Embed Size (px)
Citation preview

FAA - M1S2
HadrienGlaude
Introduction
Exempleintroductif
Proprietes
Distributionstationnaire
Convergence
Page Rank
Apprentissageetutilisations
1/33
Fondements de l’Apprentissage AutomatiqueChaınes de Markov
Hadrien [email protected]
Universite Lille 1 - CRIStAL (SequeL) - Thales Systemes Aeroportes
Master 1 Info

Plan
1 Introduction
2 Exemple introductif
3 ProprietesDistribution stationnaireConvergencePage Rank
4 Apprentissage et utilisations
2/33

FAA - M1S2
HadrienGlaude
Introduction
Exempleintroductif
Proprietes
Distributionstationnaire
Convergence
Page Rank
Apprentissageetutilisations
2/33
Chaınes de MarkovIntroduction
Modele probabiliste sur des sequences d’observationsP (x1, x2, ..., xn)
Exemple de sequences :
le langage naturel,la parole, les gestes,en finances, les valeurs boursieres,en bioinformatique, l’ADN.
Exemple d’usages :
classification (ex : soit deux chaınes M1,M2, on peutcomparer les vraisemblancesP (x1, x2, ..., xn|M1) ≶ P (x1, x2, ..., xn|M2))partitionnement (en utilisant un melange de chaıne deMarkov, voir cours precedent)prediction des prochaines observations / generation desequences

Plan
1 Introduction
2 Exemple introductif
3 ProprietesDistribution stationnaireConvergencePage Rank
4 Apprentissage et utilisations
3/33

FAA - M1S2
HadrienGlaude
Introduction
Exempleintroductif
Proprietes
Distributionstationnaire
Convergence
Page Rank
Apprentissageetutilisations
3/33
Exemple introductifRepas de l’etudiant
Supposons que l’etudiant se nourrisse exclusivement de quatreplats.
(a) Pates (b) Pizza surgelee
(c) Steak et conserve (d) Omelette
Figure: Les quatres plats de l’etudiant

FAA - M1S2
HadrienGlaude
Introduction
Exempleintroductif
Proprietes
Distributionstationnaire
Convergence
Page Rank
Apprentissageetutilisations
4/33
Exemple introductifRepas de l’etudiant
Objectif : predire le repas de ce soir

FAA - M1S2
HadrienGlaude
Introduction
Exempleintroductif
Proprietes
Distributionstationnaire
Convergence
Page Rank
Apprentissageetutilisations
5/33
Exemple introductifAnalyse statique
Premiere approche : faire un sondage dans la residenceconcernant le dernier repas pris par chaque etudiant.
Table: Resultat du sondage
Ce qui nous donne les probabilites suivantes :
P (R = omelette) = 214 ≈ 0.14 P (R = pizza) = 4
14 ≈ 0.29
P (R = steak) = 314 ≈ 0.21 P (R = pates) = 5
14 ≈ 0.36
Table: Probabilite pour le repas de ce soir
Ce soir je predis que vous allez manger des pates avec uneprobabilite de 0.36.

FAA - M1S2
HadrienGlaude
Introduction
Exempleintroductif
Proprietes
Distributionstationnaire
Convergence
Page Rank
Apprentissageetutilisations
6/33
Exemple introductifAnalyse statique
� Ah non, j’en ai deja mange hier, j’en ai marre des pates �
Le modele actuel ne prend pas en compte le repas precedent.Enrichissons notre modele.

FAA - M1S2
HadrienGlaude
Introduction
Exempleintroductif
Proprietes
Distributionstationnaire
Convergence
Page Rank
Apprentissageetutilisations
7/33
Exemple introductifAnalyse dynamique
Faisons un sondage sur les deux derniers repas manges par lesetudiants de la residence.
J1
J2
Table: Resultat du sondage
Resumons les probabilites dans une matrice
T =
o pi pa s
o 0 3/4 0 0pi 0 0 4/5 0pa 1/2 0 1/5 1s 1/2 1/4 0 0

