Embed Size (px)
Citation preview

Par SIMO Ulrich Florian Matricule : 11V0795
Mémoire Présenté en vue de l’obtention du
Diplôme de Master Recherche
Option
Statistique Appliquée
Sous la co-direction de
Dr. Ibrahim MOUKOUOP Dr. Patrice TAKAM Chargé de Cours, ENSP Assistant, UYI
Devant le jury composé de
Président : Pr. Henri GWÉT, Maître de conférences Rapporteurs : Dr. Ibrahim MOUKOUOP, Chargé de cours Dr. Patrice TAKAM, Assistant
Membres : Dr. Eugène-Patrice NDONG NGUEMA, Chargé de cours Dr. Jacques TAGOUDJEU, Chargé de cours
Année académique 2013-2014
UNIVERSITY OF YAOUNDE I
***************** NATIONAL ADVANCED SCHOOL
OF ENGINEERING ******************
DEPARTEMENT OF MATHEMATICS AND PHYSICAL SCIENCES
UNIVERSITÉ DE YAOUNDÉ I
****************** ÉCOLE NATIONALE SUPÉRIEURE
POLYTECHNIQUE ****************** DEPARTEMENT DE
MATHEMATIQUES ET SCIENCES PHYSIQUES
GESTION DE STOCK DE GPS A LA
DOUANE CAMEROUNAISE :
Prévision de la demande et du flux de retour GPS

2
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

GESTION DE STOCK DE GPS A LA
DOUANE CAMEROUNAISE :
Prévision de la demande et du ux de retour
GPS
Ulrich Florian SIMO
16 octobre 2014

2
Figure 1 GPS GARMIN Oregon 300
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

DÉDICACES i
Dédicaces
Je dédie ce mémoire à toute la grande famille SIMO.
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

REMERCIEMENTS ii
Remerciements
Je me dois tout d'abord de remercier Pr. Henri Gwét, pour avoir accepté de présider le
jury de ma soutenance. Puis, je remercie aussi tous les autres membres du jury pour avoir
accepter d'en faire partie, notamment : Dr. Ibrahim Moukouop, Dr. Patrice Takam, Dr.
Eugène-Patrice Ndong Nguéma et Dr. Jacques Tagoudjeu.
Je désire également témoigner ici de ma reconnaissance envers tous ceux qui ont suivi,
soutenu et guidé ce travail de rédaction du mémoire de six mois. Qu'ils en soient très cha-
leureusement remerciés.
Je désire adresser une marque toute particulière de ma gratitude :
à M. Henri Gwét, instigateur de cette formation, pour sa présence et ses conseils, tous
considérables, et qui, malgré ses multiples occupations, a su coordonner les enseignements
de ce master ;
à M. Ibrahim Moukouop, pour m'avoir permis d'eectuer mon stage de n de formation
dans l'organisation Polytech-Valor dont il est l'administrateur délégué, pour la constance de
son soutien et la justesse des orientations qu'il a bien voulu me suggérer ;
à M. Patrice Takam, pour ses conseils sans cesse pertinents et ses levées de doute, pour
la constance de son suivi et son soutien sans faille durant ces deux dernières années de ma
formation académique ;
à M. Eugène-Patrice Ndong-Nguéma, pour sa participation essentielle au suivi de ce tra-
vail, pour l'attention assidue qu'il a bien voulu prêter à la lecture, puis à la correction de ce
manuscrit ;
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

REMERCIEMENTS iii
à tous les autres membres du Personnel Enseignant du Master de Statistique Appliquée,
pour leur disponibilité, leur gentillesse, leurs nombreuses remarques, et pour avoir souvent
répondu à des questions bien naïves ;
à tous mes compagnons et amis de tous les jours, mes camarades de classe et de promo-
tion, qui ont contribué chacun à leur manière à l'accomplissement de ce travail.
Enn, de ma famille, je remercie inniment chaque membre et, plus particulièrement,
mes parents - pour leur soutien, leur amour, leur conseil.
Que le dernier de mes remerciements, tout particulier, soit pour Aude.
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

TABLE DES MATIÈRES iv
Table des matières
Dédicaces i
Remerciements ii
Table des gures viii
Liste des tableaux ix
Avant-propos x
Lexique des termes techniques xi
Résumé xii
Abstract xiii
Résumé Exécutif xiv
Introduction Générale 1
1 Revue de Littérature 5
2 Présentation et Analyse Descriptive des Données 13
2.1 Présentation des données . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.1.1 Comment s'eectuent les ux physiques de GPS à la douane ? . . . . 13
2.1.2 Origine des données . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.1.3 Traitement des données manquantes . . . . . . . . . . . . . . . . . . 17
2.2 Analyse descriptive des données . . . . . . . . . . . . . . . . . . . . . . . . . 17
2.2.1 Normalité, tendance et saisonnalité . . . . . . . . . . . . . . . . . . . 18
2.2.2 Le calcul de quelques statistiques de base . . . . . . . . . . . . . . . . 20
2.2.3 Etude statistique du délai de retour GPS . . . . . . . . . . . . . . . . 21
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

TABLE DES MATIÈRES v
3 Méthodologie Statistique 26
3.1 Quelques concepts fondamentaux . . . . . . . . . . . . . . . . . . . . . . . . 26
3.1.1 Processus stochastique . . . . . . . . . . . . . . . . . . . . . . . . . . 26
3.1.2 Prévision d'une série chronologique. . . . . . . . . . . . . . . . . . . . 27
3.1.3 La stationnarité . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
3.1.4 L'autocorrélation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
3.2 Le lissage exponentiel de Holt-Winters . . . . . . . . . . . . . . . . . . . . . 29
3.2.1 Méthode saisonnière . . . . . . . . . . . . . . . . . . . . . . . . . . . 30
3.2.2 Méthode non saisonnière . . . . . . . . . . . . . . . . . . . . . . . . . 30
3.3 Le modèle ARIMA saisonnier . . . . . . . . . . . . . . . . . . . . . . . . . . 31
3.3.1 Le modèle ARMA stationnaire et ses propriétés usuelles . . . . . . . 31
3.3.2 La méthodologie de Box et Jenkins . . . . . . . . . . . . . . . . . . . 33
3.4 Modèle à retards échelonnés . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
3.4.1 Méthode de Koyck . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
3.4.2 Cas de la prévision du ux de retour GPS . . . . . . . . . . . . . . . 36
3.4.3 Estimation des paramètres du modèle . . . . . . . . . . . . . . . . . . 37
3.4.4 Prévision . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
3.5 Prévision en loi de probabilité . . . . . . . . . . . . . . . . . . . . . . . . . . 41
3.5.1 Estimation par histogramme . . . . . . . . . . . . . . . . . . . . . . . 42
3.5.2 Estimateur à noyau continu . . . . . . . . . . . . . . . . . . . . . . . 46
3.5.3 Cas de la prévision en loi de la demande GPS . . . . . . . . . . . . . 48
3.6 Mesure de la qualité de la prévision . . . . . . . . . . . . . . . . . . . . . . . 48
4 Applications aux Données et Résultats 51
4.1 Modélisation et prévision de la demande eective . . . . . . . . . . . . . . . 51
4.1.1 Application de la méthode du lissage exponentiel Holt-Winters . . . . 51
4.1.2 Application de la méthode de Box et Jenkins . . . . . . . . . . . . . . 53
4.1.3 Prévision en loi de la demande eective . . . . . . . . . . . . . . . . . 56
4.2 Modélisation et prévision du ux de retour . . . . . . . . . . . . . . . . . . . 61
4.2.1 Application de la méthode du lissage exponentiel Holt-Winters . . . . 61
4.2.2 Application de la méthode de Box et Jenkins . . . . . . . . . . . . . . 63
4.2.3 Application de la méthode à retards échelonnés . . . . . . . . . . . . 66
5 Formalisation du Cadre Théorique de la Politique de Gestion de Stock 69
5.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
5.1.1 Politiques de gestion de stock classiques . . . . . . . . . . . . . . . . 69
5.1.2 Modèles de politique de gestion de stock . . . . . . . . . . . . . . . . 70
5.1.3 Cas de la gestion de stock GPS . . . . . . . . . . . . . . . . . . . . . 71
5.2 Une formalisation mathématique de la gestion de stock GPS . . . . . . . . . 72
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

TABLE DES MATIÈRES vi
5.3 Probabilité de rupture et quantité à approvisionner . . . . . . . . . . . . . . 74
5.3.1 Estimation de la probabilité de rupture à l'horizon h . . . . . . . . . 74
Conclusion Générale 78
Annexe A : Compléments mathématiques 82
Annexe B : Tests d'hypothèses (Dénitions et Exemples) 86
Annexe C : Programmes R 90
Bibliographie 112
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

TABLE DES FIGURES vii
Table des gures
1 GPS GARMIN Oregon 300 . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
2 Demande eective de GPS, prédiction Box Jenkins et bande de prédiction. . xv
3 Demande eective de GPS, prédiction en loi de probabilité suivant les jours
et bande de prédiction. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . xvi
4 Flux de retour GPS, prédiction Box Jenkins et bande de prédiction. . . . . . xvii
1.1 (a) Chaîne d'approvisionnement à sens unique, (b) Chaîne d'approvisionne-
ment en boucle fermée (reconditionnement, réutilisation) [6]. . . . . . . . . . 10
1.2 (a) Prévision de la demande, (b) Prévision des retours, approche à sens unique,
(c) Prévision des retours, approche CLSC [6]. . . . . . . . . . . . . . . . . . 11
2.1 Répartition des données disponibles dans le temps, (a) ux de sortie, (b) ux
de retour, (c) demande eective. . . . . . . . . . . . . . . . . . . . . . . . . . 17
2.2 Prol chronologique de la série journalière de la demande eective de GPS. . 18
2.3 Prol chronologique de la série hebdomadaire du ux de sortie GPS. . . . . . 19
2.4 Prol chronologique de la série journalière du ux de retour GPS. . . . . . . 20
2.5 Périodogramme de la série du ux de sortie hebdomadaire de GPS. . . . . . 21
2.6 Lag plot du ux de retour journalier de GPS. . . . . . . . . . . . . . . . . . 22
2.7 Histogrammes des séries d'observations. . . . . . . . . . . . . . . . . . . . . . 23
2.8 Boîte à moustaches pour la variable durée avant disponibilité. . . . . . . . . . 23
2.9 Ajustement par la fonction de répartition du délai de retour. . . . . . . . . . 24
3.1 Histogrammes et densité des données simulées correspondant aux nombres de
classes m = 10,m = 110 et m = 250. . . . . . . . . . . . . . . . . . . . . . . 44
4.1 Prol chronologique de la série journalière de la demande eective de GPS. . 52
4.2 Demande eective GPS, prédiction Holt-Winters et bande de prédiction. . . 52
4.3 Demande eective de GPS, ACF (gauche) et PACF (droite). . . . . . . . . . 53
4.4 Demande eective GPS diérenciée saisonnièrement, ACF (gauche) et PACF
(droite). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

TABLE DES FIGURES viii
4.5 Demande eective GPS diérenciée saisonnièrement, résidu estimé du modèle,
ACF (gauche) et PACF (droite). . . . . . . . . . . . . . . . . . . . . . . . . . 54
4.6 Demande eective GPS diérenciée saisonnièrement, résidu estimé du modèle
après ajout des deux premiers termes autorégressifs, ACF (gauche) et PACF
(droite). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
4.7 Demande eective de GPS, prédiction Box Jenkins et bande de prédiction. . 56
4.8 Autocorrélogramme de la série de la demande eective. . . . . . . . . . . . . 56
4.9 Ajustement par histogramme et par noyau de la loi de probabilité de la de-
mande eective. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
4.10 Demande eective de GPS, prédiction en loi de probabilité et bande de pré-
diction. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
4.11 Ajustement Gamma pour chaque jour de la semaine, demande eective GPS. 60
4.12 Demande eective de GPS, prédiction en loi de probabilité suivant les jours
et bande de prédiction. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
4.13 Prol chronologique de la série journalière du ux de retour GPS. . . . . . . 62
4.14 Flux de retour GPS, prédiction Holt-Winters et bande de prédiction. . . . . 62
4.15 Flux de retour GPS, ACF (gauche) et PACF (droite). . . . . . . . . . . . . . 63
4.16 Flux de retour GPS diérencié saisonnièrement, chronogramme et ACF. . . . 64
4.17 Flux de retour GPS, diérents modèles SARIMA. . . . . . . . . . . . . . . 65
4.18 Flux de retour GPS, prédiction Box Jenkins et bande de prédiction. . . . . . 66
4.19 Estimation de p et q, algorithme EM. . . . . . . . . . . . . . . . . . . . . . . 67
4.20 Flux de retour GPS, prévision par le modèle à retards échelonnés. . . . . . . 68
5.1 Loi de probabilité estimée de la demande nette. . . . . . . . . . . . . . . . . 73
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

LISTE DES TABLEAUX ix
Liste des tableaux
1.1 Espérance de yτ−i,τ+j, le nombre de retours de la période τ + j provenant des
ventes de la période τ − i, pour diérents ensembles d'informations. . . . . . 8
2.1 Statistiques descriptives usuelles pour les trois variables d'intérêt. . . . . . . 21
2.2 Statistiques descriptives usuelles pour la v.a. durée avant disponibilité. . . . . 22
3.1 Espérance de Rt−i,t+h, le ux de retour du jour t+ h provenant des sorties du
jour t− i, pour diérents ensembles d'informations. . . . . . . . . . . . . . . 40
4.1 Série de la demande, paramètres estimés et statistiques du modèle SARIMA. 55
4.2 MAPE pour les deux méthodes de prévision en valeur de la demande eective
de GPS. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
4.3 Prévision en loi de la demande eective de GPS, quelques critères calculés. . 59
4.4 Prévision en loi (version 2) de la demande eective de GPS, quelques critères
calculés. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
4.5 Série du ux de retour, paramètres estimés et statistiques du modèle SARIMA. 64
4.6 MAPE pour les deux méthodes de prévision en valeur du ux de retour GPS. 65
5.1 Notations principales adoptées dans ce chapitre. . . . . . . . . . . . . . . . . 71
5.2 Demande eective de GPS, valeurs prédites par Box-Jenkins et bornes de
l'intervalle de prédiction à 95%. . . . . . . . . . . . . . . . . . . . . . . . . . 88
5.3 Flux de retour GPS, valeurs prédites par Box-Jenkins et bornes de l'intervalle
de prédiction à 95%. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 89
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

AVANT-PROPOS x
Avant-propos
Dans le cadre de la formation des ingénieurs chercheurs statisticiens, le MASTAT prévoit
un stage d'une durée de quatre à six mois au terme de la deuxième année. Ce stage est
l'occasion, pour le futur ingénieur chercheur, de mettre en pratique les connaissances pra-
tiques et théoriques acquises pendant ses deux années de formation. Le stage a aussi pour
but de permettre à l'étudiant de s'imprégner des réalités de la vie professionnelle qui sont
évidemment diérentes des réalités académiques.
L'entreprise Polytech-Valor a bien voulu m'accueillir, pour le stage que nous avons ef-
fectué à la Direction de la Recherche. Conformément à l'un des objectifs principaux de la
politique de gestion de stock GPS à la Douane Camerounaise, qui est celle de mettre en
oeuvre un modèle d'application capable de gérer ecacement les diérents ux physiques
de GPS, an d'optimiser la quantité de GPS à pourvoir pour le lancement des voyages dans
un horizon donné, il nous a été coné la tâche de prédire la demande et le ux de retour
GPS. En outre, nous devons proposer une formalisation du cadre théorique de la politique
de gestion de stock.
Ce travail constitue, pour nous, un premier pas dans la recherche et il reste entière-
ment ouvert à toutes les critiques qui permettront de l'améliorer. Cependant, nous espérons
qu'il aidera les administrations douanières ou, de manière indirecte, les professionnels de
Polytech-Valor à proposer des solutions fortes en matière de gestion de stock aux respon-
sables douaniers.
Signalons que l'ensemble des résultats obtenus par application numérique et mentionnés
dans ce mémoire ont été obtenus grâce au logiciel R 3.0.2 [36], car il est libre, gratuit, et
c'est celui avec lequel nous avons eectué la majeure partie de notre formation pratique.
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

LEXIQUE DES TERMES TECHNIQUES xi
Lexique des termes techniques
GPS : Global Positionning System.
Transit de marchandises : Dans ce mémoire, ceci désignera le processus qui consiste
à faire passer des marchandises du port de Douala aux postes frontières.
Demande eective : Pour faire transiter les marchandises, les acteurs du secteur sol-
licitent des transporteurs (camions) appropriés auprès des autorités douanières. Or, selon la
réglementation en vigueur, à chaque camion destiné au transit est obligatoirement associé
un GPS. Dans notre étude, nous parlerons de demande eective de GPS.
Flux de sortie : Nous appellerons ux de sortie ou ux de sortie GPS , le nombre
de GPS (ou encore de voyages) mis en transit.
Durée avant disponibilité : La durée avant disponibilité ou délai de retour d'un GPS
désignera le temps qui sépare la date de début de lancement du voyage à la date de retour
au port du GPS associé.
Flux de retour : Nous appellerons ux de retour ou ux de retour GPS , le
nombre de GPS retournés à la base portuaire.
Stock : Un stock est une quantité d'articles emmagasinés. Dans notre travail, il s'agira
de stocks de GPS disponibles pour le lancement des voyages.
Gestion de stock : Ensemble des techniques permettant au gestionnaire d'obtenir la
meilleure gestion possible des ux d'entrée et de sortie. Et ce, dans l'optique de satisfaire la
clientèle tout en minimisant les coûts.
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

RÉSUMÉ xii
Résumé
Le travail présenté dans ce mémoire apporte quelques éléments de réponse à la problé-
matique générale de gestion de stock GPS à la Douane Camerounaise. Plus précisément,
nous nous concentrons sur la prévision de la demande eective et la prévision du ux de
retour GPS, en plus de proposer une formalisation du cadre théorique d'une politique de
gestion de stock. Nous considérons une méthode de prévision dite en loi de probabilité ,
et trois autres modèles de prévision en analyse des séries temporelles : le lissage exponentiel
de Holt-Winters, le modèle ARIMA saisonnier et le modèle à retards échelonnés.
Pour la prévision de la demande eective GPS, la performance prédictive de chacun des
trois premiers modèles cités est évaluée avec un indicateur d'ajustement, à savoir le critère
MAPE. L'utilisation de ce critère conduit au choix de la méthode de prévision Box et
Jenkins, comme méthode produisant les meilleurs résultats. De plus, pour des prévisions du
moment de rupture ou l'ampleur de la rupture, il nous semble judicieux de considérer la
méthode de prévision en loi de probabilité, ceci grâce au critère JRGPS introduit dans ce
mémoire.
Pour la prévision du ux de retour GPS, et, sur la base des informations disponibles
dans le cadre de ce mémoire, l'application des trois dernières méthodes citées ci-dessus nous
a conduit au choix de la méthode de Box et Jenkins, comme celle produisant les meilleurs
résultats prévisionnels en termes du critère MAPE.
Ce mémoire propose également une formalisation du cadre théorique d'une politique de
gestion de stock à point de commande adaptée au contexte des ux physiques de GPS, dans
laquelle nous apportons des éléments de réponse, notamment sur la quantité à approvisionner
et l'estimation de la probabilité de rupture. Cette formulation se base sur nos connaissances
mathématiques, notre compréhension du problème dans sa globalité et sur nos diérentes
lectures d'articles consacrés à ce domaine et présentés dans les références bibliographiques.
Mots clés : prévision, demande eective de GPS, ux de sortie GPS, ux de retour
GPS, modèles de séries temporelles, lissage exponentiel, modèle ARIMA saisonnier, modèle
à retards échelonnés, loi de probabilité, gestion de stock, GPS, transit.
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

ABSTRACT xiii
Abstract
The work presented in this paper provides some answers to the general problem of GPS
stock management at the Cameroonian custom. Specically, we focus on demand forecasting
and prediction of the return ow of GPS, in addition to providing a formalization of the
theoretical framework of the stock management policy. We consider one prediction method
called law of probability and three models in time series analysis : exponential smoothing
of Holt-Winters, the ARIMA seasonal model and the lag model.
For demand forecasting, predictive performance of the rst three models is assessed
with an adjustment indicator, such as MAPE criterion. According to this criterion, the
Box-Jenkins method seems to be the best prediction method. Besides, for the predictive of
breaking-point or rupture fullness, it could be judicious to also consider the law of probability
method, according to the JRGPS criterion.
For the prediction of the return ow and according to the informations provided, the
application of the last three methods mention above lead us to the Box-Jenkins method as
the best prediction method according to the MAPE criterion.
This thesis also propose a formalization of the theoretical framework of the GPS stock
management policy t to the physical ow context. We also propose the formulation of the
command quantity and estimation of the breaking-point probability. This formulation is ba-
sed on our mathematical knowledge, our understanding of the basic problem and our reading
of various articles devoted to this area and presented in the references.
Key words : forecasting, GPS demands, GPS exit ow, GPS return ow, time series
models, smoothing exponential model, ARIMA seasonal model, lag model, law of probability,
stock management, GPS, transit.
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

RÉSUMÉ EXÉCUTIF xiv
Résumé Exécutif
Problème. Le système de gestion de stock GPS à la Douane Camerounaise est confronté
à divers problèmes, notamment celui de la prévision de ses diérents ux physiques de GPS.
C'est à l'occasion des uctuations plus ou moins marquées de tendances de la demande ou
du ux de retour GPS que l'essentiel des pertes se réalise : soit par sur-stock, du fait d'une
demande qui échit brutalement par rapport aux prévisions, soit, au contraire, par perte de
chire d'aaires, due aux ruptures. Il est donc urgent pour le gestionnaire de stock GPS,
de disposer d'un ou plusieurs modèles de prévisions lui permettant de gérer ecacement les
stocks, an de s'éloigner des considérations totalement subjectives. Face à cette probléma-
tique, notre contribution se situe à deux niveaux : (1) construire des modèles statistiques de
prédiction en loi et en valeur pour la demande eective et le ux de retour GPS ; (2)
proposer une formalisation du cadre théorique d'une politique de gestion de stock plausible
et adaptée au contexte douanier.
Méthodes. Pour répondre à la première dimension du problème qui nous a été posé, des
échantillons de données sur nos variables d'intérêt (demande eective et ux de retour GPS)
nous ont été remis. Toutes ces données ont une structure de série chronologique. Elles per-
mettent à cet eet, de disposer des informations sur la demande eective journalière de GPS
et le ux de retour journalier de GPS. Plus précisément, ils serviront à la mise en oeuvre
des modèles de prévision. Nous avons utilisé quatre méthodes statistiques prévisionnelles, à
savoir :
∗ Une méthode de prévision en loi utilisant l'estimation de loi de probabilité ;
∗ La méthode du lissage exponentiel de Holt-Winters ;
∗ La méthode de Box et Jenkins ;
∗ La méthode à retards échelonnés.
Pour répondre à la deuxième dimension du problème, nous nous basons sur nos connais-
sances mathématiques, notre compréhension du problème et sur certaines études théoriques
présentées dans la littérature, notamment celles exposées dans [9,32].
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014
RÉSUMÉ EXÉCUTIF xv
Résultats. Comme résultats obtenus dans ce mémoire, nous avons :
1. La série du ux de retour admet une saisonnalité de 6 jours, et le délai de retour (ou
durée avant disponibilité) GPS suit une distribution de Poisson.
2. De l'application des méthodes de Holt-Winters et de Box et Jenkins sur la série jour-
nalière de la demande eective GPS, avec les observations préalablement transformées
par la fonction log, il ressort que, la méthode de prévision de Box et Jenkins s'avère la
plus performante dans la qualité des résultats prévisionnels obtenus, et ce, en termes
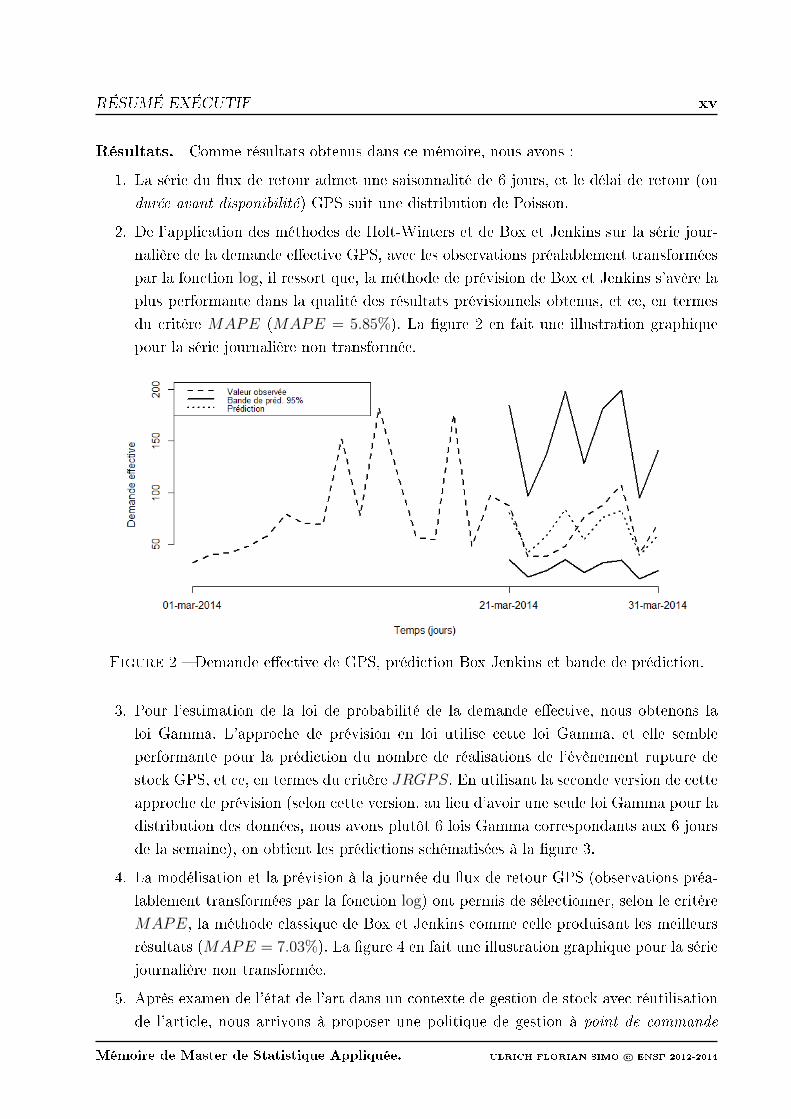
du critère MAPE (MAPE = 5.85%). La gure 2 en fait une illustration graphique
pour la série journalière non transformée.
Figure 2 Demande eective de GPS, prédiction Box Jenkins et bande de prédiction.
3. Pour l'estimation de la loi de probabilité de la demande eective, nous obtenons la
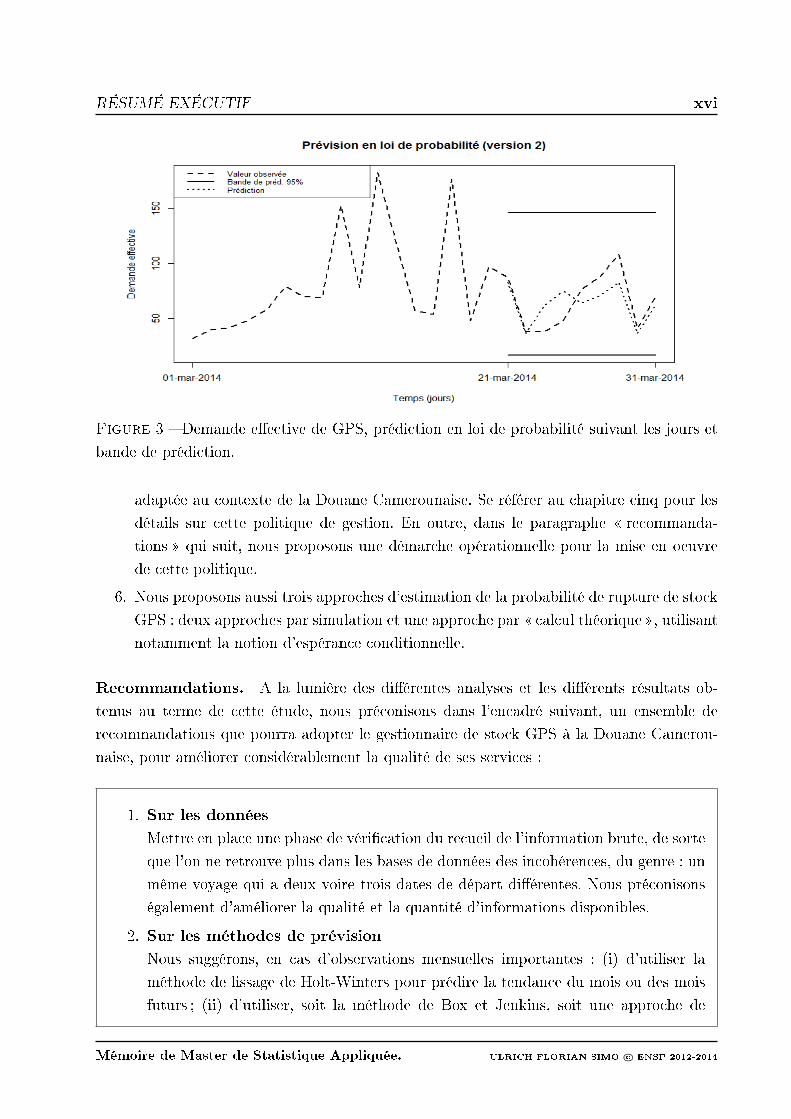
loi Gamma. L'approche de prévision en loi utilise cette loi Gamma, et elle semble
performante pour la prédiction du nombre de réalisations de l'évènement rupture de
stock GPS, et ce, en termes du critère JRGPS. En utilisant la seconde version de cette
approche de prévision (selon cette version, au lieu d'avoir une seule loi Gamma pour la
distribution des données, nous avons plutôt 6 lois Gamma correspondants aux 6 jours
de la semaine), on obtient les prédictions schématisées à la gure 3.
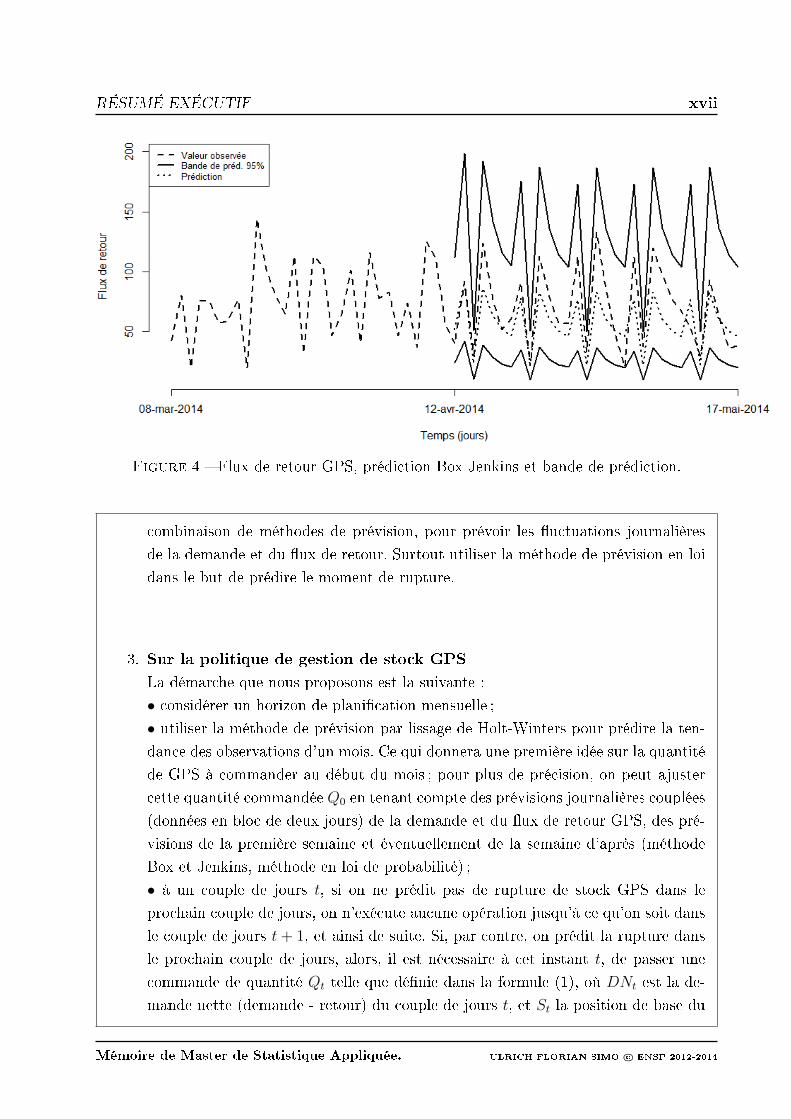
4. La modélisation et la prévision à la journée du ux de retour GPS (observations préa-
lablement transformées par la fonction log) ont permis de sélectionner, selon le critère
MAPE, la méthode classique de Box et Jenkins comme celle produisant les meilleurs
résultats (MAPE = 7.03%). La gure 4 en fait une illustration graphique pour la série
journalière non transformée.
5. Après examen de l'état de l'art dans un contexte de gestion de stock avec réutilisation
de l'article, nous arrivons à proposer une politique de gestion à point de commande
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014
RÉSUMÉ EXÉCUTIF xvi
Figure 3 Demande eective de GPS, prédiction en loi de probabilité suivant les jours et
bande de prédiction.
adaptée au contexte de la Douane Camerounaise. Se référer au chapitre cinq pour les
détails sur cette politique de gestion. En outre, dans le paragraphe recommanda-
tions qui suit, nous proposons une démarche opérationnelle pour la mise en oeuvre
de cette politique.
6. Nous proposons aussi trois approches d'estimation de la probabilité de rupture de stock
GPS : deux approches par simulation et une approche par calcul théorique , utilisant
notamment la notion d'espérance conditionnelle.
Recommandations. A la lumière des diérentes analyses et les diérents résultats ob-
tenus au terme de cette étude, nous préconisons dans l'encadré suivant, un ensemble de
recommandations que pourra adopter le gestionnaire de stock GPS à la Douane Camerou-
naise, pour améliorer considérablement la qualité de ses services :
1. Sur les données
Mettre en place une phase de vérication du recueil de l'information brute, de sorte
que l'on ne retrouve plus dans les bases de données des incohérences, du genre : un
même voyage qui a deux voire trois dates de départ diérentes. Nous préconisons
également d'améliorer la qualité et la quantité d'informations disponibles.
2. Sur les méthodes de prévision
Nous suggérons, en cas d'observations mensuelles importantes : (i) d'utiliser la
méthode de lissage de Holt-Winters pour prédire la tendance du mois ou des mois
futurs ; (ii) d'utiliser, soit la méthode de Box et Jenkins, soit une approche de
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014
RÉSUMÉ EXÉCUTIF xvii
Figure 4 Flux de retour GPS, prédiction Box Jenkins et bande de prédiction.
combinaison de méthodes de prévision, pour prévoir les uctuations journalières
de la demande et du ux de retour. Surtout utiliser la méthode de prévision en loi
dans le but de prédire le moment de rupture.
3. Sur la politique de gestion de stock GPS
La démarche que nous proposons est la suivante :
• considérer un horizon de planication mensuelle ;
• utiliser la méthode de prévision par lissage de Holt-Winters pour prédire la ten-
dance des observations d'un mois. Ce qui donnera une première idée sur la quantité
de GPS à commander au début du mois ; pour plus de précision, on peut ajuster
cette quantité commandée Q0 en tenant compte des prévisions journalières couplées
(données en bloc de deux jours) de la demande et du ux de retour GPS, des pré-
visions de la première semaine et éventuellement de la semaine d'après (méthode
Box et Jenkins, méthode en loi de probabilité) ;
• à un couple de jours t, si on ne prédit pas de rupture de stock GPS dans le
prochain couple de jours, on n'exécute aucune opération jusqu'à ce qu'on soit dans
le couple de jours t+ 1, et ainsi de suite. Si, par contre, on prédit la rupture dans
le prochain couple de jours, alors, il est nécessaire à cet instant t, de passer une
commande de quantité Qt telle que dénie dans la formule (1), où DNt est la de-
mande nette (demande - retour) du couple de jours t, et St la position de base du
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

RÉSUMÉ EXÉCUTIF xviii
stock à la n du couple de jours t.
Qt =
St − St−1 +DNt si St−1 −DNt < St,
0 sinon.(1)
∗ Comment prévoir la rupture de stock GPS ?
Pour prévoir la rupture dans le prochain couple de jours, le gestionnaire devra se
servir simultanément de tous les indicateurs de ruptures exposés dans ce mémoire,
notamment :
Pt,1, estimation de la probabilité de rupture de stock GPS à l'instant t+ 1 sachant
qu'il n'y a pas eu rupture en t et pas de réapprovisionnement entre t et t+1, donnée
par la formule (2) ;
Pt,1 = P(Dt+1 −Rt+1 > PSt+1
). (2)
IRt+1, estimation de l'indicateur de rupture de stock GPS à l'instant t+ 1, donnée
par la formule (3) ;
IRt+1 =
1 si Dt+1 −Rt+1 > PSt+1,
0 sinon.(3)
ou encore le critère JRGPS donné par la formule (4), avec hmax le nombre d'ob-
servations à prédire.
JRGPS =hmax∑h=1
1Dh>Vh(Dh − Vh). (4)
Dans chacune des formules (2)-(4), Dt est la demande totale de l'instant t, Rt le
ux de retour de l'instant t, Vt le ux de sortie de l'instant t, PSt la position du
stock au début de l'instant t et PSt la valeur prédite.
Limites et perspectives. Les deux principales limites de ce travail sont : (1) la taille
réduite des diérents échantillons de données ; (2) l'indisponibilité des articles (payants)
[16,18,19], ce qui a eu un impact non négligeable sur les valeurs prédites de la série du ux
de retour GPS, par la méthode à retards échelonnés. En eet, certains auteurs montrent que,
sous certaines hypothèses (que les données que nous disposons vérient), les informations
de type C et D présentées dans l'exposé de la méthode à retards échelonnés (cf. chapitre 3)
produisent des valeurs prédites bien meilleures que l'information du type B utilisée dans ce
mémoire.
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

RÉSUMÉ EXÉCUTIF xix
Comme perspectives futures, nous pensons qu'il serait intéressant : (1) de rendre dispo-
nible les diérents articles dont ont besoin certains travaux présentés dans ce mémoire ; (2)
pour améliorer davantage les prévisions, envisager comme dans [14] la méthode de combinai-
son des prévisions ; (3) améliorer la qualité du recueil des données et la quantité de données
disponibles, de sorte que l'on puisse mener des analyses sur une unité de temps mensuelle par
exemple ; (4) envisager un modèle de prédiction du ux de retour, non plus en considérant
uniquement une forme de loi spécique aux durées avant disponibilité de GPS, mais plutôt,
une forme de distribution plus réaliste prenant en compte les co-variables qui inuencent la
durée d'un voyage.
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

RÉSUMÉ EXÉCUTIF xx
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

INTRODUCTION GÉNÉRALE 1
Introduction Générale
Contexte
D'après Achille Mbog Pibasso (Janvier 2010) [25], Le Cameroun a entamé des discus-
sions pour l'amélioration du transit avec ses deux voisins dépourvus de façade maritime, la
Centrafrique et le Tchad, dont 80% des marchandises passent par le port de Douala. Ces
discussions sont consécutives à l'introduction, il y a quatre mois, par le Cameroun, d'un
nouveau système de contrôle et de suivi des marchandises, le Global Positionning System
(GPS) . Le système GPS est une infrastructure matérielle légère permettant l'analyse de
traces de véhicules par relevés de géo-positionnement. Son utilisateur peut ainsi être informé
en temps réel de l'évolution du transit. La Douane Camerounaise se réapprovisionne en GPS
de manière aléatoire au l du temps. Les quantités approvisionnées uctuent en fonction
des ux entrants et sortants enregistrés précédemment et, éventuellement, en fonction des
moyens nanciers disponibles (car l'acquisition de ce service intelligent exige néanmoins des
moyens nanciers conséquents).
Cependant, certains acteurs du secteur ont armé rencontrer énormément de dicultés,
principalement dues au fait qu'il n'y a pas susamment de GPS pour satisfaire la demande
de tous les opérateurs. Une première approche que la Douane a mise sur pied pour pallier
à ce problème a été d'utiliser systématiquement de grandes quantités de stock de GPS.
Mais, cette approche pose cependant des soucis majeurs. En eet, Les stocks mobilisent
de l'argent, et le succès ou l'échec de la gestion de stock aecte la situation nancière de
l'entreprise. Avoir trop de stock peut être aussi problématique que des ruptures de stock.
Trop de stock entraîne des dépenses inutiles liées aux coûts de stockage et d'obsolescence,
tandis que trop peu de stock conduit à des ruptures de stock (Verwijmeren, Van Der Vlist
et al., 1996). Par conséquent, il est indéniable que le bon fonctionnement de la Douane en ce
qui concerne les opérations de lancement des voyages repose essentiellement sur la maîtrise
de la gestion de ses ux physiques de GPS.
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

