Embed Size (px)
Citation preview

Préface
La base de données de l’AS/400, voilà un sujet qui a fait couler beaucoup d’encre ! Est-elle relationnelle ? Faut-il l’acheter à part ? Le nom de DB2/400 lui permet d’être enfin nommée et donc comparée. Il n’est pas possible de commander DB2/400 car cette fonction est intégrée à l’OS/400, livrée en standard, comprise dans le prix. C’est la seule chose qui n’ait pas changé depuis le début du système 38. La liste des améliorations est longue puisqu’elle est maintenant conforme aux différents standards des bases de données relationnelles (ANSI X3.135.1992, ISO 9075.1992, FIFS 127-2SQL). Ecrit par un professionnel de l’AS/400, aux qualités pédagogiques reconnues, ce livre est un bon complément à une formation IBM. Il apportera au lecteur une vision globale des fonctionnalités de DB2/400.
Danièle LHERMITE Responsable de la Filière Formation AS/400
IBM France

Table des matières
AVANT-PROPOS ................................................................................................................1
Néologismes et typographie ...................................................................................................2
1 - INTRODUCTION ...........................................................................................................3
DB2/400 : la base de données de l’OS/400............................................................................3 Les caractéristiques de DB2/400............................................................................................4
SGBD Relationnel ..............................................................................................................4 Les interfaces .....................................................................................................................5 La sécurité..........................................................................................................................5 La base de données distribuée ...........................................................................................6
Conclusions ............................................................................................................................6
2 - PRINCIPES GÉNÉRAUX .............................................................................................7
Introduction............................................................................................................................7 Organisation de l'information............................................................................................7 Création d'objets ................................................................................................................8
Les fichiers ...........................................................................................................................10 Généralités .......................................................................................................................10 Description externe ..........................................................................................................11 L'identificateur de format.................................................................................................12
Les enregistrements..............................................................................................................13 Ajout .................................................................................................................................13 Suppression ......................................................................................................................13

II DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Liens avec la programmation ...............................................................................................15 Exemples en langage de contrôle.....................................................................................16 Exemples en RPG.............................................................................................................19
Les DDS...............................................................................................................................22 Introduction......................................................................................................................22 La spécification A .............................................................................................................23 La hiérarchie....................................................................................................................24 Exemples ..........................................................................................................................25 Les types de données ........................................................................................................25
Conclusions ..........................................................................................................................27
3 - LES FICHIERS PHYSIQUES.....................................................................................29
Les étapes de la création d'un fichier physique par DDS......................................................30 La codification des fichiers physiques..................................................................................30
Principes ..........................................................................................................................31 Le dictionnaire .................................................................................................................31 Les clés.............................................................................................................................33 Liens avec les fichiers d'affichage....................................................................................36 Partage de format ............................................................................................................39 Valeur par défaut .............................................................................................................40 En-tête de colonne............................................................................................................40 Le traitement des dates.....................................................................................................42 Les zones de longueur variable........................................................................................44 Environnement multinational...........................................................................................46 Les principaux mots-clés des DDS...................................................................................47
La commande de création de fichiers physiques .................................................................49 Définition du fichier .........................................................................................................49 Création d'un fichier sans DDS........................................................................................50 Gravité des messages .......................................................................................................50 Les membres.....................................................................................................................51 Le chemin d'accès ............................................................................................................51 Ecriture forcée en mémoire secondaire ...........................................................................54 Les fichiers physiques et la mémoire secondaire .............................................................54 Les verrouillages..............................................................................................................58 Le partage du bloc de contrôle (ODP).............................................................................58 Les groupes d’activation et l’ODP...................................................................................63 Les enregistrements détruits.............................................................................................63 L’identificateur de format ................................................................................................64 Les opérations permises ...................................................................................................65 Le tri .................................................................................................................................66 Conclusions......................................................................................................................67 Les principaux paramètres de la commande CRTPF.......................................................67
Les membres ........................................................................................................................68 Généralités .......................................................................................................................69 Mise en œuvre ..................................................................................................................71

Table des matières III
Exemple............................................................................................................................73 Conclusions......................................................................................................................75

IV DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
La gestion des fichiers physiques .........................................................................................75 Définition .........................................................................................................................76 Destruction.......................................................................................................................76 Visualisation.....................................................................................................................76 Modification de la structure.............................................................................................76 Les membres.....................................................................................................................80 Sauvegarde.......................................................................................................................80 Réorganisation .................................................................................................................80 Les utilitaires....................................................................................................................81
Conclusions ..........................................................................................................................81 Les principales commandes..................................................................................................81 Les principaux menus...........................................................................................................82
4 - LES FICHIERS LOGIQUES .......................................................................................83
Principes...............................................................................................................................83 Présentation .....................................................................................................................83 Structure...........................................................................................................................83 Utilisation.........................................................................................................................85 Les différents types de fichiers logiques...........................................................................90 Les étapes de la création d'un fichier logique..................................................................91
Les fichiers logiques non-joints............................................................................................91 Principes ..........................................................................................................................91 La référence aux fichiers physiques .................................................................................91 Sélection et omission ........................................................................................................93 Les chemins d’accès.........................................................................................................96 Les redéfinitions de zones ................................................................................................98 Les fichiers logiques multiformats..................................................................................100 Conclusions sur les fichiers logiques non joints ............................................................105
Les fichiers logiques joints.................................................................................................106 Principes ........................................................................................................................106 La codification ...............................................................................................................106 Remarques......................................................................................................................110 Conclusions sur les fichiers logiques joints ...................................................................112
Les principaux mots-clés des DDS des fichiers logiques ..................................................112 Les DDS de niveau Fichier ............................................................................................112 Les DDS de niveau Format ............................................................................................113 Les DDS de niveau Zone ................................................................................................113 Les DDS de niveau Clé...................................................................................................114 Les DDS de niveau Sélection .........................................................................................114
La commande de création des fichiers logiques .................................................................115 Les membres...................................................................................................................115 Le programme sélecteur de format ................................................................................115 Estimation de la taille d'un fichier logique ....................................................................115 Les principaux paramètres de la commande CRTLF.....................................................116
Les membres ......................................................................................................................117

Table des matières V
Les chemins d’accès...........................................................................................................119 Performances .................................................................................................................119 Les limites.......................................................................................................................119 La reconstruction ...........................................................................................................120 La sauvegarde ................................................................................................................121
La gestion des fichiers logiques..........................................................................................121 La définition ...................................................................................................................121 La destruction.................................................................................................................121 La visualisation ..............................................................................................................121 Les membres...................................................................................................................122 La sauvegarde ................................................................................................................122 Les utilitaires..................................................................................................................122
Conclusions sur les fichiers logiques..................................................................................122 Les principales commandes................................................................................................123 Les principaux menus.........................................................................................................123
5 - SÉCURITÉ ET INTÉGRITÉ DES DONNÉES........................................................125
Introduction........................................................................................................................125 La journalisation.................................................................................................................127
Les principes ..................................................................................................................127 La journalisation des fichiers physiques ........................................................................138 La journalisation des chemins d’accès ..........................................................................141 Conclusions sur la journalisation ..................................................................................145
Le contrôle de validation....................................................................................................145 Principes ........................................................................................................................145 Mise en œuvre ................................................................................................................146 L’objet de notification ....................................................................................................149 Les journaux...................................................................................................................155 Le contrôle de validation à deux phases ........................................................................156 Conclusions sur le contrôle de validation......................................................................157
Les contraintes d’intégrité référentielle ..............................................................................157 Introduction....................................................................................................................157 Mise en œuvre ................................................................................................................159 Les clés...........................................................................................................................161 La gestion.......................................................................................................................163 La journalisation............................................................................................................164 Exemple en RPG ............................................................................................................164 Conclusions....................................................................................................................167
Les déclencheurs (triggers) ................................................................................................167 Mise en œuvre ................................................................................................................168 Le programme déclencheur............................................................................................169 Exemple en langage de contrôle ....................................................................................172 Exemple en RPG ............................................................................................................173 Remarques......................................................................................................................175 Conclusions....................................................................................................................176

VI DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
La sauvegarde et la restauration .........................................................................................176 La sécurité ..........................................................................................................................177 Les dispositifs matériels .....................................................................................................178
Le contrôle d’intégrité (checksum).................................................................................179 Les disques miroirs (mirroring) .....................................................................................181 Les disques de type RAID 5............................................................................................181
Conclusions sur la sécurité et l’intégrité.............................................................................182 Les principales commandes................................................................................................183 Les principaux menus.........................................................................................................184
6 - SQL/400.......................................................................................................................185
Introduction........................................................................................................................185 L’environnement SQL........................................................................................................186
Terminologie ..................................................................................................................187 Le catalogue...................................................................................................................187 Conventions SQL............................................................................................................187 Utiliser une collection ou non ? .....................................................................................188
Les éléments du langage SQL ............................................................................................189 Les environnements d’exécution ....................................................................................189 Les conventions ..............................................................................................................191 La définition des structures SQL....................................................................................191 La gestion des données...................................................................................................195 Les registres spéciaux ....................................................................................................202 Le contrôle de validation ...............................................................................................203 La sécurité......................................................................................................................203 La connexion à une base de données éloignée...............................................................204
SQL dans les programmes..................................................................................................205 Principes ........................................................................................................................206 Les variables locales ......................................................................................................208 Les opérations simples ...................................................................................................208 Les opérations complexes...............................................................................................213 Optimisations liées au curseur .......................................................................................217 Déplacement contrôlé dans le curseur...........................................................................219 SQL dynamique ..............................................................................................................220
Optimisations .....................................................................................................................226 L’optimiseur ...................................................................................................................226 Les index ........................................................................................................................227 SQL dynamique ..............................................................................................................227 La commande CHGQRYA..................................................................................................227 La commande PRTSQLINF................................................................................................228
Conclusions sur SQL/400...................................................................................................228 Les principaux ordres SQL.................................................................................................229 Les principales commandes................................................................................................230 Les principaux menus.........................................................................................................230
7 - GESTION DE LA BASE DE DONNÉES.................................................................231

Table des matières VII
La commande OPNQRYF.....................................................................................................231 Principes ........................................................................................................................232 Les principaux paramètres.............................................................................................235
Les commandes de copie....................................................................................................238 Les commandes de substitution..........................................................................................242 Ouverture et fermeture contrôlée des fichiers.....................................................................244 Les références croisées.......................................................................................................244
Les principales commandes ...........................................................................................245 Les API et la base de données............................................................................................245 Les principales commandes................................................................................................246 Les principaux menus.........................................................................................................246
8 - LES BASES DE DONNÉES DISTANTES...............................................................247
Les fichiers DDM...............................................................................................................247 DRDA ................................................................................................................................250 Conclusions ........................................................................................................................251 Les principales commandes................................................................................................252 Les principaux menus.........................................................................................................252
CONCLUSIONS...............................................................................................................253
A - FEUILLE DE SPÉCIFICATION A .........................................................................255
B - LES TYPES DE POSTES DE LA JOURNALISATION ........................................257
C - API ET BASE DE DONNÉES..................................................................................261
GLOSSAIRE.....................................................................................................................267
INDEX ...............................................................................................................................277

Avant-propos
Cet ouvrage s’adresse à toute personne ayant à utiliser les données de l’AS/400. L’utilisateur final découvrira comment utiliser SQL, le programmeur trouvera les mots-clés qui lui sont indispensables et le responsable d’exploitation pourra optimiser son système grâce à une meilleure compréhension des mécanismes de DB2/400.
Plusieurs ouvrages comme celui-ci suffiraient à peine à décrire toutes les caractéristiques de ce SGBD (système de gestion de base de données). Le lecteur trouvera dans ces lignes l’essentiel, c’est-à-dire la philosophie générale de DB2/400, qui lui permettra de faire les bons choix, au bon moment. De nombreux paramètres et quelques fonctions ont été volontairement omis pour garder une relative concision. Dans la même optique, les cas particuliers et les contre-exemples n’ont été que rarement traités.
La disponibilité d’un terminal relié à un AS/400 serait un atout supplémentaire pour progresser dans la connaissance de la base de données de l’OS/400. Les exemples sont simples, choisis généralement pour leur coté pédagogique. Ils peuvent être complétés et même optimisés.
Pour que ces lignes restent lisibles, nous avons volontairement omis les notions de sécurité liées à chaque opération. Pour toute action il faudrait rajouter « à condition d’avoir les droits suffisants ».

2 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Certains exemples ne peuvent être exécutés que si vous possédez des droits élevés sur les fichiers. Si vous ne disposez pas d’un tel niveau d’autorisation, prenez contact avec le responsable de votre système.
Ces lignes sont rédigées alors que l’OS/400 est en V3R1M0 (Version 3 Release 1 Modification 0). Il est fort probable que l’essentiel de cet ouvrage restera valable au-delà des nouvelles évolutions de ce système.
Ce travail complète un premier ouvrage du même auteur intitulé Principes généraux et langage de contrôle sur AS/400 (Eyrolles, 2e édition, 1995). De nombreuses références à ce livre ont pour objectif d’éviter les répétitions.
Enfin, je voudrais conclure cette liste de remarques par une pensée pour ceux qui m’ont soutenu tout au long de ce travail.
Je remercie mes collaborateurs d’Alizés Montpellier pour leurs critiques et leurs suggestions.
Danièle LHERMITE, responsable de la filière Formation AS/400, IBM France, a bien voulu préfacer cet ouvrage. Qu’elle en soit sincèrement remerciée.
Néologismes et typographie
Vous trouverez dans cet ouvrage des néologismes issus de termes anglo-saxons ou, le plus souvent, de termes propres à l’AS/400. Ils appartiennent au langage courant de l’informaticien et sont employés chaque fois qu’ils apportent un gain de lisibilité. Un glossaire, à la fin de ce volume, reprend ces néologismes et les abréviations employées.
Les conventions typographiques retenues sont :
Le style de caractère... est utilisé pour... CRTPF une commande COMMIT(*NONE) un paramètre ou une valeur particu-
lière de l’OS/400 QSYS une bibliothèque create un terme anglo-saxon FICH1 un nom propre (d’objet, de variable
ou de produit) EXFMT un programme RPG ENDPGM un programme en langage de contrôle

Avant-propos 3
AVANT-PROPOS ................................................................................................................1
NEOLOGISMES ET TYPOGRAPHIE.............................................................................................2

Chapitre 1
Introduction
Une des raisons du succès de l’AS/400 est sa base de données intégrée. Nous allons dans un premier temps essayer de comprendre pourquoi.
DB2/400 : la base de données de l’OS/400
DB2/400 est le nom attribué récemment à la base de données qui a toujours existé sur l’AS/400. Ce nom lui procure une identité qu’elle n’avait pas jusque-là car elle est totalement intégrée au système d’exploitation OS/400.
DB2/400 est un vrai SGBDR (système de gestion de base de données relationnelle) avec les mêmes fonctionnalités que ses rivaux, et parfois même plus.
Le principal atout de cette base de données réside dans le fait qu’elle est totalement intégrée au système. Parmi les avantages que cela lui procure nous pouvons relever :
• qu’elle est systématiquement à jour par rapport à l’OS/400. Avec chaque nouvelle version du système est livré DB2/400 au même niveau ;
• qu’elle est automatiquement installée avec l’OS/400 ; il n’y a pas d’opération particulière à réaliser pour rendre DB2/400 disponible ;

4 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
• que c’est le seul moyen de gérer les données. Ainsi, même si l’on travaille en environnement 36, on utilise la base de données intégrée ;
• qu’elle évolue avec le système. Si celui-ci supporte une nouvelle technologie, elle est automatiquement assimilée par la base de données ;
• que certaines fonctions sont directement implémentées au niveau du microcode, ce qui lui procure d’excellentes performances ;
• qu’il n’y a pas de nouveau langage à apprendre pour gérer la base de données. Le langage de contrôle permet de créer des fichiers, de les sauvegarder, de mettre en place la sécurité... ce qui n’est jamais le cas avec des SGBD rapportés ;
• qu’elle interagit avec l’OS/400 comme le ferait une autre fonction système, c’est-à-dire par l’intermédiaire de messages. Là aussi il n’y a pas besoin de formation complémentaire.
Les caractéristiques de DB2/400 SGBD Relationnel
DB2/400 est une base de données naturellement multi-utilisateur. Les verrouillages d’enregistrements sont automatiquement réalisés quand il le faut.
Les principes mis en œuvre pour sa conception sont issus du modèle relationnel. Les liens entre les données sont établis dynamiquement, quand on en a besoin. Il n’y a aucun pointeur qui crée des liens fixes, souvent difficiles à gérer, comme dans les SGBD de type réseau ou hiérarchique.
Il faut en tenir compte lors de la conception de la base de données. Il est prudent d’utiliser une méthode d’analyse de type Merise, par exemple, afin d’obtenir une structure dite en troisième forme normale, c’est-à-dire conforme à l’esprit relationnel. On est ainsi assuré qu’il n’y a pas de redondance (duplication inutile de l’information) et que tous les fichiers sont bien structurés.
Les termes du modèle relationnel ne sont toutefois pas utilisés (sauf dans l’environnement SQL). On parle, par exemple, couramment de fichier et non de table.
L’indépendance entre les programmes et les données est assurée par des structures qui permettent de voir les données sous une certaine forme (tri, sélection d’enregistrements et de zones...) et qui sont nommées fichiers logiques. Sous

1 - Introduction 5
certaines conditions, le format des données peut évoluer indépendamment des programmes.

6 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Les interfaces De nombreuses interfaces nous permettent de gérer la base de données en fonction de nos besoins et de nos compétences. Nous pouvons, entre autres, citer :
• DFU (Data File Utility) qui permet d’agir directement sur les enregistrements d’un fichier. Il est à considérer comme un utilitaire de bas niveau, à réserver au responsable des données pour des opérations particulières ou éventuellement au programmeur qui désire se constituer un jeu de test ;
• SQL qui est un langage très répandu, couramment associé aux SGBDR. Il permet pratiquement toutes les opérations sur les données et sur les fichiers, en interactif, en batch et même au sein de programmes ;
• les commandes de l’OS/400 telles que DSPPFM qui affiche le contenu d’un fichier ou CRTPF qui le crée ;
• Query/400 qui permet d’extraire des données de la base avec une interface de type menu. Aucun langage n’est à connaître ;
• Office Vision/400 qui peut prendre des informations dans les fichiers pour réaliser des mailings ;
• PCS/400 et son remplaçant Client Access/400 qui autorisent l’extraction et la mise à jour de données à partir d’un micro-ordinateur ;
• et enfin les programmes écrits en langage de haut niveau (RPG, Cobol, C...). Il faut noter que le langage de contrôle permet d’extraire des données mais ne peut effectuer de mise à jour.
L’OS/400 propose donc un large éventail d’outils permettant la gestion des données. Le nombre des fonctions supportées devrait encore croître au fil des annonces pour conforter la place de l’AS/400 comme serveur d’entreprise. Chacun doit pouvoir y trouver son compte, en fonction de ses besoins, de ses compétences et du système d’exploitation de son ordinateur.
La sécurité La protection des données constitue l’un des autres points forts de DB2/400. La sécurité est prise en charge par des fonctions microcodées incontournables. Sa mise en place est simple, elle requiert l’utilisation de commandes classiques. Elle peut même devenir draconienne car elle est, sous certaines conditions, conforme à la norme C2, une des plus sévères en matière de sécurité.

1 - Introduction 7
L’intégrité des données est assurée par de nombreux dispositifs, matériels ou logiciels, que chacun devra mettre en place en fonction de ses besoins et de ses contraintes.
La base de données distribuée
Nous entrons dans l’ère du client/serveur et de la base de données répartie. Il est donc essentiel que DB2/400 puisse être intégrée à ces environnements. Cette base nous permet d’avoir les données sur d’autres systèmes et de les traiter pratiquement comme si elles étaient en local. Les environnements distants peuvent être d’autres AS/400, des machines Unix (Risc/6000 d’IBM), des mainframes (systèmes 370, 390) et même des micro-ordinateurs.
Conclusions
DB2/400 est la base de données multi-utilisateur la plus diffusée au monde (plus de 300 000 exemplaires à ce jour). Elle est donc une des références en matière de SGBDR.
Aujourd’hui, elle dispose de toutes les fonctions indispensables, et même de bien plus. Elle doit profiter du fantastique essor que lui promettent les nouvelles technologies de l’AS/400 (processeurs Risc, multimédia...) et de l’engouement pour le client/serveur.
IBM a bien l’intention de faire de l’AS/400 le serveur d’entreprise de cette fin de siècle. DB2/400 est l’un de ses atouts majeurs.

8 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
INTRODUCTION 3
DB2/400 : la base de données de l’OS/400 3
Les caractéristiques de DB2/400 4 SGBD Relationnel 4 Les interfaces 6 La sécurité 6 La base de données distribuée 7
Conclusions 7
—C— Client Access/400 5
—D— DB2/400 3 DFU 5
—O— Office Vision/400 5
—P— PCS/400 5
—Q— Query/400 5
—S— sécurité 5 SGBDR 3 SQL 5

Chapitre 2
Principes généraux
Introduction
Pour bien saisir le fonctionnement de la base de données, il est important de connaître l'organisation générale de l'information pour l'OS/400. Celle-ci étant traitée dans l'ouvrage Principes généraux et langage de contrôle sur AS/400 (Eyrolles, 2e édition, 1995), nous ne verrons ici que l'essentiel.
Organisation de l'information
Depuis la version V3R1M0, plusieurs modes de gestion de l’information cohabitent dans l’OS/400. Grâce à l’IFS (Integrated File System) et à ses commandes associées, une application peut accéder à des données qui sont placées dans :
• les objets ; c’est le mode que je qualifie de natif car il existe depuis l’origine de l’AS/400 ;
• les dossiers et documents habituellement utilisés par Office Vision et par la micro-informatique (PCS/400 et CA/400) ;
• le système de fichiers destiné à la compatibilité avec Unix ;

8 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
• le serveur de fichiers LAN Serveur ; • les environnements MS-Dos et OS/2.
Dans cet ouvrage, nous ne nous intéresserons qu’à l’aspect objet de l’OS/400 car c’est lui qui nous permet de tirer pleinement partie de la base de données relationnelle.
Tout ce que l'OS/400 peut gérer directement est considéré comme objet. Ainsi, un programme, un fichier, la description d'une ligne de communication ou d'une imprimante sont des objets. Le type, associé à chaque objet, indique à quoi correspond cet objet. Par exemple, le type *PGM signifie que cet objet est un programme, *FILE indique qu'il s'agit d'un fichier et *LIND caractérise une description de ligne. A ce jour, il existe plus de 70 types.
Chaque objet est organisé en deux parties :
• la première contient la description de l'objet (son propriétaire, sa date de création, la date de dernière sauvegarde et la commande utilisée...) ;
• la seconde renferme les données portées par l'objet (le code exécutable pour un programme, les enregistrements pour un fichier...).
Chaque objet est rattaché à une bibliothèque. Les bibliothèques, qui sont aussi des objets (de type *LIB), sont toutes rattachées à la bibliothèque fondamentale de l'OS/400 qui est QSYS. L’organisation des objets n’est donc pas une arborescence complexe comme c’est le cas pour d'autres systèmes (Unix, MS-Dos, OS/2...). Il est important de noter que les objets ne sont pas situés physiquement dans les bibliothèques, ces dernières agissant seulement comme des index : pour un nom d'objet et un type, elles renvoient l'adresse réelle sur disque.
Les objets de type *FILE (les fichiers) contiennent des données qui peuvent être regroupées en membres. Les membres seront utilisés pour ranger les enregistrements correspondant à une même entité : un membre pour les données du stock de Paris, un autre pour celui de Montpellier ou bien un membre pour les données de chaque année pour la paie. Nous détaillerons cette notion fondamentale au niveau des fichiers physiques et logiques.
La figure 2.1 résume l'organisation logique des données pour l'OS/400.
Création d'objets
D'une manière générale, les objets sont créés par les commandes de l'OS/400 dont les noms commencent par les lettres CRT, abréviation de Create (créer en anglais).

2 - Principes généraux 9
QSYS
QGPL COMPTA PAYE
FICH2
MEMBRE1MEMBRE2MEMBRE3
MONTPELLIEPARISMARSEILLE
PGM1STOCK
FICH1
FICH2
*PGM*FILE
*FILE
*FILE
*LIB *LIB *LIB
*LIB
Figure 2.1 : organisation logique des données pour l'OS/400. MONTPELLIE, PARIS et MARSEILLE sont les membres du fichier STOCK.
MEMBRE1, MEMBRE2 et MEMBRE3 sont les membres de FICH1.
Trois situations principales se présentent :
• pour la création d'un objet standard de l'OS/400 seuls les paramètres de la commande suffisent. Par exemple, la commande CRTDTAARA permet la création d'une Data area (zone de données) ;
• la création d'un programme (objet de type *PGM ), nécessite la rédaction d'un source écrit dans un langage de programmation (RPG, Cobol, langage de contrôle...). Ce source est placé dans un membre (dit membre source) d'un fichier source. La commande de création (ou compilation) fera référence à ce membre ;
• un objet de type fichier (*FILE ) est créé, généralement, à partir d'un membre source écrit dans un langage de description de données appelé DDS (Data Description Specification). Ce langage est constitué de mots-clés que nous détaillerons plus loin dans cet ouvrage car ils définissent l'organisation et la structure des données dans les fichiers qui constituent le cœur de la base de données de l'AS/400. Nous verrons tout au long de cet ouvrage qu'il existe d'autres moyens de créer des fichiers, mais l'utilisation de DDS est le mode naturel.

10 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Les fichiers Généralités
Les fichiers sont tous les objets de type *FILE. Ils regroupent principalement :
• les fichiers qui portent les données, ce sont les fichiers physiques, ils ont pour attribut PF ;
• les vues (au sens relationnel) qui sont les fichiers logiques. Leur attribut est LF ;
• les fichiers d'affichage, qui définissent les écrans (attribut DSPF) ;
• les fichiers d'impression, qui déterminent le contenu et les caractéristiques des fichiers spoules (attribut PRTF) ;
• les fichiers DDM (Distributed Data Management) qui procurent un accès aux données qui sont sur un autre AS/400 (ou éventuellement sur un système qui supporte DDM comme l’IBM/36 ou l’IBM/38) ;
• et enfin les fichiers de communication (dits ICF) qui ne seront pas traités dans cet ouvrage (attribut ICFF).
Cette organisation appelle quelques remarques :
• de manière naturelle, la gestion des écrans est réalisée au travers d'un fichier d'affichage (ou fichier écran). Le fichier d'affichage contient toutes les informations relatives aux zones qui apparaîtront à l'écran (noms, emplacements, couleurs, attributs, valeurs constantes...) et à l'échange homme-écran (touches autorisées, alarmes sonores, messages d'erreur...). Le programme est totalement déchargé de cette tâche ; il n'a pas à positionner le curseur dans telle ou telle zone, ou à vérifier si une touche de fonction est autorisée. Cela simplifie énormément le travail de codification du programme source. Le même principe est utilisé pour les fichiers d'impression ;
• les fichiers base de données, c'est-à-dire les fichiers au sens strict pour d'autres systèmes, ou les tables et vues du modèle relationnel, sont les fichiers physiques, logiques et DDM. Ils correspondent aux structures de stockage de l'information et aux structures qui permettent l’accès à ces informations. Dans les programmes, les opérations que l'on peut réaliser sur ces fichiers sont identiques à celles applicables aux fichiers d'affichage et d'impression car l’intégration de la base de données dans l’OS/400 est totale. Les déclarations, la logique d'utilisation et les ordres de lecture et d'écriture sont les mêmes pour les

2 - Principes généraux 11
fichiers base de données, pour les fichiers d’impression et pour les fichiers d’affichage. Cela simplifie encore le développement d'applications ;
• la création de la plupart de ces objets de type *FILE suit le mécanisme que nous avons décrit au chapitre précédent, c'est-à-dire que ces fichiers sont, de manière naturelle, issus d'un membre source codifié en utilisant le langage DDS (à l'exception des fichiers DDM) ;
• pour un programme, la gestion des enregistrements de tous ces fichiers s'effectue seulement par des ordres de lecture et d'écriture. Tout ce qui est tri, et même éventuellement sélection d’enregistrement, est mis en œuvre directement dans les fichiers.
Description externe
Chaque fichier créé à partir de DDS possède, en interne, la description de son format , c'est-à-dire le détail de chacune des zones qui composent les enregistrements de ce fichier. Ainsi, un programme trouvera au début de ces fichiers le masque qu'il faut appliquer sur les données pour voir les enregistrements. Par exemple :
• de la position 1 à la position 10, il y a la zone NOMCLI de type alphanumérique ;
• de la 11e à la 15e, il s'agit de CODECLI, en numérique, sans positions décimales ;
• ...
Ces fichiers sont dits à description externe, sous entendu externe par rapport au programme, car la description est interne pour le fichier.
Quand un programme utilise un tel fichier, il doit seulement le déclarer par la commande adéquate du langage (DCLF en langage de contrôle, spécification F en RPG...), sans décrire les zones qui le composent. Lors de la création d'un programme, le compilateur recopie dans ce dernier les formats des fichiers déclarés. Ainsi, le programme dispose du nom, du type, de la longueur et des caractéristiques de chaque zone.
Ce mécanisme implique que le fichier existe déjà lors de la création du programme, donc :
Un fichier doit toujours être créé avant de compiler un programme qui l'utilise.

12 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Les programmes peuvent décrire en interne les zones qui composent un fichier, soit parce que le fichier n'est pas à description externe (pour les fichiers qui viennent de l'IBM/36, par exemple), soit pour pouvoir redéfinir certaines caractéristiques (le nom essentiellement). Dans ce dernier cas, il est indispensable que les deux formats, celui du fichier et celui défini dans le programme, soient compatibles (même longueur et même type pour chaque zone du programme et du fichier).
Dans la suite de cet ouvrage, et sauf contre-indication, nous ne ferons référence qu'à des fichiers à description externe, ce qui correspond à la philosophie de la base de données de l'OS/400.
L'identificateur de format
C'est donc lors de la compilation qu'un programme reçoit le détail de chacune des zones qui composent les enregistrements d'un fichier. Ces informations sont placées dans l'objet de type *PGM et ne seront plus réactualisées.
Si le format du fichier change (avec l’ajout d’une zone, par exemple), le programme est alors incapable de lire correctement les données du fichier. Le masque qu'il a mémorisé pour voir les données n'est plus adapté.
Pour être sûr que le programme et le fichier sont compatibles, le système s'appuie sur un identificateur de format. Il s'agit d'un code de 13 positions qui identifie de manière unique chaque format. Un algorithme détermine sa valeur à partir du nom des zones, de leur agencement, de leur type et de leur longueur. Si deux formats sont identiques, ils ont le même identificateur de format. Les actions suivantes modifient l'identificateur de format :
• renommer une zone ;
• changer le type, la longueur, ou le nombre de décimales d’une zone ;
• permuter l’ordre de zones ;
• ajouter ou supprimer une zone.
Par contre :
• les opérations sur la clé ;
• la modification des critères de sélection ;

2 - Principes généraux 13
• la modification des constantes, des commentaires, des couleurs ;

14 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
• et les opérations sur les domaines de validité des zones,
n'affectent pas cet identificateur.
Lors de la création d'un programme, le compilateur recopie dans l'objet programme l'identificateur de format du (ou des) fichier(s) déclaré(s) dans le source ainsi que la description des zones. A chaque exécution de ce programme, le système vérifie si l'identificateur de format stocké dans le programme correspond bien à celui du fichier qui est ouvert. En cas d'échec, l'erreur CPF4131 « Erreur de niveau... » apparaît : le fichier et le programme ne sont pas compatibles. Il suffit tout simplement de recompiler le programme pour que cet incident ne se reproduise plus. Il est inutile de recréer le fichier ! Nous verrons au niveau du paramètre LVLCHK de la commande CRTPF comment inhiber cette vérification du système, en prenant garde aux conséquences éventuellement néfastes d’une telle action.
Les enregistrements
Rappelons que les fichiers physiques sont les seuls à posséder réellement des données. Les données sont stockées dans ces fichiers sous la forme d'enregistrements qui ont la même organisation car :
Dans un fichier physique, tous les enregistrements ont le même format.
Ajout
En standard, les enregistrements sont ajoutés de manière séquentielle, les uns à la suite des autres : le dernier est placé à la fin du fichier.
Cette organisation est respectée même si le fichier a été décrit avec une clé. En effet la clé agit sur le chemin d'accès qui est une structure indiquant comment les enregistrements doivent être lus et qui n'affecte en aucune manière la structure physique des données (c'est-à-dire telles qu'elles sont organisées sur le disque).
Suppression
Pour le système, la suppression d'un enregistrement consiste simplement à le « marquer » à l'effacement. L'enregistrement est toujours présent mais ne peut plus être lu.

2 - Principes généraux 15
La suppression d'un enregistrement est irrémédiable, même si la place qu'occupait cet enregistrement est conservée : il n'y a aucun moyen de le récupérer.
Un « trou » est ainsi laissé dans le fichier : la place de l'enregistrement est toujours occupée mais il n'est plus disponible et la taille du fichier est toujours identique (figure 2.2).
Cette organisation peut être problématique pour les fichiers très actifs, où les suppressions sont fréquentes. S'ils sont nombreux, les enregistrements marqués à l'effacement peuvent perturber le système :
• en étant responsables de l'accroissement de la taille des fichiers ;
• en provoquant une dégradation des performances. En effet, le système doit lire un enregistrement avant de savoir s'il est valide (est-il marqué à l'effacement ?). Dans le cas d'une lecture séquentielle, on imagine aisément le temps perdu à traiter les enregistrements supprimés.
123456789 NOUVEAU
12345678
12345678
Effacement
Enregistrement
Suppression du 4e
enregistrementAjout d’un
enregistrement
Figure 2.2 : suppression d'un enregistrement dans un fichier physique. Représentation du fichier avant et après suppression du 4e enregistrement. Après suppression, cet enregistrement n'est plus disponible, la position relative des autres enregistrements est inchangée. Un nouvel enregistrement sera placé à la fin du fichier, la place libre n'étant pas récupérée en standard.

16 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Il existe au moins trois solutions pour pallier cet inconvénient :
• en gérant soi-même, par programme, les enregistrements détruits et en plaçant les nouveaux à la place des anciens, par mise à jour. Jusqu'à l'apparition de la version 2, cette méthode avait de nombreux adeptes ;
• depuis la version 2, le paramètre REUSDLT de la commande CRTPF nous permet de demander au système de placer un nouvel enregistrement à la place d'un autre marqué à l'effacement. Le système maintient alors une table des "places libres". Nous le verrons au chapitre consacré à cette commande ;
• enfin, la commande RGZPFM (reorganize physical file member), opère un compactage des enregistrements des membres d'un fichier. Les enregistrements valides sont décalés pour occuper la place de ceux marqués à l'effacement. Les "trous" sont ainsi comblés (figure 2.3). Cette commande a d'autres fonctions telle que la réorganisation des chemins d’accès. L'objet fichier étant bloqué pendant tout le compactage, cette fonction doit donc être lancée en dehors des périodes d'activité des applications qui utilisent ce fichier. L'emploi périodique de cette commande est vraiment nécessaire pour les fichiers à forte activité (nombreuses suppressions et insertions). Il est essentiel de procéder à une sauvegarde du fichier avant d’exécuter cette commande.
123456789
12345678
RGZPFM
Figure 2.3 : compactage d'un fichier par la commande RGZPFM.
Liens avec la programmation

2 - Principes généraux 17
Il est important de définir les principes élémentaires de la programmation avec les fichiers pour pouvoir appréhender correctement les exemples présentés tout au long de cet ouvrage. Dans un programme, la gestion des fichiers est relativement simple. Elle se compose essentiellement de deux parties, quel que soit le type de fichier :
• la déclaration ;
• les ordres de lecture/écriture.
La déclaration suffit à provoquer l’ouverture automatique du fichier, la fin du programme le fermant de manière implicite. Nous réserverons les ordres explicites d'ouverture et de fermeture de fichiers à des cas particuliers.
Toutes les zones décrites dans un fichier sont connues du programme sous la forme de variables qui ont le même nom que ces zones. Au début de la compilation, les caractéristiques de chaque zone sont ramenées en tête du programme, si bien que celui-ci dispose de toutes les informations nécessaires pour initialiser ces variables : nom, type, longueur. Il en est de même pour les indicateurs des fichiers d'affichage et d'impression. La gestion d'un enregistrement s'effectue par l'intermédiaire d'un format. Le programme va donc écrire, ou lire, des formats entiers.
Quelques exemples en langage de contrôle et en RPG vont illustrer ces principes.
Exemples en langage de contrôle
Le langage de contrôle permet de gérer les fichiers en lecture uniquement, à l'exception des fichiers d'affichage dont il peut lire les formats pour récupérer les informations saisies par un utilisateur. De ce fait, on ne peut employer ce langage pour écrire des programmes chargés de la création ou de la mise à jour d'enregistrements, ou encore destinés à générer des états à imprimer.
Une deuxième contrainte est attachée au langage de contrôle : un programme ne peut utiliser au maximum qu'un seul fichier.
Utilisation d'un fichier physique ou logique
L’exemple 2.1 décrit l'architecture classique d'un programme en langage de contrôle (dit CLP) lisant un fichier base de données (commande RCVF) :
PGM

18 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
DCLF(FICH1) /*déclaration du fichier, le fichier sera ouvert et le */ /*premier enregistrement prêt à être lu*/ DCL ... /*déclaration des variables*/ LECT : RCVF RCDFMT(FMT1) /*lecture d'un enregistrement du fichier, */ /*FMT1 est le nom du format du fichier FICH1*/ MONMSG MSGID(CPF0864) EXEC(GOTO FIN) /*test de fin de fichier*/ .../*traitement de l'enregistrement lu*/ GOTO LECT : /*lecture de l'enregistrement suivant*/ FIN : .../*traitement de fin de fichier*/ ENDPGM
Exemple 2.1 : architecture d’un programme CLP utilisant un fichier base de données. Le message CPF0864 est renvoyé par le système quand le programme essaye de lire un enregistrement au-delà de la fin du fichier. Il faut donc l’intercepter par la commande MONMSG pour détecter la fin de fichier.
L'exemple 2.2 décrit un programme qui calcule la somme de la zone SOLDE pour tous les enregistrements du fichier.
DDS du fichier FICH1 NOM FONCTION R FMT1 NUMCLI 10 SOLDE 7 2
Ce fichier contient un format FMT1 qui est constitué des zones NUMCLI , de type Alphanumérique, de longueur 10, et SOLDE de type Décimal condensé de 7 dont 2.
Programme en langage de contrôle
PGM DCLF(FICH1) /*déclaration du fichier, le fichier sera ouvert et le */ /*premier enregistrement prêt à être lu*/ DCL VAR(&TOTAL) TYPE(*DEC) LEN(9 2) VALUE(0) /*déclaration de la variable TOTAL et initialisation à 0*/ LECT : RCVF RCDFMT(FMT1) /*lecture d'un enregistrement du fichier, */ MONMSG MSGID(CPF0864) EXEC(GOTO FIN) /*test de fin de fichier*/ CHGVAR &TOTAL (&TOTAL + &SOLDE) GOTO LECT : /*lecture de l'enregistrement suivant*/ FIN : .../*traitement du total et de fin de fichier*/

2 - Principes généraux 19
ENDPGM
Exemple 2.2 : utilisation d'un fichier base de données en langage de contrôle.

20 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Utilisation d'un fichier d'affichage
Un format d'un fichier d'affichage peut être lu (commande RCVF), écrit (SNDF) ou même écrit et lu en une seule opération (SNDRCVF).
Le programme et le fichier d'affichage vont échanger des informations par l'intermédiaire d'indicateurs. Il s'agit de structures élémentaires qui sont soit en-fonction (ou vrai) soit hors-fonction (ou faux). Il y en a 99 à notre disposition, nommés 01 à 99. Dans l'exemple suivant, l'indicateur 03 a été associé à la touche de fonction F3 dans le fichier d'affichage. Si l'utilisateur appuie sur F3, l'indicateur 03 est mis en-fonction. Ainsi, les indicateurs sont utilisés pour informer le programme qu’un évènement vient de se produire. En langage de contrôle, l'indicateur 03 est associé à une variable nommée &IN03, et d’une manière générale, l’indicateur XX est associé à la variable &INXX.
PGM DCLF(ECR1) /*déclaration du fichier, le fichier est ouvert*/ DCL ... /*déclaration des variables*/ LECT : SNDRCVF RCDFMT(FMT1) /* affichage d'un écran et lecture des */ /*informations saisies par l'utilisateur*/ IF &IN03 GOTO FIN /*la condition de fin est réalisée*/ .../*traitement de l'enregistrement lu*/ GOTO LECT : /*réaffichage de l'écran*/ FIN : .../*traitement de fin de programme*/ ENDPGM
Exemple 2.3 : architecture d’un programme CLP utilisant un fichier d’affichage
L'exemple 2.4 décrit un programme qui gère le choix d'un utilisateur.
DDS du fichier d'affichage ECR1 NOM LG DEC U LIG COL FONCTIONS R FMT1 CA03(03 'fin') 1 30 'MENU GENERAL’ 10 30 '1-Comptabilité' 12 30 '2-Paie' 14 30 '3-Commercial' 16 30 'Réponse :' REP 1 0 I 16 40 RANGE(1 3) 24 10 'F3 :Fin'

2 - Principes généraux 21
Cet écran propose un choix à l'utilisateur qui répondra soit par une valeur comprise entre 1 et 3 dans la zone REP, soit en appuyant sur F3, auquel cas l'indicateur 03 sera mis en-fonction. Affichage de l’écran ECR1
MENU GENERAL 1-Comptabilité 2-Paie 3-Commercial Réponse : F3 : Fin
Programme en langage de contrôle
PGM DCLF(ECR1) /*déclaration du fichier*/ LECT : SNDRCVF RCDFMT(FMT1) /*Affichage d'un écran et lecture des informations saisies par l'utilisateur*/ IF &IN03 GOTO FIN /*la condition de fin est réalisée (appui sur F3)*/ ELSE IF (&REP = 1) CALL COMPTA ELSE IF (&REP = 2) CALL PAIE ELSE IF (&REP = 3) CALL COMMERCIAL GOTO LECT : /*réaffichage de l'écran de choix*/ FIN : .../*traitement de fin de programme*/ ENDPGM
Exemple 2.4 : programme en langage de contrôle de gestion d'un écran.
Exemples en RPG
Le RPG, au même titre que les autres langages de haut niveau tels que le Cobol, le PL1, le Pascal ou le C, permet l'écriture dans les fichiers. Il est donc utilisé pour codifier les programmes qui doivent ajouter ou modifier des enregistrements.
Le RPG/400 est un compilateur disponible depuis l’apparition de l’AS/400. Il est adapté aux programmes que je qualifie de type gestion et qui correspondent au domaine de prédilection de l’AS/400 d’origine.
Le RPG IV est un compilateur, apparu avec la V3R1M0 de l’OS/400, qui s’inscrit totalement dans le cadre de l’ILE. Il correspond à une évolution du RPG/400 et apporte une plus grande souplesse dans le développement. Il supporte les nouvelles

22 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
fonctions de l’OS/400 telles que les nouveaux types (Date, Heure et Horodatage) et la modularité.
A ce jour, ces deux compilateurs sont contenus dans le logiciel sous licence RPG. Les exemples de cet ouvrage seront, selon les besoins, présentés dans l’un ou l’autre de ces langages. Les programmes que nous verrons utilisent la logique libre, ils ne s'appuient donc pas sur le cycle logique qui traite de manière automatique les fichiers. Seules les fonctions de base sont décrites dans cet ouvrage. Pour un complément d'information nous renvoyons à l'ouvrage de C. Gauthier : RPG/400.et environnement de développement (Eyrolles, 1993).
A l'origine (dans les années 60), les programmes étaient codifiés sur des cartes perforées. Le langage RPG en a hérité une certaine rigueur dans la codification :
• chaque ligne de code appartient à un certain type (la spécification) qui dépend de la fonction à exécuter par le programme. Une spécification de type F
correspond à la déclaration d'un fichier, une spécification C décrit un traitement (une instruction exécutable) ;
• chaque spécification impose un format strict pour la codification des instructions sur cette ligne. Pour une spécification F, par exemple, le nom du fichier doit être situé à partir de la colonne 7.
La spécification F
La spécification F permet de décrire les fichiers utilisés par un programme. Nous allons rapidement présenter ses caractéristiques.
RPG/400
Colonne Libellé Valeurs 6 Définition de la spécification F
7-14 Nom du fichier 15 Type d’ouverture du fichier I : en lecture
O : en écriture U : en mise à jour C : combiné (pour les écrans)
16 Mode de traitement P : primaire S : secondaire F : logique libre
19 Description du fichier F : interne

2 - Principes généraux 23
E : externe 31 Utilisation de la clé K : prise en compte de la clé
blanc : pas d’utilisation de la clé 40-46 Type de fichier DISK : base de données
PRINTER : impression WORKSTN : écran
66 Ajout d’enregistrement A : ajouts autorisés
71-72 Contrôle de l’ouverture et de la fermeture des fichiers
UC : par l’utilisateur blanc : par le programme
RPG IV
Colonne Libellé Valeurs 6 Définition de la spécification F
7-16 Nom du fichier 17 Type d’ouverture du fichier I : en lecture
O : en écriture U : en mise à jour C : combiné (pour les écrans)
18 Mode de traitement P : primaire S : secondaire F : logique libre
22 Description du fichier F : interne E : externe
20 Ajout d’enregistrement A : ajouts autorisés 34 Utilisation de la clé K : prise en compte de la clé
blanc : pas d’utilisation de la clé 36-42 Type de fichier DISK : base de données
PRINTER : impression WORKSTN : écran
44-80 Mots-clés
Utilisation d'un fichier physique ou logique
L’utilisation des fichiers base de données est extrêmement simple en RPG. Les déclarations sont effectuées à l’aide des spécifications F. Quelques codes opérations permettent la lecture, l’écriture et la mise à jour d’enregistrements. Voici quelques exemples en RPG/400. Les opérations sont effectuées sur le fichier MODELE, à description externe, et qui a pour format FMT. Il est traité en logique libre.

24 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Lecture d’un enregistrement ...... *. 1 ...+... 2 ...+... 3 ...+... 4 ...+... 5 ...+... 6 ...+... 7 FMODELE IF E DISK C*TRAITEMENT ........ C*........ C*LECTURE D’UN ENREGISTREMENT C READ FMT 90
C... C MOVE *ON *INLR
Modification d’un enregistrement ...... *. 1 ...+... 2 ...+... 3 ...+... 4 ...+... 5 ...+... 6 ...+... 7 FMODELE UF E DISK C*TRAITEMENT ........ C*LECTURE DE L’ENREGISTREMENT C READ FMT 90 C*MODIFICATION DES ZONES C... C*MISE A JOUR D’UN ENREGISTREMENT C UPDATFMT C...
C MOVE *ON *INLR
Ajout d’un enregistrement ...... *. 1 ...+... 2 ...+... 3 ...+... 4 ...+... 5 ...+... 6 ...+... 7 FMODELE O E DISK A C*TRAITEMENT ........ C*........ C*AJOUT D’UN ENREGISTREMENT C WRITEFMT C...
C MOVE *ON *INLR
Lecture sur clé ...... *. 1 ...+... 2 ...+... 3 ...+... 4 ...+... 5 ...+... 6 ...+... 7 FMODELE IF E K DISK C*TRAITEMENT ........ C*........ C*LECTURE DU PREMIER ENREGISTREMENT QUI A POU R VALEUR DE CLE ZONE1 C ZONE1 CHAINFMT 90 C...
C MOVE *ON *INLR
Les DDS Introduction

2 - Principes généraux 25
Les DDS (Data Description Specification) constituent un langage de description de fichiers. A l'image du RPG, les DDS doivent être codifiées rigoureusement, chaque information étant placée en un endroit précis.
Les spécifications A définissent la structure de chacune des lignes du source en imposant la colonne où doit être placée chaque information. Toutes les DDS (de tous les fichiers) sont codifiées avec cette spécification.
Une hiérarchie est établie dans les DDS. Selon la ligne où est codifiée une information, son impact sera sur tout le fichier ou limité à une zone.
Malgré ces règles en apparence rigides, la codification des DDS est aisée, notamment grâce à l’éditeur de source SEU qui propose une invite nous permettant d’ignorer l’emplacement précis de chaque information. De plus, il vérifie la syntaxe et évite, ainsi, de nombreuses erreurs de codification.
La spécification A
Vous trouverez en annexe A une feuille de spécification A. Tout au long de cet ouvrage, nous allons détailler les principales valeurs que peuvent prendre chacune de ses colonnes.
Cette spécification est utilisée pour tous les types de fichiers (physiques, logiques, d'affichage, d'impression...). Les sources des objets de type *FILE ont donc tous la même organisation. Voici les principales colonnes :
Position Longueur Nom Commentaires 6 1 Spécification Indique la spécification utilisée. La valeur
A est obligatoire, un blanc est autorisé. 7 1 Commentaire Une astérisque indique au compilateur
d'ignorer la ligne. Il s'agit donc d'un commentaire.
17 1 Type Précise à quoi correspond le nom spécifié en colonne 19 : R : pour un format ; K : pour définir la clé (ou une partie de la clé) ; S ou O : pour les critères de sélection ou d'omission ; un blanc pour tout le reste.
19 10 Nom Nom du format, de la zone ou de la clé (selon la lettre codifiée en colonne 17).

26 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
30 5 Longueur Longueur de la zone. 35 1 Type de zone Type de la zone. 36 2 Décimales Nombre de positions décimales (pour les
zones numériques). 38 1 Usage Précise l'utilisation de cette zone (par
rapport au programme) : I : la zone est utilisée en entrée (le programme peut la lire mais ne peut pas la mettre à jour) ;
O : la zone est utilisée en sortie ; B : la zone est utilisée en entrée et en sortie. H : la zone est cachée.
39 3 Ligne Indique à quelle ligne doit être placée cette zone (pour fichier d'affichage et d'impression).
42 3 Colonne Indique à quelle colonne doit être placée cette zone (pour fichier d'affichage et d'impression).
45 36 Fonction C'est à ce niveau que sont codifiés les mots-clés des DDS et les constantes.
Il reste à noter que certaines colonnes ne sont applicables qu’à certains types de fichiers. Colonne et ligne, par exemple, servent à indiquer où doit être placée une information : elles sont inopérantes pour un fichier base de données.
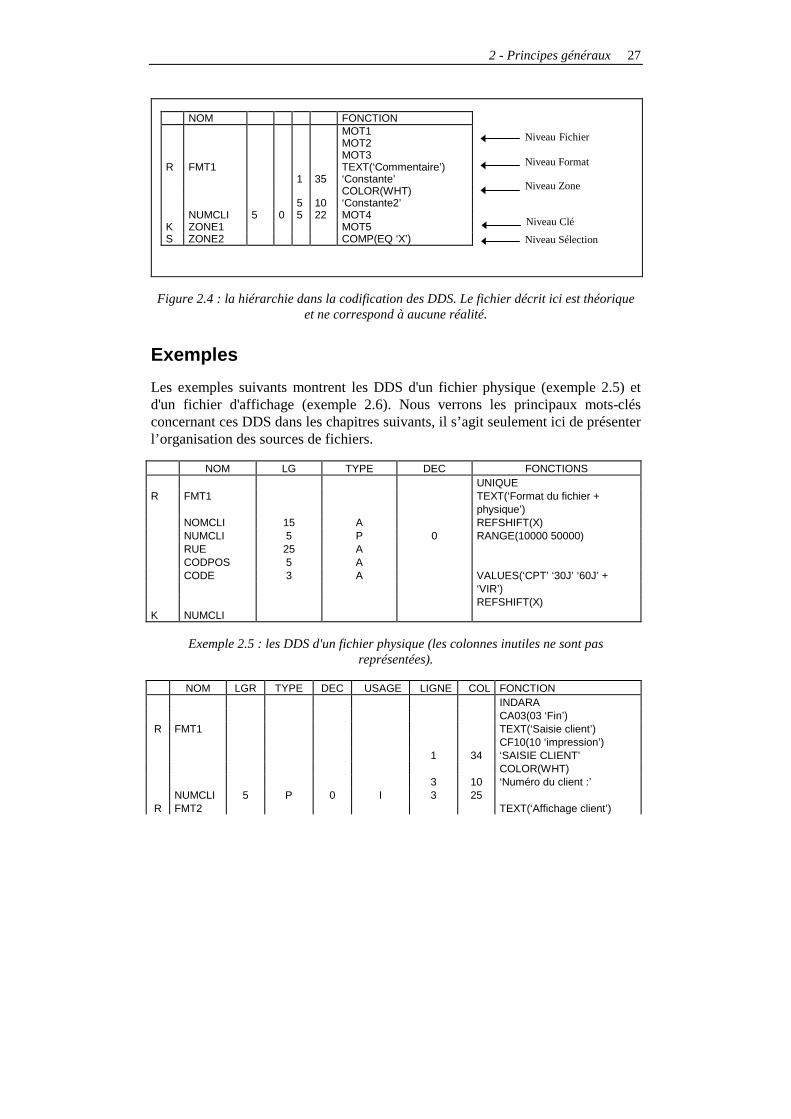
La hiérarchie
Une hiérarchie est imposée dans les DDS (figure 2.4). Les premiers mots-clés qui doivent être codifiés sont ceux de niveau Fichier. Ils ont un impact sur la totalité du fichier.
Un R en colonne TYPE (position 17) permet de saisir les mots-clés de niveau Format. Ils ont une action sur tout le format.
Les zones et les constantes sont définies à la suite, au niveau Zone. Enfin, et selon le type de fichier, on trouve les mots-clés de niveau Clé et (ou) de niveau Sélection/Omission.
2 - Principes généraux 27
NOM FONCTIONMOT1MOT2MOT3
R FMT1 TEXT(‘Commentaire’)1 35 ‘Constante’
COLOR(WHT)5 10 ‘Constante2’
NUMCLI 5 0 5 22 MOT4K ZONE1 MOT5S ZONE2 COMP(EQ ‘X’)
Niveau Fichier
Niveau Format
Niveau Zone
Niveau Clé
Niveau Sélection
Figure 2.4 : la hiérarchie dans la codification des DDS. Le fichier décrit ici est théorique et ne correspond à aucune réalité.
Exemples
Les exemples suivants montrent les DDS d'un fichier physique (exemple 2.5) et d'un fichier d'affichage (exemple 2.6). Nous verrons les principaux mots-clés concernant ces DDS dans les chapitres suivants, il s’agit seulement ici de présenter l’organisation des sources de fichiers.
NOM LG TYPE DEC FONCTIONS UNIQUE R FMT1 TEXT(‘Format du fichier + physique’) NOMCLI 15 A REFSHIFT(X) NUMCLI 5 P 0 RANGE(10000 50000) RUE 25 A CODPOS 5 A CODE 3 A VALUES(‘CPT’ ‘30J’ ‘60J’ + ‘VIR’) REFSHIFT(X) K NUMCLI
Exemple 2.5 : les DDS d'un fichier physique (les colonnes inutiles ne sont pas représentées).
NOM LGR TYPE DEC USAGE LIGNE COL FONCTION INDARA CA03(03 ‘Fin’)
R FMT1 TEXT(‘Saisie client’) CF10(10 ‘impression’) 1 34 ‘SAISIE CLIENT’ COLOR(WHT) 3 10 ‘Numéro du client :’ NUMCLI 5 P 0 I 3 25
R FMT2 TEXT(‘Affichage client’)

28 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
CF10(10 ‘impression’) 5 10 ‘Nom du client’ NOMCLI 15 A O 5 25 7 10 ‘Solde :’ SOLDE 7 P 2 O 7 25
R FMT3 TEXT(‘Touches de fonction’) 24 10 ‘F3=Fin F10=Impression’
Exemple 2.6 : les DDS d'un fichier d'affichage (les colonnes inutiles ne sont pas représentées).
Les types de données
La base de données de l’OS/400 supporte différents types de données. C’est la colonne TYPE DE DONNEES (en position 35 des DDS) qui précise le type de la zone.

2 - Principes généraux 29
Voici les principales valeurs :
Type Signification P Décimal condensé A Alphanumérique S Décimal signé B Binaire F Décimal en virgule flottante H Hexadécimal L Date T Heure Z Horodatage
Habituellement, l’OS/400 utilise le type Alphanumérique pour les zones contenant des caractères et le type Décimal condensé pour les valeurs numériques. Ces types sont pris par défaut lorsqu’aucune indication n’est donnée en position 35. Ainsi :
Si aucune information n’est codifiée en colonne TYPE DE
DONNEES, la zone est considérée comme étant de type Alphanumérique si elle ne possède pas de données décimales, et de type Décimal condensé sinon.
Les zones de type Alphanumérique sont structurées simplement : chaque caractère occupe un octet. Une zone définie avec une longueur de 10 occupe dix octets même si l’information contenue dans cette zone est plus courte.
Le calcul est un peu plus complexe pour les zones de type Décimal condensé. Il doit intégrer les éléments suivants :
• une position numérique est codifiée sur 4 bits (soit un demi-octet) ;
• la virgule n’est pas stockée ;
• 4 bits sont réservés pour le signe ;
• un nombre entier d’octets doit être utilisé.
Une zone de longueur 5 dont 2, c’est-à-dire 5 positions dont 2 décimales (par exemple +123,45), occupe 3 octets en mémoire : un demi-octet pour le signe et 5 demi-octets pour la représentation du nombre soit en tout 6 demi-octets (figure 2.5).

30 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Pour une zone de longueur 4 dont 2, on trouve 2 octets et demi, soit 3 octets en tout car il y a un nombre entier d’octets occupés. Un demi-octet est donc inutilisé.
+123,45(5 2)
+ 1 2 3 4 5
1 octet
+12,34(4 2)
+ 1 2 3 4
1 octet
Figure 2.5 : représentation de la structure d’une zone en Décimal condensé. Nous remarquons qu’une zone de longueur 5 occupe 3 octets comme une zone de longueur 4
(quel que soit le nombre de décimales).
On a donc toujours intérêt à choisir des valeurs impaires pour les longueurs des zones en Décimal condensé.
Conclusions
Les principes que vous venons de voir font que les développeurs AS/400 ont une excellente productivité. Les programmes sont limités à la description des traitements proprement dits. Tout ce qui est gestion des écrans, génération des états à imprimer et bien d’autres choses encore est géré par le système, libérant ainsi le programme de ces tâches.
La base de données est totalement intégrée à l’OS/400 ce qui fait que la gestion des données dans les programmes est la même que ce soit pour les fichiers, les impressions ou les écrans. Le travail d’apprentissage en est singulièrement raccourci.
Enfin, nous avons pu voir que de nombreux mécanismes sont mis en oeuvre pour assurer la sécurité et l’intégrité des données ; nous en verrons bien d’autres.

2 - Principes généraux 31
PRINCIPES GENERAUX...................................................................................................7
INTRODUCTION .......................................................................................................................7 Organisation de l'information............................................................................................7 Création d'objets ................................................................................................................8
LES FICHIERS.........................................................................................................................10 Généralités .......................................................................................................................10 Description externe ..........................................................................................................11 L'identificateur de format.................................................................................................12
LES ENREGISTREMENTS.........................................................................................................14 Ajout .................................................................................................................................14 Suppression ......................................................................................................................14
LIENS AVEC LA PROGRAMMATION.........................................................................................16 Exemples en langage de contrôle.....................................................................................17 Exemples en RPG.............................................................................................................21
LES DDS...............................................................................................................................24 Introduction......................................................................................................................24 La spécification A .............................................................................................................25 La hiérarchie....................................................................................................................26 Exemples ..........................................................................................................................27 Les types de données ........................................................................................................28
CONCLUSIONS.......................................................................................................................30

32 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
—B— bibliothèque 8
—C— Création 8
—D— DCLF 11 DDM 10 DDS 9
—F— fichier 10 fichier d'affichage 10 fichier d'impression 10 fichier logique 10 fichier physique 10
—I— IFS 7
—L— LAN Serveur 7
—M— membre 8
—O— OS/2 8
—R— RCVF 18 RGZPFM 15
—S— SNDF 18 SNDRCVF 18

8 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
—T— type 8

Chapitre 3
Les fichiers physiques
Les fichiers physiques sont les objets de la base de données de l'OS/400 qui servent au stockage des données. Un soin tout particulier doit être accordé à leur structure et à leur organisation. Il faut notamment garder à l'esprit que cette base de données est relationnelle. On tirera pleinement parti de sa puissance si l'on organise les données en respectant les préceptes du Modèle Relationnel (troisième forme normale...). Il est généralement indispensable de procéder à une phase d'analyse des données (MCD de Merise, par exemple) avant de codifier les fichiers physiques. Depuis l’origine de l’AS/400, les DDS constituent le mode naturel de création des fichiers physiques. Mais, SQL, en se positionnant comme un produit de plus en plus stratégique pour cette plate-forme, devient l’un des principaux langages de gestion des données ; il permet de créer des fichiers physiques appelés tables. Enfin, nous citerons pour mémoire le produit IDDU, assez peu utilisé, qui permet de créer des fichiers à partir d’un dictionnaire. Dans ce chapitre, nous ne détaillerons que les commandes et les fonctions standard de l’OS/400. Plus loin dans cet ouvrage, nous verrons ce qui concerne le langage SQL.

30 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Les étapes de la création d'un fichier physique par DDS
Un fichier physique à description externe est construit en deux étapes. Dans un premier temps, il faut codifier un membre source avec SEU, en utilisant les DDS ; cette étape permet de définir la structure des données à l'intérieur du fichier. Ensuite, ce source doit être créé ou compilé (à l'image des programmes) par la commande CRTPF. Les nombreux paramètres de cette commande définissent les caractéristiques générales de l'objet fichier (figure 3.1).
R FMT1 NOMCLI 15 NUMCLI 5 0 SOLDE 8 2
Membre sourceType PF
CRTPF
NOMCLI 15 NUMCLI 5 0 SOLDE 8 2
DESCRIPTION
Type : *FILEAttribut : PF
Figure 3.1 : les étapes de la création d'un fichier physique.
Dans un premier temps, nous allons voir la codification des fichiers physiques à description externe grâce aux DDS. Puis, nous verrons les principaux paramètres de la commande CRTPF. La gestion des membres sera abordée ensuite pour terminer avec les principales commandes de gestion des fichiers physiques.
La codification des fichiers physiques
La codification des fichiers physiques permet de définir la structure des fichiers à description externe. Elle s'appuie sur les DDS dont nous avons énoncé les principes au chapitre précédent.
La présentation des DDS se fait habituellement sous la forme d'une liste exhaustive de mots-clés répartis en niveaux (Fichier, Format, Zone et Clé). Nous abandonnerons cette démarche en préférant traiter des thèmes particuliers qui regroupent souvent plusieurs mots-clés. En fin de chapitre figure une description sommaire de tous les mots-clés.

3 - Les fichiers physiques 31
Principes
L'organisation des DDS dans un fichier physique est présentée dans la figure 3.2. NOM FONCTION REF(DICT1) UNIQUE Niveau Fichier ALTSEQ(TABLE1) R FMT1 TEXT(‘FORMAT1’) Niveau Format NUMCLI 5 0 RANGE(10000 50000) COLHDG(‘Numéro de client’) Niveau Zone CHKMSGID(MSG0001 COMPTA) NOMCLI 15 REFSHIFT(X) COLHDG(‘Nom de client’) K NUMCLI DESCEND Niveau Clé
Figure 3.2 : organisation des DDS pour un fichier physique.
Le dictionnaire
Pour répondre à des exigences de gain de productivité, il est possible de définir de manière unique l'ensemble des zones d'une application dans un dictionnaire (aussi appelé répertoire ou fichier de référence de zones). Chaque zone est décrite dans ce dictionnaire le plus précisément possible avec son type, sa longueur, ses contraintes, son en-tête de colonne...
Lors de la codification d'un fichier physique, il suffira d'indiquer au compilateur qu'il faut aller chercher la description des zones dans le dictionnaire spécifié au niveau des mots-clés REF et REFFLD.
• REF est un mot-clé de niveau Fichier. Il permet de définir le nom du dictionnaire pour les zones en regard desquelles un R a été codifié en colonne REFERENCE (position 29). Un seul dictionnaire peut ainsi être défini pour un fichier ;
• REFFLD s'applique au niveau Zone. Il fait référence à une zone dans un dictionnaire, il est utilisé dans trois cas :
– si la zone qui sert de référence n'a pas le même nom que la zone que l'on est en train de décrire ;
– si le dictionnaire qui contient la zone est différent de celui cité dans le mot-clé ref ;
– enfin, si la zone de référence appartient au source que l'on est en train de codifier.

32 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
L'exemple 3.1 résume l'utilisation de ces deux mots-clés. NOM LG DEC FONCTION REF(BIB1/DICT1) R FORMAT1 NOMCLI R NUMCLI R REFFLD(NUMERO DICT2) SOLDE 8 2 CREDIT R REFFLD(SOLDE *SRC)
Exemple 3.1 : utilisation d'un dictionnaire pour un fichier physique. NOMCLI fait référence à la zone du même nom située dans le dictionnaire DICT1 de la bibliothèque BIB1. NUMCLI fait référence à la zone NUMERO du dictionnaire DICT2 de la liste de bibliothèque. CREDIT
fait référence à SOLDE qui est décrit dans ce source.
Nature du dictionnaire
Un dictionnaire n'est rien d'autre qu'un fichier physique « classique ». C'est un choix personnel que de le nommer dictionnaire car aucune commande ne permet de transformer un fichier en dictionnaire. N'importe quel fichier physique peut servir de référence en étant cité dans les mots-clés REF ou REFFLD.
Souvent, les développeurs (ou les analystes) décident de créer un fichier qui contient la liste exhaustive de toutes les zones d'une application. Ce fichier ne possédera ni donnée, ni membre. Il est créé uniquement pour servir de référence ; c'est cet objet que l'on nomme « dictionnaire ».
Remarques
Il est important de bien comprendre le mécanisme mis en place autour du dictionnaire pour en voir les limites.
La référence à un dictionnaire est utilisée uniquement au moment de la création d'un fichier physique. Le compilateur va chercher la description des zones concernées et crée l'objet de type *FILE. Par la suite, il n'y a plus de lien entre le dictionnaire et le fichier physique.
La modification d'une zone dans le dictionnaire n'aura aucune incidence sur les fichiers qui ont été créés en faisant référence à cette zone. Si l'on désire que cette modification soit générale, il faut recompiler tous ces fichiers pour que la nouvelle description de zone soit prise en compte (attention à la perte des données).

