Embed Size (px)
Citation preview

THÈSE en vue de l’obtention du
GRADE DE DOCTEUR
délivré par
L’Institut Nationale des Sciences Appliquées de Lyon
présentée par
Farah HARRATHI
École doctorale : InfoMaths Unité de recherche : Laboratoire d'InfoRmatique en Image et Systèmes
d'information UMR 5205 CNRS Équipe d’accueil : Distribution et Recherche d'Information Multimedia
Extraction de concepts et de relations entre concepts à partir
des documents multilingues : Approche statistique et
ontologique
Soutenue le 28 Septembre 2009 devant la commission d’examen :
Jury
Benhamadou Abdelmajid Calabretto Sylvie Gammoudi Mohamed Mohsen Gargouri Faïez Jean-Marie Pinon Simonet Michel Roussey Catherine
Professeur des universités, Université de Sfax Maître de Conférences HDR, INSA de Lyon Professeur, Université de Tunis Professeur, Université de Sfax Professeur des universités, INSA de Lyon Professeur des Universités, TIMC-IMAG Maître de Conférences
Examinateur Directrice de thèse Directeur de thèse Rapporteur Examinateur Rapporteur co-directrice de thèse, invitée


-iii-
Résumé
Les travaux menés dans le cadre de cette thèse se situent dans la problématique
de recherche- indexation des documents et plus spécifiquement dans celle de
l’extraction des descripteurs sémantiques pour l’indexation. Le but de la Recherche
d’Information (RI) est de mettre en œuvre un ensemble de modèles et de systèmes
permettant la sélection d’un ensemble de documents satisfaisant un besoin
utilisateur en termes d’information exprimé sous forme d’une requête. Un Système
de Recherche d’Information (SRI) est composé principalement de deux processus.
Un processus de représentation et un processus de recherche. Le processus de
représentation est appelé indexation, il permet de représenter les documents et la
requête par des descripteurs ou des indexes. Ces descripteurs reflètent au mieux le
contenu des documents. Le processus de recherche consiste à comparer les
représentations des documents à la représentation de la requête.
Dans les SRIs classiques, les descripteurs utilisés sont des mots (simples ou
composés). Ces SRIs considèrent le document comme étant un ensemble de mots,
souvent appelé « sac de mots ». Dans ces systèmes, les mots sont considérés
comme des graphies sans sémantique. Les seules informations exploitées
concernant ces mots sont leurs fréquences d’apparition dans les documents. Ces
systèmes ne prennent pas en considération les relations sémantiques entre les
mots. Par exemple, il est impossible de trouver des documents représentés par un
mot M1 synonyme d’un mot M2, dans le cas où la requête est représentée par M2.
Aussi, dans un SRI classique un document indexé par le terme « bus » ne sera
jamais retrouvé par une requête indexée par le terme «taxi », pourtant il s’agit de
deux termes qui traitent le même thème « moyen de transport ».
Afin de remédier à ces limites, plusieurs travaux se sont intéressés à la prise en
compte de l’aspect sémantique des termes d’indexation. Ce type d’indexation est
appelé indexation sémantique ou conceptuelle. Ces travaux passent du niveau
mots au niveau concepts (les sens des mots), ainsi les descripteurs d’un document
sont des concepts.
Dans ces travaux les termes dénotant les concepts sont extraits à partir du
document en utilisant des techniques statistiques ou/et linguistiques. Ces termes
sont par la suite projetés sur une ressource sémantique (ontologie, thésaurus…)
afin d’extraire les concepts associés.

-iv-
Les approches d’indexation sémantique existantes ont été principalement
appliquées aux corpus monolingues. Dans ces corpus tous les documents sont
écrits dans une même langue. Ces approches utilisent un analyseur
morphosyntaxique (lemmatiseur et étiqueteur) de la langue du corpus pour
l’indexer. De ce fait, ils ne s’appliquent pas { des corpus multilingues où les
documents du corpus sont écrits dans plus d’une langue. L’objectif de notre travail
de thèse et de proposer une approche d’indexation sémantique adaptée aux corpus
multilingues.
Dans ce cadre nous proposons une approche statistique et ontologique
d’indexation adaptée aux documents multilingues. Nous proposons une technique
statistique exploitant les fréquences de mots afin d’extraire les termes des
documents. Par la suite le modèle d’ontologie est utilisé afin d’associer les termes à
leurs concepts. Ce modèle est aussi utilisé pour extraire les relations entre les
concepts à partir des documents. Nous proposons des algorithmes indépendants
de la langue des textes pour reconnaître des concepts et des relations de
l’ontologie dans les textes. De ce fait l’approche est « robuste » et indépendante de
la langue et du domaine du corpus. Concernant la validation, nous appliquons
notre approche sur un corpus réel, le corpus médical de la campagne d’évaluation
CLEF’2007 en utilisant le méta-thésaurus UMLS.
Mots clés : Indexation sémantique, Recherche d’information, Extraction de termes,
Extraction de concepts, extraction de relations, Documents multilingues

-v-
Abstract
The research work of this thesis is related to the problem of document search
indexing and more specifically in that of the extraction of semantic descriptors for
document indexing. Information Retrieval System (IRS) is a set of models and
systems for selecting a set of documents satisfying user needs in terms of
information expressed as a query. In IR, a query is composed mainly of two
processes for representation and retrieval. The process of representation is called
indexing, it allows to represent documents and query descriptors, or indexes.
These descriptors reflect the contents of documents. The retrieval process consists
on the comparison between documents representations and query representation.
In the classical IRS, the descriptors used are words (simple or compound). These
IRS consider the document as a set of words, often called a "bag of words".
In these systems, the words are considered as graphs without semantics. The
only information used for these words is their occurrence frequency in the
documents. These systems do not take into account the semantic relationships
between words. For example, it is impossible to find documents represented by a
word synonymous with M1 word M2, where the request is represented by M2.
Also, in a classic IRS document indexed by the term "bus" will never be found by a
query indexed by the word "taxi", yet these are two words that deal with the same
subject "means of transportation." To address these limitations, several studies
were interested taking into account of the semantic indexing terms. This type of
indexing is called semantic or conceptual indexing. These works take into account
the notion of concept in place of notion of word.
In this work the terms denoting concepts are extracted from the document by
using statistical techniques. These terms are then projected onto resource of
semantics such as: ontology, thesaurus and so on to extract the concepts involved.
Existing approaches for semantic indexing has been applied mainly to
monolingual corpus. These approaches use a morphosyntactic analyzer for
indexing. As a result, they do not apply multilingual corpus The aim of this thesis
work is to propose an approach of indexing semantics adapted to multilingual
corpus.
In this context we propose a statistical and ontological approach indexing
adapted to multilingual documents. A statistical techniques use the frequency of

-vi-
words in order to extract the terms of the documents. The ontology model is used
to associate the words into concepts. This model is also used to extract the
relations between concepts from documents. We propose algorithms independent
of the language of the texts to identify concepts and relations of the ontology in the
texts. Hence the approach is "robust" and independent of language and the domain
corpus. Regarding validation, we apply our approach on a real corpus, the corpus
of medical evaluation campaign CLEF'2007 using the UMLS meta-thesaurus.
Keywords: Semantic Indexing, Information Retrieval, Term Extraction, Concepts
extraction, Relationship extraction, Multilingual documents.

-vii-
Table des matières
1. Introduction générale .................................................................................................. 15
1.1. Contexte et problématique .............................................................................................. 15
1.2. Objectifs et contributions ................................................................................................. 17
1.3. Organisation de la thèse ................................................................................................... 18
2. Indexation sémantique et Recherche d’Information ........................................ 23
2.1. Introduction { la Recherche d’Information............................................................... 23
2.1.1. Définitions ................................................................................................................................. 23
2.1.2. Architecture d’un SRI ............................................................................................................ 24
2.1.3. Le processus d’Indexation .................................................................................................. 26
2.1.4. Le processus d'interrogation ou la formulation de requête ................................. 27
2.1.5. Le processus d’appariement document-requête et la fonction de
correspondance ................................................................................................................................... 29
2.1.6. Evaluation des SRI .................................................................................................................. 29
2.2. Les différents modèles de Recherche d’Information ............................................ 32
2.2.1. Le modèle booléen ................................................................................................................. 32
2.2.2. Le modèle vectoriel ................................................................................................................ 33
2.2.3. Le modèle probabiliste ......................................................................................................... 36
2.3. Indexation et RI multilingue ........................................................................................... 37
2.3.1. Recherche d’Information Multilingue ............................................................................ 38
2.3.2. Les problèmes liés { la Recherche d’Information MultiLingue (RIML) ........... 38
2.3.3. Les différents types de corpus multilingues................................................................ 41
2.3.3.1. Les Corpus comparables ................................................................................................................ 41
2.3.3.2. Les Corpus parallèles ...................................................................................................................... 41
2.3.3.3. Les Corpus multilingues ................................................................................................................ 41
2.3.4. Les différentes approches de l’indexation multilingue ........................................... 42
2.3.4.1. Approches basées sur un vocabulaire contrôlé .................................................................. 43
2.3.4.2. Traduction de la requête ............................................................................................................... 43
2.3.4.3. Traduction des documents ........................................................................................................... 43
2.3.4.4. Traduction de la requête et des documents ......................................................................... 44
2.4. Discussion : vers une indexation sémantique .......................................................... 44
2.5. L’indexation sémantique : apports et difficultés ..................................................... 46

-viii-
2.5.1. Les différentes ressources sémantiques et leurs utilisations en indexation . 49
2.5.1.1. Le thésaurus ........................................................................................................................................ 49
2.5.1.2. La base lexicale ou réseau sémantique WordNet .............................................................. 50
2.5.1.3. Ontologies............................................................................................................................................. 51
2.5.1.4. Les modèles de représentation des connaissances utilisés en indexation ............ 52
2.5.1.5. Les systèmes de recherche d’information utilisant une ressource sémantique.. 57
2.6. Conclusion .............................................................................................................................. 60
3. Etat de l’art sur l’extraction des descripteurs pour l’indexation .................. 65
3.1. Introduction .......................................................................................................................... 65
3.2. L’extraction des descripteurs ......................................................................................... 66
3.3. Extraction des termes ........................................................................................................ 66
3.3.1. Méthodes statistiques ou numériques d’extraction des termes ......................... 67
3.3.1.1. Les fréquences .................................................................................................................................... 67
3.3.1.2. Critères d’associations.................................................................................................................... 68
3.3.1.3. Les travaux de L. Lebart et A. Salem ........................................................................................ 69
3.3.1.4. Les travaux de Church .................................................................................................................... 70
3.3.1.5. Les travaux de R. Oueslati ............................................................................................................. 71
3.3.1.6. Conclusion : Bilan ............................................................................................................................. 71
3.3.2. Méthodes linguistiques ........................................................................................................ 72
3.3.2.1. Les travaux de David et Plante : TERMINO ........................................................................... 72
3.3.2.2. Les travaux de D. Bourigault : LEXTER ................................................................................... 73
3.3.2.3. Les travaux de C. Jaquemin : FASTER ...................................................................................... 74
3.3.2.4. Conclusion : Bilan ............................................................................................................................. 74
3.3.3. Méthodes hybrides ou mixtes ........................................................................................... 75
3.3.3.1. Les travaux de B. Daille .................................................................................................................. 75
3.3.3.2. Les travaux de F. Smadja ............................................................................................................... 76
3.3.3.3. Les travaux de K.T. Frantzi ........................................................................................................... 76
3.3.3.4. Conclusion : Bilan ............................................................................................................................. 77
3.3.4. Evaluation des systèmes d’extraction des termes .................................................... 78
3.3.4.1. Le corpus de référence ................................................................................................................... 78
3.3.4.2. La liste de référence......................................................................................................................... 78
3.3.4.3. Les mesures statistiques ............................................................................................................... 79
3.4. Extraction des termes à partir des corpus bilingues et corpus multilingues79
3.4.1. Extraction des termes à partir des corpus comparables ........................................ 79
3.4.2. Extraction des termes à partir des corpus parallèles .............................................. 80
3.4.3. Extraction des termes à partir des corpus multilingues ........................................ 81

-ix-
3.5. Structuration des termes en classes : les concepts ............................................... 82
3.5.1. La distribution contextuelle ............................................................................................... 82
3.5.2. Les travaux de P. Resnik ...................................................................................................... 83
3.5.3. Les travaux de E. Riloff ......................................................................................................... 83
3.6. Extraction des relations sémantiques ......................................................................... 84
3.6.1. Extraction des relations hiérarchiques ......................................................................... 84
3.6.1.1. Les travaux de M. Hearst ............................................................................................................... 84
3.6.1.2. Les travaux de E. Morin et C. Jaquemin .................................................................................. 86
3.6.1.3. Les travaux de R. Snow................................................................................................................... 86
3.6.2. Extraction des relations non- hiérarchiques ............................................................... 88
3.6.2.1. La relation de causalité .................................................................................................................. 88
3.6.2.2. La relation partie-de ........................................................................................................................ 89
3.6.2.3. Conclusion : Bilan ............................................................................................................................. 90
3.6.2.4. Discussion ............................................................................................................................................ 90
3.7. Conclusion .............................................................................................................................. 90
4. Une méthode statistique et ontologique d’extraction des concepts et des
relations à partir des corpus multilingues ................................................................. 95
4.1. Introduction .......................................................................................................................... 95
4.2. Fondements théoriques .................................................................................................... 96
4.2.1. La spécificité lexicale du corpus et les distances intertextuelles ........................ 96
4.2.2. La loi du moindre effort : Loi de Zipf .............................................................................. 98
4.2.3. Conjecture de Luhn ................................................................................................................ 99
4.3. Extraction des termes simples ..................................................................................... 100
4.3.1.1. Le prétraitement du corpus ...................................................................................................... 101
4.3.1.2. Calcul de l’intersection des vocabulaires ............................................................................ 101
4.3.1.3. Extraction des mots vides candidats ................................................................................... 102
4.3.1.4. Validation des mots vides candidats ..................................................................................... 102
4.3.1.5. Extraction des termes simples par élimination des mots vides ............................... 103
4.3.1.6. Pondération des termes simples ............................................................................................ 104
4.3.1.7. Algorithme d’extraction des termes simples .................................................................... 106
4.4. Extraction des termes composés ................................................................................ 107
4.4.1. Extraction des termes composés basée sur l’information mutuelle ............... 107
4.4.2. Pondération des termes composés ............................................................................... 111
4.5. Extraction des concepts .................................................................................................. 113
4.6. Extraction des relations sémantiques entre les concepts ................................. 121

-x-
4.7. Conclusion ............................................................................................................................ 122
5. Expérimentations et évaluations............................................................................ 127
5.1. Introduction ........................................................................................................................ 127
5.2. La collection du test ......................................................................................................... 127
5.2.1. Le corpus à indexer .............................................................................................................. 128
5.2.2. Le jeu de requêtes ................................................................................................................ 129
5.3. Le corpus d’appui .............................................................................................................. 129
5.4. La ressource externe : le méta thésaurus UMLS ................................................... 130
5.4.1. Présentation ............................................................................................................................ 130
5.4.2. Les concepts dans UMLS .................................................................................................... 131
5.4.3. Les relations entre les concepts et les types sémantiques .................................. 132
5.4.4. Les relations sémantiques entre les types sémantiques ...................................... 132
5.5. Les évaluations ................................................................................................................... 133
5.5.1. Le prototype MuDIBO ......................................................................................................... 133
5.5.2. Méthodologie d’évaluation ............................................................................................... 135
5.5.2.1. Description générale de la méthode d’évaluation .......................................................... 135
5.5.2.2. Mesures d’évaluation ................................................................................................................... 135
5.5.2.3. Description du système de RI sémantique utilisé comme base de référence : . 135
5.5.2.4. Notre système de RI...................................................................................................................... 138
5.5.3. Les prétraitements ............................................................................................................... 138
5.5.3.1. Prétraitements des documents et des requêtes .............................................................. 138
5.5.4. Extraction des termes simples par élimination des mots vides ........................ 140
5.5.4.1. Résultats ............................................................................................................................................. 141
5.5.4.1. Synthèse ............................................................................................................................................. 141
5.5.5. Extraction des termes composés : détermination du seuil de l’IMA ............... 141
5.5.5.1. Résultats ............................................................................................................................................. 142
5.5.5.2. Synthèse ............................................................................................................................................. 143
5.5.6. Traitement de l’ambigüité................................................................................................. 143
5.5.6.1. Résultats ............................................................................................................................................. 144
5.5.6.1. Synthèse ............................................................................................................................................. 145
5.5.7. Extraction des concepts ..................................................................................................... 145
5.5.7.1. Résultats ............................................................................................................................................. 146
5.5.7.2. Comparaison de notre approche statistique avec les approches linguistiques 147
5.5.7.3. Synthèse ............................................................................................................................................. 148

-xi-
5.5.8. Impact de la couverture du domaine par la ressource sémantique sur
l’extraction des concepts ................................................................................................................ 148
5.5.8.1. Résultats ............................................................................................................................................. 149
5.5.8.2. Synthèse ............................................................................................................................................. 151
5.5.9. Extraction des relations sémantique ............................................................................ 151
5.5.9.1. Résultats ............................................................................................................................................. 152
5.5.9.2. Synthèse ............................................................................................................................................. 152
5.6. Discussion ............................................................................................................................ 153
5.7. Conclusion ............................................................................................................................ 153
6. Conclusions et perspectives ..................................................................................... 155
6.1. Contributions ...................................................................................................................... 155
6.1.1. Sur le plan théorique ........................................................................................................... 155
6.1.2. Sur le plan pratique et technique ................................................................................... 156
6.2. Perspectives ........................................................................................................................ 157
7. Annexes ........................................................................................................................... 161
8. Bibliographie ................................................................................................................. 167

-xii-
Table des figures
Figure 2.1- Processus général de Recherche d’Information (BAZIZ, 2005) ................... 26
Figure 2.2- Répartition des documents d’un corpus suite à une interrogation (HO,
2004) ............................................................................................................................... 30
Figure 2.3- Courbe précision-rappel pour la requête de l’exemple ci_dessus ............... 32
Figure 2.4- la représention des dans l’espace d’indexation (ROUSSEY, 2001) .............. 34
Figure 2.5- Les différentes approches d’indexation multilingue .................................... 42
Figure 2.6 – Le thésaurus utilisé pour l’indexation de l’exemple ................................... 47
Figure 2.7- Exemple de réseau sémantique ................................................................... 52
Figure 2.8- Le GC : un véhicule construit par le constructeur Renault participe au
Rallye :Paris Dakar . ......................................................................................................... 54
Figure 2.9- La projection du graphe H dans le graphe G . .............................................. 55
Figure 3.1- Réseau fourni par LEXTER pour «stenose severe de le tronc commun
gauche» (HABERT et al, 1995) ........................................................................................ 73
Figure 3.2 Exemple de sortie de la méthode de J. vergne .............................................. 82
Figure 3.3- vue d’ensemble du système proposé par E. Morin et C. Jaquemin (MORIN
et al, 2004) ..................................................................................................................... 86
Figure 3.4- Exemple d’arbre de dépendance généré par MINIPAR (SNOW et al, 2005) 87
Figure 4.1- la distance intertextuelle .............................................................................. 97
Figure 4.2- la conjecture de Luhn : informativité des mots ........................................... 99
Figure 4.5- Vue d’ensemble de l’approche proposée pour l’extraction des concepts 114
Figure 4.6- Exemple d’un concept d’une ressource sémantique décrite par SKOS ..... 115
Figure 4.7- Exemple d’un concept d’une ressource sémantique décrite par SKOS ..... 117
Figure 4.8- les sens du terme « circuit » dans WordNet .............................................. 120
Figure 4.9- Exemple d’un document de la collection CLEF 2007 .................................. 122
Figure 5.1- Exemple d’un document de la collection CLEF 2007 .................................. 129
Figure 5.3- Architecture générale du prototype MuDIBO ............................................ 134
Figure 5.4- Exemple du contenu textuel du document de la Figure 5.1. ..................... 139
Figure 5.5- Variation de la MAP en fonction du seuil de l’IMA .................................... 142
Figure 5.6- Variation de la P@5 en fonction du seuil de l’IMA .................................... 142
Figure 5.7- Courbes de la précision à 11 points de rappel : sans et avec traitement de
l’ambiguité (STA, ATA) .................................................................................................. 144
Figure 5.8- Courbes de la précision à 11 points de rappel ........................................... 146
Figure 5.9- Courbe de la précision à 11 points de rappel :UMLS versus MeSH ........... 149
Figure 5.10- Courbes de la précision à 11 points de rappel :Concepts versus
Concepts+relations ....................................................................................................... 152

-xiii-
Table des tableaux
Tableau 2.1 – Les documents retournés par le SRI pour la requête de l’exemple ........ 31
Tableau 2.2 – Les valeurs de la précision et du rappel pour la requête de l’exemple ... 31
Tableau 2.3 – Les dix premières langues les plus utilisées dans internet ...................... 37
Tableau 2.4 – Les représentetions de quatre documents dans le modèle vectoriel ..... 47
Tableau 2.5 – Les représentations par les concepts des quatre documents dans le
modèle vectoriel ............................................................................................................. 48
Tableau 2.6 – Similarité entre documents selon la stratégie d’indexation .................... 48
Tableau 2.7 – Les statistiques sur le nombre des mots et de concepts dans WordNet
3.0. .................................................................................................................................. 50
Tableau 2.8 – Exemple d’ una base de connaissances composée d'un TBox et d'une
ABox ................................................................................................................................ 56
Tableau 2.9 – Exemple de représentation des relations de WordNet par les LDs
(TBox+ABox) .................................................................................................................... 57
Tableau 3.1 – Tableau de contingence du couple de lemmes ............................. 68
Tableau 3.2 – Exemple de données lexicales utilisées par J. Vergne (VERGNE, 2003).. 81
Tableau 3.3 – Les patrons utilisés par Hearst pour l’extraction de l’hyperonymie ........ 85
Tableau 3.4 – Les patrons extraits par R.Girju ............................................................... 89
Tableau 5.1 – Détails de la collection CLEF médicale 2007 de concept dans UMLS .... 128
Tableau 5.2 – Statistiques sur le corpus d’appui .......................................................... 130
Tableau 5.3 – Exemple de concept dans UMLS ............................................................ 131
Tableau 5.4 – Aperçu sur les langues de UMLS ........................................................... 132
Tableau 5.5 –Le concept C0000167 et ses types sémantiques ............................... 132
Tableau 5.6 – Une relation sémantique entre deux types sémantiques .................. 133
Tableau 5.7 –Résultat de l’analyse lexicale du document de la Figure 5.1. ................. 140
Tableau 5.8 – Variation de la MPA et de la P@5 en fonction du seuil de l’IMA ......... 143
Tableau 5.9 –Résultats en MAP et P@5 sans et avec traitement de l’ambiguité (STA,
ATA) ............................................................................................................................... 145
Tableau 5.10 – Quelques résultats de la désambigüisation. ..................................... 145
Tableau 5.11 –Résultats en MAP et P@5 pour les deux approches............................. 147
Tableau 5.12 – Aperçu sur MeSH et sa part dans UMLS .............................................. 149
Tableau 5.13 –Résultats en MAP et P@5 pour les deux extractions: UMLS Versus MeSH
...................................................................................................................................... 150
Tableau 5.14 –Précision après n documents trouvés pour la langue allemande ......... 150
Tableau 5.15 –Résultats en MAP et P@5 pour les deux sénarios: Concepts Versus
Concepts+Relations ...................................................................................................... 152


-15-
Chapitre 1
Introduction générale
1.1. Contexte et problématique
De nos jours on assiste à un développement incessant des technologies de
l’information. Ces nouvelles technologies ont permis l’évolution rapide des
techniques et des matériels de production et de gestion de l’information. Le
progrès des outils de production d’informations tels que les éditeurs de textes a
permis la production quotidienne d’une énorme masse d’information. L’évolution
des médias électroniques a permis le stockage de cette vaste quantité
d’information. Cette augmentation rapide du volume d’information a engendré le
problème de comment retrouver une information qui nous intéresse dans cette
grande masse d’information. Afin de traiter ce problème une discipline toute
entière est née. Cette discipline est appelée Recherche d’Information (RI). Elle
s’intéresse au développement des techniques et des outils qui permettent de
retrouver une information intéressante afin de satisfaire un besoin en information,
dite information pertinente. Ces outils sont appelés des Systèmes de Recherche
d’Information (SRI). Ainsi, un SRI permet de sélectionner parmi un volume
d’information, les informations pertinentes vis-à-vis d’un besoin en information.
Dans ce système, le besoin en information est exprimé sous forme de requête.
Dans un SRI, chaque document est représenté par une représentation
intermédiaire. Cette représentation est directement exploitée par le SRI. Elle
décrit le contenu du document par des descripteurs. Ces descripteurs sont des
unités significatives dans le document. Cette description est appelée l’indexation
du document. De la même manière le contenu de la requête est décrit par un
ensemble de descripteurs. Pour retrouver les documents pertinents vis-à-vis d’une
requête, le SRI compare la représentation de cette requête à la représentation de
chaque document. Cette comparaison est réalisée au moyen d’une fonction de
correspondance (Retrieval Status Value: RSV) et un score de pertinence est affecté
{ chaque document. Ces scores permettent de présenter { l’utilisateur les
documents pertinents dans un ordre de pertinence. Le processus de recherche est

1.1. Contexte et problématique
-16-
donc composé de deux processus : une phase d’indexation et une phase de mise en
correspondance.
Dans une indexation manuelle, le document est examiné par un spécialiste ou
un documentaliste et une liste de descripteurs est établie. Ce type d’indexation est
fiable et donne des bons résultats. Par conséquent les documents retournés par le
SRI en réponse { une requête utilisateur sont précis. Mais, avec l’augmentation
incessante du nombre de documents, l’indexation manuelle s’avère impossible. En
effet, l’indexation est une tâche lourde et coûteuse en terme du temps. De plus,
suite au développement rapide des technologies et surtout dans les domaines
scientifiques tels que la médecine, de nouveaux descripteurs sont ajoutés d’une
manière continue. Afin de gérer ces nouveaux ajouts, les compétences des
documentalistes et des spécialistes doivent être mises à jour continuellement. Une
automatisation du processus d’indexation s’avère une solution pour remédier aux
limites de l’indexation manuelle.
L’indexation automatique permet de décrire un document par un ensemble de
descripteurs. Cette indexation est issue des Traitements Automatiques de la
Langue Naturelle (TALN). Elle constitue un compromis entre la performance et la
faisabilité. En effet une indexation manuelle est plus efficace qu’une indexation
automatique, mais cette indexation n’est pas toujours possible surtout quand il
s’agit des corpus volumineux. Dans le cas où l’indexation automatique est guidée
par l’utilisateur, on parle de l’indexation semi-automatique ou supervisée.
En plus, des exigences imposées par les tailles des corpus, celle de l’aspect
multilingue vient s’ajouter. En effet, avec le développement des technologies de
transfert et transmission d’information et particulièrement Internet, les barrières
géographiques n’ont plus d’existence. Un utilisateur peut exprimer son besoin sous
forme de requête et le SRI renvoie les documents pertinents indépendamment de
leurs emplacements géographiques. En effet, les utilisateurs expriment leurs
requêtes dans leurs langues préférées dont l’objectif de rechercher des documents
pertinents. Ces documents ne sont pas seulement ceux qui sont écrits dans la
même langue de requête. Souvent, un utilisateur trouve des difficultés pour
exprimer son besoin dans une langue donnée malgré qu’il soit capable de bien lire
des documents écrits dans cette langue. Ces documents ne seront pas retrouvés
par le SRI monolingue. Il est donc indispensable de développer des outils et de
proposer de nouvelles techniques qui permettent de surmonter la barrière de la
langue. Pour cela, plusieurs systèmes ont été développés qui sont appelés Système
de Recherche d’Information Multilingue (SRIM). Ces SRIMs permettent de

1.2. Objectifs et contributions
-17-
retrouver des documents pertinents vis-à-vis d’une requête utilisateur
indépendamment de leurs langues.
Les SRIs classiques, considèrent les documents comme des ensembles de mots,
appelés sac de mots. Ces mots sont utilisés dans ces SRIs pour décrire le contenu
d’un document. Ainsi, ces SRIs considèrent les mots comme des graphies sans sens.
De ce fait, ils permettent de retrouver seulement des documents qui sont décrit par
les mêmes mots que la requête. Par exemple, un document indexé par un mot
synonyme d’un autre mot qui décrit la requête ne sera jamais renvoyé par ces SRIs,
malgré que ce document soit pertinent. Afin de remédier à ces limites il est devenu
indispensable de prendre en considération le sens du mot. Les descripteurs sont
alors les sens des mots : les concepts. Ce type d’indexation est appelé indexation
conceptuelle ou sémantique. L’indexation sémantique décrit le contenu du
document par des descripteurs sémantiques. Elle permet d’améliorer la
performance des systèmes de recherche d’information.
Le sujet de cette thèse se situe dans ce cadre générale de recherche
d’information. Particulièrement, nous nous intéressons { la description du
contenu des documents multilingues par des descripteurs sémantiques :
l’indexation sémantique des documents multilingues.
1.2. Objectifs et contributions
L’objectif de notre travail est de proposer une méthode d’indexation sémantique
adaptée aux documents multilingues. Ces documents sont écrits en anglais et en
langues latines. Cette indexation permet de décrire le contenu des documents par
des descripteurs sémantiques. Ainsi, notre travail consiste à extraire ces
descripteurs { partir de ces documents. Il s’agit de proposer une méthode
d’extraction des concepts et des relations sémantiques entre concepts { partir des
documents multilingues. Les difficultés résident, d’une part, dans le fait de
capturer les sens des mots (les concepts) et d’en extraire les relations et d’autre
part, dans l’évaluation de l’efficacité de cette tâche d’extraction.
Pour la première difficulté liée { l’extraction des descripteurs sémantiques, la
plupart des travaux utilisent des ressources sémantiques externes, telles que les
ontologies et les thésaurii. Dans un premier temps, les manifestations
linguistiques de ces descripteurs dans le texte sont extraites. Ces manifestations
sont les mots qui possèdent un pouvoir discriminent dans le texte : les termes. Ces
termes dénotent les concepts dans le texte. Ensuite, ces termes sont transformés

1.3. Organisation de la thèse
-18-
en concepts en utilisant la ressource sémantique. Les approches existantes
d’extraction des termes sont basées sur des propriétés de la langue naturelle. De ce
fait, elles sont dites approches linguistiques. Ces propriétés sont spécifiques à une
langue donnée. Par conséquent, l’analyse change quand la langue du document
change. Ce qui donne des analyseurs linguistiques spécifiques à la langue des
documents à analyser. Ces analyseurs ne sont pas toujours disponibles pour toutes
les langues. C’est pour cette raison que nous n’avons pas opté pour une approche
linguistique.
La deuxième difficulté est liée { l’efficacité d’une tâche d’extraction des
descripteurs. Pour ce faire, nous évaluons l’efficacité de notre approche { travers
une comparaison de ses résultats aux résultats obtenus par une approche
linguistique.
L’approche que nous proposons permet d’abord d’extraire les termes simples et
les termes composés à partir des documents multilingues. Ces termes sont par la
suite transformés en concepts. Dans cette étape de transformation nous utilisons
une ressource sémantique externe. Ensuite, cette ressource est utilisée pour
extraire les relations sémantiques entre les concepts. Ainsi, l’approche proposée
permet d’extraire automatiquement les concepts et les relations sémantiques entre
les concepts.
1.3. Organisation de la thèse
Le mémoire de thèse est organisé comme suit. Le chapitre 2 présente une
introduction sur le domaine de la recherche d'information. D’abord, nous
introduisons le processus de recherche d’information qui permet de retrouver
parmi un ensemble de documents, ceux qui sont pertinents vis-à-vis d’une requête
utilisateur. Ensuite, nous mettons l’accent sur les différentes méthodes
d’indexation { partir d’une synthèse sur les différents types d’indexation ainsi que
les ressources utilisées pour indexer les documents et les requête.
Le chapitre 3 est consacré à la présentation des travaux existants dans le
domaine d’extraction des descripteurs { partir des documents. Nous exposons les
approches existantes d’extraction des termes, des concepts et des relations
sémantiques entre concepts. En particulier, nous mettons l’accent sur les limites de
ces approches et les motivations de notre proposition.
Dans le chapitre 4, nous présentons l’approche que nous proposons pour
décrire les documents multilingues par des descripteurs sémantiques.

1.3. Organisation de la thèse
-19-
Le chapitre 5 présente les expérimentations que nous avons réalisées. Ces
expérimentations ont pour objectif d’évaluer notre approche d’extraction des
concepts et des relations entre concepts. Dans ces expérimentations nous
appliquons notre approche à des données réelles et nous comparons les résultats
obtenus { ceux obtenus par l’approche linguistique.
Enfin, dans le chapitre 6 nous concluons en présentant un bilan général de
l’ensemble de nos contributions et en évoquant de nouvelles perspectives de
recherche.


-21-
INDEXATION SEMANTIQUE ET
RECHERCHE D’INFORMATION
Résumé
Dans ce chapitre, nous présentons un état de l'art du domaine de la
recherche d'information. D’abord, nous introduisons le processus de
recherche d’information. Ce processus permet de retrouver parmi un
ensemble de documents, ceux qui sont pertinents vis-à-vis d’une requête
utilisateur. Ensuite nous mettons l’accent sur l’étape d’indexation
produisant la description des documents par des descripteurs
(l’indexation). Nous exposons une synthèse sur les différents types
d’indexation ainsi que les ressources utilisées pour indexer les
documents et la requête.


-23-
Chapitre 2
Indexation sémantique et Recherche
d’Information
2.1. Introduction à la Recherche d’Information
La Recherche d’Information (RI) est un ensemble de techniques et d’outils
traitant de l’accès { l’information ainsi que la présentation, le stockage et
l’organisation de l’information (RIJSBERGEN, 1979) (BAZIZ, 2005) (RICARDO et al,
1999). Ces techniques permettent la sélection d’un ensemble de documents
satisfaisant le besoin d’information d’un utilisateur, { partir d’une collection de
documents. La collection de documents est souvent appelée corpus ou fond
documentaire. Dans la suite nous retiendrons le terme corpus pour représenter la
collection du document.
Le but de la recherche d’information est de trouver les documents qui satisfont
un besoin utilisateur. Si l’utilisateur juge qu’un document répond { son besoin, le
document est dit pertinent. Dans un Système de Recherche d’Information (SRI),
L’utilisateur exprime son besoin d’information sous forme d’une requête. Le SRI
tente de trouver tous les documents pertinents et de rejeter les documents qui ne
sont pas pertinents. Dans la pratique, l’ensemble des documents renvoyés par un
SRI pour une requête est composé d’un sous-ensemble de documents pertinents et
un sous-ensemble de documents non pertinents. Ces sous-ensembles déterminent
la performance d’un SRI.
Avant de présenter l’architecture d’un SRI nous présentons les notions de bases
utilisés dans ce domaine :
2.1.1. Définitions
Dans cette section nous définissons les principales notions qui seront utilisés
dans notre travail de thèse. En effet, il n’existe pas un consensus sur ces définitions
(TURENNE, 2000). Ainsi, nous définissons les notions suivantes : mot, mot vide et
mot plein, terme, concept, index et descripteur.

2.1. Introduction à la Recherche d’Information
-24-
Mot : dans le dictionnaire Larousse, un mot est un élément de la langue
composé d'un ou de plusieurs phonèmes, susceptible d'une transcription écrite
individualisée et participant au fonctionnement syntacticosémantique d'un
énoncé. Ainsi, nous considérons un mot comme une chaîne de caractères délimitée
par des espaces ou des caractères de ponctuation. Un mot est dit simple s’il est
composé d’un seul mot, si non il est dit composé ou complexe.
Mot plein et mot vide : selon (BERNHARD, 2006), un mot plein est un mot qui
décrit mieux le contenu d’un document ou d’un corpus. Les mots pleins sont
souvent des noms, des verbes ou des adjectifs, Par opposition aux mots vides
comme les prépositions, les déterminants ou les pronoms. En recherche
d’information les mots pleins sont dits mots clés.
Concept : dans le dictionnaire de l'académie française, un concept est défini
comme suit : « Le concept regroupe les objets qu'il définit en une même catégorie
appelée classe». Ainsi, un concept est considéré comme une représentation
mentale d’un ensemble de notions ou d’idées. Selon (ROCHE, 2005), « Il n’y a pas
de concepts dans un texte, mais uniquement des traces linguistiques de leurs
usages ».
Terme : un terme est formé d’un mot ou d’une séquence de mots qui dénote un
concept dans un domaine particulier (RADHOUANI, 2008). Un terme peut dénoter
plusieurs concepts dans domaine différents. Un terme est dit terme simple s’il est
composé d’un seul, si non il est appelé terme composé ou complexe (BERNHARD,
2006).
Descripteur et index : Dans (FLUHR, 1992), un index est défini comme suit : «les
documents sont lus par un documentaliste qui en déduit les thèmes principaux et
les traduit en une liste de mots, dit descripteurs des documents. Cet ensemble de
mots constitue l'index du document et représente la description du contenu
sémantique de celui-ci »
2.1.2. Architecture d’un SRI
En général, un système de recherche d’information est composé principalement
de deux processus (ROUSSEY, 2001). Un processus d’indexation et un processus de
recherche. Dans une première étape, les documents et la requête sont indexés afin
d’extraire des descripteurs. Ces descripteurs reflètent au mieux le contenu des

2.1. Introduction à la Recherche d’Information
-25-
documents. Cette étape est appelée l’indexation. La deuxième étape est une étape
de recherche qui se traduit par une fonction de correspondance et qui consiste à
comparer les représentions des documents à celle de la requête afin de retrouver
des documents recherchés. Cette fonction est notée (Retrieval Status Value)
(BAZIZ, 2005) . Dans la plupart des processus d’indexation un poids est affecté {
chaque descripteur. Ce poids permet de déterminer le pouvoir discriminant du
descripteur dans le document où il est présent.
Dans un processus de RI, le besoin utilisateur est exprimé par une requête .
D’abord la requête est indexée ( ), ainsi que chaque document du corpus ( ).
Ensuite, la représentation de la requête est comparée à la représentation de
chaque document ( . Ce qui se traduit formellement par (ROUSSEY, 2001) :
(1.1)
(1.2)
(1.3)
Avec
: l’espace des requêtes,
: l’espace des documents,
: l’espace d’indexation.
2.1. Introduction à la Recherche d’Information
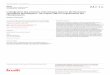
-26-
Figure 2.1- Processus général de Recherche d’Information (BAZIZ, 2005)
2.1.3. Le processus d’Indexation
Dans un processus de recherche d’information, la requête et les documents du
corpus sont difficilement exploitables { l’état brut. Une représentation de ces
documents ainsi que la requête s’avère indispensable. Afin d’aboutir { ces
représentations des techniques et des modèles sont mis en œuvre. Ces techniques
permettent de décrire les documents et la requête par un ensemble de
descripteurs. Ce processus de représentation est appelé le processus d’indexation
ou tout simplement l’indexation. L’indexation consiste { analyser les documents et
la requête afin d’extraire un ensemble de descripteurs (SALTON, 1970)
(RIJSBERGEN, 1979). Ces descripteurs sont des unités textuelles significatives dans
le document. Dans une indexation classique, les descripteurs d’un document
peuvent être des termes simples ou des termes composés .
Dans une indexation manuelle, chaque document du corpus est examiné par un
documentaliste spécialisé dans le domaine afin d’identifier les descripteurs (BAZIZ,
2005) (ROUSSEY, 2001). A la fin de cette étape d’analyse des documents, une liste
de descripteurs est établie. Ce type d’indexation est fiable et donne des bons
résultats. Par conséquent les documents retournés par le SRI en réponse à une
requête utilisateur sont précis (REN et al, 1999). Mais, avec l’augmentation
incessante du nombre de documents, l’indexation manuelle s’avère difficile. En
Un Besoin d’information
Utilisateu
r : Possède
Une requête :
Représentation de :
Un document :
d :
Représentation de :
Indexation de
:
Comparaison :
Document sélectionné selon la valeur de
Sélection
Jugement
Expression du besoin
Indexation de
:
Ressources
externes

2.1. Introduction à la Recherche d’Information
-27-
effet, l’indexation est une tâche lourde et coûteuse en temps. De plus, suite au
développement rapide des connaissances et des technologies dans les domaines
scientifiques tels que la médecine, de nouveaux mots sont ajoutés aux langues
d’une manière continue. Afin de gérer ces ajouts, les compétences des
documentalistes et des spécialistes doivent être mises à jour continuellement.
Ainsi, des méthodes et des outils d’indexation issus des Traitements Automatiques
de la Langue Naturelle (TALN) ont été proposés afin de rendre cette tâche
entièrement automatique. Cependant, comparés aux résultats de l’indexation
manuelle, les résultats obtenus par une indexation automatique sont souvent jugés
insatisfaisants (JACQUEMIN et al, 2002). Pour remédier à ce défaut, certains
travaux (JACQUEMIN et al, 2002) proposent d’exposer les résultats de l’indexation
automatique à un documentaliste. Ce dernier sélectionne les descripteurs jugés
valides parmi la liste des descripteurs exposés. Ce type d’indexation est appelé
indexation semi-automatique ou indexation supervisée.
Que ce soit le processus d’indexation manuelle, supervisée ou automatique , un
ensemble de descripteurs est associé à chaque document du corpus. L’ensemble
des descripteurs permettant de représenter les documents du corpus constituent
le langage d’indexation ou le jeu d’indexation (GAMMOUDI, 1993). Dans
l’indexation manuelle et l’indexation semi-automatique, le jeu d’indexation est
réduit { un ensemble de descripteurs jugés valides par l’expert. Chaque
descripteur extrait d’une manière automatique doit être validé par un spécialiste.
On parle alors d’un langage d’indexation contrôlé. Contrairement { l’indexation
manuelle et { l’indexation semi-automatique, en indexation automatique le jeu
d’indexation est constitué de tous les descripteurs issus de l’analyse automatique
des documents du corpus et de la requête.
Nous signalons à ce passage que dans la plupart des processus d’indexation
manuelle et d’indexation supervisée, une ressource externe lexicale ou une
ressource lexico-sémantique est utilisée pour le choix des descripteurs. Cette
ressource couvre le langage d’indexation. Dans ce cas, il s’agit d’une indexation
guidée par la ressource dite indexation sémantique. Ces ressources ainsi que
l’indexation sémantique feront l’objet d’une étude détaillée dans les sections qui
suivent.
2.1.4. Le processus d'interrogation ou la formulation de requête
A l’opposé de l’indexation qui est une tâche transparente vis à vis de
l’utilisateur, ce dernier est directement impliqué dans la formulation de la requête

2.1. Introduction à la Recherche d’Information
-28-
qui exprime son besoin d’information. La requête est exprimée par l’utilisateur
dans un langage de requête et elle est représentée sous une forme interne
compréhensible par le système. Le langage de requête est spécifique au SRI et au
modèle de recherche d’information utilisé. La formulation de la requête est une
étape primordiale et critique. En effet, la qualité des documents retournés par le
SRI dépend de la qualité de la formulation de la requête. Ainsi, les langages de
requêtes doivent être simples, afin de permettre aux utilisateurs non initiés de
formuler correctement leurs requêtes.
Dans un SRI basé sur une indexation classique, les requêtes utilisateurs sont
souvent exprimées en langage libre. Ainsi, l’utilisateur peut exprimer son besoin
d’information en spécifiant une séquence de mots. L’utilisateur n’est pas sensé
respecter une syntaxe. La séquence de mots produite par l’utilisateur ne constitue
pas forcement une phrase correcte. Le langage libre est utilisé par la plupart des
moteurs de recherche tels que Google1 et Yahoo2 etc. Ces moteurs de recherche
offrent en plus un langage spécifique aux utilisateurs initiés. Dans ce langage, une
requête est une combinaison de mots et d’opérateurs booléens : . Ce
langage est disponible dans Google3 et Yahoo4 à partir des interfaces de recherche
avancée. Il est { noter que l’utilisation de ce langage nécessite une maîtrise parfaite
par les utilisateurs de la formulation de requêtes en utilisant des opérateurs
booléens. Ainsi, ce langage est limité aux utilisateurs expérimentés en recherche
d’information (Mothe, 2000). Dans une indexation sémantique le langage
d’indexation est contrôlé. Ce langage est souvent issu d’une ressource externe. Le
jeu d’indexation utilisé pour décrire les documents est connu par le SRI. L’idée est
de proposer { l’utilisateur de construire sa propre requête { partir de ce jeu. Dans
SyDOM5 (ROUSSEY, 2001), C. Roussey propose { l’utilisateur une interface
graphique pour construire la requête à partir des glisser/déplacer des
descripteurs. Dans SyDOM les descripteurs sont des concepts et des relations entre
les concepts. Ces descripteurs sont issus d’un thésaurus sémantique du domaine.
1 http ://www.google.fr/ 2 http://fr.yahoo.com/ 3 http://www.google.fr/advanced_search?hl=fr 4 http://fr.search.yahoo.com/web/advanced?ei=UTF-8
5 Système Documentaire Multilingue

2.1. Introduction à la Recherche d’Information
-29-
2.1.5. Le processus d’appariement document-requête et la fonction de
correspondance
Dans un SRI, l’utilisateur exprime son besoin d’information sous forme de
requête. Cette requête est formulée par l’utilisateur dans le langage requête. Le SRI
représente la requête utilisateur dans une représentation interne. Cette
représentation est comparable à celle utilisée pour représenter les documents du
corpus. Ces représentations sont réalisées dans le même jeu d’indexation. Une
fonction de correspondance ou de ranking permet de comparer la représentation
de la requête à celle de chaque document du corpus. Elle consiste à calculer la
similarité entre la représentation de la requête est de chaque document. La
fonction de correspondance permet d’estimer la similarité d’un document par
rapport à une requête. Cette fonction, souvent appelée RSV (Retrieval Status
Value) prend en considération les descripteurs ainsi que leurs pondération dans la
représentation de la requête et la représentation du document.
2.1.6. Evaluation des SRI
Dans un processus de recherche d’information, l’utilisateur exprime sa requête
et le SRI retourne un ensemble de documents. Dans la majorité des SRIs, ces
documents sont classés dans l’ordre décroissant de pertinence. Un SRI idéal
ramène tous les documents pertinents et rejette les documents non pertinents.
Dans la pratique, l’ensemble des documents retournés par un SRI contient des
documents non pertinents. Ce qui génère un bruit documentaire. Aussi, un SRI
peut omettre des documents pertinents en ne les retournant pas { l’utilisateur. Ce
qui engendre un silence documentaire. Dans un SRI, l’objectif est de minimiser le
bruit et le silence. Afin d’évaluer la performance d’un SRI, deux mesures
statistiques ont été définies (RIJSBERGEN, 1979). La première mesure est la
précision et la deuxième mesure est le rappel. La précision détermine la capacité
d’un SRI { rejeter les documents non pertinents pour une requête utilisateur. Le
rappel détermine la capacité d’un SRI { retourner tous les documents pertinents
pour une requête. Ces deux mesures sont données par les formules
suivantes (RIJSBERGEN, 1979):
(1.4)
(1.5)

2.1. Introduction à la Recherche d’Information
-30-
Avec :
: l’ensemble des documents pertinents { la requête et retournés par
le SRI,
: l’ensemble des documents retournés par le SRI,
: l’ensemble des documents dans le corpus qui sont pertinents { la
requête,
, , : les nombres des documents dans les trois ensembles
considérés.
La Figure 2.2 représente la répartition des documents suite à une interrogation
utilisateur. A partir de ces ensembles de documents les deux mesures précision et
rappel sont calculées.
Figure 2.2- Répartition des documents d’un corpus suite à une interrogation (HO, 2004)
Supposons que dans un cas idéal, un SRI est capable de ramener tous les
documents pertinents du corpus et de rejeter tous les documents non pertinents
pour une requête ( ). (1.2) et (1.3) donnent.
(1.6)
(1.7)
Pour ce système idéal, la valeur précision est égale à la valeur du rappel. Cette
valeur est égale à 1.