FAA - M1S2
HadrienGlaude
Introduction
Exempleintroductif
Proprietes
Distributionstationnaire
Convergence
Page Rank
Apprentissageetutilisations
8/33
Exemple introductifMatrice de transition
Dis moi ce que tu as mange hier, je te predis ce que tumangeras ce soir. Exemple :
� Hier j’ai mange des pates �(Rt−1 = pa)
Prediction : � ce soir tu mangeras une pizza avec uneprobabilite de P (Rt = pi |Rt−1 = pa) = 0.8 ou bien encoredes pates avec une probabilite deP (Rt = pa|Rt−1 = pa) = 0.2 �
T =
o pi pa s
o 0 3/4 0 0pi 0 0 4/5 0pa 1/2 0 1/5 1s 1/2 1/4 0 0
On appelle T la matrice de transition.
FAA - M1S2
HadrienGlaude
Introduction
Exempleintroductif
Proprietes
Distributionstationnaire
Convergence
Page Rank
Apprentissageetutilisations
9/33
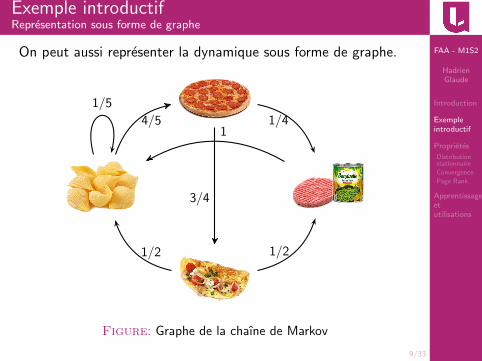
Exemple introductifRepresentation sous forme de graphe
On peut aussi representer la dynamique sous forme de graphe.
3/4
1/4
1/2 1/2
4/5
1/5
1
Figure: Graphe de la chaıne de Markov

FAA - M1S2
HadrienGlaude
Introduction
Exempleintroductif
Proprietes
Distributionstationnaire
Convergence
Page Rank
Apprentissageetutilisations
10/33
Exemple introductifVecteur d’etat
Soit rt−1 le vecteur indiquant le dernier repas. On appelle rt−1 levecteur d’etat au temps t − 1. Dans notre exemple,
rt−1 =
o 0pi 0pa 1s 0
La probabilite du prochain repas est donne par,
P (Rt |Rt−1 = pa) = rt = T rt−1 =
0
4/51/5
0

