-vité s’intéresse maintenant à une répar-tition équitable de l’utilité produite parchaque fermier. Une fonction qui convientest W (−→u ) = mini ui, car elle tend à lafois à égaliser les revenus et à les tirer versle haut. Noter l’absence d’interchangeabi-lité des utilités individuelles : un litre d’eausupplémentaire ira au fermier ayant l’uti-lité la plus faible, même si ce litre est plusproductif en utilité dans une autre ferme4.
3En supposant que l’utilité individuelle, fonction de la quan-tité d’eau reçue n’est pas décroissante, et à condition que lescontraintes d’admissibilité soient satisfaites.
4Notons que la fonction min a un inconvénient majeur, ap-pelé effet de noyade : les profils d’utilité 3, 3, 3 et 3, 5, 10
____________________________________________________________________________ Annales du LAMSADE N°8
51

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 64/415
3.2 Avec des droits inégaux
On introduit des droits inégaux ei ∈ N,
chaque ei correspondant au nombre de per-sonnes qui habitent la ferme i.
Division avec utilitarisme classique : L’utilitéreprésente le revenu de la ferme. Elle estdivisée entre chaque habitant individuelle-ment. Chaque habitant reçoit donc ui/ei.La collectivité s’intéresse au bien-être col-lectif mesuré par la somme de ce que re-çoivent tous les habitants. La CUF est doncW −→e (−→u ) = i(ei · (ui/ei)) = i ui.Division avec égalitarisme : C’est le même casde figure, mais la collectivité veut répartiréquitablement l’utilité individuelle reçuepar chacun des fermiers. Une CUF conve-nable est alors W −→e (−→u ) = mini(ui/ei).Indivision avec utilitarisme classique : Onchange maintenant de point de vue surl’utilité individuelle. L’utilité ui caracté-rise la «prospérité» de la ferme i, et me-sure en quelque sorte l’agrément d’y habi-ter, chaque habitant d’une ferme jouissantde manière équivalente de la prospérité desa ferme et de celle-ci seulement. Chaquehabitant de la ferme i reçoit donc l’utilitéui de manière indivisible. Puis, la collecti-vité cherche à maximiser l’agrément totalde tous les habitants, mesurée comme lasomme des utilités reçues par les habitants.L’utilité collective est alors la somme pon-dérée W −→e (−→u ) = i(ei · ui).Indivision avec égalitarisme : Le point devue sur l’utilité est le même que dansl’exemple précédent, mais la collectivités’intéresse maintenant à une répartitionéquitable entre chacun des habitants in-dividuellement. L’utilité collective conve-nable est W −→e (−→u ) = mini ui.
Cette série d’exemples illustre la diversitédes CUF possibles, selon le but poursuivi
par la communauté et la nature des satis-factions des agents, en présence de droits
sont équivalents au sens du min, alors que le second est collec-tivement préférable. L’ordre collectif leximin pallie cet inconvé-nient, mais pour simplifier, nous ne l’introduirons pas ici.
inégaux. Dans la suite de l’article, nouschercherons à rendre compte de manièresystématique de ces différentes formes, etéventuellement à en proposer de nouvelles.
4 Principe de duplication
Le principe de duplication est un moyende résoudre le problème de prise de dé-cision collective en présence de droits in-égaux. L’idée est de remplacer chaqueagent par autant de clones qu’il possèdede droits (ou d’un nombre de clones pro-
portionnel à ses droits si les droits ne sontpas des entiers), l’utilité reçue par chaqueagent étant répartie – d’une manière quiest discutée plus loin – entres ses clones.L’idée est ensuite de se ramener à un pro-blème de décision collective entre les mclones considérés avec des droits égaux.Le raisonnement vise à conférer à chaqueagent un «pouvoir de décision» égal ouproportionnel à son droit5.
Ce principe est proposé dans quelques tra-vaux (voir [3]), mais il est toujours ap-pliqué dans un contexte de division équi-table de ressource, qui conduit à la fonc-tion mini ui/ei, ce qui n’est pas toujourspertinent, comme nous l’avons vu dansles exemples de la section 3. Nous propo-sons donc une formalisation du principede duplication, autorisant une utilisationplus large que celle qu’on lui donne habi-tuellement et faisant intervenir deux para-mètres :– la manière dont l’utilité d’un agent est
répartie entre ses clones,– la CUF jouant sur la société des clones.D’abord nous définissons une fonction derépartition, dont le rôle est de faire corres-pondre à l’utilité ui d’un agent i et à sondroit ei l’utilité ri d’un de ses clones :
5Cette notion mérite encore d’être précisée et formalisée, àla manière des pouvoirs de vote dont la transcription dans uncontexte utilitariste ne semble pas immédiate.
Fonctions d'utilité collective avec droits exogènes inégaux ___________________________________________________________________________
52

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 65/415
Définition 1 (Fonction de répartition)Une fonction de répartition est une fonc-tion ÷ : R×N → R.
Deux fonctions de répartition sont natu-relles. D’une part la division ordinaire u ÷
edef = u/e, qui prend son sens dans le cas
d’une satisfaction devant être nécessaire-ment divisée entre les clones, nous dironslorsque les utilités individuelles sont pré-emptives, et d’autre part la simple réplica-
tion u ÷ edef = u, qui convient dans le cas
d’une satisfaction qui ne s’épuise pas lors-
qu’elle est partagée (exemple de la «pros-périté» en section 3).
Définition 2 (Principe de duplication)Soient un vecteur de droits −→e sur n agents,une CUF à droits égaux W : Rm → R ,une fonction de répartition ÷ , on définit,
par duplication, une CUF à droits inégauxW −→e par :
W −→e : Rn → R−→u → W (−→u ÷
−→e) , avec
−→u ÷−→e
def =
r1, . . . , r1 e1 fois
, . . . , rn, . . . , rn en fois
,
et ri = ui ÷ ei.
Énumérons les quatre CUF à droits in-égaux qui résultent des deux choix pos-
sibles introduits pour ÷ et pour W :
u ÷ edef = u/e u ÷ e
def = u
(division) (réplication)
W def =P(m)
(utilitarisme cl.)
X
i∈N
uiX
i∈N
(ei · ui)
W def = min(m)
(égalitarisme)mini∈N
(ui/ei) mini∈N
ui
Nous avons indiqué d’un mot-clé la carac-
téristique importante de chaque fonctionde répartition (division / réplication), et demême pour la CUF sur les clones (utilita-risme classique / égalitarisme). Les nota-tions
(m) et min(m) rappellent que ces
opérateurs portent sur m opérandes. Onnotera que la CUF mini(ui/ei) tend versl’égalité des rapports ui/ei et donc versla proportionalité des utilités individuellespar rapport aux droits.
5 Propriétés
L’introduction de droits inégaux dans ledomaine de la prise de décision collec-tive modifie non seulement la notion deCUF, mais aussi les propriétés raison-nables classiques qui permettent de ca-
ractériser ces fonctions d’utilité. Nous es-sayons ici d’abord d’adapter la définitiondes principales propriétés des CUF afinqu’elles prennent en compte les droits exo-gènes inégaux, puis nous introduisons denouvelles propriétés directement liées à lanotion de droits exogènes.
5.1 Propriétés classiques étendues
La propriété fondamentale des CUF clas-siques est la notion d’unanimité, ou, end’autres termes, de compatibilité avec larelation de Pareto. Cette propriété peuts’exprimer comme suit. Soient a et b deuxdécisions collectives. Si ∀k ∈ N, uk(b) ≥uk(a), et si ∃i ∈ N tel que ui(b) > ui(a),alors W (−→u (b)) > W (−→u (a)) : si l’on peutaméliorer le sort d’un agent sans détériorercelui des autres, on le fait. L’expression de
cette propriété ne change pas avec l’intro-duction de droits exogènes inégaux.
Outre l’unanimité, la propriété d’anony-mat est très souvent requise. Elle traduitle fait que l’utilité collective est indépen-dante de l’identité des agents, donc quela CUF est insensible à toute permutationdes composantes du profil d’utilité. En pré-sence de droits inégaux, cette définition
doit être adaptée, car l’identité d’un agents’exprime par le couple (utilité, droit) :
Définition 3 (Anonymat généralisé)Soit W −→e une CUF à droits inégaux.
____________________________________________________________________________ Annales du LAMSADE N°8
53

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 66/415
W −→e satisfait la propriété d’anonymatgénéralisé si et seulement si ∀−→u ∈ Rn
et ∀σ permutation de N , W −→e (−→u ) =
W eσ(1),...,eσ(n)(uσ(1), . . . , uσ(n)).
La propriété suivante concerne l’indépen-dance de l’utilité collective vis-à-vis desagents non concernés (IUA pour Indepen-dance of Unconcerned Agents). Cela ex-prime le fait qu’un agent ne doit pas êtrepris en compte pour le choix entre deuxdécisions si son utilité individuelle entre
ces deux décisions reste la même (il n’estpas concerné par la décision). Nous propo-sons une propriété plus forte dans le cadredes droits inégaux : ni l’utilité ni le droitde l’agent n’influent sur le choix entre lesdeux décisions.
Définition 4 (IUA généralisée) Une CUF à droits inégaux W −→e satisfait la pro-
priété d’IUA généralisée si et seulement si pour tout quadruplet de profils d’utilité (−→u , −→v , −→u , −→v ) et toute paire de vecteurs
de droits (−→e , −→e ) tels que :
– pour un agent i : ui = vi et ui = v
i , – pour tout agent k = i : uk = u
k , vk =v
k , et ek = ek ,
nous avons : W −→e (−→u ) ≤ W −→e (−→v ) ⇔W −→e (−→u ) ≤ W −→e (−→v ).
−→e , −→u et −→v sont des répliques de −→e ,−→u et −→v sauf pour l’agent i. Entre −→u et−→v , l’utilité de l’agent i ne change pas (ui = vi ), ni entre −→u et −→v , même sison droit a pu changer . Dans ces condi-tions, si collectivement on préfère −→u à −→vsous −→e , alors on doit préférer −→u à −→v
sous −→e . Si cette propriété n’est pas vé-
rifiée, alors le choix entre deux décisionsdépendra de l’utilité ou du droit de l’agenti, même si cet agent est complètement in-différent entre ces deux décisions, ce quiintuitivement peut être non souhaitable.
5.2 Propriétés relatives aux droits
L’idée intuitive liée à la notion de droits
exogènes est que plus le droit d’un agentest élevé, plus il doit bénéficier de la déci-sion collective. Cette idée informelle peutse traduire de différentes manières. La pro-priété la plus simple que l’on peut tirer dece principe est que l’augmentation du droitd’un agent ne peut pas renverser une pré-férence collective qui déjà l’avantageait.
Par exemple, soient −→u = 4, 7, 4, 2 et−→v = 1, 5, 3, 8. Supposons que, pour unvecteur de droits −→e , on ait W −→e (−→u ) ≥W −→e (−→v ). Entre les deux profils, le préféréest celui qui avantage, entre autres, l’agent2. Si nous augmentons le droit de l’agent2 sans modifier celui des autres agents,pour obtenir le vecteur −→e , nous ne pou-vons avoir W −→e (−→v ) ≥ W −→e (−→u ). Si telétait le cas, la collectivité préfèrerait unprofil d’utilité qui désavantage maintenant
l’agent 2, alors que son droit a augmenté.
Définition 5 (Conformité) Soient −→e et −→e deux vecteurs de droits tels que ek = e
k pour tout k = i , et ei < e
i , et soit W −→e uneCUF à droits inégaux. W −→e vérifie la pro-
priété de conformité si et seulement si pour toute paire de profils d’utilité (−→u , −→v ) , on
a (W −→e (−→u ) ≥ W −→e (−→v ) et ui > vi) ⇒
W −→e
(
−→
u ) ≥ W −→e
(
−→
v ).
L’intérêt principal de cette propriété portesur la décision collective optimale : sil’on augmente le droit relatif d’un certainagent,alorsilnepeutpasfiniravecuneuti-lité moindre qu’avant son augmentation6.Cette propriété n’est pas sans rappeler lepostulat du transfert relatif aux indices depouvoir et aux procédures de votes pondé-
rées [4].6Dans toute la suite, les preuves seront omises et pour-
ront être trouvées dans la version longue de l’article enhttp://www.cert.fr/dcsd/THESES/sbouveret/
ressources/MFI07/MFI07_long.pdf
Fonctions d'utilité collective avec droits exogènes inégaux ___________________________________________________________________________
54

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 67/415
Proposition 1 Soient −→e et −→e deux vec-teurs de droits tels que ek = e
k pour tous k = i , et ei < e
i , et soit W −→e une CUF. Nous notons a−→e =argmaxa∈A W −→e (−→u (a)) une décision col-lective optimale selon W −→e . Si W −→e satisfait la propriété de conformité, alors il existeune décision collective optimale a−→e selonW −→e telle que ui( a−→e ) ≥ ui( a−→e ).
La propriété de conformité est une traduc-tion possible de l’idée selon laquelle lesdroits inégaux ont un effet «positif» dans
le partage. Cette idée d’effet «positif» peutse traduire d’une manière différente : toutechose étant égale par ailleurs, il vaut mieuxchoisir la décision qui avantage, entre deuxagents ayant des droits inégaux, l’agentayant un plus grand droit.
Définition 6 (Avantage aux droits élevés)Soient −→u et −→v deux profils d’uti-lité tels que ui = v j , u j = vi et
uk = vk ∀k ∈ N \ i, j (−→v est égal au profil −→u dans lequel on a permuté ui et u j), avec ui > u j , et soit W −→e une CUF à droits inégaux. Alors W −→e avantage lesdroits élevés si et seulement si pour tout −→e , W −→e (−→v ) ≤ W −→e (−→u ) ⇔ ei ≥ e j .
Cette notion d’avantage aux droits éle-vés n’est pas équivalente à la propriété
de conformité, même si elle traduit dif-féremment la même idée intuitive, car ilexiste des CUF à droits inégaux qui sa-tisfont la propriété de conformité sans vé-rifier la propriété d’avantage aux droitsélevés (la fonction somme non pondérée,correspondant à l’utilitarisme avec divi-sion de la ressource, est un exemple d’unetelle fonction). L’existence d’un lien entrel’avantage aux droits élevés et la confor-mité, éventuellement lié aux autres pro-priétés (IUA généralisée, anonymat, una-nimité), ou aux propriétés analytiques desCUF (continuité) n’est pas encore claire.
Une dernière propriété souhaitable des
CUF prenant en compte des droits exo-gènes inégaux est leur insensibilité àune dilatation proportionnelle de l’échellecommune d’expression de ces droits in-égaux. En d’autres termes, une CUF àdroits inégaux doit classer les décisions dela même manière, que le vecteur de droitssoit −→e , 2 · −→e ou bien 100 · −→e .
Définition 7 (IDCD) Soit W −→e une CUF àdroits inégaux. W −→e est insensible à unedilatation commune des droits (IDCD) siet seulement si ∀k ∈ N , ∀−→e vecteur
de droits, et pour tout couple (−→u , −→v ) de profils d’utilité, W −→e (−→u ) ≥ W −→e (−→v ) ⇔W k·−→e (−→u ) ≥ W k·−→e (−→v ).
5.3 Application aux CUF introduites
La proposition suivante caractérise lesCUF à droix inégaux introduites précé-
demment à l’aide des propriétés définiesci-avant.
Proposition 2 Les fonctions somme,somme pondérée, min et min pondéré satisfont les propriétés marquées «oui» dela table 1, et ne satisfont pas les propriétésmarquées «non» de cette même table.
6 Applications
Dans cette section, nous appliquons leschéma méthodique proposé à quelquessituations «microéconomiques» dans les-quelles apparaissent naturellement desdroits exogènes. Si le choix de la CUF etde la fonction de répartition sont souventassez naturels, dans certains cas il peut être
discutable. Notre point de vue n’est pasnormatif (nous ne cherchons pas à impo-ser de solution); nous cherchons juste àmettre en évidence le pouvoir descriptif duschéma.
____________________________________________________________________________ Annales du LAMSADE N°8
55

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 68/415
unanimité anonymatgénéralisé
IUA géné-ralisée conformité
avantageaux droits
élevésIDCD
iei · ui oui oui oui oui oui ouii ui oui oui oui oui non oui
mini ui/ei nona oui oui oui oui ouimini ui non a oui oui oui non oui
aCe non-respect de la propriété d’unanimité est lié à l’effet de noyade de la fonction min, et non aux droits inégaux eux-mêmes.Cet inconvénient est classiquement pallié par l’introduction du préordre leximin à la place de la fonction min.
TAB . 1 – CUF à droits exogènes inégaux et leurs propriétés.
Répartition d’un bien vital Une ONG doit
répartir une quantité de riz entre diffé-rents pays sinistrés par la famine. Les pays(agents) sont de tailles (droits) différents.L’utilité reçue par un habitant est sa quan-tité de riz. La fonction de répartition estici la division. Prenant en compte le carac-tère de répartition égalitariste suggéré parla nature vitale de la ressource, on conclutà la CUF min ui/ei (allocation proportion-nelle à la taille des populations).
Banqueroute (présenté en section 1) Le casrelève assez clairement de la répartitiond’utilité par division d’une part, et d’autrepart au point de vue égalitariste sur la pré-férence collective. Ce qui conduit à la CUFmini ui/ei. Si l’utilité se mesure directe-ment en monnaie, maximiser cette fonc-tion revient à allouer l’actif proportion-nellement aux créances. C’est la solutionclassiquement proposée pour ce problème,
mais d’autres se justifient également (voirpar exemple [12, chapitre 4]).
Constitution de comité (présenté en sec-tion 1) L’utilité reçue par une circonscrip-tion est son nombre de représentants, etdans ce cas il y a une exigence égalita-riste sur la préférence collective (égalité dereprésentation pour chaque habitant). Pource qui est de la fonction de répartition, ladivision semble la plus sensée (un repré-
sentant partage son temps entre les habi-tants de sa circonscription), ce qui conduitencore à la CUF mini ui/ei, c’est-à-dire àune allocation tendant vers la proportiona-lité du nombre de représentants par rap-
port aux populations, «tendant vers», car
la difficulté de ce problème tient au faitque la proportionalité exacte peut rarementêtre atteinte, du fait que le nombre de re-présentants est entier. Maximiser la fonc-tion mini ui/ei revient alors à une attribu-tion des sièges selon la méthode de J. Q.Adams, dite du plus petit diviseur (voir [2,appendix A, proposition 3.10], qui donneaussi d’autres solutions pour ce problème).Ressource commune avec différents investisse-
ments initiaux (présenté en section 1) L’ex-ploitation en commun d’une ressource cor-respond intuitivement à la division de laressource entre les agents, et l’équité sug-gérée par la nature du problème impliquede manière naturelle la CUF égalitariste.Nous avons donc encore une fois affaire àla CUF mini ui/ei (allocation proportion-nelle à la hauteur de l’investissement).Productivités différentes (présenté en section
1) Chaque agent est ici remplacé par unensemble de clones tous également pro-ductifs, la production d’un agent étant lasomme de la production de ses clones(fonction de répartition division). Le pro-blème est utilitariste classique, car peu im-porte ce que produit chaque agent en par-ticulier, seule la production totale compte,ce qui nous donne une CUF
ui.7
Prix du kWh Une compagnie distributrice
d’électricité doit fixer un prix de vente du7Lesdroits n’ont en réalité pas«disparu», carils apparaissent
de manière cachée dans les fonctions ui(ai). On trouve unexemple analogue dans [7, page 21], traité sans l’aide des droitsinégaux.
Fonctions d'utilité collective avec droits exogènes inégaux ___________________________________________________________________________
56

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 69/415
kWh d’énergie électrique pour les utilisa-teurs de son réseau. Ces utilisateurs sontréunis en communes (les agents), et le prixde vente fixé pour une commune consti-tue une désutilité identique ui (utilité néga-tive) pour tous les habitants de cette com-mune, donc la fonction de répartition entreles «clones» d’une même commune estla réplication. La répartition du coût doitêtre égalitariste, car il s’agit d’un bien pu-blic indispensable. La fonction d’utilité àconsidérer est donc mini ui : la taille dela commune (donc le droit exogène) n’im-porte pas.
Infrastructures collectives Un nombre limitéd’infrastructures collectives, plutôt de loi-sirs, doit être alloué à un certain nombrede villes (agents) ayant des populationsde tailles différentes (droits). Soit ki lenombre d’infrastructures allouées à la villei. L’utilité de la décision k pour la ville iest ui(ki). S’agissant d’un équipement deloisir, on peut mesurer l’utilité collectivepar la somme des satisfactions de chaque
habitant. Si l’on admet que tous les ha-bitants de la ville i jouissent d’une ma-nière égale de la présence des ki théâtresde la ville, alors l’utilité de chaque habitant(clone) est aussi ui(ki) (réplication). Se-lon ce raisonnement, la CUF qu’il convientde maximiser est
i(ei · ui). Si mainte-
nant l’équipement collectif n’avait pas uncaractère de loisir mais de bien vital –comme un hôpital –, nous serions plutôt
dans le cas (égalitarisme / réplication) etla CUF convenable serait mini ui.
La radio n groupes (nos n agents) partagentun espace commun doté d’un poste de ra-dio pouvant diffuser n stations différentes.Les ei (droits) membres du groupe i sonttous amateurs de la station i, et de celle-ci seulement. Il faut donc décider de la fa-çon de partager le temps de diffusion duposte entre les n stations. Nous notons xi
la fraction de temps de diffusion dédiée àla station i (n
i=1 xi = 1) : nous consi-dérerons que l’utilité de l’agent/groupe iest égale à xi. Ici l’équité est primordiale,donc l’égalitarisme s’impose. En revanche
le choix de la fonction de répartition estsujet à deux interprétations, ce qui rendl’exemple intéressant.
La première interprétation est que l’on par-tage du temps de «satisfaction» : un agentécoutant sa station préférée pendant untemps xi sera satisfait à hauteur de xi.C’est un cas de réplication, donnant laCUF mini ui = mini xi : on alloue untemps de diffusion égal pour chaque sta-tion, sans se soucier du nombre d’ama-teurs de la station i. La seconde interpréta-tion est que l’on partage le temps pendantlequel un groupe peut choisir sa stationpréférée, et dans ce cas, l’utilité xi d’unagent est divisible entre ses clones (chaqueclone peut choisir sa station préférée pen-dant un temps xi/ei) : la fonction de ré-partition est la division, ce qui aboutit à laCUF mini ui/ei = mini xi/ei. Maximisercette fonction revient à allouer un temps dediffusion proportionnel au nombre d’ama-teurs d’une station.
Cet exemple a été traité sans l’aide dedroits exogènes inégaux dans la littéra-ture (voir [8, page 79]), de la manière sui-vante : les agents correspondent à l’en-semble des individus impliqués dans lepartage de la radio (nos clones), l’utilitéd’un agent amateur d’une station i étantla fraction xi. Dans ce contexte, la CUFutilitariste classique est difficilement jus-tifiable : elle suggère de ne diffuser quela station qui recueille le plus d’amateurs.La fonction égalitariste est celle qui cor-respond à notre première solution, et ré-sulte en un partage qui égalise le temps dediffusion de toutes les radios (xi = 1/n).[8] propose un compromis entre ces solu-tions plutôt extrêmes (soit le groupe le plusnombreux impose son choix pour toute ladurée de la diffusion, soit on ne tient pasdu tout compte du nombre d’amateurs dechaque station), en utilisant la CUF de
Nash, qui s’écrit W (−→u ) = ui. Maxi-miser cette fonction revient, dans le pro-blème de la radio, à résoudre le problèmed’optimisation sous contrainte suivant :max−→x
ni=1 xei
i , avecn
i=1 xi = 1. Ce
____________________________________________________________________________ Annales du LAMSADE N°8
57

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 70/415
problème d’optimisation classique admetcomme solution : xi = ei/n. Cette solutionalloue un temps de diffusion proportionnelau nombre d’amateurs d’une station, ce quicorrespond exactement à notre seconde so-lution (égalitarisme, division). Notons quecette solution correspond au principe dela «dictature aléatoire» : chaque agent im-pose son point de vue aux autres pendantune fraction 1/m du temps total.
7 CUF de compromis et droits
inégaux
L’utilitarisme classique et l’égalitarismesont deux visions extrêmes de la déci-sion collective8. Il existe cependant descompromis entre ces deux extrêmes, parexemple sous la forme de fonctions pa-ramétrées (voir [6]). Le but de cette sec-tion est de montrer comment le principe de
duplication peut se marier avec l’idée decompromis, par exemple avec la famille deCUF introduite par Atkinson (cité par [1,chapitre 12]; voir aussi [7, chapitre 2.6]),définie pour tout p ≤ 1 (nous supposeronsque ui > 0) :
W (n) p (−→u )
def =
1n
ni=1 u p
i
1/p
, p = 0,
(ni=1 ui)
1/n, p = 0
Lorsque p = 1, W (n)1 est la moyenne (utili-
tarisme classique) et W (n)
p tend vers le min
lorsque p tend vers −∞9, et W (n)0 est la
fonction de Nash.
En appliquant le principe de duplication,
8Par exemple l’égalitariste pur préfère 10, 10, 10à 9, 100, 100. L’utilitariste inconditionnel préfère1, 100, 100 à 66, 66, 67 et même à 2, 99, 99.
9Strictement parlant, W (n)p possède l’avantage de représen-
ter l’ordre leximin lorsque p → −∞.
on trouve, pour le cas ui ÷ ei = ui/ei :
W (n)
p,−→e ,div(−→u )
def =
1mn
i=1 e1− pi · u p
i1/p
, p = 0,ni=1
uiei
ei1/m
, p = 0
et, pour le cas ui ÷ ei = ui :
W (n)
p,−→e ,rep(−→u )
def =
1m n
i=1 ei · u pi
1/p, p = 0,
(ni=1 uei
i )1/m, p = 0
On pourra trouver des formes plus agré-ables aux fonctions ci-dessus, en utilisantla propriété selon laquelle les CUF sontsignificatives à une transformation mono-tone croissante près.
Il est intéressant de caractériser ces CUFà l’aide des propriétés introduites ci-avant.
Nous avons la proposition suivante :
Proposition 3 Les CUF W p,−→e ,div et W p,−→e ,rep vérifient les propriétés suivantes
pour tout p : unanimité, anonymat gé-néralisé, IUA généralisée et conformité.W p,−→e ,rep vérifie de plus l’IDCD pour tout
p , mais W p,−→e ,div ne vérifie cette même propriété que pour p < 1.
Il existe d’autres familles de fonctions decompromis entre la somme et le min, àl’instar de la famille des OWA [11], qu’ilest possible d’utiliser comme base pourobtenir une autre généralisation des CUFà droits inégaux. Noter que les intégralesde Choquet ne conviendraient pas ici, carelles sont conçues pour prendre en compteles interactions entre agents (ou critères),et ne sont donc pas compatibles avec lapropriété d’anonymat.
Une question naturelle reste encore en sus-pens : comment généraliser la fonction de
Fonctions d'utilité collective avec droits exogènes inégaux ___________________________________________________________________________
58

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 71/415
répartition, afin d’établir des compromisnaturels entre division et réplication10 ?
8 Droits inégaux ordinauxSi, dans de nombreux problèmes tels queceux présentés ici, le vecteur de droits in-égaux apparaît de manière naturelle, enrevanche, dans certains autres problèmes,il peut s’avérer difficile d’exprimer cesdifférences d’avantage sous forme numé-rique. Ainsi par exemple, dans un co-mité, l’avis d’un agent ayant plus d’expé-
rience ou plus d’ancienneté comptera plusque l’avis d’un autre agent, sans qu’il nesoit vraiment possible à première vue dequantifier cet avantage. Dans ce contexte,une éventuelle transcription numérique del’ordre de priorités pose autant de pro-blèmes philosophiques que la transcriptionnumérique d’un ordre de préférences : quelsens donner à d’éventuels droits numé-riques, comment attribuer ces droits aux
agents...Nous présentons ici brièvementquelques pistes de réflexion sur la prise encompte de droits exogènes sous la formed’un ordre de priorité entre les agents, dansun contexte utilitariste. Nous considére-rons dans toute la suite qu’un ordre depriorité est un préordre total sur les agents :tous les agents sont ordonnés, mais onadmet que plusieurs agents se situent aumême niveau de priorité.
S’il paraît difficile d’utiliser un ordre depriorité pour prendre une décision collec-tive en une seule phase, comme avec uneCUF à droits inégaux, en revanche, on peutenvisager des méthodes de prise de déci-sion à plusieurs phases induites par l’ordrede priorité. Deux méthodes sont intuitives :dans la première méthode (forte), l’ordrede priorité est prédominant dans le proces-sus de décision collective ; dans la seconde
10Dans l’exemple des infrastructures collectives (théâtres),nous avons choisi la réplication comme fonction de répartition :nous supposons que le fait d’exister apporte une utilité non di-visée à chaque habitant. Si maintenant le théâtre est trop petit,la fonction de répartition tend vers la division (tout le monde nepeut en profiter en même temps), avec des compromis possibles.
(faible), il sert juste à départager les ex-aequo.
Pour la méthode forte, la prise de décision
se déroule selon les phases suivantes :– On limite le problème aux agents les
plus prioritaires, et on cherche toutes lesdécisions maximisant la CUF.
– Si cet ensemble ne contient qu’un élé-ment, c’est la décision optimale (on netient pas compte des autres agents). Si-non, on restreint l’ensemble des déci-sions admissibles à cet ensemble dedécisions optimales pour la première
phase, et on maximise à nouveau laCUF, en incluant cette fois-ci les agentssitués au deuxième niveau de priorité.
– On raffine la sélection à chaque étapeen incluant les agents de priorité directe-ment inférieure, jusqu’à obtenir une dé-cision unique.
Pour la méthode faible, tous les agentscomptent dès la première phase :– On cherche toutes les décisions maximi-
sant la CUF avec tous les agents.– S’il reste des ex-aequo, on enlève lesagents les moins prioritaires, on limitel’ensemble des décisions admissibles àl’ensemble des décisions optimales pré-cédentes et on cherche à maximiser laCUF.
– On raffine la sélection à chaque étapeen excluant les agents de priorité laplus basse, jusqu’à obtenir une décisionunique.
La première méthode est pertinente uni-quement dans les problèmes pour lesquelsles premières phases laissent de nom-breuses décisions ex-aequo. L’exemple ty-pique de tels problèmes est un problèmede partage dans lequel les agents neconvoitent qu’une petite partie de la res-source : les agents les plus prioritairess’étant partagés la partie de la ressourcequ’ils convoitent, le reste de la ressource
leur est indifférent. La deuxième méthodeest pertinente dans les problèmes pourlesquels les préférences des agents sonttrès différentes, et pour lesquels il existeun certain nombre de décisions optimales
____________________________________________________________________________ Annales du LAMSADE N°8
59

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 72/415
qu’il est impossible de départager et quiavantagent toutes des agents différents.
On peut envisager des méthodes intermé-
diaires de décision entre ces deux procédésextrêmes. Nous proposons par exemple delimiter l’ensemble des décisions admis-sibles lors des premières phases, afin depermettre aux agents les moins prioritairesd’influer plus sur le processus de déci-sion. Dans le cadre du partage de ressourcecommune, cela peut se traduire par la li-mitation de la quantité de ressource dis-ponible pour le partage lors de la pre-
mière phase, et l’augmentation progressivedecettelimitejusqu’àpartagertoutelares-source lors de la dernière phase.
9 Conclusion
Cet article constitue le point de départd’une réflexion générale sur la prise encompte de droits exogènes inégaux. Nousavons proposé un cadre général pour bâ-tir des CUF prenant en compte des droitsexogènes inégaux. De plus, nous avonsintroduit un certain nombre de CUF àdroits inégaux, et caractérisé ces fonctionsà l’aide de propriétés nouvellement in-troduites. Nous avons en outre proposéquelques pistes pour la prise en comptede droits inégaux sous forme d’ordres depriorité. Il reste de nombreux travaux à ac-complir, notemment en ce qui concerne la
recherche de propriétés des CUF à droitsinégaux, du lien entre ces propriétés, et dela caractérisation des CUF à l’aide de cespropriétés. En outre, les pistes introduitesdans le domaine des droits inégaux ordi-naux restent entièrement à explorer.
Remerciements Nous remercions JérômeLang pour nos discussions communes sti-mulantes autour des problèmes de partage.
Références
[1] K.J. Arrow, A.K. Sen, and K. Suzu-mura, editors. Handbook of Social
Choice and Welfare, volume 1. El-sevier, 2002.
[2] M. L. Balinsky and H. Peyton Young.
Fair representation : meeting theideal of one man one vote. Broo-kings Institution Press, second edi-tion, 2001.
[3] S. J. Brams and A. D. Taylor. Fair Division : From Cake-cutting to Dis- pute Resolution. Cambridge Univer-sity Press, 1996.
[4] D. S. Felsenthal and M. Machover.The Measurement of Voting Power :
Theory and Practice, Problems and Paradoxes. Edward Elgar, 1998.
[5] M. Lemaître, Gérard Verfaillie, andNicolas Bataille. Exploiting a Com-mon Property Resource under a Fair-ness Constraint : a Case Study. InProc. of IJCAI-99, pages 206–211,Stockholm, Sweden, 1999.
[6] J.-L. Marichal. Aggregation Opera-
tors for Multicriteria Decision Aid .PhD thesis, Faculté des Sciences deLiège, 1999.
[7] H. Moulin. Axioms of Cooperative Decision Making. Cambridge Uni-versity Press, 1988.
[8] H. Moulin. Fair division and collec-tive welfare. MIT Press, 2003.
[9] J. Rawls. A Theory of justice. Belk-nap, 1971.
[10] A. Sen. Inequality Reexamined . Ox-ford University Press, 1995.
[11] R. Yager. On ordered weighted avera-ging aggregation operators in multi-criteria decision making. IEEE Tran-sactions on Systems, Man, and Cy-bernetics, 18 :183–190, 1988.
[12] H. P. Young. Equity in Theory and Practice. Princeton University Press,
1994.
Fonctions d'utilité collective avec droits exogènes inégaux ___________________________________________________________________________
60

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 73/415
Logique dynamique pour le raisonnement stratégiquedans les jeux extensifs
Cédric Dégremont
Jonathan A. Zvesper
Institute for Logic, Language and ComputationPlantage Muidergracht 24, 1018TV Amsterdam, Netherlands
Résumé :Cet article poursuit l’analyse logique modale dy-namique de la rationalité procédurale dans les jeuxproposée par van Benthem [5]. Nous modélisonsles jeux extensifs en utilisant une logique des préfé-
rences et proposons une analyse de processus ana-logue à l’induction à rebours. Ceci nous conduità distinguer deux types de rationalité : la rationa-lité de la décision et celle des préférences. A cesdeux types de rationalité correspondent des tran-formations de jeux, pour lesquels nous donnonsdes contreparties syntaxiques dans une logique mo-dale. Dans le modèle final auquel nous parvenonspar les transformations d’un jeu non générique, ilpeut subsister des chemins qui n’appartiennent àaucun équilibre parfait. Plus généralement la na-ture des solutions que notre approche peut induire
est incompatible avec la nature retrospective desconcepts de la théorie des jeux. Nous terminonspar quelques remarques sur l’utilité d’une telle ap-proche modale pour l’analyse des jeux en informa-tion imparfaite et en rationalité limitée.
Mots-clés : Jeux extensifs, rationalité, logique mo-dale, logique dynamique, induction à rebours
Abstract:This paper continues the dynamic modal logic ana-lysis provided by van Benthem [5] of proceduralrationality in games. Specifically we look at ex-
tensive games, and use preference logic to providea closer analysis of backward induction type al-gorithms. This results in distinguishing two kindsof rationality : decision rationality and preferencerationality. To these two kinds of rationality cor-respond game transformations, for which we givesyntactic counterparts in a modal logic. In the finalmodel arrived at through transformations of a non-generic game, there can be paths which are in nosubgame-perfect equilibrium. More generally thenature of solutions that our approach can induceis incompatible with the retrospective nature of theusual concepts of game theory. We end the paperwith some remarks on potential uses of such a mo-dal logic analysis to the cases of imperfect infor-mation or where rationality is bounded.
Keywords: Extensive games, rationality, modal lo-gic, dynamic logic, backward induction
Introduction
Les jeux extensifs représentent des si-tuations d’interaction dans lesquelles lesagents, ou joueurs, prennent des décisionsde manière séquentielle. Leur raisonne-ment stratégique, notamment à propos dela rationalité des autres joueurs, est unaspect important de l’étude de tels jeux.Nous proposons une analyse logique quiprend en charge la description des jeux ex-tensifs et la modélisation des actions cog-nitives effectuées par les joueurs lorsqu’ilsraisonnent stratégiquement.
Une importante littérature s’intéresse à lamodélisation des jeux en logique modale([13] pour une vue d’ensemble) et en par-ticulier des jeux extensifs [6]. Bonanno[10] est sans doute un des premiers à uti-liser la logique temporelle pour analyserles concepts de solutions des jeux exten-sifs, à l’instar de la logique epistemiquepour les jeux stratégiques ([24]; pour une
vue d’ensemble : [3]). Le concept d’équi-libre partfait en sous-jeux a notammentfait l’objet d’une analyse modale par Bo-nanno [10], qui identifie une partie d’un jeu extensif générique1 avec son seul équi-libre parfait. Plus récemment [12] a mon-tré comment on pouvait exprimer ce mêmeconcept, mais les outils utilisés ne sontspécifiquement modaux.
L’induction à rebours, introduite par [15],est probablement l’alogrithme de solu-tion le plus important pour l’analyse des jeux extensifs. Elle en identifie les équi-
1voir définition 2.
61

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 74/415
libres parfaits en sous-jeux selon un pro-cessus itératif, consistant à éliminer les ac-tions non-optimales des derniers joueursà agir, puis à éliminer en fonction celledes joueurs agissant juste avant, et ainside suite. van Benthem [5] explore l’ana-logie entre “élimination itérée” de partiedu jeu incompatible avec la rationalité des joueurs et restrictions de modèles épisté-miques par des annonces publiques, se fo-calisant en particulier sur les jeux straté-giques. [5] a notamment montré comment,en utilisant un concept de rationalité glo-bale, obtenir la solution de l’induction à re-
bours. Notre analyse poursuit l’explorationde l’analogie entre annonces publiques etconcept de solution de jeux extensifs.
Nous modifions légèrement cette dernièreperspective, en cherchant à définir unconcept de rationalité locale, naturelle-ment exprimable dans un langage mo-dale relativement simple2 capable d’expri-mer les préférences (cf. [8]) puis recher-
chant quels profils de stratégies peuventencore être construits à partir des seulesarêtes épargnées par l’élimination itéréedes états “irrationnels”, c’est-à-dire sup-posant que le dernier coup joué ne res-pectait pas le critère de rationalité choisi.La contribution conceptuelle principale dece papier est la distinction entre deux as-pects du raisonnement stratégique effectuépar les algorithmes de solution fonction-
nant selon un processus itératif tel que ce-lui de l’“induction à rebours”. Nous distin-guons entre la procédure d’élimination desétats localement irrationnels et la procé-dure par laquelle les préférences sont éten-dues de manière causalement cohérentedes noeuds terminaux vers la racine. Latransformation de modèles que [5] consi-dère prend la forme d’une annonce pu-blique qui réduit le modèle à une de sesparties. Ce que [10] définit statiquementdevient la partie du modèle résultant desannonces itérées. Nous analyserons l’éli-
2PDL avec intersection et converse mais sans test ni itéra-tion.
mination des états de la même façon, alorsque la généralisation des préférences àl’arbre supposera de rendre certains pointscomparables qui ne l’étaient pas préala-blement. De telles idées pour modéliser lechangement de préférences ont été notam-ment proposées par [4].
Dans §1, nous présentons les jeux exten-sifs finis en information parfaite commedes structures sur lesquelles il est natureld’interpréter un langage modal. Plus pré-cisément, nous définirons un langage quipeut exprimer des notions de rationalité
dans les jeux, comme nous le montronsdans §2. Nous définissons ensuite dans §3une logique modale dynamique avec uneexpressivité suffisante. Nous ne cherche-rons pas ici à fournir un système de preuvecomplet pour une telle logique, mais plu-tôt d’illustrer le pouvoir expressif du lan-gage relativement simple que nous présen-tons. Après avoir expliqué dans §4 quelstypes d’actions cognitives nous visons ici,
nous montrons comment le langage mo-dal dynamique permet d’exprimer celles-ci dans §5 (via la logique des annonces pu-bliques) et §6. Dans §7 nous suggéreronsquelques pistes pour étendre cette analyseaux jeux en information imparfaite et aucas des agents ayant des ressources cogni-tives limitées.
1 Structures modales
Dans cette section nous présentons les jeuxextensifs en information parfaite commedes structures sur lesquelles il est natureld’interpréter un langage modal. Nous dé-finissons un jeu G comme un tuplet de laforme
W,N,A, (i a→)a∈A,i∈N , (z
i )i∈N ,
où W est un ensemble fini non-vided’états, N est un ensemble fini de joueurs,
et A est un ensemble fini d’actions.i a→ ⊆
W × W pour chaque a ∈ A et i ∈ N définit les transitions possibles entre états :
Logique dynamique pour le raisonnement startégique [...] ___________________________________________________________________________
62

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 75/415
wi a→v signifie qu’à l’étatw, le joueur i peut
prendre l’action a pour arriver à l’état v.
Soita
→ = ∪i∈N i a
→,i
→ = ∪a∈Ai a
→ et →=∪i∈N
i→ pour chaque i ∈ N et a ∈ A. Soit
ρ(w) := i ∈ N |∃v ∈ W : wi→v
les contrôleurs de l’état w. Nous suppo-serons que les actions sont déterministeset qu’à chaque état un seul joueur joue,c’est-à-dire que si a = b ou i = j alors
(i a→ ∩
j b→) = ∅. Ceci implique que chaque
état a au plus un contrôleur.
zi exprime les préférences du joueur i.
Suivant la tradition en théorie des jeuxnous restreindrons dans un premier tempsles préférences sur les issues possibles, quicorrespondent dans notre présentation auxétats terminaux W z := w ∈ W |ρ(w) =∅, c’est-à-dire aux états sans contrôleur.Nous stipulons pour chaque i ∈ N quez
i ⊆ W z × W z est une relation bien fon-
dée, transitive et irréflexive. wz
i v signi-fiant que i préfère strictement l’état termi-nal w à l’état terminal v.
Il est immédiat de voir comment detelles structures correspondent à des jeuxextensifs en information parfaite. Dansl’exemple de jeu de la figure 1 (cf. [17]p. 96), nous avons étiqueté chaque noeudavec une lettre. Ces lettres r,s,t,u,v sontles états de nos modèles. Le jeu G cor-respondant à la figure 1 est le suivant :W = r,s,t,u,v ; N = I ,II ; A =
A,B,L,R ; rI A→s, r
I B→t, s
II L→ u, s
II R→ v ;
vzI t
zI u ; tz
II vzII u.
2 Aspects de la rationalité
Nous considérons que dans un jeu extensif,
quatre aspects distincts de la rationalité des joueurs importent au raisonnement straté-gique. Plus précisément, faire l’hypothèsede la rationalité des joueurs, c’est supposerque :
AB
L R
0, 0 2, 1
1, 2
r
st
u v
1
2
FIG . 1 – Un jeu extensif
1. les préférences des joueurs sont cohé-rentes, à la fois de manière statique
habituelle (à savoir elles sont suppo-sées être transitives et, dans leur ver-sion stricte, irreflexives.) mais aussi defaçon “causale” : les situations condui-sant à des situations préférées sontégalement préférées.
2. les joueurs choisissent toujours unedes options conduisant à une de leursissues préférées.
3. le raisonnement des joueurs est correct
- ils ne font pas d’erreurs - et completau sens où ils n’ont de limites compu-tationnelles en temps ou en espace.
4. les joueurs mettent à jour leurscroyances de façon rationnelle.
Dans l’interprétation déductive de la théo-rie des jeux et de ses concepts de solu-tion, les “joueurs cherchent à déduire lesactions rationnelles de leurs opposants àpartir des préférences de leurs opposantset de l’analyse du raisonnement de leursopposants à propos de leurs propres ac-tions rationnelles.”([16], p. 377). On pour-rait défendre l’idée que la procédure par la-quelle les joueurs éliminent de façon itéréeles parties du jeu incompatibles avec l’hy-pothèse de la rationalité des autres joueurspeut être vu comme un processus de ré-vision des croyances. Durant le proces-
sus de réduction du jeu, un joueur ré-vise sa représentation du jeu. A la suitede [5] nous défendons précisément l’idéeque ce processus peut être capturé dans lestyle dynamique epistemique (au sens de
____________________________________________________________________________ Annales du LAMSADE N°8
63

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 76/415
[11]). Néanmoins nous réservons la ques-tion de la révision des croyances aux jeuxen information imparfaite dans lesquels les joueurs peuvent avoir des ensembles d’in-formation différents et peuvent ainsi ne paspartager la même information au début du jeu.
Nous défendons l’idée que la rationalitédes agents couvre ces quatre aspects. Ladernière sorte de rationalité sera l’objetde recherche ultérieure. Pour le momentnous nous concentrerons sur les jeux eninformation parfaite. Nous considérerons
également pour commencer que les capa-cités cognitives ou computationnelles desagents sont illimitées. Enfin appelons lesdeux autre sortes de rationalité : “rationa-lité de la décision” et “rationalité des pré-férences”. Les agents prennent des déci-sion de façon cohérente avec des préfé-rences cohérentes.
Dans un premier temps la rationalité des
préférences se définira par une façon ca-nonique d’induire une relation de préfé-rence pour chaque joueur qui s’étend àl’ensemble des états contenus dans l’arbredu jeu, à partir des préférences sur les étatsterminaux. Une fois les préférences éten-dues à tous les états (plutôt qu’aux seulsétats terminaux) il devient facile de définirun langage modal dans lequel nous pou-vons exprimer certains aspects du raison-nement stratégique, et notamment le faitque la dernière action prise par un joueurait été une décision optimale. Nous décri-rons cette méthode canonique et recher-cherons comment nous pouvons définirune notion de rationalité de l’action, com-posée des deux aspects mentionnés. Plusprécisément nous montrerons comment larationalité de l’action réduit un jeu à son‘noyau rationnel’, de façon comparable àl’induction à rebours, bien que ne coïnci-
dant pas avec cette dernière.
Ainsi suivant [5] nous proposons uncadre dans lequel les actions cognitivesconstituant le raisonnement stratégique
des joueurs sont des citoyens de premièreclasse. A la suite de [5], nous explicitonsces actions dans le style des actions chan-geant le modèle de la logique des annoncespubliques [19]. Dans un premier tempsl’étape de raisonnement que nous consi-dérerons est l’élimination des états qui nepeuvent être atteints que si un joueur a agide façon irrationnelle.
La façon canonique et rationnelle d’in-duire les préférences, comme nous le no-tons dans §6 prend en charge une partie duraisonnement constituant la procédure de
réduction du jeu. Puisque que nous cher-chons à mettre au premier plan le raison-nement stratégique des joueurs, nous cher-cherons à rendre compte de l’action parlaquelle les préférences sont induites desnoeuds terminaux vers les autres dans unstyle dynamique de changement de mo-dèles.
3 Langage modal dynamique
Nous définissons un une logique dyna-mique dans l’esprit de [18]. Ainsi fixantun ensemble A d’actions et N de joueurs,nous définissons récursivement l’ensembledes actions ACT :
ACT ::= A | N | N | → | ACT ∪ACT |ACT ∩ACT |ACT c |ACT ;ACT,
A chaque action correspond une moda-lité dans le langage L. Nous supposons unensemble dénombrable de lettres proposi-tionnelles Φ :
L ::= | Φ | ¬L | L ∧ L | ACT L.
Nous utilisons les abréviations habituelles.Nous interprétons ce langage sur un jeu G de la forme
W,N,A, (i a→)a∈A,i∈N , (zi )i∈N
accompagné d’une valuation V : Φ →℘(W ). Comme nous l’avons mentionné,nous étendons la relation de préférences
Logique dynamique pour le raisonnement startégique [...] ___________________________________________________________________________
64

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 77/415
au-delà des noeuds terminaux. Nous défi-nissons pour chaque joueur i la nouvellerelation de préférence étendue à W × W inductivement comme la plus petite rela-tion contenant z
i et clos sous les règlessuivantes :
1. ((∃x : w → x) & ∀x (w → x ⇒xiv)) ⇒ wiv
2. ((∃x : w → x) & ∀x (w → x ⇒vix)) ⇒ viw
3. (∃x : (wi→x & xiv)) ⇒ wiv
Expliquons le processus d’induction despréférences. Fixons un joueur i. Nous
commençons par les états terminaux,c’est-à-dire avec i := zi . Puis
nous étendons la relation aux états non-terminaux. Dans la précondition de cha-cune des règles de clôture nous spécifions∃x : w → x, de telle sorte qu’elles nes’appliquent à un état w que si ce n’est
pas un point terminal. L’idée est de sélec-tionner deux états arbitraires w and v etde voir s’ils peuvent être comparés étant
données les préférences déjà explicites. Larègle 3 est la plus courte et sans doute laplus simple, elle énonce que si à un état wc’est à i de jouer et qu’une des actions quei peut accomplir en w le conduit à un étatqu’il (i) préfère à v, alors i préfère w à v.Les deux autre conditions sont très simi-laires, nous n’expliquons donc que la pre-mière. Elles s’appliquent même si ce n’estpas à i de jouer en w. Dans ce cas, la règle
énonce que i préféreraw à v si tous les suc-cesseurs possibles de w sont préférées à vpar i. Nous reviendrons à cette opérationd’induction des préférences §6.
Nous pouvons donc maintenant assigner àchaque action α ∈ ACT une relation Rα :
R→ = →Ra =
a→
Ri =i→
Ri = i
Rβ ∪γ = Rβ ∪ Rγ
Rβ ∩γ = Rβ ∩ Rγ
Rβ c = (v, w)|wRβ vRβ ;γ = (v, w)|∃x : vRxRw
Supposant une fonction de valuation V :Φ → ℘(W ), l’interprétation de L est stan-dard pour la logique modale :
w w p ssi w ∈ V ( p)w φ ∧ ψ ssi w φ et w ψw ¬φ ssi w φw αφ ssi ∃v : wRαv et v φ
4 Actions cognitives dans le rai-sonnement stratégique
Nous passons maintenant à la représen-tation du raisonnement stratégique des joueurs, amenant au premier plan lesétapes de ce raisonnement, que nous ap-pelons des “actions cognitives” (suivantplus ou moins le sens de [7]). Reprenantl’idée proposée pour la première fois par[5], nous utiliserons les ressources de la lo-gique des annonces publiques (PAL) pourmodéliser les actions cognitives. Une an-
nonce publique est une opération chan-geant le modèle, le restreignant à l’un deses sous-modèles. Une annonce publiqued’une formule φ assigne à un modèle Ml’un de ses sous-modèles M φ, dé-fini comme le modèle dont le domaine estl’ensemble des états w ∈ M tels queM, w φ, et dont les relations et valua-tions sont les restrictions correspondantesà celle de M à ce domaine. Syntactique-
ment, dans PAL il existe une modalité [!φ]pour chaque formule du langage en ques-tion, dont la sémantique est la suivante :
M, w [!φ]ψ ssi
(si M, w φ alors M φ,w ψ).
Selon l’interprétation déductive desconcepts de solution dans les jeux ex-tensifs, le raisonnement stratégique des
joueurs est le processus par lequel –dans un jeu joué une seule fois – les joueurs raisonnent au sujet des choix desautres joueurs sous l’hypothèse de leurrationalité. Ce raisonnement peut-être
____________________________________________________________________________ Annales du LAMSADE N°8
65

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 78/415
analysé et réduit à une série de pluspetites actions cognitives, qui peuventêtre conçues comme des annonces parlesquelles les noeuds du jeu qui sont in-compatibles avec la rationalité des joueurssont éliminés. Plus précisément, et telleest l’idée cruciale de [5], si I conclutque II ne choisira pas une certaine actionparce qu’elle est rationnelle, ceci peut êtrereprésenté comme une annonce publiquevéridique de la forme, “la joueuse II estrationnelle”. Puisque que nous supposonsque le processus de raisonnement dechaque joueur fait partie de la rationalité
même d’un joueur, nous supposons enfait que ce raisonnement est connaissancecommune entre les joueurs. En effet sile joueur I était le seul à faire ce rai-sonnement, nous devrions considérer lareprésentation que chaque joueur se faitdu jeu et le modèle résultant ne serait pasapproprié pour présenter le raisonnementcommun des joueurs au sujet du jeu. Pourrésumer, éliminer un point du modèle
revient à dire qu’aucun des joueurs nele considère plus. Il faudrait donc parlerd’une action cognitive commune, dontla légitimité repose sur la connaissancecommune de la rationalité des joueurs(dans les quatre sens mentionnés dans §2).
L’abandon de l’hypothèse d’un raison-nement commun doit avoir lieu lorsquenous acceptons non seulement l’informa-tion imparfaite (des ensembles d’informa-tion différents), mais si nous acceptons queles joueurs puissent ne pas savoir ce queles autres savent et ignorent. Dans ce cadreplus général, une analyse plus subtile desactions cognitives pourrait être proposée,permettant par exemple de modéliser le casoù un joueur accomplit une certaine étapedans son raisonnement mais n’est passêr que les autres l’ont accomplie aussi.Prendre en compte des types d’actions plus
complexes pourrait par exemple permettrede proposer une nouvelle analyse des jeuxde dé-synchronisation [1]. Mais nous lais-sons ces considérations à des recherchesfutures, pour lesquelles notre analyse des
jeux en information parfaite pourra fournirune fondation.
5 Rationalité de la décision etinduction à rebours
Nous nous intéressons maintenant à la par-tie du jeu stable sous l’annonce itérée derationalité. Plus précisément, nous nousintéressons aux chemins terminaux sur-vivant à l’annonce itérée de rationalité.On pourrait apprécier une définition de
la rationalité tels que les noeuds termi-naux accessibles après l’itération de l’an-nonce lui correspondant serait précisémentles équilibres parfait en sous-jeux du jeu.Mais plutôt que de chercher la notion mo-dale de rationalité correspondante, inver-sons la perspective et demandons : qu’est-ce qu’une notion modale naturelle de ra-tionalité, et (via son annonce itérée) quelconcept de solution induit-elle?
5.1 Quelle rationalité ?
De nombreux concepts de rationalitépeuvent être envisagés. Comme noussommes intéressés par les perspectives quela logique modale peut apporter à l’ana-lyse du raisonnement stratégique dans les jeux extensifs, nous sommes particulière-ment intéressés par la question suivante :
“Y a-t-il une manière naturelle-ment modale d’exprimer la ratio-nalité d’une décision ?”
Pour inspirer et motiver notre réponse àcette question, nous considérerons deuxslogans tirés de deux manuels, l’un de lo-gique modale, l’autre de théorie des jeux.
SLOGAN 1 (LOGIQUE MODALE) Leslangages modaux fournissent une pers-pective interne et locale sur les structuresrelationnelles.[9]
Logique dynamique pour le raisonnement startégique [...] ___________________________________________________________________________
66

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 79/415
Le second est proposé pour caractériserl’hypothèse crucial de la théorie du choixrationnel :
SLOGAN 2 (CHOIX RATIONNEL) Lorsqu’il prend une décision, un agent choisitune action qui est au moins aussi bonne,d’après ses préférences, que n’importequelle autre action disponible.[16], p. 6
Essayons de rendre le second slogan dansl’esprit du premier, c’est-à-dire en prenant
la rationalité dans un sens “local”, en re-streignant l’attention de la formule expri-mant la rationalité au dernier coup d’un joueur. L’avantage de cette notion localede rationalité est qu’elle autorise une ca-ractérisation modale simple. our la clartéde l’exposition, nous définissons la ratio-nalité de la décision comme la négationde l’ir rationalité de la décision. Un joueuri est considéré comme venant de prendreune décision irrationnelle au point w si icontrôle l’unique prédécesseur de w, di-sons v, et qu’en v, i pouvait prendre uneaction qu’il aurait emmené (en un seul pas)dansunétat u qu’il(i)préfèreàw. C’est-à-dire si i vient de faire quelque chose qu’onpourrait lui faire regretter à l’aide d’uneexplication très simple. C’est un conceptextrêmement locale d’irrationalité : dans le jeu présentée dans la figure 2, le joueur In’est irrationnel à aucun des points termi-
naux. Néanmoins, si pour commencer il vaà gauche, alors au noeud intermédiaire, ilest irrationnel.
I
II
2, 0 1, 0
3, 1
a b
L R
FIG . 2 – Un jeu illustrant la localité denotre notion d’irrationalité de la décision.
Cette localité suggère une limitation auraisonnement des joueurs, une questionque nous aborderons rapidement dans §7.
Nous pouvons définir la notion d’irrationa-lité de la décision de i avec la L-formulesuivante :
(ic; i) ∩ ic
La négation nous donne notre concept derationalité de la décision rati :
rati :=df [(ic; i) ∩ ic]⊥
rati peut être lu de la façon suivante iln’est pas possible ([]⊥) que i prenne uneaction (i) au point précédent (ic) et quecela le conduise (∩) à un état qu’il préfèreau point actuel (i
c).
5.2 Quel concept de solution ?
Une annonce de la rationalité d’un joueur
réduira (potentiellement) la taille du jeu,éliminant les états dans lequel un joueura joué de façon irrationnelle. Etant donnéla notion (c’est-à-dire l’ensemble d’opé-rations) d’induction des préférences quenous avons stipulées pour nos modèles;l’itération des annonces de la rationalité detous les joueurs peut conduire à une sériede réduction.
Par exemple, prenons le jeu donné par lafigure 1. Observons qu’en u, ratII n’estpas satisfait : il y a un état, à savoir v, telque uR(II c;II )∩II
cv. Après une annoncede ratII , nous obtenons le sous-jeu décritpar la figure 3.
Etant donné la façon dont les préférencessont stipulées dans nos modèles, il suit quele joueur I préfère désormais s à t. Dèslors une annonce de rationalité addition-
nelle, à savoir [!ratI ], et nous obtenons lesous-jeu décrit dans la figure 4.
Dans ce cas nous avons obtenu, via uneséquence d’annonces publiques, un jeu
____________________________________________________________________________ Annales du LAMSADE N°8
67

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 80/415
AB
1, 2
r
st
1
2
2, 1
R
v
FIG . 3 – Le jeu de la figure 1 après uneétape de réduction.
A
r
s
1
2
2, 1
R
v
FIG . 4 – Le jeu de la figure 1 après deuxréductions.
contenant comme unique chemin termi-nal le seul chemin terminal qui peut êtreconstruit en utilisant les actions contenuesdans l’unique équilibre parfait en sous- jeux de jeu original. En fait cette coïnci-dence ne se vérifie pas dans le cas général.Mais nous avons le résultat suivant :
PROPOSITION 1 . Un chemin maximaldans le jeu G survit à l’itération de l’an-
nonce de rationalité commune des joueurs(
i∈N rati) ssi il est composé d’arêtescontenues dans l’union des équilibres par-
faits en sous-jeux du jeu G .
Preuve. De gauche à droite, la preuve estpar induction sur la longueur du sous-jeudans lequel une action qui n’est contenuedans aucun équilibre parfait en sous-jeux
apparaît et par réduction à l’absurde.
DÉFINITION 2 Un jeu en information par-faite est générique si aucun joueur n’estindifférent entre deux noeuds terminaux,
c’est-à-dire si ∀i ∈ N ,∀w, w ∈ W z w =w → (wz
iw ∨ wz
iw).
FAIT 3 Un jeu générique ne contient qu’un seul équilibre parfait en sous-jeux.
DÉFINITION 4 ([5]) L’assertion de ratio-nalité momentanée (MR) énonce qu’àchaque étape d’une branche dans le mo-dèle actuel, celui qui doit jouer, n’a paschoisi une action dont toutes les continua-tions finissent plus mal pour lui que toutescelles suivant une autre action.
Nous obtenons comme corollaire le résul-tat suivant prouvé par [5].
COROLLAIRE 5 ([5]) Sur les arbres de jeux extensifs (en information parfaite) gé-nériques finis, l’annonce itérée de MRconduit exactement à la solution de l’in-duction à rebours.
Mais revenons au concept de solution quenous obtenons. On pourrait opposer qu’ils’agit là d’un concept de solution faible.En effet dans l’exemple de la figure 2,a, R n’est pas un équilibre parfaiten sous-jeux. Néanmoins ce profile de stra-tégie demeure dans notre procédure. Nousdéfendons l’idée que le concept d’équi-libre parfait en sous-jeux (comme plusgénéralement celui d’équilibre de Nash)est rétrospectif par nature. Un tel conceptnous indique que si la stratégie de II en sest de jouer R, alors le joueur I s’en serait mieux sorti s’il avait choisi b. Le conceptde solution que nous obtenons fonctionnelui de façon prospective et prescriptive.En ce sens une prescription répond à cer-taines contraintes de cohérence. Vous pou-vez également dire à I qu’il doit jouerb et ne pas jouer a, vous obtiendriez un
concept de solution tout aussi prescriptif mais plus fort, à savoir la maximisation duminimum. Mais si vous admettez l’actiona comme une chose que I pourrait ration-nellement faire, alors la cohérence de la
Logique dynamique pour le raisonnement startégique [...] ___________________________________________________________________________
68

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 81/415
prescription ne permet de traiter l’issue tcomme irrationnelle.
Il est à noter que cette situation est plus gé-nérale. Dès que nous sortons des jeux gé-nériques pour traiter le cas des jeux exten-sifs en information parfaite, aucun conceptde solution qui n’est pas clos sous les fu-turs rationnels ne peut être modélisé parune annonce itérée de rationalité. Plus pré-cisément si un concept de solution quin’admet pas tous les profils de stratégiesqui peuvent être construits sur la base deschemins maximaux survivant à l’itération
de l’annonce de rationalité, alors celui-cin’est pas exprimable avec l’appareil mo-dale dynamique que nous proposons. Enparticulier nous ne pouvons pas obtenirdans le cas général la solution de l’induc-tion à rebours.
Comme nous l’avons déjà mentionné, unebonne partie de ce résultat est secrète-ment encodé dans notre définition de la
façon dont les préférences sont induitesdes noeuds terminaux vers les autres. Etantdonné que notre objectif est d’expliciterles actions cognitives composant le raison-nement stratégique des agents, il est rai-sonnable de demander que ce type d’ac-tion cognitive, rendant nos préférencescausalement cohérente, soit modélisé parune action dans une logique dynamique, àl’instar de ce que nous avons fait pour larationalité de la décision. Ce que nous fai-sons dans la section suivante.
6 Préférences
Notre procédure de réduction du jeu à sonnoyau rationnel, telle que nous l’avons dé-crite, tire profit de ce que nous avons dé-crit comme la rationalité des préférences.Ainsi un aspect du processus de raison-
nement est effectuée en silence par lescontraintes qui définissent les relations depréférences généralisées à l’arbre. Ceci nerend pas justice à ce processus autonomecomme étant d’égale importance pour iso-
ler la solution du jeu. Nous altérons doncla sémantique et prenons une perspec-tive plus générale, abandonnant l’hypo-thèse selon laquelle les préférences sontautomatiquement induites de façon cano-nique à chaque fois que nous passons d’unmodèle à une de ses parties.
Nous n’irons pas ici jusqu’à considérerdes préférences qui ne sont pas “nettes”(cf. [17] p. 4) : nous n’autorisons pas l’im-précision des préférences, ni préférencesintransitives ou symétriques. Nous sup-posons des joueurs dont les préférences
sont “statiquement” cohérentes. Mais nousabandonnons ici l’idée que les préférencessont automatiquement spécifiées sur toutl’arbre afin de mettre en avant le proces-sus de raisonnement par lequel les joueurs- en analysant la structure du jeu - peuventdécider quelles options intermédiaires sontpréférables, étant donné leurs préférencessur des noeuds plus proche de l’issuedu jeu. Ce processus doit conduire à des
préférences “causalement” cohérentes. Ils’agit par exemple d’exclure comme ir-rationnel qu’un joueur d’échecs préfèreprendre la reine de son adversaire (à unautre coup), alors que cela le conduit à unnoeud duquel son adversaire possède unestratégie de victoire.
Un modèle sera dotée d’une relation i quiavant toute action cognitive ne sera pas dif-férente de z
i , exactement comme les mo-dèles traditionnels de la théorie des jeux.
Pour chaque propriété P que nous uti-lisons pour définir i et chaque joueuri ∈ N nous considérons une action “ra-tionalisant les préférences” du joueur id’une certaine façon, comme une opé-ration OP
i de (W × W )n vers W ×W . Soit OQ
I l’opération correspondantà ((∃x : w → x) ∧ ∀x (w →x ⇒ xI v)) ⇒ wI v. Par abusde langage nous écrirons OQ
I (M) pour
W,N,A, (i a→)a∈A,i∈N ,I ∪ (w, v) ∈
W × W : ∃x ∈ W ((w → x) ∧ ∀x ∈
____________________________________________________________________________ Annales du LAMSADE N°8
69

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 82/415
W (w → x ⇒ xI v)), (i)i∈N −I .Intuitivement une telle opération rendracomparables de noeuds de l’arbre entrelesquels un joueur était préalablement in-différent, selon des maximes du type “pré-fère les moyens qui te mènent à tes fins”.
Dans notre cas, l’ordre dans lequel nousappelons les différentes opérations de ra-tionalisation des préférences est sans im-portance. Pour simplifier définissons doncune opération unique pour toutes les opé-rations et tous les joueurs que nous notonsRP .
REMARQUE 6 L’axiome de ré-duction suivant donne la clé den’analyse compositionnelle dansla syntaxe de l’opération RP :
[ratPref i]iφ ≡(i[ratPref i]φ ∨
(→ ∧ [→]i[ratPref i]φ) ∨i([i
c ∩ (→c; →)]⊥ ∧ →c
[ratPref i]φ)
∨ i; i[ratPref i]φ)La formule est correcte par rapport à laclause sémantique suivante :
G , V ,w [ratPref ]φ ⇔ RP (G ), V ,w φ
où [ratPref ]φ :=
i∈N [ratPref i]φ
Cette remarque est rendue naturelle par lefait que le premier disjoint corresponde àla relation initiale alors que chacune desautres clauses correspond à une des règlesque nous utilisons pour définir i à partirde z
i dans §3.
Afin de voir que ces deux actions cogni-tives (l’une rationalisant les préférences,l’autre les décisions) peuvent cohabiter,l’ordre d’application de ces deux actionsne doit pas importer (ce qui pourrait être le
cas si nous avions choisi les versions “fai-bles” de nos opérations). De ce fait suit laversion explicite de notre précédente pro-position. Définissant RD := M → M
i∈N rati, nous obtenons :
PROPOSITION 7 . Un chemin maximaldans le jeu G survit à l’application itéréedes opérateurs RP et RD ssi il est com-
posé d’arêtes contenues dans l’union deséquilibres parfaits en sous-jeux du jeu G .
Enfin, il serait conceptuellement plus cor-rect de voir ces opérations comme la miseen oeuvre de normes de rationalité plu-tôt - comme le parallèle avec les an-nonces publiques pourrait le suggérer -que comme l’action de révéler que les joueurs sont rationnels. Elles conseillent
aux joueurs d’éviter certaines décisions, demême ces normes indiquent quels états in-termédiaires les joueurs devraient préféreratteindre. La mise en oeuvre de ces normesde rationalité est précisément ce qu’effec-tuent les actions cognitives qui constituentle raisonnement stratégique.
Une approche plus générale consisterait àlibéraliser les préférences des joueurs, au-torisant des incohérences “causales”. Au-torisant par exemple qu’un joueur i pré-fère touts les successeurs de s à ceux det mais préfère t à s. Néanmoins le pro-cessus de rationalisation ne serait plus unesimple expansion et nous ferions face àdifférentes façons de rationaliser ces préfé-rences. Donner la priorité aux préférencesentre noeuds plus proches des noeuds ter-minaux pourrait permettre d’obtenir unconcept de solution ayant un comporte-
ment régulier, mais nous laissons cettequestion à d’autres recherches.
7 Information imparfaite et ra-tionalité limitée
Nous nous sommes concentrés sur les ac-tions cognitives, car il est clair qu’ellestransforment la représentation que les
joueurs se font du jeu. Parfois toute l’infor-mation n’est pas disponible au début du jeupour tous les joueurs. Une lecture (équi-valente à la lecture classique) des jeux eninformation imparfaite repose dans l’idée
Logique dynamique pour le raisonnement startégique [...] ___________________________________________________________________________
70

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 83/415
qu’il faut parfois attendre que le jeu soit joué pour obtenir certaines informationsprécieuses. Prenons l’exemple de la figure5. Dans ce jeu, le joueur II peut élimi-
N
I I
IIII
II II
1, 1 1,−1 −1,−1 −1, 1
−1, 1 1,−1 1, 1
call call
call
call call
call put put
putput
put put
lower
−1,−1
raise
FIG . 5 – Un jeu en information imparfaite.
ner certains états irrationnels, voire figure6. Néanmoins jusqu’à ce que I joue, le
N
I I
II
II
1, 1 1,−1
1,−1 1, 1
call
call
call put
put
put
lowerraise
FIG . 6 – Le jeu de la figure 5 après uneannonce de rationalité
joueur II ne peut plus réduire l’arbre du jeu et fixer une stratégie. Nous interpré-tons les jeux en information imparfaite etincomplète comme des jeux dans lesquelsl’information fournie par les actions ef-fectives des joueurs n’est pas redondante.Nous pouvons étendre l’interprétation des
actions cognitives constituant le raisonne-ment stratégique en termes d’actions dy-namiques changeant le modèle. Généra-lisant le processus par lequel l’informa-tion est pris en compte par les joueurs
dans la représentation du jeu, de nouvellesquestions apparaissent : quelle informationpeut révéler les préférences d’un joueur,le joueur i a-t-il une stratégie rationnellequi ne révèle pas l’information qu’il pos-sède, etc. Néanmoins cette lecture d’un jeuen information imparfaite est équivalenteà celle utilisant des stratégies condition-nelles. Son principale intérêt est d’intro-duire l’idée que la temporalité des actionscognitives et des actions en général est lamême, même si, ayant à faire à des agentsidéaux, on peut aussi bien considérer lesstratégies comme définies préalablement à
toute action effective.Or l’économie et la théorie des jeuxclassiques supposent habituellement desagents ou des joueurs ayant des capacitéscognitives (ou computationnelles) illimi-tées. Il serait d’ailleurs plus exact de direque ces théories ne supposent rien du tout,puisque le calcul n’y est même pas consi-déré comme un processus consommant des
ressources. Sur le plan descriptif, les théo-ries prédisent des résultats contredits parl’expérience3. Sur le plan normatif, lesprescriptions correspondantes peuvent trèsbien se révéler largement sous-optimales.Suivant le travail fondateur de Simon [22]nous proposons de chercher une théorieplus exacte de “la façon dont les vrais êtreshumains prennent de vraies décisions dansun monde qui leur fournit rarement lesdonnées et les ressources cognitives quiseraient exigées pour appliquer, littérale-ment, les théories des manuels” [23], c’est-à-dire les théories qui ne prennent pas leprocessus de raisonnement au sérieux ou lefait que les agents aient des capacités cog-nitives limitées.
Analysant les jeux en information parfaite,nous avons nous aussi supposé que le rai-sonnement était mené à bien une fois pour
toutes, isolant les profiles de stratégies res-3Ainsi l’unique équilibre parfait en sous-jeux du dilemme
des prisonniers répété de façon finie, à savoir trahir l’autre àchaque tour, est fortement invalidée par le comportement dessujets expérimentaux (cf. e.g.[2]).
____________________________________________________________________________ Annales du LAMSADE N°8
71

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 84/415
pectant certaines contraintes de rationa-lité. Une fois ce raisonnement achevé lesagents agiraient en suivant un des che-mins terminaux restants. Mais il est clairque les agents réels ne procèdent pas ainsi(cf. [20]) : déjà dans l’Antiquité, Aristotesoulignait le fait que la délibération ne doitpas durer indéfiniment. Plus concrètement,imaginez que vous êtes devant une carte dumétro parisien à Châtelet essayant de cal-culer la façon la plus rapide de parvenir à
La rue de Tanger . Comme vous êtes déjàen retard, votre fonction d’utilité est don-née par u(t) = −(ttanger − t0)2. Il est hau-
tement improbable4 que vous vous en sor-tiriez mieux en commençant par calculerl’itinéraire optimal et commenciez seule-ment ensuite à vous déplacer. Tout cecipour indiquer que le temps de la réflexion,pendant lequel vous exécutez des actionscognitives, et le temps de l’action, pendantlequel vous agissez est bien le même.
Tout ceci était folklorique. Mais qu’est-ce
que la logique modale peut avoir à dire ausujet de la prise de décision en rationalitélimitée? D’autres réponses visent les lo-giques épistémiques [21] ou les logiquesde l’action [14]. Or, revenons à nos opéra-tions RD et RP ; nous avons pour le mo-ment admis que les agents pouvait itérerl’exécution de l’une des deux opérationssans limite avant d’agir. Autrement dit lesagents peuvent exécuter (RD ∪ RP )n où
n ∈ ω, R
1
:= R,Ri+1
:= R
i
; R, avantde prendre la moindre décision. Intégrer lalimitation cognitive en termes de temps al-loué au calcul entre chaque décision pour-rait en première approche être capturé endisant que dans la clause précédente, n nepeux pas dépasser un k certain fini, indicedes capacité cognitives de l’agent. N’im-porte quelle action survivant à toutes lescompositions de k opérations de rationali-sation serait acceptable selon le concept desolution correspondant.
4Même en faisant l’hypothèse que vous connaissez le tempsque vous aurez encore à marcher à partir des différentes stationsd’arrivée, le temps que le métro met pour parcourir une intersta-tion etc.
Il ne s’agirait pas d’isoler un sous-ensemble ou un super-ensemble des équi-libres classiques, mais à analyser l’im-pact de la limitation des ressources (entermes d’actions cognitives exécutablesentre chaque tour) sur les concepts de solu-tions. Bien entendu la complexité des dif-férentes opérations doit être analysée, pon-dérant ainsi le nombre de ressource queson exécution requiert. Il serait même en-core mieux, d’intégrer, par exemple dansun langage épistémique, les pas effectifsque requiert l’opération (vérification, sto-ckage, déduction). Par la suite il serait
intéressant de comparer les performancesde ces différentes sous-opérations cogni-tives sur différentes classes de jeux bienconnues de la littérature.
8 Conclusion
Nous avons présenté une logique modalepour raisonner sur les jeux extensifs non-coopératifs. Nous utilisons les modalitéscorrespondant aux relations de préférenceset aux actions pour caractériser ce quenous appelons la rationalité de la déci-sion. Nous avons également discuté la ra-tionalité des préférences et avons mon-tré comment ces deux notions sont liées.Nous avons également montré commentdes opérations des logiques modales dy-namiques peuvent être utilisés pour modé-liser les actions cognitives constituant leraisonnement stratégique. Nous avons vuque cette approche conduit à des conceptsde solution d’une nature plus “prospecti-ve” que ceux la littérature principale enthéorie des jeux. Nous avons égalementsuggéré qu’une notion moins globale d’ac-tion cognitive pourrait permettre d’aborder
la question de concepts de solutions pourdes agents cognitivement limitées, suggé-rant un nouveau rapprochement entre la lo-gique modale et la théorie des jeux en ra-tionalité limitée.
Logique dynamique pour le raisonnement startégique [...] ___________________________________________________________________________
72

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 85/415
Références
[1] W Brian Arthur. Inductive rea-soning and bounded rationality.
Amer. Econ. Rev., 84(2) :406–11,1994.[2] Robert Axelrod. The Evolution of
Cooperation. Basic Books, 1985.[3] Pierpaolo Battigalli and Giacomo
Bonanno. Recent results on belief,knowledge and the epistemic founda-tions of game theory. Research in
Economics, 53 :149–225, 1999.
[4] J. van Benthem and F. Liu. Dynamiclogic of preference upgrade. To ap-pear in the Journal of Applied Non-Classical Logic, 2007.
[5] Johan van Benthem. Rational dyna-mics and epistemic logic in games.to appear in International Journal of Game Theory.
[6] Johan van Benthem. Extensivegames as process models. JoLLI ,
11(3) :289–313, 2002.[7] Johan van Benthem. Cognition as in-
teraction. ILLC , PP-2005-10, 2005.[8] Johan van Benthem, Sieuwert van
Otterloo, and Olivier Roy. Prefe-rence logic, conditionals, and solu-tion concepts in games. ILLC , PP-2005(28), 2005.
[9] Patrick Blackburn, Maarten de Rijke,
and Yde Venema. Modal Logic.Cambridge, 2001.[10] Giacomo Bonanno. Branching time,
perfect information games, and back-ward induction. Games and Econo-mic Behavior , 36 :57–73, 2001.
[11] H. P. van Ditmarsch, W. van derHoek, and B. P. Kooi. Playingcards with Hintikka : An introduc-tion to dynamic epistemic logic. Aus-
tral. Journ. of Logic, 3 :108–134,2005.[12] Paul Harrenstein, John-Jules Meyer,
Wiebe van der Hoek, and Cees Wit-teveen. A modal characterization of
Nash equilibrium. Fundamenta In- formaticae, 57(2-4) :281–321, 2003.
[13] Wiebe van der Hoek and Marc Pauly.
Modal logic for games and informa-tion. In Patrick Blackburn, Johan vanBenthem, and Frank Wolter, editors,The Handbook of Modal Logic. Else-vier, 2006.
[14] Zhisheng Huang, Michael Masuch,and László Pólos. ALX, an actionlogic for agents with bounded ratio-nality. Artificial Intelligence, 82 :75–127, 1996.
[15] John von Neumann and Oskar Mor-genstern. Theory of Games and Eco-nomic Behavior . Princeton, 1944.
[16] Martin J. Osborne. An Introductionto Game Theory. Oxford, 2004.
[17] Martin J. Osborne and Ariel Rubin-stein. A Course in Game Theory.MIT Press, 1994.
[18] Solomon Passy and Tinko Tinchev.An essay in combinatory dynamiclogic. Information and Control,93(2) :263–332, 1991.
[19] Jan A. Plaza. Logics of publiccommunications. In M. L. Emrich,M. S. Pfeifer, M. Hadzikadic, andZ. W. Ras, editors, Proceedings of the4th International Symposium on Me-thodologies for Intelligent Systems,pages 201–216, 1989.
[20] John L. Pollock. Rational decision-making in resource-bounded agents.[21] Ariel Rubinstein. Modeling Bounded
Rationality. MIT Press, 1997.[22] Herbert Simon. Theories of decision-
making in economics and behavioralscience. Amer. Econ. Rev., 49 :253–283, 1959.
[23] Herbert Simon. Theories of Boun-ded Rationality vol. 3 : Empirically
Grounded Economy. 1997.[24] Robert Stalnaker. On the evaluation
of solution concepts. Theory and De-cision, 37 :49–73, 1994.
____________________________________________________________________________ Annales du LAMSADE N°8
73

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 86/415

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 87/415
Rôle de la Face et de l’Utilité dans l’Interprétation d’ÉnoncésAmbigus Question/Requête Incompréhension/Désaccord
V. Demeure
J.F. Bonnefon
É. Raufaste
Université de ToulouseCLEE (Cognition, Langues, Langage et ergonomie); UTM, EPHE, CNRS;
Maison de la recherche, Université de Toulouse le Mirail,5 allée Antonio Machado, 31058 Toulouse cedex 9, FRANCE
Résumé :De nombreux énoncés présentent une ambiguité ence qu’ils peuvent être interprétés différement selonque l’on choisisse leur signification directe ou in-directe. Nous nous penchons ici sur l’interprétationde deux de ces types d’énoncés : les énoncés pou-vant être interprétés comme (a) des questions di-rectes ou des requêtes indirectes (e.g., “Est-ce qu’ilreste du café?”) et (b) des demandes de précisionindirectes ou des désaccords indirects (e.g., “J’aipeur de ne pas vous suivre.”) Les prédictions dedeux approches de l’interprétation d’énoncés am-bigus sont ici combinées et testées : (a) l’approcheGestion de la Face qui étudie plus particulièrementle rôle des variables interpersonelles telles que le
statut, la distance affective ou la perte de face po-tentielle; et (b) l’approche Utilitariste centrée surles buts poursuivis par le locuteur au moment del’énonciation. Nos résultats soutiennent les prédic-tions, jusque là non testées, de l’approche Utili-tariste et offrent de nouvelles perspectives à l’ap-proche Gestion de la Face.
Mots-clés : Énoncés ambigus, utilité, politesse
Abstract:Many statements are ambiguous in that sensethat they can be interpreted differently as a func-tion of whether one considers their direct mea-ning or their indirect meaning(s). In this article,we examine two of these ambiguities : The di-rect question/indirect request ambiguity (e.g., “Isthere any coffee left?”); and the indirect disa-greement/indirect request for explanation ambi-guity (e.g., “I don’t follow you”). We combineand test predictions of two approaches of the in-terpretation of such ambiguities—the Face Mana-gement approach, which focuses on interpersonalvariables such as status, affective distance or po-
tential face threat; and the Utilitarian Relevanceapproach, which focuses on the speaker’s goal atthe time of the enunciation. Results wholly sup-port the untested predictions of the Utilitarian Rele-vance approach, and offer new perspectives on theFace Management approach.
Keywords: Ambigus statement, utility, politeness
En tant que locuteur, nous n’exprimons pastoujours directement ce que nous voulonsdire. Autrement dit, il y a parfois un déca-lage entre notre intention communicativeet le sens littéral de la phrase que nouschoisissons d’énoncer (c.a.d. une indirec-tion). Face à ce type d’énoncés que nousqualifierons d’ambigus, comment le desti-nataire parvient-il à interpréter ce que nousavons voulu dire? Dans la première par-tie de ce travail nous présenterons les ré-ponses qui ont été apportées, jusqu’à au- jourd’hui, à cette question. Nous verronsque parallèlement à l’approche Gestion dela Face, plusieurs approches basées sur lanotion de pertinence ont été développées.Nous examinerons ensuite l’interprétationde deux types d’énoncés ambigus : a) untype d’énoncé pouvant être interprété soitcomme une question directe soit commeune requête indirecte (expériences 1 et 2)
et b) un type d’énoncé pouvant être in-terprété soit comme une demande d’ex-plication indirecte soit comme un désac-cord indirect (expériences 3 et 4) en tes-tant conjointement les prédictions des ap-proches de Gestion de la Face et de Perti-nence Utilitariste.
1 L’Approche Gestion de la
FaceUne approche générale de l’interprétationd’énoncés ambigus consiste à assumer queles facteurs jouant un rôle dans la produc-
75

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 88/415
tion de ce type d’énoncés sont les mêmesque ceux intervenant dans leur interpréta-tion [6]. Commençons alors par nous pen-cher sur les facteurs pouvant conduire à laproduction d’énoncés ambigus.
La Théorie de la Politesse [1] développel’idée selon laquelle un locuteur, durantune conversation, tente de préserver la facede son auditeur. Préserver la face de quel-qu’un implique de (a) le laisser libre deses actions (préservation de la face néga-tive); et (b) lui donner l’image de quel-qu’un d’apprécié et d’approuvé par les
autres (préservation de la face positive)[3]. Il n’est toutefois pas toujours possiblepour le locuteur d’éviter de menacer laface de l’auditeur. Il peut par exemple de-voir faire une requête menaçant ainsi laface négative de l’auditeur. Il peut égale-ment être en désaccord avec ce que viensde dire son interlocuteur, et donc menacersa face positive. Dans ces cas là, le locu-teur tentera de limiter au maximum la me-
nace de face au moyen de différentes stra-tégies de politesse. Nous nous intéresse-rons ici à la stratégie jugée comme la pluspolie de toutes [1] : l’indirection. Elle per-metderéduirelamenacedefaceencesensqu’elle laisse à l’auditeur le choix de l’in-terprétation. Prenons l’exemple d’une per-sonne voulant que son interlocuteur ouvreune fenêtre. En disant “Vous ne trouvezpas qu’il fait chaud ici?” au lieu de “Ou-vrez la fenêtre”, il laisse l’auditeur libred’interpréter l’énoncé comme une simpleremarque sur la température ou une re-quête indirecte, protégeant ainsi sa facenégative en préservant sa liberté d’action.De même, l’indirection permet de préser-ver la face positive du locuteur. Prenonsl’exemple du désaccord qui constitue unemenace pour la face positive. Si quelqu’unsouhaite exprimer son désaccord avec laconclusion des travaux que vous venez de
présenter, vous lui serez sans doute recon-naissant s’il annonce “J’ai peur de ne pasvous suivre” plutôt que “Je ne suis abso-lument pas d’accord avec vous!”. En ef-fet, il vous laisse ainsi l’opportunité (ainsi
qu’au reste de l’assemblée) d’interpréterl’énoncé comme une demande d’explica-tion (je crois que je n’ai pas très bien com-pris ce que vous vouliez dire, pouvez vousexpliquer votre idée?), beaucoup moinsmenaçante pour votre face positive.
Maintenant que nous nous sommes pen-chés sur les motivations qui peuvent pous-ser un locuteur à utiliser l’indirection, in-téressons nous plus précisement à la façondont un auditeur interprétera un tel énoncé.
La conception de l’indirection comme
stratégie de préservation de la face a unimpact direct sur l’interprétation d’énon-cés ambigus. En effet, étant tour à tourlocuteur et auditeur, chaque individu estamené à utiliser les stratégies de politesseet donc l’indirection. En position d’audi-teur, un individu sait donc que si le locu-teur émet un énoncé ambigu, c’est très cer-tainement parce qu’il veut lui transmettrequelque chose de menaçant. Ainsi, l’audi-
teur cherchera l’interprétation de l’énoncéla plus menaçante pour sa propre face dansle contexte de la conversation. L’étude me-née par [8] teste cette hypothèse en pré-sentant aux participants de courts échangescomprenant une question et une réponsene répondant pas explicitement à la ques-tion (e.g., Question : Qu’as-tu pensé de maprésentation ? Réponse : “C’est difficile defaire une bonne présentation”). Les résul-tats montrent clairement que les partici-pants jugent qu’une telle réponse véhiculeun sens menaçant pour la face du destina-taire.
En plus de cette tendance générale, troisfacteurs relatifs au contexte d’énonciationont été identifiés comme pouvant accen-tuer cette propension à aller vers l’interpré-tation la plus menaçante [1] : la Distancesociale entre le locuteur et l’auditeur (D),
le Pouvoir relatif de l’auditeur sur le locu-teur (P), et le niveau (Rang) de menace del’acte d’un point de vue culturel (R). Nousavons choisi de nous inspirer de ces va-riables en leur apportant toutefois certaines
Rôle de la face et de l'utilité dans l'interprétation d'énoncés ambigus [...] ___________________________________________________________________________
76

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 89/415
modifications présentées ci-dessous.
1.1 Le pouvoir relatif de l’auditeur sur
le locuteur
La question qui se pose ici est la suivante :un auditeur interprétera-t-il un énoncé dela même façon si il est produit par un locu-teur ayant le même statut/pouvoir que lui,et si le locuteur a un statut/pouvoir plusbas?
Toutes choses égales par ailleurs, un locu-
teur doit être plus poli lorsqu’il s’adresseà un auditeur ayant plus de pouvoir quelui [1]. Selon la théorie de la politesse, unénoncé indirect émis par un locuteur debas statut devrait être interprété commevéhiculant un sens plus menaçant lorsquele locuteur à un statut élevé que lorsqu’ila un statut égal à celui de l’auditeur. Plusprécisement, nous faisons l’hypothèse que,lorsque l’auditeur a un statut supérieur à
celui du locuteur, un énoncé ambigu seraplus interprété :(a) comme une requête dans le casd’énoncés ambigus Question/Requêteet (b)comme un désaccord dans le casd’énoncés ambigus Incompréhension/ Désaccord.
1.2 La personnalité de l’auditeur
Nous adaptons ici la variable R de [1].Cette étude n’ayant pas de visée intercul-turelle, nous avons choisi de nous pen-cher sur les différences individuelles plu-tôt que culturelles. Plus précisément, nousnous demandons si un même énoncé am-bigu sera interprété de la même façon lors-qu’il est adressé à un auditeur ouvert d’es-prit et à l’écoute des autres, et lorsqu’il estadressé à un auditeur très susceptible qui
aime imposer son point de vue.
Nous faisons l’hypothèse qu’un énoncéambigu Question/Requête sera plus sou-vent interprété comme une requête lorsque
l’auditeur est très susceptible et aime im-poser son point de vue, que lorsqu’il estouvert d’esprit et à l’écoute des autres1.
1.3 La distance affective entre l’audi-teur et le locuteur
La théorie de la politesse postule que lanécessité d’être poli augmente avec la dis-tance entre les interlocuteurs. Elle ne dis-tingue toutefois pas la distance sociale (lesinterlocuteurs se connaissent-ils ou non ?)et la distance affective (les interlocuteurss’apprécient-ils ou non ?). Cette confusionest probablement l’explication des résul-tats mitigés dégagés des différentes étudestestant cette variable (voir [12] pour unediscussion à ce sujet).
L’étude de [11] fournit des résultats plus
clairs concernant l’impact de la dis-tance affective sur l’interprétation d’énon-cés ambigus. Manipulant indépendam-ment les distances sociale et affectives,[11] montrent que les participants tendentà interpréter de façon plus menaçante unénoncé ambigu lorsqu’il est destiné à unauditeur que le locuteur n’aime pas. Enparticulier, lorsqu’un énoncé peut être in-terprété littéralement comme un compli-ment, et indirectement comme un sar-casme, les participants tendent à l’interpré-ter indirectement si les interlocuteurs nes’aiment pas.
Nous faisons donc l’hypothèse qu’unénoncé ambigu Incompréhension/ Désac-cord sera plus interprété comme un désac-cord lorsque le locuteur et l’auditeur nes’apprécient pas2.
1La prédiction serait la même pour l’ambiguité Incompré-hension/Désaccord mais ne sera pas testée ici.
2La prédiction serait la même pour l’ambiguité Ques-tion/Requête mais ne sera pas testée ici.
____________________________________________________________________________ Annales du LAMSADE N°8
77

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 90/415
2 La reformulation Utilitaristede la Pertinence
À la suite de l’approche Gricéenne [4] dontl’assomption cruciale pour l’interprétationd’énoncés ambigus (l’interprétation indi-recte d’un énoncé n’est construite que dansles cas où l’interprétation littérale est ju-gée insatisfaisante), n’a pas été soutenueexpérimentalement de façon concluante[2], l’approche post-Gricéenne [13] qui re-groupe les différents aspects du Principede Coopération sous le principe central de
Pertinence, s’applique avec succès dans denombreuses situations de communication.Toutefois, centrée essentiellement sur laquantité d’information que l’auditeur peuttirer de l’interprétation de l’énoncé, cetteapproche nous semble plus à même de trai-ter de l’interprétation de réponses que del’interprétation de questions ou d’incom-préhension. De la même façon, caractéri-ser une requête ou un désaccord en consi-
dérant uniquement la quantité d’informa-tion qu’elle/il pourrait apporter à l’auditeursemble inapproprié. Ce qui semble cru-cial dans l’interprétation d’une requête oud’un désaccord est en lien avec les intérêts,les motivations du locuteur plutôt qu’avecl’état des connaissances de l’auditeur. Unerécente évolution de la théorie de la Perti-nence [14] amorce l’idée selon laquelle ilest important que l’auditeur garde à l’es-prit que le locuteur ne peut pas vouloir si-gnifier quelque chose qui va à l’encontrede ses préférences. La reformulation utili-tariste de la pertinence va plus loin en pos-tulant que ce sont les buts et préférencesdu locuteur qui guident l’interprétation.
Plusieurs reformulations utilitariste de lapertinence ont récemment émergé de ma-nière indépendante chez plusieurs auteurs.Toutes ces approches ont en commun le
fait qu’elles définissent la pertinence d’unénoncé en fonction des buts et préférencesdu locuteur plutôt que des effets épisté-miques sur l’auditeur. L’idée centrale ré-side dans le postulat que l’auditeur va
considérer les buts du locuteur et choisirl’interprétation de l’énoncé qui est la plusà même de l’aider à atteindre ces buts.
Cette idée a été développée dans différentschamps de recherche. Elle est au coeur dumodèle du Plan d’Action Conversationnel[5]. Elle forme aussi la base des séman-tiques des lois déontiques définies par [9].Elle justifie “l’heuristique utilitariste” que[10] supposent être à l’oeuvre dans l’in-terprétation de plusieurs actes de langage.Enfin, elle a été formalisée dans une théo-rie de la pertinence communicative inspi-
rée de la théorie des jeux [15].Selon [15], communiquer c’est tenter d’in-fluencer autrui, et chaque énoncé est pro-duit pour atteindre les buts du locuteur.La “pertinence” d’une interprétation estdéfinie ici comme l’utilité espérée pourle locuteur que l’énoncé soit interprétéen ce sens. De ce point de vue, il de-vient simple de comparer la pertinence des
deux interprétations possibles d’un énoncéambigu question/requête ou incompréhen-sion/désaccord. La pertinence d’une ques-tion ou d’une incompréhension est, pourle locuteur, l’utilité moyenne des diffé-rentes réponses possibles que l’auditeurpeut donner à cette question ou incompré-hension. La pertinence d’une requête estl’utilité moyenne, pour le locuteur, des ac-tions que l’auditeur peut effectuer en ré-ponse. Enfin, la pertinence d’un désaccordest l’utilité moyenne, pour le locuteur, desconséquences du désaccord. Nous faisonsl’hypothèse que l’auditeur choisira l’inter-prétation ayant la plus grande pertinencedéfinie en ces termes.
3 Objectifs
Notre objectif principal est de tester
conjointement les prédictions de l’ap-proche Gestion de la Face et de l’approcheUtilitariste sur deux types d’énoncés am-bigus très différents : une ambiguité ques-tion directe/requête indirecte, et une ambi-
Rôle de la face et de l'utilité dans l'interprétation d'énoncés ambigus [...] ___________________________________________________________________________
78

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 91/415
guité incompréhension indirecte et désac-cord indirect.
L’approche utilitariste conduit à l’hypo-
thèse que : (a) l’interprétation question(resp. requête) est comparativement plusfréquente lorsque la réponse à cette ques-tion (resp. l’exécution de cette requête)est plus utile au locuteur ; (b) l’interpréta-tion incompréhension (resp. désaccord) estcomparativement plus fréquente lorsquel’obtention de l’explication (resp. le fait demarquer son désaccord) est plus utile aulocuteur.
L’approche Gestion de la Face, conduità l’hypothèse que : (c) les interprétationsrequête et désaccord seront comparative-ment plus fréquentes lorsque l’auditeur estde plus haut statut que le locuteur; (d)l’interprétation requête est comparative-ment plus fréquente lorsque l’auditeur esttrès susceptible et aime imposer son pointde vue; (e) l’interprétation désaccord estcomparativement plus important lorsqueles interlocuteurs ne s’apprécient pas.
4 Expérience 1
4.1 Méthode
Soixante étudiants volontaires (30hommes et 30 femmes tous âgés d’une
vingtaine d’année et de langue maternellefrançaise) de l’université de Toulouse leMirail ont participé à l’étude. Les partici-pants commencent par lire les règles d’un jeu simple servant de base à l’expérience(et permettant une manipulation ortho-gonale rigoureuse des utilités). Il leur estdemandé d’imaginer que ce jeu est utilisédans le cadre d’un séminaire d’entreprisedans le but de faciliter la création de liensentre les salariés.
Règles du jeu. Le plateau de jeu montre4 emplacements d’une ville imaginaire,le but du jeu est de contrôler 3 des4 emplacements. Deux équipes de deux
Employé Patron
Mairie
Épicerie
Mairie
Piscine
Parc
A
B
Avez-vous la carte de l’Épicerie ?
FIG . 1 – Exemple d’une situation de jeu.
Le statut du coéquipier est plus haut , l’uti-lité de l’échange est basse, et l’utilitéd’avoir l’information est basse.
joueurs représentant des familles de ma-fieux s’affrontent pour le contrôle de laville. Chaque joueur dispose de 2 cartesqu’il cache à tous les autres joueurs. Le jeu
de carte complet se compose de 17 cartes :8 cartes portant le noms des emplacementsde la ville (soit 2 cartes pour chaque em-placement) ; 8 cartes arme et une carte po-lice. Pour qu’une équipe prenne le contrôled’un emplacement (qu’il soit déjà contrôléou non par l’équipe adverse), un des joueurs de cette équipe doit poser simulta-nément la carte portant le nom de cet em-placement et une carte arme. La carte po-lice sert quant à elle à bloquer définitive-ment l’accès à un lieu aux deux équipes,elle peut être posée uniquement sur un em-placement libre. Avant de jouer, le joueurqui a la main peut demander à son coéqui-pier s’il a une carte donnée en main, ou s’ilest d’accord pour lui échanger une cartedonnée contre une autre carte. Une foisl’information ou la carte obtenue, le joueurpeut choisir de jouer ou de passer son tour.
Une fois familiarisés avec les règles du jeu en ayant étudié un exemple, les parti-cipants se voient présenter 8 situations de jeu construites selon un plan factoriel com-plet 2× 2× 2 . Dans chaque situation, un
____________________________________________________________________________ Annales du LAMSADE N°8
79

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 92/415
joueur de l’équipe A (un employé homme)demandait à son coéquipier : “Avez-vousla carte de l’épicerie ?”.
Les trois variables indépendantes sont leStatut du coéquipier (plus haut vs égal),l’Utilité de l’échange (haute vs basse) etl’Utilité d’avoir l’information (haute vsbasse). Le Statut du coéquipier est plushaut lorsque le coéquipier est identifiécomme un patron et égal lorsqu’il est iden-tifié comme un autre employé. L’Utilité del’échange est haute lorsque le joueur n’estpas en mesure de prendre le contrôle d’un
emplacement avec les cartes qu’il possèdemais serait en mesure de prendre l’épice-rie s’il obtenait cette carte. Elle est basse sile joueur est déjà en mesure de prendre lecontrôle d’un emplacement avec les cartesqu’il a en main. L’Utilité d’avoir l’infor-mation est haute si cette information peutaider le joueur à prendre une décisionconcernant ce qu’il va jouer. Elle est bassesi l’information ne peut pas aider le joueur
dans son choix.Le plateau montrait toujours que l’équipeA contrôlait la piscine, l’équipe B contrô-lait le parc et qu’aucune équipe ne contrô-lait l’épicerie et la mairie (voir figure 1).La procédure entière durait environ 15 mi-nutes.
L’Utilité de l’échange et l’Utilité d’avoirl’information sont manipulées au travers
des cartes détenues par le joueur3.– Mairie & Arme. Avec ces cartes, le joueur peut prendre le contrôle de lamairie : l’utilité de l’échange est doncbasse. De plus, savoir si son coéquipierpossède ou non la carte de l’épicerien’aura pas de conséquence sur son choixde jeu : l’utilité d’avoir l’information est donc basse.
– Arme & Arme. Avec ces cartes, le
joueur ne peut pas prendre le contrôled’un emplacement mais il le pourrait3Un pré-test a montré que la perception de l’utilité de
l’échange et de l’information variait conformément à la mani-pulation des variables.
en échangeant une de ses cartes armecontre la carte de l’épicerie : l’utilité del’échange est donc haute. Savoir si soncoéquipier possède ou non la carte del’épicerie n’aura pas de conséquence surson choix de jeu : l’utilité d’avoir l’in-
formation est donc basse.– Épicerie & Arme. Avec ces cartes, le
joueur peut prendre le contrôle de l’épi-cerie : l’utilité de l’échange est doncbasse. Par contre, savoir si son coéqui-pier possède l’autre carte de l’épiceriepeut l’aider à décider s’il peut prendre lecontrôle de l’épicerie tout de suite sansrisquer de se faire reprendre cet empla-cement par l’équipe adverse : l’utilité d’avoir l’information est donc haute.
– Police & Arme. Avec ces cartes, le joueur ne peut pas prendre le contrôled’un emplacement mais il le pourraiten échangeant une de ses cartes armecontre la carte de l’épicerie : l’utilité del’échange est donc haute. De plus, sa-voir si son coéquipier possède ou non
la carte de l’épicerie peut l’aider à sa-voir s’il doit ou non bloquer l’épicerie en jouant sa carte police : l’utilité d’avoir l’information est donc haute
Après avoir pris connaissance d’une situa-tion, les participants jugent si le joueurveut échanger la carte (fait une requête)ou demande simplement l’information àson coéquipier (pose une question). Ils ré-pondent à la question Selon vous, que veut
le joueur ? en cochant une des 5 réponsespossibles : Je suis sûr(e) qu’il veut la carte(codé -2), Il veut probablement plus lacarte que l’information (codé -1), Je n’ar-rive pas à me décider (codé 0), Il veut pro-bablement plus l’information que la carte(codé +1), Je suis sûr(e) qu’il veut l’infor-mation (codé +2).
4.2 Résultats et Discussion
Les résultats ont été analysés à l’aided’une ANOVA à mesure répétées 2 ×2 × 2. Les réponses moyennes des par-ticipants pour chaque combinaison des
Rôle de la face et de l'utilité dans l'interprétation d'énoncés ambigus [...] ___________________________________________________________________________
80

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 93/415
TAB . 1 – Interprétation de l’énoncé dansl’Expérience 1. Les scores négatifs in-diquent que l’énoncé a été interprété
comme une requête, les scores positifs in-diquent qu’il a été interprété comme unequestion.
Statut du coéquipierUtilité de Egal Plus hautl’information : Basse
l’échange : Basse +0.3 (1.5) +0.6 (1.3)l’échange : Haute −1.1 (1.3) −0.8 (1.6)
l’information : Haute
l’échange : Basse +0.8 (1.2) +1.0 (1.2)l’échange : Haute −0.6 (1.5) −0.3 (1.5)
trois variables indépendantes sont don-nées Table 1. L’ANOVA révèle trois effetssimples et aucun effet d’interaction détec-table.
Les données supportent les prédictions del’approche Utilitariste. Lorsque l’utilité del’échange est haute, les participants in-terprètent plus l’énoncé comme une re-quête, F(1,59) = 47.9, p < .001, η2 =.35 (nous reportons tout au long de l’ar-ticle des η2 semi-partiels qui sont plusconservateurs et plus adaptés à l’ANOVAà mesures répétées. Ils représentent unepart de variance expliquée). L’interpréta-tion moyenne est de −0.7 (écart type=1.0)lorsque l’utilité de l’échange est haute, et+0.7 (0.8) lorsque l’utilité de l’échangeest basse. Une utilité d’avoir l’informa-tion haute encourage les participants à in-terpréter l’énoncé comme une question,F(1,59) = 10.0, p = .002, η2 = .08.L’interprétation moyenne est de +0.2 (0.7)lorsque l’utilité d’avoir l’information esthaute et seulement −0.3 (0.8) lorsque l’uti-lité d’avoir l’information est basse. En to-
tale contradiction avec les prédictions del’approche Gestion de la Face, lorsquele coéquipier a un statut plus élevé, lesparticipants tendent à interpréter l’énoncécomme une question, F(1,59) = 4.6, p <
.05, η2 = .03. L’interprétation moyenneest de +0.1 (0.7) que le coéquipier a unstatut plus élevé, et seulement −0.2 (0.7)lorsque le coéquipier est de même statutque le locuteur.
Deux explications peuvent être avancéesconcernant ce dernier résultat. Première-ment, il est possible que lorsque le coéqui-pier est de statut supérieur, une requêtepour un échange de carte soit trop me-naçante, même exprimée indirectement.Dans ce cas, il serait inconcevable pour lesparticipants que le locuteur fasse cette re-
quête, même indirectement.Une seconde explication pourrait êtreavancée en référence aux résultats obtenuspar [7]. Il a en effet été mis en évidenceque les participants choisissaient plus sou-vent l’interprétation requête lorsque le lo-cuteur était de statut supérieur à l’auditeur.Ce résultat s’expliquerait par un effet detaux de base lié au statut : dans la me-
sure où il est plus fréquent pour un supé-rieur de donner des ordres à ses subordon-nés, les participants tendraient à interpré-ter un énoncé ambigu produit par un su-périeur comme un ordre (une requête). Dela même façon, un effet de taux de basepourrait expliquer notre résultat : puisque,de façon générale, les subordonnés ques-tionnent davantage leur supérieur qu’ilsne lui donnent des ordres (requête), l’in-terprétation “question” paraîtrait plus pro-bable aux yeux des participants.
L’expérience 2 permet de tester ces deuxexplications concurrentes. Dans la secondeexpérience, nous manipulons la menace deface pour l’auditeur en manipulant de fa-çon orthogonale sa personnalité et son sta-tut. Considérons le cas d’un auditeur dehaut statut connu pour avoir une aversionparticulière à recevoir des ordres. Selon
notre première explication, un énoncé am-bigu question/requête adressé à cette per-sonne aura très peu de chance d’être in-terprété comme une requête. En effet, si leseul statut de cette personne rendait d’ores
____________________________________________________________________________ Annales du LAMSADE N°8
81

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 94/415
et déjà l’interprétation requête trop mena-çante, sa personnalité ne ferait qu’empirerles choses. Au contraire, si l’on considèrela seconde explication, le statut et la per-sonnalité devraient avoir des influences an-tagonistes : le statut encourageant, à tra-vers l’effet de taux de base, une interpéta-tion question; et la personnalité encoura-geant, selon l’approche Gestion de la Face,une interpétation requête.
5 Expérience 2
5.1 Méthode
Soixante étudiants volontaires de l’uni-versité Jean-François Champollion à Albiont participé à l’étude. L’échantillon étaitcomposé de 17 hommes et 43 femmesâgés de 18 à 27 ans (moyenne=20.3, écarttype=2.1) tous ayant pour langue mater-nelle le français. Le matériel et la pro-cédure étaient sensiblement les mêmesque pour l’expérience 1. Le plateau de jeu, les règles et l’énoncé à interpréterne changeaient pas. Huit situations de jeuconstruites selon un plan factoriel complet2 × 2 × 2 étaient présentées aux partici-pants. Le Statut du coéquipier (plus hautvs égal) était manipulé de la même façonque dans l’expérience 1. La personnalitédu coéquipier (rigide vs flexible) était ma-nipulée à la fois visuellement grâce à une
image, et verbalement à l’aide d’une des-cription accompagnant l’image4 (voir Fi-gure 5.1).
Finalement, deux situations de jeu dif-férentes ont été utilisées à des fins decontrôle. Dans la première situation, l’uti-lité de l’échange et l’utilité d’avoir l’infor-mation sont toutes deux hautes (le joueurpossède les cartes Police et Arme); dans
la seconde situation, l’utilité de l’échangeet l’utilité d’avoir l’information sont toutes4Un pré-test mené sur cette variable a permis de s’assurer
que la menace de face liée aux deux interprétations de l’énoncéétait perçue comme plus importante pour l’auditeur rigide
TAB . 2 – Interprétation de l’énoncé dansl’Expérience 2. Les scores négatifs in-diquent que l’énoncé a été interprété
comme une requête, les scores positifs in-diquent qu’il a été interprété comme unequestion.
Statut du coéquipierEgal Plus haut
Utilités : Basse
Coéquipier Flexible +0.3 (1.3) +0.6 (1.3)Coéquipier rigide +0.1 (1.5) +0.3 (1.5)
Utilités : Haute
Coéquipier Flexible −0.3 (1.4) −0.0 (1.3)Coéquipier Rigide −0.9 (1.2) −0.8 (1.2)
deux basses (le joueur possède les cartesMairie et Arme). Les utilités ayant toutesdeux la même valeur (haute ou basse),cette variable est appelé Valeur des utilitésen conflit (haute vs basse).
De même que dans l’expérience 1, les par-
ticipants jugeaient, pour chaque situation,si le joueur faisait une requête pour unéchange ou demandait simplement une in-formation.
5.2 Résultats et Discussion
Les résultats ont été analysés au moyend’une ANOVA à mesures répétées 2 ×2 × 2. Les réponses moyennes des par-ticipants pour chaque combinaison destrois variables indépendantes sont don-nées Table 2. L’ANOVA révèle trois effetssimples et aucun effet d’interaction détec-table.
Conformément aux prédictions de l’ap-proche Gestion de la Face (ainsi qu’à l’ex-plication basée sur un effet de taux debase lié au statut), les participants tendent
à interpréter l’énoncé comme une requêtelorsque le coéquipier a une personnalité ri-gide, F(1,59) = 8.62, p = .005, η2 = .08.L’interprétation moyenne est de +0.2 (0.6)lorsque le coéquipier a une personnalité
Rôle de la face et de l'utilité dans l'interprétation d'énoncés ambigus [...] ___________________________________________________________________________
82

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 95/415
employé très ou-vert, à l’écoutedes autres. Il at-tache de l’impor-tance à l’opinion
et aux idées d’au-trui
employé très sus-ceptible, qui détesterecevoir des ordres.Il aime contrôlerle déroulement des
choses et imposerson point de vue
Patron très ou-vert, à l’écoutedes autres. Il at-tache de l’impor-tance à l’opinion
et aux idées d’au-trui
Patron très suscep-tible, qui détesterecevoir des ordres.Il aime contrôlerle déroulement des
choses et imposerson point de vue
FIG . 2 – Images et déscriptions utilisées dans l’Expérience 2 pour manipuler la personna-lité du coéquipier. De gauche à droite : employé flexible, employé rigide, patron flexibleet patron rigide.
flexible et seulement −0.3 (0.8) lorsque le
coéquipier a une personnalité rigide. Inver-sement, et comme dans l’expérience 1, unetendance vers l’interprétation “question”est observée lorsque le coéquipier est deplus haut statut F(1,59) = 3.7, p = .058,
η2 = .03. L’interprétation moyenne est de0.0 (0.7) lorsque le coéquipier a un statutsupérieur et seulement −0.2 (0.6) lorsquele coéquipier a un statut égal. Enfin, et bienque nous n’ayons pas émis d’hypothèseconcernant cette variable, nous constatonsque les participants tendent à interpréterl’énoncé comme une requête lorsque l’uti-lité de l’échange et l’utilité d’avoir l’infor-mation sont toutes deux hautes, F(1,59) =16.7, p < .001, η2 = .17. L’interpréta-tion moyenne est de +0.3 (1.0) lorsque lesdeux utilités sont basses et seulement −0.5(0.7) lorsque les deux utilités sont hautes.
Bien que ce dernier résultat soit surpre-nant et inattendu, nous resterons prudentsquant à son interprétation. En effet, l’expli-cation la plus probable à cet effet sembleêtre celle d’un “bruit” dans la manipula-
tion des utilités (l’utilité haute de la re-
quête est peut être perçue comme plusutile que l’utilité haute de la question);les résultats obtenus lors du pré-test vontd’ailleurs dans ce sens. Ces deux pre-mières expériences nous ont permis de tes-ter avec succès les prédictions de l’ap-proche Utilitariste et d’apporter de nou-velles perspectives à l’approche Gestion dela Face. Toutefois, ces résultats se limitentà un type bien précis d’énoncé ambigu :l’ambiguité question (directe)/requête (in-
directe). Dans un souci de généralisationde nos résultats à d’autres types d’ambi-guités, nous avons choisi de tester à nou-veau ces deux approches sur une ambi-guité différente : l’ambiguité incompré-hension (indirecte)/désaccord (indirect).
6 Expérience 3
6.1 Méthode
Cent vingt et un étudiants volontaires (23hommes et 98 femmes) de l’université de
____________________________________________________________________________ Annales du LAMSADE N°8
83

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 96/415
Toulouse le Mirail ont participé à l’étude.Ils étaient âgés de 18 à 32 ans (moyenne= 20.4, écart type = 1.9) et tous avaientpour langue maternelle le français. Huit si-tuations, construites selon un plan facto-riel complet 2 × 2 × 2, sont présentéesaux participants. Dans un premier temps,on leur demande d’imaginer que les situa-tions qui vont leur être présentées se dé-roulent dans le cadre d’un séminaire d’en-treprise dont le but est de faciliter la créa-tion de liens entre salariés et dirigeants.Dans chaque situation on retrouve deux joueurs (A et B) qui font équipe pour un
jeu stratégique. Ils discutent de la straté-gie à adopter face à leurs adversaires. Le joueur B prend la parole pour expliquerla stratégie qu’il aimerait mettre en place.Pendant l’explication A interrompt B enlui disant : “J’ai peur de ne pas vous sui-vre”. Les 3 variables indépendantes sont :Le statut de B (plus haut vs égal à celuide A), l’Utilité de la demande de précision(haute vs basse) et l’utilité du désaccord
(haute vs basse). Le statut de B est plushaut lorsque B est un patron et A un em-ployé, il est égal lorsque A et B sont toutdeux des employés. L’utilité de la demandede précision est haute lorsque lorsque Butilise un langage spécifique au jeu in-connu de A, elle est basse lorsqu’il uti-lise un langage courant. L’utilité du désac-cord est haute lorsque B a la réputationde prendre de mauvaises décisions straté-giques, elle est basse lorsqu’il a la réputa-tion de prendre de bonnes décisions straté-giques.
À des fins de contrôle, deux questions ontété employées pour mesurer l’interpréta-tion de l’énoncé ; après avoir pris connais-sance d’un scénario, la moitié des partici-pants répondaient à la question : “Selonvous que veut-il en disant cela?” en co-chant une des 5 réponses possibles : Je suis
sûr(e) qu’il veut marquer son désaccordavec la stratégie proposée par B (codée -2), Il veut probablement plus marquer sondésaccord qu’avoir une réexplication de Bconcernant ce qu’il veut faire (codée -1), Je
n’arrive pas à me décider (codée 0), Il veutprobablement plus que B lui réexplique cequ’il veut faire que marquer son désaccord(codée +1), Je suis sûr(e) qu’il veut queB lui réexplique ce qu’il veut faire (codée+2). L’autre moitié de l’échantillon répon-dait à la question suivante : “Que va com-prendre le joueur B” sur une même échelleen 5 points.
6.2 Résultats et Discussion
Les résultats ont été analysés au moyen
d’une ANOVA à mesures répétées 2 ×2 × 2 (aucun effet de la question poséen’ayant été détecté lors de l’analyse, les ré-sultats présentés portent sur l’ensemble del’échantillon). Les réponses moyennes desparticipants pour chaque combinaison destrois variables indépendantes sont donnéesTable 3. L’analyse a révélé un effet simplede l’utilité de la demande de précision etun effet simple de l’utilité du désaccord.
Conformément aux prédictions de l’ap-proche Utilitariste, lorsque l’utilité de lademande de précision est haute, les par-ticipants interprètent l’énoncé comme unedemande de précision, F(1,120) = 22.4,
p < .001, η2 = .08. L’interprétationmoyenne est de +0.3 (1.2) lorsque l’uti-lité de la demande de précision est haute et−0.1 (1.1) lorsqu’elle est basse. Une uti-lité du désaccord haute encourage les par-ticipants à interpréter l’énoncé comme undésaccord, F(1,120) = 259.2, p < .001,
η2 = .54. L’interprétation moyenne est de−0.7 (1.2) quand l’utilité du désaccord esthaute et +0.9 (1.1) lorqu’elle est basse.
Le statut ne joue ici aucun rôle dans ladésambiguisation de l’énoncé. Il est pos-sible que l’effet de taux de base observésur l’ambiguité question/requête ne s’ap-
plique pas au même degré à l’ambiguitéincompréhension/désaccord. En effet, ilest possible que le schéma d’un patronexprimant son désaccord à son employésoit moins prégnant, et joue donc un rôle
Rôle de la face et de l'utilité dans l'interprétation d'énoncés ambigus [...] ___________________________________________________________________________
84

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 97/415
TAB . 3 – Interprétation de l’énoncé dansl’expérience 3. Les scores négatifs in-diquent que l’énoncé a été interprété
comme un désaccord, les scores positifsindiquent qu’il a été interprété comme unedemande de précision.
Statut de BUtilité de Egal Plus hautla précision : Basse
désaccord : Basse +0.6 (1.3) +0.7 (1.2)désaccord : Haute −0.9 (1.3) −0.8 (1.2)
la précision : Haute
désaccord : Basse +1.1 (1.1) +1.1 (1.0)désaccord : Haute −0.6 (1.2) −0.4 (1.2)
moindre, que le schéma d’un patron don-nant un ordre à son employé.
7 Expérience 4
7.1 Méthode
60 étudiants volontaires (12 hommes et 48femmes) de l’université de Toulouse le Mi-rail ont participé à l’étude. Ils étaient âgésde 17 à 57 ans (moyenne = 22, écart type =7.4) et tous avaient pour langue maternellele français. Huit situations, construites se-lon un plan factoriel complet 2 × 2 × 2,sont présentées aux participants. Les si-tuations sont similaires à celle de l’expé-rience 3 sauf qu’elles n’ont pas lieu dansle cadre d’un séminaire d’entreprise. Laphrase cible énoncée par le locuteur estla même ainsi que la question posée etl’échelle de réponse. Les trois variablesindépendantes sont : l’utilité de la de-mande de précision (haute vs basse), l’uti-lité du désaccord (haute vs basse) et la dis-tance affective entre l’auditeur et le locu-teur (grande vs faible). Les deux variables
d’utilité sont manipulées de la même fa-çon que dans l’expérience 3. La distanceaffective entre l’auditeur et le locuteur estgrande lorsque les deux hommes ne s’ap-précient pas, elle est faible lorsqu’ils sont
bons amis.
7.2 Résultats et Discussion
Les résultats ont été analysés au moyend’une ANOVA à mesures répétées 2×2×2qui a révélé deux effets simples et un effetd’interaction. Les réponses moyennes desparticipants pour chaque combinaison destrois variables indépendantes sont donnéesTable 4.
Conformément aux prédictions dérivée de
l’approche Gestion de la Face et dansla lignée des résultats de [11], lorsquela distance affective est grande, les par-ticipants interprètent l’énoncé comme undésaccord, F(1,59) = 51,1, p < .001,
η2 = .28. L’interprétation moyenne est de−0.5 (1.1) lorsque la distance affective estgrande et +0.2 (1.1) lorsqu’elle est faible.Les données supportent également les pré-dictions de l’approche Utilitariste, une uti-
lité du désaccord haute encourage les par-ticipants à interpréter l’énoncé comme undésaccord, F(1,59) = 128.2, p < .001,
η2 = .51. L’interprétation moyenne estde −0.8 (1.1) quand l’utilité du désac-cord est haute et +0.5 (1.1) lorqu’elle estbasse. Enfin, la différence liée à la dis-tance affective est plus faible lorsque l’uti-lité du désaccord est haute, F(1,59) = 5.8,
p = .02, η2 = .04. Cette interaction est
sans doute due à un effet plancher lorsquel’utilité du désaccord est haute. En effet,dans la situation où l’utilité du désaccordest haute, l’interprétation moyenne est déjàtrès basse (−0.5) lorsque les interlocuteurssont bons amis, elle ne pouvait pas des-cendre beaucoup plus lorsque les interlo-cuteurs ne s’apprécient pas.
L’effet de l’utilité de la demande de pré-cision n’est pas significatif mais intervient
de façon marginale ( p = .1) dans l’in-terprétation. Lorsque l’utilité de la de-mande de précision est haute, les partici-pants tendent à plus interpréter l’énoncécomme une demande de précision.
____________________________________________________________________________ Annales du LAMSADE N°8
85

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 98/415
TAB . 4 – Interprétation de l’énoncé dansl’expérience 4. Les scores négatifs in-diquent que l’énoncé a été interprété
comme un désaccord, les scores positifsindiquent qu’il a été interprété comme unedemande de précision.
Distance AffectiveUtilité de Faible Grandela précision : Basse
désaccord : Basse +0.9 (1.2) −0.07 (1.3)désaccord : Haute −0.6 (1.3) −1.0 (0.9)
la précision : Haute
désaccord : Basse +1.3 (0.7) +0.1 (1.2)désaccord : Haute −0.5 (1.2) −1.0 (1.1)
8 Synthèse des résultats
Au travers de ces 4 expériences, nousavons pu étayer les prédictions de l’ap-proche Utilitariste. Nous avons montré, surdeux types d’ambiguités très différentes
(l’une impliquant une interprétation lit-térale et une interprétation indirecte, etl’autre impliquant deux interprétations in-directes d’un même énoncé) que les par-ticipants tendent à choisir l’interprétationayant la plus haute utilité espérée pour lelocuteur. De plus, nous avons apporté desdonnées nouvelles à l’approche de Ges-tion de la Face en montrant que, confor-mément à ses prédictions, lorsque l’au-
diteur a une aversion particulière à rece-voir des ordres, l’énoncé ambigu ques-tion/requête est interprété comme une re-quête; et lorsque les interlocuteurs nes’apprécient pas, l’énoncé ambigu incom-préhension/désaccord est interpété commeun désaccord. Enfin, contrairement à cequi été prédit par l’approche gestion de laface, lorsque l’auditeur a un statut supé-rieur au locuteur, l’énoncé est interprétécomme une question (ce que nous identi-fions comme un effet taux de base [7]).
Enfin, dans la mesure où il a été montrédans ce travail que l’approche de Gestionde la Face et l’approche Utilitariste parti-
cipent de manière décisive à l’interpréta-tion d’énoncés ambigus question/requêteet incompréhension/désaccord, il noussemble que la prochaine étape pourraitconsister en leur intégration sous une seuleet même approche unifiée. Une approchede ce type a été initiée au niveau formel[16], mais tout reste à faire du point de vueexpérimental.
Références
[1] P. Brown and S. C. Levinson. Poli-
teness : Some universals in languageusage. Cambridge University Press,Cambridge, 1987.
[2] R.W. Gibbs. Do people always pro-cess the literal meaning of indirectrequests? Journal of ExperimentalPsychology : Learning, Memory, and Cognition, 9(3) :524–533, 1983.
[3] E. Goffman. Interaction ritual : es-
says on face to face behavior . GardenCity, New York, 1967.
[4] H.P. Grice. Logic and conversation.In P. Cole and J. Morgan, editors,Syntax and semantics 3 : Speech acts,pages 41–58. Academic Press, NewYork, 1975.
[5] D. J. Hilton, M. Kemmelmeier, andJ. F. Bonnefon. Putting ifs to work :Goal-based relevance in conversa-tional action planning. Journal of
Experimental Psychology : General,135 :388–405, 2005.
[6] T. Holtgraves. Interpreting ques-tions and replies : Effects of face-threat, question form, and gender. So-cial Psychology Quarterly, 54 :15–24, 1991.
[7] T. Holtgraves. Communication in
context : effects of speaker statuson the comprehension of indirect re-quests. Journal of Experimental Psy-chology : Learning, Memory, and Cognition, 20(5) :1205–1218, 1994.
Rôle de la face et de l'utilité dans l'interprétation d'énoncés ambigus [...] ___________________________________________________________________________
86

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 99/415
[8] T. Holtgraves. Interpreting indi-rect replies. Cognitive Psychology,37(1) :1–27, 1998.
[9] D.E. Over, K.I. Manktelow, andC. Hadjichristidis. Condition for theacceptance of deontic conditionals.Canadian Journal of ExperimentalPsychology, 52(2) :96–105, 2004.
[10] É. Raufaste, D. Longin, and J.F. Bon-nefon. Utilitarisme pragmatique etreconnaissance d’intention dans lesactes de langage indirects. Psycholo-gie de l’Interaction, 21-22 :189–202,
2005.[11] B.R. Slugoski and W. Turnbull. Cruel
to be kind and kind to be cruel :Sarcasm, banter and social relations.
Journal of Language and Social Psy-chology, 7 :101–121, 1988.
[12] H. Spencer-Oatey. Reconsidering po-wer and distance. Journal of Pragma-tics, 26 :1–24, 1996.
[13] D. Sperber and D. Wilson. La Perti-nence : Communication et cognition.Les Editions de Minuit, 1989.
[14] J-B. Van der Henst and D. Sper-ber. Experimental Pragmatics, chap-ter Testing the principle of relevance,pages 229–280. Palgrave, 2004.
[15] R. Van Rooy. Relevance of commu-nicative acts. In Proceedings of Tark .2001.
[16] R. Van Rooy. Being polite is a handi-cap : Towards a game theoretical ana-lysis of polite linguistic behavior. InProceedings of Tark 9. 2003.
____________________________________________________________________________ Annales du LAMSADE N°8
87

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 100/415

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 101/415
Actes communicatifs à effets institutionnels
R. Demolombe
V. Louis†
IRIT, Université Paul Sabatier118 Route de Narbonne – 31062 Toulouse Cedex 9 – FRANCE
†France Télécom, Recherche & Développement2, av. Pierre Marzin – 22307 Lannion Cedex – FRANCE
Résumé :Cet article présente un cadre logique général pourreprésenter des actes de langage ayant des effetsinstitutionnels. Il s’appuie sur les concepts de la
théorie des actes de langage et complète la formali-sation adoptée par l’organisme FIPA pour standar-diser son langage de communication inter-agent.La caractéristique fondamentale de notre approcheest que la force illocutoire de tous les actes de lan-gage ainsi définis est déclarative. Le langage for-mel proposé pour exprimer le contenu proposition-nel offre un grand pouvoir expressif et permet dereprésenter une grande variété d’actes de langagetels que : donner un pouvoir, nommer, ordonner,déclarer, etc.
Mots-clés : Actes de langage, effets institutionnels,
agents, logique formelle, FIPA-ACL
Abstract:A general logical framework is presented to re-present speech acts that have institutional effects. Itis based on the concepts of the Speech Act Theoryand takes the form of the Agent CommunicationLanguage standardized by the FIPA organization.The most important feature of our approach is thatthe illocutionary force of all of these speech acts isdeclarative. The formal language that is proposedto express the propositional content has a large ex-
pressive power and makes it possible to represent alarge variety of speech acts such as : to empower,to appoint, to order, to declare, etc.
Keywords: Speech acts, institutional effects,agents, formal logic, FIPA-ACL
1 Introduction
Les langages de communication agent jouent un rôle important pour formaliser et
mettre en oeuvre les interactions entre ins-titutions électroniques, en particulier dansle domaine du commerce électronique [9,10]. Ces langages doivent avoir une sé-mantiqueàlafoisclaireetintuitive,etpour
cela, devraient se baser sur des conceptsaussi proches que possible de ceux qui sontutilisés pour définir la communication enlangage naturel. C’est pourquoi la théoriedes actes de langage [29] et le concept defait institutionnel [5, 23, 22] sont généra-lement reconnus comme des cadres appro-priés pour cet objectif.
Dans cet article, nous examinons la for-malisation d’actes de langage qui ontdes effets institutionnels dans des sociétéd’agents, par exemple : créer une obliga-tion, assigner un rôle à un agent ou dé-
clarer les enchères ouvertes. Le contextede nos travaux est la formalisation d’inter-actions entre agents électroniques, et plusparticulièrement la formalisation d’actescommunicatifs entre agents.
La théorie des actes de langage, définie parSearle dans [29] et formalisée par Searle etVandervecken dans [30], a déjà été appli-quée au contexte des agents électroniques.
Notamment, la sémantique d’actes tels queinform ou request a été formalisée en lo-gique modale et adoptée comme standarddans le langage de communication inter-agent FIPA-ACL [17]. Cette formalisationest issue des travaux de Sadek présentésdans [28].
Appliquer à des agents électroniques desconcepts de la théorie des actes de langagetels que les croyances ne semble pas incon-
gru et fait même sens a priori. En revanche,attribuer des intentions à ces agents appa-raît davantage problématique. De surcroît,il n’est pas très clair si parler d’obligationsou de pouvoirs institutionnels a encore un
89

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 102/415
sens pour des agents électroniques. En ef-fet, les obligations, et les normes en géné-ral, sont destinées à influencer le compor-tement d’agents ayant un libre arbitre.
Certains auteurs, comme McCarthy dans[26], ne rejettent pas l’idée que les agentsélectroniques puissent avoir un libre ar-bitre, comme les êtres humains, et qu’ilspuissent réellement choisir leurs intentionset même violer ou respecter des obliga-tions.
Nous ne prétendons pas ici donner des ré-
ponses, ni même des éléments de réponse,à la question philosophique du libre arbitredes agents électroniques. Nous faisonssimplement l’hypothèse que les agentsélectroniques peuvent être vus commedes représentants d’agents humains, dela même façon que des agents humainspeuvent représenter des agents institution-nels, conformément à ce que proposentCarmo et Pacheco dans [2].
Dans ces conditions, nous pouvons sup-poser que les actions accomplies par desagents électroniques sont déterminées etchoisies, explicitement ou implicitement,par des agents humains. Ainsi, dans notreapproche, les actions d’agents électro-niques comptent pour des actions d’agentshumains.1
Àpartirdelà,commentrépondreàlaques-
tion : « qu’advient-il lorsqu’un agent élec-tronique viole une obligation ? »? Dans lecas où un agent doit payer une amendepour réparer une violation, on pourraitimaginer qu’il soit possible de débiterle compte de l’agent électronique (sansconsidérer ici la définition de ce que si-gnifie qu’un agent électronique détient uncompte). Cependant, dans le cas où unagent doit aller en prison pour réparer une
violation, il devient évident que l’agentélectronique ne pourra pas réparer lui-
1Nous utilisons « compter pour » dans le même sens queSearle utilise « count as » dans [29] ou Jones et Sergot dans[21].
même. Dans le cas général, la réponse àla question précédente est donc que c’est àl’agent humain, qui est représenté par leditagent électronique, d’assumer et de réparerles violations commises.
Nous sommes naturellement conscientsdes nombreuses difficultés que peut sou-lever la définition rigoureuse des relationsentre les agents humains et leurs représen-tants électroniques, notamment en termesde responsabilités. Prenons l’exemple d’unagent électronique qui ne fait pas ce qu’ilest censé faire au vu de ses spécifica-
tions, ce qui arrive généralement lorsqueson logiciel est erroné, et viole une obliga-tion. Quel agent humain est alors respon-sable? Son mandant, qui lui délègue destâches pour lesquelles il le représente? Leconcepteur du logiciel ?
En tout état de cause, dans le cadre decet article, nous laissons volontairementtoutes ces questions ouvertes. Nous nouscontentons simplement de formaliser desraisonnements généraux sur les agents,qu’ils soient électroniques ou humains.
La suite du texte est organisée commesuit. Dans la section 2, nous analysons demanière informelle les composantes desactes de langage avec effets institutionnels.Nous présentons ensuite, dans la section 3,une formalisation de chacune de ces com-posantes dans un cadre logique. Dans la
section 4, nous comparons l’approche pro-posée à d’autres travaux similaires. Enfin,en conclusion, nous résumons les résultatsprincipaux et donnons quelques perspec-tives de recherche.
2 Analyse informelle des actesde langage à effets institution-nels
Dans le cadre de ce travail, nous ne consi-dérons pas la totalité des subtilités de la dé-finition des actes de langage telle que pré-sentée dans [29]. Nous nous restreignons,
Actes communicatifs à effets institutionnels ___________________________________________________________________________
90

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 103/415
à l’instar des travaux menés par l’orga-nisme FIPA pour la standardisation du lan-gage de communication inter-agent FIPA-ACL, aux caractéristiques suivantes :
– force illocutoire,– contenu propositionnel,– préconditions de faisabilité,– effets illocutoires,– effets perlocutoires.
Dans la suite, les agents jouant le rôlede locuteur et ceux jouant le rôle d’in-terlocuteur sont respectivement qualifiés
d’« émetteur » et de « destinataire ».L’émetteur et le destinataire sont généra-lement nommés i et j dans le langage for-mel.
2.1 Force illocutoire
La force illocutoire est déterminée par ladirection de l’ajustement entre les mots etles choses. Les actes de langage que nousconsidérons ici sont ceux qui créent desfaits institutionnels. Autrement dit, leur ac-complissement « a pour fonction [...] d’in-
fluer sur les états de faits institutionnels »2,comme l’écrit K. Bach dans l’entrée « actede langage » de l’encyclopédie de philoso-phie en ligne Routledge [27]. De tels actesde langage satisfont la double direction del’ajustement et sont donc caractérisés parune force illocutoire déclarative.
Concrétisons le type de faits institution-nels auxquels nous nous intéressons parquelques exemples. En tout état de cause,nous soulignons l’importance de distin-guer clairement les faits qui sont représen-tés par des énoncés descriptifs des faits quisont représentés par des énoncés norma-tifs. Parmi les « faits institutionnels des-criptifs », nous pouvons citer :
1. les enchères sont ouvertes.2. l’agent j est titulaire du rôle de vendeur.
2Traduction de l’anglais : « have the function [...] of affecting
institutional state of affairs ».
3. l’agent j a le pouvoir institutionneld’ouvrir les enchères.
Parmi les « faits institutionnels norma-
tifs », nous pouvons citer :
4. l’agent j a l’obligation de payer la fac-ture de l’hôtel.
5. il est obligatoire d’avoir une carte decrédit.
6. l’agent j a la permission de vendre duvin.
7. l’agent j a l’interdiction de vendre de lacocaïne.
Il semble clair que la force illocutoire d’unacte de langage qui créerait des faits ins-titutionnels qui ne réfèrent pas à l’accom-plissement d’une action par le destinataire(exemples 1, 2, 3 et 5) est déclarative.
La création de faits institutionnels qui ré-fèrent à l’accomplissement d’une actionpar le destinataire, comme l’exemple 4 ci-dessus, soulève plus explicitement la ques-
tion suivante : est-ce que la force illocu-toire des actes de langage correspondantsest réellement déclarative ou simplement directive ?
En effet, on pourrait considérer que, danscet exemple, l’intention de i est que j paiela facture. Cela est le cas, par exemple, siun employé d’hôtel i donne la facture à unclient j en disant : « vous devez payer la
facture ! ».Mais on pourrait tout aussi bien considérerque l’intention de i n’est pas directementque j paie la facture, mais plus exactementqu’il soit obligatoire que j paie la facture.Dans ce cas, l’employé donne au client lafacture, qui est un document officiel, carson intention est que ce dernier sache quesa déclaration n’est pas simplement une re-quête mais plutôt un ordre, qui, par nature,rend obligatoire que le client paie.
Bien entendu, il reste vrai que l’intentionde i ne se borne pas à seulement créerl’obligation de payer, l’agent a également
____________________________________________________________________________ Annales du LAMSADE N°8
91

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 104/415
l’intention d’être payé in fine. En réalité,i croit que l’instauration de cette obliga-tion est un moyen plus efficace pour êtrepayé qu’une simple demande à j d’accom-plir l’action de payer.
En effet, si j refuse de payer, celui-ci saitqu’il viole une obligation et qu’il va de-voir s’acquitter d’une amende. L’agent isait que j le sait, ce qui le rassure surses chances d’être effectivement payé. Enoutre, si la menace d’une amende ne suf-fit pas à influencer le comportement de j,l’agent i est en droit de recourir aux forces
de l’ordre pour contraindre j à payer, et iconsidère que ces représentants de l’ins-titution auront plus de succès dans cetteentreprise qu’il n’aurait eu lui-même s’ilavait simplement demandé à j de payer.
Notre proposition est de définir, dans lescas tels que l’exemple 4 ci-dessus, deuxeffets perlocutoires pour les actes de lan-gage : (1) l’établissement d’un fait institu-
tionnel (dans cet exemple, l’obligation que j paie) et (2) l’accomplissement d’une ac-tion par le destinataire (dans cet exemple,l’action de payer la facture). Nous quali-fions ce second effet d’« effet perlocutoiresecondaire ».
Dans l’exemple 6, l’intention de i est dedonner à j la permission de réaliser uneaction (vendre du vin) mais n’est en au-cun cas que j réalise cette action. Dansl’exemple 7, il est évident que l’intentionde i n’est pas que j accomplisse une action(vendre de la cocaïne). Dans ces deux cas,la force illocutoire de l’acte est clairementdéclarative.
2.2 Contenu propositionnel
Le contenu propositionnel représente le
fait institutionnel à créer lorsque l’acte delangage est accompli. Plus précisément,cette représentation peut se décomposer enune référence à une institution (par rapportà laquelle le fait institutionnel à créer doit
être interprété), le contenu proposition-nel lui-même et éventuellement des condi-tions particulières qui doivent être véri-fiées pour que l’effet institutionnel recher-ché soit bien atteint par la réalisation del’acte de langage.
Nous avons considéré dans nos travauxdifférents types de contenus proposition-nels appropriés à des contextes applica-tifs tels que le commerce électronique. Ce-pendant, la liste proposée peut être facile-ment étendue en fonction des besoins dudomaine choisi.
Les différents types de contenus proposi-tionnels qui représentent des faits institu-tionnels descriptifs sont les suivants :
– Les contenus propositionnels représen-tant des situations dans lesquelles desactions comptent, ou ne comptent pas,pour des actions institutionnelles. Unexemple typique est la situation où les
enchères sont ouvertes, dans laquelle lesoffres ont une valeur institutionnelle. Unautre exemple est la situation où un ser-vice donné est proposé, dans laquelle,sous certaines conditions, une requêteau serveur crée des obligations pour lefournisseur de service. En langue natu-relle, les actes de langage qui créent detelles situations peuvent être appelés :« ouvrir » ou « fermer ».
– Les contenus propositionnels qui repré-sentent des situations dans lesquelles unagent est, ou n’est pas, titulaire d’unrôle. Par exemple, l’agent j est, ou n’estpas, titulaire du rôle de vendeur. Enlangue naturelle, les actes de langage quicréent de telles situations peuvent êtreappelés : « nommer » ou « destituer ».
– Les contenus propositionnels qui repré-sentent des situations dans lesquelles unagent a, ou n’a pas, un pouvoir institu-
tionnel. Par exemple, l’agent j a, ou n’apas, le pouvoir institutionnel d’ouvrir lesenchères. En langue naturelle, les actesde langage qui créent de telles situationspeuvent être appelés : « donner un pou-
Actes communicatifs à effets institutionnels ___________________________________________________________________________
92

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 105/415
voir » ou « retirer un pouvoir ».
Les contenus propositionnels qui repré-sentent des faits institutionnels normatifs
recouvrent en réalité des obligations, despermissions et des interdictions. Lorsquel’on considère des normes sur des actions,comme les obligations de faire, les actes delangage correspondants peuvent être res-pectivement appelés en langue naturelle :« ordonner », « permettre », « inter-dire ». Des verbes similaires peuvent êtreemployés dans le cas de normes sur desétats, comme l’obligation d’être.
En plus du contenu propositionnel lui-même, doivent être également préciséesles circonstances dans lesquelles les faitsinstitutionnels à créer sont reconnus parl’institution comme des conséquences « lé-gales » de l’accomplissement de l’actede langage. Dans l’exemple précédent del’employé et du client, le fait que le clientait effectivement passé une nuit à l’hôtelet que les tarifs des nuitées soient offi-ciellement affichés sont des conditions im-plicites qui rendent l’ordre de paiementde l’employé valides par rapport à la loi.Cet ordre peut donc se résumer ainsi :« attendu que vous avez passé une nuit et que le le tarif officiel est de tant, jevous ordonne de payer cette facture ». Sices conditions ne sont pas remplies, parexemple si le client n’a pas passé de nuità l’hôtel, l’acte de langage n’a pas de sens.
Pour finir, la signification intuitive de notreproposition d’acte de langage avec effetinstitutionnel peut s’exprimer plus com-plètement sous la forme : « l’émetteur dé-clare au destinataire sa volonté de changer l’état de fait institutionnel, étant donné quesont satisfaites un ensemble de conditionsqui l’autorisent, du point de vue de l’insti-tution, à créer cet état de fait ».
2.3 Préconditions de faisabilité
La précondition de sincérité est à la foisque i croit qu’il a le pouvoir institutionnel
de créer le fait institutionnel représenté parle contenu propositionnel de l’acte de lan-gage et qu’il croit que les conditions re-quises pour l’exercice de ce pouvoir sontsatisfaites.
A noter ici qu’il y a une différence signi-ficative entre ordonner de faire une action(qui est considéré comme déclaratif) et de-mander de faire une action (qui est consi-déré comme directif). Ainsi, si i demandeà j de faire α, une précondition de sincéritéest que i croit que j a la capacité de faireα, alors que si i ordonne à j de faire α,
il n’y a pas de telle précondition puisque,comme précisé plus haut, l’intention pre-mière de i en réalisant cet acte d’ordonnerest de créer l’obligation de faire α.
Dans l’exemple de l’employé et du client,l’intention de l’employé d’être payé est in-dépendante du fait que le client ait effecti-vement la capacité de payer (par exemple,puisse émettre des chèques sur un compte
bancaire suffisamment provisionné). C’estpourquoi le fait que le client puisse payern’est pas une précondition de sincérité.
La précondition de pertinence (aucontexte), à l’instar des actes de lan-gage usuels, est que i ne croit pas quel’effet perlocutoire soit déjà satisfait.
2.4 Effet illocutoire
À première vue, on pourrait définir l’effetillocutoire comme le fait que j, le destina-taire, croit que l’intention de i, l’émetteur,est que le contenu propositionnel deviennevrai.
Cependant, si l’on considère un agent tiersk observant (ou « écoutant ») l’acte de lan-
gage, la situation s’avère en réalité un peuplus complexe. Dans ce cas, l’effet illocu-toire sur k est que k croit que l’intentionde i est que j croit que le contenu proposi-tionnel devienne vrai.
____________________________________________________________________________ Annales du LAMSADE N°8
93

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 106/415
2.5 Effet perlocutoire
L’un des effets perlocutoires est que le
fait institutionnel représenté par le contenupropositionnel soit satisfait. Un autre effetperlocutoire est que le destinataire j croitque ce fait est satisfait.
Par exemple, dans le scénario de l’employéet du client, le fait que le client ait l’obliga-tion de payer n’est pas suffisant. Un autreeffet significatif est que le client soit effec-tivement informé de cette obligation. Il enva de même, par exemple, si l’effet per-locutoire est de nommer quelqu’un à unposte.
Par ailleurs, conformément à la discussionprécédente sur la force illocutoire, nousdistinguons en outre l’« effet perlocutoire
primaire » de l’« effet perlocutoire secon-daire ». Il n’y a d’effet perlocutoire secon-daire que lorsque la signification de l’actede langage est un ordre de faire une action.
Dans ce cas, l’effet secondaire est que l’ac-tion en question soit faite.
3 Formalisation
Nous adoptons la structure du langage decommunication inter-agent FIPA-ACL3,standardisé par l’organisme FIPA, pour dé-finir l’acte de langage qui nous intéresse.
Nous définissons formellement un acte delangage a avec effets institutionnels par lescomposantes suivantes :
a = < i, Declare( j, Dsn, cond) >FP = pPRE = q 1SRE = q 2
où :
– i est l’agent émetteur,– j est l’agent destinataire,– s est une institution,
3À l’unique différence que nous spécifions deux effets per-locutoires au lieu d’un seul.
– n est une une formule représentant lecontenu propositionnel,
– cond est une formule représentant unecondition,
– p est une formule représentant les pré-conditions de faisabilité,
– q 1 est une formule représentant les effetsperlocutoires primaires4,
– q 2 est une formule représentant les effetsperlocutoires secondaires.
Un tel acte de langage signifie que l’émet-teur i déclare au destinataire j son inten-tion, en accomplissant cet acte, de créer lefait institutionnel n relativement à l’insti-
tution s, étant donné le fait que cette ins-titution lui reconnaît officiellement le pou-voir de le faire lorsque les conditions condsont satisfaites.
3.1 Langage formel sous-jacent et sé-
mantique
La syntaxe du langage logique utilisé pour
exprimer les formules n, p, q 1 et q 2 est dé-finie comme suit.
Langage L0. L0 est un langage de logiqueclassique des prédicats du premier ordre.
Langage L. Si i, s et α sont des termes deL0 représentant respectivement un agent,une institution et une action, et si p etq sont des formules de L0 ou L, alorsBi p, E i p, donei(α, p), Op, Obgi(α < p),Permi(α < p), Prohi(α < p), Ds p, (¬ p),( p ∨ q ) and ( p ⇒s q ) sont des formules deL.
Nous construisons L au-dessus de L0 sim-plement afin d’éviter les complications in-hérentes aux quantificateurs hors de la por-tée des opérateurs modaux (voir [15]).
4Dans les spécifications de FIPA-ACL, l’effet perlocutoired’un acte de langage est désigné par le terme d’« effet ration-
nel », afin de rappeler sa signification intuitive comme étant laraison formelle pour laquelle l’acte en question est sélectionnédans un processus de planification. Dans cet article, nous ne re-prenons cette appellation qu’à travers les notations PRE et SREutilisées pour désigner respectivement les effets perlocutoiresprimaires et secondaires.
Actes communicatifs à effets institutionnels ___________________________________________________________________________
94

