Embed Size (px)
Citation preview

PREVISION DU PIB DANS
LES PAYS DE LA ZONE CEMAC .
Par :
Jacques Le Grand BIYICK ETOGUE
Dirigé par :
Dr. Eugène-Patrice NDONG NGUEMA
Chargé de Cours à l'ENSP de Yaoundé
Sous la supervision du :
Pr. Henri GWET
Chef de Département de Mathématiques et Sciences
Physiques à l'ENSP de Yaoundé.
Octobre 2010

Table des matières
Dédicace 3
Remerciements 4
Résumé 6
Abstract 7
Résumé exécutif 8
Introduction générale 11
1 Le PIB dans la zone CEMAC 12
1.1 La production agrégée . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
1.1.1 PIB, Valeur ajoutée et revenu . . . . . . . . . . . . . . . . . . . . . . . . 12
1.2 La composition du PIB . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
1.3 Description des données . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2 Méthodologies de prévision des données annuelles 23
2.1 Appréhender des données dans le temps : . . . . . . . . . . . . . . . . . . . . . . 23
2.1.1 serie temporelles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
2.1.2 briuts blancs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
2.1.3 tendances. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
2.1.4 Composantes Périodiques, Saisonnalités. . . . . . . . . . . . . . . . . . . 24
2.1.5 Superposition de tendance et de périodes. . . . . . . . . . . . . . . . . . 24
2.1.6 les premiers indices descriptifs . . . . . . . . . . . . . . . . . . . . . . . 24
2.1.7 Indices de tendance centrale . . . . . . . . . . . . . . . . . . . . . . . . . 24
2.1.8 Indices de disperssion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
2.1.9 Auto-covariances empiriques . . . . . . . . . . . . . . . . . . . . . . . . . 25
2.1.10 Auto-corrélation empiriques. . . . . . . . . . . . . . . . . . . . . . . 25
2.1.11 Visualisation graphique des auto-corrélations empiriques. . . . . . . . . . 26
Mémoire de Master de Statistique Appliquée. Jacques Le Grand BIYICK ETOGUE c©ENSP 2008-2010

TABLE DES MATIÈRES 2
2.1.12 Comment utiliser l'auto-corrélation ? . . . . . . . . . . . . . . . . . . . . 26
2.2 Séries Temporelles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
2.2.1 Stationnarité . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
2.2.2 Fonction d'auto covariance . . . . . . . . . . . . . . . . . . . . . . . . . . 27
2.2.3 Corrélation, fonction d'auto corrélation et fonction d'auto corrélation par-
tielle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
2.2.4 Les processus ARMA et ARIMA . . . . . . . . . . . . . . . . . . . . . . 30
2.3 Methodes de prévision . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
2.3.1 Lissage exponentiel simple . . . . . . . . . . . . . . . . . . . . . . . . . . 31
2.3.2 Le principe du lissage exponentiel double . . . . . . . . . . . . . . . . . . 33
2.3.3 La méthode non saisonnière de Holt-Winters . . . . . . . . . . . . . . . . 34
2.3.4 Prévision sur les processus ARMA et ARIMA . . . . . . . . . . . . . . . 35
3 Applications 39
3.1 Et si nous regardions juste le PIB dans le temps . . . . . . . . . . . . . . . . . . 39
3.1.1 cas du Cameroun . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
3.1.2 cas du Gabon . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
3.1.3 cas du Congo . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
3.1.4 cas de la république centra�caine . . . . . . . . . . . . . . . . . . . . . . 42
3.1.5 cas de la Guinée Equatoriale . . . . . . . . . . . . . . . . . . . . . . . . . 43
3.1.6 cas du Tchad . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
3.2 Prévision par la méthodologie de Box Jenkins . . . . . . . . . . . . . . . 45
3.2.1 Prévision du PIB nominal : cas du Cameroun . . . . . . . . . . . 45
3.2.2 Prévision du PIB nominal : cas du Gabon . . . . . . . . . . . . . 49
3.2.3 Prévision du PIB nominal :cas du Congo . . . . . . . . . . . . . . 54
3.2.4 Prévision du PIB nominal : cas de la République centrafricaine 59
3.2.5 Prévision du PIB nominal : cas de la Guinée Equatoriale . . . . 63
3.2.6 Prévision du PIB nominal : cas du Tchad . . . . . . . . . . . . . . 67
3.3 Prévision par lissage exponentiel simple,
et lissage non saisonnière de Holt-Winters . . . . . . . . . . . . . . . . . . 71
3.3.1 Prévision du PIB Nominal cas du Cameroun . . . . . . . . . . . . 71
3.3.2 Prévision du PIB Nominal cas du Gabon . . . . . . . . . . . . . . 73
3.3.3 Prévision du PIB Nominal cas de la République Centrafricaine 76
3.3.4 Prévision du PIB Nominal cas de la Guinée Equatoriale . . . . 78
3.3.5 Prévision du PIB Nominal cas du Tchad . . . . . . . . . . . . . . 81
Conclusion et Recommandations 84

Dédicace
Je dédie ce mémoire à mon Père, à ma Mère et à ma tante Marie Marcelle NGO
BIYICK , pour tout l'amour qu'ils me donnent.
Mémoire de Master de Statistique Appliquée. Jacques Le Grand BIYICK ETOGUE c©ENSP 2008-2010

Remerciements
Je tiens à remercier sincèrement les personnes qui m'ont aidé et encouragé directement ou
indirectement à réaliser ce mémoire :
Je remercie les responsables du master de Statistique appliquée de ENSP de Yaoundé
1, de m'avoir donné l'opportunité de travailler sur ce sujet .
Je remercie le Pr Henri GWET pour les critiques et les indications apportées lors des correc-
tions.
Je remercie tout les enseignants du Master de Statistique Appliquée chargée de cours :
Pr LE PENNEC, Dr NDONG NGUEMA, Pr J.C THALABARD, Pr ROYNETTE,
Dr M. NDOUMBE, Pr FREREINBACK, Dr EMVUDU, Dr YODE, Pr HILI, MR
NASHIPU, comme chargés de TD : Mr Patrice Takam, Mr W.KENGNE,Mr HO-
LAF,Mr TCHACTOUENG .
Je remercie tout l'ancien Directeur Général de la BEAC de Douala Mr JM.MONAYONG
NKOUMOU actuellement Directeur Général de la BEAC nationale de Yaoundé.
Je remercie tout le personnel du service d'Etudes et de Balance de Paiement de la
BEAC de Douala.
Je remercie TSIMI Alain, Divine NDI et son épouse, la famille Samuel SAND, la fam-
mille Jean Luc YOUNGOU, Yanick NNANGA, le Docteur Paul TCHOUA chargée
de Cours à l'Université de Ngaoundéré pour le soutien et les conseils qu'ils ont su me
donner durant les moments di�ciles.
Je remercie tout mes Frères, mes Camarades de classe et Amis pour l'aide qu'ils m'ont
donné.
Mémoire de Master de Statistique Appliquée. Jacques Le Grand BIYICK ETOGUE c©ENSP 2008-2010

Abréviations
CEMAC : Communauté Economique et Monétaire de l'Afrique Centrale.
BEAC : Banque des Etats de l'Afrique Centrale.
PIB : Produit Intérieur Brut.
Mémoire de Master de Statistique Appliquée. Jacques Le Grand BIYICK ETOGUE c©ENSP 2008-2010

Résumé
Lorsqu'on se refaire à la croissance économique d'une nation l'on porte un regard sur son PIB.
Une nation peut donc être soumise de connaître quelles dispositions prendre dans l'avenir pour
augmenter sa croissance économique. Il est important de savoir quelle sera le comportement du
PIB dans les années avenir à partir des dispositions, et des mesures actuelles. Plusieurs nations
dans le monde sont confrontées au problème de prévision du PIB. Dans ce mémoire, nous avions
eu pour objectif d'une part de prévoir le PIB nominal dans les pays de la zone CEMAC, ceci par
le truchement des méthodes de prévision compatibles aux données dont nous disposions, et aux
conditions auxquelles nous avions étés soumis qui sont : La méthode de Box Jenkins (ARIMA),
le lissage exponentiel simple, et La méthode de Holt-Winters pour séries non saisonnières. Et
d'autre part de sélectionner parmi ces di�érentes méthodes utilisées la meilleure méthode de
prévision, ceci par une technique basée sur une simple comparaison de leurs di�érents coûts,
doublé d'une pure observation critique du comportement des résultats de nos prévisions. Au
terme de notre travail, nous avons retenus parmi ces trois méthodes, les modèles obtenus par la
méthode de Box Jenkins(ARIMA) qui sont les suivants :
Cameroun : ARIMA(1,1,6) ; Gabon : ARIMA(1,1,1) ; Congo : ARIMA(1,1,1) ; République Cen-
trafricaine : ARIMA(1,1,2) ; Guinée Equatoriale : ARIMA(1,1,2) ; Tchad : ARIMA(1,1,1).
Mots Clés : PIB nominal, méthode de Box Jenkins (ARIMA), lissage exponentiel simple, et
méthode de Holt-Winters pour séries non saisonnières.
Mémoire de Master de Statistique Appliquée. Jacques Le Grand BIYICK ETOGUE c©ENSP 2008-2010

Abstract
When consider the economic growth of a nation we take a look at IRM. A nation can be
brought to know what dispositions to take in the future in other to augment her economic
growth. It is important to know what will be the behavior of the IRM in the years to come from
the dispositions, and actual measures. Many nations in the world are confronted to the problem
of foreseeing the IRM. In tis mémoir, we had a goal one way to preview the nominal IRM in the
countries of CEMAC area, this by the means of foreseeing compatible methods to the data that
we dispose, and to the conditions to which we had been submitted that are : The method of Box
Jenkins ( ARIMA ),the simple exponential smooth, and the Holt -Winters for the non seasonal
series. And otherwise to select among these di�erent methods the best method of prevision, this
can be done by a technique based on a simple comparison of their di�erent coasts, doubled by
a pure critical observation of the behaviour of the result of our previsions. At the end of our
work, we have retained among these three methods, the models obtained by the method of Box
Jenkins (ARIMA) which are the followings :
Cameroon : ARIMA(1,1,6) ; Gabon : ARIMA(1,1,1) ; Congo : ARIMA(1,1,1) ; Centrafricaine
Republic : ARIMA(1,1,2) ; Equatorial Guinea : ARIMA(1,1,2) ; Tchad : ARIMA(1,1,1).
Key words : Forecast, nominal IRM, method of Box Jenkins (ARIMA), the simple exponential
smooth, and the Holt -Winters for the non seasonal series .
Mémoire de Master de Statistique Appliquée. Jacques Le Grand BIYICK ETOGUE c©ENSP 2008-2010

Résumé exécutif
Les indicateurs macroéconomiques dans un pays, doivent être examinés avec beaucoup de
prudence et d'objectivité. L'un d'eux, à savoir le PIB, a été l'objet de notre étude.
De prime à bord, une étude descriptive nous a conduits aux remarques, et résultat suivants :
� Pendant 11 années entre 1975 à 2009, le PIB nominal au Cameroun resté dans l'intervalle
[2000 ; 4000] milliards de FCFA.
� Pendant 11 années entre 1975 à 2009, le PIB nominal au Congo est resté dans l'intervalle
[500 ; 1000] milliards de FCFA.
� Pendant 11 années entre 1975 à 2009, le PIB nominal au Gabon est resté dans l'intervalle
[1000 ; 2000] milliards de FCFA.
� Pendant 16 années de 1985 à 2009, le PIB nominal en Guinée Equatoriale est resté dans
l'intervalle [0 ; 1000] milliards de FCFA.
� Pendant 8 années entre 1975 à 2009, le PIB nominal en République Centrafricaine est resté
dans l'intervalle [300 ; 400] Milliards de FCFA, et moins un peu moins hétérogénéité que
partout dans les Pays de la Zone CEMAC.
� Pendant 18 années entre 1982 à 2009, le PIB nominal au Tchad est resté dans l'intervalle
[0 ; 1000] milliards de FCFA.
.
Le comportement du PIB nominal dans les pays de la zone CEMAC, n'est pas tout aussi
identique au vue des réalités tant sociopolitique et économique qui les lient. Dans ce mémoire,
dans les conditions dans les quelle nous avons travaillé, avec les données que nous disposions,
nous avons remarqué que : Les mesures de dispersion du PIB nominal au Tchad et au Congo
sont assez proches et montrent des dispersions plus importantes que celle de la République Cen-
trafricaine au PIB plus homogène, mais globalement moins élevés. Le Cameroun semble avoir le
meilleur rendement en PIB nominal en zone CEMAC (en terme Grandeur monétaire). Pendant
une année on peut mieux s'attendre à une valeur plus élevé (Peut être moins bonne si on consi-
dère l'investissement) du PIB au Cameroun que par tout ailleurs en zone CEMAC.
Mémoire de Master de Statistique Appliquée. Jacques Le Grand BIYICK ETOGUE c©ENSP 2008-2010

TABLE DES MATIÈRES 9
En ce qui concerne la prévision du PIB nominal : Nous avons utilisé trois méthodes appropriées
aux comportements et à la structure de nos donnés à savoir :
1. La méthode de Box jenkins (ARIMA)
2. La méthode du lissage exponentiel simple
3. La méthode de Holt-Winters pour séries non saisonnières.
Nous retenons ici les prévisions de la première méthode (La méthode de Box jenkins (ARIMA))
trouvée assez mieux que les autres du point de vue de l'objectivité.
Prévisions du PIB nominal dans la zone CEMAC pour les 7 prochaines années.
Années PIB au Cameroun PIB au Gabon PIB au CONGO
2010 11911.82 5628.761 4863.714
2011 12111.00 5748.220 5061.076
2012 12266.71 5867.369 5379.533
2013 12222.39 5986.212 5565.879
2014 12118.88 610.4750 5527.465
2015 11968.14 6222.984 5527.465
2016 12097.37 6340.913 5514.333
.
Années PIB en RCA PIB au Guinée E. PIB au Tchad
2010 1017.346 4971.468 3179.418
2011 1042.896 4823.041 3143.696
2012 1068.439 4906.311 3119.428
2013 1093.977 4859.595 3102.942
2014 1119.509 4885.803 3091.742
2015 1145.035 4871.100 3084.133
2016 1170.556 4879.349 3078.964
.
Nous remarquons ici une homogénéité assez considérable des résultats à l'intérieure de chaque
nation. Nous sommes donc tentés de penser que si certaines dispositions sont prisent en considé-
ration, il est possible d'obtenir un meilleur rendement du PIB nominal(en terme de croissance)
en zone CEMAC dans les années avenir. Parmi ces dispositions, on peut par exemple regarder

TABLE DES MATIÈRES 10
au niveau de la composition du PIB nominal (PIB=C+I+G+X-Q) quelles permis les va-
riables Consommation (C), Investissement(I), Dépenses gouvernementales(G), Exportation(X),
Importation(Q), et Investissement en stock(Is) permettent une augmentation du PIB nominal
dans chacune de ces di�érentes nations et essayer de les maximiser ou de les minimiser selon
qu'elles in�uencent sur la croissance du PIB nominal dans le pays concerné.

Introduction générale
En vu de maximiser les " pro�ts ", ou de renoncer à un investissement douteux, le plus
souvent, l'on cherche à savoir qu'elle sera le comportement futur d'un phénomène. Les pays de
la zone CEMAC sont liés par plusieurs indicateurs sociopolitiques et économiques. Ces pays
recherchent tous d'une certaine manière un essor économique. L'une des di�cultés auxquelles
ils sont heurtés est la gestion de son potentielle tant économiques, que sociale. Pour ces pays le
comportement du produit intérieur brut est aussi important comme dans d'autres pays. Dans une
certaine mesure Lorsqu'on fait de l'économie et par ricochet de la macroéconomie on fait appel à
la statistique et par conséquence à la prévision. Les Statisticiens sont prudents lorsqu'on parle de
prévision, car ils savent de prime à bord, que lorsqu'on veut faire des prévisions, la crédibilité des
résultats dépend d'une part de la �abilité et de la forme des données et d'autre part de la méthode
à appliquer. Deux des di�cultés auxquelles est confrontée la grande famille des statisticiens est
l'invention des méthodes de prévision, tout du moins la découverte des méthodes de prévision,
et le choix de la meilleure méthode de prévision. Dans ce mémoire, selon les données que nous
disposons, dans les conditions auxquelles nous sommes soumis, notre travaille va consister en la
prévision du PIB, et en le choix de la meilleure méthode de prévision du PIB dans les pays de la
zone CEMAC. Notre travail est donc réparti comme suit :d'abord dans le premier chapitre, nous
allons présenter la décomposition et la constitution du PIB dans les pays de la zone CEMAC,
ainsi qu'une présentation et une description des données, au second chapitre nous allons élaborer
les Méthodologies de prévision des données annuelles, ensuite, au chapitre trois, nous ferons une
application des méthodes abordées au chapitre précédent, et en �n nous conclurons par un choix
de la meilleure méthode de prévision basée sur une pure observation critique du comportement
de nos résultats.
Mémoire de Master de Statistique Appliquée. Jacques Le Grand BIYICK ETOGUE c©ENSP 2008-2010

Chapitre 1
Le PIB dans la zone CEMAC
Les mots production, chômage, et in�ation sont apparus plusieurs fois dans notre tour du
monde. Ils �xent les trois concepts fondamentaux de la macroéconomie. Ils faut d'abord com-
prendre rigoureusement ce qu'ils désignent et comment ils peuvent être mesurés par les statisti-
ciens.
Dans ce chapitre nous nous attarderons sur la décomposition, la constitution et la description
de la production dans les pays de la zone CEMAC.
1.1 La production agrégée
Lorsque l'économiste français François Quesnay [ Olivier Blanchard et D. Cohen, Macroé-
conomie] dresse pour la première fois un " Tableau économique" au 18 siècle, il impute des
données très hasardeuses aux achats et aux ventes. Par un système de �èches en " zigzag", il lie
entre elles les décisions des uns et des autres. Au delà de l'imprécision de ses statistiques, il lui
manque une méthode qui lui permette de saisir ce qu'est le " revenu " .Pas plus que Quesnay,
les économistes du 19 siècle ou des années trente ne disposaient d'une mesure de l'activité glo-
bale sur laquelle appuyer leurs raisonnements. Ils devaient collecter des informations partielles
et disparates, comme pour estimer ce qui se passait dans l'économie tout entière.
1.1.1 PIB, Valeur ajoutée et revenu
La mesure de la production agrégée en comptabilité nationale est le produit intérieure brut
ou PIB en abrégé. Il y a trois façons de concevoir le PIB d'une économie. Examinons-les l'une
après l'autre.
le PIB est la valeur (en FCFA, dollars, euro, etc.) des biens et services " �naux " produits
dans l'économie durant une période donnée.
Le mot important est �nal. Pour nous justi�er, considérons l'exemple suivant. Supposons que
l'économie du Cameroun soit constituée uniquement des deux entreprises.
� ACIERCAM : Société, sidérurgique produit de l'acier. Elle vent pour 100 FCFA à MARMI-
CAM, laquelle produit des marmites ACIERCAM emploie des travailleurs et des machines,
Mémoire de Master de Statistique Appliquée. Jacques Le Grand BIYICK ETOGUE c©ENSP 2008-2010

1.1 La production agrégée 13
elle paie ses employés 20 FCFA et ce qui reste constitue son pro�t.
� MARMICAM achète de l'acier et l'utilise pour produire des marmites. La vente des mar-
mites rapporte 210 FCFA. MARMICAM a embauché des employés et utilise des machines
.Des 210 FCFA de vente, 100 FCFA paient de l'acier et 70 FCFA les salaires des employés,
ce qui laisse un pro�t de 40 FCFA.
Nous pouvons résumer ces opérations dans le tableau suivant :
ACIERCAM
Revenus des ventes 100 FCFA
Dépenses (salaires) 80 FCFA
Pro�t 20 FCFA
MARMICAM
Revenus des ventes 210 FCFA
Dépenses (salaires) 70 FCFA
Dépenses (Achat d'acier) 100 FCFA
Pro�t 40 FCFA
tableau A
.
Posons-nous la question de savoir quel est le PIB de cette économie ? Est-ce la somme de
tous les biens produits (100 FCFA d'acier et 210 FCFA de marmites, soit 310 FCFA) ? Ou bien
la valeur de la production des biens �naux, ici des marmites 210 FCFA? Une brève ré�exion
laisse à penser que la bonne réponse doit être 210 FCFA. Pourquoi ? Parce que l'acier, qui est
un bien intermédiaire utilisé dans la production du bien �nal, utilisé dans la production �nal,
les marmites ne devrait pas être compté dans le PIB, qui mesure la valeur du produit �nal. On
peut considérer cet exemple d'une autre façon. Supposons que les deux entreprises fusionnent,
de sorte que la vente de l'acier devienne interne à l'entreprise nouvellement formée et ne soit plus
comptabilisé. Nous ne verrions plus qu'une entreprise vendant des marmites pour une valeur de
210 FCFA, payant ses employés 80 FCFA +70 FCFA = 150 FCFA, et réalisant 20 FCFA+40
FCFA =60 FCFA de pro�ts. Le PIB serait inchangé, comme il se doit.
Cet exemple suggère de construire le PIB en sommant les valeurs des biens �naux, ce qui est
à peu près la méthode par la quelle on obtient les vrais chi�res du PIB. Mais on peut saisir de
cet exemple une autre façon de concevoir le PIB. Un bien intermédiaire est un bien utilisé dans
la production d'un autre bien. Certains bien peuvent être à la foi des biens intermédiaires et
des biens �naux. Quand il est vendu directement, le plantain est un bien �nal quand on l'utilise
pour faire des frites, ce sont des biens intermédiaires.

1.1 La production agrégée 14
Le PIB est la somme des valeurs ajoutées créées dans l'économie au cours d'une certaine
période.
L'expression valeur ajoutée n'est pas un faux ami. La valeur ajoutée par une �rme durant le
processus de production est la valeur de sa production moins la valeur de ses consommations
intermédiaires. Dans l'exemple précédent, ACIERCAM n'utilise aucune consommation intermé-
diaire. Sa valeur ajoutée est simplement égale à la valeur de sa production, soit 100 FCFA,
MARMICAM en revanche, utilise l'acier comme un bien intermédiaire. La valeur ajoutée de
cette dernière entreprise est égale à la valeur d es marmites qu'elle produit, moins la valeur de
l'acier qu'elle utilise, 210 FCFA-100FCFA=110 FCFA. La valeur ajoutée totale dans l'économie,
ou PIB, est donc 100FCFA+ 110 FCFA=210 FCFA. Remarquons que la valeur ajoutée globale
restait la même si les deux entreprises fusionnaient. Cette dé�nition nous fournit une deuxième
façon de penser le PIB. Ensemble, les deux dé�nitions impliquent que la valeur des biens et ser-
vices �naux (première dé�nition) peut aussi être conçue comme la somme des valeurs ajoutées
par les entreprises le long de la chaine de production de ces biens �naux (deuxième dé�nition).
le PIB est la somme des revenus distribués dans l'économie au cours d'une période donnée.
Nous avons jusqu'à présent considéré le PIB du point du coté de la production. Une troisième
façon de se le présenter est de considérer les revenus .Considérons les revenus dont dispose une
entreprise après qu'elle a payé ses consommations intermédiaires.
� Une partie de ces revenus est prélevée par l'état sous la forme de taxes sur vente (il s'agit
des impôts indirects).
� Une autre partie sert à payer les salariés (cette composante s'appelle le revenu du travail).
� Le reste va dans les caisses de l'entreprise (c'est le revenu du capital).
La valeur ajoutée du point de vue du revenu, est donc la somme des impôts indirects et des
revenus et du capital et du travail. Revenons à notre exemple. Il n'y a pas d'impôts indirects.
Des 100 FCFA de valeur ajoutée créée par ACIERCAM ,80 vont aux travailleurs (revenus du
travail) et 20 restent dans l'entreprise comme pro�t (revenu du capital).Des 110 FCFA de valeur
ajoutée créée par MARMICAM, 70 entrent dans les revenus du travail et 40 dans les revenus
du capital. Pour cette économie, la valeur ajoutée totale est de 210 FCFA, dont 150 FCFA de
revenus du travail et 60 FCFA de revenus du capital. Dans cet exemple, les revenus du travail
représentent 71 les impôts direct 0
Pour résumer : on peut considérer le produit agrégé (le PIB) de trois façons di�érentes mais
équivalentes.
- Du côté de la production : le PIB est la valeur des biens et services �naux produits au cours
d'une certaine période.
- Du côté de la production, également, le PIB est la somme des valeurs ajoutées dans l'économie
durant une période.
1.1 La production agrégée 15
- Du point de vue des revenus : le PIB est la somme des revenus distribués en une période.
PIB nominal et PIB réel
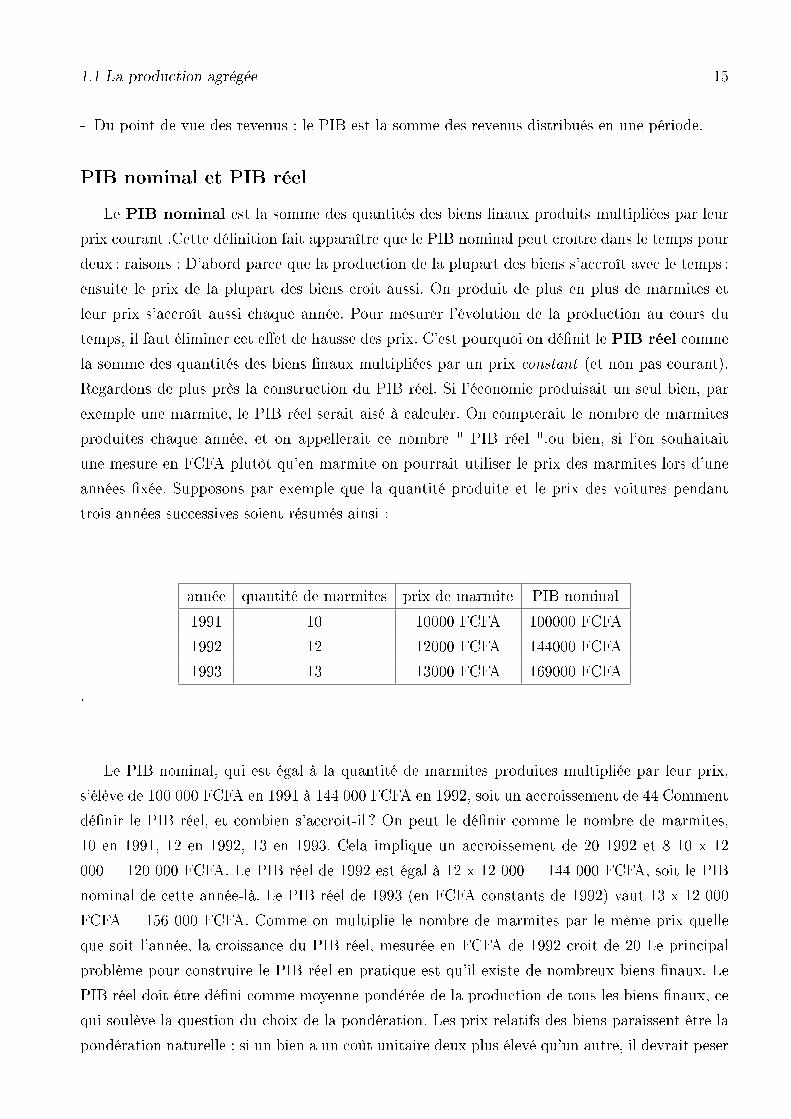
Le PIB nominal est la somme des quantités des biens �naux produits multipliées par leur
prix courant .Cette dé�nition fait apparaître que le PIB nominal peut croître dans le temps pour
deux ; raisons : D'abord parce que la production de la plupart des biens s'accroît avec le temps ;
ensuite le prix de la plupart des biens croît aussi. On produit de plus en plus de marmites et
leur prix s'accroît aussi chaque année. Pour mesurer l'évolution de la production au cours du
temps, il faut éliminer cet e�et de hausse des prix. C'est pourquoi on dé�nit le PIB réel comme
la somme des quantités des biens �naux multipliées par un prix constant (et non pas courant).
Regardons de plus près la construction du PIB réel. Si l'économie produisait un seul bien, par
exemple une marmite, le PIB réel serait aisé à calculer. On compterait le nombre de marmites
produites chaque année, et on appellerait ce nombre " PIB réel ".ou bien, si l'on souhaitait
une mesure en FCFA plutôt qu'en marmite on pourrait utiliser le prix des marmites lors d'une
années �xée. Supposons par exemple que la quantité produite et le prix des voitures pendant
trois années successives soient résumés ainsi :
année quantité de marmites prix de marmite PIB nominal
1991 10 10000 FCFA 100000 FCFA
1992 12 12000 FCFA 144000 FCFA
1993 13 13000 FCFA 169000 FCFA
.
Le PIB nominal, qui est égal à la quantité de marmites produites multipliée par leur prix,
s'élève de 100 000 FCFA en 1991 à 144 000 FCFA en 1992, soit un accroissement de 44 Comment
dé�nir le PIB réel, et combien s'accroit-il ? On peut le dé�nir comme le nombre de marmites,
10 en 1991, 12 en 1992, 13 en 1993. Cela implique un accroissement de 20 1992 et 8 10 x 12
000 = 120 000 FCFA. Le PIB réel de 1992 est égal à 12 x 12 000 = 144 000 FCFA, soit le PIB
nominal de cette année-là. Le PIB réel de 1993 (en FCFA constants de 1992) vaut 13 x 12 000
FCFA = 156 000 FCFA. Comme on multiplie le nombre de marmites par le même prix quelle
que soit l'année, la croissance du PIB réel, mesurée en FCFA de 1992 croit de 20 Le principal
problème pour construire le PIB réel en pratique est qu'il existe de nombreux biens �naux. Le
PIB réel doit être dé�ni comme moyenne pondérée de la production de tous les biens �naux, ce
qui soulève la question du choix de la pondération. Les prix relatifs des biens paraissent être la
pondération naturelle : si un bien a un coût unitaire deux plus élevé qu'un autre, il devrait peser

1.2 La composition du PIB 16
deux plus dans le PIB réel. Mais cela soulève une autre question que faire si, comme il arrive,
les prix relatifs changent au cours du temps ? Doit-on �xer les pondérations en choisissant une
année de référence, ou les modi�er ? Ceci nous pousse à une discussion plus approfondie de ces
problèmes, et nous amène à voir la façon donc le PIB est calculé en zone CEMAC. La mesure
du PIB réel en comptabilité nationale est appelée PIB réel en FCFA constants. Les expressions
PIB nominal et PIB réel ont chacune beaucoup de synonymes, que nous pouvons rencontrer au
cours de nos lectures :
� le PIB nominal s'appelle aussi PIB en FCFA courant.
� le PIB réel est aussi appelé PIB en terme de biens, PIB en FCFA constants, PIB
ajusté pour l'in�ation, ou PIB au prix de l'année de référence.
1.2 La composition du PIB
Les facteurs qui déterminent l'achat de machine par une entreprise ne sont pas les même
que ceux utilisés par les ménages pour les dépenses de nourriture, ou par le gouvernement pour
les achats d'armes de guerres. Lorsque l'on cherche à comprendre quels sont les déterminants
de la production, il faut décomposer la production agrégée(PIB) en fonction des types de biens
produits et des types d'acheteurs. Voici la décomposition traditionnelle du PIB en zone CEMAC
par les macro-économistes :
Le PIB(Y ) est composé de :
1. Consommation(C )
2. Investissement(I )
3. Dépenses gouvernementales(G)
4. Exportations nettes
Exportations(X )
Importations(Q)
5. Investissement en stock (Is)
La première composante est la consommation : C'est la composante la plus importante du
PIB, ce sont les biens achetés par les ménages, billets d'avion, vacances ou nouveau vélo. On
appelle parfois l'investissement(I) " investissement �xe " pour le distinguer de l'investissement en
stock .L'investissement se décompose en investissement des entreprises, achat par les entreprises
d'une nouvelle machines (de la turbine aux ordinateurs), nouveaux terrains, et investissement
des particuliers, achat par les ménages de nouvelles maisons ou appartements.
NB : Attention pour la plus part des gens, " investissement " signi�e achat d'or ou d'actions.
Mais les économistes utilisent le mot investissement pour désigner l'achat de nouveau capital,
des machines, des bâtiments, des appartements