FAA - M1S2
HadrienGlaude
Introduction
Exempleintroductif
Proprietes
Distributionstationnaire
Convergence
Page Rank
Apprentissageetutilisations
11/33
Exemple introductifHypothese de Markov
On peut aussi donner la probabilite du repas de demain :
rt+1 = P (Rt+1|Rt−1 = pa)
=∑r
P (Rt+1,Rt = r |Rt−1 = pa)
=∑r
P (Rt+1|Rt = r ,Rt−1 = pa) P (Rt = r |Rt−1 = pa)
Markov=
∑r
P (Rt+1|Rt = r) P (Rt = r |Rt−1 = pa)
= T rt
=
0 3/4 0 00 0 4/5 0
1/2 0 1/5 11/2 1/4 0 0
04/51/5
0
=
12/204/251/254/20
Hypothese de Markov : on a fait l’hypothese que le repas dujour ne depend que de celui de la veille.
FAA - M1S2
HadrienGlaude
Introduction
Exempleintroductif
Proprietes
Distributionstationnaire
Convergence
Page Rank
Apprentissageetutilisations
12/33
Exemple introductifHypothese de Markov
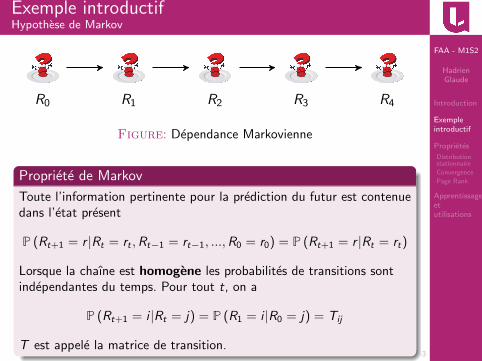
R0 R1 R2 R3 R4
Figure: Dependance Markovienne
Propriete de Markov
Toute l’information pertinente pour la prediction du futur est contenuedans l’etat present
P (Rt+1 = r |Rt = rt ,Rt−1 = rt−1, ...,R0 = r0) = P (Rt+1 = r |Rt = rt)
Lorsque la chaıne est homogene les probabilites de transitions sontindependantes du temps. Pour tout t, on a
P (Rt+1 = i |Rt = j) = P (R1 = i |R0 = j) = Tij
T est appele la matrice de transition.
FAA - M1S2
HadrienGlaude
Introduction
Exempleintroductif
Proprietes
Distributionstationnaire
Convergence
Page Rank
Apprentissageetutilisations
13/33
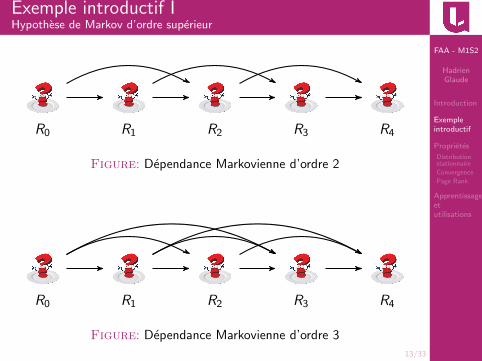
Exemple introductif IHypothese de Markov d’ordre superieur
R0 R1 R2 R3 R4
Figure: Dependance Markovienne d’ordre 2
R0 R1 R2 R3 R4
Figure: Dependance Markovienne d’ordre 3
FAA - M1S2
HadrienGlaude
Introduction
Exempleintroductif
Proprietes
Distributionstationnaire
Convergence
Page Rank
Apprentissageetutilisations
14/33
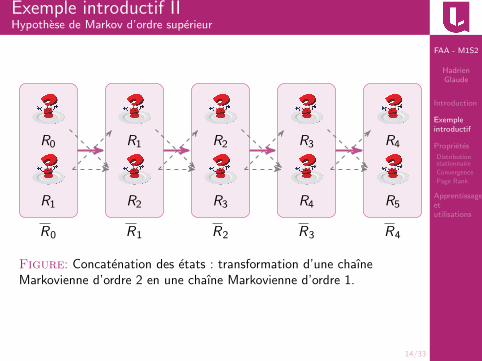
Exemple introductif IIHypothese de Markov d’ordre superieur
R0 R1 R2 R3 R4
R0 R1 R2 R3 R4
R1 R2 R3 R4 R5
Figure: Concatenation des etats : transformation d’une chaıneMarkovienne d’ordre 2 en une chaıne Markovienne d’ordre 1.

FAA - M1S2
HadrienGlaude
Introduction
Exempleintroductif
Proprietes
Distributionstationnaire
Convergence
Page Rank
Apprentissageetutilisations
15/33
Exemple introductifDistribution initiale et a t pas de temps
On appelle distribution initiale de la chaıne de Markov, ladistribution sur le premier etat de la chaıne : r0 = P (R0).Dans notre exemple, on a pris P (R0 = pa) = 1. Enl’absence d’information, on aurait pu prendre unedistribution uniforme.
La probabilite a t pas de temps s’ecrit alors,
P (Rt |R0) = T tr0

FAA - M1S2
HadrienGlaude
Introduction
Exempleintroductif
Proprietes
Distributionstationnaire
Convergence
Page Rank
Apprentissageetutilisations
16/33
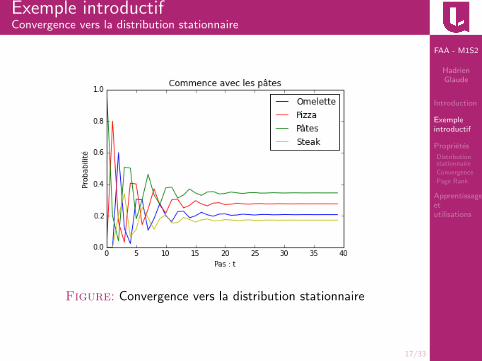
Exemple introductifConvergence vers la distribution stationnaire
Supposons que notre etudiant commence l’annee enmangeant des pates.
On peut calculer :
r0 =
0010
r1 =
0
0.20.80
r2 =
0.6
0.160.040.2
r3 =
0.12
0.0320.5080.34
r10 ≈
0.2300.3190.3030.149
r20 ≈
0.2040.2820.3460.169
r30 ≈
0.2060.2760.3450.172
r40 ≈
0.2070.2760.3450.172
FAA - M1S2
HadrienGlaude
Introduction
Exempleintroductif
Proprietes
Distributionstationnaire
Convergence
Page Rank
Apprentissageetutilisations
17/33
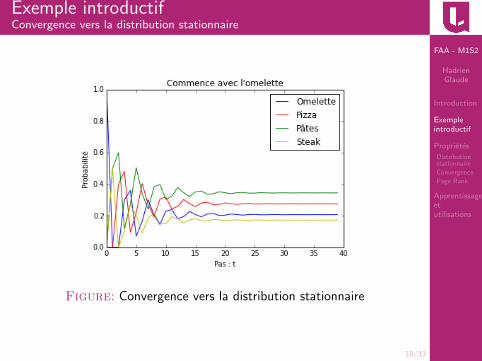
Exemple introductifConvergence vers la distribution stationnaire
Figure: Convergence vers la distribution stationnaire
FAA - M1S2
HadrienGlaude
Introduction
Exempleintroductif
Proprietes
Distributionstationnaire
Convergence
Page Rank
Apprentissageetutilisations
18/33
Exemple introductifConvergence vers la distribution stationnaire
Figure: Convergence vers la distribution stationnaire

