Embed Size (px)
Citation preview

Université Paris-Sud
Mémoire en vue de l’obtention du
Diplôme Inter Universitaire de Pédagogie Médicale
Facteurs prédictifs de réussite en PACES :
Analyse sur 5 ans au sein de
L’Université Paris-Sud
Florent BESSON Université Paris-Sud, 15 rue Georges Clémenceau, 91400, Orsay, France. AP-HP, Hôpital du Kremlin-Bicêtre, Département Biophysique et Médecine Nucléaire, 78 rue du Général Leclerc, 94270 Le Kremlin-Bicêtre, France ; Sous la direction du Pr Emmanuel DURAND (Université Paris-Sud et AP-HP, Hôpital du Kremlin Bicêtre, Service de Biophysique et Médecine Nucléaire, Le Kremlin Bicêtre, France).
Année universitaire 2015-2016

2
Résumé Rationnel : Les modalités d’inscription, de passation, d’affectation et de redoublement des épreuves PACES sont régies par la loi. Les étudiants peuvent s’inscrire à une ou plusieurs filières de leur choix (Médecine, Odontologie, Maïeutique, Pharmacie). A l’issue du second semestre PACES, les étudiants classés en rang utile sur la liste de classement de la filière choisie sont finalement affectés. Selon l’article 39 des modalités du contrôle des connaissances en PACES à l’université Paris-Sud et en conformité avec l’arrêté du 28/10/09, la possibilité de redoublement des étudiants primants ayant échoué en fin de second semestre est définie par leur rang de classement neutre sur l’ensemble du numérus clausus (filières Médecine + Odontologie + Maïeutique + Pharmacie), dont la limite est fixée à 3 fois ce numérus clausus, soit 3 x 200 = 600. Néanmoins ce seuil arbitraire pose plusieurs problèmes pédagogiques : est-il pertinent ? Quelle est la probabilité de succès à l’issue du redoublement ? Des facteurs indépendants influent-ils sur les chances de succès à l’issue du redoublement ? Comment gérer, le cas échéant, les demandes de dérogation ? But : Ce travail avait pour but, par une approche principalement exploratoire, d’identifier d’éventuels facteurs prédictifs de réussite au concours PACES chez les étudiants de l’Université Paris-Sud ayant initialement échoué en tant que primants. Méthodologie : Un recueil exhaustif mené sur l’ensemble de la population PACES de l’Université Paris-Sud durant les 5 dernières années fut réalisé. Pour chaque étudiant, les variables d’intérêt de la session PACES N furent croisées avec la variable dépendante « réussite au moins un concours » générée à partir des affectations finales de la session PACES N+1. L’analyse statistique comporta plusieurs étapes : analyses exploratoires uni et bivariées, analyses exploratoires multidimensionnelles (PCA, MDA et FAMD), et génération d’un modèle prédictif optimisé de réussite au PACES. L’influence des rangs de classement de la session PACES N sur la probabilité de réussite au concours de la session PACES N+1 fut aussi évaluée. Résultats : Parmi l’ensemble des variables d’intérêt, les variables qualitatives se révélèrent peu pertinentes et n’expliquèrent que très modestement la variance des résultats de réussite au concours. Les variables continues « Unités d’Enseignement » étaient les plus pertinentes et furent retenues pour le modèle prédictif de réussite. Ce modèle s’avéra sous optimal en sous-estimant, dans la majorité des cas, la probabilité de réussite des étudiants réellement observée. L’influence des rangs de classements sur la réussite au concours montrait une chute significative de la probabilité de réussite au concours pour le pool d’étudiants initialement classés au-delà du rang 400, comparativement au pool d’étudiants initialement classés avant le rang 300. Conclusion : Les résultats de cette étude semblent signifier que les données démographiques ou de performance, classiquement utilisées dans ce type d’étude, n’apportent qu’une partie de l’information nécessaire à la prédiction de réussite éventuelle d’un doublant en PACES, dont l’issue ne se résume probablement pas à ces quelques composantes, même pertinentes. Il semble de plus qu’au-delà du rang neutre 400 (soit deux fois le numérus clausus actuel), la probabilité de réussite ultérieure au concours soit extrêmement faible, comparativement au pool d’étudiants classés avant le rang neutre 300. Mots clés : PACES, score prédictif, étude observationnelle longitudinale

3
INTRODUCTION : Les modalités d’inscription, de passation, d’affectation et de redoublement des épreuves PACES sont régies par la loi (Loi n°2009—833 du 7 juillet 2009, arrêté du 28 octobre 2009 paru au JO du 17/11/2009, arrêté du 2 juin 2010 paru au JO du 08/06/2010) et précisées dans les modalités du contrôle des connaissances en PACES à l’université Paris-Sud (MCC-PACES, version 2016-2017). Les étudiants peuvent s’inscrire à une ou plusieurs filières de leur choix (Médecine, Odontologie, Maïeutique, Pharmacie). Conformément au Bulletin officiel n°45 du 03 décembre 2009, le programme d’enseignement PACES de l’Université Paris-Sud inclus 7 unités d’enseignement (UE) totalement mutualisées réparties en deux semestres (UE1, UE2, UE3a et UE4 pour le premier semestre, UE3b, UE5, UE6 et UE7 pour le deuxième semestre, avec coefficients de pondération différents selon la filière). Des UE optionnelles, partiellement mutualisées, dites « spécifiques », s’intègrent également dans les différentes filières. A l’issue du second semestre PACES, les étudiants classés en rang utile sur la liste de classement de la filière choisie sont finalement affectés. Selon l’article 39 des MCC-PACES (version 2016-2017) et en conformité avec l’arrêté du 28/10/09, la possibilité de redoublement des étudiants « primants » ayant échoué en fin de second semestre est définie par leur rang de classement neutre sur l’ensemble du numérus clausus (filières Médecine + Odontologie + Maïeutique + Pharmacie), dont la limite est fixée à 3 fois ce numérus clausus global. La définition simple de ce seuil de redoublement, choisi pour être assez large, présente l’avantage d’une mise en application aisée. Néanmoins il pose nécessairement différents problèmes pédagogiques, de justice et d’éthique qui restent actuellement non résolus : - Ce seuil arbitraire est-il pertinent ? - Quelle est la probabilité de succès à l’issue du redoublement ? - Des facteurs indépendants influent-ils sur les chances de succès à l’issue du
redoublement ? - Comment gérer, le cas échéant, les demandes de dérogation ? Dans ce contexte, ce travail avait donc pour but, par une approche principalement exploratoire, d’identifier d’éventuels facteurs prédictifs de réussite au concours PACES chez les étudiants de l’Université Paris-Sud ayant initialement échoué en tant que primants.