3 - Les fichiers physiques 33
C'est à ce jour une des limites de la notion de dictionnaire sur l'AS/400. Des outils peuvent être écrits pour pallier cette insuffisance en utilisant les API ou les commandes de gestion des références croisées.
Les clés
Mise au point Il est important de rappeler que, dans un fichier physique, les enregistrements sont rangés dans l'ordre de leur arrivée. Le premier enregistrement créé est le premier dans le fichier, le dernier est placé à la fin. La possibilité de définir une clé pour ces fichiers ne change en rien cette organisation. Les enregistrements sont toujours rangés en fonction de leur ordre d'arrivée. Mais, si une clé est définie, un chemin d'accès est créé et permet de « voir » les enregistrements comme triés.
Les enregistrements d'un fichier physique sont toujours rangés en fonction de leur ordre d'arrivée. Si une clé est définie pour ce fichier, un chemin d'accès permet de voir ses enregistre-ments comme s'ils étaient triés.
Les zones qui composent la clé sont citées dans l'ordre, au niveau Clé, précédées d'un K en colonne TYPE (position 17). Elles doivent être décrites au niveau Zone. L'exemple 3.2 présente les DDS d'un fichier physique qui a une clé définie sur trois zones. Les enregistrements seront « vus » triés sur la zone NOCLI, puis sur MONTANT et enfin sur DATE.
NOM LG DEC FONCTION REF(DICT1)
R FMT1 NOCLI R DATE R CDE R MONTANT R
K NOCLI K MONTANT K DATE
Exemple 3.2 : codification de la clé dans un fichier physique.
Les principaux mots-clés de niveau Clé

34 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Plusieurs mots-clés de niveau Clé nous permettent de définir l'ordre de tri pour chaque critère (exemple 3.3). En voici les principaux :
• ABSVAL : les enregistrements apparaissent triés selon la valeur absolue de cette zone ;
• DESCEND : les enregistrements apparaissent triés selon la valeur décroissante de cette zone (la plus grande valeur sera renvoyée en premier, la plus petite en dernier). Par défaut le tri est effectué selon la valeur croissante.
NOM LG DEC FONCTION
R FMT1 NOCLI 2 DATE 6 0 MONTANT 7 0
K DATE DESCEND K MONTANT ABSVAL
NOCLI DATE CDE MONTANT NOCLI DATE MONTANT 50 941104 12354 -18000 20 941105 10000 20 941105 12355 10000 10 941105 -11000 60 941105 12356 13000 70 941105 12000 70 941105 12358 12000 60 941105 13000 10 941105 12354 -11000 50 941104 -18000
Exemple 3.3 : mise en œuvre des mots-clés de niveau Clé lors de la codification d'un fichier physique. Les enregistrements apparaîtront triés sur DATE, la plus forte valeur étant renvoyée en premier, puis pour une même date, selon la valeur absolue de MONTANT. Le tableau de gauche montre les données telles qu'elles sont organisées dans le fichier, le tableau de droite présente les enregistrements dans l'ordre où ils apparaîtront lors d'une lecture sur clé.
Les mots-clés de niveau Fichier
Les mots-clés de niveau Fichier définissent les caractéristiques générales de la clé :
• UNIQUE : si ce mot-clé est codifié, le fichier ne pourra avoir deux enregistrements qui ont même valeur de clé. Lors d'une tentative d'insertion d'un enregistrement dont la valeur de clé existe déjà dans le fichier, le système enverra un message d'erreur au programme ;
• LIFO : (Last In First Out) les enregistrements ayant même valeur de clé seront vus dans l'ordre dernier arrivé, premier lu. La valeur par défaut est FIFO (First In First Out) premier arrivé, premier lu.
Séquence de tri

3 - Les fichiers physiques 35
Lors de la constitution d'un chemin d'accès sur une clé à partir de zones de type Alphanumérique, le tri standard s'effectue en fonction de la représentation hexadécimale. Il distingue donc les minuscules et les majuscules, les minuscules étant placées avant, les majuscules après.

36 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Voici une série d'enregistrements avant et après le tri :
Avant tri Après tri CCC aaa aaa bbb AAA ccc BBB AAA ccc BBB bbb CCC
Les tables de conversion permettent de redéfinir l’ordre du tri en donnant un certain poids à chaque caractère (sous la forme d'une valeur hexadécimale). C'est cette valeur qui est utilisée lors du tri. Ainsi, les caractères minuscules et majuscules peuvent avoir le même poids (a et A sont égaux devant le tri). Dans ce cas la séquence ci-dessus deviendrait :
Avant tri Après tri CCC aaa aaa AAA AAA BBB BBB bbb ccc CCC bbb ccc
La table QCASE256 de QUSRSYS est fournie à cet effet. Il n’existe pas de commandes qui permettent l’affichage du contenu d’une table. Pour voir le poids de chaque caractère devant le tri on peut soit simuler une création de table par la commande :
CRTTBL TBL (TEST) SRCFILE(*PROMPT) BASETBL(*LIBL /QCASE256)
soit utiliser la commande WRKTBL puis l’option 5 en regard de la table choisie.
Vous pourrez ainsi noter que pour la table QCASE256, le caractère de valeur hexadécimale X’81’, c'est-à-dire a, possède la valeur X’C1’ pour le tri, la même que A. Les lettres A et a ont donc le même poids devant le tri, pour cette table.
Le mot-clé ALTSEQ, de niveau Fichier, associe une table de translation à la totalité des zones de type Alphanumérique composant la clé d'un fichier. NOALTSEQ (au niveau Clé) désactive la table de translation pour la zone en regard de laquelle il est codifié (exemple 3.4).
La table ainsi définie est recopiée dans la partie descriptive du fichier. La commande DSPFD permet de le vérifier.

3 - Les fichiers physiques 37
Les paramètres SRTSEQ et LANGID de la commande CRTPF apportent des fonctionnalitées comparables.
NOM FONCTION REF(DICT1) ALTSEQ(TABLE1)
R FMT1 NOMCLI R PRODUIT R TYPE R MONTANT R
K NOMCLI K PRODUIT NOALTSEQ K TYPE
Exemple 3.4 : mise en œuvre d'une table de translation pour un fichier physique. La table TABLE1 de la liste de bibliothèque est utilisée pour les zones clés de type Alphanumérique, sauf pour la zone PRODUIT.
Liens avec les fichiers d'affichage
Les DDS nous permettent de placer dans un fichier physique, ou dans un dictionnaire, certains mots-clés associés à des zones, afin de simplifier et d'homogénéiser le travail de codification des fichiers d'affichage.
Lors de la définition d'une zone d'un fichier d'affichage, on peut faire référence à une zone d'un fichier physique (ou d'un dictionnaire) à l'aide des mots-clés REF et REFFLD que nous avons déjà définis. Si, dans le fichier physique, une contrainte de validité est associée à cette zone, elle sera automatiquement ramenée dans le fichier d'affichage avec la description de la zone. La contrainte de validité fait alors partie intégrante du fichier d’affichage. L'utilisateur ne pourra saisir à l'écran une valeur sortant du domaine de validité ainsi défini. C'est le système qui effectue ce contrôle en déchargeant totalement le programme de cette tâche.
Contrairement à une idée reçue, ces mots-clés n’ont aucune incidence directe sur les fichiers physiques. Ils n’empêchent pas un programme de placer directement dans une zone une valeur qui ne correspond pas à son domaine de validité. Ils servent uniquement à contrôler la saisie dans les fichiers d’affichage.
Les mots-clés à destination des fichiers d'affichage sont généralement de niveau Zone. Ils sont répartis en trois familles et définissent pour chaque zone :

38 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
• le domaine de validité ;
• les caractéristiques de la saisie ;
• la mise en forme.
Le domaine de validité
Voici les différents mots-clés qui déterminent un domaine de validité pour une zone :
• RANGE définit un domaine de valeurs entre deux bornes (comprises) ;
• VALUES précise les valeurs admises (jusqu’à 100) ;
• COMP permet la comparaison par rapport à une valeur à l'aide des opérateurs suivants :
EQ Egal à NE Différent de LT Plus petit que NL Pas plus petit que GT Plus grand que NG Pas plus grand que LE Plus petit ou égal à GE Plus grand ou égal à ;
• CHKMSGID associe un message d'erreur aux mots-clés COMP, RANGE, VALUES et CHECK. Ce message doit être enregistré dans un fichier de messages. Si une valeur saisie est hors du domaine de validité, le système renverra automatiquement le message spécifié.
Le contrôle de la saisie
CHECK précise les caractéristiques de la saisie. Voici les principales valeurs qui peuvent être spécifiées pour ce mot-clé :
• CHECK(ME) : au moins un caractère doit être saisi pour cette zone. Ce mot-clé est à associer aux zones qui doivent être obligatoirement renseignées (la valeur de la clé, par exemple) ;
• CHECK(MF) : si un caractère est saisi, alors chaque position de la zone doit être saisie. Ce mot-clé est à associer aux zones qui doivent être totalement remplies (le code postal, par exemple) ;

3 - Les fichiers physiques 39
• CHECK(ME MF) : combine les deux contraintes que nous venons de citer : la zone est à saisie obligatoire et tous les caractères doivent être renseignés.
REFSHIFT définit les caractéristiques du clavier lors de la saisie d'une zone. REFSHIFT(X) positionne le clavier de telle manière que seuls les caractères majuscules seront saisis.
Mise en forme Deux mots-clés d'édition permettent l'affichage ou l'impression de zones de type Décimal condensé sous un certain format. Il est classique, par exemple, d'avoir la date stockée dans une zone décimale de longueur 6, sans positions décimales, et de présenter son contenu sous la forme jour/mois/année (211196 donnant 21/11/96). EDTCDE permet une mise en forme « classique » (suppression de zéros non significatifs, ajout de ponctuation...) en employant des codes d'édition prédéfinis. L'OS/400 en met dix-huit à notre disposition, chacun ayant un comportement différent selon qu'il s'applique à un nombre positif ou négatif et en fonction de la présence ou de l'absence de positions décimales. Nous ne détaillerons pas tous les cas possibles, en voici seulement quelques exemples :
CODE VALEUR DE LA ZONE AFFICHAGE EDTCDE(Y) 011194 01/11/94 EDTCDE(1) 12345.67 12,345.67 EDTCDE(1 *) 00012.34 **,*12.34 EDTCDE(C) -1234.56 1234.56CR EDTCDE(K $) -1234.56 $1,234.56-
Au niveau de la sortie (fichier d'affichage ou fichier d'impression), il est important de prévoir une zone assez grande pour accueillir tous les caractères après mise en forme. Par exemple, une zone de longueur 6, avec un code d'édition Y, occupera 8 positions en sortie. Nous renvoyons à la documentation de l'OS/400, Data Description Specification Reference (chapitre Display File, mot-clé EDTCDE) pour avoir un tableau complet sur les différentes mises en formes apportées par ce mot-clé. En marge des valeurs proposées par l'OS/400, nous pouvons définir cinq codes d'édition (de 5 à 9) grâce à la commande CRTEDTD .

40 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Le mot-clé EDTWRD permet d'aller beaucoup plus loin dans la mise en forme, en intégrant du texte dans la zone.
Exemple L'exemple 3.5 présente la mise en œuvre des principaux mots-clés que nous venons de voir.
NOM FONCTION R FMT1 NOMCLI 5 0 CHECK(ME) RANGE(10000 50000) PRODUIT 15 REFSHIFT(X) DATE 6 0 EDTCDE(Y) MONTANT 8 2 EDTCDE(K F) CODE 2 VALUES(AC VE RE BA) REFSHIFT(X)
Exemple 3.5 : mise en œuvre des mots-clés liés aux fichiers d'affichage.La zone NOCLI est à saisie obligatoire et sa valeur doit être comprise entre 10 000 et 50 000 ; PRODUIT sera saisie en majuscules ; DATE sera présentée sous la forme xx/xx/xx ; MONTANT aura le format F123,456.78- en sortie ; CODE pourra prendre pour valeur AC, VE, RE ou BA et sera saisie en majuscules.
Remarques
Selon leur nature, les mots-clés que nous venons de voir ne seront applicables que lors de la saisie ou de l’affichage (et éventuellement de l’impression) d'une zone. Ils peuvent toujours être inhibés dans un fichier d'affichage (ou d'impression) en faisant référence à une zone d’un fichier physique par le mot-clé DLTEDT.
Partage de format
L'expérience montre que l'on a parfois à créer des fichiers qui ont le même format que des fichiers existants, par exemple quand on initialise une nouvelle année en comptabilité (le fichier qui accueillera les nouvelles écritures a le même format que le fichier de l'année qui se termine).
Pour éviter un travail long et fastidieux de codification des zones du fichier, il est possible de récupérer le format d'un fichier physique ou logique déjà créé, et qui possède la même structure, grâce au mot-clé FORMAT. L'exemple 3.6 présente une telle définition.

3 - Les fichiers physiques 41
NOM FONCTION UNIQUE R FMT1 FORMAT(BIB1/FICH1) K NOCLI
Exemple 3.6 : partage de format.
Le nom du format du nouveau fichier doit être le même que le nom du format du fichier existant. Dans l'exemple 3.6, le nom du format du fichier FICH1 de la bibliothèque BIB1 doit être FMT1.
Toutes les zones (et seulement les zones) du format partagé sont ramenées, avec leurs caractéristiques. Les mots-clés de niveau Fichier et la clé doivent être redéfinis.
En utilisant FORMAT, on ne peut décrire aucune zone, c'est-à-dire que l'on ne peut ni modifier, ni rajouter, ni enlever une zone par rapport au format partagé.
Le partage de format n'entraîne aucune dépendance entre les fichiers.
Valeur par défaut
A la création d'un enregistrement, si une zone n'est pas renseignée, elle prend pour valeur 0 si elle est de type Décimal condensé et des "blancs" si elle est de type Alphanumérique. Le mot-clé DFT associe une valeur par défaut à une zone (exemple 3.7).
NOM FONCTION R FMT1 FORMAT(BIB1/FICH1)
MOIS 2 DFT('01') JOUR 2 0 DFT(1) HEXA 2 DFT(X'D1D2')
Exemple 3.7 : définition de la valeur par défaut pour une zone. La zone MOIS, de type Alphanumérique, a '01' comme valeur par défaut, JOUR, de type Décimal condensé, a 1 et
HEXA, de type Hexadécimal, 'D1D2' (représentation partielle des DDS).
En mise à jour, cette valeur par défaut est utilisée chaque fois que la zone n'est pas renseignée, par exemple :
• lors de la création d'un enregistrement à travers un fichier logique qui ne possède pas cette zone dans son format ;
• à la création d'enregistrements grâce à la commande INZPFM ;

42 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
• et lors de l'utilisation de la commande CPYF avec FMTOPT(*MAP) si cette zone n'existe pas dans le fichier d'origine.
En lecture du fichier physique à travers un fichier logique joint, cette valeur par défaut peut être renvoyée au programme dans un cas particulier. Nous le traiterons dans le chapitre consacré aux fichiers logiques joints (mot-clé JDFTVAL).
En-tête de colonne
Le résultat d'une analyse Query est une liste dont les colonnes sont, par défaut, identifiées par le nom des zones qu'elles représentent, ce qui n'est pas toujours parlant pour un utilisateur final. De nombreux produits et utilitaires de l'OS/400 (Query, SDA, DFU, SQL...) extraient automatiquement l'en-tête de colonne associé à une zone, s'il a été codifié. Les résultats sont alors présentés sous une forme plus compréhensible pour l'utilisateur final. Il est donc important de placer ces en-têtes au niveau du fichier physique (ou encore mieux, au niveau du dictionnaire, s'il existe). C'est le mot-clé COLHDG qui permet de codifier cette fonction (exemple 3.8). L'en-tête de colonne peut être composé au maximum de 3 parties de 20 caractères. Chaque partie doit être encadrée par des quotes (') et séparée de la suivante par un espace ; lors de la génération d’un état, chaque partie est placée sur une nouvelle ligne. Dans l'exemple 3.8, l'en-tête de la zone NOMCLI est composé de 3 parties, il est donc présenté sur trois lignes. Pour PRODUIT, l'en-tête n'est composé que d'une partie et occupe donc une seule ligne. NOM FONCTION R FMT1 NOMCLI 15 COLHDG('Nom' 'du' 'client') PRODUIT 15 COLHDG('Nom du produit') TYPPRO 3 QTE 3
Nom du client Nom du produit TYPPRO QTE ARNAL CARTE TR COM 5 ARNAL CARTE ET COM 2 ARNAL MEMOIRE 16M MEM 2 DAUDET CARTE TR COM 1
Exemple 3.8 : codification de l'en-tête de colonne et résultat d'une analyse Query pour un fichier physique. Remarquer que ‘Nom du Client’ est sur trois lignes, et que ‘Nom du produit’ est sur une seule ligne.

3 - Les fichiers physiques 43
Il ne faut pas confondre COLHDG avec TEXT. Ce dernier permet de saisir un commentaire, de 50 caractères au plus, associé à une zone (ou à un format) et qui ne peut être exploité par les utilitaires de l'OS/400. Il est essentiellement à destination du programmeur car il est utilisé d'une part pour illustrer le source et d'autre part dans les commandes de l'OS/400 (DSPFFD, DSPFD...). Toutefois, si TEXT n'est pas codifié pour une zone, c'est le contenu de COLHDG qui sera utilisé par ces commandes.

44 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Le traitement des dates
Introduction
Depuis sa version V2R1M1, l'OS/400 supporte de nouvelles structures de données pour répondre aux exigences de l'architecture de base de données réparties (DRDA). Pour assurer la compatibilité avec d'autres SGBD tels que DB2 ou SQL/DS sur « gros systèmes », la base de données de l'OS/400 a dû intégrer trois nouveaux types (Date, Time et Timestamp), les zones à longueur variable et les zones à valeur indéfinie. En programmation, le traitement des dates est nettement simplifié avec les langages ILE et avec SQL qui supportent directement ces trois types.
La codification
Dans les DDS, une zone de type Date doit être déclarée avec un L en colonne TYPE (position 35). Dans le fichier, elle occupe 4 octets mais elle est renvoyée au programme avec le format qui est spécifié dans le mot-clé DATFMT (par défaut, c'est le format du travail). Le séparateur est indiqué dans le mot-clé DATSEP sauf pour quelques formats tels que *EUR, *USA ou *ISO qui ont leur propre séparateur.
Voici les principaux formats :
• *MDY , *DMY , *YMD : où M représente le mois, D le jour et Y l'année chacun occupant 2 positions ;
• *JUL : format de la date julienne. L’année est codifiée sur deux positions et le quantième du jour sur trois. Par exemple 94123 représente le 123e jour de 1994 ;
• *EUR : format européen (jj.mm.aaaa) ;
• *USA : standard USA (mm/jj/aaaa) ;
• * ISO : standard ISO (aaaa-mm-jj).
Une zone de type Heure (Time) doit être déclarée avec un T en colonne TYPE (position 35). Dans le fichier, elle occupe trois octets mais elle est renvoyée au programme avec le format qui est spécifié dans le mot-clé TIMFMT (par défaut, c'est le format hh mn ss). Le séparateur est indiqué dans le mot-clé TIMSEP sauf pour quelques formats tels que *EUR, *USA ou *ISO qui ont leur propre séparateur.

3 - Les fichiers physiques 45
Voici les principaux formats :
• *HMS : standard de l'OS/400 (hh mn ss) avec le séparateur spécifié dans le mot-clé TIMSEP ;
• *EUR et *ISO : format européen (hh.mn.ss) ;
• *USA : standard USA (hh:mn AM ou hh:mn PM).
Une zone de type Horodatage (timestamp) doit être déclarée avec un Z en colonne type. Elle occupe 10 octets dans le fichier et elle est toujours renvoyée sous le format (26 caractères) : aaaa-mm-jj-hh.mn.ss.uuuuuu. Le millionième de seconde peut ainsi être géré.
L'exemple 3.9 nous montre la codification d'un fichier physique utilisant ces différents types de données.
NOM FONCTION R FMT1 NUMCLI 5 0 DATE L DATSEP(‘-’) HEURE T TIMFMT(*USA) HOROD Z
Exemple 3.9 : codification des zones de type Date, Heure et Horodatage. Remarquer qu’aucune longueur ne doit être précisée pour ces zones.
Liens avec la programmation
Le support de ces types est complet avec SQL, mais pratiquement inexistant pour les langages non-ILE tels que le RPG/400, le Cobol ou même le langage de contrôle (jusqu’à la version V2R3M0 de l’OS/400). Avec l’arrivée des langages de type ILE, principalement avec la version V3R1M0, il n’y a plus de contraintes.
En RPG/400, par défaut, les zones de type Date, Time et Timestamp sont ignorées et donc inaccessibles. Elles seront supportées si le programme a été compilé avec l'option suivante :
CRTRPGPGM .....CVTOPT(*DATETIME )
Dans ce cas, ces zones seront vues comme du texte de longueur fixe, donc aucun calcul sur les dates ne pourra être réalisé simplement. De plus, ces zones ne pourront être utilisées comme clé ou pour des traitements entre limites.

46 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Le RPG IV, compilateur ILE, supporte directement les zones de type Date, Heure et Horodatage. Il propose même des codes opérations pour les gérer comme l’ajout ou le retrait d’une durée à une autre durée.
La commande OPNQRYF met à notre disposition des fonctions intégrées qui permettent les calculs sur les dates et les horaires.
Les zones de longueur variable
Dans un fichier physique, tous les enregistrements ont le même format, donc la même longueur. Le support des zones de longueur variable est une sorte de verrue greffée sur la base de données de l'OS/400. Le gain en octets n'est pas toujours significatif (une place importante est consommée pour la gestion des longueurs variables) et les temps de traitements sont augmentés. Cette possibilité nous semble devoir être mise en œuvre seulement pour des besoins spécifiques ou pour communiquer avec des bases de données autres que celle de l'OS/400.
Au niveau des DDS, le mot-clé VARLEN définit une zone de longueur variable (exemple 3.10). Deux longueurs sont à prendre en considération :
• la longueur maximale de la zone est celle définie en colonne LONGUEUR ;
• la place allouée dans l'enregistrement proprement dit est spécifiée dans le mot-clé VARLEN. Si aucune valeur n'est précisée, aucune place n'est réservée.
Lors de l'écriture d'une zone de longueur variable, la partie de la zone allouée dans l'enregistrement (codifiée avec VARLEN) est remplie en premier, les caractères qui ne rentrent pas sont écrits dans une zone de débordement. Pour chaque zone, 2 octets contiennent la longueur valide de cette zone (en binaire) et 8 octets pointent sur l'adresse de la zone de débordement. D’autres octets sont encore utilisés par le système pour la gestion des données en zone de débordement.
NOM LONGUEUR FONCTION R FMT1 NOMCLI 100 VARLEN(15) PRODUIT 100 VARLEN
Exemple 3.10 : mise en œuvre du mot-clé VARLEN. La zone NOMCLI a une longueur de 15 caractères allouée dans l'enregistrement de format FMT1 et pourra comporter jusqu'à 100 caractères. PRODUIT n'a pas de place réservée et pourra avoir une longueur de 100 caractères.
Les zones de ce type sont accessibles par les programmes RPG/400 qui ont été compilés avec l'option suivante :

3 - Les fichiers physiques 47
CRTRPGPGM .....CVTOPT(*VARCHAR ) Dans ces programmes, la variable générée occupe deux caractères de plus que la longueur maximale de la zone, les deux premiers octets contenant, en binaire, la longueur réelle de la zone. Il appartient au programmeur de gérer ces deux octets :
• en lecture, pour connaître la partie valide de la zone ;
• en écriture, car il faut y indiquer la longueur valide de la zone mise à jour.
En RPG/400, de nombreuses restrictions s'appliquent aux zones de ce type : elles ne peuvent être utilisées comme clés, ne permettent pas le traitement entre limites et ne supportent pas les indicateurs de rupture (Ln) ou de concordance (Mn).
Le langage de contrôle peut lire les zones de longueur variable si dans la commande DCLF le paramètre ALWVARLEN a la valeur *YES. La structure de la variable ainsi lue est la même que celle que nous avons décrite pour le RPG, c'est-à-dire deux octets en tête qui contiennent la longueur valide en binaire, suivis du nombre de caractères correspondant à la plus grande longueur possible.
Query, SQL, DFU et la commande OPNQRYF supportent les zones de longueur variable.
Les zones à valeur indéfinie
En standard, il est impossible de savoir si la valeur 0 d'une zone correspond à une valeur réellement saisie ou s'il s'agit de la valeur par défaut. Les zones autorisant les valeurs indéfinies nous permettent de faire la distinction.
Le mot-clé ALWNULL précise qu'une zone peut avoir la valeur NULL , c’est-à-dire être indéfinie. Pour chacune des zones de ce type et pour chaque enregistrement, le système tient une table de bits précisant si une valeur a été saisie ou non.
SQL, Query et les commandes CPYF et OPNQRYF supportent ces zones.
Un programme RPG/400 peut lire ces zones s'il a été créé avec l'option suivante :
CRTRPGPGM .....ALWNULL (*YES)
Si une zone a la valeur indéfinie, c'est la valeur par défaut qui est renvoyée. Aucun moyen ne nous permet donc de savoir si la zone avait la valeur indéfinie. Les mêmes restrictions que nous avons vues pour le type Date sont applicables pour le traitement de ces zones.

48 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Un programme en langage de contrôle peut lire les zones de ce type si dans la commande DCLF le paramètre ALWNULL a la valeur *YES.
Environnement multinational
Dans un environnement multinational, la gestion des caractères accentués est toujours délicate. Pour le français, par exemple, il n'est pas rare de trouver les caractères { ou } à la place des é ou è.
Les pages de code
Sur tout ordinateur, un caractère est codé sous la forme d'un certain nombre de bits. Sur l'AS/400, et pour les occidentaux, 1 caractère est stocké sur 8 bits (1 octet). Pour certaines langues orientales (coréen, japonais, chinois...), il faut 2 octets pour représenter chaque caractère. Ce type de codification est appelé DBCS (Double-Byte Character Set). Une page de code est une table qui fait le lien entre un caractère et sa représentation informatique. Les problèmes liés aux caractères accentués viennent du fait qu'il existe une page de code différente pour chaque pays (ou presque). Autrement dit, tous les caractères ne sont pas codifiés de la même manière aux États-Unis et en France. Heureusement, les principales lettres (A...Z et a...z) et les caractères 0 à 9 ont une représentation constante. Ce qui varie d'une page de code à une autre c'est essentiellement la codification des caractères accentués.
Comparons les pages de code US (037) et France (297) :
Valeur hexadécimale Page de code 297 (FRANCE)
Page de code 037 (ÉTATS-UNIS)
51 { é 54 } è C0 é { D0 è } C1 A A E9 Z Z
Il apparaît clairement que le caractère é est codifié par X'51' sur une machine qui utilise la page de code US. Ce caractère affiché sur un écran français sera traduit par {.
EBCDIC-ASCII

3 - Les fichiers physiques 49
Dans un environnement de bases de données réparties, d'autres problèmes encore plus complexes peuvent apparaître. L'AS/400 utilise une codification des caractères appelée EBCDIC (Extended Binary Coded Decimal Interchange Code), d'autres systèmes (les micro-ordinateurs, par exemple) emploient l'ASCII (American Standard Code for Information Interchange). On imagine aisément les soucis de l’utilisateur d'un micro-ordinateur (ASCII) de langue espagnole qui désire accéder aux données d'un AS/400 (EBCDIC) français.
Le CCSID
Le CCSID (Coded Character Set Identifier) est un nombre stocké sur 2 octets qui indique comment est codifiée une information de type Alphanumérique (ASCII ou EBCDIC, page de code...). Le CCSID peut être associé à un AS/400 (valeur système QCCSID), à un travail, à un utilisateur, à un fichier et même à une zone. Grâce au CCSID, l’OS/400 sait comment a été codifiée une information et assure éventuellement les conversions (à partir de tables), afin que chacun puisse voir correctement les données.
Le mot-clé CCSID employé au niveau Fichier définit la structure d'encodage utilisée pour toutes les zones alphanumériques de ce fichier. Codifié au niveau Zone, il s'applique à cette zone seulement.
Conclusions
Le CCSID n'est à utiliser que dans un environnement multinational et ne s'applique qu'à des informations de type Alphanumérique. Heureusement, la codification des zones décimales est standardisée !
Les principaux mots-clés des DDS
Les DDS de niveau Fichier
ALTSEQ définit une table de tri pour les zones clés ; CCSID indique quelle est la structure d'encodage des zones de
type Alphanumérique pour ce fichier ; REF fait référence à un dictionnaire ; UNIQUE signifie que deux enregistrements ne pourront avoir
une même valeur de clé.
Les enregistrements ayant une même valeur de clé apparaîtront triés dans l'ordre :

50 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
FCFO l’enregistrement le premier modifié est renvoyé d’abord ;
FIFO le premier écrit dans le fichier est renvoyé d’abord (valeur par défaut) ;
LIFO le dernier écrit dans le fichier est renvoyé en premier.
Les DDS de niveau Format
FORMAT duplication du format d'un fichier existant ; TEXT commentaires.
Les DDS de niveau Zone
ALIAS définit un nom de substitution pour une zone (à desti-nation des programmes) ;
ALWNULL autorise les valeurs inconnues (NULL) ; CCSID indique quelle est la structure d'encodage de cette zone ; CHECK précise les caractéristiques de la saisie ; CHKMSGID identifie le message d'erreur à renvoyer en cas de
saisie d'une valeur hors du domaine de validité ; COLHDG définit un en-tête de colonne (jusqu'à trois parties) ; COMP permet la comparaison avec une valeur ; DATFMT définit le format d'une zone de type Date ; DATSEP définit le séparateur pour une zone de type Date ; DFT définit une valeur par défaut ; EDTCDE définit un code d'édition ; EDTWRD définit un mot d'édition ; FLTPCN indique le niveau de précision des zones de type
virgule flottante ; RANGE définit un domaine de validité ; REFFLD fait référence à une zone d'un dictionnaire ou du
source ; REFSHIFT conditionne le clavier ; TEXT commentaires ; TIMFMT définit le format d'une zone de type Heure ; TIMSEP définit le séparateur pour une zone de type Heure ; VALUES donne la liste de valeurs admises ; VARLEN définit une zone de longueur variable.
Les DDS de niveau Clé

3 - Les fichiers physiques 51
Les enregistrements apparaissent triés :
ABSVAL sur la valeur absolue des zones ; DESCEND dans l'ordre décroissant ; DIGIT selon la partie numérique de la représentation
hexadécimale ; NOALTSEQ sans tenir compte, pour cette zone clé, de la table de
tri spécifiée dans le mot-clé ALTSEQ ; SIGNED en tenant compte du signe (la valeur par défaut pour
un tri classique) ; UNSIGNED en ignorant le signe ; c'est la représentation
hexadécimale qui est utilisée pour effectuer le tri ; ZONE selon la partie alphabétique de la représentation
hexadécimale.
La commande de création de fichiers physiques
L'étape que nous venons de présenter nous a permis de codifier, à l'aide des DDS, un membre source contenant la description d'un fichier physique.
L'étape suivante consiste à créer (ou compiler) ce membre, à l'aide de la commande CRTPF, pour obtenir un objet de type *FILE. Cette commande contient de nombreux paramètres ; nous allons décrire les principaux en procédant comme pour les mots-clés des DDS, c'est-à-dire en les regroupant par thèmes. Une liste exhaustive de ces paramètres sera présentée à la fin de ce chapitre.
Définition du fichier
Le seul paramètre obligatoire est le nom du fichier à créer (paramètre FILE).
Par défaut, le fichier est créé dans la bibliothèque courante, si elle existe, sinon il est placé dans la bibliothèque QGPL.
SRCMBR définit le membre source qui est utilisé. La valeur SRCMBR(*FILE) indique que le nom de ce membre est le même que celui du fichier à créer. Par défaut, il appartient au fichier source QDDSSRC de la bibliothèque courante. Ainsi, la commande :

52 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
CRTPF FILE (FICH 1)
crée le fichier FICH1 dans la bibliothèque courante (ou dans QGPL), à partir du membre FICH1 du premier fichier QDDSSRC trouvé dans la liste de bibliothèques.
Ces paramètres peuvent évidemment être modifiés comme le montre la commande suivante :
CRTPF FILE (BIB1/FICH 1) SRCFILE(BIB2/SOURCEDDS) SRCMBR(PF1)
Le fichier FICH1 est créé dans la bibliothèque BIB1 à partir du membre source PF1 contenu dans le fichier source SOURCEDDS de la bibliothèque BIB2.
Création d'un fichier sans DDS
Les DDS permettent de définir la structure des enregistrements et éventuellement la clé d'un fichier. Mais, il est toujours possible de créer un fichier physique sans DDS. La structure des enregistrements est alors imposée par le paramètre FILETYPE :
• FILETYPE(*DATA) est la valeur par défaut. Les enregistrements contiennent une seule zone de type Alphanumérique dont la longueur est définie par le paramètre RCDLEN. La zone et le format possèdent le même nom que le fichier ;
• FILETYPE(*SRC) précise que le fichier contient des sources. Le format est alors composé de trois zones :
– SRCSEQ, en Décimal étendu de 6 dont 2, qui contient le numéro de séquence de l'enregistrement ;
– SRCDAT, en Décimal étendu de 6 dont 0, pour la date de création (ou de dernière modification) de cet enregistrement ;
– SRCDTA, de type Alphanumérique, pour les données source proprement dites.
La longueur totale de l'enregistrement est donnée par le paramètre RCDLEN. Ainsi, pour une valeur de 100, la zone SRCDTA a une longueur de 88 (100 - 6 - 6). La valeur associée à RCDLEN doit donc être supérieure ou égale à 13 (6 pour SRCSEQ, 6 pour SRCDAT et au moins 1 pour SRCDTA).
Gravité des messages

3 - Les fichiers physiques 53
GENLVL est un filtre qui ne laisse passer que les messages qui ont une gravité inférieure à une certaine valeur et qui provoque la fin anormale de la compilation si cette gravité lui est supérieure ou égale.
GENLVL(20), valeur par défaut, signifie que le fichier ne sera pas créé si, lors de la compilation, un message de gravité supérieure ou égale à 20 est généré.
Les messages de gravité 0 sont des messages d'information, ceux de gravité 10 des warning, c’est-à-dire des messages d'attention (une erreur peut se cacher derrière). Au-delà (20 et plus), il s'agit vraiment d'une erreur. Il est donc conseillé de laisser la valeur GENLVL(20) afin d'assurer l'intégrité de la base de données. FLAG spécifie la gravité minimale des messages conservés dans la liste de compilation. Par défaut la valeur est 0 c'est-à-dire que tous les messages sont produits dans cette liste.
Les membres
La notion de membre est fondamentale dans l'organisation de la base de données de l'OS/400, nous la traiterons donc en détail à la suite de cette partie consacrée à la commande CRTPF. Voici trois mots-clés qui ont un rapport direct avec la notion de membre :
• MBR définit le nom du membre créé en même temps que le fichier. Aucun membre n'est ajouté au fichier s'il a pour valeur MBR(*NONE). Par défaut, MBR(*FILE) provoque la création d'un membre qui a le même nom que le fichier. Cette valeur fait que de nombreux utilisateurs ignorent la notion de membre. En standard, un membre est créé avec chaque fichier. Ce membre est ensuite pris par défaut pour toutes les opérations sur les enregistrements. La notion de membre peut donc être totalement transparente pour une utilisation de base. A sa création, un fichier peut se voir ajouter un membre au plus. La commande ADDPFM permet, par la suite, d'ajouter de nouveaux membres à un fichier physique ;
• MAXMBR indique le nombre maximum de membres que le fichier pourra posséder ;
• EXPDATE précise la date d'expiration pour tous les membres du fichier. Au-delà de cette date et lors d'une tentative d'utilisation de ce fichier, un message sera envoyé.
Le chemin d'accès

54 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Un fichier physique peut être défini avec une clé. Comme nous l'avons déjà signalé, les enregistrements ne sont pas réellement triés dans le fichier, mais apparaissent comme tels grâce à un chemin d'accès, sorte d'index, qui indique l'ordre dans lequel les enregistrements doivent être vus. Il existe un chemin d'accès par membre et, d'une manière générale, tout ce que nous allons décrire par la suite s'applique au chemin d'accès de chacun des membres des fichiers physiques.
Le chemin d'accès est une des composantes essentielles des fichiers logiques. Nous traiterons ce sujet en détail dans la section Les chemins d'accès du chapitre 4. Les mêmes raisonnements pourront être tenus pour les chemins d'accès des fichiers physiques et logiques car il s'agit de structures identiques.
Dans la commande de création des fichiers physiques, trois paramètres se rapportent au chemin d'accès. Nous allons les décrire rapidement en renvoyant au chapitre cité ci-dessus. Il s'agit de MAINT , RECOVER et FRCACCPTH.
Le paramètre MAINT
MAINT définit comment est maintenu un chemin d'accès. La maintenance est l'opération qui consiste à mettre à jour un chemin d'accès après la modification d’un enregistrement du fichier physique (par ajout, suppression ou modification de la valeur de la clé). Cette tâche peut être lourde pour le système si de nombreux chemins d'accès sont associés au fichier (par l'intermédiaire de fichiers logiques).
Si un programme travaille directement sur le fichier physique, chaque modification des enregistrements est immédiatement répercutée dans le chemin d'accès associé (au fichier physique). Si, au contraire, les enregistrements sont modifiés à travers un fichier logique, la maintenance du chemin se fera en fonction de la valeur donnée au paramètre MAINT de la commande CRTPF. Voici les différentes valeurs possibles :
• MAINT (* IMMED) indique que la maintenance est immédiate. Cette valeur est obligatoire si le mot-clé UNIQUE est spécifié dans les DDS du fichier physique. Il faut, en effet, que le système vérifie dans le chemin d'accès s'il n'existe pas déjà un enregistrement ayant même valeur de clé. C'est la valeur par défaut. Elle est souhaitable pour les fichiers physiques (avec une clé) utilisés en interactif. Cette option est la plus coûteuse en termes de ressources système mais garantit un temps d'ouverture minimal des fichiers ;
• MAINT (*REBLD) provoque la reconstruction du chemin d'accès lors de l'ouverture du fichier physique. Tant que le fichier est ouvert, la maintenance est immédiate. Une fois le fichier fermé, plus aucune maintenance n'est assurée.

3 - Les fichiers physiques 55
Le temps d'ouverture est long (surtout si le fichier est gros), mais les ressources système consommées sont faibles. Cette valeur est à choisir pour les fichiers actifs (avec de nombreuses modifications) traités en batch ;
• MAINT (*DLY) diffère la maintenance à l'ouverture du fichier. Tant que le fichier est fermé, les modifications qui doivent affecter son chemin d'accès sont stockées, la maintenance s'effectuant lors de l'ouverture du fichier. Si les modifications sont trop nombreuses (supérieures à 10 ou 25% selon les documentations IBM), le système arrête leur stockage et le chemin est totalement reconstruit à la prochaine ouverture (comparable à la valeur *REBLD). Sinon, il est seulement mis à jour, à l’ouverture, à l'aide des informations conservées. Cette valeur est à utiliser pour des fichiers traités en batch, car le temps d'ouverture peut être long, mais subissant peu de modifications.
MAINT n'est utilisable que si une clé a été définie dans les DDS du fichier physique (sinon il n'y a pas de chemin d'accès !).
Le paramètre FRCACCPTH
La maintenance du chemin d'accès est effectuée en mémoire principale et, par défaut, n'est réellement envoyée sur le disque que plus tard, soit à un moment choisi par le système, soit à la fermeture du fichier, soit, enfin, après un ordre spécifique tel que FEOD en RPG (fermeture et ouverture logique d’un fichier). Si un incident majeur (panne d’alimentation ou défaillance d’un composant) se produit entre la modification du chemin en mémoire principale et son écriture sur le disque, la mise à jour est perdue. Le fichier et son chemin d'accès ne sont plus en concordance (voir alors le paramètre RECOVER). Cet incident est heureusement rarissime.
FRCACCPTH(*YES) force l'écriture immédiate sur disque de toute modification du chemin d'accès, ce qui diminue le risque d'erreur que nous venons de citer. Cette valeur peut provoquer une augmentation sensible des temps de réponse pour ce fichier et peut même dégrader les performances générales du système si de nombreuses mises à jour sont effectuées de cette manière. La valeur par défaut est FRCACCPTH(*NO) afin de préserver des temps de réponse optimaux.
Il existe un processus comparable pour les enregistrements conditionnés par le paramètre FRCRATIO.
Le paramètre RECOVER

56 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Lors d'un incident (une coupure d'électricité, par exemple), il est possible que le chemin d'accès et le fichier physique correspondant ne soient plus en concordance. Si aucune précaution n'a été prise (par la journalisation (avec SMAPP) ou par l'écriture forcée sur disque), le système devra reconstruire le chemin d'accès. Le paramètre RECOVER indique quand cette reconstruction doit avoir lieu :
• RECOVER(*NO) : le chemin d'accès est reconstruit à la première ouverture du fichier qui de ce fait est longue ;
• RECOVER(* IPL) : le chemin d'accès est reconstruit pendant l'IPL. Cette option alourdit la phase d'initialisation du système, souvent déjà longue après un arrêt anormal. L'intérêt réside dans le fait que, dès que l'écran d'ouverture apparaît, les fichiers sont disponibles.
• RECOVER(*AFTIPL) : le chemin est reconstruit après l'IPL, qui sera plus court, mais les programmes ne peuvent accéder à un fichier tant que la construction de son chemin d'accès n'est pas terminée.
La commande EDTRBDAP permet de gérer la reconstruction des chemins d'accès après l'IPL.
Ecriture forcée en mémoire secondaire
FRCRATIO indique le nombre d'enregistrements qui seront traités avant d'être réellement écrits sur disques. Par le même mécanisme que celui que nous avons détaillé pour le mot-clé FRCACCPTH, une opération sur un enregistrement (insertion, suppression, modification) n'est pas répercutée immédiatement en mémoire secondaire, mais est conservée en mémoire principale. Tout cela est totalement transparent pour les programmes (et donc pour les utilisateurs), une opération étant considérée comme effectuée dès qu'elle est réalisée en mémoire principale. Cette mémoire est volatile. Si un incident majeur survient, tel qu'une coupure d'électricité, son contenu disparait. On peut se retrouver alors dans la situation critique où le programme (et donc l'utilisateur) a modifié l'enregistrement et où cette modification qui n'a pas été enregistrée sur disque est perdue.
A l'IPL suivant cet arrêt, la base de données peut être dans un état incohérent, certains fichiers n'étant plus à jour. Il est donc essentiel d'analyser leur contenu avant de relancer les applications.
La journalisation des fichiers physiques est un des moyens qui permet d'éviter ces soucis. Le paramètre FRCRATIO de la commande CRTPF en est un autre, moins puissant mais plus simple à mettre en œuvre. Il peut avoir deux valeurs :

3 - Les fichiers physiques 57
• FRCRATIO(*NONE) : c'est le système qui détermine quand il faut écrire les enregistrements sur disque ;
• FRCRATIO(NOMBRE) : force l'écriture sur disque lorsque NOMBRE enregistre-ments ont été traités. L'impact sur les performances pouvant être sensible, cette valeur n'est à utiliser que pour des besoins spécifiques.
Les fichiers physiques et la mémoire secondaire
Dans cette partie, nous allons voir comment est alloué l'espace disque à un fichier physique, puis nous estimerons sa taille en fonction du nombre d'enregistrements présumé pour chacun de ses membres.
La taille
Contrairement à ce qui se pratique avec d'autres systèmes, la taille d'un fichier n'est pas définie lors de sa création, aucune place ne lui est réservée, et, en principe, il s'accroît sur disque automatiquement au fur et à mesure des besoins. La présence du paramètre SIZE (taille en anglais) semble en contradiction avec ce principe. En fait, il s'agit d'un garde-fou qui permet de contrôler la croissance d'un fichier. On imagine les problèmes qui peuvent résulter de l'accroissement d'un fichier sous l'effet d'un programme qui boucle en ajoutant systématiquement un enregistrement, pour peu qu'il soit lancé la veille d'un week-end. Sans surveillance, ce fichier pourra occuper tout l'espace disque disponible provoquant un incident regrettable (arrêt anormal du système).
SIZE nous permet de contrôler la croissance d'un fichier à l'aide de trois valeurs. La première (10 000 par défaut) donne le nombre d'enregistrements qui peuvent être placés dans un membre d'un fichier. Une fois ce nombre atteint, un message est renvoyé à l'historique du système (visualisable par DSPLOG). La deuxième valeur (l'incrément) correspond au nombre d'enregistrements qui pourront ensuite être ajoutés. Il est de 1 000 en standard. Cet envoi de message et cette incrémentation s'effectuent autant de fois qu'il est indiqué dans la troisième valeur (3 par défaut). Ensuite, un message d'interrogation est envoyé à l'opérateur système (dans la file d'attente de messages QSYSOPR) lui demandant s'il faut ajouter un incrément ou arrêter le travail.
Ainsi, dans notre exemple du programme qui boucle, et si le fichier a été créé avec les valeurs par défaut, l'ajout d'enregistrements s’arrêterait à 13 000 (10 000 + (3 × 1 000)) en attente d'une réponse de l'opérateur système. Les risques de dégat sont donc vraiment limités.

58 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
La valeur SIZE(*NOMAX) permet de lever ce contrôle, le nombre d'enregistrements que l'on peut placer dans un membre d'un fichier dépendant des limites de l'OS/400 (à ce jour plus de 2 milliards, à concurrence de quelques 266 giga-octets) ou des limites des disques de votre système.
L'allocation
Nous avons déjà signalé qu'aucune place n’est réservée pour les enregistrements à la création d'un fichier. C’est une première approche théorique qui montre qu'un fichier n'est pas une boîte rigide, dont la taille est définie lors de sa création, mais plutôt un sac qui se gonfle au fur et à mesure des besoins.
Dans la pratique, le paramètre ALLOCATE définit la place initiale allouée pour les données à la création de chaque membre. Il peut avoir deux valeurs :
• ALLOCATE(*NO) est la valeur par défaut. Elle précise que c'est au système de déterminer automatiquement la place allouée aux données à la création de chaque membre. Cet espace, quelques kilo-octets contigus, sera occupé par les premiers enregistrements placés dans le membre. Les suivants seront stockés ailleurs en mémoire secondaire, peut-être sur un autre disque, en fonction de la place disponible. Juste après la création d'un membre on peut visualiser l'espace réservé pour les premières données par la commande DSPFD ;
• ALLOCATE(*YES) indique que la place définie dans la première valeur du paramètre SIZE est allouée pour chaque membre (à condition que cette valeur soit différente de *NOMAX) et si possible de manière contiguë. La place n'est pas réservée pour les incréments, ni à la création, ni lors de l'extension.
CONTIG(*YES) provoque l'envoi d'un message à la file d'attente du travail si l'allocation initiale ne peut pas s'effectuer de manière contiguë.
Enfin, le paramètre UNIT définit l'unité sur laquelle doit être stocké le fichier. UNIT(*ANY) est la valeur par défaut. Elle indique que les enregistrements du fichier peuvent être placés sur n'importe quelle unité, autrement dit sur n'importe quel disque (par blocs de 512 octets). Ceci explique que la destruction d'un disque entraîne la perte de toutes les données qui figurent sur l'ensemble des disques de l'ASP. Chaque fichier (à l’image de tous les objets de l’OS/400), pour peu qu’il soit assez gros, a des données disséminées sur chacun des disques de l’ASP. La perte d’un disque brise les liens qu’il y a entre toutes ces données ; il est alors impossible de reconstituer la plupart des objets de l’OS/400.

3 - Les fichiers physiques 59
UNIT(NUMERO), ou NUMERO est l'identifiant d'une unité, spécifie l'unité sur laquelle doit être placée la totalité du fichier (espace initial de chaque membre, extensions éventuelles et même chemins d’accès associés). La commande STRSST permet de connaître l'identifiant attribué par le système à chacune de ses unités. S’il n’y a pas assez de place, le système allouera l’espace nécessaire sur une autre unité, en envoyant un message à l’historique du système.
Mise en garde
D'une manière générale, on laissera les valeurs par défaut pour les paramètres SIZE, ALLOCATE et UNIT. On ne les modifiera que pour des besoins spécifiques et en toute connaissance de cause.
SIZE est un garde-fou que l'on doit ajuster en fonction du nombre d'enregistrements prévus pour chaque membre. La valeur *NOMAX est à déconseiller car elle inhibe toute protection.
L'allocation de l'espace total réservé aux données lors de la création de chaque membre par ALLOCATE(*YES) consomme souvent une place inutile si la valeur saisie en regard de SIZE est importante. Cette place peut faire cruellement défaut au système et entraîner une dégradation des performances. Elle n'est à conseiller que dans des cas limités, par exemple, pour diminuer les temps d’accès à un fichier lu séquentiellement.
Enfin, il n'y a à nos yeux pas (ou peu) d'intérêt à choisir l'unité sur laquelle sera placé le fichier. Si l'on désire absolument stocker un fichier sur un disque (parce qu’il est plus fiable par exemple) on préférera mettre en œuvre un ASP utilisateur qui permet, de manière sûre, d'isoler un fichier sur une unité (ou sur un groupe d'unités).
Estimation de la taille d'un fichier physique
En faisant abstraction des remarques émises à propos du paramètre ALLOCATE, nous pouvons estimer la taille d'un fichier physique à l'aide de la formule suivante :
TAILLE = (nombre d'enregistrements valides et détruits + 1) × (longueur de l'enregistrement + 1) + (5120 × nombre de membres) + 1024

60 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Il faut ajouter à cela l'espace occupé par le chemin d'accès (s'il existe), pour chacun des membres, estimé par la formule suivante :
TAILLE DU CHEMIN D 'ACCES = (nombre d'enregistrements valides × (longueur de la clé + 8) × 0,8 × 1,85) + 4096
0,8 est un cœfficient qui correspond à une compression moyenne. 1,85 est le facteur qui permet de prendre en compte la place réservée par le système pour l'extension du chemin d'accès.
Par exemple :
• un fichier avec un seul membre contenant 800 enregistrements valides (d'une longueur 100) et 200 détruits aura une taille estimée de 107 245 octets soit un peu plus de 100 Ko car :
TAILLE = (800 + 200 + 1) × (100 + 1) +5120 + 1024
• si ce fichier doit être vu trié sur une zone clé de longueur 10, sa taille est augmentée de 25 408 octets car :
TAILLE DU CHEMIN D 'ACCES = (800 × (10 + 8) × 0,8 × 1,85) + 4096
il occupera donc 125 Ko.
La commande DSPFD permet de visualiser la place réellement occupée par un fichier.
Pour être précis, il faut rajouter que le système maintient des structures qui occupent aussi un certain espace disque. Nous ne les détaillerons pas car leur taille peut être considérée comme négligeable.
Les verrouillages Dans un environnement multi-utilisateur, le système doit protéger les enregistrements qui sont en cours de traitement contre les opérations que pourraient effectuer d’autres utilisateurs. Par exemple, il pose un verrou lorsqu’un programme lit un enregistrement d’un fichier ouvert en modification (U spécifié en colonne 15 de la spécification F de description de fichier, dans un programme RPG/400). Ce verrou est tel que les autres travaux pourront seulement consulter cet enregistrement. Que se passe-t-il, alors, si un programme essaye d’accéder à cet enregistrement pour le modifier ?

3 - Les fichiers physiques 61
Le paramètre WAITRCD de la commande CRTPF définit le temps, en secondes, pendant lequel le système attendra que cet enregistrement soit libéré. Au-delà, un message d’erreur est renvoyé au programme. Par défaut, WAITRCD a la valeur 60, c’est-à-dire que le programme pourra attendre jusqu’à 60 secondes avant que l’enregistrement auquel il souhaite accéder se libère. Ce délai écoulé, il recevra un message d’erreur.
Le paramètre WAITFILE définit, toujours en secondes, le temps pendant lequel un programme pourra attendre la libération du fichier concerné. Au-delà, un message d’erreur lui sera renvoyé (CPF4128, par exemple). Par défaut, la valeur est à 0. Une erreur sera immédiatement renvoyée au programme qui désire accéder à un fichier déjà verrouillé.
Il est important de prévoir des traitements pour répondre aux erreurs liées à l’indisponibilité des fichiers ou des enregistrements. Le plus simple consiste à afficher un écran (ou une fenêtre) précisant à l’utilisateur que la ressource est indisponible et lui demandant s’il désire recommencer l’opération.
Le partage du bloc de contrôle (ODP)
Définition
Le bloc de contrôle (ou ODP pour Open Data Path) est une structure qui sert d’intermédiaire entre le programme et un fichier. Schématiquement, il contient :
• des informations générales sur le fichier ouvert ; • le buffer d’enregistrement (l’enregistrement courant et quelques enregis-
trements contigus) ;
• des informations de contrôle telles que la position du curseur, qui indique quel est l’enregistrement en cours de traitement.
Par la suite, et pour simplifier, nous représenterons l’ODP avec l’enregistrement courant et le pointeur qui définit sa position relative. Les ODP sont placés dans une structure plus importante, le PAG (pour Process Access Group), qui est en mémoire principale et qui contient toute la partie vivante du travail, c'est-à-dire, entre autres, les variables, la LDA (Local Data Area), et les indicateurs externes.
Par défaut, et à chaque lancement de programme, un ODP est créé pour chacun des fichiers déclarés dans ce programme. La place qu’il occupe est variable. Pour un

62 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
fichier d’affichage, par exemple, un sous-fichier statique est totalement contenu dans l’ODP. La taille de ce dernier peut donc être importante.
La création de ces blocs de contrôle est consommatrice de ressources. Tout d’abord de mémoire principale : l’accroissement du nombre d’ODP (autrement dit du nombre de fichiers ouverts, pour un travail, à un moment donné), entraîne l’augmentation de la taille du PAG. Or, toute occupation exagérée de la mémoire principale a une incidence notable sur les performances.
Ensuite, en ressources système : pour créer un ODP, il faut aller chercher sur disque la description du fichier et éventuellement lire les premiers enregistrements (si le fichier est ouvert en lecture ou en mise à jour). Cette dernière tâche s’effectue de manière asynchrone : ces enregistrements sont placés dans l’ODP avant même le premier ordre de lecture du programme, ils seront immédiatement disponibles au premier READ.
Pour optimiser les performances, il faut donc diminuer le nombre et la taille des ODP. Il semble difficile de jouer sur la taille. On peut, toutefois, limiter l’utilisation de sous-fichiers statiques, surtout s’ils contiennent de nombreux enregistrements, et préférer les sous-fichiers dynamiques.
En revanche, et dans certains cas, le nombre des blocs de contrôle peut être diminué grâce au paramètre SHARE de la commande CRTPF (ou des commandes associées telles que CHGPF et OVRDBF).

3 - Les fichiers physiques 63
Mise en œuvre
La valeur *YES pour le paramètre SHARE, permet à plusieurs programmes d’un même travail de partager le même ODP. Il faut pour cela qu’ils accèdent au même fichier. Les figures 3.3 et 3.4 montrent l’organisation des blocs de contrôle en mémoire principale, sans et avec partage de l’ODP.
CALL PGMACALL PGMBCALL PGMC
FARINE 10OEUF 24BEURRE 10LAIT 5SUCRE 12CREME 5
1FARINE 10
3BEURRE 10
1FARINE 10
SHARE (*NO)
PAGODP ODP ODP
PGMADCLF FICH1...RCVFCALL PGMBRCVF...
PGMBFFICH1
READREADREADCALL ‘PGMC’...
PGMCDCLF FICH1RCVF...
FICH1
Figure 3.3 : organisation des ODP en mémoire principale sans partage de l’ODP après l’exécution de la commande RCVF du programme PGMC (matérialisé par la flèche).
Sans partage, on remarque que chaque programme a sa propre structure d’accès aux fichiers et traite donc les enregistrements indépendamment des autres programmes. Le programme PGMA lit le premier enregistrement, PGMB en est au troisième et PGMC traite aussi le premier.
Dans le cas de la figure 3.4, les trois programmes partagent le même ODP pour le fichier FICH1 ; ils utilisent la même structure pour accéder à ce fichier. Il existe donc un seul pointeur d’enregistrement pour ces trois programmes. Quand PGMC est appelé, il est sur LAIT , dernier enregistrement traité par PGMB.

64 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
CALL PGMACALL PGMBCALL PGMC
FARINE 10OEUF 24BEURRE 10LAIT 5SUCRE 12CREME 5
5SUCRE 12
SHARE (*YES)
PAGODP
PGMADCLF FICH1...RCVFCALL PGMBRCVF...PGMBFFICH1
READREADREADCALL ‘PGMC’...
PGMCDCLF FICH1RCVF...
FICH1
Figure 3.4 : organisation des ODP en mémoire principale avec partage de l’ODP après l’exécution de la commande RCVF du programme PGMC (matérialisé par la flèche).
Lors du partage du bloc de contrôle, un programme appelé hérite de l’ODP du programme appelant. Si ce dernier est positionné sur le dixième enregistrement, le programme appelé se trouvera aussi sur ce dixième enregistrement.
Toute modification de l’ODP par le programme appelé (lecture d’enregistrement, par exemple) est répercutée au programme appelant.
Il est essentiel d’avoir ces notions en mémoire lors de la conception d’applications mettant en œuvre le partage de l’ODP.
Détaillons le contenu schématique de l’enregistrement courant de l’ODP lors des différentes étapes de la figure 3.4.

3 - Les fichiers physiques 65
INSTRUCTION ODP
POSITION ARTICLE QUANTITE CALL PGMA 0 RCVF 1 FARINE 10 CALL PGMB 1 FARINE 10 READ 2 ŒUF 24 READ 3 BEURRE 10 READ 4 LAIT 5 CALL PGMC 4 LAIT 5 RCVF 5 SUCRE 12 RCVF 6 CREME 5
Enfin, il est important de noter que le type d’ouverture du fichier, pour le programme qui va créer l’ODP, conditionne l’utilisation du fichier pour les programmes partageant cet ODP. Si le premier programme ouvre le fichier en lecture, le partage ne pourra s’effectuer qu’avec des programmes qui utilisent ce fichier en lecture. Sinon, un autre ODP est créé.
Il reste à noter que tout ceci est transparent pour l’utilisateur final (au temps de réponse près).
Conclusions
Le partage de l’ODP est un excellent moyen pour minimiser les temps de réponse de certaines applications. Il est couramment admis qu’un programme qui utilise un fichier est initialisé 10 fois plus vite s’il utilise un ODP déjà existant pour ce fichier. Mais, les notions que nous venons de voir doivent être totalement maîtrisées pour éviter toute erreur lors du traitement des enregistrements.
La valeur par défaut du paramètre SHARE fait qu’il n’y a pas, en standard, de partage de l’ODP. Généralement, la valeur SHARE(*NO) est laissée lors de la création d’un fichier. Le fichier peut, en effet, être parfois utilisé avec partage, pour certaines applications, et parfois sans partage pour d’autres. C’est donc au moment où l’on désire utiliser le partage qu’il faut modifier le paramètre SHARE à l’aide de la commande OVRDBF. Grâce à cette commande, le partage sera possible pour les programmes du travail en cours seulement.
Enfin, il faut rappeler que, en RPG, la mise en fonction de l’indicateur LR (ou l’ordre STOPRUN en Cobol) libère la place occupée par ce programme en mémoire principale. L’ODP, notamment, est alors détruit. Les ordres RETRN en RPG, ou EXIT en Cobol, provoquent l’arrêt du programme mais laissent l’ODP en mémoire principale. La prochaine ouverture sera plus rapide. Les gains peuvent être

66 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
significatifs lorsqu’un programme est appelé dans une boucle. Mais, attention, il existe quelques contraintes car les anciennes valeurs des structures contenues dans l’ODP (variables, sous-fichier...) sont reprises à l’ouverture. Il est donc important d’initialiser ce qui doit l’être (sous-fichier, pointeur d’enregistrement...).
Les groupes d’activation et l’ODP
Depuis la version V2R3M0 de l’OS/400, le partage de l’ODP peut être limité à une partie des applications d’un travail, une autre partie partageant éventuellement un autre ODP pour le même fichier. Cela n’est possible qu’avec des programmes résultant de langages ILE qui autorisent la création de plusieurs groupes d’activation pour un même travail. Un groupe d’activation est une structure en mémoire principale qui contient l’environnement d’exécution d’un groupe de programmes. Dans cet environnement, on trouve notamment les ODP.
L’appartenance d’un programme à un (ou des) groupe(s) d’activation est définie lors de la création des modules qui vont composer ce programme, par le paramètre ACTGRP. Lors de l’exécution de ce module, ou plus exactement de l’une des procédures composant ce module, le groupe d’activation est automatiquement créé s’il n’existe pas.
Les groupes d’activation permettent un cloisonnement entre les applications qui se déroulent dans un même travail. Chacune peut s’exécuter dans son propre environnement, en étant sûre qu’aucune autre ne viendra perturber cet environnement. La figure 3.5 montre, pour un même travail, deux groupes de programmes qui accèdent au même fichier à travers des ODP différents.
PGM1PGM2PGM3
COMPTA1COMPTA2COMPTA3
ODP
GROUPE D’ACTIVATION 1
ODP
GROUPE D’ACTIVATION 2
Figure 3.5 : partage d’ODP dans des groupes d’activation.
Les enregistrements détruits

3 - Les fichiers physiques 67
Nous avons déjà signalé à la section Les enregistrements du chapitre 2 que les enregistrements détruits étaient seulement marqués à l’effacement : leurs emplacements sont conservés dans le fichier. Il est donc important de gérer ces trous laissés dans les fichiers.
Le paramètre DLTPCT permet de gérer le nombre d’enregistrements détruits. Si, à la fermeture du fichier, le nombre d’enregistrements détruits sur le nombre total d’enregistrements est supérieur à la valeur indiquée pour ce paramètre, un message est placé dans l’historique du système. Par défaut la valeur est DLTPCT(*NONE), il n’y a pas de vérification, afin de minimiser les temps de fermeture des fichiers.
Le paramètre REUSEDLT indique si la place occupée par les enregistrements détruits peut être récupérée pour placer les nouveaux enregistrements (depuis la version 2 de l’OS/400). La valeur par défaut est REUSEDLT(*NONE) : il n’y a pas de réutilisation. Avec la valeur REUSEDLT(*YES), le système maintient, pour ce fichier, une table qui indique les emplacements libres.
Quelques contraintes sont liées à l’utilisation de cette valeur :
• les fichiers ne peuvent avoir une clé de type LIFO ou FIFO ;
• l’ordre des enregistrements dans le membre n’est plus l’ordre d’insertion. On ne peut donc se fier à la position relative d’un enregistrement ;
• certaines opérations liées à la journalisation peuvent être impossibles ;
• il n’est pas garanti d’obtenir 100 % de réutilisation ;
• l’utilisation de ces fichiers comme file d’attente est à proscrire, notamment parce que la lecture avec un délai d’attente (end of delay) n’est pas possible.
Rappelons que la commande RGZPFM permet de réorganiser un fichier, et donc d’éliminer les trous.
L’identificateur de format
L’identificateur de format est une valeur qui caractérise de manière unique un format. Il est utilisé par le système pour vérifier si un programme, et les fichiers qu’il utilise, sont bien au même niveau. Autrement dit, si les formats des fichiers réellement ouverts sont identiques aux formats qu’avaient ces mêmes fichiers lors de la compilation du programme. Ce mécanisme permet de s’assurer que le programme pourra traiter correctement les données provenant des fichiers. Si le programme et les fichiers ne sont pas au même niveau, le message d’erreur

68 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
CPF4131 « Erreur de niveau... » est renvoyé à l’utilisateur. Il faut alors recompiler le programme.
Le contrôle de l’identificateur de format peut être inhibé pour un fichier, si, lors de sa création, le paramètre LVLCHK de la commande CRTPF a pour valeur LVLCHK (*NO). Ce paramètre est aussi présent dans les commandes CHGPF et OVRDBF.
La valeur LVLCHK (*NO) est à réserver à des opérations ponctuelles en phase de développement, jamais en production car, en cas de modification du format d’un fichier, aucun garde-fou n’assurerait que le programme traite correctement les enregistrements.
Il faut tenir compte de cet identificateur de format chaque fois que l’on est amené à changer les caractéristiques d’un fichier, notamment :
• en cas de modification du format. Se reporter à la section Les fichiers – L’identificateur de format du chapitre 2 pour connaître les opérations qui ne modifient pas l’identificateur de format ;
• en cas de substitution de fichier par la commande OVRDBF. Le fichier substitué doit avoir le même identificateur de format que le fichier qui le remplace. Il en est de même pour les fichiers d’affichage (OVRDSPF) et pour les fichiers d’impression (OVRPRTF).
• et lors de l’utilisation de la commande OPNQRYF.
Les opérations permises
Le paramètre ALWDLT précise si les enregistrements de ce fichier pourront être détruits. Si la valeur ALWDLT (*NO) est précisée, la destruction des enregistrements sera impossible.
De manière identique, ALWUPD contrôle la mise à jour des enregistrements.
Pour ces deux paramètres, la valeur par défaut est *YES.
AUT définit les droits publics pour ce fichier, comme pour tout objet de l’OS/400.
Les données de chaque membre peuvent être traitées jusqu’à la date indiquée en regard du paramètre EXPDATE. Au-delà de cette date, un message est renvoyé à

3 - Les fichiers physiques 69
l’opérateur système pour toute tentative d’ouverture de ce membre, lui demandant si le travail peut continuer ou s’il doit être arrêté.
Chaque membre d’un fichier peut avoir sa propre date d’expiration.
La commande de substitution OVRDBF permet d’inhiber cette vérification de date, grâce au paramètre EXPCHK.
Le tri
La séquence de tri pour les zones de type Alphanumérique qui composent la clé peut être adaptée aux besoins de chacun. C'est-à-dire que l’on peut définir l’ordre des caractères dans le tri. A et a doivent-ils avoir le même poids devant le tri, sinon lequel doit être le premier ? Où doit-on placer les caractères tels que é, à, ç ?
Les tables de conversion (objets de type *TBL), déjà traitées aux niveau des mots-clés ALTSEQ et NOALTSEQ des DDS, permettent de redéfinir la valeur devant le tri de chacun des caractères. Les tables de séquence de tri, qui sont aussi des objets de type *TBL, permettent un meilleur support des langues nationales. Le système nous propose pour chaque page de code, c'est-à-dire pour pratiquement chaque langue, des tables de séquence de tri de deux types :
• à poids unique : chaque caractère à un poids différent devant le tri. Pour la table française, par exemple, A a la valeur 0760 et a 0750 ;
• à poids partagé : tous les caractères de la même catégorie ont la même valeur devant le tri. Pour la table française, par exemple, tous les caractères de la famille des A (A, a, à, ä, â...) ont le poids 0690 devant le tri.
Le paramètre SRTSEQ permet de définir la table de séquence de tri rattachée à un fichier. La valeur par défaut SRTSEQ(*SRC) fait référence à la table définie au niveau du mot-clé ALTSEQ. SRTSEQ(*LANGIDSHR) sélectionne la table à poids partagé correspondant à la langue citée au niveau du paramètre LANGID (par défaut, celle du travail). Enfin, SRTSEQ(*LANGIDUNQ) définit la table à poids unique pour la langue associée à LANGID .
Les tables de séquence de tri sont situées dans QSYS. Leur nom commence par Q, puis trois positions définissent le jeu de caractères, ensuite quatre valeurs numériques précisent le CCSID et enfin une dernière lettre indique si la table est à poids partagé (S) ou à poids unique (U). Ainsi, pour la France, les tables sont QLA10129U et QLA10129S (LA1 pour le jeu de caractère latin et 0129 pour le CCSID 297).

