Embed Size (px)
DESCRIPTION
Résumé :Dans un système à partage de ressources, la congestion est présente lorsque la demande en ressources dépasse la quantité des ressources diponibles. Contrairement à ce que l’on s’attendait, les technologies à haut débit n’ont fait qu’aggraver la congestion. Par conséquent, il faut concevoir de nouveaux protocoles de contrôle de congestion qui soient approporiés aux caractéristiques de tels réseaux. Le contrôle de congestion consiste à maintenir le système en dessous du seuil de congestion, tout en optimisant l’utilisation des ressources par multiplexage statistique. Il est généralement réalisé par plusieurs moyens préventifs et réactifs. Les premiers visent à rendre l’apparition de ce phénomène exceptionnelle alors que les derniers permettent de revenir à une situation normale lorsque, malgré tout, la congestion se produit. Cette deuxième classe de méthodes est très utilisée dans les réseaux ATM afin de garantir la qualité de service (QoS) des connexions déja admises. L’objectif de ce travail est de faire une synthèse sur les méthodes de contrôle de congestion dans les réseaux haut débit. Par la suite, nous étudierons de façon plus détaillée deux algorithmes de contrôle d’admission (CAC) comme exemples de contrôle préventif dans les réseaux ATM. Mots clés : réseaux à haut débit, congestion, mode de transfert asynchrone, qualité de service, évaluation de performance, simulation à évènements discrets, contrôle d’admission.AbstractIn a system with resource sharing, congestion is present when the demand for resources exceeds the quantity of available resources. Unexpectedly, new broadband technologies did nothing but worsen the congestion. Consequently, it is necessary to conceive new congestion control protocols which are appropriate to the characteristics of such networks. Congestion control consists in maintaining the system in lower part of the threshold of congestion, while optimizing the use of the resources by statistical multiplexing.It is generally carried out by several preventive and reactive means. The first aim to return the appearance of this phenomenon exceptional whereas the last make it possible to return to a normal situation when, despite everything, congestion occurs. This second class of methods is very used in ATM networks in order to guarantee quality of service (QoS) of already established connections. The aim of this thesis is to make a synthesis on the methods of congestion control in high speed networks. Thereafter, we will study in a more detailed way two algorithms of control admission (CAC) like examples of preventive control in ATM networks. . Keywords : high speed networks, congestion, asynchronous transfer mode, quality of service, performance evaluation, discrete event simulation, admission control.
Citation preview

République Algérienne Démocratique et Populaire
Ministère de l’Enseignement Supérieur et de la Recherche Scientifique
Université Abderrahmane Mira de BéjaïaFaculté des Sciences et des Sciences de l’Ingénieur
Ecole Doctorale d’Informatique Laboratoire LAMOS
Mémoire de Magistère
En Informatique
Option
Réseaux et Systèmes Distribués
Thème
Contrôle de Congestion dans les Réseaux àHaut Débit
Présenté par
Nadir BOUCHAMA
Devant le jury :
Z. Sahnoun Professeur Président Université de ConstantineD. Aissani Professeur Rapporteur Université de BéjaïaN. Djellab M.C Examinateur Université de AnnabaA. Oukaour M.C Examinateur Université de Caen (France)
Promotion 2004− 2005

Dédicaces
A mes chers parents,A mes deux frères,
A ma soeur,A mes oncles,
A ma petite nièce Yasmine et mon neveu Mohammed,A la mémoire de notre collègue Chahine Kacem,
Enfin à tous ceux que j’aime et ceux qui m’aiment,Je dédie ce modeste travail

Remerciements
MERCI à mes parents pour leur patience et leur soutien indéfectbile qui m’ontété plus qu’indispensables.
Mes très vifs remerciements vont à l’encontre de mon directeur de thèse, le Profes-seur Djamil Aissani pour avoir accepté de m’encadrer et de m’orienter tout au longde ce travail. Je le remercie également pour m’avoir acceuilli aux séminaires du LA-MOS (LAboratoire de Modélisation et d’Optimisation des Systèmes), séminaires danslesquels j’ai beaucoup appris.
Je remercie également Docteur Natalia Djellab de l’université de Annaba pour toutela documentation qu’elle a mise à ma disposition ainsi que pour tous ses conseils trèsprécieux et ses orientations qui m’ont été très bénéfiques et j’espère d’être à la hauteurde son espérance.
Je remercie vivement tous les enseignants et responsables de l’Ecole Doctorale d’In-formatique de Béjaia pour tous les efforts qu’ils ont fournis pour la réussite et l’épa-nouissement de l’Ecole.
Un grand remerciement va aussi au Professeur Zaïdi Sahnoun de l’université deConstantine pour avoir accepté de présider le jury de ma soutenance et au M.C Am-rane Oukaour de l’université de Caen pour avoir accepté de juger ce humble travail.Qu’ils trouvent ici l’expression de ma profonde reconnaissance.
Un grand remerciement va à mes collègues de l’Ecole Doctorale RESYD (REseauxet SYstèmes Distribués), notamment pour Saïd Gharout pour son aide très pré-cieuse en LATEX. Qu’il trouve ici l’expression de ma profonde gratitude.
Enfin, que tous ceux qui ont contribué de près ou de loin à l’aboutissement de cetravail trouvent ici ma reconnaissance et de ma sympatathie.

Table des matières
Introduction Générale 3
1 Panorama des Réseaux Haut Débit 41.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41.2 Taxonomie des réseaux informatiques . . . . . . . . . . . . . . . . . . . 4
1.2.1 Taxonomie selon la distance . . . . . . . . . . . . . . . . . . . . 51.2.2 Taxonomie en fonction de la topologie . . . . . . . . . . . . . . 51.2.3 Taxonomie en fonction du mode de commutation . . . . . . . . 6
1.2.3.1 Réseaux à commutation de circuits . . . . . . . . . . . 71.2.3.2 Réseaux à commutation de paquets . . . . . . . . . . . 7
1.3 Les réseaux à haut débit . . . . . . . . . . . . . . . . . . . . . . . . . . 91.3.1 Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91.3.2 Définitions d’un réseau haut débit . . . . . . . . . . . . . . . . . 111.3.3 Multiplexage statistique dans les réseaux à haut débit . . . . . . 12
1.4 Technologies pour supporter les hauts débits pour les WANs . . . . . . 141.4.1 La technologie Relais de Trames (Frame Relay) . . . . . . . . . 141.4.2 La technologie ATM (Asynchronous Transfert Mode) . . . . . . 14
1.4.2.1 Cellule ATM . . . . . . . . . . . . . . . . . . . . . . . 151.4.2.2 Les connexions ATM . . . . . . . . . . . . . . . . . . . 171.4.2.3 Qualité de Service dans ATM . . . . . . . . . . . . . . 171.4.2.4 Paramètres de qualité de service dans les réseaux ATM 181.4.2.5 Classes de services dans ATM . . . . . . . . . . . . . . 20
1.4.3 La technologie MPLS ( MultiProtocol Label Switching) . . . . . 211.5 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
2 Contrôle de Congestion dans les Réseaux Haut Débit 242.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 242.2 Terminologie et concepts de base . . . . . . . . . . . . . . . . . . . . . 24
2.2.1 Allocation de ressources . . . . . . . . . . . . . . . . . . . . . . 242.2.2 Notion d’efficacité (efficiency) . . . . . . . . . . . . . . . . . . . 252.2.3 Notion d’équité (fairness) . . . . . . . . . . . . . . . . . . . . . 25
i

2.2.4 Goulot d’étranglement . . . . . . . . . . . . . . . . . . . . . . . 262.2.5 Produit délai-bande passante (BDP, Bandwidth Delay Product) 272.2.6 Notion de Congestion . . . . . . . . . . . . . . . . . . . . . . . . 27
2.3 Nécessité d’un contrôle de Congestion . . . . . . . . . . . . . . . . . . . 292.4 Propriétés d’un bon système de contrôle de congestion . . . . . . . . . 292.5 Taxonomie des méthodes de contrôle de congestion . . . . . . . . . . . 31
2.5.1 Taxonomie selon le stade d’intervention . . . . . . . . . . . . . . 312.5.2 Taxonomie selon la couche du modèle OSI . . . . . . . . . . . . 322.5.3 Taxonomie selon la durée de la congestion . . . . . . . . . . . . 332.5.4 Taxonomie selon le mécanisme utilisé (fenêtre dynamique versus
approche débit dynamique) . . . . . . . . . . . . . . . . . . . . 342.5.5 Taxonomie selon la boucle utilisée (boucle fermée versus boucle
ouverte) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 372.5.6 Taxonomie selon la logique d’intervention (bout en bout versus
noeud par noeud) . . . . . . . . . . . . . . . . . . . . . . . . . . 372.6 Principe du contrôle de congestion dans les réseaux à commutation de
paquets . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 382.6.1 Détection de la congestion . . . . . . . . . . . . . . . . . . . . . 382.6.2 Communication de l’information de congestion . . . . . . . . . . 392.6.3 Actions prises par un commutateur . . . . . . . . . . . . . . . . 392.6.4 Contrôle de flux du côté des sources . . . . . . . . . . . . . . . . 392.6.5 Coopération entre les différents acteurs . . . . . . . . . . . . . . 40
2.7 Contrôle de Congestion dans DECBit . . . . . . . . . . . . . . . . . . . 402.8 Contrôle de congestion dans Internet . . . . . . . . . . . . . . . . . . . 42
2.8.1 Effondrement de Congestion (Congestion Collapse) . . . . . . . 432.8.2 Contrôle de Congestion dans TCP . . . . . . . . . . . . . . . . . 44
2.9 Améliorations pour TCP dans les réseaux haut débit . . . . . . . . . . 452.10 Contrôle de congestion dans les réseaux haut débit . . . . . . . . . . . 45
2.10.1 Mythes non fondés . . . . . . . . . . . . . . . . . . . . . . . . . 452.10.2 Difficultés supplémentaires . . . . . . . . . . . . . . . . . . . . . 47
2.11 Contrôle de Congestion dans ATM . . . . . . . . . . . . . . . . . . . . 482.11.1 Fonction de Contrôle d’admission (Call Admission Control) . . 48
2.11.1.1 Problème de la bande passante équivalente . . . . . . . 492.11.1.2 Contrôle d’admission basé sur les paramètres de la connexion 492.11.1.3 Contrôle d’admission basé sur les mesures . . . . . . . 502.11.1.4 Contrôle d’admission basé sur la bande et la capacité
du buffer . . . . . . . . . . . . . . . . . . . . . . . . . 502.11.2 Fonction de Contrôle des paramètres de l’utilisateur (UPC, User
Parameter Control) . . . . . . . . . . . . . . . . . . . . . . . . . 50
ii

2.11.3 Canalisation du trafic (traffic shaping) . . . . . . . . . . . . . . 512.11.4 Gestion Passive de la file d’attente . . . . . . . . . . . . . . . . 52
2.11.4.1 La méthode Drop Tail . . . . . . . . . . . . . . . . . . 522.11.4.2 la méthode Drop from Front . . . . . . . . . . . . . . . 53
2.11.5 Contrôle de flux pour la classe ABR (Available Bit Rate) . . . . 532.11.6 Réservation rapide de ressources (Fast Resource Management) . 54
2.12 Ingénierie de trafic et contrôle de congestion dans MPLS . . . . . . . . 552.13 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
3 Evaluation de Performances des Réseaux ATM 583.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 583.2 Les deux étapes de l’évaluation de performances . . . . . . . . . . . . . 59
3.2.1 Modélisation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 593.2.2 Résolution . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
3.3 Taxonomie des méthodes d’évaluation de performances . . . . . . . . . 613.3.1 Les mesures . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 613.3.2 Méthodes analytiques . . . . . . . . . . . . . . . . . . . . . . . . 623.3.3 La simulation . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
3.4 Chaînes de Markov . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 633.5 Systèmes de Files d’Attente . . . . . . . . . . . . . . . . . . . . . . . . 65
3.5.1 Notation de Kendall . . . . . . . . . . . . . . . . . . . . . . . . 653.5.2 Mesures de performance . . . . . . . . . . . . . . . . . . . . . . 67
3.6 Simulation à évènemets discrets . . . . . . . . . . . . . . . . . . . . . . 673.6.1 Notions élémentaires . . . . . . . . . . . . . . . . . . . . . . . . 673.6.2 Génération des nombres aléatoires . . . . . . . . . . . . . . . . . 683.6.3 Validation du générateur aléatoire . . . . . . . . . . . . . . . . . 683.6.4 Analyse de Convergence des processus simulés . . . . . . . . . . 683.6.5 Méthode des réplications indépendantes . . . . . . . . . . . . . 693.6.6 Calcul des intervalles de confiance (confidence intervals) . . . . 69
3.7 Quelques outils pour l’évaluation de performances . . . . . . . . . . . . 703.8 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71
4 Etude de deux algorithmes de contrôle d’admission 724.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
4.1.1 Définitions et notations élémentaires . . . . . . . . . . . . . . . 724.2 Vue hiérarchique du trafic . . . . . . . . . . . . . . . . . . . . . . . . . 734.3 Contrôle d’admission basé sur une analyse M/D/1 . . . . . . . . . . . . 74
4.3.1 Algorithme de CAC basé sur une analyse N.D/D/1 . . . . . . . 774.3.2 Etude analytique . . . . . . . . . . . . . . . . . . . . . . . . . . 77
4.4 Analyse N.D/D/1 au niveau cellule . . . . . . . . . . . . . . . . . . . . 78
iii

4.4.1 Multiplexage du trafic CBR de N sources . . . . . . . . . . . . . 784.5 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
5 Résultats et Discussions 815.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 815.2 Environnement de simulation . . . . . . . . . . . . . . . . . . . . . . . 81
5.2.1 Environnement de programmation . . . . . . . . . . . . . . . . . 815.2.2 Génération de nombre aléatoires dans avec la fonction rand() . . 825.2.3 Génération des arrivées selon une loi exponentielle . . . . . . . . 82
5.3 Résultats analytiques et résultats de simulation pour le modèle M/D/1 825.4 Résultats de la simulation de la file d’attente N.D/D/1 . . . . . . . . . 855.5 Exemple de calcul du gain statistique . . . . . . . . . . . . . . . . . . . 87
5.5.1 Discussion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 885.6 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89
Conclusion Générale et Perspectives 92
Références Bibliographiques 99
Glossaire des Abréviations 101
iv

Liste des tableaux
1.1 Comparaison des trois classes de réseaux WAN, MAN et LAN . . . . . 51.2 Comparaison entre commutation de circuits et commutation de paquets 91.3 Paramètres de Qualité de Service dans ATM . . . . . . . . . . . . . . . 191.4 Classes de service dans ATM . . . . . . . . . . . . . . . . . . . . . . . . 21
2.1 Politiques pouvant influer sur la congestion . . . . . . . . . . . . . . . . 322.2 Comparaison entre le contrôle par fenêtre et le contrôle par débit . . . 34
3.1 Comparaison des trois classes de méthodes d’évaluation de performances 64
4.1 Notations élémentaires . . . . . . . . . . . . . . . . . . . . . . . . . . . 734.2 Table de Recherche pour un système M/D/1 : Charge admissible en
fonction de la capacité du buffer et de CLP. . . . . . . . . . . . . . . . 76
5.1 Charge admissible en fonction de la taille du buffer pour l’analyse M/D/1pour CLP=10−2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 85
5.2 Gain statistique pour différentes connexions . . . . . . . . . . . . . . . 87
v

Table des figures
1.1 Architecture générale d’un réseau. . . . . . . . . . . . . . . . . . . . . . 61.2 Réseau à commutation de circuits . . . . . . . . . . . . . . . . . . . . . 71.3 Réseau à commutation de paquets . . . . . . . . . . . . . . . . . . . . . 81.4 Transport séparé de données . . . . . . . . . . . . . . . . . . . . . . . . 101.5 Accès intégré au Réseau RNIS Bande Etroite . . . . . . . . . . . . . . . 111.6 Illustation du principe du multiplexage statistique . . . . . . . . . . . . 131.7 Mode de transfert synchrone et mode de transfert asynchrone . . . . . 151.8 Format d’une cellule ATM . . . . . . . . . . . . . . . . . . . . . . . . . 161.9 Division de la capacité d’un conduit de trasmission . . . . . . . . . . . 171.10 Processus d’acheminement de paquets dans MPLS . . . . . . . . . . . . 23
2.1 Facteurs causant la congestion dans un noeud . . . . . . . . . . . . . . 272.2 Variation du débit et du délai en fonction du trafic offert. . . . . . . . . 282.3 Méthodes de contrôle de congestion en fonction de la durée. . . . . . . . 332.4 Forward Explicit Congestion Notification. . . . . . . . . . . . . . . . . . 362.5 Backward Explicit Congestion Notification. . . . . . . . . . . . . . . . . 362.6 Principe de l’algorithme DECBit. . . . . . . . . . . . . . . . . . . . . . 402.7 Cycles de régénération dans DECBit. . . . . . . . . . . . . . . . . . . . 412.8 Exemple de topologie du réseau. . . . . . . . . . . . . . . . . . . . . . . 442.9 L’introduction d’une laison à haut débit n’a fait qu’aggraver la situation. 472.10 Principe du contrôle d’admission . . . . . . . . . . . . . . . . . . . . . 482.11 Principe du seau percé (leaky bucket) . . . . . . . . . . . . . . . . . . . 512.12 Principe du seau percé à jetons . . . . . . . . . . . . . . . . . . . . . . 522.13 Congestion due au choix du plus court chemin. . . . . . . . . . . . . . . 552.14 Solution au problème de congestion par ingénierie du trafic. . . . . . . . 56
3.1 Processus de modélisation . . . . . . . . . . . . . . . . . . . . . . . . . 593.2 Illustration des Critères de Performance. . . . . . . . . . . . . . . . . . 603.3 Diagramme de transition d’une chaine de Markov. . . . . . . . . . . . . 653.4 Système de File d’Attente. . . . . . . . . . . . . . . . . . . . . . . . . . 663.5 Un réseau de Pétri à deux places et deux transitions . . . . . . . . . . . 70
vi

4.1 Les trois niveaux d’observation du trafic . . . . . . . . . . . . . . . . . . 734.2 Modèle N.D/D/1 de contrôle d’admission au niveau cellule (ici N=4) . 794.3 Multiplexage de 3 sources CBR . . . . . . . . . . . . . . . . . . . . . . 80
5.1 Charge admissible en fonction de la taille du tampon (Résulats exactspour le modèe M/D/1). . . . . . . . . . . . . . . . . . . . . . . . . . . . 83
5.2 Charge admissible en fonction de la taille du tampon (Résulats d’ap-proximation pour le modèe M/D/1)). . . . . . . . . . . . . . . . . . . . 84
5.3 Charge admissible en fonction de la taille du tampon (Résultats analy-tiques et résultats de simulation pour un CLP égale à 10−2). . . . . . . 84
5.4 Nombre de connexions admises en fonction de la taille du tampon desortie pour une charge de 100% (modèle N.D/D/1). . . . . . . . . . . . 86
vii

Résumé
Dans un système à partage de ressources, la congestion est présente lorsque la de-mande en ressources dépasse la quantité des ressources diponibles. Contrairement à ceque l’on s’attendait, les technologies à haut débit n’ont fait qu’aggraver la congestion.Par conséquent, il faut concevoir de nouveaux protocoles de contrôle de congestionqui soient approporiés aux caractéristiques de tels réseaux. Le contrôle de congestionconsiste à maintenir le système en dessous du seuil de congestion, tout en optimisantl’utilisation des ressources par multiplexage statistique. Il est généralement réalisé parplusieurs moyens préventifs et réactifs. Les premiers visent à rendre l’apparition dece phénomène exceptionnelle alors que les derniers permettent de revenir à une situa-tion normale lorsque, malgré tout, la congestion se produit. Cette deuxième classe deméthodes est très utilisée dans les réseaux ATM afin de garantir la qualité de service(QoS) des connexions déja admises. L’objectif de ce travail est de faire une synthèse surles méthodes de contrôle de congestion dans les réseaux haut débit. Par la suite, nousétudierons de façon plus détaillée deux algorithmes de contrôle d’admission (CAC)comme exemples de contrôle préventif dans les réseaux ATM.
Mots clés : réseaux à haut débit, congestion, mode de transfert asynchrone, qua-lité de service, évaluation de performance, simulation à évènements discrets, contrôled’admission.
Abstract
In a system with resource sharing, congestion is present when the demand for resourcesexceeds the quantity of available resources. Unexpectedly, new broadband technolo-gies did nothing but worsen the congestion. Consequently, it is necessary to conceivenew congestion control protocols which are appropriate to the characteristics of suchnetworks. Congestion control consists in maintaining the system in lower part of thethreshold of congestion, while optimizing the use of the resources by statistical mul-tiplexing. It is generally carried out by several preventive and reactive means. Thefirst aim to return the appearance of this phenomenon exceptional whereas the lastmake it possible to return to a normal situation when, despite everything, congestionoccurs. This second class of methods is very used in ATM networks in order to guaran-tee quality of service (QoS) of already established connections. The aim of this thesisis to make a synthesis on the methods of congestion control in high speed networks.Thereafter, we will study in a more detailed way two algorithms of control admission(CAC) like examples of preventive control in ATM networks. .
Keywords : high speed networks, congestion, asynchronous transfer mode, quality ofservice, performance evaluation, discrete event simulation, admission control.

"Verba volant, scripta manent"
Proverbe latin

Introduction Générale
LES progrès significatifs réalisés ces dernières années dans le domaine des réseauxde communication de données et de télécommuinications ont changé radicale-
ment notre façon de vivre et d’interagir. D’une première vue, ces réseaux peuvent êtredivisés selon le type de commutation utilisé en deux grandes classes : réseaux à com-mutation de circuits et réseaux à commutation de paquets. Les réseaux à commutationde circuits, très répandus dans le domaine des télécommunications, sont très adéquatspour le transfert de la voix ; alors que les réseaux à commutation de paquets conçuspar les constructeurs du matériel informatique sont destinés au transfert de donnéesinformatiques (fichiers, images, etc).
Le besoin accru en applications multimédias d’une part, et le rapprochement destélécommunications et de l’informatique ont donné naissance au RNIS-BE (RéseauNumérique à Intégration de Services, Bande Etroite). Si ce dernier, connu aussi sous lenom du RNIS de première génération a connu un grand succès lors de son apparition,il n’en est pas autant lors de l’avènement du multimédia . Ainsi, les experts de l’UIT(Union International de Télécommunications) pensèrent au RNIS-LB (RNIS à LargeBande) ou RNIS de deuxième génération. Après de longs débats, le mode de transfertasynchrone (ATM, Asynchronous Transfer Mode) a été adopté au détriment du modede transfert synchrone (STM, Synchronous Transfer Mode).
ATM est une technologie orientée connexion ; c’est à dire, elle établit un circuitvirtuel entre deux entités communicantes avant que celles-ci puissent envoyer leursdonnées sous forme de paquets de taille fixe appelés cellules. Les réseaux ATM per-mettent de supporter un grand éventail de services ayant des exigences en qualité deservice différentes. Avec la standardisation par l’UIT (Union Internationale des Télé-communications) de ATM pour le RNIS-LB, une nouvelle technique de commutationa vu le jour : la commutation de cellules. Cette nouvelle technique tire profit de laflexibilité de la commutation de paquets et de la souplesse de la commutation de cir-cuits.Cependant, un réseau ATM comme tout réseau à commutation de paquets souffre duproblème de congestion. Celle-ci peut gravement affecter la qualité de service (QoS,Quality of Service) des usagers. Elle peut même causer un effondrement de congestion(congestion collapse), situation dans laquelle le réseau est totalement "paralysé". A cet
1

Introduction Générale
effet, des méthodes de contrôle de congestion ont été définies. Ces méthodes peuventêtre classifiées selon plusieurs critères. Selon le stade d’intervention, nous avons troisclasses : méthodes réactives, méthodes préventives (appelées aussi méthodes proac-tives) et méthodes hybrides. Bien que les méthodes réactives ont fait leur preuve dansl’Internet, nous allons voir que sans l’ajonction d’autres mécanismes préventifs, ellessont inefficaces pour les réseaux ATM. Ainsi, et pour permettre de garantir une qua-lité de service pour les abonnés des réseaux ATM, les organismes de normalisation del’ATM tels que l’ATM Forum et l’UIT préconisent l’utilisation d’un contrôle préven-tif aux interfaces usager-réseau (UNI, User Network Interface) ainsi qu’aux interfacesréseau-réseau (NNI,Network to Network Interface). L’exemple le plus connu d’un telcontrôle est sans doute la fonction de contrôle d’admission (CAC, Call AdmissionControl). Ceci ne veut nullement dire qu’il faut rejeter de façon définitive le contrôleflux de bout en bout effectué dans une grande partie par le protocole TCP (Transmis-sion Control Protocol) mais, bien au contraire, il faut améliorer les performances decelui-ci qui a toutes les chances de rester prépondérant même dans les réseaux ayantun produit délai-bande passante (BDP, Bandwidth Delay Product) très grand.
Organisation du mémoire
Ce mémoire est consacré au contrôle de congestion dans les réseaux à haut débit1. Acet effet, nous l’avons scindé en cinq chapitres :
Dans le chapitre 1, nous rappelons quelques notions fondamentales dans le domainedes réseaux. Par la suite, nous introduisons quelques technologies nécessaires poursupporter les hauts débits notamment pour les réseaux à grande distance (WAN, WideArea Networks) : Relais de Trames, ATM et MPLS. Un intérêt particulier sera accordéà ATM, du fait qu’il fut adopté comme standard pour le RNIS-LB. Par la suite, nousintroquisonq la notion de qualité de service (QoS, Quality of Service) ainsi que lesparamètres et les classes de qualité de service dans les réseaux ATM.
Le chapitre 2 introduit la notion de congestion dans les réseaux à commutationde paquets ainsi que la notion d’effondrement de congestion. Nous définissons d’abordla notion de congestion et ses symptômes pour un réseau. Par la suite, nous verronscomment le contrôle de congestion est plus ardu à résoudre dans les réseaux haut débit.Nous montrerons également qu’aucune technologie matérielle actuelle ne peut réglerle problème de congestion de façon définitive sans l’ajonction de bon protocoles decontrôle de congestion. Ce chapitre étudie aussi quelques algorithmes de contrôle decongestion qui ont été proposés dans la littérature pour le contrôle de congestion dansATM, et aborde très brièvement l’ingénierie de trafic dans MPLS .
1Notons que dans ce mémoire, nous utiliserons les expressions réseaux à haut débit et réseaux hautdébit de façon interchangeable.
2

Introduction Générale
Le chapitre 3 traite de l’évaluation de performances des réseaux ATM. Nous yprésenterons les trois classes de méthodes d’évaluation de performances, à savoir :les méthodes analytiques, les mesures, et la simulation. Nous accordons un grandintérêt aux systèmes de files d’attente et à la simulation à évènements discrets. Acet effet, ce chapitre introduit des notions élémentaires manipulées pour faire unesimulation à évènements discrets : notion d’état, évènements,génération de nombrealéatoire, valisation des résultats de la simualtion, etc.
Dans le chapitre 4, nous présenterons deux algorithmes de contrôle d’admission(CAC). Le premier d’entre eux est basé sur une analyse M/D/1 et le deuxième surune analyse N.D/D/1. Nous expliquerons le principe de chacun des deux algorithmeset nous verrons comment ces deux algorithmes procèdent pour accepter ou rejeter unenouvelle connexion.
Le chapitre 5 est consacré à la présentation des résultats des simulations ainsi qu’àla discussion des résultats.
Nous terminerons notre mémoire par une conclusion générale et nous énonceronsdes prespectives de recherche.
3

Chapitre 1
Panorama des Réseaux Haut
Débit
"There is much more to life than increasing its speed."
Mahatma Ghandi
1.1 Introduction
HISTORIQUEMENT, le Réseau Téléphonique Commuté (RTC) était le premierréseau existant. L’avènement de nouvelles applications telles que la vidéocon-
férence , l’AoD (Audio on Demand) et la VoD (Video On Demand) a, non seule-ment, engendré un besoin de débit plus important, mais a introduit également descontraintes temporelles strictes dans les échanges de d’informations. Ce n’est que parune réponse architecture et réseau spécifiques : Réseaux Large Bande à Intégration deServices (RNIS-LB) qu’une solution globale à ces nouvelles exigences et contraintespeut être trouvée. Ce chapitre est consacré à quelques rappels sur les réseaux ainsiqu’à la présentation de trois technologies à haut débit pour les réseaux à grande dis-tance (WAN, Wide Area Networks), à savoir : le Relais de Trames (Frame Relay),ATM (Asynchronous Transfer Mode) et MPLS (MultiProtocol Label Switching). Nousaccorderons un intérêt particulier à la technologie ATM du fait que celle-ci a été choi-sie par l’UIT(Union Internationale des Télécommunications)1 comme standard pourle RNIS-LB.
1.2 Taxonomie des réseaux informatiques
Il n’y a pas de classification universellement admise des réseaux informatiques. Enrevanche, tout le monde reconnaît l’importance de trois caractéristiques : la techniquede commutation utilisée, la topologie du réseau et la taille de celui-ci.
1En anglais : ITU (Internationale Telecommunication Union)
4
Chapitre 1 : Panorama des réseaux haut débit
Réseau Public(WAN)
Réseau Fédéra-teur (MAN)
Réseau Local(LAN)
Taille géogra-phique
quelques milliersde kilomètres
de 1 m à 100 km de 1 m à 2 km
Nombre d’abon-nés
plusieurs millions de 2 à 1000 de 2 à 200
Opérateur différent des utili-sateurs
regroupementd’utilisateurs
l’utilisateur lui-même
Facturation volume et durée forfait gratuitDébit de 50 bit/s à 2
Mbit/sde 1 à 100 Mbit/s de 1 à 100 Mbit/s
taux d’erreurs de 10−3 à 10−6 inférieur à 10−9 inférieur à 10−9
Délai inférieur à 0.5 s de 10 ms à 100 ms de 1 à 100 ms
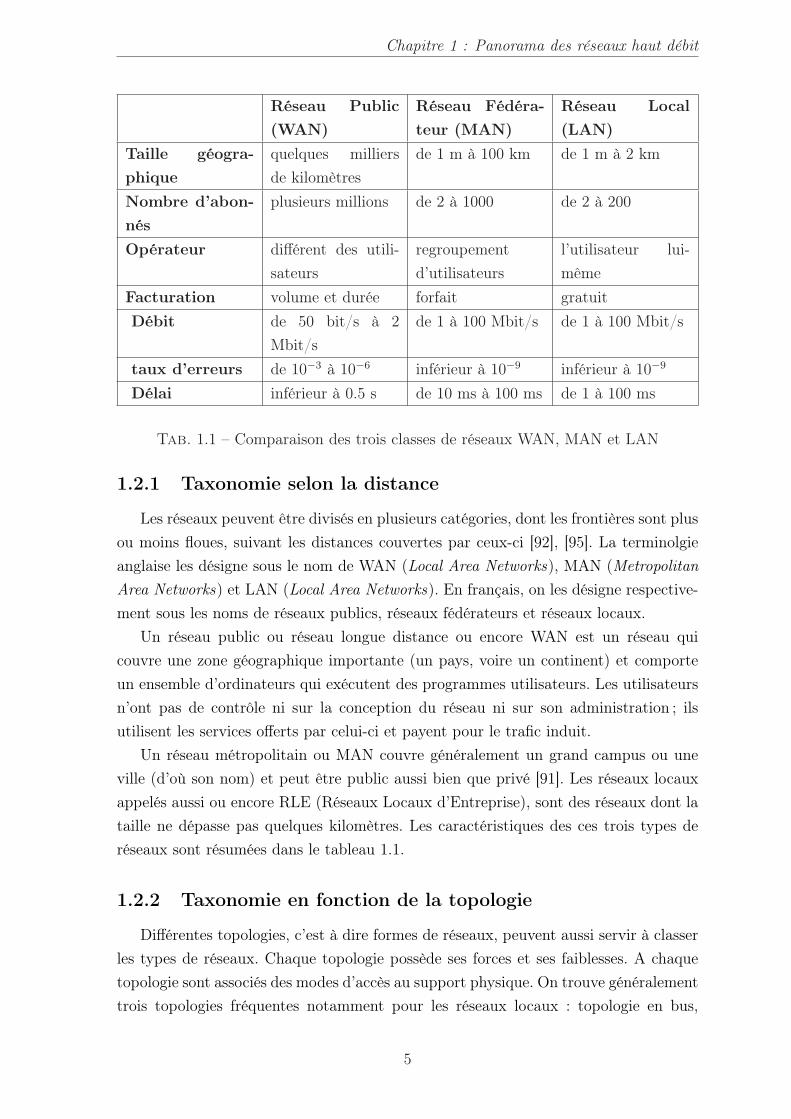
Tab. 1.1 – Comparaison des trois classes de réseaux WAN, MAN et LAN
1.2.1 Taxonomie selon la distance
Les réseaux peuvent être divisés en plusieurs catégories, dont les frontières sont plusou moins floues, suivant les distances couvertes par ceux-ci [92], [95]. La terminolgieanglaise les désigne sous le nom de WAN (Local Area Networks), MAN (MetropolitanArea Networks) et LAN (Local Area Networks). En français, on les désigne respective-ment sous les noms de réseaux publics, réseaux fédérateurs et réseaux locaux.
Un réseau public ou réseau longue distance ou encore WAN est un réseau quicouvre une zone géographique importante (un pays, voire un continent) et comporteun ensemble d’ordinateurs qui exécutent des programmes utilisateurs. Les utilisateursn’ont pas de contrôle ni sur la conception du réseau ni sur son administration ; ilsutilisent les services offerts par celui-ci et payent pour le trafic induit.
Un réseau métropolitain ou MAN couvre généralement un grand campus ou uneville (d’où son nom) et peut être public aussi bien que privé [91]. Les réseaux locauxappelés aussi ou encore RLE (Réseaux Locaux d’Entreprise), sont des réseaux dont lataille ne dépasse pas quelques kilomètres. Les caractéristiques des ces trois types deréseaux sont résumées dans le tableau 1.1.
1.2.2 Taxonomie en fonction de la topologie
Différentes topologies, c’est à dire formes de réseaux, peuvent aussi servir à classerles types de réseaux. Chaque topologie possède ses forces et ses faiblesses. A chaquetopologie sont associés des modes d’accès au support physique. On trouve généralementtrois topologies fréquentes notamment pour les réseaux locaux : topologie en bus,
5