2.1. Introduction à la Recherche d’Information
-31-
Afin d’expliquer l’évaluation d’un SRI nous utilisons un exemple similaire {
celui donné dans (STYLTSVIG, 2006). Considérons un utilisateur qui interroge un
ensemble de documents par l’intermédiaire d’une requête . La requête et le
corpus sont exposés { un expert ou un documentaliste afin d’identifier
l’ensemble des documents pertinents vis-à-vis de . Par exemple,
et . Le SRI
répond à la requête et renvoie un ensemble de documents . Par exemple,
1. 6. 11. 16.
2. 7. 12. 17.
3. 8. 13. 18.
4. 9. 14. 19.
5. 10. 15. 20.
Tableau 2.1 – Les documents retournés par le SRI pour la requête de l’exemple
Dans le Tableau 2.1, les documents jugés pertinents par l’expert et qui sont
retrouvés par le SRI sont marqués en gris. Ces documents constituent l’ensemble
. Soit le sous ensemble de qui contient les premiers documents
pertinents retrouvés par le système. , , etc. Les
valeurs de précision et de rappel pour chaque sous ensemble sont données dans le
Tableau 2.2.
Rappel Précision
Tableau 2.2 – Les valeurs de la précision et du rappel pour la requête de l’exemple
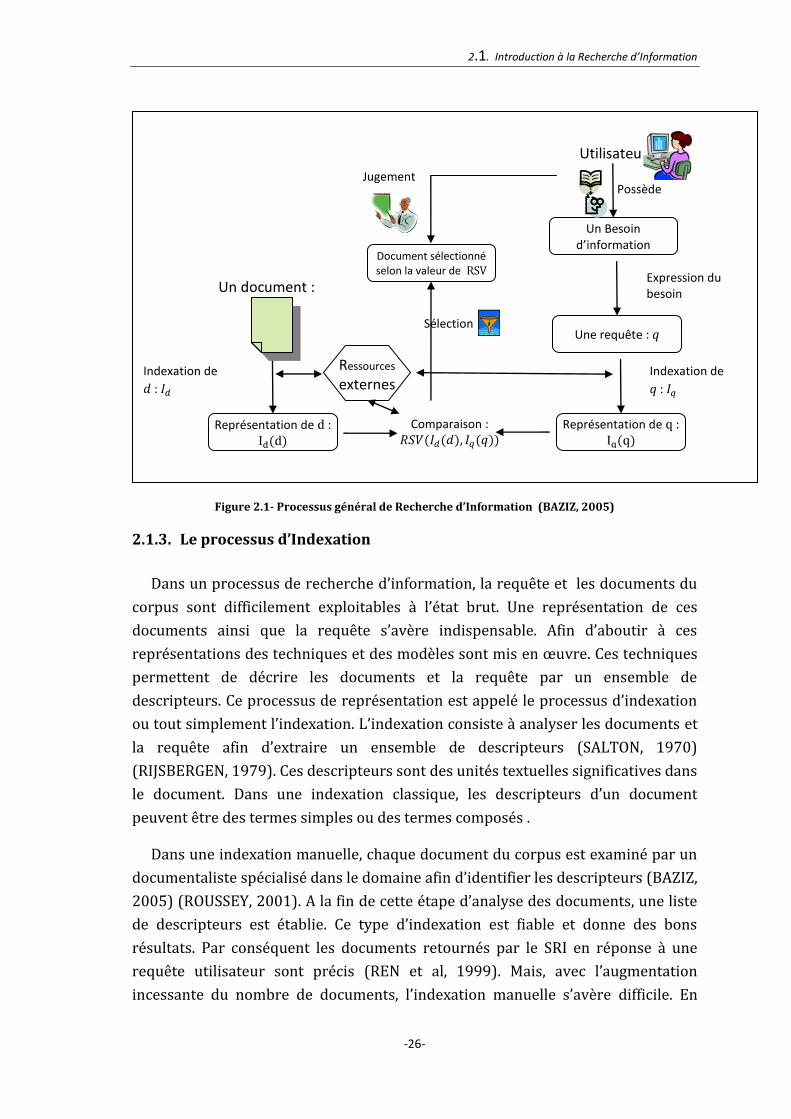
La courbe précision-rappel est donnée dans la Figure 2.3. Dans la pratique pour
évaluer un SRI plusieurs requêtes sont lancées. Pour l’ensemble des résultats
2.2. Les différents modèles de Recherche d’Information
-32-
obtenus on calcule la moyenne des valeurs de la précision et la moyenne des
valeurs du rappel. La courbe précision-rappel du système est tracée en utilisant
ces valeurs moyennes.
Figure 2.3- Courbe précision-rappel pour la requête de l’exemple ci_dessus
2.2. Les différents modèles de Recherche d’Information
Un SRI est fondé sur un modèle théorique (booléen, vectoriel, etc.) (TAMINE-
LECHANI L et al, 2006). Ce modèle permet de décrire la manière utilisée pour
représenter les documents et la requête dans l’espace d’indexation engendré par le
jeu d’indexation. Il définit aussi, la fonction de correspondance employée pour
estimer la pertinence d’un document vis-à-vis d’une requête.
Dans la littérature, de nombreux modèles de recherche d’information ont été
proposés. Nous présentons dans les sections suivantes les principaux modèles.
Nous donnons pour chacun des modèles présentés, le principe général, le
formalisme proposé pour représenter les documents et les requêtes et la fonction
de correspondance utilisée pour estimer la pertinence d’un document vis-à-vis
d’une requête.
2.2.1. Le modèle booléen
Ce modèle est le modèle le plus ancien dans le domaine de recherche
d’information. La simplicité de ce modèle a fait son succès. La requête est
0,0
0,1
0,2
0,3
0,4
0,5
0,6
0,7
0,8
0,9
1,0
0,0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1,0
Pré
cisi
on
Rappel

2.2. Les différents modèles de Recherche d’Information
-33-
représentée sous forme d’une expression logique. Dans cette expression, les
descipteurs sont combinés entre eux en utilisant les opérateurs booléens ,
et . Les documents satisfaisant l’expression logique représentant la requête
sont considérés comme pertinents. Ainsi la fonction de correspondance est la
vérification de l'implication logique (RIJSBERGEN, 1979).
Dans le modèle booléen, la pertinence des documents est une variable
booléenne ce qui ne permet pas de trier dans un ordre de pertinence les
documents retournés (BAZIZ, 2005). L’utilisateur est donc obligé de consulter tous
les documents de la réponse afin de trouver les documents recherchés. Afin de
remédier à cette limite, un modèle étendu a été proposé dans (SALTON et al,
1983). Le modèle booléen étendu affecte à chaque terme dans le document et dans
la requête une pondération.
L’inconvénient majeur du modèle booléen est qu’il ne permet pas de retrouver
des documents qui répondent partiellement à une requête. Par exemple
considérons dans ce modèle :
Un jeu d’indexation formé par les descripteurs : base, données, et
relationnel,
Une requête utilisateur .
Un document du corpus Ce
document e t représenté dans le SRI par .
Malgré que le document répond partielle , ce document
n’est pas retrouvé par le SRI. Le modèle vectoriel proposé par G. Salton (SALTON,
1968) permet de remédier à ce défaut.
2.2.2. Le modèle vectoriel
Dans le modèle vectoriel proposé par G. Salton (SALTON, 1968), les documents
ainsi que la requête sont représentés par des vecteurs dans l’espace d’indexation.
Les dimensions de l’espace d’indexation sont les descripteurs utilisés pour
l’indexation. Dans ce modèle, une pondération dans un document est attribuée à
chaque terme de l’espace d’indexation. Ainsi, dans un espace d’indexation
où les sont les descripteurs, un document est représenté par un
vecteur de poids des termes.
(1.8)

2.2. Les différents modèles de Recherche d’Information
-34-
Où est le poids du terme dans le document .
La Figure 2.4Erreur ! Source du renvoi introuvable. illustre la représentation
des documents dans l’espace d’indexation. Dans cette figure les sont les
descripteurs, les sont les documents et les sont les pondérations des
descripteurs dans le document .
Figure 2.4- la représention des documents dans l’espace d’indexation (ROUSSEY, 2001)
De la même façon une requête est représentée dans l’espace d’indexation
par un vecteur des poids des termes qui composent la requête.
(1.9)
Où est le poids du terme dans la requête .
Dans le modèle booléen, pour un document et un terme , la pondération de
dans est 1 si le terme apparait dans le document 0 si non. Cette pondération
uniforme ne permet pas de distinguer deux documents qui sont indexés par les
mêmes termes. Ainsi, il est impossible de présenter { l’utilisateur une liste triée
selon l’ordre de pertinence. Dans le modèle vectoriel la pondération des termes a
été prise en compte. La pondération des termes a été étudiée dans de nombreux
travaux (SALTON et al, 1988) (SINGHAL et al, 1996) (LEE, 1995). Elle consiste à
affecter { chaque terme d’indexation dans un document un poids. Ce poids
détermine l’importance du terme dans la représentation du document . Dans la
littérature, plusieurs mesures de pondération ont été proposées. La majorité de ces
mesures prennent en compte la pondération locale et la pondération globale. La
pondération locale traite des informations locales. Ces informations sont

2.2. Les différents modèles de Recherche d’Information
-35-
spécifiques au document dans lequel le terme d’indexation apparait. En général, la
pondération locale d’un terme dans un document , est exprimée en fonction du
nombre d’apparition ou fréquence de ce terme dans le document . Cette
pondération est notée . Plusieurs formules ont été présentées pour calculer la
mesure . Nous citons quelques unes de ces formules (ROBERTSON et al, 1997)
(SINGHAL et al, 1997):
(1.10)
(1.11)
(1.12)
Avec la fréquence du terme dans le document .
La formule permet d’atténuer les fréquences très élevées. Dans cette formule la
fréquence de chaque terme dans le document est normalisée par la valeur
maximale des fréquences des termes.
Dans la pondération globale, la distribution d’un terme dans tous les
documents est prise en compte. Elle se base sur l’hypothèse qu’un terme qui
apparait dans tous les documents ne permet pas de distinguer les documents les
uns des autres. Ce terme n’a pas de pouvoir discriminant. Ainsi, une pondération
faible est affectée à ce terme. Ainsi, les termes qui apparaissent dans peu de
documents sont utiles pour la discrimination. Une pondération importante est
alors attribuée { ces termes discriminants. La pondération globale d’un terme est
fonction du nombre total de documents dans le corpus et du nombre de documents
dans lesquels ce terme est présent. Elle est notée (Inverse Document
Frequency). Les formules les plus utilisées pour calculer la valeur de cette mesure
sont les suivantes (ROBERTSON et al, 1997) (SINGHAL et al, 1997):
(1.13)
(1.14)

2.2. Les différents modèles de Recherche d’Information
-36-
Où est le nombre de documents où le terme apparait et est le nombre
total de documents dans le corpus.
La pondération d’un terme dans un document est souvent notée .
Cette pondération est donnée par le produit de la pondération locale de dans
par sa pondération globale dans l’ensemble des documents du corpus.
Pour déterminer le degré de pertinence d’un document par rapport à une
requête , une mesure de similarité est utilisée. Cette mesure consiste à retrouver
les vecteurs des documents , qui sont proches du vecteur de la requête . Les
mesures les plus utilisées sont :
Le produit scalaire (KRAAIJ, 2004):
(1.15)
La mesure cosinus (RICARDO et al, 1999):
(1.16)
La pondération des descripteurs utilisée dans le modèle vectoriel permet de
retrouver des documents qui répondent partiellement à une requête. La mesure de
similarité permet de déterminer le degré de pertinence d’un document vis-à-vis
d’une requête utilisateur. Les valeurs de la mesure de similarité sont utilisées par
les SRIs afin de proposer { l’utilisateur des listes ordonnées selon la pertinence des
documents.
2.2.3. Le modèle probabiliste
Selon (ROBERTSON et al, 1976), dans le modèle probabiliste, les documents et
la requête sont représentés par des vecteurs dans l’espace d’indexation comme
dans le modèle vectoriel. Dans ces vecteurs les pondérations des index sont
binaires. Pour une requête q l’ensemble des documents disponibles est divisé en
deux sous ensembles : l’ensemble R des documents pertinents et l’ensemble NR
des documents non pertinents. A chaque document d on associe deux probabilités :
P(R/d) : la probabilité que le document d soit pertinent pour la requête q
P(NR/d) : la probabilité que le document d soit non pertinent pour la requête q
2.3. Indexation et RI multilingue
-37-
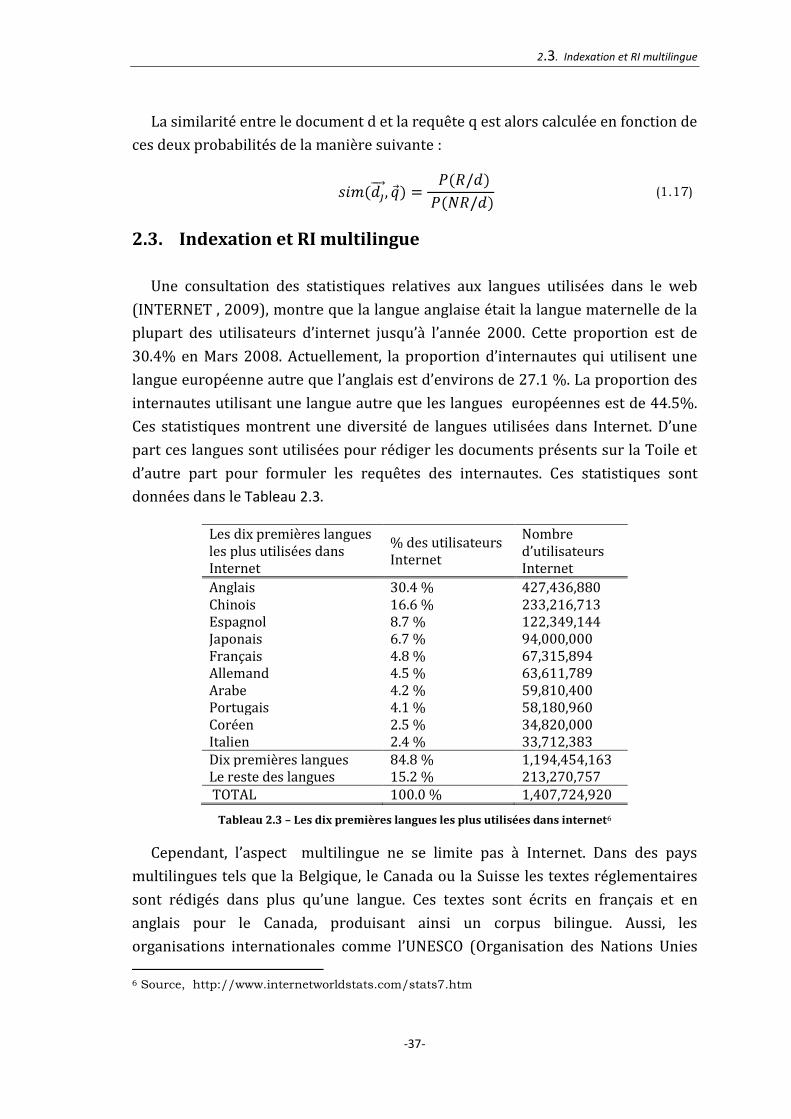
La similarité entre le document d et la requête q est alors calculée en fonction de
ces deux probabilités de la manière suivante :
(1.17)
2.3. Indexation et RI multilingue
Une consultation des statistiques relatives aux langues utilisées dans le web
(INTERNET , 2009), montre que la langue anglaise était la langue maternelle de la
plupart des utilisateurs d’internet jusqu’à l’année 2000. Cette proportion est de
30.4% en Mars 2008. Actuellement, la proportion d’internautes qui utilisent une
langue européenne autre que l’anglais est d’environs de 27.1 %. La proportion des
internautes utilisant une langue autre que les langues européennes est de 44.5%.
Ces statistiques montrent une diversité de langues utilisées dans Internet. D’une
part ces langues sont utilisées pour rédiger les documents présents sur la Toile et
d’autre part pour formuler les requêtes des internautes. Ces statistiques sont
données dans le Tableau 2.3.
Les dix premières langues les plus utilisées dans Internet
% des utilisateurs Internet
Nombre d’utilisateurs Internet
Anglais 30.4 % 427,436,880 Chinois 16.6 % 233,216,713 Espagnol 8.7 % 122,349,144 Japonais 6.7 % 94,000,000 Français 4.8 % 67,315,894 Allemand 4.5 % 63,611,789 Arabe 4.2 % 59,810,400 Portugais 4.1 % 58,180,960 Coréen 2.5 % 34,820,000 Italien 2.4 % 33,712,383 Dix premières langues 84.8 % 1,194,454,163 Le reste des langues 15.2 % 213,270,757 TOTAL 100.0 % 1,407,724,920
Tableau 2.3 – Les dix premières langues les plus utilisées dans internet6
Cependant, l’aspect multilingue ne se limite pas { Internet. Dans des pays
multilingues tels que la Belgique, le Canada ou la Suisse les textes réglementaires
sont rédigés dans plus qu’une langue. Ces textes sont écrits en français et en
anglais pour le Canada, produisant ainsi un corpus bilingue. Aussi, les
organisations internationales comme l’UNESCO (Organisation des Nations Unies
6 Source, http://www.internetworldstats.com/stats7.htm

2.3. Indexation et RI multilingue
-38-
pour l’Education, la Science et la Culture), l’ONU (Organisation des Nations Unies)
l’OMC (Organisation Mondiale du Commerce) et le Parlement européen produisent
quotidiennement des documents écrits dans plusieurs langues. Les entreprises
transnationales visant une clientèle dans différents pays produisent des
documents rédigés dans plusieurs langues, comme les manuels d’utilisation des
produits, les bons de commande, les affiches publicitaires, etc. Ainsi, avec
l’augmentation incessante de ces documents multilingues et bilingues, il est
devenu difficile de les gérer et de les exploiter. Cette difficulté est étroitement liée
{ l’aspect multilingue de ces documents. Actuellement, il est indispensable de
proposer des méthodes et des approches qui permettent de gérer et d’exploiter
ces documents. Le développement des SRIML (SRI MultiLingue) est devenu une
nécessité.
2.3.1. Recherche d’Information Multilingue
Pour accéder et retrouver des documents multilingues, les SRIML doivent
prendre en considération les particularités de chaque langue des documents. Ces
SRIML sont devenus une nécessité avec la multiplication des documents
disponibles sous format électronique. Cette nécessité a donnée naissance à une
nouvelle branche de la recherche d’information. Cette branche porte le nom de
recherche d’information multilingue ou cross-lingue (en anglais CLIR : Cross
Language Information Retrieval). Dans la recherche d’information multilingue,
l’utilisateur formule sa requête dans une langue source et tente de trouver des
documents pertinents dans des langues cibles. Du fait que la langue cible est
différente de la langue source, les documents et la requête sont représentés dans
deux jeux d’indexation différents. Le défi consiste donc { représenter les
documents et la requête dans un même jeu d’indexation.
2.3.2. Les problèmes liés à la Recherche d’Information MultiLingue (RIML)
En général, la maîtrise de la lecture des documents écrits dans une langue est
moins difficile que la maîtrise de la rédaction des documents écrits dans cette
même langue. Par conséquent, souvent les utilisateurs sont capables de lire des
documents rédigés dans une langue sans qu’ils soient capables d’écrire un
document dans cette même langue. L’expression des besoins d’information pour
ces utilisateurs dans une langue étrangère est difficile. Un utilisateur, même s’il
maîtrise partiellement une langue étrangère, trouve des difficultés dans la
formulation de sa requête dans cette langue. Les descripteurs utilisés dans la
formulation de la requête sont souvent simples et non adéquats pour trouver les

2.3. Indexation et RI multilingue
-39-
documents pertinents. La requête formulée est souvent de mauvaise qualité. Par
conséquent, le système de recherche d’information ne donne pas satisfaction {
l’utilisateur. Suite { une insatisfaction des résultats retournés par le système, cet
utilisateur se trouve incapable de reformuler correctement sa requête.
Afin de retrouver les documents pertinents, les SRIML consiste dans une
première étape, à ramener la représentation de la requête et des documents dans
le même espace d’indexation. Dans une deuxième étape, ces nouvelles
représentations sont mises en correspondance avec la nouvelle représentation de
la requête. Ainsi, le problème de RIML est reformulé en deux processus. Le
premier consiste à ramener la présentation de la requête et les représentations des
documents dans le même espace d’indexation. Le second est un processus de
recherche d’information monolingue classique. Dans ce sens, la recherche
d’information multilingue est donc une intersection entre la traduction
automatique et de la recherche d’information monolingue. On relève alors deux
types de problèmes : un problème lié au choix des éléments à traduire et un
problème lié au choix de la bonne traduction. Pour le premier problème il s’agit de
répondre à la question : faut-il traduire la requête dans toutes les langues des
documents ou traduire les documents dans la langue de la requête ou traduire les
documents et la requête dans un langage pivot ? Le deuxième problème consiste à
répondre à la question : parmi plusieurs traductions possibles d’un terme quelle
est la bonne traduction ?
Du fait de l’utilisation d’un processus de traduction automatique (pour la
requête ou pour les documents ou pour les deux) la RIML hérite les problèmes
posés par la traduction automatique. Les problèmes de la traduction automatique
sont dus { l’ambigüité sémantique des descripteurs. Ces ambiguïtés se présentent
par les phénomènes de polysémie, d’homographie et de sens large.
1. La polysémie : c’est le fait qu’un terme possède plusieurs sens (ROUSSEY,
2001). Par exemple, dans le dictionnaire encarta7 le mot en langue française
« article » possède dix sens différents.
Commerce : objet proposé à la vente Synonyme: produit (des articles de voyage)
Presse : texte écrit intégré dans une publication quotidienne ou périodique (un article de journal)
7 http://fr.encarta.msn.com

2.3. Indexation et RI multilingue
-40-
Grammaire : déterminant qui précède un substantif ou l'adjectif qui l'accompagne et dont il précise le nombre et souvent le genre (les articles définis et les indéfinis) (article partitif)
Droit : partie (d'un texte de loi, d'un traité ou d'un contrat) (l'article premier dit ceci:)
texte correspondant à une entrée de dictionnaire ou d'encyclopédie (un article consacré aux vertébrés)
point précis de morale individuelle ou sociale (elle est intraitable sur cet article)
zoologie segment du corps (de certains animaux invertébrés) (les articles d'un ver de terre)
comptabilité ligne correspondant à une dépense ou à une recette (un article de compte)
botanique fragment (d'une structure végétale) (les articles d'une tige)
informatique unité élémentaire d'information formée d'un groupe de données associées (les articles d'un fichier)
2. L’homographie : Deux mots sont homographes lorsqu'ils s'écrivent de la
même manière (ROUSSEY, 2001). Par exemple, le mot « bois » peut être la
conjugaison du verbe boire, soit il veut dire le matériau tiré de l’arbre, utilisé
comme combustible ou pour fabriquer du papier, des pièces de charpente,
des meubles ou des objets.
3. Le sens large : un terme qui a un sens très large (ROUSSEY, 2001), (exemple
: « base ») peut prendre un sens particulier dans certain domaine (« base de
donnée» et « base aérienne»)
Nous signalons que dans un processus de RIML, la seule contrainte est de garder
les thèmes d’origine que se soit pour la requête ou pour les documents. Ainsi, dans
une traduction pour la RIML nous n’avons pas besoin d’avoir des traductions
lisibles et syntaxiquement correctes.
Le processus de RIML est généralement converti en deux processus distincts. Un
processus de traduction et un processus de recherche d’information monolingue.
Selon J-Y. Nie (NIE, 2002) la séparation de ces deux tâches pose les deux problèmes
suivants :
1. Souvent, plusieurs traductions sont possibles. Une ou plusieurs traductions
sont retenues. La traduction est donc une tâche incertaine. La mesure
d’incertitude de la traduction n’est pas conservée. Par conséquent cette
mesure ne sera pas prise en compte dans le processus de recherche.

2.3. Indexation et RI multilingue
-41-
2. L’indexation des documents traduits est indépendante de la distribution des
termes dans les documents d’origines. La pondération des termes
d’indexation dans ces documents n’est pas conservée. Ainsi, un terme traduit
est choisi, mais sans qu’il possède la même valeur de discrimination pour les
documents traduits.
2.3.3. Les différents types de corpus multilingues
2.3.3.1. Les Corpus comparables
Dans (DEJEAN et al, 2002), les auteurs définissent le corpus comparable de la
manière suivante : « Deux corpus de deux langues et sont dits comparables s’il
existe une sous-partie non négligeable du vocabulaire du corpus de langue l1,
respectivement , dont la traduction se trouve dans le corpus de langue ,
respectivement ». Dans (BOWKER et al, 2002), les auteurs énoncent la définition
suivante: «des documents textuels dans des langues différentes qui ne sont pas des
traductions les uns des autres»8. Ainsi, un corpus comparable est un ensemble de
documents traitant d’un même domaine.
2.3.3.2. Les Corpus parallèles
Un corpus parallèle est constitué d’un ensemble de couples de documents tel
que, pour un couple, un des documents est la traduction de l’autre. Ces corpus sont
généralement alignés. L’alignement consiste { faire correspondre chaque mot du
texte en langue source avec chaque unité de texte en langue cible. Cette phase
d’alignement permet de construire des ressources linguistiques bilingues. Les
manuels d’utilisation des logiciels et les textes de loi dans les pays ou où il y a
plusieurs langues nationales comme le Canada ou la Confédération Helvétique,
sont des exemples de corpus parallèles (SHERIDAN et al, 1997).
2.3.3.3. Les Corpus multilingues
Un corpus multilingue peut être défini comme étant un ensemble de documents
écrits dans plusieurs langues. Les documents ne sont pas obligatoirement des
traductions les uns des autres comme dans le cas des corpus comparables.
Contrairement aux corpus parallèles et aux corpus comparables, le nombre de
langues présentes dans un corpus multilingue n’est pas limité.
8 « sets of texts in different languages, that are not translations of each other ».

2.3. Indexation et RI multilingue
-42-
2.3.4. Les différentes approches de l’indexation multilingue
Dans un contexte multilingue, la requête n’est pas écrite dans la langue des
documents. La représentation de la requête est alors dans un espace d’indexation
différent de l’espace d’indexation des documents. Dans ce contexte et afin de
rendre une recherche documentaire possible il est nécessaire d’utiliser les mêmes
descripteurs pour décrire la requête et les documents. Ceci est possible en
procédant soit par indexation en langage contrôlé soit par une indexation en texte
libre. Dans le deuxième cas il nécessaire de traduire les documents et la requête
dans la même langue avant de les indexer. On distingue donc deux types
d’approches d’indexations multilingues : les approches basées sur des descripteurs
prédéfinis et les approches basées sur la traduction. Dans les premières approches,
la liste de descripteurs est préétablie avant l’indexation et elle est utilisée pour
indexer les documents et la requête. L’élaboration de cette liste peut être
automatique ou manuelle. Afin de construire cette liste les documentalistes
peuvent utiliser les documents { indexer. C’est { dire que la liste des descripteurs
est construite sur la base du corpus { indexer. Du fait que l’ensemble des
descripteurs est réduit un ensemble prédéfini d’élément, ces approches sont
appelées approches basées sur un vocabulaire contrôlé. Comme illustré dans la
Figure 2.5, dans les approches basées sur la traduction trois alternatives sont
possibles.
1. Traduire la requête dans les langues des documents,
2. Traduire les documents dans la langue de la requête,
3. Traduire les documents et la requête dans une langue commune.
Figure 2.5- Les différentes approches d’indexation multilingue
Traduire les documents et la
requête
Traduire les documents
Traduire la requête
Construit automatiquement
Construit manuellement
Vocabulaire contrôlé
multilingue
Texte libre : traduction
Indexation multilingue

2.3. Indexation et RI multilingue
-43-
2.3.4.1. Approches basées sur un vocabulaire contrôlé
Dans les approches basées sur un vocabulaire contrôlé, le jeu d’indexation est
prédéfini. Ce jeu est utilisé pour indexer manuellement ou automatiquement les
documents. La source du jeu d’indexation est une ressource externe multilingue.
Ces ressources font l’objet d’une étude détaillée dans les sections qui suivent. Les
premiers travaux dans cette direction de recherche ont été faits par G. Salton
(SALTON, 1970). L’auteur utilise un thésaurus multilingue afin d’indexer
manuellement un corpus. L’auteur affirme que les résultats obtenus sont jugés
pertinents. Comparé { un contexte monolingue, l’auteur a obtenu une précision
moyenne de 95%.
2.3.4.2. Traduction de la requête
Dans la littérature, la traduction de la requête est l’alternative la plus adoptée.
Cela évite de multiplier l’espace de stockage. En effet, contrairement aux
documents les requêtes ne sont pas stockées et leur indexation se fait en temps
réel. Mais, une requête est souvent composée de quelques mots. En général, dans la
formulation d’une requête aucune syntaxe n’est exigée. Ce manque de contexte
implique une ambigüité, ce qui rend difficile la recherche des traductions exactes
des mots qui composent la requête. Par conséquent l’indexation de la requête sera
erronée. Une solution consiste alors à traduire les documents au lieu de traduire la
requête. Du fait que les documents sont plus longs que la requête, cette solution
permet de compenser le problème de contexte.
2.3.4.3. Traduction des documents
La deuxième alternative des approches basées sur la traduction, consiste à
traduire les documents du corpus dans la langue des documents avant de les
indexer. Deux problèmes sont posés par cette traduction. D’une part, l’espace de
stockage est multiplié puisque chaque document doit être traduit dans chaque
langue. Un document est représenté par autant d’exemplaires qu’il y a de langues
cibles. D’autre part, le choix de la méthode de traduction influe énormément sur la
qualité de l’indexation. Une traduction manuelle donne des bons résultats.
Cependant une telle traduction n’est pas envisageable avec des corpus de grande
taille. De plus même avec des corpus de petite taille le travail est énorme et
nécessite une compétence humaine souvent rare. Pour traduire des documents
d’un corpus multilingue où les documents sont écrits dans n langues, il faut n(n-
1)/2 traducteurs. Une traduction automatique { l’aide d’un logiciel de traduction
semble être une solution possible, malgré les résultats insatisfaisants. Comparés

2.4. Discussion : vers une indexation sémantique
-44-
aux résultats obtenus par la traduction de la requête, les résultats de la traduction
des documents sont meilleurs. Dans (OARD et al, 1997), les auteurs ont utilisé un
logiciel de traduction pour la traduction des documents puis de la requête. Les
auteurs ont obtenu des résultats plus précis pour la traduction des documents.
(0.217 pour la traduction des documents et 0.156 pour la traduction de la requête).
Cela s’explique par le manque du contexte pour la traduction de la requête.
2.3.4.4. Traduction de la requête et des documents
La dernière alternative consiste à traduire dans une langue commune les
documents et la requête. La langue commune peut être une langue du corpus. Par
exemple la langue anglaise pour un corpus bilingue en anglais et en français. La
langue commune peut être une langue artificielle, spécialement définie pour cette
tâche. La langue commune est appelée langue pivot. Cette solution permet de
résoudre partiellement le problème posé par la traduction. En effet, dans un
corpus où les documents sont écrits dans n langues il nous faut au pire des cas (n-
1) traducteurs. Cependant, le risque d’aboutir { une indexation erronée est doublé.
En effet, deux sources d’erreurs sont présentes : la traduction de la requête et la
traduction du document.
2.4. Discussion : vers une indexation sémantique
Dans les SRIs classiques basés sur les mots ou encore sur les termes simples, un
document est considéré comme un ensemble de mots, souvent appelé sac de mots
(RICARDO et al, 1999). Dans ces systèmes, les mots sont considérés comme des
graphies sans sémantique. Les seules informations utilisées concernant ces mots
sont leurs fréquences d’apparition dans les documents. Ces systèmes ne prennent
pas en considération le sens du mot (GENEST et al, 2005). Ils ne distinguent pas les
mots selon leurs contextes d’apparition. Cependant un mot n’a pas de sens, il a un
sens dans un contexte donné. Ces termes simples présentent une forte ambigüité.
Par conséquent, un SRI basé sur les mots peut renvoyer un document non
pertinent, bien que le document satisfasse la requête. Du fait qu’un mot peut
varier de sens selon le contexte où il apparait (phénomène de polysémie). Aussi,
les SRIs classiques ne prennent pas en compte la synonymie: deux mots
graphiquement différents peuvent avoir le même sens. Par conséquent, dans ces
systèmes, il est impossible de trouver des documents représentés par un mot
synonyme d’un mot , représentant une requête. D’ailleurs, dans les SRIs
classiques les documents et la requête sont représentés par des vecteurs dans
l’espace d’indexation. Cet espace est engendré par les termes d’indexation qui

2.4. Discussion : vers une indexation sémantique
-45-
constituent les dimensions de l’espace de l’indexation. Ces dimensions sont
considérées comme orthogonales entre elles. Ainsi, ces dimensions et par la suite
les termes d’indexation, sont supposés indépendants les uns des autres. Par
conséquent, des termes sémantiquement proches seront considérés comme
n’ayant aucun rapport entre eux. Ainsi, dans un SRI classique un document indexé
par le terme « bus » ne sera jamais retrouvé par une requête indexée par le terme
«taxi », pourtant il s’agit de deux termes qui traitent le même thème « moyen de
transport ».
De plus, l’ordre d’apparition des mots n’est pas pris en considération. Dans un
SRI basé sur les mots, une requête concernant les « bases de données » aura le
même résultat qu’une requête traitant des « données de bases ». En effet, dans les
deux cas la requête est indexée par les mots « base » et « donnée ». Il est donc
nécessaire de prendre en compte les groupes de mots dans l’ordre où ils
apparaissent. Ces groupes de mots forment des nouveaux termes d’indexation. Ces
termes seront appelés les termes composés ou les termes complexes. Comparés
aux termes simples, les termes composés sont moins ambigüs (BAZIZ, 2005). Par
exemple, un document, où les termes simples « base » et « données » apparaissent,
ne traite pas forcement du thème « base de données ». Ce document peut traiter de
« base militaire » et de « données géographiques ». Pourtant, ce document est
retrouvé par le SRI pour une requête où l’utilisateur est { la recherche des
documents traitant des « bases de données ». En général, un terme composé est
ajouté au lexique { chaque fois qu’un nouveau concept est découvert. Ainsi, le
terme « téléphone mobile » est ajouté au lexique de la langue française pour
désigner l’objet nouvellement découverte.
Afin de remédier à ces limites, plusieurs travaux (WOODS, 1997) (MOLDOVAN
et al, 2000) (ROUSSEY, 2001) (KANG, 2003) (BAZIZ, 2005) (SEYDOUX, 2006) se
sont intéressés { la prise en compte de l’aspect sémantique des termes
d’indexation. Ce type d’indexation est appelé indexation sémantique ou
conceptuelle. D’ailleurs, selon (SEYDOUX, 2006) des documents pertinents par
rapport à une requête sont des documents indexés par des descripteurs
sémantiquement proches des descripteurs de la requête. Par exemple, un
document représenté par le mot « hôpital » est pertinent par rapport à une requête
représentée par le mot « docteur ».

2.5. L’indexation sémantique : apports et difficultés
-46-
2.5. L’indexation sémantique : apports et difficultés
Comme nous l’avons déj{ cité dans la section 2.1.1, dans tout système de
recherche d’information, une étape d’indexation est nécessaire. Cette indexation
permet de décrire la requête et les documents par des descripteurs. La qualité de
l’indexation dépend de la richesse sémantique des descripteurs utilisés, { savoir :
les termes simples, les termes composés, les concepts et les relations entre les
concepts. Dans (BAZIZ et al, 2007) (STYLTSVIG, 2006) (ROUSSEY, 2001) des
ressources sémantiques externes sont utilisées dans la phase d’indexation et dans
la phase de recherche. Dans une indexation sémantique les documents sont
décrits par des concepts qui reflètent mieux le contenu des documents que s’ils
sont décrits par des mots qui sont souvent ambigus (AUSSENAC et al, 2004).
En effet l’apport essentiel de l’indexation sémantique est d’améliorer la
représentation des documents. Cette amélioration consiste à enrichir la
représentation d’un document ou d’une requête, par des descripteurs souvent
absents dans le document ou dans la requête. Ces termes d’enrichissements sont
des termes sémantiquement proches des termes d’indexation d’origine tels que, les
synonymes et les termes sémantiquement liés. Ainsi, un document contenant le
mot «hôpital » peut être indexé par le mot « docteur », sans que ce mot soit présent
dans le document. En effet, ces deux mots traitent de la même thématique « la
médecine ». Cependant, une indexation sémantique n’est possible que par
l’utilisation des connaissances externes aux documents traités (HERNANDEZ ,
2005) (SEYDOUX, 2006) (BULSKOV, 2006). Ces descripteurs sont issus des
ressources sémantique externes tels que : les réseaux sémantiques, les thésaurii et
les ontologies. L’utilisation de ces ressources sémantiques permet d’identifier les
descripteurs associés à un document. En général, une ressource sémantique est
formée par des termes, des concepts et des relations entre ces concepts.
Nous illustrons par un exemple inspiré de (SEYDOUX, 2006) l’intérêt apporté
par l’utilisation d’une indexation sémantique dans un SRI.
Supposons que dans le modèle vectoriel, quatre documents sont indexés par les
termes d’un jeu d’indexation. Ces documents sont représentés de la manière
suivante:

2.5. L’indexation sémantique : apports et difficultés
-47-
Figuier 1 0 0 0
Lion 1 1 0 2
Loup 0 1 1 1
Clématices 2 0 0 0
Coreopsis 0 0 1 0
Sapin 0 0 1 0
Lapin 0 0 1 0
Vache 0 1 0 1
Bus 1 0 0 0
voiture 0 0 1 1
Tableau 2.4 – Les représentetions de quatre documents dans le modèle vectoriel
Supposons que nous disposons d’une ressource sémantique, par exemple le
thésaurus représenté par la Figure 2.6. Dans cette ressource, deux concepts sont
reliés par une flèche traduisant la relation « est-un ».
Figure 2.6 – Le thésaurus utilisé pour l’indexation de l’exemple
Remplaçons les mots dans la représentation des documents par les concepts du
thésaurus. Chaque mot est remplacé par le concept qui lui est relié par la relation
Entité
Mammifère
Herbivore
Vache
Lapin
Carnivore
Lion
Loup
Transport
Bus
Taxi
Plante
Arbre
Sapin
Figuier
Fleur
Clématites
Coreopsis
Animale

2.5. L’indexation sémantique : apports et difficultés
-48-
« est-un » (concept dénoté par ce mot). Par exemple le mot « bus » sera remplacé
par le concept « Transport », le mot « loup » par le concept « Carnivore », etc.
L’indexation sémantique de ces quatre documents est la suivante :
Carnivore 1 2 1 3
Herbivore 0 1 1 1
Arbre 1 0 1 0
Fleur 2 0 1 0
Transport 1 0 1 1
Tableau 2.5 – Les représentations par les concepts des quatre documents dans le modèle vectoriel
Le calcul des similarités entre chaque couple des quatre documents est donné
dans le Tableau 2.6. Dans ce calcul, on a utilisé la mesure cosinus donnée par :
Indexation par mot :
(1.18)
(1.19)
Indexation par concept :
(1.20)
(1.21)
Indexation par mot 0.218 0.000 0.285 0.258 0.872 0.338
Indexation par concept 0.338 0.845 0.569 0.600 0.943 0.674
Tableau 2.6 – Similarité entre documents selon la stratégie d’indexation

2.5. L’indexation sémantique : apports et difficultés
-49-
D’après les données du Tableau 2.6, on remarque que l’indexation sémantique
rapproche le document du document . En effet, la valeur de la similarité entre
ces deux documents passe de 0 à 0.845 en utilisant les concepts au lieu des mots pour
indexer les documents. Aussi, cette indexation rend les documents et presque à
la même distance du document . Il est à noter que la détection de ces
rapprochements n’est pas possible en utilisant une indexation basée sur des mots.
Une telle détection a amélioré l’efficacité d’un SRI (SEYDOUX, 2006) . Cette
amélioration est due { l’utilisation des connaissances sémantiques externes. Ces
connaissances permettent de décrire les documents par des descripteurs souvent
absents dans le document, mais qui sont sémantiquement proches des
descripteurs qui sont présents dans le document. Par exemple les synonymes d’un
mot peuvent être ajoutés comme descripteurs d’un document même si ces
synonymes sont non présents dans le document.
2.5.1. Les différentes ressources sémantiques et leurs utilisations en
indexation
Dans un processus d’indexation, il est souhaitable de prendre en compte le
maximum d’informations concernant les descripteurs. Afin d’indexer les
documents et la requête des informations additionnelles sont utilisées (MOREAU
et al, 2006) (WITSCHEL et al, 2006). Ces informations sont issues des ressources
lexicales munies d’informations sémantiques. Le jeu d’indexation utilisé est formé
par les descripteurs d’origines présents dans les documents et des descripteurs
additionnels issus de la ressource externe. Différentes ressources externes sont
utilisées telles que les thésaurus, les bases lexicales et les ontologies. Ce qui
différencie principalement le contenu de ces ressources et l’usage pour lequel ils
ont été créés.
2.5.1.1. Le thésaurus
Un thésaurus est un vocabulaire contrôlé. Il rassemble un ensemble de termes
structurés choisis pour leur capacité à décrire un domaine. Ces termes sont
nommés descripteurs. Ces descripteurs sont utilisés pour décrire d’une manière
précise le contenu des documents. Ils sont sélectionnés et normalisés pour
l’indexation et le classement des documents. Dans un thésaurus, les termes
dénotent les concepts d'un domaine particulier. Ces concepts sont reliés entre eux
par des relations sémantiques : liens hiérarchiques (généralisation et
spécialisation), synonymie, voir aussi, définition, etc (GAMMOUDI, 1993). Chaque
concept possède un terme descripteur qui permet de le nommer facilement. Les

2.5. L’indexation sémantique : apports et difficultés
-50-
termes d'un thésaurus peuvent servir à indexer des documents comme c'est le cas
dans MDweb9 qui utilise le thésaurus GMET10 pour indexer des documents dans le
domaine de l’environnement et le projet NOESIS (PATRIARCHE et al, 2005) qui a
pour but de fournir une plateforme d’aide au diagnostic médical dans le domaine
des maladies cardiovasculaires. Les documents sont indexés en utilisant le
thésaurus UMLS11.
2.5.1.2. La base lexicale ou réseau sémantique WordNet
WordNet12 est une base lexicale électronique développée depuis 1985 à
l'université de Princeton par une équipe de psycholinguistes et de linguistes sous
la direction de G. Miller (FELLBAUM, 1998). A l’origine WordNet est conçu comme
une base lexicale. Ensuite, WordNet a été perçu comme un réseau sémantique.
Dans ce réseau sémantique, chaque nœud représente un concept. Un nœud est
constitué par un ensemble de termes synonymes (ou synsets). Ces termes
désignent le concept représenté par le nœud. Dans WordNet, les concepts sont
reliés par des relations sémantiques. La relation de synonymie est la relation de
base dans WordNet. Elle relie les termes d’un même de nœud. Les nœuds (les
concepts) sont reliés entre eux par des relations sémantiques telles que, la relation
de composition (partie-tout) et la relation hyponymie-hyperonyme (est-un)
(FELLBAUM, 1998).
Dans sa version 3.0 WordNet contient 155287 termes organisés en 117659
synsets. Le Tableau 2.7 présente des statistiques sur le nombre des mots et de
concepts dans WordNet 3.0.
Catégorie Mots Concepts Paires Mot-Sens
Nom 117798 82115 146312
Verbe 11529 13767 25047
Adjectif 21479 18156 30002
Adverbe 4481 3621 5580
Total 155287 117659 206941
Tableau 2.7 – Les statistiques sur le nombre des mots et de concepts dans WordNet 3.0.
9 http://www.mdweb-project.org/ 10 http://www.eionet.europa.eu/gemet
11 http://www.nlm.nih.gov/research/umls/umlsmain.html 12 htt ://www.cogsci.princeton.edu/~wn/

2.5. L’indexation sémantique : apports et difficultés
-51-
WordNet est à la base de nombreux travaux et projets récents en indexation
sémantique qui visent l'accès aux textes par le sens, tels qu’EuroWordNet et
MultiWordNet. EuroWordNet13 est un réseau sémantique multilingue couvrant
les langues européennes. Elle est composée de plusieurs bases lexicales (une pour
chaque langue). Les bases lexicales sont connectées { WordNet, afin d’assurer les
correspondances des termes dans différentes langues. MultiWordNet14 est une
base lexicale multilingue. Dans cette base les termes en langue italienne sont des
traductions des termes de WordNet 1.6. Les relations sémantiques reliant les
concepts sont directement importées de WordNet. La version actuelle de
MultiWordNet contient 44,400 termes dans la langue italienne organisés en 35,400
concepts.
2.5.1.3. Ontologies
La définition la plus citée présente une ontologie comme étant « une
spécification explicite et formelle d’une conceptualisation partagée » (Gruber,
1993). En d’autre terme, une ontologie est une représentation formelle d’un
domaine. C’est une conceptualisation dans le sens ou elle fournit un vocabulaire
formalisé de concepts et de leurs relations.
On distingue deux types d’ontologie : les ontologies légères et les ontologies
lourdes. Ces ontologies distinguent par la présence ou non d’axiomes (MOTHE et
al, 2007). Les ontologies légères sont constituées uniquement de concepts et de
relations entre les concepts. Ces ontologies sont dites moins formelles.
Contrairement aux ontologies légères, les ontologies lourdes sont dites formelles
(DING et al, 2001). Ces ontologies intègrent en plus des concepts et des relations,
les règles d’inférence et les axiomes.
Les ontologies utilisées dans le domaine de recherche d’information sont des
ontologies légères. Elles se limitent à la définition des concepts et des relations
entre les concepts. Les ontologies les plus utilisées sont Gene Ontology (GO), UMLS
est un meta thesaurus, WordNet et MeSH. Les systèmes OntoQuery15, Chemenet16
et CIDOC/CRM17 (CROFTS et al, 2008) sont des bons exemples d’utilisation des
ontologies en RI.
13 http://www.let.uva.nl/~ewn
14 http://multiwordnet.itc.it/) 15 http://www.ontoquery.dk/index.php
16 http://www.achemenet.com/
17 http://cidoc.ics.forth.gr/

2.5. L’indexation sémantique : apports et difficultés
-52-
2.5.1.4. Les modèles de représentation des connaissances utilisés en
indexation
Dans cette section, nous présentons les modèles de présentations des
connaissances utilisés en recherche d’information. Ces modèles sont issus des
travaux en psychologie sur la mémoire humaine et la représentation des
connaissances datent des années 60. On trouve les travaux de R. Quillian
(QUILLIAN, 1968) sur les réseaux sémantiques et les travaux de J. Sowa (SOWA,
1984) sur les graphes conceptuels. L'idée de ces travaux était de fournir un modèle
formel du stockage en mémoire de connaissances.
Les réseaux sémantiques
La représentation de connaissances par des réseaux sémantiques remonte aux
travaux du linguiste R. Quillian sur la mémoire sémantique humaine (QUILLIAN,
1968). Les réseaux sémantiques sont très utilisés dans les travaux sur la
compréhension et le traitement des langages. Dans (QUILLIAN, 1968) ,R. Quillian
définit un réseau sémantique comme étant « un format de représentation
permettant de mémoriser le sens des mots, pour rendre possible leur utilisation à
la manière de l’être humain ». L’idée de base est que la signification d’un mot
dépende des autres mots qui co-occurrent avec ce mot. Ainsi, la signification d’un
concept est liée au réseau sémantique auquel il fait partie et de ses relations avec
les autres concepts du réseau. Dans un réseau sémantique, un concept est
représenté par un nœud. Chaque relation entre deux concepts est représentée par
un arc étiqueté qui relie les nœuds associés { ces concepts. Ainsi, un réseau
sémantique est assimilé à un multigraphe18 orienté G=[S, R] dont les sommets S
sont les concepts et les relations R sont les relations sémantiques entre les
concepts de S. Un exemple de réseau sémantique représentant le sens de la phrase
« Jean possède une belle voiture » est par exemple celui représenté dans la figure
Figure 2.7- Exemple de réseau sémantique
18 Un multigraphe est un graphe tel qu’il peut exister plusieurs arêtes entre deux sommets, ici entre un sommet relation et un sommet concept.
Jean
Propriété
Possède Agent Objet
Voiture
Belle

2.5. L’indexation sémantique : apports et difficultés
-53-
En recherche d’information ce modèle est utilisé pour représenter la requête et
les documents. La fonction de correspondance est en général une opération de
matching du réseau sémantique représentant la requête sur le réseau sémantique
représentant le document.
Graphes conceptuels
Un graphe conceptuel (GC) est un modèle de représentation de connaissances
du type réseaux sémantiques. Ce modèle a été introduit par John F. Sowa en 1984
(SOWA, 1984). Ensuite, il a donné lieu à un certain nombre de travaux. Le modèle
des graphes conceptuels permet de représenter les connaissances sous forme
graphique. Un GC est un multigraphe biparti19 étiqueté. Dans un GC, on distingue
deux types de nœuds : les nœuds concepts NC et les nœuds relations NR. Dans un
GC, un NC est relié par un arc à un NR traduisant que le concept associé à NC est un
argument de la relation représentée par NR. Chaque nœud d’un GC possède une
étiquette. Un nœud est étiqueté par un type dénotant un concept, et un marqueur
correspondant à une instance du concept (GENEST et al, 2005). De la même
manière les NR sont étiquetés par un type qui correspond au nom de la relation.
Dans le modèle des graphes conceptuels, les différents types de connaissances
(type de relations, type de concepts) sont représentés par des objets distincts.
Cette séparation des types de connaissances implique une grande clarté au
moment de l’utilisation de ce modèle afin de représenter des connaissances. Dans
ce modèle, les connaissances sont présentées en utilisant un vocabulaire. Ce
vocabulaire est structuré dans un objet du modèle appelé « support ». Selon
(MUGNIER et al, 1996), un support S est un quintuple .
, ensemble de types de concepts hiérarchiquement structurés. Cet
ensemble et muni d’une relation d’ordre partielle notée . Cette relation
est une relation de spécialisation « sorte de ». possède un plus grand
élément appelé le type universel noté et un plus petit élément, type
absurde noté . Par exemple le type « docteur » généralise le type
« cardiologue » et sera noté (« cardiologue » « docteur »,
, ensemble de types de relations hiérarchiquement structurés.
, où est l’ensemble des relations d’arité , .
Chaque est muni d’une relation d’ordre partielle notée ,
19 Un graphe où il y a deux types de nœuds . Les deux types de nœuds sont : concept (qu’il
soit générique ou non) et relation.