70 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
La table définie par le paramètre SRTSEQ est recopiée dans la partie descriptive du fichier. La commande DSPFD permet de le vérifier.
Cette fonction est attrayante mais dangereuse car elle peut impliquer la recréation de chemins d’accès temporaires. En effet, le paramètre SRTSEQ existe aussi pour le travail et même pour le profil utilisateur. Un travail utilisant une table de séquence de tri et qui accède à un fichier ayant une autre table force le système à créer un chemin d’accès temporaire qui correspond à l’ordre définit pour le travail. La dégradation de performance peut être notable si le fichier contient de nombreux enregistrements. Si cette fonction doit être mise en place, il semble souhaitable que toutes les entités du système (profil utilisateur, valeur système, travail, fichiers physiques et fichiers logiques) aient la même table de séquence de tri.
Conclusions
La commande CRTPF que nous venons de décrire est le mode naturel de création d’un fichier physique. Elle peut être lancée à partir de PDM, par l’option 14. Par défaut, cette commande, comme toute commande de création lancée à partir de PDM, est alors soumise en batch, ce qui permet de ne pas surcharger inutilement le système.
La plupart des paramètres que nous avons cités peuvent être modifiés, alors que le fichier est créé, par la commande CHGPF. La modification est alors durable. La commande OVRDBF permet de substituer la valeur de certains paramètres pour le travail en cours seulement.
Les principaux paramètres de la commande CRTPF
Voici la liste des principaux mots-clés des commandes CRTPF et CHGPF, rangés par ordre alphabétique :
ALLOCATE indique si l’espace disque nécessaire pour tous les enregis-trements définis dans le paramètre SIZE est réservé à la création du membre ;
ALWDLT indique si les enregistrements pourront être détruits ; ALWUPD indique si les enregistrements pourront être mis à jour ; AUT définit les droits publics ; CCSID précise la structure d’encodage ; CONTIG précise si le système doit essayer d’allouer l’espace attribué
initialement de manière contiguë ; DLTPCT indique le pourcentage entre le nombre d’enregistrements
détruits et le nombre total d’enregistrements à partir duquel
3 - Les fichiers physiques 71
un message est envoyé à l’historique du système ; EXPDATE donne la date d’expiration des enregistrements ; FILE indique le nom du fichier à créer ; FILETYPE spécifie si le fichier créé est destiné à contenir des données
ou des sources ; FLAG indique le niveau de gravité minimal des messages pour
qu’ils soient placés dans le listing de compilation ; FRCACCPTH précise quand le chemin d’accès est réellement écrit sur
disque ; FRCRATIO indique quand le système doit écrire réellement les
enregistrements sur disque ; GENLVL indique le niveau de gravité à partir duquel le fichier ne sera
pas créé ; LVLCHK précise si l’identificateur de format doit être comparé à celui
du programme ; MAINT indique, si le fichier a une clé, comment est maintenu le
chemin d’accès ; MAXMBR précise le nombre maximal de membres que pourra contenir
le fichier ; MBR donne le nom du membre ajouté lors de la création du
fichier physique ; OPTION précise le type d’état qui est généré lors de la compilation ; RCDLEN est la longueur de l’enregistrement si le fichier est créé sans
DDS ; RECOVER précise le mode de reconstruction du chemin d’accès après
incident ; REUSEDLT indique si le système doit gérer les emplacements marqués à
l’effacement afin d’y insérer les nouveaux enregistrements ; SHARE définit s’il peut y avoir partage de l’ODP ; SIZE donne le nombre maximal d’enregistrements dans un
membre ; SRCFILE indique le nom du fichier source ; SRCMBR indique le nom du membre source ; SYSTEM spécifie le nom du système sur lequel est créé le fichier ; TEXT correspond au commentaire ; UNIT indique l’unité sur laquelle le système doit tenter de placer
le fichier et ses chemins d’accès ; WAITFILE précise le délai, en secondes, pendant lequel un programme
pourra attendre que le fichier soit libéré ; WAITRCD précise le délai, en secondes, pendant lequel un programme
pourra attendre qu’un enregistrement soit libéré.

72 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Les membres
Les membres constituent l’un des composants essentiels de DB2/400. Leur utilisation est toutefois méconnue car l’OS/400, avec ses options par défaut, peut masquer leur existence.

3 - Les fichiers physiques 73
Généralités
Dans les fichiers physiques, les données sont regroupées en ensembles appelés membres. Par défaut, un membre est créé avec chaque fichier. Ils possèdent tous deux le même nom, et toutes les données de ce fichier sont placées dans ce membre. Au cours du temps, il est parfois souhaitable d’isoler certaines données (nouvelle année en comptabilité, nouveau stock...). Il est alors possible de créer un nouveau fichier (avec un seul membre) et de placer les nouvelles données dedans. Il est alors nécessaire d’effectuer certaines opérations qui assurent que le nouveau fichier sera traité comme le précédent ; selon les environnements, il faudra, pour ce fichier :
• créer les fichiers logiques, donc copie des DDS existantes, puis modification et compilation ;
• mettre en œuvre la journalisation ;
• définir les droits d’utilisation ;
• revoir les sauvegardes (donc, éventuellement modifier les sources des programmes de sauvegarde) ;
• et parfois même, modifier les programmes de traitement des données.
Cette liste, non exhaustive, montre qu’il n’est pas toujours très simple d’intégrer un nouveau fichier dans les applicatifs.
Une autre possibilité consiste à ajouter un membre au fichier existant. Une ligne de commande suffit généralement pour cette opération. En revanche, pour pouvoir accéder à ce membre, il faut modifier, ou créer, le programme en langage de contrôle qui appelle le(s) programme(s) de traitement des données. Même si l’utilisation de fichier multimembre n’a pas été définie lors de l’analyse (et donc implémentée dans les programmes), l’ajout d’un membre est une opération relativement simple.
Il faut remarquer qu’une (petite !) économie de place est réalisée si l’on utilise un fichier multimembre plutôt que plusieurs fichiers : une seule partie descriptive de l’objet et du format est alors présente sur disque (figure 3.6).
Les chemins d’accès
Les caractéristiques du chemin d’accès (en fait la définition de la clé pour un fichier physique) sont définies au niveau du fichier. Mais le fichier lui-même n’a

74 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
pas de chemin d’accès ; ces structures sont en fait associées à chaque membre. Il n’y a donc pas de différence, à ce niveau, entre un fichier multimembre et plusieurs fichiers monomembre.
MEMBRES
PARIS
FichierPARIS
PARIS
FichierMONTPELLIE
FichierLYON
FichierSTOCK DESCRIPTION
MONTPELLIE
LYON
MULTIFICHIERMULTIMEMBRE
MONTPELLIE LYON
Figure 3.6 : comparaison des solutions fichier multimembre et multifichier.
Remarques
L’utilisation des fichiers multimembres ne limite en rien les possibilités de traitements. Les mêmes opérations peuvent être effectuées sur ces fichiers, et sur leurs données, que sur les fichiers monomembres. Toutefois, certaines limitations peuvent apparaître dans des cas particuliers faisant référence à des standards définis hors de l’OS/400 tels que SQL ou NFS (qui permet le partage de fichiers avec d’autres systèmes d’exploitation comme Unix, par exemple).
Il faut avoir à l’esprit que cette notion de membre est spécifique à l’AS/400. Elle est extrêmement performante mais est ignorée des autres systèmes. Au fur et à mesure que l’ouverture de l’OS/400 se concrétise, on se rend compte que la notion de membre n’est pas supportée par les nouvelles fonctionnalités. Pour citer un exemple récent, nous pouvons rappeler que l’un des apports majeurs de la version V3R1M0, pour la base de données de l’OS/400, est la possibilité de créer des contraintes d’intégrité référentielle. Cette fonction, tant attendue, ne supporte pas les fichiers multimembres.

3 - Les fichiers physiques 75
Pour l’utilisation dans un environnement AS/400 (ou avec Client Access/400), il n’y a pas de contraintes à l’utilisation de fichiers multimembres. En revanche, ils sont à proscrire si l’on désire travailler en liaison avec d’autres plates-formes. Lors de l’analyse, il est donc important de définir si les applications auront à fonctionner dans un environnement où les données seront réparties sur plusieurs systèmes, avant d’envisager l’utilisation de fichiers multimembres.
Les fichiers sources
Les fichiers sources constituent un bon exemple de fichiers multimembres. Ce sont des fichiers physiques classiques qui ont la particularité d’avoir trois zones : une contenant le numéro de ligne, une autre correspondant à la ligne de source proprement dite et la troisième indiquant la date de création ou de dernière modification de cette ligne. Chaque source d’un programme ou d’un fichier est placé dans un membre. La commande CRTSRCPF permet de créer un fichier source. La longueur par défaut de l’enregistrement est de 92 (6 pour le numéro de ligne, 80 pour le source et 6 pour la date). Avec des langages comme le RPG IV qui peuvent avoir des spécifications d’une longueur de 100 colonnes, il faut prévoir une longueur d’enregistrement de 112.
Mise en œuvre
Création
Le paramètre MBR de la commande CRTPF définit le nom du premier membre ajouté lors de la création du fichier physique. La valeur par défaut fait référence au nom du fichier. Ainsi le membre et le fichier ont, en standard, le même nom. La valeur MBR(*NONE) précise qu’aucun membre n’est créé avec le fichier.
Un fichier physique ne peut être créé qu’avec un membre, au maximum. Si l’on désire doter ce fichier de plusieurs membres, il faudra rajouter les suivants en exécutant des commandes lancées ultérieurement (ADDPFM ).
Le paramètre MAXMBR indique le nombre maximal de membres que peut posséder ce fichier. Par défaut, sa valeur est à MAXMBR (1) : un seul membre peut être

76 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
associé à ce fichier. La commande CHGPF permet de modifier cette valeur ultérieurement, lorsque le besoin d’un nouveau membre se fait sentir.
R FMT1Z1Z2
K Z1SOURCE
CRTPF FILE(PF1) MBR(*FILE)MAXMBR(1)
CRTPF FILE(PF1) MBR(*NONE)MAXMBR(2)
CRTPF FILE(PF1) MBR(PARIS)MAXMBR(2)
PARISPF1
PF1
LYON
CHGPF FILE(PF1) MAXMBR(2)ADDPFM FILE(PF1) MBR(LYON)
ADDPFM FILE(PF1) MBR(LYON)
LYON PARIS
LYON
Figure 3.7 : exemples de création de fichiers multimembres.
La commande ADDPFM ajoute un membre (et un seul à la fois) à un fichier physique. La figure 3.7 représente les différentes étapes de la création d’un fichier multimembre.
Le nombre de membres que peut contenir un fichier dépend des versions de l’OS/400 : à ce jour, on peut considérer qu’il est quasiment infini (32 767).
Visualisation
Le contenu d’un membre peut être visualisé, ou imprimé, par la commande DSPPFM. Le résultat est fourni soit en mode caractère, soit en représentation hexadécimale. Il faut utiliser la deuxième représentation pour interpréter correctement les zones de type Décimal condensé.
Cette commande est très pratique lorsque l’on désire vérifier si une opération s’est bien déroulée, mais elle est vite limitée lors d’une utilisation plus poussée. Il nous

3 - Les fichiers physiques 77
semble alors préférable d’utiliser Query, par exemple, qui formate correctement les données décimales, à l’aide de la commande suivante :
RUNQRY QRYFILE(FICH1)
où FICH1 est le nom du fichier dont on désire visualiser le contenu.
Sélection d’un membre
Dans un programme RPG, les spécifications F définissent les fichiers à utiliser, mais, rien ne permet de donner le nom du membre à sélectionner. Par défaut, les programmes traitent le premier membre du fichier (celui qui a été créé avec le fichier ou par la première commande ADDPFM ). Pour gérer un autre membre, il faut au préalable (et de manière externe au programme) utiliser la commande de substitution de fichier OVRDBF. Cette dernière permet notamment de traiter un membre spécifique pour un fichier. Toute opération du travail en cours sur les données de ce fichier se dérouleront sur le membre ainsi défini. C’est le seul moyen mis à notre disposition pour qu’un programme puisse accéder aux données d’un membre. L’exemple 3.11 du chapitre suivant présente cette substitution.
Exemple
L’exemple 3.11 présente un programme RPG qui utilise un fichier multimembre pour visualiser la quantité d’un article en stock.
Dans un premier temps, un programme en langage de contrôle propose à l’utilisateur de saisir le nom du stock à traiter et le numéro de l’article à visualiser. La commande de substitution permet de sélectionner le membre qui a le même nom que le stock. Le programme RPG lancé à la suite ne verra que les enregistrements de ce membre. Il ne connaît que le nom du fichier ; c’est au niveau du programme CLP que la sélection du membre est effectuée.
Le numéro de l’article, la quantité en stock et le libellé sont passés en paramètres.
Algorithme Appel du programme principal (CLP1) Affichage de l’écran de saisie Substitution Appel du programme de traitement (RPG1) Affichage de la quantité

78 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
DDS du fichier physique NOM LG FONCTION R FMTF1 TEXT(‘Fichier FICH1’) NUMART 6 LIBEL 15 QTE 6 2 K NUMART
DDS du fichier d’affichage
DSPSIZ(24 80 *DS3) R FMT2 OVERLAY 1 31'GESTION DES ARTICLES' COLOR(WHT) 6 5'Nom du stock:' 7 5'Code de l''article:' 10 5'Libellé:' 11 5'Quantité:' STOCK 10 I 6 26 NUMART 6 I 7 26 R FMT3 OVERLAY LIBEL 15 O 10 26 QTE 6 2O 11 26 R FMT1 23 38'F3=Fin' COLOR(BLU)
Représentation du fichier d’affichage
Nom du stock:Code de l’article:
Libellé:Quantité:
F3=Fin
GESTION DES ARTICLES
FormatFMT2
FormatFMT3
FormatFMT1

3 - Les fichiers physiques 79
Source du programme principal
PGM /*Affichage de la quantité d’un produit dans un stock*/ DCLF ECRAN DEBUT: SNDF RCDFMT(FMT1) /*Affichage de la ligne du bas */ SNDRCVF RCDFMT(FMT2) /*Demande du stock et du code article*/ IF &IN03 GOTO FIN OVRDBF FILE(FICH1) TOFILE(*FILE) MBR(&STOCK) CALL PGM(RPG1) PARM(&NUMART &QTE &LIBEL) SNDRCVF RCDFMT(FMT3) /*affichage du résultat*/ IF (*NOT &IN03) GOTO DEBUT FIN: /*Traitement de fin*/ ENDPGM
Source du programme RPG/400
FFICH1 IF E K DISK C *ENTRY PLIST C PARM NUMART 6 C PARM QTE 62 C PARM LIBEL 15 *ACCES SUR LA CLE C NUMART CHAINFMTF1 50 *SI L’INDICATEUR 50 EST EN FONCTION IL Y A UN PROBL EME *AUCUNE GESTION DES ERREURS C RETRN
Exemple 3.11 : utilisation d’un fichier multimembre. Par souci de lisibilité, aucun contrôle de la saisie n’est effectué.
Conclusions
Les fichiers multimembres constituent un bon outil pouvant apporter un important gain de productivité, surtout s’il sont prévus dès la phase d’analyse de la base de données. Ils ont quelques limitations dues à certaines fonctionnalités ou à certains produits issus de systèmes où la notion de membre n’existe pas. Il est probable que l’ouverture de l’OS/400 se fera au détriment de l’utilisation des membres qui s’avéraient être une excellente solution pour répondre aux besoins de l’informatique de gestion, domaine de prédilection des premiers AS/400.
La gestion des fichiers physiques
Nous allons maintenant passer en revue les principales commandes qui permettent de gérer les fichiers physiques.

80 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Définition
Les caractéristiques du fichier physique sont définies à sa création par la commande CRTPF, mais elles peuvent être modifiées par la suite à l’aide de la commande CHGPF. Les modifications ainsi apportées sont permanentes et valables pour tous les utilisateurs. La substitution, par la commande OVRDBF, permet de modifier les caractéristiques d’un fichier pour le travail en cours seulement. Le chapitre 7 traite de ce sujet en détail pour tous les types de fichier.
Destruction
Un fichier, quel qu’il soit, et à condition d’avoir les droits suffisants, peut être détruit par la commande DLTF . Il est alors irrécupérable. RMVM enlève un membre, détruisant ainsi les enregistrements qu’il contient. La structure du fichier est conservée car sa partie descriptive n’est pas touchée. On préférera cette commande à DLTF chaque fois qu’il s’agira de détruire un fichier pour le recréer par la suite. Enlever un membre est beaucoup plus rapide que la destruction complète d’un fichier et, surtout, ajouter un membre à un fichier existant n’est rien par rapport à la création d’un nouveau fichier.
CLRPFM détruit les enregistrements d’un membre tout en conservant vide le membre lui-même.
Visualisation
Les caractéristiques générales d’un fichier sont visualisables (ou même imprimables) par la commande DSPFD. On peut ainsi connaître toutes les valeurs définies pour les paramètres de la commande CRTPF ou éventuellement de CHGPF. En revanche, DSPFFD, dont la syntaxe est proche, affiche le détail de toutes les zones qui composent le fichier.
DSPPFM affiche le contenu d’un membre. On peut ainsi très simplement voir les enregistrements rangés dans ce membre. Seules les données de type Alphanumérique sont clairement visualisables ; une petite gymnastique est indispensable pour interpréter les zones d’autres types (le Décimal condensé, par exemple).
Modification de la structure
DB2/400 ne permet pas de modifier dynamiquement la structure d’un fichier physique. Pour ajouter une zone, ou pour en modifier la longueur, il faut passer par

3 - Les fichiers physiques 81
les DDS, c’est-à-dire modifier le source du fichier physique existant, puis recompiler ce source. Cette opération, qui semble relativement aisée, est lourde de conséquences car, pour créer un nouveau fichier, il faut avoir détruit l’ancien au préalable. Si l’on n’y prend garde, voici les problèmes qui peuvent être rencontrés :
• les données de l’ancien fichier sont perdues ;
• la sécurité mise en place disparaît ;
• les caractéristiques de l’ancien fichier sont à redéfinir dans le nouveau (nombre de membres autorisés, date d’expiration...) ;
• les programmes qui utilisent ce fichier devront être recompilés si l’identificateur de format du fichier a été modifié (ce qui est probablement le cas) ;
• les fichiers logiques définis sur ce fichier physique doivent être détruits au préalable, car le fichier physique ne peut lui-même être détruit si un fichier logique pointe dessus ;
• la journalisation ne permettra pas de revenir sur les opérations effectuées sur l’ancien fichier...
Voici les différentes étapes à respecter :
• d’une manière générale, il est important de sauvegarder toutes les informations associées au fichier. Le plus simple consiste à copier ce fichier grâce à la commande CRTDUPOBJ, en précisant DATA(*YES) pour que les données soient dupliquées dans le nouvel objet. La sauvegarde classique est inefficace car la restauration standard remplace le nouveau fichier par l’ancien, ce qui n’est pas le résultat escompté. Les données et les caractéristiques du fichier sont donc présentes dans l’objet résultant de la copie. Il est important d’arrêter les travaux qui pourraient modifier les données du fichier d’origine ou de le verrouiller en mode exclusif ;
• les fichiers logiques qui pointent sur le fichier physique doivent être détruits par la commande DLTF . On aura pris soin de vérifier que les sources sont toujours disponibles. La commande DSPDBR permet de connaître tous les fichiers logiques qui pointent sur un fichier physique. Elle peut renvoyer la liste à l’écran, et surtout dans un fichier, ce qui permet d’automatiser complètement toutes ces opérations. L’API QDBLDBR donne des informations comparables à travers un User Space (objet de type *USRSPC), mais les traitements sont beaucoup plus rapides. Il faut absolument noter les caractéristiques de chacun

82 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
des fichiers logiques pour pouvoir les recréer à l’identique, surtout en ce qui concerne les membres ;
• le fichier physique peut ensuite être détruit par la commande DLTF ;
• après modification des DDS, il peut être recompilé. On prendra soin de paramétrer correctement cette commande pour que le nouvel objet ait les mêmes caractéristiques que l’ancien (consulter par DSPFD la description de la copie pour voir le nombre maximal de membres, la date d’expiration...). Ce n’est pas la peine de créer un membre, car la copie de l’étape suivante le fera automatiquement ;
• mettre éventuellement en place la sécurité sur ce nouvel objet ;
• copier les données à partir de l’objet dupliqué à l’aide de la commande CPYF. Les valeurs suivantes sont importantes :
• FROMMBR(*ALL ) afin de copier les données de tous les membres,
– TOMBR(*FROMMBR) pour conserver la même structure au niveau des membres,
– MBROPT(*ADD) pour ajouter les enregistrements dans le fichier de destination,
– FMTOPT(*MAP *DROP) pour une copie intelligente, de zone à zone.
Après cette opération, les données sont dans le nouveau fichier, les nouvelles zones ont été initialisées avec la valeur par défaut ;
• les fichiers logiques peuvent être recréés ;
• les programmes gérant les fichiers dont l’identificateur de format a été modifié doivent être recompilés ;
• le fichier dupliqué peut être détruit ;
• une sauvegarde de ce fichier (et éventuellement des chemins d’accès des fichiers logiques) peut être lancée.
L’exemple 3.12 présente la structure d’un programme automatisant la recréation du fichier physique et des fichiers logiques dépendants.
Programme secondaire CRTPFLF
PGM /*CRTPFLF*/

3 - Les fichiers physiques 83
/*APPELÉ PAR DLTPFLF*/ /*PROGRAMME AUTOMATISANT LA RECREATION DE LF*/ /*FONCTIONS DE BASES SEULEMENT, A ENRICHIR SELON L ES BESOINS*/ DCLF FILE(DBR) /* OUTFILE DE DSPDBR*/ LECT: RCVF MONMSG MSGID(CPF0864) EXEC(GOTO FIN2) CRTLF FILE(&WHRELI/&WHREFI) /*CREAT ION DU LOGIQUE*/ GOTO LECT FIN2: ENDPGM
Programme principal
PGM PARM(&FICH &BIB) /*PROGRAMME DLTPFLF*/ /*PROGRAMME AUTOMATISANT LA DESTRUCTION D'UN PF ET DES LF ASSOCIÉS*/ /*FONCTIONS DE BASES SEULEMENT, A ENRICHIR SELON LE S BESOINS*/ /*RECONSTRUCTION DES LOGIQUES AVEC VALEURS PAR DEFAUT*/ DCLF QSYS/QADSPDBR /* POUR LE FORMAT DU OUTFILE DE DSPDBR*/ DCL &FICH *CHAR 10 /*NOM DU PF A RECOMPILER*/ DCL &BIB *CHAR 10 /*NOM DE LA BIBLIOTHEQUE DU PF* / DCL &DBR *CHAR 10 'DBR' /*DU FICHIER RECEVANT LA SORTIE DE DSPDBR*/ CRTDUPOBJ OBJ(&FICH) FROMLIB(&BIB) OBJTYPE(*FILE) + TOLIB(*CURLIB) NEWOBJ(FICHDUP) DATA(*YES ) DSPDBR FILE(&BIB/&FICH) OUTPUT(*OUTFILE) OUTFIL E(&DBR) OVRDBF FILE(QADSPDBR) TOFILE(&DBR) LECT: RCVF MONMSG MSGID(CPF0864) EXEC(GOTO FIN1) DLTF (&WHRELI/&WHREFI) /*DESTRUCTION D U LOGIQUE*/ GOTO LECT FIN1: DLTF (&BIB/&FICH) /*DESTRUCTION DU PHYSIQUE*/ CRTPF FILE(&BIB/&FICH) /*RECREATION DU PHYSIQU E*/ /*LE SOURCE DOIT EXISTER DANS QDD SSRC*/ CPYF FROMFILE(FICHDUP) TOFILE(&BIB/&FICH) + FROMMBR(*ALL) TOMBR(*FROM MBR) + MBROPT(*ADD) FMTOPT(*MAP *DROP) DLTOVR QADSPDBR CALL CRTPFLF /*CREATION DES LOGIQUES*/ DLTF (&DBR) DLTF (FICHDUP) ENDPGM
Exemple 3.12 : recréation automatique d’un physique et des logiques associés. Le programme DLTPFLF place les noms des fichiers logiques dépendant du fichier physique à détruire dans le fichier DBR, détruit tous les fichiers logiques et lance DLTPFLF2 pour la recréation de ces fichiers.

84 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Pour conclure sur une note optimiste, il faut signaler que la prochaine version de l’OS/400 (V3R6M0 et évolution de la V3R1M0) devrait nous permettre de modifier dynamiquement la structure d’un fichier physique (et d’une table avec ALTER TABLE ).
Les membres
ADDPFM permet d’ajouter un membre à un fichier physique et RMVM de l’enlever. Les caractéristiques d’un membre peuvent être modifiées grâce à CHGPFM . Il s’agit essentiellement du commentaire qui lui est associé et de la date de péremption de ses enregistrements. Il faut utiliser RNMM pour renommer un membre.
Il faut utiliser INZPFM pour ajouter un certain nombre d’enregistrements vierges à un membre. La valeur par défaut est prise pour les zones qui ont été codifiées dans les DDS avec le mot-clé DFT, sinon, les zones de type Alphanumérique sont remplies par des blancs et les zones numériques sont initialisées avec la valeur 0.
Sauvegarde
Les fichiers physiques doivent être régulièrement sauvegardés car ils contiennent les données, nous y reviendrons. Les commandes de sauvegarde et de restauration classiques s’appliquent aux fichiers (SAVOBJ, SAVLIB , RSTOBJ, RSTLIB ...). Il faut ajouter que les chemins d’accès peuvent aussi être sauvegardés. Non pas qu’ils soient indispensables, aucune donnée n’est perdue lors de la destruction d’un chemin d’accès, mais parce que leur reconstruction peut prendre un temps considérable. Il est donc intéressant de sauvegarder les chemins d’accès des gros fichiers pour gagner plusieurs heures lors de leur éventuelle restauration (paramètre ACCPTH). Il est à noter qu’il est préférable d’avoir le fichier physique et les fichiers logiques qui pointent dessus dans la même bibliothèque, pour faciliter la restauration des chemins d’accès.
Réorganisation
La commande RGZPFM réorganise un membre d’un fichier physique. Les trous laissés par les enregistrements marqués à l’effacement sont ainsi récupérés et les chemins d’accès sont réorganisés. D’une manière générale, les temps d’accès à un fichier réorganisé sont bien meilleurs.

3 - Les fichiers physiques 85
Cette opération est indispensable pour les fichiers à haute activité qui subissent de fréquentes modifications, insertions ou suppressions. Mais, elle est à considérer avec attention car elle touche au contenu même du fichier.
Il faut toujours effectuer une sauvegarde avant une réorganisation.
Les utilitaires
Query, lancé par STRQRY, est l’outil idéal pour générer rapidement un état en s’appuyant sur les données d’un ou de plusieurs fichiers.
DFU (data file utility) est l’outil destiné à bricoler les fichiers. Il génère très simplement un petit programme qui permet de travailler directement avec les enregistrements des fichiers. Cette simplicité masque le danger. On peut ainsi modifier ce que l’on veut, où l’on veut, dans la base de données, à condition d’en avoir les droits évidemment ! La cohérence entre les données de différents fichiers peut ainsi être perdue. DFU est donc à réserver à des cas particuliers, où on agit en toute connaissance de cause et où le bricolage est de rigueur.
SQL est traité plus loin dans cet ouvrage car il dépasse le cadre d’un simple utilitaire. Il permet, en interactif, en batch et dans des programmes, de gérer les données en local ou à distance sur d’autres AS/400 et même celles situées dans des environnements différents tels que DB2/2 sous OS/2, DB2/6000 sous AIX, DB2 sous MVS...
Il faudrait ajouter à cette liste bien d’autres utilitaires car la base de données est totalement intégrée à l’OS/400. Citons Client Access/400, anciennement PCS/400, qui extrait les données des fichiers à partir d’un micro-ordinateur, et Office Vision qui fusionne les enregistrements avec du texte.
Conclusions
Les fichiers physiques constituent le fondement de la base de données de l’AS/400 car ils contiennent les données, et ce sont les seuls à pouvoir le faire. Un soin particulier doit être donné à leur analyse, afin qu’ils soient le plus optimisés possible, et à leur gestion, pour qu’ils restent performants. Enfin, leur sauvegarde doit être régulière pour prévenir toute perte d’information.
86 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
De nombreuses fonctions, telles que la journalisation et le contrôle de validation, pourront être mises en œuvre afin de conserver l’intégrité des données. Elles seront soutenues par des dispositifs physiques comme les disques miroirs, le contrôle d’intégrité et les disques RAID 5. Nous y reviendrons...
Les principales commandes
ADDPFM ajouter un membre à un fichier physique ; CHGPF modifier les caractéristiques d’un fichier physique ;
CHGPFM modifier les caractéristiques d’un membre d’un fichier phy-sique ;
CLRPFM enlever les enregistrements d’un membre d’un fichier phy-sique ;
CPYF copier un fichier ; CRTDUPOBJ créer un objet dupliqué ; CRTPF créer un fichier physique ; CRTSRCPF créer un fichier source ; DLTF détruire un fichier ; DSPDBR afficher les relations d’un fichier ; DSPFD afficher la description d’un fichier ; DSPFFD afficher la description des zones d’un fichier ; DSPPFM afficher le contenu d’un membre ; EDTRBDAP réviser les chemins d’accès en cours de rétablissement ; OVRDBF substituer un fichier base de données ; OVRPRTF substituer un fichier d’impression ; RGZPFM réorganiser un membre d’un fichier physique ; RMVM enlever un membre ; RNMM renommer un membre ; RUNQRY lancer un programme Query ; STRDFU démarrer DFU ; STRQRY démarrer Query ; STRSQL démarrer SQL interactif ; WRKF gérer les fichiers.
Les principaux menus
FILE, FILE2, CMDPF, CMDFILE, CMDMBR, CMDDBF, CMDDB.

3 - Les fichiers physiques 87
LES FICHIERS PHYSIQUES ..........................................................................................29
LES ETAPES DE LA CREATION D'UN FICHIER PHYSIQUE PAR DDS...........................................30 LA CODIFICATION DES FICHIERS PHYSIQUES..........................................................................30
Principes ..........................................................................................................................31 Le dictionnaire .................................................................................................................31 Les clés.............................................................................................................................33 Liens avec les fichiers d'affichage....................................................................................37 Partage de format ............................................................................................................40 Valeur par défaut .............................................................................................................41 En-tête de colonne............................................................................................................42 Le traitement des dates.....................................................................................................44 Les zones de longueur variable........................................................................................46 Environnement multinational...........................................................................................48 Les principaux mots-clés des DDS...................................................................................49
LA COMMANDE DE CREATION DE FICHIERS PHYSIQUES.........................................................51 Définition du fichier .........................................................................................................51 Création d'un fichier sans DDS........................................................................................52 Gravité des messages .......................................................................................................52 Les membres.....................................................................................................................53 Le chemin d'accès ............................................................................................................53 Ecriture forcée en mémoire secondaire ...........................................................................56 Les fichiers physiques et la mémoire secondaire .............................................................57 Les verrouillages..............................................................................................................60 Le partage du bloc de contrôle (ODP).............................................................................61 Les groupes d’activation et l’ODP...................................................................................66 Les enregistrements détruits.............................................................................................66 L’identificateur de format ................................................................................................67 Les opérations permises ...................................................................................................68 Le tri .................................................................................................................................69 Conclusions......................................................................................................................70 Les principaux paramètres de la commande CRTPF.......................................................70
LES MEMBRES.......................................................................................................................72 Généralités .......................................................................................................................73 Mise en œuvre ..................................................................................................................75 Exemple............................................................................................................................77 Conclusions......................................................................................................................79
LA GESTION DES FICHIERS PHYSIQUES...................................................................................79 Définition .........................................................................................................................80 Destruction.......................................................................................................................80 Visualisation.....................................................................................................................80 Modification de la structure.............................................................................................80 Les membres.....................................................................................................................84 Sauvegarde.......................................................................................................................84 Réorganisation .................................................................................................................84

88 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Les utilitaires....................................................................................................................85 CONCLUSIONS.......................................................................................................................85 LES PRINCIPALES COMMANDES.............................................................................................86 LES PRINCIPAUX MENUS........................................................................................................86
—A— ABSVAL 33 ACCPTH 80 ACTGRP 63 ADDPFM 71; 72; 80 ALLOCATE 55 ALTSEQ 35; 66 ALWDLT 65 ALWNULL 45 ALWUPD 65 ALWVARLEN 45 avec ALTER TABLE 79 avec Client Access/400 71
—C— CCSID 47; 66 CHECK 37 chemin d’accès 69 chemin d'accès 51 CHGPF 67 CHGPFM 80 CHKMSGID 37 clé 33 CLRPFM 76 COLHDG 41 COMP 37 CPYF 40; 45; 78 CRTDUPOBJ 77 CRTEDTD 38 CRTPF 30; 49
—D— Date 42 DATFMT 42 DATSEP 42 DB2 42 DCLF 45

30 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
DDS 30; 47 DESCEND 34 DFT 40 DFU 81 dictionnaire 31 DLTEDT 39 DLTF 76 DLTPCT 64 DSPFD 35; 56; 76 DSPFFD 76 DSPPFM 72; 76
—E— EBCDIC 46 EDTCDE 38 EDTRBDAP 54 EDTWRD 38 EXIT 62 EXPCHK 66 EXPDATE 51; 65
—F— fichier d'affichage 36 fichier physique 29 fichier source 71 FIFO 34; 64 FILETYPE 50 FLAG 51 FORMAT 39 FRCACCPTH 53 FRCRATIO 53; 54
—G— GENLVL 50 groupe d’activation 63
—H— Horodatage 43
—I— IDDU 29

3 - Les fichiers physiques 31
identificateur de format 64 ILE 42 imestamp 43 INZPFM 40; 80
—J— JDFTVAL 40 journalisation 69
—L— l'ASCII 46 l'IPL 54 LANGID 35; 66 LIFO 64 LIFO 34 longueur variable 44 LVLCHK 64
—M— MAINT 52 MAXMBR 51; 71 MBR 51 membre 68 monomembre 70 multimembre 70
—N— NFS 70 NOALTSEQ 35; 66 NULL 45
—O— ODP 58 OPNQRYF 45; 65 OVRDBF 59; 62; 65; 66; 73 OVRDSPF 65 OVRPRTF 65
—P— PAG 59 page de code 46

32 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Partage de format 39
—Q— QCASE256 35 QDBLDBR 77 QDDSSRC 49 QGPL 49 QSYS 66 QSYSOPR 55 Query 45; 73; 81 QUSRSYS 35
—R— RANGE 37 RECOVER 53 REF 31; 36 REFFLD 31; 36 REFSHIFT 37 RETRN 62 REUSEDLT 64 RGZPFM 64; 80 RMVM 76; 80 RNMM 80 RPG IV 44 RPG/400 43; 45 RSTLIB 80 RSTOBJ 80
—S— SAVLIB 80 SAVOBJ 80 SHARE 60 SIZE 55 SQL 45; 70; 81 SQL/DS 42 SRCMBR 49 SRTSEQ 35; 66 STOPRUN 62 STRQRY 81 STRSST 56

3 - Les fichiers physiques 33
—T— table de conversion 66 Time 42 Timestamp 42 TIMFMT 42 TIMSEP 42 tri 34; 66
—U— UNIQUE 34; 52 UNIT 56 User Space 77
—V— Valeur par défaut 40 VALUES 37 VARLEN 44 verrouillage 58
—W— WAITFILE 58 WAITRCD 58

Chapitre 4
Les fichiers logiques
Principes Présentation
Les fichiers logiques constituent l’un des composants essentiels de la base de données de l'OS/400. Ils ne contiennent pas réellement des données, mais laissent voir les enregistrements des fichiers physiques d'une certaine manière (triés sur une zone, par exemple). Ils permettent donc une indépendance entre les données (dans les fichiers physiques) et l'utilisation que l'on peut en faire (par les programmes). L'organisation générale de la base de données DB2/400 est résumée par la figure 4.1.
Structure
Les fichiers logiques ne contiennent pas réellement les données, nous l'avons déjà signalé. Les enregistrements renvoyés aux programmes proviennent en fait des fichiers physiques, ils sont seulement mis en forme au travers du fichier logique.
Il n'y a donc pas duplication de l'information (aussi appelée redondance). C'est une des caractéristiques des systèmes de gestion de base de données relationnelle (SGBDR).

84 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
NUMFACT NUMCLI DATE TOTAL
PGM1 PGM2 PGM3
NUMCLI NOMCLI VILLE CODEP
NUMCLI VILLE CODEP
Clé: NUMCLI
NUMCLI NOMCLI NUMFACT TOTAL
Clé : NUMCLI
NIVEAU PHYSIQUE(DONNEES)
NIVEAU LOGIQUE(VUES)
PROGRAMMES
Figure 4.1 : organisation des données avec DB2/400.
Mais alors, que contient un fichier logique ? De manière théorique, tout ce passe comme si le fichier logique contenait seulement la phrase définissant les données que l'on voit ; par exemple, « voir les données du fichier PF1, triées sur la zone NUMCLI , par ordre décroissant ». Cette image, certainement caricaturale, montre qu'en détruisant un fichier logique, on ne détruit aucune donnée mais seulement la "phrase" décrivant ce qui est vu.
En fait, chaque membre d'un fichier logique possède un chemin d'accès qui lui permet d'atteindre rapidement les données du (ou des) fichier(s) physique(s). Ce chemin d'accès ne pointe que sur les enregistrements qui correspondent aux critères de sélection, triés selon la clé du fichier logique (figure 4.2).
Un chemin d'accès de fichier logique a une structure identique à celui d’un fichier physique. C'est un index qui contient la clé (si elle existe) de chaque enregistrement vu par le fichier, et organisé selon l'ordre, croissant ou décroissant, défini dans les DDS. Les enregistrements lus dans un fichier logique apparaissent donc triés sur la clé. On peut toutefois noter une légère différence entre les chemins d’accès des fichiers physiques et ceux des fichiers logiques : les premiers voient tous les enregistrements du membre concerné, alors qu’avec les seconds seuls les enregistrements qui correspondent aux critères de sélection (s'ils existent) sont pris en compte.

4 - Les fichiers logiques 85
NUMCLI NOMCLI SOLDE21 DUPOND 600012 CHRISTOPHE 50035 DUMONT 500024 DUMAS 2015 FERRET 1256 JACQUART 120
NOMCLI SOLDESOLDE > 1000CLE : NOMCLI
PGM1
CHEMIN D’ACCES de LF1
CLE ADRESSEDUMONTDUPOND
Fichier physiquePF1
Fichier logiqueLF1
Figure 4.2 : représentation schématique du chemin d'accès d'un fichier logique. Le programme PGM1 ne verra que les deux enregistrements présents dans le chemin d’accès.
Utilisation
Dans les programmes, et d'une manière générale, un fichier logique est utilisé comme un fichier physique. Les déclarations sont identiques pour ces deux types de fichiers dans tous les langages de programmation (Langage de contrôle, RPG, Cobol...), ainsi que les ordres de lecture et éventuellement d'écriture. L'utilisation de l'un ou de l'autre type de fichier est totalement transparente pour les programmes.
Les fichiers logiques peuvent être utilisés pour de nombreuses raisons. Voici les principales :
• pour assurer l'indépendance entre les programmes et les données ;
• pour la sécurité ;
• pour un meilleur accès aux données ;
• et enfin, pour répondre à certaines contraintes liées à la programmation.
Nous allons maintenant détailler ces différentes utilisations.

86 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Indépendance programmes – données
La modification de la structure d'un fichier physique entraîne la modification de son identificateur de format. Il faut donc recompiler tous les programmes qui utilisent ce fichier sous peine de voir apparaître le message CPF4131 (chapitre 3, La commande de création de fichiers physiques). Cette tâche est parfois délicate pour peu que certaines caractéristiques de ces programmes ne soient pas standards (version particulière du compilateur, observabilité...).
Les fichiers logiques peuvent servir de tampon entre les programmes et les fichiers physiques. Il est alors possible, et sous certaines conditions, de modifier la structure des fichiers physiques sans avoir à recompiler les programmes qui gèrent leurs données.
Si un nouveau besoin pour l'entreprise se traduit par la nécessité d'ajouter une zone à un fichier physique utilisé directement par un programme, il faut procéder comme suit (figure 4.3) :
• modification de la structure du fichier physique (voir à ce sujet la section La gestion des fichiers physiques – Modification de la structure du chapitre 3). Il faut notamment prendre garde au fait que la recréation du fichier physique s’accompagne de la destruction de l’objet existant, ce qui conduit à la perte de toutes les données. Une copie préalable de ces données dans un autre fichier est donc indispensable ;
• recompilation du programme (et de tous les programmes qui utilisent ce fichier).
NUMCLI NUMFACT MONTANT NUMCLI NUMFACT MONTANT DEVISE
PGM1 PGM13 - RECOMPILATION DU PROGRAMME
1 - MODIFICATION DES DDS2 - CREATION DU FICHIER
Figure 4.3 : modification du format d'un fichier physique et recompilation du programme.
Si, par contre, le programme utilise le fichier logique LF1 (figure 4.4), les étapes à suivre sont :

4 - Les fichiers logiques 87
• destruction des fichiers logiques pointant sur PF1, en ayant pris soin de conserver les sources contenant les DDS de ces fichiers ;
Cette étape est indispensable car il est impossible de détruire un fichier physique sur lequel pointe un fichier logique.
• modification de la structure du fichier PF1 ;
• recréation du fichier physique puis, des fichiers logiques.
NUMCLI NUMFACT MONTANT NUMCLI NUMFACT MONTANT DEVISE
2 - MODIFICATION DES DDS3 - CREATION DU FICHIER PHYSIQUE
PGM1
LF1 LF11- DESTRUCTION DU FICHIER LOGIQUE4 - RECOMPILATION DU FICHIER LOGIQUE
Figure 4.4 : modification du format d'un fichier physique sans recompilation du programme.
L'indépendance entre les programmes et les données est ainsi préservée : la structure des données a été modifiée sans qu'il soit besoin de recompiler les programmes. Par contre, le travail de gestion des fichiers logiques (destruction, recompilation) est plus fastidieux, mais peut être entièrement automatisé.
Cette indépendance n'est réelle que sous une certaine contrainte : l'identificateur de format du fichier logique doit être conservé. Autrement dit, les caractéristiques des zones vues au travers de ce fichier ne doivent pas changer. Dans l'exemple 4.5, il faut recompiler le programme car la structure de la zone NUMCLI est modifiée, ce qui entraîne un changement pour l'identificateur de format de LF1.
Sécurité
Les fichiers logiques permettent de donner l'accès à une partie des zones constituant le format des fichiers physiques. Ils sont donc à conseiller lorsque l'on

88 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
doit mettre à la disposition de certains utilisateurs une partie seulement de chaque enregistrement. Par exemple, pour le fichier de la paie, certaines personnes doivent pouvoir accéder au nombre de jours de vacances déjà pris par chaque employé, mais elles ont interdiction de visualiser le montant du salaire de ces mêmes employés. La figure 4.6 résume cette situation. Au travers du fichier logique CONGELF, ces utilisateurs ne voient que les zones correspondant aux congés et ne peuvent pas accéder aux données sensibles sur les salaires.
NUMCLI NUMFACT MONTANT5 6 7 dont 2
NUMCLI NUMFACT MONTANT DEVISE5 6 9 dont 2 3
2 - MODIFICATION DES DDS3 - CREATION DU FICHIER PHYSIQUE
PGM1
NUMFACT MONTANTCLE : NUMFACT
LF1 LF1
1- DESTRUCTION DU FICHIER LOGIQUE4 - RECOMPILATION DU FICHIER LOGIQUE
PGM15 - RECOMPILATION DU PROGRAMME
Figure 4.5 : modification du format d'un fichier physique et recompilation du programme malgré la présence d'un fichier logique. Le format de la zone MONTANT, de type Décimal condensé, passe de longueur 7 dont 2 à 9 dont 2. L’identificateur de format de LF1 est donc modifié et il faut recompiler le programme PGM1.
Il existe une limitation contraignante à l’utilisation des fichiers logiques pour la sécurité : un utilisateur doit avoir les droits suffisants sur les données du fichier physique. Depuis la version V3R1M0 de l’OS/400, les fichiers logiques peuvent aussi avoir des droits sur les données. Le système vérifie d’abord si les droits sur les données du fichier logique sont suffisants, puis il opère la même vérification pour le fichier physique. Autrement dit, pour qu’un utilisateur puisse voir des données à travers un fichier logique, il faut :
• qu’il ait les droits nécessaires sur les données du fichier logique ;
• qu’il ait les droits nécessaires sur les données du fichier physique.
Dans l’exemple ci-dessus, les utilisateurs concernés ont les droits suffisants sur les données du fichier physique pour la lecture. Rien ne les empêche d’attaquer

4 - Les fichiers logiques 89
directement les données de PAIEPF avec Query ou SQL, ce qui va à l’encontre de la sécurité puisqu’ils peuvent voir toutes les zones de ce fichier ! On prendra donc soin d’interdire toute action directe sur le fichier physique en enlevant les droits *OBJOPR pour ces utilisateurs grâce à la commande EDTOBJAUT , par exemple.
Malgré ces limitations, cette solution est probablement la meilleure lorsque l'on désire donner à un utilisateur l’accès à une sélection de zones d'un enregistrement en lui interdisant les autres zones.
Elle est aussi intéressante lorsque l'on désire accéder à une petite partie d'un gros enregistrement. La taille de l'ODP est ainsi réduite car les enregistrements traités par le logique sont plus petits.
NUMEMP NOMEMP SALAIRE ANCIENNETE CONGE
NUMEMP NOMEMP CONGE
PGMx
Fichier physiquePAIEPF
Fichier logiqueCONGELF
SQL
QUERY DFUPCS/400CA/400
Figure 4.6 : protection d'une zone par un fichier logique. Les zones SALAIRE et ANCIENNETE ne seront pas accessibles à partir du fichier logique CONGELF.
Rapidité d'accès
Dans un fichier physique, on ne peut définir qu'une seule clé. Si on désire accéder rapidement à un enregistrement à partir de la valeur de zones ne composant pas la clé, il faut créer des fichiers logiques pour définir de nouvelles clés. Chaque programme devra utiliser le fichier logique qui correspond à la bonne clé. Si, ces fichiers logiques avec clé ont été définis avec le mot clé UNIQUE, alors plusieurs zones (ou combinaison de zones) ne pourront avoir la même valeur dans deux enregistrements du fichier physique.
Les fichiers logiques permettent de ne traiter que les enregistrements qui correspondent à certains critères de sélection (par exemple, les enregistrements

90 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
dont la valeur de la zone SALAIRE est supérieure à 10 000). Ainsi, le programme n'a plus à lire tous les enregistrements pour les tester et éventuellement les traiter. Chaque enregistrement vu au travers du fichier logique correspondant aux critères de sélection, le gain de temps en traitement peut être considérable. De plus, les programmes sont plus simples car ils sont déchargés de toute une série de contrôle.
Autres avantages
Les fichiers logiques nous permettent de voir les zones des fichiers physiques en modifiant leurs caractéristiques : changement de type, de longueur ou de nom, extraction ou concaténation... Les programmes, par leur intermédiaire, peuvent continuer à fonctionner alors que le fichier physique a été fortement modifié, ou même qu'il a été remplacé par un (ou des) autre(s).
Les différents types de fichiers logiques Les fichiers logiques sont répartis en deux familles, selon qu'ils effectuent ou non une jointure. Ce sont :
• les fichiers logiques non-joints ;
• et les fichiers logiques joints.
Les fichiers logiques non-joints ne mettent pas en œuvre la jointure. Les enregistrements peuvent être vus à travers un seul format. C'est le cas, par exemple, si les enregistrements proviennent d'un seul fichier physique ou si les zones sont présentes dans tous les fichiers. Ces fichiers sont dits non-joints monoformat.
Les enregistrements peuvent aussi être vus sous plusieurs formats (un format pour chaque fichier physique). Les enregistrements de ces différents formats ont comme lien une même valeur de clé. C'est le cas, par exemple, pour un fichier logique qui correspond à une facture. Pour un numéro de facture (valeur de clé), il verra un enregistrement du fichier ENTETE qui décrit l'en-tête de la facture et de nombreux enregistrements du fichier DETAIL qui contiennent chacune des lignes de la facture. Ces deux fichiers sont vus à travers des formats différents. Nous expliquerons plus loin le fonctionnement de ces fichiers non-joints multiformats.

4 - Les fichiers logiques 91
Les fichiers logiques non-joints peuvent être utilisés pour la lecture et pour la mise à jour d'enregistrements (création, modification et suppression).
Les fichiers logiques joints mettent en œuvre l'opérateur de jointure. Ils permettent de voir les enregistrements de 2 à 32 fichiers physiques, joints 2 à 2, sous un seul format.
Les fichiers logiques joints peuvent être utilisés uniquement pour lire les enregistrements. La mise à jour à travers de tels fichiers est impossible.
Les étapes de la création d'un fichier logique
La création de tous les fichiers logiques se déroule comme pour les fichiers physiques, c'est-à-dire :
• création d'un membre source de type LF. La spécification A est la même que celle utilisée pour les fichiers physiques ;
• compilation par la commande CRTLF .
Le chemin d’accès est constitué dès la création du logique, ce qui explique que les fichiers physiques doivent être présents lors de cette étape.
Un fichier logique ne peut exister sans la présence des fichiers physiques sur lesquels il pointe.
Nous allons à présent décrire les principaux mots-clés des DDS utilisés pour les fichiers logiques non-joints, puis nous verrons la mise en œuvre de la jointure.
Les fichiers logiques non-joints Principes

92 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Comme pour les fichiers physiques, nous verrons les DDS regroupées par thèmes, en ne traitant que les mots-clés spécifiques aux fichiers logiques car beaucoup ont déjà été vus avec les fichiers physiques. Une liste, à la fin de ce chapitre, reprend toutes les DDS des fichiers logiques.
La référence aux fichiers physiques
Fichier physique unique
Un fichier logique s'appuie obligatoirement sur au moins un fichier physique (et il ne peut s'appuyer que sur des fichiers physiques, pas sur des fichiers logiques). C'est le mot-clé PFILE qui définit le, ou les, fichiers physiques vus par le logique. L'exemple 4.1 définit un fichier logique qui voit les zones ZONEA et ZONEB du fichier physique PF1, de la bibliothèque BIBPF. Les enregistrements apparaîtront triés sur ZONEA. NOM LG DEC FONCTION R FMTLF1 PFILE(BIBPF/PF1)
ZONEA ZONEB
K ZONEA
Exemple 4.1 : définition du fichier physique vu par un fichier logique.
Si le fichier logique voit la totalité des zones du fichier physique, on peut omettre de citer toutes ces zones si le nom du format que l'on donne au fichier logique est le même que celui du fichier physique (exemple 4.2). La description de toutes les zones est alors automatiquement ramenée dans le logique. Mais, on ne peut alors codifier aucune nouvelle zone, ni changer leur ordre. La clé est à définir, même si elle existe dans le fichier physique, car seul le format est ramené, pas la clé. NOM LG DEC FONCTION R FMTPF1 PFILE(BIBPF/PF1) K ZONEA
Exemple 4.2 : définition d'un fichier physique et récupération de son format. Toutes les zones de PF1 sont vues au travers de ce logique. FMTPF1 est le format de PF1.
L'union
L'union, au sens relationnel du terme, est matérialisée par les fichiers logiques non-joints monoformats. Ils permettent de voir les enregistrements de plusieurs fichiers physiques (jusqu'à 32) au travers d'un même format. Leur codification est

4 - Les fichiers logiques 93
représentée par l'exemple 4.3. Les zones citées dans le fichier logique doivent être présentes dans chacun des fichiers physiques. NOM LG DEC FONCTION R FMTLF1 PFILE(PF1 PF2 PF3)
ZONEA ZONEB
K ZONEA
Exemple 4.3 : définition de l'union. ZONEA et ZONEB doivent être présentes dans PF1, PF2 et PF3.
Le format de l'un des fichiers physiques peut aussi être récupéré dans sa totalité. Dans l'exemple 4.4, FMTPF1 est le nom du format de PF1, premier fichier cité après

94 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
le mot-clé PFILE. Toutes les zones de ce fichier composeront le logique. Dans l'exemple 4.5, le nom du format n'est pas celui du premier fichier cité dans PFILE, il faut alors indiquer le nom du fichier possédant ce format dans le mot-clé FORMAT. NOM LG DEC FONCTION R FMTPF1 PFILE(PF1 PF2 PF3) K ZONEA
Exemple 4.4 : définition de l'union et récupération du format du premier fichier cité dans
PFILE. FMTPF1 est le format de PF1. NOM LG DEC FONCTION R FMTPF2 PFILE(PF1 PF2 PF3) FORMAT(PF2) K ZONEA
Exemple 4.5 : définition de l'union et récupération du format d'un fichier cité dans PFILE. FMTPF2 est le format de PF2.
La figure 4.7 montre comment sont vus les enregistrements d'un fichier logique non-joint monoformat pointant sur plusieurs fichiers physiques (union).
Sélection et omission
Traditionnellement, un programme lit tous les enregistrements d’un fichier et ne traite que ceux qui correspondent à certaines contraintes. Si le fichier est gros, et si peu d’enregistrements correspondent au critères de sélection, il est clair que le programme passe énormément de temps à lire et à tester des enregistrements qui ne seront pas retenus.
Les fichiers logiques nous permettent de ne voir que les enregistrements à traiter. Le programme n’a plus à s’occuper de tester les enregistrements. Les gains, en termes de développement, de performance, et même de sécurité, sont nets.
Seuls les enregistrements correspondant aux critères de sélection figurent dans le chemin d’accès d’un fichier logique contenant des sélections/omissions.
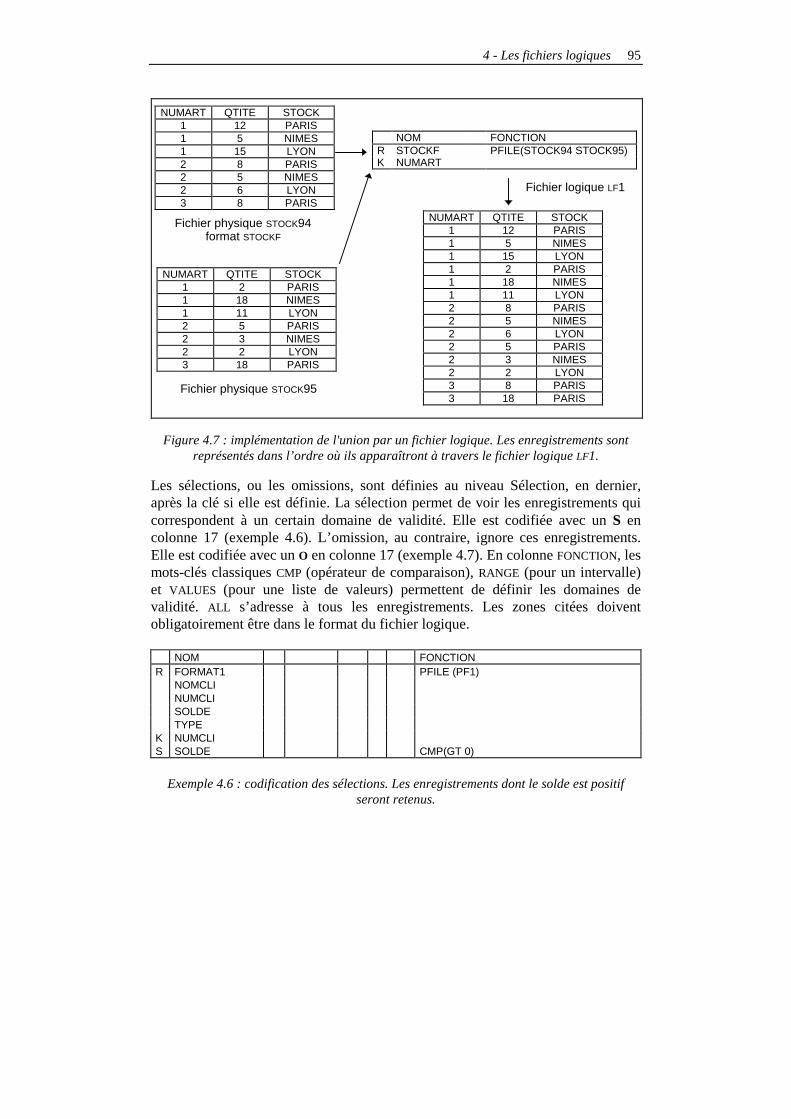
4 - Les fichiers logiques 95
NUMART QTITE STOCK1 12 PARIS1 5 NIMES1 15 LYON2 8 PARIS2 5 NIMES2 6 LYON3 8 PARIS
NUMART QTITE STOCK1 12 PARIS1 5 NIMES1 15 LYON1 2 PARIS1 18 NIMES1 11 LYON2 8 PARIS2 5 NIMES2 6 LYON2 5 PARIS2 3 NIMES2 2 LYON3 8 PARIS3 18 PARIS
Fichier physique STOCK94format STOCKF
Fichier logique LF1
NUMART QTITE STOCK1 2 PARIS1 18 NIMES1 11 LYON2 5 PARIS2 3 NIMES2 2 LYON3 18 PARIS
Fichier physique STOCK95
NOM FONCTIONR STOCKF PFILE(STOCK94 STOCK95)K NUMART
Figure 4.7 : implémentation de l'union par un fichier logique. Les enregistrements sont représentés dans l’ordre où ils apparaîtront à travers le fichier logique LF1.
Les sélections, ou les omissions, sont définies au niveau Sélection, en dernier, après la clé si elle est définie. La sélection permet de voir les enregistrements qui correspondent à un certain domaine de validité. Elle est codifiée avec un S en colonne 17 (exemple 4.6). L’omission, au contraire, ignore ces enregistrements. Elle est codifiée avec un O en colonne 17 (exemple 4.7). En colonne FONCTION, les mots-clés classiques CMP (opérateur de comparaison), RANGE (pour un intervalle) et VALUES (pour une liste de valeurs) permettent de définir les domaines de validité. ALL s’adresse à tous les enregistrements. Les zones citées doivent obligatoirement être dans le format du fichier logique. NOM FONCTION R FORMAT1 PFILE (PF1) NOMCLI NUMCLI SOLDE TYPE K NUMCLI S SOLDE CMP(GT 0)
Exemple 4.6 : codification des sélections. Les enregistrements dont le solde est positif
seront retenus.

96 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
NOM FONCTION R FORMAT1 PFILE (PF1) NOMCLI NUMCLI SOLDE TYPE K NUMCLI O TYPE RANGE(1 4) S ALL
Exemple 4.7 : codification des omissions. Les enregistrements dont le type n’est pas compris entre 1 et 4 seront retenus. La dernière ligne permet de voir tous les
enregistrements qui ne sont pas omis.
Pour des sélections/omissions simples, telles que nous les avons présentées dans les exemples ci-dessus, la codification est aisée. Si l’on désire traduire des propositions logiques complexes, avec des ET et des OU imbriqués, cela demande plus d’attention. Dans une liste de sélections/omissions où des S et des O sont codifiés en colonne 17, chaque ligne est analysée indépendamment des autres (exemple 4.8). Dès que l’enregistrement correspond à un des critères, il est retenu ou omis. Tout se passe comme si des OU logique séparaient chaque ligne. Dans l’exemple 4.8, les enregistrements retenus auront soit un solde positif, soit un type compris entre 1 et 4.
Le ET logique est traduit par un blanc en colonne 17. Ainsi, dans l’exemple 4.9 tout se passe comme si un ET séparait chaque ligne. Les enregistrements retenus ont à la fois un solde positif et un type compris entre 1 et 4. NOM FONCTION R FORMAT1 PFILE (PF1) NOMCLI NUMCLI SOLDE TYPE K NUMCLI S TYPE RANGE(1 4) S SOLDE CMP(GT 0)
Exemple 4.8 : codification du OU logique. Les enregistrements retenus ont le type compris
entre 1 et 4 ou ont un solde positif. S TYPE RANGE(1 4) SOLDE CMP(GT 0)
Exemple 4.9 : codification du ET logique. Les enregistrements retenus ont le type compris
entre 1 et 4 et ont un solde positif (représentation partielle).

4 - Les fichiers logiques 97
Dans le cas de propositions logiques complexes, l’ordre dans lequel on codifie les sélections/omissions est important sur le plan des performances. En effet, il faut placer en premier les sélections, ou les omissions, qui ont le plus de chance d’être réalisées afin de diminuer les tests que doit réaliser le système avant de retenir, ou d’éliminer, un enregistrement. Dans le même esprit, il est préférable de présenter les propositions logiques avec des OU, en jouant éventuellement sur les omissions plutôt que sur des sélections, car, dans ce cas, la décision de garder, ou d’enlever, un enregistrement est prise dès qu’une condition est remplie.
La sélection dynamique, présentée ci-dessous, peut alléger la maintenance du chemin d’accès. Elle est à considérer lors de la codification du fichier logique.
Les chemins d’accès
Pour la définition de la clé, les mots-clés étant identiques à ceux décrits pour les fichiers physiques, nous n’y reviendrons pas.
Le partage du chemin d’accès
Lors de la compilation d’un fichier logique, le système vérifie s’il peut récupérer un chemin d’accès déjà existant. Si, par exemple, il existe déjà un fichier logique avec la même clé et pointant sur le même fichier physique, il partagera son chemin d’accès. Un seul chemin d’accès sera utilisé par les deux fichiers logiques. Les économies de ressources sont claires, car une seule structure est à maintenir. Ce partage est systématique, sans que l’on précise quoi que ce soit au système, et il n’entraîne aucune dépendance entre les fichiers logiques. Il est d’ailleurs probable que bon nombre de gestionnaires des données sur l’AS/400 ignorent quels sont les fichiers qui sont soumis à un tel partage. La commande DSPFD permet de voir si un fichier utilise le chemin d’accès d’un autre.
Ce partage que nous venons de décrire est implicite, c’est le système qui décide. Le mot-clé REFACCPTH, de niveau Fichier, force le partage avec le chemin d’accès d’un fichier cité explicitement. C’est alors le programmeur qui décide. Mais, dans ce cas, on est obligé de récupérer toutes les caractéristiques de ce chemin d’accès. Les définitions de la clé et des sélections/omissions sont recopiées dans le nouveau fichier logique et il faut donc respecter les contraintes suivantes :

98 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
• on ne peut définir de nouvelle clé. La clé est celle du fichier dont on partage le chemin d’accès ;
• on ne peut indiquer de nouveaux critères de sélection ;
• les zones composant la clé et citées dans les sélections/omissions doivent être présentes dans le nouveau fichier.
Par contre, toutes les zones du format du fichier physique peuvent être citées, même si elles ne figurent pas dans le fichier dont on partage le chemin d’accès. NOM FONCTION REFACCPTH(BIB1/LF1) R FMTP1 PFILE(PF1)
Exemple 4.10 : codification du mot-clé REFACCPTH. Ce fichier fait référence au chemin d’accès du fichier logique LF1 dont il reprend la clé et les sélections/omissions. Toutes les
zones du format FMTP1, format du fichier physique PF1, seront vues.
La sélection dynamique
Le chemin d’accès d’un fichier logique qui contient des sélections/omissions et qui s’appuie sur un fichier physique très actif est sujet à de fréquentes modifications. Il suffit que la valeur contenue dans une zone soumise à sélection change pour que l’enregistrement soit ajouté, ou retiré, du chemin d’accès. Ces opérations peuvent consommer une quantité de ressources non négligeable, ce qui est peut être inutile si le fichier logique est rarement utilisé.
La sélection dynamique, mise en œuvre par le mot-clé de niveau Fichier DYNSLT, permet de n’effectuer la sélection/omission qu’au dernier moment, lors de l’ouverture du fichier. Le chemin d’accès contient, alors, tous les enregistrements, triés sur la clé. Il est plus gros mais il peut être plus facilement partagé, ce qui peut améliorer encore les performances. Lors de l’ouverture du fichier logique utilisant la sélection dynamique, tous les enregistrements sont lus, selon l’ordre de la clé, et de manière asynchrone. S’ils correspondent aux critères de sélection, ils sont retenus, sinon, ils sont ignorés. Le programme attendra que les premiers enregistrements soient disponibles. Pendant qu’il les traitera, et de manière transparente, les autres enregistrements seront renvoyés par le système. NOM FONCTION DYNSLT R FORMAT1 PFILE (PF1) NOMCLI NUMCLI SOLDE K NUMCLI

4 - Les fichiers logiques 99
S SOLDE CMP(LE 0)
Exemple 4.11 : codification de la sélection dynamique.
La sélection dynamique est à conseiller pour des fichiers logiques peu utilisés pointant sur des fichiers physiques très actifs. Elle est obligatoire pour les fichiers logiques sans clés et dans certaines configurations de fichiers logiques joints.
Les redéfinitions de zones Un fichier logique peut nous permettre de voir les zones avec des caractéristiques différentes de celles qu’elles ont dans le fichier physique. Voici les principales modifications qui peuvent être apportées :
• le nom de la zone peut être changé ;
• une zone du fichier logique peut être le résultat d’une concaténation de plusieurs zones du fichier physique ;
• une zone du fichier logique peut provenir d’une extraction d’une zone du fichier physique ;
• le type et la longueur des zones du fichier logique peuvent être différents de ceux du fichier physique ;
• on peut utiliser des tables de translations afin de convertir des zones de type Alphanumérique.
Renommer une zone On peut avoir besoin de renommer une zone pour deux raisons principales : soit parce que le programme la connaît sous un autre nom, soit parce que le langage ne supporte pas ce type de nom. C’est le cas du RPG/400, par exemple, qui n’autorise que des noms de 6 caractères de long. C’est le mot-clé RENAME qui donne un nouveau nom à la zone.
La concaténation La concaténation permet de voir le contenu de plusieurs zones au travers d’une seule. Il est préconisé, au niveau de la conception de la base de données, d’éclater au maximum les données stockées dans les fichiers physiques, afin, notamment,

100 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
d’améliorer les contrôles. C’est le cas pour les dates : le jour, le mois et l’année doivent être dans des zones distinctes. Le mot-clé CONCAT laisse voir, au travers du fichier logique, une seule zone résultant de la juxtaposition de plusieurs zones du fichier physique.