INTRODUCTION GÉNÉRALE 2
Problématique
Pour mieux situer les diérents problèmes rencontrés en gestion de la production, les dé-
cisions de gestion sont classées en trois catégories [2] : décisions stratégiques, tactiques et
opérationnelles. Les décisions stratégiques se traduisent par la formulation d'une politique
à long terme (de quelques mois à plusieurs années) de l'entreprise qui concerne le choix des
fournisseurs, des ressources, d'un mode transport, etc. Les décisions tactiques correspondent
à un ensemble de décisions à moyen terme (de quelques semaines à plusieurs mois). Parmi
les décisions tactiques, on trouve la planication de la production. Les décisions opération-
nelles assurent la exibilité quotidienne nécessaire pour faire face aux uctuations prévues
de la demande et des délais, et permettent de réagir face aux aléas dans le respect des
décisions tactiques. Parmi les décisions opérationnelles, on trouve la gestion des stocks et
l'ordonnancement. Ce mémoire s'intègre dans la problématique de gestion de stock GPS
dans une chaîne logistique en boucle fermée (nous reviendrons plus en détail sur cette ter-
minologie dans le chapitre suivant) face aux aléas tels que la demande, le ux de sortie, les
durées eectives des voyages et le ux entrant (quantité réapprovisionnée, ux de retour).
Le gestionnaire de stock douanier, dans sa prise de décision, devra tenir compte de tous ces
paramètres aléatoires simultanément. Le travail eectué dans ce mémoire se situe donc au
niveau de décisions opérationnelles à court terme (de quelques jours à plusieurs semaines).
Plus précisément, il s'agit de prévoir la demande et le ux de retour GPS.
Objectifs
Parallèlement à l'amélioration du suivi dans le transit de marchandises par l'introduction du
système GPS, les bases de données décrivant les informations liées aux voyages se ranent.
Elles permettent, entre autres, de constituer des historiques de mesures quotidiennes des
diérentes variables d'intérêts considérées. Etant donné que ces mesures ont une structure
chronologique, nous disposons à cet eet de deux séries chronologiques journalières : une série
sur la demande eective de GPS et une série sur le ux de retour GPS. L'objectif principal
de ce mémoire est de mettre en oeuvre des approches statistiques de prévision basées sur
ces observations chronologiques, et permettant d'aider le gestionnaire de stock à optimiser
la quantité de GPS à pourvoir dans un horizon h donné, et ce, pour satisfaire la demande
tout en minimisant les coûts.
An de fournir des outils permettant de donner des éléments de réponse à la probléma-
tique ci-dessus, ce travail est mené pour aboutir aux trois objectifs spéciques suivants.
Objectif 1 : Produire des prévisions à court terme pour la demande eective de GPS.
Objectif 2 : Produire des prévisions à court terme pour le ux de retour GPS.
Objectif 3 : Proposer une formalisation du cadre théorique d'une politique de gestion de
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

INTRODUCTION GÉNÉRALE 3
stock GPS adéquate pour la Douane Camerounaise.
Organisation du mémoire
Le plan de ce mémoire est organisé en se basant sur la séquence des objectifs visés. A la suite
de cette introduction générale, il s'articule autour de cinq chapitres.
Le premier chapitre propose une revue de littérature sur nos modèles d'intérêt, particu-
lièrement les modèles à retards échelonnés et les méthodes non paramétriques de prévision.
Le deuxième chapitre sera consacré à la présentation et à l'analyse descriptive des données
disponibles. Dans ce chapitre, la section 1 fera une présentation des données et la section 2
proposera une analyse descriptive des données.
Le troisième chapitre de notre travail présentera les méthodologies statistiques utilisées
dans ce mémoire, où nous décrivons un peu plus en détail quelques unes de méthodologies
retenues, déduites de la revue de littérature. Il sera composé principalement de quatre mé-
thodes : la méthode 1 portera sur le lissage exponentiel de Holt-Winters, la méthode 2 sur
le modèle ARIMA saisonnier ; la méthode 3, quant à elle, exposera le modèle à retards
échelonnés et enn une méthode de prévision en loi de probabilité .
Le quatrième chapitre se focalisera essentiellement sur l'application des méthodes statis-
tiques exposées précédemment sur les données disponibles. Dans ce chapitre, partant d'un
échantillon de données, il sera question de développer, selon la méthode de prévision em-
ployée, le principe de la modélisation conduisant à la prédiction des valeurs futures. La
section 1 abordera la prévision de la demande eective de GPS et la section 2, la prévision
du ux de retour GPS.
Le cinquième chapitre sera l'objet d'une proposition de formalisation du cadre théorique
de la politique de gestion de stock de GPS à la Douane Camerounaise.
Nous terminerons la présente étude par une conclusion générale dans laquelle nous ferons
une synthèse de tout ce qui a été évoqué dans les diérents chapitres. Après cette synthèse,
nous présenterons quelques limites et perspectives liées aux travaux réalisés dans le cadre de
ce mémoire et, préconiserons quelques recommandations. Par ailleurs, nous signalons ici que
les applications numériques de nos analyses statistiques ont été eectuées avec le logiciel R
[36].
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

INTRODUCTION GÉNÉRALE 4
Notations
Nous donnons ci-dessous les conventions d'écriture adoptées :
Abréviations et symboles :
P : probabilité ;
E : espérance ;
V : variance ;
Cov : covariance ;E(X | Y ) : espérance conditionnelle de X sachant Y ;
1A : fonction indicatrice de l'évènement A ;
v′ : transposée de v ;
AIC : Critère d'information d'Akaïke (Akaike Information Criterion) ;
MAPE : Mean Absolute Percentage Error ;
v.a. : variable aléatoire ;
i.i.d. : indépendantes et identiquement distribuées ;
Typologie des mathématiques :
caractères italiques minuscules : variables non aléatoires,
caractères italiques majuscules : variables aléatoires,
caractères grecs : paramètres.
Numérotation des théorèmes et équations :
Un théorème comprend le numéro du chapitre courant, suivi du numéro de celui-ci au
sein de ce chapitre. Il en est de même pour une dénition, une proposition, une preuve,
un lemme.
Une équation comprend le numéro du chapitre courant, suivi du numéro de celle-ci au
sein de ce chapitre.
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

REVUE DE LITTÉRATURE 5
Chapitre Premier
Revue de Littérature
Ce chapitre met en relief la littérature scientique sur les diérentes modèles de prévision
et de contrôle de stock. Il permettra de cerner, en particulier, les modèles de prévision de la
demande eective, et du ux de retour d'articles réutilisables 1 dans un contexte de gestion
d'une chaîne d'approvisionnement en boucle fermée 2. C'est à partir de cette revue et des
variables d'intérêt considérées que nous allons identier et, ainsi, construire les modèles théo-
riques, an d'atteindre les objectifs visés dans notre travail. Nous donnons ci-dessous, autant
que possible, les résumés du contenu des diérentes revues dont nous avons pris connaissance.
• Goh T. N. et Varaprasad. N. (1986), Méthodologie statistique pour l'analyse
du cycle de vie des conteneurs réutilisables.
Dans cet article, les auteurs proposent un modèle de fonction de transfert qui modélise la
relation entre les ventes et les retours. L'approche exige une série temporelle de demande
agrégée et une autre sur les données de retour agrégés. Ils utilisent cette méthode sur un
échantillon de 60 mois (l'unité de temps des observations étant le mois) pour estimer le taux
de Coca-Cola et Fanta retournés des marchés de Malaisie et Singapour. Dans leurs résul-
tats, ils ont observé que la quantité de retours d'une même vente n'était statistiquement
signicative que dans les trois premiers mois, avec près de deux tiers des conteneurs retour-
nés dans le même mois de l'émission. La proportion de conteneurs perdus était inférieur à 5%.
• Kelle P. et Silver. E. A. (1989a), Prévision des retours des conteneurs réuti-
lisables.
Dans cet article, quatre procédures de prévision diérentes, basées sur diérentes quantités
d'informations, sont développées. Les possibilités d'information supposent que, soit chaque
1. Un article réutilisable est un article utilisé pour une certaine opération, puis récupéré et réutilisé comme
article nouveau. Dans cette revue, un article désignera très souvent un conteneur, i.e. un article destiné à
contenir quelque chose (une boisson gazeuse par exemple).
2. Conceptuellement, une chaîne logistique ou d'approvisionnement représente les diérentes étapes que
suit un article de l'étape de départ à l'étape d'arrivée. Le fait que la chaîne soit en boucle fermée signie que
l'article une fois à l'arrivée retourne à l'étape de départ pour être réutilisé. En anglais, on parle de CLSC :=
Closed-Loop Supply Chain.
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

REVUE DE LITTÉRATURE 6
article est suivi individuellement période après période, soit les articles sont suivis globale-
ment dans chaque période. Les méthodes sont comparées sur un large éventail de données
simulées, y compris certains cas fondés sur des données empiriques obtenues à partir de
l'industrie. Sans surprise, ils montrent que l'utilisation d'une information supplémentaire
améliore la performance.
• Kelle P. et Silver. E. A. (1989b), Politique d'achat de nouveaux conteneurs
compte tenu des retours aléatoires de conteneurs préalablement émis.
Un certain nombre d'organisations de ventes des produits dans des conteneurs peuvent être
réutilisés. Le temps de l'émission jusqu'au retour d'un conteneur individuel n'est générale-
ment pas connu avec certitude et il y a une chance que le conteneur ne soit jamais de retour
(en raison de la perte ou des dommages irréparables). Par conséquent, même si le motif de la
demande ou la vente est connu et son niveau avec le temps, il est encore nécessaire d'acquérir
de nouveaux conteneurs de temps en temps. Dans cette revue, une politique d'achat de ces
nouveaux conteneurs est déterminée pour un horizon de temps ni de manière à minimiser
le coût total des achats et des charges de remboursement prévu dans un niveau de service
prescrit. Le modèle stochastique associé est réduit à un problème dynamique déterministe de
la otte de lotissement, avec l'apparition éventuelle de la demande négative (demande nette
= demande - retour). D'habitude, une transformation de la demande négative nous permet
d'appliquer des procédures de lotissement déterministes bien connus pour obtenir la solution.
• Toktay L. B. et al (2000), Gestion de stock d'articles manufacturés.
Les auteurs de cet article attestent que : dans les décisions de planication de la produc-
tion et de gestion des stocks, le retour, le délai et le stock disponible associés à une période
donnée sont des caractéristiques clés de l'information. Pourtant, ces quantités ne sont pas
directement disponibles dans le stade client-utilisation d'une chaîne d'approvisionnement
avec remise à neuf de l'article. La remise à neuf étant le processus par lequel les produits
utilisés sont récupérés, traités et vendus comme des produits nouveaux. Pour modéliser le
ux de retour des caméras Kodak, ils laissent les retours dépendre des ventes à travers une
probabilité de retour et une distribution du délai de retour.
Ils utilisent la statistique bayésienne et l'analyse de survie pour estimer dynamiquement
les densités de probabilité pour la probabilité de retour et le délai de retour basé sur les don-
nées de l'évolution des ventes et des retours. A cet eet, le modèle de régression dynamique
est également utilisé par ces auteurs. L'estimation des paramètres est faite de deux manières
diérentes, selon l'information disponible : si l'information au niveau de la période est dis-
ponible (les quantités d'articles vendus et retournés sont connus par période), ils supposent
qu'il y a une densité discrète pour le délai de retour rD(d). Pour une caméra vendue à la
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

REVUE DE LITTÉRATURE 7
période t, la probabilité qu'elle retourne à la période t+ k est rD(k)p, où p est la probabilité
que la caméra retourne. Comme avec Kelle P. et Silver. E. A. (1989a), Toktay L. B. et al
(2000) proposent le modèle suivant :
mt = rD(1)pnt−1 + rD(2)pnt−2 + ...+ rD(t− 1)pn1 +Nt,
où nt désigne les ventes de la période t, mt les retours de la période t, avec m1 = 0. Les
données disponibles pour les caméras Kodak portent sur 22 observations mensuelles. Ils uti-
lisent le modèle ci-dessus sur les données de 22 mois de caméras Kodak avec un décalage
géométrique de paramètre q pour chercher la densité a postériori des paramètres du ux
de retour θ = (p, q). Les formules d'estimation de p et q dérivées de la densité jointe sont
présentées en annexe de leur document. Les auteurs montrent également que l'impact des
conditions initiales sur les valeurs estimées des paramètres est minime.
Si l'information au niveau de l'article est disponible, autrement dit on connaît le temps
de vente tvente de chaque article. A un instant t donné, quelques unes des caméras sont
retournées. Pour ces caméras, on connaît exactement le délai de retour. Pour d'autres par
contre, nous savons que leur délai est plus long que t−tvente. Ce type de données est considérécomme censurées à droite dans la littérature de l'analyse de survie. Les formules d'estimation
de p et q, dérivées de l'algorithme EM, sont présentées en annexe de leur document, toujours
avec un délai de retour géométrique.
• Toktay L. B., Van der Laan E. et De Brito M. P. (2003), Gestion d'articles :
le rôle de la prévision.
Les auteurs passent en revue les méthodes basées sur les données de prévision du ux de
retour qui exploitent le fait que les retours futurs sont fonction des ventes passées. Les
notations suivantes sont adoptées dans cette revue :
s(τ), vente de la période τ ;
u(τ), retour de la période τ ;
p, probabilité qu'un article vendu nira par revenir ;
rk, probabilité qu'un article vendu revienne après k périodes, étant donné que ce sera
retourné ;
νk, probabilité qu'un article vendu revienne après k périodes (νk = p.rk) ;
νk(τ), prévision de la période τ de νk ;
yτ−i,τ+j, total des retours de la période τ + j provenant des ventes de la période τ − i ;vτ,τ−i, total des retours jusqu'à et y compris la période τ provenant des ventes de la période
τ − i ;I(τ), ensemble des données disponibles à la n de la période τ pour prévoir les retours
futurs.
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

REVUE DE LITTÉRATURE 8
Pour la prévision des retours, la première étape de tout exercice de prévision est de
construire un modèle de prévision qui modélise les variables à être prédites en fonction
des variables explicatives (Box et Jenkins, 1976). La clé de la prévision des retours est de
constater que les retours dans une quelconque période sont générés par les ventes dans les
périodes précédentes. Ils utilisent comme Goh T. N. et Varaprasad. N. (1986), le modèle de
fonction de transfert et notent également que ce modèle peut se réécrire sous la forme d'un
modèle à retards échelonnés.
Comme précédemment, ils font un classement des modèles de prévision utilisés dans la
littérature en fonction des données qu'ils exploitent. Si l'information au niveau de la période
est disponible, les données sont augmentées à chaque période dès que les informations de
ventes et de retours deviennent disponibles. Le caractère progressif de l'information reçue
fait de l'estimation bayésienne un choix naturel, comme utilisée dans Toktay L. B. et al
(2000). Habituellement, une forme spécique de distribution comportant un ou deux para-
mètres est supposée pour le délai de retour, qui réduit le nombre de paramètres à estimer
(distribution géométrique notamment). L'algorithme EM est utilisé pour l'estimation de ce
modèle lorsque c'est plutôt l'information au niveau de l'article qui est disponible.
Notons I(τ), l'information disponible à la n de la période τ qui sera utilisée pour prévoir
les retours futurs, et par ν(τ) =(ν1(τ), ν2(τ), ...
), l'estimation de la période τ du vecteur
ν = (ν1, ν2, ...). En particulier, Kelle et Silver (1989a) dénit
IA(τ) = ν(τ) (estimation de ν),
IB(τ) = ν(τ), s(τ− i), i = 0, 1, ..., τ (estimation de ν et historique de l'information
de vente au niveau de la période),
IC(τ) = ν(τ), s(τ − i), u(τ − i), i = 0, 1, ..., τ (estimation de ν et historique de
l'information de vente et de retour au niveau de la période), et
ID(τ) = ν(τ), s(τ − i), vτ,τ−i, i = 0, 1, ..., τ (estimation de ν et historique de l'in-
formation de vente et de retour au niveau de l'article).
Table 1.1 Espérance de yτ−i,τ+j, le nombre de retours de la période τ + j provenant des
ventes de la période τ − i, pour diérents ensembles d'informations.
Ensemble
d'information
E(yτ−i,τ+j|I(τ)
)i > 0 i = 0 i < 0
IA(τ) non applicable
IB(τ) νj+i(τ)s(τ − i) νj+i(τ)E(s(τ − i)
)IC(τ) νj+i(τ)s(τ − i) + c(i, j) νj(τ)s(τ) νj+i(τ)E
(s(τ − i)
)ID(τ)
νj+i(τ)
1−∑i
k=1 νk(τ)
(s(τ − i)− vτ,τ−i
)νj(τ)s(τ) νj+i(τ)E
(s(τ − i)
)
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

REVUE DE LITTÉRATURE 9
Sous l'hypothèse que toutes les demandes de la période sont mutuellement indépendantes
et les retours des diérentes demandes issues sont non corrélées, le tableau 1.1 énumère les ex-
pressions de E(yτ−i,τ+j|I(τ)
)sur la base de l'un des ensembles d'informations IA(τ), IB(τ),
IC(τ) ou ID(τ). Dans ce tableau, c(i, j) est un facteur qui tient compte de la corrélation entre
les retours observés à ce jour et les retours futurs. Une expression exacte de c(i, j) n'est pas
disponible en général, mais Kelle et Silver ont développé une approximation. La variance des
retours futurs peut aussi être estimée, même si ces expressions sont un peu plus compliquées
(Kelle et Silver, 1989a). Le nombre total de retours de la période τ + j est tout simplement
donné comme uτ+j =∑τ
i=−(j−1) yτ−i,τ+j, la moyenne et la variance de ce dernier pouvant être
estimées à partir de celles de ses éléments mutuellement indépendants. Le tableau montre
clairement que les expressions pour les retours futurs attendus E(yτ−i,τ+j|I(τ)
)ne dièrent
que par les retours des ventes au cours des périodes antérieures, à savoir i = 0, 1, ..., τ .
Les auteurs de cette revue comparent également les performances de ces méthodes de prévi-
sion dans un contexte particulier - celui de la gestion des stocks.
• Carrasco-Gallego R. et Ponce-Cueto E. (2009), Prévision des retours des
conteneurs réutilisables en chaîne d'approvisionnement en boucle fermée. Un
cas dans l'industrie du GPL.
Dans cet article, les auteurs remarquent que dans leur interaction avec les entreprises trai-
tant avec des éléments d'emballage réutilisables, les gestionnaires ont souvent fait état de
dicultés dans la gestion de ces systèmes logistiques. Les objets réutilisables, même s'ils
sont généralement un atout très coûteux, ne sont pas étroitement contrôlés et beaucoup
d'articles sont rapportés être perdus ou irrémédiablement endommagés. La décision sur le
moment d'acheter de nouveaux éléments et la façon dont le nombre doit être commandé
sont habituellement prises en fonction de considérations de marketing ou sur la disponibilité
des ressources nancières plutôt que sur la prise réelle de l'organisation opérationnelle de
besoins. Peu ou rien n'est connu au sujet de la rotation des objets dans le système et lorsque
certains savoir-faire opérationnels sur ce sujet existent, ils sont généralement basés sur des
estimations approximatives.
Toutes ces raisons leur font penser qu'il existe des possibilités pour les chercheurs de faire
des contributions dans ce domaine. C'est pourquoi ils ont identié la gestion des conteneurs
réutilisables comme un domaine de recherche intéressant et c'est l'objet de leur étude. Pour
leur étude de cas, les techniques ne nécessitant pas d'informations au niveau des articles
ont été appliquées à un ensemble de données réelles fournies par une entreprise utilisant des
contenants réutilisables de grande valeur pour la distribution de GPL (gaz de pétrole liquéé)
aux clients naux. Les informations provenant des bons de livraison étaient agrégées dans
une base mensuelle an d'obtenir de séries chronologiques de 60 observations. En revanche,
les résultats obtenus sont inattendus, et ils pensent que la principale cause de ces résultats
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

REVUE DE LITTÉRATURE 10
réside dans l'échange des conteneurs plein et vide imposées par la présente politique (poli-
tique de remplacement direct) ; les livraisons et les retours sont liés dans le temps, et donc
l'hypothèse de causalité unidirectionnelle très souvent imposée pour la validité du modèle
pourrait ne pas être respectée.
Les auteurs précisent que les prévisions des ventes futures sont faites sur la base des
valeurs passées de la même variable. A cet eet, l'approche mathématique utilisée dans
l'industrie est basée sur : les méthodes de prévision de séries chronologiques univariées. La
complexité des techniques varie de l'approche classique déterministe de méthodes telles
que le lissage exponentiel ou modèles de Winters, à l'approche contemporaine stochas-
tique de méthodes ARIMA.
Contrairement à la chaîne d'approvisionnement en sens unique (gure 1.1a), an d'avoir
une planication ecace et un processus de contrôle lorsqu'il s'agit d'une CLSC, prévoir sur
l'avenir les ventes et les retours est à la fois nécessaire (gure 1.1b).
Figure 1.1 (a) Chaîne d'approvisionnement à sens unique, (b) Chaîne d'approvisionne-
ment en boucle fermée (reconditionnement, réutilisation) [6].
Une approche possible pour obtenir des prévisions de retour serait d'appliquer des mo-
dèles de série chronologique univariée à un ensemble de données passées (gure 1.2b). Lorsque
la seule information disponible est l'historique des retours, ceci semble être une approche rai-
sonnable. Les méthodes de prévision de retour décrites dans la littérature sont fondées sur
l'idée que, avec une probabilité donnée, les ventes passées génèreront un retour futur après
un délai donné. L'approche de prévision naturelle est alors l'utilisation des modèles de ré-
gression dynamique (Pankratz 1991), qui modélise la relation entre les ventes et les retours
(gure 1.2c). Ces modèles sont également connus dans la littérature en tant que modèles de
fonction de transfert ou modèles à retards échelonnés.
• Carbon M. et Francq C. (), Estimation non paramétrique de la densité et
de la régression, prévision non paramétrique.
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

REVUE DE LITTÉRATURE 11
Figure 1.2 (a) Prévision de la demande, (b) Prévision des retours, approche à sens unique,
(c) Prévision des retours, approche CLSC [6].
Dans cet article, les auteurs donnent un aperçu sur l'estimation non paramétrique de la
densité et de la régression. Après cet aperçu, ils détaillent et interprètent une méthode de
prévision, dite prévision non paramétrique. Ils montrent les diérents aspects aussi bien
techniques que pratiques, et la compare, sur quelques exemples, à la méthodologie de Box et
Jenkins. Les diverses séries utilisées sont ou bien simulées, ou bien extraites de la littérature.
Notamment la série chronologique sur le trac voyageur (Gouriéroux 1990).
• Autres.Plusieurs autres études dans la littérature abordent le problème de gestion de stock d'articles
réutilisables dans un contexte CLSC (Closed-Loop Supply Chain). Ces études concernent
pour la plupart, l'analyse prévisionnelle des retours et des ventes, l'analyse des coûts et
des moyens mis en oeuvre pour les réduire au maximum, l'analyse de l'impact d'une dés-
information, ou encore l'analyse des politiques nouvelles et ecaces de gestion de stock en
CLSC.
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

REVUE DE LITTÉRATURE 12
Résumé du chapitre
Ce chapitre avait pour but d'exposer de manière brève, l'état de l'art sur les approches
les plus souvent utilisées pour prévoir les ux physiques de produits, et ce dans un contexte
de gestion de stock avec réutilisation du produit. Pour cela, nous avons présenté sommai-
rement les principaux articles sur lesquels nous nous sommes basés pour mettre en relief,
dans la suite de ce mémoire, les diérentes méthodes statistiques utilisées. A la lumière de
cette revue de littérature et, compte tenu de la politique de gestion de stock en vigueur
à la Douane Camerounaise, nous nous rendons à l'évidence que le travail de prévision sur
lequel est concentré ce mémoire est essentiellement basé sur deux aspects fondamentaux :
les données disponibles et les méthodes ou modèles statistiques envisageables. Pour ce faire,
le chapitre suivant met en relief la présentation et l'analyse descriptive de l'ensemble des
données disponibles pour la résolution du problème posé. Le chapitre d'après, lui, exposera
les méthodes statistiques retenues.
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

PRÉSENTATION ET ANALYSE DESCRIPTIVE DES DONNÉES 13
Chapitre Deux
Présentation et Analyse Descriptive
des Données
L'objet de ce chapitre est de se familiariser avec les données, an d'en dégager des in-
formations caractéristiques nous permettant de choisir les méthodes statistiques les plus
appropriées pour les prédire. Pour ce faire, nous donnerons tout d'abord l'origine des don-
nées et leurs types. Ensuite, un traitement sera eectué sur ces données en vue de les épurer.
Nous terminerons ce chapitre par une description sommaire des données.
2.1 Présentation des données
2.1.1 Comment s'eectuent les ux physiques de GPS à la douane ?
Les ux physiques de GPS à la Douane peuvent être résumés en trois phases, selon la
gure 1.1b. Nous parlerons de : phase d'enregistrement, phase de transit et phase de retour.
• Phase d'enregistrement
Cette phase concerne le réapprovisionnement et la demande de GPS. En eet, pour un jour
t donné, le gestionnaire va enregistrer, au courant de la journée, un certain nombre de de-
mandes (eectives) de transit de marchandises. Or, comme nous l'avons précisé auparavant,
à une demande de transit de marchandises correspond une demande de GPS. Nous intro-
duisons donc la notation De,t comme étant la v.a. modélisant la demande eective de GPS
enregistrée le jour t. Dans le contexte de gestion à la Douane, les demandes non satisfaites
sont diérées. D'après le gestionnaire, les demandes non satisfaites sont dues, pour la plu-
part, soit à des dossiers incomplets, soit à des ruptures de stock, etc. Ainsi, pour un jour t
donné, la v.a. demande totale de GPS enregistrée, notée Dt, sera égale à la v.a. demande
résiduelle du jour précédent, notée Dr,t−1, auquel on ajoute la v.a. demande eective du jour.
Ce qui nous donne la relation :
Dt = Dr,t−1 +De,t. (2.1)
De plus, au courant de la même journée t, le gestionnaire donnera l'autorisation de
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

PRÉSENTATION ET ANALYSE DESCRIPTIVE DES DONNÉES 14
lancement de voyages ou de GPS parmi les Dt demandes enregistrées (les demandes sont
servies selon l'approche FIFO, c'est-à-dire rst in, rst out, ou premier arrivé, premier servi).
En notant par Vt, la v.a. modélisant le ux de sortie GPS de la journée t, nous en déduisons
immédiatement la relation :
Dr,t = Dt − Vt. (2.2)
• Phase de transitUne fois le GPS posé sur le camion, celui-ci est autorisé à débuter le voyage. Les voyages
eectués le jour t peuvent emprunter plusieurs directions ou itinéraires possibles. De ce fait,
parmi les Vt voyages eectivement lancés au courant de la journée t, nous noterons par Nt,d
la v.a. désignant le nombre de voyages partis dans la direction d, avec d = 1, 2, ..., κ, de sorte
que
Nt,1 +Nt,2 + ...+Nt,κ = Vt.
Il est clair que chaque GPS en transit possèdera une durée de voyage avant d'arriver aux
postes frontières. Précisément, chaque voyage v eectué le jour t dans la direction d, notée
vt,d, a une durée Tv,t,d avant d'arriver à destination. Pour simplier, nous noterons Tv,X cette
durée, où X = (X1, X2, ..., Xp) est un ensemble de covariables inuençant la durée d'un
voyage. Certains résultats obtenus dans [22,23] montrent, entres autres, que les variables
telles que l'itinéraire emprunté, le poids des marchandises, la vitesse maximale du camion,
la personne cda_principal (le conducteur du camion) impactent sur la durée d'un voyage.
• Phase de retourCette phase concerne les voyages ou les GPS qui sont arrivés à destination. Pour ceux-ci, il
est indiqué qu'une fois le voyage arrivé à destination, le GPS qui lui a été assigné retourne à
la base portuaire pour être réutilisé (lors du retour, les GPS sont mis dans des sacs et trans-
portés par des véhicules). Selon les exigences des responsables de l'entreprise Polytech-Valor,
une analyse statistique a été eectuée sur les données disponibles an d'estimer le temps que
met le GPS avant de retourner à la base. Les étapes de cette analyse sont brièvement pré-
sentées à la section 2.1.2, paragraphe données sur le ux de retour GPS . Nous sommes
arrivés à la conclusion que, en fonction de l'itinéraire emprunté pour son trajet retour, le
GPS mettra un ou deux jour(s). Chaque GPS mis en transit possède donc une durée avant
disponibilité dénie par Tv,X +1 ou Tv,X +2, suivant l'itinéraire emprunté (dans ce mémoire,
κ = 3 1).
2.1.2 Origine des données
Deux bases de données nous ont été remises pour mener à bien l'étude prévisionnelle
dont il est question dans ce mémoire. Nous disposons d'une base nommée matrice de suivi
1. itinéraire 1 := Douala-Garoua Boulai ; itinéraire 2 := Douala-Kousseri ; itinéraire 3 := Douala-Bogdibo.
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

PRÉSENTATION ET ANALYSE DESCRIPTIVE DES DONNÉES 15
des opérations, qui est présentée sous le format classeur Excel, et dans laquelle est reporté
l'ensemble des informations importantes relevées sur les opérations de lancement des voyages.
Nous disposons également d'une gigantesque base de données nommée voyage 2 comportant
des centaines de milliers de lignes et une centaine de colonnes, qui présente, pour chaque
voyage (ligne) eectué, un ensemble d'informations qui le caractérise.
Données sur la demande eective de GPS. Les données sur la demande de GPS
proviennent de la matrice de suivi des opérations de lancement de voyages sur les sites de
départ. Il s'agit d'un tableau de données comportant plusieurs rubriques, parmi lesquelles
la rubrique Réception des dossiers , la rubrique Man et activités autour du GPS , la
rubrique Suite réservée aux dossiers traités et la rubrique Tops départs . En fait, les
données de la demande eective concernent principalement la rubrique Réception des dos-
siers . Précisément, c'est la colonne nombre de dossiers route reçus 3 qui constituera pour
nous la variable demande eective de GPS.
Les données utilisées pour la demande eective de GPS sont simplement obtenues par ex-
traction de la colonne nombre de dossiers route reçus dans la matrice de suivi des opérations
de lancement de voyages. Nous disposons à cet eet, d'un échantillon de 129 observations
quotidiennes (exceptés les Dimanche car pas d'activité) couvrant la période de Novembre
2013 à Mars 2014.
Données sur le ux de sortie GPS. Dans la base de données voyage, nous disposons,
entre autres, d'une date de début (jour-mois-année) pour chaque voyage. Dans ce cas, à
l'aide d'une requête SQL, nous faisons une extraction des observations quotidiennes du ux
de sortie GPS. Compte tenu de certaines lacunes que comportent la base voyage lorsqu'on
remonte à l'année 2010 (instabilité dans la mise en place du système GPS), cet échantillon
est choisi pour couvrir la période allant du Lundi 03 Janvier 2011 au Samedi 17 Mai 2014.
Soit 1056 observations (pas d'activité le Dimanche).
Données sur le ux de retour GPS. Pour avoir les données sur le ux de retour GPS,
il faut disposer, ou bien de la date de retour de chaque GPS mis en transit, ou bien de sa
durée avant disponibilité. En eet, sachant la date de début d'un voyage (jour-mois-année),
l'une de ces deux informations est susante pour déduire l'autre. Or, aucune information
dans ce sens n'est disponible dans la base de données voyage. Nous ferons dans ce mé-
2. Cette base de données provient du projet Nexus+, projet consistant à la gestion et au suivi de l'ache-
minement des marchandises en transit par géo-localisation.
3. Elle est obtenue par sommation des colonnes nombre de dossiers routes reçus entre 08h-13h et nombre
de dossiers routes reçus entre 13h01-16h.
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

PRÉSENTATION ET ANALYSE DESCRIPTIVE DES DONNÉES 16
moire, l'hypothèse 4 simplicatrice que, une fois le voyage arrivé à destination,
la durée retour du GPS qui lui a été associé, dépend uniquement de l'itinéraire
emprunté lors du transit. En eet, nous prendrons la durée retour pour un iti-
néraire comme le mode des durées qui séparent la date de n du voyage et la
date de début du voyage suivant, utilisant le même GPS .
Ainsi, la construction des données sur le ux de retour s'est faite comme suit :
1. nous prenons tous les voyages ayant un code GPS, une date de n et un itinéraire pris
parmi les trois considérés dans cette étude ;
2. connaissant le code GPS (identiant), nous regardons le temps après lequel on revoit
le GPS sur un autre voyage ;
3. nous calculons donc la diérence entre cette date où le GPS est réutilisé et la date de
n du voyage précédent ayant utilisé la même GPS. Nous obtenons une distribution
de données de durées retour par itinéraire ;
4. nous trouvons alors que, le mode (arrondi en jours) des observations est de 1 jour pour
l'itinéraire Douala-Garoua Boulaï, 2 jours pour l'itinéraire Douala-Kousseri et, 2 jours
pour l'itinéraire Douala-Bogdibo.
Nous dénissons donc la date de retour de chaque GPS comme la date de n + 1 (ou 2)
jour(s) en fonction de l'itinéraire. Ce qui est équivalent à dénir la durée avant disponibilité
de chaque GPS comme la durée du voyage + 1 (ou 2) jour(s) en fonction de l'itinéraire, où
durée voyage = date n - date début. Finalement, les données du ux de retour GPS sont
obtenues en calculant, pour chaque date de retour donnée, le nombre total de GPS retournés
à la base portuaire. Comme précédemment, nous nous restreignons à la période allant du
Lundi 03 Janvier 2011 au Samedi 17 Mai 2014, soit une taille d'échantillon de 1056 observa-
tions.
En résumé, la gure 2.1 illustre la manière dont les échantillons de données sont répartis.
Les cercles vides font référence aux observations manquantes. Comme les données sur la
demande eective, les données sur le ux de sortie possèdent des observations manquantes
avec des proportions respectives très faibles (< 5%) par rapport à la taille de l'échantillon.
Par contre, comme on peut le constater pour les données sur le ux de retour, la période
allant de Mars 2012 à Juin 2012 est quasiment dépourvue d'observations. Ceci est causé par
des dates de n de voyages non renseignées. Pour cette période uniquement, nous avons plus
de 80% de données manquantes.
4. Hypothèse approuvée par les responsables de l'entreprise Polytech-Valor.
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

