Embed Size (px)
Citation preview

Approche décentralisée pour la détection et la localisationde défauts dans une ferme photovoltaïque
Samir Hachour
Dirigé par : Alain Kibangou (UJF) et Federica Garin (INRIA)
Maître de stage : Pierre Ambs
07 septembre 2011

Résumé
Dans ce rapport nous avons présenté une solution de détection et de localisation de défauts dansune ferme solaire.Le travail consiste en premier temps en l’estimation décentralisée de l’état du système à l’aided’un réseau de capteurs sans fils. L’estimation se fait par un filtre de Kalman décentralisé quialterne itérativement l’estimation locale faite individuellement par chaque capteur et une étape decommunication.La communication entre les capteurs se fait par le moyen d’un algorithme de consensus de moyenne.Pour lequel nous avons présenté deux différents algorithmes. le premier est l’algorithme de consensusclassique qui converge asymptotiquement vers la valeur moyenne des données initiales. Pour cetalgorithme on est appelé à limiter le nombre d’itérations, ce qui fait que la valeur moyenne desdonnées n’est pas atteinte. Le second est un algorithme de consensus en temps fini qui calcule lavaleur moyenne exacte après un nombre d’itérations égal au nombre de valeur propres distinctesnon nulles de la matrice Laplacienne du graphe de communication.Après avoir fait une estimation de l’état global du système, chaque capteur est appelé à générer unsignal résiduel et le tester grâce au test de χ2.La disposition spécifique de notre réseau de capteurs permet d’utiliser les décisions locales pourélaborer un test logique permettant de localiser le défaut dans la ferme solaire.

Table des matières
1 Introduction Générale 31.1 Présentation du sujet . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31.2 Présentation de l’équipe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2 Diagnostic des défauts 62.1 Diagnostic à base de modèles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.1.1 Filtre de Kalman . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82.2 Détection et localisation de défaut . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.2.1 Test du ratio de vraisemblance . . . . . . . . . . . . . . . . . . . . . . . . . . 92.2.2 Suivi de la valeur moyenne du résidu . . . . . . . . . . . . . . . . . . . . . . . 102.2.3 Test de χ2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 122.2.4 Exemple d’application . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 122.2.5 Localisation de défaut . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.3 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
3 Estimation décentralisée 163.1 Modèle et estimation locaux . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
3.1.1 Partitionnement du modèle d’observation . . . . . . . . . . . . . . . . . . . . 163.2 Approche de Rao et Durrent-Whyte . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
3.2.1 Estimation locale . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 183.2.2 Equations d’assimilation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
3.3 Algorithme de consensus de moyenne . . . . . . . . . . . . . . . . . . . . . . . . . . . 213.3.1 Éléments de la théorie des graphes . . . . . . . . . . . . . . . . . . . . . . . . 213.3.2 Algorithme de consensus classique . . . . . . . . . . . . . . . . . . . . . . . . 223.3.3 Algorithme de consensus en temps fini . . . . . . . . . . . . . . . . . . . . . . 24
3.4 Filtre de Kalman distribué basé sur un consensus de moyenne . . . . . . . . . . . . . 253.5 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
4 Application à une ferme photovoltaïque 294.1 Description du système . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
4.1.1 Architectures des réseaux photovoltïque . . . . . . . . . . . . . . . . . . . . . 324.1.2 Exemple d’architecture pour le réseau de surveillance . . . . . . . . . . . . . 33
4.2 Estimation de l’état du système . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 374.2.1 Erreur d’estimation avec un consensus classique . . . . . . . . . . . . . . . . . 374.2.2 Erreur d’estimation avec un consensus en temps fini . . . . . . . . . . . . . . 39
1

4.3 Détection d’un défaut . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 394.4 Localisation du défaut . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 414.5 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
5 Conclusion générale 46
A Table de χ2 47
2

Chapitre 1
Introduction Générale
1.1 Présentation du sujetLa détection et l’identification des pannes dans les systèmes dynamiques, c’est à dire leur diag-
nostic, a été un sujet important de recherche dès les débuts de l’Automatique moderne. En effetdans beaucoup d’applications il s’agira souvent, au delà de considérations purement économiques,d’assurer la sécurité des personnes et de préserver leur environnement. C’est notamment le cas pourbeaucoup d’applications liées aux domaines de l’énergie, de l’eau, de l’air et des transports.La diversité des approches qui ont été développées pour le diagnostic des systèmes dynamiquessemblent être le résultat de contextes différents associés à la nature des applications visées et auxcaractéristiques propres du cahier des charges qui en résulte.Ainsi, la nature des informations disponibles sur le système ou le type de défauts à détecterconduisent à la mise en oeuvre de stratégies spécifiques.Les méthodes de diagnostic à base de modèles occupent une place importante dans la littérature.Leur utilisation, notamment dans le cadre d’applications critiques (systèmes énergétiques, systèmesde transport, industrie lourde), s’est considérablement développée.
Face au déploiement plus ou moins bien contrôlé des réseaux de communication à grande échelle,la question du diagnostic des systèmes complexes reste d’une grande délicatesse. Depuis plusieursannées plusieurs recherches ont été développées sur l’estimation décentralisée des systèmes com-plexes. Parmi les études, on peut citer celles de Rao et Durrent-Whyte [10] qui se base sur ladécentralisation du modèle d’observation du système. C’est une approche d’un grand intérêt, elleétait développée par Olfat-Saber [9]. Une autre approche qui considéré le système global commeétant un ensemble de sous-systèmes a été développée par Stankovic et al. [12] [11].L’apparition de nouveaux dispositifs sans fil à faible coût permet de mettre en oeuvre ces stratégiede surveillance dites décentralisées pour les système complexes, tel qu’une ferme solaire par exemple.
Le travail consistait en l’analyse des documents bibliographiques réunis autour du sujet. Notammentles approches d’estimation décentralisée et les tests statistiques pour la détection et la localisationde défauts.Ensuite, nous étions amenés à synthétiser une approche applicable au modèle d’une ferme solaire.Ce après avoir choisi et arranger un modèle linéaire et vérifier l’observabilté du système. Pour la
3

localisation de défauts, nous avons conçu un algorithme spécifique considérant les décisions et l’em-placement des différents capteurs dans le réseau. L’algorithme est implémenté sous Matlab et lesrésultats obtenus sont commentésLe rapport sera organisé d’une manière à présenter en centralisé le travail qu’on projette de faire endécentralisé, notamment, le filtrage de Kalman décentralisé, la détection et la localisation de défautdans le premier chapitre.Le deuxième chapitre est dédié à l’étude des approches qui traitent l’estimation à base du filtre deKalman décentralisé.Dans le troisième chapitre, on trouve la description le modèle de la ferme solaire, et les résultatsobtenus quant à l’estimation, la détection et la localisation de défaut dans un tel système.
1.2 Présentation de l’équipeL’équipe NECS (Système commandés en réseau) a pour but de développer une nouvelle ap-
proche de commande pour prendre en compte l’apparition de nouveaux composants sans fils defaible coût, l’accroissement de la complexité des systèmes et la répartition dans un réseau à re-configuration dynamique de capteurs et d’actionneurs (réseaux de capteurs). Dans ce cadre lescommandes s’effectuent sous contraintes de limitation des ressources de communication, de calculet d’énergie. L’équipe vise des avancées dans le domaine de la commande des systèmes connectésen réseau par un développement d’outils pour l’automatique combinant les aspects commande, cal-cul et communication. L’équipe-projet est bi-localisée à l’INRIA sur le site de Montbonnot et aulaboratoire GIPSA sur le campus de Grenoble.
Axes de recherche? Commande de systèmes en réseaux hétérogènes reconfigurables dynamiquement.? Conception conjointe commande et codage pour capteurs de faible coût.? Systèmes de commande intégrés, embarqués et distribués.? Modélisation et commande de processus informatiques autonomes.? Commande de systèmes avec échantillonnage non-uniforme.
Les domaines d’application du projet sont :? Commande dans les réseaux de capteurs.? Commande de véhicules et gestion intelligente de la circulation.? Surveillance et cartographie du milieu marin par flottille de sous-marins autonomes.? Contrôle énergétique dans les systèmes à circuits asynchrones.
4

? Véhicules aériens autonomes (drones).? Modélisation et commande de serveurs Web (en collaboration avec l’équipe-projet SARDES).? Automatisation de systèmes distribués (immeuble intelligent...).? Grands instruments avec actionneurs et capteurs répartis (Tokamak, télescopes).
5

Chapitre 2
Diagnostic des défauts
Tout système est susceptible de présenter des symptômes révélateurs de défauts, le défi estde pouvoir détecter et localiser ces défauts d’une manière automatique. Le principe général desurveillance d’un système autonome peut être décrit par l’organigramme (2.1), les étapes sontbrièvement expliquées comme suit :
? Prise de mesures : La mesure qu’on fait sur le système est la seule information qu’on a surl’évolution du système. Son exhaustivité par rapport à la représentation de l’état du systèmedépend de l’observabilité du système lui-même. Elle se fait à l’aide d’un capteur approprié etnécessite souvent d’une étape de filtrage.
? Détection de défauts : Souvent, il s’agit d’un test statistique traitant un signal susceptiblede contenir des informations sur l’état du système à surveiller, signal souvent appelé signalrésiduel. Une variation importante dans la valeur moyenne ou la variance de ce signal révèleun éventuel défaut dans le système.Dans la suite, nous allons prendre le soin de décrire une première approche basée sur un testd’hypothèses, puis une seconde consistant en un suivi de la moyenne du signal résiduel, etenfin, le test que nous avons utilisé dans notre algorithme, le test de χ2.
? Localisation de défauts : C’est souvent une tâche liée aux caractéristiques du système. Ils’agit d’un test logique qui nous informe sur la provenance du défaut. Parmi les approches lesplus utilisées, on peut citer celles qui se basent sur un banc d’observateurs, comme, l’archi-tecture DOS (Dedicated Observer Scheme), et GOS (Generalized Observer Scheme) à basede l’observateur de Luenberger, pour les système linéaires déterministes [2].
? Identification de défauts : Il s’agit de caractériser le défaut, d’estimer son importance etson comportement dans le temps.
6

Prise de mesures
Détection de défauts
Localisation de défauts
Identification de défauts
Décision
Correction Adaptation
Système
?
?
?
?
? ?
- �
�
Fig. 2.1 – Processus de détection et de localisation
? Décision : C’est une décision sur le type d’action à prendre pour rétablir de système.
? Correction : C’est l’action d’arrêter le système et de procéder à une maintenance corrective.
? Adaptation : C’est l’action de reconfiguration et d’adaptation de la consigne à injecter dansle système.
2.1 Diagnostic à base de modèlesLa redondance d’informations est très utilisée dans les systèmes de surveillance et de diagnostic.
Par exemple, pour être sûr de la fiabilité de la mesure, on peut utiliser une redondance matérielle,où, plus d’un capteur vont mesurer une même grandeur physique. Cette méthode présente l’incon-vénient d’être encombrante et très coûteuse.La redondance analytique d’informations offre une bien meilleure solution. Le principe consiste enla comparaison d’un modèle de référence avec le modèle dynamique réel du processus, ce qui génèreun signal résiduel sensible aux changements anormaux dans l’état du système.Pour un système linéaire déterministe ayant comme entrée u(k) et comme sortie y(k), avec y(k) lasortie estimée par l’observateur, le schéma de la redondance et de la génération du résidu r(k) peutêtre donné par la figure 2.2.
Considérons le système linéaire Gaussien suivant.
7