4 - Les fichiers logiques 101
Le changement de type
Tous les changements de types ne sont pas autorisés ; notamment, le passage de l’Alphanumérique vers le Décimal condensé et l’inverse sont impossibles.
L’extraction
L’extraction permet de voir une partie seulement d’une zone du fichier physique.
La syntaxe du mot-clé SST est la même qu’en langage de contrôle :
SST(ZONE1 DEBUT LONGUEUR)
où DEBUT est la position de début et LONGUEUR le nombre de caractères à extraire à partir de la zone ZONE1.
Son emploi est limité aux zones utilisées en lecture seulement (I codifié en colonne Usage). Elles ne peuvent servir à mettre à jour le fichier physique.
La translation
Une table de translation peut permettre de voir différemment les zones alphanumériques, chaque caractère étant éventuellement transformé en un autre caractère, en fonction du contenu de la table. Ainsi, les minuscules peuvent être automatiquement transformées en majuscules (table QSYSTRNTBL de QSYS). Son emploi est limité aux zones utilisées en lecture seulement (I codifié en colonne Usage).
Exemple NOM USAGE FONCTION R FORMAT1 PFILE(PF1) NOMCLI I TRNTBL(TABLE1) SOCIETE RENAME(NOMSOC) NUMCLI 6 0 SOLDE +2 +1 CODEP I SST(ADRESSE 1 5) DATE CONCAT(JOUR MOIS AN)
Exemple 4.12 : les principales redéfinitions de zones dans les fichiers logiques. La zone NOMCLI est vue à travers la table de translation TABLE1 ; NOMSOC est renommée SOCIETE ; NUMCLI, qui est de longueur 5 dont 0 dans le fichier physique, est vue avec une longueur de 6 dont 0 ; SOLDE occupe 2 positions de plus que dans le fichier physique avec

102 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
1 décimale supplémentaire ; CODEP correspond aux 5 premiers caractères de ADRESSE et DATE est la concaténation de JOUR, MOIS et AN. L’exemple 4.12 reprend ces différentes possibilités.
Les fichiers logiques multiformats
Les fichiers logiques multiformats permettent d’accéder aux enregistrements de plusieurs fichiers physiques (jusqu’à 32), chacun de ces fichiers étant généralement vu au travers d’un format. Le lien entre les enregistrements de ces différents formats est une valeur de clé.
Un exemple pour commencer
L’exemple classique pour illustrer ces fichiers est l’édition d’une facture. Une facture est composée d’un en-tête, provenant d’un enregistrement du fichier ENTETE, et de nombreuses lignes de détail, provenant d’autant d’enregistrements du fichier DETAIL. Tous ces enregistrements ont en commun le même numéro de facture. Un fichier logique multiformat nous permet de voir toutes les données relatives à la facture, qu’elles appartiennent au fichier FACTURE ou au fichier DETAIL. Elles seront vues sous deux formats, en fonction de leur provenance. L’exemple 4.13 illustre un tel fichier logique.
Dans l’exemple 4.13, un programme qui lit séquentiellement le fichier FACTURE verra tout d’abord un enregistrement de format FMT1 correspondant à l’en-tête de la facture 950601, puis il verra les différents enregistrements de format FMT2 correspondant au détail de cette facture. Ensuite, il verra à nouveau un enregistrement de format FMT1, pour une nouvelle facture... NOM FONCTION REF(BIB1/DICT1) R FMT1 NUMFAC R TEXT(‘Numéro de facture’) NUMCLI R TEXT(‘Numéro de client’) DATE R
Exemple 4.13a - DDS du fichier ENTETE.
NOM FONCTION REF(BIB1/DICT1) R FMT2 NUMFAC R NUMART R TEXT(‘Numéro de l’’article’) QTE R TEXT(‘Quantité de l’’article’) PRIXU R TEXT(‘Prix unitaire de l’’article’)
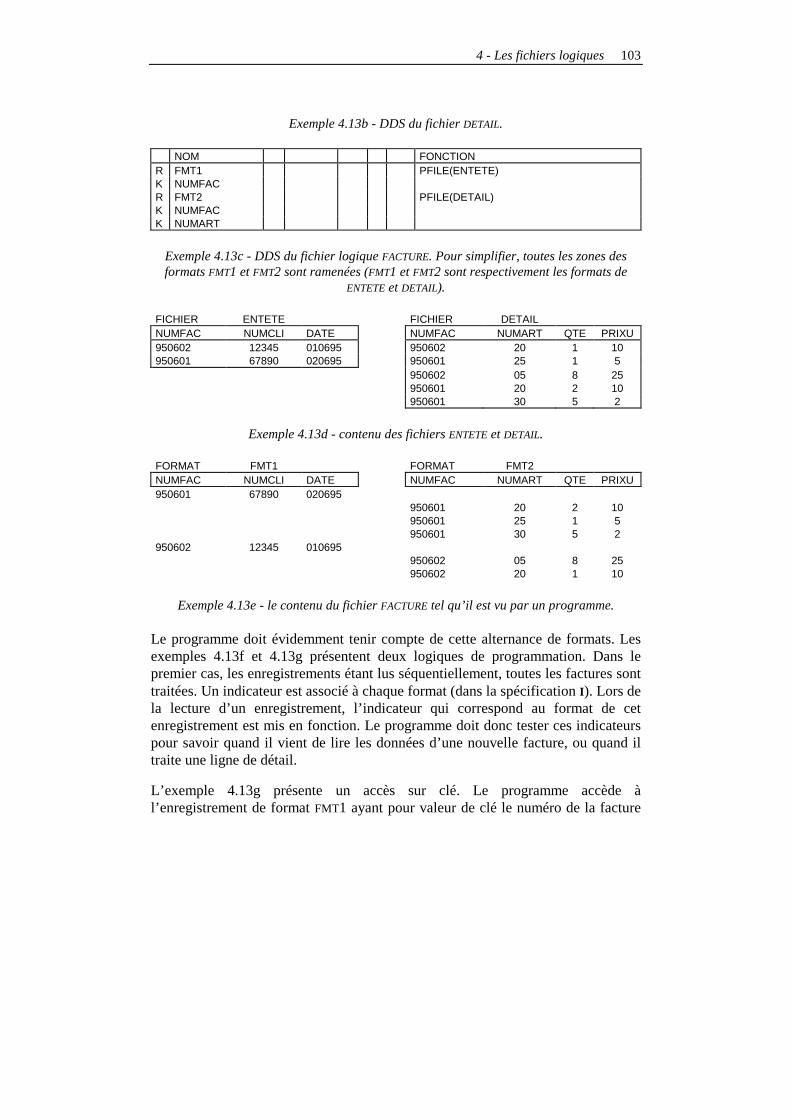
4 - Les fichiers logiques 103
Exemple 4.13b - DDS du fichier DETAIL.
NOM FONCTION R FMT1 PFILE(ENTETE) K NUMFAC R FMT2 PFILE(DETAIL) K NUMFAC K NUMART
Exemple 4.13c - DDS du fichier logique FACTURE. Pour simplifier, toutes les zones des formats FMT1 et FMT2 sont ramenées (FMT1 et FMT2 sont respectivement les formats de
ENTETE et DETAIL). FICHIER ENTETE FICHIER DETAIL NUMFAC NUMCLI DATE NUMFAC NUMART QTE PRIXU 950602 12345 010695 950602 20 1 10 950601 67890 020695 950601 25 1 5 950602 05 8 25 950601 20 2 10 950601 30 5 2
Exemple 4.13d - contenu des fichiers ENTETE et DETAIL.
FORMAT FMT1 FORMAT FMT2 NUMFAC NUMCLI DATE NUMFAC NUMART QTE PRIXU 950601 67890 020695 950601 20 2 10 950601 25 1 5 950601 30 5 2 950602 12345 010695 950602 05 8 25 950602 20 1 10
Exemple 4.13e - le contenu du fichier FACTURE tel qu’il est vu par un programme.
Le programme doit évidemment tenir compte de cette alternance de formats. Les exemples 4.13f et 4.13g présentent deux logiques de programmation. Dans le premier cas, les enregistrements étant lus séquentiellement, toutes les factures sont traitées. Un indicateur est associé à chaque format (dans la spécification I). Lors de la lecture d’un enregistrement, l’indicateur qui correspond au format de cet enregistrement est mis en fonction. Le programme doit donc tester ces indicateurs pour savoir quand il vient de lire les données d’une nouvelle facture, ou quand il traite une ligne de détail.
L’exemple 4.13g présente un accès sur clé. Le programme accède à l’enregistrement de format FMT1 ayant pour valeur de clé le numéro de la facture

104 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
sélectionné (code opération CHAIN ). Il lit ensuite séquentiellement tous les enregistrements de format FMT2 qui correspondent à cette facture (code opération READE).

4 - Les fichiers logiques 105
FFACTURE IF E K DISK FIMPFAC O E PRINTER * IFMT1 51 IFMT2 52 C* C READ FACTURE 90 C *IN90 DOWEQ*OFF C *IN51 IFEQ *ON C WRITEFMTENT C MOVE *OFF *IN51 C ELSE C WRITEFMTDET C MOVE *OFF *IN52 C ENDIF C READ FACTURE 90 C ENDDO C MOVE *ON *INLR
Exemple 4.13f - programme RPG/400 traitant en séquentiel le fichier logique FACTURE pour une édition. L’indicateur 51 est associé au format FMT1 et 52 à FMT2. Tous les enregistrements sont lus en séquentiel : si un enregistrement correspondant au format FMT1 est lu, c’est alors le format FMTENT qui est écrit, sinon c’est FMTDET, correspondant à une ligne de détail, qui est envoyé vers le fichier spoule.
FFACTURE IF E K DISK FIMPFAC O E PRINTER C* C *ENTRY PLIST C PARM NUMFAC C* C C NUMFAC CHAINFMT1 90 C *IN90 IFEQ *OFF C* C*ECRITURE DE L'ENTETE DE LA FACTURE C WRITEFMTENT C* C*BOUCLE D'ECRITURE DES ENREGISTREMENT DE DETAIL C NUMFAC READEFMT2 91 C *IN91 DOWEQ*OFF C WRITEFMTDET C NUMFAC READEFMT2 91 C ENDDO C ENDIF C*TRAITEMENT DE FIN C MOVE *ON *INLR
Exemple 4.13g - programme RPG/400 traitant en accès sélectif le fichier logique FACTURE pour une édition. Le numéro de la facture à traiter est reçu en paramètre. Une recherche sur clé (CHAIN) est effectuée sur le format FMT1 (pour ramener l’en-tête), puis une lecture séquentielle est opérée sur FMT2 (READE), tant qu’il y a correspondance de la clé (pour les

106 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
enregistrements de détail). Les formats FMTENT et FMTDET appartiennent au fichier d’impression IMPFAC.
La théorie
Dans les DDS du fichier logique multiformat, on doit décrire tous les formats en spécifiant, à chaque fois, le nom du fichier physique, l’ensemble des zones qui sont vus au travers de ce format, et la clé. L’ordre dans lequel les formats sont décrits est important. Il existe, en effet, une hiérarchie dans les clés. La clé du premier format décrit doit se retrouver dans la première partie de la clé du second (c’est elle qui fait le lien entre les enregistrements), la clé du troisième contenant aussi la clé du second et ainsi de suite pour tous les formats (exemple 4.14). NOM FONCTION R FMTLF1 PFILE(PF1) ZONEA ZONEB K ZONEA R FMTLF2 PFILE(PF2) ZONEA ZONEC ZONED K ZONEA K ZONEC R FMTLF3 PFILE(PF3) ZONEA ZONEC ZONEE K ZONEA K ZONEC K ZONEE
Exemple 4.14a : DDS d’un fichier logique multiformat.
NOM FONCTION R FMTLF3 PFILE(PF3) ZONEA ZONEE K ZONEA K *NONE K ZONEE
Exemple 4.14b : DDS d’un fichier logique multiformat avec une partie de la clé manquante. Par rapport à l’exemple 4.14a, ZONEC n’est pas présente dans le fichier PF3, elle ne peut donc pas figurer dans la clé, mais son emplacement doit être conservé par *NONE (représentation partielle).

4 - Les fichiers logiques 107
Parfois, un fichier physique vu en troisième position, ou même plus loin, ne contient pas toutes les zones qui devraient composer la clé du format correspondant. Ces zones manquantes doivent alors être remplacées par *NONE dans la description de la clé (exemple 4.14b).
Pour revenir à notre facturation, on peut admettre qu’un fichier REMISE contient les différents types de réduction à appliquer à une facture. Ces réductions s’appliquent sur le total de la facture et ne dépendent pas des articles (par exemple, 3% de remise négociées avec le commercial, plus 2 % pour paiement comptant, plus 1% pour commande dépassant 50 000F). L’exemple 4.15 reprend celui que nous avons vu précédemment (4.13) et tient compte de ce fichier REMISE. NOM FONCTION REF(BIB1/DICT1) R FMT3 NUMFAC R POURC R TEXT(‘Pourcentage de remise’) LIBEL R TEXT(‘Libellé de la remise’) CODE R TEXT(‘Code de la remise’)
Exemple 4.15a : DDS du fichier REMISE. NOM FONCTION R FMT1 PFILE(ENTETE) K NUMFAC R FMT2 PFILE(DETAIL) K NUMFAC K NUMART R FMT3 PFILE(REMISE) K NUMFAC K *NONE K POURC
Exemple 4.15b : DDS du fichier FACTURE intégrant les remises. NUMART n’est pas présent dans le fichier REMISE, il est donc remplacé par *NONE dans la clé du format FMT3.
La mise à jour
La mise à jour à travers ces fichiers logiques mérite une attention particulière. Dans le cas d’ajout, il faut préciser à quel fichier physique est destiné cet enregistrement. La première possibilité consiste à donner le nom du format concerné en regard de l’ordre d’écriture. Il n’y a aucune ambiguïté possible car le format est associé à un seul fichier physique. La seconde possibilité consiste à citer le nom du fichier logique au niveau du WRITE . Un programme, dit sélecteur de format, va définir le fichier physique qui doit recevoir les données. Ce programme sélecteur de format est associé au fichier logique. Il est à codifier avec

108 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
les règles que nous allons détailler et doit être cité au niveau du paramètre FMTSLR de la commande CRTLF . Il est très utile quand on a des données dans un fichier où les enregistrements sont sous plusieurs formats et que l’on désire les organiser en respectant l’esprit de l’AS/400 et plus généralement des bases de données relationnelles, c’est-à-dire un fichier physique par format. C’est souvent le cas pour les fichiers provenant de l’IBM/36 que l’on souhaite migrer en natif. Un premier programme lit le fichier d’origine et écrit l’enregistrement dans le fichier logique multiformat. Le programme sélecteur de format est alors automatiquement lancé et reçoit en paramètre l’enregistrement à écrire. Il renvoie le nom du format choisi dans un autre paramètre. La longueur du premier paramètre doit correspondre à la longueur du plus grand enregistrement qui peut être reçu, le second doit occuper 10 caractères.
Généralement, et toujours sur l’IBM/36, la première lettre de l’enregistrement indique quel est son format : un E pour en-tête, un D pour détail... L’exemple 4.16 décrit un programme sélecteur de format pour ce type de fichier.
C *ENTRY PLIST C PARM ENREG 60 C* 60 EST LA LONGUEUR DU PLUS GRAND ENREGISTREMENT C PARM FORMAT 10 C* PARAMETRE POUR RETOURNER LE NOM DU FORMAT CHOISI C* C MOVELENREG PREM 1 C PREM IFEQ 'E' C MOVEL'ENTETE' FORMAT C ELSE C MOVEL'DETAIL' FORMAT C ENDIF C RETRN
Exemple 4.16 : programme sélecteur de format. Le premier caractère de l’enregistrement traité est placé dans la variable PREM. Ensuite, si PREM=‘ E’ alors FORMAT prend pour
valeur ‘ENTETE’, sinon il prend pour valeur ‘DETAIL’.
Conclusions
Les fichiers logiques multiformats apportent certains avantages au niveau du développement : il n’y a qu’un seul fichier à déclarer et à utiliser. Par contre, le programme doit gérer les multiples formats, en lecture aussi bien qu’en écriture. Il reste à remarquer que, dans certains cas, l’utilisation de ces fichiers est moins performante que l’emploi de plusieurs fichiers (logiques ou physiques), avec des accès sur clé pour sélectionner les différents enregistrements.
Conclusions sur les fichiers logiques non joints

4 - Les fichiers logiques 109
Les fichiers logiques non-joints apportent une grande souplesse à la base de données de l’OS/400. Ils permettent la consultation et la mise à jour d’enregistrements. Ils sont employés de la même manière que les fichiers physiques, seule la réalisation de programmes basés sur des fichiers logiques multiformats étant plus délicate. Utilisés à bon escient, ils peuvent procurer des gains substantiels en termes de développement, de sécurité et de performance.
Les fichiers logiques joints Principes
Les fichiers logiques joints permettent de voir, sous un seul format, des données qui proviennent de plusieurs fichiers. Ils correspondent à la jointure qui est un des principes de base du modèle relationnel.
Pour bien illustrer cette jointure prenons un exemple simple : un fichier ENTETE contient le numéro de la facture, la date et le code du client. Le fichier CLIENT contient, lui, le code, le nom et l’adresse du client (figure 4.8). Pour éditer la facture, il faut toutes ces informations. En programmation classique, on extrait NUMCLI à partir d’un enregistrement du fichier ENTETE, puis on effectue une recherche (indexée si possible) dans le fichier CLIENT pour extraire les informations relatives à ce client. On peut alors générer l’en-tête de la facture.
Un fichier logique joint nous évite de faire cette recherche puisqu’il met en concordance les enregistrements des deux fichiers en fonction du contenu d’une (ou de plusieurs) zone(s). Le programme travaille directement sur ce fichier et a toutes les informations nécessaires à sa disposition. En une seule lecture, il a tout ce qui concerne une facture. L’exemple 4.17 présente les DDS de ce fichier.
La codification
La codification des fichiers logiques joints est assez simple. Elle est basée sur quelques mots-clés que nous allons détailler, en commençant par la jointure de deux fichiers.
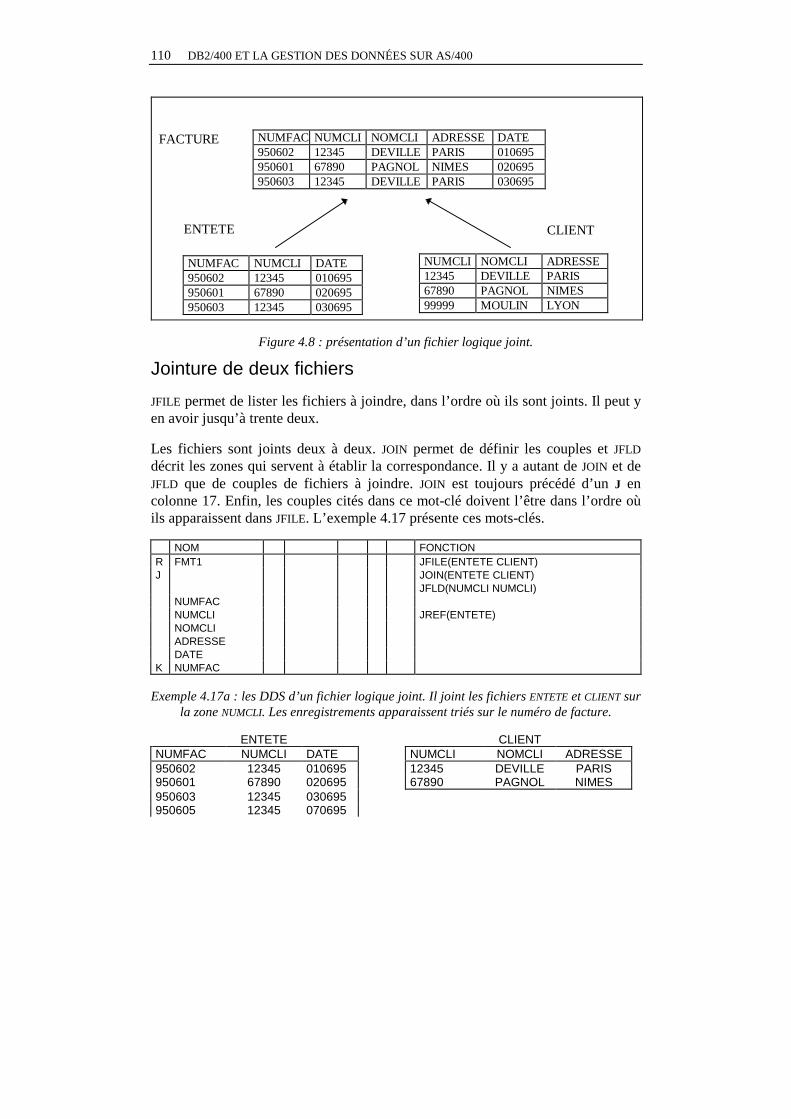
110 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
NUMFAC NUMCLI DATE950602 12345 010695950601 67890 020695950603 12345 030695
NUMCLI NOMCLI ADRESSE12345 DEVILLE PARIS67890 PAGNOL NIMES99999 MOULIN LYON
NUMFAC NUMCLI NOMCLI ADRESSE DATE950602 12345 DEVILLE PARIS 010695950601 67890 PAGNOL NIMES 020695950603 12345 DEVILLE PARIS 030695
ENTETE CLIENT
FACTURE
Figure 4.8 : présentation d’un fichier logique joint.
Jointure de deux fichiers
JFILE permet de lister les fichiers à joindre, dans l’ordre où ils sont joints. Il peut y en avoir jusqu’à trente deux.
Les fichiers sont joints deux à deux. JOIN permet de définir les couples et JFLD décrit les zones qui servent à établir la correspondance. Il y a autant de JOIN et de JFLD que de couples de fichiers à joindre. JOIN est toujours précédé d’un J en colonne 17. Enfin, les couples cités dans ce mot-clé doivent l’être dans l’ordre où ils apparaissent dans JFILE. L’exemple 4.17 présente ces mots-clés. NOM FONCTION R FMT1 JFILE(ENTETE CLIENT) J JOIN(ENTETE CLIENT) JFLD(NUMCLI NUMCLI) NUMFAC NUMCLI JREF(ENTETE) NOMCLI ADRESSE DATE K NUMFAC
Exemple 4.17a : les DDS d’un fichier logique joint. Il joint les fichiers ENTETE et CLIENT sur la zone NUMCLI. Les enregistrements apparaissent triés sur le numéro de facture.
ENTETE CLIENT NUMFAC NUMCLI DATE NUMCLI NOMCLI ADRESSE 950602 12345 010695 12345 DEVILLE PARIS 950601 67890 020695 67890 PAGNOL NIMES 950603 12345 030695 950605 12345 070695

4 - Les fichiers logiques 111
950606 99999 080695 950604 67890 050695
Exemple 4.17b : contenu des fichiers ENTETE et CLIENT.
NUMFAC NUMCLI NOMCLI ADRESSE DATE 950601 67890 PAGNOL NIMES 020695 950602 12345 DEVILLE PARIS 010695 950603 12345 DEVILLE PARIS 030695 950604 67890 PAGNOL NIMES 050695 950605 12345 DEVILLE PARIS 070695
Exemple 4.17c : le contenu du fichier logique joint tel qu’il est vu par un programme. L’enregistrement correspondant à la facture 950606 n’apparait pas car le numéro de client
n’a pas de correspondance dans le fichier CLIENT.
Certaines zones de deux fichiers physiques joints peuvent avoir le même nom. Le mot-clé JREF permet de lever toute ambiguïté sur l’origine des données de cette zone. Pour NUMCLI de l’exemple 4.17, c’est la zone du fichier ENTETE qui est retenue.
Si la zone de jonction doit rester cachée, il faut codifier un N en colonne Usage. Elle n’apparaîtra pas dans le format.
Jointure de trois fichiers
En admettant que le fichier CLIENT contienne le code du commercial (zone NUMCOM), on peut imaginer un fichier logique joignant trois fichiers physiques (exemple 4.18). Le but est d’avoir, dans un seul enregistrement, toutes les informations sur l’en-tête de la facture, sur le client à qui est destiné cette facture et sur le commercial chargé de ce client. La génération de l’état à imprimer est très rapide puisqu’il s’agit d’effectuer une seule lecture pour avoir toutes les données.
Pour alléger l’écriture, le nom des fichiers physiques peut être remplacé par un nombre qui correspond à la position du fichier dans le mot-clé JFILE (exemple 4.19). NOM FONCTION R FMT1 JFILE(ENTETE CLIENT VENDEUR) J JOIN(ENTETE CLIENT) JFLD(NUMCLI NUMCLI) J JOIN(CLIENT VENDEUR) JFLD(NUMCOM NUMCOM) NUMFAC NUMCLI JREF(ENTETE) NOMCLI ADRESSE

112 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
DATE NUMCOM JREF(VENDEUR) NOMCOM K NUMFAC
Exemple 4.18 : les DDS d’un fichier logique joint pointant sur trois fichiers physiques.
Ordre des enregistrements
La clé est constituée de zones qui sont obligatoirement dans le premier fichier cité.
Si des enregistrements ont même valeur de clé, ils peuvent alors être triés sur une zone figurant éventuellement dans un autre fichier, et spécifiée au niveau du mot-clé JDUPSEQ (exemple 4.19). Pour avoir un tri décroissant, il aurait fallu préciser JDUPSEQ(NOMCLI *DESCEND). NOM FONCTION R FMT1 JFILE(ENTETE CLIENT) J JOIN(1 2) JFLD(NUMCLI NUMCLI) JDUPSEQ(NOMCLI) NUMFAC NUMCLI JREF(1) NOMCLI ADRESSE DATE K DATE
Exemple 4.19 : codification du mot-clé JDUPSEQ. Si deux enregistrements ont même valeur
de date, ils apparaîtront triés sur le nom du client.
Enregistrements sans correspondance
Dans les exemples que nous avons vu jusqu’à présent, seuls les enregistrements du fichier primaire qui avaient une correspondance dans le fichier secondaire étaient ramenés. La facture 950606 de l’exemple 4.17 dont le contenu de la zone NUMCLI n’a pas d’équivalence dans le fichier CLIENT, n’a pas été retenue.
Pour voir aussi les enregistrements qui ne sont pas en concordance, il faut codifier JDFTVAL au niveau Fichier. Les valeurs par défaut sont alors renvoyées pour les zones correspondant au deuxième fichier. DYNSLT doit figurer avec ce mot-clé. NOM FONCTION

4 - Les fichiers logiques 113
DYNSLT JDFTVAL R FMT1 JFILE(ENTETE CLIENT) J JOIN(ENTETE CLIENT) JFLD(NUMCLI NUMCLI) NUMFAC NUMCLI JREF(ENTETE) NOMCLI ADRESSE DATE K NUMFAC
Exemple 4.20a : les DDS de l’exemple 4.17 avec le mot-clé JDFTVAL.
L’exemple 4.20 reprend la codification et le résultat de l’exemple 4.17, en intégrant JDFTVAL. Il faut remarquer que, si JREF(CLIENT) avait été codifié en regard de NUMCLI , alors la valeur par défaut aurait été renvoyée pour cette zone, puisque sa valeur serait prise dans le deuxième fichier.
NUMFAC NUMCLI NOMCLI ADRESSE DATE 950601 67890 PAGNOL NIMES 020695 950602 12345 DEVILLE PARIS 010695 950603 12345 DEVILLE PARIS 030695 950604 67890 PAGNOL NIMES 050695 950605 12345 DEVILLE PARIS 070695 950606 99999 080695
Exemple 4.20b - le contenu du fichier logique joint tel qu’il est vu par un programme. L’enregistrement correspondant à la facture 950606 apparait avec les valeurs par défaut
pour les zones NOMCLI et ADRESSE.
La jointure d’un fichier sur lui-même
Le traitement d’arborescence nous amène à opérer une jointure d’un fichier sur lui-même. C’est le cas classique du fichier EMPLOYE qui contient le code du supérieur hiérarchique, qui est lui aussi un employé avec un chef. Les nomenclatures (liste d’articles composant un article) en sont un autre exemple. La mise en œuvre est simple (exemple 4.21). NOM FONCTION R FMT1 JFILE(EMPLOYE EMPLOYE) J JOIN(1 2) JFLD(NUMSUP NUMEMP) NUMEMP JREF(1) NOMEMP JREF(1) NUMSUP JREF(1)

114 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
NOMSUP RENAME(NOMEMP) JREF(2) K NUMEMP
Exemple 4.21 : la jointure d’un fichier sur lui-même : cas du fichier EMPLOYE. NUMEMP et NOMEMP précisent le numéro et le nom de l’employé. NOMSUP correspond au nom du supérieur. On est obligé de renommer cette zone car NOMEMP sert déjà pour le nom de l’employé.
La jointure sur plusieurs zones
Si deux fichiers physiques sont joints sur plusieurs zones, on doit indiquer autant de JFLD qu’il y a de couple de zones à comparer (exemple 4.22). Pour qu’il y ait concordance, il faut que toutes les égalités soient obtenues.
Remarques
Les restrictions ci-dessous s’appliquent aux fichiers logiques joints :
• ils ne peuvent servir à mettre à jour les données des fichiers physiques ;
• leur contenu ne peut être visualisé par DFU ;
• la clé doit appartenir au premier fichier cité ;
• un seul format peut être défini. Il ne peut être celui d’un fichier déjà existant (le partage de format est impossible).
NOM FONCTION R FMT1 JFILE(FICHA FICHB) J JOIN(1 2) JFLD(ZONE1A ZONE1B) JFLD(ZONE2A ZONE2B) ZONE1A ZONE1B ZONE2A ZONE2B K ZONE1A
Exemple 4.22 : jointure de 2 fichiers sur plusieurs zones. ZONE1A et ZONE2A appartiennent à FICHA, les autres zones à FICHB. Lors de la jointure, le contenu de ZONE1A sera comparé
à celui de ZONE1B et celui de ZONE2A à celui de ZONE2B.
Les zones participant aux sélections/omissions peuvent provenir de n’importe quel fichier, à condition qu’elles soient citées dans le format. Le mot-clé DYNSLT est parfois obligatoire.

4 - Les fichiers logiques 115
Pour chaque enregistrement du fichier primaire, on voit tous les enregistrements du fichier secondaire qui sont en concordance (exemple 4.23). ENTETE CLIENT NUMFAC NUMCLI DATE NUMCLI NOMCLI ADRESSE 950602 12345 010695 12345 DEVILLE PARIS 950601 67890 020695 67890 PAGNOL NIMES 950603 12345 030695 12345 DOUBLE LYON
Exemple 4.23a : contenu des fichiers ENTETE et CLIENT.
NUMFAC NUMCLI NOMCLI ADRESSE DATE 950601 67890 PAGNOL NIMES 020695 950602 12345 DEVILLE PARIS 010695 950602 12345 DOUBLE LYON 010695 950603 12345 DEVILLE PARIS 030695 950603 12345 DOUBLE LYON 030695
Exemple 4.23b : le contenu du fichier logique joint tel qu’il est vu par un programme. Les DDS correspondent à l’exemple 4.20. Remarquer que les factures avec 12345 comme numéro de client donnent 2 enregistrements, l’un pour le client DEVILLE, l’autre pour DOUBLE.
Pour résumer les contraintes sur l’utilisation du mot-clé DYNSLT, il faut noter qu’il doit être employé dans les cas suivants :
• si aucune clé n’est précisée ;
• si le mot-clé JDFTVAL est codifié ;
• si, d’une manière générale, les zones participant aux sélections/omissions sont dans des fichiers différents.
Sur le plan des performances, il est important de noter qu’il faut :
• chaque fois que cela est possible, essayer de citer en premier le fichier qui a le plus petit nombre d’enregistrements ;
• envisager l’opportunité d’utiliser DYNSLT ;
• tenter de codifier la clé afin de partager un chemin d’accès existant ;
• penser que le système a besoin d’un chemin d’accès pour la deuxième zone citée en regard de JFLD (la plus à droite). S’il n’existe pas, ce chemin d’accès est créé.
Conclusions sur les fichiers logiques joints

116 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Les fichiers logiques joints sont indispensables pour ceux qui désirent utiliser pleinement la base de données relationnelle de l’AS/400. Ils permettent d’avoir d’un coté une bonne organisation des données, sans redondance, et de l’autre des programmes simples qui gèrent un minimum de fichiers. Ils sont cependant limités à la lecture des enregistrements, la mise à jour leur étant interdite.
Il faut noter que la jointure peut être réalisée à l’aide de certains utilitaires (Query, PCS/400 et CA/400...) et par la commande OPNQRYF. Les concordances peuvent même être établies, non plus en fonction de l’égalité des zones, mais en fonction d’un opérateur logique (plus grand que, plus petit que...).
Les principaux mots-clés des DDS des fichiers logiques Les DDS de niveau Fichier
ALTSEQ définit une table de tri pour les zones clés ; DYNSLT utilise la sélection dynamique des enregistrements ;
JDFTVAL précise que les enregistrements n’ayant pas de
correspondances sont vus (fichiers logiques joints seulement) ;
REFACCPTH indique avec quel fichier doit se faire le partage des chemins d’accès (fichiers logiques non joints seulement) ;
UNIQUE signifie que deux enregistrements ne pourront avoir une même valeur de clé.
Les enregistrements ayant une même valeur de clé apparaîtront triés dans l'ordre suivant :
FCFO l’enregistrement le premier modifié est renvoyé d’abord ;
FIFO le premier écrit dans le fichier est renvoyé d’abord (valeur par défaut) ;
LIFO le dernier écrit dans le fichier est renvoyé d’abord.
Les DDS de niveau Format
FORMAT ramène le format d'un fichier physique existant

4 - Les fichiers logiques 117
(fichiers logiques non joints seulement) ; JDUPSEQ trie les enregistrements à valeur de clé dupliquée, en
fonction d’une zone d’un fichier secondaire (fichiers logiques joints seulement) ;
JFILE liste des fichiers à joindre (fichiers logiques joints seulement) ;
JFLD définit un couple de zones dont on va comparer les valeurs pour effectuer la jointure (fichiers logiques joints seulement) ;
JOIN définit un couple de fichiers à joindre (fichiers logiques joints seulement) ;
PFILE définit le (ou les) fichier(s) physique(s) vu(s) par le fichier logique (fichiers logiques non joints seulement) ;
TEXT indique les commentaires.
Les DDS de niveau Zone
ALIAS définit un nom de substitution pour une zone (à destination des programmes) ;
CHECK précise les caractéristiques de la saisie ;
CHKMSGID identifie le message d'erreur à renvoyer en cas de saisie d'une valeur hors du domaine de validité ;
COLHDG définit des en-têtes de colonne (jusqu'à trois) ; COMP ou CMP permet la comparaison par rapport à une valeur ; CONCAT provoque la concaténation des zones du fichier
physique ; DATFMT définit le format d'une zone de type Date ; DATSEP définit le séparateur pour une zone de type Date ; EDTCDE donne la définition du code d'édition ; EDTWRD donne la définition du mot d'édition ; FLTPCN donne la précision des zones de type virgule
flottante ; JREF précise l’origine d’une zone présente dans plusieurs
fichiers (fichiers logiques joints seulement) ; RANGE définit un domaine de validité ; REFSHIFT conditionne le clavier ; TEXT précise les commentaires ; TIMFMT définit le format d'une zone de type Heure ; TIMSEP définit le séparateur pour une zone de type Heure ;

118 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
VALUES donne la liste des valeurs admises ; VARLEN définit une zone de longueur variable.
Les DDS de niveau Clé
Les enregistrements apparaissent triés :
ABSVAL sur la valeur absolue des zones ; DESCEND dans l'ordre décroissant ; DIGIT selon la partie numérique de la représentation
hexadécimale ; NOALTSEQ en inhibant, pour cette zone clé, la table de tri
spécifiée dans le mot-clé altseq ; SIGNED en tenant compte du signe (la valeur par défaut du tri
classique) ; UNSIGNED en ignorant le signe ; c'est la représentation hexadé-
cimale qui est utilisée pour effectuer le tri ; ZONE selon la partie alphabétique de la représentation hexa-
décimale.
Les DDS de niveau Sélection
ALL s’applique à tous les enregistrements ; CMP ou COMP est un opérateur de comparaison ; RANGE définit un intervalle de valeurs ; VALUES liste les valeurs permises.
La commande de création des fichiers logiques
La commande CRTLF permet de créer un fichier logique à partir des DDS. De nombreux paramètres étant identiques à ceux définis pour la commande CRTPF, nous n’y reviendrons pas. Nous ne présenterons ici que les paramètres propres aux fichiers logiques, regroupés en thèmes. Un récapitulatif de tous les mots-clés est présenté à la fin de ce chapitre.
Les membres
Comme pour les fichiers physiques, on ne peut ajouter qu’un seul membre lors de la création d’un fichier logique. Le paramètre MBR précise le nom de ce membre, s’il existe. Le paramètre DTAMBRS définit le, ou les, membre(s) du, ou des,

4 - Les fichiers logiques 119
fichier(s) physique(s) vu(s) par le fichier logique. Les rapports entre les membres des fichiers physiques et ceux du fichier logique peuvant être relativement complexes, ils feront l’objet d’un chapitre particulier.
Le programme sélecteur de format
Pour les fichiers logiques multiformats, un programme peut être utilisé pour définir, par l’intermédiaire du format, quel est le fichier qui doit recevoir un nouvel enregistrement. Le paramètre FMTSLR permet de préciser le nom et la bibliothèque de ce programme. Ce sujet à déjà été traité dans la section Les fichiers logiques multiformats - La mise à jour du présent chapitre.
Estimation de la taille d'un fichier logique
Nous pouvons estimer la taille d'un fichier logique à l'aide de la formule suivante :
TAILLE = ((nombre de membres) × 2560) + 1024
Il faut ajouter à cela l'espace occupé par le chemin d'accès, pour chacun des membres, estimé par la formule suivante :
TAILLE DU CHEMIN D'ACCES = (nombre d'enregistrements vus × (longueur de la clé + 8) × 0,8 × 1,85) + 4096
Comme pour les fichiers physiques, 0,8 est un cœfficient qui correspond à une compression moyenne. 1,85 est le facteur qui permet de prendre en compte la place réservée par le système pour l'extension du chemin d'accès.
La commande DSPFD permet de visualiser la place réellement occupée par un fichier physique, ou logique.
Pour être précis il faut rajouter que le système maintient des structures qui occupent aussi un certain espace disque. Nous ne les détaillerons pas car elles peuvent paraître comme négligeables.
Les principaux paramètres de la commande CRTLF
Voici la liste des principaux mots-clés de la commandes CRTLF , et de CHGLF , rangés par ordre alphabétique :
AUT définit les droits publics ; DTAMBRS précise les noms des différents membres des fichiers
120 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
physiques vus par le membre du fichier logique ; FILE est le nom du fichier à créer ; FILETYPE spécifie si le fichier créé est destiné à contenir des données
ou des sources ; FLAG indique le niveau de gravité minimum des messages pour
qu’ils soient placés dans le listing de compilation ; FMTSLR donne le nom du programme sélecteur de format ; FRCACCPTH précise quand le chemin d’accès est réellement écrit sur
disque ; FRCRATIO indique quand le système doit écrire réellement les
enregistrements sur disque ; GENLVL indique le niveau de gravité à partir duquel le fichier ne sera
pas créé ; LVLCHK précise si l’identificateur de format doit être comparé à celui
du programme ; MAINT indique, si le fichier a une clé, comment est maintenu le
chemin d’accès ; MAXMBR précise le nombre maximum de membres que pourra
contenir le fichier ; MBR donne le nom du membre ajouté lors de la création du
fichier physique ; OPTION précise le type d’état qui est généré lors de la compilation ;
RECOVER précise le mode de reconstruction du chemin d’accès après
incident ; SHARE définit s’il peut y avoir partage de l’ODP ; SRCFILE est le nom du fichier source ; SRCMBR est le nom du membre source ; SYSTEM spécifie le nom du système sur lequel est créé le fichier ; TEXT correspond au commentaire ; UNIT indique l’unité sur laquelle le système doit tenter de placer
le fichier et ses chemins d’accès ; WAITFILE précise le délai, en secondes, pendant lequel un programme
pourra attendre que fichier soit libéré ; WAITRCD précise le délai, en secondes, pendant lequel un programme
pourra attendre qu’un enregistrement soit libéré.
Les membres
Supposons, dans un premier temps, qu’un fichier logique voit un seul fichier physique. Si ce dernier possède un seul membre, alors le fichier logique n’aura, lui

4 - Les fichiers logiques 121
aussi, qu’un seul membre. Le schéma se complique un peu si le fichier physique a plusieurs membres. Un membre du fichier logique peut voir un membre en particulier, une série de membres et même tous les membres du fichier physique (figure 4.9). C’est le paramètre DTAMBRS de la commande CRTLF ou de ADDLFM , qui permet d’effectuer ces affectations.
STATSTOCK
PARIS
NIMES
LYON
PARIS
NIMES
SUD
FRANCE
Figure 4.9 : fichier logique pointant sur un fichier physique multimembre. Le fichier logique STAT est utilisé pour établir des statistiques sur les stocks. Le membre PARIS voit les enregistrements du membre PARIS du fichier physique ; NIMES voit le membre NIMES ; SUD voit le membre NIMES et le membre LYON ; enfin FRANCE voit tous les enregistrements de tous les membres. Selon le membre du fichier logique sélectionné, le programme de statistique traitera un stock particulier, ou le sud, ou toute la France. Les choses peuvent se compliquer à souhait quand on sait qu’un fichier logique peut voir plusieurs fichiers physiques. Chacun des membres du fichier logique peut voir, tout ou partie, des membres de chacun des fichiers physiques. Il faut d’ailleurs remarquer que le paramètre DTAMBRS possède deux lignes autorisant la saisie d’autres valeurs (avec un +). L’une est pour saisir les différents fichiers physiques, l’autre pour les différents membres de chacun de ces fichiers physiques.
La figure 4.10 présente un fichier logique s’appuyant sur deux fichiers physiques.

122 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
STAT STOCK
PARIS
NIMES
LYON
ANNEE
1994
1995
1996
A
B
C
D
Figure 4.10 : fichier logique pointant sur des fichiers physiques multimembres. Le fichier
logique STAT voit les enregistrements des fichiers physiques STOCK et ANNEE. Au maximum trente deux membres de fichiers physiques peuvent être vus par un membre d’un fichier logique.
A la création d’un fichier logique, un seul membre peut être défini. D’autres pourront être ajoutés, par la suite, avec la commande ADDLFM .
En conclusion :
Chaque membre d’un fichier logique peut être défini sur un ou plusieurs membres de chacun des fichiers physiques sur lequel il pointe.

4 - Les fichiers logiques 123
Les chemins d’accès Un fichier logique est constitué d’une partie descriptive, comme tous les objets de l’OS/400, et d’un chemin d’accès par membre. Ces derniers constituent donc la partie fondamentale de ces fichiers. Nous allons voir comment les utiliser efficacement.
Performances D’une manière générale, les chemins d’accès sont utilisés pour diminuer le temps de traitement des données dont on connaît la valeur (cette valeur étant considérée comme la clé). Ils peuvent être créés en définissant une clé dans un fichier physique ou dans un fichier logique. Pour certaines opérations et s’ils n’existent pas, le système est amené à créer ses propres chemins d’accès de manière permanente ou temporaire. Il est donc important de bien comprendre les mécanismes mis en œuvre par l’OS/400 afin d’anticiper ses besoins en créant, au préalable, les chemins d’accès qui lui seront utiles. Les temps de réponses seront alors bien meilleurs. Voici quelques fonctions du système qui utilisent ces structures :
• SQL
Le produit SQL utilise au maximum les chemins d’accès. Son optimiseur cherche systématiquement s’il en existe un qui pourrait lui convenir ;
• Le contrôle d’intégrité référentielle
Le contrôle d’intégrité référentielle définit un lien, entre un fichier parent et un fichier dépendant, qui s’appuie sur un chemin d’accès. S’il n’existe pas, il est automatiquement créé. Il n’est pas visible, mais le système le gère complètement (partage possible, sauvegarde automatique avec le fichier physique) ;
• La commande OPNQRYF
Si les critères de sélection le permettent, la commande OPNQRYF utilise les chemins d’accès existants ce qui peut nettement améliorer ses performances.
Les limites
On ne peut augmenter indéfiniment le nombre de chemins d’accès sur un système.

124 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400

4 - Les fichiers logiques 125
Voici quelques-uns des effets néfastes liés à leur prolifération :
• la maintenance, c’est-à-dire le temps que passe le système à mettre à jour les chemins d'accès, est extrêmement coûteuse en ressources (CPU, entrées/sorties disque, mémoire principale...). Nous avons vu quelques mots-clés qui permettent de limiter cette consommation, mais l’accroissement exagéré du nombre des chemins d'accès est un facteur dégradant pour les performances ;
• en cas d’arrêt anormal du système, la reconstruction des chemins d'accès qui accompagne l’IPL suivant peut prendre un temps considérable (plusieurs heures pour de gros fichiers). La phase de démarrage du système sera d’autant plus longue qu’il y a de chemins d'accès à reconstruire. Toutefois, la fonction SMAPP, que nous détaillerons avec la journalisation des fichiers logiques, peut limiter cette phase ;
• l’optimiseur (SQL, OPNQRYF...) peut devenir inefficace car s’il ne trouve pas rapidement un bon chemin d'accès, il peut abandonner la recherche avant d’avoir examiné toutes ces structures.
Il est donc important de limiter le nombre de fichiers logiques au strict minimum et de détruire ceux qui sont devenus inutiles.
La reconstruction
La reconstruction d’un chemin d'accès a lieu quand il n’est plus en concordance avec le(s) fichier(s) physique(s). L’évènement qui a généré cette discordance est généralement un arrêt anormal du système. Le paramètre RECOVER des commandes CRTPF, CRTLF , CHGPF et CHGLF précise quand le chemin d'accès associé à un fichier est reconstruit après un arrêt anormal du système (pendant ou après l’IPL, ou à l’ouverture du fichier).
Le temps de reconstruction d’un chemin d'accès peut être optimisé en fonction des considérations suivantes :
• plus la clé est longue, plus important sera le temps de reconstruction ;
• la durée de cette opération dépend directement du nombre d’enregistrements des fichiers à traiter ;
• la taille du pool de mémoire dans lequel s’effectue le travail de reconstruction influe notablement sur les performances ;

126 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
• la rapidité des disques est un facteur essentiel car tous les enregistrements doivent être lus lors d’une reconstruction ;
• même l’ordre des enregistrements dans le fichier peut influer favorablement.
Pour prévenir la reconstruction, qui est dans tous les cas coûteuse en terme de ressources, il est recommandé de journaliser les chemins d'accès ou d’utiliser la fonction SMAPP. Le système s’appuie sur les informations du journal pour remettre très rapidement en état le chemin d'accès. Une autre solution, plus radicale, consiste à restaurer le fichier physique et ses chemins d'accès qui auront été sauvegardés au préalable.
La sauvegarde
Les commandes SAVOBJ, SAVCHGOBJ et SAVLIB permettent de sauvegarder les chemins d'accès associés à un fichier physique.
La gestion des fichiers logiques La définition
Les caractéristiques du fichier logique sont définies à sa création par la commande CRTLF , mais elles peuvent être modifiées par la suite à l’aide de la commande CHGLF . Les modifications ainsi apportées sont permanentes, et valables pour tous les utilisateurs. La substitution, par la commande OVRDBF, permet de modifier les caractéristiques d’un fichier pour le travail en cours seulement. Le chapitre 7 traite ce sujet pour tous les types de fichier.
La destruction
Un fichier, quel qu’il soit, et à condition d’avoir les droits suffisants, peut être détruit par la commande DLTF . Il est alors irrécupérable. RMVM enlève un membre, détruisant ainsi les enregistrements qu’il contient. La structure du fichier est conservée car sa partie descriptive n’est pas touchée. On préfèrera cette commande à DLTF chaque fois qu’il s’agira de détruire un fichier pour le recréer par la suite. Enlever un membre est beaucoup plus rapide que la destruction complète d’un fichier et, surtout, ajouter un membre à un fichier existant n’est rien par rapport à la création d’un nouveau fichier.
La visualisation

4 - Les fichiers logiques 127
Les caractéristiques générales d’un fichier sont visualisables (ou même imprimables) par la commande DSPFD. On peut ainsi connaître toutes les valeurs définies pour les paramètres de la commande CRTLF ou éventuellement de CHGLF . DSPFFD, dont la syntaxe est proche, affiche le détail de toutes les zones qui composent le fichier.
Il n’existe pas de commande équivalente à DSPPFM qui affiche le contenu d’un membre d’un fichier physique. On devra utiliser des utilitaires tels que Query, SQL et éventuellement DFU pour les fichiers logiques non joints.
Les membres
ADDLFM permet d’ajouter un membre à un fichier logique et RMVM de l’enlever. Les caractéristiques d’un membre peuvent être modifiées grâce à CHGLFM . Il s’agit essentiellement du commentaire associé à ce membre et de la date d’expiration de ses enregistrements. RNMM est à utiliser pour renommer un membre.
La sauvegarde
Les chemins d’accès des fichiers logiques peuvent être sauvegardés. Non pas qu’ils soient indispensables – aucune donnée n’est perdue lors de la destruction d’un fichier logique – mais parce que leur reconstruction peut prendre un temps considérable. Il est donc intéressant de sauvegarder les chemins d’accès des fichiers logiques contenant de nombreux enregistrements afin de gagner plusieurs heures lors de leur éventuelle restauration. Cette opération doit être effectuée en même temps que la sauvegarde des fichiers physiques concernés pour que ces objets soient cohérents entre eux lors de la restauration.
Les commandes de sauvegarde et de restauration classiques s’appliquent aux fichiers logiques (SAVOBJ, SAVCHGOBJ, SAVLIB , RSTOBJ, RSTLIB ...).
Les utilitaires
La plupart des utilitaires traitent aussi bien, et de manière transparente, les données issues des fichiers physiques que celles vues par les fichiers logiques. La seule exception est peut-être DFU qui ne peut être utilisé avec les fichiers logiques joints.

128 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Conclusions sur les fichiers logiques
Les fichiers logiques sont vraiment des objets incontournables de la base de données de l’OS/400.
Du point de vue du développement, ils sont garant de l’indépendance entre les programmes et les données, et assurent une programmation simplifiée car les sélections d’enregistrements peuvent être réalisées à l’extérieur des programmes.
Sur le plan de la sécurité, ils jouent le rôle de filtre ne laissant voir qu’une partie des données.
Enfin, au niveau des performances, il faut contrôler leur développement car, en trop grand nombre, ils pourraient asphyxier le système qui passerait son temps à maintenir les chemins d’accès. Une bonne utilisation des mots-clés des DDS et des paramètres de la commande CRTPF procure des temps de réponses optimaux grâce à une gestion efficace des chemins d’accès.
Les principales commandes
ADDLFM ajouter un membre à un fichier logique ; CHGLF modifier les caractéristiques d’un fichier logique ; CHGLFM modifier les caractéristiques d’un membre d’un fichier
logique ; CRTLF créer un fichier logique ; DLTF détruire un fichier ; DSPFD afficher la description d’un fichier ; DSPFFD afficher la description des zones d’un fichier ; OVRDBF substituer un fichier base de données ; RMVM enlever un membre à un fichier ; RNMM renommer un membre.
Les principaux menus
CMDLF, FILE, FILE2, CMDFILE, CMDMBR, CMDDBF, CMDDB.

4 - Les fichiers logiques 129
LES FICHIERS LOGIQUES 83
Principes 83 Présentation 83 Structure 83 Utilisation 85 Les différents types de fichiers logiques 90 Les étapes de la création d'un fichier logique 91
Les fichiers logiques non-joints 91 Principes 91 La référence aux fichiers physiques 92 Sélection et omission 94 Les chemins d’accès 97 Les redéfinitions de zones 99 Les fichiers logiques multiformats 102 Conclusions sur les fichiers logiques non joints 108
Les fichiers logiques joints 109 Principes 109 La codification 109 Remarques 114 Conclusions sur les fichiers logiques joints 115
Les principaux mots-clés des DDS des fichiers logiques 116 Les DDS de niveau Fichier 116 Les DDS de niveau Format 116 Les DDS de niveau Zone 117 Les DDS de niveau Clé 118 Les DDS de niveau Sélection 118
La commande de création des fichiers logiques 118 Les membres 118 Le programme sélecteur de format 119 Estimation de la taille d'un fichier logique 119 Les principaux paramètres de la commande CRTLF 119
Les membres 120
Les chemins d’accès 123 Performances 123 Les limites 123 La reconstruction 125

130 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
La sauvegarde 126
La gestion des fichiers logiques 126 La définition 126 La destruction 126 La visualisation 126 Les membres 127 La sauvegarde 127 Les utilitaires 127
Conclusions sur les fichiers logiques 128
Les principales commandes 128
Les principaux menus 128
—A— ADDLFM 117; 122 ALL 94
—C— CA/400 112 CHAIN 101 chemin d’accès 96; 119 CHGLF 120 CHGPF 120 CMP 94 CONCAT 98 CRTLF 91; 115; 120 CRTPF 120
—D— DFU 111; 122 DLTF 121 DSPFD 96; 116 DTAMBRS 115 DYNSLT 97; 109; 111
—E— EDTOBJAUT 88 ET 95

84 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
—F— fichier logique 83 fichier logique joint 106 fichier logique multiformat 100 fichier logique non-joint 91 FMTSLR 104
—I— IBM/36 104 identificateur de format 86
—J— JDFTVAL 109 JDUPSEQ 108 JFILE 107 JFLD 107 JOIN 107
—M— membre 117
—O— omission 93 OPNQRYF 112; 119 OU 95 OVRDBF 121
—P— PCS/400 112 PFILE 91
—Q— QSYSTRNTBL 99 Query 112
—R— RANGE 94 READE 101 RECOVER 120 REFACCPTH 96 RENAME 98 RMVM 121

4 - Les fichiers logiques 85
RPG 85
—S— sauvegarde 121 Sécurité 87 sélecteur de format 104 Sélection 93 SGBDR 83 SQL 119
—U— Union 93 UNIQUE 89
—V— VALUES 94
—W— WRITE 104

Chapitre 5
Sécurité et intégrité des données
Introduction De nombreux événements tels que défaut d’un composant, incendie, inondation, sabotage... peuvent provoquer la perte de tout ou partie des données d’un système. L’OS/400 fournit de nombreuses méthodes de protection de l’information qui permettent d’assurer l’intégrité et la sécurité des données. Intégrité des données signifie que les informations contenues dans la base de données sont dans un état stable et cohérent. Les données sont valides et surtout elles sont cohérentes entre elles. La sécurité correspond à l’ensemble des fonctions qui assurent qu’un utilisateur ne fait que ce qui lui est permis de faire. Pour assurer l’intégrité et la sécurité des données, l’AS/400 propose des dispositifs logiciels et matériels résumés dans le tableau suivant : Nom Nature Description Batterie Matériel (sur
certains modè-les seulement)
Permet au système de terminer normalement les opérations en cours lors d’une coupure prolongée d’alimentation.
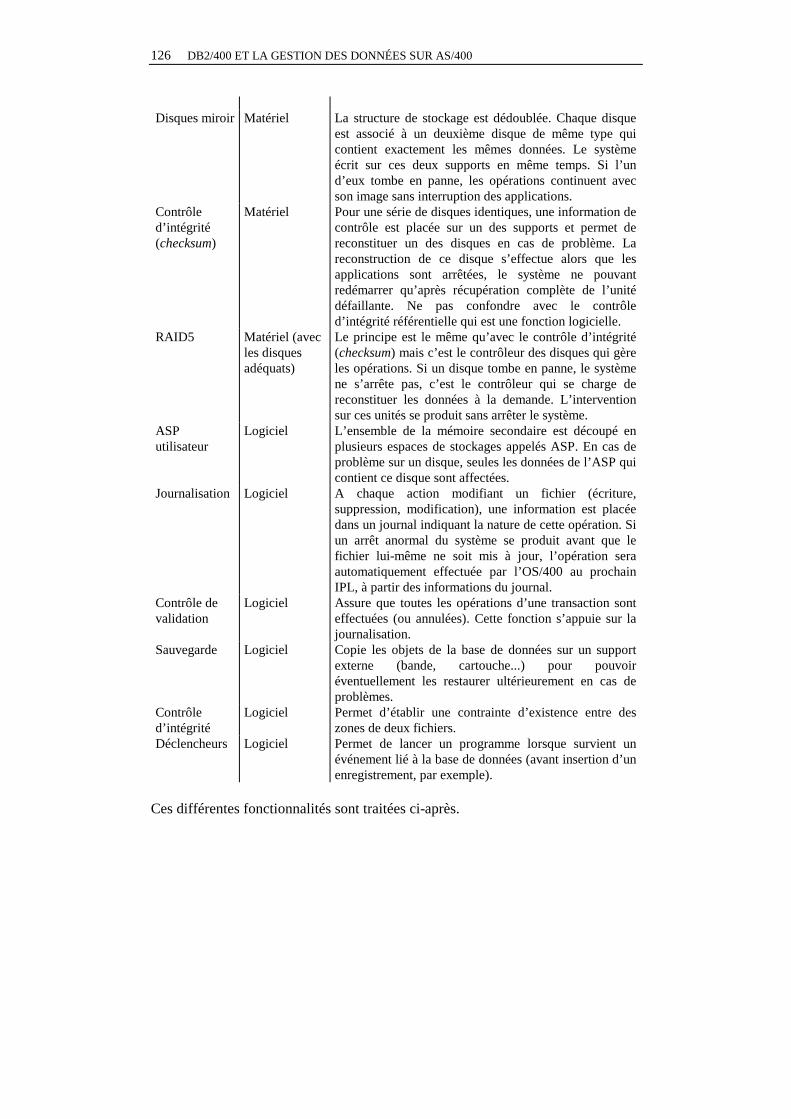
126 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Disques miroir Matériel La structure de stockage est dédoublée. Chaque disque est associé à un deuxième disque de même type qui contient exactement les mêmes données. Le système écrit sur ces deux supports en même temps. Si l’un d’eux tombe en panne, les opérations continuent avec son image sans interruption des applications.
Contrôle d’intégrité (checksum)
Matériel Pour une série de disques identiques, une information de contrôle est placée sur un des supports et permet de reconstituer un des disques en cas de problème. La reconstruction de ce disque s’effectue alors que les applications sont arrêtées, le système ne pouvant redémarrer qu’après récupération complète de l’unité défaillante. Ne pas confondre avec le contrôle d’intégrité référentielle qui est une fonction logicielle.
RAID5 Matériel (avec les disques adéquats)
Le principe est le même qu’avec le contrôle d’intégrité (checksum) mais c’est le contrôleur des disques qui gère les opérations. Si un disque tombe en panne, le système ne s’arrête pas, c’est le contrôleur qui se charge de reconstituer les données à la demande. L’intervention sur ces unités se produit sans arrêter le système.
ASP utilisateur
Logiciel L’ensemble de la mémoire secondaire est découpé en plusieurs espaces de stockages appelés ASP. En cas de problème sur un disque, seules les données de l’ASP qui contient ce disque sont affectées.
Journalisation Logiciel A chaque action modifiant un fichier (écriture, suppression, modification), une information est placée dans un journal indiquant la nature de cette opération. Si un arrêt anormal du système se produit avant que le fichier lui-même ne soit mis à jour, l’opération sera automatiquement effectuée par l’OS/400 au prochain IPL, à partir des informations du journal.
Contrôle de validation
Logiciel Assure que toutes les opérations d’une transaction sont effectuées (ou annulées). Cette fonction s’appuie sur la journalisation.
Sauvegarde Logiciel Copie les objets de la base de données sur un support externe (bande, cartouche...) pour pouvoir éventuellement les restaurer ultérieurement en cas de problèmes.
Contrôle d’intégrité
Logiciel Permet d’établir une contrainte d’existence entre des zones de deux fichiers.
Déclencheurs Logiciel Permet de lancer un programme lorsque survient un événement lié à la base de données (avant insertion d’un enregistrement, par exemple).
Ces différentes fonctionnalités sont traitées ci-après.

5 - Sécurité et intégrité des données 127
La journalisation
La journalisation est la fonction de base qui permet de préserver l’intégrité des données. Elle doit être considérée avec attention lors de la définition de la stratégie de protection de l’information.
Les principes
Introduction
La journalisation est l’une des composantes essentielles de la stratégie de sauvegarde de la base de données. Mais elle est aussi utilisée par le système pour ses propres fonctions. Nous allons, dans cette première section, définir les principes généraux de la journalisation, puis nous traiterons de son apport pour la base de données.
Quand un changement est effectué sur un fichier journalisé, des informations sur cette opération sont placées dans un objet appelé récepteur de journal (de type *JRNRCV) avant que la modification proprement dite ne soit appliquée au fichier. Cette information, appelée poste, contient des données sur le travail (utilisateur, identification du travail, programme, date, heure...), l’image de l’enregistrement après modification et éventuellement l’image de l’enregistrement avant modifica-tion.
Le système place également dans les récepteurs des informations pour identifier les actions les plus importantes effectuées sur les fichiers : sauvegarde, restauration, initialisation, réorganisation et même IPL.
Le premier intérêt de la journalisation consiste à diminuer les problèmes liés à un arrêt anormal du système. Nous avons déjà signalé au chapitre 3 que les opérations sur les enregistrements peuvent être considérées comme effectuées, pour un utilisateur, alors que les mises à jour ne sont pas réellement écrites sur disque, mais sont simplement appliquées en mémoire principale. En cas d’arrêt brutal du système, les données correspondantes peuvent être perdues. Avec la journalisation, le système vérifie à l’IPL si les récepteurs sont bien synchronisés avec les fichiers. Autrement dit, il s’assure que tout ce qui est dans les récepteurs de journaux est réellement écrit dans les fichiers. Si ce n’est pas le cas, il effectue automatique-ment les mises à jour correspondantes.
A partir du moment où l’information est placée dans un récepteur de journal, elle peut donc être considérée comme réellement écrite sur disque.

128 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Le deuxième intérêt de la journalisation réside dans la possibilité d’annuler, ou au contraire de refaire, chacune des opérations enregistrées dans le récepteur. Voici deux situations caractéristiques:
• en cas d’erreur grave sur un fichier, comme une destruction accidentelle, par exemple, il est toujours possible de restaurer la dernière version de ce fichier et d’appliquer toutes les modifications enregistrées depuis sa sauvegarde par la journalisation (sauf peut être la dernière si elle est à l’origine de la destruction). Les postes du journal doivent seulement contenir l’image des enregistrements après modification (appelée image après) ;
• en cas d’erreur de saisie, on peut enlever les opérations qui correspondent à tout ou partie d’un travail, à condition de maîtriser parfaitement les transactions concernées (plusieurs fichiers pouvant être concernés). L’image de l’enregistrement avant modification (image avant) doit alors figurer dans le journal pour pouvoir remonter les transactions.
La journalisation d’un fichier physique peut s’appliquer soit sur l’image après, soit sur les images avant et après. C’est au démarrage de la journalisation d’un fichier physique que l’on choisit le type de poste à générer. Il est clair que l’utilisation des deux types d’images est plus riche fonctionnellement, mais elle consomme un peu plus de ressources (CPU et disque). Il appartient à chacun de trouver le bon équilibre pour chacun des fichiers de son système.
La structure Pour la base de données, la journalisation s’applique aux fichiers physiques et aux fichiers logiques. Pour ces derniers, il s’agit de protéger uniquement les chemins d’accès.
Un fichier journalisé est rattaché à un journal . Cet objet, de type *JRN, ne contient aucune donnée proprement dite, mais permet seulement de définir les caractéristiques de la journalisation. Un journal est rattaché à un récepteur de journal qui va recevoir les données. Un poste est un enregistrement d’un récepteur, il correspond à tout ou partie d’une opération. La figure 5.1 présente la structure de la journalisation.
Compte-tenu des différents objets participant à la journalisation, il faut respecter des étapes bien précises avant de journaliser un fichier.