Chapitre 1 : Panorama des réseaux haut débit
Fig. 1.1 – Architecture générale d’un réseau.
topologie en anneau, et topologie en étoile [92].Sur un réseau de type bus, il n’y a à chaque instant qu’un seule machnine qui estautorisée à transmettre ses données. Toutes les autres doivent s’abstenir d’émettre.Par conséquent, il est nécessaire d’avoir un mécanisme d’arbitrage qui puisse résoudreles conflits survenants lorsque deux machines ou plus veulent simultanément émettre.Sur une topologie en anneau, chaque bit se propage de façon autonome, sans attendrele reste du paquet auquel il appartient.Dans le cas d’une topologie en étoile, le site central (généralement un hub) reçoit etenvoie tous les messages, le fonctionnement est simple, mais la panne du noeud centralparalyse tout le réseau.
1.2.3 Taxonomie en fonction du mode de commutation
La périphérie d’un réseau est constituée de commutateurs d’accès qui regroupentplusieurs abonnés et qui assurent également un rôle de multiplexeur, tandis que lesnoeuds internes du réseau commutent les communications entre un lien d’entrée versun lien de sortie en fonction d’un critère d’acheminement (Fig. 1.1). Un mode detransfert est une technique, ou un ensemble de techniques, utilisée dans un réseau detélécommunication couvrant des aspects liés à la transmission, la commutation et lemultiplexage [34]. La commutation est née de la nécessité de mettre en relation unutilisateur avec n’importe quel autre utilisateur (interconnexion totale) et de l’impos-sibilité de créer autant de liaisons directes. Deux techniques de commutation dominentdans les grands réseaux : la commutation de circuits (principalement dans le système
6

Chapitre 1 : Panorama des réseaux haut débit
Fig. 1.2 – Réseau à commutation de circuits
téléphonique) et la commutation par paquets (essentiellement pour les réseaux à trans-mission de données tels que X.25).Selon la commutation, les réseaux peuvent être divisés en deux classes, à savoir : lesréseaux à commutation de circuits et ceux à commutation de paquets.
1.2.3.1 Réseaux à commutation de circuits
Dans un réseau à commutation de circuits (circuit-switching network), un chemindestiné à la communication est établi entre deux stations à travers les noeuds du réseau.Ce chemin est une séquence connectée de liens physiques entre les différents noeudsdu réseau. Sur chaque lien, un canal logique est dédié à la connexion. Les donnéesgénérées par la source sont transmises au long du chemin dédié le plus rapidementpossible. A chaque noeud, les données entrantes sont routées ou commutées à la sor-tie appropriée. L’exemple le plus connu des réseaux à commutation de circuits est leRéseau Téléphonique Commuté (RTC).La communication de données en utilisant la commutation de circuits requiert troisphases, à savoir : l’établissement du circuit entre la source et la destination, le transfertde données entre les deux stations et enfin, la fermeture du circuit. Une caractéristiquetrès importante de ce type de commutation est le fait qu’il n’y pas de stockage inter-médiaire.
1.2.3.2 Réseaux à commutation de paquets
Une approche très différente est utilisée dans les réseaux à commutation de paquets(packet-switching networks). Dans ce cas, les données sont plutôt transmises vers lessorties en une séquence de paquets. Chaque paquet est transmis à travers le réseau d’unnoeud à un autre en passant par un chemin menant de la source à la destination. Achaque noeud, le paquet entier est reçu, stocké pour une courte durée, puis retransmisvers le noeud suivant. Des applications typiques de la commutation de paquets incluentle transfert électronique de fonds, l’approbation des cartes de crédit, le transfert desfichiers de petite taille et l’envoi du courrier électronique. Les paquets sont envoyés dela source à la destination à travers des ressources partagées en utilisant le multiplexage
7

Chapitre 1 : Panorama des réseaux haut débit
Fig. 1.3 – Réseau à commutation de paquets
statistique par division du temps. Un exemple typique des réseaux à commutation depaquet est le réseau X.25.
La commutation de circuits et la commutation par paquets présentent certaines diffé-rences. La différence majeure est que la commutation de circuits réserve statiquementet à priori un circuit et ainsi que intégralité de sa bande passante pour une communi-cation. Contrairement au réseaux à commutation de circuits, les noeuds d’un réseau àcommutation de paquets sont appelés "store-and-forward" car il ont des tampons destockage qui leur permettenet de stocker (store) temporairement les paquets dans lebut de les acheminer (forward) plus tard. La possibilité de stockage dans les noeudsde commutation sous-entend que le multiplexage statistique doit être supporté parles liens reliant ces noeuds. Le tableau 1.2 fait une étude comparative entre ces deuxtechniques de commutation.Les réseaux à commutation de paquets à leur tour peuvent être divisés en deux classes,à savoir : les réseaux à datagrammes et réseaux à circuit virtuel. Dans un réseau à da-tagrammes, les paquets provenant d’une même connexion peuvent ne pas suivre lemême chemin. Par contre, dans les réseaux à circuit virtuel, les paquets suivent lemême chemin.La commutation rapide de paquets (fast packet switching) est née du mariage de lacommutation de paquets et de la transmission de données à hauts débitsIl existe une autre technique de commutation appelée commutation de cellules quicombine la simplicité de la commutation de circuits et la flexibilité de la commuta-tion de paquets. Cette technique représente une rupture gigantesque avec la traditioncentenaire de commutation de circuits (établissement d’un circuit physique) du réseautéléphonique. Ce choix est motivé par plusieurs raisons. D’abord, la commutation decellules est très souple et s’accomode à la fois des débits constants (audio, vidéo) etdes débits variables (données). D’autre part, aux très hauts débits envisagés (gigabitspar seconde) la commutation de cellules est plus simple à réaliser que les techniquesde multiplexage traditionnelles, en particlier pour les fibres optiques. Enfin, pour latélédistribution, la diffusion est essentielle : c’est une caractéristique essentielle quepeut fournir la commutation de cellules mais pas la commutation de circuits [92].
8

Chapitre 1 : Panorama des réseaux haut débit
Type de CommutationCircuits Paquets
Circuit dédié oui nonBande passante dipo-nible
fixe dynamique
Gaspillage potentielde la bande passante
oui non
Transmission Storeand forward
non oui
Chaque paquets suit lamême route
oui oui ou non (selon le ré-seau)
Etablissement d’uncircuit par séquenced’appels
oui oui ou non (selon le ré-seau)
Quand peut appa-raître la congestion
à l’établissement du cir-cuit
à chaque paquet transmis
Principe de la factura-tion
à la distance et à la durée au volume d’informationstransmises
Tab. 1.2 – Comparaison entre commutation de circuits et commutation de paquets
1.3 Les réseaux à haut débit
1.3.1 Motivation
Depuis plus d’un siècle, le réseau téléphonique constitue l’infrastructure principalede télécommunications. Ce réseau conçu pour la transmission analogique de la voix,est inadapté aux besoins des communications modernes. Anticipant sur l’importantedemande exprimée par les utilisateurs pour les services de communications numériquesde bout en bout, les opérateurs de télécommunications internationaux se sont réunissous les auspices de l’UIT pour mener des études devant donner naissance à un seulréseau pour le transport de la voix, des images, de la vidéo et des données. Ce nou-veau système avait pour nom Réseau Numérique à Intégration de Services ou RNIS(ISDN, Integrated Services Digital Network). La motivation majeure du RNIS étaitl’offre de nouveaux services de communication. Néanmoins, il est important de consta-ter qu’aujourd’hui le transport des signaux vocaux reste une activité importante duRNIS . L’intégration de service a plusieurs avantages : une meilleure utilisation des
9

Chapitre 1 : Panorama des réseaux haut débit
Fig. 1.4 – Transport séparé de données
ressources, un coût de conception réduit, homogénéité des équipements, etc. Ce RNISde première génération qu’on appelait quelquefois RNIS-BE (RNIS à bande étroite)ne pouvait pas satisfaire les nouveaux besoins des utilisateurs dont la demande la plusimportante était le multimédia et la vidéo à la demande (VoD, Video on Demand).A cet effet, les experts de l’UIT entamèrent des études sur un nouveau système quipourrait remédier aux inconvénients du RNIS-BE. Ces études ont conduit au RNISde deuxième génération que l’on nomme couramment RNIS à large bande (RNIS-LB).Ce dernier est une infrastructure réseau publique capable de supporter les services àbande étroite (narrowband services) et les services large bande (broadband services)sur une seule plateforme flexible, et qui permet au client l’accés à travers une interfaceunique, ce qui permet de concrétiser le principe du "guichet unique" [34].La technologie qui rend le RNIS-LB possible est le mode de transfert asynchrone ouATM (Asynchronous Tansfer Mode). L’idée de base de l’ATM est de transmettre l’in-formation dans de petits paquets de taille fixe : les cellules. Une cellule fait 53 octets :5 octets d’en-tête et 48 octets de données (voir Fig.1.8).La conception d’un RNIS se base sur un compromis qui doit être établi entre deuxcomposantes principales : qualité de service (QoS, Quality of Service) offerte et le tauxd’utilisation des ressources déployées dans le réseau. Pour s’imposer sur le marché, unRNIS Large Bande (RNIS-LB) devra proposer un vaste éventail de services. Ces der-niers sont classés dans la recommandation I.211 de l’UIT en deux grandes catégories[47] :
– les services dits interactifs représentant les services de conversation, de messa-gerie et de consultation ;
– les services de distribution comprenant les services liés à la diffusion d’informationou d’images.
Face à la variété des contraintes en fonction des applications, l’UIT a défini 4 classesd’applications en fonction des critères suivants :
10

Chapitre 1 : Panorama des réseaux haut débit
Fig. 1.5 – Accès intégré au Réseau RNIS Bande Etroite
– la relation temporelle entre l’émetteur et le récepteur ; les applications serontqualifiées de d’isochrone si une relation temporelle stricte doit être maintenue oud’asynchrone si aucune relation temporelle n’existe,
– le critère de sporadicité : on distingue le trafic à débit constant (CBR, ConstantBit Rate), le critère de sporadicité est alors égal à 1 (ex. : la voix codée MIC), desapplication à débit variable(VBR, Variable Bit Rate), le critère de sporadicitéest alors supérieur à 1,
– le mode de mise en relation : cette distinction traditionnelle et télécommunicationdistingue le mode connecté (ou orienté connexion) du mode non connecté (ouorienté sans connexion). Dans le cas d’un service en mode connecté, l’utilisateurétablit au préalable une connexion, l’utilise puis la relâche. En revanche, pourun service en mode non connecté, les ressources physiques ne sont pas réservées.
Les services sont dit fiables q’ils n’engendrent pas des pertes de données. Habituelle-ment, la mise en oeuvre d’un service fiable se fait par acquittement (acknowledgement) de chaque message par le récepteur, de sorte que l’émetteur soit sûr de son arrivée.Cependant, le processus d’acquittement engendre une surcharge du réseau (overhead)et un délai supplémentaire parfois indésirables.
1.3.2 Définitions d’un réseau haut débit
Un réseau haut débit peut être défini de trois points de vue : celui de l’utilisa-teur (l’abonné), celui des technologues et enfin celui du concepteur [34]. L’utilisateurattend d’un réseau à haut débit l’offre d’un large spectre de débits avec une fine gra-nularité, des canaux de débits variables adaptés à la sporadicité de certains traficset des qualités de service. Du point de vue technologique, le terme "haut débit" estlié aux grandes fréquences auxquelles doivent fonctionner les différents équipements
11

Chapitre 1 : Panorama des réseaux haut débit
électroniques et/ou optoélectroniques du réseau (commutateurs, multiplexeurs, etc.)et aux grandes capacités des systèmes de transmission. Du point de vue du concepteur,le haut débit est le débit à partir duquel les algorithmes de partage de ressources desréseaux classiques ne sont pas adaptés et doivent donc être changés.Officiellement, un système large bande est défini selon la recommandation I.113 [49]de l’UIT comme étant : "un système qui demande des canaux de transmission capablesde supporter des débits plus grands que ceux fournis par l’accès primaire". Par accèsprimaire, on voulait dire celui du RNIS de première génération qui avait un débit de1.544 Mbit/s. Le RNIS-LB offre des interface des connexion à un débit atteignantquelquefois 622 Mbit/s.
1.3.3 Multiplexage statistique dans les réseaux à haut débit
L’économie d’échelle joue un rôle important dans l’industrie des télécommunica-tions. De ce fait, les exploitants de réseaux ont favorisé la mise en place de systèmes trèsélaborés qui permettent de partager (on dit multiplexer) entre de nombreux usagers lemême support physique de transmission. Le multiplexage a pour but de regrouper plu-sieurs connexions de transport sur une même connexion de réseau, ce qui va permettrede minimiser les ressources utilisées au niveau réseau, donc de diminuer les coûts decommunication. Dans les réseaux classiques, on trouve trois mécanismes principauxqui sont largement utilisés, à savoir : le multiplexage fréquentiel (FDM, Frequency Di-vision Multiplexing), le multiplexage temporel (TDM, Time Division Multiplexing) etle multiplexage en longueur d’onde (WDM, Wavelength Division Multiplexing) [91].
Afin d’introduire la notion de multiplexage statistique utilisé dans les réseaux àhaut débit, nous reprendrons l’exemple suivant cité dans [34]. Les trois courbes si-tuées dans la partie inférieure de la figure 1.6 représentent l’évolution du débit de troissources en fonction du temps. Ces sources ont, respectivement, un débit crête de 3,2.5, et 3 (l’unité utilisée n’a pas d’importance). Supposons que le réseau dispose d’unconduit de transmission de capacité 5.Si le réseau fait du multiplexage déterministe, c’est à dire, s’il alloue à chaque sourceson débit crête (débit maximal), une seule connexion peut être acceptée. En effet, onvoit bien que la somme des débits crêtes de deux quelconques des sources dépasse lacapacité du conduit de transmission. La courbe (S) représente la somme des débits destrois sources en fonction du temps. Ce qui est intéressant à remarquer est le fait quecette somme dépasse rarement la capacité du conduit. Ceci nous incite à penser qu’ilserait possible d’accepter les trois connexions, ce qui revient à dire que le réseau alloueà chaque source un débit inférieur à son débit crête. On dit alors que le réseau fait dumultiplexage statistique. dans ce cas, le total des débits crêtes (
n∑i=1
hi) des connexions se
partageant la même liaison peut dépasser la bande passante (C) de la ligne. Autrement
12

Chapitre 1 : Panorama des réseaux haut débit
Fig. 1.6 – Illustation du principe du multiplexage statistique
dit :n∑
i=1
hi > C (1.1)
Où :C : bande passante disponible du lien de sortie ;hi : débit crête de la connexion i ;n : nombre de connexions simultanées sur la ligne.Mais le total des débits moyens (
n∑i=1
mi) ne doit pas dépasser la bande passante de la
ligne de sortie, c’est à dire :n∑
i=1
mi ≤ C (1.2)
Le gain statistique réalisé et qui est noté SMG (Statistical Multiplexing Gain) est définialors de la façon suivante :
SMG =C
n∑i=1
hi
(1.3)
Le prix à payer est d’associer un identificateur à chaque unité d’information transféréed’une part et de prévoir des buffers capables d’absorber les pics éventuels (au momentoù la ligne de sortie ne suit pas) d’autre part.
13

Chapitre 1 : Panorama des réseaux haut débit
1.4 Technologies pour supporter les hauts débits pour
les WANs
Pour offrir une bonne qualité de service et satisfaire les besoins des utilisateursdont le nombre ne cesse d’augmenter, les opérateurs et les concepteurs des réseauxdoivent mettre en oeuvre des réseaux très performants et qui permettent de supporterdes services qui sont très gourmands en bande passante. Dans cette section, nous pré-senterons les technologies principales pour supporter les hauts débits dans les réseauxà longue distance (réseaux WAN).
1.4.1 La technologie Relais de Trames (Frame Relay)
Initialement prévue pour une utilisation sur le RNIS, la technologie relais de trames(Frame Relay) a, sous l’égide du Frame Relay Forum, évolué vers un service de liai-sons virtuelles permanentes, puis commutées utilisables sur tout support numériquehors RNIS [87], [91]. Parmi les différentes utilisations du Relais de Trames, on peutciter : le transfert de fichiers grand volume, les applications de Conception Assistée parOrdinateur (CAO) ou d’images, le multiplexage de voies basse vitesse en voies hautevitesse, etc.La technologie Frame Relay réduit au strict minimum la charge de travail accompliepar le réseau ; les données de l’usager sont envoyées sans aucun traitement intermé-diaire au niveau des noeuds du réseau. Frame Relay est typiquement utilisé commeun service de communication de données privées qui utilise des circuits virtuels et desconnections logiques (plutôt que des connections physiques) afin de donner aux usagersl’aspect et la sensation d’un réseau privé. La plupart des réseaux Frame Relay sontpublics, ce qui donne aux clients beaucoup de flexibilité et d’avantages économiques,de la même manière que choisir un taxi public est plus flexible et économique qued’acheter une voiture personnelle [38].
1.4.2 La technologie ATM (Asynchronous Transfert Mode)
La technologie ATM (Asynchronous Transfer Mode) était en concurrence avec latechnologie STM (Synchronous Transfer Mode) développée par AT&T pour le RNIS-LB. La différence majeure entre ces deux modes est le fait que dans ATM, les horlogesde la source et du réseau ne sont pas corrélées [78]. Le mode de transfert asynchrone, connu aussi sous le nom de relais de cellules 2(cell relay) est l’aboutissement d’uncertain nombre d’évolutions dans les techniques de transfert. Il est similaire en quelquesorte à la commutation de paquets sous X.25 et Frame Relay [91]. Elle constitue unbon compromis des techniques de commutation de circuits (slots et simplicité) et celles
2Il est appelé ainsi pour le distinguer du Relais de Trames (Frame Relay).
14

Chapitre 1 : Panorama des réseaux haut débit
Fig. 1.7 – Mode de transfert synchrone et mode de transfert asynchrone
de la commutation de paquets (multiplexage statistique et flexibilité) [81]. Les réseauxbasés sur le mode ATM sont caractérisés par :
– l’absence de contrôle de flux à l’intérieur du réseau à partir du moment où lacommunication a été acceptée ;
– l’absence de contrôle d’erreurs car d’une part, la transmission sur fibre optiqueprésente une bonne qualité de transmission et d’autre part, détection et reprisediminuent le débit utile ;
– un mode orienté connexion pour faciliter la réservation des ressources et assurerle séquencement des cellules ;
– l’absence de contrôle de perte au niveau du réseau car des ressources suffisantesont été allouées aux connexions lors de leurs établissements ;
– une unité de transfert appelée cellule, de taille réduite pour faciliter l’allocationmémoire dans les commutateurs et permettre un meilleur entrelacement des fluxet une commutation rapide ;
– un en-tête de cellule de taille limitée et aux fonctions réduites pour assurer unecommutation rapide ;
– utilisation du multiplexage statistique.
1.4.2.1 Cellule ATM
L’unité de donnée manipulée dans les réseaux ATM est appelée cellule. La figure 1.8nous montre la structure de la cellule à l’interface usager-réseau (UNI, User NetworkInterface) et à l’interface de noeud de réseau (NNI, Node Network Interface). Dans lesdeux cas, la cellule est composée d’un champ d’information de 48 octets et d’un en-tête de 5 octets. Les informations utilisateur sont transportées de façon transparentedans le champ d’information. En effet, aucun contrôle d’erreur n’est exercé sur ces
15

Chapitre 1 : Panorama des réseaux haut débit
Fig. 1.8 – Format d’une cellule ATM
informations dans les différents noeuds du réseau. On se propose de décrire ci-dessousles différents champs de la cellule ATM :• Les champs VPI et VCILe couple VPI/VCI est appelé champ d’acheminement. Il transporte les informationsd’identification du circuit virtuel auquel appartient la cellule.• Le champ PTILe champ d’identification du type de capacité utile (PTI, Payload Type Identifier)indique si le champ d’information de la cellule transporte des informations d’usagerou des information de gestion.• Le champ CLPLe champ de priorité de perte de cellule (CLP, Cell Loss Priority) est composé d’unseul bit. Il permet de définir deux niveaux de priorité pour les cellules (CLP = 0 in-dique la priorité haute). Le bit CLP peut être mis à 1 soit par l’usager, soit par leréseau. Un élément de réseau en état de congestion rejette les cellules en utilisant lechamp CLP.• Le champ GFCComme on le voit, le champ de contrôle de flux générique (GFC, Generic Flow Control)est défini uniquement à l’UNI. Il est "écrasé" par le premier commutateur qu’il ren-contre. Il a été conçu pour servir au contrôle de flux à l’UNI.• Le champ HECCe champ est utilisé par la couche physique pour détecter ou corriger des erreurs dansles 4 premiers octets de l’en-tête et réaliser l’alignement de la cellule.
16

Chapitre 1 : Panorama des réseaux haut débit
Fig. 1.9 – Division de la capacité d’un conduit de trasmission
1.4.2.2 Les connexions ATM
ATM est une technique orientée connexion. Ceci signifie que tout transfert d’infor-mation est composé de trois étapes : l’établissement de la connexion, le transfert del’information lui même et la fermeture de la connexion. Deux types de connexion sontdéfinis dans les documents de normalisation : les connexions de voie virtuelle (VCC,Virtual Channel Connection) et les connexions de conduit virtuel (VPC, Virtual PathConnection). Elle sont définies comme suit : La capacité de chaque connexion physiqueest divisée, logiquement, en un certain nombre de liens ATM appelés conduits virtuels(VP, Virtual Path) ou liens de conduit virtuel. Une VPC se compose d’un VP est à lafois divisée logiquement dans un certain nombre de liens ATM appelés voies virtuells(VC, Virtual Channel) ou liens de voies virtuelle. Une VCC se compse d’un VC ou dela concaténation de plusieurs VC (voir Fig. 1.9).
1.4.2.3 Qualité de Service dans ATM
La notion de qualité de service (QoS, Quality of Service) veut rendre compte,de façon chiffrée, du niveau de performances que l’utilisateur attend du réseau. Lasignification précise de la notion de Qualité de Service dépend du service envisagé.La Qualité de Service peut être évaluée de plusieurs façons. En général, elle inclut ledébit, le délai de bout en bout, les bornes sur les délais, la gigue, le taux de perte.
Dans [74], J.L Mélin définit la qualité de service comme étant " la capacité detransporter efficacement le flux de données d’une application tout en satisfaisant lesexigences (contraintes) dictées par l’utilisateur (ou l’application)". Les principaux pa-ramètres connus de la qualité de service sont :
– Disponibilité : elle est définie comme étant le rapport entre le temps de bonfonctionnement des services et le temps total d’ouverture du service. C’est laforme la plus évidente de QoS puisqu’elle établit la possibilité d’utiliser le réseau ;
– Bande passante : c’est la capacité de transmission d’une liaison du réseau me-
17

Chapitre 1 : Panorama des réseaux haut débit
surée en bits par seconde ;– Latence (délai) : elle correspond au temps que requièrt un paquet pour traverser
le réseau d’un point d’entrée a un point de sortie ;– Gigue : elle est définie comme étant la variation des délais d’acheminement (la-
tence) des paquets sur le réseau. Ce paramètre est particulièrement sensible pourles applications multimédia temps réel qui requièrent un délai inter-paquets re-lativement stable ;
– Taux de perte : c’est le rapport entre le nombre d’octets émis et le nombre d’octetsreçus. Il s’agit par conséquent de la mesure de la capacité utile de transmission.
Une définition officielle de la qualité de service est définie également dans la recom-mandation E.800 de l’UIT [48] :"La qualité de service correspond à l’effet général de la performance d’un service quidétermine le dégré de satisfaction d’un utilisateur de service."Chaque application peut avoir des besoins spécifiques. Part exemple, garantir uneborne sur le délai de transmission des paquets peut être profitable aux applicationsde téléphonie ; garantir un débit peut être nécessaire pour des applications vidéo à lademande (VoD), etc. Dans ce qui suit, nous présentons les paramètres pertinents dequalité de service concernant les réseaux ATM.
1.4.2.4 Paramètres de qualité de service dans les réseaux ATM
Lorsqu’un circuit virtuel est établi, la couche transport (un processus client sur unordinateur) et la couche ATM (un processus interne au réseau ATM) doivent conclureun contrat spécifiant la classe de service associée au circuit virtuel ; une étape denégociation est alors entreprise. Le contrat entre le client et l’opérateur comportegénéralement trois parties : le trafic susceptible d’être offert ;le service accepté d’uncommun accord et enfin les conditions de conformité requises. La première partie ducontrat s’appelle descripteur de trafic. Celui-ci caractérise la charge de trafic quipeut être assuré. La seconde partie spécifie la qualité de service souhaitée par l’usageret acceptée par le réseau. Pouir réaliser un contrat de service, le standard ATM a définiun certain nombre de paramètres de qualité de service dont les valeurs peuvent fairel’objet de négociation entre l’usager et le réseau [34], [91], [92]. Le tableau 1.3 résumeles paramètres de qualité de service les plus importants dans les réseaux ATM. Les troispremiers paramètres spécifient à quel débit l’usager souhaite pratiquer la transmissionde ses cellules :• PCR (Peak Cell Rate) : indique le débit crête de la source. Autrement dit,la valeurmaximale du débit envisagé. Le PCR est l’inverse du délai minimal entre l’arrivée dedeux-cellules.• SCR (Sustained Cell Rate) : correspond à la valeur moyenne du débit envisagésur un long intervalle de temps. Pour un trafic de type CBR (Constant Bit Rate) la
18
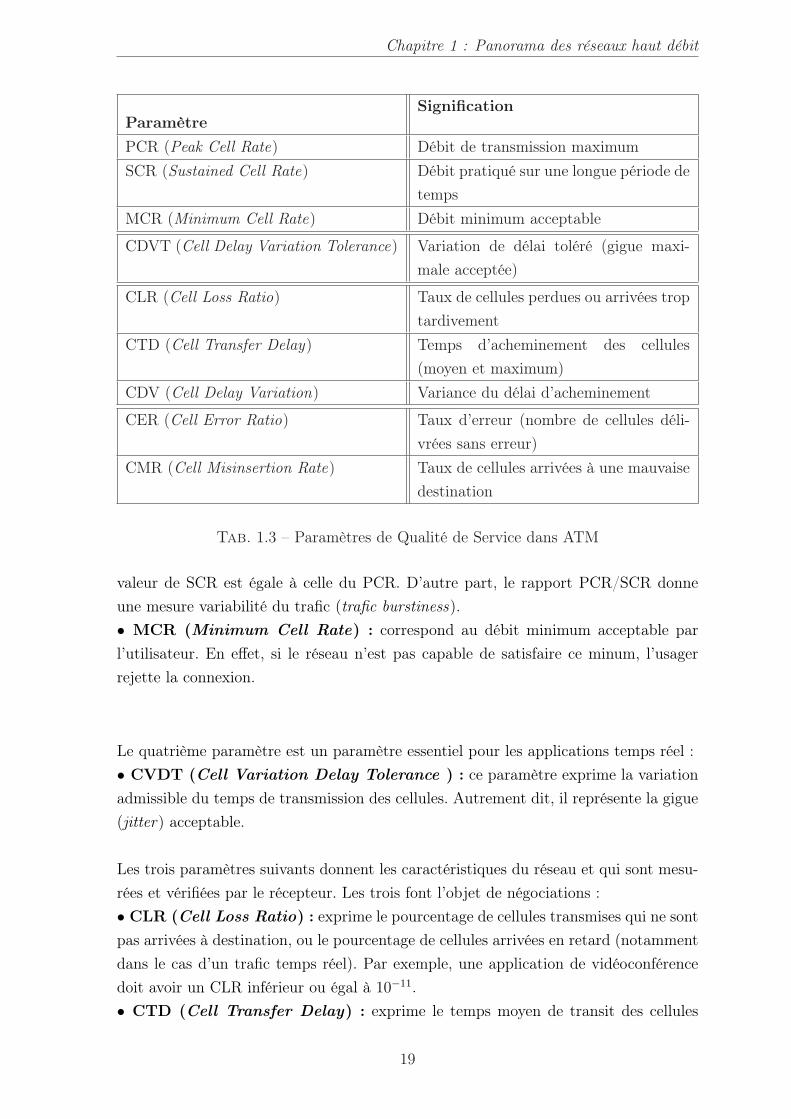
Chapitre 1 : Panorama des réseaux haut débit
ParamètreSignification
PCR (Peak Cell Rate) Débit de transmission maximumSCR (Sustained Cell Rate) Débit pratiqué sur une longue période de
tempsMCR (Minimum Cell Rate) Débit minimum acceptable
CDVT (Cell Delay Variation Tolerance) Variation de délai toléré (gigue maxi-male acceptée)
CLR (Cell Loss Ratio) Taux de cellules perdues ou arrivées troptardivement
CTD (Cell Transfer Delay) Temps d’acheminement des cellules(moyen et maximum)
CDV (Cell Delay Variation) Variance du délai d’acheminement
CER (Cell Error Ratio) Taux d’erreur (nombre de cellules déli-vrées sans erreur)
CMR (Cell Misinsertion Rate) Taux de cellules arrivées à une mauvaisedestination
Tab. 1.3 – Paramètres de Qualité de Service dans ATM
valeur de SCR est égale à celle du PCR. D’autre part, le rapport PCR/SCR donneune mesure variabilité du trafic (trafic burstiness).• MCR (Minimum Cell Rate) : correspond au débit minimum acceptable parl’utilisateur. En effet, si le réseau n’est pas capable de satisfaire ce minum, l’usagerrejette la connexion.
Le quatrième paramètre est un paramètre essentiel pour les applications temps réel :• CVDT (Cell Variation Delay Tolerance ) : ce paramètre exprime la variationadmissible du temps de transmission des cellules. Autrement dit, il représente la gigue(jitter) acceptable.
Les trois paramètres suivants donnent les caractéristiques du réseau et qui sont mesu-rées et vérifiées par le récepteur. Les trois font l’objet de négociations :• CLR (Cell Loss Ratio) : exprime le pourcentage de cellules transmises qui ne sontpas arrivées à destination, ou le pourcentage de cellules arrivées en retard (notammentdans le cas d’un trafic temps réel). Par exemple, une application de vidéoconférencedoit avoir un CLR inférieur ou égal à 10−11.• CTD (Cell Transfer Delay) : exprime le temps moyen de transit des cellules
19