PRÉSENTATION ET ANALYSE DESCRIPTIVE DES DONNÉES 17
Figure 2.1 Répartition des données disponibles dans le temps, (a) ux de sortie, (b) ux
de retour, (c) demande eective.
2.1.3 Traitement des données manquantes
Le problème du traitement des données manquantes est un vaste sujet de recherche dont
l'analyse pourrait faire l'objet d'une thématique à part entière. Nous n'en ferons pas une
dissertation étendue mais seulement, nous allons les repérer, interpréter et les imputer.
Pour les données de la demande eective, nous avons 05 valeurs manquantes, soit 3.88
% de la taille de l'échantillon, tandis que pour les données du ux de sortie, nous avons 30
valeurs manquantes, soit 2.84% de la taille de l'échantillon. Après les avoir examinées, nous
nous rendons compte que les données manquantes sont dues pour la plupart aux évènements
calendaires (jours fériés notamment). Tous les échantillons de données de cette étude ont une
structure de série chronologique. Or, pour prévoir les valeurs futures d'une série chronologique
(ce qui est l'objectif visé de ce travail), l'une des contraintes est que les observations de la
série soient régulièrement espacées dans le temps. Ainsi, dans le but de conserver la régularité
des observations, les valeurs manquantes pour les données de la demande eective et du ux
de sortie GPS sont respectivement imputées par la moyenne (arrondie) des valeurs observées,
compte tenu des précisions faites dans [1].
Pour les observations du ux de retour GPS, nous nous restreignons, dans toute la suite
de cette étude, à la période allant du Lundi 31 Décembre 2012 au Samedi 17 Mai 2014.
Soit 432 observations journalières. Il n'y a pas de valeurs manquantes pour cette période
d'analyse.
2.2 Analyse descriptive des données
Décrire les données que l'on a rassemblées pour répondre à une question est une première
étape très importante en statistique appliquée. Il s'agit, grosso modo, de faire ressortir l'en-
semble des informations notables que contiennent ces données et ce, dans l'optique de se faire
une première idée sur les outils statistiques pouvant servir à la modélisation du phénomène
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014
PRÉSENTATION ET ANALYSE DESCRIPTIVE DES DONNÉES 18
observé.
2.2.1 Normalité, tendance et saisonnalité
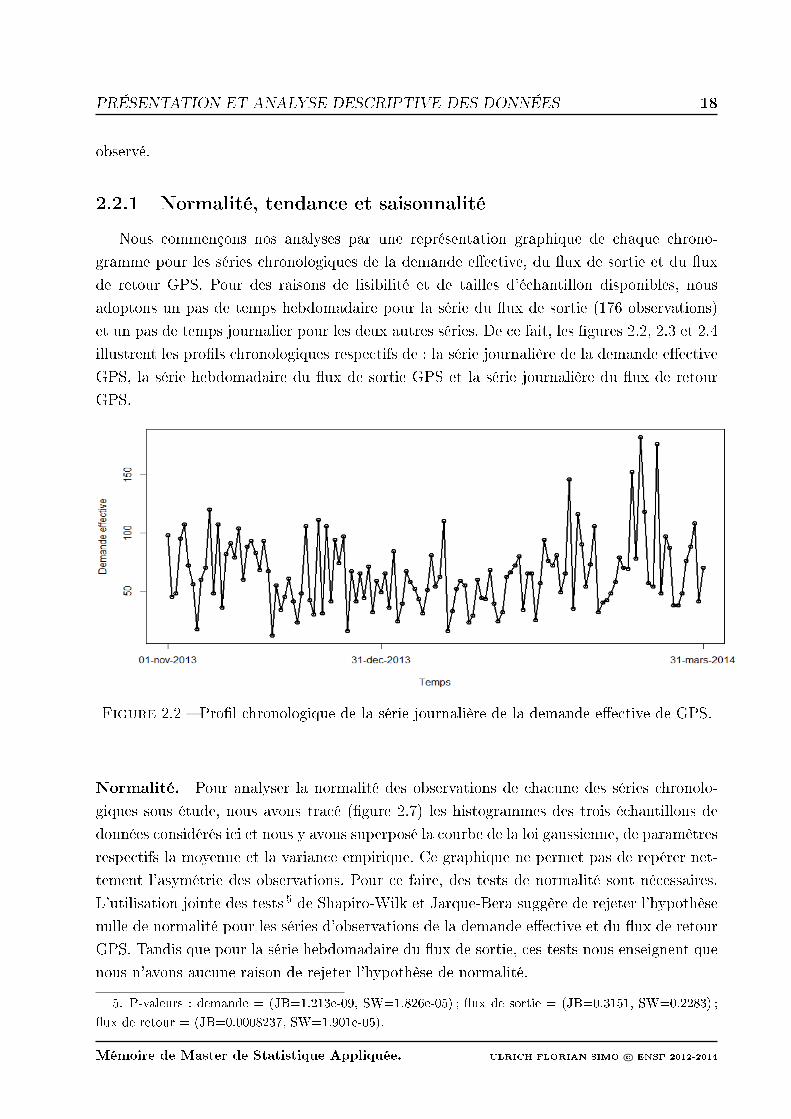
Nous commençons nos analyses par une représentation graphique de chaque chrono-
gramme pour les séries chronologiques de la demande eective, du ux de sortie et du ux
de retour GPS. Pour des raisons de lisibilité et de tailles d'échantillon disponibles, nous
adoptons un pas de temps hebdomadaire pour la série du ux de sortie (176 observations)
et un pas de temps journalier pour les deux autres séries. De ce fait, les gures 2.2, 2.3 et 2.4
illustrent les prols chronologiques respectifs de : la série journalière de la demande eective
GPS, la série hebdomadaire du ux de sortie GPS et la série journalière du ux de retour
GPS.
Figure 2.2 Prol chronologique de la série journalière de la demande eective de GPS.
Normalité. Pour analyser la normalité des observations de chacune des séries chronolo-
giques sous étude, nous avons tracé (gure 2.7) les histogrammes des trois échantillons de
données considérés ici et nous y avons superposé la courbe de la loi gaussienne, de paramètres
respectifs la moyenne et la variance empirique. Ce graphique ne permet pas de repérer net-
tement l'asymétrie des observations. Pour ce faire, des tests de normalité sont nécessaires.
L'utilisation jointe des tests 5 de Shapiro-Wilk et Jarque-Bera suggère de rejeter l'hypothèse
nulle de normalité pour les séries d'observations de la demande eective et du ux de retour
GPS. Tandis que pour la série hebdomadaire du ux de sortie, ces tests nous enseignent que
nous n'avons aucune raison de rejeter l'hypothèse de normalité.
5. P-valeurs : demande = (JB=1.213e-09, SW=1.826e-05) ; ux de sortie = (JB=0.3151, SW=0.2283) ;
ux de retour = (JB=0.0008237, SW=1.901e-05).
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014
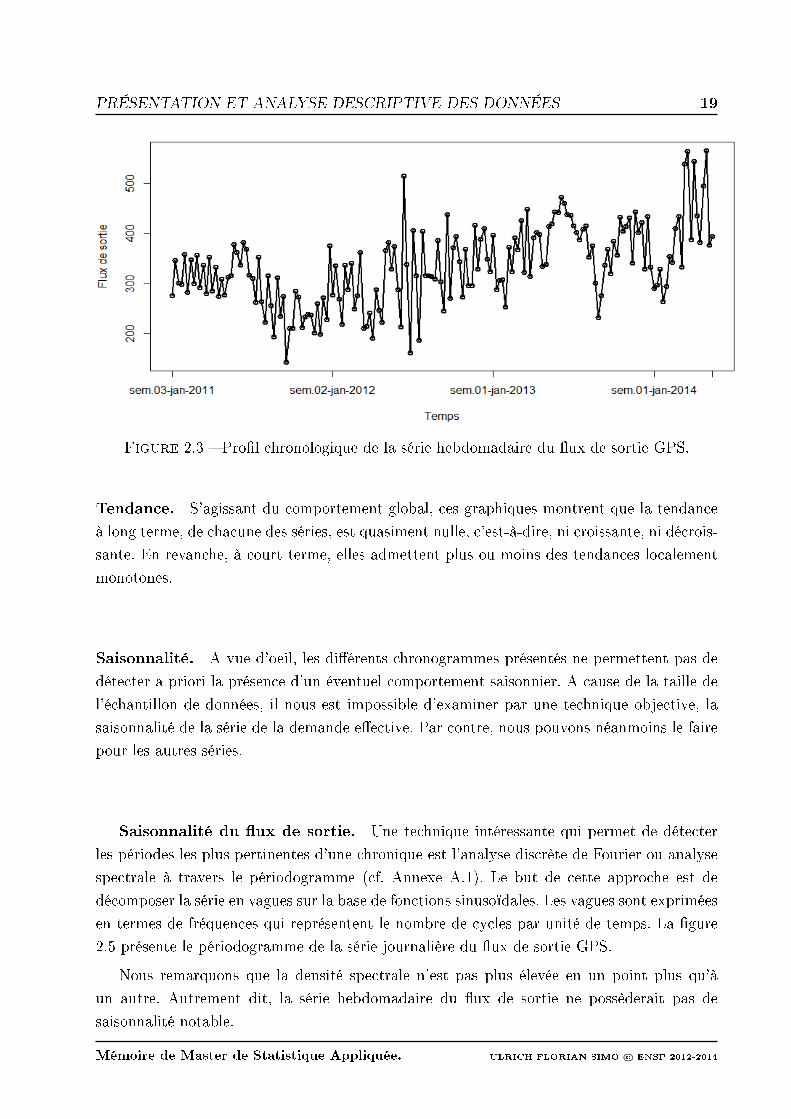
PRÉSENTATION ET ANALYSE DESCRIPTIVE DES DONNÉES 19
Figure 2.3 Prol chronologique de la série hebdomadaire du ux de sortie GPS.
Tendance. S'agissant du comportement global, ces graphiques montrent que la tendance
à long terme, de chacune des séries, est quasiment nulle, c'est-à-dire, ni croissante, ni décrois-
sante. En revanche, à court terme, elles admettent plus ou moins des tendances localement
monotones.
Saisonnalité. A vue d'oeil, les diérents chronogrammes présentés ne permettent pas de
détecter a priori la présence d'un éventuel comportement saisonnier. A cause de la taille de
l'échantillon de données, il nous est impossible d'examiner par une technique objective, la
saisonnalité de la série de la demande eective. Par contre, nous pouvons néanmoins le faire
pour les autres séries.
Saisonnalité du ux de sortie. Une technique intéressante qui permet de détecter
les périodes les plus pertinentes d'une chronique est l'analyse discrète de Fourier ou analyse
spectrale à travers le périodogramme (cf. Annexe A.1). Le but de cette approche est de
décomposer la série en vagues sur la base de fonctions sinusoïdales. Les vagues sont exprimées
en termes de fréquences qui représentent le nombre de cycles par unité de temps. La gure
2.5 présente le périodogramme de la série journalière du ux de sortie GPS.
Nous remarquons que la densité spectrale n'est pas plus élevée en un point plus qu'à
un autre. Autrement dit, la série hebdomadaire du ux de sortie ne possèderait pas de
saisonnalité notable.
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014
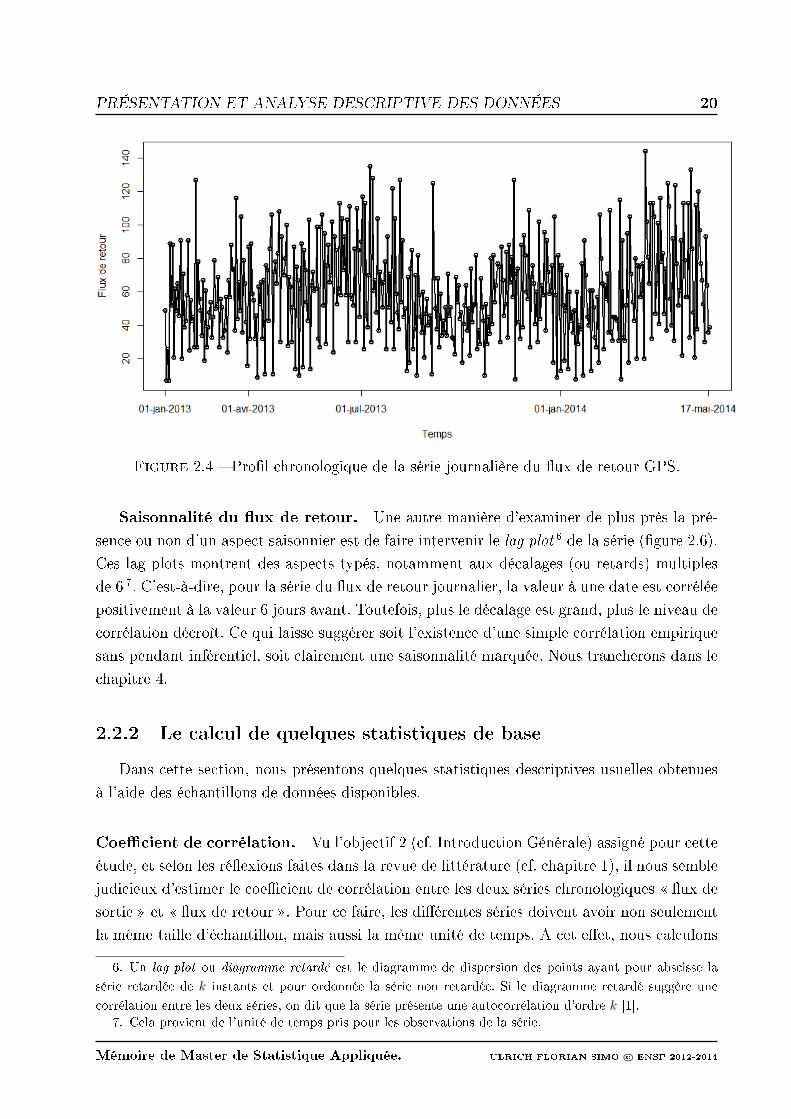
PRÉSENTATION ET ANALYSE DESCRIPTIVE DES DONNÉES 20
Figure 2.4 Prol chronologique de la série journalière du ux de retour GPS.
Saisonnalité du ux de retour. Une autre manière d'examiner de plus près la pré-
sence ou non d'un aspect saisonnier est de faire intervenir le lag plot 6 de la série (gure 2.6).
Ces lag plots montrent des aspects typés, notamment aux décalages (ou retards) multiples
de 6 7. C'est-à-dire, pour la série du ux de retour journalier, la valeur à une date est corrélée
positivement à la valeur 6 jours avant. Toutefois, plus le décalage est grand, plus le niveau de
corrélation décroît. Ce qui laisse suggérer soit l'existence d'une simple corrélation empirique
sans pendant inférentiel, soit clairement une saisonnalité marquée. Nous trancherons dans le
chapitre 4.
2.2.2 Le calcul de quelques statistiques de base
Dans cette section, nous présentons quelques statistiques descriptives usuelles obtenues
à l'aide des échantillons de données disponibles.
Coecient de corrélation. Vu l'objectif 2 (cf. Introduction Générale) assigné pour cette
étude, et selon les réexions faites dans la revue de littérature (cf. chapitre 1), il nous semble
judicieux d'estimer le coecient de corrélation entre les deux séries chronologiques ux de
sortie et ux de retour . Pour ce faire, les diérentes séries doivent avoir non seulement
la même taille d'échantillon, mais aussi la même unité de temps. A cet eet, nous calculons
6. Un lag plot ou diagramme retardé est le diagramme de dispersion des points ayant pour abscisse la
série retardée de k instants et pour ordonnée la série non retardée. Si le diagramme retardé suggère une
corrélation entre les deux séries, on dit que la série présente une autocorrélation d'ordre k [1].
7. Cela provient de l'unité de temps pris pour les observations de la série.
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014
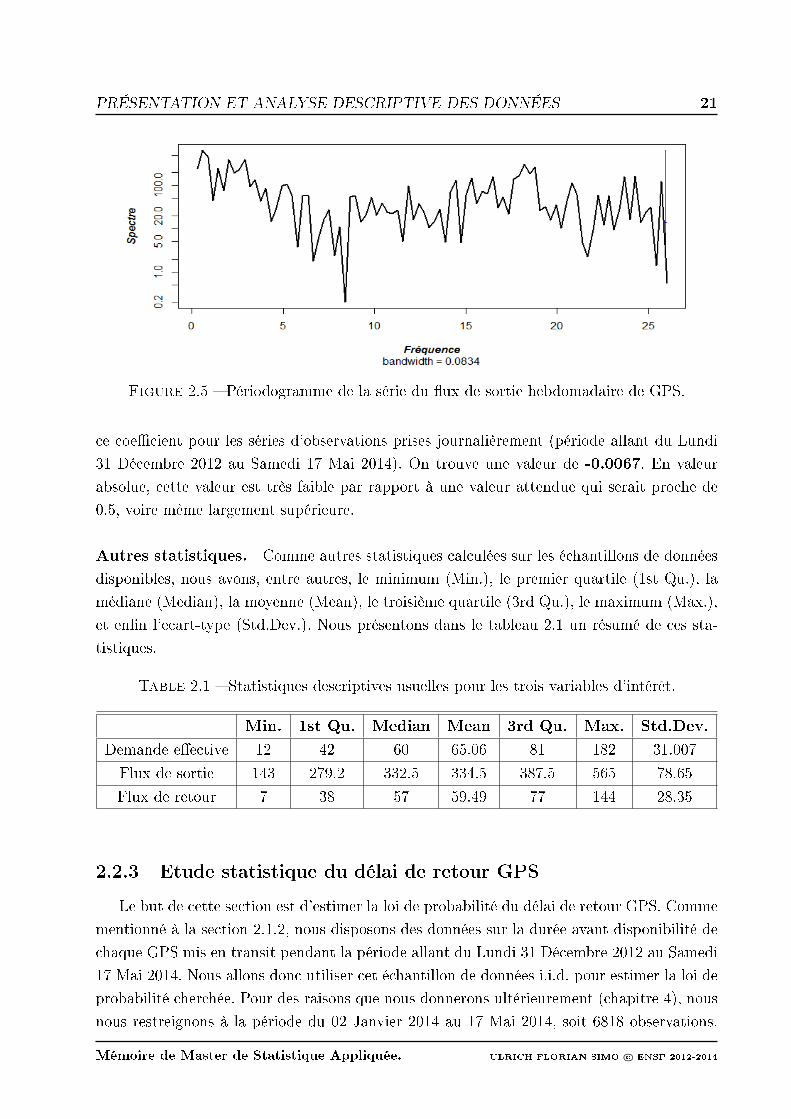
PRÉSENTATION ET ANALYSE DESCRIPTIVE DES DONNÉES 21
Figure 2.5 Périodogramme de la série du ux de sortie hebdomadaire de GPS.
ce coecient pour les séries d'observations prises journalièrement (période allant du Lundi
31 Décembre 2012 au Samedi 17 Mai 2014). On trouve une valeur de -0.0067. En valeur
absolue, cette valeur est très faible par rapport à une valeur attendue qui serait proche de
0.5, voire même largement supérieure.
Autres statistiques. Comme autres statistiques calculées sur les échantillons de données
disponibles, nous avons, entre autres, le minimum (Min.), le premier quartile (1st Qu.), la
médiane (Median), la moyenne (Mean), le troisième quartile (3rd Qu.), le maximum (Max.),
et enn l'ecart-type (Std.Dev.). Nous présentons dans le tableau 2.1 un résumé de ces sta-
tistiques.
Table 2.1 Statistiques descriptives usuelles pour les trois variables d'intérêt.
Min. 1st Qu. Median Mean 3rd Qu. Max. Std.Dev.
Demande eective 12 42 60 65.06 81 182 31.007
Flux de sortie 143 279.2 332.5 334.5 387.5 565 78.65
Flux de retour 7 38 57 59.49 77 144 28.35
2.2.3 Etude statistique du délai de retour GPS
Le but de cette section est d'estimer la loi de probabilité du délai de retour GPS. Comme
mentionné à la section 2.1.2, nous disposons des données sur la durée avant disponibilité de
chaque GPS mis en transit pendant la période allant du Lundi 31 Décembre 2012 au Samedi
17 Mai 2014. Nous allons donc utiliser cet échantillon de données i.i.d. pour estimer la loi de
probabilité cherchée. Pour des raisons que nous donnerons ultérieurement (chapitre 4), nous
nous restreignons à la période du 02 Janvier 2014 au 17 Mai 2014, soit 6818 observations.
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014
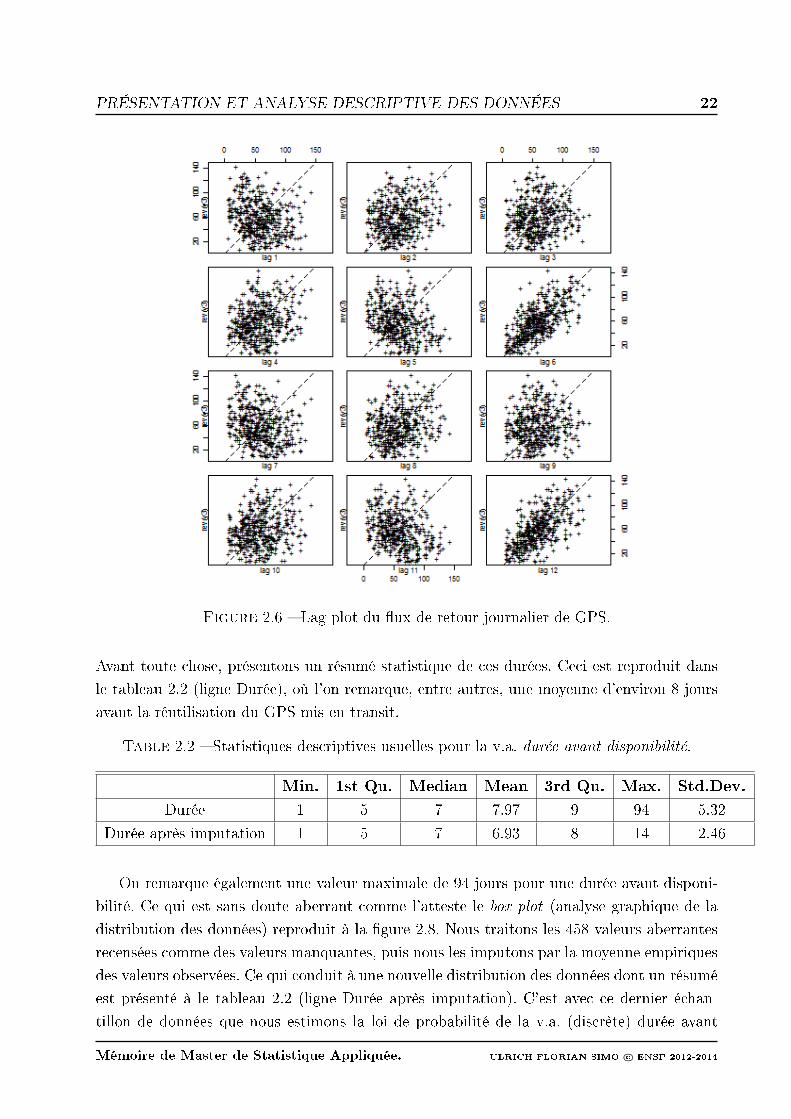
PRÉSENTATION ET ANALYSE DESCRIPTIVE DES DONNÉES 22
Figure 2.6 Lag plot du ux de retour journalier de GPS.
Avant toute chose, présentons un résumé statistique de ces durées. Ceci est reproduit dans
le tableau 2.2 (ligne Durée), où l'on remarque, entre autres, une moyenne d'environ 8 jours
avant la réutilisation du GPS mis en transit.
Table 2.2 Statistiques descriptives usuelles pour la v.a. durée avant disponibilité.
Min. 1st Qu. Median Mean 3rd Qu. Max. Std.Dev.
Durée 1 5 7 7.97 9 94 5.32
Durée après imputation 1 5 7 6.93 8 14 2.46
On remarque également une valeur maximale de 94 jours pour une durée avant disponi-
bilité. Ce qui est sans doute aberrant comme l'atteste le box plot (analyse graphique de la
distribution des données) reproduit à la gure 2.8. Nous traitons les 458 valeurs aberrantes
recensées comme des valeurs manquantes, puis nous les imputons par la moyenne empiriques
des valeurs observées. Ce qui conduit à une nouvelle distribution des données dont un résumé
est présenté à le tableau 2.2 (ligne Durée après imputation). C'est avec ce dernier échan-
tillon de données que nous estimons la loi de probabilité de la v.a. (discrète) durée avant
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014
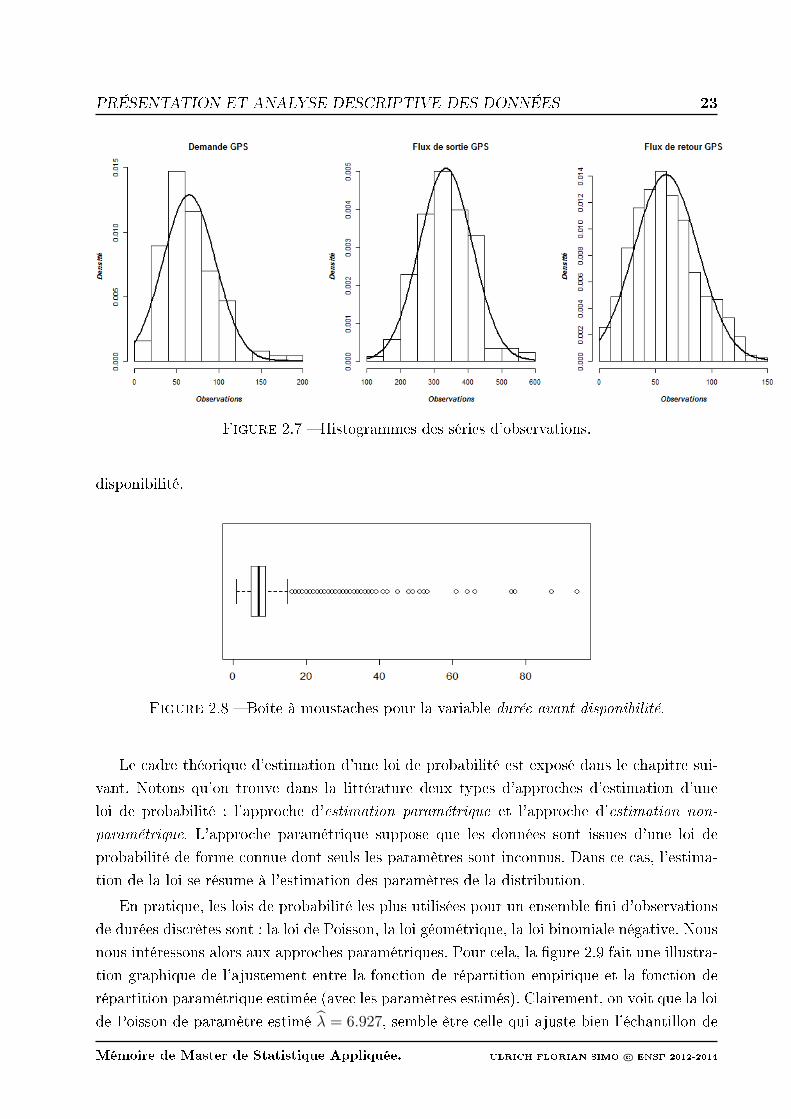
PRÉSENTATION ET ANALYSE DESCRIPTIVE DES DONNÉES 23
Figure 2.7 Histogrammes des séries d'observations.
disponibilité.
Figure 2.8 Boîte à moustaches pour la variable durée avant disponibilité.
Le cadre théorique d'estimation d'une loi de probabilité est exposé dans le chapitre sui-
vant. Notons qu'on trouve dans la littérature deux types d'approches d'estimation d'une
loi de probabilité : l'approche d'estimation paramétrique et l'approche d'estimation non-
paramétrique. L'approche paramétrique suppose que les données sont issues d'une loi de
probabilité de forme connue dont seuls les paramètres sont inconnus. Dans ce cas, l'estima-
tion de la loi se résume à l'estimation des paramètres de la distribution.
En pratique, les lois de probabilité les plus utilisées pour un ensemble ni d'observations
de durées discrètes sont : la loi de Poisson, la loi géométrique, la loi binomiale négative. Nous
nous intéressons alors aux approches paramétriques. Pour cela, la gure 2.9 fait une illustra-
tion graphique de l'ajustement entre la fonction de répartition empirique et la fonction de
répartition paramétrique estimée (avec les paramètres estimés). Clairement, on voit que la loi
de Poisson de paramètre estimé λ = 6.927, semble être celle qui ajuste bien l'échantillon de
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014
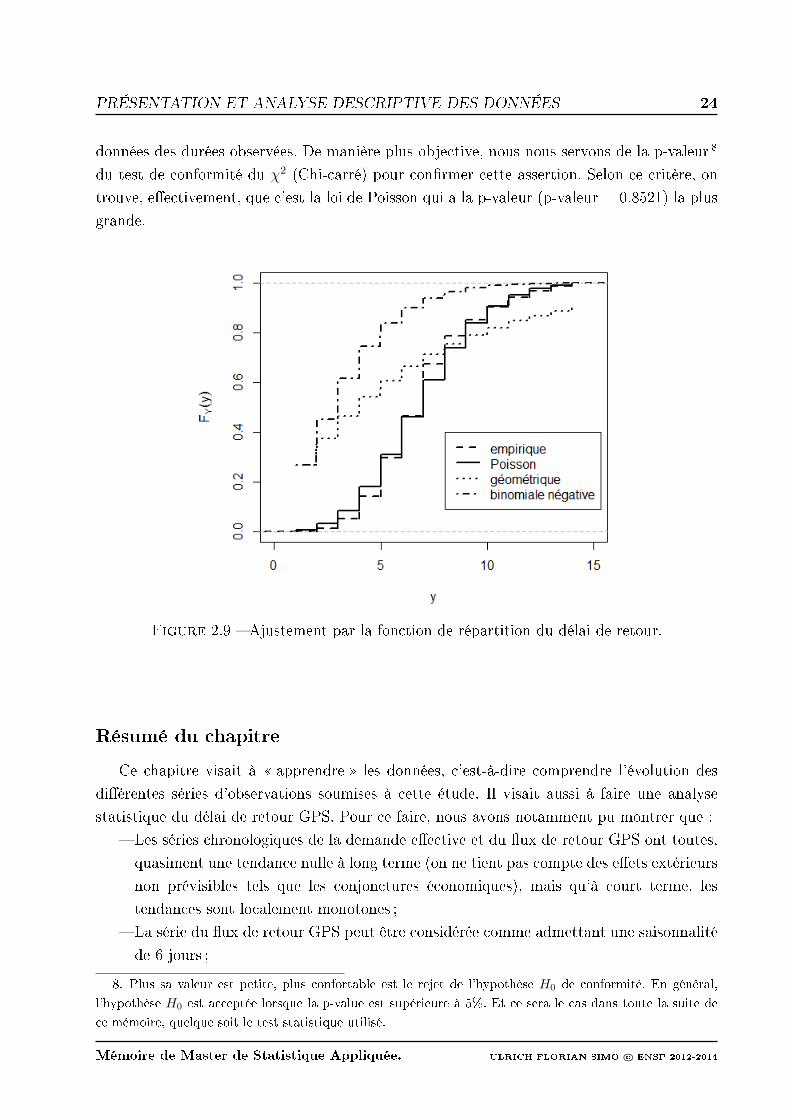
PRÉSENTATION ET ANALYSE DESCRIPTIVE DES DONNÉES 24
données des durées observées. De manière plus objective, nous nous servons de la p-valeur 8
du test de conformité du χ2 (Chi-carré) pour conrmer cette assertion. Selon ce critère, on
trouve, eectivement, que c'est la loi de Poisson qui a la p-valeur (p-valeur = 0.8521) la plus
grande.
Figure 2.9 Ajustement par la fonction de répartition du délai de retour.
Résumé du chapitre
Ce chapitre visait à apprendre les données, c'est-à-dire comprendre l'évolution des
diérentes séries d'observations soumises à cette étude. Il visait aussi à faire une analyse
statistique du délai de retour GPS. Pour ce faire, nous avons notamment pu montrer que :
Les séries chronologiques de la demande eective et du ux de retour GPS ont toutes,
quasiment une tendance nulle à long terme (on ne tient pas compte des eets extérieurs
non prévisibles tels que les conjonctures économiques), mais qu'à court terme, les
tendances sont localement monotones ;
La série du ux de retour GPS peut être considérée comme admettant une saisonnalité
de 6 jours ;
8. Plus sa valeur est petite, plus confortable est le rejet de l'hypothèse H0 de conformité. En général,
l'hypothèse H0 est acceptée lorsque la p-value est supérieure à 5%. Et ce sera le cas dans toute la suite de
ce mémoire, quelque soit le test statistique utilisé.
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

PRÉSENTATION ET ANALYSE DESCRIPTIVE DES DONNÉES 25
Le coecient de corrélation estimé entre les séries du ux de sortie et du ux de retour
est -0.0067. Ce qui est inattendu par rapport à ce que l'on pourrait s'attendre, compte
tenu de la revue de littérature exposée au chapitre précédent ;
Les données observées sur le délai de retour GPS suivent une distribution de Poisson
de paramètre estimé λ = 6.927.
L'objectif de cette étude est de générer des prévisions à court terme de la demande
eective et du ux de retour GPS à la Douane Camerounaise, pour les périodes futures.
Compte tenu des informations préliminaires obtenues au terme de ce chapitre et de la revue
de littérature exposée au chapitre 1, nous bâtirons cette recherche prévisionnelle sur la base
de quatre méthodes statistiques : la méthode du lissage exponentiel de Holt-Winters, la
méthode de Box et Jenkins, une méthode de prévision non paramétrique et la méthode à
retards échelonnés. Nous eectuerons aussi une prévision en loi de la demande eective
de GPS. La suite de ce mémoire présente le cadre théorique de modélisation sur lequel nous
nous sommes appuyés pour être à même de proposer des résultats prévisionnels.
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

MÉTHODOLOGIE STATISTIQUE 26
Chapitre Trois
Méthodologie Statistique
En statistique, on désigne par série chronologique, ou série temporelle, la modélisa-
tion d'une suite d'évènements aléatoires et séquentiellement observés, généralement sur une
échelle temporelle. La caractéristique principale d'une série temporelle est la dépendance et
d'intérêt pratique considérable liant deux observations consécutives, à l'origine de la dyna-
mique des modèles. Parmi le panel d'applications issues de la théorie, ce sont principalement
la modélisation et la prédiction qui concentrent toutes les attentions. Alors que l'on cherche,
d'un côté, à bâtir le modèle le mieux adapté à un ensemble de données sans préjuger des
évènements ayant cours en dehors de l'intervalle d'étude, on se focalise, de l'autre, sur l'ap-
prentissage optimal des observations pour en inférer le comportement futur.
Dans ce chapitre, nous présentons de manière plus détaillée les quatre méthodes retenues
dans notre étude de prévision d'une série chronologique, ainsi que la démarche adoptée pour
les estimer. Avant de présenter ces diérents modèles, nous faisons un rappel de quelques
concepts fondamentaux.
3.1 Quelques concepts fondamentaux
Nous introduisons succinctement, en guise de préambule, certains concepts fondamentaux
que nous considérerons comme convenus tout au long de cette partie du mémoire. Ces derniers
sont, d'une manière générale, intimement liés à la modélisation chronologique.
3.1.1 Processus stochastique
Considérons un espace probabilisé (Ω,A,P), un ensemble d'indices I et un espace mé-
trique E muni de la tribu borélienne B(E).
Dénition 3.1. On appelle processus stochastique, une famille de v.a. (Yt) dénies sur
(Ω,A,P), indexées par t ∈ I et à valeurs dans E. Pour toute réalisation ω ∈ Ω, la famille
(yt = Yt(ω)) est une trajectoire du processus.
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

MÉTHODOLOGIE STATISTIQUE 27
C'est à la trajectoire d'un processus observé sur un sous-ensemble de I que l'on associera
la notion de série chronologique. Cependant, pour alléger les notations, nous ne distinguerons
généralement pas le processus (Yt) d'une de ses réalisations (yt = Yt(ω)), lorsqu'il n'y aura
aucune ambiguïté quant à la grandeur que l'on manipule. Nous serons par la suite amenés
à travailler sur des processus discrets indexés par N ou Z et à valeurs dans E = R. Nousferons d'ailleurs implicitement référence à cette sous-classe à travers le terme générique de
processus.
3.1.2 Prévision d'une série chronologique.
Considérons une série chronologique (y1, y2, ..., yn), où n est la taille de l'échantillon de
données observées. A partir de ces n observations, on voudrait prévoir yn+h (h est l'horizon de
prévision). Plaçons-nous donc à la date t, et notons =t = y1, y2, ..., yt, l'information connue
à cette date. On peut donner, au moins théoriquement, la loi de probabilité conditionnelle
de Yt+h sachant =t. La prévision au sens large est donc cette loi, que l'on appellera loi
de prévision . On retrouve alors la notion de prévision au sens commun comme la valeur
moyenne de la loi de prévision, mais l'on a bien plus : on connaît les uctuations autour de
cette valeur.
Dénition 3.2. La prévision en t à l'horizon h, notée Yt+h, est
Yt+h = E(Yt+h | =t).
L'erreur de prévision 1 correspondante, notée et+h, est dénie par
et+h = E((Yt+h − Yt+h)2 | =t).
La prévision et l'erreur de prévision sont des v.a., fonctions de Yt, Yt−1, ...Y1. L'erreur de
prévision est généralement insusante pour décrire les uctuations autour de la prévision
(cas d'une loi dissymétrique par exemple), sauf dans le cas gaussien. En fait, le prévisionniste
recherche aussi un intervalle de prévision.
Dénition 3.3. Un intervalle de prévision est un intervalle contenant la prévision avec une
probabilité donnée. Ainsi, It,h(α) est un intervalle de prévision au niveau 1−α de Yt+h si et
seulement si
P(Yt+h ∈ It,h(α) | =t) = 1− α.
1. Il s'agit d'un abus de langage. L'erreur de prévision désigne, à proprement parler, l'écart entre la valeur
inconnue Yt+h et la prévision Yt+h. Il faudrait parler d'erreur quadratique moyenne de prévision.
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

MÉTHODOLOGIE STATISTIQUE 28
3.1.3 La stationnarité
Sommairement, la stationnarité traduit la capacité d'un processus à ne pas dépendre de
l'indice temporel. Le processus est dès lors entièrement décrit par sa loi stationnaire qui,
par dénition, n'évolue plus au cours du temps. On comprend ainsi qu'une telle propriété
est certes d'intérêt pratique considérable, mais possède également un fort impact théorique
puisqu'on la retrouve comme hypothèse à la base de nombreux résultats. On distingue gé-
néralement la stationnarité au sens strict de la stationnarité au sens faible. Pour les dénir,
considérons un processus (Yt) déni sur (Ω,A,P), avec, ∀t ∈ Z, Yt ∈ L2(Ω,A,P), l'ensemble
des v.a. de carré intégrable.
Dénition 3.4. On dit que le processus (Yt) est strictement stationnaire si, pour tout k ∈ N∗
et tout décalage temporel h ∈ Z, la loi du vecteur (Y1, ..., Yk) est la même que celle du vecteur
(Y1+h, ..., Yk+h).
La stationnarité stricte est une hypothèse de travail très forte, nécessairement délicate à
vérier en pratique lorsque le processus n'est pas gaussien. C'est pourquoi l'on a introduit
une notion de stationnarité moins contraignante.
Dénition 3.5. On dit que le processus (Yt) est faiblement stationnaire si, pour tout décalage
temporel h ∈ Z, E(Yh) est constant, V(Yh) est ni, et Cov(Y0, Yh) = Cov(Ys, Ys+h) pour tout
s ∈ Z.
On dit aussi que le processus est stationnaire au second ordre, en relation avec la stabili-
sation de sa variance. C'est à cette propriété de stationnarité que nous ferons implicitement
référence par la suite. Notons que la stationnarité stricte implique bien entendu la station-
narité faible. L'exemple le plus trivial de processus stationnaire est un bruit blanc.
Dénition 3.6. Un processus (εt) est qualié de bruit blanc (faible) si, pour tous t1, t2 ∈ I,on a simultanément E(εt1) = 0, V(εt1) = σ2 < +∞ et Cov(εt1 , εt2) = 0 dès que t1 6= t2.
Si (εt) est constitué de v.a. i.i.d. centrées, on parlera de bruit blanc fort. Il est tout à
fait usuel de considérer le processus des chocs aléatoires perturbant un modèle statistique
comme formant un bruit blanc, par hypothèse. Un test de blancheur résiduelle est ainsi
considéré comme un indicateur de qualité de la modélisation, dans la mesure où l'absence de
corrélation résiduelle signie que toute l'information statistique a bien été prise en compte
dans la modélisation et que, de fait, la perturbation inobservable est de nature purement
aléatoire.
3.1.4 L'autocorrélation
L'une des principales motivations de la modélisation chronologique d'un évènement aléa-
toire est sa structure de corrélation temporelle, en d'autres termes son niveau d'autocorré-
lation. Il existe, entre autres, deux outils permettant d'évaluer l'autocorrélation d'une série
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

MÉTHODOLOGIE STATISTIQUE 29
chronologique. Ces derniers sont, pour nous, d'une importance capitale puisque nous verrons
dans la section suivante qu'ils possèdent des propriétés remarquables dans le cadre du pro-
cessus ARMA stationnaire. Restons pour le moment dans le cadre plus général du processus
(Yt) stationnaire, indexé par Z et Yt ∈ L2(Ω,A,P).
La fonction d'autocorrélation Cette première fonction quantie l'inuence linéaire du
décalage temporel entre deux observations du processus par un calcul classique de corrélation.
Dénition 3.7. On appelle fonction d'autocorrélation associée au processus stationnaire
(Yt), la fonction ρ dénie, pour tout décalage temporel h ∈ N, par
ρ(h) =γ(h)
γ(0),
où γ est la fonction d'autocovariance donnée par γ(h) = Cov(Yh, Y0).
La fonction d'autocorrélation partielle Supposons désormais que l'on souhaite connaître
l'inuence exacte d'une observation passée sur la valeur courante du processus en faisant
de toutes les observations intermédiaires. Cette mesure de corrélation est plus délicate à
interpréter, mais nous pouvons malgré tout la formaliser. Nous commençons, à cet égard,
par dénir la notion de régression ane.
Dénition 3.8. Soit (Yt), un processus stationnaire. Pour tout décalage temporel h ∈ N, larégression ane de Yt sur (Yt−1, ..., Yt−h), notée Y ∗t,h, vérie la relation :
Yt = Y ∗t,h +Rt,h = λ0,h +h∑s=1
λs,hYt−s +Rt,h, (3.1)
où Rt,h est une v.a. non corrélée avec Yt−1, ..., Yt−h.
Dénition 3.9. On appelle fonction d'autocorrélation partielle associée au processus sta-
tionnaire (Yt), la fonction τ dénie par τ(0) = 1 et, pour tout décalage temporel h ∈ N∗,par
τ(h) = λh,h,
avec λh,h déni à l'équation (3.1).
3.2 Le lissage exponentiel de Holt-Winters
La prévision de valeurs à des dates futures, le présent et le passé de la série étant connus,
peut être (i) basée sur un modèle, ou bien (ii) être construite sans ajustement préalable
d'un modèle : c'est le cas du lissage exponentiel et de ses généralisations. La méthode de
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

MÉTHODOLOGIE STATISTIQUE 30
Holt-Winters est une des techniques privilégiées de lissage exponentiel dans le cas de séries
d'observations présentant à la fois un terme de tendance et une saisonnalité. En eet, elle
opère le lissage simultané de trois termes correspondant respectivement à des estimations
locales du niveau de la série désaisonnalisée at, de la pente de la tendance bt et de la
saisonnalité St. On peut citer au moins deux méthodes dont l'une est adaptée aux séries
admettant une décomposition multiplicative et l'autre correspondant aux décompositions
additives. Les prévisions obtenues sont généralement assez précises et peu coûteuses (en
termes de calculs). Nous exposons succinctement dans la suite de la présente section, la
méthode du lissage de Holt-Winters (H-W) telle que présentée dans [7,11,27].
3.2.1 Méthode saisonnière
Le modèle de Holt-Winters (saisonnière), dans sa forme additive, est spécié par l'équa-
tion suivante :
Yt+h := Yt(h) = at + bth+ St, (3.2)
où les suites at, bt et St (facteur saisonnier) vérient les équations de récurrence paramétriques
suivantes : at = α(Yt − St−s) + (1− α)(at−1 + bt−1);
bt = β(at − at−1) + (1− β)bt−1;
St = γ(Yt − at) + (1− γ)St−s.
(3.3)
avec s facteur de saisonnalisation ou le nombre de saisons. Il existe, de manière analogue,
un modèle multiplicatif. Les paramètres du modèle sont les nombres α, β et γ, appartenant
tous à l'intervalle [0,1].
La prévision de la série à l'horizon h (1 ≤ h ≤ s) s'écrit :
Yn(h) = an + bnh+ Sn+h+s. (3.4)
Il se pose un problème d'initialisation pour les coecients an et bn. Ceci se fait par
minimisation de la somme des carrés des résidus, de la manière suivante :
minan,bn
n−1∑j=0
[Yn−j −
(an + bn(n− j) + Sn
)]2. (3.5)
3.2.2 Méthode non saisonnière
La construction de cette méthode est littéralement la même que la précédente, mais avec
absence du facteur saisonnier. Autrement dit, la version non saisonnière, s'écrit :
Yt+h := Yt(h) = at + bth, (3.6)
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

MÉTHODOLOGIE STATISTIQUE 31
où les suites at et bt vérient les équations de récurrence paramétriques suivantes :at = αYt + (1− α)(at−1 + bt−1);
bt = β(at − at−1) + (1− β)bt−1.(3.7)
Les paramètres du modèle sont les nombres α et β.
Cette méthode est censée prédire la série à l'horizon h par :
Yn(h) = an + bnh, (3.8)
où les coecients an et bn sont solution de
minan,bn
n−1∑j=0
[Yn−j −
(an + bn(n− j)
)]2. (3.9)
Pour l'estimation des paramètres et la prévision par la méthode de lissage de Holt-
Winters, nous mettrons en pratique, respectivement, les fonctions HoltWinters() et predict()
de la librarie stats du logiciel R.
3.3 Le modèle ARIMA saisonnier
Le deuxième modèle retenu dans cette étude est le modèle ARIMA saisonnier. Rappelons
les hypothèses implicites à ce modèle :
1. existence d'une corrélation linéaire entre les observations présentes et passées de la
variable d'intérêt,
2. existence d'un eet linéaire aléatoire présent et passé sur la variable d'intérêt,
3. absence d'eet signicatif d'autres variables exogènes.
3.3.1 Le modèle ARMA stationnaire et ses propriétés usuelles
Soit (Yt), un processus de L2(Ω,A,P) stationnaire indexé par Z, et deux paramètres
p, q ∈ N.
Dénition 3.10. 1. Le processus stationnaire (Yt) admet une représentation ARMA(p, q)
si, pour tout t ∈ Z, il est donné par la relation récursive
Yt −p∑
k=1
ψkYt−k = µ+
q∑k=1
θkεt−k + εt, (3.10)
où (εt) est un bruit blanc de variance σ2 > 0, µ ∈ R, ψ = (ψ1, ..., ψp) ∈ Rp, θ =
(θ1, ..., θq) ∈ Rq, ψp 6= 0, θq 6= 0.
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

MÉTHODOLOGIE STATISTIQUE 32
2. Lorsque q = 0, le modèle admet la représentation AR(p) donnée, pour tout t ∈ Z par
Yt = µ+
p∑k=1
ψkYt−k + εt, (3.11)
et l'on dit que (Yt) est un processus autoregréssif d'ordre p.
3. Lorsque p = 0, le modèle admet la représentation MA(q) donnée, pour tout t ∈ Z par
Yt = µ+
q∑k=1
θkεt−k + εt, (3.12)
et l'on dit que (Yt) est une moyenne mobile d'ordre q.
Dans la dénition ci-dessus, nous pouvons, en outre, sans aucune perte de généralité,
considérer que le processus (Yt) est centré et donc que µ = 0. En eet, si l'on appelle m
l'espérance de la loi stationnaire, on a, dans (3.10) :
m =µ
1−∑p
k=1 ψk;
et l'on voit alors immédiatement que le changement de variables Zt = Yt −m nous ramène,
par simple translation, au modèle ARMA(p, q) centré, engendrant (Zt). Ainsi, dans toute la
suite, quand nous parlerons de processus ARMA, AR ou MA, nous le considérons centré,
i.e. µ = 0 dans (3.10), (3.11) et (3.12).
Pour alléger les notations, on a souvent recours à deux opérateurs chronologiques : le
retard noté B, la diérenciation notée ∆.
Dénition 3.11. On dénit l'opérateur retard, sur la classe des processus (Yt) indexés par
Z, comme associant à toute valeur courante du processus sa valeur précédente,
BYt = Yt−1.
Dénition 3.12. On dénit l'opérateur diérenciation, sur la classe des processus (Yt) in-
dexés par Z, comme associant à toute valeur courante du processus les combinaisons,
∆Yt = (1−B)Yt = Yt − Yt−1.
Nous généralisons facilement ces opérateurs pour tous h, d ∈ N par l'intermédiaire de la
convention BhYt = (B ... B)Yt = Yt−h et ∆dYt = (1−B)dYt.
Ainsi, de manière condensée, à l'aide de l'opérateur retard B, le modèle (3.10) s'écrit
encore, pour tout t ∈ Z (pour µ = 0) :
Ψ(B)Yt = Θ(B)εt, (3.13)
où l'on dénit, pour tout z ∈ C, les polynômes Ψ et Θ par
Ψ(z) = 1− ψ1z − ...− ψpzp et Θ(z) = 1 + θ1z + ...+ θqzq.
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