5 - Sécurité et intégrité des données 129
TRAVAIL
Informations de journalisation
Journal*JRN
Récepteur dejournal*JRNRCV
Un poste
Fichierphysique
Fichierlogique
Figure 5.1 : principe de la journalisation.
La mise en place Le récepteur de journal est le premier objet que l’on doit créer, ceci grâce à la commande CRTJRNRCV. Il est alors possible de créer un journal rattaché au récepteur précédemment défini en utilisant la commande CRTJRN. Il reste alors à définir les fichiers physiques et logiques qui seront associés à ce journal par les commandes STRJRNPF et STRJRNAP.
Voici un exemple simple :
/*Création du récepteur de journal RECEPT dans la bibliothèque PROD*/ CRTJRNRCV JRNRCV(PROD/RECEPT) /*Création du journal JRN dans la bibliothèque PROD*/ /*rattaché au récepteur précédemment défini*/ CRTJRN JRN(PROD/JRN) JRNRCV(PROD/RECEPT) /*Démarrage de la journalisation pour le fichier PF1 avec*/ /*images avant et après*/

130 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
STRJRNPF FILE(PROD/PF1) JRN(PROD/JRN) IMAGES(*BOTH)

5 - Sécurité et intégrité des données 131
Les récepteurs de journaux
Détachement
Un récepteur de journal est un objet sans taille qui s’agrandit au fur et à mesure des besoins (jusqu’à une limite supérieure à 2 milliards de postes, si vos disques le permettent !). Il est important de détacher un récepteur devenu trop gros pour le remplacer par un nouveau. Il est ainsi libéré du journal. Pour simplifier, et même automatiser ce travail, nous pouvons indiquer une taille, en kilo-octets, en regard du paramètre THRESHOLD de la commande CRTJRNRCV. Lorsque la taille du récepteur atteint ce seuil, le message CPF7099 est envoyé à la file d’attente de messages citée dans le paramètre MSG de la commande de création du journal (CRTJRN), par défaut QSYSOPR. Nous pouvons simplement automatiser le détachement du récepteur en associant un programme à la file d’attente ainsi définie.
Depuis la V3R1M0 de l’OS/400, la gestion des récepteurs peut être entièrement laissée au système si MNGRCV(*SYSTEM) est codifié pour le journal (dans les commandes CRTJRN ou CHGJRN).
Le détachement d’un récepteur est effectué par la commande CHGJRN. Le paramètre JRNRCV définit le nom du nouveau récepteur qui est automatiquement créé. La valeur JRNRCV(*GEN) laisse au système le soin de donner un nom au nouveau récepteur.
Dénomination
Voici les règles utilisées pour la génération automatique du nouveau nom :
• le nom sera composé au maximum de 6 caractères à gauche et se terminera par 4 positions numériques ;
• si l’ancien nom possède plus de 6 caractères à gauche, il sera tronqué à 6 ;
• si l’ancien nom possède moins de 6 caractères à gauche, ils seront conservés et ne seront pas complétés à 6 ;
• si l’ancien nom ne se termine pas par des caractères numériques, 0001 sera rajouté aux caractères de gauche déjà définis ;
• si l’ancien nom se termine par des caractères numériques, cette partie sera incrémentée de 1 ;
• une erreur sera renvoyée si la partie numérique est égale à 9999.

132 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
La figure 5.2 illustre cette génération automatique de nom. Ancien nom Nouveau nom R R0001 RCV RCV0001 RECEPTEUR RECEPT0001 RCV1 RCV2 RECEPT9999 ERREUR !
Figure 5.2 : règles utilisées pour la génération automatique de noms pour les récepteurs de journaux.
Il est donc important de bien connaître ces règles afin de choisir, dès le départ, un nom adapté, par exemple 6 caractères à gauche suivis de ‘0001’ tel que RECEPT0001.
Gestion
Une fois détaché, un récepteur de journal est dit EN LIGNE . Ses données sont disponibles pour toutes les fonctions de journalisation. Il est prudent de le sauvegarder (il est alors en état SAUVEGARDE), et si les probabilités de son utilisation sont faibles, on peut le détruire. La figure 5.3 résume les différents états des récepteurs de journaux.
R0009R0008R0007
R0007R0006
ATTACHEEN LIGNESAUVEGARDE
SAVxxx
JOURNAL
Récepteursde journaux
ETAT
Figure 5.3 : organisation des récepteurs de journaux.

5 - Sécurité et intégrité des données 133
Le récepteur R0009 est attaché au journal, c’est lui qui reçoit les postes de la journalisa-tion. R0008 est en ligne, R0007 a été sauvegardé. Les données de ces trois récepteurs sont disponibles pour des opérations liées à la journalisation. R0006 peut être restauré.
Pour des raisons évidentes de cohérence, il est important de conserver la continuité des récepteurs ; on ne peut pas, dans l’exemple de la figure 5.3 supprimer le récepteur R0008, car la chaîne des récepteurs serait alors brisée.
Les journaux
Gestion
La commande WRKJRNA permet de gérer les attributs d’un journal. Un premier écran présente les caractéristiques du journal et le récepteur attaché (figure 5.4).
Gestion des attributs de journal Journal . . . . . . : QACGJRN Bibliothèq ue . . . . : QSYS Pool mémoire sec . . : 1 Options t aille File attente messages: QSYSOPR récepte ur . . . . : *NONE Bibliothèque . . . : *LIBL Gestion récepteurs . : *USER Suppress récepteurs : *NO Texte . . . . . . . : Journal de comptabilité d es travaux Indiquez vos options, puis appuyez sur ENTREE. 8=Afficher les attributs Récepteur Option attaché Biblio COMTRA0004 COMTRA Fin F3=Exit F12=Annuler F13=Fichiers journalisés F14=Chemins d'accès journalisés F15=Gérer le rép ertoire des récepteurs
Figure 5.4 : gestion des attributs du journal QACGJRN par la commande WRKJRNA. Ce journal est utilisé par le système pour la comptabilité des travaux.
Gestion du répertoire des récepteurs Journal . . . . . . : QACGJRN Bibliothèq ue . . . . : QSYS Taille totale des récepteurs . . . . . . . . . . . . . . . . : 319488 Indiquez vos options, puis appuyez sur ENTREE. 4=Supprimer 8=Afficher les attributs Opt Récepteur Biblio Numéro attach Etat sauveg COMTRA0001 QSYS 00001 15/02/95 SAUV EGARDE 10/03/95 COMTRA0002 QSYS 00002 25/02/95 EN L IGNE 00/00/00 COMTRA0003 QSYS 00003 30/03/95 EN L IGNE 00/00/00 COMTRA0004 QSYS 00004 06/01/96 ATTA CHE 00/00/00 Fin F3=Exit F5=Réafficher F11=Taille F12=Annuler

134 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Figure 5.5 : gestion des récepteurs du journal QACGJRN par la commande WRKJRNA puis appui sur F15. Le récepteur COMTRA0004 est attaché, COMTRA0002 et COMTRA0003 sont détachés et ne sont pas encore sauvegardés, COMTRA0001 est détaché et a été sauvegardé le 10/03/95.
Sur cet écran, des touches de fonction permettent de gérer les récepteurs (F15), de visualiser les fichiers (F13) et les chemins d’accès (F14) journalisés (figure 5.5).
WRKJRN est la commande de gestion des journaux. Elle permet notamment de voir tous les journaux du système (figure 5.6).
Gestion de la journalisation Indiquez vos options, puis appuyez sur ENTREE. 2=Rétablissement avant 3=Rétablissement ar rière 5=Etat du journal 6=Rétablir journal endommagé 7=Rétablir récepteu rs de journal endommagés 9=Récepteurs associés au journal Opt Journal Biblio Texte QACGJRN QSYS Journal de comptabili té des travaux QAUDJRN QSYS QAOSDIAJRN QUSRSYS Journal for DIA files QCQJMJRN QUSRSYS JOURNAL FOR MANAGED S YSTEM LOG QDSNX QUSRSYS JOURNAL FOR DSNX LOG QLYJRN QUSRSYS QLYPRJLOG QUSRSYS QLZALOG QUSRSYS Journal for license m anagement QMAJRN QUSRSYS JOURNAL FOR ORDER DAT ABASE QO1JRN QUSRSYS QSNADS QUSRSYS Journal for SNADS fil es A suivre... Commande ===> F3=Exit F4=Invite F9=Rappel F12=Annuler
Figure 5.6 : gestion des journaux par la commande WRKJRN. Tous les journaux du système ont été sélectionnés.
Extraction d’informations
La journalisation peut être utilisée pour sécuriser la base de données, nous en reparlerons dans les sections suivantes. Elle peut aussi servir à des applications qui vont traiter les données contenues dans les postes, pour générer par exemple des rapports d’activités ou des traces lors de débogage. Cela apparaît d’autant plus intéressant quand on sait que des fonctions système comme la comptabilité des travaux et l’audit s’appuient sur la journalisation.

5 - Sécurité et intégrité des données 135
La commande DSPJRN permet d’extraire les postes d’un journal pour les placer dans un fichier, pour les afficher à l’écran ou pour les imprimer.
Chaque poste est caractérisé par un code et par un type qui indiquent à quoi correspondent les données qu’il contient. La liste des principaux types et codes est fournie dans l’annexe B. La figure 5.7 présente une copie d’un écran affiché par la commande DSPJRN.
Postes du journal Journal . . . . . . : QACGJRN Bibliothè que . . . . : QSYS Indiquez vos options, puis appuyez sur ENTREE. 5=Afficher le poste complet Opt Séquence Code Type Objet Biblio Travail Heure 5 13459 J PR PCCGS1 10:08:19 13461 A JB PREPARDATE 10:09:51 13462 A JB CLIENT1 11:50:35 13463 A JB PCCGS1 11:53:27 13464 A JB PCCGS1 11:53:29 13465 A JB CLIENT1 11:56:54 13466 A JB PCCPS2 13:48:22 13467 A JB PCCP 13:48:30 13468 A JB PCCP 13:48:33 13469 A JB QXFSERV 13:49:06 13470 A JB PCCP 14:36:28 13471 A JB PCCP 14:36:28 + F3=Exit F12=Annuler
Figure 5.7-a : écran de la commande DSPJRN appliquée au journal QACGJRN de QSYS correspondant à la Comptabilité des travaux de l’OS/400. Le premier poste (code J,
type PR) correspond au précédent récepteur. Les postes A-JB décrivent un travail.
Poste de journal Objet . . . . . . . : Bibliothèq ue . . . . : Membre . . . . . . . : Séquence . . . . . . : 13459 Code . . . . . . . . : J - Opération journal ou récepteur de journal Type . . . . . . . . : PR - Précédents récepteur s de journal Données spécifiques du poste Colonne *...+....1....+....2....+....3....+.. ..4....+....5 00001 'COMTRA0001COMTRA ' Fin Appuyez sur ENTREE pour continuer. F3=Exit F6=Données du poste seulement F10=Détai ls du poste seulement F11=Format hexadécimal F12=Annuler F24=Autre s touches
Figure 5.7-b : visualisation d’un poste du journal de type J-PR. Cet écran est affiché après la saisie de l’option 5 en regard du premier poste de la figure 5.7-a. Le précédent
récepteur était COMTRA0001 de la bibliothèque COMTRA.

136 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
La commande DSPJRN permet de sélectionner les postes à traiter en fonction de nombreux critères tels que certains récepteurs de journaux, les dates et heures de début et de fin, l’identification d’un travail, le type de poste...
L’envoi des postes vers un fichier physique permet de mettre en forme les données de la journalisation. Pour la comptabilité des travaux, par exemple, le format des enregistrements est celui du fichier QADSPJRN (ou QADSPJR2) de QSYS.
Optimisation
Une bonne utilisation des paramètres et une gestion rigoureuse assurent une journalisation sécurisée et efficace. Nous allons maintenant voir comment optimiser les principaux aspects de la journalisation.
La sécurité
Les données contenues dans les récepteurs sont utilisées pour redémarrer rapidement les applications après un incident. Elles permettent notamment de replacer la base de données dans un état stable et cohérent par application des postes sur les fichiers restaurés. A ce titre, les récepteurs peuvent être considérés comme critiques au niveau de la sécurité.
Pour augmenter la fiabilité de la journalisation, il est possible de placer les récepteurs dans un ASP différent de celui qui contient les fichiers. Il suffit pour cela de les rattacher à une bibliothèque située dans l’ASP adéquat (commande CRTJRNRCV). En cas de problème sur l’ASP qui contient les fichiers, il est simple de reconstruire la base de données à partir des sauvegardes et des récepteurs qui ont été épargnés car isolés dans un autre ASP.
Si c’est l’ASP contenant les récepteurs qui subit l’incident, cela n’a aucun effet sur les fichiers qui sont préservés par leur situation sur un autre disque.
Cette sécurité peut encore être accrue car un journal peut être attaché à 2 récepteurs (situés si possible dans des ASP différents). Les informations sont alors écrites simultanément sur ces 2 objets. En cas d’incident, on peut espérer qu’il y en aura toujours un en parfait état.
C’est dans la commande CRTJRN que l’on doit saisir le nom de ces deux récepteurs.
Place occupée
Pour la journalisation des fichiers physiques, la taille d’un poste, en octet, peut être estimée par la formule :

5 - Sécurité et intégrité des données 137
78 + taille d’un enregistrement
où 78 représente les entrées système.
Ainsi, pour un enregistrement de 122 octets de long, le poste créé occupera environ 200 octets. Si le fichier est journalisé avec image avant et après (STRJRNPF IMAGES(*BOTH)), chaque enregistrement modifié génère deux postes. Dans ce cas, la taille du récepteur est plus importante que si le fichier était journalisé en image après seulement. La différence paraît toutefois minime, à moins que les enregistrements ne soient constamment modifiés. Il est donc conseillé de choisir la journalisation complète (image avant et après) qui procure un maximum de fonctionnalités, d’autant que le supplément de CPU consommé peut paraître négligeable.
Toujours pour la journalisation des fichiers physiques, il faut ajouter aux postes directement liés aux enregistrements des postes générés par la gestion des fichiers.
Chaque opération effectuée sur un fichier journalisé crée au moins un poste. C’est le cas pour certaines commandes (CLRPFM , INZPFM , RMVM , DLTF , MOVOBJ , RNMOBJ , SAVOBJ, SAVLIB ...) et pour chaque ouverture et fermeture. Ces dernières entrées peuvent être omises du journal si OMTJRNE(*OPNCLO) est spécifié pour la commande STRJRNPF. Les performances lors de l’ouverture et de la fermeture des fichiers sont ainsi améliorées et la taille des récepteurs est diminuée. Par contre, les paramètres TOJOBO et TOJOBC des commandes APYJRNCHG et RMVJRNCHG ne seront plus utilisables car ils font référence à l’ouverture et à la fermeture des fichiers. Ces commandes sont traitées au sous-chapitre consacré à la journalisation des fichiers physiques.
Performances
La journalisation des fichiers physiques est réputée pénalisante sur le plan des performances. Il est donc important de gérer au mieux cette fonction afin d’obtenir des temps de réponse minima.
Certains paramètres permettent une relative optimisation. Nous avons déjà signalé au chapitre précédent l’intérêt du paramètre OMTJRNE pour ne pas ralentir les ouvertures et fermetures de fichiers, et de la mise en œuvre éventuelle de l’image avant seulement.
Il est important de bien comprendre le fonctionnement de la journalisation pour répartir efficacement les charges de travail des bras d’accès disques afin d’éviter les goulots d’étranglement. L’écriture d’un poste dans un récepteur peut être considérée comme synchrone dans la mesure où elle s’effectue immédiatement au

138 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
début de la phase d’écriture. La mise à jour du fichier lui-même s’effectuera ensuite une fois que le poste aura physiquement été écrit sur le disque. De plus, comme nous l’avons déjà signalé, la modification du fichier s’effectue d’abord en mémoire principale puis est répercutée sur les disques ultérieurement, en général lorsque le système le décide.
La phase d’écriture du récepteur de journal est critique car plus elle est lente et plus l’ensemble des transactions avec les fichiers journalisés est pénalisé. Il faut donc libérer au maximum toutes les ressources qui interviennent à ce niveau, notamment les bras d’accès disque. L’écriture étant synchrone, il faut attendre que la tête soit libérée pour aller écrire l’information. Si celle-ci est très occupée, les performances sont alors notablement dégradées. Il peut être intéressant de placer le récepteur dans un ASP utilisateur peu sollicité (si possible différent de celui qui contient les fichiers). Outre les avantages en terme de sécurité déjà décrits, cette organisation peut amener un gain substantiel au niveau des performances. Il faut quand même rajouter que ces points d’étranglement n’existent pratiquement pas sur les nouveaux disques IBM tels que les 9337. En effet, ils disposent d’une importante mémoire cache en écriture ce qui fait que les applications n’attendent pratiquement plus la libération des bras d’accès. L’information est considérée comme écrite dès qu’elle est placée dans la mémoire cache. Cette dernière est extrêmement rapide (elle est de type RAM) et non volatile en cas de panne (elle est auto-alimentée), ce qui lui procure des temps de réponses exceptionnels tout en assurant une sécurité optimale. Enfin, il faut noter que plus le nombre de fichiers journalisés est important, plus les performances sont dégradées. Sauvegarde et restauration Un récepteur de journal peut être sauvegardé à l’aide des commandes classiques SAVOBJ, SAVLIB et SAVCHGOBJ. Un récepteur attaché peut être sauvegardé mais il sera incomplet. Sa restauration donnera un récepteur dans un état PARTIEL, c’est-à-dire ne contenant pas tous les postes. Lors d’une restauration complète, il est important de restaurer les objets liés à la journalisation dans l’ordre suivant :
• les journaux en premier ;
• puis les fichiers physiques journalisés ;
• puis les fichiers logiques dépendants de ces fichiers physiques ;

5 - Sécurité et intégrité des données 139
• et enfin les récepteurs de journaux du plus récent au plus ancien. Après une sauvegarde effectuée par SAVLIB LIB (*NONSYS) ou SAVLIB
LIB (*ALLUSR ), la restauration ne pose aucun problème si tous les objets liés à la journalisation sont placés dans la même bibliothèque car l’ordre est automatiquement respecté par le système. Si ces objets sont dans des bibliothèques différentes, il faut s’assurer que la restauration s’effectue dans le bon ordre.

140 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Postes utilisateurs
La commande SNDJRNE permet de créer des postes utilisateurs dans un journal. Le code du poste est U et le type est défini par le paramètre TYPE de cette commande. Les données du poste sont précisées au niveau du paramètre ENTDTA.
Ces postes sont très pratiques lors de l’analyse des journaux car ils permettent de bien identifier le début et la fin d’une opération. Pour être encore plus précis, il est même possible d’associer chacune de ces entrées à un fichier physique grâce au paramètre FILE.
La journalisation des fichiers physiques
Le but
La journalisation des fichiers physiques a pour objet d’assurer l’intégrité des données lors d’incidents tels que :
• l’arrêt anormal du système ;
• la destruction accidentelle d’un fichier ;
• les erreurs de saisies majeures.
Chaque opération sur un enregistrement journalisé étant mémorisée dans un récepteur, il est simple d’effectuer à nouveau cette opération à partir d’une sauvegarde (c’est le recouvrement avant) ou de l’enlever si elle a été commise par erreur (recouvrement arrière).
Le démarrage
Nous avons déjà décrit précédemment comment créer un environnement de journalisation (récepteurs et journaux). La commande STRJRNPF permet de démarrer la journalisation d’un fichier physique. On doit y indiquer le nom du journal et du fichier physique. Le paramètre IMAGES(*AFTER) précise que seule l’image après est conservée alors que IMAGES(*BOTH) indique que les images avant et après sont retenues. Enfin, OMTJRNE(*OPNCLO) empêche la création de postes liés à l’ouverture et à la fermeture du fichier. Jusqu’à 50 fichiers peuvent être ainsi journalisés en une seule opération.

5 - Sécurité et intégrité des données 141
Dès que la journalisation est effective pour un fichier, et avant de modifier ses données, il faut obligatoirement le sauvegarder.
La sauvegarde servira de point de synchronisation en cas de recouvrement avant et il est donc essentiel qu’elle figure au tout début du récepteur. Un poste de type F-MS est ajouté lors de la sauvegarde d’un membre.
Le recouvrement avant
En cas de perte d’un fichier (par destruction accidentelle, par exemple), il est possible de restaurer le fichier et d’appliquer tous les postes contenus dans les récepteurs de journaux (sauf peut-être le dernier s’il est responsable de la perte des données) par la commande APYJRNCHG .
Les paramètres par défaut de cette commande font référence à la dernière sauvegarde (*LASTSAVE). Cette opération de reconstruction standard d’un fichier est donc extrêmement simple :
• restauration de la dernière sauvegarde ;
• application des modifications par APYJRNCHG .
Dans le cas où cette reconstruction demande l’omission de certains postes, il faut analyser les récepteurs concernés grâce à la commande DSPJRN. Dans la commande APYJRNCHG la sélection de postes peut se faire à partir de leur numéro d’ordre, en fonction d’une date et d’une heure, jusqu’à une frontière de récepteurs ou en fonction de l’identification d’un travail (à condition de ne pas avoir codifié STRJRNPF OMTJRNE(*OPNCLO)).
L’option 2 de la commande WRKJRN propose une interface au-dessus de cette commande de recouvrement avant.
Certains traitements effectués sur un fichier ne permettent pas d’exécuter un recouvrement avant car cette opération applique les modifications contenues dans les postes des récepteurs. Pour certaines opérations, aucune information liée aux enregistrements n’est contenue dans les postes. La commande DLTM , par exemple, détruit un membre et ne crée qu’un seul poste de type F-CR où ne figure aucune indication sur les données supprimées. Il en est de même pour la commande RGZPFM , pour les restaurations de membres et pour les modifications de la journalisation (arrêt, APYJRNCHG , RMVJRNCHG ).

142 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Lors du recouvrement avant, le système s’arrête dès qu’il trouve un poste correspondant à ces commandes et envoie un message dans l’historique du travail, ou même provoque une erreur (pour APYJRNCHG et RMVJRNCHG ). Il est alors important de vérifier, par la commande DSPJRN, jusqu’où a été effectué le recouvrement.
L’annexe B présente les principaux types de postes de journaux.
Rappelons que seule l’image après est nécessaire pour le recouvrement avant.
Le recouvrement arrière
Le recouvrement arrière consiste à enlever les opérations réalisées sur un fichier. Il faut pour cela disposer des images avant afin de remettre l’enregistrement dans l’état où il était avant modification.
Le recouvrement arrière est utile pour corriger une erreur de saisie ou pour enlever une partie des opérations d’une transaction qui s’est mal terminée, alors que le contrôle de validation n’a pas été mis en place. Il ne sert pas à récupérer un fichier détruit ou endommagé, ce qui est du domaine du recouvrement avant.
Aucune restauration n’étant à effectuer, le recouvrement arrière est simplement réalisé par la commande RMVJRNCHG . Il est essentiel d’avoir analysé les récepteurs de journaux (DSPJRN) pour savoir quels sont les postes à enlever. Attention aux transactions qui affectent plusieurs fichiers ! Il faudra penser à appliquer le recouvrement arrière sur tous.
Les postes à enlever peuvent être sélectionnés en fonction des récepteurs, des numéros de séquence et de l’identification d’un travail.
De la même manière que pour le recouvrement avant, le recouvrement arrière s’arrête lorsqu’il arrive sur un poste correspondant aux commandes ayant restructuré le membre telles que DLTM , SAV.. STG(*FREE), RGZPFM , RST... et même CLRPFM .
Conclusions
La journalisation des fichiers physiques est en train de devenir incontournable. Elle est plus ou moins obligatoire dans le cas où une application accède à des bases de données situées sur plusieurs systèmes (DRDA), pour le contrôle d’intégrité référentielle, pour SQL... Dans d’autres environnements, la journalisation fait partie intégrante du système de gestion de base de données et ne

5 - Sécurité et intégrité des données 143
peut être désactivée. Il paraît donc indispensable de journaliser les fichiers importants. Mais cela n’est pas (encore) dans la culture des concepteurs d’applications AS/400 car la journalisation a, dès le début, été considérée comme une fonction facultative ralentissant les applications. Avec les gains notables de puissance des machines actuelles (pour un moindre coût), la journalisation devrait être vue comme une fonction naturelle, couramment utilisée.
Avec la journalisation seule, le travail de reprise est parfois complexe dans la mesure où il faut se plonger dans l’analyse des récepteurs tout en maîtrisant parfaitement les applications, surtout si plusieurs fichiers sont concernés. Le but étant de conserver la base de données dans un état stable et cohérent, le contrôle de validation peut être rajouté à la journalisation pour laisser au système et aux applications le soin de gérer automatiquement les reprises, tout en assurant une parfaite cohérence dans les transactions.
La journalisation des chemins d’accès
Le but
Nous avons déjà signalé que l’arrêt anormal du système peut provoquer une incohérence entre un fichier physique et ses différents chemins d’accès.
Lorsque le système détecte une telle anomalie, il reconstruit les chemins d’accès concernés au moment qui est défini par le paramètre RECOVER du fichier (physique ou logique) correspondant à ce chemin d’accès. Il peut avoir pour valeur :
• * IPL : la reconstruction a lieu lors de l’IPL ;
• *AFTIPL : la reconstruction a lieu après l’IPL ;
• *NO : la reconstruction se fera à la première ouverture du fichier.
La commande EDTRBDAP permet de contrôler la reconstruction de tous les chemins d’accès concernés dès la fin de l’IPL.
Après un arrêt anormal, il est clair que la durée de l’IPL dépend directement de la taille des chemins d’accès à reconstruire. On estime généralement qu’il faut une minute au système pour reconstruire un chemin d’accès de 10 000 enregistrements. Cette estimation peut varier sensiblement en fonction du modèle d’AS/400, des types de disques et même de la version de l’OS/400.
Cette valeur nous permet d’imaginer qu’il faut environ une centaine de minutes pour recréer un chemin d’accès d’un million d’enregistrements, soit un peu plus d’une heure et demie !

144 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Il n’est pas rare d’avoir de tels fichiers. Il semble donc essentiel de protéger les chemins d’accès afin de minimiser le temps des IPL qui suivent un arrêt anormal.
La sécurité de base consiste à sauvegarder les chemins d’accès avec les fichiers physiques. La restauration de ces fichiers et des chemins d’accès est préférable (quelques minutes) à la reconstruction (jusqu’à plusieurs heures !).
La journalisation des chemins d’accès assure une parfaite synchronisation entre le fichier physique et ses chemins d’accès. Elle permet ainsi de fortement diminuer le temps de l’IPL qui suit un arrêt anormal.
Il faut remarquer que ces deux fonctions (sauvegarde et journalisation) ne protègent aucune donnée, mais qu’elles permettent seulement de conserver une cohérence entre un fichier physique et ses chemins d’accès.
Le démarrage
La commande STRJRNAP permet de lancer la journalisation d’un chemin d’accès.
Sa syntaxe est extrêmement simple :
STRJRNAP FILE (NOMFICH) JRN(NOMJRN)
où NOMFICH est le nom de un à cinquante fichiers (physiques ou logiques) et NOMJRN est le nom du journal.
Si le nom d’un fichier physique est cité, seul le chemin d’accès de ce fichier (celui défini au niveau Clé des DDS) est journalisé. Il faut penser à lancer cette commande pour tous les fichiers logiques qui pointent sur ce fichier.
Les chemins d’accès de tous les membres d’un fichier sont ainsi journalisés, on ne peut choisir tel ou tel membre.
Quelques restrictions
Tous les fichiers physiques sous-jacents à un fichier logique et ce fichier logique doivent être journalisés dans le même journal.
Les chemins d’accès journalisés doivent avoir été créés avec les paramètres suivants :
• MAINT (* IMMED) ou MAINT (*DLY) ;

5 - Sécurité et intégrité des données 145
• FRCACCPTH(*NO).
Les fichiers physiques sous-jacents doivent être journalisés en image avant et après (IMAGE(*BOTH)). Ci cela n’est pas le cas, c’est-à-dire si seule l’image après a été retenue (IMAGE(*AFTER)), le système ajoutera automatiquement l’option image avant pour ces fichiers.
La commande ENDJRNAP permet d’arrêter la journalisation d’un chemin d’accès.
La consommation de ressources de cette fonction est considérée comme relativement faible car l’écriture des postes concernant les chemins d’accès et des postes relatifs aux enregistrements est effectuée dans la même opération d’entrée/sortie. Autrement dit, le système ne mobilise la tête d’accès disque qu’une seule fois.
La journalisation des chemins d’accès est une fonction essentielle pour une bonne gestion de son AS/400, si bien qu’elle est maintenant totalement prise en charge par le système avec SMAPP
SMAPP
SMAPP (System Managed Access Path Protection) est une fonction totalement intégrée au système depuis la version V3R1M0 de l’OS/400.
Le principe est simple : on indique au système le temps maximum qu’il doit passer à reconstruire les chemins d’accès lors d’un IPL après arrêt anormal du système, et c’est tout ! SMAPP fait le reste, c’est-à-dire qu’il journalise automatiquement les chemins d’accès qu’il juge sensibles (les plus gros, en général).
Cette fonction est totalement transparente si bien que bon nombre de possesseurs d’AS/400 ignorent son existence.
Configuration
A partir de la V3R1M0 de l’OS/400, SMAPP est automatiquement démarrée avec un temps standard de reconstruction de cent cinquante minutes (2H30). La commande EDTRCYAP permet de modifier en interactif cette durée (figure 5.8). Chaque ASP peut être géré indépendamment et des indications sont données sur l’espace disque occupé par les données de journalisation.
Révision du rétablissement des chemins d'accès ALIZES 06 06 95 17:07:09 Estimation temps de rétablissement par le système : 35 Minutes Total de la mémoire disque utilisée . . . . . . . : 0,024 Mo

146 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
% de mémoire disque utilisée . . . . . . . . . . : 0,002 Indiquez vos modifications, puis appuyez sur ENTRE E. Temps de rétablissement par système . . 60 *SYSDFT, *NONE, *MIN, *OFF, Temps -Temps de rétablissement des chemins d'accès- Mémoire disque utilisée ASP Visé (minutes) Estimé (minutes) Mé gaoctets % ASP (Aucun ASP utilisateur configuré ou aucune informa tion disponible) F3=Exit F4=Invite F5=Réafficher F12=Annuler
Figure 5. 8 : écran de la commande EDTRCYAP. Le temps minimal de recouvrement est fixé à 10 minutes et peut atteindre 24 heures. Il est clair que plus ce délai est court et plus le nombre de chemins d’accès à journaliser est grand et, donc, plus l’impact sur les performances est sensible.
La commande CHGRCYAP permet de modifier les caractéristiques de SMAPP dans un programme en langage de contrôle, sans interaction avec un utilisateur. DSPRCYAP est à utiliser pour afficher des informations sur cette fonction.
La valeur *NONE au niveau de la durée arrête cette fonction. Elle ne pourra être relancée qu’en passant en mode restreint.
Fonctionnement
A l’IPL, le système examine tous les chemins d’accès et, en fonction du temps de reconstruction estimé et de la limite qui lui a été fixée, il détermine ceux qu’il doit protéger.
Si les fichiers physiques sous-jacents aux chemins d’accès sélectionnés sont journalisés, le système utilisera leurs journaux. Sinon, il se servira de ses propres structures. Il n’y a donc aucun objet à créer ou à maintenir. Le système s’occupe de tout, même de faire le ménage auprès des récepteurs devenus inutiles.
Ne sont pas protégés les chemins d’accès suivants :
• les temporaires (provenant de SQL, OPNQRYF, Query) ;
• ceux placés dans QTEMP ;
• ceux créés avec MAINT (*REBLD) ;
• ceux qui sont trop petits ;
• et ceux dont les fichiers physiques sous-jacents ne sont pas tous journalisés, ou le sont dans différents journaux.

5 - Sécurité et intégrité des données 147
Conclusion sur SMAPP
Cette fonction est vraiment à prendre en compte car elle assure des IPL après arrêt anormal du système relativement courts. Il est important de bien choisir une durée adaptée à ses besoins afin d’obtenir une bonne adéquation entre les ressources consommées et le temps d’IPL.
Elle remplace, ou plus exactement elle encapsule, la journalisation des chemins d’accès qu’il devient inutile de gérer soi-même.
Conclusions sur la journalisation La journalisation est l’un des éléments fondamentaux d’une stratégie cohérente de protection des données. Elle devrait être obligatoire pour les fichiers sensibles de l’entreprise mais souffre, sur l’AS/400, d’un relatif dédain.
Dans d’autres environnements, le journalisation est incontournable et fait partie intégrante du système de gestion de base de données. A l’origine de l’AS/400, les machines de faible puissance obligèrent à considérer cette fonction comme facultative. C’est à mon sens ce qui fait qu’aujourd’hui elle n’est pas passée dans les mœurs comme une fonction vitale, mais comme une sorte de gadget consommateur de ressources.
La journalisation est obligatoire dès que l’on travaille dans un environnement de base de données réparties. SQL, d’ailleurs, l’utilise systématiquement dans ses collections. Enfin, les nouvelles fonctionnalités de la V3R1M0 de l’OS/400 obligent pratiquement à journaliser certains fichiers physiques. Il est donc temps de s’y investir...
Le contrôle de validation
Principes
Lors d’une écriture comptable classique, au moins deux opérations sont effectuées, la première au crédit d’un compte, la seconde au débit d’un autre. Ces deux opérations forment un tout et l’on imagine aisément que la base de données se retrouverait dans un état incohérent si une seule de ces écritures était prise en compte.

148 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Une transaction est un ensemble d’opérations indissociables. Le contrôle de validation a pour objet d’assurer l’intégrité des transactions.
La loi du tout ou rien est appliquée. Toutes les opérations d’une transaction sous contrôle de validation doivent être réalisées ou, au contraire, toutes doivent être annulées.
Le contrôle de validation s’appuie sur la journalisation. Il est relativement simple à mettre en place si les transactions à protéger ont été mises en évidence lors de l’analyse.

5 - Sécurité et intégrité des données 149
Mise en œuvre Le contrôle de validation débute toujours par un programme en langage de contrôle qui prépare l’environnement grâce à la commande STRCMTCTL . Le programme qui effectue la gestion des enregistrements est ensuite appelé. Enfin, la commande ENDCMTCTL arrête cette fonction. La structure de base du programme principal est donc:
STRCMTCTL CALL RPGXXX ENDCMTCTL
Les verrouillages Quand les enregistrements d’un fichier sous contrôle de validation sont lus, ils peuvent être verrouillés par le système. Le paramètre LCKLVL de la commande STRCMTCTL permet de définir précisément le mode de verrouillage. Ses différentes valeurs peuvent être :
• LCKLVL (*CHG) : un enregistrement lu en vue d’une mise à jour est verrouillé. Si cet enregistrement est modifié, ou supprimé, il reste verrouillé jusqu’à la fin de la transaction, sinon il est libéré à la lecture de l’enregistrement suivant ;
• LCKLVL (*CS) : tout enregistrement traité est verrouillé. Dans le cas d’une lecture, un enregistrement qui n’est pas modifié est libéré lors de l’accès à l’enregistrement suivant. Les autres seront libérés à la fin de la transaction ;
• LCKLVL (*ALL ) : tous les enregistrements traités sont bloqués jusqu’à la fin de la transaction.
Il est clair que LCKLVL (*ALL ) assure une plus grande cohérence mais peut verrouiller les enregistrements plus longtemps, même dans le cas de lecture simple. Il est donc important de bien concevoir les applications pour ne pas provoquer des blocages inutiles par des lectures inopportunes.
Validation, invalidation Une transaction débute avec la première opération sur un enregistrement d’un fichier sous contrôle de validation et se termine soit par un ordre explicite du langage (COMIT , ROLBK en RPG/400), soit par une commande de l’OS/400

150 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
(COMMIT , ROLLBACK ) soit, enfin, par une action implicite du système (lors de la fin anormale du travail).
La validation (ou commit) consiste à terminer la transaction en acceptant toutes les modifications qui ont été effectuées. Elle est provoquée par l’ordre COMIT du RPG/400 ou par la commande COMMIT .
L’invalidation (ou rollback) correspond à l’annulation de toute la partie de la transaction qui a déjà été réalisée. Elle est émise par un ROLBK en RPG/400 ou par la commande ROLLBACK .
Le système provoque une invalidation si une transaction est en cours à la fin d’un travail sous contrôle de validation. Si c’est un arrêt anormal du système qui a provoqué cette interruption, l’invalidation sera effectuée à l’IPL suivant, sinon elle aura lieu dès la fin du travail. C’est cette fonction qui assure la loi du tout ou rien pour une transaction.
La validation ne modifie pas la position des pointeurs d’enregistrements (qui indiquent les enregistrements en cours de traitement). Par contre une rollback replace les fichiers dans l’état où ils étaient avant le début de la transaction invalidée. Les pointeurs d’enregistrements sont alors déplacés.
Structure du programme en langage de contrôle
Un programme en langage de contrôle doit préparer l’environnement de validation par la commande STRCMTCTL . Il peut aussi servir à clore des transactions complexes faisant intervenir plusieurs programmes à l’aide des commandes COMMIT et ROLLBACK .
La commande ROLLBACK peut être systématiquement utilisée après l’appel d’un programme qui modifie les données. Si ce programme se termine en erreur, un message est renvoyé au programme qui l’a appelé par l’intermédiaire de sa PGMQ. Il suffit de l’intercepter et d’émettre une invalidation pour être sûr que la transaction soit close et que les enregistrements soient libérés. Sinon ils pourraient rester bloqués jusqu’à la fin du travail et les opérations de la transaction incomplète pourraient participer à la transaction suivante et être validées au prochain commit. L’exemple 5.1 représente cette interception.
PGM STRCMTCTL LCKLVL(*ALL) CALL PGMxx MONMSG MSGID(RPG0000) EXEC(ROLLBACK)

5 - Sécurité et intégrité des données 151
ENDCMTCTL ENDPGM
Exemple 5.1 : invalidation d’une transaction à la suite de la fin anormale du programme RPGXX.
Il faut remarquer que dans le cas où la transaction s’est bien terminée malgré la fin anormale du programme, la commande ROLLBACK n’a eu aucun effet car aucune transaction n’est en cours.
Structure d’un programme RPG
La structure d’un programme RPG utilisant le contrôle de validation est relativement simple. Dans les spécifications F, il faut définir les fichiers concernés avec le caractère de continuation K suivi de COMIT .
La transaction débute avec l’accès au premier enregistrement d’un fichier sous contrôle de validation. La fin de cette transaction est caractérisée par les codes opération COMIT ou ROLBK dans les spécifications C. La transaction suivante commencera avec le prochain accès aux données.
L’exemple 5.2 présente la structure d’un programme RPG mettant en œuvre le contrôle de validation.
FFICH1 O E DISK KCOM IT A FFICH2 UF E DISK KCOM IT C* C... C*Début de la transaction C WRITEFMT1 C... C READ FMT2 C UPDATFMT2 C DELETFMT1 c... C*Demande de confirmation par exemple C EXFMTCONFIR C* C*SI F12 ANNULATION DEMANDÉE = ROLLBACK C *IN12 IFEQ '1' C ROLBK C ENDIF C* C*SI F03 FIN NORMALE = COMMIT C *IN03 IFEQ '1' C COMIT C ENDIF C*TRAITEMENT DE FIN DE FICHIER C... C MOVE *ON *INLR

152 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Exemple 5.2 : structure d’un programme RPG/400 avec contrôle de validation. Les spécifications C suivies de trois points correspondent à des traitements spécifiques
de l’application non représentés.
Liens avec les sous-fichiers
Un sous-fichier sert d’intermédiaire entre les données contenues dans les fichiers et un utilisateur. Son chargement est effectué à partir d’enregistrements qui sont lus dans la base de données mais ne sont pas verrouillés. On peut donc travailler avec des données qui sont dans un sous-fichier et qui ne reflètent plus la réalité, un utilisateur ayant pu modifier les données initiales.
Le contrôle de validation permet de placer un verrou sur les enregistrements dès la première lecture et de ne les libérer qu’à la fin de la transaction. On est ainsi assuré que les données contenues dans le sous-fichier sont à jour. Il suffit pour cela de démarrer un contrôle de validation avec la commande suivante :
STRCMTCTL LCKLVL (*ALL )
Cette méthode a quand même le gros inconvénient de verrouiller de nombreux enregistrements. On peut de ce fait facilement arriver à des situations où les utilisateurs passent leur temps à attendre la libération des données.
L’objet de notification
Principe
En cas d’arrêt anormal d’un travail ou du système, l’utilisateur ne sait pas toujours si les opérations qu’il était en train de saisir lors de l’incident ont vraiment été enregistrées.
Avec les objets de notification, le système permet de connaître la dernière transaction valide. Le principe est relativement simple : le nom d’un fichier (*FILE), d’une zone de données (*DTAARA) ou d’une file d’attente de messages (*MSGQ) est cité dans la commande STRCMTCTL au niveau du paramètre NFYOBJ. En cas d’incident, le système écrit dans cet objet des informations sur la dernière transaction validée. Ces informations proviennent de données associées au commit. En RPG, il s’agit d’une variable citée en facteur 1 de la ligne contenant le code opération COMIT . En langage de contrôle, c’est la valeur associée au paramètre CMTID de la commande COMMIT .

5 - Sécurité et intégrité des données 153
Fonctionnement
Lorsque le système détecte la fin anormale d’un travail sous contrôle de validation laissant une transaction incomplète, il émet une invalidation. Il s’appuie sur les postes contenus dans les journaux. Il recherche ensuite la dernière transaction validée de ce travail matérialisée par un poste de code C et de type CM. Les données de ce poste correspondent en fait au contenu de la variable associée au commit. Il place ensuite ces informations dans l’objet de notification. Cet objet ne contient des données que lorsque le système a émis une invalidation automatique.
Au lancement d’un programme mettant en œuvre le contrôle de validation, il suffit de vérifier si des données ont été placées dans l’objet de notification. Si c’est le cas, il faut extraire cette information et informer l’utilisateur afin qu’il ressaisisse la transaction invalidée.
La structure de l’objet de notification est libre, c’est à chacun de la déterminer en fonction des informations qu’il désire y trouver. La variable associée au commit devra avoir un format compatible.
En RPG, par exemple, on prendra soin de définir une data-structure qui contiendra toutes les informations nécessaires : nom du travail, utilisateur, date et heure, identifiant de la transaction... C’est cette structure qui sera associée au code opération COMIT .
Les types Les objets de notification peuvent être soit des fichiers, soit des zones de données ou soit des files d’attente de messages.
Les zones de données ont pour inconvénient de ne contenir qu’une série d’informations provenant d’une seule invalidation. Elles ne sont donc à utiliser que si un seul travail effectue de la saisie sous contrôle de validation. Le cas où plusieurs utilisateurs seraient en train de mettre à jour les données lors d’un arrêt anormal du système ne pourrait être traité avec ce type d’objet.
Les fichiers et files d’attente de messages peuvent contenir autant d’enregistrements qu’il peut y avoir d’invalidations de transactions à la suite d’un arrêt anormal du système. Il faut alors prendre soin de placer dans les données des informations qui permettront d’identifier le travail ou (et) l’utilisateur afin de rechercher pour chacun quelle a été la dernière transaction validée.

154 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Si le programme de traitement est écrit en RPG, il est préférable de choisir un fichier comme objet de notification. Le traitement de ces objets est simple dans ce langage alors que la gestion des files d’attente de messages nécessite l’emploi d’API.
Une fois que le contenu de l’objet de notification a été traité, il faut le remettre à blanc pour se replacer dans les conditions initiales.

5 - Sécurité et intégrité des données 155
Exemple L’exemple 5.3 traite une application complète de saisie de factures sous contrôle de validation. L’objet de notification est une zone de données, il a été choisi pour que le source conserve une relative concision. DDS du fichier d’affichage NOTIF Cet écran sert à informer l’utilisateur qu’une invalidation automatique a été réalisée par le système et indique quelle est la dernière facture validée.
DSPSIZ(24 80 *DS3) CA03(03) R FMTNOTIF 1 30'CONTROLE DE VALIDATION ' COLOR(WHT) 4 3'Un incident a provoqué un arrêt - brutal du travail.' COLOR(BLU) 5 3'Le dernier enregistrem ent sauvegar- dé est le suivant:' COLOR(BLU) 8 3'Nom du travail:' NOM 10 O 8 20 8 32'Utilisateur:' JOB 10 O 8 46 8 58'Facture:' NOFAC 6 O 8 68 23 3'F3=Arrêt'
DDS du fichier physique ENTETE Il contient la description de l’en-tête de la facture.
R FMT1 NUMFAC 6 NUMCLI 5 DATE 6 0
DDS du fichier physique DETAIL Il contient les lignes de détail de toutes les factures.
R FMT2 NUMFAC 6 NUMART 5 QTE 6 1 PRIXU 5 2

156 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400

5 - Sécurité et intégrité des données 157
Source du programme principal en langage de contrôle (NOTIF ) Ce programme vérifie si des données sont présentes dans l’objet de notification et éventuellement les traite. Il place ensuite le travail dans un environnement de validation et lance le programme RPG1 de traitement des données.
PGM DCLF GAYTE/NOTIF DCL &INFO *CHAR 26 /*TEST DU CONTENU DE L'OBJET DE NOTIFICATION*/ RTVDTAARA DTAARA(GAYTE/NOTIF) RTNVAR(&INFO) IF (&INFO *NE ' ') DO CHGVAR &NOM %SST(&INFO 1 10) CHGVAR &JOB %SST(&INFO 11 10) CHGVAR &NOFAC %SST(&INFO 21 6) /*AFFICHAGE DES INFORMATIONS DE NOTIFICATION*/ SNDRCVF RCDFMT(FMTNOTIF) IF &IN03 GOTO FIN /*REMISE A BLANC DE LA DTAARA*/ CHGDTAARA GAYTE/NOTIF ' ' ENDDO /*DEMARRAGE DU CONTROLE DE VALIDATION*/ STRCMTCTL LCKLVL(*ALL) NFYOBJ(NOTIF *DTAARA) /*EXTRACTION DES DONNEES DE L'ENVIRONNEMENT*/ RTVJOBA JOB(&JOB) USER(&NOM) /*APPEL DU PGM DE GESTION DES DONNEES*/ CALL RPG1 PARM(&NOM &JOB) MONMSG MSGID(RPG0000) EXEC(ROLLBACK) ENDCMTCTL FIN: ENDPGM
Opérations effectuées pour préparer l’environnement La journalisation doit être démarrée pour les fichiers physiques et la zone de données doit exister :
CRTJRNRCV JRNRCV(NOTIF) CRTJRN JRN(NOTIF) JRNRCV(NOTIF) STRJRNPF FILE(ENTETE DETAIL) JRN(NOTIF) IMAGES(*BOT H) CRTDTAARA DTAARA(NOTIF) TYPE(*CHAR) LEN(26)

158 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Source du programme de saisie des factures en RPG/400 (RPG1)
Pour chaque facture, l’utilisateur doit saisir un enregistrement du fichier ENTETE et un nombre variable d’enregistrements du fichier DETAIL. F3 permet de passer à la facture suivante avec validation de la saisie et F12 provoque une invalidation. NOTIF est une data-structure qui contient les données associées à l’objet de notification. Ce programme reçoit en paramètre les noms de l’utilisateur et du travail.
FDETAIL O E DISK KCOM IT A FENTETE O E DISK KCOM IT A FFACT CF E WORKSTN F* INOTIF DS I 1 10 NOMN TF I 11 20 JOBN TF I 21 26 FACN TF C*RECEPTION DES PARAMETRES C *ENTRY PLIST C PARM NOM 10 C PARM JOB 10 C*INITIALISATION DES VARIABLES POUR NOTIFICATION C MOVE NOM NOMNTF C MOVE JOB JOBNTF C*SAISIE D'UNE NOUVELLE FACTURE C SAISIE TAG C WRITECDE C EXFMTFMTENT C *IN03 CABEQ'1' FIN C*ECRITURE DU FORMAT ENTETE C WRITEFMT1 C MOVE NUMFAC FACNTF C*BOUCLE DE LECTURE DES LIGNES DETAIL C DO *HIVAL C EXFMTFMTDET C*SI F12 ANNULATION DEMANDEE = ROLLBACK C *IN12 IFEQ '1' C ROLBK C LEAVE C ENDIF C*SI F03 FIN NORMALE = COMMIT C *IN03 IFEQ '1' C NOTIF COMIT C LEAVE C ENDIF C*SINON ECRITURE DANS LE FICHIER C WRITEFMT2 C ENDDO C*RENVOI VERS UNE NOUVELLE FACTURE C GOTO SAISIE C*TRAITEMENT DE FIN DE FICHIER C FIN TAG

5 - Sécurité et intégrité des données 159
C MOVE *ON *INLR
DDS du fichier d’affichage FACT
Ce fichier d’affichage permet la saisie des données de chaque facture. Il est appelé par le programme RPG1.
DSPSIZ(24 80 *DS3) CA03(03) CA12(12) R FMTENT OVERLAY 1 32'SAISIE DE FA CTURE' COLOR(WHT) 4 4'Code facture :' NUMFAC 6 I 4 19 4 33'Code client: ' NUMCLI 5 I 4 47 4 57'Date:' DATE 6 0I 4 63 R FMTDET PROTECT OVERLAY 9 4'Code article :' NUMART 5 I 9 19 9 34'Quantité:' QTE 6 1I 9 45 9 55'Prix unit:' PRIXU 5 2I 9 65 R CDE 23 3'F3=Fin F12=A nnu- lation de la saisie' COLOR(BLU)
Exemple 5.3 : mise en œuvre du contrôle de validation s’appuyant sur un objet de notification. Cette application est à lancer en appelant le programme NOTIF.
Remarques
L’objet de notification doit avoir des droits publics suffisants pour que n’importe quel utilisateur effectuant de la saisie à travers le programme sous contrôle de validation puisse l’utiliser. La valeur *CHANGE pour ces droits est un minimum.
Si l’arrêt anormal du travail se produit lors de la saisie de la première transaction, le système ne place aucune information dans l’objet de notification car il ne trouve aucun commit antérieur pour ce travail. L’utilisateur ne sera donc pas informé que cette transaction a été invalidée. Pour éviter ce désagrément, on place au début du programme de traitement des données un commit associé à une structure de données initialisée avec une valeur spéciale. Si cette valeur est contenue dans

160 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
l’objet de notification, il faut informer l’utilisateur qu’aucune donnée n’a été validée lors de sa dernière saisie (exemple 5.4).
... I I '999999' 21 26 FACN T C *ENTRY PLIST C PARM NOM 10 C PARM JOB 10 C*INITIALISATION DES VARIABLES POUR NOTIFICATION C MOVE NOM NOMNTF C MOVE JOB JOBNTF C NOTIF COMIT C* C*SAISIE D'UNE NOUVELLE FACTURE C SAISIE TAG C WRITECDE C...
Exemple 5.4: ajout d’un commit à l’exemple 5.3 pour gérer l’invalidation de la première transaction. Les lignes en gras sont celles qui sont modifiées ou ajoutées. Le programme traitant l’objet de notification devra tester si le numéro de facture est égal à ‘999999’. Dans ce cas, il doit informer l’utilisateur qu’aucune transaction n’a été validée lors de la dernière saisie.
Les journaux
Le contrôle de validation s’appuie sur la journalisation des fichiers physiques. Celle-ci place dans les journaux des postes de code C et dont le type dépend de l’opération effectuée. L’annexe B décrit ces différents postes.
La figure 5.9 présente les informations de journalisation liées au programme de l’exemple 5.4. La première partie est générée par une invalidation automatique, la seconde correspond à une transaction validée. Cette information est donnée par la commande DSPJRN.
Postes générés par une invalidation automatique
N° Code Type Fichier Utilisateur Travail Heure 360 F OP ENTETE GAYTE ECRAN1 10:03:18 362 C BC ECRAN1 10:03:18 363 F OP DETAIL GAYTE ECRAN1 10:03:19 364 C SC ECRAN1 10:03:19 365 C CM ECRAN1 10:03:19 366 C SC ECRAN1 10:03:24 367 R PT ENTETE GAYTE ECRAN1 10:03:24 368 R PT DETAIL GAYTE ECRAN1 10:03:27 369 F CL ENTETE GAYTE ECRAN1 10:03:33 370 F CL DETAIL GAYTE ECRAN1 10:03:33

5 - Sécurité et intégrité des données 161
372 R DR DETAIL GAYTE ECRAN1 10:03:41 374 R DR ENTETE GAYTE ECRAN1 10:03:41 375 C RB ECRAN1 10:03:42 376 C EC ECRAN1 10:03:42
Postes générés par une transaction validée
N° Code Type Fichier Utilisateur Travail Heure 378 F OP ENTETE GAYTE ECRAN1 10:35:49 380 C BC ECRAN1 10:35:50 381 F OP DETAIL GAYTE ECRAN1 10:35:50 382 C SC ECRAN1 10:35:50 383 C CM ECRAN1 10:35:50 384 C SC ECRAN1 10:35:55 385 R PT ENTETE GAYTE ECRAN1 10:35:55 386 R PT DETAIL GAYTE ECRAN1 10:35:58 387 R PT DETAIL GAYTE ECRAN1 10:36:02 388 C CM ECRAN1 10:36:03 389 F CL ENTETE GAYTE ECRAN1 10:36:08 390 F CL DETAIL GAYTE ECRAN1 10:36:09 391 C EC ECRAN1 10:36:09
Figure 5.9 : postes générés par le contrôle de validation de l’exemple 5.3. Les quatre premiers postes correspondent à l’ouverture des fichiers et au démarrage du contrôle de validation. Les postes 365 et 383 ont été générés par le commit décrit dans l’exemple 5.4. Un enregistrement du fichier ENTETE puis des enregistrements du ficher DETAIL sont écrits. Les fichiers sont fermés soit après un commit (poste 388) soit par une fin anormale du travail. Une invalidation est alors émise (postes 372 à 375). Le contrôle de validation peut alors se terminer (poste de type EC).
Le contrôle de validation à deux phases
Le contrôle de validation à deux phases (ou two phases commit) permet d’assurer l’intégrité des transactions dans un environnement de bases de données réparties. Il est possible depuis la V3R1M0 de l’OS/400 (avant, une transaction ne pouvait être à cheval sur plusieurs systèmes).
Dans un programme, il est maintenant possible de mettre à jour des enregistrements dans différentes bases de données et d’effectuer une validation (ou une invalidation) sur l’ensemble de cette transaction. Le contrôle de validation est plus complexe que ce que nous avons décrit jusque-là car il faut être sûr que la validation a bien été effectuée dans toutes les bases de données.
Entre le système client (celui qui fait tourner le programme) et les systèmes serveurs (ceux qui hébergent les données), s’instaure une conversation en deux étapes. Dans un premier temps, le client demande à chaque serveur s’il est en mesure d’effectuer l’opération. Ce dernier écrit et verrouille alors les enregistre-ments, puis répond.

162 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Si une impossibilité est détectée sur un système, un rollback général est émis. Sinon, quand toutes les modifications ont été réalisées, le système client demande un commit. Un second message est alors envoyé à chaque serveur pour les informer de la validation. Ces derniers libèrent les enregistrements verrouillés et renvoient une confirmation.
Le contrôle de validation à deux phases est sécurisé. Si un système s’arrête ou si une ligne de communication est coupée, l’intégrité de la transaction sera assurée soit par l’émission d’une invalidation générale (dans le cas où l’incident se produit avant le commit du client), soit par la prise en compte des opérations effectuées mais non encore validées.
Cette fonction est supportée par DDM et par SQL. DDM peut être utilisé dans le cas où les échanges ont lieu entre AS/400. SQL permet d’accéder aux bases de données de DRDA (l’architecture de bases de données répartie), par exemple DB2/6000 sur Risc/6000, DB2/2 sous OS/2, DB2 sous MVS... Au chapitre consacré à ce langage, nous verrons comment intégrer des requêtes SQL dans des programmes RPG.
Conclusions sur le contrôle de validation
Le contrôle de validation est le seul moyen d’assurer l’intégrité des transactions. Il est assez facile à mettre en œuvre dans les programmes à condition d’avoir bien défini les frontières de transaction lors de l’analyse.
Mais il est nécessaire de démarrer la journalisation des fichiers concernés...
Les contraintes d’intégrité référentielle Introduction
Principes
Dans une base de données relationnelle, on est souvent amené à établir des contraintes entre des zones de différents fichiers. Par exemple, le numéro de client de chaque enregistrement du fichier FACTURE doit correspondre à un numéro de client du fichier CLIENT. Cette valeur permet de faire une jointure (fichier logique joint) ou un accès direct sur clé pour récupérer le nom et l’adresse du client pour chaque facture.

5 - Sécurité et intégrité des données 163
Traditionnellement, une telle contrainte est implémentée dans les programmes. Lors de la saisie de la facture, une recherche indexée (CHAIN en RPG) est effectuée sur le fichier CLIENT afin de vérifier si ce client existe bien. En cas d’échec de cette requête, une nouvelle saisie (ou éventuellement une création de client) est proposée à l’utilisateur.
Depuis la version V3R1M0 de l’OS/400, ce contrôle peut être automatisé grâce aux contraintes d’intégrité référentielle (que je nommerai parfois CIR). Le principe de base est extrêmement simple : une (ou plusieurs) zone(s) d’un fichier dépendant est mise en relation avec une (ou plusieurs) zone(s) d’un fichier parent. Dans notre exemple, le fichier dépendant est FACTURE, le parent est CLIENT (figure 5.10).
A chaque tentative d’écriture d’un enregistrement dans le fichier FACTURE, le système vérifie automatiquement si le contenu de la zone NUMCLI correspond à une valeur de NOCLI du fichier CLIENT. En cas de succès, la mise à jour est effectuée et le programme continue son déroulement. En cas d’échec, un message d’erreur de type *ESCAPE est renvoyé au programme. Ce message doit être intercepté sinon il remonte à l’utilisateur par l’intermédiaire de la file d’attente externe.
CLIENT(parent)
FACTURE(dépendant)
NUMCLINOCLI
502005025
2550200
Figure 5.10 : contrainte d’intégrité référentielle entre deux fichiers.
La dépendance, comme nous venons de le voir, fonctionne dans le sens fichier dépendant vers fichier parent mais elle est aussi active dans l’autre sens. Un client ne pourra être détruit s’il a encore une facture en cours. Autrement dit, on ne peut supprimer un enregistrement d’un fichier parent s’il est en relation avec un enregistrement du fichier dépendant.
Les chemins d’accès

164 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Pour effectuer rapidement les recherches, le système s’appuie sur des chemins d’accès. Ces structures doivent donc être créées pour chacun des deux fichiers si elles n’existent pas déjà. Le chemin d’accès du fichier parent possède les caractéristiques particulières suivantes :
• il est unique. Il ne peut y avoir deux enregistrements du fichier parent qui ont même valeur de clé. Dans notre exemple, deux clients ne pourront avoir le même numéro ;
• sous certaines conditions, il peut être créé automatiquement par le système lors de l’établissement de la contrainte. Si ces conditions ne sont pas remplies, il faut le générer à l’aide d’une commande. Nous y reviendrons ;
• si ce chemin d’accès existe déjà et s’il a été défini avec le mot-clé UNIQUE, il sera partagé.
Mise en œuvre
La commande ADDPFCST (add physical file constraint) permet de mettre en place une CIR (figure 5.11).
Ajouter contrainte fich phys (ADDPFCST) Indiquez vos choix, puis appuyez sur ENTREE. Fichier . . . . . . . . . . . . FILE > FAC TURE Bibliothèque . . . . . . . . . *LIBL Type de contrainte . . . . . . . TYPE > *R EFCST Clé de la contrainte . . . . . . KEY > NO CLI + si autres valeurs Nom de la contrainte . . . . . . CST *G EN Fichier parent . . . . . . . . . PRNFILE > CL IENT Bibliothèque . . . . . . . . . *LIBL Clé parente . . . . . . . . . . PRNKEY > NU MCLI + si autres valeurs Règle de suppression . . . . . . DLTRULE *N OACTION Règle de mise à jour . . . . . . UPDRULE *N OACTION Fin F3=Exit F4=Invite F5=Réafficher F12=Annuler F13=Mode d'emploi invite F24=Autres touches
Figure 5.11 : écran de la commande ADDPFCST avec TYPE(*REFCST).
Voici les caractéristiques des paramètres de cette commande (avec TYPE(*REFCST)):

5 - Sécurité et intégrité des données 165
• FILE : définit le nom du fichier dépendant ;
• TYPE : dans ce contexte doit avoir la valeur TYPE(*REFCST) (établissement d’une CIR) ;
• KEY : permet de donner la liste des zones du fichier dépendant qui vont composer la clé ;
• CST : précise le nom de la contrainte. Le système propose de le générer automatiquement ;
• PRNFILE : indique le nom du fichier parent ;
• PRNKEY : permet de donner la liste des zones du fichier parent qui vont composer la clé. Ces zones doivent être compatibles une à une avec celles qui composent la clé du fichier dépendant ;
• DLTRULE : précise l’action entreprise par le système lors d’une tentative de sup-pression d’un enregistrement du fichier parent :
– *NOACTION : l’enregistrement est détruit s’il n’existe pas un enregistre-ment du fichier dépendant qui lui est associé (même valeur de clé). Le programme déclencheur associé à l’événement *AFTER-*DELETE (après suppression) est lancé, s’il a été défini, même si la suppression a échouée,
– *RESTRICT : l’enregistrement est détruit s’il n’existe pas un enregistre-ment du fichier dépendant qui lui est associé (même valeur de clé). Le programme déclencheur associé à l’événement *AFTER-*DELETE (après suppression) n’est pas lancé,
– *CASCADE : tous les enregistrements du fichier dépendant qui sont associés à l’enregistrement du fichier parent seront détruits avec lui. Dans notre exemple, si l’on supprime un client, toutes ses factures seront détruites avec lui. Il est important de procéder avec attention car si le fichier dépendant est lui même parent avec DLTRULE(*CASCADE) pour une autre contrainte, cela peut provoquer des destructions en chaîne désastreuses,
– *SETDFT : l’enregistrement du fichier parent est détruit et les clés associées du fichier dépendant prennent les valeurs par défaut,
– *SETNULL : l’enregistrement du fichier parent est détruit et les clés associées du fichier dépendant prennent la valeur indéfinie. Il faut que cela soit permis au niveau des DDS de ce fichier ;

166 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
• UPDRULE : précise l’action à effectuer par le système en cas de mise à jour d’un enregistrement du fichier parent :
– *NOACTION : le programme déclencheur associé à l’événement *AFTER-*UPDATE est lancé. Il n’y a pas de mise à jour s’il y a des enregistrements du fichier dépendant en relation avec l’enregistrement du fichier parent à modifier,
– *RESTRICT : aucune modification de l’enregistrement du fichier parent n’est possible s’il y a une dépendance. Le programme associé à l’événement *AFTER-*UPDATE n’est pas lancé.
Si tout se passe bien, la CIR est établie immédiatement, sinon un message d’erreur (généralement CPF32B0), placé dans l’historique du travail, donne des indications claires sur les causes de l’échec. Voici les principales :
• le fichier est endommagé ;
• le fichier ne peut pas contenir plus d'un membre ;
• le fichier doit être un fichier à description externe ;
• une contrainte de clé primaire existe déjà ;
• une contrainte unique dupliquée existe.
Il faut enfin noter quelques limitations aux contraintes d’intégrités référentielles :
• seuls les fichiers physiques peuvent participer aux contrain-tes d’intégrité référentielles ;
• les CIR ne peuvent s’établir sur des fichiers multimembres. Le seul fait d’avoir MAXMBR supérieur à 1 suffit à faire échouer toute tentative.
L’ordre SQL ALTER TABLE permet aussi de définir une contrainte d’intégrité référentielle.
Les clés Avec cette fonction est apparue une nouvelle distinction dans la notion de clé.

5 - Sécurité et intégrité des données 167
Le premier chemin d’accès créé pour un fichier physique est considéré comme primaire . Cette distinction est importante car le système n’est capable de créer automatiquement que des chemins d’accès primaires. Ainsi, la commande ADDPFCST que nous venons de décrire ci-dessus (avec TYPE(*REFCST)), ne générera le chemin d’accès du fichier parent que si c’est le premier. Sinon, il faudra le faire à l’aide de la commande ADDPFCST mais avec, cette fois, les paramètres suivants :
• FILE : qui est le nom du fichier parent ;
• TYPE : qui doit avoir pour valeur TYPE(*UNQCST) pour créer un chemin d’accès unique. Eventuellement, la valeur TYPE(*PRIKEY) permet de créer un chemin d’accès primaire, le système étant capable de le faire tout seul ;
• KEY : qui représente la liste des zones qui composent la clé ;
• CST : qui est le nom de la contrainte.
Pour la création automatique du chemin d’accès du fichier parent par la commande ADDPFCST TYPE(*REFCST) plusieurs cas peuvent se présenter :
• si le chemin d’accès est déjà créé et s’il est unique il y aura partage de la structure existante ;
• s’il n’est pas unique, il ne peut y avoir partage. Il existe alors deux solutions. La première consiste à créer un nouveau chemin d’accès de type *UNQCST. Il y aura alors deux chemins d’accès à maintenir. La seconde consiste à recréer l’ancien en lui ajoutant l’unicité. Cette solution peut être parfois lourde surtout si le chemin d’accès est codifié dans les DDS du fichier physique (au niveau Clé) car il faut recompiler le fichier, donc le détruire au préalable avec tout ce que cela implique ;
• si le chemin d’accès n’existe pas, il sera automatiquement créé s’il est le premier, sinon il faudra utiliser la commande ADDPFCST TYPE(*UNQCST). La figure 5.12 résume ces situations. Notons qu’il n’y a aucun problème de cet ordre pour le fichier dépendant, le chemin d’accès n’étant pas unique.