Chapitre 1 : Panorama des réseaux haut débit
entre la source et la destination.• CDV (Cell Delay Variation) : mesure la variance admissible du temps d’ache-minement des cellules au destinataire.
Les deux derniers paramètres de QoS spécifient des caractéristiques propres au ré-seau :• CER (Cell Error ratio) : mesure le nombre moyen de cellules arrivant à destina-tion avec au moins un bit erroné.• CMR (Cell Misinsertion ratio) : mesure le nombre moyen de cellules/secondequi sont remises à une mauvaise destination par suite d’une erreur non détectée dansleur en-tête.
1.4.2.5 Classes de services dans ATM
Lorsqu’une connexion est établie, elle résulte d’une négociation entre l’usager et leréseau qui stipule la classe de transfert retenue. L’ATM-Forum a organisé les servicesofferts par les réseaux ATM en cinq catégories (voir 1.3) :
1. La classe CBR (Constant Bit Rate) : La classe CBR définit une transmis-sion à débit constant. La connexion est équivalente à un circuit téléphonique ;cela revient à émuler un support de transmission (un câble électrique ou unefibre optique). Cette classe est importante dans ATM. Elle permet d’écouler unflux de données temps réel ou interactif, comme le trafic téléphonique, l’audio oula vidéo.
2. La classe RT-VBR (Real Time Variable Bit Rate) : la classe RT-VBRest spécifique aux services qui ont un service variable combiné à des exigences detemps réel importantes, par exemple la vidéo comprimée (comme la vidéocon-férence) ou l’échange d’images codées MPEG (Moving Picture Expert Group).Poue cette classe de trafic, le réseau ATM doit contrôler le temps moyen d’ache-minement des cellules et ainsi que la variation moyenne du délai d’acheminementdes cellules.
3. La classe NRT-VBR (Non Real Time Variable Bit Rate) : la classe NRT-VBR est destinée au trafic non temps réel où l’instant de remise est important,même si les applications concernées tolèrent une certaine gigue. Comme exemple,on peut citer le transfert d’un document multimédia.
4. La classe ABR (Available Bit Rate) : la classe ABR définit un débit possible.Cette classe permet d’écouler du trafic sporadique dont la bande passante (ou ledébit) nécessaire est difficilement prévisible.
5. La classe UBR (Unspecified Bit Rate) : la classe UBR ne définit aucundébit et ne délivre pas non plus d’information de retour en cas de congestion.
20

Chapitre 1 : Panorama des réseaux haut débit
Classe Description ExempleCBR Débit constant garanti Téléphone
RT-VBR Débit variable : trafic temps réel Vidéoconférence en temps réelNRT-VBR Débit variable : trafic non temps
réelTransfert d’un document multi-média
ABR Débit possible Surf sur le WebUBR Débit non spécifié Transfert de fichier en tâche de
fond
Tab. 1.4 – Classes de service dans ATM
Cette classe est typique de la transmission de données en mode datagrammes,comme par exemple les datagrammes IP. En effet, un tel service est dit " serviceau mieux" ou best effort : aucune garantie n’est faite par le réseau pour l’arrivéedes paquets à destination. Dans la classe UBR, toutes les cellules envoyées dansle réseau sont acceptées. Si la capacité instantanée du réseau est suffisante lescellules sont transmises sans problème jusqu’à destination. Par contre, en casde surcharge du réseau, les cellules seront détruites en priorité, sans que lesexpéditeurs respectifs soient avertis, ni même qu’il leur soit demandé de réduireleur trafic.
1.4.3 La technologie MPLS ( MultiProtocol Label Switching)
Afin de combiner les avantages de la commutation rapide de la technologie ATMet ceux des protocoles efficaces de routage IP tout en évitant les problèmes de "scala-bilité", une technique de commutation de labels a été proposée. Cette technique offreun support de la qualité de service au protocole IP et permet un découplage des tech-niques de routage (routing) et de relayage (forwarding) [68]. Un groupe de travail ausein de l’IETF a été créé dans le but de standardiser cette technique de commutationde labels sous le nom de MPLS (Multi Protocol Label Switching) (voir RFC)
MPLS est une technique destinée à répondre à plusieurs problèmes liés à la trans-mission des paquets dans un environnement d’intéréseau moderne. Cette technologiede pointe a de nombreuses utilisations, que ce soit dans un environnement de fournis-seur de services (service provider) ou dans un réseau d’entreprise. Actuellement, MPLSest surtout déployé pour la mise en place de réseaux virtuels (VPN, Virtual PrivateNetwork). La différence essentielle entre MPLS et les technologies WAN traditionnellestient à la manière dont les labels sont attribués et à la capacité de transporter une pilede labels attachés à un paquet [79].
21

Chapitre 1 : Panorama des réseaux haut débit
Avant d’expliquer le principe de commutation de MPLS, nous donnons d’abord lesdéfinitions suivantes :• Etiquette (label) : c’est un entier associé à un paquet lorsqu’il circule dans unréseau MPLS et sur lequel ce dernier s’appuie pour prendre des décisions.• MPLS Ingress node : c’est un routeur d’entrée MPLS qui gère le trafic qui entredans un domaine MPLS.• MPLS Egress node : c’est un routeur de sortie est gère le trafic sortant d’un do-maine MPLS.• Routeur LSR (Label Switch Router) : c’est un routeur d’un réseau MPLS quiest capable de retransmettre les paquets au niveau de la couche 3 en se basant seule-ment sur le mécanisme de labels.• Routeur LER (Label Edge Router) : c’est un LSR qui fait l’interface entre leréseau MPLS et le monde extérieur. C’est ce routeur qui est chargé d’étiqueter lespaquets lorsqu’ils entrent dans le réseau MPLS.Le fonctionnemnt de MPLS s’appuie sur une technique qui permet d’attribuer uneétiquette à chaque flux de données TCP/IP. Cette étiquette courte, de longueur fixe,correspond à un bref résumé de l’en-tête de datagramme IP ; elle fournit des infor-mation sur le chemin que le paquet doit parcourir, afin qu’il puisse être commuté ourouté plus rapidement sur les réseaux utilisant différents types de protocoles (ATM,Relais de Trames, Ethernet). Comme illustré dans la figure 1.10, la propagation d’unpaquet IP sur une épine dorsale MPLS (MPLS backbone) compte trois grandes étapesqui sont les suivantes :
1. Le routeur LER reçoit un paquet IP, range le paquet dans une classe d’équiva-lence de transmission (FEC, Forward Equivalence Class) et libelle le paquet avecla pile de labels sortante qui correspond à la FEC sélectionnée ;
2. A l’intérieur du domaine MPLS, des LSR reçoivent ce paquet libellé. Ils se serventdes tables de transmission de labels pour échanger le label d’entrée dans le paquetentrant avec le label de sortie qui correspond à la même classe FEC.
3. Lorsque le LER de la classe FEC en question reçoit le paquet libellé, il supprimele label et réalise une consultation classique de couche 3 sur la paquet IP.
Pour plus de détails sur le protocole MPLS, le lecteur intéressé pourra consulter [5],[7], [18], et [79].
22

Chapitre 1 : Panorama des réseaux haut débit
Fig. 1.10 – Processus d’acheminement de paquets dans MPLS
1.5 Conclusion
Les futures applications demanderont une bande passante en augmentation constanteavec un trafic très hétérogène (voix, données, images). De plus, les utilisateurs souhaite-ront payer suivant la qualité de service qu’ils demandent. Les réseaux ATM permettentjustement de garantir cette qualité de service indépendamment des caractéristiques duservice transporté. Cependant, la volonté d’universalité des réseaux ATM a conduit àun pari difficile : assurer un qualité de service comparable à celle des réseaux synchronetout en offrant la souplesse des réseaux de paquets desquels ATM a hérité la vulnéra-bilité aux problèmes de congestion. De ce fait, la définition de mécanismes de contrôlede trafic et de congestion s’avère primordiale pour garantir la qualité de service requisepar les utilisateurs. L’étude du phènomène de congestion et des solutions proposéespour y remédier fera l’objet du chapitre suivant.
23

Chapitre 2
Contrôle de Congestion dans les
Réseaux Haut Débit
"Popular myths that cheaper memory, high-speed links, and high-speed processorswill solve the problem of congestion in computer networks are shown to be false."
Raj Jain [53]
2.1 Introduction
LES avancées technologiques dans le domaine des réseaux locaux ainsi que l’avène-ment de la fibre optique ont permis d’offrir un grand éventail de débits pouvant
atteindre des centaines de mégabits par seconde. Toutefois, ces nouvelles technologiesdoivent coexister avec les anciens médias tels que les paires torsadées (twisted pairs).Cette hétérogénéité a donné naissance à une grande disparité entre les taux d’arrivée etde service dans les noeuds intermédiaires dans le réseau, causant ainsi des délais d’at-tente plus grands, et des phénomènes de congestion. La plupart des réseaux déployés(reposant sur TCP et ATM) implémentent des méthodes de contrôle de congestion.Dans ce chapitre, nous nous intéresserons au phénomène de congestion. Ses causesseront identifiées et les mécanismes proposés seront étudiés. Nous attarderons sur lesmécanismes de contrôle de congestion dans les réseaux ATM et aborderons très briè-vement l’ingénierie de trafic dans MPLS.
2.2 Terminologie et concepts de base
Dans cette section, nous donnons des définitions générales qui seront nécessaires àla compréhension de ce mémoire.
2.2.1 Allocation de ressources
Dans un réseau à commutation de paquets, le mot ressource inclut les tamponsde stockage temporaire, les bandes passantes des différents liens, le temps d’exécution
24

Chapitre 2 : Contrôle de congestion dans les réseaux haut débit
sur les processeurs, etc. D’une façon générale, le problème d’allocation de ressourcesdans les réseaux est le suivant : on se donne un réseau avec une certaine topologie,un ensemble de ressources, et un ensemble d’utilisateurs avec des besoins éventuel-lement différents les uns des autres ( une personne consultant ses mails n’a pas lesmêmes besoins qu’une autre utilisant une application vocale ou audio). Le problèmeest alors de choisir une façon de partager les ressources du réseau entre les utilisateursen respectant deux propriétés fondamentales : l’efficacité et l’équité.
2.2.2 Notion d’efficacité (efficiency)
Nous comparons l’efficacité des différentes techniques de partage de ressources ense basant sur le nombre total de paquets (Q) transmis par toutes les sources pour unepériode de temps bien déterminée et un scénario donné. Les paquets qui sont retransmisà plusieurs reprises (pour une raison ou une autre) en cours d’une connexion ne sontcomptabilisés qu’une seule fois. Il s’agit d’un bilan au niveau de la couche transportdu modèle OSI, un bilan sur l’utilité tirée du réseau. Pratiquement, si on a n sources,et si qi représente la quantité transmise par la ime source durant la période considérée,alors :
Q =n∑
i=1
qi (2.1)
Enfin, on calculera le rapport τU entre cette qauantité et la valeur optimale qui résul-terait d’un fonctionnement idéal du réseau. C’est à dire :
τU =Q
Qopt
(2.2)
τU représente alors le taux d’utilisation du réseau.
2.2.3 Notion d’équité (fairness)
Dans un environnement partagé, le débit alloué à une source dépend de la demandede l’ensemble des utilisateurs. Quel critère devons-nous prendre pour déterminer si unpartage donné est équitable ou non ? Dans le domaine des réseau, le critère le plussouvent utilisé est le critère du max-min [10], [56], [14], [64]. L’idée de base consiste àattribuer le maximum de ressources possible à la source qui en recevra le moins parmiles ressources concurrentes.. Nous nous proposons de définir ci-dessous la procéduredu max-min :Soit une configuration ayant n sources concurrentes, avec xi la quantité de ressourcesallouée à la ime source. On définit alors un vecteur d’allocation de ressources commesuit :
v = [x1, x2, .., xn] (2.3)
25

Chapitre 2 : Contrôle de congestion dans les réseaux haut débit
Ce vecteur servira à sauvegarder l’allocation xi faite à chaque source i. Le nombre devecteurs d’allocation possibles est infini pour chaque situation. Considérons maintenantl’ensemble de ces vecteurs Vk défini comme suit :
Vk = {vi |vi est un vecteur d′allocation possible} (2.4)
Soit xmin la plus faible allocation de chaque vecteur d’allocation. L’ensemble des solu-tions restant possibles est toujours infini. On réduit le problème en retirant la sourcequi s’est vue attribuer la plus faible quantité de ressources et on répète l’opérationpour les (n−1) sources restantes. On réitère ce processus jusqu’à ce que chaque sourcese soit vue attribuer le maximum de ressources qu’elle pouvait espérer.Maintenant nous pouvons évaluer un algorithme au niveau de son équité en comparantsa répartition à celle qui est dite optimale selon notre critère de max-min . Nous allonsévaluer l’indice d’équité ( fainess index ) d’une répartition des ressources de la façonsuivante [56] :
Pour ce faire, supposons que l’algorithme dont on étudie l’équité fournisse la ré-partition v = [x1, x2, .., xn] au lieu de la répartition optimale définie par :
vopt = [x1,opt, x2,opt, ..., xn,opt] (2.5)
Nous calculons la répartition normalisée x̃i pour chaque source comme suit :
x̃i =xi
xi,opt
(2.6)
L’indice d’équité τE est alors :
τE =
(n∑
i=1x̃i
)2
nn∑
i=1x̃i
2(2.7)
Notons que l’équité max-min a été adoptée par l’ATM forum pour le service Avai-lable Bit Rate (ABR) de l’ATM.
2.2.4 Goulot d’étranglement
Un goulot d’étranglement est défini comme étant une ressource dont la capacitéest en moyenne juste égale ou inférieure au besoin. Une définition plus formelle d’ungoulot d’étranglement est donnée dans [14] et [94].Selon William Stallings [90], on peut classifier les goulots d’étranglement d’un réseau endeux classes : goulots d’étranglement logiques (logical bottlenecks) et goulots d’étran-glement physiques (physical bottlenecks). Les goulots d’étranglement physiques sontinhérents aux équipement utilisées (commutateurs, routeurs, les tampons mémoires,liaisons à faible débit, vitesse des processeurs, etc). Les goulots d’étranglement logiques,quant à eux , sont dus à la "logique" utilisée dans les ressources très demandées. Onpeut citer par exemple : la complexité des algorithmes de routage, algorithmes d’or-donnancement (scheduling), etc.
26

Chapitre 2 : Contrôle de congestion dans les réseaux haut débit
Fig. 2.1 – Facteurs causant la congestion dans un noeud
2.2.5 Produit délai-bande passante (BDP, Bandwidth Delay
Product)
Lorsque’on veut analyser les performances des réseaux, on travaille souvent avec leproduit délai-bande passante (appelé aussi produit largeur de bande-délai) [60],[67],[92]. On obtient celui-ci en multipliant la capacité (en bit/s) par le temps de boucle(en secondes) appelé RTT (Round Trip Time) ou encore RTD (Round Trip Delay). Ceproduit est alors la capacité du tube (pipe) en bits entre l’émetteur et le récepteur, etréciproquement. Par exemple, considérons l’envoi de données entre deux villes A et B
avec un tampon récepteur de 64 Ko. Supposons que nous avons une liaison à 1 Gbit/set un délai de transmission de 20 ms. Le produit largeur de bande-délai est alors :
(20 ms ∗ 2) ∗ 109 bit/s = 4.107 bits (2.8)
En d’autres termes, l’émetteur peut transmettre 40 millions de bits avant de recevoirl’accusé de réception. Par conséquent, pour des réseaux présentant un produit délai-bande passante suffisament grand, le contrôle de flux par fenêtre de congestion (commec’est le cas du protocole TCP) est très inefficace [4], [89].
2.2.6 Notion de Congestion
Etymologiquement, le mot congestion a pour origine le verbe latin congerere,qui veut dire "accumuler". Dans le domaine des télécommunications et des réseauxinformatiques, on peut définir la congestion 1 comme étant un état de certains élémentsd’un réseau pour lequel les objectifs de performance fixés ne peuvent pas être atteints[34]. Ceci arrive quand il y pénurie de ressources. Autrement dit,
∑Demandes >
∑Ressources disponibles (2.9)
Un réseau dans le quel une telle situation survient est appelé alors réseau congestionné(congested network).
1Dans la littérature, on parle parfois d’encombrement, d’engorgement, ou encore d’embouteillage.Dans le présent mémoire, nous adopterons le terme congestion.
27
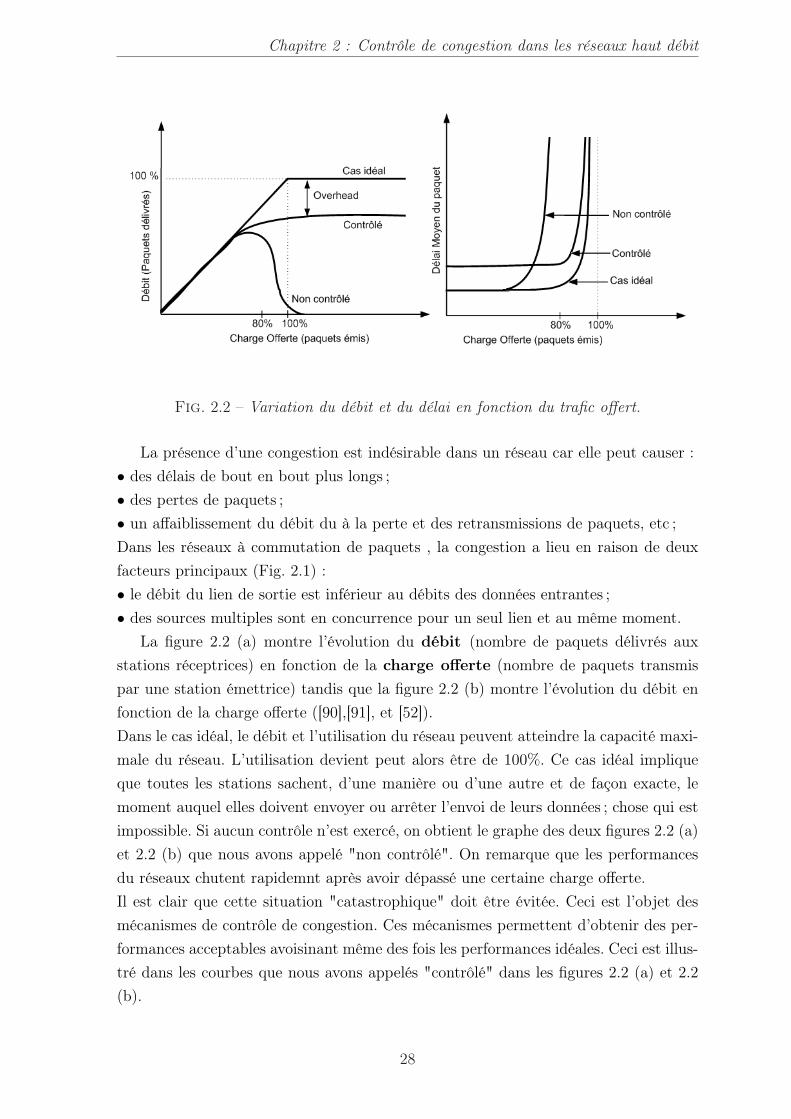
Chapitre 2 : Contrôle de congestion dans les réseaux haut débit
Fig. 2.2 – Variation du débit et du délai en fonction du trafic offert.
La présence d’une congestion est indésirable dans un réseau car elle peut causer :• des délais de bout en bout plus longs ;• des pertes de paquets ;• un affaiblissement du débit du à la perte et des retransmissions de paquets, etc ;Dans les réseaux à commutation de paquets , la congestion a lieu en raison de deuxfacteurs principaux (Fig. 2.1) :• le débit du lien de sortie est inférieur au débits des données entrantes ;• des sources multiples sont en concurrence pour un seul lien et au même moment.
La figure 2.2 (a) montre l’évolution du débit (nombre de paquets délivrés auxstations réceptrices) en fonction de la charge offerte (nombre de paquets transmispar une station émettrice) tandis que la figure 2.2 (b) montre l’évolution du débit enfonction de la charge offerte ([90],[91], et [52]).Dans le cas idéal, le débit et l’utilisation du réseau peuvent atteindre la capacité maxi-male du réseau. L’utilisation devient peut alors être de 100%. Ce cas idéal impliqueque toutes les stations sachent, d’une manière ou d’une autre et de façon exacte, lemoment auquel elles doivent envoyer ou arrêter l’envoi de leurs données ; chose qui estimpossible. Si aucun contrôle n’est exercé, on obtient le graphe des deux figures 2.2 (a)et 2.2 (b) que nous avons appelé "non contrôlé". On remarque que les performancesdu réseaux chutent rapidemnt après avoir dépassé une certaine charge offerte.Il est clair que cette situation "catastrophique" doit être évitée. Ceci est l’objet desmécanismes de contrôle de congestion. Ces mécanismes permettent d’obtenir des per-formances acceptables avoisinant même des fois les performances idéales. Ceci est illus-tré dans les courbes que nous avons appelés "contrôlé" dans les figures 2.2 (a) et 2.2(b).
28

Chapitre 2 : Contrôle de congestion dans les réseaux haut débit
2.3 Nécessité d’un contrôle de Congestion
Puisque la surcharge provient d’une augmentation inconsidérée du trafic offert auréseau, les mécanismes de contrôle vont avoir comme tâche de mesurer et de limiterce trafic. Une autre contrainte qu’on leur impose est d’accomplir cette limitation dela manière la plus rentable, c’est à dire de permettre au réseau de fonctionner au plusprès de sa capacité maximale. Enfin, la contrainte d’équité (equity) est aussi invoquée.Dans la recommandation I.371 [50], le contrôle de trafic est défini comme étant :"l’ensemble des actions qui peuvent être prises par le réseau pour empêcher toutecongestion", alors que le contrôle de congestion est défini comme étant " lesactions qui peuvent être prises par le réseau pour minimiser l’intensité, l’étendue, etla durée de la congestion".Il est intéressant de montrer la différence entre ces deux notions, tant leurs rapportssont très subtils 2. Le contrôle de congestion est un problème global, qui tient comptedu comportement des ordinateurs et des routeurs, mais aussi du mécanisme de re-transmission des paquets à l’intérieur des routeurs et de bien d’autres facteurs qui onttendance à diminuer la capacité de transport du sous-réseau. Le contrôle de flux (flowcontrol) se rapporte au trafic point-à-point entre un émetteur et un récepteur particu-liers. Son rôle consiste à s’assurer qu’un émetteur rapide ne transmette pas des paquetsde façon continue, plus rapidement que le récepteur peut les absorber. Le contrôle deflux implique presque toujours un retour d’information du récepteur vers l’émetteurafin de préciser comment les choses se passent à l’arrivée. Les deux objectifs antago-nistes que doit réconcilier un mécanisme de contrôle de congestion sont de garantir laqualité de service pour les connexions déjà établies (aucune congestion) d’une part ;et d’utiliser de façon efficace les capacités de transmission du réseau (utilisation dumultiplexage statistique) d’autre part [93].
2.4 Propriétés d’un bon système de contrôle de conges-
tion
Malgré le nombre énorme d’algorithmes de contrôle de congestion proposés dans lalittérature, ce domaine fait toujours l’objet d’intenses recherches. Selon Raj Jain [53],il y a deux raisons à cela. La première est due aux exigences contradictoires que l’ondoit satisfaire, et la seconde vient de la difficulté à concevoir un algorithme performantet adéquat pour toutes les architectures de réseaux.
La difficulté du contrôle provient en majeure partie du caractère distribué dessources du réseau qui fait que le trafic émanant de différentes sources soit non coor-
2Certains auteurs préfèrent ne pas faire de distinction entre les deux notions ( voir par exemple[18]
29

Chapitre 2 : Contrôle de congestion dans les réseaux haut débit
donné, et de l’absence d’un organe de contrôle central qui régulerait le trafic en fonctionde l’état global du réseau. Un bon mécanisme de contrôle de congestion doit tenterde satisfaire un certain nombre de proprétés fondamentales que nous étudierons danscette section. En pratique, la plupart des algorithmes ne satisfont que quelques unesde ces propriétés qui sont les suivantes :
1. Simplicité (Simplicity)La simplicité a été toujours un avantage. Il est très important de réduire lacomplexité d’un algorithme de contrôle de congestion pour faciliter son implé-mentation sur matériel (hardware) aussi bien que sur logiciel (software).
2. Efficacité (Efficiency)Il existe deux aspects d’efficacité d’une méthode de contrôle de congestion. Pre-mièrement, l’overhead que la méthode de contrôle de congestion impose au réseau. En effet, les paquets de contrôle eux-mêmes empirent la situation de congestiondans un réseau. part conséquent, une bonne méthode de contrôle de congestiondoit minimiser les données de contrôle. Deuxièmement, on doit maximiser l’uti-lisation des ressources du réseau.
3. Equité (Fairness)L’équité peut ne pas être très importante au moment où le réseau n’est pas sur-chargé et toutes les demandes peuvent être satisfaites. Par contre, durant les pé-riodes de congestion où les ressources disponibles sont inférieures aux demandes,il est très important que ces ressources soient partagées de façon équitable.
4. Extensibilité (Scalability)Les réseaux peuvent être classifiées selon leurs étendues géographiques , le nombrede noeuds, le débit ou le nombre d’usagers. Un bon système de contrôle decongestion ne doit pas être limité à une gamme de vitesses, à une distance ou àun nombre particulier de commutateurs. Ceci garantira que ce même système decontrôle de congestion puisse être utilisé pour les réseaux locaux (LANs) aussibien que pour les réseaux étendus (WANs).
5. Robustesse (Robustness)Par robustesse, on entend l’insensibilité de l’algorithme de contrôle de congestionaux petites déviations. Par exemple, une petite perte des messages de contrôlene doit pas causer un effondrement des capacités du réseau. Notons que chezcertains auteurs , cette propriété est appelé stabilité (stability).
6. Implémentabilité (Implementability)Un algorithme de contrôle de congestion ne doit pas dicter un architecture par-ticulière pour les commutateurs du réseau.
30

Chapitre 2 : Contrôle de congestion dans les réseaux haut débit
2.5 Taxonomie des méthodes de contrôle de conges-
tion
Un bon nombre d’algorithmes de contrôle de congestion sont bien connus des spé-cialistes. la question que l’on se pose ici est comment classifier toute cette armadade méthodes. En effet, cette taxonomie peut être faite selon plusieurs critères ( voirpar exemple [53], [58],[64], et [102]). Nous résumons dans ce qui suit ces critères declassification.
2.5.1 Taxonomie selon le stade d’intervention
Selon le stade d’intervention, nous pouvons classer les mécanismes de contrôle detrafic essentiellement en trois classes : mécanismes de contrôle réactifs, mécanismes decontrôle préventifs et enfin mécanismes de contrôle hybrides.
Dans un mécanisme préventif de contrôle de congestion, chaque source doit décrire,a priori, son trafic au réseau. Le réseau réserve en conséquent les ressources (e.g.mémoire et bande passante) correspondant aux paramètres décrivant le trafic. En casd’insuffisance de ressources, le réseau n’accepte pas le trafic en question. Ceci permetde minimiser les chances d’une congestion.
Contrairement au contrôle préventif, le contrôle réactif agit en fonction de l’évo-lution de l’état du réseau. Sa philosophie est de pouvoir partager les ressources parle maximum de connexions pour optimiser l’utilisation du réseau. Le principe est lesuivant : chaque source doit, de façon dynamique, ajuster son trafic pour partageréquitablement (entre les différentes sources) les ressources du réseau. Pour ce faire,le réseau doit indiquer, de façon explicite ou implicite, aux sources les changementsd’états . Chaque changement doit se traduire par un ajustement du trafic de la source.Le contrôle réactif suppose que le réseau ou le service n’effectue pas une réservationde ressources, i.e. toutes les connexions/flux sont acceptées sans que le réseau ne ga-rantisse une QoS. Plusieurs algorithmes réactifs ont été proposés et utilisés dans lesréseaux de paquets. L’exemple le plus simple est le contrôle le mécanisme de fenêtrede TCP défini par Van Jacobson [51].
Les mécanimes hybrides combinent les caractéristiques du contrôle préventif etcelles du contrôle réactif que nous avons décrits ci-dessus. Le principe de ce type demécanismes est le suivant : le réseau réserve pour chaque source un minimum de res-sources correspondant aux paramètres de trafic spécifiés. Les sources sont autorisées àexcéder le trafic spécifié pendant les périodes où les ressources du réseau ne sont pastoutes réservées ou utilisées (inactivité d’autres sources). Dans ce cas, le réseau n’offrepas de garanties au trafic excédant celui spécifié au départ.
Dans les réseaux ATM, Les trafics du type CBR et VBR utilisent un schéma de
31

Chapitre 2 : Contrôle de congestion dans les réseaux haut débit
Couche Voies d’action• Politique de retransmission
Couche • Politique de l’accusé de réceptionTransport • Politique du contrôle de flux
• Définition des intervalles de temps hors délais (time out)• Circuits virtuels ou datagramme• Politique de mise en file d’attente et de distribution de paquets
Couche • Politique de destruction de paquetsRéseau • Politique de routage
• Gestion de la durée de vie des paquetsCouche • Politique de retransmissionLiaison • Politique de l’accusé de réception
• Politique du contrôle de flux
Tab. 2.1 – Politiques pouvant influer sur la congestion
contrôle de congestion préventif alors que le trafic ABR utilise un schéma de contrôlede congestion de type réactif [58]. Les mécanismes réactifs de contrôle de congestionont été utilisés dans les réseaux classiques. Cependant, ils ne peuvent pas être adaptéspour les réseaux haut débit pour des raisons qu’on verra dans ce chapitre (voir aussi[2], [34], et [68]).
2.5.2 Taxonomie selon la couche du modèle OSI
Une des façons de classifier les algorithmes de contrôle de congestion se fait enfonction de la couche du système de référence OSI (Open System Interconnection) auniveau duquel s’applique l’algorithme (voir Tab 2.1).
• Regardons, par exemple, la couche liaison de données (link layer) ; la politiquede retransmission est en rapport avec la vitesse de réaction et le comportement d’unémetteur face à des paquets transmis et dont les accusés de réception sont hors délais.Certains émetteurs "impatients" estiment trop rapidement que les temps sont hors dé-lais et retransmettent, consèquement, tout paquet non encore acquitté, ce qui provoqueune surcharge du sous-réseau. La politique de l’accusé de réception influe égalementsur la congestion. Si chaque paquet est acquitté immédiatement, les paquets créentaussi une surcharge de trafic.
• Au niveau de la couche réseau, le choix entre circuit virtuel et mode datagrammea une influence majeure sur la congestion. En effet, un bon nombre d’algorithmes decontrôle de congestion ne fonctionnent que sur des circuits virtuels. La politique de
32