Fig. 2.2 – Redondance analytique
{x(k + 1) = Fx(k) +Gw(k)z(k) = Hx(k) + v(k)
(2.1)
Où, F est la matrice d’état, G la matrice qui pondère le bruit d’état w(k). z(k) représente la mesure,H la matrice de sortie et v(k) le bruit de mesure.Avec, v(k) et w(k) sont des bruits gaussiens, indépendants, de moyenne nulle. Leurs matrices decovariance sont données respectivement par : E[vvT ] = R, et E[wwT ] = Q.
? L’observateur : En connaissant le modèle du système, la tâche de l’observateur est d’estimerl’état du système, à partir des mesures de la sortie du processus.
Pour l’estimation de ce genre de processus aléatoires, le filtre de Kalman et connu comme optimal.
2.1.1 Filtre de KalmanIl est utilisé dans plusieurs domaines technologiques (radars, vision artificielle,...etc.). Un exemple
d’utilisation peut être la mise à disposition d’informations telles que la position ou la vitesse d’unobjet à partir d’une série d’observations relative à sa position, incluant éventuellement des erreursde mesures.Par exemple, pour le cas des radars où l’on désire suivre une cible, des données sur sa position, savitesse et son accélération sont mesurées à chaque instant mais avec des perturbations importantesdues au bruit ou aux erreurs de mesure. Le filtre de Kalman [5] fait appel à la dynamique de lacible qui définit son évolution dans le temps pour obtenir de meilleures données, éliminant ainsil’effet du bruit. Ces données peuvent être calculées pour l’instant présent (filtrage), dans le passé(lissage), ou sur un horizon futur (prédiction).Pour notre cas, on utilise ces données comme estimation de l’état du système à surveiller (2.1).L’algorithme récursif du filtre de Kalman est donné comme suit.
Pour le système (2.1), le filtre de Kalman calcule une estimation x(k/k) de l’état x(k) à partirde la mesure z(k). Ce calcul se fait en deux phases principales, une de prédiction d’état x(k/k− 1)et de la matrice de covariance de l’erreur d’estimation P (k/k−1)(2.2), (2.3) et une deuxième phasede mise à jour des valeurs prédites(2.6), (2.4).
8

x(k + 1/k) = Fx(k/k) (2.2)
P (k + 1/k) = FP (k/k)FT +GQ(k)GT (2.3)
P−1(k + 1/k + 1) = P−1(k + 1/k) +HTR−1H (2.4)
Le gain du filtre K(k) est donnée par l’équation (2.5).
K(k + 1) = P (k + 1/k + 1)HTR−1 (2.5)
x(k + 1/k + 1) = x(k + 1/k) +K(k + 1)[z(k + 1)−Hx(k + 1/k)] (2.6)
Le filtre de Kalman part des valeurs initiales x(0/0), P (0/0) et calcule itérativement l’estimationde l’état x(k + 1/k) en alternant entre la phase de prédiction et celle de mise à jour.
2.2 Détection et localisation de défautDans cette section, nous allons décrire et étudier quelques tests statistiques dédiés à la détection
de défauts.Sachant que l’analyse du signal résiduel peut se faire sur sa variance ou bien sa valeur moyenne,c’est sur ce deuxième critère que se basent les tests que nous allons décrire.
Pour simplifier, nous considérons dans cette section le cas où la mesure z(k) est scalaire. Dansce cas le résidu est défini comme suit :
r(k) = z(k)−Hx(k/k)
2.2.1 Test du ratio de vraisemblanceC’est un test pour un problème de décision binaire. On considère un nombre n de réalisations
r(1), ..., r(n) d’une variable aléatoire gaussienne de variance σ2, on sait que sa valeur moyenne,notée m, ne peut prendre que deux valeurs.H0 : m = 0, hypothèse que le système en fonctionnement normal.H1 : m = α, hypothèse que le système est défectueux.On désire déterminer laquelle des deux valeurs de m correspond aux observations effectuées.Pour résoudre ce problème on doit d’abord déterminer la fonction de densité des observations souschaque hypothèse. L’indépendance des réalisations permet d’écrire :
P (r/H0) =n∏k=1
P (r(k)/H0)
P (r/H1) =n∏k=1
P (r(k)/H1)
9

où r = (r(1), ..., r(n)).On définit le rapport de vraisemblance comme suit :
Λ(r) =P (r/H1)P (r/H0)
Après développement, sous l’hypothèse gaussienne, on aboutit à la formule suivante :
Λ(r) = exp−(nm
2σ2
)· exp
(mσ2
n∑k=1
r(k))
Le test peut se faire en comparant la valeur de Λ à un seuil bien déterminé. On peut aussi utiliserle rapport de vraisemblance logarithmique.La prise de décision sur l’état du système se fait de la manière suivante :Si ln Λ(r) ≤ ν, le système est en fonctionnement normal.Si ln Λ(r) > ν, le système est dans un état défectueux.Avec, ν un seuil à déterminer au préalable, il est en fonction des densités de probabilité initialesdes deux hypothèses.
Ce test est applicable dans le cas où le signal r est gaussien et de moyenne nulle en fonction-nement normal. Dans notre cas le test sera appliqué au signal résiduel.L’utilisation de ce test nécessite la connaissance de la valeur moyenne du signal résiduel m dans lecas défectueux, chose qui n’est pas évidente pour les système à comportement aléatoire.
2.2.2 Suivi de la valeur moyenne du résiduL’idée est de comparer la valeur du signal résiduel r(k) à un certain seuil s, tel que :{
Si r(k)> s Détection de défaut.Si r(k)< s Fonctionnement normal.
(2.7)
La comparaison de la valeur instantanée du résidu au seuil considéré s’avère très exposée auxfausses alarmes et aux non détections des défauts.Pour remédier ce problème nous nous sommes proposés de ne pas prendre une décision sur l’état dusystème à l’issue d’une seule valeur instantanée du résidu, mais de comparer au seuil une moyenned’un nombre donné d’échantillons de ce résidu qu’on notera av.{
Si av(k)> s Détection de défaut.Si av(k)< s Fonctionnement normal.
(2.8)
La valeur moyenne du résidu av sera explicitement définie dans les paragraphes suivants.
Test sur la moyenne av
Fenêtre glissante Cette technique compare au seuil s la moyenne des d derniers échantillons durésidu.
10

Par définition la moyenne sur une fenêtre glissante de d échantillons est donnée par (2.9).
av(t) =1d
t∑k=t−(d−1)
r(k) (2.9)
Son implementation récursive est initialisée par le calcul de la moyenne des d premiers échantillonsde la séquence. L’évolution se fait par l’intégration des nouvelles valeurs du résidu et la soustractiondes plus anciennes. {
av(d− 1) = 1d
∑d−1k=0(r(k))
av(t) = av(t− 1)− r(t−(d))d + r(t)
d
(2.10)
Le résultat de détection avec une fenêtre glissante est plus au moins robuste selon la largeur de lafenêtre utilisée. Voir l’exemple de la section suivante.
Fenêtre amortie Dans cette technique, l’influence des valeurs anciennes de r(k) décroît expo-nentiellement avec le temps. Par définition la moyenne sur une fenêtre amortie est donnée par(2.11) :
av(t) = (1− p)t∑
k=0
pkr(t− k), 0 < p < 1 (2.11)
p est le facteur d’oubli, sa valeur peut avoir un impact sur la robustesse de la détection par rapportaux fausses alarmes et aux non détections, cela sera mis en évidence dans l’exemple d’applicationde la section suivante.
La formule récursive permettant d’implémenter la fenêtre amortie est donnée par (2.12)
av(t) = av(t− 1) · p+ r(t) · (1− p) (2.12)
Choix du seuil s Le cas où av > s et que le système est en fonctionnement normale, la détectionsera considérée comme étant une fausse alarme. Le test présente une non détection dans le cas oùav ≤ s et que le système est dans un état défectueux.
L’objectif est de garantir une probabilité de fausses alarmes inférieure ou égale à un niveau α :
P (|av − µ| ≥ s/système en fonctionnement normal)
Pour une variable aléatoire X de moyenne µ et de variance σ2, et pour tout s > 0, l’inégalité deTchebichev est donnée par (2.13).
P (|X − µ| ≥ s) ≤ σ2
s2(2.13)
Nous allons appliquer cette inégalité à av, en considérant que sa moyenne en fonctionnement normalest égale à zero et sa variance est approximativement égale à celle du bruit de mesure v(k). Nous
11

obtenons ainsi :
P (|av − µ| ≥ s/système en fonctionnement normal) ≤ σ2
s2(2.14)
Donc, pour déterminer le seuil garantissant notre objectif, il suffit de choisir s tel que : α = σ2
s2 :
s =
√σ2
α
2.2.3 Test de χ2
C’est un test proposé par Yang et al [13], il se base de l’innovation du filtre de Kalman qu’onnotera γ(k)
γ(k) = z(k)−Hx(k + 1/k)
C’est la différence entre la mesure et sa prédiction par le filtre de Kalman.Quand le système est en fonctionnement normal, γ(k) suit une loi gaussienne de moyenne nulle.L’occurrence d’un défaut provoque un saut de moyenne ce qui est révélateur d’un défaut dans lesystème. Cela peut être testé par la fonction suivante :
λ(k) = γT (k)U−1(k)γ(k) (2.15)
avec :U(k) = HP (k + 1/k)HT +R (2.16)
Les deux dernières équations sont calculables avec le filtre de Kalman.
La fonction λ(k) dans (2.15) suit une loi χ2 de m degrés de liberté, m est la dimension duvecteur de mesures.Le test de détection se fait par la comparaison de la fonction λ(k) par rapport à un seuil s.{
si λ(k) > s Système défectueuxsi λ(k) ≤ s Système en fonctionnement normal
(2.17)
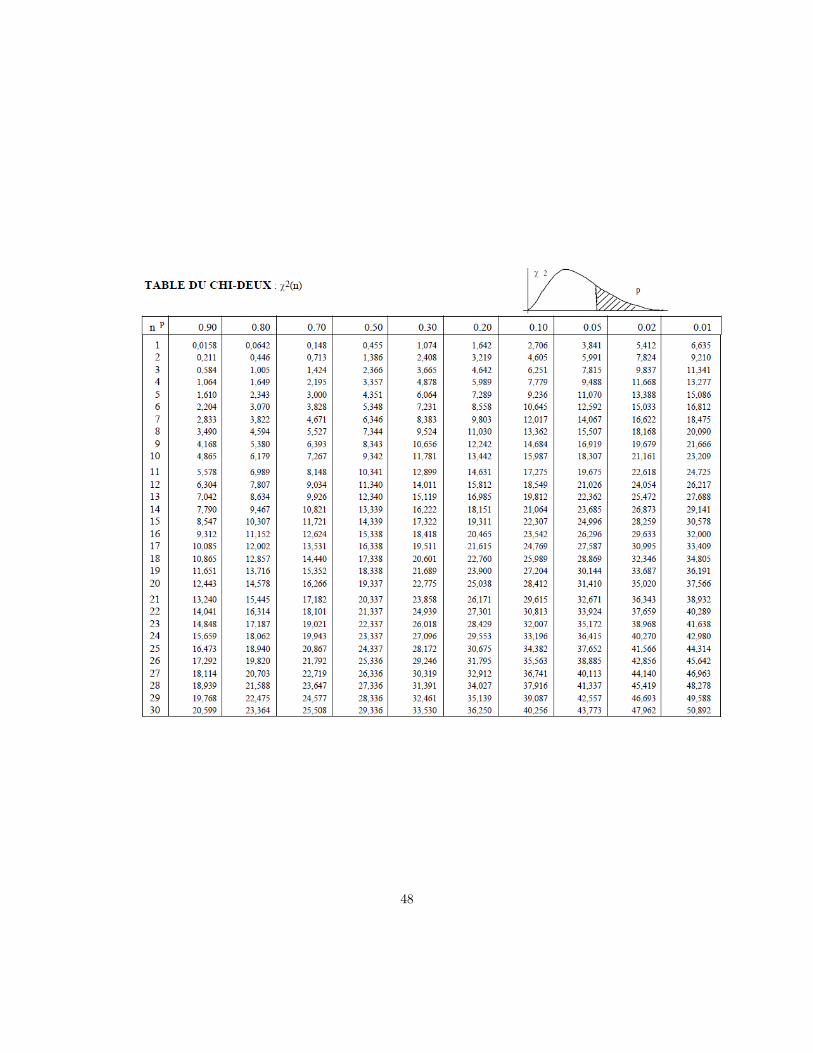
Le seuil s garantit un taux de fausse alarmes que l’on se fixe à priori, α. Il est tiré de la table de χ2
(voir annexe).
2.2.4 Exemple d’applicationPour simuler le processus de génération de résidu et de détection de défaut, nous avons considéré
un système dynamique (2.1), avec une matrice d’état F donnée par (2.18) :
12
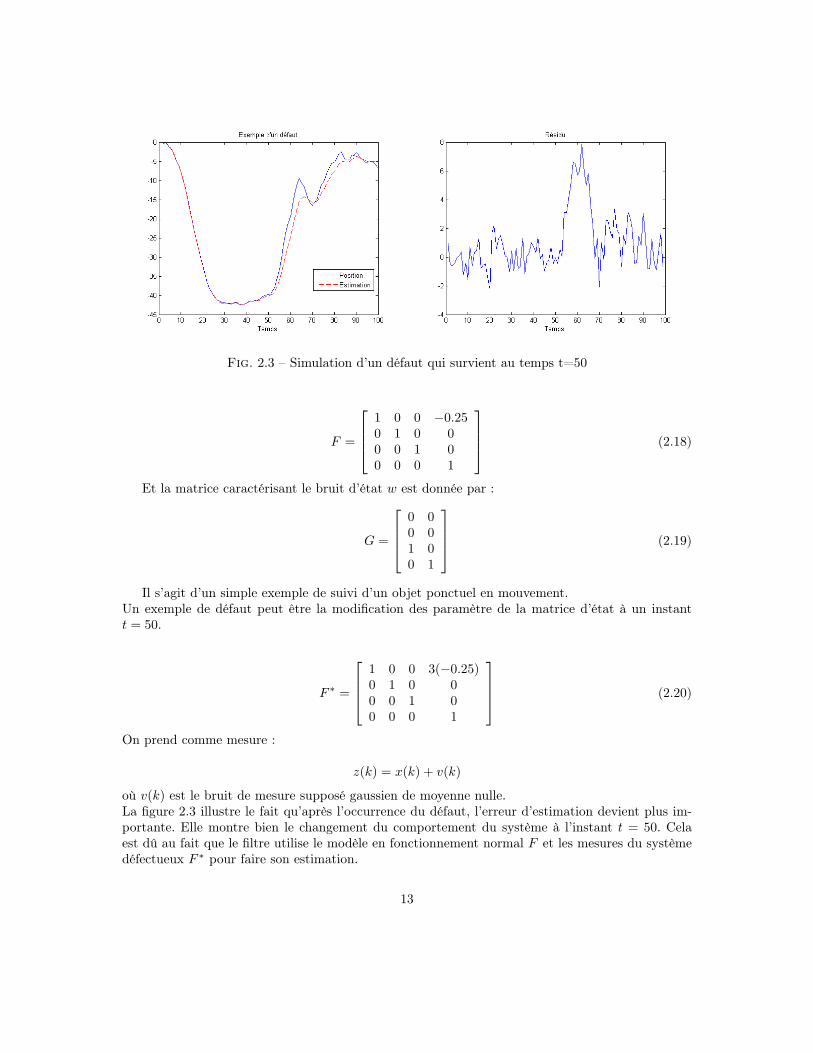
Fig. 2.3 – Simulation d’un défaut qui survient au temps t=50
F =
1 0 0 −0.250 1 0 00 0 1 00 0 0 1
(2.18)
Et la matrice caractérisant le bruit d’état w est donnée par :
G =
0 00 01 00 1
(2.19)
Il s’agit d’un simple exemple de suivi d’un objet ponctuel en mouvement.Un exemple de défaut peut être la modification des paramètre de la matrice d’état à un instantt = 50.
F ∗ =
1 0 0 3(−0.25)0 1 0 00 0 1 00 0 0 1
(2.20)
On prend comme mesure :
z(k) = x(k) + v(k)
où v(k) est le bruit de mesure supposé gaussien de moyenne nulle.La figure 2.3 illustre le fait qu’après l’occurrence du défaut, l’erreur d’estimation devient plus im-portante. Elle montre bien le changement du comportement du système à l’instant t = 50. Celaest dû au fait que le filtre utilise le modèle en fonctionnement normal F et les mesures du systèmedéfectueux F ∗ pour faire son estimation.
13
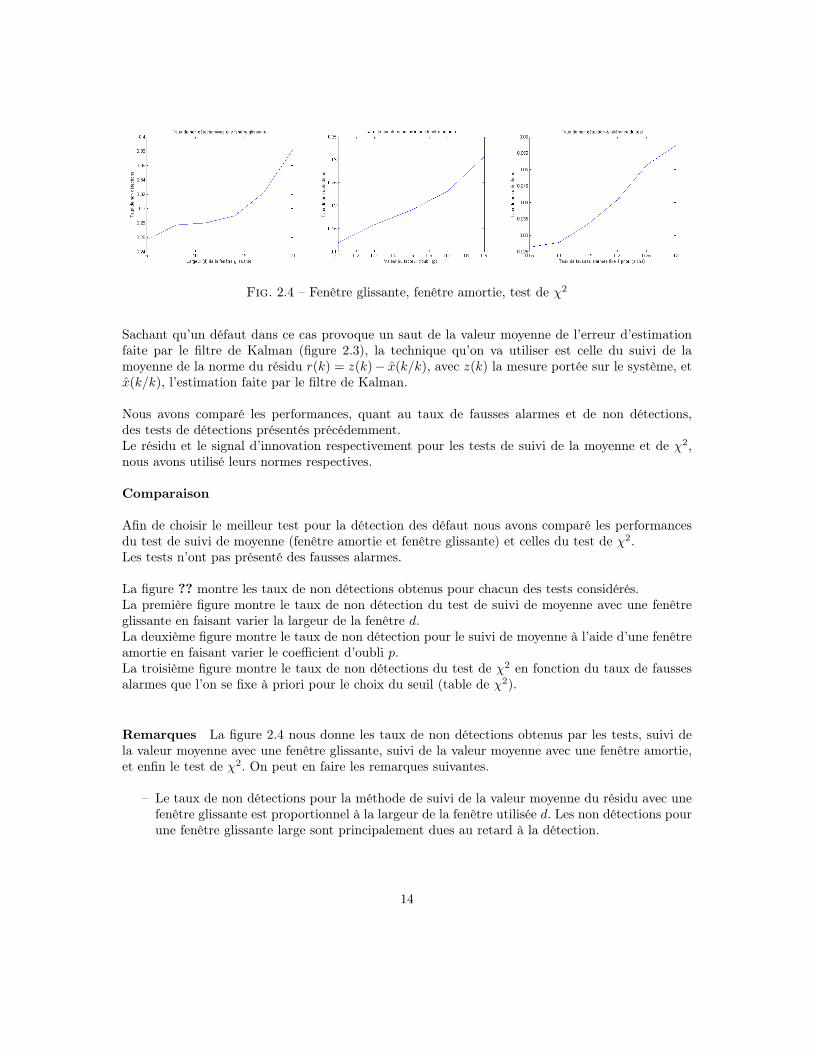
Fig. 2.4 – Fenêtre glissante, fenêtre amortie, test de χ2
Sachant qu’un défaut dans ce cas provoque un saut de la valeur moyenne de l’erreur d’estimationfaite par le filtre de Kalman (figure 2.3), la technique qu’on va utiliser est celle du suivi de lamoyenne de la norme du résidu r(k) = z(k)− x(k/k), avec z(k) la mesure portée sur le système, etx(k/k), l’estimation faite par le filtre de Kalman.
Nous avons comparé les performances, quant au taux de fausses alarmes et de non détections,des tests de détections présentés précédemment.Le résidu et le signal d’innovation respectivement pour les tests de suivi de la moyenne et de χ2,nous avons utilisé leurs normes respectives.
Comparaison
Afin de choisir le meilleur test pour la détection des défaut nous avons comparé les performancesdu test de suivi de moyenne (fenêtre amortie et fenêtre glissante) et celles du test de χ2.Les tests n’ont pas présenté des fausses alarmes.
La figure ?? montre les taux de non détections obtenus pour chacun des tests considérés.La première figure montre le taux de non détection du test de suivi de moyenne avec une fenêtreglissante en faisant varier la largeur de la fenêtre d.La deuxième figure montre le taux de non détection pour le suivi de moyenne à l’aide d’une fenêtreamortie en faisant varier le coefficient d’oubli p.La troisième figure montre le taux de non détections du test de χ2 en fonction du taux de faussesalarmes que l’on se fixe à priori pour le choix du seuil (table de χ2).
Remarques La figure 2.4 nous donne les taux de non détections obtenus par les tests, suivi dela valeur moyenne avec une fenêtre glissante, suivi de la valeur moyenne avec une fenêtre amortie,et enfin le test de χ2. On peut en faire les remarques suivantes.
– Le taux de non détections pour la méthode de suivi de la valeur moyenne du résidu avec unefenêtre glissante est proportionnel à la largeur de la fenêtre utilisée d. Les non détections pourune fenêtre glissante large sont principalement dues au retard à la détection.
14