1.3 Description des données 17
Les dépenses gouvernementales(G), correspondent aux achats des biens et services par le
gouvernement, que ce soient les autorités locales ou nationales. Les biens vont des avions aux
fournitures de bureau.les services sont les services o�erts par les fonctionnaires. Ont considère
que le gouvernement achète les services de ses fonctionnaires (qu'il o�re ensuite au public). La
valeur de ces services (pour lesquels il n'existe pas de prix) est simplement estimée à leur coût.
Notons que les dépenses du gouvernement n'incluent pas les transferts opérés par le gouverne-
ment (assurance sociale), ni les intérêts payés sur la dette publique. Bien que ce soient de toute
évidence les dépenses faites par le gouvernement, ce ne sont ni des achats de biens ni les achats
de services. La somme des trois premières composantes du PIB, donne les dépenses de biens et
services par les ménages, les entreprises et le gouvernement. Pour obtenir l'ensemble de toutes
les dépenses, il faut encore deux étapes. D'abord, il faut retrancher les importations (Q), achat
de bien et services étrangers par les ménages, les entreprises et le gouvernement. Ensuite, il faut
ajouter les exportations (X), achat par les étrangers de biens et services nationaux. La di�é-
rence entre importations et exportions est appelée exportation nette, ou balance commerciales
les exportations dépassent les importations, le pays connaît alors un excédent commercial. En
revanche ; si ce sont les importations qui dépassent les exportations, le pays connaît un dé�cit
commercial. La somme des quatre premières composantes donne les achats (qui correspondent
aussi à des ventes) de biens et services. Pour obtenir la production, il faut encore une dernière
étape. Certains biens produits ne sont pas vendus l'année même, mais l'année suivante. De même,
certains biens vendus lors d'une année ont été produits l'année précédente. La di�érence entre
les biens produits et les biens achetés pour une année donnée est appelée variation de stocks et
est noté Is. Nous pouvons résumer cette décomposition fondamentale de la façon suivante :
Y = C + I + G + X - Q (1.1)
Le PIB est égal à la somme des achats �naux, consommation, investissement, dépense du
gouvernement et balance commerciale.
1.3 Description des données
Les données dont nous disposons proviennent d'une part du Document N o 212 Novenbre -
Decembre 1994 Etudes Statistiques de la Banques des Etats de l'Afrique Cenbtrale (BEAC) et
d'autre part du site Web de la BEAC (rubrique statistique ) consulté au mois de MAI 2010.
Notre base de données est constituée de deux variables parmi lesquelles la variable années et la
variable pibnominal en milliard de FCFA. Ces deux variables varient d'un pays à un autre et
représentent respectivement les années, et le PIB nominal. Ainsi nous avons le PIB nominal au
Cameroun, au Gabon, et au Congo de 1977 à 2009, en Guinée Equatoriale de 1985 à 2009, au
Tchad de 1982 à 2009.
1.3 Description des données 18
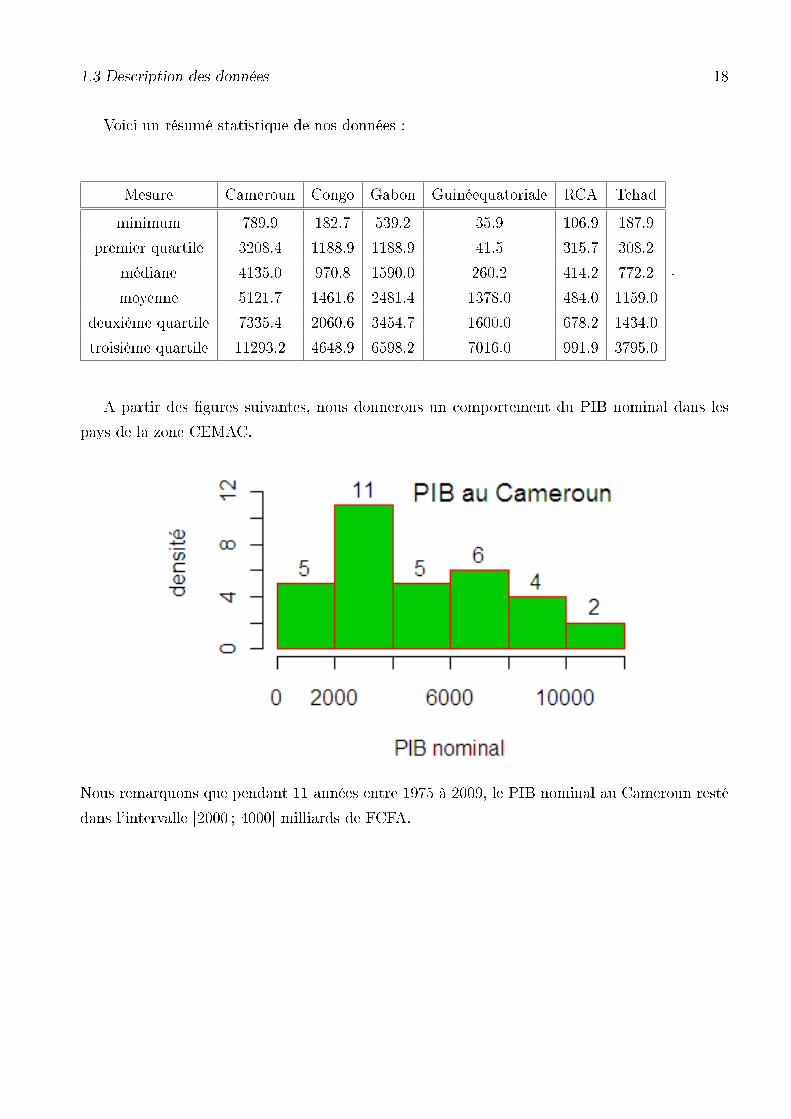
Voici un résumé statistique de nos données :
Mesure Cameroun Congo Gabon Guinéequatoriale RCA Tchad
minimum 789.9 182.7 539.2 35.9 106.9 187.9
premier quartile 3208.4 1188.9 1188.9 41.5 315.7 308.2
médiane 4135.0 970.8 1590.0 260.2 414.2 772.2
moyenne 5121.7 1461.6 2481.4 1378.0 484.0 1159.0
deuxième quartile 7335.4 2060.6 3454.7 1600.0 678.2 1434.0
troisième quartile 11293.2 4648.9 6598.2 7016.0 991.9 3795.0
.
A partir des �gures suivantes, nous donnerons un comportement du PIB nominal dans les
pays de la zone CEMAC.
Nous remarquons que pendant 11 années entre 1975 à 2009, le PIB nominal au Cameroun resté
dans l'intervalle [2000 ; 4000] milliards de FCFA.
1.3 Description des données 19
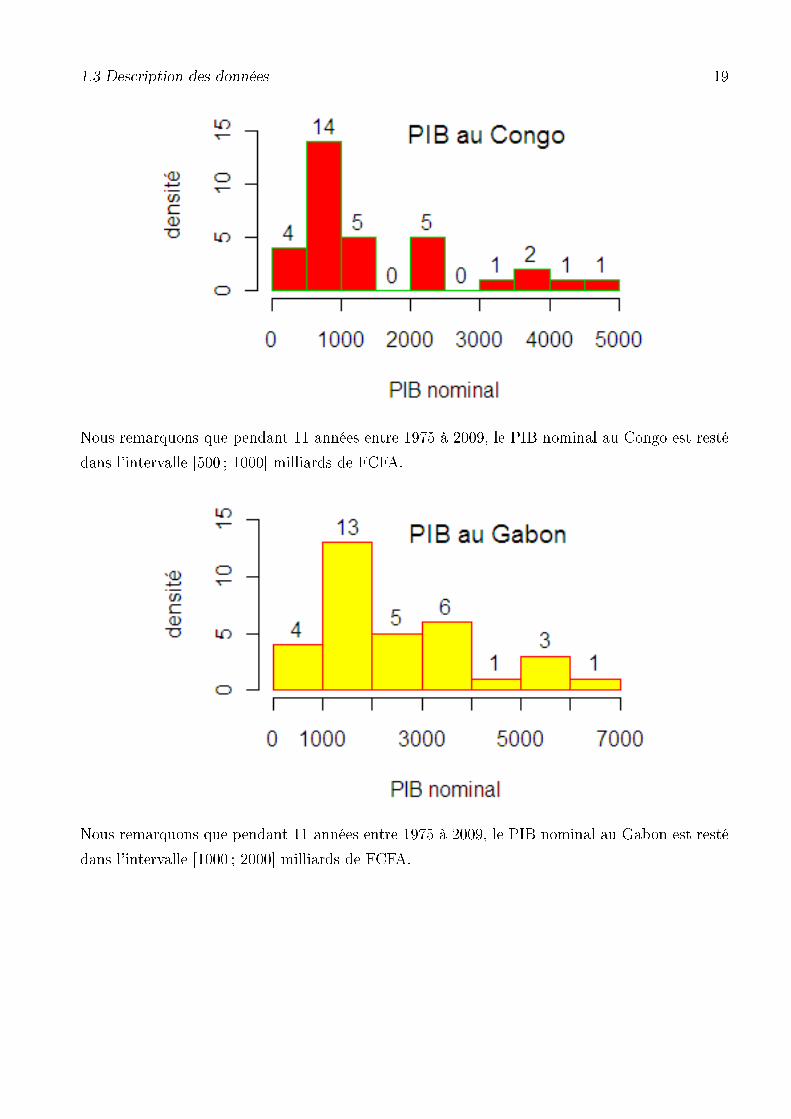
Nous remarquons que pendant 11 années entre 1975 à 2009, le PIB nominal au Congo est resté
dans l'intervalle [500 ; 1000] milliards de FCFA.
Nous remarquons que pendant 11 années entre 1975 à 2009, le PIB nominal au Gabon est resté
dans l'intervalle [1000 ; 2000] milliards de FCFA.
1.3 Description des données 20
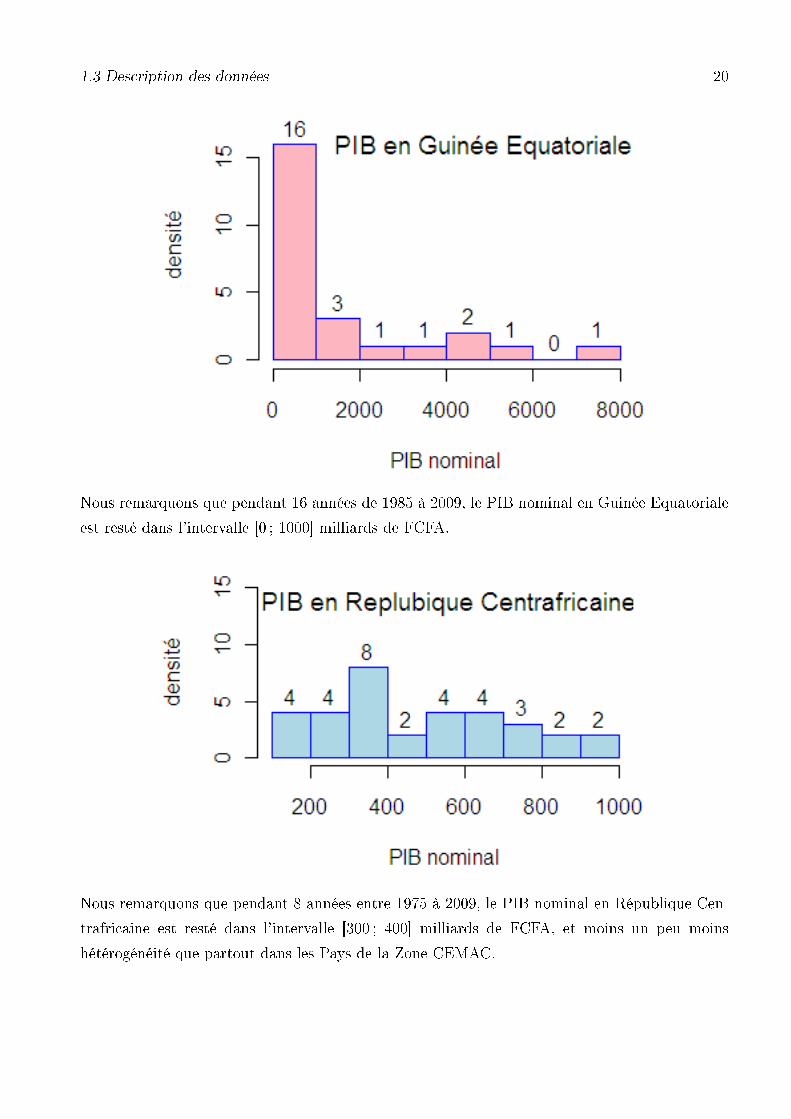
Nous remarquons que pendant 16 années de 1985 à 2009, le PIB nominal en Guinée Equatoriale
est resté dans l'intervalle [0 ; 1000] milliards de FCFA.
Nous remarquons que pendant 8 années entre 1975 à 2009, le PIB nominal en République Cen-
trafricaine est resté dans l'intervalle [300 ; 400] milliards de FCFA, et moins un peu moins
hétérogénéité que partout dans les Pays de la Zone CEMAC.
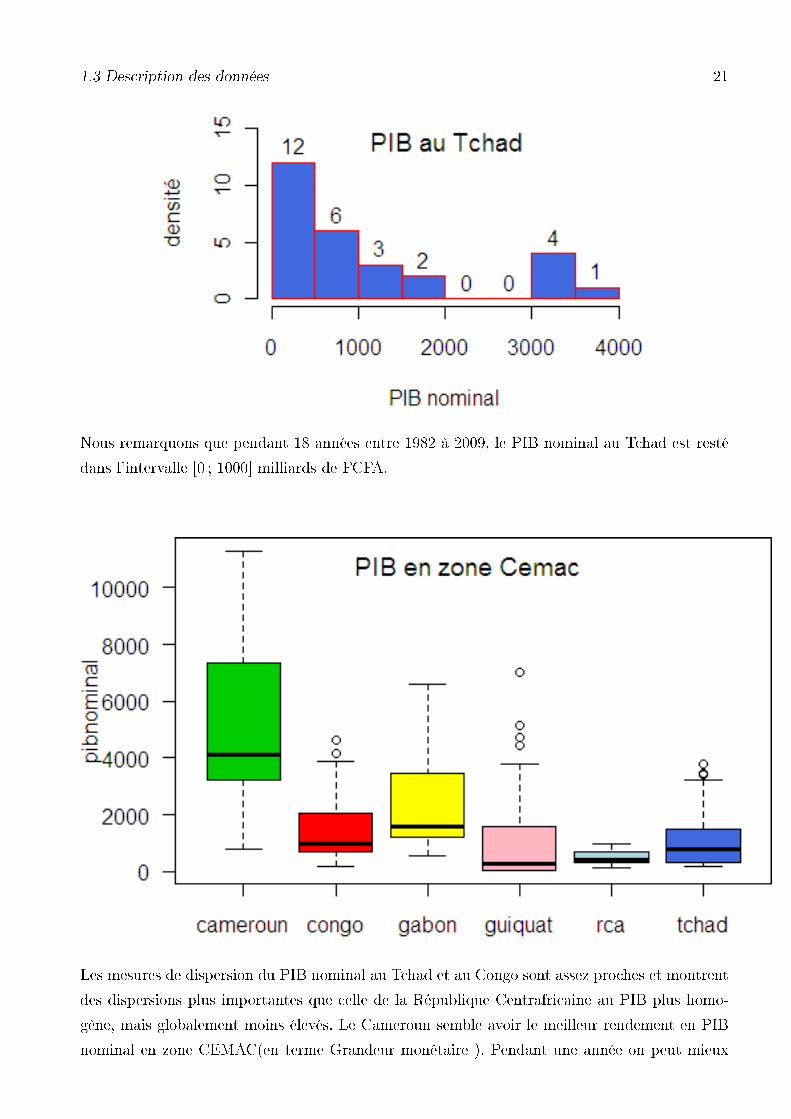
1.3 Description des données 21
Nous remarquons que pendant 18 années entre 1982 à 2009, le PIB nominal au Tchad est resté
dans l'intervalle [0 ; 1000] milliards de FCFA.
Les mesures de dispersion du PIB nominal au Tchad et au Congo sont assez proches et montrent
des dispersions plus importantes que celle de la République Centrafricaine au PIB plus homo-
gène, mais globalement moins élevés. Le Cameroun semble avoir le meilleur rendement en PIB
nominal en zone CEMAC(en terme Grandeur monétaire ). Pendant une année on peut mieux

1.3 Description des données 22
s'attendre à une valeur plus élevé (Peut être moins bonne si on considère l'investissement) du
PIB au Cameroun que par tout ailleurs en zone CEMAC.

Chapitre 2
Méthodologies de prévision des
données annuelles
2.1 Appréhender des données dans le temps :
Dé�nitions
2.1.1 serie temporelles
Une série temporelle (ou encore une série chronologique) est une suite �nie (x1,...,xn) de
données indexées par le temps. L'indice temps peut être selon les cas la minute, l'heure, le jour,
l'année etc.... Le nombre n est appelé la longueur de la série. Il est la plupart du temps bien utile
de représenter la série temporelle sur un graphe construit de la manière suivante : en abscisse le
temps, en ordonnée la valeur de l'observation à chaque instant. Pour des questions de lisibilité,
les points ainsi obtenus sont reliés par des segments de droite. Le graphe apparaît donc comme
une ligne brisée.
2.1.2 briuts blancs
� Un processus e=(et,tεZ) est un bruit i.i.d si e est une suite i.i.d centrée. Si la loi commune
des et est L, on notera e i.i.d(L) et e i.i.d(0, σ2) si L est centrée et de variance �nie σ2,
e i.i.d(N(0, σ2)) si la loi commune est gaussienne centrée de variance σ2.
� un proccesus e=(et,tεZ) est un bruit blanc faible (notéBB) si e est stationnaire au second
ordre, centré, avec Cov(et,es)=0 si s 6=t. On notera e BB(0,σ2) si Var(et)=E(e2t )=σ
2.
2.1.3 tendances.
� On parle de tendance linéaire lorsque la série peut se décomposer en
xn = an+ b+ en n = 1, 2...
Plus généralement, on parle de tendance polynômiale lorsque la série peut se décomposer en
xn = a1np + ap−1
2 + ...+ ap+1 + en n = 1, 2, ...
Mémoire de Master de Statistique Appliquée. Jacques Le Grand BIYICK ETOGUE c©ENSP 2008-2010

2.1 Appréhender des données dans le temps : 24
expression dans laquelle en est un résidu, où ne �gure plus la tendance et qui, de ce fait, a une
allure relativement homogène dans le temps.
De même on pourra dé�nir des tendances logarithmiques, exponentielles etc...
� La tendance peut être multiplicative dans certaines séries :
xn = tnen n = 1, 2...
Ou tn prend l'une des formes (linéaire, polynômiale etc...) évoquées plus haut. C'est alors le
logarithme des données (si elles sont positives !) qui présente une tendance additive.
2.1.4 Composantes Périodiques, Saisonnalités.
On parle de composante périodique, ou de périodicité, lorsque la série se décompose en
xn = sn + en n = 1, 2...
où sn est périodique (c'est à dire sn+T=sn pour tout n, où T est la période, supposée entière) et
où en est un résidu non-périodique et sans tendance.
Par exemple sn = cosnπ6
a une période T = 12. Lorsque la période T est de 6 mois ou un an,
comme c'est le cas dans beaucoup de phénomènes socio-économiques, on a plutôt l'habitude de
parler de saisonnalité ou de composante saisonnière.
� Comme précédemment, il arrive qu'on ait recours à un modèle multiplicatif.
2.1.5 Superposition de tendance et de périodes.
On peut bien imaginer des modèles de type
xn = s(1)n + s(2)
n + tn + en n = 1, 2, ...
dans lequel se superposent deux séries périodiques de périodes T1 et T2 et une tendance. Moyen-
nant une légère modi�cation (en l'occurrence le passage au logarithme gomme l'e�et d'augmen-
tation de la dispersion) .
2.1.6 les premiers indices descriptifs
Il est bien plus utile de disposer de quelques indices numériques qui "résument" une série
(x1, ..., xn).
2.1.7 Indices de tendance centrale
Ce sont, classiquement, la moyenne et la médiane.
xn =1
n
n∑j=1
xj

2.1 Appréhender des données dans le temps : 25
2.1.8 Indices de disperssion
Les plus courants sont la variance empirique (ou plus exactement l'écart type empirique qui
en est la racine carrée) et l'étendue (di�érence entre la plus grande valeur et la plus petite). Elles
indiquent la dispersion des observations autour de leur indice de tendance centrale.
σn(0) =1
n
n∑j=1
(xj − xn)2
Indices de dépendence
2.1.9 Auto-covariances empiriques
Ces indices σn(1),σn(2),...donnent une idée de la dépendance entre les données.Plus exacte-
ment
σn(1) =1
n
n−1∑j=1
(xj − xn)(xj+1 − xn)
indique la dépendance entre deux données successives,
σn(2) =1
n
n−2∑j=1
(xj − xn)(xj+2 − xn)
indique la dépendance entre deux données écartées de deux unités de temps et ainsi de suite
jusqu'à
σn(n− 1) =1
n(x1 − xn)(xn − xn).
En réalité ce dernier indice, qui ne fait intervenir que la première et la dernière donnée, n'a pas
grand sens statistique, surtout di la longueur n de la série est grande.il en est de même pour
σn(n−1). Le bon sens, ainsi que des considérations de convergence, recommandent de ne prendre
en considération que les auto-covariances empiriques σn(1), ...,σn(h) pour un h "pas trop grand"
par rapport à la longueur de la série.
2.1.10 Auto-corrélation empiriques.
Ce sont les quotients des covariances par la variance :
ρn(j) =σn(j)
σn(0), j = 0, ..., h.
Évidemment σn(0)=1, si bien qu'en passant des auto-covariances aux auto-corrélations on perd
une information : la dispersion de la série autour de sa moyenne. Il faut garder ce fait en
mémoire. Ceci dit, ce sont ces auto-corrélations qui caractérisent les dépendances. Pour le voir,

2.1 Appréhender des données dans le temps : 26
il faut remarquer par exemple que
ρn(1) =
n−1∑j=1
(xj − xn)(xj+1 − xn)
n−1∑j=1
(xj − xn)2
est presque le coe�cient de corrélation entre la série (x1, x2, ..., xn−1) et la série décalée d'une
unité de temps (x1, x2, ..., xn),
2.1.11 Visualisation graphique des auto-corrélations empiriques.
Soit N1est le nuage de points :
(xj, xj+1), j = 1, ..., n− 1, .
N1 constitue une bonne illustration de la valeur de ρn(1). Si cette auto-corrélation est proche de
±1, le nuage de points est allongé selon une droite. La pente de cette droite a le signe de ρn(1).
Le nuage est d'autant plus "arrondi " que ρn(1) est plus proche de zéro.
Un commentaire analogue(en remplaçant ρn(1))par ρn(k) peut être fait pour les nuages Nk pour
k = 2, ..., h :
(xj, xj+k), j = 1, ..., n− k.
2.1.12 Comment utiliser l'auto-corrélation ?
L'auto-corrélation est surtout utilisée sur les séries résiduelles en qui s'ajoutent aux tendances
et aux saisonnalités. La démarche habituelle consiste à retirer de la série la tendance que l'on
a détecté, puis, si il y a lieu de la désaisonnaliser. Sur la série résiduelle, on calcule les auto-
covariances empiriques qui serviront à mettre un modèle prédictif sur ces résidus.
Cependant, il est très utile de comprendre quelle sera l'allure de cette auto-corrélation sur une
série brute, comportant tendance ou/et saisonnalité.
En résumé, pour une longue série présentant une tendance polynômiale, l'auto-corrélation ρn(k)
est positive et assez proche de 1 lorsque k évolue tout en restant petit devant n. Pour une série
une présentant périodicité, cette périodicité se voit bien sur l'auto-corrélation.

2.2 Séries Temporelles 27
2.2 Séries Temporelles
Propriétés de base des séries stationnaires
2.2.1 Stationnarité
La stationnarité est la clef de l'analyse des séries temporelles. Une série Yt est dite strictement
stationnaire si la distribution conjointe de (Yt1 , ..., Ytk) est identique à celle de (Yt1+t, ..., Ytk+t),
quel que soit t, où k est un entier positif arbitraire et (t1, ..., tk) une liste de k entiers positifs
arbitraires. Autrement dit, la stationnarité stricte dit que la distribution conjointe de (Yt1 , ..., Ytk)
est invariante quand on fait glisser le temps. Cette condition est di�cile à véri�er et on utilise en
général, une version plus faible de stationnarité. On dit qu'une série temporelle Yt est faiblement
stationnaire si la moyenne de Yt et la covariance entre Yt et Yt−l sont invariantes par translation
du temps. Précisément, Yt est faiblement stationnaire si :
(a) E(Yt) = µ où µ est une constante indépendante de t,
(b) cov(Yt Yt−l) ne dépend que de l, entier
La stationnarité faible (ou du second ordre) implique que le graphe de la série en fonction du
temps montre des �uctuations autour d'un niveau moyen, �uctuations qui se ressemblent, quel
que soit la date autour de laquelle on examine la série.
2.2.2 Fonction d'auto covariance
La covariance γl = cov(Yt, Yt−l) est appelée auto covariance d'ordre l (ou de décalage) l (lag-l
auto covariance). Pour chaque décalage l, il y a une auto covariance.
De�nition 2.2.1. . La fonction : l γl est la fonction d'auto covariance de Yt. Cette fonction
a trois propriétés importantes :
(a) γ0=var(Yt)
(b)|γh|≤|γ0|
(c) γl=γ−l, car :
γl = cov(Yt, Yt+l) = cov(Yt−l, Yt−l+(l))
= cov(Yt−l, Yt) = cov(Yt, Yt−l)
= γ−l
Autre notation. On écrit aussi γY (l), en particulier pour distinguer la fonction d'auto covariance
d'une série Yt, de celle d'une autre série.

2.2 Séries Temporelles 28
2.2.3 Corrélation, fonction d'auto corrélation et fonction d'auto cor-
rélation partielle
Rappel 2.2.1. :Le coe�cient de corrélation entre deux variables aléatoires X etY de moyennes
µX et µY est dé�ni par :
ρX,Y =COV (X, Y )√
V AR(X)V AR(Y )=
E[(X − µX)(Y − µY )]√E(X − µX)2E(Y − µY )2
Ce coe�cient est compris entre -1 et 1. Il mesure la force de la dépendance linéaire entre X et
Y. Si on dispose d'un échantillon (xt,yt), t = 1, ..., T d'observations indépendantes de (X,Y).
Fonction d'auto corrélation (ACF)
Considérons une série (faiblement) stationnaire Yt. On est souvent intéressé par décrire la dé-
pendance de Yt par rapport à son passé, notamment pour expliquer le niveau actuel de la série
par le niveau à une date précédente. Si une dépendance est linéaire, elle est bien décrite par le
coe�cient d'auto corrélation. Par dé�nition, le coe�cient d'auto corrélation d'ordre l est
ρl =cov(Yt, Yt−l)√var(Yt)var(Yt−l)
Mais var(Yt−l)=var(Yt)=γ0 donc :
ρl =cov(Yt, Yt−l)
var(Yt)=γlγ0
En�n en terme d'espérance mathématique et notant que par la stationnarité : E(Yt)=µ,
indépendant de t, on a :
ρl =E[(Yt − µ)(Yt−l − µ)]
E(Yt − µ)2.
ρl est une mesure de la dépendance de la valeur Y en une date par rapport à sa valeur à une
date décalée de l intervalles de temps.
De�nition 2.2.2. : La fonction
l ρl, l = 0, 1, 2, ...
est appelée fonction d'auto corrélation (théorique), FAC (ou ACF en anglais) de la serie
Yt.
De la dé�nition on voit que ρ0=1, et -1≤ρl≤ 1.
Etant donné un échantillon yt, t = 1, ..., T , de Yt stationnaire, notons la moyenne empirique,

2.2 Séries Temporelles 29
y=T∑t=1
yt/T . lecoe�cient d'auto corrélation empirique d'ordre 1 est :
ρ1 =
T∑t=2
(yt − y)(yt−l − y)
T∑t=1
(yt − y)2
.
Le coe�cient d'auto corrélation empirique d'ordre l≥ 1 est
ρl =
T∑t=l+1
(yt − y)(yt−l − y)
T∑t=1
(yt − y)2
, 0 ≤ l ≤ T − 1
ρl est un estimateur convergent de ρl.
De�nition 2.2.3. La fonction
l ρl, l = 1, 2, ...
est appelée fonction d'auto corrélation empirique de la serie Yt.
De�nition 2.2.4. La fonction d'auto corrélation partielle(FACP) de Yt, est dé�nie par :{α(1) = corr(Y2, Y1) = ρ(1)
α(k) = corr(Yk+1 − Psp{1,Y2,...,Yk}Yk+1, Y1 − Psp{1,Y2,...,Yk}Y1)
où Psp{1,Y2,...,Yk} est la projection sur le sous-espace engendré par 1, Y2, ..., Yk.
α(k) = φkk, k ≥ 1 avec φkk tel que :
ρ0 ρ1 . . . ρk−1
ρ1 ρ0 . . . ρk−2
......
. . ....
ρk−1 ρk−2 . . . ρ0
φk1
φk2
...
φkk
=
ρ1
ρ2
...
ρk
.
Tests de non corrélation

2.2 Séries Temporelles 30
Résultat. Si Yt est une suite de v.a i.i.d, de moment d'odre 2 �ni, E(Y 2t )<∞, alors les coe�-
cients d'auto corrélation ρl sont approximativement indépendants et normalement distribués, de
moyenne 0, de variance 1T. Ce résultat peut être utilisé pour di�érents tests.
� Etant donnée une réalisation y1,...,yT d'une serie, on peut calculer pour un décalage l
particulier :√T (ρl-0) et voir si ça peut être considéré comme la valeur d'une v.a N(0, 1).
� Etant donnée une réalisation y1,...,yT d'une série véri�ant les hypothèses du résultat ci-
dessus, on devrait avoir environ 95% des coe�cients d'auto corrélation empirique dans
l'intervalle ±1,96√T. Si la proposition observée est loin de cette valeur, on peut conclure que
les observations ne sont pas indépendantes.
Test de Box-Pierce ou Ljung-Box(Box)
La statistique Q de Ljung-Box permet de tester l'hypothèse d'indépendance sérielle d'une
série (ou que la série est bruit blanc). Plus spéci�quement cette statistique teste l'hypothèse que
les n coe�cients d'auto-corrélation sont nuls. Elle est basée sur la somme des auto-corrélations
de la série et elle est distribuée selon une loi Chi-carrée avec T degrés de liberté. L'hypothèse
nulle est alors donnée par :
H0 : ρ1 = ρ2 = ρ3 = ... = ρT = 0
La statistique du test est alors :
Q = T (T + 2)h∑j=1
ρ2j
T − j
2.2.4 Les processus ARMA et ARIMA
Ces processus sont souvent utilisés pour l'identi�cation et l'estimation des modèles des séries
temporelles.
De�nition 2.2.5. Un processus (Yt)tεZ est auto régressif d'ordre p, que l'on note AR(p)
si :
1. (Yt)tεZ est stationnaire.
2. Yt = µ+ φ1Yt−1 + ...+ φpYt−p + εt
où εt ∼ BB(0, σ2), µεR, ∀ i = 1, ..., p, φiεR. On note aussi Φ(L)Yt = µ + εt où Φ(L) =
I − (φ1L+ ...+ φpLp) et LiYt = Yt−i.
De�nition 2.2.6. Un processus (Yt)tεZ est Moyenne mobile d'ordre q que l'on note MA(q)
si :