4
MATERIEL ET METHODE Il s’agissait d’une étude observationnelle longitudinale monocentrique avec recueil exhaustif mené sur l’ensemble de la population PACES de l’Université Paris-Sud durant les 5 dernières années. Tous les étudiants justifiant d’une inscription pédagogique en PACES à l’Université Paris-Sud entre 2011 et 2016 (Médecine, Kinésithérapie, Odontologie, Maïeutique, Pharmacie) furent évalués. Toutes les analyses statistiques ont été réalisé à l’aide du logiciel R, disponible gratuitement à l’adresse https://www.rstudio.com 1)Préparation de la base de données
a. Sélection des étudiants La base de donnée initiale, anonymisée, incluait sur la période 2011-2016 un total de 6697 observations. Compte tenu de l’absence de données antérieures pour les doublants de la session 2011 et des redondances d’observations (un étudiant ayant pu s’inscrire plusieurs fois, notamment en tant que doublant ou éventuellement triplant), un premier travail de sélection des observations fut réalisé, afin de ne conserver pour les analyses que les étudiants ayant passé deux fois le concours PACES. Les données obtenues incluaient donc exclusivement 2 observations pour chaque étudiant (année PACES « primant » et année PACES « doublant »).
b. Paramètres étudiés Un grand nombre de variables était à disposition et incluait, de manière exhaustive :
- Données démographiques générales : appartenance ou non à l’union européenne (EEE), sexe, année de naissance (DDN), département de naissance, Pays de naissance, nationalité, situation professionnelle du père (CSP père), de la mère (CSP mère), ville de résidence.
- Données scolaires antérieures : année d’obtention/série/mention du bac, code et libellé d’établissement du bac, type d’établissement fréquenté avant le concours PACES (lycée ou autre)
- Données relatives à chaque concours PACES : situation sociale (boursier ou
non), le type d’inscription pédagogique (Médecine, Odontologie, Maïeutique, Pharmacie, uniques ou combinées), l’année d’inscription et le lieu d’enseignement (Chatenay-Malabry ou Orsay), la filière affectée, variables de performances pour chaque filière d’inscription et global (points, note moyenne et rang de l’étudiant, notes moyennes obtenues pour chaque unité d’enseignement du tronc commun UE1 à UE7).
Un deuxième travail de formatage a donc consisté à présélectionner et standardiser les différentes variables jugées « d’intérêt potentiel » comme suit : - Données démographiques générales retenues :

5
Les données Sexe, EEE et nationalité ont été retenues (variables binaires Homme/Femme, OUI/NON et Français/Autre respectivement). De plus, la variable Age (variable continue) a été générée, pour chaque étudiant, comme suit : Age = [Année concours – année de naissance]. Les variables CSP père et CSP mère, également retenues, comportaient initialement plus de 30 niveaux différents chacune, et furent donc standardisées en 8 niveaux selon la nomenclature officielle en vigueur (nomenclature PCS, Insee, Desrosière, Goy et Thévenot 1982, révisée en 2003) :
1. Agriculteurs exploitants 2. Artisans, commerçants et chefs d’entreprise 3. Cadres et professions intellectuelles supérieures 4. Professions intermédiaires 5. Employés 6. Ouvriers 7. Retraités 8. Autres personnes sans activité professionnelle
- Données scolaires antérieures : La variable série bac comportant initialement plus de 15 niveaux a été redéfinie en 5 niveaux : « S, ES, L, Professionnel, Etranger » La variable mention bac, également retenue, comportait 4 niveaux : « NON, AB, B, TB ». - Données relatives à chaque concours PACES : Le nombre d’années passées entre le secondaire et l’inscription PACES (Nbre_années_prec, variable continue) a été générée comme suit : Nbre années prec = [Année concours – Année obtention bac]. La variable situation sociale a été redéfinie en 2 niveaux : « Normal, Boursier », Parmi les variables de performances, les variables continues « UE » ont été conservées, car nécessairement corrélées au rang, note moyenne et points totaux. La variable réussite_au_moins_un_concours (binaire) a été définie comme suit : Affectation à l’une des filières correspondant à l’inscription pédagogique de l’étudiant « OUI/NON » Pour trouver d’éventuels facteurs prédictifs de réussite au concours, les informations Primant-Doublant de chaque étudiant ont été croisées comme suit : Les variables d’intérêt standardisées « Sexe », « EEE », « nationalité », « Age », « CSP père et mère », « série bac », « mention bac », « Nbre_années_prec », « UE » de l’année PACES N-1 ont été croisées avec la variable binaire « réussite au moins un concours » de l’année PACES N. Par conséquent, la base de donnée finale fusionnait, pour chaque étudiant (1 observation par étudiant), les variables explicatives de l’année N (soit en tant que primant) avec la variable dépendante binaire « réussite au moins un concours » de l’année N+1.

6
c. Problématique spécifique du seuil de redoublement
Afin de tester plus spécifiquement le seuil de redoublement, une variable « Seuil Rang de Classement » (année N), comportant 6 niveaux (Niveau 1 : rangs < 300 ; Niveau 2 : rangs 300-400 ; Niveau 3 : rangs 400-500 ; Niveau 4 : rangs 500-600 ; Niveau 5 : rangs 600-700 ; Niveau 6 : rangs >700) a également été générée et croisée avec la variable dépendante binaire « réussite au moins un concours » de l’année N+1. 2) Analyse exploratoire multidimensionnelle et modèle prédictif
A. Approche exploratoire univariée Pour chacune des variables explicatives, la base de donnée finale a été dans un premier temps explorée. L’objectif principal de cette étape était triple :
- D’une part vérifier le profil de distribution des données quantitatives (distribution gaussienne des valeurs, préalable indispensable à l’application des traitements statistiques ultérieurs),
- D’autre part détecter le nombre de données manquantes, dont la fréquence peut altérer les traitements statistiques ultérieurs (un seuil de 5% de données manquantes est classiquement établi).
- Enfin avoir un aperçu global de la répartition des variables quantitatives (minimum, maximum, moyenne, écart type, écart type de la moyenne) et des variables qualitatives (proportions).
B. Approche exploratoire bivariée standard
Cette étape, complémentaire de la précédente, avait pour but de tester, au moyen de régressions logistiques simples (odds ratios), l’association de chaque variable explicative avec la variable dépendante binaire « réussite au moins un concours ». La même approche fut utilisée pour tester plus spécifiquement le seuil de redoublement.
C. Approche exploratoire « multidimensionnelle » Une approche exploratoire complémentaire dite « multidimensionnelle » fut également réalisée. Les techniques d’analyse en composante principale (PCA) pour les variables quantitatives (PCA), leur équivalent pour les données qualitatives (analyse multi-dimensionnelle, MDA) et l’approche combinée (analyse factorielle de données combinées quanti et qualitatives, FAMD) permettent :
- D’avoir une représentation graphique simplifiée des corrélations éventuelles entre différentes variables explicatives et une variable dépendante
- D’observer d’éventuels groupes de variables explicatives inter-corrélées.
D. Modèle prédictif Enfin, un modèle prédictif de régression logisitque, de type [Réussite = a * Variable 1 + b * Variable 2 + c * Variable 3 + intercept] fut généré à partir des variables explicatives explorées durant les étapes A, B et C. L’application de ce modèle comportait plusieurs étapes :
- Binarisation des variables d’intérêt retenues, - Calibration et optimisation du modèle : La base de donnée a été séparé en
deux échantillons. Le premier échantillon (années 2011 à 2013), dit « d’entrainement », a permis d’optimiser la sélection des variables. Le deuxième
7
échantillon (années 2014-2016) fut utilisé pour valider le modèle, et donc le généraliser.
- Une pénalisation permettait de limiter la sur-optimisation du modèle, en imposant un seuil maximal des valeurs d’odds ratios obtenus.
