Embed Size (px)
Citation preview

PRÉVISION DU NOMBRE DE VOYAGES DEMARCHANDISES EN TRANSIT SUR UN
ITINÉRAIRE AU CAMEROUN
Par:
FOUDA NorbertMaster 1 de Statistique Appliquée
Sous la direction de:
Dr. Eugène-Patrice NDONG NGUEMAChargé de Cours à l’ENSP de Yaoundé
Sous la supervision du:
Pr. Henri GWÉTChef de Département de Mathématiques et Sciences
Physiques à l’ENSP de Yaoundé,Responsable du Master de Statistique Appliquée
Novembre 2012


Dédicaces
i

Remerciements
Je tiens à exprimer toute ma gratitude à toutes les personnes qui ont permis, de prèsou de loin, que nous puissions bénéficier d’une formation d’un niveau si élevé dans un cadreaussi agréable.En particulier, je pense aux :
– Pr AWONO ONANA, Directeur de l’Ecole Nationale Supérieure Polytechnique(ENSP) qui a mis à notre disposition un cadre et des outils de travail stimulants ;
– Pr Henri GWÉT, Chef de Département de Mathématiques et des Sciences Physiquesde l’ENSP, Responsable du Master de Statistique Appliquée, qui a assuré un suivi deproximité tout au long des 2 années de formation à travers l’écoute et la résolution denos problèmes ;
– Dr E.P. NDONG NGUEMA, Chargé de cours à l’ENSP, pour la qualité de sesenseignements et de l’encadrement dont j’ai bénéficié tout au long de mon stage ;
– à tous les professionnnels du domaine des Douanes qui ont oeuvré à la production dece mémoire, en particulier M. LIBII LIBII Paul Olivier, Inspecteur des Douanesen poste au Secteur du Sud Ouest, pour les critiques et suggestions qu’il a apportéesà ce travail et les échanges enrichissantes que nous avions entretenus ;
– à tous ceux qui ont eu à enseigner, à disposer de leur précieux temps, à mettre à ladisposition du MASTAT des cours ou quelque facilités que ce soit trouvent ici l’expres-sion de ma profonde gratitude ;
– à tous mes camarades du Master en Statistique, pour la convivialité, la sympathieet la joie des fréquentations quotidiennes qui ont rendu digestes les 2 années passéesensemble, un temps finalement bref, mais plein de souvenirs inoubliables.
ii

Table des matières
Dédicaces i
Remerciements ii
Table des matières iii
Liste des figures iv
Liste des tableaux v
Abréviations vi
Glossaire des termes techniques vii
Avant-propos viii
Résumé x
Abstract xi
Résumé exécutif xii
Introduction 1
1 Contexte, présentation et traitement des données 21 Cadre de l’étude . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.1 Situation de la Douane Camerounaise . . . . . . . . . . . . . . . . . . 21.2 Rôle de la Douane en matière de transit des marchandises . . . . . . 31.3 Problèmes rencontrés . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2 Présentation des données . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42.1 Observation de départ . . . . . . . . . . . . . . . . . . . . . . . . . . 52.2 Informations collectées . . . . . . . . . . . . . . . . . . . . . . . . . . 6
iii

TABLE DES MATIÈRES iv
2.3 Problèmes rencontrés sur les données . . . . . . . . . . . . . . . . . . 73 Traitement des données . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
3.1 Gestion des données manquantes . . . . . . . . . . . . . . . . . . . . 83.2 Découpage des itinéraires . . . . . . . . . . . . . . . . . . . . . . . . . 83.3 Configuration des prédictions temporelles . . . . . . . . . . . . . . . . 9
2 Exploration des voyages de marchandises en transit au Cameroun 131 Bureaux de départ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
1.1 Répartition des voyages par guichet de départ . . . . . . . . . . . . . 141.2 Caractéristiques du guichet de départ par itinéraire . . . . . . . . . . 15
2 Bureau frontière . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 152.1 Présentation des guichets frontières . . . . . . . . . . . . . . . . . . . 152.2 Caractéristiques des guichets frontières par itinéraire . . . . . . . . . 17
3 Date de départ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 173.1 Présentation des dates de départ des transits . . . . . . . . . . . . . . 173.2 Caractéristiques des dates de départ par itinéraire . . . . . . . . . . . 17
4 Date d’arrivée . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 184.1 Étude conjointe des dates de départ et d’arrivée . . . . . . . . . . . . 18
5 Durée du transit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
3 Fondements théoriques et outils 201 Généralités sur les séries chronologiques . . . . . . . . . . . . . . . . . . . . . 20
1.1 Définitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 201.2 Objectifs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 201.3 Présentation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
2 Décomposition d’une série chronologique . . . . . . . . . . . . . . . . . . . . 212.1 Composantes d’une série chronologique . . . . . . . . . . . . . . . . . 212.2 Modèles de décomposition déterministes . . . . . . . . . . . . . . . . 222.3 Choix du modèle de décomposition . . . . . . . . . . . . . . . . . . . 222.4 Estimation des composantes . . . . . . . . . . . . . . . . . . . . . . . 232.5 Prévision . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
3 Méthode de BOX & JENKINS . . . . . . . . . . . . . . . . . . . . . . . . . . 254 PROCESSUS LINEAIRE . . . . . . . . . . . . . . . . . . . . . . . . . . . . 275 Processus auto-regressifs(AR) . . . . . . . . . . . . . . . . . . . . . . . . . . 276 Processus MA et ARMA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
6.1 Processus autorégressif et à moyenne mobile (A.R.M.A.) . . . . . . . 286.2 Introduction aux modèles ARIMA . . . . . . . . . . . . . . . . . . . . 286.3 La méthodologie de Box et Jenkins . . . . . . . . . . . . . . . . . . . 30
7 Qualité de la prévision . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
Mémoire de Master de Statistique Appliquée. FOUDA Norbert © ENSP 2010-2012

TABLE DES MATIÈRES v
4 Application, analyse et résultats 351 Description des séries des observations par itinéraire . . . . . . . . . . . . . . 35
1.1 Chronogramme du nombre de voyages hebdomadaires sur l’itinéraire 1 351.2 Chronogramme du nombre de voyages hebdomadaires sur l’itinéraire
2 et l’itinéraire 3 respectivement . . . . . . . . . . . . . . . . . . . . . 361.3 Chronogramme du nombre de voyages hebdomadaires sur l’itinéraire
4 et l’itinéraire 5 respectivement . . . . . . . . . . . . . . . . . . . . . 371.4 Chronogramme du nombre de voyages hebdomadaires sur l’itinéraire
6 et l’itinéraire 7 respectivement . . . . . . . . . . . . . . . . . . . . . 381.5 Résumé du nombre de voyages sur les différents itinéraires . . . . . . 40
2 Estimation des composantes des séries du nombre hebdomadaire de voyagessur l’itinéraire 1 et l’itinéraire 5 . . . . . . . . . . . . . . . . . . . . . . . . . 412.1 Estimation de la tendance générale des séries . . . . . . . . . . . . . . 412.2 Estimation de la saisonnalité des séries : itiner1 et itiner5 . . . . . . . 44
3 Modélisation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 493.1 Expression du modèle . . . . . . . . . . . . . . . . . . . . . . . . . . 493.2 Prédiction de la partie déterministe . . . . . . . . . . . . . . . . . . . 493.3 Méthode de prévision bootstrap . . . . . . . . . . . . . . . . . . . . . 503.4 Valeurs des prévisions déterministes sur les 2 prochains mois . . . . . 50
Conclusion 51
Annexes 52
Bibliographie 64
Mémoire de Master de Statistique Appliquée. FOUDA Norbert © ENSP 2010-2012

Table des figures
2.1 Effectif par guichet . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 142.2 Liaison entre les dates d’arrivée et de départ . . . . . . . . . . . . . . . . . . 192.3 Résidu de la liaison date arrivée-départ . . . . . . . . . . . . . . . . . . . . . 19
4.1 Évolution du nombre de voyages hebdomadaires sur l’itinéraire 1 . . . . . . . 354.2 Évolution du nombre de voyages hebdomadaires sur l’itinéraire 2 et l’itinéraire
3 respectivement . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 364.3 Évolution du nombre de voyages hebdomadaires sur l’itinéraire 4 et l’itinéraire
5 respectivement . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 374.4 Évolution du nombre de voyages hebdomadaires sur l’itinéraire 6 et l’itinéraire
7 respectivement . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 384.5 Évolution du nombre de voyages hebdomadaires sur l’itinéraire 1 (à gauche),
accompagnée de sa tendance (en pointillée) ; à droite, c’est celle de l’itinéraire 5 44
vi

Liste des tableaux
1.1 Liaison des 2 principaux corridors . . . . . . . . . . . . . . . . . . . . . . . . 31.2 Taux de réduction des marchandises en transit au Cameroun . . . . . . . . . 31.3 Présentation d’une partie des données du travail . . . . . . . . . . . . . . . . 51.4 Variables du jeu de données . . . . . . . . . . . . . . . . . . . . . . . . . . . 61.5 Effectif des données manquantes par variable . . . . . . . . . . . . . . . . . . 71.6 Présentation des itinéraires . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.1 Situation des guichets de départ . . . . . . . . . . . . . . . . . . . . . . . . . 152.2 Nombre de voyages enregistré par bureau frontière . . . . . . . . . . . . . . . 162.3 Découpage du nombre de voyages par bureau frontière . . . . . . . . . . . . 172.4 Période des voyages par itinéraire . . . . . . . . . . . . . . . . . . . . . . . . 18
3.1 Décomposition d’une série chronologique . . . . . . . . . . . . . . . . . . . . 213.2 Présentation des modèles de composition . . . . . . . . . . . . . . . . . . . . 223.3 Variation saisonnière et coefficients saisonniers . . . . . . . . . . . . . . . . . 24
4.1 Paramètres de position par itinéraire . . . . . . . . . . . . . . . . . . . . . . 404.2 Paramètres de dispersion par itinéraire . . . . . . . . . . . . . . . . . . . . . 414.3 Résumé de l’estimation de la tendance générale de la série itiner1 . . . . . . 424.4 Disposition des résidus de la régression de la série itiner1 . . . . . . . . . . . 424.5 Résumé de l’estimation de la tendance générale de la série itiner5 . . . . . . 434.6 Disposition des résidus de la régression de la série itiner5 . . . . . . . . . . . 434.7 Tendance bootstrap et intervalle de confiance de l’itinéraire 1 . . . . . . . . . 434.8 Tendance bootstrap et intervalle de confiance de l’itinéraire 5 . . . . . . . . . 444.9 Estimation des coefficients saisonniers centrés des séries itiner1 et itiner5 . . 464.10 Coefficients saisonniers bootstrap de l’itinéraire 1 . . . . . . . . . . . . . . . 474.11 Coefficients saisonniers bootstrap de l’itinéraire 5 . . . . . . . . . . . . . . . 484.12 Situation du bureau CMCLB . . . . . . . . . . . . . . . . . . . . . . . . . . 524.13 Situation du bureau CMDLP . . . . . . . . . . . . . . . . . . . . . . . . . . 534.14 Situation du bureau CMDLP (suite) . . . . . . . . . . . . . . . . . . . . . . 54
vii