Chapitre 2 : Contrôle de congestion dans les réseaux haut débit
Fig. 2.3 – Méthodes de contrôle de congestion en fonction de la durée.
mise en file d’attente des paquets concerne les routeurs qui gérent les différents fluxselon une politique d’ordonnancement (scheduling) donnée.
• Au niveau de la couche transport, une difficulté supplémentaire apparaît : ladéfinition des intervalles de temps hors délai lors de la gestion des paquets. En effet,ce temps est plus difficile d’estimer ce paramètre entre deux sources qu’entre deuxrouteurs : si on prend ce temps très court, des paquets supplémentaires inopportunssont retransmis ; s’il est plus long, c’est le temps de réponse qui en souffrira à chaquefois qu’un paquet est perdu.
2.5.3 Taxonomie selon la durée de la congestion
La congestion survenant dans un réseau peut être à :
1. Court-terme : Concerne la congestion due aux phénomènes transitoires dansle réseau (arrivée d’une rafale) et au problème de partage de ressources. Ellen’est pas contrôlable à partir de la source sa durée est inférieure au temps depropagation entre le noeud congestionné et la source.
2. Moyen-terme : Congestion plus symptômatique, due à un manque de ressourcesdisponibles sur une période de temps plus importante que celle du transitoire.Ce type de congestion est contrôlable à partir de la source.
3. Long-terme : Congestion récurrente qui résulte du manque de bande passante,mémoire et puissance de calcul dans l’architecture du réseau concerné. Elle estd’une durée infinie si aucune mesure n’est prise pour redimmnesionner le réseauet augmenter les ressources de celui-ci.
Le choix d’une méthode de contrôle de congestion dépend du degré et de la duréede celle-ci. La figure 2.3 montre comment la durée de la congestion affecte le choix
33
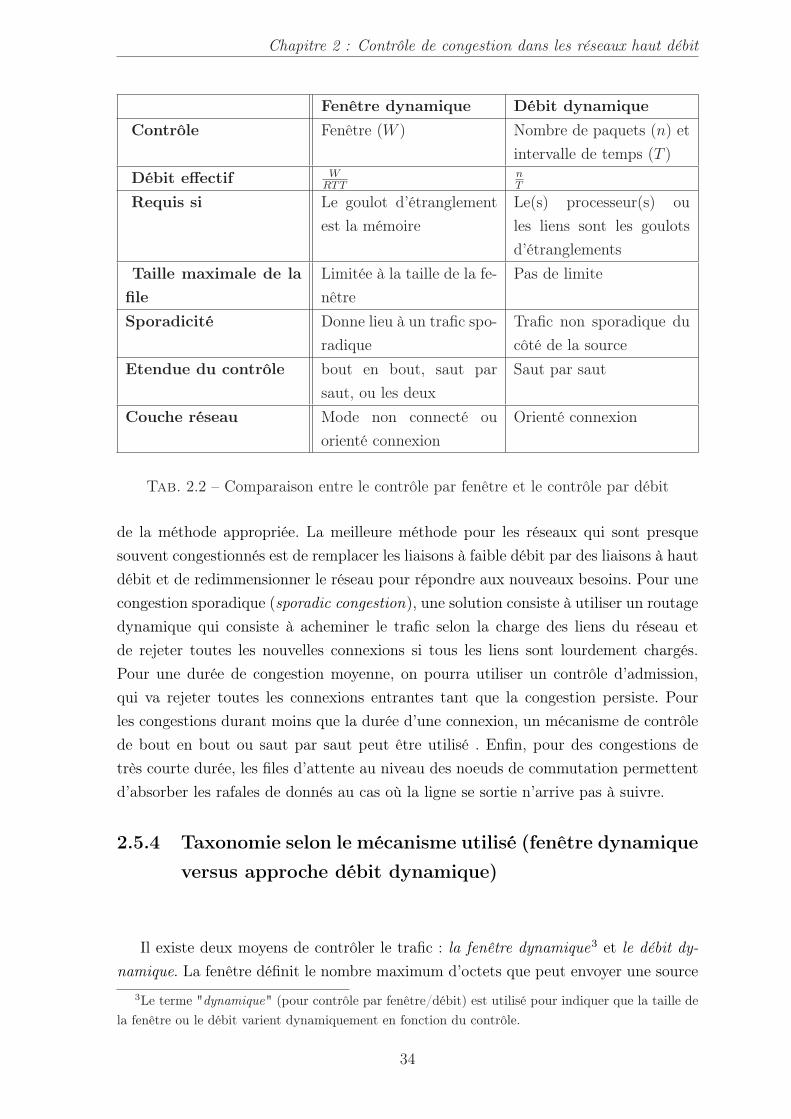
Chapitre 2 : Contrôle de congestion dans les réseaux haut débit
Fenêtre dynamique Débit dynamiqueContrôle Fenêtre (W ) Nombre de paquets (n) et
intervalle de temps (T )Débit effectif W
RTTnT
Requis si Le goulot d’étranglementest la mémoire
Le(s) processeur(s) oules liens sont les goulotsd’étranglements
Taille maximale de lafile
Limitée à la taille de la fe-nêtre
Pas de limite
Sporadicité Donne lieu à un trafic spo-radique
Trafic non sporadique ducôté de la source
Etendue du contrôle bout en bout, saut parsaut, ou les deux
Saut par saut
Couche réseau Mode non connecté ouorienté connexion
Orienté connexion
Tab. 2.2 – Comparaison entre le contrôle par fenêtre et le contrôle par débit
de la méthode appropriée. La meilleure méthode pour les réseaux qui sont presquesouvent congestionnés est de remplacer les liaisons à faible débit par des liaisons à hautdébit et de redimmensionner le réseau pour répondre aux nouveaux besoins. Pour unecongestion sporadique (sporadic congestion), une solution consiste à utiliser un routagedynamique qui consiste à acheminer le trafic selon la charge des liens du réseau etde rejeter toutes les nouvelles connexions si tous les liens sont lourdement chargés.Pour une durée de congestion moyenne, on pourra utiliser un contrôle d’admission,qui va rejeter toutes les connexions entrantes tant que la congestion persiste. Pourles congestions durant moins que la durée d’une connexion, un mécanisme de contrôlede bout en bout ou saut par saut peut être utilisé . Enfin, pour des congestions detrès courte durée, les files d’attente au niveau des noeuds de commutation permettentd’absorber les rafales de donnés au cas où la ligne se sortie n’arrive pas à suivre.
2.5.4 Taxonomie selon le mécanisme utilisé (fenêtre dynamiqueversus approche débit dynamique)
Il existe deux moyens de contrôler le trafic : la fenêtre dynamique3 et le débit dy-namique. La fenêtre définit le nombre maximum d’octets que peut envoyer une source
3Le terme "dynamique" (pour contrôle par fenêtre/débit) est utilisé pour indiquer que la taille dela fenêtre ou le débit varient dynamiquement en fonction du contrôle.
34

Chapitre 2 : Contrôle de congestion dans les réseaux haut débit
avant de se bloquer en attente d’acquittements. Chaque acquittement fait glisser lafenêtre et déclenche l’envoi de nouveaux paquets. Parmi les mécanismes de contrôle detrafic basés sur l’utilisation d’une fenêtre nous citons le Slow-start utilisé dans TCP[51] et DECBit [83].Le principe du contrôle par fenêtre (appelé aussi contrôle de flux par crédit) est lesuivant : une source se voit allouer un certain nombre W de crédits. Elle peut émettreun paquet à condition d’avoir un crédit. Un fois le paquet envoyé, le crédit correspon-dant est consommé. Le récepteur acquitte les paquets reçus et l’accusé de réception(acknowledgement) régénère les crédits de l’émetteur, l’autorisant ainsi à poursuivre.Le contrôle de flux par fenêtre est un mécanisme simple à mettre en oeuvre et il a étéutilisé pour plusieurs années dans les réseaux existants. Malheureusement, ceci poseun certain nombre de problèmes qui sont détaillés ci-dessous :
1. Taille de la fenêtre : De façon schématique on peut dire que sous le contrôlepar fenêtre, la source demande au réseau quel est sont état. Si la réponse estqu’il y un risque de congestion, la source réduit son débit. Cette réponse esten fait donnée de façon implicite par un retard des acquittements. Le problèmeest que pour les réseaux avec de grandes valeurs du produit bande passantefois délai de propagation (BDP,Bandwidth Delay Product), le délai pour obtenirun réponse est trop important.Par exemple, les performances de TCP chutentde façon dramatique dans des réseaux ayant un BDP relativement grands parrapport aux réseaux classiques.
2. Garantie de débit : Le contrôle de flux par fenêtre a été développé pour les réseauxde données. les applications utilisant ce type de réseaux ont la caractéristiquesuivante : elles peuvent réduire leurs débits si le réseau le leur demande. parcontre, pour les réseaux à haut débit (ATM par exemple), ceci n’est pas possible.En effet, les réseaux à large bande ont été conçus pour le tranport du traffic tempsréel et multimédia. Ce type d’application requiert une garantie de bande passanteque le contrôle de flux ne permet pas d’offrir.
3. Qualités de services spécifiques : Il n’est pas facile d’offrir des qualités de servicespécifiques quand les mécanisme de contrôle de trafic utilisé est le contrôle de fluxpar fenêtre. En effet, certaines applications temps réel qui ont des contraintes trèsstrictes en termes de gigue et du délai de bout en bout ne peuvent pas réduireleur trafic même si celui-ci cause une congestion.
L’autre moyen de contrôler le trafic est l’utilisation d’un contrôle par débit dynamique(rate-based control). Une source doit envoyer les paquets successifs espacés par unintervalle de temps qui est fonction du débit de la source. L’exemple le plus connude contrôle par débit est l’ABR (Available Bit Rate) [11]. Dans l’approche débit, lasource utilise des informations du réseau pour déterminer le débit maximal auquel ellepeut transmettre. Ces informations sont transportées soit par des cellules de gestion de
35

Chapitre 2 : Contrôle de congestion dans les réseaux haut débit
Fig. 2.4 – Forward Explicit Congestion Notification.
Fig. 2.5 – Backward Explicit Congestion Notification.
ressources RM (Resource Management), soit par le biais d’une indication explicite dedébit (ERI, Explicite Rate Indication), soit sous la forme d’une indication de conges-tion codée sur un bit (mode binaire). La notification explicite de congestion ou ECN(Explicit Congestion Notification) en est un exemple : un commutateur détectant unrisque de congestion en informant la source soit directement en utilisant la méthodeBECN (Backward Explicit Congestion Notification) soit indirectement en utilisant laméthode FECN (Forward Explicit Congestion Notification )[34].Après un long débat "religieux" qui a duré plus d’une année entre les tenants desmécanismes de contrôle par débit dynamique (opérateurs et constructeurs de télécom-munications publiques) et les tenants des mécanismes de contrôle par fenêtre dyna-mique (constructeurs de matériel informatique), l’ATM Forum a adopté l’approchedébit pour le contrôle de flux dans ABR et a rejeté l’approche fenêtre ( voir [44], [45],[55], [85],[84], [88], et [89]). La raison essentielle du rejet du contrôle par crédit est lefait qu’il nécessite des mécanismes de mise en file d’attente très complexes au niveaudes commutateurs du réseau, ce qui le rend très lourd à implémenter.
36

Chapitre 2 : Contrôle de congestion dans les réseaux haut débit
2.5.5 Taxonomie selon la boucle utilisée (boucle fermée versusboucle ouverte)
Un certain nombre de problèmes propres aux systèmes complexes, tels que ceuxrencontrés dans les réseaux d’ordinateurs, peuvent être analysés selon la théorie ducontrôle ou de la commande. Cette démarche d’analyse conduit à diviser les systèmesen deux catégories : les systèmes en boucle ouverte (open loop systems), et les systèmesen boucle fermée (closed loop systems).Dans les systèmes en boucle ouverte, on essaye de résoudre au mieux le système lorsde sa conception, essentiellement en s’assurant q’un problème n’arrivera pas. Dès quele système est en cours de fonctionnement aucune correction même mineure, n’estpossible. Les moyens de contrôle d’un système en boucle ouverte peuvent être, parexemple, de décider à quel moment accepter : d’augmenter le trafic, de recevoir denouveaux paquets, de détruire des paquets et de décider lesquels, de prendre des déci-sions d’ordonnancement à divers endroits du réseaux.Le contrôle par boucle fermée, quant à lui, consiste à à envoyer les informations re-latives à la congestion de l’endroit où la congestion est apparue vers l’endroit où l’onpeut réagir pour résoudre le problème. L’essentiel pour le commutateur qui détectela congestion, est de transmettre un paquet (ou des paquets) à la destination ou versla source d’émission de paquets concernés pour leur annoncer le problème. Une ca-ractéristique importante des systèmes utilisant la boucle fermée est le fait que le leurperformance dépend au délai de la notification (feedback). Cette notification peut êtreimplicite (c’est le cas de TCP [51]) ou explicite (c’est le cas de DECBit [83]).
2.5.6 Taxonomie selon la logique d’intervention (bout en boutversus noeud par noeud)
Le contrôle de bout en bout (end to end) se fait au niveau de la couche transportdu modèle de référence OSI. Son rôle essentiel est le contrôle de flux qui consiste às’assurer que le débit de la source n’est pas trop important pour le récepteur. Parconséquent, il représente un contrôle "égoïste" de contrôle de flux.Le contrôle noeud par noeud (hop by hop), quant à lui, se fait au niveau de la couche ré-seau du modèle OSI. Son principe consiste à permettre aux routeurs adjacents d’échan-ger des messages sur leur état de congestion. Ainsi un routeur peut demander à unrouteur connecté à l’une de ses entréees de réduire, voire de stopper totalement l’envoide paquets lorsqu’il est congestionné. Il existe plusieurs variantes qui se basent surce même principe, certaines plus complexes et côuteuses que les autres. L’idée est depouvoir agir rapidement, directement au niveau des routeurs afin d’éviter la perte depaquets.Dans le cas d’un contrôle de bout en bout, on voit le réseau comme étant une boîte noire
37

Chapitre 2 : Contrôle de congestion dans les réseaux haut débit
dont les composants internes (noeuds de commutations) ne nous intéressent pas ; tandisqu’un contrôle noeud par noeud, on voit le réseau comme étant une boîte blanche.
2.6 Principe du contrôle de congestion dans les ré-
seaux à commutation de paquets
Nous avons vu que les réseaux à commutation de paquets offrent plusieurs avantagestels que la flexibilité. En contrapartie, le prix à payer est le risque de congestion.
En effet, un réseau à commutation de paquets est par essence un réseau de filesd’attente. Ces dernières sont d’une taille limitée ; quand le taux d’arrivée des paquetsdans un noeud (routeur ou commutateur) dépasse le temps moyen de service, cecipeut mener à une débordement des buffers de ce noeud causant des phénomènes decongestion.
Le contrôle de congestion 4 dans les réseaux à commutation de paquets (packetswitching networks ) a suscité un grand intérêt au sein de la communauté scientifiquedepuis le début des années 80 [37]. En effet, il est très important d’éviter les pertesde paquets dans un réseau car quand un paquet est perdu avant qu’il atteigne sadestination, toutes les ressources qu’il a consommées durant son transit sont gaspillées.Dans un réseau à commutation de paquets caractérisé par la non réservation préalablede ressources, le contrôle de congestion doit être réactif. Un tel contrôle est implémentéà deux niveaux :
1. au niveau des commutateurs où la congestion survient ;
2. au niveau des sources qui augmentent et réduisent leur trafic en fonction dusignal de congestion.
Typiquement, un commutateur utilise quelques métriques pour détecter le début d’unecongestion. Par la suite, il notifie cette congestion soit implicitement soit explicitementaux sources qui , comme réponse, réduisent leur trafic.Même si un tel schéma paraît facile, il doit résoudre les problèmes suivants [63] :
2.6.1 Détection de la congestion
Pour détecter une congestion, un commutateur utilise plusieurs alternatives :• le moyen le plus connu est de notifier que les buffers du commutateur n’ont plus deplace pour les paquets arrivants ;• un commutateur peut aussi surveiller le taux d’utilisation de la ligne de sortie. Eneffet, Il a été montré que la congestion survient quand l’utilisation de la ligne de sortiedépasse un certain seuil (typiquement 90 %). Par conséquent, cette métrique peut
4A cette époque, contrôle de flux et contrôle de congestion étaient utilisés de façon interchangeable
38

Chapitre 2 : Contrôle de congestion dans les réseaux haut débit
être utilisée comme signal de congestion. Le problème de cette métrique est la phasede l’évitement de la congestion (congestion avoidance) peut laisser la ligne de sortieinutilisée menant ainsi à une inefficacité du réseau ;• une source peut aussi surveiller les RTTs (Round Trip Times). Une augmentationdans ces derniers signale une augmentation dans la taille des files d’attente et parconséquent un risque de congestion ;• une source peut aussi maintenir un temporisateur (timer) qui déclenche une alarmequand un paquet n’est pas acquitté à temps [82]. Une fois l’alarme déclenchée, lacongestion est alors suspectée.
2.6.2 Communication de l’information de congestion
La communication de l’information de congestion (ou notification de congestion)peut être faite de façon explicite ou implicite. Quand l’information est explicite, lescommutateurs envoient la notification de congestion sous forme d’un bit dans l’en-tête des paquets, ou dans des paquets indépendants (Source Quench) tels que ICMP.Le problème majeur des méthodes explicites est l’overhead (surcharge supplémentaire)qu’elle ajoutent au réseau. Les méthodes implicites ne souffrent pas de ce problème. Enrevanche, une source n’est pas capable de distinguer entre une congestion et d’autresproblèmes de performances.
2.6.3 Actions prises par un commutateur
Un commutateur congestionné peut signaler la congestion aux sources concernées,ou au pire des cas rejeter les paquets arrivant dans ses buffers d’entrée. Le problèmerevient alors à choisir soit une source à laquelle le commutateur demande de réduirele trafic ou tout simplement choisir quels paquets rejeter. L’équité d’un schéma decontrôle de congestion dépend étroitement de ce choix.
2.6.4 Contrôle de flux du côté des sources
Un nombre de mécanismes de contrôle de congestion ont été conçus pour opérer auniveau des sources. De tels mécanismes utilisent la perte de paquets ou la réception despaquets de sondage (choke paquets) comme signal pour réduire le débit des sources.Dans un schéma de congestion utilisant un sondage de paquets (packet choke), unesource arrête carrément son trafic quand elle détecte la congestion. Après une durée detemps, la source est autorisée à envoyer de nouveau. une telle stratégie n’est pas du toutefficace car elle est sujette à des oscillations. Par contre, dans un schéma à contrôle dedébit (rate-based control scheme), quand une source détecte une congestion, elle réduitle débit auquel elle envoit ses paquets. L’avantage de cette approche par rapport ausondage de paquets est qu’elle permet une transition graduelle dans le débit d’envoi
39

Chapitre 2 : Contrôle de congestion dans les réseaux haut débit
Fig. 2.6 – Principe de l’algorithme DECBit.
des sources. Par conséquent, elle présente une bonne alternative pour le contrôle decongestion. L’analyse de la stabilité et de l’efficacité de cette approche est donnée dans[63].
2.6.5 Coopération entre les différents acteurs
Dans une situation de congestion ou de façon plus générale de partage de ressources,on fait toujours l’hypothèse que les sources coopérent entre elles afin d’aboutir à un par-tage équitable des ressources et une utilisation plus efficace du réseau. Cependant, unetelle hypothèse ne sera pas toujours vraie dans les grands réseaux où quelques sourcesne coopèrent pas et se comportent de façon byzantine. Malheureusement, beaucoupde schémas de contrôle de congestion laissent passer inapercu ce point très important.Par exemple, dans DECBit [83], si une source "malhonnête" choisit d’ignorer le bitde notification de congestion qui a été positionné par un commutateur pour indiquerune congestion, les autres sources "honnêtes" vont automatiquement donner plus dela bande passante à cette source. TCP souffre du même problème dans la version deVan jacobson et Karels [51]. Pour plus de détails sur la coopération entre sources , lelecteur intéressé peut se référer à [94]. Comme exemple d’algorithme de contrôle decongestion dans les réseaux à commutation de paquets, nous nous proposons d’étu-dier l’algorithme DECBit conçu par K.K. Ramakrishnan et R. Jain aux laboratoiresde Digital Equipment Corporation (DEC) à la fin des années 80. OAr la suite, nousabordrons le contrôle de congestion dans TCP.
2.7 Contrôle de Congestion dans DECBit
Dans DECBit[83], les sources ajustent la taille de la fenêtre basée sur un feed-back explicite reçu du réseau. Tous les paquets ont un bit appelé Bit d’évitement deCongestion (Congestion Avoidance Bit) (Fig 2.6). Le but de DECbit est de contrôlerla congestion tout en maintenant une file d’attente non vide et de taille très petite
40
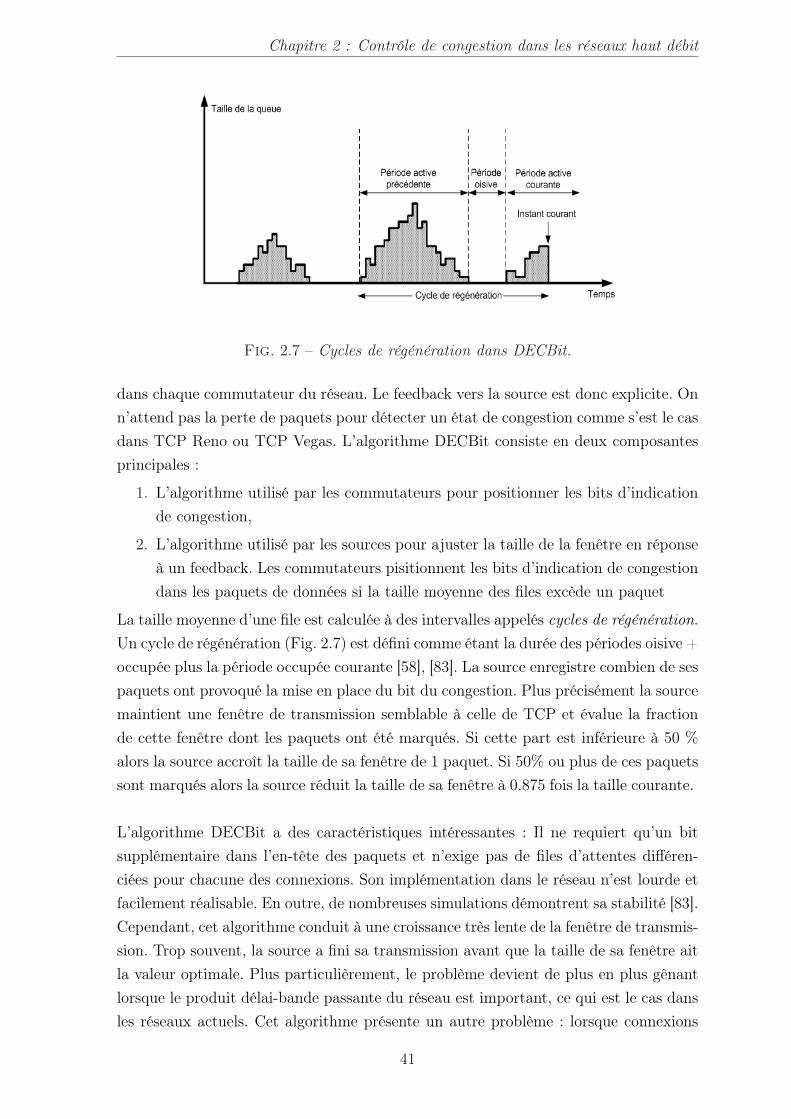
Chapitre 2 : Contrôle de congestion dans les réseaux haut débit
Fig. 2.7 – Cycles de régénération dans DECBit.
dans chaque commutateur du réseau. Le feedback vers la source est donc explicite. Onn’attend pas la perte de paquets pour détecter un état de congestion comme s’est le casdans TCP Reno ou TCP Vegas. L’algorithme DECBit consiste en deux composantesprincipales :
1. L’algorithme utilisé par les commutateurs pour positionner les bits d’indicationde congestion,
2. L’algorithme utilisé par les sources pour ajuster la taille de la fenêtre en réponseà un feedback. Les commutateurs pisitionnent les bits d’indication de congestiondans les paquets de données si la taille moyenne des files excède un paquet
La taille moyenne d’une file est calculée à des intervalles appelés cycles de régénération.Un cycle de régénération (Fig. 2.7) est défini comme étant la durée des périodes oisive +occupée plus la période occupée courante [58], [83]. La source enregistre combien de sespaquets ont provoqué la mise en place du bit du congestion. Plus précisément la sourcemaintient une fenêtre de transmission semblable à celle de TCP et évalue la fractionde cette fenêtre dont les paquets ont été marqués. Si cette part est inférieure à 50 %alors la source accroît la taille de sa fenêtre de 1 paquet. Si 50% ou plus de ces paquetssont marqués alors la source réduit la taille de sa fenêtre à 0.875 fois la taille courante.
L’algorithme DECBit a des caractéristiques intéressantes : Il ne requiert qu’un bitsupplémentaire dans l’en-tête des paquets et n’exige pas de files d’attentes différen-ciées pour chacune des connexions. Son implémentation dans le réseau n’est lourde etfacilement réalisable. En outre, de nombreuses simulations démontrent sa stabilité [83].Cependant, cet algorithme conduit à une croissance très lente de la fenêtre de transmis-sion. Trop souvent, la source a fini sa transmission avant que la taille de sa fenêtre aitla valeur optimale. Plus particulièrement, le problème devient de plus en plus gênantlorsque le produit délai-bande passante du réseau est important, ce qui est le cas dansles réseaux actuels. Cet algorithme présente un autre problème : lorsque connexions
41

Chapitre 2 : Contrôle de congestion dans les réseaux haut débit
différentes ont des délais inégaux, DECBit devient biaisé contre les connexions à longsdélais [58]. En outre, dans les périodes de congestion, il signale la congestion pas seule-ment aux connexions surchargeantes mais aussi aux connexions qui ont des exigencesen dessus de celles du partage max-min équitable . Comme il a été montré dans [19]que la combinaison de mécanismes AIMD (Additive Increase Multiplicative Decrease)avec un marquage sélectif (selective marking) mène à un système stable et équitable,cette solution a été apportée par la suite à DECBit.
2.8 Contrôle de congestion dans Internet
Historiquement, les premiers réseaux à large distance (WANs) étaient les réseauxtéléphoniques à commutation de circuits. Du moment que ces réseaux transportaientdes données de même type et que le trafic est bien connu, il était alors possible d’éviterla congestion en réservant suffisamment de ressources au début de chaque appel. Enrevanche, les ressources du réseau sont sous-utilisées en cas des silences. L’émergencedes réseaux de communication de données a connu une accrue de grande ampleur de-puis les années 80. Cette croissance a engendré un trafic de données très importantessentiellement pour les réseaux d’interconnexions tels que Internet.L’architecture protocolaire d’Internet basée sur un service en mode non connecté, debout-en-bout a fait ses preuves en matière de flexiblilité et de robustesse. En contre-partie, et contrairement aux réseaux à commutation de circuits, il faudrait plus devigilance pour continuer à fournir un bon service même quand le système est sur-chargé. Dans certains cas, ceci peut même mener à un effondrement de congestion(congestion collapse), une situation où une augmentation de la charge du réseau pro-voque une diminution de la charge utile écoulée ([14], [94]). Un tel phénomène a étéobservé durant la première phase de croissance d’Internet au milieu des années 80 (voirle RFC 896 [75] et [63]). Dans le but de pallier aux pertes dues à ces congestion et auxerreurs de transmission, un protocole pouvant les détecter et les corriger a été conçu :il s’agit du fameux protocole TCP (Transmission Control Protocol).
La spécification originale de TCP dans le RFC 793 [82] a inclu un contrôle de fluxbasé sur le mécanisme de fenêtre glissante (sliding window) comme un moyen pour unrécepteur pour contrôler la quantité de données envoyées par une source. Ce contrôlede flux a été utilisé pour prévenir le débordement des tampons du côté du récepteur.Ainsi, Le RFC 793 [82] rapporta que des segments TCP peuvent être perdus, soità cause d’erreurs de transmission, soit à cause de la congestion. En revanche, il n’apas inclu un mécanisme d’ajustement dynamique de la fenêtre de contrôle de flux enréponse à la congestion.Nous présenterons d’abord la notion d’effondrement de congestion. Par la suite,nous verrons les améliorations apportées pour le protocole TCP afin qu’il continue de
42

Chapitre 2 : Contrôle de congestion dans les réseaux haut débit
garantir un contrôle de flux de façon efficace dans les réseaux WAN.
2.8.1 Effondrement de Congestion (Congestion Collapse)
Pour présenter la notion d’effondrement de congestion (congestion collapse), exami-nons le réseau dont la topologie est donnée dans la figure 2.8. Nous ferons les hypothèsessuivantes :
– La seule ressource à allouer est bande passante des liens,– Si le trafic offert sur un lien ` dépasse la capacité C` du lien, alors toutes les
ressources doivent réduire de façon proportionnelle leurs trafics offerts. Noussupposons également que le mécanisme d’ordonnancement utilisé est FIFO (FirstIn First Out).
De façon imagée, on peut faire une analogie avec les fluides et considérer les donnéescirculant sur un réseau comme un fluide. Les liens sont alors des canalisations, et lesfiles d’attentes des réservoirs. Elle revient à dire dans notre cas que les paquets vontêtre envoyées sur le lien dans l’ordre d’arrivée dans le buffer, l’ordonnanceur étant lavanne entre le réservoir et le canal [94].Les sources S1 et S2 envoient du trafic aux destinations D1 et D2 respectivement. Lescapacités (en kb/s) et les noms de chaque lien sont donnés dans la figure 2.8. Lessources ne sont limités que par la bande passante de leur premier lien et ne reçoiventpas de notification de congestion du réseau. Soient λi le débit d’émission de la sourcei et λ′i son débit sortant. Par exemple, pour notre réseau, on a λ1= 100 kb/s et λ2=1000 kb/s. Mais λ′1= λ′2 = 10 kb/s ! !.En effet, la source S1 peut seulement envoyer à 10 kb/s car elle est en compétitionavec la source S2 qui envoie à un débit plus grand que celui de la source S1 sur lelien . Par contre, la source S2 est limitée à 10 kb/s à cause du lien L5. Si la source S2
est au courant de la situation globale du réseau et si elle "coopère", alors elle pourraenvoyer à un débit de 10 kb/s seulement sur le lien L2, ce qui va permettre à la sourceS1 d’envoyer son trafic à un débit de 100 kb/s sans toutefois que la source S2) nesoit pénalisée. Ainsi, le debit global du réseau sera 110 kb/s. Ainsi, on pourra tirer laconclusion suivante :
Dans un réseau à commutation de paquets, les sources doivent limiter leurs débitsd’émission en prenant en compte l’état du réseau. Sinon, il y a un risque d’effondrementde congestion.Cette situation a déja eu lieu au milieu des années 80 (voir [63] et [51]). Le facteurprincipal qui a mené à cette situation était l’absence de contrôle de flux dans lesréseaux TCP/IP à cette époque. D’autre facteurs tels la fragmentation IP ont aggravéla situation en causant l’effet "avalanche". Dans le RFC 2914 [28], Sally Floyd étudieen détails les raison qui pousse à la situation d’effondrement de congestion.
43

Chapitre 2 : Contrôle de congestion dans les réseaux haut débit
Fig. 2.8 – Exemple de topologie du réseau.
2.8.2 Contrôle de Congestion dans TCP
Des études récentes du trafic réseau dans plusieurs campus indiquent que plus de90% du trafic est transporté par le protocole TCP (Transmission Control Protocol)qui a été défini dans le RFC 793 [82]. Les mécanismes de contrôle de congestion pourles protocoles TCP/IP ont été longtemps étudiés et de nombreux algorithmes ont étéproposés dans la littérature. Le contrôle de congestion dans TCP continue d’être unsujet de recherche. Par exemple, dans [15] les auteurs ont montré que l’on pouvaitaméliorer le débit de TCP de 40 à 70 % en gérant l’horloge de façon plus précise, enprévoyant des congestions avant que les temporisateurs (timers)expirent et en utili-sant ces anticipations d’alarme pour améliorer l’algorithme du Slow Start. Le protocoleTCP, inventé en 1981 (voir [82]), est un protocole de la couche transport du modèleOSI (Open System Interconnection)qui assure l’arrivée des paquets envoyés leur des-tination et qui prend en charge la numérotation des paquets, et contrôle la congestiondu réseau due à l’envoi trop intensif du trafic . Pour ce faire, il se sert de mécanismesbasés sur des accusés de réception (acknowledgments) pour s’assurer de l’arrivée despaquets à bonne destination et de mécanismes à fenêtres (voir [21]) de transmission etde réception pour gérer les congestions.
Plusieurs versions de TCP ont été proposées dans la littérature pour améliorer lesperformances de TCP dans Internet :Dans TCP Tahoe, Van Jacobson donne les premières améliorations de TCP au ni-veau de ses algorithmes de contrôle de congestion [51]. Il définit un nouveau conceptimportant qui est la fenêtre de congestion (congestion window) sur laquelle se basedeux algorithmes principaux de TCP : Les algorithmes de Slow Start et de CongestionAvoidance. Cette version de TCP porte le nom de TCP Tahoe et date de 1988. par lasuite, vinrent d’autres versions : TCP Reno, TCP Vegas, TCP New Reno, etc [16].
44