– Le taux de non détections pour la méthode de suivi de la valeur moyenne du résidu avec unefenêtre amortie est proportionnel à la valeur du facteur d’oubli p utilisé. Tel que plus le facteurd’oubli est proche de 1, l’influence des anciennes valeurs du résidu soit importante, et doncun lissage plus important du signal résiduel, ce qui mène à un important retard à la détection.
– En fonction du taux de fausses alarmes α que l’on se fixe à priori, on peut avoir de diffé-rents seuils plus au moins prudents, c’est pour quoi, on obtient un taux de non détectionsrelativement important pour les valeurs importantes de α.
Les résultats présentés dans la figure 2.4 montrent que les taux de non détections obtenus avec letest de χ2 sont moins importants que ceux obtenus avec les autres méthodes. C’est pour quoi nousavons opté à l’utilisation du test de χ2 dans notre travail en choisissant α assez petit pour ne pasavoir de fausses alarmes.
2.2.5 Localisation de défautLa localisation de défaut consiste souvent en un test logique qui nous permet d’isoler le défaut.
L’approche la plus utilisée pour le diagnostic à base de modèles est celle d’un banc d’observateurs,c’est le cas des observateurs DOS et GOS qui permettent de localiser les défauts de capteurs no-tamment.Le même principe à été utilisé dans [3], ce pour une approche décentralisée. Les défauts qui peuventaffecter le système sont supposés connus. Un banc d’observateurs de Kalman est établi, chacunfonctionne avec le modèle du système entaché d’un défaut bien déterminé. Les observateur compa-rés au modèle du système en fonctionnement normal gênèrent des résidus capables de détecter etd’isoler le défaut.Pour notre cas de figure, nous avons utilisé un test logique de localisation adapté aux contraintesde notre système d’application, qui est la détection de défaut dans les modules d’une ferme depanneaux solaires.
2.3 ConclusionDans ce premier chapitre nous avons présenté, d’une manière générale, le principe du diagnostic
à base de modèle.Nous nous sommes intéressés aux systèmes stochastiques linéaires gaussiens, où la tâche commencepar une estimation de l’état du système à l’aide d’un filtre de Kalman.Ensuite, vient la tâche de la détection et d’isolation de défaut, où nous avons présenté le principede génération d’un signal résiduel révélateur de défaut.Les tests statistiques qui servent à l’analyse du résidu sont présentés et leur robustesse par rapportaux fausses alarmes et aux non détections est comparée.Pour des systèmes relativement peu complexes, l’estimation, la detection et la localisation de dé-fauts peut bien être faite d’une manière centralisée.Dans le chapitre suivant, nous verrons comment est ce qu’on parvient à estimer l’état d’un systèmecomplexe, en partant de mesures locales, et en faisant, en plus de la tâche de l’estimation locale,une étape de communication.
15

Chapitre 3
Estimation décentralisée
On considère un système complexe qui peut être décrit par le modèle linéaire (2.1), le vecteurde mesure z(k) étant de dimension importante et spatialement réparti sur le système.La surveillance d’un tel système d’une manière centralisée peut engendrer une paralysie totale duprocessus de surveillance en cas de défaillance du centre de fusion. A cela, une solution a été ap-portée par Rao et Durrent-Whyte [10].Un autre inconvénient majeur de la surveillance centralisée, c’est la complexité de calculs. L’ap-proche décentralisée proposée par Olfati-Saber [9] s’affranchit de ce problème, elle propose descalculs en parallèle par les unités du réseau de surveillance.
Dans cette section, nous nous intéresserons à la tâche de l’estimation décentralisée par un réseaude capteurs.
3.1 Modèle et estimation locauxUn système de surveillance décentralisé peut être vu comme étant un réseau de capteurs qui
prennent des mesures partielles du système, à l’aide desquelles ils font des estimations locales. L’ob-jectif étant de pouvoir estimer l’état global du système, ces capteurs nécessitent d’une étape decommunication leur permettant de compléter leurs estimations.
3.1.1 Partitionnement du modèle d’observationDans le cas d’un système décentralisé, des hypothèses par rapport au modèle d’observation des
différentes unités du réseau doivent être faites, elles sont expliquées dans ce qui suit.
Supposons qu’on a un système de dimension m, qu’on désire surveiller à l’aide de N capteurs(nœuds), la mesure z(k) peut être partitionnée de la manière suivante :
z(k) = [zT1 (k)zT2 (k)...zTN (k)]T
16

Avec(z1(k)z2(k)...zN (k)) sont les mesures portées par les nœuds (1,2, ...n) entachées respective-ment par des bruits de mesure qui peuvent âtre partitionnés de la manière suivante :
v = [vT1 vT2 ...v
TN ]T
Si en plus ces bruits sont décorrelés, on peut écrire leur covariance R de la manière suivante :
R = E[vvT ] = blockdiag(R1R2...RN )
Ainsi, on aura pour le modèle d’observation, la matrice de sortie suivante :
H = [HT1 H
T2 ...H
TN ]T
L’ensemble des suppositions et partitionnements permettent d’écrire le modèle spécifique à chacundes nœuds sous la forme suivante :{
x(k + 1) = Fx(k) +Gw(k)zi(k) = Hix(k) + vi
(3.1)
On note que la première équation dans (3.1) reste la même pour tous les nœuds, puisque elle décritle fonctionnement global du système.
Plus encore, ces hypothèses nous permettent d’écrire les équivalences suivantes (3.2).{HTR−1H =
∑Ni=1H
Ti R−1i Hi
HTR−1z(k) =∑Ni=1H
Ti R−1i zi(k)
(3.2)
On va voir dans ce qui va suivre que la communication entre les différents nœuds du réseau se basesur les deux équations dans (3.2).
3.2 Approche de Rao et Durrent-WhyteEn considérant le modèle local (3.1) et les deux équivalences dans (3.2), Rao et Durrent-Whyte
ont pu élaborer un algorithme d’estimation décentralisé. Ce à condition que chacun des nœuds duréseau puisse calculer la valeur moyenne des données reçues de tous les autres nœuds du réseau.La formulation de l’algorithme est donnée par les étapes suivantes.
17