LISTE DES TABLEAUX viii
4.15 Situation du bureau CMNDR . . . . . . . . . . . . . . . . . . . . . . . . . . 54
Mémoire de Master de Statistique Appliquée. FOUDA Norbert © ENSP 2010-2012

Abréviations
CEMAC : Communauté Economique et Monétaire de l’Afrique CentraleCNUCED : Conférence des Nations Unies pour le Commerce et le DéveloppementSYDONIA : Système Douanier Informatisé
ix

Glossaire des termes techniques
x

Avant-propos
Le Master de Statistique est une formation de 3e cycle ouverte cette année 2004 à l’Uni-versité de Yaoundé I. Il s’agit d’une formation professionnalisante et d’initiation à la re-cherche, qui bénéficie de la collaboration et du soutien de plusieurs institutions Françaiseset Africaines (Universités de Paris Orsay, Paris 5, Versailles, Paris Dauphine, l’INSERM,l’Université de Cocody et l’institut National Polytechnique de Côte d’Ivoire).
Son objectif général est de donner aux étudiants, cadres supérieurs d’entreprise et d’ad-ministration, et tout utilisateur de la statistique, une formation de haut niveau très pratique,classique quant aux techniques mathématiques utilisées, aussi moderne que possible, quantà l’informatique et aux logiciels spécialisés utilisés. Le Master apporte aux étudiants ayantles acquis fondamentaux en mathématiques et en statistique, une formation professionnellecomplémentaire dans le domaine du traitement de l’information et de son exploitation.
L’admission au Master de statistique se fait sur étude de dossiers. Pour la premièreannée, sont admissibles les personnes titulaires d’une licence de mathématiques ou d’un di-plôme jugé équivalent, et pour la deuxième année, les personnes titulaires d’une maîtrise demathématiques ou d’un diplôme jugé équivalent. Le recrutement est étendu aux médecins,agronomes et biologistes. Ces derniers suivent des cours de mise à niveau en mathématiqueset en statistique.
Dans le souci de permettre aux étudiants de mettre en pratique les connaissances ac-quises tout au long de la formation, il leur est demandé d’effectuer un stage académiqued’une durée de trois à six mois en entreprise. Ce stage consiste pour l’étudiant, à apporterune contribution à la résolution des problèmes statistiques auxquels l’entreprise est confron-tée. Le respect de cette déontologie nous a conduit de juillet à septembre 2012, à effectuerun stage au Laboratoire des Mathématiques Appliquées de l’ENSP sous l’encadrement duDr E.P. NDONG NGUEMA. Notre cahier de charge était axé essentiellement sur laprévision du nombre de voyages de cargaisons en transit au Cameroun suivant un découpageque nous avons préalablement fait.
xi

AVANT-PROPOS xii
Le déroulement de ces travaux a été fait sur la base de certaines hypothèses. Citons endeux exemples. La première hypothèse, d’ordre pratique, est de considérer sept itinérairesservant au transit tout au long de l’étude. Et la deuxième, d’ordre théorique, est de considérerla période de la saisonnalité, p = 17 semaines sur chaque itinéraire, résultat que nous tenonsde l’étude menée, à partir de telles données, sur l’étendue du territoire national, par DrE.P. NDONG NGUEMA. Nous vous sommes reconnaissant de nous faire parvenir lesinsuffisances que pourrait présenter ce travail et nous vous invitons à formuler les critiqueset suggestions, à l’adresse mail : [email protected], en vu de l’améliorer.
Mémoire de Master de Statistique Appliquée. FOUDA Norbert © ENSP 2010-2012

Résumé
La prévision du nombre de voyages de marchandises en transit au Cameroun est unproblème de premier plan pour la Douane camerounaise. En effet, la connaissance a prioride ce nombre viendrait clarifier les Responsables de la Douane sur les questions de gestionet de planification de leurs différentes ressources d’une part, et, d’autre part, la connaissanceà priori de ce nombre offrirait une vision sur les recettes douanières à venir. L’approchepour résoudre ce problème consiste à préciser un itinéraire, défini uniquement sur la basedu guichet de départ et celui d’arrivé qui sont les mêmes, et ensuite d’effectuer la prévisionselon le modèle de décomposition "tendance + saisonnalité + résidu" d’une série temporelle.L’itinéraire considéré dans cette étude est constitué des voyages partant du guichet CMDLPet arrivant au guichet frontière CMGBL|CFBGF. Du 06 septembre 2010 au 31 décembre2011, les voyages sur cet itinéraire sont au nombre de 7546. Et sur les trois mois à venir oùil est question d’effectuer une prévision, l’étude anticipe :
– 464 voyages pour le mois de janvier 2012 variant dans l’intervalle [273, 671],– 537 voyages pour le mois de fevrier 2012 avec un intervalle de confiance de [541, 745],– et le mois de mars 2012 est anoncé avec 522 voyages compris dans un intervalle de
confiance de [326, 726].Outre la prévision proprement dite effectuée dans cette étude, l’intérêt peut être signalé surl’application des méthodes de prévision sur une série ayant au départ peu d’observations etde saisonnalité inconnue.
xiii

Abstract
The prediction of the number of trips of goods in transit in Cameroon is a problem tothe Cameroon Customs. In effect, the prior knowledge of this number will help clarify theauthorities of the Cameroon Customs on management questions and planification of theirdifferent resources on one hand, and on the other hand, the prior knowledge of this num-ber will offer a vision on the customs futur recipes. The approach to solve this problemconsists of precising an itinerary, defined uniquely on the basis of the teller at the startingpoint and that at the point of arrival which are the same, and hence, carry out predic-tions to using time series methods of prediction. The itinerary considered in this work isconstituted of trips starting from teller CMDLP to teller CMGBL|CFBGF. From the 6th ofseptember 2010 to the 31st december 2011, the trips on this itinerary were 7546 in number.In the next 3 months where there is a question of carrying out a prediction, the study shows :
– 464 trips for the month of january 2012 varying in the interval [273, 671],– 537 trips for the month of february 2012 with a ask confidence interval [541, 745],– and the month of march 2012 is announced with 522 trips defined in the confidence
interval [326, 726].Appart from the prediction carried out in this study, interest can be pointed out on
the application of prediction methods on a series having at the beginnig a small number ofobservations and unknown saisonality.
xiv

Résumé exécutif
Le résumé exécutif...
xv

RÉSUMÉ EXÉCUTIF xvi
Mémoire de Master de Statistique Appliquée. FOUDA Norbert © ENSP 2010-2012

Introduction
Les échanges internationaux, clé de voûte de la mondialisation, sont effectués par presquetous les pays du globe terrestre. Vivre de nos jours, sans avoir besoin des biens et services del’autre, apparaît indéniablement comme un fait impossible. Dans ce climat d’interdépendanceavéré, les pays sous développés payent un fort prix. Le Cameroun, de par sa position de paysde transit grâce à sa façade sur l’océan atlantique et partageant ses frontières avec deux paysenclavés, de par la part des recettes douanières dans le budget de l’État estimée à 33% selonle GUIDE DE LA DOUANE, se doit de protéger son espace économique tout en assurantla sécurité des marchandises en transit sur son territoire. Pour assurer un fonctionnementefficace du système douanier, la douane a mis sur pied un système permettant, entre autres,de collecter des données de voyages de transit, de suivre le mouvement des marchandises dèsleur départ au port jusqu’à la frontière du pays de destination à l’aide du "Global PositioningSystem"(GPS). Se souciant d’équiper chaque voyage d’un GPS, la douane voudrait prévoirà court terme le nombre de voyages nécessitant ce dispositif. L’étude que voici se propose deprévoir, sur un horizon de deux mois, le nombre de voyages de marchandises en transit sur leterritoire national suivant un itinéraire. De cette façon, la part des recettes douanières dans lebudget de l’État qui sont estimées au tiers, sera sécurisée. Mais aussi la position déterminantequ’occupent la Douane dans la politique économique du pays sera maintenue. Pour ressortircette information stratégique, élément important tant pour la Douane camerounaise quepour les pays voisins destinataires des dites marchandises, aussi bien pour les transitairesque pour les particuliers pouvant s’investir dans le transit, cette étude se déroulera en quatretemps. Elle commencera par présenter le contexte, les données et le traitement de celles-ci.Ensuite suivra l’exploration des données. Après, il sera question de ressortir les outils et lathéorie qui serviront concrètement à la prévision. L’étude s’achèvera par l’application desoutils et méthodes ci-dessus assortie des résultats.
1

Chapitre 1
Contexte, présentation ettraitement des données
1 Cadre de l’étude
Le service de l’Administration publique chargé de percevoir les taxes sur l’entrée et lasortie des marchandises et d’empêcher les importations ou les exportations prohibées, nomméDouane, est le domaine dans lequel porte notre travail.
1.1 Situation de la Douane Camerounaise
Le Cameroun est limitrophe de deux pays sans littoral : la Centrafrique et le Tchad. Et depar sa position géographique, avec une façade sur l’Océan Atlantique, il sert au passage desmarchandises à destination de ces deux pays enclavés. Il se présente donc comme un exempletypique de pays en développement concerné par les enjeux de la facilitation des échanges. Lamise en place d’un système de transit régional s’appuyant principalement sur les 2 corridorsDouala-Bangui (pour la Centrafrique) et Douala-Ndjamena (pour le Tchad), parsemé pardes points de contrôle (check points) aux missions bien définies et situés à des points fixes,concourt à la facilitation des échanges. Le tableau 1.1 montre les distances parcourues sur leterritoire camerounais associées au mode de transport utilisés.
2