2.5. L’indexation sémantique : apports et difficultés
-54-
est une application qui associe à chaque élément de une
signature. La signature de la relation spécifie l’arité de et le plus
grand type possible. . le argument de est
noté ,
est l’ensemble des marqueurs individuels (instances de type de
concept). Chaque de identifie un individu de la base de connaissance.
En plus de , un marqueur générique noté permet de représenter un
individu non spécifié,
est une application de dans qui associe à chaque marqueur son
type. .
Figure 2.8- Le GC : un véhicule construit par le constructeur Renault participe au Rallye :Paris Dakar .
L’exemple de la Figure 2.8 peut être interprété par : un véhicule construit par le
constructeur Renault participe au rallye Paris-Dakar. Ce graphe peut être
représenté par la séquence:
[Véhicule :*]->(construit par)->[ Constructeur : Renault] ;[Véhicule :*]->(participe)->[ Course : Rallye]
Le raisonnement sur les graphes conceptuels repose sur l’opérateur de
projection défini par J. Sowa. L’operateur de projection permet de comparer deux
graphes H et G. comme montre l’exemple de la Figure 2.9, il existe une projection de
H dans G si pour chaque concept c de H il existe un concept c’ plus spécifique de c
dans G ( ). On dit que G est une spécialisation de H,
Par exemple, prenons le graphe de la Figure 2.8 comme base de recherche et
posons la question suivante : « quelles sont les véhicules qui participent aux
courses de Rallye ? ». Cette question est représentée par le graphe conceptuel H :
[Véhicule :?x]->(participe)->[ Course : Rallye]
Véhicule :*
Constructeur : Renault
Construit par
1
2
Rallye : Paris-Dakar Participe 1 2

2.5. L’indexation sémantique : apports et difficultés
-55-
Répondre à cette question revient à répondre à la question : est ce que G est une
spécialisation de H. c'est-à-dire est ce que il existe une projection de H dans G.
Figure 2.9- La projection du graphe H dans le graphe G .
En recherche d’information un document est considéré pertinent vis-à-vis
d’une requête si le graphe conceptuel représentant est une spécialisation
du graphe représentant , .
Les logiques de description
Les Logiques de Description (LDs) appelées également Logiques
Terminologiques sont une famille de formalismes de représentation des
connaissances (BRACHMAN, 1977). KL-ONE est le premier système représentant
les LDs (BRACHMAN et al, 1985). Avec KL-ONE, les auteurs visent à présenter un
langage dont la sémantique est formelle et fondée sur la logique. Formelle dans le
sens où la sémantique est indépendante de la représentation et des algorithmes
qui agissent sur cette sémantique. Les connaissances d’un domaine sont
représentées avec les LDs à travers des concepts atomiques et des rôles atomiques.
Les concepts atomiques correspondent à des prédicats unaires spécifiant les objets
du domaine. Les rôles atomiques correspondent à des prédicats binaires qui
décrivent les relations entre les concepts du domaine. Dans les LDs un langage
formel permet de construire les concepts { l’aide des constructeurs fournis par ce
Véhicule :*
Constructeur : Renault
Construit par
1
2
Rallye : Paris-Dakar
Participe 1 2
Véhicule :* Rallye : Paris-Dakar
Participe 1 2
Relation de spécialisation
Le graphe G
Le graphe H

2.5. L’indexation sémantique : apports et difficultés
-56-
langage. Si L est un langage de description dénote une LD quelconque, un concept
construit en utilisant les constructeurs de L s’appelle un L concept. Avec les LDs,
les connaissances d'un domaine sont modélisées en deux niveaux : la TBox et la
ABox.
La TBox (Terminogical Box) correspond au niveau terminologique. Il décrit les connaissances générales d'un domaine. Ce niveau est un niveau descriptif il permet de décrire les concepts du domaine en fonction d’autres concepts à partir des relations. La TBox comprend la définition des concepts et des rôles.
La ABox (Assertional Box) correspond au niveau des assertions. Il décrit les individus (instances des concepts). Dans la ABox les individus sont nommés et des assertions portant sur ces individus nommés sont données en fonction des concepts et des rôles.
Nous reprenons le même exemple de la figure 1.7. Le tableau 1.8 décrit un
domaine qui contient trois concepts, le concept constructeur, le concept véhicule et
le concept course. En plus de ces concepts, ce domaine contient deux relations : la
relation « construitpar » et la relation « participe ». Les concepts et les relations
sont décrits dans la TBox. Dans la ABox, trois instances du concept vehicule (v1, v2,
v3), une instance du concept constructeur (Renault) et une instance du concept
Rallye (Paris-Dakar). La ABox contient aussi cinq assertions. L’assertion
construitpar (v1, Renault) traduit l’idée que v1 est construit par le constructeur
Renault.
TBox ABox
Tableau 2.8 – Exemple d’ una base de connaissances composée d'un TBox et d'une ABox
Pour répondre à la question : quels sont les véhicules construits par le
constructeur Renault qui participent au Rallye Paris-Dakar. Autrement dit, quelles

2.5. L’indexation sémantique : apports et difficultés
-57-
sont les instances du concept Vehicule qui sont reliées à la fois par la relation
construitpar à une instance du concept constructeur nommée Renault et par la
relation participe à une instance du concept Rallye nommée Paris-Dakar. Une
formulation en utilisatiant les LDs est la suivante:
.
Ainsi, les LDs sont utilisés pour modéliser les connaissances du domaine. Ils
permettent de représenter les concepts d’un domaine particulier et les relations
entre ces concepts. Les LDs permettent aussi la représentation des individus
(instances de concept). Dans le Tableau 2.9, nous présentons un exemple de
représentations des relations de WordNet. Ces relations peuvent être représentées
avec les LDs de la manière suivante :
Relations LD Wordnet
Tableau 2.9 – Exemple de représentation des relations de WordNet par les LDs (TBox+ABox)
2.5.1.5. Les systèmes de recherche d’information utilisant une ressource
sémantique
L’intérêt de l’utilisation de ressources sémantiques en recherche d’information
a été montré depuis les années 70 avec les travaux de G. Salton (SALTON, 1970).
L’utilisation de ces ressources vise l’amélioration des performances des SRIs. Dans
(SALTON, 1970), l’auteur utilise un thésaurus multilingue afin d’indexer
manuellement un corpus. Les travaux de G. Salton ont donné lieu à de nombreux
travaux similaires utilisant des ressources sémantiques. Ces travaux se basent sur
des formalismes différents de représentation des connaissances. Le système
OntoSeek (GUARINO et al, 1999) a été développé pour les services de pages jaunes
ou des catalogues de produits. Les documents (le contenu des pages jaunes) et la
requête sont représentés par des graphes conceptuels. A ce formalisme de
représentation est couplé un mécanisme de recherche par le contenu sémantique
(l’ontologie SENSUS basée sur WORDNET). Dans le domaine de la recherche
d’information médicale, de nombreux thésaurus ont été développés, tels que MeSH
(Medical Subject Heading) et UMLS20 (Unified Medical Language System). Le
20 http://www.nlm.nih.gov/research/umls/umlsmain.html

2.5. L’indexation sémantique : apports et difficultés
-58-
projet NOESIS (PATRIARCHE et al, 2005) a pour but de fournir une plateforme
d’aide au diagnostic médical dans le domaine des maladies cardiovasculaires. Ce
système comprend un outil de recherche d’information guidé par une ressource
sémantique. Les auteurs utilisent le thésaurus MeSH pour annoter les documents.
Les termes extraits (environ 700 concepts) sont ensuite enrichis par des termes
dans cinq langues issues d’UMLS. Les termes sont représentés en OWL (Web
Ontology Language). En plus, les auteurs utilisent des balises SKOS afin de
représenter les termes préférés pour un concept dans chaque langue. Le thésaurus
MeSH a été utilisé aussi dans les systèmes NLM21 (The National Library of
Medicine), Hon22(Health On the Net) et CisMEF23(Catalogue et Index des Sites
Médicaux Francophones), pour le même objectif d’indexation des documents
médicaux (SOUALMIA et al, 2004).
Dans le prototype ELEN proposé par J.P. Chevallet (CHEVALLET, 1992), l’auteur
utilise une ressource sémantique de domaine spécialisé (le génie logiciel). La
ressource utilisée est un thésaurus. Elle sert à reconnaitre le sens de chaque mot,
ainsi que les relations sémantiques entre ces mots. ELEN exploite les graphes
conceptuels comme formalisme structuré de représentation des connaissances.
Plus tard, l’auteur signale que la méthodologie adaptée dans ELEN est difficile à
appliquer à des corpus couvrant des domaines variés (NIE et al, 1997). Dans
(ROUSSEY, 2001), C. Roussey présente un système de recherche d’information
multilingue fondé sur un thésaurus sémantique du domaine, intitulé SyDOM
(Système Documentaire Multilingue). Ce système permet de retrouver un
document répondant à une requête écrite dans une langue différente. Dans
SYDOM, le thésaurus est utilisé pour indexer manuellement les documents, pour
formuler les requêtes des utilisateurs et enfin pour comparer la représentation
d’une requête avec celle des documents. Que se soit durant l’indexation des
documents ou durant la formulation des requêtes, l’utilisateur est guidé par un
thésaurus. Dans SYDOM les documents et la requête sont représentés par des GCs.
L’auteur considère que les opérations (projection) du modèle des GCs sont
orientées «recherche de réponses exactes». Afin de trouver des documents
partiellement pertinents à une requête. C. Roussey propose un nouvel opérateur, la
pseudo-projection. Cet opérateur permet de juger la pertinence des documents vis-
à-vis d’une requête et fournis un classement des documents pertinents.
21 http://www.nlm.nih.gov/ 22 http://www.hon.ch/ 23 http://www.chu-rouen.fr/cismef/

2.5. L’indexation sémantique : apports et difficultés
-59-
Egalement, D. Genest (GENEST, 2000) utilise le modèle des GCs comme
formalisme pour représenter les documents et la requête. A ce modèle, Il propose
des extensions afin de retrouver les documents partiellement pertinents. Pour
indexer les documents l’auteur utilise le thésaurus Rameau. Les travaux de D.
Genest ont aboutis à un SRI dont les résultats ont été jugés satisfaisants. Le
prototype WebKB24 de P. Martin est fondé sur ces prédécesseurs WebKB-1 et
WebKB-2 et sur les travaux de thèse P. Martin, sous la direction de R. Dieng-Kuntz
sur l’utilisation des ontologies dans les SRI. Dans (MARTIN, 1996), l’auteur
propose l’outil CGKAT (Conceptual Graph Knowledge Acquisition Tool). Dans cet
outil, l’idée a été d’associer aux documents des GCs. Ces graphes permettent de
décrire le contenu sémantique de ces documents. Les graphes conceptuels
reposent sur un modèle de description des concepts manipulés et des relations
entre ces concepts, l’ontologie du domaine. L’ontologie utilisée est une extension
de WordNet. CGKAT a été testé en collaboration avec l’INRETS dans le domaine de
l’accidentologie. Dans le domaine de la géologie le projet e-WOK_HUB25 (E-
WOK_HUB, 2008) propose une architecture orientée services pour l'accès aux
ressources par le biais de portails conçus sémantiquement appelés « HUBS ». Dans,
e-WOK_HUB un outil d’annotation des documents est proposé. Afin d’annoter les
documents les auteurs utilisent une ontologie légère du domaine. Cette ontologie
est développée dans le cadre du projet.
A l’opposé de ces travaux visant l’indexation des documents et de la requête par
l’utilisation des ressources sémantiques externes, d’autres travaux utilisent la
ressource pour reformuler la requête dans un SRI. Dans (BAZIZ, 2005) (BAZIZ et
al, 2007) (BUSCALDI et al, 2005) (BULSKOV, 2006), les auteurs proposent une
reformulation des requêtes guidée par une ressource externe. Cette reformulation
ou expansion de la requête consiste à réécrire la requête utilisateur en prenant en
compte les relations de synonymie et les relations de méronymie présentes dans la
ressource externe. Ainsi, la requête est enrichie par les termes sémantiquement
proches des termes d’origines de la requête. Ces termes proches sémantiquement
sont issus de la ressource WordNet. Dans (HEARST et al, 1997) (GUO et al, 2004)
les auteurs procèdent de la même manière que les travaux précédents et utilisent
le thésaurus UMLS afin de rechercher des documents dans un corpus médical.
24 http://www.cit.gu.edu.au/~phmartin/WebKB/
25 http://www-sop.inria.fr/edelweiss/projects/ewok/

2.6. Conclusion
-60-
2.6. Conclusion
La performance d’un SRI est dépendent du processus d’indexation. En effet,
suite à une requête représentée par des descripteurs riches sémantiquement et un
ensemble de documents représentés de la même manière, la fonction de
comparaison peut fournir des documents qui répondent d’une manière pertinente
aux besoins utilisateurs. Raison pour la quelle plusieurs travaux se sont intéressés
{ l’indexation sémantique.
Le calcul de la pondération utilise des mesures statistiques. Ces mesures
exploitent des informations sur les descripteurs et leurs répartitions dans le
document et dans le corpus.. Ces mesures s’appuient sur des informations
quantitatives. Par la suite elles ne sont pas rattachées aux langues des documents.
Ces mesures ne font pas l’objet d’une étude particulière de notre part.
Afin de remédier aux limites de l’indexation classique basée sur les mots,
l’indexation sémantique a été proposée comme une alternative. Cette indexation
prend en considération le sens des mots. L’indexation sémantique consiste {
associer à chaque document les concepts dénotés par les termes du document.
Plusieurs problèmes ont été posés par l’utilisation des concepts. Ces problèmes
sont causés par l’ambigüité des mots, la polysémie par exemple. Pour résoudre ces
problèmes des mécanismes de désambigüisation ont été proposés.
Dans un contexte multilingue et c’est la majorité des cas, une phase de
traduction est nécessaire afin d’indexer les documents et la requête. Cette
traduction vise à représenter les documents et la requête dans le même espace
d’indexation, pour rendre leurs comparaisons possibles. Dans ce cadre, la
performance d’un SRI multilingue dépend étroitement de la qualité des
traductions. Il est donc indispensable d’utiliser une traduction exacte et fiable.
Malgré ces résultats de bonne qualité, une traduction manuelle n’est pas
envisageable dans le cas des corpus multilingue volumineux et même dans le cas
d’un corpus multilingue de petite taille où le nombre des langues des documents
est assez élevé. Une traduction automatique s’avère une solution réalisable malgré
les mauvaises qualités des traductions produites. Dans le cadre de notre travail
nous nous ne procédons pas par traduction. Nous pensons que l’utilisation d’une
ressource sémantique multilingue peut résoudre le problème lié au
multilinguisme.
Dans la partie qui suit nous présentons un état de l’art sur l’extraction des
concepts et des relations entre les concepts à partir des documents.

2.6. Conclusion
-61-


-63-
ETAT DE L’ART SUR L’EXTRACTION
DES DESCRIPTEURS SEMANTIQUES
POUR L’INDEXATION
Résumé
Dans ce chapitre nous présentons un état de l'art général sur les
travaux existants dans le domaine d’extraction des descripteurs à partir
des documents. Nous exposons les approches existantes d’extraction des
termes, des concepts et des relations sémantiques entre concepts. En
particulier, nous mettons l’accent sur les limites de ces approches et les
motivations qui ont poussé à choisir une technique statistique.


-65-
Chapitre 3
Etat de l’art sur l’extraction des descripteurs
pour l’indexation
3.1. Introduction
Le développement d’internet et des nouvelles technologies de stockage, de
transfert et de traitement de l’information ont causé une forte augmentation du
volume de documents numériques. Cette augmentation est accompagnée par une
croissance des besoins des utilisateurs en information. En effet l’utilisateur ne se
contente plus de subir l’information en spectateur, il navigue sur le Web, il cherche,
il trouve, il compare et il échange les informations qu’il rencontre. De spectateur, il
devient acteur dans la nouvelle société de l’information en diffusant sa propre
information (GARÇON, 2005).
Afin de satisfaire ces besoins utilisateurs qui tentent à rechercher une
information pertinente, les outils de gestion de l’information ont besoin d’extraire
des descripteurs déjà existantes dans ces documents (ZWEIGENBAUM et al, 2003).
Cependant, l’acquisition ou l’extraction de ces descripteurs est toujours un
problème crucial et d’actualité.
L’extraction des descripteurs d’une manière manuelle est une tâche lourde et
coûteuse à cause de la masse et de la diversité des volumes de documents à traiter
(RASTIER et al, 1994). Cette diversification porte sur plusieurs aspects : langues,
domaines couverts par ces documents. Ainsi, l’extraction manuelle des
descripteurs nécessite une mise { jour des compétences humaines pour s’adapter
à une nouvelle langue ou à un nouveau domaine.
Il est donc nécessaire, de disposer des systèmes automatiques ou semi-
automatiques d’extraction des descripteurs à partir des documents, tels que les
extracteurs de terminologie, les classifieurs, les concordanciers, etc (JACQUEMIN,
1999) (BOURIGAULT et al, 2000). Ces outils permettent une représentation du
domaine en repérant les entités du domaine (les concepts) et les relations entre
ces entités.

3.2. L’extraction des descripteurs
-66-
3.2. L’extraction des descripteurs
L’extraction des descripteurs permet de déterminer pour un domaine donnée
l’ensemble des descripteurs pertinents pour ce domaine (HERNANDEZ , 2005)
(BAZIZ, 2005). La tâche d’extraction peut être réalisée d’une manière automatique,
semi-automatique ou manuelle. Cette dernière est effectuée par un expert de
domaine est s’avère très couteuse. Cette tâche peut être représentée formellement
par la fonction telle que (CLAVEAU, 2003):
(2.1)
Où
est le domaine pour lequel on veut déterminer les descripteurs
sémantiques,
est le jeu d’indexation de .
Afin d’extraire les descripteurs d’un domaine d’une manière automatique ou
semi-automatique, un corpus de spécialité de est utilisé. Sur ce corpus on
applique des techniques de traitement automatique de la langue. La fonction
s’écrira alors :
(2.2)
Où
est un corpus de spécialité de D,
est le jeu d’indexation de D qui existent dans .
Pour extraire tous les descripteurs du domaine d’une manière automatique
c'est-à-dire , il est indispensable d’utiliser un corpus qui couvre la quasi-
totalité du domaine .
3.3. Extraction des termes
Dans la littérature, les différents travaux d’extraction des termes { partir des
corpus textuels utilisent deux approches : l’analyse statistique ou numérique et
l’analyse linguistique ou structurelle (CLAVEAU, 2003). L’analyse statistique se
base sur l’étude des contextes d’utilisation et les distributions des termes dans les
documents. L’analyse linguistique exploite des connaissances linguistiques, telles
que les structures morphologiques ou syntaxiques des termes. D’autres travaux

3.3. Extraction des termes
-67-
couplent ces deux approches et constituent une approche dite «approche hybride
ou mixte».
3.3.1. Méthodes statistiques ou numériques d’extraction des termes
Les méthodes statistiques ou numériques sont basées sur des techniques
quantitatives. Ces méthodes sont souvent utilisées pour les traitements des corpus
volumineux. Avec l’évolution incessante des nouvelles technologies, les documents
numériques sont devenus facilement disponibles facilitant ainsi la constitution de
ces corpus volumineux. De ce fait ces méthodes continuent à connaitre un grand
succès. Elles présentent l’avantage de ne pas nécessiter de connaissances
linguistiques a priori et s’appliquent sur des corpus pour lesquels aucune
ressource externe (dictionnaire, stop liste, ontologie…) n’a été élaborée. Ces
méthodes ont recours à des mesures connues dans le domaine de la statistique.
Nous présentons deux mesures que nous utiliserons par la suite :
Les fréquences,
Les critères d’associations.
3.3.1.1. Les fréquences
La fréquence d’une séquence s est le nombre d’apparition de s. Cette séquence
peut être un lexème26, un lemme27, un mot, un terme, etc. Cette mesure est utilisée
dans tous les modèles statistiques, ce qui explique le soin apporté pendant les
calculs de cette mesure. Ces modèles utilisent souvent quatre fréquences (DAILLE,
1994) :
La fréquence d’un couple de séquences dans un document et/ou
dans un corpus,
La fréquence des couples de séquences , où la séquence apparait
comme premier élément d’un couple,
La fréquence des couples de séquences , où la séquence donné
apparait comme deuxième élément d’un couple,
26
Un lexème est une entrée lexicale, issue de l’analyse lexicale qui décompose le texte en unités lexicales selon des
grammaires. Ces unités sont généralement des chaînes alphabétiques. 27
Un lemme permet de définir une forme canonique pour les entrées lexicales (les lexèmes). Cette forme est
représentée par l’infinitif pour les verbes et par le masculin singulier pour les substantifs. Grâce à cette étape de lemmatisation, il est possible d’établir la correspondance entre les formes conjuguées des verbes (par exemple, creüssent et croyent) et entre des dérivés morphologiquement distincts (par exemple, commençaille et commencement).

3.3. Extraction des termes
-68-
La fréquence totale des couples (pour chaque couple ) dans un
document et/ou dans un corpus.
3.3.1.2. Critères d’associations
«D’un point de vue statistique, les deux lemmes qui forment un couple sont
considérés comme deux variables qualitatives dont il s’agit de tester la liaison»
(DAILLE, 1994). B. Daille (DAILLE, 1994) considère que les lemmes qui forment un
couple sont considérés comme des variables qualitatives pour lesquelles elle teste
le degré d’association ou de liaison. Ainsi, les données définies à partir des
fréquences citées précédemment, sont représentées sous forme d’un tableau
croisé, dit tableau de contingence. Dans ce tableau on associe à chaque couple de
lemmes , les valeurs a, b, c et d qui décrivent les fréquences du couple.
Tableau 3.1 – Tableau de contingence du couple de lemmes
est la fréquence du couple li est le premier élément et le
second
est la fréquence des couples où est le premier élément d’un couple et
n’est pas le deuxième
est la fréquence des couples où est le deuxième élément du couple et
n’est pas le premier,
est la fréquence de couples où ni ni n’apparaissent,
La somme , notée N est le nombre total d’occurrences de
tous les couples trouvés.
La majorité des mesures statistiques exploitent les données du tableau de
contingence afin de déterminer le degré de liaison de deux lemmes donnés. En
résumé, il s’agit de tester d’indépendance des lexèmes pris deux à deux.
Les mesures statistiques qui seront présentées par la suite, sont les plus
utilisées dans le domaine de l’extraction de terminologie. Cependant, dans la
littérature on trouve de nombreuses autres mesures qui ont déjà été évaluées dans
des travaux ultérieurs (DAILLE, 1994). Dans ces meures, les fréquences a, b, c et d
sont données dans le Tableau 3.1.

3.3. Extraction des termes
-69-
Coefficient de Proximité simple (SMC : Simple Matching
Coefficient)
Ce score varie de 0 à 1
Coefficient de 2 (PHI)
Cette mesure est utilisée dans les travaux de W.Gale (GALE et al, 1991) pour
l’alignement de mots dans les phrases.
Score d’association ou l’information mutuelle (IM)
Il s’agit d’un score d’association d’un couple de lexèmes (li, lj), noté IM. Cette
mesure a été décrite par P. Brown (BROWN et al, 1988) (BROWN et al, 1990) et
par K. Church (CHURCH et al, 1990) dans le cadre d’extraction des termes { partir
des corpus bilingues et monolingues. L’information mutuelle permet de comparer
la probabilité d’observer ces deux lexèmes et ensemble avec la probabilité de
les observer séparément. IM se définit comme suit :
Si IM est fortement positive, cela signifie que et apparaissent très souvent
ensemble. Si IM est proche de 0, alors et n’ont aucun rapport et enfin, si IM est
fortement négative, alors et ont des distributions complémentaires.
Coefficient de vraisemblance : Loglike
Cette mesure introduite par T. Dunning (DUNNING, 1993), représente le
rapport de vraisemblance appliqué { une loi binomiale. Ce score s’exprime de la
manière suivante :
NNdcdc
dbdbcaca
babaddccbbaaLogLike
log)log()(
)log()()log()(
)log()(loglogloglog
3.3.1.3. Les travaux de L. Lebart et A. Salem
La méthode présentée dans les travaux menés par L. Lebart et A. Salem
(LEBART et al, 1988) (LEBART et al, 1988) (LEBART et al, 1994) (LEBART et al,

3.3. Extraction des termes
-70-
1994) consiste à repérer des séquences de mots qui se répètent plus d’une fois
côte à côte dans un texte. Les auteurs étudient les segments répétés dans un
corpus afin d’extraire un ensemble de termes dits « termes complexes ou termes
composés ». Le texte est alors considéré comme étant un enchainement de mots et
de segments répétés. Un segment répété est une séquence de deux ou plusieurs
mots voisins et qui apparaissent plus d’une fois dans le texte. En pratique il s’agit
de compter le nombre d’occurrences d’un couple (l1, l2), afin de vérifier si ce
nombre est supérieur à une valeur de seuil fixée expérimentalement. Si c’est le cas,
la séquence formée par (l1, l2) est considérée comme étant un terme composé et il
sera repris dans le processus. Ce processus s’arrête si aucune nouvelle séquence
n’a été repérée. Le nombre d’occurrences d’un couple (l1, l2) correspondant { la
valeur dans le tableau de contingence. Afin de regrouper des séquences qui
diffèrent d’un point de vue graphique (par exemple : phénomène fréquent,
phénomènes fréquents), les auteurs utilisent des corpus textuels lemmatisés. En
reprenant la définition formelle de l’extraction des descripteurs { partir des
documents textuels, énoncée ci-dessus, ces techniques peuvent être formalisées de
la manière suivante :
Où
est un corpus de spécialité de D,
est l’ensemble des descripteurs sémantiques de D qui existent dans
.
est un lemme du corpus ,
est la taille maximale en nombre de lemme du segment répété,
valeur à fixer par l’expérience,
désignent le nombre d’apparition de la séquence
.
3.3.1.4. Les travaux de Church
Dans (CHURCH et al, 1990), les auteurs proposent une méthode d’extraction des
termes composés. Cette méthode se base sur une mesure statistique : l’information
mutuelle. Les auteurs considèrent que les mots qui apparaissent souvent ensemble
d’une manière statistiquement significative ont une grande chance de former des

3.3. Extraction des termes
-71-
termes complexes. Ainsi, ils évaluent la probabilité d’apparition des mots ensemble
en la comparant { la probabilité d’apparition de ces mots séparément.
Où
est un corpus de spécialité de D,
est l’ensemble des descripteurs sémantiques de D qui existent dans
.
valeur à fixer par l’expérience.
un mot simple
un mot simple ou un mot composé
3.3.1.5. Les travaux de R. Oueslati
Dans ces travaux de thèse, R. Oueslati (OUESLATI, 1999) reprend le principe des
segments répétés présentés précédemment. L’objectif de l’auteur est la réalisation
d’un système d’aide { la construction de la terminologie d’un domaine spécialisé,
tel que la médecine. La méthode proposée fait appel aux travaux sur les segments
répétés durant l’étape d’extraction des termes. Les termes extraits sont validés par
un linguiste ou terminologue. Ensuite, il cherche à construire des classes de termes
sémantiquement proches on utilisant la distribution contextuelle.
3.3.1.6. Conclusion : Bilan
Les méthodes statistiques présentent l’avantage d’être rapides et simples {
mettre en œuvre. En effet, ces méthodes s’appuient sur des formules statistiques et
sur de simples calculs des fréquences. Ces méthodes ne nécessitent ni de
connaissances spécifiques des langues des corpus, ni des domaines couverts par
ces corpus. Les approches statistiques peuvent être qualifiées d’autonomes du fait
qu’elles n’utilisent pas des ressources linguistiques externes au corpus
(dictionnaire, stop liste…). Ces ressources sont généralement constituées
manuellement et nécessitent beaucoup de temps et d’effort.
Cependant il est à noter que malgré leurs autonomies, les résultats obtenus par
les approches statistiques sont fortement reliés aux corpus étudiés et ne peuvent
pas être généralisés en dehors de ce contexte. Ces approches sont performantes

3.3. Extraction des termes
-72-
sur des corpus de taille suffisamment grande. Elles ne sont pas applicables sur des
corpus de petites tailles.
3.3.2. Méthodes linguistiques
Ces méthodes sont qualifiées de linguistique puisqu’elles font appel { des
techniques d’analyse se basant sur les connaissances de la langue et de sa
structure. La majorité de ces méthodes exploitent des connaissances syntaxiques,
lexicales ou morphologiques.
3.3.2.1. Les travaux de David et Plante : TERMINO
L’outil TERMINO compte parmi les premiers outils opérationnels d’acquisition
automatique de termes. Ce système a été élaboré dans le cadre d’une collaboration
entre une équipe du Centre d’ATO de l’Université du Québec { Montréal et l’Office
de la langue française du Québec (DAVID et al, 1990). La version actuelle TERMINO
se nomme NOMINO (PERRON, 1996).
TERMINO est construit sur la base d’un formalisme pour l’expression de
grammaires du langage naturel, l’atelier FX. Dans TERMINO, les seules structures
supposées productrices des termes sont les syntagmes nominaux. Ainsi, ces
syntagmes nominaux seront repérés afin de produire les candidats termes appelés
“ synapsies ”. La chaîne de traitement de TERMINO se compose de trois
étapes (BENVENISTE, 1966):
1. Prétraitement du texte : Dans cette étape, le texte est découpé en lexèmes
puis filtré et les caractères de mise en forme sont éliminés. Cette étape est
nécessaire dans tout processus d’extraction de terminologie à partir du
corpus textuels. En effet, les corpus comportent souvent des passages non
textuels.
2. Lemmatisation des lexèmes: Dans cette étape, chaque lexème identifié est
soumis à une analyse morphosyntaxique afin de lui attribuer une catégorie
grammaticale.
3. Désambiguïsation : cette étape consiste à effectuer une analyse syntaxique
en contexte, afin de désambiguïser les lexèmes qui ont plus d’une catégorie
grammaticale { la fin de l’étape de lemmatisation. A l’issue de cette étape,
tous les lexèmes du texte ne possèdent qu’une seule catégorie grammaticale.

3.3. Extraction des termes
-73-
3.3.2.2. Les travaux de D. Bourigault : LEXTER
LEXTER a été élaboré par D. Bourigault (BOURIGAULT, 1992) (BOURIGAULT,
1994) dans le cadre de ces travaux de thèse. L’outil est dédié initialement {
l’enrichissement des thésaurii d’un système d’indexation automatique des corpus
textuels. Par la suite LEXTER a été utilisé pour l’extraction et la modélisation des
connaissances à partir de corpus textuels en langue française.
Contrairement à TERMINO, les corpus traités par LEXTER sont étiquetés et
désambiguïsés (BOURIGAULT, 1996). Pour extraire les termes candidats, LEXTER
effectue une analyse syntaxique de surface afin de repérer les syntagmes
nominaux susceptibles d’être des termes. Par la suite, les termes extraits sont liés
les uns aux autres pour former un réseau.
LEXTER se focalise sur des formes syntaxiques prédéfinies susceptibles d’être
des candidats termes, des formes simples, noms, adjectifs et verbes et des formes
composés. Les termes composés candidats sont des syntagmes nominaux (SN) ou
des syntagmes adjectivaux (SAj). Chaque terme candidat composé est décomposé
en deux parties : la partie tête (T) et la partie expansion (E). Ainsi, le SN «moteur
de recherche» est décomposé en deux termes simples «moteur» et « recherche ».
Les candidats termes extraits du corpus sont structurés en réseau terminologique,
en se basant sur la décomposition de ces termes en tête et expansion. Dans ce
réseau, chaque terme est relié à sa tête et à son expansion, et chaque tête et chaque
expansion sont reliées aux termes composés dont ils font partie. Par exemple, sur
la séquence «stenose de le tronc commun gauche», on obtient le réseau suivant :
T
E
Det
E
Adj
Prep
T
T
T
T
T Adj
E
Adj
N
N
E
stenose severe de le tronc commun gauche
Figure 3.1- Réseau fourni par LEXTER pour «stenose severe de le tronc commun gauche» (HABERT et al, 1995)
SYNTEX, la version actuelle de LEXTER (BOURIGAULT et al, 2000), permet
l’extraction { partir d’un corpus textuel, d’un ensemble de syntagmes nominaux,

3.3. Extraction des termes
-74-
verbaux et adjectivaux. Il a été utilisé dans de nombreux travaux sur l’extraction
des connaissances à partir des textes. Dans (LE MOIGNO et al, 2002), il est utilisé
dans une méthode de construction d’une ontologie { partir d’un corpus du
domaine de la réanimation chirurgicale.
3.3.2.3. Les travaux de C. Jaquemin : FASTER
FASTER est un outil qui repose sur des analyses syntaxiques dont le but est de
reconnaître les termes qui apparaissent dans un corpus et qui figurent dans une
liste de termes fournie au système (JACQUEMIN, 1997) (JACQUEMIN, 1998)
(JACQUEMIN, 1999). L’auteur part du principe que les termes apparaissent sous
différentes formes linguistiques. Pour les identifier FASTER utilise un ensemble de
règles préétablies. Par exemple:
1. Coordination: «patron et schéma syntaxique » est une variante syntaxique
du terme « patron syntaxique ».
2. Modification: il s’agit d’insérer un modificateur dans un terme. L’auteur
considère que si le modificateur inséré est un terme connu alors on peut
substituer le nouveau avec modificateur terme par le terme sans
modificateur. Par exemple: «caractéristique du concept» et «caractéristique
linguistique du concept»28, linguistique est le modificateur ajouté au terme.
On considérera que la caractéristique linguistique du concept est une
occurrence de caractéristique du concept
3. Dérivation:
(Nom – Nom) : «analyseur de texte» est une dérivation (Nom analyseur –
Nom analyse) de «analyse de texte».
(Nom – Verbe) : « traitement de texte » est une dérivation (Nom
traitement – Verbe traiter) de « traiter le texte »
(Nom – Adjectif) : « pression de l’atmosphère » est une dérivation (Nom
atmosphère – Adjectif atmosphérique) de « pression atmosphérique ».
3.3.2.4. Conclusion : Bilan
Les résultats obtenus par les méthodes linguistiques sont jugés pertinents.
Cependant l’utilisation de ces approches nécessite une maîtrise complète des
28 Si « caractéristique du concept » est un terme, « caractéristique linguistique du concept » est une
substitution de « caractéristique du concept »

3.3. Extraction des termes
-75-
langues des corpus étudiés. L’extraction des termes simples et des termes
composés nécessite une connaissance parfaite des règles syntaxiques de dérivation
dans la langue du corpus. Les méthodes linguistiques sont basées sur des
propriétés linguistiques de la langue naturelle. Ces propriétés sont intrinsèques à
la langue du corpus d’étude en particulier le français. Elles ne sont pas, de ce fait,
généralisables { d’autres langues.
Il est à souligner que les propriétés et les règles utilisées dans ces méthodes
sont issues d’un traitement manuel du corpus d’étude. Ces éléments sont difficiles
à dégager à partir des corpus volumineux. En effet, pour dégager une règle il est
indispensable de feuilleter la quasi-totalité du corpus d’étude. Cette tâche n’est pas
aisée dans le cas ou le corpus est de grande taille.
En conclusion les approches linguistiques trouvent leurs performances dans des
corpus bien spécifiques sur lesquels une étude linguistique détaillée a été réalisé.
Ces approches ne peuvent pas être généralisées sur des corpus de langue
différente, de taille différente et de spécialité différente.
3.3.3. Méthodes hybrides ou mixtes
Dans les modèles hybrides ou mixtes, les approches statistiques et les
approches linguistiques sont associées ou couplées. L’ordre dans lequel cette
association est effectuée varie d’un système { un autre. En effet, dans certains
systèmes les résultats obtenus par une analyse linguistique sont validés et filtrés
par une analyse statistique, tandis que dans d’autres systèmes les résultats de
l’analyse statistique sont validés par une analyse linguistique.
3.3.3.1. Les travaux de B. Daille
L’outil ACABIT a été élaboré par B. Daille (DAILLE, 1994) au sein de la société
IBM, il est dédié uniquement { l’extraction des termes composés { partir du corpus.
Cet outil extrait les termes composés candidats { partir d’un corpus en langue
française préalablement étiqueté.
Dans une première étape, B. Daille reprend les techniques linguistiques
empruntées par TERMINO et LEXTER (DAILLE, 1994) (DAILLE, 1999). Ainsi,
ACABIT repère des syntagmes nominaux susceptibles de décrire un terme
composé en utilisant des automates. Dans une deuxième étape, les techniques
statistiques sont employées afin de déterminer le degré de liaison entre les mots
associés dans les termes composés extraits dans la première étape. Pour effectuer
ces calculs statistiques, Daille se base sur un corpus de référence et une liste de

3.3. Extraction des termes
-76-
termes valides. Selon T. Dunning (DUNNING, 1993) la mesure statistique logLike
semble être la mieux adaptée pour représenter les liens termes candidats.
3.3.3.2. Les travaux de F. Smadja
L’outil XTRACT a été élaboré par F.Smadja (SMADJA, 1993), durant ses travaux
portant sur l’indexation automatique des textes. Il consiste { repérer des
collections de structures prédéfinies telles que : nom+nom, nom de nom,
nom+adjectif, sujet+verbe, verbe+sujet, etc. Dans un premier temps, XTRACT
exploite les techniques statistiques essentiellement basées sur l’information
mutuelle entre mots et dans un deuxième temps, il utilise des techniques
linguistiques. Partant d’un corpus étiqueté, l’outil repère les couples de mots
fortement associés en utilisant l’information mutuelle dans une fenêtre de 5 mots.
Les couples ainsi extraits sont repris afin de former des couples de plus de deux
mots, les n-grammes. Afin de filtrer les n-grammes obtenus précédemment,
l’ensemble est soumis { une analyse syntaxique qui permet d’attribuer une
catégorie grammaticale ou syntaxique aux différents mots de la collection. Par
exemple, dans la forme nom+nom telle que « ammonium nitrate » l’auteur calcule
les fréquences d’apparition du mot «nitrate» à une distance -1 du mot
« ammonium ». Dans XTRACT, la validation des termes doit être effectuée par un
spécialiste du domaine, comme dans l’exemple suivant :
Mots co-occurrents avec « trade » fréquence totale Fréquence position (p-1)
Free 8031 7918
Our 1147 449
On remarque que le mot «trade» est plus lié au mot « free » qu’au mot «our». Le
choix du terme valide est laissé { l’utilisateur : un linguiste ou un spécialiste du
domaine.
Nous soulignons { ce passage qu’il n’existe pas de grande différence entre le
système XTRACT et le système ACABIT de B. Daille. Dans XTRACT de F. Smadja, les
résultats obtenus par des méthodes statistiques sont soumis à un filtrage par des
techniques linguistiques. Dans ACABIT, on trouve le chemin inverse en procédant à
un filtrage par des techniques statistiques des résultats obtenus par des techniques
linguistiques. La seule différence réside dans la mesure statistique utilisée : le
LogLike par B. Daille et l’information mutuelle par F. Smadja.
3.3.3.3. Les travaux de K.T. Frantzi
Dans (FRANTZI et al, 1997) (FRANTZI et al, 1999), K.T. Frantzi présente une
technique d’extraction des termes basée sur des grammaires ou encore sur des
règles. La méthode identifie les termes composés (CT) dans un corpus en anglais

3.3. Extraction des termes
-77-
étiqueté. Le corpus utilisé est étiqueté par l’étiqueteur d’E. Brill (BRILL, 1992). Les
séquences retenues par la méthode présentée correspondent à la grammaire
suivante :
(Nom | Adjectif)+ Nom
Ainsi, les séquences formées par des noms ou des adjectifs sont suivies d’un
nom sont repérées. Dans cette méthode, un terme composé est soit un nom, soit
une séquence de noms ou d’adjectif suivie d’un nom. Les termes extraits sont
validés par un indice statistique : la C-value. Cette dernière métrique prend en
considération la fréquence du terme composé et sa longueur. Le C-value se calcule
de la manière suivante (FRANTZI et al, 1997):
Où
: le terme à valider,
: est un terme composé qui inclue comme par exemple pour «fibre» et
«fibre optique»,
et : les fréquences de et ,
: longueur de ,
: l’ensemble des termes qui incluent le
: le nombre de terme dans .
Le c-value d’un terme qui ne fait pas partie d’aucun autre terme est calculé par
la première forme. Dans le cas contraire il est calculé par la deuxième forme.
3.3.3.4. Conclusion : Bilan
Les approches hybrides fournissent des résultats de qualité. Elles présentent un
compromis entre les méthodes statistiques et les méthodes linguistiques. L’idée
d’associer ces deux dernières méthodes est pertinente. En effet, cette association
profite de la finesse des analyses linguistiques et de la robustesse des analyses

3.3. Extraction des termes
-78-
numériques. La puissance des méthodes hybrides provient de l’adoption de
modèles traitant de l’information comme étant un ensemble de variables
qualitatives (DAILLE, 1994), offrant ainsi la possibilité de traitement des corpus de
taille volumineux. En plus, les méthodes linguistiques permettent un filtrage des
résultats obtenus afin de diminuer le bruit.
L’approche hybride profite de la rapidité et de l’indépendance par rapport au
domaine des méthodes statistiques. Cette indépendance se manifeste par l’absence
d’utilisation des ressources linguistiques spécialisées, les dictionnaires. Cependant
cette indépendance reste partielle et limitée, en effet les méthodes linguistiques
nécessitent une connaissance parfaite de la langue du corpus à traiter.
3.3.4. Evaluation des systèmes d’extraction des termes
L’évaluation des systèmes d’extraction des termes se focalise sur la qualité de la
terminologie obtenue par ce système. Elle ne prend pas en compte de nombreux
autres facteurs tels que la vitesse de traitement, la portabilité et la robustesse
(PAROUBEK et al, 2000) (DAILLE, 2002). Ces méthodes d’évaluation se basent
toutes sur un corpus, une liste de référence et des mesures statistiques.
3.3.4.1. Le corpus de référence
Le corpus de référence pour l’évaluation doit couvrir un domaine unique (PERY-
WOODLEY, 1995). Les documents du corpus doivent être monolingues et
suffisamment variés afin d’être représentatifs du domaine de spécialité du corpus.
3.3.4.2. La liste de référence
Il s’agit, d’une liste contenant des termes dits, de référence avec lesquels les
résultats obtenus par les systèmes d’extraction des termes sont comparés
(DAILLE, 2002). Cette liste peut être construite { partir d’un dictionnaire spécialisé
de même domaine que le corpus. Elle peut être aussi obtenue par l’extraction
manuelle des termes du corpus d’étude, celle-ci est effectuée par des experts du
domaine.
Cependant, un jugement humain d’un expert peut remplacer la liste de
référence, dans le cas où il s’agit d’évaluer un seul outil. En effet, si plusieurs
systèmes sont mis en compétition il est impossible de juger si l’expert n’a pas été
influencé par les résultats des évaluations précédentes.