Chapitre 2 : Contrôle de congestion dans les réseaux haut débit
2.9 Améliorations pour TCP dans les réseaux haut
débit
Plusieurs études ont montré l’incompatibilité qui existe entre les mécanismes decontrôle de congestion de TCP et les fonctions de contrôle de trafic des réseaux ATM(voir par exemple [2], [22], [26], et [30]). Ceci vient du fait que, contrairement à TCP quioffre un contrôle de congestion réactif, les réseaux ATM implémentent un mécanismede contrôle préventif.Cependant, le protocole TCP a toutes les chances de rester prépondérant pour de trèslongues années, dans les réseaux filaires (wired networks) tels que ATM aussi bienque dans les réseaux sans fils (wireless networks). L’ouvrage [41] étudie de façon trèsdétaillée les problèmes de TCP dans les réseaux à fibre optique, les réseaux satellitaires,les réseaux sans fils et les réseaux asymétriques.
L’analyse mathématique révèle que le comportement de TCP devient oscillatoire etinstable quand le produit délai-bande passante devient relativement grand [73]. L’autreproblème dont souffre TCP est l’inefficacité. Ceci est du au mécanisme de l’AdditiveIncrease de TCP qui limite sa capacité de bénéfécier des grands débits offerts par lesmédias de transmission moderne tels que la fibre optique qui peuvent atteindre desdébit de l’ordre du gigabit/s [73].
Plusieurs améliorations ont été apportées dans la littérature à TCP pour qu’ilsoit efficace dans les réseaux à grand produit bande passante-délai. On peut citer parexemple : Scalable TCP [62], FAST TCP [24], High Speed TCP [29] et XCP [61], [60].Dans ce dernier, les auteurs développent un protocole baptisé XCP (eXplicit ControlProtocol) qui est demeure efficace, équitable et stable même quand le RTT ou le BDPdeviennent grands. Le protocole XCP généralise la proposition de l’ECN (ExplicitCongestion Notification) proposée dans le RFC 2841 [?]. En effet, au lieu d’utiliserun seul bit dans ECN, les routeurs supportant XCP doivent informer les sources nonseulement si une congestion existe ou non mais indiquent également le degré ce cettecongestion. Ainsi, pour XCP la congestion n’est pas représentée comme une variablebinaire mais plutôt à des dégrés . Une autre notion très importante aussi dans XCPest le découplage du contrôle d’efficacité et du contrôle d’équité.
2.10 Contrôle de congestion dans les réseaux haut
débit
2.10.1 Mythes non fondés
La congestion se produit dans un réseau quand la demande est plus grande que lesressources disponibles. Ceci a mené à de fausses croyances au sein de la communauté
45

Chapitre 2 : Contrôle de congestion dans les réseaux haut débit
scientifique [53], [55] concernant des solutions possibles à ce problème . On peut citerpar exemple :
1. La congestion est causée par le déficit en terme d’espace mémoire dans les com-mutateurs et les routeurs, et ceci va être résolu quand le coût de la mémoire vabaisser ;
2. La congestion est causée par les liens à faible débit ; ceci va alors être résolu avecl’avènement de liens à haut débit ;
3. La congestion est causée par les processeurs très lents. Le problème va être résoluquand la vitesse des processeurs sera suffisamment grande ;
4. Si aucun des points ci-dessus n’est la vraie raison causant la congestion, alorsl’avènement d’une technologie répondant aux trois exigences ci-dessus réglera leproblème de congestion de façon définitive.
Raj Jain nous montre dans [53], de façon simple, que de telles idées ne sont que desmythes. En effet :
– L’augmentation de la taille des tampons dans les différents noeuds du réseaucausera des délais d’attente plus grands. Nagle a montré dans [76], et [77] quemême si les routeurs disposaient d’une file d’attente infinie, la congestion serait enfait bien pire. Ceci est lié au fait que le temps mis par les paquets pour atteindrela tête de la file est largement supérieur au temps imparti à la transmission d’unpaquet (time out). Il en découle que des paquets dupliqués risquent d’arriver surles entrées du routeur car les sources ont, elles aussi, atteint le temps au boutduquel elles doivent retransmettre un paquets qui n’a pas été acquitté. Tousces paquets seront donc retransmis plusieurs fois aux routeurs suivants, ce quiaugmente d’autant la surcharge du réseau sur la quasi-totalité des destinations.
– L’accroissement des débits supportés causera une mésalliance entre les différentsacteurs du réseaux aggravant ainsi de plus en plus la congestion.
– L’amélioration des vitesses des processeurs dans les différents noeuds du réseauquant à elle ne garantira pas de pallier ce problème.
Pour étayer ses propos, il nous donne l’exemple suivant (Fig. 2.9) qui montre que l’in-troduction d’une liaison haut débit, sans l’adjonction d’un mécanisme de contrôle decongestion adéquat, peut conduire à une réduction considérable des performances. Eneffet, on s’attendait à réduire le délai de bout en bout du transfert du fichier. Or, ceque c’est passé est tout à fait l’inverse : le temps de transfert est passé de 5 min à7 heures ! Ceci est justifié par le fait que le débit à l’entrée du premier routeur estdevenu largement plus important qu’à sa sortie, conduisant à l’accumulation puis à laperte de paquets dans sa file d’attente. Or, les pertes de paquets donnent lieu à desretransmissions des paquets perdus, qui à leur tour, se font avec un très fort taux deperte et ainsi de suite jusqu’à ce que le fichier soit entièrement transféré.
46

Chapitre 2 : Contrôle de congestion dans les réseaux haut débit
Fig. 2.9 – L’introduction d’une laison à haut débit n’a fait qu’aggraver la situation.
Cet exemple nous illustre à merveille que le contrôle de congestion devient primor-dial lorsque le réseau est hétérogène, c’est à dire lorsque des liaisons hauts débits sontconnectées à des réseaux de plus faibles débits. La congestion à l’interconnexion de-vient un véritable problème, et les performances obtenues peuvent être inférieures àcelles précédant l’intégration de la liaison haut débit. Ainsi, le renforcement d’un seulélément d’un système ne permet pas d’améliorer fortement ses performances ; le plussouvent cela se traduit par un simple déplacement du problème. Le vrai problème estla différence de performances qui existe entre les éléments du système. De ce fait, lacongestion persistera aussi longtemps que cette différence demeure [92].
2.10.2 Difficultés supplémentaires
Le contrôle de congestion est plus ardu à résoudre dans les réseaux haut débit !Ceci est justifié par les points suivants :
– Les liaisons à haut débit doivent coexister avec les liaisons à faible débit. En effet,pour des raisons économiques, on ne peut pas se permettre de changer toutes lesliason à faible débit par d’autrtes à haut débit ;
– Le produit bande passante-délai est très élevé rendant le contrôle de flux parfenêtre inapplicable ;
– La congestion survient plus vite que dans les réseaux à faible débit. Par exemple,si on dispose d’un buffer de taille 64 kilo octets, les résultats montrent que lacongestion surviendra chaque 8.2 secondes si le lien d’entrée a une capacité de 64ko/s, et seulement à chaque 0.52 millisecondes si le lien d’entrée a une capacitéde 1 gigabit/s ;
– Le trafic est très sporadique dans ce type de réseaux, ce qui rend imprévisible labande passante que l’on doit lui allouer ;
– La qualité de service des connexions déja établies doit être toujours garantie ;– Hétérogénéité des services supportés par ces réseaux, etc.
47

Chapitre 2 : Contrôle de congestion dans les réseaux haut débit
Fig. 2.10 – Principe du contrôle d’admission
2.11 Contrôle de Congestion dans ATM
Le contrôle de congestion dans ATM correspond aux actions prises par le réseauafin de minimiser l’intensité, la durée et l’étendue de la congestion. Malheureusemnt, laplupart des schémas de contrôle de congestion conçus pour les réseaux à commutationde paquets ne sont pas applicables pour les réseaux ATM, et ceci à cause des raisons quenous avons citées ci-dessus. Par conséquent, d’autres protocoles prenant en compte lescaractéristiques des réseaux à haut débit ont été conçus et proposés dans la littérature[80]. Dans cette section, nous étudierons les les plus connus de ces algorithmes.
2.11.1 Fonction de Contrôle d’admission (Call Admission Control)
Pendant la négociation du contrat de trafic la source doit caractériser le traficqu’elle va présenter au réseau. Un paramètre de trafic est défini comme la spécificationd’un aspect particulier du trafic, tel que son débit crête, son débit moyen, sa taillemaximale de rafale, etc. Un paramètre de trafic peut être qualitatif (par exemple,la source déclare qu’il s’agit d’un service téléphonique) ou quantitatif (en termes deparamètres de QoS). Le descripteur de trafic est un ensemble ou une liste de tousles paramètres de trafic qui peuvent être utilisés par une source pour caractériser sontrafic [33].
Dans la recommandation I.371 [50] de l’UIT, le contrôle d’admisssion a été définicomme étant "l’ensemble des actions prises par le réseau pendant la phase d’établis-semnt de l’appel (ou durant la renégociation de l’appel) pour établir si une connexionpeut être acceptée ou doit être rejetée". La définition de la même fonction est donnéede façon très similaire dans L’ATM Forum. Une connexion ne peut être acceptée ques’il y a des ressources disponibles, dans tous les éléments du réseau que la connexiontraverse, pour garantir la QoS négociée tout en continuant de respecter les engage-ments pris avec les autres connexions préalablement établies [17], [87]. La fonction
48

Chapitre 2 : Contrôle de congestion dans les réseaux haut débit
CAC est invoquée pour chaque lien du réseau ATM entre le point d’origine de l’appelet la destination.
2.11.1.1 Problème de la bande passante équivalente
La complexité du trafic hétérogène dans les réseaux haut débit rend la décisiond’accepter un nouveau appel très difficile. En effet, dans un mode de transfert utilisantun multiplexage déterministe la décision d’admettre une nouvelle connexion peut êtrebasé tout simplement sur le débit crête (PCR) requis par l’appel et de la bande passantedisponible dans le réseau au moment de l’arrivée de cet appel. Par contre , dans le casd’un mode de multiplexage statistique, une telle décision pour un nouveau appel estplus compliquée car les exigences en bande passante des débits crêtes peuvent dépasserla capacité du lien de sortie. Dans ATM, le réseau ne réserve pas explicitement unebande passante aux différentes connexions. Par contre, le besoin en bande passante estcalculé selon plusieurs approches qu’on trouvera dans [18].Il est possible de développer des algorithmes de CAC en se basant sur des hypothèsesde trafic. Par exemple, si on suppose que les trafics sont poissoniens, l’étude de lafile M/D/1/k permet d’indiquer le montant de ressources nécessaires pour accepter laconnexion (voir Chapitre 4). De même, si on fait l’hypothèse que le trafic est de typeON/OFF (rafales suivies de silences de longueurs exponentiellement distribuées), ilest possible de développer un algorithme de contrôle d’admission correspondant [40].Dans la littérature, beaucoup d’algorithmes de contrôle d’admission ont été proposés :
2.11.1.2 Contrôle d’admission basé sur les paramètres de la connexion
Ce type d’algorithmes utilise les caractéristiques d’une connexion qui sont spéci-fiées par l’usager pour décider s’il va accepter ou rejeter cette connexion [57]. Ce typed’algorithmes peut être à son tour divisé en deux sous-classes : algorithmes à allocationstatistique et ceux à allocation non-statistique.Contrôle d’admission à allocation non statistiqueLes algorithmes à allocation non statistique (appelée aussi allocation par débit crête)forment la classe la plus simple parmi tous les algorithmes de contrôle d’admission.La seule information requise pour faire une décision sur l’acceptation ou le rejet d’uneconnexion est le debit crête (PCR). Le principe est de s’assurer que la somme desressources requises est bornée par la capacité du lien de sortie. Le problème majeur detels algorithmes est qu’il n’y a pas de gain statistique. Cependant, vu leur simplicitéet la très bonne qualité de service (aucune cellule n’est perdue) qu’ils offrent, ces al-gorithmes ont été largement implémentés dans les commutateurs ATM.Contrôle d’admission à allocation statistiqueCes algorithmes ont une philosophie plus compliquée : ils n’acceptent pas une connexionen se basant seulement sur le débit crête mais plutôt la bande passante allouée est si-
49

Chapitre 2 : Contrôle de congestion dans les réseaux haut débit
tuée entre le débit crête (PCR) et le débit moyen (MCR). Par conséquent, il peutarriver que la somme des débits crête dépasse la bande passante du lien de sortie cau-sant ainsi des pertes de cellules. L’avantage de ces algorithme est le gain statistiqueconsidérable qu’il permettent d’offrir surtout pour des sources sporadiques. Par contre,dans des situations de congestion sévère, ils deviennent très difficiles à manipuler [80].
2.11.1.3 Contrôle d’admission basé sur les mesures
Ces algorithmes utilisent les mesures pour estimer la charge courante du traficexistant. Par conséquent, ils ne peuvent être évalués qu’en utilisant des réseaux ATMdéja existants ou en utilisant la simulation [96]. Ces algorithmes facilitent la tâche del’usager qui n’est pas obligé à chaque fois de spécifier les paramètres de sa connexion.
2.11.1.4 Contrôle d’admission basé sur la bande et la capacité du buffer
Dans les algorithmes basés sur la la bande et la capacité du buffer, chaque sessionest représentée par un couple (σ, ρ) où σ et ρ représentent respectivement l’espace dansle tampon et la bande passante allouée à la connexion dans chaque commutateur. Untel schéma garantit la qualité de service pour la connexion et s’avère très flexible car lataille du buffer et la bande passante peuvent être dynamiquement alloués en se basantsur les ressources existantes et les connexions déja admises. La taille du buffer σ peutêtre diminuée en augmentant la bande passante ρ et vice versa [20].
D’autres fonctions CAC existent dans la littérature . Le lecteur intéressé peut consulterpar exemple [6], [17], [18], et [31].
2.11.2 Fonction de Contrôle des paramètres de l’utilisateur(UPC, User Parameter Control)
La fonction CAC est responsable de l’admission de nouvelles connexions réseau sicelui-ci peut satisfaire la qualité de service exigée. Par contre, cette fonction n’a aucunsens si aucun mécanisme d’UPC n’est utilisé. En effet, les utilisateurs peuvent inten-tionnellement ou non excéder les paramètres de trafic déclarés lors de l’établissementde la connexion. Par conséquent, ceci peut surcharger le réseau. Pour éviter un tel scé-nario, une fonction de contrôle des paramètres de l’utilisateur (UPC,User ParameterControl ) doit être définie aussi proche que possible de la source du trafic. L’objectifde l’UPC est de détecter toute violation du contrat de trafic établi et de prendre lesactions appropriées. Seul le débit crête doit être obligatoirement contrôlé. Les actionsque peut réaliser une fonction d’UP sont les suivantes [56], [63] :
– laisser passer la cellule ;– retarder la cellule ;
50

Chapitre 2 : Contrôle de congestion dans les réseaux haut débit
Fig. 2.11 – Principe du seau percé (leaky bucket)
– rejeter la cellule ;– marquer la cellule avec un bit CLP positionné à 1 ;– informer l’entité qui gère la connexion pour que celle-ci décide de fermer la
connexion.Une fonction UPC idéale doit être capable de détecter les cellules violant les paramètresdéclarés, transparente aux connexions respectant leurs paramètres d’admission et sontemps de réponseDivers mécanismes ont été proposés pour implémenter l’UPC. On peut citer parexemple : la fenêtre glissante (sliding window) et la fenêtre sautante (jumping win-dow) [31].
2.11.3 Canalisation du trafic (traffic shaping)
L’une des cause principales de la congestion provient du fait que le trafic est aléa-toire et très souvent sous forme de données en rafales (bursts) ou en saccades incon-trôlées. Une des techniques de contrôle de congestion en boucle ouverte qui permetd’améliorer sensiblement le traitement de la congestion en s’efforçant de maintenirle trafic le plus constant possible dans le réseau est la canalisation du trafic (trafficshaping) qui consiste à réguler la vitesse et le rythme saccadé d’écoulement des don-nées dans le réseau. En comparaison ,la fenetre coulissante du protocole TCP limitela quantité de données
A cet effet, L’algorithme du seau percé (leaky bucket) a été défini pour la premièrefois par Turner [97]. Imaginons un seau d’eau dont le fond est percé d’un trou par lequell’eau s’écoule en goutte à goutte. Peu importe à quel débit l’eau arrive dans le seau,son écoulement par le trou se fait à une vitesse constante tant qu’il y a de l’eau dans leseau ; l’écoulement s’interrompt dès qu’il n’y a plus d’eau dans le seau. Evidemment,lorsque le seau est plein le surplus d’eau arrivant est perdu, le seau déborde sans que
51

Chapitre 2 : Contrôle de congestion dans les réseaux haut débit
Fig. 2.12 – Principe du seau percé à jetons
cela n’influe sur l’écoulement de l’eau par le trou (Fig. 2.11). Ce principe peut êtretransposé sans difficulté à la transmission de paquets dans un réseau : un ordinateurn’est autorisé à insérer un paquet dans le réseau qu’à chaque top d’horloge. Ainsi, cemécanisme transforme un flux irrégulier de paquets provenant d’un processus clientinterne à un ordinateur source en un flux régulier de paquets sur le réseau permettantainsi de faire disparaître les pics de trafic qui causent souvent des phénomènes decongestion . Une amélioration du seau percé est l’algorithme du seau percé à jeton(token bucket) ( Fig. 2.12). L’idée de base de cet algorithme est la suivante : quandune nouvelle cellule arrive dans le réseau elle doit se procurer un ticket (token) d’unseau de taille β qui contient des jetons . Un fois la cellule transmise, le nombre dejetons est décrémenté. Si la cellule ne trouve aucun jeton, alors elle doit soit attendres’il a assez de places dans la file d’attente qui d’une taille K ; soit rejetée si le filed’attente est pleine. La génération des jetons se fait à un débit ρ
2.11.4 Gestion Passive de la file d’attente
La gestion passive de la file d’attente (Passive Queue Management) est la méthodela plus simple pour supprimer les paquets en cas de congestion. Son principe est derejeter tout paquets arrivant quand la file est pleine. Plusieurs versions ont été propo-sées dans la littérature pour implémenter cette méthode. Nous en étudierons quelquesune dans cette section.
2.11.4.1 La méthode Drop Tail
L’algorithme du Drop tail est le plus simple des algorithmes de rejet de paquets.Son principe est de rejeter tout paquets arrivant lorsque les files d’attente dans les rou-teurs sont pleines. Aucune notification explicite de perte ne sera envoyée aux sources.
52

Chapitre 2 : Contrôle de congestion dans les réseaux haut débit
En effet, il incombe au protocole TCP de détecter implicitement ces pertes soit parl’expiration des temporisateurs, soit par les acquittements reçus. L’avantage du Droptail est sa simpilcité de mise en oeuvre. En revanche, Drop Tail a plusieurs inconvé-nients. Le premier inconvénient est qu’il n’est pas capable de faire une isolation entreles differents flux, ce qui sera très gênant pour les application temps réel telles la vi-déo, l’audio, et la vidéoconférence. L’inéquité est un autre problème dont souffre DropTail. En effet, les connexions avec un large RTT (Rount Trip Delay) ont tendance àaugmenter les tailles de leurs fenêtres de façon plus lente que celles (les connexions)qui ont des RTTs plus petits. Un troisième inconvénient est le fait de ne pas agir contreles sources qui se comportent de façon illégale, et ne répondent pas aux indications decongestion (implicites ou explicites) et qui transmettent plus qu’il leur est toléré. cessources occuperont un grand espace dans les files d’attente des routeurs augementantaisi les taux de perte pour les autres sources qui se comportent de façon lus ou moinslégale.
2.11.4.2 la méthode Drop from Front
D’autres approches ont été proposée dans la littérature qui différent un peu deDrop Tail. Lakshman et al proposent de rejeter les paquets à partir de la tête de lafile d’attente au lieu de la queue quand la file est pleine . Une telle approche est diteDrop from Front. dans cette approche, TCP va détecter les pertes de paquets plusrapidement que dans Drop Tail. D’autre part, Drop from Front améliore le débit etl’équité en évitant des pertes sporadiques et en évitant les synchronisations entre lesdifférentes sources.
2.11.5 Contrôle de flux pour la classe ABR (Available Bit Rate)
Dans les cas des trafic CBR et VBR, il est impossible de demander à l’émetteurde réduire sa production de cellules, même en présence de congestion, étant donné lecaractère temps réel des flux d’information. Par contre, dans le cas d’un trafic UBR(Unspecified Bit Rate) ceci est possible. La capacité de transfert ABR se caractérisepar le fait que la bande passante utilsable varie au cours du temps après l’établissementde la connexion, et peut éventuellement atteindre des valeurs très élevées proches dela bande passante de la ligne de transmission. L’idée maîtresse de la capacité ABR(Available Bit Rate) est la suivante : une fois une connexion établie, les ressources duréseau seront mieux utilisées si la source s’adapte à l’état du réseau plutôt l’inverse. Unefois une connexion ABR établie, deux types de contrôle de flux doivent être exécutéspar le réseau
– Les différents éléments du réseau doivent calculer les ressources disponibles pourla connexion et en informar la sources tout au long de la connexion
53

Chapitre 2 : Contrôle de congestion dans les réseaux haut débit
– L’UPC doit contrôler que la source obéit au comportement de référence.Après de nombreuses discussions et de longs débats [84], deux propositions furentparticulièrement appréciées. L’une proposée par Kung et Morris [66] était basée surun crédit d’accès, l’autre proposée par Bonomi et Fendick [11] était basée sur le débitmoyen. On trouvera dans [59] et [89] une synthèse sur les différentes méthodes decontrôle de flux pour la classe ABR.
2.11.6 Réservation rapide de ressources (Fast Resource Mana-
gement)
Souvent, il est très difficile de caractériser des flux très sporadiques avec les para-mètres de trafic proposés par l’UIT. Pour faire face à ce problème, une autre approchea été proposée dont le principe est le suivant : la source donne des informations sur letrafic pendant la connexion. par exemple, la source peut informer le réseau avant detransmettre une nouvelle rafale. Par conséquent, le réseau pourra faire une réservationde ressources afin de satisfaire cette demande. ce principe est appelé réservation ra-pide de ressources. On trouve dans la littérature deux deux protocoles de ce types etqui sont proposé par le Centre National d’Etudes des Télécommunications de France(CNET). dans le premier protocole appelé FRP/DT (Fast Reservation Protocol withDelayed Transmission), la source attend une confirmation du réseau avant de trans-mettre la rafale. Ainsi, la qualité de service en terme probabilité de perte de cellules estgarantie pour les rafales acceptées. Avec le deuxième protocole appelé FRP/IT (FastReservation Protocol with Immediate Transmission), la source envoit la rafale tout desuite après la cellule de réservation. Dans ce cas, la rafale est perdue s’il n’y a pasde ressources disponibles dans le réseau. Notons que le protocole FRP-IP est mieuxadapté aux services temps réel tandis que le FRP-Dt est meiux adapté aux servicesde données pour lesquels le retard des rafales ne pose pas de problème. La propositionde la réservation rapide de ressources n’a pas été accepté à l’ATM Forum. Cette pro-position faite par France Telecom requiert qu’une source envoie des cellule de contrôle(RM cells).Dans la littérature on trouve d’autres solutions essayant de faire en sorte que les dif-férents schémas de contrôle de congestion étudiés supra "coopèrent" entre eux afind’aboutir à de meilleurs performances. Ces approches utlisent l’intelligence artificielleet les systèmes multi-agent (voir par exemple [36] et [35]).
54

Chapitre 2 : Contrôle de congestion dans les réseaux haut débit
Fig. 2.13 – Congestion due au choix du plus court chemin.
2.12 Ingénierie de trafic et contrôle de congestion
dans MPLS
Dans cette section ,nous abordons très brièvement la notion d’ingénierie de traficdans les réseaux MPLS. Par ingénierie de trafic (TE, Traffic Engineering), on veutdire le processus qui tente de balancer le trafic de manière à éviter la congestion dansun réseau et d’optimiser l’utlisation des ressources du réseau [101],[100],[43], [86]. Eneffet, dans les réseaux classiques, le trafic est routé en se basant sur le principe sautpar saut (hop by hop) et le protocole IGP (Internet Gateway Protocol) utilise toujoursl’algorithme du plus court chemin OSPF (Open Shortest Path First) pour acheminerle trafic. Or, OSPF présente deux grands inconvénients[18] :
1. les plus courts chemins de plusieurs connexions peuvent se chevaucher sur unlien commun causant ainsi une congestion sur ces liens ;
2. Le trafic émanant d’un routeur source à un routeur desination peut excéder lacapacité des plus courts chemins alors que les chemins les plus longs entre cesdeux routeurs sont sous-utlisés.
Nous donnons ici un exemple d’ingénierie de trafic dans MPLS tiré de [18]. La figure2.13 montre un domaine MPLS ayant 8 routeurs. Il y a deux chemins menant du rou-teurs C au routeur E. Ces deux chemins sont indiqués sur la même figure par 1 et 2.Si le routeur applique l’algorithme du plus court chemin de C à E (qui est C-D-E),alors ce chemin supportera tout le trafic destiné pour E et passant par C. Ceci peutévidemment causer une congestion tandis que l’autre chemin C-F-G-H-E est inutilisé.Afin de maximiser la performance globale du réseau, il serait intéressant de contour-ner une fraction du trafic d’un lien du réseau à l’autre. Pour résoudre ce problème,
55

Chapitre 2 : Contrôle de congestion dans les réseaux haut débit
Fig. 2.14 – Solution au problème de congestion par ingénierie du trafic.
l’IETF (Internet Engineering Task Force) a introduit le routage basé sur contraintes(constraint-based routing)[23] et une amélioration au protocole IGP appelée "enhancedlink state IGP". Avec l’aide de MPLS, une solution peut être apportée au problème decongestion en utilisant un équilibrage de charge (load balancing). Par exemple, on voitdans la figure 2.14, MPLS a balancé la charge de telle sorte que le réseau soit utliséde façon efficace.
L’ingénierie du trafic offre plusieurs avantages, à savoir [3] :
1. Avec MPLS, les capacités d’ingénierie du trafic sont intégrées à la couche 3, cequi optimise le routage du trafic IP en fonction des contraintes imposées par lacapacité et la topologie du backbone ;
2. Elle achemine les flux de trafic IP à travers le réseau en se basant sur les ressourcesdont le flux a besoin, et sur les ressources diponibles dans le réseaux ;
3. Elle utilise le routage basé sur les contraintes (constraint-based routing)dans le-quel un chemin pour un flux est choisi selon la distance, la bande passante requise,et la priorité du flux ; permettant ainsi de garantir une bonne qualité de service ;
4. Elle permet de s’adapter à un nouvel ensemble de contraintes en cas de présencede défaillance dans les liens du réseau ou en cas de changement de la topologiedu réseau.
56

Chapitre 2 : Contrôle de congestion dans les réseaux haut débit
2.13 Conclusion
Dans ce chapitre, nous avons mis en évidence le fait que les technologies haut débit,tellement attendues pour résoudre le problème de congestion, n’ont fait qu’aggraver lasituation. Par conséquent, il faut investir d’avantage dans la conception de nouveauxmécanismes et protocoles pour faire face à ce problème. Nous avons également vu queorganismes de standardisation de ATM préconisent un contrôle préventif pour garantirune certaine qualité de service. Cependant, le contrôle réactif est aussi présent notam-ment pour la classe de service ABR. Le choix d’un mécanisme donné au détriment d’unautre se fait selon une métrique de performance. Cette dernière peut être objective (vi-sion du concepteur du réseau) ou subjective (vision des utilisateurs). Nous verrons dansle chapitre qui suit quelques problèmes liés à l’évaluation des performances de réseauxATM.
57

Chapitre 3
Evaluation de Performances des
Réseaux ATM
"Contrary to common belief, performance evaluation is an art."
Raj Jain [54]
3.1 Introduction
LES administrateurs, les utilisateurs et les concepteurs de systèmes informatiquessont tous intéressés par l’évaluation de performances. En effet, si on néglige l’étape
de l’évaluation et on passe directement à l’implémentation réelle et la mise en oeuvredu système, les coûts peuvent être sévères en cas de non-conformité du système aux exi-gences temporelles requises pour les applications. Prenons comme exemple les réseauxATM : quand des centaines ou des milliers de réseaux d’ordinateurs sont interconnec-tés, il se produit des interactions complexes aux conséquences parfois imprévisibles.Cette complexité conduit souvent à des performances médiocres sans même que l’onsache pourquoi. Par conséquent, on doit recourir à des méthodes et des techniquespour éviter de tels scénarios.La nécessité de l’évaluation de performances des réseaux ATM commence à partir dela phase d’installation et jusqu’à la mise en oeuvre opérationelle du réseau. Lorsque leréseau est installé et les indices de performances sont évalués, on pourra s’intéresserà un choix meilleur de la configuration du système. Ainsi, il convient de comparer lesperformances de deux ou plusieurs réseaux.Notons que l’évaluation de performance peut se faire de deux manières : qualitative etquantitative. L’aspect qualitatif implique l’utilisation de méthodes efficaces capables decontrôler le comportement logique du système alors que l’aspect quantitatif comprendl’utilisation de méthodes permettant d’obtenir les paramètres numériques dans le butd’analyser les performances du système.
58

Chapitre 3 : Evaluation de performances des réseaux ATM
Fig. 3.1 – Processus de modélisation
3.2 Les deux étapes de l’évaluation de performances
L’évaluation de performances peut être partagée en deux étapes distinctes, à sa-voir : la modélisation qui consiste en le développement d’une description formelle dusystème ; et la résolution qui consiste en l’obtention des prédictions de performancesdu système [27].
3.2.1 Modélisation
la modélisation (modelling) joue un rôle primordial dans la conception ou la main-tenance des systèmes informatiques, de production et de télécommunications. Avantd’introduire la notion de modèle, nous définissons d’abord la notion de système.
Définition 1 (Système) Un système est définie comme étant un ensemble d’élé-ments qui interagissent entre eux afin de résoudre un tâche bien déterminée.
Parfois, il impossible d’étudier le système directement du fait qu’il soit inaccessible,ou trop coûteux pour qu’on puisse l’expérimenter directement. Par conséquent, on faitrecours à des modéles. Un modèle est défini comme suit :
Définition 2 (Modèle) Un modèle est une représentation de la réalité dans unformalisme donné. Il est développé pour répondre à des questions déterminées et com-porte certaines limitations, c’est une abstraction du système réel [9].
Le choix d’un modèle dépend essentiellement de la mesure de performance qui nousintéresse. A partir du modèle, nous voulons obtenir des résultats sur le système étudié.Certains résultats peuvent nous amener à modifier notre vision du système, et nousinciter à calculer de nouveaux résultats sur le modèle. Pour cela, nous pouvons êtreamenés à complexifier le modèle pour rajouter des informations. De même, nous pou-vons nous rendre compte que certains résultats ou éléments du modèle sont inutiles
59

Chapitre 3 : Evaluation de performances des réseaux ATM
Fig. 3.2 – Illustration des Critères de Performance.
pour calculer les indices de performances recherchés, et par conséquent, nous pouvonsainsi parfois simplifier le modèle pour faciliter sa résolution. Pour finir, nous compa-rons les résultats obtenus avec le comportement du système réel , et nous pouvonsalors concevoir le système qui donne les performances optimales. L’avantage de la mo-délisation par rapport aux mesures directes est qu’elle peut être employée aussi bienpendant les phases de conception d’un système que durant les phases de l’exploitationopérationnelle.
3.2.2 Résolution
Dans cette deuxième phase, la question que l’on se pose est la suivante :
" Quels sont les critères (ou les indices) de performance qui nous intéresssent ?"
Ces critères peuvent êtres définis principalement selon trois angles de vue [46] : pointde vue de l’utilisateur, celui de l’administrateur, et enfin celui du concepteur du réseau.Ces critères sont parfois contradictoires comme c’est illustré dans la figure 3.2.L’utilisateur s’intéresse à son expérience avec le réseau et non à la performance tech-nique de celui-ci comme c’est le cas de l’administrateur. Généralement, il s’intéresseaux délais de bout en bout mais d’autres critères peuvent l’intéresser également : dis-poniblité du système à tout moment, confidentialité des données, équité du réseau, etc.L’administrateur, quant à lui, voudrait maximiser l’utilisation du réseau pour en tirerun maximum de profit.Enfin, le concepteur mesure la performance du réseau dans le but de vérifier commentla performance actuelle s’accorde avec la performance prédite. Il s’intéresse surtout àla capacité des rampons de stockage, à l’efficacité des protocoles de communication età l’efficacité du contrôle de flux.
60