Contexte, présentation et traitement des données 3
Tab. 1.1 – Liaison des 2 principaux corridorsRoute Chemin de fer
Corridor CentrafriqueDouala – Bangui 1500 Km
Douala – Ngaoundéré – Bangui 867 Km 922 KmDouala – Belabo – Bangui 670 Km
Corridor TchadDouala –N’Djamena 2100 Km
Douala – Ngaoundéré 750 Km 922 KmNgaoundéré -N’Djamena 1350 Km
Les marchandises en transit au Cameroun, destinées au Tchad ou à la Centrafrique,bénéficient des réductions des taxes considérables. Les réductions appliquées sur les différentsservices dont elles bénéficient, sont consignées dans le tableau 1.2.
Tab. 1.2 – Taux de réduction des marchandises en transit au CamerounDésignation de la réduction Taux de réduction
taxes de chargement et déchargement 50%manutention à terre à l’importation 25%tarifs de manutention à terre à l’exportation 50%tarifs de stationnement des marchandises en entrepôts 75%
La particularité du statut de ces marchandises ne pourraît-elle pas susciter chez les autresusagers de la Douane des idées allant dans le sens de chercher à bénéficier de cette préroga-tive ? D’où la quasi certitude de faux voyages de marchandises déclarées en transit, mais enfait, destinées au territoire camerounais.
1.2 Rôle de la Douane en matière de transit des marchandises
L’une des principales missions de l’Administration de la Douane est la protection del’espace économique. Dans cette perspective, la douane doit s’assurer que toutes les mar-chandises introduites sur le marché national s’acquitent régulièrement de leurs droits ettaxes. Aussi, les marchandises déclarées sous un régime suspensif des droits et taxes tel quele transit doivent être suivies jusqu’à leur sortie du territoire afin de s’assurer qu’elles ne se-ront pas frauduleusement reversées sur le marché national. Et c’est pour garantir la fiabilitéde cette opération du suivi que la Douane Camerounaise a mis sur en place le Système deGéolocalisation des cargaisons en transit (GPS) évoqué supra.
Mémoire de Master de Statistique Appliquée. FOUDA Norbert © ENSP 2010-2012

Contexte, présentation et traitement des données 4
Bien que ce rôle demeurera en grande partie le même, les responsabilités liées aux mou-vements internationaux de marchandises se sont élargies et continueront de s’étendre, allantdu rôle traditionnel de recouvrement des droits et taxes dont sont passibles les marchan-dises en trafic international pour alimenter le Trésor Public, aussi l’exécution de contrôleset d’activités répondant à une série d’objectifs plus vaste du gouvernement. La raison pourlaquelle la douane sera appelée à jouer un rôle élargi résulte du fait que les marchandisesqui traversent les frontières sont soumises au contrôle de la douane, de la somme des com-pétences et des qualifications spécialisées présentes dans la douane et qui sont requises pourassurer ces tâches et du savoir-faire dont la douane dispose dans les domaines du commerceinternational, des chaînes logistiques et des entreprises. Les Administrations des Douanes negèrent pas uniquement les échanges, mais possèdent également le savoir-faire et le position-nement uniques pour gérer les crises liées aux mouvements transfrontaliers de marchandises.Au regard de ces exigences, n’est-il pas indiqué de savoir si cette douane rencontre desdifficultés ?
1.3 Problèmes rencontrés
En 2002, l’Organisation Mondiale des Douanes (OMD), a entamé une réflexion sur lesprincipales questions qui auront une incidence sur le fonctionnement efficace et rentable desdouanes à l’avenir. Au cours des huit premières années du 21ème siècle, la douane a dû faireface à des demandes considérables, et parfois contradictoires, découlant de la mondialisationdes échanges. D’une part, il est apparu nécessaire de sécuriser et de contrôler effectivementles chaînes logistiques internationales alors que, d’autre part, les demandes en vue de faciliterdavantage les échanges légitimes se faisaient de plus en plus pressantes. L’élaboration d’unmodèle aux fins de la gestion des échanges et des frontières, avoir une meilleure connaissancepar la douane des chaînes logistiques et de leur gestion, permettront à la douane de protégerles intérêts fiscaux et financiers de l’État, de protéger les économies nationales contre lesmouvements illicites de marchandises, de soutenir le système commercial international enassurant des règles de jeu équitables pour toutes les entreprises, de faciliter le commercelégitime et de protéger la société. Le cadre de cette étude étant ainsi présenté, partant dela situation de la douane camerounaise aux problèmes qu’elle rencontre, en passant par lesobjectifs à elle assignés, nous passons à la présentation des données nécessitant une analysestatistique visant à répondre à la problématique.
2 Présentation des données
Les données de cette étude ont été collectées pendant la période allant du 06 septembre2010 au 31 décembre 2012 à l’aide de SYDONIA (Système Douanier Informatisé). Installé
Mémoire de Master de Statistique Appliquée. FOUDA Norbert © ENSP 2010-2012
Contexte, présentation et traitement des données 5
dans plus de 80 pays sur tous les continents, SYDONIA (Asycuda dans sa version anglo-phone) est un logiciel de la Conférence des Nations unies pour le Commerce et le Dévelop-pement (CNUCED) qui gère la chaîne de dédouanement depuis l’arrivée des cargaisons, parvoies terrestre, maritime ou aérienne, jusqu’à leur libération du contrôle douanier. SYDO-NIA traite les manifestes, les déclarations en douane, le paiement, la sortie des marchandises,suivant un système modulaire qui permet aux pays de n’automatiser que quelques segmentsde la procédure ou son intégralité comme au Cameroun notamment.
À l’origine de ce développement, en 1981, l’objectif était de produire des statistiques ducommerce extérieur. Il s’est avéré que la production de statistiques fiables passait par leursaisie directe au moment du passage en douane. Par la suite, à la demande des pays, laCNUCED a développé plus spécifiquement les fonctionnalités douanières. Actuellement, laplupart des pays utilisent SYDONIA++ (la troisième version) qui supporte une architectureclient/serveur sous Oracle et Linux notamment. La dernière version, Sydonia World, proposeune plate-forme utilisant des outils récents tels que Java et améliore des fonctionnalités dontle transit des marchandises. L’installation de SYDONIA favorise la communication entre tousles acteurs (douanes, professionnels du dédouanement, compagnies maritimes et aériennes,Trésor, banques) en même temps qu’il leur propose des procédures normalisées au niveauinternational. Utilisé au Cameroun depuis janvier 2007, SYDONIA couvre la mise en placedu système de transit régional s’appuyant principalement sur les corridors Douala-Bangui etDouala-Ndjamena. La présente partie pose un regard sur quelques données produites par cesystème.
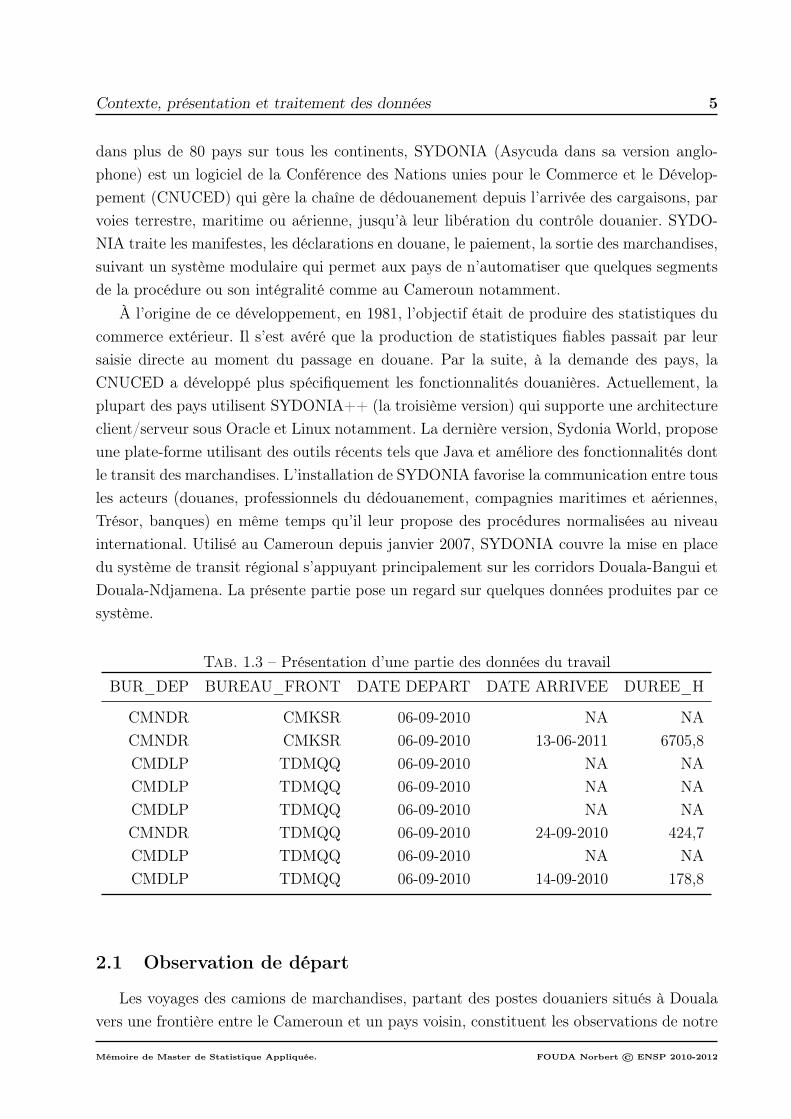
Tab. 1.3 – Présentation d’une partie des données du travailBUR_DEP BUREAU_FRONT DATE DEPART DATE ARRIVEE DUREE_H
CMNDR CMKSR 06-09-2010 NA NACMNDR CMKSR 06-09-2010 13-06-2011 6705,8CMDLP TDMQQ 06-09-2010 NA NACMDLP TDMQQ 06-09-2010 NA NACMDLP TDMQQ 06-09-2010 NA NACMNDR TDMQQ 06-09-2010 24-09-2010 424,7CMDLP TDMQQ 06-09-2010 NA NACMDLP TDMQQ 06-09-2010 14-09-2010 178,8
2.1 Observation de départ
Les voyages des camions de marchandises, partant des postes douaniers situés à Doualavers une frontière entre le Cameroun et un pays voisin, constituent les observations de notre
Mémoire de Master de Statistique Appliquée. FOUDA Norbert © ENSP 2010-2012

Contexte, présentation et traitement des données 6
jeu de données. Elles sont regroupées dans un fichier de 42606 lignes et 5 colonnes. Chaqueligne correspond à un voyage de marchandises en transit au Cameroun entre le 06 septembre2010 et le 31 décembre 2011, et chaque colonne est une variable observée sur chacun de cesvoyages. Le tableau 1.3 montre le début de ce fichier. Les observations sont portées sur laligne indiquant le voyage. Ainsi, nous avons comme individu ou unité statistique
i : un voyage d’un véhicule de marchandises en transit au Cameroun partant deDouala, jusqu’à une frontière pendant cette période.
Au total, le jeu de données contient 42 606 voyages enregistrés, représentant le flux detransit de marchandises supposées partir de Douala jusqu’aux frontières, durant la périodedu 06 septembre 2010 au 31 décembre 2012. Pour chacun de ces voyages, un certain typed’informations nous sont utiles pour prédire à court terme le volume de transit dans le mêmesens.
2.2 Informations collectées
Les informations recueillies sur chaque voyage dans notre jeu de données sont principa-lement :
– le nom du bureau de départ ;– le nom du bureau d’arrivée ;– la date de départ ;– la date d’arrivée ;– et la durée du voyage qui est fonction de la date de départ et d’arrivée.
À côté de ces informations, il y a aussi le numéro du voyage qui sert d’identifiant. Celui-ci aété retiré du tableau 1.3.
Le tableau de données est donc constitué de 5 variables, présentées dans le tableau 1.4.
Tab. 1.4 – Variables du jeu de donnéesVariable Description Type
BUR_DEP Bureau du départ du voyage QualitativeBUREAU_FRONT Bureau frontalier d’arrivée Qualitative
DATE DEPART Jour de départ du port de Douala Quantitative discrèteDATE ARRIVEE Jour d’arrivée au poste frontalier Quantitative discrète
DUREE_H Durée de la traversée du pays Quantitative continue
L’entrée des marchandises en transit sur le territoire national est donnée par la variablebureau de départ. Le transit prend fin sur la base de l’information donnée par la variablebureau frontière, et c’est à ce niveau que le transit est considéré comme réalisé.
Mémoire de Master de Statistique Appliquée. FOUDA Norbert © ENSP 2010-2012