3.4. Extraction des termes à partir des corpus bilingues et corpus multilingues
-79-
3.3.4.3. Les mesures statistiques
Traditionnellement, les mesures utilisées pour juger la justesse de l’extraction
des termes sont la précision et le rappel.
La précision permet d’évaluer le nombre correct de termes extraits et le rappel
permet d’évaluer la proportion des termes corrects qui n’ont pas été extraits
(DAILLE, 2002).
3.4. Extraction des termes à partir des corpus bilingues et
corpus multilingues
L’extraction des termes { partir des corpus bilingues consiste { extraire les
termes et leurs traductions. Il s’agit donc, d’identifier le terme dans une langue
source et une langue cible puis de faire la correspondance. La plupart des travaux
menés dans ce contexte visent la construction des ressources linguistiques
multilingues comme le dictionnaire Oxford-Hachette (ROBERTS el al, 1996) et le
dictionnaire bilingue canadien (GRUNDY, 1996). Dans (VERONIS, 2000), les
traitements effectués comportent deux étapes : une étape d’extraction de
terminologie monolingue et une étape d’alignement des termes extraits durant la
première étape.
L’extraction des termes à partir des corpus bilingues traitent deux types de
corpus, les corpus comparables et les corpus parallèles.
3.4.1. Extraction des termes à partir des corpus comparables
Les travaux qui se sont intéressés { l’extraction de termes { partir des corpus
comparables se basent sur la distribution contextuelle présentée dans la section
1.5.1.1, c’est-à-dire le regroupement des termes qui apparaissent dans des
contextes similaires. Selon M. Rajman (RAJMAN et al, 1992) le sens d’un terme
peut être décrit par sa distribution dans un ensemble de contexte. Ainsi, un terme
dans une langue l1 et un terme dans une langue l2 qui ont une distribution
contextuelle proche ont une forte probabilité d’être la traduction l’un de l’autre.
Par exemple si «médecin» et «infirmière» ont les mêmes distributions

3.4. Extraction des termes à partir des corpus bilingues et corpus multilingues
-80-
contextuelles et si «doctor» et «nurse» ont des distributions similaires, si
« infirmière» est la traduction de «nurse». Alors «médecin» a une grande
probabilité d’être la traduction de «doctor».
Les méthodes présentées dans (CHIAO et al, 2002) (FUNG et al, 1998) (RAPP,
1999), sont fondées sur la distribution contextuelle. Elles consistent à déterminer
la distribution des termes dans différentes langues. Ces méthodes associent à
chaque terme un vecteur de contexte qui contient le contexte droit et le contexte
gauche. Le contexte droit (respectivement gauche) est l’ensemble des termes qui
occurrent avec le terme étudié et qui sont à droite (respectivement à gauche) de ce
terme. Le contexte est pris dans une fenêtre de longueur n mots. Ces vecteurs sont
ensuite traduits d’une langue { une autre en utilisant des ressources linguistiques
bilingues (CHIAO et al, 2002) (FUNG et al, 1998) (RAPP, 1999) (MORIN et al,
2004). Des calculs de similarité entre les vecteurs traduits et les vecteurs dans la
langue source sont effectués afin de déterminer les meilleurs vecteurs candidats à
la traduction. Ces calculs se basent sur des mesures statistiques.
Dans (DEJEAN et al, 2002), les auteurs reprennent la même démarche suivie
dans (CHIAO et al, 2002) (FUNG et al, 1998) (RAPP, 1999). Ils utilisent le thésaurus
MeSH, pour comparer le vecteur de contexte du terme à traduire avec le vecteur
des entrées dans le thésaurus. Cette comparaison se base sur le cosinus de l’angle
entre les vecteurs. L’étape précédente permet de déterminer les classes
conceptuelles associées au terme à traduire. Ensuite un modèle probabiliste est
utilisé pour estimer la probabilité que deux termes soient la traduction l’un de
l’autre.
3.4.2. Extraction des termes à partir des corpus parallèles
Divers travaux (VAN DER EIJK, 1993) (SMADJA et al, 1996) (DAGAN et al, 1997)
(RESNIK et al, 1997) (FUNG et al, 1997) (HIEMSTRA et al, 1997) (HIEMSTRA D.,
1998) (GAUSSIER, 1998) (EVEOL et al, 2005) se sont intéressés { l’extraction des
termes à partir des corpus parallèles. Ces corpus sont rares et ils sont limités à des
domaines de spécialités comme la médecine (CHIAO, 2004). Ils sont constitués des
textes et de leurs traductions. De ce fait, la qualité de la traduction des textes a une
influence directe sur la performance de l’extraction des termes { partir de ces
corpus.
Dans la majorité des travaux le processus d’extraction des termes { partir des
corpus parallèles est ramené à trois sous-processus (CHIAO, 2004). Deux
processus d’extraction des termes monolingues chacun dans une langue du corpus
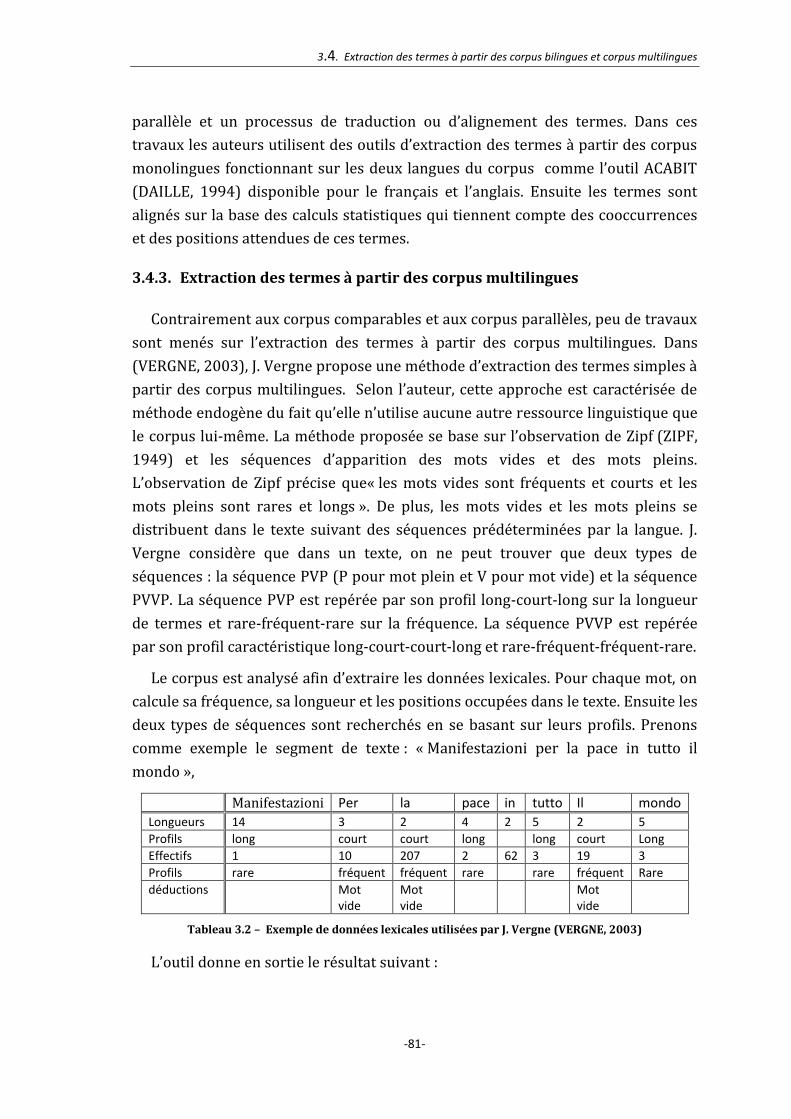
3.4. Extraction des termes à partir des corpus bilingues et corpus multilingues
-81-
parallèle et un processus de traduction ou d’alignement des termes. Dans ces
travaux les auteurs utilisent des outils d’extraction des termes { partir des corpus
monolingues fonctionnant sur les deux langues du corpus comme l’outil ACABIT
(DAILLE, 1994) disponible pour le français et l’anglais. Ensuite les termes sont
alignés sur la base des calculs statistiques qui tiennent compte des cooccurrences
et des positions attendues de ces termes.
3.4.3. Extraction des termes à partir des corpus multilingues
Contrairement aux corpus comparables et aux corpus parallèles, peu de travaux
sont menés sur l’extraction des termes { partir des corpus multilingues. Dans
(VERGNE, 2003), J. Vergne propose une méthode d’extraction des termes simples {
partir des corpus multilingues. Selon l’auteur, cette approche est caractérisée de
méthode endogène du fait qu’elle n’utilise aucune autre ressource linguistique que
le corpus lui-même. La méthode proposée se base sur l’observation de Zipf (ZIPF,
1949) et les séquences d’apparition des mots vides et des mots pleins.
L’observation de Zipf précise que« les mots vides sont fréquents et courts et les
mots pleins sont rares et longs ». De plus, les mots vides et les mots pleins se
distribuent dans le texte suivant des séquences prédéterminées par la langue. J.
Vergne considère que dans un texte, on ne peut trouver que deux types de
séquences : la séquence PVP (P pour mot plein et V pour mot vide) et la séquence
PVVP. La séquence PVP est repérée par son profil long-court-long sur la longueur
de termes et rare-fréquent-rare sur la fréquence. La séquence PVVP est repérée
par son profil caractéristique long-court-court-long et rare-fréquent-fréquent-rare.
Le corpus est analysé afin d’extraire les données lexicales. Pour chaque mot, on
calcule sa fréquence, sa longueur et les positions occupées dans le texte. Ensuite les
deux types de séquences sont recherchés en se basant sur leurs profils. Prenons
comme exemple le segment de texte : « Manifestazioni per la pace in tutto il
mondo »,
Manifestazioni Per la pace in tutto Il mondo
Longueurs 14 3 2 4 2 5 2 5
Profils long court court long long court Long
Effectifs 1 10 207 2 62 3 19 3
Profils rare fréquent fréquent rare rare fréquent Rare
déductions Mot vide
Mot vide
Mot vide
Tableau 3.2 – Exemple de données lexicales utilisées par J. Vergne (VERGNE, 2003)
L’outil donne en sortie le résultat suivant :

3.5. Structuration des termes en classes : les concepts
-82-
Figure 3.2 Exemple de sortie de la méthode de J. vergne
Où chaque mot est symbolisé par un ovale blanc pour les mots vides, et un ovale
noir pour les mots non vides.
Ainsi la méthode proposée dans (VERGNE, 2003), permet d’affecter { chaque
mot une catégorie. Un mot est catégorisé soit vide soit plein. Le processus de
catégorisation examine les mots dans leurs contextes d’apparition : la phrase. Par
conséquent, le même mot peut être catégorisé plein dans un contexte et vide dans
un autre.
3.5. Structuration des termes en classes : les concepts
Dans les travaux de l’extraction des connaissances { partir de textes il n’existe
pas une définition exacte de la notion de concept. Un terme spécifique qui décrit
une partie d’un domaine est souvent appelé concept. Un terme est généralement
porteur de sens ou significatif dans un corpus spécialisé. Ces termes sont utilisés
dans des applications liées au traitement automatique des langues telles que
l’indexation, la génération automatique des résumés et les systèmes de questions
réponses.
Dans le dictionnaire Larousse, le terme concept est défini comme l’ « Idée
générale et abstraite que se fait l’esprit humain d’un objet de pensée concret ou
abstrait, et qui lui permet de rattacher à ce même objet les diverses perceptions
qu’il en a, et d’en organiser les connaissances ».
Ainsi, le terme concept est souvent utilisé comme se référant à toute notion, de
l’idée au lexème, en passant par l’entité et la catégorie. Selon L. Medin (MEDIN,
1989), un concept est une idée qui inclut tout ce qui est caractéristiquement
associé à elle.
La majorité des travaux effectués dans ce domaine se basent sur l’analyse
distributionnelle ou la distribution contextuelle. Ils se basent sur l’idée que si deux
termes ont des distributions similaires alors ils font partie d’un même concept.
3.5.1. La distribution contextuelle
La distribution contextuelle d’un terme dans un corpus peut être définie par les
différents contextes d’utilisation de ce terme dans le corpus (OUESLATI, 1999).

3.5. Structuration des termes en classes : les concepts
-83-
Considérons les représentations formelles suivantes des premières phrases d’un
corpus (les termes sont représentées par les symboles Ti) :
1) T1 T2 4) T3 T2 T5 7) T5 T4 T3 2) T3 T4 T1 5) T3 T4 T5 8) T3 T2 T1 3) T5 T2 T3 6) T1 T4
D’après ces phrases la distribution de T2 par exemple sera : (T1), (T5-T3), (T3-
T5), (T3-T1) et celle de T4 sera :(T3-T1), (T3-T5), (T1), (T5-T3).
On remarque que les termes T2 et T4 ont les mêmes distributions. On peut
supposer que ces deux termes font partie d’une même classe et par conséquent, ils
appartiennent au même concept.
3.5.2. Les travaux de P. Resnik
Les travaux de P. Resnik (RESNIK, 1993) (RESNIK, 1995) exploitent l’analyse
distributionnelle en remplaçant les termes de contexte par leurs classes
sémantiques afin de mettre en évidence les relations sémantiques associées. Le
corpus utilisé par P. Resnik est étiqueté et lemmatisé. Ensuite, et un algorithme de
désambigüisation des groupes nominaux est utilisé. Ainsi, on peut déterminer dans
une structure (verbe+nom), la classe sémantique la plus pertinente pour le terme.
Ces classes sont obtenues en exploitant les liens génériques de WordNet (MILLER
et al, 1990).
Exemple : les termes « infirmier » et « docteur » sont remplacés par la classe
« profession de santé » de WordNet.
3.5.3. Les travaux de E. Riloff
Dans le cadre de ces travaux d’extraction d’information, E.Riloff (RILOFF, 1993)
utilise le même principe présenté dans les travaux de P. Resnik. Ainsi, la méthode
proposée, consiste { générer des patrons syntaxiques des instances d’une classe
dans un corpus spécialisé. E. Riloff cherche à extraire des schémas d’extraction de
membre de classes conceptuelles en utilisant un dictionnaire contenant un
ensemble de termes associés à un concept. Pour une classe conceptuelle donnée et
un terme instance de cette classe, il effectue une analyse syntaxique sur toutes les
phrases qui contiennent ce terme pour proposer un schéma candidat et de repérer
un autre terme comme instance de la classe conceptuelle.

3.6. Extraction des relations sémantiques
-84-
Exemple :
Classe: cibles des terroristes
Terme de la classe : ambassade
Patron défini: (Instance de la classe) a été bombardée
Instance du Patron: l’ambassade a été bombardée
Dans la phrase : Maison Blanche a été bombardée
Résultat : « Maison Blanche » appartient à la classe des « cibles des terroristes ».
La distribution contextuelle est utilisée dans les processus de construction des
ressources linguistiques de corpus en examinant les contextes d’apparition des
mots dans ce corpus afin de former les classes conceptuelles associées: les
concepts.
3.6. Extraction des relations sémantiques
La majorité des travaux liés { l’extraction des relations sémantiques à partir des
corpus textuels, ont été effectuées dans des cadres de construction et
d’enrichissement des ontologies ou des thésaurii. Ils s’intéressent { l’extraction de
deux types de relation : les relations hiérarchiques et les relations non-
hiérarchiques (PUNURU, 2008).
3.6.1. Extraction des relations hiérarchiques
Les techniques existantes d’extraction et de repérage des relations
hiérarchiques se basent sur des patrons syntaxiques ou lexico-syntaxiques. Dans
un premier temps, un ensemble de patrons lexico-syntaxiques est défini (un pour
chaque relation). Dans un deuxième temps, ces patrons seront projetés sur le
corpus de texte afin de repérer les instances des relations. La construction des
patrons lexico-syntaxiques est alors une étape préliminaire afin de découvrir les
relations dans un corpus. Précisément, il s’agit d’une acquisition des marqueurs de
relations à partir du corpus étudié.
3.6.1.1. Les travaux de M. Hearst
M. Hearst (HEARST, 1992) dans ses travaux sur l’extraction des liens
d’hyperonymie { partir de textes, propose la méthode itérative suivante :
1. Sélectionner le type de relation R,
2. Etablir une liste de termes pour lesquels on a identifié cette relation,
3. Trouver dans le corpus des phrases où les termes reliés sont co-occurrents,
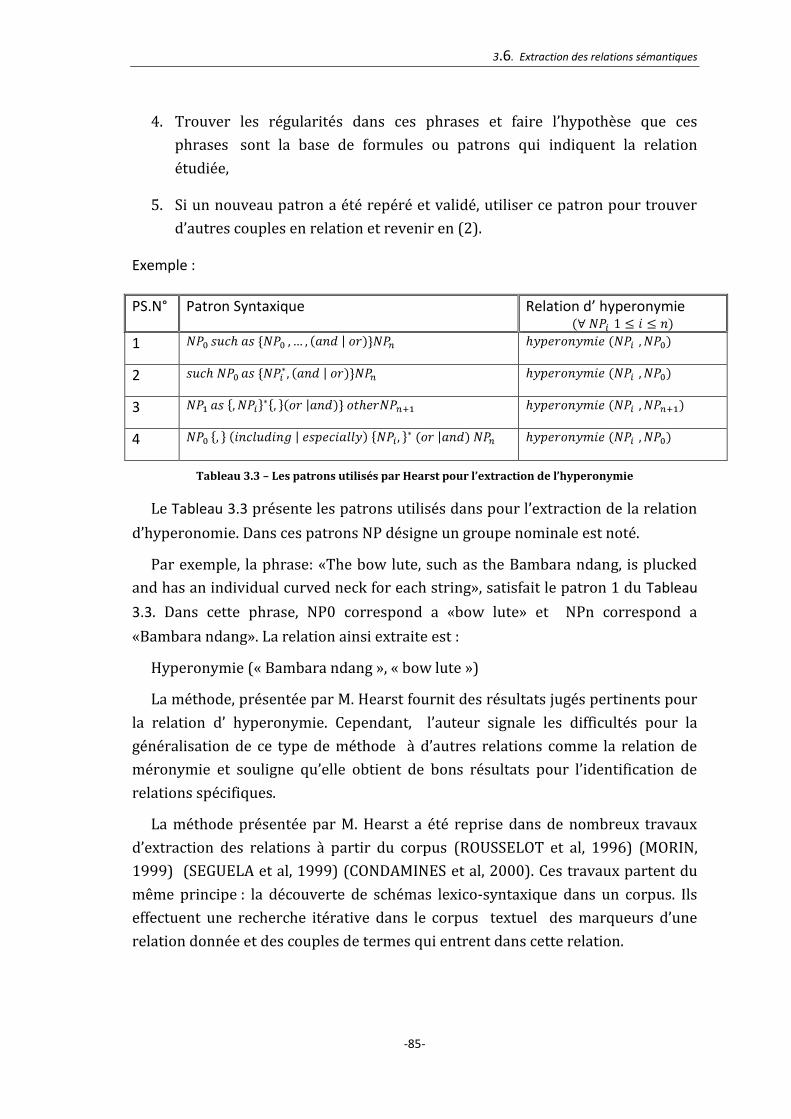
3.6. Extraction des relations sémantiques
-85-
4. Trouver les régularités dans ces phrases et faire l’hypothèse que ces
phrases sont la base de formules ou patrons qui indiquent la relation
étudiée,
5. Si un nouveau patron a été repéré et validé, utiliser ce patron pour trouver
d’autres couples en relation et revenir en (2).
Exemple :
PS.N° Patron Syntaxique Relation d’ hyperonymie
1
2
3
4
Tableau 3.3 – Les patrons utilisés par Hearst pour l’extraction de l’hyperonymie
Le Tableau 3.3 présente les patrons utilisés dans pour l’extraction de la relation
d’hyperonomie. Dans ces patrons NP désigne un groupe nominale est noté.
Par exemple, la phrase: «The bow lute, such as the Bambara ndang, is plucked
and has an individual curved neck for each string», satisfait le patron 1 du Tableau
3.3. Dans cette phrase, NP0 correspond a «bow lute» et NPn correspond a
«Bambara ndang». La relation ainsi extraite est :
Hyperonymie (« Bambara ndang », « bow lute »)
La méthode, présentée par M. Hearst fournit des résultats jugés pertinents pour
la relation d’ hyperonymie. Cependant, l’auteur signale les difficultés pour la
généralisation de ce type de méthode { d’autres relations comme la relation de
méronymie et souligne qu’elle obtient de bons résultats pour l’identification de
relations spécifiques.
La méthode présentée par M. Hearst a été reprise dans de nombreux travaux
d’extraction des relations { partir du corpus (ROUSSELOT et al, 1996) (MORIN,
1999) (SEGUELA et al, 1999) (CONDAMINES et al, 2000). Ces travaux partent du
même principe : la découverte de schémas lexico-syntaxique dans un corpus. Ils
effectuent une recherche itérative dans le corpus textuel des marqueurs d’une
relation donnée et des couples de termes qui entrent dans cette relation.

3.6. Extraction des relations sémantiques
-86-
3.6.1.2. Les travaux de E. Morin et C. Jaquemin
Dans le même but d’extraire des relations d’hyperonymie, le système présenté
par E. Morin et C. Jaquemin (MORIN et al, 2004) est une association de :
1. Promothee : outil de structuration de termes simples en réseaux
sémantiques (MORIN, 1999a)
2. ACABIT : outil d’extraction de termes composés (DAILLE, 1996)
3. FASTR : outil de détection des variations morphosyntaxiques des termes
dans le corpus (JACQUEMIN, 1996)
Figure 3.3- vue d’ensemble du système proposé par E. Morin et C. Jaquemin (MORIN et al, 2004)
Pour trouver les relations entre les termes dans différentes phrases, le système
tente d’identifier les variations des termes pour lesquels les relations sont déj{
déterminées. Par exemple, si la relation hiérarchique entre «fruits» et « pomme»
est connue, alors la relation entre les termes composés «jus de fruits» et «jus de
pomme» est également marquée comme une relation hiérarchique. Les relations
sémantiques entre les termes composés t1t2 et t1’t2’, se référant { des relations
sémantiques entre les termes simples qui les constituent, sont marquées si l’une
des trois contraintes suivantes est satisfaite :
1. une relation sémantique est connue entre t1 et t2 et/ou t1’et t2’,
2. il existe un schéma de relation dans lequel t1 et t2 sont des têtes et t1’et
t2’sont des arguments,
3. il existe une relation sémantique connue entre t1t2 et t1’t2’.
3.6.1.3. Les travaux de R. Snow
Dans (SNOW et al, 2004), R. Snow propose une méthode d’apprentissage
supervisée qui utilise les dépendances des chemins afin de chercher des patrons

3.6. Extraction des relations sémantiques
-87-
syntaxiques pour l’extraction des relations d’ hyperonymie. Ces dépendances des
chemins sont générées par des parseurs d’arbres de dépendance. Un parseur de
dépendance produit un arbre des dépendances qui représente les relations
syntaxiques entre les termes d’une liste de la forme (LIN et al, 2001): (terme1 :
catégorie1 : Relation : catégorie2 : terme2). Dans cette liste :
les termes sont les formes singulières (les lemmes) des termes trouvés dans les phrases, par exemple « auteurs » devient « auteur », et ils correspondent { un nœud dans l’arbre de dépendance.
les catégories sont les catégories grammaticales des termes considérés, par exemple nom et préposition.
les relations sont les relations syntaxiques réalisées entre les termes, par exemple, la relation «objet » et la relation «modifier », et correspondent à des liens spécifiques dans l’arbre.
Dans l’arbre de dépendance, l’ensemble des plus courts chemins de longueur
inférieure { cinq définit l’ensemble des patrons syntaxiques des relations
sémantiques. La Figure 3.4 montre l’arbre de dépendance pour le fragment de la
phrase « ...such authors as Herrick and Shakespeare» générés par le parseur
MINIPAR29 (LIN, 1998).
Figure 3.4- Exemple d’arbre de dépendance généré par MINIPAR (SNOW et al, 2005)
D’autres techniques d’extraction des relations hiérarchiques à partir des corpus
sont présentées dans (FOTZO et al, 2004) (RYU P et al, 2004) (KASHYAP et al,
2004). Les techniques présentées dans (RYU P et al, 2004) (KASHYAP et al, 2004)
sont spécifiques aux corpus spécialisés couvrant le domaine de la médecine. Dans
(FOTZO et al, 2004), les auteurs utilisent des règles de subsumption dans une
collection de documents afin de trouver les relations hiérarchiques. Pour repérer
la relation d’hyponymie entre deux termes t1 et t2, les auteurs utilisent la
fréquence relative. Cette fréquence relative consiste à comparer le nombre des
documents contenant t1 et t2 au nombre des documents contenant t2 seul.
29 http://www.cs.ualberta.ca/~lindek/minipar.htm

3.6. Extraction des relations sémantiques
-88-
3.6.2. Extraction des relations non- hiérarchiques
En général, l’identification des relations non-hiérarchiques consistent à trouver
dans un premier temps les paires ou les couples de termes qui forment les
arguments d’une relation. Et dans un deuxième temps l’identification de l’étiquette
pour la relation sémantique qui relie les termes arguments de la relation. Par
exemple, dans le couple (« société », « produit »), l’étiquette de la relation peut être
de « vendre », « fabrication », ou « consommer ».
Les travaux menés sur l’extraction des relations non-hiérarchiques à partir de
corpus textuels, se sont limités à un certain nombre de relations. Dans la suite
nous présentons deux relations : la relation de causalité et la relation partie-de.
3.6.2.1. La relation de causalité
Le système COATIS élaboré par D. Garcia (GARCIA, 1998) a pour but le repérage
des relations de causalité dans le corpus textuel. Ce système utilise des schémas de
relations comprenant vingt-cinq relations de causalité, par exemple «créer»,
«empêcher», «faciliter» ou «pousser-{» dont l’élaboration se base sur le modèle
proposé pour l’anglais par L. Talmy (TALMY, 1988). La technique utilisée consiste
{ déclarer puis repérer un ensemble d’indicateurs linguistiques de la causalité,
appelés « marqueurs de la relation ». Ces marqueurs sont en général des verbes,
tels que « provoquer » ou « causer ». Et aussi des verbes tels que « gêner »,
« modifier » ou « contribuer », dont la valeur sémantique causale est confirmée par
la coprésence dans le texte d’indices linguistiques complémentaires aux
indicateurs. Les termes arguments, cause et effet, sont identifiés de la même façon,
mais en utilisant d’autres indicateurs linguistiques.
Cette même démarche a été reprise par E. Cartier (CARTIER, 1997) pour
l’identification des définitions et par B. Goujon (GOUJON, 1999) pour la veille
technologique en anglais.
Dans (GIRJU et al, 2002), R. Girju présente une technique semi-automatique
d’extraction des patrons syntaxiques de la relation cause-effet. Cette technique
relie un corpus volumineux à WordNet. La méthode proposée consiste à
sélectionner à partir de WordNet un ensemble de couples de noms pour lesquels la
relation cause-effet est identifiée. Par la suite, l’ensemble des couples est projeté
dans le corpus afin de repérer les phrases dans lesquelles un couple est présent.
Les phrases repérées sont de la forme < NP1 verbe | verbe expression NP2 >, où
NP1 et NP2 sont des groupes nomineaux. Un filtrage des couples de noms est
effectué. Il ne conserve que les couples dont le second argument appartient { l’une

3.6. Extraction des relations sémantiques
-89-
des classes de WordNet «action de l’homme», «phénomène», «état», «fonction
psychologique», et «événement». Les noms qui correspondent à NP1 doivent être
une sous-classe de la classe «agent causal».
3.6.2.2. La relation partie-de
De nombreux travaux (BERLAND et al, 1999) (GIRJU et al, 2003) (TURNEY,
2006) ont été intéressés par l’extraction de ce type de relation. Ils se basent tous
sur les patrons syntaxiques. Ces travaux différent par la manière avec laquelle
s’effectue l’extraction des patrons.
Dans (BERLAND et al, 1999), M. Berland présente une technique d’extraction de
la relation partie-de { partir d’un large corpus textuel anglais. L’auteur utilise deux
indicateurs linguistiques : «basement» et «building», pour extraire les phrases
dans lesquelles ces indicateurs sont présents. A partir de ces phrases, l’auteur
extrait les patrons des relations. Après une validation manuelle, deux patrons ont
été retenus. Les patrons sont ensuite projetés dans le corpus pour extraire d’autres
paires reliées par la même relation. Les paires extraites sont triées en utilisant une
métrique statistique se basant sur la probabilité conditionnelle.
Les travaux par R. Girju (GIRJU et al, 2003) peuvent être présentés, comme une
extension des travaux de M. Berland (BERLAND et al, 1999). R. Girju fait une
analyse syntaxique du corpus, le corpus : TREC-9. Cette analyse permet l’extraction
de trois patrons de la relation partie-de. Ces patrons sont représentés dans le
Tableau 3.4.
PS.N° Patrons syntaxiques
1 NP1 of NP2
2 NP1’s NP2
3 NP1 Verb NP2
Tableau 3.4 – Les patrons extraits par R.Girju
Pour identifier les paires valides susceptibles d’être des arguments de la
relation « partie-de » ,l’auteur extrait les phrases du corpus satisfaisant l’un des
patrons retenus. Ensuite, il utilise une technique d’apprentissage supervisée basée
sur l’algorithme de l’arbre de décision C4.5 (QUINLAN, 1993) pour l’apprentissage
des contraintes sémantiques. En cas d’ambigüité, l’auteur remplace les termes
ambigus par des classes plus spécifiques de WordNet.

3.7. Conclusion
-90-
3.6.2.3. Conclusion : Bilan
Malgré le grand nombre de travaux qui se sont intéressés { l’extraction des
relations sémantiques entre les termes et entre les concepts, cette tâche reste
toujours une tâche difficile à réaliser. Les différentes techniques proposées dans
ces travaux, sont basées sur les patrons syntaxiques des relations. Ces patrons
doivent être définis manuellement, et ensuite projetés dans le corpus spécialisé
afin d’extraire d’autres patrons { partir des phrases satisfaisant les patrons de
départ. La contrainte majeure de ces approches est qu’elles nécessitent un effort
manuel non négligeable pour chaque domaine. Elles ne sont pas donc adaptables à
d’autre domaine (JACQUEMIN, 1996).
3.6.2.4. Discussion
Dans le cadre bilingue, l’extraction des termes consiste à extraire les termes et
leurs traductions. On distingue deux types de corpus : les corpus parallèles et les
corpus comparables. Les corpus parallèles contiennent des couples de textes dont
l’un et la traduction de l’autre. Les textes comparables sont des textes de langues
différentes regroupés selon les domaines. Contrairement aux corpus comparables
les corpus parallèles sont rares et limités à des domaines spécifiques. Ils sont
généralement de petite taille comparés aux corpus monolingues. La qualité des
connaissances extraites à partir de ces corpus dépend essentiellement de la qualité
de traductions effectuées pour les obtenir. Les corpus comparables sont plus
disponibles que les corpus parallèles et ils sont de bonne qualité. En effet, aucune
transformation linguistique de ces corpus n’a été réalisée. Le processus
d’extraction de termes { partir des corpus bilingues est ramené { un problème
d’extraction des termes monolingues ou { un problème d’identification de la
traduction d’un terme.
Les corpus multilingues, sont des mélanges de documents textuels écrits dans
différents langues. Les langues de ces documents sont inconnues au moment du
traitement, ce qui rend l’adaptation des modèles linguistiques très difficile. Ce qui
explique le nombre limité des travaux qui sont intéressés { l’extraction des
connaissances à partir des corpus multilingues.
3.7. Conclusion
En raison des caractéristiques non formelles des langages naturels, la tâche
d’extraction des connaissances { partir des documents textuels est une tâche
difficile. Cette tâche consiste à extraire les concepts et les relations entre ces

3.7. Conclusion
-91-
concepts. Elle vise deux domaines d’application la construction des ressources
linguistiques et l’indexation sémantique des documents textuels.
L’extraction des concepts consiste à extraire les termes et regrouper les termes
sémantiquement proches en classes. L’extraction des relations consiste { repérer
des couples de termes sémantiquement reliés par une relation spécifique au
domaine du corpus d’étude.
Les approches existantes se basent sur des calculs statistiques: les fréquences,
les cooccurrences, les indices d’association, (etc.) et sur des patrons linguistiques
ou schémas de relation. Ces patrons sont construits manuellement pour chaque
relation du domaine. Le patron d’une relation doit être reconstruit si on change de
langue. En effet, Il est spécifique à une relation dans une langue donnée
(JACQUEMIN, 1996). Les résultats obtenus par ces approches sont jugés
satisfaisants. Ces approches traitent des corpus monolingues et bilingues. Dans la
majorité des travaux, les corpus sont étiquetés et lemmatisés.
Dans un contexte multilingue, les approches traitant des corpus bilingues et
monolingues ne sont pas directement applicables. En effet, ces approches ne sont
pas portables d’une langue { une autre et ne peuvent pas être généralisées dans un
contexte où les langues des documents sont mélangées.
Dans la littérature, on remarque que peu de travaux se sont intéressés à
l’extraction des connaissances à partir des corpus multilingues.
Ce chapitre était consacré { l’état de l’art des techniques d’extractions des
descripteurs à partir des documents textuels. Nous avons ainsi présenté les
méthodes statistiques, les méthodes linguistiques et les méthodes hybrides. Nous
avons aussi donné un aperçu des travaux liés aux corpus multilingues.
Le chapitre suivant présente la démarche que nous avons élaborée pour
l’extraction des concepts et des relations entre les concepts { partir des corpus
multilingues. Cette méthode permet de décrire chaque document par les concepts
et des relations constituant : un graphe conceptuel.


-93-
UNE METHODE STATISTIQUE ET
ONTOLOGIQUE D’EXTRACTION DES
CONCEPTS ET DES RELATIONS A
PARTIR DE CORPUS MULTILINGUES
Résumé
Nous présentons dans ce chapitre une nouvelle approche d’extraction
automatique des descripteurs sémantiques à partir des documents
multilingues. Étant donné la diversité des langues ainsi que leurs
complexités nous restreignons l’application de notre approche sur la
langue anglaise et les langues latines. Les descripteurs extraits sont les
concepts et les relations sémantiques entre concepts. L’approche consiste
à extraire tout d’abord les termes simples et les termes composés.
Ensuite, ces termes sont transformés en concepts. Enfin les relations
entre ces concepts sont extraites.


-95-
Chapitre 4
Une méthode statistique et ontologique
d’extraction des concepts et des relations à
partir des corpus multilingues
4.1. Introduction
Dans ce chapitre, nous présentons notre méthode d’extraction des descripteurs
sémantiques à partir des corpus multilingues. Nous proposons une méthode qui
permet l’extraction des concepts et des relations sémantiques entre ces concepts.
Ces descripteurs reflètent au mieux le contenu de chaque document du corpus
multilingue.
Nous fixons pour cela trois objectifs dans le premier consiste à extraire les
termes à partir des documents du corpus. Ces termes sont les manifestations
linguistiques des concepts dans le texte. Le deuxième consiste à identifier les
concepts dénoté par les termes précédemment extraits. Le troisième est
l’extraction des relations entre les concepts.
Afin d’atteindre le premier objectif nous se basons sur une technique statistique.
Le choix d’une technique statistique se justifie par le fait que les techniques
linguistiques sont dépendantes des langues. Ces techniques utilisent des
propriétés de la langue naturelle, telles que utilisées dans XTRACT pour le
repérage des termes composés. Ces propriétés sont spécifiques à la langue du
corpus. Elles sont extraites d’une manière locale. De ce fait, elles nécessitent une
redéfinition ou une traduction { chaque fois qu’on veut les appliquer sur un autre
corpus. Pour atteindre le deuxième et le troisième objectif nous faisons appel à une
ressource sémantique externe.
Avant de détailler notre méthode, nous présentons les fondements théoriques
sur les quelles elle se base, à savoir : la spécificité lexicale du corpus et les
distances intertextuelles, la loi de Zipf (ZIPF, 1949) et la conjecture de Luhn
(LUHN , 1958).

4.2. Fondements théoriques
-96-
4.2. Fondements théoriques
4.2.1. La spécificité lexicale du corpus et les distances intertextuelles
La spécificité lexicale d’un corpus s’intéresse au dépistage des contenus qui
caractérise ce corpus. Elle permet d’identifier les formes lexicales qui marquent la
spécificité du vocabulaire utilisé le corpus (DUCHASTEL et al, 1992). De
nombreux travaux se sont intéressés aux spécificités lexicales des corpus. Ils
procèdent à une comparaison des vocabulaires utilisés dans deux corpus afin de
déterminer le degré de ressemblance ou de divergence du vocabulaire de l’un par
rapport au vocabulaire de l’autre. Le vocabulaire d’un corpus est l’ensemble des
mots différents utilisés dans ce corpus. Dasns (LAFON, 1980) (LEBART et al, 1988)
(LEBART et al, 1988) (LEBART et al, 1994) (LEBART et al, 1994) les auteurs
utilisent un corpus de référence afin d’extraire les termes d’un corpus d’analyse. Le
corpus de référence est un corpus général, non spécialisé composé d’articles de
journaux. Le corpus d’analyse est un corpus technique. Pour chaque terme du
corpus d’analyse, les auteurs calculent la différence entre la fréquence théorique,
obtenue à partir du corpus de référence et la fréquence observée dans le corpus
d’analyse. Dans (SAGER, 1980), les auteurs procèdent à une extraction du
vocabulaire spécifique du domaine d’un corpus. Ils se basent sur le fait que dans un
corpus spécialisé le vocabulaire spécifique au domaine est plus fréquent comparé à
son utilisation dans un corpus non spécialisé.
Dans le même principe de comparaison du vocabulaire des corpus, des travaux
ont été effectués qui traitent le problème du degré de ressemblance ou de
dissemblance entre deux textes: la distance intertextuelle. Dans (BAAYEN et al,
1996) (BAAYEN et al, 1996) (HOLMES, 1995) (LABBE et al, 2001) (LABBE et al,
2001) (RUDMAN , 1998), les auteurs utilisent la distance intertextuelle afin de
déterminer l’auteur d’un texte. Ils cherchent à répondre à la question : étant donné
un texte dont l’auteur est inconnu, peut-on déterminer, avec un degré de certitude,
l’auteur de ce texte (LABBE et al, 2006). La distance intertextuelle est utilisée aussi
pour construire, de manière automatique, des collections homogènes selon
différents points de vue : vocabulaires, genres et thèmes. Ces collections sont
constituées à partir de vastes ensembles de textes électroniques disponibles.
Les calculs de distance intertextuelle sont inspirés d’indices de Jaccard
(HUBALEK, 1982). Dans ces calculs, on compte la présence ou l’absence des mots
dans les textes comparés. Dans (LABBE et al, 2003) (LABBE et al, 2006), deux
formules de calcul des distances textuelles ont été proposées. Elles se basent sur le

4.2. Fondements théoriques
-97-
raisonnement suivant : pour deux textes A et B, la distance intertextuelle entre A et
B est la réunion de A et B moins l’intersection de A et B.
Figure 4.1- la distance intertextuelle
(4.1)
(4.2)
Où
: le vocabulaire du texte A,
: le vocabulaire du texte B,
: la fréquence du mot i dans le texte A,
: la fréquence du mot i dans le texte B,
: nombre de mots du texte A,
: nombre de mots du texte B.
On remarque que: les formules (4.1) et (4.2) sont équivalentes si les textes sont
de même taille : Na = Nb. Si les deux textes comparés ne partagent aucun mot, les
formules (4.1) et (4.2) donnent un indice de 1. Ces calculs sont indépendants des
langues des textes.
Nous nous inspirons des travaux sur la spécificité lexicale et les distances
textuelles afin de proposer une méthode d’extraction automatique des termes
simples. L’utilisation d’une distance lexicale nous évite de déterminer des seuils
comme utilisés dans la loi Zif et la conjoncture de Luhn. Aussi, le calcul de cette
distance est indépendant de la langue. En effet, ce calcul se base sur une mesure
quantitative (les fréquences).
A cette étape, nous ne sommes intéressés que par les fréquences des mots. On
ne fait pas d’analyse syntaxique ou sémantique des documents du corpus. Les mots
sont pris comme des variables qualitatives sur lesquelles on effectue des

4.2. Fondements théoriques
-98-
traitements purement statistiques. Dans la littérature, les travaux sur les
spécificités lexicales et les distances intertextuelles ont été réalisés sur des corpus
monolingues. Le repérage du vocabulaire spécialisé a été effectué uniquement sur
des corpus écrits dans la même langue. Dans notre travail, nous cherchons à
déterminer le vocabulaire d’un corpus multilingue. Dans (FERRET et al, 2001), les
auteurs utilisent les mêmes techniques afin d’identifier les variations thématiques
dans des corpus monolingues. Ils visent l’identification du domaine traité par les
documents du corpus. Dans notre cadre d’étude, le domaine du corpus est connu et
nous connaissons la spécialité traitée par les documents du corpus.
Nous proposons une nouvelle technique basée sur « la distance intertextuelle
interdomaine ». Cette dernière mesure reprend à la fois la notion de spécificité et
la notion du vocabulaire : le vocabulaire spécifique à un domaine. Dans notre
approche nous utilisons un corpus d’appui afin d’extraire les termes pertinents {
partir d’un corpus multilingue. Le corpus d’appui est multilingue et au moins
toutes les langues du corpus d’étude doivent être présentes dans le corpus d’appui.
Les domaines du corpus d’appui et du corpus { analyser doivent être disjoints.
4.2.2. La loi du moindre effort : Loi de Zipf
En 1935, le linguiste de H.G Zipf (ZIPF, 1949) a constaté que les mots dans un
document se distribuent en suivant une loi. Il vérifie manuellement que dans un
corpus textuel, la fréquence (f) d’un mot est inversement proportionnelle { son
rang (r). Le rang d’un mot est sa position dans la liste des fréquences triées dans
l’ordre décroissant des mots du corpus. Dans cette liste le mot le plus fréquent est
de rang 1. La loi portant son nom est formellement exprimée de la manière
suivante :
(4.3)
Où
: un mot,
: l’ensemble des mots du corpus C,
: la fréquence du mot dans le corpus,
: le rang du mot dans la liste ordonnée décroissante des
fréquences des mots du corpus.
La loi de Zipf se vérifie dans de nombreux autres domaines tels que, la
répartition de la population des villes d’un état (HILL, 1970) (BRACKENRIDGE,
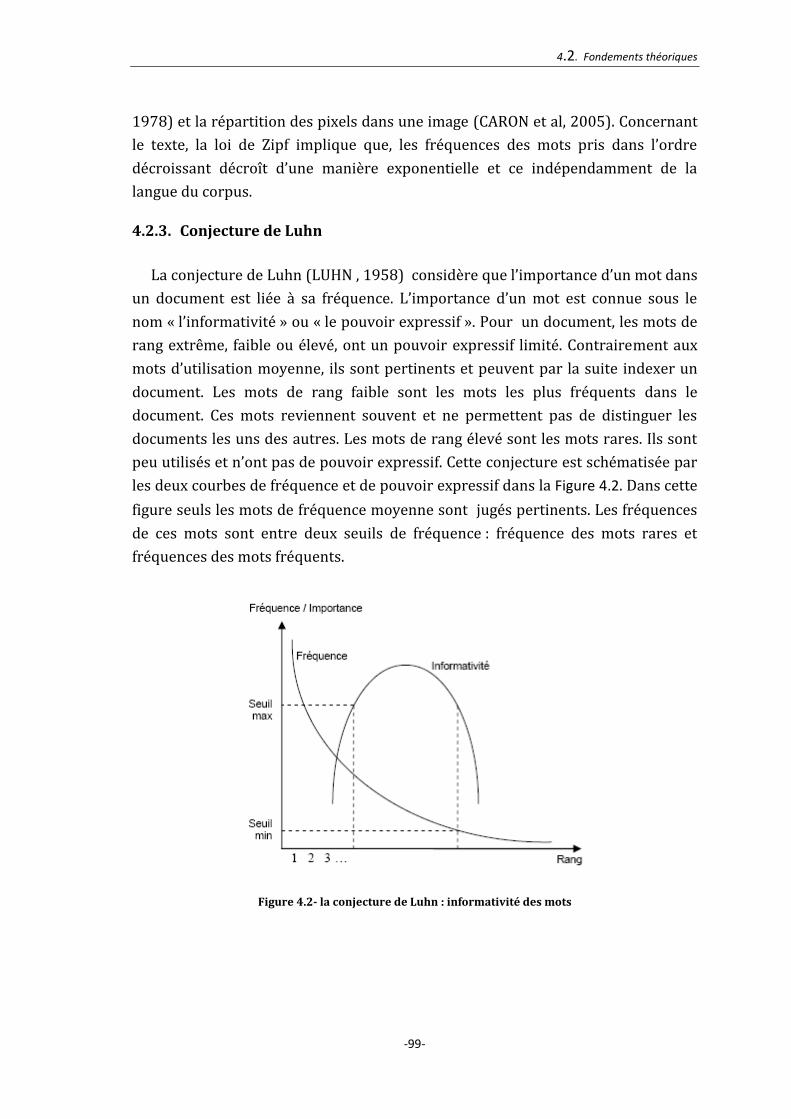
4.2. Fondements théoriques
-99-
1978) et la répartition des pixels dans une image (CARON et al, 2005). Concernant
le texte, la loi de Zipf implique que, les fréquences des mots pris dans l’ordre
décroissant décroît d’une manière exponentielle et ce indépendamment de la
langue du corpus.
4.2.3. Conjecture de Luhn
La conjecture de Luhn (LUHN , 1958) considère que l’importance d’un mot dans
un document est liée à sa fréquence. L’importance d’un mot est connue sous le
nom « l’informativité » ou « le pouvoir expressif ». Pour un document, les mots de
rang extrême, faible ou élevé, ont un pouvoir expressif limité. Contrairement aux
mots d’utilisation moyenne, ils sont pertinents et peuvent par la suite indexer un
document. Les mots de rang faible sont les mots les plus fréquents dans le
document. Ces mots reviennent souvent et ne permettent pas de distinguer les
documents les uns des autres. Les mots de rang élevé sont les mots rares. Ils sont
peu utilisés et n’ont pas de pouvoir expressif. Cette conjecture est schématisée par
les deux courbes de fréquence et de pouvoir expressif dans la Figure 4.2. Dans cette
figure seuls les mots de fréquence moyenne sont jugés pertinents. Les fréquences
de ces mots sont entre deux seuils de fréquence : fréquence des mots rares et
fréquences des mots fréquents.
Figure 4.2- la conjecture de Luhn : informativité des mots

4.3. Extraction des termes simples
-100-
4.3. Extraction des termes simples
Dans cette section, nous présentons la méthode proposée afin d’extraire
automatiquement les termes simples à partir des corpus multilingues. Comme
présentée dans la Figure 4.3 les étapes de cette méthode sont :
1. Le prétraitement des corpus
2. Le calcul de l’intersection des vocabulaires,
3. L’extraction des mots vides candidats,
4. La validation des mots vides candidats,
5. L’extraction des termes simples,
6. La pondération des termes simples.
Le détail de chaque étape sera présenté dans les sections qui suivent. Cette
approche se base sur la distance intertextuelle interdomaine et sur la loi de Zipf.
Nous commençons par définir la distance intertextuelle entre deux corpus…
Figure 4.3- Vue d’ensemble de l’approche proposée pour l’extraction automatique des les termes simples à partir des corpus multilingues

4.3. Extraction des termes simples
-101-
4.3.1.1. Le prétraitement du corpus
Le prétraitement du corpus est l’étape préliminaire pour identifier les données
lexicales à partir des textes des documents. Afin d’assurer l’adaptabilité de notre
modèle à de nouveaux corpus nous avons travaillé sur des textes bruts. Le
prétraitement consiste à segmenter le texte en phrases puis en mots en se basant
sur des délimiteurs.
Segmentation en phrases
Les textes sont segmentés en phrases en utilisant les marqueurs de
ponctuation: «.», «?» et «!». Nous n’avons pas traité les cas particuliers avec la
présence du point tels que : les adresses mail ([email protected]) et les
abréviations. La segmentation en phrases permet d’attribuer { chaque phrase du
document un identifiant, son rang d’apparition dans le document. Ces identifiants
des phrases sont utilisés dans les étapes ultérieures pour déterminer si deux
termes occurrents dans la même phrase.
Segmentation des mots
Il s’agit de segmenter les phrases en une suite de mots { l’aide des caractères
non-alphabétiques, «blanc», «tabulation», «.», «]», etc. Les dates et nombres ne sont
pas pris en compte dans la segmentation en mots.
4.3.1.2. Calcul de l’intersection des vocabulaires
Dans cette étape nous calculons l’intersection des vocabulaires de deux corpus
spécialisés. Cette intersection contient les mots qui sont partagés par les deux
corpus. Nous partons de la définition suivante d’un corpus spécialisé : «un corpus
spécialisé est un corpus limité à une situation de communication, ou à un domaine.
Il s’intéresse aux langages de spécialité et aux sous-langages. Selon Harris, ces sous
langages se caractérisent par un lexique limité et un nombre fini de schémas
syntaxiques» (Observatoire, 2006).
Selon cette définition les mots vides apparaissent dans l’intersection des
vocabulaires des deux corpus multilingues spécialisés, et de domaine
disjoints et . En effet, ces mots sont utilisés dans les deux corpus du fait qu’ils
sont d’usage général. Formellement, si et sont les vocabulaires des corpus A
et B alors (HARRATHI et al, 2009):
: est le vocabulaire de spécialité du corpus ,
: est le vocabulaire de spécialité du corpus ,