MÉTHODOLOGIE STATISTIQUE 33
Proposition 3.1. Le processus stationnaire centré (Yt) est engendré par une modélisation
minimale MA(q) si et seulement si ρ(q) 6= 0 et ρ(h) = 0 pour tout h > q.
Proposition 3.2. Le processus stationnaire centré (Yt) est engendré par une modélisation
minimale AR(p) si et seulement si τ(p) 6= 0 et τ(h) = 0 pour tout h > p.
La série intégrée : le modèle ARIMA. En bref, un processus (Yt) de L2(Ω,A,P),
indexé par Z admet la modélisation ARIMA(p, d, q), I pour integrated, si le processus doit
être diérencié d fois pour être stationnarisé sous forme d'ARMA.
La série saisonnière : le modèle ARIMA saisonnier (SARIMA). Le modèle SARIMA(p, d, q)×(P,D,Q)s a été introduit dans le but de modéliser un comportement ARMA stationnaire
sur une série éventuellement intégrée et munie d'une périodicité s ∈ N∗, ce pourquoi l'on
ajoute un S comme seasonal. Le processus est alors déni, pour tout t ∈ Z, par
Ψs(B)Ψ(B)(1−Bs)D(1−B)dYt = Θs(B)Θ(B)εt,
où, pour tout z ∈ C, Ψs(z) = 1−α1zs− ...−αP zPs et Θs(z) = 1+β1z
s+ ...+βQzQs, avec les
paramètres α = (α1, ..., αP ) ∈ RP et β = (β1, ..., βQ) ∈ RQ, et par analogie avec le modèle
ARIMA, le triplet (P,D,Q) ∈ N3.
L'opérateur de diérenciation saisonnière pour une période s, noté ∇s, déni par ∇sYt =
Yt − Yt−s, permet également d'alléger les notations en remarquant que ∇s = 1−Bs.
3.3.2 La méthodologie de Box et Jenkins
Etant donnée une série d'observations, une question essentielle est le choix d'un modèle
le mieux adapté. Box et Jenkins [4] ont proposé une démarche systématique permettant
d'aboutir, si c'est possible, au choix d'un modèle de type ARIMA saisonnier. Elle repose
sur plusieurs étapes qui peuvent être détaillées comme suit.
Etape 1 : Préparation des données (Stationnarisation). A la suite d'une éventuelle
préparation des données (étude descriptive de la série ; traitement des données manquantes,
aberrantes et d'éventuelles anomalies ; détection et élimination de la tendance et saisonnalité ;
stabilisation de la variance), cette étape consiste à se ramener à une série stationnaire, au
cas où les tests statistiques appropriés rejettent l'hypothèse de stationnarité de la série. Elle
se décompose en deux phases :
utilisation d'une transformation ;
diérentiation (simple et/ou saisonnière), éventuellement répétée.
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

MÉTHODOLOGIE STATISTIQUE 34
Etape 2 : Sélection d'un modèle. Il s'agit de choisir à partir des données transformées
y1, y2, ..., yn, un modèle de type SARIMA(p, d, q)×(P,D,Q)s. L'examen des fonctions d'au-
tocorrélation (ACF) et d'autocorrélation partielle (PACF) permettent souvent à lui seul de
sélectionner un bon candidat.
Compte tenu des propositions 3.1 et 3.2, on peut espérer reconnaître au moins les processus
autorégressifs ou moyenne mobile purs. Cependant, on doit se contenter d'estimations de
ρ(h) et de τ(h) (puisque les processus sont inconnus), ρ(h), τ(h). La sélection s'eectue en
examinant les corrélations signicatives (on considère qu'une valeur à l'intérieur des bornes
±1.96n−1/2 n'est pas signicative quel que soit le modèle). On préfère très souvent se limiter
à des corrélations pour h < n/5, car, lorsque h devient grand, l'estimation ρ(h) (par exemple)
devient de plus en plus mauvaise (car utilise de moins en moins de données).
Etape 3 : Estimation des paramètres. Nous considérons ici le cas d'un ARMA(p, q).
Il s'agit alors d'estimer les paramètres ψ = (ψ1, ..., ψp) ∈ Rp et θ = (θ1, ..., θq) ∈ Rq associés
à la relation condensée (3.13), ainsi que l'estimation de la variance σ2 du bruit blanc.
Sous l'hypothèse de loi (εt) ∼ N (0, σ2), on peut utiliser des méthodes du type maximum
de vraisemblance. En eet, les erreurs étant normalement distribuées et indépendantes, le
vecteur (ε1, ..., εn)′ est un vecteur gaussien. Les composantes du vecteur Y = (Y1, ..., Yn)′
étant obtenues par combinaisons linéaires des composantes du vecteur (ε1, ..., εn)′, Y sera un
vecteur gaussien. La vraisemblance est alors :
Vn(ψ, θ, σ2;Y ) =1
(2πσ2)n/2√|Σ|
exp(− 1
2σ2Y ′Σ−1Y ), (3.14)
où σ2Σ est la matrice n× n des covariances du vecteur Y .
La méthode du maximum de vraisemblance revient alors à chercher la valeur des para-
mètres qui maximise la log-vraisemblance. Lorsque l'hypothèse de normalité des erreurs n'est
pas vériée, on fait recours aux méthodes du type CSS pour Sum Squared Conditionnal, ou
la méthode de Yule-Walker lorsque la parie MA est inexistante dans le modèle [34].
Etape 4 : Validation du modèle. La validation du modèle est réalisée à l'aide de
tests. Sont à distinguer ceux qui portent sur les propriétés du résidu de l'estimation de ceux
qui portent sur la signicativité de chaque paramètre estimé (test de Student).
Les tests relatifs au résidu consistent à tester l'hypothèse de bruit blanc, c'est-à-dire,
principalement, l'hypothèse de non-corrélation (test de Ljung-Box, par exemple, ou de Box
Pierce), de normalité (test de Shapiro-Wilk, de Jarque-Bera, ou test non paramétrique de
Kolmogorov-Smirno). Parmi ces propriétés, la non corrélation est fondamentale. Ainsi, si
l'hypothèse de normalité n'est pas validée, le calcul de la vraisemblance peut être remis en
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

MÉTHODOLOGIE STATISTIQUE 35
cause, mais les estimateurs peuvent néanmoins avoir de bonnes propriétés de convergence
asymptotique. En revanche, l'hypothèse de non corrélation du résidu est fondamentale, car
son rejet conduit nécessairement à revoir la spécication du modèle.
En pratique, toutes les propriétés du résidu ne sont pas testées : la non corrélation et
la normalité le sont, et, si elles sont validées, l'indépendance en est déduite. Les tests de
Student attestant de la signicativité de chaque paramètre s'eectuent en dernier, puisqu'ils
ne sont praticables que si les tests portant sur le résidu ont été concluants.
Après cette étape de validation à proprement parler, la performance empirique du modèle
est évaluée à l'aide de critères. Ceux-ci visent à évaluer la qualité d'ajustement du modèle,
ou son pouvoir de prédiction. Il existe, à cet eet, une panoplie de critères de performance
empirique (AIC, BIC, etc.). Cependant, nous nous intéresserons particulièrement au critère
AIC, qui est déni par :
AIC = −2Vn + 2×nombre de paramètres,
avec Vn la vraisemblance donnée par la méthode du maximum de vraisemblance exacte dé-
nie par l'équation (3.14).
La procédure d'estimation des paramètres du modèle est implémentée dans la fonction
arima() de la librairie stats, tandis que celle de la prévision des valeurs futures est implémentée
dans la fonction forecast() de la librairie forecast du logiciel R. On peut se référer à la partie
Annexe C pour la mise en oeuvre sur les échantillons de données disponibles.
3.4 Modèle à retards échelonnés
Dans cette quatrième section du chapitre, nous allons étudier les modèles de régression
dynamique dits à retards échelonnés. Un modèle à retards échelonnés a pour spécication
[31] :
Yt = b+k∑i=0
νiXt−i + εt, t = k + 1, ..., n, (3.15)
où Yt est la variable dépendante, Xt une variable explicative et εt ∼ N (0, σ2) le bruit. Les
coecients à estimer sont b, ν0, ν1, ..., νk. Ici, contrairement aux modèles autorégressifs, ce
sont les valeurs décalées de Xt qui entrent dans la liste des variables explicatives. Ce type
de modèle traduit l'existence d'un eet progressif de l'impact d'une augmentation de la va-
riable Xt sur la variable Yt. Le paramètre ν0 mesure l'impact de court terme de X sur Y , et
ν+ = ν0 + ν1 + ...+ νk désigne l'impact de long terme.
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

MÉTHODOLOGIE STATISTIQUE 36
L'estimation des paramètres du modèle (3.15) par la méthode des moindres carrés ordi-
naires pose un certain nombre de problèmes : (i) le choix du décalage maximal k n'est pas aisé
et la théorie économique ne fournit généralement aucune indication ; (ii) la multicolinéarité
existante entre les diérentes variables explicatives (Xt, Xt−1, ..., Xt−k) impacte l'estimation
et l'exercice d'inférence.
3.4.1 Méthode de Koyck
Une solution originale a été introduite par Koyck, et ceci pour l'estimation du modèle à
retards échelonnés d'ordre inni, soit :
Yt = b+∞∑i=0
νiXt−i + εt. (3.16)
La démarche adoptée par Koyck consiste à transformer le modèle à retard inni en un
modèle estimable, en supposant que les paramètres νi, i = 0, 1, 2, ... admettent la paramétri-
sation suivante :
νi = ν0βi, i = 0, 1, 2, ..., (3.17)
où 0 < β < 1 désigne le taux de décroissance des paramètres. Il s'agit d'une décroissance de
type géométrique, où les paramètres νi sont de même signe puisque β > 0.
3.4.2 Cas de la prévision du ux de retour GPS
Nous utiliserons le modèle (3.16) de Koyck pour modéliser la prévision du ux de retour
GPS, avec les notations suivantes :
Xt, ux de sortie GPS du jour t ;
Yt, ux de retour GPS du jour t.
La clé de la prévision des retours GPS est de constater que les retours Y dans un quel-
conque jour sont générés par les sorties X dans les jours précédents. Une façon courante
de modéliser ceci est de supposer que le ux de sortie le jour actuel va générer un ux de
retour i jours plus tard, avec une probabilité νi, i = 1, 2, ..., ou ne générera rien du tout.
Introduisons aussi les notations suivantes :
p, probabilité qu'un GPS en transit nira par revenir ;
ri, probabilité qu'un GPS mis en transit revienne après i jours, sachant qu'il sera
éventuellement retourné ;
νi, probabilité qu'un GPS mis en transit revienne après i jours (νi = p.ri) ;
νi(t), estimation du jour t de νi ;
Rt−i,t+j, nombre total de retours GPS du jour t+ j provenant des GPS mis en transit le
jour t− i ;
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

MÉTHODOLOGIE STATISTIQUE 37
vt,t−i, nombre total de retours GPS jusqu'au jour t provenant des GPS mis en transit le
jour t− i ;I(t), ensemble des données disponibles à la n du jour t pour prévoir les retours futurs de
GPS.
Compte tenu du dispositif en vigueur à la Douane Camerounaise et de notre connaissance
des données, nous avons Y1 = 0, c'est-à-dire, parmi les X1 GPS mis en transit le jour 1, aucun
ne sera retourné au port le même jour. Ce qui est raisonnable, puisque la durée (en jours)
avant disponibilité d'un GPS est toujours supérieure à 1. De plus, nous faisons une hypothèse
de loi discrète sur le délai de retour GPS. La loi géométrique de paramètre q en l'occurrence
(i.e. ri = (1− q)i−1q). En eet, comme nous l'avons montré dans le chapitre 1, c'est cette loi
qui est largement utilisée en pratique. Signalons cependant que, d'après l'étude statistique
eectuée à la section 2.2.3, il serait plus approprié ici d'utiliser la loi de Poisson. Ainsi, nous
nous appuierons désormais sur la relation suivante :
νi = p(1− q)i−1q, i = 1, 2, ... . (3.18)
Le modèle s'écrit alors
Yt = ν1Xt−1 + ν2Xt−2 + ...+ εt, pour t = 2, 3, ..., N, (3.19)
avec N , le nombre de dates retours diérentes observées dans l'échantillon de données.
3.4.3 Estimation des paramètres du modèle
Une caractéristique particulière des données du délai de retour est qu'elles sont censu-
rées à droite : a un moment donné, si un GPS n'a pas été retourné, nous ne savons pas s'il
sera retourné ou pas. Pour estimer avec précision le modèle, il est important d'utiliser une
méthode d'estimation qui prend en compte le fait que certains éléments qui n'ont pas encore
été retournés ne le seront jamais.
On classe les modèles de prévision utilisés dans la littérature en fonction des données
qu'ils exploitent. Nous disons que l'information au niveau du jour est disponible si le total
des sorties et le volume des retours de chaque jour sont connus. Nous disons que l'information
au niveau de l'article (GPS) est disponible si les dates de sortie et de retour de chaque article
sont connues.
Information disponible au niveau du GPS. On parle d'information disponible au
niveau du GPS lorsque les GPS sont suivis sur une base individuelle. Il est alors possible
d'observer le réel délai de retour de chaque GPS retourné. Autrement dit, on connait le temps
de sortie tsortie de chaque GPS. Ainsi, à un instant t, quelques uns des GPS sont retournés.
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

MÉTHODOLOGIE STATISTIQUE 38
Pour ces GPS, nous connaissons exactement la durée avant disponibilité. Pour d'autres,
par contre, nous savons seulement que leur délai de retour est plus long que t − tsortie, ouinni éventuellement. Dempster et al. (1977) introduisent l'algorithme EM (Expectation-
Maximisation) pour calculer les estimations du maximum de vraisemblance des paramètres
pour des échantillons de données incomplètes. Cet algorithme peut être ecacement utilisé
pour estimer la distribution du délai de retour en utilisant les données de délais censurés
[10]. Nous décrivons d'abord cet algorithme et, par la suite, présentons sa mise en oeuvre
sur un échantillon de données.
Algorithme EM. [29,33]
Soit T = (T1, ..., Tn), n v.a. i.i.d. qui pourraient être observées s'il n'y avait pas de cen-
sure (n ici désigne le nombre de GPS en activité pendant les N dates retours diérentes
considérées.), et soit θ, le paramètre de la distribution des Ti. Soit zi, l'observation actuelle
(éventuellement censurée) de l'individu (GPS) i, et soit δi = 0 si l'observation est censurée,
et 1 sinon. Posons z = (z1, ..., zn) et δ = (δ1, ..., δn). Précisons qu'un GPS mis en transit est
dit censuré à un instant donné si, à cet instant, il n'est pas encore retourné pour être réutilisé.
Pour θ, dénissons l0(θ) = l0(θ;T), la log-vraisemblance de θ basée sur les observations
non censurées T = (T1, ..., Tn), et l(θ) = l(θ; z, δ), la log-vraisemblance pour les obser-
vations (z, δ). Dénissons Q(θ′, θ) = E(l0(θ
′;T) | z, δ; θ), l'espérance conditionnelle de la
log-vraisemblance de θ′ basée sur T, étant donné les observations (z, δ). Partant d'une va-
leur initiale θ1 pour θ, les deux étapes de l'algorithme EM sont :
• étape d'espérance : Calculer Q(θ′, θj). (Ici θ′ est une variable muette et θj est l'estimation
courante de θ).
• étape de maximisation : Chercher la valeur de θ′ qui maximise Q(θ′, θj). Ceci est la nouvelle
estimation θj+1.
Cette procédure récursive produit une séquence d'estimations, θj, j = 1, ... qui, sous cer-
taines hypothèses, converge vers l'estimateur du maximum de vraisemblance de θ basé sur
les observations (zi, δi), i = 1, ..., n.
Mise en oeuvre. Dans notre cas, les estimations de θ = (p, q) dans la relation (3.18)
obtenues par l'algorithme EM sont construites de la manière suivante.
• si = temps de sortie du GPS i, i = 1, ..., n (tous observés) ;
• ri = temps de retour du GPS i, i = 1, ...,m, où m ≤ n ;
• nous admettons que ri =∞ pour les GPS qui ne seront pas retournés ;
• soit T = (T1, ..., Tn), n v.a. i.i.d. représentant le temps écoulé de la sortie au retour au port
pour les n GPS répertoriés dans l'étude ;
• nous admettons ici que le délai de retour des GPS suit une distribution géométrique de
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

MÉTHODOLOGIE STATISTIQUE 39
paramètre q, et nous notons p, la probabilité de retour pour chaque GPS.
Soit t, le temps courant. Alors zi = min(ri − si, t− si) et δi = 1ri≤t.
S'il n'y avait pas de censure (i.e. les vraies valeurs de ri, i = m + 1, ..., n sont connues),
la fonction de vraisemblance serait∏i|ri<∞
pq(1− q)ri−si∏
i|ri=∞
(1− p) = (1− p)n−apaqa(1− q)∑i|ri<∞
(ri−si), (3.20)
où a =∑n
i=1 δi, est égal au nombre de GPS éventuellement réutilisés. La log-vraisemblance
est donnée par
l0(p, q;T) = a log p+ (n− a) log(1− p) + a log q +∑
i|ri<∞
(ri − si) log(1− q).
Et son espérance conditionnelle est donnée par
Q(p′, q′, p, q) = E(l0(p
′, q′;T | z, δ; p, q))
= E(a | z, δ; p, q) log p′ − log(1− p′) + log q′+ n log(1− p′)+ E
(∑ni=1 1ri≤∞(ri − si) | z, δ; p, q
)log(1− q′),
où
E(a | z, δ; p, q) = m+n∑
i=m+1
p(1− q)t−si+1
1− p+ p(1− q)t−si+1, (3.21)
et
E( n∑i=1
1ri≤∞(ri−si) | z, δ; p, q)
=m∑i=1
(ri−si)+n∑
i=m+1
(t−si+
1− qq
) p(1− q)t−si+1
1− p+ p(1− q)t−si+1.
(3.22)
En prenant les dérivés de Q(p′, q′, p, q) par rapport à p′ et q′ égales à zéro et en résolvant
par rapport à p′ et q′, nous obtenons la relation récursive suivante pour les estimations p et
q.
pj+1 =1
n
[m+
n∑i=m+1
pj(1− qj)t−si+1
1− pj + pj(1− qj)t−si+1
],
qj+1 =m+
∑ni=m+1
pj(1−qj)t−si+1
1−pj+pj(1−qj)t−si+1
m+∑m
i=1(ri − si) +∑n
i=m+1(t− si +1−qjqj
) p(1−q)t−si+1
1−pj+pj(1−qj)t−si+1
.
L'on démontre que la suite de couples de nombres (pj, qj), pour j = 1, ... converge vers
l'estimation du maximum de vraisemblance (pMV , qMV ) de (p, q). Pour simplier les écritures,
notons p = p(t) et q = q(t) les estimations respectives du MV de p et q, obtenues pour le
temps courant t. Il vient que, pour i = 1, 2, ...
νi := νi(t) = p(1− qi−1)q. (3.23)
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

MÉTHODOLOGIE STATISTIQUE 40
Remarque. Les formules (3.20), (3.21) et (3.22) sont démontrées en Annexe A.3.
3.4.4 Prévision
Les prévisions des valeurs futures sont calculées en utilisant les estimations des paramètres
obtenues à partir de (3.23) et l'historique de l'information [32]. Notons I(t), l'information
disponible à la n du jour t, qui sera utilisée pour prédire les valeurs futures de la v.a. Y , et
par ν(t), l'estimation du jour t du vecteur ν = (ν1, ν2, ...). Posons :
• IB(t) = ν(t), xt−i, i = 1, ..., t− 1 (estimation de ν et historique de l'information du
ux de sortie GPS au niveau de la journée) ;
• IC(t) = ν(t), xt−i, yt−i, i = 1, ..., t− 1 (estimation de ν et historique de l'information
du ux de sortie et du ux de retour GPS au niveau de la journée) ;
• ID(t) = ν(t), xt−i, vt,t−i, i = 1, ..., t− 1 (estimation de ν et historique de l'information
du ux de sortie et du ux de retour au niveau du GPS).
Théorème 3.1. Sous l'hypothèse que toutes les sorties GPS de la journée sont mutuellement
indépendantes et que les retours GPS des diérentes sorties sont non corrélées, le tableau 3.1
énumère les expressions de E(Rt−i,t+h | I(t)
)sur la base de l'un des ensembles d'informations
IB(t), IC(t), ID(t).
Table 3.1 Espérance de Rt−i,t+h, le ux de retour du jour t+ h provenant des sorties du
jour t− i, pour diérents ensembles d'informations.
Ensemble
d'informations
E(Rt−i,t+h | I(t)
)i > 1 i = 1
IB(t) νh+ixt−i
IC(t) νh+ixt−i + c(i, h) νhxt
ID(t) νh+i
1−∑i
l=1 νl(xt−i − vt,t−i) νhxt
Preuve 3.1. La preuve de ce théorème peut être retrouvée dans [18].
Dans ce tableau, c(i, h) est un facteur qui tient compte de la corrélation entre les retours
GPS observés au jour i et les retours futurs. Une expression exacte de c(i, h) n'est pas
disponible en général, mais Kelle et Silver ont développé une approximation dans [18]. La
variance des retours futurs peut aussi être calculée, même si ces expressions sont un peu
plus compliquées. Le ux de retour GPS du jour t + h est tout simplement donné comme
Yt+h =∑t−1
i=−(h−1)Rt−i,t+h. Par conséquent, connaissant tout le passé, soit les observations
de 1, ..., t, le modèle à retards échelonnés prédit le ux de retour Yt+h, pour le jour t+h, par
la relation :
Yt+h = E(Rt+h−1,t+h | I(t)
)+ ...+ E
(R1,t+h | I(t)
). (3.24)
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

MÉTHODOLOGIE STATISTIQUE 41
3.5 Prévision en loi de probabilité
L'objet de cette partie est de présenter la méthode d'estimation de loi de probabilité
d'une v.a. sur laquelle on se basera pour produire des prévisions en loi de la demande
eective de GPS, en ce sens que, on utilisera plutôt la loi de probabilité estimée de la variable
pour proposer des valeurs futures.
En statistique classique, l'utilisation d'un échantillon de données pour estimer une loi de
probabilité suppose que celui-ci soit composé de valeurs indépendantes. Or, les séries chro-
nologiques ont des valeurs naturellement corrélées. De ce fait, dans le cadre de l'estimation
de loi de probabilité que nous mettrons en oeuvre dans ce mémoire, et comme cela est très
souvent fait dans la littérature académique, l'hypothèse de stationnarité et d'ergodicité d'une
série sera assimilée à l'hypothèse d'indépendance et identiquement distribué des observations
de la série.
Pour caractériser un phénomène aléatoire sous-jacent à un ensemble ni d'observations, il
est souvent pertinent d'estimer la fonction de répartition (probabilité cumulée) ou la fonction
de densité (densité de probabilité). Ces deux fonctions sont reliées par le fait que la fonction
de densité est la dérivée de la fonction de répartition. Même si les fonctions de répartition
et de densité caractérisent toutes les deux la loi de probabilité d'une v.a., la densité a un
net avantage sur le plan visuel. En fait, la forme d'une densité est beaucoup plus facile à
interpréter que celle de la fonction de répartition. Par exemple, voir la symétrie ou la mul-
timodalité de la loi d'une v.a. est beaucoup plus facile sur une fonction de densité que sur
une fonction de répartition.
On trouve dans la littérature deux types d'approches très complémentaires d'estimation
de la densité de probabilité : l'approche d'estimation paramétrique et l'approche d'estimation
non paramétrique. L'approche paramétrique suppose que les données sont issues d'une loi de
probabilité de forme connue dont seuls les paramètres sont inconnus. Si par contre, la loi de
probabilité est inconnue, ou s'il s'agit justement de trouver la forme de cette loi sans a priori
pour ensuite en réaliser une estimation paramétrique, on doit se tourner vers une méthode
non paramétrique dans laquelle les données parlent d'elles mêmes. Nous nous intéressons ici
plutôt aux approches non paramétriques. Nous présentons deux méthodes d'estimation de
la densité : la méthode d'estimation par histogramme (estimation naturelle de la densité), et
la méthode d'estimation par noyau qui peut être vue comme une extension de la méthode
d'estimation par histogramme. Les propriétés statistiques de chaque méthode d'estimation,
de même que la théorie présentée ici peuvent se retrouver dans [8].
Soit (Yt), un processus de L2(Ω,A,P), stationnaire et ergodique, indexé par N. Tout au
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

MÉTHODOLOGIE STATISTIQUE 42
long de cette section, on suppose que Y1, ..., Yn sont des variables indépendantes de même loi
(i.i.d.) de densité (cas continu) ou de masse de probabilité (cas discret) f .
Dénition 3.13. La fonction de répartition de la v.a. Y , notée F , est dénie par :
∀y ∈ R, F (y) = P(Y ≤ y),
la valeur prise par la fonction de répartition au point y est la probabilité de l'évènement
]−∞, y].
Dénition 3.14. (Densité de probabilité) Soit Y une v.a. et F sa fonction de répartition.
S'il existe une fonction f positive de l'ensemble des fonctions mesurables intégrables au sens
de Lebesgue sur R, telle que
∀y ∈ R, F (y) =
∫ y
−∞f(u)du,
alors f s'appelle la densité de probabilité de la v.a. Y. De plus, f vérie :∫ +∞
−∞f(y)dy = 1.
Lorsqu'on connait la densité de probabilité f de Y , il est possible de calculer la probabilité
d'appartenance d'une v.a. Y à n'importe quel ensemble A ⊆ R :
P(Y ∈ A) =
∫A
f(y)dy.
3.5.1 Estimation par histogramme
Sans perte de généralité, nous pouvons supposer que le support de f est inclus dans
l'intervalle [a, b[. Pour commencer, on choisit une partition uniforme C1, ..., Cm de l'intervalle
[a, b[ : Cj = [αj, αj+1[, j = 1, ...,m. Si f est supposée être continue, pour m susamment
grand, elle est bien approchée par des fonctions en escalier, constantes par morceaux sur les
intervalles Cj. On pose ` = 1/m et on approche f en tout point y ∈ [a, b[ par la fonction
f `(y) =m∑j=1
pj`1Cj
(y),
où pj =∫Cjf(y)dy. On ramène ainsi le problème d'estimation de f au problème d'estimation
d'un paramètre m-dimensionnel p = (p1, ..., pm). Ceci peut se faire en utilisant, par exemple
la méthode généralisée des moments. En eet, il est évident que
pj =
∫Cj
f(y)dy = Ef [1Cj(Y1)],∀j = 1, ...,m.
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

MÉTHODOLOGIE STATISTIQUE 43
Par conséquent, il est naturel d'estimer le vecteur p par
p = (p1, ..., pm), avec pj =1
n
n∑i=1
1Cj(Yi).
Observons au passage que chaque pj représente la proportion des observations Yi se trou-
vant dans l'intervalle Cj. Si la taille de l'échantillon est grande, il est légitime de s'attendre à
ce que cette proportion, dite empirique, converge vers la proportion théorique correspondant
à la probabilité qu'une observation tirée au hasard selon la densité f appartient à l'intervalle
Cj. Par substitution, nous dénissons l'estimateur de f par histogramme à m classes comme
suit :
f`(y) =1
`
m∑j=1
pj1Cj(y). (3.25)
On dit que chaque Cj est une classe et la longueur des classes ` est une fenêtre. Il est
aisé de remarquer que f` est une densité de probabilité.
Exemple sur des données simulées. A titre d'exemple, considérons un échantillon de
d'observations de taille n = 400 simulé selon la loi N (0, 1). Nous avons tracé dans la gure
3.1 ci-dessous les histogrammes des données simulées basées sur 10, 110 et 250 classes et
nous y avons superposé la courbe de la loi gaussienne. On constate que ces trois graphiques
présentent des diérences très importantes. Plus précisément, le graphe qui correspond à
m = 10 est bien plus régulier que les deux autres. Dans la terminologie statistique, on dit que
l'histogramme de gauche est trop lissé (en anglais oversmoothing) alors que l'histogramme
de droite n'est pas lissé susamment (undersmoothing). Un problème crucial du point de
vue des applications est donc de trouver la fenêtre ` qui correspond au lissage optimal.
L'une des méthodes les plus utilisées fournissant une fenêtre proche de l'optimale est
la méthode de validation croisée. La dénition précise de cette méthode sera donnée dans
la suite. Notons simplement qu'elle consiste à dénir une fonction J de ` (ou, de façon
équivalente, de m) qui est une estimation du risque de l'estimateur f`. Naturellement, la
valeur de ` est choisie en minimisant ce risque estimé.
Risque de l'estimateur par histogramme. Comme on a constaté sur l'exemple des
données simulées, la qualité de l'estimateur par histogramme dépend fortement de la fenêtre
`. An de quantier cette dépendance, nous introduisons le risque quadratique de f` au point
y ∈ [a, b[ comme étant la moyenne de l'erreur quadratique :
MSEf (y, `) = Ef[(f`(y)− f(y)
)2],
où l'abréviation MSE correspond à Mean Squared Error.
An d'avoir une évaluation globale valable pour tout point y ∈ [a, b[, on considère le risque
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014
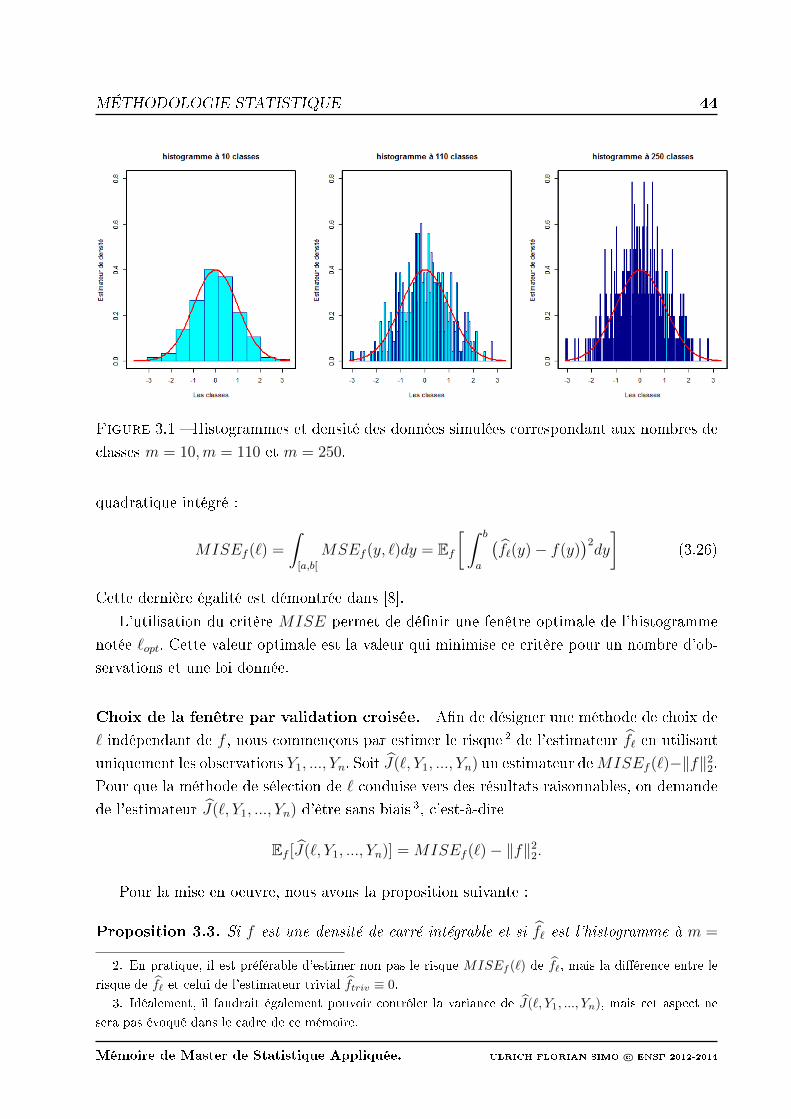
MÉTHODOLOGIE STATISTIQUE 44
Figure 3.1 Histogrammes et densité des données simulées correspondant aux nombres de
classes m = 10,m = 110 et m = 250.
quadratique intégré :
MISEf (`) =
∫[a,b[
MSEf (y, `)dy = Ef[ ∫ b
a
(f`(y)− f(y)
)2dy
](3.26)
Cette dernière égalité est démontrée dans [8].
L'utilisation du critère MISE permet de dénir une fenêtre optimale de l'histogramme
notée `opt. Cette valeur optimale est la valeur qui minimise ce critère pour un nombre d'ob-
servations et une loi donnée.
Choix de la fenêtre par validation croisée. An de désigner une méthode de choix de
` indépendant de f , nous commençons par estimer le risque 2 de l'estimateur f` en utilisant
uniquement les observations Y1, ..., Yn. Soit J(`, Y1, ..., Yn) un estimateur deMISEf (`)−‖f‖22.Pour que la méthode de sélection de ` conduise vers des résultats raisonnables, on demande
de l'estimateur J(`, Y1, ..., Yn) d'être sans biais 3, c'est-à-dire
Ef [J(`, Y1, ..., Yn)] = MISEf (`)− ‖f‖22.
Pour la mise en oeuvre, nous avons la proposition suivante :
Proposition 3.3. Si f est une densité de carré intégrable et si f` est l'histogramme à m =
2. En pratique, il est préférable d'estimer non pas le risque MISEf (`) de f`, mais la diérence entre le
risque de f` et celui de l'estimateur trivial ftriv ≡ 0.
3. Idéalement, il faudrait également pouvoir contrôler la variance de J(`, Y1, ..., Yn), mais cet aspect ne
sera pas évoqué dans le cadre de ce mémoire.
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

MÉTHODOLOGIE STATISTIQUE 45
1/` classes basé sur l'échantillon Y1, ..., Yn ayant f pour densité de probabilité, alors
J(`, Y1, ..., Yn) =2
(n− 1)`− n+ 1
(n− 1)`
m∑j=1
p2j (3.27)
est un estimateur sans biais de MISEf (`)− ‖f‖22.
Nous pouvons à présent énoncer la méthode de validation croisée basée sur la relation
(3.27). Nous allons le faire en posant a = mini Yi et b = maxi Yi et pour tout m ∈ N choisir la
fenêtre ` = (b−a)/m. On dénit alors les classes Cj = [a+(j−1)`, a+j`[ pour j = 1, ...,m−1
et Cm = [b− `, b].
Algorithme de validation croisée pour choisir la fenêtre d'un histogramme.
Entrée : Y1, ..., Yn ;
Sortie : V C ;Dénir a← mini Yi
b← maxi Yi
Initialiser
m← 1
mV C ← 1
JV C ← −1
Tant que (m < n) faire
J ← 2m
n− 1− (n+ 1)m
n− 1
m∑j=1
( 1
n
n∑i=1
1Cj(Yi)
)2Si (J < JV C) alors
mV C ← m
JV C ← J
FinSi
m← m+ 1
Fin Tant queV C ← (b− a)/mV C
Source [8]
Une fois la fenêtre V C déterminée, nous pouvons calculer et tracer la courbe de l'histo-
gramme ayant comme fenêtre V C .Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

MÉTHODOLOGIE STATISTIQUE 46
3.5.2 Estimateur à noyau continu
L'estimation de la densité par histogramme est une méthode naturelle très répandue car
elle est facilement implémentable. Cependant, les histogrammes sont des fonctions qui ne
sont même pas continues. Il est naturel alors de vouloir lisser les histogrammes. On
s'attend alors à ce que le résultat du lissage améliore non seulement l'aspect visuel de l'esti-
mateur, mais produise de plus un estimateur plus proche de la vraie densité que l'estimateur
par histogramme.
L'estimateur simple de densité, appelé aussi la méthode d'estimation par les histo-
grammes mobiles, en un point y ∈ R, consiste à construire autour de y un intervalle (ou
fenêtre) de largeur ` ([y − `2, y + `
2]) et à compter le nombre d'observations dans cet inter-
valle. Partons du lien existant entre la densité de probabilité f et la fonction de répartition
F :
∀y ∈ R, F (y) =
∫ y
−∞f(u)du,
on peut écrire
f(y) = lim`→0
P(y − `2≤ yi ≤ y + `
2)
`
= lim`→0
F (y + `2)− F (y − `
2)
`.
L'estimateur simple de f , notée f`, peut alors être déni, pour tout y ∈ R par :
f`(y) =1
`
Cardi : y − `2≤ yi ≤ y + `
2
n
=1
n`
n∑i=1
1[y− `2,y+ `
2](yi)
=1
n`
n∑i=1
1[− 12, 12]
(y − yi`
). (3.28)
La relation (3.28) peut aussi s'écrire
f`(y) =1
n`
n∑i=1
$(y − yi
`
), (3.29)
où $ est une fonction de poids qui n'est autre que la densité de probabilité uniforme sur
l'intervalle [−12, 12].
L'estimateur simple de la densité donné par (3.29) peut être généralisé en remplaçant la
fonction de poids $ par une fonction de poids plus générale, notée K (qui est une densité
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

MÉTHODOLOGIE STATISTIQUE 47
de probabilité quelconque). On obtient l'estimateur
f`(y) =1
n`
n∑i=1
K(y − Yi
`
),
qui est continu et même d-fois continûment diérentiable du moment où la fonction K l'est.
On arrive nalement à la dénition suivante.
Dénition 3.15. Soit K : R −→ R une fonction quelconque et soit ` un réel positif. On
appelle estimateur à noyau la fonction
f`(y) =1
n`
n∑i=1
K(y − Yi
`
). (3.30)
On dit alors que K est le noyau de cet estimateur et ` la fenêtre ou constante de lissage.
Selon cette dénition, toute fonction K peut servir comme noyau d'estimation d'une
densité f . Les noyaux les plus couramment utilisés en pratique sont
le noyau rectangulaire :
K(u) =1
21[−1,1](u);
le noyau triangulaire :
K(u) = (1− |u|)1[−1,1](u);
le noyau d'Epanechnikov :
K(u) =3
4(1− u2)1[−1,1](u);
le noyau gaussien :
K(u) =1√2π
exp(−u2
2).
Lorsqu'on dénit un estimateur à noyau, on a non seulement le choix de la fenêtre ` > 0
mais aussi celui du noyau K. Le choix du noyau n'a pas d'impact très signicatif sur la
qualité d'estimation, dans le sens où si la fenêtre est bien choisie, les diérents noyaux précités
produisent des estimateurs de qualités comparables. Par contre, le choix de ` dépend de n
et de l'échantillon.
Validation croisée. Pour désigner une méthode automatique pour le choix de la fenêtre
`, on utilise souvent la méthode de la validation croisée. Il s'agit de proposer dans un premier
temps (pour un ` xé) un estimateur J(`) sans biais de la quantité J(`) = MISE(f`)−‖f‖22et, dans un deuxième temps, de minimiser cet estimateur J(`) dans un ensemble ni de
candidats pour `. Dans [8], on trouve que
J(`) =2
n(n− 1)`
n∑i=1
n∑j=1,j 6=i
K(Yi − Yj
`
)− ‖f‖22. (3.31)
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

MÉTHODOLOGIE STATISTIQUE 48
Il sut alors de minimiser cette fonction et on obtient
opt = arg min
`>0
(J(`)
). (3.32)
3.5.3 Cas de la prévision en loi de la demande GPS
On considère la v.a. De,t suivant la loi L de paramètre γt, on note De,t ∼ L(γt) (loi de
probabilité dynamique). Une manière de prévoir les réalisations futures de la demande D est
d'utiliser cette loi de probabilité.
Mise en oeuvre. Pour mettre en oeuvre cette approche prévisionnelle, il nous semble ju-
dicieux d'utiliser par exemple un pas de temps mensuel, c'est-à-dire, pour une année donnée,
nous supposons connue L(γt), t = 1, 2, ..., 12. On se place à la n d'un instant (mois) t. On
peut alors prévoir de manière ad hoc la demande GPS de l'instant suivant par la relation
suivante (déduite de l'équation (2.1), cf. chapitre 2) :
Dt+1 = Dr,t + E(De,t+1). (3.33)
En pratique, si on est à la n du mois t et qu'on connait Dr,t, prédire Dt+1 revient
tout simplement à calculer E(De,t+1), ce qui revient à trouver L(γt), soit tout simplement à
estimer γt. Par ailleurs, comme pour toute méthode de prévision, nous dénissons aussi un
intervalle de prévision It,1(α) de niveau 1− α pour Dt+1, donné par la relation suivante :
It,1(α) = [Quα/2, Qu1−α/2], (3.34)
où Quα/2 et Qu1−α/2 sont respectivement le quantile d'ordre α/2 et 1−α/2 de la distribution
des observations de la v.a. De,t, auxquelles nous ajoutons Dr,t (supposée connue).
Remarque. Dans le cadre de ce mémoire, nous prendrons un pas de temps journalier
pour les observations de la demande eective de GPS et, nous travaillerons avec
une loi de probabilité statique. Autrement dit, il s'agira non plus d'estimer estimer γt,
pour t = 1, ..., 12, mais uniquement γ ∈ R2+.
3.6 Mesure de la qualité de la prévision
La performance des prévisions dépend de l'importance des erreurs de prévision. Ainsi, on
va comparer les prévisions avec les valeurs réellement observées. Il existe diérentes mesures
de performance prévisionnelle, ou plus exactement, de la grandeur des erreurs de prévision.
Avant de les présenter, il y a lieu d'abord d'étudier les sources potentielles d'erreurs de
prévision. En eet, les erreurs de prévision peuvent provenir de diverses sources [14] :
les modèles utilisés ;
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