Contexte, présentation et traitement des données 7
Aussi, les dates de départ et d’arrivée nous situent-elles sur le jour, par rapport à l’axedu temps, du passage des marchandises aux bureaux de départ et d’arrivée. Quant à la duréedu voyage, c’est le temps mis par un véhicule pour traverser le pays.
Ainsi, pour chaque voyage de marchandises en transit au Cameroun, partant de Doualavers un pays voisin, on est censé connaître les informations listées ci-dessus. Mais à côté deces attentes, notre jeu de données est loin d’être parfait. Non seulement certains voyages ontdes données manquantes, mais en plus il renferme certaines incohérences qui nous posentproblème.
2.3 Problèmes rencontrés sur les données
Les problèmes rencontrés dans nos données se regroupent en 2 catégories :– les voyages avec donnée(s) manquante(s) au nombre de : 1142 ;– les voyages avec donnée(s) incohérente(s) au nombre de : 12.
Les incohérences soulignées dans nos données portent essentiellement sur le fait que l’on aitune date d’arrivée antérieure à la date de départ. Les données aberrantes relatives à une duréede voyages exagérée n’ont pas explicitement fait partie des incohérences, faute d’informationsur la qualité des tronçons et des tranches des durées de référence.La proportion des donnéesmanquantes se chiffre à 2,7%. Le bilan des données manquantes, par variable, est résumédans le tableau 1.5.
Tab. 1.5 – Effectif des données manquantes par variableVariable Effectif Pourcentage
Bureau de départ 4 0.0%Bureau d’arrivée 2 0.0%
Date de départ 0 0%Date d’arrivée 1139 0.03%
Durée du trajet 1139 0.03%
Afin de mener à bien notre étude et d’obtenir des résultats fiables, il est impératif deprocéder à un traitement minutieux des données. La section ci-dessous révèle l’approcheadoptée dans le traitement de nos données.
3 Traitement des données
La collecte des données de cette étude n’a pas, à première vue, intégré les objectifs de laprésente étude. Le traitement de celles-ci consistera à déterminer les critères d’éligibilité quipermettront à certaines observations, de servir de support pour notre étude.
Mémoire de Master de Statistique Appliquée. FOUDA Norbert © ENSP 2010-2012

Contexte, présentation et traitement des données 8
3.1 Gestion des données manquantes
Le travail dont il est question consiste à prévoir le nombre de voyages de camions de mar-chandises qui partent de Douala à une frontière du pays afin de mieux apprêter la logistiquenécessaire pour l’acheminement à bon port de ces marchandises. Pour ce faire, nous avonsà notre disposition les dates des voyages, les points de départ et d’arrivée de ces voyages.Rappelons aussi que le transit est effectué au moment où nous sommes sûrs que les marchan-dises ont réellement traversé le Cameroun. Le cas échéant, il n’est pas judicieux de considérerces dernières comme ayant transité par le Cameroun. Ceci dit, nous ne saurons garder dansnotre étude les voyages qui n’ont pas de bureau de départ, encore moins de bureau d’arrivée.
Quant aux dates, leur importance vient du fait que la prévision que nous nous proposonsde faire est fonction du temps qui, dans ce cas, est donné par la date. Les voyages n’ayant pasde dates de départ sont, de ce fait, très embarrassants, et donnent lieu à plusieurs interpré-tations. Nous les mettrons de côté du fait du manque d’informations complémentaires pourprocéder à leur imputation. Les dates d’arrivée manquantes peuvent par contre être impu-tées, en les situant sur un itinéraire via le bureau de départ et celui d’arrivée et moyennantla fréquence des durées de voyages de la tranche de la période considérée. Dans notre cas, lecentre d’intérêt porte sur les voyages en transit à partir de leurs dates de départ. Cependant,les voyages n’ayant pas de dates d’arrivées seront simplement mis de côté puisqu’ils sont enfaible proportion. De même pour ce qui est des voyages avec données incohérentes.
3.2 Découpage des itinéraires
En formulant les hypothèses :– la fréquence des voyages est fonction de l’itinéraire à prendre ;– les camions de transport sont identiques, toutes choses étant égales par ailleurs.Il ressort que prévoir le nombre de voyages en transit à un moment donné revient à le
prévoir sur chaque itinéraire et sommer ceux-ci. De ce fait, qu’entend-t-on par itinéraire etquels sont nos différents itinéraires ? On entend par itinéraire, le chemin parcouru pour relierun bureau de départ et un bureau d’arrivée. Dans notre jeu de données, nous n’avons quele bureau de départ et le bureau frontière de chaque voyage, et non le chemin suivi. Nousconsidérerons donc comme voyage ayant pris le même itinéraire, l’ensemble des voyages ayantle même bureau de départ et le même bureau frontière. Vu sous cet angle, nous aurons droità 62 itinéraires, conformément au nombre de bureaux frontières existant durant la périodede collecte des données.
Notre jeu de données renferme 4 itinéraires principaux contenant un nombre de voyagesconsidérables selon la considération de l’itinéraire faite ci-dessus. Aussi, suivant la colorationque le reste des voyages présentait, avons nous construit 3 groupes assez homogènes etassimilé chacun de ces groupes à un itinéraire. Ce qui, dans l’ensemble, propulse le nombre
Mémoire de Master de Statistique Appliquée. FOUDA Norbert © ENSP 2010-2012

Contexte, présentation et traitement des données 9
d’itinéraires à 7 dont les informations utiles sont contenues dans le tableau 1.6.
Tab. 1.6 – Présentation des itinérairesItinéraires Bureaux de départ Bureaux d’arrivée Nombre de voyages
itiner_1 CMNDR CMTBR|CMTBR 8308itiner_2 CMDLP CMGBL|CFBGF 7546itiner_3 CMNDR CMKSR|CMKSR 7194itiner_4 CMDLP CMKSR|TDNDJ 4711itiner_5 CMCLB quelconque 5752itiner_6 CMDLP CMTBR|... 5634itiner_7 CMNDR ou CMDLP Reste des bureaux 2321
TOTAL 41466
Les itinéraires tels que présentés ne renferment pas de voyages avec données manquantes.Donc nous sommes déjà en possession de données réellement exploitables pour notre étude.Étant donné notre objectif qui est de prévoir le nombre de voyages à un moment ultérieu-rement proche, il nous faut, en plus, organiser ces données telles que les techniques desprévisions temporelles le voudraient.
3.3 Configuration des prédictions temporelles
Les prédictions temporelles, comme le nom l’indique, ont pour objectif de prédire laréalisation d’un évènement dans un temps futur. Cet évènement pourra être de type qualitatifou quantitatif ; qualitatif dans la mesure où on voudrait par exemple savoir s’il ferait beautemps à Yaoundé la prochaine fois que le 28 décembre sera un vendredi. Généralement, onrencontre dans la littérature des prévisions de type quantitatif. Néanmoins, quelque soitle type de prévision qu’on veuille faire, on doit déjà avoir eu à observer sur un temps,de préférence long, le phénomène en question, ou être capable de se prononcer sur desphénomènes connexes au problème afin de déduire notre prévision. Bien évidemment, l’étudene sera intéressante que si le phénomène à prédire varie au cours du temps.
Structuration de l’information
L’objectif du présent travail, celui de réaliser la prévision du nombre de voyages demarchandises en transit au Cameroun, nous impose d’avoir déjà eu à observer au mieux cetype de voyages sur un certain temps. Le phénomène que nous observons ici et qui varie aucours du temps, mathématiquement appelé variable aléatoire, est le nombre de voyages dece type en fonction du temps. Notons le X.
Pour définir formellement X, considérons l’espace probabilisé fini (Ω,A, p) où :
Mémoire de Master de Statistique Appliquée. FOUDA Norbert © ENSP 2010-2012

Contexte, présentation et traitement des données 10
Ω ≡ ensemble des dates du 06 septembre 2010 au 31 décembre 2011,
A = P(Ω) est la tribu discrète sur Ω,
p : A −→ [0, 1] est une probabilité sur (Ω,A).
Ainsi,
X : (Ω,A) −→ (R,BR)
A 7−→ X(A)
est l’application qui, pour tout sous ensemble de dates de Ω, compte le nombre total devoyages réalisé par ce sous ensemble.
Revenons un instant sur la construction de Ω, numérotons les jours à partir du 1er janvierde l’an 2010.
Le 01 janvier 2010 −→ 1 (jour 1),
le 02 janvier 2010 −→ 2 (jour 2),...
le 31 décembre 2011 −→ 730 (jour 730)
Ainsi, Ω tel que définit plus haut équivaut à :
Ω = 249, 250, . . . , 730.
Définissons les applications :
f : Ω −→ T
x 7−→ f(x) =
⌈x− 248
7
⌉où :
dxe est le plus petit entier supérieur ou égal à x,
T = 1, 2, . . . , 69 est l’ensemble des temps d’observation ;
g : T −→ A7ord ⊂ A
t 7−→ At =
x ∈ Ω/t =
⌈x− 248
7
⌉où :
At est la semaine numéro t,
A7ord = A1, A2, . . . , A69 est l’ensemble des semaines d’observations ordonnées
dans le temps.
C’est-à-dire :
Mémoire de Master de Statistique Appliquée. FOUDA Norbert © ENSP 2010-2012