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 107/415
La signification intuitive des opérateursmodaux du langage L, ainsi que celle duconnecteur non standard ⇒s est la sui-vante :
Bi p : l’agent i croit que la proposition p estvraie.
E i p : l’agent i vient juste de faire en sorteque la proposition p soit vraie.
donei(α, p) : l’agent i vient juste de réali-ser l’action α et la proposition p était vraie juste avant la réalisation de α.
Op : il est obligatoire que la proposition psoit vraie.
Obgi(α < p) : il est obligatoire que l’agenti réalise l’action α avant que la proposition p devienne vraie.
Permi(α < p) : il est permis que l’agent iréalise l’action α avant que la proposition p devienne vraie.
Prohi(α < p) : il est interdit que l’agent iréalise l’action α avant que la proposition p devienne vraie.
Ds p : la proposition p est reconnue dansle contexte de l’institution s comme étantvraie.
p ⇒s q : dans le contexte de l’institutions, la proposition p compte pour la propo-
sition q , i.e. q est reconnue comme vraiepar l’institution dès lors que p est recon-nue comme vraie.
Les autres connecteurs logiques ∧, → et↔ sont définis classiquement en fonctiondes connecteurs ¬ et ∨. La permissionet l’interdiction qu’une proposition p soitvraie peuvent également être définies clas-siquement à partir de Op (respectivementpar ¬O¬ p et O¬ p).
Nous avons introduit les opérateursObgi(α < p), Permi(α < p) etProhi(α < p) car les obligations defaire n’ont de sens que si un délai leur
est explicitement associé (ici ce délai estspécifié par l’instant où la proposition pdevient vraie), afin de pouvoir vérifier sielles ont été violées ou non.
Nous laissons ouverte la possibilité de dé-finir des actions composites à partir d’ac-tions primitives avec des constructeursstandards tels que la séquence, le choix in-déterministe, le test, etc.
Enfin, nous introduisons les notations sui-vantes :
donei(α)def
= donei(α, true)
power(i,s,cond,α,f )def =
(cond ∧ donei(α))⇒s f ,où cond et f sont des formules de L.
donei(α) ne s’intéresse qu’au fait qu’unagent i vient juste de réaliser une action α,sans s’intéresser aux propositions qui pou-vaient être vraies juste avant la réalisationde cette action.
power(i,s,cond,α,f ) signifie que l’ins-titution s reconnaît à l’agent i a le pou-voir de créer une situation dans laquellela proposition f devient un fait institution-nel (relatif à l’institution s) en accomplis-sant l’action α dans des circonstances oùles conditions cond sont vérifiées.
En reprenant l’analyse informelle propo-sée à la section 2.2, les actes de langageà effets institutionnels dont la significationintuitive est ouvrir ou fermer sont formali-sés par un contenu propositionnel n de laforme : p ou ¬ p, où p est une formule deL0.
Si holds(i, r) est un prédicat signifiant quel’agent i est titulaire du rôle r (la notion derôle est alors définie dans le cadre d’une
institution, voir [8]), alors les actes de lan-gage nommer et destituer sont respecti-vement formalisés par un contenu propo-sitionnel n de la forme : holds(i, r) ou¬holds(i, r).
____________________________________________________________________________ Annales du LAMSADE N°8
95

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 108/415
Les actes de langage signifiant don-ner un pouvoir ou retirer un pou-voir sont respectivement formaliséspar un contenu propositionnel n dela forme : power(i,s,cond,α,f ) ou¬ power(i,s,cond,α,f ).
Les actes de langage signifiant ordonner , permettre ou interdire de faire une actionα avant un délai d sont respectivement for-malisés par un contenu propositionnel dela forme : Obgi(α < d), Permi(α < d) ouProhi(α < d).
D’une façon générale, l’expressivité dulangage L permet de définir des actes delangage à effets institutionnels ayant dessignifications potentiellement plus com-plexesquecellesdesactesexprimésparlesverbes usuels de la langue naturelle.
L’objet de ce travail n’étant pas directe-ment de définir la sémantique formellepour les opérateurs modaux du langage L,nous donnons seulement quelques indica-
tions sur leur sémantique et adoptons, tantque faire se peut, des définitions volontai-rement simples.
Pour l’opérateur épistémique Bi, nousadoptons un système de logique modalestandard KD (selon la terminologie deChellas [3]). L’opérateur dynamique doneiest défini comme une variante et une res-triction (voir [24]) de la logique propo-
sitionnelle dynamique spécifiée par Ha-rel dans [20]. L’opérateur dynamique E idéfini par un système de logique modaleconstruit avec les axiomes RE, C, ¬N et T.
Concernant l’opérateur d’obligation d’êtreO, nous adoptons un système de logiquedéontique standard, à savoir un système delogique modale KD. Concernant les opé-rateurs d’obligation de faire Obgi, Permi
et Prohi, nous adoptons la sémantique dé-finie dans [7], qui étend le système de lo-gique déontique dynamique défini par Se-gerberg dans [31].
Enfin, pour permettre le raisonnement sur
les faits institutionnels, nous adoptons,pour l’opérateur modal Ds et le connec-teur logique⇒s, la sémantique définie parJones et Sergot dans [21].
3.2 Composantes d’un acte de langage
avec effets institutionnels
Nous disposons maintenant des outils lo-giques adéquats pour définir formellementles différentes composantes d’un acte delangage avec effets institutionnels.
Contenu propositionnelLe contenu propositionnel est formé desdeux expressions Dsn et cond, où n etcond sont des formules logiques de L.
Préconditions de faisabilité
La précondition de sincérité exprime lefait que (1) l’agent émetteur i croit qu’ila le pouvoir institutionnel de créer le
fait institutionnel représenté par la for-mule Dsn en accomplissant l’acte de lan-gage a dans des circonstances où la condi-tion cond est vérifiée et que (2) ce mêmeagent i croit que cette condition est véri-fiée dans la situation courante. Cette pré-condition s’exprime donc par la formule :Bi( power(i,s,cond,a,Dsn) ∧ cond).
La précondition de pertinence (aucontexte) s’exprime par la formule :¬BiDsn, à savoir que l’agent émetteuri ne pense pas que le fait institutionnelreprésenté par la formule Dsn est (déjà)reconnu dans la situation courante parl’institution s.
Les préconditions de faisabilité d’un actede langage à effets institutionnels sontdonc formalisées par :
FP = Bi( power(i,s,cond,a,Dsn) ∧ cond)∧¬BiDsn
Effet illocutoire
Actes communicatifs à effets institutionnels ___________________________________________________________________________
96

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 109/415
Le fait que l’agent destinataire j croit quel’intention de l’agent émetteur i est queDsn soit satisfait s’exprime par la for-mule : B jI iDsn. Le fait qu’un agent ob-servateur k croit que l’intention de l’agentémetteur i porte sur le fait précédent s’ex-prime alors par la formule : BkI iB jI iDsn.
Il en résulte l’effet illocutoire E suivant :
E = BkI iB jI iDsn
Effets perlocutoires
L’effet perlocutoire primaire, à savoir queDsn soit satisfait et que l’agent destina-taire j croit que Dsn est satisfait, se for-malise par :
PRE = Dsn ∧B jDsn
L’effet perlocutoire secondaire dépend dela nature du contenu propositionnel n. Parexemple, si n estdelaforme Obgk(α < d),
où k peut désigner soit l’agent émetteur isoit l’agent destinataire j, l’effet perlocu-toire secondaire s’exprime par la formuledonek(α < d), à savoir que l’action α soitaccomplie par l’agent k avant le délai d. Ànoter que si k désigne l’émetteur, la signi-fication de l’acte de langage est un engage-ment. Dans le cas général, l’effet perlocu-toire secondaire est formalisé comme suit :
SRE =- donek(α < d), si n = Obgk(α < d),- ¬donek(α < d), si n = Forbk(α <
d),- true, dans les autres cas.
L’effet perlocutoire primaire Dsn estatteint dès lors que l’agent émetteuri a le pouvoir institutionnel approprié power(i,s,cond,a,Dsn), que les condi-tions cond sont satisfaites dans la situa-
tion courante (à savoir celle résultant del’accomplissement de l’acte de langagea) et que l’acte de langage a vient justed’être accompli. Formellement, c’est le caslorsque la formule suivante est vérifiée :
power(i,s,cond,a,Dsn) ∧ cond ∧
donei(a)
De la même façon, l’effet perlocutoire pri-maire B jDsn est atteint dès lors que la for-mule suivante est vérifiée :
B j( power(i,s,cond,a,Dsn) ∧cond∧donei(a))
L’effet perlocutoire secondaire donek(α <d) est atteint dès lors que l’agent k (émet-teur ou destinataire) adopte l’intention
d’accomplir l’action α avant le délai d etqu’il a effectivement la capacité d’accom-plir α. Dans cet article, nous ne formali-sons pas explicitement ces conditions carl’expression formelle de la notion de capa-cité est à elle seule un problème dur et nontrivial (voir [12]).
Remarquons que, même dans le cas d’unengagement, c’est-à-dire lorsque k désignel’agent émetteur i, il peut arriver que lesconditions pour atteindre l’effet perlocu-toire ne soient pas satisfaites. Par exemple,dans le scénario de l’employé et du client,si l’acte locutoire accompli par le clientconsiste à signer un document officiel danslequel il déclare qu’il paiera la factureavant la fin de la semaine, il se peut néan-moins qu’il n’ait pas réellement l’intentionde payer ou qu’il n’en ait pas la capacité.
L’effet perlocutoire secondaire¬donek(α < d) est atteint dès lorsque l’agent k (émetteur ou destinataire)adopte l’intention de s’abstenir d’accom-plir l’action α jusqu’à expiration du délaid et qu’il a effectivement la capacité de lefaire.
4 Comparaison avec d’autres
travaux
Il y a relativement peu de littérature ayantproposé une formalisation d’actes de lan-gage avec effets institutionnels.
____________________________________________________________________________ Annales du LAMSADE N°8
97

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 110/415
Dans [11], Dignum et Weigand consi-dèrent des actes de langage ayant pour ef-fet de créer des obligations, des permis-sions et des interdictions. Leur analyse estégalement fondée sur les concepts de lathéorie des actes de langage.
Une différence notable avec notre ap-proche est que, dans la leur, la force illo-cutoire des actes de langage étudiés est di-rective. Une autre différence est que leurseffets perlocutoires sont atteints dès lorsque l’émetteur a le pouvoir d’obliger ledestinataire à accomplir une action ou que
le destinataire a autorisé l’émetteur à or-donner de faire cette action. La premièrecondition, qui lie l’émetteur et le desti-nataire par une relation de « pouvoir »,se rapproche beaucoup de notre notion depouvoir institutionnel. Par contre, la se-conde, qui lie l’émetteur et le destina-taire par une relation d’« autorisation »,s’avère d’une nature assez différente etmanque, selon nous, de clarté quant au sta-
tut des obligations créées : ces obligationscomptent-elles pour des obligations offi-ciellement reconnues par une institutiondonnée?
Nous pouvons également noter quele pouvoir expressif de leur logiqueest plus limité que celui de la nôtre.Par exemple, l’acte de langage re-présenté par DIR p(i,j,α) dans leurformalisme est considéré dans le nôtrecomme un cas particulier d’acte de lan-gage avec effets institutionnels de laforme : < i, Declare( j, DsObg j(α <true),true) >. En outre, dans leur for-malisme, l’institution s, dans le cadre delaquelle les faits institutionnels sont re-connus, n’est pas spécifiée explicitement.
Dans [14], Firozabadi et Sergot intro-duisent l’opérateur Declaresin, qui signi-
fie que l’agent i déclare que n est vrai, oùn est supposé représenter un fait institu-tionnel. Ils définissent également l’opéra-teur P owin, qui signifie que l’agent i a lepouvoir de créer le fait institutionnel n. La
relation entre ces deux opérateurs est spé-cifiée par la propriété suivante :[DECL] Declaresin ∧ P owin → n
où [DECL] « exprime l’exercice d’un pouvoir de créer [le fait institutionnel] n par l’agent désigné par i »5. Il y a uneanalogie certaine entre cette propriété et lapropriété suivante qui caractérise notre ap-proche :
cond ∧ donei(a)∧ power(i,s,cond,a,n)→ Dsn
où a est l’acte de langage< i, Declare( j, Dsn, cond) >.
Il y a cependant quelques différences tech-niques mineures. L’opérateur Declaresinne fait pas de référence explicite au desti-nataire de l’acte de langage. Et le pouvoirinstitutionnel P owin reste indépendant ducontexte (il n’y a pas de condition condpour préciser les modalités d’exercice du
pouvoir).Une différence plus significative avec nostravaux est qu’il n’est pas fait de distinc-tion entre ce que nous appelons les effetsperlocutoires primaires et secondaires.
Dans [4], Cohen et Levesque montrentcomment les performatives peuvent êtreutilisés comme des requêtes ou des asser-tions, mais ils ne considèrent pas la créa-
tion de faits institutionnels.Dans [19], Fornara, Viganò et Colombettisoutiennent que tous les actes communi-catifs peuvent se spécifier en termes dedéclarations. Ils définissent une syntaxeformelle pour un langage de communi-cation agent qui repose sur les conceptsde la théorie des actes de langage etdes concepts d’institutions. Chaque type
d’acte communicatif est spécifié par despréconditions et postconditions. Mais cesconditions diffèrent des préconditions de
5Traduction de l’anglais : « expresses the exercise of a power
to create n by designated agent i ».
Actes communicatifs à effets institutionnels ___________________________________________________________________________
98

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 111/415
faisabilité et des effets perlocutoires. Deplus, il n’y a pas support logique formelpour définir la sémantique de ce langage.
Dans [13], El Fallah-Segrouchni et Le-maitre analysent informellement les dif-férents types d’interactions communica-tives entre agents électroniques ou groupesd’agents électroniques qui représententdes entreprises. Cependant, la contributionformelle de leur travail se limite aux dé-finitions formelles des obligations de fairepour des groupes d’agents.
Dans cet article, nous présentons une ex-tension possible du standard FIPA-ACLaux actes de communication à effets ins-titutionnels. Sous cet angle, il est intéres-sant de situer notre proposition, fondéesur la spécification des états mentaux desagents (dans la continuité de l’approcheFIPA), par rapport aux autres courants deformalisation des langages de communica-tion inter-agents, en particulier ceux fon-
dés sur la notion d’« engagements so-ciaux », qui sont défendus par des auteurscomme Singh [32, 33], Colombetti et al.[6, 18, 19] ou Chaib-draa et Pasquier [16].
Dans [19], les auteurs écrivent : « le princi- pal avantage de cette approche [fondée surles engagements sociaux] est que les enga-gements sont objectifs et indépendants dela structure interne de l’agent et qu’il est
possible de vérifier [extérieurement] si unagent se comporte en conformité avec lasémantique définie »6.
Remarquons que dans notre approche,les agents peuvent créer des engagements(que nous assimilons à des obligations en-vers soi-même) et bien d’autres formes desituations normatives comme des interdic-tions ou des permissions. Il est égalementpossible de vérifier si un acte de langage
à effets institutionnels a effectivement créé6Traduction de l’anglais : « the main advantage of this ap-
proach is that commitments are objective and independent of
agent’s internal structure, and that it is possible to verify whe-
ther an agent is behaving according to the given semantics ».
la situation normative attendue. En effet,cela ne dépend que du fait que l’institutionreconnaît à l’émetteur le pouvoir institu-tionnel correspondant, ce qui peut se véri-fier objectivement au niveau de ladite ins-titution, indépendamment de l’état mentalde l’émetteur ou du destinataire.
Cependant, conformément aux approchesfondées sur les états mentaux, il n’y a pasde moyen « extérieur » de vérifier, parexemple, si l’agent est sincère ou si l’inten-tion de l’agent en accomplissant l’acte delangage était bien d’en créer l’effet ration-
nel. Malgré leur caractère incertain, quiest par ailleurs une caractéristique inhé-rente des systèmes ouverts auxquels s’inté-resse l’organisme de standardisation FIPA,les actes mentaux restent néanmoins trèsutiles dans les perspectives de générationde plan et de reconnaissance d’intentionpar des agents autonomes.
5 Conclusion
Dans cet article, nous présentons une dé-finition formelle générale pour les actesde langage dont les effets visent à créerdes faits institutionnels. L’originalité dece travail réside dans le fait que tous lesactes de cette nature, y compris les ordres,sont considérés comme des déclaratifs. Enoutre, la formalisation proposée est par-faitement compatible et homogène aveccelle des assertifs et des directifs déjà spé-cifiés dans le langage de communicationinter-agent standardisé par FIPA. Les ré-sultats présentés peuvent ainsi constituerune proposition d’extension de ce langage.Dans un autre contexte (non abordé dans lecadre de l’article), nous avons égalementvérifié l’applicabilité de notre approche aucas de la procédure de la Lettre de Créditprésenté dans [1].
Par la suite, sur le plan théorique, ilnous faut encore examiner comment lesaxiomes qui spécifient la planificationd’actes de langage par un agent ration-
____________________________________________________________________________ Annales du LAMSADE N°8
99

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 112/415
nel doivent être adaptés pour prendre encompte ce nouveau type d’acte. Sur le planpratique, nous envisageons de mettre enoeuvre les actes de langage à effets insti-tutionnels et les concepts sous-jacents (no-tamment obligations, rôles et pouvoirs ins-titutionnels), par exemple en s’appuyantsur la brique « JADE Semantics Add-on »,disponible en open source, qui implante di-rectement les spécifications formelles dustandard FIPA-ACL [25].
Références
[1] G. Boella, J. Hulstin, Y-H. Tan, and L. van derTorre. Transaction trust in normative multiagent systems. In AAMAS Workshop on Trust in Agent Societies, 2005.
[2] J. Carmo and O. Pacheco. Deontic and ac-tion logics for collective agency and roles. InR. Demolombe and R. Hilpinen, editors, Pro-ceedings of the 5th International workshop on Deontic Logic in Computer Science. ONERA,2000.
[3] B. F. Chellas. Modal Logic : An introduction.
Cambridge University Press, 1988.[4] P. R. Cohen and H. Levesque. Performatives
in a Rationally Based Speech Act Theory. InR. C. Berwick, editor, Proc. of 28th Annualmeeting of Association of Computational Lin-guistics. Association of Computational Lin-guistics, 1990.
[5] R. M. Colomb. Information systems techno-logy grounded on institutional facts. In Work-shop on Information Systems Foundations :Constructing and Criticising. The Australian
National University, Canberra, 2004.[6] M. Colombetti and M. Verdicchio. An ana-
lysis of agent speech acts as institutional ac-tions. In C. Castelfranchi and W. L. Johnson,editors, Proceedings of the first international joint conference on Autonomous Agents and Multiagent Systems, pages 1157–1166. ACMPress, 2002.
[7] R. Demolombe, P. Bretier, and V. Louis. For-malisation de l’obligation de faire avec délais.In Troisièmes Journées francophones ModèlesFormels de l’Interaction, 2005.
[8] R. Demolombe and V. Louis. Normes, Pou-voirs et Rôles : vers une formalisation en lo-gique. In Actes des Treizièmes Journées fran-cophones sur les Systèmes Multiagents (JF-SMA), pp. 51–63, 2005.
[9] F. Dignum. Software agents and e-business,Hype and Reality. In R. Wieringa andR. Feenstra, editors, Enterprise InformationSystems III . Kluwer, 2002.
[10] F. Dignum. Advances in Agent Communica-tion. Springer verlag LNAI 2922, 2003.
[11] F. Dignum and H. Weigand. Communi-cation and Deontic Logic. In R. Wieringaand R. Feenstra, editors, Information Systems,Correctness and Reusability. World Scientific,1995.
[12] D. Elgesem. Action Theory and Modal Logic.PhD thesis, University of Oslo, Department of Philosophy, 1992.
[13] A. El Fallah-Seghrouchni and C. Lemaitre. Aframework for social agents’ interaction basedon communicative action theory and dynamicdeontic logic. In Proceedings of MICAI 2002, LNAI 2313. Springer Verlag, 2002.
[14] B. S. Firozabadi and M. Sergot. Power andPermission in Security Systems. In B. Chris-tianson, B. Crispo, and J. A. Malcolm, editors,Proc. 7th International Workshop on SecurityProtocols. Springer Verlag, LNCS 1796, 1999.
[15] M. Fitting and R. L. Mendelsohn. First-Order Modal Logic. Kluwer, 1998.
[16] R. Flores, P. Pasquier, and B. Chaib-draa.Conversational semantics with social com-mitments. In M-P. Huget R. van Eijk andF. Dignum, editors, International Workshop on Agent Communication (AAMAS’04), 2004.
[17] Foundation for Intelligent Physi-cal Agents. FIPA Communicative ActLibrary Specification. Technical report,http ://www.fipa.org/specs/fipa00037/, 2002.
[18] N. Fornara and M. Colombetti. Defining in-
teraction protocols using a commitment-basedagent communication language. In Procee-dings of the second international joint confe-rence on Autonomous Agents and Multi Agent Systems, pages 520–527. ACM Press, 2003.
[19] N. Fornara, F. Viganò, and M. Colombetti.Agent communication and institutional reality.In R. van Eijk, M. Huget, and F. Dignum, edi-tors, Developments in Agent Communication.Springer Verlag LNAI 3396, 2005.
[20] D. Harel. Dynamic logic. In D. Gabbay andF. Guenthner, editors, Handbook of Philoso- phical Logic, volume 2. Reidel, 1984.
[21] A. J. Jones and M. Sergot. A formal characte-risation of institutionalised power. Journal of the Interest Group in Pure and Applied Logics,4(3), 1996.
Actes communicatifs à effets institutionnels ___________________________________________________________________________
100

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 113/415
[22] S. O. Kimbrough and S. A. Moore. On auto-mated message processing in Electronic Com-merce and Work Support Systems : SpeechAct Theory and Expressive Felicity. ACM
Transactions on Information Systems, 15(4),1997.
[23] S. O. Kimbrough and Y-H. Tan. On leanmessaging with unfolding and unwrapping forElectronic Commerce. International Journalof Electronic Commerce, 5(1), 2000.
[24] V. Louis. Conception et mise en oeuvre demodèles formels du calcul et du suivi de plansd’actions complexes par un agent rationneldialoguant . PhD thesis, Université de Caen,France, 2002.
[25] V. Louis and T. Martinez. Un cadre d’inter- prétation de la sémantique de FIPA-ACL dans JADE . In Actes des Treizièmes Journées fran-cophones sur les Systèmes Multiagents (JF-SMA), pp. 101–113, 2005.
[26] J. McCarthy. Free will - even for robots. Jour-nal of Experimental and Theoretical Artificial Intelligence, (to appear).
[27] Routledge Encyclopedia of Philosophy On-line (version 2.0), consultable sur le web à :http ://www.rep.routledge.com
[28] D. Sadek. A study in the logic of intention.In Proc. of the 3rd Conference on Principlesof Knowledge Representation and Reasoning(KR’92), 1992.
[29] J. R. Searle. Speech Acts : An essay in the philosophy of language. Cambridge Univer-sity Press, New-York, 1969.
[30] J. R. Searle and D. Vanderveken. Foundationsof Illocutionary Logic. Cambridge UniversityPress, Cambridge, 1984.
[31] K. Segerberg. Some Meinong/Chisholm the-sis. In K. Segerberg and K. Sliwinski, editors, Logic, Law, Morality. A festrichft in honor of Lennart Aqvist , volume 51, pages 67–77. Upp-sala Philosophical Studies, 2003.
[32] M. P. Singh. Social and psychological com-mitments in multiagent systems. In AAAI FallSymposium on Knowledge and Action at So-cial and Organizational Levels, 1991.
[33] M. P. Singh. A social semantics for agentcommunication languages. In F. Dignum andM. Greaves, editors, Issues in Agent Commu-nication, pages 31–45. Springer Verlag, 2000.
____________________________________________________________________________ Annales du LAMSADE N°8
101

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 114/415

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 115/415
Un modèle d’interaction réaliste pour la simulation de marchésfinanciers
J. Derveeuw B. Beaufils P. Mathieu O. Brandouy†
Laboratoire d’Informatique Fondamentale de LilleUniversité des Sciences et Technologies de Lille
59655 Villeneuve d’ascq cédex – FRANCEderveeuw,beaufils,[email protected]
† Lille Economie et Management104 Avenue du Peuple Belge
59043 Lille cédex – [email protected]
Résumé :Dans les modèles de marché multi-agents utiliséshabituellement, la structure du marché est presquetoujours réduite à une équation qui aggrège les dé-cisions des agents de façon synchrone pour mettreà jour le prix de l’action à chaque pas de temps. Surles marchés réels, ce processus est totalement diffé-rent : le prix de l’action émerge d’interactions sur-venant de manière asynchrone entre les acheteurs etles vendeurs. Dans cet article, nous introduisons unmodèle de marché artificiel conçu pour être le plus
proche possible de la structure des marchés réels.Ce modèle est basé sur un carnet d’ordres à tra-vers lequel les agents échangent des actions de ma-nière asynchrone. Nous montrons que, sans émettred’hypothèses particulières sur le comportement desagents, ce modèle exhibe de nombreuses proprié-tés statistiques des marchés réels. Nous soutenonsque la plupart de ces propriétés proviennent de lamanière dont les agents interagissent plutôt que deleurs comportements. Ce résutat expérimental estvalidé et renforcé grâce à l’utilisation de nombreuxtests statistiques utilisés par les économistes pour
caractériser les propriétés des marchés réels. Nousfinissons par quelques perspectives ouvertes par lesavantages de l’utilisation de tels modèles pour ledéveloppement, le test et la validation d’automatesd’investissement.
Mots-clés : Systèmes Multi-Agents, Marchés Fi-nanciers, Simulation
Abstract:In usual multi-agent stock market models, marketstructure is mostly reduced to an equation matching
supply and demand, which synchronously aggre-gates agents decisions to update stock price at eachtime steps. On real markets, the process is however
0Ce travail est cofinancé par le contrat de plan Etat-Région
et les fonds européen FEDER
very different : stock price emerges from one-to-one asynchronous interactions between buyers andsellers at various time step. In this article, we intro-duce an artificial stock market model designed to beclose to real market structure. The model is basedon a centralized orderbook through which agentsexchange stocks asynchronously. We show that, wi-thout making any strong assumption on agents be-haviors, this model exhibits many statistical proper-ties of real stock markets. We argue that most of market features are implied by the exchange pro-
cess more than by agents behaviors. This experi-mental result is validated and strengthen using se-veral tests used by economists to characterize realmarket. We finally put in perspective the advan-tages of such a realistic model to develop, test andvalidate behavior of automated trading agents.
Keywords: Multi-Agent Systems, Stock Markets,Simulations
1 Introduction
Les modèles de marché artificiels sontconçus pour capturer les propriétés es-sentielles des marchés d’actions réels etainsi pouvoir reproduire, analyser ou com-prendre les dynamiques des marchés avecdes expériences computationnelles. En ef-fet, de nombreuses questions restent sansréponse malgré les avancées de la re-cherche moderne en finance : par exemple,
les dynamiques de marché exhibent desparticularités statistiques particulières, ap-pelées faits stylisés, dont l’origine estpresque inconnue. Comme les marchésréels sont des systèmes complexes, il n’est
103

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 116/415
pas envisageable de mener des études surl’origine de ces faits directement : detrop nombreux paramètres restent hors decontrôle. Les simulations multi-agents deces marchés semblent donc être la cléd’une meilleure compréhension de leurspropriétés.
Concevoir de tels modèles implique desimplifier la réalité le plus possible, pourn’en garder que les propriétés et les carac-téristiques essentielles. Dans la littérature(cf par exemple [1], [3] ou [7]), la com-plexité structurale des marchés est la plu-
part du temps évitée : elle est remplacéepar une équation qui pondère l’offre et lademande qui sert de modèle de formationdu prix. Cette simplification est en com-plète contradiction avec la réalité des mar-chés d’actions où les prix émergent des in-teractions entre les agents à traver un car-net d’ordres, qui n’agit pas comme une en-tité centralisatrice mais comme un point derencontre utilisé par les agents pour inter-
agir et réaliser des échanges.
Il peut être objecté que les équations deformation du prix et les carnets d’ordressont presque équivalents comme cela estgénéralement admis en théorie écono-mique standard. Cette hypothèse est vraieà un niveau macroscopique, mais noussoutenons que considérer uniquement ledéséquilibre entre l’offre et la demandedans des simulations multi-agents, où onse concentre sur le niveau micro, n’estpas suffisant pour obtenir des résultats ex-périmentaux robustes. En effet, l’équationatténue les conséquences des événementsrares et extrêmes sur les dynamiques deprix. De plus, les conséquences de lamicrostructure du marché et des interac-tions entre agents sur ces dynamiques sontmises de côté, ce qui perturbe le dévelop-pement du comportement des agents : il est
nécessaire de les complexifier à outrancepour obtenir des faits stylisés proches dela réalité, ce qui affaiblit les conclusionsqui peuvent être tirées des expériences.De plus, les comportements de ces agents
sont déconnectés de la réalité des marchéspuisque les entrées et sorties de leurs stra-tégies ne correspondent pas à celles desmarchés réels. Ceci est un problème ma-
jeur : les compagnies financières aime-raient pouvoir tester des automates d’in-vestissement sur des marchés artificielsavant de leur laisser libre champs sur lesmarchés réels, ce qui n’est pas possible sile marché artificiel est trop loin de la réa-lité.
Pour répondre à ce problème, nous pro-posons donc un modèle de marché artifi-ciel qui tient compte des caractéristiquesdes marchés réels : l’activité de tradingse déroule de manière continue, grâce àun mécanisme asynchrone. Les agents in-teragissent à travers le marché en postantdes ordres dans un carnet d’ordres, qui estune sorte de tableau noir , comme cela sepasse sur les marchés réels. Les comporte-ments des agents utilisés dans nos simu-lations ne sont pas spécifiquement déve-
loppés pour reproduire une quelconque lo-gique d’investissement : ils sont volontai-rement conçus pour influer le moins pos-sible sur les résultats obtenus, afin d’étu-dier les effets du modèle d’interactions (dela structure de marché) sur la dynamiquedes prix.
Dans cet article, nous présentons d’abordles propriétés statistiques des marchésréels, qui nous servent à valider notremodèle. Nous présentons ensuite les mo-dèles de marché traditionnels qui utilisentune équation pour remplacer la structuredu marché. Nous présentons finalementnotre modèle de marché basé sur un car-net d’ordres, et montrons qu’il permet dereproduire les caractéristiques principalesdes marchés réels sans faire d’hypothèsesspécifiques sur la manière dont les agents
se comportent. Pour finir, nous discutonsdes implications de ces résultats sur la ma-nière de concevoir des modèles de marchéet exposons quelques perspectives de nostravaux.
Un modèle d'interaction réaliste pour la simulation de marchés financiers ___________________________________________________________________________
104

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 117/415
2 Finance, statistique et valida-tion
Les propriétés statistiques des marchésd’actions réels (appelées faits stylisés) ontété très largement étudiés depuis le milieudu 20ème siècle : de nombreux tests sta-tistiques ont été développés pour caracté-riser ces propriétés, qui sont maintenantrelativement facile à décrire avec des mo-dèles mathématiques. Cependant, leur ori-gine est quasiment inconnue : ces proprié-tés apparaissent-elles à cause de la struc-
ture du marché ? Sont-elles une consé-quence des stratégies d’investissement desagents ? Personne ne peut encore prétendrerépondre de manière ferme à cette ques-tion.
FIG . 1 – Rendements journaliers du titreBMW et leur distribution
La simulation multi-agents des marchéssemble être la clé d’une meilleure com-préhension de la manière dont ces faitsstylisés émergent : chaque partie du mar-ché, de sa structure à ses acteurs, peut êtreanalysée, controllée et observée en profon-deur, ce qui n’est pas possible sur des mar-chés réels. Pour s’assurer qu’un tel modèlefonctionne, les séries temporelles obtenuespar simulation doivent être validées, c’est-à-dire que leur degré de similitude avec lesséries temporelles provenant des marchésréels doit être quantifié.
De nombreux tests statistiques peuventêtre utilisés pour atteindre ce but mais ils
peuvent être classés en deux catégoriesprincipales. La première catégorie de testsa pour objectif de caractériser la formede la distribution des rendements1. Il estadmis que pour des données journalières,cette distribution est leptokurtique, c’està dire que les événements moyens et ex-trêmes y surviennent plus fréquemmentque dans une distribution normale (cf parexemple la partie droite de la figure 1). Laseconde catégorie de tests statistiques s’in-téresse aux dépendances existant entre lestermes de la série. La théorie économiquenous dit que les rendements devraient être
indépendamment et identiquement distri-bués : il ne devrait donc pas être possibled’exprimer un rt en fonction des rt−i, i ∈[1, t − 1]. Sur les données provenant desmarchés réels, les séries de rendements ex-hibent bien cette propriété, qui peut êtrevérifiée avec différentes méthodes (régres-sion vers un modèle théorique connu [5],test BDS, etc). Cependant, en regardantla série des rendements en valeur abso-
lue (i.e. la série des |rt|), les données ex-périmentales exhibent une dépendance àcourt terme. Ce phénomène, qui est unedes caractéristiques majeures des marchésfinanciers, est présenté à la figure 2. Sur lagauche est dessiné la fonction d’autocor-rélation des rendements de l’action BMW,opposée à celle de sa valeur absolue surla droite : il apparaît clairement que la sé-rie des rendements en valeur absolue ex-
hibe une dépendance significative à courtterme.
3 Modèles de marché basés surdes équations
Depuis que les premiers modèles multi-agents de marchés ([10]) ont été publiésau début des années 90, un grand nombre
de modèles de marché ont été développés.Ils ont tous des objectifs différents : cer-tains ont été développés pour reproduire
1par rendements, nous désignons la série définie par
rt = log( pt) − log( pt−1) où pt est une série de prix
____________________________________________________________________________ Annales du LAMSADE N°8
105

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 118/415
FIG . 2 – Fonction d’autocorrélation desrendements du titres BMW et de leur va-leur absolue
des phénomènes particuliers comme les
bulles et les krachs ([4]), d’autres pour étu-dier des places de marché spécifiques ([9])ou pour mieux comprendre les relationscachées entre les acteurs du marché et ladynamique des prix.
External world MarketAgents
influence desires
results
FIG . 3 – Architecture générale d’un mo-dèle de marché
Ces modèles sont composés de trois par-ties distinctes : le marché lui-même, quipermet aux agents d’échanger des actions,les agents et éventuellement un modèledu monde, qui peut influencer les déci-sions des agents avec des informations.Cette situation est résumée à la figure 3 :
les agents communiquent leurs désirs aumarché, influencés par des informationsexogènes. Le marché informe ensuite lesagents de la satisfaction de leurs désirs.Chacun des trois modules présenté à la fi-gure 3 peut être modélisé de différentesfaçons : le marché peut être une équationou une structure de communication com-plexe, les agents peuvent être cognitifs, ré-actifs ou remplacés par une équation. End’autres termes, un modèle de marché ar-
tificiel peut être plus ou moins agent .
Les modèles qui réduisent la structure dumarché à une équation sont la plupart dutemps développés par des économistes uti-
lisant les simulations multi-agents avecun point de vue mathématique sur les si-mulations, ce qui pourrait expliquer l’ab-sence de prise en compte des interactions
entre les agents. Cette équation pondère labalance entre l’offre et la demande pourproduire un prix. Cela implique que cesmarchés artificiels sont synchrones et quechaque agent doit parler à chaque pas detemps. Chaque agent émet une direction(acheter, vendre ou ne rien faire) qui estensuite mise en relation avec les décisionsdes autres agents. Un prix pt est alors gé-néré à chaque pas de temps avec un pro-
cessus du type :
pt = pt−1 + β (Bt −Ot) + t
où Bt est le nombre d’agents désireuxd’acheter et Ot le nombre d’agents dési-reux de vendre au temps t. Cette équationsignifie que si plus d’agents sont désireuxd’acheter que de vendre, le prix augmenteet inversement. Cette famille d’équations apour but de prendre en compte la théoriemacroéconomique connue sous le nom deloi de l’offre et de la demande, qui dit queplus un grand nombre de personnes sontdésireuses d’acheter un bien, plus son prixaugmente.
Cependant, cette propriété est macrosco- pique. Les simulations réalisées avec cesmodèles sont donc biaisées : elles utilisentune loi macroscopique (observée expéri-mentalement) pour reproduire des proprié-tés provenant d’entités microscopiques,sans tenir compte des relations existantentre elle. En effet, comme ces équationsimpliquent que les agents prennent leursdécisions de manière synchrone, ils n’in-teragissent pas ! Ils communiquement uni-quement leurs désirs au marché au tempst, qui les informe au temps t + 1 du résul-
tat de leur demande. Sur les marchés réels,les agents observent au contraire constam-ment les désirs des autres agents sur un ta-bleau noir public (appelé carnet d’ordres)et peuvent y réagir immédiatement.
Un modèle d'interaction réaliste pour la simulation de marchés financiers ___________________________________________________________________________
106

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 119/415
4 Notre modèle
Nous avons vu dans la section précédente
que le coeur d’un modèle de marché multi-agents ne peut être réduit à une équationpour reproduire un marché de manière réa-liste. Dans la lignée de [11], nous avonsdonc conçu notre modèle en respectantla façon dont les agents interagissent surles marchés réels : notre modèle est cen-tré sur un carnet d’ordres qui permet auxagents de confronter leurs désirs. Ce choixa quelques conséquences sur la manière de
penser le marché et le comportement desagents :
– Les agents ne prennent plus leurs dé-cisions de manière aveugle, sans tenircompte des décisions des autres agentscomme dans les modèles équationnels.Ils peuvent observer les croyances etdésirs des autres agents en temps réeldans le carnet d’ordres et donc prendredes décisions relatives aux positions desautres. Ce n’est pas le cas dans les mo-dèles équationnels, où les agents basentleurs stratégies sur les décisions passéesdes autres agents, à cause du processusde prise de décision centralisé et syn-chrone.
– Les stratégies des agents doivent fournirune sortie plus complète que précedem-ment : alors que dans les modèles équa-tionnels, ils peuvent uniquement donnerun signal (acheter ou vendre), le carnet
d’ordres nécessite une direction, un prixet une quantité. Ces prérequis complexi-fient les comportements mais permettentde disposer d’un plus grand nombre destratégies à étudier, et d’être plus prochede la réalité. De plus, les comportementsd’agents déjà existants peuvent être faci-lement adaptés à ce modèle sans effort.
4.1 Le modèle de carnet d’ordres
Le carnet d’ordres, qui est le coeur denotre modèle de marché, est conçu pourêtre aussi minimal que possible : comme
notre but est d’étudier les effets des in-teractions entre les agents sur les dyna-miques de marché, nous voulons éviter aumaximum de devoir paramétrer outranciè-
rement notre modèle pour éviter les ef-fets de bords non souhaités. Le carnetd’ordres peut être relié au concept de ta-bleau noir (cf par exemple [6] pour plus dedétails sur ces systèmes), bien connu dansles autres champs d’application des simu-lations multi-agents : les agents publientleurs désirs (acheter ou vendre des actionsà un certain prix) dans le carnet d’ordrespour rendre cette information publique, et
attendent que d’autres agents interagissentavec eux.
Carnet d’ordres et ordres. Le carnetd’ordres est composé, comme sur lesmarchés réels, de deux listes triées : lapremière regroupe les ordres d’achat etla seconde les ordres de vente. Ces listessont ordonnées en fonction des prix as-sociés aux ordres (un ordre d’achat plus
généreux sera placé avant un ordre moinsgénéreux) et selon leur date d’émission(si deux ordres avec le même prix et lamême direction sont émis, le premier àêtre rentré dans le carnet est le premierà être satisfait). La figure 4 présente unexemple typique de carnet d’ordres.
50.45 $ 21 000
35 00050.60 $
49.60 $ 28 000
47 00049.37 $
Buy orders
Sell orders
best limits
FIG . 4 – Exemple de carnet d’ordres
Les ordres sont tous des ordres limites, cequi signifie que les prix qui leur sont asso-
____________________________________________________________________________ Annales du LAMSADE N°8
107

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 120/415
ciés sont le prix maximum (respectivementminimum) auquel l’agent est prêt à acheter(vendre) ses actions. Ces ordres sont com-posés d’une direction (acheter ou vendre),d’un prix limite, d’une quantité et d’undate d’émission.
Quand un ordre est envoyé au carnetd’ordres par un agent, il est comparé auxordres qui sont déjà dans le carnet pourvoir si l’un d’eux lui correspond :– Si c’est le cas, une transaction inter-
vient entre les deux agents qui pos-sèdent les ordres compatibles. Cela si-
gnifie que l’un des agents donne del’argent à l’autre en échange d’actions.Cette configuration correspond au cas 2de la figure 5.
– S’il n’existe aucune contrepartie dans lecarnet d’ordres, l’ordre est inséré dansune des deux listes en accord avec lescritères présentés précedemment (voir lecas 1 de la figure 5).
Gestion du temps. Dans les simulationsbasées sur des modèles équationnels, letemps est divisé en pas de temps durantlesquels les agents doivent prendre leursdécisions. Ces décisions sont prises en pa-rallèle, ce qui signifie que les ensemblesd’informations dont ils disposent incluentseulement des informations passées.
Dans les modèles à carnet d’ordres, la ges-
tion du temps ne partage pas du tout lamême logique : le système de cotation cen-tral n’aggrège pas les décisions des agentsà des pas de temps particuliers et les par-ticipants au marché sont libres de par-ler quand ils le veulent. Ils peuvent parexemple réagir instantanément à une infor-mation endogène (un nouvel ordre dans lecarnet) ou exogène (une nouvelle). Avecles modèles équationnels, cela ne peut pasêtre simulé puisque les agents réagissentsimultanément à un événement au pas detemps suivant.
Dans les simulations informatiques, faireprendre des décisions en temps réel
aux agents doit être simulé. C’est unproblème classique dans les simulationsmulti-agents, spécialement quand le pro-tocole de communication utilisé est un ta-bleau noir (cf par exemple [2]). La mé-thode naïve consiste à encapsuler chaqueagent dans un thread système, méthode laplus simple pour simuler des processus pa-rallèles. Cependant, les threads sont dé-pendants du système et leur comportementne peut être garanti sur la plupart d’entreeux. C’est un problème majeur : les simu-lations ne peuvent pas être reproduite etsont perturbées par les autres applications
utilisant le processeur, ce qui altère la qua-lité des résultats expérimentaux.
Une autre possibilité est de simuler lefonctionnement des threads pour garder uncontrôle sur leur comportement et doncéviter les problèmes mentionnés précé-demment. Il est donc nécessaire de déve-lopper un scheduler . Le premier élémentà prendre en compte est que la parole
doit être donnée aux agents dans un ordrenon déterministe, pour éviter que certainsd’entre eux utilisent leur position pour pro-fiter d’autres agents.
Cependant, la gestion du temps n’est pasaussi simple : il existe de nombreuses fa-çons pour donner la parole aléatoirement àdes agents. La première est de donner l’op-portunité de parler à tous les agents dansun ordre aléatoire. Si un agent est autoriséà parler, il ne pourra plus reprendre la pa-role avant que tous les autres agents aientparlé. C’est un tirage aléatoire sans remise,qui garantit une équité de temps de paroleentre tous les agents, mais qui empêche unagent de parler deux fois de suite, ce quin’est pas réaliste.
La seconde possibilité est de donner la pa-role à un agent aléatoirement, sans tenir
compte du fait qu’il ait parlé ou non. L’in-convénient majeure de ce tirage avec re-mise est que certains agents peuvent res-ter hors du marché (ne peuvent jamais par-ler) à cause de certaines séquences géné-
Un modèle d'interaction réaliste pour la simulation de marchés financiers ___________________________________________________________________________
108

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 121/415
50.45 $ 21 000
35 00050.60 $
49.60 $ 28 000
47 00049.37 $
Buy orders
Sell orders
50.45 $ 21 000
35 00050.60 $
49.60 $ 28 000
47 00049.37 $
Buy orders
Sell orders
new buy order
Buy orders
Sell orders
49.37 $ 47 000
28 00049.60 $
case 1
new buy order50.45 $ 21 000
35 00050.60 $
Buy orders
Sell orders
49.37 $ 47 000
12 000
case 2
50.50 $ 37 000
50.60 $ 35 000
50.50 $ 16 000
... ...
49.52 $49.60 $ 28 000
49.52 $ 12 000
FIG . 5 – Fonctionnement d’un carnet d’ordres
rées par le générateur de nombres aléa-toires utilisé dans le scheduler. Cependant,cette situation est plus réaliste que la pré-cédente : sur les marchés réels, certains
agents sont très actifs alors que d’autresinterviennent très rarement sur le marché.Pour ces raisons, nous utilisons ce principed’ordonnancement dans nos simulations.
4.2 Agents
La microstructure d’un modèle de marchéartificiel ne peut être testée ou évaluée sansdes agents échangeant des actions à tra-
vers elle. Nous avons vu que dans la litté-rature, les agents sont cognitifs et exhibentdes comportements complexes. De plus,ils utilisent souvent des modèles élabo-rés d’information pour prendre en comptedes évenements provenant de l’extérieurdu marché dans leur processus de prise dedécision. Ces facteurs amènent tellementde complexité au marché artificiel qu’il estvraiment très difficile de répondre à des
questions concernant les dynamiques deprix obtenues par simulation : leurs pro-priétés proviennent-elles du comportementdes agents ? de la structure du marché ?du modèle d’informations qui influence les
agents dans leur prise de décision ? d’unmélange de tous ces facteurs ?
Pour être capable de donner des éléments
de réponses à ces questions, nous avonschoisi de concevoir des comportementsaléatoires, dans la lignée des travaux de[8], ce qui permet de minimiser l’influencedu modèle d’agent sur les résultats obte-nus. En effet, si les agents émettent desordres avec des prix tirés au hasard demanière uniforme et que la dynamique deprix en sortie de simulation suit une distri-bution non-uniforme (une gaussienne parexemple), il devient plus facile d’éliminer
l’hypothèse que ce résultat est dû à un ef-fet de bord des comportements qu’avec descomportements complexes. De plus, nosagents sont purement réactifs, ce qui im-plique que nous ne faisons pas d’hypo-thèses fortes sur leurs capacités de raison-nement, ni sur les informations qu’ils uti-lisent pour prendre leurs décisions, commecela est fait dans la plupart des autres tra-vaux. Le choix d’utiliser des comporte-
ments d’agents extrêmement simples estdonc totalement délibéré dans cet article :notre but n’est pas de concevoir des agentsles plus réalistes possibles, mais de validerla structure de notre modèle de marché sé-
____________________________________________________________________________ Annales du LAMSADE N°8
109

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 122/415
parément des deux autres composants dumodèle.
Nos agents peuvent être assimilés à des zero intelligence trader qui postent desordres dans une direction aléatoire, pourun prix et une quantité aléatoire d’actions.Chaque fois qu’ils doivent passer un nou-vel ordre, nos agents prennent une décisionen fonction des règles suivantes :
– Si un des deux côtés du carnet d’ordresest vide, l’agent émet un ordre dans cettedirection, avec un prix tiré au hasard
dans [1, +∞[. Cette règle est nécessairepour initialiser le carnet d’ordres.
– Si ce n’est pas le cas, les agents choi-sissent aléatoirement entre émettre unordre de marché et un ordre limite :– Un ordre de marché est un ordre qui
est contrepartie de la meilleure limited’un des côtés du carnet d’ordres. Enpratique, cela signifie que l’agent tireune direction au hasard (acheter ou
vendre) et émet un ordre dont le prixest égal à la meilleure limite de l’autrecôté du carnet. En d’autres termes,c’est un ordre pour acheter ou vendreà n’importe quel prix.
– Pour émettre un nouvel ordre limite,l’agent choisit aléatoirement une di-rection et, en fonction de celle-ci, tirealéatoirement un prix dans :– [meilleure limite à l’achat, +∞[
pour un ordre de vente– [1, meilleure limite à la vente] pour
un ordre d’achat
Dès qu’un agent a émis un nouvel ordre,il arrête d’en émettre de nouveaux jusqu’àce que cet ordre soit satisfait ou jusqu’àce qu’il ait dépassé son délai de validité .Ce délai de validité est assigné de ma-nière aléatoire à chaque agent au début dela simulation et reste constant au cours du
temps. Cela garantit principalement qu’unordre dont le prix est trop loin des limitescourantes du carnet n’y reste pas jusqu’à lafin de la simulation sans jamais être satis-fait.
4.3 Expérimentations
Nous avons vu dans la première section
que les données expérimentales obtenuespar simulation peuvent être validées en uti-lisant de nombreux tests statistiques quiassurent que ces séries temporelles repro-duisent correctement les caractéristiquestypiques d’un marché financier (les faitsstylisés). Cette section présente les résul-tats obtenus avec notre modèle basé sur lesinteractions.
Nos expériences2 sont toutes réalisées avec
1000 agents pendant environ 20000 pas detemps. Ces informations sont données àtitre purement indicatif : les expériencespeuvent être réalisées avec un nombred’agents beaucoup plus important pour lesmêmes résultats, la seule limite étant letemps et la mémoire nécessaire au déroule-ment de la simulation. En d’autres termes,des simulations large échelle peuvent êtreenvisagées, mais elles ne changeront pas la
qualité des résultats obtenus.
Forme de la distribution des rendements.
Nous avons vu dans la première sectionque la forme de la distribution des rende-ments devrait être une normale avec un ex-cès de kurtosis d’approximativement 4, si-gnifiant que la distribution des rendementsprésente des queues épaisses. La table 1montre les résultats obtenus avec notre
modèle : la kurtosis mesurée oscille autourde 4.5, ce qui est similaire à ce qui peut êtreobservé avec les données provenant desmarchés réels (cf colonne de droite pourune comparaison). De plus, ce résultat estmeilleur que ceux obtenus par [1] avec unmodèle équationnel. La figure 6 montre laforme de la distribution des rendements,très similaire à celle d’un marché réel (cf figure 1).
Autocorrélation des rendements. Nousavons vu précedemment que l’une des
2Le simulateur utilisé pour réaliser ces expérimentations est
disponible sur simple demande aux auteurs
Un modèle d'interaction réaliste pour la simulation de marchés financiers ___________________________________________________________________________
110

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 123/415
Description Résultat(expéri-mental)
Résultat(donnéesréelles)
Excess kurtosis 4.52 4.158
Aug. Dickey-Fuller -20.47 -18.47ARCH 100% 100%
TAB . 1 – Résultats statistiques obtenusavec notre modèle basé sur les interac-tions, comparés à ceux obtenus avec desdonnées réelles
FIG . 6 – Exemple de série de rendements
obtenus avec notre modèle et leur distribu-tion
caractéristiques majeures des rendementsest qu’ils n’exhibent pas d’autocorrélationsignificative mais qu’une dépendance àcourt terme existe lorsqu’on s’intéresse àleurs valeurs absolues. La figure 7 présentele tracé de la fonction d’autocorrélationdes rendements et de leur valeur absoluepour un jeu de données généré par notremodèle. Si on les compare à ceux obtenussur des données réelles (cf figure 2),nous pouvons voir clairement que despropriétés similaires à celles observablesen réalité peuvent être reproduites avecnotre modèle. Ces propriétés peuvent êtrevérifiées numériquement en utilisant letest de l’Augmented Dickey Fuller quiteste l’hypothèse nulle La série possède
une racine unitaire. La table 1 montreles résultats de ce test avec nos séries :l’hypothèse de la présence d’une racineunitaire est rejetée à un très fort taux deconfiance, comme avec les données réelles
(cf colonne de droite).
FIG . 7 – Fonction d’autocorrélation d’unesérie de rendements obtenus par simula-tion et de leur valeur absolue
Nous avons vu dans cette section que la sé-rie temporelle obtenue avec notre modèleexhibe les mêmes propriétés statistiquesque les jeux de données réels. Ces résultatsconfirment et améliorent les résultats pré-liminaires obtenus dans [11]. Cela montreque notre modèle de marché asynchroneet continu est à même de reproduire la
plupart des caractéristiques des marchésfinanciers sans faire d’hypothèse particu-lière sur le comportement des agents ou surun éventuel modèle du monde.
5 Conclusion
Nous avons présenté dans cet article notremodèle de marché, basé sur un carnet
d’ordres. L’utilisation de ce modèle d’in-teractions, semblable à un tableau noir, im-plique une cotation asynchrone et continuecomme sur les marchés réels. Il est opposéaux modèles classiques, qui aggrègent lesdécisions des agents de manière synchroneavec une équation qui sert de substitut aumécanisme d’interaction du marché.
Les résultats obtenus avec notre modèlemontrent qu’il est possible de reproduire
la plupart des faits stylisés observables surles marchés réels avec un modèle de mar-ché multi-agents basé uniquement sur lesinteractions. Ces résultats sont fortementsimilaires à ceux obtenus dans la littérature
____________________________________________________________________________ Annales du LAMSADE N°8
111

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 124/415
avec les modèles équationnels. Cependant,notre modèle est beaucoup plus réaliste :nous respectons le protocole utilisé par lesagents pour interagir à travers le marché,ce qui n’est pas les cas des modèles précé-dents.
Nous soutenons donc que de tels modèles,continus et asynchrones, doivent être uti-lisés pour simuler le fonctionnement desmarchés financiers. Le modèle de carnetd’ordres est si proche de la réalité qu’au-cun problème de validation ne subsiste auniveau de la manière dont les agents inter-
agissent, c’est-à-dire échangent des titres.De plus, développer de nouveaux compor-tements pour les agents est simplifié : lesstratégies usuelles de trading peuvent êtreimplémentées telles quelles, sans avoir àmodifier leurs entrées et sorties pour lesadapter au modèle de marché artificiel.
Concernant des considérations techniques,nous pouvons remarquer que le carnet
d’ordres ne nécessite pas de paramètres :cette particularité permet de ne pas avoir àles régler de manière hasardeuse pour fairefonctionner le modèle correctement. Deplus, notre modèle est conçu sur des basessolides : en adaptant des techniques d’or-donnancement bien connues dans d’autresdomaines de la simulation multi-agents,nous assurons qu’aucun effet de bord in-désirable ne pertube nos simulations.
Maintenant que nous avons montré quenotre modèle basé sur les interactions per-met de reproduire les faits stylisés obser-vables sur les marchés, nous allons nousconcentrer sur l’élaboration de nouveauxcomportements d’agents pour essayer demieux comprendre certains phénomènesde marché comme les bulles et les krachs,dont les origines sont encore mal com-prises par les économistes de nos jours.
Références
[1] B. Le Baron, W.B. Arthur, and R. Palmer.Time series properties of an artificial stock
market. Journal of Economic Dynamics and Control, 23 :1487–1516, 1999.
[2] N. Carver and V. Lesser. The evolution of blackboard control architectures. Expert Sys-
tems with Applications, 7 :1–30, 1994.[3] S. Cincotti, L. Ponta, and S. Pastore.
Information-based multi-assets artificialstock market with heterogeneous agents. InWorkshop on the Economics of Heteroge-neous Interacting Agents 2006 WEHIA06 ,2006.
[4] J. Derveeuw. Market dynamics and agents be-haviors : a computational approach. Artificial Economics, 564 :15–27, 2005.
[5] Robert F. Engle. Garch 101 : The use of
arch/garch models in applied econometrics. Journal of Economic Perspectives, 15 :157–168, 2001.
[6] R. Englemore and T. Morgan. Blackboard Systems. 1988.
[7] F. Ghoulmie, R. Cont, and J.P. Nadal. Hetero-geneity and feedback in an agent-based mar-ket model. Journal of Physics : Condensed Matter , 17 :1259–1268, 2005.
[8] Dhananjay K. Gode and Shyam Sunder. Al-locative efficiency of markets with zero-intelligence traders : Market as a partial sub-stitute for individual rationality. Journal of Political Economy, 101 :119–137, 1993.
[9] M. Marchesi, S. Cincotti, S. M. Focardi, andM. Raberto. The Genoa artificial stock mar-ket : microstructure and simulation, volume521 of Lecture Notes in Economics and Ma-thematical Systems, pages 277–289. Springeredition, 2003.
[10] R.G. Palmer, W.B. Arthur, J.H. Holland,B. LeBaron, and P. Tayler. Artificial econo-mic life : A simple model of a stockmarket.
Physica D, 75 :264–274, 1994.[11] M. Raberto, S. Cincotti, C. Dose, S.M. Fo-
cardi, and M. Marchesi. Price formation in anartificial market : limit order book versus mat-ching of supply and demand. Nonlinear Dy-namics and Heterogenous Interacting Agents,2005.
Un modèle d'interaction réaliste pour la simulation de marchés financiers ___________________________________________________________________________
112

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 125/415
Le rôle de l’impact émotionneldans la communication des événements
J-L. Dessallesdessal l es@enst . f rwww. enst . f r / ~j l d
ParisTech – ENST (CNRS-LTCI, UMR 5141)75013 Paris – FRANCE
Résumé :L’impact émotionnel d’un événement est un fac-teur essentiel pour prédire le fait qu’il serarapporté. Nous montrons qu’un modèle minimalde l’impact émotionnel, basé sur la loi de Fechner, permet de déduire un certains nombre de faitsconcernant la rapportabilité des événements lorsdes interactions spontanées. Ce modèle offre desapplications potentielles pour l’analyse des mé-dias, l’interaction humain machine et la veille
informationnelle.Mots clés : émotions, intérêt, conversation.
Abstract :The emotional impact of an event is an essentialelement in predicting that this event will be re- ported. We show that a minimal model of emotional impact, based on Fechner law, can pre-dict various facts about event reportability duringspontaneous interactions. This model has potentialapplications for the study of mass media, human-computer interaction and informational watch.Keywords: emotions, interest, conversation.
1 Émotion et interactionLes aspects émotionnels de la communi-cation ont été surtout modélisés sousl’angle de l’expression des émotions.Dans le cadre de l’IHM, l’objectif peutêtre de rendre des agents conversationnelscapables d’exprimer et de faire partager des émotions (Adam & Evrard 2005), par exemple au moyen d’intonations et d’ex- pressions faciales (Ochs et al. 2006). Le
propos de ce papier est tout autre. Il s’agitd’étudier comment l’anticipation d’unimpact émotionnel joue sur la sélectiondes événements rapportés.
L’enjeu de cette recherche est de parvenir à modéliser la sélection des contenusspontanément échangés par le langage. Nous nous intéressons ici plus particuliè-
rement aux narrations conversationnelles,qui représentent environ la moitié des in-teractions humaines spontanées (Dessalles 2005), même si elles fontl’objet de peu d’études en comparaisondes interactions argumentatives. La com- préhension du mode de sélection desévénements rapportés en conversation estessentielle si nous voulons amener la ma-
chine à satisfaire ce besoin commu-nicationnel fondamental humain.
La communication événementielle reposesur deux paramètres fondamentaux. Le premier est le caractère inattendu del’événement, qui se modélise par un dif-férentiel de complexité (Dessalles 2006 ;2007). Le second paramètre, l’impactémotionnel, fait l’objet du présent article.
2 Conversations émotionnellesParmi les histoires que chacun échange aucours de ses conversations quotidiennes,
113

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 126/415
pendant les une ou deux heures consa-crées en moyenne à la communicationévénementielle (Dessalles 2005), nom- breuses sont celles qui comportent deséléments émotionnels. Dans l’exemplequi suit, la locutrice tente de partager sonémotion sur le caractère ‘affreux’ de la précédente tempête.
Z1- Drôle d’hiver, quand même, drôle de…
cette tempête avant-hier soir, oh quelle horreur,toute la nuit. Affreux ! hein ? J’ai cru que la cigo-gne [en métal] allait tomber mais non, elle a tenule coup hé
P1- Elle est lourde
Z2- Elle est lourde mais quand même, hein
L1- Sont habitués ces animaux là
Z3- Les pattes, j’avais eu peur que les pattescassent, moi
P2- Ca n’offre pas beaucoup de prise au vent
Z4- Non. Mais ça faisait peur, hé, comme çasoufflait, hein, c’était…
La partie narrative de cet extrait estcontenue dans les interventions Z1 et Z4.Elle est entrecoupée d’une partie argu-mentative allant de P1 à P2. On noteral’emphase avec laquelle Z soulignel’attitude émotionnelle qu’elle essaie defaire partager (‘affreux’, ‘horreur’, ‘ça
faisait peur’). L’extrait suivant est unexemple de tournoi narratif qui montrel’enchaînement de deux histoires (d’après Norrick 2000, p. 149. Détails de trans-cription omis).
Mark: you know what happened to my one of myaunt’s friends out in Iowa? Like when- when shewas younger, she had a headgear from braces, andthese two girls were wrestling around just playing
around, wrestling. And one girl pulled her head-gear off her mouth and let it snap back. And it slidup her face and stuck in her eyes and blinded her.
Jacob: wow.
Mark: isn’t that horrid? That’s horrid.
Jacob: when my-Mark: blinded her for life. Isn’t that horrid. That’s just- I mean just from goofing around, just fromscrewing a little bit of screwing around. And if-and another thing, it- it- it’s terrible the things thatcan happen. That’s why I don’t like people scre-wing around with swords and trying to throw people in the showers and stuff like that, and eve-rything like that.
Jacob: you know what happened to my aunt Flo-rence when she was a little girl?
Mark: ooh what happened.Jacob: she was like screwing around like aroundChristmas time? And like she, I- I guess this waslike when they had candles on trees? She lit her hair on fire.
Mark: oh wow.
L’intérêt des deux histoires résulte de leur aspect inattendu (des petites causes quientraînent de grands effets) et du carac-
tère dramatique des situations décrites :une enfant rendue aveugle et une enfantqui enflamme ses cheveux. Il suffitd’atténuer l’aspect émotionnel (e.g. rem- placer l’enfant par un adulte) pour quel’intérêt baisse de manière appréciable.
L’extrait suivant porte sur une bonnenouvelle concernant un ami commun desinterlocuteurs.
L1- Je t’ai dit que la candidature de Pierre étaitacceptée [pour son stage au Japon] ?
J1- Non. C’est super !
L2- Il y avait cinq dossiers [de candidature], ilsen ont pris deux.
Les différents extraits qui précèdent dé-montrent la variété des émotions qui peu-vent être mises en jeu lors des narrations.
Il importe de noter que l’émotion dontnous parlons ici est discursive et non mé-ta-discursive. Il ne s’agit pas d’attitude à propos de la relation d’interaction, com-me dans le cas où un locuteur chercherait
Le rôle de l'impact émotionnel dans la communication des événements ___________________________________________________________________________
114

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 127/415
à se montrer amical, autoritaire, agressif ou soumis. Les attitudes émotionnellesdont il est question ici portent sur les évé-nements relatés : Z déclare sa peur et sonhorreur face à la tempête ; Mark se dithorrifié par ce qui est arrivé à l’amie desa tante ; J1 exprime sa joie de voir lacandidature de Pierre acceptée.
Notre objectif est de montrer comment
l’anticipation d’un impact émotionnelconduit les locuteurs à rapporter un évé-nement. Le fait que les locuteurs soientcapables de montrer leur propre émotionen rapportant un événement, même s’ilest révélateur, n’est pas essentiel pour no-tre propos. Par exemple, L ne montreaucune émotion particulière dans l’extrait précédent, de même que Jacob lorsqu’il
rapporte l’accident de sa tante.L’important, du point de vue de la modé-lisation, est que le locuteur soit capable,lors de la sélection des événements rela-tés, d’anticiper un effet émotionnel sur l’auditeur, la prédiction étant que cet effetconditionne le succès de la narration.
Relater des événements émotionnels n’est pas systématique. Nombre de situations
rapportées, une coïncidence par exemple,sont simplement inattendues (Dessalles2005). Il est certes possible de considérer que la surprise, parfois intense, qui ac-compagne ces récits est une émotioncomme une autre (Reisenzein 2000). Nous ne souhaitons pas effectuer cetteassimilation, pour trois raisons. Premiè-rement, comme nous allons le voir, notre
modèle suggère que l’inattendu opère demanière orthogonale aux autres émotions.Deuxièmement, les situations inattendues peuvent ne présenter aucun enjeu (par exemple la sortie d’un tirage de loto re-
marquable comme 2-4-6-8-10-12, alorsque l’on n’a pas joué), tandis que les si-tuations émotionnelles peuvent systé-matiquement se traduire par un enjeu.1 Troisièmement, le caractère inattendud’une situation est une attitude de natureessentiellement épistémique, alors que lesémotions qui accompagnent la perceptionou l’évocation d’une situation s’accom- pagnent de manifestations somatiques particulières (Damasio 1994).
Notre entreprise peut sembler irréalisablesi l’on pose comme préalable le fait dedisposer d’un inventaire des émotions possibles, ou mieux d’une théorie généra-tive des émotions, choses qui semblentdurablement hors d’atteinte (Ortony &Turner 1990). Certes, le caractère spécifi-
que des émotions, au-delà de leur simplevalence positive ou négative, a une in-fluence décisive sur la prise de décision, par exemple dans la perception du risque(Lerner & Keltner 2000). L’anticipationde l’intérêt narratif d’une situation obéit,semble-t-il, à un mécanisme plus restric-tif. Nous montrons ci-dessous qu’unmodèle qui ne fait appel qu’à l’intensité des émotions, indépendamment de la ri-chesse de leur phénoménalité, peut serévéler utile pour prédire la sélection desévénements rapportables.
Une autre objection vient de ce que lesémotions sont par essence des phénomè-nes privés. Puisque les locuteurs ne peuvent pas connaître la vraie nature desémotions d’autrui, comment faire reposer
le succès de la communication sur une
1 Jerry Fodor (1993, communication personnelle) propose demesurer cet enjeu en demandant aux sujets quelle sommed’argent ils sont prêts à donner a priori pour que l’événementait lieu ou au contraire n’ait pas lieu.
____________________________________________________________________________ Annales du LAMSADE N°8
115

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 128/415
base aussi incertaine ? La réponse est quele succès de la communication ne présup- pose pas une correspondance parfaiteentre les expériences des interlocuteurs. Ilsuffit que le locuteur soit en mesured’anticiper l’intensité de ce que pourraéprouver son auditoire, ce qu’un niveaulimité d’empathie permet d’assurer. Lacommunication émotionnelle repose sur le fait que les interlocuteurs partagent cer-taines préoccupations, certaines préféren-ces, certains goûts et certaines aversions,au moins dans le contexte limité del’événement considéré. L’exemple de lacandidature de Pierre fournit une bonneillustration de cette exigence : la nouvellede l’acceptation de son dossier aurait étésans aucun intérêt pour quelqu’un qui nese soucie pas du futur de Pierre.2
Dans ce qui suit, nous proposons un mo-dèle minimal de l’impact émotionnel desévénements, puis nous examinons le ca-ractère prédictif du modèle avant d’endiscuter la portée.
3 Un modèle minimalLe modèle présenté ici est censé représen-
ter l’estimation qu’un locuteur effectuedans le domaine émotionnel pour antici- per l’intérêt d’une histoire pour sonauditoire.
3.1 Contraste émotionnel
L’intérêt d’un événement rapporté dépendde manière cruciale du changement émo-tionnel, défini comme la différence entre
2 Notons que le fait de partager les émotions n’est même pasun prérequis de la communication événementielle. Si A saitque B se soucie de C, alors A peut donner à B une nouvelleconcernant C sans pour autant nourrir le même sentiment queB vis-à-vis de C.
l’intensité émotionnelle de la situationobservée et de l’intensité émotionnelle dela situation attendue.
V = eobs – eexp (1)
Cette définition et le principe qui en faitdépendre l’intérêt narratif constituent unfait important et non trivial de la commu-nication événementielle. Elle est à
rapprocher de l’autre composante del’intérêt narratif, l’inattendu, qui se défi-nit également comme un décalage entre lasituation attendue et la situation observée, portant cette fois sur la complexité (Des-salles 2006 ; 2007). La présencenécessaire d’un décalage est propre à lacommunication événementielle, mais nese généralise pas à l’ensemble de la
communication humaine. Par exemple,l’existence persistante d’un problème peut amener des interlocuteurs à en discu-ter sur le mode argumentatif, même si ce problème est récurrent depuis des mois.Lorsque l’on perd son emploi, le chan-gement émotionnel, et donc le caractèreévénementiel, est de courte durée, alorsque le caractère problématique demeure.
Le principe de fonder l’intérêt sur lechangement émotionnel rejoint certainesobservations concernant la sensibilité dessujets aux différences entre les situations plus qu’à une estimation absolue de leur caractère désirable ou indésirable. Par exemple, les sujets montrent une attitudeface au risque qui dépend de l’espérancede gain : ils fuient le risque en cas de gain positif et le recherchent en cas de perte ;or l’allocation préalable d’une sommed’argent ne change pas ce comportement(Kahneman & Tversky 1979, pp. 273,277), bien qu’elle puisse transformer les
Le rôle de l'impact émotionnel dans la communication des événements ___________________________________________________________________________
116

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 129/415
pertes en gains. Les sujets semblent neconsidérer que les changements d’utilitéet ignorent ce qui est commun aux termesd’une alternative.
Supposons que la situation observée estexclusive et complémentaire d’une autresituation non observée, comme dansl’exemple de la candidature de Pierre quiest acceptée au lieu d’être refusée. Carac-
térisons ces situations exclusivesrespectivement par les probabilités p et(1– p) et par les intensités émotionnelleseobs et enobs. Nous pouvons écrire3 : eexp = p eobs + (1 – p) enobs, et donc :
V = (1– p)∆e (2)
où ∆e = eobs – enobs est le contraste émo-tionnel produit par l’événement lorsqu’on
l’insère dans une alternative. Laformule (2) s’applique chaque fois quel’événement observé est contrasté avecune situation prototypique. Dans ce cas,enobs est calculée d’après cette situation prototypique. Pour cette raison, ∆e estd’un accès plus facile que le changementémotionnel V , puisque le terme eexp sup- pose une moyenne sur l’ensemble de
toutes les possibilités. Noter que dans beaucoup de cas d’intérêt pratique,l’émotion attachée au prototype peut êtreconsidérée comme négligeable, si bienque ∆e = eobs. C’est le cas pour l’extraitde Norrick, où les deux accidents rappor-tés peuvent être contrastés avec unesituation normale non émotionnelle.
3 Cette écriture peut être remise en question de deux manières.La prospect theory (Kahneman & Tversy 1979) remplace p et(1–p) par des coefficients de pondération dont la somme estinférieure à 1, de manière à prendre en compte certaines for-mes d’aversion au risque. Il est aussi possible de considérer que la pondération probabiliste ne s’applique pas aux émotionselles-mêmes, mais au stimulus.
La formule (2) nous permet de faire uncertain nombre de prédictions que nousexaminons tour à tour.
3.2 Les effets de distance
L’un des aspects les plus spectaculairesde la formule (2) est l’influence de la proximité. Imaginons qu’un enfantmeure. C’est une terrible nouvelle si elle
concerne un voisin de palier. De la for-mule (2) nous pouvons dériver V = exp(– ve /V e)∆e, où 1/V e est la densité spatiale dece genre d’événement, et ve est la plus petite région isotrope égocentrée conte-nant l’événement (Dessalles 2005).4 Cetterelation prédit que le changement émo-tionnel va décroître de manière exponen-tielle avec le carré de la distance. Comme
le rappelle Carl Warren (1934, p. 18) :The person who yawns over a report that fa-mine has swept a million Chinese to their graves will snap to attention if he learns hisneighbor’s child is in the hospital.
De manière analogue, le changementémotionnel varie exponentiellement avecla distance temporelle (figure 1) ainsi queselon d’autres formes plus abstraites de
distance.5
3.3 L’habituation
La présence du facteur (1– p) dans la for-mule (2) explique pourquoi nous pouvonsdevenir insensibles aux drames répétitifs.La plupart des personnes restent impassi-
4 La probabilité p qu’au moins un événement de ce type se produise est donnée par la formule de Poisson: p = 1–exp(– ve /V e).5 Dans le cas de la ‘distance sociale’, nous avons une simplefonction puissance, car le paramètre à prendre en compte est lelogarithme de cette ‘distance’ (exemple log2 n si n est le degréde parenté, ou α log n si n est le nombre de nœuds de sépara-tion dans un réseau social à invariance d’échelle).
____________________________________________________________________________ Annales du LAMSADE N°8
117

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 130/415
bles en apprenant la mort d’une centainede personnes sur la route en un week-end,alors que ces mêmes personnes peuventêtre catastrophées d’apprendre qu’un ac-cident ferroviaire a causé le mêmenombre de victimes. Cette incohérenceapparente s’explique par la différence de probabilité des deux événements.
FIG 1: Décroissance en fonction dutemps de l’inattendu U (en noir) et duchangement émotionnel V pour diffé-rentes valeurs du contraste émotionnel∆e (en gris).
3.4 Du stimulus à l’émotion partagée
3.4.1 Échelle ouverte et échelle fermée
L’émotion causée par un événement dé- pend souvent d’un paramètre graduel lié àcet événement, comme une sommed’argent gagnée ou perdue, un nombre devictimes, une quantité de temps perdue ouun nombre de débris satellitaires répandusdans l’espace et oblitérant l’avenir del’utilisation de l’espace proche. Dans denombreuses situations, le stimulus qui
cause l’émotion est d’un accès plus aiséque l’émotion elle-même ; il est donc es-sentiel d’établir directement l’influencedu stimulus en question sur l’intérêt nar-ratif. Un aspect crucial de cette
dépendance est lié au caractère borné ounon borné du stimulus.
Nous faisons l’hypothèse que la sensibili-té au stimulus considéré suit une loi deWeber-Fechner, comme la plupart desrelations stimulus-sensation en psycho- physique. Ceci signifie que nous sommessensibles aux variations relatives du sti-mulus. Le phénomène est manifeste dans
le cas des sommes d’argent dont les va-riations sont toujours données en pourcentage. Un surcoût de cent eurossera jugé intolérable pour l’achat d’unécran d’ordinateur et négligeable pour l’achat d’un appartement. Un phénomèneanalogue contribue à expliquer la crois-sance non proportionnelle de l’émotionen cas de drame. Après le tremblement de
terre survenu à Bâm, en Iran, le 26 dé-cembre 2003, la nouvelle des premiersmilliers de victimes causa une grandeémotion dans le monde ; lorsque l’on ap- prit quelques heures plus tard que les pertes humaines s’élevaient, non à 4000,mais à plus de 20 000, l’émotion ne crût pas en proportion, comme si les mortsadditionnelles avaient moins d’impact sur le public.
Notre hypothèse est que l’intensité émo-tionnelle e suit une loi logarithmique enfonction du stimulus w. Il y a mathémati-quement deux possibilités, selon que w est borné supérieurement ou non, ce quidonne respectivement :
e = e0 log(1+w/w0) (3)
( )W wee
−=
11 log0 (4)
La figure 2 montre la variation del’intensité émotionnelle dans les deux cas.
Le rôle de l'impact émotionnel dans la communication des événements ___________________________________________________________________________
118

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 131/415
FIG. 2 : Intensité émotionnelle dans lecas d’une échelle ouverte (en noir) ou bornée (en gris).
La sur-représentation des petites causes,dans le cas d’une échelle ouverte, permetd’expliquer que les individus puissentchoisir de communiquer à propos dechangements presque insignifiants,comme dans l’exemple suivant qui met en
scène deux adultes qui, par temps chaud, pénètrent dans un vieux bâtiment.
JC- Ca fait du bien un peu de fraîcheur
P- C’est vrai que c’est agréable
Il semble qu’en toute rigueur, tout stimu-lus doive être considéré comme borné.C’est certainement le cas de la tempéra-ture qu’un être humain peut supporter. Ilest important de noter, cependant, qu’iln’est pas question ici d’échelle objecti-vement bornée ou non bornée. Nous nenous intéressons pas non plus à une inten-sité émotionnelle objective, telle qu’on pourrait la mesurer par exemple par destechniques d’électrophysiologie. Une telleapproche purement physicaliste passeraità côté de la question, car les émotionssont des phénomènes privés qui ne sont
pas communiqués en tant que tels. Lacommunication porte sur l’événement lui-même et sur les attitudes émotionnelles,qui transparaissent dans les choix lexi-caux, l’emphase, les expressions faciales,
etc. Il y a bien sûr un lien entre l’émotionressentie et ce qui est communiqué, quirepose sur le fait non trivial que bonnombre d’émotions ne peuvent pas êtreaisément feintes. On peut également sup- poser que ce même lien rend possiblel’empathie, puisque le locuteur peut anti-ciper l’effet de son histoire sur l’interlocuteur en observant sa propre
émotion. Il faut cependant garder àl’esprit la différence entre les émotionsressenties et l’attitude publique que l’onadopte vis-à-vis des situations qui lescausent.
La plage de variation à prendre en compte pour le stimulus est donc celle qui estconsidérée par le locuteur lorsqu’il choisitde communiquer à propos d’une situation
en fonction de son impact émotionnel.Dans l’exemple précédent, la variationmaximale pertinente ne se compte pas enmillions de °K, mais est celle des aléasmétéorologiques de la région. Les formu-les (3) et (4) s’appliquent donclocalement.
3.4.2 L’effet de mur
Le caractère borné ou non borné du sti-mulus est une question d’attitude, commeon le vérifie sur l’exemple suivant. Dansle film ‘Saving Private Ryan’ de S. Spiel- berg, le problème n’est pas tant de sauver la vie d’un soldat. Le soldat en questionest le dernier d’une fratrie dont les troisautres membres viennent d’être tués dansla même guerre. Ces trois victimes nesont pas perçues dans le contexte non borné de toutes les victimes possibles dela guerre, mais au sein du réservoir limitéde vies qu’une seule famille peut offrir.L’impact émotionnel lié à la proximité de
____________________________________________________________________________ Annales du LAMSADE N°8
119

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 132/415
l’absolue limite qui marque l’exter-mination totale des enfants mâles de cettefamille est supposé assez fort pour émou-voir le général Marshall, pourtant parfai-tement au fait du nombre total devictimes de la journée. Ce phénomène est bien prédit par la formule (4).
On peut s’inquiéter du fait que la for-mule (4) produise des valeurs infinies.6
Est-ce que le public éprouverait une peineinfinie lors de la mort du soldat Ryan ? (ilsemble que cette mort ait été évitée dansle film.) Bien que par empathie, on ima-gine la peine insupportable du personnagede la mère du soldat, l’excitation émo-tionnelle du public reste dans des limitesraisonnables. L’explication, encore unefois, vient de ce que la formule (4) ne dé-
crit pas directement les émotions, maisles attitudes vis-à-vis de ces émotions.Tant que la limite W n’est pas atteinte,tant que cette limite peut être conçuecomme inatteignable, la formule (4) offreune bonne image de l’intensité émotion-nelle qui peut être partagée dansl’interaction. Dès que la situation estconçue comme pouvant aller au-delà deW , la formule (4) cesse de s’appliquer.Une limite franchissable n’est plus unelimite. La mort du soldat Ryan, une foisconsidérée, ramène la situation à celle dela disparition de toute une famille. Cetévénement est alors conçu parmi d’autrescas analogues (avec la différence qu’à lafin du film, le spectateur peut en quelquesorte comme un proche de cette famille).
6 Le fait en soi n’est pas choquant, puisque certaines émotions peuvent pousser au suicide. Le problème apparent vient du faitque la formule prédit l’émotion anticipée chez l’interlocuteur,ou ici le spectateur.
L’effet de mur, ou ‘effet soldat Ryan’, permet d’expliquer de nombreux phéno-mènes liés aux interactions langagières.Ainsi, les participants d’une conversation peuvent déplorer la progression inexora- ble de la ville du Caire parce qu’elles’approche dangereusement du site des pyramides de Giseh. De même, la mort demilliers de grands singes infectés par le
virus Ebola peut être présentée commeabsolument dramatique en raison du ré-servoir limité des derniers représentantsde nos espèces sœurs. Plus généralement,l’effet de mur explique l’importance émo-tionnelle de l’approche des échéancesdécisives, qui est largement exploitéesdans les ‘thrillers’ cinématographiques.
L’effet de mur permet également de pro-
poser une explication parcimonieuse pour la dissymétrie bien connue entre l’impactdes nouvelles négatives et des nouvelles positives. Comme dit l’adage des journa-listes anglo-saxons, “Bad news sells.Good news does not”. La nouvelle, enseptembre 2004, par les firmes Renault etPeugeot de la création de quelque 10 000emplois nouveaux ne fut presque pascommentée. En avril 2005, lorsque Rover annonça 5000 licenciements en GrandeBretagne, l’émoi suscita des commentai-res et des éditoriaux pendant plusieurs jours, même dans les pays voisins. Lesemplois nouveaux sont mesurés sur uneéchelle ouverte, tandis que la perted’emploi se mesure naturellement par rapport au réservoir limité des employésactuels. À l’échelon individuel également,
perdre son emploi revient à perdre une partie de ce qui rend la vie possible, tan-dis qu’un nouvel emploi constitue justeune opportunité, considérée au sein d’unréservoir illimité de perspectives positi-
Le rôle de l'impact émotionnel dans la communication des événements ___________________________________________________________________________
120

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 133/415
ves. Ceci contribue à expliquer pourquoil’empathie est plus grande lorsque l’on parle de licenciement que lorsqu’il s’agitd’emploi nouveau. Plus généralement,cela explique pourquoi les interactionslangagières portent plus souvent sur desévénements négatifs que sur des événe-ments positifs.7 Cette dissymétrie entre bonnes et mauvaises nouvelles n’est bien
entendu qu’une tendance, liée à la pré-sence plus fréquente d’un effet de mur ducôté négatif. Lorsque l’effet de mur jouedu côté de la bonne nouvelle, on s’attendà une émotion plus intense dans le sens positif. Ainsi, une diminution répétée dunombre de morts sur les routes, commecelle qui s’est produite en France dans lesannées 2005, a suscité une émotion sou-tenue dans le public ; la raison peut enêtre que le nombre de victimes est estiméavec zéro morts en point de mire.
La dissymétrie entre perspectives positi-ves et négatives est un phénomèneclassiquement observé en théorie de ladécision. La prospect theory traduit le faitque la fonction d’utilité est concave pour les gains et convexe pour les pertes, ce
qui permet d’expliquer les différencesd’attitude par rapport au risque selon quele jeu est positif ou négatif (Kahneman &Tversky 1979). Par symétrie par rapport àl’origine, c’est bien ce que prévoit la for-mule (3) si les gains et les pertes sontestimés sur des échelles ouvertes, ce quisemble être le cas dans les expériences deKahneman et Tversky où les enjeux res-tent limités.8 Pour des enjeux négatifs
7 Ceci indépendamment du fait que les événements négatifssont plus facilement convertis en problèmes et peuvent de cefait donner lieu à une argumentation.8 Ces auteurs mentionnent l’existence de seuils qui peuventinverser la convexité de la fonction d’utilité (p. 279). Noter
importants, la prise en compte de l’effetde mur prévoit que l’aversion au risquesera restaurée, ce qui explique que les in-dividus choisissent de s’assurer même sicela est au prix d’une perte certaine.
3.5 L’intérêt narratif
Selon notre modèle, l’intérêt narratif I puise dans deux sources, l’inattendu U et
le changement émotionnel V .
I = U + V (5)
Si nous prenons comme expression de la probabilité p=2
–U (Dessalles 2006), on parvient à deux expressions de l’intérêtnarratif, selon que l’on applique la for-mule (3) ou la formule (4).
( ) ( )
p
ww I
pe −+
=
10
01 log (6)
( ) ( ) peW w p
I −
−
=101
1 log (7)
Ces deux formules peuvent être vuescomme des généralisations de la formulede Shannon qui définit l’informationcomme log2(1/ p). La figure 3 montre lesvariations correspondantes.
Selon ce modèle, les valeurs de I offrentune prédiction de l’acceptation des narra-tions conversationnelles. En tant quefonction de la probabilité perçue (Dessal-les 2005) et du stimulus émotionnel,l’intérêt narratif doit excéder un certain
que notre modèle permet deux échelles ouvertes indépendantes pour les émotions liées aux gains et liées aux pertes, mais iln’explique pas que la seconde croisse plus vite que la pre-mière.
____________________________________________________________________________ Annales du LAMSADE N°8
121

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 134/415
seuil pour produire une narration accep-table.
I ( p,w) > I 0 (8)
(a)
(b)FIG. 3: Interêt narratif I d’un événe-ment, fonction de la probabilité perçue p et du stimulus émotionnel w pour un stimulus ouvert (a) et borné(b).
Le seuil d’intérêt I 0 dépend de manièreévidente de toute une gamme de facteurs,comme le nombre de participants de laconversation, leur degré de familiarité,leurs statut social relatif, leur dispositiond’esprit l’un envers l’autre au moment del’interaction, la présence de contraintessociales, institutionnelles ou culturelles,
la durée du silence depuis que le précé-dent sujet de conversation s’est terminé,et ainsi de suite. Cependant, compte tenude ces complications, la prédiction restevalide. Dans tout contexte interactionnelfixant I 0, on peut atteindre un niveaud’intérêt trop faible pour être acceptable par les interlocuteurs. Inversement, unniveau d’intérêt élevé garantit
l’acceptation conversationnelle (à moinsqu’une contrainte sociale ou culturelle,comme la politesse, n’ait été violée).
On peut dire que la formule (8) exprimel’interface entre deux couches autonomesde l’analyse du langage. D’un côté, I ( p,w)modélise l’orientation cognitive de l’êtrehumain vers ce qui excite son intérêt. Del’autre côté, le seuil I 0 concentre de nom-
breux facteurs sociologiques qui sontlargement indépendants de ce qui est dit àce moment de l’interaction.
3.6 Courbes iso-axiologiques
Si nous supposons que le seuil I 0 a étéfixé indépendamment en fonction de lasituation sociale de l’interaction, il est possible de définir une zone de banalité
dans laquelle la combinaison des paramè-tres produit un intérêt narratif inférieur à I 0. La figure 4 montre comment lecontraste émotionnel doit varier en fonc-tion de l’inattendu pour garantir un intérêtnarratif suffisant. Sous chaque courbe, lazone de banalité constitue une zone inter-dite dans laquelle le minimum d’intérêtrequis n’est pas assuré. Ces courbes sont
dites iso-axiologiques car elles lient desévénements d’égal intérêt.9 On vérifie que
9 Ce néologisme est formé à partir des racines de grec ancieniso-, qui signifie “égal”, et le mot axiologos (αξιο -λογοζ ), quisignifie “digne d’être mentionné”.
Le rôle de l'impact émotionnel dans la communication des événements ___________________________________________________________________________
122

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 135/415
de faibles valeurs de l’inattendu U de-mandent en compensation que lecontraste émotionnel soit élevé, ce quisuppose un niveau d’empathie élevé.
La figure 5 représente les courbes iso-axiologiques dans le plan ( p,w) pour unstimulus non borné ou borné. On vérifieque les faibles valeurs du stimulus sontsuffisantes pour éveiller l’intérêt dans le
premier cas, tandis que les valeurs pro-ches du mur peuvent être excitantes dansle deuxième cas même pour des événe-ments relativement probables.
Figure 4: Les courbes iso-axiologiques définissent trois zones de banalité (surfaces grisées) pour 8, 12et 16 bits respectivement. Les deux paramètres ici sont l’inattendu et le
contraste émotionnel.
4 ConclusionUn aspect fondamental des interactionslangagières repose sur la sélection desfaits et des situations qui sont dignesd’être communiquées. Le présent article présente un modèle propre à prédire lasélection des situations à caractère émo-tionnel. Bien qu’une connaissance fine dela richesse des émotions humaines soitcertainement nécessaire pour mettre enœuvre une telle sélection, leur seule in-tensité semble intervenir dans
l’estimation de l’intérêt narratif des situa-tions qu’elle retient. La formule (2)résume cette contribution. Sous la simplehypothèse que la loi de Fechner s’applique aux différents stimuli émo-tionnels, nous avons dérivé deuxexpressions de l’information généralisée(formules (6) et (7)). Ces expressions permettent d’étudier l’influence des pa-
ramètres p et w sur l’intérêt narratif, etdonc de prédire l’acceptabilité del’événement rapporté dans l’interaction.
Ce modèle présente un intérêt scientifi-que. Certes, la mise à l’épreuve des faitsest délicate, dans la mesure où les para-mètres e0, w0, W et I 0, ainsi que lesvaleurs des variables p et w, sont diffici-les à estimer en pratique. Cependant, ils
ne sont pas par principe inaccessibles à lamesure. De plus, le modèle se prête à di-vers tests portant sur ses prédictions,concernant notamment l’habituation, leseffets de distance et l’effet de mur.
Ce modèle ouvre la voie à des applica-tions. Pouvoir disposer d’une mesure del’intérêt est fondamental :
- pour la gestion des interactions humain-machine en langue naturelle. La valeur d’une telle interaction se juge en partie àla capacité de la machine à formuler desinteractions intéressantes. Il est facile de permettre à un agent conversationneld’accéder à un ensemble inépuisabled’événements. Le problème se pose desélectionner ceux qui, à un moment don-né de l’interaction, pourront intéresser
l’interlocuteur. Notre modèle offre unmoyen simple (sous réserve del’estimation de ses paramètres !)d’anticiper l’intérêt et de hiérarchiser lesinformations qui seront données. Inver-
____________________________________________________________________________ Annales du LAMSADE N°8
123

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 136/415
sement, il permet à l’agent de comprendreen quoi les événements mentionnés par l’utilisateur sont dignes d’intérêt.
- pour les moteurs de recherche. Le mo-dèle offre idéalement une mesure directede l’impact émotionnel, ce qui pourrait permettre d’augmenter la pertinence desréponses à certains types de requête. Bienentendu, la même réserve doit être faite
quant à la nécessité préalable d’estimer les paramètres du modèle pour l’utilisateur.
(a)
(b)
Figure 5: Les zones de banalité sontles surfaces grisées sous les troiscourbes, calculées pour des seuilsd’intérêt narratif de 8, 12 et 16 bitsrespectivement. (a) correspond à un
stimulus non borné et (b) à un stimu-lus borné par W (e0=6).
- pour la veille informationnelle et certai-nes formes de fouille de données.
- pour l’analyse des médias. L’étude de lavaleur médiatique des événements(newsworthiness) est un domaine quireste largement empirique (Galtung &
Ruge 1965 ; Berkowitz 1990). La contri- bution théorique de la proximité, le phénomène d’habituation, la dépendancelogarithmique par rapport au stimulus,sont de nature à améliorer la compréhen-sion de l’impact émotionnel desévénements, ce qui n’est pas négligeablecompte tenu de l’importance économiquede ce secteur.
Beaucoup d’efforts ont été consacrés,dans l’étude de l’interaction humain-machine, à la forme de l’interaction, peut-être plus qu’à son contenu. En ce quiconcerne le contenu, l’essentiel des ef-forts s’est porté sur la gestion del’argumentation. La présente contributionse justifie par le fait que la moitié des in-teractions langagières spontanéeshumaines porte sur des récitsd’événements. L’impact émotionnel étantune composante essentielle de l’intérêtnarratif, nous avons jugé important d’en proposer une modélisation. Celle-ci a étéconçue sous des hypothèses restrictives,qu’il conviendra peut-être de réviser à lalumière des expérimentations.
Références
Adam, C. & Evrard F. (2005). "Donner des émotions aux agents conversation-nels". In: Workshop Francophone sur les Agents Conversationnels Animés. Greno- ble: IMAG, 135-144.
Le rôle de l'impact émotionnel dans la communication des événements ___________________________________________________________________________
124

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 137/415
www-leibniz.imag.fr/WACA/articles/Adam-Evrard-05.pdf
Berkowitz, D. (1990). "Refining the gate-keeping metaphor for local televisionnews". Journal of Broadcasting & Elec-tronic Media 34(1), 55-68.
Damasio, A.R. (1994). L'erreur de Des-cartes. Paris: Odile Jacob, ed. 1995.
Dessalles, J-L. (2005). "Vers une modéli-sation de l'intérêt". In: A. Herzig, Y.Lespérance & A.-I. Mouaddib (Eds), Mo-dèles formels de l'interaction (MFI-05).Toulouse: Cépaduès Editions, 113-122.www.enst.fr/~jld/papiers/pap.conv/Dessalles_04122102.pdf
Dessalles, J-L. (2006). "Intérêt conversa-tionnel et complexité : le rôle de
l'inattendu dans la communication spon-tanée". Psychologie de l'Interaction 21-22, 259-281.www.enst.fr/~jld/papiers/pap.conv/Dessalles_04082404.pdf
Dessalles, J-L. (2007). "Complexité co-gnitive appliquée à la modélisation del'intérêt narratif". Intellectica 45.
Elster, J. (1996). "Rationality and the
emotions". The Economic Journal 106(438), 1386-1397.www.geocities.com/hmelberg/elster/AR96RATE.HTM
Galtung, J. & Ruge M. H. (1965). "Thestructure of foreign news". Journal of In-ternational Peace Research 1, 64-90.
Kahneman, D. & Tversky A. (1979)."Prospect theory: An analysis of decision
under risk". Econometrica 47(2), 263-291.
Lerner, J. S. & Keltner D. (2000). "Be-yond valence: Toward a model of emotion-specific influences on judgementand choice". Cognition and emotion 14(4), 473-493.http://computing.hss.cmu.edu/lernerlab/pdfs/Lerner_Keltner_2000_CE_Paper.pdf
Norrick, N. R. (2000). Conversationalnarrative : storytelling in everyday talk .Amsterdam: John Benjamins PublishingCompany.
Ochs, M., Niewiadomski R. & et al.(2006). "Expressions intelligentes desemotions". Revue d'Intelligence Artifi-cielle 20(4-5).http://www.iut.univ-
paris8.fr/~pelachaud/AllPapers/RIA-Ochs.pdf Ortony, A. & Turner T. J. (1990). "What's basic about basic emotions".Psychological Review 97(3), 315-331. www.cs.northwestern.edu/~ortony/papers/basic%20emotions.pdf
Reisenzein, R. (2000). "The subjectiveexperience of surprise". In: H. Bless & J.P. Forgas (Eds), Subjective experience insocial cognition and social behavior .Philadelphia, PA: Psychology Press, 262-279.
Warren, C. N. (1934). Modern news re- porting. New York: Harper & Brothers,ed. 1959.
____________________________________________________________________________ Annales du LAMSADE N°8
125

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 138/415

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 139/415
Raisonnement sur les actions :de Toronto à Amsterdam
Hans van Ditmarsch†[email protected]
Andreas Herzig‡[email protected]
Tiago de Lima‡[email protected]
†Université d’Otago, Nouvelle Zelande‡Institut de Recherche en Informatique de Toulouse, France
Résumé :
Nous montrons comment en raisonnement sur lesactions la fameuse solution de Reiter du problèmedu décor peut être modélisée en logique épisté-
mique dynamique, et nous proposons une méthodede régression optimale. Notre méthode étend la so-lution de Reiter en intégrant des actions d’observa-tion et des opérateurs modaux de connaissance, ettraduit le formalisme de Reiter (le Calcul des situa-tions) dans une logique des actions et des connais-sances comprenant des opérateurs d’annonce etd’affectation. En étendant la méthode de réductionde Lutz de la logique des annonces publiques auxaffectation, nous établissons des résultats de com-plexité pour la régression. Nous montrons que cesrésultats sont optimaux : le problème de décider la
satisfiabilité d’une formule est NP-complet pour unagent, PSPACE-complet pour plusieurs agents etEXPTIME-complet dans la présence de l’opérateurde connaissance commune.
Mots-clés : raisonnement sur les actions et change-ment ; logiques épistémique dynamique ; systèmesmulti-agents ; régression.
Abstract:
We show how in the propositional case Reiter’s
well-known solution to the frame problem can bemodelled in dynamic epistemic logic, and pro-vide an optimal regression algorithm. Our me-thod is as follows : we extend Reiter’s solution byintegrating observation actions and modal opera-tors of knowledge, and encode the resulting for-malism in a dynamic epistemic logic with an-nouncement and assignment operators. By exten-ding Lutz’ recent satisfiability-preserving reduc-tion for public announcement logic to assignments,we establish optimal complexity results for re-gression : satisfiability is NP-complete for oneagent, PSPACE-complete for multiple agents andEXPTIME-complete when common knowledge isinvolved.
Keywords: reasoning about actions and change;epistemic dynamic logics ; multiagent systems ; ré-gression.
1 Introduction
Dans [14] Thielscher distingue deux ver-sions du problème du décor. La version re-présentationelle est le problème de conce-voir un langage logique et une sémantiquetelle que les domaines peuvent être décritssans expliciter l’interaction entre toutes lesactionsetlesfluents:quandilya n actionset m fluents, la description du domainedoit être beaucoup plus petite que 2 × n ×m. La version inférentielle du problème dudécor est plus exigeante : étant donnée unesolution pour la version représentationelle,
il s’agit du problème de concevoir une pro-cédure de décision ‘efficace’, c’est-à-dire,dont la complexité n’est pas trop élevée.
Reiter [10] a résolu la version représen-tationelle du problème du décor en utili-sant ce qu’il appelle des axiomes de l’étatsuivant ("successor state axioms" , SSAs).Dans le cas propositionnel, les fluents ontseulement des situations comme argument,
et les SSAs prennent la forme :∀x∀s( p(do(x, s)) ↔ (¬Poss (x, s)∨
(x = a1 ∧ γ +(a1,p ,s)) ∨ . . .
∨ (x = an ∧ γ +(an,p ,s))∨
( p(s) ∧ ¬(x = a1 ∧ γ −(a1,p ,s)) ∧ . . .
∧ ¬(x = am ∧ γ −(am,p ,s)))))
où a1, . . . , an sont les actions pouvant (po-
tentiellement) rendre p vrai, et a1, . . . , amsont les actions pouvant (potentiellement)rendre p faux. Pour une action donnéeai, soit Eff +(ai) l’ensemble des fluentsqui peuvent devenir vrais par l’exécution
127

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 140/415
de ai, et Eff −(ai) l’ensemble des fluentsqui peuvent devenir fausse par l’exécu-tion de ai (dans [10] ces ensembles sotlaissé implicites). Donc, pour tout fluent p ∈ Eff +(ai), la formule γ +(ai,p ,s) ca-ractérise les conditions dans lesquelles airend p vrai, et γ −(ai,p ,s) caractérise lesconditions dans lesquelles ai rend p faux.γ +(ai,p ,s) et γ −(ai,p ,s) doivent être uni-
formes en s, ce qui signifie en particulierqu’ils ne peuvent pas contenir la fonctiondo.1
L’idée centrale de Reiter est que, grâce
au principe de l’inertie, les ensemblesEff +(ai) et Eff −(ai) sont des ‘petits’sous-ensembles de l’ensemble des fluentsdu langage. Pour cette raison la taille del’ensemble de tous les SSAs peut être demême ordre que le nombre d’actions etdonc, beaucoup plus petite que le pro-duit du nombre d’actions par le nombre defluents.CelasignifiequelesSSAsàlaRei-ter comptent comme une solution du pro-
blème du décor. Cette solution a été étendupar [12] aux actions épistémiques.
Quand les SSAs sont disponibles pourtouts les fluents p, on peut réduire (‘régres-ser’) toute formule ϕ à une formule équi-valente red(ϕ) qui ne contient pas d’opéra-teur d’action. Ceci fournit alors une procé-dure de décision dans le cas proposition-nel. Cette procédure a été implanté dansle langage GOLOG. Cependant, la for-mule réduite peut être exponentiellementplus longue que celle d’origine ; en consé-quence la version inférentielle du pro-blème du décor n’a pas été résolu ni parReiter ni par Scherl & Levesque.
Dans cet article, nous étendons la solu-tion de Reiter et résolvons la version infé-rentielle du problème du décor. Pour l’ex-tension à la connaissance, parmi les ac-
tions épistémiques nous considérons uni-quement les observations : tous les agents1Plus tard, Reiter et col. généralisent SSAs à des équiva-
lences ∀x∀s( p(do(x, s))↔ ψ(a, s). Nous ne considérons pascette extension ici.
observent que une proposition donnée estvraie dans le monde, et mettent à jourleurs état de connaissance en fonction.2Nous proposons une transformation po-lynomiale qui préserve la satisfiabilité deformules et élimine les opérateurs d’ac-tion. Ceci nous permet de définir une mé-thode optimale pour raisonner sur les ac-tions dans ce scénario : dans le cas debase sans l’opérateur de connaissance ainsique dans le cas d’un seul agent, la pro-cédure est dans NP; dans le cas multi-agents, elle est dans PSPACE; et dans lecas avec connaissance commune, elle est
dans EXPTIME. Ces résultats sont opti-males puisqu’ils coïncident avec la com-plexité de la logique épistémique de base.
Techniquement, notre approche est basésur les avances récentes en logiques épis-témiques dynamiques. Dans cette famillede logiques, les situations sont laissées im-plicites, et il n’y a pas de quantificationsur les actions. Donc, l’outil central de
la solution de Reiter n’est pas disponible.Cependant nous montrons que nous pou-vons transposer cette solution sans sa pré-sence et reconstruire cette solution en lo-gique épistémique dynamique DELC
N , pro-posé par [16, 6]. Les annonces peuventêtre utilisées pour modéliser les obser-vations, tandis que les affectations per-mettent de modéliser les actions de chan-gement du monde (dites actions ontiques).
DELC N étant une extension de la logiquedes annonces publiques de Plaza, nous
étendrons la procédure de décision op-timale de Lutz pour la dernière ([7]) àDELC
N , et nous montrerons que nous pou-vons préserver l’optimalité de la procé-dure : la vérification de satisfiabilité de for-mules dans DELC
N est démontré avoir lamême complexité que la vérification de sa-tisfiabilité dans la logique épistémique de
base.2Notons que les observations sont différentes des actions de
perception (sensing) introduites dans [12]. En exécutant ces der-nières, les agents observent si une proposition donnée est vraieou non.
Raisonnement sur les actions : de Toronto à Amsterdam ___________________________________________________________________________
128

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 141/415
2 Base : logique épistémiqueELC
N
Soit P un ensemble infinie et dénombrablede lettres propositionnelles, et soit N unensemble finie d’agents. Par commodité,nous abusons de la notation et identifionsN avec l’ensemble d’entier 1, . . . , |N |.Le langage LELC N
de la logique épisté-mique avec connaissance commune est dé-finie par la BNF :
ϕ ::= p | ¬ϕ | ϕ ∧ ϕ | Kiϕ | CGϕ
où p est un élément de P , i est un élémentde N , et G est un élément de ℘(N ). Laformule Kiϕ signifie : ‘l’agent i sait queϕ’, et CGϕ signifie : ‘il est connaissancecommune parmi les agents du groupe Gque ϕ’. Nous utilisons les abréviation ha-bituelles pour ‘∨’, ‘→’, ‘↔’, et Eiϕ, poursous-ensembles G de N . Nous rappelonsque le dernier est définie par : EGϕ =
i∈GKiϕ. Le langage LELN est obtenu du
langage LELC N par exclusion de l’opérateurde connaissance commune du dernier.
Un ELC N -modèle est une tuple M =
W,K,V où :– W est un ensemble non-vide des
mondes possibles ;– K : N → ℘(W × W ) associe une rela-
tion d’équivalence K i à chaque i ∈ N .– V : P → ℘(W ) associe une interpréta-
tion V ( p) ⊆ W à chaque p ∈ P .Par commodité, nous définissons K i(w) =w | (w, w) ∈ K i. La relation K i modé-lise la connaissance de l’agent i : K i(w)est l’ensemble des mondes que l’agent iconsidère possible en w.
La relation de satisfaction ‘’ est définiede façon habituelle :
M, w p ssi w ∈ V ( p)
M, w ¬ϕ ssi not M, w ϕM, w ϕ ∧ ψ ssi M, w ϕ and
M, w ψM, w Kiϕ ssi K i(w) ⊆ ϕM
M, w CGϕ ssi (
i∈GK i)∗(w) ⊆ ϕM
où ϕM = w ∈ W | M, w ϕ estl’extension de ϕ dans le modèleM etle‘∗’dans la dernière clause signifie la clôturereflexive et transitive.
Comme d’habitude nous disons que ϕ estvalide dans M (notation : M ϕ) ssiϕM = W ; ϕ est ELC
N -valide (notation :|=ELC N
ϕ) ssi M ϕ pour tout ELC N -
modèle M ; ϕ est satisfiable dans ELC N ssi
|=ELC N ¬ϕ. Des notions similaires sont dé-
finie pour la variante ELN sans connais-sance commune.
Nous rappelons que le problème de déci-der la ELN -satisfiabilité d’une formule estNP-complet si N = 1, PSPACE-completsi N ≥ 2, et que la ELC
N -satisfiabilité estEXPTIME-complet [4].
3 Théories d’actions à la Reiter
Nous étendons [3], où les théories d’ac-
tions à la Reiter sont formulées en logiquedynamique propositionnelle (PDL).
3.1 Descriptions d’action
Dans [10] et [12] plusieurs hypothèses desimplification sont faites. Les plus impor-tantes sont :
H1 : Toute les lois d’actions sont connu par
tous les agents.H2 : Toute occurrence d’action est pu-blique.
H3 : Toute action est déterministe.H4 : Chaque action est ou bien ontique
ou bien épistémique, mais jamais lesdeux à la fois.
H5 : Une action ne peut pas changer la va-leur de vérité d’un nombre infinie de
fluents.H6 : L’ensemble de fluents affectés par uneaction est beaucoup plus petit quel’ensemble P de tous les fluents dulangage.
____________________________________________________________________________ Annales du LAMSADE N°8
129

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 142/415
Les deux premières hypothèses garan-tissent que la connaissance des agents surles types d’actions (H1) et ses instances(H2) sont correctes. H4 est basé sur la dis-tinction entre actions ontiques et actionsépistémiques : les actions du premier typemodifient les faits, tandis que les actionsdu second type provoquent la mise à jourdes états de connaissance des agents. Cettehypothèse est aussi basée sur le fait quechaque action peut être divisée en une ac-tion ontique et une action épistémique. Ceconstat est du ‘folklore’ dans la literaturedu raisonnement sur les actions (voir, par
exemple, [13]). Les deux dernières hypo-thèses garantissent que le formalisme deReiter résout la version représentationelledu problème du décor. Elles sont justi-fiées par l’hypothèse de base de l’iner-tie : les actions (ontiques) ne changentqu’une petite partie du monde. Notons queReiter n’énonce pas explicitement l’hypo-thèse H5 ; cependant elle est indispensablequand les fluents sont propositionnels.
En plus, Scherl & Levesque supposentqu’il n’y a qu’un seul agent. Nous ne fai-sons pas cette restriction dans le présentarticle, et considérons aussi le cas multi-agent.
Soit A un ensemble infini dénombrablede lettre d’actions (actions atomiques abs-traites), et supposons A = Ao ∪ Ae, oùAo et Ae sont des ensembles disjoints de
lettres d’actions ontiques et épistémiquesrespectivement. Nous supposons que Ae
ne contient que des observations.
Définition 1 Nous définissons une des-cription d’actions comme étant une tuple
D = Poss ,Eff +,Eff −, γ +, γ −,Obs
tel que :– Poss : A → LELC N
attribue une formule
à chaque action qui décrit sa précondi-tion d’exécutabilité ;– Eff + : A → ℘(P ) attribue un en-
semble finie d’effets positives possiblesà chaque action ;
– Eff − : A → ℘(P ) attribue un en-semble finie d’effets négatives possiblesà chaque action;
– γ + est une famille de fonctions γ +(a) :Eff +(a) → LELC N . Elle attribue une for-mule à chaque pair (a, p) qui décrit laprécondition pour que l’action a rende pvraie;
– γ − est une famille de fonctions γ −(a) :Eff −(a) → LELC N
. Elle attribue une for-mule à chaque pair (a, p) qui décrit laprécondition pour que l’action a rende pfausse ; et
– Obs : A → LELC N attribue une formuleà chaque action dont la valeur de véritéest connue après l’exécution de l’action.
Nous convenons aussi que : si a est on-tique (i.e., a ∈ Ao), alors Obs (a) = ;si a est épistémique (i.e., a ∈ Ae), alorsEff +(a) = Eff −(a) = ∅ ; et si p ∈Eff +(a), alors γ +(a, p) = ⊥, ainsi commepour γ −(a, p).
H1 et H2 garantissent que les fonctionsdans D ne dépendent pas des agents. Àcause de H3, pour toute action a, ses ef-fets peuvent être caractérisés par γ +(a)et γ −(a). H4 justifie la partition de l’en-semble des actions en Ao et Ae. La finitudede Eff + et Eff − est due à H5. Finalement,H6 permet d’affirmer que la version repré-sentationelle du problème du décor est ré-solu par ce type de description d’action.
En plus, Reiter (et nous) supposons :H7 : Les formules γ +(a, p) ∧ γ −(a, p) sont
inconsistantes dans ELC N .
L’exécution d’une action épistémique aapprend à l’agent que Obs (a) est vraie.Nous supposons que les observations sontfiables :
H8 : Les formules Poss (a) ∧ ¬Obs (a) sont
inconsistantes dans ELC
N .Notons que [12] restreint le codomaine dePoss , γ +, γ − et Obs aux formules pro-positionnelles. Nous avons étendu ce co-domaine aux formules dans ∧ELC
N . Ceci
Raisonnement sur les actions : de Toronto à Amsterdam ___________________________________________________________________________
130

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 143/415
permet la formalisation des actions comme‘faire un appel téléphonique’, dont la pré-condition d’exécution est de connaître lenuméro de téléphone de l’interlocuteur.
Pour illustrer ce nouveau type de des-cription d’action, nous introduisons unexemple simple avec une action ontique etdeux actions épistémiques.
Exemple 2 Un robot ne sait pas si la lu-mière est allumé ou non. L’action ontiquedisponible est d’appuyer sur le bouton dela lumière (“toggle”) avec Poss (toggle ) =
, Eff +(toggle ) = Eff −(toggle ) =light , γ +(toggle , light ) = ¬light , etγ −(toggle , light ) = light . Les obser-vations sont oDark et oBright , avecPoss (oDark ) = Obs (oDark ) = ¬light ,et Poss (oBright ) = Obs (oBright ) =light .
3.2 Modèles pour les descriptions
d’actions
Soit D une description d’actions pour lesactions dans A = Ao ∪ Ae. Les modèlespour D sont obtenus en rajoutant des re-lations de transition aux modèles de la lo-gique épistémique.
Soit a un élément de Ao ∪ Ae, et soient oet e respectivement des éléments de Ao et
Ae.Définition 3 Nous définissons un D-modèle comme étant une 4-upletM = W,K,T,V , où W,K,V estun ELC
N -modèle et– T : A → ℘(W × W ) associe une rela-
tion T a à chaque a ∈ A.
La relation T a modélise la relation de tran-
sition associée à l’action abstraite a : sinous posons T a(w) = w | (w, w) ∈T a, alors T a(w) est l’ensemble des résul-tats possibles de l’exécution de l’action adans w.
Les D-modèles doivent satisfaire les res-trictions suivantes :1. “No-Forgetting” : (T a K i)(w) ⊆
(K i T a)(w).2. “No-Learning” : si T a(w) = ∅, alors(K i T a)(w) ⊆ (T a K i)(w).
3. Déterminisme : si v1, v2 ∈ T a(w),alors v1 = v2.
4. Éxécutabilité : T a(w) = ∅ ssiW,K,V , w Poss (a).
5. Préservation (épistémique) : si v ∈T e(w), alors
v ∈ V ( p) ssi w ∈ V ( p) for all p ∈ P
6. Pos-condition (ontique) : si v ∈T o(w), alors– p ∈ Eff +(o) et w ∈ V ( p) implique
v ∈ V ( p) ;– p ∈ Eff −(o) et w ∈ V ( p) implique
v ∈ V ( p) ;– p ∈ Eff +(o) et W,K,V , w
γ +(o, p) implique v ∈ V ( p) ;– p ∈ Eff −(o) et W,K,V , w
γ −(o, p) implique v ∈ V ( p) ;– p ∈ Eff +(o) et W,K,V , w
γ +(o, p) et w ∈ V ( p) implique v ∈V ( p) ;
– p ∈ Eff −(o) et W,K,V , w γ −(o, p) et w ∈ V ( p) implique v ∈V ( p).
La restriction 1 implante H1 et H2. Ellegarantie que tous les mondes dans (T a K i)(w) ont un antécédent. Cette restric-tion est appelée “perfect recall” dans [4].Cet-à-dire, il n’y a pas d’action capablede faire les agents oublier des faits. Larestriction 2 est motivée par H1–H3 pourles actions ontiques. Pour les actions épis-témiques, le fait d’apprendre l’occurrenced’une observation suffit pour faire évoluerl´état épistémique de chaque agent : l’exé-
cution d’une action d’observation e éli-mine les mondes possibles où Obs e) estfausse. 1 et 2 ensemble correspondent auxSSAs de Scherl & Levesque pour les ac-tions ontiques. La restriction 3 est motivée
____________________________________________________________________________ Annales du LAMSADE N°8
131

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 144/415
par l’hypothèse H3. La restriction 4 définitla condition pour qu’une action soit exécu-table. La restriction 5 nous donne un SSApour les actions épistémiques. La restric-tion 6 correspond au SSA de Reiter pourles faits (en opposition à la connaissance).Notons que sa consistance est garantie parH7 : sinon il pourrait y avoir un mondew où les deux γ +(a, p) et γ −(a, p) sontvraies, dans ce cas nous devrions avoir etv ∈ V ( p), et v ∈ V ( p) pour tout v ∈T a(w).
La sémantique des actions atomiques étant
en termes d’une fonction totale T a, il n’ya pas de concurrence. Néanmoins, les ac-tions concurrentes pourraient être modéli-sée par entrelacement (“interleaving”), cequi ne laisse pas de doutes pour leur inter-prétation.
3.3 Axiomes de réduction
Maintenant nous introduisons une combi-
naison de la logique épistémique et PDLdans laquelle on peut parler des validi-tés pour D-modèles. Le langage LD étendLELC N
avec des opérateurs dynamiques, etest définie par la BNF :
ϕ ::= p | ¬ϕ | ϕ ∧ ϕ | Kiϕ | CGϕ | [a]ϕ
où p est un élément de P , i est un élémentde N et a est un élément de A = Ao ∪ Ae.La formule [a]ϕ signifie ‘ϕ est vraie aprèstoute exécution possible de a’. Nous uti-lisons l’abbreviation habituelle aϕ =¬[a]¬ϕ.Donc a exprime que a est exé-cutable, et [a]⊥ exprime que a n’est pasexécutable.
Nous définissons la relation de satisfaction‘’ comme pour ELC
N , plus :
M, w [a]ϕ ssi T a(w) ⊆ ϕM
La formule ϕ ∈ LD est valide dans un D-modèle M (notation : M ϕ) ssi ϕM =W . Une formule ϕ ∈ LD est D-valide (no-tation : |=D ϕ) ssi M ϕ pour tout D-modèle M .
1. [e] p ↔ (Poss (e) → p)2. [e]¬ϕ ↔ (Poss (e) → ¬[e]ϕ)
3. [e](ϕ1 ∧ ϕ2) ↔ ([e]ϕ1 ∧ [e]ϕ2)4. [e]Kiϕ ↔ (Poss (e) → Ki[e]ϕ)5. [o] p ↔ (Poss (o) → p)
if p ∈ Eff +(o) ∪ Eff −(o)
6. [o] p ↔ (Poss (o) → (γ +(o, p) ∨ p))
if p ∈ Eff +(o) and p ∈ Eff −(o)
7. [o] p ↔ (Poss (o) → (¬γ −(o, p) ∧ p))
if p ∈ Eff +(o) and p ∈ Eff −(o)
8. [o] p ↔ (Poss (o) → (γ +(o, p)
∨(¬γ −(o, p) ∧ p)))
if p ∈ Eff +(o) ∩ Eff −(o)9. [o]¬ϕ ↔ (Poss (o) → ¬[o]ϕ)10. [o](ϕ1 ∧ ϕ2) ↔ ([o]ϕ1 ∧ [o]ϕ2)11. [o]Kiϕ ↔ (Poss (o) → Ki[o]ϕ)
TAB . 1 – D-validités pertinentes.
Pour notre exemple nous avons
|=D [toggle ]Kilight
|=D [oDark ][toggle ]Kilight
|=D ¬Ki¬light → [toggle ]¬Kilight
Notons aussi que [e]Obs (e) n’est pas D-
valide. En effet, considérons une action etelle que Obs (e) est la ‘phrase de Moore’ p∧¬Ki p : après avoir appris que p∧¬Ki pl’agent sait que p, donc ¬Ki p n’est plusvraie.
Soit D une descriptions d’actions. Le Ta-bleau 1 montre plusieurs équivalences D-valides.3 Dans chaque validité la com-plexité de la formule dans le champ
de l’opérateur dynamique [ ] décroît degauche à droite. Pour les formules sansopérateur de connaissance commune, cecinous permet de définir une procédure
3Notons que |=D Poss(a) implique Obs(a) par H8.
Raisonnement sur les actions : de Toronto à Amsterdam ___________________________________________________________________________
132

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 145/415
regD, appelée régression par [11], qui ap-plique récursivement ces validités jusqu’àce que la formule résultante ne contienneplus d’opérateurs dynamiques. Donc, pourtoute description D et formule ϕ sansl’opérateur CG nous avons :
|=D ϕ ssi |=ELC N regD(ϕ)
Par exemple, [toggle ]Kilight est toutd’abord réduit à Poss (toggle ) →Ki[toggle ]light (par l’axiome 11) etaprès à Ki¬light (par l’axiome 8); et[oDark ]Ki¬light est d’abord réduit
à Poss (oDark ) →K
i[oDark ]¬light (par l’axiome 4) et ensuite à ¬light →Ki(¬light → ¬light ) (par l’axiome 1).Comme le dernier est ELN -valide, alors|=D [oDark ][toggle ]Kilight .
Notons que regD est sous-optimal, puisqueil y a des formules tel que regD(ϕ) est ex-ponentiellement plus long que ϕ [11, Sec-tion 4.6].
4 Logique épistémique dyna-mique DELC
N
Une tradition différente dans la modélisa-tion de connaissance et changement a étésuivi par, par exemple, [9, 2, 15]. La lo-gique de [16, 6] se situe dans cette tradi-tion. Elle est basée sur les annonces pu-bliques et les affectations publiques.
4.1 Syntaxe
Le langage de la logique épistémiquedynamique avec connaissance communeLDELC N
est définie par la BNF :
ϕ ::= p | ¬ϕ | ϕ ∧ ϕ | Kiϕ | [!ϕ]ϕ | [σ]ϕσ ::= p :=ϕ | p :=ϕ, σ
où p estunélémentde P et i est un élémentde N .
De nouveau , la formule [α]ϕ signifie ‘ϕest vraie après toute exécution possible
de α’. L’action !ϕ est l’annonce publiquede ϕ.4 L’action p := ϕ est l’affectation pu-blique de la valeur de vérité de ϕ à l’atome p. Par exemple, p := ⊥ est une affectationpublique, etKi[ p := ⊥]¬ p est une formule.Quand des affectations sont faites en pa-rallel, le même atome ne peut apparaîtrequ’une seule fois à la gauche de l’opéra-teur ‘:=’. Par commodité, nous identifions( p1 :=ϕ1, . . . , pn := ϕn) avec l’ensemble p1 := ϕ1, . . . , pn :=ϕn. Nous utilisonsaussi l’abbreviation suivante :
[αif ϕ]ψ
def
= ϕ → [α]ψ
Lefragmentde DELC N sans affectations est
la logique des annonces publiques de Plaza(PALC
N ) [9], dont nous notons le fragmentsans connaissance commune PALN .
Les annonces modélisent les actions épis-
témiques, tandis que les affectations mo-délisent les actions ontiques. Par exemple,l’action épistémique oDark de l’Exemple2 est modélisée par !¬light , et l’actionontique toggle par l’affectation σtoggle =(light := ¬light ). Cet-à-dire, la valeur devérité de light est inversé.
4.2 Sémantique
Un DELC N -modèle est un tuple M =
W,K,V défini comme pour ELC N . La re-
lation de satisfaction ‘’ est comme avant,plus :
M, w [!ϕ]ψ ssi M, w ϕ implique
M !ϕ, w ψ
M, w [σ]ϕ ssi M σ
, w ϕ
4Notons que l’opérateur d’annonce est différent de l’opéra-teur de test de PDL (habituellement noté ϕ?) : le premier a deseffets épistémiques, mais le second n’en a pas.
____________________________________________________________________________ Annales du LAMSADE N°8
133

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 146/415
[!ϕ] p ↔ (ϕ → p)[!ϕ]¬ψ ↔ (ϕ → ¬[!ϕ]ψ)
[!ϕ](ψ1 ∧ ψ2) ↔ ([!ϕ]ψ1 ∧ [!ϕ]ψ2)[!ϕ]Kiψ ↔ (ϕ → Ki[!ϕ]ψ)[σ] p ↔ σ( p)[σ]¬ϕ ↔ ¬[σ]ϕ[σ](ϕ ∧ ψ) ↔ ([σ]ϕ ∧ [σ]ψ)[σ]Kiϕ ↔ Ki[σ]ϕ
TAB . 2 – DELC N -validitées pertinentes.
où M !ϕ et M σ sont des modifications dumodèle M définies par :
M !ϕ = W !ϕ,K !ϕ, V !ϕW !ϕ = W ∩ ϕM
K !ϕi = K i ∩ (ϕM × ϕM )
V !ϕ( p) = V ( p) ∩ ϕM
etM σ = W,K,V σV σ( p) = σ( p)M
et où σ( p) est une formule affecté à p dansσ. S’il n’y a pas d’occurrence de p :=ϕdans σ, alors σ( p) = p.
Comme d’habitude, ϕ est valide dans M (notation : M ϕ) ssi ϕM = W , etϕ est DELC
N -valide (notation : |=DELC N ϕ)
ssi M ϕ pour tout modèle épistémiqueM . Par exemple, Ki p → [q := p]Kiq estDELC
N -valide.
Plusieurs DELC N -validités pertinentes sont
listées dans le Tableau 2.
Quand il n’y a pas d’occurrence de l’opé-rateur de connaissance commune, les équi-valences du Tableau 2 permettent la dé-
finition d’une procédure de régressionregDELN , qui élimine les opérateurs dyna-miques de l’expression en question [16] :
|=DELC N ϕ ssi |=ELC N
regDELN (ϕ)
Pourtant, la DELN -régression a lemême problème que la D-régression :la formule résultante regDELN (ϕ)peut être exponentiellement pluslongue que ϕ (un exemple est. . . . . .¬Ki¬¬K j¬¬Ki¬).De plus, il n’existe pas d’équivalence decet type pour l’opérateur de connaissancecommune [2].
Dans les sections suivantes, nous propo-sons une solution alternative qui évite l’ex-plosion exponentielle. Le premier pas est
la formalisation de la liaison entre la des-cription d’action à la Reiter D d’un coté,et DELC
N de l’autre.
5 Traduction des théories à laReiter dans DELC
N
Les D-validités présentées dans le Tableau1 sont similaires à celles du tableau 2.Nous observons aussi que (1) les precondi-tions d’exécutabilité Poss dans D peuventêtre modélisées dans DELN comme la par-tie ‘if’ d’une action conditionnelle, commedans α if Poss (a) ; (2) les actions d’obser-vation e peuvent être vues comme des an-nonces publiques; et (3) les actions on-tiques o peuvent être vues comme des af-
fectations publiques.
La traduction δ D de LD dans LDELC N est
donc évidente.
Définition 4 Soit une D description d’ac-tion, soit o ∈ Ao une action ontique, et soit
e ∈ Ae une observation. Alors nous défi-nissons
δ D(e) = !Obs (e) if Poss (e)δ D(o) = σo if Poss (o)
Raisonnement sur les actions : de Toronto à Amsterdam ___________________________________________________________________________
134

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 147/415
où σo est l’affectation complexe :
p := γ +(o, p) ∨ p |
p ∈ Eff +(o) and p ∈ Eff −(o)∪
p := ¬γ −(o, p) ∧ p |
p ∈ Eff +(o) and p ∈ Eff −(o)∪
p := γ +(o, p) ∨ (¬γ −(o, p) ∧ p) |
p ∈ Eff +(o) ∩ Eff −(o)
Notons que δ D(o) est bien définie puisqueEff +(o) et Eff −(o) sont finis par H5. Par
exemple, δ D(oDark ) = !¬light if
¬light ,et δ D(toggle ) = light := ¬light ∨(¬light ∧light ), ce qui peuvent être simplifié enδ D(toggle ) = light := ¬light .
Nous étendons cette définition à toute for-mule dans LD.5
δ D( p) = pδ D(¬ϕ) = ¬δ D(ϕ)δ D(ϕ ∧ ψ) = δ D(ϕ) ∧ δ D(ψ)
δ D(Kiϕ) = Ki(δ D(ϕ))δ D([a]ϕ) = [δ D(a)]δ D(ϕ)
Soit | · | une fonction qui donne la longueurd’une expression (y compris les paren-thèses, virgules, etc). Nous avons la corres-pondance suivante entre les formules dans∧D et dans ∧DELC
N (cf. Tableaux 1 et 2).
Théorème 5 Soit D une description finie
d’action à la Reiter, et soit ϕ ∈ LD. Alorsϕ est D-satisfiable si et seulement si δ D(ϕ)est DELC
N -satisfiable, et |δ D(ϕ)| ≤ |ϕ| ×|D|).
La preuve est par induction sur la structurede ϕ. Observons que D est une tuple de 5éléments, et donc |D| ≥ 9.
Donc δ D est polynomial, et le problème
de décider si pour une D et ϕ, ϕ est D-satisfiable peut être transformé de façon5Notons que les formules dans ∧D n’ont pas d’occurrence
de l’opérateur de connaissance commune. Il n’y a donc pas declause pour cet opérateur.
polynomiale dans un problème de DELC N -
satisfiabilité.
6 Une régression optimale pourDELC
N
Maintenant nous montrons une réductionpolynomiale de DELC
N dans ELC N . L’idée
est d’éliminer d’abord les affectations, etensuite d’appliquer la réduction de Lutzpour éliminer les annonces [7].
6.1 Élimination des affectations
Nous appliquons une technique qui eststandard en démonstration automatique[8].
Proposition 6 Soit[ p1 := ϕ1, . . . , pn := ϕn]ψ une sous-formule d’une formule χ dans LDELC N
.
Soit ψ une formule obtenue de ψ parsubstitution de toute occurrence de pkpar x pk où x pk est un nouveau atomequi n’apparaît pas dans χ. Soit χ
obtenue de χ par remplacement de[ p1 := ϕ1, . . . , pn := ϕn]ψ par ψ. Soit Bl’abréviation de
1≤k≤n(x pk ↔ ϕk).
1. Si χ ∈ LDEL1 , alors χ est DEL1-satisfiable ssi
χ ∧KiB
est DEL1-satisfiable.
2. Si χ ∈ LDELN , N ≥ 2, alors χ estDELN -satisfiable ssi
χ ∧
≤md(ψ)
EN B
est DELN -satisfiable, où le degré mo-dal md(ψ) est le plus grand nombred’opérateurs modaux enchâssés dansψ, et En
Gϕ abrège ‘EG . . .EGϕ, n ≥ 0fois’.
____________________________________________________________________________ Annales du LAMSADE N°8
135

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 148/415
3. Si χ ∈ LDELC N , alors χ est DELC
N -satisfiable ssi
χ ∧CN B
est DELC N -satisfiable.
Preuve. Pour simplifier supposons que lasous-formule de χ est [ p := ϕ]ψ.
⇒ : Supposons que M = W,K,V est un ELC
N -modèle tel que M, w χ.Nous construisons un ELC
N
-modèle M xp =W,K,V xp, où V xp( p) = V ( p) for all p =x p, et V xp(x p) = ϕM . Nous démontronsque M xp [ p := ϕ]ψ ↔ ψ, d’où les troiscas suivent.
⇐ : Nous supposons que M est généré parw, et observons que Ki est une ‘modalitémaître’ (master modality) pour ELN avecun seul agent, ainsi que CG pour ELC
N ,
et ainsi que la conjunction des opérateursEG jusqu’au degré modal de ψ pour ELN
multi-agents. Par exemple, quand M, w
CGχ, alors M CGχ.
Le renommage évite l’explosion exponen-tielle. Ceci nous permet la définition desopérateurs de reduction redDEL1 , redDELN et redDELC N qui éliminent itérativementtous les affectations.
Par exemple, considérons laformule E DELN suivante :¬[!¬light ][light := ¬light ]Kilight . Saréduction est ¬[!¬light ]Kixlight ∧Ki(xlight ↔ ¬light ).
Proposition 7 redDEL1, redDELN etredDELC N
sont des transformations poly-nomiales, et ils préservent la satisfiabilité
dans les logiques respectives.
Preuve. La préservation de la satisfiabilitéest impliqué par la Proposition 6.
Pour les cas d’un seul agent et de connais-sance commune nous montrons que la lon-gueur de la reduction de χ est bornée par|χ|×(|χ|+6),etpourlecasde DELN nousmontrons que la longueur de la réductionde χ est bornée par |χ2×(|χ|+6). En plus,dans la Proposition 6 la longueur de χ estbornée par |χ|, la longueur de chaque équi-valence dans B est bornée par |χ| + 4, et lenombre des équivalences est borné par lenombre d’affectations (atomiques) dans χ,ce qui ne dépasse pas |χ|. Dans le cas del’opérateur E, le nombre d’équivalencesdoit être multiplié par le degré modal deχ, qui est borné par |χ|.
6.2 Élimination des annonces
Une fois les affectations sont éliminées,nous pouvons éliminer les annonces en uti-lisant la procédure de Lutz. Nous n’avonspas la place pour montrer les details, alorsnous mettons ici seulement le théorème le
plus relevant.6
Proposition 8 ([7]) Le problème de laPALN -satisfiabilité est NP-complet siN = 1, et PSPACE-complet si N ≥ 2.Le problème de la PALC
N -satisfiabilité estEXPTIME-complet.
Via le Théorème 5 nous obtenons :
Corollaire 9 Le problème de la D-satisfiabilité sans l’opérateur CG estNP-complet si N = 1, et PSPACE-complet si N ≥ 2. Le problème de laD-satisfiabilité avec l’opérateur CG estEXPTIME-complet.
7 Conclusions
Nous avons modelisé le problème du décordans la logique épistémico-dynamique par
6Pour une exposition extensive, le lecteur peut se rendre à[7].
Raisonnement sur les actions : de Toronto à Amsterdam ___________________________________________________________________________
136

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 149/415
la proposition d’une traduction des opéra-teurs d’actions ontiques et d’actions d’ob-servation du calcul de situations, et nousavons également identifié la complexité duproblème de satisfiabilité des formules tra-duite par cette méthode.
L’extension de la solution de Reiter pro-posée par Scherl & Levesque ne permetnon seulement la formalisation des obser-vations, mais aussi la formalisation des ac-tions de perception (sensing ?ϕ, qui testentsi une proposition ϕ est vraie. Un tel typed’action peut être vu comme une composi-
tion non-déterministe, c’est-à-dire, une ab-breviation : ?ϕ = !ϕ∪!¬ϕ. L’expansion del’opérateur de choix non-déterministe ‘∪’provoque une explosion exponentielle dela formule qui ne permet pas l’integrationde cet type d’action comme primitive dansnotre approche. Il n’est pas clair pour nouscomment le SSA associé
[?ϕ]Kiψ
↔ ((ϕ → Ki(ϕ → [?ϕ]ψ))∧(¬ϕ → Ki(¬ϕ → [?ϕ]ψ)))
pourrait être intégré dans la transformationpolynomial de Lutz. Une autre indice quela présence des actions de perception (sen-sing) augmente la complexité est donnéepar le résultat de [5], qui affirme que la vé-rification de plan est Π p
2-complet dans cecas. Nous avons l’intention de généraliser
nos résultats aux actions non-publiques,comme dans [2, 1].
Remerciements
Hans van Ditmarsch est soutenu par le pro- jet ‘Games, Action and Social Software’du NIAS (Netherlands Institute for Advan-ced Study in the Humanities and SocialSciences) et le NWO (Netherlands Orga-nisation for Scientific Research) CognitionProgram for the Advanced Studies (grantNWO 051-04-120).
Tiago de Lima est supporté par le Pro-
gramme Alßan, programme de boursesde haut niveau de l’Union Européennepour l’Amérique latine, bourse numéroE04D041703BR.
Les auteurs remercient également les troisrelecteurs anonymes pour leurs commen-taires extrêmement pertinents.
Références
[1] F. Bacchus, J.Y. Halpern, and H. Le-vesque. Reasoning about noisy sen-
sors in the situation calculus. Ar-tificial Intelligence, 111 :131–169,1999.
[2] A. Baltag, L. Moss, and S. Solecki.The logic of public announcementsand common knowledge. In Proc.TARK’98, 1998.
[3] R. Demolombe, A. Herzig, andI. Varzinczak. Regression in modallogic. J. of Applied Non-Classical
Logics, 13(2) :165–185, 2003.[4] R. Fagin, J. Halpern, Y. Moses, and
M. Vardi. Reasoning about Know-ledge. The MIT Press, 1995.
[5] Andreas Herzig, Jérôme Lang, Domi-nique Longin, and Thomas Polacsek.A logic for planning under partial ob-servability. In Proc. AAAI’2000,Aus-tin, Texas, August 2000.
[6] B. Kooi. Expressivity and complete-ness for public update logic via re-duction axioms. Journal of Applied
Non-Classical Logics, 17(2), 2007.To appear.
[7] C. Lutz. Complexity and succint-ness of public announcement logic.In Proc. of AAMAS , pages 137–144,2006.
[8] A. Nonnengart and C. Weiden-bach. Computing small clause nor-mal forms. In Handbook of Automa-ted Reasoning, pages 335–367. NorthHolland, 2001.
____________________________________________________________________________ Annales du LAMSADE N°8
137

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 150/415
[9] J. Plaza. Logics of public communi-cations. In M. L. Emrich et al., edi-tors, Proc. of ISMIS , pages 201–216,1989.
[10] R. Reiter. The frame problem inthe situation calculus : A simple so-lution (sometimes) and a complete-ness result for goal regression. InV. Lifschitz, editor, Papers in Honor of John McCarthy, pages 359–380.Academic Press Professional Inc.,1991.
[11] R. Reiter. Knowledge in Action :
Logical Foundations for Specifyingand Implementing Dynamical Sys-tems. The MIT Press, 2001.
[12] R. Scherl and H. Levesque. Know-ledge, action and the frame problem.
Artificial Intelligence, 144(1–2) :1–39, 2003.
[13] S. Shapiro, M. Pagnucco, Y. Lespé-rance, and H. J. Levesque. Iteratedbelief change in the situation calcu-
lus. In Proc. of KR, pages 527–538,2000.[14] M. Thielscher. From Situation Calcu-
lus to Fluent Calculus : State updateaxioms as a solution to the inferen-tial frame problem. Artificial Intelli-gence, 111(1–2) :277–299, 1999.
[15] J. van Benthem. One is a lonely num-ber. In P. Koepke et al., editors, Proc.
of LC&CL, 2002.[16] H. van Ditmarsch, W. van der Hoek,and B. Kooi. Dynamic epistemic lo-gic with assignment. In Proc. of AA-
MAS , pages 141–148. ACM, 2005.
Raisonnement sur les actions : de Toronto à Amsterdam ___________________________________________________________________________
138

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 151/415
Model Checking Logic Puzzles
Hans van Ditmarsch⋆
Ji Ruan†
⋆Computer Science, University of Otago, New Zealand
†Computer Science, University of Liverpool, United Kingdom
Résumé :Dans les puzzles épistémiques les annonces d’igno-rance, ou des séquences de tels annonces, sou-vent résultent en connaissances. Nous présentonsle puzzle ‘Quelle Somme ?’, et le modèlisent dansla logique des annonces publiques – un langage
logique avec des opérateurs dynamiques et épisté-miques. La solution du puzzle est controlée avec laprogramme de vérification DEMO.
Mots-clés : communications multi-agent, vérifica-tion des modèles, logique dynamique épistémique,annonce publique
Abstract:A common theme in logic puzzles involvingknowledge and ignorance is that announcementsof ignorance may eventually result in knowledge.
We present the ‘What Sum’ riddle. It is modelledin public announcement logic, a modal logic withboth dynamic and epistemic operators. We then
solve the riddle in the model checker DEMO.1
Keywords: agent communication, model check-ing, dynamic epistemic logic, public announce-ment
1 Introduction
The following riddle (transcribed in ourterminology) appeared in Math Horizonsin 2004, as ‘Problem 182’ in a regularproblem section of the journal, edited byA. Liu [8].
Each of agents Anne, Bill, and Cath has a positive integer on its forehead. They can
1We acknowledge input from David Atkinson, Jan van Eijck,
Wiebe van der Hoek, Barteld Kooi, and Rineke Verbrugge. We
thank the anonymous MFI referees for their comments. Hansappreciates support from the NIAS (Netherlands Institute for
Advanced Study in the Humanities and Social Sciences) project
‘Games, Action, and Social Software’ and the NWO (Nether-
lands Organisation for Scientific Research) Cognition Program
for the Advanced Studies grant NWO 051-04-120.
only see the foreheads of others. One of thenumbers is the sum of the other two. Allthe previous is common knowledge. Theagents now successively make the truthfulannouncements:
i. Anne: “I do not know my number.”
ii. Bill: “I do not know my number.”
iii. Cath: “I do not know my number.”
iv. Anne: “I know my number. It is 50.”
What are the other numbers?
You know your own number if and only if you know which of the three numbers isthe sum. This ‘What is the sum?’, fromnow on ‘What Sum’, riddle combines fea-tures from wisemen or Muddy Childrenpuzzles [12] with features from the Sumand Product riddle [3, 10]. A common fea-ture in such riddles is that we are givena multi-agent interpreted system, and thatsuccessive announcements of ignorance fi-nally result in its opposite, typically fac-tual knowledge. In a global state of an in-terpreted system [2] each agent or proces-sor has a local state, and there is commonknowledge that each agent only knows itslocal state, and what the extent is of thedomain. If the domain consists of thefull cartesian product of the sets of lo-cal state values, it is common knowledgethat agents are ignorant about others’ lo-
cal states. In that case an ignorance an-nouncement has no informative value. Forignorance statements to be informative, thedomain should be more restrictive than thefull cartesian product; and this is the case
139

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 152/415
in all such riddles. As in Muddy Chil-dren, we do not take the ‘real’ state of the agent (the number on its forehead) asits local state, but instead the informationseen on the foreheads of others (the othernumbers). This change of perspective is,clearly, inessential. ‘Sum and Product’2 isalso about numbers, and even about sumsof numbers, and the announcements aresimilar. But the structure of the back-ground knowledge is very different (whichwill become clearer after introducing thelogic to describe both riddles).
Other epistemic riddles involve cryptog-raphy and the verification of informationsecurity protocols (‘Russian Cards’, see[19]), or involve communication protocolswith private signals involving diffusion of information in a distributed environment(‘100 prisoners and a lightbulb’, see [21]).
The understanding of such riddles is facili-tated by the availability of suitable specifi-
cation languages. For ‘What Sum’ we pro-pose the logic of public announcements,wherein succinct descriptions in the log-ical language are combined with conve-nient relational structures on which to in-terpret them. We also benefit from theavailability of verification tools, to aid in-terpreting such descriptions on such struc-tures. In our case we have used DEMO,an epistemic model checker developed byVan Eijck (see homepages.cwi.nl/~jve/demo/ and [20]). Some adjust-ments are required (we need a finite ver-sion of the model) to make this modelchecking work. This results in possibly in-
2A says to S and P : I have chosen two integers x, y such
that 1 < x < y and x+y ≤ 100. In a moment, I will inform S
only of s = x+y , and P only of p = xy. These announcements
remain private. You are required to determine the pair (x, y).
He acts as said. The following conversation now takes place:
i. P says: “I do not know it.”
ii. S says: “I knew you didn’t.”
iii. P says: “I now know it.”
iv. S says: “I now also know it.”
Determine the pair (x, y).[3, translated]
teresting versions of the riddle.
Even though such riddles are often piv-otal to the development and spreading of
a specialisation area—who doesn’t knowabout the ‘Muddy Children’ puzzle?—thedetailed and rockbottom analysis of theirhighly proceduralised features is not nec-essarily considered a serious enough pur-suit to increase our understanding of mul-tiagent system dynamics. May our originalanalysis of ‘What Sum’ be seen as a wor-thy contribution.
Section 2 provides an introduction intopublic announcement logic, and in Sec-tion 3 we analyse ‘What Sum’ in thislogic. Section 4 ‘preprocesses’ the rid-dle for model checking and discusses someversions of the riddle. In Section 5 we in-troduce DEMO, and in Section 6 we spec-ify and verify a finite version of the riddlein that model checker.
2 Public Announcement Logic
Public announcement logic is a dynamicepistemic logic and is an extension of stan-dard multi-agent epistemic logic. Intuitiveexplanations of the epistemic part of thesemantics can be found in [2, 19]. We givea concise overview of, in that order, thelanguage, the structures on which the lan-guage is interpreted, and the semantics.
Given are a finite set of agents N and afinite or countably infinite set of atomsP . The language of public announcementlogic is inductively defined as
ϕ ::= p | ¬ϕ | (ϕ ∧ ψ) | K nϕ | C Bϕ | [ϕ]ψ
where p ∈ P , n ∈ N , and B ⊆ N are ar-bitrary. Other propositional and epistemicoperators are introduced by abbreviation.
For K nϕ, read ‘agent n knows formula ϕ’.For example, if Anne knows that her num-ber is 50, we can write K a50a, where astands for Anne and some set of atomicpropositions is assumed that contains 50a
Model checking logic puzzles ___________________________________________________________________________
140