MÉTHODOLOGIE STATISTIQUE 49
les données (indisponibilité, collecte, période d'échantillon choisie pour estimer le mo-
dèle) ;
l'interaction entre les modèles et les données ;
les chocs ne pouvant pas être anticipés.
An d'examiner et de comparer la précision des diérentes méthodes de prévision consi-
dérées, il est nécessaire de choisir une mesure particulière de précision ou de performance pré-
visionnelle. La mesure la plus fréquemment utilisée en pratique est l'erreur absolue moyenne
en pourcentage (MAPE : Mean Absolute Percentage Error) [14]. D'autres mesures d'erreurs
de prévision comportent laMAE, laMSPE et la RMSPE. Cependant, puisque ces critères
sont moins utilisés comparés à la MAPE, nous avons choisi, dans cette étude, d'évaluer la
précision des résultats prédictifs des diérents modèles selon laMAPE, qui se calcule comme
suit.
Pratiquement, on divise l'intervalle de temps en deux parties dans l'ordre chronologique :
la première détermine les données servant à la modélisation et la seconde utilisée comme zone
de test. On tronque alors la série de hmax observations, i.e. n − hmax observations pour la
modélisation, et on compare les prévisions obtenues avec les réalisations sur les hmax valeurs
restantes. La MAPE se calcule donc comme suit :
MAPE =1
hmax
n∑t=n−hmax+1
| Yt − Yt || Yt |
. (3.35)
La meilleure méthode de prévision correspond à la MAPE la plus faible.
Prévision du moment de rupture. Nous introduisons dans le contexte d'étude de ce
mémoire, un critère de choix de modèle de prévision en loi , dénommé jour GPS de rupture.
Nous donnons d'abord quelques dénitions avant d'expliciter ce critère.
on dira qu'il y a rupture de stock GPS le jour t si Vt, le ux de sortie enregistré, est
strictement inférieur à Dt, la demande totale enregistrée ;
sur une période de hmax jours, on pourra donc calculer le nombre de jours où il y a eu
rupture de stock GPS. En posant NJR cette v.a., on aura :
NJR =hmax∑h=1
1Dh>Vh. (3.36)
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

MÉTHODOLOGIE STATISTIQUE 50
En pratique, il ne sut pas de prédire le moment de rupture. En réalité, le fait de
savoir que l'évènement rupture de stock GPS aura lieu est une chose. Mais, connaître
eectivement l'impact de la rupture en est une autre 4. Raison pour laquelle, le principal
indicateur de la mesure réelle de l'ampleur de la rupture est le critère jour GPS de rupture,
que nous notons JRGPS, et il est déni par la somme des quantités manquantes lorsque
l'évènement rupture de stock GPS a lieu, c'est-à-dire :
JRGPS =hmax∑h=1
(Dh − Vh)1Dh>Vh. (3.37)
La meilleure méthode de prévision en loi de probabilité est celle dont le critère JRGPS
se rapproche le plus de la réalité.
Résumé du chapitre
En résumé, ce chapitre se voulait essentiellement une introduction sur la théorie des
séries chronologiques et quelques uns de ses modèles. À cet eet, les caractéristiques et les
principales méthodes de prévision quantitatives utilisées en pratique ont été abordées, à
savoir la méthode du lissage exponentiel de Holt-Winters, la méthode de Box et Jenkins
avec leur modèle ARIMA saisonnier, la méthode à retards échelonnés et une méthode de
prévision en loi de probabilité. Toutes ces approches sont employées pour faire les prévisions
des séries chronologiques de la demande eective et du ux de retour GPS. Nous le faisons
dans le chapitre suivant.
4. A la douane, on explique d'ailleurs que, être en rupture d'un GPS n'a pas le même impact que d'être
en rupture de 20 GPS par exemple.
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

APPLICATIONS AUX DONNÉES ET RÉSULTATS 51
Chapitre Quatre
Applications aux Données et
Résultats
Ce chapitre est dédié à l'application des modèles de prévision précédemment présentés,
application qui servira à produire, comme résultats, les valeurs futures de la demande eective
et du ux de retour GPS. La mise en oeuvre et l'estimation des paramètres des modèles sont
basées sur des échantillons de données. Nous aborderons à la section 4.1, la modélisation et
la prévision de la demande eective. Ensuite, la section 4.2 portera sur la modélisation et la
prévision du ux de retour.
4.1 Modélisation et prévision de la demande eective
Le but de cette section est de construire des modèles basés sur l'échantillon de données
de la demande eective de GPS, pour prédire les valeurs futures. Pour ce faire, que ce soit le
modèle de lissage exponentiel de Holt-Winters, le modèle de Box et Jenkins ou la méthode
de prévision en loi de probabilité, nous commencerons par une phase de vérication des dif-
férentes hypothèses sous-jacentes à l'applicabilité des méthodes. Tout d'abord, représentons
à nouveau le chronogramme pour cette série de la demande eective (gure 4.1). Nous consi-
dérons tout au long de cette section, sauf mention contraire, le logarithme des observations
de la demande eective de GPS. On travaillera donc avec la série transformée. Ainsi,
quand nous parlerons de série journalière de la demande eective, il s'agira de
la série journalière transformée.
4.1.1 Application de la méthode du lissage exponentiel Holt-Winters
La gure 4.1 montre bien que la série admet une tendance locale non nulle. L'aspect
saisonnier par contre, ne peut pas être analysé du fait de la taille d'échantillon. De ce fait,
un quelconque schéma de décomposition additif ou multiplicatif n'est pas envisageable dans
le choix de la valeur du paramètre seasonal de la fonction HoltWinters() du logiciel R. En n
de compte, nous retenons la version non saisonnière du lissage de H-W présenté à la section
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014
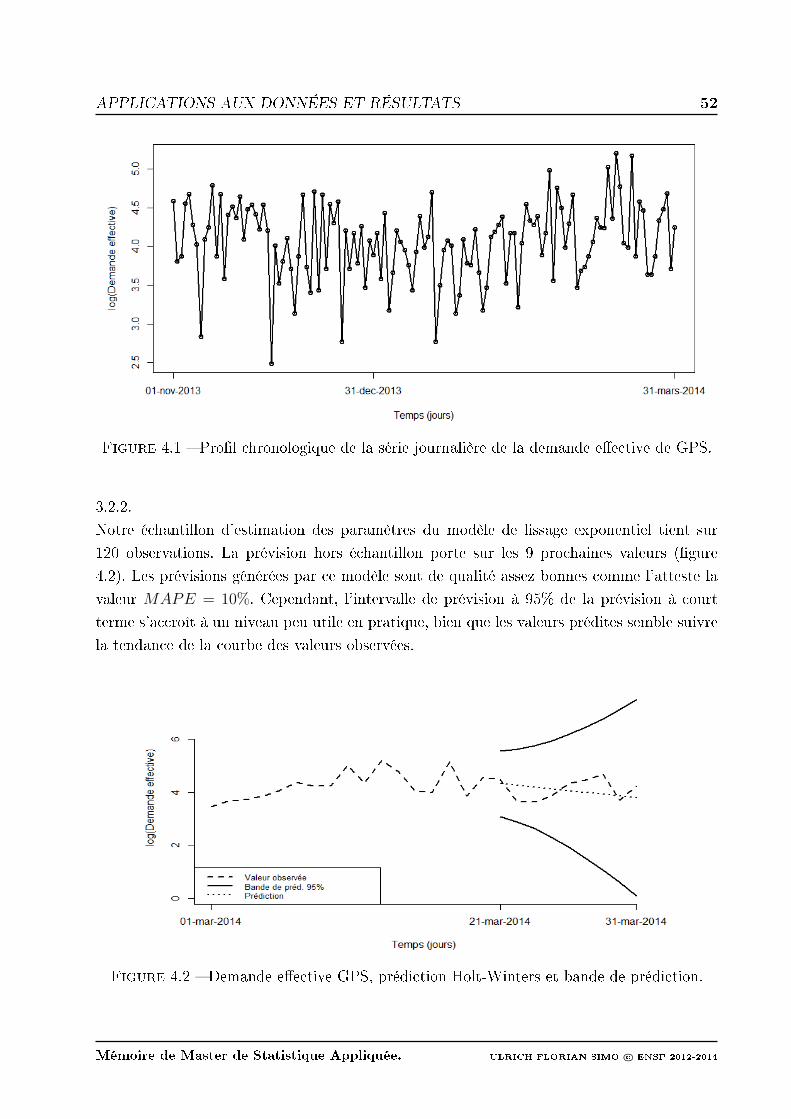
APPLICATIONS AUX DONNÉES ET RÉSULTATS 52
Figure 4.1 Prol chronologique de la série journalière de la demande eective de GPS.
3.2.2.
Notre échantillon d'estimation des paramètres du modèle de lissage exponentiel tient sur
120 observations. La prévision hors échantillon porte sur les 9 prochaines valeurs (gure
4.2). Les prévisions générées par ce modèle sont de qualité assez bonnes comme l'atteste la
valeur MAPE = 10%. Cependant, l'intervalle de prévision à 95% de la prévision à court
terme s'accroît à un niveau peu utile en pratique, bien que les valeurs prédites semble suivre
la tendance de la courbe des valeurs observées.
Figure 4.2 Demande eective GPS, prédiction Holt-Winters et bande de prédiction.
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014
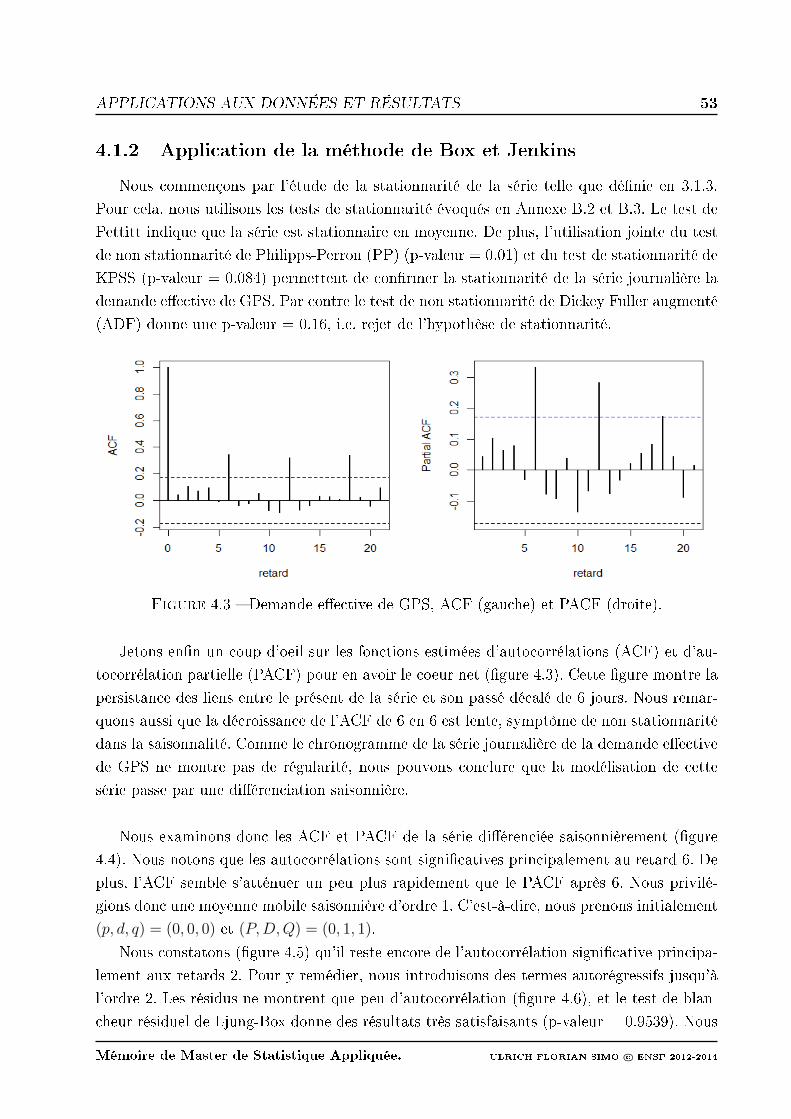
APPLICATIONS AUX DONNÉES ET RÉSULTATS 53
4.1.2 Application de la méthode de Box et Jenkins
Nous commençons par l'étude de la stationnarité de la série telle que dénie en 3.1.3.
Pour cela, nous utilisons les tests de stationnarité évoqués en Annexe B.2 et B.3. Le test de
Pettitt indique que la série est stationnaire en moyenne. De plus, l'utilisation jointe du test
de non stationnarité de Philipps-Perron (PP) (p-valeur = 0.01) et du test de stationnarité de
KPSS (p-valeur = 0.084) permettent de conrmer la stationnarité de la série journalière la
demande eective de GPS. Par contre le test de non stationnarité de Dickey Fuller augmenté
(ADF) donne une p-valeur = 0.16, i.e. rejet de l'hypothèse de stationnarité.
Figure 4.3 Demande eective de GPS, ACF (gauche) et PACF (droite).
Jetons enn un coup d'oeil sur les fonctions estimées d'autocorrélations (ACF) et d'au-
tocorrélation partielle (PACF) pour en avoir le coeur net (gure 4.3). Cette gure montre la
persistance des liens entre le présent de la série et son passé décalé de 6 jours. Nous remar-
quons aussi que la décroissance de l'ACF de 6 en 6 est lente, symptôme de non stationnarité
dans la saisonnalité. Comme le chronogramme de la série journalière de la demande eective
de GPS ne montre pas de régularité, nous pouvons conclure que la modélisation de cette
série passe par une diérenciation saisonnière.
Nous examinons donc les ACF et PACF de la série diérenciée saisonnièrement (gure
4.4). Nous notons que les autocorrélations sont signicatives principalement au retard 6. De
plus, l'ACF semble s'atténuer un peu plus rapidement que le PACF après 6. Nous privilé-
gions donc une moyenne mobile saisonnière d'ordre 1. C'est-à-dire, nous prenons initialement
(p, d, q) = (0, 0, 0) et (P,D,Q) = (0, 1, 1).
Nous constatons (gure 4.5) qu'il reste encore de l'autocorrélation signicative principa-
lement aux retards 2. Pour y remédier, nous introduisons des termes autorégressifs jusqu'à
l'ordre 2. Les résidus ne montrent que peu d'autocorrélation (gure 4.6), et le test de blan-
cheur résiduel de Ljung-Box donne des résultats très satisfaisants (p-valeur = 0.9539). Nous
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014
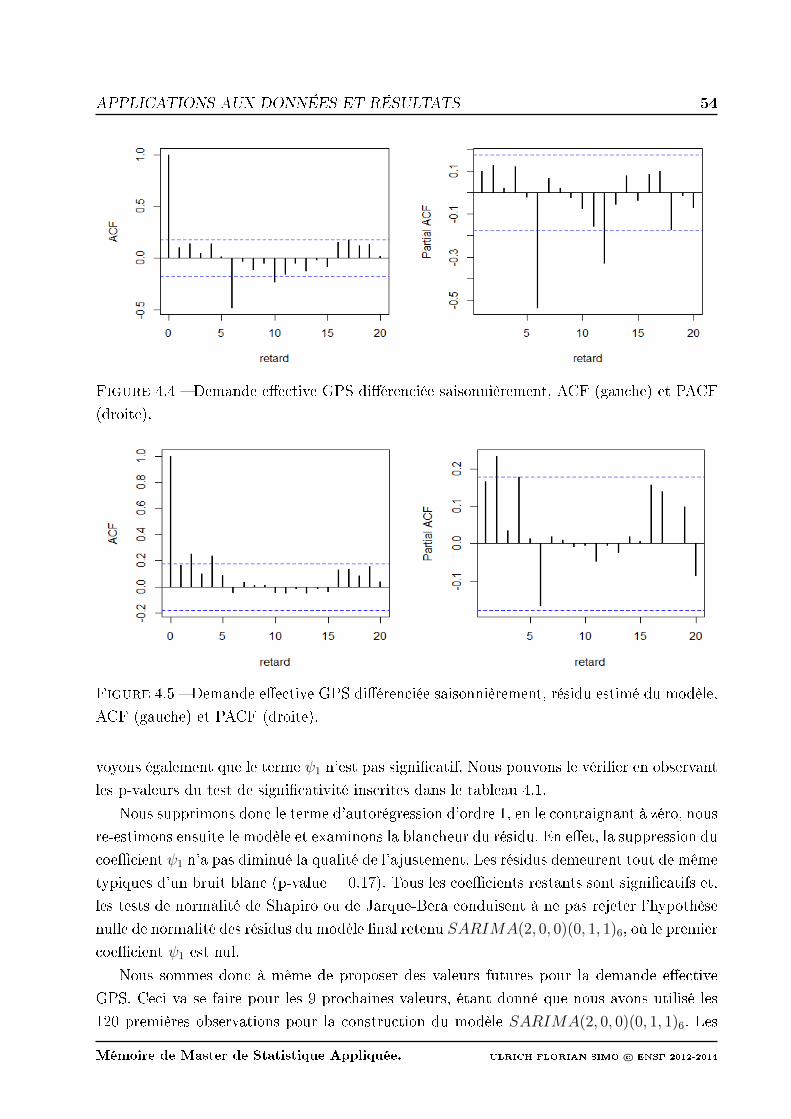
APPLICATIONS AUX DONNÉES ET RÉSULTATS 54
Figure 4.4 Demande eective GPS diérenciée saisonnièrement, ACF (gauche) et PACF
(droite).
Figure 4.5 Demande eective GPS diérenciée saisonnièrement, résidu estimé du modèle,
ACF (gauche) et PACF (droite).
voyons également que le terme ψ1 n'est pas signicatif. Nous pouvons le vérier en observant
les p-valeurs du test de signicativité inscrites dans le tableau 4.1.
Nous supprimons donc le terme d'autorégression d'ordre 1, en le contraignant à zéro, nous
re-estimons ensuite le modèle et examinons la blancheur du résidu. En eet, la suppression du
coecient ψ1 n'a pas diminué la qualité de l'ajustement. Les résidus demeurent tout de même
typiques d'un bruit blanc (p-value = 0.17). Tous les coecients restants sont signicatifs et,
les tests de normalité de Shapiro ou de Jarque-Bera conduisent à ne pas rejeter l'hypothèse
nulle de normalité des résidus du modèle nal retenu SARIMA(2, 0, 0)(0, 1, 1)6, où le premier
coecient ψ1 est nul.
Nous sommes donc à même de proposer des valeurs futures pour la demande eective
GPS. Ceci va se faire pour les 9 prochaines valeurs, étant donné que nous avons utilisé les
120 premières observations pour la construction du modèle SARIMA(2, 0, 0)(0, 1, 1)6. Les
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014
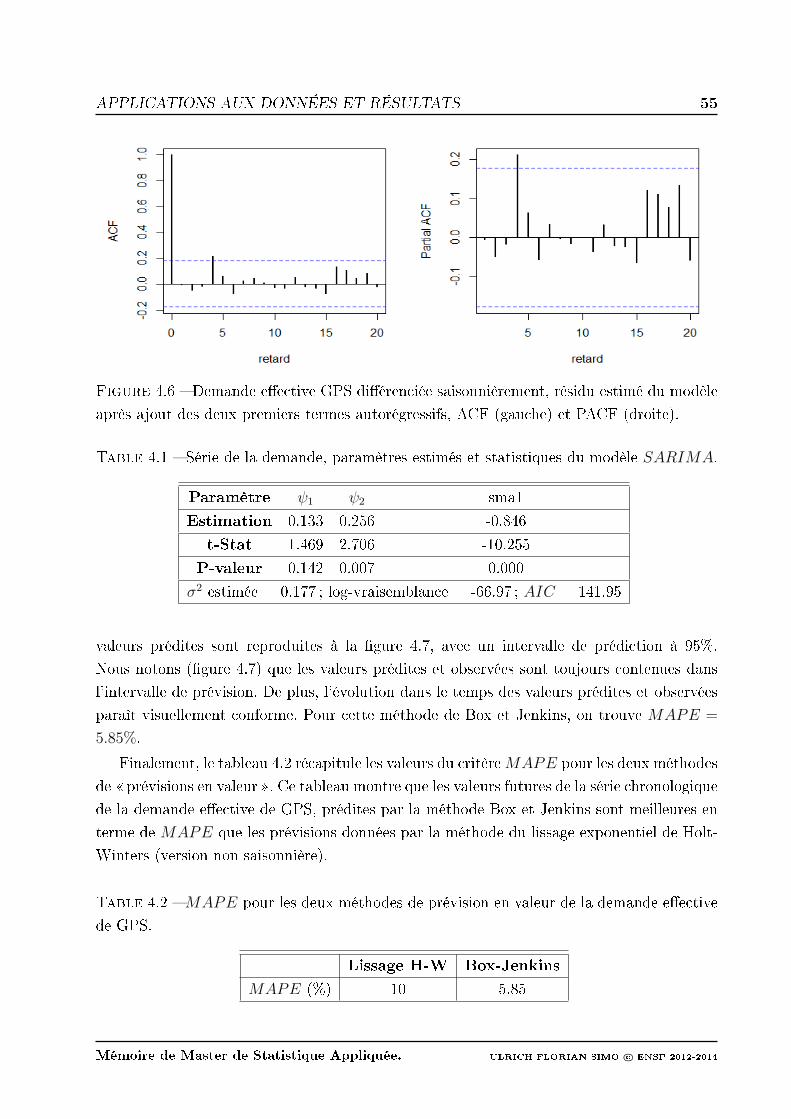
APPLICATIONS AUX DONNÉES ET RÉSULTATS 55
Figure 4.6 Demande eective GPS diérenciée saisonnièrement, résidu estimé du modèle
après ajout des deux premiers termes autorégressifs, ACF (gauche) et PACF (droite).
Table 4.1 Série de la demande, paramètres estimés et statistiques du modèle SARIMA.
Paramètre ψ1 ψ2 sma1
Estimation 0.133 0.256 -0.846
t-Stat 1.469 2.706 -10.255
P-valeur 0.142 0.007 0.000
σ2 estimée = 0.177 ; log-vraisemblance = -66.97 ; AIC = 141.95
valeurs prédites sont reproduites à la gure 4.7, avec un intervalle de prédiction à 95%.
Nous notons (gure 4.7) que les valeurs prédites et observées sont toujours contenues dans
l'intervalle de prévision. De plus, l'évolution dans le temps des valeurs prédites et observées
paraît visuellement conforme. Pour cette méthode de Box et Jenkins, on trouve MAPE =
5.85%.
Finalement, le tableau 4.2 récapitule les valeurs du critèreMAPE pour les deux méthodes
de prévisions en valeur . Ce tableau montre que les valeurs futures de la série chronologique
de la demande eective de GPS, prédites par la méthode Box et Jenkins sont meilleures en
terme de MAPE que les prévisions données par la méthode du lissage exponentiel de Holt-
Winters (version non saisonnière).
Table 4.2 MAPE pour les deux méthodes de prévision en valeur de la demande eective
de GPS.
Lissage H-W Box-Jenkins
MAPE (%) 10 5.85
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014
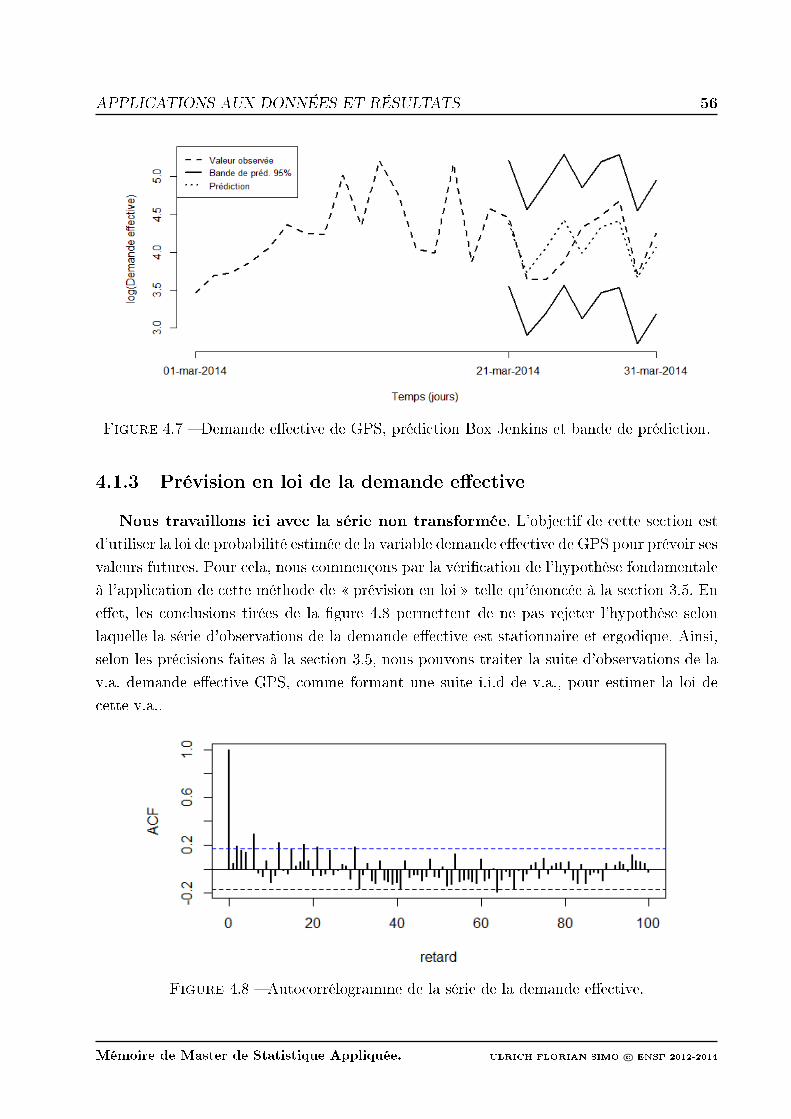
APPLICATIONS AUX DONNÉES ET RÉSULTATS 56
Figure 4.7 Demande eective de GPS, prédiction Box Jenkins et bande de prédiction.
4.1.3 Prévision en loi de la demande eective
Nous travaillons ici avec la série non transformée. L'objectif de cette section est
d'utiliser la loi de probabilité estimée de la variable demande eective de GPS pour prévoir ses
valeurs futures. Pour cela, nous commençons par la vérication de l'hypothèse fondamentale
à l'application de cette méthode de prévision en loi telle qu'énoncée à la section 3.5. En
eet, les conclusions tirées de la gure 4.8 permettent de ne pas rejeter l'hypothèse selon
laquelle la série d'observations de la demande eective est stationnaire et ergodique. Ainsi,
selon les précisions faites à la section 3.5, nous pouvons traiter la suite d'observations de la
v.a. demande eective GPS, comme formant une suite i.i.d de v.a., pour estimer la loi de
cette v.a..
Figure 4.8 Autocorrélogramme de la série de la demande eective.
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