Chapitre 3 : Evaluation de performances des réseaux ATM
3.3 Taxonomie des méthodes d’évaluation de perfor-
mances
L’évaluation de performances des réseaux ATM fait appel à plusieurs méthodesqui peuvent être classée en trois classes principales : méthodes analytiques, mesures,et simulation. Le tableau 3.1 fait une étude comparative entre ces trois classes deméthodes [54]. Dans ce qui suit, nous présentons de façon plus détaillée ces trois classesde méthodes avec la discussion des avantages et inconvénients de chaque méthode.
3.3.1 Les mesures
L’objectif principal de cette technique est de cumuler les statistiques sur les événe-ments divers, des les interpréter en termes de performances du sustème opérationnelet de régler les paramètres du réseau pour atteindre la performance la plus optimalepossible. Ces techniques permettent de comprendre le vrai comportement du système,mais faire des mesures sur des systèmes réels n’est pas toujours possible car ceci pour-rait gêner le fonctionnement du système ou aussi pour des problèmes de coûts (systèmenon encore existant, instruments de mesure complexes, etc). On peut classifier les me-sures de performances en deux catégories : mesures orientées utilisateurs et mesuresorientées système [65]. Les mesures concernat l’utlisateur sont souvent subjectives :elles peuvent différer d’un utlisateur à l’autre. Ainsi, un réseau est performanr pourun utlisateur donné alors qu’il ne l’est pas pour un autre utlisateur.
La réalisation des mesures nécessite l’emploi de deux types de moniteurs : des mo-niteurs matériels (hardware monitors) et des moniteurs logiciels (software monitors).Les moniteurs matériels servent à observer l’état des composantes matérielles du réseauet de faire des statistiques sur le nombre d’évènements durant un intervalle de tempsbien déterminé ; ces évènements peuvent être ,par exemple, le nombre de messagesentrant et quittant le réseau, l’utilisation d’une ressource, etc. L’avantage principal dece type de moniteurs est la précission des résultats obtenus.Les moniteurs logiciels sont constitués de routines du système. Ils cumulent l’informa-tion concernant le statut du système.On distingue deux types de moniteurs logiciels : moniteurs à traçage d’évènements etmoniteurs échantillonneurs.Un moniteur à traçage d’évènements fournit des statistiques concernant la façon dontprogresse les demandes individuelles dans le système. Par exemple, le nombre de noeudsqu’un message traverse avant d’atteindre sa destination et le temps de réponse d’unmessage. Un moniteur échantillonneur tient le statut instantané du système dans desintervalles périodiques. Il donne des statistiques momentanées comme les longueursdes files d’attente au niveau des noeuds.selon un autre angle de vue, les moniteurs logiciels peuvent être intrusifs ou non in-
61

Chapitre 3 : Evaluation de performances des réseaux ATM
trusifs. Les premiers altèrent le comportement du système car il génèrent des donnéesde contrôle supplémentaires, tandis que les deuxièmes sont passifs et, par conséquent,les mesures qu’il fournissent reflètent le vrai comportement du système.Souvent, il est nécessaire de tester la validité d’un moniteur logiciel en le comparant àun moniteur matériel.
Il existe une troisième catégorie de moniteurs appelés moniteurs hybrides qui com-binent les avantages des moniteurs matériels (vitesse et précision) avec ceux des mo-niteurs logiciels (flexibilité et accès aux informations logicielles).
3.3.2 Méthodes analytiques
Quand on parle de méthodes analytiques, on entend des méthodes qui nous per-mettent d’écrire une relation fonctionnelle entre les paramètres d’entrée du système etles critères de performance qui nous intéressent [99]. L’avantage de ces méthodes estqu’elles nécessitent un effort minimal et un coût réduit. Cependant, il arrive que l’ons’affronte dans certaines situations à des systèmes dont la modélisation devient trèsardue et quasi impossible. Pour évaluer les performances d’un système, les méthodesanlytiques réduisent le système en un modèle mathématique et l’analysent numéri-quement. Cette approche est parfois rapide à réaliser, mais présente le souci de lareprésentation fidèle du système. Il parfois très complexe (voire impossible) de modéli-ser le comportement réel du système considéré mathématiquement. Généralement, onse pose des hypothèses qui simplifient l’étape de modélisation du système et rendentl’évaluation numérique faisable. Il existe dans la littérature plusieurs méthodes analy-tiques :
1. Les chaînes de Markov (Markov chains) ;
2. Les sytèmes de files d’attente (queuing systems) ;
3. Les automates à états finis (Finite State Automata) ;
4. Les réseaux de Pétri (Petri nets) ;
5. Les approches probabilistes ;
6. Les approches déterministes : analyse du pire temps de réponse, Network Calcu-lus [12], etc.
Parmi ces méthodes , les chaînes de Markov et la théorie des files d’attente (queuingtheory) jouent un rôle très important dans l’analyse de performances des réseayx ATM.A cet effet, nous les étudierons de façon plus détaillée.
3.3.3 La simulation
Vu la complexité et la taille des réseaux actuels tels que les réseaux basé sur leprotocole TCP/IP et les réseaux ATM, il devient très difficile de faire des investigations
62

Chapitre 3 : Evaluation de performances des réseaux ATM
sur les valeurs de performances en utilisant des méthodes analytiques. Par conséquent,le recours aux techniques de simulation est obligatoire. L’utilisation de la simulationest préconisée notamment, lorsque le processus original :
– est trop rapide pour qu’on puisse suivre son évolution avec les instruments àdisposition (réactions chimiques, processus physiques),
– est trop lent pour qu’on puisse en mesurer le comportement en un temps utile(croissance des arbres, mouvements migratoires, évolution des espèces),
– est trop dangereux ou occasionnerait trop d’ennuis à l’entourage si l’on l’expéri-mentait (réaction nucléaire, simulateur de vol) ;
– n’existe pas encore (processus industriels, systèmes de transport)– est trop cher pour que l’on puisse en tester le comportement de plusieurs va-
riantes.Le champ d’application de la simulation ne se limite pas aux questions quantitatives.En particulier, elle est aussi utilisée avec succès à la vérification et la validation dubon fonctionnement de mécanismes complexes. Les différentes méthodes de simulationpeuvent être classifiées selon plusieurs critères : (i) modèles de simulation dynamiquesversus modèles de simulation statiques, (ii) modèles de simulation déterministes versusmodèles de simulation stochastiques et (iii) modèles continus versus modèles discrets[13], [71].Un modèle de simulation statique est une représentation d’un système dans un tempsparticulier, ou un modèle dans lequel le temps ne joue aucun rôle. Un exemple d’un telmodèle est le modèle de simulation "Monte Carlo". Par contre, un modèle de simulationdynamique est un modèle qui représente comment un système évolue dans le temps.Si un modèle de simulation ne contient pas de composant qui se comporte de façonstochastique (autrement dit de façon aléatoire) alors il est dit modèle déterministe.Dans un tel modèle, les entrées sont déterminées à base des entrées spécifiées dumodèle. Malheureusement, la plupart de systèmes réels contiennent des composantesayant un comportement aléatoire. de tels systèmes ne doivent pas alors être simuléspar un modèle de simulation déterministe mais bien au contraire par un modèle desimulation stochastique. La simulation à temps continu s’intéresse à l’évolution d’unsystème dont les variables d’état change continuellement avec le temps. Ce type desimulation nécessite l’utilisation d’équation différentielles. En revanche, la simulationà évènements discrets s’intéresse à la modélisation d’un système dans le temps, maiscette fois en ne considérant que des instants particuliers dans le temps.
3.4 Chaînes de Markov
Les chaînes de Markov constituent un moyen robuste, flexible, et efficace pourla représentation et l’analyse des propriétés dynamiques d’un système informatique
63

Chapitre 3 : Evaluation de performances des réseaux ATM
Critère Méthodes analytiques Simulation MesuresA Quel stade n’importe n’importe le système à étudier
l’utiliser doit existerTemps requis court moyen longOutils utilisés humain ordinateurs moniteurs matériels ou
logicielsExactitude dépend du modèle modérée variable
Coût bas moyen haut
Tab. 3.1 – Comparaison des trois classes de méthodes d’évaluation de performances
[8]. En principe, chaque système de files d’attente peut être traduit sous forme deprocessus de markov et par conséquent être évalué mathématiquement par celui-ci. Lesprocessus de Markov constituent la classe la plus classe la plus importante des processusstochastiques alors que ces derniers peuvent être considérés comme un généralisationdes variables aléatoires. On distingue deux types de chaînes de Markov : chaînes deMarkov à temps continue (CTMC, Continuous Time Markov Chain) et les chaines deMarkov à temps discret (DTMC, Discrete Time Markov Chain).Une chaîne de Markov à temps discret présente la propriété usuelle des procesus deMarkov : son comportement futur dépend seulement de sont état courant et non pasdes états passés par lesquels elle a éventuellement passé. Soit l’ensemble des étatsS = {0, 1, 2, ...}. Alors, la propriété de markov a la forme suivante :
Pr(Xn+1 = in+1/X0 = i0, .., Xn = in) = Pr(Xn+1 = in+1/Xn = in) (3.1)
Où i0, .., in+1 ∈ S. Une chaîne de Markov à temps discret peut être représentée graphi-quement par un graphe dont les sommets représentent les états et les arcs représententles transistions. La figure 3.3 montre un exemple d’une chaîne de Markov [42].
Une chaîne de markov peut aussi être représentée par sa matrice de transition :P = (pi,j) . Par exemple, pour la figure 3.3, la matrice de transition est donnée par :
P =1
10
6 2 2
1 8 1
6 0 4
(3.2)
Cette matrice de transition est toujours une matrice stochastique : la somme des élé-ments de chaque ligne est égal à 1. Autrement dit, chaque ligne est un vecteur sto-chastique. Un de prblèmes majeurs auxquel s’affronte la modélisation markovienne estl’explosion de l’espace des états. Par conséquent, plusieurs approches ont été intro-duites pour réduire la taille de l’espace des états [27].En pratique, plusieurs systèmes réels peuvent être modélisés à l’aide des chaînes de
64

Chapitre 3 : Evaluation de performances des réseaux ATM
Fig. 3.3 – Diagramme de transition d’une chaine de Markov.
Markov à temps continu. La plupart des propriétés des chaines de Markov à tempsdiscret sont applicables aux chaînes de Markov à temps continu.
3.5 Systèmes de Files d’Attente
La théorie des files d’attente a joué un grand rôle dans la modélisation des systèmestéléphoniques au début du vingtième siècle . Elle continue de jouer ce rôle aussi mêmedans le domaine des réseaux de communication de données et dans les réseaux de télé-communications [1]. Le modèle général d’un système d’attente (queuing system) peutêtre résumé comme suit : des " clients " arrivent à un certain endroit et demandentun certain " service ". Les instants d’arrivée et les durées de service sont généralementdes quantités aléatoires. Si un poste de service est libre, le client qui arrive se dirigeimmédiatement vers ce poste où il est servi, sinon il prend sa place dans la file d’attentedans laquelle les clients se rangent suivant leur ordre d’arrivée. Ainsi,un système d’at-tente contient un espace de service avec une ou plusieurs stations de service montéesen parallèle, et un espace d’attente dans lequel se forme une éventuelle file d’attente.
3.5.1 Notation de Kendall
Pour identifier un système à files d’attentes, le formalisme suivant a été proposépour la première fois par D.G. Kendall en 1953 et ,par la suite, complété par A.M. Lee[70] :
A/B/n/K/N (3.3)
65

Chapitre 3 : Evaluation de performances des réseaux ATM
Fig. 3.4 – Système de File d’Attente.
• La première lettre A identifie la loi des processus des arrivées avec les conventions :– M : loi "sans mémoire" (arrivées poissonniennes, service exponentiel)1 ;– D : loi déterministe ;– Ek : loi Erlang-k"– Hk : loi "hyperexponentielle" d’ordre k ;– GI : loi générale, les variables successives étant indépendantes ;– G : loi générale, sans hypothèse d’indépendance.
• La deuxième lettre B identifie la durée de service d’un client avec les mêmes conven-tions pour la loi des arrivées.• La troisième lettre n concerne le nombre de serveurs du système• La quatrième lettre K concerne la taille de la file d’attente. Si elle n’est pas men-tionnée, alors elle cinsidérée comme étant infinie.• LA cinquième lettre N concerne la discipline de service de mise en file d’attente :FIFO (First In First Out), LIFO (Last In First Out), Shortest Job First, etc.
Donnons un exemple concret : un système M/D/1/k est un système :• dont les arrivées sont poissoniennes, i.e :
Pr(avoir k arrivees pendant une duree de temps T ) =(λ.T )
k!.e−λ.T (3.4)
• La durée de service suit une loi déterministe ;• Le nombre de serveur est 1 ;• La taille de la file est k ;• la politique de service est FIFO (First In First Out).
1M veut dire Markov ou Memoryless
66

Chapitre 3 : Evaluation de performances des réseaux ATM
3.5.2 Mesures de performance
Quand on évalue les performances d’un système de files d’attente, on s’intéressegénéralement aux mesures pertinentes suivantes [8] :• Nombre de clients dans le système : Il est souvent possible de décrire le compor-tement d’un système de files d’attente en utilisant le vecteur de probabilité du nombrede clients dans le système Pk :
Pk = P (Il y a k clients dans le systeme) (3.5)
• Taux d’utilisation du serveur : Dans le cas d’un système de files d’attente à unseul serveur, le taux d’utilisation ρ (appelé aussi taux d’occupation du serveur) est lafraction de temps dans laquelle le serveur est occupé. Il est défini par :
ρ =Temps moyen de service
Temps moyen d′inter− arrivees=
Taux d′arrivee
Taux de service=
λ
µ(3.6)
• Temps de réponse T : le temps de réponse, connu aussi sous le nom du temps deséjour est le temps total qu’un client passe dans le système.• Temps d’attente W : Le temps d’attente est le temps qu’un client passe dans lafile d’attente avant d’être servi. Ainsi, on a :
Temps de reponse = Temps d′attente + Temps de service (3.7)
• Longueur de la file Q : la longueur de la file est le nombre de clients qu’ellecontient.
Dans les réseaux ATM, on s’intéresse généralement à deux critères de performanceset qui sont aussi deux paramètres pertinents de qualité de service, à savoir : le délaide bout en bout (end to end delays), et le taux de perte de cellules CLR (Cell LossRatio).
3.6 Simulation à évènemets discrets
Dans la simulation des systèmes stochastiques, le paradigme le plus répandu est cer-tainement l’approche par évènements discrets. Cela signifie que le simulateur va sauterd’un événement au suivant. L’exécution d’un événement est instantanée (dans le tempsdu modèle). Chaque événement engendre d’autres événements. Puisque "il ne se passerien" entre les événements, c’est à dire puisque les variables significatives n’évoluentqu’à ces instants, il n’est pas utile de considérer les périodes inter-événements.
3.6.1 Notions élémentaires
• Dans une simulation discrète, une variable particulière, appelée horloge (simu-lation clock), indique en permanence le temps simulé écoulé depuis le début de la
67

Chapitre 3 : Evaluation de performances des réseaux ATM
simulation. Le temps indiqué par l’horloge de simulation n’a aucune relation directeavec le temps physique réellement écoulé pendant le déroulement de la simulation.• On appellera état d’un système l’ensemble des valeurs prises par les variables décri-vant le système : nombre de clients dans le système, nombre de clients servis, etc.• On appellera également système discret un système dans lequel la descriptiond’état ne comporte que des variables discrètes (i.e. à variation non continue).• Les instants d’évolution de l’état surviennent donc de façon "discrète" (c’est à direqu’il n’y en a qu’un nombre fini dans un intervalle de temps fini). On les appelle desévénements.
3.6.2 Génération des nombres aléatoires
La génération de nombre aléatoires est très importante dans les méthodes de simu-lation. Plusieurs méthodes algorithmiques ont été proposées dans la littérature pourgénérer des nombres aléatoires. On peut citer par exemple :
– La méthode congruentielle multiplicative ;– La méthode congruentielle additive ;– La méthode congruentielle mixte, etc.
Généralement, la première méthode est la plus utilisée est la prémière méthode.
3.6.3 Validation du générateur aléatoire
Pour valider un générateur de nombre aléatoire, celui ci doit répondre aux proprié-tés suivantes :
– uniformité : les nombres générés sont uniformes dans l’intervalle ]0,1[ ;– indépendance :les nombressont indépendants entre eux : absence de corrélation
entre les nombre générés. ;– efficacité : dans une expérience de simulation, il arrive qu’on refasse des millions
de fois la même expérience et, par conséquent, l’algorithme de génération desnombres aléatoires doit être aussi rapide que possible.
3.6.4 Analyse de Convergence des processus simulés
Lorsque on simule un système stochastique, on le fait souvent dans le but d’évaluerson comportement et ses performances. La question que nous pouvons poser alors est lasuivante : "Quand faut-il arrêter la simulation ?".Plus précisément, il faut déterminerle nombre de réplications de l’expérience. Une des méthodes les plus utlisée est laméthodes des réplication indépendantes que nous décrivons ci-dessous.
68

Chapitre 3 : Evaluation de performances des réseaux ATM
3.6.5 Méthode des réplications indépendantes
Dans cette méthode on fait passer le programme représentant le modèle de simu-lation plusieurs fois, en utilisant différentes entrées du générateur, à chaque passage.
{Y ji } 1 ≤ i ≤ n et 1 ≤ j ≤ m (3.8)
La moyenne du jième passage est donnée par :
Y(j)
=n∑
i=1
Y(j)i
n1 ≤ j ≤ m (3.9)
L’ensemble {Y (j)1 ≤ j ≤ m} forme m variables indépendantes identiquement dis-
tribuées. Les estimateurs de la moyenne et de la variance de Y(j) sont :
Y =1
m
m∑
j=1
Y(j)
=1
m ∗ n
m∑
j=1
n∑
i=1
Y(j)i (3.10)
et :S2
Y =1
m− 1
m∑
j=1
(Y(j) − Y )
2(3.11)
3.6.6 Calcul des intervalles de confiance (confidence intervals)
Le calcul des intervalles de confiance est très important pour la validation desrésultats d’un simulation. Afin de calculer ces intervalles, nous procédons comme suit :Soit un échantillon X1, X2, ..X3 de mesures obtenus pour une simulation donnée. Lamoyenne de l’échantillon est alors donnée par :
X =1
n
n∑
i=1
Xi (3.12)
A cette moyenne, on pourra alors asocier un intervalle de confiance donné par :
V ar(X) =1
n− 1
n∑
i=1
(X −Xi)2 (3.13)
On s’intéressse généralement à obtenir une caractérisation plus précise de l’erreur entrela vraie moyenne notée M et la moyenne estimée X. Autrement dit, on cherche àtrouver un intervalle Iα =]X − α, X + α[ qui contient la vraie moyenne M avec unprobabilité d’au moins (1− α) ∗ 100 %.α est dit dans ce cas niveau de confiance et Iα intervalle de confiance associé à α. Lesvaleurs typique de Iα sont 0.1, 0.05 et 0.01.
Pour n suffisament grand, l’intervalle de confiance sera donné par :
Iα =]X − 1.96 ∗√
V ar(X)
n,X + 1.96 ∗
√V ar(X)
n[ (3.14)
69

Chapitre 3 : Evaluation de performances des réseaux ATM
Fig. 3.5 – Un réseau de Pétri à deux places et deux transitions
3.7 Quelques outils pour l’évaluation de performances
Chaque outil de modélisation a sa propre place dans le domaine de l’évaluation deperformances. Par exemple, les réseaux de Pétri offrent un moyen graphique aussi bienqu’une méthode de notation pour la spécification formelle de systèmes. Un réseau dePétri est composé de quatre éléments : des places, des transitions, des arcs ,et enfin desjetons. Une place représente un état dans lequel le système ou une partie du systèmese trouve. Par exemple dans la figure 3.5 montre une réseau de Pétri à deux places Aet B symbolisées chacune par un cercle. Le jeton, situé dans la place A, indique quele système se trouve dans l’état A. Une barre horizontale ou verticale symbolise unetransition. Chaque transition peut avoir zéro, un ou plusieurs arcs en entrée provenantdes places situées en entrée. Elle peut également avoir zéro, un ou plusieurs arcs ensortie allant vers des places situées en sortie. Un transition est dite franchissable sichacune des de ses places en entrée possède au moins un jeton. Lorsqu’une transitionfranchissable est franchie, on enlève un jeton de chacune des places d’entrée et onajoute un jeton à chacune des places en sortie. Plusieurs extensions ont été faites pourles réseaux de Pétri. Par exemple, nous trouvons :
– Les réseaux de Pétri stochastiques ;– Les réseaux de Pétri stochastiques généralisés ;– Les réseaux de Pétri de haut niveau (réseaux colorés) ;– Les réseaux de Pétri stochastiques généralisés superposés, etc [8], [32].
Les réseaux de Pétri servent surtout à décrire et à valider les protocoles de communi-cation et les algorithmes d’exclusion mutuelle dans les systèmes d’exploitation.
Un autre outil très utlisé aussi pour l’évaluation de performnaces des réseaux ATMest les réseaux de neurones. Ces derners offrent un très bon outil mathématique pour laclassification de données. Ils ont été largement utilisés dans le domaine de télécommu-nications (voir par exemple l’ouvrage [103]). Dans la littérature, on trouve beaucoupd’applications des réseaux de neurones pour les réseaux ATM. Par exemple, dans [25],DU et al utilisent les réseaux de neurones pour le contrôle d’admission dans les réseauxATM.
70

Chapitre 3 : Evaluation de performances des réseaux ATM
3.8 Conclusion
Nous avons vu dans ce chapitre que plusieurs méthodes et outils existent pourl’évaluation de performances des réseaux ATM. Ces outils peuvent être classés en troisclasses principales : les méthodes analytiques, les mesures, et la simulation. L’avantagemajeur de cette dernière classe est le fait qu’elle permette d’évaluer les performancesd’un réseau sans que celui-ci soit disponible contrairement aux méthodes mesures quiexigent que le réseau soit disponible pour l’expérimenter. Dans le chapitre 4, nousnous intéresserons à une étude comparative de deux algorithmes de contrôle d’admis-sion dans les réseaux ATM. Nous ferons également un comparaison entre les résultatsanalytiques et ceux obtenus par la simulation.
71

Chapitre 4
Etude de deux algorithmes de
contrôle d’admission
"The net that likes to say YES !."
J.M. Pitts and J.A. Schormans [81]
4.1 Introduction
LES performances globales d’un réseau ATM perçues par l’usager sont liées de fa-çon trés étroite aux mécanismes de contrôle dans tous les composants du réseau.
Parmi ces mécanismes de contrôle, on trouve la fonction de contrôle d’admission. Celle-ci offre un contrôle de congestion préventif dans le réseau. Par conséquent, elle a étéstandardisée par l’UIT et l’ATM Forum. Cependant, ces deux organismes de normali-sation n’ont pas spécifié un algorithme particulier pour son implémentation . Ainsi, ilincombe aux opérateurs et aux concepteurs du réseau d’implémenter la fonction CACqui leur paraît la plus appropriée.En guise d’application, nous choisissons deux exemples significatifs pour notre problé-matique ; le premier basé sur une analyse M/D/1 étant approprié au trafic variable(VBR), tandis que le deuxième, basé sur une analyse N.D/D/1, est adéquat pour lamodélisation d’un trafic constant (CBR). Nous donnerons le principe de chaque algo-rithme, ses avantages ainsi que ses inconvénients.
4.1.1 Définitions et notations élémentaires
Nous commençons d’abord par quelques définitions et notations élémentaires (Tab.4.1) que nous utiliserons plus tard.
Définition 3 (trafic lourd (heavy traffic)) Un trafic lourd est défini comme étantun trafic dans lequel la charge du réseau dépasse 0.80.
Définition 4 (Charge admisssible (admissible load)) La charge admissible no-tée ρ avec 0 < ρ < 1 est définie comme étant une charge maximale que l’algorithme deCAC ne doit pas permettre de dépasser.
72

Chapitre 4 : Etude de deux algorithmes de contrôle d’admission
Notation Description
λ Nombre moyen d’arrivées par unité de tempsµ Taux de serviceρ Taux d’utilisation du serveur
CLPi Probabilité de Perte de Cellules de la connexion i
n Nombre de connexions en courshi Débit crête de la connexion i
mi Débit moyen de la connexion i
C Capacité du lien de sortiex Taille du buffer
Tab. 4.1 – Notations élémentaires
Fig. 4.1 – Les trois niveaux d’observation du trafic .
4.2 Vue hiérarchique du trafic
Les articles publiés sur ATM ont suggéré de considérer le trafic transporté par unréseau dans l’un des trois niveaux d’observation principaux suivants (Fig.4.1) :
1. Niveau appel (call level) : A ce haut niveau, il est possible de déterminerla probabilité de pouvoir accéder au réseau (voir [17], [18], et [31]) de façonanalogique à la probabilité d’être rejeté pour un appel téléphonique classique àcause de la pénurie des ressources.
2. Niveau rafale (burst level) : A ce niveau, on s’intéresse aux rafales de trafic.Les rafales de données constituent un facteur clé de la perte de cellules et de la
73

Chapitre 4 : Etude de deux algorithmes de contrôle d’admission
variation de délai de bout en bout.
3. Niveau cellule (cell level) : Ce niveau représente le comportement statis-tique de la génération de cellules (par exemple, on pourra s’intéresser à la duréeminimale d’inter-arrivée de deux cellules consécutives). Dans ce cas, les évène-ments à considérer sont l’arrivée des cellules. Par exemple, dans une connexiontypique, les cellules sont transmises sur des lien ayant une bande passante de155.52 Mbit/s, le débit d’envoi de cellule est de 366792 cellule/s et le temps deservice d’une cellule est de 2.726 µs, ce qui veut dire que le temps d’inter-arrivéeentre deux cellules consécutives est de l’ordre de 3 µs. Notons qu’à ce niveau, ilest souhaitable de vérifier deux propriétés fondamentales, à savoir l’isolation desflux pour minimiser l’interférence entre les différente connexions et le l’équité departage la bande passante [39].
Dans le cadre de notre étude, nous nous intéresserons à deux niveaux seulement :niveau rafale et au niveau cellule.
4.3 Contrôle d’admission basé sur une analyse M/D/1
Cette modélisation est adaptée pour le contrôle d’admission dans le cas d’un traficvariable dans le temps [81]. Les hypohèses faites sont les suivantes :• Les arrivées sont poissoniennes ; c’est à dire elle suivent une loi de Poisson de para-mètre λ :
Pr(avoir k arrives pendant une duree de temps T ) =(λ.T )
k!.e−λ.T (4.1)
Autrement dit, la durée d’inter-arrivées de cellules suit une loi exponentielle de para-mètre 1
λ:
Pr(Temps d′inter − arrivee ≤ t) = 1− eλ.t (4.2)
• Le taux de service est égal à µ. Autrement dit : les durées de services sont détermi-nistes et sont égales à 1/µ. Dans ce chapitre ainsi que dans le chapitre qui suit, nousconsidérons que la durée de service est égale à 2.83 µsecondes.La charge admissible est alors ρ définie comme suit :
ρ =λ
µ(4.3)
Notons que dans l’analyse mathématique d’un buffer ATM, la synchronisation est sou-vent négligée. Ainsi, on suppose qu’une cellule reçoit le service immédiatement aprèsavoir trouvé le tampon vide au lieu d’attendre le début du slot suivant.
Une approximation dans le cas d’un trafic lourd pour le système M/D/1 nous donne(voir [81]) :
ρ =2.x
2.x− ln(CLP )(4.4)
74

Chapitre 4 : Etude de deux algorithmes de contrôle d’admission
Avec :
ρ : Charge du réseau ;x : Taille du buffer (la file d’attente) ;CLP : Probabilité de perte des cellules (Cell Loss Probability).
Dans cette équation, nous avons la charge maximale admissible (ρ) en fonction dela taille de la file d’attente (x) et de la probabilité de perte (CLP ).
Comment peut-on utiliser ce résultats d’approximation ?Dans le cas d’une modélisation de la fonction CAC par une file d’attente M/D/1, lecontrat de trafic est basé seulement sur deux paramètres, à savoir :•hi : le débit crête (PCR, Peak Cell Rate),• CLPi : Probabilité de perte des cellules (Cell Loss Probability) de la connexion i
(où i = 1, 2, 3, ..n désigne l’ensemble des connexions qui ont été déja acceptées par lafonction CAC, et qui sont toujours en progrès, c’est à dire qu’elles ne sont pas encoresupprimées).On s’intéresse maintenant à la connexion n + 1 :Peut-on accepter cette connexion ou doit-on la rejeter ?Cet algorithme va procéder de la façon suivante : La connexion va être acceptée sil’inéquation suivante est vérifiée :
hn+1
C+
n∑
i=1
hi
C≤ 2.x
2.x− ln(
mini=1→n+1
(CLPi)) (4.5)
Avec C : Capacité (bande passante maximale) du lien de sortie.
Il est important de signaler que toutes les connexions souffrent du problème de pertede cellules car elles passent toutes par le même lien partagé. Par conséquent, les CLPminimum (que nous avonc noté min
i=1→n+1(CLPi) dans l’inégalité 4.5 est le CLP qui donne
la limite la plus rigoureuse et la plus sévère sur la charge acceptée. Ce que nous voyonsen fait dans l’inéquation 4.5 dans l’inéquation 4.4 ne sont que des approximations pourun trafic lourd (heavy trafic), c’est à dire pour le cas où la charge du réseau dépasse80%.Par exemple, pour une taille du tampon égale à 40 cellules et un CLP égal à 10−10,l’équation 4.4 donne une charge admissible maximale égale à 77.65%, valeur qui estlégèrement supérieure à 74.5% obtenue en utilisant une méthode analytique exacte [81].Cette dernière méthode, bien qu’elle donne des résultats très exacts, demeure lourdepour l’implémentation car elle demande beaucoup d’itérations pour atteindre l’étatstationnaire et par conséquent elle consomme beaucoup de temps. Une alternativeà cela est l’utilisation des tables de recherche (Look-up tables) dans lesquelles sontsauvegardés les résultats de la méthode analytique exacte ( voir Tab. 4.2).
75
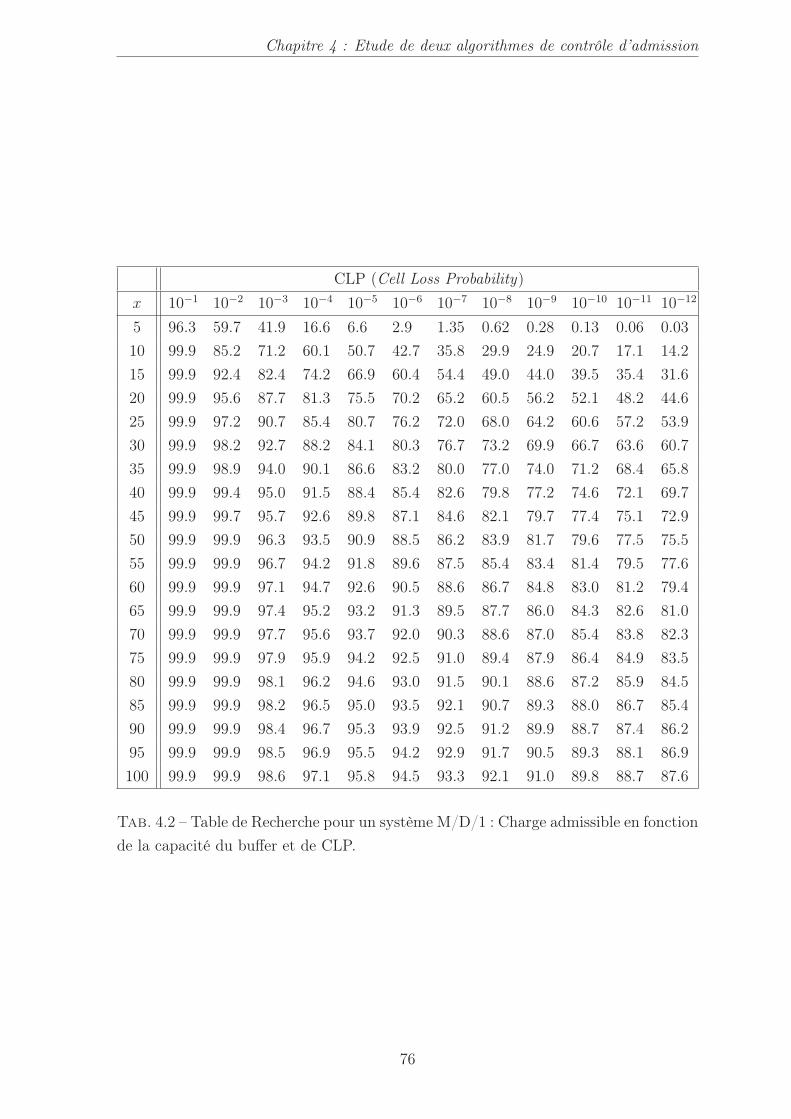
Chapitre 4 : Etude de deux algorithmes de contrôle d’admission
CLP (Cell Loss Probability)x 10−1 10−2 10−3 10−4 10−5 10−6 10−7 10−8 10−9 10−10 10−11 10−12
5 96.3 59.7 41.9 16.6 6.6 2.9 1.35 0.62 0.28 0.13 0.06 0.0310 99.9 85.2 71.2 60.1 50.7 42.7 35.8 29.9 24.9 20.7 17.1 14.215 99.9 92.4 82.4 74.2 66.9 60.4 54.4 49.0 44.0 39.5 35.4 31.620 99.9 95.6 87.7 81.3 75.5 70.2 65.2 60.5 56.2 52.1 48.2 44.625 99.9 97.2 90.7 85.4 80.7 76.2 72.0 68.0 64.2 60.6 57.2 53.930 99.9 98.2 92.7 88.2 84.1 80.3 76.7 73.2 69.9 66.7 63.6 60.735 99.9 98.9 94.0 90.1 86.6 83.2 80.0 77.0 74.0 71.2 68.4 65.840 99.9 99.4 95.0 91.5 88.4 85.4 82.6 79.8 77.2 74.6 72.1 69.745 99.9 99.7 95.7 92.6 89.8 87.1 84.6 82.1 79.7 77.4 75.1 72.950 99.9 99.9 96.3 93.5 90.9 88.5 86.2 83.9 81.7 79.6 77.5 75.555 99.9 99.9 96.7 94.2 91.8 89.6 87.5 85.4 83.4 81.4 79.5 77.660 99.9 99.9 97.1 94.7 92.6 90.5 88.6 86.7 84.8 83.0 81.2 79.465 99.9 99.9 97.4 95.2 93.2 91.3 89.5 87.7 86.0 84.3 82.6 81.070 99.9 99.9 97.7 95.6 93.7 92.0 90.3 88.6 87.0 85.4 83.8 82.375 99.9 99.9 97.9 95.9 94.2 92.5 91.0 89.4 87.9 86.4 84.9 83.580 99.9 99.9 98.1 96.2 94.6 93.0 91.5 90.1 88.6 87.2 85.9 84.585 99.9 99.9 98.2 96.5 95.0 93.5 92.1 90.7 89.3 88.0 86.7 85.490 99.9 99.9 98.4 96.7 95.3 93.9 92.5 91.2 89.9 88.7 87.4 86.295 99.9 99.9 98.5 96.9 95.5 94.2 92.9 91.7 90.5 89.3 88.1 86.9100 99.9 99.9 98.6 97.1 95.8 94.5 93.3 92.1 91.0 89.8 88.7 87.6
Tab. 4.2 – Table de Recherche pour un système M/D/1 : Charge admissible en fonctionde la capacité du buffer et de CLP.
76