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 153/415
to represent ‘Anne has the number 50.’ ForC Bϕ, read ‘group of agents B commonlyknow formula ϕ’. For example, we havethat C abc(20b → K a20b): it is commonknowledge to Anne, Bill, and Cath, thatif Bill’s number is 20, Anne knows that(because she can see Bill’s number on hisforehead)—instead of a,b,c we oftenwrite abc. For [ϕ]ψ, read ‘after public an-nouncement of ϕ, formula ψ (is true)’. Forexample, after Anne announces “(I knowmy number. It is 50.)” it is commonknowledge that Bill’s number is 20. Thisis formalised as [K a50a]C abc20b.
The basic structure is the epistemic model.This is a Kripke structure, or model,wherein all accessibility relations areequivalence relations. An epistemic modelM = S, ∼, V consists of a domain S of (factual) states (or ‘worlds’), accessi-bility ∼ : N → P (S × S ), where each∼ (n) is an equivalence relation, and a val-
uation V : P → P (S ). For s ∈ S ,(M, s) is an epistemic state (also knownas a pointed Kripke model). For ∼ (n) wewrite ∼n, and for V ( p) we write V p. Ac-cessibility ∼ can be seen as a set of equiv-alence relations ∼n, and V as a set of val-uations V p. Given two states s, s′ in thedomain, s ∼n s′ means that s is indistin-guishable from s′ for agent n on the basisof its information. For example, at the be-ginning of the riddle, triples (2, 14, 16) and(30, 14, 16) are indistinguishable for Annebut not for Bill nor for Cath. Therefore, as-suming a domain of natural number triples,we have that (2, 14, 16) ∼a (30, 14, 16).The group accessibility relation ∼B is thetransitive and reflexive closure of the unionof all accessibility relations for the individ-uals in B: ∼B ≡ (
n∈B ∼n)∗. This re-
lation is used to interpret common knowl-edge for group B. Instead of ‘∼B equiv-
alence class’ (∼n equivalence class) wewrite B-class (n-class).
For the semantics, assuming an epistemic
model M = S, ∼, V :
M, s |= p iff s ∈ V pM, s |= ¬ϕ iff M, s |= ϕM, s
|=ϕ
∧ψ iff M, s
|=ϕ and M, s
|=ψ
M, s |= K nϕ iff for all t ∈ S :s ∼n t implies M, t |= ϕ
M, s |= C Bϕ iff for all t ∈ S :s ∼B t implies M, t |= ϕ
M, s |= [ϕ]ψ iff M, s |= ϕ impliesM |ϕ, s |= ψ
where model M |ϕ = S ′, ∼′, V ′ is de-fined as
S ′ = s′ ∈ S | M, s′ |= ϕ∼′
n= ∼
n∩ (S ′ × S ′)
V ′ p = V p ∩ S ′
The dynamic modal operator [ϕ] is inter-preted as an epistemic state transformer.Announcements are assumed to be truth-ful, and this is commonly known by allagents. Therefore, the model M |ϕ is themodel M restricted to all the states whereϕ is true, including access between states.The dual of [ϕ] is ϕ: M, s |= ϕψ iff
M, s |= ϕ and M |ϕ, s |= ψ. Formula ϕ isvalid on model M , notation M |= ϕ, iff forall states s in the domain of M : M, s |= ϕ.Formula ϕ is valid, notation |= ϕ, iff forall models M : M |= ϕ.
A proof system for this logic is presented,and shown to be complete, in [1], withprecursors—namely for public announce-ment logic without common knowledge—in [15, 5]. A concise completeness proof is given in [19]. The logic is decidableboth with and without common knowledge[15, 1]. Results on the complexity of bothlogics can be found in [9]. The original[15] also contains a version of the seman-tics (no completeness results) with ‘know-value’-operators that can be said to for-malise infinitary conjunctions (or disjunc-tions), including announcements of suchformulas with corresponding restriction of
the domain to those states where the for-mula is true. To analyse ‘What Sum’ weneed to refer to that extension (that we pre-fer to leave informal for the sake of the ex-position).
____________________________________________________________________________ Annales du LAMSADE N°8
141

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 154/415
In public announcement logic, not all for-mulas remain true after their announce-ment, in other words, [ϕ]ϕ is not a prin-ciple of the logic. Some formulas involv-ing epistemic operators become false afterbeing announced! For a simple example,consider that Bill were to tell Anne (truth-fully) at the initial setting of the riddle:“Your number is 50 but you don’t knowthat.” Interpreting ‘but’ as a conjunction,this is formalised as 50a ∧ ¬K a50a. Af-ter the announcement, Anne knows thather number is 50: K a50a. Therefore theannounced formula, that was true before
the announcement, has become false afterthe announcement. In the somewhat dif-ferent setting that formulas of form p ∧¬K n p cannot be consistently known thisphenomenon is called the Moore-paradox[11, 7]. In the underlying dynamic settingit has been described as an unsuccessfulupdate [5, 19]. Similarly, ignorance state-ments in ‘What Sum’ such as Anne sayingthat she does not know her number, may in
due time lead to Anne knowing her num-ber, the opposite of her ignorance.
3 Formalisation of ‘What Sum’
The set of agents a,b,c represent Anne,Bill and Cath, respectively. Atomic propo-sitions in represent that agent n has naturalnumber i on its forehead. Therefore the setof atoms is in | i ∈ N+ and n ∈ a,b,c.
If Anne sees (knows) that Bill has 20 onhis forehead and Cath 30, we describethis as K a(20b ∧ 30c). If an upper boundmax for all numbers were specified in theriddle, the number of states would be fi-nite and “knowing the others’ numbers”would be described as
y,z≤max K a(yb ∧
z c). For model checking it is relevant topoint out that this expression is equiva-
lent to
y,z≤max(yb ∧ z c) → K a(yb ∧ z c),given that different Bill/Cath number pairsare mutually exclusive, and using standardvalidities for the logic. The latter formis ‘cheaper’ to model check than the for-
mer, because the truth of the boolean con-dition in the conjuncts of the latter can bedetermined in a given state, whereas anepistemic statement requires checks in thatagent’s entire equivalence class.
For ‘What Sum’, Anne seeing the num-bers of Bill and Cath is therefore describedas the infinitary
y,z∈N+ K a(yb ∧ z c), and
Anne saying: “I don’t know my number”is similarly described as ¬
x∈N+ K axa
(or
x∈N+(xa → ¬K axa)). Infinitary de-scriptions are, unlike infinitely large mod-els, not permitted in this (propositional)
logic. Our model checking results will befor a finite version of the riddle.
The epistemic model T = S, ∼, V is de-fined as follows, assuming positive naturalnumbers x,y,z .
S ≡ (x,y,z) | x = y+z or y = x+z or z = x+y
(x,y,z) ∼a (x′, y′, z′) iff y = y′ and z = z′
(x,y,z) ∼b (x′, y′, z′) iff x = x′ and z = z′
(x,y,z) ∼c (x′, y′, z′) iff x = x′ and y = y′
(x,y,z) ∈ V xa(x,y,z) ∈ V yb(x,y,z) ∈ V zc
The fine-structure of the epistemic modelT is not apparent from its formal defini-tion. A relevant question is what the back-ground knowledge is that is available tothe agents, i.e., what the abc-classes in themodel are (an abc-class, or a,b,c equiv-alence class, of a state s in the model con-
sists of all states t such that s ∼a,b,c t,where ∼a,b,c = (∼a ∪ ∼b ∪ ∼c)∗,as above). Such a computation was per-formed by Panti [14] for ‘Sum and Prod-uct’ (see footnote 2), which revealed threeclasses: either (in two of the three classes)the solution of the problem is already com-mon knowledge in the initial state, or theagents commonly know that the sum of the numbers is at least 7. This means that
in ‘Sum and Product’ not very much iscommonly known. In contrast, a model T for ‘What Sum’ has a very different struc-ture, with many more common knowledgeclasses. It is therefore quite informative to
Model checking logic puzzles ___________________________________________________________________________
142

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 155/415
know what they are, and we will describethem in detail.
An abc-class in T can be visualised as
an infinite binary tree. The depth of thetree reflects the following order on num-ber triples in the domain of T : (x,y,z ) >(u,v,w) iff (x > u and y = v and z = w)or (x = u and y > v and z = w) or(x = u and y = v and z > w). If (x,y,z ) > (u,v,w) according to this def-inition, (x,y,z ) is a child of (u,v,w) inthat tree. Every node except the root hasone predecessor and two successors, as in
Figure 1.. . .
(|x − y|,x ,y)
(x + y,x,y)
(x + y, x + 2y, y) (x + y,x, 2x + y). . . . . .
a
b c
Figure 1: Modulo agent symmetry, all parts of the model T branch as here. Arcs connecting nodes
are labelled with the agent who cannot distinguishthose nodes.
The root of each tree has label (2x,x,x)or (x, 2x, x) or (x,x, 2x). Differently said,given three natural numbers such that oneis the sum of the other two, replace thatsum by the difference of the other two;one of those other two has now becomethe sum; if you repeat the procedure, youalways end up with two equal numbersand their sum. An agent who sees twoequal numbers, immediately infers that itsown number must be their sum (twice thenumber that is seen), because otherwise itwould have to be their difference 0 whichis not a positive natural number. It will beobvious that: the structure truly is a for-est (a set of trees), because each node onlyhas a single parent; all nodes except rootsare triples of three different numbers; and
all trees are infinite. All abc-trees are iso-morphic modulo (i) a multiplication fac-tor for the numbers occurring in the ar-guments of the node labels, and modulo(ii) a permutation of arguments and a cor-
responding swap of agents, i.e., swap of arc labels. For example, the numbers oc-curring in the tree with root (6, 3, 3) arethrice the corresponding numbers in thetree with root (2, 1, 1); the tree with root(2, 1, 1) is like the tree for root (1, 2, 1) byapplying permutation (213) to argumentsand (alphabetically ordered) agent labelsalike. The left side of Figure 3 showsthe trees with roots (2, 1, 1), (1, 2, 1), and(1, 1, 2). For simplicity, we write 211 in-stead of (2, 1, 1), etc. In the left tree,for Bill (2, 1, 1) is indistinguishable from(2, 3, 1) wherein his number is the sum of
the other two instead of their difference;for Anne triple (2, 3, 1) is indistinguish-able from (4, 3, 1), etc.
Processing Announcements The result of anannouncement (whether described infini-tary or not) is the restriction of the modelto all states where the announcement istrue. We can also apply this to the igno-rance announcements of agents in ‘What
Sum’. Consider an abc-tree T in T . Letn be an arbitrary agent. Either the rootof T is a singleton n-class, or all its n-classes consist of two elements: a two-element class represents the agent’s uncer-tainty about its own number. An ignoranceannouncement by agent n in this riddlecorresponds to removal of all singleton n-classes from the model T . This means thatsome of the model’s trees are split into two
subtrees (with both children of the originalroot now roots of infinite trees).
An ignorance announcement may havevery different effects on abc-classes thatare the same modulo agent permutations.For example, given abc-classes in T withroots 121, 112, and 211, the effect of Annesaying that she does not know her numberonly results in elimination of 211, as onlythe first abc-class contains an a-singleton.
Given 211, Anne knows that she has num-ber 2 (as 0 is excluded). But triple 112 shecannot distinguish from 312, and 121 notfrom 321. Thus one proceeds with all threeannouncements. See also Figure 2.
____________________________________________________________________________ Annales du LAMSADE N°8
143

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 156/415
211
231 213
431 235 413 253
451 437 835 275 473 415 853 257. . . . . . . . . . . . . . . . . . . . . . . .
b c
a c a b
bc a
b bc a c
231 213
431 235 413 253
451 437 835 275 473 415 853 257. . . . . . . . . . . . . . . . . . . . . . . .
a c a b
b c a b b c a c
213
431 235 413 253
451 437 835 275 473 415 853 257. . . . . . . . . . . . . . . . . . . . . . . .
a b
b c a b b c a c
431 413 253
451 437 835 275 473 415 853 257. . . . . . . . . . . . . . . . . . . . . . . .
b c b c a c
Figure 2: The results of three ignorance an-nouncements on the abc-class with root (2, 1, 1).
Solving the riddle We have now sufficientbackground to solve the riddle. We applythe successive ignorance announcementsto the three classes with roots (2, 1, 1),(1, 2, 1), and (1, 1, 2), determine the tripleswherein Anne knows the numbers, andfrom those, wherein Anne’s number di-vides 50. See Figure 3—note that intriple (8, 3, 5) Anne also knows her num-ber: the alternative (2, 3, 5) wherein hernumber is 2 has been eliminated by Cath’s,last, ignorance announcement. The uniquetriple wherein Anne’s number divides 50is (5, 2, 3). In other words, the unique abc-tree in the entire model T where Anneknows that she has 50 after the three ig-norance announcements, is the one withroot (10, 20, 10). The solution to the riddle
is therefore that Bill has 20 and Cath has30. After the three announcements in theabc-class with root (10, 20, 10), the triple(50, 20, 30) remains wherein Anne knowsthat Bill has 20 and Cath 30.
211
23 1 21 3
431 235 413 253
451 437 835 275 473 415 853 257. . . . . . . . . . . . . . . . . . . . . . . .
b c
a c a b
b c a b b c a c
431 413 253
4 51 4 37 835 275 473 415 853 257. . . . . . . . . . . . . . . . . . . . . . . .
b c b c a c
121
32 1 1 23
341 325 143 523
541 347 385 725 743 145 583 527. . . . . . . . . . . . . . . . . . . . . . . .
a c
b c b a
a c b a a c b c
321
341 325 143 523
541 347 385 725 743 145 583 527. . . . . . . . . . . . . . . . . . . . . . . .
b c
a c b a a c b c
112
132 3 12
134 532 314 352
154 734 538 572 374 514 358 752. . . . . . . . . . . . . . . . . . . . . . . .
b a
c a c b
b a c b b a c a
132 312
134 532 314 352
154 734 538 572 374 514 358 752. . . . . . . . . . . . . . . . . . . . . . . .
c a c b
b a c b b a c a
Figure 3: On the left, abc-classes of the model T
with root 211, 121, and 112. Any other abc-classis isomorphic to one of these, modulo a multipli-cation factor. The results of the (combined) threeignorance announcements on those abc-classes areon the right. The triples in bold are those whereAnne knows her number.
The original riddle could have more re-strictive: in the quoted version [8] it isnot required to determine who holds which
other number, but as we have seen this canalso be determined. It also occurred tous that the original riddle could have beenposed differently (and we tend to think, farmore elegantly) as follows:
Each of agents Anne, Bill, and Cath has a positive integer on its forehead. They canonly see the foreheads of others. One of thenumbers is the sum of the other two. Allthe previous is common knowledge. The
agents now successively make the truthfulannouncements:
i. Anne: “I do not know my number.”
ii. Bill: “I do not know my number.”
iii. Cath: “I do not know my number.”
What are the numbers, if Anne now knowsher number and if all numbers are prime?
Consulting Figure 3, it will be obvious thatthe answer should be: ‘5, 2, and 3’.
Model checking logic puzzles ___________________________________________________________________________
144

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 157/415
4 Towards Model Checking
To be able to use a model checker we need
a finite approximation of the model. Sup-pose we use an upper bound max for thenumbers. Let T max be the correspond-ing epistemic model. An abc-tree is nowcut at the depth where nodes (x,y,z ) oc-cur such that the sum of two of the ar-guments x,y,z exceeds max. This finiteapproximation may not seem a big dealbut it makes the problem completely dif-ferent: abc-classes will not just have roots
wherein the agent may know his number(because the other numbers are equal) butwill also have leaves wherein the agentmay know his number (because the sumof the other two numbers exceeds max).In other words, we have far more single-ton equivalence classes. Let max = 10.Node (2, 5, 7) in the abc-class with root(2, 1, 1) has only a b-child (2, 9, 7) and ac-parent (2, 5, 3), and not an a-child, as5 + 7 = 12 > max. So Anne immedi-ately knows that her number is 2. All roots(2x,x,x) with 3x > max form singletonabc-classes in T max, for the same reason.
In such models it is no longer the casethat all equivalence classes are isomorphicmodulo a multiplication factor and swap-ping of agent labels. For a given upperbound max we still have that, if x > y, theabc-class T with root (2x,x,x) is a prefix
(in a partially ordered sense) of the abc-class T ′ with root (2y,y,y), which impliesthat T ⊆ T ′ (modulo a factor y
xfor num-
bers occurring in T ). For different upperbounds max,max′ we have that (literally)
T max ⊆ T max′
iff max ≤ max′.
Under these circumstances it is less clearwhat constitutes an exhaustive search of ‘all possibilities that remain after an an-
nouncement’. Fortunately, we are nowtalking about formal announcements in thelanguage of public announcement logic.The following non-trivial result is essen-tial. Let T, T ′ be different epistemic mod-
els T for ‘What Sum’ (i.e., for differentupper bounds max) or, modulo a multi-plication factor, different abc-classes in agiven T model.
If T ⊆ T ′ and ϕ is a sequence of ignoranceannouncements executable in both T and T ′ , then T | ϕ ⊆ T ′| ϕ.
The proof is simple, and by induction onthe number of such announcements. Con-sider a next ignorance announcement ψbeing made, by agent n. As said, it re-moves singleton equivalence classes for
that agent. If T ⊆ T ′ it may be thatsome singleton n-classes in T were two-state n-classes in T ′. These will there-fore be omitted when executing the an-nouncement of ψ in T , whereas they wouldhave been preserved when executing thesame announcement in T ′. There areno other differences in execution: all n-classes that were singleton in both T andT ′ will be omitted anyway as a result of
the ψ-announcement. Therefore, we stillhave that T |ψ ⊆ T ′|ψ.
This may seem obvious. But it is far fromthat: for arbitrary M ′ ⊆ M and arbitrary ϕwe do not have that M ′|ϕ ⊆ M |ϕ. Let usgive a counterexample. Given agents a, band state variables p, q (in 10 p is true andq is false) consider the (two-state) modelM ′ = 11|a|10, which is a restriction of the (three state) model M = 11|a|10|b|01.Consider ϕ = K bq ∨K b¬q , for ‘Bill knowswhether q .’ Then M ′|ϕ = M ′, whereasM |ϕ is the singleton model consisting of state 11 wherein a and b have commonknowledge of p and q . Therefore M ′ ⊆ M but M ′|ϕ ⊆ M |ϕ.
Apart from having an upper bound we dis-cuss one other, less essential, change: sup-pose we start counting from 0 instead of
1. In that case each abc-equivalence classwith root (2x,x,x) is extended with onemore node: the new root (0, x , x) is indis-tinguishable from (2x,x,x) for Anne. Anagent who sees a 0, infers that his number
____________________________________________________________________________ Annales du LAMSADE N°8
145

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 158/415
must be the other number that (s)he sees.If there is a 0, two of the three agents seethat. Therefore, the root has just one child(2x,x,x); if the triple is (0, x , x) Bill and
Cath know that their number is x.3
The abc-class with root 011 from the epis-temic model T 100 (upper bound 10, lowerbound 0) is displayed on the left in Fig-ure 4. The result of the three ignoranceannouncements is displayed on the right.We can now investigate different versionsof the problem. The model checker is thenhelpful because some versions are hard to
verify with pencil and paper, or mere men-tal computation. For example, we consid-ered the version: If 0 ≤ x,y,z ≤ max,for which values of max does Anne al-ways know the numbers after the three an-nouncements? This range is 8 ≤ max ≤13 (so, for 7 not all three announcementscan be made truthfully, and for 14 it maybe that Anne does not know her num-ber) and this includes max = 10. Fig-
ure 4 shows that from abc-class with root011 the triples 211 and 213 remain. Inboth cases Anne knows her number. Sim-ilar computations show that from the abc-classes with root 101 and 110 no triples re-main. In other words, the announcementscould not all three have been made (truth-fully) if the number triple occurs in eitherof those two classes. Using the proper-ties of inclusion for different abc-classes,
we have now ruled out all classes of typex0x and xx0 and only have to check otherclasses of type 0xx. From class 022, thetriples 242 and 246 remain after the threeannouncements (and the ones with root033 and beyond are empty again). There-fore, whatever the numbers, Anne now
3Suppose there is no upper bound but 0 is still allowed—
every audience being presented with this riddle for positive in-
tegers contains at least one person asking if 0 is allowed. This is
an interesting variation. Anne will still learn her own number if
it is 50 from the three ignorance announcements, but the reader(‘problem solver’) can now no longer deduce Bill’s and Cath’s
number in that case: these can now also be 25 and 25. The
reader should be able to determine this easily by contemplating
Figure 3. From the models resulting from the three ignorance
announcements, only one now looks different. Which one?
011
211
231 213
431 235 413 253
451 437 835 275 473 415 853 257
297651 459 A37 279 A73 615 495 297
671
871
891
A91
617
817
819
A19
a
b c
a c a b
b c a b b c a c
a c a c a a b b
b
a
b
a
c
a
c
a
211
213
c
Figure 4: The abc-class with root 011 in model
T 100
, and the result of three ignorance announce-ments. The horizontal order of branches has nomeaning. Symbol A represents 10.
knows her number. But the problem solvercannot determine what that number is (itmay be 1, or it may be 2) and also cannotdetermine what the other numbers are, noteven if it is also known what Anne’s num-ber is (if it is 1, the other numbers may be2 and 1, or 2 and 3; and similarly if it is 2).
5 Model Checker DEMO
Epistemic model checkers with dynamicfacilities have been developed to ver-ify properties of interpreted systems,knowledge-based protocols, and variousother multi-agent systems. Examples areMCK [4], MCMAS [16], and recent workby Su [17]. All those model checkers usethe interpreted systems architecture, andexploration of the search space is based onordered binary decision diagrams. Theirdynamics are expressed in temporal ortemporal epistemic (linear and/or branch-ing time) logics.
A different model checker, not basedon a temporal epistemic architecture, isDEMO. It has been developed by VanEijck [20]. DEMO is short for Dynamic
Model checking logic puzzles ___________________________________________________________________________
146

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 159/415
Epistemic MOdelling. It allows mod-elling epistemic updates, graphical displayof Kripke structures involved, and for-mula evaluation in epistemic states. Thisgeneral purpose model checker has alsomany other facilities. DEMO is writtenin the functional programming languageHaskell.
The model checker DEMO implementsthe dynamic epistemic logic of [1]. Inthis ‘action model logic’ the global stateof a multi-agent system is represented byan epistemic model. But more epistemic
actions are allowed than just public an-nouncements, and each epistemic actionis represented by an action model. Justlike an epistemic model, an action modelis also based on a multi-agent Kripkeframe, but instead of carrying a valuationit has a precondition function that assignsa precondition to each point in the actionmodel. A point in the action model domainstands for an atomic action.
The epistemic state change in the systemis via a general operation called the update
product : this is a way to produce a singlestructure (the next epistemic model) fromtwo given structures (the current epistemicmodel and the current action model). Wedo not give details, as we restrict our atten-tion to very simple action models, namelythose corresponding to public announce-ments. Such action models have a single-ton domain, and the precondition of thatpoint is the announced formula. The nextepistemic model is produced from the cur-rent epistemic model and the singleton ac-tion model for the announcement by themodel restriction introduced in Section 2.
The recursive definition of formulasin DEMO includes (we omitted theclause for updates) Form = Top | Prop
Prop | Neg Form | Conj [Form] |Disj [Form] | K Agent Form | CK
[Agent] Form . Formula Top stands for⊤, Prop Prop for atomic propositionalletters (the first occurrence of Prop means
that the datatype is ‘propositional atom’,whereas the second occurrence of Prop isthe placeholder for an actual propositionletter, such as P 3), Neg for negation, Conj
[Form] stands for the conjunction of a listof formulas of type Form, similarly forDisj, K Agent stands for the individualknowledge operator for agent Agent, andCK [Agent] for the common knowledgeoperator for the group of agents listed in[Agent].
The pointed and singleton action modelfor a public announcement is created by
a function public with a precondition(the announced formula) as argument.The update operation is specified as upd
:: EpistM -> PoAM -> EpistM ; hereEpistM is an epistemic state and PoAM is apointed action model, and the update gen-erates a new epistemic state. If the in-put epistemic state EpistM corresponds tosome (M, s), then in case of the truthfulpublic announcement of ϕ the resultingEpistM has the form
(M
|ϕ, s
). We can
also update with a list of pointed actionmodels: upds :: EpistM -> [PoAM]
-> EpistM .
Complexity Each model restriction M |ϕrequires determining the set s ∈ D(M ) |M, s |= ϕ. Given a model M , a states, and a formula ϕ, checking whetherM, s |= ϕ can be solved in time O(|M | ×|ϕ|), where |M | is the size of the modelas measured in the size of its domain plusthe number of pairs in its accessibility re-lations, and where |ϕ| is the length of theformula ϕ. This result has been estab-lished by the well-known labelling method[6, 2]. This method is based on dividing ϕinto subformulas. One then orders all thesesubformulas, of which there are at most|ϕ|, by increasing length. For each subfor-mula, all states are labelled with either the
formula or its negation, according to thevaluation of the model and based on theresults of previous steps. This is a bottom-up approach, in the sense that the labellingstarts from the smallest subformulas. So
____________________________________________________________________________ Annales du LAMSADE N°8
147

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 160/415
it ensures that each subformula is checkedonly once in each state.
In DEMO (v1.02) the algorithm to check
whether M, s |= ϕ does not employthis bottom-up approach. Instead, it usesa top-down approach, starting with theformula ϕ and recursively checking itslargest subformulas. For example, tocheck whether M, s |= K aψ, the algo-rithm checks whether M, s′ |= ψ for alls′ such that s ∼a s′, and then recursivelychecks the subformulas of ψ. This algo-
rithm is O(|M ||ϕ|), since each subformula
may need to be checked |M | times, andthere are at most |ϕ| subformulas of ϕ. So,theoretically, DEMO’s algorithm is quiteexpensive.
In practice it is less expensive, because theHaskell language and its compiler and in-terpreter support a cache mechanism: afterevaluating a function, it caches some re-sults in memory for reuse (see e.g. [13]).
Since it is hard to predict what resultswill be cached and for how long, we can-not give an estimate how much the cachemechanism influences the computationalresults for DEMO. See also [18]. Compu-tational results for the experiments in thenext section are given in footnote 5.
6 ‘What Sum’ in DEMO
The DEMO program SUMXYZ.hs, dis-played in Figure 5, implements the‘What Sum’ problem for upper boundmax = 10.4 The list triples =
triplesx ++ triplesy ++ triplesz
(this is a union (++) of three lists) cor-responds to the set of possible triples(x,y,z ) for the given bound 10—note thatin Haskell we are required to define suchsets as lists. The next part of the program
constructs the domain based on that list:this merely means that each member of thelist must be associated with a state name.
4The program is original but should be considered a version
of the DEMO program for ‘Sum and Product’ in [18].
module SUMXYZ
where
import DEMO
upb = 10
-- constrained triples (x,y,z) with x,y,z <= upb
triplesx = [(x,y,z)|x<-[0..upb], y<-[0..upb],
z<-[0..upb], x==y+z]triplesy = [(x,y,z)|x<-[0..upb], y<-[0..upb],
z<-[0..upb], y==x+z]
triplesz = [(x,y,z)|x<-[0..upb], y<-[0..upb],
z<-[0..upb], z==x+y]
triples = triplesx ++ triplesy ++ triplesz
-- associating states with number triples
numtriples = llength(triples)
llength [] =0
llength (x:xs) = 1+ llength xs
itriples = zip [0..numtriples-1] triples
-- initial multi-pointed epistemic model
three :: EpistM
three =
(Pmod [0..numtriples-1] val acc [0..numtriples-1])
where
val = [(w,[P x,Q y,R z])|(w,(x,y,z))<-itriples]
acc = [(a,w,v)| (w,(x1,y1,z1))<-itriples,
(v,(x2,y2,z2))<-itriples,y1==y2,z1==z2]++
[(b,w,v)| (w,(x1,y1,z1))<-itriples,
(v,(x2,y2,z2))<-itriples,x1==x2,z1==z2]++
[(c,w,v)| (w,(x1,y1,z1))<-itriples,
(v,(x2,y2,z2))<-itriples, x1==x2, y1==y2]
-- agents a,b,c say: I do not know my number
fagxnot = Conj [(Disj[Neg (Prop (P x)),
Neg (K a (Prop (P x))) ])| x <-[0..upb]]
aagxnot = public (fagxnot)
fagynot = Conj [(Disj[Neg (Prop (Q y)),
Neg (K b (Prop (Q y))) ])| y <-[0..upb]]
aagynot = public (fagynot)
fagznot = Conj [(Disj[Neg (Prop (R z)),
Neg (K c (Prop (R z))) ])| z <-[0..upb]]aagznot = public (fagznot)
-- model restriction from announcements
result =
showM (upds three [aagxnot, aagynot, aagznot])
Figure 5: The DEMO program SUMXYZ.hs
State names must be consecutive numbers,counting from 0. The association is ex-
plicit in the list itriples that consists of pairs of which the first argument is a num-ber (from the list [0..numtriples-1])and the second argument is one of thetriples (x,y,z ) in the list triples. Theinitial model T 100 is then represented asthree in the program. The expression(Pmod [0..numtriples-1] val acc
[0..numtriples-1]) defines three asan epistemic model (Pmod), with domain
[0..numtriples-1], valuation val, aset (list) of accessibility relations acc
(and [0..numtriples-1] points—leftunexplained here). In val we find forexample (67,[p6, q8, r2]) which says
Model checking logic puzzles ___________________________________________________________________________
148

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 161/415
that state number 67 corresponds to triple(6, 8, 2). Given (43,[p10, q8, r2]) wenow find (a,43,67) in acc.
Anne’s announcement that she does notknow her number is represented as the ac-tion model aagxnot constructed from theannouncement formula fagxnot by thefunction public. The formula fagxnot isdefined as Conj [(Disj[Neg (Prop (P
x)), Neg (K a (Prop (P x))) ])|x
<-[0..upb]] . This specifies that what-ever x is (x <-[0..upb]), if Anne has itshe does not know it (Disj[Neg (Prop
(P x)), Neg (K a (Prop (P x))) ]).The last corresponds to ¬xa ∨ ¬K axa,which is equivalent to xa → ¬K axa.Therefore, the whole expression corre-sponds to
0≤x≤10 xa → ¬K axa. This
is the computationally cheaper versionalso formalised as ¬
0≤x≤10 K axa, see
Section 3.
The final line in the program asks to dis-play the results of the three ignorance an-nouncements. Its output is
==> [0,1,2,3]
[0,1,2,3]
(0,[p2,q1,r1])(1,[p1,q3,r2])
(2,[p1,q3,r4])(3,[p2,q1,r3])
(a,[[0],[1],[2],[3]])
(b,[[0],[1],[2],[3]])
(c,[[0,3],[1,2]])
States are sequentially renumbered start-
ing from 0 after each update. The four re-maining triples 211, 132, 134, and 213 areclearly shown, see also Figure 4. Anne al-ways knows her number, as her partitionon the set of four states is the identity (andso does Bill, but not Cath).5
5We did experiments in a PC configured as Windows XP,
AMD CPU 1.8Ghz, with 1G RAM. We use the Glasgow Haskell
Compiler Interactive (GHCi) version 6.4.1, enabling the option
“:set +s” to display information after evaluating each expres-
sion, including the elapsed time and number of bytes allocated.
The results for time and space consumption of the crucial upds
msnp [aagxnot,aagynot,aagznot] are as follows: for
upb=10, time: 1.59 seconds, and space: 29,075,432 bytes; to
give an impression of how this scales up: for upb=20, time:
30.31 seconds, and space: 334,474,032 bytes; for upb=30,
time: 193.20 seconds, and space: 1,706,593,672 bytes.
We hope that this rather summaryoverview of DEMO nevertheless re-veals its enormous versatility as a modelchecker. E.g., to check which statesremain when a different upper bound ischosen, one merely has to replace the lineupb = 10 in the program by that otherupper bound. In general, the enormousadvantage of this model checker is that itallows for a separate specification of theinitial model and the subsequent dynamicfeatures, as in the original riddle (and,typically, as in the specification of thedynamics of a multiagent system to be
formally modelled).
7 Conclusions
We presented an original analysis of anepistemic riddle, and formalised a finiteversion of the riddle with the use of publicannouncement logic and epistemic modelchecking. Crucial in the analysis was to
model the riddle as an interpreted system,and to focus on the description of the back-ground knowledge, i.e., abc-equivalenceclasses of the epistemic model. We intro-duced the model checker DEMO and thespecification of the riddle in DEMO.
We think that detailed analysis of logicpuzzles contributes to the understandingof logical tools and formalisms, and howto apply them to model multiagent sys-tem dynamics. In particular, the specifi-cation of security protocols in DEMO is,we think, promising. In our experienceswith specifying such protocols, DEMOcompares favourably to other state-of-the-art model checkers MCK and MCMAS—of course we would not dare to suggestthat DEMO is ‘better’: when specifyinga problem in which public announcementsare essential, it is not surprising that a
tool specially developed for such dynam-ics functions well.
Future development of DEMO may in-volve (Jan van Eijck, personal communi-
____________________________________________________________________________ Annales du LAMSADE N°8
149

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 162/415
cation) facilities to model not merely in-formation change, such as incoming newinformation, but also factual change. Thiswould expand the use of this tool to modelplanning protocols, security protocols thatinclude key exchange, etc. We are muchlooking forward to that development.
References
[1] A. Baltag, L.S. Moss, and S. Solecki.The logic of public announcements, com-mon knowledge, and private suspicions. InI. Gilboa, editor, Proceedings of TARK VII ,
pages 43–56, 1998.
[2] R. Fagin, J.Y. Halpern, Y. Moses, and M.Y.Vardi. Reasoning about Knowledge. MITPress, Cambridge MA, 1995.
[3] H. Freudenthal. (formulation of the sum-and-product problem). Nieuw Archief voor Wiskunde, 3(17):152, 1969.
[4] P. Gammie and R. van der Meyden. MCK:Model checking the logic of knowledge. InR. Alur and D. Peled, editors, Proceedings of
CAV 04, pages 479–483. Springer, 2004.
[5] J.D. Gerbrandy. Bisimulations on Planet Kripke. PhD thesis, University of Amster-dam, 1999. ILLC Dissertation Series DS-1999-01.
[6] J.Y. Halpern and M.Y. Vardi. Model check-ing vs. theorem proving: a manifesto. InV. Lifschitz, editor, Artificial intelligence and mathematical theory of computation: papersin honor of John McCarthy, pages 151–176,
San Diego, CA, USA, 1991. Academic PressProfessional, Inc.
[7] J. Hintikka. Knowledge and Belief . CornellUniversity Press, Ithaca, NY, 1962.
[8] A. Liu. Problem section: Problem 182. Math Horizons, 11:324, 2004.
[9] C. Lutz. Complexity and succinctness of pub-lic announcement logic. In Proceedings of AAMAS 06 , pages 137–144, 2006.
[10] J. McCarthy. Formalization of two puzzlesinvolving knowledge. In V. Lifschitz, ed-itor, Formalizing Common Sense : Papersby John McCarthy. Ablex Publishing Cor-poration, Norwood, N.J., 1990. originalmanuscript dated 1978–1981.
[11] G.E. Moore. A reply to my critics. InP.A. Schilpp, editor, The Philosophy of G.E. Moore, pages 535–677. Northwestern Univer-sity, Evanston IL, 1942. The Library of Liv-
ing Philosophers (volume 4).[12] Y.O. Moses, D. Dolev, and J.Y. Halpern.
Cheating husbands and other stories: a casestudy in knowledge, action, and communica-tion. Distributed Computing, 1(3):167–176,1986.
[13] N. Nethercote and A. Mycroft. The cachebehaviour of large lazy functional programson stock hardware. SIGPLAN Notices, 38(2supplement):44–55, 2003.
[14] G. Panti. Solution of a number theoreticproblem involving knowledge. International Journal of Foundations of Computer Science,2(4):419–424, 1991.
[15] J.A. Plaza. Logics of public communications.In M.L. Emrich et al., editors, Proceedings of the 4th International Symposium on Method-ologies for Intelligent Systems, pages 201–216. Oak Ridge National Laboratory, 1989.
[16] F. Raimondi and A.R. Lomuscio. Verifica-tion of multiagent systems via ordered bi-
nary decision diagrams: An algorithm and itsimplementation. In Proceedings of AAMAS 04, pages 630–637. IEEE Computer Society,2004.
[17] K. Su. Model checking temporal logics of knowledge in distributed systems. In D. L.McGuinness and G. Ferguson, editors, Pro-ceedings of AAAI 04, pages 98–103. AAAIPress / The MIT Press, 2004.
[18] H.P. van Ditmarsch, J. Ruan, and R. Ver-brugge. Sum and product in dynamic epis-
temic logic. Journal of Logic and Computa-tion, 2007. To appear.
[19] H.P. van Ditmarsch, W. van der Hoek, andB.P. Kooi. Dynamic Epistemic Logic, volume337 of Synthese Library. Springer, 2007.
[20] J. van Eijck. Dynamic epistemic modelling.Technical report, Centrum voor Wiskunde enInformatica, Amsterdam, 2004. CWI ReportSEN-E0424.
[21] W. Wu. 100 prisoners and a lightbulb. www.
ocf.berkeley.edu/~wwu/papers/100prisonersLightBulb.pdf, 2001.
Model checking logic puzzles ___________________________________________________________________________
150

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 163/415
Incremental Plan Recognition in an Agent Programming Framework
Alexandra Goultiaeva
Yves Lespérance†
Department of Computer Science, University Of TorontoToronto, ON Canada M5S 1A4
†Department of Computer Science and Engineering, York UniversityToronto, ON Canada M3J 1P3
Résumé :Dans cet article, nous proposons un modèle formelde la reconnaissance de plans en vue de l’incluredans un formalisme de programmation d’agent.
Le modèle est basé sur le calcul des situations etle langage de programmation d’agent ConGolog.Ceci fournit un langage très riche pour la spéci-fication des plans à reconnaitre. Notre modèlesupporte aussi la reconnaissance incrémentale, oùl’ensemble des hypothèses de plans exécutés estfiltré à mesure que les actions sont observées. Lemodèle est spécifié en termes d’un système de tran-sitions pour le langage de plans. Le modèle sup-porte aussi les plans structurés hiérarchiquement etreconnait les relations entre un plan et les sous-planqu’il contient.
Mots-clés : Reconnaissance de plans, raison-nement sur l’action, langages de programmationd’agent
Abstract:In this paper, we propose a formal model of planrecognition for inclusion in a cognitive agent pro-gramming framework. The model is based on theSituation Calculus and the ConGolog agent pro-gramming language. This provides a very rich planspecification language. Our account also supportsincremental recognition, where the set of matching
plans is progressively filtered as more actions areobserved. This is specified using a transition sys-tem account. The model also supports hierarchi-cally structured plans and recognizes subplan rela-tionships.
Keywords: Plan recognition, reasoning about ac-tion, agent programming languages
1 Introduction
The ability to recognize plans of otherscan be useful in a wide variety of applica-tions, from office assistance (where a pro-gram might provide useful reminders, orgive hints on how to correct a faulty plan),
to monitoring and aiding astronauts, pro-viding assistance to people with cognitiveor memory problems to allow them to liveindependently, etc.
There has been a lot of work in the areaof plan recognition; see [4] for a recentsurvey. Some of this work develops sym-bolic techniques for identifying plans thatmatch the observations. For instance,[1] uses a decision tree to match obser-vations to plan steps and graph traversalto identify branches that represent con-
sistent hypotheses. To deal with uncer-tainty and identify most likely hypotheses,some work uses probabilistic techniques;for instance [3], uses an extension of Hid-den Markov Models for this. Other workcombines symbolic and probabilistic ap-proaches, e.g. [2]. Many approaches (in-cluding the ones just cited) support hier-archical task network-type plans, allowingmethods to have several alternative decom-positions, as well as looping tasks. How-
ever, these approaches do not support con-currently executing plans.
Our approach is based on the ConGologagent programming language [5], whichsupports very rich plans, including con-current processes. We think that develop-ing a unified agent programming frame-work that supports plan recognition as wellas plan synthesis and behavior specifica-
tion would have a number of benefits, in-cluding ease of use, and reuse of domainspecifications and reasoning methods. Ourwork is closely related to the plan recogni-tion framework of [8], where plans are rep-
151

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 164/415
resented as Golog1 programs, with two ad-ditional constructs: σ, which matches anysequence of actions, and α1 − α2, whichmatches an execution of plan α1 as long as
it does not also match an execution of α2.α1 − α2 is quite a useful and powerful con-struct, which allows one to specify plansin terms of what must not happen in ad-dition to what can happen. This cannot bedone in most other plan recognition frame-works.
In this paper, we provide an alternative for-malization and implementation of the plan
recognition framework of [8]. Plans arerepresented as procedures, which may in-clude calls to other procedures. Becauseof this, the plan recognition frameworkprovides additional information, such asthe call hierarchy, which details the pro-cedures that are in progress or have com-pleted, which procedure called which, andwhat remains to execute.
Another major difference between our ap-proach and that of [8] is that we supportincremental plan recognition. Given a setof hypotheses about what plans may beexecuting and a new observed action, ourformalization defines what the revised setof hypotheses should be. Plan recognitionis specified in terms of a structural opera-tional semantics (single-step transitions) inthe style of [12] for the plan specificationlanguage. [8] used a different semantics
where programs were mapped into com-plete executions.
We have implemented a plan recognitionsystem based on this formalization. Itcan be executed “on-line” and constantlykeeps track of what plans may be execut-ing, without having to recalculate them foreach new observed action. Focusing onprocedures rather than complete plans al-lows plans to be hierarchical and modular,and the result of the recognition is moreinformative and meaningful.
1Golog [9] is a precursor of ConGolog that does not support
concurrency.
In the rest of the paper, we first give anoverview of the Situation Calculus andConGolog, and then present our formalmodel of plan recognition. Then, we give
some examples to illustrate how the frame-work is used. Following this, we brieflydescribe our implementation of the model.We conclude the paper with a discussionof the novel features and limitations of ouraccount, and provide suggestions for fu-ture work.
2 The Situation Calculus and
ConGologThe technical machinery that we use to de-fine high-level program execution is basedon that of [5]. The starting point in the def-inition is the situation calculus [11]. Wewill not go over the language here exceptto note the following components: there isa special constant S 0 used to denote theinitial situation; there is a distinguished
binary function symboldo
wheredo
(a, s
)denotes the successor situation to s result-ing from performing the action a; rela-tions whose truth values vary from situa-tion to situation, are called (relational) flu-ents, and are denoted by predicate sym-bols taking a situation term as their lastargument. There is a special predicatePoss(a, s) used to state that action a is ex-ecutable in situation s.
Within this language, we can formulatedomain theories which describe how theworld changes as a result of the availableactions. Here, we use action theories of the following form:
• Axioms describing the initial situa-tion, S 0.
• Action precondition axioms, one for
each primitive actiona
, characterizingPoss(a, s).
• Successor state axioms, one for eachfluent F , which characterize the con-ditions under which F (x, do(a, s))
Incremental plan recognition in an agent programming framework ___________________________________________________________________________
152

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 165/415
holds in terms of what holds in situa-tion s; these axioms may be compiledfrom effects axioms, but provide a so-lution to the frame problem [13].
• Unique names axioms for the primi-tive actions.
• A set of foundational, domain inde-pendent axioms for situations Σ as in[14].
Next we turn to programs. The programswe consider here are based on the Con-Golog language defined in [5], providinga rich set of programming constructs, in-cluding the following:
α, primitive actionφ?, wait for a conditionδ 1; δ 2, sequenceδ 1 | δ 2, nondeterministic branchπ x . δ , nondeterministic choice of
argumentδ ∗, nondeterministic iterationif φ then δ 1 else δ 2 endIf , conditionalwhile φ do δ endWhile, while loopδ 1 δ 2, concurrency with equal priorityδ 1 δ 2, concurrency with δ 1 at a higher
priority
δ ||, concurrent iteration φ → δ , interrupt
p( θ), procedure call
Among these constructs, we notice thepresence of nondeterministic constructs.These include (δ 1 | δ 2), which nondeter-ministically chooses between programs δ 1and δ 2, π x . δ , which nondeterministicallypicks a binding for the variable x and per-forms the program δ for this binding of x, and δ ∗, which performs δ zero or moretimes. Also notice that ConGolog includesconstructs for dealing with concurrency. Inparticular (δ 1 δ 2) denotes the concurrentexecution (interpreted as interleaving) of the programs δ 1 and δ 2.
In [5], a single step transition seman-tics in the style of [12] is defined for
ConGolog programs. Two special pred-icates Trans and Final are introduced.Trans(δ,s,δ , s) means that by executingprogram δ starting in situation s, one can
get to situation s in one elementary stepwith the program δ remaining to be exe-cuted. Final(δ, s) means that program δ may successfully terminate in situation s.
3 Formalizing plan recognition
Recognizing a plan means that given asequence of observed actions, the system
must be able to determine which plan(s)the user may be following. The frame-work described here relies on a plan li-brary, which details the possible plans asprocedures in ConGolog. Given the se-quence of actions performed, the systemshould be able to provide the following in-formation: the plan that the user is cur-rently following; the stage in the plan thatthe user is following – what has alreadybeen done and what remains to be done;
and which procedures that plan is part of –is the user doing it as part of a larger plan?
The framework is specified in terms of ConGolog, to which a few extensions aremade. Note that what is described be-low could have alternatively been done bymodifying the semantics of the language.The following formalization is designed tobuild on top of the existing framework as
much as possible.First, we introduce two special prim-itive actions: startProc(name(args))and endProc(name(args)). These areannotation actions, present only in theplan library, but never actually observed.The two actions are used to repre-sent procedure invocation and comple-tion. It is assumed that every pro-cedure that we want to distinguish in
the plan library starts with the actionstartProc(name(args)) and ends withthe action endProc(name(args)), wherename is the name of the procedure inwhich the actions occur, and args are its
____________________________________________________________________________ Annales du LAMSADE N°8
153

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 166/415
arguments. This markup can be generatedautomatically given a plan library.
Our transition system semantics for plans
fully supports concurrency. Environmentsinvolving multiple agents can also be dealtwith if we assume that the agent of eachaction is specified (say as a distinguishedparameter of the action). However, if there is concurrency over different pro-cedures run by the same agent, the an-notated situation as currently defined isnot generally sufficient to determine whichthread/procedure an observed action be-
longs to. Additional annotations will needto be introduced to specify this. We leavethis for future work.
After the inclusion of the annotation ac-tions, for each sequence of actions thereare two situations: the real (observed)situation, and the annotated situation,which includes the actions startProc andendProc. Given the annotated situation, itis straightforward to obtain the state of the
execution stack (which procedures are cur-rently executing), determine what actionswere executed by which procedures, anddetermine the remaining plan. An actionstartProc( proc) means that the procedure proc was called, and should be added tothe stack. The action endProc( proc) sig-nals that the last procedure has terminated,and should be removed from the stack.Note that for a given real situation, theremay be multiple annotated situations thatwould match it. Each of those situationswould show a different possible executionpath in the plan library. For example, if theplan library contained the following proce-dures:
proc p1startProc( p1); a; b; endProc( p1)
endProcproc p2
startProc( p2); a; c; endProc( p2)endProc
then the real situation do(a, S 0)
would have two possible anno-tated situations that would matchit: do(a,do(startProc( p1), S 0)) anddo(a,do(startProc( p2), S 0)). In thiscontext, the plan recognition problemreduces to the following: given the ob-served situation and a plan library, find thepossible annotated situations.
The first two predicates defined for thenew formalism are aTrans and rTrans.The predicate aTrans is a form of Transthat allows only a transition step that can-not be observed: either an annotation ac-
tion or a test/wait action. The predicaterTrans is a form of Trans which only al-lows observable actions. The helper pred-icate Annt is true if and only if the actionpassed to it is an annotation action:
Annt(a)def
= ∃n . a = startProc(n) ∨∃n . a = endProc(n)
aTrans(δ,s,δ , s)def
=Trans(δ,s,δ , s) ∧(∃a . (s = do(a, s) ∧ Annt(a)) ∨ s = s)
rTrans(δ,s,δ , s)def
= Trans(δ,s,δ , s) ∧∃a . s = do(a, s) ∧ ¬Annt(a)
We also define aTrans∗ as the reflexivetransitive closure of aTrans.
The transition predicatenTrans(δ, sr, sa, δ , sr, s
a) is the mainpredicate in our plan recognition frame-work. It holds when δ is the programremaining from δ after performing anynumber of annotation actions or tests, fol-lowed by an observable action. Situationsr is the real situation before performingthose steps, and s
r is the real situation af-ter. Situation sa is the annotated situation(which reflects the annotations as well as
the real actions) before the program steps,and s
a is the annotated situation after.Effectively, our definition below amountsto nTrans being equivalent to aTrans∗
composed with rTrans:
Incremental plan recognition in an agent programming framework ___________________________________________________________________________
154

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 167/415
nTrans(δ, sr, sa, δ , sr, s
a)def
=∃δ , s
a,a.aTrans∗(δ, sa, δ , sa)
∧ rTrans(δ , sr, δ , do(a, sr))∧ s
r = do(a, sr) ∧ sa = do(a, s
a).
Just as nTrans is the counterpart toTrans which deals with annotation ac-tions, nFinal is the counterpart to Final,which allows any number of annotation ac-tions or tests to be performed:
nFinal(δ, s) def = ∃δ , s.aTrans∗(δ,s,δ , s) ∧ Final(δ , s)
As mentioned in [8], in many cases itwould be useful for the procedures to leavesome actions unspecified, or to place ad-ditional constraints on the plans. So theyintroduced two new constructs. The first isanyBut(actionList), which allows one to
execute an arbitrary primitive action whichis not in its argument list. For example,anyBut([b, d]) would match actions a orc, but not b or d. It is a useful shorthandfor writing general plans which might in-volve unspecified steps. For example, aplan might specify that a certain conditionneeds to hold for its continuation, but leaveunspecified what action(s) was performedto achieve the condition. It is simply an ab-breviation, included for convenience. An-
other shorthand construct, any, can be de-fined to match any action without excep-tions. We can define these as follows:2
anyBut([a1,...,an])def
=πa.(if (a = a1 ∧ ... ∧ a = an) then a
else False?endIf )any
def
= anyBut([])
The second construct is minus(δ, δ ). Thismatches any execution that would match
2When n = 0, by convention the condition is equivalent to
True.
δ , as long as it does not match δ . Thisconstruct allows the plan to place addi-tional constraints on the sequences of ac-tions that would be recognized within acertain procedure. For example, the pro-cedure that corresponds to a task of clean-ing the house could include unspecifiedparts, and would match many different se-quences of actions, but not if they involvebrushing teeth. Assuming cleanUp andbrushTeeth are procedures in the plan li-brary, then it is possible to specify theabove as minus(cleanUp, brushTeeth).
To define this construct, we need to definewhat a step of execution for this constructis, and the remaining program. Also, note
that δ must match all observable actionsperformed by δ , but might do different an-notation and test actions; those differencesshould be ignored.
An additional axiom is added to specifyTrans for the minus construct:
Trans(minus(δ, δ ),s ,δ , s) ≡∃δ .aTrans(δ,s,δ , s) ∧
δ = minus(δ , δ ) ∨∃δ ,a.rTrans(δ,s,δ , do(a, s)) ∧s = do(a, s) ∧(¬∃δ ssi.nTrans(δ ,s,s, δ , do(a, s), si)
∧ δ = δ ∨∃δ ssi.nTrans
(δ ,s,s, δ , do(a, s), si)∧ ¬nFinal(δ , do(a, s))∧ δ = minus(δ , δ )).
This says the following: if the next step of the plan δ is not an observable action, thenthe remaining program is what remains of
δ minus δ ; if δ performs an observable ac-
tion, and δ cannot match that action, thenthe remaining program is what remains of
δ ; if δ can match the observable action per-formed by δ but it is not final, then the re-
maining program is what remains of δ mi-nus what remains of δ .
Note that whether Trans holds forminus(δ, δ ) depends on whether nTrans
____________________________________________________________________________ Annales du LAMSADE N°8
155

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 168/415
holds for δ and the latter depends onaTrans∗ and ultimately Trans, so thedefinition might not appear to be wellfounded. We ensure that it is well foundedby imposing the restriction that no minus
can appear in the second argument δ of aminus. So in the axiom, we use nTrans
which is defined just like nTrans, exceptthat it is based on a version of Trans,Trans, that does not support the minusconstruct and does not include the Transaxiom for the minus construct. So Trans
is just the existing Trans from [5], whichis well defined, and nTrans is defined
in terms of it. Then we can define thenew Trans that supports minus in termsof nTrans and we have a well foundeddefinition. The same approach is used todefine Final for minus. The constructminus is considered finished when δ isfinished, but δ is not:
Final(minus(δ, δ ), s) ≡
Final(δ, s) ∧ ¬nFinal
(δ, s).
We use C to denote the extended Con-Golog axioms: C together with the abovetwo. Note that recursive procedures can behandled as in [5].
The above definition relies on a conditionimposed on the δ that may appear as sec-ond argument in a minus: for any se-
quence of transitions involving the sameactions, δ should have only one possibleremaining program. More formally:
Trans∗(δ ,s, δ 1, s1) ∧Trans(δ 1, s1, δ , do(a1, s1)) ∧Trans∗(δ ,s, δ 2, s2) ∧Trans(δ 2, s2, δ , do(a2, s2)) ∧do(a1, s1) = do(a2, s2)
⊃ δ = δ
This restriction seems quite natural be-
cause δ is a model of what is not allowed.
If there are many possibilities about whatis not allowed after a given sequenceof transitions, then the model seems illformed or at least hard to work with.
An example of what is not allowed asδ would be the program (a; b)|(a; c),because after observing the action a,there could be two possible remain-ing programs: b or c. Then we haveTrans(minus((a; c), (a; b)|(a; c)), s,minus(c, b), do(a, s)) which is wrongbecause a; c is also ruled out. If rewrittenas a; (b|c), this program is allowed. 3
Based on the above definition, to getthe annotated situation from an observ-able one, we only need to apply nTransa number of times, until the observ-able situation is reached. We de-fine nTrans∗ as the reflexive transi-tive closure of nTrans. The predicateallTrans(sr, sa, δ rem) means that sa de-notes a possible annotated situation thatmatches the observed situation sr, and
δ rem is the remaining plan:
allTrans(sr, sa, δ rem)def
=nTrans∗( planLibrary, S 0, S 0, δ rem, sr, sa)
where S 0 is the initial situation and planLibrary is a procedure that representsthe plan library.
The set of all the remaining programs δ and their corresponding annotated situa-tions S a for a given real situation S can bedefined as follows:
allPlans(S )def
=(δ, S a)| D ∪ C |= allTrans(S, S a, δ )
where D is the action theory for the do-main.
3We could try to drop this restriction and collect all the re-
maining δ, but it is not clear that these can always be finitely
represented, e.g. πn.(PositiveInteger(n)?; a; b(n)).
Incremental plan recognition in an agent programming framework ___________________________________________________________________________
156

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 169/415
As mentioned earlier, our account alsoallows incremental calculation of the setof plans that the agent may be execut-ing. If (δ , S a) ∈ allPlans(S ) and D ∪C |= nTrans(δ , S , S a,δ,do(A, S ), S a),then (δ, S a) ∈ allPlans(do(A, S )). Theconverse is also true under some condi-tions that typically hold.
4 Examples
The main example described here is a sim-ulation of activities in a home. There are
four rooms: the bedroom, kitchen, liv-ing room, and bathroom. There are alsofour objects: the toothbrush, book, spoon,and cup. Each object has its own place,where it should be located. The toothbrushshould be in the bathroom, the book in theliving room, and the spoon and cup in thekitchen.
Initially, all objects are where they are sup-posed to be, except for two: the book is
in the kitchen, and the toothbrush is in theliving room. The location of the monitoredagent is originally in the bedroom.
There are four possible primitive actions:
• goTo(room): changes the location of the agent to be room;
• pickUp(object): only possible if the
agent is in the same room as the ob- ject; this causes the object to be held;
• putDown(object): only possible if the agent holds the object; puts the ob-
ject down;
• use(object): only possible if the agentholds the object.
We use the following fluents:
• loc: the room in which the agent is;
• loc(thing): the room in which thething is;
• Hold(thing): true if the agent holdsthe thing, false otherwise.
We also use the following non-fluent pred-icates:
• Room(r): r is a room;
• Object(t): t is an object;
• InPlace(thing, room): holds if thing is in its place when it is inroom.
There are five procedures in the plan li-brary:
• get(thing): go to the room wherething is, and pick it up;
• putAway(thing): go to the roomwhere the thing should be, and put itdown;
• cleanUp: while there are objects thatare not in their places, get such an ob-
ject, or put it away;
• brushTeeth: get the toothbrush, usethe toothbrush, and either put away thetoothbrush, or put it down (where theagent is);
• readBook: get the book, use the book,and either put away the book, or put it
down.
The procedures are defined below. We alsouse the following procedure:
proc getTo(r)Room(r)?;if loc = r then goTo(r) endIf
endProc
getTo checks if the current location is al-ready the destination room r. If not, theaction goTo is executed. It is a helperprocedure, which was only introduced for
____________________________________________________________________________ Annales du LAMSADE N°8
157

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 170/415
convenience, and was not deemed impor-tant enough to appear in the annotations.Hence, it does not have startProc andendProc actions. So, when the program
is executed, the procedure getTo will notappear in the stack.
The definition of most of the other proce-dures is straightforward:
proc get(t)startProc(get(t)); ¬Hold(t)?;getTo(loc(t)); pickU p(t);endProc(get(t))
endProc;proc putAway(t)
startProc( putAway(t)); Hold(t)?;π r.InPlace(t, r)?;getTo(r); putDown(t);endProc( putAway(t))
endProc;proc brushTeeth
startProc(brushTeeth);get(toothbrush); use(toothbrush);( putAway(toothbrush)|
putDown(toothbrush));endProc(brushTeeth)
endProc;proc readBook
startProc(readBook);get(book); use(book);( putAway(book)| putDown(book));endProc(readBook)
endProc;
Procedures brushTeeth and readBookhave options: either the agent might putthe thing away in its place, or it might putthe thing down wherever it happens to be.In practice, a person might do either, andboth executions should be recognized aspart of the procedure.
Perhaps the most complex procedure in
this example is cleanUp. The main ideais that when executing this procedure, theagent will, at each iteration, get a thingthat is not in its proper place, or put awaysomething it already holds.
proc cleanUpstartProc(cleanUp);
while ∃t.Object(t) ∧ ¬InPlace(t,loc(t))do π t.Object(t) ∧¬InPlace(t,loc(t))?;
(get(t)| putAway(t))endWhile;endProc(cleanUp)
endProc
The main plan library chooses some pro-cedure to execute nondeterministically and
repeats this zero or more times:
proc planLibrary(cleanUp|brushTeeth|
readBook|(πt.get(t)))∗.endProc
Let’s look at an execution trace for theabove example. Suppose that the first ac-
tion was goTo(kitchen). The followingpossible scenarios are then output by thesystem:
proc get(book) -> goTo(kitchen)proc get(cup) -> goTo(kitchen)proc get(spoon) -> goTo(kitchen)proc readBook -> proc get(book)
-> goTo(kitchen)proc cleanUp -> proc get(book)
-> goTo(kitchen)
The system is trying to guess what the useris doing by going to the kitchen. It liststhe five plans from the library that mighthave this first action. Note that the possi-bilities of doing cleanUp by getting a cupor a spoon are not listed. This is becauseboth the spoon and cup are already in theirplaces, so if the agent picked them up, itwould not be cleaning up.
Now suppose that the next action is pickU p(book). Then, the system candiscard some of the above possibilities,namely those which involve taking some-thing else. The new possible scenarios are:
Incremental plan recognition in an agent programming framework ___________________________________________________________________________
158

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 171/415
proc get(book)-> goTo(kitchen); pickUp(book)
proc readBook -> get(book)-> goTo(kitchen); pickUp(book)
proc cleanUp -> proc get(book)-> goTo(kitchen); pickUp(book)
The next action is use(book). The planget(book) is finished, but there is no planin the library that could start with the ac-tion use(book). So, this possibility canbe discarded. The next action of cleanUp
cannot match the observed actions as well.Thus the only remaining possible plan isreadBook:
proc readBook -> proc get(book)-> goTo(kitchen); pickUp(book);use(book)
Now, let us consider a different scenario.In order to demonstrate the use of theminus and anyBut constructs, we can de-fine two variants of cleanUp. In the firstone, cleanUpu, an arbitrary action is al-lowed at the end of every iteration of theloop. The second one, cleanUpm, togetherwith the optional arbitrary action, intro-duces a constraint: a sequence of actions
will not be matched if it involves the exe-cution of procedure brushTeeth. This isachieved by using the minus construct.
proc cleanUpustartProc(cleanUpu);while ∃t.Object(t) ∧ ¬InPlace(t,loc(t))
do π t.Object(t) ∧
¬InPlace(t,loc(t))?;(get(t)| putAway(t));(any|nil)
endWhile;endProc(cleanUpu)])
endProc
proc cleanUpmstartProc(cleanUpm);minus(
while ∃t.Object(t) ∧¬InPlace(t,loc(t)) doπ t.Object(t) ∧
¬InPlace(t,loc(t))?;(get(t)| putAway(t));(any|nil);
endWhile,[brushTeeth]);
endProc(cleanUpm)endProc
Suppose that the sequence of ob-served actions starts with the twoactions goTo(livingRoom) andtake(toothbrush). All three variantsof cleanUp would match those actions,and produce the same scenario:
proc cleanUp_k ->proc get(toothbrush) ->
goTo(livingRoom);pickUp(toothbrush)
where k is either nothing, or u or m, de-pending on the version of the procedureused.
Now suppose that the next action isuse(toothbrush). The original version of cleanUp does not match the observed ac-tion. The other two variants, cleanUpuand cleanUpm, would still match the situ-
ation, because the new action matches theunspecified action at the end of the loop.
If the next action is goTo(bathroom), thenboth remaining procedures match this aswell:
proc cleanUp_k ->proc get(toothbrush) ->
goTo(livingRoom);pickUp(toothbrush);
use(toothbrush);proc putAway(toothbrush) ->
goTo(bathroom)
where k can only be u or m.
____________________________________________________________________________ Annales du LAMSADE N°8
159

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 172/415
Now, if the next step is putDown(toothbrush), then cleanUpumatches it. However, cleanUpm doesnot. That is because cleanUpm has the
minus construct, and the observed actionsmatched the exception part of it. Theaction putDown(toothbrush) can beconsidered the last action of brushTeeth,which was ruled out by the minus incleanUpm. So, cleanUpm cannot matchthis sequence of actions. cleanUpu, whichis identical to cleanUpm except for theminus construct, does match the action,and produces the following scenario:
proc cleanUp_u ->proc get(toothbrush) ->
goTo(livingRoom);pickUp(toothbrush);
use(toothbrush);proc putAway(toothbrush) ->
goTo(bathroom);putDown(toothbrush)
Another example that the system wastested on is that from [8] involving aircraftflying procedures. There is a single pro-cedure called fireOnBoard. It involvesthree actions, performed sequentially, withpossibly other actions interleaved. Thethree actions are fuelOff , fullThrottle,and mixtureOff . The only restriction isthat while executing this procedure, the ac-tion fuelOn must not occur. In our frame-work, this example can be represented asfollows:
proc fireOnBoardstartProc(fireOnBoard),minus([fuelOff ; any∗; fullThrottle;
any∗; mixtureOff ],[(anyBut([fuelOn]))∗; fuelOn]);
endProc(fireOnBoard)endProc
The above examples are kept simple to il-
lustrate how the various constructs work.The system was tested on both of the aboveexamples, and more complicated ones. Allof the above traces were generated by theimplementation.
5 Implementation and Experi-mentation
Our plan recognition system was imple-mented using a Prolog-based version of In-diGolog, an extension of ConGolog intro-duced in [6]. The implementation closelyfollows the definitions, without any opti-mization for performance. The implemen-tation assumes that the axioms specifyingthe initial situation are represented as Pro-log clauses and makes the closed world as-sumption.
The system uses a user-defined domainspecification and plan library. All proce-dures in the library need to satisfy somerestrictions. Each procedure P that is tobe reflected in the scenario has to startand end with actions startProc(P ) andendProc(P ), respectively. The proce-dures can also use constructs anyBut andminus.
The implementation can be used in inter-active mode. Then the user is expectedto enter the observed actions one by one.Also, at any point the user can issue oneof the following commands: prompt - listall current hypotheses, reset - forget theprevious actions and start fresh, and exit -finish execution.
We ran some experiments on the home
activities domain discussed above,with a slight modification: the lastoption in the plan library is now(πt.[get(t), putDown(t)]) instead of (πt.get(t)). This was done ensure thatthere are arbirarily long executions of theplan library. For each n, where n is thelength of an observed action sequence,we randomly selected 200 sequences of nactions that could be generated by the planlibrary. We then ran the plan recognition
system on all of those and averaged therunning time. The results appear in Figure1. We can see that our system can identifymatching plans for a sequence of 80observed actions in less than one second
Incremental plan recognition in an agent programming framework ___________________________________________________________________________
160

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 173/415
on average in this test domain. As well,for this domain the running time seemsto grow linearly with the length of theobserved action sequence.
Figure 1: Average runtime (seconds) ver-sus the length of the action sequence
6 Discussion
In this paper, we have described a frame-work for plan recognition in the SituationCalculus. The ConGolog programminglanguage is used to specify plans. The sys-tem matches the actions of the monitoredagent against the plan library and returns
some scenarios, representing the executionpaths that the agent may have followed.
The main differences between our accountof plan recognition and the one describedby [8] are that ours is able to model pro-cedure calls within plans and that it is in-cremental. Because our approach to planrecognition concentrates on procedures, itis able to distinguish sub-procedures fromeach other as well as from top-level plans.
This allows the scenarios to be fairly de-tailed both as to how and why a certainplan was being executed.
Because our formalism is incremental, itdoes not need to know the whole sequenceof actions to interpret the next step; nordoes it need to re-compute matching sce-narios from scratch whenever a new ac-tion is made. It would be well-suited forreal-time applications or continuous mon-itoring.
The framework described here is easily ex-tended with new annotations to specify, forexample, the goals and preconditions of
each plan and/or possible reactions to itby the monitoring system. As mentionedearlier, to fully support the recognition of concurrent executions of plans, additional
annotations to track which process per-formed each action should be introduced.Another possible extension would be toassign probabilities to actions and plans,similarly to what was done in [7]. Thiswould make it possible to rank the possi-ble execution hypotheses, select the mostprobable ones and use this to predict whichactions the agent is more likely to executenext. One could also look at qualitative
mechanisms for doing this. More exper-imental evaluation of our system is alsoneeded.
There has already been work on home careapplications for a plan recognition system.For example, [10] describes a plan recog-nition system that includes strategies formonitoring and obtaining actions, as wellas using learning to modify the plan li-braries. Both of those techniques can po-tentially work with our system.
References
[1] Dorit Avrahami-Zilberbrand andGal A. Kaminka. Fast and completesymbolic plan recognition. In Proc.of IJCAI-05, Edinburgh, UK, 2005.
[2] Dorit Avrahami-Zilberbrand andGal A. Kaminka. Hybrid symbolic-probabilistic plan recognition: Initialstepsd. In Gal Kaminka, DavidPynadath, and Christopher Geib,editors, Modeling Others from Ob-servations: Papers from the 2006
AAAI Workshop, Technical ReportWS-06-13. American Associationfor Artificial Intelligence, MenloPark, CA., 2006.
[3] Hung H. Bui. A general model foronline probabilistic plan recognition.In Proc. of IJCAI’03, pages 1309–1318, 2003.
____________________________________________________________________________ Annales du LAMSADE N°8
161

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 174/415
[4] Sandra Carberry. Techniques forplan recognition. User Model-ing and User-Adapted Interaction,11(31–48), 2001.
[5] Giuseppe De Giacomo, YvesLespérance, and Hector J. Levesque.ConGolog, a concurrent program-ming language based on the situationcalculus. Artificial Intelligence,121:109–169, 2000.
[6] Giuseppe De Giacomo and Hector J.Levesque. An incremental interpreterfor high-level programs with sens-
ing. In Hector J. Levesque and FioraPirri, editors, Logical Foundations
for Cognitive Agents, pages 86–102.Springer-Verlag, 1999.
[7] Robert Demolombe and AnaMara Otermin Fernandez. Intentionrecognition in the Situation Calculusand Probability Theory frameworks.In Computational Logic in Multi
Agent Systems, pages 358–372,
London, 2005.
[8] Robert Demolombe and Erwan Ha-mon. What does it mean that anagent is performing a typical proce-dure? A formal definition in the Sit-uation Calculus. In C. Castelfranciand W. Lewis Johnson, editors, Pro-ceedings of the 1st International Joint Conference on Autonomous Agentsand Multiagent Systems, pages 905–911, Bologne, 2002. ACM Press.
[9] H. Levesque, R. Reiter, Y. Lesper-ance, F. Lin, and R. Scherl. GOLOG:A logic programming language fordynamic domains. Journal of LogicProgramming, 31:59–84, 1997.
[10] C. Lin and J.Y. Hsu. IPARS: In-telligent portable activity recognitionsystem via everyday objects, human
movements, and activity duration. InGal Kaminka, David Pynadath, andChristopher Geib, editors, Model-ing Others from Observations: Pa-
pers from the 2006 AAAI Workshop,
Technical Report WS-06-13. Ameri-can Association for Artificial Intelli-gence, Menlo Park, CA., 2006.
[11] John McCarthy and Patrick Hayes.Some philosophical problems fromthe standpoint of artificial intelligence. In B. Meltzer and D. Michie,editors, Machine Intelligence, vol-ume 4, pages 463–502. EdinburghUniversity Press, 1979.
[12] Gordon Plotkin. A structural ap-proach to operational semantics.Technical Report DAIMI-FN-19,
Computer Science Dept., AarhusUniversity, Denmark, 1981.
[13] Raymond Reiter. The frame prob-lem in the situation calculus: A sim-ple solution (sometimes) and a com-pleteness result for goal regression.In V. Lifschitz, editor, Artificial In-telligence and Mathematical Theoryof Computation: Papers in Honor of John McCarthy, pages 359–380.Academic Press, 1991.
[14] Raymond Reiter. Knowledge in Ac-tion: Logical Foundations for Spec-ifying and Implementing DynamicalSystems. MIT Press, 2001.
Incremental plan recognition in an agent programming framework ___________________________________________________________________________
162

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 175/415
Communication, consensus et ordre de parole. Qui veut parler enpremier?
N. Houy
L. Ménager†
THEMAUniversité Cergy-Pontoise
33 Boulevard du Port95011 Cergy-Pontoise – FRANCE
†Université Paris 1 Panthéon-SorbonneCentre d’Economie de la Sorbonne
106-112 Boulevard de l’Hôpital75647 Paris Cedex 13 – FRANCE
Résumé :Parikh et Krasucki [1990] montrent que si desagents communiquent la valeur d’une fonction f selon un protocole sur lequel ils se sont préalable-ment entendus, alors ils atteindront un consensussur la valeur de f , à condition que le protocole soitéquitable et la fonction f convexe. On remarqueque la valeur consensuelle de f ainsi que le montantd’information apprise par les agents au cours duprocessus de communication dépendent du proto-cole choisi. Si les agents communiquent afin d’ap-prendre de l’information, il est alors possible quecertains d’entre eux soient en désaccord quant auprotocole de communication à utiliser. On montreque s’il est connaissance commune que deux agentsont des préférences opposées sur deux protocoles,alors le consensus qui émergerait de l’utilisation del’un ou l’autre protocole est le même.
Mots-clés : Connaissance commune, consensus,protocoles de communication.
Abstract:Parikh and Krasucki [1990] showed that if rationalagents communicate the value of a function f ac-cording to a protocol upon which they have agreedbeforehand, they will eventually reach a consensusabout the value of f , provided a fairness conditionon the protocol and a convexity condition on thefunction f . In this article, we address the issue of how agents agree on a communication protocol inthe case where they communicate in order to learninformation. We show that if it is common know-ledge among a group of agents that some of themdisagree about two protocols, then the consensusvalue of f must be the same according to the twoprotocols.
Keywords: Common knowledge, consensus, com-munication protocols.
1 Introduction
Considérons l’exemple introductif suivant.Alice et Bob sont assis l’un en face del’autre, chacun portant un chapeau dontils ne savent pas la couleur, mais dontils savent qu’il peut être rouge ou blanc.Supposons que les deux chapeaux soient
blancs, et que quelqu’un demande auxenfants la probabilité qu’ils attribuent àl’événement “Les deux chapeaux sont rou-ges”. Comme chacun des enfants voit quele chapeau de l’autre est blanc, chacun saitque la probabilité que les deux chapeauxsoient rouges est 0. Supposons qu’Alices’exprime la première, et dise que la pro-babilité est 0. Bob le savait déjà, maisl’annonce d’Alice lui permet d’apprendreque son propre chapeau est blanc. En ef-fet, si son chapeau avait été rouge, alorsAlice n’aurait pas pu éliminer complète-ment la possibilité que les deux chapeauxsoient rouges. Si Bob s’exprime à son tour,et dit qu’il pense aussi que la probabilitéest 0, alors Alice n’apprendra rien, ni surla probabilité de l’événement “Les deuxchapeaux sont rouges”, ni sur la couleurde son chapeau. En effet, puisqu’elle saitqu’elle a révélé à Bob que son chapeau
à lui était blanc, elle sait aussi qu’il saitdésormais qu’il n’y a aucune chance queles deux chapeaux soient rouges, indépen-damment de la couleur de son chapeauà elle. Par conséquent, si Alice veut ap-
163

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 176/415
prendre la couleur de son chapeau, ellen’a aucun intérêt à parler la première. Cetexemple illustre le fait suivant. Lorsque lesindividus communiquent dans le but d’ap-prendre de l’information les uns des autres,l’ordre de parole est important : l’issued’un processus d’échange d’informationsentre les individus dépend, de manière cru-ciale, de la façon dont la communicationest structurée.
On sait depuis Geanakoplos et Polemar-chakis [1982] que lorsque des agents ra-tionnels communiquent puis révisent les
probabilités a posteriori qu’ils attribuentà un événement donné selon un proto-cole de communication public et simul-tané, alors ces agents atteignent un consen-sus sur la probabilité de cet événement,c’est-à-dire finissent par tous communi-quer la même probabilité. Cave [1983] etBacharach [1985] ont étendu ce résultat aucas où les agents communiquent des déci-sions, en supposant que la manière dont les
agents forment leurs décisions satisfait àune condition de cohérence, appelée stabi-lité par l’union. Cependant, dans la plupartdes situations où les individus sont amenésà échanger entre eux des informations, lacommunication n’est pas simultanée. Lesindividus s’expriment, en général, les unsà la suite des autres, selon un protocolede communication donné. Parikh et Kra-sucki [1990] étudièrent le cas dans lequelles membres d’un groupe communiquentdeux-à-deux la valeur privée d’une cer-taine fonction f . Ils identifient des condi-tions sur la fonction f et sur le protocolede communication qui garantissent que lesagents atteignent un consensus sur la va-leur de la fonction. Ils montrent que sile protocole de communication est équi-table, c’est-à-dire tel que chaque partici-pant reçoive de l’information, même indi-rectement, de la part de tous les autres par-
ticipants, et si la fonction dont les valeurssont communiquées est convexe, c’est à-dire si pour toute paire d’événements dis-
joints X, X , il existe a ∈]0, 1[ tel quef (X ∪X ) = af (X )+(1−a)f (X ), alors
la communication permet aux agents d’at-teindre un consensus sur la valeur de f .
Dans cet article, on s’intéresse aux consé-quences du choix d’un protocole de com-munication, dans un cadre où les individusveulent apprendre le plus d’informationpossible des autres. La valeur du consen-sus atteint, ainsi que la quantité d’informa-tion apprise par les agents au cours du pro-cessus de communication, dépendent duprotocole choisi pour communiquer (quiparle quand). En particulier, il peut arri-ver qu’un agent apprenne plus d’informa-
tion en communiquant avec les autres se-lon un certain protocole que selon un autre.Il peut également arriver que les proto-coles les plus informatifs ne soient pasles mêmes pour tous les agents. Ainsi, sil’on fait l’hypothèse que les agents com-muniquent afin d’apprendre de l’informa-tion, il peut arriver qu’ils soient en désac-cord quant au protocole de communica-tion à utiliser. Selon l’état du monde, Alice
et Bob peuvent préférer parler en pre-mier ou en second, ou être indifférents.Si ni Alice, ni Bob ne veut parler en pre-mier, la communication ne peut pas avoirlieu. Cependant, pouvons nous en conclurequ’Alice et Bob n’apprendront rien l’unde l’autre ? Le fait même que chaque en-fant ne veuille pas parler en premier estinformatif pour l’autre. L’objet de cet ar-ticle est précisément d’étudier les infé-rences que des agents rationnels peuventfaire de la connaissance commune que cer-tains d’entre eux sont en désaccord quantau protocole de communication à utiliser.
Nous montrons que les situations suivantessont possibles. Tout d’abord, il peut êtreconnaissance commune dans un grouped’agents que certains d’entre eux préfèrentle même protocole de communication. En-suite, il peut être connaissance commune
que deux agents soient en désaccord quantau protocole qu’ils préfèrent utiliser pourcommuniquer. Cependant, on montre lerésultat surprenant que dans ce cas, leconsensus qui émergera de l’utilisation de
Communication, consensus et ordre et parole. Qui veut parler en premier ? ___________________________________________________________________________
164

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 177/415
l’un ou l’autre protocole sera le même. Atitre d’exemple, s’il est connaissance com-mune entre Alice et Bob que tous les deuxpréfèrent parler en deuxième, alors la pro-babilité sur laquelle ils se mettront d’ac-cord à l’issue du processus de communica-tion sera la même, qu’Alice ou Bob parleen premier.
L’article est organisé de la manière sui-vante. En section 2, on présente le modèleet on rappelle le résultat de Parikh et Kra-sucki [1990]. En section 3, on définit lespréférences sur les protocoles de commu-
nication et on présente le résultat principal.En Section 4, on donne une série de résul-tats de possibilité autour du résultat prin-cipal, et on discute de la manière dont ondéfinit les préférences en section 5. La dé-monstration du théorème est présentée enannexe.
2 Notions préliminaires
Soit Ω l’ensemble des états du monde, sup-posé fini, et 2Ω l’ensemble des événementspossibles de Ω. On considère N agents,chaque agent i étant informé par une par-tition Πi de Ω. Lorsque l’état ω ∈ Ω seréalise, l’agent i est informé que l’état dumonde appartient à Πi(ω), c’est-à-dire àla cellule de la partition de i qui contientω. On dit qu’une partition Π est plus finequ’une partition Π si et seulement si pourtout ω, Π(ω) ⊂ Π(ω) et s’il existe ω
tel que Π(ω) Π(ω). Une partition Π
est plus grossière qu’une partition Π si etseulement si Π est plus fine que Π. La par-tition Πi représente la capacité de l’agent ià distinguer entre eux les états du monde.Ainsi, plus la partition d’un agent est fine,plus son information est précise, dans lesens où l’agent est capable de mieux dis-tinguer les états du monde. On dit qu’un
agent i muni d’une partition Πi sait l’évé-nement E sous l’état ω si et seulement siΠi(ω) ⊂ E . On définit l’union des parti-tions individuelles Π1, Π2, . . . , ΠN commele plus fin grossissement commun de ces
partitions, c’est-à-dire la plus fine partitionM telle que pour tout ω ∈ Ω et pour touti = 1, . . . , N , Πi(ω) ⊂ M (ω).
Un événement E est dit connaissancecommune sous l’état ω dans un grouped’agents lorsque E est réalisé sous ω, quechacun sait sous ω que E est réalisé, quechacun sait sous ω que chacun sait que E s’est réalisé etc... Aumann [1976] montraque, étant donné un groupe de N agents,l’union de leurs N partitions individuellesest la partition de connaissance communedans le groupe d’agents. Par conséquent,
on dit qu’un événement E est connais-sance commune en ω si et seulement siM (ω) ⊂ E .
Avant de communiquer, les agents semettent d’accord sur un protocole de com-munication qui sera appliqué tout au longdu débat. Le protocole détermine quelsagents sont autorisés à s’exprimer et quelsagents sont autorisés à écouter à chaquedate.
Définition 1 Un protocole α est une pairede fonctions (s, r) définies de N dans
21,...,N × 21,...,N . Si s(t) = S et r(t) =R , alors on interprète S et R comme lesensembles d’émetteurs et de récepteurs dela communication qui a lieu à la date t.
Notons que le type de protocoles que l’onconsidère ici est plus général que celuiconsidéré par Parikh et Krasucki, car l’onpermet à plusieurs agents d’être émet-teurs et récepteurs de la communication aumême moment.
Au cours du débat, les agents commu-niquent en envoyant des messages, donton suppose qu’ils sont délivrés instantané-ment. Autrement dit, à la date t, les mes-
sages sont simultanément envoyés par lesagents i ∈ s(t) et reçus par les agents j ∈r(t). On suppose que le message envoyépar un agent est la valeur privée d’une cer-taine fonction f , définie de l’ensemble des
____________________________________________________________________________ Annales du LAMSADE N°8
165

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 178/415
événements 2Ω dans R. Autrement dit, unagent dont l’information privée est X ⊂ Ωcommunique la valeur f (X ).
Enfin, l’ensemble des états du monde Ω,les partitions individuelles (Πi)i, ainsi quela règle de message f définissent un mo-dèle d’information I = Ω, (Πi)i, f .
Décrivons à présent la manière dont l’in-formation privée des agents évolue aucours du du processus de communication.A la date t, tous les émetteurs i ∈ s(t) sé-lectionnés par le protocole α = (s, r) en-voient un message qui est entendu par tousles récepteurs j ∈ r(t). Chaque agent in-fère alors l’ensemble des états du mondecompatibles avec les messages éventuelle-ment envoyés, et révise sa partition d’in-formation en fonction. Etant donnés unmodèle d’information Ω, (Πi)i, f et unprotocole de communication α, on définitpar récurrence sur t l’ensemble Πα
i (ω, t)des états possibles pour l’agent i en ω et à
la date t, étant donné le protocole de com-munication α :
Παi (ω, 0) = Πi(ω) et pour tout t ≥ 1,
Παi (ω, t + 1) = Πα
i (ω, t) ∩ ω ∈ Ω |f (Πα
j (ω, t)) = f (Πα j (ω, t)) ∀ j ∈ s(t)
si i ∈ r(t),Πα
i (ω, t + 1) = Παi (ω, t) sinon.
Deux hypothèses sont faites sur le proto-cole de communication α et sur la fonc-tion f pour garantir que la communicationitérative de la valeur de f conduise à unconsensus sur f . A l’instar de Parikh etKrasucki, on suppose que le protocole decommunication est équitable. Nous adop-tons la définition de Koessler [2001], quiadapte celle de Parikh et Krasucki au typede protocoles que l’on considère : un pro-tocole est équitable si et seulement si tous
les participants à ce protocole commu-niquent directement ou indirectement avectous les autres. Cette condition est néces-saire pour qu’aucun agent ne soit exclu dela communication.
Hypothèse 1 (A1) Le protocole α est équitable, i.e. pour toute paire d’indivi-dus (i, j), i = j , il existe un nombre in-
fini de suites finies t1 < · · · < tK , avec
tk ∈ N pour tout k ∈ 1, . . . , K , tellesque i ∈ s(t1) et j ∈ r(tK ).
Hypothèse 2 (A2) f est convexe, i.e. pour toute paire d’événements E, E ⊂ Ω telsque E ∩ E = ∅ , il existe α ∈]0, 1[ tel quef (E ∪ E ) = αf (E ) + (1 − α)f (E ).
Cette condition est satisfaite par les pro-babilités conditionnelles, et implique lacondition de stabilité par l’union1 à laCave [1983].
Le prochain résultat établit que, sous leshypothèse d’équité du protocole et deconvexité de la fonction f , f (Πα
i (ω, t))admet une valeur limite pour tout ω qui
ne dépend pas de i. Autrement dit, sousles hypothèses A1 et A2, les participantsau protocole convergent vers un consensussur la valeur de f .
Proposition 1 (Parikh and Krasucki (1990))
Soit Ω, (Πi)i, f un modèle d’informa-tion, et α un protocole de communica-tion. Sous les hypothèses A1 et A2 , il
existe une date T telle que pour tout ω , pour tous i, j , et tous t, t ≥ T ,f (Πα
i (ω, t)) = f (Πα j (ω, t)).
Dans la suite, on notera Παi (ω) la valeur li-
mite de Παi (ω, t), et Πα
i sera appelée la par-tition d’information de l’agent i au consen-sus. La valeur limite de f (Πα
i (ω, t)), quine dépend pas de i, sera notée f (Πα(ω)) et
sera appelée valeur consensuelle de f sousl’état ω, étant donné le protocole α.
1f est stable par l’union si pour tous E, E ⊂ Ω tels que
E ∩E = ∅, f (E ) = f (E ) ⇒ f (E ∪E ) = f (E ) = f (E ).
Communication, consensus et ordre et parole. Qui veut parler en premier ? ___________________________________________________________________________
166

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 179/415
3 Qui veut parler en premier ?Un théorème d’impossibilité.
On fait l’hypothèse que les agents sontdes preneurs de décision, qui désirentêtre mieux informés au sens de Blackwell[1983]. Une partition Π est plus informa-tive, au sens de Blackwell, qu’une partitionΠ, si et seulement si Π est plus fine queΠ. Ainsi, on dira qu’un agent est mieuxinformé avec un protocole α qu’avec unprotocole β si, au bout du compte, il aune partition au consensus plus fine avec
α qu’avec β . La préférence pour plus d’in-formation induit alors une préférence dé-pendante des états pour chaque agent surl’ensemble des protocoles. On dit qu’unagent préfère un protocole α à un proto-cole β sous l’état ω si il croit, lorsque l’étatω s’est réalisé, qu’il aura une partition plusfine avec α qu’avec β .
Définition 2 (Préférences) Soit
I := Ω, (Πi)1i0, f un modèle d’infor-mation, et α, β deux protocoles distincts.
L’événement “i préfère α à β ” est noté BI
i (α, β ) , et est défini de la manière
suivante : BI i (α, β ) = ω ∈ Ω | ∀ω ∈
Πi(ω), Παi (ω) ⊂ Πβ
i (ω) et ∃ ω ∈Πi(ω) s.t. Πα
i (ω) Πβ i (ω)
Considérons à nouveau l’exemple desdeux enfants donné en introduction, et dé-crivons le formellement. Il y a quatre étatsdu monde, chaque état décrivant les cou-leurs des chapeaux d’Alice et de Bob.Ainsi, un état est noté (AcBc), avec c, c ∈r, w désignant les couleurs des deuxchapeaux. Supposons sans perte de géné-ralité qu’Alice et Bob aient une probabi-lité a priori uniforme sur l’ensemble desétats du monde. Ils expriment chacun leur
tour la probabilité a posteriori qu’ils attri-buent au fait que les deux chapeaux soientrouges, c’est-à-dire leur valeur privée dela fonction f (.) = P ((ArBr) | .).Chacun des enfants observe le chapeau de
l’autre, mais ne connaît pas la couleur deson propre chapeau. Par conséquent, Aliceet Bob sont munis des partitions d’infor-mation suivantes :2
ΠA : (ArBr), (AwBr) 1
2
(ArBw), (AwBw)0
ΠB : (ArBr), (ArBw) 1
2
(AwBr), (AwBw)0
Si Alice parle en premier (protocole α), lespartitions individuelles au consensus sont :
ΠαA : (ArBr)1 (AwBr)0 (ArBw), (AwBw)0
ΠαB : (ArBr)1 (ArBw)0 (AwBr)0
(AwBw)0
Si Bob parle en premier (protocole β ), lespartitions individuelles au consensus sont :
ΠβA : (ArBr)1 (AwBr)0 (ArBw)0
(AwBw)0
Πβ
B
: (ArBr)1 (ArBw)0 (AwBr), (AwBw)0
Si les deux chapeaux sont blancs, (i.e.dans l’état (AwBw)), Alice et Bob sonttous les deux mieux informés lorsqu’ilsparlent en second. Que se passe-t-il dansce cas ? Supposons que l’état (AwBw) seréalise, et qu’Alice et Bob attendent, faceà face, que l’autre se décide à parler en pre-mier. Alice sait que l’état du monde appar-tient à (ArBw), (AwBw). Puisque Bob
ne veut pas parler en premier, elle com-prend que le vrai état du monde n’est pas(ArBw), puisque Bob aurait été indifférententre parler en premier et en second danscet état. De même, Bob sait que l’état dumonde appartient à (AwBr), (AwBw). Ildéduit du fait qu’Alice ne veut pas par-ler en premier que l’état du monde n’estpas (AwBr), puisque, dans cet état, Aliceaurait été indifférente entre parler en pre-
mier et en deuxième. Ainsi, le fait de sa-voir que l’autre ne veut pas parler en pre-mier permet à Alice et Bob de comprendre
2L’indice indique la probabilité a posteriori correspondante
à chaque cellule.
____________________________________________________________________________ Annales du LAMSADE N°8
167

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 180/415
que l’état du monde est (AwBw), c’est-à-dire que les deux chapeaux sont blancs.A partir de ce moment, ils possèdent tousles deux la même information privée sousl’état (AwBw), et deviennent tous les deuxindifférents entre parler en premier et endeuxième. Cet exemple soulève ainsi laquestion de savoir s’il peut être connais-sance commune entre deux agents qu’ilssoient en désaccord quant au protocole decommunication qu’ils préfèrent pour com-muniquer. Plus généralement, quelles in-férences des agents rationnels peuvent-ilsfaire de la connaissance commune que cer-
tains d’entre eux sont en désaccord sur leprotocole de communication à utiliser ?
On présente maintenant le résultat princi-pal de cet article, qui établit en particulierque, dans ce cas, la valeur du consensusatteint sera la même, quel que soit le pro-tocole utilisé.
Théorème 1 Soit I = Ω, (Πi)i, f un
modèle d’information tel que A1 et A2sont satisfaites, et α et β deux proto-coles distincts. Considérons a1, a2, b1, b2 ∈α, β , avec a1 = a2 et b1 = b2 , et consi-dérons deux agents i = j.
Enfin, considérons les trois assertions sui-vantes :
(1) BI i (a1, a2) et BI
j (b1, b2) sont connais-sance commune en ω.
(2) ω ∈ BI i (a1, a2)∩BI
j (b1, b2) et a1 = b2.
(3) f (Πα(ω)) = f (Πβ (ω)).
Les assertions (1) , (2) , et (3) ne peuvent pas être vraies simultanément.
L’assertion (1) signifie que les préférencesde i et de j concernant α et β sont connais-sance commune en ω. L’assertion (2) si-
gnifie que i et j sont en désaccord quant auprotocole qu’ils préfèrent en ω (soit i pré-fère α et j préfère β en ω, soit i préfère β et j préfère α en ω). L’assertion (3) signifieque la valeur consensuelle de f sous l’état
ω n’est pas la même selon le protocole uti-lisé. La signification de ce théorème dansl’exemple donné en introduction est la sui-vante :
• Si (1) et (2) sont vraies, c’est-à-dire s’ilest connaissance commune en ω qu’Aliceet Bob préfèrent parler en deuxième, alors(3) est fausse, i.e la valeur consensuelle def sous ω est la même, qu’Alice ou Bobparle en premier.
• Si (1) et (3) sont vraies, c’est-à-dire s’ilest connaissance commune en ω qu’Alicepréfère a1 ∈ α, β et que Bob préfèreb1 ∈ α, β , et si la valeur consensuellede f diffère selon que le protocole est α ouβ , alors (2) est fausse, i.e Alice et Bob pré-fèrent le même protocole en ω (a1 = b1).
• Si (2) et (3) sont vraies, c’est-à-dire siAlice et Bob ont des préférences opposéessur α et β en ω, et si la valeur consensuelle
de f diffère selon que le protocole est α ouβ , alors (1) est fausse, i.e les préférencesd’Alice ou de Bob ne sont pas connais-sance commune en ω.
4 Résultats de possibilité
Dans cette section, on donne quelques ré-sultats de possibilités autour du Théorème
1. Notons d’abord que le résultat d’impos-sibilité du Théorème 1 n’est pas dû au faitque deux des trois assertions ne peuventpas être vraies simultanément. En effet, ilsuffit de retirer n’importe laquelle des troisassertions pour restaurer la possibilité.
Proposition 2 (i) Les assertions (1) et (2) du Théorème 1 peuvent être vraiessimultanément.
(ii) Les assertions (1) et (3) du Théorème1 peuvent être vraies simultanément.
(iii) Les assertions (2) et (3) du Théorème1 peuvent être vraies simultanément.
Communication, consensus et ordre et parole. Qui veut parler en premier ? ___________________________________________________________________________
168

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 181/415
Dans le cadre de l’exemple d’Alice et Bob,cette proposition établit que (i) il peutêtre connaissance commune entre eux queAlice et Bob préfèrent différents proto-coles, (ii) il peut être connaissance com-mune entre eux qu’Alice et Bob préfèrentle même protocole entre α et β , et quela valeur consensuelle de f ne soit pas lamême selon α ou β , et (iii) Alice et Bobpeuvent avoir des préférences opposées surα et β , alors que α et β conduisent à desvaleurs consensuelles de f différentes.
On montre le point (i) à l’aide de
l’exemple suivant, qui décrit une situa-tion où il est connaissance commune entreAlice et Bob que tous les deux préfèrentparler en second. Le fait qu’ils préfèrentparler en second est relativement intui-tif : lorsqu’un individu n’est pas le pre-mier à parler, le premier message qu’il en-tend ne dépend que de l’information privéede l’autre agent. Cependant, il peut êtreconnaissance commune que deux agents
préfèrent parler en premier.3
Exemple 1 Soit Ω = 1, 2, 3, 4, 5, 6, 7l’ensemble des états du monde. Supposonsqu’Alice et Bob soient munis d’une proba-bilité a priori P uniforme sur Ω. Ils com-muniquent tour à tour leur valeur privéede la fonction f (.) = P (1, 2, 7 | .) ,et sont dotés des partitions d’informationsuivantes :
ΠA = 1, 213, 405, 6, 71/3
ΠB = 1, 712, 3, 61/34, 50
Si Alice parle en premier (protocole α),les partitions d’information au consensussont :
ΠαA = 1, 213, 405, 6071
ΠαB = 11213040506071
3Cet exemple n’est pas présenté ici car il implique 288 états
du monde, mais il est disponible sur demande.
Si Bob parle en premier (protocole β ),les partitions d’information au consensussont :
Πβ A = 11213040506071
Πβ B = 1, 71213, 604, 50
Dans chaque état du monde, Alice et Bobpréfèrent parler en second : BA(β, α) =BB(α, β ) = Ω. Il est, par conséquent,connaissance commune en chaque état dumonde qu’Alice préfère le protocole β etBob le protocole α. Cependant, cela necontredit pas le Théorème 1, puisque pourtout ω, f (Πα(ω)) = f (Πβ (ω)).
On montre le point (ii) à l’aide del’exemple suivant, dans lequel il estconnaissance commune que deux agentspréfèrent le même protocole parmi α et β ,alors que la valeur consensuelle de f n’estpas la même selon que le protocole utiliséest α ou β .
Exemple 2 Soit Ω = 1, . . . , 9 l’en-semble des états du monde. Supposonsqu’Alice et Bob aient une probabilité a
priori P uniforme sur Ω. Ils commu-niquent tour à tour leur valeur privée dela fonction f (.) = P (1, 6, 7, 9 | .) ,et sont dotés des partitions d’informationsuivantes :
ΠA = 1, 2, 4, 5, 9 2
5
3, 6, 7, 8 1
2
ΠB = 1, 3, 71
3
2, 5, 804, 6, 9 2
3
Si Alice parle en premier (protocole α),les partitions d’information au consensussont :
ΠαA = 112, 504, 9 1
2
3, 71
2
6180
ΠαB = 112, 504, 912 3, 7 1
26180
Si Bob parle en premier (protocole β ),les partitions d’information au consensus
____________________________________________________________________________ Annales du LAMSADE N°8
169

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 182/415
sont :
Πβ A = 1, 4, 9 2
3
2, 503, 6, 7 2
3
80
Πβ
B = 1, 3, 723 2, 5, 804, 6, 9 2
3
Dans chaque état du monde, Alice et Bobpréfèrent que Alice parle en premier :BA(α, β ) = BB(α, β ) = Ω. Il est,par conséquent, connaissance communeentre eux qu’Alice et Bob préfèrent leprotocole α. Cependant, cela ne contreditpas le Théorème 1, puisque f (Πα(1)) =
f (Πβ
(1)).
Enfin, on montre le point (iii) avecl’exemple suivant, dans lequel la valeurconsensuelle de f n’est pas la même avecα et β en un certain état, alors même queles deux agents sont en désaccord quant auprotocole qu’ils préfèrent parmi α et β encet état.
Exemple 3 Soit Ω = 1, . . . , 13 l’en-semble des états du monde. Supposons que
Alice et Bob aient une probabilité a prioriP uniforme sur Ω. Ils communiquent tour à tour la valeur privée de la fonctionf (.) = P (2, 3, 4, 8, 12 | .) , et sont dotésdes partitions d’information suivantes :
ΠA = 1, 3, 7, 8 1
2
2, 6, 11, 12 1
2
4, 5, 10 1
3
90130
ΠB = 1, 3, 5 1
3
214, 7, 9, 10, 12, 13 1
3
6, 81/2110
Si Alice parle en premier (protocole α),les partitions d’information au consensussont :
ΠαA = 1, 3, 7, 8 1
2
211106, 12 1
2
4, 10 1
25090130
ΠαB = 1, 3 1
2
50214, 10 1
2
7, 121
2
9, 1306, 8 1
2
110
Si Bob parle en premier (protocole β ),les partitions d’information au consensussont :
Πβ A = 1, 3, 7 1
3812160110121
4, 5, 101
3
90130
Πβ B = 1, 3, 5 1
3
214, 7, 10, 1
3
121
9, 1306081110
La partition de connaissance commune estM = Ω. Sous l’état 1, Alice et Bob pré-fèrent tous les deux parler en deuxième, etf (Πα(1)) = 1/3 = f (Πβ (1)) = 1/2. Ce-pendant, cela ne contredit pas le résultat duThéorème 1, puisqu’il n’est pas connais-sance commune que Bob préfère parler endeuxième. En effet, Bob préfère parler enpremier dans les états 6 et 8.
Le Théorème 1 montre en particulier quela connaissance commune en ω que i et
j sont en désaccord à propos de α et β implique que la valeur consensuelle de f en ω est la même avec les protocoles αet β . Soulignons ici que ce résultat n’estpas dû au fait que, dans ce cas, les événe-ments devenus connaissance commune enω entre les agents, à l’issue de la commu-nication, sont les mêmes, quelque soit leprotocole. Si c’était le cas, l’égalité des va-leurs consensuelles de f émergerait alors
comme une conséquence.
Proposition 3 Soit I = Ω, (Πi)1iN , f un modèle d’information tel que A1 et A2sont satisfaites, et α, β deux protocolesde communication distincts. Considéronsa1, a2, b1, b2 ∈ α, β , avec a1 = a2 et b1 = b2 , et considérons i = j. Enfin, consi-dérons les trois assertions suivantes :
(1) BI i (a1, a2) et BI j (b1, b2) sont connais-sance commune en ω.
(2) ω ∈ BI i (a1, a2)∩BI
j (b1, b2) et a1 = b2.
(3) Πα(ω) = Πβ (ω).
Communication, consensus et ordre et parole. Qui veut parler en premier ? ___________________________________________________________________________
170

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 183/415
Les assertions (1), (2), et (3) peuvent êtrevraies simultanément.
On montre cette proposition grâce àl’Exemple 1, dans lequel il est connais-sance commune en chaque état du mondeque Alice et Bob préfèrent parler en se-cond. Dans cet exemple, les partitions deconnaissance commune au consensus sontΠα = 1, 23, 45, 67 si Alice parle
en premier, et Πβ = 1, 723, 64, 5si Bob parle en premier. Sous l’état 1 parexemple, Πα(1) = 1, 2 = Πβ (1) =
1, 7, bien que l’on ait f (Πα(1)) =f (Πβ (1)) d’après le Théorème 1.
On sait depuis Geanakoplos et Polemar-chakis [1982] que le consensus obtenugrâce à la communication peut être inef-ficace, au sens où la valeur consensuellede la fonction peut être différente de cellequi aurait été obtenue si tous les individus
avaient “partagé” leur information privée.Formellement, étant donné un protocole α,il est possible que f (Πα(ω)) = f (J (ω)),où J (ω) =
i∈I Πi(ω). Lorsque deux in-
dividus sont en désaccord à propos de α etβ , alors chacun d’entre eux a une partitionau consensus plus fine avec l’un des deuxprotocoles. On peut ainsi se demander sila connaissance commune que deux agentssont en désaccord, à propos de deux pro-
tocoles, a des répercussions positives surl’efficacité du consensus qui en résultera.
Le contre-exemple suivant montre que laconnaissance commune que deux agentssont en désaccord à propos de α et β n’im-plique pas que le consensus obtenu avec αet β soit efficace.
Exemple 4 Soit Ω = 1, . . . , 19 l’en-
semble des états du monde, et suppo-sons que Alice et Bob aient une pro-babilité a priori P uniforme sur Ω.
Ils communiquent tour à tour leur va-leur privée de la fonction f (.) =
P (1, 3, 6, 7, 8, 9, 13, 17, 18 | .) , et sont dotés des partitions d’information sui-vantes :
ΠA = 1, 7, 8, 16 3
42, 3, 12, 15 1
45, 190
4, 10, 14, 18 1
4
6, 11, 17 2
3
9, 131
ΠB = 1, 2, 17 2
3
3, 4, 6, 7 3
4
5, 9, 14, 16 1
4
8, 12, 13, 18 3
4
10, 19011, 150
Si Alice parle en premier (protocole α),les partitions d’information au consensussont :
ΠαA = 1, 7, 811602, 1503, 12 1
2
11010, 1404, 18 1
2
5, 1906, 1719, 131
ΠαB = 11201713, 4 1
2
617150911401608112, 18 1
2
131100190150
Si Bob parle en premier (protocole β ),les partitions d’information au consensussont :
ΠβA = 117, 81160203, 12 1
2
501004, 18 1
2
1501401906111017191131
ΠβB = 1, 171203, 4 1
2
6, 718, 131
5, 14, 1609112, 18 12
10, 19011, 150
Dans chaque état du monde, Alice etBob préfèrent parler en second. D’aprèsle Théorème 1, la probabilité consensuellesera alors la même qu’Alice ou Bob parleen premier, dans chaque état du monde.Cependant, on peut remarquer que la pro-
babilité consensuelle est 1/2 sous l’état 3,alors qu’elle aurait été f (2, 3, 12, 15 ∩3, 4, 6, 7) = f (3) = 1 si Alice etBob avaient révélé l’information privéeque chacun a reçu sous l’état 3.
____________________________________________________________________________ Annales du LAMSADE N°8
171

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 184/415
5 Discussion
Dans cet article, on s’est intéressé à
la question des conséquences du choixd’un protocole de communication dans ungroupe d’agents, dans un cadre où les indi-vidus préfèrent apprendre de l’informationles uns des autres. On a montré que s’ilest connaissance commune entre les agentsque certains d’entre eux sont en désaccordsur le protocole de communication qu’ilspréfèrent utiliser parmi deux protocoles,alors le consensus qui émergera de l’uti-lisation de l’un ou l’autre protocole sera lemême.
La manière dont on a défini les préférencessur les protocoles a deux conséquences.Tout d’abord, elle implique que les agentspréfèrent être plus informés toutes choseségales par ailleurs, et s’applique par consé-quent uniquement aux situations de déci-sion dans lesquelles les agents valorisentl’information toujours positivement. Dans
les situations de jeux, les agents ne peuventpas préférer les protocoles grâce aux-quels ils sont plus informés toutes choseségales par ailleurs, puisqu’ils se préoc-cupent également du montant d’informa-tion apprise par leurs opposants au coursdu processus de communication.
Une deuxième conséquence de la manièredont on définit les préférences sur les pro-tocoles est qu’elles ne sont pas complètes.En effet, il est possible qu’un agent nesoit pas capable de comparer deux proto-coles, puisque deux partitions d’informa-tion ne peuvent pas toujours être ordon-nées dans le sens du raffinement. Une ma-nière de compléter les préférences serait deles définir de la manière suivante, plus gé-nérale. Supposons que chaque agent i aitune fonction d’utilité U i : Di × Ω → R, oùDi l’ensemble d’action de l’agent i. On dit
que l’agent i préfère un protocole α à unprotocole β sous l’état ω il anticipe sous ωqu’il aura une plus grande espérance d’uti-lité avec le protocole α qu’avec le pro-tocole β , i.e. si E [maxd∈Di
E (U i(d, .) |
Παi (.)) | Πi(ω)] > E [maxd∈Di
E (U i(d, .) |Πβ
i (.)) | Πi(ω)]. Cependant, on n’auraitpas le résultat du Théorème 1 dans ce
cas : avec de telles préférences, il peut êtreconnaissance commune que deux agentssoient en désaccord à propos de deux pro-tocoles, sans que cela n’implique l’égalitédes valeurs de consensus.
Exemple 5 Soit Ω = 1, 2, 3, 4, 5, 6, 7l’ensemble des états du monde, et consi-dérons trois agents, munis d’une probabi-lité a priori P uniforme sur Ω. Les trois
agents communiquent la valeur de la fonc-tion f (.) = P (1, 5 | .) selon deux pro-tocoles round-robin. Dans le protocole α ,l’agent 1 parle secrètement à l’agent 3, qui
parle secrètement à l’agent 2, qui parle se-crètement à l’agent 1, etc... Dans le pro-tocole β , l’agent 2 parle secrètement àl’agent 3, qui parle secrètement à l’agent 1, qui parle secrètement à l’agent 2, etc...
Les trois agents sont munis des partitions
d’information suivantes :Π1 = 1, 2, 6, 7 1
4
3, 4, 51
3
Π2 = 1, 2, 3, 7 1
4
4, 5, 61
3
Π3 = 1, 3, 4 1
3
2, 5, 6, 71
4
Si le protocole α est utilisé, les partitionsd’information au consensus sont :
Πα1 = 112, 6, 703, 4051
Πα
2 = 112, 3, 704, 6051Πα3 = 113, 402, 6, 7051
Si le protocole β est utilisé, les partitionsd’information au consensus sont :
Πβ 1 = 1, 6 1
2
2, 703, 5 1
2
40
Πβ 2 = 1, 3 1
2
2, 70405, 6 1
2
Πβ 3 = 1, 3 1
2
402, 705, 6 1
2
On peut facilement trouver une fonctiond’utilité commune aux agents 1 et 2 tellesqu’il soit connaissance commune entre lesagents 1, 2 et 3 qu’ils ont des préférences
Communication, consensus et ordre et parole. Qui veut parler en premier ? ___________________________________________________________________________
172

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 185/415
opposées sur α et β . Supposons que l’en-semble d’actions des agents 1 et 2 soitD = x, y, et qu’ils soient munis de lafonction d’utilité suivante :
U (x, ω) =
1 si ω ∈ 1, 3, 40 sinon
U (y, ω) =
1 si ω ∈ 2, 5, 6, 70 sinon
Munis de cette fonction d’utilité, les déci-sions des agents 1 et 2 à l’issue du pro-
cessus de communication seraient les sui-vantes :
Agent 1 :
Πα1 = 1x2, 6, 7y3, 4x5y
Πβ 1 = 1, 6x ou y2, 7y3, 5x ou y4x
Agent 2 :
Πα2 = 1x2, 3, 7x ou y4, 6x ou y5y
Πβ 2 = 1, 3x2, 7y4x5, 6y
L’agent 1 ne commet d’erreur dans aucunétat à l’issue du protocole α, alors qu’il encommet nécessairement une dans les états1, 6, 3 et 5 à l’issue du protocole β . Ainsi,l’agent 1 préfère α à β dans tous les étatsdu monde. De même, l’agent 2 ne commetd’erreur dans aucun état à l’issue du pro-tocole β , alors qu’il en commet nécessai-rement une dans les états 2, 3, 7, 4 et 6à l’issue du protocole α. Ainsi, l’agent 2préfère β à α dans tous les états du monde.Par conséquent, il est connaissance com-mune entre les agents 1, 2 et 3 que 1 et2 ont des préférences opposées sur α et β ,
bien que la valeur consensuelle de f ne soitpas la même avec α et β . Sous l’état 1 parexemple, la valeur consensuelle de la pro-babilité de 1, 5 est 1 avec le protocole α,et est 1/2 avec le protocole β .
Annexe : Démonstration duThéorème 1
Soit un modèle d’information I =Ω, (Πi)i, f , et α, β deux protocoles dis-tincts. Montrons que si les assertions (1) et(2) du Théorème 1 sont vraies, alors l’as-sertion (3) est fausse. On montre que s’ilexiste deux agents i, j et un état ω telsque BI
i (α, β ) and BI j (β, α) sont connais-
sance commune en ω, alors f (Πα(ω)) =f (Πβ (ω)). Clairement, le résultat tient tou-
jours si l’on échange α et β .
Rappelons que M (ω) désigne l’union despartitions individuelles avant que la com-munication n’ait lieu : M =
ni=1 Πi, et
que Πα désigne l’union des partitions indi-viduelles au consensus, étant donné le pro-tocole α : Πα =
ni=1 Πα
i .
Si BI i (α, β ) et BI
j (β, α) sont connaissance
commune en ω, alors on a
M (ω) ⊆ Bi(α, β ) ∩ B j(β, α)
Comme Πα(ω) ⊆ M (ω) et Πβ (ω) ⊆M (ω) ∀ ω, on a Πα(ω) ∩ Πβ (ω) ⊆M (ω) ∀ ω. Par conséquent, on a
Πα(ω) ∩ Πβ (ω) ⊆ BI i (α, β ) ∩ BI
j (β, α)
(1)Soit ω ∈ Πα(ω) ∩ Πβ (ω) (qui n’est pas
vide puisque ω ∈ Πα(ω) ∩ Πβ (ω)). Pardéfinition de l’union des partitions, on a
Παi (ω) ⊆ Πα(ω) et Πβ
i (ω) ⊆ Πβ (ω).
Comme ω ∈ Πα(ω) ∩ Πβ (ω), o n a
Πα(ω) = Πα(ω) et Πβ (ω) = Πβ (ω). Parconséquent,
Παi (ω) ⊆ Πα(ω) et Πβ i (ω) ⊆ Πβ (ω)
(2)
D’après (1), ω ∈ BI i (α, β ). Cela im-
plique que Παi (ω) ⊆ Πβ
i (ω). Cependant,
____________________________________________________________________________ Annales du LAMSADE N°8
173

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 186/415
Πβ i (ω) ⊆ Πβ (ω) by (2). On a par consé-
quent
Παi (ω) ⊆ Πα(ω) ∩ Πβ (ω)
Comme c’est le cas pour tout ω ∈Πα(ω) ∩ Πβ (ω), on a
Πα(ω) ∩ Πβ (ω) =
ω∈Πα(ω)∩Πβ(ω)
Παi (ω)
D’après la Proposition 1 et Parikh etKrasucki [1990], ∀ i, j, f (Πα
i
(ω)) =f (Πα
j (ω)) pour tout ω. Par définition de
l’union, cela implique que ∀ ω ∈ Πα(ω),f (Πα
i (ω) = f (Παi (ω)). Comme f est
convexe, f est aussi stable par l’union,et par conséquent f (Πα(ω) ∩ Πβ (ω)) =f (Πα(ω)).
Le même raisonnement appliqué à Πβ j (ω)
implique que f (Πα(ω) ∩ Πβ (ω)) =
f (Πβ (ω)).
Ainsi, f (Πα(ω)) = f (Πα(ω))
Références
[1] Aumann R. J., [1976], Agreeing toDisagree, The Annals Of Statistics, 4,1236-1239.
[2] Bacharach M., [1985], Some Ex-tensions of a Claim of Aumann inan Axiomatic Model of Knowledge,
Journal of Economic Theory, 37,167-190.
[3] Blackwell D., [1953], EquivalentComparison of Experiments, Annalsof Mathematical Statistics, 24, pp265-272.
[4] Cave J., [1983], Learning To Agree,
Economics Letters, 12, 147-152.[5] Geanakoplos J., Polemarchakis H.,
[1982], We Can’t Disagree Forever, Journal Of Economic Theory, 26,363-390.
[6] Koessler F., [2001], Common know-ledge and consensus with noisycommunication, Mathematical So-cial Sciences, 42, pp 139-159.
[7] Parikh R., Krasucki P., [1990], Com-munication, Consensus and Know-ledge, Journal of Economic Theory,52, 178-189.
[8] Sebenius and Geanakoplos J., [1983],Don’t bet on it : contingent agree-ments with asymmetric information, Journal of the American Statistical
Association, 78, 424-426.
Remerciements
Nous remercions Françoise Forges,John Geanakoplos, Frédéric Koessler,Yaw Nyarko, Dov Samet, Jean-MarcTallon, Jean-Christophe Vergnaud et Ni-colas Vieille, ainsi que trois rapporteursanonymes, pour leur nombreux commen-taires. Ce travail a été réalisé avec le
soutien financier du Ministère Françaisde la Recherche (Actions ConcertéesIncitatives).
Communication, consensus et ordre et parole. Qui veut parler en premier ? ___________________________________________________________________________
174

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 187/415
Fusion de bases propositionnelles : une méthode basée sur lesR-ensembles
Hue Julien†
Wurbel Eric†
Papini Odile‡
†LSIS UMR CNRS 6168 - Équipe INCAUniversite du Sud Toulon-Var
Avenue de l Université - BP2013283957 LA GARDE CEDEX - FRANCE
‡LSIS UMR CNRS 6168 - Équipe INCAUniversité de la Méditerranée - ESIL Avenue de Luminy
13288 MARSEILLE CEDEX - FRANCE
Résumé :
La prise de décision collective conduit à l’interac-tion de plusieurs agents afin d’élaborer une déci-sion commune cohérente. D’un point de vue in-formatique, ce problème peut se ramener à celuide la fusion de différentes sources d’informations.Dans le domaine de la représentation des connais-sances pour l’intelligence artificielle, plusieurs ap-proches ont été proposées pour la fusion de basesde croyances propositionnelles, cependant, la plu-part d’entre elles l’ont été sur un plan sémantiqueet sont peu utilisables en pratique. Ce papier pro-pose une nouvelle approche syntaxique pour la fu-sion de bases de croyances, appelée Fusion par R-ensembles (ou RSF). La notion de R-ensemble, ini-tialement définie dans le contexte de la révisionde croyances, est étendue à la fusion et la plu-part des opérations classiques de fusion sont cap-turées syntaxiquement par RSF. Afin d’implanterefficacement RSF, ce papier montre comment RSFpeut être codé en un programme logique avec sé-mantique des modèles stables, puis présente uneadaptation du système Smodels permettant de cal-culer efficacement les R-ensembles. Finalement,
une étude expérimentale préliminaire montre quela mise en œuvre utilisant la programmation lo-gique avec sémantique des modèles stables sembleprometteuse pour réaliser la fusion de bases decroyances sur des applications réelles.
Mots-clés : Fusion de croyances, Raisonnementsur les croyances, Représentation des connais-sances
Abstract:
Collective decision making leads to interaction bet-ween agents in order to elaborate a consistent com-
mon decision. From a data-processing point of view, this problem can be brought back to the mer-ging of different sources of information. In know-ledge representation for artificial intelligence, se-veral approaches have been proposed for proposi-tional bases fusion, however, most of them are de-
fined at a semantic level and are untractable. Thispaper proposes a new syntactic approach of belief bases fusion, called Removed Sets Fusion (RSF).The notion of removed-set, initially defined in thecontext of belief revision is extended to fusion andmost of the classical fusion operations are syntacti-cally captured by RSF. In order to efficiently imple-ment RSF, the paper shows how RSF can be enco-ded into a logic program with answer set semantics,then presents an adaptation of the smodels systemdevoted to efficiently compute the removed sets inorder to perform RSF. Finally a preliminary expe-
rimental study shows that the answer set program-ming approach seems promising for performing be-lief bases fusion on real scale applications.
Keywords: Belief merging, reasoning about be-liefs,Knowledge representation
1 Introduction
Dans le contexte de la prise de déci-sion collective, plusieurs experts ou agentsintelligents sont amenés à interagir afind’élaborer une décision commune de façonrationnelle. La prise de décision collectivea été étudiée dans le domaine de la théoriedu choix social et de récents travaux [28],[26], [15] ont montré le lien entre ces tra-vaux et ceux développés dans le domainede l’intelligence artificielle, en particulierconcernant la fusion. La fusion d’infor-mations issues de différentes sources est
un problème important dans plusieurs do-maines de l’informatique comme la repré-sentation des connaissances pour l’intelli-gence artificielle, la prise de décision oules bases de données. Le but de la fu-
175

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 188/415
sion est d’obtenir un point de vue globalexploitant la complémentarité des diffé-rentes sources, résolvant les conflits pos-sibles et enlevant les redondances exis-tantes entre les sources. Parmi les diffé-rentes approches de la fusion d’informa-tions provenant de sources multiples, lesapproches logiques ont obtenues un in-têret croissant ces dix dernières années[1, 23, 16, 24, 5]. La plupart de ces ap-proches ont été définies dans le cadre dela logique classique, le plus souvent pro-positionnelle, et ont été définies séman-tiquement. Différents postulats caractéri-
sant le comportement rationnel des opé-rateurs de fusion ont été proposés [12] etplusieurs opérateurs ont été définis selonque des priorités (implicites ou explicites)sont prises en compte ou non [14], [13],[7], [25], [19]. Plus récemment, de nou-velles approches ont été proposées commela fusion sémantique de bases proposition-nelles, notamment à partir de la distancede Hamming [11] ou la fusion syntaxique
dans le cadre possibiliste [8, 2] qui est unvéritable avantage du point de vue de l’ef-ficacité calculatoire.
Ce papier propose une nouvelle approchepour la fusion syntaxique de bases decroyances propositionnelles. Nous mon-trons que les opérateurs classiques de fu-sion, Card, Σ, Max, Gmax, initialementdéfinis au niveau sémantique, peuventêtre capturés dans notre cadre syntaxique.
Nous montrons ensuite qu’une implanta-tion efficace de ces opérateurs, basée sur laprogrammation logique avec sémantiquedes modèles stables, peut être réalisée. Enparticulier, ce papier se concentre sur lestrois points suivants :
– Nous étendons la Revision par R-ensembles (RSR1) à la fusion de basesde croyances propositionnelles, que
nous appelons Fusion par R-ensembles(RSF2). Nous montrons comment la no-tion de R-ensemble, c’est à dire les sous-1RSR : Removed Set Revision en anglais2RSF : Removed Set Fusion en anglais
ensembles de clauses à retirer pour res-taurer la cohérence, initialement défi-nie dans le contexte de la révision debases de croyances [21, 29] est géné-ralisée au cas de fusion de bases decroyances. Nous montrons ensuite com-ment les opérateurs classiques de fusionsont capturés dans ce cadre en associantà chaque stratégie de fusion une relationde préférence entre les sous-ensemblesde clauses.
– Ces dix dernières années, la programma-tion logique avec sémantique des mo-dèles stables est apparue comme étant
un outil efficace pour manipuler des sys-tèmes de raisonnement non-monotone.De plus, plusieurs systèmes efficaces ontété développés [9], [4], [22], [20], [18].Nous proposons de formaliser la Fu-sion par R-ensembles dans le cadre dela programmation logique avec séman-tique des modèles stables et d’adapter lesystème Smodels pour calculer les mo-dèles stables préférés qui correspondent
aux R-ensembles ce qui permet de défi-nir une méthode effective de fusion.– Une étude expérimentale préliminaire
permet d’illustrer le comportement deRSF pour les stratégies Card et Σ quisemble prometteur pour réaliser la fu-sion sur des applications réelles.
Ce papier est organisé comme suit. Lasection 2 fixe les notations et donne unrappel sur la fusion, la Revision par R-ensembles et la programmation logiqueavec sémantique des modèles stables. Lasection 3 présente ensuite la Fusion parR-ensembles. La section 4 montre com-ment la Fusion par R-ensembles est miseen œuvre dans la programmation logiqueavec sémantique des modèles stables etprésente une adaptation du système Smo-dels pour le calcul des modèles stablespréférés et la réalisation de la Fusion par
R-ensembles. La section 5 présente en-suite une première étude expérimentale quimontre que cette implantation, grâce à laprogrammation logique avec sémantiquedes modèles stables, semble prometteuse
Fusion de bases propositionnelles : une méthode basée sur les R-ensembles ___________________________________________________________________________
176

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 189/415
avant de conclure en section 6.
2 Préliminaires et notations
On considère un langage propositionnel Ldéfini sur un alphabet P d’atomes. Un lit-téral est un atome ou la négation de cetatome. Les connecteurs usuels de la lo-gique propositionnelle sont notés : ¬, ∧,∨ et on note Cn la conséquence logique.Une base de croyances K est un ensemblefini de formules propositionnelles définiessur le langage propositionnel L.
2.1 Fusion
Soit E = K 1, . . . , K n un multi-ensemble de n bases de croyances co-hérentes à fusionner, E est appelé en-semble de croyances. Les n bases decroyances K 1, . . . , K n ne sont pas néces-sairement différentes et l’union des basesde croyances prenant en compte la répéti-
tion est notée ; la conjonction et la dis- jonction sont respectivement notées
et. Pour simplifier les notations, on note K
l’ensemble de croyances constitué du sin-gleton E = K .
L’opération de fusion ∆ est définie commeétant une fonction qui, à chaque en-semble de croyances, associe une base decroyances cohérente, notée ∆(E ). Dans la
littérature, ∆(E ) est généralement définiede deux manières différentes : en tenantcompte ou pas de l’existence d’une prioritéimplicite. Ce papier ne tient pas comptedes priorités implicites.
Il y a deux façons immédiates de définir∆(E ) selon que les sources sont conflic-tuelles ou pas, la conjonction classique :∆(E ) =
K i∈E K i dans le cas où les
sources ne sont pas contradictoires et la
disjonction classique : ∆(E ) =K i∈E K i
dans le cas de sources conflictuelles. Entreces deux cas opposés, plusieurs méthodesont été proposées suivant l’importance desdifférentes bases.
En particulier, les opérateurs classiques defusion suivants ont été proposés. L’opéra-teur de cardinalité, noté Card [1], tient encompte du nombre de bases de croyancesde E . L’opérateur Somme, noté Σ [17, 23],suit le point de vue de la majorité. L’opé-rateur Max [24] essaie de satisfaire aumieux toutes les bases de E . L’opéra-teur Gmax [12], qui est un raffinement del’opérateur Max.
Différents postulats permettant de caracté-riser le comportement rationnel des opé-rateurs de fusion ont été proposés [12] et
ces opérateurs ont été classés en deux fa-milles : les opérateurs majoritaires et lesopérateurs d’arbitrage.
2.2 La programmation logique avec
sémantique des modèles stables
Un programme logique normal P est unensemble de règles de la forme c ←
a1, . . . , an, not b1, . . . , not bm où lesc, ai(1 ≤ i ≤ n), b j(1 ≤ j ≤m) sont des atomes et le symbole notreprésente la négation par échec. Pourune règle r comme ci-dessus, on in-troduit les notations tete(r) = c etcorps(r) = a1, · · · , an, b1, · · · , bm. Deplus, corps+(r) = a1, · · · , an repré-sente l’ensemble des atomes positifs pré-sents dans le corps et corps−(r) =
b1, · · · , bm en représente l’ensembledes atomes négatifs. Enfin, corps(r) =corps+(r) ∪ corps−(r).
Soit r une règle, r+ représente la règletete(r) ← corps+(r), que l’on obtient àpartir de r en supprimant tous les atomesnégatifs dans le corps de r.
Un ensemble d’atomes X est clos sous unprogramme P ssi ∀r ∈ P , tete(r) ∈ X
lorsque corps(r) ⊆ X . Le plus petit en-semble d’atomes qui est clos sous un pro-gramme P est noté CN (P ).
La réduction, ou transformation de
____________________________________________________________________________ Annales du LAMSADE N°8
177

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 190/415
Gelfond-Lifschitz [10], P X , est un pro-gramme P qui est défini, relativement à unensemble X d’atomes, par : P X = r+ |
r ∈ P et corps
−
(r) ∩ X = ∅.Un ensemble d’atomes X est un modèlestable de P ssi CN (P X ) = X .
Définition 1. Soit L un ensemble de litté-raux et A un ensemble d’atomes. On dit que L couvre A ssi A ⊆ Atome(L).
L’exemple suivant permet d’illustrer leconcept de modèle stable.
exemple. Les modèles stables sont lesconséquences que l’on peut tirer du pro-gramme logique. Soit P le programme lo-gique constitué des trois règles suivantes :
p f ← p, not h h ← p, not f
Pour le programme précédent, les modèlesstables du programme P sont p, h et
p, f . Contrairement à la programmationlogique standard, comme par exemple,PROLOG, où on dispose d’un seul en-semble de conséquences, appelé mo-dèle minimal, (intersection des modèlesde Herbrand associés au programme) laprogrammation logique avec sémantiquedes modèles stables fournit plusieurs en-sembles de conséquences qui peuvent êtrecontradictoires et permet de formaliser le
raisonnement non monotone.
2.3 Smodels
Smodels est la première et la plus simpledes méthodes de calcul de modèles stables[27]. C’est un algorithme de Branch andBound (voir Algorithme 1) qui construit,au fur et à mesure, un ensemble d’atomesA représentant un modèle stable potentiel.
Pour ce faire, il utilise les fonctions sui-vantes : expand(A) qui calcule les consé-quences immédiates de A, conflict(A)qui détecte les conflits qui peuvent se pro-duire et heuristic(A) qui tente de réduire
la taille de l’espace de recherche en choi-sissant l’atome qui permet le plus de dé-ductions. La fonction heuristic(A) tentede réduire le nombre d’atomes qu’il resteà choisir et permet une détection plus ra-pide des conflits.
Algorithme 1 smodels(A)
A ← expand(A)si conflict(A) alors
renvoyer Fauxsinon si A couvre Atome(E ) alors
renvoyer Vrai
sinonx ← heuristic(A)si smodels(A ∪ x) alors
renvoyer Vraisinon
renvoyer smodels(A ∪ not x)finsi
finsi
2.4 Revision par R-ensembles
Nous rappelons brièvement l’approcheRevision par R-ensembles (RSR). L’ap-proche RSR [29] traite de la révision d’unensemble de formules propositionnellespar un ensemble de formules proposition-nelles3. Soient K et A deux ensembles fi-nis de clauses. L’approche RSR consiste àchoisir un ensemble minimal de clauses à
retirer de K , appelé R-ensemble [21], afinde restaurer la cohérence de K ∪ A. Plusformellement :
Définition 2. Soient K et A deux en-sembles de clauses cohérents tels que K ∪A est incohérent. R , un sous-ensemble declauses de K , est un R-ensemble de K ∪A ssi (i) (K \R) ∪ A est cohérent ; (ii)∀R ⊆ K , si (K \R) ∪ A est cohérent,
alors | R |≤| R
|4
.3À partir de maintenant, on considère les formules proposi-
tionnelles dans leurs formes normales conjonctives (CNF) asso-ciées.
4| R | représente le nombre de clauses de R.
Fusion de bases propositionnelles : une méthode basée sur les R-ensembles ___________________________________________________________________________
178

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 191/415
On note R(K ∪ A) la collection des R-ensembles de K ∪ A, la Revision par R-ensembles est définie comme suit :
Définition 3. Soient K et A deux en-sembles de clauses cohérents. La Revision
par R-ensembles est définie par : K RSRA =def
R∈R(K ∪A) Cn((K \R) ∪ A).
3 Fusion par R-ensembles
Nous proposons un nouveau cadre syn-taxique, la Fusion par R-ensembles (RSF),
qui consiste à fusionner plusieurs bases decroyances propositionnelles. L’approcheconsiste à retirer un sous-ensemble desclauses de l’union des bases de croyances,d’après une stratégie P donnée, dans le butde restaurer la cohérence. Ce cadre captureles opérateurs classiques de fusion et peutêtre mis en œuvre efficacement. Elle gé-néralise l’approche RSR que nous avonsbrièvement rappelée, et requiert donc la
généralisation de la notion de R-ensemble.Soient E = K 1, . . . , K n un ensemblede croyances où K i, 1 ≤ i ≤ n est unebase de croyances cohérente et X, X deuxsous-ensembles de K 1 . . . K n.
Définition 4. Soit E = K 1, . . . , K n unensemble de croyances tel que K 1 . . . K n est incohérent, X ⊆ K 1 . . . K n est un R-ensemble Potentiel de E ssi (K 1
. . . K n)\X est cohérent.
Exemple. Soient 3 bases de croyancespropositionnelles, K 1 = ¬d, s∨o, K 2 =¬s, d ∨ o, ¬d ∨ ¬o, K 3 = s,d,o.
Les R-ensembles potentiels de E = K 1 K 2 K 3 sont :– R1 = s ∨ o, d ∨ o,s,d,o ;– R2 = ¬s, d ∨ o,d,o ;
– R3 = d, s ;– R4 = ¬s, d ;– R5 = ¬d,s,o,s ∨ o ;– R6 = ¬d,o, ¬s ;– R7 = ¬d,s, ¬d ∨ ¬o ;
– R8 = ¬d, ¬s, ¬d ∨ ¬o.Ainsi que tous leurs sur-ensembles.
Le nombre de R-ensembles Potentiels estexponentiel par rapport au nombre declauses de E . Ainsi, seuls les R-ensemblesPotentiels les plus pertinents, selon la stra-tégie P choisie, doivent être sélectionnés.Pour cela, une relation de préférence se-lon la stratégie P , notée ≤P , est définie surl’ensemble des R-ensembles potentiels etX ≤P X signifie que X est préféré à X
selon la stratégie P .
Définition 5. Soit E = K 1, . . . , K n unensemble de croyances tel que K 1 . . . K n est incohérent, X ⊆ K 1 . . . K n est un R-ensemble de E selon P ssi
1. X est un R-ensemble Potentiel de E ;
2. Il n’existe pas de R-ensemble potentielX ⊆ K 1 . . . K n tel que X <P X .
On note F P R(E ) la collection des R-
ensembles5 de E selon P . La Fusion parR-ensembles est définie comme suit.
Définition 6. Soit E = K 1, . . . , K n unensemble de croyances. L’opération de fu-sion ∆P (E ) est définie par :
∆P (E ) =
X ∈F P R(E )
Cn(K 1. . .K n\X )
Nous montrons maintenant comment cap-turer les opérateurs classiques de fusiondans notre cadre.
3.1 Représentation des opérateurs
classiques de fusion avec RSF
Les différentes stratégies de fusion corres-
pondant aux opérateurs classiques peuventêtre capturées grâce à une relation de pré-férence définie sur les R-ensembles Poten-tiels.
5Si K 1 . . . K n est cohérent F P R(E ) = ∅.
____________________________________________________________________________ Annales du LAMSADE N°8
179

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 192/415
L’opérateur Card. L’opérateur Card estcapturé dans notre cadre comme suit :
– Soient X et X deux R-ensemblesPotentiels de E : X ≤Card X ssi| X |≤| X |.
– Soit F CardR(E ) la collection des R-ensembles de E selon Card, l’opéra-tion de fusion Card est représentée par :∆Card(E ) =
X ∈F CardR(E )Cn((K 1
. . . K n)\X )
La stratégie Card minimise le nombrede clauses à retirer de E et ne tient pascompte des répétitions. Elle est équiva-lente à l’opérateur Comb4 défini dans [1].
L’opérateur Σ. L’opérateur Σ est capturédans notre cadre comme suit :
– Soient X et X deux R-ensemblesPotentiels de E : X ≤Σ X ssi
1≤i≤n | X ∩K i |≤
1≤i≤n | X
∩K i |.– Soit F ΣR(E ) la collection de R-
ensembles de E selon Σ, L’opération defusion Σ est représentée par : ∆Σ(E ) =X ∈F ΣR(E )Cn((K 1 . . . K n)\X )
La stratégie Σ minimise le nombre declauses à retirer de E en prenant en comptela répétition. Il est identique à l’opérateurintersection développé dans [25].
L’opérateur Max. L’opérateur Max estcapturé dans notre cadre comme suit :
– Soient X et X deux R-ensemblespotentiels de E : X ≤max X ssimax1≤i≤n | X ∩ K i |≤ max1≤i≤n |X ∩ K i | et X ⊆ X .
– Soit F MaxR(E ) la collection de R-ensembles de E selon Max, l’opéra-tion de fusion Max est représentée par :∆Max(E ) =
X ∈F MaxR(E )Cn((K 1
. . . K n)\X )
La stratégie Max essaie de répartir aumieux les clauses à retirer entre les basesde croyances de E et minimise le nombrede clauses à retirer dans la base decroyance la plus impliquée dans l’incohé-rence.
L’opération Gmax. L’opérateur Gmax estcapturé dans notre cadre comme suit :
– Pour chaque R-ensemble Potentiel X etchaque base de croyances K i, on définit
piX =| X ∩ K i |. Soit LE X la séquence
( p1X , . . . , pnX ) triée par ordre décrois-
sant. Soient X et X deux R-ensemblesPotentiels de E : X ≤Gmax X ssiLE X <lex LE
X 6.
– Soit F GmaxR(E ) la collection deR-ensembles de E selon Gmax,l’opération de fusion Gmax estreprésentée par : ∆Gmax(E ) =X ∈F GmaxR(E )Cn((K 1 . . .
K n)\X )
La stratégie Gmax est un raffinement de lastratégie Max, elle retire les clauses dansles bases de croyances d’après l’ordre dé-croissant du nombre de clauses impliquéesdans l’incohérence.
Exemple. Nous illustrons notre approchegrâce à l’exemple suivant, tiré de [23].Considérons la situation suivante : Un pro-
fesseur demande à ses élèves quels lan-gages, parmi les suivants, ils souhaitentétudier:SQL(notés), O2 (noté o), Datalog(noté d). Le premier souhaite étudier SQLou O2 mais pas Datalog (K 1 = ¬d, s ∨o). Le second veut étudier seulement Da-talog ou O2 mais pas les deux (K 2 =¬s, d ∨ o, ¬o ∨ ¬d). Le troisième veutétudier les trois (K 3 = s,d,o). Danscet exemple, le décideur est le professeur,
et les trois groupes d’étudiants peuventêtre assimilés à trois agents. Le profes-seur doit prendre une décision en respec-tant au mieux le choix des étudiants selon
6On note <lex l’ordre lexicographique
Fusion de bases propositionnelles : une méthode basée sur les R-ensembles ___________________________________________________________________________
180

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 193/415
une stratégie donnée. Soit E = K 1K 2 K 3 l’ensemble de croyances correspon-dant. Dans cette situation, le résultat de lafusion sera :
– F CardR(E ) = ¬s, d, s, d and∆Card(E ) = ¬d, s ∨ o, d ∨ o, ¬o ∨¬d,s,o, ¬d, s ∨ o, ¬s, d ∨ o, ¬o ∨¬d, o ;
– F ΣR(E ) = F CardR(E ) and∆Σ(E ) = ∆Card(E ) ;
– F MaxR(E ) = ¬s, d and∆Max(E ) = ¬d, s ∨ o, d ∨ o, ¬o ∨¬d,s,o ;
– F GmaxR(E ) = ¬s, d and∆Gmax(E ) = ¬d, s ∨ o, d ∨ o, ¬o ∨¬d,s,o.
Nous présentons maintenant une implanta-
tion de l’approche RSF pour les stratégiesCard et Σ.
4 Mise en œuvre de RSF parla programmation logiqueavec sémantique des modèlesstables
Nous montrons maintenant commentconstruire un programme logique, notéP E , tel que les modèles stables préférés deP E correspondent au R-ensembles de E .
D’abord, nous montrons comment traduirela Fusion par R-ensembles en un pro-gramme logique, dans le même esprit que
[20], afin d’obtenir une bijection entre lesmodèles stables de P E et les R-ensemblesPotentiels de E . Puis, nous définissons lanotion de modèle stable préféré afin de réa-liser la Fusion par R-ensembles.
4.1 La traduction en un programme
logique
Soit E = K 1, . . . , K n un ensemble decroyances. L’ensemble de tous les littérauxpositifs de P E est noté V +. L’ensemble detous les littéraux négatifs de P E est notéV −. L’ensemble de tous les atomes repré-sentant les clauses sont définis par R+ =ric | c ∈ K i et CL(ric) représente lesclauses de K i correspondant à ric dans P E ,autrement dit ∀ric ∈ R+, CL(ric) = c. Àchaque modèle stable S de P E , nous as-
socions le R-ensemble Potentiel CL(R+ ∩S ).
1. Dans la première étape, nous in-troduisons des règles permettant deconstruire une bijection entre les mo-dèles stables de P E et les interpréta-tions de V +. Pour chaque atome, a ∈V + on introduit deux règles : a ←not a et a ← not a où a ∈ V − estl’atome négatif correspondant à a.
2. Dans la seconde étape, nous excluonsles modèles stables S qui corres-pondent aux interprétations qui ne sontpas des modèles de (K 1 . . .K n)\C iavec C i = c | rc ∈ S . Pourchaque clause c of K j telle que c =¬bo ∨ . . . ∨ ¬bn ∨ bn+1 ∨ . . . ∨ bm,on introduit la règle suivante r jc ←
bo, . . . , bn, b
n+1, . . . , b
m.
Cette traduction permet de générer l’en-semble des modèles possibles ainsi queles ensembles de règles qui leurs sont as-sociés. Grâce au traitement décrit dans lasection 4.2, nous pourrons définir quelssont les ensembles préférés selon la straté-gie choisie. Elle est différente de celle pro-posée dans [3] pour RSR car nous consi-
dérons uniquement les atomes positifs R+
représentant les clauses.
Exemple. Soit E = K 1 K 2K 3 définidans l’exemple. Nous avons :
____________________________________________________________________________ Annales du LAMSADE N°8
181

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 194/415
– V + = s,d,o ;– V − = s, d, o ;– R+ = r1
¬d, r1s∨o, r2
¬s, r2d∨o, r2
¬d∨¬o, r3s , r3
d, r3o.
La traduction en un programme logiqueP E correspondant au problème de fusionest la suivante :
s ← not s s ← not s d ← not d
d ← not d o ← not o o ← not or1¬d ← d r1
s∨o ← s, o r2¬s ← s
r2d∨o ← d, o r2
¬d∨¬o ← d, o r3s ← s
r3d ← d r3
o ← o
Soit S un ensemble d’atomes, on définit I S comme étant I S = a | a ∈ S ∪ ¬a |a ∈ S . La proposition suivante établit lacorrespondance entre les modèles stablesde P E et les interprétations de (K 1 . . . K n)\CL(R+ ∩ S ).
Proposition 1. Soit E = K 1, . . . , K nun ensemble de croyances. Soit S ⊆ V unensemble d’atomes. S est un modèle stablede P E ssi I S est une interprétation de V +
qui satisfait (K 1 . . .K n)\CL(R+ ∩S ).
Afin de calculer les modèles stables cor-respondant aux R-ensembles, nous intro-duisons la notion de modèles stables pré-férés d’après une stratégie P .
Définition 7. Soit P E un programme lo-gique. Soient S et S deux ensemblesd’atomes de P E . S est un modèle stable
préféré de P E selon P ssi :1. S est un modèle stable de P E ;
2. Pour chaque modèle stable S de P E ,S n’est pas préféré à S selon P .
La correspondance entre les modèlesstables préférés et les R-ensembles estdonnée par la proposition suivante pour lesstratégies Card et Σ.
Proposition 2. Soit E = K 1, . . . , K nun ensemble de croyances. X est un R-ensemble de E selon la stratégie P ssi ilexiste un modèle stable préféré S de P E selon P tel que CL(R+ ∩ S ) = X .
Preuve. La proposition précédente peutêtre réexprimée comme CL(S ∩ R+) |S est un modèle stable préféré selon P =F P R(E ). Pour simplifier, la preuve nesera donnée que pour Card, la trame resteidentique pour Σ.
On cherche donc à prou-ver que CL(S ∩ R+) |S est un modèle stable préféré selon P =F CardR(E ).
Dans un premier temps, onmontre que CL(S ∩ R+) |
S est un modèle stable préféré selon P ⊆F CardR(E ). Pour cela, on suppose qu’ilexiste un ensemble S appartenant àl’ensemble des modèles stables pré-férés de P E selon Card et qu’il estimpossible que le R-ensemble potentielcorrespondant ne fasse pas partie desR-ensembles de E selon Card. Ainsi,on pose X = CL(S ∩ R+). Par laproposition 1, (K 1 . . . K n)\X est
cohérent. Supposons maintenant que X n’appartienne pas à F CardR(E ), il existedonc X tel que (K 1 . . . K n)\X
est cohérent et X <Card X . On peuten déduire qu’il existe une interprétationI S sur l’ensemble des atomes de E quisatisfait (K 1 . . . K n)\X . S est lemodèle stable associé à X et S = a :a ∈ I S ∪ a : ¬a ∈ I S ∪ rc : c ∈ X .On sait que X = CL(S ∩ R+) et, parla proposition 1, que S est un modèlestable de P E . Cela entraine que S estpréféré à S car |X | = |S ∩ R+| ce qui estcontradictoire avec l’hypothèse que S estun modèle stable préféré.
On montre maintenant queF CardR(E ) ⊆ CL(S ∩ R+) |S est un modèle stable préféré selon P .X est un R-ensemble de E donc(K 1 . . . K n)\X est cohérent. Il
existe donc une interprétation I S surl’ensemble des atomes de E qui satisfait(K 1 . . . K n)\X . On note S le modèlestable de P E correspondant à X . Parla proposition 1, on sait que S est un
Fusion de bases propositionnelles : une méthode basée sur les R-ensembles ___________________________________________________________________________
182

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 195/415
modèle stable de P E . Supposons que S nesoit pas un modèle stable préféré de P E selon Card, cela suppose qu’il existe S
tel que |CL(S ∩ R+)| = |S ∩ R+| <|CL(S ∩ R+)| = |S ∩ R+|. MaisX = CL(S ∩ R+) et (K 1 . . . K n)\X
est cohérent. X n’appartiendrait doncpas à F CardR(E ) ce qui est contraire àl’hypothèse.
Exemple. Soit P E le programme logiquecorrespondant à l’exemple précédent. Lacollection des modèles stables préférésde
P E selon les stratégies
Cardet
Σest : S 1 = s, d,o ,r2¬s, r3
d, S 2 =s, d,o ,r3
s , r3d.
Etant donné que R+ =r1
¬d, r1s∨o, r2
¬s, r2d∨o, r2
¬d∨¬o, r3s , r3
d, r3o les
R-ensembles sont CL(R+∩S 1) = ¬s, det CL(R+ ∩ S 2) = s, d.
4.2 Calcul des modèles stables préfé-
rés : l’algorithme rsf
L’algorithme rsf calcule les modèlesstables préférés correspondant aux R-ensembles. Cet algorithme est une modifi-cation de celui de Smodels qui sélectionneles modèles stables préférés selon la straté-gie P choisie. Il construit, étape par étape,une collection de modèles stables candi-dats. À la fin du calcul, cette collection
contient tous les modèles stables préféréscorrespondant aux R-ensembles.
La sélection des modèles stables pré-férés est réalisée grâce à la fonctionConditionP (A), où A est un ensembled’atomes. Cette fonction compare le mo-dèle stable candidat A en cours à ceuxqui ont déjà été calculés. Les troiscomportements possibles de la fonction
ConditionP (A) sont :1. A ne peut plus conduire à aucun mo-dèle stable préféré. Dans ce cas, le cal-cul est arrêté et l’algorithme revient enarrière;
2. L’interprétation qui correspond à A estcomplète et A est aussi préféré que lesmeilleurs modèles stables déjà calcu-lés. Dans ce cas, A est ajouté à la col-lection des modèles stables candidats;
3. L’interprétation qui correspond à A estcomplète et A est préféré aux modèlesstables précédemment calculées. Dansce cas, la collection constituée par lesingleton A remplace la collection desmodèles stables candidats.
Une autre adaptation de Smodels concernel’heuristique originale heuristic(A). Si un
atome a est choisi, alors l’atome a ne peutplus être déduit. Les seuls autres atomespouvant être déduit sont ceux qui repré-sentent les règles ric.
L’utilisation de l’heuristique standardconduit à maximiser le nombre de ricdéduit, ce qui est contradictoire avec lesobjectifsdeRSFetnetendpasàtirerprofitde la réduction de l’espace de recherche.
Nous modifions cette heuristique afin desélectionner les atomes qui minimisent lenombre d’atomes déduits. De cette ma-nière, le premier modèle stable aura plusde chances d’être un modèle stable préféréd’après la stratégie choisie. Cette nouvellefonction est appelée mheuristic(A).
Les adaptations de l’algorithme original deSmodels consistent à : (i) ne pas calcu-
ler des sous-ensembles de R+
conduisantà des modèles stables qui retirent plus declauses que les meilleurs modèles déjà cal-culés; (ii) ne pas calculer plusieurs foisles mêmes sous-ensembles de littéraux deR+ ; (iii) tirer avantage d’élagages dansl’arbre de recherche.
5 Etude expérimentale prélimi-
naire
Nous présentons les résultats d’une étudeexpérimentale préliminaire sur l’approcheRSF. Les tests ont été conduit sur un Cen-
____________________________________________________________________________ Annales du LAMSADE N°8
183