2.3 Methodes de prévision 31
1. (Yt)tεZ est stationnaire.
2. Yt = m+ θ1εt−1 + ...+ θpεt−p
où εt ∼ BB(0, σ2), mεR, ∀ i = 1, ..., q, θiεR. On note aussi Yt = m + Θ(L)εt où Θ(L) =
I + θ1L+ ...+ θqLq et Liεt = εt−i.
De�nition 2.2.7. Un processus (Yt)tεZ est Auto-Régressif Moyenne Mobile que l'on note
ARMA(p,q) si :
1. (Yt)tεZ est stationnaire.
2. Φ(L)Yt = Θ(L)εt
où εt ∼ BB(0, σ2), Θ(L) = I + θ1L+ ...+ θqLq et Liεt = εt−i. Φ(L) = I − (φ1L+ ...+ φpL
p) et
LiYt = Yt−i. ∀ i = 1, ..., q, θiεR, φiεR.
De�nition 2.2.8. Un processus (Yt)tεZ est Auto-Régressif Moyenne Mobile Intégré que
l'on note ARIMA(p,d,q) si (I − L)dYt est unARMA(p,q).
2.3 Methodes de prévision
2.3.1 Lissage exponentiel simple
Les méthodes de lissages consistent à extrapoler une série en vue de faire de la prévision. Or,
une extrapolation simple (linéaire en l'occurrence) dépend fortement du type de résultats que l'on
cherche à avoir : prévision à court, moyen, ou long terme.
On dispose d'une série temporelle (Y1, ..., YT ). On suppose qu'on se trouve à la date T et l'on
désire prévoir le valeur de YT+h. On notera Y (h), une telle prévision et hεN∗ est appelé l'horizonde la prévision.
De�nition 2.3.1. La prévision YT (h) fournie par la méthode de lissage exponentiel simple, avec
la constante de lissage β, 0 < β < 1 est
YT (h) = (1− β)T−1∑j=0
βjYT−j (2.1)
Cette dé�nition repose sur une idée simple : on suppose que les observations in�uencent
d'autant moins la prévision qu'elles sont éloignées de la date T à laquelle on fait la prévision ;
en outre, on suppose que les observations in�uencent d'autant moins la prévision qu'elles sont
éloignées de la dates T à laquelle on fait la prévision ; en outre, on suppose que cette in�uence
décroît exponentiellement. On voit facilement que

2.3 Methodes de prévision 32
� plus la constante de lissage β est proche de 1, plus l'in�uence des observations passées
remonte loin dans le temps et plus la prévision est rigide, c'est à dire peu sensible aux
�uctuations conjoncturelles.
� au contraire, plus la constante β est proche de zéro, plus la prévision est in�uencée par les
observations récentes (prévision souple)
Si β ne dépend pas de h, donc YT (h)=YT .Cette valeur YT est la prévision faite en T de la valeur
en T + 1. Nous appellerons cette série YT (série lissée à la date t). Nous utiliserons dans la suite
YT au lieu de YT (h).
Proposition 2.3.1. La formule (2.1) s'écrit aussi :
YT = βYT−1 + (1− β)YT . (2.2)
démonstration
YT (h) = (1− β)T−1∑j=0
βjYT−j + (1− β)YT
= (1− β)T−2∑j=0
βj+1YT−1−j + (1− β)YT
= (1− β)βT−1∑j=0
βjYT−1−j + (1− β)YT
= βYT−1 + (1− β)YT
La prévision YT apparaît donc comme une moyenne pondérée entre la prévision YT−1 faite à la
date T − 1 et la dernière observation YT , le poids donné à, cette observation étant d'autant plus
fort que β est faible.
Soit le problème de minimisation suivant :trouver aεR
a = arg minaεR
T−1∑j=0
βj(YT−j − a)2 (2.3)
Une dérivation de la fonction a 7→T−1∑j=0
βj(YT−j − a)2 donne immédiatement :
a =1− β
1− βTT−1∑j=0
βjYT−j
Donc pour T assez grand a≈ (1 − β)T−1∑j=0
βjYT−j .Par conséquent, YT s'interprète comme la
constante qui s'ajuste le mieux à la série au voisinage de T . L'expression voisinage se traduisant

2.3 Methodes de prévision 33
par le problème (2.2).
NB : La méthode par lissage exponentiel simple est sans doute la plus utilisée lorsqu'il s'agit du
lissage. En revanche, la dernière interprétation faite sur l'expression de la prévision montre bien
que la méthode ne pourra être utilisable que si la série peut être approchée par un constante au
voisinage de T. Elle est donc à éviter lorsque la série présente une tendance non constante ou
des �uctuations.
Choix de la constante de lissage
En pratique, le choix de β est souvent fondé sur les critères subjectifs de rigidité ou de souplesse
de prévision. Il existe cependant une méthode plus objective qui consiste à choisir la constante
qui minimise la sommes des carrés des erreurs de prévision aux dates 1, 2, ..., T − h0 (pour un
horizon h0 donné) :T−h0∑t=1
[Yt+h0 − Yt(h0)]2
Ceci suppose bien sûr avoir un peu plus d'informations sur le processus. On montre par exemple
que si le processus (Yt)tεZ est autorégressif de racine sε]0, 1[, alors les meilleures valeurs de β
sont autour de 0.7 et 0.8. Notons aussi que si on n'a pas assez d'information sur le processus, on
peut choisir β de façon itérative comme suit :
Etape 1 : on se donne l'intervalle I =]0, 1[
Etape 2 : on divise I en 100 sous-intervalles égaux de façon à obtenir β1, ..., β100 ,
Etape 3 : on retient parmi les 100 valeurs de β ci-dessus, celle qui donne la plus petite erreur
de prévision à la date T − h0 que l'on βj ,
Etape 4 :I ←−]βj−1, βj+1[
Etape 5 : Retour à l'étape 1.
On e�ectue donc ces itérations jusqu'à ce que l'écart entre les erreurs de prévision de deux
étapes consécutives ne soient plus trop considérables. Et on retient la dernière valeur de β.
2.3.2 Le principe du lissage exponentiel double
On a vu dans le paragraphe précédent que la méthode du lissage exponentiel simple était
adaptée au cas où la série pouvait être ajustée à une droite horizontale au voisinage de T . Une
façon naturelle de généraliser cette méthode est de supposer que la série peut être ajustée à une
droite quelconque au voisinage de T .
yt = a1 + (t− T )a2

2.3 Methodes de prévision 34
Cela conduit à proposer comme prévision la fonction
YT (k) = a1(T ) + ka2(T ),
telle quea1(T ) et a2(T ) réalisent le minimum en a1, a2 de :
Q =T−1∑j=0
βj(YT−j − a1 + a2j)2.
Nous obtenons les expressions de a1(T ) et a1(T ) à partir du systhème suivant.∂Q∂a1
= −2T−1∑j=0
βj(YT−j − a1 + a2j)2 = 0
∂Q∂a2
=T−1∑j=0
jβj(YT−j − a1 + a2j)2 = 0
Les formules de mise à jour sont les suivantes
a1(T ) = a1(T − 1) + a2(T − 1) + (1− β2)[YT − YT−1(1)] (2.4)
a2(T ) = a2(T − 1) + (1− β)2[YT − YT−1(1)] (2.5)
2.3.3 La méthode non saisonnière de Holt-Winters
Les méthodes de Brown (lissage exponentielle double et lissage exponentiel généralisé) ont
pour origine une généralisation de la méthode du lissage exponentiel simple considérée comme
un ajustement local d'une droite horizontale. Holt et Winters(1960) ont adopté une approche
di�érente.
La méthode de Holt-Winters sans saisonnalité est fondée, comme la méthode du lissage expo-
nentielle double, sur l'hypothèse qu'un ajustement au voisinage de T , d'une droite quelconque,
d'équation y1 = a1 + (t − T )a2, est préférable à l'ajustement d'une droite horizontale. Plus
précisément Holt-Winters propose des formule de mise à jour pour a1 et a2 du type :
a1(T ) = (1− α)YT + α[a1(T − 1) + a2(T − 1)] 0 < α < 1 (2.6)
a2(T ) = (1− γ)[a1(T ) + a1(T − 1)] + γa2(T − 1) 0 < γ < 1. (2.7)
La formule (2.6) s'interprète comme une moyenne pondérée de deux informations sur le "niveau"
a1 de la série à la date T : L'observation XT et la prévision faite à T − 1. La formule (2.7)
s'interprète comme une moyenne pondérée de deux informations sur la "pente" a2 de la série à
la date T : La di�érence entre les niveaux estimés à T − 1 et T et la pente estimée en T − 1.
Pour utiliser (2.6) et (2.7) il faut auparavant initialiser la séquence [a1(t), a2(t)] ; On prend en
général a1(2) = Y2 et a2(2) = Y2 − Y1. La prévision est
YT (k) = a1(T ) + ka2(T )

2.3 Methodes de prévision 35
cette méthode est plus �exible que la méthode du lissage exponentiel double dans la mesure
où elle fait intervenir deux constante (α et γ) au lieu d'une (β) ; plus présicement, les équations
(2.4) et (2.5) s'écrivent :
a1(T ) = (1− β)2YT + β2[a1(T − 1) + a2(T − 1)] (2.8)
a2(T ) = a2(T − 1) +(1− β)2
1− β2[a1(T ) + a1(T − 1) + a2(T − 1)] (2.9)
sont indentiques aux équations (2.6) et (2.7), si on prend :
α = β2 et γ = 1− (1− β)2
1− β2=
2β
1 + β
la contrepartie de cette plus grande �exibilité est évidemment d'avoir à choisir deux constantes
au lieu d'une, soit par des méthodes subjectives (α et γ proches de 1 impliquent des prévisions
très "lisses", puisque le poids du passé est fort), soit par des méthodes plus objectives comme la
minimisation en α et γ deT−1∑i=1
[Yt+1 − Yt(1)].
2.3.4 Prévision sur les processus ARMA et ARIMA
Les modèles ARIMA et ARMA sont couramment utilisé dans l'étude des données écono-
miques.
Identi�cation d'un modèle ARMA et ARIMA On dispose d'observation y1, ..., yT de
Y1, ..., YT . Comment modéliser par un ARMA ou un ARIMA? Deux cas peuvent se présenter :
� Le processus (Yt)tεZest stationnaire, auquel cas il faut estimer un modèle ARMA(p,q),
� ∀k = 0, 1, ..., d− 1, le processus (1−L)kYt est non stationnaire mais (1−L)dYt est station-
naire, auquel cas il faut estimer un modèle ARIMA(p,d,q).
La démarche pour l'identi�cation est la suivante : choix de d, de (p, q), estimation des paramètres
et validation du modèle. La méthode la plus utilisée est celle de Box-Jenkins (1970). Le principe
de cette dernière méthode est la suivante :
1. représentation graphique de la série brute. Ceci a pour but de détecter les tendances et les
saisonnalités éventuelles qui sont les symptômes d'une série non stationnaire ;
2. analyse graphique du corrélogramme pour avoir une idée sur la nature de la décroissance
de la fonction d'auto-corrélation vers 0. Pour une série stationnaire, la fonction d'auto-
corrélation tend exponentiellement vers 0. Si la décroissance vers 0 est linéaire ou lente, on
dit qu'il y a persistance des chocs et la série n'est pas stationnaire ;
3. test de racine unité ou test de stationnarité. C'est ici qu'on décide en général de la dif-
férentiation ou non de la série. Les tests principaux les plus utilisés dans la littérature
sont les tests de Dickey-Fuller et de Phillips-Perron pour lesquelles l'hypothèse nulle est la
non-stationnarité de la série étudiée.

2.3 Methodes de prévision 36
4. si le processus admet des racines unitaires (est non stationnaire), on pose Xt = (1− L)Yt
retour à l'étape 1 avec Yt ;
5. on arrive ici avec une série stationnaire qu'on a di�érenciée d fois (qui possède une racine
unité d'ordre d). On passe à l'analyse graphique des corrélogrammes du processus Zt =
(1 − L)dYt pour déterminer les ordres qmax (valeur du dernier décalage pour laquelle
la fonction d'auto corrélation est signi�cative) et pmax (valeur du dernier décalage pour
laquelle la fonction d'auto corrélation partielle est signi�cative). Tout modèle obtenu avec
le couple (p, q) , pε{0, 1, ..., pmax} et qε{0, 1, ..., qmax} est dit admissible ;
6. véri�cation a posteriori : on véri�e ici la signi�cativité des paramètres de chacun des mo-
dèles admissibles ainsi que la validation de l'hypothèse de bruit blanc de leurs résidus
respectifs. Le test de Box-Pierce permet d'identi�er les processus de bruit blanc. L'hypo-
thèse nulle de ce test est la nullité de tous les auto-corrélations de décalage inférieur ou égal
à un ordre désiré que l'on précisera dans le test. Plusieurs modèles peuvent être retenus à
l'issue de cette étape ;
7. choix d'un modèle : le modèle �nal est choisi parmi les modèles retenus ci-dessus selon un
critère qui est le plus souvent �xé par le statisticien en fonction des objectifs de l'étude.
On distingue le critère de pouvoir prédictif (il s'agit du modèle qui prédit mieux). Dans la
pratique, on retient le modèle ayant la plus petite variance du résidu et le critère d'infor-
mation (il s'agit du modèle qui s'ajuste le mieux aux données réelles). Dans la pratique,
on retient le modèle ayant le plus petit AIC).
Estimation des paramètres d'un modèle ARIMA
Soit (Yt)tεZ un processus ARIMA(p, d, q), alors la relation suivante est véri�ée
Φ(L)∆2Yt = θ0 + Θ(L)εt
où εt est un bruit blanc. Si on pose Yt = ∆2Yt alors, le processus (Xt)tεZ est un ARMA(p, q) et
la relation ci-dessus devient :
Φ(L)Xt = θ0 + Θ(L)εt
Par conséquent, il su�t de présenter l'estimation des paramètres d'un ARMA(p, q).
Soit X = (x1, ..., xT ) les observations d'un ARMA(p, q).
1. La méthode de maximum de vraisemblance : Elle propose comme estimateur, ce-
lui qui maximise la vraisemblance du processus. Si on pose Ψ = (Φ = (φ1, ..., φp),Θ =
(θ1, ..., θq)) le paramètre du processus,σ2= cov(X). Sous l'hypothèse de la normalité des
bruits, la vraisemblance du processus est :
L(X,Ψ, σ2) =1
(2πσ2)n2
1
(det((XX t))−1)12
exp(− 1
2σ2(XX t))
La maximisation ou même le calcul de cette vraisemblance n'est pas dans des cas vraiment
pratique possible en raison de l'inverse de la matrice (XX) dont l'ordre est la taille de
série.

2.3 Methodes de prévision 37
2. La méthode des moindres carrés de Box et Jenkins
L'idée de base est qu'un ARMA(p, q) a une représentation moyenne mobile∑∞
i=0 φiεt−1 et
qu'il peut donc être approché par un MA(q) de la forme∑q
i=0 φiεt−1.
En Φ = (φ1, ..., φp),Θ = (θ1, ..., θq) telle que :
(Φ,Θ) = arg min(Φ,Θ)
(T∑
i=1−q
εt−1)
Théorème 2.3.1. Théorème de Wold
Soit X un processus stochastique stationnaire au sens faible. Elle peut être représentée sous la
forme :
Xt = Dt +∞∑i=0
φiεt−1
où Dt est la composante déterministe, εt un bruit blanc iid (0, σ2ε) et {φ} ={φ0, φ1, φ2, φ3, ...} un
ensemble de coe�cients réels non aléatoires.
Proposition 2.3.2. On considère un processus ARMA (p, q) de la forme suivante : ∀n
xn + a1xn−1 + ...+ apxn−p = εn + b1εn−1 + ...+ b1εn−q
En appliquant le théorème de Wold et en considérant la forme MA(∞) correspondante :
xn =∞∑j=0
πjεn−j, π0 = 1
la meilleure prévision que l'on peut faire de xn+1 compte tenu de toute l'information disponible
jusqu'à la date xn, notée xn(1), est donnée par :
xn(1) = E(xn+1|xn, xn−1, ..., x0) = E(xn+1|xn, xn−1, ..., x0) =∞∑i=0
φiεn+1−j
L'erreur de prédiction est alors de :
xn+1 − xn(1) = εn+1
Le procédé précédent peut être généralisé à une prévision à un horizon h
xn(h) =∞∑j=0
πjεn+h−j, π0 = 1
d'erreur de prédiction :
xn(h) =h−1∑j=0
πjεn+h−j, π0 = 1

2.3 Methodes de prévision 38
Déterminons un intervalle de con�ance sur la prévision xn(h), sous l'hypothèse de normalité des
résidus εn :
lorsque n 7−→ ∞
xn+h − xn(h)
var(xn+h − xh)1/2
L−→ N(0, 1)
Comme
E[(xn+h − xn(h))2] = E[(h−1∑j=0
πjεn+h−j)2] =
h−1∑j=0
π2jσ
2ε
On a alors lorsque n 7−→ ∞
xn+h − xn(h)
σε[h−1∑j=0
π2j ]
1/2
L−→ N(0, 1)
Ainsi, on obtient l'intervalle de con�ance suivant de niveau α :[xn(h)− tα2 (
k−1∑i=0
π2j )
12 σε; xn(h) + t
α2 (
k−1∑i=0
π2j )
12 σε
].
Proposition 2.3.3. Si (Yt)tεZ un processusARIMA(p, d, q) où y−s+1, ..., y−s+p est le mécanicme
de démarrage, p′ = p+ d et sεN. Alors (Yt) admet la réprésentation
Yt = −t+s−p′−1∑
i=1
πiYt−i +s−1∑
j=s−p′π∗jYt−j + εt ∀t > −s− p′ − 1,
où le processus (εt)tεZ est un bruit blanc.
c'est la réprésentation auto-régressive (AR) du processus (Yt)tεZ
Suite à cette dernière proposition nous avons
YT+H = −T+h+s−p′−1∑
i=1
πiYT+h−i +s−1∑
j=s−p′π∗j,TY−j + εT+h ∀t > −s− p′ − 1,
En négligeant les termes faisant intervenir les valeurs initiales(mécanisme de démarrage), on a :
YT+H = −T+h+s−p′−1∑
i=1
πiYT+h−i + εT+h
Ayant les réalisations du processus (Yt)tεZ jusqu'à la date T , une prévision de (Yt). à un horizon
h est :
YT+H = −T+h+s−p′−1∑
i=1
πiYT+h−i avec YT+h−i =
{YT (h− i) pour i < h
YT+h−i pour i ≥ h