3.2.1 Estimation localeLe filtre de Kalman local qui permet à chacun des nœuds de faire une estimation locale, est
représenté par les équations suivantes :
xi(k + 1/k) = Fxi(k/k) (3.3)
Pi(k + 1/k) = FPi(k/k)FT +GQi(k)GT (3.4)
P−1i (k + 1/k + 1) = P−1
i (k + 1/k) +HTi R−1i Hi (3.5)
Le gain Ki(k + 1) du filtre local est donné par l’équation (3.6).
Ki(k + 1) = Pi(k + 1/k + 1)HTi R−1i (3.6)
xi(k + 1/k + 1) = xi(k + 1/k) +Ki(k + 1)[zi(k + 1)−Hixi(k + 1/k)] (3.7)
(Tilde) veut dire que x(k/k) et P (k/k) ne sont mises à jour que localement, selon les états obser-vables par la mesure disponible au niveau de chacun des nœuds.
Pour avoir l’information complète sur l’état du système et l’erreur d’estimation commise et aprèsavoir fait sa propre estimation, chacun des nœuds doit compléter son estimation à l’aide des équa-tions dites d’assimilation que nous allons décrire ci-dessous.
3.2.2 Equations d’assimilationL’objectif étant de parvenir à écrire les équivalences dans (3.2) en fonction des quantités calcu-
lées localement (x(k/k) et P (k/k)), la procédure est éclairée par les démonstrations suivantes.
? Correction de la matrice P (k/k) :
Les équations de mise à jour de la matrice P(k/k), respectivement du filtre de Kalman centra-lisé(2.4) et du filtre de Kalman décentralisé (3.5), nous permettent d’écrire les deux équationssuivantes (3.8) : {
HTR−1H = P−1(k + 1/k + 1)− P−1(k + 1/k)HTi R−1i Hi = P−1
i (k + 1/k + 1)− P−1i (k + 1/k)
(3.8)
Par identification à la première équation dans le système (3.2), on peut écrire l’équivalencesuivante :
P−1(k + 1/k + 1) = P−1(k + 1/k) +n∑i=1
[P−1i (k + 1/k + 1)− P−1
i (k + 1/k)] (3.9)
Cette équation appliquée à un nœud i donne l’équation (3.10) qui permet de mettre à jour lamatrice de covariance de l’erreur d’estimation, elle s’écrit comme suit :
P−1i (k + 1/k + 1) = P−1
i (k + 1/k) +N∑j=1
[P−1j (k + 1/k + 1)− P−1
j (k + 1/k)] (3.10)
18

L’équation (3.10) veut dire qu’un nœud corrige la matrice P (k/k), en se basant sur la va-leur de P(k+1/k) déjà prédite et la somme des erreurs d’estimation faites par l’ensemble desnœuds du réseau.
? Correction de l’estimation de l’état x(k/k) :
La démonstration de la formule permettant la mise à jour complète de l’état du systèmese fait à travers les étapes suivantes :
• La pré-multiplication de la première équation du système (3.8) par P (k + 1/k + 1) avecutilisation de la formule du gain en (2.5), on aboutit à l’équation suivante (3.11) :
I −K(k + 1)H = P (k + 1/k + 1)P−1(k + 1/k) (3.11)
• La pré-multiplication de l’équation de mise à jour de x(k/k) dans le filtre centralisé (2.6)par P−1(k+ 1/k+ 1) avec utilisation de la formule (3.11), après rearrangement on aboutità l’équation suivante(3.12) :
HTR−1z(k) = P−1(k + 1/k + 1)x(k + 1/k + 1)− P−1(k + 1/k)x(k + 1/k) (3.12)
En appliquant les deux dernières étapes respectivement à la deuxième équation du système(3.8), et l’équation de mise à jour locale de l’état x(k/k) dans (3.7), on obtient l’équationsuivante :
HTi R−1i zi(k) = P−1
i (k + 1/k + 1)xi(k + 1/k + 1)− P−1i (k + 1/k)xi(k + 1/k) (3.13)
Par identification à la deuxième équation dans (3.2) et réarrangement, on aura la formulepermettant à un nœud (i) de mettre à jour son estimation (3.14) :
xi(k + 1/k + 1) = Pi(k + 1/k + 1)[P−1i (k + 1/k)xi(k + 1/k) (3.14)
+N∑j=1
[P−1j (k + 1/k + 1)xj(k + 1/k + 1)− P−1
j (k + 1/k)xj(k + 1/k)]
Cette dernière formule veut dire qu’un nœud i met à jour les états du système à l’aide de lamatrice de covariance corrigée (3.10), sa prédiction et les erreurs d’estimation locales faitespar l’ensemble des nœds du réseau.
Si on pose :
Φ(k) =N∑j=1
[P−1j (k + 1/k + 1)− P−1
j (k + 1/k)]
et
Ψ(k) =N∑j=1
[P−1j (k + 1/k + 1)xj(k + 1/k + 1)− P−1
j (k + 1/k)xj(k + 1/k)],
19

on obtient les deux équations d’assimilation suivantes :
P−1i (k + 1/k + 1) = P−1
i (k + 1/k) + Φ(k). (3.15)
xi(k + 1/k + 1) = Pi(k + 1/k + 1)[P−1i (k + 1/k)xi(k + 1/k) + Ψ(k)]. (3.16)
Ces deux dernières équations permettent à chacun des nœuds de corriger sont estimations.
L’algorithme suivant récapitule les étapes qu’un nœud doit exécuter pour pouvoir imiter un esti-mateur centralisé :
1. Initialisation de l’état du système xi(0/0) et Pi(0/0).k = 0
2. Prédiction de l’état xi(k + 1/k) et la matrice Pi(k + 1/k).xi(k + 1/k) = Fxi(k/k).Pi(k + 1/k) = FPi(k/k)FT +GQi(k)GT .
3. Mise à jour locale de Pi(k + 1/k + 1).P−1i (k + 1/k + 1) = P−1
i (k + 1/k) +HTi R−1i Hi
4. Calcul du gain Ki(k + 1) du filtre :Ki(k + 1) = Pi(k + 1/k + 1)HT
i R−1i .
5. Acquisition de la mesure z(k).
6. Mise à jour locale de l’état du système xi(k + 1/k + 1) :xi(k + 1/k + 1) = xi(k + 1/k) +Ki(k + 1)[zi(k + 1)−Hixi(k + 1/k)].
7. Communication et Calcul de :Φ(k) =
∑Nj=1 P
−1j (k + 1/k + 1)− P−1
j (k + 1/k).Ψ(k) =
∑Nj=1[P−1
j (k + 1/k + 1)xj(k + 1/k + 1)− P−1j (k + 1/k)xj(k + 1/k)].
8. Mise à jour complète la matrice Pi(k + 1/k + 1).P−1i (k + 1/k + 1) = P−1
i (k + 1/k) + Φ(k).
9. Mise à jour complète de l’état du système :xi(k + 1/k + 1) = Pi(k + 1/k + 1)[P−1
i (k + 1/k)xi(k + 1/k) + Ψ(k)].
10. k = k + 1, retour à l’étape 2.
Après avoir fait une estimation locale de l’état (étape 6 de l’algorithme), chaque nœud doit re-cueillir les données de tous les autres nœuds du réseau permettant de calculer φ(k) et ψ(k). Cesderniers lui permettent de compléter l’estimation de l’état (étape 9).
20

Cet algorithme nécessite une communication ( all to all), autrement dit, un graphe complet, donc,chaque nœud du réseau sera vu comme étant un nœud centralisé.Ceci nous fait comprendre que l’apport de cet algorithme peut être principalement, l’extensibilitédu système mais aussi si un nœud tombe en panne, le système de surveillance peut continuer safonction. ce qui ne peut pas être le cas dans l’approche centralisée.
En plus de ces avantages, l’algorithme de Olfati-Saber nous fait profiter aussi de celui de la ré-duction de la complexité des calculs.Dans ce cas le graphe peut ne pas être complet, et la communication entre ces nœuds se fait à l’aided’un algorithme de consensus simple à calculer.
3.3 Algorithme de consensus de moyenneLe consensus de moyenne est un algorithme distribué où un ensemble d’agents communiquent
à travers les liens du graphe de communication.L’objectif de cet algorithme est de calculer la valeur moyenne des données provenant des différentsagents.
3.3.1 Éléments de la théorie des graphesÉtant donné un réseau composé de N capteurs, un graphe G = (V, E) est le moyen le plus
naturel pour la modélisation d’un tel réseau. Où, les N capteurs seront représentés par l’ensembledes nœuds du graphe V = {1, ..., N}, et les liens E ⊆ V×V représente l’ensemble des communicationsqui existent entre les différents nœuds du réseau : si un nœud i peut envoyer des informations aunœud j, alors (i, j) ∈ E .
Graphe complet Un graphe complet est un graphe dont tous les nœuds sont adjacents les unsdes autres.
Graphe non orienté Un graphe non orienté est un graphe qui représente un réseau où lescommunications sont bidirectionnelles. Elles sont représentées par des liens sans flèches dans legraphe. Dans un graphe non orienté, si le lien (i, j) ∈ E alors (j, i) ∈ E , i, j représentent deuxnœuds différents.
Degré d’un nœud On définit le voisinage d’un nœud :
N(i) = {j/(j, i) ∈ E , i 6= j}
Le degré d’un nœud est le nombre de liens dont ce nœud est une extrémité.
d(i) =| N(i) |
21

Fig. 3.1 – Graphe, matrice d’adjacence et matrice Laplacienne
Matrices associées au graphe? La matrice d’adjacence :A = [aij ] ∈ <N×N est la matrice d’adjacence du graphe G d’ordre N .
aij =
{1 Si (i, j) ∈ E0 Autrement
(3.17)
? Matrice des degrés :C’est une matrice diagonale contenant les degrés de tous les nœuds du réseau.
∆ = diag(d(i))
? Matrice Laplacienne :
L = ∆−A
Sur la figure (3.3.1), on donne un exemple de graphe d’ordre 5, non complet et non orienté,sa matrice d’adjacence A et sa matrice Laplacienne L.
3.3.2 Algorithme de consensus classiqueC’est un algorithme récursif qui converge asymptotiquement vers la valeur moyenne des données
reçues en entrée (3.18) [1].
Ave(x(0)) =1N
N∑i=1
xi(0). (3.18)
L’algorithme du consensus peut être vu comme étant un système dynamique (3.19), dont la stabilitéet la vitesse de convergence dépendent des valeur propres de la matrice P (k).
x(k + 1) = P (k)x(k). (3.19)
La matrice P (k) peut être constante, variante dans le temps, ou bien, aléatoire, selon le type decommunication entre qu’il y’a entre les nœuds.La matrice P (k) est compatible avec le graphe, ce qui signifie que Pij(k) = 0 s’il n’y a pas de lienentre les deux agents i, j.
22

Dans notre travail, on s’intéresse au cas où le graphe de communication est fixe, ce qui permet dechoisir une matrice P (k) = P constante. Dans ce cas, on a :
x(k) = P kx(0)
limk→∞
P k =1N11T
Pour cela, il suffit que la matrice P (k) soit doublement stochastique.P = [Pi,j ] est dite doublement stochastique si :
Pi,j ≥ 0 ∀i,j∑Ni=1 Pi,j = 1 ∀j∑Nj=1 Pi,j = 1 ∀i
(3.20)
Nous présentons ici quelques exemples de choix des coefficients de la matrice P tels qu’ils sontdécrits dans [1].
? Simple random walkDans cette méthode, chaque nœud pondère uniformément son propre état et l’état des nœudsde son voisinage.
Pi,j =
{1
d(i)+1 j ∈ N(i) ∪ {i}0 autrement.
(3.21)
La matrice P resultant est stochastique mais, en général n’est pas doublement stochastique,donc, le point de convergence de l’algorithme de convergence n’est pas forcement la valeurmoyenne des données reçues xi.
? Maximum-degree weightsDans cette méthode chaque nœud a besoin de calculer le plus grand degré de connectivité d(3.22) pour pondérer son état et l’état des nœuds qui lui sont voisins.
d = maxj∈N(i)
d(i) = maxj∈N(i)
|N(j)|. (3.22)
La pondération de la matrice P se fait comme suit (3.23).
Pi,j =
1d+1 j ∈ N(i)1− d(i)
d+1 i = j
0 autrement.(3.23)
Si, le graphe de communication n’est pas orienté, la matrice P resultant est symétrique, cequi permet une convergence vers la valeur moyenne des données collectées.Pour le cas d’un graphe de communication fixe, le calcul de d se fait une seule fois.
23

? Metropolis weightsPour cette approche la pondération est à base du degré de connectivité maximum entre lesdeux nœuds partageant le même lien. La pondération se fait comme suit (3.24) :
Pi,j =
1
max[d(i),d(j)]+1 j ∈ N(i)
1−∑k∈N(i) Pi,k i = j
0 autrement.
(3.24)
La matrice obtenue par cette méthode est aussi stochastique, et doublement stochastique sile graphe n’est pas orienté. Cette méthode est plus intéressante du moment qu’elle ne calculepas de degré de connectivité maximum d à travers tout le réseau, donc, elle peut facilementêtre mise en œuvre dans le cadre d’un système distribué.
La maîtrise de la matrice P (k) implique la maîtrise de la dynamique de l’algorithme du consensusutilisé. Donc, on peut parameter sa vitesse de convergence par exemple.
Après avoir donner un aperçu de l’algorithme de consensus classique, la convergence étant asymp-totique dont la performance est liée au nombre d’itération exécutées par l’algorithme en question.
3.3.3 Algorithme de consensus en temps finiPlus récemment, un algorithme de consensus calculant la moyenne exacte en un nombre fini
d’itérations a été conçu [6]. Contrairement à l’algorithme du consensus classique qui se base surune seule matrice P pour contrôler la dynamique de l’algorithme, où, la matrice est prise dou-blement stochastique pour assurer une convergence asymptotique vers la moyenne des donnéesentrant, cette deuxième approche considère, selon le nombre D de valeurs propres distinctes etnon nulles de la matrice Laplacienne correspondant au graphe, un ensemble de matrices Wi nouspermettent de calculer 1
N 11T après un nombre d’itérations en général égal à D et égal à la partie
entière de N2 dans le cas d’une topologie en cercle. Avec N , le nombre de nœuds dans le graphe,
et 11, la matrice unité et D+1 le nombre de valeurs propres distinctes de la matrice Laplacienne L.
Donc, on rappelle que l’objectif est de trouver l’ensemble des matrices Wi compatibles avec legraphe, diagonalisables et ayant 1 comme vecteur propre pour assurer la convergence.
D∏i=1
Wi =1N11T
Pour ce faire, on définit une matrice dont on connait les propriétés, compatible avec le grapheA = dmaxI− L, avec dmax, le degré maximum dans le graphe.On pose : Wi = αiI + βA.La décomposition en valeurs propres de la matrice A est une alternative qui ramène le problème àla résolution d’un système ayant un nombre d’équation égal au nombre de valeurs propres distinctesde L où les variables sont les paramètres αi et β.La solution est donné par le théorème suivant :
24