4.3. Extraction des termes simples
-102-
: est le vocabulaire qui n’est pas de spécialité (les domaines de
et sont disjoints) et donc c’est un vocabulaire d’usage général et
grammatical c’est-à-dire des mots vides.
Ainsi, nous définissions la distance intertextuelle interdomaine comme la
comparaison des vocabulaires de deux corpus spécialisés qui couvre deux
domaines disjoints.
Nous utilisons cette distance pour la catégorisation des mots en mots vides et
mots pleins.
4.3.1.3. Extraction des mots vides candidats
Un mot vide candidat est un mot susceptible d’être un mot vide. Dans cette
étape nous affectons à chaque mot une catégorie : vide ou plein. Les mots vides (ou
stop words en anglais) sont des mots qui sont communs à tous les textes dans une
même langue. Ils ont une utilité fonctionnelle. En français, les mots vides évidents
pourraient être « le », « la », « de », « du », « ce », « ça », etc. Dans un contexte
monolingue où tous les documents du corpus sont rédigés dans une même langue,
les mots vides sont principalement des mots caractéristiques de cette langue tels
que les pronoms, les prépositions, les articles, etc. dans ce contexte les mots vides
ont dits encore mots grammaticaux. Alors il est inutile de les indexer ou de les
utiliser dans un processus de recherche d’information. Dans un texte, un mot vide
est un mot non significatif contrairement à un mot plein.
Comme mentionné dans la section 4.3.1.2, les mots vides se trouve dans
l’intersection des vocabulaires de deux corpus. Dans le cas où les domaines
couverts par les deux corpus sont disjoints, l’intersection est formée par des mots
dont la majorité sont des mots vides. Ainsi, l’ensemble des mots vides candidats est
identifié par le calcul de l’intersection des deux vocabulaires de deux corpus
spécialisés qui couvrent de domaines disjointes.
A l’issu de cette étape nous obtenons la liste des mots vides candidats.
4.3.1.4. Validation des mots vides candidats
Dans l’étape précédente nous avons déterminé la liste mots vides candidats.
Cette liste est composé par les mots qui sont situés dans l’intersection des
vocabulaires des deux corpus. Cependant, cette liste ne contient pas seulement les
mots vides, mais on peut trouver aussi des mots de spécialité (des mots pleins). En
effet, deux domaines disjoints peuvent partager des mots ayant une sémantique
différente dans chaque domaine. Ainsi, un mot peut être utilisé dans différents
contextes ou différent domaine. A titre d’exemple, le mot « Laser » est utilisé dans

4.3. Extraction des termes simples
-103-
le domaine de la médecine et dans le domaine de l’informatique. C’est pourquoi
nous passons par l’étape de validation des mots vides simples. L’objectif de la
validation est d’éliminer les parasites, résultat des partages des mots de spécialité
entre des domaines disjoints. Ainsi nous vérifions si un mot vide candidat est un
mot vide ou un mot de spécialité commun (mot plein). Dans cette étape nous
utilisons la loi de Zipf (ZIPF, 1949) et la conjecture de H. Luhn (LUHN , 1958).
Dans (GIGUET, 1998), l’auteur montre que l’application de la loi de Zipf (ZIPF,
1949) et la conjecture de Luhn (LUHN , 1958) permet d’obtenir deux listes de
mots : la liste des mots vides et la liste des mots pleins. La première liste contient
les mots à usage général. Cette liste regroupe les mots dont leurs fréquences sont
extrêmes. La deuxième est une liste regroupant les mots spécifiques au domaine :
les mots pleins. Ces mots ont une fréquence moyenne. Le repérage de ces deux
listes indépendant du type de corpus d’étude : homogénéité des documents et
leurs langues. Ces deux listes seront mieux distinguées dans un corpus de
documents traitant d’un même domaine que dans un corpus de documents
général. Dans (VERGNE, 2005), J. Vergne confirme qu’il est possible de construire
la liste des mots vides en se basant sur la loi de Zipf. Cette loi énoncée par G. K. Zipf
(ZIPF, 1949) considère que plus un mot est fréquent plus il est court30. Ainsi, la
liste des mots vides est construite sur la base des longueurs et des fréquences de
ces mots dans le corpus.
Dans cette étape de validation nous rejoignons les idées de J. Vergne (VERGNE,
2005). Ainsi, nous considérons comme mots vides les mots qui sont à la fois courts
est fréquents dans le corpus . Ce test est effectué sur les mots situés dans
l’intersection des vocabulaires du corpus d’appui et du corpus d’étude. A l’issue de
l’étape de validation un ensemble de mots vides est obtenu. Cet ensemble est
formé par : l’ensemble des mots présents dans le corpus d’analyse et absent dans
le corpus d’appui, et l’ensemble des mots qui apparaissent dans les deux corpus et
qui ne vérifient pas la loi de Zipf (ZIPF, 1949) .
A l’issu de cette étape on obtient une liste des mots vides.
4.3.1.5. Extraction des termes simples par élimination des mots vides
Afin d’extraire les termes simples, nous procédons par élimination des mots
vides. L’ensemble des mots du corpus est constitué de deux sous-ensemble : un
ensemble de mots vides et un ensemble de mots pleins. Nous considérons un mot
plein comme terme simple. Ainsi, les termes simples sont identifiés par
30 « the length of a morpheme tends to bear an inverse ratio to its relative frequency of occurrence »

4.3. Extraction des termes simples
-104-
l’élimination des mots vides de l’ensemble des mots qui composent le vocabulaire
du corpus.
4.3.1.6. Pondération des termes simples
Dans cette étape nous affectons à chaque terme un poids qui représente son
pouvoir discriminant et son pouvoir représentatif dans le document où il apparait.
En effet, un terme ne représente d’une manière adéquate le document que si son
degré d’importance dans ce document est significatif. Afin de pondérer ces termes
nous utilisons la mesure TF*IDF.
La mesure TF*IDF
En recherche d’information, la mesure TF*IDF permet d’affecter { chaque terme
un poids traduisant son importance dans un document par rapport à un corpus
(SINGHAL et al, 1997) (ROBERTSON et al, 1997) (SPARCK JONES , 1991) (SPARCK
JONES et al, 1976). Dans la littérature on distingue deux types de pondération : la
pondération locale et la pondération globale.
La pondération locale consiste à mesurer le pouvoir représentatif d’un terme
dans un document du corpus (BAZIZ, 2005). Elle utilise des informations locales du
terme dans un document donné. Cette pondération est calculée de la manière
suivante :
(4.4)
Où est le nombre d’apparition du terme i dans le document j et n est le
nombre d’apparition du terme k dans le document j. Le dénominateur est le
nombre d’occurrence de termes dans le document considéré. Et est l’ensemble
des termes dans le corpus.
D’autres formules ont été présentées. Elles ont pour objectifs d’atténuer les
effets de différences de fréquences entre les termes dont leurs fréquences sont
extrêmes. Dans ces formules la fréquence d’un terme dans un document est
normalisée. Elles procèdent par une division de la fréquence du terme considéré
par la plus grande fréquence observée dans le document. L’une de ces formules est
la suivante :
(4.5)

4.3. Extraction des termes simples
-105-
La pondération globale permet d’affecter { un terme une mesure reflétant son
importance dans le corpus des documents. Elle utilise des informations globales du
terme dans le corpus. Un terme qui apparait dans la majorité des documents est
moins utile pour distinguer les documents les uns des autres. Ainsi, un degré de
pertinence moins important doit être affecté à ce terme. De ce fait, cette
pondération est inversement proportionnelle à la fréquence dans le corpus. La
pondération globale souvent désignée par IDF (Inverse of Document Frequency).
Elle est calculée de la manière suivante :
(4.6)
Où est le nombre de documents contenant terme i et est le nombre total
des documents dans le corpus.
La pondération d’un terme i dans un document j est le produit de la pondération
globale du terme i dans le corpus par la pondération locale de ce terme dans le
document considéré. Elle détermine la pertinence d’un terme dans un document
d’un corpus donné. Cette pondération est désignée par TF*IDF. La formule de
calcul de cette mesure est la suivante :
) (4.7)
La pondération TF*IDF est une bonne évaluation de la pertinence d’un terme
dans un document du corpus. Cependant dans cette mesure les termes
appartenant aux documents longs sont plus favorisés que les termes qui figurent
dans les documents de petites tailles. En effet, dans un document long les mêmes
termes sont utilisés plusieurs fois d’une manière répétitive (SINGHAL et al, 1996) .
Afin de remédier à cette limite, dans (SINGHAL et al, 1997) (BUCKLEY et al, 1995)
(ROBERTSON et al, 1997) les auteurs proposent des formules de normalisation qui
prennent en compte la taille des documents et leurs variations dans le corpus.
Dans (CALLAN et al, 1992) les auteurs proposent de normaliser la pondération de
la manière suivante :
(4.8)
Où
: est la pondération locale du terme i dans le document j,

4.3. Extraction des termes simples
-106-
: est la longueur du document j,
: est la moyenne des longueurs des documents du corpus.
Cette dernière formule de calcul de la pondération d’un terme dans un
document est utilisée dans le système INQUERY de J. P. Callan (CALLAN et al,
1992).
Dans notre approche, la mesure TF*IDF n’a pas l’objectif d’éliminer des termes
simples qui ont été déj{ validés dans l’étape précédente. Mais, elle permet de trier
ces termes par ordre d’importance.
4.3.1.7. Algorithme d’extraction des termes simples
L’algorithme de notre approche d’extraction des termes simples { partir des
documents multilingue est le suivant :
Algorithme Extraction des Termes Simples
Entréé : Ca : corpus d’appui Ce : corpus d’etude Seuil_frequence : valeur du seuil de la fréquence Seuil_longueur : valeur du seuil de la longueur
Sortie : Lts : liste des termes simples du corpus Ce Lmve : liste des mots vides du corpus Ce Ltsp : liste des termes simples pondérés
Variables : Lmca : liste des mots de Ca Lmce : liste des mots de Ce Lm : liste des mots de l’intersection de Lmca et Lmce m : un mot doc : un document
Début // prétraitement
Lmca prétraitement(Ca) Lmce prétraitement(Ce)
//calcul de l’intersection Pour chaque mot m de Lmca faire
Si m est dans Lmce alors Ajouter m à Lm
Finsi Finpour
//Extraction des mots vides candidats Pour chaque m dans Lm faire
Ajouter m à Lmve Finpour
//validation des mots vides candidats Pour chaque mot m dans Lmve faire

4.4. Extraction des termes composés
-107-
Si fréquence (m) < Seuil_frequence ou longueur(m)> Seuil_longueur alors Supprimer m de Lmve
Finsi Finpour
//Extraction des termes simple Pour chaque mot m dans Lmca faire
Si m n’appartient pas à Lmve alors Ajouter m à Lts
Finsi Finpour
//pondération des termes simples
Pour chaque mot m dans Lts faire Pour chaque document doc du corpus Ce faire
Ajouter (Calculer la pondération de m dans doc) à Ltsp Finpour
Finpour Fin
Algorithme 1 : Extraction des termes simples et leurs pondérations
4.4. Extraction des termes composés
4.4.1. Extraction des termes composés basée sur l’information mutuelle
Pour désigner un nouveau concept dans un domaine, le principe est d’éviter de
créer un terme nouveau et ce qui engendrerait une explosion rapide du lexique
(HARRATHI et al, 2005). Ce nouveau terme, terme composé ou terme complexe,
est crée à partir de données lexicales préexistantes. Ces termes composés sont des
combinaisons de deux ou de plusieurs mots (SMADJA, 1993). Avec un nouveau
concept il n’y a pas de nouveaux termes mais il y’a des nouvelles combinaisons des
mots pour le désigner. Ces combinaisons sont des séquences de mots qui seront
considérés comme des nouveaux termes. C’est sur ce principe que se base notre
approche d’extraction de termes nouveaux, les termes composés ou construits {
partir de la liste de termes simples extraits dans l’étape d’extraction des termes
simples.
Dans la littérature on trouve de nombreuses définitions de la notion de termes
complexes intitulées « collection de mots » (HAUSMANN, 1979) (COWIE, 1981)
(BENSON, 1989) (SMADJA, 1993). Dans (BENSON, 1989), l’auteur propose la
définition : « une collection est une combinaison arbitraire et récurrente de mots ».
Dans cette définition l’auteur ne considère pas la fréquence d’utilisation de cette
collection. La fréquence d’apparition est prise en compte par F. SMADJA (SMADJA,

4.4. Extraction des termes composés
-108-
1993) qui énonce la définition suivante : « une combinaison récurrente de mots qui
se trouvent ensemble plus souvent que par le simple fait du hasard et qui
correspondent à une utilisation arbitraire ». Nous nous inspirons de cette dernière
définition de la notion de collection. Ainsi, nous considérons un terme composé
comme étant une combinaison itérative des mots qui apparaissent souvent
ensemble.
Comme mentionné dans l’état de l’art, trois approches ont été adoptées pour
l’extraction des termes composés { partir des documents textuels :
1. l’approche linguistique basée sur les patrons,
2. l’approche mixte,
3. l’approche statistique.
La première approche est basée sur les patrons syntaxiques. Elle est utilisée
dans le système LEXTER de D. Bourigault (BOURIGAULT, 1996). L’approche mixte
est un couplage de l’approche linguistique et l’approche statistique. Cette approche
est utilisée par B. Daille dans son prototype ACABIT (DAILLE, 1996). Afin
d’identifier les termes, ACABIT utilise dans un premier temps des patrons
syntaxiques : Nom+Adjectif, Nom+Nom, Nom+à(Det)+Nom, Nom+de(Det)+Nom
det enfin Nom+Prep+Nom. Dans un deuxième temps, les candidats termes sont
classés par ordre décroissant d’importance en se basant sur une mesure
statistique : le coefficient de vraisemblance (DUNNING, 1993). Les résultats
obtenus ont été jugés pertinents. Cependant, ACABIT ne permet pas l’identification
de termes composés qui ne commencent pas par un Nom. Aussi, il n’est pas
possible d’extraire des termes composés contenant plus de deux mots pleins tels
que « train à grande vitesse » et « ministère des affaires étrangères». Dans
(SMADJA, 1993), F. Smadja utilise l’approche statistique et propose le système
XTRACT. XTRACT procède en deux étapes pour extraire les termes composés. Dans
une première étape, XTRACT extrait l’ensemble des séquences de longueur deux
dont la mesure statistique dépasse une valeur de seuil prédéfinie par l’utilisateur.
Cette valeur de seuil est déterminée par l’expérience. Dans une deuxième étape,
XTRACT étudie le contexte de chaque séquence de mots de longueur deux retenue
et il repère les séquences de mots de longueur trois dont la probabilité de
cooccurrence de ses composants est supérieure à un certain seuil. Le processus est
itératif et termine lorsqu’aucun nouveau terme composé n’est repéré. XTRACT
présente une faiblesse majeure due { l’utilisation d’une valeur de seuil globale. En
effet, l’identification d’un terme composé de longueur n+1 dépend largement de
l’identification des termes complexes de longueur n. Par exemple l’identification
du terme « laboratoire de recherche » dépend de l’identification du terme

4.4. Extraction des termes composés
-109-
« laboratoire de ». Ce dernier terme possède une mesure très faible du fait de la
forte fréquence du mot « de » dans l’ensemble des documents et il ne sera
probablement pas retenu.
Dans notre approche nous adoptons la démarche F. Smadja (SMADJA, 1993) et
nous proposons une technique statistique qui permet d’identifier les termes
composés { partir d’un corpus de documents textuels multilingues. Cette approche
se base sur une variante de l’information mutuelle. Afin de résoudre le problème
de la construction des termes composés de longueur n+1 à partir des termes
composés de longueur n, nous proposons de ne pas prendre en compte la
fréquence d’un mot vide durant la construction. Par exemple pour le terme
« laboratoire de» la fréquence du mot vide « de » ne sera pas prise en compte et
elle sera substituée par la valeur de la fréquence du terme simple « laboratoire ».
Durant le processus d’extraction des termes composés, le terme « laboratoire de»
est marqué comme étant un « terme de construction ». Ce terme est supprimé à
l’itération suivante. Ainsi, nous définissons une nouvelle mesure : l’information
mutuelle adaptée. Pour un couple de mots ( l’information mutuelle adaptée
est calculée de la manière suivante :
(4.9)
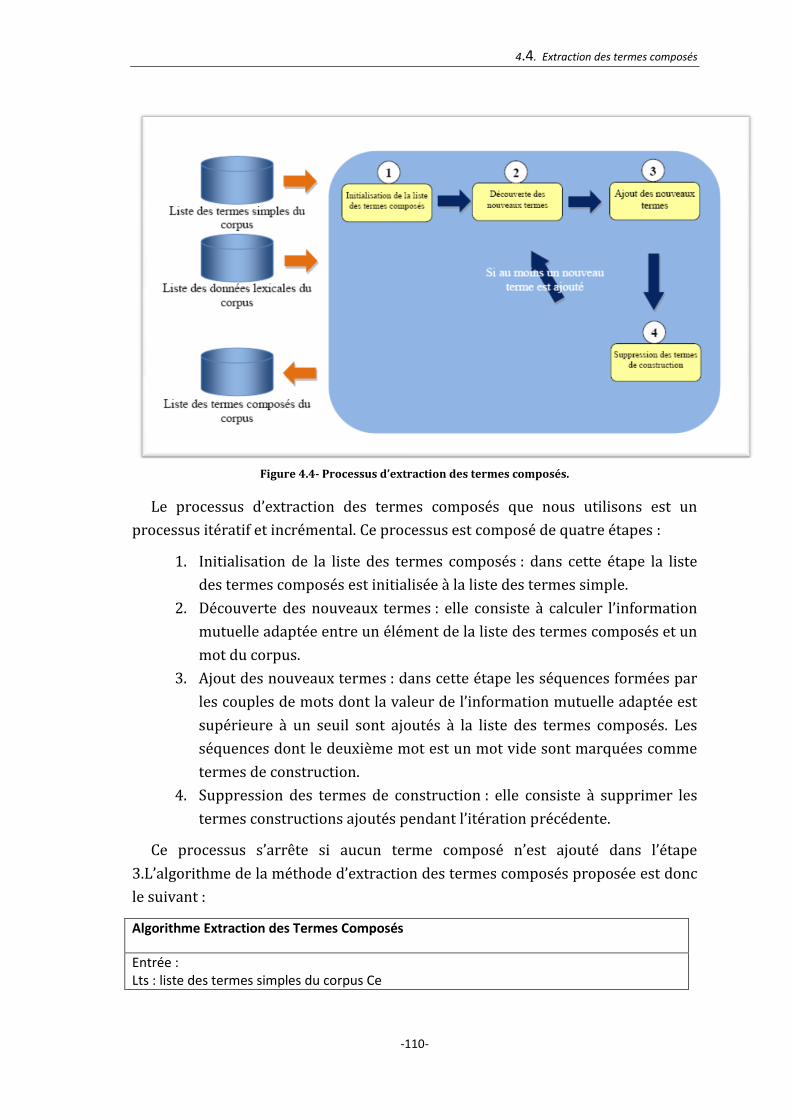
4.4. Extraction des termes composés
-110-
Figure 4.4- Processus d’extraction des termes composés.
Le processus d’extraction des termes composés que nous utilisons est un
processus itératif et incrémental. Ce processus est composé de quatre étapes :
1. Initialisation de la liste des termes composés : dans cette étape la liste
des termes composés est initialisée à la liste des termes simple.
2. Découverte des nouveaux termes : elle consiste { calculer l’information
mutuelle adaptée entre un élément de la liste des termes composés et un
mot du corpus.
3. Ajout des nouveaux termes : dans cette étape les séquences formées par
les couples de mots dont la valeur de l’information mutuelle adaptée est
supérieure à un seuil sont ajoutés à la liste des termes composés. Les
séquences dont le deuxième mot est un mot vide sont marquées comme
termes de construction.
4. Suppression des termes de construction : elle consiste à supprimer les
termes constructions ajoutés pendant l’itération précédente.
Ce processus s’arrête si aucun terme composé n’est ajouté dans l’étape
3.L’algorithme de la méthode d’extraction des termes composés proposée est donc
le suivant :
Algorithme Extraction des Termes Composés
Entrée : Lts : liste des termes simples du corpus Ce

4.4. Extraction des termes composés
-111-
Lm : liste des mots du corpus Ce seuil_IMA: valeur du seuil de l’informations mutuelle adaptée
Sortie : Ltc : liste des termes composés du corpus Ce
Variables : m : un mot t : un terme Nouvelle_ découverte : booléenne
Début // initialisation de la liste des termes composés
Ltc Lts Répéter Nouvelle_ découverteFaux //Découverte des nouveaux termes
Pour chaque terme t de Ltc faire Pour chaque mot m de Lm faire
Calculer la valeur de l’IMA (t,m) Finpour
Finpour //Ajout de nouveaux termes
Pour tout terme t de Ltc faire Pour chaque mot m de Lm faire
Si la valeur de l’IMA (t,m) > seuil_IMA alors Ajouter concaténation (t, « », m) à Ltc Si m appartient à Lmv alors
Marquer (t, « », m) comme terme de construction Finsi Nouvelle_ découverteVrai
Finsi
Finpour Finpour
//Suppression des termes de construction Pour chaque terme t dans Ltc faire
Si t est un terme de construction ajouté à l’itération précédente alors Supprimer t de Ltc
Finsi Finpour
Jusqu'à (Nouvelle_ découverte=Faux) Fin
Algorithme 2 : Extraction des termes composés
4.4.2. Pondération des termes composés
A cette étape nous cherchons à affecter à chaque terme composé extrait dans
l’étape précédente une pondération qui reflète son importance dans le document.
Dans (BAZIZ, 2005) (BAZIZ et al, 2007), l’auteur affirme que les termes composés

4.4. Extraction des termes composés
-112-
ont en général un seul sens même si les termes qui les composent ont plus qu’un
seul sens. Par la suite, ces termes ne requièrent pas de désambiguïsation
sémantique. Ils sont sémantiquement plus riches que les termes simples qui les
composent. Ainsi, nous proposons une nouvelle mesure de pondération qui
favorise les termes composés, que nous appelons (CTF pour Compound
Term Frequencey). Nous pensons que plus le terme composé est long, plus il est
expressif et non ambigü. La pondération d’un terme composé dans un document
dépend de quatre facteurs : la fréquence du terme composé dans ce document, la
fréquence du terme composé dans le corpus, les pondérations des termes simples
qui le composent et la longueur du terme composé. Dans la mesure proposée nous
prenons en compte ces quatre facteurs. Les trois premiers facteurs sont
représentés par la mesure classique . La pondération d’un terme
composé est proportionnelle à sa longueur. Nous augmentons la valeur de cette
pondération par . La mesure est donc exprimée en
fonctions de ces facteurs de la manière suivante :
(4.10)
Où
: un terme composé,
: un document,
: un terme simple,
: la pondération du terme i dans le document j,
: le nombre de terme simples qui participe dans la
construction du terme composé i,
: la pondération du terme i dans le document j,
Dans le cas où i est un terme simple nous retrouvons la valeur de la mesure
. En effet, et i ne contient pas de terme simple.

4.5. Extraction des concepts
-113-
Par exemple la pondération pour le terme composé « ministère des affaires
étrangères » est calculée comme suit :
CTF*IDF (« ministère des affaires étrangères ») = +TF*IDF (« ministère
des affaires étrangères ») + [TF*IDF (« ministère») + TF*IDF (« affaires») +
TF*IDF (« étrangères »)].
Dans (BAZIZ, 2005) (BAZIZ et al, 2007), Baziz propose une pondération des
termes composés qui prend en compte ces quatre facteurs. Elle consiste à
augmenter la fréquence du terme composé par une somme. Cette dernière est une
fonction de la longueur du terme composé, la longueur des termes simples qui
composent ce terme et leurs fréquences. Cette pondération est définie comme
suit :
(4.11)
N est le nombre de documents du corpus et df est le nombre de document
contenant le terme T.
4.5. Extraction des concepts
Le but de cette étape est d’extraire les concepts { partir des documents
multilingues. Ces concepts sont dénotés dans les documents textuels par des
termes simples ou composés. Ces termes ont été extraits pendant les étapes
précédentes. A ce stade, nous effectuons la correspondance entre les termes et les
concepts qui sont associés à ces termes. Pour ce faire nous nous basons sur une
ressource sémantique multilingue externe telle qu’une ontologie multilingue
légère ou un thésaurus. Dans ce qui suit nous exposons notre démarche pour
l’extraction des concepts. Cette démarche est présentée dans la Figure 4.5.
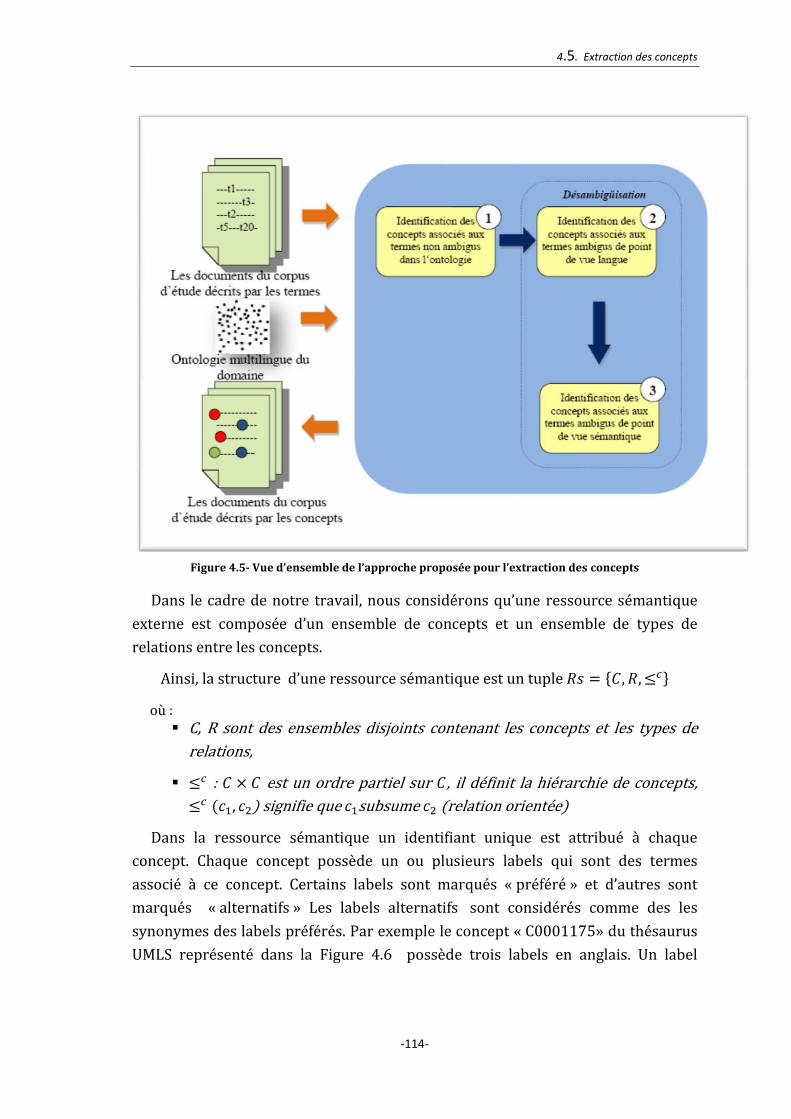
4.5. Extraction des concepts
-114-
Figure 4.5- Vue d’ensemble de l’approche proposée pour l’extraction des concepts
Dans le cadre de notre travail, nous considérons qu’une ressource sémantique
externe est composée d’un ensemble de concepts et un ensemble de types de
relations entre les concepts.
Ainsi, la structure d’une ressource sémantique est un tuple
où : C, R sont des ensembles disjoints contenant les concepts et les types de
relations,
: est un ordre partiel sur , il définit la hiérarchie de concepts,
) signifie que subsume (relation orientée)
Dans la ressource sémantique un identifiant unique est attribué à chaque
concept. Chaque concept possède un ou plusieurs labels qui sont des termes
associé à ce concept. Certains labels sont marqués « préféré » et d’autres sont
marqués « alternatifs » Les labels alternatifs sont considérés comme des les
synonymes des labels préférés. Par exemple le concept « C0001175» du thésaurus
UMLS représenté dans la Figure 4.6 possède trois labels en anglais. Un label

4.5. Extraction des concepts
-115-
préféré, le terme « Acquired Immunodeficiency Syndromes» et deux labels
alternatifs le terme « AIDS» et le terme « AIDS - HIV-1 stage ».
Figure 4.6- Exemple d’un concept d’une ressource sémantique décrite par SKOS
Les ressources sémantiques sont décrites en utilisant des langages formels de
description de vocabulaires contrôlés et structurés, tels que SKOS, DAML+OIL,
OWL. Ces langages sont construits sur la base du langage RDF. Ils permettent la
publication de vocabulaires structurés tels que les thésaurus et les ontologies.
Dans SKOS le concept de la Figure 4.6 est décrit de la manière suivante :
<rdf:RDF
<skos:Concept rdf:about="C0001175">
<skos:prefLabel> Acquired Immunodeficiency Syndrome
</skos:prefLabel>
<skos:altLabel> AIDS </skos:altLabel>
<skos:altLabel> AIDS - HIV-1 stage 6</skos:altLabel>
</skos:Concept>
</rdf:RDF>
Dans la ressource sémantique un ensemble de termes est utilisé afin de labéliser
les concepts et les relations entre les concepts. Cet ensemble forme le vocabulaire
de la ressource et sera noté .
C0001175
Acquired Immunodeficiency
Syndrome
AIDS - HIV-1 stage 6
AIDS
skos:altLabel skos:prefLabel
skos:altLabel

4.5. Extraction des concepts
-116-
Où
: l’ensemble termes utilisés pour dénoter les concepts de la ressource
sémantique,
: l’ensemble termes utilisés pour dénoter les relations de la ressource
sémantique.
Sur l’ensemble on défini l’opérateur , que nous appelons « opérateur de
référence de terme » et qui permet de déterminer le concept (ou les concept)
dénoté par un terme et l’opérateur inverse , que nous appelons « opérateur de
référence de concept» la manière suivante :
Ainsi pour le concept de l’exemple de la Figure 4.6 on aura :
Dans un contexte multilingue, on associe { chaque concept de l’ontologie
multilingue un ensemble de labels préférés, un label pour chaque langue de
l’ontologie. De la même façon, { ces concepts un ou plusieurs labels alternatifs sont
associés. La Figure 4.7 représente un exemple de concept dans une ontologie
multilingue.
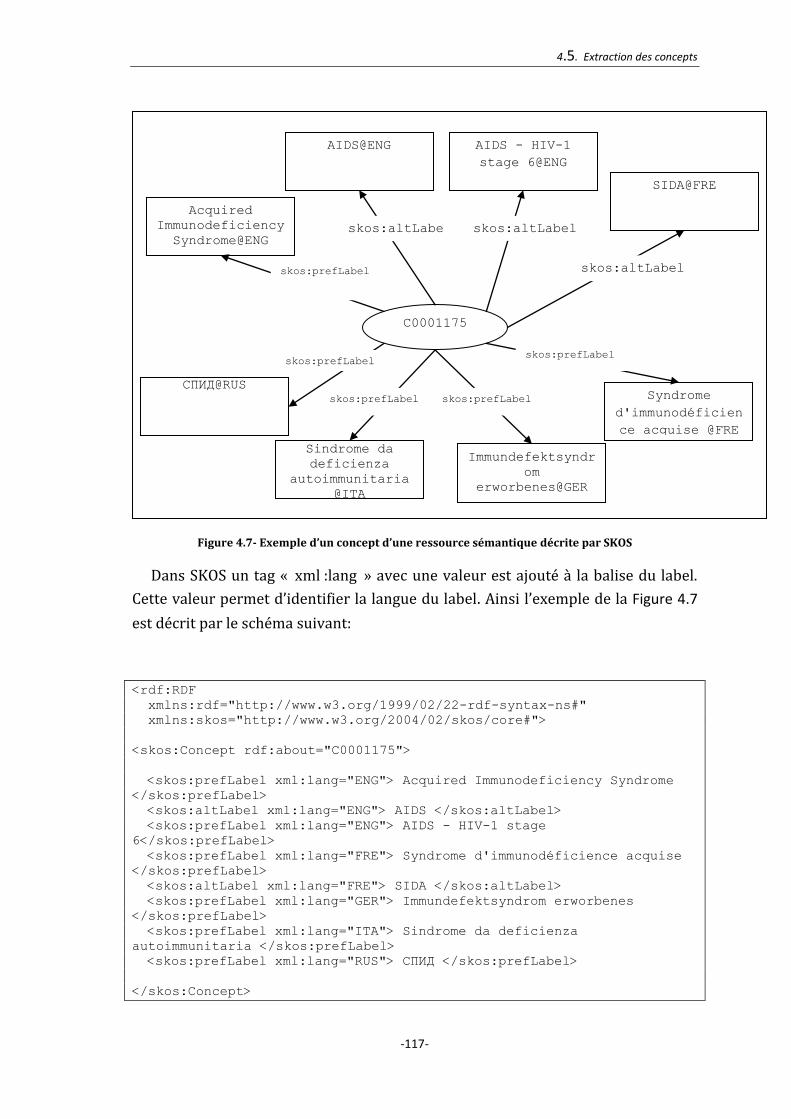
4.5. Extraction des concepts
-117-
Figure 4.7- Exemple d’un concept d’une ressource sémantique décrite par SKOS
Dans SKOS un tag « xml :lang » avec une valeur est ajouté à la balise du label.
Cette valeur permet d’identifier la langue du label. Ainsi l’exemple de la Figure 4.7
est décrit par le schéma suivant:
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:skos="http://www.w3.org/2004/02/skos/core#">
<skos:Concept rdf:about="C0001175">
<skos:prefLabel xml:lang="ENG"> Acquired Immunodeficiency Syndrome
</skos:prefLabel>
<skos:altLabel xml:lang="ENG"> AIDS </skos:altLabel>
<skos:prefLabel xml:lang="ENG"> AIDS - HIV-1 stage
6</skos:prefLabel>
<skos:prefLabel xml:lang="FRE"> Syndrome d'immunodéficience acquise
</skos:prefLabel>
<skos:altLabel xml:lang="FRE"> SIDA </skos:altLabel>
<skos:prefLabel xml:lang="GER"> Immundefektsyndrom erworbenes
</skos:prefLabel>
<skos:prefLabel xml:lang="ITA"> Sindrome da deficienza
autoimmunitaria </skos:prefLabel>
<skos:prefLabel xml:lang="RUS"> СПИД </skos:prefLabel>
</skos:Concept>
C0001175
Acquired
Immunodeficiency
Syndrome@ENG skos:altLabel
skos:prefLabel
skos:altLabe
l
skos:prefLabel
skos:altLabel
skos:prefLabel
AIDS@ENG
AIDS - HIV-1
stage 6@ENG
SIDA@FRE
Syndrome
d'immunodéficien
ce acquise @FRE
Immundefektsyndr
om
erworbenes@GER
Sindrome da
deficienza
autoimmunitaria
@ITA
skos:prefLabel
СПИД@RUS
skos:prefLabel

4.5. Extraction des concepts
-118-
</rdf:RDF>
De la même manière que pour les ressources sémantiques monolingues, sur
l’ensemble on défini l’opérateur , que nous appelons « opérateur de
référence de terme multilingue» et qui permet de déterminer le concept (ou les
concept) dénoté par un terme dans une langue donnée et l’opérateur inverse ,
que nous appelons « opérateur de référence de concept multilingue » la manière
suivante :
Ainsi pour le concept de l’exemple de la Figure 4.7on aura :
La méthode que nous proposons pour l’extraction des concepts { partir des
documents multilingue consiste { affecter chaque terme d’un document les
concepts associés. Afin d’identifier les concepts associés à chaque terme, nous
utilisons les relations et définies précédemment. Cependant le problème
d’ambigüité des termes se pose lors de l’association des termes aux concepts. Nous
distinguons deux situations d’ambigüité: une ambigüité langagière et une
ambigüité sémantique.

4.5. Extraction des concepts
-119-
1. Ambigüité langagière : deux termes appartenant à des langues différentes
peuvent avoir la même forme dans un texte, cette relation peut être vue
comme une relation d’homonymie multilingue. Par exemple le mot « table »
existe en français et en anglais. Dans ce cas, nous cherchons dans le
document le terme le plus proche non ambigu du point de vue langue. La
langue de ce terme situé à proximité du terme ambigu définira la langue du
terme ambigu. Si un tel terme n’existe pas, on prend toutes les langues du
terme ambigu.
2. Ambigüité sémantique ou polysémie : cas où plusieurs concepts sont
dénotés par le même terme c’est-à-dire qu’un même terme peut être le label
de plusieurs concepts dans l’ontologie. Ainsi ce terme renvoi { des concepts
différents. Par exemple en consultant WordNet31 nous constatons que le
terme « circuit » possède sept sens comme nom et un sens comme verbe
dans cette ressource. Ces sens sont donnés dans la Figure 4.8. Le terme
« circuit » peut donc renvoyer à huit concepts différents. Dans le cas de la
polysémie, nous procédons de la manière suivante. Pour un terme ambigu
nous cherchons dans le document un label d’un concept en relation, dans
l’ontologie, avec un concept dénoté par le terme ambigu . Si existe on
prend comme étant le concept dénoté par ce terme. Si non, on prend tous
les concepts dénotés par le terme considéré.
Noun S: (n) circuit#1, electrical circuit#1, electric circuit#1 (an electrical device
that provides a path for electrical current to flow) S: (n) tour#1, circuit#2 (a journey or route all the way around a particular
place or area) "they took an extended tour of Europe"; "we took a quick circuit of the park"; "a ten-day coach circuit of the island"
S: (n) circuit#3 (an established itinerary of venues or events that a particular group of people travel to) "she's a familiar name on the club circuit"; "on the lecture circuit"; "the judge makes a circuit of the courts in his district"; "the international tennis circuit"
S: (n) circumference#2, circuit#4 (the boundary line encompassing an area or object) "he had walked the full circumference of his land"; "a danger to all races over the whole circumference of the globe"
S: (n) circuit#5 ((law) a judicial division of a state or the United States (so-called because originally judges traveled and held court in different locations); one of the twelve groups of states in the United States that is covered by a particular circuit court of appeals)
31
www.wordnet.princeton.edu/

4.5. Extraction des concepts
-120-
S: (n) racing circuit#1, circuit#6 (a racetrack for automobile races) S: (n) lap#5, circle#4, circuit#7 (movement once around a course) "he drove
an extra lap just for insurance" Verb S: (v) circuit#1 (make a circuit) "They were circuiting about the state"
Figure 4.8- les sens du terme « circuit » dans WordNet
Dans le cas de la polysémie, nous procédons de la manière suivante. Pour un
terme ambigü nous cherchons dans le document un concept en relation, dans
l’ontologie, avec un concept dénoté par le terme ambigü . Si existe on prend
comme étant le concept dénoté par ce terme. Si non, on prend tous les concepts
dénotés par le terme considéré.
Dans le processus d’extraction des concepts nous effectuons deux passes. Dans
le premier nous ne traitons que les termes non ambigus. Cela nous permet de les
utiliser pour désambigüiser les termes ambigus dans la deuxième passe.
L’algorithme de la méthode d’extraction des concepts est le suivant :
Algorithme Extraction des concepts
Entréé : Lts : liste des termes simples Ltc : liste des termes composés
Sortie : Lcp : liste des concepts pondérés
Variables : Lt : liste des termes // formée par les termes simples et les termes composés t,t1 : des termes c,c1 :des concepts C : ensemble de concepts doc : un document
Début // initialisation de la liste des termes
Lt Lts Ltc //identification des concepts associés aux termes non ambigus
Pour chaque document doc faire Pour chaque terme t dans doc faire
Identifier les concepts associés à t // on utilise Sc Si t n’est pas ambigu alors
Ajouter (doc, c, poids(t,doc)) // c est le concept identifié
Finsi Finpour
Finpour
//identification des concepts associés aux termes ambigus de point de vue langue Pour chaque document doc faire

4.6. Extraction des relations sémantiques entre les concepts
-121-
Pour chaque terme t ambigu de point de vue langue dans doc faire Chercher dans doc un terme t1 non ambigu Si t1 existe alors
Identifier les concepts associés à t en utilisant la langue du terme t1 // on utilise Smc avec la langue de t1 Ajouter (doc, c, poids(t,doc))// c est le concept identifié
Si non Ajouter (doc, C,(somme des poids des termes/le nombre des termes))// C est l’ensemble des concepts associés à t
Finsi Finpour
Finpour // identification des concepts associés aux termes ambigus de point de vue sémantique
Pour chaque document doc faire Pour chaque terme t ambigu de point de vue sémantique dans doc faire
Identifier les concepts associés à t Chercher dans doc un c1 dénoté par un terme t1 qui apparait dans une même phrase que t Si c1 existe alors
Cl’ensemble des concepts dénoté par t qui sont en relation dans la ressource avec le concept c1 Ajouter (doc, C,(somme des poids des termes/le nombre des termes
Si non Ajouter (doc, C,(somme des poids des termes/le nombre des termes)) // C est l’ensemble des concepts associés à t
Finsi Finpour
Finpour
Algorithme 3 : Extraction des concepts
4.6. Extraction des relations sémantiques entre les concepts
Afin d’extraire les relations sémantiques entre les concepts nous nous basons
sur la ressource sémantique utilisée durant la phase d’extraction des concepts. Ces
relations sont définies dans la ressource par les types de relations. Nous utilisons
l’hypothèse «qu’une relation existe entre deux concepts d’un document si ces deux
concepts apparaissent dans la même phrase et si la ressource sémantique définit
cette relation sémantique » (MAISONNASSE, 2008) .
Par exemple : Dans le document de la collection CLEF 2007 présenté dans la
Figure 4.9 et en utilisant la ressource sémantique UMLS on détecte les deux
concepts C0334046 et C1302773 dénotés dans le texte respectivement par les
termes «mild dysplasia » et « low grade squamous intraepithelial lesion ». Dans la

4.7. Conclusion
-122-
ressource sémantique ces deux concepts sont reliés par la relation
« is_finding_of_disease » (la relation R54390434 dans UMLS).
<?xml version="1.0" encoding="iso-8859-1" standalone="yes"?>
<DOC>
<ID>006278</ID>
<Diagnosis>mild dysplasia of squamous epithelium CIN I, LSIL ---
(6278)
low grade squamous intraepithelial lesion, coilocyte. </Diagnosis>
<Description>Atypical cells corresponding to a mild dysplasia. Small
air bubbles.</Description>
</DOC>
Figure 4.9- Exemple d’un document de la collection CLEF 2007
L’algorithme de la méthode d’extraction des relations sémantiques entre
concepts est le suivant :
Algorithme Extraction des relations concepts
Entréé : Concepts: liste des concepts
Sortie : Lr : liste des relations
Variables : ph : une phrase doc : un document
Début Pour chaque document doc faire
Pour chaque phrase ph dans doc Pour chaque couple de concepts C1 et C2 dans ph faire
Ajouter à Lr toutes les relations de la ressource sémantique qui relient C1 à C2
Finpour Finpour
Finpour
Fin
Algorithme 4 : Extraction des relations sémantiques entre concepts
4.7. Conclusion
Dans ce chapitre nous avons présenté une méthode d’extraction des concepts {
partir des corpus multilingues. Elle est fondée sur, la distance intertextuelle
interdomaine, sur des mesures statistiques et sur une ressource sémantique
externe tels qu’une ontologie ou un thésaurus. Ainsi, nous avons proposé une
méthode de catégorisation des mots en mots vides et mots pleins : les termes
simples. Cette méthode est basée sur la distance intertextuelle interdomaine. Une

4.7. Conclusion
-123-
nouvelle mesure de degré d’association entre les termes est introduite,
l’information mutuelle adaptée (IMA). Cette mesure est utilisée pour l’extraction
des termes composés. Comparée à l’information mutuelle (IM), l’information
mutuelle adaptée permet l’extraction des termes composés de longueur supérieure
{ deux. Une pondération est affectée { chaque terme d’un document donnée. Cette
pondération est basée sur la mesure CTF*IDF (CTF pour Compound Term
Frequency). A l’opposé, de la mesure statistique classique, TF*IDF qui est issu du
domaine de la recherche d’information, la mesure introduite, CTF*IDF est capable
de déterminer la pondération d’un terme composé (de longueur plus que un) dans
un document donné. Aussi nous avons présenté une approche pour décrire les
documents par des concepts. Nous avons défini l’opérateur de référence de terme
et l’opérateur de référence de terme multilingue , ainsi que leur relations
inverses et . Ces opérateurs sont utilisés pour identifier les concepts
associés aux termes. Durant cette dernière étape nous avons utilisé une ressource
sémantique multilingue. Au sujet de l’ambigüité des termes, nous avons proposé
une démarche de désambigüisation. Cette démarche consiste à examiner les
termes ambigus dans le contexte où ils apparaissent, le document. Deux types
d’ambigüité ont été traités : l’ambigüité langagière et l’ambigüité sémantique. Nous
avons aussi, proposé une méthode d’extraction des relations entre concepts {
partir des documents multilingue. Cette méthode est basée sur une ressource
sémantique.
Nous signalons que toute au long du processus d’extraction des concepts les
langues de documents ne sont pas diagnostiqués. Ce processus n’utilise aucune
connaissance spécifique à une langue du corpus. La démarche est entièrement
automatique et ne nécessite pas d’intervention de l’utilisateur.
Dans le chapitre suivant nous présentons les expérimentations réalisées pour
valider notre proposition.


-125-
EXPERIMENTATIONS ET
EVALUATIONS
Résumé
Dans ce chapitre, nous présentons une validation expérimentale de
l’approche que nous avons proposée. Cette validation se traduit par une
évaluation expérimentale de notre système et en le comparant avec les
travaux les plus récentes à notre connaissance. Pour cela, des collections
(benchmark) ont été utilisées à savoir : la collection CLEF Médicale 2007.
Dans le domaine de la recherche d’information, les approches sont
évaluées sur des collections de tests et en comparant leurs résultats à
ceux obtenus par d’autres systèmes. Ces collections de tests sont
constitués d’un corpus de documents et d’un ensemble de requêtes pour
les quelles en connait l’ensemble des documents pertinents dans le
corpus de la collection. D’abord, nous présentons la collection du test
utilisée durant notre expérimentation ainsi que la ressource sémantique
utilisée. Ensuite nous exposons les expérimentations mises en œuvre
ainsi que les résultats obtenus.


-127-
Chapitre 5
Expérimentations et évaluations
5.1. Introduction
Dans le chapitre précédent, nous avons présenté une approche d’indexation
sémantique adaptée aux documents multilingues. Cette méthode permet
l’extraction des concepts et des relations entre concepts { partir des documents
multilingues écrits en anglais et en langues latines. Elle permet de décrire le
contenu d’un document par des descripteurs sémantiques : des concepts et des
relations sémantiques. La méthode proposée est fondée sur, la distance
intertextuelle interdomaine, des mesures statistiques et une ressource sémantique
externe (l’ontologie multilingue du domaine). Le processus d’extraction des
concepts et des relations entre concepts s’adapté { différents langues latines. Aussi,
il s’adapte { plusieurs domaines différents pour les quels on dispose d’une
ressource sémantique externe. Ce chapitre présente les expérimentations que nous
avons réalisées. Ces expérimentations ont pour objectif de valider notre méthode.
Pour ce faire, nous appliquons notre méthode d’indexation { une collection de test
réel : la collection CLEF médicale 2007. Dans la suite nous décrivons ces
expérimentations. Nous commençons par la présentation des données de test,
ensuite nous présentons les résultats.
5.2. La collection du test
Nous expérimentons notre approche d’indexation sémantique multilingue dans
un cadre réel de recherche d’information multilingue. Il s’agit de la tâche CLEF
médicale 2007. Depuis 2004 cette tâche fait partie de la campagne d’évaluation
CLEF (Cross Language Evaluation Forum). CLEF permet d’évaluer des systèmes de
recherche d’information monolingue et multilingue. L’utilisation de données
réelles permet de tester notre proposition et de positionner notre méthode
d’indexation par rapport aux autres approches existantes. CLEF médicale propose
des données de test qui sont constituées d’un corpus multilingue et d’un jeu de
requêtes multilingues.