Contexte, présentation et traitement des données 11
A1 −→ semaine du lundi 06-09-2010 au dimanche 12-09-2010 ;
A2 −→ semaine du lundi 13-09-2010 au dimanche 19-09-2010 ;...
A69 −→ semaine du lundi 26-12-2011 au samedi 31-12-2011.
Les applications f et g sont biens définies. En plus, f est surjective d’où l’application gfexiste.
L’application gf, pour nous résumer, prend en entrée une date d’observation et la rangeen sortie dans la semaine correspondant à sa date. Donc elle découpe et numérote nos ob-servations en semaines.
Globalement, la variable aléatoire qui nous donne le nombre d’observations regroupé ensemaines est définie ci-dessous :
Xt : (Ω,A) −→ (R,BR)
A 7−→ Xt(A) =
X(A) si A = At ∈ A7
ord
0 sinon
avec
t ∈ T = 1, 2, . . . , 69,Xt(A) est le nombre total de voyages observés en A au temps t.
Le nombre de voyages pouvant aussi varier avec l’espace (ou le milieu, ou l’environnement, oumême l’itinéraire), nous allons considérer un vecteur aléatoire de R7 où chaque composantereprésente le nombre de voyages de marchandises en transit sur un itinéraire par unité detemps. Le vecteur aléatoire ainsi considéré est donc :
X = (X1, X2, · · · , X7) ∈ R7
Chaque X i est le nombre de voyages de l’itinéraire i(i = 1, 2, . . . , 7).
Finalement, notre vecteur aléatoire est défini de la manière suivante :
Xt : (Ω,A) −→(R7,B⊗7
R)
A 7−→ Xt(A) =(X1
t (A), X2t (A), . . . , X7
t (A))
avec
X it : (Ω,A) −→ (R,BR)
A 7−→ X it(A) = Xt(A
i)
où :
Mémoire de Master de Statistique Appliquée. FOUDA Norbert © ENSP 2010-2012

Contexte, présentation et traitement des données 12
Ai est la trace de A sur l’itinéraire i,
X it(A) est le nombre de voyages de marchandises en transit sur l’itinéraire i au
temps t,
avec i = 1, 2, · · · , 7 ; et t = 1, 2, · · · , 69.
Motivations du choix de l’unité du temps
Notre unité de temps d’observation, la semaine, a été choisie intuitivement et soutenuepar 3 principales raisons :
– il nous faut une unité de temps conséquente pour se projeter dans l’avenir. Partir desobservations journalières pour se projeter dans 3 mois par exemple peut générer unesuccession d’erreurs du fait de la portée de la prévision trop longue ;
– ensuite, il faut se référer sur une grande quantité d’observations pour effectuer desprévisions fiables. Les observations mensuelles ne nous offrent pas un grand historiqueen la matière ;
– enfin, observer chaque semaine, outre le fait que cela ne rencontre pas les problèmesénoncés ci-dessus, mais en plus c’est une unité de temps assez homogène de par lenombre de jours ouvrables presque identiques sur une suite de 7 jours successifs.
En guise de conclusion de ce chapitre, il convient de garder à l’esprit que : premièrement,nous n’avons retenu pour cette étude que des voyages n’ayant pas de données manquantes ;deuxièmement, nous avons subdivisé le trafic en 7 itinéraires ; et qu’enfin, la semaine a étéretenue comme unité de temps d’observation. Les données ainsi présentées nécessitent uneétude quantitative afin d’apprécier au mieux le volume du trafic du transit au Cameroundurant la période du 06/09/2010 au 31/12/2011.
Mémoire de Master de Statistique Appliquée. FOUDA Norbert © ENSP 2010-2012

Chapitre 2
Exploration des voyages demarchandises en transit au
Cameroun
Revenons un temps soit peu sur le jeu de données avant de nous pencher sur notre variabled’intérêt : nombre de voyages défini à la fin du chapitre précédent. La présente partie sepropose de décrire globalement les différentes variables retenues pour cette étude, et, plusspécifiquement, il sera question de ressortir les principales caractéristiques de ces variablessur nos itinéraires. Les informations contenues dans notre jeu de données sont renferméesdans 5 variables comme le montrait le tableau 1.3.
L’étude du transit des marchandises au Cameroun présente une complexité de par lemoyen de transport sollicité : camions ou le train (sur une partie du tronçon), et de par lamultiplicité des routes reliant Douala et les différents bureaux frontières. Face à cette gammevariée de possibilités offertes aux transitaires, la maîtrise du transit des marchandises auCameroun nécessiterait qu’on prenne en compte non seulement le type de véhicules utilisé,mais aussi la qualité du tronçon. Ne possédant pas ces informations dans la présente étude,nous allons considérer que la distance parcourue par les transitaires partant d’un point Avers un point B est sensiblement la même, quelque soit le moyen de transport utilisé et laqualité du tronçon. Partant de ce fait, nous avons pu dégager 4 itinéraires présentant unflux de voyages considérable, le reste des voyages étant regroupé en fonction des bureaux dedépart.
1 Bureaux de départ
Les marchandises en transit font l’objet d’une déclaration modèle IM8 au bureau desdouanes d’entrée appelé bureau de départ.
13

Exploration des voyages de marchandises en transit au Cameroun 14
1.1 Répartition des voyages par guichet de départ
Le bureau de départ correspond à un guichet de départ censé enregistré les départs desvoyages. En réalité, ce sont des postes douaniers qui libèrent les marchandises en transitaprès vérification du respect des modalités y afférentes. Dans ce cas, nous dénombrons 3guichets de départ. Les codes SYDONIA pour désigner ces 3 unités sont :
1. CMCLB (Bureau Principal Hors Classe des Douanes de Cap Limboh) s’occupe essen-tiellement des produits pétroliers en provenance de la SONARA et à destination duTchad et de la Centrafrique ;
2. CMDLP (Bureau Principal Hors Classe des Douanes de Douala Port) s’occupe desmarchandises divers et ;
3. CMNDR (Bureau Principal Hors Classe des Douanes de Ngaoundéré) s’occupe desmarchandises en rupture de charge c’est-à-dire qui ont été acheminées dans un premiertemps par train jusqu’à Ngaoundéré avant d’être chargées dans des camions.
Le nombre de voyages par guichet de départ de notre jeu de données est représenté par legraphique de la figure 2.4.
Fig. 2.1 – Effectif par guichet
L’activité du guichet CMDLP est plus dense avec 19628 voyages enregistrés durant lapériode d’étude. Tandis que le guichet CMNDR vient en deuxième position et le guichetCMCLB présente un faible flux, soit 29,7% de l’activité du guichet CMDLP et 13,6% de
Mémoire de Master de Statistique Appliquée. FOUDA Norbert © ENSP 2010-2012

Exploration des voyages de marchandises en transit au Cameroun 15
volume de transit sur l’ensemble des voyages de l’étude. Le tableau 2.1 résume la situationd’ensemble du bureau de départ.
Tab. 2.1 – Situation des guichets de départBUREAU_EMETTEUR CMCLB CMDLP CMNDR
Part de bureaux desservis 18/62 44/62 16/62Nombre de voyages enregistrés 5764 19628 17210
Date du premier départ 04/10/2010 06/09/2010 06/09/2010Date du premier arrivée 20/10/2010 14/09/2010 13/06/2011Date du dernier départ 25/11/2011 31/12/2011 31/12/2011Date du dernier arrivée 02/12/2011 07/01/2012 02/01/2012
1.2 Caractéristiques du guichet de départ par itinéraire
Le tableau 1.6 qui révèle les différents guichets de départ desservant nos itinéraires,présente le guichet CMNDR comme desservant les itinéraires 1 et 3 (tout seul), et se joignantau guichet CMDLP pour ravitailler l’itinéraire 7. Le guichet CMDLP dessert aussi, à lui toutseul, les itinéraires 2, 4 et 6. Tandis que le guichet CMCLB dessert uniquement, et à lui toutseul, l’itinéraire 5.
2 Bureau frontière
Le bureau frontière est le dernier bureau des douanes camerounais avant la sortie duterritoire. En matière de transit, c’est ce bureau qui constate la sortie de la marchandisedu territoire attestant ainsi de l’effectivité du transit. C’est également à ce niveau que lesappareils GPS initialement posés sur les cargaisons par les soins des bureaux de départ sontretirés. Nous assimilerons la frontière au point d’arrivée d’un voyage dans nos données. Lavariable "bureau frontière" est constituée des guichets tout comme la variable "bureau dedépart".
2.1 Présentation des guichets frontières
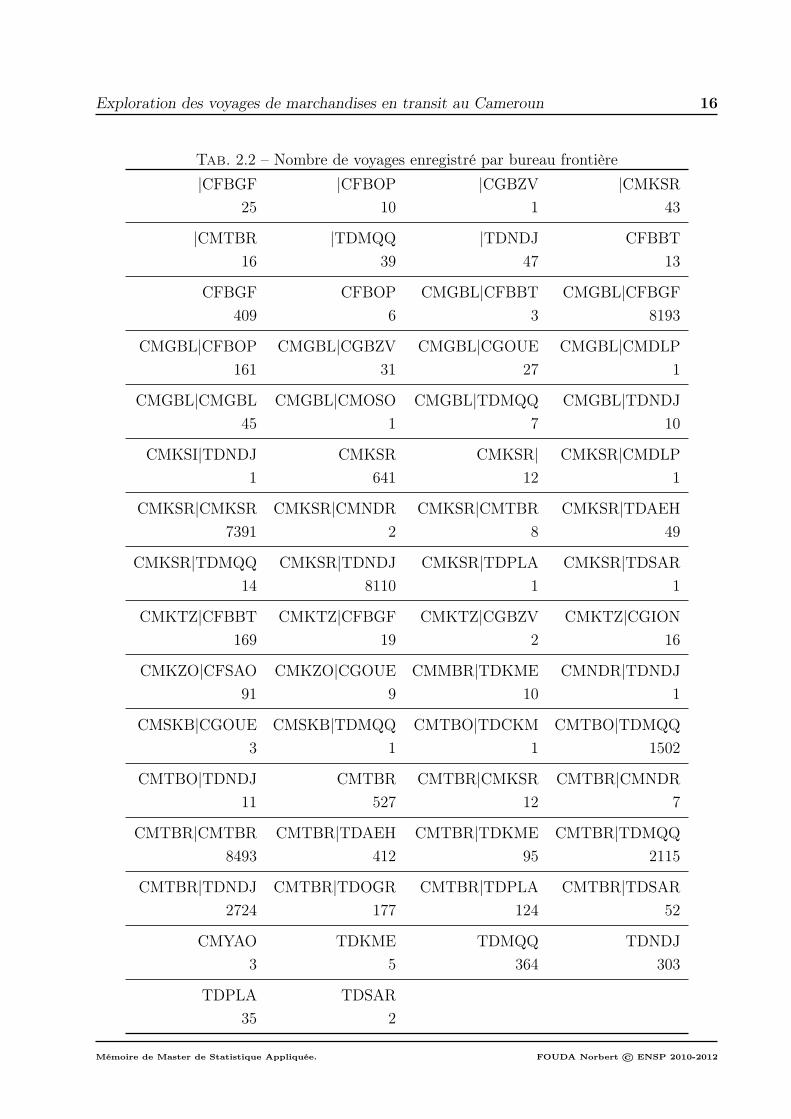
Les guichets frontières sont au nombre de 62 guichets. les noms et le nombre de voyagesenregistrés dans ces guichets au cours de la période d’étude sont donnés par le tableau 2.2.Remarquons qu’un bon nombre de guichets présente un faible nombre de voyages.
Mémoire de Master de Statistique Appliquée. FOUDA Norbert © ENSP 2010-2012
Exploration des voyages de marchandises en transit au Cameroun 16
Tab. 2.2 – Nombre de voyages enregistré par bureau frontière|CFBGF |CFBOP |CGBZV |CMKSR
25 10 1 43
|CMTBR |TDMQQ |TDNDJ CFBBT16 39 47 13
CFBGF CFBOP CMGBL|CFBBT CMGBL|CFBGF409 6 3 8193
CMGBL|CFBOP CMGBL|CGBZV CMGBL|CGOUE CMGBL|CMDLP161 31 27 1
CMGBL|CMGBL CMGBL|CMOSO CMGBL|TDMQQ CMGBL|TDNDJ45 1 7 10
CMKSI|TDNDJ CMKSR CMKSR| CMKSR|CMDLP1 641 12 1
CMKSR|CMKSR CMKSR|CMNDR CMKSR|CMTBR CMKSR|TDAEH7391 2 8 49
CMKSR|TDMQQ CMKSR|TDNDJ CMKSR|TDPLA CMKSR|TDSAR14 8110 1 1
CMKTZ|CFBBT CMKTZ|CFBGF CMKTZ|CGBZV CMKTZ|CGION169 19 2 16
CMKZO|CFSAO CMKZO|CGOUE CMMBR|TDKME CMNDR|TDNDJ91 9 10 1
CMSKB|CGOUE CMSKB|TDMQQ CMTBO|TDCKM CMTBO|TDMQQ3 1 1 1502
CMTBO|TDNDJ CMTBR CMTBR|CMKSR CMTBR|CMNDR11 527 12 7
CMTBR|CMTBR CMTBR|TDAEH CMTBR|TDKME CMTBR|TDMQQ8493 412 95 2115
CMTBR|TDNDJ CMTBR|TDOGR CMTBR|TDPLA CMTBR|TDSAR2724 177 124 52
CMYAO TDKME TDMQQ TDNDJ3 5 364 303
TDPLA TDSAR35 2
Mémoire de Master de Statistique Appliquée. FOUDA Norbert © ENSP 2010-2012