Théorème :Pour un graphe connecté et non orienté auquel est associée la matrice Laplacienne L, l’ensembledes matrices sont données par :
Wk = (αk + dmaxβ)I)− βL.
Avec : k = 1, ..., D, β 6= 0.Ces matrices permettent d’atteindre la valeur moyenne comme consensus au bout deD itérations si :
1. D + 1 est le nombre de valeurs propres distinctes de la matrice Laplacienne.2. les paramètres αi et β sont donnés par :
β =1∏D+1
i=2D√λi
αk =λk+1 − dmax∏D+1
i=2D√λi
Avec : λi, i = 2, ..., D+1 sont les valeurs propres distinctes de la matrice L différentes de zero.La preuve de la solution donnée dans le théorème peut être trouvée dans [6].Pour récapituler, on dira que cette méthode utilise une dynamique variable faisant en sorte de cal-culer la valeur moyenne des données initiales en un temps fini.
3.4 Filtre de Kalman distribué basé sur un consensus de moyennePlus récemment Olfati-Saber a proposé une approche du filtre de Kalman décentralisé uti-
lisant l’algorithme du consensus pour calculer la valeur moyenne des données locales suivantes(HT
i R−1i Hi, H
Ti R−1i zi(k)).
D’après (3.8) et (3.2) :
Φ = HTR−1H =n∑i=1
HTi R−1i Hi
On notera que c’est un cas particulier oùHi et Ri sont des matrices constantes, donc, Φ est constant.D’après les équations (3.12) et (3.13) identifiées au système (3.2), on voit que :
Ψ(k) = HTR−1z(k) =N∑i=1
HTi R−1i zi(k)
L’algorithme de consensus permet de calculer (exactement ou approximativement, selon l’algo-rithme utilisé) les grandeurs qu’on va noter (Φet Ψ(k)) et qui sont respectivement exprimées commesuit :
Φ =1N
Φ =1N
N∑i=1
HTi R−1i Hi (3.25)
25

Ψ(k) =1N
Ψ(k) =1N
N∑i=1
HTi R−1i zi(k) (3.26)
En remplaçant HTR−1H, dans l’équation (2.4) du filtre centralisé par (N Φi) on aura l’équationde mise à jour de la matrice de covariance de l’erreur d’estimation applicable au nœud i (3.27).
P−1i (k + 1/k + 1) = P−1
i (k + 1/k) +N Φi (3.27)
En remplaçant dans l’équation (2.6), le gain par sa formule (3.6) et en utilisant les formules(3.25) et (3.26), on aura l’équation qui permet à chaque nœud de mettre à jour son estimation(3.28).
xi(k + 1/k + 1) = xi(k + 1/k) + Pi(k + 1/k + 1)[NΨi(k + 1)−N Φixi(k + 1/k)] (3.28)
Cette dernière équation est équivalente à l’équation de mise à jour de l’algorithme précédent (3.16).
Équivalence entre les deux équations de mise à jour (3.28) et (3.16)De l’équation (3.27) :
P−1i (k + 1/k) = P−1
i (k + 1/k + 1)−N Φi
En remplaçant cette dernière équation dans (3.16) on aura :
xi(k + 1/k + 1) = Pi(k + 1/k + 1)[(P−1i (k + 1/k + 1)−N Φi)xi(k + 1/k) +NΨi] (3.29)
= Pi(k + 1/k + 1)[P−1i (k + 1/k + 1)xi(k + 1/k)−N Φixi(k + 1/k) +NΨi(k)]
= xi(k + 1/k) + Pi(k + 1/k + 1)[NΨi(k)− Φixi(k + 1/k)]
Le filtre de Kalman local que chaque nœud doit executer est donné par les équations suivantes :
xi(k + 1/k) = Fxi(k/k) (3.30)
Pi(k + 1/k) = FPi(k/k)FT +GQi(k)GT (3.31)
P−1i (k + 1/k + 1) = P−1
i (k + 1/k) +N Φi (3.32)
xi(k + 1/k + 1) = Pi(k + 1/k + 1)[P−1i (k + 1/k)xi(k + 1/k) +NΨi(k)] (3.33)
Dans le cas du calcul exact du consensus les Φi et Ψi sont les mêmes au niveau de tous les nœudsdu réseau.On peut remarquer que le filtre dans ((3.30),(3.31),(3.32),(3.33)) est une version compacte du pré-cédent. Contrairement au premier qui suppose que le graphe de communication est complet pourcalculer exactement les sommes (Φ(k) et Ψ(k)), ce dernier utilise un algorithme de consensus quifait propager les informations dans le graphe et qui calcule les valeurs moyennes des quantitésHTi R−1i Hi et HT
i R−1i zi(k) respectivement Φ et Ψ(k).
Si en plus , comme dans notre cas (Hi et Ri) sont des matrices constantes, l’execution de l’algo-rithme de consensus calculant (Φ) peut se faire hors ligne.
26

L’algorithme suivant est récapitulatif des étapes qu’un nœud doit executer pour pouvoir imiterun filtre centralisé.
1. calcul du consensus hors ligne :Φi = cons({HT
j R−1j Hj}Nj=1)
.2. Initialisation de l’état du système xi(0/0) et Pi(0/0).k = 0
3. Prédiction de l’état xi(k + 1/k) et la matrice Pi(k + 1/k).xi(k + 1/k) = Fxi(k/k).Pi(k + 1/k) = FPi(k/k)FT +GQi(k)GT .
4. Mise à jour de Pi(k + 1/k + 1).P−1i (k + 1/k + 1) = P−1
i (k + 1/k) +N Φi
5. Acquisition de la mesure zi(k + 1).
6. Calcul de Ψi :Ψi(k) = cons({HT
j R−1j zj(k + 1)}Nj=1)
.7. Mise à jour complète de l’état du système :xi(k + 1/k + 1) = Pi(k + 1/k + 1)[P−1
i (k + 1/k)xi(k + 1/k) +NΨi(k)].
8. k = k + 1, retour à l’étape 2.
Yi = cons({Uj}Nj=1) c’est la fonction représentant l’algorithme du consensus qui reçoit en entrée lesgrandeurs locales Uj et retourne exactement ou approximativement, en sortie, leur valeur moyenneYi.Pour faire une estimation globale de l’état du système, chaque nœud doit combiner avec son esti-mation partielle deux étapes de communication (Consensus de moyenne). Le consensus à obtenirdans le cas d’utilisation de l’algorithme de consensus classique dépend du temps de convergencequi lui est accordé, cela fait que les différents nœuds du réseau ne feront pas exactement la mêmeestimation.Par contre dans le cas d’utilisation de l’algorithme de consensus en temps fini, les nœuds ferontexactement la même estimation qu’un algorithme centralisé.La différence dans la qualité d’estimation pour l’utilisation des deux algorithmes de consensus seraprésentée dans le chapitre suivant.
3.5 ConclusionDans ce chapitre, nous avons abordé la problématique d’estimation décentralisée de l’état d’un
système.Nous avons vu que c’est une tâche qui est faite en deux étapes principales : une estimation locale
27

à l’aide d’une mesure locale au niveau de chaque nœud du réseau et une étape de communication.Le premier algorithme que nous avons décrit suppose que le graphe de communication et complet,de telle manière que chacun des nœuds puisse calculer la valeur moyenne des données qu’il reçoitde tous les autres nœuds du réseau.Dans le second algorithme, le graphe de communication n’est pas forcément complet. La communi-cation entre les nœuds est assurée par un algorithme de consensus.Pour ce dernier nous avons présenté deux différents algorithmes, le premier est dit classique, ilconverge vers la valeur moyenne des données partiellement calculées, avec la condition que la ma-trice décrivant sa dynamique soit doublement stochastique. Le second est un algorithme qui calculela valeur moyenne exacte des données partielles en un nombre d’itérations égal au nombre de valeurspropres distinctes et non nulles de la matrice Laplacienne du graphe de communication. Dans lechapitre suivant, nous allons présenter l’application de l’algorithme du filtre de Kalman distribué àl’estimation de l’etat d’une ferme solaire.Une stratégie de détection et de localisation de défauts sera aussi présentée.
28

Chapitre 4
Application à une fermephotovoltaïque
Une ferme photovoltaïque peut contenir des centaines, voire des milliers de modules solaires.La stabilité et la puissance électrique globales dépendent de l’état de fonctionnement de chacun desmodules photovoltaïques.Le principal problème du maintien en fonctionnement normal d’une station photovoltaïque est dansla tâche de détection et de localisation de défautsParmi tous les éventuels défauts qui peuvent apparaître dans un tel système, on s’intéressera à ceuxqui causent une baisse dans la puissance électrique produite par manque d’ensoleillement : problèmed’ombrage ou accumulation de la poussière par exemple.
4.1 Description du systèmeLa puissance électrique générée par une station photovoltaïque dépend grandement de l’irra-
diance solaire. Cependant, les fluctuations de l’irradiance solaire font que la modélisation du sys-tème soit difficile. Dans [8], une étude expérimentale de l’effet de l’irradiance est faite à l’aide d’unbanc de données d’une seconde sur une période d’un an. Ce sur six stations solaires différentes.Une analyse dans le domaine fréquentiel des données expérimentales a permis de modéliser un mo-dule solaire par une fonction de transfert de premier ordre.
Fonction de transfert et équation différentielle L’équation différentielle représentant letransfert entrée/sortie au niveau d’un module solaire est donnée par (4.1)
P (s)G(s)
=K
1 +√S
2πλs(4.1)
P représente la puissance électrique exprimée en watt, G représente l’irradiance solaire expriméeen watt/m2, K représente le gain exprimé en (m2) et λ = 0.02 est un paramètre déterminé expéri-
29
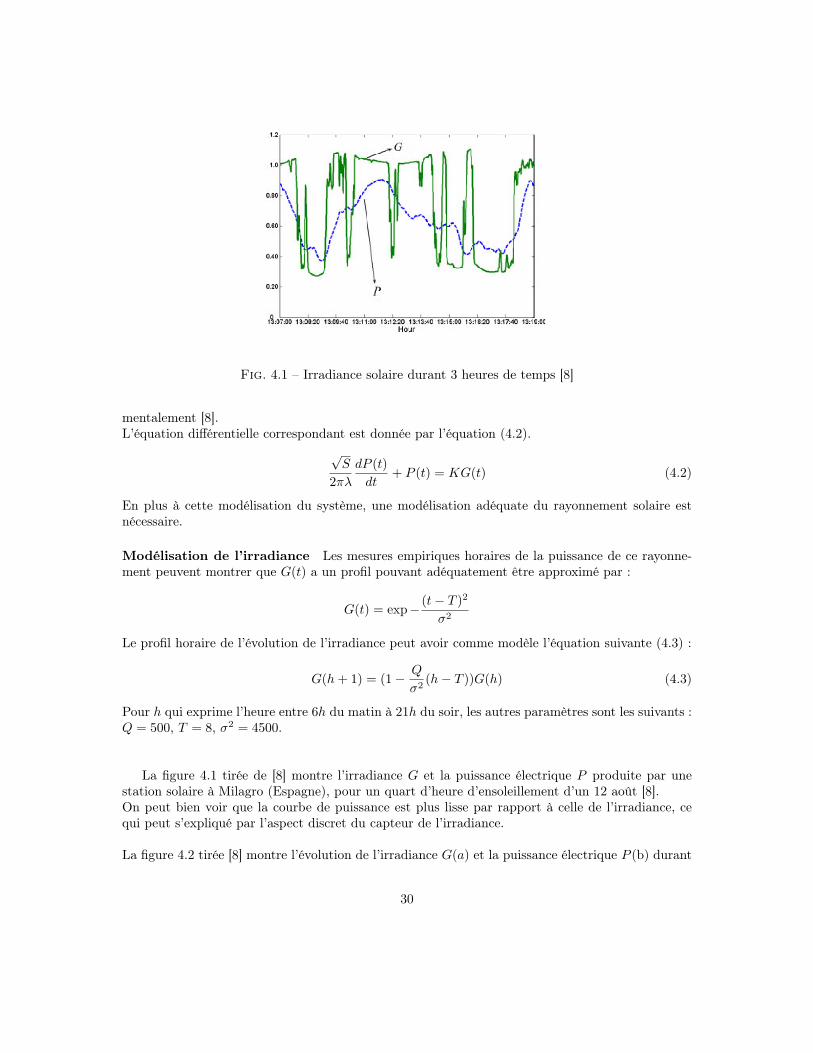
Fig. 4.1 – Irradiance solaire durant 3 heures de temps [8]
mentalement [8].L’équation différentielle correspondant est donnée par l’équation (4.2).
√S
2πλdP (t)dt
+ P (t) = KG(t) (4.2)
En plus à cette modélisation du système, une modélisation adéquate du rayonnement solaire estnécessaire.
Modélisation de l’irradiance Les mesures empiriques horaires de la puissance de ce rayonne-ment peuvent montrer que G(t) a un profil pouvant adéquatement être approximé par :
G(t) = exp− (t− T )2
σ2
Le profil horaire de l’évolution de l’irradiance peut avoir comme modèle l’équation suivante (4.3) :
G(h+ 1) = (1− Q
σ2(h− T ))G(h) (4.3)
Pour h qui exprime l’heure entre 6h du matin à 21h du soir, les autres paramètres sont les suivants :Q = 500, T = 8, σ2 = 4500.
La figure 4.1 tirée de [8] montre l’irradiance G et la puissance électrique P produite par unestation solaire à Milagro (Espagne), pour un quart d’heure d’ensoleillement d’un 12 août [8].On peut bien voir que la courbe de puissance est plus lisse par rapport à celle de l’irradiance, cequi peut s’expliqué par l’aspect discret du capteur de l’irradiance.
La figure 4.2 tirée [8] montre l’évolution de l’irradiance G(a) et la puissance électrique P (b) durant
30