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 196/415
Algorithme 2 rsf (A)
A ← expand(A)si conflict(A) alorsrenvoyer Faux
finsisi (1) ConditionP (A) = 1 alors
renvoyer Fauxsinon si A conduit à un R-ensemble déjàcalculé alors
renvoyer Fauxsinon si A couvre Atome(E ) alors
si (2) ConditionP (A) = 0 alorsA est ajouté à l’ensemble des solu-tionsrenvoyer Vrai
sinon(3)A devient l’ensemble des so-lutionsrenvoyer Vrai
finsifinsix ← mheuristic(A)rsf (A ∪ x)rsf (A ∪ not x)
trino cadencé à 1,73GHz et équipé d’un1GO de RAM.
À notre connaissance, il n’existe pasd’autres implantations réalisant la fusionde bases de croyances propositionnelles, nide plateforme de tests pour la fusion. Lestests préliminaires suivants ne sont pas as-sez exhaustifs pour conclure sur l’effica-cité de RSF. Néanmoins, ils montrent laviabilité de l’approche. Afin de pouvoirconclure sur l’efficacité de RSF, nous de-vrons développer une plateforme de testsplus complète.
Les tests sont générés aléatoirementd’après plusieurs paramètres : le nombrede bases (nb), le nombre de clauses danschacune des bases (nc), le nombre de va-riables dans les bases (nv), la taille desclauses (sc) et un paramètre qui mesure àquel point les bases diffèrent les unes desautres (d).
Les bases de tests sont construites commesuit. Nous construisons une interpréta-tion I. Ensuite, nous générons aléatoire-ment des clauses qui sont ajoutées si ellessatisfont I. D’une base à l’autre, nouschangeons l’interprétation d’après le pa-ramétre (d) qui représente le pourcentagede variables changées. Pour chaque en-semble de paramètres, nous avons testé10 ensembles de bases de tests différents.Un test est considéré comme un échecsi, au bout de 300 secondes, il n’a pasabouti. Nous conservons le temps d’exé-cution moyen des tests réussis. Les ta-bleaux suivants présentent le pourcentagede tests réussis et, en secondes, le tempsd’exécution pour le calcul de tous les R-ensembles.
La table 1 montre le comportement de l’al-gorithme RSF pour 3 bases de clauses ter-
naires. L’approche RSF réalise la fusionde 3 bases dans un temps raisonnable jus-qu’à un total de 3000 clauses pour 8000variables. En faisant varier nv/nc, la table2 exhibe un pic de difficulté lorsque nv/nc
Fusion de bases propositionnelles : une méthode basée sur les R-ensembles ___________________________________________________________________________
184

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 197/415
nc nv Succes(%) Temps(s)100 1000 100 2, 1200 2000 100 7, 2400 4000 100 37, 6600 6000 100 105, 2800 8000 100 221, 4
1200 12000 0 −
TAB . 1 – Resultats pour nb = 3, sc = 3 etd = 20%.
nc nv Succes(%) Temps(s)400 200 40 68, 7400 400 20 13, 5400 800 70 17, 5200 100 90 2, 2200 200 90 11, 1200 400 90 2, 1
TAB . 2 – Resultats pour nb = 3, sc = 3 etd = 20%.
se rapproche de 1.
En analysant le temps d’exécution, nousavons observé que l’heuristique permettantde choisir l’atome consomme beaucoup detemps et doit être améliorée encore.
6 Conclusion
Ce papier présente une approche nou-velle pour réaliser la fusion syntaxique deplusieurs bases de croyances proposition-nelles et montre que les opérateurs clas-siques de fusion Card, Σ, Max, Gmax,initialement définis au niveau semantiquepeuvent être capturés dans notre cadre syn-taxique.
Ce papier montre que RSF peut être traduitde manière efficace en un programme lo-gique avec sémantique des modèles stablespour les stratégies Card et Σ et proposeune implantation à partir du système Smo-
dels. Une étude expérimentale prélimi-naire est présentée et les résultats semblentprometteurs pour la réalisation de la fu-sion de bases de croyances sur des applica-tions réelles. Nous envisageons égalementd’implanter RSF pour les stratégies Maxet Gmax.
Une expérimentation plus profonde devraêtre conduite sur des applications réellesafin de pouvoir donner une évaluation plusprécise des performances de l’approcheRSF. Cette expérimentation sera conduite
dans le cadre d’un projet européen pour lafusion d’information spatiale. De plus, ledéveloppement d’une plateforme de testspour la fusion sera utile, non seulementpour tester RSF, mais, plus globalement,pour d’autres futurs travaux portant surl’implantation des opérateurs de fusion.
La Fusion par R-ensembles rend possiblel’implantation efficace des opérateurs clas-
siques de fusion Card et Σ, et, il géné-ralise RSR car la révision de bases decroyances peut être considérée comme lafusion de deux bases de croyances l’uneétant préférée à l’autre [6]. De ce fait, RSRrevient à fusionner deux sources selon lastratégie Card.
Notre cadre peut être étendu dans plusieurs
directions. Par exemple, permettre de gérerles contraintes que la fusion de bases decroyances ∆(E ) doit satisfaire ou la fusionde bases de croyances avec priorité.
Un travail futur détaillera la caractérisa-tion sémantique de la méthode de Fusionpar R-ensembles. Cette caractérisation re-pose sur l’ensemble de clauses falsifiées deK 1 . . . K n par une interprétation. Se-
lon la stratégie P de fusion choisie, un pré-ordre peut être défini sur les interprétationsà partir d’une relation de préférence, selonP , sur l’ensemble des clauses falsifiées deK 1 . . . K n.
____________________________________________________________________________ Annales du LAMSADE N°8
185

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 198/415
7 Remerciements
Ce travail a été réalisé avec le soutien de
Communauté Européenne à travers le pro- jet VENUS (contrat IST034924) du pro-gramme ” Information Society Technolo-gies (IST) of the 6th FP of RTD”. Les au-teurs sont seuls responsables du contenude cet article. Il ne représente pas l’opi-nion de la Communauté Européenne et laCommunauté Européenne n’est pas res-ponsable de l’utilisation qui pourrait êtrefaite des données figurant dans cet article.
Références
[1] Chitta Baral, Sarit Kraus, Jack Min-ker, and V. S. Subrahmanian. Com-bining knowledge bases consisting of first order theories. In ISMIS , pages92–101, 1991.
[2] S. Benferhat, D. Dubois, S. Kaci, andH. Prade. Possibilistic Merging and
Distance-based Fusion of Propositio-nal Information. AMAI’02, 34((1-3)) :217–252, 2002.
[3] J. Bennaim, S. Benferhat, O. Papini,and E. Würbel. An answer set pro-gramming encoding of prioritized re-moved sets revision : application togis. In J. Alferes and Springer VerlagJ. Leite, editors, Proc. of JELIA’04,pages 604–616, Lisbonne, Portugal,
Septembre 2004. Lecture notes in Ar-tificial Intelligence. Logics for AI.
[4] P. Cholewinski, V. Marek, A. Miki-tiuk, and M. Truszczynski. Compu-ting with default logic. AI , 112 :105–146, 1999.
[5] L. Cholvy. Reasoning about merginginformation. Handbook of Defeasible
Reasoning and Uncertainly Manage-
ment Systems, 3 :233–263, 1998.[6] J. Delgrande, D. Dubois, and J. Lang.Iterated revision as prioritized mer-ging. In Proc. of KR’06 , pages 210–220, Windermere, GB, 2006.
[7] James Delgrande, Didier Du-bois, and Jérôme Lang. Iteratedrevision as prioritized merging.In International Conference onPrinciples of Knowledge Repre-sentation and Reasoning (KR),
Lake District (UK), 02/06/2006-05/06/2006 , pages 210–220,http ://www.aaai.org/Press/press.php,2006. AAAI Press.
[8] D. Dubois, J. Lang, and H. Prade.Possibilistic Logic. in Handbook of Logic in Artificial Intelligenceand Logic Programming,3:439–513,1994.
[9] T. Eiter, N. Leone, C. Mateis, G. Pfei-fer, and F. Scarcello. the kr sys-tem dlv : progress report, comparisonand benchmarks. In Proc. of KR’98 ,pages 406–417, 1998.
[10] Michael Gelfond and Vladimir Lif-schitz. The stable model semanticsfor logic programming. In Robert A.
Kowalski and Kenneth Bowen, edi-tors, Proc. of the Fifth Int. Confe-rence on Logic Programming, pages1070–1080, Cambridge, Massachu-setts, 1988. The MIT Press.
[11] S. Konieczny, J. Lang, and PierreMarquis. Distance-based merging :A general framework and some com-plexity results. In Proc. of KR’02,pages 97–108, 2002.
[12] S. Konieczny and R. Pino Pérez. Onthe logic of merging. In Proc. of KR’98 , pages 488–498, 1998.
[13] Sébastian Konieczny. On the dif-ference between merging knowledgebases and combining them. In An-thony G. Cohn, Fausto Giunchiglia,and Bart Selman, editors, KR2000 :Principles of Knowledge Representa-
tion and Reasoning, pages 135–144,San Francisco, 2000. Morgan Kauf-mann.
[14] C. Lafage and J. Lang. Logical re-presentation of preferences for group
Fusion de bases propositionnelles : une méthode basée sur les R-ensembles ___________________________________________________________________________
186

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 199/415
decision making. In Proc. of KR’00,pages 457–468, Breckenridge, CO,2000.
[15] Jérôme Lang. Some representa-tion and computational issues in so-cial choice. In L. Godo, edi-tor, European Conference on Sym-bolic and Quantitative Approachesto Reasoning with Uncertainty (ECS-QARU’05) - LNAI 3571, Barce-lone, 06/07/05-08/07/05, pages 15–26, Berlin Heidelberg, juillet 2005.Springer-Verlag. L010.
[16] J. Lin. Integration of weighted know-ledge bases. AI , 83 :363–378, 1996.[17] J. Lin and A. O. Mendelzon. Mer-
ging databases under constraints. IJ-CIS’98 , 7(1) :55–76, 1998.
[18] T. Linke. More on nomore. In Proc.of NMR’02, 2002.
[19] T. Meyer, A. Ghose, and S. Chopra.Syntactic representations of semanticmerging operations, 2001.
[20] I. Niemelä and P. Simons. An imple-mentation of stable model and well-founded semantics for normal logicprograms. In Proc. of LPNMR’97 ,pages 420–429, 1997.
[21] O. Papini. A complete revisionfunction in propositionnal calculus.In B. Neumann, editor, Proc. of
ECAI92, pages 339–343. John Wileyand Sons. Ltd, 1992.
[22] P. Rao, K. Sagonas, Swift, D. S. War-ren, and J. Friere. Xsb : A system forefficiently computing well-foundedsemantics. In Proc. of LPNMR’97 ,pages 430–440, 1997.
[23] P. Z. Revesz. On the semantics of theory change : arbitration betweenold and new information. 12th ACM SIGACT-SGMIT-SIGART symposium
on Principes of Databases, pages 71–92, 1993.[24] P. Z. Revesz. On the semantics of
arbitration. Journal of Algebra and Computation, 7(2) :133–160, 1997.
[25] R.Fagin, G.M.Kuper, J.D.Ullman,and M.Y.Vardi. Updating logical da-tabases, 1986.
[26] Konieczny S. and Pino Pérez R.Propositionnal belief base mergingor how to merge belief/goals co-ming from several sources and somelinks with social choice theory. Eu-ropean Journal of Operational Re-search, 160(3) :785–802, 2005.
[27] P. Simons. Extending and imple-menting the stable model semantics,2000.
[28] Meyer T., Ghose A., and ChopraS. Social choice, merging, and elec-tions. In Proceedings of ECSQA-
RU’01, volume LNAI 1695, pages466–477, 2001.
[29] E. Würbel, R. Jeansoulin, and O. Pa-pini. Revision : An application inthe framework of gis. In Anthony G.Cohn, Fausto Giunchiglia, and BartSelman, editors, Proc. of KR’00,
pages 505–516, Breckenridge, Co-lorado, USA, April 2000. KR, inc.,Morgan Kaufmann.
____________________________________________________________________________ Annales du LAMSADE N°8
187

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 200/415

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 201/415
SBGM: Conciliation et mesures de conflits
Sébastien Konieczny
CRIL - CNRS, Université d’Artois, Lens, France
Résumé :Nous proposons la définition de nouveaux opéra-teurs de conciliation. Ces opérateurs sont basés surun processus itératif de sélection/affaiblissementdes croyances/buts des agents, jusqu’à trouver unconsensus (accord) entre les agents. Pour définir unopérateur particulier, il faut donc choisir la fonctionde sélection et la fonction d’affaiblissement. Dans
les travaux précédents la fonction de sélection étaitdéfinie arbitrairement. Nous proposons de prendrecomme fonction de sélection une mesure de conflitbasée sur la valeur de Shapley, qui permet de défi-nir la part de conflit imputable à chaque agent. Celamène à une formalisation plus intuitive de ces pro-cessus de négociation abstraits.
Mots-clés : Négociation, conciliation, mesure deconflit
Abstract:
We propose to define new conciliation operators.Those operators are based on an iterative selec-tion/weakening process of the beliefs/goals of theagents, until a consensus (agreement) is found bet-ween the agents. To define a particular operator, it
just need to choose a choice function and a weake-ning function. In previous works the choice func-tion was defined arbitrarily. We propose to take aschoice function a measure of conflict based on theShapley value, that allows to define the quantity of conflict due to each agent. This leads to a more in-tuitive formalization of those abstract negotiationprocesses.
Keywords: Negotiation, conciliation, measure of conflict
1 Introduction
La négociation se définit comme un pro-cessus ayant pour but de trouver un ac-cord entre différents agents. De nombreuxprotocoles de négociation ont été propo-
sés dans la littérature multi-agents. Beau-coup de ces protocoles sont basés sur l’ar-gumentation, les jeux de dialogue, etc.La plupart de ces travaux sont descrip-tifs, c’est-à-dire qu’ils proposent une mé-
thode effective pour réaliser un processusde négociation entre agents. Toutes ces ap-proches ont en commun qu’elles peuventêtre vues comme un jeu entre les agents,contraint par un protocole fixé, où chaqueagent propose quelque chose, et où lesautres agents peuvent accepter ce qui aété proposé, le contester, ou proposer uneautre solution, etc. Ces protocoles de né-gociation peuvent donc être vus commedes jeux (non-coopératifs) à informationincomplètes, puisque, comme les échangesentre les agents s’effectuent dans le cadred’un protocole fixé, le résultat de la né-gociation ne prend pas en compte l’inté-gralité de l’opinion de chaque agent, maissimplement ce qui a été déclaré lors de
l’interaction. Cela signifie en particulierque 1) il se peut qu’un accord optimal nesoit pas trouvé parce que des points im-portants n’ont pas été évoqués au coursde l’interaction 2) le résultat du processusde négociation peut varier suivant l’ordredans lequel les agents ont pris la parole.Ces problèmes peuvent être vus commedes défauts inhérents à ce genre de pro-tocoles, qui ne peuvent pas garantir qu’un
“accord optimal” est atteint.
Une question intéressante est de tenter dedéfinir ce que pourrait être cet “accord op-timal”. Il n’y a pas de réponse définitiveà cette question : ce qu’est le meilleur ac-cord entre plusieurs agents qui poursuiventleurs propres buts est une des questionsprincipales qui est étudiée en théorie des
jeux depuis des années. Le problème demarchandage (bargaining problem [14])peut être considéré comme la forme la pluspure/typique de la négociation : parmi unensemble d’issues possibles1 un ensemble
1Habituellement on suppose que l’ensemble des issues est
189

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 202/415
de joueurs (deux dans le cas typique) doitse mettre d’accord sur une issue. S’ils n’ar-rivent pas à se mettre d’accord, le résul-tat sera une issue déterminée à l’avance.Le problème est alors, étant données cesseules hypothèses, de déterminer quel estle résultat optimal/juste pour ce marchan-dage. Comme on peut s’y attendre il n’y apas une unique définition de cette optima-lité, et cela laisse la place à de nombreuxconcepts de solution [17]. Ce problèmeforme une partie centrale de la théorie des
jeux coopératifs. Les jeux coopératifs, oùles agents peuvent “signer des accords”,
se distinguent des jeux non-coopératifs, oùles agents doivent participer à une interac-tion afin de tenter d’atteindre le meilleurrésultat de leur point de vue. Il est connuque pour la plupart des jeux la solution co-opérative est meilleure pour tous les agentsque la solution non-coopérative.
Les protocoles de négociation usuelspeuvent être vus comme des jeux non-
coopératifs. Une question intéressante estdonc d’étudier quelle pourrait être leurcontrepartie en terme de jeux coopératifs.Cela permettrait de trouver de meilleuressolutions qu’avec ces protocoles. Nous ap-pelons ce type d’opérateurs des opérateursde conciliation [4].
Cela ne signifie pas que les opérateurs deconciliation sont meilleurs que les proto-coles de négociation. Ils peuvent trouverde meilleures solutions, mais en contrepar-tie ils ne prennent pas en compte les pro-blèmes de communication qui se posentlors d’applications réelles, ils supposentque les agents fournissent l’intégralité deleurs opinions et qu’ils sont suffisam-ment coopératifs pour accepter qu’un autreagent détermine quel est le résultat. Ceshypothèses sont très fortes si l’on consi-dère des agents autonomes, néanmoins les
opérateurs de conciliation peuvent être vuscomme une idéalisation de la négociation,lorsque les limitations imposées par l’im-
un ensemble compact (fermé et borné) convexe.
plémentation n’interfèrent pas avec la re-cherche de l’accord optimal.
Le problème de la modélisation de la né-gociation commence à être étudié sousl’angle de la théorie du changement decroyances [1, 2, 3, 18, 13, 12, 10, 4].Le problème est de définir des opérateursqui prennent comme donnée un profil decroyances (i.e un multi-ensemble de basesde croyances exprimées en logique pro-positionnelle) et qui produisent un nou-veau profil contenant moins de conflits.L’idée suivie dans [2, 3, 10] pour définir
des opérateurs de conciliation est d’utili-ser un processus itératif : à chaque étapeun ensemble d’agents est sélectionné. Cesagents doivent alors assouplir leur point devue (i.e. affaiblir logiquement leur base).Ce processus s’arrête lorsqu’un accord,appelé consensus, est atteint. Plusieursopérateurs intéressants peuvent être défi-nis lorsque l’on fixe la fonction de sélec-tion (la fonction qui sélectionne les agents
devant s’affaiblir à chaque tour) et la fonc-tion d’affaiblissement. Dans [10] la fonc-tion de sélection est basée sur une notionde distance. Cela peut être justifié lorsquecette distance a un sens pour une appli-cation particulière, mais sinon, ce n’estqu’un choix arbitraire.
Ce que nous proposons dans cet article estd’utiliser comme fonction de sélection unemesure de conflit, qui permettra de savoirla quantité de conflit imputable à chaqueagent. Et les agents qui devront affaiblirleur point de vue seront donc ceux qui ap-portent le plus de conflits. Nous montre-rons que les mesures d’incohérences exis-tantes ne sont pas satisfaisantes pour cela,et nous utiliserons des mesures d’incohé-rences basées sur la valeur de Shapley(un concept de solution issue de la théo-rie des jeux coopératifs) proposées récem-
ment [9].
Après une brève section préliminaire, nousintroduirons le cadre des Belief Game Mo-dels à la section 3. Section 4 nous don-
SBGM: concialiation et mesures de conflits ___________________________________________________________________________
190

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 203/415
nerons les définitions des principales me-sures d’incohérence et nous définirons lesmesures d’incohérence de Shapley. Sec-tion 5 nous définirons les opérateurs deBelief Game Models utilisant les valeursd’incohérence de Shapley. Nous conclu-rons avec quelques perspectives de ce tra-vail section 7.
2 Préliminaires
On considère un langage propositionnel Lsur un alphabet fini P de variables propo-
sitionnelles. Une interprétation est une ap-plication de P vers 0, 1. L’ensemble detoutes les interprétations est noté W . Uneinterprétation ω est un modèle d’une for-mule ϕ ∈ L si et seulement si elle la rendvraie au sens usuel. mod(ϕ) dénote l’en-semble des modèles de la formule ϕ, i.e.mod(ϕ) = ω ∈ W | ω |= ϕ. Inverse-ment, si X est un ensemble d’interpréta-tions, form(X ) dénote la formule (à équi-
valence logique près) dont l’ensemble desmodèles est X . ϕ est cohérente si et seule-ment si elle possède au moins un modèle.
Une base ϕ est une formule proposition-nelle (ou un ensemble de formules propo-sitionnelles considéré conjonctivement),qui représente les croyances ou les butsd’un agent (on parlera d’opinion dans lasuite). Soit n bases ϕ1, . . . , ϕn, on ap-pelle profil le multi-ensemble composé deces n bases Ψ = (ϕ1, . . . , ϕn) (on uti-lise un multi-ensemble car plusieurs agentspeuvent avoir des bases identiques).
On note
Ψ la conjonction des bases deΨ, c’est-à-dire
Ψ = ϕ1 ∧ . . . ∧ ϕn. On
dit que le profil Ψ est cohérent, si
Ψ estcohérent. L’union sur les multi-ensemblesest notée et l’inclusion sous ensemblisteest notée ⊆. Le cardinal d’un ensemble ou
d’un multi-ensemble Ψ est noté #(E ).
Soit K l’ensemble de toutes les bases co-hérentes, et E l’ensemble de tous les profilsfinis non-vides.
Deux profils Ψ1 et Ψ2 sont équivalents(Ψ1 ≡ Ψ2) si et seulement si il existe unebijection entre Ψ1 et Ψ2 tel que chaquebase de Ψ1 est logiquement équivalente àson image dans Ψ2.
3 Belief Game Model
Dans [1, 2] Richard Booth introduitles Belief Negotiation Models, qui sontdes opérateurs de conciliation qui per-mettent d’atteindre un consensus entre lesagents grâce à un processus de sélection-affaiblissement. Cette approche est uneabstraction intéressante de la négociation.L’idée est que la négociation a pour butde trouver un consensus entre plusieursagents ayant des points de vue conflictuels(i.e. des bases dont la conjonction est in-cohérente). Pour y parvenir certains agentsdevront affaiblir leur point de vue afin depouvoir parvenir à un consensus (i.e à desbases dont la conjonction est cohérente).
Une itération de ce processus se composed’une étape de sélection, où l’on choisitles agents qui doivent affaiblir leur pointde vue (on peut choisir l’un agent aprèsl’autre, choisir les agents les plus problé-matiques, etc.). Une fois cette sélection ef-fectuée la seconde étape est d’affaiblir lesbases des agents choisis. Ce processus estitéré jusqu’à ce qu’un consensus soit at-teint.
Ce travail a été repris dans [10], où uneclasse particulière d’opérateurs, les Belief Game Models (appelés BGM dans la suite)a été définie. Voir [10] pour les détails surle lien exact entre les Belief NegotiationModels et les BGM. Nous nous intéresse-rons aux BGM dans la suite :
Définition 1 Une fonction de sélection est une fonction g : E → E telle que
– g(Ψ) Ψ – Si
Ψ ≡ , alors∃ϕ ∈ g(Ψ) t.q.ϕ ≡ – Si Ψ ≡ Ψ , alors g(Ψ) ≡ g(Ψ)
____________________________________________________________________________ Annales du LAMSADE N°8
191

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 204/415
La fonction de sélection a pour but dedeterminer les agents qui doivent s’affai-blir à chaque itération. Comme la fonctiond’affaiblissement doit affaiblir les bases, etcomme il n’y a pas de base plus faible lo-giquement que la base tautologique, la se-conde condition indique qu’au moins unebase non tautologique doit être sélection-née. Cela signifie donc qu’à chaque itéra-tion au moins une base sera affaiblie. Ladernière condition est une condition d’ano-nymat (ou d’indépendance à la syntaxe),qui indique que la sélection des bases àaffaiblir ne dépend que du contenu de ces
bases et pas de leur “nom”, ou de la façondont ce contenu est représenté.
Définition 2 Une fonction d’affaiblisse-ment est une fonction : L → L telleque :
– ϕ (ϕ) – Si ϕ ≡ (ϕ) , alors ϕ ≡ – Si ϕ ≡ ϕ , alors (ϕ) ≡ (ϕ)
La fonction d’affaiblissement doit per-mettre d’affaiblir logiquement la base desagents qui ont été sélectionnés. Les deuxpremières conditions assurent que la basesera remplacée par une base strictementplus faible logiquement (à moins que labase soit déjà une tautologie). La der-nière condition est une condition d’indé-pendance de syntaxe : le résultat de la
fonction d’affaiblissement ne dépend quedu contenu informationnel des bases, etpas de leur syntaxe.
La fonction d’affaiblissement s’étend surles profils : soit Ψ un sous-ensemble deΨ,
Ψ(Ψ) =ϕ∈Ψ
(ϕ)
ϕ∈Ψ\Ψ
ϕ
Donc les seules bases Ψ qui sont affai-blies sont celles de Ψ, les autres bases nechangent pas.
Dans certains cas le résultat de la négo-ciation doit obéir à certaines contraintes(contraintes physiques, normes, etc.). Onsupposera que ces contraintes d’intégritésont représentées par une formule proposi-tionnelle, notée µ. Un opérateur BGM estdonc défini par :
Définition 3 La solution de la concilia-tion d’un profil Ψ pour un BGM N =g, sous les contraintes d’intégrité µ ,noté N µ(Ψ) , est le profil Ψµ
N défini par : – Ψ0 = Ψ
– Ψi+1 =g(Ψi)(Ψi) – Ψµ
N est le premier Ψi qui est cohérent avec µ
La solution de la conciliation d’un pro-fil est donc le résultat d’un “jeu” basésur les opinions/croyances des agents. Achaque itération certaines bases sont sé-lectionnées pour être affaiblies, jusqu’à cequ’un consensus soit atteint.
Voyons à présent deux exemples de fonc-tions d’affaiblissement et deux familles defonctions de sélection.
Définition 4 Soit une base ϕ. – La fonction d’affaiblissement drastique
oublie toutes les informations d’unebase, i.e. : (ϕ) = .
– La fonction d’affaiblissement par dilata-
tion est définie par :
mod(δ(ϕ)) = ω ∈ W | ∃ω |= ϕ
dH (ω, ω) ≤ 1
où dH est la distance de Hamming entreinterprétations, i.e. le nombre de va-riables propositionnelles sur lesquellesles deux interprétations diffèrent. Soient deux interprétations ω et ω , alors
dH (ω, ω
) = |a ∈ P | ω(a) = ω
(a)|.
Avant de donner des exemples de fonctionde choix, nous avons besoin de quelquesdéfinitions :
SBGM: concialiation et mesures de conflits ___________________________________________________________________________
192

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 205/415
Définition 5 Une (pseudo)distance dentre deux bases est une fonction d : L×L → IN telle que d(ϕ, ϕ) = 0 ssiϕ ∧ ϕ ⊥ et d(ϕ, ϕ) = d(ϕ, ϕ).
Deux exemples de telles distances sont :
dD(ϕ, ϕ) =
0 si ϕ ∧ ϕ ⊥1 sinon
dH (ϕ, ϕ) = minω|=ϕ,ω|=ϕ
dH (ω, ω)
Définition 6 Une fonction d’agrégationest une fonction f qui associe un en-tier naturel à chaque tuple d’entiers na-turels satisfaisant les propriétés de (non-décroissance) , (minimalité) et d’(identité) .
– Si x ≤ y , alors f (x1, . . . , x , . . . , xn) ≤f (x1, . . . , y , . . . , xn).
(non-décroissance) – f (x1, . . . , xn) = 0 si et seulement si
x1 = . . . = xn = 0. (minimalité)
– f (x) = x. (identité) On dit qu’un fonction d’agrégation est sy-métrique si elle satisfait également :
– Pour toute permutation σ ,f (x1, . . . , xn) = f (xσ(1), . . . , xσ(n))
(symétrie)
Définition 7 Une fonction de sélection sy-
métrique à base de modèles gd,h
est dé- finie par : gd,h(Ψ) = ϕi ∈ Ψ |h(d(ϕi, ϕ1), . . . , d(ϕi, ϕn)) est maximaleoù h est une fonction d’agrégation symé-trique, et d une distance entre bases.
Ces fonctions de sélection choisissentdonc les bases qui sont les “plus loin” desautres, selon une distance déterminée.
Une autre famille de fonctions de sélectionse base sur les sous-ensembles maximauxcohérents de bases. Ces sous-ensemblesmaximaux cohérents peuvent être considé-rés comme les éléments les plus proches de
la cohérence (et donc du consensus) dansle profil. Les bases sélectionnées sont alorscelles qui ont le plus mauvais “score” parrapport à ces sous-ensembles maximauxcohérents. Naturellement il y a plusieursfaçons de définir ce score, ce qui donnedifférentes fonctions.
Définition 8 Soit MAXCONS(Ψ) l’en-semble des maxcons de Ψ , i.e. les sous-ensembles maximaux (pour l’inclusionensembliste) cohérents de Ψ. Formelle-ment, MAXCONS(Ψ) est l’ensemble de
tous les multi-ensembles M tels que : – M Ψ , –
M |= ⊥ et – si M M Ψ, alors
M |= ⊥.
Définition 9 Une fonction de sélection àbase de formules gmc est définie par :
gmc(Ψ) = ϕi ∈ Ψ |
h(ϕi, MAXCONS(Ψ)) est minimal
On peut définir de nombreuses telles fonc-tions, nous n’en citerons qu’une.
Définition 10
hmc1(ϕ, MAXCONS(Ψ)) = #(M |M ∈ MAXCONS(Ψ) et ϕ ∈ M )
Pour cette fonction de sélection le scored’une base est le nombre de maxcons aux-quels cette base appartient.
Illustrons à présent sur un exemple [16]quel est le comportement de quelques opé-rateurs BGM, les opérateurs gdH ,Σ,δ,
gdH ,max,δ, et gmc1,δ.
Exemple 1 Considérons trois agentsΨ = ϕ1, ϕ2, ϕ3 avec les basessuivantes ϕ1 = ¬b ∧ (a ∨ c) ,ϕ2 = (¬a ∧ b ∧ ¬c) ∨ (¬a ∧ ¬b ∧ c) ,
____________________________________________________________________________ Annales du LAMSADE N°8
193

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 206/415
ϕ3 = a ∧ b ∧ c. Pour les cal-culs donnés ci-dessous il est plussimple de considérer ces basescomme l’ensemble de leurs modèles :
Mod(ϕ1) = (1, 0, 0), (0, 0, 1), (1, 0, 1) ,Mod(ϕ2) = (0, 1, 0), (0, 0, 1) ,Mod(ϕ3) = (1, 1, 1). Il n’y a pasde contraintes pour le résultat, doncµ = .
gdH ,Σ,δ : Comme Ψ n’est pas co-hérent, effectuons la première itération.d(ϕ1, ϕ2) = 0 , d(ϕ1, ϕ3) = 1 , d(ϕ2, ϕ3) =2. Donc hΣ
Ψ(ϕ1) = 1 , hΣΨ(ϕ2) = 2 ,
hΣΨ(ϕ3) = 3. Cela donne gdH ,Σ(Ψ) =ϕ3. Donc ϕ3 est remplacé par ϕ31 = δ(ϕ3) = form((1, 1, 1), (1, 1,0), (1, 0, 1), (0, 1, 1)). Nous n’avonstoujours pas obtenu un profil Ψ co-hérent, il est nécessaire d’effectuer une seconde itération. Calculons lesnouvelles distances. d(ϕ1, ϕ2) = 0 ,d(ϕ1, ϕ31) = 0 , d(ϕ2, ϕ31) = 1. Donc
hΣΨ(ϕ1) = 0 , hΣ
Ψ(ϕ2) = 1 , hΣΨ(ϕ31) = 1.
Cela donne gdH ,Σ(Ψ) = ϕ2, ϕ31 ,et ϕ2 est remplacé par ϕ21 = δ(ϕ2) =form((0, 1, 0),(0, 0, 1),(1, 1, 0),(0, 0, 0),(0, 1, 1), (1, 0, 1)) , et ϕ31 est remplacé
par ϕ32 = δ(ϕ31) = form((1,1, 1), (1, 1, 0), (1, 0, 1), (0, 1, 1), (0, 1, 0),(1, 0, 0), (0, 0, 1)). Nous avons atteint un
profil cohérent, le résultat est le donc le profil Ψ = ϕ1, ϕ21 , ϕ32 , et la conjonc-tion (consensus) est la base dont les
modèles sont (0, 0, 1), (1, 0, 1).
gdH ,max,δ : Comme Ψ n’est pas co-hérent, il faut effectuer une premièreitération. d(ϕ1, ϕ2) = 0 , d(ϕ1, ϕ3) = 1 ,d(ϕ2, ϕ3) = 2. Donc hmax
Ψ (ϕ1) = 1 ,hmaxΨ (ϕ2) = 2 , hmax
Ψ (ϕ3) = 2. Cela
donne gdH ,max(Ψ) = ϕ2, ϕ3. Doncϕ2 est remplacé par ϕ21 = δ(ϕ2) =form((0, 1, 0),(0, 0, 1),(1, 1, 0),(0, 0, 0),
(0, 1, 1), (1, 0, 1)) , et ϕ3 est remplacé par ϕ31 = δ(ϕ3) = form((1,1, 1), (1, 1, 0), (1, 0, 1), (0, 1, 1)). Le
profil obtenu est cohérent, le résultat est donc Ψ = ϕ1, ϕ21, ϕ31 , et le modèle de
la conjonction est (1, 0, 1).
gmc1,δ : Ψ n’est pas cohérent, et MAXCONS(Ψ) = ϕ1, ϕ2, ϕ3.
hmc1Ψ (ϕ1) = hmc1
Ψ (ϕ2) = hmc1Ψ (ϕ3) = 1 ,
et gmc1(Ψ) = Ψ. Il faut donc affai-blir les trois bases : ϕ11 = δ(ϕ1) =form((1, 0, 0),(0, 0, 1),(1, 0, 1),(0, 0, 0),(1, 1, 0), (0, 1, 1), (1, 1, 1)) , ϕ21 =δ(ϕ2) = form((0, 1, 0), (0, 0, 1), (1, 1,0), (0, 0, 0), (0, 1, 1), (1, 0, 1)) , et ϕ31 =δ(ϕ3) = form((1, 1, 1), (1, 1, 0), (1, 0,1), (0, 1, 1)). Ce profil est cohérent, lerésultat est donc Ψ = ϕ11 , ϕ21, ϕ31.
4 Mesures d’incohérence deShapley
Nous souhaitons utiliser comme fonctionde sélection pour les BGM, des fonctionsprenant en compte la quantité de conflitimputable à chaque base. Ce seront doncles agents/bases qui posent le plus de pro-
blèmes qui devront s’affaiblir.
Nous allons commencer par introduire lesmesures d’incohérences usuelles. Le pro-blème est que ces mesures sont définiespour une unique base/source/agent, et nepermettent pas d’imputer à chaque agentd’un groupe sa part de conflit.
4.1 Mesures d’incohérences basées sur
les variables
Une méthode pour évaluer l’incohérenced’un ensemble de formules est de regarderquelle est la proportion du langage concer-née par l’incohérence. Il n’est donc paspossible d’utiliser la logique classique àcette fin puisque l’incohérence contamine-rait l’ensemble de la base (et du langage).Mais si on compare les deux profils Ψ1 =
a, ¬a, b∧c, d et Ψ2 = a, ¬a, b∧¬c, c∧¬b,d, ¬d, on remarque que dans Ψ1 l’in-cohérence concerne principalement la va-riable a, alors que dans Ψ2 toutes les va-riables sont incluses dans un conflit. C’est
SBGM: concialiation et mesures de conflits ___________________________________________________________________________
194

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 207/415
ce genre de distinctions que ces approchespermettent.
Une méthode afin de circonscrire l’inco-hérence aux variables directement concer-nées est d’utiliser des logiques multi-valuées, et plus précisément des logiquestri-valuées, avec une troisième “valeur devérité” indiquant qu’il y a un conflit surla valeur de vérité (vrai ou faux) de la va-riable.
Nous n’avons pas ici la place de détaillerl’ensemble des mesures qui ont été pro-
posées, voir [5, 7, 11, 8, 6] pour plus dé-tails sur ces approches. Nous ne donne-rons ici qu’un seul exemple de mesure, quiest un cas spécial des degrés de contradic-tion définis dans [11]. L’idée de la défini-tion de ces degrés est que, étant donné unensemble de tests sur la valeur de véritéde certaines formules du langage (typique-ment sur les variables propositionnelles),le degré de contradiction est le coût mini-
mal (grossièrement le nombre de tests né-cessaires) d’un plan de test qui assure deretrouver la cohérence.
La mesure définie ici est le nombre (nor-malisé) minimum de variables proposi-tionnelles ayant la valeur de vérité conflic-tuelle dans les LP m-modèles [15] de labase. Introduisons tout d’abord la relationde LP m-conséquence.
Une interprétation ω pour LP m associe àchaque variable propositionnelle une destrois “valeurs de vérité” F,B,T, la troi-sième valeur de vérité B signifiant intui-tivement “à la fois vrai et faux”. 3P estl’ensemble de toutes les interprétations deLP m. Les “valeurs de vérité” sont ordon-nées comme suit : F <t B <t T.
– ω() = T, ω(⊥) = F
– ω(¬α) =B
ssi ω(α) =B
ω(¬α) = T ssi ω(α) = F
– ω(α ∧ β ) = min≤t(ω(α), ω(β ))
– ω(α ∨ β ) = max≤t(ω(α), ω(β ))
L’ensemble des modèles d’une formule ϕ
est :
ModLP (ϕ) = ω ∈ 3P | ω(ϕ) ∈ T,B
On définit ω! comme l’ensemble des va-riables “incohérentes” d’une interprétationw, i.e. ω! = x ∈ P | ω(x) = B.
Les modèles minimaux d’une formule sontalors les “plus classiques” :
min(ModLP (ϕ)) = ω ∈ ModLP (ϕ) |
ω ∈ ModLP (ϕ) t.q. ω! ⊂ ω!
La relation de LP m-consequence est alors
définie par :ϕ |=LP m ϕ ssi
min(ModLP (ϕ)) ⊆ ModLP (ϕ)
Donc ϕ est une consequence de ϕ si tousles modèles les “plus classiques” de ϕ sontdes modèles de ϕ.
Les modèles d’un profil Ψ étant les inter-prétations qui sont modèles de chacune de
ses bases, on définit la mesure d’incohé-rence LP m, notée I LP m :
Définition 11 Soit un profil Ψ.
I LP m =minω∈ModLP (Ψ)(| ω! |)
| P |
La mesure d’incohérence d’une base estdonc définie comme le nombre minimum
de variables (divisé par le nombre total devariables) concernées par une incohérencedans les LP m-modèles de cette base. Cequi signifie intuitivement que la mesured’incohérence d’une base exprime à quelpoint le moins incohérent des modèles decette base est incohérent.
Exemple 2 Soit Ψ4 = a, ¬a, b ∧ c, ¬b.
On trouve I LP m(Ψ4) =
2
3
Donc les mesures d’incohérences baséessur les variables, comme celle-ci, per-mettent de décrire finement la quantité de
____________________________________________________________________________ Annales du LAMSADE N°8
195

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 208/415
conflit d’une base (ou d’un profil), maissont incapables de prendre en compte ladistribution de ce conflit entre les for-mules. En fait la mesure serait identiqueavec la base Ψ4 = a ∧ ¬a ∧ b ∧ ¬b ∧ c.C’est un gros problème si on veut utiliserces mesures pour les BGM, puisque nousvoulons être capables de savoir quelle estla part du conflit imputable à chaque for-mule (agent). A cette fin, nous allons utili-ser une notion issue de la théorie des jeux.
4.2 Jeux coalitionnels - Valeur de Sha-
pley
Dans cette section nous donnons la défini-tion des jeux coalitionnels et de la valeurde Shapley.
Définition 12 Soit un ensemble de n joueurs N = 1, . . . , n. Un jeu coalition-
nel est défini par une fonction v : 2N → IR,
telle que v(∅) = 0.
Ce cadre définit un jeu d’une manière trèsabstraite, en se focalisant sur les diffé-rentes coalitions possibles. Une coalitionest juste un sous-ensemble de N . Cettefonction exprime le gain que peut obtenirchaque coalition dans le jeu v lorsque tousses membres coopèrent. Le problème estalors de savoir comment ce gain doit être
partagé entre les joueurs2 Expliquons cecisur un exemple.
Exemple 3 Soit N = 1, 2, 3 , et soit le jeu coalitionnel v suivant :
v(1) = 1, v(1, 2) = 10,v(2) = 0, v(1, 3) = 4,v(3) = 1, v(2, 3) = 11,
v(1, 2, 3) = 122On se place ici dans le cas d’utilités transférables (TU),
c’est-à-dire qu’on suppose que l’utilité est une unité commune
à tous les joueurs et qu’elle est partageable à l’envie (grossière-
ment on peut la voir comme une “monnaie”).
La grande coalition (formée de tous les joueurs) peut apporter 12 aux trois joueurs.C’est la plus grande utilité atteignable parle groupe. Mais ce n’est pas le but prin-cipal de chacun des joueurs. En particu-lier on peut remarquer que deux coalitionspeuvent apporter quasiment autant : la coa-lition 1, 2 donne 10 et la coalition 2, 3apporte 11, qui ne doivent être partagésqu’entre deux joueurs. On peut égalementremarquer que tous les joueurs ne par-tagent pas la même situation dans ce jeu.En particulier le joueur 2 est toujours d’ungrand intérêt pour toute coalition qu’il re-
joint. Il semble donc en position d’espé-rer un meilleur gain que les autres joueursdans ce jeu. Par exemple il peut proposerau joueur 3 de former la coalition 2, 3,ce qui apporte 11, qui seraient partagés en8 pour le joueur 2 et 3 pour le joueur 3.Comme il sera difficile pour le joueur 3 degagner plus que cela avec une autre coali-tion, il sera tenté d’accepter.
Un concept de solution pour les jeux coa-litionnels doit prendre en compte ce genred’arguments. Cela signifie que si l’on dé-sire résoudre ce jeu en définissant quel estl’utilité qui est due à chaque agent, celanécessite d’être capable de quantifier l’uti-lité qu’un agent est en droit de revendiquerétant donné le pouvoir que lui confère saposition dans le jeu.
Définition 13 Une valeur est une fonctionqui associe à chaque jeu v un vecteur d’utilité S (v) = (S 1, . . . , S n) dans IRn.
Cette fonction donne l’utilité que peut es-pérer chaque agent i dans le jeu v, c’est àdire qu’elle mesure, en un sens, le pouvoirde i dans le jeu v.
Shapley propose une solution à ce pro-blème en définissant une valeur dont l’idéepeut être expliquée comme suit :
On considère que les coalitions se formentsuivant un ordre donné (un premier joueur
SBGM: concialiation et mesures de conflits ___________________________________________________________________________
196

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 209/415
entre dans la coalition, puis un second,etc.), et que l’utilité imputée à chaque
joueur est son utilité marginale (c’est-à-dire l’utilité qu’il apporte à la coalition
existante), donc pour une coalition C quine contient pas i, l’utilité marginale de i estv(C ∪i)−v(C ). Comme on ne peut fairea priori aucune hypothèse sur l’ordre danslequel les coalitions se forment, on sup-pose qu’ils sont tous équiprobables. Celamène à la formule suivante :
S i(v) =
C ⊆N
(c − 1)!(n − c)!
n! (v(C ) − v(C \ i))
où c est la cardinalité de C .
Exemple 4 La valeur de Shapley du jeudéfini dans l’exemple 3 est (17
6, 356
, 206
).
Ces valeurs montrent que c’est le joueur2 qui a la meilleure position dans ce jeu,comme nous l’avions expliqué intuitive-ment lorsque nous avons donné l’exemple3.
4.3 Mesures d’incohérences utilisant
la valeur de Shapley
Etant donné une mesure d’incohérence,l’idée est de l’utiliser comme la fonctiondéfinissant un jeu coalitionnel, et ensuited’utiliser la valeur de Shapley pour calcu-ler la part de conflit qui peut être imputéeà chaque base du profil [9].
Cela permet de combiner la puissance desvaleurs d’incohérences basées sur les va-riables et d’utiliser la valeur de Shapleypour connaître la part de responsabilité de
chaque formule.
On ne demande que quelques propriétés àla mesure d’incohérence.
Définition 14 Une mesure d’incohérenceI est appelée mesure d’incohérence ba-sique si elle satisfait les propriétés sui-vantes :
• I (ϕ) = 0 ssi ϕ est consistant (Consistance)
• 0 ≤ I (ϕ) ≤ 1 (Normalisation)
• I (ϕ ∪ ϕ) ≥ I (ϕ) (Monotonie)
• Si α est une formule libre3 de ϕ ∪ α ,alors I (ϕ ∪ α) = I (ϕ) (FFI)
• Si α β et α ⊥ , alorsI (ϕ ∪ α) ≥ I (ϕ ∪ β ) (Dominance)
La propriété de consistance impose qu’unebase consistante a un degré d’incohérencenul. La propriété de monotonie exprime lefait que la quantité de conflit d’une basene peut qu’augmenter lorsqu’on ajoutede nouvelles formules (construites sur lemême langage). La propriété FI indiquequ’ajouter une formule qui n’apporte au-cun conflit dans la base ne change pas le
degré de conflit. La propriété de domi-nance exprime le fait que ce sont les for-mules logiquement fortes qui sont suscep-tibles de générer le plus de conflits. La pro-priété normalisation n’est pas aussi indis-pensable que les autres, elle n’est là quepour simplifier l’expression des degrés.
On peut à présent définir les valeurs d’in-cohérences de Shapley [9] :
Définition 15 Soit une mesure d’incohé-rence basique I . La valeur d’incohérencede Shapley (SIV) correspondante, notéeS I , est définie comme la valeur de Shapleydu jeu coalitionnel défini par la fonction I ,i.e. en notant n la cardinalité de Ψ et c lacardinalité de C , soit ϕ ∈ Ψ :
S ΨI (ϕ) =
C ⊆Ψ
(c − 1)!(n − c)!
n! (I (C ) − I (C \ ϕ))
3Une formule libre d’une base K est une formule de K qui
n’appartient à aucun sous-ensemble minimal inconsistant de la
base.
____________________________________________________________________________ Annales du LAMSADE N°8
197

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 210/415
Notons que cette SIV donne une valeurpour chaque base du profil Ψ, donc si onconsidère la base Ψ comme le vecteur Ψ =(ϕ1, . . . , ϕn), alors S I (Ψ) exprime le vec-teur de la SIV correspondant, i.e.
S I (Ψ) = (S ΨI (ϕ1), . . . , S ΨI (ϕn))
Voyons cela sur l’exemple suivant 1.
Exemple 5 Considérons trois agents Ψ =ϕ1, ϕ2, ϕ3 avec les bases suivantes ϕ1 =¬b∧(a∨c) , ϕ2 = (¬a∧b∧¬c)∨(¬a∧
¬b ∧ c) , ϕ3 = a ∧ b ∧ c.
Alors I LP m(ϕ1) = I LP m(ϕ2) =I LP m(ϕ3) = I LP m(ϕ1, ϕ2) = 0.
I LP m(ϕ1, ϕ3) = 13 , I LP m(ϕ2, ϕ3) = 2
3 ,
I LP m(ϕ1, ϕ2, ϕ3) = 23
.
Donc S I LP m (ϕ1) = 118
, S I LP m(ϕ2) = 418
, et
S I LP m (ϕ3) = 718
.
Donc, d’après cette valeur d’incohérencede Shapley, c’est l’agent ϕ3 qui génère leplus de conflits dans le groupe (profil), etϕ1 est l’agent le moins problématique.
A notre connaissance, les SIV sont lesseules valeurs d’incohérences qui per-mettent de discriminer finement les inco-hérences, en examinant la proportion dulangage impliquée dans les incohérences,
tout en décrivant la distribution du conflitentre les différentes bases/formules.
Voir [9] pour plus de détails sur lespropriétés de ces valeurs d’incohérences.Voyons à présent comment utiliser cetteidée pour définir des opérateurs BGM.
5 Shapley Belief Game Model
L’idée est donc de définir des BGM qui uti-lisent une SIV comme fonction de sélec-tion, afin de disposer d’une méthode plus
adéquate pour sélectionner les bases quidevront s’affaiblir.
Une SIV indique quelle part du conflit glo-
bal est imputable à chaque agent. La fonc-tion de sélection choisit alors les agents lesplus conflictuels, et la base de ces agentsest alors affaiblie à l’aide de la fonctiond’affaiblissement.
Définition 16 Un Shapley Belief GameModel (SBGM) est un BGM N = S I , ,où S I est une SIV.
La solution d’un profil Ψ pour un SBGM N = S I , sous les contraintes d’inté-grité µ , noté N µ(Ψ) , est le profil Ψµ
N défini par : – Ψ0 = Ψ – Ψi+1 = argmax(S I (Ψi))(Ψi) – Ψµ
N est le premier Ψi qui est cohérent avec µ
Voyons à présent un exemple de SBGM.
Exemple 6 Considérons le SBGM N =S I LP m ,δ. Soient trois agents Ψ =ϕ1, ϕ2, ϕ3 avec les bases suivantes :ϕ1 = ¬b ∧ (a ∨ c) , ϕ2 = (¬a ∧ b ∧¬c) ∨ (¬a ∧ ¬b ∧ c) , ϕ3 = a ∧ b ∧ c.
Comme calculé exemple 5, on aS I LP m(
ϕ1) =
1
18 , S
I LP m (ϕ2) =
4
18 ,
et S I LP m(ϕ3) = 718
. La valeur maxi-
male est celle de S I LP m (ϕ3) , donc ϕ3
est l’agent le plus conflictuel, il est donc choisi pour l’affaiblissement.ϕ31 = δ(ϕ3) = form((1, 1, 1),(1, 1, 0), (1, 0, 1), (0, 1, 1)). Nousn’avons toujours pas atteint un profilcohérent à cette étape, il faut donc recom-mencer le processus. Les nouvelles va-
leurs d’incohérence sont : S I LP m (ϕ1) = 0 ,S I LP m( ϕ2) = 1
6 , et S I LP m (ϕ31) = 1
6.
Les deux bases les plus problématiquessont ici ϕ2 et ϕ31 , elles doivent doncêtre affaiblies. ϕ2 est remplacé par
SBGM: concialiation et mesures de conflits ___________________________________________________________________________
198

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 211/415
ϕ21 = δ(ϕ2) = form((0, 1, 0),(0, 0, 1), (1, 1, 0), (0, 0, 0), (0, 1, 1),(1, 0, 1)) , et ϕ31 est remplacé par ϕ32 = δ(ϕ31) = form((1, 1, 1),(1, 1, 0), (1, 0, 1), (0, 1, 1), (0, 1, 0),(1, 0, 0), (0, 0, 1)). Un profil cohé-rent est obtenu, le résultat est doncΨ = ϕ1, ϕ21, ϕ32.
6 Propriétés des SBGM
Il n’y a pas de caractérisation logiquegénérale des opérateurs de conciliations,
néanmoins certains auteurs ont étudiédes propriétés d’opérateurs de conciliationparticuliers. Par exemple Booth définit lesopérateurs de contraction sociale à l’aidedes propriétés suivantes (nous reformu-lons ces propriétés avec nos notations, voir[3] pour la formulation originale). NotonsΨ = ϕ1, . . . , ϕn le profil initial et Ψ∗ =ϕ∗
1, . . . , ϕ∗n le profil obtenu par contrac-
tion sociale. Pour simplifier on ne considé-
rera que le cas sans contraintes d’intégritéici.
(sc1) ∀ϕ∗i ∈ Ψ∗, ϕi ϕ∗i(sc2) Ψ∗ est consistant
(sc3) Si Ψ est consistant, alors Ψ∗ = Ψ
Il est facile de montrer que :
Proposition 1 Tout SBGM satisfait (sc1) ,(sc2) , et (sc3).
Booth propose également des propriétéssupplémentaires, comme par exemple :
(sc5) Si ϕi ∧
ϕ∗
j∈Ψ∗,j=i ϕ∗
j est cohérent,
alors ϕ∗i = ϕi
(sc5) n’est pas satisfait par les SBGM,mais cette propriété est montrée tropcontraignante dans [3]. SBGM satisfont lapropriété plus faible :
(free) Si ϕi est une base libre4 de Ψ, alorsϕ∗i = ϕi.
Dans [12] Meyer et al. définissent des opé-rateurs de concession (qui sont des opé-rateur de conciliation définis uniquementpour 2 agents). Leurs opérateurs satis-font les propriétés de Booth (sc1), (sc2),et (sc3). Ils demandent également deuxpropriétés supplémentaires. Reformuléesavec nos notations, cela donne, avec Ψ =ϕ1, ϕ2 :
(C5) Si ϕ∗1 ∧ ϕ2 est consistant alors ϕ∗1 ∧ϕ∗2 ϕ1 ∨ ϕ2.
(C6) Si ϕ∗1 ∧ ϕ2 est consistant et ϕ∗
2 ∧ ϕ1
n’est pas consistant, alors ϕ∗1 ∧ ϕ∗
2 ∧(ϕ1 ∨ ϕ2) n’est pas consistant.
Les auteurs justifient ces deux propriétéspar des arguments d’équité entre agents.Le résultat de la concession (ϕ∗
1 ∧ ϕ∗2) doit
être soit incohérent avec les bases origi-nales (ϕ1 ∨ ϕ2), ou il doit impliquer leurconjonction. Ces propriétés semblent ap-porter une certaine équité entre les agents(par exemple le résultat de la concessionne peut pas être consistant avec seulementune des bases initiales). Mais cela est ob-tenu avec des conditions très restrictives.Il est souligné dans [13] que les BNMde Booth ne satisfont pas ces propriétés.Les SBGM, qui sont un cas particulier de
BNM, ne les satisfont pas non plus.
7 Perspectives
Ce travail est un premier pas vers l’étudedes opérateurs de conciliation et desSBGM. Il reste beaucoup à faire. Il se-rait intéressant par exemple de caractéri-ser logiquement les opérateurs de conci-
liation, comme des opérateurs abstraits denégociation. Plus spécifiquement, il serait
4Une base libre K de Ψ est une base qui appartient à tout
sous-ensemble maximal (pour l’inclusion ensembliste) consis-
tant Ψ de Ψ.
____________________________________________________________________________ Annales du LAMSADE N°8
199

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 212/415
intéressant d’étudier plus précisément lespropriétés logiques des SBGM. Une autrequestion intéressante est de déterminer siles SBGM sont implémentables, ou ap-proximables, par un protocole de négocia-tion.
Remerciements
Ce travail a bénéficié du financement de larégion Nord-Pas-de-Calais et du FEDER.
Références[1] R. Booth. A negotiation-style fra-
mework for non-prioritised revision.In Proc. of TARK’01, pages 137–150,2001.
[2] R. Booth. Social contraction and be-lief negotiation. In Proc. of KR’02,pages 374–384, 2002.
[3] R. Booth. Social contraction and be-lief negotiation. Information Fusion,7(1) :19–34, 2006.
[4] O. Gauwin, S. Konieczny, andP. Marquis. Conciliation andconsensus in iterated belief merging.In Proc. of ECSQARU’05, pages514–526, 2005.
[5] J. Grant. Classifications for incon-sistent theories. Notre Dame Journal
of Formal Logic, 19 :435–444, 1978.[6] J. Grant and A. Hunter. Mea-
suring inconsistency in knowledge-bases. Journal of Intelligent Informa-tion Systems, 2006.
[7] A. Hunter. Measuring inconsistencyin knowledge via quasi-classical mo-dels. In Proc. of AAAI’2002, pages68–73, 2002.
[8] A. Hunter and S. Konieczny. Ap-proaches to measuring inconsistentinformation. In Inconsistency To-lerance, volume LNCS 3300, pages189–234. Springer, 2005.
[9] A. Hunter and S. Konieczny. Sha-pley inconsistency values. In Proc.of KR’06 , pages 249–259, 2006.
[10] S. Konieczny. Belief base mer-ging as a game. Journal of Applied Non-Classical Logics, 14(3) :275–294, 2004.
[11] S. Konieczny, J. Lang, and P. Mar-quis. Quantifying information andcontradiction in propositional logicthrough epistemic tests. In Proc. of
IJCAI’03, pages 106–111, 2003.
[12] T. Meyer, N. Foo, D. Zhang, and
R. Kwok. Logical foundations of ne-gotiation : Outcome, concession andadaptation. In Proc. of AAAI’04,pages 293–298, 2004.
[13] T. Meyer, N. Foo, D. Zhang, andR. Kwok. Logical foundations of ne-gotiation : Strategies and preferences.In Proc. of KR’04, pages 311–318,2004.
[14] J. Nash. The bargaining problem. Econometrica, 28 :155–162, 1950.
[15] G. Priest. Minimally inconsistent LP.Studia Logica, 50 :321–331, 1991.
[16] P. Revesz. On the semantics of arbi-tration. International Journal of Al-gebra and Computation, 7 :133–160,1997.
[17] W. Thomson. Handbook of GameTheory with Economic Applications,volume 2, chapter Cooperative Mo-dels of Bargaining, pages 1237–1284. North-Holland, 1994.
[18] D. Zhang, N. Foo, T. Meyer, andR. Kwok. Negotiation as mutual be-lief revision. In Proc. of AAAI’04,pages 317–322, 2004.
SBGM: concialiation et mesures de conflits ___________________________________________________________________________
200

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 213/415
Application de la théorie de la révision à l’adaptation enraisonnement à partir de cas : l’adaptation conservatrice
LORIA (UMR 7503 CNRS — INRIA — Universités de Nancy),BP 239, 54 506 Vandœuvre-lès-Nancy, FRANCE
Résumé :Le raisonnement à partir de cas a pour objectif derésoudre un problème par adaptation de la solu-tion d’un problème déjà résolu qui a été sélectionnédans une base de cas. Cet article présente une ap-
proche de l’adaptation appelée adaptation conser-vatrice et qui consiste à garder le plus possible dela solution à adapter, tout en assurant la consis-tance avec le contexte du problème à résoudre etles connaissances du domaine. Cette idée peut êtreliée à la théorie de la révision : la révision d’uneancienne base par une nouvelle consiste à effec-tuer un changement minimal sur la première touten étant cohérent avec la deuxième. Cela conduità une formalisation de l’adaptation conservatricesur la base d’un opérateur de révision en logiquepropositionnelle. Puis, cette théorie de l’adapta-
tion conservatrice est confrontée à une applica-tion à l’aide à la décision à partir de cas en can-cérologie : un problème de cette application estla description d’un patient atteint d’un cancer dusein et une solution, une recommandation théra-peutique. Des adaptations effectuées par des ex-perts qui peuvent être modélisées par des adapta-tions conservatrices sont présentées. Ces exemplesmontrent par exemple une façon d’adapter des trai-tements contre-indiqués ou des traitements inappli-cables.
Mots-clés : raisonnement à partir de cas, raison-
nement à partir de cas et de connaissances du do-maine, adaptation, adaptation conservatrice, théo-rie de la révision, représentation logique des cas,application en cancérologie
Abstract:Case-based reasoning aims at solving a problemby the adaptation of the solution of an already sol-ved problem that has been retrieved in a case base.This paper defines an approach to adaptation cal-led conservative adaptation; it consists in keepingas much as possible from the solution to be adap-ted, while being consistent with the context of the
problem to be solved and with the domain know-ledge. This idea can be related to the theory of re-vision: the revision of an old knowledge base by anew one consists in making a minimal change onthe former, while being consistent with the latter.This leads to a formalization of conservative adap-
tation based on a revision operator in propositio-nal logic. Then, this theory of conservative adapta-tion is confronted to an application of case-baseddecision support to oncology: a problem of thisapplication is the description of a patient ill with
breast cancer, and a solution, a therapeutic recom-mendation. Examples of adaptations that have ac-tually been performed by experts and that can becaptured by conservative adaptation are presented.These examples show a way of adapting contrain-dicated treatment recommendations and treatmentrecommendations that cannot be applied.
Keywords: case-based reasoning, knowledge-intensive case-based reasoning, adaptation, conser-vative adaptation, theory of revision, logical repre-sentation of cases, application to oncology
1 Introduction
Le raisonnement à partir de cas(RÀPC [21]) a pour objectif de résoudreun problème à l’aide d’un ensemble deproblèmes déjà résolus. Le problème àrésoudre s’appelle problème cible, dénotépar cible dans cet article, et les pro-blèmes déjà résolus sont les problèmessources, dénotés par srce. Un cas est lareprésentation d’un épisode de résolutionde problème, c’est-à-dire qu’il repré-sente au moins un problème pb et unesolution Sol(pb) de pb : un tel cas estdénoté par un couple (pb, Sol(pb)). Unproblème source, srce, est un problèmequi a déjà été résolu en une solutionSol(srce). Le couple (srce, Sol(srce))est un cas source et l’ensemble des cas
sources est la base de cas. On distingueclassiquement trois étapes du RÀPC : laremémoration, l’adaptation et la mémo-risation. La remémoration sélectionne uncas source (srce, Sol(srce)) jugé simi-
201

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 214/415
laire à cible, selon un certain critère desimilarité. L’adaptation a pour objectif derésoudre cible en s’appuyant sur le casremémoré (srce, Sol(srce)). Ainsi, uneadaptation qui réussit donne une solutionSol(cible) de cible, en général parmodification de Sol(srce). Finalement,la mémorisation évalue l’utilité de stockerle nouveau cas (cible, Sol(cible)) dansla base de cas et le stocke effectivement,si c’est utile. Les approches knowledge in-tensive (à défaut de trouver une traductionsatisfaisante) du RÀPC sont celles pourlesquelles les connaissances du domaine
jouent un rôle fondamental (et pas unique-ment la base de cas) [1]. C’est le cas pourl’adaptation conservatrice, comme nousallons le voir ci-dessous.
Le RÀPC et l’adaptation. En général, onconsidère que le RÀPC s’appuie sur leprincipe suivant :
Des problèmes similaires ont des solutionssimilaires. (principe du RÀPC)
Ce principe a été formalisé dans [9] par
T (Sol(srce), Sol(cible)) S (srce, cible)
(traduit avec nos notations) où S et T sont des mesures de similarité respective-
ment entre problèmes et entre solutions.Il y a plusieurs façons de spécifier l’étaped’adaptation en accord avec le principedu RÀPC, à commencer par l’adaptationnulle :
Sol(cible) := Sol(srce)(adaptation nulle)
L’adaptation nulle est justifiée dans [21]par la phrase « People often do very lit-
tle adaptation. » Une limite de l’adap-tation nulle est le fait que l’affirma-tion « Sol(srce) résout cible» peut êtrecontradictoire avec les connaissances dudomaine. Dans ce cas, une stratégie pour
l’adaptation est la suivante :
Sol(cible) est obtenue en gardant deSol(srce) le plus possible tout enconservant la cohérence.
(adaptation conservatrice)
L’adaptation conservatrice tend à res-pecter le principe du RÀPC au sensoù elle tend à rendre la similaritéT (Sol(srce), Sol(cible)) maximale.
Plan de l’article. La section 2 décrit le
principe de l’adaptation conservatrice plusen détail. Elle fait le lien entre cette ap-proche de l’adaptation et la théorie de larévision : les deux s’appuient sur la no-tion de changement minimal. La section 3présente les principes de base de la théo-rie de la révision. Cette théorie consisteen un ensemble de postulats qu’un opé-rateur de révision doit satisfaire. La sec-tion 4 donne une formalisation de l’adap-tation conservatrice fondée sur un opéra-teur de révision donné. Ce travail est mo-tivé d’un point de vue pratique par uneapplication en cancérologie : le systèmeKASIMIR, pour lequel un problème repré-sente une classe de patients et une solu-tion, une proposition de traitement pources patients. La section 5 montre commentcertaines adaptations effectuées par les ex-perts dans ce cadre peuvent être modéli-sées par l’adaptation conservatrice. La sec-
tion 6 discute ce travail et la section 7 pré-sente des conclusions et des perspectives.
2 Principe de l’adaptationconservatrice
Considérons l’exemple suivant :
Exemple 1 Léon a invité Carole et veut lui
préparer un repas qui lui plaise. Son pro-blème cible peut être défini par les carac-téristiques alimentaires de Carole. Sup-
posons que Carole soit végétarienne (dé-noté par la variable propositionnelle v) et
Application de la théorie de la révision [...] ___________________________________________________________________________
202

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 215/415
qu’elle a d’autres caractéristiques (déno-tées collectivement par a), non détailléesdans cet exemple : cible = v ∧ a. De sonexpérience en tant que hôte, Léon se rap-
pelle avoir invité Simone il y a quelquestemps et il pense que celle-ci ressemblebeaucoup à Carole, du point de vue de sesgoûts alimentaires, à l’exception du fait qu’elle n’est pas végétarienne : srce =¬v ∧ a. Il a proposé à Simone un repasavec une salade (s), du bœuf (b) et un des-sert (d), et elle a apprécié les deux pre-miers mais n’a pas mangé de dessert. Léona alors retenu le cas (srce , Sol(srce ))
avec Sol(srce ) = s∧b ∧¬d. Par ailleurs, Léon a certaines connaissances a proposde l’alimentation : il sait que le bœuf est de la viande, que la viande et le tofu sont des aliments riches en protéines et que lesvégétariens ne mangent pas de viande. Sesconnaissances du domaines sont donc mo-délisées par :
CD Léon = (b→ vi)∧(vi → p)∧(t→ p)∧(v → ¬vi)
où b , vi , t et p sont les variables pro- positionnelles pour « il existe du bœuf/dela viande/du tofu/de la nourriture richeen protéine qui est apprécié(e) par l’in-vitée ». Selon l’adaptation conservatrice,quel repas devrait être proposé à Carole ?Sol(srce ) n’est pas une solution satisfai-sante pour cible : Sol(srce ) ∧ cible ∧CD Léon est insatisfiable. Cependant, les in-
formations s et ¬d peuvent être gardéesdans Sol(srce ) afin de résoudre cible .
De plus, la contradiction porte sur le fait que le bœuf proposé est de la viande, passur le fait que c’est une nourriture richeen protéine. Ainsi, une solution de cible
suivant le principe de l’adaptation conser-vatrice pourrait être s ∧ p ∧ ¬d. Une autre
pourrait être de remplacer le bœuf par dutofu : s ∧ t ∧ ¬d.
Comme cet exemple l’illustre, le processus
d’adaptation consiste en un déplacementdu contexte source vers le contexte cible.Si ce processus est conservateur, alors cedéplacement doit se faire avec un chan-gement minimal et, en même temps, doit
conduire à une solution cohérente avec lecontexte cible. Les deux concepts sont in-terprétés dans le cadre de connaissances«permanentes», i.e. indépendantes d’uncontexte particulier, à savoir les connais-sances du domaine. Ainsi, l’adaptationconservatrice s’appuie sur trois types deconnaissances :(BC1) Les connaissances précédentes, qui
peuvent être modifiées (mais doiventl’être de façon minimale) : ce sont lesconnaissances en lien avec le contextedu problème source et de sa solution ;
(BC2) Les nouvelles connaissances, qui nepeuvent pas être modifiées durant ceprocessus : ce sont les connaissancesliées au contexte du problème cible ;
(CD) Les connaissances permanentes(vraies dans tout contexte), i.e., lesconnaissances du domaine du systèmede RÀPC considéré, p. ex., l’ontologiecontenant les termes du vocabulaireavec lequel les cas sont représentés.
La question qui se pose est « Quel change-ment minimal doit être effectué sur la basede connaissances BC1 pour être en cohé-rence avec la base de connaissances BC2 ? »Quand BC1 et BC2 ne sont pas contradic-toires, il n’y a pas de raison de changerBC1 et l’adaptation conservatrice donneraun résultat impliquant logiquement BC1, cequi revient à une adaptation nulle.
Ce principe du changement minimal debase de connaissances se retrouve dans lathéorie de la révision : étant donné deuxbases de connaissances ψ et µ, la révisionde ψ par µ est une base de connaissancesψ µ qui entraîne µ et effectue un change-ment minimal sur ψ pour être cohérent [3].
BC1 et BC2 doivent chacun être cohérentavec les connaissances du domaine CD.Ainsi, l’adaptation conservatrice consiste,
étant donné un opérateur de révision ,à calculer (CD ∧ BC1) (CD ∧ BC2) et àinférer de cette nouvelle base de connais-sances les informations qui sont relatives àSol(cible).
____________________________________________________________________________ Annales du LAMSADE N°8
203

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 216/415
Par conséquent, avant de formaliserl’adaptation conservatrice, il est néces-saire d’introduire la notion d’opérateur derévision.
3 Révision d’une base deconnaissances
La révision d’une base de connaissances aété formalisée indépendamment d’une lo-gique particulière par la « théorie AGM dela révision [3]». Les postulats AGM ontété adaptés au cas propositionnel dans le
cadre d’une approche sémantique de la ré-vision par [15] et c’est ce travail qui estprésenté ici, puisque notre papier se limiteà ce formalisme.
Préliminaires. Les formules proposition-nelles sont construites sur V , un ensemblede variables propositionnelles, supposéfini dans cet article. Une interprétation
I est une fonction de V dans la paire
vrai, faux. Si a ∈ V , I (a) est aussi dé-noté par a I . I est étendu à l’ensemble desformules de la manière usuelle ((f ∧g) I =vrai ssi f I = vrai et g I = vrai, etc.).Un modèle d’une formule f est une inter-prétation I telle que f I = vrai. Mod(f )dénote l’ensemble des modèles de f . f estsatisfiable signifie que Mod(f ) = ∅. f en-traîne g (resp., f est équivalente à g) estdénoté par f g (resp., f ≡ g) et si-
gnifie que Mod(f ) ⊆ Mod(g) (resp., queMod(f ) = Mod(g)), pour deux formules f et g. Finalement, g f h (resp., g ≡f h)signifie que g entraîne h (resp., g est équi-valente à h) étant donné f : f ∧ g h(resp., f ∧ g ≡ f ∧ h).
Postulats de Katsuno et Mendelzon. Soit un opérateur de révision. ψ µ est uneformule exprimant la révision de ψ par µ,
selon l’opérateur : ψ est l’« ancienne »base de connaissances (qui doit être révi-sée), µ est la nouvelle base de connais-sances (qui contient les connaissances ré-visant l’ancienne). Les postulats qu’un
opérateur de révision en logique proposi-tionnelle doivent satisfaire sont :
(R1) ψ µ µ (l’opérateur de révision
doit retenir toutes les connaissancesde la base de connaissances µ) ;
(R2) Si ψ ∧ µ est satisfiable, alors ψ µ ≡ ψ ∧ µ (si la nouvelle base deconnaissances n’est pas en contra-diction avec l’ancienne, alors toutesles connaissances des deux basesdoivent être gardées) ;
(R3) Si µ est satisfiable alors ψ µ est
également satisfiable ( ne conduitpas à une base de connaissancesinsatisfiable, à moins que la nou-velle base de connaissances soit elle-même insatisfiable) ;
(R4) Si ψ ≡ ψ et µ ≡ µ alors ψ µ ≡ψ µ (l’opérateur de révision suitle principe de non pertinence de lasyntaxe);
(R5) (ψ µ) ∧ φ ψ (µ ∧ φ) ;
(R6) Si (ψ µ) ∧ φ est satisfiable alorsψ (µ ∧ φ) (ψ µ) ∧ φ.
pour ψ, ψ, µ, µ et φ, cinq formules pro-positionnelles. (R5) et (R6) sont moins fa-ciles à comprendre que (R1) à (R4), maissont expliquées dans [15]. Ces deux postu-lats sont liés avec l’idée selon laquelle unopérateur de révision est censé effectuer unchangement minimal : ψ µ garde «leplus possible» de ψ tout en étant cohérentavec µ.
Les opérateurs de révision s’appuyant sur unedistance et l’opérateur de Dalal. Dans [15],une caractérisation et une étude bibliogra-phique des opérateurs de révision en lo-gique propositionnelle est présentée. Cepapier met en évidence une classe d’opéra-teurs de révision fondé chacun sur une dis-
tance entre interprétations. Soit dist unetelle distance. Pour un réel δ 0, soit Gδ
la fonction qui associe à une formule pro-positionnelle ψ construite sur un ensemblede variables V une autre formule Gδ(ψ)
Application de la théorie de la révision [...] ___________________________________________________________________________
204

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 217/415
sur V , telle que :
Mod(Gδ(ψ)) =
I
I : interprétation sur V et dist(Mod(ψ), I ) δ
Gδ réalise une généralisation : ψ Gδ(ψ)pour toute formule ψ et tout réel δ 0. Deplus, G0(ψ) ≡ ψ. Finalement, si 0 δ ε, alors Gδ(ψ) Gε(ψ). Pour ψ et µ, deuxformules satisfiables sur V , soit ∆ la pluspetite valeur δ telle que Gδ(ψ)∧µ est satis-fiable (∆ = dist(Mod(ψ), Mod(µ)) réalisececi : G∆(ψ)∧µ est satisfiable et si δ < ∆
alors G
δ
(ψ) ∧ µ est insatisfiable). ψ dist µpeut être défini par : ψ dist µ = G∆(ψ) ∧µ. Si l’un au moins de ψ et µ est insatis-fiable, alors ψ dist µ ≡ µ. Alors ψ dist µpeut être interprété comme suit : elle estobtenue en généralisant ψ de façon mini-male (suivant l’échelle (Gδ(ψ)δ,))afind’être cohérente avec µ, et ensuite, elle estspécialisée par conjonction avec µ.
L’intuition du changement minimal de ψ àψ dist µ est lié à la distance dist entreinterprétations : ψ dist µ est la base deconnaissances dont les interprétations sontles interprétations de µ qui sont les plusproches de celles de ψ, selon dist.
L’opérateur de révision de Dalal D [5]est un tel opérateur de révision. Il corres-pond à la distance de Hamming entre in-terprétations définie par : dist( I , J ) est
le nombre de variables propositionnellesa ∈ V telles que a I = aJ . C’est cet opéra-teur qui a été choisi dans les exemples decet article.
4 Formalisation de l’adaptationconservatrice
La -adaptation conservatrice. On suppose
que les cas et connaissances du domainedu système de RÀPC considéré sontreprésentés en logique propositionnelle.Pour appliquer le principe de l’adaptationconservatrice présenté dans la section 2,
on définit les bases de connaissances sui-vantes :
BC1 = srce∧Sol(srce) BC2 = cible
Soit un opérateur de révision. La -adaptation conservatrice consiste d’abordà calculer CCAC = (CD ∧ BC1) (CD ∧ BC2), où CD dénote les connais-sances du domaine, puis à déduire deCCAC des connaissances pertinentes pourrésoudre cible (CCAC représente lesconnaissances sur la cible inférées paradaptation conservatrice).
Exemple. L’exemple 1 (section 2) peutêtre traité comme suit :
CD = CDLéon
BC1 = ¬v ∧ a ∧ s ∧ b ∧ ¬d BC2 = v ∧ a
Avec D, l’opérateur de révision de Dalal,on peut montrer que
CCAC = (CD ∧ BC1) D(CD ∧ BC2)≡CDLéon v ∧ a
(a)
∧ s ∧ ¬b ∧ ¬vi ∧ p ∧ ¬d (b)
Le problème cible = v ∧ a = (a)est conséquence de CCAC : cela sera vraiquel que soit l’opérateur de révision choisi,d’après le postulat (R1).
Dans l’exemple 1, deux solutions plau-sibles étaient proposées : Sol1(cible) =s ∧ p ∧ ¬d et Sol2(cible) = s ∧ t ∧ ¬d.La première peut être déduite de CCAC :(b) Sol1(cible). Mais (b) indique plusprécisément qu’un aliment riche en pro-téine qui n’est pas de la viande est (devraitêtre) apprécié par l’invitée : ¬vi ∧ p. Celan’entraîne pas qu’elle appréciera le tofu.À présent, considérons CD
Léon la connais-
sance de Léon avec la connaissance ad-ditionnelle que le seul aliment riche enprotéine et disponible chez Léon en de-hors de la viande est le tofu : CD
Léon =CDLéon ∧ ( p → vi ∨ t). En substituant CDLéon
____________________________________________________________________________ Annales du LAMSADE N°8
205

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 218/415
par CDLéon il vient :
CCAC = (CD
Léon ∧ BC1) D(CD
Léon ∧ BC2)
≡CD
Léonv ∧ a
(a)
∧ s ∧ ¬b ∧ ¬vi ∧ t ∧ p ∧ ¬d (b)
et (b) Sol2(cible).
Les postulats de la révision et l’adaptationconservatrice. Nous pouvons reconsidérerà présent les postulats (R1) à (R6) dans lecadre de l’adaptation conservatrice.
(R1) appliqué à l’adaptation conservatrice
donne CCAC CD ∧ cible. Si cette as-sertion était violée, cela signifierait qu’ilexiste un modèle I de CCAC tel que
I ∈ Mod(CD ∧ cible) = Mod(CD) ∩Mod(cible), ce qui entrerait en contradic-tion :– Soit avec la définition du problème
cible (ce qui signifierait que l’adaptationconservatrice résoudrait un autre pro-blème cible !) ;
– Soit les connaissances du domaine (qui
doivent être respectées par ce moded’adaptation).
Ainsi, le postulat (R1) empêche ces deuxtypes de contradiction.
Supposons que CD ∧ BC1 ∧ BC2 soit satis-fiable : autrement dit srce ∧ Sol(srce) ∧cible est consistant étant donné la basede connaissances CD. Alors, (R2) entraîneCCAC ≡ CD ∧ BC1 ∧ BC2. Donc, CCAC
srce ∧ Sol(srce) ∧ cible : si cible estconsistant avec srce ∧ Sol(srce) dansCD, alors, on peut inférer de l’adapta-tion conservatrice que Sol(srce) résoutcible. Cela est cohérent avec le principede cette adaptation : Sol(cible) est ob-tenu en gardant de Sol(srce) le plus pos-sible, et si l’affirmation « Sol(srce) ré-sout cible» n’est pas contradictoire avecCD, alors, l’adaptation conservatrice re-vient à une adaptation nulle.
(R3) donne : si CD ∧ BC2 est satisfiablealors CCAC est satisfiable. La satisfiabi-lité de CD ∧ BC2 = CD ∧ cible signi-fie que la spécification du problème cible
ne contredit pas les connaissances du do-maine. Ainsi, (R3) entraîne que dès que leproblème cible est spécifié de façon cohé-rente avec les connaissances du domaine,l’adaptation conservatrice donne un résul-tat satisfaisant.
(R4) signifie simplement que l’adaptationconservatrice suit le principe de non perti-nence de la syntaxe.
(R5) et (R6) traduisent, selon [15], l’idéede changement minimal et, dans lecontexte de l’adaptation conservatrice, le
fait que celle-ci fait un changement mini-mal sur le contexte source pour être en ac-cord avec le contexte cible.
5 Application : adaptationconservatrice de traitementsdu cancer du sein
La projet KASIMIR a pour objet la gestionde référentiels en cancérologie (similairesà des protocoles de décision). De tels réfé-rentiels doivent être adaptés pour certainscas médicaux. Cette section montre deuxexemples de telles adaptations effectuéespar des experts cancérologues et commentces exemples sont modélisés par l’adapta-tion conservatrice.
Le projet KASIMIR. Un grand effort derecherche a été mis sur la cancérologiedurant ces dernières décennies dans lemonde. Par voie de conséquence, la com-plexité de la prise de décision a beau-coup augmenté dans ce domaine. Le pro- jet KASIMIR a pour objet la gestion desconnaissances décisionnelles en cancéro-logie. Une grande partie de cette connais-sance est constituée par des référentiels.Par exemple, le référentiel du traitement du
cancer du sein est un document indiquantcomment un patient atteint de cette mala-die devrait être traité. Ainsi, ce référentielpeut être vu comme un ensemble de règlesPat −→ Ttt, où Pat dénote une classe
Application de la théorie de la révision [...] ___________________________________________________________________________
206

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 219/415
de patients et Ttt, un traitement pour lespatients dans Pat.
Malheureusement, pour environ un tiers
des patients, ce référentiel ne peut être ap-pliqué (par exemple à cause de contre-indications). En effet, il est impossible enpratique de lister toutes les situations spé-cifiques qui empêchent l’application du ré-férentiel : cela constitue une instance duproblème de la qualification [19]. Il a étémontré que, dans la plupart de ces situa-tions, les cancérologues adaptent le réfé-rentiel pour trouver une recommandation
de traitement (ce qui signifie qu’ils réuti-lisent le référentiel mais ne se contententpas de l’appliquer littéralement). Plus pré-cisément, étant donné la description d’unpatient cible, cible, une règle Pat −→Ttt telle que Pat est similaire à cibleest sélectionnée dans le référentiel, et Tttest adapté pour correspondre aux parti-cularités de cible. Si on assimile lesrègles Pat −→ Ttt à des cas sources
(srce, Sol(srce)) — srce = Pat etSol(srce) = Ttt — alors ce proces-sus est un processus de RÀPC, avec laparticularité que les cas sources sont descas généraux (aussi appelés ossified casesdans [21]).
Le système KASIMIR. Le système KASI-MIR a pour objectif d’assister les méde-cins dans leurs prises de décision. La der-
nière version de KASIMIR est implanté enun portail sémantique (i.e., un portail duWeb sémantique [10]), utilisant OWL DLcomme formalisme de représentation, quiest équivalent à la logique de descriptionsSHOIN (D) [22].
Ce système effectue des applications du ré-férentiel : étant donné un référentiel écriten OWL DL et la description d’un patient,il met en évidence les traitements que le
référentiel recommande. Il implante aussiun processus d’adaptation fondé sur desconnaissances d’adaptation [8]. Les étudesactuelles visent à acquérir cette connais-sance d’adaptation de la part des experts
et de façon semi-automatique [7, 6].
L’adaptation conservatrice apparaîtcomme une direction prometteuse de
recherche pour KASIMIR, comme lemontre la suite de cette section.
Exemples. Deux exemples correspondantà des situations réelles sont présentéesci-dessous et modélisées par des adapta-tions conservatrices. Le premier est l’adap-tation d’un traitement contre-indiqué. Ledeuxième est l’adaptation d’un traite-ment inapplicable. D’autres exemples
d’adaptation conservatrice liés à KASI-MIR sont présentés dans le rapport de re-cherche [18]. Notons que ces exemples ontété simplifiés et que les connaissances pré-sentées ne sauraient être utilisées commeconnaissances médicales.
Exemple 2 Certaines hormones du corpshumain facilitent la multiplication des cel-
lules. En particulier, les œstrogènes faci-litent le développement de certaines cel-lules cancéreuses, en particuliers, cellesdu sein. Une hormonothérapie est un trai-tement long qui vise à inhiber les effetsdes hormones afin de réduire le risqued’avoir une nouvelle tumeur qui se déve-loppe après que les autres types de trai-tement (chirurgie, chimiothérapie et ra-diothérapie) aient été appliqués. Le ta-moxifène est une drogue d’hormonothé-rapie qui inhibe l’action des œstrogènessur les cellules cancéreuses. Malheureu-sement, le tamoxifène est contre-indiqué
pour les personnes ayant une maladie du foie. Le référentiel du traitement du can-cer du sein ne tient pas compte de cettecontre-indication et les médecins doivent substituer le tamoxifène par un autre trai-tement ayant le même bénéfice thérapeu-tique (ou un bénéfice thérapeutique si-
milaire). Par exemple, il peuvent utiliser des anti-aromatases (drogues non contre-indiquées pour les personnes souffrant du
foie) à la place du tamoxifène, ou un trai-tement consistant en l’ablation des ovaires
____________________________________________________________________________ Annales du LAMSADE N°8
207

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 220/415
(qui sont des organes produisant des œs-trogènes).
Cet exemple peut être formalisé commesuit. Les règles du référentiel conduisant àrecommander le tamoxifène sont formali-sées par c1 → tam, c2 → tam, . . . cn → tam.Cela peut s’exprimer par une seule règlec → tam, où c = c1 ∨ c2 ∨ . . . ∨cn. Cette règle correspond au cas source(srce, Sol(srce)) avec srce = c etSol(srce) = tam. Considérons à pré-sent une femme atteinte d’un cancer du
sein telle que (1) l’application du réfé-rentiel conduit à recommander du tamoxi-fène et (2) qui souffre d’une maladie dufoie. Ce cas médical peut être formalisépar cible = γ ∧ maladie-foie, où γ est telque γ CD c (voir ci-dessous). Les connais-sances du domaine sont :
CD = (γ → c) ∧ (maladie-foie → ¬tam)
∧ (tam → anti-oestrogènes)
∧ (anti-aromatases → anti-oestrogènes)∧ (ovariectomie → anti-oestrogènes)
maladie-foie → ¬tam représente lacontre-indication au tamoxifène pourles personnes souffrant d’une mala-die du foie. x → anti-oestrogènes pourx ∈ tam, anti-aromatases, ovariectomieindique que si le traitement x est recom-mandé alors un traitement anti-œstrogènes
est recommandé. L’ovariectomie consisteen l’ablation des ovaires.
La D-adaptation conservatrice donne :
CCAC = (CD ∧ c ∧ tam)
D(CD ∧ γ ∧ maladie-foie)≡CD cible ∧ ¬tam ∧ anti-oestrogènes
Si les seuls traitements anti-œstrogènesqu’on puisse effectuer dans l’unité de
soin en-dehors du tamoxifène sont lesanti-aromatases et l’ovariectomie, alorsla connaissance suivante peut être ajou-tée à CD : anti-oestrogènes →(tam ∨anti-aromatases ∨ ovariectomie).
Avec cette connaissance additionnelle,anti-aromatases ∨ ovariectomie est déduitde CCAC. On peut noter que cet exempleest très similaire à l’exemple 1 : la viandeest, en un sens, contre-indiquée par lesvégétariens.
Exemple 3 La grande majorité des per-sonnes souffrant du cancer du sein sont des femmes (environ 99%). Cela explique
pourquoi le référentiel du traitement ducancer du sein a été élaboré pour elles.Quand des médecins sont confrontés au
cas d’un homme atteint de ce cancer,ils adaptent le référentiel. Par exemple,considérons un homme ayant les carac-téristiques c , tel que, pour une femmeayant les mêmes caractéristiques, le réfé-rentiel recommande une mastectomie to-tale (ablation du sein), une chimiothéra-
pie au FEC 100 (FEC est un ensemblede drogues et 100 correspond à la dose)et une ovariectomie. La chirurgie et la
chimiothérapie peuvent toutes deux êtreappliquées à un homme, mais pas l’ova-riectomie (pour des raisons évidentes).
L’adaptation consiste en général à gar-der la chirurgie et la chimiothérapie et à remplacer l’ovariectomie par un traite-ment anti-œstrogènes, tel que le traitement au tamoxifène ou aux anti-aromatases.
La règle du référentiel utilisédans cet exemple est le cassource (srce, Sol(srce)) avecsrce = c ∧ femme et Sol(srce) =mastectomie-totale ∧ FEC-100 ∧ovariectomie : mastectomie-totale (resp.,FEC-100, ovariectomie) dénote lespersonnes pour lesquelles une mastec-tomie totale (resp., une chimiothérapieau FEC 100, une ovariectomie) estrecommandée. Le problème cible estcible = c ∧ homme. Les connaissancesdu domaine sont celles de l’exemple 2(dénotées ci-dessous par CDex. 2), le faitque l’ovariectomie est impossible pour unhomme et le fait que les hommes ne sont
Application de la théorie de la révision [...] ___________________________________________________________________________
208

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 221/415
pas des femmes :
CD =CDex. 2 ∧ (homme → ¬ovariectomie)
∧ (¬ femme ∨ ¬homme)
L’adaptation conservatrice donne :
CCAC ≡CDcible ∧ mastectomie-totale
∧ FEC-100 ∧ ¬ovariectomie
∧ anti-oestrogènes
Si les seules thérapies anti-œstrogènespossibles dans l’unité de soin sont les troismentionnées ici, CD peut être remplacé
par :CD = CD ∧anti-oestrogènes →
tam ∨ anti-aromatases
∨ovariectomie
Alors, la D-adaptation conservatricedonne CCAC tel que CCAC ≡ CCAC∧(tam∨anti-aromatases).
6 Discussion
Plusieurs propositions de taxonomies desapproches de l’adaptation ont été pro-posées dans la littérature du RÀPC.Dans [18], l’adaptation conservatrice estsituée dans plusieurs de ces taxonomies.Ci-dessous, la partie principale de ce tra-vail est présenté.
Adaptation conservatrice et adaptation par gé-néralisation et spécialisation. Dans [21] estintroduite l’approche par abstraction et re-spécialisation de l’adaptation qui consisteen (1) abstraire la solution Sol(srce) desrce en une solution Sol(A) d’un pro-blème abstrait A et (2) spécialisation deSol(A) afin de résoudre cible. Selon [4],cette adaptation devrait plutôt être quali-fiée d’approche par généralisation et spé-cialisation (versus une approche par abs-traction et raffinement), mais cette distinc-tion n’est pas faite dans [21].
Chaque exemple d’adaptation conserva-trice présenté dans cet article peut être vu
comme application d’une adaptation pargénéralisation et spécialisation. En parti-culier, dans l’exemple 3, Sol(srce) estgénéralisé en remplaçant ovariectomie paranti-oestrogènes puis spécialisé en tam ∨anti-aromatases. Cette propriété de la D-adaptation conservatrice peut être com-prise grâce à la définition des opérateursde révision dist (cf. section 3).
Adaptation conservatrice et décomposition deproblème. Dans [13], l’adaptation estconsidérée selon trois taxonomies. Uned’entre elles est celle des opérateursd’adaptation. Considérons les deux typesopérateurs suivants : (1) les opérateurs dedécomposition en sous-buts et (2) les opé-rateurs d’interaction entre buts. (1) Unopérateur de décomposition en sous-butsvise à décomposer la tâche d’adaptation ensous-tâches. (2) Un opérateur d’interactionentre buts gère les interactions entre lesparties de la solution : il détecte et répareles mauvaises interactions. On peut consi-
dérer que l’adaptation conservatrice effec-tue une combinaison des opérations destypes (1) et (2). La spécification du pro-blème cible — la formule cible — peutêtre vue comme la spécification d’un but(le but étant de trouver une solution consis-tante avec cible). Si cible ≡ cible1 ∧cible2 alors cible1 et cible2 sont deuxsous-buts du problème cible. L’adaptationconservatrice donne une solution qui est
consistante avec ces sous-buts. Par consé-quent, cette approche de l’adaptation gèrel’interaction entre sous-buts de la mêmefaçon qu’une combinaison d’opérateurs detypes (1) et (2). Cependant, si l’opérateurde révision est considéré comme une boîtenoire, alors la distinction entre (1) et (2)n’est pas visible.
Adaptation conservatrice et adaptaiton par co-
pie, modification et test. Dans [11], un mo-dèle général de l’adaptation en RÀPC estprésenté dans un formalisme de tâches : ens’appuyant sur l’analyse de plusieurs sys-tèmes de RÀPC implantant un processus
____________________________________________________________________________ Annales du LAMSADE N°8
209

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 222/415
d’adaptation, est proposé une décomposi-tion hiérarchique de l’adaptation en tâcheset sous-tâches. L’idée est que, en général,les procédures d’adaptations par transfor-mation implantées dans les systèmes deRÀPC peuvent être modélisées suivant ceschéma, en considérant un sous-ensemblede ces tâches. L’adaptation conservatricepeut être vue comme une façon d’instan-cier le sous-ensemble de tâches suivant :– Copie de la solution (similaire à une
adaptation nulle) ;– Sélection et modification des différences
(en enlevant, substituant et/ou ajoutant
des informations) ;– Test de consistance.En fait, pour l’adaptation conservatrice,c’est l’opérateur de révision qui effectueces tâches : il effectue un changement mi-nimal qui peut être vu comme une sé-quence des tâches de copie, modificationet test. De plus, elle utilise les connais-sances du domaine afin de sélectionner lescaractéristiques à modifier pour obtenir la
consistance.Par conséquent, l’adaptation conservatricepeut également être vu comme une ins-tanciation des étapes réutiliser et réviser du cycle de RÀPC de [2] : l’étape réutili-ser est effectuée par une simple copie etl’étape réviser par un opérateur de révi-sion. On peut noter que, à notre connais-sance, l’étape réviser de ce cycle n’a pasencore été liée à la théorie AGM de la révi-sion : nous n’avons trouvé qu’un article surune approche du RÀPC utilisant des tech-niques de révision [20], pas pour le raison-nement en lui-même, mais pour la mainte-nance de la base de cas et d’une base derègles suite à des évolutions dans le temps(selon [14], il s’agit plus d’une probléma-tique de mise à jour que de révision).
7 Conclusion et perspectivesL’adaptation est souvent considéréecomme une tâche difficile du raisonne-ment à partir de cas, en comparaison
avec la remémoration qui est censée êtreplus simple à concevoir et à implanter.Cet article présente une approche del’adaptation qui s’appuie sur la théoriede la révision : elle consiste à garder leplus possible du cas source tout en étantcohérente avec le problème cible et lesconnaissances du domaine. L’adaptationconservatrice est définie et formaliséedans le cadre de la logique proposition-nelle. De plus, des exemples montrentque l’adaptation conservatrice modélisecertaines adaptations effectuées par lesexperts en cancérologie. Cette approche
de l’adaptation s’appuie fortement surles connaissances du domaine : une deses caractéristiques notables est que lesconnaissances d’adaptation sur lesquelleselle s’appuie font partie des connais-sances du domaine CD, par opposition, parexemple, aux approches de l’adaptationqui s’appuient sur un ensemble de règlesd’adaptation.
La section 6 met en évidence les ressem-blances entre l’adaptation conservatrice etd’autres approches générales de l’adapta-tion définies dans la littérature du RÀPC,en particulier, le maintien de la cohérence,l’extension de l’adaptation nulle et, aumoins pour les dist-adaptations conserva-trices, le fait qu’elles soient des approchespar généralisation et spécialisation.
Plusieurs aspects théoriques de l’adap-tation conservatrice ont été abordésdans [18] et qui requièrent une étudeplus approfondie. Certains d’entre euxsont présentés ci-dessus. L’un deux est laconception d’une remémoration appro-priée pour une adaptation conservatrice.Une telle remémoration s’appuie sur l’hy-pothèse selon laquelle le résultat d’uneadaptation conservatrice est meilleur que
celui d’une autre adaptation conservatricesi la première effectue moins de change-ment que la deuxième. Cela conduit à pré-férer le cas source (srce1, Sol(srce1))au cas source (srce2, Sol(srce2)) si
Application de la théorie de la révision [...] ___________________________________________________________________________
210

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 223/415
∆1 < ∆2, avec
∆i = dist(Mod(CD ∧ srcei ∧ Sol(srcei)),
Mod(CD ∧ cible)) (i ∈ 1, 2)Les limites de ce critère de préférence sontd’une part qu’il est insuffisant pour distin-guer deux cas sources ayant le même ∆i etd’autre part que son implantation naïve estcomplexe.
La connaissance sur laquelle l’adaptationconservatrice s’appuie est CD. Or, cetteconnaissance est généralement incomplète
(cf. le problème de la qualification men-tionné à la section 5), ce qui fait qu’une so-lution inférée par cette adaptation peut êtrecontradictoire avec les connaissances del’expert (mais pas avec CD). De l’analysede cette contradiction, certaines connais-sances du domaine peuvent être acquiseset ajoutées à CD : en s’inspirant de [12], unsystème de RÀPC peut apprendre de nou-velles connaissances à partir de ses échecs.
Un travail en cours étudie la mise en placepratique de cette idée.
L’adaptation conservatrice ne modéliseque certaines adaptations effectuées parles experts. D’autres adaptations peuventêtre modélisées grâce à des extensionsde cette approche de l’adaptation, commecela est montré dans [18]. Par exemple,une approche de l’adaptation consiste en(1) trouver une substitution σ telle queσ(srce) ≡CD cible, (2) appliquer σ surSol(srce) pour obtenir une première so-lution Sol1(cible) de cible, et (3) ré-parer Sol1(cible) afin de la rendre co-hérente avec les connaissances du do-maine. L’étape (3) peut être effectuée parun opérateur de révision. En particulier,dans [18], l’exemple bien connu de l’adap-tation de la recette du bœuf aux haricotsverts en une recette du bœuf aux broco-
lis effectuée par le système CHEF [12]est redécrite en s’appuyant sur l’opérateurde révision D. Cela montre aussi, plusgénéralement, que les opérateurs de révi-sions peuvent être utilisés de différentes
manières comme des outils pour concevoirdes processus d’adaptation.
Une autre perspective est la
combinaison de plusieurs cassources (srce1, Sol(srce1)), ...(srcen, Sol(srcen)) pour résoudreun seul problème cible cible. Il est en-visagé d’étudier cette question grâce à lanotion de fusion de bases de connaissancespropositionnelles [16] : étant donné unmulti-ensemble ψ1, . . . ψn de bases deconnaissances à fusionner et une base deconnaissances consistante µ (représentant
les contraintes d’intégrité), un opérateurde fusion construit une base de connais-sances µ(ψ1, . . . ψn) qui est cohérenteavec µ et garde «le plus d’informationspossible » des ψi. Cela étend la notion derévision : défini par ψ µ = µ(ψ)est un opérateur de révision. De la mêmefaçon, une approche de combinaison descas qui étend l’adaptation conservatriceconsiste à calculer µ(ψ1, . . . ψn) avec
ψi = CD ∧ srcei
∧ Sol(srcei
), pouri ∈ 1, 2, . . . n et µ = CD ∧ cible. Lapertinence de cette approche pour desproblèmes pratiques de combinaison decas en RÀPC reste à étudier.
D’un point de vue pratique, le développe-ment et l’utilisation d’un outil d’adapta-tion conservatrice à intégrer dans le sys-tème KASIMIR sont des perspectives. Unepremière implantation de
Da été effec-
tuée mais pas optimisée (à titre d’exemple,l’opération de révision la plus complexeprésentée dans [18] s’appuie sur 16 va-riables propositionnelles et demande envi-ron 25 secondes sur un PC actuel).
Une autre perspective pratique est l’inté-gration de l’adaptation conservatrice dansle système KASIMIR, ce qui soulève deuxdifficultés. La première est que les cas et
les connaissances du domaine de KASI-MIR sont représentés en OWL DL, forma-lisme équivalent à la logique de descrip-tions SHOIN (D). Par conséquent, soitles problèmes d’adaptation exprimés en
____________________________________________________________________________ Annales du LAMSADE N°8
211

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 224/415
OWL DL sont traduits en logique propo-sitionnelle et résolus dans ce formalismesoit un opérateur de révision est implantépour une logique de descriptions compa-tible avec KASIMIR (ce qui demanderaitune formalisation de l’adaptation conser-vatrice en logique de descriptions; unepremière proposition pour cela a été faitedans [18]).
Le deuxième problème d’intégration estlié au module d’adaptation déjà existantdans KASIMIR [8], qui s’appuie sur desrègles d’adaptation. Comment l’adaptation
conservatrice et cette approche par règlesde l’adaptation peuvent être intégrées afinde donner un unique module d’adapta-tion permettant des processus d’adaptationcomplexes (chacun d’eux étant composéd’une adaptation conservatrice et d’adap-tations par règles)? Cette question devraitêtre traitée grâce à des travaux antérieurssur la composition et la décomposition del’adaptation [17].
Remerciements
L’auteur tient à remercier Pierre Marquisqui, il y a quelques années, lui a appris lesbases de la théorie de la révision, a, plusrécemment, suggéré des références inté-ressantes sur cette théorie et a fait des re-marques constructives sur le rapport de re-cherche [18] (par exemple, l’idée d’utiliser
un opérateur de fusion est de lui). Il remer-cie également les relecteurs pour leurs re-marques qui serviront également de base àdes réflexions futures. Enfin, il remercie safille qui, pour quelque raison mystérieuse,est à l’origine de ce travail.
Références
[1] Aamodt (A.). – Knowledge-Intensive
Case-Based Reasoning and SustainedLearning. In : Proceedings of the9th European Conference on Artifi-cial Intelligence (ECAI’90), éd. parAiello (L. C.). – August 1990.
[2] Aamodt (A.) et Plaza (E.). – Case-based Reasoning : Foundational Is-sues, Methodological Variations, andSystem Approaches. AI Communica-tions, vol. 7, n1, 1994, pp. 39–59.
[3] Alchourrón (C. E.), Gärdenfors (P.) etMakinson (D.). – On the Logic of Theory Change : partial meet func-tions for contraction and revision.
Journal of Symbolic Logic, vol. 50,1985, pp. 510–530.
[4] Bergmann (R.). – Learning Plan Abs-tractions. In : GWAI-92, 16 th Ger-
man Workshop on Artificial Intelli-gence, éd. par Ohlbach (H. J.), pp.187–198. – Springer Verlag, Berlin,1992.
[5] Dalal (M.). – Investigations into atheory of knowledge base revision :Preliminary report. In : AAAI , pp.475–479. – 1988.
[6] d’Aquin (M.), Badra (F.), Lafrogne(S.), Lieber (J.), Napoli (A.) et Szath-mary (L.). – Case Base Mining forAdaptation Knowledge Acquisition.
In : Proceedings of the 20th In-ternational Joint Conference on Ar-tificial Intelligence (IJCAI’07). pp.750–755. – Morgan Kaufmann, Inc.,2007.
[7] d’Aquin (M.), Lieber (J.) et Napoli(A.). – Adaptation Knowledge Ac-
quisition : a Case Study for Case-Based Decision Support in Oncology.Computational Intelligence (an In-ternational Journal), vol. 22, n3/4,2006, pp. 161–176.
[8] d’Aquin (M.), Lieber (J.) et Napoli(A.). – Case-Based Reasoning withinSemantic Web Technologies. In :Twelfth International Conference on
Artificial Intelligence : Methodology,
Systems, Applications (AIMSA-06),pp. 190–200. – 2006.
[9] Dubois (D.), Esteva (F.), Garcia (P.),Godo (L.), de Màntaras (R. L.) etPrade (H.). – Fuzzy set modelling
Application de la théorie de la révision [...] ___________________________________________________________________________
212

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 225/415
in case-based reasoning. Int. J. of In-telligent Systems, vol. 13, 1998, pp.345–373.
[10] Fensel (D.), Hendler (J.), Lieberman(H.) et Wahlster (W.) (édité par).– Spinning the Semantic Web. –Cambridge, Massachusetts, The MITPress, 2003.
[11] Fuchs (B.) et Mille (A.). – AKnowledge-Level Task Model of Adaptation in Case-Based Reaso-ning. In : Case-Based Reasoning Re-search and Development — Third
International Conference on Case- Based Reasoning (ICCBR-99), éd.par Althoff (K.-D.), Bergmann (R.)et Branting (L. K.). pp. 118–131. –Springer, Berlin, 1999.
[12] Hammond (K. J.). – Case-BasedPlanning : A Framework for Planningfrom Experience. Cognitive Science,vol. 14, n3, 1990, pp. 385–443.
[13] Hanney (K.), Keane (M. T.), Smyth
(B.) et Cunningham (P.). – Sys-tems, Tasks and Adaptation Know-ledge : Revealing Some RevealingDependencies. In : Case-Based Rea-soning Research and Development – First International Conference, ICC-
BR’95, Sesimbra, Portugal, éd. parVeloso (M.) et Aamodt (A.), pp. 461–470. – Springer Verlag, Berlin, 1995.
[14] Katsuno (H.) et Mendelzon (A.). –
On the Difference Between Updatinga Knowledge Base and Revising It. In : KR’91 : Principles of Know-ledge Representation and Reasoning,éd. par Allen (James F.), Fikes (Ri-chard) et Sandewall (Erik), pp. 387–394. – San Mateo, California, Mor-gan Kaufmann, 1991.
[15] Katsuno (H.) et Mendelzon (A.). –Propositional knowledge base revi-
sion and minimal change. Artificial Intelligence, vol. 52, n3, 1991, pp.263–294.
[16] Konieczny (S.), Lang (J.) et Marquis(P.). – DA2 merging operators. Ar-
tificial Intelligence, vol. 157, n 1-2,2004, pp. 49–79.
[17] Lieber (J.). – Reformulations and
Adaptation Decomposition. In : For-malisation of Adaptation in Case- Based Reasoning, éd. par Lieber (J.),Melis (E.), Mille (A.) et Napoli (A.).– Third International Conferenceon Case-Based Reasoning Workshop,ICCBR-99 Workshop number 3, S.Schmitt and I. Vollrath (volume edi-tor), LSA, University of Kaiserslau-tern, 1999.
[18] Lieber (J.). – A Definition and a For-malization of Conservative Adapta-tion for Knowledge-Intensive Case-
Based Reasoning – Application to Decision Support in Oncology (APreliminary Report). – Rapport derecherche, LORIA, 2006.
[19] McCarthy (J.). – EpistemologicalProblems of Artificial Intelligence.
In : Proceedings of the 5th Interna-
tional Joint Conference on Artificial Intelligence (IJCAI’77), Cambridge(Massachussetts), pp. 1038–1044. –1977.
[20] Pavón Rial (R.), Laza Fidalgo (R.),Gómez Rodriguez (A.) et CorchadoRodriguez (J. M.). – Improvingthe Revision Stage of a CBR Sys-tem with Belief Revision Techniques.Computing and information systems
journal, vol. 8, n2, 2001, pp. 40–45.[21] Riesbeck (C. K.) et Schank (R. C.).
– Inside Case-Based Reasoning. –Hillsdale, New Jersey, Lawrence Erl-baum Associates, Inc., 1989.
[22] Staab (S.) et Studer (R.) (édité par).– Handbook on Ontologies. – Berlin,Springer, 2004.
____________________________________________________________________________ Annales du LAMSADE N°8
213

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 226/415

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 227/415
Debating over heterogeneous descriptions
M. Morge⋆
Jean-Christophe Routier⋆⋆
⋆Dipartimento di InformaticaUniversity of Pisa
Largo B. Pontecorvo, 3 I-56127 Pisa, Italy⋆⋆ LIFL - USTL
Batiment M3 - F-59655 VILLENEUVE D’ASCQ Cedex FRANCE
Résumé :L’hétérogénéité sémantique des ontologies est unobstacle majeur à l’interopérabilité dans les sys-
tèmes multi-agents ouverts. Nous proposons danscet article un cadre formel pour que les agents dé-battent à partir de terminologies hétérogènes. Àcette intention, nous proposons un cadre de repré-sentation argumentatif qui permet de gérer des des-criptions conflictuelles. Nous présentons égalementun modèle d’agents qui expliquent les termes qu’ilsutilisent et prennent en compte les explications deleurs interlocuteurs. Finalement, nous proposonsun système dialectique permettant aux agents departicper à un dialogue pour atteindre un accord surune terminologie commune.
Mots-clés : Intelligence artificielle, Système Multi-Agents, Dialogue, Argumentation, Ontologie, Lo-gique de Description
Abstract:A fundamental interoperability problem is causedby the semantic heterogeneity of agents’ontolo-gies in open multi-agent systems. In this paper,we propose a formal framework for agents de-bating over heterogeneous terminologies. For thispurpose, we propose an argumentation-based re-
presentation framework to manage conflicting des-criptions. Moreover, we propose a model for thereasoning of agents where they justify the descrip-tion to which they commit and take into account thedescription of their interlocutors. Finally, we pro-vide a dialectical system allowing agents to parti-cipate in a dialogue in order to reach an agreementover heterogeneous ontologies.
Keywords: Artificial Intelligence, Multi-agent sys-tem, Dialogue, Argumentation, Ontology, Descrip-tion logic
1 Introduction
Traditionally, ontologies have been used toachieve semantic interoperability between
applications, such as software agents. Inopen systems that agents can dynamically join or leave, a fundamental interopera-bility problem is caused by the seman-tic heterogeneity of agents at the know-ledge level. The current approaches suchas standardization, adopted by [5], and on-tology alignment, considered by [4], arenot suitable in open systems. Since stan-dardization requires that all parties invol-ved reach a consensus on the ontology,this idea seems very unlikely. On the otherhand, ontology alignment uses some map-
pings to translate messages. However, wedo not know a priori which ontologiesshould be mapped within an open multi-agent system.
Argumentation is a promising approachfor (1) reasoning with inconsistent infor-mation, (2) facilitating rational interaction,and (3) resolving conflicts. In this pa-per, agents have their own definitions of concepts and they discover through thedialogue whether or not they share thesedefinitions. If not, they are able to learnthe definition of their interlocutor. For thispurpose, we extend the formal frameworkfor inter-agents dialogue based upon theargumentative techniques proposed by [7].(1) We propose here an argumentation-based representation framework, offering away to manage contradictory concept de-
finitions and assertions. (2) We propose amodel of agent reasoning to put forwardsome representations and take into accountthe representations of their interlocutors.(3) Finally, we provide a dialectical system
215

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 228/415
in which a protocol enables two agents toreach an agreement about their representa-tions.
Paper overview. Section 2 introduces theexample of dialogue that will illustrate ourframework. In Section 3, we provide thesyntax and the semantics of the descrip-tion logic which is adopted in this paper.Section 4 presents the argumentation fra-mework that manages interaction betweenconflicting representations. In accordancewith this background, Section 5 describesour agent model. In Section 6, we define
the formal area for agents debate. Sec-tion 7 describes the protocol used to reachan agreement. Section 8 presents some re-lated works. Section 9 draws some conclu-sions and future works.
2 Natural language
[11] defines a dialogue as a coherent se-
quence of moves from an initial situationto reach the goal of participants. For ins-tance, the goal of a dialogue may consistin resolving a conflict about a representa-tion.
Before we start to formalize such dia-logues, let us first discuss the following na-tural language dialogue example betweena customer and a service provider :
1. customer : Do you know free softwareto view my PDF?2. provider : acrobat is free software.
3. customer : Why is it a free software ?
4. provider : acrobat is free because it isa freeware.
5. customer : In my humble opinion,acrobat is not a free software.
6. provider : Why is it not free software?
7. customer : Since acrobat is freeware, itis not free software.
8. provider : OK, however xpdf is freesoftware.
9. customer : Why is it free software ?10. provider : xpdf is free software be-
cause it is opensource.
11. customer : Why is it opensource ?12. provider : xpdf is opensource becauseit is copyleft.
13. customer : OK, I will consider xpdf.In this dialogue, two participants share theconcept “free”. However, their definitionsare divergent. On one side, the customerconsiders free software as non-proprietarysoftware. On the other side, the serviceprovider considers free software as a zero
price software. This dialogue reveals theconflict in the definitions of this conceptand resolves it. Throughout the followingwe will assume the service provider givespriority to the customer’s concepts.
3 Description Logic
In this section, we provide the syntax andthe semantics for the well-known
ALC language proposed by [8] and which isadopted in the rest of the paper.
The data model of a knowledge base(KBase, for short) can be expressed bymeans of the Description Logic (DL, forshort) which has a precise semantic andeffective inference mechanisms. Moreo-ver, most ontologies markup languages(e.g. OWL) are partly founded on DL.
The syntax of the representation adoptedhere is taken from standard constructorsproposed in the DL literature. In ALC ,concepts, denoted C , D , . . . are interpretedas unary predicates and primitive roles, de-noted R , S , . . ., as binary predicates. Wecall description a complex concept whichcan be built using constructors. The syntaxof ALC is defined by the following BNFdefinition : C → ⊤|⊥|C |¬C |C ⊔ D|C ⊓
D|∃R.C |∀R.C . The semantics is definedby an interpretation I = (∆ I , · I ), where∆ I is the non-empty domain of the inter-pretation and · I stands for the interpreta-tion function.
Debating over heterogeneous descriptions ___________________________________________________________________________
216

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 229/415
A KBase K = T , A contains a T-boxT and an A-box A. The T-box includes aset of concept definition (C ≡ D) whereC is the concept name and D is a des-cription given in terms of the languageconstructors. The A-box contains exten-sional assertions on concepts and roles.For example, a (resp. (a, b)) is an ins-tance of the concept C (resp. the role R)iff a I ∈ C I (resp. (a I , b I ) ∈ R I ). We call
claims, the set of concept definitions andassertions contained in the KBase. A no-tion of subsumption between concepts isgiven in terms of the interpretations. LetC, D be two concepts. C subsumes D (de-noted C ⊒ D) iff for every interpretation
I its holds thatC I ⊇ D I . Indeed, C ≡ D amounts toC ⊒ D and D ⊒ C . Similarly, C ⊓D ≡ ⊥ amounts to C ≡ ¬D and D ≡¬C . The KBase can contain partial de-finitions, i.e. axioms based on subsump-tion (C ⊒ D). Below we will use ALC in our argumentation-based representation
framework.
4 Argumentation-based repre-sentation framework
The seminal work of [3] formalizes theargumentation reasoning within a frame-work made of abstract arguments and acontradiction relation to determine their
acceptance. We present in this section, anargumentation framework built around theunderlying logic language ALC , whereclaims (concept definitions and assertions)can be conflicting and have different re-levances depending on the considered au-dience.
The KBase is a set of sentences in acommon language, denoted ALC , associa-ted with a classical inference, denoted ⊢,
and shared by a set of audiences (denotedA = a1, . . . , an). The audiences sharea value-based KBase, i.e. a set of claimspromoting values :
Definition 1 Let A = a1, . . . , an be aset of audiences. The value-based KBase
AK = K, V, promote is defined by atriple where :
– K = T , A is a KBase, i.e. a finite set of claims in ALC ;
– V is a non-empty finite set of valuesv1, . . . , vt ;
– promote : K → V is a total mapping from the claims to values.
We say that the claim φ relates to the va-lue v if φ promotes v. For every φ ∈ K ,
promote(φ) ∈ V .
Values are arranged in hierarchies. Forexample, an audience will value both jus-tice and utility, but an argument may re-quire the determination of a strict prefe-rence between the two. The relevance of an argument is the value promoted by themost general claims in its premise. Sinceaudiences are distinguished by their hierar-chies of values, the values have differentpriorities for different audiences. Each au-
dience ai is associated with an individualvalue-based KBase which is a 4-tupleAKi = K, V, promote, ≪i where :– AK = K, V, promote is a value-based
KBase as previously defined ;– ≪i is the priority relation of the au-
dience ai, i.e. a strict complete orderingrelation on V .
A priority relation is a transitive, irre-flexive, asymmetric, and complete rela-
tion on V . It stratifies the KBase into fi-nite non-overlapping sets. The priority le-vel of a non-empty KBase K ⊆ K (writtenleveli(K )) is the most important value pro-moted by one element in K . Arguments,that are consequence relations between apremise and a conclusion, are built on thiscommon KBase.
Definition 2 Let K be a KBase in ALC .
An argument is a pair A = Φ, φ , whereφ is a claim and Φ ⊆ K is a non-emptyset of claims such that : Φ is consistent and minimal (for set inclusion), and Φ ⊢φ. Φ is the premise of A , written Φ =
____________________________________________________________________________ Annales du LAMSADE N°8
217

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 230/415
premise(A) , and φ is the conclusion of A ,written φ = conc(A).
In other words, the premise is a set of claims from which the conclusion can beinferred. A′ is a sub-argument of A if thepremise of A′ is included in the premiseof A. A′ is a trivial argument if the pre-mise of A′ is a singleton (premise(A′) =conc(A′)). Since the KBase K can be in-consistent, the set of arguments (denotedA(K)) may contain conflicting arguments.
Definition 3 Let K be a KBase in ALC and A = Φ, φ, B = Ψ, ψ ∈ A(K )two arguments. A attacks B iff : ∃Φ1 ⊆Φ, Ψ2 ⊆ Ψ such that ∃χ ∈ L Φ1 ⊢χ and Ψ2 ⊢ ¬χ.
Because each audience is associated witha particular priority relation, audiences in-dividually evaluate the relevance of argu-ments.
Definition 4 Let AK i =K, V, promote, ≪i be the value-based argumentation KBase of the audienceai and let A = Φ, φ ∈ A(K) be anargument. According to AK i , the relevanceof A (written relevancei(A)) is the most important value promoted by one claim inthe premise Φ.
In other words, the relevance of argumentsdepends on the priority relation. A fixedordering is simply assumed, revealing theordering between claims. In order to givea criterion that will allow an audience toprefer one argument over another, we pre-fer the arguments built upon the most ge-neral claims. Since audiences individuallyevaluate arguments’relevance, an audience
can ignore that an argument attacks ano-ther. According to an audience, an argu-ment defeats another argument if they at-tack each other and the second argumentis not more relevant than the first one :
Definition 5 Let AK i =K, V, promote, ≪i be the value-based argumentation KBase of the audience aiand A = Φ, φ , B = Ψ, ψ ∈ A(K)two arguments. A defeats B for theaudience ai (written defeatsi(A, B))iff ∀Φ1 ⊆ Φ, Ψ2 ⊆ Ψ ,
(∃χ ∈ L, Φ1 ⊢ χ and Ψ2 ⊢ ¬χ) ⇒¬(leveli(Φ1) ≪i leveli(Ψ2)).Similarly, we say that a set S of argumentsdefeats B if B is defeated by one argument in S .
By definition, two equally relevant argu-ments both defeat each other.
Considering each audience own view-point, we define the subjective acceptancenotion :
Definition 6 Let AK i =K, V, promote, ≪i be the value-based KBase of the audience ai. Let A ∈ A(K)
be an argument and S ⊆ A(K) a set of arguments. A is subjectively acceptableby the audience ai with respect to S iff ∀B ∈ A(K) defeatsi(B, A) ⇒defeatsi(S, B).
The following example illustrates ourargumentation-based representation fra-mework.
Example 1 Let us consider the case pre-sented in Section 2. The value-based KBase of two different audiences a1 and a2are represented in the figure 1 and in the fi-gure 2. The different claims φ1(x), . . . , φ72
in a KBase relate to the different va-lues v1, . . . , v7. On one side, the claimsφ1(x), . . . , φ61(x) are in the T-box. On theother side, φ71 and φ72 are in the A-box.The more general the claim is, the higher
the promoted value is. According to an au-dience, a value above another one in atable has priority over it. In order to de-cide if acrobat is a free software, The five
following arguments must be considered :
Debating over heterogeneous descriptions ___________________________________________________________________________
218

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 231/415
FIG . 1 – The value-based KBase of the first audience≪1 V 1 K1
v1 φ1(x) : Soft(x) ⊒ Free(x) ⊔ Nonfree(x)
v2 φ2(x) : Nonfree(x) ⊒ Freeware(x) B′2B2
v3 φ3(x) : Free(x) ⊒ Freeware(x) B′1
v4 φ4(x) : Free(x) ⊓ Nonfree(x) ≡ ⊥ B1
v5 φ5(x) : Free(x) ⊒ Opensource(x)v6 φ61(x) : Opensource(x) ⊒ Copyleft(x)v7 φ71 : Freeware(acrobat) B′
φ72 : Copyleft(xpdf )
FIG . 2 – The value-based KBase of the second audience
≪2 V 2
K2
v1 φ1(x) : Soft(x) ⊒ Free(x) ⊔ Nonfree(x)v3 φ3(x) : Free(x) ⊒ Freeware(x) B′
1B1
v2 φ2(x) : Nonfree(x) ⊒ Freeware(x) B′2
v4 φ4(x) : Free(x) ⊓ Nonfree(x) ≡ ⊥ B2
v5 φ5(x) : Free(x) ⊒ Opensource(x)v6 φ61(x) : Opensource(x) ⊒ Copyleft(x)v7 φ71 : Freeware(acrobat) B′
φ72 : Copyleft(xpdf )
– B′ = [Freeware(acrobat )],Freeware(acrobat ) ;
– B′1
= [Freeware(acrobat ),Free(x) ⊒ Freeware(x))],Free(acrobat ) ;
– B′2
= [Freeware(acrobat ), Nonfree(x) ⊒ Freeware(x))], Nonfree(acrobat ) ;
– B1 = [Freeware(acrobat ),Free(x) ⊒ Freeware(x),
Free(x) ⊓ Nonfree(x) ≡ ⊥],¬ Nonfree(acrobat ) ;
– B2 = [Freeware(acrobat ), Nonfree(x) ⊒ Freeware(x),Free(x) ⊓ Nonfree(x) ≡ ⊥],¬Free(acrobat ) ;
B′ is a sub-argument of B′1
(resp. B′2)
which is a sub-argument of B1 (resp. B2).B1 and B′
2(resp. B′
1and B2) attack each
other. The relevance of B1 and B′1
is v3.
The relevance of B2 and B′2 is v2. Accor-ding to the first audience, B′
2(resp. B2)
defeats B1 (resp. B′1) but B1 (resp. B′
1)
does not defeat B′2 (resp. B2). Therefore,
the set B′, B′2, B2 is subjectively accep-
table wrt A(K). According to the second audience, B1 (resp. B′
1) defeats B′
2(resp.
B2) but B′2
(resp. B2) does not defeat B1
(resp. B′1). Therefore, the set B, B′
1, B1is subjectively acceptable wrt A(K).
We have defined here the representationframework to manage interactions bet-ween conflicting claims. In the next sec-
tion, we present a model of agents whichputs forward claims and takes into accountother claims coming from their interlocu-tors.
5 Model of agents
In a multi-agent setting it is natural to as-sume that all the agents do not use exactlythe same ontology. Since agents represen-
tations can be common, complementary orcontradictory, agents have to exchange as-sumptions and to argue. Our agents indi-vidually evaluate the perceived commit-ments with respect to the estimated repu-
____________________________________________________________________________ Annales du LAMSADE N°8
219

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 232/415
tation of the agents from whom the infor-mation is obtained.
Agents, which have their own private re-
presentations, record their interlocutorscommitments. Moreover, agents indivi-dually valuate their interlocutors reputa-tion. Therefore, an agent is defined as fol-lows :
Definition 7 The agent ai ∈ A is defined by a 6-tuple
ai = Ki, V i, ≪i, promotei, ∪ j=iCS i j , ≺i
where : – Ki is a personal KBase, i.e. a set of per-
sonal claims in ALC ; – V i is a set of personal values ; – promotei : Ki → V i maps from the per-
sonal claims to the personal values ; – ≪i is the priority relation, i.e. a strict
complete ordering relation on V i ;
– CS i j is a commitment store, i.e. a set of
claims in ALC . CS i j(t) contains propo-
sitional commitments taken before or at time t , where agent a j is the debtor and agent ai the creditor ;
– ≺i is the reputation relation, i.e. a strict complete ordering relation on A.
The personal KBases are not necessarilydisjoint. The commonsense claims are ex-plicitly shared by all the agents. We call
common KBase the set of commonsenseclaims explicitly shared by the agents1 :KΩA
⊆ ∩ai∈AKi. Similarly, we call com-mon values the values explicitly shared bythe agents : V ΩA ⊆ ∩ai∈AV i. The com-mon claims relate to the common values.For every φ ∈ KΩA
, promoteΩA
(φ) =v ∈ V ΩA . The personal KBase can be com-plementary or contradictory. Some claimscan be shared without the agents being
aware of it. These similarities betweenagents will be discovered during the dia-logue. We call joint KBase the set of
1We qualify with ΩA a value obtained through an intersec-tion over A
claims distributed in the system : KA =∪ai∈AKi. The agent’s own claims relateto the agent’s own values. For every φ ∈Ki − KΩA
, promotei
(φ) = v ∈ V i − V ΩA .
Reputation is a local perception of the in-terlocutor, a social concept that links anagent to her interlocutors, and a leveled re-lation. The different reputation relations,which are transitive, irreflexive, asymme-tric, and complete relations on A, pre-serve these properties. a j ≺i ak denotesthat an agent ai trusts an agent ak morethan another agent a j . In order to take into
account the claims notified in the commit-ment stores, each agent is associated withthe following extended KBase :
Definition 8 The extended KBase of theagent ai is the value-based KBase
AK ∗i = K∗i , V ∗i , promote∗i , ≪∗
i where :
– K∗i = Ki ∪ [
j=i CS i j] is the agent ex-
tended personal KBase composed of its personal KBase and the set of perceived commitments ;
– V ∗i = V i∪ [ j=ivi j] is the agent exten-
ded set of personal values composed of the set of personal values and the repu-tation values associated with her inter-locutors ;
– promote∗i : K∗i → V ∗i is the extension
of the function promotei mapping claimsin the extended personal KBase to theextended set of personal values. On theone hand, personal claims relate to per-sonal values. On the other hand, claimsin the commitment store CS i j relate to the
reputation value vi j ;
– ≪∗i is the agent extended priority rela-
tion, i.e. an ordered relation on V ∗i .
Since the debate is a collaborative socialprocess, agents share common claims of
prime importance. That is the reason whywe consider that the common values havepriority over the other values.An agent a1may estimate herself more competent thanher interlocutor a2 and her personal values
Debating over heterogeneous descriptions ___________________________________________________________________________
220

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 233/415
have priority over v12, i.e. the reputation va-
lue of the agent a2. In this case, the ex-tended priority relation of the agent a1 isconstrained as follows : ∀vω ∈ V ΩA∀v ∈V 1 − V ΩA (v12 ≪∗
1 v ≪∗1 vω). We can ea-
sily demonstrate that the extended priorityrelation is a strict complete ordering rela-tion. The one-agent notion of conviction isthen defined as follows :
Definition 9 Let ai ∈ A be an agent as-sociated with the extended KBase
AK ∗i = K∗i , V ∗i , promote∗i , ≪∗
i and let
φ ∈ ALC be a claim. The agent ai isconvinced by the claim φ iff φ is theconclusion of an acceptable argument for the audience ai with respect to A(K∗
i ). Theset of acceptable arguments for the au-dience ai with respect to A(K∗
i ) is denoted by S ∗i .
Let us know consider how claims areproduced. Agents utter messages to ex-
change their representations. The syntaxof messages is in conformance with thecommon communication language, CL.A message M k = S k, H k, Ak ∈ C Lhas an identifier M k. It is uttered by aspeaker (S k = speaker(M k)) and addres-sed to an hearer (H k = hearer(M k)).Ak = act(M k), the message speechact, is composed of a locution and acontent. The locution is one of the
following : question, requestassert, propose, refuse,unknow, concede, challenge,withdraw. The content, also calledassumption, is a claim or a set of claims inALC .
Speech acts have a public semantic, sincecommitments enrich the extended KBaseof the creditors, and an argumentativesemantic, since commitments are justi-
fied by the extended KBase of the deb-tor. For example, Figure 3 shows thesemantics associated with the assertionof an assumption. An agent can pro-pose an assumption if she has an ar-
gument for it. The corresponding com-mitments stores are updated. The speechact propose has the same argumenta-tive/public semantics. refuse(φ) is equi-valent to assert(¬φ). As we will seein Section 7, these latter do not have thesame place in the sequence. The rationalconditions for the assertion and for theconcession of the same assumption by thesame agent are different. Agents can assertan assumption whether they are supportedby a trivial argument or not. By contrast,agents do not concede all the assumptionsthey hear in spite of all assumptions are
supported by a trivial argument.The others speech acts (question,request, unknow, challenge, andwithdraw) are used to manage the se-quence of moves (see Section 7). Theyhave no particular effects on commitmentsstores, neither particular rational condi-tions of utterance. We assume that thecommitments stores are cumulative, i.e. nocommitment can be retracted. This is thereason why the speech act withdraw(h)has no effect on the commitments stores.
The assumptions which are received mustbe valuated. For this purpose, commit-ments will be individually considered inaccordance with the speaker estimated re-putation. The following example illus-trates this principle.
Example 2 Let us consider two agents,a service provider (denoted prov) and acustomer (denoted cust). It is worth re-calling that the service provider considersthat customer’s claims make authorityand adjust her own representation toadopt these claims. The initial personalKBase of the service provider is the set φ1(x), φ3(x)φ4(x), φ5(x), φ61(x), φ71, φ72and the personal KBase of the customer
is the set φ1(x), φ2(x), φ4(x), φ62(x). If the customer utters the two followingmessages :
– M 1 = cust , prov,assert(¬Free(acrobat )) ,
____________________________________________________________________________ Annales du LAMSADE N°8
221

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 234/415
FIG . 3 – Semantics for asserting an assumption φ at time t• MESSAGE : M l = ai, a j , assert(φ)– ARGUMENTATIVE SEMANTICS : ∃A ∈ A(K∗
i ) conc(A) = φ
– PUBLIC SEMANTICS : For any agent ak in the audienceif φ ∈ A(K∗
k) then CSki (t) = CSki (t − 1) ∪ φ
– M 2 = cust , prov,assert(φ2(acrobat ), φ4(acrobat ), φ71).
then the extended KBase of the service provider is represented as in Table 1. Theextended KBase of the service provider is composed of her personal claims and
the claims advanced by the customer.The extended set of personal values iscomposed of the set of personal valuesand the reputation value of the customer.The common claim φ1(x) is related tothe common value v1. The claims in thecommitments is related to the reputationvalue of the customer. By uttering themessage M 1 , the customer advances thetrivial argument B3 =
[¬
Free(acrobat )],¬
Free(acrobat ).
Despite the service provider is convinced by this assumption, she cannot concede it.
Indeed, this assumption is only supported by a trivial argument in the commitment stores. By uttering the message M 2 , thecustomer advances the non-trivial argu-ment B2 bearing on the service provider own claims. Therefore, this last one canconcede ¬Free(acrobat ). The only freesoftware she can propose is xpdf.
We have presented here a model of agentswho exchange assumptions and argue. Inthe next section, we provide a dialecticalsystem where debates take place.
6 Dialectical system
When a set of social and autonomous
agents argue, they reply to each other inorder to reach the goal of the interaction.We provide a dialectical system, which isinspired by [7] and adapted to the dialogueon representations.
During exchanges, the speech acts arenot isolated but they respond each other.The syntax of moves is in conformancewith the common moves language : MLdefined as follows : a move movek =M k, Rk, P k ∈ M L has an identifier
movek. It contains a message M k as de-fined before. The moves are messageswith some attributes to control the se-quence. Rk = reply(movek) is the iden-tifier of the move to which movek re-sponds. A move (movek) is either an ini-tial move (reply(movek) = nil) or a re-plying move (reply(movek) = nil). Pk =protocol(movek) is the name of the proto-col which is used during the dialogue.
A dialectical system is composed of twoagents. In this formal area, two agents playmoves to check an initial assumption, i.e.the topic.
Definition 10 Let AK ΩA = KΩA
, V ΩA , promoteΩAbe a common value-based KBaseand φ0 a claim in ALC . The dia-
lectical system on the topic φ0 isa quintuple DS ΩM
(φ0, AK ΩA) =N,H,T, protocol, Z where :
– N = init, part ⊂ A is a set of twoagents called players : the initiator and the partner ;
– H is the set of histories, i.e. the se-quences of well-formed moves s.t. thespeaker of a move is determined at eachstage by a turn-taking function and the
moves agree with a protocol ; – T : H → N is the turn-taking func-
tion determining the speaker of a move. If |h| = 2n then T (h) = init elseT (h) = part ;
Debating over heterogeneous descriptions ___________________________________________________________________________
222

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 235/415

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 236/415
TAB . 2 – Set of speech acts and their potential answers.Sequences rules Speech acts Resisting replies Surrendering repliessrQ/A question(φ) assert(φ) unknow(φ)
assert(¬φ)srR/P request(φ(x)) propose(φ(a)) unknow(φ(x))srA/W assert(Φ) challenge(φ), φ ∈ Φ concede(Φ)
refuse(φ), φ ∈ ΦsrC/A challenge(φ) assert(Φ), Φ ⊢ φ withdraw(φ)
over representations by verbal means. Thefollowing example illustrates such a dia-logue.
Example 3 Let us consider again the dia-logue presented in Section 2. Table 3shows how, using the protocol, the twoagents play the dialogue. This table detailsthe different moves corresponding to theclaims of the natural language dialogue.We can see that the commitments storesare the results of moves. At the beginningof the dialogue, φ1 is the only claims ex-
plicitly shared by the agents (KΩA). Du-
ring exchanges, the service provider de-tects that she shares φ4 with the custo-mer. At the end of the dialogue, the set of claims explicitly shared increases. In other terms, the agents co-build a common onto-logy during the dialogue.
8 Related works
[6] provides a framework for agents toreach an agreement over ontology align-ment. Argumentation is used to select acorrespondence among candidate corres-pondences, according to the ontologicalknowledge and the agents’ preferences.This approach is static because alignmentshave been achieved off-line. [10] proposesthe ANEMONE approach for solving se-
mantic integration problems. Instead of trying to solve ontology problems at de-sign time, ANEMONE provides agentswith tools to overcome ontology problemsat agent interaction time and focus on the
layered communication mechanism. [9]proposes a framework to solve on-line thesemantic heterogeneity by exploiting the
topological properties of the representa-tion. This work considers one-shot inter-action steps. As we have already said, wehave extended the formal framework forinter-agents dialogue based upon the ar-gumentative techniques proposed by [7].Since the denotational semantics of thedescription logic is adapted to the know-ledge representation, the background logichas shift from the first order logic program
to the description logic.
9 Conclusion
In this paper, we have proposed a frame-work for inter-agents dialogue to reach anagreement, which formalizes a debate inwhich divergent representations are dis-cussed. For this purpose, we have propo-sed an argumentation-based representationframework which manages the conflictsbetween claims with different relevancesfor different audiences to compute their ac-ceptance. Moreover, we have proposed amodel for the reasoning of agents wherethey justify the claims to which they com-mit and take into account the claims of their interlocutors. We provide a dialec-tical system in which two agents partici-pate in a dialogue to reach an agreement
about a conflict in representations. In thiswork, we have focused on multi-agent sys-tems but, as suggested by the example, ourapproach is also relevant to the SemanticWeb, where different services performing
Debating over heterogeneous descriptions ___________________________________________________________________________
224

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 237/415
TAB . 3 – Dialogue to reach an agreement. Natural language sentences, corresponding tothe dialogue presented in 2, are given in association with their dialogue , then the new thecommitment stores and the reached game situation are given.
K∗cust − KΩA
KΩAK∗
prov − KΩA
φ1
Kcust CScustprov Game situation CSprov
cust Kprov
φ2(x), φ4(x) ∅ 0cust ∅ φ3(x), φ4(x), φ5(x),φ62(x). φ61(x), φ71, φ72.
Do you know free software to view my PDF ?→ move1 = cust, prov, request(Free(x)), nil, ReqMultiResPersProto →
idem ∅ 1prov ∅ idemacrobat is free software.
← move2 = prov, cust, propose(Free(acrobat)), move1, ReqMultiResPersProto ←idem Free(acrobat) 2.2cust ∅ idem
Why is it free software ?→ move3 = cust, prov, challenge(Free(acrobat)), move2, ReqMultiResPersProto →
idem Free(acrobat) 3.3prov ∅ idemacrobat is free because this is freeware.
← move4 = prov, cust, assert(φ3(acrobat), φ71), move3, ReqMultiResPersProto ←idem Free(acrobat), φ3(acrobat), φ71 4.3cust ∅ idem
In my humble opinion, acrobat is not free software.→ move5 = cust, prov, refuse(Free(acrobat)), move2, ReqMultiResPersProto →
idem Free(acrobat), φ3(acrobat), φ71 3.1prov ¬Free(acrobat) idemWhy is it not free software ?
← move6 = prov, cust, challenge(¬Free(acrobat)), move5, ReqMultiResPersProto ←idem Free(acrobat), φ3(acrobat), φ71. 4.1cust ¬Free(acrobat). idem
Since acrobat is freeware, this is not free software.→ move7 = assert(φ2(acrobat), φ4(acrobat), φ71), move6, ReqMultiResPersProto →
idem Free(acrobat), φ3(acrobat), φ71. 5.2prov ¬Free(acrobat), φ2(acrobat). idemOK, however xpdf is free software.
← move8 = prov, cust, propose(Free(xpdf )), move1, ReqMultiResPersProto ←idem Free(acrobat), φ3(acrobat), φ71, 2.2cust ¬Free(acrobat), φ2(acrobat). idem
Free(xpdf ).Why is it free software ?
→ move9 = cust, prov, challenge(Free(xpdf )), move8, ReqMultiResPersProto →idem Free(acrobat), φ3(acrobat), φ71, 3.3prov ¬Free(acrobat), φ2(acrobat). idem
Free(xpdf ). xpdf is free software because it is opensource.
← move10 = prov, cust, assert(Opensource(xpdf ), φ5(xpdf )), move9, ReqMultiResPersProto ←idem Free(acrobat), φ3(acrobat), φ71, 4.3cust ¬Free(acrobat), φ2(acrobat). idem
Free(xpdf ), Opensource(xpdf ), φ5(xpdf ).Why is it opensource ?
→ move11 = prov, cust, challenge(Opensource(xpdf )), move10, ReqMultiResPersProto →idem Free(acrobat), φ3(acrobat), φ71, 5.5prov ¬Free(acrobat), φ2(acrobat). idem
Free(xpdf ), Opensource(xpdf ), φ5(xpdf ). xpdf is opensource because it is copyleft.
← move12 = prov, cust, assert(φ72(xpdf ), φ61(xpdf )), move11, ReqMultiResPersProto ←idem Free(acrobat), φ3(acrobat), φ71, 6.2cust ¬Free(acrobat), φ2(acrobat). idem
Free(xpdf ), Opensource(xpdf ), φ5(xpdf ),φ72(xpdf ), φ61(xpdf ).
OK, I will consider xpdf ?→ move13 = prov, cust, concede(Free(xpdf )), move8, ReqMultiResPersProto →
idem Free(acrobat), φ3(acrobat), φ71, 3.2 ¬Free(acrobat), φ2(acrobat), idemFree(xpdf ), Opensource(xpdf ), φ5(xpdf ),
φ72(xpdf ), φ61(xpdf ).
____________________________________________________________________________ Annales du LAMSADE N°8
225

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 238/415
the same tasks may advertise their capabi-lities differently, or where service requests,and service offers may be expressed byusing different ontologies, and thus needto be reconciled dynamically at run time.While this work focuses on single dia-logues between two heterogeneous agents,future investigations must explore how thissolution, when it will be implemented,scales to multi-agent systems where dia-logues are amongst multiple parties andsequenced.
Acknowledgements
The authors like to thank Yann Secq, Jean-Paul Sansonnet, and Philippe Mathieu fortheir willingness to discuss this issue withus. Thanks are also due to Fariba Sadri andPaolo Mancarella for their advice to im-prove the English of this paper. We wouldlike to thank the anonymous reviewers fortheir detailed comments on this paper. The
first author is supported by the Sixth Fra-mework IST programme of the EC, un-der the 035200 ARGUGRID project. Thesecond author is supported by the CPERTAC of the region Nord-Pas de calais andthe european fund FEDER.
Références
[1] S. Bailin and W. Truszkowski On-tology negotiation between intelligent information agents Knowledge En-gineering Review, 17(1), pages 7–19,Cambridge University Press (2002).
[2] T.J.M Bench-Capon. Value based argumentation frameworks. In Pro-ceedings of NMR’02, pages 444–453,Toulouse, France (2002).
[3] Phan Minh Dung. On the acceptabi-
lity of arguments and its fundamentalrole in nonmonotonic reasoning, logic
programming and n-person games Ar-tificial Intelligence, 77(2), pages 321–357, Springer-Verlag (1995).
[4] Jérôme Euzenat and Petko ValtchevSimilarity-Based Ontology Alignment in OWL-Lite in Proc. of ECAI, pages333-337, IOS Press (2004).
[5] Thomas R. Gruber Toward prin-ciples for the design of ontologies used
for knowledge sharing Internatio-nal Journal of Human-Computer Stu-dies, 43(5-6), pages 907–928, Acade-mic Press (1995).
[6] Loredana Laera Valentina Tamma,Jérôme Euzenat, Trevor Bench-Caponand Terry Payne Reaching agreement
over ontology alignments. In Proc.of ISWC, pages 371-384, Springer-Verlag (2006).
[7] Maxime Morge Collective decisionmaking process to compose divergent interests and perspectives Artificial In-telligence and Law, 13(1), pages 75-92, Springer-Verlag, (2005).
[8] Schmidt-Schauß M. and Smolka, G. Attributive concept descriptions with
complements Artificial Intelligence,48(1), pages 1–26, Springer-Verlag(1991).
[9] Erika Valencia and Jean-Paul Sanson-net Building Semantic Channels bet-ween Heterogeneous Agents with To-
pological Tools In Proc. of ESAW,Barcelona, Spain (2004).
[10] Van Digglen Jurriaan, Beun Robbert-
Jan, Dignum Frank, Van Eijk Rogierand Meyer John-Jules Anemone : Aneffective minimal ontology negotiationenvironment In Proc. of AAMAS,pages 899–906, ACM Press (2006).
[11] Douglas N. Walton and Eric C. W.Krabbe Commitment in Dialogue,SUNY Press (1995).
Debating over heterogeneous descriptions ___________________________________________________________________________
226

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 239/415
Vers un modèle formel des émotionsd’un agent rationnel dialoguant empathique
M. Ochs† D. Sadek C. Pelachaud†
Orange Labs, Francemagalie.ochs, [email protected]†Laboratoire LINC, Université Paris 8, France
Résumé :Les travaux présentés dans cet article visent à
concevoir et mettre en oeuvre des agents rationnelsdialoguants capables d’exprimer des émotions, etplus particulièrement des émotions d’empathie, du-rant leur interaction avec l’utilisateur afin d’amé-liorer l’interaction humain-machine. Pour ce faire,les agents rationnels dialoguants doivent être ca-pables d’identifier les situations d’interaction danslesquelles leur interlocuteur peut ressentir des émo-tions. A partir de la littérature en psychologie cog-nitive et d’une analyse d’un corpus de dialoguesréels humain-machine, nous avons identifié cer-taines circonstances de déclenchement d’émotionspositives et négatives pouvant apparaître dans uneinteraction humain-machine. Sur cette base, un mo-dèle formel d’émotions d’un agent rationnel dia-loguant a été construit. Les conditions de déclen-chement d’émotions sont représentées par des étatsmentaux particuliers, i.e. par des combinaisons par-ticulières de croyances, d’incertitudes et d’inten-tions. L’intensité de l’émotion est calculée à partirde l’état mental de l’agent. Cette formalisation desémotions permet de représenter les émotions d’em-pathie envers d’autres agents.
Mots-clés : Émotions, empathie, agent rationnel
dialoguant
Abstract:The work presented in this paper aims to developrational dialog agents able to express emotions, andmore particularly empathic emotions, during theirinteraction with a user in order to enhance human-machine interaction. An empathic rational dialogagent should know the circumstances under whicha user may feel an emotion. Relying on psychologi-cal theory of emotion elicitation and on a study of real human-machine dialogs during which the user
expresses emotions, we have highlighted some si-tuations that may lead to a user’s emotion elicita-tion. From the descriptions of these emotional si-tuations, a formal model of emotions for a rationaldialog agent has been designed. The conditions of emotion elicitation are represented in terms of par-
ticular mental states, i.e. particular combinations of beliefs, uncertainties, and intentions. The intensity
of emotions is computed from the agent’s mentalstate. This formalization of emotions is used to re-present empathic emotions.
Keywords: Emotions, empathy, rational dialogagent
1 Introduction
Ces dernières années, un intérêt grandis-
sant est apparu pour la conception et ledéveloppement d’agents conversation-nels capables de dialoguer naturellementavec un utilisateur. Ces agents sont sou-vent utilisés pour interpréter des rôlestypiquement incarnés par des humains,comme par exemple le rôle de tuteur [Johnson et al., 2000]. Des recherchesrécentes ont montré que les expressionsd’émotions d’agents virtuels permettentde créer une illusion de vie et ainsi d’aug-menter leur crédibilité (traduction duterme anglais believability) [Bates, 1994].De plus, comme l’a souligné Picard[Picard, 1997], l’utilisateur ressent denombreuses émotions durant son inter-action avec un ordinateur. Il peut, parexemple, ressentir et exprimer des émo-tions négatives lors de défaillances dusystème informatique ou des émotionspositives lorsqu’il réalise une tâche avec
succès. Les premières recherches semblentmontrer que l’expression d’émotions em- pathiques d’un agent conversationnelpermet d’améliorer la perception qu’al’utilisateur de l’agent, d’induire des
227