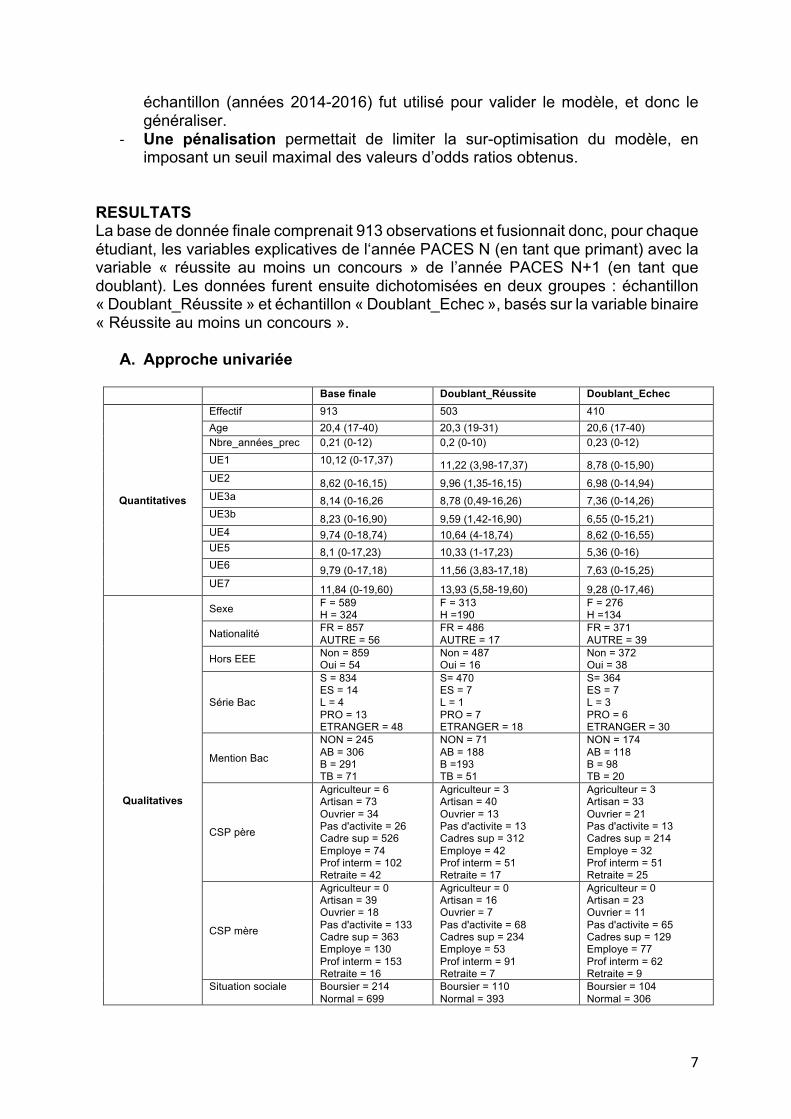
RESULTATS La base de donnée finale comprenait 913 observations et fusionnait donc, pour chaque étudiant, les variables explicatives de l‘année PACES N (en tant que primant) avec la variable « réussite au moins un concours » de l’année PACES N+1 (en tant que doublant). Les données furent ensuite dichotomisées en deux groupes : échantillon « Doublant_Réussite » et échantillon « Doublant_Echec », basés sur la variable binaire « Réussite au moins un concours ».
A. Approche univariée
Base finale Doublant_Réussite Doublant_Echec
Quantitatives
Effectif 913 503 410 Age 20,4 (17-40) 20,3 (19-31) 20,6 (17-40) Nbre_années_prec 0,21 (0-12) 0,2 (0-10) 0,23 (0-12) UE1 10,12 (0-17,37) 11,22 (3,98-17,37) 8,78 (0-15,90) UE2 8,62 (0-16,15) 9,96 (1,35-16,15) 6,98 (0-14,94) UE3a 8,14 (0-16,26 8,78 (0,49-16,26) 7,36 (0-14,26) UE3b 8,23 (0-16,90) 9,59 (1,42-16,90) 6,55 (0-15,21) UE4 9,74 (0-18,74) 10,64 (4-18,74) 8,62 (0-16,55) UE5 8,1 (0-17,23) 10,33 (1-17,23) 5,36 (0-16) UE6 9,79 (0-17,18) 11,56 (3,83-17,18) 7,63 (0-15,25) UE7 11,84 (0-19,60) 13,93 (5,58-19,60) 9,28 (0-17,46)
Qualitatives
Sexe F = 589 H = 324
F = 313 H =190
F = 276 H =134
Nationalité FR = 857 AUTRE = 56
FR = 486 AUTRE = 17
FR = 371 AUTRE = 39
Hors EEE Non = 859 Oui = 54
Non = 487 Oui = 16
Non = 372 Oui = 38
Série Bac
S = 834 ES = 14 L = 4 PRO = 13 ETRANGER = 48
S= 470 ES = 7 L = 1 PRO = 7 ETRANGER = 18
S= 364 ES = 7 L = 3 PRO = 6 ETRANGER = 30
Mention Bac
NON = 245 AB = 306 B = 291 TB = 71
NON = 71 AB = 188 B =193 TB = 51
NON = 174 AB = 118 B = 98 TB = 20
CSP père
Agriculteur = 6 Artisan = 73 Ouvrier = 34 Pas d'activite = 26 Cadre sup = 526 Employe = 74 Prof interm = 102 Retraite = 42
Agriculteur = 3 Artisan = 40 Ouvrier = 13 Pas d'activite = 13 Cadres sup = 312 Employe = 42 Prof interm = 51 Retraite = 17
Agriculteur = 3 Artisan = 33 Ouvrier = 21 Pas d'activite = 13 Cadres sup = 214 Employe = 32 Prof interm = 51 Retraite = 25
CSP mère
Agriculteur = 0 Artisan = 39 Ouvrier = 18 Pas d'activite = 133 Cadre sup = 363 Employe = 130 Prof interm = 153 Retraite = 16
Agriculteur = 0 Artisan = 16 Ouvrier = 7 Pas d'activite = 68 Cadres sup = 234 Employe = 53 Prof interm = 91 Retraite = 7
Agriculteur = 0 Artisan = 23 Ouvrier = 11 Pas d'activite = 65 Cadres sup = 129 Employe = 77 Prof interm = 62 Retraite = 9
Situation sociale Boursier = 214 Normal = 699
Boursier = 110 Normal = 393
Boursier = 104 Normal = 306
8
Pour les données quantitatives, les résultats sont présentés sous forme de moyenne (min-max). Pour les données qualitatives, les résultats étaient exprimés en effectifs. Les histogrammes montraient des distributions relativement gaussiennes pour toutes les variables quantitatives d’intérêt potentiel, excepté les variables « Age » et « Nbre d’années prec », qui furent donc écartées pour la suite des analyses (cf Annexe 1).