5.2. La collection du test
-128-
5.2.1. Le corpus à indexer
CLEF médicale propose une collection d’images (MULLER et al, 2007). A chaque
image de cette collection est associé un diagnostic qui représente une description
textuelle de l’image. Ces descriptions sont écrites en trois langues : la langue
anglaise, la langue française et la langue allemande. Dans la collection CLEF 2007,
le même diagnostic peut être associé à un ou à plusieurs images. Le Tableau 5.1
présente les détails de cette collection.
Nombre d’image Nombre de diagnostic Langues 66662 55485 Anglais, Allemand, Français
Tableau 5.1 – Détails de la collection CLEF médicale 2007 de concept dans UMLS
La Figure 5.1 illustre un exemple d’un document de la collection CLEF 2007.
<?xml version="1.0" encoding="iso-8859-1" standalone="yes"?>
<DOC>
<ID>vq049</ID>
<IMAGES>
Upper study: First and fourth column are aerosol ventilation images. Second
and third column are perfusion images. Ventilatory and perfusion images
corresponding to the same projections are adjacent to each other.
Lower study: Frontal chest radiograph performed the same day as the
ventilation-perfusion examination.
View main image(vq) in a separate image viewer
View second image(xr). PA and lateral chest radiographs performed two days
prior to the ventilation-perfusion examination.
View third image(gs). Scout, frontal and left anterior oblique abdominal
images from an upper gastrointestinal series performed one year prior to the
ventilation-perfusion examination.
View fourth image(fl). Four select spot images of the gastroesophageal
junction from same upper gastointestinal series examination.
</IMAGES>
<FINDINGS>
Ventilation-perfusion Scintigraphy: There is uniform deposition of aerosol on
the ventilation images. The perfusion images show a physiologic distribution
of pulmonary perfusion. Thus, this is a normal ventilation-erfusion
examination. Incidental note is made of Tc-99m DTPA activity in the esophagus
consistent with swallowed Tc-99m DTPA aerosol.
Frontal chest radiograph: The heart size is at the upper limits of normal.
There is atelectasis or scarring in both lung bases without significant change
from a prior comparison study. No focal infiltrate, effusion or suspicious
masses are identified.
PA and lateral comparison chest radiograph: The heart size is normal. There is
atelectasis or scarring in the both lower lobes. Calcified left lung
granulomas and an old healed left 7th rib fracture are noted. An air fluid
level is noted in the middle mediastinum consistent with the known patulous
esophagus.
Upper GI series: The scout radiograph demonstrates surgical clips consistent
with cholecystectomy and a normal bowel gas pattern. Sutures in the lower mid
pelvis are noted.
The distal esophagus is dilated and there is pooling of contrast material and
debris. There is delayed passage of the contrast agent through the
gastroesophageal (GE) junction. The GE junction is below the diaphragm. A
medially directed contrast-filled tongue like defect at the level of the GE
junction is consistent with a fundoplication wrap.
Additional images (not shown) demonstrated a normal stomach and duodenum with
normal gastric emptying. No gastroesophageal reflux was elicited with

5.3. Le corpus d’appui
-129-
provocative maneuvers. The small bowel follow-through examination was normal
except for an incidentally noted proximal jejunal diverticulum.
</FINDINGS>
</DOC>
Figure 5.1- Exemple d’un document de la collection CLEF 2007
5.2.2. Le jeu de requêtes
En plus de la collection d’images, la CLEF médicale propose un jeu de requête.
Chaque requête de la collection CLEF 2007 est composée d’une image exemple et
d’une partie textuelle. La partie textuelle d’une même requête est écrite dans trois
langues de la collection : l’anglais, l’allemand et le français. Comme nous
n’indexons que le contenu textuel, seule la partie textuelle de la requête de la
collection sera utilisée dans nos expérimentations. La Figure 5.2 présente un
exemple d’une requête de la collection CLEF médicale 2007.
<topic>
<ID>74</ID>
<EN_DESCRIPTION> xray hip fracture </EN_DESCRIPTION>
<FR_DESCRIPTION> Radio d'une fracture de la hanche </FR_DESCRIPTION>
<DE_DESCRIPTION> Röntgenbild eines Hüftbruches </DE_DESCRIPTION>
</topic>
Figure 5.2- Exemple du partie textuel d’une requête de la collection CLEF médicale 2007
5.3. Le corpus d’appui
Afin d’extraire les mots vides notre approche se base sur la distance
intertextuelle du domaine. Il s’agit de déterminer le lexique commun de deux
corpus de domaine disjoints et qui sont écrits dans les mêmes langues. Le premier
corpus est le corpus { indexer et le deuxième est le corpus d’appui. Dans nos
expérimentations, nous utilisons le corpus du parlement européen32 comme
corpus d’appui. Ce corpus est un ensemble de 10 corpus parallèles écrits dans 11
langues (PHILIPP, 2005). Le corpus est collecté à partir des proceedings33 du
parlement européen. Dans nos expérimentations nous avons utilisé le corpus
parallèle anglais-allemand et le corpus parallèle anglais-français. Notre corpus
multilingue d’appui résulte est constitué des documents écrits dans la langue
anglaise, les documents écrits dans la langue allemande et les documents écrits
dans la langue française. Le Tableau 5.2 donne quelques statistiques sur ce corpus.
32 http://www.statmt.org/europarl/
33 http://www3.europarl.eu.int/omk/omnsapir.so/calendar?APP=CRE&LANGUE=EN

5.4. La ressource externe : le méta thésaurus UMLS
-130-
Langue Nombre de mots Taille en MO
ENG 39618240 201
GER 37614344 223
FRE 44688872 229
Tableau 5.2 – Statistiques sur le corpus d’appui
5.4. La ressource externe : le méta thésaurus UMLS
Dans cette section nous présentons la ressource sémantique UMLS qui a été
choisie pour nos expérimentations. UMLS nous permet dans un premier temps
d’identifier les concepts associés aux termes et dans un deuxième temps
d’identifier les relations entre ces concepts.
5.4.1. Présentation
La ressource UMLS est un méta-thésaurus multilingue qui couvre le domaine
médical. Cette ressource a été crée dans le but de faciliter la recherche et
l'intégration d'informations provenant des multiples sources d'information
biomédicales électroniques (NLM, 2009). Le méta-thésaurus UMLS est maintenu à
jour par le National Library of Medicine (NLDM). Il est la fusion de plusieurs
ressources sémantiques (111 ressources). Ces ressources sont écrites dans
plusieurs langues (19 langues). UMLS est la fusion de plusieurs ressources tels que
MSH, SNOMEDCT et RXNORM. Ces ressources représentent chacune un point de
vue. De ce fait, UMLS représente plus qu’un point de vue. A ce propos, les auteurs
de UMLS mentionnent qu’il est souhaitable de n’utiliser que les ressources
pertinentes à une tâche et un point de vue. Ce dernier est en libre utilisation sous
réserve d’enregistrement. Il est distribué au format Rich Release Format (RRF).
UMLS est formé de deux composantes principales:
1. Le méta-thésaurus : il regroupe principalement les concepts (2125396
concepts) et les termes (7581706 termes) associés à ces concepts. Ces
termes sont écrits dans une ou plusieurs langues. Ces concepts et termes
sont issus de différentes ressources sémantiques. Des variations syntaxiques
et lexicales des termes sont parfois données.
2. Le réseau sémantique : le réseau sémantique définit l’organisation des
concepts et les relations entre ces concepts. Dans UMLS, les concepts sont
organisés en classe. A chaque concept au moins une classe est associée. Ces
classes forment des types sémantiques (135 types sémantiques). Ces types
sont reliés entre eux par des relations sémantiques (54 relations).

5.4. La ressource externe : le méta thésaurus UMLS
-131-
UMLS intègre aussi des outils de traitement automatique de la langue naturelle.
Ces outils sont destinés à la langue anglaise. Ils permettent de déterminer les
variations syntaxiques des termes dans cette langue.
UMLS est l’une des meilleures ressources sémantiques pour indexer des
documents multilingues couvrant le domaine de la médecine (DELBECQUE et al,
2005) (MAISONNASSE, 2008). En effet, d’une part UMLS couvre la quasi-totalité du
domaine et d’autre part les concepts sont associés { des termes écrits dans
différentes langues.
Dans la suite nous décrivons les concepts, les types sémantiques et les relations
entre ces types que nous utilisons dans nos expérimentations.
5.4.2. Les concepts dans UMLS
Dans UMLS chaque concept est identifié par un identificateur unique (CUI :
Unique Identifier for Concept). Un concept est relié à une ou plusieurs chaînes de
caractères (STR), les termes qui dénotent le concept. Le STR sera utilisé dans nos
expérimentations pour identifier les concepts associés aux termes (CUI). Les STRs
sont liés à une langue (LAT : Language of term) et à un indicateur (ISPREF : Atom
status - preferred (Y) or not (N) for this string within this concept) qui indique si
le terme est préféré ou non. Pour chaque concept, la source du concept est
mentionnée (SAB : Abbreviated source name). Le Tableau 5.3 montre un exemple
de concept dans UMLS.
CUI LAT ISPREF STR SCUI C0001175 ENG Y Acquired
Immunodeficiency Syndromes
MSH
C0001175 ENG N AIDS SNOMEDCT C0001175 ENG Y Acquired
immunodeficiency syndrome
SNOMEDCT
C0001175 FRE Y SIDA SPID C0001175 RUS Y SPID SPID
Tableau 5.3 – Exemple de concept dans UMLS
Il est à noter que même si les concepts de UMLS sont décrits dans plusieurs
langues, la langue anglaise est la langue dominante dans UMLS. Cela ne rend pas
aisé l’utilisation de UMLS pour l’indexation dans une langue autre que l’anglais. Le
Tableau 5.4 donne un aperçu sur les langues dans UMLS.
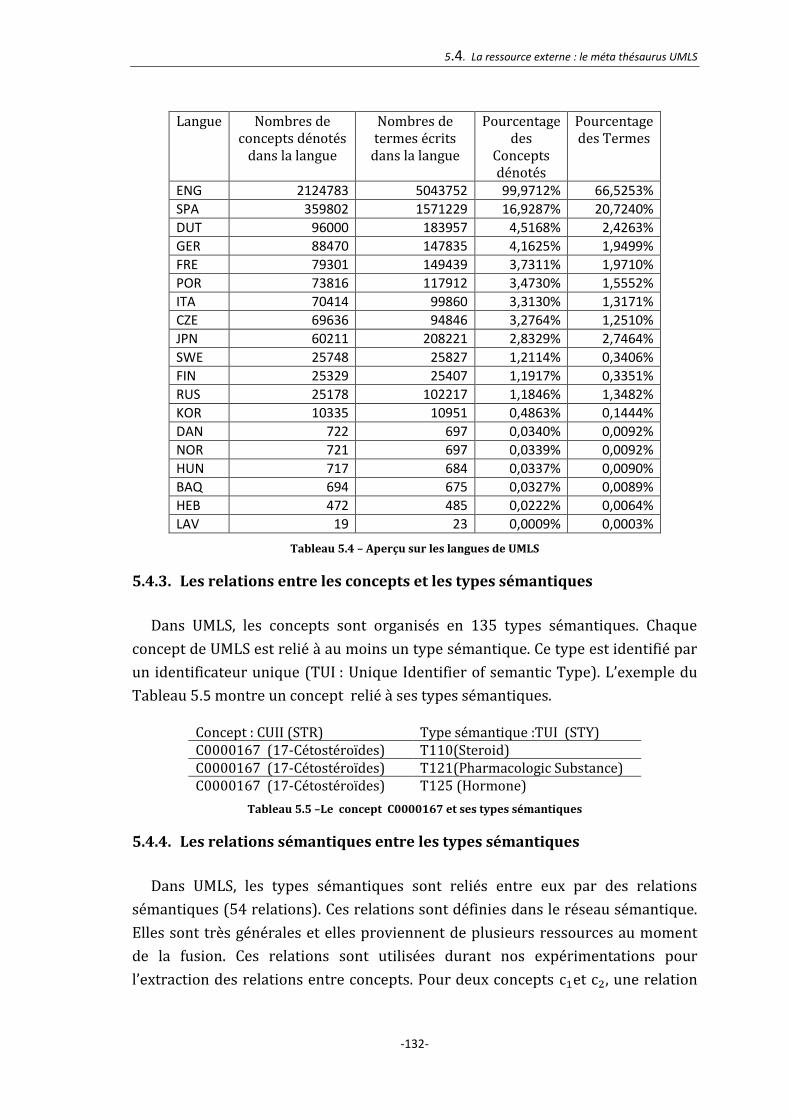
5.4. La ressource externe : le méta thésaurus UMLS
-132-
Langue Nombres de concepts dénotés
dans la langue
Nombres de termes écrits
dans la langue
Pourcentage des
Concepts dénotés
Pourcentage des Termes
ENG 2124783 5043752 99,9712% 66,5253%
SPA 359802 1571229 16,9287% 20,7240%
DUT 96000 183957 4,5168% 2,4263%
GER 88470 147835 4,1625% 1,9499%
FRE 79301 149439 3,7311% 1,9710%
POR 73816 117912 3,4730% 1,5552%
ITA 70414 99860 3,3130% 1,3171%
CZE 69636 94846 3,2764% 1,2510%
JPN 60211 208221 2,8329% 2,7464%
SWE 25748 25827 1,2114% 0,3406%
FIN 25329 25407 1,1917% 0,3351%
RUS 25178 102217 1,1846% 1,3482%
KOR 10335 10951 0,4863% 0,1444%
DAN 722 697 0,0340% 0,0092%
NOR 721 697 0,0339% 0,0092%
HUN 717 684 0,0337% 0,0090%
BAQ 694 675 0,0327% 0,0089%
HEB 472 485 0,0222% 0,0064%
LAV 19 23 0,0009% 0,0003%
Tableau 5.4 – Aperçu sur les langues de UMLS
5.4.3. Les relations entre les concepts et les types sémantiques
Dans UMLS, les concepts sont organisés en 135 types sémantiques. Chaque
concept de UMLS est relié à au moins un type sémantique. Ce type est identifié par
un identificateur unique (TUI : Unique Identifier of semantic Type). L’exemple du
Tableau 5.5 montre un concept relié à ses types sémantiques.
Concept : CUII (STR) Type sémantique :TUI (STY) C0000167 (17-Cétostéroïdes) T110(Steroid) C0000167 (17-Cétostéroïdes) T121(Pharmacologic Substance) C0000167 (17-Cétostéroïdes) T125 (Hormone)
Tableau 5.5 –Le concept C0000167 et ses types sémantiques
5.4.4. Les relations sémantiques entre les types sémantiques
Dans UMLS, les types sémantiques sont reliés entre eux par des relations
sémantiques (54 relations). Ces relations sont définies dans le réseau sémantique.
Elles sont très générales et elles proviennent de plusieurs ressources au moment
de la fusion. Ces relations sont utilisées durant nos expérimentations pour
l’extraction des relations entre concepts. Pour deux concepts et , une relation

5.5. Les évaluations
-133-
est possible si le type sémantique associé à et le type sémantique associé à
sont reliés par une relation sémantique. Le Tableau 5.6 montre un exemple d’une
relation sémantique entre deux types sémantiques dans UMLS.
Type sémantique : TUI (STY)
Relation : TUI (STY)
Type sémantique : TUI (STY)
T110(Steroid) T147 (causes) T047 (Disease or Syndrome)
Tableau 5.6 – Une relation sémantique entre deux types sémantiques
5.5. Les évaluations
Dans cette section, nous présentons les évaluations de notre approche
d’extraction des concepts et des relations entre concepts. D’abord nous présentons
l’architecture générale du prototype développé. Ensuite, nous décrivons les
prétraitements des corpus et du jeu des requêtes. Par la suite, nous exposons la
méthodologie adoptée pour l’évaluation. Nous présentons les métriques utilisées
et la représentation intermédiaire ainsi que la fonction de correspondance (RSV).
Enfin nous illustrons les résultats de nos expérimentations.
5.5.1. Le prototype MuDIBO
Afin de réaliser nos expérimentations nous avons développé un prototype. Ce
prototype nous a permis d’une part de valider notre approche d’extraction des
concepts et des relations et d’autre part de montrer sa faisabilité. Dans cette
section nous présentons l’architecture générale de ce prototype appelé MuDIBO
(Multililingual Documents Indexing Based on Ontology). MuDIBO constitue un
outil permettant d’indexer des documents multilingues. L’outil proposé offre une
interface graphique permettant de paramétrer le processus d’indexation.
L’architecture du prototype MuDIBO est présentée dans la Figure 5.3.
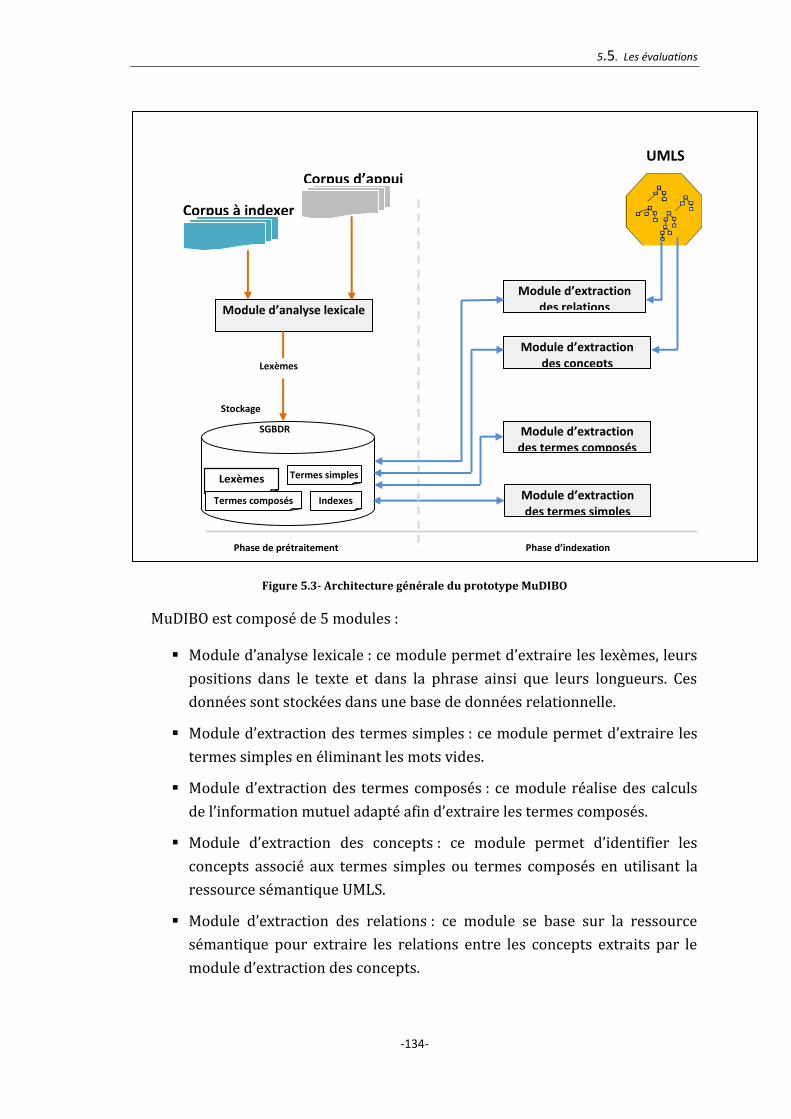
5.5. Les évaluations
-134-
Figure 5.3- Architecture générale du prototype MuDIBO
MuDIBO est composé de 5 modules :
Module d’analyse lexicale : ce module permet d’extraire les lexèmes, leurs
positions dans le texte et dans la phrase ainsi que leurs longueurs. Ces
données sont stockées dans une base de données relationnelle.
Module d’extraction des termes simples : ce module permet d’extraire les
termes simples en éliminant les mots vides.
Module d’extraction des termes composés : ce module réalise des calculs
de l’information mutuel adapté afin d’extraire les termes composés.
Module d’extraction des concepts : ce module permet d’identifier les
concepts associé aux termes simples ou termes composés en utilisant la
ressource sémantique UMLS.
Module d’extraction des relations : ce module se base sur la ressource
sémantique pour extraire les relations entre les concepts extraits par le
module d’extraction des concepts.
Corpus d’appui
Module d’analyse lexicale
Lexèmes
SGBDR
UMLS
Phase de prétraitement Phase d’indexation
Corpus à indexer
Stockage
Module d’extraction des termes simples
Termes simples
Termes composés Indexes
Lexèmes
Module d’extraction des termes composés
Module d’extraction des concepts
Module d’extraction des relations

5.5. Les évaluations
-135-
5.5.2. Méthodologie d’évaluation
Nous présentons dans cette section la méthodologie adoptée pour évaluer notre
proposition. D’abord, nous décrivons la méthode d’évaluation. Par la suite, Ensuite,
nous exposons les mesures que nous utilisons dans nos évaluations. Ensuite, nous
présentons le SRI de référence.
5.5.2.1. Description générale de la méthode d’évaluation
L’objectif de notre travail de thèse est de proposer une méthode d’extraction
des concepts et de relations sémantiques à partir de corpus multilingues. Cette
méthode permet l’indexation sémantique des documents du corpus. Ainsi, la
méthode proposée peut être évaluée par l’étude de la performance d’un SRI
existant en intégrant notre méthode dans son processus d’indexation. Dans cette
étude, nous comparons l’efficacité de notre méthode (statistique) { celle d’une
méthode basée sur des analyses linguistiques. Cette comparaison est réalisée à
travers l’étude de la performance d’un même SRI en variant la méthode
d’indexation.
5.5.2.2. Mesures d’évaluation
Dans nos expérimentations, nous utilisons le programme trec_eval34. Ce
programme est fourni par la conférence de recherche d’information TREC35 (Text
Retrieval Conference). trec_eval calcule, entre autre, la précision moyenne (MAP)
et la précision { 5 documents (P@5). Afin d’évaluer les résultats de nos
expérimentations, nous utilisons MAP et P@5 comme des métriques d’évaluations.
En effet, la précision moyenne donne un aperçu général de l’efficacité de notre
approche. Et d’autre, part la précision { 5 documents donne un jugement de
l’efficacité de cette approche sur les documents les plus consultés par un
utilisateur d’un SRI.
5.5.2.3. Description du système de RI sémantique utilisé comme base de
référence
Dans (MAISONNASSE et al, 2009), les auteurs exposent des évaluations de
différentes méthodes d’extraction des concepts { partir de la collection Clef
médicale 2007. Ils utilisent trois outils basés sur l’approche linguistique afin
d’extraire les concepts. Ensuite ils comparent les différents résultats obtenus par
34 http://trec.nist.gov/trec_eval/index.html 35 http://trec.nist.gov/

5.5. Les évaluations
-136-
ces outils. Les auteurs utilisent un modèle de langue ( ) défini sur des concepts.
Dans (MAISONNASSE et al, 2009), pour extraire les concepts à partir des
documents multilingues, les auteurs utilisent trois outils linguistiques : MetaMap,
TreeTagger et MiniPar.
MetaMap est un analyseur morphosyntaxique qui permet d’extraire les concepts
à partir des documents. Cet analyseur est fourni avec UMLS et ne traite que les
documents écrits en anglais. MetaMap procède dans une première étape à
l’extraction des termes candidats avec leurs variations lexicales et syntaxiques.
Dans une deuxième étape il projette les termes candidats sur UMLS pour détecter
les concepts associés à ces termes.
MiniPar permet d’extraire les termes { partir des documents écrits dans la
langue anglaise. Dans (MAISONNASSE et al, 2009), les auteurs extraient les termes
{ l’aide de MiniPar ensuite ils projettent ces termes extraits sur UMLS afin de
détecter les concepts associés.
TreeTagger permet d’extraire les termes à partir des documents écrits dans la
langue anglaise, la langue française et la langue allemande. Les termes issus de
l’analyse par TreeTagger sont par la suite projetés sur UMLS pour identifier les
concepts associés.
Après cette phase d’extraction des concepts pour chaque document, une
représentation intermédiaire est établie. Un peu comme dans le modèle vectoriel
proposé par G. Salton (SALTON, 1968), chaque document est représenté par un
vecteur dans l’espace d’indexation. Les dimensions de l’espace d’indexation sont
les concepts de la ressource sémantique utilisée (UMLS) dans la tâche d’extraction
des concepts. Le vecteur représentant le document est formé par les pondérations
de chaque concept dans ce document. Ainsi, dans un espace d’indexation
où les sont les concepts de la ressource sémantique, un document
est représenté par un vecteur de poids des concepts.
(5.1)
Où est le poids du concept dans le document .
La pondération consiste à affecter à chaque concept qui apparaît dans un
document un poids. Ce poids détermine l’importance du concept dans la
représentation du document . Comme dans la majorité des travaux, cette mesure

5.5. Les évaluations
-137-
est composée d’une pondération locale et d’une pondération globale. La
pondération locale traite des informations locales reliées au document. La
pondération globale prend en considération la distribution du concept dans toute
la collection. La pondération proposée dans (MAISONNASSE et al, 2009), inspirée
des modèles de langue (PONTE et al, 1998). Cette pondération peut être
considérée comme une variante de (HIEMSTRA, 2002). Elle est notée
et elle se calcule par une combinaison d’un maximum de vraisemblance
et un lissage de Jelinek-Mercer :
(5.2)
Où
(respectivement ) est la fréquence du concept dans le
document (respectivement dans la collection ,
est le lissage de Jelinek-Mercer qui est estimé sur une base
d’apprentissage.
Comme pour les documents, la requête est représentée par un vecteur de
pondérations. Ces pondérations sont les nombre d’apparition des concepts dans la
requête considérée. Ainsi une requête est représentée par :
(5.3)
Où est la fréquence du concept dans la requête .
Dans (MAISONNASSE et al, 2009), les auteurs utilisent une mesure de similarité
(RSV) afin de déterminer le degré de pertinence d’un document par rapport à
une requête . Cette mesure consiste à retrouver les vecteurs des documents qui
sont proches du vecteur de la requête . Cette mesure est notée et elle
est donnée par la formule 5.4:
(5.4)
Où

5.5. Les évaluations
-138-
est la pondération du concept dans le document . Cette
pondération est donnée dans l’équation 5.2,
est la fréquence du concept dans la requête ,
est l’ensemble de concepts du domaine.
5.5.2.4. Notre système de RI
Dans nos expérimentations nous avons volontairement utilisé la même
représentation des documents et de la requête ainsi que la même fonction de
correspondance (RSV) utilisé dans le SRI de référence. Comme dans
(MAISONNASSE et al, 2009), les auteurs, traitent la même collection, la collection
Clef médical 2007, cela nous permet de comparer directement nos résultats aux
résultats obtenus par des analyses linguistiques. Cela est justifié par le fait que la
démarche adoptée dans (MAISONNASSE et al, 2009) a permis aux auteurs
d’obtenir la première place dans la campagne d’évaluation Clef médicale 2007 et
d’obtenir la troisième place dans la campagne d’évaluation Clef médicale 2008. Une
telle comparaison nous permet de positionner notre proposition par rapport à une
proposition robuste de référence.
5.5.3. Les prétraitements
Le prétraitement est la première étape de notre processus. Il permet de
collecter les informations locales sur les documents ainsi que sur les requêtes. Ces
informations seront exploitées dans le reste du processus.
5.5.3.1. Prétraitements des documents et des requêtes
Les documents de la collection que nous utilisons dans nos expérimentations
sont celles de CLEF médicale 2007. Ces documents sont au format XML. Comme
nous ne tenons pas compte de la structure du document, nous indexons
uniquement le contenu textuel du document XML. Ainsi, ce contenu est converti au
format texte bruts comme montre la Figure 5.4.
Upper study: First and fourth column are aerosol ventilation images. Second
and third column are perfusion images. Ventilatory and perfusion images
corresponding to the same projections are adjacent to each other.
Lower study: Frontal chest radiograph performed the same day as the
ventilation-perfusion examination.
View main image(vq) in a separate image viewer
View second image(xr). PA and lateral chest radiographs performed two days
prior to the ventilation-perfusion examination.
View third image(gs). Scout, frontal and left anterior oblique abdominal
images from an upper gastrointestinal series performed one year prior to the
ventilation-perfusion examination.
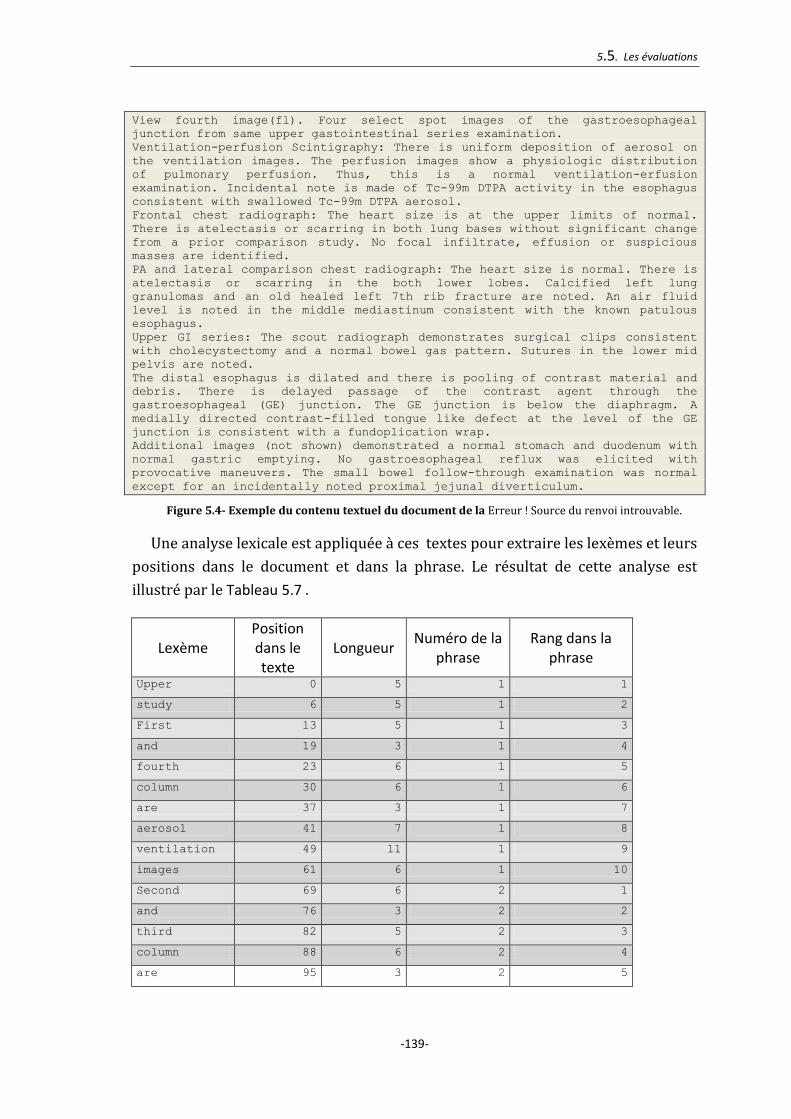
5.5. Les évaluations
-139-
View fourth image(fl). Four select spot images of the gastroesophageal
junction from same upper gastointestinal series examination.
Ventilation-perfusion Scintigraphy: There is uniform deposition of aerosol on
the ventilation images. The perfusion images show a physiologic distribution
of pulmonary perfusion. Thus, this is a normal ventilation-erfusion
examination. Incidental note is made of Tc-99m DTPA activity in the esophagus
consistent with swallowed Tc-99m DTPA aerosol.
Frontal chest radiograph: The heart size is at the upper limits of normal.
There is atelectasis or scarring in both lung bases without significant change
from a prior comparison study. No focal infiltrate, effusion or suspicious
masses are identified.
PA and lateral comparison chest radiograph: The heart size is normal. There is
atelectasis or scarring in the both lower lobes. Calcified left lung
granulomas and an old healed left 7th rib fracture are noted. An air fluid
level is noted in the middle mediastinum consistent with the known patulous
esophagus.
Upper GI series: The scout radiograph demonstrates surgical clips consistent
with cholecystectomy and a normal bowel gas pattern. Sutures in the lower mid
pelvis are noted.
The distal esophagus is dilated and there is pooling of contrast material and
debris. There is delayed passage of the contrast agent through the
gastroesophageal (GE) junction. The GE junction is below the diaphragm. A
medially directed contrast-filled tongue like defect at the level of the GE
junction is consistent with a fundoplication wrap.
Additional images (not shown) demonstrated a normal stomach and duodenum with
normal gastric emptying. No gastroesophageal reflux was elicited with
provocative maneuvers. The small bowel follow-through examination was normal
except for an incidentally noted proximal jejunal diverticulum.
Figure 5.4- Exemple du contenu textuel du document de la Erreur ! Source du renvoi introuvable.
Une analyse lexicale est appliquée à ces textes pour extraire les lexèmes et leurs
positions dans le document et dans la phrase. Le résultat de cette analyse est
illustré par le Tableau 5.7 .
Lexème Position dans le texte
Longueur Numéro de la
phrase Rang dans la
phrase
Upper 0 5 1 1
study 6 5 1 2
First 13 5 1 3
and 19 3 1 4
fourth 23 6 1 5
column 30 6 1 6
are 37 3 1 7
aerosol 41 7 1 8
ventilation 49 11 1 9
images 61 6 1 10
Second 69 6 2 1
and 76 3 2 2
third 82 5 2 3
column 88 6 2 4
are 95 3 2 5
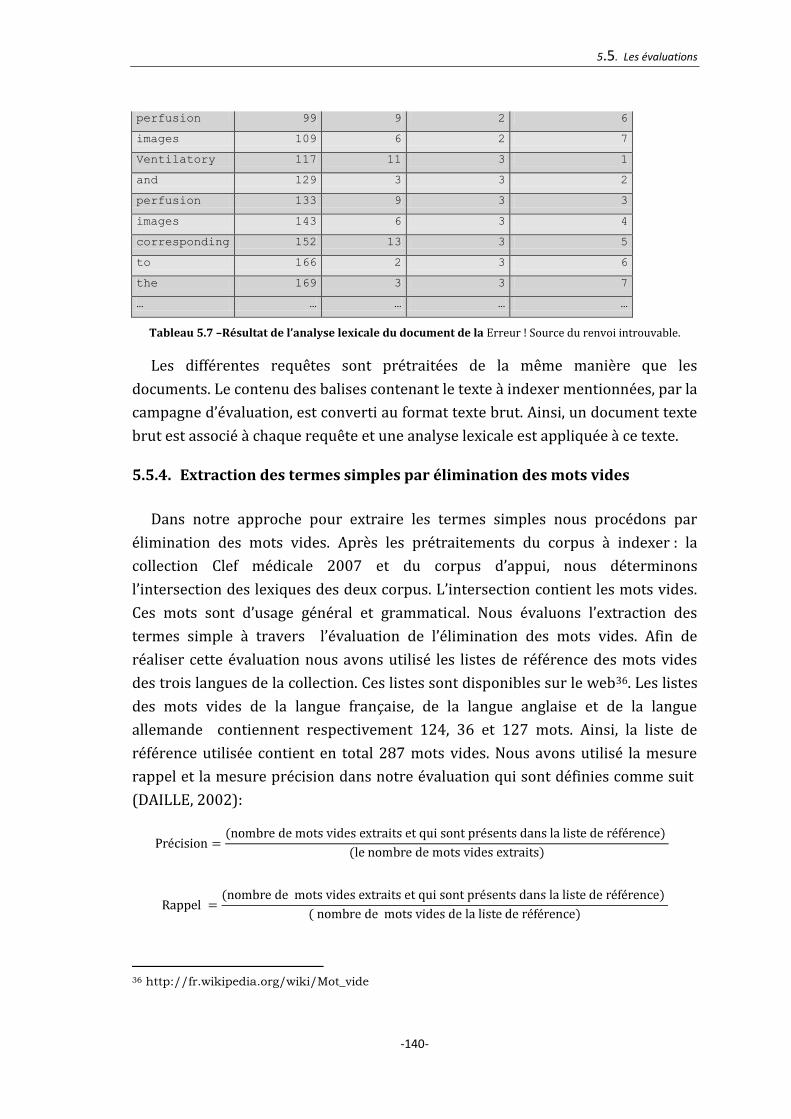
5.5. Les évaluations
-140-
perfusion 99 9 2 6
images 109 6 2 7
Ventilatory 117 11 3 1
and 129 3 3 2
perfusion 133 9 3 3
images 143 6 3 4
corresponding 152 13 3 5
to 166 2 3 6
the 169 3 3 7
… … … … …
Tableau 5.7 –Résultat de l’analyse lexicale du document de la Erreur ! Source du renvoi introuvable.
Les différentes requêtes sont prétraitées de la même manière que les
documents. Le contenu des balises contenant le texte à indexer mentionnées, par la
campagne d’évaluation, est converti au format texte brut. Ainsi, un document texte
brut est associé à chaque requête et une analyse lexicale est appliquée à ce texte.
5.5.4. Extraction des termes simples par élimination des mots vides
Dans notre approche pour extraire les termes simples nous procédons par
élimination des mots vides. Après les prétraitements du corpus à indexer : la
collection Clef médicale 2007 et du corpus d’appui, nous déterminons
l’intersection des lexiques des deux corpus. L’intersection contient les mots vides.
Ces mots sont d’usage général et grammatical. Nous évaluons l’extraction des
termes simple { travers l’évaluation de l’élimination des mots vides. Afin de
réaliser cette évaluation nous avons utilisé les listes de référence des mots vides
des trois langues de la collection. Ces listes sont disponibles sur le web36. Les listes
des mots vides de la langue française, de la langue anglaise et de la langue
allemande contiennent respectivement 124, 36 et 127 mots. Ainsi, la liste de
référence utilisée contient en total 287 mots vides. Nous avons utilisé la mesure
rappel et la mesure précision dans notre évaluation qui sont définies comme suit
(DAILLE, 2002):
36 http://fr.wikipedia.org/wiki/Mot_vide