Chapitre 4 : Etude de deux algorithmes de contrôle d’admission
4.3.1 Algorithme de CAC basé sur une analyse N.D/D/1
4.3.2 Etude analytique
le modèle N.D/D/1 a été étudié dans [98] et dans d’autres travaux. Dans ce modèle, on fait les hypothèses suivantes :• Il y a N sources, chacune ayant la loi des arrivées suit une loi déterministe.
D’après l’analyse du système N.D/D/1, la charge admissible (admissible load) peutêtre plus grande que celle donnée par le système M/D/1 pour une CLP donnée [81].Le problème avec le système N.D/D/1 est qu’il modélise le multiplexage de sourcesà trafic homogène (par exemple le trafic du type CBR). En pratique, ceci n’est pastoujours le cas. Cependant, pour une charge fixée ρ et un nombre constant de sourcesN , ce modèle constitue la situation pire cas de perte de cellules dans le cas d’un trafichomogène. Par conséquent, on peut utiliser les résultats de ce modèle et les appliqueren général pour les cas où nous avons N sources ayant différents débits crête (PCR).Comme dans les cas du système M/D/1, nous manipulons les approximations pour la
charge lourde pour le système N.D/D/1. Nous avons l’équation suivante :
CLP = e−2x( xN
+ 1−ρρ ) (4.6)
D’où nous pouvons tirer les résulat suivant :
ρ =2.x.N
2.x.N − (2.x2 + N. ln (CLP ))(4.7)
Si nous remarquons bien, cette formule peut donner des valeurs de ρ plus grandes que100% quand :
2.x2 + N. ln (CLP ) > 0 (4.8)
Il est évident qu’une telle charge du réseau peut causer une perte de cellules plusgrande que celle tolérée violant ainsi l’engagement du réseau à garantir la qualité deservice des connexions. Cependant, elle nous fournit un premier test pour le contrôled’admission basée sur cette analyse. C’est à dire, si :
n + 1 ≤ − 2.x2
ln(
mini=1→n+1
(CLPi)) (4.9)
alors dans ce cas, nous pouvons occuper le lien jusqu’à 100%. Autrement dit, on peutaccepter la connexion pourvu que :
hn+1
C+
n∑
i=1
hi
C≤ 1 (4.10)
77

Chapitre 4 : Etude de deux algorithmes de contrôle d’admission
Sinon, si on a :
n + 1 > − 2.x2
ln(
mini=1→n+1
(CLPi)) (4.11)
alors dans ce cas on acceptera la connexion si :
hn+1
C+
n∑
i=1
hi
C≤ 2.x.(n + 1)
2.x.(n + 1).[2.x2 + (n + 1). ln
(min
i=1→n+1(CLPi)
)] (4.12)
Nous signalons que l’analyse N.D/D/1 est seulement requise si le nombre de connexionsdépasse le nombre de places mémoire dans le buffer de sortie. Autrement dit, si on aN < x. Si par contre, on a moins de sources que de place mémoire, alors la chargeadmissible est de 100%.
Cet algorithme basé sur une analyse N.D/D/1 est approprié pour un trafic de typeCBR (Constant Bit Rate). les paramètres requis sont la probabilité de perte de cellulesCLPi pour chaque source i , la taille du buffet x, la capacité de transmission du liende sortie C ainsi que le nombre de connexions qui sont en progrès n. Notons aussi qu’ilest possible d’avoir un trafic constant (CBR) et un trafic variable (VBR), pourvu quele débit crête d’un source est utilisé dans le calcul de la charge admissible et de labande passante allouée à la connexion.
4.4 Analyse N.D/D/1 au niveau cellule
Au niveau cellule, il est souvent possible d’approximer le modèle d’arrivée de cellulesd’une large collection de sources CBR qui envoient leurs données vers un buffer parun processus de Poisson. Cependant, une meilleure analyse est donnée par le modèleN.D/D/1. Chaque source envoit à un débit constant de 167 cellules/s, alors le tauxd’arrivée de cellules ne va jamais dépasser le taux de service du buffer de sortie et sinous avons N ∗ 167 < 353208 cellules/s alors même le taux total d’arrivée de cellulesne vas pas faire déborder le buffer. Le nombre maximum de sources à admettre est de :353208 /167 =2115 sources. Autrement dit, chaque source produit une cellule chaque2115 slots. Le problème qui se pose est la synchronisation des sources de telle sortequ’elles envoient au même slot leurs cellules.
4.4.1 Multiplexage du trafic CBR de N sources
La figure 4.3 explique le principe de multiplexage de N sources CBR. Dans cettefigure, nous avons trois sources qui envoient leurs trafics à un débit constant égal à unecellule chaque trois slots. On remarque que les arrivées des cellules ne se chevauchentpas. Mais ceci n’est pas toujours le cas : il arrive des fois que les cellules envoyées
78

Chapitre 4 : Etude de deux algorithmes de contrôle d’admission
Fig. 4.2 – Modèle N.D/D/1 de contrôle d’admission au niveau cellule (ici N=4)
par les N sources se chevauchent. Si dans un tel cas nous avons le nombre de sourcesqui dépasse le nombre de places mémoire dans le buffer, ceci causerait des pertes decellules. Ceci n’est pas tolérable dans le cas d’un trafic de voix par exemple qui estun cas typique du trafic CBR. Prenons un exemple concret. Si on prend 1000 sourcesidépendantes alors chaque source a une période de 2115 slots. L’analyse que nousfaisons suppose que la taille du buffer est infinie et la probabilité de perte de cellule estapproximée par la probabilité (notée Q(x)) que la taille du buffer dépasse une certainetaille x. on pourra alors écrire :
CLP ≈ Q(x) =N∑
n=x+1
{N !
n!.(N − n)!.(
n− x
D
)n
.[1−
(n− x
D
)]N−n
.D −N + x
D − n + x
}
(4.13)Cependant, pour une charge lourde (heavy load), c’est à dire une charge dépassant
80%, on peut approximer Q(x) par la formule suivante :
Q(x) = e−2x( xN
+ 1−ρρ ) (4.14)
Avec :N : Nombre de connexions admises (dans le cas où nous avons N>x) ;
Une telle approximation est en fait très importante car elle permet de réduire considé-rablement les temps de calcul pour la fonction CAC. En contrepartie, le prix à payerest une perte dans la précision.
79

Chapitre 4 : Etude de deux algorithmes de contrôle d’admission
Fig. 4.3 – Multiplexage de 3 sources CBR
4.5 Conclusion
Le choix d’une algorithme de contrôle d’admission dépend de façon très étroite dutrafic considéré. Un mauvais choix d’un modèle implique de mauvais résultats et demauvaises performances. Si nous avons un trafic dont le débit est constant dans letemps, il est très facile de prévoir la bande passante à lui allouer. En effet, il suffit delui allouer comme bande passante son débit crête. Par contre, si le trafic est variabledans le temps alors la prévision de la bande passante à allouer. Plusieurs approches ontété proposées : allocation du débit moyen, allocation de la moyenne du débit moyen etdu débit crête, et allocation du débit crête lui-même. On verra dans le chapitre suivantquel est l’avantage, et quel est l’inconvénient de cette dernière approche.
80

Chapitre 5
Résultats et Discussions
"In fact, however, a simulation is a computer-based statistical sampling experiment."
Averill M. Law and W. David Kelton [69]
5.1 Introduction
DANS ce chapitre, nous faisons une étude comparative entre les deux algorithmesde contrôle de congestion vus dans le chapitre précédent. Les deux critères utilisés
pour la comparaison étant le nombre de connexions admises pour les deux algorithmes,et la charge admissible. Par la suite, nous verrons comment calculer le gain statistiquesi on utilise une allocation statistique au lieu d’une allocation déterministe, et ce pourun trafic de type VBR. Ce facteur est l’un des critère de performances des algorithmesde contrôle d’admission.
5.2 Environnement de simulation
Avant de présenter les résultats obtenus, nous donnons ci-dessus l’environnementde programmation ainsi que quelques détails d’implémentation.
5.2.1 Environnement de programmation
Beaucoup d’environnements de simulation à évènements discrets existent actuelle-ment sur le marché. Ces environnements de simulation peuvent être classés principa-lement en deux classes principales : langages de simulation (SIMSCRIPT, QNAP,etc)et simulateurs orienté application (Network Simulator, OPNET, etc) [72].Nous avons utilisé dans notre travail le langage C++ sous l’environnement C++ Buil-der 6. Cet environnement nous offre plusieurs bibliothèques mathématiques telles quela bibliothèque < math.h > qui contient entre autre des fonctions de génération denombres aléatoires (rand()) selon une loi normale. D’autre part, cet environnementnous offre une bibliothèque de composants visuels (VCL, Visual Component Library),ce qui facilite la conception des interfaces graphiques de notre application.
81

Chapitre 5 : Résultats et Discussions
5.2.2 Génération de nombre aléatoires dans avec la fonctionrand()
Dans une simulation d’un système informatique, c’est un générateur pseudo-aléatoirequi fournira, à chaque appel, une variable selon la loi de probabilité choisie. La fonctionrand() implémente un générateur de nombres aléatoires selon une loi normale avec unepériode de 232. Il est basé sur la méthode congruentielle multiplicative.
5.2.3 Génération des arrivées selon une loi exponentielle
Pour générer des variables selon une loi quelconque (exponentielle, Cox, géomé-trique, etc), la fonction rand() tire des variables uniformément distribuées dans l’in-tervalle ]0,1[. Par la suite, il suffit d’utiliser cette fonction pour générer des arrivéesselon la loi voulue. Par exemple, pour générer les arrivées selon une loi de Poisson,nous avons utilisé le code source suivant :
Code Source 1 : Génération de variable aléatoires selon une loi exponentielle
double expntl(double x){double z ; // Nombre Uniforme entre 0 et 1do{z = ((double) rand() / RAND_MAX) ;}while ((z == 0) || (z == 1)) ;return(-x * log(z)) ;}
5.3 Résultats analytiques et résultats de simulation
pour le modèle M/D/1
Dans cette section, nous présentons d’abord un les résultats analytiques du modèleM/D/1, ensuite les résultats de simulation que nous avons obtenus et qui concernentl’estimation la charge admissible en fonction de la taille du buffer et de la probabilitéde perte de cellule CLP.Nous commençons d’abord par les résultats obtenuus avec laméthode analytique exacte, nous présentons les résultats analytiques approximatifs.La figure 5.1 donne les résultats exacts de la charge admissible en fonction du CLPet de la taille du buffer x pour un modèle M/D/1 tandis que la figure 5.2 en donne
82
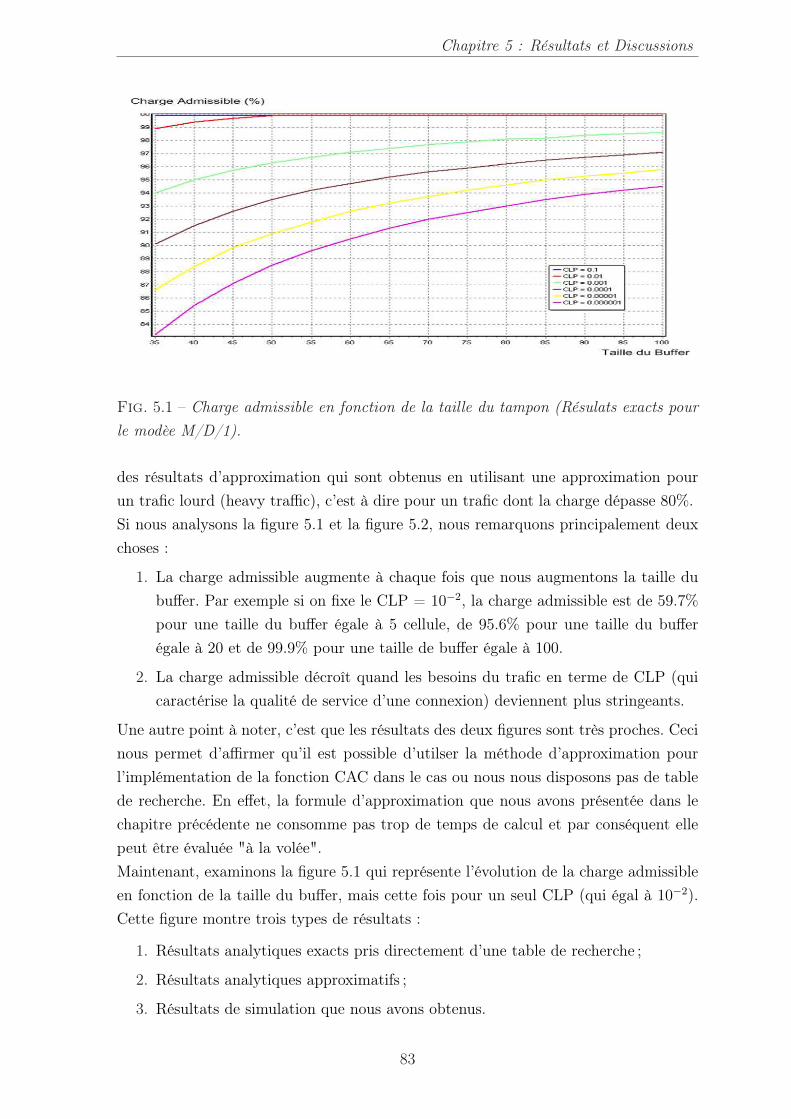
Chapitre 5 : Résultats et Discussions
Fig. 5.1 – Charge admissible en fonction de la taille du tampon (Résulats exacts pourle modèe M/D/1).
des résultats d’approximation qui sont obtenus en utilisant une approximation pourun trafic lourd (heavy traffic), c’est à dire pour un trafic dont la charge dépasse 80%.Si nous analysons la figure 5.1 et la figure 5.2, nous remarquons principalement deuxchoses :
1. La charge admissible augmente à chaque fois que nous augmentons la taille dubuffer. Par exemple si on fixe le CLP = 10−2, la charge admissible est de 59.7%
pour une taille du buffer égale à 5 cellule, de 95.6% pour une taille du bufferégale à 20 et de 99.9% pour une taille de buffer égale à 100.
2. La charge admissible décroît quand les besoins du trafic en terme de CLP (quicaractérise la qualité de service d’une connexion) deviennent plus stringeants.
Une autre point à noter, c’est que les résultats des deux figures sont très proches. Cecinous permet d’affirmer qu’il est possible d’utilser la méthode d’approximation pourl’implémentation de la fonction CAC dans le cas ou nous nous disposons pas de tablede recherche. En effet, la formule d’approximation que nous avons présentée dans lechapitre précédente ne consomme pas trop de temps de calcul et par conséquent ellepeut être évaluée "à la volée".Maintenant, examinons la figure 5.1 qui représente l’évolution de la charge admissibleen fonction de la taille du buffer, mais cette fois pour un seul CLP (qui égal à 10−2).Cette figure montre trois types de résultats :
1. Résultats analytiques exacts pris directement d’une table de recherche ;
2. Résultats analytiques approximatifs ;
3. Résultats de simulation que nous avons obtenus.
83
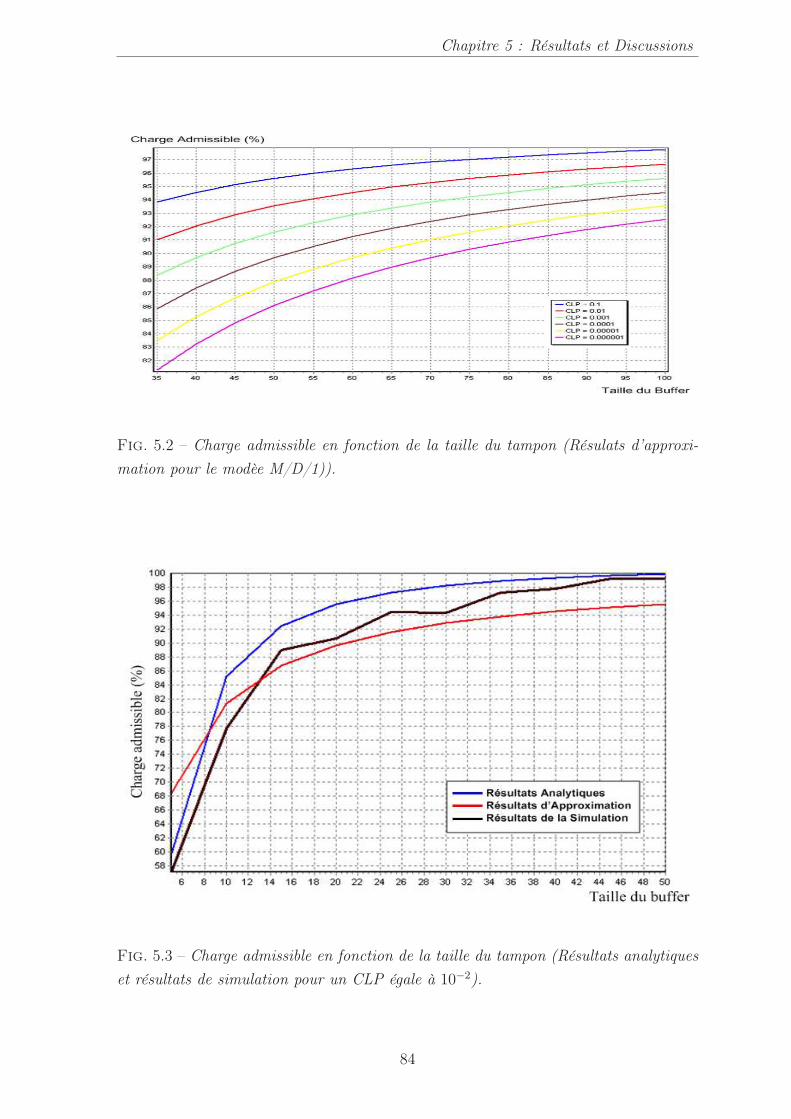
Chapitre 5 : Résultats et Discussions
Fig. 5.2 – Charge admissible en fonction de la taille du tampon (Résulats d’approxi-mation pour le modèe M/D/1)).
Fig. 5.3 – Charge admissible en fonction de la taille du tampon (Résultats analytiqueset résultats de simulation pour un CLP égale à 10−2).
84
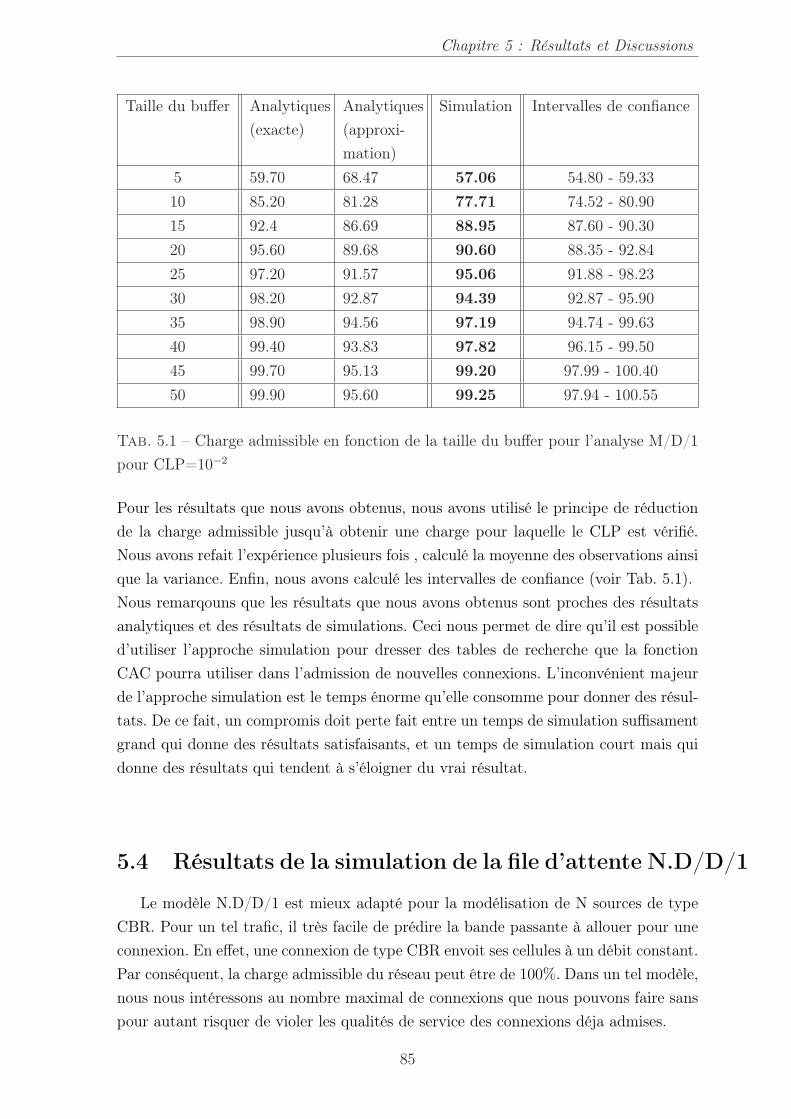
Chapitre 5 : Résultats et Discussions
Taille du buffer Analytiques(exacte)
Analytiques(approxi-mation)
Simulation Intervalles de confiance
5 59.70 68.47 57.06 54.80 - 59.3310 85.20 81.28 77.71 74.52 - 80.9015 92.4 86.69 88.95 87.60 - 90.3020 95.60 89.68 90.60 88.35 - 92.8425 97.20 91.57 95.06 91.88 - 98.2330 98.20 92.87 94.39 92.87 - 95.9035 98.90 94.56 97.19 94.74 - 99.6340 99.40 93.83 97.82 96.15 - 99.5045 99.70 95.13 99.20 97.99 - 100.4050 99.90 95.60 99.25 97.94 - 100.55
Tab. 5.1 – Charge admissible en fonction de la taille du buffer pour l’analyse M/D/1pour CLP=10−2
Pour les résultats que nous avons obtenus, nous avons utilisé le principe de réductionde la charge admissible jusqu’à obtenir une charge pour laquelle le CLP est vérifié.Nous avons refait l’expérience plusieurs fois , calculé la moyenne des observations ainsique la variance. Enfin, nous avons calculé les intervalles de confiance (voir Tab. 5.1).Nous remarqouns que les résultats que nous avons obtenus sont proches des résultatsanalytiques et des résultats de simulations. Ceci nous permet de dire qu’il est possibled’utiliser l’approche simulation pour dresser des tables de recherche que la fonctionCAC pourra utiliser dans l’admission de nouvelles connexions. L’inconvénient majeurde l’approche simulation est le temps énorme qu’elle consomme pour donner des résul-tats. De ce fait, un compromis doit perte fait entre un temps de simulation suffisamentgrand qui donne des résultats satisfaisants, et un temps de simulation court mais quidonne des résultats qui tendent à s’éloigner du vrai résultat.
5.4 Résultats de la simulation de la file d’attente N.D/D/1
Le modèle N.D/D/1 est mieux adapté pour la modélisation de N sources de typeCBR. Pour un tel trafic, il très facile de prédire la bande passante à allouer pour uneconnexion. En effet, une connexion de type CBR envoit ses cellules à un débit constant.Par conséquent, la charge admissible du réseau peut être de 100%. Dans un tel modèle,nous nous intéressons au nombre maximal de connexions que nous pouvons faire sanspour autant risquer de violer les qualités de service des connexions déja admises.
85
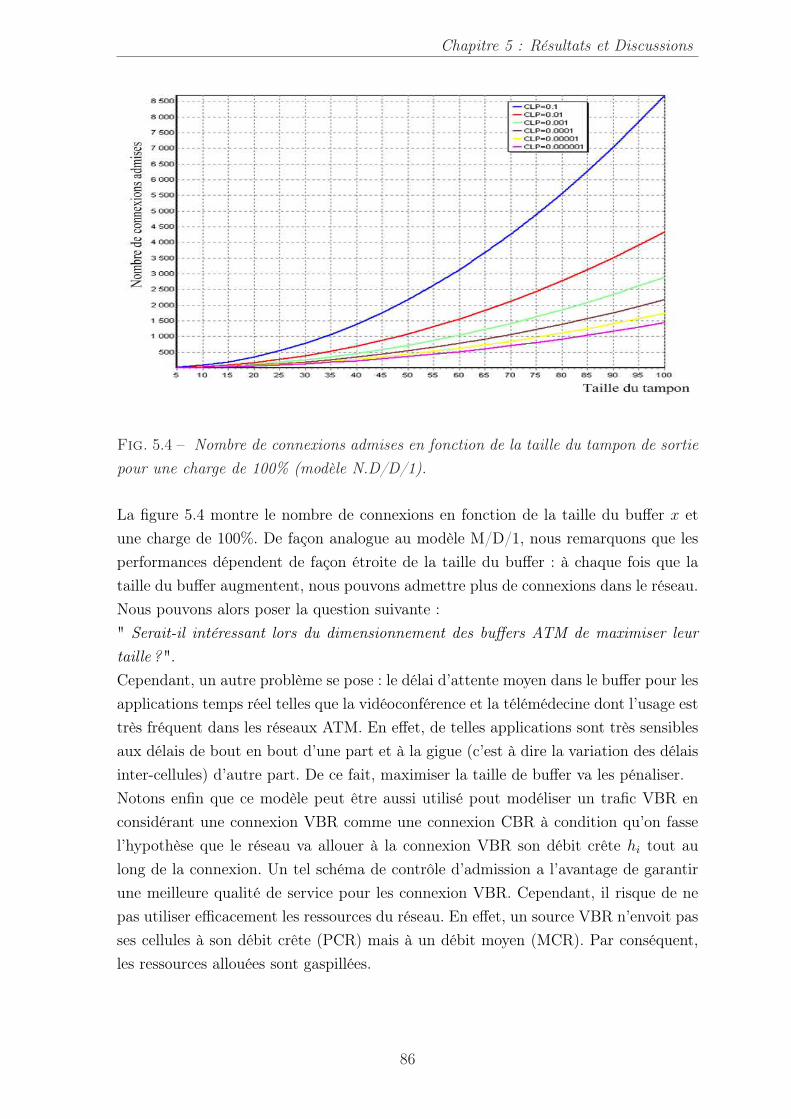
Chapitre 5 : Résultats et Discussions
Fig. 5.4 – Nombre de connexions admises en fonction de la taille du tampon de sortiepour une charge de 100% (modèle N.D/D/1).
La figure 5.4 montre le nombre de connexions en fonction de la taille du buffer x etune charge de 100%. De façon analogue au modèle M/D/1, nous remarquons que lesperformances dépendent de façon étroite de la taille du buffer : à chaque fois que lataille du buffer augmentent, nous pouvons admettre plus de connexions dans le réseau.Nous pouvons alors poser la question suivante :" Serait-il intéressant lors du dimensionnement des buffers ATM de maximiser leurtaille ?".Cependant, un autre problème se pose : le délai d’attente moyen dans le buffer pour lesapplications temps réel telles que la vidéoconférence et la télémédecine dont l’usage esttrès fréquent dans les réseaux ATM. En effet, de telles applications sont très sensiblesaux délais de bout en bout d’une part et à la gigue (c’est à dire la variation des délaisinter-cellules) d’autre part. De ce fait, maximiser la taille de buffer va les pénaliser.Notons enfin que ce modèle peut être aussi utilisé pout modéliser un trafic VBR enconsidérant une connexion VBR comme une connexion CBR à condition qu’on fassel’hypothèse que le réseau va allouer à la connexion VBR son débit crête hi tout aulong de la connexion. Un tel schéma de contrôle d’admission a l’avantage de garantirune meilleure qualité de service pour les connexion VBR. Cependant, il risque de nepas utiliser efficacement les ressources du réseau. En effet, un source VBR n’envoit passes cellules à son débit crête (PCR) mais à un débit moyen (MCR). Par conséquent,les ressources allouées sont gaspillées.
86
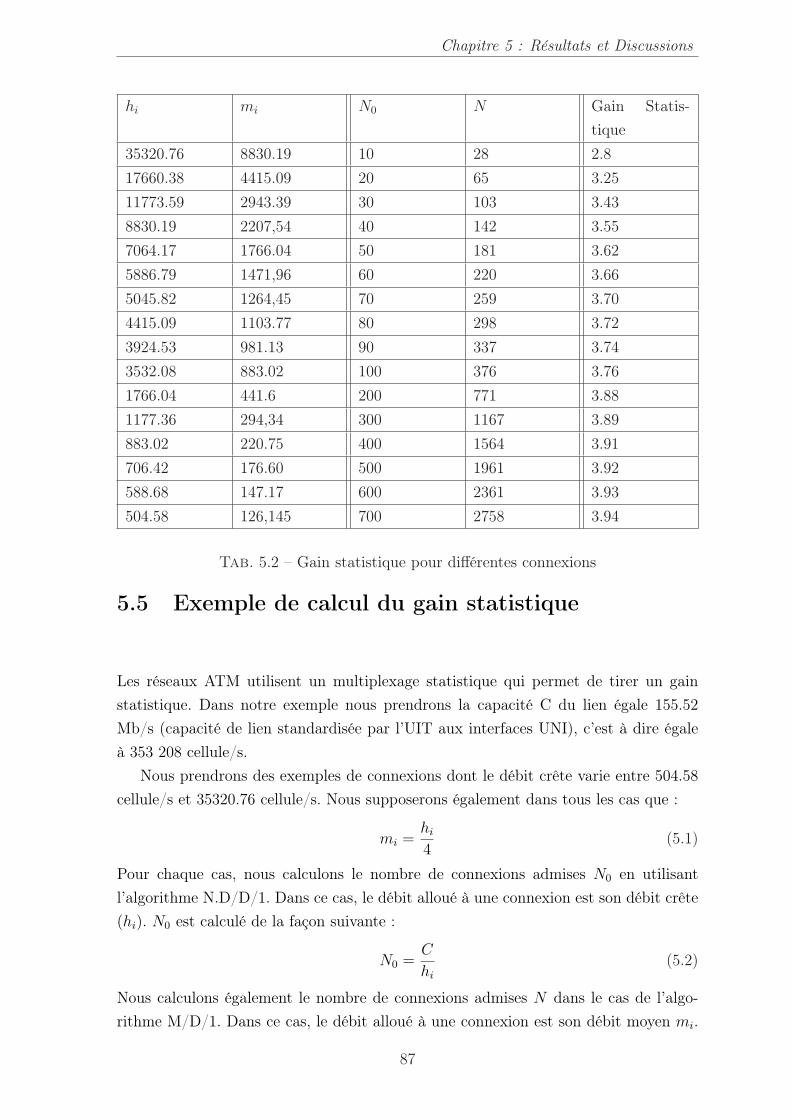
Chapitre 5 : Résultats et Discussions
hi mi N0 N Gain Statis-tique
35320.76 8830.19 10 28 2.817660.38 4415.09 20 65 3.2511773.59 2943.39 30 103 3.438830.19 2207,54 40 142 3.557064.17 1766.04 50 181 3.625886.79 1471,96 60 220 3.665045.82 1264,45 70 259 3.704415.09 1103.77 80 298 3.723924.53 981.13 90 337 3.743532.08 883.02 100 376 3.761766.04 441.6 200 771 3.881177.36 294,34 300 1167 3.89883.02 220.75 400 1564 3.91706.42 176.60 500 1961 3.92588.68 147.17 600 2361 3.93504.58 126,145 700 2758 3.94
Tab. 5.2 – Gain statistique pour différentes connexions
5.5 Exemple de calcul du gain statistique
Les réseaux ATM utilisent un multiplexage statistique qui permet de tirer un gainstatistique. Dans notre exemple nous prendrons la capacité C du lien égale 155.52Mb/s (capacité de lien standardisée par l’UIT aux interfaces UNI), c’est à dire égaleà 353 208 cellule/s.
Nous prendrons des exemples de connexions dont le débit crête varie entre 504.58cellule/s et 35320.76 cellule/s. Nous supposerons également dans tous les cas que :
mi =hi
4(5.1)
Pour chaque cas, nous calculons le nombre de connexions admises N0 en utilisantl’algorithme N.D/D/1. Dans ce cas, le débit alloué à une connexion est son débit crête(hi). N0 est calculé de la façon suivante :
N0 =C
hi
(5.2)
Nous calculons également le nombre de connexions admises N dans le cas de l’algo-rithme M/D/1. Dans ce cas, le débit alloué à une connexion est son débit moyen mi.
87