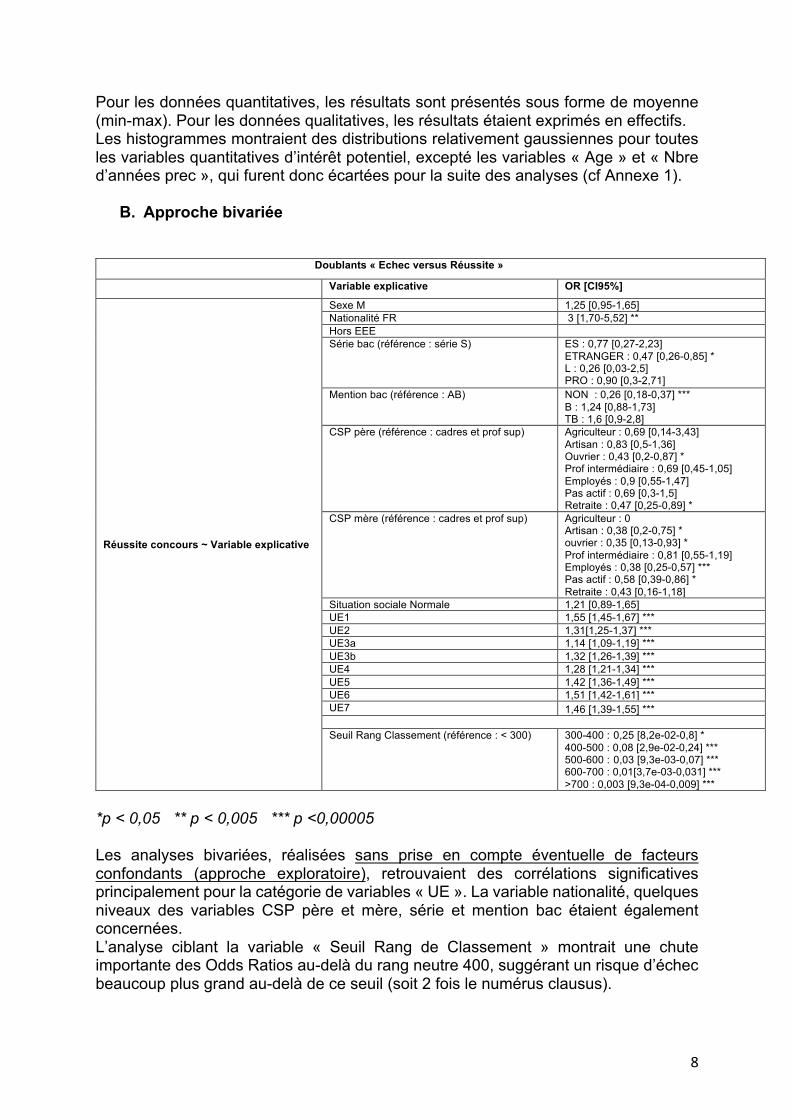
B. Approche bivariée
Doublants « Echec versus Réussite »
Variable explicative OR [CI95%]
Réussite concours ~ Variable explicative
Sexe M 1,25 [0,95-1,65] Nationalité FR 3 [1,70-5,52] ** Hors EEE Série bac (référence : série S) ES : 0,77 [0,27-2,23]
ETRANGER : 0,47 [0,26-0,85] * L : 0,26 [0,03-2,5] PRO : 0,90 [0,3-2,71]
Mention bac (référence : AB) NON : 0,26 [0,18-0,37] *** B : 1,24 [0,88-1,73] TB : 1,6 [0,9-2,8]
CSP père (référence : cadres et prof sup) Agriculteur : 0,69 [0,14-3,43] Artisan : 0,83 [0,5-1,36] Ouvrier : 0,43 [0,2-0,87] * Prof intermédiaire : 0,69 [0,45-1,05] Employés : 0,9 [0,55-1,47] Pas actif : 0,69 [0,3-1,5] Retraite : 0,47 [0,25-0,89] *
CSP mère (référence : cadres et prof sup) Agriculteur : 0 Artisan : 0,38 [0,2-0,75] * ouvrier : 0,35 [0,13-0,93] * Prof intermédiaire : 0,81 [0,55-1,19] Employés : 0,38 [0,25-0,57] *** Pas actif : 0,58 [0,39-0,86] * Retraite : 0,43 [0,16-1,18]
Situation sociale Normale 1,21 [0,89-1,65] UE1 1,55 [1,45-1,67] *** UE2 1,31[1,25-1,37] *** UE3a 1,14 [1,09-1,19] *** UE3b 1,32 [1,26-1,39] *** UE4 1,28 [1,21-1,34] *** UE5 1,42 [1,36-1,49] *** UE6 1,51 [1,42-1,61] *** UE7 1,46 [1,39-1,55] *** Seuil Rang Classement (référence : < 300) 300-400 :0,25 [8,2e-02-0,8] *
400-500 : 0,08 [2,9e-02-0,24] *** 500-600 :0,03 [9,3e-03-0,07] *** 600-700 : 0,01[3,7e-03-0,031] *** >700 : 0,003 [9,3e-04-0,009] ***
*p < 0,05 ** p < 0,005 *** p <0,00005 Les analyses bivariées, réalisées sans prise en compte éventuelle de facteurs confondants (approche exploratoire), retrouvaient des corrélations significatives principalement pour la catégorie de variables « UE ». La variable nationalité, quelques niveaux des variables CSP père et mère, série et mention bac étaient également concernées. L’analyse ciblant la variable « Seuil Rang de Classement » montrait une chute importante des Odds Ratios au-delà du rang neutre 400, suggérant un risque d’échec beaucoup plus grand au-delà de ce seuil (soit 2 fois le numérus clausus).

9
C. Approche exploratoire « multidimensionnelle »
Pour les données quantitatives, l’approche PCA montrait un effet significatif de l’ensemble des UE sur la part de variance de réussite à au moins un concours (cf Annexes 1 à 3). Il est intéressant de noter qu’une part de la variance expliquée, certes faible (14%, Annexe 2 dimension 2), se décompose en UE étiquetées plutôt « sciences dures » versus UE étiquetées plutôt « par cœur ». L’approche MDA, qui s’applique aux données qualitatives, ne permettait pas d’identifier de variable qualitative pertinente (cf Annexe 5). Notamment la nationalité, la CSP, ainsi que la série et mention au bac dont certains niveaux apparaissaient significatifs en approche bivariée, apparaissaient finalement peu probantes. Finalement, l’approche combinée FAMD confirmait les résultats de la PCA et de la MDA : parmi toutes les variables évaluées (qualitatives et quantitatives), les variables « UE » étaient les plus pertinentes.