Exploration des voyages de marchandises en transit au Cameroun 17
2.2 Caractéristiques des guichets frontières par itinéraire
Nous dénombrons 10 guichets qui ont enregistré chacun un seul voyage, 3 guichets ontenregistré chacun 2 voyages, et le même nombre de guichets a enregistré chacun 3 voyages.Dans l’ensemble, 1/4 des guichets frontières ont enregistré au plus 4 voyages, de même 1/4des guichets ont enregistré entre 152 et 8493 voyages, et le reste des guichets (la moitié) aun flux compris entre 4 et 152 voyages. La situation est résumée dans le tableau 2.3.
Tab. 2.3 – Découpage du nombre de voyages par bureau frontièreMin 1er Quartile Médiane 3ème Quartile Max
1 4 16 152 8493
3 Date de départ
La date de départ marque le commencement du transit, ce qui équivaut aussi au momentoù l’on part du bureau de départ.
3.1 Présentation des dates de départ des transits
La date de départ est parfaitement renseignée dans notre jeu de données : tous les voyagesont leur date de départ. Les départs des voyages vont du 06/09/2010 au 31/12/2011. De parsa collecte presque exhaustive au moins tout au long de l’année 2011, la date des départsdes voyages en transit consolide l’importance qu’on lui accorde pour cette étude.
3.2 Caractéristiques des dates de départ par itinéraire
Les caractéristiques des dates de départ sont résumées dans le tableau 2.4. Ce tableaunous dit par exemple que, sur la ligne "itiner_1" :
– les voyages en transit ont commencé à être collectés le 06/10/2010 sur l’itinéraire 1 ;– le quart (1/4) du flux des voyages pendant la période d’étude a été atteint sur cet
itinéraire à la date du 13/01/2011 ;– la moitié des voyages a été enregistré le 10/05/2011 ;– 3/4 du flux ont été enregistré le 03/09/2011 ;– le dernier voyage, pendant la période d’étude, est parti le 31/12/2011.
Aussi, est-il à noter que le trafic a été plus dense entre le 03/09/2011 et le 31/12/2011 carchaque période délimitée par deux dates successives sur la ligne "itiner_1" représente lamême part du volume du trafic. Il en ressort que l’activité durant ce temps était intense.
Mémoire de Master de Statistique Appliquée. FOUDA Norbert © ENSP 2010-2012

Exploration des voyages de marchandises en transit au Cameroun 18
Tab. 2.4 – Période des voyages par itinéraire1er départ 1er Quartile Médiane 3e Quartile dernier départ
itiner_1 06/10/2010 13/01/2011 10/05/2011 03/09/2011 31/12/2011itiner_2 01/10/2010 02/02/2011 03/06/2011 09/09/2011 31/12/2011itiner_3 07/10/2010 15/01/2011 23/04/2011 01/09/2011 31/12/2011itiner_4 06/10/2010 10/02/2011 31/05/2011 01/09/2011 31/12/2011itiner_5 04/10/2010 07/01/2011 05/04/2011 06/07/2011 25/11/2011itiner_6 06/09/2010 16/12/2010 14/03/2011 06/06/2011 30/12/2011itiner_7 06/09/2010 17/09/2010 25/09/2010 08/10/2010 29/12/2011
4 Date d’arrivée
Les dates d’arrivées peuvent aussi être abordées de la même manière qu’à la sectionprécédente. Nous ne le referons pas pour une double raison. D’abord, l’objet de la présenteétude ne porte pas directement sur le comportement à l’arrivée. Par ailleurs, l’étude de ladurée du transit permettra, à partir des dates de départ, d’apprécier les dates d’arrivée.
4.1 Étude conjointe des dates de départ et d’arrivée
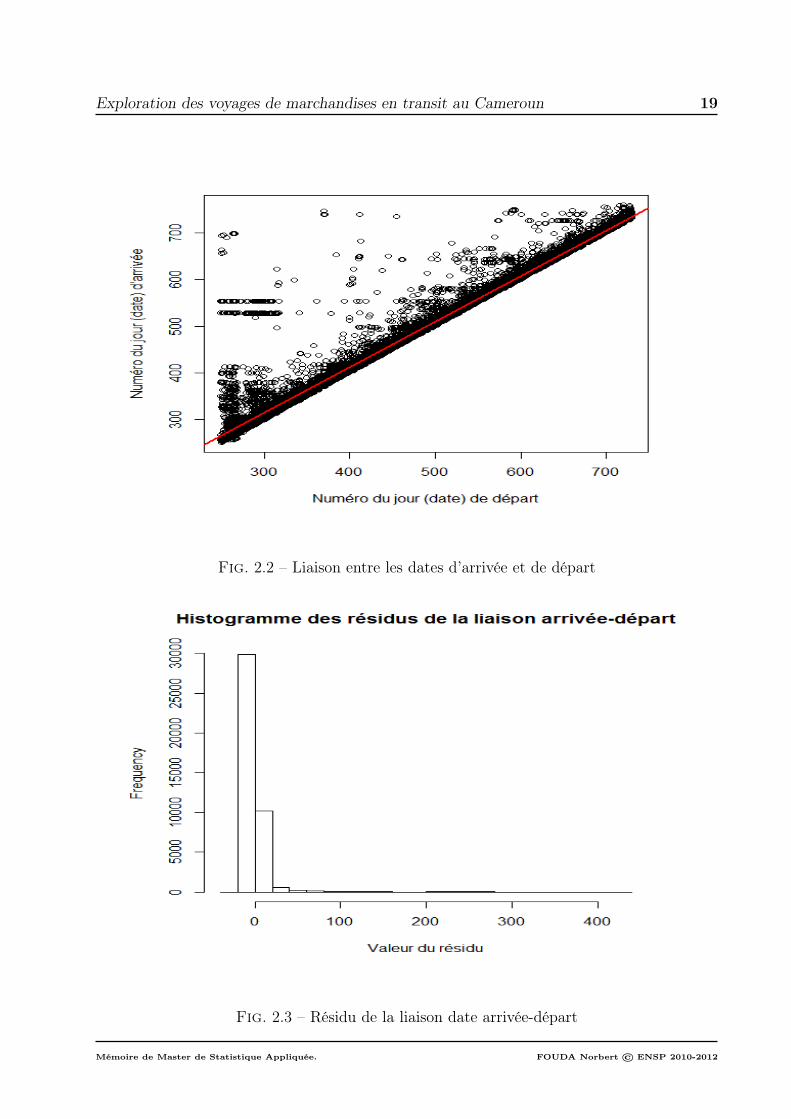
On s’attendrait tout de même à ce que la durée soit liée avec les dates de départ etd’arrivée. Et dans une moindre mesure, elle devrait être fonction de l’itinéraire. Le graphedans la figure 2.2 présente le nuage de points de la date d’arrivée en fonction de date dedépart.
Les résidus de cette régression dans la figure 2.3 montre que les dates de départs nesuffisent pas à elles seules à expliquer les dates d’arrivées, car manifestement ceux-ci nesuivent pas une distribution normale. De ce fait, la date de départ ne suffit pas pour expliquela date d’arrivée.
5 Durée du transit
La durée du transit est le temps mis par un voyage pour traverser le territoire national.Elle est évaluée en moyenne à 239,7 heures. Il faut noter que cette durée dépend de l’itiné-raire et même de la période dans l’année. En effet, la fréquence des voyages ne saurait êtresemblable entre juin ou décembre et février par exemple à cause de l’état des routes nonbitumées qui deviennent moins praticables en saison des pluies.
Mémoire de Master de Statistique Appliquée. FOUDA Norbert © ENSP 2010-2012
Exploration des voyages de marchandises en transit au Cameroun 19
Fig. 2.2 – Liaison entre les dates d’arrivée et de départ
Fig. 2.3 – Résidu de la liaison date arrivée-départ
Mémoire de Master de Statistique Appliquée. FOUDA Norbert © ENSP 2010-2012