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 240/415
émotions positives et d’augmenter lesperformances et l’engagement de l’uti-lisateur dans la réalisation d’une tâchedurant l’interaction [Brave et al., 2005,Helmut and Mitsuru, 2005].
Les travaux présentés dans cet articlevisent à concevoir et mettre en oeuvredes agents conversationnels capables d’ex-primer des émotions, et plus particuliè-rement des émotions d’empathie, durantleur communication avec l’utilisateur afind’améliorer l’interaction humain-machine.L’empathie se définit comme “la capacité
de se mettre mentalement à la place d’au-trui afin de comprendre ce qu’il éprou-ve” [Pacherie, 2004]. Lors du processusd’empathie, un individu simule mentale-ment une situation vécue par une autrepersonne; il s’imagine à sa place (c’est-à-dire avec les mêmes buts et les mêmescroyances et dans cette même situation)et imagine alors l’émotion ressentie parcette personne. Par cette simulation émo-
tionnelle, l’individu peut être amené à res-sentir une émotion similaire, appelée dansce cas émotion empathique [Poggi, 2004].
Dans une interaction humain-machine, unagent conversationnel exprime une émo-tion empathique lorsqu’il pense que dansla situation de l’utilisateur il “ressenti-rait” la même émotion. Cette croyancesur l’état émotionnel potentiel de l’uti-lisateur doit être issue non pas de laperception de l’émotion (dans ce casil s’agirait d’une contagion émotionnelle[Poggi, 2004]), mais de la simulation duprocessus de déclenchement des émo-tions de l’utilisateur. En d’autres termes,un agent conversationnel empathique doit,en adoptant la perspective de l’utilisa-teur, en déduire ses émotions. Par consé-quent, il doit connaître les conditionsdans lesquelles un individu peut poten-
tiellement ressentir une émotion. A par-tir d’une analyse de corpus de dialogueshumain-machine dans lesquels l’utilisa-teur exprime des émotions et à la lumièrede théories de psychologie cognitive, nous
avons mis en évidence les circonstances dedéclenchement de certaines émotions del’utilisateur. Dans cet article, nous propo-sons une modélisation et une formalisationde ces émotions et de leurs conditions dedéclenchement. Les agents conversation-nels auxquels nous nous intéressons plusparticulièrement sont les agents rationnelsdialoguants, des agents de type BDI fon-dés sur une théorie formelle de l’interac-tion, appelée Théorie de l’Interaction Ra-tionnelle [Sadek, 1991]. Afin de doter cesagents de la capacité d’inférer les émotionspotentiellement ressenties par l’utilisateur
durant l’interaction, les conditions de dé-clenchement d’émotions sont décrites àpartir des attitudes mentales de croyance,d’incertitude et d’intention d’un agent ra-tionnel. L’intensité des émotions est calcu-lée à partir de l’état mental de l’agent.
Dans une première partie, nous décri-vons les caractéristiques des émotions etde leur condition de déclenchement. Dansune seconde partie, après avoir introduit leconcept d’agent rationnel dialoguant, nousprésentons une formalisation des émotionset de leur intensité.
2 Les émotions dans une inter-action humain-machine
Afin de déterminer à quel moment ex-primer une émotion empathique, l’agentconversationnel doit connaître les situa-tions d’interaction dans lesquelles l’uti-lisateur pourrait potentiellement ressentirune émotion. Notre approche pour déter-miner les conditions de déclenchement desémotions d’un utilisateur durant l’interac-tion est fondée à la fois sur des théories
cognitives des émotions (appelées théoriesde l’évaluation cognitive) et sur une ana-lyse de corpus de dialogues réels humain-machine où l’utilisateur exprime des émo-tions.
Vers un modèle formel des émotions d'un agent rationnel dialoguant empathique ___________________________________________________________________________
228

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 241/415
2.1 Les conditions de déclenchement
des émotions
Les théories de l’évaluation cognitive.Les théories de l’évaluation cogni-
tive (appraisal) (e.g. [Scherer, 2000,Roseman, 2001, Ortony et al., 1988])visent à expliquer ce qui conditionnel’émergence d’une émotion particu-lière pour un individu donné. Selonces théories, une émotion est issue del’évaluation subjective d’un évènement[Scherer, 2000]. Un évènement est géné-
rateur d’émotion seulement si l’individupense que cet évènement affecte un deses buts [Lazarus, 2001]. Un des élémentsdéterminant dans le déclenchement d’uneémotion est la relation entre l’évènement et le but de l’individu (i.e. l’impact del’évènement sur le but). Par exemple, uneémotion de peur est déclenchée chez unindividu lorsqu’il pense que son but desurvie est menacé. Généralement, uneémotion positive est générée quand l’évè-nement facilite ou permet de réaliser unbut. Elle est négative lorsque l’évènemententrave la réalisation d’un but. L’interpré-tation de l’évènement, et par conséquentl’émotion déclenchée, dépendent princi-palement des buts de l’individu et de sescroyances (sur l’évènement et ses consé-quences). L’implication de ces attitudesmentales propres à chaque individu dansle déclenchement des émotions permet
d’expliquer les réactions émotionnellesdifférentes d’individus distincts face à unemême situation.
L’analyse des corpus de dialogues humain-
machine.
Afin d’identifier plus concrètement lesconditions de déclenchement des émotionsd’un utilisateur lors de son interaction avecun agent conversationnel, nous avons ana-
lysé des dialogues qui ont amené l’utili-sateur à exprimer des émotions. L’objectif est de déterminer les caractéristiques dessituations dialogiques génératrices d’émo-tions dans le contexte de dialogue humain-
machine. Les dialogues ont été annotésafin de mettre en évidence les croyanceset les buts des utilisateurs dans les situa-tions émotionnelles. Les dialogues analy-sés sont issus de deux applications vocalesdéveloppées à Orange Labs où l’utilisa-teur interagit oralement avec un agent dia-loguant pour obtenir une information dansun domaine particulier (transactions bour-sières, guide de restaurants). Un schémade codage, fondé à la fois sur des théoriesde l’évaluation cognitive [Scherer, 2000,Ortony et al., 1988] et sur la théorie desactes de langage [Austin, 1962], a été
utilisé pour l’annotation (pour plus dedétails sur le schéma de codage, desexemples de dialogues et l’analyse descorpus voir [Ochs et al., 2006]). L’analysedes dialogues annotés a permis de mettreen évidence les hypothèses ci-dessoussur les situations génératrices d’émotionsnégatives1 dans une interaction humain-machine. Un évènement peut être déclen-cheur d’émotions négatives chez l’utilisa-
teur lorsqu’il entraîne l’une des situationssuivantes :
– l’échec d’une tentative de satisfactiond’intention2 de l’utilisateur qu’il pensaitpouvoir satisfaire ;
– un conflit de croyance sur une intention :l’utilisateur pense que l’agent conversa-tionnel considère que l’utilisateur a uneintention que celui-ci n’a pas.
Les théories de l’évaluation cognitive etles hypothèses issues de l’analyse de cor-pus de dialogues permettent de mettreen évidence certaines situations dans les-quelles des émotions (positives ou néga-tives) d’un utilisateur peuvent être déclen-chées. Par ailleurs, un agent conversation-nel empathique doit aussi être capable dese représenter une émotion.
1Dans le corpus de dialogues, aucun cas d’expressiond’émotion positive n’a pu être étudié.
2Dans les dialogues humain-machine étudiés, nous avonsplus particulièrement observé les intentions de l’utilisateur etde l’agent. Une intention est un but persistant d’avoir agi pour
atteindre une situation donnée [Sadek, 1991].
____________________________________________________________________________ Annales du LAMSADE N°8
229

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 242/415
2.2 La représentation des émotions
d’un agent conversationnel
Généralement, une émotion est représen-tée par différentes caractéristiques. Nousprésentons ci-dessous celles nécessaires àla description des émotions d’un agentconversationnel.
Les types d’émotion.
Une émotion est généralementdécrite par son type (comme parexemple la joie, la satisfaction, la
colère, la frustration, etc.). Selonles théories de l’évaluation cognitive[Scherer, 2000, Ortony et al., 1988], cesont les conditions de déclenchementde l’émotion qui déterminent son type.Le type d’une émotion renseigne géné-ralement sur la valence (positive versusnégative) de l’émotion. Dans cet article,nous distinguons les types d’émotionsuivant leur valence : nous regroupons les
types d’émotion positive (respectivement
négative) sous le terme émotion positive(respectivement négative).
Les émotions dirigées vers autrui.
Certains types d’émotion ont commecible autrui. Par exemple, on est en colèrecontre quelqu’un ou on admire quelqu’un.Ces types d’émotions sont alors caractéri-sées par la personne vers qui est dirigée
l’émotion.Les émotions d’empathie, quelles que soitleur type, sont, elles aussi, par définitiondes émotions dirigées vers une autre per-sonne, celle pour laquelle on a de l’empa-thie. On est par exemple joyeux pour quel-qu’un ou triste pour quelqu’un d’autre.Elles sont donc caractérisées par la per-sonne vers qui est dirigée l’émotion d’em-pathie. De plus, dans le cas de certains
types d’émotions d’empathie comme lacolère ou l’admiration, l’émotion est diri-gée vers deux individus distincts : l’indi-vidu pour qui on a de l’empathie et l’indi-vidu cible. Par exemple, dans le cas de la
colère, un individu a une émotion d’empa-thie de colère pour un individu a contre unindividu b.
Comme dans le modèle OCC[Ortony et al., 1988], nous distinguonsles émotions empathiques des émotionsnon empathiques. Par conséquent, le faitqu’un agent soit joyeux pour quelqu’unne signifie pas qu’il a une émotion nonempathique de joie.
L’intensité d’une émotion.
A une émotion est généralement as-
sociée une valeur numérique représen-tant son intensité. L’intensité des émo-tions est déterminée par des valeurs devariables appelées variables d’intensité [Ortony et al., 1988]. Dans le contexte dudialogue humain-machine, nous considé-rons les variables d’intensité suivantes :– le degré de certitude d’une informa-
tion représente la probabilité qu’une in-formation soit vraie selon l’individu.
D’après notre analyse de corpus (§ 2.1),dans le cas de l’échec d’une tenta-tive de satisfaction d’une intention, l’in-tensité de l’émotion négative sembleêtre proportionnelle au degré de cer-titude : plus un agent était certain(avant l’évènement) de pouvoir satis-faire son intention par l’évènement quivient d’avoir lieu, plus l’émotion né-gative générée par l’échec est forte. Al’inverse, nous supposons, fondé sur lemodèle OCC [Ortony et al., 1988], quel’intensité d’une émotion positive est in-versement proportionnelle au degré decertitude : plus un agent était incertainavant l’évènement (i.e. plus le degré decertitude était faible) de pouvoir satis-faire son intention par l’évènement quivient d’avoir lieu, plus l’émotion posi-tive générée par la satisfaction de l’in-tention est forte.
– l’effort investi par un individu pour ten-ter d’atteindre un but va influencer l’in-tensité de l’émotion déclenchée. L’in-tensité de l’émotion est généralementd’autant plus forte que l’effort pour
Vers un modèle formel des émotions d'un agent rationnel dialoguant empathique ___________________________________________________________________________
230

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 243/415
tenter de satisfaire le but est impor-tant [Ortony et al., 1988]. Ainsi, lors del’échec d’une tentative de satisfactiond’une intention d’un individu, l’émotiondéclenchée sera d’autant plus forte qu’ilaura investi beaucoup d’effort pour ten-ter de la satisfaire.
– le potentiel de réaction : lors de l’échecd’une tentative de satisfaction d’une in-tention, nous émettons l’hypothèse quesi l’individu pense pouvoir satisfaire sonintention par une autre action, l’intensitéde l’émotion déclenchée est moins forte.
– l’importance pour l’individu que son
intention soit satisfaite : lorsqu’unévènement permet la satisfaction ouengendre l’échec d’une tentative de sa-tisfaction d’une intention de l’individu,l’intensité de l’émotion est proportion-nelle à l’importance pour l’individu quecette intention soit satisfaite. Typique-ment, l’intention de “fermer une porte”est généralement moins importante quecelle d’“être heureux”. Lors de l’échec
de l’intention de “fermer la porte”,l’intensité de l’émotion déclenchée estmoins forte que dans le cas de l’échecde l’intention d’“être heureux”.
En résumé, une émotion peut être repré-sentée par ses conditions de déclenche-ment lesquelles vont déterminer son type,sa direction et son intensité .
3 Modélisation et formalisationdes émotions d’un agent ra-tionnel dialoguant
A partir de la description des caractéris-tiques d’une émotion introduite ci-dessus,un modèle formel de l’émotion fondé surun modèle des états mentaux d’un agent
rationnel dialoguant a été construit. Aprèsune introduction du concept d’agent ra-tionnel dialoguant, nous présentons plusen détails la modélisation et la formalisa-tion des émotions.
3.1 Le concept d’agent rationnel dia-
loguant
Nous nous appuyons sur un modèled’agent rationnel fondé sur une théorie for-melle de l’interaction (appelée Théorie del’Interaction Rationnelle [Sadek, 1991])reposantsuruneapprochedetypeBDI.Unagent rationnel dialoguant utilise les atti-tudes mentales suivantes pour raisonner etagir sur son environnement :– La croyance : une proposition consti-
tue une croyance d’un agent si celui-ci
considère que cette proposition est vraie.La croyance est l’attitude mentale par la-quelle un agent dispose d’un modèle dumonde dans lequel il évolue.
– L’incertitude : une proposition consti-tue une incertitude d’un agent si celui-ci n’est pas tout à fait certain que cetteproposition est vraie.
– Le choix : une proposition constitue unchoix d’un agent si celui-ci préfère que
le monde actuel satisfasse cette proposi-tion.– L’intention : une proposition constitue
l’intention d’un agent lorsque (1) ilpense que la proposition n’est actuel-lement pas vérifiée, (2) il désire defaçon persistante que cette propriétésoit réalisée jusqu’à ce qu’il pense cetteproposition satisfaite ou impossible àsatisfaire et (3) il souhaite accomplirle début de toute séquence d’actions(éventuellement multi-agent) qui peutaboutir à la satisfaction de la proposi-tion.
Dans la Théorie de l’Interaction Ration-nelle [Sadek, 1991], les concepts d’atti-tudes mentales décrits ci-dessus sont for-malisés dans le cadre d’une logique mo-dale du premier ordre. Nous introduisonsbrièvement les aspects du formalisme dont
nous nous servons. Dans la suite les sym-boles ¬, ∧ ,∨ , ⇒ et ⇔ représententles connecteurs logiques classiques de né-gation, conjonction, disjonction, implica-tion et équivalence. Les symboles ∃ et
____________________________________________________________________________ Annales du LAMSADE N°8
231

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 244/415
∀ représentent les quantificateurs existen-tiels et universels, φ et ψ des formules,c, c1 des variables numériques, i, j et kdes variables schématiques dénotant desagents, type une variable représentant untype d’émotion, e, e1, e2 des séquencesd’évènements éventuellement vides. Lesattitudes mentales de croyance, d’incerti-tude et de choix sont formalisées respecti-vement par les opérateurs modaux B, U etC telqueBiφ peut être lue comme “l’agenti pense que φ est vraie”; U i,prφ peut êtrelue comme “l’agent i considère que φ aune probabilité pr d’être vraie” avec pr ∈
]0, 1[ ; C iφ peut être lue comme “l’agenti a le désir que φ soit vraie”. L’opérateurmodal composite d’intention I est définià partir des opérateurs de croyance et dechoix. La formule I iφ peut être lue comme“l’agent i a l’intention que φ soit vraie”.
Un agent passe d’un état mental à unautre suite à l’occurrence d’un évène-ment. La notion de temps est définie par
rapport aux évènements et formalisée àtravers les opérateurs Faisable et Fait.Faisable(e, φ) signifie que l’évènement epeut avoir lieu après quoi φ sera vraie.Cette opérateur décrit le futur proche. Laformule Fait(e, φ) signifie que l’évène-ment e vient juste d’avoir lieu avant quoi φétait vraie (Fait(e) ≡ Fait(e,vrai)). Cetopérateur décrit le passé proche. La notionde souvenir permet à un agent de compa-rer ses croyances courantes à ses croyancesantérieures à un évènement. Le souvenirde la croyance d’une proposition φ d’unagent i avant un évènement e est for-malisé par l’attitude mentale de croyancesuivante : Bi(Fait(e,Biφ)). L’abréviationUnitaire(e) signifie que e dénote un évè-nement unitaire. La formule Agent(i, e)est vrai si et seulement si l’agent i est l’au-teur de l’évènement e.
Les opérateurs B, C , Faisable et Faitobéissent à une sémantique des mondespossibles avec pour chaque opérateur unerelation d’accessibilité. La logique de lacroyance est KD45 (pour plus de détails
voir [Sadek, 1992]).
3.2 Modélisation et formalisation des
émotions d’un agent rationnel dia-loguant
La représentation d’une émotion déclenchée.
Un évènement ayant lieu dans l’envi-ronnement d’un agent peut générer uneémotion lorsqu’il affecte une de ses in-tentions (ou une intention de son interlo-cuteur)3. Nous appelons émotion déclen-chée une émotion qui vient d’être déclen-chée par un évènement. Elle est représen-tée par son type, son intensité , l’agent chezqui l’émotion a été déclenchée, l’agent vers qui elle est dirigée, l’évènement quil’a déclenché et l’intention affectée parl’évènement.
Pour modéliser les émotions déclenchéesnon empathiques, le langage logique estenrichi d’un opérateur modal d’émotion
Emotioni pour chaque agent i. La for-mule Emotioni(type,c,j,e,φ) peut êtrelue comme “l’agent dénoté par i a uneémotion non empathique de type type etd’intensité c envers l’agent j ; cette émo-tion est déclenchée par l’évènement eayant affecté l’intention de l’agent i deréa-liser la propriété dénotée par φ”. Lorsque iet j désigne le même agent, la formule re-présente une émotion non dirigée vers un
autre agent (§ 2.2). En effet, l’agent dé-notépar i représente à la fois celui chez quil’émotion est déclenchée et celui vers quielle est dirigée (une émotion non dirigéevers un autre agent est représentée par uneémotion dirigée vers l’agent lui-même).
Une émotion déclenchée d’empathie del’agent i pour l’agent j est représentée parl’opérateur modal Emotion_empi,j. Laformule Emotion_empi,j(type,c,k,e,φ)
3Dans cet article, nous nous intéressons exclusivement auxémotions déclenchées lorsqu’une intention de l’agent est affec-tée. Nous ne prenons pas en compte les émotions reliées auxchoix (au sens défini dans [Sadek, 1991]) et standards (au sensdéfini dans [Ortony et al., 1988]) de l’agent
Vers un modèle formel des émotions d'un agent rationnel dialoguant empathique ___________________________________________________________________________
232

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 245/415
peut être lue comme “l’agent dénoté par ia une émotion d’empathie envers l’agent jde type type et d’intensité c dirigée versl’agent k, cette émotion est déclenchéepar l’évènement e ayant affecté l’intentionde réaliser la propriété dénotée par φ del’agent j”. Le type de l’émotion représen-tée est non dirigée si j et k désignent lemême agent. Pour représenter l’émotiond’empathie de l’agent i pour l’agent j di-rigée vers l’agent k (comme par exemplel’empathie de l’agent i pour l’agent j decolère contre l’agent k), j et k doivent êtredistincts.
Une émotion déclenchée se définit par sesconditions de déclenchement, lesquellesvont déterminer le type de l’émotion,l’agent chez qui l’émotion est déclen-chée, l’agent vers qui est dirigée l’émo-tion, l’évènement déclencheur et l’inten-tion affectée. L’intensité de l’émotion dé-pend de ces paramètres. Nous introduisonsci-dessous une modélisation et formalisa-
tion des variables d’intensité utilisées dansla suite pour calculer l’intensité de l’émo-tion déclenchée. Nous définissons ensuiteformellement les émotions déclenchées.
L’intensité des émotions déclenchées.
A partir des descriptions des variablesd’intensité (présentées en § 2.2), nousavons modélisé et formalisé ces dernièrescomme suit.
Le degré de certitude de l’agent iconcernant la faisabilité d’une proposi-tion φ par un évènement e est notédeg_cert(i,e,φ) ∈ [0, 1] tel que :
deg_cert(i,e,φ) =0 ssi Bi(¬Faisable(e, φ))d_c ∈]0, 1[ ssi U i,d_c(Faisable(e, φ))1 ssi Bi(Faisable(e, φ))
En d’autres termes, si un agent pense quela proposition φ n’est pas satisfiable parl’évènement alors son degré de certitudeest nul. Dans le cas contraire, le degré decertitude est égal à 1. Enfin, si l’agent est
incertain quant à la satisfaction de la pro-position φ par l’évènement alors le de-gré de certitude est égal à la probabilitéavec laquelle l’agent pense cette proposi-tion faisable.
On note potentiel_reaction(i, φ) le po-tentiel de réaction de l’agent i face àl’échec d’une tentative de satisfactiond’une intention φ. Pour le calcul du po-tentiel de réaction, nous proposons les for-mules suivantes :
potentiel_reaction(i, φ) =
0 ssi Bi(∀e¬Faisable(e, φ))d_c ssi d_c = max proba|U i,proba(Faisable(e, φ)
1 ssi (∃eBi(Faisable(e, φ))
En d’autres termes, si un agent pensequ’il n’existe pas d’évènement permet-tant de satisfaire son intention qui vientd’échouer, le potentiel de réaction est nul.Dans le cas contraire, il est égal à la plushaute probabilité selon l’agent qu’une sé-
quence d’évènements lui permet de satis-faire son intention. Le potentiel de réactionest égal à 1 si l’agent pense qu’il existe uneséquence d’évènements permettant de sa-tisfaire son intention.
On définit l’effort d’un agent i pour ten-ter de satisfaire une intention φ (notéeffort(i, φ)) par le nombre d’actions ef-fectuées par l’agent pour tenter de satis-faire son intention φ :
effort(i, φ) = n, n ∈ N tel queSoit Evt = e1, . . . , em tel queBi(Fait(e1; . . . ; em,
Faisable(e1; . . . ; em, φ)))
n = carde ∈ Evt,Unitaire(e)∧
∃e, eFait(e; e; e) ∧ Agent(i, e)
Remarque : Les séquences d’évènementse
et e
(pouvant être vides) sont intro-duites dans la formule ci-dessus afin de ca-ractériser l’ensemble des évènements réa-lisés par l’agent lui-même et pas unique-ment le dernier évènement qui vient d’être
____________________________________________________________________________ Annales du LAMSADE N°8
233

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 246/415
réalisé par l’agent (qui se traduirait par laformule Fait(e) ∧ Agent(i, e)).
L’importance d’une intention φ pour un
agent i notée imp(i, φ) est un nombre réelpositif (imp(i, φ) ∈ +). Cette valeur re-présente l’importance pour l’agent que sonintention soit satisfaite. Elle doit être fixéepar le concepteur mais cela peut dériverd’un modèle de préférences de l’agent.
La fonction d’intensité détermine l’inten-sité d’une émotion suivant le degré decertitude, le potentiel de réaction, l’effort
et l’importance de l’intention. Ces quatreéléments constituent les paramètres de lafonction. Nous proposons la fonction d’in-tensité f _intensite suivante :
f _intensite(deg_cert(i,e,φ),
potentiel_reaction(i, φ),
effort(i, φ),imp(i, φ)) =
deg_cert(i,e,φ) ∗ potentiel_reaction(i, φ)∗
effort(i, φ) ∗ imp(i, φ)
Définitions formelles des émotions déclenchées.
Fondées sur la littérature et sur notreanalyse d’un corpus de dialogues (§2.1),les conditions de déclenchement des émo-tions ainsi que leur intensité sont modéli-sées et formalisées comme suit.
Nous introduisons tout d’abord quelques
définitions nous permettant de décrire dansla suite les conditions de déclenchementdes émotions :– l’échec d’une tentative de satisfaction
d’une intention ; soit φ une intention del’agent i, e l’évènement qui vient justed’avoir lieu :
echec_intentioni(e, φ) ≡def
Bi(Fait(e, I iφ ∧ (U i,p_r(Faisable(e, φ))
∨ Bi(Faisable(e, φ)))) ∧ ¬φ)
L’échec d’une tentative de satisfactiond’une intention signifie ainsi que (1)l’agent i pense qu’un évènement e
vient de se produire (Bi(Fait(e))),(2) l’agent avait avant l’évènement el’intention φ (I iφ), (3) il pensait avecune probabilité p_r (ou il était certainde) pouvoir satisfaire son intention φ parl’évènement e (U i,p_r(Faisable(e, φ)) ∨Bi(Faisable(e, φ))) et (4) après l’oc-currence de l’évènement e, l’intentionφ de l’agent n’est toujours pas satisfaite(Bi(¬φ)).
– la satisfaction d’une intention ; soit φune intention de l’agent i, e l’évènementqui vient juste de se produire :
real_intentioni(e, φ) ≡def
Bi(Fait(e, I iφ ∧ ¬Bi(Faisble(e, φ)) ∧ φ)
La formule de satisfaction d’une in-tention signifie que (1) l’agent i pensequ’un évènement e vient d’avoir lieu(Bi(Fait(e))), (2) l’agent avait avantl’évènement e l’intention φ (I iφ), (3)il n’avait pas la croyance que l’occur-
rence de l’évènement e allait permettrela satisfaction de son intention φ(¬Bi(Faisable(e, φ)) et (4) après l’oc-currence de l’évènement e, l’intention φde l’agent est satisfaite (Bi(φ)).
– le conflit de croyance sur une intentionapparaît lorsqu’un agent considère queson interlocuteur pense qu’il a une inten-tion particulière que l’agent ne pense pas
avoir. Soit φ une propriété, i un agentet j son interlocuteur, e l’évènement quivient juste d’avoir lieu :
conflit_croyance_inti(e,φ,j) ≡def
Bi(Fait(e,¬B j(I i(φ)) ∧ ¬I i(φ))
∧ B j(I i(φ)) ∧ ¬I i(φ))
La formule de conflit de croyancesur une intention signifie que l’agenti pense qu’un évènement e vientde se produire (Bi(Fait(e))). Avantcet évènement, l’agent i n’avait pasl’intention φ (¬I i(φ)) et pensait quel’agent j n’avait pas la croyance qu’il
Vers un modèle formel des émotions d'un agent rationnel dialoguant empathique ___________________________________________________________________________
234

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 247/415
avait cette intention (Bi(¬B j(I i(φ)))).Après l’évènement e, l’agent i n’atoujours pas l’intention φ mais penseque l’agent j croit qu’il a cette intention(Bi(B j(I i(φ))))
Les émotions déclenchées positives non empa-
thiques.
Une émotion positive non empathique(et non dirigée) d’intensité c est déclen-chée chez l’agent i par un évènemente par rapport à une intention φ (notéeEmotioni( pos, c, i, e, φ)) lorsque l’évène-ment a entraîné la satisfaction d’une inten-tion de l’agent :
Emotioni( pos, c, i, e, φ) ≡def
real_intentioni(e, φ)avecc = f _intensite(1 − deg_cert(i,e,φ),
1,effort(i, φ),imp(i, φ))
L’intensité de l’émotion est alors propor-tionnelle à “1 - le degré de certitude del’agent quant à la faisabilité de son inten-tion par l’évènement”, proportionnelle àl’effort investi par l’agent et à l’importancepour lui que l’intention soit satisfaite. Lepotentiel de réaction n’est calculé que lorsde l’échec d’une intention (§ 2.2) (la va-leur passée en paramètre de la fonction estdonc 1).
Dans le modèle présenté ici, nous ne défi-nissons pas les émotions déclenchées po-sitives dirigées vers un autre agent (telleque l’admiration par exemple). Ces typesd’émotion semblent apparaître rarementdans le cadre d’une interaction humain-machine.
Les émotions déclenchées négatives non empa-
thiques.Une émotion négative (et non dirigée)
d’intensité c est déclenchée chez l’agent ipar un évènement e par rapport à une in-tention φ (notée Emotioni(neg,c,i,e,φ))
si l’évènement a entraîné l’échec d’unetentative de satisfaction d’une intention del’agent :
Emotioni(neg,c,i,e,φ) ≡def
echec_intentioni(e, φ)avecc = f _intensite(deg_cert(i,e,φ),
1 − potentiel_reaction(i, φ),
effort(i, φ),imp(i, φ))
L’intensité de l’émotion est proportion-nelle au degré de certitude, à l’effort et àl’importance de l’intention et à “1 - le po-tentiel de réaction”.
Une émotion négative causée par unautre agent est dirigée contre ce dernier.Une émotion négative de l’agent i en-vers l’agent j d’intensité c déclenchée parun évènement e ayant affecté la satisfac-tion d’une intention φ de l’agent est notéeEmotioni(type,c,j,e,φ). Cette émotion
est déclenchée lorsque l’échec d’une ten-tative de satisfaction d’intention (une émo-tion déclenché négative) est causé par unautre agent suite à un conflit de croyancesur cette intention.
Emotioni(neg,c,j,e,φ) ≡def
conflit_croyance_inti(e,ψ,j)∧
Emotioni(neg,c,i,e,φ)avecc = f _intensite(deg_cert(i,e,φ),
1 − potentiel_reaction(i, φ),
effort( j, ψ)+
effort(i, φ),imp(i, φ))
L’intensité de l’émotion est proportion-nelle au degré de certitude, à l’impor-tance de satisfaire l’intention, aux effortsde l’agent j et i et à “1 - le potentiel deréaction”.
Cette formalisation des émotions permetà un agent rationnel dialoguant d’identi-fier les situations dans lesquelles une émo-
____________________________________________________________________________ Annales du LAMSADE N°8
235

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 248/415
tion est potentiellement déclenchée chezun autre agent.
Les émotions déclenchées empathiques.L’agent rationnel dialoguant est empa-
thique.Ainsi,lefaitquel’agentauneémo-tion d’empathie envers un autre agent si-gnifie qu’il pense que ce dernier a uneémotion particulière. Nous définissons lesémotions déclenchées d’empathie commesuit :
Emotion_empi,j(type,c,k,e,φ) ≡def
Bi(Emotion j(type,c,k,e,φ) ∧ γ
En d’autres termes, le fait que l’agent i aune émotion d’empathie pour l’agent j detype type dirigée vers l’agent k et d’inten-sité c suite à l’évènement e ayant affectéune intention φ signifie que l’agent i penseque l’agent j a une émotion déclenchée(non empathique) de même type et demême intensité envers l’agent k suite à
l’évènement e ayant affecté une intentionφ de j. Les conditions de déclenchementd’une émotion d’empathie représentée parγ doivent être vérifiée. Elle représente lefait que l’agent i “aime bien” (au sensdéfini dans [Ortony et al., 1988]) l’agent j. Nous les supposons vraies dans notremodèle.Remarque : (1) Nous ne nous limi-tons pas aux deux types d’émotiond’empathie content pour quelqu’un
et désolé pour quelqu’un introduitsdans [Ortony et al., 1988]. En effet, uneémotion d’empathie est par définition[Poggi, 2004] du type de l’émotion res-sentie par celui envers qui l’émotiond’empathie est dirigée. Ainsi, on peutpar exemple avoir peur pour quelqu’un.(2) Nous supposons que l’émotion d’em-pathie est de même intensité que l’émotionde l’agent vers qui est dirigée l’émotion
d’empathie. Pour affiner le modèle, unefonction pour le calcul de l’intensité del’émotion d’empathie suivant l’intensitéde l’émotion de l’agent vers qui est dirigéecette émotion pourrait être introduite.
Axiomes propres.
Dans le contexte d’une interactionhumain-machine, on peut souhaiter que sil’agent pense que son interlocuteur a uneémotion positive ou négative non empa-thique dirigée vers lui alors l’agent lui-même aura cette émotion. Par exemple, sil’agent pense que l’utilisateur est en co-lère contre lui alors l’agent sera en co-lère contre lui-même. Ceci se traduit parl’axiome suivant :
Bi(Emotion j(type,c,i,e,φ))
⇒ Emotioni(type,c,i,e,φ)
De plus, nous ne souhaitons pas qu’unagent puisse adopter l’intention qu’unautre agent ressente des émotions néga-tives. Nous imposons donc au modèlel’axiome suivant :
¬I i(Emotion j(neg,c,k,e,φ))
Théorèmes.Étant donné l’axiome ci-dessus, uneémotion positive (resp. négative) ne peutêtre déclenchée par une émotion négative(resp. positive) d’un autre agent.
¬Emotioni( pos, c, i, e,
(Emotion j(neg,c1, z , e1, φ)))
¬Emotioni(neg,c,z,e,
(Emotion j( pos, c1, j ,e1, φ)))
Un même évènement ne peut pas déclen-cher à la fois une émotion positive et néga-tive par rapport à une même intention :
¬(Emotioni( pos, c, i, e, φ)∧
Emotioni(neg,c1,j ,e ,φ))
Il en est de même pour les émotions d’em-pathie :
¬(Emotion_empi,j( pos, c, j, e, φ)∧
Emotion_empi,j(neg,c1, z ,e ,φ))
Vers un modèle formel des émotions d'un agent rationnel dialoguant empathique ___________________________________________________________________________
236

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 249/415
La preuve découle des définitions desémotions empathiques et non empa-thiques.
L’agent est capable de s’introspecter surses propres émotions :
Emotioni(type,c,j,e,φ) ⇔
Bi(Emotioni(type,c,j,e,φ))
¬Emotioni(type,c,j,e,φ) ⇔
Bi(¬Emotioni(type,c,j,e,φ))
La preuve découle des définitions desémotions et du fait que la logique régissantl’opérateur de croyance est de type KD45.
Les modèles d’émotions existants.
Étant donnée l’étroite relationentre le déclenchement d’une émo-tion et les croyances et les buts d’unindividu, des modèles d’émotionsconstruits à partir d’attitudes men-
tales ont d’ores et déjà été propo-sés [Dyer, 1987, DeRosis et al., 2003,Meyer, 2006, Adam et al., 2006]. Lestravaux présentés dans cet article se dis-tinguent de ces derniers principalementpar l’originalité de la formalisation desémotions empathiques, non empathiqueset des variables d’intensité. De plus,contrairement aux modèles d’émotionsexistants, les conditions de déclenche-
ment d’émotions auxquelles nous nousintéressons sont fondées à la fois sur desthéories en psychologie cognitive et surune analyse de corpus de dialogues.
4 Conclusion et perspectives
Pour être capable d’exprimer des émotionsd’empathie envers un utilisateur, un agentrationnel dialoguant doit pouvoir identi-
fier les situations d’interaction dans les-quelles son interlocuteur peut ressentir desémotions observables. A partir de la litté-rature en psychologie cognitive et d’uneanalyse d’un corpus de dialogues réels
humain-machine, nous avons identifié cer-taines conditions dans lesquelles des émo-tions positives et négatives peuvent ap-paraître. Sur ces bases, un modèle for-mel d’émotions d’un agent rationnel dia-loguant a été construit. Les émotions sontdéfinies par leur condition de déclenche-ment lesquelles sont représentées par desétats mentaux particuliers, i.e. par descombinaisons particulières de croyances,d’incertitudes et d’intentions. L’intensitédel’émotionestcalculéeàpartirdecetétatmental. Cette formalisation permet la re-présentation des émotions d’empathie en-
vers d’autres agents. Les conditions de dé-clenchement d’émotions positives et néga-tives utilisées peuvent être enrichies afinde formaliser des types d’émotions plusfins, comme la joie, la satisfaction ou lafrustration.
Ce modèle d’émotions a été intégré dansun agent rationnel dialoguant couplé avecun visage parlant capable d’adopter diffé-
rentes expressions faciales suivant l’émo-tion déclenchée. La prochaine étape vise àévaluer, dans des situations réelles de dia-logue d’utilisateurs avec cet agent, la per-tinence des conditions de déclenchementdes émotions d’empathie de l’agent ainsique leur impact sur la satisfaction de l’uti-lisateur et sa perception du système.
Références
[Adam et al., 2006] Adam, C., Gaudou,B., Herzig, A., and Longin, D. (2006).Occ’s emotions : a formalization in abdi logic. In the Proceedings of the In-ternational Conference on Artificial In-telligence : Methodology, Systems, Ap-
plications.[Austin, 1962] Austin, J. (1962). How to
do things with words. Oxford Univer-
sity Press, London.[Bates, 1994] Bates, J. (1994). Therole of emotion in believable agents.Communications of the ACM (CACM),37(7) :122–125.
____________________________________________________________________________ Annales du LAMSADE N°8
237

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 250/415
[Brave et al., 2005] Brave, S., Nass, C.,and Hutchinson, K. (2005). Compu-ters that care : Investigating the effectsof orientation of emotion exhibited byan embodied computer agent. Interna-tional Journal of Human-Computer Stu-dies, 62 :161–178.
[DeRosis et al., 2003] DeRosis, F., Pela-chaud, C., Poggi, I., Carofiglio, V., andCarolis, B. D. (2003). From greta’smind to her face : Modelling the dyna-mics of affective states in a conversatio-nal embodied agent. International Jour-nal of Human-Computer Studies, 59(1-2) :p. 81–118.
[Dyer, 1987] Dyer, M. G. (1987). Emo-tions and their computations : threecomputer models. Cognition and Emo-tion, 1(3) :323–347.
[Helmut and Mitsuru, 2005] Helmut, P.and Mitsuru, I. (2005). The empa-thic companion : A character-basedinterface that addresses users’ affective
states. International Journal of Applied Artificial Intelligence, 19 :297–285.[Johnson et al., 2000] Johnson, W., Ri-
ckel, J., and Lester, J. (2000). Animatedpedagogical agents : Face-to-face inter-action in interactive learning environ-ments. International Journal of Artifi-cial Intelligence in Education, 11 :47–78.
[Lazarus, 2001] Lazarus, R. S. (2001).
Relational meaning and discrete emo-tions. In Scherer, K., Schorr, A., andJohnstone, T., editors, Appraisal Pro-cesses in Emotion : Theory, Methods,
Research, pages 37–69. Oxford Univer-sity Press.
[Meyer, 2006] Meyer, J. (2006). Reaso-ning about emotional agents : Researcharticles. International Journal of Intel-ligent Systems, 21(6) :601–619.
[Ochs et al., 2006] Ochs, M., Pelachaud,C., and Sadek, D. (2006). Les condi-tions de déclenchement des émotionsd’un agent empathique. In Work-shop Francophone sur les Agents
Conversationnels Animés (WACA)(http ://www.irit.fr/WACA/).
[Ortony et al., 1988] Ortony, A., Clore,
G., and Collins, A. (1988). The cogni-tive structure of emotions. CambridgeUniversity Press, United Kingdom.
[Pacherie, 2004] Pacherie, E. (2004).L’empathie et ses degrés. In Berthoz,A. and Jorland, G., editors, L’empathie,pages 149–181. Editions Odile Jacob.
[Picard, 1997] Picard, R. (1997). AffectiveComputing. MIT Press.
[Poggi, 2004] Poggi, I. (2004). Emotionsfrom mind to mind. In Proceedings of the Workshop on Empathic Agents. AA-
MAS , pages 11–17.[Roseman, 2001] Roseman, I. J. (2001). A
model of appraisal in the emotion sys-tem. In Klaus Scherer, Angela Schorr,T. J., editor, Appraisal Processes in
Emotion : Theory, Methods, Research,pages 68–91. Oxford University Press.
[Sadek, 1991] Sadek, D. (1991). Atti-tudes mentales et interaction ration-nelle : vers une théorie formelle de lacommunication. PhD thesis, UniversitéRennes 1.
[Sadek, 1992] Sadek, D. (1992). A studyin logic of intention. In Proceedingof the 3rd Internatinal Conference onPrinciples of Knowledge Representa-tion and Reasoning (KR’92).
[Scherer, 2000] Scherer, K. (2000). Emo-tion. In Hewstone, M. and Stroebe, W.,editors, Introduction to Social Psycho-logy : A European perspective, pages151–191. Oxford Blackwell Publishers,Oxford.
Vers un modèle formel des émotions d'un agent rationnel dialoguant empathique ___________________________________________________________________________
238

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 251/415
Doit-on dire la vérité pour se comprendre ?Principes d’un modèle collaboratif du dialogue basé sur la notion
d’acceptationSylvie Saget
Marc [email protected]
Institut de Recherche en Informatique et Systèmes Aléatoires (LLI-ENSSAT)Université de Rennes 1
22305 LANNION – FRANCE
Résumé :Garrod et Pickering ([16]) prétendent que l’étude
fine de la nature collaborative du dialogue doit me-ner à lever ou à modifier un ensemble d’hypothèsesfondamentales qui sont sources de complexité pourles modèles de dialogue. Dans des travaux pré-cédents, il a été proposé que l’une de ces hypo-thèses est la sincérité des partenaires de dialogue([35, 37]). Le traitement des énoncés, plus précisé-ment des références, y est ainsi vu comme un pro-cessus orienté par un but. L’objet de cet article estde présenter les principes d’un modèle collaboratif du dialogue basé sur une attitude mentale dépen-dante du contexte : l’acceptation.
Mots-clés : Modèle de dialogue, pragmatique, col-laboration, attitude mentale, croyance, acceptation
Abstract:Garrod and Pickering ([16]) claim that consideringspoken dialogue as a collaborative activity mustlead to avoid or to modify the fundamental hypo-thesis which are responsible for complexity limita-tions of existing spoken dialogue systems. In pre-vious works, we argue that one of these hypothesisis the sincerity of dialogue partners ([35, 37]). Ut-terance treatment, more precisely reference treat-
ment, is then viewed as a goal-oriented process.The aim of this article is to present the principlesof a collaborative model of dialogue based on acontext-dependant mental attitude : acceptance.
Keywords: Dialogue model, pragmatics, collabo-ration, mental attitude, belief, acceptance
Introduction
Le dialogue tient un rôle crucial dans
la réalisation des activités collaborativescar il permet d’établir et de maintenirles coordinations nécessaires entre lesmembres d’une équipe. En outre, dans lalignée de nombreux travaux fondateurs
([9, 32]), le dialogue en lui-même estconsidéré comme une activité collabora-
tive. Le dialogue se caractérise par le butpartagé entre les partenaires du dialoguede se comprendre mutuellement. Voirla modélisation du dialogue comme lamodélisation d’une activité collaborativepermet, entre autres, de fournir un modèleexplicatif à de nombreux phénomènesdialogiques tels que les sous-dialoguesde négociation portant sur l’interaction(négociation sémantique, négociation
des références, etc.). La modélisationfine des phénomènes en question permetd’accroître la flexibilité des systèmes dedialogue.
Comment formaliser le dialogue commeétant explicitement une activité collabora-tive (i.e. comment formaliser un modèlecollaboratif du dialogue)? Il s’agit làd’un problème particulièrement difficileet ceci pour deux raisons. Tout d’abord,de manière générale, la définition et lamodélisation des phénomènes intervenantdans les activités collaboratives ne sontpas encore clairement définis ([23]). En-suite, l’étude de la nature collaborative dudialogue est relativement récente ([12, 9]),de nombreux aspects sont toujours àdéfinir et des problèmes difficiles restent àrésoudre. En particulier :• La spécification du but partagé de se
comprendre, de manière à pouvoir êtreintégré dans un modèle de dialogue ([15,24, 41]),
• La spécification du critère de suffisance("grounding criterion") : ce critère est
239

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 252/415
fortement contextuel. Il varie selonles activités, les individus et il varieégalement au cours du dialogue ([7]).
Que signifie "atteindre une inter-compréhension" ? L’un des buts despartenaires du dialogue est d’atteindreune inter-compréhension vis-à-vis del’intention communicative du locuteur.Cette dernière devant être reconnue parl’auditeur suite à la compréhension età l’interprétation de l’énoncé prononcé.L’intention communicative correspond à"ce que le locuteur veut dire" ("speaker’s
meaning",[18]), elle doit être distinguéeclairement de la sémantique de l’énoncé(ou encore du contenu propositionnel del’acte de dialogue correspondant) ([15]).Quelle est la relation entre l’intentioncommunicative du locuteur et la séman-tique de l’énoncé? De la maxime deQualité de Grice ([18]), en passant par lesnotions de présuppositions et de terraincommun de Stalnaker ([38, 39]) jusqu’au
modèle collaboratif du dialogue de Clark([9, 12]), on exploite l’hypothèse que l’in-tention communicative et la sémantiquesont liées par une relation de valeur devérité (Hypothèse de Sincérité). Dans lemodèle collaboratif du dialogue proposépar Clark, cela se traduit par l’usagedu terrain commun établi ou supposécomme étant un pré-requis au succès del’inter-compréhension des partenaires du
dialogue. Par exemple, si le locuteur veutréférer à un objet o en prononçant une ex-pression référentielle dont la sémantiqueest ιx.descr(x), alors un pré-requis ausuccès de cette référence est :
M BLA(descr(o)), où :
– MBi,j(φ) correspond à "φ est unecroyance mutuelle entre les agents i et j, du point de vue de i",– On peut définir formellement lacroyance mutuelle par :MBi,j(φ) ≡ Bi(φ ∧ MB j,i(φ)),
– L dénote le locuteur et A l’auditeur.
Le terrain commun entre les partenairesdu dialogue, modélisé par un état épisté-mique au niveau des modèles formels dudialogue, est alors considéré comme lecontexte à prendre en compte lors de lagénération et l’interprétation des énoncés.
Cette hypothèse de sincérité et cettevision de l’usage du terrain commun dansle traitement des énoncés est source denombreuses limitations et incohérencesthéoriques et pratiques. Ce constat a menéà les remettre en question. Nous propo-sons, comme alternative, de considérer le
dialogue comme étant dirigé par le but de se comprendre et non par la vérité ([35, 37, 36]). Un énoncé (par exten-sion, sa sémantique) est alors considérécomme un outil permettant d’atteindrece but. Afin de prendre en compte cetteproposition d’un point de vue formel,l’acceptation (attitude mentale dépendantedu contexte) d’un énoncé comme étantutile pour permettre l’inter-compréhension
est appropriée.L’objet de cet article est de présenter lesprincipes d’un modèle collaboratif dedialogue basé sur la notion d’acceptation,en se penchant tout particulièrement surle cas des références. Dans la premièrepartie, les fondements de cette approchesont explicités. Dans la seconde partie,les principes du modèle collaboratif dedialogue sont présentés.
1 Quand la sincérité n’est pasde mise
1.1 Limites et incohérences
Le modèle collaboratif du dialogue deClark [12, 9] sert de référence à la grandemajorité des modèles formels de dialogue
([42, 20]) utilisés au niveau des systèmesde dialogue. Dans ce type de modèle, leterrain commun, représenté par un étatépistémique, est utilisé dans le traitementdes énoncés (et donc des références) afin
Doit-on dire la vérité pour se comprendre ? [...] ___________________________________________________________________________
240

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 253/415
de garantir le succès des actes de dialogue.Cette hypothèse conduit à un ensemblede problèmes et d’incohérences au niveaudu modèle collaboratif du dialogue. Nouspassons en revue les principaux.
Complexité.
1. Les partenaires du dialogue ont desétats mentaux dissemblables et sou-vent des états épistémiques différents.De plus, ils n’ont qu’un accès indi-rect aux état mentaux des autres parti-cipants. Il existe donc des incertitudeset des différences de point de vuevis-à-vis de leur terrain commun. Lespartenaires du dialogue doivent alorss’adapter au point de vue de l’autrelors d’un dialogue ([38, 39]). Taylor etal. [40] ont montré que ceci est diffi-cile à mettre en application. Ceci enraison de la complexité de maintenirles états épistémiques requis et en rai-son de la complexité des processusde raisonnement associés. En consé-
quence, la plupart des systèmes de dia-logue ne supportent pas les croyancesimbriqués 1 au delà du second niveaud’imbrication.
2. L’analyse sémantique d’un énoncépeut être également une source decomplexité. C’est le cas en particulierdes énoncés vagues ([33]).
Incohérence vis-à-vis du comportement humain.
De prime abord une telle complexitésemble incompatible avec l’efficacité desêtres humains au cours d’un dialogue. En-suite, la considération de Clark vis-à-visde l’usage du terrain commun ("Initial De-sign Model") dans la génération des énon-cés a été remise en question par de nom-breuses études ([21] : "Monitoring & Ad- justment model", [2]). Il y est montré queles êtres humains peuvent faire preuve
d’une attitude beaucoup plus "égoïste" 2 et1"Nested beliefs", permettant de modéliser en particulier le
point de vue d’un agent sur l’état épistémique d’un autre agent.2i.e. tenir compte de l’ensemble de ses croyances sans se
soucier si elles sont partagées par exemple.
ceci s’accentue en particulier lorsque lescontraintes temporelles croissent.Ainsi, les humains utilisent différentesstratégies (considération de leur croyancepropres, du terrain commun, du point devue de l’auditeur de leur terrain commun,etc.) plus ou moins coûteuses lors de la gé-nération des énoncés.
Difficultés pour caractériser la rationalité des
partenaires du dialogue. La rationalité despartenaires du dialogue est caractériséenotamment par la cohérence de leurscroyances et par leur sincérité ([27]). Or, il
est très fréquent que le locuteur (ou l’au-diteur) génère (ou acquiesce) un énoncéprésupposant une croyance contradictoireavec ses propres croyances ([11]). Dansle modèle de Clark, ceci s’explique par leprocessus d’adaptation, par l’un des parte-naires du dialogue, à la différence de pointde vue sur le terrain commun qu’il a avecson interlocuteur.Malgré tout, comment caractériser ce type
de comportement comme étant rationnelalors qu’il enfreint l’hypothèse de sincé-rité? Il existe deux grandes catégories desolutions :1. Caractériser ce comportement par un
raisonnement restreint à un contextelocal ([4]). Ce type de méthode n’estpas utilisé en pratique en raison de lacomplexité requise.
2. Ajouter une attitude mentale supplé-
mentaire, comme l’a proposé Stalna-ker [39], dans une caractérisation duterrain commun nécessaire3 :"Une catégorie d’attitudes proposi-tionnelles (...) qui inclut la croyance,mais également d’autres attitudes (la
présomption, l’hypothèse, l’accepta-tion au profit d’une argumentationou d’une requête) qui diffèrent de lacroyance et les unes des autres. Accep-
ter une proposition c’est accepter de3"A category of propositional attitudes (...) that includes be-
lief, but also some attitudes (presumption, assumption, accep-
tance for the purposes of argument or an inquiry) that contrast
with belief and with each other. To accept a proposition is to
treat it as true for some reason."
____________________________________________________________________________ Annales du LAMSADE N°8
241

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 254/415
la traiter comme si elle était vraie." Le but est ici de séparer clairementl’état épistémique d’un agent des pré-supposition qu’il va "accepter", afinque la contrainte de cohérence entreles deux soit levée. Nous proposonsd’aller encore plus loin, en utilisantune autre définition de l’acceptationqui permet d’éviter "de faire semblantd’être sincère".
Incohérence entre les propriétés des états épis-
témiques et celles des éléments identifiés du Ter-
rain Commun Conversationnel. Dans le cas
particulier du traitement des références,même pour des tâches quotidiennes, né-cessitant des objets qui possèdent desnoms communs pour y faire référence, ilexiste un large panel de manières possiblespour y faire référence. Afin de garantir uneintercompréhension, les humains4 "asso-cient les objets avec des expressions (et les
perspectives qu’elles transcrivent), autre-ment dit en faisant des pactes conceptuels,
ou des accords temporaires et flexibles deconsidérer un objet d’une façon particu-lière" [5]. Ces pactes conceptuels font par-tie du Terrain Commun Conversationnel(TCC, le Terrain Commun spécifique audialogue). Selon le modèle collaboratif dudialogue de Clark, le TCC doit être mo-délisé par des croyances partagées ou parun état épistémique plus faible. Mais lespropriétés identifiées des pactes concep-
tuels (flexibilité importante, durée limitéeà celle du dialogue, spécifique à un parte-naire) ne correspondent pas avec les pro-priétés de la croyance (idéal d’aggloméra-tion, non limitée dans le temps, indépen-dante du contexte, etc.) ([35, 37]).
1.2 Se comprendre : une activité orien-
tée par des buts
Les buts liés à l’intercompréhension. Kron-feld, [25], définit les buts des actes de ré-4"associate objects with expressions (and the perspectives
they encode), or else from achieving conceptual pacts, or tempo-
rary, flexible agreements to view an object in a particular way"
férence comme suit :
1. Le but littéral ("Literal goal") : en ré-sultat de la reconnaissance par l’audi-
teur d’un groupe nominal, l’auditeurgénérera une interprétation qui déter-mine le même objet.
2. Le but lié à la tâche ("Discourse pur-pose") : l’auditeur doit appliquer diffé-rentes opérations à l’ensemble indivi-dualisant de telle sorte qu’il respecterales contraintes d’identification appro-priées.
Le but lié à la tâche est, pour les dialoguesfinalisés, un pont reliant le dialogue enlui-même à la tâche motivant le dialogue(l’activité de base). Les contraintes d’iden-tification correspondent aux propriétés del’objet que le destinataire doit connaîtreafin d’être en mesure de réaliser la tâche.C’est par ce biais que la valeur de véritéd’un énoncé peut être imposée ([36]).
En outre, selon Clark et al. [10], le
but littéral doit être décomposé en deuxbuts interdépendants :
1.1. Identification : le locuteur tente defaire en sorte que le destinataire identi-fie un référent particulier à partir d’unedescription particulière.
1.2. Grounding : le locuteur et le destina-taire tentent d’établir le fait que le des-tinataire a identifié le référent suffi-
samment bien par rapport à leurs butscourants.
Une expression référentielle, et par exten-sion sa sémantique, n’est donc qu’un ou-til dans la réalisation de ces buts. La sin-cérité5 peut être utile mais pas nécessaire.Elle est coûteuse et peut être un mauvaischoix si les contraintes temporelles sontstrictes. Sans compter que le but n’est pasici d’établir la vérité vis-à-vis des proprié-
tés d’un objet, mais d’être capable de secomprendre suffisamment (sur l’objet dont
5Autrement dit, la croyance de l’existence d’un unique objet(dans le cas de descriptions définies) respectant effectivement ladescription spécifiée par l’expression référentielle.
Doit-on dire la vérité pour se comprendre ? [...] ___________________________________________________________________________
242

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 255/415
il est question) afin de réaliser la tâche mo-tivant le dialogue, dans le cadre de dia-logues finalisés.
Le dialogue finalisé : une activité subordonnée.
En effet, dans le cadre des dialogues fina-lisés, il est important de faire la distinctionentre deux types de sous-activités : lesactivités qui sont des sous-parties d’uneautre activité (activité de base) et les(sous-)activités subordonnées. Les sous-
activités qui sont des sous-parties d’uneautre activité reflètent la compositionalitédes activités de base. Les (sous-)activitéssubordonnées désignent les sous-activitésau service d’une autre activité, tellesque la planification, la résolution de pro-blèmes, l’interaction avec d’autres agents(dialogues finalisés), etc. Ces activitéssubordonnées comprennent les différentesfonctions remplies par la macrocognition
définies par Klein et al. [22].D’un point de vue logique, la rationa-lité des agents est traduite par un étatmental cohérent et par la notion d’actionrationnelle [14, 34]. Par exemple, lescroyances et les intentions forment unensemble consistant et les actions desagents sont également consistantes avecleurs croyances et leurs intentions.Au premier abord, la cohérence d’uneaction d’un agent avec ses croyancessemble être irréfutable. Mais, étant donnéque le succès d’une activité subordonnéeest gouverné par une généralisation ducritère de suffisance et les contraintestemporelles, on peut raisonnablement pré-tendre que la rationalité d’un agent engagédans une activité subordonnée n’impliquepas de manière stricte la cohérence entreles actions qui font partie de l’activitésubordonnée et l’état épistémique des
agents concernés.
Cette distinction est importante tantau niveau de la distinction des différentsterrains communs mis en jeu lorsque la
tâche est de nature collaborative ([35])6
qu’au niveau des différents degrés d’effortdéployés pour chacune des tâches ([8]).
2 Un modèle de dialogue basésur la notion d’acceptation
2.1 L’acceptation : une attitude men-
tale dépendante du contexte
L’interaction entre les différents domainesconcernés par les activités collabora-tives peut être une source de richesses etd’avancées significatives. En particulier,en philosophie, la nécessité de distinguerl’attitude mentale dépendante du contexte(pragmatique) qu’est l’acceptation, de l’at-titude mentale indépendante du contextequ’est la croyance a été (re)mise en avantpar de nombreux philosophes tels queCohen ([13]).
L’acceptation et la croyance diffèrentpar leur rôle fonctionnel : la croyanceest orientée par la vérité, alors que l’ac-ceptation est orientée par un (des) but(s)[31] :
Croyance vs AcceptationBi(φ) vs Acci(ψ)
orientée par vs orientée par
la vérité vs un butφ est vraie ψ est appropriée
pour le succèsd’un certain but
⇓ ⇓involontaire vs volontaire
graduelle vs tout-ou-rienindépendante vs dépendantedu contexte du contexte
Ainsi, la croyance et l’acceptation ont dif-férents critères de correction a posteriori :
6Il faut alors distinguer le terrain commun lié à la tâche duterrain commun spécifique au dialogue
____________________________________________________________________________ Annales du LAMSADE N°8
243

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 256/415
Bi(φ) est correcte si elle se révèle cor-respondre à l’état actuel du mondeAcci(ψ) est correcte si les choix faits etles actions réalisées en se basant sur cequi est accepté font que le choix de ψ serévèlent porter ses fruits
Cette distinction et les différents travauxphilosophiques qui en découlent ont étémis à profit au niveau des modèles formelsde l’interaction :• Dans le domaine des SMAs, Gaudou
et al. ([17]) utilisent la notion d’accep-tation collective afin de modéliser les
"faits publics" de manière cohérente.• Dans le cadre des dialogues argumen-tatifs, Baker [1] considère que le résul-tat d’une négociation est une accepta-tion collective. Paglieri & Castelfran-chi ([31]) utilisent la distinction entrecroyance et acceptation afin de distin-guer les argumentaires dirigés par la vé-rité des argumentaires dirigés par un but.
• Au niveau du dialogue en lui-même,
dans le cadre d’un modèle collaboratif du dialogue, nous avons mis en avantl’intérêt de cette distinction pour séparerclairement la sémantique d’un énoncéde l’intention communicative du locu-teur ([35, 37, 36]).
Dans les derniers travaux, la notion d’ac-ceptation est utilisée pour traduire le faitqu’un énoncé est vu comme un outil per-
mettant de déterminer l’intention com-municative du locuteur. La négociationde l’interprétation est alors considéréecomme la co-construction d’un outil lin-guistique permettant aux partenaires dudialogue d’atteindre un niveau d’inter-compréhension suffisant vis-à-vis de leuractivité courante. Le résultat de cette co-construction est modélisé par une accepta-tion collective.
2.2 Le modèle rationnel de référence
Les modèles rationnels de dialogue, basésprincipalement sur les travaux de Cohen
et Levesque [14], peuvent être considéréscomme une reformulation logique desmodèles de dialogue différentiels (mo-dèles à base de plans). Ils intègrent, enplus, une formalisation précise des étatsmentaux des partenaires du dialogue (leurscroyances, leurs choix (ou désirs) et leursintentions) et de l’équilibre rationnel quiles relie entre eux et qui relie les attitudesmentales d’un agent avec ses actions.En outre, les préconditions et les effetsdes actes de dialogue sont exprimés enfonction des états mentaux des partenairesdu dialogue.
Le modèle choisi, fondé sur le modèlerationnel proposé par Sadek [34], se basesur un ensemble de principes (de schémasd’axiomes) dont les actes de dialoguedécoulent. Un système de dialogue estalors considéré comme un agent rationnelqui a une attitude coopérative envers lesautres agents (tel que l’utilisateur de cesystème). Ce système étant capable de
communiquer avec les autres agents.Les états mentaux (croyances, intentions,etc.) et les actions sont formalisées dansune logique modale du premier ordre.Dans la suite de cet article, les symboles¬, ∧, ∨, ⇒ désignent les connecteursde la logique classique (respectivementla négation, la conjonction, la disjonc-tion et l’implication); ∀, ∃ désignent lesquantificateurs universel et existentiel; pdésigne une formule close dénotant uneproposition; i, j dénotent des agents, φ estun schéma d’axiome et ψ est une formulecomplexe. Nous avons seulement besoind’introduire ici deux attitudes mentales, lacroyance et l’intention :
Bi( p) signifie "i croit que p est vraie"I i( p) signifie "i a l’intention d’établir p"
Les expressions d’actions sont formées
à partir d’actes primitifs, par (a1; a2)qui désigne une action séquentielle (oùa1 et a2 sont des expressions d’actions)et par (a1|a2) qui désigne le choix non
Doit-on dire la vérité pour se comprendre ? [...] ___________________________________________________________________________
244

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 257/415
déterministe.
Faisable(a, p) : "a peut être réalisée, etsi elle l’est, alors p sera vraie"Faisable(a) = Faisable(a,true)Fait(a) : "a vient d’être réalisée"
Le modèle des actes communicatifs est :< i, T ypeActeCommunicatif ( j, φ) >PF (Préconditions de Faisabilité) : lesconditions qui doivent être satisfaitesafin de planifier l’actionEP (Effet Perlocutoire) : la raison pourlaquelle l’acte a été sélectionné
Par exemple, le modèle de l’acte commu-nicatif de "i informant j que φ" est :
< i,INFORM ( j, φ) >PF : Bi(φ) ∧ ¬Bi(B j(φ))EP : B j(φ)
Dans ce modèle, les processus de géné-ration et d’interprétation des énoncés sontvus comme des activités individuelles iso-
lées. Ainsi, l’interprétation du locuteur estsupposée réalisée et correcte dès lors quel’énoncé est prononcé. Le dialogue et laréférence ne sont pas considérés commeétant des activités collaboratives.
2.3 Modèle collaboratif du dialogue
Il n’existe pas de consensus sur la défi-nition d’une activité collaborative. Nousconsidérons ici qu’un groupe d’agentsest engagé dans une activité collaborativedès lors qu’ils partagent une intentioncollective.
Comment formaliser le dialogue commeétant une activité collaborative? Par unmodèle rationnel intégrant la notion d’in-tention collective permettant de spécifierexplicitement l’intention des partenaires
du dialogue de se comprendre mutuel-lement? Ceci est à proscrire dans unepremier temps car, comme stipulé dansl’introduction, les formalisations exis-tantes de ce but sont impossibles à mettre
en oeuvre ([15, 24, 41]).Faut-il intégrer la notion de plan partagé ?Le concept de plan partagé est utilisépour modéliser le plan correspondant à laréalisation concrète d’une activité colla-borative. Ce plan doit être mutuellementconnu à un certain degré, afin que lesmembres de l’équipe puissent coordonnerleurs actions. Ce paradigme est utilisédans les systèmes de dialogue pour modé-liser une tâche (motivant le dialogue) quiest de nature collaborative ([19, 29]) etnon pour modéliser la nature collaborativedu dialogue.
De notre point de vue, l’utilisation d’unplan partagé pour spécifier la nature colla-borative du dialogue n’est pas nécessairecar le dialogue est une activité acquise aucours de l’enfance, elle fait donc appelà des routines ([28]). De plus, étant uneactivité sociale, elle est régie par tout unensemble de lois et de normes.
Notre modèle collaboratif du dialogue
considère donc que le processus de né-gociation de l’interprétation, par lequell’inter-compréhension est atteinte, est uneco-construction d’un outil linguistique(d’une expression référentielle) permet-tant d’atteindre une inter-compréhensionsuffisante de l’intention communica-tive du locuteur. Le résultat de cetteco-construction étant modélisé par uneacceptation collective :
AccCollLA(refererPar(o, ıx.descr(x))),où :– AccCollij(ψ) correspond à "ψ est col-
lectivement acceptée par les agents i et j, du point de vue de i",
– refererPar(R, D) correspond à "le ré-férent R est référé par la description D",
– o est une représentation mentale de Ld’un objet.
Le succès d’une telle co-constructionaboutit donc à une inter-compréhension :
AccCollLA(refererPar(o, ıx.descr(x)))⇒ MBLA(I L(referLA(o))), où :
____________________________________________________________________________ Annales du LAMSADE N°8
245

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 258/415
– I i(referij(o)) correspond à "l’intentioncommunicative de i de référer à o, le
destinataire étant j".• L’acceptation collective est une attitude
mentale intentionnelle, i.e. qui est for-mée suite à des actions réalisées par lesagents mis en jeu :
((∃α, β ∈ i, j ∧ ∃a).Fait(Propαβ (ψ)); a; Acceptβα(ψ))⇒ AccCollij(ψ)où :– Propij(ψ) correspond à "i propose à
j de considérer ψ",– Accept ji(ψ) correspond à " j accepte
de considérer ψ (vis-à-vis de i)",– Propij(ψ) et Accept ji(ψ) sont des ac-
tions individuelles,– a est une expression d’action.
• Suite à une proposition, l’autre agentest obligé de réagir en raison d’une loi
sociale :
Fait(Propi,j(ψ))⇒ (I j(Fait(( Accept j,i(ψ)
|(Prop j,i(ψ))|(Propi,j(ψ))|(Reporter)|(Stopper)))))
∧((ψ = ψ) ∧ (ψ = ψ)))où :– Reporter est une action individuelle
qui permet de reporter la réaction, dela "mettre en suspend",
– Stopper est une action individuellequi permet de sortir de la négotiation.
Dans la lignée des travaux de Boella etal. [3], nous considérons que les obliga-tions sociales en tant que pro-attitudesne sont pas nécessaires pour formaliser
le dialogue. Le locuteur procède à unecoordination par anticipation. Ce phéno-mène est gouverné par une loi sociale,acquise au cours d’interactions socialesprécédentes. Cette loi sociale est transcrite
par son usage répété en réaction à laréalisation d’une action particulière (dupoint de vue du locuteur) et en réactionà l’occurrence d’un événement qui estl’occurrence d’une action particulière (dupoint de vue de l’auditeur). Étant donnéqu’une réaction est une action non inten-tionnelle, nous devons étendre la catégoriedes actions tolérées par notre modèle debase. En effet, ce modèle ne considère queles actions intentionnelles. Nous appelonsici actions intentionnelles les actions d’unagent qui sont générées par une chaîned’intentions. Dans le modèle de Sadek
([34]), elles sont générées par l’activationde l’axiome rationnel suivant :
I i( p) ⇒ I i(Fait(a1| · · · |an))L’intention de l’agent, de réaliser un butdonné, génère l’intention de réaliser l’undes actes satisfaisant les conditions sui-vantes :
1. (∃x)Bi(ak = x) ≡ Bref i(ak) :L’agent i connaît l’action ak,
2. EP ak = p et
3. ¬I i(¬Faisable(Fait(ak))).
Il faut donc rajouter les réactions auxactions intentionnelles. Les réactions d’unagent sont définies comme les actionsgénérées par l’activation d’un axiome telque :
φ ⇒ I i(Fait(a1| · · · |an))où φ résulte de la perception d’un évè-nement ou de l’occurrence d’une action.
Considérons à présent le cas particu-lier des références. Tout d’abord, il fautpréciser qu’un modèle collaboratif du dia-logue nécessite de considérer la référencecomme un acte de dialogue à part entière,[15], comme c’est le cas dans les travaux
de Kronfeld [26].Quand le locuteur veut référer à un objet,sa première tentative se concrétise par unacte de référence qui :
Doit-on dire la vérité pour se comprendre ? [...] ___________________________________________________________________________
246

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 259/415
1. A pour effet la reconnaissance parl’auditeur de l’intention du locuteur deréférer à un certain objet :
BA((∃o)I L(referij(o)))
2. A pour effet de générer chez l’audi-teur l’adoption de l’intention de com-prendre le locuteur, c’est-à-dire deconstruire ou d’identifier une repré-sentation mentale correcte :
I A(Bref A(o)) ∧RepMemeObj(o, o), où :
– o et o sont des représentations men-tales d’objets ;
– RepMemeObj(o, o) signifie que"les représentations mentales o et o
représentent le même objet".
3. Correspond à l’engagement dans unprocessus de négociation entre lespartenaires du dialogue. En générantune expression référentielle, le locu-teur propose à l’auditeur de considé-rer sa description comme permettant
de construire ou d’identifier une repré-sentation mentale qui soit correcte.En raison de la loi sociale, le locuteurattend une réaction de l’auditeur à saproposition. La loi sociale oblige éga-lement l’auditeur à réagir à la proposi-tion du locuteur.
Ceci est synthétisé dans l’extension dumodèle des actes de références [6] que
nous proposons. L’acte de référence d’unagent i envers un autre agent j, en utilisantla conceptualisation x (qui correspondà la sémantique de l’expression référen-tielle) de référer à un objet o est formalisécomme suit :
< i, REF ER( j, x, o) >PF : I i(referij(o)) ∧ Bref i(o)EP : B j((∃o)I i(referij(o)))
∧ I j(Bref j(o))∧ RepMemeObj(o, o)∧ Fait(Propi,j(refererPar(o, x)))∧B j(Fait(Propi,j(refererPar(o, x))))
2.4 Formalisation de l’acceptation
L’acceptation collective est formée par un
processus de négociation qui fait interve-nir les actions Propij(ψ) et Acceptij(ψ).La précondition de ces deux actions estidentique : l’acceptation individuelle deψ par i. Dans cette section, nous propo-sons les premiers éléments de formalisa-tion de l’opérateur modal d’acceptation in-dividuelle.
Cadre philosophique. Il n’existe pas de
consensus sur la caractérisation de l’accep-tation7. Nous adoptons ici la vision de Pa-glieri, introduite en 2.1., en raison de sasimplicité et de notre adéquation avec sonpoint de vue.Par définition, les acceptations sont consi-dérées comme étant le seul arrière-plancognitif à la délibération. Le modèle tra-ditionnel BDI devient donc ([30], p.36) :
(Desire + Acceptation) ⇒ Intention
Les croyances tiennent un rôle indirect etnon nécessaire dans le raisonnement pra-tique. En effet, elles sont une raison fré-quente d’accepter.
Formalisation. Qu’est-ce qui est accepté?Tout ce qui peut permettre et/ou faire
avancer le raisonnement va être soumis àl’acceptation. D’après Paglieri ([30]), celacomprend :• les relations qui permettent d’arriver à
ses fins qui instancient une action adé-quate pour un but,
• les préconditions des actions que l’on al’intention de réaliser,
• les préconditions nécessaires pour avoir une intention particulière, l’intentionn’est pas déjà réalisée et est réalisable,
• les résultats des actions, afin de pouvoird’évaluer si le but a été atteint ou si ondoit continuer dans la ligne d’action7Pour plus de détails sur ce débat, consulter [30], Chap.1.
____________________________________________________________________________ Annales du LAMSADE N°8
247

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 260/415
courante.
À notre connaissance il n’existe pas de ca-ractérisation logique de l’acceptation tellequ’elle est définie ci-dessus. Voici les pre-miers éléments d’une proposition de for-malisation :– Acci(ψ, φ) signifie que "L’agent i ac-
cepte ψ dans l’optique de réaliser φ",où :
– Acci(ψ, φ)≡ Acci(ψ) ⇒ Bi(∃e.Faisable(e, φ))
Notre opérateur modal d’acceptation in-dividuelle respecte l’axiomatique suivante(axiomatique KD45) :(K)(Acci(ψ)∧Acci(ψ ⇒ ψ)) ⇒ Acci(ψ)(D) Acci(ψ) ⇒ ¬Acci(¬ψ)(5) ¬Acci(ψ) ⇒ Acci(¬Acci(ψ))(4) Acci(ψ) ⇒ Acci(Acci(ψ))La relation d’accessibilité est ainsi défi-nie comme étant RAcc transitive, eucli-dienne et sérielle. Le système axioma-tique proposé est donc complet et adéquat.Il est également intéressant de remarquerque notre opérateur a la même axioma-tique que celle couramment utilisée pourla croyance. De plus, RAcc et RB ne sont niréflexives, ni ni symétriques. Cependant, laraison en diffère : RAcc n’est ni sérielle, niréflexive par définition car le rôle fonction-nel de l’acceptation n’a rien à voire avec laréalité objective.
Conclusion
Dans cette article, nous avons proposéune alternative à la considération dutraitement des énoncés comme étant desprocessus orientés par la vérité (et leterrain commun) en mettant au premierplan le caractère finalisé de ces processus.La distinction entre les attitudes mentales
que sont la croyance et l’acceptation estnécessaire pour prendre en compte cettealternative dans un modèle rationnel dedialogue.
Ces travaux sont porteurs de nombreusesperspectives. Au niveau des extensions :• La génération d’un énoncé est vu
comme la détermination d’un outil ac-ceptable, au niveau individuel, c’est-à-dire utile pour atteindre une inter-compréhension suffisante,
• Le processus dual d’interprétation d’unénoncé est vu comme l’évaluation del’acceptabilité de l’énoncé par le desti-nataire.
Incorporer l’acceptation individuelle, etétudier ses propriétés logiques, au ni-veau du modèle collaboratif du dialogue
consiste donc à faire le lien avec lesprocessus de traitement des énoncés.
Ces travaux procurent également desperspectives intéressantes vis-à-vis de laprise en compte du contexte, l’acceptationétant une attitude mentale dépendante ducontexte :• Dans le modèle collaboratif du dialogue
décrit ci-dessus, le contexte qui sert
de base à l’interprétation des énoncésn’est plus systématiquement l’état épis-témique (les croyances) des participants.Il peut donc être élargi en incorporant lecontexte motivationnel, les contraintestemporelles, etc.
• L’hypothèse de sincérité étant levée,les partenaires du dialogue ont le choixentre différentes stratégies possibles :considération uniquement de leurspropres croyances (attitude "égoïste"),
de celles de son interlocuteur (attitudecoopérative), de baser une interprétationsur la reconnaissance des mots-clés, etc.
RemerciementsCes travaux sont financés par la subventionA3CB22 / 2004 96 70 de la Région Bre-tagne.
Références
[1] M. J. Baker. A model for negotiationin teaching-learning dialogues. Jour-nal of Artificial Intelligence in Edu-cation, 5(2) :199–254, 1994.
Doit-on dire la vérité pour se comprendre ? [...] ___________________________________________________________________________
248

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 261/415
[2] E. G. Bard, A. H. Anderson, Y. Chen,H. Nicholson, and C. Havard. Let’syou do that : Enquiries into the cog-nitive burdens of dialogue. In Pro-ceedings of DIALOR’05, 2005.
[3] G. Boella, R. Damiano, andL. Lesmo. Social goals in conversa-tional cooperation. In Proceedingsof the First SIGdial Workshop on
Discourse and Dialogue, pages84–93. ACL, Somerset, New Jersey,2000.
[4] A. Bonomi. Truth and reference
in context. Journal of Semantics,23(2) :107–134, 2006.[5] S. E. Brennan and H. H. Clark.
Conceptual pacts and lexical choicein conversation. Journal of Experi-mental Psychology : Learning, Me-mory and Cognition, 22 :482–1493,1996.
[6] P. Bretier, F. Panaget, and M. D. Sa-dek. Integrating linguistic capabili-
ties into the formal model of ratio-nal agent : Application to cooperativespoken dialogue. In AAAI-95, FallSymposium of Rational Agency, Stan-ford, MA, 1995.
[7] J. E. Cahn and S. E. Brennan. A psy-chological model of grounding andrepair in dialog. In Proceedings of the AAAI Fall Symposium on Psycho-logical Models of Communication inCollaborative Systems, pages 25–33,1999.
[8] M. Cherubini and J. van der Pol.Grounding is not shared understan-ding : Distinguishing grounding at anutterance and knowledge level. InProceedings of CONTEXT’05, 2005.
[9] H. H. Clark. Using language. Cam-bridge University Press, Cambridge,
UK, 1996.[10] H. H. Clark and A. Bangerter.Changing conceptions of reference.In I. Noveck & D. Sperber, edi-tor, Experimental pragmatics, pages
25–49. Palgrave Macmillan, Basing-stoke, England, 2004.
[11] H. H. Clark and C. R. Marshall. Defi-
nite reference and mutual knowledge.In Elements of discourse understan-ding, pages 10–63. Cambridge Uni-versity Press, Cambridge, 1981.
[12] H. H. Clark and D. Wilkes-Gibbs.Referring as a collaborative process.Cognition, 22 :1–39, 1986.
[13] J. L. Cohen. An Essay on Belief and Acceptance. Oxford UniversityPress, Oxford, 1992.
[14] P. R. Cohen and H. J. Levesque.Rational interaction as the basisfor communication. In Intentionsin Communication, pages 221–256.MIT Press, Cambridge, MA, 1990.
[15] P. R. Cohen and H. J. Levesque. Pre-liminaries to a collaborative modelof dialogue. Speech Communication,15 :265–274, 1994.
[16] S. Garrod and M. J. Pickering. Whyis conversation so easy? Trends inCognitive Sciences, 8 :8–11, 2004.
[17] B. Gaudou, A. Herzig, and D. Lon-gin. A logical framework forgrounding-based dialogue analysis.In IJCAI’05, Proceedings of LCMAS 2005, Edinburgh, 2005.
[18] P. Grice. Logic and conversation.In Syntax and semantics. Academic
Press, 1975.[19] B. J. Grosz and C. Sidner. Plans for
dicourse. In Intentions in Communi-cation. The MIT Press, 1990.
[20] P. A. Heeman and G. Hirst. Collabo-rating on referring expressions. Com-
putational Linguistics, 21(3) :351–382, 1995.
[21] W. S. Horton and B. Keysar. When
do speakers take into account com-mon ground ? Cognition, 59 :91–117,1996.
[22] G. Klein, K. G. Ross, B. M. Moon,D. E. Klein, R. R. Hoffman, and
____________________________________________________________________________ Annales du LAMSADE N°8
249

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 262/415
E. Hollnagel. Macrocognition. IEEE Intelligent Systems, 18(3) :81–85,2003.
[23] G. Klein, D. D. Woods, J. Brad-shaw, R. R. Hoffman, and P. J. Fel-tovich. Ten challenges for makingautomation a ’team player’ in jointhuman-agent activity. IEEE Intelli-gent Systems, pages 91–95, Novem-ber/December 2004.
[24] K. Korta. Mental states in conver-sation. Technical Report ILCLI-95-LIC-2, ILCLI, Donostia, 1995.
[25] A. Kronfeld. Goals of referringacts. Proceedings of TINLAP-3,pages 143–149, 1987.
[26] A. Kronfeld. Reference and Compu-tation : An Essay in Applied Philoso-
phy of Language. Cambridge Univer-sity Press, 1990.
[27] M. Lee. Rationality, cooperation andconversational implicature. In Pro-
ceedings of the AICS’97 , 1997.[28] A. N. Leont’ev. Activity, Conscious-
ness, Personality. Englewood Cliffs,NJ, Prentice Hall, 1978.
[29] K. Lochbaum. The use of know-ledge preconditions in language pro-cessing. In Proceedings of IJCAI’95.
[30] F. Paglieri. Belief dynamics : From formal models to cognitive architec-
tures, and back again. PhD thesis,University of Siena, 2006.
[31] F. Paglieri and C. Castelfranchi. Be-lief and acceptance in argumentation.Towards an epistemological taxo-nomy of the uses of argument. InProceedings of ISSA’06 , 2006.
[32] M. J. Pickering and S. Garrod. To-ward a mechanistic psychology of
dialogue. Behavioral and BrainSciences, 27(169-225), 2004.
[33] G. Pitel and J. P. Sansonnet. A dif-ferential representation of predicatesfor extensional reference resolution.
In Proceeding of the 2003 Interna-tional Symposium on Reference Re-solution and its Application to Ques-tions Answering and Summurization,Venice, Italy, 2003.
[34] M. D. Sadek. Communication theory= rationality principles + commu-nicative act models. In AAAI-94,Workshop on Planning for Interagent Communication, 1994.
[35] S. Saget. In favour of collective ac-ceptance : Studies on goal-orienteddialogues. Collective IntentionalityV, Helsinki, Finland, 2006.
[36] S. Saget. Using collective accep-tance for modelling the conversatio-nal common ground : Consequenceson referent representation and on re-ference treatment. In IJCAI-07, Pro-ceedings of the Workshop on Know-ledge and Reasoning in Practical
Dialog Systems, pages 55–58, Hyde-rabad, India, 2007.
[37] S. Saget and M. Guyomard. Goal-oriented dialog as a collaborative su-bordinated activity involving colla-borative acceptance. In Proceedingsof Brandial’06 , pages 131–138, Uni-versity of Potsdam, Germany, 2006.
[38] R. Stalnaker. Pragmatic presupposi-tions. In Semantics and Philosophy.New York University Press, 1974.
[39] R. Stalnaker. Common ground. Lin-
guistics and Philosophy, 25 :701–721, 2002.[40] J. A. Taylor, J. Carletta, and C. Mel-
lish. Requirements for belief modelsin cooperative dialogue. User Mo-deling and User-Adapted Interaction,6(1) :23–68, 1996.
[41] M. Tirassa. Mental states in commu-nication. In Proceedings of ECCS’97 ,pages 103–114, Manchester, UK,
1997.[42] D. Traum. A computational theoryof grounding in natural languageconversation. PhD thesis, Universityof Rochester, 1994.
Doit-on dire la vérité pour se comprendre ? [...] ___________________________________________________________________________
250

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 263/415
ARTICLES COURTS

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 264/415

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 265/415
De DEL à EDL ou comment illustrer la puissance des événementsinverses
Guillaume Aucher
Andreas Herzig
IRIT, Université Paul Sabatier,31062 Toulouse Cedex (France)
Résumé :La logique épistémique dynamique (DEL) intro-duite par Baltag et col. et la logique proposition-nelle dynamique (PDL) proposent différentes sé-mantiques aux événements. La seconde se prête fa-
cilement à l’introduction d’événements inverses etde relations d’accessibilité épistémiques. Nous ap-pelons EDL le formalisme résultant. Nous mon-trons alors que DEL peut être traduit dans EDLgrâce à cet emploi d’événements inverses. Il s’en-suit que EDL est plus expressive et générale queDEL .
Mots-clés : Logique dynamique épistémique, lo-gique propositionnelle dynamique
Abstract:Dynamic epistemic logic (DEL) as viewed by Bal-tag et col. and propositional dynamic logic (PDL)offer different semantics of events. It turns out thatconverse events and epistemic accessibility rela-tions can be easily introduced in PDL . We callEDL the resulting formalism. We then show thatDEL can be translated into EDL thanks to this useof converse events. It follows that EDL is more ex-pressive and general than DEL .
Keywords: dynamic epistemic logic, propositionaldynamic logic
1 Introduction
But : raisonner sur la perception d’événements.
Rendre compte des modes variés de per-ception d’événements est le but d’unefamille de systèmes formels appelés lo-giques épistémiques dynamiques. Ces sys-tèmes ont été proposés dans une sériede publications, principalement par Plaza,Baltag, Gerbrandy, van Benthem, van Dit-
marsch et Kooi [9, 7, 6, 13, 15, 16]. Les lo-giques épistémiques dynamiques ajoutentdu dynamisme à la logique épistémiqued’Hintikka en transformant les modèlesépistémiques.
La logique épistémique dynamique seconcentre sur des événements particuliersappelés updates. Les updates peuvent êtrevus comme des annonces faites aux agents.
La forme la plus simple d’update estl’annonce publique à la Plaza ; quand lecontenu de l’annonce est propositionnelune telle annonce correspond à l’opéra-tion d’expansion d’AGM [1]. Un autreexample d’update est l’annonce de groupeà la Gerbrandy [6, 7]. Notons que DEL-updates différent des Katsuno-Mendelzon-updates qui sont étudiés dans la littératureIA [8].
Dans [2, 4, 3] et ailleurs, Baltag et col. pro-posèrent une logique épistémique dyna-mique qui eut beaucoup d’influence. Nousfaisons référence à cette logique par leterme DEL. Il a été montré que leur ap-proche subsume toutes les autres logiquesépistémiques dynamiques, ce qui justifienotre acronyme. La sémantique de DEL
est basée sur deux types de modèle : unmodèle statique M s (appelé “state mo-
del” par Baltag) et un modèle dynamiquefini M d (appelé modèle d’action épisté-mique par Baltag). M s modèlise le monderéel et les croyances des agents s’y rap-portant. Ce n’est rien d’autre qu’un bonvieux modèle épistémique à la Hintikka.M d modèlise l’événement réel qui a lieuet les croyances des agents s’y rapportant.Les croyances des agents peuvent être in-complètes (l’événement a a eu lieu mais
l’agent ne peut pas distinguer l’occurencede a de celle de a) et même erronées(l’événement a a eu lieu mais l’agent l’aperçu comme étant a par erreur). M s etM d sont alors combinés par une construc-
253

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 266/415

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 267/415
2 Les langages
Nous supposons donné un ensemble
de symboles propositionnelsPROP
= p, q, . . ., des symboles d’agents AGT =i , j , . . ., et des symboles d’événementsEVT = a ,b , . . .. Tous ces ensemblespeuvent être infinis (alors que dans DELAGT et EVT doivent être finis). A partirde ces ingrédients, le langage multi-modalest construit de façon standard à l’aide desopérateurs booléens ¬ et ∧, d’une familled’opérateurs épistémiques B i, pour touti ∈ AGT et d’une famille d’opérateurs dy-namiques [a] et [a−], pour a ∈ EVT .
La formule B iϕ se lit “l’agent i croit queϕ”. [a]ϕ se lit “ϕ est vrai après n’importequelle execution possible de l’événement
a”. Les opérateurs modaux duaux B i, aand a− sont définis de façon usuelle :
B iϕ abrège ¬B i¬ϕ ; aϕ abrège ¬[a]¬ϕ ;a−ϕ abrège ¬[a−]¬ϕ.
Le langage LEDL de EDL est le lan-gage entier. Le langage LDEL de DEL
est l’ensemble des formules de LEDL
qui ne contiennent pas d’opérateur in-verse [a−]. Enfin, le langage épistémiqueLEL est l’ensemble des formules qui necontiennent pas d’opérateur dynamique,c’est à dire construits à partir de PROP ,les opérateurs booléens et l’opérateur B iuniquement. Par exemple [a]B i[a
−]⊥ est
une LEDL-formule (qui n’appartient pas àLDEL).
3 EDL : logique dynamiqueépistémique avec inverse
Quand on construit des modèles quitraitent des notions de croyance et d’évé-nement, le problème central est de rendre
compte de l’interaction entre ces diffé-rentes notions. Dans notre sémantique ba-sée sur PDL, ce problème est résolu enproposant des contraintes sur les relationsd’accessibilité respectives.
3.1 Sémantique
Les EDL-modèles sont de la forme M =
W,V , Aaa∈EVT , B ii∈AGT où W estun ensemble de mondes possibles, V :
PROP −→ 2W une valuation, et les Aa ⊆W × W et B i ⊆ W × W sont des re-lations d’accessibilité sur W . La relationA−1
a est l’inverse de Aa. On considèreparfois les relations d’accessibilité commedes applications qui associent un ensemblede mondes à un monde, et écrivons parexemple A−1
a (w) = v : w, v ∈ A−1a =
v
: v, w
∈ Aa.
Nous supposons que les EDL-modèles sa-tisfont les contraintes suivantes appelés no
forgetting, no learning et epistemic deter-minism :
(nf) Si v(Aa B i A−1b )v alors vB iv.
(nl) Si (Aa B i A−1b )(v) = ∅ alors (B i
Ab)(v) ⊆ (Aa B i)(v).
(ed) Si w1, w2 ∈ Aa(v) alors B i(w1) =
B i(w2).Informellement, le principe no-forgetting(aussi connu sous le nom de perfect re-call [5]) nous dit que chaque monde, telque l’occurence d’un événement b dans cemonde donne comme résultat une alter-native possible pour l’agent i après l’oc-curence de a, est une alternative possiblepour l’agent i avant l’occurence de a.Formellement, supposons que w résulte
de l’occurence de l’événement a dans lemonde v ; si dans le monde w, le monde w
est une alternative pour l’agent i, et w ré-sulte de l’événement b dans un monde v,alors v était déjà possible pour l’agent idans le monde v.
(nf ) : vAb / / w
vAa
/ /
Bi
O O
w
Bi
O O
Pour comprendre le principe no-learning(aussi connu sous le nom de no miracle
____________________________________________________________________________ Annales du LAMSADE N°8
255

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 268/415
[14]), supposons que l’agent i perçoitl’occurrence de a comme étant celle deb1, b2, . . .ou bn. Alors, informellement, leprincipe no-learning nous dit que chaquemonde résultant de l’occurrence de b1,b2, . . .ou bn dans une des alternatives pos-sibles de l’agent i avant l’occurrence dea est bien une alternative possible aprèsa pour l’agent i. Formellement, supposonsque l’agent i perçoit b comme une alterna-
tive possible de a ((AaB iA−1b )(v) = ∅).
Si dans le monde v le monde w est un ré-sultat possible de l’occurrence de b pourl’agent i, alors le monde w est une alterna-
tive possible pour l’agent i dans un mondew ∈ Aa(v).
(nl) : . Ab / / w
. Ab / / .
vAa / /
Aa + +
D H K O R T W
Bi
E E
.
Bi
O O
w
Bi
U U
#
&
*
Pour comprendre (ed), supposons quenous avons vAaw1 et vAaw2. Alors (ed)impose aux états épistémiques de w1 et w2
d’être identiques : B i(w1) = B i(w2). Celadécoule de note hypothèse que les évé-nements sont feedback-free (aussi connus
sous le nom d’ uninformative events[?]) : les agents ne peuvent pas distin-guer entre leurs différents résultats non-déterministes. Ce sont des événementsdont les agents apprennent seulement leuroccurrence, mais pas leur résultat. Unexemple de tel événement est l’action de
jeter une pièce de monnaie sans regar-der le résultat. Un exemple d’événementnon feedback-free est l’action de jeter unepièce de monnaie et regarder le résultat :ici la contrainte de déterminisme épisté-mique est violée.
La valeur de vérité d’une formule ϕ dansun monde w d’un modèle M est notée
(ed) : w
v
Aa
/ /
Aa ' '
w1
Bi
O O
w2
Bi
W W
$
) .
M, w |= ϕ et est définie comme d’habi-tude par :
M, w |= p ssi w ∈ V ( p)
M, v |= B iϕ ssi M, v |= ϕ pour toutw ∈ B i(v)
M, v |= [a]ϕ ssi M, w |= ϕ pour toutw ∈ Aa(v)
M, w |= [a−]ϕ ssi M, v |= ϕ pour toutv ∈ A−1
a (w)
La valeur de vérité d’une formule ϕ dansunEDL-modèleM est notée M |= ϕ et estdéfinie par : M, w |= ϕ pour tout w ∈ W .Soit Γ un ensemble de LEDL-formules. Larelation de conséquence (globale) est défi-nie par :
Γ |=EDL ϕ ssi pour tout EDL-modèle M ,si M |= ψ pour tout ψ ∈ Γ alors M |= ϕ.
Par exemple nous avons[b]ϕ, aB ib
− |=EDL [a]B iϕ et|=EDL (B i[b]ϕ ∧ aB ib
−) → [a]B iϕ. (*)
Considérons ϕ = ⊥ dans (*) : B i[b]⊥ si-gnifie que la perception de l’événement bétait inattendue pour l’agent i, tandis queaB ib
− signifie que l’agent i perçoiten réalité l’occurrence de a comme étantcelle de b.
De notre contrainte no-forgetting, il s’en-suit que [a]B i⊥ (ce qui est possible carnous n’avons pas supposé que la relationd’accessibilité B i était sérielle).
De DEL à EDL ou comment illustrer la puissance des événements inverses ___________________________________________________________________________
256

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 269/415
En fait, il serait préférable d’éviter que lescroyances des agents deviennent inconsis-tantes : dans de telles situations l’on de-vrait effectuer une révision des croyances.
3.2 Complétude
L’axiomatique de EDL est composée desprincipes de la logique multimodale K
pour tous les opérateurs modaux B i, [a] et[a−], plus les axiomes (Conv1), (Conv2),(NF) et (NL) ci-dessous :
(Conv1) EDL ϕ → [a]a−ϕ
(Conv2) EDL ϕ → [a−]aϕ
(NF) EDL B iϕ → [a]B i[b−]ϕ
(NL) EDL aB ib− → ([a]B iϕ →B i[b]ϕ)
(ED) EDL aB iϕ → [a]B iϕ
(Conv1) et (Conv2) sont les axiomes d’in-version standards de la logique temporelleet de converse PDL. (NF), (NL) et (ED)axiomatisent respectivement no forgetting,no learning et epistemic determinism.
Nous écrivons Γ EDL ϕ quand ϕ est prou-vable à partir de l’ensemble de formules Γdans ce système axiomatique.
EDL possède la complétude forte :
Proposition 3.1 Pour tout ensemble deLEDL-formules Γ et LEDL-formules ϕ ,
Γ |=EDL ϕ si et seulement si Γ EDL ϕ.
Proof. La preuve découle du théorème deSahlqvist [10] : tous nos axiomes (NF),(NL), (ED) sont de la forme requise, et cor-respondent respectivement aux contraintessémantiques (nf), (nl), (ed). QE D
4 DEL : modèles statiques, mo-dèles dynamiques, et leursproduits
Nous présentons ici la version sans itéra-tion de la logique épistémique dynamiqueDEL de Baltag [4, 3].
4.1 Sémantique
Les Modèles Statiques sont juste des mo-
dèles de la forme M s
= W ,V , s
−→ii∈AGT , où W est un ensemble arbitraire,V : PROP −→ 2W une valuation et les
s−→i ⊆ W × W sont des relations d’acces-sibilité sur W .
Les Modèles dynamiques sont de la forme
M d = EVT ,Pre, d
−→ii∈AGT , oùPre : EVT −→ LEL est une fonction deprécondition associant des formules épis-
témiques aux événements, et les d−→i ⊆EVT ×EVT sont des relations d’accessi-bilité sur EVT . Par exemple l’événementa tel que Pre(a) = correspond au ‘skip’(rien ne se passe) de PDL et Pre(b) = pcorrespond à l’action d’apprendre que p
est vraie. Quand nous avonsd
−→i (a) =b alors l’occurrence de a est perçue parl’agent i comme celle de b.
Nous rappelons que EVT est l’ensembledes événements atomiques. Dans DEL il
est supposé fini. De plus, toutd
−→i est sup-posé être sériel : pour tout a ∈ EVT il y
a au moins un b ∈ EVT tel que ad
−→i b.(Rappelons que nous n’avons pas supposéla sérialité pour les relations d’accessibilitéstatiques.)
Etant donnés M s = W ,V , s−→ii∈AGT
et M d = EVT ,Pre, d
−→ii∈EVT , leur
produit M s ⊗ M d est un modèle statiquedécrivant la situation après que l’événe-
____________________________________________________________________________ Annales du LAMSADE N°8
257

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 270/415
ment décrit par M d a eu lieu dans M s :
M s ⊗ M d = W ,V , s
−→i
i∈AGT
où le nouvel ensemble de mondes pos-sibles est W = w, a : M s, w |=Pre(a), la nouvelle valuation est V ( p) =w, a : w ∈ V ( p), et les nouvellesrelations d’accessibilité statiques sont dé-finies par
w1, a1s
−→i
w2, a2 ssi w1
s−→i w2 et
a1d
−→i a2.
Alors que la condition de vérité pour l’opé-rateur épistémique est identique à celle dela logique épistémique d’Hintikka et celled’EDL, la construction par produit res-treint donne une sémantique à l’opérateur[a] qui est bien différente de celle de PDLet EDL :
M s, w |= [a]ϕ ssi M s, w |= Pre(a)implique M s ⊗ M d, w, a |= ϕ
Finalement, la validité de ϕ dans DEL (no-tée |=DEL ϕ) est définie comme d’habitudecomme la vérité dans tous les mondes detous les DEL-modèles. Notons que la va-lidité signifie la validité par rapport à unmodèle dynamique M d fixé.
La condition de vérité pour l’opérateur dy-namique met en valeur le fait que DEL
est une extension dynamique de la logiqueépistémique tandis que EDL est une exten-sion épistémique de PDL.
4.2 Complétude
Supposons donné un modèle dynamiqueM d. L’axiomatique de DEL est composée
des principes de la logique multimodale Kpour les opérateurs modaux B i et [a], plusles axiomes ci-dessous [4, 3].
(A1) DEL [a] p ↔ (Pre(a) → p)
(A2) DEL [a]¬ϕ ↔ (Pre(a) →¬[a]ϕ)
(A3) DEL [a]B iϕ ↔ (Pre(a) →B i[b1]ϕ ∧ . . . ∧
B i[bn]ϕ)où b1, . . . , bn est la liste de tous
les b tels que ad
−→i b.
On note DEL ϕ lorsque ϕ est prouvable àpartir de ces principes.
5 De DEL à EDL
Dans cette section nous montrons queDEL peut être injecté dans EDL. Nous lefaisons en construisant une EDL-théorieparticulière qui capture un DEL mo-dèle dynamique M d donné et simule laconstruction produit.
Definition 5.1 Soit M d =EVT ,Pre,
d−→ii∈AGT un modèle
dynamique. L’ensemble des formules
Γ(M d
) associé à M d
(‘la théorie de M d
’)est constituée des axiomes non-logiquessuivant :(1) p → [a] p et ¬ p → [a]¬ p, pour touta ∈ EVT et p ∈ PROP ;
(2) a ↔ Pre(a), pour tout a ∈ EVT ;
(3) [a]B i(b−1 ∨ . . . ∨ b−
n ),où b1, . . . , bn est la liste de tous les b tels
que ad
−→i b ;
(4) B iPre(b) → [a]B ib−, pour tout
a, b ∈ d−→i.Notons que Γ(M d) est finie car dans DELl’ensemble des événements EVT et l’en-semble des agents AGT sont tous les deuxfinis. ¡
L’axiome de déterminisme est en fait uneconséquence logique de Γ(M d) dans EDL.
Lemma 5.2 Pour tout LEDL-formule ϕnous avons Γ(M d) |=EDL aϕ → [a]ϕ.
Nous avons alors le résultat essentiel sui-vant.
De DEL à EDL ou comment illustrer la puissance des événements inverses ___________________________________________________________________________
258

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 271/415
Theorem 5.3 Soit M d unDELmodèle dy-namique. Soit ψ une formule de LDEL.
Alors
|=DEL ϕ ssi Γ(M d
) |=EDL ϕ
Il s’ensuit que
DEL ϕ ssi Γ(M d) EDL ϕ
Cela fournit donc une nouvelle axiomati-sation des validités de DEL.
6 Discussion et conclusion
Nous avons présenté une logique dyna-mique épistémique EDL dont la séman-tique diffère de de celle de la logique épis-témique dynamique DEL de Baltag et col.Nous avons montré que DEL peut être in-
jectée dans EDL. Ce résultat nous per-met de conclure que EDL est une alter-native intéressante à la logique de Bal-
tag et col. Cependant, EDL est plus ex-pressive que DEL car elle permet de par-ler d’événements passés. Un autre de sesavantages est que l’on peut décrire partiel-lement un événement ayant lieu et quandmême en tirer des conséquences, alors quedans DEL le modèle d’action doît tout spé-cifier. Plus généralement, EDL semble êtreplus flexible pour décrire des événements.Cela permet de modéliser des événements
qui ne peuvent pas être modélisés dansDEL.
Nous allons démontrer ce dernier pointpar un exemple. Considérons la situationoù il y a deux agents i et j, e t i l y adeux annonces privées possibles a et bavec pour préconditions respectives p et¬ p. Supposons que les agents ne saventrien de ce qui s’est passé excepté que aou b ont eu lieu, c’est à dire formellement
que a−∨b− est connaissance com-mune. De cela nous devrions en conclureque les agents ne savent rien du tout dela perception que l’autre agent a de l’évé-nement (ce qui est en fait vrai en réalité).
Nous pouvons modéliser ce dernier pointcomme suit. D’abord on défini récursive-ment l’ensemble suivant de formules.
– Φ0i = Φ0 j = a−, b−– Φn
i = B iϕ j : ϕ j ∈ Φn−1 j ∪
ϕj :ϕj∈Φn−1j
B iϕ j
Par exemple on a
Φ1
i = B ia−,B ib
−, B ia− ∧
B ib− et
Φ2
j = B jB ia−
,B jB ib−
,B j(B ia−
∧B ib
−) ∪ B jB ia− ∧ B jB ib
− ∧
B j(B ia− ∧ B ib
−).
Naturellement, nous affirmons que l’en-semble de tous les ((
Φni ) ∧ (
Φn j ) re-
présente le fait que les agents ne saventrien à propos de la perception qu’a l’autreagent de l’événement. Nous pouvons alorsprouver par induction sur n que a− ∨
b− EDL (
Φni ) ∧ (
Φn j ) pour tout
n.2 Cela nous indique que la connaissanceincomplète des agents de ce qui se passeest correctement représentée par a−∨b−.
De telles situations ne peuvent pas être dé-crites dans DEL car cela nécessiterait uneinfinité d’événements atomiques, et le mo-dèle dynamique M d devrait être infini.
Une autre approche qui associe DEL à lalogique dynamique propositionnelle avecautomate est [17]. Il n’a pas recours auxévénements inverses et traduit les modèlesdynamiques par une transformations surles programmes de PDL. Comme nousl’avons dit dans la section 1, Yap a in-troduit les événements inverses dans DELmais elle n’est pas arrivée à donner des
axiomes de réduction pour l’opérateur mo-dal inverse. Comme nous, elle ne traitepas de la révision des croyances et nous
2L’observation clé est que EDL B i(a− ∨ b−) →
(B ia− ∨ B ib− ∨ (B ia− ∧ B ib−))
____________________________________________________________________________ Annales du LAMSADE N°8
259

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 272/415
repoussons l’intégration de tels mécha-nismes à de futurs travaux.
Références[1] Carlos Alchourrón, Peter Gärdenfors,
and David Makinson. On the logic of theory change : Partial meet contrac-tion and revision functions. J. of Sym-bolic Logic, 50 :510–530, 1985.
[2] Alexandru Baltag. A logic of epis-temic actions. Technical report,CWI, 2000. http://www.cwi.
nl/~abaltag/papers.html.[3] Alexandru Baltag and Lawrence S.
Moss. Logics for epistemic pro-grams. Synthese, 139(2) :165–224,2004.
[4] Alexandru Baltag, Lawrence S.Moss, and Slawomir Solecki. Thelogic of public announcements,common knowledge, and privatesuspicions. In Proc. TARK’98 , pages
43–56. Morgan Kaufmann, 1998.[5] Ronald Fagin, Joseph Y. Halpern, Yo-
ram Moses, and Moshe Y. Vardi. Reasoning about knowledge. MITPress, 1995.
[6] Jelle Gerbrandy. Bisimulations onPlanet Kripke. PhD thesis, Univer-sity of Amsterdam, 1999.
[7] Jelle Gerbrandy and Willem Groene-
veld. Reasoning about informationchange. J. of Logic, Language and Information, 6(2), 1997.
[8] Hirofumi Katsuno and Alberto O.Mendelzon. On the difference bet-ween updating a knowledge base andrevising it. In Peter Gärdenfors, edi-tor, Belief revision, pages 183–203.Cambridge University Press, 1992.
[9] J. A. Plaza. Logics of public com-
muncations. In M. L. Emrich, M. Z.Pfeifer, M. Hadzikadic, and Z. W.Ras, editors, Proc. 4th Int. Sympo-sium on Methodologies for Intelligent Systems, pages 201–216, 1989.
[10] H. Sahlqvist. Completeness and cor-respondence in the first and secondorder semantics for modal logics. InStig Kanger, editor, Proc. 3rd Scandi-navian Logic Symposium 1973, num-ber 82 in Studies in Logic. North Hol-land, 1975.
[11] Krister Segerberg. Belief revisionfrom the point of view of doxastic lo-gic. Bulletin of the IGPL, 3 :534–553,1995.
[12] Krister Segerberg. Two traditions inthe logic of belief : bringing them to-
gether. In Hans Jürgen Ohlbach andUwe Reyle, editors, Logic, Languageand Reasoning : essays in honour of
Dov Gabbay, volume 5 of Trends in Logic, pages 135–147. Kluwer Aca-demic Publishers, Dordrecht, 1999.
[13] Johan van Benthem. One is a lonelynumber : on the logic of communica-tion. In Z. Chatzidakis, P. Koepke,and W. Pohlers, editors, Logic Col-
loquium’02, pages 96–129. ASL &A.K. Peters, Wellesley MA, 2006.Tech Report PP-2002-27, ILLC Am-sterdam (2002).
[14] Johan van Benthem and Eric Pacuit.The tree of knowledge in action : To-wards a common perspective. In Ad-vances in Modal Logic, pages 87–106, 2006.
[15] Hans P. van Ditmarsch. Descrip-
tions of game actions. J. of Logic, Language and Information (JoLLI),11 :349–365, 2002.
[16] Hans P. van Ditmarsch, Wiebevan der Hoek, and Barteld Kooi.
Dynamic Epistemic Logic. KluwerAcademic Publishers, 2007.
[17] Jan van Eijck. Reducing dynamicepistemic logic to pdl by programtransformation. Technical Report
SEN-E0423, CWI, 2004.[18] Audrey Yap. Product update and loo-
king backward. prepublications PP-2006-39, ILLC, 2006.
De DEL à EDL ou comment illustrer la puissance des événements inverses ___________________________________________________________________________
260

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 273/415
Considérations relatives à la décidabilité et à la complexité duproblème de la composition de services
Philippe.Balbiani Fahima. Cheikh Guillaume. Feuillade
Université Paul Sabatier, Institut de recherche en informatique de Toulouse118, route de Narbonne 31062 Toulouse Cedex 9
Résumé :Le problème de la composition de services consisteà combiner des services afin de répondre à la re-quête d’un client. Dans cet article, nous considé-rons un modèle orienté service dans lequel les ser-
vices sont capables de mettre à jour un systèmed’informations et d’échanger des messages. Dansce modèle, le problème de la composition est indé-cidable. Pour cette raison, nous considérons un mo-dèle simplifié pour lequel le problème de la compo-sition de services est décidable.
Mots-clés : Composition de services, automatesconditionnels, complexité.
Abstract:Services composition problem consists in combi-ning services in order to answer a client request.In this paper, we consider a service oriented modelwhere services are able to update an informationsystem and to exchange messages. In this modelthe composition problem is undecidable. For thisreason, we consider a simplified model for whichthe composition problem is decidable.
Keywords: Services composition, conditional au-tomata, complexity.
1 Introduction
Les applications orientées services [11]sont à l’origine d’un nouveau paradigmede programmation distribuée qui modifiela façon dont les applications sont spéci-fiées, implémentées et exécutées. Toute-fois, avant que les services ne deviennentune réalité, un certain nombre de défiscomme la sécurité des services et la com-position des services, doivent être relevés.Avant d’accorder l’accès aux ressources
dont ils ont la responsabilité, les servicesétablissent leurs politiques de sécurité etdécrivent les conditions sous lesquellestelle ou telle ressource peut être légale-ment utilisée. Par conséquent, les services
interagissent avec leurs clients et avecd’autres services par le biais de protocolescryptographiques afin d’obtenir leurs certi-ficats et de caractériser leurs droits. La sé-
curité des services traite de la confidentia-lité, de l’intégrité et de la disponibilité enrapport avec la problématique de la combi-naison et de l’intégration des protocoles etdes politiques. Les services permettent deréaliser des parcs d’organisations capablesd’exporter leurs services à des clients et decoopérer en composant des services via lesréseaux. Par suite, les services sont des élé-ments logiciels indépendants qui peuventêtre composés en vue de faire collabo-rer entre elles des applications distribuées.La composition des services étudie les si-tuations où les demandes des clients nepeuvent être satisfaites qu’en combinantles services disponibles de manière appro-priée [2, 10]. Il y a cinq sections princi-pales dans cet article. Dans la section 2,nous présenterons brièvement un modèlede services et nous élaborerons un modèleformel de la composition. Le problème de
la composition évoqué dans la section 2étant indécidable, nous présenterons, dansla section 3, un modèle simplifié de ser-vices basé sur les automates finis. Dans lasection 4, nous définirons les concepts quinous permettront de comparer les servicesentre eux : équivalence de services (équi-valence de trace et bisimulation) et inclu-sion de services (inclusion de trace et si-mulation). Nous attaquerons, dans les sec-
tions 5 et 6, l’étude de la complexité al-gorithmique du problème de l’équivalencede services et du problème de l’inclusionde services.
261

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 274/415
2 Modèle général
Nous présentons un modèle d’applications
orientées services (voir la figure 1) qui re-prend et généralise le modèle élaboré parBerardi et al [3]. Ensuite, nous définironsle problème de la composition. Notre mo-dèle est constitué des éléments suivants :un système d’informations IF , une com-munauté de services C = S 1, . . . , S n, unservice but S but, un service client S 0 munid’un ensemble de certificats et un ser-vice médiateur S med qui s’interpose entrele client et les services de la commu-nauté. Un système d’informations IF peutêtre vu comme un ensemble d’objets (pro-duits manufacturés, fichiers, etc.) caracté-risés en termes d’attributs tels que le prix,la taille, etc. Les services d’une commu-
FIG . 1 – Modèle d’application orientéesservices
nauté C mettent à jour le système d’infor-mations IF en exécutant des commandes.
Ils obtiennent des informations sur IF aumoyen d’échanges de messages avec lesautres services. Les services sont représen-tés par des automates conditionnels danslesquels la transition d’un état à un autre
n’est possible que si une certaine condi-tion est vérifiée. Les conditions peuventconcerner la valeur d’une variable localeau service, la valeur d’un attribut pour unobjet donné dans IF ou la valeur d’un descertificats du client. Ici, les certificats sontdes assertions sur les clients des services.Ils sont émis par les services de la com-munauté. Les services de la communauté,tels que nous les avons définis, seront uti-lisés par d’autres services appelés servicesclients (notés S 0). Leur objectif est d’obte-nir des informations sur le système d’in-formations. Deux états suffisent pour les
définir complètement. A partir de ces états,un service client ne peut qu’émettre ou re-cevoir des messages. Les conditions destransitions du client sont toujours vérifiées.La requête d’un utilisateur est représentéepar un service S but appelé service but etqui ne fait pas partie de la communauté.Les services médiateurs, notés S med, ef-fectuent uniquement des échanges de mes-sages. Leur rôle est de s’interposer entre
le service client et les services de la com-munauté. Les conditions des transitionsdans S med ne concernent que les valeursde ses variables locales. Lorsqu’un clientveut effectuer des calculs à partir d’un sys-tème d’informations et qu’aucun des ser-vices de la communauté ne peut réaliserseul ces calculs, une solution est de com-biner entre eux les services de la commu-nauté. Le problème de la composition desservices consiste alors à lier ces servicesentre eux. Formellement, le problème de lacomposition de services est le problème dedécision suivant : soient une communauté C = S 1,..., S n , un ensemble de certifi-cats C ert , un service client S 0 et un servicebut S but , existe-t-il un service médiateur S med tel que pour tout système d’informa-tions IF , le comportement de S 0 ,S butest équivalent à celui de S 0, S med ∪ C .Dans cette définition, l’équivalence entre
S 0,S but et S 0, S med∪C est basée sur labisimulation, la simulation, l’équivalencede trace ou l’inclusion de trace. Ainsi dé-fini, le problème de la composition de ser-
Considérations relatives [...] au problème de la composition de services ___________________________________________________________________________
262

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 275/415
vices est indécidable. En effet, il nous aété possible [1] de réduire le problème del’arrêt des machines de Minsky [7] au pro-blème de la composition défini ci-dessus.
3 Modèle simplifié
Notre modèle simplifié des services estbasé sur les automates finis.
3.1 Automates finis
Un automate fini est une structure de laforme A = (Q, Σ, →, q 0), dans laquelle Qest un ensemble fini d’états, Σ est un en-semble fini de symboles, →⊆ Q × Σ × Qest une relation de transition et q 0 ∈ Qest un état. Pour tout q ∈ Q, pour touta ∈ Σ et pour tout q ∈ Q, si (q,a,q ) ∈→alors nous écrivons q →a q . Nous di-rons que A est déterministe lorsque pourtout q ∈ Q et pour tout a ∈ Σ, il
existe au plus un q
∈ Q tel que q →aq . Un chemin pour A est une suite fi-nie de la forme (q 0, a1, q 1), (q 1, a2, q 2),. . .,(q n−1, an, q n), telle que pour tout i ∈1, . . . , n,q i−1 →ai q i. Le mot a1 . . . an
est sa trace. L’ensemble des traces de tousles chemins pour A est noté T r(A).
3.2 Automates conditionnels
Nous présentons maintenant notre modèlesimplifié des services. Ce modèle simpli-fié est celui des automates conditionnelset semble n’avoir jamais fait l’objet d’au-cune recherche. Soit At un ensemble deformules atomiques. L’ensemble des lit-téraux sur At est défini par Li(At) =At ∪ ¬ p : p ∈ At. Nous dirons d’unepartie I de Li(At) qu’elle est maximaleconsistante lorsque pour toute formule ato-
mique p ∈ At on a p ∈ I et ¬ p /∈I , ou ¬ p ∈ I et p /∈ I . Un automateconditionnel est une structure de la formeA = (Q,At,Ac,δ,q 0, I 0), dans laquelleQ est un ensemble fini d’états, At est un
ensemble fini de formules atomiques, Acest un ensemble fini d’actions, δ : Q ×Ac × Q −→ 22Li(At)×2Li(At) est une fonc-
tion de transition, q 0 ∈ Q est un étatet I 0 ⊆ Li(At) est une partie maximaleconsistante de Li(At). Pour tout q ∈ Q,et pour tout a ∈ Ac et pour tout q ∈ Q,δ (q,a,q ) décrit l’ensemble possible descauses et des effets de l’exécution de l’ac-tion a entre les états q et q . L’apparte-nance d’un couple (I, I ) d’ensemble delittéraux sur At à δ (q,a,q ) signifie que I est l’ensemble des préconditions et I estl’ensemble des postconditions pour l’exé-
cution de l’action a entre les états q et q .Ces préconditions et postconditions cor-respondent aux certificats et à leur évo-lution dont nous avons parlé dans la sec-tion 2. A chaque automate conditionnelA = (Q,At,Ac,δ,q 0, I 0), nous associonsl’automate fini AF (A) = (Q, Σ, →, q 0)défini par : Q = (q, I ) : q ∈ Q et I ⊆Li(At) est une partie maximale consis-tante de Li(At), Σ = Ac, →⊆ Q ×
Σ
× Q
est la relation de transition dé-finie par (q, I ) →
a (q , I ) ssi il existe(J, J ) ∈ δ (q, a, q ) tel que J ⊆ I et I =(I \ ¬J ) ∪ J où ¬J = p : ¬ p ∈ J ∪¬ p : p ∈ J et q 0 = (q 0, I 0). Nous obser-vons qu’un temps exponentiel par rapportà la taille de l’automate conditionnel Aest suffisant pour construire l’automate finiAF (A). Nous observons également que lataille de l’automate fini AF (A) est expo-
nentielle par rapport à la taille de l’auto-mate conditionnel A.
3.3 Produits d’automates
L’analyse de la complexité algorithmiquedu problème de la composition de servicesnécessitera, dans les sections 5 et 6, l’uti-lisation du produit d’automates finis. Soitn ≥ 2. Pour tout i = 1, . . . , n, soit Ai =
(Qi, Σi, →i, q 0i) un automate fini déter-ministe. Le produit asynchrone des auto-mates finis A1, . . . , An, noté A1⊗. . .⊗An
est l’automate fini A = (Q, Σ, →, q 0)défini par : Q = Q1 × . . . × Qn, Σ =
____________________________________________________________________________ Annales du LAMSADE N°8
263

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 276/415
Σ1 ∪ . . . ∪ Σn, q 0 = (q 01, . . . , q 0n) et →⊆Q × Σ × Q est la relation de transitiondéfinie par : pour tout q = (q 1, . . . , q n) ∈Q, pour tout a ∈ Σ et pour tout q =(q 1, . . . , q n) ∈ Q, q →
a q ssi il existe i ∈1, . . . , n tel que a ∈ Σi, q i →a q i et pourtout j ∈ 1, . . . , n, si j = i alors q j = q j. Soit n ≥ 2. Pour tout i = 1, . . . , n, soitAi = (Qi, Ati, Aci, δ i, q 0i, I 0i) un auto-mate conditionnel. Le produit asynchronedes automates conditionnels A1, . . . , An,noté A1 ⊗ . . . ⊗ An est l’automate condi-tionnel A = (Q,At,Ac,δ,q 0, I 0) définipar : Q = Q1 × . . . × Qn, At = At1 ∪
. . . ∪ Atn, Ac = Ac1 ∪ . . . ∪ Acn, q 0 =(q 01, . . . , q 0n), I 0 = I 01 ∪ . . . ∪ I 0n et
δ : Q × Ac × Q → 22Li(At)×2Li(At) estla fonction de transition définie par : pourtout q = (q 1, . . . , q n) ∈ Q, pour touta ∈ Ac, pour tout q = (q 1, . . . , q n) ∈ Q,pour tout J ⊆ Li(At) et pour tout J ⊆Li(At), (J, J ) ∈ δ (q,a,q ) ssi il existei ∈ 1, . . . , n tel que a ∈ Aci, (J, J ) ∈δ i(q i,a ,q i) et pour tout j ∈ 1, . . . , n, si
j = i alors q j = q j . Nous observons quele produit A1 ⊗ . . . ⊗ An n’est défini quesi I 01 ∪ . . . ∪ I 0n constitue un ensembleconsistant de littéraux. Exemple Consi-dérons l’automate conditionnel A1 repré-senté par la figure 2 et l’automate condi-tionnel A2 représenté par la figure 3. L’au-tomate conditionel A1 ⊗ A2 est représentépar la figure 4.
FIG . 2 – Le service A1
4 Equivalences et préordres
Afin de pouvoir comparer entre eux lesautomates conditionnels et leurs produits,nous devons définir ce que sont l’inclu-
FIG . 3 – Le service A2
FIG . 4 – Le service A1 ⊗ A2
sion de trace, l’équivalence de trace, la si-mulation et la bisimulation pour les au-tomates finis. Soit A = (Q, Σ, →, q 0) etA = (Q, Σ, →, q 0) des automates fi-nis. Nous dirons que A est inclus pour latrace dans A, noté A ≤tr A, lorsqueT r(A) ⊆ T r(A). Nous dirons que Aet A sont équivalents pour la trace, noté
A ≡tr A, lorsque T r(A) = T r(A). Unesimulation de A par A est une relation bi-naire Z ⊆ Q × Q telle que q 0Zq 0 et pourtout q ∈ Q et pour tout q ∈ Q, si qZq
alors pour tout r ∈ Q et pour tout a ∈ Σ,si q →a r alors il existe r ∈ Q tel querZr et q →a r . Nous dirons que A estsimulé par A, noté A ≤si A, lorsqu’ilexiste une relation binaire Z ⊆ Q × Q
telle que Z est une simulation de A par
A
. Nous dirons que A et A
sont bisimi-laires, noté A ≡bi A, lorsqu’il existe unerelation binaire Z ⊆ Q × Q telle que Z est une simulation de A par A et Z −1 estune simulation de A par A. La relation bi-
Considérations relatives [...] au problème de la composition de services ___________________________________________________________________________
264

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 277/415
naire Z ⊆ Q × Q sera alors appelée bi-simulation entre A et A. Rappelons qu’ilexiste des automates finis A et A tels queA ≤si A, A ≤si A et non A ≡bi A [5].Nous dirons que A et A sont isomorphesssi Σ = Σ et il existe une bijection g :Q → Q telle que pour tout état q 1, q 2 ∈ Qet pour toute action a ∈ Σ, q 1 →a q 2 ssig(q 1) →
a g(q 2). Soit A et A des auto-mates conditionnels. Nous dirons que Aest inclus pour la trace dans (resp. simulépar) A lorsque AF (A) est inclus pourla trace dans (resp. simulé par) AF (A).Nous dirons que A et A sont équivalents
pour la trace (resp. bisimilaires) lorsqueAF (A) et AF (A) sont équivalents pourla trace (resp. bisimilaires). Remarquonsque l’équivalence de trace et la bisimila-rité sont des relations d’équivalence tandisque l’inclusion de trace et la similarité sontdes relations de préordre.
5 Réductions polynomiales
Nous analysons maintenant la difficulté in-trinsèque qu’il y a à comparer entre euxles automates conditionnels ou les produitsd’automates conditionnels, le problème dela comparaison de produits d’automatesconditionnels étant celui que nous consi-dérons comme étant le plus proche du pro-blème de la composition des services évo-qué dans la section 2. Dans cette section,nous caractérisons les bornes inférieuresde complexité. Nous allons d’abord mon-trer que les problèmes suivants : (P acbi ) :soient deux automates conditionnels Aet A , déterminer si A et A sont bisi-milaires, (P acet ) : soient deux automatesconditionnels A et A , déterminer si Aet A sont équivalents pour la trace et(P acit ) : soient deux automates condition-nels A et A , déterminer si A est inclus
pour la trace dans A. sont respectivement
EXPTIME-difficile, EXSPACE-difficile etEXSPACE-difficile. Pour cela, nous al-lons réduire le problème de la bisimula-tion entre des réseaux de Petri saufs, quiest EXPTIME-difficile [6], au problème
(P acbi ) et nous allons réduire le problèmede l’équivalence de trace (resp. inclusionde trace) des réseaux de Petri saufs, quiest EXSPACE-difficile [6], au problème
(P acet ) (resp. (P acit )). Un réseau de Petrisauf [8] est une structure de la forme
N = (P,T,F, Σ, l ,m0), dans laquelleP = p1, . . . , pn est un ensemble fini deplaces, T = t1, . . . , tm est un ensemblefini de transitions, F ⊆ (P × T ) ∪ (T × P )est un ensemble fini d’arcs, Σ est un en-semble fini de symboles, l : T → Σ estune fonction et m0 : P → 0, 1 est unefonction. La fonction m0 est appelée mar-
quage initial de N . De façon générale, unmarquage m : P → 0, 1 pour N décritune répartition de jetons dans les places.Pour chaque transition t ∈ T , nous défi-nissons deux sous-ensembles de places :•t = p : p ∈ P et ( p, t) ∈ F ett• = p : p ∈ P et (t, p) ∈ F . L’en-semble •t contient les places qui ont un arcen direction de t tandis que l’ensemble t•
contient les places qui ont un arc en pro-
venance de t. Une transition t ∈ T estdite active (resp. inactive) au marquage msi pour toute place p ∈ •t, m( p) = 1(resp. il existe une place p ∈ •t telle quem( p) = 0). Lorsque la transition t est ac-tive au marquage m, nous définissons le tir de la transition t par l’action qui modifiele marquage m en un marquage m définipour toute place p ∈ P par
– m
( p) =
m( p) si p ∈ •t ∪ t•
1 si p ∈ t•
0 sinon
Nous notons m[t lorsque la transitiont est active au marquage m et m[tm
lorsque m est le résultat du tir de t de-puis m. A chaque réseau de Petri sauf
N = (P,T,F, Σ, l , m0) nous associonsl’automate fini AF ( N ) = (Q, Σ, →, q 0)défini par Q = M où M est l’ensembledes marquages pour N , Σ=Σ, →⊆ Q ×
Σ × Q est la relation de transition défi-nie par m →
a m ssi il existe une transi-tion t ∈ T tel que l(t) = a et m[tm etq 0 = m0. Nous définissons, entre réseauxde Petri saufs, les mêmes relations d’équi-
____________________________________________________________________________ Annales du LAMSADE N°8
265

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 278/415
valence et de préordre que celles considé-rées dans la section 4 :
– N ≤tr N ssi AF ( N ) ≤tr AF ( N ),
– N ≡tr N
ssi AF ( N ) ≡tr AF ( N
),– N ≤si N ssi AF ( N ) ≤si AF ( N ) et– N ≡bi N ssi AF ( N ) ≡bi AF ( N ).
A chaque réseau de Petri sauf N = (P,T,F, Σ, l , m0), nous as-socions l’automate conditionnelR( N ) = (Q,At,Ac,δ,q 0, I 0), définipar : Q = q , At = P , Ac = Σ,δ (q,a,q ) = (h(m), h(m)) : m[tm etl(t) = a q 0 = q et I 0 = h(m0). Dans la
définition ci-dessus, h : M → 2Li(At) estla fonction qui associe à chaque marquagem ∈ M le sous-ensemble h(m) = p :m( p) = 1 ∪ ¬ p : m( p) = 0 de Li(At).Notons que pour tout marquage m ∈ M ,h(m) est une partie maximale consistantede Li(At). Nous allons montrer que :(1) R est calculable par une machine deTuring déterministe en utilisant un espacelogarithmique, (2) les automates finis
AF ( N ) et AF (R( N )) sont isomorphes.Concernant (1), étant donné un réseau dePetri sauf N , une machine de Turing Mcalcule R( N ) de la façon suivante : (a)écrire l’ensemble q contenant l’uniqueétat de R( N ). Ensuite, écrire l’ensembleAt = P des formules atomique de R( N ),l’ensemble Ac = Σ des actions de R( N )et l’état initial q 0 = q de R( N ) ; (b) écrirela partie maximale consistante I 0 = h(m0)de Li(At). Pour chaque place p, lire lavaleur de m0( p) et ajouter p ou ¬ p à I 0selon que cette valeur est 1 ou 0; (c)pour finir, écrire la fonction de transi-tion δ de R( N ). Pour ce faire, utiliserdeux compteurs i et j. Le compteur i vasuccessivement prendre comme valeursles transitions de N . Pour chaque valeurde i écrire l’ensemble δ (q,a,q ) où a estl’action correspondant à la transition i viala fonction l. Pour ce faire, donner succes-
sivement à j comme valeurs les places de N . Toutes ces étapes peuvent bien sûr êtrefaites de façon déterministe en utilisantun espace logarithmique. Concernant(2), nous procédons de la façon suivante.
Les états de AF ( N ) sont des marquagespour N . Les états de AF (R( N )) sontdes couples de la forme (q, I ) où q estl’unique état de R( N ) et I est une partiemaximale consistante de Li(At). Soit g lafonction qui associe à chaque marquagem pour N le couple (q, h(m)). Nouslaissons le soin au lecteur de vérifier queg est une bijection telle que pour toutmarquage m1, m2 pour N et pour touteaction a ∈ Σ, m1 →a m2 (dans AF ( N ))ssi g(m1) →a g(m2) (dans AF (R( N ))).Donc :
Théorème 1 (P acbi ) est EXPTIME-difficileet (P acet ) et (P acit ) sont EXPSPACE-difficiles.
Démonstration. Il suffit de rappeler que leproblème de la bisimulation entre réseauxde Petri saufs est EXPTIME-difficile [6]et que les problèmes de l’équivalence detrace et de l’inclusion de trace entre ré-
seaux de Petri saufs sont EXPSPACE-difficiles [6]. Nous allons ensuite mon-trer que le problème suivant : (P acsi ) :soient deux automates conditionnels A et A , déterminer si A est simulé par A,est EXPTIME-difficile. Pour cela, nous al-
lons réduire le problème, (P afdsi ) : soient A , B 1, . . . , B n des automates finis dé-terministes, déterminer si A est simulé
par B 1 ⊗ . . . ⊗ B n, qui est EXPTIME-difficile [9], au problème (P ac
si
). Soit A =(QA, ΣA, →A, q 0A) un automate fini dé-terministe. Considérons l’automate condi-tionnel R(A) = (Q,At,Ac,δ,q 0, I 0) telque : Q = QA, At = ∅, Ac = ΣA,δ (q,a,q ) = (∅, ∅) : q →a
A q ,q 0 = q 0A et I 0 = ∅. Soit n ≥ 2.Pour tout i ∈ 1, . . . , n, soit B i =(Qi, Σi, →i, q 0i) un automate fini détermi-niste et B = (QB , ΣB, →B , q 0B) leurproduit asynchrone. Sans perte de généra-
lité, nous supposons que | Q1 |= . . . =|Qn |. Soit t = log2(| Q1 |) =. . . = log2(| Qn |). Pour tout i ∈1, . . . , n, nous considérons un ensembleAti = ri1, . . . , rit de t atomes. Notons
Considérations relatives [...] au problème de la composition de services ___________________________________________________________________________
266

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 279/415
que les ensembles At1, . . . , A tn sont deuxà deux disjoints. Soit f : Q1 ∪ . . . ∪Qn → 2Li(At1∪...∪Atn) une fonction bijec-tive telle que pour tout
i ∈ 1
, . . . , net
pour tout q ∈ Qi, f (q ) est une partie maxi-male consistante de Li(Ati). Considéronsl’automate conditionnel R(B 1, . . . , B n) =(Q, At, Ac, δ , q 0, I 0) tel que : Q = q ,At = At1 ∪ . . . , A tn, Ac = Σ1 ∪. . . ∪ Σn, δ (q ,a ,q ) = (f (u), f (v)) :i ∈ 1, . . . , n,u ,v ∈ Qi et u →a
i v,q 0 = q et I 0 = f (q 01) ∪ . . . ∪ f (q 0n).Nous allons montrer que : (1) R et R
sont calculables par une machine de Tu-
ring déterministe en utilisant un espace lo-garithmique, (2) les automates finis A etAF (R(A)) sont isomorphes, (3) les au-tomates finis B et AF (R(B 1, . . . , B n))sont isomorphes. Concernant (1), l’argu-ment est le même que celui que nousavons développé dans la section ??. L’au-tomate conditionnel R(A) étant la simpleréécriture de l’automate fini déterministeA nous laissons le soin au lecteur de vé-
rifier (2). Concernant (3), nous procédonsde la façon suivante. Les états de B sontdes n-uplet d’états (q 1, . . . , q n) où q i, i ∈1, . . . , n, est un état de B i. Les étatsde AF (R(B 1, . . . , B n)) sont des couplesde la forme (q , I ) où q est l’uniqueétat de R(B 1, . . . , B n) et I est une par-tie maximale consistante de Li(At). Soitg la fonction qui associe à chaque n-uplets d’états (q 1, . . . , q n) de B le couple
(q
, I ) où I = f (q 1) ∪ . . . ∪ f (q n).Nous laissons le soin au lecteur de vé-rifier que g est une bijection telle quepour tout n-uplet d’états (q 11, . . . , q 1n),(q 21, . . . , q 2n) de B et pour toute actiona ∈ ΣB, (q 11, . . . , q 1n) →a
B (q 21, . . . , q 2n)ssi g(q 11, . . . , q 1n) →a g(q 21, . . . , q 2n)(dans AF (R(B 1, . . . , B n))). La discussionci-dessus implique que :
Théorème 2 (P
ac
si ) est EXPTIME-difficile.
Démonstration. Il suffit de rappeler que
(P afdsi ) est EXPTIME-difficile [9].
6 Classes de complexité
Dans cette section, nous caractérisons les
bornes supérieures de complexité. Pour cequi concerne (P acbi ), rappelons que le pro-blème de la bisimulation entre automatesfinis est dans P [5]. Considérons l’algo-rithme suivant : (1) Construire l’automatefini AF (A) ; (2) Construire l’automate finiAF (A) ; (3) Déterminer si AF (A) etAF (A) sont bisimilaires. Sachant qu’untemps exponentiel par rapport à la taillede A et A est suffisant pour construireAF (A) et AF (A) à partir de A et A, sa-chant qu’un temps polynomial par rapportà la taille de AF (A) et AF (A) est suffi-sant pour déterminer si AF (A) et AF (A)sont bisimilaires, il en résulte que :
Théorème 3 (P acbi ) est dans EXPTIME.
Un argument semblable à l’argument pré-cédent montrerait que :
Théorème 4 (P acsi ) est dans EXPTIME et (P acet ) et (P acit ) sont dans EXPSPACE.
Démonstration. Il suffit de rappeler que leproblème de la simulation entre automatesfinis est dans P [5], que le problème del’équivalence de trace entre automates finisest dans PSPACE [4] et que le problèmede l’inclusion de trace entre automates fi-nis est dans PSPACE [4].
Considérons le problème suivant : (P ac⊗bi ) :soient A , B 1, . . . , B n des automates condi-tionnels, déterminer si A et B 1 ⊗ . . . ⊗B n sont bisimilaires. Bien entendu, lethéorème 1 implique que (P ac⊗bi ) estEXPTIME-difficile. Par ailleurs, sachantqu’un temps doublement exponentiel parrapport à la taille des B 1, . . . , B n est suffi-
sant pour construire AF (B 1 ⊗ . . . ⊗ B n),sachant qu’un temps exponentiel par rap-port à la taille de A est suffisant pourconstruire AF (A), il en résulte que (P ac⊗bi )est dans 2-EXPTIME. Nous pouvons, de
____________________________________________________________________________ Annales du LAMSADE N°8
267

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 280/415
la même façon, montrer que les problèmessuivants : (P ac⊗si ) : soient A , B 1, . . . , B ndes automates conditionnels, déterminer si A est simulé par B
1⊗ . . . ⊗ B n ,
(P ac⊗et ) : soient A , B 1, . . . , B n des auto-mates conditionnels, déterminer si A et B 1⊗. . .⊗B n sont équivalents pour la traceet (P ac⊗it ) : soient A , B 1, . . . , B n des au-tomates conditionnels, déterminer si A est inclus pour la trace dans B 1 ⊗ . . . ⊗ B n ,sont respectivement dans 2-EXPTIME, 2-EXPSPACE et 2-EXPSPACE. Nous neconnaissons pas l’exacte complexité de(P ac⊗
bi), (P ac⊗
si), (P ac⊗
et) et (P ac⊗
it). Les pro-
blèmes (P ac⊗bi ), (P ac⊗si ), (P ac⊗et ) et (P ac⊗it )sont ceux que nous considérons commeétant les plus proches du problème dela composition des services évoqué dansla section 2. Dans ces problèmes, en ef-fet, A représente le service but S but tan-dis que B 1, . . . , B n représentent la commu-nauté C = (S 1, . . . , S n).
7 Conclusion
Nous avons présenté dans la section 2 unmodèle orienté service et nous avons poséle problème de la composition. Ce pro-blème étant indécidable en général, nousavons considéré dans la section 3 une abs-traction des services sous la forme d’au-tomates conditionnels. Nous avons ensuiteétudié la complexité du problème de lacomposition de services dans ce modèlesimplifié. Les résultats obtenus montrentque la composition est un problème diffi-cile (EXPTIME-difficile ou EXPSPACE-difficile selon qu’il s’agit de bisimulationou d’équivalence de trace). Nous avonsenfin donné des procédures de décisionpour l’ensemble des problèmes étudiés.Une question demeure : celle de l’exis-
tance de classes d’automates condition-nels pour lesquelles les problèmes de dé-cision que nous avons étudiés deviennentsolubles en temps polynomial ou en espacepolynomial.
Références
[1] P. Balbiani et F. Cheikh. Computatio-nal analysis of interactiong Web ser-
vices : a logical approach. Rapport in-terne de l’Irit, 2006.
[2] D. Berardi. Automatic service compo-sition. Models techniques and tools.Thèse de l’université La Sapienza,2005.
[3] D. Berardi, D. Calvanese, G. De Gia-como, R. Hull et M. Mecella. Automa-tic composition of transition-based se-mantic Web services with messaging.
In Proc. 31st Int. Conf. Very Large Data Bases, VLDB 2005, K. Böhm, C.Jensen, L. Haas, P. Larson et B. ChinOoi, 613-624, 2005.
[4] M. Garey et D. Johnson. Computersand Intractability. A Guide to theTheory of NP-Completeness. H. Free-man and Company, 1991.
[5] H. Hüttel et S. Shukla. On the Com- plexity of Deciding Behavioural Equi-valences and Preorders, A Survey.Rapport dans la série BRICS, 1996.
[6] L. Jategaonkar et A. Meyer. Deci-ding true concurrency equivalences onsafe, finite nets. Theoretical Computer Science, 154(1), 107-143, 1996.
[7] M. Minsky. Computation Finite and Infinite Machines. Prentice-Hall, 1967.
[8] T. Murata. Petri Nets : Properties, ana-
lysis and applications. In Proc. of the IEEE , 77(4), 541-580, 1989.
[9] A. Musholl et I. Walukiewicz. A lowerbound on Web services composition.A paraître.
[10] M. Pistore, A. Marconi, P. Bertoliet P. Traverso. Automated composi-tion of Web services by planning atthe knowledge level. In Proc. Int. Joint Conf. on Artificiel Intelligence, IJCAI
2005, L. Kaelbling et A. Saffiotti,1252-1259, 2005.
[11] M. Singh et M. Huhns. Service-Oriented Computing. Semantics, Pro-cess, Agents. Wiley, 2005.
Considérations relatives [...] au problème de la composition de services ___________________________________________________________________________
268

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 281/415
Caractérisation de Requêtes d’Assistance à partir de corpus
François Bouchet
Jean-Paul Sansonnet
LIMSI-CNRSUniversité Paris-Sud XI
BP 133, F-91403 Orsay Cedex
Résumé :La modélisation formelle de l’interaction entre lesusagers grand public et les systèmes informatiquesa un rôle crucial à jouer au niveau de la Fonctiond’Assistance. Il s’agit préalablement de caractéri-ser sémantiquement, en termes de couverture et deprécision, des phénomènes liés à l’assistance pourproposer à terme un agent rationnel assistant gé-nérique capable de réactions pertinentes aux re-quêtes des usagers. Dans cet article, nous présen-tons notre approche de construction d’un langagepour des agents conversationnels assistants, baséesur l’étude préalable d’un corpus de requêtes re-cueillies dans des situations effectives d’assistance.
Mots-clés : Agents conversationnels assistants,corpus de requêtes d’assistance, langage de re-quêtes
Abstract:Formal modeling of the interaction between ordi-nary users and computer-based systems has a ma- jor part to play in the Assistance Function. A firstobjective is to characterize semantically, both incoverage and precision, the phenomena associatedwith the Assistance Function to provide a genericassisting rational agent capable of pertinent reac-tions to users’ requests. In this paper, we presentour approach to the construction of a language fora class of assisting conversational agents, based on
the study of a corpus of users’ requests registeredin actual assisting experimentations.
Keywords: Assisting conversational agents, assis-tance requests corpus, requests language
1 Cadre de l’étude
1.1 La Fonction d’Assistance
Le développement de l’informatique grandpublic a entraîné une forte augmentationdu nombre d’usagers novices en infor-matique n’ayant ni le temps ni l’envied’utiliser les manuels papiers ou les FAQ
de logiciels de plus en plus complexes(en dépit des progrès ergonomiques), dontpar ailleurs ils ne maîtrisent pas le vo-cabulaire spécifique. Des systèmes d’aidecontextuelle (CHS – Contextual Help Sys-tems [5]) ont été développés pour mieuxs’adapter à leurs besoins, un ami expertest toujours préféré pour réaliser une tâchedonnée dans une application [3]. Parallè-lement, les agents conversationnels animésdotés de capacités de dialogue et de raison-nement [11] ont mis en évidence les avan-tages d’une présence virtuelle pour facili-ter l’interaction homme-machine [8].Pour répondre à ce besoin d’assistance, le
projet DAFT mené au LIMSI-CNRS [13]se propose de développer des AgentsConversationnels Assistants (ACA), ca-pables d’analyser des requêtes en languenaturelle écrite non contrainte d’usagersnovices en situation réelle d’utilisationd’applications de complexité croissante(applets, pages web, sites actifs, traite-ments de texte...), pour fournir une assis-tance pertinente en contexte à la manière
des CHS avec les bénéfices liés à la pré-sence d’agents conversationnels animés.
1.2 Traitement des requêtes
Le système d’assistance DAFT vise àfournir un noyau d’agent rationnel. L’ar-chitecture du système d’assistance (cf.fig. 1) contient classiquement : le moduled’analyse sémantique des requêtes usa-
ger (GRASP) construisant les requêtes for-melles1, le module de raisonnement sur le1par opposition à la forme en langue naturelle. La question
de la sémantique opérationnelle associée aux requêtes, définiepar les réactions de l’agent rationnel, n’est pas traitée ici.
269

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 282/415
Usagernovice
Analyseur sémantiquedes questions (GRASP)
Composantassisté
Expression multimodaledes réactions (EVA)
Langage formel desrequêtes / réactionsd’assistance (DAFT)
Agent Rationnel :raisonnement sur le
modèle symbolique du
composant
FIG . 1 – Architecture générale de la chaîne de traitement des requêtes d’assistance
modèle de l’application qui retourne uneréponse formelle, et le module d’expres-sion de cette réponse (EVA) selon troismodes, éventuellement conjoints :
1. Réplique de l’agent en langue naturelle :selon plusieurs modalités : bulle de texte,synthèse de parole, popup d’aide ;2. Interaction avec l’application assistée :consultation et/ou modification des com-posants via un modèle de l’application;3. Animation de l’agent : le personnageanimé peut exprimer certains états del’agent (désaccord, incompréhension. . .)ou désigner les composants mentionnés.
1.3 Caractérisation du langage formel
Pour caractériser le langage de requêtes,nous étions précédemment [10] partis dela modélisation interne des composants del’application, mais des expérimentationsavec des usagers effectifs ont révélé desphénomènes de dérive cognitive signifi-catifs [7] montrant qu’il faut prendre encompte en priorité le point de vue de l’usa-ger : sa perception cognitive de l’appli-cation mais aussi ses attitudes mentales,exprimées dans les groupes verbaux sous-tendant les actes de langage (cf. §3.1).C’est pourquoi il nous faut un corpus derequêtes d’assistance, permettant de cer-ner le domaine de langue concerné parla Fonction d’Assistance et d’étudier la
distribution des phénomènes associés, quisera présenté dans la section 2. Nous pré-senterons ensuite les spécifications du lan-gage de requêtes, puis une évaluation deson adaptation à notre domaine d’étude.
2 Présentation du corpus
2.1 Recueil du corpus
Peu de données publiques sont effec-tivement disponibles en dialogue écrit Homme/Machine, et nous nous situonsdans le cadre assez différent des NLI (Na-tural Languages Interfaces [1]), traitant derequêtes isolées et non de sessions dialo-giques. Enfin, il était nécessaire de contrô-ler précisément les conditions expérimen-tales de recueil des requêtes centrées surla Fonction d’Assistance, aussi avons-nousété amenés à recueillir notre propre corpus.
Le corpus DAFT comprend 11 000 re-quêtes issues également de trois sources :1. Sur une période de deux ans (juin 2004- juin 2006), des sujets ont été placés de-vant divers types d’applications assistéespar le système DAFT (1.0) : trois appletsJava (modales et amodales i.e. contenantdes threads), deux sites web (dont un édi-table par les usagers) ;2. Des requêtes construites manuellementà partir de deux thésaurus afin d’assurerune couverture linguistique élargie ;3. Des FAQ de deux logiciels de traitementde texte très utilisés (Latex et Word).
Une étude comparative du corpus DAFTavec quatre autres corpus de dialogue
existants (DAMSL/Switchboard [6], Map-Task [4] et Bugzilla [9]) valide la perti-nence de notre démarche de recueil d’uncorpus spécifique, et la section suivante enrésumera certaines conclusions [2].
Caractérisation de requêtes d'assistance à partir de corpus ___________________________________________________________________________
270