Plan
1 Introduction
2 Exemple introductif
3 ProprietesDistribution stationnaireConvergencePage Rank
4 Apprentissage et utilisations
19/33

Plan
1 Introduction
2 Exemple introductif
3 ProprietesDistribution stationnaireConvergencePage Rank
4 Apprentissage et utilisations
19/33

FAA - M1S2
HadrienGlaude
Introduction
Exempleintroductif
Proprietes
Distributionstationnaire
Convergence
Page Rank
Apprentissageetutilisations
19/33
Distribution stationnaireDefinition
Distribution stationnaire
Soit une chaıne de Markov homogene, S ses etats et T samatrice de transition, le vecteur π est une distributionstationnaire si, pour tout etat j ∈ S ,
∀j ∈ S 0 ≤ πj ≤ 1∑i∈S
πi = 1
π = Tπ
Ainsi tout vecteur propre de T associe a la valeur propre 1 estune distribution stationnaire.

FAA - M1S2
HadrienGlaude
Introduction
Exempleintroductif
Proprietes
Distributionstationnaire
Convergence
Page Rank
Apprentissageetutilisations
20/33
Distribution stationnaireExistence
Dans la suite du cours, on suppose que l’espace d’etat est fini.
Recurrence
Un etat r est dit recurrent si la probabilite que la chaıne deMarkov repasse par cet etat au bout d’un temps fini vaut 1.
P (inf n ≥ 1,Rn = r < +∞) = 1
Sinon, l’etat est dit transitoire.
Un chaıne de Markov fini possede au moins un etat recurrent.Soit r un etat recurrent, alors la chaıne de Markov possede aumoins une distribution stationnaire π tel que πi > 0.

FAA - M1S2
HadrienGlaude
Introduction
Exempleintroductif
Proprietes
Distributionstationnaire
Convergence
Page Rank
Apprentissageetutilisations
21/33
Distribution stationnaireExistence
1/2
1/2
1
11
Figure: Pates est le seul etat recurrent.

FAA - M1S2
HadrienGlaude
Introduction
Exempleintroductif
Proprietes
Distributionstationnaire
Convergence
Page Rank
Apprentissageetutilisations
22/33
Distribution stationnaireUnicite
Chaıne de Markov irreductible
Une chaıne de Markov est irreductible si pour chaque coupled’etat il existe un chemin dans son graphe les reliant.
∀i , j ∈ S , ∃k , P (Rk = i |R0 = j) > 0
Une chaıne de Markov irreductible possede au plus unedistribution stationnaire.
Ainsi, une chaıne de Markov fini irreductible possede une uniquedistribution stationnaire. De plus, tous ses etats sont recurrents.

FAA - M1S2
HadrienGlaude
Introduction
Exempleintroductif
Proprietes
Distributionstationnaire
Convergence
Page Rank
Apprentissageetutilisations
23/33
Distribution stationnaireExistence
Figure: La chaıne n’est pas irreductible.