Chapitre 3
Applications
3.1 Et si nous regardions juste le PIB dans le temps
3.1.1 cas du Cameroun
1. Les données
Nous disposons un objet camerounpib qui est composé de deux variables de type numérique,
la première est de années et la seconde est pibnominal. qui représente respectivement les
années de prélèvement du PIB de 1977 à 2009 et le PIB nominal de ces même années
2. Série temporelle : cas du Cameroun
transformons les données sous forme de tableau en série temporelle et pour cela, nous
utilisons la commande ts qui va créer un objet de classe ts à partir d'un vecteur (série
temporelle simple) ou d'une matrice (Série temporelle multiple), et des options qui carac-
térisent la série.
3. Visualisation des données : cas du Cameroun
Avant d'analyser cette série commençons par regarder son évolution par rapport au temps,
recherché : des changements brusques, valeurs atypiques rechercher une éventuelle ten-
dance, une éventuelle saisonnalité (périodicité).
Mémoire de Master de Statistique Appliquée. Jacques Le Grand BIYICK ETOGUE c©ENSP 2008-2010
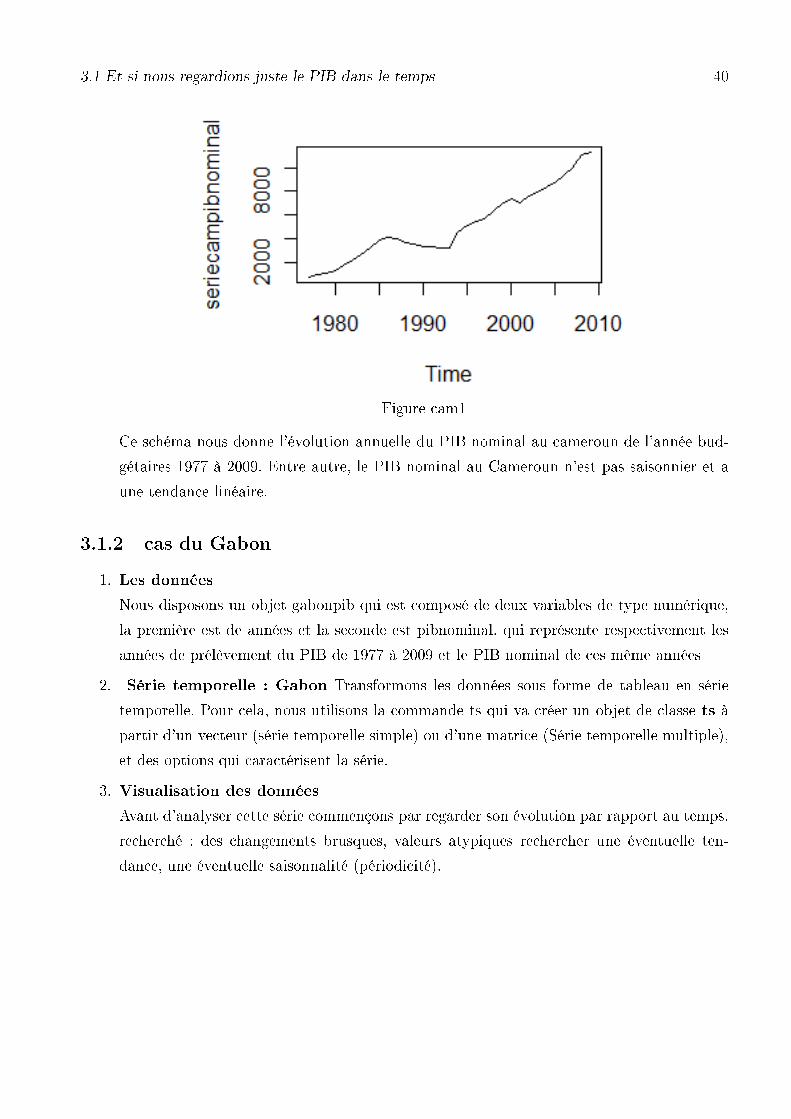
3.1 Et si nous regardions juste le PIB dans le temps 40
Figure cam1
Ce schéma nous donne l'évolution annuelle du PIB nominal au cameroun de l'année bud-
gétaires 1977 à 2009. Entre autre, le PIB nominal au Cameroun n'est pas saisonnier et a
une tendance linéaire.
3.1.2 cas du Gabon
1. Les données
Nous disposons un objet gabonpib qui est composé de deux variables de type numérique,
la première est de années et la seconde est pibnominal. qui représente respectivement les
années de prélèvement du PIB de 1977 à 2009 et le PIB nominal de ces même années
2. Série temporelle : Gabon Transformons les données sous forme de tableau en série
temporelle. Pour cela, nous utilisons la commande ts qui va créer un objet de classe ts à
partir d'un vecteur (série temporelle simple) ou d'une matrice (Série temporelle multiple),
et des options qui caractérisent la série.
3. Visualisation des données
Avant d'analyser cette série commençons par regarder son évolution par rapport au temps,
recherché : des changements brusques, valeurs atypiques rechercher une éventuelle ten-
dance, une éventuelle saisonnalité (périodicité).
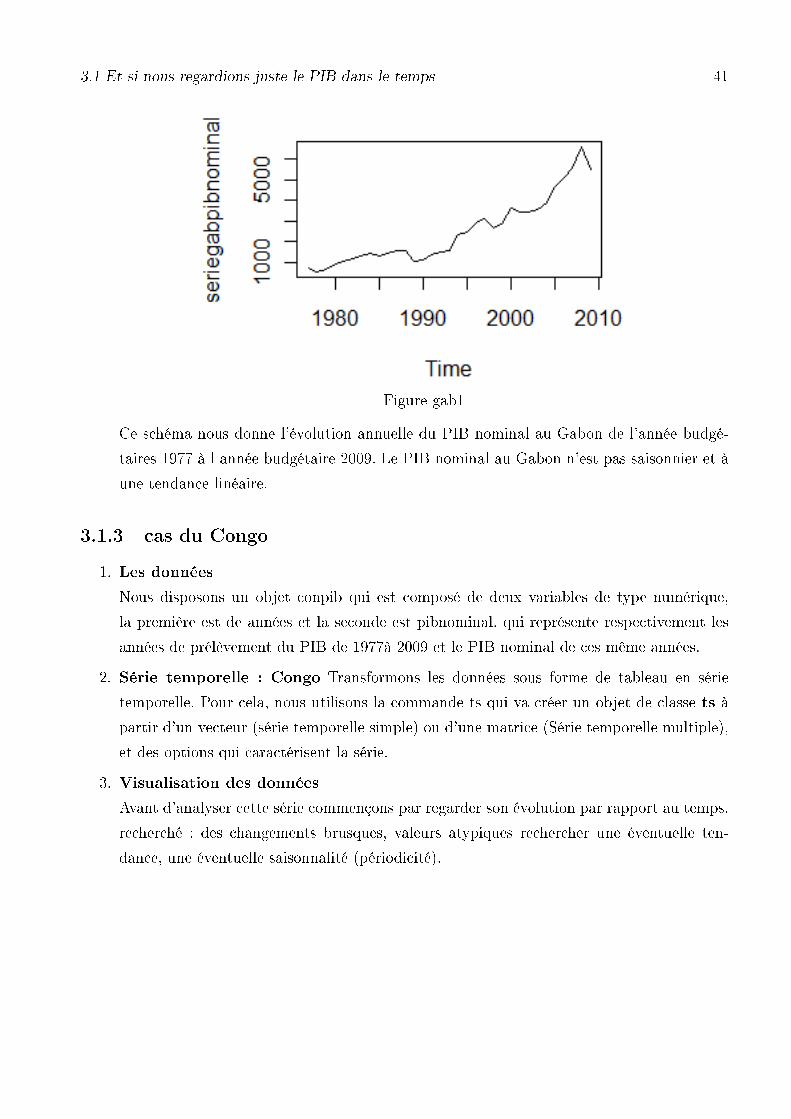
3.1 Et si nous regardions juste le PIB dans le temps 41
Figure gab1
Ce schéma nous donne l'évolution annuelle du PIB nominal au Gabon de l'année budgé-
taires 1977 à l année budgétaire 2009. Le PIB nominal au Gabon n'est pas saisonnier et à
une tendance linéaire.
3.1.3 cas du Congo
1. Les données
Nous disposons un objet conpib qui est composé de deux variables de type numérique,
la première est de années et la seconde est pibnominal. qui représente respectivement les
années de prélèvement du PIB de 1977à 2009 et le PIB nominal de ces même années.
2. Série temporelle : Congo Transformons les données sous forme de tableau en série
temporelle. Pour cela, nous utilisons la commande ts qui va créer un objet de classe ts à
partir d'un vecteur (série temporelle simple) ou d'une matrice (Série temporelle multiple),
et des options qui caractérisent la série.
3. Visualisation des données
Avant d'analyser cette série commençons par regarder son évolution par rapport au temps,
recherché : des changements brusques, valeurs atypiques rechercher une éventuelle ten-
dance, une éventuelle saisonnalité (périodicité).
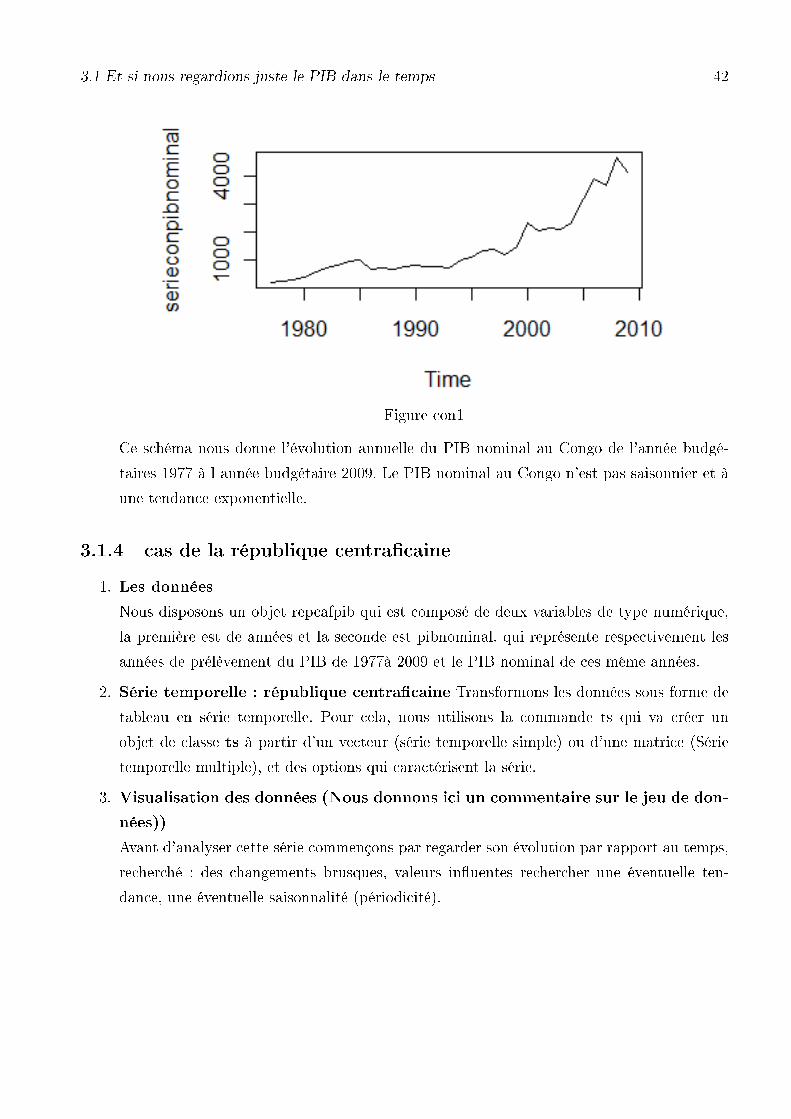
3.1 Et si nous regardions juste le PIB dans le temps 42
Figure con1
Ce schéma nous donne l'évolution annuelle du PIB nominal au Congo de l'année budgé-
taires 1977 à l année budgétaire 2009. Le PIB nominal au Congo n'est pas saisonnier et à
une tendance exponentielle.
3.1.4 cas de la république centra�caine
1. Les données
Nous disposons un objet repcafpib qui est composé de deux variables de type numérique,
la première est de années et la seconde est pibnominal. qui représente respectivement les
années de prélèvement du PIB de 1977à 2009 et le PIB nominal de ces même années.
2. Série temporelle : république centra�caine Transformons les données sous forme de
tableau en série temporelle. Pour cela, nous utilisons la commande ts qui va créer un
objet de classe ts à partir d'un vecteur (série temporelle simple) ou d'une matrice (Série
temporelle multiple), et des options qui caractérisent la série.
3. Visualisation des données (Nous donnons ici un commentaire sur le jeu de don-
nées))
Avant d'analyser cette série commençons par regarder son évolution par rapport au temps,
recherché : des changements brusques, valeurs in�uentes rechercher une éventuelle ten-
dance, une éventuelle saisonnalité (périodicité).
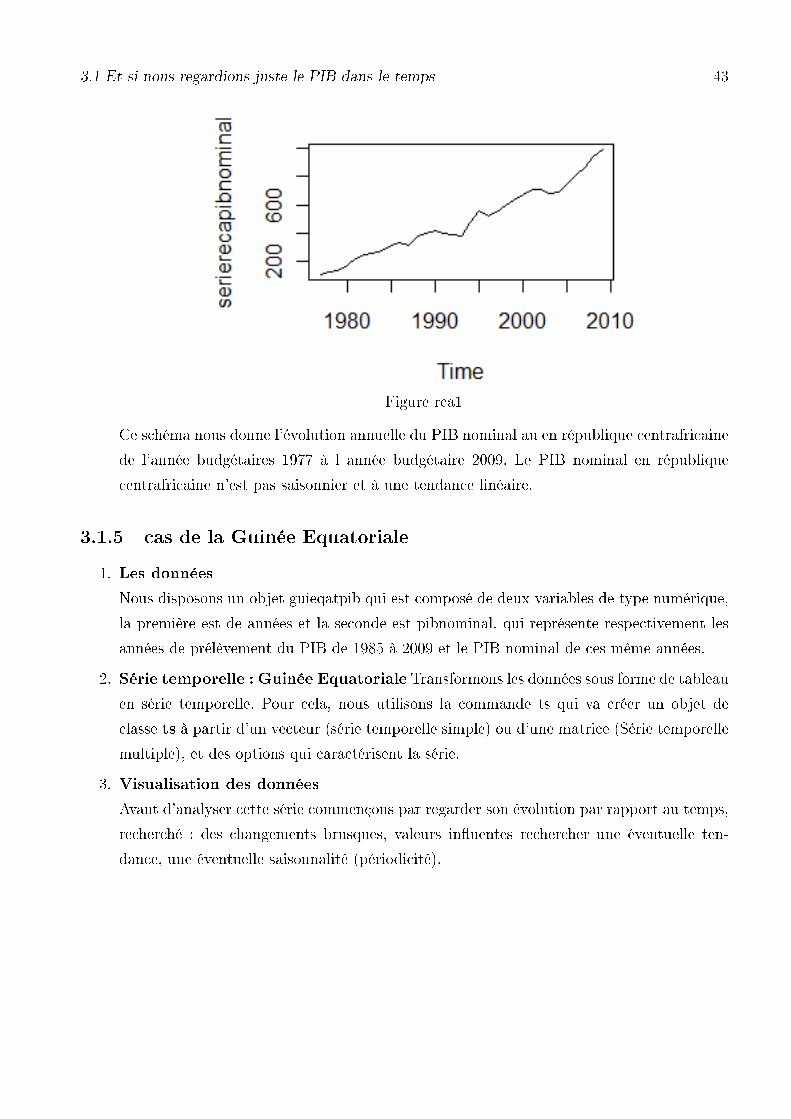
3.1 Et si nous regardions juste le PIB dans le temps 43
Figure rca1
Ce schéma nous donne l'évolution annuelle du PIB nominal au en république centrafricaine
de l'année budgétaires 1977 à l année budgétaire 2009. Le PIB nominal en république
centrafricaine n'est pas saisonnier et à une tendance linéaire.
3.1.5 cas de la Guinée Equatoriale
1. Les données
Nous disposons un objet guieqatpib qui est composé de deux variables de type numérique,
la première est de années et la seconde est pibnominal. qui représente respectivement les
années de prélèvement du PIB de 1985 à 2009 et le PIB nominal de ces même années.
2. Série temporelle : Guinée Equatoriale Transformons les données sous forme de tableau
en série temporelle. Pour cela, nous utilisons la commande ts qui va créer un objet de
classe ts à partir d'un vecteur (série temporelle simple) ou d'une matrice (Série temporelle
multiple), et des options qui caractérisent la série.
3. Visualisation des données
Avant d'analyser cette série commençons par regarder son évolution par rapport au temps,
recherché : des changements brusques, valeurs in�uentes rechercher une éventuelle ten-
dance, une éventuelle saisonnalité (périodicité).
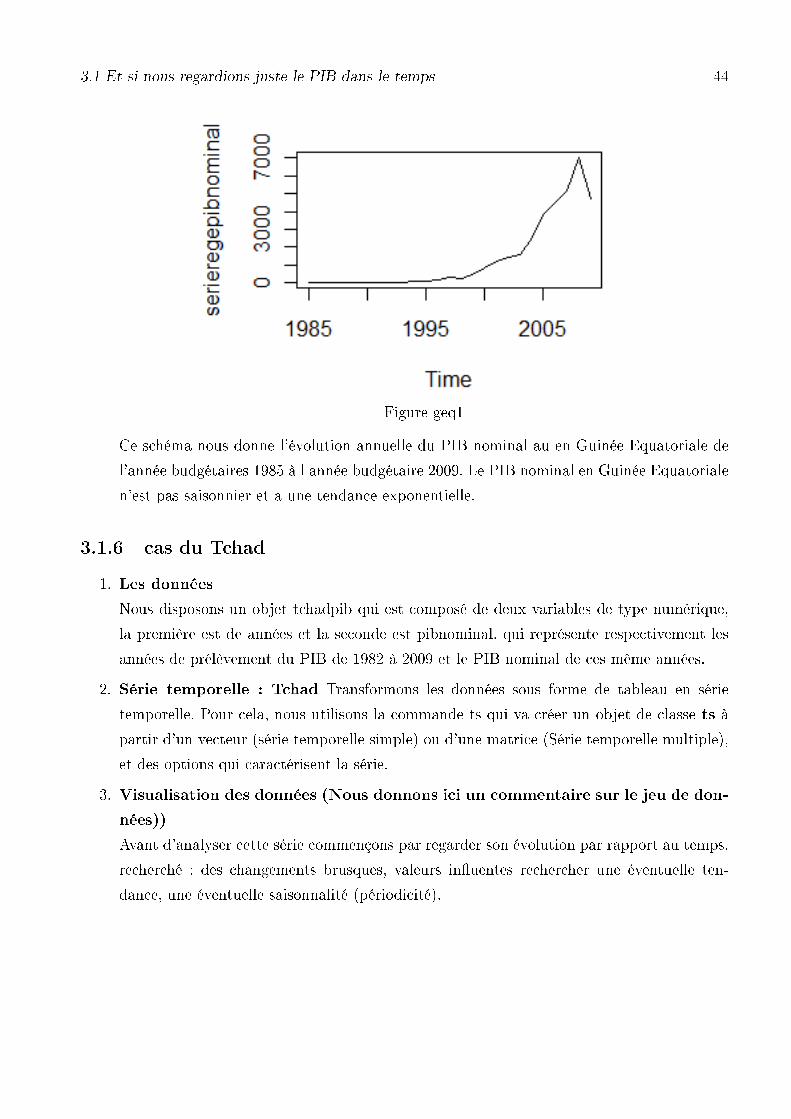
3.1 Et si nous regardions juste le PIB dans le temps 44
Figure geq1
Ce schéma nous donne l'évolution annuelle du PIB nominal au en Guinée Equatoriale de
l'année budgétaires 1985 à l année budgétaire 2009. Le PIB nominal en Guinée Equatoriale
n'est pas saisonnier et a une tendance exponentielle.
3.1.6 cas du Tchad
1. Les données
Nous disposons un objet tchadpib qui est composé de deux variables de type numérique,
la première est de années et la seconde est pibnominal. qui représente respectivement les
années de prélèvement du PIB de 1982 à 2009 et le PIB nominal de ces même années.
2. Série temporelle : Tchad Transformons les données sous forme de tableau en série
temporelle. Pour cela, nous utilisons la commande ts qui va créer un objet de classe ts à
partir d'un vecteur (série temporelle simple) ou d'une matrice (Série temporelle multiple),
et des options qui caractérisent la série.
3. Visualisation des données (Nous donnons ici un commentaire sur le jeu de don-
nées))
Avant d'analyser cette série commençons par regarder son évolution par rapport au temps,
recherché : des changements brusques, valeurs in�uentes rechercher une éventuelle ten-
dance, une éventuelle saisonnalité (périodicité).
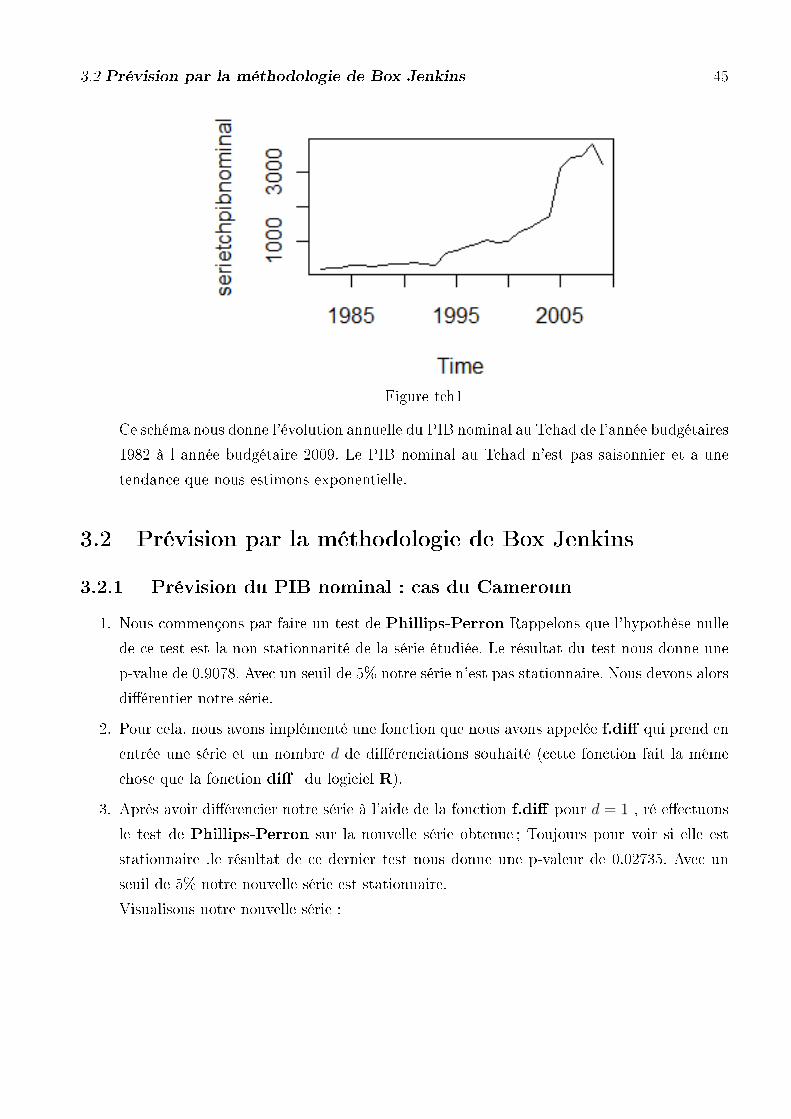
3.2 Prévision par la méthodologie de Box Jenkins 45
Figure tch1
Ce schéma nous donne l'évolution annuelle du PIB nominal au Tchad de l'année budgétaires
1982 à l année budgétaire 2009. Le PIB nominal au Tchad n'est pas saisonnier et a une
tendance que nous estimons exponentielle.
3.2 Prévision par la méthodologie de Box Jenkins
3.2.1 Prévision du PIB nominal : cas du Cameroun
1. Nous commençons par faire un test de Phillips-Perron Rappelons que l'hypothèse nulle
de ce test est la non stationnarité de la série étudiée. Le résultat du test nous donne une
p-value de 0.9078. Avec un seuil de 5% notre série n'est pas stationnaire. Nous devons alors
di�érentier notre série.
2. Pour cela, nous avons implémenté une fonction que nous avons appelée f.di� qui prend en
entrée une série et un nombre d de di�érenciations souhaité (cette fonction fait la même
chose que la fonction di� du logiciel R).
3. Après avoir di�érencier notre série à l'aide de la fonction f.di� pour d = 1 , ré e�ectuons
le test de Phillips-Perron sur la nouvelle série obtenue ; Toujours pour voir si elle est
stationnaire .le résultat de ce dernier test nous donne une p-valeur de 0.02735. Avec un
seuil de 5% notre nouvelle série est stationnaire.
Visualisons notre nouvelle série :
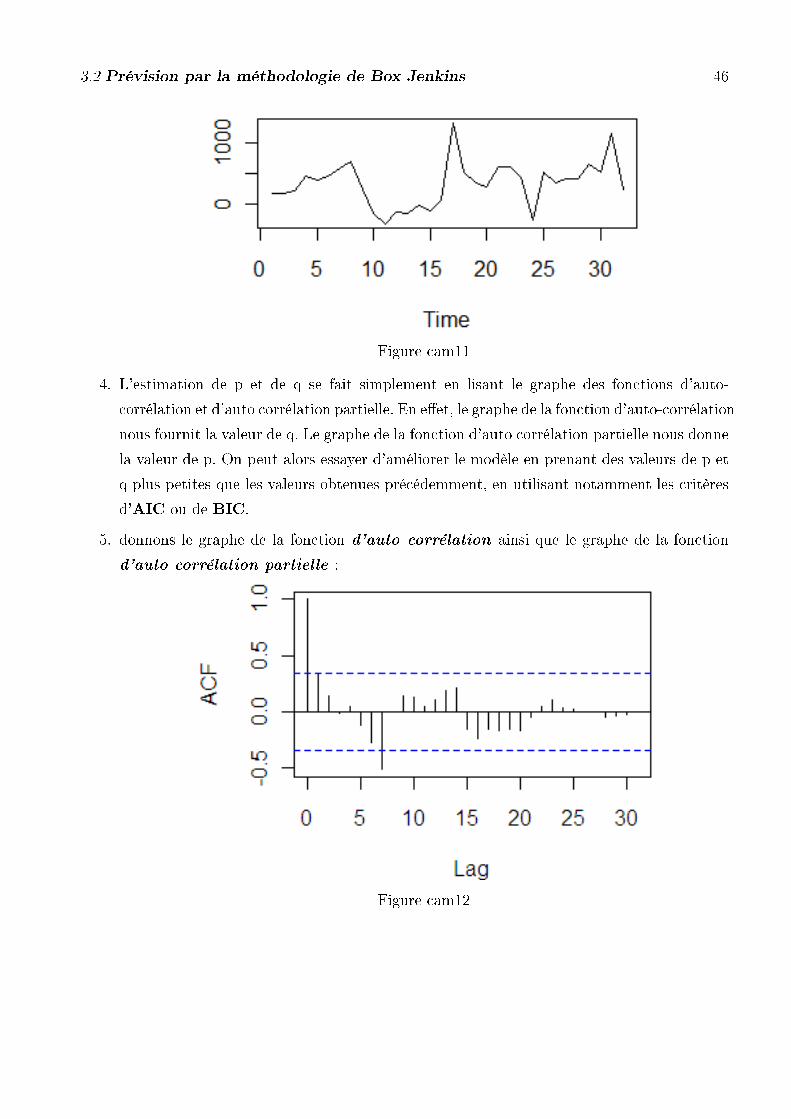
3.2 Prévision par la méthodologie de Box Jenkins 46
Figure cam11
4. L'estimation de p et de q se fait simplement en lisant le graphe des fonctions d'auto-
corrélation et d'auto corrélation partielle. En e�et, le graphe de la fonction d'auto-corrélation
nous fournit la valeur de q. Le graphe de la fonction d'auto corrélation partielle nous donne
la valeur de p. On peut alors essayer d'améliorer le modèle en prenant des valeurs de p et
q plus petites que les valeurs obtenues précédemment, en utilisant notamment les critères
d'AIC ou de BIC.
5. donnons le graphe de la fonction d'auto corrélation ainsi que le graphe de la fonction
d'auto corrélation partielle :
Figure cam12
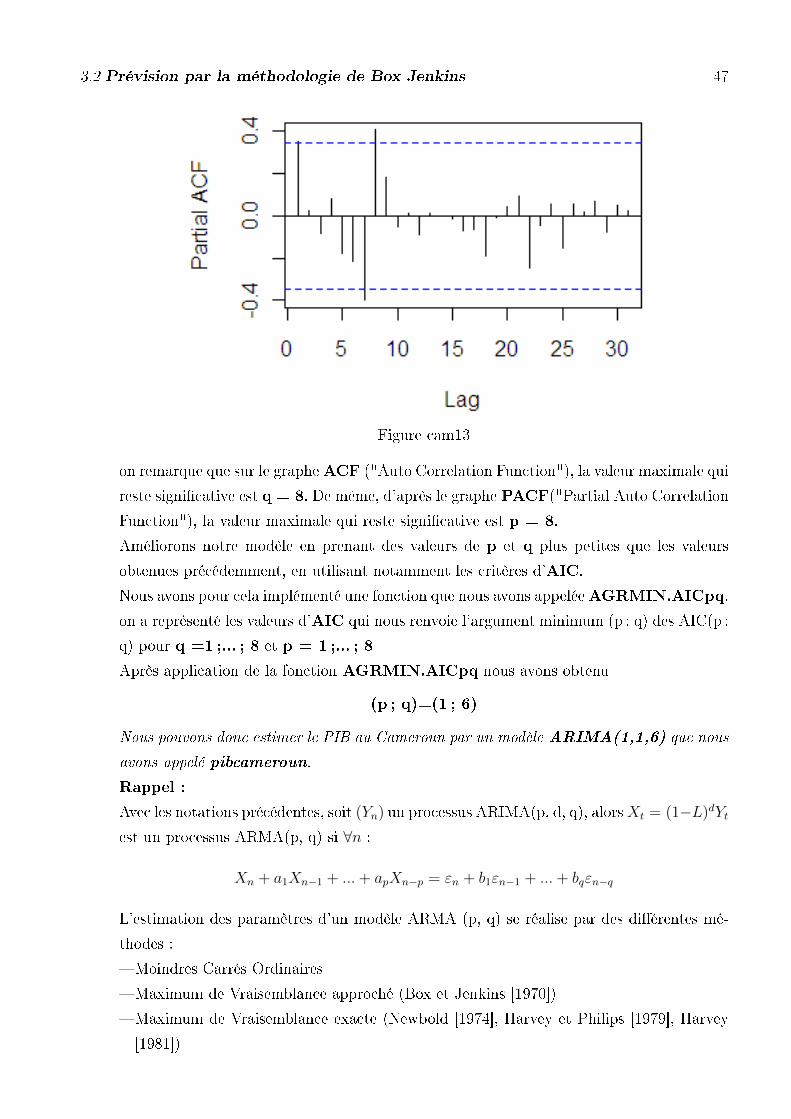
3.2 Prévision par la méthodologie de Box Jenkins 47
Figure cam13
on remarque que sur le grapheACF ("Auto Correlation Function"), la valeur maximale qui
reste signi�cative est q = 8. De même, d'après le graphe PACF("Partial Auto Correlation
Function"), la valeur maximale qui reste signi�cative est p = 8.
Améliorons notre modèle en prenant des valeurs de p et q plus petites que les valeurs
obtenues précédemment, en utilisant notamment les critères d'AIC.
Nous avons pour cela implémenté une fonction que nous avons appeléeAGRMIN.AICpq,
on a représenté les valeurs d'AIC qui nous renvoie l'argument minimum (p ; q) des AIC(p ;
q) pour q =1 ;... ; 8 et p = 1 ;... ; 8
Après application de la fonction AGRMIN.AICpq nous avons obtenu
(p ; q)=(1 ; 6)
Nous pouvons donc estimer le PIB au Cameroun par un modèle ARIMA(1,1,6) que nous
avons appelé pibcameroun.
Rappel :
Avec les notations précédentes, soit (Yn) un processus ARIMA(p, d, q), alorsXt = (1−L)dYt
est un processus ARMA(p, q) si ∀n :
Xn + a1Xn−1 + ...+ apXn−p = εn + b1εn−1 + ...+ bqεn−q
L'estimation des paramètres d'un modèle ARMA (p, q) se réalise par des di�érentes mé-
thodes :
� Moindres Carrés Ordinaires
� Maximum de Vraisemblance approché (Box et Jenkins [1970])
� Maximum de Vraisemblance exacte (Newbold [1974], Harvey et Philips [1979], Harvey
[1981])

3.2 Prévision par la méthodologie de Box Jenkins 48
Pour comparer des di�érents modèles ainsi obtenus, on peut utiliser les critères suivants :
� Critère de Akaika ou AIC : le meilleur des modèles ARMA(p,q) est le modèle qui mini-
mise la statistique :
AIC(p, q) = T log(σ2ε ) + 2(p+ q)
� Critère d'information bayésien ou BIC : le meilleur des modèles ARMA(p,q) est le modèle
qui minimise la statistique :
BIC(p, q) = T log(σ2ε )− (n−p+ q)log[1− p+ q
T] + (p+ q)log(T ) + log[(p+ q)−1(
σ2ε
σ2ε − 1
)]
� Critère de Schwarz [1978]
SC(p, q) = T log(σ2ε ) + (p+ q)log(T )
� Critère de Hannan-Quin [1979]
HQ(p, q) = log(σ2ε ) + (p+ q)[
log(T )
T]
6. Nous estimerons les paramètres de notre modèle (pibcameroun) par la méthode du Maxi-
mum de Vraisemblance approché (Box et Jenkins [1970])
Element Valeur
a1 -0.8573366
b1 1.4237416
b2 1.0925687
b3 1.2506025
b4 1.3467325
b5 1.2600196
b6 0.7878988
nous obtenons donc le modèle suivant pour prévoir le PIB nominal au Cameroun
(1 + a1B)Xn = (1 + b1B + b2B2 + b3B
3 + b4B4 + b5B
5 + b6B6)εn
De la �gure cam14 ci-dessous nous constatons que les résidus tendent à être centrés les auto
corrélations tendent à être signi�cativement di�érent de zéro et la blancheur des résidus
est assez bonne.
Nous pouvons également e�ectuer d'autres véri�cations. Commençons par regarder si les
résidus de cette modélisation sont bien indépendants. Nous e�ectuerons le test de Box-
Pierce ou de Ljung-Box connu aussi sur le nom de test 'portemanteau' l'hypothèse nulle
est la série est bruit blanc On obtient une p-valeur de 0.4826, au seuil 5% dans les conditions
dans lesquelles nous avons travaillé, nous concluons que : Les résidus de ce modèle suivent
un bruit blanc.
En construisant le graphe des résidus

3.2 Prévision par la méthodologie de Box Jenkins 49
Figure cam14
7. Prévisions
Faisons des prévisions du PIB nominal au Cameroun pour les 7 prochaines années.
Années PIB Estimé
2010 11911.82
2011 12111.00
2012 12266.71
2013 12222.39
2014 12118.88
2015 11968.14
2016 12097.37
3.2.2 Prévision du PIB nominal : cas du Gabon
1. Nous commençons par faire un test de Phillips-Perron Rappelons que l'hypothèse nulle
de ce test est la non stationnarité de la série étudiée. Le résultat du test nous donne une
p-value de 0.5837. Avec un seuil de 5% notre série n'est pas stationnaire. Nous devons alors
di�érentier notre série.
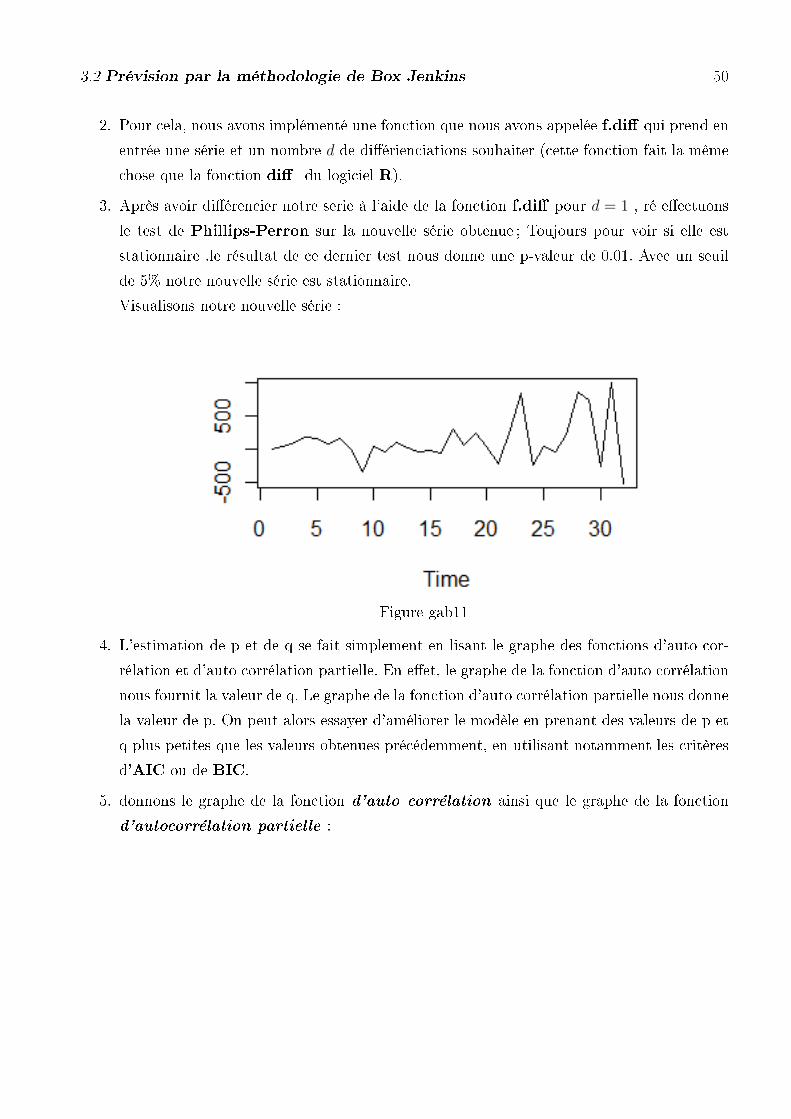
3.2 Prévision par la méthodologie de Box Jenkins 50
2. Pour cela, nous avons implémenté une fonction que nous avons appelée f.di� qui prend en
entrée une série et un nombre d de di�érienciations souhaiter (cette fonction fait la même
chose que la fonction di� du logiciel R).
3. Après avoir di�érencier notre serie à l'aide de la fonction f.di� pour d = 1 , ré e�ectuons
le test de Phillips-Perron sur la nouvelle série obtenue ; Toujours pour voir si elle est
stationnaire .le résultat de ce dernier test nous donne une p-valeur de 0.01. Avec un seuil
de 5% notre nouvelle série est stationnaire.
Visualisons notre nouvelle série :
Figure gab11
4. L'estimation de p et de q se fait simplement en lisant le graphe des fonctions d'auto cor-
rélation et d'auto corrélation partielle. En e�et, le graphe de la fonction d'auto corrélation
nous fournit la valeur de q. Le graphe de la fonction d'auto corrélation partielle nous donne
la valeur de p. On peut alors essayer d'améliorer le modèle en prenant des valeurs de p et
q plus petites que les valeurs obtenues précédemment, en utilisant notamment les critères
d'AIC ou de BIC.
5. donnons le graphe de la fonction d'auto corrélation ainsi que le graphe de la fonction
d'autocorrélation partielle :
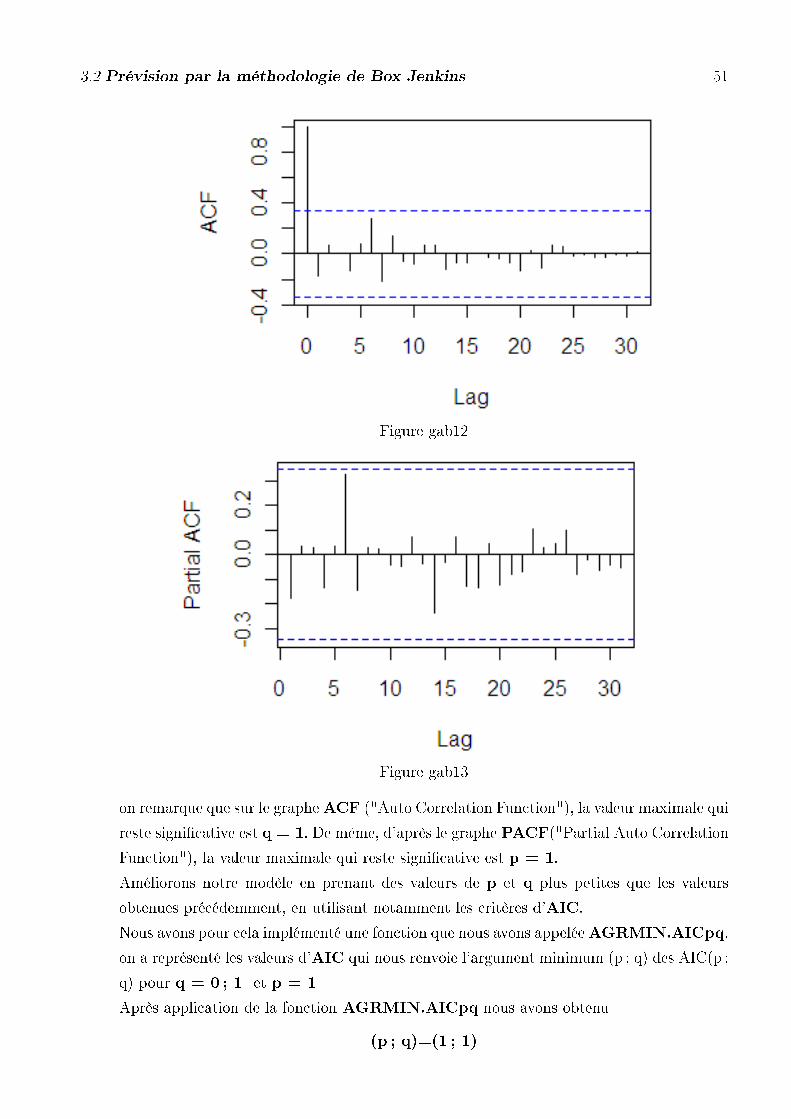
3.2 Prévision par la méthodologie de Box Jenkins 51
Figure gab12
Figure gab13
on remarque que sur le grapheACF ("Auto Correlation Function"), la valeur maximale qui
reste signi�cative est q = 1. De même, d'après le graphe PACF("Partial Auto Correlation
Function"), la valeur maximale qui reste signi�cative est p = 1.
Améliorons notre modèle en prenant des valeurs de p et q plus petites que les valeurs
obtenues précédemment, en utilisant notamment les critères d'AIC.
Nous avons pour cela implémenté une fonction que nous avons appeléeAGRMIN.AICpq,
on a représenté les valeurs d'AIC qui nous renvoie l'argument minimum (p ; q) des AIC(p ;
q) pour q = 0 ; 1 et p = 1
Après application de la fonction AGRMIN.AICpq nous avons obtenu
(p ; q)=(1 ; 1)

3.2 Prévision par la méthodologie de Box Jenkins 52
Nous pouvons donc estimer le PIB au gabon par un modèle ARIMA(1,1,1) que nous
avons appelé pibgabon.
Rappel :
Avec les notations précédentes, soit (Yn) un processus ARIMA(p, d, q), alorsXt = (1−L)dYt
est un processus ARMA(p, q) si ∀n :
Xn + a1Xn−1 + ...+ apXn−p = εn + b1εn−1 + ...+ bqεn−q
L'estimation des paramètres d'un modèle ARMA (p, q) se réalise par des di�érentes mé-
thodes :
� Moindres Carrés Ordinaires
� Maximum de Vraisemblance approché (Box et Jenkins [1970])
� Maximum de Vraisemblance exacte (Newbold [1974], Harvey et Philips [1979], Harvey
[1981])
Pour comparer des di�érents modèles ainsi obtenus, on peut utiliser les critères suivants :
� Critère de Akaika ou AIC : le meilleur des modèles ARMA (p, q) est le modèle qui
minimise la statistique :
AIC(p, q) = T log(σ2ε ) + 2(p+ q)
� Critère d'information bayésien ou BIC : le meilleur des modèles ARMA (p, q) est le
modèle qui minimise la statistique :
BIC(p, q) = T log(σ2ε )− (n−p+ q)log[1− p+ q
T] + (p+ q)log(T ) + log[(p+ q)−1(
σ2ε
σ2ε − 1
)]
� Critère de Schwarz [1978]
SC(p, q) = T log(σ2ε ) + (p+ q)log(T )
� Critère de Hannan-Quin [1979]
HQ(p, q) = log(σ2ε ) + (p+ q)[
log(T )
T]
6. Nous estimerons les paramètres de notre modèle (pibgabon) par la méthode du Maximum
de Vraisemblance approché (Box et Jenkins [1970])
Element Valeur
a1 0.997431
b1 -0.976369
nous obtenons donc le modèle suivant pour prévoir le PIB nominal au Gabon
(1 + a1B)Xn = (1 + b1B)εn
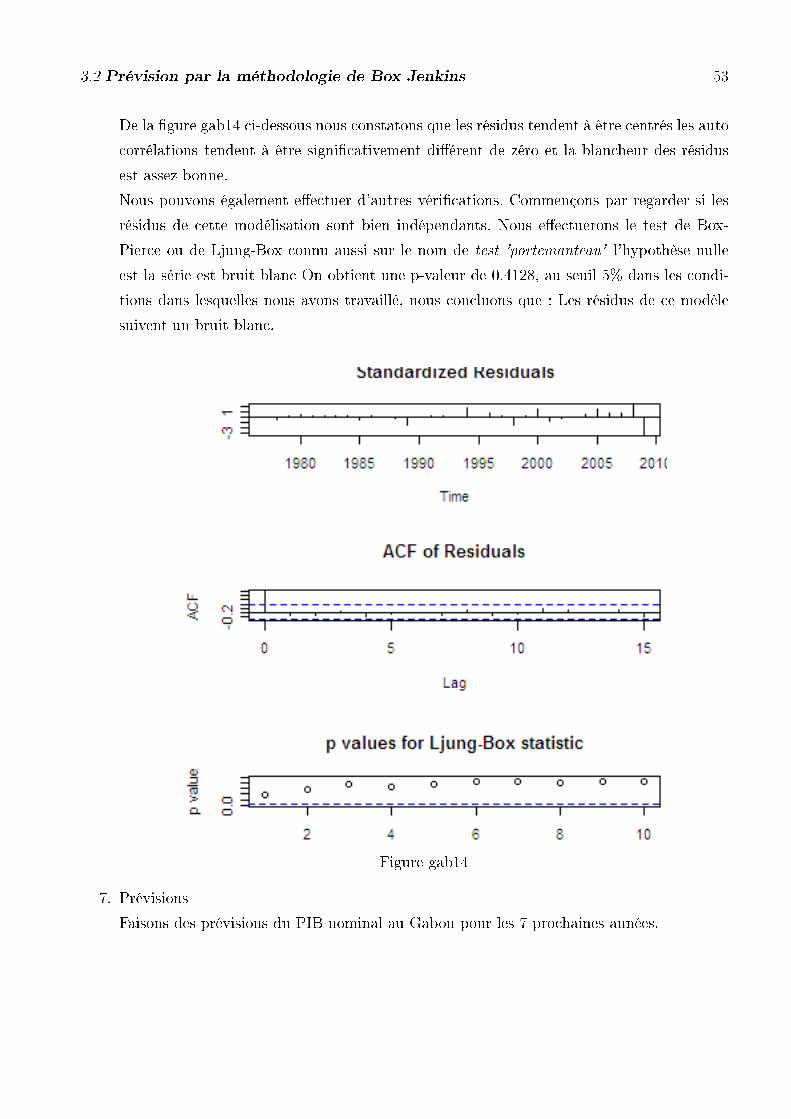
3.2 Prévision par la méthodologie de Box Jenkins 53
De la �gure gab14 ci-dessous nous constatons que les résidus tendent à être centrés les auto
corrélations tendent à être signi�cativement di�érent de zéro et la blancheur des résidus
est assez bonne.
Nous pouvons également e�ectuer d'autres véri�cations. Commençons par regarder si les
résidus de cette modélisation sont bien indépendants. Nous e�ectuerons le test de Box-
Pierce ou de Ljung-Box connu aussi sur le nom de test 'portemanteau' l'hypothèse nulle
est la série est bruit blanc On obtient une p-valeur de 0.4128, au seuil 5% dans les condi-
tions dans lesquelles nous avons travaillé, nous concluons que : Les résidus de ce modèle
suivent un bruit blanc.
Figure gab14
7. Prévisions
Faisons des prévisions du PIB nominal au Gabon pour les 7 prochaines années.