APPLICATIONS AUX DONNÉES ET RÉSULTATS 57
Cas où la demande est une variable continue
L'hypothèse de continuité est très souvent en relation avec une approximation de la réa-
lité. En considérant la variable demande eective de GPS comme continue, nous écartons
immédiatement un nombre conséquent de lois candidates pour la modélisation telles que les
lois discrètes. Ajoutons que, dans notre contexte, la modélisation de la demande par une loi
normale pose un problème (au moins sur le plan théorique) car une variable normale, quelles
que soient les valeurs de ses paramètres, a une probabilité non nulle de prendre des valeurs
négatives. Nous ferons l'estimation de loi selon deux approches telles que spéciées dans le
chapitre précédent.
a. Ajustement paramétrique de la loi à l'histogramme optimal
∗ Partant de notre échantillon de données d'apprentissage de taille n = 120, nous esti-
mons d'abord le nombre de classes optimale mV C par validation croisée. Nous nous servons
pour cela de la fonction VC_hist() et, on trouve mV C = 7. Ceci nous permet de représenter
l'histogramme à 7 classes pour ce jeu de données.
∗ Il s'agit désormais de trouver parmi la famille restreinte de densités standard (loi
gamma, loi log-normale, loi de Weibull, loi de Pareto, loi exponentielle négative, etc.) celle
dont la courbe de la densité estimée s'approche le mieux de cet histogramme. Après quelques
tâtonnements et éliminations, deux lois de probabilité ressortent comme potentiellement can-
didates pour la modélisation stochastique de la demande eective de GPS. Il s'agit de la loi
gamma et de la loi log-normale.
∗ En utilisant la p-valeur du test de Kolmogorov (p-valeur loi gamma = 0.9957, p-valeur
loi log-normale = 0.9218), il vient que la loi gamma de paramètre estimé γ = (4.269, 0.066)
est celle qui ajuste le mieux l'échantillon d'apprentissage. La gure 4.9 (à gauche) fait une
illustration graphique de cet ajustement, où nous superposons sur l'histogramme la courbe
de la densité estimée. Bien que bon nombre de revues scientiques font état d'une distribu-
tion normale pour la demande d'articles, ce résultat reste toutefois conforme à ceux obtenus
dans [13,30].
b. Ajustement paramétrique de la loi à l'estimateur du noyau optimal
De même, par la méthode du noyau, on se sert de la fonction VC_kern() pour obteniropt = 10.707. On reproduit également (gure 4.9, droite), l'ajustement de la densité de la loi
gamma estimée, de paramètre estimé γ = (4.269, 0.066) (qui s'est avérée la plus appropriée
suivant la p-valeur du test de Kolmogorov) et la fonction de densité estimée par la méthode
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014
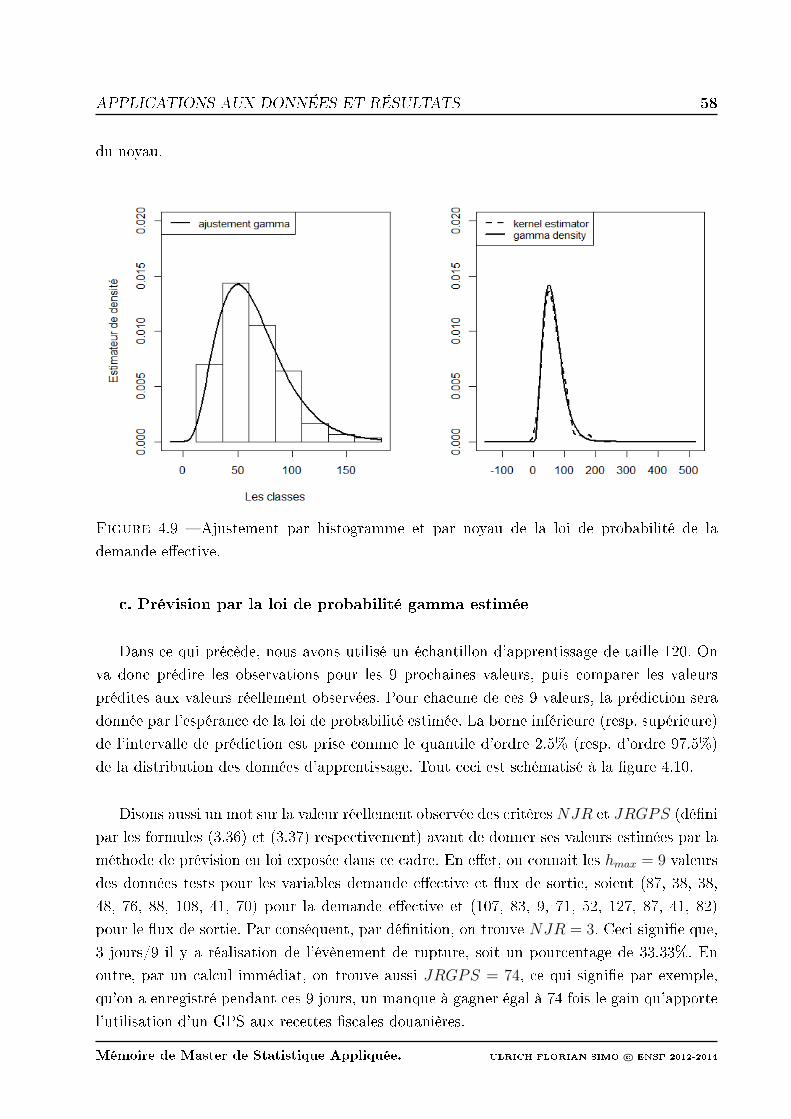
APPLICATIONS AUX DONNÉES ET RÉSULTATS 58
du noyau.
Figure 4.9 Ajustement par histogramme et par noyau de la loi de probabilité de la
demande eective.
c. Prévision par la loi de probabilité gamma estimée
Dans ce qui précède, nous avons utilisé un échantillon d'apprentissage de taille 120. On
va donc prédire les observations pour les 9 prochaines valeurs, puis comparer les valeurs
prédites aux valeurs réellement observées. Pour chacune de ces 9 valeurs, la prédiction sera
donnée par l'espérance de la loi de probabilité estimée. La borne inférieure (resp. supérieure)
de l'intervalle de prédiction est prise comme le quantile d'ordre 2.5% (resp. d'ordre 97.5%)
de la distribution des données d'apprentissage. Tout ceci est schématisé à la gure 4.10.
Disons aussi un mot sur la valeur réellement observée des critères NJR et JRGPS (déni
par les formules (3.36) et (3.37) respectivement) avant de donner ses valeurs estimées par la
méthode de prévision en loi exposée dans ce cadre. En eet, on connait les hmax = 9 valeurs
des données tests pour les variables demande eective et ux de sortie, soient (87, 38, 38,
48, 76, 88, 108, 41, 70) pour la demande eective et (107, 83, 9, 71, 52, 127, 87, 41, 82)
pour le ux de sortie. Par conséquent, par dénition, on trouve NJR = 3. Ceci signie que,
3 jours/9 il y a réalisation de l'évènement de rupture, soit un pourcentage de 33.33%. En
outre, par un calcul immédiat, on trouve aussi JRGPS = 74, ce qui signie par exemple,
qu'on a enregistré pendant ces 9 jours, un manque à gagner égal à 74 fois le gain qu'apporte
l'utilisation d'un GPS aux recettes scales douanières.
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014
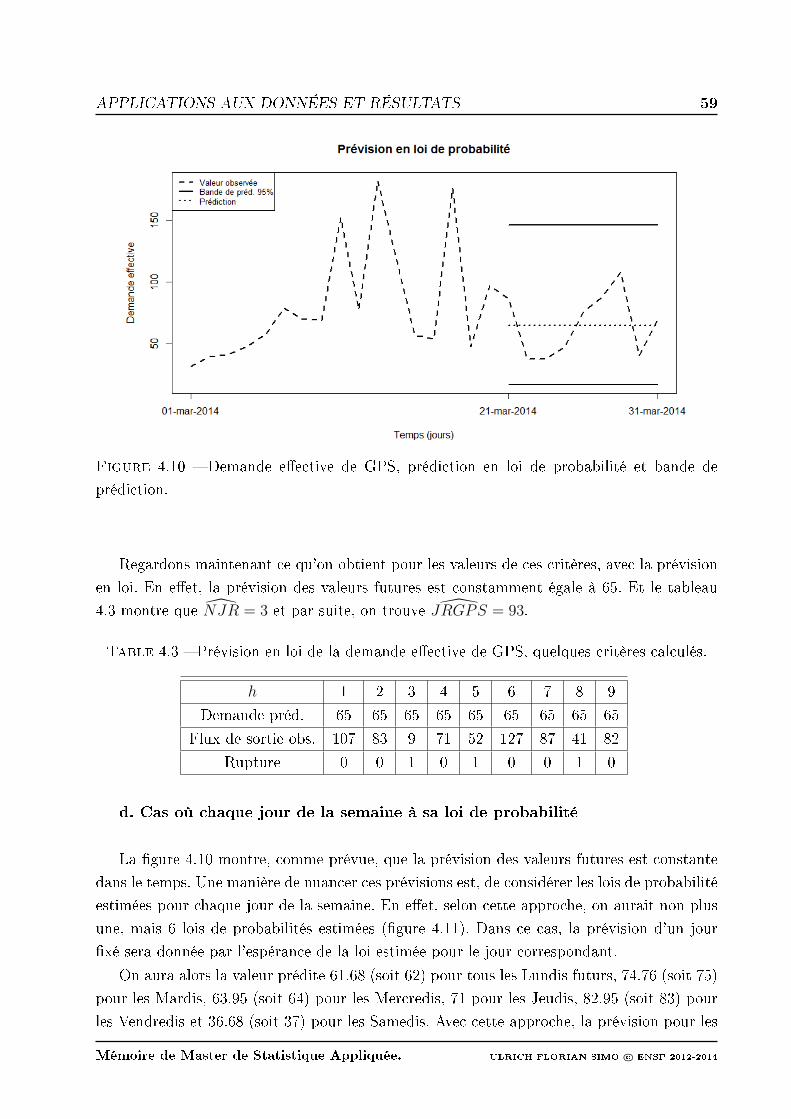
APPLICATIONS AUX DONNÉES ET RÉSULTATS 59
Figure 4.10 Demande eective de GPS, prédiction en loi de probabilité et bande de
prédiction.
Regardons maintenant ce qu'on obtient pour les valeurs de ces critères, avec la prévision
en loi. En eet, la prévision des valeurs futures est constamment égale à 65. Et le tableau
4.3 montre que NJR = 3 et par suite, on trouve JRGPS = 93.
Table 4.3 Prévision en loi de la demande eective de GPS, quelques critères calculés.
h 1 2 3 4 5 6 7 8 9
Demande préd. 65 65 65 65 65 65 65 65 65
Flux de sortie obs. 107 83 9 71 52 127 87 41 82
Rupture 0 0 1 0 1 0 0 1 0
d. Cas où chaque jour de la semaine à sa loi de probabilité
La gure 4.10 montre, comme prévue, que la prévision des valeurs futures est constante
dans le temps. Une manière de nuancer ces prévisions est, de considérer les lois de probabilité
estimées pour chaque jour de la semaine. En eet, selon cette approche, on aurait non plus
une, mais 6 lois de probabilités estimées (gure 4.11). Dans ce cas, la prévision d'un jour
xé sera donnée par l'espérance de la loi estimée pour le jour correspondant.
On aura alors la valeur prédite 61.68 (soit 62) pour tous les Lundis futurs, 74.76 (soit 75)
pour les Mardis, 63.95 (soit 64) pour les Mercredis, 71 pour les Jeudis, 82.95 (soit 83) pour
les Vendredis et 36.68 (soit 37) pour les Samedis. Avec cette approche, la prévision pour les
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014
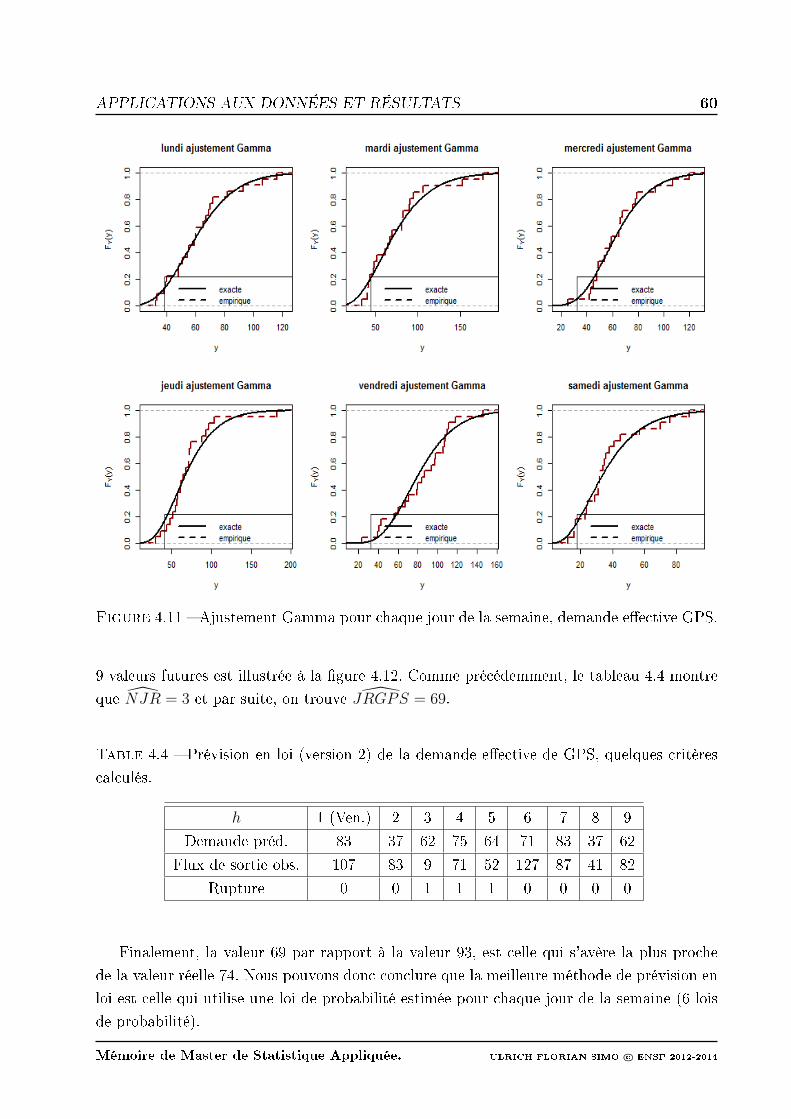
APPLICATIONS AUX DONNÉES ET RÉSULTATS 60
Figure 4.11 Ajustement Gamma pour chaque jour de la semaine, demande eective GPS.
9 valeurs futures est illustrée à la gure 4.12. Comme précédemment, le tableau 4.4 montre
que NJR = 3 et par suite, on trouve JRGPS = 69.
Table 4.4 Prévision en loi (version 2) de la demande eective de GPS, quelques critères
calculés.
h 1 (Ven.) 2 3 4 5 6 7 8 9
Demande préd. 83 37 62 75 64 71 83 37 62
Flux de sortie obs. 107 83 9 71 52 127 87 41 82
Rupture 0 0 1 1 1 0 0 0 0
Finalement, la valeur 69 par rapport à la valeur 93, est celle qui s'avère la plus proche
de la valeur réelle 74. Nous pouvons donc conclure que la meilleure méthode de prévision en
loi est celle qui utilise une loi de probabilité estimée pour chaque jour de la semaine (6 lois
de probabilité).
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014
APPLICATIONS AUX DONNÉES ET RÉSULTATS 61
Figure 4.12 Demande eective de GPS, prédiction en loi de probabilité suivant les jours
et bande de prédiction.
4.2 Modélisation et prévision du ux de retour
Le but de cette partie est de construire des modèles basés sur l'échantillon de données
du ux de retour GPS pris sous diérents formats (en fonction de la méthode utilisée),
pour prédire les valeurs futures. Pour cela, nous implémenterons dans cette partie, quatre
des méthodes exposées au chapitre 3 (Holt-Winters, Box et Jenkins, non paramétrique et à
retards échelonnés). Comme dans le cas précédent, nous considérons tout au long de cette
section, sauf mention contraire, le logarithme des observations du ux de retour GPS. On
travaillera donc avec la série transformée. Ainsi, quand nous parlerons de série
journalière du ux de retour, il s'agira de la série journalière transformée.
Rappelons qu'au chapitre 2, nous avons montré, à l'aide du lag plot, que la série non trans-
formée du ux de retour admettait des aspects typés, principalement aux retards multiples
de 6. Ce résultat et bien d'autres resteront valables dans ce cadre de série transformée.
4.2.1 Application de la méthode du lissage exponentiel Holt-Winters
Étant donné les précisions faites ci-dessus, et puisque la série journalière du ux de
retour (gure 4.13) montre une tendance non nulle à court terme, nous devons certainement
utiliser la version saisonnière de la méthode du lissage de H-W. Cependant, l'application de
la fonction HoltWinters() sur la série journalière du ux de retour pose un problème de taille
d'échantillon pour pouvoir prendre en compte la présence du facteur saisonnier. Selon cette
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014
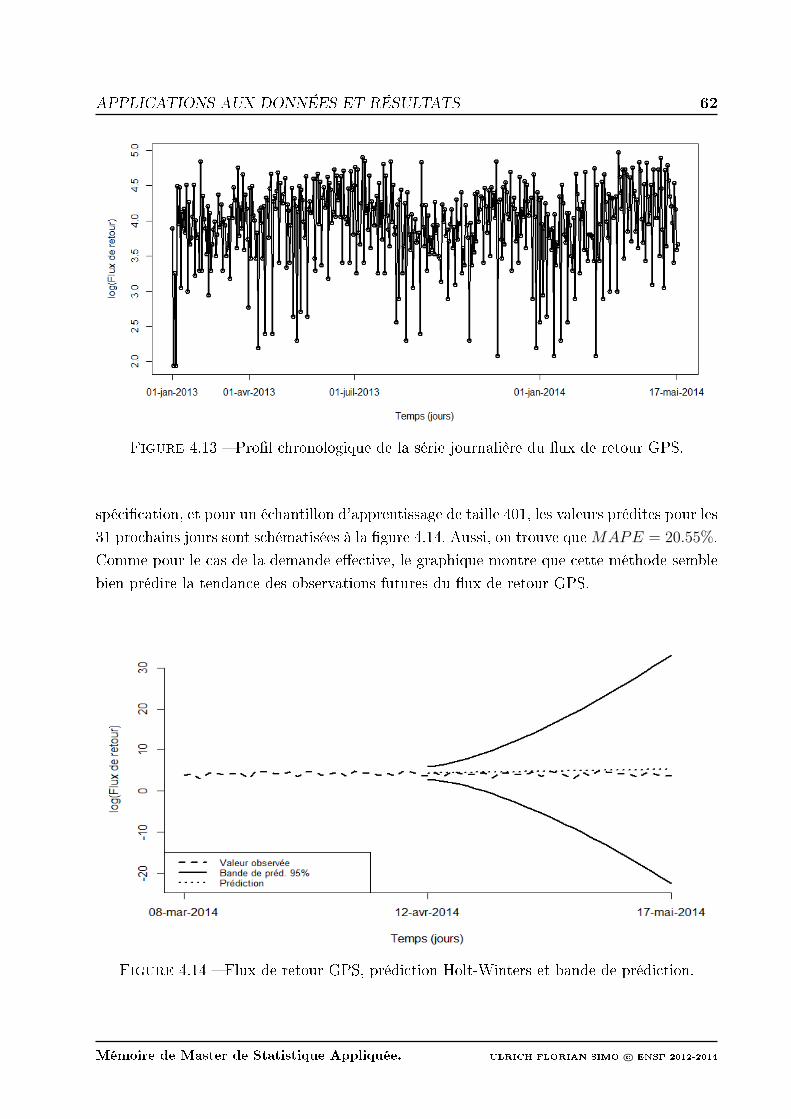
APPLICATIONS AUX DONNÉES ET RÉSULTATS 62
Figure 4.13 Prol chronologique de la série journalière du ux de retour GPS.
spécication, et pour un échantillon d'apprentissage de taille 401, les valeurs prédites pour les
31 prochains jours sont schématisées à la gure 4.14. Aussi, on trouve queMAPE = 20.55%.
Comme pour le cas de la demande eective, le graphique montre que cette méthode semble
bien prédire la tendance des observations futures du ux de retour GPS.
Figure 4.14 Flux de retour GPS, prédiction Holt-Winters et bande de prédiction.
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014
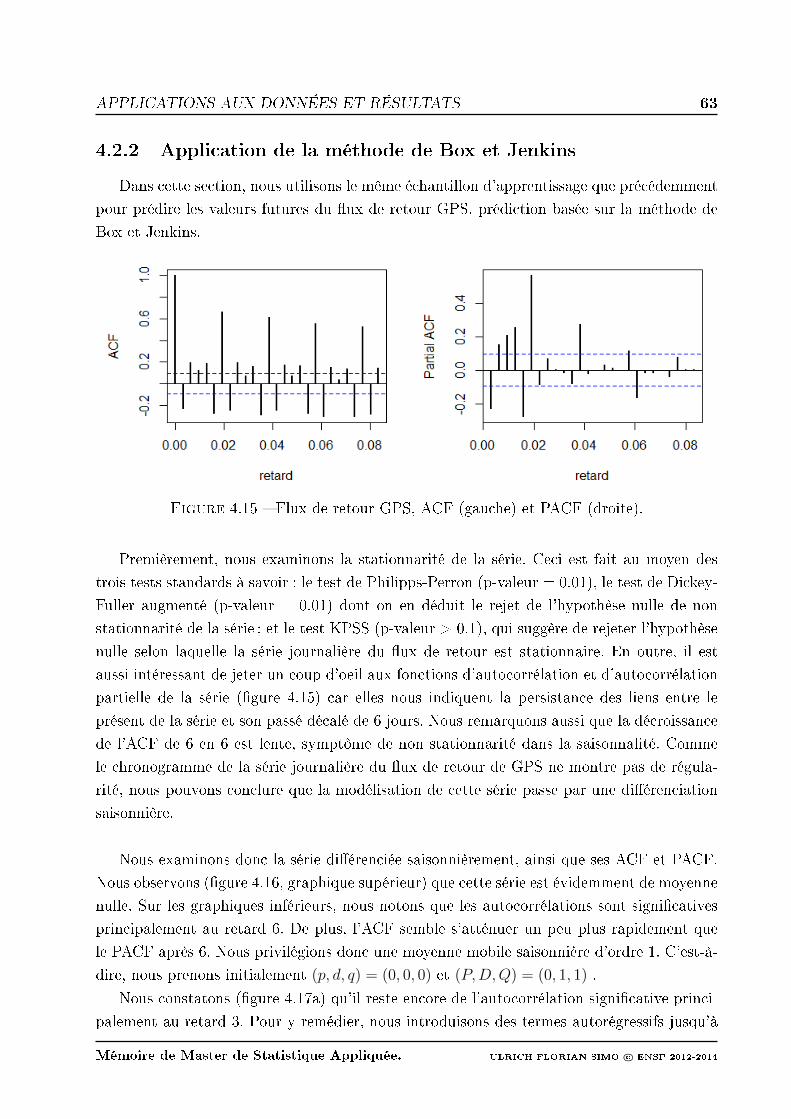
APPLICATIONS AUX DONNÉES ET RÉSULTATS 63
4.2.2 Application de la méthode de Box et Jenkins
Dans cette section, nous utilisons le même échantillon d'apprentissage que précédemment
pour prédire les valeurs futures du ux de retour GPS, prédiction basée sur la méthode de
Box et Jenkins.
Figure 4.15 Flux de retour GPS, ACF (gauche) et PACF (droite).
Premièrement, nous examinons la stationnarité de la série. Ceci est fait au moyen des
trois tests standards à savoir : le test de Philipps-Perron (p-valeur = 0.01), le test de Dickey-
Fuller augmenté (p-valeur = 0.01) dont on en déduit le rejet de l'hypothèse nulle de non
stationnarité de la série ; et le test KPSS (p-valeur > 0.1), qui suggère de rejeter l'hypothèse
nulle selon laquelle la série journalière du ux de retour est stationnaire. En outre, il est
aussi intéressant de jeter un coup d'oeil aux fonctions d'autocorrélation et d'autocorrélation
partielle de la série (gure 4.15) car elles nous indiquent la persistance des liens entre le
présent de la série et son passé décalé de 6 jours. Nous remarquons aussi que la décroissance
de l'ACF de 6 en 6 est lente, symptôme de non stationnarité dans la saisonnalité. Comme
le chronogramme de la série journalière du ux de retour de GPS ne montre pas de régula-
rité, nous pouvons conclure que la modélisation de cette série passe par une diérenciation
saisonnière.
Nous examinons donc la série diérenciée saisonnièrement, ainsi que ses ACF et PACF.
Nous observons (gure 4.16, graphique supérieur) que cette série est évidemment de moyenne
nulle. Sur les graphiques inférieurs, nous notons que les autocorrélations sont signicatives
principalement au retard 6. De plus, l'ACF semble s'atténuer un peu plus rapidement que
le PACF après 6. Nous privilégions donc une moyenne mobile saisonnière d'ordre 1. C'est-à-
dire, nous prenons initialement (p, d, q) = (0, 0, 0) et (P,D,Q) = (0, 1, 1) .
Nous constatons (gure 4.17a) qu'il reste encore de l'autocorrélation signicative princi-
palement au retard 3. Pour y remédier, nous introduisons des termes autorégressifs jusqu'à
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014
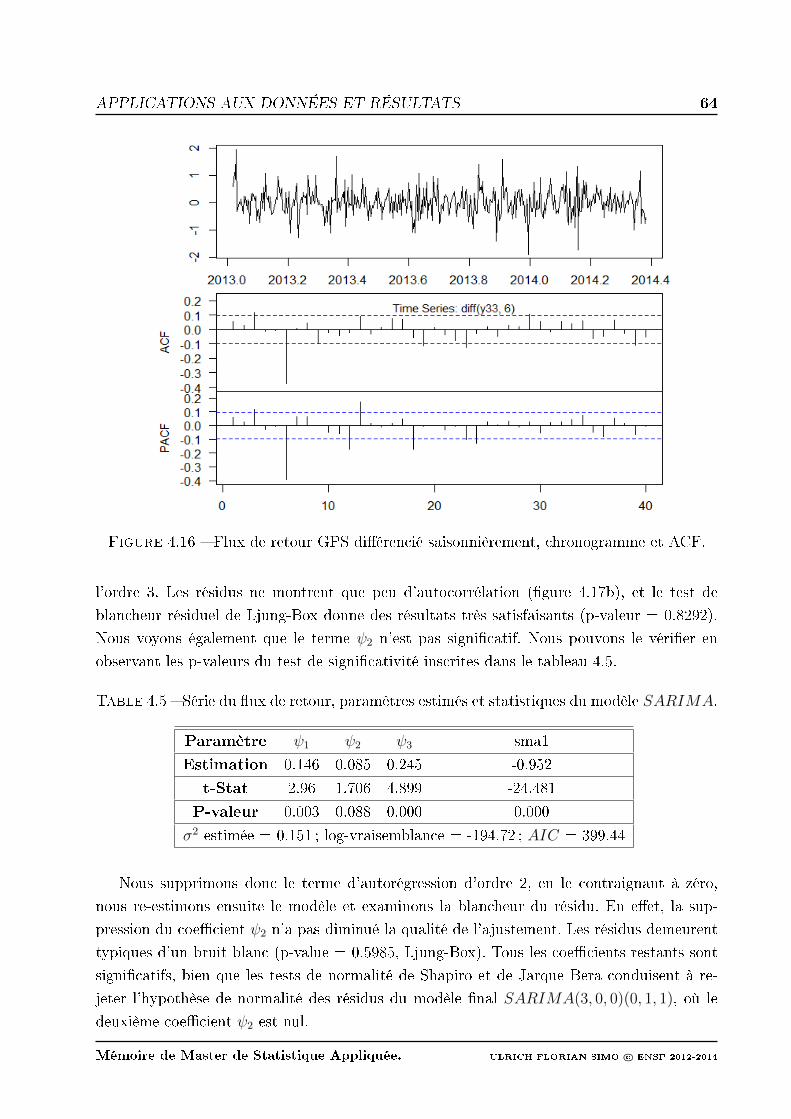
APPLICATIONS AUX DONNÉES ET RÉSULTATS 64
Figure 4.16 Flux de retour GPS diérencié saisonnièrement, chronogramme et ACF.
l'ordre 3. Les résidus ne montrent que peu d'autocorrélation (gure 4.17b), et le test de
blancheur résiduel de Ljung-Box donne des résultats très satisfaisants (p-valeur = 0.8292).
Nous voyons également que le terme ψ2 n'est pas signicatif. Nous pouvons le vérier en
observant les p-valeurs du test de signicativité inscrites dans le tableau 4.5.
Table 4.5 Série du ux de retour, paramètres estimés et statistiques du modèle SARIMA.
Paramètre ψ1 ψ2 ψ3 sma1
Estimation 0.146 0.085 0.245 -0.952
t-Stat 2.96 1.706 4.899 -24.481
P-valeur 0.003 0.088 0.000 0.000
σ2 estimée = 0.151 ; log-vraisemblance = -194.72 ; AIC = 399.44
Nous supprimons donc le terme d'autorégression d'ordre 2, en le contraignant à zéro,
nous re-estimons ensuite le modèle et examinons la blancheur du résidu. En eet, la sup-
pression du coecient ψ2 n'a pas diminué la qualité de l'ajustement. Les résidus demeurent
typiques d'un bruit blanc (p-value = 0.5985, Ljung-Box). Tous les coecients restants sont
signicatifs, bien que les tests de normalité de Shapiro et de Jarque Bera conduisent à re-
jeter l'hypothèse de normalité des résidus du modèle nal SARIMA(3, 0, 0)(0, 1, 1), où le
deuxième coecient ψ2 est nul.
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014
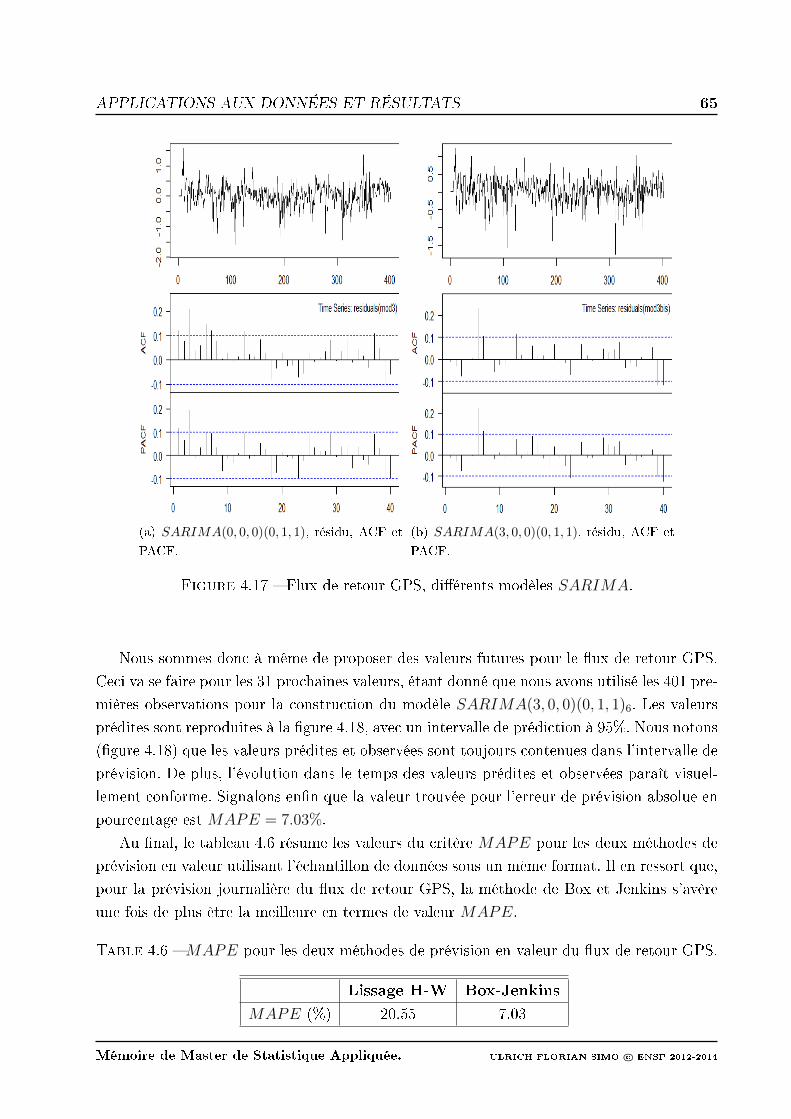
APPLICATIONS AUX DONNÉES ET RÉSULTATS 65
(a) SARIMA(0, 0, 0)(0, 1, 1), résidu, ACF et
PACF.
(b) SARIMA(3, 0, 0)(0, 1, 1), résidu, ACF et
PACF.
Figure 4.17 Flux de retour GPS, diérents modèles SARIMA.
Nous sommes donc à même de proposer des valeurs futures pour le ux de retour GPS.
Ceci va se faire pour les 31 prochaines valeurs, étant donné que nous avons utilisé les 401 pre-
mières observations pour la construction du modèle SARIMA(3, 0, 0)(0, 1, 1)6. Les valeurs
prédites sont reproduites à la gure 4.18, avec un intervalle de prédiction à 95%. Nous notons
(gure 4.18) que les valeurs prédites et observées sont toujours contenues dans l'intervalle de
prévision. De plus, l'évolution dans le temps des valeurs prédites et observées paraît visuel-
lement conforme. Signalons enn que la valeur trouvée pour l'erreur de prévision absolue en
pourcentage est MAPE = 7.03%.
Au nal, le tableau 4.6 résume les valeurs du critère MAPE pour les deux méthodes de
prévision en valeur utilisant l'échantillon de données sous un même format. Il en ressort que,
pour la prévision journalière du ux de retour GPS, la méthode de Box et Jenkins s'avère
une fois de plus être la meilleure en termes de valeur MAPE.
Table 4.6 MAPE pour les deux méthodes de prévision en valeur du ux de retour GPS.
Lissage H-W Box-Jenkins
MAPE (%) 20.55 7.03
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014
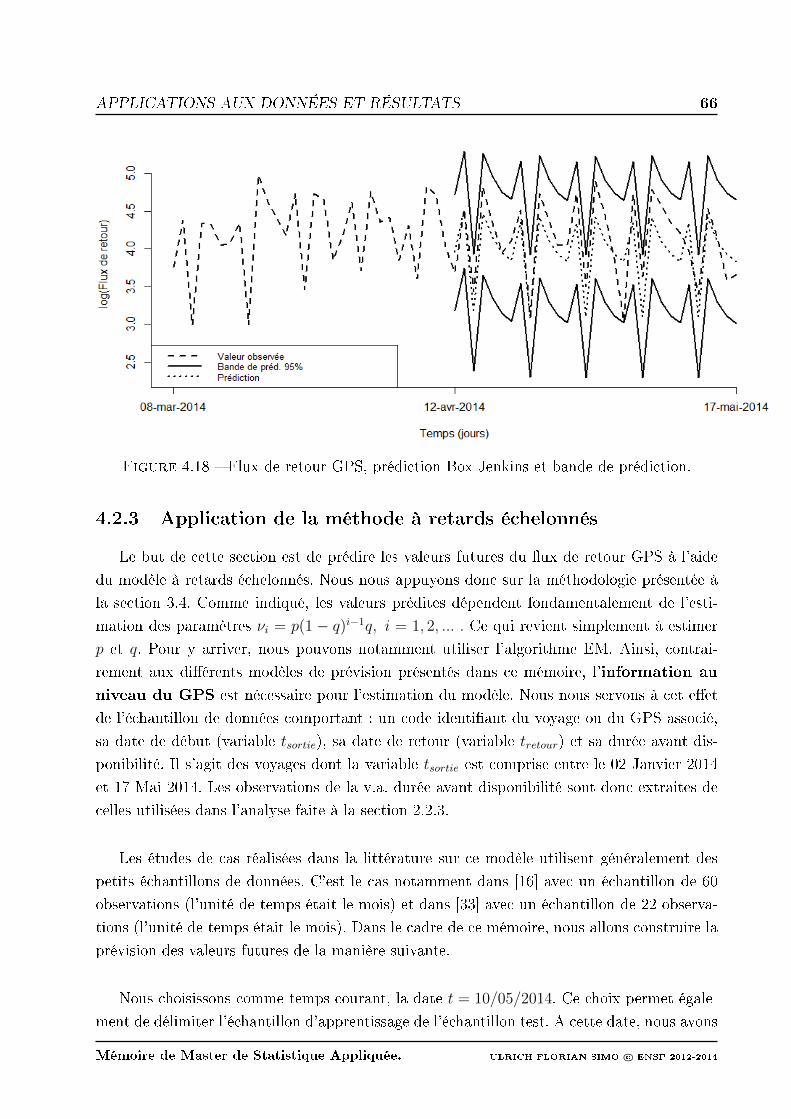
APPLICATIONS AUX DONNÉES ET RÉSULTATS 66
Figure 4.18 Flux de retour GPS, prédiction Box Jenkins et bande de prédiction.
4.2.3 Application de la méthode à retards échelonnés
Le but de cette section est de prédire les valeurs futures du ux de retour GPS à l'aide
du modèle à retards échelonnés. Nous nous appuyons donc sur la méthodologie présentée à
la section 3.4. Comme indiqué, les valeurs prédites dépendent fondamentalement de l'esti-
mation des paramètres νi = p(1 − q)i−1q, i = 1, 2, ... . Ce qui revient simplement à estimer
p et q. Pour y arriver, nous pouvons notamment utiliser l'algorithme EM. Ainsi, contrai-
rement aux diérents modèles de prévision présentés dans ce mémoire, l'information au
niveau du GPS est nécessaire pour l'estimation du modèle. Nous nous servons à cet eet
de l'échantillon de données comportant : un code identiant du voyage ou du GPS associé,
sa date de début (variable tsortie), sa date de retour (variable tretour) et sa durée avant dis-
ponibilité. Il s'agit des voyages dont la variable tsortie est comprise entre le 02 Janvier 2014
et 17 Mai 2014. Les observations de la v.a. durée avant disponibilité sont donc extraites de
celles utilisées dans l'analyse faite à la section 2.2.3.
Les études de cas réalisées dans la littérature sur ce modèle utilisent généralement des
petits échantillons de données. C'est le cas notamment dans [16] avec un échantillon de 60
observations (l'unité de temps était le mois) et dans [33] avec un échantillon de 22 observa-
tions (l'unité de temps était le mois). Dans le cadre de ce mémoire, nous allons construire la
prévision des valeurs futures de la manière suivante.
Nous choisissons comme temps courant, la date t = 10/05/2014. Ce choix permet égale-
ment de délimiter l'échantillon d'apprentissage de l'échantillon test. A cette date, nous avons
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014
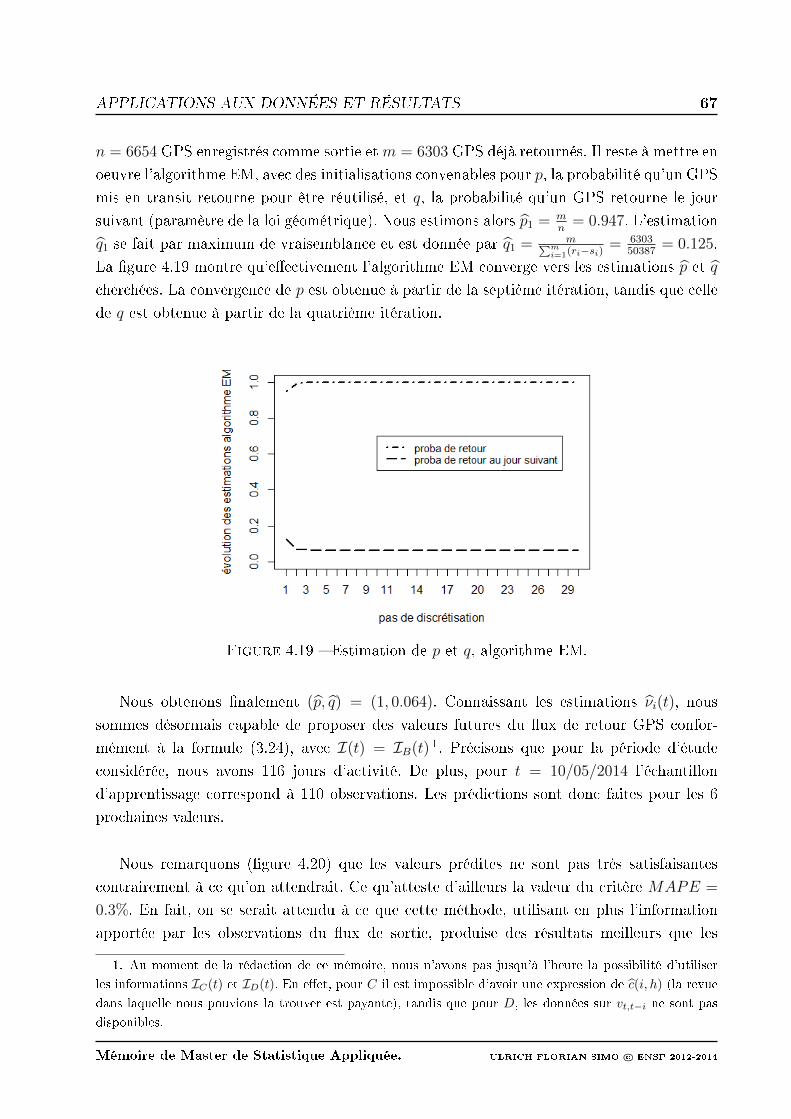
APPLICATIONS AUX DONNÉES ET RÉSULTATS 67
n = 6654 GPS enregistrés comme sortie etm = 6303 GPS déjà retournés. Il reste à mettre en
oeuvre l'algorithme EM, avec des initialisations convenables pour p, la probabilité qu'un GPS
mis en transit retourne pour être réutilisé, et q, la probabilité qu'un GPS retourne le jour
suivant (paramètre de la loi géométrique). Nous estimons alors p1 = mn
= 0.947. L'estimation
q1 se fait par maximum de vraisemblance et est donnée par q1 = m∑mi=1(ri−si)
= 630350387
= 0.125.
La gure 4.19 montre qu'eectivement l'algorithme EM converge vers les estimations p et q
cherchées. La convergence de p est obtenue à partir de la septième itération, tandis que celle
de q est obtenue à partir de la quatrième itération.
Figure 4.19 Estimation de p et q, algorithme EM.
Nous obtenons nalement (p, q) = (1, 0.064). Connaissant les estimations νi(t), nous
sommes désormais capable de proposer des valeurs futures du ux de retour GPS confor-
mément à la formule (3.24), avec I(t) = IB(t) 1. Précisons que pour la période d'étude
considérée, nous avons 116 jours d'activité. De plus, pour t = 10/05/2014 l'échantillon
d'apprentissage correspond à 110 observations. Les prédictions sont donc faites pour les 6
prochaines valeurs.
Nous remarquons (gure 4.20) que les valeurs prédites ne sont pas très satisfaisantes
contrairement à ce qu'on attendrait. Ce qu'atteste d'ailleurs la valeur du critère MAPE =
0.3%. En fait, on se serait attendu à ce que cette méthode, utilisant en plus l'information
apportée par les observations du ux de sortie, produise des résultats meilleurs que les
1. Au moment de la rédaction de ce mémoire, nous n'avons pas jusqu'à l'heure la possibilité d'utiliser
les informations IC(t) et ID(t). En eet, pour C il est impossible d'avoir une expression de c(i, h) (la revue
dans laquelle nous pouvions la trouver est payante), tandis que pour D, les données sur vt,t−i ne sont pas
disponibles.
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014
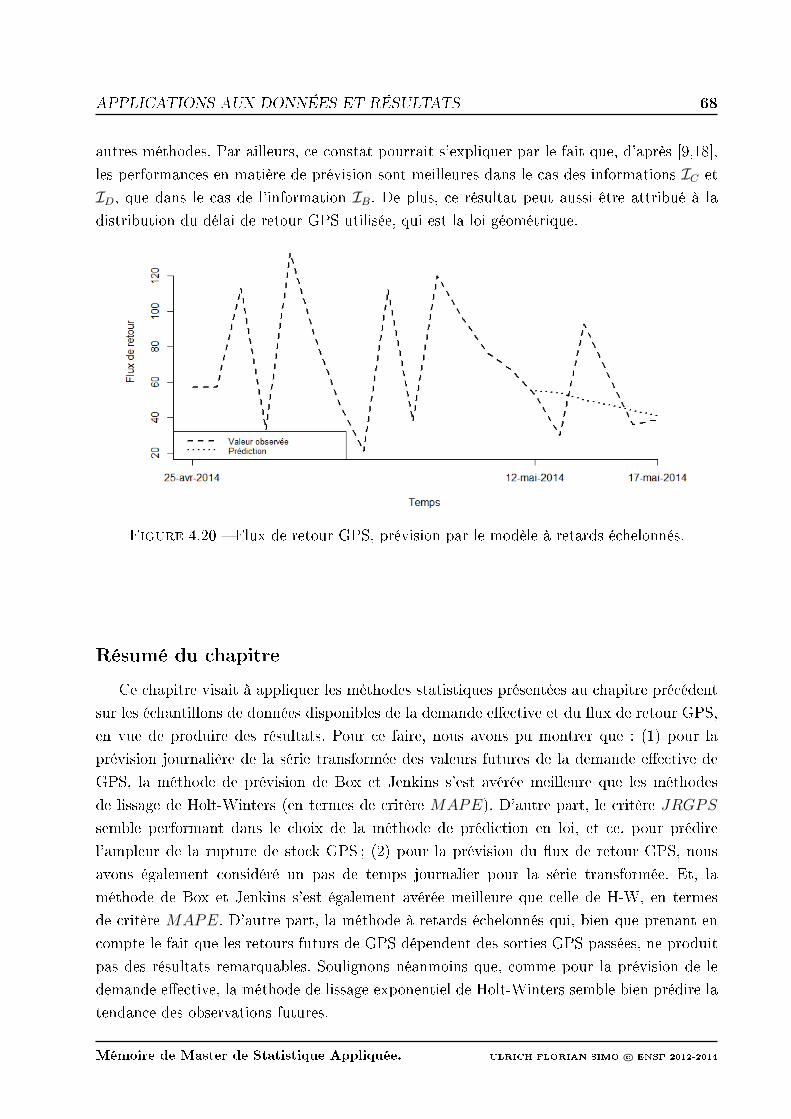
APPLICATIONS AUX DONNÉES ET RÉSULTATS 68
autres méthodes. Par ailleurs, ce constat pourrait s'expliquer par le fait que, d'après [9,18],
les performances en matière de prévision sont meilleures dans le cas des informations IC et
ID, que dans le cas de l'information IB. De plus, ce résultat peut aussi être attribué à la
distribution du délai de retour GPS utilisée, qui est la loi géométrique.
Figure 4.20 Flux de retour GPS, prévision par le modèle à retards échelonnés.
Résumé du chapitre
Ce chapitre visait à appliquer les méthodes statistiques présentées au chapitre précédent
sur les échantillons de données disponibles de la demande eective et du ux de retour GPS,
en vue de produire des résultats. Pour ce faire, nous avons pu montrer que : (1) pour la
prévision journalière de la série transformée des valeurs futures de la demande eective de
GPS, la méthode de prévision de Box et Jenkins s'est avérée meilleure que les méthodes
de lissage de Holt-Winters (en termes de critère MAPE). D'autre part, le critère JRGPS
semble performant dans le choix de la méthode de prédiction en loi, et ce, pour prédire
l'ampleur de la rupture de stock GPS ; (2) pour la prévision du ux de retour GPS, nous
avons également considéré un pas de temps journalier pour la série transformée. Et, la
méthode de Box et Jenkins s'est également avérée meilleure que celle de H-W, en termes
de critère MAPE. D'autre part, la méthode à retards échelonnés qui, bien que prenant en
compte le fait que les retours futurs de GPS dépendent des sorties GPS passées, ne produit
pas des résultats remarquables. Soulignons néanmoins que, comme pour la prévision de le
demande eective, la méthode de lissage exponentiel de Holt-Winters semble bien prédire la
tendance des observations futures.
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

FORMALISATION DU CADRE THÉORIQUE DE LA POLITIQUE DE GESTION DESTOCK 69
Chapitre Cinq
Formalisation du Cadre Théorique
de la Politique de Gestion de Stock
L'objet de ce chapitre est de proposer une formalisation du cadre théorique d'une politique
de gestion de stock GPS adapté au contexte douanier. Il se compose de deux sections : la
section introductive 5.1, présente les politiques de gestion de stock classiques existantes dans
la littérature et les modèles associés ; la section 5.2 présente le cadre mathématique de la
politique proposée pour la gestion de stock GPS.
5.1 Introduction
5.1.1 Politiques de gestion de stock classiques
Une politique de gestion de stock peut être dénie comme étant l'ensemble des voix et
moyens mis en oeuvre pour contrôler et optimiser les ux physiques, minimiser le coût total
engendré par les activités de stockage et de transport, tout en satisfaisant les demandes du
client sur un horizon donné. Il existe, en pratique, quelques politiques de gestion de stock
classiques qui peuvent se dénir par les réponses qu'elles apportent aux deux questions de
base suivantes [2,15].
• Quand approvisionner ? La réponse à cette question réside en le choix de l'une des
trois méthodes de réapprovisionnement ci-dessous
Gestion de stock au point de commande : l'approvisionnement du stock est déclenché
lorsque le stock descend au-dessous d'un niveau xé appelé point de commande.
Gestion calendaire : l'approvisionnement du stock est déclenché à des intervalles de
temps réguliers.
Gestion calendaire conditionnelle : l'approvisionnement du stock est déclenché à des
intervalles de temps réguliers, mais uniquement lorsque le stock descend en dessous
d'un certain seuil du point de commande.
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

FORMALISATION DU CADRE THÉORIQUE DE LA POLITIQUE DE GESTION DESTOCK 70
• Quelle quantité approvisionner ? Il existe deux méthodes de base qui répondent à
cette question :
Approvisionnement par quantité xe : chaque commande porte sur la même quantité
xe. C'est le cas notamment lorsqu'il y a des contraintes de conditionnement ou de
transport ou des seuils tarifaires qui impliquent un achat minimum. Ceci suppose bien
évidemment une fréquence d'approvisionnement variable.
Approvisionnement par quantité variable : lors de chaque commande, le stock théorique
est mesuré pour commander une quantité qui permet de re-compléter ce stock.
5.1.2 Modèles de politique de gestion de stock
Dans la littérature [2,15], nous retrouvons plusieurs modèles de politique de gestion de
stock prédénis. Nous présentons ci-dessous quelques politiques de gestion de stocks les plus
utilisées en pratique :
(s, S) : Dans cette politique, dès que le niveau du stock descend en dessous d'un seuil
xé s, une commande d'approvisionnement du stock est passée immédiatement pour
tenter de ramener le niveau du stock à son niveau initial S.
(R, S) : Dans cette politique, à chaque R unités de temps, une commande d'approvi-
sionnement du stock est passée pour tenter de ramener le niveau du stock à son niveau
initial S.
(R, s, S) : Dans cette politique, à chaque R unités de temps, le niveau du stock est
contrôlé et s'il est en dessous d'un seuil xé s, une commande d'approvisionnement du
stock est passée pour tenter de ramener le niveau du stock à son niveau initial S.
(s,Q) : Dans cette politique, dès que le niveau du stock est en dessous d'un seuil xé
s, une commande d'approvisionnement d'une quantité xe Q est passée.
(R, s,Q) : Dans cette politique, à chaque R unités de temps, le niveau du stock est
contrôlé et s'il est en dessous d'un seuil xé s, une commande d'approvisionnement
d'une quantité xe Q est passée.
(S − 1, S) : C'est un cas particulier de la politique (s, S) avec s = S − 1 et un contrôle
continu du niveau du stock.
Ces politiques peuvent être classées comme suit :
• Politiques avec révision continue : il s'agit des politiques (s, S), (s,Q) et (S − 1, S)
où l'état du stock est inspecté continuellement.
• Politiques avec révision périodique : il s'agit des politiques (R, s, S), (R, S) et (R,Q)
où l'état du stock est inspecté périodiquement.
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

FORMALISATION DU CADRE THÉORIQUE DE LA POLITIQUE DE GESTION DESTOCK 71
Des coûts logistiques sont liés à ces politiques. Ces coûts peuvent être classés en trois
familles selon la littérature. Les coûts de commande, les coûts de possession et les coûts
de rupture. Lors de l'optimisation des décisions relatives à l'inventaire, il faut prendre en
compte tous ces coûts.
5.1.3 Cas de la gestion de stock GPS
Plusieurs incertitudes rythment le quotidien du gestionnaire de stock GPS à la Douane
Camerounaise. En eet, le système de gestion de stock est soumis à une demande aléatoire et
répétitive, une durée avant disponibilité aléatoire et, à des coûts liés aux diérentes activités.
La seule certitude se situe au niveau du délai de réapprovisionnement, qui est de deux jours à
compter de la date où une commande est eectuée. La gestion de stock de GPS à la Douane
Camerounaise est donc un problème particulier qui rend son traitement complexe par des
politiques classiques. De ce fait, nous allons proposer un cadre mathématique de formalisation
d'une politique de gestion de stock adaptée au contexte douanier. Nous proposerons aussi
une méthodologie d'estimation par simulation de la probabilité de rupture de stock. A cet
eet, nous introduisons nos propres notations et adoptons certaines utilisées dans [20,32].
Les notations retenues et harmonisées sont données dans le tableau 5.1, où une période
est comprise comme un jour, un bloc de deux jours, une semaine ou encore un mois. Nous
noterons indiéremment at ou a(t) pour la valeur en t d'une variable a variant dans le temps.
Table 5.1 Notations principales adoptées dans ce chapitre.
Dt v.a.r. (v.a. représentant) la demande de la période t
DNt v.a.r., la demande nette (demande - retour) de la période t
L Délai de réapprovisionnement
DNL(t) v.a.r., la demande nette pendant le temps L (période t+ 1, t+ 2, ..., t+ L)
Dr,t v.a.r., la demande résiduelle de la période t
De,t v.a.r., la demande eective de la période t
Vt v.a.r., le ux de sortie de la période t
Rt v.a.r., le ux de retour de la période t
k Facteur de sécurité
p Probabilité de retour
q Paramètre de la distribution du délai de retour
Qt Quantité commandée à la n de la période t
At Quantité achetée pendant la période t
IRt Indicateur de rupture de la période t
St Position de base du stock à la n de la période t
PSt Position du stock au début de la période t
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