5.5. Les évaluations
-141-
5.5.4.1. Résultats
Dans nos expériences, nous avons extrait 235 mots vides. Ces mots sont
présents dans liste de référence ce qui donne une valeur de la précision égale à
100%. La valeur du rappel est égale à 81.88%, cette valeur montre que certains
mots vides ne sont pas extraits par le processus d’extraction. Cela s’explique d’une
part, par le fait que ces mots sont absents dans le corpus de la collection Clef. Par
exemple les mots « dedans », « dehors » et « force ». Et d’autre part par le fait que
nous avons fixé la valeur du seuil de la longueur des mots à 4. Cette valeur ainsi
que la valeur du seuil de la fréquence font l’objet d’une étude plus approfondie
dans des futurs travaux.
5.5.4.1. Synthèse
Nous avons évalué l’extraction des termes simples { travers l’évaluation de
l’extraction des mots vides. Cette étude montre que notre méthode { l’avantage
d’extraire les termes simples sans utiliser des stop-liste comme c’est le cas des
approches linguistiques. Nous signalons que dans UMLS, des mots vides tels que
« of », « « the » et « in » sont associés à des concepts.
5.5.5. Extraction des termes composés : détermination du seuil de l’IMA
Pour extraire les termes composés, nous utilisons un processus itératif et
incrémental. Il permet de découvrir de nouveaux termes, des termes composés à
partir de ceux existants. Le processus procède { l’extraction de nouveaux termes {
partir d’une liste initiale de termes connus en utilisant une mesure statistique :
l’Information Mutuelle Adaptée (IMA). Nous partons de la liste des termes simples.
Nous calculons par la suite la valeur de l’IMA de chaque couple de mots. Les
couples des termes dont la valeur de l’IMA est inférieure à une valeur seuil sont
acceptés comme des termes composés. Le processus s’arrête si { une itération
aucun nouveau terme n’est extrait. Autrement, si le processus ne produit pas de
nouveaux termes composés pertinents. Afin de déterminer la valeur du seuil de
l’IMA adéquate { utiliser pour extraire les termes composés nous évaluons, la
précision moyenne et la précision à 5 documents { différentes valeurs de l’IMA. La
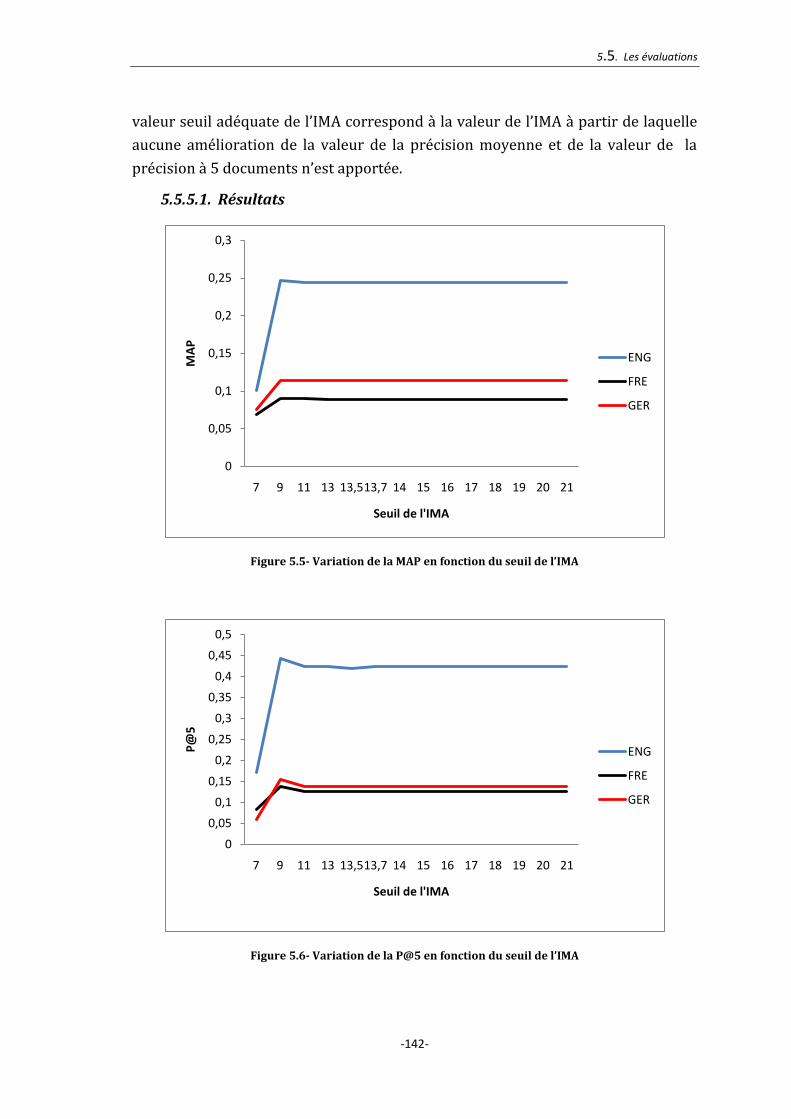
5.5. Les évaluations
-142-
valeur seuil adéquate de l’IMA correspond { la valeur de l’IMA { partir de laquelle
aucune amélioration de la valeur de la précision moyenne et de la valeur de la
précision { 5 documents n’est apportée.
5.5.5.1. Résultats
Figure 5.5- Variation de la MAP en fonction du seuil de l’IMA
Figure 5.6- Variation de la P@5 en fonction du seuil de l’IMA
0
0,05
0,1
0,15
0,2
0,25
0,3
7 9 11 13 13,513,7 14 15 16 17 18 19 20 21
MA
P
Seuil de l'IMA
ENG
FRE
GER
0
0,05
0,1
0,15
0,2
0,25
0,3
0,35
0,4
0,45
0,5
7 9 11 13 13,513,7 14 15 16 17 18 19 20 21
P@
5
Seuil de l'IMA
ENG
FRE
GER
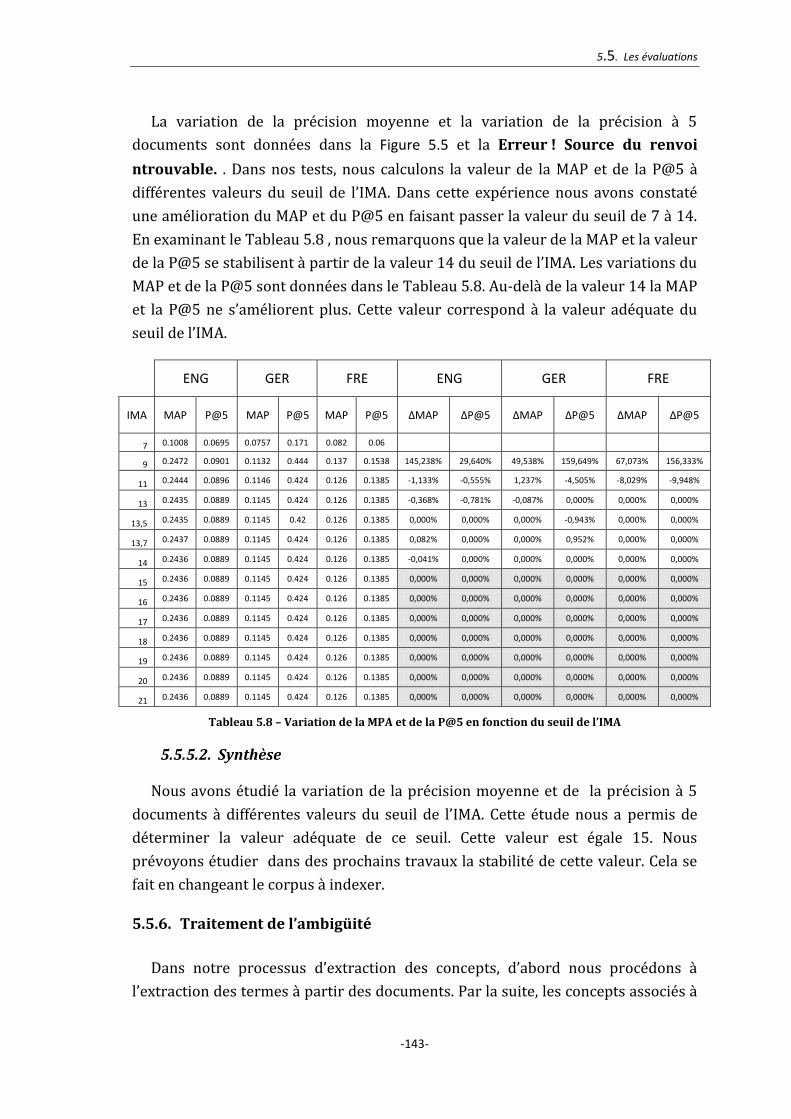
5.5. Les évaluations
-143-
La variation de la précision moyenne et la variation de la précision à 5
documents sont données dans la Figure 5.5 et la Erreur ! Source du renvoi
ntrouvable. . Dans nos tests, nous calculons la valeur de la MAP et de la P@5 à
différentes valeurs du seuil de l’IMA. Dans cette expérience nous avons constaté
une amélioration du MAP et du P@5 en faisant passer la valeur du seuil de 7 à 14.
En examinant le Tableau 5.8 , nous remarquons que la valeur de la MAP et la valeur
de la P@5 se stabilisent { partir de la valeur 14 du seuil de l’IMA. Les variations du
MAP et de la P@5 sont données dans le Tableau 5.8. Au-delà de la valeur 14 la MAP
et la P@5 ne s’améliorent plus. Cette valeur correspond { la valeur adéquate du
seuil de l’IMA.
ENG GER FRE ENG GER FRE
IMA MAP P@5 MAP P@5 MAP P@5 ∆MAP ∆P@5 ∆MAP ∆P@5 ∆MAP ∆P@5
7 0.1008 0.0695 0.0757 0.171 0.082 0.06
9 0.2472 0.0901 0.1132 0.444 0.137 0.1538 145,238% 29,640% 49,538% 159,649% 67,073% 156,333%
11 0.2444 0.0896 0.1146 0.424 0.126 0.1385 -1,133% -0,555% 1,237% -4,505% -8,029% -9,948%
13 0.2435 0.0889 0.1145 0.424 0.126 0.1385 -0,368% -0,781% -0,087% 0,000% 0,000% 0,000%
13,5 0.2435 0.0889 0.1145 0.42 0.126 0.1385 0,000% 0,000% 0,000% -0,943% 0,000% 0,000%
13,7 0.2437 0.0889 0.1145 0.424 0.126 0.1385 0,082% 0,000% 0,000% 0,952% 0,000% 0,000%
14 0.2436 0.0889 0.1145 0.424 0.126 0.1385 -0,041% 0,000% 0,000% 0,000% 0,000% 0,000%
15 0.2436 0.0889 0.1145 0.424 0.126 0.1385 0,000% 0,000% 0,000% 0,000% 0,000% 0,000%
16 0.2436 0.0889 0.1145 0.424 0.126 0.1385 0,000% 0,000% 0,000% 0,000% 0,000% 0,000%
17 0.2436 0.0889 0.1145 0.424 0.126 0.1385 0,000% 0,000% 0,000% 0,000% 0,000% 0,000%
18 0.2436 0.0889 0.1145 0.424 0.126 0.1385 0,000% 0,000% 0,000% 0,000% 0,000% 0,000%
19 0.2436 0.0889 0.1145 0.424 0.126 0.1385 0,000% 0,000% 0,000% 0,000% 0,000% 0,000%
20 0.2436 0.0889 0.1145 0.424 0.126 0.1385 0,000% 0,000% 0,000% 0,000% 0,000% 0,000%
21 0.2436 0.0889 0.1145 0.424 0.126 0.1385 0,000% 0,000% 0,000% 0,000% 0,000% 0,000%
Tableau 5.8 – Variation de la MPA et de la P@5 en fonction du seuil de l’IMA
5.5.5.2. Synthèse
Nous avons étudié la variation de la précision moyenne et de la précision à 5
documents { différentes valeurs du seuil de l’IMA. Cette étude nous a permis de
déterminer la valeur adéquate de ce seuil. Cette valeur est égale 15. Nous
prévoyons étudier dans des prochains travaux la stabilité de cette valeur. Cela se
fait en changeant le corpus à indexer.
5.5.6. Traitement de l’ambigüité
Dans notre processus d’extraction des concepts, d’abord nous procédons {
l’extraction des termes { partir des documents. Par la suite, les concepts associés {
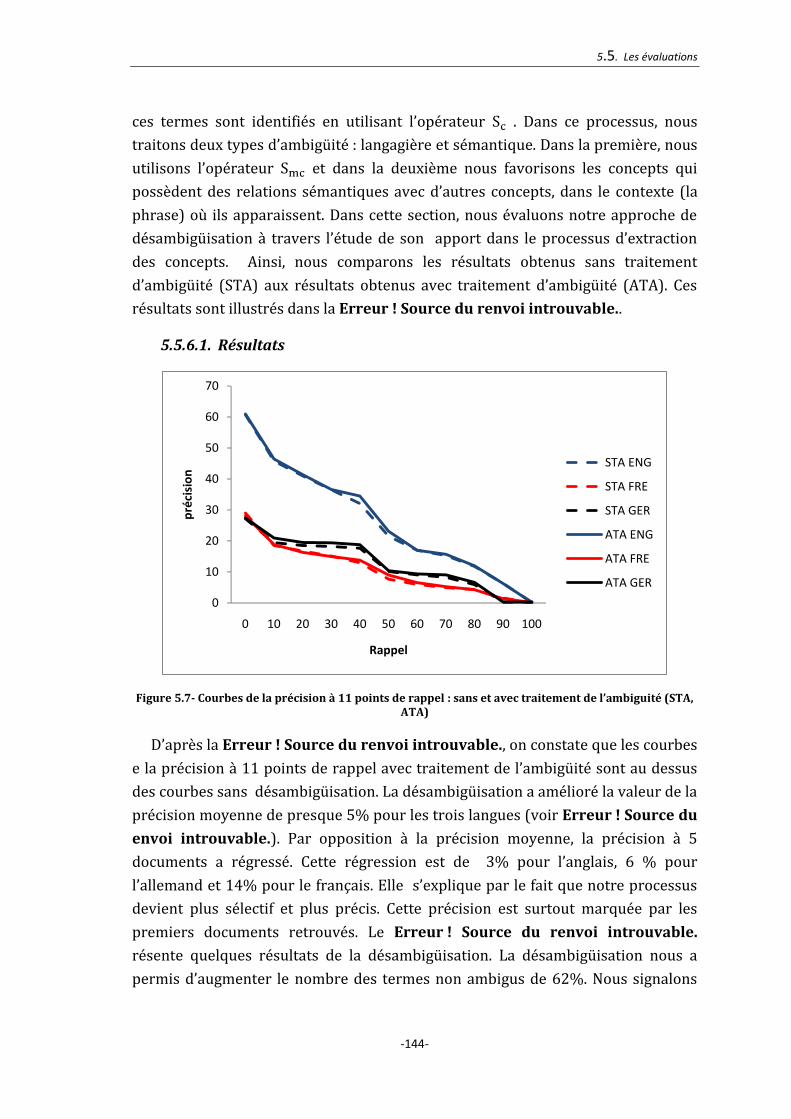
5.5. Les évaluations
-144-
ces termes sont identifiés en utilisant l’opérateur . Dans ce processus, nous
traitons deux types d’ambigüité : langagière et sémantique. Dans la première, nous
utilisons l’opérateur et dans la deuxième nous favorisons les concepts qui
possèdent des relations sémantiques avec d’autres concepts, dans le contexte (la
phrase) où ils apparaissent. Dans cette section, nous évaluons notre approche de
désambigüisation { travers l’étude de son apport dans le processus d’extraction
des concepts. Ainsi, nous comparons les résultats obtenus sans traitement
d’ambigüité (STA) aux résultats obtenus avec traitement d’ambigüité (ATA). Ces
résultats sont illustrés dans la Erreur ! Source du renvoi introuvable..
5.5.6.1. Résultats
Figure 5.7- Courbes de la précision à 11 points de rappel : sans et avec traitement de l’ambiguité (STA, ATA)
D’après la Erreur ! Source du renvoi introuvable., on constate que les courbes
e la précision { 11 points de rappel avec traitement de l’ambigüité sont au dessus
des courbes sans désambigüisation. La désambigüisation a amélioré la valeur de la
précision moyenne de presque 5% pour les trois langues (voir Erreur ! Source du
envoi introuvable.). Par opposition à la précision moyenne, la précision à 5
documents a régressé. Cette régression est de 3% pour l’anglais, 6 % pour
l’allemand et 14% pour le français. Elle s’explique par le fait que notre processus
devient plus sélectif et plus précis. Cette précision est surtout marquée par les
premiers documents retrouvés. Le Erreur ! Source du renvoi introuvable.
résente quelques résultats de la désambigüisation. La désambigüisation nous a
permis d’augmenter le nombre des termes non ambigus de 62%. Nous signalons
0
10
20
30
40
50
60
70
0 10 20 30 40 50 60 70 80 90 100
pré
cisi
on
Rappel
STA ENG
STA FRE
STA GER
ATA ENG
ATA FRE
ATA GER
5.5. Les évaluations
-145-
aussi que la désambigüisation a baissé le taux d’ambigüité pour d’autres termes.
Par exemple le nombre des termes qui sont associés à 2 concepts est passé de
159711 à 175657. Ce qui veut dire que (175657-159711) termes sont passés
d’une ambigüité élevée { une plus base. En effet, ces termes ont été associés à plus
de 2 concepts avant la désambigüisation.
STA ATA
Langue MAP P@5 MAP P@5 ∆MAP ∆P@5
ENG 0.238 0.439 0.244 0.425 3% -3%
GER 0.109 0.148 0.115 0.139 6% -6%
FRE 0.086 0.148 0.089 0.127 3% -14%
Tableau 5.9 –Résultats en MAP et P@5 sans et avec traitement de l’ambiguité (STA, ATA)
STA ATA ∆NT
Nombre de Termes non ambigus 252977 410129 62%
Nombre de Termes associés à 2 concepts 159711 175657 10%
Tableau 5.10 – Quelques résultats de la désambigüisation.
5.5.6.1. Synthèse
Nous avons comparé les résultats de notre approche d’extraction des concepts
obtenus sans traitement de l’ambigüité aux résultats obtenus avec traitement de
l’ambigüité. Le traitement de l’ambigüité nous permet d’améliorer la valeur de la
MAP et de diminuer la valeur de la P@5. Notre processus est plus efficace avec une
prise en compte du traitement de l’ambigüité. La méthode de désambigüisation
que nous avons proposée s’avère performante et donne des bons résultats. Elle
nous a permis d’augmenter le nombre de termes non ambigus de 62% et de
diminuer le taux d’ambigüité pour les autres termes.
5.5.7. Extraction des concepts
Dans nos expérimentations nous évaluons l’extraction des concepts au moyen
de la précision moyenne (MAP) et la précision à 5 documents (P@5). La précision
moyenne nous permet d’avoir une vue globale de la performance de notre
approche. La précision { 5 documents nous donne un aperçu sur l’efficacité de
cette approche sur les 5 premier documents retournés par un SRI. Ces documents
sont les documents les plus regardés par les utilisateurs des SRIs. Les valeurs de
ces mesures sont obtenues { l’aide du programme trec_eval.
Comme mentionné dans le chapitre précédent, l’extraction des concepts est
réalisée en trois grandes étapes :
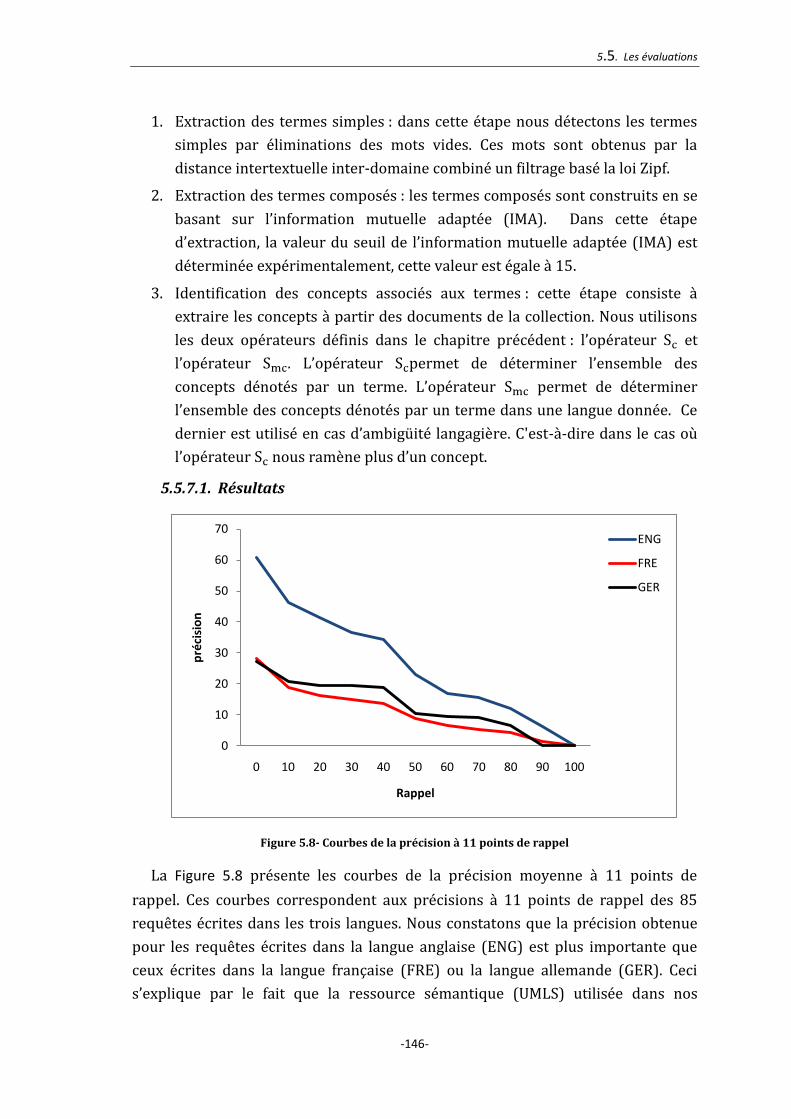
5.5. Les évaluations
-146-
1. Extraction des termes simples : dans cette étape nous détectons les termes
simples par éliminations des mots vides. Ces mots sont obtenus par la
distance intertextuelle inter-domaine combiné un filtrage basé la loi Zipf.
2. Extraction des termes composés : les termes composés sont construits en se
basant sur l’information mutuelle adaptée (IMA). Dans cette étape
d’extraction, la valeur du seuil de l’information mutuelle adaptée (IMA) est
déterminée expérimentalement, cette valeur est égale à 15.
3. Identification des concepts associés aux termes : cette étape consiste à
extraire les concepts à partir des documents de la collection. Nous utilisons
les deux opérateurs définis dans le chapitre précédent : l’opérateur et
l’opérateur . L’opérateur permet de déterminer l’ensemble des
concepts dénotés par un terme. L’opérateur permet de déterminer
l’ensemble des concepts dénotés par un terme dans une langue donnée. Ce
dernier est utilisé en cas d’ambigüité langagière. C'est-à-dire dans le cas où
l’opérateur nous ramène plus d’un concept.
5.5.7.1. Résultats
Figure 5.8- Courbes de la précision à 11 points de rappel
La Figure 5.8 présente les courbes de la précision moyenne à 11 points de
rappel. Ces courbes correspondent aux précisions à 11 points de rappel des 85
requêtes écrites dans les trois langues. Nous constatons que la précision obtenue
pour les requêtes écrites dans la langue anglaise (ENG) est plus importante que
ceux écrites dans la langue française (FRE) ou la langue allemande (GER). Ceci
s’explique par le fait que la ressource sémantique (UMLS) utilisée dans nos
0
10
20
30
40
50
60
70
0 10 20 30 40 50 60 70 80 90 100
pré
cisi
on
Rappel
ENG
FRE
GER
5.5. Les évaluations
-147-
expérimentations couvre mieux la langue anglaise que les autres langues. Le
pourcentage de cette langue dans UMLS est 27 fois plus important que la langue
française et 24 fois plus important que la langue allemande (voir Tableau 5.4). La
précision moyenne obtenue pour les requêtes (GER) et les requêtes (FRE) sont
presque similaires. Dans UMLS, ces deux langues sont couvertes d’une manière
identiques, 2.55% pour la langue française et 2.84% pour la langue allemande
(voir Tableau 5.4). D’ailleurs, la légère différence dans ces pourcentages est bien
manifestée dans les courbes précision rappel des requêtes écrites dans ces deux
langues. Dans la Figure 5.8 la courbe GER est légèrement au dessus de la courbe
FRE.
5.5.7.2. Comparaison de notre approche statistique avec les approches
linguistiques
Dans cette section, nous comparons les résultats de notre approche aux
résultats obtenus par des approches linguistiques. Ces résultats sont obtenus en
appliquant notre méthode sur la collection multilingue CLEF 2007 et en utilisant
les requêtes écrites dans la langue anglaise. Contrairement à ces approches notre
approche n’utilise aucune analyse linguistique ni de connaissance sur les langues
des documents. Elle est basée sur des mesures statistiques. Les langues des
documents ne sont pas diagnostiquées tout au long du processus d’extraction. Pour
extraire les termes dénotant les concepts, notre approche construit ces ressources
{ partir des documents et n’utilise aucune stop-liste ni anti-dictionnaire.
Nous réalisons notre comparaison au moyen de la comparaison des valeurs des
métriques MAP et P@5 obtenues par notre approche à ceux présentées dans
(MAISONNASSE et al, 2009).
Approche Analyse MAP P@5 ∆MAP37 ∆P@538
MM 0.246 0.357 -0.81% 19.05%
Linguistique MP 0.246 0.424 -0.81% 0.24%
TT 0.258 0.462 -5.43% -8.01%
Statistique STAT 0.244 0.425
Tableau 5.11 –Résultats en MAP et P@5 pour les deux approches
Où
37
38

5.5. Les évaluations
-148-
MM désigne l’analyseur MetaMap,
MP désigne l’analyseur MiniPar,
TT désigne l’analyseur TreeTagger,
STAT notre analyse statistique.
Dans (MAISONNASSE et al, 2009), les auteurs utilisent une approche
linguistique pour extraire les concepts. Ils exploitent trois analyseurs linguistiques
MetaMap (MM), MinPar(Mp) et TreeTagger(TT). Les résultats obtenus par ces
différents analyseurs ainsi que ceux abtenus par notre approche statistique
(STAT) sont donnés dans le Tableau 5.11. Nous constatons qu’en précision
moyenne, les méthodes linguistiques sont légèrement meilleures que les méthodes
statistiques. En terme de précision moyenne les méthodes linguistiques donnent
des résultats meilleurs que notre approche. En utilisant une approche statistique,
la valeur de la précision moyenne a diminué en moyenne de 2.35%39 . Par contre
en précision à 5 documents notre approche donne des résultats meilleurs.
L’augmentation de la valeur de la précision { 5 documents est de 3.76%40 en
moyenne.
5.5.7.3. Synthèse
La comparaison en terme de précision Moyenne et en terme de Précision à 5
documents, nous montre que l’approche statistique que nous proposons donne des
résultats similaires aux résultats obtenus par des analyses linguistiques. Notre
approche statistique et les approches linguistiques ont les mêmes performances.
Cependant, notre approche présente l’avantage de ne pas être liée { la langue des
documents. De ce fait, elle est portable et s’applique { tous les corpus multilingues
où les documents sont écrits dans différentes langues.
5.5.8. Impact de la couverture du domaine par la ressource sémantique sur
l’extraction des concepts
Dans cette section, nous étudions la couverture du domaine par la ressource
sémantique utilisée dans le processus d’extraction des concepts sur la
performance de la méthode. Nous avons envisagé deux scénarios d’extraction des
concepts à partir de la collection Clef médicale 2007. Le premier utilise UMLS
39 2.35=((-0.81)+(-0.81)+(-5.43))/3
40 3.76=((19.05)+( 0.24)+( -8.01))/3
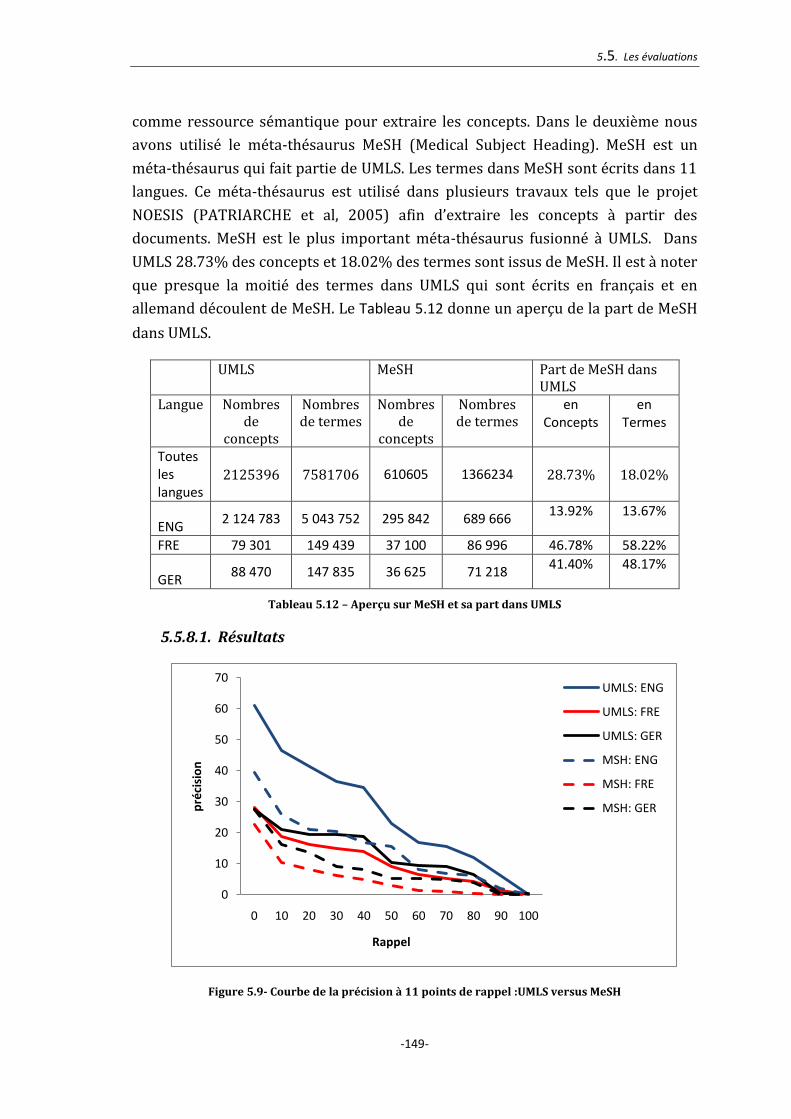
5.5. Les évaluations
-149-
comme ressource sémantique pour extraire les concepts. Dans le deuxième nous
avons utilisé le méta-thésaurus MeSH (Medical Subject Heading). MeSH est un
méta-thésaurus qui fait partie de UMLS. Les termes dans MeSH sont écrits dans 11
langues. Ce méta-thésaurus est utilisé dans plusieurs travaux tels que le projet
NOESIS (PATRIARCHE et al, 2005) afin d’extraire les concepts { partir des
documents. MeSH est le plus important méta-thésaurus fusionné à UMLS. Dans
UMLS 28.73% des concepts et 18.02% des termes sont issus de MeSH. Il est à noter
que presque la moitié des termes dans UMLS qui sont écrits en français et en
allemand découlent de MeSH. Le Tableau 5.12 donne un aperçu de la part de MeSH
dans UMLS.
UMLS MeSH Part de MeSH dans UMLS
Langue Nombres de
concepts
Nombres de termes
Nombres de
concepts
Nombres de termes
en Concepts
en Termes
Toutes les langues
2125396 7581706 610605 1366234 28.73% 18.02%
ENG 2 124 783 5 043 752 295 842 689 666
13.92% 13.67%
FRE 79 301 149 439 37 100 86 996 46.78% 58.22%
GER 88 470 147 835 36 625 71 218
41.40% 48.17%
Tableau 5.12 – Aperçu sur MeSH et sa part dans UMLS
5.5.8.1. Résultats
Figure 5.9- Courbe de la précision à 11 points de rappel :UMLS versus MeSH
0
10
20
30
40
50
60
70
0 10 20 30 40 50 60 70 80 90 100
pré
cisi
on
Rappel
UMLS: ENG
UMLS: FRE
UMLS: GER
MSH: ENG
MSH: FRE
MSH: GER
5.5. Les évaluations
-150-
Les résultats des deux scénarios sont illustrés dans la Figure 5.9. Nous
constatons que pour les trois langues : FRE, ENG et GER les courbes du premier
scénario sont toujours en dessus des courbes du deuxième scénario. L’utilisation
de MeSH au lieu de UMLS a engendré une baisse importante de la précision
moyenne (MAP). D’après le Tableau 5.13, cette baisse est de 50.00% pour la langue
anglaise, 40.26% pour la langue allemande et 56.07% pour la langue française. A
l’exception de la langue allemande une diminution importante de la valeur de la
précision à 5 documents est aussi observée. Cette dégradation est de 46.35% pour
l’anglais et 29.92% pour le français. Cette dégradation est attendue et s’explique
par le fait que UMLS couvre mieux le domaine médicale que MeSH.
UMLS MeSH
Langue MAP P@5 MAP P@5 ∆MAP ∆P@5
ENG 0.244 0.425 0.122 0.228 -50.00% -46.35%
GER 0.115 0.139 0.0687 0.160 -40.26% 15.11%
FRE 0.089 0.127 0.0391 0.089 -56.07% -29.92%
Tableau 5.13 –Résultats en MAP et P@5 pour les deux extractions: UMLS Versus MeSH
Contrairement { la langue anglaise et la langue française, l’utilisation de MeSH a
amélioré la P@5 pour l’allemand. Cette augmentation est de 15.11%. Afin
d’expliquer cette augmentation inattendue nous avons consulté la table précision
après n documents obtenue par trec_eval. Cette table est présentée dans le Tableau
5.14. D’après ce tableau, cette augmentation n’est pas maintenue pour une
précision à autre que 5 documents. Nous considérons cette augmentation comme
non significative et elle ne fait pas l’objet d’une étude supplémentaire de notre part
dans le cadre de cette thèse.
UMLS MeSH ∆ Precision (UMLS/MeSH)
Precision Precision
At 5 docs 0.1385 0.1600 116%
At 10 docs 0.1423 0.1350 95%
At 15 docs 0.1256 0.1167 93%
At 20 docs 0.1269 0.1125 89%
At 30 docs 0.1308 0.1350 103%
At 40 docs 0.0973 0.0810 83%
At 100 docs 0.0723 0.0648 90%
At 500 docs 0.0439 0.0306 70%
At 1000 docs 0.0290 0.0212 73%
Tableau 5.14 –Précision après n documents trouvés pour la langue allemande

5.5. Les évaluations
-151-
5.5.8.2. Synthèse
Afin d’étudier l’impact de la couverture du domaine par la ressource
sémantique utilisée dans le processus d’extraction des concepts, nous avons testé
notre méthode d’extraction de concepts avec deux ressources différentes. Dans la
première nous avons utilisé UMLS et dans la deuxième nous avons utilisé MeSH.
Nous sommes aperçu la couverture du domaine par la ressource sémantique influe
énormément sur les résultats de l’extraction. Nous estimons obtenir de meilleurs
résultats en utilisant des ressources qui couvrent mieux le domaine
5.5.9. Extraction des relations sémantique
Dans UMLS, les concepts sont organisés en classes. Ces classes constituent les
types sémantiques définis dans le réseau sémantique. Chaque concept d’UMLS est
relié à un ou plusieurs types sémantiques. Ces types sont reliés entre eux par des
relations sémantiques. Nous utilisons cette organisation afin d’extraire les
relations entre concepts. Pour un couple de concepts ( ) qui apparaissent dans
une même phrase d’un même document la relation est détectée si :
1. un type sémantique associé à , et
2. un type sémantique associé à , et
3. et sont reliés par la relation dans le réseau sémantique de UMLS.
Le modèle que nous avons utilisé précédemment pour évaluer l’extraction des
concepts est défini sur des concepts et ne prend pas en compte les relations
sémantiques. Nous utilisons alors le modèle décrit dans (MAISONNASSE et al,
2008). Ce modèle est aussi issu des modèles de la langue comme le modèle que
nous avons utilisé précédemment. Le choix de garder des modèles issus des
modèles de la langue, nous permet par la suite d’évaluer directement l’apport de
l’extraction des relations.
Le modèle choisi est un modèle défini sur les concepts et les relations. C'est-à-
dire sur les graphes conceptuels (GC). Dans ce modèle le document et la requête
sont représentés par des GC. La fonction de correspondance est une pseudo-
projection du graphe de la requête sur le graphe du document. (MAISONNASSE et
al, 2008)
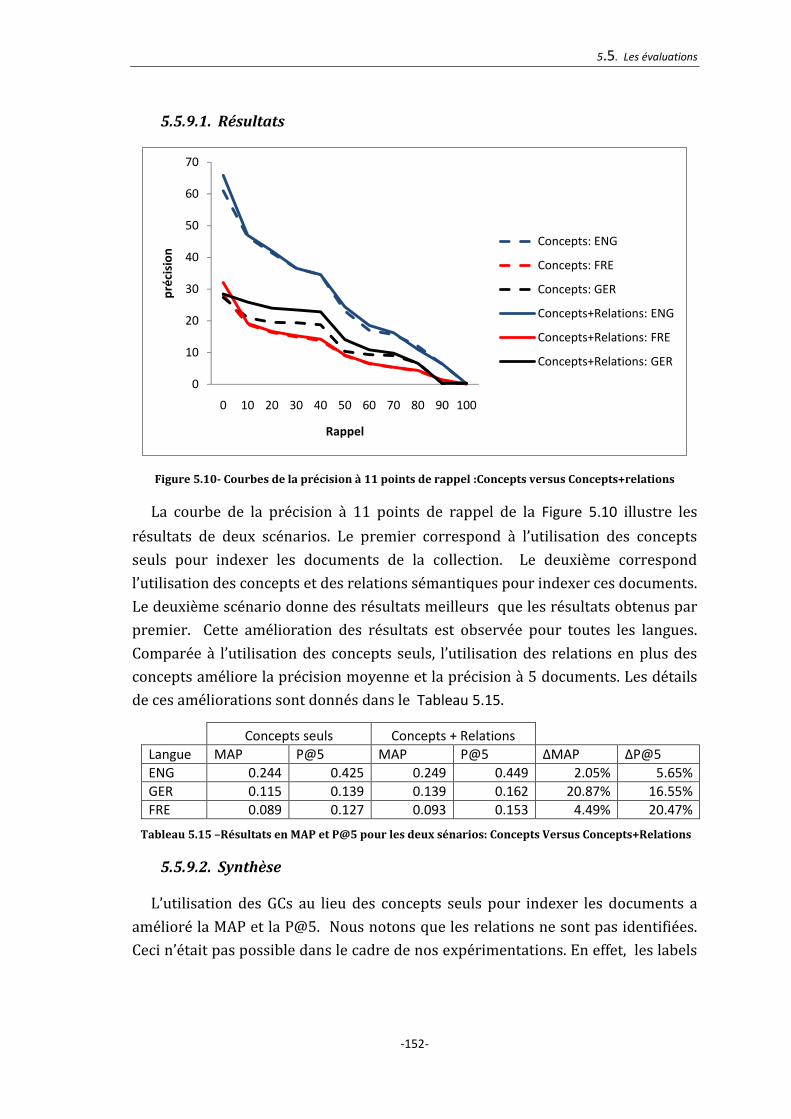
5.5. Les évaluations
-152-
5.5.9.1. Résultats
Figure 5.10- Courbes de la précision à 11 points de rappel :Concepts versus Concepts+relations
La courbe de la précision à 11 points de rappel de la Figure 5.10 illustre les
résultats de deux scénarios. Le premier correspond { l’utilisation des concepts
seuls pour indexer les documents de la collection. Le deuxième correspond
l’utilisation des concepts et des relations sémantiques pour indexer ces documents.
Le deuxième scénario donne des résultats meilleurs que les résultats obtenus par
premier. Cette amélioration des résultats est observée pour toutes les langues.
Comparée { l’utilisation des concepts seuls, l’utilisation des relations en plus des
concepts améliore la précision moyenne et la précision à 5 documents. Les détails
de ces améliorations sont donnés dans le Tableau 5.15.
Concepts seuls Concepts + Relations
Langue MAP P@5 MAP P@5 ∆MAP ∆P@5
ENG 0.244 0.425 0.249 0.449 2.05% 5.65%
GER 0.115 0.139 0.139 0.162 20.87% 16.55%
FRE 0.089 0.127 0.093 0.153 4.49% 20.47%
Tableau 5.15 –Résultats en MAP et P@5 pour les deux sénarios: Concepts Versus Concepts+Relations
5.5.9.2. Synthèse
L’utilisation des GCs au lieu des concepts seuls pour indexer les documents a
amélioré la MAP et la P@5. Nous notons que les relations ne sont pas identifiées.
Ceci n’était pas possible dans le cadre de nos expérimentations. En effet, les labels
0
10
20
30
40
50
60
70
0 10 20 30 40 50 60 70 80 90 100
pré
cisi
on
Rappel
Concepts: ENG
Concepts: FRE
Concepts: GER
Concepts+Relations: ENG
Concepts+Relations: FRE
Concepts+Relations: GER

5.6. Discussion
-153-
des relations dans UMLS ne sont donnés que dans la langue anglaise. Ceci rend
difficile l’application des opérateurs et .
5.6. Discussion
Dans les expérimentations que nous avons réalisées, nous avons d’abord évalué
la méthode d’extraction des termes simples { travers l’évaluation de l’élimination
des mots vides. Ensuite, nous avons déterminé la valeur adéquate du seuil de
l’information mutuelle adaptée pour l’extraction des termes composés en testant la
méthode d’extraction des concepts { différentes valeurs de ce seuil. Par la suite,
nous avons évalués l’efficacité de la méthode de désambigüisation des termes en
étudiant son apport dans le processus d’extraction des concepts. Ensuite, nous
avons évalué la méthode de l’extraction des concepts en la comparant une
méthode linguistique de référence. Aussi nous avons étudié l’impact de la
couverture du domaine par la ressource sémantique utilisé sur l’efficacité de la
méthode d’extraction des concepts en utilisant MeSH au lieu de UMLS. Enfin, nous
avons évalué la méthode que nous avons proposée pour l’extraction des relations.
Cette évaluation est réalisée en étudiant l’apport d’une indexation basée sur les
concepts et les relations dans le processus de recherche d’information. Nous avons
comparé les résultats obtenus en utilisant les concepts seuls comme index des
documents à ceux obtenus en indexant ces documents par des concepts et des
relations sémantiques.
Nos expérimentations nous ont permis de juger la performance de notre
approche. Ce jugement est obtenu par comparaison des résultats obtenus par
notre approche { ceux obtenus par l’approche linguistique. D’après cette
comparaison nous avons constaté que notre approche possède la même
performance que l’approche linguistique. Mais de plus, elle présente l’avantage
d’être indépendante de la langue des documents à traiter. De ce fait, elle est
facilement applicable { d’autres corpus multilingues. Cependant, notre approche
présente une limite. Elle ne trouve sa performance que sur des corpus volumineux.
En effet, cette approche est basée sur des mesures statistiques, ces mesures sont
significatives seulement sur des corpus de grandes tailles.
5.7. Conclusion
Dans ce chapitre, nous avons évalué notre approche d’extraction des concepts et
des relations à partir de corpus multilingues. Ce corpus contient des documents
qui sont écrits en anglais, en français et en allemand. Le processus d’extraction des

5.7. Conclusion
-154-
concepts est composé de trois étapes : l’extraction des termes simples, l’extraction
des termes composés et l’identification des concepts associés aux termes. Nous
avons évalué la première étape { l’aide de la mesure de précision et la mesure
rappel. Le reste du processus est évalué en comparant l’approche proposée {
l’approche linguistique. Nous avons utilisé la précision moyenne et la précision { 5
documents comme mesures de d’évaluation. Dans cette évaluation, nous avons
comparé les résultats obtenus par notre approche aux résultats obtenus par
l’utilisation des analyseurs linguistiques: MetaMap, MiniPar et TreeTagger. Ces
résultats sont présentés dans un travail jugé robuste par la campagne d’évaluation
Clef. Notre approche donne des résultats comparables à ceux obtenus par
l’approche linguistique. De ce fait, la méthode que nous proposons pour extraire
les concepts et les relations peut s’appliquer { différentes langues et montrer des
résultats comparables à ceux travaillant sur une analyse linguistique. La méthode
d’extraction des relations entre concepts est évalué en étudiant l’apport des
relations extraites dans le processus de recherche d’information.

-155-
Chapitre 6
Conclusions et perspectives
Dans le cadre de cette thèse, nous nous sommes intéressés aux techniques et aux
outils de recherche et d’indexation d’informations textuelles. Nous avons exposé le
problème d’indexation des documents multilingues et la nécessite de développer
des techniques permettant l’indexation de ces documents. Nous avons montré que
la prise en compte des informations sémantiques dans le processus d’indexation
peut améliorer la performance d’un SRI. Ces informations sont issues des
ressources sémantiques telles que les ontologies et les thésaurii. Ces ressources
sont de plus en plus disponibles. Par conséquent, l’utilisation des informations
sémantiques dans le processus d’indexation est devenue plus facile. Nous avons
étudié les approches d’indexation existantes. A partir de cette étude, nous avons
proposé une démarche permettant d’indexer les documents multilingues écrits en
anglais et en langues latines. Cette indexation consiste à extraire les descripteurs
sémantiques à partir des documents. Ces descripteurs sont les concepts et les
relations sémantiques entre ces concepts. Ainsi, le contenu de chaque document
est décrit par un ensemble de concepts reliés par des relations : un graphe
sémantique. Dans la suite nous exposons nos principales contributions et les
perspectives ouvertes par nos travaux.
6.1. Contributions
6.1.1. Sur le plan théorique
1. Nous avons proposé une méthode automatique d’extraction des termes
simples. Dans cette méthode, nous nous sommes basés sur la distance
intertextuelle inter-domaine. Nous identifions les termes simples (les mots
pleins) par l’identification des mots vides. Nous avons signalé qu’il n’existe
pas des mots vides et des mots pleins dans l’absolu. Un mot n’est catégorisé
plein ou vide que par rapport à un domaine. Notre méthode prend en
compte le domaine de ces mots à fin de les catégoriser pleins ou vides. Les

6.1. Contributions
-156-
mots sont examinés dans le contexte où ils apparaissent, les documents du
corpus du domaine considéré.
2. Nous avons introduit une nouvelle mesure statistique : l’information
mutuelle adaptée (IMA). Cette mesure est l’adaptation de la mesure
existante, l’information mutuelle. IMA est utilisée pour extraire les termes
composés. Ces termes sont formés par des termes simples et des mots vides.
De ce fait, ces termes composés sont moins ambigus que les termes simples.
Nous avons introduit une nouvelle pondération des termes composés,
CTF*IDF (CTF pour Compound Term Frequency). Dans cette pondération les
termes composés les plus long (en nombre de termes simples) sont
favorisés. Une pondération plus élevée est attribuée aux termes composés
les plus longs.
3. Afin de prendre en compte les informations sémantiques issues d’une
ressource externe, nous transformons les termes en concepts. Ainsi, nous
avons défini l’opérateur et son opérateur inverse . L’opérateur
permet de déterminer le sens ou les sens d’un terme donné. Ces sens
représentent les concepts dénotés par ce terme dans la ressource
sémantique.
4. Nous avons traité deux types d’ambigüité : l’ambigüité langagière et
l’ambigüité sémantique ou polysémie. Ainsi, Nous avons proposé une
démarche de désambigüisation. Afin de traiter l’’ambigüité langagière nous
avons défini l’opérateur . Cet opérateur sera utilisé à la place de
l’opérateur , en spécifiant une langue d’un terme non langagièrement
ambigu. Pour traiter le deuxième type d’ambigüité, nous favorisons les
concepts en relation avec un concept non ambigu de la même phrase.
5. Nous avons également proposé une méthode d’extraction des relations
sémantiques entre les concepts. Une relation sémantique est détectée entre
deux concepts d’une même phrase s’il existe une relation dans la ressource
sémantique qui les relie.
6.1.2. Sur le plan pratique et technique
Nous avons évalué notre proposition sur le domaine médical à travers la
collection CLEF 2007. Cette collection nous a permis de mener nos tests dans un
cadre réel. Nous avons testé la performance de l’approche que nous avons
proposée, en utilisant des métriques issues du domaine de la recherche
d’information. Durant nos expérimentations nous avons effectué une comparaison
entre les résultats obtenus par notre approche et les résultats obtenus par

6.2. Perspectives
-157-
l’approche linguistique. Cette comparaison nous a permis de juger la performance
de l’approche proposée et de bien la positionner par rapport { l’approche
linguistique.
Les expérimentations réalisées prouvent que notre approche possède presque
la même performance que l’approche linguistique avec un écart de 2.4% en terme
de MAP et de (-2.7%) en terme de P@5. Cependant notre approche présente
l’avantage d’être indépendante de la langue des documents.
Egalement, nous avons validé notre proposition de désambigüisation à travers
l’étude de son impact sur le processus d’extraction des concepts. Nous avons
constaté que la désambigüisation améliore les résultats du processus. Nous avons
étudié l’impact de la qualité de la ressource sémantique sur le processus
d’extraction des concepts. Cette étude nous a montré que l’utilisation d’une
ressource de bonne qualité améliore la performance de ce processus. Nous avons
aussi testé l’effet d’une variation de la valeur du seuil de l’IMA sur l’efficacité du
processus. Ce test nous a permis de déterminer la valeur adéquate. Cette valeur est
souvent difficile à déterminer.
Pour finir nos expérimentations nous avons étudié l’apport de l’utilisation des
relations sémantiques dans un processus de recherche d’information. Cette étude
nous permet de valider notre proposition d’extraction des relations sémantiques
entre concepts. Nous avons constaté que l’utilisation des concepts et des relations
au lieu des concepts seuls pour décrire les documents a un effet positif sur le
processus de recherche d’information.
Sur un plan technique, nous avons développé une plateforme logicielle appelée
MuDIBO (Multililingual Documents Indexing Based on Ontology). Cet outil permet
d’indexer des documents multilingues. Il est basé sur l’approche que nous avons
proposée. MuDIBO est facilement applicable { d’autres corpus et en utilisant
d’autres ressources sémantiques. Dans cet outil, le processus d’indexation est
entièrement automatique et aucune intervention utilisateur n’est nécessaire.
6.2. Perspectives
Les travaux réalisés dans cette thèse ouvrent diverses perspectives.
Extraction des termes composés
D’une part, la méthodologie d’extraction des termes composés que nous avons
proposée est itérative. Elle consiste, à chaque itération à calculer la valeur de
l’information mutuelle adaptée entre les couples des termes extraits { l’itération

6.2. Perspectives
-158-
précédente. Les couples de termes possédant une valeur de l’IMA inférieure { un
seuil sont ajoutés { la liste des termes composés. Ce processus s’arrête si { une
itération aucun nouveau terme n’est découvert. La valeur du seuil est inconnue au
départ et elle est déterminée par la suite par l’expérience durant le processus
d’extraction. Nous prévoyons d’effectuer des tests sur d’autres corpus pour voir s’il
n’existe pas de valeur de seuil universel. Les premiers tests, que nous avons
réalisés dans cette thèse, nous ont montré que cette valeur est indépendante de la
langue (15 pour les trois langues de la collection CLEF 2007). Reste à vérifier si
cette valeur est indépendante du domaine et de la taille du corpus.
D’autre part, une partie des termes composés qui ont été extraits par notre
approche n’ont pas pu être transformé en concepts. Cela s’explique par deux
raisons. La première est que la ressource sémantique ne couvre pas la totalité du
domaine du corpus. La deuxième, est que ces termes qui ne dénotent pas des
concepts dans la ressource sémantique sont mal extraits. Afin de vérifier ces
hypothèses une étude approfondie de ces termes doit être effectuée.
Transformation des termes en concepts
Nous avons défini l’opérateur afin de transformer les termes en concepts. Cet
opérateur permet de déterminer les concepts dénotés par un terme. Il consiste à
projeter le terme sur la ressource sémantique. Cette projection est stricte et ne
prend pas en considération les variations lexicales et syntaxiques des termes. Cet
opérateur trouve sa performance à travers la bonne qualité de la ressource
sémantique utilisée, par exemple comme UMLS où les variations des termes sont
souvent données. Nous pensons qu’un perfectionnement de l’opérateur est
nécessaire. Une solution possible est de coupler à cet opérateur une procédure de
calcul de similarités lexicales entre mots. Ces procédures sont utilisées dans les
éditeurs de texte et les correcteurs d’orthographe. Elles se basent sur des distances
lexicales, telles que la distance de Levenshtein (LEVENSHTEIN, 1966).
Intégration de notre approche dans un SRI multilingue
L’approche que nous avons proposée permet d’indexer des documents
multilingues. Elle consiste à décrire les contenus de ces documents par des graphes
conceptuels. Nous prévoyons { court terme d’intégrer notre approche à un SRI
multilingue basé sur les GCs. Il s’agit du système SyDOM (ROUSSEY, 2001).

6.2. Perspectives
-159-
SyDoM se compose de différents modules, chacun de ces modules est dédié à
une étape des processus d'indexation et de recherche des documents. SyDoM
comprend :
1. un module de gestion des thésaurus sémantiques, permettant de construire
un langage documentaire utilisé pour annoter et interroger les documents.
Ce langage se compose d'une modélisation du domaine à laquelle sont
associés plusieurs vocabulaires.
2. un module de recherche, permettant de construire une requête sous forme
de graphes conceptuels et de récupérer la liste des documents répondant à
cette requête.
3. un module d'indexation manuelle de documents en XML, permettant
d'annoter les documents par des graphes conceptuels .
Dans SyDOM, le module d’indexation étant manuel ce qui n’a pas permis le
passage { l’échelle dans la taille du corpus. L’intégration de notre approche { ce
système permet d’automatiser le processus d’indexation dans SyDOM.