3.2 Prévision par la méthodologie de Box Jenkins 54
Années PIB Estimé
2010 5628.764
2011 5748.220
2012 5867.369
2013 5986.212
2014 6104.750
2015 6222.984
2016 6340.913
3.2.3 Prévision du PIB nominal :cas du Congo
1. Nous commençons par faire un test de Phillips-Perron Rappelons que l'hypothèse nulle
de ce test est la non stationnarité de la série étudiée. Le résultat du test nous donne une
p-value de 0.9102. Avec un seuil de 5% notre série n'est pas stationnaire. Nous devons alors
di�érentier notre série.
2. Pour cela, nous avons implémenté une fonction que nous avons appelée f.di� qui prend en
entrée une série et un nombre d de di�érenciations souhaiter (cette fonction fait la même
chose que la fonction di� du logiciel R).
3. Après avoir di�érencier notre série à l'aide de la fonction f.di� pour d = 1 , ré e�ectuons
le test de Phillips-Perron sur la nouvelle série obtenue ; Toujours pour voir si elle est
stationnaire .le résultat de ce dernier test nous donne une p-valeur de 0.01. Avec un seuil
de 5% notre nouvelle série est stationnaire.
Visualisons notre nouvelle serie :
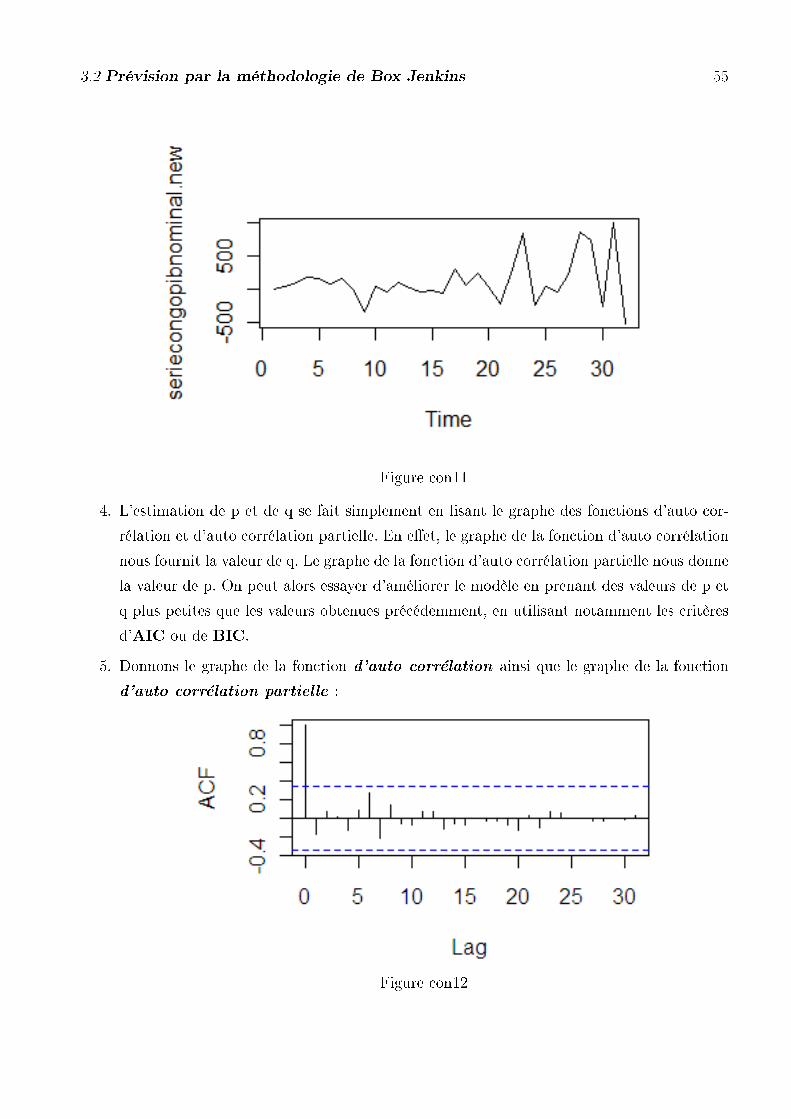
3.2 Prévision par la méthodologie de Box Jenkins 55
Figure con11
4. L'estimation de p et de q se fait simplement en lisant le graphe des fonctions d'auto cor-
rélation et d'auto corrélation partielle. En e�et, le graphe de la fonction d'auto corrélation
nous fournit la valeur de q. Le graphe de la fonction d'auto corrélation partielle nous donne
la valeur de p. On peut alors essayer d'améliorer le modèle en prenant des valeurs de p et
q plus petites que les valeurs obtenues précédemment, en utilisant notamment les critères
d'AIC ou de BIC.
5. Donnons le graphe de la fonction d'auto corrélation ainsi que le graphe de la fonction
d'auto corrélation partielle :
Figure con12
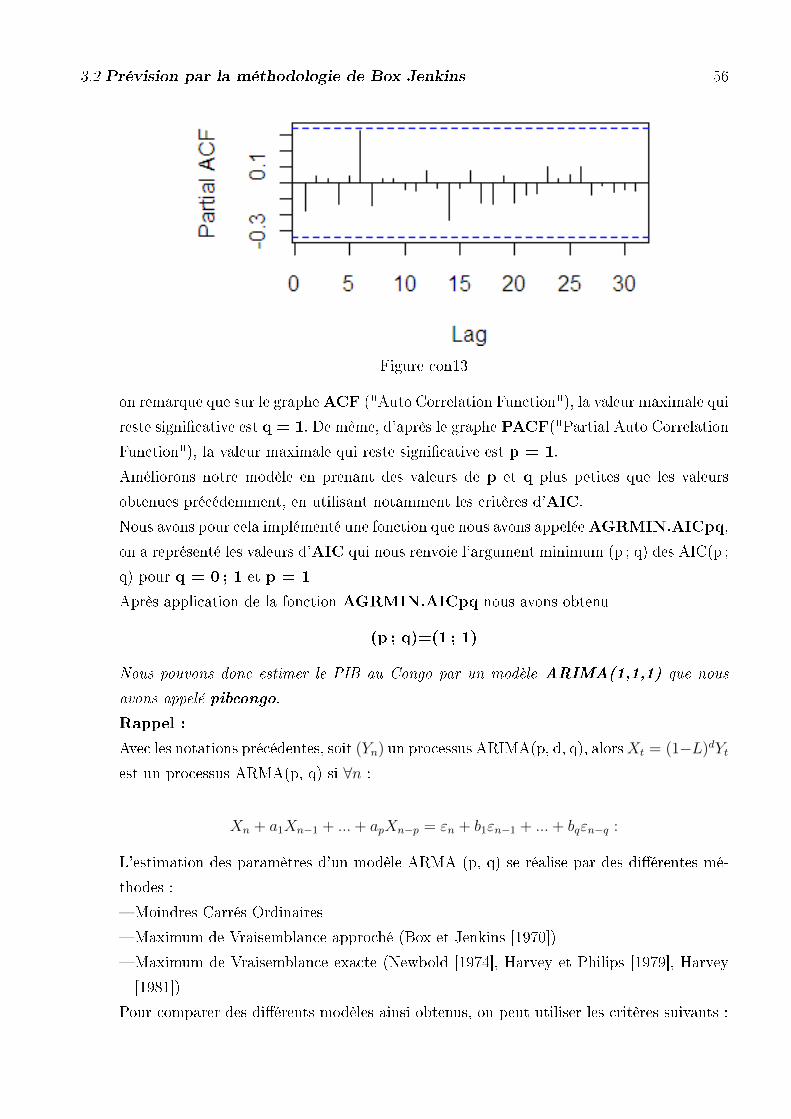
3.2 Prévision par la méthodologie de Box Jenkins 56
Figure con13
on remarque que sur le grapheACF ("Auto Correlation Function"), la valeur maximale qui
reste signi�cative est q = 1. De même, d'après le graphe PACF("Partial Auto Correlation
Function"), la valeur maximale qui reste signi�cative est p = 1.
Améliorons notre modèle en prenant des valeurs de p et q plus petites que les valeurs
obtenues précédemment, en utilisant notamment les critères d'AIC.
Nous avons pour cela implémenté une fonction que nous avons appeléeAGRMIN.AICpq,
on a représenté les valeurs d'AIC qui nous renvoie l'argument minimum (p ; q) des AIC(p ;
q) pour q = 0 ; 1 et p = 1
Après application de la fonction AGRMIN.AICpq nous avons obtenu
(p ; q)=(1 ; 1)
Nous pouvons donc estimer le PIB au Congo par un modèle ARIMA(1,1,1) que nous
avons appelé pibcongo.
Rappel :
Avec les notations précédentes, soit (Yn) un processus ARIMA(p, d, q), alorsXt = (1−L)dYt
est un processus ARMA(p, q) si ∀n :
Xn + a1Xn−1 + ...+ apXn−p = εn + b1εn−1 + ...+ bqεn−q :
L'estimation des paramètres d'un modèle ARMA (p, q) se réalise par des di�érentes mé-
thodes :
� Moindres Carrés Ordinaires
� Maximum de Vraisemblance approché (Box et Jenkins [1970])
� Maximum de Vraisemblance exacte (Newbold [1974], Harvey et Philips [1979], Harvey
[1981])
Pour comparer des di�érents modèles ainsi obtenus, on peut utiliser les critères suivants :

3.2 Prévision par la méthodologie de Box Jenkins 57
� Critère de Akaika ou AIC : le meilleur des modèles ARMA (p,q) est le modèle qui
minimise la statistique :
AIC(p, q) = T log(σ2ε ) + 2(p+ q)
� Critère d'information bayésien ou BIC : le meilleur des modèles ARMA(p, q) est le
modèle qui minimise la statistique :
BIC(p, q) = T log(σ2ε )− (n−p+ q)log[1− p+ q
T] + (p+ q)log(T ) + log[(p+ q)−1(
σ2ε
σ2ε − 1
)]
� Critère de Schwarz [1978]
SC(p, q) = T log(σ2ε ) + (p+ q)log(T )
� Critère de Hannan-Quin [1979]
HQ(p, q) = log(σ2ε ) + (p+ q)[
log(T )
T]
6. Nous estimerons les paramètres de notre modèle (pibcongo) par la méthode du Maximum
de Vraisemblance approché (Box et Jenkins [1970])
Element Valeur
a1 0.3418564
b1 -0.5729866
b2 0.5852395
b3 -0.4134327
b4 0.3146088
b5 0.5895541.
nous obtenons donc le modèle suivant pour prévoir le PIB nominal au Congo
(1 + a1B)Xn = (1 + b1B + b2B2 + b3B
3 + b4B4 + b5B
5)εn
De la �gure con14 ci-dessous nous constatons que les résidus tendent à être centrés les au-
tocorrélations tendent à être signi�cativement di�érent de zéro et la blancheur des résidus
est assez bonne.
Nous pouvons également e�ectuer d'autres véri�cations. Commençons par regarder si les
résidus de cette modélisation sont bien indépendants. Nous é�ectuerons le test de Box-
Pierce ou de Ljung-Box connu aussi sur le nom de test 'portemanteau' l'hypothèse nulle
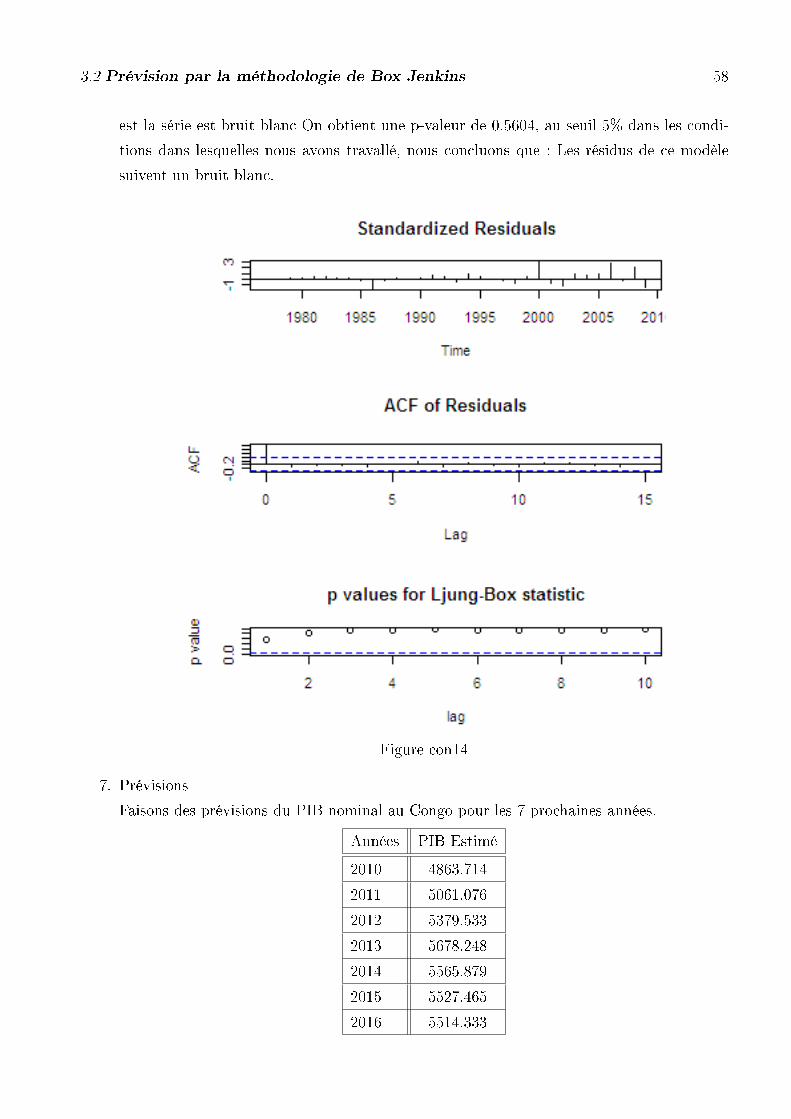
3.2 Prévision par la méthodologie de Box Jenkins 58
est la série est bruit blanc On obtient une p-valeur de 0.5604, au seuil 5% dans les condi-
tions dans lesquelles nous avons travallé, nous concluons que : Les résidus de ce modèle
suivent un bruit blanc.
Figure con14
7. Prévisions
Faisons des prévisions du PIB nominal au Congo pour les 7 prochaines années.
Années PIB Estimé
2010 4863.714
2011 5061.076
2012 5379.533
2013 5678.248
2014 5565.879
2015 5527.465
2016 5514.333
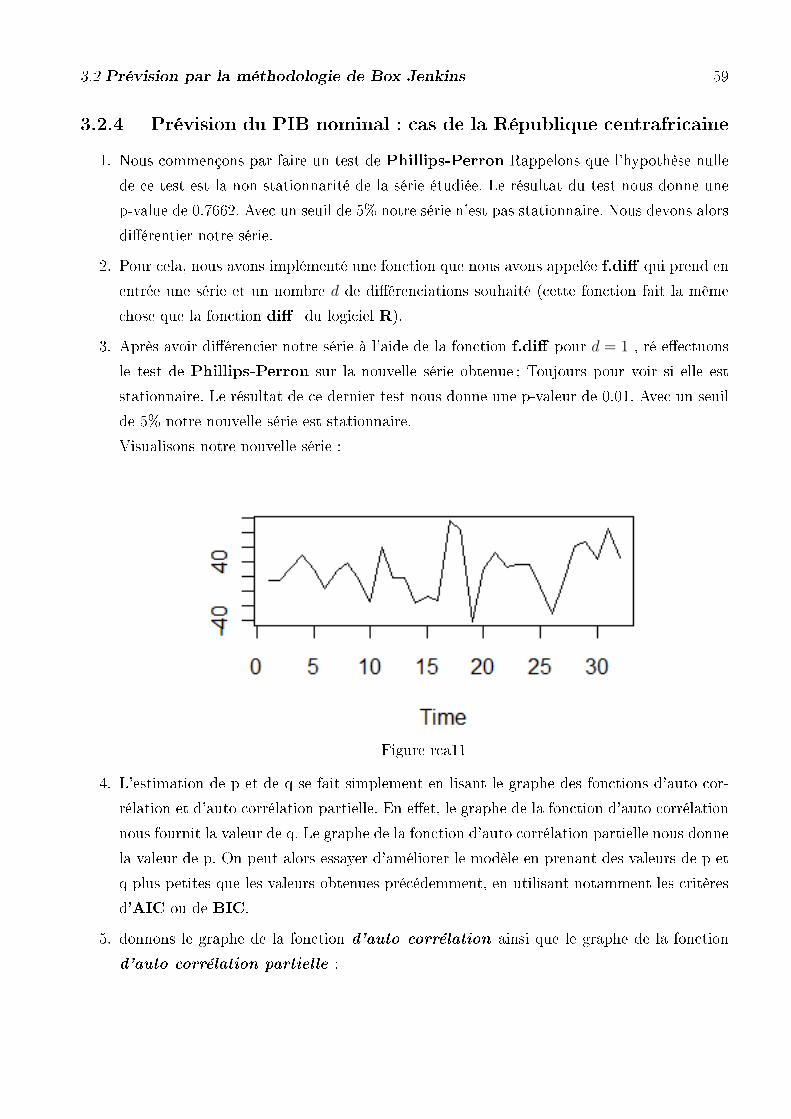
3.2 Prévision par la méthodologie de Box Jenkins 59
3.2.4 Prévision du PIB nominal : cas de la République centrafricaine
1. Nous commençons par faire un test de Phillips-Perron Rappelons que l'hypothèse nulle
de ce test est la non stationnarité de la série étudiée. Le résultat du test nous donne une
p-value de 0.7662. Avec un seuil de 5% notre série n'est pas stationnaire. Nous devons alors
di�érentier notre série.
2. Pour cela, nous avons implémenté une fonction que nous avons appelée f.di� qui prend en
entrée une série et un nombre d de di�érenciations souhaité (cette fonction fait la même
chose que la fonction di� du logiciel R).
3. Après avoir di�érencier notre série à l'aide de la fonction f.di� pour d = 1 , ré e�ectuons
le test de Phillips-Perron sur la nouvelle série obtenue ; Toujours pour voir si elle est
stationnaire. Le résultat de ce dernier test nous donne une p-valeur de 0.01. Avec un seuil
de 5% notre nouvelle série est stationnaire.
Visualisons notre nouvelle série :
Figure rca11
4. L'estimation de p et de q se fait simplement en lisant le graphe des fonctions d'auto cor-
rélation et d'auto corrélation partielle. En e�et, le graphe de la fonction d'auto corrélation
nous fournit la valeur de q. Le graphe de la fonction d'auto corrélation partielle nous donne
la valeur de p. On peut alors essayer d'améliorer le modèle en prenant des valeurs de p et
q plus petites que les valeurs obtenues précédemment, en utilisant notamment les critères
d'AIC ou de BIC.
5. donnons le graphe de la fonction d'auto corrélation ainsi que le graphe de la fonction
d'auto corrélation partielle :
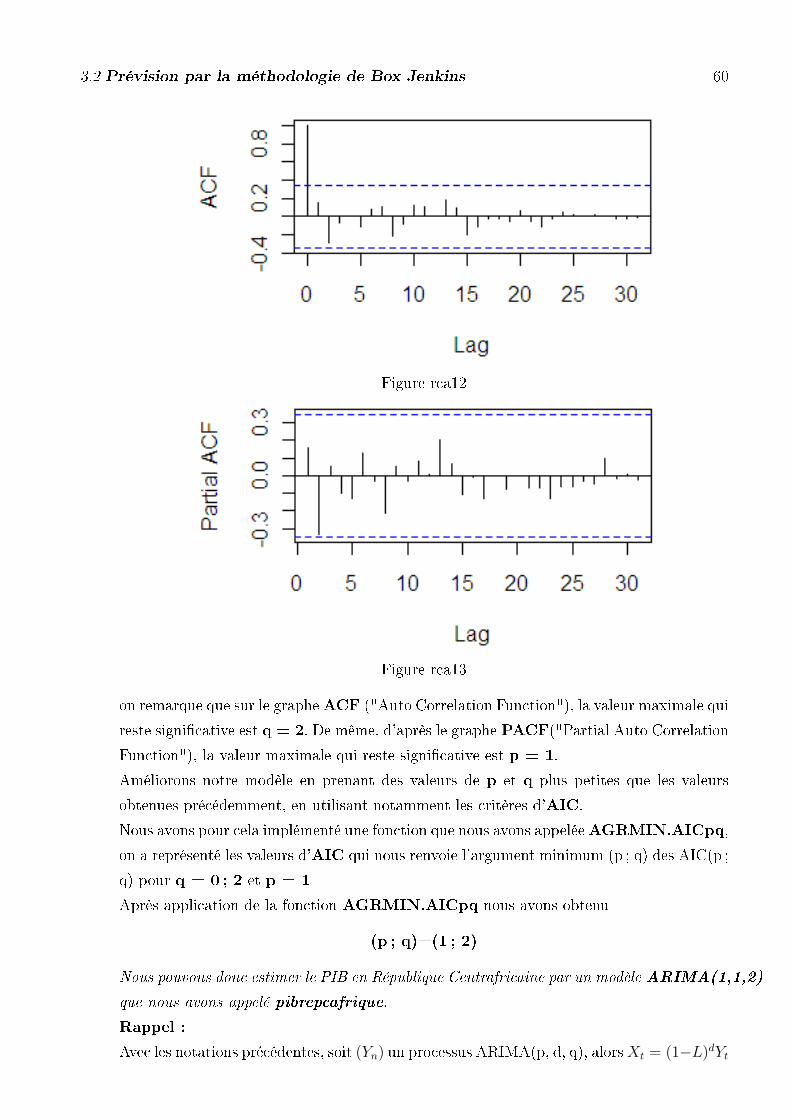
3.2 Prévision par la méthodologie de Box Jenkins 60
Figure rca12
Figure rca13
on remarque que sur le grapheACF ("Auto Correlation Function"), la valeur maximale qui
reste signi�cative est q = 2. De même, d'après le graphe PACF("Partial Auto Correlation
Function"), la valeur maximale qui reste signi�cative est p = 1.
Améliorons notre modèle en prenant des valeurs de p et q plus petites que les valeurs
obtenues précédemment, en utilisant notamment les critères d'AIC.
Nous avons pour cela implémenté une fonction que nous avons appeléeAGRMIN.AICpq,
on a représenté les valeurs d'AIC qui nous renvoie l'argument minimum (p ; q) des AIC(p ;
q) pour q = 0 ; 2 et p = 1
Après application de la fonction AGRMIN.AICpq nous avons obtenu
(p ; q)=(1 ; 2)
Nous pouvons donc estimer le PIB en République Centrafricaine par un modèle ARIMA(1,1,2)
que nous avons appelé pibrepcafrique.
Rappel :
Avec les notations précédentes, soit (Yn) un processus ARIMA(p, d, q), alorsXt = (1−L)dYt

3.2 Prévision par la méthodologie de Box Jenkins 61
est un processus ARMA(p, q) si ∀n :
Xn + a1Xn−1 + ...+ apXn−p = εn + b1εn−1 + ...+ bqεn−q :
L'estimation des paramètres d'un modèle ARMA (p, q) se réalise par des di�érentes mé-
thodes :
� Moindres Carrés Ordinaires
� Maximum de Vraisemblance approché (Box et Jenkins [1970])
� Maximum de Vraisemblance exacte (Newbold [1974], Harvey et Philips [1979], Harvey
[1981])
Pour comparer des di�érents modèles ainsi obtenus, on peut utiliser les critères suivants :
� Critère de Akaika ou AIC : le meilleur des modèles ARMA (p, q) est le modèle qui
minimise la statistique :
AIC(p, q) = T log(σ2ε ) + 2(p+ q)
� Critère d'information bayésien ou BIC : le meilleur des modèles ARMA (p, q) est le
modèle qui minimise la statistique :
BIC(p, q) = T log(σ2ε )− (n−p+ q)log[1− p+ q
T] + (p+ q)log(T ) + log[(p+ q)−1(
σ2ε
σ2ε − 1
)]
� Critère de Schwarz [1978]
SC(p, q) = T log(σ2ε ) + (p+ q)log(T )
� Critère de Hannan-Quin [1979]
HQ(p, q) = log(σ2ε ) + (p+ q)[
log(T )
T]
6. Nous estimerons les paramètres de notre modèle (pibrepcafrique) par la méthode du Maxi-
mum de Vraisemblance approché (Box et Jenkins [1970])
Element Valeur
a1 0.9997758
b1 -0.6261650
b2 -0.3565987.
nous obtenons donc le modèle suivant pour prévoir le PIB nominal au République cen-
trafricaine
(1 + a1B)Xn = (1 + b1B + b2B2)εn

3.2 Prévision par la méthodologie de Box Jenkins 62
De la �gure rca14 ci-dessous nous constatons que les résidus tendent à être centrés les auto
corrélations tendent à être signi�cativement di�érent de zéro et la blancheur des résidus
est assez bonne.
Nous pouvons également e�ectuer d'autres véri�cations. Commençons par regarder si les
résidus de cette modélisation sont bien indépendants. Nous e�ectuerons le test de Box-
Pierce ou de Ljung-Box connu aussi sur le nom de test 'portemanteau' l'hypothèse nulle
est la série est bruit blanc On obtient une p-valeur de 0.5244, au seuil 5% dans les condi-
tions dans lesquelles nous avons travaillé, nous concluons que : Les résidus de ce modèle
suivent un bruit blanc.
Figure rca14
7. Prévisions
Faisons des prévisions du PIB nominal en République Centrafrique pour les 7 prochaines
années.
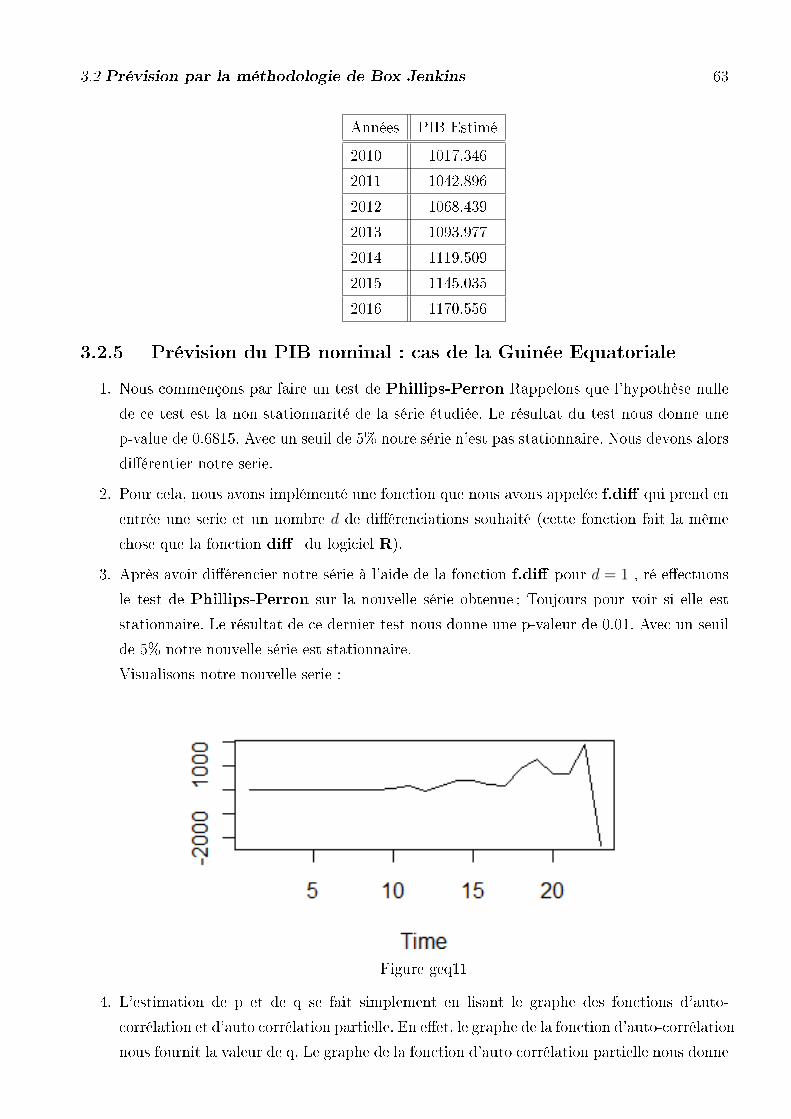
3.2 Prévision par la méthodologie de Box Jenkins 63
Années PIB Estimé
2010 1017.346
2011 1042.896
2012 1068.439
2013 1093.977
2014 1119.509
2015 1145.035
2016 1170.556
3.2.5 Prévision du PIB nominal : cas de la Guinée Equatoriale
1. Nous commençons par faire un test de Phillips-Perron Rappelons que l'hypothèse nulle
de ce test est la non stationnarité de la série étudiée. Le résultat du test nous donne une
p-value de 0.6815. Avec un seuil de 5% notre série n'est pas stationnaire. Nous devons alors
di�érentier notre serie.
2. Pour cela, nous avons implémenté une fonction que nous avons appelée f.di� qui prend en
entrée une serie et un nombre d de di�érenciations souhaité (cette fonction fait la même
chose que la fonction di� du logiciel R).
3. Après avoir di�érencier notre série à l'aide de la fonction f.di� pour d = 1 , ré e�ectuons
le test de Phillips-Perron sur la nouvelle série obtenue ; Toujours pour voir si elle est
stationnaire. Le résultat de ce dernier test nous donne une p-valeur de 0.01. Avec un seuil
de 5% notre nouvelle série est stationnaire.
Visualisons notre nouvelle serie :
Figure geq11
4. L'estimation de p et de q se fait simplement en lisant le graphe des fonctions d'auto-
corrélation et d'auto corrélation partielle. En e�et, le graphe de la fonction d'auto-corrélation
nous fournit la valeur de q. Le graphe de la fonction d'auto corrélation partielle nous donne
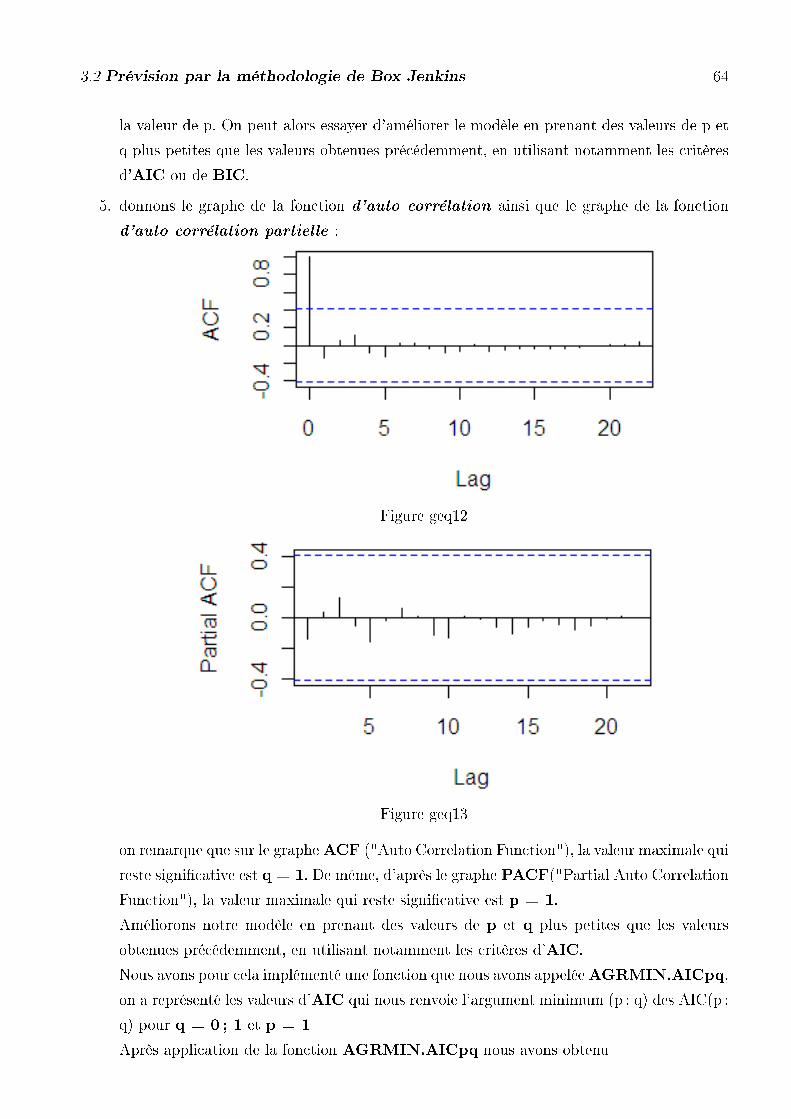
3.2 Prévision par la méthodologie de Box Jenkins 64
la valeur de p. On peut alors essayer d'améliorer le modèle en prenant des valeurs de p et
q plus petites que les valeurs obtenues précédemment, en utilisant notamment les critères
d'AIC ou de BIC.
5. donnons le graphe de la fonction d'auto corrélation ainsi que le graphe de la fonction
d'auto corrélation partielle :
Figure geq12
Figure geq13
on remarque que sur le grapheACF ("Auto Correlation Function"), la valeur maximale qui
reste signi�cative est q = 1. De même, d'après le graphe PACF("Partial Auto Correlation
Function"), la valeur maximale qui reste signi�cative est p = 1.
Améliorons notre modèle en prenant des valeurs de p et q plus petites que les valeurs
obtenues précédemment, en utilisant notamment les critères d'AIC.
Nous avons pour cela implémenté une fonction que nous avons appeléeAGRMIN.AICpq,
on a représenté les valeurs d'AIC qui nous renvoie l'argument minimum (p ; q) des AIC(p ;
q) pour q = 0 ; 1 et p = 1
Après application de la fonction AGRMIN.AICpq nous avons obtenu