FORMALISATION DU CADRE THÉORIQUE DE LA POLITIQUE DE GESTION DESTOCK 72
5.2 Une formalisation mathématique de la gestion de stock
GPS
Dans cette section, nous développons un modèle mathématique d'inventaire pour un stock
de GPS réutilisables dans lequel les ux de retour aléatoires dépendent explicitement de la
demande ou des ux de sortie. Une situation similaire est également discutée dans [20] mais
avec une délai de retour xe pour chaque article. Nous allons étendre cette hypothèse au
cas où le délai de retour est aléatoire, suivant une distribution de Poisson de paramètre λ.
Pour simplier, nous considérons aussi un horizon de planication ni, limité à T jours (par
exemple T = 30 pour un mois). Sans perte de généralité, nous prenons la longueur d'une
période égale à 1 et la période est numérotée par t = 1, 2, ... .
Chaque demande individuelle de GPS non satisfaite est immédiatement diérée. Dans
ce cas, une politique de gestion de stock à point de commande simple est optimale lorsque
l'espérance et la variance de la demande nette pendant le temps de réapprovisionnement,
DNL(t) = DL(t)−RL(t), sont connues pour chaque période [18,19].
• Nous utilisons des échantillons de données agrégées en bloc de deux jours 1 de la de-
mande eective et du ux de retour GPS pour la période allant du Vendredi 01 Novembre
2013 au Samedi 29 Mars 2014, pour obtenir les valeurs de la v.a. DNL. En utilisant la mé-
thode d'estimation paramétrique de densité, nous montrons que DNL suit une distribution
normale, comme le montre la gure 5.1 et le conrment les tests de Shapiro (p-valeur =
0.774) et de Kolmogorov (p-valeur = 0.941). Par conséquent, d'après [32], le niveau du stock
de base est déni par S = E(DNL) + k√
V(DNL), pour une politique de gestion de stock
GPS à point de commande, où le facteur de sécurité k est déterminé suivant le niveau de
performance souhaité.
•Dans [18] également, les auteurs développent des approximations normales deDNL(t) | I(t),
la demande nette conditionnelle sur le délai de réapprovisionnement, étant donné l'informa-
tion jusqu'à et y compris la période t. Ils utilisent notamment les quatre ensembles d'informa-
tion A,B,C et D dénis au chapitre 1. Des expressions mathématiques de E[DNL(t) | I(t)]
et V[DNL(t) | I(t)] sous ces quatre ensembles d'informations y sont mentionnées 2. Notons
par St, le niveau de stock de base à la n de la période t. Alors
St = E[DNL(t) | I(t)] + k√
V[DNL(t) | I(t)], (5.1)
1. Par exemple, pour une semaine ouvrable donnée, au lieu d'avoir 6 observations, nous en aurons 3, en
additionnant les observations de Lundi-Mardi, Mercredi-Jeudi et Vendredi-Samedi.
2. Au moment de la rédaction de ce mémoire, cette revue [18] et celles de [19],[16] n'ont pas été disponibles
car sont payantes.
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014
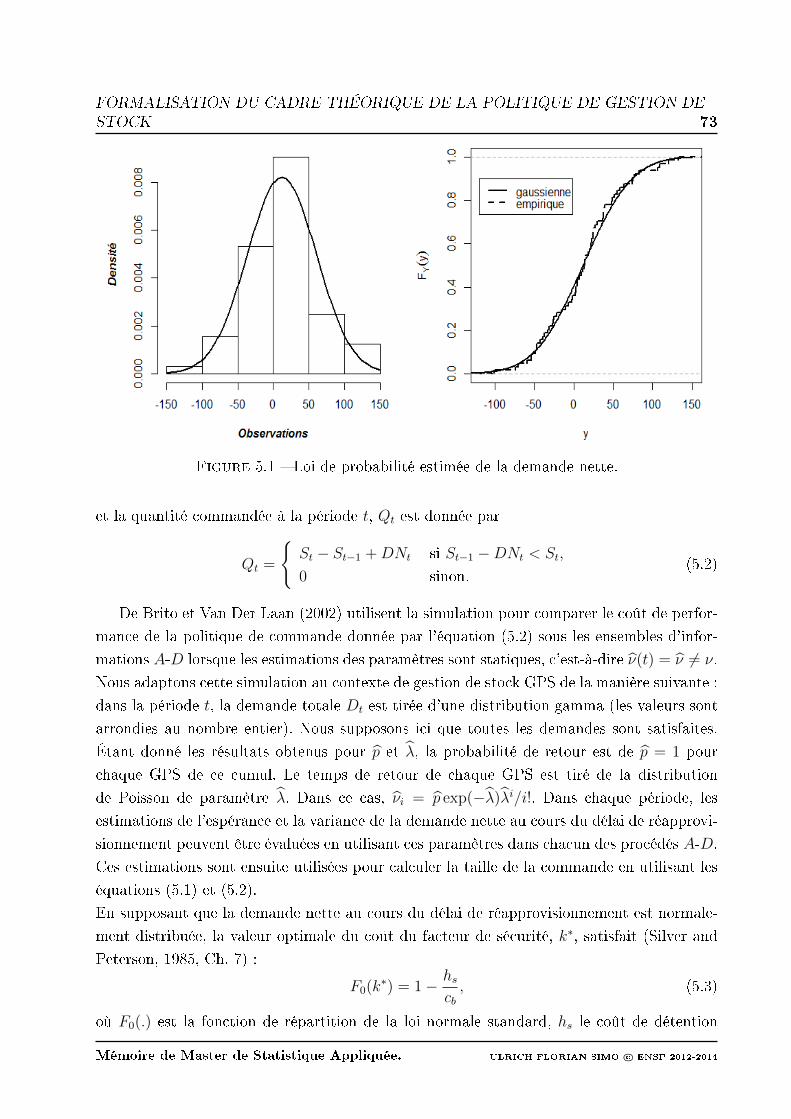
FORMALISATION DU CADRE THÉORIQUE DE LA POLITIQUE DE GESTION DESTOCK 73
Figure 5.1 Loi de probabilité estimée de la demande nette.
et la quantité commandée à la période t, Qt est donnée par
Qt =
St − St−1 +DNt si St−1 −DNt < St,
0 sinon.(5.2)
De Brito et Van Der Laan (2002) utilisent la simulation pour comparer le coût de perfor-
mance de la politique de commande donnée par l'équation (5.2) sous les ensembles d'infor-
mations A-D lorsque les estimations des paramètres sont statiques, c'est-à-dire ν(t) = ν 6= ν.
Nous adaptons cette simulation au contexte de gestion de stock GPS de la manière suivante :
dans la période t, la demande totale Dt est tirée d'une distribution gamma (les valeurs sont
arrondies au nombre entier). Nous supposons ici que toutes les demandes sont satisfaites.
Étant donné les résultats obtenus pour p et λ, la probabilité de retour est de p = 1 pour
chaque GPS de ce cumul. Le temps de retour de chaque GPS est tiré de la distribution
de Poisson de paramètre λ. Dans ce cas, νi = p exp(−λ)λi/i!. Dans chaque période, les
estimations de l'espérance et la variance de la demande nette au cours du délai de réapprovi-
sionnement peuvent être évaluées en utilisant ces paramètres dans chacun des procédés A-D.
Ces estimations sont ensuite utilisées pour calculer la taille de la commande en utilisant les
équations (5.1) et (5.2).
En supposant que la demande nette au cours du délai de réapprovisionnement est normale-
ment distribuée, la valeur optimale du coût du facteur de sécurité, k∗, satisfait (Silver and
Peterson, 1985, Ch. 7) :
F0(k∗) = 1− hs
cb, (5.3)
où F0(.) est la fonction de répartition de la loi normale standard, hs le coût de détention
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

FORMALISATION DU CADRE THÉORIQUE DE LA POLITIQUE DE GESTION DESTOCK 74
par GPS en sur-stock à la n de chaque période, et cb la peine de rupture de stock GPS
par occurrence. A la n de chaque expérience de simulation, le coût total moyen par période
peut être calculée comme le coût total de possession plus les frais de rupture de stock par
période. Plus de détails concernant la conguration de la simulation peuvent être trouvés
dans [9].
5.3 Probabilité de rupture et quantité à approvisionner
De manière formelle, l'évènement rupture de stock a lieu lorsque la demande est su-
périeure à l'ore. Dans le contexte de gestion de stock GPS, la demande sera assimilée à la
demande totale de GPS (eective plus résiduelle), tandis que l'ore est comprise comme la
quantité totale de GPS disponible en stock, y compris les GPS réapprovisionnés et les GPS
retournés. Ainsi, avec les notations du tableau 5.1, nous avons l'équivalence
rupture de stock à la période t ⇐⇒ Dt > PSt + At +Rt. (5.4)
L'objectif est de prédire le moment de rupture de stock par estimation de la probabilité
que l'évènement se réalise. Supposons qu'il n'y a pas eu de rupture pendant les
périodes t, t+ 1, ..., t+h−1 et pas de réapprovisionnement en GPS entre t et t+h.
Alors
Dénition 5.1. La probabilité de rupture de stock GPS en t+ h est dénie par
Pt,h = P(Dt+h > PSt+h +Rt+h).
Nous nous proposons de répondre aux deux questions suivantes :
1. Donner une estimation de la probabilité de rupture de stock à la période t+ h ;
2. Quelle est la quantité de GPS à approvisionner pour que cette probabilité soit inférieure
à un seuil xé α ?
5.3.1 Estimation de la probabilité de rupture à l'horizon h
La réponse à la première question revient à déterminer une estimation de Pt,h. Ceci peut
se faire par simulation. En eet, en pratique, on ne peut pas avoir de manière objective une
valeur pour Pt,h. On peut néanmoins avoir un indicateur de rupture IRt+h, donné comme
suit :
Soit t la période courante. Nous supposons disposer des observations de la variable R (resp.
V ), pour les périodes t, t+ 1, ..., t+ h. Nous les notons Rt, ..., Rt+h (resp. Vt, ..., Vt+h), obser-
vations obtenues par prédiction à l'aide de modèles statistiques. De plus, nous connaissons
PSt, et on note PSt sa valeur. On a alors
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

FORMALISATION DU CADRE THÉORIQUE DE LA POLITIQUE DE GESTION DESTOCK 75
IRt+h =
1 si Dt+h − Rt+h > PSt+h,
0 sinon.(5.5)
où
PSt+h = PSt + Rt + Rt+1 + ...+ Rt+h−1 − Vt − Vt+1 − ...− Vt+h−1
= PSt +h−1∑j=0
Rt+j −h−1∑j=0
Vt+j.
Approche par simulation. L'approche par simulation que nous mettons en oeuvre fait
l'hypothèse que Dt+h (resp. Rt+h) suit une loi de probabilité LD (resp. LR) de paramètres uni
ou bi-dimensionnel γD (resp. γR). Dans ce cas, une estimation de la probabilité de rupture
cherchée est :
Pt,h = P(Dt+h −Rt+h > PSt+h
)= P
(Dt+h −Rt+h > ct,h
), avec ct,h = PSt+h. (5.6)
Nous proposons dans l'encadré suivant, un algorithme de simulation de cette probabilité
de rupture de stock GPS.
Algorithme 1 de simulation de la probabilité de rupture à l'horizon h.
Entrée : h horizon choisi
ct,h valeur prédite de la position du stock au début de la période t+ h
n taille de l'échantillon de données simulées
B nombre de répétitions
Sortie : pt,h probabilité de rupture estimée
1. Connaissant les lois de probabilité respectives des v.a. Dt et Rt, tirer un n-échantillon
de données suivant chacune des lois : dt,1, ..., dt,n et rt,1, ..., rt,n
2. Calculer probh par : probh = 1n
∑ni=1 1dt,i−rt,i>ct,h
3. Répéter 1. et 2. B fois et retourner pt,h = 1B
∑Bb=1 probh,b.
Alternative. Une alternative à l'estimation de la probabilité de rupture revient à utiliser
la notion d'espérance conditionnelle pour ré-écrire la relation (5.6). Nous procédons de la
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

FORMALISATION DU CADRE THÉORIQUE DE LA POLITIQUE DE GESTION DESTOCK 76
manière suivante :
P = P(D −R > c)
= E(1D−R>c
)= E
(E(1D−R>c | R)
)= E
(ϕ(R)
),
où
ϕ(x) = E(1D−x>c | R = x
)= E
(1D−x>c
), car D indépendant de R
= E(1D>x+c
)=
∫ ymax
x+c+1
yfD(y)µ(dy),
où µ est considérée ici comme la mesure de comptage sur N si D est supposée discrète, ou
comme la mesure de Lebesgue sur R+ si D est supposée continue, et fD est la densité (cas
continue) ou la masse (cas discret) de probabilité de la v.a. D.
Une estimation de la probabilité de rupture est donc donnée par
P =
∫ xmax
0
∫ ymax
x+c+1
xyfD(y)fR(x)µ(dx)µ(dy), (5.7)
avec fR la densité (cas continue) ou la masse (cas discret) de probabilité de la v.a. R.
Alternative 2. Nous proposons dans l'encadré suivant un second algorithme pour simuler
la probabilité de rupture à l'horizon h, étant donné un instant xé t. On suppose ici que
toutes les demandes sont satisfaites, sinon on prendrait le ux de sortie à la place de la
demande.
Algorithme 2 de simulation de la probabilité de rupture à l'horizon h.
Entrée : h horizon choisi
nSIM nombre de simulation
γ paramètre connu de la loi de la demande
λ = (λ1, λ2, λ3) paramètres connus de la loi des durées sur chaque itinéraire
Sortie : ph probabilité de rupture estimée
1. Tirer un échantillon de taille h suivant la loi Gamma de paramètre γ, soit d1, d2, ..., dh
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

FORMALISATION DU CADRE THÉORIQUE DE LA POLITIQUE DE GESTION DESTOCK 77
2. Parmi les dj demandes (j = 1, ..., h− 1), tirer aléatoirement les itinéraires empruntés
lors du transit, itinéraires pris parmi les trois considérés dans ce mémoire
3. On connait pour chaque j = 1, ..., h− 1, le nombre de GPS lancés dans chaque
itinéraire, soit nj,k, avec k = 1, 2, 3 : on tire alors nj,k durées suivant la distribution de
Poisson de paramètre λk4. On construit la variable indicatrice δ qui prend la valeur 1 si le GPS retourne le jour
h et 0 sinon, comme suit : en posant Tij la durée avant disponibilité du GPS i lancé le
jour j et tj sa date de départ, alors
δi,h =
1 si tj + Tij = h,
0 sinon.
5. On calcule rh =∑
i δi,h, le nombre de GPS retourné le jour h
6. Calculer probh par
probh =
1 si dh − rh > 0,
0 sinon.
7. Répéter 1-6 nSIM fois, et prendre nalement ph = 1nSIM
∑nSIMb=1 probh,b.
Résumé du chapitre
En résumé, ce chapitre se veut être une première tentative dans la mise en place d'une
politique (scientiquement recevable) de gestion de stock GPS. A cet eet, nous avons mon-
tré, dans ce chapitre, qu'il était possible d'adapter une politique de gestion de stock GPS à
point de commande pour le contexte de la Douane Camerounaise. De plus, nous avons
pu proposer deux à trois techniques d'estimation de la probabilité de rupture de stock entre
deux instants t et t+h, sous l'hypothèse qu'il n'y a pas de rupture, ni de réapprovisionnement
de GPS dans cet intervalle de temps (fermé à gauche et ouvert à droite).
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

CONCLUSION GÉNÉRALE 78
Conclusion Générale
L'objet de ce mémoire était de mettre en oeuvre des modèles de prévision capables
de prédire ecacement les valeurs futures de la demande et du ux de retour GPS à la
Douane Camerounaise, d'une part. D'autre part, d'élaborer une première tentative de for-
malisation du cadre théorique de politique de gestion appropriée au contexte de la Douane.
Nous avons mis en oeuvre quatre méthodes de prévision : trois méthodes de prévision en
valeur (lissage exponentiel de Holt-Winters, Box et Jenkins, retards échelonnés) et une
méthode de prévision en loi .
Pour la demande eective de GPS, nous avons utilisé les données journalières transformées
en logarithme (période de Novembre 2013 à Mars 2014) pour tester des modèles de prévision
à court terme . Les modèles de prévision en valeur, tels que le lissage exponentiel de Holt-
Winters, le modèle de Box et Jenkins ont été appliqués, et en termes de critère MAPE, la
méthode de Box et Jenkins s'est avérée être la plus performante (MAPE = 5.85%).
Une autre approche utilisée sur les données non transformées de la demande eective
de GPS est l'approche de prévision en loi . Avec celle-ci, nous avons montré que les
résultats prévisionnels obtenus sont satisfaisants, en termes de prédiction du nombre de fois
que l'évènement rupture aura lieu et aussi grâce au critère JRGPS.
Nous en déduisons que, pour les prévisions journalières de la demande eective de GPS,
la méthode de Box et Jenkins, auquel on associera la méthode de prévision en loi de proba-
bilité semble être la recette idéale.
Pour la prévision du ux de retour GPS, nous avons également utilisé les données jour-
nalières transformées en logarithme (période de Janvier 2013 à Mai 2014) pour estimer les
trois modèles envisagés : lissage exponentiel de Holt-Winters, Box et Jenkins et à retards
échelonnés. Il en ressort que, une fois de plus que, la méthode de Box et Jenkins est celle qui
performe le mieux, en termes de critère MAPE (MAPE = 7%). La méthode de prévision à
retards échelonnés pourrait également être considérée avec intérêt au cas où des informations
supplémentaires sont disponibles.
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

CONCLUSION GÉNÉRALE 79
En dénitive, pour la prévision des diérents ux physiques de GPS et compte de tenu
des résultats obtenus dans ce mémoire, nous pouvons retenir de manière uniforme et avec le
plus grand intérêt, la méthode de prévision en valeur de Box et Jenkins, qui donne des
valeurs prédites journalières plus proches de la réalité que ne l'est la méthode de lissage de
Holt-Winters, la méthode à retards échelonnés. Aussi, considérer la méthode de prévision
en loi de probabilité , notamment pour la prédiction de l'ampleur de la rupture de stock
GPS. D'autre part, en ce qui concerne la formalisation du cadre théorique de la politique
de gestion de stock au port de Douala, s'appuyant sur des études théoriques existantes dans
la littérature académique et sur nos propres connaissances, nous avons présenté tour à tour
une adaptation de la politique de point de commande , trois approches de calcul de la
probabilité de rupture de stock de GPS.
Limites. Les deux principales limites de ce travail sont : (1) la taille réduite des diérents
échantillons de données. C'est la raison pour laquelle il nous a été dicile d'appréhender
des aspects caractéristiques (comme la saisonnalité) dans la courbe d'évolution de nos deux
variables d'intérêt. En eet, pour des phénomènes liés aux conjonctures économiques tels que
ceux étudiés dans ce mémoire, il nous semble judicieux de prime abord de penser à la présence
d'une éventuelle saisonnalité trimestrielle ou annuelle. Ainsi, les analyses statistiques menées
sur ces séries chronologiques seraient plus indiquées si les observations sont mensuelles. La
preuve en est que nous avons pu repérer une saisonnalité de 4 mois dans la série du ux
de retour GPS, mais impossible de la modéliser vu la taille d'échantillon disponible ; (2)
l'indisponibilité des articles (payants) [16,18,19], ce qui a eu un impact non négligeable sur
les valeurs prédites de la série du ux de retour GPS. En eet, certains auteurs montrent que,
sous certaines hypothèses (que les données que nous disposons vérient), les informations
de type C et D présentées dans l'exposé de la méthode à retards échelonnés produisent des
valeurs prédites bien meilleures que l'information du type B utilisée dans ce mémoire.
Perspectives. Comme perspectives futures, nous pensons qu'il serait intéressant : (1) de
rendre disponible les diérents articles dont ont besoin certains travaux présentés dans ce
mémoire ; (2) pour améliorer davantage les prévisions, envisager comme dans [14] la méthode
de combinaison des prévisions, méthode qui a fait preuve d'ecacité prévisionnelle dans la
littérature générale de prévision en comparaison avec les modèles individuels, mais, qui a été
rarement utilisée dans la prédiction de la demande touristique et la demande du transport
aérien de passagers ; (3) améliorer la qualité du recueil des données et la quantité de données
disponibles, de sorte que l'on puisse mener des analyses sur une unité de temps mensuelle par
exemple ; (4) envisager un modèle de prédiction du ux de retour, non plus en considérant
uniquement une forme de loi spécique aux durées avant disponibilité de GPS (comme c'est
le cas dans ce mémoire avec la loi géométrique ou de Poisson), mais plutôt, une forme de
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

CONCLUSION GÉNÉRALE 80
distribution plus réaliste prenant en compte les co-variables qui inuencent la durée d'un
voyage.
Recommandations. A la lumière des diérentes analyses et les diérents résultats ob-
tenus au terme de cette étude, nous préconisons dans l'encadré suivant, un ensemble de
recommandations que pourront adopter le gestionnaire de stock GPS à la Douane Camerou-
naise, pour améliorer considérablement la qualité de ses services :
1. Sur les données
Tout au long de notre travail, nous avons constaté une instabilité dans l'évolution
chronologique des diérentes séries d'observations, et donc une instabilité dans les
données. Pour y faire face à l'avenir, nous préconisons de mettre en place une phase
de vérication du recueil de l'information brute, de sorte que, l'on ne retrouve plus
dans les bases de données des incohérences, du genre : un même voyage qui a deux
dates de départ diérentes. Nous préconisons également d'améliorer la qualité et la
quantité d'informations disponibles. Ce qui favorisera les agrégations de données
(en mois par exemple) et, sans doute la production des résultats prévisionnels
meilleurs.
2. Sur les méthodes de prévision
Dans ce mémoire, la méthode de prévision de Box et Jenkins semble être la plus
indiquée pour prévoir les valeurs futures des séries journalières transformées de la
demande eective et du ux de retour GPS. A cette méthode, peut être associée la
méthode de prévision en loi de probabilité pour prédire aussi l'ampleur de la rupture
de stock GPS. Nous suggérons, en cas d'observations mensuelles importantes : (i)
d'utiliser la méthode de lissage de Holt-Winters pour prédire la tendance du mois
ou des mois futurs ; (ii) d'utiliser, soit la méthode de Box et Jenkins, soit une
approche de combinaison de méthodes de prévision, pour prévoir les uctuations
journalières de la demande et du ux de retour. Cette approche de combinaison de
prévision suppose que l'on aecte un poids à chaque méthode selon le niveau de
précision souhaité.
3. Sur la politique de gestion de stock GPS
La politique de gestion de stock GPS actuelle à la Douane Camerounaise fait
face à d'énormes dicultés, notamment la gestion de ses ux de GPS. An de
s'éloigner des considérations subjectives du gestionnaire de stock et, ainsi dénir
de manière objective une politique de gestion adéquate, nous suggérons de mettre
en place une politique à point de commande adaptée au contexte douanier. En
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

CONCLUSION GÉNÉRALE 81
eet, la démarche que nous proposons est la suivante :
• considérer un horizon de planication mensuelle ;
• utiliser la méthode de prévision par lissage de Holt-Winters pour prédire la ten-
dance des observations d'un mois. Ce qui donnera une première idée sur la quantité
de GPS à commander au début du mois ; pour plus de précision, on peut ajuster
cette quantité commandée Q0 en tenant compte des prévisions journalières couplées
(données en bloc de deux jours) de la demande et du ux de retour GPS, des pré-
visions de la première semaine et éventuellement de la semaine d'après (méthode
Box et Jenkins, méthode en loi de probabilité) ;
• à un couple de jour t, si on ne prédit pas de rupture de stock GPS dans le prochaincouple de jour, on n'exécute aucune opération jusqu'à ce qu'on soit dans le couple
de jour t+ 1, et ainsi de suite. Si par contre, on prédit la rupture dans le prochain
couple de jour, alors, il est nécessaire à cet instant t, de passer une commande de
quantité Qt telle que dénie dans la formule (5.2).
comment prévoir la rupture de stock GPS ?
Pour prévoir la rupture dans le prochain couple de jour, le gestionnaire devra se
servir simultanément de tous les indicateurs de ruptures exposés dans ce mémoire,
notamment : Pt,1 donnée par la formule (5.6) ou (5.7), IRt+1 donnée par la formule
(5.5), ou encore la critère JRGPS donné par la formule (3.37).
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

COMPLÉMENTS MATHÉMATIQUES 82
Annexe A : Compléments
mathématiques
A.1. La densité spectrale [26]
La densité spectrale des processus stationnaires est une notion étroitement liée avec leurs
propriétés de corrélation. En eet, il est bien connu que les autocovariances d'un processus
stationnaire (Yt) coïncident avec les coecients de Fourier d'une mesure positive (appelée
mesure spectrale) dont on peut supposer qu'elle admet une densité par rapport à la mesure
de Lebesgue sur [−π, π]. Par souci de simplication, nous considérons ici les processus à
mémoire courte dont la fonction d'autocovariance est absolument sommable. Cela implique
par ailleurs que γ(h) tend vers zéro quand h grandit.
Dénition 5.2. Soit un processus (Yt) stationnaire de fonction d'autocovariance γ. Alors,
pour tout λ ∈ [−π, π], on appelle densité spectrale du processus, la fonction
fY (λ) =1
2π
∑h∈Z
γ(h) exp(−iλh).
De manière réciproque par transformation de Fourier inverse, on a également, pour tout
h ∈ Z,γ(h) =
∫[−π,π]
fY (λ) exp(iλh)dλ.
Lorsqu'on représente graphiquement une densité spectrale ou un spectre, on construit un
périodogramme.
A.2. Quelques détails sur la vraisemblance complète en cas de cen-
sure à droite
D'une manière générale, en analyse de survie, la censure est représentée par une variable
aléatoire C admettant la densité q, la fonction de répartition Q et la fonction de survie Q.
Dans le contexte usuel de censure à droite, l'information disponible est
T = min(X,C) et ∆ = 1X≤C .
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

COMPLÉMENTS MATHÉMATIQUES 83
Posons
∗ C1, ..., Cn ∼ L(q,Q,Q), où q est la densité de probabilité, Q est la fonction de répartition,
Q = 1−Q est la fonction de survie ;
∗ X1, ..., Xn ∼ g, la densité de probabilité ;
∗ λz = Pθ(Z = z) ;
∗ fz(x) = Pθ(X = x | Z = z) ⇔ Fz(x) = Pθ(X ≤ x | Z = z) ⇔ F z(x) = Pθ(X > x | Z =
z).
où Z est l'observation latente (non observée), et donc le triplet (T,∆, Z) ≡ (t, δ, z) forme les
données complètes.
On a alors :
Pθ(T = t, δ = 1, Z = z) = Pθ(X = t,X ≤ C | Z = z)Pθ(Z = z)
= Pθ(X ≤ C | X = t, Z = z)Pθ(X = t | Z = z)Pθ(Z = z)
= Pθ(C ≥ t | X = t, Z = z)Pθ(X = t | Z = z)Pθ(Z = z)
= Pθ(C ≥ t | X = t)Pθ(X = t | Z = z)Pθ(Z = z)
car X = t, Z = z ≡ X = t= Pθ(C ≥ t)Pθ(X = t | Z = z)Pθ(Z = z)
car C indépendant de X (Hypothèse de censure non informative).
De même, nous avons :
Pθ(T = t, δ = 0, Z = z) = Pθ(T = t,X > C | Z = z)Pθ(Z = z)
= Pθ(C = t,X > C | Z = z)Pθ(Z = z)
= Pθ(X > C | C = t, Z = z)Pθ(C = t | Z = z)Pθ(Z = z)
= Pθ(X > t | C = t, Z = z)Pθ(C = t | Z = z)Pθ(Z = z)
= Pθ(X > t | Z = z)Pθ(C = t)Pθ(Z = z).
Comme
Pθ(t, δ, z) =[λzfz(t)Q(t)
]δ[λzq(t)F z(t)
]1−δ,
alors, la vraisemblance complète Vc s'écrit :
Vc =n∏i=1
Pθ(ti, δi, zi)
=n∏i=1
[λzifzi(ti)Q(ti)
]δi[λziq(ti)F zi(ti)]1−δi
=n∏i=1
[λzifzi(ti)
]δi[λziF zi(ti)]1−δi[Q(ti)
]δi[q(ti)]1−δi .Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

COMPLÉMENTS MATHÉMATIQUES 84
Et la log-vraisemblance devient :
logVc =n∑i=1
log[λzifzi(ti)
]δi[λziF zi(ti)]1−δi[Q(ti)
]δi[q(ti)]1−δi=
n∑i=1
log f c(ti, δi, Zi | θ),
où f c(t, δ, Z | θ) =[λzfz(t)
]δ[λzF z(t)
]1−δ × [Q(t)]δ[q(t)
]1−δ.
A.3. Preuves pour les équations (3.21) et (3.22)
E(a | z, δ; p, q) = E( n∑i=1
δi | z, δ; p, q)
=n∑i=1
P(δi | z, δ; p, q)
= m+n∑
i=m+1
P(δi | z, δ; p, q)
= m+n∑
i=m+1
P(z, δ | δi = 1; p, q)P(δi = 1; p, q)
P(z, δ; p, q)
= m+n∑
i=m+1
P(z, δ | δi = 1; p, q)P(δi = 1 | p, q)P(p, q)
P(z, δ | p, q)P(p, q)
= m+n∑
i=m+1
P(z, δ | δi = 1; p, q)P(δi = 1 | p, q)P(z, δ | p, q)
= m+n∑
i=m+1
P(z, δ | δi = 1; p, q)P(δi = 1 | p, q)P(z, δ | δi = 0; p, q) + P(z, δ | δi = 1; p, q)
= m+n∑
i=m+1
p(1− q)t−si+1
1− p+ p(1− q)t−si+1;
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

COMPLÉMENTS MATHÉMATIQUES 85
E( n∑i=1
1ri<∞(ri − si) | z, δ; p, q)
=n∑i=1
E(1ri<∞(ri − si) | z, δ; p, q
)=
m∑i=1
(ri − si) +n∑
i=m+1
E(1ri<∞(ri − si) | z, δ; p, q
)=
m∑i=1
(ri − si) +n∑
i=m+1
E(ri − si | ri <∞, z, δ; p, q
)× P(ri <∞ | z, δ; p, q) car E(X1A) = E(X | A)P(A)
=m∑i=1
(ri − si) +n∑
i=m+1
E(ri − t+ t− si | ri <∞, z, δ; p, q
)× P(ri <∞ | z, δ; p, q)
=m∑i=1
(ri − si) +n∑
i=m+1
[(ri − t) + E
(t− si | ri <∞, z, δ; p, q
)]× P(ri <∞ | z, δ; p, q)
=m∑i=1
(ri − si) +n∑
i=m+1
[(ri − t) + E
(t− si | ri <∞, z, δ; p, q
)]× P(δi | z, δ; p, q).
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

TESTS D'HYPOTHÈSES (DÉFINITIONS ET EXEMPLES) 86
Annexe B : Tests d'hypothèses
(Dénitions et Exemples)
Nous donnons, sommairement, ci-après, la dénition basique d'un test d'hypothèse, à
la suite de laquelle nous présenterons quelques exemples, notamment en rapport avec ceux
utilisés dans le cadre de ce mémoire.
B.1. Test d'hypothèse
Un test statistique est un outil pratique d'aide à la décision quand il s'agit de vérier
une hypothèse. Il nous permet de trancher entre deux hypothèses, l'une dite nulle ou
fondamentale (notée habituellement H0) et l'autre alternative (H1), au vu des résultats
d'un échantillon. La décision conduira à retenir l'une d'entre elles, en commettant un risque
de se tromper. Une fois les hypothèses formulées, la deuxième étape consiste à xer la pro-
babilité α (probabilité de rejeter H0 alors que H0 est vraie).
Ensuite, il importe de choisir une variable de décision, ou statistique de test , dont
la distribution sous H0 doit être connue, an de pouvoir y situer la valeur que prend la
statistique pour l'échantillon que l'on dispose.
B.2. Le test de Pettitt, test de rupture en moyenne
Pettitt reprend le fondement du test de Mann-Whitney en le modiant. Le test de Pettitt est
un test de rang : il est donc non paramétrique. Ce test est réputé robuste et ses performances
en termes de puissance sont supérieures à celles du test de Wilcoxon et de sa version adaptée
à l'étude de la stationnarité. Les hypothèses du test sont :
H0 : L'absence de rupture dans l'évolution moyenne de la série (yi) de taille n;
H1 : Présence de rupture dans l'évolution moyenne de la série (yi) de taille n.
La mise en oeuvre du test suppose que ∀t = 1, ..., n les séries chronologiques (yi)i=1,...,t
et (yi)t+1,...,n appartiennent à la même population. La variable à tester est le maximum en
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

TESTS D'HYPOTHÈSES (DÉFINITIONS ET EXEMPLES) 87
valeur absolue de la variable Ut,n dénie par :
U1,n =t∑i=1
n∑j=t+1
sgn(yi − yj),
où
sgn(y) =
1 si y > 0
0 si y = 0
−1 si y < 0
(5.8)
Si l'hypothèse nulle est rejetée, une estimation de la date de rupture est donnée par l'instant t
dénissant le maximum en valeur absolue de la variable Ut,n. On noteKn = maxt=1,...,n−1 |Ut,n|.A partir du test de rang, Pettitt montre que si kn désigne la valeur de Kn prise sur la série,
sous H0, la probabilité de dépassement de la valeur kn est donnée par :
pkn = P(Kn > kn) ≈ 2 exp(−6k2nn3 + n2
).
Au risque α, pkn < α entraine le rejet de H0.
B.3. Comment détecter en amont la présence d'une non stationnarité ?
Pour détecter en amont la présence d'une non stationnarité dans la série chronologique, une
panoplie de tests statistiques existent en pratique. Mais les plus utilisés dans le domaine
de la prévision sont : les tests de présence d'une racine unitaire (le test de Dickey-Fuller
augmenté, que l'on note communément test ADF pour augmented Dickey-Fuller et le
test de Phillips-Perron, noté test PP .) et les tests de stationnarité (le test de Kwiatkowski-
Phillips-Schmidt-Shin, noté test KPSS ). On peut retrouver toute la théorie sous-jacente
à ces diérents tests statistiques dans [1,26].
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014
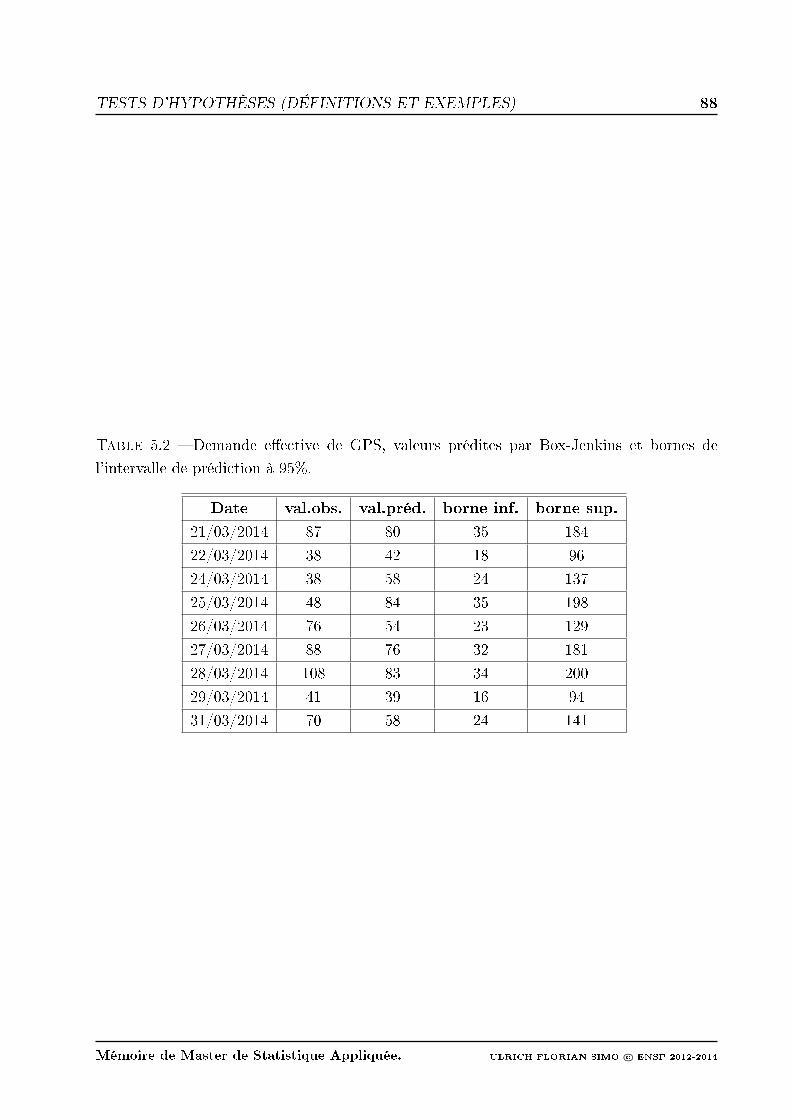
TESTS D'HYPOTHÈSES (DÉFINITIONS ET EXEMPLES) 88
Table 5.2 Demande eective de GPS, valeurs prédites par Box-Jenkins et bornes de
l'intervalle de prédiction à 95%.
Date val.obs. val.préd. borne inf. borne sup.
21/03/2014 87 80 35 184
22/03/2014 38 42 18 96
24/03/2014 38 58 24 137
25/03/2014 48 84 35 198
26/03/2014 76 54 23 129
27/03/2014 88 76 32 181
28/03/2014 108 83 34 200
29/03/2014 41 39 16 94
31/03/2014 70 58 24 141
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014
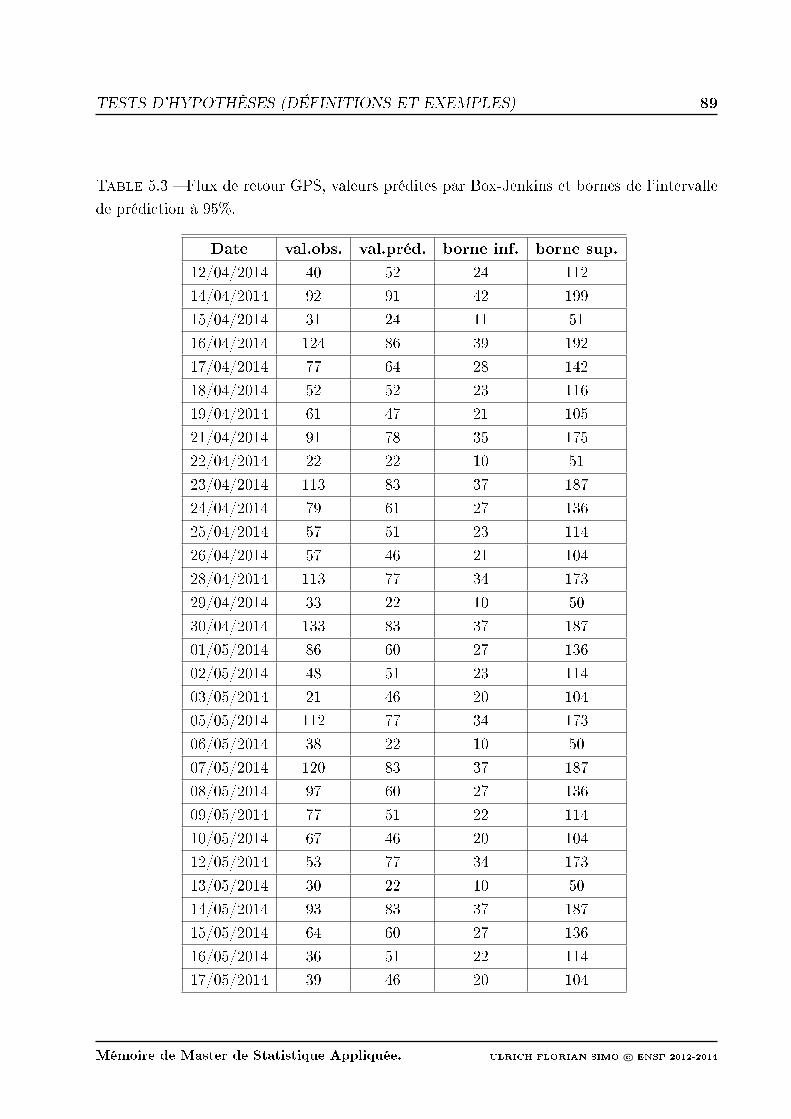
TESTS D'HYPOTHÈSES (DÉFINITIONS ET EXEMPLES) 89
Table 5.3 Flux de retour GPS, valeurs prédites par Box-Jenkins et bornes de l'intervalle
de prédiction à 95%.
Date val.obs. val.préd. borne inf. borne sup.
12/04/2014 40 52 24 112
14/04/2014 92 91 42 199
15/04/2014 31 24 11 51
16/04/2014 124 86 39 192
17/04/2014 77 64 28 142
18/04/2014 52 52 23 116
19/04/2014 61 47 21 105
21/04/2014 91 78 35 175
22/04/2014 22 22 10 51
23/04/2014 113 83 37 187
24/04/2014 79 61 27 136
25/04/2014 57 51 23 114
26/04/2014 57 46 21 104
28/04/2014 113 77 34 173
29/04/2014 33 22 10 50
30/04/2014 133 83 37 187
01/05/2014 86 60 27 136
02/05/2014 48 51 23 114
03/05/2014 21 46 20 104
05/05/2014 112 77 34 173
06/05/2014 38 22 10 50
07/05/2014 120 83 37 187
08/05/2014 97 60 27 136
09/05/2014 77 51 22 114
10/05/2014 67 46 20 104
12/05/2014 53 77 34 173
13/05/2014 30 22 10 50
14/05/2014 93 83 37 187
15/05/2014 64 60 27 136
16/05/2014 36 51 22 114
17/05/2014 39 46 20 104
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

PROGRAMMES R 90
Annexe C : Programmes R
Nous donnons, dans cette section, l'ensemble des codes R qui nous semble substantiel
pour l'implémentation ou la ré-implémentation des résultats exposés dans ce mémoire.
## chargement des packages R complémentaires
require(caschrono)
require(tseries)
require(forecast)
require(fBasics)
require(FinTS)
#############################
## Préparation des données ##
#############################
## importation des données (stringsAsFactors évite que les entiers ou les chaines
## ne soient transformés en facteurs)
donnee1.chr <- read.csv("C:/Users/FLORIAN/Desktop/donneeDemandeGPS.csv",sep=";",
stringsAsFactors=FALSE)
donnee2.chr <- read.csv("C:/Users/FLORIAN/Desktop/donneeFluxsortieGPS.csv",sep=";",
stringsAsFactors=FALSE)
donnee3.chr <- read.csv("C:/Users/FLORIAN/Desktop/donneeRetourGPS.csv",sep=";",
stringsAsFactors=FALSE)
## examen de la structure de l'objet obtenu après importation
str(donnee1.chr,width=60,strict.width="cut")
str(donnee2.chr,width=60,strict.width="cut")
str(donnee3.chr,width=60,strict.width="cut")
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