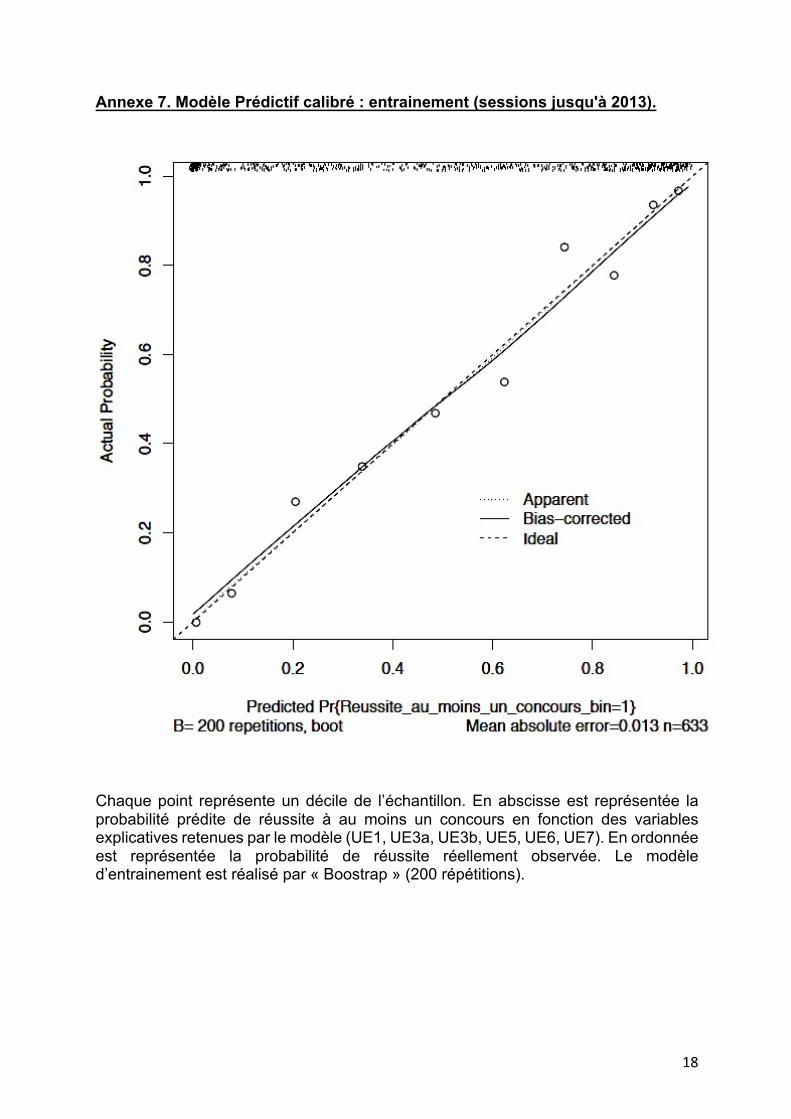
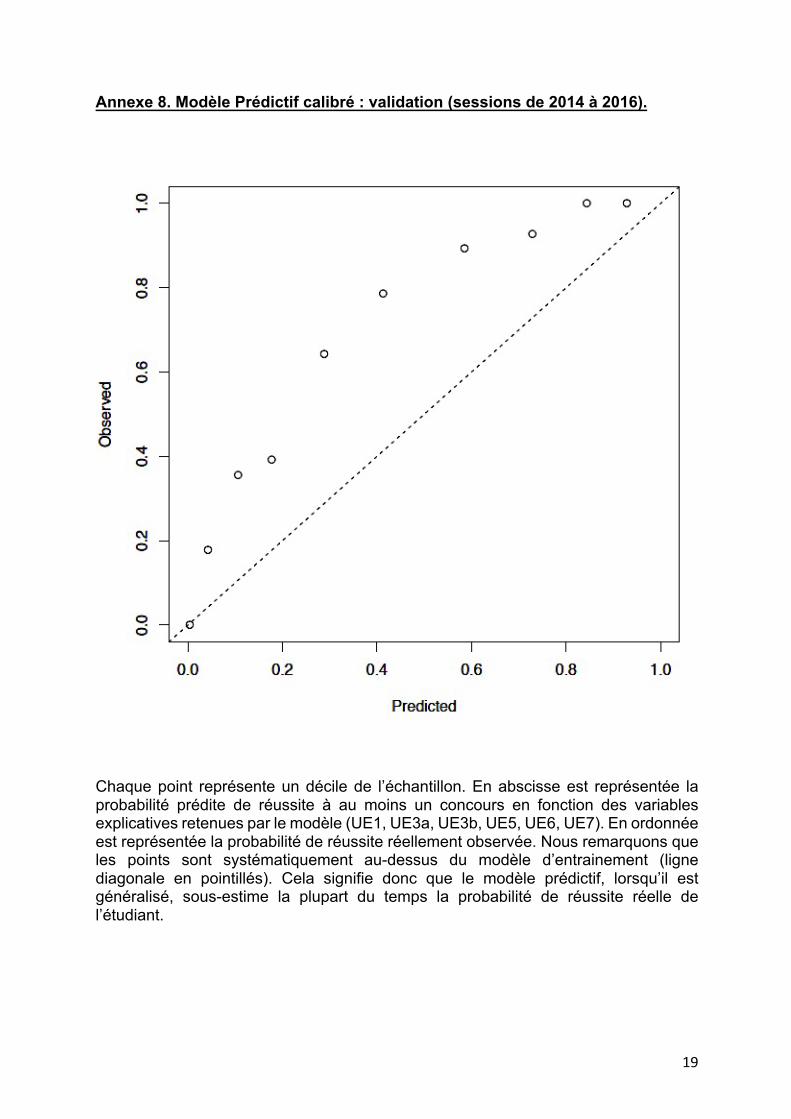
D. Modèle prédictif Le modèle prédictif optimisé a finalement retenu comme variables explicatives les plus probantes les variables UE1, UE3a, UE3b, UE5, UE6 et UE7. Modèle proposé : Réussite = 0,227665 * UE1 + 0,1381852 * UE3a + 0,1146349 * UE3b + 0,1664641 * UE5 + 0,1332507 * UE6 + 0,1239778 * UE7 - 8,805812. La courbe de calibration « Entraînement » réalisée sur l’échantillon jusqu’à 2013 permettait de retenir le modèle puisque les probabilités de réussite prédites correspondaient aux probabilités de réussite observées pour l’ensemble des déciles de l’échantillon : les points correspondant aux déciles étaient quasiment confondus avec la droite représentant une prédiction correcte à 100% (cf Annexe 7). Néanmoins sa généralisation réalisée sur l’échantillon « Validation » montrait la plupart du temps une sous-estimation de la probabilité de réussite des étudiants par le modèle (cf Annexe 8).