3.2 Prévision par la méthodologie de Box Jenkins 65
(p ; q)=(1 ; 2)
Nous pouvons donc estimer le PIB en Guinée Equatoriale par un modèle ARIMA(1,1,2)
que nous avons appelé pibguiequat.
Rappel :
Avec les notations précédentes, soit (Yn) un processus ARIMA(p, d, q), alorsXt = (1−L)dYt
est un processus ARMA(p, q) si ∀n :
Xn + a1Xn−1 + ...+ apXn−p = εn + b1εn−1 + ...+ bqεn−q :
L'estimation des paramètres d'un modèle ARMA (p, q) se réalise par des di�érentes mé-
thodes :
� Moindres Carrés Ordinaires
� Maximum de Vraisemblance approché (Box et Jenkins [1970])
� Maximum de Vraisemblance exacte (Newbold [1974], Harvey et Philips [1979], Harvey
[1981])
Pour comparer des di�érents modèles ainsi obtenus, on peut utiliser les critères suivants :
� Critère de Akaika ou AIC : le meilleur des modèles ARMA (p, q) est le modèle qui
minimise la statistique :
AIC(p, q) = T log(σ2ε ) + 2(p+ q)
� Critère d'information bayésien ou BIC : le meilleur des modèles ARMA (p, q) est le
modèle qui minimise la statistique :
BIC(p, q) = T log(σ2ε )− (n−p+ q)log[1− p+ q
T] + (p+ q)log(T ) + log[(p+ q)−1(
σ2ε
σ2ε − 1
)]
� Critère de Schwarz [1978]
SC(p, q) = T log(σ2ε ) + (p+ q)log(T )
� Critère de Hannan-Quin [1979]
HQ(p, q) = log(σ2ε ) + (p+ q)[
log(T )
T]
6. Nous estimerons les paramètres de notre modèle (pibguiequat) par la méthode du Maximum
de Vraisemblance approché (Box et Jenkins [1970])
Element Valeur
a1 -0.5610
b1 0.4751.
nous obtenons donc le modèle suivant pour prévoir le PIB nominal au Guinée Equato-
riale
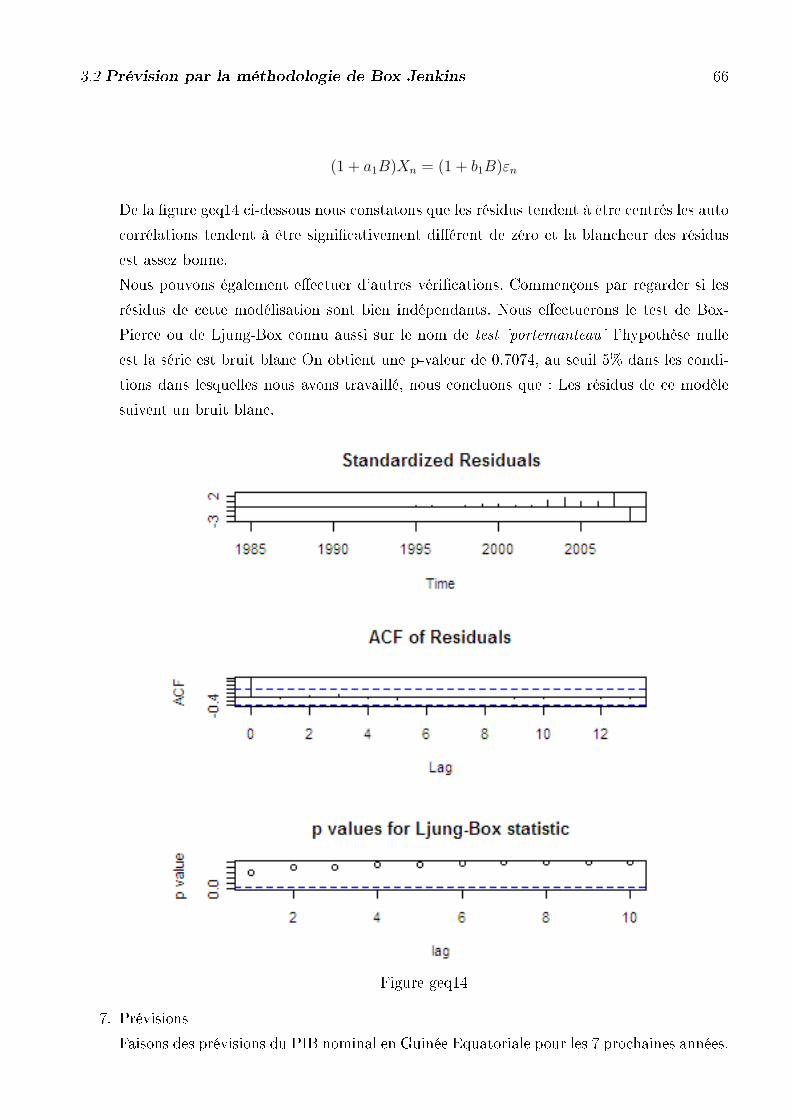
3.2 Prévision par la méthodologie de Box Jenkins 66
(1 + a1B)Xn = (1 + b1B)εn
De la �gure geq14 ci-dessous nous constatons que les résidus tendent à être centrés les auto
corrélations tendent à être signi�cativement di�érent de zéro et la blancheur des résidus
est assez bonne.
Nous pouvons également e�ectuer d'autres véri�cations. Commençons par regarder si les
résidus de cette modélisation sont bien indépendants. Nous e�ectuerons le test de Box-
Pierce ou de Ljung-Box connu aussi sur le nom de test 'portemanteau' l'hypothèse nulle
est la série est bruit blanc On obtient une p-valeur de 0.7074, au seuil 5% dans les condi-
tions dans lesquelles nous avons travaillé, nous concluons que : Les résidus de ce modèle
suivent un bruit blanc.
Figure geq14
7. Prévisions
Faisons des prévisions du PIB nominal en Guinée Equatoriale pour les 7 prochaines années.
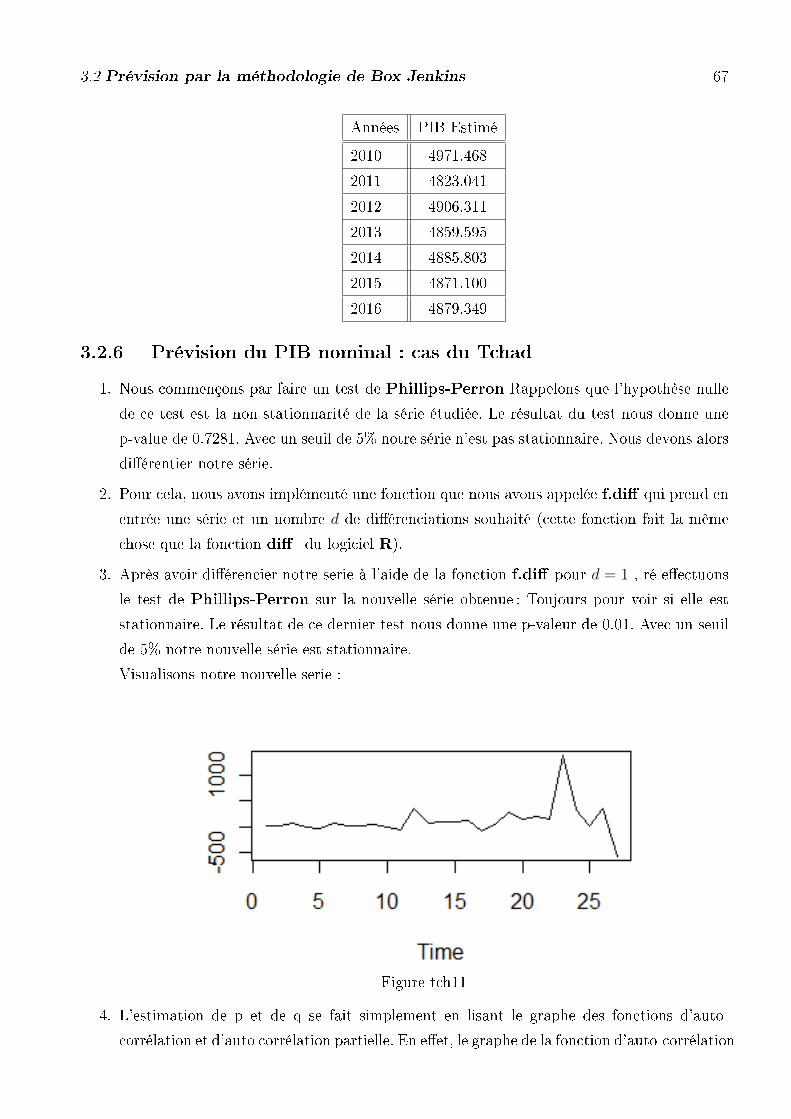
3.2 Prévision par la méthodologie de Box Jenkins 67
Années PIB Estimé
2010 4971.468
2011 4823.041
2012 4906.311
2013 4859.595
2014 4885.803
2015 4871.100
2016 4879.349
3.2.6 Prévision du PIB nominal : cas du Tchad
1. Nous commençons par faire un test de Phillips-Perron Rappelons que l'hypothèse nulle
de ce test est la non stationnarité de la série étudiée. Le résultat du test nous donne une
p-value de 0.7281. Avec un seuil de 5% notre série n'est pas stationnaire. Nous devons alors
di�érentier notre série.
2. Pour cela, nous avons implémenté une fonction que nous avons appelée f.di� qui prend en
entrée une série et un nombre d de di�érenciations souhaité (cette fonction fait la même
chose que la fonction di� du logiciel R).
3. Après avoir di�érencier notre serie à l'aide de la fonction f.di� pour d = 1 , ré e�ectuons
le test de Phillips-Perron sur la nouvelle série obtenue ; Toujours pour voir si elle est
stationnaire. Le résultat de ce dernier test nous donne une p-valeur de 0.01. Avec un seuil
de 5% notre nouvelle série est stationnaire.
Visualisons notre nouvelle serie :
Figure tch11
4. L'estimation de p et de q se fait simplement en lisant le graphe des fonctions d'auto-
corrélation et d'auto corrélation partielle. En e�et, le graphe de la fonction d'auto-corrélation
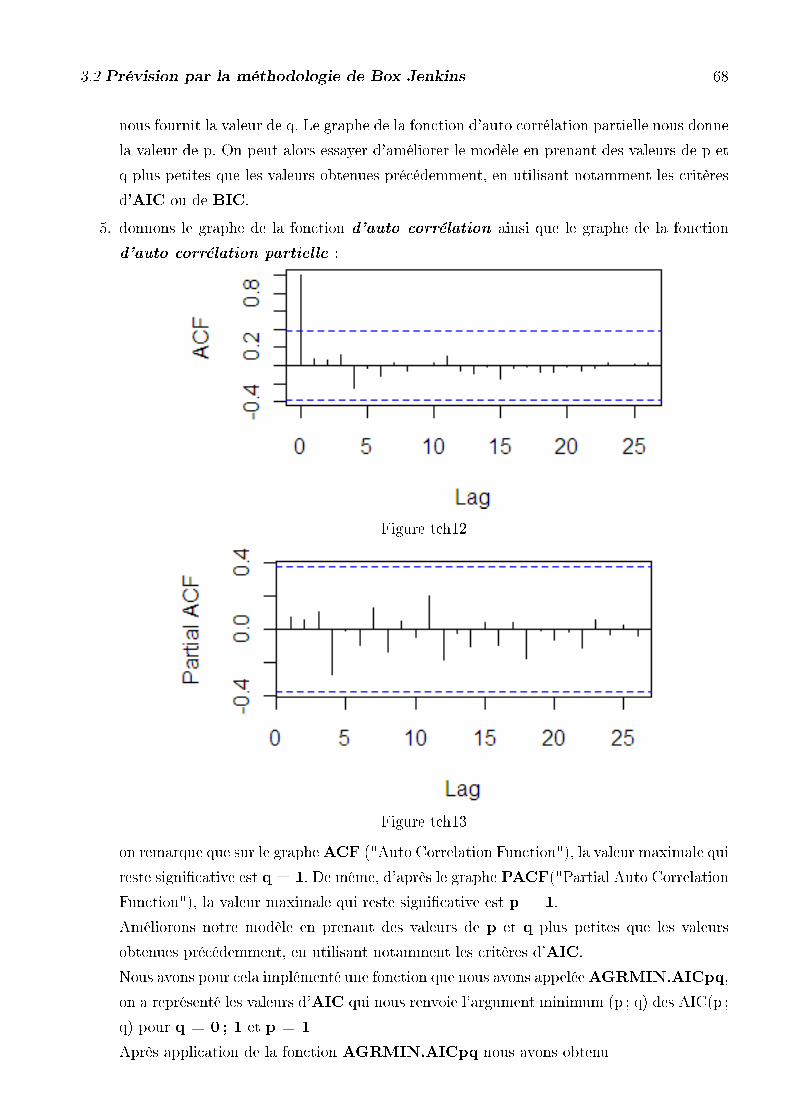
3.2 Prévision par la méthodologie de Box Jenkins 68
nous fournit la valeur de q. Le graphe de la fonction d'auto corrélation partielle nous donne
la valeur de p. On peut alors essayer d'améliorer le modèle en prenant des valeurs de p et
q plus petites que les valeurs obtenues précédemment, en utilisant notamment les critères
d'AIC ou de BIC.
5. donnons le graphe de la fonction d'auto corrélation ainsi que le graphe de la fonction
d'auto corrélation partielle :
Figure tch12
Figure tch13
on remarque que sur le grapheACF ("Auto Correlation Function"), la valeur maximale qui
reste signi�cative est q = 1. De même, d'après le graphe PACF("Partial Auto Correlation
Function"), la valeur maximale qui reste signi�cative est p = 1.
Améliorons notre modèle en prenant des valeurs de p et q plus petites que les valeurs
obtenues précédemment, en utilisant notamment les critères d'AIC.
Nous avons pour cela implémenté une fonction que nous avons appeléeAGRMIN.AICpq,
on a représenté les valeurs d'AIC qui nous renvoie l'argument minimum (p ; q) des AIC(p ;
q) pour q = 0 ; 1 et p = 1
Après application de la fonction AGRMIN.AICpq nous avons obtenu

3.2 Prévision par la méthodologie de Box Jenkins 69
(p ; q)=(1 ; 1)
Nous pouvons donc estimer le PIB au Tchad par un modèle ARIMA(1,1,1) que nous
avons appelé pibtchad.
Rappel :
Avec les notations précédentes, soit (Yn) un processus ARIMA(p, d, q), alorsXt = (1−L)dYt
est un processus ARMA(p, q) si ∀n :
Xn + a1Xn−1 + ...+ apXn−p = εn + b1εn−1 + ...+ bqεn−q :
L'estimation des paramètres d'un modèle ARMA (p, q) se réalise par des di�érentes mé-
thodes :
� Moindres Carrés Ordinaires
� Maximum de Vraisemblance approché (Box et Jenkins [1970])
� Maximum de Vraisemblance exacte (Newbold [1974], Harvey et Philips [1979], Harvey
[1981])
Pour comparer des di�érents modèles ainsi obtenus, on peut utiliser les critères suivants :
� Critère de Akaika ou AIC : le meilleur des modèles ARMA(p,q) est le modèle qui mini-
mise la statistique :
AIC(p, q) = T log(σ2ε ) + 2(p+ q)
� Critère d'information bayésien ou BIC : le meilleur des modèles ARMA (p,q) est le
modèle qui minimise la statistique :
BIC(p, q) = T log(σ2ε )− (n−p+ q)log[1− p+ q
T] + (p+ q)log(T ) + log[(p+ q)−1(
σ2ε
σ2ε − 1
)]
� Critère de Schwarz [1978]
SC(p, q) = T log(σ2ε ) + (p+ q)log(T )
� Critère de Hannan-Quin [1979]
HQ(p, q) = log(σ2ε ) + (p+ q)[
log(T )
T]
6. Nous estimerons les paramètres de notre modèle (pibtchad) par la méthode du Maximum
de Vraisemblance approché (Box et Jenkins [1970])
Element Valeur
a1 0.6793525
b1 -0.4834612.
nous obtenons donc le modèle suivant pour prévoir le PIB nominal au Tchad

3.2 Prévision par la méthodologie de Box Jenkins 70
(1 + a1B)Xn = (1 + b1B)εn
De la �gure tch14 ci-dessous nous constatons que les résidus tendent à être centrés les au-
tocorrélations tendent à être signi�cativement di�érent de zéro et la blancheur des résidus
est assez bonne.
Nous pouvons également e�ectuer d'autres véri�cations. Commençons par regarder si les
résidus de cette modélisation sont bien indépendants. Nous é�ectuerons le test de Box-
Pierce ou de Ljung-Box connu aussi sur le nom de test 'portemanteau' l'hypothèse nulle
est la série est bruit blanc On obtient une p-valeur de 0.6435, au seuil 5% dans les condi-
tions dans lesquelles nous avons travallé, nous concluons que : Les résidus de ce modèle
suivent un bruit blanc.
Figure tch14
7. Prévisions
Faisons des prévisions du PIB nominal au Tchad pour les 7 prochaines années.
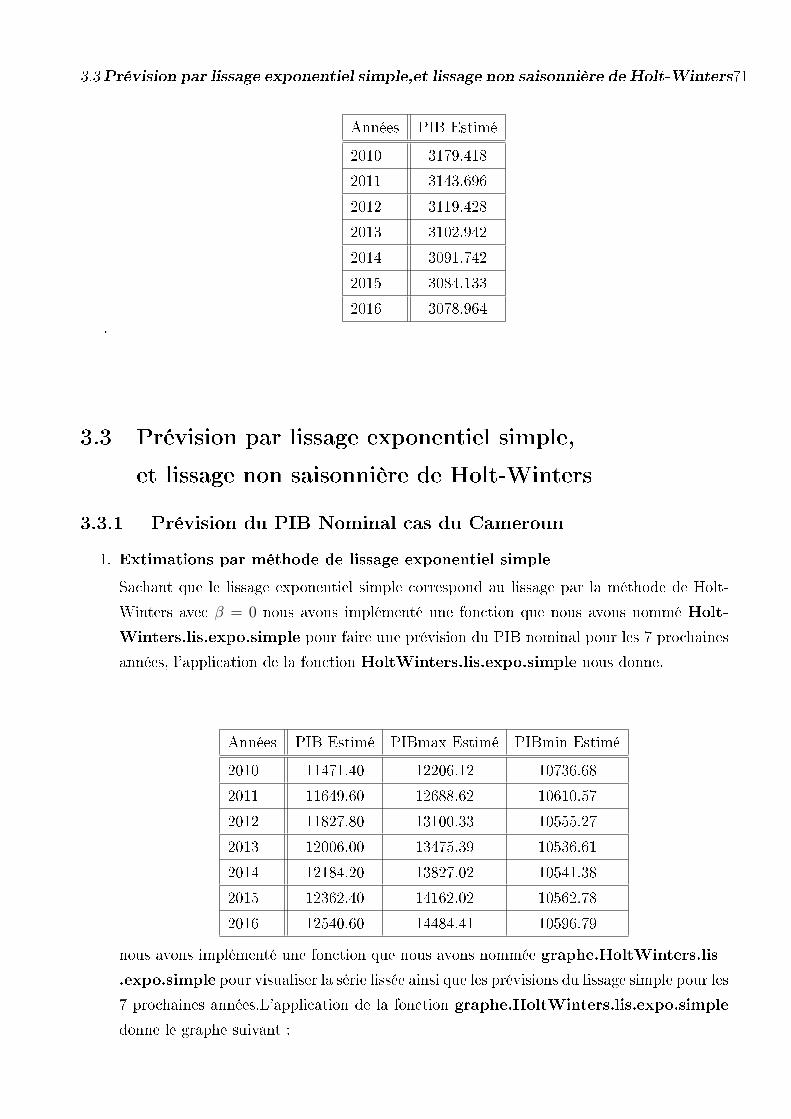
3.3Prévision par lissage exponentiel simple,et lissage non saisonnière de Holt-Winters71
Années PIB Estimé
2010 3179.418
2011 3143.696
2012 3119.428
2013 3102.942
2014 3091.742
2015 3084.133
2016 3078.964.
3.3 Prévision par lissage exponentiel simple,
et lissage non saisonnière de Holt-Winters
3.3.1 Prévision du PIB Nominal cas du Cameroun
1. Extimations par méthode de lissage exponentiel simple
Sachant que le lissage exponentiel simple correspond au lissage par la méthode de Holt-
Winters avec β = 0 nous avons implémenté une fonction que nous avons nommé Holt-
Winters.lis.expo.simple pour faire une prévision du PIB nominal pour les 7 prochaines
années, l'application de la fonction HoltWinters.lis.expo.simple nous donne.
Années PIB Estimé PIBmax Estimé PIBmin Estimé
2010 11471.40 12206.12 10736.68
2011 11649.60 12688.62 10610.57
2012 11827.80 13100.33 10555.27
2013 12006.00 13475.39 10536.61
2014 12184.20 13827.02 10541.38
2015 12362.40 14162.02 10562.78
2016 12540.60 14484.41 10596.79
nous avons implémenté une fonction que nous avons nommée graphe.HoltWinters.lis
.expo.simple pour visualiser la série lissée ainsi que les prévisions du lissage simple pour les
7 prochaines années.L'application de la fonction graphe.HoltWinters.lis.expo.simple
donne le graphe suivant :
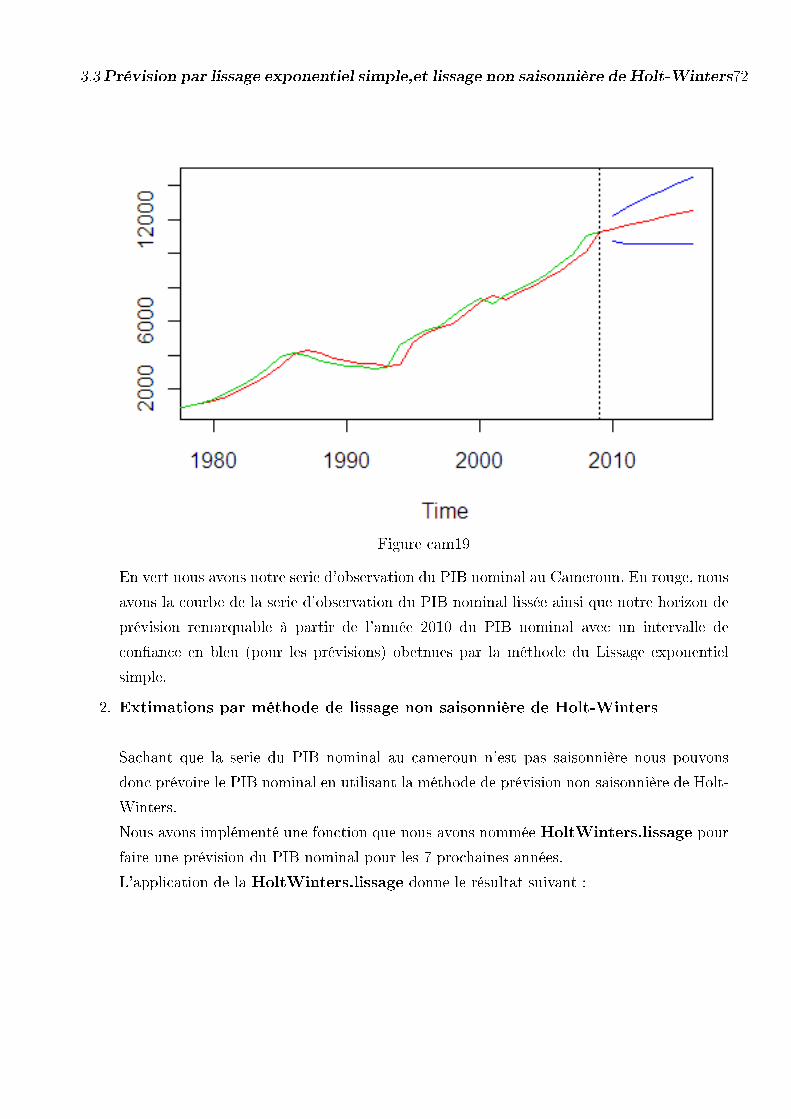
3.3Prévision par lissage exponentiel simple,et lissage non saisonnière de Holt-Winters72
Figure cam19
En vert nous avons notre serie d'observation du PIB nominal au Cameroun. En rouge, nous
avons la courbe de la serie d'observation du PIB nominal lissée ainsi que notre horizon de
prévision remarquable à partir de l'année 2010 du PIB nominal avec un intervalle de
con�ance en bleu (pour les prévisions) obetnues par la méthode du Lissage exponentiel
simple.
2. Extimations par méthode de lissage non saisonnière de Holt-Winters
Sachant que la serie du PIB nominal au cameroun n'est pas saisonnière nous pouvons
donc prévoire le PIB nominal en utilisant la méthode de prévision non saisonnière de Holt-
Winters.
Nous avons implémenté une fonction que nous avons nommée HoltWinters.lissage pour
faire une prévision du PIB nominal pour les 7 prochaines années.
L'application de la HoltWinters.lissage donne le résultat suivant :
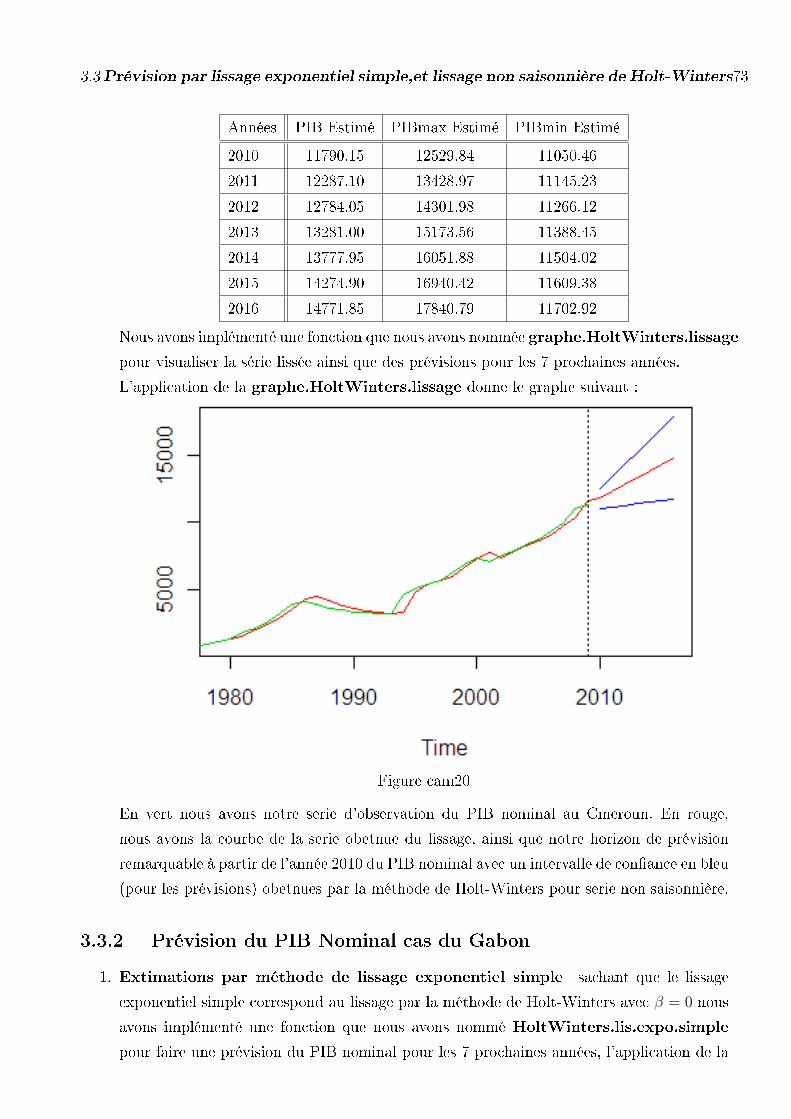
3.3Prévision par lissage exponentiel simple,et lissage non saisonnière de Holt-Winters73
Années PIB Estimé PIBmax Estimé PIBmin Estimé
2010 11790.15 12529.84 11050.46
2011 12287.10 13428.97 11145.23
2012 12784.05 14301.98 11266.12
2013 13281.00 15173.56 11388.45
2014 13777.95 16051.88 11504.02
2015 14274.90 16940.42 11609.38
2016 14771.85 17840.79 11702.92
Nous avons implémenté une fonction que nous avons nommée graphe.HoltWinters.lissage
pour visualiser la série lissée ainsi que des prévisions pour les 7 prochaines années.
L'application de la graphe.HoltWinters.lissage donne le graphe suivant :
Figure cam20
En vert nous avons notre serie d'observation du PIB nominal au Cmeroun. En rouge,
nous avons la courbe de la serie obetnue du lissage, ainsi que notre horizon de prévision
remarquable à partir de l'année 2010 du PIB nominal avec un intervalle de con�ance en bleu
(pour les prévisions) obetnues par la méthode de Holt-Winters pour serie non saisonnière.
3.3.2 Prévision du PIB Nominal cas du Gabon
1. Extimations par méthode de lissage exponentiel simple sachant que le lissage
exponentiel simple correspond au lissage par la méthode de Holt-Winters avec β = 0 nous
avons implémenté une fonction que nous avons nommé HoltWinters.lis.expo.simple
pour faire une prévision du PIB nominal pour les 7 prochaines années, l'application de la
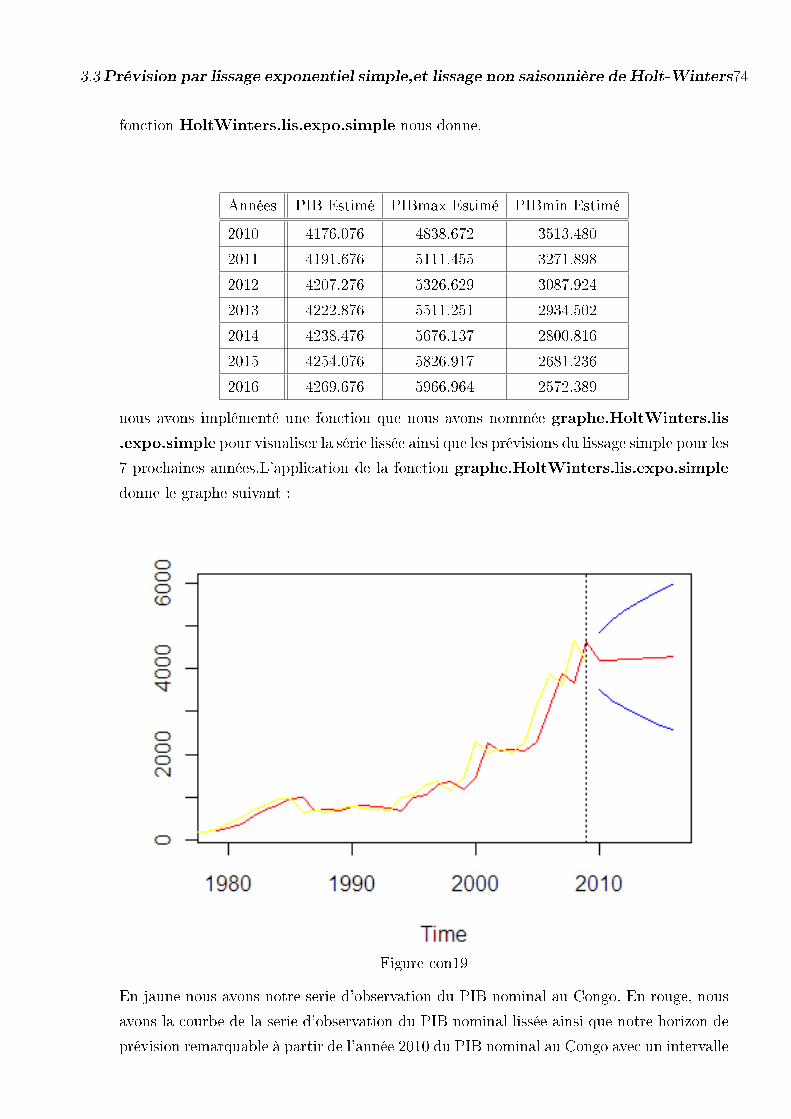
3.3Prévision par lissage exponentiel simple,et lissage non saisonnière de Holt-Winters74
fonction HoltWinters.lis.expo.simple nous donne.
Années PIB Estimé PIBmax Estimé PIBmin Estimé
2010 4176.076 4838.672 3513.480
2011 4191.676 5111.455 3271.898
2012 4207.276 5326.629 3087.924
2013 4222.876 5511.251 2934.502
2014 4238.476 5676.137 2800.816
2015 4254.076 5826.917 2681.236
2016 4269.676 5966.964 2572.389
nous avons implémenté une fonction que nous avons nommée graphe.HoltWinters.lis
.expo.simple pour visualiser la série lissée ainsi que les prévisions du lissage simple pour les
7 prochaines années.L'application de la fonction graphe.HoltWinters.lis.expo.simple
donne le graphe suivant :
Figure con19
En jaune nous avons notre serie d'observation du PIB nominal au Congo. En rouge, nous
avons la courbe de la serie d'observation du PIB nominal lissée ainsi que notre horizon de
prévision remarquable à partir de l'année 2010 du PIB nominal au Congo avec un intervalle
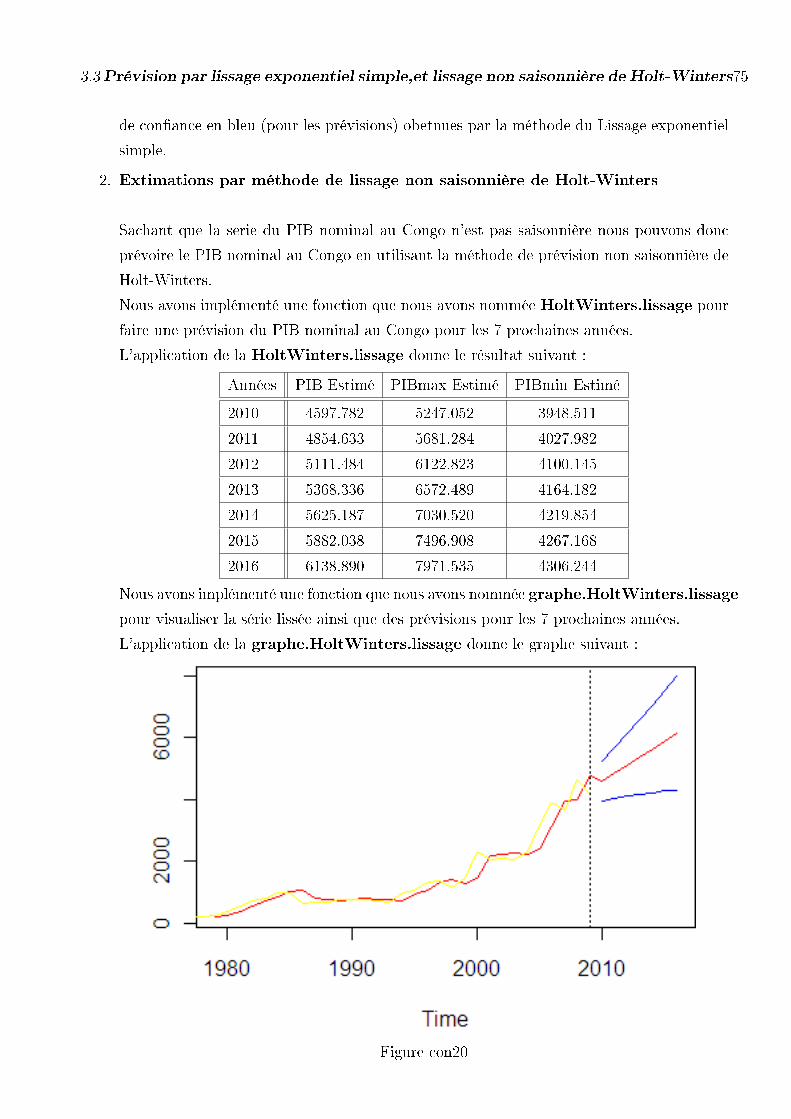
3.3Prévision par lissage exponentiel simple,et lissage non saisonnière de Holt-Winters75
de con�ance en bleu (pour les prévisions) obetnues par la méthode du Lissage exponentiel
simple.
2. Extimations par méthode de lissage non saisonnière de Holt-Winters
Sachant que la serie du PIB nominal au Congo n'est pas saisonnière nous pouvons donc
prévoire le PIB nominal au Congo en utilisant la méthode de prévision non saisonnière de
Holt-Winters.
Nous avons implémenté une fonction que nous avons nommée HoltWinters.lissage pour
faire une prévision du PIB nominal au Congo pour les 7 prochaines années.
L'application de la HoltWinters.lissage donne le résultat suivant :
Années PIB Estimé PIBmax Estimé PIBmin Estimé
2010 4597.782 5247.052 3948.511
2011 4854.633 5681.284 4027.982
2012 5111.484 6122.823 4100.145
2013 5368.336 6572.489 4164.182
2014 5625.187 7030.520 4219.854
2015 5882.038 7496.908 4267.168
2016 6138.890 7971.535 4306.244
Nous avons implémenté une fonction que nous avons nommée graphe.HoltWinters.lissage
pour visualiser la série lissée ainsi que des prévisions pour les 7 prochaines années.
L'application de la graphe.HoltWinters.lissage donne le graphe suivant :
Figure con20