PROGRAMMES R 91
## récupération de la date
date1 <- as.Date(donnee1.chr$date,"%d/%m/%Y")
donnee1.date <- data.frame(weekdays(date1),date1,donnee1.chr$nombre)
colnames(donnee1.date) <- c("jour","date","nombre")
#View(donnee1.date)
## repérage des manquants et interprétations
jour1.off <- donnee1.date$jour[which(is.na(donnee1.chr$nombre)==TRUE)]
date1.off <- donnee1.date$date[which(is.na(donnee1.chr$nombre)==TRUE)]
paste(jour1.off,date1.off,sep=" ")
## vérifions qu'il n y a pas de jours manquants
data1 <- seq(from = as.Date("01/11/2013","%d/%m/%Y"),to = as.Date("31/03/2014",
"%d/%m/%Y"),by = "day")
aa1 <- which(weekdays(data1)!= "dimanche")
c(nrow(donnee1.date),length(aa1))
## imputations des manquants
index1.off <- which(is.na(donnee1.date$nombre)==TRUE)
nb1 <- donnee1.date$nombre
donnee1.date$nombre[index1.off] <- round(mean(nb1,na.rm=TRUE),0)
## récupération de la date
date2 <- as.Date(donnee2.chr$date,"%d/%m/%Y")
donnee2.date <- data.frame(weekdays(date2),date2,donnee2.chr$nombre)
colnames(donnee2.date) <- c("jour","date","nombre")
## vérifions qu'il n y a pas de jours manquants
data2 <- seq(from = as.Date("03/01/2011","%d/%m/%Y"),to = as.Date("17/05/2014",
"%d/%m/%Y"),by = "day")
aa2 <- which(weekdays(data2)!= "dimanche")
c(nrow(donnee2.date),length(aa2))
## imputations des manquants
index2.off <- which(is.na(donnee2.date$nombre)==TRUE)
nb2 <- donnee2.date$nombre
donnee2.date$nombre[index2.off] <- round(mean(nb2,na.rm=TRUE),0)
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

PROGRAMMES R 92
## récupération de la date
date3 <- as.Date(donnee3.chr$date,"%d/%m/%Y")
donnee3.date <- data.frame(weekdays(date3),date3,donnee3.chr$nombre)
colnames(donnee3.date) <- c("jour","date","nombre")
## vérifions qu'il n'y a pas de jours manquants
data3 <- seq(from = as.Date("31/12/2012","%d/%m/%Y"),to = as.Date("17/05/2014",
"%d/%m/%Y"),by = "day")
aa3 <- which(weekdays(data3)!= "dimanche")
c(nrow(donnee3.date),length(aa3))
nb1 <- donnee1.date$nombre
nb2 <- donnee2.date$nombre
nb3 <- donnee3.date$nombre
###################################################
## Section 2.2 : Analyse descriptive des données ##
###################################################
#### Chonogramme des observations ####
## série de la demande effective
y1 <- ts(nb1,start=c(2013,11+(4/7)),frequency=1)
t1 <- time(y1)
plot(y1,xlab="Temps",ylab="Demande effective",xaxt="n",lwd=2,type="o",cex.lab=1.5)
axis(1,at=c(t1[1],t1[52],t1[129]),labels=c("01-nov-2013","31-dec-2013",
"31-mars-2014"))
## série du flux de sortie
#agrégation des données en semaine
sem2 <- c()
for (i in 1:176) sem2[i] <- sum(nb2[(6*(i-1)+1):(6*(i-1)+6)])
y2 <- ts(sem2,start=c(2011,1+(1/4)),frequency=52)
t2 <- time(y2)
plot(y2,xlab="Temps",ylab="Flux de sortie",xaxt="n",lwd=2,type="o",cex.lab=1.5)
axis(1,at=c(t2[1],t2[53],t2[105],t2[157],t2[176]),
labels=c("sem.03-jan-2011","sem.02-jan-2012","sem.01-jan-2013","sem.01-jan-2014",
"sem.17-mai-2014"))
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

PROGRAMMES R 93
## série du flux de retour
y3 <- ts(donnee3.date$nombre,start=c(2013,1+(2/7)),frequency=312)
t3 <- time(y3)
plot(y3,xlab="Temps",ylab="Flux de retour",xaxt="n",cex.lab=1.5,lwd=2,type="o")
axis(1,at=c(t3[1],t3[67],t3[156],t3[314],t3[431]),
labels=c("01-jan-2013","01-avr-2013","01-juil-2013","01-jan-2014","17-mai-2014"))
#### Normalité des séries d'observations ####
par(mfrow=c(1,3))
hist(y1,freq=FALSE,xlab="Observations",ylab="Densité",font.lab=4,main="Demande GPS")
curve(dnorm(x,mean(y1),sd(y1)),type="l",add=TRUE,lwd=2)
hist(y2,freq=FALSE,xlab="Observations",ylab="Densité",font.lab=4,main="Flux de sortie GPS")
curve(dnorm(x,mean(y2),sd(y2)),type="l",add=TRUE,lwd=2)
hist(y3,freq=FALSE,xlab="Observations",ylab="Densité",font.lab=4,main="Flux de retour GPS")
curve(dnorm(x,mean(y3),sd(y3)),type="l",add=TRUE,lwd=2)
layout(1)
## test de normalité
shapiro.test(y1)
shapiro.test(y2)
shapiro.test(y3)
jarqueberaTest(y1)
jarqueberaTest(y2)
jarqueberaTest(y3)
#### Etude de la saisonnalité ####
## périodogramme flux de sortie
spectrum(y2,xlab="Fréquence",ylab="Spectre",font.lab=4,lwd=2,main="")
## lag plot des observations du flux de retour
lag.plot(rev(y3),12,layout=c(4,3),pch="+",do.lines=FALSE,diag.col=1)
## périodogramme flux de retour
spectrum(y3,xlab="Fréquence",ylab="Spectre",font.lab=4,lwd=2,main="")
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

PROGRAMMES R 94
#### Calcul de quelques statistiques usuelles ####
## coefficient de corrélation
cor(nb2[625:1056],nb3)
## statistiques descriptives usuelles
summary(y1)
sd(y1)
summary(y2)
sd(y2)
summary(y3)
sd(y3)
#### Loi de probabilité du délai de retour GPS ####
## importation des données
duree_avd <- read.table("C:/Users/FLORIAN/Desktop/Duree_avd.csv", quote="\"")
duree_avd <- duree_avd$V1
summary(duree_avd)
sd(duree_avd)
## distribution des données
boxplot(duree_avd,horizontal=TRUE)
Q1 <- quantile(duree_avd,probs = 0.25,na.rm = TRUE)
Q3 <- quantile(duree_avd,probs = 0.75,na.rm = TRUE)
aa <- which(duree_avd >= Q3+1.5*(Q3-Q1))
length(aa)
duree_avd[aa] <- NA
duree_avd[aa] <- round(mean(duree_avd,na.rm=TRUE),0)
## résumé statistique après imputation
summary(duree_avd)
sd(duree_avd)
## estimation paramétrique de la loi
# geometrique
q <- 1/mean(duree_avd)
# poisson
lambda <- mean(duree_avd)
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

PROGRAMMES R 95
# binomiale négative
r <- mean(duree_avd)^2/(var(duree_avd) + mean(duree_avd))
p <- mean(duree_avd)/(var(duree_avd) + mean(duree_avd))
## graphique comparatif
x <- seq(1,14,length=1000)
plot(ecdf(duree_avd),verticals=TRUE,col=1,col.01line="gray70",pch = 16,lty=2,
ylab=expression(F[Y](y)),xlab="y",main=" ",lwd=2,do.points=FALSE)
F1 <- ppois(x,lambda,lower.tail=TRUE)
lines(x,F1,type="l",lwd=2,col=1,lty=1)
F2 <- pgeom(x,q,lower.tail=TRUE)
lines(x,F2,type="l",lwd=2,col=1,lty=3)
F3 <- pnbinom(x,r,p,lower.tail=TRUE)
lines(x,F3,type="l",lwd=2,col=1,lty=4)
legend(x=8,y=0.4,legend=c("empirique","Poisson","géométrique","binomiale négative"),
lwd=2,col=1,lty=c(2,1,3,4))
##########################################################
## Chapitre 4 : Applications aux Données et Résultats ##
##########################################################
# Nous présentons tout d'abord les quelques fonctions auxiliaires
# que nous avons implémenté dans le cadre de ce chapitre
################################################################
## Fonction R : test de détection d'un point de rupture en ##
## moyenne dans la série ##
##------------------------------------------------------------##
## ** Données : ##
## - y : une série d'observations ##
##------------------------------------------------------------##
## ** Résultat : ##
## - prob : probabilité critique ##
## - rupture : indicateur de rupture ##
################################################################
testdepettitt <- function (y)
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

PROGRAMMES R 96
N <- length(y)
rupture <- 0
Kcal <- 0
p.min <- .05
for (t in 1:(N-1))
u <- 0
for (i in 1:t)
for (j in (t+1):N)
Dij <- sign(y[i]-y[j])
u <- u + Dij
if (abs(u) > Kcal) Kcal <- abs(u)
prob <- 2*exp(-6*Kcal*Kcal/(N*N*N+N*N))
if (prob < p.min) rupture <- 1
return(c(prob,rupture))
################################################################
## Fonction R : validation croisée pour les histogrammes [8] ##
##------------------------------------------------------------##
## ** Données : ##
## - y : échantillon d'apprentissage ##
##------------------------------------------------------------##
## ** Résultat : nombre de partition optimale ##
################################################################
VC_hist <- function(y)
n <- length(y); a <- min(y); b <- max(y); m_VC <- 1
J0 <- 2/(n-1); J <- 1:(n-1)
for (m in 2:(n-1))
l <- (b-a)/m
hatp <- 1:m
A <- (1:m)%*%t((1:n)*0+1)
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

PROGRAMMES R 97
yy <- ( (1:m)*0 + 1 ) %*% t((y-a)/l)
hatp <- rowSums( ((A-1) <= yy) * (yy < A) ) / n
J[m-1] <- 2-(n+1) * sum(hatp^2)
remove(hatp)
J[m-1] <- J[m-1]/((n-1)*l)
if (J[m-1] < J0)
m_VC <- m
J0 <- J[m-1]
op <- par(mfcol=c(1,2),pty="m",omi=c(0,0,0,0))
plot(1:(n-1),J,type="l",lwd=2,col=1,xlab="nb de classes",ylab="VC",
main="La courbe de la fonction de validation croisée")
l <- (b-a)/m_VC
hatf <- 1:m_VC
n <- length(y)
m <- m_VC
for (j in 1:m)
hatf[j] <- sum( ( a + (j-1)*l <= y ) * (y < a+ j*l) ) / (n*l)
yleft <- a - l + (1:m)*l
yright <- yleft + l
ybottom <- (1:m)*0
ytop <- hatf
plot(c(a-l/n,yleft,b),c(0,hatf,0),type="n",xlab="Les classes",
ylab="Estimateur de densité",main="Histogramme avec le nb de classes optimal")
rect(yleft, ybottom, yright, ytop, border = 1, lwd = 1)
par(op)
return(m_VC)
################################################################
## Fonction R : trace le graphe de l'histogramme à m classes ##
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

PROGRAMMES R 98
##------------------------------------------------------------##
## ** Données : ##
## - y : échantillon d'apprentissage ##
## - m : nombre de classe ##
##------------------------------------------------------------##
## ** Résultat : un graphique ##
################################################################
histogram <- function(y,m,add,...)
a <- min(y); b <- max(y); l <- (b-a)/m ; hatf <- 1:m ; n <- length(y)
for (j in 1:m)
hatf[j] <- sum ( ( a + (j-1)*l <= y ) * ( y < a + j*l ) ) / (n*l)
yleft <- a - l + (1:m)*l
yright <- yleft + l
ybottom <- (1:m)*0
ytop <- hatf
if (add == F)
plot(c(a-l,yleft,b),c(0,hatf,0),type="n",xlab="Les classes",
ylab="Estimateur de densité",...)
rect(yleft, ybottom, yright, ytop, border = 1, lwd = 1)
else rect(yleft, ybottom, yright, ytop, border = 1, lwd = 1)
################################################################
## Fonction R : valeur de la fenêtre optimale qui minimise ##
## le critère de validation croisée [8] ##
##------------------------------------------------------------##
## ** Données : ##
## - y : échantillon d'apprentissage ##
##------------------------------------------------------------##
## ** Résultat : valeur de la fenêtre optimale ##
################################################################
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

PROGRAMMES R 99
VC_kern <- function(y)
n <- length(y) ; a <- min(y) ; b <- max(y) ; l_VC <- (b-a)/n
J0 <- 2*dnorm(0)/(n*l_VC)
yy <- ( (1:n)*0+1 ) %*% t((y)) - t( ((1:n)*0+1) %*% t((y)) )
J <- 1:n
for (m in 1:n)
l <- m*(b-a)/n
J[m] <- 2*dnorm(0)/(n*l)+(1/(n^2*l))*sum(dnorm(yy/l,0,sqrt(2))-2*dnorm(yy/l))
if (J[m] < J0)
l_VC <- l
J0 <- J[m]
op <- par(mfcol=c(1,2),pty="m",omi=c(0,0,0,0))
plot((1:n)*(b-a)/n,J,type="l",lwd=2,col=1,xlab="fenêtre",ylab="VC"
main="La courbe de la fonction de validation croisée")
n <- length(y)
a <- min(y)
b <- max(y)
tt <- ( a+(b-a)*(1:500)/500 ) %*% t((1:n)*0 + 1)
yy <- ((1:500)*0+1) %*% t(y)
z <- (yy-tt)/l_VC
hatf <- (1/(n*l_VC)) * as.vector(rowSums(dnorm(z)))
plot(a+(b-a)*(1:500)/500,hatf,type="l",col=1,lwd=2,xlab="",ylab=""
main="Estimateur à noyau avec la fenêtre optimale")
par(op)
return(l_VC)
############################################################
## Section 4.1 : Prévision de la demande effective de GPS ##
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014
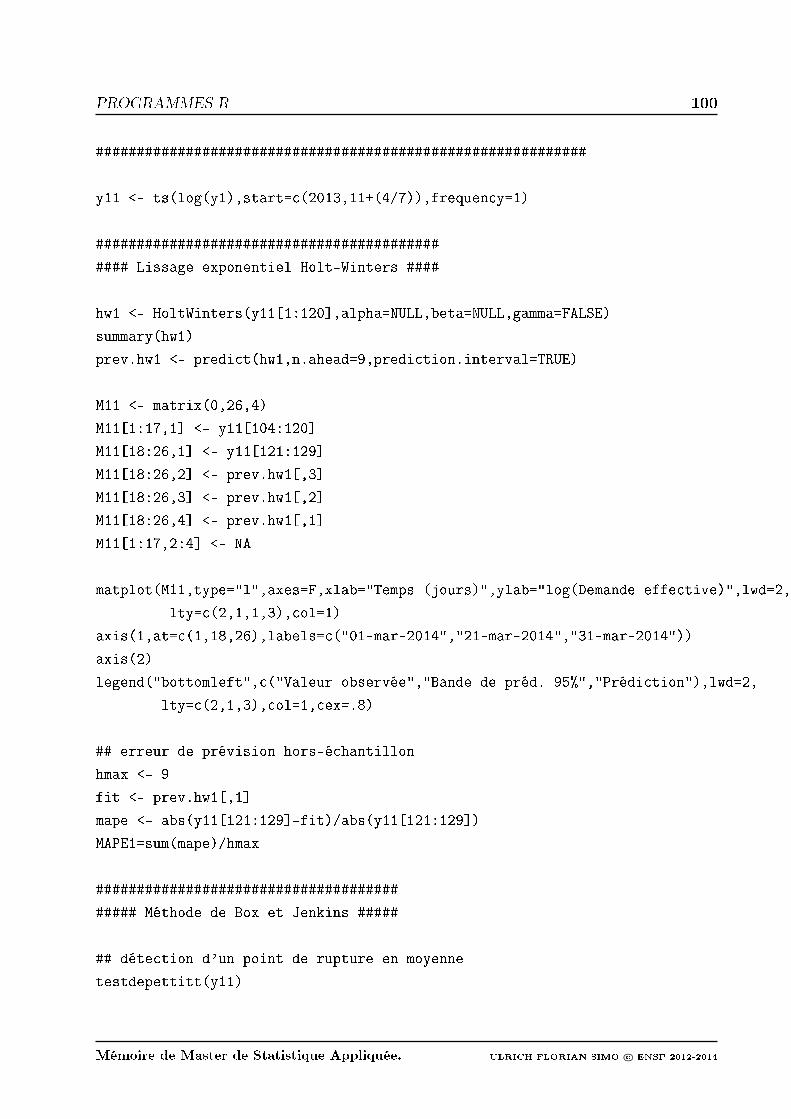
PROGRAMMES R 100
############################################################
y11 <- ts(log(y1),start=c(2013,11+(4/7)),frequency=1)
##########################################
#### Lissage exponentiel Holt-Winters ####
hw1 <- HoltWinters(y11[1:120],alpha=NULL,beta=NULL,gamma=FALSE)
summary(hw1)
prev.hw1 <- predict(hw1,n.ahead=9,prediction.interval=TRUE)
M11 <- matrix(0,26,4)
M11[1:17,1] <- y11[104:120]
M11[18:26,1] <- y11[121:129]
M11[18:26,2] <- prev.hw1[,3]
M11[18:26,3] <- prev.hw1[,2]
M11[18:26,4] <- prev.hw1[,1]
M11[1:17,2:4] <- NA
matplot(M11,type="l",axes=F,xlab="Temps (jours)",ylab="log(Demande effective)",lwd=2,
lty=c(2,1,1,3),col=1)
axis(1,at=c(1,18,26),labels=c("01-mar-2014","21-mar-2014","31-mar-2014"))
axis(2)
legend("bottomleft",c("Valeur observée","Bande de préd. 95%","Prédiction"),lwd=2,
lty=c(2,1,3),col=1,cex=.8)
## erreur de prévision hors-échantillon
hmax <- 9
fit <- prev.hw1[,1]
mape <- abs(y11[121:129]-fit)/abs(y11[121:129])
MAPE1=sum(mape)/hmax
#####################################
##### Méthode de Box et Jenkins #####
## détection d'un point de rupture en moyenne
testdepettitt(y11)
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

PROGRAMMES R 101
## test de stationnarité
PP.test(y11)
adf.test(y11)
kpss.test(y11)
## autocorrélogramme
par(mfrow=c(1,2))
acf(y11,xlab="retard",main="",lwd=2)
pacf(y11,xlab="retard",main="",lwd=2)
layout(1)
dy11 <- diff(y11,6)
xy.acfb(diff(y11,6),numer=FALSE)
## autocorrélogramme de la série différenciée
par(mfrow=c(1,2))
acf(dy11,xlab="retard",main="",lwd=2)
pacf(dy11,xlab="retard",main="",lwd=2)
layout(1)
## modèle
mod <- arima(y11[1:120],seasonal=list(order=c(0,1,1),period=6),
include.mean=FALSE,method="ML")
summary(mod)
t_stat(mod)
## autocorrélogramme des résidus estimés
par(mfrow=c(1,2))
acf(residuals(mod),xlab="retard",main="",lwd=2)
pacf(residuals(mod),xlab="retard",main="",lwd=2)
layout(1)
## modèle
modbis <- arima(y11[1:120],order=c(2,0,0),seasonal=list(order=c(0,1,1),
period=6),include.mean=FALSE,method="ML")
t_stat(modbis)
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

PROGRAMMES R 102
Box.test(residuals(modbis),type="Box-Pierce")
Box.test(residuals(modbis),type="Ljung-Box")
## autocorrélogramme des résidus estimés
par(mfrow=c(1,2))
acf(residuals(modbis),xlab="retard",main="",lwd=2)
pacf(residuals(modbis),xlab="retard",main="",lwd=2)
layout(1)
summary(modbis)
modbisbis <- arima(y11[1:120],order=c(2,0,0),seasonal=list(order=c(0,1,1),period=6),
include.mean=FALSE,
fixed=c(0,NA,NA),method="ML")
summary(modbisbis)
Box.test(residuals(modbisbis),type="Box-Pierce")
Box.test(residuals(modbisbis),type="Ljung-Box")
t_stat(modbisbis)
shapiro.test(residuals(modbisbis))
jarqueberaTest(residuals(modbisbis))
## prévision
prev1 <- forecast(modbisbis,h=9,level=95)
M12 <- matrix(0,26,4)
M12[1:17,1] <- y11[104:120]
M12[18:26,1] <- y11[121:129]
M12[18:26,2] <- prev1$lower
M12[18:26,3] <- prev1$upper
M12[18:26,4] <- prev1$mean
M12[1:17,2:4] <- NA
matplot(M12,type="l",axes=F,xlab="Temps (jours)",ylab="log(Demande effective)",lwd=2,
lty=c(2,1,1,3),col=1)
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

PROGRAMMES R 103
axis(1,at=c(1,18,26),labels=c("01-mar-2014","21-mar-2014","31-mar-2014"))
axis(2)
legend("topleft",c("Valeur observée","Bande de préd. 95%","Prédiction"),lwd=2,
lty=c(2,1,3),col=1,cex=.8)
## erreur de prévision hors-échantillon
hmax <- 9
mape <- abs(y11[121:129]-prev1$mean)/abs(y11[121:129])
MAPE1=sum(mape)/hmax
################################################################
## Section 4.2 : Prévision en loi de la demande effective GPS ##
################################################################
## nombre de classe optimal
mVC = CV_hist(nb1)
## histogramme avec ce nombre de partitionnement
nb <- nb1[1:120]
n <- length(nb)
m1 <- mean(nb)
a1 <- (m1^2)/var(nb)
lamb1 <- m1/var(nb)
yb <- log(nb)
mu1 <- mean(yb)
sigma1 <- sd(yb)
histogram(nb,mVC,add=F,main="ajustement Gamma",ylim=c(0,0.020))
curve(dgamma(x,a1,lamb1),type="l",col=1,add=TRUE,lwd=2)
## test de la distance de Kolmogorov pour le choix final
ks.test(nb,"pgamma",a1,lamb1)$p.value
ks.test(nb,"plnorm",mu1,sigma1)$p.value
## choix de la fenêtre par validation croisée
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

PROGRAMMES R 104
lVC = CV_kern(nb1)
## trace côte à côte l'histogramme et l'estimateur à noyau optimaux
op=par(mfcol=c(1,2),pty="m",omi=c(0,0,0,0))
histogram(nb,mVC,add=F,ylim=c(0,0.02))
curve(dgamma(x,a1,lamb1),type="l",col=1,add=TRUE,lwd=2,lty=1)
legend("topleft",legend=c("ajustement gamma"),col=1,lty=1,lwd=2,cex=.9)
f=KernelEst(nb,lVC,"Gaus",ylim=c(0,0.02),lty=2)
curve(dgamma(x,a1,lamb1),col=1,add=TRUE,lwd=2,lty=1)
legend("topleft",legend=c("kernel estimator","gamma density"),col=1,lty=c(2,1),lwd=2,cex=.9)
par(op)
Q1 <- quantile(nb, probs = 0.025, na.rm = TRUE)
Q3 <- quantile(nb, probs = 0.975, na.rm = TRUE)
M14 <- matrix(0,26,4)
M14[1:17,1] <- y1[104:120]
M14[18:26,1] <- y1[121:129]
M14[18:26,2] <- rep(Q1,9)
M14[18:26,3] <- rep(Q3,9)
M14[18:26,4] <- rep(a1/lamb1,9)
M14[1:17,2:4] <- NA
matplot(M14,type="l",xaxt="n",xlab="Temps (jours)",ylab="Demande effective",lwd=2,
lty=c(2,1,1,3),col=1,main="Prévision en loi de probabilité")
axis(1,at=c(1,18,26),labels=c("01-mar-2014","21-mar-2014","31-mar-2014"))
axis(2)
legend("topleft",c("Valeur observée","Bande de préd. 95%","Prédiction"),lwd=2,
lty=c(2,1,3),col=1,cex=.8)
###################################################
## Section 4.2 : Prévision du flux de retour GPS ##
###################################################
y33 <- ts(log(y3),start=c(2013,1+(2/7)),frequency=312)
##########################################
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

PROGRAMMES R 105
#### Lissage exponentiel Holt-Winters ####
hw3 <- HoltWinters(y33[1:400],alpha=NULL,beta=NULL,gamma=FALSE)
c(hw3$alpha, hw3$beta, hw3$gamma)
summary(hw3)
prev.hw3 <- predict(hw3,n.ahead=31,prediction.interval=TRUE)
M31 <- matrix(0,61,4)
M31[1:30,1] <- y33[372:401]
M31[31:61,1] <- y33[402:432]
M31[31:61,2] <- prev.hw3[,3]
M31[31:61,3] <- prev.hw3[,2]
M31[31:61,4] <- prev.hw3[,1]
M31[1:30,2:4] <- NA
matplot(M31,type="l",axes=F,xlab="Temps (jours)",ylab="log(Flux de retour)",lwd=2,
lty=c(2,1,1,3))
axis(1,at=c(1,31,61),labels=c("08-mar-2014","12-avr-2014","17-mai-2014"))
axis(2)
legend("bottomleft",c("Valeur observée","Bande de préd. 95%","Prédiction"),lwd=2,
lty=c(2,1,3),cex=.8)
## erreur de prévision hors-échantillon
hmax <- 31
fit <- prev.hw3[,1]
mape <- abs(y33[402:432]-fit)/abs(y33[402:432])
MAPE3=sum(mape)/hmax
#####################################
##### Méthode de Box et Jenkins #####
## test de stationnarité
PP.test(y33)
adf.test(y33)
kpss.test(y33)
## autocorrélogramme
par(mfrow=c(1,2))
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

PROGRAMMES R 106
acf(y33,xlab="retard",main="",lwd=2)
pacf(y33,xlab="retard",main="",lwd=2)
layout(1)
dy33 <- diff(y33,6)
xy.acfb(diff(y33,6),numer=FALSE)
## modèle
mod3 <- arima(y33[1:401],seasonal=list(order=c(0,1,1),period=6),include.mean=FALSE,
method="ML")
t_stat(mod3)
xy.acfb(residuals(mod3),numer=FALSE)
mod3bis <- arima(y33[1:401],order=c(3,0,0),seasonal=list(order=c(0,1,1),period=6),
include.mean=FALSE,method="ML")
t_stat(mod3bis)
xy.acfb(residuals(mod3bis),numer=FALSE)
Box.test(residuals(mod3bis),type="Box-Pierce")
Box.test(residuals(mod3bis),type="Ljung-Box")
summary(mod3bis)
mod3bisbis <- arima(y33[1:401],order=c(3,0,0),seasonal=list(order=c(0,1,1),period=6),
include.mean=FALSE,fixed=c(NA,0,NA,NA),method="ML")
summary(mod3bisbis)
Box.test(residuals(mod3bisbis),type="Box-Pierce")
Box.test(residuals(mod3bisbis),type="Ljung-Box")
t_stat(mod3bisbis)
shapiro.test(residuals(mod3bisbis))
jarqueberaTest(residuals(mod3bisbis))
## prévision
prev3 <- forecast(mod3bisbis,h=31,level=95)
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

PROGRAMMES R 107
M32 <- matrix(0,61,4)
M32[1:30,1] <- y33[372:401]
M32[31:61,1] <- y33[402:432]
M32[31:61,2] <- prev3$lower
M32[31:61,3] <- prev3$upper
M32[31:61,4] <- prev3$mean
M32[1:30,2:4] <- NA
matplot(M32,type="l",axes=F,xlab="Temps (jours)",ylab="log(Flux de retour)",lwd=2,
lty=c(2,1,1,3))
axis(1,at=c(1,31,61),labels=c("08-mar-2014","12-avr-2014","17-mai-2014"))
axis(2)
legend("bottomleft",c("Valeur observée","Bande de préd. 95%","Prédiction"),lwd=2,
lty=c(2,1,3),cex=.8)
## erreur de prévision hors-échantillon
hmax <- 31
mape <- abs(y33[402:432]-prev3$mean)/abs(y33[402:432])
MAPE3=sum(mape)/hmax
#################################################
## Section 4.3.4 : Modèle à retards échelonnés ##
#################################################
donnee4.chr <- read.csv("C:/Users/FLORIAN/Desktop/donneeMRE.csv",sep=";",
stringsAsFactors=FALSE)
str(donnee4.chr,width=60,strict.width="cut")
date4.1 <- as.Date(donnee4.chr$t_sortie,"%d/%m/%Y")
date4.2 <- as.Date(donnee4.chr$t_retour,"%d/%m/%Y")
donnee4.date <- data.frame(donnee4.chr$code_voyage,date4.1,date4.2,
donnee4.chr$duree_av_dispo)
colnames(donnee4.date) <- c("code_voyage","t_sortie","t_retour","duree_av_dispo")
## place le data frame dans l'itinéraire de recherche
attach(donnee4.date)
## période d'étude
c(min(t_sortie),max(t_sortie))
## temps courant i.e. temps à partir duquel on fera les prévisions
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

PROGRAMMES R 108
#ce temps délimite également l'échantillon d'apprentissage
t_current <- as.Date("10/05/2014","%d/%m/%Y")
## valeurs de n, m et initialisations des paramètres
n <- length(which(t_sortie <= t_current))
m <- length(which(t_retour <= t_current))
p_chapo <- m/n
q_chapo <- m/sum(duree_av_dispo[which(t_retour <= t_current)])
j_max <- 29
aa <- c(); bb <- c(); cc <- c(); dd <- c()
index <- which(t_sortie <= t_current & t_retour > t_current)
for (j in 1:j_max)
aa <- t_current - t_sortie[index]
aa <- as.numeric(aa)
for (i in 1:length(index))
bb[i] <- (p_chapo[j]*(1 - q_chapo[j])^(aa[i] + 1))
cc[i] <- 1 - p_chapo[j] + bb[i]
dd[i] <- t_current - t_sortie[i] + (1-q_chapo[j])/q_chapo[j]
p_chapo[j+1] <- (m + sum(bb/cc))/n
q_chapo[j+1] <- (n*p_chapo[j+1])/(m + sum(duree_av_dispo[which(t_retour <=
t_current)]) + sum(dd*(bb/cc)))
################################################################
## Fonction R : prévision des retours futurs de GPS ##
##------------------------------------------------------------##
## ** Données : ##
## - t_current : date courante ##
## - info : information disponible pour prévoir ##
## - hmax : nombre d'observations à prédire ##
## - C : matrice des corrélations ##
## - p : probabilité qu'un GPS retourne ##
## - q : probabilité qu premier retour d'un GPS ##
##------------------------------------------------------------##
## ** Résultat : valeurs prédites ##
################################################################
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

PROGRAMMES R 109
predict_retour <- function (t_current,info,hmax,C,p,q)
## position du t_current dans le data frame
pos_current <- 110
y_chapo <- list(); y_prev <- c()
for (h in 1:H)
y_chapo[[h]] <- matrix(0,1,pos_current-1)
if (info == "B")
x <- table(t_sortie)
for (i in 1:pos_current-1)
y_chapo[[h]][i] <- round(p*q*(1-q)^(h+i-1) * x[[pos_current-i]],0)
y_prev[h] <- sum(y_chapo[[h]])
else if (info == "C")
x <- table(t_sortie)
i<-1
y_chapo[[h]][i] <- round(p*q*(1-q)^(h-1) * x[[pos_current]],0)
for (i in 2:pos_current-1)
y_chapo[[h]][i] <- round(p*q*(1-q)^(h+i-1) * x[[pos_current-i]],0)
+ C[i,h]
y_prev[h] <- sum(y_chapo[[h]])
return(y_prev)
## prédiction des valeurs futures
prevMRE <- predict_retour(t_current,information="B",H=6,C,p=1,q=0.064)
## ôte le data frame de l'itinéraire de recherche
detach(donnee4.date)
table(t_retour)
valeur.obs <- c(53,30,93,64,36,39)
M34 <- matrix(0,20,2)
M34[1:14,1] <- y3[413:426]
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

PROGRAMMES R 110
M34[15:20,1] <- y3[427:432]
M34[15:20,2] <- prevMRE
M34[1:14,2] <- NA
matplot(M34,type="l",axes=F,xlab="Temps",ylab="Flux de retour",lwd=2,lty=c(2,3),col=1)
axis(1,at=c(1,15,20),labels=c("25-avr-2014","12-mai-2014","17-mai-2014"))
axis(2)
legend("bottomleft",c("Valeur observée","Prédiction"),lwd=2,lty=c(2,3),col=1,cex=.8)
## erreur de prévision hors-échantillon
hmax <- 6
mape <- abs(valeur.obs-prevMRE)/abs(valeur.obs)
MAPE=sum(mape)/hmax
##########################################################
## Section 5.2 : Loi de probabilité de la demande nette ##
##########################################################
aa <- donnee1.date$nombre[1:128]
bb <- donnee3.date$nombre[263:390]
# données agrégées en bloc de deux jours
DN <- c()
for(i in 1 : 64)
DN[i] <- (aa[2*(i-1)+1] + aa[2*(i-1)+2]) - (bb[2*(i-1)+1] + bb[2*(i-1)+2])
op = par(mfrow=c(1,2),pty="m",omi=c(0,0,0,0))
hist(DN,freq=FALSE,xlab="Observations",ylab="Densité",font.lab=4,main="")
curve(dnorm(x,mean(DN),sd(DN)),type="l",add=TRUE,lwd=2)
x <- seq(-150,150,length=400)
plot(ecdf(DN),verticals=TRUE,col=1,pch = 16,lty=2,
ylab=expression(F[Y](y)),xlab="y",main="",lwd=2,do.points=FALSE)
F <- pnorm(x,mean(DN),sd(DN),lower.tail=TRUE)
lines(x,F,type="l",lwd=2,col=1,lty=1)
legend(x=-120,y=0.9,legend=c("gaussienne","empirique"),col=1,lty=1:2,lwd=2)
par(op)
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

PROGRAMMES R 111
shapiro.test(DN)
ks.test(DN,"pnorm",mean(DN),sd(DN))
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

BIBLIOGRAPHIE 112
Bibliographie
[1] Aragon Y. (2011), Séries temporelles avec R : Méthodes et cas, Université Toulouse 1 -
Capitole, Springer Paris Berlin Heidelberg New York.
[2] Bahloul K. (2011), Optimisation combinée des coûts de transport et de stockage dans un
réseau logistique dyadique, multi-produits avec demande probabiliste, Thèse de doctorat,
Ecole doctorale 512 Informatique et Mathématique de Lyon.
[3] Bourbonnais R. (2001), Prévision des ventes, Polycopié du produit multimédia, Univer-
sité de Paris-Dauphine.
[4] Box G.E.P., Jenkins G.M. and Reinsel G.C. (1976) : Time Series Analysis, Forecasting
and Control, Holden-Day, Third Edition, Series G.
[5] Carbon M. et Francq C., Estimation non paramétrique de la densité et de la régres-
sion - Prévision non paramétrique, Laboratoire de Probabilités et Statistique, Vil-
leneuve d'Ascq, France. http://www.modulad.fr/archives/numero-15/Carbon-15/
estimationnonparametrique.pdf [16/10/2014]
[6] Carrasco-Gallego R. and Ponce-Cueto E. (2009), Forecasting the returns in reusable
containers' closed-loop supply chains, A case in the LPG industry. 3rd International
Conference on Industrial Engineering and Industrial Management, Barcelona-Terrassa.
[7] Charpentier A. (2012), Modèles de prévision des séries temporelles, UQAM, ACT6420.
[8] Dalalyan A.S., Statistiques Avancées : Méthodes non-paramétriques, Ecole Centrale de
Paris. http://certis.enpc.fr/~dalalyan/Download/poly.pdf [16/10/2014]
[9] De Brito M.P. and Van Der Laan E.A. (2002), Inventory management with product
returns : the impact of (mis)information, Econometric Institute Report EI 2002-29,
Erasmus University Rotterdam, the Netherlands.
[10] Dempster A. P., Laird N. M. and Rubin D. B. (1977). Maximum Likelihood from In-
complete Data via the EM Algorithm (with Discussion).J. Royal Stat. Soc. Series B. 339
1-22.
[11] Desgraupes M. (2014), Cours de Statistiques et Économétrie, Séries temporelles avec R,
Université Paris Ouest Nanterre La Défense.
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

BIBLIOGRAPHIE 113
[12] Djomgwe T.B. (2013), Moteur de Scoring pour la sélectivité en douane, Mémoire d'In-
génieur Informatique, Ecole Polytechnique, Yaoundé, Cameroun.
[13] El-Merouani M. (2010), Modélisation Stochastique de la demande pour les stocks de dis-
tribution par une loi de probabilité Log-normale, Université Abdelmalek Essaâdi, Maroc.
[14] Gasmi A. (2008), Prévision du trac aérien de passagers : cas des aéroports tunisiens,
Mastère Modélisation Economique et Econométrie, Ecole Polytechnique de Tunisie.
[15] Giard V. (2005), Gestion de la production et des ux, 3e édition Economica.
[16] Goh T.N. and Varaprasad N. (1986), A statistical methodology for the analysis of the
LifeCycle of Reusable Containers, IIETransactions, 18, pp. 42-47.
[17] Gouriéroux C. et Monfort A. (1990), Séries temporelles et modèles dynamiques Econo-
mica.
[18] Kelle P. and Silver E.A. (1989a), Forecasting the Returns of Reusable Containers, Jour-
nal of Operations Management, Vol.8, No.1, pp. 17-35.
[19] Kelle P. and Silver E.A (1989b), Purchasing Policy of New Containers Considering the
Random Returns of Previously Issued Containers, IIE Transactions, 21(4), pp.349-354.
[20] Kiesmuller G. and Van Der Laan E.A. (2001), An inventory model with dependent
product demands and returns, International Journal of Production Economics, 72 (1)
73-87.
[21] Leeux V. (2007), Modèles semi-paramétriques appliqués à la prévision des séries tem-
porelles : Cas de la consommation d'électricité, Thèse de doctorat, Ecole Doctorale -
Humanités et Sciences de l'Homme, Université de Rennes 2 - Haute Bretagne.
[22] Logamou S.L. (2012), Classication des marchandises expédiées en direction de la zone
CEMAC et transitant par le Cameroun, Mémoire de Master de Statistique Appliquée,
Ecole Polytechnique, Yaoundé, Cameroun.
[23] Nshare N.E.C. (2012), Analyse statistique de la loi des durées dans le but de proposer un
indicateur relatif aux délais de voyage sur les corridors douaniers : Douala-N'Djamena
et Douala-Bangui, Mémoire de Master de Statistique Appliquée, Ecole Polytechnique,
Yaoundé, Cameroun.
[24] Pankratz A. (1991), Forecasting With Dynamic Regression Models. New York : Wiley.
[25] Pibasso A. M. (2010), Transit Cameroun-Centrafrique et Tchad, le GPS de la discorde
http://centrafrique-presse.over-blog.com/article-transit-cameroun-centrafrique-\
\et-tchad-le-gps-de-la-discorde-42557782.html [16/10/2014]
[26] Proïa F. (2013), Autocorrélation et Stationnarité dans le Processus Autorégressif, Thèse
de doctorat, Ecole Doctorale de Mathématiques et Informatique, Université de Bordeaux
I.
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014

BIBLIOGRAPHIE 114
[27] Roustant O. (2008), Introduction aux séries chronologiques : axe méthodes statistiques
et applications, Ecole Nationale Supérieure des Mines, Saint-Etienne.
[28] Silver E.A., Peterson R. and Pyke D.F. (1998), Inventory management and production
planning and schedulling, 3rd edition, John Wiley & Sons, New York.
[29] Singh A. (2005), The EM Algorithm.
http://www.cs.cmu.edu/~awm/15781/assignments/EM.pdf [16/10/2014]
[30] Tadikamalla and Pandu R. (1984), A comparison of several approximations to the lead
time demand distribution, Omega, vol. 12, issue 6, pp. 575-581.
[31] Tokpavi S. (2011), Cours d'économétrie, les modèles dynamiques, Master 1 Economie,
Université Paris X.
[32] Toktay L.B., Van Der Laan E.A and De Brito M.P. (2003), Managing Product Returns :
The Role of Forecasting. Econometric Institure Report EI.
[33] Toktay L.B., Wein L.M. and Zenios S.A. (2000), Inventory Management of Remanufac-
turable Products. Management Science. 46 (11) 1412-1426.
[34] Toussile F.W. (2014), Cours de Séries Chronologiques, Master de Statistique Appliquée,
Ecole Polytechnique, Yaoundé, Cameroun.
[35] Verwijmeren M., Van Der Vlist P. et al. (1996), Networked inventory management in-
formation systems : Materializing supply chain management. International Journal of
Physical Distribution and Logistics Management vol. 26, n 6 : pp. 16-31.
[36] R Core Team (2013). R : A language and environment for statistical computing. R
Foundation for Statistical Computing, Vienna, Austria. http://www.R-project.org/
Mémoire de Master de Statistique Appliquée. ULRICH FLORIAN SIMO c© ENSP 2012-2014





