Fig. 4.2 – Irradiance solaire durant 14 jours [8]
14 jours d’ensoleillement.On remarque bien que l’évolution de l’irradiance peut approximativement être modélisée par unprofil Gaussien (4.3) pour une journée d’ensoleillement.
Pour une période d’échantillonnage donnée et en considérant l’erreur de modélisation νG qui estvu comme étant un bruit Gaussien de moyenne nulle, l’évolution récursive de l’irradiance peut êtredonnée par l’équation (4.4)
G(k + 1) = γkG(k) + νG(k + 1) (4.4)
Pour une heure de temps et une période d’échantillonnage égale ∆T γk est donné comme suit :γk = ∆T
√1− Q
σ2 (h− T )
Représentation d’état du système La discrétisation de l’équation différentielle (4.2) peut êtredonnée par la formule suivante (4.5)
P (k + 1) = (1− 2πλ∆T√S
)P (k) +2πλ∆TK√
SG(k). (4.5)
Ainsi donc, pour n modules solaires, on peut avoir la représentation d’état suivante (4.6).
x(k + 1) =
P1(k + 1)P2(k + 1)
...Pn(k + 1)G(k + 1)
=
α1 0 . . . 0 β1
0 α2 . . . 0 β2
......
. . ....
...0 0 . . . αn βn0 0 . . . 0 γk
P1(k)P2(k)
...Pn(k)G(k)
+
00...01
νG(k + 1)
avec, αi = 1− 2πλ∆T√Si
et βi = 2πλ∆TK√Si
.L’état de notre système a comme composantes les puissances électriques produites au niveau de
31

Fig. 4.3 – Connexion en série des modules solaires
chaque module solaire du réseau et l’irradiance qui est suppose être la même pour tous les modulesphotovoltïque.
4.1.1 Architectures des réseaux photovoltïqueDans cette section, nous présentons quelque architectures concernant les connexions usuelles des
modules solaires ainsi que certains de leurs avantages [7].
Connexion en série, figure 4.3 Pour cette architecture, le courant en sortie de la station estégal au courant au niveau de chacun des modules solaire.
I = I1 = I2 = ... = In
Le voltage à la sortie de la station est égale à la somme des tensions au niveau de tous les modulede la station.
V =n∑i=1
Vi
La puissance électrique totale produite par la station est donnée par :
P = V I
Étant donné que le courant qui circule dans tous les modules solaires est le même, si un moduletombe en panne, ce dernier va automatiquement affecter les puissances délivrées par les autres mo-dules.En plus, il s’avère très difficile de détecter et de localiser le module défectueux.
Connexion en parallèle, figure 4.4 Le courant à la sortie de la station est égale à la sommedes courants délivrés par les différents modules.
I =n∑i=1
Ii
32

Fig. 4.4 – Connexion en parallèle des modules solaires
La tension à la sortie du système est égale à la tension au niveau de de chaque module du réseau.
V = V1 = V2 = ... = Vn
La puissance globale est égale à la somme des puissance produites localement par les différentsmodules :
P = V I = V
n∑i=1
Ii =n∑i=1
Pi
Une panne sur un module solaire n’affecte pas la puissance délivrée par les autres modules, ce quifait de cette architecture la configuration la plus robuste par rapport aux défauts d’occultation del’irradiance solaire.La tension électrique de sortie relativement faible limite son utilisation pour la génération de l’élec-tricité.
Connexion parallèle-série, figure 4.5 C’est une connexion qui combine l’architecture parallèleet l’architecture série.Elle a donc l’avantage d’être robuste aux défauts d’ombrage et délivre en sortie une tension utili-sable pour la génération d’électricité.
4.1.2 Exemple d’architecture pour le réseau de surveillanceNous allons considérer une connexion électrique parallèle entre les modules solaire.
? Mesures :Nous allons considérer un réseau de n modules solaires connectés en parallèle.Notre objectif est de déployer un ensemble de nœuds de N unités (N ≤ n) où chaque nœuddispose d’un capteur qui mesure l’irradiance solaire et d’un capteur de puissance (déduite dela mesure du courant et de la tension). La figure 4.6 montre la manière dont les capteurs sontdisposés sur la ferme solaire.
33
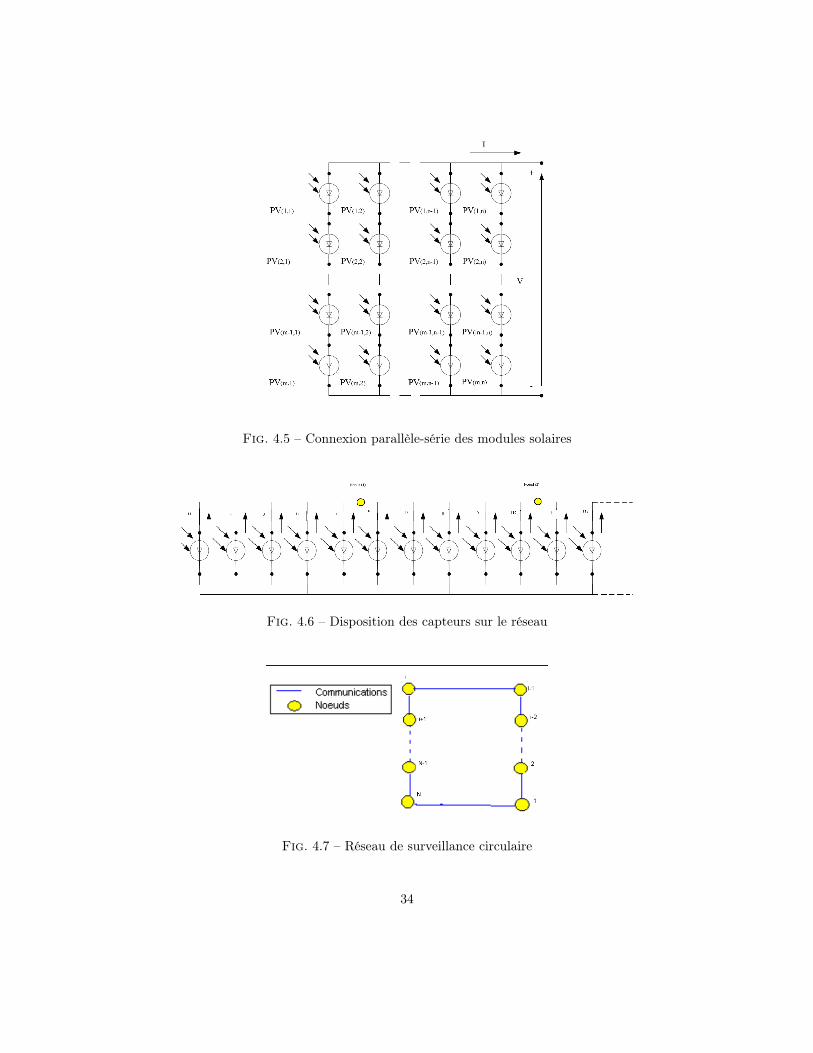
Fig. 4.5 – Connexion parallèle-série des modules solaires
Fig. 4.6 – Disposition des capteurs sur le réseau
Fig. 4.7 – Réseau de surveillance circulaire
34

Comme le montre la figure 4.13 les nœuds du réseau de surveillances sont déployés d’unemanière à former un graphe de communication en cercle.Le modèle d’observation de chacun des nœuds, figure 4.13, peut être donné comme suit :
Pq(k) =5q∑i=1
Pi(k) + yq(k)
Iq(k) = G(k) + bq(k)
Pq, q = 1, .., N , est la mesure de puissance faite par le nœud q. Avec, yq = (y1,q, y2,q, ..., yn,q)le bruit affectant la mesure de la puissance.IN , la mesure de l’irradiance faite par nœud q. Avec, bN , le bruit affectant cette mesure.
La mesure zN donc, est donné comme suit :
zq =[Pq(k)Iq(k)
]=[
1T5q 0n−5q+1
0n 1
]P1(k)P2(k)
...Pn(k)G(k)
+
y1,q
y2,q
...yn,qbq(k)
(4.6)
Avec comme matrice d’observation :
Hq =[
1T5q 0n−5q+1
0n 1
](4.7)
? Observabilité du systèmeNous allons démontrer l’observabilité du système pour deux modèle d’observation différents.Le cas où on ne prend qu’une seule mesure et le cas où on déploie un réseau de capteurs deN = 20 unités pour surveiller une station de n = 100 module solaires.
Cas d’une mesure En considérant une mesure particulière dont la matrice d’observabilitéest donnée par :
H =[
1 1 . . . 1 00 0 . . . 0 1
](4.8)
on veut démonter que le système est complètement observable.
Pour ce faire, il suffit de démonter que la matrice d’observabilité O =
HHF...
HFn
est de rang
plein.Il est facile de voire que :
HF i =[α1n α2
n . . . αin xi0 0 . . . 0 yi
](4.9)
Avec αn = 1− 2πλ∆T√Sn
et xi, yi sont des éléments non nuls.
35

Avec une permutation de ligne appropriée Π, la matrice d’observanilité O peut s’écrire sousla forme (4.11).
ΠO =[V x0 y
](4.10)
où, V ∈ <(n+1)×n est une matrice de Vandermonde de pôles α1, ..., αn. x et y sont deuxvecteurs non nuls.Il s’en suit que :
rang(O) = rang(ΠO) = rang(V ) + 1
Grâce à la structure de Vandermonde de la matrice V, nous savons qu’elle est de rang pleinsi et seulement si tous les pôles αi sont distincts. En d’autres termes, si les modules sont tousde surfaces §i distinctes, alors le système est observable.
Cas du réseau considéré L’idée est de démontrer l’observabilité du système avec le lemodèle d’observation du réseau de capteurs où on a comme matrice d’observation globale :
H =
1T5 0n−5+1
1T10 0n−10+1
......
1Tn 01
0n 1...
...0n 1
La matrice H est de dimension (2q × n + 1). Avec q = 1, .., N et 15q par un vecteur unitairede dimension 5q.
Avec une permutation de ligne appropriée Γ, la matrice d’observabilité O du système peuts’écrire sous la forme suivante (4.11).
ΓO =
V1 (0) x1
. . ....
(∗) VN xN0 . . . 0 y
(4.11)
x1, ..., xn, y sont des vecteur distincts.Avec :
Vi =
1 . . . 1
α5(i−1)+1 . . . α5i
α25(i−1)+1 . . . α2
5i
......
...αn5(i−1)+1 . . . αn5i
(4.12)
36