168 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Est-il unique ? Est-ce le premier ?
Partage duchemin existant
Echec !Il faut recréer
un chemind’accès unique(*UNQCST)
Créationautomatique
Le chemin d’accès existe-t-il ?
OUI
OUI
NON
NON
OUI
Figure 5.12 : la création des chemins d’accès et la commande ADDPFCST.
La gestion
La commande WRKPFCST permet de gérer les CIR (figure 5.13). Sur l’écran affiché on peut visualiser les contraintes d’intégrité référentielle (de type *REFCST), les clés primaires (*PRIKEY) et les chemins d’accès uniques (*UNQCST). L’option 2, ou la commande CHGPFCST STATE(*DISABLED ), permettent de désactiver momentanément une CIR. Le responsable des données peut ainsi faire le ménage dans les fichiers, notamment modifier ou supprimer des enregistrements du fichier parent. Une fois ce bricolage terminé, l’option 6 en regard de la contrainte concernée nous permet de vérifier si tout est cohérent. Cette option affiche les enregistrements du fichier dépendant qui ne correspondent pas à la CIR. S’ils existent, il faudra les supprimer avant de rétablir la contrainte. Cette dernière opération est effectuée avec l’option 2, ou la commande CHGPFCST, mais cette fois avec la valeur STATE(*ENABLED).
Gestion des contraintes de fichier physique Indiquez vos options, puis appuyez sur ENTREE. 2=Modifier 4=Enlever 6=Afficher enreg en ins tance de vérif Vérification en Opt Contrainte Fichier Biblio Type Etat instance NUMCLI > DEPENDANT V310 *REFCS T ETB/ACT NON NOMCLI > DEPENDANT2 V310 *REFCS T ETB/DES OUI QSYS_PAREN > PARENT V310 *PRIKE Y CLE_NOMCLI > PARENT V310 *UNQCS T

5 - Sécurité et intégrité des données 169
Fin Paramètres pour les options 2, 4, 6 ou commande ===> F3=Exit F4=Invite F5=Réafficher F12=Annule r F15=Trier F16=Repositionner F17=A partir de F22=Nom de contrainte
Figure 5.13 : écran de la commande WRKPFCST.
La commande RMVPFCST, et l’option 4 de la commande WRKPFCST, permettent de détruire une contrainte.
La visualisation de la partie descriptive d’un fichier par DSPFD montre les contraintes d’intégrité auxquelles le fichier est soumis.
Les droits *OBJREF sur un fichier sont nécessaires pour pouvoir gérer ses CIR.
La journalisation
La journalisation des fichiers physiques participants aux contraintes d’intégrité référentielle est obligatoire sauf :
• si les règles de modification et de suppression des enregistrements du fichier parent sont DLTRULE(*RESTRICT) et UPDRULE(*RESTRICT) ;
• si aucune action (modification, suppression) n’est intentée sur les enregistrements du fichier parent. DFU, par exemple ne peut être lancé pour modifier un fichier parent s’il n’est pas journalisé.
En fait, la journalisation doit être considérée comme indispensable. Le système se sert de ces journaux et place ses propres postes pour le contrôle de validation qu’il met automatiquement en place.
Il reste à noter que les deux fichiers (parent et dépendant) doivent utiliser le même journal.
Exemple en RPG
L’utilisation des CIR allège la programmation car elle enlève bon nombre de contrôles. Pour bien faire, il faut toutefois intercepter les éventuels messages d’erreurs renvoyés par le système et informer l’utilisateur. En RPG, tout message

170 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
d’erreur est traduit par l’excitation de l’indicateur associé à l’ordre d’entrée/sortie (WRITE , UPDAT). Si cet indicateur est en fonction c’est que l’écriture n’a pu être réalisée. On peut alors imputer cet échec à la CIR, mais cela est un peu simpliste car il peut y avoir d’autres causes (notamment les déclencheurs). Il faut donc récupérer le message reçu par le programme et le traiter. En fonction de son identification, on sait quel est l’événement qui a empêché l’écriture. La CIR renvoie le message CPF502D pour une tentative d’insertion d’un enregistrement dans le fichier dépendant qui n’a pas de correspondance dans le fichier parent. Le message CPF503A est émis lors d’une tentative infructueuse de suppression d’un enregistrement du fichier parent.
En RPG, un message d’erreur peut être récupéré au moins de deux manières : par l’INFDS et par les API. Ces deux possibilités sont présentées dans l’exemple 5.6.
DDS du fichier physique dépendant
R FMT NOCLI 5 MONTNT 7 2 DATE 6
DDS du fichier physique parent
R FMTP NOCLI 5 NOMCLI 15 ADRESSE 20
DDS du fichier d’affichage SAISIE DSPSIZ(24 80 *DS3) CA03(03) R FMT1 1 30'SAISIE DES RE GLEMENTS' COLOR(WHT) 5 3'Numéro du cl ient:' 5 37'Montant:' 5 61'Date:' NOCLI 5 I 5 21 52 ERRMSG('Ce cl ient n''existe + pas' 52) MONTNT 7 2I 5 47 DATE 6 I 5 67
Source du programme RPG utilisant l’INFDS
FREGLMT O E K DISK KINFD S DATA FSAISIE CF E WORKSTN IDATA DS

5 - Sécurité et intégrité des données 171
I 46 52 IDMS G * C DO *HIVAL C EXFMTFMT1 C *IN03 IFEQ '1' C LEAVE C ENDIF C WRITEFMT 9 0 C *IN90 IFEQ '1' C EXSR ERREUR C ENDIF C ENDDO C MOVE *ON *INLR C* C************SOUS ROUTINE ERREUR******************* ***** C ERREUR BEGSR C IDMSG IFEQ 'CPF502D' C*LE CLIENT N'EXISTE PAS C MOVE *ON *IN52 C ENDIF C*PROCEDER AINSI POUR TOUS LES MESSAGES POSSIBLES: C* IDMSG IFEQ 'CPF503A' C*IMPOSSIBLE DE SUPPRIMER CE CLIENT C* MOVE *ON *IN53 C* ENDIF C ENDSR
Source du programme RPG/400 utilisant une API
FREGLMT O E K DISK FSAISIE CF E WORKSTN IINFO DS I 13 19 IDMS G IERR DS I I 00 B 1 40LGER R I* I*AUCUNE GESTION DES ERREURS DE L’API ! C* C DO *HIVAL C EXFMTFMT1 C *IN03 IFEQ '1' C LEAVE C ENDIF C WRITEFMT 9 0 C *IN90 IFEQ '1' C EXSR ERREUR C ENDIF C ENDDO C MOVE *ON *INLR C* C************SOUS ROUTINE ERREUR******************* ***** C* C*EXTRACTION DU MESSAGE PAR API C ERREUR BEGSR C CALL 'QMHRCVPM'

172 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
C PARM INFO C PARM X'19' LG 4 C PARM 'RCVM0100'FMTRCV 8 C PARM '*' PGMQ 10 C PARM X'00' STK 4 C PARM '*LAST' TYPE 10 C PARM CLE 4 C PARM X'00' TIME 4 C PARM '*SAME' ACTION 10 C PARM ERR C*LE TRAITEMENT EST LE MÊME QUE PRECEDEMMENT C IDMSG IFEQ 'CPF502D' C*LE CLIENT N'EXISTE PAS C MOVE *ON *IN52 C ENDIF C*PROCEDER AINSI POUR TOUS LES MESSAGES POSSIBLES C* IDMSG IFEQ 'CPF503A' C*IMPOSSIBLE DE SUPPRIMER CE CLIENT C* MOVE *ON *IN53 C* ENDIF C ENDSR
Exemple 5.6 : programme RPG/400 s’appuyant sur une contrainte d’intégrité référentielle
en utilisant soit l’INFDS, soit une API.

5 - Sécurité et intégrité des données 173
Conclusions
Cette fonction était très attendue et son absence était considérée comme une fâcheuse lacune de la base de données de l’AS/400. Avec la version V3R1M0 de l’OS/400 elle apparaît comme fondamentale. Sa mise en œuvre est extrêmement simple et ses performances semblent excellentes car elle n’est pas activée à travers des programmes déclencheurs, comme sur certains SGBD, mais directement par des fonctions système.
Elle doit surtout être utilisée pour les nouvelles applications. Il est en effet inutile de l’implémenter pour des fichiers attaqués par des programmes qui effectuent eux-mêmes les contrôles. Il y aurait alors double traitement, ce qui est inutile.
Ce qui est important c’est qu’une fois mise en place, elle est incontournable. Il faut considérer qu’elle est au niveau des données. Que ce soit avec DFU, par du client/serveur, avec des applications classiques en RPG ou Cobol, ou même au travers de DRDA (l’architecture de base de données réparties d’IBM), la CIR est toujours activée. Elle fait partie intégrante du fichier et elle est sauvegardée avec lui. Lors de la restauration elle sera automatiquement activée si cela est possible. Il est donc préférable de toujours restaurer un fichier parent avant ses dépendants. Enfin, la commande CRTDUPOBJ recopie les contraintes d’intégrité d’un fichier dépendant dans le nouvel objet qui sera donc associé au même parent.
Tous ces mécanismes assurent une parfaite intégrité de la base de données.
La contrainte gérée ici est une égalité entre le contenu de deux zones, ou de deux séries de zones. Pour des contraintes plus complexes on peut utiliser ses propres programmes de validation par l’intermédiaire des déclencheurs.
Les déclencheurs ( triggers)
Depuis la version V3R1M0 de l’OS/400, on peut associer un programme à un événement lié à la base de données. Si cet événement se produit, ce programme dit déclencheur (ou trigger en anglais) est automatiquement lancé. Cette nouvelle fonction ouvre de nouveaux horizons, quasiment illimités.
Les déclencheurs sont associés aux fichiers physiques. Dès que l’événement correspondant se produit, le programme est lancé quel que soit l’origine de cet événement. On peut ainsi placer juste au dessus des données une couche logicielle qui devra être obligatoirement traversée pour accéder aux enregistrements.

174 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Les déclencheurs existent dans d’autres bases de données où ils sont parfois codés avec un langage spécial propre à cette fonction. Pour l’OS/400, le programme est n’importe quel objet de type *PGM (RPG IV, RPG/400, CLP, Cobol...) ou même une procédure Rexx, et c’est une excellente chose. Il n’y a pas de nouveau langage à appréhender.
Pour un fichier, six événements permettent le déclenchement et peuvent chacun être associés à un programme. Ce sont :
• *BEFORE-* INSERT : avant insertion ;
• *AFTER-* INSERT : après insertion ;
• *BEFORE-*UPDATE : avant modification ;
• *AFTER-*UPDATE : après modification ;
• *BEFORE-*DELETE : avant suppression ;
• *AFTER-*DELETE : après suppression.
Mise en œuvre
La commande ADDPFTRG permet, pour un fichier physique, de lier un programme à un événement. La syntaxe est simple, les paramètres sont les suivants :
• FILE : nom du fichier (seuls les fichiers physiques peuvent être associés à des déclencheurs) ;
• TRGTIME : moment par rapport à l’action de déclenchement, soit avant (*BEFORE) soit après (*AFTER) ;
• TRGEVENT : action qui déclenche l’événement. Les valeurs peuvent être :
– * INSERT : insertion ;
– *DELETE : destruction ;
– *UPDATE : modification ;
• PGM : nom et bibliothèque du programme à appeler si cet événement survient ;
• RPLTRG : action à entreprendre si un déclencheur est déjà défini pour cet événement. Si la valeur est *YES l’ancien programme est remplacé par le nouveau, sinon aucune modification n’est effectuée pour ce déclencheur ;

5 - Sécurité et intégrité des données 175
• TRGUPDCND : indique le comportement du déclencheur lors de la mise à jour d’un enregistrement avec des valeurs identiques. Le programme est lancé si sa valeur est *ALWAYS .
Ainsi, la commande pour associer le programme TRG de la bibliothèque BIB à l’événement avant insertion pour le fichier FICH est :
ADDPFTRG FILE(FICH) TRGTIME(*BEFORE) TRGEVENT(*INSERT) PGM(BIB /TRG)
Il est préférable de qualifier le nom du programme car n’importe quel travail peut déclencher cet événement et il n’est pas évident qu’il ait la bonne bibliothèque dans sa liste de bibliothèque.
Les droits *OBJALTER sur un fichier sont indispensables pour agir sur ses déclencheurs.
Si la mise en œuvre de cette fonction est extrêmement simple au niveau du fichier, la codification du programme associé est, par contre, un peu plus complexe.
Le programme déclencheur
Le programme déclencheur doit respecter certaines règles au niveau des paramètres qu’il reçoit et au niveau de l’information à retourner au programme appelant en cas de problème.
Les paramètres
Lorsqu’il est appelé, le programme déclencheur reçoit deux paramètres. Le premier est une structure contenant toutes les informations sur l’opération en cours, y compris les images de l’enregistrement tel qu’il était avant et tel qu’il sera après cette opération s’il y a lieu. Le tableau suivant décrit les principaux éléments de cette structure (les informations concernant les zones à valeur indéfiniées (NULL) ont été omises) :
Offset Type Lg Description 0 CHAR 10 Nom du fichier 10 CHAR 10 Nom de la bibliothèque 20 CHAR 10 Nom du membre 30 CHAR 1 Type d’opération : 1 = insertion ; 2 = destruction ; 3 = modifica-
tion 31 CHAR 1 Moment par rapport à l’opération : 1 = après ; 2 = avant 32 CHAR 1 Type de verrouillage : de 0 = *NONE à 3 = *ALL 36 BIN 4 CCSID 48 BIN 4 Offset de l’image avant

176 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
52 BIN 4 Longueur de l’image avant 64 BIN 4 Offset de l’image après 68 BIN 4 Longueur de l’image après * Image avant * Image après
Voici quelques principes qui permettent de gérer correctement ces informations :
• l’offset indiqué pour une zone peut être défini comme le nombre de caractères qui sont devant cette zone. Ainsi, le nom du membre qui a un offset de 20 commence à la position 21 car il y a vingt caractères devant ;
• pour extraire l’image avant, on doit procéder en deux étapes :
– tout d’abord, il faut extraire le contenu de la zone située en position 53 (offset 52) sur une longueur de 4. Le résultat est un nombre binaire qu’il faut convertir en Décimal condensé, et qui contient l’offset de l’image avant. En lui ajoutant 1, on obtient la position du premier caractère de cet enregistrement,
– il suffit alors d’aller à la position ainsi calculée pour extraire les données de l’enregistrement tel qu’il était avant l’opération. Sa longueur est donnée par la zone d’offset 52, toujours en binaire de longueur 4. On procédera de la même manière pour extraire l’image après ;
• ce mode de positionnement (offset, données en binaire) est caractéristique des fonctions avancées de l’OS/400. Elles sont couramment utilisées avec les API système ;
• l’image avant est renseignée dans les cas de suppression et de modification, l’image après est valide lors d’un ajout ou d’une modification.
Le second paramètre indique la longueur valide du premier paramètre dans une variable binaire de longueur 2. Les informations contenues dans ces deux paramètres permettent d’écrire des programmes génériques qui fonctionnent avec n’importe quel fichier.
Les traitements Le programme déclencheur peut effectuer n’importe quel traitement (mise à jour d’autres fichiers et même du fichier en cours) à condition de ne pas modifier l’ODP du programme appelant. Il ne faut donc pas partager le même ODP que ce programme.

5 - Sécurité et intégrité des données 177
Il est fortement déconseillé de faire du contrôle de validation dans les programmes déclencheurs. En effet, le programme appelant utilise peut-être cette fonction et l’appel d’un commit ou d’un rollback dans le déclencheur provoquerait une interférence entre les deux cycles de validation, ce qui pourrait avoir de fâcheuses répercussions.
Le message de type *ESCAPE
Le programme déclencheur peut servir à vérifier si une action sur un fichier physique est autorisée. Si tout se passe bien, il doit se terminer normalement, sinon il doit renvoyer au programme appelant une information lui signifiant que l’opération a échouée.
Cette information est un message de type *ESCAPE qui provoque l’arrêt de l’opération sur les données. Le programme appelant qui reçoit ce message doit l’intercepter et le traiter à la manière de ce que nous avons vu pour les contraintes d’intégrité référentielles (exemple 5.6). Sinon, le message CPF502B est émis à destination de l’utilisateur via la file d’attente externe.
L’identification du message de type *ESCAPE n’a aucune importance pour le système. C’est le type qui est important car il provoque un arrêt. On choisira donc un message clair car il figurera dans l’historique du travail. J’utilise couramment les messages CPF9897 et CPF9898 du fichier de message QCPFMSG de QSYS car ils permettent de placer le texte que l’on désire dans un message préenregistré, ce type de message étant obligatoire pour l’envoi d’un message *ESCAPE par la commande SNDPGMMSG. CPF9898 se distingue de CPF9897 par la présence d’un point.
L’architecture d’un programme déclencheur est représenté dans l’exemple 5.7.
PGM PARM(&VAR &LG) DCL &VAR *CHAR 200 /*La longueur de la variable dépend de la taille de + l’enregistrement*/ DCL &LG *CHAR 2 /*Extraction des informations reçues en paramètres* / CHGVAR ..... CHGVAR ..... /*Si problème envoi du message*/ IF COND(.....) THEN(DO) SNDPGMMSG MSGID(CPF9897) MSGF(QCPFMSG) + MSGDTA('Erreur déclencheur !') MSGTYPE(*ESCAPE)

178 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
GOTO FIN ENDDO ELSE DO /*Tout est correct*/ .../*Traitement des données*/ ENDDO FIN: /*Traitements de fin*/ ENDPGM
Exemple 5.7 : structure d’un programme déclencheur. Le langage de contrôle est choisi pour sa lisibilité.
La codification de l’envoi de message est relativement simple en langage de contrôle (grâce à la commande SNDPGMMSG) mais nécessite l’emploi des API en RPG. Nous allons maintenant présenter des exemples complets dans chacun de ces deux langages. Ils peuvent être facilement testés avec DFU.
Exemple en langage de contrôle
Le programme décrit dans l’exemple 5.8 extrait une partie des données d’un enregistrement à supprimer et demande une confirmation à l’utilisateur par l’intermédiaire de la file d’attente externe. Il n’a probablement pas grand intérêt dans le cadre d’une exploitation mais montre assez simplement comment fonctionne un déclencheur. Il est à associer au fichier FICH et à l’événement avant suppression.
Commande de définition du déclencheur
ADDPFTRG FILE(FICH) TRGTIME(*BEFORE) TRGEVENT(*DELETE) PGM(TRG)
Source du programme en langage de contrôle TRG
PGM PARM(&VAR &LG) DCL &VAR *CHAR 150 DCL &LG *CHAR 2 DCL &REP *CHAR 1 DCL &OFSTAVT *DEC (5 0) DCL &NOCLI *CHAR 5 DCL &MSG *CHAR 80 /*Extraction de l'offset de l'image avant en décima l*/ CHGVAR &OFSTAVT %BIN(&VAR 49 4) /*Conversion offset => position*/ CHGVAR &OFSTAVT (&OFSTAVT + 1) /*Extraction de la zone NOCLI sur 5 caractères*/ CHGVAR &NOCLI %SST(&VAR &OFSTAVT 5) /*Envoi du message dans la file d'attente externe*/ SNDUSRMSG MSGID(CPF9897) MSGF(QCPFMSG) MSGDTA('Voulez +

5 - Sécurité et intégrité des données 179
vous détruire l''enregistrement ' *CAT &NOCLI *CA T ' O/N ?') + VALUES('O' 'N') DFT('N') TOMSGQ(*EXT) MSGRPY(&REP ) /*Récupération de la réponse dans &rep*/ /*Si &REP=N envoi du message d'annulation*/ CHGVAR &MSG ('Annulation utilisateur pour NOCLI = ' *CAT &NOCLI) IF COND(&REP = 'N') THEN(SNDPGMMSG + MSGID(CPF9897) MSGF(QCPFMSG) MSGDTA(&MSG) MSGTYPE(*ESCAPE)) ENDPGM
DDS du fichier FICH
R FMT NOCLI 5 NOMCLI 15 ADRES 20
Historique du travail supprimant les enregistrements (DSPJOBLOG)
Voulez vous détruire l'enregistrement abcde O/N ? ? O Voulez vous détruire l'enregistrement 12345 O/N ? ? N Annulation utilisateur pour NOCLI = 12345 Une erreur s'est produite dans le programme décl encheur. Une erreur s'est produite dans le programme décl encheur.
Exemple 5.8 : programme déclencheur et langage de contrôle. A chaque suppression d’un enregistrement du fichier FICH, un message est envoyé à l’utilisateur via la file d’attente externe pour lui demander une confirmation. Il peut confirmer (‘O’) ou annuler (‘N’) l’opération. Dans l’historique du travail présenté, l’utilisateur a confirmé la première suppression et a infirmé la seconde. Le texte associé au message CPF9897 est clair, il permet d’identifier clairement la cause de l’annulation.
Le message CPF9897 devra être intercepté par le programme appelant à la manière de ce qui est décrit pour les contraintes d’intégrité référentielle dans l’exemple 5.6.
Le langage de contrôle permet d’écrire des programmes déclencheurs relativement simples. Il est limité car il permet difficilement d’extraire des zones de type Décimal condensé dans les images avant et après. De plus, il ne permet pas d’écrire dans les fichiers.
Le RPG est bien plus approprié mais il impose l’utilisation des API pour envoyer le message de type *ESCAPE.
Exemple en RPG

180 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
En cas de modification d’un enregistrement, ce programme vérifie que la nouvelle valeur pour la zone salaire est supérieure ou égale à l’ancienne. Il ne sera lancé que lorsque le nouvel enregistrement est différent de l’ancien. DDS du fichier FICH
R FMT CODEMP 5 NOMEMP 15 MNTSAL 7 2

5 - Sécurité et intégrité des données 181
Source du programme RPG/400 TRGRPG
*DS DECOUPANT LE PARAMETRE IENREG DS I B 49 520AVT I B 65 680APR I 69 150 FIN *DS DECOUPANT L'IMAGE AVANT IIMGAVT DS I 1 5 CDEB I 6 20 NOMB I P 21 242MNTB *DS DECOUPANT L'IMAGE APRES IIMGAPR DS I 1 5 CEMA I 6 20 NOMA I P 21 242MNTA *DS POUR DIVERSES DECLARATIONS IDIVERS DS I I 'QCPFMSG QSYS' 1 20 MSGF I I 'ANNULATION DEMANDEE' 21 39 DATA I I 0 B 40 430ERR I I 19 B 44 470LGDT A I I 1 B 48 510STCK C* C*DEFINITION DES PARAMETRES C* C *ENTRY PLIST C PARM ENREG C PARM LG 2 C* C*INITIALISATION DES VARIABLES POUR IMG AVANT ET AP RES C 1 ADD AVT PAVT 50 C 1 ADD APR PAPR 50 C 24 SUBSTENREG:PAVTIMGAVT C 24 SUBSTENREG:PAPRIMGAPR C* C*TEST SI LE NOUVEAU MONTANT EST < A L'ANCIEN C MNTA IFLT MNTB C* C*SI OUI APPEL DE L'API D'ENVOI DE MESSAGE C CALL 'QMHSNDPM' C PARM 'CPF9897' MSGID 7 C PARM MSGF C PARM DATA C PARM LGDTA C PARM '*ESCAPE' TYPE 10 C PARM '*' PGMQ 10 C PARM STCK C PARM CLE 4 C PARM ERR C ENDIF C*FIN DU PROGRAMME C RETRN

182 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Commande de définition du déclencheur
ADDPFTRG FILE(FICH) TRGTIME(*BEFORE) TRGEVENT(*UPDATE) + PGM(TRGRPG) TRGUPDCND(*CHANGE)
Historique du travail modifiant les enregistrements (DSPJOBLOG)
ANNULATION DEMANDEE Une erreur s'est produite dans le programme déclenc heur. Une erreur s'est produite dans le programme déclenc heur. Le message CPF502B a été émis.
Exemple 5.9 : programme déclencheur et RPG/400. Il vérifie si la nouvelle valeur de la zone MNTSAL est bien supérieure à l’ancienne.
Remarques Les contraintes d’intégrité référentielle et les déclencheurs peuvent cohabiter pour le même fichier.
Le programme déclencheur s’exécute dans le travail du programme appelant, avec ses autorisations et ses contraintes. Il est prudent de mettre des droits publics suffisants au déclencheur et aux différents objets qu’il gère afin que n’importe quel travail puisse l’utiliser.
Le déclencheur est appelé à chaque opération sur un fichier pour laquelle il a été défini dans la commande ADDPFTRG. Son impact sur les performances des applications est donc direct. Il est donc essentiel de tout mettre en œuvre pour qu’il soit optimisé au maximum en suivant les règles classiques :
• en RPG/400, terminer le programme par le code opération RETRN plutôt que par le classique SETON LR pour diminuer le temps de chargement lors de l’appel suivant. Il faut avoir à l’esprit que le lancement du déclencheur est un CALL dynamique ;
• éviter les gros programmes et les interactions avec l’utilisateur par l’intermédiaire d’un fichier d’affichage (le programme appelant sera peut être exécuté en batch) ;
• limiter au strict minimum le nombre de fichiers à traiter, la création des ODP correspondants étant très pénalisante.

5 - Sécurité et intégrité des données 183
Les enregistrements du fichier qui est associé au déclencheur sont traités un par un. SEQONLY(*YES) permettant de grouper les opérations sur les données ne peut donc être utilisé.
Conclusions
La notion de déclencheur telle quelle est implémentée dans l’OS/400 apparaît aujourd’hui comme une réussite. Sa mise en œuvre est relativement simple et les programmes déclencheurs peuvent être écrits dans le langage de notre choix. Avec cette fonction, on peut maintenant mettre en place des contraintes d’intégrité complexes, impliquant plusieurs zones et même plusieurs fichiers, on peut réaliser des espions qui garderont une trace de ce qui est modifié dans les fichiers sensibles et bien d’autres choses encore.
Avec les contraintes d’intégrité référentielle, les déclencheurs forment une couche logicielle indépendante des applications qu’il faut obligatoirement traverser pour accéder aux données. Ainsi, on peut facilement homogénéiser les contrôles même pour des environnements aussi variés que le client/serveur, la base de données répartie et le local.
Les déclencheurs font partie intégrante des fichiers et sont visualisables par la commande DSPFD.
La sauvegarde et la restauration
Comme pour tous les systèmes, les sauvegardes sont obligatoires sur AS/400. Elles constituent le point de départ de la reprise après la perte de fichiers et permettent de retrouver la base de données dans un état stable et cohèrent.
Pour qu’elles soient efficaces, les sauvegardes doivent tout d’abord être régulières et fréquentes, sinon la version des fichiers restaurés risque d’être très ancienne. Ensuite, elles doivent avoir lieu au moment où la base de données est dans un état stable et cohérent afin d’avoir sur le support externe (bande, cartouche...) une version que l’on pourra restaurer sans soucis. La sauvegarde lors de la mise à jour des données (paramètre SAVACT) est à utiliser avec prudence et si possible en arrêtant la mise à jour jusqu’à l’établissement du point de synchronisation.
Il va de soi que les supports de sauvegarde doivent être si possible rangés dans un endroit sûr, à l’abri d’une catastrophe toujours possible (inondation, incendie...).

184 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Les commandes qui permettent de sauvegarder les objets de la base de données sont les classiques SAVOBJ, SAVCHGOBJ et SAVLIB .
Le paramètre ACCPTH de ces commandes précise si les chemins d’accès d’un fichier physique sont sauvegardés avec lui. Il faut remarquer que :
• seuls les chemins d’accès des membres sauvegardés sont pris en compte ;
• tous les fichiers physiques sur lesquels s’appuie un fichier logique doivent être dans la même bibliothèque mais cette dernière peut être différente de celle du fichier logique ;
• si le fichier logique et les fichiers physiques sont dans des bibliothèques différentes et s’il manque certains de ces objets lors de la restauration, les chemins d'accès seront reconstruits et non restaurés ce qui est généralement beaucoup plus long.
Il est donc conseillé de placer les fichiers physiques et les fichiers logiques d’une même application dans une seule bibliothèque.
Rappelons que la sauvegarde des chemins d'accès ne protège aucune donnée mais permet seulement de reconstruire plus rapidement la base de données en cas d’incident.
Par défaut, des informations sur la sauvegarde sont placées dans la partie descriptive de l’objet et sont visualisables par la commande DSPOBJD. Le paramètre UPDHST(*NO) inhibe la mise à jour de ces données.
La sécurité
La sécurité est une des fonctions essentielles de l’OS/400. Elle fait partie intégrante de la base de données et elle est très simple à mettre en œuvre à condition d’avoir procédé à une bonne analyse des droits et des interdictions de chacun.
La sécurité étant traitée en détail dans l’ouvrage Principes généraux et langage de contrôle sur AS/400 (Eyrolles, 2e édition, 1995), je n’y reviendrai pas et décrirai seulement ce qui est spécifique à la base de données.

5 - Sécurité et intégrité des données 185
Les droits sur les fichiers sont, comme pour tout objet, scindés en deux parties : ceux qui concernent l’objet lui même et ceux qui protègent les données qu’il contient.
Au niveau de l’objet, on trouve les droits :
• d’opération, qui permettent d’utiliser cet objet et de visualiser ses attributs ;
• de gestion, qui définissent la possibilité de gérer son niveau de sécurité, de le déplacer ou de le copier ;
• d’existence, qui autorisent le contrôle de son existence et le rattachement à un propriétaire.
Les droits sur les données portent sur la lecture, l’ajout, la modification et la suppression. Pour les fichiers physiques, ils contrôlent les opérations que l’on peut effectuer sur les enregistrements. Les fichiers logiques n’ont pas à proprement parler de données et leurs droits protègent l’accès aux enregistrements des fichiers physiques. Nous avons déjà signalé au chapitre 4 que pour accéder à des enregistrements à travers un fichier logique l’utilisateur doit disposer des droits suffisants sur les données des fichiers physique et logique.
Signalons que cette sécurité est incontournable et qu’une fois mise en place n’importe quel travail doit disposer des droits nécessaires pour accéder à une information de DB2/400 que ce soit au travers du client/serveur (à partir de Client Access/400, par exemple), à partir de DRDA ou à l’aide de tout autre moyen.
Depuis la V2R3M0 de l’OS/400, la fonction d’audit permet de savoir qui a utilisé un objet, notamment un fichier. Elle peut être mise en place à l’aide des valeurs système QAUDLVL et QAUDCTL et s’appuie sur la journalisation (journal QAUDJRN de QSYS).
Pour conclure sur la sécurité, et pour montrer sa puissance, il faut signaler que l’OS/400 peut, sous certaines conditions, répondre à la norme C2 qui est une des plus draconiennes en matière de sécurité (elle a été établie par le DOD (Departement Of Defense) des États-Unis).
Les dispositifs matériels Des dispositifs matériels permettent de protéger la base de données contre la défaillance d’un disque ou d’un des dispositifs qui lui sont associés (contrôleur,

186 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
IOP, bus...). Ils sont complémentaires de la journalisation qu’ils ne remplacent pas et ne dispensent en aucun cas d’effectuer des sauvegardes.
A ce jour, on peut identifier trois modes de protection matérielle :
• le contrôle d’intégrité où l’information stockée sur un disque permet de reconstruire une unité défaillante ;
• le RAID 5 qui est comparable au contrôle d’intégrité sur le principe mais beaucoup plus efficace ;
• le mirroring qui consiste à doubler chaque disque par une unité identique qui contient son image (disque miroir).
Le détail de ces fonctions sortant du cadre de la base de données, je me contenterai donc de décrire leurs principales caractéristiques.
Le contrôle d’intégrité ( checksum)
Principes
Le contrôle d’intégrité s’applique à une série de disques identiques. Le système prend, par exemple, le premier bit de la première piste de chaque disque (sauf du dernier). Il effectue sur ces données un OU exclusif. Le résultat est placé dans le bit correspondant du dernier disque. Il servira à reconstruire, par l’opération inverse, le bit d’un disque défaillant. Cette opération est effectuée pour tous les bits de toutes les pistes des disques protégés par le contrôle d’intégrité.
Dans la figure 5.14, l’opération logique pour le premier bit est :
1 OU 0 = 1
Le résultat est placé dans le bit correspondant du troisième disque.

5 - Sécurité et intégrité des données 187
1010 0011
1001
1010+
00111001
Figure 5.14 : OU logique utilisé pour le contrôle d’intégrité. Tout se passe comme si un disque protégeait les autres, mais en fait l’information de contrôle est répartie sur toutes les unités concernées ce qui évite de surcharger un bras d’accès. Chaque disque héberge donc une portion de l’information qui permettra de reconstruire la partie correspondante d’un autre disque défaillant.
Il faut rajouter à cela que toutes les données placées sur les disques n’ont pas besoin d’être protégées. Certaines n’ont d’intérêt que pour les travaux en cours, ou ne sont utilisées que temporairement par le système. Elles sont donc placées dans une partie non protégée des disques. Nous ne détaillerons pas ici le calcul de cet espace.
La configuration type d’une série de disques protégés par le contrôle d’intégrité est représenté en figure 5.15.

188 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Non protégéNon protégéNon protégé
Disque 1 Disque 2 Disque 3
Figure 5.15 : structure d’une série de disques sous contrôle de validation. Les parties grisées représentent les données de contrôle.
On constate que cette fonction consomme pratiquement un disque quel que soit le nombre d’unités protégées (au maximum 8).
Le contrôle d’intégrité est mis en place à partir du menu Dedicated Service Tools lors d’un IPL sous contrôle de l’opérateur.
Reprise
En cas d’incident sur un disque protégé par le contrôle d’intégrité, le système s’arrête. Il faut alors remplacer le disque défaillant et reconstruire les données à partir des informations situées sur les autres unités. Cette opération est parfois longue et pénalisante car les applications ne peuvent être actives.
Performances
Le contrôle d’intégrité est consommateur de ressources car le processeur de l’AS/400 effectue beaucoup plus de travail. On estime à environ 10 % l’utilisation de CPU supplémentaire, ce qui est important !
Conclusions
Le contrôle d’intégrité était couramment utilisé au début de l’AS/400. Il est consommateur de ressources CPU, de disques et même de mémoire principale. Il ne permet pas un rétablissement rapide sans arrêter le système et s’avère inefficace dans le cas de la panne simultanée de deux disques (exceptionnelle, il est vrai !).

5 - Sécurité et intégrité des données 189
Il est abandonné petit à petit au profit des disques miroirs ou des unités 9337 RAID 5.
Les disques miroirs ( mirroring)
Il s’agit d’un dispositif physique qui consiste à doubler la structure de stockage d’un ASP. Chaque disque à son image exacte sur un autre disque de même type. Le système écrit sur ces deux unités en même temps et peut lire sur l’une ou l’autre selon la disponibilité des bras d’accès.
En cas de panne de l’un des disques, le système continue à fonctionner sans interruption. Un message remonte dans QSYSOPR pour prévenir que le mirroring est désactivé pour cette unité. Les opérations continuent avec l’autre disque, qui n’est plus protégé.
Le changement du disque défectueux peut même, sur certains modèles, être réalisé sans arrêt du système. Le mirroring est mis en place lors d’un IPL sous contrôle de l’opérateur, par le menu Dedicated Service Tools. La protection peut être réalisée pour les disques seulement, mais elle peut aussi être activée au niveau du contrôleur, de l’IOP et même du bus à condition, bien évidemment, de doubler ces dispositifs.
Le mirroring est certainement la méthode de protection la plus fiable mais elle est relativement onéreuse car elle impose l’acquisition de nombreux disques. Elle reste le meilleur moyen pour sécuriser les anciens disques tels que les 9332, 9335, 9336... Dans les nouvelles configurations on préfère généralement utiliser des disques de type RAID 5 (tels que les IBM 9337) qui demandent un investissement moins important tout en procurant une excellente protection.
Les disques de type RAID 5
Principes
Avec la V2R2M0 de l’OS/400 sont apparus les disques IBM 9337 disposant du mode RAID 5. D’autres constructeurs proposent aujourd’hui de telles configurations qui ont tout ou partie des caractéristiques de ces disques IBM. Ces nouveaux supports sont en tous points remarquables et ne cessent d’évoluer en terme de capacité de stockage, de quantité de mémoire cache, de performance...
Les modèles 9337 RAID 5 dits à haute disponibilité disposent d’une protection comparable, dans le principe, à ce que nous avons vu pour le contrôle d’intégrité (figure 5.14). Il n’y a toutefois pas d’espace non protégé. La grande différence

190 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
réside essentiellement dans le fait que ce n’est plus la CPU de l’AS/400 qui travaille mais le contrôleur. L’impact sur les performances n’est pas négatif comme pour le contrôle d’intégrité, bien au contraire. Les mémoires cache en écriture et en lecture procurent des temps de réponse jamais atteints jusque là.
Reprise
Lors de la défaillance d’un disque, le système ne s’arrête pas et les applications peuvent continuer à fonctionner. Le contrôleur reconstitue les données du disque manquant à la demande à l’aide des données des autres disques. Il continue même à simuler l’écriture sur ce disque en mettant à jour les informations de contrôle dans la partie correspondante d’un autre disque. L’utilisateur aura seulement des temps de réponse dégradés.
Le remplacement de l’unité défaillante est effectué sans arrêter le système. Une fois cette opération terminée, le contrôleur reconstruit les données sur le nouveau disque (à temps perdu !) tout en continuant à servir les données pour les applications.
Conclusions sur les disques RAID 5
Les disques RAID 5 constituent aujourd’hui la meilleure adéquation entre le prix, la disponibilité et la protection des données. Le mirroring est à préférer pour les données hautement sensibles, ou pour des configurations disposant encore de disques 9332, 9335, 9336 ou compatibles.
Conclusions sur la sécurité et l’intégrité
L’AS/400 dispose de tous les atouts lui permettant d’avoir une sécurité optimale, adaptée aux besoins de chacun, tout en préservant l’intégrité des données dans tous les cas de figure.
Un système correctement protégé doit avoir un niveau de sécurité (valeur système QSECURITY) supérieur ou égal à 30. La journalisation (et éventuellement le contrôle de validation) doit être appliqué sur les fichiers sensibles de l’entreprise. Pour les systèmes où la disponibilité doit être quasiment permanente, il faut absolument mettre en place un dispositif tel que les disques RAID 5 ou éventuellement le mirroring.
Enfin, les sauvegardes constituent la base de la reprise. Elles doivent toujours être considérées comme un des éléments essentiels de la protection des données.
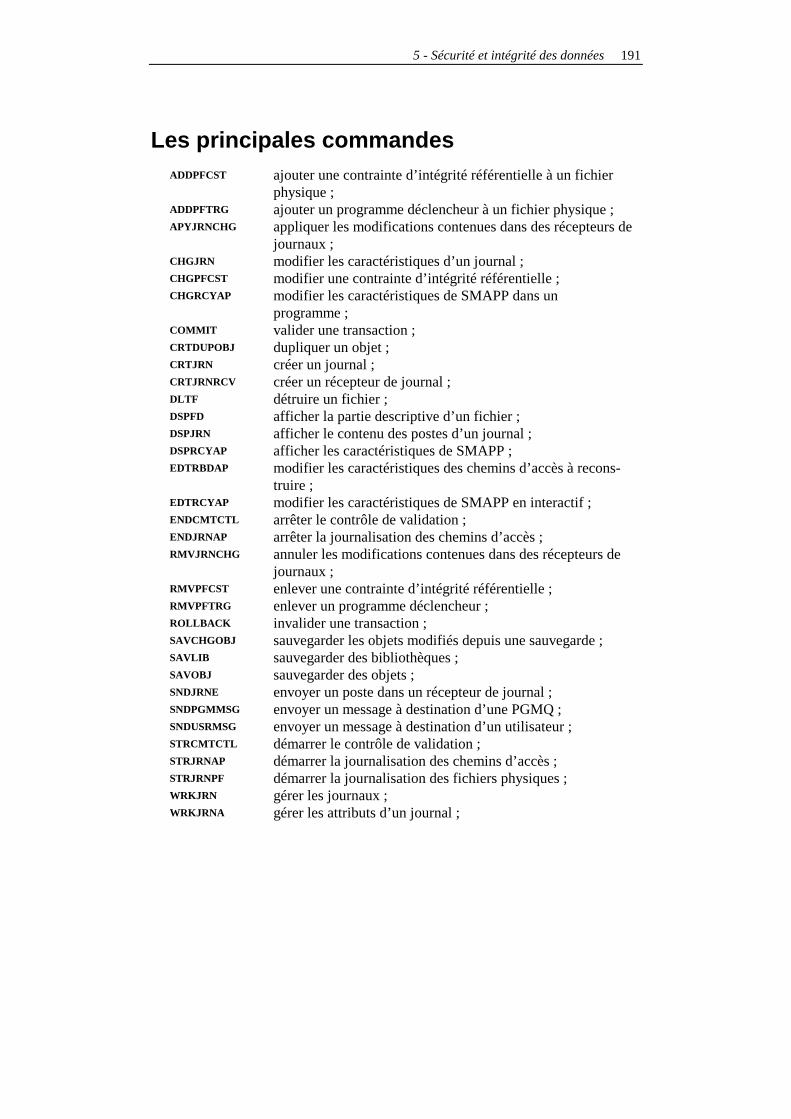
5 - Sécurité et intégrité des données 191
Les principales commandes
ADDPFCST ajouter une contrainte d’intégrité référentielle à un fichier physique ;
ADDPFTRG ajouter un programme déclencheur à un fichier physique ; APYJRNCHG appliquer les modifications contenues dans des récepteurs de
journaux ; CHGJRN modifier les caractéristiques d’un journal ; CHGPFCST modifier une contrainte d’intégrité référentielle ; CHGRCYAP modifier les caractéristiques de SMAPP dans un
programme ; COMMIT valider une transaction ; CRTDUPOBJ dupliquer un objet ; CRTJRN créer un journal ; CRTJRNRCV créer un récepteur de journal ; DLTF détruire un fichier ; DSPFD afficher la partie descriptive d’un fichier ; DSPJRN afficher le contenu des postes d’un journal ; DSPRCYAP afficher les caractéristiques de SMAPP ; EDTRBDAP modifier les caractéristiques des chemins d’accès à recons-
truire ; EDTRCYAP modifier les caractéristiques de SMAPP en interactif ; ENDCMTCTL arrêter le contrôle de validation ; ENDJRNAP arrêter la journalisation des chemins d’accès ; RMVJRNCHG annuler les modifications contenues dans des récepteurs de
journaux ; RMVPFCST enlever une contrainte d’intégrité référentielle ; RMVPFTRG enlever un programme déclencheur ; ROLLBACK invalider une transaction ; SAVCHGOBJ sauvegarder les objets modifiés depuis une sauvegarde ; SAVLIB sauvegarder des bibliothèques ; SAVOBJ sauvegarder des objets ; SNDJRNE envoyer un poste dans un récepteur de journal ; SNDPGMMSG envoyer un message à destination d’une PGMQ ; SNDUSRMSG envoyer un message à destination d’un utilisateur ; STRCMTCTL démarrer le contrôle de validation ; STRJRNAP démarrer la journalisation des chemins d’accès ; STRJRNPF démarrer la journalisation des fichiers physiques ; WRKJRN gérer les journaux ; WRKJRNA gérer les attributs d’un journal ;

192 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
WRKPFCST gérer les contraintes d’intégrité référentielle.
Les principaux menus
CMDPF, FILE, FILE2, CMDFILE, CMDMBR, CMDDBF, CMDDB, CMDCMT, CMDBACK , CMDJRN, CMDJRNRCV, CMDROLL.

5 - Sécurité et intégrité des données 193
SECURITE ET INTEGRITE DES DONNEES 125
Introduction 125
La journalisation 127 Les principes 127 La journalisation des fichiers physiques 140 La journalisation des chemins d’accès 143 Conclusions sur la journalisation 147
Le contrôle de validation 147 Principes 147 Mise en œuvre 149 L’objet de notification 152 Les journaux 160 Le contrôle de validation à deux phases 161 Conclusions sur le contrôle de validation 162
Les contraintes d’intégrité référentielle 162 Introduction 162 Mise en œuvre 164 Les clés 166 La gestion 168 La journalisation 169 Exemple en RPG 169 Conclusions 173
Les déclencheurs (triggers) 173 Mise en œuvre 174 Le programme déclencheur 175 Exemple en langage de contrôle 178 Exemple en RPG 179 Remarques 182 Conclusions 183
La sauvegarde et la restauration 183
La sécurité 184
Les dispositifs matériels 185 Le contrôle d’intégrité (checksum) 186 Les disques miroirs (mirroring) 189 Les disques de type RAID 5 189

194 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Conclusions sur la sécurité et l’intégrité 190
Les principales commandes 191
Les principaux menus 192

5 - Sécurité et intégrité des données 195
—9— 9337 137; 181
—A— ACCPTH 176 ADDPFCST 159 ADDPFTRG 168 ALTER TABLE 161 APYJRNCHG 136; 139 ASP 126
—B— Batterie 125
—C— C2 178 CALL 175 CHAIN 157 checksum 126; 179 chemin d’accès 158 CHGPFCST 163 clé 161 Client Access/400 178 client/serveur 178 CLRPFM 136; 140 CMTID 149 COMIT 146 COMMIT 146; 170 contrainte d’intégrité référentielle 157 contrôle d’intégrité 126; 179 contrôle de validation 126; 145 CRTJRN 129; 135 CRTJRNRCV 129; 135
—D— DDM 157 déclencheur 126; 167 DFU 164 disque miroir 126; 181 DLTM 139; 140 DRDA 140; 167; 178 DSPFD 163; 176 DSPJRN 133; 139
—E— EDTRBDAP 141 EDTRCYAP 143 ENDCMTCTL 146 ENDJRNAP 142 ENTDTA 138
—F— FILE 138
—I— image après 128 image avant 128 intégrité 125 invalidation 146 INZPFM 136 IPL 144; 181
—J— journal 128; 155 Journalisation 126; 127; 143
—L— l’ASP 135 l’INFDS 164 l’IPL 141 LCKLVL 146
—M— MAINT 144 MAXMBR 161 mirroring 181 MOVOBJ 136
—N— NFYOBJ 149
—O— objet de notification 149 OMTJRNE 136; 138

126 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
OPNQRYF 144
—P— performance 136 poste 127
—Q— QAUDCTL 178 QAUDJRN 178 QAUDLVL 178 QCPFMSG 171 QSECURITY 182 QSYSOPR 181 QTEMP 144 Query 144
—R— RAID 181 RAID5 126 RECOVER 141 RETRN 175 RGZPFM 139; 140 RMVJRNCHG 136; 140 RMVM 136 RMVPFCST 163 RNMOBJ 136 ROLBK 146 ROLLBACK 146; 170 RPG IV 168 RPG/400 168
—S— S.M.A.P.P. 143
sauvegarde 137 SAVACT 176 SAVCHGOBJ 137; 176 SAVLIB 136; 137; 176 SAVOBJ 136; 137; 176 sécurité 125; 177 SNDJRNE 138 SNDPGMMSG 171 sous-fichier 149 SQL 144; 157 STRCMTCTL 146 STRJRNAP 129; 142 STRJRNPF 129; 136; 138
—T— trigger 167 TYPE 138
—U— un récepteur de journal 128 UNIQUE 159 UPDAT 164
—V— validation 146
—W— WRITE 164 WRKJRN 133; 139 WRKJRNA 132 WRKPFCST 163

Chapitre 6
SQL/400
SQL/400 est l’implémentation de la norme SQL dans l’OS/400. Il représente en fait un langage, des outils facilitant la saisie et le lancement de requêtes, un précompilateur permettant d’inclure des ordres SQL dans des programmes et des commandes de gestion de l’environnement.
Introduction SQL (Structured Query Language) est un standard, à la fois au niveau du marché (il est disponible sur un nombre incalculable de produits et de plates-formes) et au niveau des organismes de normalisation (ANSI, ISO, IBM avec SAA...). C’est le langage le plus utilisé pour accéder aux données d’un SGBD relationnel et, à ce titre au moins, il se devait d’être supporté par l’OS/400. Cette large implantation fait de SQL un langage idéal pour travailler dans un environnement de bases de données réparties. Il constitue notamment l’armature de DRDA et permet le développement d’applications de type client/serveur. Par tous ces aspects, SQL devient incontournable sur l’AS/400, comme sur beaucoup de systèmes. Il permet de gérer les données et les différents composants de la base de données. C’est un véritable environnement.

186 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
SQL est simple d’approche : on indique ce que l’on veut et non pas comment on doit faire pour y arriver. Sa syntaxe est proche du langage naturel et s’appuie sur un petit nombre de mots-clés. Son apprentissage est donc rapide.
Autre avantage, ce langage est le même pour l’utilisateur final, pour le développeur et pour le gestionnaire des données.
SQL/400 correspond à un logiciel sous licence (code 5738-ST1 en version 2 et 5763-ST1 en version 3 de l’OS/400). Il apporte principalement :
• une interface interactive ;
• Query Manager, un produit comparable à Query/400 mais générant du SQL ;
• et un précompilateur qui permet d’inclure des requêtes SQL dans des langages de haut niveau (RPG, Cobol...). Il est important de préciser que ces programmes, une fois compilés, pourront être exécutés sur n’importe quel système, même s’il ne dispose pas du logiciel SQL.
Il pourrait faire, à lui seul, l’objet d’un ouvrage complet. Je ne présenterai ici que les bases de ce langage et les particularités de SQL/400. Pour plus de détails, je renvoie le lecteur à des ouvrages spécialisés.
L’environnement SQL
Sur l’AS/400, on peut utiliser SQL de deux manières :
• sur des objets de type *FILE créés à partir de DDS ;
• sur des structures appartenant à un environnement SQL.
Cette notion est importante car elle signifie que l’on peut créer des fichiers à partir de DDS et gérer leurs données avec SQL. Il est courant, par exemple, d’utiliser SQL en interactif pour un besoin précis sur un fichier qui est habituellement traité avec des programmes classiques en RPG ou en Cobol.
Mais SQL propose en plus un environnement complet appelé collection. Une collection peut être considérée comme une base de données à part entière. Elle contient les données, les vues sur ces données, un journal et son récepteur, et même des structures pour se gérer elle-même.
Avant d’aller plus loin dans la description de ce langage, il est important de définir les termes que nous devons utiliser.

6 - SQL/400 187
Terminologie
Les termes à employer dans l’environnement SQL sont hérités du modèle relationnel. Voici une équivalence avec les objets ou structures de l’OS/400 :
Terminologie SQL Terminologie AS/400 Collection Bibliothèque Table Fichier physique Vue Fichier logique sans clé Index Chemin d’accès Colonne Zone Ligne Enregistrement
Une collection est implémentée sous la forme d’une bibliothèque. Elle regroupe notamment des tables qui contiennent les données, les vues qui sont des manières de voir ces données et des index qui permettent l’accès rapide à partir de clés. On y trouve même une sorte de dictionnaire sous la forme de fichiers dont le nom commence par QIDC.
Pour gérer une collection, SQL utilise des vues extraites de fichiers système placés dans QSYS et dont les noms commencent par QADB. Ces vues sont rangées dans la collection elle-même en version 2 de l’OS/400 et dans la bibliothèque QSYS2 en version 3. L’ensemble de ces vues est appelé catalogue.
Le catalogue
Voici les principales vues composant le catalogue :
SYSCOLUMNS contient la liste de toutes les colonnes utilisées par les tables et les vues ;
SYSINDEXES contient des informations sur tous les index ; SYSKEYS contient la liste de toutes les colonnes composant les
clés des index ; SYSPACKAGE contient la liste de tous les objets de type *SQLPKG ; SYSTABLES contient la liste de toutes les tables et de toutes les vues ; SYSVIEWS contient des informations sur toutes les vues.
Il est aisé d’utiliser ces vues (avec SQL !) pour extraire des informations sur une collection.
Conventions SQL

188 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Dans les commandes de l’OS/400, le nom de la bibliothèque et le nom de l’objet qualifié sont séparés par le caractère /. La norme SQL préconise de séparer le nom de la collection du nom de l’objet (table, vue...) par le point (.). L’une ou l’autre de ces conventions peuvent être utilisée sur l’AS/400 à condition de le préciser à l’environnement dans le paramètre NAMING (par les commandes STRSQL, CRTSQLCOL , RUNSQLSTM...). Dans les exemples suivants nous utiliserons la convention SQL, c’est-à-dire que la table TAB1 de la collection COL1 sera qualifiée par :
COL1.TAB1 Le caractère ‘/’ n’est pas reconnu par les autres systèmes comme séparateur. Il ne pourra être utilisé que dans le cas où la base de données (locale ou distante) est située sur un AS/400.
Utiliser une collection ou non ? Nous avons déjà signalé que SQL peut gérer des données placées dans des fichiers situés en dehors d’une collection. Alors pourquoi utiliser une collection ? Voici quelques éléments de réponse :
• une collection est un environnement complet, homogène, contenant même un journal. C’est une base de données à part entière ;
• les tables placées dans une collection sont automatiquement journalisées et le contrôle de validation peut être simplement mis en place par le paramètre COMMIT des commandes lançant SQL (STRSQL, RUNSQLSTM...) ;
• le contrôle de validation est obligatoire si on désire accéder à une base de données AS/400 à partir d’une autre plate-forme. Dans ce cas, l’utilisation d’une collection simplifie le travail de mise en place de l’environnement ;
• le catalogue permet de gérer les différentes structures de la collection. Mais la mise en œuvre d’une collection a ses détracteurs. La création d’une collection est une opération lourde pour le système et la journalisation associée au contrôle de validation ne favorise pas les performances. D’une manière générale, on peut dire que si l’on désire travailler dans un environnement purement SQL, comme on peut le faire sur d’autres plates-formes, il est préférable de se placer dans le cadre d’une collection. Sinon, on peut se

6 - SQL/400 189
contenter de ranger les fichiers dans des bibliothèques classiques. Il est alors prudent de les journaliser.

190 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Les éléments du langage SQL
Dans cette partie, nous allons voir les éléments de base du langage SQL qui nous permettront de mieux cerner ses caractéristiques et d’exécuter nos premières transactions. Mais avant tout, nous allons rapidement décrire les environnements avec lesquels nous allons saisir et lancer ces requêtes.
Les environnements d’exécution
Pour une meilleure compréhension de ce chapitre et surtout de SQL, il est intéressant de disposer d’un terminal relié à un AS/400 possédant ce produit.
SQL interactif
Le plus simple pour tester SQL est de lancer l’environnement interactif par la commande STRSQL. On se retrouve alors devant un écran qui nous permet de saisir nos requêtes, puis de les exécuter grâce à la touche ENTREE. Leur exécution a lieu tout de suite et le résultat éventuel est renvoyé à l’écran. Ce mode est idéal pour apprendre SQL, mais les responsables d’exploitation sont parfois réticents à le mettre à la disposition des utilisateurs car il peut provoquer des dégradations notables de performances s’il est mal utilisé. On peut, en effet, lancer des requêtes qui vont analyser des fichiers de plusieurs millions d’enregistrements, parfois sans le savoir, ou sans en avoir réellement besoin, juste pour tester.
Une invite est disponible par l’intermédiaire de la touche F4. Elle nous permet d’ignorer une grande partie de la syntaxe.
Query Manager
Query Manager est un outil livré avec SQL qui permet de saisir des requêtes, de mettre en forme les rapports générés, de gérer les tables et même de limiter les actions de certains utilisateurs. C’est un véritable environnement lancé par la commande STRQM. Pour la saisie de requêtes, il dispose de deux interfaces :
• la première, nommée SQL, présente un éditeur de type SEU qui nous laisse entrer les instructions. Une aide à la saisie, du même type que l’invite du mode interactif, est disponible avec la touche F4 ;

6 - SQL/400 191
• la seconde, nommée PROMPT, est comparable à Query/400. Elle nous permet d’ignorer le langage SQL. Une analyse ainsi créée peut être transformée en requête SQL.
Le choix entre ces deux interfaces est effectué en utilisant la touche F19 au niveau du menu général de gestion des requêtes.
Le mode SQL autorise la saisie de variables. Leur nom est précédé du caractère & comme en langage de contrôle. Au moment de l’exécution, le système demande à l’utilisateur de saisir la valeur de cette variable via la file d’attente de messages externe.
Les requêtes peuvent être enregistrées, puis rappelées et modifiées. La commande STRQMQRY lance leur exécution.
Query Manager permet de gérer le format des rapports ce qui est impossible avec SQL interactif. On peut ainsi définir le titre et le formatage des colonnes, l’en-tête et le pied de page...
Enfin, ce produit permet de définir des caractéristiques pour chaque utilisateur (options par défaut, ordres SQL autorisés et interdits...) dans l’environnement Query Manager.
La commande RUNSQLSTM
Avec la V2R3M0 de l’OS/400 est apparue une commande qui permet de lancer une requête SQL en batch. Son utilisation est très simple :
• saisie de la requête dans un membre source (de type TXT, par exemple, car il n’y a pas de vérification de la syntaxe par l’éditeur) ;
• soumission de cette requête par la commande RUNSQLSTM dans un SBMJOB.
Pour lancer en batch la requête contenue dans le membre source REQ1 du fichier BD400, la commande est :
SBMJOB CMD(RUNSQLSTM SRCFILE(*LIBL/BD400) SRCMBR(REQ1))
Lors de l’exécution du travail batch, les ordres SQL sont interprétés, il n’y a aucune compilation.
Conclusions

192 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Nous avons rapidement décrit les différentes possibilités qu’un utilisateur a à sa disposition pour lancer des requêtes SQL. Le programmeur pourra inclure des ordres SQL dans des programmes RPG, Cobol ou autres, mais nous verrons cela plus tard, lorsque nous aurons défini plus précisément les caractéristiques de ce langage.
Les conventions Les conventions suivantes ont été choisies pour illustrer les exemples :
• le point sépare le nom d’une collection (ou d’une bibliothèque) du nom d’une table ou d’une vue. SQL doit donc être démarré avec le paramètre NAMING(*SQL). Mais, d’une manière générale, le nom des objets n’est pas qualifié dans nos exemples ; c’est alors la base de données par défaut qui est choisie. Celle-ci peut être définie au niveau du paramètre DFTRDBCOL des commandes de création de programme (CRTSQLRPG...) ou être tout simplement citée dans la liste de bibliothèque ;
• la présentation des requêtes sur plusieurs lignes ne répond à aucune contrainte syntaxique, elle a seulement pour ambition de faciliter la lecture ;
• pour une meilleure lisibilité, les ordres SQL sont en caractères majuscules et les données spécifiques à l’exemple sont en minuscules, mais les deux types de caractères peuvent être utilisés indifféremment ;
• seuls les principaux ordres sont décrits.
La définition des structures SQL
CREATE COLLECTION
Cet ordre permet de créer une collection. Sur l’AS/400, il définit une bibliothèque et place dedans de nombreux objets, notamment :
• le journal QSQJRN et son récepteur QSQJRN0001;
• le catalogue, c'est-à-dire des tables et des vues ;
• un dictionnaire, objet de type *DTADCT, qui a le même nom que la collection.
La création d’une collection est une tâche relativement lourde pour le système, à effectuer, si possible, en dehors des périodes de forte activité.

6 - SQL/400 193
Exemple
CRTCOL db400 crée la collection DB400.

194 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
CREATE TABLE
Cet ordre permet de créer une table (au sens SQL) ou un fichier physique pour l’OS/400, dans une collection ou plus généralement dans une bibliothèque. Pour une collection, la table est référencée dans le catalogue et se trouve automatiquement journalisée.
A la suite de cet ordre on doit indiquer le nom (qualifié) de la table et décrire les zones qui la composent.
Les types
Voici les principaux types qui peuvent être définis pour les colonnes et leur équivalence sur l’AS/400 :
Type SQL Type sur l’AS/400 CHAR Alphanumérique ; DECIMAL Décimal condensé ; DATE Date ; TIME Time ; TIMESTAMP Timestamp ; VARCHAR Zone de longueur variable. ALLOCATE permet de définir la
longueur de la partie fixe ; SMALLINT Binaire défini sur 2 octets ; INTEGER OU INT Binaire de longueur 4 ; FLOAT Nombre en virgule flottante.
Valeur indéfinie
Par défaut avec SQL, une zone peut prendre la valeur indéfinie (NULL). Pour inhiber cette possibilité qui n’est pas standard sur l’AS/400, et qui n’est pas bien supportée par des langages comme le RPG/400, il faut préciser NOT NULL en regard de chaque zone décrite. WITH DEFAULT initialise ces zones avec la valeur par défaut (0 pour du numérique, des blancs pour de l’alphanumérique).
Exemple
CREATE TABLE db400.tab1 (zone1 CHAR(5) NOT NULL, zone2 DECIMAL(8,2) NOT NULL , zone3 DATE NOT NULL, zone4 INT)
crée la table TAB1 dans la collection DB400. Elle contient ZONE1 de type Alphanumérique de longueur 5, ZONE2 de type Décimal condensé pouvant avoir

6 - SQL/400 195
8 positions dont 2 derrières la virgule (123456.78), ZONE3 de type Date et ZONE4 de type Binaire de longueur 4 qui peut avoir la valeur indéfinie. Contrainte d’intégrité référentielle
Lors de la création d’une table, on peut lui associer une contrainte d’intégrité référentielle, une clé primaire ou une clé unique comme avec la commande ADDPFCST. La CIR peut être ajoutée à une table dépendante lors de sa création par l’ordre CREATE TABLE ou ensuite avec ALTER TABLE .
L’exemple suivant définit la table TAB1, dépendante de TAB2. La contrainte s’appuie sur la colonne ZONE1 des 2 tables et porte le nom CTR1 :
CREATE TABLE db400.tab1 (zone1 CHAR(5) NOT NULL, zone2 DECIMAL(8,2) NOT NULL , CONSTRAINT ctr1 FOREIGN KEY (zone1) REFERENCES tab2 (zone1) ON DELETE NO ACTION ON UPDATE RESTRICT)
CREATE VIEW
Cet ordre permet de créer une vue. Rappelons qu’une vue peut être assimilée à un fichier logique sans clé. C’est une manière de voir les enregistrements d’une ou de plusieurs tables ou vues. Le tri est défini lors de la sélection des enregistrements. Il est donc établi dynamiquement en s’appuyant éventuellement sur un index existant.
Une requête SQL est associée au CREATE VIEW . Elle définit les tables, les vues, les enregistrements et les colonnes qui seront accessibles au travers de cette structure.
Exemple
CREATE VIEW vue1 AS SELECT zone4, zone1, zone2 FROM tab1 WHERE zone2 > 0
crée la vue VUE1 qui s’appuie sur TAB1 et voit les zones ZONE4, ZONE1 et ZONE2 pour les enregistrements dont le contenu de ZONE2 est supérieur à 0.
CREATE INDEX

196 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Cet ordre crée un index. Un index est un chemin d’accès qui s’appuie obligatoirement sur un fichier physique. Il est utilisé par l’optimiseur s’il le juge utile, notamment pour vérifier l’unicité des clés et lorsqu’un tri est demandé dans une requête (avec les ordres ORDER BY et GROUP BY). Exemples
CREATE INDEX ind1 ON tab1 (zone2)
crée l’index nommé IND1 s’appuyant sur ZONE2 de la table TAB1 ;
CREATE UNIQUE INDEX ind2 ON tab1 (zone1, zone3)
crée l’index IND2 à partir de la clé composée de ZONE1 et de ZONE3. Deux enregistrements de la table TAB1 ne pourront avoir même valeur de clé ;
CREATE INDEX ind3 ON tab1 (zone1 ASC, zone3 DESC)
crée l’index IND3 à l’aide duquel les enregistrements apparaîtront triés de façon ascendante sur ZONE1 et descendante sur ZONE3.
CREATE SCHEMA Cet ordre permet de définir tout un environnement en une seule opération car il autorise la création d’une collection, de tables, de vues et d’index et permet même de définir des droits sur ces objets. Il est apparu en V2R3M0 de l’OS/400 et doit être codifié dans un membre source, puis lancé avec la commande RUNSQLSTM, donc en batch. Exemple
CREATE SCHEMA col1 CREATE TABLE tab1 (zone1 CHAR(5) NOT NULL, zone2 DECIMAL(8,2) NOT NULL) CREATE INDEX ind1 ON tab1 (zone2) GRANT ALL ON tab1 TO pgmr1

6 - SQL/400 197
crée la collection COL1, la table TAB1 et l’index IND1. Tous les droits (au sens SQL) sont donnés à l’utilisateur PGMR1.

198 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
DROP
Cet ordre détruit une structure SQL. DROP COLLECTION efface une collection et tout ce qui est dedans. DROP TABLE détruit une table et tout ce qui s’y rapporte (vues, index, autorisations).
Exemple
DROP TABLE DB400.tab1 détruit la table TAB1 ainsi que les vues et les index qui lui sont associés.
ALTER TABLE
Habituellement, cet ordre est utilisé pour modifier la structure d’une table, mais cela est impossible sur l’AS/400 (à ce jour, car cette fonction est prévue pour la prochaine version du système). Il est apparu avec la V3R1M0 de l’OS/400 pour une autre utilisation. Il sert à associer une contrainte d’intégrité référentielle à une table qui existe déjà. Pour une nouvelle table, la contrainte peut être définie dans le CREATE TABLE . En dehors de l’environnement SQL, on peut utiliser la commande ADDPFCST qui a les mêmes fonctionnalités.
Exemple
ALTER TABLE tabdep ADD CONSTRAINT nomcont FOREIGN KEY (zone1, zone2) REFERENCES nompar (z1, z2) ON DELETE NO ACTION ON UPDATE RESTRICT
ajoute une contrainte nommée NOMCONT entre le fichier dépendant TABDEP et le fichier parent NOMPAR (se reporter à la description des CIR du chapitre 5 pour avoir plus d’information sur ces différentes valeurs).
La gestion des données
SELECT
Cet ordre est probablement le plus utilisé, car il permet d’extraire des enregistrements de la base de données, choisis selon certains critères, puis triés sur

6 - SQL/400 199
une ou plusieurs colonnes. Il est extrêmement puissant mais sa syntaxe est simple : c’est une des forces de SQL.