Plan
1 Introduction
2 Exemple introductif
3 ProprietesDistribution stationnaireConvergencePage Rank
4 Apprentissage et utilisations
24/33

FAA - M1S2
HadrienGlaude
Introduction
Exempleintroductif
Proprietes
Distributionstationnaire
Convergence
Page Rank
Apprentissageetutilisations
24/33
Distribution stationnaireConvergence
Etat aperiodique
Un etat est aperiodique si la chaıne peut retourner dans cet etata des temps irreguliers. L’etat r est aperiodique si,
∃t ′ ∀t ≥ t ′P (Rt = r |R0 = r) > 0
Un chaıne de Markov dont tous les etats sont aperiodiques estdıtes aperiodique.
Dans une chaıne de Markov irreductible, si un etat estaperiodique alors la chaıne l’est.Dans une chaıne de Markov fini irreductible et aperiodique, T t
converge vers une matrice dont chaque colonne correspond a ladistribution stationnaire π.

FAA - M1S2
HadrienGlaude
Introduction
Exempleintroductif
Proprietes
Distributionstationnaire
Convergence
Page Rank
Apprentissageetutilisations
25/33
Distribution stationnaireConvergence
1
1 1
1
Figure: La chaıne n’est pas aperiodique.

Plan
1 Introduction
2 Exemple introductif
3 ProprietesDistribution stationnaireConvergencePage Rank
4 Apprentissage et utilisations
26/33

FAA - M1S2
HadrienGlaude
Introduction
Exempleintroductif
Proprietes
Distributionstationnaire
Convergence
Page Rank
Apprentissageetutilisations
26/33
Page rankDefinition
Lors d’une recherche sur internet, de nombreuse pages webpeuvent contenir les mots de la requete. Dans quel ordre lesafficher ?
En 1998, deux etudiants de Stanford proposent d’utiliser lePageRank. Ils donnent naissance a Google.
Premiere definition du PageRank
La fonction Page Rank PR verifie, pour une page i
PR(i) =∑j∈Si
PR(j)
L(j)
ou Si est l’ensemble des pages qui ont un lien vers i et L(j) est lenombre de pages accessible depuis j . On considere que chaque pagepointe vers elle-meme et donc L(j) ≥ 1. De plus, on contraint PR aetre normalise : ∑
i∈S
PR(i) = 1

FAA - M1S2
HadrienGlaude
Introduction
Exempleintroductif
Proprietes
Distributionstationnaire
Convergence
Page Rank
Apprentissageetutilisations
27/33
Page rankIntuition
Popularite : une page est populaire si de nombreuses pagespopulaires pointent vers elle et surtout vers elle.
Marche aleatoire :
Imaginons un internaute naviguant aleatoirement de pageen page.La probabilite qu’il passe de la page i a la page j vautTi j = 1
L(i) si i possede un lien vers la page j , 0 sinon.
Representons ce processus par chaıne de Markov ou lesetats sont les pages.Soit π un vecteur tel que πi = PR(i) alors,
π = Tπ
π est donc une distribution stationnaire de cette chaıne deMarkov.
Algorithme : π est aussi le point fixe de T . En pratique, ontrouve π par iterations successives : π = lim
k→+∞T kπ0

FAA - M1S2
HadrienGlaude
Introduction
Exempleintroductif
Proprietes
Distributionstationnaire
Convergence
Page Rank
Apprentissageetutilisations
28/33
Page rankUnicite
Probleme : certains pages sont des culs-de-sac, la chaınen’est donc pas irreductible et la fonction PageRank n’estpas unique.
Deuxieme definition du PageRank
PR(i) =1− d
N+ d
∑j∈Si
PR(j)
L(j)
ou d = 0.85 est le facteur d’amortissement (damping factor).
La chaıne de Markov associee a cette fonction estirreductible et aperiodique.� PageRank can be thought of as a model of user behavior.We assume there is a ”random surfer” who is given a webpage at random and keeps clicking on links, never hitting”back” but eventually gets bored and starts on anotherrandom page. �

Plan
1 Introduction
2 Exemple introductif
3 ProprietesDistribution stationnaireConvergencePage Rank
4 Apprentissage et utilisations
29/33