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 283/415
9%
36%
15%
40%
Contrôle
Assistance directe
Assistance indirecte
Clavardage
FIG . 2 – Répartition des requêtes du cor-pus DAFT par classes d’activités.
2.2 Catégorisation des activitésconversationnelles du corpus
Lors de la phase de recueil du corpus, lessujets humains devaient réaliser certainestâches, en faisant appel si nécessaire à unagent présent dans l’application pour lesassister, mais pouvaient agir et s’exprimerde manière non contrainte. Quatre classes
de comportements conversationnels ont puêtre observées :– activité de contrôle : corpus constitué
de commandes, afin que l’agent agisse lui-même sur l’application ;– activité d’assistance directe : regrou-pant des demandes d’aide explicitementformulées comme telles par l’utilisateur ;– activité d’assistance indirecte : cor-pus de jugements de l’usager sur l’applica-tion constituant des demandes d’aide sous-entendues, perceptibles uniquement au ni-veau pragmatique ;– activité de clavardage : réunissant lereste des interactions essentiellement cen-trées sur l’agent, ainsi que des expressionsmétalinguistiques, phatiques et de back-channeling.
La figure 2 donne la distribution de cesclasses et la table 1 présente des exemples
de phrases issues de chacune de cesclasses. L’existence des sous-corpus decontrôle et de clavardage montre que l’uti-lisateur attend non seulement d’un ACAqu’il l’aide à utiliser l’application, mais
aussi qu’il soit capable d’agir lui-mêmesur celle-ci, ainsi que de répondre à descommentaires annexes indépendants de latâche à accomplir où il devient lui-mêmele centre d’attention (phénomène lié à laprésence visuelle de l’agent).
3 Le langage de requêtes DAFT
3.1 Structure générale
L’étude menée à partir du corpus DAFTnous a permis de dégager une structure gé-
nérale des requêtes (dans la suite nous par-lerons de schémas de requêtes – en abrégé,de schémas), décomposables en trois ni-veaux imbriquables, donnés ci-dessous enpartant de la couche externe :– Les Modalités (notées Mi) : elles corres-pondent partiellement aux actes de langageau sens de Searle [14]. Elles donnent unevaleur particulière, éventuellement liée àl’usager l’exprimant, à un contenu prédi-
catif (interrogation, doute, volonté. . .).– Les Prédicats (notés Pi) : il s’agit es-sentiellement de verbes d’action (modi-fier, déplacer...) ou de descriptions d’états(faire partie de. . .).– Les Références (notées Ri) : au sensde Références Extensionnelles Associa-tives [12] (toute mention ultérieure sera àprendre dans ce sens) ; elles correspondentgénéralement aux groupes nominaux.
3.2 Syntaxe et notations
Les modalités et prédicats sont tous dotésd’un schéma qui les lie à un ensembled’unités sémantiques spécifiques appeléeschamps. On notera une modalité :
SYMBOLE-MODALITE(ch1, ..., chn)
et un prédicat s’écrira :
SymbolePrédicat(ch1, ..., chn)où ch1,...,chn représentent des champs.Un champ est lui-même constitué d’uncouple attribut-valeur et s’écrit :
attribut=valeur
____________________________________________________________________________ Annales du LAMSADE N°8
271

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 284/415
TAB . 1 – Quelques exemples de requêtes du corpus DAFTNo Corpus Phrase→ Transcription
1 Contrôle glisser le disque de droite à gauche→ Move(obj="le disque", from="droite", to="gauche")
2 Contrôle Donne moi la liste des projets → Show(obj="la liste des projets")
3 Ass. dir. c quoi le GT ACA→ ASK(INFOS(about="le GT ACA"))
4 Ass. dir. comment faire pour gagner ?→ ASK(WAY(goal=Win()))
5 Ass. dir. d’après toi, y a t-il des fonctions d’annulation dans cette application ?
→ ASK(KNOWLEDGE(of="system", about=EXISTENCE(of=FUNCTION(doing=Cancel(), in="cette appli"))))
6 Ass. dir. j’ai bien peur qu’il n’y ait pas moyen de changer la taille de la police qui est trop petite
→ FEAR(agent="user", fear=NEG(POSSIBILITY(todo=Modify(obj="la police...", property="taille"))))
7 Ass. dir. quelles sont les couleurs disponibles ?→ ASK(OBJECT(isa="couleur", ppt="disponible"))
8 Ass. dir. ya un truc de couleur rouge? → ASK(EXISTENCE(of=OBJECT(isa="truc", ppt="couleur",val="red")))
9 Ass. ind. le bouton “fermer” est semblable au bouton “quitter”
→ NEG(DIFFERENCE(between="le bouton ’fermer’", and="le bouton ’quitter’"))
10 Ass. ind. probablement que le bouton NEXT ne marche pas correctement
→ PROBABILITY(degree="2", of=PROBLEM(with="le bouton NEXT"))
11 Clav. Absolument → ACK()
12 Clav. bonjour je suis Arthur → HELLO(),VALUE(object="user", property="nom", value="Arthur")
13 Clav. sais-tu chanter ?→ - non traitée -
Les valeurs possibles des champs sontfortement liées au type de ces champs (cf.
§3.3) et ont trois natures possibles :– une référence (entre guillemets) issuede la requête en langue naturelle (ex : “lebouton”).– un marqueur symbolique (entre guille-mets et en majuscule) dépendant du typedu champ et indirectement issu de larequête de l’usager (ex : “TRUE” pour unbooléen, “PAST” pour un temporel).– une modalité ou un prédicat (uniquement
lorsqu’il s’agit d’un champ de modalité).La syntaxe générale d’une requête for-melle est alors de la forme :
M1(...Mn(a1 = P1(a’1 = R1, ...,
a’l = Rl), ..., am = Pm(...)) ...)
Expression dans laquelle :M1 - Mn sont des modalités,P1 - Pm sont des prédicats,a1 - am, a’1 - a’l sont des attributs,R1 - Rl sont des références.
Plusieurs modalités peuvent s’imbriquerentre elles et contenir plusieurs prédicatscoordonnés (i.e. au même niveau) conte-nant chacun une ou plusieurs références.
3.3 Les types de champs
Tous les champs de modalités et de prédi-cats sont dotés d’un type, et les attributsde ces champs ne peuvent être remplis quepar une référence de type compatible2.Les 11 types définis au fur et à mesurede la transcription des phrases selon lanature des références sont définis dans latable 23. Les schémas typés aident aussià choisir le bon schéma lorsque plusieurssont possibles, si les types des champs de
l’un ne correspondent pas aux types desréférences de la requête langagière.Pour gérer l’imbrication de schémas, ondéfinit un type global pour les modalitéspouvant être imbriquées (le type globaldes prédicats est toujours [act]). Ainsila phrase “y a-t-il un minimum pour lavitesse ?” se transcrit :
2Cela suppose que l’analyse sémantique détermine le(s)type(s) des références ; actuellement, ceci se fait par l’attribu-
tion des types au niveau d’environ 1500 clés sémantiques (re-groupant lemmes et locutions, équivalent de synsets Wordnet).
3En dépit des exemples, il n’y a pas d’équivalence lemme-type (voir “couleur” dans les phrases 7 et 8) ; la désambiguisa-tion peut s’effectuer à l’aide d’informations grammaticales four-nies par le module GRASP.
Caractérisation de requêtes d'assistance à partir de corpus ___________________________________________________________________________
272

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 285/415
TAB . 2 – Liste des 11 types de champs du langage DAFTType Signification Exemples
[act] Action Prédicats d’action (cf. table 4)
[con] Concept abstrait “les actions sur les tables”, “une nouvelle partie”. . .[obj] Objet de l’application “une page”, “un disque”, “ça”. . .[ppt] Propriété “couleur”, “le plus récent”. . .[val] Valeur “bloqué”, “vrai”, “bleu”. . .[typ] Type “page”, “lien”, “projet”, “membre”. . .[per] Personne utilisateur ou système uniquement
[man] Manière “à l’envers”, “un tout petit peu”, “bêtement”. . .[pla] Lieu ou zone de l’application “le site”, “au début”, “l’application”. . .[tim] Instant ou durée “PAST”, “NOW”, “ALWAYS”. . .[boo] Booléen “TRUE” et “FALSE”
ASK(EXISTENCE(time="NOW", of=VALUE(
object="vitesse", asked="min")))
où EXISTENCE a un champ of attendantun élément de type [obj] : le type globalde VALUE est donc [obj].
3.4 Modalités, prédicats, références
L’annotation du corpus a permis de déter-miner 39 modalités, regroupées selon leurstructure ou leur signification en 8 catégo-ries (cf. table 3), distinguables selon :– Leur profondeur dans la requête DAFT :sans détailler les règles d’imbrication, lesmodalités de jugement ou d’expressionde sentiments se situent plutôt dans lescouches externes des requêtes (ex : phrase6 de la table 1), tandis que les modalitésd’informations sont plutôt sur les couchesinternes près des prédicats (ex : phrase 5).– La complexité des schémas de requêtes :les marqueurs (cf. table 3) ne prennentqu’un argument unique, tandis que desschémas comme OBLIGATION en prennent4 ou 5, même si tous les champs sont rare-ment remplis simultanément.– La complexité d’identification du phé-nomène sémantique représenté : des mo-
dalités comme PLACE ou MOMENT sontparfois implicites et difficiles à élici-ter, ainsi : “je ne trouve pas X”, sous-entend “l’endroit où est X”, alors que dans“stoppe le compteur à 1000”, on devra éli-
citer : “quand il vaut 1000”.– Leur fréquence : comme souvent avecdes phénomènes linguistiques, la distribu-tion des modalités suit une loi de Zipf.– Leur généricité : les modalités circons-tancielles et de jugement sont plutôt clas-siques dans ce type d’approche [6]. Parcontre, celles de la catégorie “assistance”
sont très liées au domaine de langue étu-dié, ce qui démontre l’intérêt du corpus.
Nous avons aussi défini les schémas de 46prédicats (cf. table 44), dont la fréquencesuit également une loi de Zipf, constituantune base assez complète d’actions pourles sous-corpus de contrôle et d’assistancedans le cadre des applications testées.
Les références ont été généralementgardées sous forme brute, mais lamodalité OBJET permet de les en-capsuler pour aider l’identificationde l’entité référencée dans l’applica-tion (pour la phrase 2, on pourraitécrire objet = OBJET(isa="liste",
property="projets")).La principale difficulté (outre la résolutionde la référence) est d’automatiser cettedécomposition, et elle est liée au problème
d’identification des types (cf. § 3.3).4Les types suffisent bien souvent à la compréhension puis-
qu’ils sont liés à la structure actancielle classique du verbe –en cas d’ambiguïté, nous précisons un nom ou un exemple deréférence possible (entre guillemets).
____________________________________________________________________________ Annales du LAMSADE N°8
273

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 286/415
TAB . 3 – Liste des 39 modalités Mi de DAFTInformations structurelles et fonctionnelles d’une entité
INFOS (Avoir) des informations/plus d’informations sur un sujet.
MEANING Le sens de quelque chose, d’après quelqu’un.
TYPE Le type d’un objet est tel type.
VALUE La valeur (de la propriété d’un objet / d’un objet) est valeur.
PROPERTY La propriété ’propriété’ d’un objet vaut une valeur.
FUNCTION La fonction faisant une action déterminée pour des objets donnés dans un cadre particulier, et ayant certaines propriétés.
ROLE Le rôle d’un objet / concept / personne par rapport à un référentiel.
LIMIT Limites dans un objet / des propriétés d’un objet.
FUNCTIONING Le fonctionnement d’un objet.
Identification d’entités
EXISTENCE Existence de quelque chose dans un endroit.
OTHER Un objet / Une action autre que celui / celle considéré(e).OBJECT Un objet ayant un type, des propriétés et situé en un lieu donné. Peut servir à effectuer une action ou être objet de celle-ci.
Relations inter-entités
DIFFERENCE Différences entre une entité et une autre selon un critère.
ORDER Réalisation d’un ensemble d’actions étape par étape, la dernière étant considérée comme le but de la procédure.
Capacités, droits et devoirs d’une entité
POSSIBILITY Possibilités offertes à quelqu’un par une autorité (de réaliser quelque chose / au sujet d’un objet) pour quelqu’un.
KNOWLEDGE (Connaissance/Savoir/Compréhension/Capacité) de quelqu’un/quelque chose (pour faire une action / au sujet d’un objet).
OBLIGATION Obligation d’une personne par une autre à faire quelque chose / d’un objet.
WILL Volonté de quelqu’un qu’une action soit réalisée par une personne / d’un objet.
PROBABILITY Probabilité d’une action / d’un objet à un certain degré.Circonstancielles
WAY Moyen d’atteindre un but.
EFFECT L’effet d’une action / d’un objet est une autre action.
REASON La raison/cause de quelque chose.
PLACE Emplacement de quelque chose / où faire quelque chose.
INSTANT Instant où une action se fait / où un événement a lieu.
NUMBER Nombre d’éléments dans un espace donné.
Sentiments
LIKE Un agent aime un objet aimé (quelqu’un ou quelque chose).
FEAR Un agent a peur d’une crainte.BOTHER Le gêné est incommodé par une gêne.
DOUBT Un doute d’une personne au sujet de quelque chose (absence de certitude).
SURPRISE Un agent est surpris par quelque chose.
REGRET Un agent a des regrets au sujet de quelque chose.
HAPPY Un agent est heureux au sujet de quelque chose.
Assistance
PROBLEM Situation insatisfaisante, résultat inattendu. Problème d’une personne avec un objet ou pour faire une action.
MISTAKE Acte involontaire/inadapté. Un responsable commet une erreur sur une action ou un objet.
HELP Un demandeur réclame l’aide d’un assistant, (pour réaliser une action / au sujet d’une entité), en faisant quelque chose.
TELL Un locuteur s’adresse à un interlocuteur pour lui parler d’un sujet ou lui exposer une action à réaliser.
Marqueurs
CHECK Marqueur de demande de vérification d’une information.
ASK Marqueur d’interrogation, pour toute interrogation qui n’est pas un CHECK.
NEG Marqueur de négation précédant une action ou modalité (sa position est alors à prendre en compte pour retrouver le sens).
Caractérisation de requêtes d'assistance à partir de corpus ___________________________________________________________________________
274

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 287/415
TAB . 4 – Liste des 46 actions du langage DAFT (ordonnée par le nombre de champs)Bip() Start([obj]) MakeAMove([pla]from,[pla]to)
End () – sens contextuel Swap([obj]) Sort([obj],[man]"en sens inverse")
Scroll() Use([obj]) Update([obj],[per]by )
Activate([obj]) Win([man]"facilement") Add ([obj],[pla]in,[man]"sans risque")
Cheat([man]"un peu") Belong([obj],[obj]to) Click([per],[obj],[man])
Check([obj]) Cancel([act],[obj]) Exceed ([ppt],[obj]of ,[val])
Contact([per]) Close([obj],[tim]when) Give([per]from,[obj],[per]to)
Count([man]"rebours") Control([obj],[ppt]) Go([pla]to,[tim]at,[man])
Create([obj]) Delete([obj],[man]) Operate([per]operator ,[obj],[man])
Download ([obj]) Handle([per],[act]) Modify([obj],[ppt],[val],[man])
Happen([tim]when) Join([per],[obj]) Stop([act],[obj],[tim]when,[tim]during )
Hide([obj]) Restart([obj],[per]) Play([per],[per]for,[obj],[tim]"next turn",[man])
Quit([obj]) Restore([obj],[val]) Show([per]shower ,[per]to,[obj],[man],[pla]in)
Recommend ([obj]) Revert([act],[con]) Move([obj],[per],[pla]in,[pla]from,[pla]to,[man])
Repeat([con]"partie") Save([obj],[pla]in)
Replay([con]"jeu") See([obj],[per])
TAB . 5 – Taux de couverture des 4 sous-corpus par le langage DAFT
Sous-corpus Ctrl Ass. dir. Ass. ind. Clav.*
Couverture 92,3% 96,7% 70,2% 82,4%
*(hors dialogue)
4 Discussion et évaluation
4.1 Adéquation et robustesse
Une fois une première version du corpusDAFT recueillie (environ 5000 requêtes),le traitement a été effectué manuellementà partir de deux sous-ensembles au 1/10e
(1075 phrases). Parmi elles, 698 ont ététranscrites en requêtes DAFT respectant lasyntaxe définie en 3.2, offrant une couver-ture (rapport nombre de phrases transcrites / nombre de phrases totales) globalementcorrecte mais inégale (cf. table 5)5.
L’ajout de nouvelles requêtes d’assistance
dans le corpus ne doit entraîner ni re-5Une partie du sous-corpus de clavardage de dialogue avec
l’agent (202 phrases) n’a pas été prise en compte : la structurede ces requêtes est proche des requêtes d’assistance, mais il fau-drait étendre le vocabulaire des prédicats.
mise en question de la structure adop-tée, ni ajout de nombreux prédicats. Nousavons donc étudié une nouvelle tranche de1/10e du corpus retranscrite en DAFT (uni-
quement pour les sous-corpus de contrôleet d’assistance) et avons ainsi pu esti-mer que seules 2 modalités de quantifica-tion (TOO, ENOUGH) et 4 prédicats d’action(Bloquer, Communiquer, Choisir, Agir)supplémentaires seraient nécessaires, soitun ajout de l’ordre de 5% pour une aug-mentation de 50% de la taille du corpus.De plus, la structure même de la syntaxeproposée n’a pas été mise en défaut, confir-mant que la méthodologie employée (sous-ensembles au 1/10e) n’a pas biaisé le lan-gage de requêtes.
4.2 Perspectives
Il reste à savoir s’il est computationnel-lement possible de produire des réactionscorrectes, ce qui nécessite de relier leséléments des requêtes aux éléments de
l’application assistée; mais surtout perti-nentes6. La conception d’un système inté-grant le langage de requêtes proposé pour
6En particulier, en cas d’échec du système de raisonnementsur la structure du composant, il est toujours possible de sim-
____________________________________________________________________________ Annales du LAMSADE N°8
275

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 288/415
une large classe de composants assistésconstitue la suite directe de cette étude, etpermettra une évaluation plus approfondiedes choix effectués.
Références
[1] Ion Androutsopoulos and Maria Are-toulaki. The Oxford Handbook of Computational Linguistics, chapterNatural Language Interfaces, pages629–649. Oxford University Press,March 2003.
[2] François Bouchet and Jean-Paul San-sonnet. Étude d’un corpus de re-quêtes en langue naturelle pour desagents assistants. In Proc. of WACA2006 , October 2006.
[3] Antonio Capobianco and Noëlle Car-bonell. Conception d’aides enligne pour le grand public : défiset propositions. In J.-M. RobertA. Drouin, G. Eude, editor, Proc.
ERGO-IA’2002, pages 309–335, Oc-tober 2002.
[4] Jean Carletta, Amy Isard, StephenIsard, Jacqueline Kowtko, GwynethDoherty-Sneddon, and Anne Ander-son. Hcrc dialogue structure codingmanual. Technical report, HCRC,University of Edinburgh, June 1996.
[5] Bernard J. Jansen. Seeking and
implementing automated assistanceduring the search process. Infor-mation Processing and Management ,41(4) :909–928, July 2005.
[6] Daniel Jurafsky, Rebecca Bates,Noah Coccaro, Rachel Martin,Marie Meteer, Klaus Ries, ElizabethShriberg, Andreas Stolcke, PaulTaylor, and Carol Van Ess-Dykema.Switchboard discourse language
modeling project final report. Tech-nical report, Center for Speech and
plifier les requêtes afin de parvenir à une réponse vide comme" Désolé, je ne peux donner d’explication au fait que le compteur
s’est arrêté.", correcte mais pas réellement pertinente.
Language Processing, Johns HopkinsUniversity, 1998.
[7] David Leray and Jean-Paul Sanson-
net. Ordinary user oriented modelconstruction for assisting conversa-tional agents. In CHAA’06 at IEEE-WIC-ACM Conference on Intelligent
Agent Technology, 2006.[8] James C. Lester, Sharolyn A.
Converse, Susan H. Kahler, Ste-ven Todd Barlow, Brian A. Stone,and Ravinder S. Bhogal. The PersonaEffect : Affective impact of animated
pedagogical agents. In CHI ’97 :Proceedings of the SIGCHI conf. on Human factors in comp. syst., pages359–366, New York, NY, USA,March 1997. ACM Press.
[9] Gabriel Ripoche. Sur les traces de Bugzilla. PhD thesis, Univ. Paris XI,June 2006.
[10] Nicolas Sabouret and Jean-Paul San-sonnet. Un modèle de requêtes sur
le fonctionnement de composants ac-tifs. In Proc. MFI 01, volume 3,pages 419–436, May 2001.
[11] David Sadek, Philippe Bretier, andE. Panaget. Artimis : Natural dia-logue meets rational agency. In IJCAI (2), pages 1030–1035, August 1997.
[12] Susanne Salmon-Alt. Référence et dialogue finalisé : de la linguistique
à un modèle opérationnel. PhD the-sis, Univ. H. Poincaré, Nancy 1, May2001.
[13] Jean-Paul Sansonnet, Karl Le Guern,and Jean-Claude Martin. Une ar-chitecture médiateur pour des agentsconversationnels animés. In Proc.WACA’01, pages 31–39, June 2005.
[14] John Rogers Searle. Speech Acts : An essay in the Philosophy of lan-
guage. Cambridge University Press,new edition, January 1969.
Caractérisation de requêtes d'assistance à partir de corpus ___________________________________________________________________________
276

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 289/415
La décision multi-critère pour la coordination locale dans lessystèmes multi-agents
M. Boussard M. Bouzid
mboussar,bouzid,[email protected]. Mouaddib
GREYC - Université de caen
Résumé :A la différences des systèmes mono-agent, la plani-fication multi-agent doit résoudre des conflits entreles intérêts individuels d’un agent et l’intérêt dugroupe. Dans cet article, nous utilisons un proces-sus décisionnel de Markov décentralisé valué par
des vecteurs (2V-DEC-MDP) en vue de résoudrece problème. Le cadre formel considéré, celui desMDP à valuation vectorielle, utilise une fonctionde valeur qui retourne un vecteur représentant à lafois l’intérêt personnel et l’intérêt du groupe. L’in-térêts individuel d’un agent, calculé hors-ligne, re-pose sur sa politique optimale . L’intérêt du groupeest calculé en ligne par les agents à partir de leursobservations locales. Afin de tenir compte de cesdeux critères dans un processus de décision, nousavons développé un algorithme basée sur le regret àpartir de la norme de Tchebychev. L’objectif est de
trouver un bon compromis entre l’intérêt du groupeet celui de l’agent. Ces résultats sont illustrés par unexemple.
Mots-clés : Processus décisionel de Markov, sys-tème multi-agents, décision multi-critère
Abstract:In spite of mono-agent systems, multi-agent pla-ning addresses the problem of resolving conflictsbetween individual interests and group interest. Inthis paper, we are using a Decentralized Vector Va-lued Markov Decision Process (2V-DEC-MDP) inorder to solve this problem. This formal frame-
work, the Vector valued MDP, uses an utility func-tion which is returning a vector representing bothindividual interest and group interest. The indivi-dual interest of an agent, computed off-line, is ba-sed on is optimal policy. Group interest is compu-ted on-line by the agent using local observations. Inorder to take into account both criteria in a decisionprocess, we develop a regret-based algorithm fromthe Tchebychev Norm. The goal is to find a goodtrade-off between the group interest and the agentone. This results are illustrated by an example.
Keywords: Markov Decision Process, Multi-Agents Systems, Multi-Criteria
1 IntroductionPlanifier des tâches avec un agent unique, im-plique d’optimiser l’acomplissement de ses objec-
tifs. Néanmoins, la même optimisation au sein d’ungroupe d’agents ne sera pas nécéssairement opti-male, ni même acceptable. Lorsqu’il s’agit d’opti-miser le comportement global du groupe, l’une desdifficultés est de résoudre les conflits entre l’intérêtpersonnel et l’interêt du groupe. Afin d’optimiser
dans ce contexte, il est nécéssaire de d’établir leslois sociales, qui conduiront le groupe à opter pourun solution satisfaisante. Un outil bien connu pourétudier de tels systèmes multi-agents est la théoriedes jeux de Von-Neumann-Morgenstern. Chaqueagent calcule sa décision optimale, en supposantque tous les autres feront de même. Aucun agentne regrette alors son choix, en effet choisir un autrecomportement conduirait à une diminution de songain. Dans un tel contexte chaque agent ne cherchequ’à maximiser égoïstement son profit individuel.Le problème de dériver des préférences de groupe
à partir des préférences individuelles à été large-ment étudié. L’objectif ici est de, étant donné unordre de préférences pour chaque agent du groupe,d’avoir une manière de combiner ces préférencesafin d’assurer un ordre concistent des préférencesdu groupe.
Nous considérons ainsi un système constituéd’agents, ayant chacun un ensemble d’objectifs àatteindre. Chaque agent utilise un processus déci-sionnel de Markov (MDP) pour définir une poli-tique afin de résoudre son problème. L’accomplis-sement des objectifs d’un agent peut avoir des ef-
fets sur l’accomplissement des objectifs des autresagents. Ce problème est directement lié à l’intelli-gence collective (COIN) qui traite des effets d’ac-tions individuelles sur le bien-être général tout enn’exhibant que des utilités locales sans définir lecomportement global souhaité [12].
Dans cet article nous proposons un cadre formelpour représenter les relations entre les objectifs,ainsi qu’un modèle décisionnel utilisant un proces-sus décisionel de Markov décentralisé à valuationvectorielle(2V-DEC-MDP) où la fonction de ré-compense vectorielles d’un agents premet de repré-
senter ses intérêts, ainsi que ceux du groupe. Pourl’intérêt du groupe, nous faisons la distinction entredeux critères : un effet positif (l’action d’un agentaugmente la satisfaction d’autres agents) et un effetnégatif (l’action d’un agent dégrade la satisfactiond’autres). Le vecteur des valeurs considéré permet
277

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 290/415
ainsi à un agent de représenter sa satisfaction per-sonnelle ainsi que ses effets positifs et négatifs surle groupe.Ainsi, pour préférer une décision à une autre, un
agent a besoin d’un opérateur permettant de com-parer (d’ordonner) des vecteurs de valeurs [11].Pour cela, nous utilisons des résultats de la théo-rie de la décision multi-critères. La suite de cet ar-ticle est organisé comme suit : dans la section 2nous présentons l’exemple qui a motivé notre ap-proche. La section 3 est consacrée à la décisionmulti-critères. Dans la section 4, nous présentonsles MDP multi-critères (2V-MDP pour Vector Va-lue MDP), et un opérateur décisionel multi-critère :le LexDiff. Ces résultats seront illustrés par des ex-périmentations dans la section 6 et comparé avecd’autre approche dans la section 7. La section 8conclue notre article.
2 MotivationsCe travail a été motivé par le problème posé parune simulation de situation de crise, la Robocu-pRescue (Figure 1). Il y est simulé la survenu d’untremblement de terre dans une ville, le but est demaximisé un score, prennant en compte les dé-gats sur la ville ainsi que le nombre de victimes.Nous disposons comme moyen pour intervenir dif-férent types d’agents (pompiers, ambulanciers etpolicier), ceux-ci disposent de peu de moyens decommunications ainsi que d’une observabilité par-tielle de la ville. Il est néanmoins nécéssaire qu’ilsse coordonnent afin, par exemple, de ne pas bloquerinutilement des routes. Notre approche vise donc àpermettre la coordination des agents à partir seule-ment de leur but personnel (eteindre un feu), et deleurs perceptions locale.
CIVILS
AMBULANCIERS
POMPIERS
POLICIERS
ROUTES
BLOQUEES
DEPARTS
DE FEUX
XXX
FIG . 1: Légende RobocupRescue
3 Décision multi-critèreCe travail est fondé sur la théorie de la décisionmulti-critère. Nous y ferons référence tout au long
de cet article. Le but de la décision multi-critère[10] est de choisir une solution préférée dans unensemble de choix prenant en compte plusieur as-pects(critères), comme par exemple le prix, la qua-
lité, l’apparence, etc . . .. Ces critères peuvent êtrecontradictoire (comme la qualité et le prix). Le faitd’avoir des critères multiples au sein du proces-sus décisionnel implique que, d’un certain pointde vue, un choix, constitué d’un ensemble de cri-tères, peut être arbitrairement préféré à un autre,sans faire pour autant un “mauvais” choix. Ceciimplique que l’on ne puisse plus définir aisémentl’opérateur max utilisé traditionelement pour defi-nir le choix optimal. Ainsi, avant de présenter l’al-gorithme pour dériver une politique à partir du 2V-DEC-MDP, il est important de faire une introduc-tion à la décision multicritères.
Définition 1 Un point x = (c1, c2, . . . , ci, . . . , cn)domine un autre point x , ci ∈ R si :
∧
∀i, ci ≥ ci∃i, ci > ci
La solution à un problème de décision multi-critères ne doit pas être dominée par une autre.Elle doit en effet faire partie de l’ensemble pareto-optimal.
Définition 2 L’ensemble pareto-optimal est formé des éléments non-dominés.
Nous introduisons deux points de références, lepoint Ideal et le Anti-Ideal [2].
Définition 3 Le point Ideal =(c1, . . . , ci, . . . , cn) est definit comme étant le
point maximisant tout les critères simultanément.C’est un point de référence, il n’appartient pasnécessairement à un choix possible. Soit pour unensemble de choix E ∈ Rn ,
Ideali = maxj
vj(c
i), vj ∈ E
Le point AntiIdeal est son opposé, c’est a direqu’il minimise tous les critères. Il sert de référencecomme étant le pire choix.
Anti − Ideali = minj
vj(c
i), vj ∈ E
Avec ces deux points nous obtenons un enca-drement partant du plus mauvais choix jusqu’au
meilleur.Nous avons seulement présenté ici le vocabulairede la décision multi-critère. Pour plus de détails,le lecteur est invité à consulter [6, 5]. Dans la par-tie suivante, nous allons construire un processus dedécision complet.
La décision multi-critère pour la coordination locale dans les systèmes multi-agents ___________________________________________________________________________
278

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 291/415
4 Processus décisionnel de Mar-kov multi-critères
Comme nous l’avons indiqué en introduction, nous
nous plaçons dans un environnement incertain.Nous utilisons donc le formalisme des processusdécisionnel de Markov (MDP) pour décrire nosproblèmes. La prise de décision dépend de plusieurcritère. Aussi nous utilisons nous présentons direc-tement le formalisme des MDP multicritère (2V-MDP)[7].Soit Z = z1, z2, . . . , zn un vecteur de critèreszi, ou chaque zi représente un des critère du résul-tat. Une action aj prise dans un ensemble d’actions
A = a1, a2, . . . , am agit sur un certain nombrede critères (quelques-uns ou tous) transformant levecteur Z en Z
= z1
, z2
, . . . , zn
. Il convientdonc de modifier la définition du MDP afin d’in-sérer la prise en compte de ces critères. Ainsi, unMDP multicritères se définit par :– un ensemble d’états S – un ensemble d’actions A– une fonction de transition p(s,a,s), s , s ∈
S, a ∈ A
– une fonction de récompense−−→r(s) =
r1(s), r2(s), . . . , ri, . . . , rn(s) où chaqueri(s) représente la récompense obtenue dansl’état s pour le critère i (de la même maniere
que dans les MDP monocritère).Reprenons maintenant l’équation de Bellman quipermet de dériver, par le calcul de la recompenseéspérée de chaque état V (s), une politique opti-male. Dans sa formulation monocritère, elle s’écritsous la forme :
V (s) = R(s) + maxa
s
p(s,a,s)V (s)
Dans le cas multicritères, la fonction de récom-pense retourne un vecteur. Plus formelement, soit :
−→V (s) =
v1(s)v2(s)
. . .vn(s)
=
r1(s)r2(s)
. . .rn(s)
+maxa
s
p(s,a,s) ∗
v1(s)v2(s)
. . .vn(s)
Où chaque vi, i ∈ 1 . . . n sont les valeurs des dif-férents critères. Il apparait que, dans le cas général,
l’application directe de l’opérateur max est impos-sible, une même action ne satisfaisant pas simulta-nément tous les critères. L’opérateur max à doncbesoin d’être redéfinit dans le cadre multi-critère.Pour cela, nous nous basons sur la norme pondéréede Tchebychev [2].
Définition 4 Norme pondérée de Tchebychev :
∀ p, q ∈ Rn, s∞ω,q( p) = maxi∈1,...,n
ωi pi − q i
Cette norme nous permet de définir, pour un point p, une distance à un point de référence q . Pourq , nous choisissons le point Ideal(Définition 3). Ilreste à définir les poids ωi de la norme. Nous lesutiliserons afin de normaliser tous les critères entreeux. Les ωi sont donc définis :
ωi =αi
Ideali − AntiIdeali
où le paramètre αi permet de réintroduire au be-soin des prioritées entre les critères. L’intérêt d’uti-liser cette norme (avec la normalisation) est de pou-voir exprimer pour chaque action le regret qu’a unagent d’avoir choisie une action par rapport à unel’action ideale. A partir de cette norme, nous pou-vons construire un opérateur de décision qui rem-placera le max de l’équation de Belleman dans les2V-MDP.
Un opérateur décisionnel : le LexDiff
Soit vi la valeur de la politique courante pour lecritère i et v∗i la fonction valeur optimale (toujourspour le critère i).Nous définissons un nouveau vecteur, appelé vec-
teur d’utilité et noté −→V u, construit à partir de lanome pondérée de Tchebychev, représentant pourchaque critère la distance normalisée(par les ωi) aupoint Ideal q = (v∗1 , v∗2 , . . . , v∗n)(pondérée si nécés-saire par les coefficients αi présents dans les ωi).Ainsi, pour un état s ∈ S :
−→V u(s) =
vu0 (s) = ω0 ∗ v0(s) − v∗0(s)vu1 (s) = ω1 ∗ v1(s) − v∗1(s)
...
vun(s) = ωn ∗ vn(s) − v∗n(s)
Une fois ce vecteur calculé, l’action est sélection-née par un tri selon un ordre lexicographique, encherchant à minimiser les maximaux. Cet opérateurnous garantit une solution pareto-optimale, tout enpréservant une société égalitaire. C’est à dire quela solution choisie ne laissera aucun critère trop sedégrader, même si pour cela, elle perd un peu enutilité globale [3].
Pour déterminer ce vecteur−→V u(s) il est donc né-
céssaire d’effectuer n optimisations mono-critère.
Il est facile de calculer une valeur optimale pourune politique ne prenant en compte qu’un critèreunique, en utilisant l’algorithme value iteration parexemple. Pour n critères, nous devons donc déter-miner n fonctions de valeur optimales. Cela n’aug-mente pas nécéssairement de beaucoup le temps de
____________________________________________________________________________ Annales du LAMSADE N°8
279

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 292/415
calcul global. En effet, comme toutes ces optimisa-tions sont indépendantes, il est facile de les paral-léliser. Il est aussi possible d’accélérer ce calcul enoptimisant un critère tout en gardant les valeurs des
autres critères qui, par la suite, serviront à initialiserles calculs des critères suivants.
5 Un cadre fondé sur les 2V-MDP pour coordonner desagents
5.1 L’impact des actions des agents sur
le groupe
Nous présentons ici un formalisme pour exprimerl’impact des décisions de l’agent sur la société.Ce travail suit celui de AI Mouaddib et al. dans[8]. Pour prendre sa décision, l’agent se pose deuxquestions :– “quelles vont être les impacts de mon action sur
la société ?”– “quelles peuvent être les impacts des actions des
autres agents sur moi ?”Ces idées sont illustrées figure 2. Pour l’agent B, lefait de choisir l’action E (aller a l’Est) empecheraC d’aller au Nord et D d’aller à l’Ouest, mais,dans le même temps liberera l’action E de A. Demême, l’action O de B, qui n’est dans l’état actuel
du monde impossible, peut-être rendue possible parun déplacement de A. Enfi, si B va au Nord, il nerisque pas de conflit avec un autres agents, et deplus, il liberera une action pour A. A partir de toutces éléments B pourra prendre en compte l’impactde ses actions sur les autres agents, et perdre un peuen esperance de gain personnel afin de donner plusde liberté au groupe, ou bien déclancher une ac-tion impossible mais raportant énormement en es-perant que l’agent bloquant bouge (exemple figure2, agent B avec l’action Ouest).
A B
C
D E
N
S
O?
FIG . 2: Exemple de prise de décision enligne
Pour formaliser ce type de répercutions, nous défi-nissons quatre ensembles : E(Enable), D(Disable),
Eb(Enable by), Db(Disable by). Chaque ensemblereprésente respectivement les actions :– rendues possibles chez les autres agents,– inhibées,– possible si . . .,– impossible si . . ..
Avant de le présenter en detail ces ensembles,nous allons avoir besoin de quelques définitions.Le monde dans lequel évoluent les agents est repré-senté par un MDP < S, A, T, R >. Un état s ∈ S
est constitué d’un ensemble d’observations sur lemonde o ∈ O a un instant t, nous notons s = Ot.Bien que nous utilisons un ensemble d’observa-tions, nous ne nous plaçons pas dans un contextede processus de Markov partiellement observable,ces observations représentant l’état réel de l’agent.
Définition 5 Soit i un agent possédant un en-semble d’actions Ai ⊂ A. Les pré-conditions né-cessaires au déclenchement d’une action a ∈ Ai
dans un état (consitué d’un ensemble d’observa-tions a un instant t) Ot sont notées :
in(a) : Ot
→ true, false, t > 0Définition 6 Etant donné un état et une action,l’état résultant est donné par :
out(a) : A × Ot → Ot+1
A partir de tout cela, nous pouvons definir lesquatre ensembles qui mesurerons l’impact socialdes différentes actions. Un agent i calcule ainsi :– E i(Ot
i , a) = b ∈ Aj=i|in(a) ⊂ Oti ∧ in(b)
Oti ∧ ∃Ot+1
i ∈ out(a) : in(b) ⊂ Ot+1i
– Di(Oti , a) = b ∈ Aj = i|in(a) ⊂ Ot
i∧in(b) ⊆Oti ∧ ∃Ot+1
i ∈ out(a) : in(b) Ot+1i .
– EBi(Oti , a) = b ∈ Aj=i|in(a) Ot
i∧in(b) ⊂Oti ∧ ∃Ot+1
i ∈ out(b) : in(a) ⊂ Ot+1i .
– DBi(Oti , a) = b ∈ Aj=i|in(a) ⊂ Ot
i ∧in(b) ∈Oti ∧ ∃Ot+1
i ∈ out(b) : in(a) Ot+1i .
Sur l’exemple 2 :
E tB DtB EbtB Dbtb
Nord (A,O) ∅ ∅ ∅Sud (A,O) (C,O) ∅ (C,O)Est (A,O) (C,N) ∅ (C,N)
(D,O) (D,O)Ouest ∅ ∅ (A,N) ∅
(A,S)Ainsi chaque agent peut évaluer les degrés de li-berté qu’il enlèvera ou ajoutera aux autres agents,ainsi que les actions dont il peut, ou ne peut plusdisposer à cause d’actions d’autres agents.Nous pouvons remarquer que ces équations re-tournent des ensembles d’actions, et non pas desvaleurs numériques. Il est donc nécessaire, afind’intégrer ces informations dans notre processus dedécision, de définir une valuation de ces différents
éléments. Une fois cette valuation définie, on peutconstituer un petit MDP multicritères local permet-tant de déterminer l’action qui conduira au meilleurcompromis. On utilisera pour cela la méthode derésolution des MDP multi-critères telle qu’elle a étéprésentée dans la partie précédente.
La décision multi-critère pour la coordination locale dans les systèmes multi-agents ___________________________________________________________________________
280

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 293/415
5.2 Résoudre le 2V-DEC-MDP
Pour cet exemple, nous nous limiterons au critèreDi pour l’aspect social et à Ri, la valeur de sa po-
litique optimale, pour l’intérêt personnel de l’agenti.
– Chaque agent calcule sa politique optimale hors-ligne, avec un algorithme standard tel que valueiteration ou policy iteration etc. . .
– Une fois cette partie hors-ligne effectuée, toutesles décisions s’effectuent en ligne. Avant chaquedécision, chaque agent calcule le vecteur de va-leur pour toutes ses actions. Le premier élémentdu vecteur est la valeur dans l’état suivant, tellequelle est définie dans l’équation de Bellman.Le second élèment est donc la valuation de l’en-semble Di. Pour terminer, nous utilisons l’opé-rateur LexDiff pour sélectionner l’action à effec-tuer.
Un des principaux problèmes de se coordonnersans communication apparaît dans des situationssymétriques (deux agents face à une porte parexemple). Pour éviter ces situations, nous introdui-sons une matrice de coûts similaire à la matricedes gains de la théorie des jeux connue de tousles agents. Ceci est plus de l’ordre de l’implémen-tation qu’une réelle solution, mais cela nous per-met déjà de débloquer de nombreux cas d’inter-blocage. Nous présentons maintenant le schéma de
calcul pour déterminer un des composant du vec-teur d’impact social (tel que Di). Nous avons seule-ment besoin de sommer sur la valeur de l’état sui-vant la probabilité de transition. Comme les obser-vations représentent l’état effectif, nous pouvonscalculer Di de cette manière : Si deux agents a etb se trouvent sur le même état après leurs action,ils sont en collision, ils prennent alors une pénalitéselon une matrice de coûts de collision.
Di(s, a) =
b∈Aj=i
O
t+1
i
( p(s0, a , s1)(s2, b , s1)C (i, j))
L’adaptation de la politique hors-ligne au contextecourant (présence d’autres agents) se fait par l’al-gorithme 1. Il s’exécute rapidement, car, bien qu’ilénumère des ensembles potentiellement grand, larestriction à une exploration locale très restreintefait que seul une petite partie de ces ensembles esten réalité pris en compte.
Aucune supposition n’est faite sur les actions que
les autres agents vont réellement choisir. Chaqueensemble représente donc ce qu’il pourrait arriver,ces ensembles sont ainsi pris en compte afin de raf-finer le processus de décision. La fonction PrefAc-tion(E) retourne l’action sélectionné par l’opérateurLexDiff dans l’ensemble E .
E ← ∅pour tous les ai ∈ Ai faire
penality ← 0reward
←0
pour tous les s ∈ S fairereward ← r + p(s, si, ai)pour tous les a j ∈ A j , ( j = i)faire
penality ← p(si, ai, s
)∗ p(s j, a j, s)∗C (i, j)
E ← E ∪ (ai, penality, reward)retourner PrefAction(E)
Algorithme 1 : module en ligne des 2V-DEC-MDP
6 ExpérimentationsDans les figures des sections 6.1 et 6.2, nous utili-sons les représentations suivantes :– Chaque état est représenté par un hexagone,– les agents sont représentés par des cercles,– les hexagones foncés représentent des murs.Les agents on sept actions : avancer d’une casedans chacune des six directions, et rester sur place.Toutes les actions ont le même coût.
6.1 Expérimentation 1 : coordination
spatiale locale
Nous montrons ici les résultats fournis par l’algo-rithme pour une coordination spatiale locale.
a) Un groupe d’agents est placé en bas.
b) Les agents se dispersent pour casser le groupedense en un groupe plus clairsemé.
c) Ils suivent leur politique optimale jusqu’à cequ’ils atteignent le mur.
d) Afin de ne pas gêner les premiers agents, lesderniers préfèrent bouger sur la droite.
e) Ils suivent leur politique optimale.
f) Stabilisation autour de l’état but.
6.2 Expérimentation 2 : émergence de
formation de coalition
Cet expérience a pour but de montrer comment
grâce à cet algorithme, nous pouvons obtenir uncomportement en essaim.
a) Un groupe d’agents est placé au centre dumonde, et des buts dans chacun des angles.
b) Formation d’un groupe clairsemé.
____________________________________________________________________________ Annales du LAMSADE N°8
281

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 294/415
(a) (b)
(c) (d)
(e) (f)
FIG . 3: Coordination spatiale locale
(a) (b)
(c) (d)
(e) (f)
FIG . 4: Formation de Coalitions et coordi-nation spatiale
La décision multi-critère pour la coordination locale dans les systèmes multi-agents ___________________________________________________________________________
282

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 295/415
c) Ils continuent vers leurs buts individuels, en es-sayant de ne pas nuire aux groupe, nous obte-nons alors quatre groupes diffus.
d) Ces groupes formés, chaque agent suit sa poli-
tique optimale.e) Quand ils convergent vers leurs états but, les
agents doivent à nouveau modifier leurs poli-tiques afin de ne pas se retrouver en conflit avecd’autre agents
f) Finalement nous aboutissons principalement àdeux types d’équilibres ; un (comme les deuxgroupes sur la gauche) où les agents se placede manière clairsemé et régulière près de l’étatbut, et l’autre (comme dans le coin supérieurdroit) où tous les agents se placent autour. Cesdifférences proviennent du fait que les actionssont non ordonnées, ainsi si pour un agentdeux actions sont équivalentes en termes de ré-compense, l’agent choisit au hasard. Selon lesactions choisies, le groupe adoptera l’une oul’autre des formes.
7 Travaux connexesCe travail est un début vers de nouvelles ap-proches pour traiter les problèmes d’intelligencecollective (COIN), qui a pour but de coordon-ner un groupe d’agent sans exhiber le compor-
tement global voulu. Wolpert et al. définissentles foncions de World Utility(WU) et Wonder- ful Life Utility comme étant une somme de Ri
tandis que dans notre approche, ils sont repré-senté part la fonction de récompense augmen-tée ARi. Nous utilisons une représentation vecto-rielle car parfois, contrairement au COIN, les fonc-tions Ri, E i, Di, EBi, DBi peuvent ne pas êtredu même type. Cette fonction augmentée évited’avoir des agents travaillant à contresens (la priseen compte de Di, DBi et E i, EBi) et conduit àune certaine coordination entre agents. Cette ap-proche contribue aussi aux systèmes multi-agents(SMA) car il parvient à surmonter la principale dif-ficulté rencontré dans la définissions des problèmede SMA : la mise au point de structure de coordi-nation artificielle pour imposer la coordination. Detel structures de coopération rendent le passage àl’échelle difficile et souvent non robuste.Cette approche est dans l’esprit de nombreux mo-dèle existant de MDPs avec des fonctions valeursvectorielle [11, 9] et des algorithmes appropriéspour les résoudre, où la plupart utilise le chaînagearrière, policy iteration et value iteration en sub-stituant les opérations (+, ×) par (max, min)dans
les calculs. D’autre approches se sont intéresséesà l’utilisation d’une version qualitative des MDPainsi qu’aux MDP algébriques [9]. Non loin deces résultats positifs, nous proposons une alterna-tive aux MDP standart en combinant une mesurede regret similaire à la norme pondérée de Tcheby-
chev munie d’un ordre lexicographique appropriéet d’un algorithme de chainage arrière pour déri-ver une politique satisfaisante. L’algorithme basésur le regret respecte les conditions présenté dans
[9] et est similaire à l’algorithme de Jacobi mo-difié adapté aux problèmes de planification multi-agents.
8 Conclusion
Nous n’avons pas pour but ici d’apporter des so-lutions au problème de la décision multi-crititère,nous cherchons à montrer comment la priseen compte de critères supplémentaires permetune amélioration du comportement d’un grouped’agents. De ce fait, nous ne cherchons pas pourle moment à établir des propriétés sur nos opéra-teurs, mais seulement à montrer qu’ils permettentd’aboutir à un comportement satisfaisant. Nousavons apporté trois contributions : (1) Nous avonsintroduit un cadre formel pour exprimer les liensentre les objectifs, (2) un modèle décisionnel atta-ché utilisant un processus décisionnel de Markovdécentralisé à valuation vectorielle et (3) un algo-rithme pour résoudre le DEC-MDP obtenu. Nousavons montré que résoudre ce DEC-MDP peutconduire, sous certaines conditions, à des com-portements sociaux plus satisfaisants que l’appli-cation des politiques optimales mono-agent, cette
approche réduisant le nombre de conflits. Des ex-périences et analyses sont nécessaires afin de ca-ractériser plus finement le comportement émergentglobal. Les travaux futurs aborderons l’utilisationd’apprentissage par renforcement multi-critère [4]des Ri ainsi que des poids αi de la norme pondé-rée de Tchebychev et de leurs effets sur le com-portement émergent et sur la coordination (ou ledésordre) des politiques locales. Notre approche nepeut garantir la coordination des politiques localesdans tous les états mais peut réduire le désordreen évaluant les ensembles Di, DBi, E i, EBi. Ap-
prendre ces mesures peut permettre une meilleurcoordination. Nous développons des agents pourla RobocupRescue [1] afin de valider ces résultatsdans une simulation plus complète.
Références
[1] www.rescuesystem.org/robocuprescue/.
[2] M.J. Bellosta, I. Brigui, S. Kornman, S. Pin-son, and D. Vanderpooten. Un mécanismede négociation multicritère pour le commerceélectronique. In Reconnaissance des Formes
et Intelligence Artificielle, RFIA 2004, pages1009–1016, 2004. 28-30 Janvier, Toulouse.
[3] Matthieu Boussard. Processus décisionnelsde markov multi-critère, 2005. Rapport deMaster 2.
____________________________________________________________________________ Annales du LAMSADE N°8
283

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 296/415
[4] Zoltan Gabor, Zsolt Kalmar, and Csaba Sze-pesvari. Multi-criteria reinforcement lear-ning. In ICML, pages 197–205, 1998.
[5] L. Galand. Recherche d’un chemin de
meilleur compromis dans un graphe multicri-tère. In 7ème Congrés de la Société Fran-çaise de Recherche Opérationnelle et d’Aideà la Décision, pages 121–136. Presses Uni-versitaires de Valenciennes, 2006.
[6] M. Grabisch and P. Perny. Agrégation multi-critère. In Logique floue, principes, aide à ladécision, pages 81–120. 2002.
[7] AI Mouaddib. Towards techniques to solvevector-valued mdps. Technical report, 2005.
[8] Bouzid maroua Mouaddib Abdel-Illah, Bous-
sard mattthieu. Towards a formal frameworkfor multi-objective multi-agent planning. In AAMAS 2007 , 2007.
[9] P. Weng P. Perny, O. Spanjaard. Algebraicmarkov decision processes. In 19th Interna-tional Joint Conference on Artificial Intelli-gence, pages 1372–1377, 2005.
[10] P. Vincke. L’aide multicritère à la décision.Statistique et mathématiques appliquées. Edi-tion de l’université de bruxelles, edition el-lipses edition, 1989.
[11] K. Wakuta and K. Togawa. Solution pro-cedures for multi-objective Markov decision
processes. 1998.
[12] D.H. Wolpert and K. Tumer. Introduction tocollective intelligence. Handbook of AgentTechnology. AAAI Press / MIT Press, 2000.
La décision multi-critère pour la coordination locale dans les systèmes multi-agents ___________________________________________________________________________
284

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 297/415
Le modèle des cartes cognitives contextuelles
L. Chauvin D. Genest
lionelc,genest,[email protected]
S. Loiseau
LERIA - Université d’Angers2 boulevard Lavoisier 49045 Angers Cedex 01
Résumé :Le modèle des cartes cognitives offre une représen-tation graphique d’un réseau d’influences entre dif-férentes notions. Une carte cognitive peut contenirun grand nombre de liens d’influence ce qui renddifficile son exploitation. De plus ces influences nesont pas toujours pertinentes pour des utilisationsdifférentes de la carte. Nous proposons une exten-sion de ce modèle qui précise le contexte de validitéd’une influence à l’aide de graphes conceptuels etnous fournissons un mécanisme de filtrage des in-fluences en fonction d’un contexte d’utilisation.
Mots-clés : cartes cognitives, contexte, graphesconceptuels
Abstract:A cognitive maps is a network of influences bet-ween concepts. A cognitive map can contain a greatnumber of influence what makes difficult its exploi-
tation. Moreover these influences are not always re-levant for different use of a map. We propose anextension of this model which specifies the contextof validity of an influence using conceptual graphsand we provide a filtering mechanism of the in-fluences according to a context of use.
Keywords: cognitive maps, context, conceptualgraphs
1 Introduction
Une décision peut être vue comme unchoix parmi plusieurs alternatives dans lebut d’atteindre un objectif . Un systèmed’aide à la décision manipule des connais-sances et fournit des mécanismes à l’uti-lisateur lui facilitant la prise de décision.Un tel système peut présenter une solutionà l’utilisateur puis lui expliquer commentcette solution a été déterminée comme op-timale selon des critères prédéfinis. Il peut
aussi être plus souple en donnant la possi-bilité à l’utilisateur de naviguer parmi lesalternatives pour effectuer son choix.
Une carte cognitive [1] représente graphi-
quement un réseau d’influence entre dif-férentes notions. Ce type de représenta-tion visuelle offre un moyen de commu-nication simple entre plusieurs personnes.Les cartes cognitives ont été utilisées dansde nombreux domaines pour expliquer lefonctionnement de systèmes complexescomme par exemple en biologie [1], enécologie pour décrire des éco-systèmes[2][3], en sociologie pour décrire des com-portements sociaux [3]. Les cartes cog-nitives ne sont pas uniquement un outilde représentation, elles facilitent la prisede décision. En effet, le parcours des in-fluences de notion en notion représenteles étapes mentales qu’un individu effec-
tue pour évaluer les conséquences d’unedécision possible. Les différents cheminsd’influence arrivant sur un objectif repré-sentent les alternatives possibles permet-tant de l’atteindre. Les cartes cognitivesont donc des applications dans des do-maines nécessitant une prise de décision,comme dans les domaines politiques etéconomiques [4][5]. La représentation in-formatique d’une carte cognitive et l’au-
tomatisation du parcours des influencessont relativement aisés. C’est la faculté descartes cognitives à servir de support à lacommunication et d’aide à la décision parl’intermédiaire d’un outil informatique quinous intéresse dans ce travail.
Bien qu’elles permettent de représenter defaçon simple un système où les notionss’influencent entre elles, les cartes cogni-
tives de grande taille sont difficiles à ap-préhender par un utilisateur. Une telle cartepeut être le fruit d’un travail collabora-tif ou le rassemblement des connaissancesde plusieurs individus. Certaines parties
285

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 298/415
peuvent être fortement liées à des pointsde vue ou aux centres d’intérêts des per-sonnes qui ont exprimé ces connaissances,ce qui peut rendre l’ensemble de la cartepeu homogène. Le concepteur d’une carteplace une influence entre deux notions enpensant à un contexte précis. Un observa-teur extérieur ne connaissant pas cette in-formation de contexte peut trouver cetteinfluence contestable.
Notre travail est une extension du mo-dèle des cartes cognitives. Son originalitéconsiste à fournir au(x) concepteur(s) la
possibilité d’expliciter le contexte de va-lidité de chaque influence d’une carte. Unmécanisme permet à l’utilisateur de filtrerles informations de la carte en fonction ducontexte d’utilisation qui l’intéresse.
Pour ce faire, notre modèle de cartes cog-nitives contextuelles utilise une ontolo-gie. Il associe un graphe conceptuel [6] àchaque influence pour décrire son contextede validité . On garde ainsi la simplicitéd’utilisation d’un modèle graphique touten fournissant un vocabulaire. Pour mani-puler une carte, l’utilisateur décrit à l’aided’un graphe conceptuel le contexte danslequel il l’utilise. L’opération de projec-tion des graphes conceptuels permet de fil-trer les influences qui ont un sens dansce contexte d’utilisation. L’utilisateur peutalors exploiter plus facilement cette cartesimplifiée.
Dans la partie 2, nous décrivons le modèledes cartes cognitives contextuelles. La par-tie 3 traite de l’exploitation de ce modèle.Enfin nous présenterons dans la partie 4 leprototype que nous avons développé utili-sant ce modèle.
2 Le modèle des cartes cogni-
tives contextuelles
Rappelons dans un premier temps la défi-nition du modèle de graphe conceptuel uti-lisé pour représenter les contextes d’utili-
sation d’une carte. Le modèle des graphesconceptuels utilisé ici, est une version sim-plifiée de celui défini dans [7]. Tout grapheconceptuel est défini sur un support qui or-ganise, à l’aide de relations “sorte de”, unvocabulaire composé de types de conceptset de types de relations.
Définition (support):Un support S est un couple (T C , T R) telque :– T C , ensemble des types de concepts, est
un ensemble partiellement ordonné parune relation “sorte de” (notée ≤) pos-
sédant un plus grand élément (noté )appelé type universel.
– T R, ensemble des types de relations,est un ensemble partiellement ordonné,partitionné en sous-ensembles de typesde relations de même arité. T R =T R1∪. . .∪T Rp, où T Ri est l’ensemble destypes de relations d’arité i. Tout T Ri ad-met un plus grand élément (noté i).
Exemple:Le support décrit en figure 1 définit destypes de concepts tels que Ville (qui est unesorte de Lieu) et des types de relations bi-naires tels que agent .
état
2
T
T
Etre Vivant Lieu Action Période
Personne Ville Campagne Accident Jour Nuit
Homme Femme Autoroute Route départementale
agent lieu temps
T
T
C
R
Mort
Piéton
Véhicule
Voiture Cyclomoteur
utiliser
FIG . 1 – Un support
Un graphe conceptuel est un graphe conte-
nant deux sortes de sommets. Les sommetsde ces deux classes sont étiquetés respecti-vement par des noms de “concepts” et desnoms de “relations conceptuelles” entreces concepts. Les noms de “concepts” et
Le modèle des cartes cognitives contextuelles ___________________________________________________________________________
286

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 299/415
de “relation” étant préalablement définisdans le support. Les sommets concepts etles sommets relations sont reliés par desarêtes numérotées.
Définition (graphe conceptuel):Un graphe conceptuel G =(C G, RG, E G, etiq G) défini sur un supportS , est un multigraphe non orienté, bipartioù :– C G est l’ensemble des sommets
concepts.– RG l’ensemble des sommets relations.– E G est l’ensemble des arêtes. Toutes les
arêtes d’un graphe conceptuel G ont uneextrémité dans C G et l’autre dans RG.
– etiq G est une application qui à tout som-met de C G, de RG et à toute arête deE G associe une étiquette : si r ∈ RG,etiq G(r) ∈ T R ; si c ∈ C G, etiq G(c) ∈T C ; si e ∈ E G, etiq G(e) ∈ N. L’en-semble des arêtes adjacentes à tout som-met relation r est totalement ordonné,ce que l’on représente en étiquetant les
arêtes de 1 au degré de r.
Exemple:Le graphe conceptuel de la figure 2 repré-sente un accident mortel (accident dans le-quel une personne est morte)
Accident Personne Mortagent état1 12 2
FIG . 2 – Un graphe conceptuel
Une carte cognitive contextuelle est repré-sentée sous la forme d’un graphe orienté.Les noeuds du graphe sont étiquetés parun intitulé décrivant une notion. Pour sim-plifier nous supposons qu’il n’existe pasdeux noeuds de la carte étiquetés par lemême intitulé, nous emploierons donc lemot notion pour parler du contenu d’une
étiquette et du noeud lui-même. Les arcsdans le graphe représentent des liens d’in-
fluence. Un lien d’influence est une rela-tion de causalité possible entre deux no-tions. Les arcs du graphe sont étiquetés par
un signe + ou - pour signifier qu’une no-tion peut avoir une influence négative oupositive sur une autre. Le concepteur d’unecarte cognitive contextuelle peut exprimerà l’aide de graphes conceptuels le contextede validité de chaque influence.
Définition (carte cognitive contextuelle):Une carte cognitive contextuelle définiesur un support S est un graphe orientéX = (N X , LX , C X , etiq X ) où :– N X est l’ensemble des noeuds du
graphe.– LX est l’ensemble des arcs du graphe,
appelés liens d’influence de la carte.– C X un ensemble de graphes concep-
tuels.– etiq X est une fonction d’étiquetage qui :
– à tout élément n de N X associe un in-titulé décrivant la notion.
– à tout élément l de LX associe uncouple (s, c) avec s ∈ +, − re-présentant le signe de l’influence l etc ∈ C X un graphe conceptuel appelé
contexte de validité de l’influence l.Un contexte de validité particulier ap-pelé contexte vide est associé aux in-fluences toujours valides.
Notation:Soit X = (N X , LX , C X , etiq X ) une cartecognitive contextuelle. Soit l ∈ LX , onnote source(l) la notion qui est à l’originede l’arc et cible(l) celle qui est à l’extré-
mité. On note cont_val(l) le contexte devalidité de l. Le contexte de validité videest représenté par le symbole . Un nomunique peut être associé à chaque contextede validité.
Exemple:La carte cognitive de la figure 3 s’inspiredes problèmes de sécurité routière et peut
être utilisée afin de sensibiliser des per-sonnes à ces problèmes. Il est possible deconsidérer une notion comme un évène-ment, dans ce cas, un lien d’influence po-sitif entre deux notions pourrait se décrire
____________________________________________________________________________ Annales du LAMSADE N°8
287

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 300/415
de la façon suivante : si la première no-tion se produit alors il est probable que laseconde se produise. A l’inverse, un liend’influence négatif peut se décrire par :si la première notion se produit alors ilest moins probable que la seconde se pro-duise. Par exemple, si l’on prend les no-tions mettre sa ceinture et accident mor-tel, le fait de mettre sa ceinture diminueles risques d’avoir un accident mortel.
FIG . 3 – Carte cognitive
A chaque influence de la carte de la fi-gure 3 est associé un des contextes de va-lidité représentés dans la figure 4.
Par exemple, certaines influences commela "fatigue" qui influence les "erreurs hu-maines" sont toujours pertinentes quel quesoit le contexte d’utilisation de la carte, lecontexte vide leur est donc associé (fi-
gure 4A). Utiliser un "passage pour pié-ton" diminue les risques d’accidents mor-tels pour un piéton (figure 4B). L’influenced’une "mauvaise tenue de route" sur les"accidents mortels" est vraie pour un au-tomobiliste (figure 4C).
Pieton:
Automobiliste: Personne Voitureutiliser1 2
PiétonB:
C:
Contexte vide:A:
FIG . 4 – Ensemble des contextes de vali-dité des influences
Une carte cognitive contextuelle n’est passeulement un outil de représentation maisest aussi un système d’aide à la décisionqui permet à l’utilisateur de déduire lesconséquences d’une notion sur une autre.Certaines notions peuvent être des consé-quences indirectes, c’est pourquoi il estpossible de définir un mécanisme de pro-pagation de l’influence dans le graphe.L’influence propagée d’une notion sur unautre est définie en fonction des cheminsqui existent dans la carte entre ces deux no-tions, et des étiquettes portées par les liens.Cet effet peut être positif (noté +), néga-
tif (-), nul (0) ou ambigu ( ?). L’influencepropagée entre deux notions est positive(respectivement négative) lorsque le cumuldes influences de tous les chemins entreces deux notions est positif (respective-ment négatif). L’influence propagée entredeux notions est nulle lorsqu’il n’existepas de chemins entre ces deux notions. En-fin l’influence propagée est ambiguë lors-qu’il existe deux chemins dont les cumuls
des influences sont de signes différents.
Définition (propagation de l’influencedans une carte cognitive):Soit X = (N X , LX , C X , etiq X ) une cartecognitive contextuelle définie sur un sup-port S ,l’influence I de X est une application deN X × N X dans +, −, 0, ? telle que :
I (ni, n j) =
H ∈H i,j
i∈[1,|H |−1]
I 1(hi, hi+1)
H i, j étant l’ensemble des chemins ayantpour pour premier sommet ni et commedernier sommet n j . Chacun de ces cheminsétant de la forme H = (h1, . . . , hk) aveck = |H |.I 1 étant une application de N X × N X dans
+, −, 0 telle que I 1(ni, n j) = etiq X (l)si il existe un l = (ni, n j) dans LX
et 0 sinon. ⊕ et ⊗ étant des applica-tions de +, −, 0, ? × +, −, 0, ? dans+, −, 0, ? définies ainsi :
Le modèle des cartes cognitives contextuelles ___________________________________________________________________________
288

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 301/415
⊕ + - 0 ?
+ + ? + ?
- ? - - ?
0 + - 0 ?
? ? ? ? ?
⊗ + - 0 ?
+ + - 0 ?
- - + 0 ?
0 0 0 0 0
? ? ? 0 ?
Exemple:Sur la carte de la figure 3 l’influence posi-tive de la notion Circuler sur autoroute surla notion Accident sur autoroute peut êtreinterprétée de la façon suivante : "Circuler sur autoroute augmente les risques d’avoir un accident sur autoroute" . De même l’in-
fluence négative de la notion Femme surla notion Circuler sur autoroute peut s’in-terpréter par : "Une femme circule peu sur autoroute" . Le mécanisme de propagationpermet de déduire : "Etre une femme di-minue les risques d’avoir un accident sur autoroute" .
3 Exploitation
Une fois la carte établie, une fois quedes contextes ont été associés aux in-fluences, un utilisateur peut manipuler lacarte cognitive contextuelle. Pour cela ilprécise d’abord le contexte dans lequel ilsouhaite l’utiliser. Le mécanisme de fil-trage présenté dans cette section activeles influences et les notions valides dansle contexte défini. Une carte restreinte aucontexte est ainsi déterminée. L’utilisa-
teur peut enfin utiliser le mécanisme depropagation sur cette carte restreinte pourconnaître l’influence de n’importe quellenotion sur une autre.
Définition (contexte d’utilisation de lacarte):Un contexte d’utilisation cont_util est ungraphe conceptuel défini sur un support S .Le contexte d’utilisation vide est noté .
Exemple:L’utilisateur construit un nouveau grapheconceptuel pour décrire le contexte d’uti-lisation de la carte. Dans les prochains
exemples nous considèrons que l’utilisa-teur choisi d’utiliser pour contexte d’uti-lisation l’un des graphes conceptuels pié-ton et automobiliste qui sont utilisés pourdécrire les contextes de validité des in-fluences (figure 4). Le contexte d’utilisa-tion n’est pas toujours l’un des contextesde validité des influences de la carte, en ef-fet, les contextes de validité des influencessont généralement moins spécialisés que lecontexte d’utilisation ce qui permet à uneinfluence de s’activer dans plusieurs cas.
Le mécanisme de filtrage s’appuie surl’opération de projection d’un grapheconceptuel dans un autre.
Définition (projection):Une projection d’un graphe G =(C G, RG, E G, etiq G) dans un grapheH = (C H , RH , E H , etiq H ) est uneapplication Π : N G → N H (avecN G = C G ∪ RG et N H = C H ∪ RH ), telle
que :– les arêtes et les étiquettes des arêtessont conservées : pour toute arête rc deE G, Π(r)Π(c) est une arête de E H etetiq G(rc) = etiq H (Π(r)Π(c)) ;
– les étiquettes des sommets peuvent êtrespécialisées : pour tout n de N G,etiq H (Π(n)) ≤ etiq G(n).
Exemple:Le concept Voiture est défini dans le sup-port comme étant une “sorte de” Véhicule.De façon intuitive, le graphe utilisateur d’un véhicule se projette dans le grapheautomobiliste car l’information représen-tée par le graphe utilisateur d’un véhicule(voir figure 5) est incluse dans le grapheautomobiliste.
Pour modifier le raisonnement selon lecontexte d’utilisation, les influences qui nesont plus pertinentes dans ce contexte nesont pas prises en compte dans la propa-gation. Une influence est désactivée si son
____________________________________________________________________________ Annales du LAMSADE N°8
289

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 302/415
Voiture
VéhiculePersonne utiliser1 2
Personne utiliser1 2
Utilisateur
d’un véhicule:
Automobiliste:
FIG . 5 – Projection du graphe conceptuelutilisateur de véhicule dans le graphe au-tomobiliste
graphe conceptuel associé ne se projettepas dans le graphe conceptuel représentantle contexte d’utilisation de la carte. On dé-finit ainsi l’ensemble des influences acti-vées.
Définition (ensemble des influencesactivées):Soit X = (N X , LX , C X , etiq X ) une cartecognitive contextuelle définie sur un sup-port S ,soit cont_util un contexte d’utilisation,active(LX ,cont_util) = l ∈ LX |(cont_val(l) = ∨ ∃ une projectionde cont_val(l) dans cont_util)
Une notion qui est reliée à aucune in-fluence activée dans le contexte d’utilisa-tion a peu d’intérêt pour l’utilisateur, nousdéfinissons donc qu’une notion est activéesi elle est reliée à au moins une influenceactivée. Les notions désactivées peuventne pas être présentées à l’utilisateur.
Définition (ensemble des notions acti-vées):Soit X = (N X , LX , C X , etiq X ) une cartecognitive contextuelle définie sur un sup-port S ,soit contutil un contexte d’utilisation,active(N X ,cont_util) = n ∈ N X | ∃ l ∈active(LX ) tq source(l) = n ∨ cible(l) =n
Une fois que les sous-ensembles des in-fluences et des notions activées sont dé-terminés à l’aide du contexte d’utilisationde la carte, ils forment une nouvelle carte,plus simple et plus adaptée au contexte.
Sur cette carte il est possible d’appli-quer les mécanismes de propagation d’in-fluence vus précédemment.
Définition (carte restreinte au contexte):Soit X = (N X , LX , C X , etiq X ) une cartecognitive contextuelle définie sur un sup-port S , la carte restreinte de X au contextecont_util est le sous graphe qui vérifie :(active(N X ,cont_util),active(LX ,cont_util), C X , etiq X )
Une fois la carte restreinte obtenue, il estpossible d’utiliser le mécanisme de propa-
gation d’influence sur celle-ci.
Définition (propagation d’influence se-lon un contexte d’utilisation):Soit X = (N X , LX , C X , etiq X ) une cartecognitive contextuelle définie sur un sup-port S ,soit cont_util un contexte d’utilisation,l’influence I de X dans le contexte d’utili-sation cont_util est l’influence I de
X
= (active(N X ,cont_util),active(LX ,cont_util), C X , etiq X )
Exemple:La carte cognitive de la figure 7 a pour butde sensibiliser les piétons aux problèmesde la route, elle est obtenue en masquantles influences dont le graphe conceptuelassocié n’est pas égale à T et qui ne seprojette pas dans le contexte d’utilisation"Piéton" . Dans un contexte de sensibilisa-tion des piétons aux problèmes de la route,les informations qui sont liées à l’utilisa-tion de véhicules comme par exemple l’in-fluence de l’excès de vitesse sur les acci-dents mortels sont masquées. La carte estalors plus simple, et permet d’effectuer desraisonnements plus adaptés à cette utilisa-tion. Par exemple, pour un piéton, circu-ler en ville augmente ses risques d’avoir
un accident mortel, ce qui n’est pas le caspour un automobiliste (figure 6).La carte cognitive contextuelle présentéedans cette exemple pourrait être amélio-rée pour s’adapter à d’autre cas d’utili-
Le modèle des cartes cognitives contextuelles ___________________________________________________________________________
290

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 303/415
sations. Elle pourrait par exemple servirà la sensibilisation de cyclomotoristes oude conducteurs de camions. Les influencesqui seraient valides à la fois pour des au-tomobilistes, des cyclomotoristes et desconducteurs de camions recevraient pourcontexte de validité le graphe conceptuelutilisateur de véhicule de la figure 5
FIG . 6 – Utilisation pour une voiture
FIG . 7 – Utilisation pour un piéton
4 Prototype
Nous avons développé un prototype1 (fi-gure 8) en Java permettant de construire etde manipuler des cartes cognitives contex-
tuelles. Les composants graphiques néces-saires à la représentation d’une carte cog-nitive, des graphes conceptuels et du sup-
1téléchargeable à l’adresse : http://forge.info.
univ-angers.fr/~lionelc/CCdeGCjava/
port sont développés à l’aide de la bi-bliothèque d’édition et de manipulation degraphes : JGraph 2 Au cours de la manipu-lation d’une carte cognitive contextuelle,l’utilisateur édite le contexte d’utilisationde la carte. Les notions et les influencesdésactivées sont alors automatiquementgrisées. Cette fonctionnalité de filtrage uti-lise l’opération de projection qui est implé-mentée de manière efficace par Cogitant 3.Dans la capture d’écran de notre prototype(figure 8), les notions et les influences quine sont pas valides dans le contexte d’uti-lisation d’une voiture sont grisées comme
par exemple la notion Défaillance tech-nique. Nous avons implémenté les méca-nismes de propagation permettant à l’utili-sateur de demander l’influence d’une no-tion sur un autre. Les résultats sont pré-sentés de façon ergonomique grâce à uncode de couleur : vert pour une influencepositive, rouge pour une influence négativeet orange pour une influence ambiguë. Lacapture (figure 8) montre que l’influence
de "Circuler la nuit" sur "Accident mortel" est positive car la notion "Accident mor-tel" est de couleur verte. Par un chemin quiest affiché en vert : "Circuler la nuit" aug-mente la "Fatigue" qui augmente les risqued’"Erreur humaine" , ce qui augmente lesrisques d’"Accident mortel" . Par un autre,"Circuler la nuit" à un effet négatif surla "Bonne visibilité" et "Etre bien visible" (affichés en rouge). Ces deux notions di-
minuent les "Accident pour cause de mau-vaise visibilité" (affiché en vert) donc parce chemin "Circuler la nuit" augmente lesrisques d’"Accident mortels" .
5 Conclusion
L’extension du modèle des cartes cogni-tives présentée ici facilite l’exploitation de
cartes complexes grâce à un mécanisme defiltrage. Une carte de grande taille difficileà comprendre est simplifiée pour ne pré-
2http://www.jgraph.com3http://cogitant.sourceforge.net
____________________________________________________________________________ Annales du LAMSADE N°8
291

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 304/415
FIG . 8 – Prototype : Utilisation de la cartecognitive
senter que les informations intéressantesdans le contexte d’utilisation. D’abord cemécanisme fournit une base intéressantepour la construction de carte, en permet-tant de séparer les parties associées à despoints de vue différents, un point de vue
pouvant être considéré comme un contextede validité. Ensuite cette extension permetd’effectuer des raisonnements plus exactscar les influences non pertinentes dans lecontexte ne sont pas prises en compte dansle mécanisme de propagation. Des che-mins de la carte dont les signes sont diffé-rents et qui appartiennent à des contextesdifférents n’apparaissent pas en mêmetemps, les résultats des calculs de propa-gation d’influence sont alors moins sou-vent ambigus. Enfin l’idée de paramétraged’une carte en fonction du contexte pour-rait s’appliquer à des modèles de cartescognitives plus complexes que celui pré-senté dans cet article. Le modèle des cartescognitives floues [8] considère les notionsde la carte comme des variables et associeaux influences des valeurs réelles (com-prises entre -1 et 1) représentant la forcede l’influence d’une notion sur une autre.
Dans notre modèle une influence positivepeut être désactivée dans un contexte auprofit d’une influence négative, de la mêmemanière le mécanisme de filtrage appliquéau modèle des cartes cognitives floues per-
met d’obtenir des valeurs de force qui va-rient en fonction du contexte d’utilisation.Dans notre modèle le sens de chaque no-tion est défini à l’aide d’un intitulé for-mulé en langage naturel ce qui peut me-ner à des différences d’interprétation entreplusieurs utilisateurs d’une même carte.Notre modèle peut être utilisé en complé-ment d’une autre extension des cartes cog-nitives : le modèle des cartes cognitivesde graphes conceptuels[9]. Cette extensionprécise le sens d’une notion en la décrivantà l’aide d’un graphe conceptuel. L’opéra-tion de projection des graphes conceptuels
est utilisée dans cette extension pour sélec-tionner de notions sémantiquement liées etainsi fournir des mécanismes de propaga-tion entre deux ensembles de notions.
Références
[1] Edward C. Tolman. Cognitive maps in rats andmen. The Psychological Review, 55(4) :189–208, 2006.
[2] Filiz Dadaser Celik, Uygar Ozesmi, and Asu-man Akdogan. Participatory ecosystem ma-nagement planning at tuzla lake (turkey) usingfuzzy cognitive mapping, 2005.
[3] Poignonec D. Apport de la combinaison car-tographie cognitive/ontologie dans la compré-hension de la perception du fonctionnement d’un écosystème récifo-lagonaire de Nouvelle-Calédonie par les acteurs locaux. PhD thesis.
[4] Axelrod R. Structure of decision : the cognitivemaps of political elites. Princeton UniversityPress, 1976.
[5] Cossette P. Introduction, Cartes cognitives et organisations. Les presses de l’université deLaval, cossette ed. edition, 1994.
[6] Sowa J. F. Conceptual structures : Informationprocessing in mind and machine. 1984.
[7] Mugnier M.L. and Chein M.L. Représenter desconnaissances et raisonner avec des graphes.(10) :7–56, 1996.
[8] Kosko B. Neural networks and fuzzy systems :a dynamical systems approach to mahine in-telligence. Prentice-Hall, Engelwood Cliffs,
1992.[9] Genest D and Loiseau S. Modélisation, classi-
fication et propagation dans des réseaux d’in-fluence. 2007.
Le modèle des cartes cognitives contextuelles ___________________________________________________________________________
292

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 305/415
Règles Naturelles Optimales pour l’Argumentation
Y. Chevaleyre
N. Maudet
LAMSADEUniv. Paris-Dauphine
75775 Paris Cedex 16 – FRANCE
Résumé :Deux agents défendent des points de vue antago-nistes à propos d’un point en discussion, qui dé-pend d’un nombre (fixe) de critères, ou aspects,qu’ils connaissent tous deux. Supposons mainte-nant, qu’en tant qu’arbitre, vous souhaitiez prendreune décision basée sur ce que vont reporter les deuxagents. Malheureusement, ce que peuvent commu-niquer les agents est limité. Comment alors conce-voir les règles du protocole, de façon à minimiserles erreurs induites par ces contraintes de commu-nication? Cet article discute ce modèle introduitpar Glazer et Rubinstein [2] dans une version li-mitée, et introduit des résultats préliminaires d’uneexploration combinatoire de ce problème.
Mots-clés : Argumentation, Conception de méca-nismes.
Abstract:Two players hold contradicting positions regardinga given issue, which depends on a (fixed) numberof aspects or criteria they both know. Suppose, asa third-party, that you want to make a decision ba-sed on what will report the players. Unfortunately,what the players can communicate is limited. Howshould you design the rules of your protocol so asto minimize the mistakes induced by these commu-nication constraints? This paper discusses this mo-del originally due to [2] in a specific case variant,and introduces preliminary results of a combinato-rial exploration of this problem.Keywords: Argumentation, Mechanism design.
1 Introduction
Nous considérons la situation suivante :deux débatteurs opposent leurs points devue à propos d’un problème donné; etnous supposons que ce problème dépend
exclusivement d’un ensemble donné decritères. Les valeurs de ces critères étantdonnées, il est possible de déterminer ladécision à prendre : c’est le résultat d’unerègle de décision qui est appliquée sur la
valeur des critères. Dans notre contexte,les décisions envisagées sont binaires (ladécision défendue par le premier joueur,et la décision défendue par le deuxième joueur), ainsi que les critères, qui dé-fendent soit la position du premier joueur,ou celle du deuxième joueur. Enfin, larègle de décision est connue des deux joueurs (il s’agit par exemple de choisir ladécision défendue par une majorité de cri-tères). Les deux joueurs sont d’accord etconnaissent l’état du monde réel : il saventdonc quelle décision devrait logiquementêtre choisie. Mais imaginons maintenant laprésence d’un tiers, un arbitre qui n’a pas
accès à l’état réel du monde. Cet arbitrepeut néanmoins observer l’échange d’ar-guments qui a lieu entre les deux joueurs,suite à quoi il devra décider quelle décisionprendre. Dans le cas où la communicationentre les agents est limitée, on se trouveface à un problème délicat de concep-tion de mécanisme (mechanism design) :concevoir les règles du débat de manièreà maximiser la probabilité d’opter pour la
“bonne” décision , c’est-à-dire celle qui se-rait choisie si l’information était complète.
Ce problème a été introduit par Glazer etRubinstein dans [2], dans les termes quisuivent. Un débat est constitué de deux élé-ments.– les règles procédurales spécifient le pro-
tocole, les règles contraignant les argu-ments que les débatteurs peuvent avan-cer (on supposera en particulier ici
qu’un agent ne peut avancer que des ar-guments qui consistent à révéler qu’uncritère est en sa faveur) ;
– les règles de persuasion spécifient larègle employée par l’observateur pour
293

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 306/415
prendre la décision finale, sur la base desarguments avancés au cours du débat.
En ce qui concerne les règles procédurales,les auteurs distinguent trois types de dé-bats : le cas du débat à interlocuteur unique(single-speaker debate);lecasdudébatsi-multané (simultaneous debate), où les ar-guments sont révélés de manières simul-tanée par les débatteurs; et enfin le casdu débat séquentiel (sequential debate) quicorrespond évident plus intuitivement à lanotion naturelle de débat. Dans [2], lesauteurs étudient les trois types de débat,mais dans le contexte restreint où la dé-
cision n’est basée que sur 5 critères dif-férents, et où le nombre d’arguments quipeut être communiqué est limité à 2. Ilsmontrent en particulier que la règle opti-male, dans ce contexte-là, est nécessaire-ment séquentielle. Dans cet article, nousamorçons une étude du comportement ex-trémal de ce problème (lorsque le nombrede critères sur lequel est basée une déci-sion est important).
Le reste de cet article se présente commesuit. Dans la section suivante, nous intro-duisons les notions élémentaires que nousutiliserons. La section 3 présente ensuitel’analyse de différentes règles “naturelles”que l’arbitre pourrait vouloir employerpour prendre sa décision. Par naturelles,nous entendons ici qu’elles doivent pou-voir être énoncées naturellement en lan-gage naturel. Nous proposons ensuite uneétude analytique de deux règles simples :“montre-moi n’importe quel ensemble detaille k”, et "montre-moi cet ensemble”),et explorons expérimentalement le largeterritoire des règles qui tombent entre cesdeux extremes. Enfin, nous concluons etévoquons quelques liens avec des travauxconnexes.
2 Définitions
Dans cette section nous présentons plusformellement le problème, tel qu’il est in-troduit dans [2], en intégrant lorsque c’est
utile nos propres notations.
Nous représenterons un état comme unvecteur binaire 0, 1n, et chaque joueur
(débatteur) (0,1) “contrôle” les arguments(bits) qui lui sont favorables (c’est-à-direqu’il ne peut pas mentir, et ne peut pasrévéler d’arguments favorables à son ad-versaire). Nous appelons un état objecti-vement gagnant pour un agent x si un ar-bitre ayant accès à la totalité des argu-ments choisirait effectivement x commevainqueur. Par exemple, l’état 0, 1, 1, 1, 1signifie que le premier argument est en fa-
veur de l’agent 0, tandis que les quatreautres défendent le point de vue de l’agent1. C’est un état objectivement gagnantpour l’agent 1, si nous supposons que nousemployons la règle de majorité.
Typiquement, les débats auxquels nousnous intéressons seront limités à k bits decommunication, et évidemment plus préci-sément k < n/2 puisque nous utilisons larègle de majorité.
Une règle de persuasion peut être définieen extension comme un ensemble
E = S 1, S 2, . . . , S n
où chaque ensemble S i est un sous-ensemble de [n] de taille k (k-subset).Une telle règle doit être interprétée commesuit : “Je vous déclare vainqueur si vous
me montrez tous les arguments de S 1, outous ceux de S 2, etc. sont en votre fa-veur”. Par exemple, la règle de persua-sion E = 1, 2, 2, 3 signifie quel’agent concerné doit soit révéler les argu-ments 1 et 2, ou 2 et 3 (mais 1 et 3 n’estpas suffisant) afin d’être déclaré vainqueur.Dans cet article, nous nous intéresseronsaux règles de persuasion qui peuvent êtreexprimées simplement en langage naturel(parce que, typiquement, elles exploitentdes propriétés de k-subsets qui composentla règle).
Le ratio d’erreur () induit par une règleest le nombre d’états où vous prendriez
Règles naturelles optimales pour l'argumentation ___________________________________________________________________________
294

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 307/415

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 308/415
FIG . 1 – Taux d’erreur pour la règle“Montre-moi n’importe quel k-subset(n = 20)
Quel serait le taux d’erreur induit parcette règle? Notons pour commencer quele nombre d’erreurs majoritaires est nullorsque k ∈ [1, n
2]. En général, le nombre
total d’erreurs serait donc égal au nombrede situations perdantes couvertes par larègle (cm). Prenons t comme le nombre debits à placer pour faire une situation per-dante lorsque la règle est couverte. On endénombre
nerr = cm =
n/2t=k
n
t
ce qui indique que le nombre d’erreursest donné par la somme des coefficientsbinomiaux de k à n/2. Cela signifie quecette règle est en général très inefficace :c’est seulement lorsque le nombre de bitspermis pour la communication approchen/2 que le taux d’erreur devient acceptable(voir Fig. 1). Cela correspond en effet àl’intuition : si vous pouviez demander àl’agent de communiquer un nombre arbi-traire de bits, cette règle serait évidemmentla règle optimale que vous utiliseriez. En
demandant à l’agent de montrer n/2 argu-ments en faveur de son point de vue, vousvous assurez de ne pas être mystifié dansune situation perdante, tout en ne ratant au-cune situation gagnante.
3.2 “Montre-moi cet ensemble”
Dans ce cas, nous supposons que l’arbitre
demande juste à l’agent de lui montrer ununique ensemble (|E | = 1), de taille ar-bitraire k. (Nous supposons aussi n im-pair.) Les couvertures minoritaires et ma- joritaires sont les suivantes :
cm =
n/2−ki=0
n − k
i
cM =n−k
i=n/2−k
n − k
i
Dans ce cas, nous avons cM ≥ cm.
En observant que cM + cm = 2n−k, nousconcluons que :
nerr = cm + 2
n−1
− (2
n−k
− cm)= 2cm + (2n−1 − 2n−k)
Le taux d’erreur est donc :
=2cm + (2n−1 − 2n−k)
2n
=cm
2n−1+
1
2− 2−k
Nous allons à présent montrer que c’estune fonction monotone croissante.
Lemme 1 Pour les valeurs impaires, den et pour k ≥ 1 , le taux d’erreur dela règle “Montre-moi cet ensemble” aug-mente avec k.
Preuve. Nous allons montrer quenerr−2n−1
2= cm − 2n−k−1 est une fonction
croissante de k. Plus précisément, nousallons montrer que cm décroît quand kcroît, mais que 2n−k−1 décroît plus vite,
Règles naturelles optimales pour l'argumentation ___________________________________________________________________________
296

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 309/415
garantissant ainsi que nerr augmente aveck. Pour cela, il nous suffit de montrer queckm − ck+1m ≤ 2n−k−1 − 2n−k−2 ≤ 2n−k−2.Dans ce qui suit, nous utilisons la relationbinomiale
xy
=x−1y−1
+x−1y
.
ckm − c
k+1m
=n
2−k
i=1
n−ki
−n
2−k−1
i=1
n−k−1
i
=n
2−k−1
i=1
n−ki
−n−k−1
i
+n−kn2−k
=n
2−k−1
i=1
n−k−1i−1
+n−k
n2−k
=n
2−k−2
i=0
n−k−1
i
+n−kn2−k
=
n2−k−2
i=0 n−k−1
i +
n−k−1n2−k−1
+
n−k−1n2−k
=
n
2 −k
i=0
n−k−1
i
Tout d’abord, on vérifie aisément quen2
− k ≤n−k−1
2− 1
pour tout k ≥
1 et n ≥ 1. En utilisant le fait quex−12
i=0
xi
≤ 2x−1 pour n’importe quel
x ∈ N, et en substituant x pour n − k − 1,on peut finalement conclure que :
ckm − ck+1m ≤
n−k−12
−1i=0
n − k − 1
i
≤ 2n−k−2
Qu’est ce que cela nous révèle? Sim-plement que si l’arbitre ne peut deman-der qu’un unique ensemble d’arguments(quelque soit le nombre d’arguments com-posant cet ensemble), alors la solution op-
timale consiste à demander à l’agent de ré-véler le plus petit ensemble d’arguments.Autrement dit, il faut simplement deman-der à l’agent de révéler un bit. Bien en-tendu, on ne peut pas s’attendre dans cecas à un un très bon taux d’erreur (parexemple, pour n = 20, le taux d’erreur estde 40% pour le singleton, et tend vers 50%lorsque k croît).
3.3 Entre ces extrêmes : une région es-sentiellement non naturelle
Jusque là, nous avons étudié deux cas ex-trêmes de règles naturelles : le cas où
seul un ensemble peut être demandé, etle cas où n’importe quel k-subset peutêtre demandé. Il serait à présent intéres-sant de se pencher sur le cas des règlesqui tombent entre les deux, c’est-à-direlorsque le nombre d’ensembles composantla règle de persuasion est compris entre cesdeux bornes. Évidemment, dans la majo-rité des cas, les règles considérées ne se-ront pas naturelles au sens où nous l’en-tendons.
Pour cela, nous avons tout d’abord dérivéune formule analytique qui représente le
taux d’erreur dans le cas général. Malheu-reusement, obtenir des bornes supérieureset inférieures pour cette formule s’avèretrès complexe, et nous n’avons pas encoreobtenu de résultats satisfaisants. Pour cetteraison, nous avons mis en place une étudeexpérimentale, dont les résultats sont re-portés dans la figure 2 (pour n = 21, unnombre |E | de k-subsets sont générés aléa-toirement pour créer une règle de persua-
sion). Notez bien que l’axe représentant
FIG . 2 – Taux d’erreur pour les règles gé-nérées aléatoirement de taille |E |, en fonc-tion de k
la cardinalité de E est exprimé sur uneéchelle logarithmique (log10|E |). En effet,
nous avons observé que la valeur de k pourlaquelle le taux d’erreur est minimisé dé-pendait logarithmiquement de la taille deE . Au cours de toutes nos expérimenta-tions, nous avons remarqué que, tandis que
____________________________________________________________________________ Annales du LAMSADE N°8
297

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 310/415
nous mesurions le taux d’erreur commeune fonction de k (les autres paramètresétant fixés), le taux d’erreur décroît tou- jours jusqu’à ce que k atteigne une valeurdonnée que nous appellerons kopt (cette va-leur dépend des autres paramètres), puiscroît de nouveau. Cette observation s’ap-plique également aux deux règles ex-trêmes discutées plus avant. Considéronstout d’abord la règle “Montre-moi cet en-semble” (|E |=1). Son taux d’erreur est op-timal pour k = 1 on a donc (kopt=1),comme nous l’avons démontré, puis il aug-mente. A l’inverse, le taux d’erreur pour
la règle “Donne-moi n’importe quel en-semble” (|E | =
nn/2
) décroît comme une
fonction de k, jusqu’à atteindre n2. Ainsi,
on a bien kopt = n2. Ainsi, il apparaît que
déterminer cette valeur kopt est très perti-nent pour notre problème.
De plus amples expérimentations, quenous ne reportons pas ici, suggère forte-ment que la valeur optimale, pour n = 21,suit de manière linéaire log10|E |. La fi-gure Fig. 2 montre le résultats des expé-rimentations pour cette valeur. La “vallée"bleue décrit la zone dans laquelle se si-tue kopt : par exemple pour log10(|E |) =1 (10 k-subsets), nous avons kopt = 2,quand log10(|E |) = 2, kopt = 4, et quandlog10(|E |) = 5, nous avons finalementkopt = 9 (le taux d’erreur est alors de 8%).
3.4 Partitions d’ensembles de
“Montre-moi k bits parmi cet
ensemble”
Nous discutons brièvement pour finir uncas d’intérêt historique, qui représente unfamille de règles particulières (plutôt na-turelles, voir [4]) qui permet de grouperensemble les arguments. Commençons par
rappeler que dans le cas n = 5, il a étéprouvé par [2] que la règle optimale pource type de débat consistait à demanderde montrer deux arguments, appartenantsoit à 1, 2, 3 soit à 4, 5. Cette règle
pourrait être représentée en extension parE = 1, 2, 2, 3, 1, 3, 4, 5, maisson intérêt provient évidemment du faitque l’utilisation d’un opérateur de type IN(“Montre-moi k arguments parmi cet en-semble”), qui permet une représentationcompacte de la règle; en plus du fait quela règle obtenue est une partition.
Afin de nous donner quelques indices per-mettant de déterminer si ce type de combi-naison d’opérateurs de type OR et IN esteffectivement optimal lorsque n devientgrand, nous avons conduit quelques expé-
rimentations très limitées. Nous obtenonspar exemple, que pour n = 21 et k =3, les taux d’erreurs1 sont de 47% pour3 IN-subsets, de 36% pour 5 IN-subsets,de 26% for 6 IN-subsets, pour finalementatteindre 21% pour une partition consis-tant de exactement 7 IN-subsets de taille3. Cela semble suggérer que le taux d’er-reur décroît de manière constante lorsquele nombre de IN-subsets augmente. Si cela
peut paraître surprenant à première vue,il faut bien noter que lorsque le nombrede IN-subsets augmente, la cardinalité deE (définie en extension comme des k-subsets) décroît. D’une certaine manière,on peut donc se demander si cette famillerègle ne fournit pas une approximationsimple permettant de tomber dans la ré-gion précédemment évoquée. Si cela, seconfirme, nous aurions donc comme règleoptimale une règle composée de n/2 IN-subsets de taille k (ou k+1), même si cetteconclusion demande largement à être véri-fiée. Notons toutefois que ce serait cohé-rent avec le résultat reporté dans [2].
4 Perspectives
Notre but dans ce travail a été d’initierl’Étude du comportement extrémal d’un
problème de mechanism design introduitdans [2]. Les résultats préliminaires quenous obtenons ici concernent deux types
1Nous reportons ici les taux d’erreurs optimaux obtenusaprès génération aléatoire de telles règles.
Règles naturelles optimales pour l'argumentation ___________________________________________________________________________
298

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 311/415
simples de règles : “Montre-moi n’im-porte quel ensemble de taille k”, ainsique “Montre-moi cet ensemble”. Même sila première règle est la seule optimale sile débat n’est pas restreint, elle s’avèrevite très inefficace lorsque l’on pose descontraintes de communication. Quant à larègle “Montre-moi cet ensemble”, notrerésultat montre de manière remarquablequ’il s’avère alors optimal de demanderà l’agent de seulement révéler un argu-ment (même si il est possible de com-muniquer plus d’arguments). Ces résultatssont complétés par des expérimentations
qui montrent, pour les instances du pro-blème que nous avons étudiées, que la va-leur de kopt pour laquelle le taux d’er-reur est minimal dépend logarithmique-mentdelataillede E .Pourfinir,nousnoussommes brièvement intéressés au cas despartitions de IN-subsets (où nous permet-tons à l’agent de montrer k bits parmi unensemble donné, quelque soient ces argu-ments), qui s’avèrent être une généralisa-
tion de la règle optimale de [2].Ce travail peut être développé selon plu-sieurs axes. Pour commencer, nous de-vrons affiner notre compréhension desrègles étudiées ici. Il faut noter parexemple que les résultats expérimentauxreportés sont des moyennes sur les règlesgénérées aléatoirement, et il s’avérerasans doute lors d’Études plus poussées
que certaines caractéristiques (comme parexemple le taux de recouvrement entre lessubsets générés) ont une influence impor-tante sur la qualité des règles. Il pourraitêtre intéressant, pour commencer, d’étu-dier non la moyenne mais le max pour lesrègles générées (c’est ce que nous avonsfait pour les partitions). A plus long terme,l’Étude des autres types de débats présen-tés dans [2] sera certainement aussi très
riche en enseignement, en particulier lesdébats séquentiels.
Plusieurs liens peuvent être Établis avecdes travaux connexes. En termes combi-
natoires, les règles de persuasion sont desset systems, des objets largement étudiésdans cette littérature, voir par exemple[1]. Pour autant, nous n’avons pas trouvéde notions se rapprochant des propriétésque nous étudions ici. Un autre domainede recherche qui semble très concernépar les questions évoquées ici est ce-lui de la complexité communication. Lacomplexité communication s’intéresse à laquantité minimale de bits qu’il est néces-saire d’échanger afin de calculer mutuel-lement la valeur d’une fonction dont lesdonnées sont distribuées [3]. Une diffé-
rence essentielle est que dans ce contexteles agents sont supposés être coopératifs,alors que dans notre cas ils sont en com-pétition pour convaincre l’arbitre. De plus,la complexité communication s’attache ty-piquement à déterminer des bornes sur lenombre de bits à échanger pour calculer lafonction sans aucune erreur, alors que dansnotre cas nous partons d’une contrainte surla quantité de communication et essayons
de minimiser l’erreur inévitablement in-duite dans le calcul de la fonction.
Références
[1] B. Bollobas. Combinatorics : Set Sys-tems, Hypergraphs, Families of Vec-tors, and Combinatorial Probability.Cambridge University Press, 1986.
[2] J. Glazer and A. Rubinstein. Debates
and decisions : On a rationale of argu-mentation rules. Games and Economic
Behaviour , 36 :158–173, 2001.[3] E. Kushilevitz and N. Nisan. Commu-
nication Complexity. Cambridge Uni-versity Press, 1997.
[4] A. Rubinstein. Economics and Lan-guage. Cambridge University Press,2000.
____________________________________________________________________________ Annales du LAMSADE N°8
299

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 312/415

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 313/415
Modélisation de réglementations pour le partage d’information dansun SMA
Laurence Cholvy
[email protected] Garion†
[email protected] Saurel
ONERA Centre de Toulouse2 avenue Édouard Belin
31055 Toulouse† SUPAERO
10 avenue Édouard Belin31055 Toulouse
Résumé :L’objectif de cet article est de définir un langage lo-gique pour exprimer des politiques de partage d’in-formation dans un système multi-agents. Nous pro-posons d’utiliser un langage fondé sur la logique dupremier ordre pour exprimer des politiques via desconcepts comme le temps, les actions, le contexte,les rôles dans une organisation et des notions dé-ontiques. Nous définissons alors les propriétés decohérence et de complétude d’une telle politique.
Mots-clés : partage d’information, logique, SMA
Abstract:The aim of this paper is to define a logical languageto express information sharing policies for multi-agent systems, which have to cope with dynamicalenvironments. We propose to use a first-order lo-gic base language to express policies via conceptslike time, action, context, roles in organizations anddeontic notions. We define then consistency for asharing policy and propose two definitions for po-licy completeness.
Keywords: information sharing, logics, MAS
1 Introduction
Les systèmes multi-agents (SMA) offrentun cadre de modélisation pour de nom-breux systèmes existant ou à conce-voir, systèmes dans lesquels des entités(qu’elles soient simples ou déjà locale-ment organisées en systèmes), coopèrentafin de remplir une tâche globale. Dans
un tel contexte, ces entités, que l’on ap-pellera alors agents, doivent nécessaire-ment s’échanger de l’information, notam-ment afin d’avoir une vision commune etpartagée de l’environnement.
Si dans certains systèmes ces échangesd’information sont laissés libres et noncontrôlés, à l’inverse, dans d’autres sys-tèmes, ils sont réglementés par une poli-tique, notamment en vue de satisfaire cer-taines contraintes de sécurité (confidentia-lité de l’information par exemple) ou d’ef-ficacité (diffusion large de l’informationpertinente). C’est à ce type de systèmesque nous nous intéressons ici.
L’exemple illustratif que nous prendronstout au long de cet article est celui du planORSEC (ORganisation des SECours)[1],qui est un plan de secours dont la Francedispose en cas de catastrophe majeure etdont le but est d’organiser et de coordon-ner cinq services : les sapeurs-pompiers,le SAMU, la police, le STI (Service deTransmission de l’Intérieur) et la DDE.D’autres moyens peuvent également êtreutilisés dans le plan ORSEC, comme parexemple des organisations internationales(Croix Rouge, ...) ou des individus pouraider à secourir des victimes. ORSEC créedonc un système multi-agents composé desdifférents services et organisations pour ré-agir efficacement. Ce SMA est géré cen-tralement par le DOS (Direction des Opé-ration de Secours).
Dans un tel système, les unités de com-mande et de contrôle des différents ser-vices ont besoin de partager l’informationprovenant de différentes sources (commepar exemple des unités de renseignement)
301

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 314/415
pour pouvoir avoir une vue globale de lasituation de crise et prendre ainsi des dé-cisions cohérentes en vue d’achever leurmission. Elles doivent également utiliserdes informations partielles, avec des tempstrès courts de traitement de ces informa-tions. De plus, ce partage d’informationa lieu dans un environnement très risqué[14] : les relations de confiance entre lesservices peuvent changer avec le temps,elles peuvent ne pas être symétriques et lesindividus peuvent changer leur rôle dansl’organisation et donc changer ce qu’ilsont besoin de savoir. Dans de telles condi-
tions, il y a un risque assez grand de vio-ler des propriétés de sécurité de l’informa-tion, comme la confidentialité ou la dispo-nibilité. Cela peut avoir des conséquencesdésastreuses pour l’efficacité des secours.Par exemple, il peut être nécessaire de ca-cher des informations à la population pouréviter un mouvement de panique.
Pour que les utilisateurs aient confiance
dans le système, il est nécessaire decontrôler et de réguler la diffusion de l’in-formation dans le système au moyen d’unepolitique. Une politique d’échange peutdonc être vue comme une réglementationqui spécifie les diffusions obligatoires, per-mises ou interdites à l’intérieur du systèmed’agents. Mais pour être réellement utile,une telle politique doit satisfaire un certainnombre de propriétés, notamment la pro-priété de cohérence et celle de complétude.
Comme ce problème est proche de laproblématique de sécurité de l’informa-tion, nous nous sommes inspirés d’une ap-proche connue dans ce domaine consis-tant à définir des politiques de sécuritépour préserver les propriétés de sécuritéde l’information (principalement la confi-dentialité, disponibilité et intégrité). D’uncôté, comme les agents du SMA que nous
considérons sont souvent des services of-ficiels, nous pouvons utiliser les modèles« obligatoires » [2, 3], où les droits desutilisateurs sont définis par leur organisa-tion. Avec cette approche, les droits ne
peuvent pas être facilement changés ni dé-légués à d’autres utilisateurs. D’un autrecôté, les modèles de contrôle d’accès dis-crétionnaires [12] autorisent chaque sujetà donner ses droits d’accès sur un ob- jet à d’autres sujets. Malheureusement, ilspeuvent conduire à des fuites d’informa-tion et ainsi violer la confidentialité. Cesdeux modèles ne régulent explicitementque les permissions d’accès, l’obligationétant gérée implicitement par les spéci-fications du système d’information. Dansnotre cas, nous avons besoin explicitementde l’obligation pour exprimer des règles
(pour la disponibilité et le bien-fondé desinformations) et pour pouvoir vérifier despropriétés sur l’ensemble des règles departage de l’information.
L’objectif de cet article est de définir unformalisme permettant d’exprimer une po-litique de partage (section 2). Ce forma-lisme se fonde sur des concepts déontiqueset une logique du premier ordre. Nous dé-
finissons ensuite dans ce cadre les proprié-tés de cohérence et de complétude pourune politique de partage dans les sections 3et 4. Nous listons enfin les perspectivesmajeures de travaux que cette étude ouvre.
2 Un formalisme pour expri-mer des politiques de partaged’information
Dans cette section, nous présentons lesconcepts utilisés dans notre formalisme etun cadre logique pour représenter et rai-sonner sur ces concepts.
2.1 Présentation informelle des
concepts utiles
Pour pouvoir exprimer une politique de
partage, nous avons besoin de conceptsprimitifs comme le temps, les actions, lesmodalités déontiques (obligation, permis-sion, interdiction) et les propriétés sur lesystème et son environnement.
Modélisation de réglementations pour le partage d'information dans un SMA ___________________________________________________________________________
302

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 315/415
Le temps est un concept important, carles notions déontiques associées au partaged’information changent au cours du temps.Nous avons besoin de distinguer trois di-mensions temporelles : le temps auquelune information est valide, le temps auquelun agent reçoit une information, le tempsauquel un agent envoie une information.
Ces trois notions sont nécessaires. Parexemple, nous pouvons exprimer qu’unagent est obligé d’envoyer une informationdès qu’il l’a reçue et avant un certain lapsde temps.
Dans ce travail consacrée à l’étude dupartage d’information, nous ne considé-rerons que deux actions : l’action d’ap-prendre une information et l’action d’en-voyer une information. Ainsi, nous de-vrons être capable d’exprimer qu’un agentapprend telle information à telle date etqu’un agent envoie telle information à telautre agent à telle date.
Comme nous voulons exprimer desnormes, i.e. des règles qui spécifient cequi doit, peut ou ne doit pas être fait, nousavons besoin de modalités déontiques,particulièrement à propos du partage d’in-formation. Pour cela, nous introduisonsles concepts déontiques classiques d’obli-gation, de permission et d’interdiction quenous ferons porter uniquement sur l’action« envoyer de l’information ».
Par ailleurs, conformément à la plussimple des logiques déontiques, SDL [8],nous exprimerons la permission et l’inter-diction en fonction de l’obligation (fairel’action A est permis si et seulement si nepas faire A n’est pas obligatoire et fairel’action A est interdit si et seulement si nepas faire A est obligatoire) ainsi que la co-hérence de l’obligation (pour toute actionA, il est faux qu’il soit obligatoire de faireA et qu’il soit obligatoire de ne pas faireA).
Enfin, les propriétés sur le système etson environnement peuvent être dépen-
dantes du temps ou non. Par exemple, lefait qu’une information concerne un thèmedonné est une propriété atemporelle. Parcontre, le fait qu’un agent joue tel rôledans l’organisation considérée est dépen-dante du temps.
Notons enfin que parmi ces propriétés,la notion de contexte est importante ici.Notre SMA évoluera dans un environ-nement dynamique : situations de crisesou calmes, occurrences d’événements etc.Et les modalités de partage d’informa-tion dépendent souvent du contexte. Par
exemple, une diffusion large d’informa-tion devient plus restreinte en contexte decrise. Ainsi, les contextes seront utilisésdans les règles de partage d’informationcomme des prémisses restreignant l’appli-cation des normes.
2.2 Un formalisme logique
Afin de modéliser et raisonner sur lesconcepts introduits précédemment, nousproposons d’utiliser une logique du pre-mier ordre plutôt que d’utiliser une lo-gique modale déontique du premier ordre,et ce afin de réutiliser des algorithmes ef-ficaces (comme un algorithme d’abductionque nous verrons plus loin) qui ont été dé-finis dans le cas du premier ordre unique-ment.
Comme nous verrons ci-dessous, cette so-lution va nous obliger à représenter les mo-dalités déontiques par des prédicats et dereprésenter les évènements créés par lesenvois d’information par des termes quiseront arguments de ces prédicats.
Comme d’habitude, l’alphabet du langagelogique que nous définissons, L, sera com-posé de trois groupes distincts de sym-
boles : les symboles de constantes, de pré-dicats et de fonctions. Enfin, comme nousvoulons typer notre langage, nous distin-guerons des groupes différents de sym-boles dans ces catégories.
____________________________________________________________________________ Annales du LAMSADE N°8
303

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 316/415
Definition 1 Nous distinguons quatre en-sembles de constantes :
– les I-constantes qui représentent des va-leurs du domaine des attributs du mo-dèle d’information.
– les Ag-constantes qui représentent lesagents qui partagent de l’informationdans le SMA.
– les T-constantes qui représentent desdates temporelles.
– les autres constantes sont des O-constantes.
Definition 2 Nous caractérisons les sym-boles de prédicats de la façon suivante :
– Obligatory, Permitted et Forbiddensont des prédicats unaires appelés D-
prédicats. – Learn(.,.,.) est un symbole de prédicat
ternaire. – les contextes sont exprimés à travers des
prédicats ayant au moins un paramètre pour le temps. Nous les appelons C- prédicats.
– les P-prédicats seront utilisés pour ex- primer toutes sortes de propriétés sur l’information, les agents etc.
Definition 3 Les fonctions sont caractéri-sées de la façon suivante :
– les I-fonctions représentent les relations
entre les objets. Par exemple position(.,.)est une fonction représentant la relationentre un objet et ses coordonnées géo-graphiques.
– send(.,.,.,.) est une fonction à quatre ar-guments représentant l’action d’envoyer une information.
– not(.) est une fonction unaire servant à représenter la négation. Elle porterauniquement sur la fonction send et ser-vira à exprimer l’action de ne pas en-voyer une information.
Nous pouvons maintenant définir les for-mules de L.
Definition 4 Les formules de L sont défi-nies récursivement comme suit :
– Si f est une I-fonction, si t1, . . . , tn sont
des I-constantes ou des variables, alorsf (t1, . . . , tn) et not(f (t1, . . . , tn)) sont des I-termes.
– Si t1, . . . , tn sont des constantes ou desvariables, si C est un C-prédicat, alorsC (t1,...,tn) est un C-littéral et une for-mule de L.
– Soient x une Ag-constante, i un I-termeou une variable, t une T-constante ouune variable. Alors Learn(x,i,t) est un
L-littéral et une formule de L. – Soient x et y des Ag-constantes ou desvariables, i un I-terme ou une variable,t une T-constante ou une variable.
Alors Obligatory (send (x,i,y,t)) ,Permitted (send (x,i,y,t)) et Forbidden (send (x,i,y,t)) sont des
D-littéraux et des formules de L. – Si t1, . . . , tn sont des constantes ou des
variables, si P est un P-prédicat, alors
P (t1
, . . . , tn) est un P-littéral et une for-mule de L. – Soient F 1 et F 2 des formules de L et x
une variable. Alors ¬F 1 , F 1∧F 2 , F 1∨F 2 ,∀x F 1 et ∃x F 1 sont des formules de L et sont définies comme d’habitude.
2.3 Définition d’une politique de par-
tage d’information
Dans cette section, nous définissons desrègles pour définir une politique de partaged’information avec le langage logique pré-cédemment défini.
Une politique de parage d’information estun ensemble de formules de L qui sont desclauses définies1 l1∨l2∨. . .∨ln telles que :
– ln est le seul littéral positif et est un D-
littéral,– ∀i ∈ 1, . . . , n − 1, li est un C-littéral,L-littéral, P-littéral ou D-littéral négatif,1Une clause définie est une clause dans laquelle seul un lit-
téral est positif.
Modélisation de réglementations pour le partage d'information dans un SMA ___________________________________________________________________________
304

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 317/415
– si x est une variable de ln, alors ∃i ∈1, . . . , n−1 tel que li est un littéral né-gatif et contient la variable x. Cette der-nière définition provient de la définitiond’un domaine restreint dans le mondedes bases de données : il permet de ca-ractériser des formules significatives.
Example 1 Considérons une politique de partage stipulant que dans un contexte decrise, une information portant sur le sujet « risque d’explosion » doit être envoyée àl’agent B à partir du moment où A a ap-
pris l’information et le fait qu’elle portesur le thème « risque d’explosion ». Cetterègle peut être exprimée par la formulesuivante :
(R1) ∀i ∀t ∀t Crisis (t) ∧ Learn (A,i,t)∧
Learn (A, topic (i, ExpRisk ), t) →
Obligatory (send (A,i,B, max (t, t)))
3 Cohérence d’une politique departage d’informations
Étant données une situation et une poli-tique de partage, nous voulons éviter dedéduire qu’il est à la fois obligé et inter-dit pour un agent a (ou permis et interdit)de transmettre une information à un agentb. Dans ce cas, a serait confronté à un di-
lemme. Nous définissons donc la propriétéde cohérence pour une politique de par-tage.
Soit Dom l’ensemble de connaissances dudomaine et les méta-connaissances du do-maine (par exemple, il contient les re-lations entre les thèmes). Dom pourraitpar exemple contenir les informations sui-vantes :
(D1) ∀x ∀y ∀z ∀a ∀t Learn (a, type (x, y), t)
→ Learn (a, topic (type (x, y), y), t)∧
Learn (a, topic (position (x, z), y), t)
(D1) signifie que si un agent a apprend autemps t que le type de x est y, alors à lamême date il apprend que les informations« le type de x est y » et « la position de x
est z » traitent toutes les deux du thème y.
(D2) ∀t ¬(Quiet (t) ∧ Crisis (t))
(D2) signifie qu’on ne peut pas être enmême temps dans un contexte calme et decrise.
Nous ajoutons également les axiomes sui-vants à propos des D-prédicats, comme ex-pliqué intuitivement dans 2.12 :
(A1) ∀x Permitted (x) ↔ ¬Obligatory (not (x))
(A2) ∀x Forbidden (x) ↔ Obligatory (not (x))
(D) ∀x Obligatory (not(x)) ↔ ¬Obligatory (x)
(neg)∀x Obligatory (not 2n(x)) ↔ Obligatory (x)
D’un point de vue formel, (neg) est un
raccourci d’écriture pour une infinité deformules (on considère que n ∈ N dans(neg)).
Nous pouvons maintenant introduire notredéfinition de cohérence d’une politique.
Definition 5 Soit P une politique de par-tage, définie comme un ensemble de for-mules de L (cf. 2.2). P est cohérente siet seulement si il n’existe pas d’ensembleS de clauses sans D-littéral tel que S ∪Dom est cohérent et la théorie logiqueP ∪ (A1), (A2), (D), (neg) ∪ S ∪ Domsoit incohérente.
Si nous pouvons trouver un tel ensembleS , alors S est l’ensemble des circonstancesqui amène à la contradiction.
Example 2 Soit P une politique de par-tage qui exprime qu’en contexte de crise :2On pourra remarquerqu’il s’agit essentiellement de traduire
dans notre formalisme du premier ordre l’axiome D de SDL [8]et les liens entre obligation, permission et interdiction.
____________________________________________________________________________ Annales du LAMSADE N°8
305

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 318/415
– (R1) tout agent x doit envoyer à tout agent y toute information concernant le thème « risque d’explosion » (noté ExpRisk ) dès qu’il l’apprend :
(R1) ∀x ∀i ∀y ∀t ∀t Crisis (t)∧
Learn (x,i,t)∧
Learn (x, topic (i,ExpRisk ), t) →
Obligatory (send (x,i,y,max(t, t)))
– (R2) il est interdit pour tout agent d’en-voyer une information concernant le
thème « risque bactériologique » (noté Bac ) à quelqu’un qui ne joue pas unrôle officiel (modélisé ici par un rôle No-nOff) :
(R2) ∀x ∀i ∀y ∀t ∀t ∀tCrisis (t)∧
Learn (x,i,t) ∧ t > max(t, t)∧
Learn (x, topic (i,Bac ), t)∧
Playsrole (y, NonOff ) →Forbidden (send (x,i,y,t))
Considérons que Dom comprend les deuxrègles (D1) et (D2). Considérons mainte-nant le scénario suivant :
– il y a un contexte de crise. – à 10 :00, a apprend la position d’un
événement E et que E peut inclure un
risque bactériologique. – à 10 :15, a apprend que E implique unrisque d’explosion.
Avec P , on peut déduire que d’après (D1) ,à 10 :00 a apprend que l’informationconcernant la position de E est du thèmeBac . Dans ce cas, en utilisant (R2) , il est interdit pour a d’envoyer la position de E à partir de l’instant 10 :00 à tout agent qui n’est pas une organisation officielle, en
particulier à un agent b qui n’en est pasune.
Mais comme a apprend à 10 :15 que E implique un risque d’explosion, a apprend
également d’après (D1) que l’informationconcernant la position de E est du thèmeExpRisk . Dans ce cas, d’après (R1) , aest obligé immédiatement d’envoyer l’in-
formation à tout agent, donc en particulier à b.
À 10 :15, a est donc face à un dilemme :envoyer ou ne pas envoyer la position deE à b.
Considérons S =Learn (a, type (o,Bac ), 10 : 00 ),Learn (a, type (o,ExpRisk ), 10 : 15 ),
Crisis (10 : 00 ). On peut montrer que S ∪ Dom est cohérent et queP ∪ (A1), (A2), (D), (neg) ∪ S ∪ Domest incohérent. Cela signifie que P est incohérent d’après notre définition.
4 Complétude d’une politiquede partage d’information
Nous souhaitons maintenant définir la no-tion de complétude pour une politique departage. Intuitivement, la complétude per-met de savoir dans n’importe quelle si-tuation et pour n’importe quel agent cequi lui est interdit, autorisé ou obligé defaire. Nous proposons ici une définitionplus faible de la complétude qui est res-treinte à certains cas.
Definition 6 Soit P une politique de par-tage définie sur L. Soient D(x,i,y,t) une
formule de L et C une information repré-sentant un contexte. P est dite complètepour D et C pour chaque couple d’agentsx et y si et seulement si :
– P |= C → (∀x ∀i ∀y ∀t D(x,i,y,t) →Obligatory (send (x,i,y,t))) ou
– P |= C → (∀x ∀i ∀y ∀t D(x,i,y,t) →Forbidden (send (x,i,y,t))) ou
– P |= C → (∀x ∀i ∀y ∀t D(x,i,y,t) →Permitted (send (x,i,y,t)))
Example 3 Reprenons l’exemple 2 enchangeant le contexte de la règle (R2)
Modélisation de réglementations pour le partage d'information dans un SMA ___________________________________________________________________________
306

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 319/415

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 320/415
Enfin, dans un SMA, le besoin d’infor-mation pour un agent est plus contraintpar le rôle joué par l’agent dans le SMAque par l’agent lui-même. Plusieurs agentspeuvent jouer le même rôle dans le SMA,le rôle d’un agent peut changer durant lamission du SMA etc. Nous pourrions fa-cilement étendre notre cadre pour intro-duire des prédicats comme PlaysRole (in-troduit dans les exemples) pour modéliserces notions [4, 7]. Ceci permettrait d’ex-primer des conditions sur les rôles, ce quiest moins fastidieux que d’exprimer desconditions sur les agents.
Références
[1] Décret numéro 2005-1157 du 13 sep-tembre 2005 relatif au plan ORSECet pris pour application de l’article14 de la loi numéro 2004-811 du13 août 2004 de modernisation dela sécurité civile. Journal Offi-ciel de la République Française,
15 septembre 2005. http://www.legifrance.gouv.fr/texteconsolide/PRHV8.htm.In French.
[2] D.E. Bell and L.J. LaPadula. Securecomputer systems : unified exposi-tion and multics interpretation. Tech-nical report, The MITRE corporation,1975.
[3] K.J. Biba. Integrity consideration forsecure computer systems. Techni-cal report, The MITRE corporation,1977.
[4] G. Boella and L. van der Torre. At-tributing mental attitudes to roles :The agent metaphor applied to or-ganizational design. In Proceedingsof ICEC’04, pages 130–137. ACMPress, 2004.
[5] J. Broersen. On the logic of ’beingmotivated to achieve ρ before δ ’. InJ. J. Alferes and J. Leite, editors,
Logics in Artificial Intelligence, 9thEuropean Conference JELIA 2004,
number 3229 in Lecture Notes in Ar-tificial Intelligence, pages 334–346.Springer, 2004.
[6] J. Carmo and A. Jones. Handbook of Philosophical Logic, volume 8 :Extensions to Classical Systems 2,chapter Deontic Logic and Contrary-to-Duties, pages 265–343. Klu-wer Publishing Company, 2nd edi-tion, 2002.
[7] J. Carmo and O. Pacheco. Deonticand action logics for organized col-lective agency, modeled through ins-
titutionalized agents and roles. Fun-damenta Informaticae, 48(2,3) :129–163, 2001.
[8] B.F. Chellas. Modal logic. An intro-duction. Cambridge University Press,1980.
[9] R. Chisholm. Contrary-to-duty impe-ratives and deontic logic. Analysis,24 :33–36, 1963.
[10] L. Cholvy. Checking regulationconsistency by using SOL-resolution.In International Conference on Artifi-cial Intelligence and Law, pages 73–79, 1999.
[11] P. Gardenfors. Knowledge in Flux : Modelling the Dynamics of EpistemicStates. MIT Press, 1988.
[12] M.A. Harrison, W.L. Ruzzo, andJ.D. Ullman. Protection in opera-
ting systems. In Communications of the ACM , volume 8, pages 461–471.ACM Press, 1976.
[13] K. Inoue. Linear resolution forconsequence finding. Journal of
Artificial Intelligence, 56 :301–353,1992.
[14] C. E. Phillips, T. C. Ting, and S. A.Demurjian. Information sharing andsecurity in dynamic coalitions. InSACMAT , pages 87–96, 2002.
Modélisation de réglementations pour le partage d'information dans un SMA ___________________________________________________________________________
308

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 321/415
Influence du protocole sur l’issue des négociations
Sylvia Estivie
LAMSADEUniversité Paris-Dauphine
Paris, FRANCE
Résumé :Dans le domaine des Systèmes MultiAgents, la trèslarge majorité des recherches dédiées à l’allocationde ressources indivisibles se focalisent sur le pro-blème centralisé des enchères combinatoires. Onpeut aborder le problème par une autre approche
en distribuant cette prise de décision et en recou-rant à la négociation entre agents. Dans un pro-blème d’allocation de ressources décentralisé, l’is-sue des négociations est souvent conditionnée parde nombreux paramètres et celle-ci n’est pas tou-
jours optimale au sens du bien-être social que l’onchoisit d’étudier. Dans cet article, nous avons choiside nous focaliser sur le protocole de négociationutilisé par les agents et à son influence sur l’issuedes négociations. La question qui sous-tend cetterecherche est donc la suivante : dans quel mesureun protocole de négociation influe-t-il sur l’issuedes négociations ? Nous verrons que selon les pa-
ramètres utilisés, il est possible d’améliorer le ca-ractère égalitaire de l’allocation finale.
Mots-clés : Simulation Multi-agent, Allocation deressources, Négociation, Protocole, Bien-être so-cial
Abstract:In this paper, we study a framework where allo-cations of goods result from distributed negotia-tion conducted by autonomous agents implemen-ting very simple deals. Assuming that these agentsare strictly self-interested, we study the impact of
different negotiation protocols over the outcomesof such negotiation. We first discuss a number of negotiation protocols. By running different experi-ments, we identify parameters which have an in-fluence on individual welfare of agents and on ega-litarian social welfare. We finally identify value of protocol favouring equitable outcomes.
Keywords: MultiAgent Simulation , Resource Al-location, Negotiation, Protocol, Social Welfare
1 Introduction
Les recherches, dans le domaine de l’in-telligence artificielle, concernant le pro-blème de l’allocation de ressources se sontconcentrées autour du problème centra-lisé des enchères combinatoires [1]. Dans
ce contexte, les enchérisseurs exprimentau commissaire-priseur leurs préférencesconcernant différents lots d’objets. Dansce cas-là, le problème de la déterminationde l’allocation optimale (au sens où elle
maximise le gain du commissaire-priseur)est connu pour être NP-complet. Même sides algorithmes de plus en plus perfor-mants sont développés [7], il paraît clairque cette approche centralisée est inadap-tée lorsque le nombre de ressources excèdeune certaine limite [6], ainsi que dans lessituations où il n’existe pas d’agent pou-vant tenir le rôle du commissaire-priseur(ou encore si celui-ci n’est pas digne deconfiance).
Une manière alternative d’aborder le pro-blème consiste à distribuer la prise dedécision, en recourant à la négociationentre agents. Dans ce cas-là, les agentscontractent de manière autonome des tran-sactions les uns avec les autres, sur la basede critères locaux de rationalité. Partantd’une allocation initiale, les agents pro-gressent donc pas à pas, chaque transactionpermettant de passer à une nouvelle alloca-
tion. Le rôle du concepteur de l’applicationest alors de réguler les échanges, de tellefaçon que certaines propriétés puissent êtregaranties, en particulier que l’allocation fi-nale sera effectivement optimale. Cette ap-proche représente selon nous un enjeu ma-
jeur pour la communauté multiagent et arécemment retenu l’attention de plusieursauteurs [8, 2, 3].Un résultat fondamental, dû à Sandholm,montre que des échanges d’une complexitéarbitraire peuvent être nécessaires pour at-teindre une allocation optimale au sens dela somme des bien-être individuels (utili-taire). Il est pourtant peu pertinent de seplacer dans ce cadre général, car les tran-
309

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 322/415
sactions utilisées en pratique sont extrê-mement simples : elles n’impliquent sou-vent que deux agents ainsi qu’un nombretrès restreint de ressources [8]. Comment
alors continuer à garantir des propriétés in-téressantes pour le système ? Une solutionconsiste à émettre des hypothèses quantà la structure utilisée pour représenter lespréférences des agents.Dans cet article, nous nous plaçons dansle cadre restreint (mais cependant très réa-liste) des transactions simples et où lespréférences des agents sont représentées àl’aide de fonctions d’utilité additives. Dansce cadre, nous savons que des négociationsutilisant uniquement des transactions ra-tionnelles mènent à l’allocation optimaleau sens du bien-être social utilitaire maisqu’elles ne garantissent pas une issue op-timale du point de vue du bien-être socialégalitaire. Il a été montré dans [5] qu’il estpossible d’influer sur le caractère égalitairede l’allocation atteinte à l’issue des négo-ciations avec des fonctions de paiement.Cependant, il est apparu que ceci n’est pas
l’unique solution, et que le protocole denégociation peut également influer sur lecaractère égalitaire de l’allocation finale.
La question qui sous-tend cette rechercheest donc la suivante : le protocole de né-gociation peut-il influer sur le caractèreégalitaire de l’allocation finale et si ouiquels sont les paramètres influant du pro-tocole et les valeurs pouvant être prise parces derniers favorisant une issue égalitaire.A l’aide d’une étude expérimentale, nousidentifierons un paramètre ayant une forteinfluence à la fois au niveau local (BE in-dividuel) et au niveau global (BE Social).Nous proposerons également une valeurpour ce paramètre, basé sur une heuris-tique, favorisant le caractère égalitaire del’allocation finale.
La structure de ce papier est la suivante.La section 2 décrit le cadre de l’alloca-tion de ressources. Nous nous intéresse-rons ensuite au sujet central de cette étudequi est le protocole de négociation (sec-tion 3) et nous tenterons de lister de façonexhaustive les différents protocoles exis-tants. Dans la suite de ce travail, nous nous
intéresserons principalement à trois pro-tocoles, et nous les comparerons à l’aided’une étude expérimentale. La section 4est dédiée à l’identification des paramètres
influants, à l’aide d’une étude des bien-être individuels des agents. Ensuite, dansla section 5, nous nous focaliserons surle caractère égalitaire de l’allocation finaleen fonction de différentes valeurs de cer-tains paramètres du protocole. Enfin, nousconclurons en évoquant quelques pistes derecherches ouvertes par ce travail.
2 Allocation de ressources
2.1 Agents et ressources
Dans ce cadre, un ensemble fini de nagents (noté A) négocient la possessiond’un ensemble fini de m ressources (notéR). Ces ressources ont la particularitéd’être non-divisibles (il n’est pas pos-sible de segmenter la ressource) et non-
partageables (à un instant de la négocia-tion, un agent seulement peut posséder une
ressource donnée). On suppose égalementque toute ressource doit être attribuée àun agent. Une allocation (notée A) estdonc une partition de R parmi A qui at-tribue chaque ressource à un agent. Ainsi,A(i) = r1, r4 signifie que dans l’alloca-tion A, l’agent i possède les ressources r1et r4. Le moyen dont disposent les agentspour faire évoluer l’allocation est d’effec-tuer des transactions avec un ou plusieursautres agents qui peuplent la société du-
rant lesquelles une ou plusieurs ressourceschangent de propriétaire. Formellement,une transaction δ est simplement le pas-sage d’une allocation à une autre (i.e. δ =(A, A)), qui peut impliquer un nombre ar-bitraire d’agents et de ressources. Evidem-ment, dans la réalité, il n’est pas envisa-geable d’implémenter des transactions tropcomplexes. On s’intéresse donc générale-ment à des catégories de transactions plusrestreintes, en particulier les transactionssimples, qui n’impliquent que le passaged’une ressource d’un agent à un autre [8].On considère aussi que les transactionspeuvent être facilitées par des compensa-tions monétaires (cf. sect. 2.3).
Influence du protocole sur l'issue des négociations ___________________________________________________________________________
310

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 323/415
2.2 Préférence des agents
Chaque agent évalue sa satisfaction à pos-séder un lot de ressources1 à l’aide d’unefonction de valuation vi : 2R → R. Soitvi(A) la valuation de l’agent i à détenir lesressources qui lui sont assignées par l’al-location A. On fait ici l’hypothèse que cesfonctions ne traduisent pas d’externalités2.
Il est fréquent de représenter les préfé-rences des agents avec des valuations ad-ditives, qui ont l’avantage d’être simples,compactes et facilement interprétables.Malgré qu’elles soient peu expressives,elles ont la particularité d’être très na-turelles pour l’expression des préférencesdes agents dans de nombreux domainesd’application, où il n’est pas nécessaired’exprimer des synergies entre les res-sources. En associant un coefficient αi
rà chaque resource r, une valuation addi-tive vi peut s’écrire sous la forme d’unesomme.
Définition 2.1 (Fonction de valuation ad-
ditive). Une valuation est dite additive ssi pour chaque ressource r, il existe un coeffi-cient αi
r tel que
vi(R) =
r∈R
αi
r
Pour alléger l’écriture ces valuations ad-ditives seront représentées sous la formed’une combinaison linéaire. Par exemplevi(R) = 2×r1 +3×r2 +7×r3 avec ri ∈ 0, 1.
2.3 Bien-être individuel et argent
Lors des transactions bilatérales où uneseule ressource passe d’un agent à unautre, une phase de paiement peut êtremise en place pour compenser la perte debien-être que subit l’agent qui donne la res-source (cette perte de bien-être n’est pasobligatoire mais cependant très fréquente).
Cette phase de paiement peut être modé-
liser en utilisant une fonction de paiement p : A → R tel que
i∈Ap(i) = 0
1qu’il peut se voir attribuer au cours de la négociation2au sens où un agent calcule son bien-être sur la base des
ressources qu’il possède seulement
Une valeur positive de p(i) indique quel’agent i va donner de l’argent et une né-gative qu’il en reçoit. On associe à chaqueallocation A, atteinte à l’issue d’une sé-
quence de transaction, une fonction π :A→ R représentant la somme des paie-ments que les agents ont échangés, et nousavons également
i∈A
π(i) = 0. Un état dusystème est donc un couple (A, π) d’uneallocation A et d’une balance de paiement π. On notera donc π(i) la balance des paie-ments de l’agent i. D’autre part, afin deprendre en compte l’argent cumulé par lesagents lors du calcul de leur bien-être, nous
allons définir une fonction d’utilité ui quicombine la valuation résultant du lot deressources possédées vi avec la balancemonétaire : ui(A) = vi(A) + πi. Dans la lit-térature, de telles utilités sont souvent ap-pelées utilités quasi-linéaires, où v est lavaluation et u l’utilité réelle [1].
2.4 Rationalité des agents
C’est leur satisfaction personnelle immé-
diate qui va motiver les agents à accep-ter ou refuser une transaction. En ce sens,la rationalité des agents est clairementégoiste et myopique 3. On définit l’accepta-bilité des transactions grâce à la notion derationalité suivante :
Définition 2.2 (Rationalité Individuelle).Une transaction δ = (A, A) avec paie-ment compensatoire est rationnelle ssi ilexiste un vecteur de paiement −→ p ∈ R
n
telle que
vi(A)− vi(A) > p(i) pour tout i ∈ A4
2.5 Bien-être Social
Au cours des négociations, où les agentss’échangent les ressources en fonction deleurs préférences et de leurs critères de ra-tionalité, le bien-être de chacun va évoluer
et il en sera de même pour le bien-être de lasociété. Mais comment définir le bien-être
3ils ne sont pas capable d’anticiper sur des gains futurs4excepté pour les agents non impliqués dans cette transaction
(agents i tels que A(i) = A(i)) où p(i) = 0 .
____________________________________________________________________________ Annales du LAMSADE N°8
311

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 324/415
de la société dans sa globalité ? Répondre àcette question revient à définir une mesurede bien-être social (BES). La mesure laplus couramment employée dans le cadre
de la communauté multiagents est sans nuldoute la mesure utilitariste, définie commela somme des utilités des agents.
Définition 2.3 (BES utilitaire2). Le BES utilitaire swu(A) d’une allocation de res-sources A est défini comme suit :
swu(A) =
i∈A
ui(A)
La littérature économique donne de mul-tiples autres exemples de mesures de BESqui tentent de favoriser les allocations nonseulement efficaces (au sens utilitariste),mais aussi « justes », « équitables » ou“égalitaire”. Dans cet article, on s’inté-resse à la mesure de BES égalitariste quiconsiste à maximiser l’utilité de l’agent lemoins satisfait de la société.
Définition 2.4 (BES Egalitaire5). Le BES
égalitaire swe(A) d’une allocation de res-sources A est défini comme suit :
swe(A) = minui(A) | i ∈ AAutour de ces mesures de BES, on rap-pellera informellement pour commencerle résultat essentiel suivant, du à Sand-holm [8] : n’importe quelle séquence detransactions rationnelles mène à une allo-cation optimale au sens utilitariste. Mal-heureusement, ce résultat ne tient que si
l’on autorise des échanges de complexitéarbitraire. Dès que des contraintes sont po-sées sur le type de transactions autorisées,il n’est, en général, plus possible de garan-tir cette issue optimale de la négociation.On s’intéresse alors à des scénarios de né-gociation restreints, comme dans le cas destransactions simples, où l’on sait que dansle cadre de scénarios additifs, n’importequelle séquence de transactions simples ra-tionnelles mène à une allocation optimale
au sens utilitariste [4]. Ce résultat positif 5On notera que le calcul de ces bien-être sociaux est fait, non
pas à partir des valuations du bien-être des agents, mais à partir
de leurs utilités réelles c’est à dire en prenant en compte l’argent
échangé au cours des transactions.
indique que les transactions simples suf- fisent à garantir l’atteinte d’une allocationoptimale au sens utilitariste. Mais ce n’estpas le cas du BES égalitaire où l’issue des
négociations n’est pas garantie optimale.
3 Protocoles de négociation
Lors du processus de négociation, lesagents vont prendre la parole à tour derôle afin de proposer aux autres agents lesressources qu’ils possèdent. La gestion deces prises de parole va être confiée à unprotocole de négociation. C’est pourquoi,
il apparaît nécessaire de s’interroger surle protocole de négociation utilisé par lesagents et sur son influence sur l’issue dela négociation. Observons que le protocolen’a d’influence sur l’issue des négociationsque lorsque celle-ci n’est pas garantie op-timale.
3.1 Décomposition du protocole
Le protocole de négociation gère l’ordre
des communications entre les agents aucours de la négociation. Un agent ne com-munique avec un autre que lorsque le pro-tocole lui en donne l’autorisation et souscertaines contraintes. Afin d’étudier l’in-fluence de ce protocole, il est nécessairedans un premier temps de le decomposerafin d’en extraire les paramètres. Le pro-cessus de négociation se compose d’unesuite de dialogues impliquant deux agents,l’un étant l’initiateur (i.e. celui qui pro-
pose des transactions) et l’autre le rece-veur (i.e. celui qui accepte ou refuse lestransactions). L’initiateur va donc proposerune transaction, traitant d’une ressource,qui sera acceptée où non par le receveur.Lorsque ce dernier accepte, alors il obtientune nouvelle ressource qu’il pourra soitgarder, soit proposer à son tour dans unetransaction. Ces dialogues entre les agentsse regroupent en tour de négociation. Dansun tour, tous les agents auront eu la possi-bilité de communiquer avec tous les autresagents de la société. Une fois un tour ter-miné, un autre sera relancé. La conditiond’arrêt du processus de négociation seraqu’il n’y ai plus aucune transaction pos-
Influence du protocole sur l'issue des négociations ___________________________________________________________________________
312

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 325/415
sible, ce qui revient à ce qu’un tour com-plet ait été exécuté sans qu’aucune transac-tion n’ait eu lieu.
Le premier paramètre du protocole serale choix de l’ordre des initiateurs : Com-ment le protocole va-t-il choisir l’agentqui prend la parole ? L’initiateur peut êtrechoisi de différente façon : soit linéaire-ment6, soit de façon totalement aléatoire,ou selon une heuristique choisie par leconcepteur du système.La prise de parole de l’initiateur peut du-rer plus ou moins longtemps. Il peut avoirla parole uniquement pour communiquer
avec un autre agent, ou avec un ensembled’agents, voire tous les autres agents.L’initiateur va donc s’adresser aux autresagents mais dans un ordre spécifié par leprotocole. Ce ordre de choix du receveursera donc lui aussi un paramètre du pro-tocole. Enfin, l’agent initiateur va propo-ser ses ressources à l’agent receveur. Ledernier paramètre sera donc le choix del’ordre de proposition de ces ressources7.
3.2 Paramètres du protocole
Nous allons donc nous intéresser aux pro-tocoles résultant de la combinaisons de cestrois paramètres :– Initiateur : L’ordre du choix de l’ini-
tiateur. Il peut être linéaire, aléatoire oubasé sur une heuristique telle que lebien-être individuel des agents.
– single/multi : la durée de la prise deparole. Le protocole spécifie le nombred’agent que l’initiateur contacte lors-qu’il a la parole. Cela pourra être unagent, n agents ou tous les autres agents.
– Receveur : L’ordre du choix du re-ceveur. Comme l’initiateur, le receveurpourra être choisi de façon linéaire, aléa-toire ou selon une heuristique.
6c’est à dire que le premier agent va prendre la parole, puis
le deuxième et ainsi de suite7Nous laisserons de coté le choix de l’ordre des ressources
car celui-ci n’a aucune influence sur l’acceptation des transac-
tions compte tenu que les valuations des agents sont additives
et qu’il n’y a donc pas de synergie entre les ressources (le fait
qu’un agent possède une ressource ou non n’influera pas sur
l’acceptation d’une transaction par ce dernier).
3.3 Les différents protocoles
Nous venons de voir que les différents pa-ramètres pouvaient prendre plusieurs va-
leurs. Le choix de l’initiateur peut se faireselon au moins trois possibilités, il en estde même pour le choix du récepteur, et ladurée de prise de parole peut elle prendreau moins deux valeurs. A partir de cela, ilest donc possible de construire au moins18 protocoles. Pour une meilleure compré-hension de chacun d’entre eux, nous allonsregarder un ensemble d’exemples d’ordrede prise de parole sur une société compo-sée de quatre agents (figure 1).
Afin de différencier les protocoles nousutiliserons une notation faisant appel à tousles paramètres qui nous intéressent. Parexemple :
init
I 1:x−→
recev
R
init ∈ lin, ?,heu 8
recev ∈ lin, ?,heux ∈ 1, n 9
La valeurlin
I nous informe que les initia-
teurs sont choisis linéairement,
?
R que lesreceveurs sont choisis de façon aléatoire et(1 : n) que la prise de parole est multiple.Regardons en détail certains des protocolesproposés ci-dessus.lin
I 1:n−→
?
R : Dans celui-ci, l’initiateur est choi-sis de façon linéaire et le receveur de façonaléatoire. De plus, l’initiateur a la parole letemps de contacter tous les agents (multi).lin
I 1:1−→
lin
R : Le changement avec le proto-
cole précédent est que l’initiateur ne prendla parole que pour contacter un seul agent(single)10.
3.4 Protocole et heuristique
Nous venons de présenter un ensemble deprotocole basé sur des choix d’ordres li-néaires ou aléatoires. Or nous verrons quele choix de certains paramètres (« ordre
8linéaire, hasard, heuristique9soit un agent, soit tous les agents
10Cependant, durant un tour il contacte quand même tous les
agents. On notera que quand un agent reprend la parole, il re-
prend ses propositions à l’agent suivant d’où il s’était arrêté.
L’ordre des receveurs est toujours linéaire.
____________________________________________________________________________ Annales du LAMSADE N°8
313

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 326/415
lin
I 1:n−→
lin
RInit 1 1 1 2 2 2 3 3 3 4 4 4
Rec 2 3 4 1 3 4 1 2 4 1 2 3
lin
I 1:1
−→lin
RInit 1 2 3 4 1 2 3 4 1 2 3 4
Rec 2 1 1 1 3 3 2 2 4 4 4 3
lin
I 1:n
−→
?
R
Init 1 1 1 2 2 2 3 3 3 4 4 4
Rec 4 2 3 3 1 4 4 1 2 3 2 1
lin
I 1:1
−→?
RInit 1 2 3 4 1 2 3 4 1 2 3 4
Rec 3 1 4 2 1 4 2 3 2 3 1 1
?
I 1:n−→
lin
RInit 3 3 3 1 1 1 4 4 4 2 2 2
Rec 1 2 4 2 3 4 1 2 3 1 3 4
?
I 1:1−→
lin
RInit 1 2 3 4 1 2 3 4 1 2 3 4
Rec 1 1 1 2 2 4 2 3 3 3 4 4
?
I 1:n−→
?
RInit 3 3 3 4 4 4 1 1 1 2 2 2
Rec 2 3 1 1 3 2 4 2 3 3 1 4
?
I 1:1−→
?
RInit 2 3 2 4 4 3 4 1 3 1 2 1
Rec 4 2 3 3 1 4 2 2 1 4 1 3
FIG . 1 – Exemples de protocoles
des agents ») ont une influence sur le bien-être individuel des agents. C’est pourquoi,il parait intéressant de construire de nou-veaux protocoles où le choix de l’ordredes initiateurs et des receveurs serait basésur des heuristiques nous permettant detendre vers un critère social (égalitarisme,élitisme,...). Une idée sera donc de choi-
sir l’ordre des receveurs en fonction sur lesbien-être individuels des agents. Or nousavons choisi de nous intéresser au BESégalitaire, c’est pourquoi nous étudieronsdans la section 5 un protocole où le choixdes receveurs se fera par ordre croissantdes bien-être individuels des agents (i.e.les agents les plus pauvres seront toujourscontactés en premier).
4 Protocole et bien-être indivi-duel
Afin d’étudier l’influence du protocole denégociation, nous avons choisi de faire unensemble d’expérimentations 11.
4.1 Non-Influence de l’initiateur
Compte tenu que nous sommes dans uncadre où les fonctions d’utilité des agents
sont additives, il n’existe pas de syner-11Afin d’avoir une bonne valeur moyenne, les tests sont ef-
fectués sur 10000 runs. Pour ces expérimentations, le nombre
d’agent (n) est fixé à 10, le nombre de ressources (m) à 50, et
chaque fonction d’utilité additive est composée de 10 termes (l).
gie entre les ressources. Ceci implique queles transactions ne dépendront uniquementque d’une ressource et le fait que l’agentinitiateur ou receveur possède ou non une
autre ressource n’influera en rien sur lestransactions. A partir de cette remarque,on peut déduire que le fait qu’un agentpropose en premier ou en dernier ses res-sources n’influera pas sur les transactionsd’une manière globale.
4.2 Influence du choix des receveurs
Pour l’étude de l’influence de l’ordre du
receveur, nous nous sommes appuyés surune étude expérimentale en observant deuxprotocoles totalement identiques où seul leparamètre du choix du receveur varie :
lin
I 1:n−→
lin
RI 1 1 1 2 2 2 3 3 3 4 4 4
R 2 3 4 1 3 4 1 2 4 1 2 3
lin
I 1:n−→
?
RI 1 1 1 2 2 2 3 3 3 4 4 4
R 4 2 3 3 1 4 4 1 2 3 2 1
La figure 2 nous montre les valeurs des
bien-être individuels de chaque agent. Ilapparaît nettement que lorsque l’on utilise
le protocolelin
I 1:n−→
lin
R, où le choix des rece-veurs est fait de façon linéaire, les premiersagents ont en moyenne un bien-être trèslargement supérieur aux autres. D’un autrecoté, on remarque que lorsque l’on utilisel’autre protocole où le choix des receveursest aléatoire, alors le bien-être individuelde tous les agents est identique12. Une pre-
mière interprétation de ce phénomène estque le protocole linéaire a tendance à nette-ment favoriser les premiers agents. Avec cedernier, le bien-être de l’agent a1 est deuxfois supérieur à celui de l’agent a10
13.
Lors de la négociation, chaque ressourceva passer d’agent en agent qui la value tou-
jours un peu plus à chaque fois, jusqu’àatteindre celui qui la value le plus. Or un
12Certes il n’est pas identique sur une instance de négociation,mais sur 10000 tests, les agents ont en moyenne le même bien-
être.13On notera également que les quatre premiers agents ont un
bien-être supérieur à la moyenne, alors que les 5 derniers en ont
un inférieur.
Influence du protocole sur l'issue des négociations ___________________________________________________________________________
314