200 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Sélection simple
La sélection de base consiste à citer les colonnes à extraire au niveau de la clause SELECT et à nommer la table ou la vue concernée à l’aide de FROM . Par exemple :
SELECT zone1, zone2 FROM tab1
renvoie le contenu de ZONE1 et de ZONE2 pour tous les enregistrements de TAB1.
Une colonne peut aussi être le résultat d’un calcul :
SELECT zone1, salaire / 12 mensuel FROM tab1
renvoie dans la deuxième colonne le contenu de SALAIRE divisé par 12. Celle-ci est renommée MENSUEL (à partir de la V3R1M0 de l’OS/400).
Le caractère * permet de sélectionner toutes les colonnes. Par exemple,
SELECT * FROM SYSTABLES
renvoie le contenu de toutes les zones pour tous les enregistrements de SYSTABLES. Cette table est un des éléments du catalogue qui contient des informations sur toutes les tables d’une collection (ou de toutes les collections à partir de la V3R1M0 de l’OS/400 ; elle est alors placée dans QSYS2).
La clause DISTINCT supprime les lignes en double. Elle doit être citée immédiatement après SELECT.
SELECT DISTINCT zone1, zone2 FROM tab1
Critères de sélection
La clause WHERE permet de faire une sélection des enregistrements à extraire. Sa syntaxe est aussi très simple :
SELECT * FROM tab1 WHERE zone2 > 10
ramène toutes les colonnes pour les enregistrements qui ont ZONE2 supérieur à 10.
La proposition logique associée au WHERE peut être relativement complexe car elle autorise :

6 - SQL/400 201
• les opérateurs AND et OR :
SELECT * FROM tab1 WHERE (zone2 > 10 OR zone1 < 5) AND (zone3 = 15 OR zone4 =’A’)
• le prédicat BETWEEN pour définir un domaine de valeurs, bornes comprises :
SELECT * FROM tab1 WHERE zone2 BETWEEN 10 AND 50
• le prédicat LIKE pour rechercher une chaîne dans une colonne de type Alphanumérique. Le caractère ‘% ’ remplace un nombre quelconque de caractères, ‘_’ en substitue un seul. Par exemple :
SELECT * FROM tab1 WHERE zone3 LIKE ’%AB%’ AND zone4 LIKE ’_X%’
sélectionne les enregistrements qui ont ZONE3 contenant la chaîne AB à n’importe quelle position et ZONE4 ayant un X en deuxième position ;
• de définir une liste de valeurs avec le prédicat IN :
SELECT * FROM tab1 WHERE zone3 IN (5, 15, 25)
• le test des valeurs indéfinies par IS NULL ou IS NOT NULL :
SELECT * FROM tab1 WHERE zone5 IS NOT NULL
Tri
Les enregistrements peuvent apparaître triés selon les colonnes définies grâce à la clause ORDER BY :
SELECT * FROM tab1 WHERE zone2 > 10 ORDER BY zone1
Les colonnes sur lesquelles s’effectue le tri doivent être citées dans le SELECT. Leur nom peut être remplacé par leur position dans la liste, par exemple :
SELECT zone1, zone2, zone3 FROM tab1 WHERE zone2 > 10 ORDER BY 1

202 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
provoque le tri sur la colonne ZONE1, citée en premier dans le SELECT.
Fonctions scalaires
Les fonctions scalaires permettent d’effectuer des opérations pour chaque ligne renvoyée. Elles contiennent essentiellement :
• des fonctions mathématiques (sinus, cosinus, racine carrée, logarithme...) ;
• des fonctions de conversion de types ;
• des fonctions de traitement des chaînes de caractères ;
• des fonctions de traitement de date.
Par exemple :
SELECT COS(zone1), SQRT(zone2) FROM tab1
renvoie, pour chaque ligne, le cosinus de ZONE1 et la racine carrée de ZONE2.
Fonctions de colonnes
Ces fonctions permettent d’effectuer un calcul sur l’ensemble des valeurs d’une colonne. On peut ainsi calculer pour une colonne la moyenne (AVG), la somme (SUM), l’écart type (STDDEV), la variance (VAR), la plus grande (MAX ) et la plus petite (MIN ) de toutes les valeurs renvoyées. Le nombre d’enregistrements répondant aux critères de sélection est donné par COUNT(*) . Toutes les colonnes citées dans le SELECT doivent être de ce type car un seul enregistrement est retourné (nous verrons une exception avec l’ordre GROUP BY). Par exemple :
SELECT SUM(zone1), MAX(zone2), COUNT(*) FROM tab1 WHERE zone1 > 0
renvoie une seule ligne contenant la somme de toutes les valeurs de ZONE1, la plus grande valeur contenue dans ZONE2 et le nombre d’enregistrements satisfaisant à cette requête.
Totalisations
Les fonctions de colonnes que nous venons de voir renvoient un seul enregistrement. Il est parfois intéressant d’avoir des récapitulations intermédiaires, par groupes d’enregistrements ayant les mêmes valeurs pour certaines zones. Par exemple, on veut extraire le montant des factures non réglées, par client. On doit

6 - SQL/400 203
obtenir autant d’enregistrements que de clients qui répondent aux critères de sélection.
La clause GROUP BY permet de définir les zones qui servent à établir les groupes sur lesquels sont effectués les calculs. Au niveau du SELECT, ne peuvent figurer que les zones associées au GROUP BY et des fonctions colonnes. Par exemple :
SELECT nocli, SUM(totalfact), COUNT(*) FROM facture GROUP BY nocli ORDER BY nocli
renvoie, pour chaque client une ligne contenant son numéro, le total des factures dues et le nombre de factures impayées, le tout trié par numéro de client.
La clause HAVING permet de donner des critères de sélection sur les groupes. On peut ainsi préciser dans la requête ci-dessus que seuls les client ayant plus de deux factures impayées doivent apparaître. La clause WHERE définit les enregistrements qui sont retenus dans la base de données, alors que HAVING sert à définir les caractéristiques des groupes, composés eux-mêmes à partir des enregistrements précédemment retenus. Par exemple :
SELECT tbname, COUNT(*) FROM test.syscolumns GROUP BY tbname HAVING COUNT(*) > 10
renvoie le nom des tables et des vues contenues dans la collection TEST ayant plus de 10 colonnes. SYSCOLUMNS est une vue du catalogue contenant la liste de toutes les zones d’une collection. GROUP BY TBNAME provoque un regroupement par tables et vues. HAVING COUNT (*) ne retient que celles qui ont plus de 10 colonnes.
Jointure
La liaison entre plusieurs tables est effectuée par une jointure et correspond à ce que nous avons déjà défini pour les fichiers logiques joints. Les différentes tables doivent être citées dans la clause FROM . Au niveau du SELECT, les colonnes dont le nom est ambigu, car présent dans plusieurs tables, doivent être préfixées par le nom de la table pour indiquer leur origine. Pour éviter les lourdeurs de codification, les tables peuvent être renommées dans la clause FROM . On leur donne généralement un nom plus court, sur un ou deux caractères.
La clause WHERE est importante car elle définit les zones et les conditions de la jointure. Si elle n’existe pas, toutes les lignes de la première table sont mises en relation avec chacune des lignes de la seconde. Si chaque table contient cent

204 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
enregistrements, le résultat donnera alors 10 000 lignes. Il faut procéder prudemment dans ce domaine sous peine de provoquer l’effondrement du système.
Pour extraire dans une même requête des données sur une facture et des indications sur le client, on peut imaginer l’exemple suivant :
SELECT c.nocli, nomcli, adresse, nofact, f.total FROM client c, facture f WHERE f.nocli = c.nocli
où la table CLIENT est renommée C et FACTURE, F. La jointure est effectuée sur la zone NOCLI des deux tables.
Sélections imbriquées
Dans la clause WHERE , un des éléments constituant les critères de sélection peut être le résultat d’une requête. On obtient donc des SELECT imbriqués.
La sous-requête peut renvoyer une seule valeur ou une liste de valeurs. Les opérateurs ne sont pas les mêmes dans ces deux cas :
• pour une valeur unique les opérateurs sont de type comparaison (=, >, <...) ;
• pour une liste de valeurs les opérateurs sont de type ensembliste (IN , ALL , ANY , SOME).
La sous-requête ne doit concerner qu’une colonne.
L’exemple suivant présente une requête qui extrait les employés qui ont le plus haut salaire de la société :
SELECT noemp, salaire FROM employe WHERE salaire = (SELECT MAX(salaire) FROM employe)
le SELECT imbriqué est exécuté le premier. Il ramène la valeur du plus haut salaire. Il suffit alors d’extraire le nom des employés ayant ce salaire.
Des SELECT imbriqués peuvent aussi être utilisés dans la clause HAVING . L’exemple suivant permet d’extraire les clients dont la moyenne des factures est supérieure à la moyenne des factures de tous les clients :
SELECT nocli, AVG(montant) FROM facture GROUP BY nocli

6 - SQL/400 205
HAVING AVG(montant) > (SELECT AVG(montant) FROM facture) ORDER BY nocli
Des requêtes plus complexes les unes que les autres permettent de résoudre quantité de cas d’école et sont les cauchemars des élèves en informatique. Nous ne rentrerons pas dans ce cycle infernal...
INSERT INTO
Cet ordre ajoute des enregistrements dans une table ou dans une vue. L’utilisation la plus simple consiste à insérer un enregistrement en précisant les valeurs de chaque colonne. Par exemple :
INSERT INTO tab1 VALUES (50, ’CYCLOMOTEUR’)
ajoute un enregistrement ayant la valeur numérique 50 dans la première zone et la chaîne CYCLOMOTEUR dans la seconde.
Pour les cas plus complexes où toutes les colonnes ne sont pas traitées, il est possible de citer les colonnes de la table qui recevront les données. Leur ordre doit correspondre à l’ordre des données :
INSERT INTO tab1 (code, nom) VALUES (50, ’CYCLOMOTEUR’)
la zone CODE recevra la valeur 50 et la zone NOM la chaîne CYCLOMOTEUR.
Une table pouvant être alimentée à partir d’une requête, SELECT remplace donc VALUES . Il faut s’assurer que les colonnes sont dans le bon ordre ou, éventuellement, définir leur position. Par exemple :
INSERT INTO tab1 (code, nom) SELECT codeart, nomart FROM article WHERE codeart > 100
copie dans TAB1 le code et le nom des articles qui ont CODEART supérieur à 100.
Il existe, enfin, une autre possibilité d’insérer plusieurs enregistrements en une seule opération mais cela est du ressort de la programmation et sera donc vu plus loin.

206 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
UPDATE
Cet ordre permet de modifier une série d’enregistrements. La clause WHERE définit les enregistrements à mettre à jour, SET donne la nouvelle valeur et

6 - SQL/400 207
UPDATE précise le nom de la table ou de la vue :
UPDATE tab1 SET zone2 = 50 WHERE zone1 = 500
les enregistrements dont ZONE1 est égal à 500 se verront attribuer la valeur 50 pour ZONE2. La proposition associée à la clause WHERE est importante car elle identifie les enregistrements à modifier. Une erreur est vite commise ! L’exemple suivant permet de modifier plusieurs colonnes en une seule opération (ZONE3 est augmentée de 5 %) :
UPDATE tab1 SET zone2 = 50, zone3 = zone3 * 1.05 WHERE zone1 = 500
DELETE Cet ordre permet de supprimer une série d’enregistrements. Sa syntaxe est simple :
DELETE FROM tab1 WHERE zone1 = 500
provoque la destruction de tous les enregistrements qui ont ZONE1 égal 500.
Les registres spéciaux Les registres spéciaux nous donnent des informations sur l’environnement. Ils sont à utiliser comme des variables, c’est-à-dire qu’ils sont substitués par leur contenu lors de l’exécution de la requête. Voici les principaux registres :
Registre Contenu CURRENT DATE Date courante, type Date ; CURRENT TIME Heure courante, type Time ; CURRENT TIMESTAMP Horodatage courant, type Horodatage ; CURRENT SERVER Nom de la base de données. C’est une zone de
longueur variable d’un maximum de 18 ; USER Nom du profil utilisateur. C’est une zone de
longueur variable d’un maximum de 18.

208 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400

6 - SQL/400 209
La requête suivante place dans un nouvel enregistrement de la table TAB1 le numéro de la commande et la date courante :
INSERT INTO tab1 (numcom, date) VALUES (154, CURRENT DATE)
Le contrôle de validation
Nous avons déjà signalé que la journalisation des tables dans une collection est automatique. Le contrôle de validation est donc simple à mettre en œuvre. Il est initialisé grâce au paramètre COMMIT lors du lancement de l’environnement SQL (STRSQL, RUNSQLSTM) ou lors de la création d’un programme (CRTSQLxx), il n’y a donc pas à préparer l’environnement par la commande STRCMTCTL comme en programmation classique.
Par défaut, SQL interactif est lancé avec COMMIT(*NONE), c’est-à-dire sans contrôle de validation. Les programmes incluant des requêtes SQL sont compilés avec l’option COMMIT(*CHG). Si aucun ordre COMMIT ne figure dans ces programmes, toutes les opérations modifiant les données seront automatiquement invalidées à la fin de leur exécution, même si ces programmes se terminent normalement. Il faut donc soit désactiver cette fonction avec COMMIT(*NONE), soit utiliser l’ordre COMMIT .
Les ordres COMMIT et ROLLBACK permettent de valider ou d’invalider une transaction. Aucun objet de notification ne peut être utilisé.
La sécurité
SQL met à notre disposition des ordres pour gérer la sécurité. Sur l’AS/400, cette puissante fonction est totalement intégrée au système, si bien que les fonctions SQL ne sont qu’un habillage des commandes GRTOBJAUT et RVKOBJAUT . Ils sont par contre indispensables pour assurer une compatibilité avec les bases de données d’autres plates-formes.
GRANT donne des droits à un utilisateur sur une table ou sur une vue. Une partie seulement des possibilités offertes par l’OS/400 est disponible au travers de mots-clés tels que ALL , DELETE, INSERT, SELECT... Les modifications effectuées par cet ordre peuvent être visualisées par les commandes EDTOBJAUT et DSPOBJAUT. Voici trois exemples :
GRANT SELECT, INSERT ON tab1 TO pgmr1, pgmr2

210 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
donne le droit d’exécuter des requêtes SELECT et INSERT sur la table TAB1 aux utilisateurs PGMR1 et PGMR2 ;
GRANT UPDATE ON tab1 TO PUBLIC
donne le droit de mise à jour des enregistrements de TAB1 à tous les utilisateurs n’ayant pas fait l’objet d’autorisations particulières (comparable à *PUBLIC de l’OS/400) ;
GRANT ALL ON tab1 TO pgmr1
donne tous les droits (au sens SQL) sur la TAB1 à l’utilisateur PGMR1. Ces droits sont plus restrictifs que ceux attribués par la valeur *ALL de l’OS/400. REVOKE permet de retirer des droits. Sa syntaxe est la même que pour GRANT :
REVOKE UPDATE ON tab1 TO pgmr1
enlève le droit de mise à jour des données de TAB1 pour l’utilisateur PGMR1.
Il faut rappeler que Query Manager propose de gérer, pour chaque utilisateur, les ordres SQL qui lui sont autorisés ou interdits.
La connexion à une base de données éloignée Au sein de DRDA, SQL permet simplement de se connecter à une base de données distante. Son nom doit être défini au niveau du répertoire de bases de données. Associées à ce nom, figurent des informations sur le système distant qui permettront à l’OS/400 d’établir la communication. La commande WRKRDBDIRE et ses commandes associées (ADDRDBDIRE , CHGRDBDIRE ...) permettent de gérer le répertoire de base de données.
La connexion est demandée avec l’ordre CONNECT TO. Un profil utilisateur et un mot de passe peuvent être spécifiés. Par exemple :
CONNECT TO aslyon USER pgmr1 USING ’ABCDEF’
provoque la connexion à la base de données ASLYON sous le profil PGMR1 avec le mot de passe ’ABCDEF’.

6 - SQL/400 211
En cas d’échec (la communication est impossible, la base de données n’est pas dans le répertoire...), l’application reste connectée à l’ancienne base.

212 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Dans le cas où le contrôle de validation est actif, l’ordre CONNECT ne peut être émis qu’à une frontière de transaction, c’est-à-dire :
• au début de l’application ;
• après un COMMIT ;
• après un ROLLBACK .
Rappelons que le contrôle de validation est obligatoire pour se connecter à DB2/400 à partir d’un autre système.
CONNECT RESET libère les communications avec le système distant et connecte l’application avec la base de données locale.
SQL dans les programmes
Une des forces du langage SQL est de pouvoir être incorporé dans des programmes écrits en langage de haut niveau. On possède ainsi la puissance de ces langages pour la gestion des écrans, des données, des impressions... et les avantages de SQL pour l’accès aux données. Cette solution est incontournable pour écrire des applications portables sur des systèmes hébergeant des SGBD relationnels.
Tous les langages de haut niveau de l’AS/400 peuvent contenir des requêtes SQL (RPG/400, RPG IV, Cobol, C ILE, PL1 ... et même Rexx). Seul le langage de contrôle, qui n’est pas fait pour modifier les données, ne le supporte pas.
Nous verrons des exemples en RPG (400 et IV) qui est le compilateur le plus couramment utilisé sur l’AS/400, mais les principes sont les mêmes pour les autres langages. Il faut noter que le mode d’inclusion des requêtes SQL dans un langage est pratiquement le même pour la plupart des SGBD relationnels (Oracle, Ingres...).
Le produit SQL/400 est indispensable pour développer des programmes contenant des requêtes SQL, mais il n’est pas utilisé lors de l’exécution de ces programmes. On peut donc développer de telles applications même si le système qui doit les héberger ne possède pas SQL/400.
Lorsque la requête est totalement définie dans le source, elle est dite statique. Le précompilateur peut efficacement l’optimiser. Il est aussi possible de constituer la

6 - SQL/400 213
requête au dernier moment, lors de l’exécution, en fonction de l’environnement ou des besoins de l’utilisateur : elle est alors dite dynamique. Dans un premier temps nous ne considérerons que celles qui sont statiques.
Principes Les sources de programmes contenant des requêtes SQL sont de type SQLXXX où XXX identifie le langage dans lequel il sont codifiés : SQLRPG pour le RPG/400, SQLRPGLE pour le RPG IV, SQLCBL pour le Cobol...
La création de l’objet *PGM s’effectue en deux étapes :
• tout d’abord, la précompilation transforme dans le source les requêtes SQL en instructions qui sont compatibles avec le langage de programmation ;
• la compilation proprement dite (ou la génération du module en environnement ILE) peut alors avoir lieu.
Les ordres EXEC SQL et END-EXEC doivent encadrer les requêtes. Ils servent uniquement au précompilateur qui détermine ainsi ses domaines d’intervention. Les instructions en dehors de ces limites ne seront pas affectées. On ne peut placer qu’une seule requête SQL entre ces bornes.
Le précompilateur génère un source (placé dans le fichier QSQLTEMP de QTEMP) qui est repris par le compilateur (figure 6.1). Pour visualiser son contenu, il faut compiler en interactif car la bibliothèque QTEMP du travail batch n’est pas accessible.
...EXEC SQLSELECT ...END-EXEC...
DS...CALL QSQROUTE...
Précompilation Compilation
*PGMSource Source temporaire
Figure 6.1 : la compilation d’un programme contenant des requêtes SQL.
L’exemple 6.1 présente un source RPG/400 contenant une requête SQL et le source temporaire généré par le précompilateur.

214 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Le fichier spoule généré lorsque le précompilateur rencontre une erreur grave est nommé QSYSPRT.

6 - SQL/400 215
Source RPG/400
FECRFAC CF E WORKSTN C EXFMTFMT1 C/EXEC SQL C+ DELETE FROM TAB1 C+ WHERE NOCLI = 50 C/END-EXEC C EXFMTFMT2 C RETRN
Source généré par le précompilateur
FECRFAC CF E WORKSTN ISQLCA DS I* SQL communications area I 1 8 SQLA ID I B 9 120SQLA BC I B 13 160SQLC OD I B 17 180SQLE RL I 19 88 SQLE RM I 89 96 SQLE RP I 97 120 SQLE RR I B 97 1000SQLE R1 I B 101 1040SQLE R2 I B 105 1080SQLE R3 I B 109 1120SQLE R4 I B 113 1160SQLE R5 I B 117 1200SQLE R6 I 121 131 SQLW RN I 121 121 SQLW N0 I... I 131 131 SQLW NA I 132 136 SQLS TT I* End of SQLCA C EXFMTFMT1 C*EXEC SQL C* DELETE FROM TAB1 C* WHERE NOCLI = 50 C*END-EXEC C Z-ADD00001 SQLER6 C CALL 'QSQROUTE' C PARM SQLCA C EXFMTFMT2 C RETRN
Exemple 6.1 : source RPG/400 et source généré par le précompilateur. Remarquez que les instructions SQL sont mises en commentaires.
Une partie de la data-structure SQLCA a été enlevée.

216 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
En RPG, les requêtes SQL doivent être codifiées en spécification C. EXEC SQL et END-EXEC doivent être précédés du caractère ‘/’. Les instructions composant la requête doivent commencer par le caractère ‘+’ suivi d’une espace.
Rappelons que par défaut un programme contenant des requêtes SQL est compilé en demandant le contrôle de validation. Tout programme qui ne se termine pas par un COMMIT voit ses opérations automatiquement invalidées. Cette fonction peut être désactivée en compilant le programme avec le paramètre COMMIT(*NONE).
Les variables locales
Il est fondamental de pouvoir travailler avec les variables du programme ce qui permet notamment de paramétrer les requêtes.
A l’intérieur d’un couple formé par EXEC SQL et END-EXEC, le nom des variables du programme est préfixé par le caractère ‘:’. Ainsi, l’exemple suivant en RPG permet de détruire l’enregistrement dont le numéro est contenu dans la variable NUMART :
C*Saisie du numéro de l’article à détruire dans NUM ART C EXFMTFMT1 C/EXEC SQL C+ DELETE FROM TAB1 C+ WHERE numart = :numart C/END-EXEC C*numart est le nom de la colonne de la table, C* :numart celui de la variable du programme
Les opérations simples
SELECT INTO
L’ordre SELECT INTO permet de placer le résultat d’une sélection dans les variables du programme. Il faut s’assurer qu’un seul enregistrement est renvoyé, sinon l’opération est plus complexe (voir le chapitre suivant). Par exemple :
C/EXEC SQL C+ SELECT zone1, zone2, zone3 C+ INTO :var1, :var2, :var3 C+ FROM tab1 C+ WHERE zone4 = :var4 C/END-EXEC
place dans la variable VAR1 le contenu de la colonne ZONE1, dans VAR2 celui de ZONE2...

6 - SQL/400 217
L’exemple 6.2 présente un programme qui demande un numéro d’article, qui affiche ses caractéristiques et qui permet de les modifier.
Source RPG/400
FECRART CF E WORKSTN C EXFMTSAISIE C 03 MOVE *ON *INLR C* C*RECHERCHE DE L'ENREGISTREMENT C/EXEC SQL C+ SELECT NOMART, QUANT INTO :NOMART, :QUANT C+ FROM ART1 C+ WHERE NOART= :NOART C/END-EXEC C* C*VERIFICATION DES ERREURS DE SAISIE C SQLCOD IFEQ 0 C EXFMTMODIF C *IN25 IFEQ '1' C*SI UNE MODIFICATION A ETE EFFECTUEE C* C/EXEC SQL C+ UPDATE ART1 C+ SET NOMART = :NOMART, QUANT = :QUANT C+ WHERE NOART= :NOART C/END-EXEC C* C*VALIDATION DE LA TRANSACTION C* C/EXEC SQL C+ COMMIT C/END-EXEC C ENDIF C ENDIF C 03 MOVE *ON *INLR
DDS du fichier d’affichage ECRART
DSPSIZ(24 80 *DS3) CA03(03 'Sortie') R SAISIE 1 28'Modification d''un art icle' COLOR(WHT) 4 5'Numéro de l''article à modifier:' NOART 5 0I 4 37 R MODIF OVERLAY CHANGE(25 'Modification ') 8 6'Libellé:' NOMART 15 B 8 16 8 35'Quantité:' QUANT 7 2B 8 46
218 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Affichage du format SAISIE
Modification d'un article Numéro de l'article à modifier: 1
Affichage du format MODIF Libellé: un Quantité: 13
Source RPG IV
FECRART CF E WORKSTN C EXFMT SAISIE C IF *IN03 = '0' C* C*RECHERCHE DE L'ENREGISTREMENT C* C/EXEC SQL C+ SELECT NOMART, QUANT INTO :NOMART, :QUANT C+ FROM ART1 C+ WHERE NOART= :NOART C/END-EXEC C* C*VERIFICATION DES ERREURS DE SAISIE C* C IF SQLCODE = 0 C EXFMT MODIF C IF *IN25 C* C*SI UNE MODIFICATION A ETE EFFECTUEE C* C/EXEC SQL C+ UPDATE ART1 C+ SET NOMART = :NOMART, QUANT = :QUANT C+ WHERE NOART= :NOART C/END-EXEC C* C*VALIDATION DE LA TRANSACTION C* C/EXEC SQL C+ COMMIT C/END-EXEC C ENDIF C ENDIF C ENDIF C IF *IN03 C MOVE *ON *INLR C ENDIF

6 - SQL/400 219

220 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
DDS du fichier ART1
R FART NOART 5 0 NOMART 15 QUANT 7 2 K NOART
Figure 6.2 : programme (en RPG/400 et RPG IV) de modification d’un article incluant des requêtes SQL. Si ART1 est un fichier non journalisé, il faut enlever la ligne contenant l’ordre COMMIT. Remarquer que les tables traitées par SQL ne sont pas déclarées en spécification F.
INSERT INTO
Cet ordre accompagné de ROWS VALUES permet d’insérer un certain nombre d’enregistrements en une seule opération. Une variable associée doit contenir les données à insérer, par exemple :
IDATA DS 5 I.description de la data-structure à occurrence mul tiple ... C*initialisation de la data-structure DATA C... C/EXEC SQL C+ INSERT INTO tab1 C+ 5 ROWS VALUES (:data) C/END-EXEC
insère cinq enregistrements à partir du contenu de la data-structure DATA. Il est évident que son organisation doit être compatible avec les données des cinq enregistrements ajoutés.
Gestion des erreurs
Des informations sur le déroulement de la requête qui vient de s’achever nous sont renvoyées dans une structure appelées SQLCA (pour SQL Communications Area). Elle représente un ensemble de variables qui sont mises à jour après l’exécution de chaque requête. En RPG cette structure est automatiquement incluse dans le programme (remarquer la data-structure SQLCA de l’exemple 6.1).
SQLCODE est une des informations de la SQLCA, elle permet de savoir comment s’est terminée la requête. Si :
• sa valeur est égale à 0, tout s’est bien terminé ; • elle est négative, une erreur s’est produite ;

6 - SQL/400 221
• elle est comprise entre 0 et 100, une erreur mineure est survenue. Le SQLCODE peut être géré par l’ordre WHENEVER qui est utilisé de trois manières :
• WHENEVER NOT FOUND permet de tester la valeur 100 (utile pour traiter les sélections qui renvoient plus d’un enregistrement, nous le verrons plus loin) ;
• WHENEVER SQLERROR pour les valeurs négatives (donc liées à une erreur) ;
• WHENEVER SQLWARNING pour identifier les incidents mineurs.
Une action doit être associée à cet ordre afin de déterminer le traitement à effectuer. Cette action peut être soit d’ignorer l’événement (CONTINUE ), soit de se dérouter vers le label cité après un GOTO. Par exemple :
C/EXEC SQL C+ WHENEVER SQLERROR GOTO erreur C/END-EXEC
provoque le saut au label ERREUR si une erreur survient ;
C/EXEC SQL C+ WHENEVER SQLWARNING CONTINUE C/END-EXEC
ignore les incidents mineurs.
Généralement, WHENEVER est placé au début du source, le test du SQLCODE est ainsi automatiquement réalisé après toutes les requêtes SQL du programme.
Il est important de tester le SQLCODE afin d’être sûr que tout s’est bien passé. Une autre méthode consiste à effectuer le contrôle sans passer par les fonctions SQL. En RPG, par exemple, la variable correspondante s’appelle SQLCOD. Elle est de type numérique, il est donc aisé de vérifier si elle est égale à 0 pour savoir si la requête s’est bien terminée. Le traitement associé peut ainsi être un code opération autre que GOTO qui est une des limites de WHENEVER (exemple 6.2).
D’autres informations sont contenues dans la SQLCA, on peut noter que :
• SQLERRMC (ou SQLERM en RPG) contient les données associées au message d’erreur ;
• SQLERRD (ou SQLER1 à SQLER6 en RPG) renvoie différentes informations. Par exemple, SQLER3 en RPG permet de connaître le nombre d’enregistrements traités par un INSERT, un UPDATE, un DELETE ou un FETCH , SQLER5 donne des indications sur la base de données après un CONNECT ;

222 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
• SQLSTATE (ou SQLSTT en RPG) contient un code retour et permet de gérer les problèmes lors d’accès à des bases de données éloignées.
Les opérations complexes
Lorsque la requête renvoie un nombre variable d’enregistrements, il faut utiliser une structure intermédiaire appelée curseur. Son utilisation requiert plusieurs étapes qui sont :
• la déclaration de la requête qui correspond au curseur ;
• l’ouverture du curseur, c'est-à-dire le lancement de la requête. Le curseur apparaît alors comme une structure contenant les lignes extraites de la base de données ;
• la lecture de ces lignes dans une boucle de traitement.
La déclaration
L’ordre DECLARE CURSOR FOR définit la requête associée à un curseur. Il n’effectue aucune action sur les données. Par exemple :
C/EXEC SQL C+ DECLARE crs1 CURSOR FOR C+ SELECT zone1, zone2, zone3 C+ FROM tab1 C+ WHERE zone1 = 50 C+ ORDER BY zone2 C/END-EXEC
associe une sélection au curseur CRS1.
Ouverture du curseur
L’ouverture d’un curseur par l’ordre OPEN provoque le lancement de la requête qui lui est associée. Les données renvoyées par le SELECT apparaissent alors comme étant placées dans le curseur. Elles sont en fait rangées dans une table résultat, le curseur étant un pointeur sur la ligne courante de cette structure. Selon le type de contrôle de validation choisi les enregistrements lus peuvent être verrouillés. Si ce n’est pas le cas, les données d’origine peuvent être modifiées sans que les mises à jour soient répercutées en direction du curseur. De ce fait, les lignes traitées par le programme SQL peuvent ne plus correspondre à la réalité du

6 - SQL/400 223
moment.

224 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Par exemple :
C/EXEC SQL C+ OPEN crs1 C/END-EXEC
lance la requête associée au curseur CRS1. Le curseur est fermé par l’ordre CLOSE ou par une fin de transaction (COMMIT , ROLLBACK ) si le contrôle de validation est actif.
Traitement des données Une fois le curseur ouvert, il faut lire les lignes qui ont été extraites de la base de données. L’ordre FETCH INTO permet de lire la ligne courante et de placer les données dans des variables du programme, par exemple :
C/EXEC SQL C+ FETCH crs1 C+ INTO :zone1, :zone2, :zone3 C/END-EXEC
place le contenu de la ligne courante dans les variables ZONE1, ZONE2 et ZONE3. Pour traiter toutes les données renvoyées par la requête, l’ordre FETCH doit être placé dans une boucle, la condition de sortie étant SQLCODE égal à 100 (il n’y a plus de ligne à lire). Cette valeur peut être testée soit par l’ordre SQL WHENEVER
NOT FOUND, soit par les fonctions du langage. Rappellons que cette dernière option est plus puissante car elle est permet le déclenchement de n’importe quel traitement. Toutefois, la description de la SQLCA doit être ramenée dans le programme avec un ordre propre au langage de type :
INCLUDE SQLCA sauf en RPG où une data-structure est automatiquement décrite. L’ordre WHENEVER NOT FOUND peut être placé au début du programme. Lors de la précompilation, il est remplacé par un test de SQLCODE après chaque ordre SQL (de type SELECT, FETCH , INSERT INTO , UPDATE et DELETE ). S’il a une valeur de 100, alors le programme se déroute vers le label qui lui est associé.

6 - SQL/400 225
Algorithme général
Voici l’algorithme d’un programme type utilisant un curseur :
/*Déclaration des variables*/ ... /*Déclaration du curseur*/ EXEC SQL DECLARE crsx CURSOR FOR SELECT zonex, zoney FROM tabx WHERE zonex = y ORDER BY zonex END-EXEC /*Eventuellement gestion de la condition de fin par SQL*/ /*Cet appel peut être remplacé par des tests de SQLCODE*/ EXEC SQL WHENEVER NOT FOUND GOTO fin END-EXEC /*Ouverture du curseur*/ EXEC SQL OPEN crsx END-EXEC lecture: EXEC SQL FETCH crsx INTO :zonex, :zoney END-EXEC /*Traitement des données*/ GOTO lecture fin: /*Traitement de fin*/ EXEC SQL CLOSE crsx END-EXEC
Dans le cas où des modifications sont apportées à la base de données, l’ordre CLOSE peut être remplacé par une validation (COMMIT ).
Exemple
L’exemple 6.3 s’appuie sur l’algorithme que nous venons de définir. Le test de SQLCODE par les fonctions du langage a été choisi à la place de WHENEVER car il permet de rester dans une programmation de type structurée.
226 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Source du programme RPG/400
FECRART CF E WORKSTN C* C*DECLARATION DU CURSEUR C* C/EXEC SQL C+ DECLARE CRS1 CURSOR FOR C+ SELECT NOMART, QUANT, NOART C+ FROM ART1 C/END-EXEC C* C*OUVERTURE DU CURSEUR C* C/EXEC SQL C+ OPEN CRS1 C/END-EXEC C* C*BOUCLE DE LECTURE DES ENREGISTREMENTS C* C SQLCOD DOUEQ100 C *IN03 OREQ '1' C/EXEC SQL C+ FETCH CRS1 INTO :NOMART, :QUANT, :NOART C/END-EXEC C* C SQLCOD IFNE 100 C EXFMTMODIF2 C *IN25 IFEQ '1' C* C*SI UNE MODIFICATION A ETE EFFECTUEE C* C/EXEC SQL C+ UPDATE ART1 C+ SET NOMART = :NOMART, QUANT = :QUANT C+ WHERE CURRENT OF CRS1 C/END-EXEC C ENDIF C ENDIF C ENDDO C* C*VALIDATION DE LA TRANSACTION C* C/EXEC SQL C+ COMMIT C/END-EXEC C MOVE *ON *INLR
Affichage du format MODIF 2 Numéro: 1234 Libellé: un Quantité: 13

6 - SQL/400 227
DDS du fichier d’affichage
R MODIF2 CHANGE(25 'Modification ') 8 2'Numéro:' NOART 5 0O 8 10 8 16'Libellé:' NOMART 15 B 8 26 8 45'Quantité:' QUANT 7 2B 8 56
Exemple 6.3 : programme RPG/400 affichant les enregistrements d’une table un par un et
autorisant la modification. Il s’appuie sur l’exemple 6.2. La validation par SQL est effectuée une seule fois à la sortie du programme.
Optimisations liées au curseur
Certaines déclarations peuvent accroître les performances des requêtes SQL. Elles sont toutefois à utiliser avec prudence, en toute connaisance de cause.
En lecture
Lors de la déclaration du curseur, on peut indiquer à SQL que les données ramenées seront uniquement lues, il pourra ainsi les traiter par blocs (FOR FETCH
ONLY ). La clause OPTIMIZE précise que la stratégie d’accès devra être optimisée pour un certain nombre de lignes. Par exemple :
C/EXEC SQL C+ DECLARE crs1 CURSOR FOR C+ SELECT zone1, zone2, zone3 C+ FROM tab1 C+ FOR FETCH ONLY C+ OPTIMIZE FOR 5 ROWS C/END-EXEC
optimise la requête pour 5 lignes ; les données seront utilisées en lecture uniquement.
Il faut noter qu’il est inutile de citer FOR FETCH ONLY quand la table résultat ne peut être traitée qu’en lecture, notamment lorsque :
• plusieurs tables ou vues sont citées dans le FROM ;
• la clause DISTINCT est citée dans le SELECT principal ;
• des fonctions de colonnes sont utilisées dans le SELECT principal.

228 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
La lecture des données à partir de la table résultat peut se faire par blocs de plusieurs lignes ; il faut alors prévoir une structure capable de les recevoir. L’ordre FETCH curseur FOR x ROWS INTO :var permet de lire x lignes et de les placer dans la structure de données VAR. Par exemple :
C/EXEC SQL C+ FETCH crs1 FOR 3 ROWS INTO :enreg3 C/END-EXEC
lit trois lignes à partir de la table résultat et les place dans ENREG3. En RPG, cette variable peut être une data-structure à occurrences multiples définie de la manière suivante :
en RPG/400 IENREG3 DS 3 I 1 10 ZONE 1 I 11 20 ZONE 2
en RPG IV Denreg3 DS OCCURS(3) D zone1 10 D zone2 10
Enfin, il est important de signaler que le nombre de lignes réellement lues est placé dans SQLERRD3 (SQLER3 en RPG/400) de la SQLCA. Il faut tester cette valeur afin de connaître le nombre exact d’enregistrements à traiter.
En modification
L’ordre FOR UPDATE OF permet de préciser le nom des colonnes qui pourront être modifiées pour n’importe lequel des enregistrements renvoyés. Par défaut, toutes les colonnes citées dans le SELECT sont modifiables si :
• elles ne sont pas nommées dans la clause ORDER BY, auquel cas FOR UPDATE
OF est indispensable ;
• FOR FETCH ONLY n’est pas précisé ;
• la table ou la vue n’est pas en lecture seulement.
Une colonne qui n’apparaît pas dans le SELECT peut être modifiée si elle est définie par FOR UPDATE OF.

6 - SQL/400 229

230 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Par exemple :
C/EXEC SQL C+ DECLARE crs1 CURSOR FOR C+ SELECT zone1, zone2 C+ FROM tab1 C+ ORDER BY zone1 C+ FOR UPDATE OF zone1, zone3 C/END-EXEC
permet la modification, pour chaque ligne renvoyée, des colonnes ZONE1 et ZONE3, même si cette dernière n’apparaît pas dans le SELECT.
La modification de la ligne courante (celle qui a été extraite de la table résultat par le dernier FETCH) est déclenchée avec l’ordre UPDATE dans lequel on spécifie WHERE CURRENT OF suivi du nom du curseur. L’exemple 6.3 en est l’illustration.
La modification de la ligne courante ne modifie pas le pointeur associé au curseur. Pour passer à l’enregistrement suivant il faut utiliser à nouveau l’ordre FETCH .
En insertion
Comme pour la lecture, l’insertion de lignes peut être effectuée par blocs. Par exemple :
C/EXEC SQL C+ INSERT INTO tab1 C+ 3 ROWS VALUES(:ENREG3) C/END-EXEC
insère trois enregistrements correspondant chacun à une occurence de la data-structure ENREG3.
Il est là aussi essentiel de tester la SQLCA pour vérifier que l’insertion s’est correctement déroulée.
Déplacement contrôlé dans le curseur
Jusque-là, nous avons traité les lignes de la table résultat dans l’ordre où elles étaient renvoyées par la requête, FETCH étant assimilé à un ordre de lecture séquentielle. DECLARE SCROLL CURSOR définit un curseur qui permet de se déplacer dans la table résultat dans le sens souhaité (avant ou arrière) ou de se positionner sur une ligne particulière (début, fin...). Ce curseur ne peut être utilisé que pour des lectures de données. DYNAMIC associé à SCROLL permet la modification des enregistrements à travers le curseur.

6 - SQL/400 231
Par exemple :
C/EXEC SQL C+ DECLARE crs1 DYNAMIC SCROLL CURSOR FOR C+ SELECT zone1, zone2 C+ FROM tab1 C/END-EXEC
Un mot-clé associé à l’ordre FETCH définit la position de la ligne à lire. Voici la liste de ces mots-clés :
Mot-clé Description AFTER Positionnement après la dernière ligne BEFORE Positionnement avant la première ligne CURRENT Ne change rien FIRST Lecture de la première ligne LAST Lecture de la dernière ligne NEXT Lecture de la ligne suivante (c’est la valeur par défaut) PRIOR Lecture de la ligne précédente RELATIVE Se positionne en fonction d’une variable ou d’une valeur
numérique. Par exemple, -1 provoque la lecture de la ligne précédente et +1 de la suivante
Exemples
Ces deux exemples doivent être précédés par la déclaration d’un curseur contenant le mot-clé SCROLL .
C/EXEC SQL C+ FETCH PRIOR FROM crs1 C+ INTO :zone1, :zone2, :zone3 C/END-EXEC
place le contenu de la première ligne dans les variables ZONE1, ZONE2 et ZONE3.
C/EXEC SQL C+ FETCH RELATIVE :cpt FROM crs1 C+ INTO :zone1, :zone2, :zone3 C/END-EXEC
se positionne en fonction du contenu de la variable CPT.
SQL dynamique
La requête SQL peut être définie au dernier moment selon le choix d’un utilisateur ou en fonction de l’environnement. C’est une possibilité importante de ce langage qui permet de réaliser des applications qui ne peuvent l’être en RPG ou Cobol.

232 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Les opérations à effectuer par le programmeur ne sont pas les mêmes selon que les requêtes contiennent un SELECT ou un autre ordre, et selon que les colonnes sont connues au moment de la compilation ou sont choisies au dernier instant, au cours de l’exécution du programme.
Sélection Il est parfois utile de donner à l’utilisateur la possibilité de choisir ses propres critères de sélection ou de tri tout en lui imposant la table et les colonnes qu’il peut gérer. Les colonnes qui seront ramenées par la requête sont connues au moment de la compilation. La réalisation de telles applications est relativement simple ; l’algorithme du programme peut être résumé ainsi :
• définir les éléments manquants de la requête (demander, par exemple, à l’utilisateur d’indiquer ses critères de sélection et de tri) ;
• constituer le texte de la requête grâce à une data-structure ;
• préparer la requête avec l’ordre PREPARE ;
• déclarer le curseur de manière classique (DECLARE ) ;
• ouvrir le curseur et traiter les lignes extraites comme pour une application SQL statique.
L’exemple 6.4 présente un programme qui demande à l’utilisateur de choisir les caractéristiques des enregistrements à traiter.
DDS du format REQUETE
R REQUETE 1 30'Critères de sélection: ' 4 7'WHERE:' WHERE 37 I 4 15
Affichage du format REQUETE et exemple de saisie
Critères de sélection:
WHERE: NOART > 3 ORDER BY NOART

6 - SQL/400 233
Source du programme RPG/400
FECRART CF E WORKSTN I DS I 1 80 REQ I I 'SELECT NOMART,QUANT,- 1 43 SELE CT I ' NOART FROM ART1 - I 'WHERE ' I 44 80 WHER E C* C*DEMANDE DU CRITERE DE SELECTION C* C EXFMTREQUETE C* C*PREPARATION DU CURSEUR C* C/EXEC SQL C+ PREPARE REQUEST FROM :REQ C/END-EXEC C* C*DECLARATION DU CURSEUR C* C/EXEC SQL C+ DECLARE CRS1 CURSOR FOR REQUEST C/END-EXEC C* C*OUVERTURE DU CURSEUR C* C/EXEC SQL C+ OPEN CRS1 C/END-EXEC C* C*BOUCLE DE LECTURE DES ENREGISTREMENTS C* C SQLCOD DOUEQ100 C *IN03 OREQ '1' C/EXEC SQL C+ FETCH CRS1 INTO :NOMART, :QUANT, :NOART C/END-EXEC C* C SQLCOD IFNE 100 C EXFMTMODIF2 C *IN25 IFEQ '1' C* C*SI UNE MODIFICATION A ETE EFFECTUEE C* C/EXEC SQL C+ UPDATE ART1 C+ SET NOMART = :NOMART, QUANT = :QUANT C+ WHERE CURRENT OF CRS1 C/END-EXEC

234 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
C* C*VALIDATION DE LA TRANSACTION C* C/EXEC SQL C+ COMMIT C/END-EXEC C ENDIF C ENDIF C ENDDO C*FIN DU PROGRAMME C MOVE *ON *INLR
Exemple 6.4 : mise en œuvre d’un SELECT dynamique. Il s’appuie sur l’exemple 6.3. La
saisie proposée permet de modifier les enregistrements dont le numéro d’article est supérieur à 3. Les articles apparaîtront triés sur la colonne NOART.
Si les colonnes ne sont pas connues au moment de la compilation, le traitement est plus complexe car il faut récupérer des informations de type Pointeur dans une structure appelée SQLDA. Cela est impossible en RPG/400 mais supporté en RPG IV. Le traitement de ces informations est relativement fastidieux et sort du cadre de cet ouvrage.
Autres Requêtes
Si tous les ordres SQL ne peuvent pas être utilisés en dynamique, les principaux sont toutefois à notre disposition (CREATE , DROP, COMMIT , ROLLBACK , DELETE , INSERT, UPDATE, GRANT , REVOKE ). Parmi ceux à proscrire, on peut noter CONNECT et dans certains cas SELECT INTO .
Sans paramètres
Si la requête est totalement définie dans une variable du programme, elle peut être lancée par un ordre EXECUTE IMMEDIATE . On peut ainsi demander à un utilisateur de taper sa propre requête dans une zone de saisie de type Alphanumérique. Celle-ci ne peut extraire des données car l’ordre SELECT INTO est interdit.
L’exemple 6.5 propose à un utilisateur de saisir sa requête et l’exécute. Par soucis de lisibilité, la saisie est sans contrôle. DDS du fichier d’affichage ECRSQL
DSPSIZ(24 80 *DS3) R REQUETE CA03(03) 1 30'Saisie de la requête:' 4 2'Requête:' REQ 100 I 4 11

6 - SQL/400 235

236 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Affichage du format REQUETE et exemple de saisie
Saisie de la requête: Requête: CREATE TABLE COL1.ART2 (Z1 CHAR(10) NOT N ULL, Z2 CHAR(5) NOT NULL)
Exemple RPG/400
FECRSQL CF E WORKSTN * C*SAISIE DE LA REQUETE C EXFMTREQUETE C* C*EXECUTION IMMEDIATE C* C/EXEC SQL C+ EXECUTE IMMEDIATE :REQ C/END-EXEC C MOVE *ON *INLR
Exemple 6.5 : exécution immédiate d’une requête SQL dynamique.
Lors d’une exécution immédiate, la requête étant comme interprétée, l’optimiseur n’a pu préparer aucune action.
Avec paramètres
Une partie de la requête peut être connue lors de la compilation. On sait, par exemple, que l’on va effectuer la suppression d’un enregistrement mais la valeur du critère de sélection ne sera connue qu’au dernier moment, par l’intermédiaire d’une variable du programme.
L’algorithme du programme peut alors se résumer à :
• initialisation d’une variable contenant le texte connu de la requête, les emplacements des données variables étant définis par le caractère ? ;
• préparation de la requête avec l’ordre PREPARE ;
• exécution de la requête avec l’ordre EXECUTE USING. Les points d’interrogation sont alors automatiquement remplacés, dans l’ordre, par le contenu des variables citées après USING.
L’exemple 6.6 présente un programme qui détruit un enregistrement dans la table ART1 définie dans les exemples précédents.

6 - SQL/400 237
DDS du fichier d’affichage
DSPSIZ(24 80 *DS3) R DEL CA03(03) 1 26' Suppression d''enregi strement’ 3 6'Numéro d''enregistreme nt à + détruire:' NOART 5 0I 3 42
Affichage du format DEL et exemple de saisie
Suppression d'enregistrement
Numéro d'enregistrement à détruire: 12345
Source du programme RPG/400
FECRSQL CF E WORKSTN I DS I I 'DELETE FROM ART1 - 1 32 REQT I 'WHERE NOART = ?' C* C*DEMANDE DE L'ENREGISTREMENT A DETRUIRE C* C EXFMTDEL C *IN03 IFEQ *OFF C* C*PREPARATION DU CURSEUR C* C/EXEC SQL C+ PREPARE REQUEST FROM :REQT C/END-EXEC C* C*EXECUTION C* C/EXEC SQL C+ EXECUTE REQUEST USING :NOART C/END-EXEC C* C*VALIDATION DE LA TRANSACTION C* C/EXEC SQL C+ COMMIT C/END-EXEC C ENDIF C*FIN DU PROGRAMME C MOVE *ON *INLR
Exemple 6.6 : destruction d’un enregistrement par un programme SQL dynamique.

238 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400

6 - SQL/400 239
Optimisations
De très nombreux éléments intervenant sur les performances des requêtes SQL, nous citerons les principaux, indispensables à une bonne gestion de SQL/400.
L’optimiseur
L’optimiseur est une des composantes essentielles de la base de données DB2/400. Il doit déterminer qu’elle est la manière la plus rapide pour accéder aux données. Il n’est pas propre à SQL mais est utilisé par tous les produits tels que Query/400, PCS/400, Client Access/400 et par la commande OPNQRYF. En fait, ils s’appuient tous sur le même moteur d’accès aux données. Ce n’est pas le cas pour les programmes classiques (n’incluant pas SQL), qui attaquent directement la base de données.
Lors de l’exécution d’un programme contenant des requêtes SQL, l’optimiseur détermine la meilleure stratégie pour accéder aux données. Il envisage, par exemple :
• la lecture séquentielle des enregistrements ;
• l’utilisation d’un index ou d’un chemin d’accès existant ;
• la création d’un index temporaire.
Il s’appuie aussi sur le modèle d’AS/400, sur le nombre d’enregistrements à traiter et même sur des statistiques du système.
Les plans d’accès sont des structures associées à un programme contenant du SQL. Chacun comporte toutes les indications pour accéder aux tables et vues d’une requête (il indique notamment la présence d’un index). Il contient un miniplan visible lorsque l’on effectue le dump d’un programme par la commande DMPOBJ.
Si la requête est statique, le plan d’accès est défini lors de la compilation et peut être éventuellement révisé lors de l’exécution car l’environnement peut avoir évolué (un nouvel index a-t’il été créé ?). Pour du SQL dynamique, il ne peut être généré que lorsque tous les éléments sont connus.
Les plans d’accès composent les packages, objets de type *SQLPKG, qui sont transmis au système distant lors de l’utilisation d’une base de données éloignée dans le cadre de DRDA.

240 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Enfin, rappellons que certains ordres SQL peuvent aider l’optimiseur à choisir les bonnes solutions (section Optimisations liées au curseur, de ce chapitre).
Les index
SQL peut accéder aux données d’une table soit en séquentiel, toutes les lignes sont alors lues, soit directement à partir d’un index (ou chemin d’accès), s’il existe. De ce fait, les index constituent l’un des éléments de base de l’optimisation de SQL. Ils doivent être créés chaque fois que cela est nécessaire, par l’ordre CREATE INDEX ou en même temps que les fichiers physiques ou logiques avec clés, par les commandes CRTPF et CRTLF . Dans certains cas, si le chemin d’accès n’existe pas, SQL peut être amené à le reconstruire. Si le fichier est gros, les temps de réponses peuvent être désastreux.
Un index est systématiquement utilisé dans les situations suivantes :
• lorsque les ordres GROUP BY ou ORDER BY sont cités ;
• lors de jointures.
La définition du critère de sélection (WHERE) est aussi un élément important, car il peut conditionner l’utilisation d’un index existant. Si LIKE est cité, par exemple, l’index ne pourra pas être utilisé si un caractère de substitution (% ou _) est placé en premier. Il est aussi important de définir les valeurs de comparaison avec les mêmes caractéristiques que la colonne sur laquelle s’appuie l’index. Si, par exemple, celle-ci est de type Alphanumérique de longueur 5 on préfèrera :
WHERE nocli = ’123 ’
plutôt que : WHERE nocli = ’123’
SQL dynamique
Il est évident que pour une requête SQL dynamique, la partie du travail qui n’a pu être réalisée lors de la compilation le sera lors de l’exécution. Les temps de réponse sont donc dégradés par rapport à la même requête définie en statique. On essaiera donc de limiter l’utilisation de SQL dynamique aux seuls cas où cela est indispensable.
La commande CHGQRYA

6 - SQL/400 241
La commande CHGQRYA apparue avec le V3R1M0 de l’OS/400 permet de limiter les possibilités d’un travail en lui interdisant les requêtes abusives. La paramètre QRYTIMLMT précise le temps CPU que pourra consommer une requête. Si l’optimiseur prévoit une valeur supérieure, le message CPA4259 est renvoyé à QSYSOPR lui demandant de continuer ou d’arrêter cette action. Des informations sur le plan d’accès utilisé par la requête accompagnent ce message.
Cette commande permet aussi d’autoriser le parallélisme, c’est-à-dire que plusieurs bras d’accès disques peuvent être mobilisés en même temps pour accéder aux données d’un fichier. Ainsi, le processeur n’attend plus que les données soient disponibles pour ce travail, ce qui peut améliorer nettement ses performances (tout en dégradant aussi nettement celles des autres travaux !).
La commande PRTSQLINF
La commande PRTSQLINF est apparue avec la V3R1M0 de l’OS/400. Elle génère un fichier spoule contenant des informations sur un programme contenant du SQL. On y trouve notamment la liste des requêtes et les options de compilation.
Conclusions sur SQL/400
La question que se posent de nombreux responsables informatique est de savoir s’il faut utiliser SQL/400 ou continuer avec les classiques READ et WRITE du RPG. Les avantages de SQL sont nombreux, nous pouvons citer :
• c’est un standard universellement reconnu qui assure une excellente portabilité ;
• c’est un langage connu par un très grand nombre de développeurs. Les jeunes diplômés en informatique, notamment, ont généralement suivis des cours sur ce sujet ;
• il autorise l’accès à des bases de données distantes et hétérogènes ;
• il permet la réalisation d’applications laissant à l’utilisateur la possibilité de définir tout ou partie de la requête grâce au SQL dynamique ;
• il dispose de plusieurs interfaces : interactive, batch, Query Manager et précompilateur pour être inclus dans des programmes ;
• avec une collection, c’est un environnement automatiquement sécurisé avec la journalisation et même, éventuellement, avec le contrôle de validation ;

242 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
• il est idéal pour le traitement de masse. Augmenter le prix de tous les articles de 10 % est une opération très simple en SQL.
Parmi les inconvénients, on lui reproche souvent :
• d’être relativement peu performant, mais il s’améliore de version en version et les critiques émises à son origine ne sont plus vraiment d’actualité ;
• de ne pas être dans la culture des informaticiens spécialistes des mini IBM (34, 36, 38).
Il appartient à chacun de se faire une opinion en fonction des ses besoins et de ses contraintes. Il est toutefois évident que SQL/400 apparaît aujourd’hui comme un produit stratégique pour IBM, chaque nouvelle annonce sur l’AS/400 le confirmant.
Les principaux ordres SQL
CREATE TABLE crée une table ; CREATE COLLECTION crée une collection ; SELECT extrait des enregistrements ; CLOSE ferme un curseur ; COMMIT valide une transaction ; CONNECT se positionne sur une base de données distante ; CREATE INDEX crée un index ; CREATE SCHEMA crée en une seule requête tout un environnement
SQL (collection, tables, index, vues, autorisa-tions...) ;
CREATE VIEW crée une vue ; DECLARE CURSOR définit un curseur ; DELETE détruit un enregistrement ; DROP détruit un objet SQL (table, vue, collection...) ; EXECUTE lance une requête préparée dynamiquement en
utilisant éventuellement des variables du programme comme des paramètres ;
EXECUTE IMMEDIATE prépare et exécute une requête dynamique ; FETCH lit une ligne (ou une série de lignes) dans la table
résultat par l’intermédiaire d’un curseur ; GRANT accorde une autorisation ; INSERT insère un enregistrement ou une série d’enregis-
trements groupés ;

6 - SQL/400 243
OPEN ouvre un curseur, c’est-à-dire lance la requête associée ;
PREPARE prépare une requête dynamique ; REVOKE enlève une autorisation ;
ROLLBACK invalide une transaction ; UPDATE met à jour un enregistrement ; WHENEVER teste une condition particulière et déroute le
programme vers un label.
Les principales commandes
CHGQRYA permet d’interdire les requêtes abusives consommant trop de CPU ;
CRTSQLRPG crée une programme RPG/400 contenant du SQL ; CRTSQLRPGI crée une programme RPG IV contenant du SQL ; PRTSQLINF donne des indications sur la stratégie d’accès d’un
programme contenant des requêtes SQL ; RUNSQLSTM lance l’interpréteur SQL batch ; STRSQL lance l’interpréteur SQL interactif.
Les principaux menus
CMDSQL.

244 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
SQL/400.............................................................................................................................185
INTRODUCTION ...................................................................................................................185 L’ ENVIRONNEMENT SQL ....................................................................................................186
Terminologie ..................................................................................................................187 Le catalogue...................................................................................................................187 Conventions SQL............................................................................................................187 Utiliser une collection ou non ? .....................................................................................188
LES ELEMENTS DU LANGAGE SQL.......................................................................................190 Les environnements d’exécution ....................................................................................190 Les conventions ..............................................................................................................192 La définition des structures SQL....................................................................................192 La gestion des données...................................................................................................198 Les registres spéciaux ....................................................................................................207 Le contrôle de validation ...............................................................................................209 La sécurité......................................................................................................................209 La connexion à une base de données éloignée...............................................................210
SQL DANS LES PROGRAMMES.............................................................................................212 Principes ........................................................................................................................213 Les variables locales ......................................................................................................216 Les opérations simples ...................................................................................................216 Les opérations complexes...............................................................................................222 Optimisations liées au curseur .......................................................................................227 Déplacement contrôlé dans le curseur...........................................................................230 SQL dynamique ..............................................................................................................231
OPTIMISATIONS...................................................................................................................239 L’optimiseur ...................................................................................................................239 Les index ........................................................................................................................240 SQL dynamique ..............................................................................................................240 La commande CHGQRYA..................................................................................................240 La commande PRTSQLINF................................................................................................241
CONCLUSIONS SUR SQL/400...............................................................................................241 LES PRINCIPAUX ORDRES SQL ............................................................................................242 LES PRINCIPALES COMMANDES...........................................................................................243 LES PRINCIPAUX MENUS......................................................................................................243
—A— ADDPFCST 193; 195 ADDRDBDIRE 204 ALTER TABLE 193; 195 AND 196
—B— BETWEEN 197
—C— CHGQRYA 227 CHGRDBDIRE 204

186 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Client Acces/400 226 collection 188 COMMIT 188; 203; 205; 208; 215 CONNECT 205 CREATE
COLLECTION 191 INDEX 193 SCHEMA 194 TABLE 192 VIEW 193
CRTLF 227 CRTPF 227 CRTSQLCOL 188 curseur 213
—D— DECLARE 213; 221 DELETE 202 DFTRDBCOL 191 dictionnaire 191 DISTINCT 196; 217 DMPOBJ 226 DRDA 185; 226 DROP 195 DSPOBJAUT 203 DYNAMIC 219
—E— EDTOBJAUT 203 END-EXEC 206 erreur 211 EXECUTE
IMMEDIATE 223 USING 224
—F— FETCH 214; 218 FOR FETCH ONLY 217 FOR UPDATE OF 218 FROM 196; 199; 217
—G— GOTO 212
GRANT 203 GROUP BY 199; 227 GRTOBJAUT 203
—H— HAVING 199
—I— IN 197 index 193; 227 INSERT INTO 201
—L— l’ordre CREATE INDEX 227 LIKE 197; 227
—M— miniplan 226
—N— NAMING 191 NULL 192; 197
—O— OPEN 213 OPNQRYF 226 optimiseur 226 OPTIMIZE 217 OR 196 ORDER BY 197; 218; 227
—P— par COUNT(*) 198 PCS/400 226 plans d’accès 226 PREPARE 221; 224 PRTSQLINF 228

6 - SQL/400 187
—Q— QSQJRN 191 QSQLTEMP 206 QSYS 187 QSYSOPR 228 QSYSPRT 206 QTEMP 206 Query 226 Query Manager 189 Query/400 189
—R— REVOKE 204 Rexx 205 ROLLBACK 203; 205 ROWS VALUES 211 RPG IV 205 RPG/400 205 RUNSQLSTM 188; 190; 203 RVKOBJAUT 203
—S— SBMJOB 190 SCROLL 219
sécurité 203 SELECT 195; 213; 217; 221 SELECT INTO 208; 223 SGBD 205 SQL 185 SQL/400 185 SQLCA 211; 214; 218 SQLCBL 206 SQLCODE 211 SQLDA 223 SQLRPG 206 SQLRPGLE 206 STRCMTCTL 203 STRQM 189 STRQMQRY 190 STRSQL 188; 189; 203 SYSTABLES 196
—U— UPDATE 201; 219
—W— WHENEVER 212 WHERE 196; 200; 227 WRKRDBDIRE 204

Chapitre 7
Gestion de la base de données
L’OS/400 met à notre disposition diverses commandes liées à la base de données qui sont indispensables à la gestion courante des fichiers et des programmes. Elles permettent d’éditer des références croisées, d’utiliser les membres et de faciliter encore plus l’accès aux données. Les API sont des programmes et procédures qui permettent de développer des applications avancées. Certaines ont un rapport avec la base de données. Ces différents thèmes sont abordés dans ce chapitre fourre-tout qui apporte une vision plus large de DB2/400.
La commande OPNQRYF
La commande OPNQRYF (Open Query File) peut être considérée comme une extension des fichiers logiques car elle crée une structure temporaire permettant de voir des enregistrements. Mais elle est beaucoup plus puissante à de nombreux titres :
• elle ne s’appuie pas sur des DDS qui sont figées dans un membre source. Les caractéristiques des données sont définies au dernier moment dans ses paramètres. Son utilisation est donc extrêmement souple ;
• les données sont vues à partir de fichiers physiques et logiques. On obtient donc une structure comparable à un fichier logique qui peut s’appuyer sur des fichiers logiques ;

232
• elle possède des fonctions de traitement de chaînes de caractères et de nombreuses fonctions mathématiques ;
• elle permet de définir des zones qui sont le résultat d’un calcul sur d’autres zones ;
• elle autorise le traitement de zones récapitulatives ;
• elle s’appuie sur le même optimiseur que SQL et utilise donc tous les chemins d'accès et tous les index existants ;
• enfin, elle peut aussi renvoyer les données vers un fichier physique.
La structure créée par cette commande est souvent nommée Open Query File. Je reprendrai cette appellation.
Il faut avoir à l’esprit que si les fichiers sous-jacents sont gros, le temps de mise en place de l’Open Query File peut être long et les ressources consommées importantes, car le système récupère dynamiquement les enregistrements lors de l’exécution de la commande OPNQRYF. C’est un des inconvénients de cette fonction, surtout en interactif.
Principes
La commande OPNQRYF crée dynamiquement une structure temporaire permettant de voir des données. Elle est créée quand on en a besoin et peut être détruite quand elle est devenue inutile.
Avant de lancer cette commande il faut effectuer un certain nombres d’opérations de manière à préparer l’environnement (figure 7.1).
Il faut tout d’abord compiler le programme qui doit utiliser l'Open Query File en s’appuyant sur un fichier de même format. La structure résultant de la commande OPNQRYF étant temporaire, le compilateur ne peut s’en servir pour ramener la description des zones. Il doit donc s’appuyer sur un autre fichier.
Si l'Open Query File est utilisé seulement pour extraire une sélection d’enregistrements correspondant à certains critères, le fichier vu par le programme peut être le fichier à partir duquel on traite les données. Sinon, c'est-à-dire chaque fois que l'Open Query File a un format différent du fichier qui est à l’origine des données, il faut créer un fichier intermédiaire, ne contenant aucune donnée, mais ayant le même format que l'Open Query File. Ce fichier permet au compilateur de ramener dans le programme la description de toutes les zones. C’est le cas chaque fois que la commande OPNQRYF s’appuie sur

233
plusieurs fichiers ou qu’elle modifie les caractéristiques des zones (agencement, ajout, suppression...).
1 - Compilation du programme
*PGM *FILEODP
2 - Partage de l’ODP et création de l'Open Query File
*PGM *FILE
ODP
Open query file
OVRDBF SHARE(*YES)
OPNQRYF
Création
Partage
Figure 7.1 : organisation d’une application utilisant la commande OPNQRYF.
La commande OVRDBF permet de substituer le fichier connu du programme par l'Open Query File. Pour se faire, ces deux structures doivent partager le même ODP, le paramètre SHARE(*YES) doit donc être spécifié pour cette commande.
Il suffit alors d’exécuter la commande OPNQRYF en définissant les caractéristiques des enregistrements à ramener. La structure temporaire est créée, le programme de traitement des données peut être lancé. Grâce au partage de l’ODP, il croit attaquer le fichier avec lequel il a été compilé mais il traite, en fait, les enregistrements vus par l'Open Query File.
Une fois le travail sur les enregistrements terminé, l'Open Query File peut être détruit par la commande CLOF et la substitution peut être enlevée par un DLTOVR .
L'Open Query File est toujours mis en place à partir d’un programme en langage de contrôle (il peut aussi être défini à partir des API mais nous oublierons cette possibilité !). L’exemple 7.1 présente un programme qui lance un Open Query File simple, c'est-à-dire qu’il a le même format que le fichier sous-jacent.

234
PGM /*PARTAGE DE L'ODP*/ OVRDBF FILE(FICH1) SHARE(*YES) /*DEFINITION ET LANCEMENT DE L'OPNQRYF*/ OPNQRYF FILE((FICH1)) QRYSLT('zone1 *EQ 50') /*LANCEMENT DU PROGRAMME DE TRAITEMENT DES DONNEES*/ CALL PGM(PGMXX) /*FERMETURE DE L'OPNQRYF*/ CLOF OPNID(FICH1) /*DESTRUCTION DU PARTAGE DE L'ODP*/ DLTOVR FILE(FICH1) ENDPGM
Exemple 7.1 : structure d’un programme en langage de contrôle mettant en place un Open Query File. Le programme de traitement des données (PGMXX) utilise le fichier FICH1 qui contient les données et qui a le même format que l'Open Query File.
Lorsque la commande OPNQRYF s’appuie sur plusieurs fichiers, il faut créer un fichier qui a le même format que l'Open Query File et qui servira uniquement à la compilation. Dans le programme en langage de contrôle, l’appel des commandes OVRDBF et OPNQRYF est un peu plus complexe (figure et exemple 7.2).
PGM
OVRDBF FILE(FMTOQF) TOFILE(FICH1) SHARE (*YES)
OPNQRYF FILE(FICH1 FICH2) FORMAT(FMTOQF) .....CALL PGMxx
F*Programme de traitement des donnéesFFMTOQF...
Figure 7.2 : organisation d’un Open Query File complexe. Le fichier FMTOQF est créé pour la compilation du programme de traitement des données. Il est substitué par le premier
fichier utilisé dans la commande OPNQRYF. PGM /*Partage de l'ODP*/

235
/*Le fichier connu du programme est substitué par l e + premier fichier utilisé dans l'Open Query File */ OVRDBF FILE(FICHOQF) TOFILE(FICH1) SHARE(*Y ES) /*DEFINITION ET LANCEMENT DE L'OPNQRYF*/ OPNQRYF FILE((FICH1) (FICH2)) FORMAT(FICHO QF) + JFLD((FICH1/ZONE1 FICH2/ZONE1 *EQ) ) /*LANCEMENT DU PROGRAMME DE TRAITEMENT DES DONNEES*/ /*IL UTILISE LE FICHIER FICHOQF*/ CALL PGM(PGMXX) /*FERMETURE DE L'OPNQRYF*/ CLOF OPNID(FICH1) /*DESTRUCTION DU PARTAGE DE L'ODP*/ DLTOVR FILE(FICH1) ENDPGM
Exemple 7.2 : structure d’un programme en langage de contrôle mettant en place un Open
Query File. Une jointure est réalisée entre FICH1 et FICH2 sur ZONE1. FICHOQF sert à indiquer le format de l'Open Query File au programme PGMXX.
Les principaux paramètres Les paramètres de la commande OPNQRYF permettent d’intervenir sur de nombreux critères de sélection, sur des jointures, sur la création de zones résultat... Ils montrent la puissance et la souplesse de cette commande.
Sélection d’enregistrements
L’Open Query File ne laissera voir que les enregistrements qui correspondent aux critères de sélections définis au travers du paramètre QRYSLT, par exemple :
OPNQRYF FILE( FICH1) QRYSLT(’ ZONE1 * EQ ” MONTPELLIER” ’) ne sélectionne que les enregistrements qui ont ZONE1 égal à ’MONTPELLIER’.
La syntaxe utilisée pour codifier le critère de sélection associé au paramètre QRYSLT est relativement complexe. D’une manière générale, il doit être placé entre apostrophes(’ ) et les chaînes de caractères doivent être définies entre des guillemets (” ).