Chapitre 3
Fondements théoriques et outils
En théorie, pour effectuer des prévisions dans le temps d’une variable à partir des obser-vations passées de celles-ci, les techniques d’approche de la résolution de cette problématiquese retrouvent dans la branche de Statistique dénommée séries chronologiques encore appeléeséries temporelles.
1 Généralités sur les séries chronologiques
1.1 Définitions
Une série chronologique est constituée par une succession d’observations, sur un mêmesujet ou sur un même phénomène, régulièrement espacées dans le temps. On note : Yt, où tdésigne le temps.
Une série chronologique peut aussi se définir comme une série statistique bidimensionnelle(t; Yt) où t est le temps et Yt ∈ X.
1. Lorsque X peut être inclus dans un espace de dimension 1, la série est unidimension-nelle.
2. Si, par contre, les éléments de X sont des uplets, la série est multidimensionnelle.
N.B :– Les données des séries chronologiques sont rangées dans l’ordre chronologique ;– Il est conseillé d’avoir des temps d’observation équidistants (série discrète).
1.2 Objectifs
L’analyse des séries chronologiques est un outil statistique de prévision parmi ceux dontdispose le conjoncturiste pour planifier et faire face au changement. Il est d’usage de consi-dérer l’intérêt des séries temporelles selon trois perspectives : descriptive, explicative etprévisionnelle.
20

Fondements théoriques et outils 21
1. Description– permet de connaître la structure de la série de données étudiées ;– peut être utilisée pour comparer une série à d’autres séries.
2. Explication– Les variations d’une série peuvent être expliquées par une autre série (exposition
météorologique, pollution atmosphérique, etc.) ;– Il est possible de modéliser une intervention externe grâce à l’analyse des séries
temporelles.
3. Prévision– La prévision a priori permet la planification ;– La prévision a posteriori permet d’estimer l’impact d’une perturbation (dépistage,
par exemple) sur la variable expliquée ;– Des scénarios pour le futur, enfin, peuvent être réalisés.
1.3 Présentation
On peut présenter une série chronologique sous la forme d’un tableau à 2 colonnes et n
lignes. Les colonnes indiquant les dates et les valeurs des observations, et les lignes indiquantla date et la valeur d’une observation.
2 Décomposition d’une série chronologique
2.1 Composantes d’une série chronologique
W.M. Persons a proposé, en 1919, une décomposition d’une série chronologique en termesde composantes tendancielle (tendance séculaire), cyclique (fluctuation cyclique), saisonnière(variation saisonnière) et accidentelle (variation irrégulière). Ces quatres composantes ex-priment chacune un aspect particulier du mouvement des valeurs de la série chronologique.Leurs rôles sont consignés dans le tableau 3.1.
Tab. 3.1 – Décomposition d’une série chronologiqueComposante Désignation Rôle
T tendance séculaire traduit le mouvement à long termeS variations saisonnières représentent les changements saisonniersC fluctuations cycliques variations périodiques mais non saisonnièresε variations irrégulières autres sources de variations
Mémoire de Master de Statistique Appliquée. FOUDA Norbert © ENSP 2010-2012

Fondements théoriques et outils 22
2.2 Modèles de décomposition déterministes
On suppose que les valeurs prises par la variable aléatoire Yt sont déterminées par unerelation entre les quatre composantes précédentes. Le tableau 3.2 présente divers modèles dedécomposition d’une série chronologique.
Tab. 3.2 – Présentation des modèles de compositionModèles de décomposition Expression mathématique du modèle
Modèle additif Yt = Tt + Ct + St + εt
modèle multiplicatif Yt = Tt × Ct × St × εt
modèle mixte Yt = St + (Tt × Ct × εt), ou Yt = Ct + (Tt × St × εt)
N.B.
1. On peut passer d’un modèle de composition à un autre à l’aide d’un changement devariable, i.e. en transformant les valeurs des observations par une fonction f , qui doitêtre un difféomorphisme (f différentiable, bijective et f−1 différentiable) servant à lierun modèle de composition à un autre. On utilise régulièrement la fonction logarithme
(lg) qui permet de passer du modèle multiplicatif au modèle additif.
Yt = Tt × Ct × St × εt donne lg (Yt) = lg (Tt) + lg (Ct) + lg (St) + lg (εt) .
Bien évidemment, il faut que Yt > 0, ∀ t.
2. Lorsque la série chronologique ne porte pas sur une trop longue période, on regroupela tendance séculaire et les fluctuations cycliques en une seule composante appeléemouvement extra-saisonnier.
2.3 Choix du modèle de décomposition
Il existe plusieurs méthodes pour déterminer le modèle de la série chronologique qu’onobserve. Nous présentons ici trois méthodes fréquemment utilisées.
Méthode de la bande
Elle consiste à représenter 2 droites sur le graphe de la série. Une passant par les minimalocaux, l’autre passant par les maxima locaux. Principe du choix :
– Si ces 2 droites sont à peu près parallèles, alors le modèle est additif.– Si ces 2 droites ne sont pas parallèles, le modèle est multiplicatif.
Mémoire de Master de Statistique Appliquée. FOUDA Norbert © ENSP 2010-2012

Fondements théoriques et outils 23
Méthode du profil
On subdivise la série en période. On représente, de manière superposée, la courbe dechaque période sur un même graphe.
– Si les différentes courbes sont à peu prés parallèles : le modèle est additif– Sinon : le modèle est multiplicatif.
Méthode du tableau de Buys et Ballot
C’est une méthode analytique. Elle consiste à :– Calculer pour chaque période la moyenne et l’écart type– Considérer la série bidimensionnelle des points d’abscisse la moyenne et d’ordonnée
l’écart type de la même période.– Déterminer la droite des moindres carrés.
On conclut que le modèle est additif si la pente de la droite des moindres carrés est trèsproche de 0 et multiplicatif sinon.
L’analyse d’une série chronologique consiste à faire une description mathématique deséléments qui la composent, c’est-à-dire à estimer séparément les quatre composantes.
2.4 Estimation des composantes
Estimation de la tendance
Moyennes mobiles simplesOn représente le graphe de la série des moyennes mobiles sur le graphe de la série brute.
La tendance présente une faible courbure. Le but d’un lissage par moyenne mobile est de faireapparaître l’allure de la tendance. L’expression ci-dessous permet de calculer les moyennesmobiles simples d’ordre p à un temps t.
MMp(t) =
0.5×Yt−k+Yt−(k−1)+...+Yt+(k−1)+0.5×Yt+k
psi p = 2× k,
Yt−k+Yt−(k−1)+...+Yt−1+Yt+Yt+1+...+Yt+k
psi p = 2× k + 1.
Ajustement de la tendanceOn utilise généralement la méthode des moindres carrés. Après avoir déterminé la forme
analytique générale de l’expression de l’équation de la tendance yt = f(t), les coefficients destermes de cette équation sont obtenus en minimisant l’expression :
t=n∑t=0
(Yt − yt)2 , où la série à ajuster est Yt.
Mémoire de Master de Statistique Appliquée. FOUDA Norbert © ENSP 2010-2012

Fondements théoriques et outils 24
Dans le cas de la tendance linéaire par exemple, on a :
yt = a× t + b, et les coefficients a et b sont : a =cov(t, Yt)
var(t)et b = Y − a× t
Estimation de la saisonnalité
La détermination des coefficients saisonniers est fonction du modèle de décomposition dela série. Leur détermination est résumé dans le tableau 3.3. où
Tab. 3.3 – Variation saisonnière et coefficients saisonniersModèle de décomposition Variations saisonnières Coefficients saisonniers
Modèle additif Yt − Tt Si = 1m
∑mj=1(yij − Tij)
Modèle multiplicatif Yt
TtSi = 1
m
∑mj=1(
yij
Tij)
– yij ≡ valeur de la ie obervation de la je saison ;– Tij ≡ valeur de la tendance de la ie observation de la je saison.N.B :
On fait disparaître la composante saisonnière de période p avec la moyenne mobile d’ordrep. L’ordre p est donc la périodicité des variations saisonnières
Série desaisonnalisée
Notée CVS, c’est la série chronologique Yt − St pour un modèle additif (ou Yt
Stpour un
modèle multiplicatif) à laquelle on a enlevé les variations saisonnières corrigées.Les données la série CVS sont directement comparables. A partir de la série CVS, on
peut réévaluer la tendance.
Série ajustée
Elle est obtenue par :
Yt =
Tt + St si le modèle est additifTt × St si le modèle est multiplicatif
Elle représente l’évolution des variations tendancielles et saisonnières si celles-ci auraient étéparfaitement périodiques en l’absence des variations accidentelles.
Mémoire de Master de Statistique Appliquée. FOUDA Norbert © ENSP 2010-2012

Fondements théoriques et outils 25
Variations accidentelles
Elles sont obtenues par :
εt =
Yt − Yt si le modèle est additif.Yt
Ytsi le modèle est multiplicatif.
C’est la partie stochastique du modèle de décomposition.
2.5 Prévision
La valeur de la série à une date h ultérieure est prédite par :
Yh =
Th + Sh + εh si le modèle est additifTh × Sh × εh si le modèle est multiplicatif
Il reste à estimer εh. Pour se faire, nous soumettons ce problème à la Méthode de BOX &JENKINS.
3 Méthode de BOX & JENKINS
La démarche de BOX et JENKINS est fondée sur la notion de processus ARMA etelle comprend 4 phases : l’identification a priori, l’estimation du modèle ARMA identifié,l’identification a posteriori et la prévision.
[Fonction d’autocovariance(acf)] Soit Xt une serie temporelle, la fonction d’autocova-riance pour Xt est donnée par :
γ(t, s) = E(Xs − µs)(Xt − µt)
si t = s, γ(t, s) = E(Xt − µt)2
La fonction d’autocorrelation de Xt est donnée par :
ρ(t, s) =γ(t, s)√
γ(s, s)γ(t, t)
par application de l’inégalité de Cauchy, −1 ≤ ρ(t, s) ≤ 1.
Soit Xt et Yt deux series temporelles.La fonction de covariance croisée des series Xtet Yt est donnée par :
γxy(t, s) = E(Xs − EXs)(Yt − EYt)
et la fonction de correlation croisée est donnée par :
ρxy(t, s) =γxy(t, s)√
γx(s, s)γy(t, t)
Mémoire de Master de Statistique Appliquée. FOUDA Norbert © ENSP 2010-2012