10
DISCUSSION L’objectif de ce mémoire était de tenter d’identifier d’éventuels facteurs prédictifs de réussite au concours PACES chez les étudiants de l’Université Paris-Sud ayant initialement échoué en tant que primants. L’étude, principalement exploratoire, ne se basait sur aucun « a priori » ou test d’hypothèse statistique préalable. La méthodologie, hiérarchisée, nécessita un travail substantiel de préparation des données (filtrage, standardisation, recodage) afin de pouvoir appliquer les tests statistiques de manière adaptée. Sur la base de donnée PACES des 5 dernières années de l’Université Paris-Sud, nous n’avons finalement retenu pour l’étude que 14% de l’effectif initial, ce qui correspond à une base de donnée :
- Ciblée (étudiants doublants avec leurs informations primants disponibles) - Méthodologiquement propre (redondances exclues, données standardisées) - De taille acceptable (913 étudiants)
Lors des analyses statistiques exploratoires, les données qualitatives semblaient n’expliquer qu’une part très faible de la variabilité observée dans la réussite des doublants. Notamment, il est intéressant de noter que la mention au bac expliquait très peu la réussite au concours, ce qui pourrait paraître paradoxal. On notera toutefois une tendance à la réussite accrue avec des mentions B ou TB dont la non significativité dans cette étude est peut-être liée à un manque de puissance. Les variables les plus pertinentes, retenues finalement par le modèle prédictif, étaient les notes aux UE1 (Biochimie), UE3a et UE3b (Biophysique), UE5 (Anatomie), UE6 (Médicament) et UE7 Sciences humaines et sociales). L’analyse sur les rangs de classement neutres montrait une diminution très importante et significative des odds ratios au-delà du rang neutre 400, ce qui correspond à un seuil de redoublement de 2 fois le numérus clausus actuel. Le modèle prédictif, performant sur l’échantillon d’entrainement, montrait des limitations quand il était extrapolé à l’échantillon de validation, avec une tendance, la plupart du temps, à la sous-estimation de la probabilité de réussite au concours PACES. Cette discordance pourrait être liée d’une part à la différence de taille des deux échantillons (633 et 280 étudiants respectivement), et d’autre part à un éventuel effet « promotion ». Conclusion Bien qu’un modèle prédictif de réussite au PACES relativement acceptable ai pu être généré à partir de variables d’intérêt optimisées, les résultats de cette étude semblent signifier que les données démographiques ou de performance, classiquement utilisées dans ce type d’étude, n’apportent qu’une partie modérée de l’information nécessaire à la prédiction de réussite éventuelle d’un doublant en PACES, dont l’issue ne se résume probablement pas à ces quelques composantes, même pertinentes. Il semble de plus que les primants classés au-delà du rang neutre 400 (soit deux fois le numérus clausus actuel) aient une chance de réussite au concours statistiquement beaucoup plus faible lors du redoublement, comparativement aux candidats dont les rangs neutres se situent avant 400.

11
REMERCIEMENTS : Je tiens à vivement remercier le Dr Astrid CHEVANCE, Normalienne, Médecin Psychiatre et Biostatisticienne (Unité Inserm 1153, équipe METHODS, Pr Ravaud, Hôtel Dieu, Paris, Service Hospitalo-Universitaire, Hôpital Sainte-Anne, Pr Krebs et Pr Gaillard) pour ses précieux conseils quant à la stratégie d’approche globale et la réalisation du modèle statistique prédictif. Je remercie également l’unité de recherche clinique du CHU Bicêtre pour leurs conseils fructueux. Ce travail n’aurait pas été possible sans la formation en ligne, gratuite, du MOOC « Introduction à la statistique avec R (FUN-MOOC, Bruno Falissard, Université Paris-Sud et Christophe Lalanne, Université Paris-Diderot), d’une rare qualité pédagogique, qui m’a permis d’acquérir quelques mois plus tôt les rudiments d’utilisation du logiciel R nécessaires à la réalisation de ce travail. Enfin, je remercie mon chef de service, le Pr Emmanuel Durand, de m’avoir permis, par la réalisation de ce travail, de renforcer ma pratique du logiciel R tout en explorant une problématique pédagogique d’intérêt.
12
ANNEXES Annexe 1. Histogrammes des données d’intérêt
13
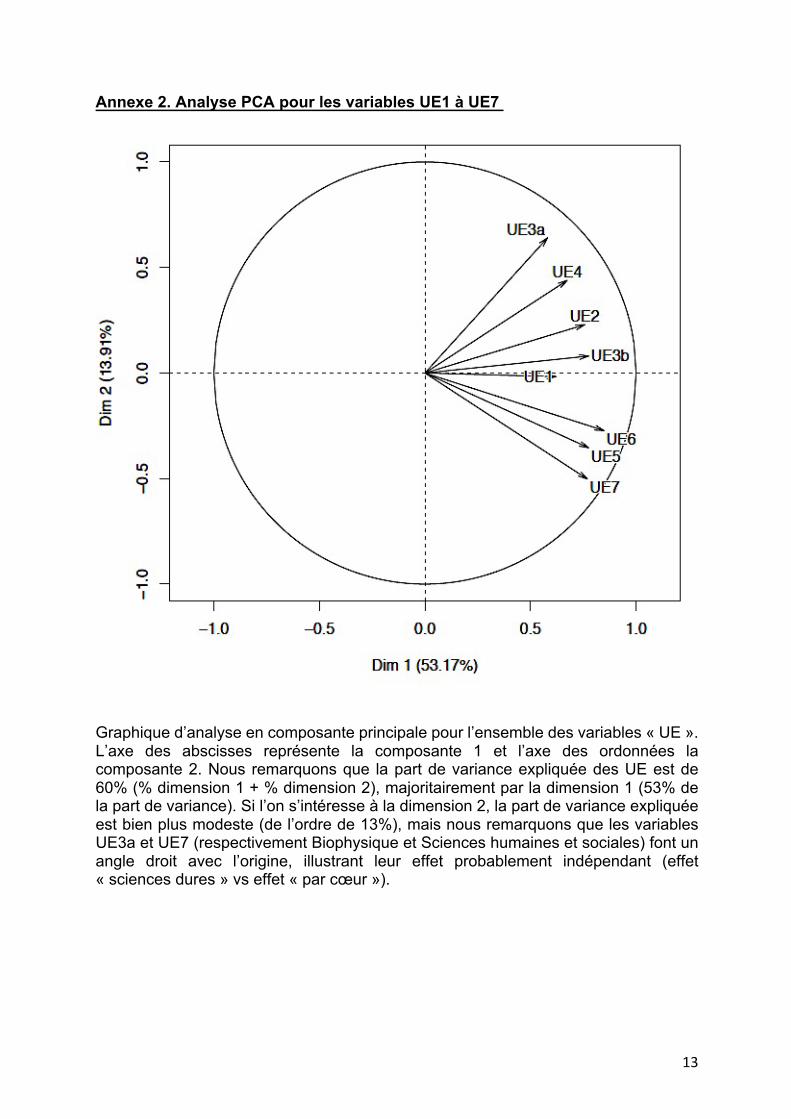
Annexe 2. Analyse PCA pour les variables UE1 à UE7
Graphique d’analyse en composante principale pour l’ensemble des variables « UE ». L’axe des abscisses représente la composante 1 et l’axe des ordonnées la composante 2. Nous remarquons que la part de variance expliquée des UE est de 60% (% dimension 1 + % dimension 2), majoritairement par la dimension 1 (53% de la part de variance). Si l’on s’intéresse à la dimension 2, la part de variance expliquée est bien plus modeste (de l’ordre de 13%), mais nous remarquons que les variables UE3a et UE7 (respectivement Biophysique et Sciences humaines et sociales) font un angle droit avec l’origine, illustrant leur effet probablement indépendant (effet « sciences dures » vs effet « par cœur »).