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 327/415
150
200
250
300
350
400
450
1 2 3 4 5 6 7 8 9 10
B i e n - e t r e
i n d i v i d u
e l
Numero de l’agent
initiateur lineaire - multi - receveur lineai reinitiateur lineaire - multi - receveur aleatoire
FIG . 2 – influence du choix du receveur
agent gagne de l’utilité à chaque transac-tion dans laquelle il est impliqué. On en dé-duit que les agents ont intérêt à être impli-qués dans le plus de transaction possible.Nous allons donc plus formellement étu-dier la probabilité que les agents entre enpossession d’une ressource.
Dans le cadre du protocole linéaire, sa-chant que les numéros des agents sont aléa-toires ainsi que l’allocation initiale, on peutdonc en déduire que si l’agent a1 ne pos-sède pas la ressource ri dans l’allocationinitiale, alors la probabilité que cet agententre en possession de cette ressource estégale à la probabilité que l’agent a1 va-lue plus la ressource ri que l’agent quila possède dans l’état initial. Or sachantque les fonctions d’utilités des agents sont
générées de façon totalement aléatoire etque les coefficients sont tirés aléatoire-ment sur un intervalle pré-définis, on a : p(a1 possède ri) = 1
2. De plus, la pro-
babilité que l’agent a1 ne possède pas laressource à l’état initial est p = n−1
n
et tend rapidement vers 1. On a donc : p(ri transite par a1) → 1
2De même, on calcule la probabilité quela ressource transite par l’agent an :
p(ri transite par an) → 1nCeci nous permet de conclure, en accordavec les expérimentations, que le proto-cole où les receveurs sont choisis de fa-çon linéaire, favorise très largement cer-
tains agents en fonction de leur identité14.Au regard de cette influence du protocolesur le bien-être individuel des agents, unequestion se pose : quand est-il du point de
vu de la société et des différentes mesuresde bien-être social.
5 Protocole et bien-être social
Nous allons maintenant étudier l’influencedu protocole sur le caractère égalitaire del’issue des négociations et nous allons pro-poser un protocole permettant de maximi-ser le bien-être social égalitaire. Dans cette
section, nous allons observer les consé-quences de cette partialité du protocoleprésenté dans la section précédente sur lebien-être social égalitaire atteint à l’issuedes négociations. De plus, nous allons ex-ploiter cette partialité dans le but de favori-ser les agents en fonction de leur pauvreté.Pour cela, on utilisera un protocole où lechoix du receveur est basé sur une heuris-tique qui va favoriser les agents en fonctionde leur bien-être individuel (on favorisera
le plus pauvre).L’ordre des receveur sera choisi en fonc-tion du bien-être croissant des agents15. Leprincipe de cette heuristique est de favori-ser les agents pauvres en les contactant enpremiers. Par conséquence ils auront plusde chance de prendre part à des transac-tions et ils auront également plus souventla possibilité de voir une ressource transi-ter par eux et donc le gagner sur l’achatpuis la revente de celle-ci.
La figure 3 nous montre une séried’expérimentations utilisant les protocoleslin
I 1:n−→
lin
R,lin
I 1:n−→
?
R etlin
I 1:n−→
heu
R qui dif-fèrent par le choix d’ordre du receveur (li-néaire, aléatoire et selon l’heuristique pré-senté ci-dessus). Nous observons les va-leurs du bien-être égalitaire de l’allocationfinale lorsque le nombre de ressources va-
14Contrairement à cela, avec un protocole choisissant les rece-
veurs de façon aléatoire, la probabilité qu’une ressource transitepar un agent est la même pour tous les agents. Un agent ne sera
donc pas plus favorisé qu’un autre.15c’est à dire que une proposition sera d’abord faite à l’agent
le plus pauvre, puis auxautres agents mais selon un l’ordre crois-
sant de leur bien-être
____________________________________________________________________________ Annales du LAMSADE N°8
315

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 328/415
0
200
400
600
800
1000
1200
1400
50 100 150 200 250
E g a l i t a r i a n S o c i a l W
e l f a r e
Number of resources
SWe, final, uniform, heurSWu/n, final, uniform, alea
SWe, final, uniform, linea
FIG . 3 – Evolution du BES égalitaire
rie. D’une manière générale, on observeque l’issue du protocole aléatoire est bienmeilleure que celle du linéaire du point devue du bien-être social égalitaire. De plus,il apparaît nettement que c’est le proto-cole basé sur l’heuristique qui distribue lemieux les richesses dans la société16.Ces résultats nous confirment que le pro-tocole utilisant un choix de receveur li-néaire présente un très gros biais en favo-
risant les agents en fonction de leur iden-tité. Ce biais est visible au niveau locallorsque l’on regarde le bien-être indivi-duel des agents comme dans la section pré-cédente, mais aussi au niveau global dupoint de vue du bien-être social égalitaire.Celui-ci est très mauvais car les derniersagents se retrouvent souvent très pauvreset le bien-être social égalitaire est donc trèsfaible.
6 Conclusion
Nous venons de montrer qu’il existe diffé-rentes méthodes pour influer sur l’issue desnégociations. Dans [5], différentes fonc-tions de paiements ont été proposées afind’influer sur le caractère égalitaire des né-gociations. Ici, nous voyons que cette solu-
16Plus précisément, on remarque que lorsque le nombre de
ressources est petit (50), le bien-être social obtenu avec le proto-
cole linéaire est de 180, celui obtenu avec le protocole aléatoireest de 210 et enfin celui obtenu avec le protocole suivant l’heu-
ristique est de 340. Du point de vue du bien-être social égalitaire,
le gain obtenu entre le protocole aléatoire et celui utilisant l’heu-
ristique est de plus de 61%. On notera également que lorsque le
nombre d’agents augmente, l’influence du protocole diminue.
tion n’est pas la seule, et qu’il est possiblede proposer des heuristiques pour le proto-cole de négociation qui favorisent le carac-tère équitable de l’allocation finale.
Une prochaine étape à ce travail pourraitêtre de proposer d’autres heuristiques pourle choix de l’ordre du receveur. Une heuris-tique pourrait être que les premiers agentscontactés pour une ressource soient ceuxqui valuent le moins cette ressource. Ceciaurait pour conséquence de faire transiterla ressource par le maximum d’agent etdonc de répartir entre le plus d’agent pos-sible le surplus généré par le passage dela ressource entre sa place initiale et saplace finale. Enfin, une autre perspectiveserait d’étendre ce travail à d’autres me-sures de bien-être social dont il est connuque l’allocation optimale du point de vuede cette mesure n’est pas atteinte à l’issuedes négociations (bien-être social élitiste,absence d’envie, ...).
Références[1] P. Cramton, Y. Shoham, and R. Steinberg.
Combinatorial Auctions. MIT Press, 2006.[2] Paul E. Dunne, Michael Wooldridge, and Mi-
chael Laurence. The complexity of contract ne-gotiation. Artificial Intelligence, 164(1–2) :23–46, 2005.
[3] Ulle Endriss, Nicolas Maudet, Fariba Sadri,and Francesca Toni. Negotiating socially opti-mal allocations of resources. Journal of Artifi-cial Intelligence Research, 25 :315–348, 2006.
[4] Ulrich Endriss, Nicolas Maudet, Fariba Sadri,and Francesca Toni. On optimal outcomes of negotiations over resources. In AAMAS-2003.
ACM Press, 2003.[5] Sylvia Estivie, Yann Chevaleyre, Ulle Endriss,and Nicolas Maudet. How equitable is rationalnegotiation ? In AAMAS-2006 , pages 866–873,May 2006.
[6] Peter Gradwell and Julian Padget. Distribu-ted combinatorial resource scheduling. In Pro-ceedings of the 1st International Workshop onSmart Grid Technologies (SGT-2005), 2005. Toappear.
[7] T. W. Sandholm. Optimal winner determina-tion algorithms. In P. Cramton, Y. Shoham, andR. Steinberg, editors, Combinatorial Auctions.MIT Press, 2006.
[8] Tuomas W. Sandholm. Contract types for satis-ficing task allocation : I Theoretical results. InProceedings of the AAAI Spring Symposium :Satisficing Models, 1998.
Influence du protocole sur l'issue des négociations ___________________________________________________________________________
316

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 329/415
An Optimistic Approach for the Specification of more
Flexible Roles Behavioural Compatibility Relations in MAS Nabil Hameurlain
nabi l . hameur l ai n@uni v- pau. f r
Laboratoire LIUPPA, Université de Pau
Avenue de l’Université 64012 Pau – FRANCE
Résumé :
Dans cet article, nous nous focalisons sur unenouvelle approche de définition d’unecompatibilité plus flexible des rôles dans lesSMA. Nous proposons une architecture formelle pour la spécification des rôles et leur composition, prenant en compte la préservation de propriétéscomme la complétion et la terminaison propre desrôles. Nous mettons en évidence le lien existantentre la compatibilité et la substitutabilité desrôles, et plus particulièrement, nous montrons queles relations de compatibilité ainsi définies sont
préservées par la substitutabilité.Mots-clés : Rôles, interaction, compatibilitéoptimiste, substitutabilité.
Abstract :In this paper we focus on a new approach to thedefinition of more flexible roles compatibility inMAS. We provide a formal framework for modeling roles together with their composition,taking into account the property preservation suchas the completion and the proper termination of roles. We show the existing link between rolescompatibility and substitutability, namely the preservation of the proposed compatibilityrelations by substitutability.Keywords: Roles, interaction, components,optimistic compatibility, substitutability.
1 Introduction
Roles are basic buildings blocks for
defining the organization of multi-agentsystems (MAS), together with the behaviour of agents and the requirements
on their interactions. Usually, it isvaluable to reuse roles previously definedfor similar applications, especially whenthe structure of interaction is complex. Tothis end, roles must be specified in anappropriate way, since the composition of independently developed roles can lead tothe emergence of unexpected interactionamong the agents.
Although the concept of role has been
exploited in several approaches [2, 3, 9]in the development of agent-basedapplications, no consensus has beenreached about what is a role and how itshould be specified and implemented. Inour previous work [4], we have shownthat the facilities brought by theComponent Based Development (CBD)approach [8] fit well the issues raised bythe use of roles in MAS. In this context,we have proposed RICO (Role-basedInteractions COmponents) model for specifying complex interactions, andstudy the compatibility semantics of roles. The RICO model is based on theComponent-nets formalism whichcombines Petri nets and the component- based approach.
In this paper, we focus on a new approachto the definition of role-componentscompatibility, and provide a formalframework for modelling roles and their
317

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 330/415
composition. The contributions of this paper are: (1) to provide a new approach
to the definition of more flexible role-components compatibility andsubstitutability relations, (2) to show theexisting link between compatibility andsubstitutability relations, namely the preservation of the compatibility bysubstitutability.
2 Roles modelling
2.1 The Component-nets formalism
Backgrounds on Labelled Petri nets. Amarked Petri net N = (P, T, W, M N)consists of a finite set P of places, a finite
set T of transitions where P ∩ T = ∅, a
weighting function W : P × T ∪ T × P →
N, and M : P ⎯→ N N is an initial
marking. A transition t ∈ T is enabledunder a marking M, noted M (t >, if W(p,
t) ≤ M(p), for each place p. In this case tmay occur, and its occurrence yields thefollower marking M', where M'(p) = M(p)- W(p, t) + W(t, p), noted M(t> M'. Theenabling and the occurrence of a
sequence of transitions σ ∈ T*
aredefined inductively. The preset of a node
x ∈ P ∪ T is defined as
x = y ∈ P ∪ T,
W(y, x) ≠ 0, and the postset of x ∈ P ∪
T is defined as x
= y ∈ P ∪ T, W(x, y)
≠ 0. We denote as LN = (P, T, W, M N, l)the (marked, labelled) Petri net in whichthe events represent actions, which can beobservable. It consists of a marked Petrinet N = (P, T, W, M N) with a labelling
function l: T ⎯→ A ∪ λ. Let ε be the
empty sequence of transitions, l isextended to an homomorphism l*: T
*
⎯→ A* ∪ λ in the following way: l(ε)
= λ where ε is the empty string of T*, and
l*(σ.t) = l
*(σ) if l(t) ∈ λ, l
*(σ.t) =
l*(σ).l(t) if l(t) ∉ λ. In the following,
we denote l* by l, LN by (N, l), and if LN= (P, T, W, M N, l) is a Petri net and l' isanother labelling function of N, (N, l')denotes the Petri net (P, T, W, M N, l'),that is N provided with the labelling l'. A
sequence of actions w ∈ A* ∪ λ is
enabled under the marking M and itsoccurrence yields a marking M', noted
M(w>> M', iff either M = M' and w = λ
or there exists some sequence σ ∈ T*
such that l(σ) = w and M(σ> M'. The first
condition accounts for the fact that λ isthe label image of the empty sequence of transitions. For a marking M, Reach (N,
M) = M'; ∃ σ ∈ T*; M(σ> M' is the set
of reachable markings of the net N fromthe marking M.
Components nets (C-nets). AComponent-net involves two special places: the first one is the input place for instance creation of the component, andthe second one is the output place for instance completion of the component. AC-net (as a server) makes some servicesavailable to the nets and is capable of rendering these services. Each offered
service is associated to one or severaltransitions, which may be requested by C-nets, and the service is available whenone of these transitions, called accept-transitions, is enabled. On the other handit can request (as a client) services fromother C-net transitions, called request-transitions, and needs these requests to befulfilled. These requirements allowfocusing either upon the server side of aC-net or its client side.
An optimistic approach for the specification of more flexible roles [...] ___________________________________________________________________________
318

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 331/415
Definition 2.1 (C-net) Let CN = (P ∪ I,O, T, W, M N, lProv, lReq) be a labelled
Petri net. CN is a Component-net (C-net)if and only if:
l. The labelling of transitions consists of two labelling functions lProv and lReq, such
that: lProv : T ⎯→ Prov ∪ λ, where
Prov ⊆ A is the set of provided services,
and lReq : T ⎯→ Req ∪ λ, where Req
⊆ A is the set of required services.
2. Instance creation: the set of placescontains a specific Input place I, such thatI = ∅,
3. Instance completion: the set of places contains a specific Output place O, such
that O = ∅.
Notation. We denote by [I] and [O],which are considered as bags, the
markings of the Input and the Output place of CN, and by Reach (CN, [I]), theset of reachable markings of thecomponent-net CN obtained from itsinitial marking M N within one token in itsInput place I. Besides, when we deal withthe graphical representation of the C-nets,we use ! and ? keywords for the usualsending (required) and receiving
(provided) services together with thelabeling function l instead of the twolabeling functions lProv and lReq.
Definition 2.2 (soundness) Let CN = (P
∪ I, O, T, W, M N, l) be a Component-net (C-net). CN is said to be sound iff thefollowing conditions are satisfied:
1. Completion option: ∀ M ∈ Reach(CN,
[I]), [O] ∈ Reach(CN, M).
2. Reliability option: ∀ M ∈ Reach(CN,
[I]), M ≥ [O] implies M = [O].
The Completion option states that, if starting from the initial state, i.e.
activation of the C-net , it is always possible to reach the marking with onetoken in the output place O. Reliability option states that the moment a token is put in the output place O corresponds tothe termination of a C-net without leavingdangling references.
Composition of C-nets. The parallel
composition of C-nets, noted ⊕ : C-net ×
C-net → C-net, is made bycommunication places allowinginteraction through observable services inasynchronous way. Given a client C-netand a server C-net, it consists inconnecting, through the communication places, the request and the accepttransitions having the same servicenames: for each service name, we add one
communication-place for receiving therequests/replies of this service. Then, allthe accept-transitions labelled with thesame service name are provided with thesame communication-place, and the clientC-net is connected with the server C-netthrough these communication places byan arc from each request-transitiontowards the suitable communication-
place and an arc from the suitablecommunication-place towards eachaccept-transition.
2.2 Specification of roles
In our RICO model [4], a role componentis considered as a component providing aset of interface elements (either attributesor operations, which are provided or
required features necessary to accomplishthe role’s tasks), a behaviour (interfaceelements semantics), and properties(proved to be satisfied by the behaviour).
____________________________________________________________________________ Annales du LAMSADE N°8
319

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 332/415
In this paper, we only consider behavioural interface of roles that is their
behaviour specified by the C-netstogether with the set of (provided andrequired) services.
Definition 2.3 (Role Component) A
Role Component for a role ℜ, noted RC,is a 2-tuple RC = (Behav, Serv), where,
• Behav is a C-net describing the life-
cycle of the role ℜ.
• Serv is an interface, a set of publicelements, through which RC interactswith other role components. Serv =(Req, Prov), where Req is a set of required services, and Prov is the setof provided services by RC.
Since the life-cycle of roles is specified by C-nets, we say that a component rolesatisfies the completion (resp. terminates
successfully) if and only if its behaviour that is its underlying C-net satisfies thecompletion option (resp. terminatessuccessfully). The composition of tworole-components is also a role-component, and this composition isassociative.
Definition 2.4 (Roles composition) ARole RC = (Behav, Serv) can be
composed from a set of (primitive) Roles,RCi = (Behavi, Servi), i = 1, …, n, noted
RC = RC1 ⊗… ⊗RCn, as follows:
• Behav = Behav1⊕ …⊕ Behavn.
• Serv = (Req, Prov), Req = ∪ Reqi, and
Prov = ∪Provi, i=1, …, n.
3 Compatibility of roles
In component-based softwareengineering, classical approaches for components compatibility deal with
components composition together withtheir property preservation [1]. In our
previous work, we have used thisapproach for role-based interactioncomponents and study some compatibilityrelations [5]. In this paper, the basic idea behind the optimistic approach for role-components compatibility is to consider explicitly the context of use of roles(environment) in the definition of rolescompatibility relations. First, let define
the notion of role’s environment. Definition 3.1 (Environment) Let RC1 =(Behav1, Serv1) and RC2 = (Behav2,Serv2), be two roles such that Servi =(Reqi, Provi), i=1, 2.
CP2 is called an environment-role (or environment) of CR 1, and vice versa, iff Req1 = Prov2, Req2 = Prov1.
We let ENV(RC), the set of theenvironments of the role component RC.
The role component RC1 is considered an environment of RC2 iff both their sets of interfaces completely match.
Given a role-component and itsenvironment, it is possible to reasonabout the completion and the proper termination of their composition. Basedon that, we define two notions of usability:
Definition 3.2 (usability)
1. RC is weakly usable iff ∃ Env ∈
ENV(RC), Env ⊗ RC satisfies thecompletion option. We say that Env weakly utilizes RC.
2. RC is strongly usable iff ∃ Env ∈ ENV(RC), Env ⊗ RC terminatessuccessfully. We say that Env stronglyutilizes RC.
An optimistic approach for the specification of more flexible roles [...] ___________________________________________________________________________
320
7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 333/415
a !
b ? c ?
2a ?
b ! c !
2
RC1 RC2
Fig 1. RC1 weakly utilizes RC2, where
l(a)= Ticket, l(b) = Visa, l(c) = eCash.1
a ?
c !
a ?
b !
a ?
b ! c !
a !
b ? c ?
RC3 RC4 RC5
Fig 2. RC3 strongly utilizes RC5, RC4 strongly utilizes RC5.
a !
c ?
a !
b ?
RC’
Fig 3. RC’ is not weakly usable.
1 The names of transitions are drawn into the box.
Example 1: Let’s take the example of theticket service and the customer. Figure 1
shows RC1 representing the behaviour of the customer, and RC2 the behaviour of the Ticket-service. The Ticket serviceinitiates the communication by sending
(two) Ti cket s and waits of their
payment (VI SA and/or eCash) . By
receiving the Ti cket s , the customer
determines the kind of payment of thesetwo tickets. It is easy to prove that roles
RC1 and RC2 are weakly usable, sinceRC1 weakly utilizes RC2 and vice versa.The role RC1 is not strongly usable, sincethe unique (weakly usable) environment
of RC1 is the role RC2, and RC1 ⊗ RC2
satisfies the completion option but doesnot terminate successfully. In figure 2, theticket service RC5 initiates de
communication by sending one Ti cket
and waits of the payment (either Vi saor eCash) . The role components RC3
and RC4 are two examples of thecustomer’s behaviour. By receiving the
Ti cket , they solve an internal conflict
and determine the kind of payment. Theroles RC3 and RC5 (resp. RC4 and RC5)are strongly usable, since for instanceRC3 strongly utilizes RC5 (resp. RC4
strongly utilizes RC5) and vice versa. Last but not least, let us take the ticket serviceRC’ shown in figure 3. RC’ is not weaklyusable since there is no environmentwhich can weakly utilize it. Indeed, rolesRC3 and RC4 are the two possible role-environments of RC’ (according to the behaviour of RC’ described by the
language Ti cket !. Vi sa?,
Ti cket !. eCash?), nevertheless, for instance the occurrence of the sequence
Ti cket !. Ti cket ?.eCash! in RC3 ⊗
RC’ (as well as in RC4 ⊗ RC’) yields a
____________________________________________________________________________ Annales du LAMSADE N°8
321

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 334/415
deadlock- marking that is a markingwhere no transition is enabled. This is
because of an error in role-componentRC’: an internal decision is made (either
Vi sa? or eCash?) , when sending the Ti cket , and not communicated properly
to the environment [1].
We are finally ready to give adequatedefinitions for roles behavioural
optimistic compatibility relations, whichare based on the weak and the strongusability.
Definition 3.3 (compatibility) Let RC1 and RC2 be two weakly (resp. strongly)usable roles.
RC1 and RC2 are Weakly (resp. Strongly)Optimistic Compatible, noted RC1 ≈WOC
RC2 (resp. RC1 ≈
SOC RC2), iff RC1 ⊗ RC2 is weakly (resp. strongly) usable.
Example 2: As an example, it is easy to prove that roles RC1 and RC2, shown infigure 1, are weakly optimisticcompatible that is RC1 ≈WC RC2 holds
since RC1 ⊗ RC2 is weakly usable.
Indeed, RC1 ⊗ RC2 satisfies thecompletion option. Besides, the two roles
RC3 and RC5 shown in figure 2 arestrongly optimistic compatible that is RC3
≈SOC RC5 holds since RC3 ⊗ RC5 is
strongly usable. Indeed, RC3 ⊗ RC5 terminates successfully.
Property 3.1 (Hierarchy of compatibility) Compatibility relations
form a hierarchy: ≈SOC ⇒ ≈WOC
4 Substitutability of roles
We show the existing link betweencompatibility and substitutability
concepts, and namely their combination,which seems necessary, when we deal
with incremental design of usablecomponents-role. Our main interest is todefine behavioural subtyping relations(reflexive and transitive) capturing the principle of substitutability [7]. We definetwo subtyping relations based upon the preservation of the (weakly and strongly)utilizing of the former role by any role of its environment.
Definition 4.1 (behavioural subtyping) Let RCi = (Behavi, Servi) , Servi = (Reqi,Provi), i=1,2, be two roles, such that:
Prov1 ⊆ Prov2 and Req1 ⊆ Req22.
1. RC2 is less equal to RC1 w.r.t Weak
Substitutability, denoted RC2 ≤WS RC1, iff
∀ Env ∈ ENV(RC1), Env weakly utilizes
RC1 ⇒ Env weakly utilizes RC2.
2. RC2 is less equal to RC1 w.r.t Weak
Substitutability, denoted RC2 ≤SS RC1, iff
∀ Env ∈ ENV(RC1), Env strongly
utilizes RC1 ⇒ Env strongly utilizes RC2.
Weak (resp. Strong) Substitutabilityguarantees the transparency of changes of roles to their environment. In both weak and strong subtyping relations , the
(super-) role component RC1 can besubstituted by a (sub-) role componentRC2 and the environment of the former role RC1 will not be able to notice thedifference since: (a) the sub-role has alarger set of required and provided
services (Req1 ⊆ Req2 and Prov1 ⊆ Prov2)than the super-role, and (b) anyenvironment that weakly (resp. strongly)
2 The sub-role component has a larger set of (required
and provided) services (Req1 ⊆ Req2and Prov1 ⊆
Prov2) than the super-role component.
An optimistic approach for the specification of more flexible roles [...] ___________________________________________________________________________
322

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 335/415
utilizes the former role is also able toweakly (resp. strongly) utilize the new
role.
Example 3: As an example, consider the
roles RC4 and RC1. RC1 ≤WS RC4 holdssince the unique environment that weakly
utilizes RC4 is the role RC5, and RC5 ⊗ RC1 satisfies the completion option.These two roles RC1 and RC4 are notrelated by the strong subtyping relation
that is RC1 ≤SS RC4 does not hold, sinceRC5 ⊗ RC1 does not terminatesuccessfully. Last but not least, consider
the roles RC4 and RC3; RC3 ≤SS RC4 holds since the role RC5 (which is theunique environment) that strongly utilizesRC4 also strongly utilizes RC3. Indeed
RC5 ⊗ RC3 terminates successfully.
Property 4.1 (Hierarchy of subtyping)
The relations ≤H, H ∈ WS, SS, are preorder (reflexive and transitive) and
form a hierarchy: ≤SS ⇒ ≤WS.
The following core theorem of this paper states two fundamental properties of rolescompatibility and substitutabilityrelations. First, substitutability relations
are compositional: in order to check if Env ⊗ RC2 ≤H Env ⊗ RC1, H ∈WS,
SS, it suffices to check RC2 ≤H RC1,since the latter check involves smaller roles and it is more efficient. Second,substitutability and compatibilityrelations are related as follows: we canalways substitute a role CR 1 with a sub-role CR 2, provided that RC1 and RC2 are
connected to the environment Env =(Behav, Serv) by the same provided
services that is: Req ∩ Prov2 ⊆ Req ∩ Prov1. This condition is due to the fact
that if the environment utilizes services provided by CR 2 that are not provided by
CR 1, then it would be possible that newincompatibilities arise in the processingof these provided services.
Theorem 4.1 (compositionality andcompatibility preservation) Let RC1 =(Behav1, Serv1) , RC2 = (Behav2, Serv2) betwo roles where Servi = (Reqi, Provi), i =1, 2. Let Env = (Behav, Serv) such that
Req ∩ Prov2 ⊆ Req ∩ Prov1.
1. Env ≈WOC RC1 and RC2 ≤WS RC1 ⇒
Env ≈WOC RC2 and Env ⊗ RC2 ≤WS Env
⊗ RC1.
2. Env ≈SOC RC1 and RC2 ≤SS RC1 ⇒ Env
≈SOC RC2 and Env ⊗ RC2 ≤SS Env ⊗ RC1.
5 Conclusion and related work
The aim of this paper is to present a newand optimistic approach to the definitionof role-components behaviouralcompatibility and substitutabilityrelations. The paper provides aframework for modelling usable role-components together with their composition. This framework is discussedin terms of roles compatibility and
substitutability relations. We furthermoreinvestigated the link betweencompatibility and substitutabilityrelations by showing that substitutabilityis compositional and the compatibility is preserved by the substitutability.
Related work. The optimistic approachto the definition of componentscompatibility has been originallyintroduced in [1] for interface automata.Unlike traditional uses of automata, theauthors proposed an optimistic approach
____________________________________________________________________________ Annales du LAMSADE N°8
323

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 336/415
to automata composition. Two interfaceautomata are (optimistic) compatible, if
there exists a legal environment for thesetwo automata, i.e. an environment suchthat no deadlock state is reachable in theautomata obtained by the composition of the two interface automata and thatenvironment. This work is close to ours,since our weak optimistic compatibilityrelation for role-components is related tothe optimistic compatibility relation
defined for automata composition. Our approach can be seen as an extension of this work, since it deals in addition withstrong optimistic compatibility, which isrelated to the proper termination property.In [6], the concept of usability is used for analyzing web service based business processes. The authors defined the notionof usability of workflow modules, andstudied the soundness of a given webservice, considering the actualenvironment it will by used in. Based onthis formalism together with the notion of usability, the authors presentcompatibility and equivalence definitionsof web services. This approach is close toours, since the compatibility of twoworkflow modules is related to our strongoptimistic compatibility of role-
components. Our approach can be seen asan extension of this work, since we definein addition the notion of weak optimisticcompatibility and study the existing link between compatibility andsubstitutability.
References
[1] L. De Alfaro, T.A. Henzinger.
Interface Automata. In Proc. of ESEC/FSE, Vol. 26, 5 of SoftwareEngineering Notes, ACM (2001).
[2] M. Dastani, V. Dignum, F. Dignum.Role Assignment in Open Agent
Societies. AAMAS’03, ACM 2003.
[3] G. Cabri, L. Leonardi, F.Zambonelli. BRAIN: a Framework for Flexible Role-based Interactionsin Multi-agent Systems. CoopIS2003.
[4] N. Hameurlain, C. Sibertin-Blanc.Specification of Role-based
Interactions Components in MAS.In Software Engineering for Multi-Agent Systems III. LNCS, pp 180-197, Vol. 3390, Springer, 2005.
[5] N. Hameurlain. FormalizingCompatibility and Substitutabilityof Role-based InteractionsComponents in MAS.CEEMAS’05, LNAI/LNCS Vol.
3690, pp 153-162, 2005.[6] A. Martens. Analyzing Web
Service Based Business.FASE’2005, pp 19-33, Vol. 3442,LNCS, Springer, 2005.
[7] B. H. Liskov, J. M. Wing. ABehavioral Notion of Subtyping. InACM TPLS, Vol 16, n° 6, Nov.1994.
[8] C. Szyperski. Component Software-Beyond Object-OrientedProgramming. Addison-Wesley,2002.
[9] F. Zambonelli, N. Jennings, M.Wooldridge. DevelopingMultiagent Systems : The GaiaMethodology. ACM TSEM, Vol
12, N° 3, July 2003, pp317-370.
An optimistic approach for the specification of more flexible roles [...] ___________________________________________________________________________
324

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 337/415
Logique doxastique graduelle
Laverny Noël
[email protected]; http://clsl.chez-alice.fr
Institut de Recherche en Informatique de Toulouse
Résumé :La modélisation des croyances est un sujet très im-portant de l’intelligence artificielle. Nous présen-tons ici une logique modale permettant de raison-ner sur des croyances plus ou moins fortes d’unagent sur le système. Nous définissons un lan-gage permettant de gradualiser les croyances : dela croyance faible jusqu’à la conviction en passantpar divers degrés. Nous donnons une axiomatiqueet une sémantique (complète et adéquate) basée surles modèles de Kripke. Nous montrons ensuite quetoute formule peut se réduire à une formule sansmodalités imbriquées. Nous définissons alors desmodèles numériques basés sur les fonctions condi-tionnelles ordinales de Spohn.
Mots-clés : Logique modale, croyances, croyancesgraduelles, fonction conditionnelle ordinale
Abstract:
Reasoning about beliefs is an important issue in ar-tificial intelligence. We present here a modal logicallowing for reasoning about more or less strongbeliefs held by an agent. We define a language forgraded beliefs. We give then an axiomatics and asemantics based on Kripke models, together with asoundness and completeness result. We show thatany formula can be reduced to a formula withoutnested modalities. We discuss an alternative se-mantics based on Spohn’s ordinal conditional func-tions.
Keywords: Modal logic, beliefs, graded beliefs, or-dinal conditional function
1 Introduction
La représentation de la connaissance (oude la croyance) est un domaine déjà bienétudié de l’intelligence artificielle. Pourautant, les convictions que peut avoir unhomme sur tel ou tel fait sont plus com-
plexes qu’une simple connaissance (voirecroyance). Celles-ci sont en constante évo-lution et remises en question. Nous fai-sons ici un premier pas dans la modélisa-tion d’un “état épistémique” (l’ensemble
des convictions d’un individu à un mo-ment donné) en considérant des degrésde croyances rassemblés dans la logiquedoxastique graduelle.La première personne à écrire sur la lo-gique épistémique est le philosophe G.H.
von Wright dans son livre “An essay inmodal logic” en 1953 [18]. Son étudeest uniquement axiomatique, sans utilisa-tion de la sémantique des mondes pos-sibles. Les travaux sur la logique épisté-mique de la plupart des philosophes sui-vants ont consisté à défendre ou attaquerles axiomes établis par von Wright. Cen’est qu’après “l’invention” de la séman-tique des logiques modales (modèles deKripke), que, dans les années soixante,les sujets sur la logique épistémique fleu-rissent. Les champs d’applications sontmultiples : la théorie des jeux, les systèmesdistribués, la théorie de la décision, la né-gociation etc. On peut citer deux livres im-portants : “Reasoning about knowledge”[2] et “Epistemic Logic for AI and Com-puter Science” [13].Dans la section 2 nous rappelons la dé-finition du système modal de base per-
mettant de raisonner sur connaissances etcroyances. Puis nous définissons dans lasection 3 un système graduel de croyances,nous en donnons les propriétés ainsiqu’une sémantique bâtie sur les OCFs.Nous discutons ensuite, dans la section 6,des travaux existant sur la “gradualisation”des croyances.
2 Connaissances et croyances
Les opérateurs habituellement utilisés sont“K” (comme Knowledge) et “B” (commeBelief). Leur interprétation est épisté-
325

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 338/415
mique (KΨ signifie “je sais que Ψ”)et doxastique (BΨ signifie “je croisque Ψ”). Les langages utilisés ici se-ront donc L(PS, K) (PS désignant unensemble fini de symboles proposition-nels, L(PS, K) est l’ensemble des for-mules bien formées à partir de PS et K),L(PS, B) ou L(PS, K,B) (l’agentpourra avoir des connaissances et descroyances). Ceux-ci sont assez expressifset puissants pour raisonner sur les connais-sances ou les croyances. Par exemple, iln’y a pas de restriction sur la portée desopérateurs, pouvant nous conduire à une
formule du typeKB p (“je sais que je crois p”) ou B¬K p (“je crois que je ne sais pas p”).
2.1 Le système KB
Définition 1 Le système KB est la lo-gique réunissant les axiomes du systèmeS5 pour K , les axiomes de KD45 pour Bet les axiomes d’interactions suivants : A1.
KΨ → BΨ et A2. BΨ → KBΨ
La connaissance doit donc être vraie et doitvérifier l’introspection positive et l’intros-pection négative. La croyance, elle, n’estpas forcement vraie, mais doit être consis-tante, et doit vérifier aussi l’introspec-tion positive et l’introspection négative. Laconnaissance implique la croyance (A1)et l’agent est conscient de ses croyances(A2).Tous ces axiomes constituent les basesde notre raisonnement sur connaissanceset/ou croyances, ils sont assez simpleset intuitifs et suffiront pour notre pro-pos. Notons toutefois qu’il y a discus-sion possible sur l’ensemble des proprié-tés que doivent vérifier les connaissances,les croyances et les interactions entre lesdeux. Si nous faisons l’hypothèse appe-
lée par Lenzen [11] entailment property(Kϕ → Bϕ), ainsi que l’hypothèse deconviction des croyances (Bϕ → BKϕ),Lenzen, Lammarre et Shoham montrent([11, 8]) que l’agent ne peut pas avoir de
fausses croyances. Plusieurs solutions sontproposées :– Dans [19], Voorbraak supprime l’ “en-
tailment property” et dans [5], Halpernl’affaiblit simplement aux formules ob-
jectives (formules où n’intervient au-cune modalité B ni K).
– Dans [4, 7, 14], les auteurs suppriment lapropriété de “conviction des croyances”.Il parlent alors de croyance faible, paropposition à la croyance forte, ou certi-tude.
– Dans [11, 8, 19], les auteurs affaiblissentles propriétés de la connaissance. La
modalitéK ne satisfait plus S5 mais unelogique plus faible située entre S4 et S5 .
Le système que nous avons choisi corres-pond à des “croyances faibles” et possèdela propriété suivante :
Proposition 1 Toute formule deL(PS, K,B) est équivalente à une
formule de profondeur modale inférieureou égale à un1.
2.2 Quelques exemples
1. K(SurTable(livre) ∧ Dehors(Lunette)) ex-prime : “l’agent sait que le livre est surla table et les lunettes dehors”
2. Michel est parti à Toulouse. Je nesais pas où Michel est parti, mais jesais qu’il est parti à Bordeaux ou àToulouse, je crois plutôt Toulouse :K(Bordeaux ∨ Toulouse) ∧BToulouse. Jedécide de lui téléphoner pour savoir ;quand je lui aurai téléphoné, j’aurai :KBordeaux ∨ KToulouse. Je lui télé-phone, et maintenant : KToulouse .
3 La logique KD45G
L’étude précédente nous montre que la
classe de modèles KB rallie expressi-vité et simplicité puisque toute formule
1une propriété analogue est démontrée dans [5] où l’axiome
Kϕ → Bϕ ne s’applique qu’aux formules objectives et avec
l’axiome de certitude des croyances Bϕ → BKϕ
Logique doxastique graduelle ___________________________________________________________________________
326

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 339/415
a son équivalente sans modalités imbri-quées. Ceci assure une taille raisonnabledes formules et modère ainsi la complexitédes problèmes de validité et de satisfiabi-lité.Cependant, on ne peut pas, avec seulementles modalités K et B, exprimer des degrésde conviction plus ou moins forts sur tel outel fait. Reprenons l’exemple précédent où
je sais que Michel est parti à Bordeaux (B)ou à Toulouse (T), mais je crois plutôt Tou-louse. Ceci s’exprime par :K(B∨T) ∧BT.Imaginons que quelqu’un me dise : « Moiaussi, je crois qu’il est parti à Toulouse ».
A ce moment là, ma croyance : “Michel estparti à Toulouse” s’est renforcée, ce que
je ne peux exprimer avec L(PS, K,B).Ou encore, j’entends : « Ah, tu crois ? c’estplutôt Bordeaux, non ? ». Là, au contraire,ma croyance est affaiblie : si elle étaittrès forte, j’y crois encore, si elle étaitmoyenne, je n’ai maintenant plus aucuneidée et si elle était faible, je crois mainte-nant que Michel est parti à Bordeaux. Se
posent là deux problèmes :1. Comment exprimer des croyances
plus ou moins fortes ?
2. Comment réaliser la révision decelles-ci en les combinant avecd’autres croyances graduelles ?
Le premier point nécessite la création d’unnouveau langage et d’une nouvelle axio-matique. On pourra s’inspirer avantageu-
sement de L(PS, K,B) pour cela2
.
3.1 Le langage des croyances gra-
duelles
L’idée est de remplacer la modalité B parune famille de modalités B = Bi : i ∈IN∗3. Bi signifiant : « Je crois avec un de-
gré de conviction i que... ». Plus le de-
gré est grand, plus la croyance sera forte.A priori il n’y a pas lieu de se limiter à
2Nous avons traité le deuxième point dans [10]3IN
∗désignant l’ensemble des entiers naturels privé de zéro
et augmenté de l’infini (symbole∞)
un degré de conviction maximum, on iramême jusqu’au degré infini (B∞). Formel-lement le langage que nous allons utiliser
est L(PS
, Bi
: i ∈ IN
∗
) = L
g
B.Biϕ signifie : « l’agent croit “ϕ” avec undegré de conviction égal à i ». B∞ϕ si-gnifie : « l’agent sait4 “ϕ” ». Le langagepermet bien sûr l’imbrication de modalitéscomme B1¬B2ϕ ou B∞B3(ϕ ∨B1ϕ)
3.2 Le système KD45G
Définition 2 Le système KD45G est nor-
mal pour Bi : i ∈ IN∗ et possèdeles axiomes du système S5 pour B∞ , lesaxiomes de KD45 pour chaqueBi , i 1 et les schémas d’axiomes d’interaction sui-vants :
A3. BiΨ → B jΨ , si i > j A4. B jΨ → B∞B jΨ
Autrement dit, B∞ exprime la connais-
sance, c’est une modalité S5. Chaque mo-dalité Bi, exprimant la croyance au de-gré i, est une modalité de KD45. La “hié-rarchie” prévue dans cette famille de mo-dalités se retrouve dans l’axiome (A3).L’axiome (A4) est en quelque sorte l’ho-mologue de l’axiome (A2), il exprime que,pour tout j, l’agent est conscient de sescroyances au degré j.
3.3 La classe de modèles KD45G
Nous définissons maintenant une séman-tique pour interpréter les formules de Lg
B.
Définition 3 KD45G est la classe des mo-dèles de Kripke M = (W, R, π) où
– W est l’ensemble des mondes possibles
– R = Ri : i ∈ IN∗ est un ensemble de
relations d’accessibilité 4Nous pourrions nous en tenir à : l’agent a la conviction que
“ϕ”, mais il est plus simple et plus raisonnable compte tenu des
exemples que nous prendrons liés à la robotique, d’admettre que
“tout ce dont est convaicu l’agent est vrai”.
____________________________________________________________________________ Annales du LAMSADE N°8
327

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 340/415
– π : W → PS → 0, 1 établit la va-leur de vérité de chaque symbole propo-sitionnel dans chaque monde.
Chaque Ri pour i < ∞ (correspondant àla modalité Bi) est sérielle, euclidienne et transitive et R∞ (correspondant à la mo-dalité B∞) est une relation d’équivalence.
De plus, pour tous i , j : i > j on a :R∞ R j ⊆ R j et R j ⊆ Ri.
La valeur de vérité d’une formule Φ dansun monde w d’un modèle M ∈ KD45G ,notée (M, w) |= Φ est définie de ma-nière classique pour Φ ∈ PS , ¬ et ∧et par : (M, w) |= BiΦ ⇔ (∀v ∈W (Riwv ⇒ (M, w) |= Φ)).
La validité dans un modèle (M |= Φ), laconséquence (Φ |=KD45G Ψ) et l’équiva-lence (Φ ≡KD45G Ψ), sont définies de ma-nière classique.
Proposition 2 KD45G est adéquat et com- plet vis-à-vis de KD45G .
Proposition 3 Toute formule de LgB est
équivalente à une formule de profondeur modale inférieure ou égale à un.
Exemple 1 Pour toute formule objectiveϕ , les formules suivantes sont des théo-rèmes :.
– B1B2ϕ ↔ B2ϕ – B2¬B1ϕ ↔ ¬B1ϕ – B2(ψ ∨B3ϕ) ↔ B2ψ ∨B3ϕ – B1(B1ψ ∧B3ϕ) ↔ B1ψ ∧B3ϕ
Remarque 1 Intuitivement, on pourrait s’attendre à une simplification du type
|=KD45G BiB jϕ ↔ Bmin(i, j)ϕ (1)
On a bien |=KD45G BiB jϕ → Bmin(i, j)ϕ ,
mais la “réciproque”,|=KD45G
Bmin(i, j)ϕ → BiB jϕ , elle, n’est pasvraie. On peut même montrer que l’ajout dans l’axiomatique de cette propriété conduit à une dégénérescence des Bi.
4 Les “OCFs” : des modèlespour KD45G
On va montrer dans ce paragraphe quetoute formule consistante est satisfiabledans un modèle défini par une fonctionordinale5 sur S (où S est l’ensemble detoutes les valuations possibles des sym-boles popositionnels : 2PS). On introduitces modèles parce qu’ils quantifient les de-grés de conviction des croyances. Leur uti-lisation facilitera, par de simples opéra-tions arithmétiques, le calcul des combi-
naisons, au niveau sémantique, de diffé-rentes croyances ([10]). Commençons pardéfinir formellement les fonctions ordi-nales.
4.1 Les fonctions ordinales
Définition 4 Une fonction ordinale sur l’ensemble des mondes (Ordinal Conditio-nal Function [15] : OCF) est une fonction
κ : S −→ IN, telle que mins∈S κ(s) = 0. κ peut s’étendre aux formules objectives par κ(ϕ) = min κ(s) | s |= ϕ .
Intuitivement, κ(s) est le degré d’excep-
tionnalité 6 de s. En particulier– κ(s) = 0 veut dire que s est un monde
normal (un monde normal n’est excep-tionnel à aucun degré)
– κ(s) = 1 veut dire que s est “simple-ment exceptionnel” ;
– κ(s) = 2 veut dire que s est “double-ment exceptionnel” ;
– κ(s) = ∞ veut dire que s est impos-sible. Tout monde s tel que κ(s) < ∞est appelé monde possible .
La contrainte de normalisationmins∈S κ(s) = 0 impose qu’il existeau moins un monde normal. L’OCF κvide
est défini par κvide(s) = 0 pour tout s.5inspirées de celles de Spohn [15]6κ(s) est usuellement interprété en termes de probabilités
infinitésimales κ(s) = k < +∞ signifie prob(s) = o(εk), où
ε est infiniment petit.
Logique doxastique graduelle ___________________________________________________________________________
328

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 341/415
On utilisera la notation classique
κ = s1 : n1
s2 : n2
s3 : n3
qui signifie que κ(si) = ni pour i =1, 2 et 3 et par convention que les autresétats s de S , absents dans la représentation,sont impossibles i.e. κ(s) = ∞.
4.2 Vérité d’une formule doxastique-
ment interprétable dans une OCF
Toute combinaison booléenne de formulesdu type Biϕ est dite doxastiquement inter- prétable.
Définition 5 Si ϕ est une formule objec-tive et κ une OCF,
κ |= Biϕ ⇔ κ(¬ϕ) i
Ceci veut dire que κ |= Biϕ est vraie dès
que tous les modèles s de ¬ϕ sont excep-tionnels au moins au degré i (on pourradire aussi i-exceptionnels) i.e. sont tels queκ(s) i. Ou encore, tous les états s
tels que κ(s) < i (i.e. au plus (i − 1)-exceptionnels) satisfont ϕ.En particulier, B1ϕ est vraie lorsque toutles états normaux (i.e. κ(s) = 0) satis-font ϕ, et B∞ϕ est vraie lorsque tous lesétats possibles (i.e. κ(s) < ∞) satisfont ϕ.
Cette propriété est importante car on seraamené à utiliser ces formules pour repré-senter les croyances graduelles d’un agent.Une formule doxastique positive décrira ceque croit l’agent sur l’état du monde à tousles degrés de convictions possibles.
Exemple 2 Soit PS = a, b et κ définie
par :nous donn7
κ =
ab : 1ab : 0ab : 1ab : ∞
7ab désigne l’état où a est vrai et b est faux.
Alors – κ |= B1a ∧ ¬B2a : l’ agent croit a au
degré 1 (car le (seul) monde normal, i.e.
ab , satisfait a), mais cette croyance n’est pas plus forte : a n’est pas cru au degré 2, car il y a ¬a-monde s tel que κ(s) =1 , il s’agit de ab.
– κ |= B∞(a ∨ b) , car tous les états pos-
sibles (i.e., ab , ab et ab) satisfont a ∨ b ; – κ |= ¬B1b , car le monde normal ab ne
satisfait pas b.
Proposition 4 Soit Φ une formule doxas-
tiquement interprétable, les deux proposi-tions suivantes sont équivalentes : (1) Φest satisfiable dans un KD45G-modèle.(2) Φ est satisfiable dans un OCF-modèle.
4.3 Correspondance entre les formules
et les OCFs
Définition 6 Une formule est dite normaledoxastique positive (on raccourcira avecle sigle NDP : Normal Doxastic Positive)lorsque Φ = B∞ϕ∞ ∧Bnϕn ∧ . . . ∧B1ϕ1
où ϕ∞, ϕ1, . . . , ϕn sont des formules ob- jectives telles que pour tous i et j > i ona, |= ϕi → ϕ j
Quand on écrit une formule normaledoxastique positiveB∞ϕ∞ ∧Bnϕn ∧ . . . ∧B1ϕ1 , on peut supprimer les sous for-mules Biϕi telle que ϕi+1 ≡ ϕi, ainsique les tautologies de la forme Bi. Parexemple,B∞∧ . . .∧B4∧B3a ∧B2a ∧B1(a ∧ b) est simplement remplacée parB3a ∧B1(a ∧ b).Les formules NDPs expriment tout ce quel’agent croit, elles sont satifaites par unefamille d’OCFs (κ j) possédant un plus pe-
tit élément que l’on appellera modèle mi-nimal.
Proposition 5 La fonction H qui à toute formule normale doxastique positive (w.r.t.
____________________________________________________________________________ Annales du LAMSADE N°8
329

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 342/415
équivalence), associe son modèle (OCF)minimal, est bijective .
Cette propriété est primordiale pour lasuite pour les raisons suivantes :
1. Elle établit une caractérisation séman-tique des formules doxastiques posi-tives qui traduisent tout ce que l’agentcroit (à tous les degrés) à un momentdonné. Elle établit aussi une caractéri-sation syntaxique (par une formule po-sitive) de tout modèle.
2. Cette correspondance permettra depasser du cadre syntaxique au cadresémantique (ou vice-versa) en appli-quant la fonction H (ou sa réciproqueG = H −1). Les deux cadres ont néan-moins leur utilité. Le cadre séman-tique est plus puissant pour définir lesrègles de révisions et de mises à jourdes croyances (c’est d’ailleurs celuiqui est le plus utilisé dans la littéra-
ture). Le cadre syntaxique, lui, per-met une représentation plus compactedes croyances, il est, computationnel-lement parlant, plus efficace que lecadre sémantique.
Nous noterons désormais B S l’ensembledes états de croyances. Un état decroyances peut être représenté soit par uneOCF κ, soit par une formule NDP Φ.Nous pouvons remarquer, cependant, queles formules NDPs (Φ = B∞ϕ∞∧Bnϕn ∧. . . ∧ B1ϕ1 ) n’ont pas un modèle unique.En effet, tout κ supérieur ou égal à H (Φ)est aussi un modèle de Φ. Ceci vient du faitque les formules NDPs n’expriment queles croyances positives de l’agent, alorsqu’un modèle (une OCF) véhicule davan-tage d’information et notamment tout ceque l’agent ne sait pas et ne croit pas (àtous les degrés de conviction). Pour ob-
tenir, syntaxiquement, toutes les informa-tions “contenues” dans une OCF, on peutenrichir le langage d’une nouvelle famillede modalités, servant à décrire tout ce quel’agent croit .
5 Modalité “je crois seulement”
Levesque, dans [12], a introduit la notion
de “only knowing” avec un agent. Cettenotion a été revue et étendue à plusieursagents par Halpern et Lakemeyer dans [6].Nous l’étendons ici aux croyances gra-duelles (pour un agent).
5.1 “only knowing”
Le langage L(PS, B) est enrichi d’unemodalité N. De plus, la formule OΦ est
le raccourci de BΦ ∧N¬Φ. Où BΦ signi-fie (comme précédemment) “l’agent croitau moins Φ”, NΦ signifie “l’agent croitau plus ¬Φ” et OΦ signifie “l’agent croitseulement Φ”.Levesque en donne une sémantique et uneaxiomatique qu’il prouve adéquate et com-plète.
5.2 Modalité “croire seulement” pour
KD45G
On enrichit le langage d’une famille N =N∞,N1,N2, . . . et d’une famille O =O∞,O1,O2, . . . dans le même esprit
que chez [12, 6]. Où Ni¬ϕ signifie :“au degré i, l’agent croit au plus ϕ”, etl’opérateur Oi est le raccourci de Biϕ ∧Ni¬ϕ. L’étude complète de la logique
définie à partir du langage L(PS, B ∪N ∪ O) s’éloignant trop de notre pro-pos nous nous contenterons ici de don-ner quelques propriétés de l’opérateur Oi.Le langage permettant donc d’exprimer ceque l’agent croit et seulement ce qu’il croitest L(PS, B ∪ N ∪ O) = Lg
O.
La vérité d’une formule (doxastique-ment interprétable) dans une OCF κ est
définie par : κ |= Ni
¬ϕ ⇔ ∀s(s |=ϕ ⇒ κ(s) < i) et, puisque
κ |= Biϕ ⇔ ∀s(κ(s) < i ⇒ s |= Φ)on a, pour Oiκ |= Oiϕ ⇔ ∀s(s |=Φ ⇔ κ(s) < i).
Logique doxastique graduelle ___________________________________________________________________________
330

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 343/415
κ |= Oiϕ est vraie dès que tous les étatsexceptionnels au moins au degré i sont lesseuls à satisfaire ¬ϕ, ou bien, de manièreéquivalente, les états exceptionnels au plusau degré i − 1 sont les seuls à satisfaireϕ. En particulier O1ϕ est satisfaite quandtous les états “normaux” satisfont ϕ, etque ce sont les seuls.Notons que O1 signifie que l’agent necroit rien au degré 1, par conséquent, riennon plus au degré 2, etc. Le seul OCF κsatisfaisantO1 est κvide.
Proposition 6 Pour tout ϕ , les formulessuivantes sont des théorèmes :
1. Oiϕ → Biϕ
2. Oiϕ ↔ Biϕ ∧
s|=ϕ ¬Bi(ϕ ∧ ¬Form(s))
Exemple 3 Soit PS = a, b et κ définie par
κ =
ab : 1
a¯b : 0ab : 1
ab : ∞
.
Alors – κ |= O1(a∧¬b) , car a∧¬b est satisfaite
seulement par tous les états normaux. – κ |= O∞(a ∨ b).
– κ |= B1a , mais κ |= O1a
Définition 7 Pour toute formule normaledoxastique positive (NDP) Φ = B∞ϕ∞ ∧Bnϕn ∧ . . . ∧ B1ϕ1 , Only(Φ) est la for-mule
O∞ϕ∞ ∧On+1ϕ∞ ∧Onϕn ∧ . . . ∧O1ϕ1.
Ces formules expriment la totalité descroyances d’un agent ; elles sont satisfaitesdans l’ unique OCF κΦ = H (Φ) définie se-
lon la définition 5. La propriété suivantenous assure de l’existence d’une corres-pondance bi-univoque entre les NDPs etles OCFs (w.r.t. équivalence dans KD45G)ainsi qu’une équivalence d’expressivité.
Proposition 7 Pour toute formule NDPΦ = B∞ϕ∞ ∧Bnϕn ∧ . . . ∧B1ϕ1 ,
κ |= Only(Φ) ⇔ κ = κΦ
6 Travaux connexes
La logique possibiliste. La sémantique four-nie par les OCFs est très proche de celledes distributions de possibilités (voir [1]pour plus de détails à ce sujet). Du pointde vue syntaxique notre langage est plus
complet que celui de la logique possibilistepuisqu’il permet, par exemple, de raison-ner sur les croyances de croyances.Par ailleurs, un langage de logique mo-dale avec une sémantique basée sur les dis-tributions de possibilités est proposé dans[3]. Il se rapproche du notre mais lui non-plus ne considère pas les croyances sur lescroyances.
Des croyances graduelles basées sur un comp-tage des mondes. Dans [16], Meyer et vander Hoek développent des modalités gra-duelles en logique épistémique, le systèmeGr(S 5).Dans leur sémantique, la croyance en unfait “ϕ” est d’autant plus forte que lenombre de mondes du modèle satisfaisantϕ est grand. La modalité Bi exprimant ledegré de croyance ne possède alors pas
les mêmes propriétés que la nôtre et s’ap-plique donc à des exemples bien différentsdes nôtres.
L’approche de Hans van Ditmarsch. Dans“Prolegomena to dynamic logic for belief revision” [17] van Ditmarsch développe unmodèle (de Kripke) M = S,<,V basésur la fonction « < » qui à chaque s de S associe une relation <s de S × S dite re-
lation de “plausibilité” dans l’état s. Lesmodalités Bi qu’il utilise sont identiquesaux nôtres et ont les mêmes propriétés.Ces résultats furent établis en parallèle desnôtres [10, 9].
____________________________________________________________________________ Annales du LAMSADE N°8
331

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 344/415
Références
[1] D. Dubois and H. Prade. A syntheticview of belief revision with uncertain
inputs in the framework of possibilitytheory. Int. J. of Approximate Reaso-ning, 17(2–3) :295–324, 1997.
[2] R. Fagin, J. Halpen, Y. Moses, andM. Vardi. Reasoning about Know-ledge. MIT Press, 1995.
[3] L. Fariñas del Cerro and A. Herzig.Modal logics for possibility theory.In Proceedings of the First Interna-tional Conference on the Fundamen-tals of AI Research (FAIR’91). Sprin-ger Verlag, 1991.
[4] N. Friedman and J.Y. Halpern. Aknowledge based frameword for be-lief change part I : foundations. InR. Fagin, editor, Proceedings of theFifth Conference on Theoretical as-
pects of reasoning about knowledge,pages 44–64, 1994.
[5] J. Y. Halpern. Should knowledge en-tail belief ? Journal of Philosophical Logic, 25(5) :483–494, 1996.
[6] Joseph Y. Halpern and Gerhard Lake-meyer. Multi-agent only knowing. InYoav Shoham, editor, Theoretical As-
pects of Rationality and Knowledge :Proceedings of the Sixth Conference(TARK 1996), pages 251–265. Mor-gan Kaufmann, San Francisco, 1996.
[7] S. Kraus and D. Lehmann. Know-ledge, belief, and time. Theoreti-cal Computer Science, 58 :155–174,1988.
[8] P. Lamarre and Y. Shoham. Know-ledge, certainty, belief and conditio-nalisation. In Proceedings of the 4th
International Conference on Prin-ciples of Knowledge Representationand Reasoning (KR’94), pages 415–
424, 1994.[9] N. Laverny and J. Lang. From
knowledge-based programs to gradedbelief based programs, part I : on-linereasoning. Synthese.
[10] N. Laverny and J. Lang. Fromknowledge-based programs to gradedbelief based programs, part I : on-linereasoning. In Proceedings of ECAI-04, pages 368–372, 2004.
[11] W. Lenzen. Recent work in episte-mic logic. Acta Philosophica Fen-nica, 30 :1–129, 1978.
[12] Hector J. Levesque. All i know : astudy in autoepistemic logic. Artifi-cial Intelligence, 42(2-3) :263 – 309,1990.
[13] J.-J. Meyer and W. van der Hoek.
Epistemic Logic for AI and Compu-ter Science. Number 41 in Cam-bridge Tracks in Theoretical Compu-ter Science, 1995.
[14] Y. Moses and Y. Shoham. Belief asdefeasible knowledge. Artificial In-telligence, 64(2) :299–322, 1993.
[15] W. Spohn. Ordinal conditional func-tions : a dynamic theory of episte-
mic states. In William L. Harper andBrian Skyrms, editors, Causation in Decision, Belief Change and Statis-tics, volume 2, pages 105–134. Klu-wer Academic Pub., 1988.
[16] W. van der Hoek and J.-J.Ch. Meyer.Graded modalities for epistemic lo-gic. Logique et Analyse, 133-134 :251–270, 1991.
[17] H. van Ditmarsch. Prolegomena to
dynamic belief revision. Techni-cal report, University of Otago, NewZealand, 2004.
[18] G.H. von Wright. An essay in modallogic. Nortf-Holland, 1953.
[19] F. Voorbraak. Generalized kripkemodels for epistemic logic. In Y. O.Moses, editor, Theoretical Aspectsof Reasoning about knowledge :Proc. 4th Conference, pages 214–218. Morgan Kaufman, 1992.
Logique doxastique graduelle ___________________________________________________________________________
332

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 345/415
Donner corps aux interactions(l’interaction enfin concrétisée)
P. Mathieu
S. Picault
J.-C. Routier
Laboratoire d’Informatique Fondamentale de LilleUniversité des Sciences et Technologies de Lille
59655 Villeneuve d’Ascq cédex – FRANCE
Résumé :Depuis plusieurs années, nous utilisons IODAcomme méthode de description et de réalisationde simulations multi-agents. Cette méthode a pouroriginalité de concrétiser les interactions de ma-nière à ce qu’elles soient génériques et réutilisablesdans différents contextes. Cet article a pour objec-tif d’identifier les problèmes durs dans ce type desimulation et de montrer comment IODA apporteune aide à leur résolution.
Mots-clés : Interactions concrètes, sélection d’ac-tion, comportement, simulation
Abstract:Since several years, we use in our team the IODAmethodology to describe and realize multi-agent si-
mulations. This method is original and not similarto the others because it makes Interactions beco-ming concrete and then able to become sufficientlygeneral to be reused in many contexts. The aim of this paper is to identify some hard problems in thiskind of simulation and to show how IODA can behelful to solve them.
Keywords: Concrete Interactions, selection of ac-tions, behaviour, simulation
1 Introduction
Le formalisme que nous proposons icis’inscrit dans le contexte plus vaste de lasimulation par agents où des entités auto-nomes (les agents) sont dotées d’un com-
portement individuel.
Dans ce cadre, de nombreux modèlesd’analyse et d’implémentation ont étéconçus afin de représenter les compor-
tements des agents. La notion d’interac-tion a également été intégrée à de nom-breuses méthodologies de conception de
0Ce travail est cofinancé par le contrat de plan Etat-Régionet les fonds européen FEDER
SMA, comme par exemple dans l’ap-proche Voyelles [1]. Toutefois l’interac-tion reste un concept utilisé lors de la
phase d’analyse, sans pour autant conduireà une implémentation informatique aucœur de la simulation. Ainsi, les interac-tions entre agents, même lorsqu’elles sontprises en compte lors de la modélisation,finissent par être codées dans un compor-tement d’agent centré sur l’agent .
Nous soutenons donc qu’il est nécessaire,dans de nombreuses situations de simula-
tion, de définir les interactions d’une façonindépendante des agents, de formaliser trèsfinement la façon de mettre en relation cesinteractions et les agents qui peuvent leseffectuer ou les subir, et de les coder expli-citement dans le simulateur. C’est ce quenous appelons « l’approche centrée inter-action » par opposition à l’approche clas-sique dans les simulations distribuées, quiest centrée agent. À l’heure actuelle, au-cun simulateur multi-agent n’applique unetelle distinction de bout en bout de la tâchede simulation, c’est-à-dire de la modélisa-tion au codage.
Nous avons formalisé et expérimenté leconcept d’interaction à travers le projetIODA1 [3]. Nous présentons d’abord lemodèle formel qui permet, au sein de ceprojet, de donner une définition opération-nelle de l’interaction. Nous décrivons en-
suite la méthode d’analyse de IODA, quidécrit comment les interactions doiventêtre affectées aux agents, ce qui se tra-duit immédiatement par une implémenta-
1Pour : Interaction-Oriented Design of Agent simulations
333

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 346/415
tion univoque. Nous montrons à cette oc-casion le fonctionnement du moteur desimulation, réalisé actuellement dans la
plate-forme IODA-light. Cet outil montreque nos concepts n’en restent pas au stadede la seule méthodologie mais permettentde donner une réalité logicielle aux inter-actions.
2 L’approche centrée interac-tion
Les Systèmes Multi-Agents sont construitssur un schéma d’emboîtement de compé-tences qui semble aller de soi : l’environ-nement modélise le monde physique; ilcontient des agents qui représentent les en-tités de ce monde ; eux-mêmes contiennentdes architectures de sélection d’action quigouvernent le choix de comportements, etceux-ci reposent sur des primitives de per-ception, de cognition et d’action propres àl’agent.
Or, si l’interaction reste cantonnée à laphase d’analyse, c’est en grande partieparce qu’il est difficile de réifier cette no-tion au moyen de comportements « encap-sulés » dans les agents. Nous prenons doncle contre-pied de cette hiérarchisation :dans le modèle que nous proposons, nouscherchons donc à donner un poids opéra-tionnel égal tant aux entités du système
qu’aux activités auxquelles elles prennentpart.
2.1 Le modèle formel de l’interactiondans IODA
Notre modèle d’interaction s’appuie surdes primitives de base qui fixent le ni-veau de granularité le plus petit qui
puisse être représenté dans une simula-tion donnée. Nous distinguons des primi-tives de perception (stimuli, communica-tion, croyance, ...) et des primitives d’ac-tion (déplacement, modification interne,destruction, création, ...).
Les interactions sont définies comme desensembles de primitives qui impliquentsimultanément plusieurs agents et qui
constituent un bloc sémantique dans unesimulation donnée [2]. Par exemple man-ger ou ouvrir ne sont pas de simplesactions atomiques, mais correspondent àdes ensembles structurés d’actions met-tant en jeu deux agents différents et quine peuvent être effectuées qu’à certainesconditions, peu dépendantes des spécifici-tés des agents concernés.
DÉFINITION 1 (INTERACTION)Une interaction est une séquence d’ac-tions primitives, s’appliquant à plusieursagents, déclenchées par des perceptionsspécifiques et soumises à certaines condi-tions d’exécution.Ces perceptions et ces actions primitives
peuvent être réalisées selon des modalitésvariables par les agents, mais leur enchaî-nement logique est décrit de façon géné-rale par leur structuration sous la forme d’une interaction (cf. fig. 1).
DÉFINITION 2 (SOURCES / CIBLES)Les agents qui prennent part à une interac-tion ne jouent généralement pas le même rôle. On distingue dont entre des agentssources qui peuvent effectuer l’interac-tion, et des agents cibles qui peuvent la subir . Pour avoir lieu, une interaction doit mettre en relation des agents sources et des
agents cibles.N.B. : Dans les interactions symétriques,on peut évidemment intervertir sources et cibles.
Une interaction, en tant qu’expression abs-traite d’un comportement, doit formulerles conditions portant sur la réalisationde la séquence d’actions primitives. Nous
avons distingué deux composantes dansles tests exprimant les pré-requis néces-saires à une interaction : le déclencheur ,qui exprime une motivation pour les agentsà effectuer l’interaction et la condition pro-prement dite, qui exprime les pré-requis
Donner corps aux interactions (l'interaction enfin concrétisée) ____________________________________________________________________________
334

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 347/415
Décl encheur Condit ions
Actions
Faim(X) Possède(X,Y)
X.energie++
detruire(Y)
(a) (b)
FIG . 1 – (a) Représentation générale d’une inter-action. L’interaction est constituée d’un ensemblede perceptions (déclencheur d’une part, conditionsd’exécution d’autre part) qui, lorsqu’elles sontréunies, permettent la réalisation d’une séquenced’actions. (b) Exemple : l’interaction manger(X,Y)se décrit de façon générale à partir d’une motiva-tion interne (la faim) qui sert de déclencheur, de
conditions d’exécution (posséder l’objet à manger)et de la séquence d’actions résultant de l’interac-tion : augmentation de l’énergie de l’agent sourceX (celui qui effectue manger ) et destruction del’agent cible Y (celui qui subit manger ).
matériels ou logiques pour pouvoir effec-tuer la séquence d’action (cf fig.1).
Ainsi formulée, cette notion d’interac-tion apparaît complètement dissociée desagents qui les utiliseront. Une même in-teraction peut alors être réutilisée dansdifférentes simulations et appliquée à desagents sources ou cibles différents : ainsi,l’interaction ouvrir a évidemment la mêmesémantique, et répond à la même fonc-
tionnalité, qu’il s’agisse d’une simulationd’évacuation de bâtiment en cas d’urgenceou d’une chasse au trésor dans un jeuvidéo. Concevoir une simulation consistedonc d’abord à établir les primitives debase qui pourront être utilisées, à ensuiteles agréger dans des interactions, et enfinaffecter celles-ci aux agents, et ce aussibien lors de l’analyse du problème qu’aumoment de l’implémentation de la simu-
lation. Nous décrivons au § 3.1 commentces interactions peuvent être affectées auxagents pour les doter d’un comportementet au § 4 comment le moteur de la simu-lation choisit les interactions à réaliser ausein du système.
2.2 Structure des agents dans IODA
Dans IODA, les agents se réduisent à des
spécifications simples qui permettent d’in-tégrer n’importe quel agent à notre modèlede simulation centré interactions.
DÉFINITION 3Un agent est une entité autonome dont les caractéristiques minimales sont les sui-vantes :– il est doté d’un état ;– il dispose de primitives de perception et
d’action ;– perception et action ne s’étendent pas
à tout l’environnement : elle se re-streignent à un halo H propre à l’agent qui est une fonction retournant un sousensemble de l’environnement ; en par-ticulier l’agent ne perçoit pas tous lesautres agents mais seulement ses voi-sins , c’est-à-dire ceux présents dans sonhalo de perception ;
– il se voit affecter la liste des interac-tions qu’il peut effectuer ou subir, cha-cune avec un niveau de priorité et une garde de distance.
DÉFINITION 4Le voisinage V d’un agent x est l’en-semble des agents perçus par x, i.e. pré-sents dans son halo de perception :V (x) = y|y ∈ H(x)
2.3 Cardinalité des interactions
Un cas trivial d’interaction fait appel àune source et une cible, par exemple man-ger ou ouvrir . Toutefois, la complexité desproblèmes à simuler nécessite de prendreen compte d’autres situations que nous al-lons examiner pour montrer qu’on peut lesreformuler sous une forme normale qui nerequiert qu’une source.
DÉFINITION 5On appelle cardinalité d’une interactionle couple composé du nombre de sources
____________________________________________________________________________ Annales du LAMSADE N°8
335

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 348/415
et du nombre de cibles nécessaires pour la réalisation de l’interaction.
Une source, une cible (cardinalité 1/1) Enpremière approche, une interaction peutêtre effectuée par une source sur une cible.La source est un agent qui peut effectuer l’interaction, et la cible un agent qui peut la subir , ces deux informations étant éta-blies lors de l’analyse puis traduites dansune matrice d’interaction (cf. § 3.1).
Une source, aucune cible (1/0) Par extensionon peut concevoir des interactions sanscibles définies. Celles-ci correspondent àdeux situations : L’interaction réflexive (unagent qui agit sur lui-même), l’interactionavec l’environnement (un agent agit surl’état du monde sans que d’autres agentssoient impliqués).
Une source, plusieurs cibles (1/n)IODA per-met également de spécifier des interac-
tions s’appliquant à plusieurs cibles simul-tanément (toujours à partir d’une sourceunique) pour représenter des activités né-cessitant une coordination entre agents,soit de même classe, soit de classes diffé-rentes. Cela s’exprime en indiquant dansla matrice d’interaction les cardinalités ap-propriées (cf. § 3.1).
Plusieurs sources, une cible (n/1) Le cas sy-métrique impliquant plusieurs sources etune cible n’est pas utilisé dans IODA,dans la mesure où il peut se ramenersystématiquement au précédent en expri-mant l’interaction à la voix passive. Parexemple, pour faire transporter un meublepar plusieurs déménageurs, on n’utiliserapas l’interaction transporter qui requerrait
l’action simultanée de plusieurs sources(les déménageurs) sur une même cible(le meuble), mais plutôt l’interaction êtretransporté qui, elle, ne fait appel qu’à unesource (le meuble) interagissant simulta-nément avec plusieurs cibles.
Plusieurs sources, plusieurs cibles (n/p) DansIODA l’interaction simultanée entre plu-sieurs sources et plusieurs cibles est ra-
menée systématiquement sous la forme1/ (n − 1 + p), ou à plusieurs interactions1/n. Cette solution, bien que critiquable,donne satisfaction dans tous les cas quenous avons traités. Cela reste néanmoinsun problème dur.
DÉFINITION 6 (FORME NORMALE)Une interaction est écrite sous forme nor-male lorsqu’elle fait intervenir exactement
une source.Toute interaction peut s’écrire sous forme normale :– les interactions de cardinalité 1/0, 1/1 ou
1/n sont déjà sous forme normale ;– une interaction I de cardinalité n/1 peut
s’exprimer à la voix passive (« être I -é ») pour se ramener à une cardinalité 1/n;
– dans une interaction de cardinalité n/p,on peut choisir comme source unique l’un des n agents sources et reléguer lesautres parmi les cibles, soit se ramener à une cardinalité 1/(n-1+p).
Dans le reste de cet article, nous considére-rons que toutes les interactions sont écritessous forme normale.
3 La méthode d’analyse IODAAttaquer un problème de simulation sup-pose d’identifier à la fois les entités qui, se-lon le modèle du domaine ciblé, sont sup-posées interagir les unes avec les autrespour produire le phénomène étudié, et cesinteractions elles-mêmes. Dans un modèlede simulation centré agents, l’identifica-tion se focalise sur les entités, que l’on
dote ensuite de comportements destinésà produire les interactions voulues. Lesfonctions abstraites associées aux interac-tions sont ainsi perdues et « engluées »dans la spécificité des agents. Nous suggé-rons au contraire de mener de front l’ana-
Donner corps aux interactions (l'interaction enfin concrétisée) ____________________________________________________________________________
336

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 349/415
lyse des agents et des interactions, de fa-çon à garder une vue abstraite des fonc-tionnalités assurées par les agents.
La méthodologie IODA propose ainsi troisétapes pour la conception d’une simulationcentrée interactions :
1. Identifier d’abord les interactions(fonctionnalités abstraites, processusélémentaires). Cela conduit à dresserune matrice entre sources et cibles po-tentielles (cf. tab. 1) dans laquelle onfait apparaître ensuite les interactions
génériques.2. Écrire les déclencheurs, conditions et
actions de ces interactions.
3. Identifier les caractéristiques desagents concernés (attributs), ainsi queles primitives de perception et d’action(par exemple faim, détruire...),d’après les déclencheurs, conditionset actions constituant les interac-
tions auxquelles ces agents devrontparticiper.
4. Spécifier, pour toute affectation d’uneinteraction à des agents source etcible(s), la priorité relative de cette in-teraction et sa garde de distance. Celaconduit à raffiner la matrice précé-dente.
5. Déterminer enfin la dynamique du sys-
tème, c’est-à-dire la façon dont, aufil des interactions et pendant la si-mulation, évolue cette matrice (et parconséquent, les possibilités d’interac-tion des agents). Voir [3] pour plus dedétails.
3.1 La matrice d’affectation des inter-actions aux agents
Une fois définies les interactions suscep-tibles d’être réalisées au cours d’une simu-lation, il est en général facile de détermi-ner quels agents seront cibles ou sources.Il reste néanmoins deux points à préciser :
– La condition de distance entre la sourceet la cible pour que l’interaction puissese produire. En effet, les agents n’in-
teragissent potentiellement qu’avec desagents suffisamment « proches », qu’ils’agisse d’une distance spatiale dansl’environnement ou d’une mesure deproximité dans un espace d’états.
– La priorité que prend une interactiondonnée lorsqu’elle est affectée à unagent donné, par rapport aux autresinteractions qu’il est susceptible d’ef-fectuer. Pour qu’un comportement ra-tionnel puisse résulter des interactionsentre agents, il faut en effet hiérarchi-ser ces interactions les unes par rapportaux autres, et ce d’une façon qui dé-pend assez étroitement des caractéris-tiques fonctionnelles des agents sourcesde cette interaction.
C’est lors de cette phase d’affectationdes interactions génériques à des agentsconcrets, et lors de la définition des prio-rités et des gardes de distance associées à
chaque interaction pour un agent donné,que l’on peut affiner les comportementsproduits au cours de la simulation. Aureste, rien n’exige que cette affectationreste inchangée au cours du déroulementde la simulation.
DÉFINITION 7 (ASSIGNATION)On appelle assignation des interactionsI 1, I 2 . . . I n entre une source S et une cible
(ou un groupe de cibles) T , un ensemble de 4-uplets de la forme (I k, ck, pk, dk)avec :– I k : l’interaction pouvant être effectuée
par S et subie par T – ck : la cardinalité de l’interaction
(nombre de cibles de type T attendues) – pk : la priorité donnée à l’interaction I k
de ce 4-uplet par rapport à toutes cellesque la source peut effectuer
– dk : la garde de distance S / T en deçà de laquelle l’interaction est réalisable (fa-cultative si la garde se conforme au halo de perception de la source, ou si ck = 0).
L’assignation aS ,T décrit donc l’ensemble des interactions que S et T peuvent réali-
____________________________________________________________________________ Annales du LAMSADE N°8
337
7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 350/415
ser conjointement.N.B.1 : lorsque ck > 1 et que deux cibles au moins appartiennent à des caté-
gories différentes, on notera plutôt T =(T 1 . . . T n).N.B.2 : la garde de distance dk peut être arbitrairement grande, mais elle est en pra-tique bornée par le halo H de l’agent.
S / T ∅ F P S . . .
F
(Create-Soldier;0;1;—)
(Create-Peasant;0;0;—)
(Give-Task;
1;2;—)
(Give-Task;
1;3;—)
. . .
L(Give-Path;1;0;5)
. . .
M . . .
S
(Become-Chief;0;2;—)(Move;0;0;—)
(Protect;1;1;2)
. . .
E
(Become-Chief;0;4;—)(Move;0;0;—)
(Destroy;1;1;2)
(Fight;1;2;5)
(Fight;1;3;5)
. . .
P(Move;0;0;—)
(PutGold;1;1;0)
. . .
TAB . 1 – Extrait de la matrice des interactionsréalisables dans la simulation « Age of Empires »testée sur notre plate-forme. On trouve en ligne les
sources et en colonne les cibles. Agents : F, forum(crée des paysans et des soldats) ; M, mines (four-nissent des ressources); P, paysans (exploitent lesmines et déposent l’or au forum); S, soldats (dé-fendent paysans et forum contre les soldats enne-mis); E, ennemis (soldats d’invasion); L, limites(bornes entre lesquelles patrouillent les soldats).Chaque case aij de la matrice contient une assi-gnation, i.e. une liste donnant les interactions quipeuvent être effectuées par la source i sur la cible j,avec une cardinalité (nombre de cibles), un niveaude priorité (relatif à l’ensemble des interactions que
i peut effectuer) et une garde de distance qui peutêtre vide.
DÉFINITION 8On appelle matrice d’interac-
tion la matrice M = (ai,j) de toutes les assignations ( ai,j =(I 1, c1, p1, d1), . . . (I n, cn, pn, dn)) entre
sources et cibles dans la simulation. Cessources et cibles peuvent être aussi biendes agents individuels que des catégoriesabstraites (classes, groupes, équipes, etc).Par conséquent, dans toute simulation qui comporte des interactions sans cibles (i.e.de cardinalité 1/0), il existe dans la matrice d’interaction une colonne (ai,∅).
La forme générale de cette matrice est don-née sur un exemple dans le tableau 1.
3.2 Critères d’éligibilité d’une interac-tion
DÉFINITION 9 (ÉLIGIBILITÉ)Pour un agent x, une interaction I est dite éligible si x peut être source de I et s’il existe dans le voisinage V de x desagents pouvant être cibles de I , en res-
pectant les gardes de distances. N.B. L’éli-gibilité porte sur des critères syntaxiques(possibilité d’être source ou cible d’aprèsla matrice d’interaction), et non séman-tiques : une interaction éligible n’est réa-lisable en pratique que si les déclencheurset les conditions sont vérifiés.
Le moteur de simulation repose principale-ment sur l’évaluation des critères d’éligibi-lité des interactions susceptibles d’être ef-fectuées par chaque agent du système. Onpeut formuler le critère d’éligibilité pour3 cas, selon la cardinalité de l’interactionconsidérée (on désigne ci-dessous la ma-trice d’interaction par M ) :
– pour une interaction de cardinalité 1/0
(pas de cible) : la possibilité d’effectuerl’interaction I ne dépend que de l’agentsource xCritère d’éligibilité (1/0) :
éligible(x,I,∅) ⇐⇒ ∃aS ∈ M tel que x ∈ S et (I, 0,p ,d) ∈ aS
Donner corps aux interactions (l'interaction enfin concrétisée) ____________________________________________________________________________
338

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 351/415
– pour une interaction de cardinalité 1/1(une seule cible) : la possibilité d’ef-fectuer I dépend de la source x et du
choix d’une cible potentielle y dans levoisinage V (x) appartenant à une ciblespécifiée dans la matrice d’interactionCritère d’éligibilité (1/1) :
∀y ∈ V (x), éligible(x,I ,y) ⇐⇒∃aS ,T ∈ M tel que x ∈ S , y ∈ T ,(I, 1,p ,d) ∈ aS ,T et dist (x, y) ≤ d
– pour une interaction de cardinalité 1/n(plusieurs cibles) : outre la source x,il faut considérer les parties de V (x)de cardinal n (i.e. les arrangements den cibles yi possibles, chacune devanta priori appartenir à une catégorie T ispécifiée dans la matrice d’interaction)Critère d’éligibilité (1/n) :
∀(yi)i∈[1,n] ∈ P n(V (x)), éligible(x,I, (yi))⇐⇒ ∃aS ,(T 1...T n) ∈ M tel que
x ∈ S , ∀i ∈ [1, n] yi ∈ T i,(I,n,p,d) ∈ aS ,(T 1...T n) et dist (x, yi) ≤ d
Il reste à définir concrètement, dans le mo-
teur, l’algorithme de choix des interactionsparmi toutes celles qui peuvent être effec-tuées à un moment donné dans tout le sys-tème multi-agents. Nous en proposons uneréalisation au § 4.
4 De la méthodologie à l’implé-mentation
La plateforme que nous avons baptisé« IODA-light » vise à donner une implé-mentation exacte (sans heuristique) de laméthodologie IODA, ce qui en fait unedes seules qui permette de passer de façonunivoque de l’analyse au code. Elle nouspermet de prototyper des modèles centrésinteractions et d’en étudier les propriétés.Elle est disponible surhttp://www.lifl.fr/SMAC/projects/ioda
Restriction de cardinalité. En raison desconsidérations de complexité mentionnéesci-dessus pour les interactions de cardina-lité 1/n, elle est destinée à ne traiter quedes interactions de cardinalité 1/0 ou 1/1,
en faisant l’hypothèse qu’on peut décom-poser assez souvent une interaction expri-mée en cardinalité 1/n par une succession
d’interactions de cardinalité 1/1 voire parl’utilisation de macro-agents.
Le moteur de sélection d’interaction. Lors dudéroulement de la simulation, le rôle dumoteur de sélection d’interaction consiste,pour chaque agent source, à choisir defaçon équitable une interaction réalisableparmi toutes celles également réalisableset de même priorité, et à l’exécuter.
DÉFINITION 10Une interaction I de cardinalité n est réali-sable par x sur les cibles T = y1 . . . yn(noté (x,I ,T )) si elle est éligible pour ces cibles et que son déclencheur et sa condition sont tous deux vérifiés pour la source et les cibles.(x,I ,T ) ⇐⇒ éligible(x,I ,T )∧déclencheur (x,I ,T )∧ condition(x,I ,T )
N.B. : dans le contexte de IODA-light, ona n ≤ 1 dont T se réduit soit à l’ensemble vide (cardinalité 1/0), soit à une cible y(cardinalité 1/1).
DÉFINITION 11On appelle potentiel d’interaction de ni-veau p de l’agent x, noté P p(x), l’en-semble des couples formés par les interac-tions de priorité p réalisables par x et les
cibles sur lesquelles elles peuvent être ef-fectuées :P p(x) = (I, T = y1 . . . yn) | n =card x(I ) ∧ p = prio x(I ) ∧ (x,I ,T )où card x(I ) et prio x(I ) désignent respec-tivement la cardinalité et la priorité de I dans l’assignation correspondante pour la source x.N.B. : dans le contexte de IODA-light, ona n ≤ 1.
On peut alors décrire l’algorithme qui per-met au moteur de sélection d’interactionde veiller à ce que chaque agent puisse ef-fectuer ou subir au plus une interaction par
____________________________________________________________________________ Annales du LAMSADE N°8
339

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 352/415
pas de temps.À chaque pas de temps :
1. Mettre à jour l’état de l’environne-ment.
2. Rendre tous les agents activables (i.e.leur permettre d’effectuer ou de subirune interaction).
3. Pour chaque agent activable x :
(a) Percevoir les caractéristiques del’environnement dans le haloH(x) ;
(b) Percevoir les agents voisins V (x),puis retirer de V (x) les agents quine sont plus activables (i.e. quiont déjà participé à une interac-tion);
(c) Mettre à jour l’état interne del’agent x ;
(d) Déterminer les interactions éli-gibles ;
(e) Initialiser le niveau de priorité pau niveau maximal pour x ;
(f) Calculer P p(x) ; si P p(x) = ∅,décrémenter p et recommencer;
(g) Si on arrive à P 0(x) = ∅, alorsl’agent ne peut être source d’au-cune interaction et son pas detemps s’achève (mais x reste ac-tivable)
(h) Sinon (i.e. dès qu’on a un niveaude priorité p pour lequel P p(x) =∅), choisir au hasard un couple(I ∗, T ∗) ∈ P p(x) ;
(i) Effectuer les actions de I ∗ avec xcomme source et T ∗ comme ciblepuis désactiver x et les agents deT ∗.
Cet algorithme garantit le choix équitabledes interactions du niveau de priorité leplus élevé pour chaque agent ; en outre, ladésactivation (étape i) évite qu’un agent neprenne part plusieurs fois à une interactionau cours du même pas de temps.
5 Conclusion
La complexité de plus en plus grande des
simulations à agents situés et la montéeà l’échelle de ces applications nécessited’avoir un guide méthodologique allant dela phase d’analyse du problème au codeinformatique. Lors de précédents articlesnous avons proposé une approche cen-trée Interactions, nommée IODA, qui al’avantage de concrétiser les interactionsentre les agents offant ainsi une facilité deconception et une réutilisatibilité du code
fortement améliorée par rapport à une ap-proche classique. Après avoir résumé cetteapproche, cet article présente d’une part ladifférence entre IODA et l’approche tradi-tionnelle sur un exemple concret et d’autrepart les problèmes difficiles à résoudre ausensdesInteractionsetdesclassesdecom-plexité algorithmiques associées. Dans unsecond temps, le paquetage Ioda-Light, quifournit les classes nécessaires à l’applica-tion de cette méthode est décrit. Ce paque-tage, initialement proposé à des fins péda-gogiques, est une restriction de IODA auxinteractions 1 :1 . Le passage de IODAet ses tableaux au squelette du code issude IODA-ligth est quasi automatique, aupoint qu’une de nos perspectives à courtterme est de fournir un outil de dévelop-pement graphique pour réaliser ce type desimulation.
Références[1] Y. Demazeau. From Interactions to Collective
Behaviour in Agent-BasedSystems. In Procee-dings of the 1st European Conference on Cog-nitive Science, Saint-Malo, 1995.
[2] P. Mathieu, S. Picault, and J.-C. Routier. Simu-lation de comportements pour agents rationnelssitués. In Actes de la conférence Modèles For-mels pour l’Interaction (MFI’03), pages 277–282, Lille, 2003.
[3] Philippe Mathieu and Sébastien Picault. To-wards and interaction-based design of beha-viors. In Marie-Pierre Gleizes, editor, Pro-ceedings of the Third European Workshop on Multi-Agent Systems (EUMAS’05), 2005.
Donner corps aux interactions (l'interaction enfin concrétisée) ____________________________________________________________________________
340

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 353/415
Interprétation de commandes en langage naturel pour les agentsconversationnels à base d’ontologie
L. Mazuel
N. Sabouret
Laboratoire d’Informatique de Paris 6 (LIP6)104 av du Président Kennedy
75016 Paris – FRANCE
Résumé :Dans cet article, nous nous intéressons à l’inter-prétation des commandes en langue naturelle d’unutilisateur à un agent artificiel. Nous proposons
une architecture pour le traitement de ces com-mandes adaptable à différents types d’applications.Les algorithmes de traitement dépendent unique-ment du code de l’agent et de l’ontologie de do-maine de cet agent. Nous présentons ensuite uneévaluation comparative de trois approches : l’ap-proche descendante, reposant sur les contraintessyntaxique du langage de description de l’applica-tion, l’approche ascendante, reposant sur l’utilisa-tion de connaissances sur l’ensemble des actionspossibles de l’agent et finalement une propositiond’approche combinée.
Mots-clés : Communication humain-agent, intros-pection, ontologie de domaine, approche ascen-dante et descendante, evaluation comparative
Abstract:This paper focuses on a generic architecture pro-vided with a natural language (NL) algorithm forcommand interpretation that can be adapted to dif-ferent agent’s domains for human-agent communi-cation. Our NL architecture only depends on theagent’s code and its domain ontology. We consi-der two approaches for NL command interpreta-
tion : the top-down approach and the bottom-upapproach. We propose to combine both approachesin a bottom-up based algorithm that makes use of agent’s constraints. We propose a comparative eva-luation of these three algorithms.
Keywords: Human-Agent communication, intros-pection, domain ontology, top-down and bottom-upapproach, comparative evaluation
1 Introduction
1.1 Présentation du problème
La communauté des Systèmes Multi-Agent (SMA) s’intéressent particulière-
ment et depuis longtemps à la résolutionde problèmes par des agents cognitifs au-tonomes [4]. A ce titre, elle étudie les pro-
tocoles et modèles d’interaction formelsentre agents. Ainsi, il n’existait initiale-ment que peu de travaux sur la communi-cation humain-agent qui reste une problé-matique très ouverte.
D’autre part, la communauté AgentsConversationnels Animés s’intéresse par-ticulièrement à l’interaction en languenaturel entre un utilisateur humain et
un agent artificiel. Elle obtient de trèsbon résultats dans le domaine de l’in-teraction multi-modale[2] et des expres-sions d’émotions [9]. Cependant, au ni-veau compréhension des langues, ces ap-proches s’appuient essentiellement sur desalgorithmes de pattern-matching ad-hocsans réelle analyse sémantique [1]. D’autrepart, la communauté des systèmes de dia-logues utilise les ontologies pour s’appro-cher d’une architecture plus générique [7].L’idée importante sous-jacente à l’utilisa-tion d’ontologies est de pouvoir générali-ser les algorithmes de traitement séman-tique afin de les faire dépendre unique-ment de son formalisme. Ainsi, ces appli-cations ne sont plus dépendantes que del’ontologie et du résolveur de problèmespécifique de la tache à accomplir. Parexemple, certains systèmes utilisent ainsil’ontologie pour paramétrer un parseur gé-
nérique [8]. Cependant, pour obtenir debons résultats, ils imposent un formalismede description d’ontologie très contraint,efficace pour un sous-ensemble d’applica-tion, mais loin des modèles ouvert clas-
341

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 354/415
siques. De plus, ce type d’ontologie dé-crit le modèle de l’application et non ledomaine de travail de l’application. Nouspensons qu’il est possible d’extraire la sé-mantique des actions du code de l’applica-tion directement. L’ontologie ne serait plusalors une deuxième description de l’ap-plication, mais une description des lienssémantiques entre les différents conceptsprésents dans le domaine de l’application(ce qui constitue le rôle initial d’une onto-logie).
1.2 Plan de l’articleNous allons essayer de montrer qu’il estpossible de définir un système d’inter-prétation de commandes en langue natu-rel (LN) basé uniquement sur une onto-logie de domaine et des agents capablesd’introspection. Nous proposons pour celatrois strategies, les approches descendante,ascendante et combiné.
Dans la seconde section, nous donneronsune description générale de notre modèled’agent. La section 3 présente la chaînede base de TAL et le gestionnaire de dia-logue qui sont les parties de l’architecturecommune aux trois algorithmes. Dans lasection 4, nous introduisons les trois algo-rithmes génériques différents pour l’inter-prétation de commandes. La section 5 pré-sente une évaluation préliminaire de ces al-gorithmes. La section 6 conclue l’article.
2 Notre modèle d’agent
2.1 Le modèle VDL
Nos agents sont programmés en utilisantle langage VDL (View Design Language)1.
Le modèle VDL est basé sur la réécritured’arbre XML : la description de l’agentest un arbre dont les noeuds représentent
1http://www-poleia.lip6.fr/~sabouret/
demos
ses données ou ses actions. L’agent réécritl’arbre à chaque étape de l’exécution sui-vant un certain nombre de mots-clés dulangage présent dans les noeuds. Ce mo-dèle permet aux agents d’accéder à l’exé-cution à la description de leurs actions afinde raisonner dessus pour de la planifica-tion, pour répondre à des questions d’étatsformelles [11], pour modéliser son com-portement, etc.
Dans le modèle VDL, chaque agent estnanti d’une ontologie OWL. Cette on-tologie doit contenir au minimum tout
les concepts utilisés par l’agent (i.e. lesconcepts VDL)2. Il existe donc une fonc-tion injective de l’ensemble des conceptsVDL de l’agent vers l’ensemble desconcepts définis dans l’ontologie.
2.2 Modèle d’actions
En VDL, les réactions3 sont activées pardes évènements, i.e. noeuds XML envoyésà l’agent en guise de commande. Ils sont lareprésentation formelle (i.e. en VDL) descommandes. Les réactions décrivent com-ment ces messages (envoyés par un utilisa-teur ou même un autre agent) doivent êtretraités. L’objectif du système décrit ici estde construire des évènements VDL à partird’une commande utilisateur en LN.
En VDL, comme dans la plupart des mo-
dèles de représentation des actions, nousreprésentons une action par un tuple r =nom,P,E où nom est le nom de l’ac-tion, P l’ensemble des préconditions del’action et E son ensemble d’effets. Nouspouvons définir quatre types de précondi-tions pour une réaction r de R, l’ensembledes réactions possible :
– P e(r) est l’ensemble des préconditionsd’évènement. Elles sont utilisées pour2Ces concepts sont présent dans le code XML de l’agent soit
comme étiquette (i.e. tag), comme attributs ou contenu texte.3Cet article traitant d’interaction utilisateur, nous limiterons
nos actions aux réactions (par opposition au comportementproactif d’un agent).
Interprétation de commandes en langage naturel [...] ___________________________________________________________________________
342

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 355/415
aiguiller une certaine forme d’évène-ment vers une certaine classe de réac-tions, ou pour rejeter les évènementsglobalement mal formés.
– P s(r) est l’ensemble des préconditionsde structure. Elles sont utilisées pour vé-rifier la syntaxe précise d’un message etassurer que la réaction a toutes les in-formations nécessaires pour s’exécutersans erreurs. Les préconditions de P s(r)ne dépendent donc pas de l’état courantde l’agent, mais uniquement de la struc-ture détaillée de l’évènement.
– P c(r) est l’ensemble des préconditions
de contexte. Ces préconditions ne dé-pendent que du contexte courant del’agent.
– P cs(r) est l’ensemble des préconditionscontextuelles-structurelles, i.e. précon-ditions dépendantes de l’évènement et du contexte courant de l’agent.
Nous noterons P e = ∪r∈RP e(r). Pour toute ∈ P e, nous noterons Re(evt) = r ∈
R|evt
∈ P e(r
)l’ensemble des réactions
dont l’exécution donnera lieu à des effetspar l’évènement evt.
3 Architecture globale
Cette section présente les modules de LNcommuns aux trois algorithmes d’interpré-tation.
3.1 Outils de base de TAL
Dans notre projet (figure 1), le modulelexical de base est celui du projet OpenSource OpenNLP4. Ce module contientun étiqueteur, un lemmatiseur (simple lienvers le lemmatiseur WordNet contenu dansJWNL). Comme nous l’avions constatédans l’évaluation de [10], l’utilisation d’un
analyseur syntaxique n’est pas efficacepour les commandes en langue naturelle.En effet, les utilisateurs emploient plussouvent des mots clefs que des phrases
4http://opennlp.sourceforge.net/
FIG . 1 – Architecture générale
bien structurées (e.g. “drop object low” ou"take blue”). Nous utilisons dans cet articleune représentation du type “sac de mots”(après avoir enlevé les mots blancs repéréspar leur étiquette)5.
Notre objectif en analyse sémantique estd’utiliser les ontologies pour l’apparie-ment des concepts utilisateurs avec ceuxde l’agent VDL. Dans cet article, nousn’utilisons que la synonymie (owl :sa-meAs) de l’ontologie pour faire cet appa-riement. Cette analyse repose sur l’hypo-
thèse de connectivité sémantique [12] enri-chie par l’utilisation de la relation owl :sa-meAs : chaque concept qui apparaît dansune commande correcte est soit directe-ment associé à un concept VDL, soit enrelation owl :sameAs dans l’ontologie avecun concept VDL. Nous notons C l’en-semble de tous les concepts VDL liés (soitdirectement, soit via la relation owl :sa-meAs) à un terme apparaissant dans la
commande utilisateur. C’est à partir de cetensemble que nous construirons les évène-ments VDL au moyen des algorithmes dé-crits dans la section 4.
La dernière partie de notre chaîne estun générateur d’anglais qui transforme unnoeud VDL en une phrase anglaise. Lerésultat grammaticalement incorrect, maissuffisant pour que les utilisateurs com-prennent les propositions du système dans
5L’objet de cet article n’étant pas l’interprétation syntaxiqueet sémantique des commandes, nous nous contenterons d’uneversion très simplifiée, afin de nous focaliser sur l’étude com-parative. Nous n’évaluerons pas dans la section 5 les résultatsuniquement liés à cette simplification.
____________________________________________________________________________ Annales du LAMSADE N°8
343

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 356/415

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 357/415
liées à l’application. C’est pourquoi nousn’utilisons que les préconditions de sub-somption (P e) et l’état courant de l’agentpour construire l’évènement VDL à par-tir des concepts compris de l’utilisateur(C ). Les préconditions de subsumptionpermettent de définir le squelette des évè-nements possibles pour un concept donné.Une analyse plus profonde de l’état in-terne de l’agent permet d’enrichir le sque-lette avec les concepts possibles. Plutôtque d’utiliser des règles strictes de gram-maire, nous proposons de définir une mé-thode de construction d’évènements basée
sur la syntaxe VDL et d’appliquer des heu-ristiques pour contraindre la constructionselon la sémantique opérationnelle VDL.
Soit E = e ∈ P e|tag(e) ∈ C et ∀e ∈ E ,soit C e = C \tag(e). Pour chaque e ∈E , notre algorithme considère l’ensembledes feuilles Le de e et cherche à l’intérieurdu code les noeuds t ∈ Le qui contiennentau moins un concept c ∈ C e dans leurs
sous-éléments. ∀e ∈ E , nous notons Γel’ensemble de ces noeuds et Γ =e∈E Γe.
Puis, nous appliquons un algorithme de fu-sion qui permet de lier les différentes par-ties instanciées d’un même squelette de Γ(correspondant à différents concepts de lacommande) en un seul évènement. Soit Γ∗
l’ensemble des parties de l’ensemble Γ.
G =
N ∈maxcardΓ∗fusion(N )
Remarquons bien que l’approche descen-dante ne garantit pas que les évènementssoient possibles ou non : elle construitsimplement l’ensemble d’évènements quis’apparie le mieux à la commande. Uneconséquence de cette remarque est queE = E max et F = F max.
Cependant, du fait que Γ peut être très
grand et que le calcul de fusion est NP-Difficile, nous réduisons Γ par l’utilisa-tion d’une heuristique de profondeur mi-nimale : pour un couple donné (e, c) ∈E × C e, nous ne gardons dans Γeque les
noeuds dont la profondeur depth(c j) estminimale. L’heuristique est basée sur l’in-terprétation future des évènements (selonla sémantique opérationnelle VDL). Ellen’a aucun impact sur les évènements ré-sultats : l’algorithme construira l’ensemblecomplet des meilleurs évènements.
4.2 L’approche ascendante
L’approche ascendante (i.e. bottom-up)classique utilise une liste préétablie decompétences et essaye de relier la com-
mande en LN à une de ces compétences(e.g. [8]). Cette approche permet au dé-veloppeur d’écrire des algorithmes géné-riques, au sens dépendant uniquement duformalisme de la liste de compétences. Ce-pendant, ces listes sont définies de manièrestatique, le système n’a aucune consciencede ce qu’il est possible ou non de fairedans l’état courant. En pratique, ces listesdoivent décrire toutes les situations de dia-
logues possibles (en tenant compte des er-reurs possibles de l’utilisateur) ainsi que latraduction en requête formelle.
Pour éviter ce problème, nous propo-sons d’adopter une approche ascendanteconstructive basée sur l’analyse des pré-conditions. Notre approche utilise lesinformations contextuelles (obtenues del’agent à l’exécution) pour déterminerquels évènements peuvent être acceptéspar l’agent dans l’état courant. Ainsi, notresystème construit la liste des évènementspossibles, d’un point de vue agent, sanschercher à utiliser la commande de l’uti-lisateur.
L’approche ascendante utilise les précon-ditions d’évènement (P e) pour fournirles squelettes initiaux (comme l’approchedescendante). Puisque notre objectif est de
construire les évènements possibles (cor-respondant à la liste de compétences dansles approches classiques), nous retirons dela liste des squelettes P e tout ceux quisont liés à une action impossible dans l’état
____________________________________________________________________________ Annales du LAMSADE N°8
345

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 358/415
courant (c’est-à-dire pour lesquels une pré-condition de contexte rend l’exécution del’action impossible). Nous obtenons alorsl’ensemble P e+c =
e ∈ P e|∀ p ∈
r∈Re(e)
P c(r),Ψ( p, e) =
avec Ψ( p, e) la fonction booléenne véri-fiant si l’évènement e valide la precondi-tion p.P e+c est l’ensemble des squelettesqui seront forcement acceptés par l’agent
dans l’état courant. C’est à partir de cetensemble que nous allons construire l’en-semble d’événements G .
L’idée de l’approche ascendante construc-tive est d’utiliser les préconditions structu-relles (P s et P cs) comme un ensemble decontraintes sur les évènements pour com-pléter les squelettes. Pour tout e ∈ P e+c,nous noterons τ (e, r) ∈ Υ l’évènement
construit à partir du squelette e et de la ré-action r ∈ Re(e) (en n’analysant donc queP s et P cs) par l’utilisation de notre algo-rithme de génération des cas de test. L’al-gorithme complet pour la méthode τ esttrop long pour être présenté ici. Il reposefortement sur la sémantique opérationnelledu modèle VDL. Il est basé sur une in-terprétation récursive des termes VDL as-socié à un certain nombre de règle pourchaque mot-clé du langage.
L’ensemble G est ainsi calculé :
G = τ (e, r),∀e ∈ P e+c,∀r ∈ Re(e)|∀ p ∈ P s(r) ∪ P cs(r),Ψ( p, τ (e, r)) =
Remarquons que G est l’ensemble des évè-
nements possibles : tous les évènements deG sont possibles pour l’agent et tous lesévènements possibles de l’agent sont dansG . Comme conséquence, nous aurons pourle GD que E =G et F = ∅.
4.3 L’algorithme combiné
L’approche ascendante constructive pos-
sède néanmoins une limitation : le sys-tème n’est pas capable de comprendre lescommandes impossibles (au contraire del’approche descendante). Contre ce pro-blème, les approches à base de liste decompétences proposent d’utiliser des sous-compétences associées afin de traiter lesdifférentes situations (action possible, im-possible, paramètre incomplet, etc.). Demanière similaire, nous voudrions quenotre algorithme final possède cette capa-cité sans perdre l’aspect constructif.
Pour cela, nous avons combiné l’algo-rithme ascendant avec l’idée de l’algo-rithme descendant de gestion des com-mandes impossibles. Soit G bu l’ensembledes évènements possible calculé par l’ap-proche ascendante, notre objectif est decréer un ensemble G tel que G bu ⊆ G , lapartie supplémentaire représentant les évè-
nements “actuellement impossible” (i.e.évènements qui ne peuvent pas être ac-cepté par l’agent à l’état courant, mais quile serait dans un état diffèrent).
Pour cela, nous utilisons le principe derelaxation de contrainte sur les précondi-tions de contexte (incluant les précondi-tions contextuelles structurelles). Nous nepouvons pas relâcher les préconditions destructures, sous peine d’obtenir des évène-ments mal structuré :
G = τ (e, r),∀e ∈ P e,∀r ∈ Re(e)|∀ p ∈ P s(r),Ψ( p, τ (e, r)) =
5 Évaluation préliminaire
5.1 Protocole
Notre expérience a été faite avec un agentsimple appelé Jojo6 inspiré du monde
6Vous pouvez essayer Jojo sur la page demo : http://www-poleia.lip6.fr/~sabouret/demos.
Interprétation de commandes en langage naturel [...] ___________________________________________________________________________
346

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 359/415
FIG . 2 – État initial et final du protocole
de cube de Winograd [14]. Cet agentpossède deux actions : prendre un ob- jet et poser un objet sur une “grille”.Un objet est caractérisé par sa forme,
sa couleur et sa taille. Une position estun couple de upper, center, lower ×right,middle,left.
Douze personnes ont fait l’expérience,quatre pour chaque algorithme. Aucune deces personnes n’avaient utilisées le sys-tème auparavant. Ils n’avaient aucune in-formation sur les capacités en TAL du sys-tème. L’objectif d’une personne était d’at-teindre un état particulier de l’environne-ment de l’agent (figure 2), sans limitationde temps. Après l’expérience, un question-naire permettait aux sujets de l’expériencede noter leurs impressions, commentaireslibres et de donner une note sur certainscritères.
5.2 Résultats principaux
La figure 3 montre la moyenne des tempsmis pour atteindre l’objectif et la moyennedes notes donnée par les utilisateurs pourchaque algorithme. Il apparaît clairementque les utilisateurs préfèrent les approchesdu type ascendante (classique ou combi-née). En effet, le retour à l’utilisateur etles propositions faites par l’agent sont lespoints les plus importants d’après l’évalua-tion des questionnaires. Ils réduisent d’en-viron 65% le temps requis pour l’accom-plissement de la tache.
Une analyse plus profonde des traces desinteractions lors de l’expérience confirmela nécessité pour l’utilisateur de savoir :
FIG . 3 – Moyennes des temps et des notes
1) ce qu’attend l’agent, ce qu’il nepeut pas faire. C’est ce qui expliqueles meilleurs résultats de l’approche as-cendante sur l’approche descendante. Parexemple, lorsque l’utilisateur dit “dropon the lower line”, l’approche ascendantepropose la liste des cases vide en bas de lagrille (sauf lorsqu’il n’en reste qu’une).
2) pourquoi il ne peut pas le faire. C’estce qui permet, dans l’approche combinée,de corriger l’état de l’agent par rapportau souhait de l’utilisateur. Par exemple :la commande “Take the red figure”, si lamain est déjà pleine, est gérée par une ré-ponse du type “i can’t because the hand isnot empty”. En réponse du retour contex-tualisé sur l’état de l’agent, les utilisateurs
choisissent quasi systématiquement la pro-position du système.
6 Conclusion & perspectives
Dans cet article, nous avons proposé unsystème d’interprétation de commande enLN uniquement paramétré que par le codede l’agent et l’ontologie du domaine. Bien
que nous utilisions un langage agent spéci-fique, notre approche en est indépendanteet peut être aisément adaptée à d’autreslangages de description d’actions capabled’introspection.
____________________________________________________________________________ Annales du LAMSADE N°8
347

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 360/415
La force de l’approche descendante estde pouvoir expliquer pourquoi une com-mande donnée ne peut être comprise, tan-dis que celle de l’approche ascendanteest d’aider l’utilisateur en lui proposantles différentes actions possibles prochelorsque la commande est mal comprise oupartielle. Notre approche combinée pro-pose les avantages des deux, alliée à notregestionnaire de dialogue sans règle spéci-fique dépendante de l’application.
Dans la version qui est présentée ici, notresystème ne fonctionne que sur une ana-
lyse sémantique minimale sur l’ontologie(synonymie). Par conséquent, il ne peutcomprendre que les commandes formuléesavec des concepts présents dans le code del’agent. Notre objectif à terme est d’utiliserun calcul de similarité sémantique entreles concepts [3], afin de donner un scoreà l’approximation entre les concepts del’agent et ceux de l’ontologie. Ceci devraitpermettre au système de comprendre descommandes plus complexe et moins liéesau code brut de l’agent.
Références
[1] S. Abrilian, S. Buisine, C. Rendu, andJ.-C. Martin. Specifying Cooperationbetween Modalities in Lifelike Ani-mated Agents. In Working notes of the International Workshop on Life-like Animated Agents : Tools, Func-tions, and Applications, pages 3–8,2002.
[2] T. W. Bickmore. Unspoken rules of spoken interaction. Commun. ACM ,47(4) :38–44, 2004.
[3] A. Budanitsky and G. Hirst. Evalua-ting wordnet-based measures of se-mantic distance. Computational Lin-guistics, 32(1) :13–47, March 2006.
[4] J. Ferber. Les systèmes multi-agents :Vers une intelligence collective. In-terEditions, 1995.
[5] P. Maes. Agents that reduce workloadand information overload. Commu-
nications of the ACM , 37(7) :30–40,1994.
[6] L. Mazuel and N. Sabouret. Ge-
neric command interpretation al-gorithms for conversational agents.In Proc. Intelligent Agent Techno-logy (IAT’06), pages 146–153. IEEEComputer Society, 2006.
[7] D. Milward and M. Beveridge.Ontology-based dialogue systems. InProc. 3rd Workshop on Knowledgeand reasoning in practical dialoguesystems (IJCAI03), pages 9–18, Au-gust 2003.
[8] E.C. Paraiso, J.P. A. Barthès, andC. A. Tacla. A speech architecturefor personal assistants in a knowledgemanagement context. In Proc. Euro-
pean Conference on AI (ECAI),pages971–972, 2004.
[9] C. Pelachaud. Modelling gaze be-haviour for conversational agents.In Proc. Intelligent Virtual Agent
(IVA’2003), pages 93–100, 2003.[10] N. Sabouret and L. Mazuel. Com-mande en langage naturel d’agentsVDL. In Proc. 1st Workshop sur les Agents Conversationnels Animés(WACA), pages 53–62, 2005.
[11] N. Sabouret and J.P. Sansonnet. Au-tomated Answers to Questions abouta Running Process. In Proc.CommonSense 2001, pages 217–227,
2001.[12] D. Sadek, Ph. Bretier, and E. Pana-get. Artimis : Natural dialogue meetsrational agency. In IJCAI (2), pages1030–1035, 1997.
[13] S. Shapiro. Sneps : a logic for natu-ral language understanding and com-monsense reasoning. Natural lan-guage processing and knowledge re-
presentation : language for know-
ledge and knowledge for language,pages 175–195, 2000.[14] T. Winograd. Understanding Natu-
ral Language. New York AcademicPress, 1972.
Interprétation de commandes en langage naturel [...] ___________________________________________________________________________
348

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 361/415
Représentations syntaxique et sémantique d’un acte
B. Menoni
J.-Ch. Vergnaud†
Panthéon-Sorbonne-Économie, Université Paris 1 & CREST-LFAMaison des Sciences Économiques106 - 112 boulevard de L’Hôpital
75647 Paris cedex 13† Panthéon-Sorbonne-Économie, CNRS & Université Paris 1
Maison des Sciences Économiques106 - 112 boulevard de L’Hôpital
75647 Paris cedex 13
Résumé :Dans la plupart des modèles proposés en théoriede la décision individuelle, les agents sont douésd’omniscience logique. Nous proposons ici uncadre formel pour distinguer ce qui relève d’unepart du savoir, résultat des capacités computation-nelles éventuellement limitées d’un agent et cequi relève d’autre part des degrés de croyance quel’agent se forme sur ce qu’il juge incertain. Pourcela nous explicitons le langage syntaxique quidécrit les actes sur lesquels portent les préférencesde l’agent. Nous proposons un théorème généralde représentation des préférences à la Schmeidler[5] fondé axiomatiquement. Nous donnons unecondition sous laquelle existe une représentationsémantique recourrant à des mondes éventuelle-ment "impossibles". Nous caractérisons ensuite lescomportements par rapport à l’incertain et nousexplicitons les conditions sous lesquelles un agentest logiquement omniscient et se comporte commesi ces croyances ne portaient que sur des mondespossibles.
Mots-clés : décision dans l’incertain, omnisciencelogique, logique épistémique
Abstract:In individual decision theory, the models generallyassume that the decision maker (DM) is logicallyomniscient. In this paper, we build a model thatallows to distinguish between knowledge, that isthe product of the DM’s computational abilities,and the various degrees of belief the DM holdsover what she thinks as being uncertain. In orderto achieve our objective, we explicitly introducea syntactic language that describes the acts the
preferences of the DM are defined on. We offer ageneral representation theorem of preferences ala Schmeidler [5]. Then, we provide a conditionunder which there exists a semantic representationthat may require "impossible" worlds. Finally, wespecify the DM’s behavior towards uncertainty
and precise the conditions under which a DM islogically omniscient and behaves as if her beliefswhere defined exclusively on possible worlds.
Keywords: decision under uncertainty, logical om-niscience, epistemic logic
1 Introduction
Si certains paradoxes en théorie de la dé-cision (paradoxes de Allais, d’Ellsberg...)ont trouvé des solutions par le recoursà des modèles généralisant le modèle del’utilité espérée, pour d’autres paradoxestel celui de Linda, aucun modèle n’a étéencore proposé. Rappelons cet exemplede violation de la règle de conjonction(conjunction fallacy) mis en évidence ex-périmentalement par Tversky et Kahne-mann [6]. Après avoir appris quelques élé-ments biographiques portant sur Linda, unpersonnage fictif, les sujets doivent ré-pondre à la question suivante : « check which of the two alternatives (is) more pro-bable
Linda is a bank teller (T ). Linda is a bank teller and active in the
feminist movement (T ∧ F ) ».Parmi les 142 sujets auxquels cet exer-
cice a été posé, 85 % ont répondu quela proposition T ∧ F est plus probableque la proposition T . En terme séman-tique, les sujets accordent donc un de-gré de croyance plus élevé à l’événement
349

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 362/415
T ∧ F qu’à l’événement T . Dans un mo-dèle de logique modale classique, l’évé-nement T ∧ F est un sous-événement del’événement T . A notre connaissance, iln’existe pas de modèle de décision per-mettant l’expression de telles croyances :même le modèle très général de Schmeid-ler ne le permet pas puisque les croyancesobtenues dans le théorème de représenta-tion sont des capacités (fonction mono-tone) sur les événements. Dans le mêmearticle, Tversky et Kahnemann [6] relatentune étude lors de laquelle ils ont demandéà deux groupes d’étudiants de l’University
of British Columbia, en avril 1982, d’éva-luer la probabilité pour l’un de l’événe-ment (F ) « a massive flood somewhere in
North America in 1983, in which morethan 1000 people drown », pour l’autrecelle de l’événement (E ∧ F ) « an ear-thquake in California sometime in 1983,causing a flood in which more than 1000
people drown ». Il ressort de leur étudeque la probabilité estimée de l’événement
(E ∧ F ) est significativement supérieureà celle de l’événement (F ). Là encore, iln’est pas possible de transcrire de tellescroyances dans un modèle existant de déci-sion individuelle. Dans ces deux exemples,les sujets semblent souffrir de problème decohérence logique.
En théorie des jeux, Geanakoplos [2] apour sa part popularisé l’idée de rationalitécognitive limitée en reprenant une histoirede Sherlock Holmes. Alors que SherlockHolmes et son adjoint Watson enquêtentsur la disparition d’un cheval1, le détectivefait état d’un curieux incident– "Is there any point to which you would
wish to draw my attention ?"– "To the curious incident of the dog in the
night-time."– "The dog did nothing in the night-time."– "That was the curious incident," remar-
ked Sherlock Holmes.Sherlock Holmes et Watson cherchent àsavoir si un inconnu s’est introduit de nuit
1Cette enquête est relatée dans Silver Blaze, nouvelle écritepar Sir Arthur Conan Doyle et parue en 1893.
dans l’écurie (notons I cette proposition).La présence d’un chien, plus particulière-ment le fait que ce dernier n’a pas aboyé(désignons par ¬A cette proposition), aidele détective à decider si I est vraie ou non.Holmes en déduit ¬I par le raisonnementsuivant. Premièrement, il sait que si un in-connu entre dans l’étable alors le chienaboit (soit la proposition I → A) ; il endéduit par la règle du modus tollens queI → A ≡ ¬A → ¬I ; il en déduit fina-lement par la règle du modus ponens que¬I . Watson quant à lui n’a pas réussi à me-ner ce raisonnement à terme. Si nous élici-
tions les croyances de Watson, nous obser-verions qu’il croit avec certitude ¬A ainsique I → A mais qu’il est incertain ausujet de I . En terme sémantique, on peutici, contrairement aux exemples de viola-tion de la règle de conjonction, transcrireformellement les croyances de Watson parune capacité sur les événements d’un mo-dèle de logique modale classique. Néan-moins, on peut douter que ceci ait du sens.
On sait en effet que si on s’en tenait à ceque Watson croît avec certitude, alors unmodèle de Kripke ne permettrait pas de re-présenter les croyances de Watson et qu’ilest nécessaire d’utiliser un modèle séman-tique plus général ne reposant pas sur l’hy-pothèse d’omniscience logique.
Pour modéliser des agents dont les capa-cités cognitives sont éventuellement limi-tées, nous proposons tout d’abord de dé-finir précisément les actes, c’est à dire lesobjets de choix sur lesquels porte les pré-férences. En théorie de la décision à la Sa-vage, les actes sont des fonctions d’un es-pace d’états de la nature dans un ensemblede conséquences. Même si la terminolo-gie évoque l’idée d’une sémantique, il n’ya pas de formalisme explicite définissantcet espace d’états et le reliant à des élé-ments syntaxiques.2 Le cadre formel que
nous proposons et qui semble naturel est2Par contre, les axiomatiques des préférences peuvent en-
suite conduire à des croyances révélées (probabilités subjec-tives, capacités convexes, capacités...) vérifiant certaines pro-priétés correspondant à de l’omniscience logique.
Représentations syntaxique et sémantique d'un acte ___________________________________________________________________________
350

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 363/415
de définir les actes en recourant à unesyntaxe. Nous retranscrivons alors dansce cadre l’axiomatique de Schmeidler [5]et obtenons un théorème général de re-présentation des préférences. Nous mon-trons ensuite l’intérêt de cette approchequi permet de distinguer ce qui relève descroyances certaines de l’agent de ces de-grés de croyance sur les contingences in-certaines.
2 Le modèle
Dans l’objectif de décrire précisément unacte à la Savage, il est naturel de décrireles contingences possibles en termes syn-taxiques.
2.1 Les briques du modèle
Soit Φ0 un ensemble fini de propositionsatomiques. Φ désigne la clôture de Φ0
sous les connecteurs de de négation, ¬
de disjonction, ∨, de conjonction, ∧ etd’implication matérielle →. Nous consi-dérons également que l’ensemble des pro-positions Φ contient la tautologie et lacontradiction ⊥. Si deux propositions ϕet ψ de Φ, sont logiquement équivalentesau sens du calcul propositionnel classique,nous noterons ϕ ≡ Φ.
Soit I ⊂ N, I fini. La famille de proposi-
tions (αi)i∈I ⊂ Φ est appelée support si etseulement si(i) ∀(i, j) ∈ I 2, i = j, αi ∧ α j ≡⊥ ;
(ii) ∨i∈I αi ≡ .Un support est une liste finie de proposi-tions deux à deux logiquement contradic-toires et dont la disjonction est logique-ment équivalente à la tautologie. S estl’ensemble des supports.
SoitC un ensemble non vide et convexe deconséquences. Un acte est défini par rap-port à un support et indique quelle consé-quence sera obtenue si une proposition du
support est vraie. Formellement, on noteraun acte X = (xi, αi)i∈I où (αi)i∈I est unsupport et (xi)i∈I un ensemble de consé-
quences dansC
.X
désigne l’ensemblede tous les actes. On suppose que X estun espace de mélange. On notera σ(X )le support de X et pour αi dans σ(X )on notera X (αi) la conséquence obtenuesi αi est vraie. Enfin, pour toute consé-quence c ∈ C on notera σ(X )(c) l’en-semble α ∈ σ(X ) | X (α) = c, c’està dire l’ensemble des propositions du sup-port pour lesquelles on obtient c.
Soit S ∈ S un support. Nous notons X S ,l’ensemble des actes dont le support est S .
Définition 1 (Acte S −constants). Pour tout support S ∈ S , ∀c ∈ C , cS est l’actetel que pour tout α ∈ S , cS (α) = c.
2.2 Représentation des préférences
La définition que nous avons proposédes actes est justifiée si l’on considèreque le problème de décision auquel seraconfronté l’agent est défini par un tiers, parexemple un expérimentateur. Dans ce cas,la description des actes doit être cohérente.Au contraire, si c’était l’agent lui mêmequi devait décrire explicitement les actesauxquels il fait face, il n’est pas évidentque la description qu’il en proposerait res-pecterait les contraintes introduites.
Nous considérons une relation de préfé-rence sur les actes : désigne une relationbinaire sur X . Pour tout support S ∈ S ,S désigne la restriction de àX S .Nousretranscrivons dans ce cadre l’axiomatiquede Schmeidler qui nous permet d’obtenirun théorème de représentation pour chaque
restriction S .Axiome 1 (Pré-ordre continu). Pour tout support S ∈ S , S est un pré-ordrecontinu (au sens de Jensen).
____________________________________________________________________________ Annales du LAMSADE N°8
351

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 364/415
Définition 2. ∀ S ∈ S , ∀(c, c) ∈ C 2 ,
c S C
c ⇔ cS S
cS .
Définition 3. Soient S ∈ S un support
et (X, Y ) ∈X S
2un couple d’actes
dont le support – commun – est S ∈ S .Ces deux actes sont dits comonotones si et seulement pour tout couple (α, β ) ∈ S 2 ,
X (α) S C X (β ) ⇔ Y (α) S
C Y (β ).
Axiome 2 (Indépendance comonotone).Soit S ∈ S un support. Pour tout triplet
d’actes (X, Y, Z ) ∈X S
3deux à deux
comonotones, pour tout réel λ ∈]0; 1[ ,
X S Y ⇒ λX +(1−λ)Z S λY +(1−λ)Z.
Axiome 3 (C est borné). ∀ S ∈ S ,∃ (cS , cS ) ∈ C 2 | ∀ c ∈ C , cS S
C c S
C
cS .
Axiome 4 (Non dégénérescence). Pour tout support S ∈ S , cS S
C cS .
Axiome 5 (Dominance). Pour tout sup- port S ∈ S , pour tout couple d’actes
(X, Y ) ∈X S
2
∀α ∈ S, X (α) S C
Y (α)
⇒ X S Y.
Proposition 1 (Schmeidler [5]). Les
axiomes 1 à 5 sont satisfaits si et seule-ment si pour tout support S il existe uneapplication uS : C → R et ν S telles que :
– ν S est une capacité sur 2S ; – S peut-être représentée par
U S (X ) = uS x(n)
+
n−1i=1
ν S
α(1), . . . , α(i)
uS
x(i)
− uS
x(i+1)
.
avec S = αi, 1 ≤ i ≤ n ,X = (xi, αi)1≤i≤n et le réordonnement
x(1) S C
x(2) S C
. . . S C
x(n).
De plus, pour tout support S , uS est uniqueà une transformée linéaire croissante prèset ν S est unique.
Les résultats obtenus par Tversky et Kah-neman [6] rappelés en introduction de cepapier sont compatibles avec l’inégalitésuivante
ν T ∧F, ¬(T ∧F )(T ∧ F ) > ν T, ¬T (T ).(1)
2.3 Représentation indépendante du
support et équivalence du théo-
rème 1 avec une représentation sé-
mantique
Tout d’abord nous spécifions deux condi-tions sous lesquelles les fonctions d’uti-lité et de croyance dans le théorème de re-présentation deviennent indépendantes dusupport. Pour cela nous considérons des
préférences sur des actes de support diffé-rent, ce que nous n’avions pas considéré jusque là.
Axiome 6 (Réduction). Pour tout couplede supports (S, S ) ∈ S 2 , pour toute
conséquence c ∈ C , cS ∼ cS .
Sous cet axiome, nous notons C la rela-tion binaire – commune à tous les supports– ordonnant C .
Axiome 7 (Saillance des gains). Soit uncouple de supports (S, S ) ∈ S 2
tels que S ∩ S = ∅. Sans perte degénéralité, nous supposons que S =(α1, . . . ,αk, αk+1, . . . , αn) et S =(α1, . . . , αk, α
k+1, . . . , αm). Alors
(c, α1; . . . ; c, αk; c, αk+1; . . . ; c, αn) ∼c, α1; . . . ; c, αk; c, αk+1; . . . ; c, αm
.
Sous ces deux axiomes supplémentaires, lethéorème de représentation devient
Représentations syntaxique et sémantique d'un acte ___________________________________________________________________________
352

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 365/415
Proposition 2. Les axiomes 1 à 7 sont sa-tisfaits si et seulement si il existe une appli-cation u : C → R et ν :
S ∈S 2S → R
telles que : – ν restreint à 2S est une capacité ; – peut-être représentée par
U (X ) = ux(n)
+
n−1i=1
ν
α(1), . . . , α(i)
ux(i)
− u
x(i+1)
.
avec S = αi, 1 ≤ i ≤ n ,X = (xi, αi)1≤i≤n et le réordonnement x(1) C x(2) C . . . C x(n).
De plus, u est unique à une transforméelinéaire croissante près et ν est unique.
Nous pouvons sous ces deux axiomes sup-plémentaires proposer une représentationsémantique des préférences.
Nous nommons état du monde toute appli-cation ω : Φ → 0; 1 telle que ω() =1 et ω(⊥) = 0. Nous notons (ωv, ωf ) lapartition de Φ telle que ωv = ω−1(1) etωf = ω−1(0). Un monde ω est dit– faiblement non contradictoire si pour
toute proposition ϕ ∈ Φ,
ω(ϕ) = 1 ⇒ ω(¬ϕ) = 0,
– fortement non contradictoire si pourtoutes propositions (ϕ, ϕ) ∈ Φ 2,
ϕ∧ϕ =⊥⇒ ω(ϕ) = 1 ⇒ ω(ϕ) = 0,
– complet si pour toute proposition ϕ ∈ Φ,
ω(ϕ) = 0 ⇒ ω(¬ϕ) = 1,
– possible s’il est à la fois fortement noncontradictoire et complet.
Ω désigne l’ensemble des états du mondeet ΩP le sous ensemble des mondespossibles. Enfin, pour toute propositionψ ∈ Ψ, nous notons ψ ω ∈ Ω | ψ ∈ ωv.
Définition 4. Soit X un acte dont le sup- port σ(X ) = (αi)i∈I . Le représentant sé-mantique de l’acte X , notée f X , est l’ap-
plication à valeurs dans C et définie sur Ω par
f X (ω) maxJ ⊆ I |
∨ j∈J α j ∈ ωv
min j ∈ J
X (α j).
Nous sommes désormais en mesure d’éta-blir un théorème de représentation despréférences exprimé dans une sémantique
proche, à tout le moins d’un point devue formel, des modèles de décision clas-siques.Proposition 3. Si les axiomes 1 à 7 sont satisfaits alors il existe une capacité µ :2Ω → [0; 1] telle que la représentation U de la proposition 2 peut se récrire comme
U (X ) =
Ω
u f X dµ.
Dans cette représentation sémantique, leproblème de Linda se transcrit dans lestermes suivants :
µ ( T ∧ F ) > ν ( T ) . (2)
Les sujets accordent un poids plus impor-tant à l’évenement ( T ∧ F ) qu’à l’évé-nement ( T ) µ étant une capacité, nousen déduisons qu’il est nécessaire que T ∧
F T .Cecin’estpaspossibledanslesous ensemble des mondes possibles. Celasignifie qu’il est nécessaire que les sujetsconsidèrent comme possible des mondesω∗ ∈ T ∧ F tel que ω∗ /∈ T , c’est àdire des mondes logiquement impossibles.
3 Application
3.1 Comportement par rapport à l’in-certain
On peut dans le cadre proposé caractéri-ser les comportements dans l’incertain en
____________________________________________________________________________ Annales du LAMSADE N°8
353

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 366/415
retranscrivant les définitions proposées parSchmeidler [5].
Définition 5. Un agent
– est averse à l’incertain si pour tous actesX et X définis sur le même support,X ∼ X ⇒ αX + (1 − α)X X
pour tout α ∈ [0, 1] – est neutre à l’incertain si pour tous actes
X et X définis sur le même support,X ∼ X ⇒ αX + (1 − α)X ∼ X
pour tout α ∈ [0, 1] – aime l’incertain si pour tous actes X et
X définis sur le même support, X ∼
X
⇒ αX + (1 − α)X
X pour tout α ∈ [0, 1]
Proposition 4. Sous les conditions de la proposition 1, un agent – est averse à l’incertain ssi pour tout sup-
port S , ν S est une capacité convexe sur 2S ,
– est neutre à l’incertain ssi pour tout sup- port S , ν S est une mesure additive sur 2S ,
– aime l’incertain ssi pour tout support S ,ν S est une capacité concave sur 2S ,
Sous les axiomes supplémentaires de la proposition 3, si un agent – est averse à l’incertain alors il existe une
capacité convexe µ : 2Ω → [0; 1] qui re- présente ses croyances sur les mondes,2S ,
– est neutre à l’incertain alors il existe unemesure additive µ : 2Ω → [0; 1] qui re-
présente ses croyances sur les mondes, – aime l’incertain alors il existe une capa-
cité concave µ : 2Ω → [0; 1] qui repré-sente ses croyances sur les mondes.
Watson est un agent qui bien qu’ayantdes capacités déductives défaillantes peutnéanmoins avoir des croyances probabi-listes.
Exemple 1 (Watson). Supposons que les préférences de Watson soient représen-tables par un modèle sémantique où sescroyances sont telles qu’il considère équi-
probables deux mondes. Le monde ω1 est
un monde possible avec ωv1 qui contient
¬A ∧ ¬I ainsi que toutes les proposi-tions qui s’en déduisent logiquement alorsque ω2 est un monde impossible avec
¬A , I , I → A, ¬A ∧ I ⊂ ωv2 .
En ce qui concerne le support S =(A ∧ I, A ∧ ¬I, ¬A ∧ I, ¬A ∧ ¬I ) , ν est
une mesure additive sur 2S avec ν (¬A ∧I ) = ν (¬A∧¬I ) = 1
2et ν (A∧I ) = ν (A∧
¬I ) = 0. Par ailleurs, nous vérifions queν (A) = 0 , ν (¬A) = 1 , ν (I ) = ν (¬I ) =12 , ν (I → A) = 1 et ν [¬(I → A)] = 0.
3.2 Caractérisation de la rationalitécognitive
Quelles sont les caractéristiques d’unagent qui ne souffre pas de limitation cog-nitive, c’est à dire dont les croyances cer-taines sont logiquement cohérentes? In-tuitivement, on se doute qu’il s’agit d’unagent qui reconnaît les équivalences lo-
giques. Pour traduire ceci axiomatique-ment, nous définissons tout d’abord unenotion d’acte logiquement équivalent.
Définition 6. Soient X et X deux actes.On dira que X et X sont logique-ment équivalents si pour tout c ∈ C
∨α∈σ(X )(c)α ≡ ∨α∈σ(X )(c)α
Axiome 8 (Omniscience logique). Soient X et X deux actes. Si X et X sont logi-
quement équivalents alors X ∼ X
On peut remarquer que cet axiome im-plique les axiomes 6 et 7.
Proposition 5. Sous les conditions de la proposition 1, un agent vérifie l’axiome 8 ssi
– pour tout support S = (αi)i∈I , pour tout
J ⊂ I , ν (∨ j∈J α j) = ν (α j) j∈J ;
– pour toute représentation sémantiqueµ des croyances de l’agent, pour tout
proposition ϕ ∈ Φ , µ ( ϕ ) =µ ϕ ∩ ΩP
.
Représentations syntaxique et sémantique d'un acte ___________________________________________________________________________
354

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 367/415
Exemple 2 (Watson (suite)). Si nous re- prenons l’exmple précédent, nous consta-tons que µ ( I ) = µ (ω2) = 1
2= 0 =
µ I ∩ Ω
P .
4 Conclusion
Le cadre formel proposé nous permet dereprésenter les préférences dans l’incer-tain d’agents ayant une rationalité cogni-tive limitée. Ceci nous permet de distin-guer deux niveaux épistémiques différents
chez l’agent : celui de son savoir, c’est-à-dire ses croyances certaines, et celui deses degrés de croyance. Avoir une ratio-nalité cognitive parfaite, c’est avoir descroyances qui traduisent de l’omnisciencelogique. Traditionnellement en théorie dela décision, on considère qu’un agent estrationnel s’il est bayésien. Nous avonssuggéré qu’un agent pouvait être bayésientout en ayant une rationalité cognitive limi-
tée. Ceci revient à considérer que la ratio-nalité bayésienne est une rationalité d’unautre ordre. De fait, les arguments norma-tifs avancés pour le bayésianisme est queseul un agent bayésien est rationnel dansun processus de décision séquentiel avecacquisition d’information. Un objectif fu-tur de nos travaux est de montrer que desaxiomes de cohérence dynamique n’im-pose pas à l’agent d’avoir une rationalitécognitive parfaite.
Références
[1] Brian F. Chellas, (1980), Modal logic : an in-troduction. Cambridge University Press.
[2] Geanakoplos, J. (1989), Game Theory Wi-thout Partitions, and Applications to Specula-tion and Consensus, Cowles Foundation Dis-cussion Papers No. 914, Cowles Foundation,Yale University .
[3] Hintikka, J. (1975), ‘Impossible PossibleWorlds Vindicated’, Journal of Philosophical Logic 4(4), 475–84.
[4] Savage, L. (1972), The Foundations of Statis-tics, Dover Publications INC., New York.
[5] Schmeidler, D. (1989), ‘Subjective Probabilityand Expected Utility without Additivity’, Eco-nometrica 57(3), 571–87.
[6] Tversky, A., Kahneman, D. (1983), ‘Extensio-nal Versus Intuitive Reasoning : The Conjunc-tion Fallacy in Probability Judgment’, Psycho-
logical Review 90(4), 293–315
____________________________________________________________________________ Annales du LAMSADE N°8
355

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 368/415

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 369/415
The hedgehog and the foxAn argumentation-based decision support system
Maxime Morge†
Paolo Mancarella†
†Dipartimento di InformaticaUniversity of Pisa
Largo B. Pontecorvo, 3 I-56127 Pisa, Italy
Résumé :
Nous présentons dans cet article un Systèmed’Aide à la Décision (SDA). À cette intention,nous proposons un cadre d’argumentation pour leraisonnement pratique. Celui-ci s’appuie sur unlangage logique qui sert de stucture de donnéesconcrète afin de représenter les connaisances, lesbuts et les décisions possibles. Différentes priori-tés y sont associées afin de de représenter la fia-bilité des connaisances, les préférences de l’uti-lisateur, et l’utilité espérée des alternatives. Cesstructures de données constitue l’épine dorsale desarguments. De part la nature abductive du rai-sonnement pratique, les arguments sont construitsà partir des conclusions. De plus, nous les défi-nissons comme des structures arborescentes. De
cette manière, notre SDA suggère à l’utilisateur lesmeilleures solutions et propose une explication in-teractive et compréhensible de ce choix.
Mots-clés : Intelligence artificielle, Raisonnementpratique, Argumentation
Abstract:
We present here a Decision Support System (DSS).For this purpose, we propose an ArgumentationFramework for practical reasoning. A logic lan-guage is used as a concrete data structure for hol-ding the statements like knowledge, goals, and ac-tions. Different priorities are attached to these itemscorresponding to the reliability of the knowledge,the preferences between goals, and the expectedutilities of alternatives. These concrete data struc-tures consist of information providing the back-bone of arguments. Due to the abductive nature of practical reasoning, we build arguments by reaso-ning backwards. Moreover, arguments are definedas tree-like structures. In this way, our DSS sug-gests some solutions and provides an interactiveand intelligible explanation of the choices.
Keywords: Artificial Intelligence, Practical reaso-ning, Argumentation
1 Introduction
Decision making is the cognitive process
leading to the selection of a course of ac-tion among alternatives based on estimatesof the values of those alternatives. Indeed,when a human identifies her needs andspecifies them with high-level and abstractterms, there should be a way to select anexisting solution. Decision Support Sys-tems (DSS) are computer-based systemsthat support decision making activities in-cluding expert systems and Multi-Criteria
Decision Analysis (MCDA). In this paper,we propose a DSS which suggests somesolutions and provides an interactive andintelligible explanation of the choices.
In this paper, we present our Decision Sup-port System (DSS). This computer sys-tem is built upon an Argumentation Fra-mework (AF) for decision making. For thispurpose, we consider practical reasoningas the vehicle of decision making, whichis a knowledge-based, goal-oriented, andaction-related reasoning. A logic languageis used as a concrete data structure forholding the statements like knowledge,goals, and actions. Different priorities areattached to these items corresponding tothe reliability of the knowledge, the pre-ferences between goals, and the expec-ted utilities of alternatives. These concretedata structures consist of information pro-
viding the backbone of arguments. Dueto the abductive nature of practical reaso-ning, arguments are built by reasoning ba-ckwards. Moreover, arguments are definedas tree-like structures. In this way, our DSS
357

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 370/415
suggests some solutions, as other classi-cal approaches, but also provides an inter-active and intelligible explanation of thischoice.
Section 2 presents the principle and thearchitecture of our DSS. Section 3 intro-duces the walk-through example. In orderto present our Argumentation Framework(AF) for decision-making, we will browsethe following fundamental notions. First,we define the object language (cf Sec-tion 4). Second, we will focus on the inter-nal structure of arguments (cf Section 5).
We present in Section 6 the interactionsamongst them. These relations allow usto give a declarative model-theoretic se-mantics to this framework and we adopt adialectical proof procedure to implementit (cf Section 7). Section 8 draws someconclusions and directions for future work.
2 Principle and architecture
Basically, decision makers are categorizedas either “hedgehogs”, which know onebig thing, or “foxes”, which know manylittle things [1]. While most of the DSS areaddressed to “hedgehogs”, we want to pro-vide one for both.
An “hedgehog” is an expert of a particu-lar domain, who has intuitions and strongconvictions. A “fox” is not an expert but
she knows many different thinks in dif-ferent domains. She decides by interac-ting with other and she is able to changeher mind. Most of the DSS are addres-sed to “hedgehogs”. These computer sys-tems provide a way to express qualitativeand/or quantitative judgements and syn-thesizes them to suggest an action. Ho-wever the analytic skills needed for good judgments are those of foxes. We want toprovide a DSS for the effective manage-ment of teams including both hedgehogsand foxes.
The current architecture of our DSS ba-sed upon an assistant agent. The mind of
the agent relies upon an argumentative en-gine. The system only communicates withthe users, i.e. the hedgehog and the fox,and the latter takes the final decision. Onone side, the hedgehog informs the assis-tant agent in order to structure the deci-sion making problem, to consider the dif-ferent needs, to identify the alternatives,and to gather the required knowledge. Onthe other side, the fox can ask for a pos-sible solution (question). The argumenta-tive engine suggests some solutions (as-sert ). The reasons supporting these admis-sible solutions can be interactively explo-
red (challenge/argue).
3 Walk-through example
We consider here the decision making pro-blem for selecting a suitable business loca-tion.
The assistant agent is responsible for sug-
gesting some suitable locations, based onthe explicit users’needs and on their know-ledge. The main goal, that consists in se-lecting the location, is addressed by a de-cision, i.e. a choice between some alterna-tives (e.g. Pisa or London). The main goal(g0) is split into sub-goals and sub-goals of these sub-goals, which are criteria for eva-luating different alternatives. The locationmust offer a “good” regulation (g1) and a“great” accessibility (g
2). These are abs-
tract goals, revealing the user’s needs. Theknowledge about the location is expressedwith predicates such as : Sea(x) (the lo-cation is accessible by sea transports), orRoad(x) (the location is accessible by roadtransports).
Figure 1 provides a simple graphical re-presentation of the decision problem calledinfluence diagram [2]. The elements of the
decision problem, i.e. values (representedby rectangles with rounded corners), deci-sions (represented by squares) and know-ledge (represented by ovals), are connec-ted by arcs where predecessors are inde-
The hedgehog and the fox: an argumentation-based decision support system ___________________________________________________________________________
358

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 371/415
pendent and affect successors. We consi-der here a multiattribute decision problemcaptured by a hierarchy of values wherethe abstract values (represented by rec-tangles with rounded corner and doubleline) aggregate the independent values inthe lower levels. While the influence dia-gram displays the structure of the decision,the object language reveals the hidden de-tails of the decision making.
Recommended location (g0)
Regulation (g1) Accessibility (g2)
Taxes (g3) Permit (g4) Assistance (g5) Sewage (g6) Transport (g7)
Decision
Sea ? Road ?
FIG . 1 – Influence diagram to structure thedecision
4 The object language
Since we want to provide a computatio-nal argumentation model of practical rea-soning and we want to instantiate it for oursimple case study, we need to specify aparticular logic.
The object language expresses rules andfacts in logic-programming style. In orderto address a decision making problem, Wedistinguish :– a set of goals, i.e. some propositional
symbols which represent the featuresthat the decision must exhibit (denotedby g0, g1, g2, . . . ) ;
– a decision, i.e. a predicate symbol whichrepresents the action which must be per-formed (denoted by D) ;
– a set of alternatives, i.e. some constantssymbols which represent the mutually
exclusive solutions for the decision(e.g. pisa or london) ;
– a set of beliefs, i.e. some predicate sym-bols which represent epistemic state-ments (denoted by words such as Sea,or Road).
Since we want to consider conflictinggoals, mutual exclusive alternatives, andcontradictory beliefs in this object lan-guage, we need some form of negation.For this purpose, we consider strong ne-gation, also called explicit or classical ne-gation. Since we restrict ourselves to lo-gic programs, we cannot express in a com-
pact way the mutual exclusion between al-ternatives. For this purpose, we define theincompatibility relation (denoted by I )as a binary relation over atomic formulaswhich is symmetric. Obviously, L I ¬Lfor each atom L, and D(a1) I D(a2), a1
and a2 being different alternatives.
Definition 1 (Theory) A theory T is an
extended logic program, i.e a finite set of rules of the form R : L0 ←L1, . . . , Ln with n ≥ 0, each Li being astrong literal. The literal L0 , called thehead of the rule, is denoted by head (R).The finite set L1, . . . , Ln , called thebody of the rule, is denoted by body(R).The body of a rule can be empty. In thiscase, the rule, called a fact , is an uncondi-tional statement. R , called the name of therule, is an atomic formula.
In the theory, we distinguish :– goal rules of the form
R : g0 ← g1, . . . , gn with n > 0. Eachgi is a goal. According to this rule, thehead goal is reached if the goals in thebody are reached;
– epistemic rules of the formR : B0 ← B1, . . . , Bn with n ≥ 0. EachBi is a belief literal ;– decision rules of the formR : g ← D(a), B1, . . . , Bn with n ≥ 0.The head of this rule is a goal and thebody include a decision literal (D(a))
____________________________________________________________________________ Annales du LAMSADE N°8
359