Une matrice Vandermonde. Elle est de rang plein, si tous ces pôles α5(i−1)+1, ..., α5i sont dis-tincts, ce qui correspond à des surfaces S5(i−1)+1, ..., S5i distinctes.Alors rang(Vi) = 5.Ainsi donc d’après les propriétés du rang d’une matrice bloc diagonale [4], on peut dire que :
rang(O) = rang(ΓO) = rang(V1) + ...+ rang(VN ) + 1
rang(O) = 5N + 1
4.2 Estimation de l’état du systèmeDans cette section, on applique l’algorithme d’estimation décentralisée à un système de n = 100
modules solaires et évaluera l’erreur quadratique moyenne de l’estimation faite par l’algorithme enutilisant un consensus classique et un consensus en temps fini.
Erreur quadratique moyenne d’estimation Le critère de performance est l’erreur quadratiquemoyenne que fait l’ensemble des nœuds (4.14) sur l’estimation de l’état du système au cours dutemps. L’erreur quadratique moyenne que fait un seul nœud i est donnée par (4.13).
EQMi(k) =1m‖ei(k)‖2, Avec,ei(k) = (x(k)− xi(k/k)) (4.13)
x(k) est l’état réel du système, xi(k/k) est l’etat estimé par le nœud i etm la dimension du système.L’erreur quadratique moyenne que fait l’ensemble des nœuds du réseau est donnée par la sommedes erreurs individuelles :
EQM(k) =1N
N∑i=1
EQMi(k). (4.14)
4.2.1 Erreur d’estimation avec un consensus classiqueDans la figure 4.8, on peut voir l’erreur quadratique moyenne que fait l’algorithme décentralisé
en fonction du nombre d’itérations accordées à l’algorithme de consensus classique.On remarque que la performance de l’algorithme décentralisé n’approche celle de l’algorithme cen-tralisé qu’après environ 40 itérations.
La première figure dans 4.9 représente l’erreur quadratique moyenne pour 10 itérations de l’al-gorithme de consensus classique.
On voit bien que l’erreur quadratique moyenne à 10 itérations est importante par rapport à celleobtenue avec 60 itérations, figure 2 dans 4.9. Pour 60 itérations l’erreur quadratique moyenne del’algorithme décentralisé est approximativement égale à celle de l’algorithme centralisé.
37
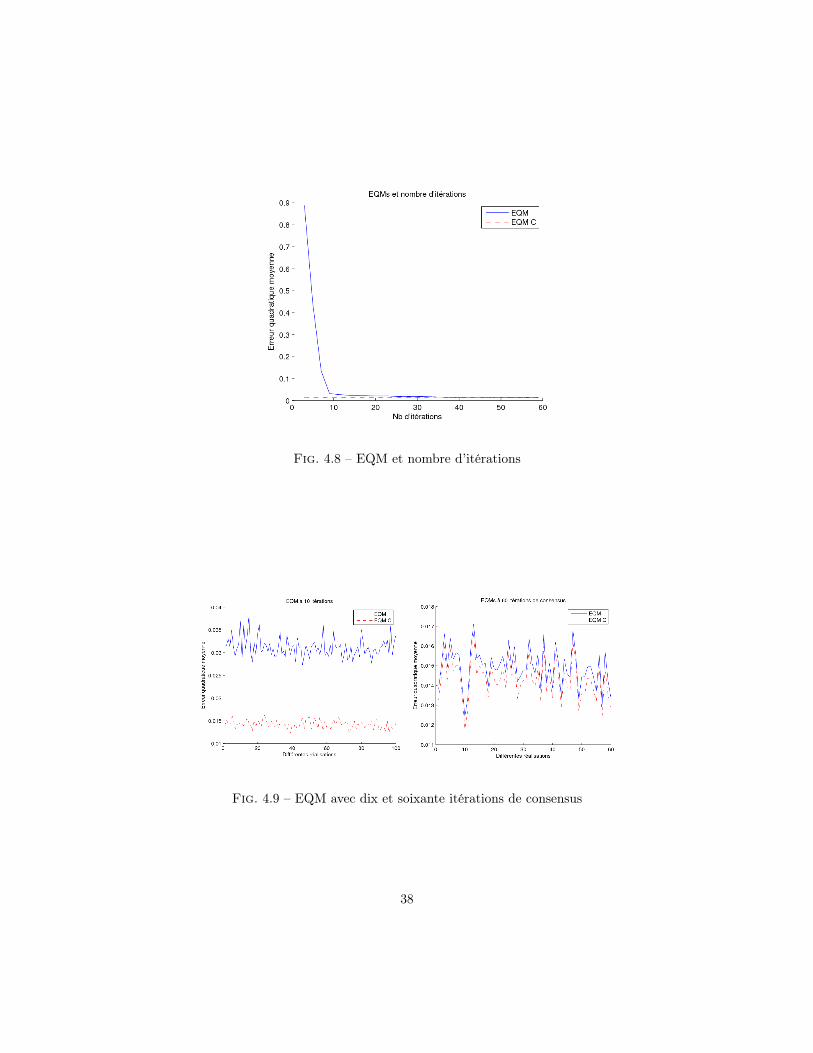
Fig. 4.8 – EQM et nombre d’itérations
Fig. 4.9 – EQM avec dix et soixante itérations de consensus
38

Prise de mesures
Consensus (φ, ψ(k))
KF1 KFN
DL1 DLN
Localisation
nœud (i) défectueux
? ? ?
? ?
? ?
? ?
?
. . . . . .
. . . . . .
. . . . . .. . . . . .
Fig. 4.10 – Processus de détection et de localisation
4.2.2 Erreur d’estimation avec un consensus en temps finiAprès D = 19 itérations, l’algorithme décentralisé fait exactement la même erreur quadratique
moyenne que l’estimateur centralisé. Cela est possible grâce au calcul exact de la moyenne des don-nées provenant des voisins de chacun des nœuds du réseau.
4.3 Détection d’un défautLe schéma dans 4.10 représente la stratégie adoptée pour la détection et la localisation d’un
défaut dans le réseau de capteurs considéré.
Les prises de mesures locales et le consensus sont deux opérations qui permettent aux filtresde Kalman locaux (KF1, ...,KFN ) de faire une estimation globale de l’état du système, commedécrit dans la section 3.4.Les résidus locaux générés par les différents filtres de Kalman sont testés localement à l’aide du testde χ2 (voir la section 2.2.3)Une fois qu’un défaut est détecté, on rassemble l’ensemble des décisions (DL1, ..., DLN ) pour pro-
39
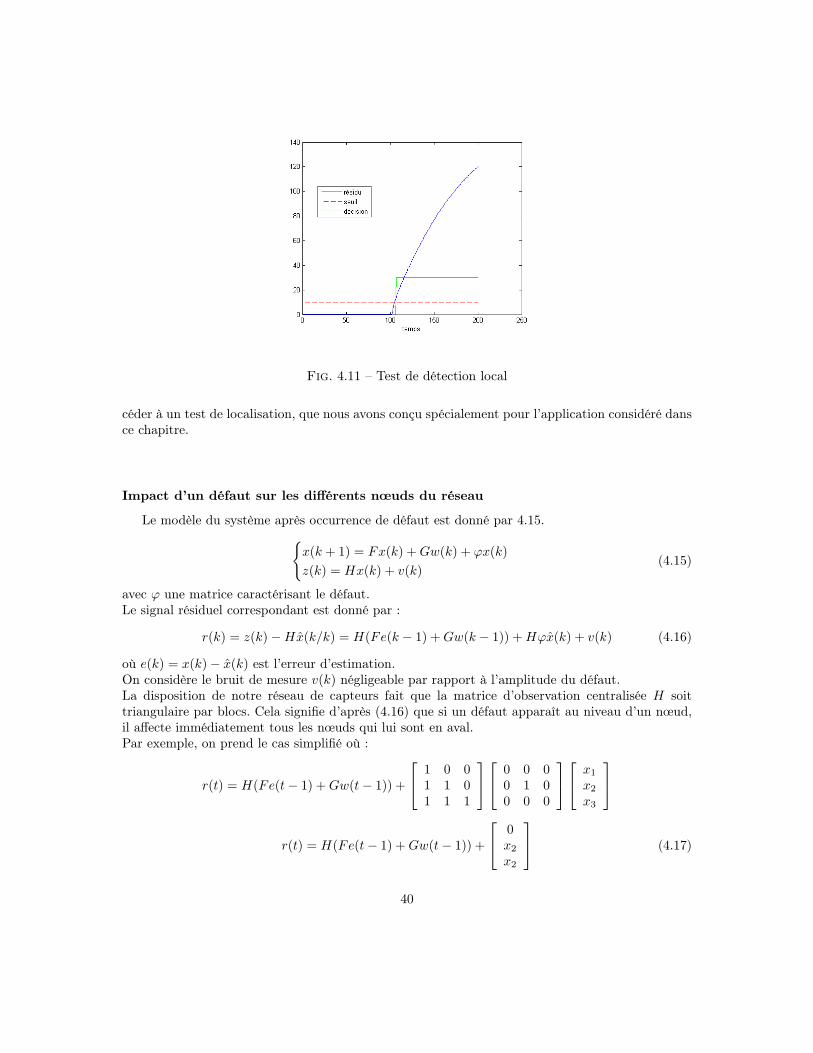
Fig. 4.11 – Test de détection local
céder à un test de localisation, que nous avons conçu spécialement pour l’application considéré dansce chapitre.
Impact d’un défaut sur les différents nœuds du réseau
Le modèle du système après occurrence de défaut est donné par 4.15.{x(k + 1) = Fx(k) +Gw(k) + ϕx(k)z(k) = Hx(k) + v(k)
(4.15)
avec ϕ une matrice caractérisant le défaut.Le signal résiduel correspondant est donné par :
r(k) = z(k)−Hx(k/k) = H(Fe(k − 1) +Gw(k − 1)) +Hϕx(k) + v(k) (4.16)
où e(k) = x(k)− x(k) est l’erreur d’estimation.On considère le bruit de mesure v(k) négligeable par rapport à l’amplitude du défaut.La disposition de notre réseau de capteurs fait que la matrice d’observation centralisée H soittriangulaire par blocs. Cela signifie d’après (4.16) que si un défaut apparaît au niveau d’un nœud,il affecte immédiatement tous les nœuds qui lui sont en aval.Par exemple, on prend le cas simplifié où :
r(t) = H(Fe(t− 1) +Gw(t− 1)) +
1 0 01 1 01 1 1
0 0 00 1 00 0 0
x1
x2
x3
r(t) = H(Fe(t− 1) +Gw(t− 1)) +
0x2
x2
(4.17)
40