FAA - M1S2
HadrienGlaude
Introduction
Exempleintroductif
Proprietes
Distributionstationnaire
Convergence
Page Rank
Apprentissageetutilisations
29/33
ApprentissageEstimation des parametres de la chaınes de Markov
Naturellement, les probabilites de transition ont eteestimees par comptage. Est-ce justifie ?
Oui, par le maximum de vraisemblance.
Soit N sequences Dl = {r l0, ..., r lti} d’observations. Oncherche les parametres Θ = {π,T} qui maximise
L(D; Θ) = log P (D1, ...DN |Θ) =N∑l=1
log P(r l0, ..., r
ltl
∣∣∣Θ)avec,
P(r l0, ..., r
ltl
∣∣∣Θ) = P(r l0
∣∣∣π) tl∏t=1
P(r lt
∣∣∣r lt−1,T)

FAA - M1S2
HadrienGlaude
Introduction
Exempleintroductif
Proprietes
Distributionstationnaire
Convergence
Page Rank
Apprentissageetutilisations
30/33
Apprentissage IEstimation des parametres de la chaınes de Markov
On introduit les variables z ltk tel que, z ltk = 1 si r lt = k , 0sinon. Ainsi,
P(r l0, ..., r
ltl
∣∣∣Θ) =∏k
πz l0kk ×
tl∏t=1
∏i
∏j
Tz lti×z
l(t−1)j
ij
On revient a la log vraisemblance
L(D; Θ) =N∑l=1
∑k
z l0k log(πk) +
tl∑t=1
∑i
∑j
(z lti × z l(t−1)j) log(Tij)
On definit les comptes suivants :
Nk =N∑l=1
z l0k Nij =N∑l=1
tl∑t=1
z ltizl(t−1)j
(nombre de fois ou le premier etat vaut k et nombre detransitions observees entre i et j)

FAA - M1S2
HadrienGlaude
Introduction
Exempleintroductif
Proprietes
Distributionstationnaire
Convergence
Page Rank
Apprentissageetutilisations
31/33
Apprentissage IIEstimation des parametres de la chaınes de Markov
On peut reecrire,
L(D; Θ) =∑k
Nk log(πk) +∑i
∑j
Nij log(Tij)
que l’on cherche a maximiser sous la contrainte∑k
πk = 1 ∀j∑i
Tij = 1
Ce qui donne le Lagrangien suivant,
L(π, θ, λ, {γj} =∑k
Nk log(πk) +∑i
∑j
Nij log(Tij)
+ λ(1−∑k
πk) +∑j
γj(1−∑i
Tij)

FAA - M1S2
HadrienGlaude
Introduction
Exempleintroductif
Proprietes
Distributionstationnaire
Convergence
Page Rank
Apprentissageetutilisations
32/33
Apprentissage IIIEstimation des parametres de la chaınes de Markov
En derivant et en annulant, on retrouve bien
πk =Nk
NTij =
Nij∑k Nik
Cela correspond bien aux formules que l’on a utilise dansl’exemple sans justification.

FAA - M1S2
HadrienGlaude
Introduction
Exempleintroductif
Proprietes
Distributionstationnaire
Convergence
Page Rank
Apprentissageetutilisations
33/33
Utilisation des chaınes de MarkovModelisation du langage
Modelisation statistique du langage = probabilite de distributionsur des sequences de mots. Utilisations :
Completion de phrase : predire le mot suivant en fonctiondes precedents
Classification de texte : associer une chaıne a chaque typede texte (C1, ..., Cn). Trouver la chaıne qui maximise lavraisemblance des donnees arg maxi P (X1, ...,Xt |Ci ).
Partitionnement de documents : apprendre un melange deK chaınes de Markov. Associer chaque documents a unechaıne de Markov.
Generation de texte aleatoire : echantillonner selonP (X1, ...,Xt)

Plan
5 TP
1/1

FAA - M1S2
HadrienGlaude
TP
1/1
Completion de phrase
1 Telecharger un corpus de texte francais ou anglais
http://corpora.uni-leipzig.de/download.html
2 Apprendre les probabilites de transitions d’une chaıne deMarkov ou les etats sont les mots apparaissant dans lecorpus.
3 Generer les prochains mots les plus probables apres :
Le but de la vie est ...
4 Recommencer en utilisant un modele d’ordre 2 puis d’ordre3.











![Cours4-Barres-17 [Mode de compatibilité] - Collège de France](https://img.pdfslide.fr/doc/110x75/62684343bb44fa34bf484c6d/cours4-barres-17-mode-de-compatibilit-collge-de-france.jpg)
