14
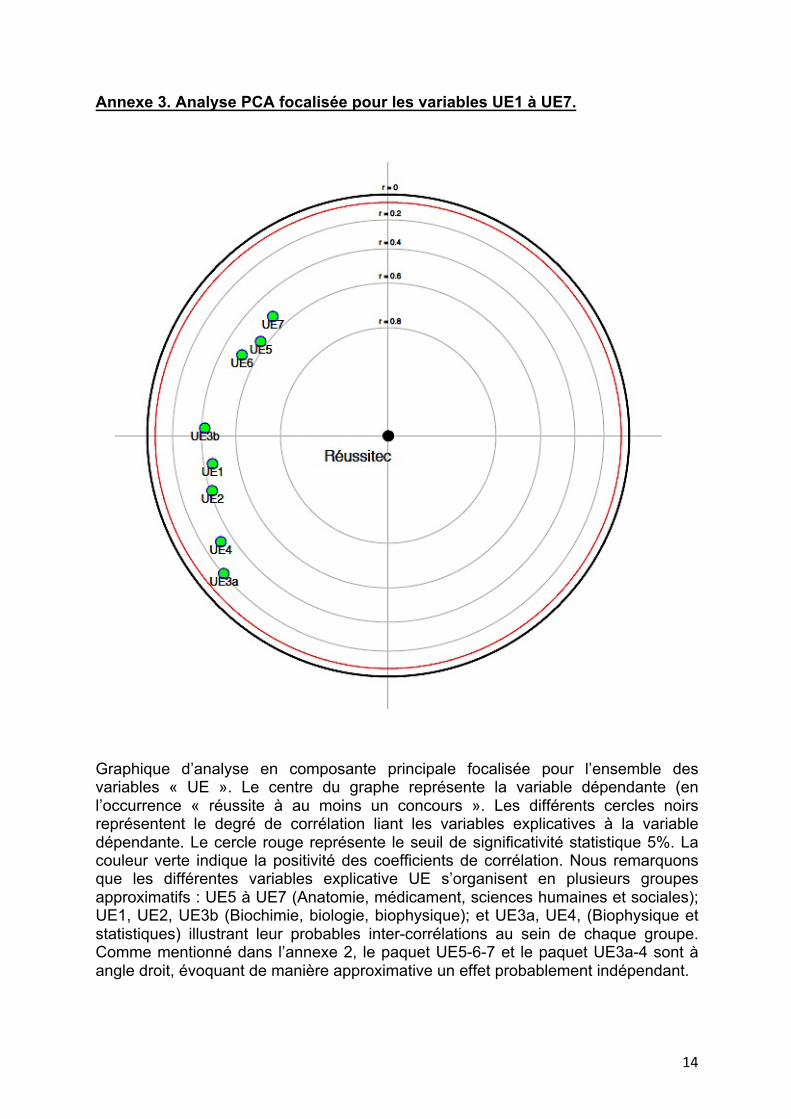
Annexe 3. Analyse PCA focalisée pour les variables UE1 à UE7.
Graphique d’analyse en composante principale focalisée pour l’ensemble des variables « UE ». Le centre du graphe représente la variable dépendante (en l’occurrence « réussite à au moins un concours ». Les différents cercles noirs représentent le degré de corrélation liant les variables explicatives à la variable dépendante. Le cercle rouge représente le seuil de significativité statistique 5%. La couleur verte indique la positivité des coefficients de corrélation. Nous remarquons que les différentes variables explicative UE s’organisent en plusieurs groupes approximatifs : UE5 à UE7 (Anatomie, médicament, sciences humaines et sociales); UE1, UE2, UE3b (Biochimie, biologie, biophysique); et UE3a, UE4, (Biophysique et statistiques) illustrant leur probables inter-corrélations au sein de chaque groupe. Comme mentionné dans l’annexe 2, le paquet UE5-6-7 et le paquet UE3a-4 sont à angle droit, évoquant de manière approximative un effet probablement indépendant.
15
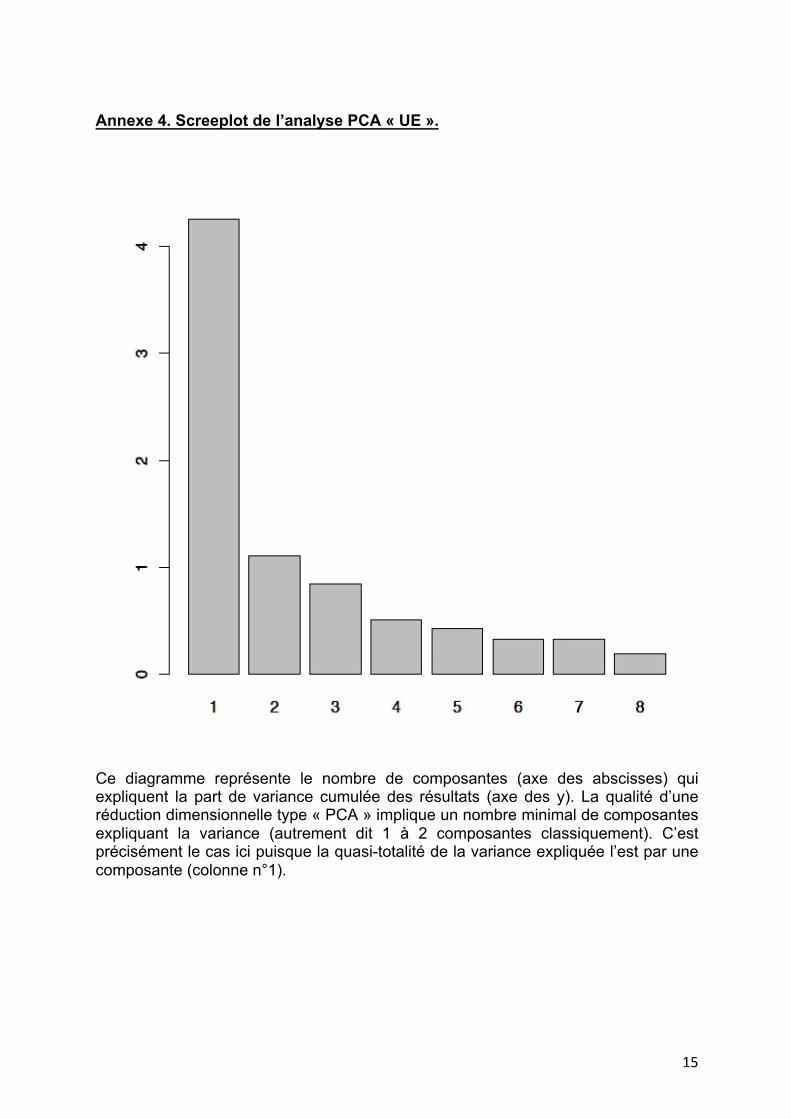
Annexe 4. Screeplot de l’analyse PCA « UE ».
Ce diagramme représente le nombre de composantes (axe des abscisses) qui expliquent la part de variance cumulée des résultats (axe des y). La qualité d’une réduction dimensionnelle type « PCA » implique un nombre minimal de composantes expliquant la variance (autrement dit 1 à 2 composantes classiquement). C’est précisément le cas ici puisque la quasi-totalité de la variance expliquée l’est par une composante (colonne n°1).