3.3Prévision par lissage exponentiel simple,et lissage non saisonnière de Holt-Winters76
En jaune nous avons notre serie d'observation du PIB nominal au Congo. En rouge, nous
avons la courbe de la serie obetnue du lissage, ainsi que notre horizon de prévision remar-
quable à partir de l'année 2010 du PIB nominal avec un intervalle de con�ance en bleu
(pour les prévisions) obetnues par la méthode de Holt-Winters pour serie non saisonnière.
3.3.3 Prévision du PIB Nominal cas de la République Centrafricaine
1. Extimations par méthode de lissage exponentiel simple
sachant que le lissage exponentiel simple correspond au lissage par la méthode de Holt-
Winters avec β = 0 nous avons implémenté une fonction que nous avons nomméHoltWin-
ters.lis.expo.simple pour faire une prévision du PIB nominal en République Centrafri-
caine pour les 7 prochaines années, l'application de la fonctionHoltWinters.lis.expo.simple
nous donne.
Années PIB Estimé PIBmax Estimé PIBmin Estimé
2010 1005.799 1071.727 939.8699
2011 1019.699 1112.934 926.4634
2012 1033.599 1147.787 919.4101
2013 1047.499 1179.352 915.6456
2014 1061.399 1208.814 913.9828
2015 1075.299 1236.784 913.8129
2016 1089.199 1263.623 914.7743
nous avons implémenté une fonction que nous avons nommée graphe.HoltWinters.lis
.expo.simple pour visualiser la série lissée ainsi que les prévisions du lissage simple pour les
7 prochaines années.L'application de la fonction graphe.HoltWinters.lis.expo.simple
donne le graphe suivant :
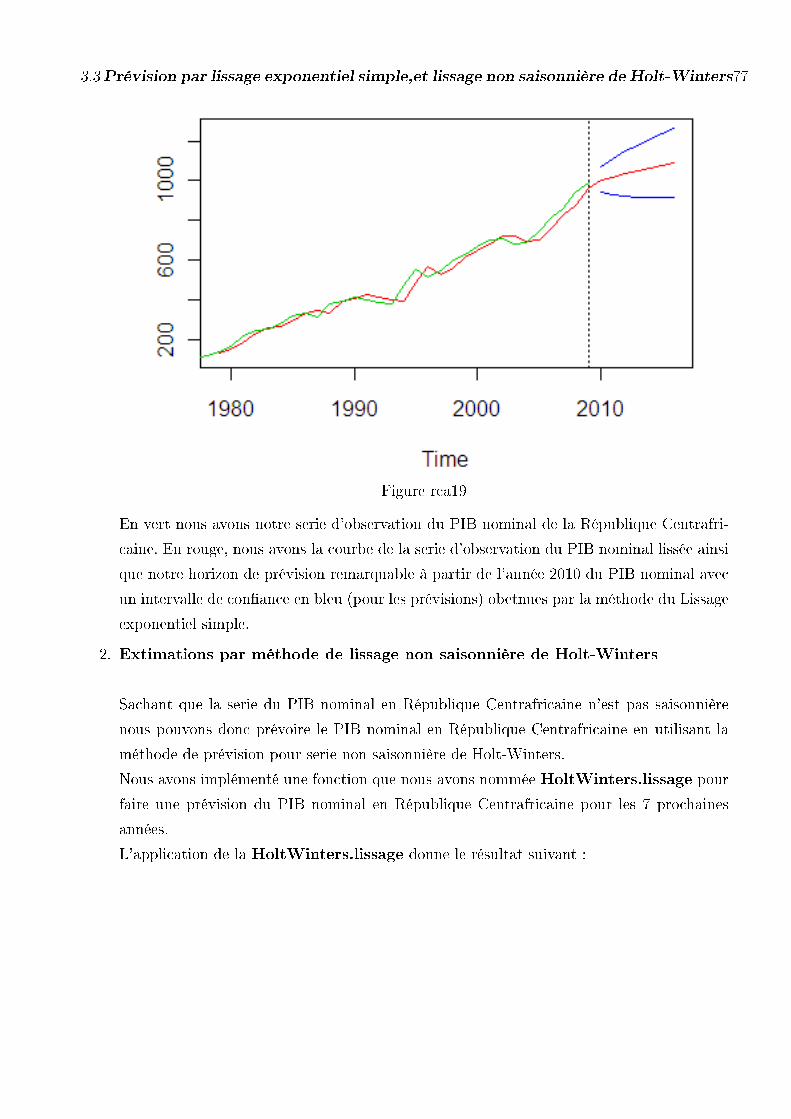
3.3Prévision par lissage exponentiel simple,et lissage non saisonnière de Holt-Winters77
Figure rca19
En vert nous avons notre serie d'observation du PIB nominal de la République Centrafri-
caine. En rouge, nous avons la courbe de la serie d'observation du PIB nominal lissée ainsi
que notre horizon de prévision remarquable à partir de l'année 2010 du PIB nominal avec
un intervalle de con�ance en bleu (pour les prévisions) obetnues par la méthode du Lissage
exponentiel simple.
2. Extimations par méthode de lissage non saisonnière de Holt-Winters
Sachant que la serie du PIB nominal en République Centrafricaine n'est pas saisonnière
nous pouvons donc prévoire le PIB nominal en République Centrafricaine en utilisant la
méthode de prévision pour serie non saisonnière de Holt-Winters.
Nous avons implémenté une fonction que nous avons nommée HoltWinters.lissage pour
faire une prévision du PIB nominal en République Centrafricaine pour les 7 prochaines
années.
L'application de la HoltWinters.lissage donne le résultat suivant :
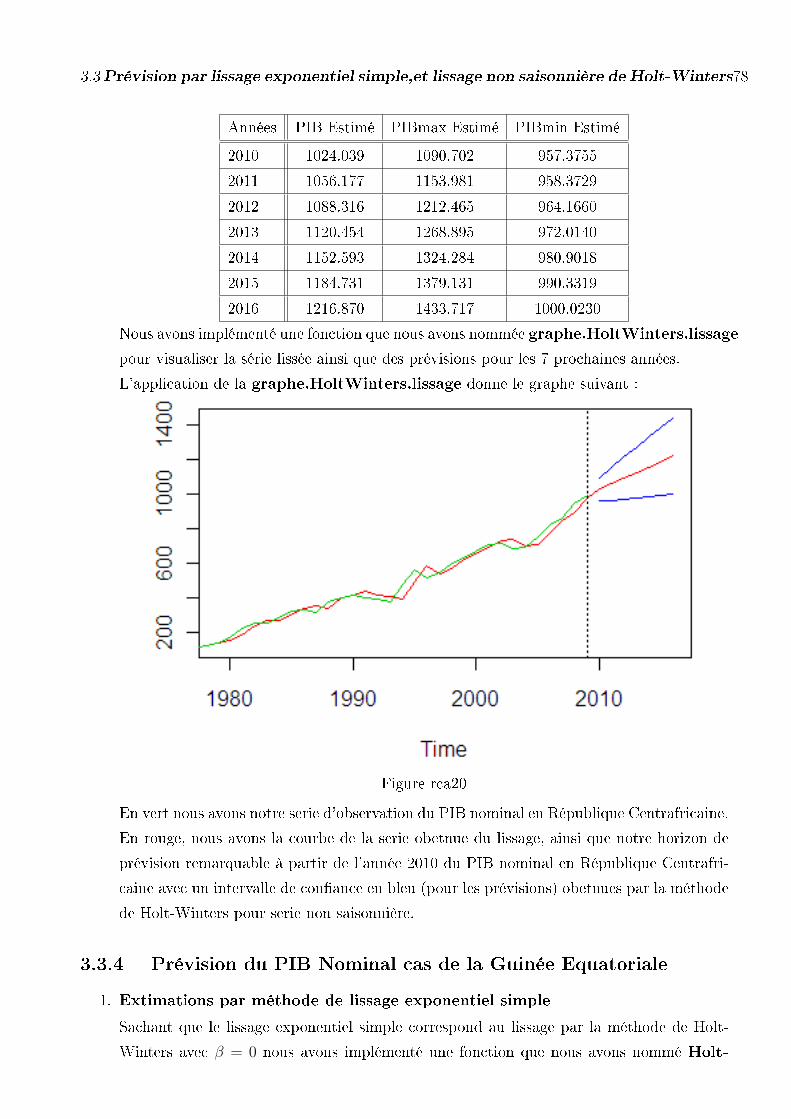
3.3Prévision par lissage exponentiel simple,et lissage non saisonnière de Holt-Winters78
Années PIB Estimé PIBmax Estimé PIBmin Estimé
2010 1024.039 1090.702 957.3755
2011 1056.177 1153.981 958.3729
2012 1088.316 1212.465 964.1660
2013 1120.454 1268.895 972.0140
2014 1152.593 1324.284 980.9018
2015 1184.731 1379.131 990.3319
2016 1216.870 1433.717 1000.0230
Nous avons implémenté une fonction que nous avons nommée graphe.HoltWinters.lissage
pour visualiser la série lissée ainsi que des prévisions pour les 7 prochaines années.
L'application de la graphe.HoltWinters.lissage donne le graphe suivant :
Figure rca20
En vert nous avons notre serie d'observation du PIB nominal en République Centrafricaine.
En rouge, nous avons la courbe de la serie obetnue du lissage, ainsi que notre horizon de
prévision remarquable à partir de l'année 2010 du PIB nominal en République Centrafri-
caine avec un intervalle de con�ance en bleu (pour les prévisions) obetnues par la méthode
de Holt-Winters pour serie non saisonnière.
3.3.4 Prévision du PIB Nominal cas de la Guinée Equatoriale
1. Extimations par méthode de lissage exponentiel simple
Sachant que le lissage exponentiel simple correspond au lissage par la méthode de Holt-
Winters avec β = 0 nous avons implémenté une fonction que nous avons nommé Holt-
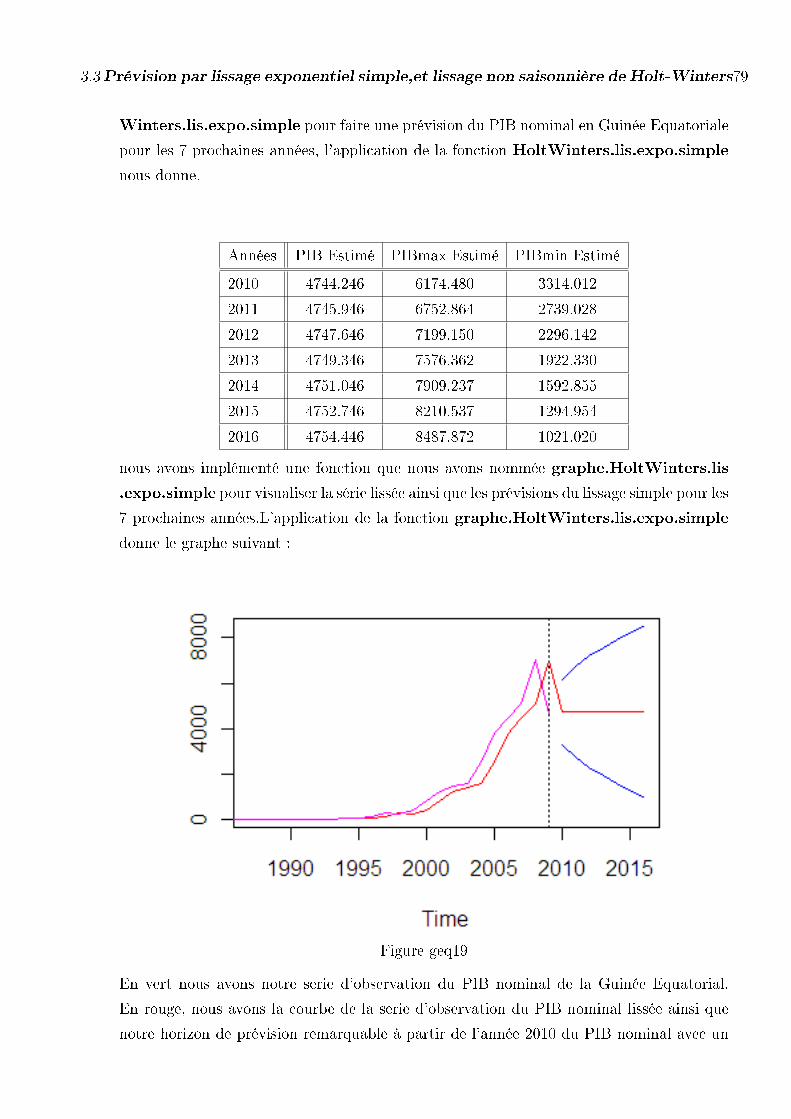
3.3Prévision par lissage exponentiel simple,et lissage non saisonnière de Holt-Winters79
Winters.lis.expo.simple pour faire une prévision du PIB nominal en Guinée Equatoriale
pour les 7 prochaines années, l'application de la fonction HoltWinters.lis.expo.simple
nous donne.
Années PIB Estimé PIBmax Estimé PIBmin Estimé
2010 4744.246 6174.480 3314.012
2011 4745.946 6752.864 2739.028
2012 4747.646 7199.150 2296.142
2013 4749.346 7576.362 1922.330
2014 4751.046 7909.237 1592.855
2015 4752.746 8210.537 1294.954
2016 4754.446 8487.872 1021.020
nous avons implémenté une fonction que nous avons nommée graphe.HoltWinters.lis
.expo.simple pour visualiser la série lissée ainsi que les prévisions du lissage simple pour les
7 prochaines années.L'application de la fonction graphe.HoltWinters.lis.expo.simple
donne le graphe suivant :
Figure geq19
En vert nous avons notre serie d'observation du PIB nominal de la Guinée Equatorial.
En rouge, nous avons la courbe de la serie d'observation du PIB nominal lissée ainsi que
notre horizon de prévision remarquable à partir de l'année 2010 du PIB nominal avec un
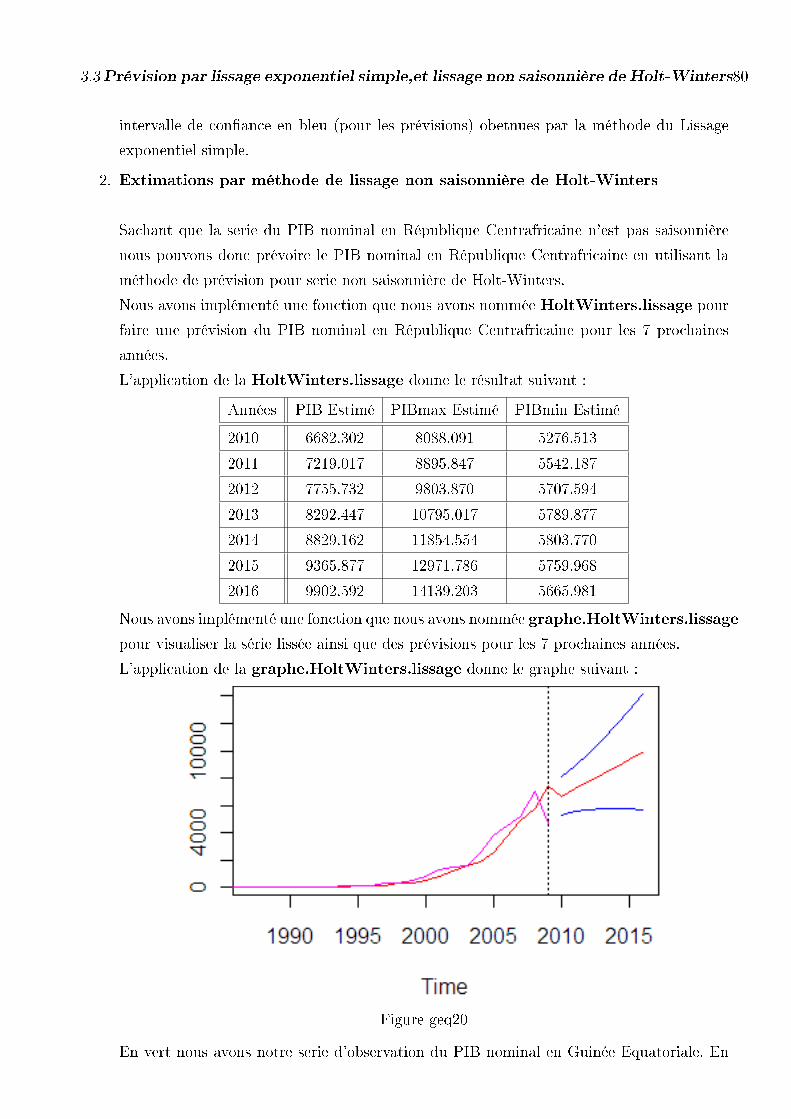
3.3Prévision par lissage exponentiel simple,et lissage non saisonnière de Holt-Winters80
intervalle de con�ance en bleu (pour les prévisions) obetnues par la méthode du Lissage
exponentiel simple.
2. Extimations par méthode de lissage non saisonnière de Holt-Winters
Sachant que la serie du PIB nominal en République Centrafricaine n'est pas saisonnière
nous pouvons donc prévoire le PIB nominal en République Centrafricaine en utilisant la
méthode de prévision pour serie non saisonnière de Holt-Winters.
Nous avons implémenté une fonction que nous avons nommée HoltWinters.lissage pour
faire une prévision du PIB nominal en République Centrafricaine pour les 7 prochaines
années.
L'application de la HoltWinters.lissage donne le résultat suivant :
Années PIB Estimé PIBmax Estimé PIBmin Estimé
2010 6682.302 8088.091 5276.513
2011 7219.017 8895.847 5542.187
2012 7755.732 9803.870 5707.594
2013 8292.447 10795.017 5789.877
2014 8829.162 11854.554 5803.770
2015 9365.877 12971.786 5759.968
2016 9902.592 14139.203 5665.981
Nous avons implémenté une fonction que nous avons nommée graphe.HoltWinters.lissage
pour visualiser la série lissée ainsi que des prévisions pour les 7 prochaines années.
L'application de la graphe.HoltWinters.lissage donne le graphe suivant :
Figure geq20
En vert nous avons notre serie d'observation du PIB nominal en Guinée Equatoriale. En

3.3Prévision par lissage exponentiel simple,et lissage non saisonnière de Holt-Winters81
rouge, nous avons la courbe de la serie obetnue du lissage, ainsi que notre horizon de
prévision remarquable à partir de l'année 2010 du PIB nominal en Guinée Equatoriale
avec un intervalle de con�ance en bleu (pour les prévisions) obetnues par la méthode de
Holt-Winters pour serie non saisonnière.
3.3.5 Prévision du PIB Nominal cas du Tchad
1. Extimations par méthode de lissage exponentiel simple sachant que le lissage
exponentiel simple correspond au lissage par la méthode de Holt-Winters avec β = 0 nous
avons implémenté une fonction que nous avons nommé HoltWinters.lis.expo.simple
pour faire une prévision du PIB nominal du Tchad pour les 7 prochaines années, l'appli-
cation de la fonction HoltWinters.lis.expo.simple nous donne.
Années PIB Estimé PIBmax Estimé PIBmin Estimé
2010 3258.446 3867.068 2649.824
2011 3284.846 4145.534 2424.158
2012 3311.246 4365.355 2257.136
2013 3337.646 4554.819 2120.473
2014 3364.046 4724.881 2003.211
2015 3390.446 4881.163 1899.729
2016 3416.846 5027.001 1806.691
nous avons implémenté une fonction que nous avons nommée graphe.HoltWinters.lis
.expo.simple pour visualiser la série lissée ainsi que les prévisions du lissage simple pour les
7 prochaines années.L'application de la fonction graphe.HoltWinters.lis.expo.simple
donne le graphe suivant :
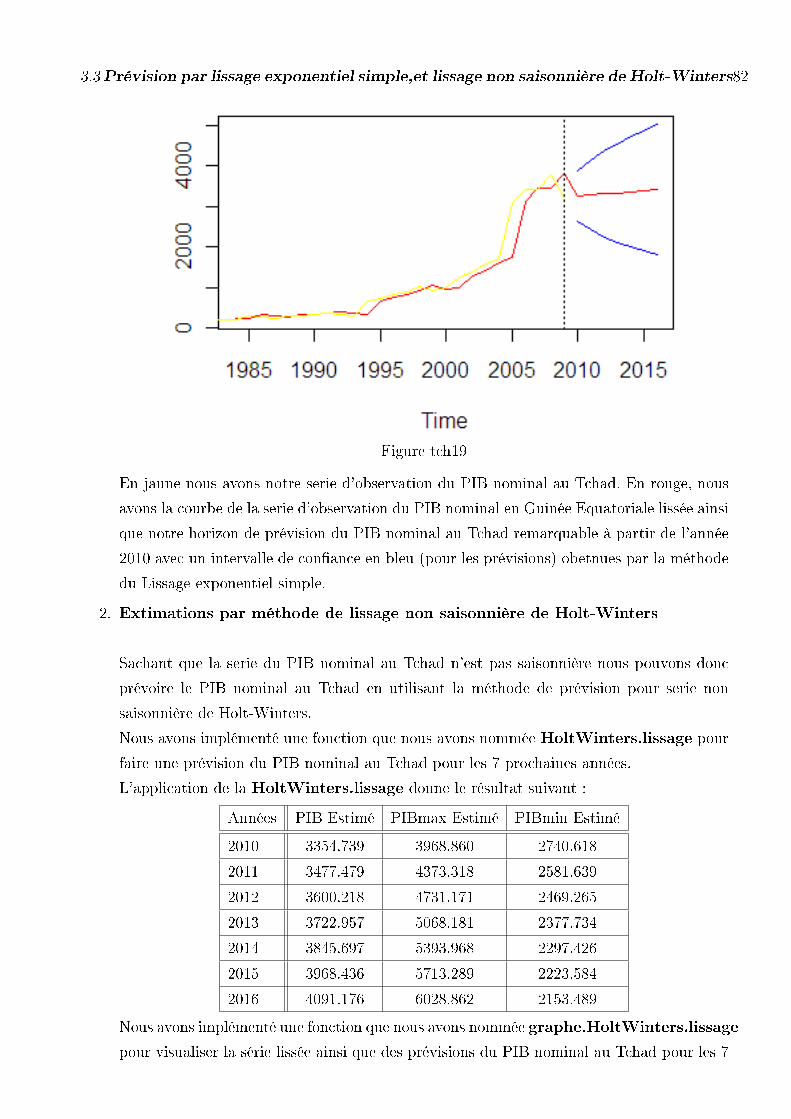
3.3Prévision par lissage exponentiel simple,et lissage non saisonnière de Holt-Winters82
Figure tch19
En jaune nous avons notre serie d'observation du PIB nominal au Tchad. En rouge, nous
avons la courbe de la serie d'observation du PIB nominal en Guinée Equatoriale lissée ainsi
que notre horizon de prévision du PIB nominal au Tchad remarquable à partir de l'année
2010 avec un intervalle de con�ance en bleu (pour les prévisions) obetnues par la méthode
du Lissage exponentiel simple.
2. Extimations par méthode de lissage non saisonnière de Holt-Winters
Sachant que la serie du PIB nominal au Tchad n'est pas saisonnière nous pouvons donc
prévoire le PIB nominal au Tchad en utilisant la méthode de prévision pour serie non
saisonnière de Holt-Winters.
Nous avons implémenté une fonction que nous avons nommée HoltWinters.lissage pour
faire une prévision du PIB nominal au Tchad pour les 7 prochaines années.
L'application de la HoltWinters.lissage donne le résultat suivant :
Années PIB Estimé PIBmax Estimé PIBmin Estimé
2010 3354.739 3968.860 2740.618
2011 3477.479 4373.318 2581.639
2012 3600.218 4731.171 2469.265
2013 3722.957 5068.181 2377.734
2014 3845.697 5393.968 2297.426
2015 3968.436 5713.289 2223.584
2016 4091.176 6028.862 2153.489
Nous avons implémenté une fonction que nous avons nommée graphe.HoltWinters.lissage
pour visualiser la série lissée ainsi que des prévisions du PIB nominal au Tchad pour les 7
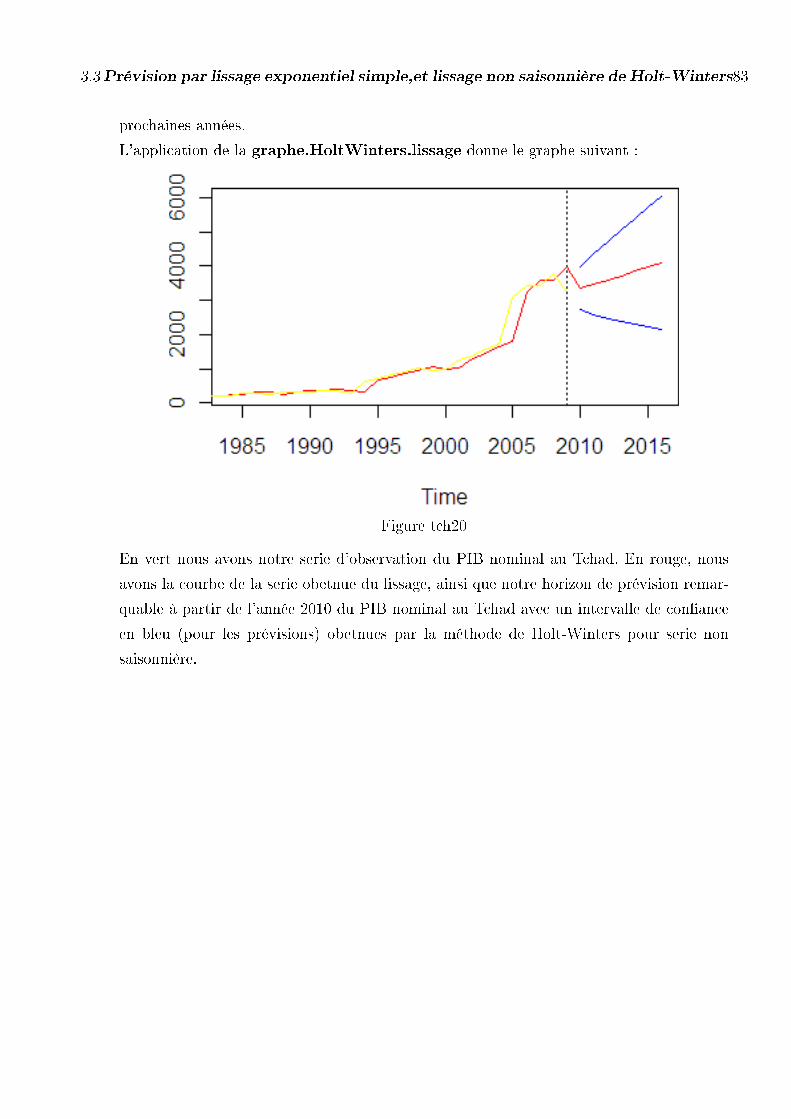
3.3Prévision par lissage exponentiel simple,et lissage non saisonnière de Holt-Winters83
prochaines années.
L'application de la graphe.HoltWinters.lissage donne le graphe suivant :
Figure tch20
En vert nous avons notre serie d'observation du PIB nominal au Tchad. En rouge, nous
avons la courbe de la serie obetnue du lissage, ainsi que notre horizon de prévision remar-
quable à partir de l'année 2010 du PIB nominal au Tchad avec un intervalle de con�ance
en bleu (pour les prévisions) obetnues par la méthode de Holt-Winters pour serie non
saisonnière.