Chapitre 5 : Résultats et Discussions
Notons aussi que la charge admissible dans ce cas n’est pas égale à 100% comme c’estle cas de l’algorithme N.D/D/1, mais il est en fonction de la probabilité de perte CLPi
et de N0. ceci est donné dans l’équation suivante :
CLP ≈ 1
(1− ρ)2.N0
.(ρ.N0)
[N0]!
[N0]
.e−ρ.N0 (5.3)
OùL’équation 5.3 est utilisée pour dresser une table de recherche (qu’on peut trouverdans [81]) qui donne ρ en fonction de CLP et de N0. Nous calculerons alors le gainstatistique défini par :
G =N
N0
(5.4)
Avec :N =
ρ.C
mi
(5.5)
et :N0 =
C
hi
(5.6)
Pour différentes connexions, nous avons obtenus les résultats illustrés dans le tableau5.2.
5.5.1 Discussion
La table 5.3 montre une comparaison entre le nombre de connexions admises parla fonction CAC pour les deux algorithmes étudiés. Remarquons que le nombre deconnexions admises par l’algorithme M/D/1 est toujours supérieur au nombre deconnexions admises par l’algorithme N.D/D/1 dans le cas de connexions VBR. rap-pelons que de telles connexions sont caractérisées par un débit moyen strictementinférieur au débit crête. Dans le cas d’un trafic CBR, le nombre de connexions admisespar les deux algorithmes sera le même. Par conséquent, le gain statistique sera égal à1.Remarquons également que le gain statistique tiré du réseau est inversement propor-tionnel au rapport débit moyen/débit crête. Ainsi, nous pouvons conclure que l’algo-rithme M/D/1 est plus adéquat au contrôle d’admission pour un trafic de type VBR,et ce, en terme de gain statistique.
88

Chapitre 5 : Résultats et Discussions
5.6 Conclusion
Un algorithme de contrôle d’admission est primordial dans un réseau ATM pour as-surer un contrôle de congestion préventif et présever la qualité de service des connexionsédja admises . Le choix d’un tel algorithme dépend essentiellement du type de traficconsidéré (CBR, VBR, ABR, etc), le trafic le plus facile à étudier et à modéliser étantde loin le trafic CBR. Pour ce dernier, il faut allouer à chaque connexion son débitcrête. En revanche, ceci n’est pas le cas pour des connexions VBR, sinon aucun gainstatistique ne sera tiré du réseau. La question est alors quelle bande passante allouerà ce type de connexion ? dans notre étude, nous avons alloué le débit moyen. En pra-tique, il existe d’autres approches qui procèdent chacune à sa façon. Les une cherchentà maximiser l’utmisation du réseau et, par conséquent, allouent un strict minimumde bande passante à la connexion alors que les autres visent à garantir à tout prixla qualité de service de la connexion, et de cefait allouent à la connexion un débitavoisinant sont débit crête.
89

Conclusion Générale
L’ÉTUDE réalisée dans ce mémoire a été consacrée au contrôle de congestion dansles réseaux haut débit, plus particulièrement dans les Réseaux Numériques à
Intégration de Services à Large Bande (RNIS-LB). Ce dernier a été conçu par l’UIT(Union Internationale des Télécommunications) pour supporter une large gamme deservices avec une fine granularité. Après un long débat, l’UIT a opté pour le mode detransfert asynchrone (ATM, Asynchronous Transfer Mode) au détriment du mode detransfert synchrone (STM, Synchronous Transfer Mode) et a choisi une taille de celluleégale à 53 octets.
Dans le chapitre 1, nous avons présenté les technologies proposées pour suppor-ter les hauts débits dans les réseaux à grande distance ; nous avons commencé parla technologie Relais de Trames (Frame Relay), ensuite la technologie ATM et enfinla technologie MPLS (Multi Protocol Label Switching) qui est une technologie pro-metteuse pour garantir la qualité de service dans les réseaux de demain. Nous avonségalement défini la notion de qualité de service (QoS, Quality of Service) et présentéles paramètres de qualité de service ainsi que les classes de service de ATM. Enfin, nousavons donné un bref aperçu sur la technologie MPLS et le principe de commutationd’étiquettes introduit par celle-ci.
Dans le chapitre 2, nous avons vu que comme tout réseau à commutation de pa-quet, ATM souffre du problème de congestion. Pire encore , et contrairement à quelquesfausses idées, ce problème est plus aigu et plus ardu à résoudre dans ATM à cause deplusieurs facteurs : large produit délai-bande passante , exigences très strictes du tra-fic en terme de qualité de service, hétérogénéité du trafic, etc. Nous avons évoquél’importance des mécanismes de contrôle de congestion dans le RNIS-LB ainsi que lespropiétés que doivent vérifier ces mécanismes. Parmi ces propriétés, nous en citonsdeux et qui sont souvent difficiles à concilier : l’efficacité et l’équité. Le point essentielque nous avons dégagé dans ce chapitre est le suivant :Aucune technnologie moderne ne peut résoudre de façon définitive le problème decongestion dans les réseaux haut débit sans l’adjonction de bons protocoles de contrôlede congestion. Nous avons aussi vu que le protocole TCP (Transmission Control Proto-col) conçu pour assurer un contrôle de congestion dans Internet s’est avéré inadéquatpour les réseaux à haut débit caractérisés par un produit délai-bande passante très
90

Conclusion générale et Perspectives
large. Par conséquent, des modifications doivent être apportées à ce protocole pours’adapter aux réseaux à haut débit. Dans la littérature, beaucoup de solutions ont étéproposées : Fast TCP, High Speed TCP, Scalable TCP, etc.
Dans le chapitre 3, nous avons introduit les méthodes d’évaluation de performancesdes réseaux ATM. A première vue, ces méthodes peuvent être classées en trois classes :méthodes analytiques, mesures, et simulation. Cette dernière est une approche trèsprometteuse pour l’évaluation de performances des réseaux qui n’existent pas encorepour l’expérimentation. Nous avons introduit la notion de simulation à évènementsdiscrets (DES, Discrete Event Simulation) et son principe. Par la suite, nous avons vucomment valider les résultats d’une simulation.
Contrairement à Internet qui utilise un contrôle de congestion réactif, ATM pré-conise l’utilisation d’un contrôle de congestion de préventif. Un exemple de tels méca-nismes est le contrôle d’admission (CAC). En effet, la fonction CAC implémentée dansles interfaces UNI (User Network Interface) et les interfaces NNI (Network to NetworkInterface) agit de façon à éviter que la congestion n’apparaîsse dans le réseau. Sonprincipe consiste à admettre une nouvelle connexion si il y a des ressources suffisantespour satisfaire la qualité de service (QoS) de cette nouvelle connexion d’une part, etde ne pas violer la qualité de service des connexions déja admises d’autre part. Dansle cas contraire, la connexion est soit rejetée soit renégociée. A cet effet, la fonctionCAC doit définir un seuil de charge appelé charge admissible qui ne doit jamais êtredépassé.
Dans le chapitre 4, nous avons étudié deux algorithmes de contrôle d’admission.Le premier est basé sur une analyse M/D/1 et le deuxième est basé sur une analyseN.D/D/1. Le premier algorithme est adéquat pour une trafic variable dans le tempsalors que le deuxième est adéquat pour un trafic constant dans le temps tel que lavoix qui est très utilisée dans les réseaux ATM. Cependant, le deuxième algorithmereste aussi applicable pour la modélisation d’un trafic variable dans le temps : il suffitd’allouer à une connexion VBR son débit crête (PCR) et de faire abstraction totalede son débit moyen (MCR). Une telle allocation permet d’offrir une bonne qualité deservice en terme de perte de cellules. Cependant, elle n’offre aucun gain statistique.En effet, les résultats montrent que plus le rapport MCR/PCR augmente, plus nousperdons de gain statistique. A cet effet, il serait intéressant, pour un trafic variable,d’utiliser l’analyse M/D/1 au lieu de N.D/D/1.
Dans le chapitre 5, nous avons fait une étude comparative entre ces deux algo-rithmes selon le nombre de connexions admises et la charge admissible. La conclusionque nous avons tirée est que le gain statistique obtenu en allouant le débit moyenaugmente avec l’augmentation de la différence entre le débit moyen et le débit crête.
En guise de conclusion générale, nous pouvons dire que la congestion est un pro-blème qui persistera dans les réseaux de demain aussi longtemps que l’hétérogénéité
91

Conclusion générale et Perspectives
des équipements existera. Pour apporter une solution à ce problème, il faut ne pastrop compter sur les technologies matérielles mais bien au contraire, il faut investirdans la conception de bon schémas de contrôle de congestion qui doivent permettrede coordonner les efforts des différents acteurs du réseau afin de tirer un maximum deprofit de celui-ci et d’offrir de meilleures performances.
Comme perspectives, il serait intéressant d’étendre notre étude pour étudier lesmécanismes de contrôle de congestion et d’équilibrage de charge ainsi que l’ingénieriedu trafic dans MPLS d’une part, et d’étudier les améliorations apportées au contrôlede flux du protocole TCP pour les réseaux utilisant des liaisons satellitaires d’autrepart. Il serait également intéressant d’aborder le problème de congestion de façon plusgénérale, mais cette fois en se basant sur la théorie du Network Calculus.
92

Bibliographie
[1] D. Aissani and A. Aissani. La Théorie des Files d’Attente : Fondements Histo-riques et Applications à l’Evaluation des Performances. Ecole Doctorale d’Infor-matique de Béjaia, 2004.
[2] O. Ait Hellal. Contrôle de Flux dans les Réseaux à Haut Débit. PhD thesis,Université de Nice-Sophia Antipolis, Novembre 1998.
[3] V. Alwayn. Advanced MPLS Design and Implementation. O’Reilly and Asso-ciates, 2002.
[4] C. Barakat, E. Altman, and W. Dabbous. On TCP Performance in a Heteroge-neous Network : A Survey. IEEE Communications Magazine, Janvier 2000.
[5] R.J. Bates. Broadband Telecommunications Handbook. The McGraw-Hill Com-panies, 2002.
[6] S. Bates. Traffic Characterization and Modelling for Call Admission ControlSchemes on Asynchronous Transfer Mode Networks. PhD thesis, The Universityof Edinburgh, Septembre 1997.
[7] S. Beker. Techniques d’Optimisation pour le Dimensionnement et la Reconfigu-ration des Réseaux MPLS. PhD thesis, Ecole Nationale Supérieure des Télécom-munications, Avril 2004.
[8] G. Belch, S. Greiner, H. De Meer, and K.S. Trivedi. Queueing Networks andMarkov Chains : Modeling and Performance Evaluation with Computer ScienceApplications. Wiley & Sons, 1998.
[9] A. Benoit. Méthodes et Algorithmes Pour l’Evaluation des Performances desSystèmes Informatiques à Grand Espace d’Etats. PhD thesis, Instiut NationalPolytechnique de Grenoble, Juin 2003.
[10] D. Bertsekas and R. Gallagher. Data Networks. Englewood Cliffs, New Jersey,1992.
[11] F. Bonomi and K.W. Fendick. The Rate-Based Flow Control Framework for theAvailable Bit-Rate ATM Service . IEEE Network Magazine, 9 :25–39, Mars/Avril1995.
[12] J.Y.L. Boudec. Network Calculus, A Theory of Deterministic Queuing Systemsfor the Internet. Springer Verlag, Mai 2004.
93

Bibliographie
[13] J.Y.L. Boudec. Performance Evaluation of Computer and Communications Sys-tems. Ecole Polytechnique Fédérale de Lausanne (EPFL), 2004.
[14] J.Y.L. Boudec. Rate adaptation, Congestion Control and Fairness : ATutorial. Ecole Polytechnique Fédérale de Lausanne (EPFL). URL :http ://ica1www.epfl.ch/perfeval/, Février 2005.
[15] L.S. Brakmo, S.W. Omalley, and L.L. Peterson. TCP Vegas : New Techniques forCongestion Detection and Avoidance. Proceedings of SIGCOMM’94 Conference,pages 24–35, ACM 1994.
[16] J. Cannau. Evaluation de performances d’une amélioration de TCP WestWood.Mémoire de DEA. Université Libre de Bruxelles, 2003.
[17] Y.H. Cao. Performance Evaluation of Admission Control Policies for High SpeedNetworks. Master’s thesis, Université de Saskatchewan (Canada), 1994.
[18] H.J. Chao and X. Guo. Quality of Service Control in High-Speed Networks. Wiley& Sons, Février 2002.
[19] D.M. Chiu and R. Jain. Analysis of Increase and Decrease Algorithms for Conges-tion Avoidance in Computer Networks. Computer Networks and ISDN Systems,17 :1–14, 1989.
[20] C. Chong and S. Li. (σ, ρ)- Characterization Based Connection Control forGuaranteed Services in High Speed Networks. IEEE INFOCOM’95, pages 835–844, 1995.
[21] D. Clark. RFC 813 : Window and Acknowledgement Strategy in TCP, Juillet1982.
[22] D. Comer. Internetworking with TCP/IP, volume 1. Prentice Hall, 2000.
[23] E. Crawley, R. Nair, B. Rajagopalan, and H. Sandick. RFC 2386 : A Frameworkfor QoS-Based Routing in the Internet, Août 1998.
[24] C.J. David, X. Wei, and S.H. Low. FAST TCP : Motivation, Architecture,Algorithms, Performance. IEEE Infocom, Hong Kong, Mars 2004.
[25] S.X. Du and S.Y. Yuan. Congestion Control for ATM Multiplexers Using Neu-ral Networks : Multiple Sources/Single Buffer Scenario. Journal of ZhejiangUniversity SCIENCE, 5(9) :1124–1129, 2004.
[26] O. Elloumi. TCP au-dessus de ATM : Architecture et Performance. PhD thesis,Université de Rennes I, Mai 1998.
[27] P.H.L. Fernandes. Méthodes Numériques pour la Solution de Systèmes Marko-viens à Grand Espace d’Etats. PhD thesis, Institut National Polytechnique DeGrenoble, Février 1998.
[28] S. Floyd. Congestion control principles. RFC2914, Octobre 1999.
94

Bibliographie
[29] S. Floyd. HighSpeed TCP for Large Congestion Windows. Internet draft draft-floyd-tcp-highspeed-02.txt. URL : http ://www.icir.org/floyd/hstcp.html, Fé-vrier 2003.
[30] S. Floyd and A. Romanow. Dynamics of TCP Traffic over ATM Networks. inProceedings of ACM SIGCOMM’94, pages 79–88, Septembre 1994.
[31] P.C.F. Fonseca. Traffic Control Mechanisms with Cell-Rate Simulation for ATMNetworks. PhD thesis, University of London, Avril 1996.
[32] P.J. Fortier and H.E. Michel. Computer Systems Performance Evaluation andPrediction. Digital Press, 2003.
[33] R.L. Freeman. Practical Data Communications. Wiley & Sons, 2001.
[34] M. Gagnaire et D. Kofman. Réseaux Haut Débit, Tome I : Réseaux ATM etRéseaux Locaux. Dunod, 1999.
[35] D. Gaïti and N. Boukhatem. Cooperative Congestion Control Schemes in ATMNetworks. IEEE Communications Magazine, Novembre 1996.
[36] D. Gaïti and G. Pujolle. Performance Management Issues in ATM Networks :Traffic and Congestion Control. IEEE/ACM Transactions on Networking, 4(2),Avril 1996.
[37] M. Gerla and L.Kleinrock. Flow Control : A Comparative Survey. IEEE Tran-sactions on Communications, COM-28(4), 1980.
[38] W. Goralski. Frame Relay for High Speed Networks. Wiley & Sons, 1999.
[39] S. Gupta. Performance Modeling and Management of High-Speed Networks. PhDthesis, Université de Pennsylvanie, 1993.
[40] M. Hamdi. Contrôle de trafic ATM pour sources vidéo à débit variable. PhDthesis, ENST de Bretagne, 1997.
[41] M. Hassan and R. Jain. High Performance TCP/IP Networking. Prentice Hall,2003.
[42] B.R. Haverkort. Performance of Computer Communication Systems. Wiley &Sons, 1998.
[43] F.M. Holness. Congestion Control Mechanisms within MPLS Networks. PhDthesis, Queen Mary and Westfield College, University of London, Septembre2000.
[44] D. Hughes and P. Daley. Limitations of Credit based Flow Control. AF-TM94-0776, Septembre 1994.
[45] D. Hughes and P. Daley. More ABR Simulations Results. AF-TM 94-0777,Septembre 1994.
95

Bibliographie
[46] M. Ilyas and H.T. Mouftah. Performance Evaluation of Computer Communica-tions Networks. IEEE Communications Magazine, 23(4) :18–29, Avril 1985.
[47] ITU-T Recommendation E.211. B-ISDN Service Aspects. International Tele-communications Union, Helsinki, Mars 1993.
[48] ITU-T Recommendation E.800. Terms and Definitions Related to Quality ofService and Network Performance Including Dependability. International Tele-communications Union, Août 1994.
[49] ITU-T Recommendation I.113. Vocabulary of Terms for Broadband Aspects ofISDN. International Telecommunications Union, Helsinki, Mars 1993.
[50] ITU-T Recommendation I.371 . Traffic Control and Congestion Control in B-ISDN. Août 1996.
[51] V. Jacobson and J. Karels. Congestion Control and Avoidance. SIGCOMM’88,Novembre 1988.
[52] R. Jain. A Delay Based Approach for Congestion Avoidance in Interconnec-ted Heterogeneous Computer Networks. Computer Communications Review,19(5) :56–71, Octobre 1989.
[53] R. Jain. Congestion Control in Computer Networks : Issues and Trends. IEEENetwork Magazine, pages 24–30, Mai 1990.
[54] R. Jain. Art of Computer Systems Performance Analysis : Techniques For Expe-rimental Design Measurements Simulation And Modeling. Wiley & Sons, 1991.
[55] R. Jain. Myths about Congestion Management in High-Speed Networks. Inter-networking Research and Experience, 3(3) :101–113, Septembre 1992.
[56] R. Jain. Congestion Control and Traffic Management in ATM Networks : RecentAdcances and A Survey. Computer networks and ISDN Systems, 27, Novembre1995.
[57] S. Jamin, S. Shenker, and P. Danzig. Comparison of Measurement-based Ad-mission Control Algorithms for Controller-Load Service. IEEE INFOCOM’97,pages 973–980, 1997.
[58] L. Kalampoukas. Congestion Management in High Speed Networks. PhD thesis,Université de Californie, Septembre 1997.
[59] S. Kalyanaraman. Traffic Management for the Available Bit Rate (ABR) Ser-vice in Asynchronous Transfert Mode (ATM) Networks. PhD thesis, Ohio StateUniversity, 1997.
[60] D. Katabi. Decoupling Congestion Control and Bandwidth Allocation PolicyWith Application to High Bandwidth-Delay Product Networks. PhD thesis, Mas-sachusetts Institute of Technology, Mars 2003.
96

Bibliographie
[61] D. Katabi, M. Handley, and C. Rohrs. Congestion Control for High-Bandwidth-Delay Product Networks. SIGCOMM’02, Aout 2002.
[62] T. Kelly. Scalable TCP : Improving Performance in Highspeed Wide Area Net-works . Submitted for publication, Décembre 2002.
[63] S. Keshav. Congestion Control in Computer Networks. PhD thesis, Departmentof EECS at UC Berkeley, Aôut 1991.
[64] S. Keshav. An Engineering Approach to Computer Networking. Addison-Wesley,1997.
[65] H. Kobayashi. Modeling and Analysis, An Introduction to System PerformanceEvaluation methodology. Addison-Wesley Publishing Company, 1978.
[66] H.T. Kung and R. Morris. Credit-based Flow Control for ATM Networks. IEEENetwork Magazine, 9 :40–48, Mars/Avril 1995.
[67] T.V. Lakshman and U. Madhow. The Performance of TCP/IP for Networks withHigh Bandwidth-Delay Products and Random Loss. IEEE/ACM Transactionson Networking, 5(3), Juin 1997.
[68] L. Lamti-Ben-Yakoub. Une Architecture pour la Gestion du Traffic Sortant d’UnRéseau Local. PhD thesis, Université de Rennes I, Décembre 1999.
[69] A.M. Law and W.D. Kelton. Simulation Modeling and Analysis. McGraw-Hill,2000.
[70] A.M. Lee. Applied Queuing Theory. Mac Millan, 1966.
[71] E. Liu. A Hybrid Queueing Model for Fast Broadband Networking Simulation.Master’s thesis, University of London, Mars 2002.
[72] A. Maria. Introduction to Modeling and Simulation. Proceedings of the 1997Winter Simulation Conference, 1997.
[73] R. Marquez, E. Altman, and S.S. Solé-Alvarez. Modeling TCP and High SpeedTCP : A Nonlinear Extension to AIMD Mechanisms. HSNMC 2004, pages 132–143, 2004.
[74] J.L. Mélin. Qualité de Service sur IP. Eyrolles, 2001.
[75] J. Nagle. RFC 896 : Congestion Control in IP/TCP Internetworks, Janvier 1984.
[76] J. Nagle. RFC 970 : On Packet Switches With Infinite Storage, Décembre 1985.
[77] J. Nagle. On Packet Switches with Infinite Storage. IEEE Transactions onCommunication, COM-35 :435–438, Avril 1987.
[78] A. Pattavina. Switching Theory : Architecture and Performance in BroadbandATM Networks. Wiley & Sons, 1998.
[79] I. Pepelnjak and J. Guichard. MPLS and VPN Architectures. Cisco Press, 2000.
97

Bibliographie
[80] H. Perros and K. Elsayed. Call Admission Control Schemes : A Review. IEEECommunications Magazine, 34(11), Novembre 1996.
[81] J.M. Pitts and J.A. Schormans. Introduction to IP and ATM Design Perfor-mance. Wiley & Sons, 2000.
[82] J. Postel. RFC 793 : Transmission Control Protocol, Septembre 1981.
[83] K.K. Ramakrishnan and R. Jain. A Binary Feedback Scheme for CongestionAvoidance in Computer Networks. ACM Transactions on Computer Systems,8(2) :158–181, Mai 1990.
[84] K.K. Ramakrishnan and P.Newman. ATM FLow Control : Inside the GreatDebate. Data Communication, pages 111–120, Juin 1995.
[85] K.K. Ramakrishnan and J. Zavgren. Credit Where Credit Is Due. AF-TM94-0916, Septembre 1994.
[86] E. Salvadori and R. Battiti. A Load Balancing Scheme for Congestion Controlin MPLS Networks. Proceedings of the Eighth IEEE International Symposiumon Computers and Communication (ISCC’03), 2003.
[87] C. Servin et S. Ghernaouti-Hélie. Les Hauts Débits en Télécom. Intereditions,1998.
[88] R.J. Simcoe and L. Roberts. The Great Debate Over ATM Congestion Control.Data Communications, pages 75–80, Septembre 1994.
[89] D. Sisalem. Rate Based Congestion Control and its Effects on TCP over ATM.Diplomarbeit thesis. Technical University of Berlin, Mai 1994.
[90] W. Stallings. ISDN and BroadBand ISDN with Frame Relay and ATM. Prentice-Hall, 2001.
[91] W. Stallings. Data and Computer Communication. Prentice Hall, 2003.
[92] A. Tanenbaum. Réseaux, Cours et Exercices. Coédition :Dunod (Paris) et Pren-tice Hall International (London), 1999.
[93] K.L. Thai and V. Veque et S. Znaty. Architecture des Réseaux Haut Débit :Cours, Exercices et Corrigés. Hermès, 1995.
[94] C. Touati. Les Principes d’Equité Appliqués aux Réseaux de Télécommunications.PhD thesis, Université de Nice Sophia-Antipolis, Septembre 2003.
[95] L. Toutain. Réseaux Locaux et Internet , Des Protocoles à l’Interconnexion.Hermès, 1999.
[96] D. Tse and M. Grossglauser. Measurement-based Call Admission Control : Ana-lysis and Simulation. IEEE INFOCOM’97, pages 981–989, 1997.
[97] J.S. Turner. New Directions in Conmmunications (or Which Way to the Infor-mation Age). IEEE Communications Magazine, 24 :8–15, Octobre 1986.
98

Bibliographie
[98] J.T. Virtamo. An exact Analysis of D1 + ...+Dk/D/1 Queue. 7th ITC Seminar,Morriston, New Jersey, Paper 11.1. 1990.
[99] A. Willig. Performance Evaluation Techniques. Universität Potsdam, Juin 2004.
[100] X. Xiao, A. Hannan, B. Bailey, and L. Ni. Traffic Engineering with MPLS. IEEENetworking, 14(2) :28–33, Mars/Avril 2000.
[101] X. Xiao and L.M. Ni. Internet QoS : A Big Picture. IEEE Networks, Mars/Avril 1999.
[102] C.Q. Ynag and A.V.S. Reddy. A Taxonomy for Congestion Control Algorithmsin Packet Switching Networks. IEEE Networks Magazine, 9 :34–45, Juillet/Août1995.
[103] B. Yuhas and N. Ansari. Neural Networks in Telecommunications. Kluwer Aca-demic Publishers, 1994.
99

Glossaire des Abréviations
Glossaire des Abréviations
AAL Atm Adaptation LayerABR Available Bit RateAoD Audio on DemandATM Asynchronous Transfert ModeBDP Bandwidth Delay ProductB-ISDN BroadBand Integrated Services Digital NetworkCAC Call (ou Connection) Admission ControlCBR Constant Bit RateCER Cell Error Ratio CLR Cell Loss RatioCDV Cell delay VariationCLP Cell Loss PriorityDES Discrete Event SimulationDQDB Distributed Queue Dual BusGFC General Flow ControlFDDI Fiber Distributed Data InterfaceFDM Frequency Division MultiplexingIEEE Institute of Electrical and Electronics EngineersIETF Internet Engineering Task ForceISDN Integrated Services Digital NetworkISO International Standards OrganisationISP Internet Service ProviderLAN Local Area NetworkMAC Medium Acces ControlMAN Metropolitan Area NetworkMCR Mean Cell RateMPEG Moving Picture Expert GroupMPLS Multi Protocol Label SwitchingN-ISDN Narrowband Integrated Services Digital NetworkNNI Network Network InterfaceOSI Open System InterconnectionPCR Peak Cell RateQoS Quality of ServiceRFC Request For Comments
100

Glossaire des Abréviations
RM Ressource ManagementRM Resource ManagementRNIS Réseau Numérique à Intégration de ServicesRTC Réseau Téléphonique CommutéSCR Sustained Cell RateSDM Space Division MultiplexingSTM Synchronous Transfert ModeTCP Transmission Control ProtocolUBR Unspecified Bit RateTDM Time Division MultiplexingUDP User Datagram ProtocolUIT Union Internationale des TélécommunicationsUNI User Network InterfaceUPC User Parameter ControlVBR Variable Bit RateVCC Virtual Channel ConnectionVCI Virtual Channel IdentifierVoD Video on DemandVPC Virtual Path ConnectionWAN Wide Area NetworkWDM Wavelength Division Multiplexing
101

Résumé
Dans un système à partage de ressources, la congestion est présente lorsque la de-mande en ressources dépasse la quantité des ressources diponibles. Contrairement à ceque l’on s’attendait, les technologies à haut débit n’ont fait qu’aggraver la congestion.Par conséquent, il faut concevoir de nouveaux protocoles de contrôle de congestionqui soient approporiés aux caractéristiques de tels réseaux. Le contrôle de congestionconsiste à maintenir le système en dessous du seuil de congestion, tout en optimisantl’utilisation des ressources par multiplexage statistique. Il est généralement réalisé parplusieurs moyens préventifs et réactifs. Les premiers visent à rendre l’apparition dece phénomène exceptionnelle alors que les derniers permettent de revenir à une situa-tion normale lorsque, malgré tout, la congestion se produit. Cette deuxième classe deméthodes est très utilisée dans les réseaux ATM afin de garantir la qualité de service(QoS) des connexions déja admises. L’objectif de ce travail est de faire une synthèse surles méthodes de contrôle de congestion dans les réseaux haut débit. Par la suite, nousétudierons de façon plus détaillée deux algorithmes de contrôle d’admission (CAC)comme exemples de contrôle préventif dans les réseaux ATM.
Mots clés : réseaux à haut débit, congestion, mode de transfert asynchrone, qua-lité de service, évaluation de performance, simulation à évènements discrets, contrôled’admission.
Abstract
In a system with resource sharing, congestion is present when the demand for resourcesexceeds the quantity of available resources. Unexpectedly, new broadband technolo-gies did nothing but worsen the congestion. Consequently, it is necessary to conceivenew congestion control protocols which are appropriate to the characteristics of suchnetworks. Congestion control consists in maintaining the system in lower part of thethreshold of congestion, while optimizing the use of the resources by statistical mul-tiplexing. It is generally carried out by several preventive and reactive means. Thefirst aim to return the appearance of this phenomenon exceptional whereas the lastmake it possible to return to a normal situation when, despite everything, congestionoccurs. This second class of methods is very used in ATM networks in order to guaran-tee quality of service (QoS) of already established connections. The aim of this thesisis to make a synthesis on the methods of congestion control in high speed networks.Thereafter, we will study in a more detailed way two algorithms of control admission(CAC) like examples of preventive control in ATM networks. .
Keywords : high speed networks, congestion, asynchronous transfer mode, quality ofservice, performance evaluation, discrete event simulation, admission control.