236
Voici d’autres exemples :
OPNQRYF FILE( FICH1) QRYSLT(’ ZONE2 * GT 50’)
ne laisse voir que les enregistrements tels que ZONE2 est supérieur à 50 ;
OPNQRYF FILE( FICH1) QRYSLT(’ ZONE1 * EQ %WLDCRD”_ O* L*” ’)
sélectionne les enregistrements qui ont pour ZONE1 un O en deuxième position puis un L n’importe où après le O ;
OPNQRYF FILE( FICH1) QRYSLT(’ ZONE1 * EQ %CURDATE’)
renvoie les enregistrements tels que ZONE1 contienne la date du jour. ZONE1 est de type Date ;
OPNQRYF FILE( FICH1) QRYSLT(’ ZONE1 * CT ” MONT” ’)
extrait les enregistrements qui contiennent MONT n’importe où dans ZONE1. Ne pas confondre l’opérateur *EQ qui implique une égalité totale avec *CT qui demande que la sous-chaîne soit contenue à partir d’une position quelconque de la zone.
De très nombreux exemples pourraient être ajoutés à cette liste car le paramètre QRYSLT est extrêmement puissant. Il permet notamment d’utiliser des variables du langage de contrôle, dispose de nombreuses fonctions mathématiques, de plusieurs opérateurs arithmétiques et apporte des possibilités de traitement des chaînes de caractères.
La définition de nouvelles zones
Des zones n’existant pas dans le (ou les) fichier(s) d’origine(s) peuvent être créée dans l’Open Query File pour diverses raisons :
• pour des raisons de compatibilités avec le programme pour qui elles sont définies dans le format ;
• pour permettre de faire une sélection sur ces zones ;
• pour générer des données récapitulatives sur les enregistrements renvoyés ;
• et éventuellement pour renommer une zone dont le nom est ambigu car présent dans plusieurs fichiers.
Le paramètre MAPFLD permet de définir une nouvelle zone.

237
Par exemple :
OPNQRYF FILE( FICH1) FORMAT( FMT1) MAPFLD(( AN ’ ZONE1’) ( TTC ’ HT * TVA ’) ( SIN ’%SIN ( ZONE2)’))
ajoute les trois nouvelles zones AN et TTC et SINUS dont la description figure dans le fichier FMT1. AN contient les données de ZONE1, TTC reçoit le produit des zones HT et TVA et SIN correspond au sinus de ZONE2.
Les traitements de groupes
L’Open Query File peut nous renvoyer des données récapitulatives sur des groupes d’enregistrements.
Le paramètre GRPFLD définit la zone sur laquelle est effectuée le groupage à la manière du GROUP BY de SQL. Des fonctions mathématiques permettent de connaître la somme (%SUM), le nombre (%COUNT), l’écart type (%STDDEV), la variance (%VAR) et la plus grande (%MAX ) ou la plus petite (%MIN) des valeurs d’une zone renvoyée, par groupe d’enregistrements. Ainsi :
OPNQRYF FILE( FACT) FORMAT( FMT1) GRPFLD( NOCLI) MAPFLD(( NB
’%COUNT’) ( SOMME ’%SUM( MONTANT)’) ( DEPUIS ’%MIN( DATE)’))
groupe les enregistrements du fichier FACT (pour facture) par numéro de client (NOCLI). Pour chacun de ces clients, NB est le nombre total de facture en cours, SOMME est le montant total de ce qui est dû et DEPUIS est la plus petite date.
Le tri
Le paramètre KEYFLD présente les enregistrements triés sur une ou plusieurs zones.
La jointure
La jointure mise en œuvre pour l’Open Query File est beaucoup moins restrictive que celle des fichiers logiques joints. En effet, pour ces derniers seule l’égalité des zones mises en concordance est vérifiée. Avec le paramètre JFLD, la jointure peut être effectuée sur n’importe quel opérateur de comparaison (égal, supérieur, inférieur...). Par exemple :
OPNQRYF FILE( FICH1 FICH 2) FORMAT( FMT1) JFLD (1/ Z1 2/ Z1 * EQ)
établit une jointure entre les zones Z1 des fichiers FICH1 et FICH2.

238
Performances
La commande OPNQRYF s’appuie sur l’optimiseur que nous avons déjà décrit pour SQL. Les mêmes remarques s’y appliquent donc. Il faut remarquer que les chemins d’accès (ou index) existants peuvent être utilisés si l’optimiseur le décide.
Conclusions
OPNQRYF ou DDS ? Beaucoup se posent la question !
Les avantages de l’Open Query File sont nombreux :
• les critères de sélection sont totalement définis au dernier moment ce qui laisse une grande souplesse aux applications ;
• certaines de ses fonctions ne sont pas disponibles dans les DDS (groupage, sélection sur une variable, fonctions mathématiques et arithmétiques...).
Son principal inconvénient réside dans le fait que les opérations de sélection sont effectuées au dernier moment, ce qui provoque des consommations de ressources importantes (CPU et disques) et des temps de réponses dissuasifs pour l’interactif si le nombre d’enregistrements à traiter est important. Il est alors essentiel d’aider l’optimiseur par la création de chemins d’accès et par l’utilisation de requêtes adaptées.
Les commandes de copie
La commande CPYF est une puissante fonction de copie de fichier. Elle permet d’effectuer une sélection des enregistrements à copier à partir de nombreux critères. Elle facilite, par exemple, la création de jeux de tests en phase de développement et la création d’un nouvel environnement à partir d’un environnement déjà existant (une nouvelle comptabilité peut éventuellement hériter d’une partie du plan comptable d’une autre).
Les fichiers
Le fichier (physique ou logique) contenant les données d’origine est défini dans le paramètre FROMFILE et le fichier de destination dans TOFILE. S’il n’existe pas, ce dernier peut être automatiquement créé si CRTFILE(*YES) est spécifié. Il aura le même format que le fichier d’origine.
Les membres

239
Si le fichier d’origine possède plusieurs membres la copie peut créer un nombre variable de membres en fonction des valeurs des paramètres FROMMBR et TOMBR.
FROMMBR définit les membres du fichier d’origine qui vont être copiés et TOMBR indique où ils vont être copiés. Par exemple :
CPYF FROMFILE(ORIGINE) TOFILE(DESTINAT) FROMMBR(*ALL ) TOMBR(*FIRST) MBROPT(*REPLACE)
copie tous les enregistrements du fichier ORIGINE dans le premier membre du fichier DESTINAT, en écrasant les anciennes données de ce membre ;
CPYF FROMFILE(ORIGINE) TOFILE(DESTINAT) FROMMBR(*ALL ) TOMBR(*FROMMBR) MBROPT(*REPLACE)
conserve la même structure, au niveau des membres et des données, entre les deux fichiers. Les membres d’origines qui ne sont pas présent dans le fichier de destination seront automatiquement créés. Les membres du fichier de destination qui ne sont pas présents dans le fichier d’origine ne seront pas touchés.
MBROPT(*REPLACE) supprime les enregistrements du membre de destination avant d’insérer les nouveaux, MBROPT(*ADD) ajoute les nouveaux enregistrements aux anciens.
Impression
La copie peut s’effectuer à destination d’un fichier spoule si TOFILE(*PRINT) est codifié. Le format d’impression peut alors être sous forme hexadécimale (OUTFMT(*HEX)) ou sous forme de caractères (OUTFMT(*CHAR)). Le fichier d’impression utilisé par le système est QSYSPRT et l’état généré aura le même nom.
Le paramètre PRINT précise les caractéristiques de l’état récapitulatif. Le fichier spoule généré contient soit la liste des enregistrements sélectionnés (PRINT(*COPIED)) soit celle de ceux qui sont exclus de la copie (PRINT(*EXCLD)).
La sélection d’enregistrements
Les enregistrements à copier peuvent être définis selon les critères suivants :
• en fonction de la position relative de l'enregistrement : de l’enregistrement situé à la position spécifiée dans le paramètre FROMRCD jusqu’à celui correspondant à TORCD ;

240
• en fonction de la valeur de clé. La copie est effectuée de l’enregistrement qui a la valeur de clé associée à FROMKEY jusqu’à celui ayant TOKEY ;
• la copie affectera un nombre maximal d’enregistrement spécifié dans NBRRCDS ;
• seuls les enregistrements contenant certaines valeurs seront copiés. Il faut utiliser le paramètre INCCHAR pour tester le contenu d’une zone de type Alphanumérique. INCREL sert à définir une proposition logique à laquelle doit satisfaire les zones. Par exemple :
CPYF FROMFILE( ORIGINE) TOFILE ( DESTINAT) FROMMBR(* ALL)
TOMBR(* FROMMBR) MBROPT(* REPLACE) INCCHAR( ZONE1 2 * CT FRA)
INCREL((* IF ZONE 2 * GT 50) (* AND ZONE3 * EQ 0)
ne copie que les enregistrements qui ont FRA contenu dans ZONE1, à partir de la deuxième position, ZONE2 supérieur à 50 et ZONE3 égal à 0.
Vérification
Le paramètre FMTOPT permet une véritable copie intelligente lorsque les formats du fichier d’origine et ceux du fichier de destination sont différents. Par défaut, les deux formats doivent être identiques. La copie est alors très rapide sans vérification. Sinon, la valeur FMTOPT(*NOCHK) provoque une copie de l’enregistrement d’origine dans celui de destination, octet par octet à partir de la gauche, sans aucune vérification. Il faut parfaitement maîtriser le résultat pour utiliser une telle valeur.
FMTOPT(*MAP) recherche dans le fichier de destination les zones qui ont le même nom que celles du fichier d’origine. Cette option est indispensable si une zone a changé de place dans le format ; cette vérification la retrouvera et lui transmettra les données de la zone d’origine ayant le même nom. Si la zone a aussi changé de description, il est possible que la copie se fasse mal. Prenons, par exemple, la valeur 123 qui est contenue dans une zone du fichier d’origine de longueur 3 dont 0. Si la zone de destination fait maintenant 2 dont 0, la copie ne pourra s’effectuer normalement et la zone de destination héritera de la valeur par défaut. Ceci est moins flagrant pour les zones alphanumériques car elles peuvent être tronquées.
Les zones du format de destination qui n’ont pas d’équivalence sont initialisées avec leur valeur par défaut.
Lorsque des zones du format d’origine n’ont pas d’équivalence dans le format de destination il faut codifier FMTOPT(*DROP) afin qu’elles soient ignorées par la copie. La valeur *MAP peut être codifiée avec *DROP (figure 7.3).

241
ZONE1 ZONE3 ZONE2 ZONE512345 0 ABCDEF 0
ZONE1 ZONE2 ZONE3 ZONE412345 ABCDEFGHIJKL 1234567890 98765
CPYF FMTOPT(*MAP *DROP)
Figure 7.3 : le paramètre FMTOPT de la commande CPYF. ZONE2 et ZONE3 peuvent être copiées bien qu’elles soient inversées dans le fichier de destination car FMTOPT(*MAP) est codifié. ZONE4 est ignorée car elle n’entre pas dans la composition du format de destination et car FMTOPT(*DROP) est spécifié. Il faut remarquer que le format de ZONE3 ayant changé, la zone de destination ne peut accueillir les données d’origine ; elle est donc initialisée avec sa valeur par défaut.
Vers un fichier source
La commande CPYF permet aussi de copier à destination d’un fichier source. Les paramètres SRCOPT et SRCSEQ définissent la numérotation des lignes insérées dans le membre source.
Les enregistrements supprimés
Les enregistrement du fichier d’origine peuvent être supprimés de la copie si COMPRESS(*YES) est précisé. C’est la valeur par défaut.
Les différentes commandes de copie
Il existe d’autres commandes de copie, voici les principales :
CPYFRMDKT copie à partir d’un fichier disquette ; CPYFRMTAP copie à partir d’un fichier bande ; CPYSPLF copie un fichier spoule à destination d’un fichier ; CPYSRCF copie à partir d’un fichier source ; CPYTODKT copie d’un fichier vers un fichier disquette ; CPYTOTAP copie d’un fichier vers un fichier bande.

242
Si les données à copier sont en provenance, ou à destination, d’un système autre que l’AS/400, on peut utiliser l’une des fonctions suivantes :
• Client Access/400 (ou PCS/400) pour transférer des données vers, ou depuis, un micro-ordinateur sous DOS, Windows ou OS/2 ;
• FTP, qui s’appuie sur TCP/IP, pour échanger des fichiers avec toute plate-forme qui supporte ce protocole (en particulier les systèmes Unix) ;
• ODBC, qui permet à une application s’exécutant sous Microsoft-Windows d’être indépendante de la base de données. L’utilisateur peut choisir au dernier moment où il va chercher les données. Il sélectionne pour cela un pilote ODBC (couramment nommé driver). L’OS/400 fournit un pilote pour accéder à sa base de données depuis la V2R3M0, sous forme de trois PTF au début, puis totalement intégré à Client Access/400 ensuite.
Les commandes de substitution
La substitution de fichier nous permet de leurrer un programme dans le sens ou ce dernier croit travailler avec un fichier alors que le système lui en renvoie un autre. Cette fonction est utilisée principalement dans les cas suivants :
• lorsqu’un fichier doit être remplacé par un autre de même format (nouvelle année en comptabilité, nouveau stock, nouvelle agence...) sans que l’on retouche le programme ;
• lorsque l’on désire travailler sur un membre particulier ;
• et d’une manière générale chaque fois que l’on désire modifier les caractéristiques d’un fichier.
Les commandes de substitution agissent pour le travail en cours seulement et n’ont donc pas d’effet pour le reste du système. Leur effet est aussi limité dans le temps car les substitutions disparaissent au maximum à la fin du travail. Pour modifier un fichier de manière permanente et pour tous les utilisateurs on utilisera une commande de type CHGxx.
La commande OVRDBF permet de modifier les caractéristiques d’un fichier base de données (physique ou logique) pour un travail. Voici ses principaux paramètres :
• FILE permet de donner le nom du fichier à substituer ;
• TOFILE définit le nom du fichier qui remplace celui qui est spécifié dans le paramètre FILE.

243
Par exemple :
OVRDBF FILE( FICH95) TOFILE ( FICH96)
provoque pour le travail en cours la substitution du fichier FICH95 par FICH96. Après cette commande, un programme utilisant FICH95 recevra les données de FICH96 à condition que ces deux fichiers aient le même format ;
• MBR précise le nom du membre qui est vu. Ainsi :
OVRDBF FILE( STOCK95) TOFILE (* FILE ) MBR( HERAULT)
met le membre HERAULT à disposition des applications qui utilisent STOCK95. Ce type de substitution est le seul moyen (avec la commande OPNDBF) qui permette de traiter les enregistrements d’un membre qui n’est pas le premier dans un fichier ;
• POSITION indique où se place le pointeur d’enregistrement, autrement dit définit le premier enregistrement qui sera lu (le premier, le dernier, celui placé en position N, celui qui a une certaine valeur de clé...) ;
• SHARE permet le partage de l’ODP entre plusieurs programmes d’un même travail, ou d’un même groupe d’activation ;
• OVRSCOPE définit la portée de la substitution. Elle peut être limitée :
– *ACTGRPDFN : au groupe d’activation du programme qui appelle cette commande,
– *JOB : au travail,
– *CALLLVL : au niveau d’appel en cours. La valeur du niveau d’appel peut être visualisée par la commande DSPJOBLOG. Elle correspond aux nombres placés à gauche des commandes ;
• et un ensemble de paramètres déjà définis pour les commandes CRTPF et CRTLF .
La substitution est valable jusqu’à l’émission de la commande DLTOVR ou jusqu’à la fin du travail.
La commande DSPOVR permet de visualiser les substitutions pour le travail en cours.

244
Il existe d’autres commandes de substitution. Voici les principales :
OVRPRTF substitue un fichier d’impression ; OVRDSPF substitue un fichier d’affichage ; OVRMSGF substitue un fichier de messages ; OVRSAVF substitue un fichier de sauvegarde ; OVRTAPF substitue un fichier bande.
Ouverture et fermeture contrôlée des fichiers
Les programmes qui utilisent des fichiers les ouvrent et les ferment automatiquement. Le développeur peut choisir de contrôler ces opérations pour des besoins particuliers. Les commandes OPNQRYF et CLOF permettent d’ouvrir et de fermer des fichiers dans un programme. Par exemple :
OPNDBF FILE( FICH1) MBR( HERAULT) ACCPTH(* ARRIVAL)
force l’ouverture du fichier FICH1. Les enregistrement traités seront ceux du membre HERAULT, ils seront vus selon l’ordre d’arrivée même si un chemin d’accès est défini pour ce fichier.
La commande POSDBF permet de positionner le pointeur d’enregistrement au début ou à la fin du membre.
Le fichier est fermé par la commande CLOF .
Les langages de haut niveau permettent aussi de gérer l’ouverture et la fermeture des fichiers. En RPG, il faut codifier UC (User Control) dans la spécification F du fichier puis utiliser les codes opération OPEN et CLOSE. Mais il s’agit là uniquement de décider quand un fichier doit être ouvert et non pas comment il doit l’être. La différence avec la commande OPNDBF est donc fondamentale.
Les références croisées
L’OS/400 ne donne aucun outil pour gérer les références croisées. Il est, par exemple, assez difficile de connaître tous les programmes qui utilisent un fichier ou tous les fichiers qui référencent une zone du dictionnaire. Et cela est pourtant indispensable quand on doit faire évoluer un système d’information.
Quelques commandes renvoient la description d’objets (programmes et fichiers). Elles permettent d’écrire des programmes en langage de contrôle automatisant le traitement de certaines références croisées. Les API apportent beaucoup plus de

245
puissance et de rapidité de traitement. Elles demandent, par contre, de maîtriser quelques techniques de développement réputées complexes.
Les principales commandes
Parmi les principales commandes qui nous permettent d’établir des références croisées nous pouvons remarquer :
• DSPPGMREF qui liste les différents objets utilisés par un programme ;
• PRTCMDUSG qui génère un fichier spoule indiquant quels sont les programmes, en langage de contrôle, utilisant une ou plusieurs commandes ;
• DSPDBR qui précise les relations d’un fichier (par exemple, tous les fichiers logiques qui pointent sur un fichier physique) ;
• DSPFD qui donne des informations sur un fichier ;
• DSPFFD qui liste les zones contenues dans un fichier et quelques informations sur le fichier.
Ces commandes ne permettent pas la création d’applications vraiment complexes, c’est alors que les API doivent intervenir.
Les API et la base de données
Une série d’API sur la base de données permettent d’extraire très rapidement des informations sur les fichiers. Nous ne rentrerons pas dans les principes de programmation liés aux API, il faudrait un tome supplémentaire, mais un exemple complet est présenté en annexe C. Pour un fichier, il liste les membres qui le composent et propose des informations complémentaires (taille du chemin d’accès, nombre d’enregistrements...). Pour des raisons de concision, il est relativement simple et peut (et doit) être enrichi.
Voici les principales API liées à la base de données :
QUSLMBR liste les membres d’un fichier ; QDBLDBR liste les relations d’un fichier (comparable à la commande
DSPDBR) ; QUSLFLD liste les zones d’un format ; QUSLRCD liste les formats d’un fichier ; QUSMBRD extrait des informations sur un membre.

246
On peut ajouter à cette liste diverses API qui sont indépendantes de la base de données mais qui peuvent s’avérer utiles pour le traitement de références croisées :
• QCLRPGMI , qui extrait des informations sur un programme, notamment s’il contient des requêtes SQL ;
• les API de sécurité qui permettent de connaître les droits et les interdictions à partir des objets ou des profils utilisateur.
Enfin, il faut signaler que les API sur les User Index (objet de type *USRIDX) nous permettent des traitements rapides sur les données tels que les tris et les recherches par index.
Les principales commandes
CLODBF ferme un fichier base de données ; CPYF copie à partir d’un fichier base de données ; CPYFRMQRYF copie à partir d’un Open Query File ; CPYSPLF copie à partir d’un fichier spoule ; DLTOVR arrête une substitution ; DSPDBR affiche les relations d’un fichier ; DSPFD affiche la description d’un fichier ; DSPFFD affiche la description des zones d’un fichier ; DSPPGM affiche la description d’un programme; DSPPGMREF affiche les objets utilisés par un programme ; OPNDBF ouvre un fichier base de données ; OPNQRYF ouvre un Open Query File ; OVRDBF substitue un fichier base de données ; OVRDSPF substitue un fichier d’affichage ; OVRMSGF substitue un fichier de messages ; OVRPRTF substitue un fichier d’impression ; PRTCMDUSG affiche la liste des programmes qui utilisent une commande.
Les principaux menus
CMDCPY, CMDOPN, CMDOVR, CMDCPY.

247
GESTION DE LA BASE DE DONNEES.......................................................................231
LA COMMANDE OPNQRYF....................................................................................................231 Principes ........................................................................................................................232 Les principaux paramètres.............................................................................................235
LES COMMANDES DE COPIE.................................................................................................238 LES COMMANDES DE SUBSTITUTION....................................................................................242 OUVERTURE ET FERMETURE CONTROLEE DES FICHIERS......................................................244 LES REFERENCES CROISEES.................................................................................................244
Les principales commandes ...........................................................................................245 Les API et la base de données........................................................................................245
LES PRINCIPALES COMMANDES...........................................................................................246 LES PRINCIPAUX MENUS......................................................................................................246
—A— API 245
—C— chemin d’accès 245 Client Access/400 242 CLOF 233; 244 CLOSE 244 CPYF 238
—D— DDS 238 DLTOVR 233; 243 DSPDBR 245 DSPFD 245 DSPFFD 245 DSPJOBLOG 243 DSPOVR 243 DSPPGMREF 245
—F— fichier source 241 FMTOPT 240 FROMFILE 238 FROMKEY 239 FROMMBR 239 FROMRCD 239 FTP 242
—G— GROUP BY 237
—I— Impression 239 INCCHAR 240 INCREL 240
—J— JFLD 237 jointure 237
—M— MAPFLD 236 MBROPT 239 membre 238
—O— ODBC 242 ODP 233 OPEN 244 OPNDBF 244 OPNQRYF 231; 244 OVRDBF 233; 242
—P— PCS/400 242 POSDBF 244

232
PRINT 239 PRTCMDUSG 245
—Q— QRYSLT 235 QSYSPRT 239
—S— sécurité 246 SRCOPT 241 SRCSEQ 241
—T— TCP/IP 242 TOFILE 238 TOKEY 239 TOMBR 239 TORCD 239 tri 237
—U— User Index 246

Chapitre 8
Les bases de données distantes
Pour concrétiser son ouverture, l’AS/400 doit permettre l’accès aux informations placées dans une base de données répartie. L’OS/400 met deux fonctions à notre disposition pour travailler dans un tel environnement : DDM et DRDA. L’aspect communication n’est pas abordé dans cet ouvrage car il sort du domaine de la base de données. Il devrait être traité par Rémi Borrelly, dans un livre sur l’AS/400 et les communications, à paraître aux Éditions Eyrolles.
Les fichiers DDM DDM (Distributed Data Management) est une architecture qui permet l’échange de données entre systèmes du monde IBM. Il est disponible sur les plates-formes IBM/36 et IBM/38, sous les systèmes CICS et OS/2 (avec quelques restrictions) et se trouve totalement intégré à l’OS/400.
Il permet à un utilisateur d’accéder, de manière transparente, à des données sans savoir où elles sont stockées (en local, sur un autre AS/400 ou sur une autre plate-forme).
DDM s’appuie sur deux types de systèmes : le système source qui exécute le programme qui demande les données et le système cible qui possède ces données. L’AS/400 peut être l’un ou l’autre.

248 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Un fichier DDM placé sur l’AS/400 source contient toutes les informations pour accéder à un fichier distant (identification du système dans le réseau, nom du fichier...). Il est créé par la commande CRTDDMF , sans codification de DDS. En effet, ce type de fichier ne possède aucun enregistrement, donc aucun format. Les seuls éléments à préciser lors de sa création concernent l’accès au fichier éloigné et les paramètres de la commande de création suffisent.
Le programme source ne voit que le fichier DDM, il ne connaît pas le fichier distant (figure 8.1). Cela est important car, lors de la compilation, le programme doit récupérer la description du format du fichier qui contient les données. Pour se faire, il existe deux manières de procéder :
• si la communication n’est pas établie avec le système distant lors de la compilation, il faut créer un fichier local de même format que le fichier éloigné et citer son nom dans le programme. Il suffira, lors de l’exécution, de substituer le fichier local par le fichier DDM grâce à la commande OVRDBF. Cette méthode permet de tester le programme, sans mettre en œuvre les communications, en plaçant des données dans le fichier local ;
• si l’environnement est en place lors de la compilation (fichier DDM créé et communication établie), le format du fichier distant est automatiquement ramené dans le programme. Dans ce cas, c’est le nom du fichier DDM qui doit être spécifié dans le programme.
DDM1*FILE
PGM1*PGM
COMMUNICATIONS
CRTDDMF DDM1
AS/400 LOCAL SYSTEME DISTANT
FICH1*FILE
Figure 8.1 : utilisation d’un fichier DDM.

8 - Les bases de données distantes 249
Le fichier distant peut être un fichier qui contient les données ou un fichier logique (si le système cible est un autre AS/400 ou un IBM/38). Les opérations que l’on peut effectuer sur ce fichier, à travers le fichier DDM, sont :
• la gestion des données (lecture, écriture, mise à jour, insertion) à partir des ordres spécifique au langage (WRITE , READ, UPDAT en RPG, par exemple) ;
• l’ouverture et la fermeture ;
• la copie des données à l’aide de la commande CPYF (à partir, ou vers, le système cible) ;
• la gestion des membres (création, destruction, effacement des enregistrements) si le système cible le supporte (AS/400 et IBM/38) ;
• le verrouillage (ALCOBJ ) et la libération (DLCOBJ). Le fichier DDM et le fichiers distants sont concernés ;
• l’affichage d’informations par les commandes DSPFD et DSPFFD ;
• et, d’une manière générale, tout ce qui concerne la gestion des fichiers : la destruction (DLTF ), la création (CRTPF, CRTSRCPF et éventuellement CRTLF ), la modification (CHGPF, CHGLF )...
Le support est donc complet et permet, vraiment, de travailler avec un fichier distant comme s’il était local.
Un fichier DDM peut aussi être utilisé pour lancer une commande sur le système cible. Il faut, pour cela, utiliser la commande SBMRMTCMD . Par exemple :
SBMRMTCMD CMD('CRTDTAARA DTAARA (BIB1/DTA1) TYPE(*CHAR) LEN(100) TEXT(''POUR COMPTABILITE '')') DDMFILE(LYON)
crée, sur le système cible défini par le fichier DDM LYON, la data area DTA1 dans la bibliothèque BIB1. Le fichier DDM avait été créé auparavant par la commande :
CRTDDMF FILE(LYON) RMTFILE(DB400/FICH1) RMTLOCNAME(ASLYON)
Quelques restrictions, souvent logiques, sont à noter. Voici les principales :
• les commandes provoquant un affichage ne sont pas utilisables à distance (il faut imaginer que le travail sur le système cible est comparable à un batch) ;

250 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
• les fichiers spoules sont, en standard, générés sur le système cible. A partir de la V3R1M0 de l’OS/400, il est éventuellement possible de les redescendre automatiquement vers le système source ;
• les commandes de substitution sont interdites sur le système cible.
Enfin, les fichiers DDM peuvent, aussi, être utilisés pour accéder à des dossiers de l’AS/400 à partir d’un système distant.
DRDA
DRDA (Distributed Relational Database Architecture) est une architecture qui permet d’obtenir une base de données distribuée entre différents systèmes du monde SAA (qui peut être défini comme étant le monde des ordinateurs de gestion IBM). Elle s’appuie sur le langage SQL et permet à un utilisateur de gérer, de manière transparente, des informations qui proviennent des bases de données suivantes :
• DB2/400 pour l’AS/400 ;
• DB2 sous MVS ;
• SQL/DS sous VM ;
• DB2/6000 pour les Risc/6000 sous AIX (l’Unix IBM) ;
• DB2/2 sous OS/2 ;
• et d’autres SGBD qui pourraient rejoindre cette liste.
DRDA s’appuie sur les fonctions de communication de DDM, mais cela est pratiquement transparent pour l’utilisateur.
Pour créer des programmes DRDA, il faut avoir le produit SQL/400 sur le système de développement, car ce langage est la base de la gestion des données dans cet environnement. Mais il n’est pas indispensable si l’AS/400 est seulement source des données.
Si la base de données distante a été définie au niveau du système (par la commande WRKRDBDIRE ), l’ordre SQL CONNECT suffit à se positionner dessus. Toute opération sur les données qui suivra s’effectuera sur cette base jusqu’au CONNECT suivant, qui déportera sur une autre base. La gestion des données distantes est donc extrêmement simple.

8 - Les bases de données distantes 251
Nous avons déjà signalé, au chapitre 7, que la stratégie d’accès aux données était définie lors de la création d’un programme contenant des requêtes SQL. Lorsqu’un tel programme se connecte à une base de données distante, il faut concevoir cette stratégie sur la machine éloignée. Les informations correspondantes sont alors placées dans des objets de type *SQLPKG. Ces structures, couramment nommées SQL package, sont donc placées sur le système qui héberge les données et correspondent à la stratégie d’accès pour un programme distant. Pour chaque programme, il doit y avoir un SQL package par base de données éloignée. Mais, lors de la compilation, on ne peut citer qu’un seul nom de base de données. Les autres packages sont donc à créer par la suite, à l’aide de la commande CRTSQLPKG . Les objets de type *SQLPKG peuvent être gérés par des commandes de l’OS/400 comme les autres objets. Ils peuvent être sauvegardés, restaurés et même envoyés vers un autre système à condition qu’ils restent dans la même bibliothèque. Pour détruire un package devenu inutile, on peut utiliser la commande DLTSQLPKG ou l’ordre SQL DROP PACKAGE. Le système place une sorte d’identificateur de format dans le programme, afin de s’assurer que le package utilisé est bien le bon.
Conclusions Les deux fonctions que nous venons de décrire rapidement assurent que l’AS/400 peut totalement s’intégrer à une base de données distribuée sur plusieurs système. Dans ces deux cas, la mise en place est relativement simple et, surtout, reste totalement transparente pour l’utilisateur (aux temps de réponses près !). Il faudrait rajouter les commandes SNDNETF et RCVNETF qui, dans le cadre de SNADS, permettent d’envoyer et de recevoir un fichier sur un système distant. Il s’agit là d’une base de données distribuée entre des systèmes répondant à SAA, donc essentiellement IBM. La véritable ouverture passe par le support d’autres standards. C’est aujourd’hui le cas car l’AS/400 peut être totalement intégré à des réseaux de type TCP/IP et OSI. Pour TCP/IP, nous avons déjà le support de FTP, protocole de transfert de fichiers entre plates-formes hétérogènes et de NFS, qui rend l’AS/400 serveur de fichiers et de documents (à l’aide du produit File Server Support/400). L’intégration, promise

252 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
par IBM, de l’AS/400 dans le réseau Internet sera un élément déterminant dans le processus d’ouverture. Chaque AS/400 pourra ainsi devenir un serveur de données à l’échelle planétaire, dépassant largement le cadre des ordinateurs IBM.

8 - Les bases de données distantes 253
Les principales commandes
ADDRDBDIRE ajouter une entrée au répertoire de base de données ; CHGRDBDIRE modifier une entrée du répertoire de base de données ; CRTDDMF créer un fichier DDM ; CRTSQLCBL créer un programme Cobol contenant des requêtes SQL ; CRTSQLPKG créer un SQL package ; CRTSQLRPG créer un programme RPG contenant des requêtes SQL ; DLTSQLPKG détruire un SQL package ; DSPRDBDIRE afficher les entrées du répertoire de base de données ; RCVNETF recevoir un fichier ; SBMRMTCMD soumettre une commande à un système distant via DDM ; SNDNETF envoyer un fichier ; SNDNETSPLF envoyer un fichier spoule ; WRKRDBDIRE gérer les entrées du répertoire de base de données.
Les principaux menus
CMDSND, CMDTCP, CMDRCV, CMDRDB.

254 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
LES BASES DE DONNEES DISTANTES.....................................................................247
LES FICHIERS DDM.............................................................................................................247 DRDA ................................................................................................................................250 CONCLUSIONS.....................................................................................................................251 LES PRINCIPALES COMMANDES...........................................................................................253 LES PRINCIPAUX MENUS......................................................................................................253
—A— ALCOBJ 249
—C— CHGLF 249 CHGPF 249 CICS 247 CONNECT 250 CPYF 249 CRTDDMF 248 CRTLF 249 CRTPF 249 CRTSQLPKG 251 CRTSRCPF 249
—D— DB2 250 DB2/2 250 DB2/400 250 DB2/6000 250 DDM 247; 250 DDS 248 DLCOBJ 249 DLTF 249 DLTSQLPKG 251 DRDA 250 DROP PACKAGE 251
—F— FTP 251
—I— IBM/36 247 IBM/38 247
Internet 251
—M— MVS 250
—N— NFS 251
—O— OS/2 247 OSI 251
—P— package 251
—R— RCVNETF 251 READ 249
—S— SBMRMTCMD 249 SGBD 250 SNDNETF 251 SQL/DS 250
—T— TCP/IP 251
—U— UPDAT 249

248 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
—W— WRITE 249 WRKRDBDIRE 250

Glossaire
Ce glossaire reprend les néologismes utilisés, définit les sigles et abréviations, et décrit les termes techniques.
API (Application Program Interface) Primitive à insérer dans des programmes (RPG, Cobol, langage de contrôle...) pour disposer de fonctionnalités évoluées. Certaines API sont livrées avec des produits tels que PCS/400 ou Office Vision/400, d'autres sont disponibles en standard et permettent d'utiliser les données et les fonctions avancées du système.
Architecture Unifiée d'Applications (Systems Application Architecture ou SAA) Stratégie définie par IBM en 1987 pour augmenter la productivité des programmeurs et des utilisateurs, en normalisant 3 domaines:
• l'interface utilisateur (voir CUA) ; • les communications (voir CCS) ; • la programmation (voir CPI).
ASP (Auxiliary Storage Pools) Un pool de mémoire secondaire est une portion (ou la totalité) de la mémoire secondaire. L'ASP système est la partie gérée directement par le système ; il peut occuper tous les disques et est obligatoire. Un ASP utilisateur est une partie facultative de la mémoire secondaire où le système n'est pas libre d'agir. Il ne placera des objets que sur l’ordre de l’utilisateur. C'est un moyen d'isoler les objets liés à la journalisation et les fichiers de sauvegarde, des données d'origine.

268 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Base de données Ensemble des objets et des programmes qui permettent la gestion des données (souvent qualifié de SGBD pour Système de Gestion de Base de Données). L'AS/400 est livré en standard avec un système de gestion de base de données relationnelle : DB2/400. C'est le seul moyen de gérer les données sur ce système.
Batch Travail se déroulant en tâche de fond, sans interaction avec un utilisateur. Ce type de travail est opposé à l'interactif.
Bibliothèque Objet de type *LIB qui permet de classer les objets. Une bibliothèque n'est pas un espace réservé sur le disque mais elle est constituée d'un index qui pointe sur des objets répartis n'importe où sur le disque. Elle n'a donc pas de taille limite. Toute bibliothèque est rattachée à QSYS.
CCS (Common Communications Support) Composant de l'Architecture Unifiée d'Applications qui définit l'architecture et les protocoles permettant la communication entre les différentes plates-formes SAA.
Chemin d'accès Composant des fichiers physiques et logiques comparable à un index qui permet à un programme de voir les enregistrements d'une certaine manière. Il contient la clé des enregistrements correspondant aux critères de sélection, et leur adresse.
CIR Voir contrainte d’intégrité référentielle.
CL 1
er sens : les membres sources de type CL contiennent des instructions qui seront
interprétées lors de la soumission d'un flot de travaux ;
2e sens : (Control Language) les programmes compilés contenant des commandes du
langage de contrôle sont souvent appelés « Programmes CL ». Les membres sources de ces programmes sont de type CLP. Pour éviter toute confusion avec les flots de travaux (voir le premier sens), nous avons préféré la terminologie CLP (voir CLP).
CLP Type de membre source. Ce membre, contenant des commandes du langage de contrôle, sera compilé pour donner un programme (objet de type *PGM). Dans cet ouvrage, ces programmes seront nommés « Programmes CLP ».

Glossaire 269
Commit Voir validation.
Contrainte d’intégrité référentielle Fonction de DB2/400 permettant d’assurer l’intégrité de la base de données. Une (ou plusieurs) zone(s) d’un fichier dépendant est associée à une (ou plusieurs) zone(s) d’un fichier parent. Chaque zone du fichier dépendant, ainsi définie, ne pourra recevoir qu’une valeur existant déjà dans la zone du fichier parent qui lui est associée.
Contrôle de validation Processus associé à la journalisation qui permet de s'assurer qu'une transaction s'est bien terminée. Toute transaction incomplète sera annulée afin de conserver l'intégrité de la base de données.
CPI (Common Programming Interface) Composant de l'Architecture Unifiée d'Applications (SAA) définissant les langages de programmation et les outils de développement. Cette normalisation assure une portabilité optimale des programmes entre les différentes plates-formes SAA et une meilleure productivité des programmeurs.
CUA (Common User Acces) Composant de l'Architecture Unifiée d'Applications (SAA) définissant les interactions avec l'utilisateur. L'utilisation des touches de fonction et l'aspect des écrans sont normalisés.
DDS (Data Description Specification) Langage de définition des objets de type fichier. Les DDS sont composées de mots-clés et doivent être codifiées en respectant un colonage rigoureux. Un membre source composé de DDS sera compilé par une commande CRTxx pour donner un objet de type fichier (*FILE). Ce dernier peut être un fichier d'affichage (attribut DSPF), un fichier d'impression (attribut PRTF) ou un fichier base de données (attribut PF pour les fichiers physiques ou LF pour les fichiers logiques). Les autres types de fichiers ne seront pas vus dans cet ouvrage. Certains utilisent le terme de SDD pour Spécification de Description de Données, mais, pour éviter toute confusion au niveau de la documentation, nous avons gardé le terme anglo-saxon comme il est de coutume pour l'AS/400.
DDM (Distributed Data Management) Fonction de l’OS/400 permettant à une application d’accéder à des données situées sur un système distant (AS/400, IBM/36 et IBM/38 essentiellement).

270 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Déclencheur (trigger) Fonction de DB2/400 associant un programme (dit déclencheur) à un événement, pour un fichier physique. Si cet événement se produit, le programme déclencheur est lancé.

Glossaire 271
DFU (Data File Utility) Utilitaire de la base de données utilisé pour la maintenance des fichiers.
Document Un document est un élément bureautique produit par Office Vision/400 ou un fichier provenant du monde de la micro-informatique grâce à PCS/400 ou à Client Access/400. L'AS/400 gère les documents mais ne sait pas ce qu'il y a à l'intérieur.
Dossier Structure qui regroupe des documents et des dossiers.
DRDA (Distributed Relational Database Architecture) Architecture de base de données répartie d’IBM.
DTAARA (data area) Une zone de données est un objet de type *DTAARA. Elle contient une seule information dont le type et la longueur sont définis lors de sa création (voir LDA).
DUMP Extraction du contenu d’une structure. Le dump d’un objet est une image héxadécimale de son contenu (partie descriptive et données) obtenue par la commande DMPOBJ. Pour un document, il faut utiliser DMPDLO . La commande DMPJOB renvoie des informations sur un travail. Les informations générées par ces commandes sont placées dans un fichier spoule nommé QPSRVDMP.
Fichier de sauvegarde Objet de type *FILE, attribut SAVF, destiné à recevoir une sauvegarde.
Fichier logique Structure de la base de données permettant au programme de voir les enregistrements d'un (ou de plusieurs) fichier(s) physique(s) d'une certaine manière. Cette vue comprend des tris, des sélections d'enregistrements sur certains critères, des projections de zones et des jointures (au sens relationnel). Un fichier logique est codifié à partir de DDS, il est de type *FILE, attribut LF. Il ne contient pas d'enregistrements, mais seulement la manière de voir ces enregistrements.
Fichier physique Structure de la base de données contenant les enregistrements. Un fichier physique est codifié à partir de DDS, il est de type *FILE, attribut PF.
Fichier source Objet de type *FILE, attribut SRC-PF, dont les membres contiennent les sources de programmes ou les DDS de fichiers.

272 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Fichier spoule (spool file) Un fichier spoule représente un état à imprimer. Ce n’est pas réellement un fichier, ni même un objet de l’OS/400. Il est rattaché à une file d’attente en sortie (OUTQ).
FTP Protocole de transfert de fichiers sous TCP/IP.
Giga-octet Milliard de caractères.
Guide opérateur Voir invite.
IFS (Integrated File System) Fonction de l’OS/400 (à partir de la V3R1M0) qui assure le support des systèmes de fichiers de type Unix, Lan serveur, micro-informatique (MS/DOS, OS/2), en cohabitation avec la gestion native des objets et des documents dans les dossiers.
Indicateur Variable de type logique permettant d'échanger une information élémentaire dans les programmes. Nous avons 99 indicateurs à notre disposition (appelés 01 à 99), d'autres ont une signification particulière pour le système. Un indicateur est soit égal à 1, auquel cas il est en-fonction ou vrai, soit égal à 0, il est alors hors-fonction ou faux.
Interactif Travail nécessitant une interaction avec un utilisateur par l'intermédiaire d'un poste de travail.
Invalidation (rollback) Opération du contrôle de validation consistant à annuler l’ensemble des opérations d’une transaction.
Invite (prompt) Fonction d'assistance permettant de saisir les valeurs des différents paramètres d'une commande. Pour y accéder, il suffit de taper le nom de la commande sur la ligne "Option commande" et d'appuyer sur F4.
IPL (Initial Program Load)

Glossaire 273
Phase de démarrage qui charge le système en mémoire à partir d'un support magnétique, qui vérifie le matériel et qui met en place les fonctions qui vont permettre aux travaux de s'exécuter.

274 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
JOBD Une description de travail est un objet de type *JOBD. Elle décrit l'environnement d'exécution d'un travail.
JOBQ Une file d'attente de travaux est un objet de type *JOBQ. Elle accueille les travaux qui ont été soumis, avant qu'ils ne s'exécutent dans un sous-système.
Journal Objet de type *JRN qui, avec les récepteurs de journaux, recueille toutes les modifications qui ont affecté les objets qui lui sont associés.
Journalisation Mise en place de journaux qui vont recenser toutes les modifications qui ont lieu sur les objets journalisés.
LDA (Local Data Area) Zone de données (DTAARA) particulière qui est créée automatiquement avec chaque nouveau travail. Elle n'est accessible qu'à partir des différents programmes de ce travail, sous le nom de *LDA. Elle est initialisée avec un type Alphanumérique d’une longueur de 1024 caractères.
LF (Logical File) Voir fichier logique.
Méga-octet Million de caractères.
Membre Les membres sont des composants des fichiers physiques et logiques. Ils correspondent à un ensemble de données. Par défaut, un fichier a un membre qui porte le même nom.
Membre source Membre d'un fichier source contenant les instructions d'un programme ou les DDS d'un fichier.
Mémoire secondaire Ensemble des disques durs. Sa taille se mesure en giga-octet (milliard de caractères).
MSGQ

Glossaire 275
Une file d'attente de messages est un objet de type *MSGQ. Elle accueille les messages à destination d'un utilisateur, d'un objet ou d'un programme.
Objet La notion d'objet désigne les structures sur lesquelles l'OS/400 peut effectuer des opérations. Ces objets ont une partie descriptive et une partie qui contient les données propres à cet objet. Le type de l'objet définit le format de ses données. Toutes les notions abordées ici se réfèrent au concept d'objet. Il existe aussi un autre mode de gestion de l'information sur l'AS/400 qui n'utilise pas la notion d'objet, mais la notion de documents dans des dossiers.
Objet de notification Objet de type *MSGQ, *FILE ou *DTAARA associé au contrôle de validation, qui permet de connaître la dernière transaction validée.
Octet Série de huit informations élémentaires (bits) permettant de coder un caractère.
Office Vision/400 Programme sous licence assurant les tâches de bureautique de l’AS/400.
Optimiseur Composante de la base de données chargée de définir la stratégie d’accès pour SQL, pour la commande OPNQRYF, pour Client Access/400...
OS/400 (Operating System/400) Système d'exploitation de l'AS/400.
OUTQ Les files d'attente en sortie sont des objets de type *OUTQ. Elles accueillent les états en attente d'impression.
Package Voir SQL package.
Paramètre Élément d'une commande qui précise le type du traitement à effectuer (sur qui, comment...).
PCS/400 Logiciel sous licence permettant à un micro-ordinateur de type PC/PS de se connecter de manière intelligente à un AS/400. Il assure les fonctions de terminal,

276 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
d'échange de données, de partage des ressources (imprimantes, disques...). A partir de la version 3 de l’OS/400, il est nommé Client Access/400.
PDM (Programming Development Manager) Environnement de développement utilisable pour tous les langages de l’AS/400.
PF (Physical File) Voir Fichier physique.
PGMQ C'est une file d'attente de messages qui reçoit les messages destinés à un programme. Elle constitue une partie de la file d'attente de messages associée au travail.
Profil utilisateur Objet de type *USRPRF qui regroupe les informations propres à chaque utilisateur. On y trouve son nom, son mot de passe (non visualisable), des données liées à la sécurité, et enfin la définition de son environnement de travail. C'est un des composants essentiels de la sécurité, et de l'organisation des travaux sur l'AS/400.
PTF (Program Temporary Fix) Correction logicielle ou nouvelle fonctionnalité apportées à un problème particulier.
QGPL (General-Purpose Library) Bibliothèque contenant certains objets liés au système et les objets créés par des utilisateurs sans qu'une bibliothèque puisse être attribuée (objets non qualifiés et absence de bibliothèque courante).
QPJOBLOG Fichier spoule correspondant à l'historique d'un travail.
QSYS Bibliothèque fondamentale qui contient la majeure partie de l'OS/400, les objets liés à la sécurité et les bibliothèques.
QSYSOPR File d'attente de messages associée à l'opérateur système. C'est un objet standard.
Query/400 Utilitaire permettant d’interroger simplement la base de données.
Restauration (recovery) Opération qui permet de ramener en mémoire secondaire le contenu d'une sauvegarde.

Glossaire 277
RLU (Report Layout Utility) Utilitaire d'aide à la génération de fichiers d'impression.
Rollback Voir invalidation.
RPG (Report Program Generator) Langage de programmation de la mini-informatique IBM, anciennement appelé GAP (Générateur Automatique de Programme). Le RPG/400 était le langage de programmation phare sur l'AS/400. Il cohabite maintenant avec le RPG IV, compilateur ILE, apparu avec la V3R1M0 de l’OS/400. Il existe aussi sur d'autres plates-formes.
SAA (Systems Application Architecture) Voir Architecture Unifiée d'Applications.
Sauvegarde (backup) Opération qui consiste à dupliquer des informations sur un support différent dans le but de pouvoir les récupérer si les données d'origine étaient perdues ou détruites.
SAVF (save file) Voir fichier de sauvegarde.
SDA (Screen Design Aid) Outils de développement et de test des fichiers d'affichage et des menus.
SDD (Spécification de Description de Données) Voir DDS.
SEU (Source Entry Utility) Éditeur de source intégré à l'environnement de développement.
SMAPP Fonction standard de l’OS/400 assurant l’intégrité des chemin d'accès pour raccourcir le temps des IPL après arrêt anormal (depuis la V3R1M0 de l’OS/400).
SNADS (Systems Application Architecture Distribution Services) Fonction de l’OS/400 permettant la distribution de fichiers, d’impressions, du courrier et de messages entre systèmes distants appartenant à SAA.

278 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
SQL (Structured Query Language) Langage de gestion et de manipulation des données couramment utilisé avec les bases de données relationnelles.
SQL package Objet de type *SQLPKG définissant la stratégie d’accès aux données d’un programme distant, contenant des requêtes SQL.

Glossaire 279
TCP/IP Protocole de communication couramment utilisé dans les environnements non-SAA (Unix, par exemple). Le parc installé est considérable. Ce protocole est notamment à la base des échanges à l’intérieur d’Internet.
Transaction Ensemble d’opérations ininterruptibles sur lequel s’applique la loi du tout ou rien. Ou toutes les opérations s’effectuent normalement ou aucune de ces opérations ne doit être réalisée.
Trigger Voir déclencheur.
Type d'objet Le type d'un objet définit la nature de l'objet : programme, fichier...
User Index Objet de type *USRIDX permettant de gérer des données à la manière d’un fichier. Les accès peuvent s’effectuer en séquentiel ou sur clé. Ils sont utilisables seulement avec les API ou avec le langage C.
User Space Objet de type *USRSPC qui est utilisé par les API de liste pour renvoyer des informations en nombre variable. Ces objet doivent être gérés avec des API. Ils peuvent être comparés à des Data Area de grande taille (jusqu’à 16 Méga octets).
Valeurs système Ensemble de paramètres propres au système qui permettent de configurer les AS/400 en fonction des besoins de chaque entreprise. Ces valeurs système vont de la définition de l'heure, à la détermination du niveau de sécurité, en passant par l'attribution d'une imprimante par défaut. A ce jour, il existe une centaine de ces valeurs.
Validation (commit) Opération du contrôle de validation consistant à valider les différentes opérations d’une transaction.

280 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
GLOSSAIRE 267
—A— API 267 ASP 267
—B— bibliothèque 268
—C— chemin d'accès 268 contrôle de validation 269
—D— DDM 269 DDS 269 DFU 270 DMPDLO 270 DMPJOB 270 DMPOBJ 270 document 270 dossier 270 DRDA 270 DUMP 270
—F— fichier source 270 FTP 271
—I— IFS 271 indicateur 271 Internet 276 IPL 271
—J— JOBD 272 JOBQ 272 journal 272
—L— LDA 272
—M— membre 272 membre source 272
—O— objet de notification 273 Office Vision/400 273 OUTQ 273
—P— PCS/400 273 PGMQ 274 PTF 274
—Q— QGPL 274 QPJOBLOG 274 Qsys 274 Query 274
—R— restauration 274
—S— SAA 267; 275 sauvegarde 275 SDA 275 SGBD 268 SNADS 275 SQL 275 SQL package 275

268 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
—T— TCP/IP 276 trigger 269; 276
—U— user Space 276

Conclusions
Les avantages de DB2/400 sont nombreux, nous avons pu en juger tout au long de cet ouvrage. Retenons sa totale intégration à l’OS/400, son support de SQL et son ouverture. Avec l’arrivée de la V3R1M0, la base de données de l’AS/400 est devenue mature. Le support des contraintes d’intégrité référentielle et des déclencheurs, qui lui faisait cruellement défaut, est maintenant réalité. Ces fonctions, longues à arriver, sont très bien intégrées au système et devraient connaître un réel succès. On peut seulement reprocher à DB2/400 l’impossibilité de modifier dynamiquement la structure d’un fichier sans avoir à le recréer mais cela devrait arriver avec la prochaine version, et son manque d’outils pour gérer les références croisées. Mais les éditeurs de logiciels ont su pallier cette lacune en proposant des produits adaptés. DB2/400 peut être totalement intégré à des bases de données réparties et hétérogènes appartenant au monde IBM, évidemment, mais aussi à des réseaux TCP/IP et OSI. DB2/400 est un des atouts majeurs de l’OS/400. Gageons qu’IBM mettra tout en œuvre pour que cette base de données reste un des fleurons des SGBD relationnels. Pour l’heure, l’AS/400 affiche une santé florissante (plus de

254 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
300 000 unités vendues dans le monde). Il s’ouvre aux nouvelles technologies (multimédia, CD-Rom, interface graphique, processeur Risc) et supporte pratiquement tous les protocoles de communication. DB2/400 a donc un bel avenir devant lui. Il pourrait notamment profiter de l’explosion du réseau planétaire, dans lequel il devrait totalement s’intégrer en devenant serveur Internet.

255
CONCLUSIONS...............................................................................................................253
—D— DB2/400 253
—I— Internet 254
—M— multimédia 254
—O— OSI 253
—T— TCP/IP 253

Annexe A
Feuille de spécification A
La page suivante présente un exemple de feuille de spécification A.

256 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400

Annexe A 257
16/01/2007
FEUILLE DE SPECIFICATION A................................................................................255

Annexe B
Les types de postes de la journalisation
Voici les principaux codes et types codifiés dans les postes des journaux. Code A : ces postes sont en relation avec la comptabilité des travaux. Ils proviennent du journal QACGJRN de QSYS.
Code Type Description A DP Impression directe A JB Information sur les travaux A SP Information sur les impressions
Code C : ces postes concernent le contrôle de validation.
Code Type Description C BC Début du contrôle de validation (STRCMTCTL) C CM Validation (COMMIT) C EC Fin du contrôle de validation (ENDCMTCTL) C RB Annulation (ROLLBACK) C SC Début de cycle de validation

258 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Code F : ces postes contiennent des informations sur les fichiers.
Code Type Description F AY Recouvrement avant (APYJRNCHG) F CL Membre fermé F CR Membre effacé (CLRPFM) F EJ Arrêt de la journalisation (ENDJRNPF) F EP Arrêt de la journalisation des chemin d’accés (ENDJRNAP) F IU Membre en cours d’utilisation lors d’arrêt anormal du système F IZ Initialisation d’un membre (INZPFM) F JM Début de journalisation d’un fichier physique (STRJRNPF) F JP Début de journalisation d’un chemin d’accés (STRJRNAP) F MD Membre détruit (DLTF ou RMVM) F MF Membre sauvegardé avec libération de la mémoire F MM Fichier physique (et membre) déplacé (MOVOBJ) F MN Fichier physique ou membre renommé (RNMM ou RNMOBJ) F MR Membre restauré (RSTOBJ ou RSTLIB) F MS Membre sauvegardé (SAVLIB, SAVOBJ, SAVCHGOBJ) F OP Membre ouvert F RC Recouvrement arrière pour un membre (RMVJRNCHG) F RG Fichier réorganisé (RGZPFM) F SA Début d’application d’un recouvrement avant (APYJRNCHG) F SR Début d’application d’un recouvrement arrière (RMVJRNCHG) F SS Début de la sauvegarde en mise à jour
Code J : ces postes sont liés à la journalisation.
Code Type Description J IA IPL près arrêt anormal J IN IPL après arrêt normal J NR Nom du récepteur suivant J PR Nom du récepteur précédent J RR Restauration d’un récepteur de journal J RS Sauvegarde d’un récepteur de journal
Code R : ces entrées correspondent à des opérations sur les enregistrements.
Code Type Description R DL Enregistrement détruit R DR Enregistrement détruit par un ROLLBACK R PT Enregistrement ajouté

Annexe B - Les types de postes de la journalisation 259
R UP Image après d’un enregistrement mis à jour

260 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Code S : ces postes sont liés à SNADS.
Code Type Description S AL Alerte pour un point focal S ER Une erreur a été détecté par SNADS S LG Une opération d’envoi ou de réception s’est bien terminée
Code T : les informations contenues dans ces postes sont associées au journal d’audit.
Code Type Description T AF Défaut de droits T CA Modification des droits d’un objet T OR Objet restauré T OW Changement de propriétaire T PW Mot de passe utilisé invalide T RA Restauration d’un objet avec modification des droits T RP restauration d’un programme adoptant les droits du
propriétaire T SV Modification d’une valeur système
Code U : Poste créé par l’utilisateur, le type et la description font parties de la commande SNDJRNE.
Code Type Description U

Annexe B - Les types de postes de la journalisation 261
LES TYPES DE POSTES DE LA JOURNALISATION 257

Index
—9—
9337 137, 181
—A—
ABSVAL 33 ACCPTH 176 ACCPTH 80 ACTGRP 63 ADDLFM 117, 122 ADDPFCST 159, 193, 195 ADDPFM 71, 72, 80 ADDPFTRG 168 ADDRDBDIRE 204 ALCOBJ 249 ALL 94 ALLOCATE 55 ALTER TABLE 79, 161, 193, 195 ALTSEQ 35, 66 ALWDLT 65 ALWNULL 45
ALWUPD 65 ALWVARLEN 45 AND 196 API 245, 267 APYJRNCHG 136, 139 ASCII 46 ASP 126, 135, 267
—B—
batterie 125 BETWEEN 197 bibliothèque 8, 268
—C—
C2 178 CA/400 112 CALL 175 CCSID 47, 66 CHAIN 101 CHAIN 157

278 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
CHECK 37 checksum 126, 179

Index 279
chemin d’accès 51, 69, 158, 245, 96, 119, 268,
CHGLF 120, 249 CHGPF 67, 120, 249 CHGPFCST 163 CHGPFM 80 CHGQRYA 227 CHGRDBDIRE 204 CHKMSGID 37 CICS 247 clé 33, 161 Client Access/400 5, 71, 178, 226,
242 client/serveur 178 CLOF 233, 244 CLOSE 244 CLRPFM 76, 136, 140 CMP 94 CMTID 149 COLHDG 41 collection 188, 191 COMIT 146 COMMIT 146, 170 COMMIT 188, 203, 205, 208, 215 COMP 37 CONCAT 98 CONNECT 205, 250 contrainte d’intégrité référentielle
157 contrôle d’intégrité 126, 179 contrôle de validation 126, 145, 269 COUNT(*) 198 CPYF 40, 45, 78, 238, 249 Création 8 CREATE INDEX 227 CRTDDMF 248 CRTDUPOBJ 77 CRTEDTD 38 CRTJRN 129, 135 CRTJRNRCV 129, 135 CRTLF 91, 115, 120, 227, 249
CRTPF 30, 49, 120, 227, 249 CRTSQLCOL 188 CRTSQLPKG 251 CRTSRCPF 249 curseur 213
—D—
Date 42 DATFMT 42 DATSEP 42 DB2 42, 250 DB2/2 250 DB2/400 3, 250, 253 DB2/6000 250 DCLF 11, 45 DDM 10, 157, 247, 250, 269 DDS 9, 30, 47, 238, 248, 269 DECLARE 213, 221 déclencheur 126, 167 DELETE 202 DESCEND 34 DFT 40 DFTRDBCOL 191 DFU 5, 81, 111, 122, 164, 270 dictionnaire 31, 191 disque miroir 126, 181 DISTINCT 196, 217 DLCOBJ 249 DLTEDT 39 DLTF 76, 121, 249 DLTM 139, 140 DLTOVR 233, 243 DLTPCT 64 DLTSQLPKG 251 DMPDLO 270 DMPJOB 270 DMPOBJ 226, 270 document 270 dossier 270 DRDA 140, 167, 178, 185, 226, 250,

280 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
270 DROP 195 DROP PACKAGE 251 DSPDBR 245 DSPFD 35, 56, 76, 96, 116, 163, 176,
245 DSPFFD 76, 245 DSPJOBLOG 243 DSPJRN 133, 139 DSPOBJAUT 203 DSPOVR 243 DSPPFM 72, 76 DSPPGMREF 245 DTAMBRS 115 DUMP 270 DYNAMIC 219 DYNSLT 97, 109, 111
—E—
EBCDIC 46 EDTCDE 38 EDTOBJAUT 88, 203 EDTRBDAP 54, 141 EDTRCYAP 143 EDTWRD 38 END-EXEC 206 ENDCMTCTL 146 ENDJRNAP 142 ENTDTA 138 erreur 211 ET 95 EXECUTE EXIT 62 EXPCHK 66 EXPDATE 51, 65
—F—
FETCH 214, 218 fichier 10 fichier d'affichage 10, 36
fichier d'impression 10 fichier logique 10, 83 fichier logique joint 106 fichier logique multiformat 100 fichier logique non-joint 91 fichier physique 10, 29 fichier source 71, 241, 270 FIFO 34, 64 FILE 138 FILETYPE 50 FLAG 51 FMTOPT 240 FMTSLR 104 FOR FETCH ONLY 217 FOR UPDATE OF 218 FORMAT 39 FRCACCPTH 53 FRCRATIO 53, 54 FROM 196, 199, 217 FROMFILE 238 FROMKEY 239 FROMMBR 239 FROMRCD 239 FTP 242, 251, 271
—G—
GENLVL 50 GOTO 212 GRANT 203 GROUP BY 199, 227, 237 groupe d’activation 63 GRTOBJAUT 203
—H—
HAVING 199 Horodatage 43
—I—
IBM/36 104, 247

Index 281
IBM/38 247 IDDU 29 identificateur de format 64, 86 IFS 7 271 ILE 42 image après 128 image avant 128 IMMEDIATE 223 Impression 239 IN 197 INCCHAR 240 INCREL 240 INDEX 193 index 193, 227 indicateur 271 INFDS 164 INSERT INTO 201 intégrité 125 Internet 251, 254, 276 invalidation 146 INZPFM 40, 80, 136 IPL 54, 141, 144, 181, 271
—J—
JDFTVAL 40, 109 JDUPSEQ 108 JFILE 107 JFLD 107, 237 JOBD 272 JOBQ 272 JOIN 107 jointure 237 journal 128, 155, 272 journalisation 69, 126, 127, 143
—L—
LAN Serveur 7 LANGID 35, 66 LCKLVL 146 LDA 272
LIFO 34, 64 LIKE 197, 227 longueur variable 44 LVLCHK 64
—M—
MAINT 52, 144 MAPFLD 236 MAXMBR 51, 71, 161 MBR 51 MBROPT 239 membre 8, 68, 117, 238, 272 membre source 272 miniplan 226 mirroring 181 monomembre 70 MOVOBJ 136 multimédia 254 multimembre 70 MVS 250 NAMING 191
—N—
NFS 70, 251 NFYOBJ 149 NOALTSEQ 35, 66 NULL 45, 192, 197
—O—
objet de notification 149, 273 ODBC 242 ODP 58, 233 Office Vision/400 5, 273 omission 93 OMTJRNE 136, 138 OPEN 213 244 OPNDBF 244 OPNQRYF 45, 65, 112, 119, 144, 226,
231, 244

282 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
optimiseur 226 OPTIMIZE 217 OR 196 ORDER BY 197, 218, 227 OS/2 8, 247 OSI 251, 253 OU 95 OUTQ 273 OVRDBF 59, 62, 65, 66, 73, 121, 233,
242 OVRDSPF 65 OVRPRTF 65
—P—
package 251 PAG 59 page de code 46 Partage de format 39 PCS/400 5, 112, 226, 242, 273 performance 136 PFILE 91 PGMQ 274 plans d’accès 226 POSDBF 244 poste 127 PREPARE 221, 224 PRINT 239 PRTCMDUSG 245 PRTSQLINF 228 PTF 274
—Q—
QAUDCTL 178 QAUDJRN 178 QAUDLVL 178 QCASE256 35 QCPFMSG 171 QDBLDBR 77 QDDSSRC 49 QGPL 49, 274
QPJOBLOG 274 QRYSLT 235 QSECURITY 182 QSQJRN 191 QSQLTEMP 206 QSYS 66, 187, 274 QSYSOPR 55, 181, 228 QSYSPRT 206, 239 QSYSTRNTBL 99 QTEMP 144, 206 Query 5, 45, 73, 81, 112, 144, 189,
226, 274 Query Manager 189 QUSRSYS 35
—R—
RAID5 126, 181 RANGE 37, 94 RCVF 18 RCVNETF 251 READ 249 READE 101 récepteur de journal 128 RECOVER 53, 120, 141 REF 31, 36 REFACCPTH 96 REFFLD 31, 36 REFSHIFT 37 RENAME 98 restauration 274 RETRN 62, 175 REUSEDLT 64 REVOKE 204 Rexx 205 RGZPFM 15, 64, 80, 139, 140 RMVJRNCHG 136, 140 RMVM 76, 80, 121, 136 RMVPFCST 163 RNMM 80 RNMOBJ 136 ROLBK 146

Index 283
ROLLBACK 146, 170, 203, 205 ROWS VALUES 211 RPG 85 RPG IV 44, 168, 205 RPG/400 43, 45, 168, 205 RSTLIB 80 RSTOBJ 80 RUNSQLSTM 188, 190, 203 RVKOBJAUT 203
—S—
SAA 267, 275 sauvegarde 121, 137, 275 SAVACT 176 SAVCHGOBJ 137, 176 SAVLIB 80, 136, 137, 176 SAVOBJ 80, 136, 137, 176 SBMJOB 190 SBMRMTCMD 249 SCHEMA 194 SCROLL 219 SDA 275 sécurité 5 87, 125, 177, 203, 246 SELECT 195, 213, 217, 221 SELECT INTO 208, 223 sélecteur de format 104 Sélection 93 SGBDR 3, 83, 205, 250, 268 SHARE 60 SIZE 55 SMAPP 143 SNADS 275 SNDF 18 SNDJRNE 138 SNDNETF 251 SNDPGMMSG 171 SNDRCVF 18 sous-fichier 149 SQL 5, 45, 70, 81, 119, 144, 157,
185, 275 SQL package 275
SQL/400 185 SQL/DS 42, 250 SQLCA 211, 214, 218 SQLCBL 206 SQLCODE 211 SQLDA 223 SQLRPG 206 SQLRPGLE 206 SRCMBR 49 SRCOPT 241 SRCSEQ 241 SRTSEQ 35, 66 STOPRUN 62 STRCMTCTL 146, 203 STRJRNAP 129, 142 STRJRNPF 129, 136, 138 STRQM 189 STRQMQRY 190 STRQRY 81 STRSQL 188, 189, 203 STRSST 56 SYSTABLES 196
—T—
table 192 table de conversion 66 TCP/IP 242, 251, 253, 276 Time 42 Timestamp 42 TIMFMT 42 TIMSEP 42 TOFILE 238 TOKEY 239 TOMBR 239 TORCD 239 tri 34, 66, 237 trigger 167, 269, 276 TYPE 8, 138
—U—

284 DB2/400 ET LA GESTION DES DONNÉES SUR AS/400
Union 93 UNIQUE 34, 52, 89, 159 UNIT 56 UPDAT 164, 249 UPDATE 201, 219 User Index 246 User Space 77, 276 USING 224
—V—
validation 146 VALUES 94 VIEW 193
—W—
WHENEVER 212 WHERE 196, 200, 227 WRITE 104, 164, 249 WRKJRN 133, 139 WRKJRNA 132 WRKPFCST 163 WRKRDBDIRE 204, 250

Index 285
INDEX 277