Fig. 4.12 – Résidus et décisions
Si on considère ϕ =
0 0 00 1 00 0 0
comme étant un défaut qui apparaît directement sur la deuxième
composante du résidu r(t) à l’instant t, on voit bien que ce défaut n’affecte pas uniquement ladeuxième composante de r(t) mais aussi la troisième.
Pour notre système décrit dans la section 4.1, cela signifie que si un défaut apparaît au niveaud’un nœud i, tous les nœuds j ≥ i seront immédiatement affectés.La figure 4.12 montre les résidus et les décisions locales des 20 nœuds de notre réseau à l’instantd’occurrence d’un défaut au niveau du treizième nœud.
Les différentes simulations effectuées montrent que le test utilisé pour la détection de défaut neprésente pas de fausses alarmes, mais pour des bruits de mesure à variance élevée, il présente desnon détections.
La figure 4.13 représente le taux de non détection en fonction de la variance du bruit de me-sure.
On remarque que le taux de non détections augmente avec la croissance de la variance du bruitde mesure. (2.16).
4.4 Localisation du défautDans cette section, on va exploiter le fait que si un défaut survient en un nœud i, tous les autres
nœuds qui lui sont en aval seront immédiatement affectés (voir la section 4.3), ainsi des décisionslocales de tous les nœuds du réseau on aura un profil décisionnel d’un échelon qui change de valeurau nœud défectueux.Pour une variance de bruit de mesure importante, un nøud non affecté par le défaut peut présenterune fausse alarme. Cela fait que le profil décisionnel à obtenir n’est pas exactement un echelon. Ce
41
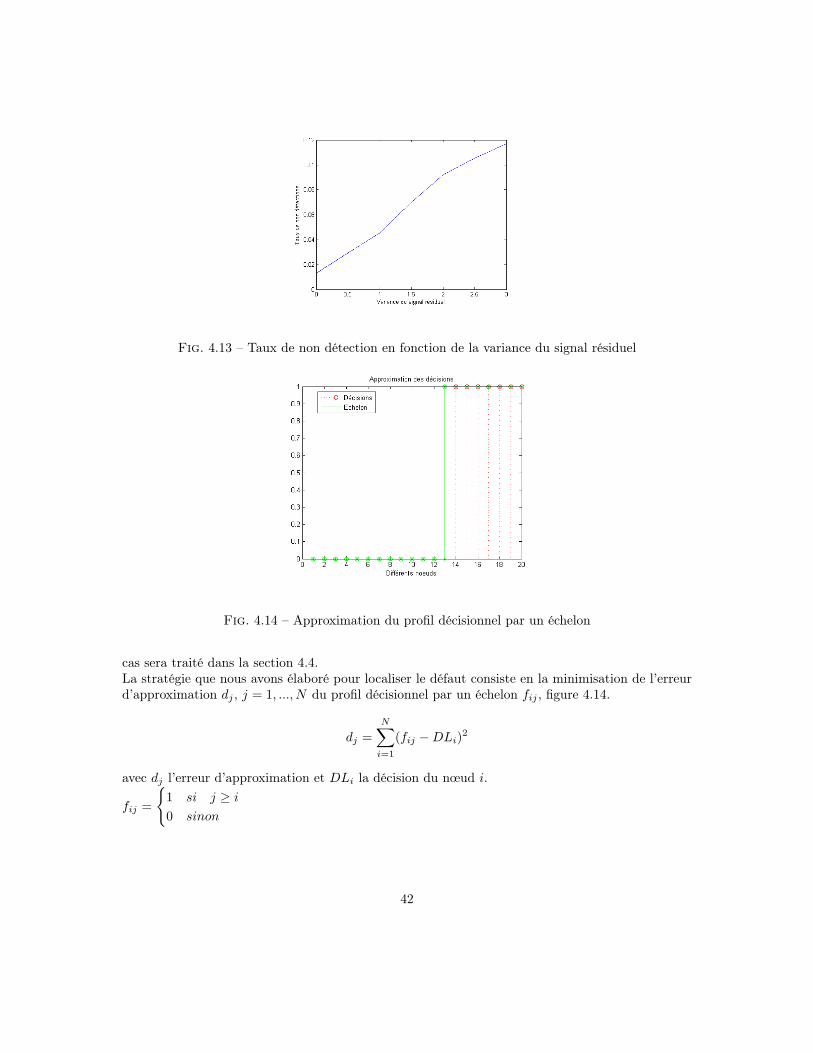
Fig. 4.13 – Taux de non détection en fonction de la variance du signal résiduel
Fig. 4.14 – Approximation du profil décisionnel par un échelon
cas sera traité dans la section 4.4.La stratégie que nous avons élaboré pour localiser le défaut consiste en la minimisation de l’erreurd’approximation dj , j = 1, ..., N du profil décisionnel par un échelon fij , figure 4.14.
dj =N∑i=1
(fij −DLi)2
avec dj l’erreur d’approximation et DLi la décision du nœud i.
fij =
{1 si j ≥ i0 sinon
42
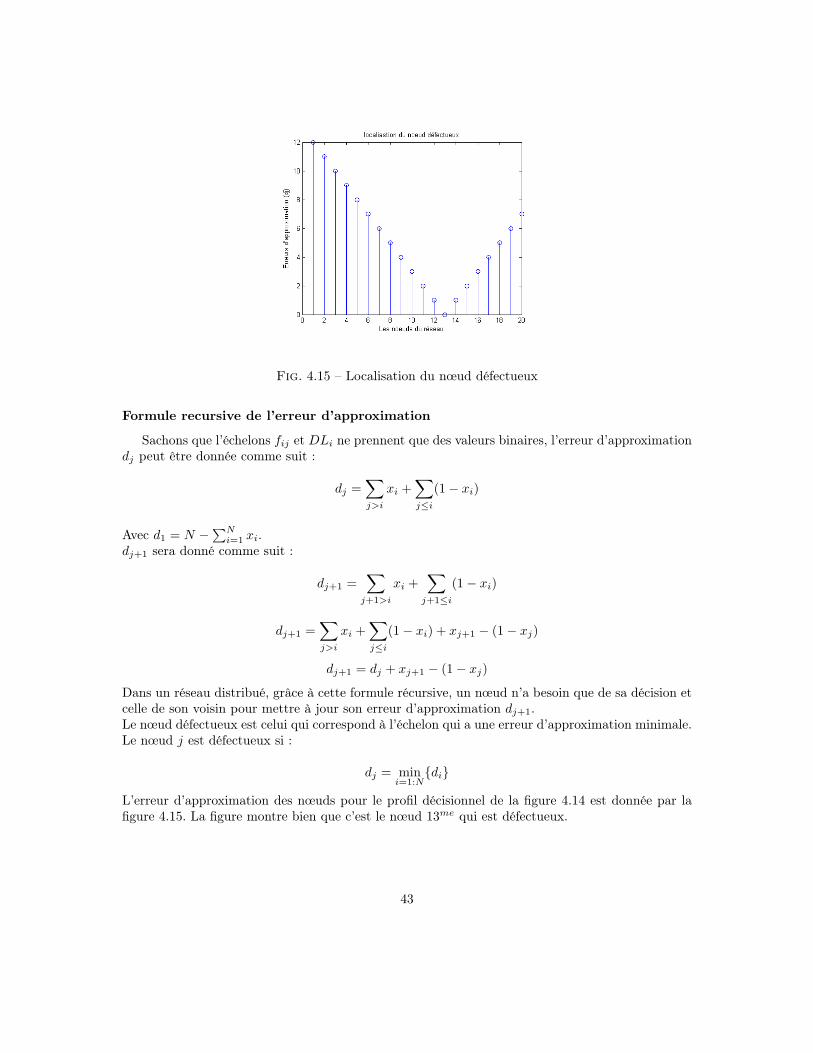
Fig. 4.15 – Localisation du nœud défectueux
Formule recursive de l’erreur d’approximation
Sachons que l’échelons fij et DLi ne prennent que des valeurs binaires, l’erreur d’approximationdj peut être donnée comme suit :
dj =∑j>i
xi +∑j≤i
(1− xi)
Avec d1 = N −∑Ni=1 xi.
dj+1 sera donné comme suit :
dj+1 =∑j+1>i
xi +∑j+1≤i
(1− xi)
dj+1 =∑j>i
xi +∑j≤i
(1− xi) + xj+1 − (1− xj)
dj+1 = dj + xj+1 − (1− xj)
Dans un réseau distribué, grâce à cette formule récursive, un nœud n’a besoin que de sa décision etcelle de son voisin pour mettre à jour son erreur d’approximation dj+1.Le nœud défectueux est celui qui correspond à l’échelon qui a une erreur d’approximation minimale.Le nœud j est défectueux si :
dj = mini=1:N
{di}
L’erreur d’approximation des nœuds pour le profil décisionnel de la figure 4.14 est donnée par lafigure 4.15. La figure montre bien que c’est le nœud 13me qui est défectueux.
43
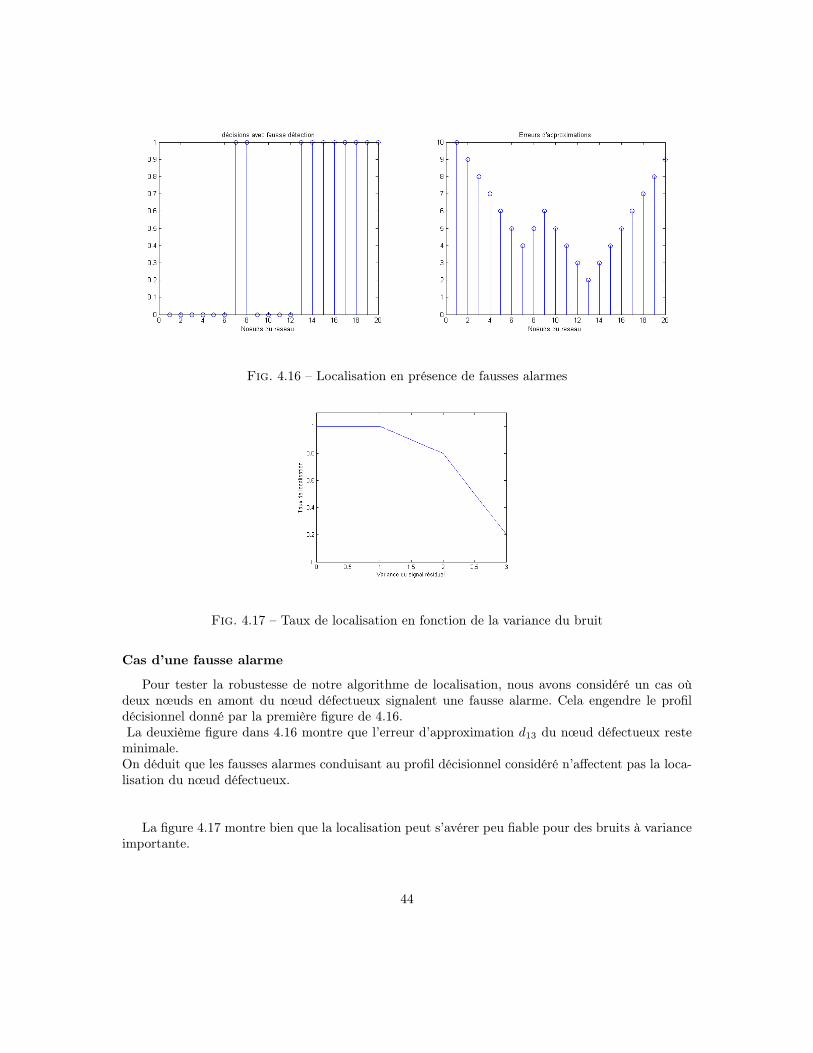
Fig. 4.16 – Localisation en présence de fausses alarmes
Fig. 4.17 – Taux de localisation en fonction de la variance du bruit
Cas d’une fausse alarme
Pour tester la robustesse de notre algorithme de localisation, nous avons considéré un cas oùdeux nœuds en amont du nœud défectueux signalent une fausse alarme. Cela engendre le profildécisionnel donné par la première figure de 4.16.La deuxième figure dans 4.16 montre que l’erreur d’approximation d13 du nœud défectueux resteminimale.On déduit que les fausses alarmes conduisant au profil décisionnel considéré n’affectent pas la loca-lisation du nœud défectueux.
La figure 4.17 montre bien que la localisation peut s’avérer peu fiable pour des bruits à varianceimportante.
44

Les capteurs de l’irradiance solaire sont moins précis que les capteur de courant et de tension quisont jugé très précis, mais cela nous permet de considérer des bruits de mesures à variance largementinférieur à 0.5 ce qui nous assure la fiabilité de notre test de localisation.
4.5 ConclusionDans cette section nous avons considéré une ferme solaire comme étant un système complexe à
surveiller à l’aide d’un réseau de capteurs.Nous avons présenté le système comme étant un modèle linéaire stochastique et nous avons adoptéune stratégie de surveillance à base de filtre de Kalman décentralisé.A partir d’une estimation locale et un d’algorithme de communication, tous les nœuds parviennentà estimer l’état global du système.Les nœuds utilisent leurs estimations pour générer des résidus locals qui leur servent à produire desdécision locales sur l’état défectueux ou normal du système. Puis, pour la configuration de notreréseau de capteurs, nous avons pu élaborer un test logique sur les décision locales qui permet delocaliser le défaut.
45

Chapitre 5
Conclusion générale
L’un des plus grands progrès théoriques de ces dernières années en automatique concerne lediagnostic des systèmes complexes. Ces système sont dits complexes par rapport à leur compositiond’un ensemble d’éléments spatialement répartis.
La technologies moderne offre une panoplie de nouveaux dispositifs parfaitement adaptés à la sur-veillance de tels systèmes. Notamment des capteurs intelligents, sans fil, et à faible coût énergétiquepour la surveillance d’une station nucléaire ou solaire.L’idée est d’embarquer avec chacun des capteurs un algorithme lui permettant d’estimer l’état del’ensemble du système collaborativement avec les autres capteurs du réseau de surveillance.A travers des mesures locales, grâce aux filtres de Kalman locaux, chacun des capteurs parvient àestimer les composantes de l’état qui lui sont observables. Une autre tâche très importante consisteen la fusion des données provenant des différents capteurs d’une manière optimale, en un tempsminimal. Pour cela nous avons comparé l’algorithme de consensus classique qui converge asymp-totiquement vers le résultat désiré et le consensus en temps fini qui calcule exactement le résultatdésiré en un nombre réduit d’itérations.Après avoir estimé l’état du système, il revient à chaque capteur de générer un résidu qui comparel’état estimé et l’état réel du système.Un test de χ2 est mis en oeuvre pour tester le signal résiduel et permettre à chacun des capteursde détecter d’éventuels défauts dans le système.Le déploiement considéré du réseau de surveillance nous permet d’utiliser les décisions des différentscapteurs pour faire un test de localisation susceptible de nous ramener au capteur défectueux, ainsidonc localiser le défaut dans le réseau de modules solaires.On note que dans notre travail, nous n’avons considéré que le cas d’un seul défaut dû à l’occultationde l’irradiance solaire. Donc, une première suite à ce travail s’impose, c’est celle de faire une étudeplus exhaustive quant au traitement des défauts, à considérer les défauts internes aux modulessolaires, les défauts de capteurs,...etc. Pour cela des modèle plus explicites du système doivent êtreadoptés.Des formalisme de décision qui tiennent en compte des incertitudes et de l’ignorance, comme parexemple le formalisme croyantiste, peuvent être adoptés pour la fusion de données et la prise dedécision.
46

Annexe A
Table de χ2
47
48

Bibliographie
[1] S. Del Favero. Analysis and Development of Consensus based Estimation Schemes. PhD thesis,Università degli Studi di Padova, 2010.
[2] R. Fellouah. Contribution au Diagnostic de Pannes pour les Systèmes Différentiellement Plats.PhD thesis, Université de Toulouse, 2007.
[3] E. Franco, R. Olfati-Saber, T. Parisini, and M. M. Polycarpou. Distributed fault diagnosisusing sensor networks and consensus-based filters. In Proceedings of the 45th IEEE Conferenceon Decision and Control (CDC 2006), pages 386–391, 2006.
[4] R. A. Horn and C. R. Johnson. Matrix Analysis. Cambridge university Press, 1990.[5] R. E. Kalman. A new approach to linear filtering and prediction problems. Transactions of
the ASME–Journal of Basic Engineering, 82(Series D) :35–45, 1960.[6] A. Kibangou. Finite-time average consensus based protocol for distributed estimation over
AWGN channels. In Proceedings of the 50th IEEE Conference on Decision and Control andEuropean Control Conference 2011 (CDC-ECC 2011), 2011. To appear.
[7] Y. Liu, B. Li, and Z. Cheng. Research on PV module structure based on fault detection.In Proceedings of the 2010 Chinese Control and Decision Conference (CCDC 2010), pages3891–3895. IEEE, 2010.
[8] J. Marcos, L. Marroyo, E. Lorenzo, D. Alvira, and E. Izco. From irradiance to output powerfluctuations : the PV plant as a low pass filter. Progress in Photovoltaic : Research andApplications, DOI : 10.1002/pip, 2011.
[9] R. Olfati-Saber. Distributed Kalman filter with embedded consensus filters. In Proceedingsof the 44th IEEE Conference on Decision and Control and 2005 European Control Conference(CDC-ECC ’05), pages 8179–8184, 2005.
[10] B. S. Rao and H. F. Durrant-Whyte. Fully decentralised algorithm for multisensor Kalmanfiltering. 138(5) :413–420, 1991.
[11] S. Stankovic, N. Ilic, Z. Djurovic, M. Stankovic, and K. H. Johansson. Consensus basedoverlapping decentralized fault detection and isolation. In 2010 IEEE Conference on Controland Fault-Tolerant Systems (SysTol), pages 570–575, 2010.
[12] S.S. Stankovic, M.S. Stankovic, and D.M. Stipanovic. Consensus based overlapping decentra-lized estimation with missing observations and communication faults. Automatica, 45 :1397–1406, 2009.
[13] F. Yang, C. Cheng, Q. Pan, and G. Zhang. Practical integrated navigation fault detectionalgorithm based on sequential hypothesis testing [j]. Journal of Systems Engineering andElectronics, 22 :146–149, 2011.
49