Conclusion
Le comportement du PIB nominal dans les pays de la zone CEMAC, n'est pas tout aussi
identique au vue des réalités tant sociopolitique et économique qui les lient. Dans ce mémoire,
dans les conditions dans les quelle nous avons travaillé, avec les données que nous disposions,
nous avons remarqué que : Les mesures de dispersion du PIB nominal au Tchad et au Congo
sont assez proches et montrent des dispersions plus importantes que celle de la République
Centrafricaine au PIB plus homogène, mais globalement moins élevés. Le Cameroun semble
avoir le meilleur rendement en PIB nominal en zone CEMAC (en terme Grandeur monétaire).
Pendant une année on peut mieux s'attendre à une valeur plus élevé (Peut être moins bonne si
on considère l'investissement) du PIB au Cameroun que par tout ailleurs en zone CEMAC. Suite
à la structure de nos données, pour prévoir le PIB nominal, nous avons appliqué les méthodes
suivantes :
1. La méthode de Box jenkins (ARIMA).
2. La méthode du lissage exponentiel simple.
3. La méthode de Holt-Winters pour séries non saisonnières.
Parmi toutes ces méthodes, la méthode qui a le coût le plus considérable est la méthode de
Box-Jenkins (ARIMA) surtout lorsque nous incluons le critère AIC pour sélectionner le bon
modèles. Sachant aussi qu'à long terme les méthodes du lissage exponentiel simple et de Holt-
Winters ne sont pas conseillées, nous avons aussi remarqué que, en appliquant les méthodes du
lissage exponentiel simple et de Holt-Winters si le taux de croissance des deux premières valeurs
de prévision est positif alors les prévisions seront aussi croissantes, et décroissante dans le cas
contraire. Ce qui n'est pas un atout si l'on veut prendre un certains nombres de décisions suite
aux résultats des prévisions. Pour nous ici, nous avons retenu et recommandons les prévisions
de la méthode de Box-Jenkins (ARIMA). Les modèles ainsi retenus par la méthode de Box
Jenkins(ARIMA) sont les suivants :
Pour prévoir le PIB nominal au Cameroun : ARIMA(1,1,6) ; Pour prévoir le PIB nominal au
Gabon : ARIMA(1,1,1) ; pour prévoir le PIB nominal au Congo : ARIMA(1,1,1) ; Pour prévoir
le PIB nominal en République Centrafricaine : ARIMA(1,1,2) ; Pour prévoir le PIB nominal en
Guinée Equatoriale : ARIMA(1,1,2) ; Pour prévoir le PIB nominal au Tchad : ARIMA(1,1,1).
Mémoire de Master de Statistique Appliquée. Jacques Le Grand BIYICK ETOGUE c©ENSP 2008-2010

ANNEXE
Tests statistiques
Test de Box-Pierce ou Ljung-Box(Box)
La statistique Q de Ljung-Box permet de tester l'hypothèse d'indépendance sérielle d'une
série (ou que la série est bruit blanc). Plus spéciquement cette statistique teste l'hypothèse que
les n coe�cients d'auto-corrélation sont nuls. Elle est basée sur la somme des auto-corrélations
de la série et elle est distribuée selon une loi Chi-carrée avec T degrés de liberté. L'hypothèse
nulle est alors donnée par :
H0 : ρ1 = ρ2 = ρ3 = ... = ρT = 0
La statistique du test est alors :
Q = T (T + 2)h∑j=1
ρ2j
T − j
Test de Shapiro
Le test de Shapiro, aussi appelé test de Shapiro et Wilk, est un test de normalité d'une série
d'observations d'une variable quantitative. Soit X une variable aléatoire réelle et X1, X2, ..., Xn,
n réalisations de X. On range alors ces observations par ordre croissant :
X1 ≤ X2 ≤ X3 ≤ ... ≤ Xn
le test de Shapiro se réalise alors en 6 étapes :
1. On calcule la moyenne de cette série de mesures :
X =1
n
n∑i=1
Xi
2. On le nombre Tn dé�ni par :
Tn =1
n
n∑i=1
(Xi − X)2
Mémoire de Master de Statistique Appliquée. Jacques Le Grand BIYICK ETOGUE c©ENSP 2008-2010

3.3Prévision par lissage exponentiel simple,et lissage non saisonnière de Holt-Winters86
3. On calcule les di�érences suivantes :
d1 = Xn −X1d2 = Xn−1 −X1di = Xn+i−1 −Xi
4. On calcule alors le nombre W dé�ni par :
W =1
Tn
∑i=1
p(ajdj)2
où les coe�cients aj sont données par la table des coe�cients aj pour le test de Shapiro
et Wilk.
5. O choisi un risque de (5% ou 1%) et on compare la valeur de W à une valeur Wcrit, dite
valeur critique, lue dans la table Shapiro et Wilk.
6. La règle du test est alors la suivante :
- SiW > Wcrit on accepte, au risque choisi, l'hypothèse de normalité de la série de mesure.
- Si W < Wcrit on rejette l'hypothèse de normalité de la série de mesure.
Statistique Descriptive
1. Description des données
donneepib<-read.table('C:\\Users\\user\\Desktop\\tage
\\donneepib.txt',header=T)
summary(camerounpib$pibnominal)
summary(gabonpib$pibnominal)
summary(congopib$pibnominal)
summary(tchadpib$pibnominal)
summary(guiequatpibnominal$pibnominal)
summary(recapibnominal$pibnominal)
2. Comparaison du Pib nominal en zone CEMAC
hist(camerounpib$pibnominal,
col = 3, border = 2,
xlab = "PIB nominal", ylab = "densité",ylim=c(0,13),label=T)
par(usr=c(0,1,0,1))
text(.4,.95,"PIB au Cameroun",adj=c(0,1),cex=1.2)

3.3Prévision par lissage exponentiel simple,et lissage non saisonnière de Holt-Winters87
hist(congopib$pibnominal,
col = 2, border = 3,
xlab = "PIB nominal", ylab = "densité",ylim=c(0,16),label=T)
par(usr=c(0,1,0,1))
text(.4,.95,"PIB au Congo",adj=c(0,1),cex=1.2)
hist(gabonpib$pibnominal,
col = 7, border = 2,
xlab = "PIB nominal", ylab = "densité",ylim=c(0,15),label=T)
par(usr=c(0,1,0,1))
text(.4,.95,"PIB au Gabon",adj=c(0,1),cex=1.2)
hist(guiequatpibnominal$pibnominal,
col ="lightpink" , border = 4,
xlab = "PIB nominal", ylab = "densité",ylim=c(0,17),label=T)
par(usr=c(0,1,0,1))
text(.2,.95,"PIB en Guinée Equatoriale",adj=c(0,1),cex=1.2)
hist(recapibnominal$pibnominal,
col = "lightblue", border = 4,
xlab = "PIB nominal", ylab = "densité",ylim=c(0,15),label=T)
par(usr=c(0,1,0,1))
text(.01,.95,"PIB en Replubique Centrafricaine",adj=c(0,1),cex=1.2)
hist(tchadpib$pibnominal,
col ="royalblue", border = 2,
xlab = "PIB nominal", ylab = "densité",ylim=c(0,15),label=T)
par(usr=c(0,1,0,1))
text(.3,.95,"PIB au Tchad",adj=c(0,1),cex=1.2)
boxplot(donneepib$pibnominal~donneepib$pays,
col = c(3,2,7,"lightpink", "lightblue","royalblue"),
ylab = "pibnominal",las = 1)
par(usr=c(0,1,0,1))
text(.3,.95,"PIB en zone Cemac",adj=c(0,1),cex=1.2)
Et si nous regardions juste le PIB dans le temps
cas du Cameroun
1. Saisie des données : cas du Cameroun

3.3Prévision par lissage exponentiel simple,et lissage non saisonnière de Holt-Winters88
camerounpib<-read.table('C:\\Users\\user\\Desktop\\tage\\campib.txt',header=T)
2. Créer un objet de type série temporelle : cas du Cameroun
transformons les données sous forme de tableau en série temporelle et pour cela, nous
utilisons la commande ts qui va créer un objet de classe ts à partir d'un vecteur (série
temporelle simple) ou d'une matrice (Série temporelle multiple), et des options qui carac-
térisent la série.
seriecampibnominal=ts(camerounpib$pibnominal,start=1977,frequency=1)
3. Visualisation des données : cas du Cameroun
plot.ts(seriecampibnominal)
cas du Gabon
1. Saisie des données : cas du Gabon
camerounpib<-read.table('C:\\Users\\user\\Desktop\\tage\\campib.txt',header=T)
2. Créer un objet de type série temporelle : cas du Gabon
transformons les données sous forme de tableau en série temporelle et pour cela, nous
utilisons la commande ts qui va créer un objet de classe ts à partir d'un vecteur (série
temporelle simple) ou d'une matrice (Série temporelle multiple), et des options qui carac-
térisent la série.
seriecampibnominal=ts(gabonpib$pibnominal,start=1977,frequency=1)
3. Visualisation des données : cas du Gabon
plot.ts(seriegabpibnominal)
cas du Congo
1. Saisie des données cas : cas du Congo
congopib<-read.table('C:\\Users\\user\\Desktop\\tage\\conpibnominal.txt',header=T)
2. Créer un objet de type série temporelle : cas du Congo
Transformons les données sous forme de tableau en série temporelle et pour cela, nous
utilisons la commande ts qui va créer un objet de classe ts à partir d'un vecteur (série
temporelle simple) ou d'une matrice (Série temporelle multiple), et des options qui carac-
térisent la série.
serieconpibnominal=ts(congopib$pibnominal,start=1977,frequency=1)
3. Visualisation des données : cas du Congo
plot.ts(serieconpibnominal)

3.3Prévision par lissage exponentiel simple,et lissage non saisonnière de Holt-Winters89
cas de république centrafricaine
1. Saisie des données : cas de république centrafricaine
recapib<-read.table('C:\\Users\\user\\Desktop\\tage
\\repcafpibnominal.txt', header=T)
2. Créer un objet de type série temporelle : cas de république centrafricaine Trans-
formons les données sous forme de tableau en série temporelle et pour cela, nous utilisons
la commande ts qui va créer un objet de classe ts à partir d'un vecteur (série temporelle
simple) ou d'une matrice (Série temporelle multiple), et des options qui caractérisent la
série.
serierecapibnominal=ts(recapib$pibnominal,start=1977,frequency=1)
3. Visualisation des données : cas de république centrafricaine
plot.ts(serierecapibnominal)
cas de la Guinée équatoriale
1. Saisie des données : cas de la Guinée équatoriale
geqtpib<-read.table('C:\\Users\\user\\Desktop
\\tage\\geqatpibnominal.txt',header=T)
2. Créer un objet de type série temporelle : cas de la Guinée équatoriale Trans-
formons les données sous forme de tableau en série temporelle et pour cela, nous utilisons
la commande ts qui va créer un objet de classe ts à partir d'un vecteur (série temporelle
simple) ou d'une matrice (Série temporelle multiple), et des options qui caractérisent la
série.
serieregepibnominal=ts(geqtpib$pibnominal, start=1985, frequency=1)
3. Visualisation des données : cas de la Guinée équatoriale
plot.ts(serieregepibnominal)
cas du Tchad
1. Saisie des données : cas du Tchad
tchadpib<-read.table('C:\\Users\\user
\\Desktop\\tage\\tchadpibnominal.txt',header=T)

3.3Prévision par lissage exponentiel simple,et lissage non saisonnière de Holt-Winters90
2. Créer un objet de type série temporelle : cas du Tchad Transformons les données
sous forme de tableau en série temporelle et pour cela, nous utilisons la commande ts qui
va créer un objet de classe ts à partir d'un vecteur (série temporelle simple) ou d'une
matrice (Série temporelle multiple), et des options qui caractérisent la série.
serietchpibnominal=ts(tchadpib$pibnominal,start=1982,frequency=1)
3. Visualisation des données : cas du Tchad
plot.ts(serietchpibnominal)
EXTIMATIONS :METHODOLOGIE DE BOX JENKINS
Prévision du PIB Nominal cas du Cameroun
1. )
PP.test(seriecampibnominal)
2. )
f.diff=function(x,d)
{
td=1:length(x)
td1=td[(d+1):length(td)]
x.new=sapply((d+1):length(td),function(i)a=x[i]-x[i-d])
return(x.new)
}
3. )
seriecampibnominal.new=f.diff(seriecampibnominal,1)
PP.test( seriecampibnominal.new)
4. )
plot.ts(seriecampibnominal.new)
5. )
acf(seriecampibnominal.new,lag.max=32)
pacf(seriecampibnominal.new,lag.max=32)

3.3Prévision par lissage exponentiel simple,et lissage non saisonnière de Holt-Winters91
AGRMIN.AICpq=function(p,d,q)
{
a=c()
b=c()
t=0
b=list()
for ( i in 1:q)
{
for ( i in 1:p)
{
t=t+1
a[t]=AIC(arima(seriecampibnominal,order=c(p,d,i)))
b[[t]]=c(i,p)
}
}
b[[which.min(a)]]
}
AGRMIN.AICpq(8,1,8)
pibcameroun=arima(seriecampibnominal,order=c(1,1,6))
6. )
pibcameroun$coef
Box.test(pibcameroun$residuals)
plot(pibcameroun$residuals,col=3)
tsdiag(pibcameroun)
7. )
predseriecampibnominal=predict(pibcameroun,n.ahead=7)
predseriecampibnominal
Prévision du PIB Nominal cas du Gabon
1. )
PP.test(seriegabonpibnominal)
2. )

3.3Prévision par lissage exponentiel simple,et lissage non saisonnière de Holt-Winters92
f.diff=function(x,d)
{
td=1:length(x)
td1=td[(d+1):length(td)]
x.new=sapply((d+1):length(td),function(i)a=x[i]-x[i-d])
return(x.new)
}
3. )
seriegabonpibnominal.new=f.diff(seriegabonpibnominal,1)
PP.test(seriegabonpibnominal.new)
4. )
plot.ts( seriegabonpibnominal.new)
5. )
acf(seriegabonpibnominal.new,lag.max=32)
pacf(seriegabonpibnominal.new,lag.max=32)
AGRMIN.AICpq=function(p,d,q)
{
a=c()
b=c()
t=0
b=list()
for ( i in 1:q)
{
t=t+1
a[t]=AIC(arima(seriegabonpibnominal,order=c(p,d,i)))
b[[t]]=c(i,p)
}
b[[which.min(a)]]
}
AGRMIN.AICpq(1,1,1)
pibgabon=arima(seriegabonpibnominal,order=c(1,1,1))

3.3Prévision par lissage exponentiel simple,et lissage non saisonnière de Holt-Winters93
6. )
pibgabon$coef
Box.test(pibgabon$residuals)
tsdiag(pibgabon)
7. )
predseriegabpibnominal=predict(pibgabon,n.ahead=7)
predseriegabpibnominal
Prévision du PIB Nominal cas du Congo
1. )
PP.test( seriecongopibnominal)
2. )
f.diff=function(x,d)
{
td=1:length(x)
td1=td[(d+1):length(td)]
x.new=sapply((d+1):length(td),function(i)a=x[i]-x[i-d])
return(x.new)
}
3. )
seriecongopibnominal.new=f.diff( seriecongopibnominal,1)
PP.test(seriecongopibnominal.new)
4. )
plot.ts(seriecongopibnominal.new)
5. )
acf( seriecongopibnominal.new,lag.max=32)
pacf( seriecongopibnominal.new ,lag.max=32)

3.3Prévision par lissage exponentiel simple,et lissage non saisonnière de Holt-Winters94
AGRMIN.AICpq=function(p,d,q)
{
a=c()
b=c()
t=0
b=list()
for ( i in 2:q)
{
t=t+1
a[t]=AIC(arima( seriecongopibnominal,order=c(p,d,i)))
b[[t]]=c(i,p)
}
b[[which.min(a)]]
}
AGRMIN.AICpq(1,1,1)
pibcongo=arima(seriecongopibnominal,order=c(1,1,1))
6. )
pibcongo$coef
Box.test(pibcongo$residuals)
tsdiag(pibcongo)
7. )
predserieconpibnominal=predict(pibcongo,n.ahead=7)
predserieconpibnominal
Prévision du PIB Nominal cas du Republique Centafricane
1. )
PP.test(serierecapibnominal)
2. )
f.diff=function(x,d)
{
td=1:length(x)
td1=td[(d+1):length(td)]

3.3Prévision par lissage exponentiel simple,et lissage non saisonnière de Holt-Winters95
x.new=sapply((d+1):length(td),function(i)a=x[i]-x[i-d])
return(x.new)
}
3. )
serierecapibnominal.new=f.diff(serierecapibnominal,1)
PP.test(serierecapibnominal.new)
4. )
plot.ts(serierecapibnominal.new)
5. )
acf( serierecapibnominal.new,lag.max=32)
pacf( serierecapibnominal.new,lag.max=32)
AGRMIN.AICpq=function(p,d,q)
{
a=c()
b=c()
t=0
b=list()
for ( i in q)
{
t=t+1
a[t]=AIC(arima( serierecapibnominal,order=c(p,d,i)))
b[[t]]=c(i,p)
}
b[[which.min(a)]]
}
AGRMIN.AICpq(1,1,2)
pibrepcafrique=arima(serierecapibnominal,order=c(1,1,2))
6. )
pibrepcafrique$coef

3.3Prévision par lissage exponentiel simple,et lissage non saisonnière de Holt-Winters96
Box.test(pibrepcafrique$residuals)
tsdiag(pibrepcafrique)
7. )
predseriercapibnominal=predict(pibrepcafrique,n.ahead=7)
predseriercapibnominal
Prévision du PIB Nominal cas du Guinée Equatoriale
1. )
PP.test(serieguiequatpibnominal)
2. )
f.diff=function(x,d)
{
td=1:length(x)
td1=td[(d+1):length(td)]
x.new=sapply((d+1):length(td),function(i)a=x[i]-x[i-d])
return(x.new)
}
3. )
serieguiequatpibnominal.new=f.diff(serieguiequatpibnominal,1)
PP.test(serieguiequatpibnominal.new)
4. )
plot.ts(serieguiequatpibnominal.new)
5. )
acf( serieguiequatpibnominal.new,lag.max=23)
pacf( serieguiequatpibnominal.new,lag.max=23)
AGRMIN.AICpq=function(p,d,q)
{
a=c()
b=c()
t=0
b=list()

3.3Prévision par lissage exponentiel simple,et lissage non saisonnière de Holt-Winters97
for ( i in 1:q)
{
t=t+1
a[t]=AIC(arima( serieguiequatpibnominal,order=c(p,d,i)))
b[[t]]=c(i,p)
}
b[[which.min(a)]]
}
AGRMIN.AICpq(1,1,1)
pibguiequat=arima(serieguiequatpibnominal,order=c(1,1,1))
6. )
pibguiequat$coef
Box.test(pibguiequat$residuals)
tsdiag(pibguiequat)
7. )
predserieequatpibnominal=predict(pibguiequat,n.ahead=7)
predserieequatpibnominal
Prévision du PIB Nominal cas du Tchad
1. )
PP.test(serietchadpibnominal)
2. )
f.diff=function(x,d)
{
td=1:length(x)
td1=td[(d+1):length(td)]
x.new=sapply((d+1):length(td),function(i)a=x[i]-x[i-d])
return(x.new)
}
3. )

3.3Prévision par lissage exponentiel simple,et lissage non saisonnière de Holt-Winters98
serietchadpibnominal.new=f.diff(serietchadpibnominal,1)
PP.test(serietchadpibnominal.new)
4. )
plot.ts(serietchadpibnominal.new)
5. )
acf( serietchadpibnominal.new,lag.max=28)
pacf( serietchadpibnominal.new,lag.max=28)
AGRMIN.AICpq=function(p,d,q)
{
a=c()
b=c()
t=0
b=list()
for ( i in 0:q)
{
t=t+1
a[t]=AIC(arima(serietchadpibnominal,order=c(p,d,i)))
b[[t]]=c(i,p)
}
b[[which.min(a)]]
}
AGRMIN.AICpq(1,1,5)
pibtchad=arima(serietchadpibnominal,order=c(1,1,1))
6. )
pibtchad$coef
Box.test(pibtchad$residuals)
tsdiag(pibtchad)
7. )
predserietchadpibnominal=predict(pibtchad,n.ahead=7)
predserietchadpibnominal

3.3Prévision par lissage exponentiel simple,et lissage non saisonnière de Holt-Winters99
Extimations par méthode de lissage exponentiel
simple et par méthode de lissage non saisonnière
de Holt-Winters
Prévision du PIB Nominal cas du Cameroun
1. Extimations par méthode de lissage exponentiel simple
HoltWinters.lis.expo.simple=function(serie)
{
u=HoltWinters(serie,beta=0,gamma=FALSE)
e=predict(u,7,prediction.interval=TRUE)
return(e)
}
HoltWinters.lis.expo.simple(seriecampibnominal)
graphe.HoltWinters.lis.expo.simple=function(serie)
{
u=HoltWinters(serie,beta=0,gamma=FALSE)
e=predict(u,7,prediction.interval=TRUE)
plot(u,e,col=3)
}
grahe.HoltWinters.lis.expo.simple(seriecampibnominal)
2. Extimations par méthode de lissage non saisonnière de Holt-Winters
HoltWinters.lissage=function(serie)
{
u=HoltWinters(serie,gamma=FALSE)
e=predict(u,7,prediction.interval=TRUE)
return(e)
}

3.3Prévision par lissage exponentiel simple,et lissage non saisonnière de Holt-Winters100
HoltWinters.lissage(seriecampibnominal)
graphe.HoltWinters.lissage=function(serie)
{
u=HoltWinters(serie,gamma=FALSE)
e=predict(u,7,prediction.interval=TRUE)
plot(u,e,col=3)
}
graphe.HoltWinters.lissage(seriecampibnominal)
Prévision du PIB Nominal cas du Gabon
1. Extimations par méthode de lissage exponentiel simple
HoltWinters.lis.expo.simple=function(serie)
{
u=HoltWinters(serie,beta=0,gamma=FALSE)
e=predict(u,7,prediction.interval=TRUE)
return(e)
}
HoltWinters.lis.expo.simple(seriegabonpibnominal)
graphe.HoltWinters.lis.expo.simple=function(serie)
{
u=HoltWinters(serie,beta=0,gamma=FALSE)
e=predict(u,7,prediction.interval=TRUE)
plot(u,e,col=6)
}
graphe.HoltWinters.lis.expo.simple(seriegabonpibnominal)
2. Extimations par méthode de lissage non saisonnière de Holt-Winters

3.3Prévision par lissage exponentiel simple,et lissage non saisonnière de Holt-Winters101
HoltWinters.lissage=function(serie)
{
u=HoltWinters(serie,gamma=FALSE)
e=predict(u,7,prediction.interval=TRUE)
return(e)
}
HoltWinters.lissage(seriegabonpibnominal)
graphe.HoltWinters.lissage=function(serie)
{
u=HoltWinters(serie,gamma=FALSE)
e=predict(u,7,prediction.interval=TRUE)
plot(u,e,col=6)
}
graphe.HoltWinters.lissage(seriegabonpibnominal)
Prévision du PIB Nominal cas du Congo
1. Extimations par méthode de lissage exponentiel simple
HoltWinters.lis.expo.simple=function(serie)
{
u=HoltWinters(serie,beta=0,gamma=FALSE)
e=predict(u,7,prediction.interval=TRUE)
return(e)
}
HoltWinters.lis.expo.simple(seriecongopibnominal)
graphe.HoltWinters.lis.expo.simple=function(serie)
{
u=HoltWinters(serie,beta=0,gamma=FALSE)
e=predict(u,7,prediction.interval=TRUE)
plot(u,e,col=7)

3.3Prévision par lissage exponentiel simple,et lissage non saisonnière de Holt-Winters102
}
graphe.HoltWinters.lis.expo.simple(seriecongopibnominal)
2. Extimations par méthode de lissage non saisonnière de Holt-Winters
HoltWinters.lissage=function(serie)
{
u=HoltWinters(serie,gamma=FALSE)
e=predict(u,7,prediction.interval=TRUE)
return(e)
}
HoltWinters.lissage(seriecongopibnominal)
graphe.HoltWinters.lissage=function(serie)
{
u=HoltWinters(serie,gamma=FALSE)
e=predict(u,7,prediction.interval=TRUE)
plot(u,e,col=7)
}
graphe.HoltWinters.lissage(seriecongopibnominal)
Prévision du PIB Nominal cas du Republique Centrafricaine
1. Extimations par méthode de lissage exponentiel simple
HoltWinters.lis.expo.simple=function(serie)
{
u=HoltWinters(serie,beta=0,gamma=FALSE)
e=predict(u,7,prediction.interval=TRUE)
return(e)
}

3.3Prévision par lissage exponentiel simple,et lissage non saisonnière de Holt-Winters103
HoltWinters.lis.expo.simple(serierecapibnominal)
graphe.HoltWinters.lis.expo.simple=function(serie)
{
u=HoltWinters(serie,beta=0,gamma=FALSE)
e=predict(u,7,prediction.interval=TRUE)
plot(u,e,col=3)
}
graphe.HoltWinters.lis.expo.simple(serierecapibnominal)
2. Extimations par méthode de lissage non saisonnière de Holt-Winters
HoltWinters.lissage=function(serie)
{
u=HoltWinters(serie,gamma=FALSE)
e=predict(u,7,prediction.interval=TRUE)
return(e)
}
HoltWinters.lissage(serierecapibnominal)
graphe.HoltWinters.lissage=function(serie)
{
u=HoltWinters(serie,gamma=FALSE)
e=predict(u,7,prediction.interval=TRUE)
plot(u,e,col=3)
}
graphe.HoltWinters.lissage(serierecapibnominal)
Prévision du PIB Nominal cas de la Guinée Equatoriale
1. Extimations par méthode de lissage exponentiel simple

3.3Prévision par lissage exponentiel simple,et lissage non saisonnière de Holt-Winters104
HoltWinters.lis.expo.simple=function(serie)
{
u=HoltWinters(serie,beta=0,gamma=FALSE)
e=predict(u,7,prediction.interval=TRUE)
return(e)
}
HoltWinters.lis.expo.simple(serieguieqatpibnominal)
graphe.HoltWinters.lis.expo.simple=function(serie)
{
u=HoltWinters(serie,beta=0,gamma=FALSE)
e=predict(u,7,prediction.interval=TRUE)
plot(u,e,col=6)
}
graphe.HoltWinters.lis.expo.simple(serieguieqatpibnominal)
2. Extimations par méthode de lissage non saisonnière de Holt-Winters
HoltWinters.lissage=function(serie)
{
u=HoltWinters(serie,gamma=FALSE)
e=predict(u,7,prediction.interval=TRUE)
return(e)
}
HoltWinters.lissage(serieguieqatpibnominal)
graphe.HoltWinters.lissage=function(serie)
{
u=HoltWinters(serie,gamma=FALSE)

3.3Prévision par lissage exponentiel simple,et lissage non saisonnière de Holt-Winters105
e=predict(u,7,prediction.interval=TRUE)
plot(u,e,col=6)
}
graphe.HoltWinters.lissage(serieguieqatpibnominal)
Prévision du PIB Nominal cas du Tchad
1. Extimations par méthode de lissage exponentiel simple
HoltWinters.lis.expo.simple=function(serie)
{
u=HoltWinters(serie,beta=0,gamma=FALSE)
e=predict(u,7,prediction.interval=TRUE)
return(e)
}
HoltWinters.lis.expo.simple(serietchadpibnominal)
graphe.HoltWinters.lis.expo.simple=function(serie)
{
u=HoltWinters(serie,beta=0,gamma=FALSE)
e=predict(u,7,prediction.interval=TRUE)
plot(u,e,col=7)
}
graphe.HoltWinters.lis.expo.simple(serietchadpibnominal)
2. Extimations par méthode de lissage non saisonnière de Holt-Winters
HoltWinters.lissage=function(serie)
{
u=HoltWinters(serie,gamma=FALSE)
e=predict(u,7,prediction.interval=TRUE)
return(e)

3.3Prévision par lissage exponentiel simple,et lissage non saisonnière de Holt-Winters106
}
HoltWinters.lissage(serietchadpibnominal)
graphe.HoltWinters.lissage=function(serie)
{
u=HoltWinters(serie,gamma=FALSE)
e=predict(u,7,prediction.interval=TRUE)
plot(u,e,col=7)
}
graphe.HoltWinters.lissage(serietchadpibnominal)

Bibliographie
[1] C. GOURIEROUX & A. MONFORT. Cours de séries temporelles : Collectoin �ECO-
NOMIE ET STATISTIQUES AVANCEES� ; Ed.ECONOMICA, 1983.
[2] OLIVIER BLANCHARD & DANIEL COHEN. Macroéconomie : Ed.PEARSON EDU-
CATION, 2003
[3] A.HAMON & N.JEGOU. Statistique Descriptive : Collection�DICDACT STATIS-
TIQUE� ; Ed.PRESSES UNIVERSITAIRE DE RENNES, 2008
[4] YVES ARAGON. Introduction aux séries temporelles, théorie et applications Sep-
tembre 2004.
[5] OUAGNINA HILI. Cours de séries temporelles : Master de mathématique appliquée
option Statistique ENSP de Yaoundé I 2010.
[6] ARTHUR CHARPENTIER. Cours de séries temporelles, théorie et applications :
DESS Atuariat et DESS Mathématiques de la décision.
[7] XAVIER GUIYON. Séries temporelles : Modèles statistiques : Master-2 "Statistiques
appliquées aux sciences du vivant" de l'Université de Cotonou, novembre 2008.
[8] BEAC. Etudes et Statistiques : Numéro 212 Novembre-Décembre 1994.
[9] EMMANUEL PARADIS. R pour les débutants : Août 2002.
Mémoire de Master de Statistique Appliquée. Jacques Le Grand BIYICK ETOGUE c©ENSP 2008-2010





