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 372/415
and a possible empty set of belief li-terals. According to this rule, the goalcan be eventually reached by the de-cision D(a), provided that conditionsB1, . . . , Bn are satisfied.
Considering statements in the theory is notsufficient to take a decision, since all re-levant pieces of information should be ta-ken into account, such as the reliability of knowledge, the preferences between goals,or the expected utilities of the different al-ternatives. We consider that the priorityP is a (partial or total) preorder on T .R1 P R2 can be read “R1 has priority
over R2”. R1\P R2 can be read “R1 doesnot have priority over R2”, either since R1
and R2 are ex æquo (denoted R1 ∼ R2),i.e. R1 P R2 and R2 P R1, or since R1 andR2 are not comparable, i.e. ¬(R1 P R2)and ¬(R2 P R1).
In this work, we consider that all rules arepotentially defeasible and that the priori-ties are extra-logical and a domain-specific
features. The priority of concurrent rulesdepends of the nature of rules. Rules areconcurrent if their heads are the same orincompatible. We define three priority re-lations :– the priority over goal rules comes from
their levels of preference. Let us consi-der two goal rules R1 and R2 with thesame head g0. R1 has priority over R2
if the achievement of the goals in thebody of R1 are more “important” thanthe achievement of the goals in the bodyof R2 as far as reaching g0 is concerned;
– the priority over epistemic rules comesfrom their levels of certainty. Let usconsider, for instance, two concurrentfacts F 1 and F 2. F 1 has priority over F 2if the first is more likely to hold than thesecond one ;
– the priority over decision rules comesfrom the expected utilities of decisions.
Let us consider two rules R1 and R2
with the same head. R1 has priority overR2 if the expected utility of the firstconditional decision is greater than thesecond one.
TAB . 1 – The goal theory
R012 : g0 ← g1, g2
R1345 : g1 ← g3, g4, g5R267 : g2 ← g6, g7R145 : g1 ← g4, g5R01 : g0 ← g1R13 : g1 ← g3R26 : g2 ← g6R02 : g0 ← g2R14 : g1 ← g4R27 : g2 ← g7R15 : g1 ← g5
TAB . 2 – The epistemic theory
F 1 : Road( pisa) ←F 2 : Sea( pisa) ←F 3 : ¬Road( pisa) ←
In order to illustrate the notions introducedpreviously, let us go back to our example.The goal rules, the epistemic rules, andthe decision rules are represented in Table1, Table 2, and Table 3, respectively. Arule above another one has priority overit. To simplify the graphical representationof the theories, they are stratified in non-overlapping subsets, i.e. different levels.The ex æquo rules are grouped in the samelevel. Non-concurrent rules are arbitrarilyassigned to a level.
According to the goal theory in Table 1,the achievement of both g4 and g5 is re-quired to reach g1, but this constraint canbe relaxed and the achievement of g4 ismore important than the achievement of g5 to reach g1. According to the episte-mic theory in Table 2, the assistant agentdoes not know if London is accessible
by sea/road transports. Due to conflic-ting sources of information, the agent hasconflicting beliefs about the road accessi-bility of Pisa. Since these sources of infor-mation are more or less reliable, F 1 P F 3.
The hedgehog and the fox: an argumentation-based decision support system ___________________________________________________________________________
360

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 373/415
TAB . 3 – The decision theory
R32 : g3 ← D(pisa)R41 : g4 ← D(london)R51 : g5 ← D(london)R71(x) : g7 ← D(x), Sea(x)R31 : g3 ← D(london)R42 : g4 ← D(pisa)R52 : g5 ← D(pisa)R61 : g6 ← D(london)R62 : g6 ← D(pisa)R72(x) : g7 ← D(x), Road(x)
According to the decision theory in Table3, Pisa has a greater expected utility thanLondon to reach g3. The expected utilitiesof these alternatives with respect to g7 de-pends on the knowledge : a location ac-cessible by sea is preferred than a locationaccessible by road (R71 P R72). We willbuild now arguments in order to compare
the alternatives.
5 Arguments
In this Section, we define and construct ar-guments by reasoning backwards due tothe abductive nature of the practical rea-soning. Since we adopt a tree-like struc-ture of arguments, our framework not only
suggests some solutions but also providesan intelligible explanation of them.
In order to consider the recursive natureof arguments, we adopt and extend thetree-like structure for arguments proposedin [5].
Definition 2 (Argument) An argument has a conclusion, top rules, premises, sup-
positions, and sentences. These elementsare abbreviated by the corresponding prefixes. An argument A is :
1. a supposal argument built upon an un-conditional ground statement.
If L is a ground literal such that thereis no rule R in T which can be ins-tantiated in such a way that L =head (R) , then the argument, which isbuilt upon this ground literal is defined as follows :
conc(A) = L,top(A) = ∅, premise(A) = ∅,supp(A) = L,sent(A) = L.
or
2. a trivial argument built upon an un-conditional ground statement.
If F is a fact in T , then the argument A , which is built upon the ground ins-tance F g of F , is defined as follows :
conc(A) = head (F g),top(A) = F g, premise(A) = head (F g),supp(A) = ∅,sent(A) = head (F g).
or
3. a tree argument built upon an ins-tantiated rule such that all the lite-rals in the body are the conclusionof subarguments. If R is a rule in T ,we define the argument A built upona ground instance Rg of R as fol-lows. Let body (Rg) = L1, . . . , Lnand sbarg (A) = A1, . . . , An be acollection of arguments such that, for each Li ∈ body (Rg) , conc(Ai) =
Li (each Ai is called a subargument of A). Then :
conc(A) = head (Rg),top(A) = Rg, premise(A) = body (Rg),supp(A) = ∪A′∈sbarg (A)supp(A′),sent(A) = ∪A′∈sbarg (A)sent(A′)
∪ body (Rg).The set of arguments built upon T is deno-
ted A(T ).
As in [5], we consider atomic arguments(2) and composite arguments (3). Moreo-ver, we distinguish supposal arguments (1)
____________________________________________________________________________ Annales du LAMSADE N°8
361

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 374/415
and built arguments (2/3). Due to the ab-ductive nature of practical reasoning, wedefine and construct arguments by reaso-ning backwards. Therefore, arguments donot include irrelevant information such assentences not used to prove the conclusion.
Contrary to the other definitions of argu-ments (pair of premises - conclusion, se-quence of rules), our definition considersthat the different premises can be challen-ged and can be supported by compositearguments. In this way, arguments are in-telligible explanations. Triples of conclu-
sions - premises - suppositions are simplerepresentations of arguments. Let us consi-der the previous decision making example.Some of the arguments concluding g7 arethe following :–
B1 = g7, (D(pisa), Sea(pisa)),((D(pisa));
–
B2 = g7, (D(pisa), Road(pisa)),((D(pisa));
–
A1 = g7, (D(london), Sea(london)),(D(london), Sea(london));
–
A2 = g7, (D(london), Road(london)),
(D(london), Road(london)).The tree argument B1 contains twosubarguments : one supposal argument(D(pisa), ∅, (D(pisa)))) and one trivialargument (Sea(pisa), (Sea(pisa)), ∅).Due to their structure and their nature,arguments interact with one another.
6 Interactions amongst argu-
ments
The interactions between arguments maycome from their nature, from the incom-patibility of their sentences, and from the
priority relation between the top rules of built arguments. We examine in turn thesedifferent sources of interaction.
Since sentences are conflicting, argumentsinteract with one another. For this purpose,we define the attack relation. An argumentattacks another argument if the conclusionof the first one is incompatible with onesentence of the second one.
Definition 3 (Attack relation) Let Aand B be two arguments. A attacksB (denoted by attacks (A, B)) iff
conc(A) I sent(B).
This attack relation, often called under-mining attack, is indirect, i.e. directed toa “subconclusion”. The attack relation isuseful to build an argument which is an ho-mogeneous explanation.
Due to the nature of argument, argumentsare more or less hypothetical.
Definition 4 (Supposition size) Let A bean arguments. The size of suppositions
for A , denoted suppsize(A) , is defined such that :
1. if A is a supposal argument, thensuppsize(A) = 1 ;
2. if A is a trivial argument, thensuppsize(A) = 0
3. if A is a tree argument and sbarg (A) = A1, . . . , An isthe collection of subargumentsof A , then suppsize(A) =ΣA′∈sbarg (A)suppsize(A′).
Since arguments have different natures(supposal or built) and the top rules of builtarguments are more or less strong, they in-teract with one another. For this purpose,
we define the strength relation.
Definition 5 (Strength relation) Let A1
be a supposal argument, and A2, A3 betwo built arguments.
The hedgehog and the fox: an argumentation-based decision support system ___________________________________________________________________________
362

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 375/415
1. A2 is stronger than A1 (denoted A2 P A A1) ;
2. If (top(A2) P top(A3)) ∧
¬(top(A3) P top(A2)) , thenA2 P A A3 ;
3. If (top(A2)\P top(A3)) ∧(suppsize(A2) ≤suppsize(A3)) , then A2 P A A3 ;
Since P is a preorder on T , P A is apreorder on A(T ). The strength relation isuseful to choose (when it is possible) bet-
ween homogeneous concurrent explana-tions, i.e. non conflicting arguments withthe same conclusions.
The two previous relations can be com-bined to choose (if possible) betweennon-homogeneous concurrent explana-tions, i.e. conflicting arguments withthe same conclusion or with conflictingconclusions.
Definition 6 (Defeats) Let A and B betwo arguments. A defeats B (writtendefeats (A, B)) iff :
1. attacks (A, B) ;
2. ¬(B P A A).
Similarly, we say that a set S of argumentsdefeats an argument A if A is defeated byone argument in S .
By definition, two equally relevant argu-ments both defeat each other.
Let us consider our previous example.The arguments in favor of London (A1
and A2) and the arguments in favor of Pisa (B1 and B2) attack each other. Sincethe top rule of A1 and B1 (i.e. R71)
has priority over the top rule of A
2
andB2 (i.e. R72), and suppsize(B1) =suppsize(B2) = 1 andsuppsize(A1) = suppsize(A1) = 2,B1 (resp. A1) defeats A2 (resp. B2) and
B1 is stronger than A1. If we only considerthese four arguments, the assistant suggestPisa and justify it with the availability of sea transports. In this section, we have de-fined the interactions between argumentsin order to give them a status. Determiningwhether a solution is ultimately sugges-ted requires a complete analysis of allarguments and subarguments.
7 Semantics and procedures
We can consider our AF abstracting away
from the logical structures of argumentsand equip it with various semantics, whichcan be computed by dialectical proof pro-cedures.
Given an AF, [3] defines the following no-tions of “acceptable” sets of arguments :
Definition 7 (Semantics) An AF is a pair A, defeats where A is a set of argu-
ments and defeats ⊆ A × A is the defeat relationship1 for AF. For A ∈ A an argu-ment and S ⊆ A a set of arguments, wesay that :
– A is acceptable with respect to S (denoted A ∈ S S A) iff ∀B ∈A, defeats (B, A) ∃C ∈ S such that defeats (C, B) ;
– S is conflict-free iff ∀A, B ∈S ¬ defeats (A, B) ;
– admissible iff S is conflict-free and ∀A ∈ S, A ∈ S S A ;
The admissible semantics sanctions a setof arguments as acceptable if it can suc-cessfully dispute every arguments againstit, without disputing itself. However, theremight be several conflicting admissiblesets. Since a DSS involves an ultimatechoice of the user between various admis-sible set of alternatives, we adopt this se-mantics. The decision D(a1) is suggested iff D(a1) is a supposition of one argument
1Actually, in [3] the defeat relation is called attack.
____________________________________________________________________________ Annales du LAMSADE N°8
363

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 376/415
in an admissible set. Let us focus on thegoal g6 in the previous example, i.e. on thefollowing theory T = R62, R61. SinceA3 = g
6, (D(london)), (D(london))
and B3 = g6, (D(pisa)), (D(pisa))are both admissible, Pisa and London mustbe suggested as different alternatives toreach g6.
Since our practical application requires tospecify the internal structure of arguments,we adopt the procedure proposed in [4] tocompute admissible arguments. If the pro-cedure succeeds, we know that the argu-
ment is contained in a preferred set.
We have implemented our AF, calledMARGO2 (Multiattribute ARGumenta-tion framework for Opinion explanation).For this purpose, we have translated ourAF in an assumption-based AF (ABF forshort). CaSAPI3 computes the admissiblesemantics in the ABF by implementing theprocedure proposed in [4]. Moreover, we
have developed a CaSAPI meta-interpreterto relax constraints on the goals achie-vements and to make suppositions in or-der to compute the admissible semanticsin our concrete AF. In this section, wehave shown how arguments in the frame-work can be categorized in order to sug-gest some solutions.
8 Conclusions
In this paper we have presented a DSSwhich suggests some solutions and pro-vides an interactive and intelligible ex-planation of these choices. For this pur-pose, we have proposed and implemen-ted a concrete AF for some applicationsof practical reasoning. A logic languageis used as a concrete data structure for
holding the statements like knowledge,goals, and actions. Different priorities areattached to these items corresponding to
2https ://margo.sourceforge.net/ 3http ://www.doc.ic.ac.uk/ ∼dg00/casapi.html
the reliability of the knowledge, the pre-ferences between goals, and the expec-ted utilities of alternatives. These concretedata structures consist of information pro-viding the backbone of arguments. Dueto the abductive nature of practical reaso-ning, arguments are built by reasoning ba-ckwards. To be intelligible, arguments aredefined as tree-like structures. Due to theirnature, the incompatibility of their sen-tences, and the priority relation betweenthe top rules of built arguments, the ar-guments interact with one another. Sincea DSS involves an ultimate choice of the
user between various admissible set of al-ternatives, we have adopted an admissiblesemantics. Future investigations must ex-plore how this proposal scales to driveargumentation-based negotiations.
9 Acknowledgements
This work is supported by the Sixth Fra-mework IST programme of the EC, un-der the 035200 ARGUGRID project. Wewould like to thank the anonymous revie-wers for their detailed comments on thispaper.
Références
[1] Sir Isaiah Berlin. The Hedgehog and the Fox. Simon & Schuster, 1953.
[2] Robert Taylor Clemen. Making Hard Decisions. Duxbury. Press, 1996.[3] Phan Minh Dung. On the acceptability
of arguments and its fundamental rolein nonmonotonic reasoning, logic pro-gramming and n-person games. Artif.
Intell., 77(2) :321–357, 1995.[4] Phan Minh Dung, Paolo Mancarella,
and Francesca Toni. A dialectic pro-cedure for sceptical, assumption-based
argumentation. In Proc. of COMMA.IOS Press, 2006.[5] Gerard Vreeswijk. Abstract argu-
mentation systems. Art. Intel., 90(1-2) :225–279, 1997.
The hedgehog and the fox: an argumentation-based decision support system ___________________________________________________________________________
364

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 377/415
Interactions Collaboratives en Situations Co-localisée et Distante
Alexandre Pauchet François Coldefy Liv Lefebvre Stéphane Louis Dit Picard
Arnaud Bouguet Laurence Perron Joël Guerin Daniel Corvaisier Michel Collobert
France Télécom R&D, 2 Av. Pierre Marzin, 22307 Lannion[alexandre.pauchet, francois.coldefy]@orange-ftgroup.com
Résumé :Les Mixed Presence Groupware (MPG) désignentla connexion de plusieurs interfaces partagées envue d’une collaboration distante. Nous essayonsde répondre à la question suivante : pouvons-nouscollaborer efficacement en médiatisant les interac-tions par MPG ? Afin de réduire le fossé existant
entre interactions distante et co-localisée, la plate-forme DIG ITABLE a été conçue. Une étude des in-teractions collaboratives durant une tâche d’assem-blage de mosaïques sur DIG ITABLE est présentéeici. Bien que DIG ITABLE n’apporte pas le mêmesentiment de présence en situations distante et co-localisée, la collaboration à distance ne semble plusentravée par la médiatisation des interactions.
Mots-clés : Interactions médiatisées, collaboration,interfaces partagées
Abstract:
Mixed Presence Groupwares (MPG) are theconnection of two or more remote shared inter-faces, for distant collaboration. We strive to answerto the question : does the mediation of interactionwith MPG enable efficient collaboration ? We pro-pose DigiTable, an experimental platform we hopelessen the gap between co-present and distant inter-action. We present an experiment using DigiTablefor a collaborative task of mosaic completion. Al-though DigiTable does not provide the same pre-sence feeling in distant and or co-localized situa-tion, it seems that mediation of interaction does nothinder collaboration anymore.
Keywords: Mediation of interaction, collabora-tion, shared interfaces
1 IntroductionL’utilisation de systèmes de communi-cations médiatisés permet de limiter lenombre de déplacements professionnels.Cependant, certaines tâches sont difficilesà réaliser à distance avec la même ai-
sance qu’en co-présence. Il est donc né-cessaire de développer des outils géné-riques supportant une interaction collabo-rative de qualité. Le paradigme "une per-sonne, un ordinateur" des interfaces per-
sonnelles n’est pas adapté à la communi-cation verbale directe. Avec les interfacespartagées, les données sont accessibles àtous simultanément et le phénomène detour si artificiel avec les systèmes person-nels disparaît. L’objectif est de concevoirdes interfaces partagées qui permettent unecollaboration distante de qualité : l’interac-tion distante médiatisée doit se rapprocherde l’interaction co-localisée.
Nous nous intéressons aux interactionscollaboratives entre groupes distants etaux Mixed Presence Groupware (MPG)[4] (groupe constitué de personnes co-localisées et distantes), via la connexion
d’interfaces partagées distantes. La col-laboration distante doit préserver la flui-dité des interactions et la conscience si-tuationelle qui existe en co-présence. Sui-vant les recommandations de Tang et al.[13], nous nous concentrons en particuliersur la visualisation des gestes d’un utilisa-teur distant. Les gestes distants permettentde transmettre des informations indispen-sables à la communication, comme l’iden-tité des actions (qui fait quoi), l’intention-nalité (qui a l’intention de faire quoi) etla désignation. Une nouvelle plate-formecollaborative baptisée DIGITABLE est pro-posée ici. Elle combine une table tactilepermettant à plusieurs utilisateurs d’agirsimultanément, un système de communi-cation vidéo permettant la visualisation àtaille réelle de l’interlocuteur distant et lecontact visuel, un système de son spatia-lisé pour transmettre les interactions orales
et un module de vision par ordinateur afinde reproduire le geste distant. La ques-tion soulevée dans cet article est la sui-vante : ce type d’outil permet-il de colla-borer à distance aussi efficacement qu’en
365

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 378/415
co-présence ? Les situations distante et co-localisée sont comparées en termes d’effi-cacité au cours d’une tâche collaborative etdu sentiment de présence.
Cet article est organisé comme suit : la sec-tion 2 présente un état de l’art sur l’inter-action médiatisée par interfaces partagéeset la collaboration distante. La section 3précise nos objectifs. La section 4 décritla plate-forme DIG ITABLE, tandis que la 5détaille l’expérimentation réalisée. Les ré-sultats de cette expérimentation sont résu-més section 6. Enfin, la section 7 est consa-
crée aux conclusions et aux travaux futurs.
2 Travaux existantsLe développement d’interfaces partagéess’appuient sur l’émergence de nouvellessurfaces de visualisation (murs-écrans,tables-écrans, etc.), et sur le développe-ment de systèmes à entrées multiples etindépendantes. En 1993, Pederson et al.[9] proposa Tivoli, tableau blanc électro-
nique supportant jusqu’à 3 utilisateurs in-teragissant simultanément par stylos élec-troniques. Stewart et al. [12] définirentle concept des Single Display Groupware(SDG) : groupe de personnes travaillantsur un même écran. Une expérimenta-tion a montré que les écoliers à qui étaitproposée une application de dessin par-tagé sur PC préféraient nettement l’implé-mentation multi-souris à la version mono-
souris. Beaucoup plus récemment, Micro-soft Research India s’est également em-paré du problème des interactions multi-souris, toujours pour l’enseignement, maisdans des pays en voie de développementdont les salles de classes ne disposent quede très peu d’équipements informatiques(un PC pour 10 utilisateur) [8]. Ils ont ainsiproposé une application permettant l’utili-sation simultanée de 5 souris.
Du point de vue des interactions engroupe, Gutwin analyse la conscience del’espace de travail dans les groupes de tra-vail distants [4]. Tang et al. [13] étendentle concept du SDG au MPG, en connectant
ensembles plusieurs SDG situés sur dessites différents. Les auteurs se concentrentsur les disparités du sentiment de pré-sence, induisant une collaboration diffé-rente entre collaborateurs co-localisés etdistants. Ils proposent de personnifier lesactions distantes à l’aide de télépointeursou d’une visualisation du geste distant.
Les tables tactiles semblent particulière-ment adaptées à la conception d’inter-faces partagées car elles permettent le tra-vail simultané de plusieurs collaborateurs,une prise de décision équitablement répar-tie et un accès à l’information identiquepour tous les participants [10]. L’utilisa-tion de tables tactiles comme dispositif d’entrées/sorties est un domaine interdis-ciplinaire émergeant intégrant réalité aug-mentée, visualisation de données, interfaceutilisateur et interaction multi-modale etmulti-utilisateurs (voir [1]). Dietz et al. [2]présentent la Diamond Touch de Merl, unetable tactile pour laquelle chaque interac-tion tactile est identifiée à un utilisateur.
Elle permet jusqu’à 8 utilisateurs d’agir si-multanément sur la table. Cependant, lesactions bi-manuelles et les contacts mul-tiples pour un même utilisateur sont limi-tés par le matériel qui ne distingue pas lesdifférents contacts mais retourne unique-ment la boîte englobant tous ces contacts.Plusieurs systèmes multi-contacts ([5], [6],etc.) existent désormais mais la DiamondTouch est actuellement la seule table tac-
tile multi-contacts commercialisée.
3 MotivationsCette étude s’intéresse aux interactionscollaboratives entre groupes distants etvise à concevoir une plate-forme préser-vant au mieux les caractéristiques du face-à-face co-localisé. Notre approche s’ap-puie sur les travaux de Gutwin [4] surl’analyse de la conscience de l’espace
de travail, la conscience situationelle (si-tuational awareness), la communicationconséquentielle (consequential communi-cation) et l’arrière plan conversationnel(conversational grounding).
Interactions collaboratives en situations co-localisée et distante ___________________________________________________________________________
366

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 379/415
La conscience situationnelle est la recon-naissance des modifications de l’environ-nement par la perception de l’environ-nement et de l’activité des autres utili-sateurs. Elle s’appuie sur la communica-tion conséquentielle, les artefacts de ma-nipulation, et la communication intention-nelle. La communication conséquentielleest l’information qui émerge de l’activitéd’une personne. Elle est non intentionnelleet se transmet par la canal visuel (position,mouvements des mains, etc). Les artefactssont la seconde source d’information surles actions courantes (e.g. le son caracté-
ristique d’une action). Enfin, la communi-cation intentionelle, à travers la conversa-tion et les gestes, complète les informa-tions communicationnelles. La consciencesituationelle permet la mise à jour des mo-dèles mentaux de l’environnement et la re-présentation les objets de la tâche et desactivités. Elle facilite la planification de cequi doit être dit ou fait ainsi que la coordi-nation du discours et des actions.
Les informations visuelles participentgrandement à la communication, en per-mettant aux personnes de s’assurer que lesmessages sont compris correctement, no-tamment grâce aux informations fourniespar les expressions verbales (e.g. un mar-monnement) ou non verbales (e.g. un ho-chement de tête). Elles facilitent la consti-tution d’un arrière plan commun et la com-préhension mutuelle des interlocuteurs. Il
y a très peu de travaux concernant l’ap-port des informations visuelles sur la réali-sation d’une tâche collaborative.
Nous cherchons à concevoir une plate-forme collaborative qui préserve laconscience situationelle entre groupesdistants, afin de favoriser une interactionde qualité. La plate-forme DIG ITABLE
que nous proposons s’articule autourd’une Diamond Touch de Merl [2] comme
interface partagée. L’utilisation d’unetable tactile est motivée par le fait quel’interaction autour d’une table est équi-tablement répartie entre participants [10].A cette table tactile s’ajoutent un système
de communication vidéo permettant lavisualisation l’interlocuteur et un modulede vision afin de reproduire le gestedistant. Ces deux informations visuellesparticipent, nous l’espérons, à transmettredes informations visuelles pertinentesfavorisant conscience mutuelle et senti-ment de présence. Elles permettent auxutilisateurs d’identifier précisément quifait quoi, et participent ainsi à la compré-hension et à l’anticipation des actions desparticipants distants. La plupart des règlessociales sont conservées, et les conflitsinvolontaires à propos de la disponibilité
des objets sont évités. Enfin, la communi-cation intentionnelle est possible car lesparticipants peuvent pointer vers un objetpour le désigner ou expliquer une action.
4 La plate-forme DIGITABLEDIG ITABLE est une plate-forme com-binant une table-écran tactile multi-utilisateurs (la Diamond Touch [2]), unsystème de communication vidéo permet-
tant le contact visuel et la visualisationà échelle réelle de l’utilisateur distant,un module de vision par ordinateur pourla visualisation du geste distant et unsystème de son spatialisé (voir FIG . 1).
FIG . 1 – DIG ITABLE intègre une DiamondTouch, un système de communication vidéo, unsystème de son spatialisé et un module de visionpar ordinateur.
La Diamond Touch de Merl [2] est une
____________________________________________________________________________ Annales du LAMSADE N°8
367

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 380/415
dalle tactile passive sur laquelle l’imagede l’application informatique est projetéepar le haut à l’aide d’un vidéo-projecteur(vidéo-projecteur 1 de la FIG . 1).
Le système de communication vidéo uti-lise une caméra espion cachée dans unpanneau de bois servant d’écran. Cettecaméra pointe vers l’utilisateur à traversun trou de 3mm de diamètre. Un secondvidéo-projecteur (vidéo-projecteur 2 de laFIG . 1) projette sur l’écran la vidéo captu-rée par la caméra cachée de façon symé-trique sur le site distant. Le contact visuel
est garanti en positionnant la caméra à hau-teur des yeux d’une personne assise.
Le module de vision utilise une camérapointant vers la table. Un processus de seg-mentation détecte tout objet placé sur latable en comparant l’image capturée par lacaméra et l’image projetée sur la table dubureau. Il produit un masque des objets dé-tectés extrait de l’image de la caméra. Cemasque est envoyé à travers le réseau vers
le site distant. A distance, l’image est ajou-tée à l’image du bureau avant d’être proje-tée sur la table. Ce module de vision estsimilaire à celui utilisé dans VideoArms[13], mais probablement plus robuste.
La FIG . 2 montre les gestes de 2 utili-sateurs et leur représentation sur le sitedistant. L’image en bas à gauche montrel’image en provenance du site 2 (imageen haut à droite). L’image en bas à droite
montre la représentation des gestes du site1 (image en haut à gauche).
5 Étude utilisateurUne application d’assemblage de mo-saïques a été conçue comme tâche expé-rimentale. Les résolutions collaborativesde mosaïques, effectuées par 2 utilisateursen situations distante et co-localisée, sontcomparées. Les objectifs sont de com-
prendre les effets de la médiatisation entermes d’expérience utilisateur et de cri-tères pertinents comme l’efficacité à réa-liser la tâche, la progression de l’activité,les accès et l’utilisation des ressources et la
FIG . 2 – Visualisation du geste distant : en haut,vue des tables distantes et en bas, vue des imagesprojetées sur les bureaux. L’application concernel’assemblage collaboratif de mosaïques.
collaboration. Nous nous intéressons aussià l’impact de l’orientation des objets sur lacoordination selon la configuration colla-borative (côte-à-côte ou face-à-face).
Les mosaïques sont composées de piècescarrées. L’assemblage de puzzles textuels
sur table a déjà été étudié par Kruger et al.[7], qui ont observé 3 rôles dans l’orien-tation des pièces : la compréhension (ex :lecture), la coordination (un espace privéimplicite est créé en orientant une piècevers soi) et la communication (l’orienta-tion d’une pièce vers un autre utilisateur envue d’attirer son attention). Nous souhai-tons étendre leurs travaux à l’assemblagede mosaïques digitales en situations co-
localisée et distante médiatisée.En situation co-localisée, les utilisateurssont assis côte-à-côte au bord d’une Dia-mond Touch, car c’est la configuration laplus naturelle pour une tâche d’assemblagede puzzles. En situation distante, les uti-lisateurs sont virtuellement face-à-face, dechaque côté de la table, et utilisent la plate-forme DIGITABLE. Nous pensons que cetarrangement est le plus agréable pour la
communication distante car il est compa-tible avec le système de communication vi-déo mis en place. De plus, nous suivonsen cela les recommandations de Tang [14]pour qui la collaboration face-à-face appa-
Interactions collaboratives en situations co-localisée et distante ___________________________________________________________________________
368

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 381/415
raît plus adaptée pour les interactions ver-bales et non-verbales. Enfin, cette situationcorrespond à une configuration littérale-ment située [4], i.e. une situation représen-tant littéralement (non symbolique) des in-formations visuelles distantes sur l’espacede travail, à l’endroit où elles se situent.Elle est cohérente avec la manière dontles gens interagissent habituellement, im-pliquant un mécanisme perceptuel de feed-through1, d’information conséquentielle etla communication gestuelle [4].
L’expérimentation réalisée est l’assem-
blage en binôme de 6 mosaïques, 3 en si-tuation co-localisée et 3 en situation dis-tante. Les mosaïques sont composées de5x5 pièces carrées. Pour chaque situation,3 types différents de mosaïques sont as-semblées (abstraite, figurative et textuelle).Une mosaïque textuelle représente un texte(ici un poème) : l’orientation "correcte"de chaque pièce est facilement reconnue àl’aide des mots et de la ponctuation. Unemosaïque figurative représente une scèneou un portrait : l’orientation correcte dechaque pièce est plus ambiguë et peut né-cessiter l’assemblage de plusieurs piècesavant d’être connue. Une mosaïque abs-traite représente une peinture abstraite ouune fractale : la seule contrainte pour lespièces est qu’elles aient toutes la mêmeorientation à la fin de l’assemblage.
Pour résoudre les mosaïques, une applica-
tion Java a été conçue pour fonctionner lo-calement et à distance sur des DiamondTouch. Deux actions sont possibles : le dé-placement et la rotation. Une pièce peutêtre déplacée le long d’une grille invisibleen touchant approximativement le centrede la pièce concernée et en la faisant glis-ser sur la table. Une pièce peut aussi êtretournée par pas de 90°, de façon à ce queses côtés restent toujours parallèles aux cô-tés de la table. Pour cela, l’utilisateur doit
sélectionner l’un des 4 coins de la pièce1Comme Dix et al. le remarquent [3], quand des objets
sont manipulés, cette manipulation transmet des informations de
feedback à la personne réalisant l’action et des informations de
feedthrough aux personnes qui observent l’action en question.
et lui faire faire un mouvement de rota-tion. Une indication visuelle est fournieaux utilisateurs pour les informer de l’ac-tion qu’ils sont en train d’effectuer sur lapièce (une croix fléchée pour un déplace-ment et un cercle fléché pour une rotation).
Durant l’assemblage des mosaïques, lesbinômes ont été filmés, et leurs actions en-registrées (pièces touchées, types d’action- rotation ou déplacement, localisation etorientation de ces pièces).
12 binômes de sujets (24 sujets) ont par-ticipé à cette étude. Un binôme était
composé de 2 femmes, 6 binômes de2 hommes et 5 binômes étaient mixtes.Tous les participants étaient de catégo-rie socio-professionnelle élevée (Bac+5) etavaient une vision normale ou corrigée à lanormale. Durant l’expérimentation, l’ordrede résolution des mosaïques était contre-balancé suivant la situation (co-localiséeou distante) et le type de mosaïque (abs-traite, figurative ou textuelle). Les binômes
de sujets ont d’abord complété individuel-lement une mosaïque d’entraînement avantl’assemblage collaboratif des 6 mosaïques.
6 Résultats6.1 Mesures objectivesEffet du type de mosaïques
Les temps d’assemblage des 3 types demosaïques ont été comparés à l’aide d’une
Anova de Friedman et une différence si-gnificative a pu être observée (F(2)=30.3,p<0.001). Les comparaisons post-hoc ontrévélé une différence significative dans lestemps d’assemblage entre chaque paire demosaïques. Les mosaïques figuratives ontété assemblées plus rapidement (M=362s,E.T.=182s) que les mosaïques textuelles(M=435s, E.T.=394s). Les mosaïques abs-traites prenaient le plus de temps (M=565s,
E.T.=394s). La même hiérarchie a été ob-servée pour les deux situations, respective-ment : (F(2)=7.64, p<0.02) en co-localiséet (F(2)=24.33, p<0.001) à distance.
Les 3 types de mosaïques ont aussi été
____________________________________________________________________________ Annales du LAMSADE N°8
369

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 382/415
comparés du point de vue des actionsavec une Anova de Friedman, et une dif-férence significative a pu être observée(F(2)=33.1, p<0.001). Les comparaisonspost-hoc ont permis de faire apparaître unedifférence significative entre chaque pairede mosaïques. Les mosaïques textuellesont été assemblées avec moins de rotations(M=29, E.T.=5) que les mosaïques figu-ratives (M=59, E.T.=31). Les mosaïquesabstraites demandaient le plus de rotationspour être assemblées (M=86, E.T.=52). Lamême observation a été faite pour les deuxsituations (co-localisée et distante) sépa-
rément. Ces différences reflètent la diffi-culté pour trouver la "bonne" orientationdes pièces des mosaïques abstraites parrapport aux autres types de mosaïques.
Effet de la situation
Pour chaque type de mosaïques et pourtoutes les mosaïques prises ensemble, untest de Wilcoxon (les données observéesne suivaient pas de loi paramétrique) aété effectué, qui n’a révélé aucune diffé-rence significative entre les temps d’as-semblage des mosaïques en co-présence(M=397s, E.T.=221s) et en situation dis-tante (M=441s, E.T.=237s).
Pour les mosaïques textuelles, aucune dif-férence significative n’a été observée surles temps de résolution, les nombres de ro-tations et de déplacements entre situationsdistante et co-localisée.
Interactions collaborativesEn situation côte-à-côte/co-localisée, lessujets utilisent une plus grande surfa-ce sur la table qu’en situation face-à-fa-ce/distante (voir FIG . 3) et les stratégiesutilisées sont différentes. En situation côte-à-côte/co-localisée, les sujets commencentpar se répartir la tâche et les pièces, puistravaillent plutôt seuls, avant de réunir lefruit de leur travail : 2 zones distinctes se
détachent sur l’image de droite. Ils inter-agissent surtout au début et à la fin de la ré-solution. En situation face-à-face/distante,les sujets travaillent plus souvent ensemblesur la même zone de la table (une seule
zone principale se distingue sur l’imagegauche FIG . 3). Les interactions se répar-tissent tout au long de la résolution.
FIG . 3 – Localisations dominantes des pièces du-rant l’assemblage des mosaïques.
L’orientation dominante des pièces de mo-saïques textuelles est différente en situa-tions côte-à-côte et face-à-face : dans lepremier cas l’orientation des pièces n’estpas conflictuelle, tandis que dans le se-cond cas les sujets négocient pour choisirune orientation qui les satisfasse. Sans au-cune surprise, en situation côte-à-côte, lespièces sont majoritairement orientées pour
pouvoir être lues par les deux sujets. Ensituation face-à-face, deux stratégies sontutilisées de façon équivalente par les su-
jets : orienter les pièces vers un des deuxsujets ou bien perpendiculairement.
6.2 Ressenti utilisateurIl a été demandé aux sujets de commen-ter leur vécu de l’expérimentation en seconcentrant sur l’application elle-même et
sur les différences qui pouvaient existerentre les situations distante et co-localisée.
L’application d’assemblage de mosaïques
A la première question ("Que pensez-vous de l’application Mosaïque ?"), les re-marques les plus courantes ont été :
– Il est parfois difficile de tourner lespièces (19 sujets).
– Il manque le déplacement simultané de
plusieurs pièces (14 sujets).– Il manque la rotation simultanée de plu-sieurs pièces (9 sujets).
Ces remarques confirment que les binômesde sujets s’étant réparti les tâches et ayant
Interactions collaboratives en situations co-localisée et distante ___________________________________________________________________________
370

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 383/415
travaillé séparément aurait aimé trouverdes outils leur permettant de réunir plus fa-cilement deux sous-parties de mosaïques.
ConfigurationsA la seconde question ("Pouvez-vous com-parer la résolution de mosaïques en si-tuations co-localisée et distante?"), les re-marques les plus courantes ont été :
– Le système de vidéo-communicationsemble inutile, alors que la sonorisationparait indispensable (14 sujets).
– Le plus gros problème a été la lecture ensituation face-à-face (distante) des mo-
saïques textuelles (13 sujets).– La représentation du geste distant est in-
téressante car elle améliore la communi-cation et transmet des informations surles intentions (7 sujets).
– Les mêmes sujets remarquent aussi qu’iln’était pas toujours évident de distinguerles mains de l’interlocuteur (7 sujets).
– 6 sujets ont trouvé l’assemblage des mo-saïques plus plaisant en situation co-
localisée, 3 en situation distante et 2sujets ont trouvé les 2 situations iden-tiques. Les autres sujets n’ont pas com-paré les deux situations en ces termes.
En raison de la tâche choisie, les sujetsn’avaient pas besoin de parler pour se co-ordonner. Ils ont donc trouvé inutile le sys-tème de vidéo-communication. Seulement6 sujets sur 24 préfèrent la collaborationen situation co-localisée, les autres sont
indifférents dans le pire des cas. Grâce àla visualisation du geste distant, la colla-boration en situations co-localisée et dis-tante sont deux expériences différentesmais tout aussi valables. Les problèmesliés à l’orientation des pièces textuellesen situation face-à-face sont plus critiques,mais ils ne sont pas dus à la médiatisationdes interactions.
6.3 DiscussionA partir des résultats issus de mesuresobjectives, aucune différence significativen’a pu être mise à jour entre les situa-tions distante et co-localisée, aussi bien
en considérant les temps de résolution,les types de mosaïques et les actions surles pièces. La collaboration entre deuxgroupes distants sur une tâche d’assem-blage de mosaïques semble être aussi ef-ficace que la collaboration co-localisée.
Cependant, les configurations distantes etco-localisées diffèrent en terme de cou-
plage. Le couplage (coupling) [11] qua-lifie le degré de collaboration entre per-sonnes. Cela peut aller du couplage faiblequand deux personnes travaillent sansavoir besoin de se transmettre d’infor-mation, jusqu’au couplage fort quand ilsdoivent collaborer. Ces différences obser-vées dans l’expérimentation peuvent êtredues à la configuration spatiale (côte-à-côte vs. face-à-face) ou à la médiatisationde l’interaction (co-localisé vs. distant). Ensituation côte-à-côte, les sujets ont ten-dance à se gêner dans la manipulation etl’accès aux pièces. Cela favorise une pre-mière phase durant laquelle les sujets es-saient d’assembler chacun une partie indé-
pendante de la mosaïque (couplage faible).Un tel couplage est limité par le fait quel’application ne facilite pas la réunion dedeux sous-parties d’une même mosaïque :il n’est pas possible de déplacer et de tour-ner en une seule fois un groupe de pièces.
Du point de vue du ressenti utilisateur,le sentiment de présence est radicalementdifférent entre situations distante et co-localisée. Cela peut être dû au fait que DI-GI TABLE respecte bien la plupart des re-commandations de Gutwin à propos de laconscience de l’espace de travail (des ou-tils sont fournis pour transmettre la com-munication intentionnelle et conséquen-tielle), mais peu d’efforts ont été faitsconcernant les artefacts et le feedthrough.La visualisation du geste distant manqueaussi de substance, d’"incarnation". Laprésence du partenaire distant est souvent
ressentie de manière abstraite, trop im-matérielle. Elle pourrait être améliorée enajoutant une sonorisation liée à la manipu-lation des pièces comme feedthrough afind’incarner un peu plus les actions.
____________________________________________________________________________ Annales du LAMSADE N°8
371

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 384/415
7 Conclusion et travaux futursDans le cadre de la conception d’une plate-forme collaborative, DIG ITABLE combine
une table tactile, un système de vidéo com-munication, un système de son spatialiséet un module de vision afin de représenterle geste distant. Une première évaluationde DIGITABLE a été faite sur une tâchecollaborative d’assemblage de mosaïques.Bien que DIG ITABLE ne fournisse pasle même sentiment de présence en situa-tions distante et co-localisée, la médiatisa-tion des interactions semble ne plus être
un frein à l’efficacité de la collaboration.Collaborations co-localisée et distante sontdeux expériences à part entière avec leursqualités et défauts propres, certains expri-mant spontanément leurs préférences pourl’une ou l’autre des configurations. De plusamples expérimentations sont néanmoinsnécessaires pour conclure sur l’influencede chaque paramètre sur les stratégies decollaboration et sur l’interaction.
DIG ITABLE nécessite quelques perfec-tionnements techniques pour augmenterle sentiment de présence : améliorer laqualité de la vidéo et du son, augmenterl’opacité de la représentation des mainset prendre en compte de feedthroughcomme les bruits de frottement. En cequi concerne l’application d’assemblagede mosaïques, les problèmes concernant larotation des pièces peuvent être solution-
nés en augmentant la surface dédiée à ladétection de l’outil de rotation. Enfin, cetteapplication doit pouvoir supporter la créa-tion de conteneurs permettant de déplacerou tourner un ensemble de pièces simul-tanément, afin de pouvoir fusionner deuxsous-parties de mosaïques assemblées sé-parément. Ce dernier point devrait ame-ner davantage de couplage faible durant latâche collaborative.
Une nouvelle série d’expérimentation estactuellement en cours, maintenant quetoutes ces améliorations techniques ont étéintégrées. Le rôle de la communicationvidéo et l’importance de la visualisation
des mains sur le site distant doivent aussiêtre évalués par des critères objectifs, ainsique leur influence mutuelle. L’impact de laconfiguration collaborative (face-à-face vs.côte-à-côte) selon la situation (distante vs.co-localiée) doit être étudié.
Références[1] Tabletop 2006, Adelaide, Australia. IEEE
Computer Society, 2006.
[2] P. H. Dietz and D. Leigh. Diamondtouch : Amulti-user touch technology. In UIST , 2001.
[3] A. Dix, J. Finlay, G. Abowd, and R. Beale. Human-Computer Interaction. 1993.
[4] C. Gutwin and S. Greenberg. A descriptiveframework of workspace awareness for real-time groupware. Computer Supported Co-operative Work, Special Issue on Awarenessin CSCW , 11, 2002.
[5] J. Han. Low-cost multi-touch sensing throughfrustrated total internal reflection. In UIST ,2005.
[6] G. Hollemans, T. Bergman, V. Buil, K. vanGelder, M. Groten, J. Hoonhout, T. Lashina,E. van Loenen, and S. van de Wijdeven. En-tertaible : multi-user multi-object concurent
input. In UIST , 2006.[7] R. Kruger, S. Carpendale, S. Scott, and
S. Greenberg. How people use orientationon tables : comprehension, coordination andcommunication. In GROUP, 2003.
[8] U. S. Pawar, J. Pal, and K. Toyoma. Mul-tiple mice for computers in education in de-veloping countries. In ICTD, 2006.
[9] E. R. Pederson, K. McCall, T. P. Moran, andF. G. Halasz. Tivoli : an electronic whiteboardfor informal workgroup meeting. In interCHI ,
1993.[10] Y. Rogers and S. E. Lindley. Collaboratingaround vertical and horizontal large interac-tive displays : which way is best ? Interactingwith Computers, 6, 2004.
[11] T. Salvador, J. Scholtz, and J. Larson. Thedenver model for groupware design. SIGCHI Bulletin archive, 28, 1996.
[12] J. Stewart, B. B. Bederson, and A. Druin.Single display groupware : a model for co-present collaboration. In CHI , 1999.
[13] A. Tang, C. Neustaedter, and S. Greenberg.
Videoarms : embodiments in mixed presencegroupware. In BCS-HCI , 2006.
[14] J. C. Tang. Findings from observational stu-dies of collaborative work. Int. Journal of Man-Machine Studies, 34(2), 1991.
Interactions collaboratives en situations co-localisée et distante ___________________________________________________________________________
372

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 385/415
Un dialogue de persuasion pour l’accès et l’obtention d’informations
L. Perrussel S. Doutre J.-M. Thévenin P. McBurney†
IRIT - Université Toulouse 12 rue du doyen Gabriel Marty – 31042 Toulouse Cedex 9 – France
laurent.perrussel,sylvie.doutre,[email protected]
†Dpt. of Computer Science - University of LiverpoolLiverpool L693BX – United [email protected]
Résumé :
Obtenir une information peut s’avérer essentielpour des agents autonomes dans l’accomplissementde leurs buts. Les agents sont pour cela amenés àdialoguer avec d’autres agents pour demander etobtenir cette information. Or son accès peut êtrecontrôlé et nécessiter une permission, que seuls cer-tains agents sont autorisés à donner ou non. Dansle cas où un agent n’a pas l’autorisation d’accé-der à une information, il doit pouvoir essayer deconvaincre l’agent contrôleur de l’accès de chan-ger de position et de lui donner cette autorisation.Pour représenter une telle situation, nous propo-sons un protocole de dialogue de recherche d’infor-
mation faisant appel à de la persuasion basée surl’argumentation pour obtenir une permission. Ceprotocole est basé sur un système d’argumentationoù chaque agent possède une notion d’acceptabilitéspécifique.
Mots-clés : Dialogue, argumentation, permission
Abstract:
Obtaining relevant information is essential foragents engaged in autonomous, goal-directed beha-vior. To this end, agents have to dialog with otheragents to request and get this information. Howe-ver, access to information is usually controlled byother agents. In the situation where an agent isnot allowed to access some information, it may tryto convince the agent that controls the access tochange its mind and give it the permission. To re-present such situations, we design a protocol fordialogs between two autonomous agents for see-king and granting authorization to access some in-formation. This protocol uses argumentation-basedpersuasion. It is based on an argumentation fra-mework where agents handle specific acceptabilityover arguments.
Keywords: Dialogue, argumentation, permission
1 Introduction
Cet article montre comment deux agents,un client et un serveur, peuvent dialoguerde telle sorte que le client essaie d’ob-tenir l’accès à une information possédéepar le serveur, alors que le serveur essaiede convaincre le client qu’il ne peut paslui donner cet accès. Un dialogue dans cecontexte peut être vu comme étant basésur l’échange d’arguments et de contre-
arguments dans le but de déterminer si unepermission d’accès peut être octroyée ounon. Les arguments avancés par un agentreprésentent son propre point de vue, au-trement dit ce sont des arguments qu’il
juge acceptables.
Des systèmes d’argumentation permettantde prendre en compte des points de vuemultiples ont déjà été proposés ([1, 2] parexemple), et les dialogues basés sur l’ar-gumentation pour la recherche d’informa-tion et la persuasion ont déjà fait l’ob-
jet de nombreuses études ([11, 9, 12, 13]par exemple). Par contre, très peu de tra-vaux se sont intéressés au problème derecherche d’information dans le cas oùl’accès à celle-ci requiert une permission([3, 5]). De plus, parmi ces travaux, au-cun ne décrit un lien explicite entre per-missions et arguments pour ou contre ces
permissions. Ce lien est pourtant essentielpour justifier pourquoi l’accès à une infor-mation est ou n’est pas autorisé.
Dans cet article, nous décrivons de ma-
373

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 386/415
nière informelle un protocole de recherched’information qui fait appel à un proto-cole de persuasion pour obtenir la permis-sion d’accéder à l’information (voir [10]pour une description formelle). Ce proto-cole fait apparaître un lien explicite entrepermissions et arguments. De plus, les ar-guments échangés par le client et le ser-veur sont sélectionnés et évalués en fonc-tion de leur propre notion d’acceptabilité.
L’article est organisé comme suit : la sec-tion 2 présente comment lier permissionset arguments. La section 3 décrit la syn-
taxe et les règles du protocole de dialogue.Nous concluons l’article en section 4.
2 Permissions et arguments
Dans cette section, nous présentons lesconcepts de droit d’accès (ou permissions)et d’argumentation, sur lequels se basenotre protocole de dialogue.
Nous introduisons quelques notations pré-liminaires. Soit Ag l’ensemble des identi-fiants (id) d’agents. Un id d’agent est re-présenté par une lettre romaine en minus-cule (x, y, ...). L’information demandée estreprésentée par une lettre grecque en mi-nuscule (φ, ψ...). Inf dénote l’ensemble detoutes les informations possibles. Un argu-ment est représenté par une lettre romaineen majuscule (A, B...).
2.1 Permissions d’accès
La permission qu’un agent x a d’accéderà une information φ est dénotée par unefonction perm(y,x,φ) : perm(y,x,φ) =1 (resp. 0) signifie que l’agent y peut don-ner (resp. ne peut pas donner) accès àl’agent x au contenu de l’information φ.
La notion de permission est intimementliée à celle de contrôle. Un agent ne peutdéfinir une permission sur une informationφ que s’il en contrôle effectivement l’ac-cès. Si tel n’était pas le cas, un agent pour-
rait se donner à lui-même (ou à d’autresagents) des permissions sur des informa-tions sur lesquelles il n’a aucun contrôle.Nous représentons cette notion de contrôlepar une fonction control qui associe agentset informations : control : Ag → 2Inf .
Formellement, le lien entre permission etcontrôle est le suivant : pour tous les agentsy et x, perm(y,x,φ) → φ ∈ control(y).
2.2 Système d’argumentation
Le système d’argumentation sur lequelvont se baser nos dialogues doit per-mettre aux agents de partager un même en-semble d’arguments, et une même visiondes interactions entre arguments. L’inter-action considérée ici est une relation decontrariété. De plus, chaque agent z doitêtre capable de déterminer quels sont,de son point du vue, les arguments ac-ceptables (caractérisés par une fonctionacceptable(z)) ; ce sont ces arguments que
z utilisera pour contrer, si nécessaire, lesarguments avancés par les autres agentsdans un dialogue.
Les arguments et la relation de contra-riété peuvent être représentés de manièreclassique en utilisant le système d’argu-mentation de Dung [7]. Dans ce système,la structure interne et l’origine des argu-ments, tout comme la relation de contra-
riété, sont abstraites. Ce niveau d’abs-traction rend le système suffisamment gé-néral pour être instancié dans différentscontextes (voir par exemple [4]).
Pour représenter les différents points devue concernant l’acceptabilité des argu-ments, un manière simple consiste à uti-liser différentes relations de préférenceentre arguments. Le travail de [1] est uneextension du système de Dung qui montre
comment combiner plusieurs relations depréférence en une seule, dans le but decaractériser les arguments acceptables dusystème résultant. Ne cherchant pas à uni-fier les différents points de vue des agents,
Un dialogue de persuasion pour l'accès et l'obtention d'informations ___________________________________________________________________________
374

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 387/415
cette approche n’est pas appropriée pournos dialogues. [2] a présenté une autre ex-tension du système de Dung où des valeurs(au sens de valeur morale, éthique, ...)sont associées aux arguments et où chaqueagent définit sa propre relation de préfé-rence entre les valeurs (et ainsi entre lesarguments) ; chaque agent détermine en-suite quels sont ses arguments acceptablesen fonction de ses préférences. L’utilisa-tion des valeurs donne indéniablement dusens à l’origine des préférences des agents,mais ce besoin de sens n’est pas nécessairedans notre approche.
De manière générale, la définition de l’ac-ceptabilité pour un agent dépendra despolitiques d’accès. Par exemple, dans uncontexte où l’information est sensible, lanotion d’acceptabilité sera restrictive (lasémantique d’acceptabilité basique de [7]irait dans ce sens), alors que des notionsd’acceptabilité plus souples (par exemplela sémantique préférée de [7]) pourront
être considérées dans d’autres contextes.
Dans cet article, nous ne présentons pas endétail un système d’argumentation et unenotion d’acceptabilité qui satisfont les spé-cifications énoncées ci-dessus ; nous invi-tons le lecteur à consulter [10] pour uneprésentation détaillée.
2.3 Lier arguments et permissions
Le lien entre permission et argument estdéfini comme suit : une permission argu-mentée est un tuple A,y,x,φ,ι où A estun argument, y et x sont des ids d’agents,φ est une information et ι est une valeur depermission (ι ∈ 0, 1). A,y,x,φ,ι si-gnifie que l’agent y possède l’argument Aen faveur de (ι = 1) ou contre (ι = 0) l’oc-troi de la permission à l’agent x d’accéder
à l’information φ.
Une permission définie par un agent y pourun agent x et une information φ est consis-tante avec un ensemble de permissions ar-
gumentées si les deux conditions suivantessont satisfaites :
(i) deux arguments A et B qui se contra-
rient ne peuvent être simultanément enfaveur (ou contre) l’octroi de la permis-sion, et
(ii) il existe une permission argumentéeA,y,x,φ,ι telle que A appartient àacceptable(y).
3 Dialogue de persuasion pourl’octroi d’une permission
Dans cette section, nous décrivons un sys-tème de dialogue pour l’obtention d’uneinformation qui nécessite une permission,et qui fera pour cela appel à de la persua-sion.
3.1 Définition
Nos dialogues impliquent deux partici-pants : un Client (qui demande l’informa-tion), et un Serveur (qui contrôle l’accèsà l’information). Avant qu’un dialogue nedébute, le Client a pour but d’obtenir duServeur toutes les informations dont il abesoin, en utilisant la persuasion si néces-saire. Le Serveur a lui pour but de fournirau Client l’information qu’il demande enfonction des permissions qui lui sont asso-
ciées. Le Client et le Serveur peuvent avoirdes bases de connaissances disjointes. Labase de connaissance du Serveur incluedes permissions argumentées relatives àchaque Client pour diverses informations.
L’ensemble des locutions d’un dialoguedoit permettre d’ouvrir et de fermer le dia-logue, de demander de l’information, defournir le contenu d’une information de-mandée, d’indiquer que le contenu d’une
information ne peut être fourni, et d’ar-gumenter sur les permissions relatives àune information demandée. Ces locutionspeuvent être basées sur les standards de laFIPA [8].
____________________________________________________________________________ Annales du LAMSADE N°8
375

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 388/415
Un dialogue est une structure qui combinedes permissions, un système d’argumen-tation, un ensemble de permissions argu-mentées, et une séquence de locutions.
3.2 Protocole
Nous présentons maintenant de manièreinformelle un protocole pour nos dialoguesde recherche d’information avec permis-sions (voir [10] pour une description for-melle).
Après avoir ouvert le dialogue, le Client(id x) demande au Serveur (id y) une in-formation φ. Plusieurs cas de figure se pré-sentent :
– Si le Serveur contrôle effectivementl’accès à φ, et si le Client a la permis-sion d’y accéder, le Serveur doit fournirle contenu de φ au Client ; le dialogueest ensuite fermé par le Client ou le Ser-veur.
– Si le Serveur ne contrôle pas l’accès à φ,il doit fermer le dialogue.
– Le cas qui nous intéresse le plus ici estcelui où le Serveur contrôle l’accès à φ,mais où le Client n’a pas la permissiond’accéder à φ ; il existe donc dans la basede connaissance du Serveur une permis-sion argumentée A,y,x,φ, 0. Le Ser-veur doit alors indiquer au Client qu’ilrefuse de lui fournir le contenu de φ et
explique son refus en avançant l’argu-ment A.
Suite à ce dernier cas, une étape de persua-sion basée sur l’argumentation commence.Le Client va essayer de convaincre le Ser-veur de lui donner la permission d’ac-cès, alors que le Serveur va essayer deconvaincre le Client qu’il ne peut changerla permission. Dans ce but, Client et Ser-veur vont présenter des arguments accep-
tables selon leur point de vue pour contre-carrer les arguments de leur opposant.
Concentrons-nous dans un premier tempssur l’attitude du Client lorsqu’il reçoit un
argument du Serveur.
– Le Client x considère tout d’abord tousles arguments de acceptable(x) qui at-
taquent l’argument reçu et les présentecomme contre-arguments au Serveur.
– Si l’argument reçu appartient àacceptable(x), et si pour tout argu-ment envoyé par le Serveur, le Clientx a présenté tous les contre-argumentspossibles, alors le dialogue se termine ;le Client n’a pas pu convaincre le Ser-veur de changer la permission, il nepourra donc pas accéder au contenu de
l’information φ.
Concentrons-nous à présent sur l’attitudedu Serveur. Le principe est similaire à ce-lui du Client : le Serveur présente au Clienttous les arguments qu’il possède pour leconvaincre qu’il ne lui donnera pas la per-mission d’accéder à l’information. Plusprécisément :
– Le Serveur y considère tous les argu-
ments de acceptable(y) qui attaquentl’argument reçu et les présente au Client.
– Si y ne peut présenter de tels arguments,il présente tous les arguments A des per-missions argumentées A,y,x,φ, 0.
Une fois que tous les arguments des per-missions argumentées ont été présentés,que tous les arguments présentés par leClient ont été contrés, alors le Serveur doit
évaluer l’ensemble des arguments envoyéspar le Client. De cette évaluation, soit leServeur décide de changer la permission(et fournit le contenu de l’information φ auClient), soit il reste sur sa position. Le dia-logue se termine ensuite.
3.3 Persuasion et mise-à-jour des per-
missions
Nous proposons deux manières pour leServeur y d’évaluer l’ensemble des argu-ments envoyés par le Client :
Prudence Si l’un des arguments avancé
Un dialogue de persuasion pour l'accès et l'obtention d'informations ___________________________________________________________________________
376

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 389/415
par le Serveur n’a pas été contré par leClient, alors le Serveur conserve uneraison de ne pas changer la permis-sion. Il reste sur sa position.
Confiance Si l’un des arguments pré-senté par le Client appartient àacceptable(y), i.e. est acceptable pourle Serveur, et si cet argument n’appa-raît dans aucune permission argumen-tée contre la permission, alors le Ser-veur considère qu’il a une bonne rai-son de changer la permission.
Dans ce dernier cas, le Serveur changel’ensemble des permissions argumentéesde manière à ce que la permission qu’ilvient d’accorder soit consistante. Concrè-tement, tout argument A envoyé par leClient qui est acceptable du point devue du Serveur fait l’objet de l’ajoutd’une nouvelle permission argumentéeA,y,x,φ, 1.
3.4 Terminaison
Les règles qui viennent d’être décrites ga-rantissent que les dialogues de notre sys-tème sont bien formés. A la fin de ces dia-logues, le contenu de l’information φ estdévoilé au Client :
– soit parce que le Client possédait la per-mission d’accéder au contenu de φ avant
même le début du dialogue,– soit sinon parce que par l’échange d’ar-guments et de contre-arguments relatifsà des permissions argumentées, le Ser-veur a été convaincu de changer la per-mission du Client pour qu’il accéde aucontenu de φ.
4 Conclusion
Nous avons présenté un système de dia-logue pour l’obtention d’une informa-tion nécessitant une permission d’accès.Notre contribution est double. Première-ment, nous avons représenté à travers un
lien explicite entre arguments et permis-sions pourquoi un agent accepte ou nonde donner une information sujette à per-mission. Deuxièmement, nous avons pro-posé une classe de dialogues spécifique,les dialogues pour l’obtention d’une in-formation qui nécessite une permission ;ces dialogues permettent de caractériserdeux modes de changement de permission(prudence et confiance). Ce protocole peutêtre utilisé avec différents systèmes d’ar-gumentation. Une formalisation de ce pro-tocole, utilisant un système d’argumenta-tion basé sur des préférences multiples, est
présentée dans [10]. Un tel protocole pour-rait être implémenté suivant la méthodeproposée dans [6].
Pour la suite, nous envisageons de raffinerle protocole pour prendre en compte unenotion de confiance : si un client est ca-pable de convaincre un serveur de lui don-ner la permission d’accéder à une infor-mation, alors ce résultat peut jouer le rôle
d’un argument en faveur du client pouraccéder à d’autres informations ; le dia-logue de persuasion peut être vu commeune preuve de confiance.
Remerciements
Peter McBurney est reconnaissant pour lesoutien du projet européen ArgumentationService Platform with Integrated Compo-nents (ASPIC) (IST-FP6-002307). LaurentPerrussel est reconnaissant pour le soutiendu projet ANR Social trust analysis and
formalization (ForTrust).
Références
[1] L. Amgoud, S. Parsons, and L. Per-russel. An Argumentation Fra-
mework based on contextual Prefe-rences . In Proc. of FAPR’00, Lon-don, pages 59–67, January 2000.
[2] T. J. M. Bench-Capon. Persuasion inpractical argument using value-based
____________________________________________________________________________ Annales du LAMSADE N°8
377

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 390/415
argumentation frameworks. J. Log.Comput., 13(3) :429–448, 2003.
[3] G. Boella, J. Hulstijn, and L. van der
Torre. Argument games for inter-active access control. In Proc. of WI 2005, pages 751–754. IEEE CS,2005.
[4] A. Bondarenko, P. M. Dung, R. A.Kowalski, and F. Toni. An abstract,argumentation-theoretic approach todefault reasoning. Artif. Intell.,93 :63–101, 1997.
[5] P. Dijkstra, F.J. Bex, H. Prakken, andC.N.J. De Vey Mestdagh. Towards amulti-agent system for regulated in-formation exchange in crime inves-tigations. Artificial Intelligence and
Law, 13 :133–151, 2005.
[6] S. Doutre, P. McBurney, andM. Wooldridge. Law-governedlinda as a semantics for agent dia-logue protocols. In AAMAS , pages1257–1258, 2005.
[7] P.M. Dung. On the Acceptability of Arguments and its Fundamental Rolein Nonmonotonic Reasoning, LogicProgramming, and N-Person games.
Artificial Intelligence, 77(32) :321–357, 1995.
[8] FIPA. FIPA, ’Agent communica-tion language’, FIPA 97 Specifica-tion, Foundation for Intelligent Phy-
sical Agents edition, 1997.[9] S. Parsons, M. Wooldridge, and
L. Amgoud. Properties and com-plexity of some formal inter-agent dialogues. J. Log. Comput.,13(3) :347–376, 2003.
[10] L. Perrussel, S. Doutre, J.-M. Théve-nin, and P. McBurney. A PersuasionDialog for Gaining Access to Infor-
mation. In ArgMAS 2007 , 2007.[11] H. Prakken. Coherence and flexibi-
lity in dialogue games for argumen-tation. J. Log. Comput., 15(6) :1009–1040, 2005.
[12] I. Rahwan, S. Ramchurn, N. Jen-nings, P. McBurney, S. Parsons, andL. Sonenberg. Argumentation-basednegotiation. The Knowledge Engi-neering Review, 18 :343–375, 2003.
[13] D. Walton and E. Krabbe. Commit-ments in Dialogue : Basic Conceptsof Interpersonal Reasoning. SUNYPress, 1995.
Un dialogue de persuasion pour l'accès et l'obtention d'informations ___________________________________________________________________________
378

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 391/415
Autour du problème du consensus
Clément PIRA
Amal El Fallah Seghrouchni
Laboratoire d’Informatique de Paris 6Université Pierre et Marie Curie
104, avenue du Président Kennedy75016 Paris – FRANCE
Résumé :Dans ce papier, le problème d’atteinte de consen-sus est étudié relativement à trois domaines : ladécision collective, la théorie des jeux et l’algo-rithmique répartie. Le premier domaine étudie lesconditions générales d’existence d’un consensus(i.e. existence de fonctions d’agrégation). Les deuxautres tentent d’en comprendre la dynamique. Il enressort deux problématiques de l’implémentation :1) pour l’algorithmique répartie, il s’agit de s’as-surer de la diffusion suffisante de la connaissanceau sein d’un système pouvant par exemple tolé-rer les fautes (répartition) ; 2) pour la théorie des
jeux, il s’agit de trouver une correspondance entre“équilibre” stratégique et “optimum” social (com-pétition). De notre point de vue, le consensus mul-tiagent réunit ces deux problèmes, d’où le besoin de
développer un cadre commun aux deux domaines.Mots-clés : Agent, consensus, répartition
Abstract:In this paper, the consensus problem is studiedthrough three fields : collective decision, gametheory and distributed algorithmic. We identify twoimplementation problems : 1) in distributed algo-rithmic, we have to deal with communications andprocesses faults (distribution) ; 2) in game theory,we want to find an equilibrium which might be dif-
ferent from the optimal solution (competition). Amodel for multiagent system is presented as a com-promise between models from game theory anddistributed algorithmic.
Keywords: Agent, consensus, distribution
1 Introduction
Objectif. L’objectif de ce papier1 est deproposer un modèle permettant d’étudierle problème du consensus dans les sys-tèmes multiagents. Selon nous, les mo-dèles opérationnels de SMA se trouvent
1Ce travail est financé par la DGA
à la croisée entre les modèles de théoriedes jeux (permettant de capturer la no-tion de rationalité et de compétition) etles modèles d’algorithmique répartie (in-
sistant plus sur les propriétés de cohérenceet de terminaison, à travers l’étude des mé-canismes tels que la communication ou lasynchronisation). Nous tentons ainsi d’enprésenter les points communs et les diffé-rences profondes. Dans le domaine mul-tiagent, les modèles de théorie des jeuxsont bien connus (les décisions au seind’un SMA sont en effet élaborées par desagents possédant des intérêts individuels
qu’il faut respecter lors du passage à larationalité collective). Cependant, ils per-mettent surtout de donner une descriptionde haut niveau du comportement d’un sys-tème. A plus bas niveau interviennent desproblèmes étudiés par l’informatique ré-partie et généralement moins connus.
Problème de l’implémentation. L’approche“classique” de la décision collective fait
intervenir la notion de fonction d’agré-gation F : X A → X et cherche parexemple à ramener cette fonctionnelle àune intégrale de Choquet (ou à un poly-nôme latticiel) pondérée par un jeu coali-tionnel ν (un jeu simple). Ce jeu représentele poids donné aux coalitions d’agents. Ondémontre ainsi des théorèmes “à la Riesz”établissant des bijections entre des classesde jeux coalitionnels (structures décision-
nelles) et des types de fonctions d’agréga-tions [4, 1] :
ν →
x → (C )
A
x dν
379

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 392/415
A un niveau plus abstrait, il s’agit d’étu-dier la possibilité d’agréger des données enfonction de la topologie de l’espace sous-
jacent [2]. Cependant, une fonction d’agré-gation n’est pas une implémentation. Nousdistinguons en particulier deux problé-matiques d’implémentation associées à laconcurrence :
La distribution : Pour réaliser une procé-dure de décision dans un système ré-parti, on est confronté aux problèmesde la transmission imparfaite de l’in-formation ou encore aux défaillances
du système. La difficulté supplémen-taire concerne ici la distribution asyn-chrone.
La compétition : En théorie des jeux,implémenter c’est réaliser un choixcollectif pour lequel on connait unesolution optimale par un ensembled’agents individualistes (mecanismdesign). Dans ce cas, c’est la no-tion d’équilibre qui prévaut. Et elle
ne correspond par à la notion d’opti-mum, d’où des situations paradoxalesde type “dilemme du prisonnier”. Ladifficulté, c’est la compétition.
La distribution et la compétition ont conduit à deux types de solutions répon-dant à deux grandes problématiques :celle de la cohérence globale du systèmeet celle de la rationalité collective. Dans
les deux cas, il faut développer un mo-dèle de la dynamique du système. Ce-
pendant un modèle de théorie des jeuxinsistera plus sur la représentation de larationalité individuelle des agents tout en limitant la modélisation de l’environ-nement ou du système de communicationtandis qu’un modèle d’informatique ré-
partie prendra le point de vue inverse.
Problème du consensus. L’informatique ré-partie étudie également des tâches de déci-sion ; en particulier des tâches de consen-sus T : X A → P(X ). Cependant il im-porte ici avant tout de garantir :
– l’atteinte d’un accord : tous les agentscorrects décident la même valeur ;
– la terminaison du processus : tous lesagents corrects finissent pas décider.
Le défaut de cette approche, lorsqu’onl’applique aux systèmes multiagents, est lafaible rationalité imposée à cette tâche deconsensus. Généralement on impose unecondition d’unanimité (si tous les proces-sus sont d’accord initialement, alors leur valeur doit être choisie collectivement ),bien plus faible que celles classiquementimposées à une fonction d’agrégation en
théorie de la décision.
La théorie de la décision et l’informa-tique répartie sont toutes deux confrontéesà des résultats d’impossibilité. Notre butest ainsi de comprendre les compromis àfaire entre cohérence, terminaison et ratio-nalité, pour garantir l’existence de proto-coles implémentant certaines tâches de dé-cision.
2 Modèle proposé
Le modèle proposé repose sur différentscomposants. Certains d’entre eux, commela représentation des stratégies, s’inspirentd’outils classiques en théorie des jeux,alors que d’autres s’inspirent des conceptsissus de l’algorithmique répartie commel’exécution asynchrone ou encore la com-
munication.
Réaction du système. Soit Ω un ensemblede configurations (représentant les états dusystème dans sa globalité2) et A un en-semble d’actions pouvant s’y produire per-mettant ainsi de passer d’une configurationà une autre. Soit finalement ω0 ∈ Ω une
configuration initiale et•
−→: A×Ω → P(Ω)une fonction de transition non déterministe
entre configurations. La réaction du sys-tème dans sa globalité est ainsi décrite par
un automate Ω,A,•
−→, ω0, généralement
2Aucun n’agent n’aura accès à l’intégralité de cet état.
Autour du problème du consensus ___________________________________________________________________________
380

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 393/415
un arbre enraciné en ω0 (arbre de décisionou arbre de synchronisation en fonction dudomaine). Si a ∈ A est une action s’appli-quant à une configuration ω conduisant àune configuration ω, on notera :
ωa
−→ ω
Actions simultanées ou alternées. Le modèled’actions collectives le plus simple est ce-
lui des actions simultanées. Dans ce cas ondéfinit A =
α∈A Aα (une action globaleest un vecteur d’actions individuelles). Lebut pour un agent α est de définir une stra-tégie déterministe sα : Ω → Aα (ou sto-chastique sα : Ω → π(Aα)). Ensuite, dansune configuration ω donnée, chaque agentdéroule sa stratégie et propose ainsi uneaction. Le vecteur d’actions est ensuite ap-pliqué au système qui réagit et produit unenouvelle configuration ω.
ω(sα1(ω),··· ,sαn(ω))−−−−−−−−−−→ ω
Un autre modèle est celui des actions alter-nées (et donc sérialisées). Dans ce cas ondéfinit A = α∈A Aα (une action globale
est un couple composé d’un agent et del’action qu’il propose). Il faut alors déciderqui peut prendre une décision et quand. Unmodèle simple est d’associer un décideurpar configuration, au moyen d’une fonc-tion ag : Ω → A, ce qui revient à partition-ner Ω en (Ωα)α∈A. Chaque agent doit alorsproposer une stratégie sα : Ωα → Aα.Dans une configuration ω, l’agent qui ala main déroule sa stratégie. L’action ainsi
produite s’applique au système qui réagitpour donner une nouvelle configuration.
ω(ag(ω),sag(ω)(ω))−−−−−−−−−→ ω
Ordonnancement généralisé.
En théorie des jeux, on parle de jeux syn-chrones et asynchrones pour désigner
les modèles d’actions simultanées et al-ternées. Nous n’adopterons pas cette dé- finition dans la mesure où l’on souhaite faire le lien avec les modèles d’algo-rithmique répartie. En effet, dans ce do-maine, l’asynchronisme fait référence àl’absence de temps global, d’horlogesou de deadlines ; et dans ce sens les mo-dèles de théorie des jeux sont toujourssynchrones.
Pour définir une notion de jeu réellementasynchrone, on commence par générali-ser la notion d’action. Entre les deux ex-trêmes donnés par les modèles d’actionssimultanées et alternées, on peut définirun modèle pour lequel, dans une confi-guration donnée, un sous-ensemble desagents est autorisé à agir. Ils produisentdonc une action partielle à valeur dansA = A[A] = α∈A (Aα + ⊥) (3). D’autre
part, plutôt que de fixer les agents ayant ledroit d’agir au niveau de chaque configura-tion, on définit séparément un ordonnance-ment comme une suite de sous-ensemblesd’agents ayant le droit d’agir. On note Σ =P(A)N l’ensemble des ordonnancements(schedules).
Soit g ∈ Ω un but (une configuration dé-sirée par les agents) et soit S ∈ P(A)
un sous-ensemble d’agents. Si tout che-min depuis la configuration initiale ω0 jus-qu’à ce but g contient un sous-chemind’une longueur fixée faisant intervenir si-multanément tous les agents de S , cela ex-prime le fait que les agents de S doiventd’une certaine manière se synchroniser aumoins une fois lors de l’exécution s’ilssouhaitent atteindre ce but g ; et donc quele problème n’a pas de solution en asyn-
chrone. En particulier, dans un systèmeasynchrone, toute suite d’actions doit pou-voir être sérialisée. La synchronisation est
3X + ⊥ désigne l’ensemble X augmenté d’un élément sup-
plémentaire ⊥.
____________________________________________________________________________ Annales du LAMSADE N°8
381

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 394/415
une composante essentielle de la coordi-nation. C’est même une condition mini-male pour qu’un groupe d’agents puisseagir comme un seul. Généralement, elleest supposée acquise en théorie des jeuxqui se focalise sur une coordination deplus haut niveau (coordination des intérêtsdes agents). Cependant, d’un point de vuepragmatique, ce type de coordination estimpossible sans un accord préalable sur letemps (quand peut-on agir ? quand prendfin la décision ? etc.).
D’autre part, il s’avère également néces-saire de décrire plus finement le système.Classiquement en théorie des jeux, la réac-tion du système est décrite comme un tout
par une relation de transition•
−→ (une fonc-tion τ ) ; et les agents sont décrits princi-palement par leur stratégie comportemen-
tale sα et par leur vision du système (fonc-tion de projection πα décrite plus loin). Ilsn’ont pas d’états internes à partir desquelsla configuration globale peut être calcu-lée. Dans un modèle de système réparti,le point de vue est radicalement opposé :l’évolution d’un agent est décrite locale-ment par un automate et celle du systèmepar le produit de ces automates. Lorsqu’unagent peut communiquer avec un grouped’agents de manière atomique, il peut êtreassuré du fait que les états de croyancesde ces agents sont cohérents les uns parrapport aux autres. Inversement, dans lecas contraire où les communications sefont entre deux agents, un agent malicieuxpeut profiter de cette propriété du systèmepour induire des états de croyances incohé-rents chez les autres agents (par exemplefaire croire deux choses incompatibles àdeux agents différents) : c’est le principe
des agents byzantins. Ici, la question n’estdonc plus, pour un ensemble d’agents, deproduire simultanément une action, maisde subir une même action comme un seulagent .
Notre modèle est similaire aux modèlesd’automate entrée/sortie [8] dans lesens où il permet de modéliser une com-munication impliquant un émetteur et unrécepteur au moyen d’actions d’émis-sion sur un canal. Cependant ces canauxnous servent ensuite à redéfinir finement la notion d’état puis de configuration dusystème. Finalement, le modèle d’exécu-tion d’un agent se rapproche plus de lanotion de stratégie comportementale dé-veloppée en théorie des jeux.
Soitˆ
A un ensemble de composants4
etC un ensemble de canaux entre ces com-posants. On note respectivement C (α, β )l’ensemble des canaux d’origine α et d’ex-trémité β , C (α, •) ceux d’extrémité quel-conque ou encore C (α, ∗) ceux d’extré-mité autre que α (absence de boucle). Demanière symétrique, on définit C (•, β ) etC (∗, β ).
X
Y
Z
b
a
c f
g
h
i
d
e
FIG . 1 – Trois composants X,Y ,Z re-liés par neuf canaux a,b,c,d,e,f,g,h,i
A chaque canal c ∈ C est associé un typeT c représentant le type de données pouvantl’emprunter. On le complète en T c + ⊥pour représenter l’éventualité d’un canalvide. Si C est un ensemble de canaux, onlui associe naturellement le type produitT [C ] =
c∈C (T c + ⊥). Le type T [C] est as-
similé à l’ensemble des actions globalesA.Ceci nous permet également de préciser laforme des actions que peut produire ou su-
bir un agent α. On note ainsi A∗,α (resp.Aα,∗) le type d’entrée (resp. de sortie) de
4A ⊆ A, par exemple A = ensemble d’agents A +environnement ε.
Autour du problème du consensus ___________________________________________________________________________
382

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 395/415
l’agent α :
A∗,α = T [C(∗,α)] =
c∈C(∗,α)
(T c + ⊥)
Finalement, on définit Xα = Aα,α, l’en-semble des valeurs des canaux bouclantsur un composant α. Cet ensemble peutêtre identifié à l’ensemble des états in-ternes du composants5. Une configurationest quant à elle constituée des états locauxde chaque agent ainsi que de l’état du sys-tème de communication (mémoire ou sys-tème de messages) :
Ω =α∈A
Xα = Xε ×α∈A
Xα
Le comportement d’un agent α est alorsdécrit par deux fonctions (stratégie com-portementale et fonction de transition in-terne) laissant apparaître une symétrieentre une partie proactive et une partie ré-active :
ς α : Xα → Xα × Aα,∗τ α : A∗,α ×Xα → Xα
La partie proactive décrit la part du com-portement de l’agent qu’il déclenche lors-qu’il est autorisé à agir par l’ordonnan-ceur. Soit S ∈ P(A) est un ensembled’agents auxquels l’ordonnanceur a attri-bué un pas de calcul. On définit le compor-tement proactif d’un agent α ∈ A durant
ce laps de temps par :
x →
ς α(x) si α ∈ S (x, (⊥, · · · , ⊥)) sinon
La partie réactive décrit la part du compor-tement de l’agent activé en réaction à soncontexte d’exécution (par exemple l’envi-ronnement). Si tous les canaux d’entréed’un agent α ∈ A sont vides, l’agent ne
doit pas réagir d’où la contrainte :
τ α((⊥, · · · , ⊥), x) = x
5Le fait de produire sur un canal ce que l’on récupérera au
tour suivant constitue le principe d’une mémoire.
Finalement, on donne ci-dessous (figure2) la formalisation d’une exécution asyn-chrone d’un ensemble d’agents décrits parleurs stratégies comportementales et leursfonctions de transitions internes, le tout pa-ramétré par un ordonnancement.
procedure execute(σ : Σ,
ς :Q
α∈A (Xα → Aα,•),
τ :Q
α∈A (A•,α → Xα))
var x : A ;
begin
forall [r ∈ N] do // r = n tour
begin
forall [α ∈ σr] do x[C(α, •)] ← ς α(x[C(α,α)])forall [α ∈ A \σr] do x[C(α, ∗)] ← (⊥, · · · ,⊥)
forall [α ∈ A] do x[C(α,α)] ← τ α(x[C(•, α)])
end
end
FIG . 2 – Exécution paramétrée par un or-donnancement σ
Cette construction permet d’isoler lacontribution de l’ordonnanceur dans la dé-cision collective. Chaque agent proposeune stratégie et celui-ci propose un ordon-nancement σ dans l’ensemble Σ = P(A +ε)N. On peut alors étudier le problèmede la décision en fonction de contraintesfaites sur cet ensemble : restriction àdes ordonnancements plus ou moins syn-chrones, ajout d’une mesure de probabi-lité indiquant la vraisemblance d’appari-
tion des ordonnancements, etc.
Observation partielle. De nombreux résul-tats en informatique répartie repose sur lefait que chaque agent n’a qu’une visionpartielle du monde et que certaines confi-gurations sont donc indistinguables de sonpoint de vue. On définit ainsi Xα commele type de données que perçoit l’agent αde l’ensemble des configurations Ω. On le
dote également d’une fonction de projec-tion πα : Ω → Xα. On le restreint finale-ment à utiliser une stratégie sα uniforme,c’est-à-dire qu’étant donné deux configu-rations qu’il ne peut distinguer, l’agent α
____________________________________________________________________________ Annales du LAMSADE N°8
383

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 396/415
doit prendre la même décision dans lesdeux cas :
πα(x) = πα(y) ⇒ sα(x) = sα(y)
On peut de manière équivalente doterchaque agent α d’une relation d’équiva-lence ∼α: Ω × Ω → B indiquant que deuxconfigurations sont indistinguables de sonpoint de vue. Celle-ci peut être définie àpartir de πα par x ∼α y ⇔ πα(x) = πα(y).Dans la mesure où une stratégie uniformedonne un même résultat pour deux confi-
gurations x ∼α y, cela revient à considérerune stratégie comportementale locale défi-nie sur l’ensemble quotient Xα = Ω/∼α
:
sα : Xα → Aα
En algorithmique répartie, la perception del’environnement par un agent n’est plusune simple projection πα fournie par le
modèle, mais est plutôt “calculée” dyna-miquement.
Topologie “épistémique”. La représentationde la vision partielle d’un agent par une re-lation d’équivalence peut être généralisée[6]. Soit φ un ensemble de configuration(un prédicat ). Le système peut être actuel-lement dans l’une des configurations de φsans pour autant qu’un agent α le sache
(il ne dispose pas de toute l’information).On définit κα(φ) comme l’ensemble desconfigurations dans lesquelles α sait qu’ilse trouve dans une configuration de φ. Cetopérateur de connaissance κα doit asseznaturellement vérifier un certain nombred’axiomes :
A0 κα(Ω) = Ω (hypothèse de mondeclos : l’agent sait toujours qu’il setrouve dans une configuration de Ω) ;
A1 ∀(φ, ψ) ∈ P(Ω)2, κα(φ ∩ ψ) =κα(φ) ∩ κα(ψ) (axiome de distribu-tion) ;
A2 ∀φ ∈ P(Ω), κα(φ) ⊆ φ (axiome devérité : l’agent ne peut connaître quedes vérités6) ;
A3 ∀φ ∈ P(Ω), κα(φ) ⊆ κα(κα(φ))(axiome d’introspection positive) ;
Cela revient à définir κα comme un opé-rateur d’intérieur (ouverture topologique)sur l’espace Ω : contractant [A2], idem-
potent [A2+A3], et “stable” (par inter-section finie) [A0+A1]. L’ensemble imageT κα = img(κα) = κα(φ) | φ ∈P(Ω) définie une topologie sur Ω. En
fait, étant donné un ensemble de configu-rations φ, l’opérateur κα associe l’intérieurde φ pour la topologie T κα (le plus grandouvert de T κα inclus dans φ). Ainsi, unagent ne connaît pas exactement la confi-guration actuelle du système mais il saitqu’il est dans son adhérence. Cela géné-ralise l’approche par les relations d’indis-tinguabilité où l’adhérence d’une configu-ration est donnée par sa classe d’équiva-
lence pour la relation ∼α (correspondantau concept d’information set ). En ajou-tant l’axiome [A4], ci-dessous, on exprimele fait que tout ouvert est également unfermé ce qui fait de T κα une topologie to-talement discontinue. On peut alors mon-trer qu’une telle topologie découle néces-sairement d’une relation d’équivalence ∼α
et qu’inversement une topologie associéeà une relation d’équivalence vérifie cet
axiome.
A4 ∀φ ∈ P(Ω), κα(φ) ⊆ κα(κα(φ))(axiome d’introspection négative).
La notion généralisant de manière natu-relle le concept de stratégie uniforme estcelle de stratégie continue sα : Ω, T κα →Aα,P(Aα). Ainsi dans le cas d’une to-
pologie discrèteP
(A
α) sur l’ensemble desactions de α, pour toute action que l’agententreprend dans une configuration ω, il
6C’est en particulier ce qui distingue une connaissance d’une
croyance.
Autour du problème du consensus ___________________________________________________________________________
384

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 397/415
existe un ouvert O de configurations au-tour de ω tel que l’agent doive y prendre lamême décision.
Exécution et protocole. Une exécution delongueur k (un chemin de longueur k) sur
Ω,A,•
−→ est une suite de configurations(ω0, · · · ωk) en alternance avec des évé-nements (e1, · · · , ek) telle que pour tout
i ∈ 1, k, on ait ωi−1ei−→ ωi :
ω0e1−→ ω1
e1−→ ω2 · · · ωk−1ek−→ ωk
On note Ωk l’ensemble de ces chemins delongueur k et Ω =
k∈N
Ωk l’ensemblede toutes les exécutions finies. L’ensemble Ω0 est identifié à Ω ce qui permet de plon-
ger ce dernier dans Ω. La construction faiteprécédemment sur l’ensemble des configu-rations peut alors facilement être générali-
sée à l’ensemble des exécutions Ω. En par-ticulier, une notion de topologie peut êtredéfinie sur l’ensemble des exécutions etlorsque l’environnement est déterministe(mémoire partagée), l’algorithme donné enfigure 2 permet de ramener l’étude de cetespace d’exécution à l’étude de l’espacedes ordonnancements Σ. L’idée est alorsde représenter un protocole de décision
comme une fonction continue δ : Ω → X (ou δ : Σ → X ) à valeur dans l’ensembleX des décisions [9] :
Ωδ
> > > >
> > > >
X A
ι
> > T / / X
3 Système de processus asyn-chrone
Trois problématiques sont relativementclassiques en informatique répartie, à sa-voir les pannes de l’environnement [5], les
processus byzantins (agents jouant contre
le système [7]) et l’asynchronisme [3].Nous avons en particulier cherché à com-prendre ce qu’impliquent les hypothèsesfaites sur le système dans chacun de cescas en termes topologiques. Par manquede place, nous ne présenterons ici que lesrésultats concernant le troisième point, àsavoir les résultats sur les systèmes asyn-chrones. Dans ce cadre, le résultat suivantest classique :
FISCHER, LYNCH & PATERSON, 1983: Dans un système totalement asyn-chrone, composé de processus déter-ministes, le problème du consensus est insoluble à partir du moment où unseul processus est incorrect [3].
Si n désigne le nombre d’agents, on dit quedeux configurations sont adjacentes si (n−1) agents ne peuvent les distinguer :
∼ = |S |≥n−1
α∈S
∼α
L’idée de la preuve de ce théorème estalors simple : on commence par montrerque l’ensemble des configurations initialesX A est connecté pour la relation ∼. Puis,on montre que pour toute configurationω, l’ensemble de ses successeurs immé-diats est également connecté pour la rela-
tion ∼. On en déduit de proche en procheune connexité au niveau des exécutions E =
x∈X A
Ω(x, •). Le théorème FLP seramène ainsi à une propriété de connexitésur l’ensemble des exécutions. On peuten effet partitionner l’ensemble des exé-
cutions E en F 0 (resp. F 1) : celles pourlesquelles certains agents décident 0 (resp.1). Imposer la non trivialité et la terminai-son du protocole revient à dire que l’en-
semble des exécutions intersecte simulta-nément F 0 et F 1 et qu’il est inclus dans
leur union. D’après la connexité de E ,on en déduit que F 0 ∩ F 1 = ∅ et doncqu’il existe des exécutions pour lesquelles
____________________________________________________________________________ Annales du LAMSADE N°8
385

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 398/415
certains agents décident 0 et d’autres 1.D’où l’impossibilité d’obtenir systémati-quement un consensus.
Connexité de plus haut niveau. On se rendainsi compte que le problème posé parle consensus est finalement assez simplepuisqu’il se ramène à une simple notion deconnexité. Des problèmes plus générauxtels que l’accord dans un k-ensemble [9](au plus k valeurs distinctes peuvent êtrechoisies par les agents) n’ont pas de so-
lutions aussi évidentes. C’est dans ces caslà que les résultats de topologie montrenttout leur intérêt. On ne fait alors plus ap-pel à une notion de connexité (0-connexité≈ il est toujours possible de relier deuxpoints par un chemin continu), mais àdes notions de connexité d’ordre supé-rieur (k-connexité ≈ il est toujours pos-sible d’étendre continument une k-sphèreen une (k + 1)-boule).
Poids d’un agent. Au début de l’article,nous rappelions la notion de poids déci-sionnel d’un agent. Cependant le poids del’agent dans la décision dépend de sonpoids dans le calcul, c’est à dire du tempsqui lui est accordé par l’ordonnanceur. Ona ainsi affaire à deux notions de pondéra-tion. En décision classique, le poids d’unagent dans la décision est donné par un jeucoalitionnel (ou une fédération). La priseen compte de la dynamique superpose unautre poids relatif au temps de calcul im-parti à un agent par l’ordonnanceur.
On ne peut donc pas a priori garantir d’accorder un poids décisionnel précisà un agent car l’ordonnanceur peut mo-
duler ce poids en terme de temps de cal-cul : un agent, aussi influent soit-il, quine dispose d’aucun temps de calcul est nécessairement de poids nul dans la dé-cision.
4 Conclusion
Pour conclure, nous synthétisons quelques
réflexions inspirées par notre étude et quiconstituent, à notre avis, des pistes de re-cherche à approfondir.
Mélange des problèmes. Tout d’abord, ilest difficile de prendre en compte l’en-semble des problèmes : environnement in-correct, agents byzantins et ordonnanceur.En fait, les problèmes d’asynchronismedevraient théoriquement empêcher la co-
ordination des byzantins autant que desagents corrects. On suppose ainsi que l’or-donnanceur, l’environnement et les byzan-tins agissent de concert contre les agentscorrects. De leur côté, les agents cor-rects forment eux-mêmes une coalitionpour jouer contre le système et perdent dumême coup leurs propres intérêts. On seramène donc à un jeu à deux coalitions et àsomme nulle permettant de faire une étudedans le pire des cas : l’ensemble des agents
corrects unis contre le reste du système.
Connaissance v.s. rationalité. Une décisionest simultanément guidée par la connais-sance qu’ont les agents de la situation etpar leurs préférences. Cependant en théo-rie des jeux, la synchronisation est ac-quise et la communication peu fréquente.Le modèle des connaissances est basiqueet la notion de préférence relativement
fine. En informatique répartie, le modèledes connaissances est plus subtile, il prenden compte la difficulté posée par la syn-chronisation, mais la notion de préférenceest grossière (les buts acceptables sont lesconfigurations cohérentes, sinon ils sontinacceptables). De plus, tous les agentscorrects sont d’accord sur le but (situationnon-compétitive).
SMA et informatique répartie. L’informa-tique répartie se donne souvent pour but dedessiner les contours de ce qui est réali-sable. Elle étudie ainsi des conditions ex-trêmes. Le domaine des systèmes multia-
Autour du problème du consensus ___________________________________________________________________________
386

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 399/415
gents se veut plus pragmatique en se pla-çant dans des contextes plus consensuels.Il faut donc faire des compromis parfoisdifficiles entre des critères “naturels” telsque la sûreté ou la vivacité et d’autres cri-tères dépendant de l’application (rationa-lité encapsulée au niveau des agents). Cecompromis cohérence/vivacité/rationalitéreste à établir : l’informatique répartie seconcentre sur les deux premiers points tan-dis que les SMA (et la théorie des jeux)développent la notion de rationalité localeaux agents, mais insistent moins sur la co-hérence/vivacité.
Références
[1] J.-P. Barthélemy and M.F. Janowitz. Aformal theory of consensus. In Siam.
J. Discr. Math., volume 4, pages 305–322, 1991.
[2] C. Chichilnisky and G. Heal. Neces-sary and sufficient conditions for a re-solution of the social choice paradox.
Journal of Economic Theory, 31 :68–87, 1983.
[3] M.J. Fischer, N.A. Lynch, and M.S.Paterson. Impossibility of distribu-ted consensus with one faulty process.
Journal of the ACM , 32(2) :374–382,1985.
[4] J. Goubault-Larrecq. Une introductionaux capacités, aux jeux et aux prévi-
sions. Technical report, INRIA Futursprojet SECSI, mars 2006.
[5] J.Y. Halpern and Y. Moses. Know-ledge and common knowledge in a dis-tributed environment. Journal of the
ACM , 37(3) :549–587, 1990.
[6] F. Koessler. Common knowledge andinteractive behaviors : A survey. Euro-
pean Journal of Economic and SocialSystems, 14(3) :271–308, 2000.
[7] L. Lamport, R. Shostak, and M. Pease.The byzantine generals problem. ACM Transactions on Programming Lan-guages and Systems, 4(3) :382–401,1982.
[8] N.A. Lynch. Distributed Algorithms.Morgan-Kaufmann, 1996.
[9] M. Saks and F. Zaharoglou. Wait-
free k-set agreement is impossible :the topology of public knowledge.In STOC’93, pages 101–110. ACMPress, 1993.
____________________________________________________________________________ Annales du LAMSADE N°8
387

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 400/415

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 401/415
Un modèle pour caractériser des participants autonomesdans un processus de médiation1*
Jorge-Arnulfo Quiané-Ruiz2†
Philippe [email protected]
Patrick [email protected]
INRIA and LINAUniversité de Nantes
2 rue de la houssinière, 44322 Nantes Cedex 3, France
Résumé :Nous considérons les systèmes d’information dis-tribués dans lesquels les participants sont nonseulement libres de quitter le système, mais
peuvent aussi manifester différents intérêts. La plu-part des travaux dans ce contexte sont centrés surla performance (répartition de charge, temps de ré-ponse. . . ) sans tenir compte des intérêts des partici-pants. Pourtant, le non respect de leurs intérêts par-ticuliers peut conduire les participants à quitter lesystème. Nous proposons une nouveau modèle quiaide à caractériser la satisfaction des participantssur le long terme ainsi que leur adéquation.
Mots-clés : Autonomie des participants, satisfac-tion, comportement à long terme
Abstract:We consider distributed information systems whereparticipants are autonomous and have also specialinterests. Most of the works in this context are cen-tered on the performences but do not take parti-cipants’ particular interest into account. However,not respeter the particular interests of the partici-pants can lead them to leave the system. We pro-pose a new model that helps to characterize theparticipants’ satisfaction in the long-run as well astheir adequation.
Keywords: Participants’ autonomy, satisfaction,long-run behavior
1 Introduction
Nous nous intéressons aux systèmes d’in-formation distribués où des participantsfournisseurs et clients) hétérogènes et au-tonomes interagissent. L’autonomie fait ici
∗Travail en partie financé par ARA “Massive Data" of theFrench ministry of research (projects MDP2P and Respire) andthe European Strep Grid4All project.
†Cet auteur est supporté par le Conseil National de Scienceet Technologie du Mexique (CONACyT).
référence à la possibilité de quitter le sys-tème suite à une décision individuelle lo-cale et ce, sans aucune contrainte.
Chaque requête doit être allouée à desfournisseurs peuvant la traiter. De nom-breux travaux dans ce domaine ontconcentré leurs efforts sur la répartition decharge (QLB) [1, 3, 7]. Cependant, les par-ticipants peuvent manifester certaines at-tentes en dehors des seules performances.Par exemple, un fournisseur représentantune firme pharmaceutique peut souhaiter,à une période donnée, faire la promotion
d’une lotion anti-moustique. Il manifesteraalors un intérêt plus marqué pour les re-quêtes relatives à ce type de produits etaura tendance à les privilégier par rapportaux autres requêtes de son domaine.
Intuitivement, dans ces conditions, un en-vironnement est satisfaisant pour les parti-cipants s’il leur permet de répondre à leursattentes. Pour cela, le système d’allocation
des requêtes doit tenir compte de leurs in-tentions. Ces intentions peuvent être le ré-sultat de la combinaison de plusieurs infor-mations comme les préférences, la charge,les stratégies. Les préférences d’un clientpeuvent leur permettre de faire le choixentre différents fournisseurs (par exempleen utilisant la réputation). Celles d’unfournisseur peuvent être fondées sur leurscentres d’intérêt. Nous considérons ici queles preferences sont plutôt statiques (i.e.peu sujettes à évolution), alors que les lesintentions sont plus dynamiques.
Dans l’idéal, le système devrait satisfairetous les participants à chaque allocation.
389

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 402/415
Cependant, cela n’est pas toujours pos-sible. Par exemple, pour une requête don-née, lorsqu’aucun fournisseur ne souhaitetraiter la traiter, il y aura nécessairementdes insatisfaits. Ils seront soit du coté“client”, si la requête est rejetée par le sys-tème, soit du coté “fournisseur”, si le trai-tement de la requête leur est imposé. Unevue à long terme de la satisfaction est doncplus réaliste.
A notre connaissance, il n’existe pas detravaux qui permettent de caractériser lacapacité d’un système à satisfaire les in-
tentions des participants sur le long terme.Les systèmes économiques considèrentl’utilité, qui est liée à la notion de satis-faction mais sans lui correspondre exac-tement. Nous proposons donc un nouveaumodèle permettant de déterminer si un sys-tème satisfait les participants sur le longterme et s’il est “juste” avec eux.
La suite de cet article est structurée de
la manière suivante. La section 2 présenteun scénario motivant la démarche. La sec-tion 3 présente quelques concepts préli-minaires. Le modèle permettant d’évaluerun système du point de vue de la satis-faction est présenté à la section 4. Dansla section 5, nous définissons les proprié-tés permettant d’évaluer la qualité des mé-thodes d’allocation. Finalement, les liensavec d’autres travaux sont présentés à lasection 6 avant la section 7 qui conclue.
2 Motivation
Pour illustrer le problème des systèmesd’information distribués avec des partici-pants autonomes, considérons par exempleun système incluant des centaines descientifiques (biologistes, docteurs en mé-decine, généticiens...) travaillant sur le
génôme humain. Ils sont répartis sur laplanête et ils partagent leurs informations.Chaque site, qui représente un scientifique,déclare ses capacités au système et gère lo-calement ses préférences et intentions.
TAB . 1 – Fournisseur ayant les capacitésde traiter la requête d’Emma.
Fournisseurs Charge Intention Cons. Int.Mark 15% Oui Non
Robert 43% Non Oui
Johnson 78% Oui Non
William 85% Non Oui
Mary 100% Oui Oui
Considérons un scénario simple. Emma(Dr. en médecine) vient de découvrir ungène responsable d’une maladie de lapeau. Elle interroge le système pour trou-ver des liens éventuels avec d’autres mala-dies. Pour une vue plus générale, elle sou-haite avoir des réponses de plusieurs col-lègues, disons 2 pour simplifier l’exemple.
Dans un premier temps, le système doitidentifier les fournisseurs capables de trai-ter la requête. Un algorithme de match-
making [10] permet de résoudre ce pre-mier problème. Supposons que pour cetexemple, il y en ait 5. La seconde étapeconsiste à obtenir les intentions de cesfournisseurs par rapport à cette requête(supposées binaires dans cet exemple). Letableau 1 regroupe les différentes donnéesde cet exemple.
Mary est la plus chargée (elle n’a plus deressource disponible). Robert et Williamne désirent pas traiter cette requête pourdes raisons qui leurs sont propres. D’unautre coté, pour des raisons de confianceenvers leurs résultats, Emma ne souhaitepas que Mark ou Johnson traitent sa re-quête.
Quoi qu’il en soit, à la demande d’Emma,le système doit choisir deux fournisseurspour leur allouer la requête. Mark et Ro-
bert sont les moins chargés. C’est donc àeux que les méthode basées sur la réparti-tion de charge alloueraient la requête. Celaaurait pour conséquence de mécontenterRobert et Emma. Répétées, de telles déci-
Un modèle pour caractériser des participants autonomes dans un processus de médiation ___________________________________________________________________________
390

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 403/415
sions pourraient conduire ces participantsà quitter le système. Ici la seule réponsecorrecte du point de vue des intentions estMary. Malheureusement, cette allocationn’est pas satisfaisante du point de vue dela répartition de charge. De plus, Emma ademandé à ce que la requête soit envoyéeà deux scientifiques. C’est donc un cas quigénèrera du mécontentement d’un coté oude l’autre.
Plusieurs questions restent donc ouvertes :Que doit faire le système dans ce cas?
Doit-il privilégier les intentions du client
(ici Emma) ? les intentions des four-nisseurs ? Doit-il prendre en compte lacharge des fournisseurs ? Dans cet article,nous ne répondons pas à ces questions,mais nous proposons un modèle qui per-met d’analyser le comportement d’un sys-tème de ce type. Les notions présentéespeuvent aussi servir à une méthode de mé-diation dans ses prises de décisions.
3 Préliminaires
Nous considérons un système dans lequelinteragissent des clients, des fournisseurset des médiateurs. Les ensembles de cesparticipants, non nécessairement disjoints,sont notés respectivement C , P , et M . Lesrequêtes sont exprimées sous forme d’untriplet q = < c, d, n > où q.c ∈ C
est l’identifiant du client ayant émis la re-quête; q.d, la description de la tâche de-mandée; et q.n ∈ N∗, le nombre de four-nisseurs demandés. P q dénote l’ensembledes fournisseurs ayant les capacités de trai-ter une requête q · Les clients envoient leursrequêtes à un médiateur m ∈ M qui, sic’est possible, alloue toute requête q à q.nfournisseurs choisis parmi ceux ayant lescapacités de le faire1. Un client c (resp.un fournisseur p) peut exprimer ses inten-
tions −→CI qc[ p] (resp. P I p(q )) pour allouer
1Convention : un médiateur suit les directives des clientsdans la mesure où les fournisseurs sont assez nombreux pourcela.
(resp. traiter) une requête q . Ces intentionssont des valeurs réelles dans [−1..1]. Aucontraire d’une valeur négative, une in-tention positive dénote le désir d’allouer(resp. de traiter) la requête
4 La modélisation
Notre attention s’est portée sur deux ca-ractériques des participants qui permettentde comprendre comment ils peuvent per-cevoir le système dans lequel ils inter-agissent.
La première de ces caractéristiques estl’adéquation. En fait, deux adéquationsdoivent être considérées. a) adéquation dusystème par rapport à un participant e.g.un système dans lequel un fournisseur nepeut trouver aucune requête correspondantà ses attentes n’est pas adéquat pour cefournisseur; b) adéquation d’un partici-
pant au système e.g. un client qui émet des
requêtes qui n’intéressent aucun fournis-seur n’est pas adéquat par rapport au sys-tème. A travers ces notions il est possibled’évaluer si un participant a une chanced’atteindre ses objectifs dans un système.À moins d’avoir une connaissance globaledu système, un participant ne peut détermi-ner lui même ce que les autres pensent delui. Aussi, nous considérons l’adéquationd’un participant au système comme une
caractéristique globale (cf. Section 4.3).La seconde caractéristique est la satis-
faction. Comme pour l’adéquation, deuxsortes de satisfaction peuvent être consé-dérées : a) la satisfaction d’un partici-
pant vis-à-vis du système e.g. un client quireçoit des résultats de fournisseurs qu’ilne souhaitait pas solliciter n’est pas satis-fait ; et b) la satisfaction d’un participant
par rapport au système de médiation e.g.
un fournisseur devant traiter des requêtesqu’ils ne désirait pas met en cause le sys-tème de médiation lorsqu’il constate qu’ilexiste des requêtes lui convenant mieux,mais ne lui étant pas allouées. Ces deux
____________________________________________________________________________ Annales du LAMSADE N°8
391

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 404/415
notions de satisfaction peuvent avoir unimpact important sur le système dans lamesure où elles peuvent fonder une déci-sion de départ d’un participant.
Nous supposons que les participants ontune mémoire limitée et qu’ils ne mémo-risent donc que leurs k dernières interac-tions avec le système2. Nous allons doncdéfinir les différentes notions présentéesci-dessus par rapport à la mémoire desparticipants. Deux remarques suppémen-taires. Il est évident que ces notions évo-luent au cours du temps, mais pour éviter
d’alourdir les notations, le temps n’appa-raîtra pas. Enfin, ces notions peuvent êtredéfinies soit à partir des préférences desparticipants, soit à partir de leurs inten-tions. Si les définitions formelles sont si-milaires, les valeurs obtenues présententquelques différences. Pour des raisons deplace, nous ne pouvons en présenter iciqu’une seule version. Dans la mesure oùles préférences sont souvent considérées
comme des données privées, ce sont lesintentions affichées auprès des médiateursqui serviront de base à nos définitions.
4.1 Caractérisation locale d’un client
Un client est caractérisé à partir des infor-mations qu’il peut obtenir du système. In-tuitivement, les caractéristiques présentéesci-après sont utiles pour répondre à des
questions de la forme “Dans quelle me-sure mes intentions correspondent à cellesdes fournisseurs pouvant traiter mes re-quêtes?”– adéquation d’un client par rap-
port au sytème – “Dans quelle mesure lesfournisseurs ayant traité mes dernières re-quêtes me satisfont?” – Satisfaction d’unclient – “La méthode d’allocation des re-quêtes me satisfait-elle?” – Satisfactiond’un client par rapport à l’allocation –.
Ces notions seront basées sur la mémoired’un client qui sera notée IQkc .
2Notons que k peut être différent d’un participant à l’autre.Cependant, dans un souci de simplification, nous supposeronsici que ce paramètre est identique pour tous les participants.
Adéquation. L’adéquation du système pour un client caractérise la vision dusystème qu’a le client. Dans le scénarioprésenté section 2, le système est relative-ment adéquat pour Emma car bon nombredes fournisseurs lui conviennent. Plusformellement, l’adéquation du systèmepar rapport au client c et pour une requêteq , notée δ sca(c, q ), est définie comme étantla moyenne des intentions de c par rapportà l’ensemble des fournisseurs pouvanttraiter q (P q). La valeur de cette notion estvolontairement amenée dans l’intervalle[0..1].
δ sca(c, q ) = 1
||P q||
p∈P q
−→CI qc [ p]
+ 1
2 (1)
L’adéquation du système par rapport àun client c, est alors définie comme lamoyenne des adéquations pour les k der-nières requêtes.
Définition 1 Adéquation du système par rapport àun client.
δ sca(c) =1
||IQkc ||
q∈IQk
c
δ sca(c, q )
Plus la valeur est proche de 1, plus le clientconsidère le système comme adéquat.
Satisfaction. La satisfaction d’un client cconcernant le traitement d’une de ses re-quêtes q , notée δ s(c, q ) est liée aux four-nisseurs auxquels sa requête a été allouée( P q). La moyenne semble une techniqueintuitive. Cependant, elle ne permet pas deprendre en compte le souhait d’un clientd’avoir plusieurs résultats de fournisseursdifférents. Par exemple, dans le scénariode la section 2, Emma a demandé 2 four-
nisseurs. Si le système ne lui en allouequ’un seul la satisfaction d’Emma ne peutêtre totale, même si ce fournisseur est par-fait. L’équation suivante tient compte de cepoint.
Un modèle pour caractériser des participants autonomes dans un processus de médiation ___________________________________________________________________________
392

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 405/415
δ s(c, q ) = 1
n
p∈cP q
−→CI qc [ p]
+ 1
2 (2)
où n abbrège q.n. Les valeurs de δ s(c, q )sont dans l’intervalle [0..1].
La satisfaction d’un client c est alors ob-tenue en faisant la moyenne des satisfac-tions par rapport aux k dernières requêtestraitées.
Définition 2 Satisfaction d’un client
δ s(c) =1
||IQkc ||
q∈IQk
c
δ s(c, q )
Cette notion de satisfaction ne tient aucuncompte du contexte. Elle ne permet doncpas au client d’évaluer les efforts consen-tisparlesystèmed’allocationpourlesatis-faire. Par exemple, en reprenant le scénario
delasection2,supposequ’Emmaaunein-tention de 1 (resp. 0.9, 0.7) pour que la re-quête soit allouée à Robert (resp. Williamet Mary). Allouer la requête à Williamest dans l’absolu satisfaisant. Cependant, ilexiste un autre fournisseur dans le systèmequi serait encore plus satisfaisant. La sa-tisfaction d’un fournisseur par rapport ausystème d’allocation, notée δ as(c) (défini-tion 3) permet de rendre compte des effortseffectués en ce sens par la méthode d’allo-cation. Cette satisfaction prend ses valeursdans l’intervalle [0..∞].
Définition 3 Satisfaction d’un client par rapport àla méthode d’allocation
δ as(c) =1
||IQkc ||
q∈IQk
c
δ s(c, q )
δ sca(c, q )
Si la valeur ainsi obtenue est supérieure à1,leclientpeutenconclurequelaméthoded’allocation agit en sa faveur. Par contre,si cette valeur est proche de 0 la méthodedéfavorise le client.
4.2 Caractérisation locale d’un four-
nisseur
Cette section est consacrée à la caractérisa-tion d’un fournisseur. Intuitivement, nouscherchons à répondre à des questions dela forme : “dans quelle mesure les re-quêtes émises sur le sytème correspondentaux intentions du fournisseur?” – Adéqua-tion du système –; “dans quelle mesureles dernières requêtes que le fournisseur aeu à traiter lui conviennent?” – Satisfac-tion du fournisseur – ; “la méthode d’allo-
cation est-elle statisfaisante?” – Satisfac-tion du fournisseur par rapport à la mé-thode d’allocation –. Ces caractéristiquesseront définies par rapport aux intentionsexprimées par le fournisseurs sur les k der-nières requêtes qu’il est capable de mémo-riser (
−→P I k p).
Adéquation. L’adéquation du système par rapport à un fournisseur aide ce fournis-seur à déterminer si le système dans lequelil évolue correspond à ses attentes. Parexemple, dans le scénario de la section 2,on peut considérer que le système est adé-quat par rapport à Marc dans la mesure oùla seule requête émise par Emma corres-pond à ses intentions. Cependant, il est dif-ficile de conclure en ne considérant qu’uneseule requête. Une moyenne est plus infor-mative.
Définition 4 Adéquation du sytème par rapport àun fournisseur
δ spa( p) =
1
||P Qk p ||
q∈PQk
p
−→P I k p[q ]
+ 1
2
0 si P Qk p = ∅
Les valeurs que peut prendre cette adé-quation sont dans l’intervalle [0..1]. Plusla valeur est proche de 1, plus le sys-tème est adéquat par rapport au fournisseurconcerné.
____________________________________________________________________________ Annales du LAMSADE N°8
393

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 406/415
Satisfaction. Contrairement à l’adéqua-tion, la satisfaction d’un fournisseur ne dé-pend que des requêtes qu’il a eu à traiter.En revenant encore une fois au scénario dela section 2, et en supposant que le systèmealloue la requête d’Emma à Robert, Ro-bert ne sera pas satisfait car il ne souhaitepas la traiter. La satisfaction d’un fournis-seur, δ s( p),estdoncdéfiniecommeétantlamoyenne des satisfactions obtenues sur lesrequêtes traitées par le fournisseur (SQk
p)parmi les k dernières requêtes (P Qk
p). Lavaleur est ramenée sur l’intervalle [0..1].
Plus la valeur est proche de 1, plus le four-nisseur est satisfait.
Définition 5 Satisfaction d’un fournisseur
δ s( p) =
1
||SQk p ||
q∈SQk
p
−→P I k p[q ]
+ 1
2
0 si SQk p = ∅
Avec cette définition, un fournisseur peutévaluer s’il obtient des requêtes lui permet-tant d’atteindre ses objectifs, ou au moins,satisfaisant ses intentions. D’un autre coté,les efforts déployés par la méthode d’allo-cation pour l’aider peuvent aussi l’intéres-ser. Nous définissons la satisfaction d’un
fournisseur par rapport à la méthode d’al-location comme étant la ratio de sa satis-faction sur son adéquation (définition 6).Les valeurs sont dans l’intervalle
[0..∞]
.
Définition 6 Satisfaction d’un fournisseur par rapport à la méthode d’allocation
δ as( p) =δ s( p)
δ spa( p)
Plus la satisfaction d’un fournisseur parrapport à la méthode d’allocation est su-
périeure à 1 plus l’effort de la méthoded’allocation en faveur du fournisseur estimportant. A contrario, plus la valeur estproche de 0, plus la méthode est pénali-sante pour le fournisseur.
4.3 Caractérisations des participants
du point de vue du système
Les participants, tant les fournisseurs queles clients, sont ici caractérisés d’un pointde vue global. L’objectif est de pouvoir ré-pondre à des questions de la forme : “Dansquelle mesure les requêtes d’un client cor-respondent aux attentes des fournisseurs”– Adéquation d’un client par rapport ausystème – “Dans quelle mesure un fournis-seur répond-il aux attentes des clients?” –
Adéquation d’un fournisseur par rapport
au système –L’adéquation d’un client par rapport ausystème système permet d’évaluer si ceclient correspond aux attentes des fournis-seurs. En reprenant le scénario de la sec-tion 2, la requête d’Emma est adéquate ausystème car une grande partie des fournis-seurs sont prêts à la traiter. En accord aveccette intuition, l’adéquation d’une requêteq d’un client c, notée δ csa(c, q ), est définie
comme la moyenne des intentions décla-rées par les fournisseurs. Les valeurs sontramenées dans l’intervalle [0..1].
δ csa(c, q ) = 1
||P q||
p∈P q
P I p(q )
+ 1
2 (3)
L’adéquation du client par rapport au sys-tème est simplement définie comme lamoyenne de ces valeurs.
Définition 7 Adéquation d’un client par rapport au système
δ csa(c) =1
||IQkc ||
q∈IQk
c
δ csa(c, q )
L’adéquation du fournisseur par rapport au système permet d’évaluer si les clientssont intéressés par ce fournisseur. En re-venant au scénario de la section 2, Emma
Un modèle pour caractériser des participants autonomes dans un processus de médiation ___________________________________________________________________________
394

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 407/415
ne souhaite pas que Mark traite sa re-quête. Cela ne joue pas en faveur de Mark.L’adéquation d’un fournisseur par rapportau système, δ psa( p), est définie comme lamoyenne des intentions montrées à sonégard par les clients sur les k dernières re-quêtes proposées. Les valeurs sont rame-nées entre [0..1]. Plus la valeur est prochede 1, plus le fournisseur est adéquat.
Définition 8 Adéquation d’un fournisseur par rap- port au système
δ psa( p) =
1
||P Qk
p||
q∈PQk
p
−→CI qc[ p]
+ 1
2
0 if PQk p = ∅
5 Mesures
Les mesures proposées sont identiquespour les clients et les fournisseurs, et sontapplicables aux différentes notions présen-tées plus haut. Pour éviter les redites, la
fonction g dénotera l’une ou l’autre des no-tions présentées, et S un ensemble de four-nisseurs ou de clients.
La moyenne (µ) permet de mesurer correc-tement l’efficacité.
µ(g, S ) =1
||S ||
s∈S
g(s) (4)
L’indice d’équité proposé par [5] (Equa-
tion 5) apporte quant à lui des informa-tions sur la répartition des valeurs. Il esttoujours compris entre 0 et 1. Plus la va-leur est proche de 1, plus le mécanisme estéquitable.
f (g, S ) =
s∈S
g(s)2
||S ||s∈S
g(s)2 (5)
Lorsque l’on s’intéresse à la répartition decharge, le ratio Min/Max est aussi large-ment utilisé. Tel que défini par l’équation 6
où c0 > 0 est une constante positive pré-définie, il mesure l’écart maximal entre lesvaleurs, et donc il qualifie la balance entreles différents éléments. Plus la valeur ob-tenue est grande meilleure est la balance.
σ(g, S ) =mins∈S
g(s) + c0
maxs∈S
g(s) + c0(6)
6 Travaux connexes
Il existe une litérature substantielle rela-tive au problème de “query load balan-ce”. Dans le contexte des systèmes large-ment distribués, la plupart des travaux al-louent la requête aux fournisseurs qui sontles moins chargés. Azar et al. [1] explorentle problème d’allouer n tâches en choi-
sissant le serveur le moins chargé parmid serveurs choisis aléatoirement. Vöcking[11] a montré que l’usage de l’a-symétrieaméliore les résultats. Mitzenmacher et al.[6] améliorent les deux propositions pré-cédentes en introduisant une mémoire desm derniers serveurs utilisés. Cependant,tous ces travaux font l’hypothèse que lesfournisseurs (et les requêtes) sont homo-gènes et ne se généralisent pas aux sys-tèmes hétérogènes. Des travaux ont consi-déré d’autres notions comme le CPU [4],ou la combinaison de plusieurs notionsI/O, mémoire, CPU [9], ou encore des scé-narii avec plusieurs ressources [7]. Cepen-dant, aucun ne considère les intentions quece soient celles des fournisseurs ou desclients. Plusieurs approches [2, 8] s’ap-prochent de la notion d’intention en pré-sentant des modèles économiques, maisl’économie introduit d’autres aspects (liés
à l’auto-régulation des systèmes écono-miques) qui ne sont pas directement liéesaux intentions. De plus, l’étude sur lelong terme (k requêtes) n’est pas toujoursclaire.
____________________________________________________________________________ Annales du LAMSADE N°8
395

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 408/415
7 Conclusion
Cet article est centré sur les systèmes d’in-
formation distribués où les participants(fournisseurs comme clients) sont libres dequitter le système quand ils le souhaitent etont des intérêts particuliers.
Nous avons proposé un modèle de ré-partition des requêtes dont les principalescaractéristiques sont 1) prise en comptedes intentions des participants sur le longterme; 2) indépendance par rapport à lastratégie utilisée pour obtenir les inten-
tions et par rapport à la technique utiliséepour effectuer la répartition des requêtes ;d’où, 3) applicablilité à tous les systèmesexistants pour mesurer leurs capacités àrespecter les intentions des participants etdonc à les satisfaire; et, 4) présentationde notions pouvant guider la conceptionde nouvelles techniques d’allocation de re-quêtes.
En utilisant les différentes mesures propo-sées, nous pensons qu’il est possible deprévoir les départs des participants d’unsystème et d’en déterminer les raisons.
Dans de futurs travaux, nous allons analy-ser des méthodes d’allocations existantesen utilisant ce modèle et vérifier concrète-ment s’il permet d’effectuer des prévisionscorrectes.
Références
[1] Y. Azar, A. Z. Broder, A. R. Kar-lin, and E. Upfal. Balanced Allo-cations. SIAM Journal Computing,29(1), 1999.
[2] D. Ferguson, Y. Yemini, and C. Niko-laou. Microeconomic Algorithms forLoad Balancing in Distributed Com-
puter Systems. In Procs. of ICDCS Conference, 1988.[3] P. Ganesan, M. Bawa, and H. Garcia-
Molina. Online balancing of range-partitioned data with applications to
peer-to-peer systems. In Procs. of VLDB Conference, 2004.
[4] M. Harchol-Balter and A. B. Dow-
ney. Exploiting process lifetime dis-tributions for dynamic load balan-cing. ACM TOCS , 15(3), 1997.
[5] R. K. Jain, D.-H. Chiu, and W. R.Hawe. A quantitive measure of fair-ness and discrimination for resourceallocation in shared computer sys-tems, DEC-TR-301. Technical re-port, 1984.
[6] M. Mitzenmacher, B. Prabhakar, and
D. Shah. Load balancing with me-mory. In Procs. of FOCS Conference,2002.
[7] E. Rahm and R. Marek. Dynamicmulti-resource load balancing in pa-rallel database systems. In Procs. of VLDB Conference, 1995.
[8] M. Stonebraker, P. Aoki, W. Lit-win, A. Pfeffer, A. Sah, J. Sidell,
C. Staelin, and A. Yu. Mariposa :A wide-area distributed database sys-tem. VLDB Journal, 5(1), 1996.
[9] M. Surdeanu, D. I. Moldovan,and S. M. Harabagiu. Perfor-mance analysis of a distributedquestion/answering system. IEEE Transactions on Parallel and Distri-buted Systems, 13(6), 2002.
[10] K. P. Sycara, M. Klusch, S. Widoff,
and J. Lu. Dynamic service match-making among agents in open infor-mation environments. SIGMOD Re-cord , 28(1), 1999.
[11] B. Vocking. How asymmetry helpsload balancing. In Procs. of FOCS Conference, 1999.
Un modèle pour caractériser des participants autonomes dans un processus de médiation ___________________________________________________________________________
396

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 409/415
Vers un Support des Communications Multi-Parties pour lesSystèmes Multi-Agents
J. Saunier
F. Balbo,†
LAMSADE, Université Paris-DauphinePlace du Maréchal de Lattre de Tassigny
75775 Paris cedex 16 – FRANCE
†Institut National de Recherche sur les Transports et leur Sécurité2 avenue du Général Malleret-JoinvilleF-94114 ARCUEIL Cedex – FRANCE
Résumé :Bien que les dialogues bi-parties soient les plusétudiés dans la communauté des Systèmes Multi-Agents (SMA), certains nouveaux modèles telsque l’écoute flottante et les communications multi-parties ont émergé récemment. Ces modèles ontmontré des gains d’efficacité et de cohérence desSMA. Dans cet article, nous introduisons un cadregénérique pour le support des communicationsmulti-parties. Nous décrivons un modèle formeld’environnement appelé EASI (Environment asActive Support of Interaction). Des algorithmespour la mise en oeuvre effective du modèle sont
également proposés, et nous discutons la validitéde cette approche à travers une série de tests.
Mots-clés : Interaction, environnement, communi-cations multi-parties
Abstract:Although two-party dialogues are the most-studiedcommunication type in the Multi-Agent Systems(MAS) community, new models such as overhea-ring and multi-party communications have emer-ged recently. These models have been shown to im-prove the efficiency and the coherence of the MAS.In this article, we introduce a generic frameworkfor multi-party communication support. Then weintroduce a formal environment model called EASI(Environment as Active Support of Interaction). Wealso propose algorithms to support effectively thismodel, and we discuss the validity of this approachthrough a series of tests.
Keywords: Interaction, Environment, multi-partycommunications
1 Introduction
La forme de communication la plus étu-diée est le dialogue, dans lequel deux
participants échangent les rôles d’émet-teur et de destinataire. Cependant, des tra-vaux récents, inspirés par l’étude de situa-tions réelles, mettent en exergue la possi-bilité d’exploiter des formes de commu-nications plus complexes, impliquant denouveaux rôles. Ainsi, l’écoute flottante[6] est l’écoute de communications entred’autres agents, sans être impliqué direc-tement dans la communication ni mêmenécessairement que les participants en aitconnaissance.
En section 2, nous introduisons de fa-çon générique les communications multi-parties. Nous décrivons en section 3 le mo-dèle formel EASI (Environment as ActiveSupport of Interaction). En section 4, nousintroduisons des algorithmes de gestion dece modèle qui dépendent de la dynamiquedu SMA et nous montrons une implémen-
tation et discutons la performance du mo-dèle et des algorithmes.
2 Les Communications Multi-Parties
De façon générale, les communicationsmulti-parties présentent la spécificitéd’avoir un émetteur, des destinataires
prévus et des récepteurs inattendus. Uneétude plus fine est nécessaire pour extraireles différents types de rôles possibles.
Sur la base des travaux existants dans
397

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 410/415
le domaine des SMA [5], mais aussi dela psychologie et des sciences sociales[2], nous proposons 3 critères détermi-nant le rôle de l’agent dans la communi-cation : (1) l’intention : le récepteur est-il prévu, et si oui pour participer active-ment à l’échange ou pour l’écouter pas-sivement ? (2) La connaissance : l’agentest-il connu des autres participants ? (3)L’initiateur de la réception : est-ce une ini-tiative de l’émetteur ou du récepteur ? Cescritères vont nous permettre de définir lesprincipaux rôles pouvant être joués dans lacommunication. Ainsi, le destinataire est
un récepteur prévu et connu par l’émet-teur, qui participe au dialogue, et pour le-quel la réception s’est effectuée à l’initia-tive de l’émetteur. Un auditeur aura lesmêmes caractéristiques, hormis qu’il n’estpas sensé participer à la conversation. Unécouteur est un récepteur non-prévu, quipeut ne pas être connu de l’émetteur, etqui perçoit le message par son initiativepropre. Le cas d’un “groupe de destina-
tion” est le moins classique, il s’agit d’uneinitiative de l’émetteur envers un groupedont les membres ne sont pas nécessaire-ment connus. Par exemple, faire une an-nonce au club photographie de l’universitén’implique pas de connaître chacun de sesmembres. Enfin, un écouteur indiscret estun récepteur indésirable. Ce cas ne sera engénéral pas recherché, hormis par exempledans le cadre de simulations.
Un système permettant la présence si-multanée de destinataires et d’écouteursdoit résoudre la problématique de la miseen corrélation d’initiatives d’origines dif-férentes pour la décision de distributiondes messages. La possibilité de récep-teurs imprévus, voir inconnus, impliqueque l’émetteur ne maîtrise pas nécessai-rement le canal de communication, parexemple une émission en clair sur un ré-
seau wifi. Dans le cadre de réseaux clas-siques, ceci n’est réalisable que par le biaisd’un middleware. Il est nécessaire de ca-ractériser comment s’exprime l’ “initia-tive” permettant la connexion entre l’in-
formation et les récepteurs. Une solutionest de représenter chaque composant duSMA par une description observable, etde permettre aux agents d’utiliser ces des-criptions pour gérer leurs interactions enajoutant des conditions. Les composant duSMA sont les agents, les percepts (mes-sages, traces) ou tout autre objet.
Exemple Illustratif. Au long de cet article,nous développons un exemple de servicede communication dédié à une Applicationd’Intelligence Ambiante (AIA). Cette ap-plication doit faciliter les interactions entreles employés d’une entreprise et leurs vi-siteurs. Un agent employé appartient à unservice, et a une disponibilité. L’entre-prise est composée de salles de service,de salles de réunion et d’une réception.L’objectif sera de proposer une applica-tion permettant le support des différentsbesoins d’interaction de façon standardi-sée. Par exemple, pour un visiteur, les be-soins d’interaction directe seront liés à la
recherche d’un certain employé (situationnotée S di1), ou à la recherche d’un em-ployé disponible dans un service déter-miné (S di2). Un exemple d’interaction in-directe sera lié à la libération d’une salle.Cet évènement devra être perçu par lesagents intéressés (S ind). Enfin, l’applica-tion doit supporter des modèles d’interac-tion plus complexes comme l’écoute flot-tante. Par exemple, un agent peut sur-
veiller l’activité du SMA en écoutant lesemployés en présence de clients dans lessalles d’un service particulier (S mon).
3 L’Environnement, SupportActif de l’Interaction
L’originalité d’EASI est de modéliser l’in-teraction dans son ensemble et de consi-
dérer les agents comme une partie de cetensemble. Le problème de connexion estrésolu par l’environnement en fonction dela description qu’il a des composants del’interaction, agents ou percepts ; et la réi-
Vers un support des communications multi-parties pour les systèmes multi-agents ___________________________________________________________________________
398

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 411/415
fication de chaque problème de connexionsera appelée un filtre. Dans la suite, nousappellerons “connexion” la mise en re-lation d’un percept avec un ou plusieursagent. Toutes les informations sur les com-posants du SMA nécessaires à l’interactionsont regroupées dans l’environnement. Defaçon à être facilement utilisable, ce re-groupement doit reposer sur une organi-sation efficace, c’est pourquoi EASI estfondé sur l’Analyse de Données Symbo-liques (ADS) [1]. L’ADS est un modèlede classification et d’analyse de grands en-sembles de données qualitatives, quantita-
tives et complexes.
Notre modèle d’environnement com-prend un ensemble de m entités,Ω = ω1,...,ωm et un ensemble dek filtres, F = f 1,...,f k. Une entité ωl
possède une description d’un composantdu SMA (agent, percept, objet) par le biaisde ses propriétés observables. Un filtre f jest la description de contraintes sur les
propriétés observables des entités liéesà un problème de connexion j, qui serautilisé pour la transmission des percepts.Soit P = p1,...,pn l’ensemble des npropriétés observables d’un SMA, unepropriété observable pi est une fonctionqui donne pour une entité ωl une valeur :∀ pi ∈ P , pi : Ω → di∪unknown, null,avec di le domaine de description de pi.di peut être quantitatif, qualitatif, ou unensemble fini de données.
La figure 1 décrit un exemple simplede notre modélisation pour l’AIA. Il ya quatre entités, Ω = ω1, ω2, ω3, ω4qui ont respectivement la description del’agent visiteur v1, des agents employé e1 et e2 et du message m1. Les agentsont entre autres une propriété appelée
pos (pour position), le domaine de des-cription de cette propriété d pos est l’en-
semble des salles du bâtiment. La va-leur de pos(ω1) est la réception ; la valeur pos(ω2) est unknown car l’agent ω2 nel’a pas renseignée, enfin la valeur pos(ω4)est null car ω4 ne possède pas cette pro-
priété dans sa description. La valeur d’unepropriété peut être modifiée dynamique-ment lors de l’exécution, excepté pournull, qui exprime l’absence de cette pro-priété. Il y a trois filtres, F = di1, di2,ind. Un agent devant résoudre un pro-blème de connexion ajoute un filtrele décrivant dans l’environnement. Parexemple, les agents employé ont deuxfiltres en commun, di1, di2, et l’agentemployé e2 a ajouté le filtre ind. De mêmeque pour les filtres, les agents modifientl’environnement en ajoutant, retirant oumettant à jour des entités. Par exemple,
l’agent visiteur v1 ajoute dans l’environ-nement l’entité ω4, qui représente le mes-sage m1. Grâce à l’ensemble des descrip-tions des composants du SMA, un pro-cessus d’appariement entre messages etagents (détaillé en section 4) permet de ré-soudre le problème de connexion pour m1
via les filtres de F .
Tous les composants du SMA sont au
même niveau d’abstraction, c’est à dire desentités. Afin d’obtenir des catégories d’en-tités, nous utilisons l’information struc-turelle d’existence des propriétés obser-vables (valeur de pi égale à null). Ainsi,une catégorie est un sous-ensemble d’en-tités décrites par un même sous-ensemblede propriétés. Lors de la connexion, laclassification est faite de manière préciseen ajoutant des conditions que les enti-
Environment
Employeeagent e2
Employee agent e1
Visitor agent
Ω : set of entities
F : set of filters
Filter direct1
Filter direct2
Filter indirect
ω3: <id, “e2”>, <available, 15>, <position,unknown>, <service, “marketing”>
ω2: <id, “e1”>, <available, 14>, <position,room 1>, <service, “marketing”>
ω1: <id, “v1”>, <visitSubject, “e1”>,<position, reception>
ω4: <sender, “v1”>, <receiver, “e1”>,
Matching
Algorithm
interaction
Description relationPut/retract Filter
Put/retract percept
FIG . 1 – Exemple de modélisation des in-teractions avec EASI
____________________________________________________________________________ Annales du LAMSADE N°8
399

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 412/415
tés doivent satisfaire. En ADS, un objetsymbolique est une description cohérented’une entité. Une assertion est un cas parti-culier d’objet symbolique, une conjonctionde tests élémentaires. Une assertion est unedescription en intention, et son extensiondans Ω contient toutes les entités satisfai-sant cette description. Un filtre sera doncun objet symbolique décrivant les entitésqui sont liées à un besoin en connexionparticulier.
Definition 1 (Filtre) Un filtre f ∈ F est
un tuple f ag, f pe, [f co], nf où : – f ag est la description en intention del’agent récepteur telle que : a ∈A, f ag(a) = ∧ pi∈P f ag
[ pi(a)Rf ag pi d
f ag pi ].
– f pe est la description en intention du percept telle que : ω ∈ Ω , f pe(ω) =
∧ pi∈P f pe[ pi(ω)R
f pe pi d
f pe pi ].
– f co est la description en intention (op-tionnelle) du contexte telle que :C ⊂ Ω ,f
co(C ) = ∧∀
c∈C
f co
(c) , avecf co(c) = ∧ pi∈P c [ pi(c) Rc
pidc pi
]. – nf est le nom du filtre.
La description du récepteur (définition 1)est fondée sur les propriétés qu’un agentdoit posséder pour être un récepteur poten-
tiel. Avec Rf ag pi , le tuple des opérateurs de
comparaison et df ag pi le tuple des valeurs et
variables, l’assertion f ag
décrit les condi-tions à satisfaire pour être récepteur. Dela même façon, la description du percept àrecevoir est donnée par l’assertion f pe. Lecontexte de l’interaction, i.e. les autres en-tités sur lesquelles portent des conditions,est donné par l’objet symbolique f co. Lecontexte est donc une partie de l’état ob-servable du SMA. De façon à décrire uneinteraction, les deux premières assertionssont obligatoires.
Pour l’AIA, le filtre décrivant S di2 est :f S di2 = [dep(a) =?x] ∧ [ava(a) =true], [dep(io) =?x], ∅, “di2Les variables sont données préfixées avec
un ?, comme ?x dans l’exemple. Cefiltre décrit la condition sur les agents([dep(a) =?x] ∧ [ava(a) = true]), etsur les percepts ([dep(io) =?x]). C’est unexemple de groupe de destination : l’émet-teur choisit un groupe dont il connaît lescritères, mais dont il ne connaît pas néces-sairement les membres.
Le modèle EASI est générique car cesont les filtres qui déterminent le mo-dèle d’interaction utilisé, et tous les filtressont traités de la même façon. Ainsi, lesagents peuvent utiliser de façon standar-
disée n’importe quel modèle en fonctionde leurs besoins. La distinction peut êtreeffectuée en étudiant l’initiateur du filtrepar rapport aux percepts. Soit f un filtre,si l’agent initiateur de f n’appartient pas àl’extension E (f ag), ceci signifie qu’il n’estpas dans les récepteurs potentiels de cefiltre. C’est donc que le filtre décrit lesagents avec lesquels l’initiateur désire in-teragir, ce qui est de l’interaction directe.Pour l’exemple AIA, les filtres de com-munication direct sont liés à S di1 et S di2.La définition f S di1 est : f S di1 = [id(a) =?x], [receiver(io) =?x], “di1Dans ce cas, le récepteur est de type des-tinataire, car il est prévu et connu parl’émetteur, lequel a initié la connexion. Sil’initiateur fait partie de E (f ag), c’est àdire qu’il fait partie des récepteurs poten-tiels de son filtre, alors f pe décrit les per-cepts qu’il souhaite recevoir. C’est une in-
teraction indirecte, à l’initiative du récep-teur. L’exemple de filtre pour AIA d’inter-action indirecte est : f S ind = [id(a) =“e2], [ pos(io) ∈ MR] ∧ [sub(io) =“available], “indL’agent avec la propriété id à valeur “e2
percevra tous les percepts liés à la dis-ponibilité des salles de réunion. C’estun écouteur , puisque c’est à son initia-tive qu’il accède aux informations. En-
fin, pour les interactions de type écouteflottante, l’initiateur appartient à E (f ag),mais le percept est initialement adresséà d’autres agents. L’exemple AIA sera :f S mon
= [id(a) = ”e3”], [sender(io) =
Vers un support des communications multi-parties pour les systèmes multi-agents ___________________________________________________________________________
400

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 413/415
?y], [ pos(ax) ∈ MR] ∧ [ pos(ax) =?x] ∧[ pos(ay) =?x] ∧ [dep(ax) = ”sav”] ∧[id(ax) =?y], “mon avec ax,ay ∈ A.L’agent “e3 est aussi un écouteur puis-qu’il est à l’initiative du filtre et qu’il estrécepteur potentiel.
4 Appariement
Une des difficultés du problème deconnexion est de trouver un algorithmegénérique permettant de gérer les inter-actions quelle que soit la dynamique du
SMA. Dans le cadre d’EASI, le critèreprincipal d’évaluation de la dynamique estla fréquence de mise à jour des propriétés.Notre proposition est donc un algorithmed’appariement générique qui utilise lesensembles construits selon deux niveauxde description, l’existence des propriétéset les contraintes. L’algorithme d’apparie-ment sera fondé sur la relation de validitésuivante : Soit a ∈ A,io ∈ IO,C ⊂ Ω,
V : A × Ω × P (Ω) × F → true, false,V (a,io,C,f ) = f ag(a) ∧ f pe(io) ∧ f co(C )
A chaque fois qu’une connexion est réali-sée, un destinataire reçoit un percept. Au-trement dit, lorsque V (a,io,C,f ) est va-lide, l’agent a reçoit P erf , tel que C ⊂C, Perf = io,C , nf . L’ensemble desinformations perçues en même temps quel’io est composé du nom du filtre, et d’unsous-ensemble du contexte de validation,i.e. une partie des entités de C . Un avan-tage d’EASI sera ainsi que le récepteurconnaît le contexte dans lequel il reçoit unpercept. Pour chaque percept ajouté dansl’environnement, l’algorithme doit asso-cier les agents qui sont liés à ce perceptpar des filtres, en fonction du contexte. Laréception effective est dénotée par la pri-mitive receive(a,Perf ), qui signifie la ré-ception par l’agent a de l’ensemble de per-
ception P erf . Nous ne faisons aucune hy-pothèse sur l’architecture des agents. Enconsidérant donc un ensemble P K a, lesconnaissances privées de l’agent a, la pri-mitive sera représentée algorithmiquement
par : receive(a,Perf ) ⇔ P K a ← P K a ∪P erf
Il faut trouver les ensembles les plus pe-tits liés à chaque filtre. Une première so-lution est donc de ne calculer la valida-tion que pour les entités possédant les pro-priétés requises. L’extension d’un filtre f est le tuple E (P f ag), E (P f pe), E (P f co).Ces ensembles sont calculables pour unedescription du SMA donnée. Un perceptpeut être reçu par plusieurs agents grâceau même filtre. Par exemple, pour le mêmepercept, f S di2 sera valide pour tous les
agents disponibles du même service. Deplus, un même percept peut être perçugrâce à plusieurs filtres. Par exemple, f S di1et f S mon
peuvent être valides pour unmême percept. La difficulté est donc detrouver pour un percept io tous les récep-teurs potentiels, en fonction des filtres liésà cet io.
Nous définissons Chaio comme l’en-
semble des filtres f liés au percept iotel que cet io appartient à l’extensionde chaque f (les définitions sont don-nées en figure 2). Pour chaque filtre f dans Chaio, on peut calculer l’ensembledes récepteurs potentiels et l’ensemble descontextes. Recio est l’ensemble des agentsappartenant aux extensions des filtres ap-partenant à Chaio, et Coio est l’ensembledes contextes appartenant aux extensionsde ces filtres. Enfin, sur le même principe,nous définissions FPera (pour filtres deperception) comme l’ensemble des filtres
Nom DéfinitionChaio f ∈ F |io ∈ E (P f pe)Recio a ∈ A|∃f ∈ Chaio,
a ∈ E (P f ag )Coio C ⊂ Ω|∃f ∈ Chaio,
C ∈ E (P f co)FPera f ∈ F |a ∈ E (P f ag)
FCoC f ∈ F |C ∈ E (P f co)
FIG . 2 – Définitions des ensembles pourl’appariement structurel.
____________________________________________________________________________ Annales du LAMSADE N°8
401

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 414/415
liés à un agent a, c’est à dire que l’agentappartient à l’extension de chacun de cesfiltres. F CoC (contextes de perception)est l’ensemble des contextes appartenantà l’extension de ces filtres. Chacun desensembles est réduit aux entités et filtrespotentiels. Par exemple, au lieu d’utili-ser l’ensemble des agents A, nous avonsRecio, i.e. le sous-ensemble des agentspossédant les propriétés requises. Pour unpercept io, un agent a ∈ Recio et uncontexte C ∈ Coio, l’ensemble minimaldes filtres pouvant effectuer la connexionest (FPera ∩ Chaio ∩ F CoC ). Cet algo-
rithme limite la recherche d’appariementà l’espace des entités qui ont été classi-fiées en fonction de leur description enintention, ce qui améliore la résolutionde la connexion. La valeur des proprié-tés n’étant pas prise en compte, ce niveaude description n’est pas sensible à la fré-quence de mise à jour du SMA.
Algorithm 1 Algorithme d’appariement
structurelPour chaque (io ∈ IO)Pour chaque (a ∈ Recio)Pour chaque (C ∈ Coio)Pour chaque (f ∈ (FPera ∩ Chaio ∩
F CoC )Si (V (a,io,C,f )) Alors
receive(a,Perf )Fin si
Fin pourFin pourFin pour
Fin pour
Lorsque les propriétés observables ont untaux de mise à jour raisonnable, il est pos-sible d’anticiper qu’un sous-ensemble derécepteurs potentiels, au sens possédantles propriétés requises, ne satisfont pascertaines conditions en terme de valeurs.
Dans l’algorithme précédant, on évaluetout de même ces entités. Nous proposonsdonc un nouvel algorithme, qui tout en sui-vant le même déroulement sera fondé nonplus sur les descriptions en intention, mais
sur les extensions des descriptions des en-tités, i.e. E (f ag), E (f pe) et E (f co) dans Ω.Ces extensions sont rarement calculablesentièrement, car les appariements réalisésdans les filtres peuvent mettre en corres-pondance des propriétés de plusieurs en-sembles d’entités. Nous proposons doncde modifier l’algorithme 1 en ôtant desensembles d’appariement les entités dontla valeur des propriétés ne satisfait pasles conditions des filtres. Sur l’ensembleChaio, la sélection sera donc faite formel-lement par : Chav
io = f ∈ Chaio|∀ pi ∈
P f pe [ pi(io)Rf pei d
f pei ] = false
Ceci signifie l’ensemble des filtres pourlesquels il n’y a pas de test élémentaire quiinvalide l’io. Par exemple, f S ind n’est va-lide que pour les io dont la propriété sub apour valeur “available.
Par continuité, nous utiliserons dans ce se-cond algorithme les ensembles restreintsde récepteurs potentiels Receivervio et defiltres FPerva que l’agent peut satisfaire.
Ce calcul peut être fait pour tous les en-sembles de l’algorithme précédent. Il enrésulte que le processus d’appariement estplus rapide grâce à un parcours d’en-sembles plus petits, par contre le coûtde maintenance des ensembles sera plusélevé. En effet, lorsqu’une entité met à
jour ses propriétés, elle peut passer pourun filtre donné de “valide” à “invalide” ouinversement.
Expérimentations
De façon à évaluer la performance de nosalgorithmes, nous avons mis en place unesérie de tests comparatifs comprenant ladiffusion classique (Broadcast) et nos deuxalgorithmes, respectivement notés E1 etE2. Nous nous sommes intéressés en par-
ticulier à la dépendance entre le taux demise à jour, le nombre d’agents et la per-formance du système. Les tests sont dessimulations de l’exemple AIA décrit danscet article.
Vers un support des communications multi-parties pour les systèmes multi-agents ___________________________________________________________________________
402

7/18/2019 Annale du Lamsade n°8 - Mai, 2007
http://slidepdf.com/reader/full/annale-du-lamsade-n8-mai-2007 415/415
0
50000
100000
150000
200000
0 50 100 150 200 250 300 350 400Agents
T i m e
Broadcast
EASI1
EASI2
0
5000
10000
15000
20000
25000
30000
35000
40000
45000
01020304050
Update
T i m e
Broadcast
EASI1
EASI2
0
500
1000
1500
2000
2500
3000
0246810
EASI1
EASI2
FIG . 3 – Broadcast - Algorithmes EASI.Temps d’exécution en fonction du nombred’agent (haut) et du taux de mise à jour(bas).
Par broadcast, la résolution du problèmede connexion est décentralisée, i.e. chaqueagent calcule les récepteurs de ses mes-sages, tandis qu’EASI centralise au niveaude l’environnement ce calcul. Pour pou-voir comparer ces deux approches, nous
devons donc évaluer la performance dusystème dans son ensemble. Ainsi, à lafois le processus de décision des agentset la gestion de l’environnement sont me-surés dans un simulateur centralisé. Il està noter que nous ne mesurons donc pasles coûts en bande passante des différentessolutions. A chaque pas de temps et dansun ordre aléatoire, chaque agent vérifie sesmessages, puis choisit et exécute un com-
portement, comme répondre à un message,ajouter un filtre, etc. La moitié des agentssont des agents employé , l’autre moitié desagents visiteur Chaque agent met à jour sa
le nombre d’agents. C’est la limite clas-sique du broadcast, qui le rend inutilisablesi le nombre de messages et/ou d’agentsdevient important. Nous avons pu véri-fier que nos alorithmes pouvaientt gérerun nombre assez important d’agents avecles deux algorithmes EASI : Nous avonsexécutés des tests jusqu’à 1000 agents en9 minutes, ce qui représente 22 millionsde messages. Pour moins de 30 agents, letemps d’exécution d’E2 est plus long quecelui d’E1, tandis que pour plus d’agentsc’est le contraire. En effet, la création et lagestion des ensembles utilisés par E2 né-
cessitent plus de calculs que pour les en-sembles utilisés par E1, tandis que l’ap-pariement d’un message sera plus rapidepour E2. Pour un petit nombre d’agents,le surcoût du calcul des ensembles n’estpas rentabilisé par le gain de gestion, maisl’avantage d’E2 augmente à mesure dunombre d’agents.
Le second graphique (Fig. 3, bas et droite)
montre le temps d’exécution en fonctiondu taux de mise à jour. A nouveau, lebroadcast est clairement désavantagé parrapport à nos algorithmes. Puisqu’E1 uti-lise des ensembles calculés à partir dela classification structurelle des entités, letaux de mise à jour n’a pas d’effet sur l’al-gorithme lui-même. Finalement, le tempsd’exécution d’E2 est sensible à une fortedynamique des propriétés : lorsque la fré-quence de mise à jour est supérieure à 1/2il devient moins efficace à cause du coûtde mise à jour des ensembles. Ces testsmontrent donc que le modèle EASI et nos
____________________________________________________________________________ Annales du LAMSADE N°8





![Laboratoire ’Aide à la Décision UMR 7243 lamsade...In Plato, discrete appears more concretely and with more constructive details. In his dialogue T o& (Timaios, [17]), Plato develops](https://img.pdfslide.fr/doc/110x75/6135f0bb0ad5d2067647b2a5/laboratoire-aaide-la-dcision-umr-7243-lamsade-in-plato-discrete-appears.jpg)