16
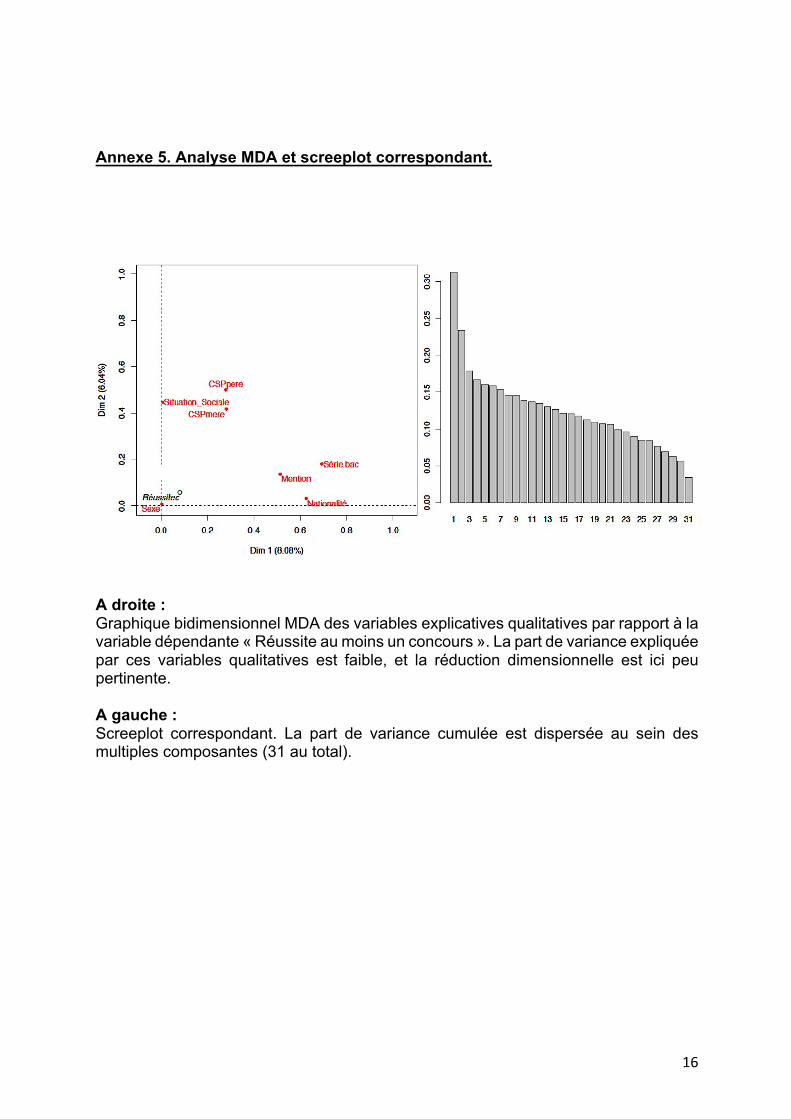
Annexe 5. Analyse MDA et screeplot correspondant.
A droite : Graphique bidimensionnel MDA des variables explicatives qualitatives par rapport à la variable dépendante « Réussite au moins un concours ». La part de variance expliquée par ces variables qualitatives est faible, et la réduction dimensionnelle est ici peu pertinente. A gauche : Screeplot correspondant. La part de variance cumulée est dispersée au sein des multiples composantes (31 au total).
17
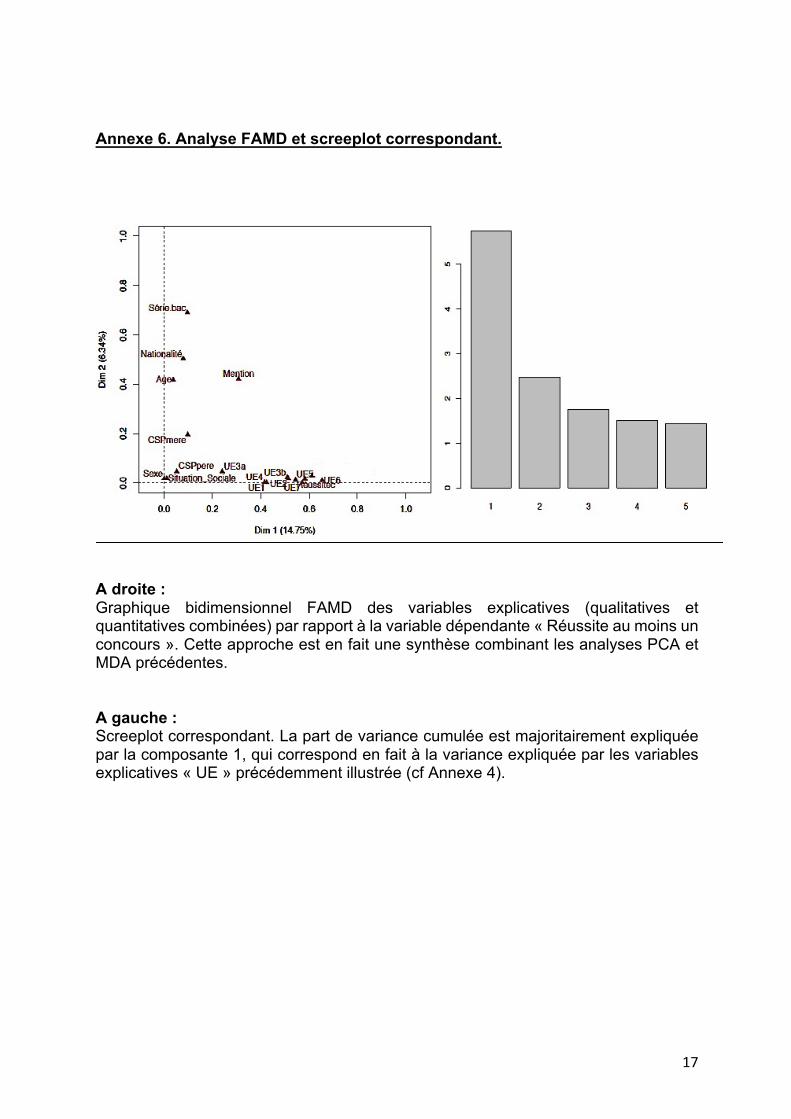
Annexe 6. Analyse FAMD et screeplot correspondant.
A droite : Graphique bidimensionnel FAMD des variables explicatives (qualitatives et quantitatives combinées) par rapport à la variable dépendante « Réussite au moins un concours ». Cette approche est en fait une synthèse combinant les analyses PCA et MDA précédentes. A gauche : Screeplot correspondant. La part de variance cumulée est majoritairement expliquée par la composante 1, qui correspond en fait à la variance expliquée par les variables explicatives « UE » précédemment illustrée (cf Annexe 4).
18
Annexe 7. Modèle Prédictif calibré : entrainement (sessions jusqu'à 2013).
Chaque point représente un décile de l’échantillon. En abscisse est représentée la probabilité prédite de réussite à au moins un concours en fonction des variables explicatives retenues par le modèle (UE1, UE3a, UE3b, UE5, UE6, UE7). En ordonnée est représentée la probabilité de réussite réellement observée. Le modèle d’entrainement est réalisé par « Boostrap » (200 répétitions).
19
Annexe 8. Modèle Prédictif calibré : validation (sessions de 2014 à 2016).
Chaque point représente un décile de l’échantillon. En abscisse est représentée la probabilité prédite de réussite à au moins un concours en fonction des variables explicatives retenues par le modèle (UE1, UE3a, UE3b, UE5, UE6, UE7). En ordonnée est représentée la probabilité de réussite réellement observée. Nous remarquons que les points sont systématiquement au-dessus du modèle d’entrainement (ligne diagonale en pointillés). Cela signifie donc que le modèle prédictif, lorsqu’il est généralisé, sous-estime la plupart du temps la probabilité de réussite réelle de l’étudiant.





