-161-
Annexes
Exemple de document de la collection CLEF médicale 2007 (le document
3331)
<DOC>
<ID>
<sentence>
3331
</sentence>
</ID>
<Description>
<sentence>
Coupe axiale CT au niveau de C4, en fenêtre osseuse. Le CT permet de
mesurer les diminutions du canal rachidien. Dans ce cas, le diamètre
antéro-postérieur, mesuré entre le mur postérieur du corps vertébral
et l'arc neural est de 10 mm.
</sentence>
</Description>
<Diagnosis>
<sentence>
Sténose congénitale du canal rachidien.
</sentence>
</Diagnosis>
<Sex>
</Sex>
<CaseID>
</CaseID>
<ClinicalPresentation>
</ClinicalPresentation>
<Commentary>
<sentence>
Le CT en coupe axiale permet d'apprécier parfaitement la forme et les
dimensions du canal rachidien et des canaux radiculaires. La forme du
canal rachidien varie selon le niveau concerné. Elle peut être ronde,
ovalaire, ou en "trèfle".
Il existe certaines variantes anatomiques de forme et de dimension. Le
canal rachidien lombaire dont le diamètre A-P est inférieur à 12 mm.
est un canal étroit de type constitutionnel. Dans une situation
pareille, même des lésions dégénératives discrétes peuvent devenir
symptomatiques.
</sentence>
</Commentary>
<KeyWords>
</KeyWords>
…
…
</sentence>
</OGraft>
<WEBURL>
<sentence>
http://129.195.254.38:5000/4DMETHOD/_HTML_MCase/3331
</sentence>
</WEBURL>
</DOC>

6.2. Perspectives
-162-
Exemple de requête (la requête 74)
<DOC >
<ID>74</ID>
<EN-desc>xray hip fracture</EN-desc>
<DE-desc>Ultraschallbild mit rechteckigem Sensor</DE-desc>
<FR-desc>Radio d'une fracture de la hanche</FR-desc>
</DOC>
Exemple de fichier index (portion pour le document 3331)
…………
…………
<DOC ID="3331" >
<LUNIT>
<CON ID="C1555015" />
</LUNIT>
<LUNIT>
<CON ID="C1556084" />
</LUNIT>
<LUNIT>
<CON ID="C0034599" />
<CON ID="C0029408" />
<CON ID="C0022408" />
</LUNIT>
<LUNIT>
<CON ID="C0205064" />
<CON ID="C0728985" />
<CON ID="C0037949" />
</LUNIT>
<LUNIT>
<CON ID="C0175677" />
</LUNIT>
<LUNIT>
<CON ID="C0014938" />
<CON ID="C0600510" />
<CON ID="C0013806" />
<CON ID="C1849011" />
<CON ID="C1550227" />
<CON ID="C0086881" />
</LUNIT>
<LUNIT>
<CON ID="C1550227" />
<CON ID="C1850808" />
<CON ID="C0086881" />
<CON ID="C0037922" />
<CON ID="C0013806" />
<CON ID="C0600510" />
<CON ID="C0439200" />
<CON ID="C1532563" />
<CON ID="C1334803" />
<CON ID="C0014938" />
</LUNIT>
<LUNIT>
<CON ID="C1152393" />
<CON ID="C0439534" />
</LUNIT>
<LUNIT>

6.2. Perspectives
-163-
<CON ID="C0041600" />
…………
…………
</DOC>
…………
…………
Exemple de jugement de pertinence fourni par CLEF 2007(pour la requête
74)
…………
…………
74 0 2560 0
74 0 2561 0
74 0 10059 0
74 0 2570 0
74 0 2571 0
74 0 2594 0
74 0 2605 0
74 0 2677 0
74 0 2696 2
74 0 2705 0
74 0 2751 0
74 0 2753 0
74 0 2758 0
74 0 2759 0
74 0 2761 0
74 0 2778 0
74 0 2785 0
74 0 10805 2
74 0 2798 0
74 0 2818 2
74 0 2871 0
74 0 2969 0
74 0 2981 0
74 0 11723 0
74 0 2990 0
74 0 2995 0
74 0 11734 0
74 0 3020 0
74 0 3024 0
74 0 3025 0
74 0 3039 0
74 0 3065 0
74 0 3070 0
…………
…………
Exemple de sortir trec_eval
…………
…………
Queryid (Num): 730
Total number of documents over all queries
Retrieved: 1000
Relevant: 156
Rel_ret: 72
Interpolated Recall - Precision Averages:

6.2. Perspectives
-164-
at 0.00 1.0000
at 0.10 0.8571
at 0.20 0.7619
at 0.30 0.7015
at 0.40 0.5888
at 0.50 0.0000
at 0.60 0.0000
at 0.70 0.0000
at 0.80 0.0000
at 0.90 0.0000
at 1.00 0.0000
Average precision (non-interpolated) over all rel docs
0.3319
Precision:
At 5 docs: 1.0000
At 10 docs: 0.8000
At 15 docs: 0.8667
At 20 docs: 0.8500
At 30 docs: 0.7333
At 100 docs: 0.6000
At 200 docs: 0.3550
At 500 docs: 0.1440
At 1000 docs: 0.0720
R-Precision (precision after R (= num_rel for a query) docs
retrieved):
Exact: 0.4551
Queryid (Num): 41
Total number of documents over all queries
Retrieved: 36264
Relevant: 3584
Rel_ret: 1953
Interpolated Recall - Precision Averages:
at 0.00 0.6097
at 0.10 0.4643
at 0.20 0.4139
at 0.30 0.3659
at 0.40 0.3449
at 0.50 0.2309
at 0.60 0.1700
at 0.70 0.1571
at 0.80 0.1200
at 0.90 0.0627
at 1.00 0.0020
Average precision (non-interpolated) over all rel docs
0.2436
Precision:
At 5 docs: 0.4244
At 10 docs: 0.4098
At 15 docs: 0.3870
At 20 docs: 0.3659
At 30 docs: 0.3276
At 100 docs: 0.1961
At 200 docs: 0.1400
At 500 docs: 0.0796
At 1000 docs: 0.0476
R-Precision (precision after R (= num_rel for a query) docs
retrieved):
Exact: 0.2653
6.2. Perspectives
-165-
Exemple d’analyse lexicale réalisé par MuDIBO
urlshort IndiceDebut Lexeme NumPhrase Rang
3331 0 Coupe 1 1
3331 6 axiale 1 2
3331 13 CT 1 3
3331 16 Au 1 4
3331 19 niveau 1 5
3331 26 De 1 6
3331 29 C4 1 7
3331 33 En 1 8
3331 36 fenêtre 1 9
3331 44 osseuse 1 10
3331 53 Le 2 1
3331 56 CT 2 2
3331 59 permet 2 3
3331 66 De 2 4
3331 69 mesurer 2 5
3331 77 Les 2 6
3331 83 diminutions 2 7
3331 95 Du 2 8
3331 98 canal 2 9
3331 104 rachidien 2 10
3331 115 Dans 3 1
3331 120 Ce 3 2
3331 123 Cas 3 3
3331 128 Le 3 4
3331 131 diamètre 3 5
3331 140 antéro-postérieur 3 6
… … … … …


-167-
Bibliographie
ARNOLD et al. (1994). ARNOLD D., BALKAN L., MEIJER S., HUMPHREYS R. L, SADLER L.
Representation and Processing, In Machine Translation: an Introductory
Guide, chapter 3, p. 37–62. NCC Blackwell Ltd.
AUSSENAC et al. (2004). AUSSENAC G N., MOTHE J. Ontologies as Background
Knowledge to Explore Document Collections, In Actes de la Conférence sur la
Recherche d'Information Assistée par Ordinateur (RIAO), pp 129-142 .
BAAYEN et al. (1996). BAAYEN H., VAN HALTEREN H., TWEEDIE F. Outside the Cave of
Shadows : Using Syntactic Annotation to Enhance Authorship Attribution,
Literary and Linguistic Computing 11, 3, p: 121-131.
BAZIZ. (2005). BAZIZ M. indexation conceptuelle/sémantique guidée par ontologie
pour la recherche d'information, Thèse de Doctorat en informatique effectuée
à l'Institut de Recherche en Informatique de Toulouse (IRIT) .
BAZIZ et al. (2007). BAZIZ M., BOUGHANEM M., PASI G., PRADE H. An Information
Retrieval Driven by Ontology from Query to Document Expansion .
Proceedings of the 8th Conference on Large-Scale Semantic Access to Content
(Text, Image, Video and Sound), RIAO 2007 .
BENSON. (1989). BENSON M. The Structure of the Collocational Dictionary, in
International Journal of Lexicography.
BENVENISTE. (1966). BENVENISTE E. Formes nouvelles de la composition nominale,
dans Bulletin de la société linguistique de Paris, repris dans Problèmes de
linguistique générale, tome 2, Paris, Gallimard, 1974, p: 163-176.
BERLAND et al. (1999). BERLAND M., CHARNIAK E. Finding parts in very large corpora.
In Annual meeting of Association of Computational Linguisitcs.
BERNHARD. (2006). BERNHARD D. Apprentissage de connaissances morphologiques
pour l’acquisition automatique de ressources lexicales. Thèse de doctorat en
sciences cognitives, Université Joseph Fourier – Grenoble I .
BOITET. (2001). BOITET C. Méthodes d’acquisition lexicale en TAO: des dictionnaires
spécialisés propriétaires aux bases lexicales généralistes et ouvertes. In D.

<Bibliographie
-168-
MAUREL,Ed., Actes de TALN 2001 (Traitement automatique des langues
naturelles), Tours: Université de Tours .
BOURIGAULT. (1992). BOURIGAULT D. Surface Grammatical Analysis for the
Extraction of Terminological Noun Phrases, dans Proceedings of the
Fourteenth International Conference on ComputationalLinguistics-COLING 92,
Nantes, p. 977-981.
BOURIGAULT. (1994). BOURIGAULT D. Un logiciel d’extraction de terminologie:
Application à l’acquisition de connaissances à partir de textes, thèse de
doctorat, Paris, École des Hautes Études en Sciences Sociales, 352 p.
BOURIGAULT. (1996). BOURIGAULT D. LEXTER, a Natural Language Processing tool
for terminology extraction. Proceedings of the 7th EURALEX International
Congress, Goteborg .
BOURIGAULT et al. (2000). BOURIGAULT D., FABRE C. Approche linguistique pour
l'analyse syntaxique de corpus. Cahiers de grammaire, Vol.25, p: 131-151 .
BOWKER et al. (2002). BOWKER L., PEARSON J. Working with Specialized Language :
A Practical Guide to Using Corpora, London/New York : Routeledge .
BRACHMAN. (1977). BRACHMAN R.,. A Structural Paradigm for Representing
Knowledge, Ph.D. thesis, Harvard University, USA .
BRACHMAN et al. (1985). BRACHMAN R. J., SCHMOLZE J.G. An Overview of the KL-
ONE Knowledge Representation System, Cognitive Science, 9, p: 171-216.
BRACKENRIDGE. (1978). BRACKENRIDGE C.J. A study of phenotypic arrays derived
from seven genetic systems in an Australian population sample, Annals of
Human Biology, p: 381-388 .
BRILL. (1992). BRILL E. A simple rule-based part of speech tagger, Proceedings of the
Third Conference on Applied Computational Language (ACL) Processing,
Trento .
BROWN et al. (1988). BROWN P., COCKE J., DELLA PIETRA S., DELLA PIETRA V.,
JELINEK F., MERCER R., ROOSSIN P. A statistical approach to language
translation. In: Proceedings of the 12th conference on Computational
linguistics . Budapest, Hungry .
BROWN et al. (1990). BROWN P., COCKE J., DELLA PIETRA S., DELLA PIETRA V.,
JELINEK F., MERCER R., ROOSSIN P. A statistical calcul approach to machine
translation. Computational linguistics .valume 16, n°2 .

<Bibliographie
-169-
BRUNET. (1988). BRUNET E. Une mesure de la distance intertextuelle : la connexion
lexicale, Le nombre et le texte. Revue informatique et statistique dans les
sciences humaines 24 ,p: 81-116.
BUCKLEY et al. (1995). BUCKLEY C., SINGHAL A.,MITRA M. . New Retrieval Approaches
Using SMART: TREC 4. TREC 1995.
BULSKOV. (2006). BULSKOV H. Ontology-based Information Retrieval, PhD Thesis,
Roskilde University, Denmark, Mai 2006 .
BUSCALDI et al. (2005). BUSCALDI D., ROSSO P., MONTES-Y-GOMEZ M.,. Context
Expansion with Global Keywords for a Conceptual Density-Based WSD.
CICLing, pp: 263-266.
CALLAN et al. (1992). CALLAN J. P., CROFT W.B, HARDING S.M. The INQUERY Retrieval
System. DEXA 1992, pp: 78-83.
CANCEDDA et al. (2003). CANCEDDA N., DÉJEAN H., GAUSSIER E., RENDERS J.M,
VINOKOUROV A. Report on CLEF-2003 experiments: two ways of extracting
multilingual resources from corpora. In C. PETERS, Ed., Proceedings of Cross
Language Evaluation Forum (CLEF2003), Trondheim, Norway: Springer .
CARON et al. (2005). CARON Y., MAKRIS P., VINCENT N. Zipf Law Models for Image
Analysis, Fractals In Engineering 2005, CDROM, TOURS (FRANCE), pp: 22-24
juin 2005.
CARTIER. (1997). CARTIER E. La définition dans les textes scientifiques et techniques :
présentation d'un outil d'extraction automatique de relations définitoires .
Actes des deuxièmes rencontres Terminologie et Intelligence Artificielle
(TIA'97), pp 127-140. Toulouse.
CEDERBERG et al. (2003). CEDERBERG S.,WIDDOWS D. (2003). Using lsa and noun
coordination information to improve the precision and recall of the hyponymy
extraction. In conference on Natural Language Learning.
CHEVALLET. (1992). CHEVALLET J.P. Un modèle logique de Recherche d'Information
appliqué au formalisme des graphes Conceptuels. Le prototype ELEN et son
expérimentation sur un corpus de composants logiciels. Thèse de l'Université
Joseph Fourier Grenoble I .
CHIAO. (2004). CHIAO Y.-C. Extraction lexicale bilingue à partir de textes médicaux
comparables : application à la recherche d’information translangue, thèse,
UNIVERSITÉ PARIS 6 .

<Bibliographie
-170-
CHIAO et al. (2002). CHIAO Y.-C., ZWEIGENBAUM P. Looking for candidate
translational equivalents in specialized, comparable corpora. In Proceedings of
the American Medical Informatics association 2002 Annual Symposium, pp:
150–154, San Antonio, Texas.
CHURCH et al. (1990). CHURCH .K. W., HANKS P. Word association norms, mutual
information and lexicography. Computational Linguistic, vol 1, Mars 1990, pp:
22-29 .
CIARAMITA et al. (2005). CIARAMITA M., GANGEMI A., RATSCH E., SARIC J., ROJAS I.
Unsupervised learning of semantic relations between concepts of a molecular
biology ontology. In International Joint Conference on Artificial Intelligence.
CLAVEAU. (2003). CLAVEAU V. Acquisition automatique de lexiques sémantiques pour
la recherche d'information, Thèse de doctorat, Université de Rennes 1 .
CONDAMINES et al. (2000). CONDAMINES A, REBEYROLLES J. Construction d'une base
de connaissances terminologiques à partir de textes : expérimentation et
définition d'une méthode. In CHARLET J, ZACKLAD M., KASSEL G. &
BOURIGAULT D. éds. Ingénierie des connaissances .
COWIE. (1981). COWIE A. The Treatment of Collocations and Idioms in Learners’
Dictionaries, in Applied Linguistics, Vol. 11, pp: 223-23.
CROFTS et al. (2008). CROFTS N., DOERR M., GILL T., STEAD S., STIFF M. Definition of
the CIDOC Conceptual Reference Model, March 2008.
DAGAN et al. (1997). DAGAN I., CHURCH K. Termight: Coordinating man and machine
in bilingual terminology acquisition. Machine Translation, 12(1-2), pp: 89–107.
DAILLE. (1994). DAILLE B. Approche mixte pour l’extraction de terminologie :
statistiquel exicale et filtres linguistiques. Rapport interne, Université de Paris
7. Thèse de Doctorat en Informatique Fondamentale .
DAILLE. (1996). DAILLE B. Study and implementation of combined techniques for
automatic extraction of terminology. In J. KLAVANS & P. RESNICK, Eds., The
Balancing Act :Combining Symbolic and Statistical Approaches to Language, p.
49–66. MIT Press .
DAILLE. (1999). DAILLE B. Identification des adjectifs relationnels en corpus. Actes de
la Conférence de Traitement Automatique du Langage Naturel (TALN'99),
Cargèse.

<Bibliographie
-171-
DAILLE. (2002). DAILLE B. Découvertes linguistiques en corpus, Mémoire
d'Habilitation à Diriger des Recherches en Informatique, Université de Nantes.
DAVID et al. (1990). DAVID S., PLANTE P. De la nécessité d'une approche morpho-
syntaxique en analyse de textes, dans Intelligence Artificielle et Sciences
Cognitives au Québec, vol. 2, no 3, septembre, pp: 140-155.
DEJEAN et al. (2002). DEJEAN H., GAUSSIER E. Une nouvelle approche à l’extraction
de lexiques bilingues à partir de corpus comparables. Lexicometrica, numéro
spécial sur Alignement lexical dans les corpus multilingues, pp: 1–22 .
DELBECQUE et al. (2005). DELBECQUE H., JACQUEMART P. , ZWEIGENBAUM P.
Utilisation du réseau sémantique de l'UMLS pour la définition de types
d'entités nommées médicales dans un système de questions-réponses : impact
de la source des documents explorés. In CORIA pages 101-115, Grenoble,
2005. CLIPS .
DING et al. (2001). DING Y., ENGELS R. IR and AI: Using co-occurrence Theory to
Generate Lightweight Ontologies. DEXA Workshop 2001, pp: 961-965.
DUCHASTEL et al. (1992). DUCHASTEL J., ARMONY V. . « Étude d'un corpus de
dossiers de la Cour juvénile de Winnipeg à l'aide du Système d'analyse de
textes par ordinateur (SATO) », in M. BÉCUE, L. LEBART et N. RAJADELL (dir.),
Jornades Internacionals d'Anàlisi de Dades Textuals, Bar .
DUNNING. (1993). DUNNING T. Accurate Methods for the Statistics of Surprise and
Coincidence, Computational Linguistics, vol. 19, n°1, pp: 71-74, Mars 1993 .
ENGUEHARD. (1994). ENGUEHARD C. Automatic natural acquisition of a terminology.
In Proceedings of the 2nd International Conference of Quantitative Linguistics
(QUALICO’94), pp: 83–88, Moscow .
ENGUEHARD et al. (1992). ENGUEHARD C., MALVACHE P., TRIGANO P. Indexation de
textes : l’apprentissage automatique de concepts. In Actes du XVème colloque
international en linguistique informatique, pp: 1197–1202, Nantes.
EVEOL et al. (2005). EVEOL A., OZDOWSKA S. NExtraction bilingue de termes
médicaux dans un corpus parallèle anglais/français. EGC, Paris .
E-WOK_HUB. (2008). E-WOK_HUB Consortium. Semantic Hubs for Geological
Projects, ESWC'2008 Workshop on Semantic Metadata Management and
Applications (SeMMA'2008), June 2, 2008, Teneriffe, Spain .

<Bibliographie
-172-
FELLBAUM. (1998). FELLBAUM C. WordNet, an Electronic Lexical Database. The MIT
Press .
FERRET et al. (2001). FERRET O., GRUAU B. Utiliser des corpus pour amorcer une
analyse thématique, dans Traitement automatique de la langue, no 2, vol. 42,
Paris, Hermès,pp: 517-545.
FLUHR. (1992). FLUHR C. Le traitement du langage naturel dans la recherche
d’information. In Interface intelligente dans l’information scientifique et
technique, Klingenthal : INRIA,1992. p103-130.
FOTZO et al. (2004). FOTZO H. N., GALLINARI P. Information access via topic
hierarchies and thematic annotations from document collections. In
International Conference on Enterprise Information Systems, pages 69-76.
FRANTZI et al. (1997). FRANTZI K. T., ANANIADOU S. Automatic Term Recognition
Using Contextual Cues, dans Proceedings of the 3rd DELOS Workshop, Zurich,
tiré à part, 8 p.
FRANTZI et al. (1999). FRANTZI K. T., ANANIADOU S., TSUJII J. Classifying Technical
Terms , dans Proceedings Third ICCC/IFIP Conference on Electronic Publishing,
Ronneby, p. 144-155.
FUNG et al. (1997). FUNG P., MCKEOWN K. Finding Terminology Translations from
Non-Paralle Corpora. In Proceedings of the 5th Annual Workshop on Very
Large Copora, volume 1, p. 192–202, Hong Kong.
FUNG et al. (1998). FUNG P., YEE L. Y. An IR approach for translating new words from
nonparallel, comparable texts. In Proceedings of the 17th International
Conference on Computational Linguistics and 36th Annual Meeting of the
Association for Computational Linguisti .
GALE et al. (1991). GALE W., CHURCH K. A program for aligning sentences in bilingual
corpora , Proceedings of the 29th Annual Meeting of the Association for
Computational Linguistics, 1991, Berkley, California, p. 177-184 .
GAMMOUDI. (1993). GAMMOUDI M. M. . Méthode de décomposition rectangulaire
d'une relation binaire : une base formelle et uniforme pour la génération
automatique des thesaurus et la recherche documentaire. Thèse de doctorat
de l'Université de Nice-Sophia Antipolis. Spécialité informatique .
GARCIA. (1998). GARCIA D. Analyse automatique des textes pour l'organisation
causale des actions, Réalisation du système informatique COATIS. Thèse de
doctorat. Université de Paris-Sorbonne.

<Bibliographie
-173-
GARÇON. (2005). GARÇON J. L. NTIC & ÉTHIQUES… QUELLE VALEUR POSSÈDE
L’INFORMATION EN LIGNE? Enjeux liés à l’information et conséquences de la
rencontre entre Marketing et information en ligne. Mémoire de DESS,
INSTITUT NATIONAL DES LANGUES ET CIVILISATIONS ORIENTALES .
GAUSSIER. (1998). GAUSSIER E. Flow network models for word alignment and
terminology extraction from bilingual corpora. In C. BOITET & P. WHITELOCK,
Eds., Proceedings of the Thirty-Sixth Annual Meeting of the Association for
Computational Linguistics and Seventeent .
GENEST et al. (2005). GENEST D., CHEIN M. A Content-search Information Retrieval
Process Based on Conceptual Graphs, Knowledge And Information Systems,
volume 8, numéro 3, pages 292-309. Springer .
GENEST. (2000). GENEST D. Extension du modèle des graphes conceptuels pour la
recherche d'informations, Université Montpellier II, Décembre 2000.
GIGUET. (1998). GIGUET E. Méthode pour l'analyse automatique de structures
formelles sur documents multilingues. Thèse de doctorat, spécialité
Informatique. Université de Caen .
GIRJU et al. (2002). GIRJU R., MOLDOVAN D. Text mining for causal relations. In
15sup th international Florida Artificial Intelligence Research Society
Conference, pp: 360-364.
GIRJU et al. (2003). GIRJU R., BADULESCU A., MOLDOVAN D. Learning semantic
constraints for the automatic discovery of part-whole relations. In Human
Language Technologies and North Ameircan Association of Computational
Linguisitcs, pages 80-87.
GOUJON. (1999). GOUJON B. Extraction d'informations techniques pour la veille par
exploration de notions indépendantes d'un domaine . Terminologies nouvelles
n° 19. pp 33-42.
GOWER. (1985). GOWER J. C. « Measures of similarity, dissimilarity and distance », in
Kotz S., Johnson N.-L. & Read C.-B. (eds), Encyclopedia of Statistical Sciences,
vol. 5. New York : Wiley, 397-405.
GRUBER. (1993). GRUBER T. R. Toward Principles for the design of Ontologies used for
Knowledge Sharing. in Proc of International Workshop on Formal Ontology,
Padova, Italy, March.

<Bibliographie
-174-
GRUNDY. (1996). GRUNDY V. L’utilisation d’un corpus dans la rédaction du
dictionnaire bilingue. In B. H. & T. P, Eds., Les dictionnaires bilingues, p. 127–
149. Louvain-la-Neuve, Duculot.
GUARINO et al. (1999). GUARINO N., MASOLO C, VETERE G.,. OntoSeek: Content-
Based Access to the Web, IEEE Intelligent System.
GUARINO. (1997). GUARINO N. Semantic Matching: Formal Ontological Distinctions
for Information Organization, Extraction, and Integration. SCIE 1997: 139-170.
GUO et al. (2004). GUO Y., HARKEMA H., GAIZAUSKAS R. Sheffield University and the
TREC 2004 Genomics Track : Query Expansion Using Synonymous terms, 2004.
HABERT et al. (1995). HABERT B., BARBAUD P., DUPUIS F. ET JACQUEMIN C. Simplifier
des arbres d'analyse pour dégager les comportements syntaxico-sémantiques
des formes d'un corpus. Cahiers de Grammaire, n20, 1995, pp. 1-32.
HARRATHI et al. (2005). HARRATHI F. , CALABRETTO S. , ROUSSEY C. . . Indexation
semi automatique de corpus multilingues basée sur une ontologie. Dans
Colloque Indice, Index, indexation, Ismail TIMIMI, Susan KOVACS ed. Lille. pp.
203-219. Sciences et Techniques de l'information . ADBS 25 rue Claude Tillier
75012 Paris.
HARRATHI et al. (2009). HARRATHI F., ROUSSEY C., CALABRETTO S., MAISSONNACE
L., GAMMOUDi M.M. Une approche d’indexation sémantique des documents
multilingues guidée par une ontologie. Dans RISE (Recherche d’Information
SEmantique) dans le cadre de la conférence INFORSID’2009 .
HAUSMANN. (1979). HAUSMANN F. Un dictionnaire des collocations est-il possible?,
in Travaux de linguistique et de littérature, Vol. 17, 187-195.
HEARST et al. (1997). HEARST M.A., KARADI C. Cat-a-Cone: an interactive interface
for specifying searches and viewing retrieval results using a large category
hierarchy, Conference on Research and Development in Information Retrieval
(SIGIR), pp: 246-257.
HEARST. (1992). HEARST M. Automatic acquisition of hyponyms from large text
corpora. In 14sup th International Conference on Computational Linguistics.
HERNANDEZ . (2005). HERNANDEZ N. Ontologies de domaine pour la modélisation du
contexte en Recherche d'information. Thèse de doctorat de l'Université Paul
Sabatier de Toulouse, Spécialité Informatique .

<Bibliographie
-175-
HERNANDEZ et al. (2004). HERNANDEZ N., MOTHE J. An approach to evaluate
existing ontologies for indexing a document corpus, Actes de AIMSA, pp: 11-
21.
HERNANDEZ et al. (2006). HERNANDEZ N., MOTHE J. TtoO: une méthodologie de
construction d’ontologie de domaine à partir d’un thésaurus et d’un corpus de
référence. Rapport de recherche, IRIT/RR—2006-04--FR, IRIT, février.
HIEMSTRA et al. (1997). HIEMSTRA D., DE JONG F., KRAAIJ W.HIEMSTRA. A domain
specific lexicon acquisition tool for cross-linguage information retrieval. In L.
DEROYE & C. CHRISMENT, Eds., Proceedings of RIAO97 Conference on
Computer-Assisted Searching on the Internet, p. 217–232, .
HIEMSTRA. (1998). HIEMSTRA D. Multilingual domain modeling in Twenty-One:
automatic creation of a bi-directional translation lexicon from a parallel
corpus. In H. V. H. PETER-ARNO COPPEN & L. TEUNISSEN, Eds., Proceedings of
the eightth CLIN meeting, p. 41–58.
HIEMSTRA. (2002). HIEMSTRA D. Term-Specific Smoothing for the Language
Modeling Approach to Information Retrieval: The Importance of a query Term.
In Proc. ACM SIGIR conference, (2002) 35–41 .
HILL. (1970). HILL B. M. Zipf's law and prior distributions for the composition of a
population, Journal of the American Statistical Association, 65:1220-1232.
HO. (2004). HO B Q. Vers une indexation structurée basée sur des syntagmes
nominaux (impact sur un SRI en vietnamien et la RI multilingue). thèse de
doctorat , UNIVERSITE JOSEPH FOURIER – GRENOBLE I.
HOLMES. (1995). HOLMES D. The Federalist revisited : new directions in autorship
attribution, Literary and Linguistic Computing 10, 2 : 111-127.
HUBALEK. (1982). HUBALEK Z. « Coefficients of Association and Similarity, based on
Binary (Presence Absence) Data : an Evaluation », Biol. Rev. 57 : 669-689.
INTERNET . (2009). INTERNET WORD STATS. Internet Usage World Stats - Internet
and Population Statistics [en ligne], disponible à
http://www.internetworldstats.com/, (consulté le 28/03/2009) .
JACQUEMIN et al. (2002). JACQUEMIN C., DAILLE B., ROYANTE, J., AND POLANCO X.
In vitro evaluation of a program for machine-aided indexing. Inf. Process.
Manage. 38, 6 (Nov. 2002), 765-792.

<Bibliographie
-176-
JACQUEMIN. (1996). JACQUEMIN C. A Symbolic and Surgical Acquisition of Terms
Through Variation. In Wermter S., Riloff E., Scheler G. (eds.), Connectionist,
Statistical and Symbolic Approaches to Learning for Natural Language
Processing. Springer, Heidelberg, pp. 425–438.
JACQUEMIN. (1997). JACQUEMIN C. Variation terminologique : Reconnaissance et
acquisition automatiques de termes et de leurs variantes en corpus. Mémoire
d'habilitation à diriger des recherches en informatique fondamentale,
Université de Nantes.
JACQUEMIN. (1998). JACQUEMIN C. Analyse et inférence de terminologie. Revue
d'Intelligence Artificielle. 12(2), pp: 163-205.
JACQUEMIN. (1999). JACQUEMIN C. Syntagmatic and paradigmatic representations
of term variation. Proceedings of the 37th Annual Meeting of the Association
for Computational Linguistics (ACL'99), pages 341-348, University of
Maryland.
JOUIS. (1993). JOUIS C. Contribution à la conceptualisation et à la modélisation des
connaissances à partir d'une analyse linguistique de textes, Réalisation d'un
prototype : le système SEEK, Thèse de Doctorat, EHESS, Paris.
KANG. (2003). KANG B.Y. A novel approach to semantic indexing based on concept.
Dans ACL ’03 : Proceedings of the 41st Annual Meeting on Association for
Computational Linguistics, (p. 44–49) (Association for Computational
Linguistics, Morristown, NJ, USA). ISBN 0-111-456789.
KASHYAP et al. (2004). KASHYAP V., RAMAKRISHNAN C., THOMAS C., BASSU D., RIND-
ESCH T. C., SHETH A. Taxaminer: An experimental on framework for
automated taxonomy bootstrapping. Technical report, University of Georgia.
KAVALEC et al. (2004). KAVALEC M., MAEDCHE A., SVATEK V. Discovery of lexical
entries for non-taxonomic relations in ontology learning. In SOFSEM.
KRAAIJ. (2004). KRAAIJ WESSEL. Variations on Language Modeling for Information
Retrieval. PhD thesis, University of Twente.
LABBE et al. (2003). LABBE C., LABBE D. La distance intertextuelle, Corpus, Numéro 2,
La distance intertextuelle - décembre 2003, 2003, [En ligne], mis en ligne le 15
décembre 2004. URL : http://corpus.revues.org/document31.html. Consulté
en juin 2006 .

<Bibliographie
-177-
LABBE et al. (2001). LABBE C., LABBE D. Inter-Textual Distance and Authorship
Attribution Corneille and Moliere, Journal of Quantitative Linguistics 8, 3 :
213-231.
LABBE et al. (2006). LABBE C., LABBE D. A Tool for Literary Studies: Intertextual
Distance and Tree Classification, Literary and Linguistic Computing, 2006,
Vol.21, N°3, pp. 311-326.
LAFON. (1980). LAFON P. Sur la variabilité de la fréquence des formes dans un corpus,
dans MOTS, no 1, p. 128-165.
LE MOIGNO et al. (2002). LE MOIGNO S., CHARLET J., BOURIGAULT D., JAULENT M.
Construction d’une ontologie à partir de corpus : expérimentation et
validation dans le domaine de la réanimation chirurgicale, In IC 2003, Rouen .
LE PRIOL. (2000). LE PRIOL F. Extraction et capitalisation automatique de
connaissances à partir de documents textuels. SEEK-JAVA : identification et
interprétation de relations entre concepts, Thèse de Doctorat en Informatique,
Université Paris-Sorbonne, 2000.
LEBART et al. (1988). LEBART L., SALEM A. Analyse statistique des données textuelles :
questions ouvertes et lexicométrie. Paris: Dunod .
LEBART et al. (1994). LEBART L., SALEM A. Statistique textuelle. Paris: Dunod.
LEE. (1995). LEE J.H. Combining multiple evidence from different properties of
weighting schemes. Dans EIGHTEENTH ACMSIGIR (edité par Ewdard A. Fox),
(p. 180–188) (Seattle, Washington). — cité en page(s) 13 .
LEVENSHTEIN. (1966). LEVENSHTEIN V. I. Binary codes capable of correcting
deletions, insertions and reversals. Sov. Phys. Dokl., 6:707-710, 1966.
LIN et al. (2001). LIN D., PANTEL P. Discovery of Inference Rules for Question
Answering. Natural Language Engineering, 7(4), pp. 343–360 .
LIN. (1998). LIN D. Dependency-based Evaluation of MINIPAR. Workshop on the
Evaluation of Parsing Systems, Granada, Spain .
LUHN . (1958). LUHN H. The automatic creation of literature abstracts. IBM Journal of
Research and Development, Vol 2, N° 2, pp :159–165.
MAISONNASSE et al. (2008). MAISONNASSE L., GAUSSIER E.,CHEVALLET J. P. Multi-
Relation Modeling on Multi Concept Extraction, LIG participation at
ImageClefMed, in Workshop CLEF 2008 17-19 September, Aarhus, Denmark.

<Bibliographie
-178-
MAISONNASSE et al. (2009). MAISONNASSE L., GAUSSIER E.,Chevallet J-P.
Combinaison d’analyses sémantiques pour la recherche d’information
médicale. Dans RISE (Recherche d’Information SEmantique) dans le cadre de
la conférence INFORSID’2009, Toulouse 2009 .
MAISONNASSE. (2008). MAISONNASSE L. . Les supports de vocabulaires pour les
systèmes de recherche d’information orientés précision : application aux
graphes pour la recherche d’information médicale. Université Joseph Fourier –
Grenoble . I. Thèse de Doctorat en Informatique.
MARTIN. (1996). MARTIN P. Exploitation de graphes conceptuels et de documents
structurés et hypertextes pour l'acquisition de connaissances et la recherche
d'informations. Thèse de l’Université de Nice - Sophia Antipolis, 1996 .
MEDIN. (1989). MEDIN D. L. Concepts and conceptual structure. American
Psychologist, volume 44, n°12, pp::1469-1481 .
MIHALCEA et al. (2000). MIHALCEA R., MOLDOVAN D.I. Semantic Indexing using
WordNet Senses, Actes de ACL Workshop on IR & NLP,
acl.ldc.upenn.edu/W/W00/W00-1104.pdf, 2000.
MILLER et al. (1990). MILLER G., BECKWITH R., FELLBAUM C., GROSS D., MILLER K.
Five papers on WordNet. Rapport interne, Cognitive Science Laboratory,
Princeton University.
MOLDOVAN et al. (2000). MOLDOVAN D.I. , MIHALCEA R. Using WordNet and Lexical
Operators to Improve Internet Searches. IEEE Internet Computing, tome 4(1)
:p. 34–43. ISSN 1089-7801. — cité en page(s) 18 .
MOREAU et al. (2006). MOREAU F., CLAVEAU V. . Extension de requêtes par relations
morphologiques acquises automatiquement. In Actes de la Troisième
Conférence en Recherche d’Informations et Applications CORIA 2006, pages
181–192.
MORIN et al. (2004). MORIN E., JACQUEMIN C. Automatic Acquisition and Expansion
of Hypernym Links. Computers and the Humanities (CHUM), Kluwer, 38(4), p:
363–396 .
MORIN et al. (2004). MORIN E., DUFOUR-KOWALSKI S., DAILLE B. Extraction de
terminologies bilingues à partir de corpus comparables, Actes, 11ème
Conférence annuelle sur le Traitement Automatique des Langues Naturelles
(TALN) .

<Bibliographie
-179-
MORIN. (1999). MORIN E. Des patrons lexico-syntaxiques pour aider au
dépouillement terminologiques, Traitement Automatique des Langues,
volume 40, Numéro 1, pages 143-166 .
MORIN. (1999a). MORIN E. Extraction de Liens Sémantiques Entre Termes à Partir de
Corpus de Textes Techniques. PhD thèse, Université de Nantes .
MOTHE et al. (2007). MOTHE J., HERNANDEZ N., . TtoO: Mining thesaurus and texts
to build and update a domain ontology, In: Data Mining with Ontologies:
Implementations, Findings, and Frameworks. H. O. Nigro, S. G. Císaro, and
D.Xodo. Idea Group Inc .
MUGNIER et al. (1996). MUGNIER M., CHEIN M. Représenter des connaissances et
raisonner avec des graphes, Revue d’Intelligence Artificielle, vol. 10, n° 1, p. 7-
56, 1996.
MULLER et al. (2007). MULLER H, DESELAERS T, LEHMANN T, CLOUGH P and HERSH
W. Overview of the ImageCLEFmed 2006 medical retrieval and annotation
tasks . Evaluation of Multilingual and Multi-modal Information Retrieval --
Seventh Workshop of the Cross-Language Evaluation Forum .
MULLER. (1977). MULLER C. Principes et méthodes de statistique lexicale. Paris :
Hachette.
NIE et al. (1997). NIE J-Y, CHEVALLET J.P. , CHIARAMELLA Y. Vers la recherche
d'informations a base de termes, in 1eres Journees Scientifiques et Techniques
du Reseau Francophone de l'Ingerierie de la Langue de l'AUPELF-URF, Avignon
- France, pp119-125, 15-16 Avril.
NIE. (2002). NIE J-Y. Torwards a Unified Approach to CLIR and Multilingual IR – SIGIR
2002, 2002.
NLM. (2009). NLM. Unified Medical Language System Fact Sheet [en ligne].
Disponible sur: http://www.nlm.nih.gov/pubs/factsheets/umls.html. (consulté
le 23/04/2009) .
OARD et al. (1997). OARD D. W., HACKETT P. Document Translation for Cross-
Language Text Retrieval at the University of Maryland. TREC 1997: 687-696.
Observatoire. (2006). Observatoire. Observatoire du Traitement Informatique des
Langues et de l'Inforoute, C - Lexique de l'inforoute et du traitement
informatique des langues, http://www.owil.org/lexique/c.htm, consulté en
Décembre 2006.

<Bibliographie
-180-
OUESLATI. (1999). OUESLATI R. Aide à l’acquisition de connaissances à partir de
corpus. Rapport interne, Université Louis Pasteur Strasbourg. Thèse de
Doctorat en Informatique.
PANTEL et al. (2002). PANTEL P., LIN D. Discovering Word Senses from Text. In
Proceedings of ACM SIGKDD Conference on Knowledge Discovery and Data
Mining 2002. pp. 613-619. Edmonton, Canada .
PAROUBEK et al. (2000). PAROUBEK P., RAJMAN M. Etiquettage morphosyntaxique ,
danss Ingenierie des Langues , Collection Information Commande
Communication , aux Editions Hermes Science ISBN 2-7462-0113-5, october
2000 pp 131-148.
PATRIARCHE et al. (2005). PATRIARCHE R., GEDZELMAN S., DIALLO G., BERNHARD D.,
BASSOLET C., FERRIOL S., GIRARD A., MOURIES M., PALMER P, SIMONET M.
Noesis Annotation Tool: Un outil pour l’annotation textuelle et conceptuelle de
documents. Ingenierie des Connaissances IC'2005, Nice (France) Mai 2005.
PERRON. (1996). PERRON J. ADEPTE-NOMINO : un outil de veille terminologique ,
dans Terminologies nouvelles, no 15, juin et décembre, Bruxelles, RINT, p. 32-
47.
PERY-WOODLEY. (1995). PERY-WOODLEY M.P. Quels corpus pour quels traitements
automatiques ? Traitement Automatique de la Langue (TAL), volume 36, n°
1et 2 .p : 213-232.
PHILIPP. (2005). PHILIPP K. Europarl: A Parallel Corpus for Statistical Machine
Translation. In MT Summit 2005.
PONTE et al. (1998). PONTE J M. and CROFT W B. A Language Modeling Approach to
Information Retrieval, Research and Development in Information Retrieval:
75-281.
PUNURU. (2008). PUNURU J. R. Knowledge-Based Methods for Automatic Extraction
of Domain-Specific Ontologies. Phd thesis, Louisiana State University, degree
of Doctor of Philosophy.
PURANDARE. (2003). PURANDARE A. . Discriminating Among Word Senses Using
Mcquitty's Similarity Analysis, Actes de HLT-NAACL 03 - Student Research
Workshop.
QUILLIAN. (1968). QUILLIAN R. Semantic memory. Semantic information processing,
pages 227-270.

<Bibliographie
-181-
QUINLAN. (1993). QUINLAN R. J. C4.5: Programs for Machine Learning. Morgan
Kaufmann.
RADHOUANI. (2008). RADHOUANI S. Un modèle de Recherche d'Information orienté
précision fondé sur les dimensions de domaine. Ph.D. Thesis, University of
Geneva, Geneva, Switzerland, Joseph Fourier University, Grenoble, France .
RAJMAN et al. (1992). RAJMAN M., BONNET A. Corpora-base linguistics: new tools for
natural language processing. In Proceedings of the 1st Annual Conference of
the Association for Global Strategic Information, Bad Kreusnach, Germany.
RAPP . (2003). RAPP R. Word Sense Discovery Based on Sense Descriptor Dissimilarity,
Actes deMachine Translation Summit IX.
RAPP. (1999). RAPP R. Automatic identification of word translations from unrelated
English and German corpora. In Proceedings of the 37th Annual Meeting of
the Association for Computational Linguistics (ACL), College Park, MD.
RASTIER et al. (1994). RASTIER F., CAVAZZA M., ABEILLE A. . Sémantique pour
l'analyse. Paris : Masson . 234 pages.
REN et al. (1999). REN F., FAN L., NIE J-Y. SAAK Approach: How to Acquire Knowledge
in an Actual Application System, IASTED International Conference on Artificial
Intelligence and Soft Computing, Honolulu, 1999, pp.136-140.
RESNIK et al. (1997). RESNIK P., MELAMED I. Semi-automatic acquisition of domain-
specific translation lexicons. In Proceedings of the 7th ACL Conference on
Applied Natural Language Processing, Washington, DC.
RESNIK. (1993). RESNIK P. Selection and Information: A Class-based Approach to
Lexical Relationships. PhD thesis.
RESNIK. (1995). RESNIK P. Disambiguating noun grouping with respect to wordnet
senses. In Proceedings of the 3th Workshop on Very Large Corpora,
Cambridge, USA.
RICARDO et al. (1999). RICARDO B Y., BERTHIER R N. Modern information retrieval,
ACM (Association for Computing Machinery) .
RIJSBERGEN. (1979). RIJSBERGEN VAN , C. J. Information Retrieval (Second Edition).
London: Butterworth,1979.

<Bibliographie
-182-
RILOFF. (1993). RILOFF E. Automatically contructing a dictionary for information
extraction tasks. In Proceedings of the Eleventh National Conference on
Artificial Intelligence, p. 811–816: AAAI Press/MIT Press.
ROBERTS el al. (1996). ROBERTS R. P., MONTGOMERY C. The use of corpora in
bilingual lexicography, In Proceedings of the Seventh EURALEX International
Congress on Lexicography, p. 457–464, Göteborg: Göteborg University.
ROBERTSON et al. (1997). ROBERTSON S. E, WALKER S. On relevance weights with
little relevance information. In Proceedings of the 20th annual international
ACM SIGIR conference on Research and development in information retrieval,
pages 16–24. ACM Press.
ROBERTSON et al. (1976). ROBERTSON SE , JONES SPARCK K. Journal of the American
Society for Information Science, Vol. 27, No. 3. (1976), pp. 129-146.
ROCHE. (2005). ROCHE C. Terminologie et Ontologie. Langages, N° 157 pages:48–62.
ROUSSELOT et al. (1996). ROUSSELOT F., FRATH P. et OUESLATI R. Extracting
concepts and relations from corpora, Proceedings workshop on Corpus-
Oriented Semantic Analysis, Proceddings of the 12th European Conference on
Artificial Intelligence (ECAI’96) .
ROUSSEY. (2001). ROUSSEY C. Une méthode d’indexation sémantique adaptée aux
corpus multilingues, informatique, Lyon, thèse de l’INSA de Lyon, , 2001, 150
pages.
RUDMAN . (1998). RUDMAN J. « The State of Authorship Attribution Studies : Some
Problems and Solutions », Computers and the Humanities 31 : 351-365.
RYU P et al. (2004). RYU P., CHOI K. S. Measuring the specificity of terms for
automatic hierarchy construction. In European Conference on Artificial
Intelligence Workshop on Ontology Learning and Population.
SAGER. (1980). SAGER J. C. DUNGWORTH, David et Peter F. MCDONALD.
(1980).English Special Languages. Principles and Practice in Science and
Technology, Wiesbaden, Brandstetter, 368 p.
SALTON et al. (1983). SALTON G., FOX E. A., WU H. Extended Boolean information
retrieval system. CACM 26(11), pp. 1022-1036, 1983.
SALTON et al. (1988). SALTON G., BUCKLEY C. Term weighting approaches in
automatic text retrieval. IPM, tome 24 :p. 513–523. — cité en page(s) 13, 14 .

<Bibliographie
-183-
SALTON. (1968). SALTON G. Automatic Information Organization and Retrieval.
McGraw-Hill computer science series. (McGraw-Hill, New York.). — cité en
page(s) 6, 8, 18 .
SALTON. (1970). SALTON G. Automatic processing of foreign language document –
Journal of the American Society for Information Science, 21(3):187-194, May.
SCHUTZ et al. (2005). SCHUTZ A., BUITELAAR P. Relext: A tool for relation extraction
from text in ontology extension. In Fourth International Semantic Web
Conference.
SEGUELA et al. (1999). SEGUELA P., AUSSENAC-GILLES N. Extraction de relations
sémantiques entre termes et enrichissement de modèles du domaine, Actes de
la conférence Ingénierie des Connaissances (IC'99), pp 79-88, Paris .
SEYDOUX. (2006). SEYDOUX F. Exploitation de connaissances sémantiques externes
dans les représentations vectorielles en recherche documentaire, thèse en
informatique, Ecole polytechnique fédérale de LAUSANNE.
SHERIDAN et al. (1997). SHERIDAN, P., BRASCHLER, M., SCHAÜBLE, P. Cross-Langage
Information Retrieval in a Multilingual Legal Domain. In Proceedings of the 1st
European Conference on Digital Libraries (ECDL’97), Pisa Italy, 1997. p 253-
268. (Lecture Notes in Computer Science, Vo .
SINGHAL et al. (1996). SINGHAL A., BUCKLEY C., MITRA M. Pivoted Document Length
Normalization. In Proceedings of SIGIR'1996. pp.21-29 .
SINGHAL et al. (1997). SINGHAL A., MITRA M., BUCKLEY C. Learning routing queries in
a query zone. In Proceedings of the 20th Annual international ACM SIGIR
Conference on Research and Development in information Retrieval
(Philadelphia, Pennsylvania, United States, July 27 - 31, 1997) .
SMADJA et al. (1996). SMADJA F., MCKEOWN K. R., HATZIVASSILOGLOU V.
Translating collocations for bilingual lexicons: A statistical approach.
Computational Linguistics, 22(1), 1–38.
SMADJA. (1993). SMADJA F. Retrieving collocations from text: Xtract. Computational
Linguistics, 19(1), pp: 143-177.
SNOW et al. (2004). SNOW R, JURAFSKY D., ANDREW Y. Learning syntactic patterns
for automatic hypernym discovery. In Advances in Neural information
Processing Systems.

<Bibliographie
-184-
SNOW et al. (2005). SNOW R, JURAFSKY D., ANDREW Y. Learning syntactic patterns
for automatic hypernym discovery. NIPS 17, 2005.
SOUALMIA et al. (2004). SOUALMIA LN., GOLBREICH C. , DARMONI SJ. Representing
the MeSH in OWL : Towards a semi-automatic Migration. In First International
Workshop on Formal Biomedical Knowledge Representation, collocated with
KR 2004. p. 1-12. Whistler, Canada.
SOWA. (1984). SOWA J. Conceptual Structures: information processing in mind and
machine. In The System Programming Series, Reading: Addison Wesley
publishing Company, 1984. 481 pages.
SPARCK JONES . (1991). SPARCK JONES K. Automatic keywords classification for
information retrieval. 1971.
SPARCK JONES et al. (1976). SPARCK JONES K., VAN RIJSBERGEN C.J. Progress in
documentation Journal of Documentation, Vol. 32, Num. 1, Pages 59-75 .
STYLTSVIG. (2006). STYLTSVIG H B. Ontology-based information retrieval. Thèse de
doctorat, Roskilde University, computer Science Section.
TALMY. (1988). TALMY L. Force Dynamics in Language and Cognition. In Cognitive
Science 12, pp 49-100.
TAMINE-LECHANI L et al. (2006). TAMINE-LECHANI L. , BOUGHANEM M. ,
CHRISMENT C. . Accès personnalisé à l'information : Vers un modèle basé sur
les diagrammes d'influence. nformation interaction intelligence ISSN 1630-
649X , vol. 6, no1, pp. 69-90 .
TURENNE. (2000). TURENNE N. Apprentissage statistique pour l’extraction de
concepts à partir de textes. Application au filtrage d’informations textuelles.
Thèse de doctorat en sciences, spécialité informatique, Université Louis
Pasteur, Strasbourg .
TURNEY. (2006). TURNEY P. D. Expressing implicit semantic relations without
supervision. In 21sup st international conference on computational linguistics,
pages 313-320.
VAN DER EIJK. (1993). VAN DER EIJK P. Automating the acquisition of bilingual
terminology. In Proceedings of the 6th Conference of the European Chapter of
the ACL (EACL’93), p. 113–119, Utrecht, Netherland.
VERGNE. (2005). VERGNE J. Une méthode indépendante des langues pour indexer les
documents de l’internet par extraction de termes de structure contrôlée. In

<Bibliographie
-185-
Actes de la Conférence Internationale sur le Document Électronique (CIDE 8),
Beyrouth, Liban.
VERGNE. (2003). VERGNE J. Un outil d’extraction de terminologie endogène et
multilingue, TALN 2003, Batz-sur-Mer, 11-14 juin.
VERONIS. (2003). VERONIS J. . Cartographie lexicale pour la recherche d’information,
Actes de TALN 2003, pp. 265-274.
VERONIS. (2000). VERONIS J. From Rosetta stone to the information society: A survey
of parallel text processing. In (Véronis, 2000b), chapter 1, p. 1–24.
WITSCHEL et al. (2006). WITSCHEL H F. ,BIEMANN C. Rigorous dimensionality
reduction through linguistically motivated feature selection for text
categorization. In Werner, S., éditeur : Proceedings of the 15th NODALIDA
conference, Joensuu 2006, volume 1, pages 197–204, J .
WOODS. (1997). WOODS W.A. Conceptual indexing : A better way to organize
knowledge. Rapport technique TR-97-61, Sun Microsystems Laboratories. —
cité en page(s) 18 .
YATES et al. (1999). YATES B. R.,NETO R. B. Modern Information Retrieval. Addison
Wesley.
ZIPF. (1949). ZIPF G. K. Human Behavior and the Principle of Least Effort, New York,
Harper, réédition 1966.
ZIPF. (1968). ZIPF G. K. The Psycho-biology of Language. An Introduction to Dynamic
Philology. The M.I.T. Press, Cambridge, second paperback printing (first
edition : 1935) édition.
ZWEIGENBAUM et al. (2003). ZWEIGENBAUM P., BAUD R., BURGUN A., NAMER F.,
ÉRIC JARROUSSE, GRABAR N., RUCH P., DUFF F. L., THIRION B. & DARMONI S.
UMLF: construction d’un lexique médical francophone unifié. In Actes des 10
Journées Francophones d’Informatique Médicale, Tunis.