Fondements théoriques et outils 26
Un processus stochastique est une famille de variablesaléatoires Xt, t ∈ T Définies sur le même espace de probabilité (Ω,A, P ).
Une série temporelle est dite strictement stationnaire, si la distribution de toute collectionXt1 , . . . , Xtn est identique à celle de la collection translatée Xt1+h, . . . , Xtn+h.C’est-à-dire,
P (Xt1 ≤ C1, . . . , Xtn ≤ Cn) = P (Xt1+h ≤ C1) . . . P (Xtn+h ≤ Cn),
On dit que Xt, t ∈ Z est (faiblement) stationnaire ou stationnaire au 2nd ordre si,
1. EX2t < +∞, ∀t ∈ Z
2. EXt = µ ∀t ∈ Z
3. cov(Xs, Xs+t) = rt, ∀t, s ∈ Z, où rt =la fonction d’autocovariance de Xt
ρ(t) =rt
r0
≡ fonction d’autocorrelation deXt.
On a :
1. r0 ≥ 0
2. |rt| ≤ r0, ∀t ∈ Z
3. rt = r−t, ∀t ∈ Z
On a :– Xt strictement stationnaire et EX2
t < +∞⇒ Xt est stationnaire au 2nd ordre.– Xt strictement stationnaire ; Xt stationnaire au 2nd ordre.
En effet Xtiid∼Cauchy, ; Xt est strictement stationnaire,
mais EXt n’existe pas, ⇒ Xt n’est pas stationnaire au 2nd ordre– Xt stationnaire au 2nd ordre ; Xt strictement stationnaire.
En effet,considérons Xt une serie de variables aléatoires indépendantes.
Xt =
exp(1) si t = 2k + 1
N (1, 1) si t = 2k, k ∈ Z
Xt est stationnaire au 2nd ordre, mais Xt n’est pas strictement stationnaire.Si Xt est stationnaire, alors Yt = tµ+Xt ne l’est pas.Mais Zt = Yt−Yt−1 = µ+Xt−Xt−1
est stationnaire. Deux séries temporelles Xt et Yt sont dites conjointement stationnairessi,
γxy(h) = E(Xt+h − µXt)(Yt − µYt)
Dans ce cas, ρxy(h) = γxy(h)√γx(0)γy(0)
.
Une série temporelle Xt, t ∈ Z est dite gaussienne si (Xt1 , . . . , Xtn) a une distributiongaussienne multivariée de dimension n,∀n ≥ 1, t1, . . . , tn ∈ Z. Une distribution gaussienne
Mémoire de Master de Statistique Appliquée. FOUDA Norbert © ENSP 2010-2012

Fondements théoriques et outils 27
est parfaitement descriptible si sa moyenne et sa variance sont connues et par conséquence,une serie temporelle gaussienne sera identifié par sa moyenne et sa acf.
Application :
1. Construction d’intervalles de confiance ou faire des tests d’hypothèses.Exemple : (H0) : µ = 0 contre (H1) : µ 6= 0
2. Si εt ∼ N (0, σ2ε ) ⇒ Kε = 0
3.∫ π
−πf 2(ω)
ei(t−s)ω + ei(t+s)ω
dω existe car f(ω) = σ2
ε |b(ω)|2 est bornée.
4 PROCESSUS LINEAIRE
εt, t ∈ Z variable aléatoire est appelée– Bruit blanc strict si→ εt est i.i.d→ Eεt = 0
→ var(εt) = σ2ε < +∞
– Bruit blanc si→ εt ⊥ εs, ∀s, t s 6= t
→ Eεt = 0, ∀t→ var(εt) = σ2
ε < +∞Un processus stationnaire Xt, t ∈ Z,
Xt =∑+∞
k=−∞ bkεt−k, t ∈ Z,∑
k b2k < +∞ est appelée
1. Processus lineaire si εt est bruit blanc strict.
2. Processus lineaire généralisé si εt esi bruit blanc.
5 Processus auto-regressifs(AR)
Xt, t ∈ Z est appelée processus auto-regressif d’ordre p (AR(P)) si
Xt ≡P∑
k=1
αkXt−k + εt, t ∈ Z, αP 6= 0 (?)
εt, t ∈ Z est un bruit blanc.
Théorème 5.1. Soit Xt, t ∈ Z AR(1), c’est-à-dire Xt = αXt−1 + εt et supposons |α| < 1
[a]L’unique solution stationnaire est donnée par :
ηt =+∞∑k=0
αkεt−k
Mémoire de Master de Statistique Appliquée. FOUDA Norbert © ENSP 2010-2012

Fondements théoriques et outils 28
avec L(X0) prédéfinie, on a :
Xt = ηt + Φt, t ≥ 1, avec Φt = αtΦ0 et Φ0 = X0 − η0.
Xt, t ∈ Z AR(1) avec |α| < 1
1.2.1. EXt = 0
2. var(Xt) = σ2ε
1−α2
3. rt = σ2ε
α|t|
1−α2
On définit :
1. Soit l’opérateur de translation U défini sur H = spanXt, t ∈ Z par U(Xt) := Xt+1
⇒ Uk(Xt) = Uk−1(U(Xt)) = Xt+k
U−1(Xt) = Xt−1
2. A(z) = 1 − α1z − . . . − αP zP , z ∈ C est appelé polynôme générateur de l’AR(P) siXt =
∑Pk=1 αkXt−k + εt.
6 Processus MA et ARMA
Un processus Xt, t ∈ Z est appelé MA(q) (Moving Average d’ordre q ≥ 0) si,
Xt =
q∑k=1
θkεt−k + εt, avec εt, t ∈ Z bruit blanc.
Un processus Xt, t ∈ Z est appelé ARMA(p,q) (ARMA d’ordre p ≥ 0 et q ≥ 0) si,
Xt =
p∑k=1
αkXt−k +
q∑k=1
θkεt−k + εt, avec εt, t ∈ Z bruit blanc.
On reconnaît qu’une série suit un processus MA(q) si sa fonction d’autocorrélation ACFs’annule à partir d’un décalage q, ou qu’elle suit un processus AR(p) si sa fonction d’auto-corrélation partielle PACF s’annule à partir d’un décalage p.
6.1 Processus autorégressif et à moyenne mobile (A.R.M.A.)
6.2 Introduction aux modèles ARIMA
La classe des modèles ARIMA [Box et Jenkins, 1976] a été introduite pour reconstituerle comportement de processus soumis à des chocs aléatoires4 au cours du temps : entredeux observations successives d’une série de mesures portant sur l’activité du processus,
Mémoire de Master de Statistique Appliquée. FOUDA Norbert © ENSP 2010-2012

Fondements théoriques et outils 29
un événement aléatoire appelé perturbation vient affecter le comportement temporel dece processus et ainsi modifier les valeurs de la série chronologique des observations. Lesmodèles ARIMA permettent de combiner trois types de processus temporels : les processusautorégressifs (AR-AutoRegressive), les processus intégrés (I-Integrated), et les moyennesmobiles (MA-Moving Average). Dans le cas le plus général, un modèle ARIMA combineles trois types de processus aléatoires5, la contribution de chacun d’eux étant précisée parla notation ARIMA(p,d,q), où p est l’ordre du processus autorégressif AR(p), d le degréd’intégration d’un processus I(d), et q l’ordre de la moyenne mobile MA(q).
Les processus auto-régressifs
Pour un processus autorégressif, chaque valeur de la série est une combinaison linéaire desvaleurs précédentes de la série. Si la valeur de la série à l’instant t, Y t, ne dépend que de lavaleur précédente Y t.1 à une perturbation aléatoire près εt, le processus est dit autorégressifdu premier ordre et noté AR(1) :
Yt = φtYt−1 + εt
Le coefficient φ exprime la force de la liaison linéaire entre deux valeurs successives. Unprocessus autorégressif où la valeur de la série à l’instant t, Yt, dépend des p précédentesvaleurs est dit d’ordre p et noté AR(p). Ainsi un processus AR(2) s’écrit :
Yt = φ1Yt−1 + φ2Yt−2 + εt
On peut dire qu’un processus autorégressif possède une "mémoire" au sens où chaque valeurest corrélée à l’ensemble des valeurs qui la précède. Par exemple, dans un processus AR(1),la valeur a l’instant t, Y t, est fonction de la valeur précédente Yt−1, elle-même fonction dela valeur Yt−2, elle-même fonction de la valeur Yt−3, etc. Si la valeur absolue du coefficientde régression φ1 est inférieure à 1 (autrement dit si −1 < φ1 < +1), l’effet de chaqueperturbation aléatoire sur le système tend à décroître au cours du temps. Un processusautorégressif d’ordre p, AR(p), pourra être noté comme un modèle ARIMA(p, 0, 0).
Les processus intégrés
Le comportement des séries chronologiques peut être affecté par l’effet cumulatif de cer-tains processus. Par exemple, l’état des stocks est modifié à chaque instant par les consomma-tions et les approvisionnements, cependant le niveau moyen de ces stocks dépend essentiel-lement de l’effet cumulé des changements instantanés sur la période entre deux inventaires.Même si sur le court terme les valeurs du stock peuvent fluctuer avec des aléas importantsautour de cette valeur moyenne, le niveau de la série sur le long terme demeurera inchangé.Une série chronologique déterminée par l’effet cumulatif d’une activité appartient à la classe
Mémoire de Master de Statistique Appliquée. FOUDA Norbert © ENSP 2010-2012

Fondements théoriques et outils 30
des processus intégrés. Même si le comportement d’une série est instable, les différences d’uneobservation à la prochaine peuvent être relativement faibles voire osciller autour d’une valeurconstante pour un processus observé à différents intervalles de temps. Cette stationnarité dela série des différences pour un processus intégré est une caractéristique importante du pointde vue de l’analyse statistique des séries chronologiques. Les processus intégrés constituentl’archétype des séries non stationnaires.
Un exemple de processus I(1), intégre d’ordre 1, est la marche aléatoire définie par :Yt =
Yt−1 + εt où la perturbation aléatoire φt est un bruit blanc. On utilise le terme de marchealéatoire car la valeur courante est définie comme une étape aléatoire à partir de la valeurprécédente. La marche aléatoire est également un processus autorégressif d’ordre 1, AR(1),dont le coefficient de régression φt est égal a 1. Ainsi, la marche aléatoire possède une"memoire parfaite" mais limitée à l’observation précédente. Un processus est intégré d’ordre1, noté I(1), si la série des différences premières est stationnaire. De même un processus estintégre d’ordre 2, noté I(2), si la série des différences secondes (les différences des différences)est stationnaire. Un processus intégré d’ordre d, I(d), pourra être noté comme processusARIMA(0, d, 0).
Les moyennes mobiles
La valeur courante d’un processus de moyenne mobile est définie comme une combinaisonlinéaire de la perturbation courante avec une ou plusieurs perturbations précédentes.L’ordrede la moyenne mobile indique le nombre de périodes précédentes incorporées dans la valeurcourante. Ainsi, une moyenne mobile d’ordre 1, MA(1), est définie par équation suivant :Yt = εt − θ1 × εt−1
Pour une moyenne mobile, chaque valeur est une moyenne pondérée des plus récentes pertur-bations tandis que pour un processus autorégressif c’est une moyenne pondérée des valeursprécédentes. L’effet d’une perturbation aléatoire décroit tout au long de la série au fur et àmesure que le temps s’écoule dans un processus autorégressif tandis que dans une moyennemobile la perturbation aléatoire affecte la série temporelle pour un nombre fini d’observa-tions (l’ordre de la moyenne mobile) puis au-dela cesse brutalement d’exercer une quelconqueinfluence.
6.3 La méthodologie de Box et Jenkins
Dans la méthodologie d’analyse des séries chronologiques synthétisée par Box et Jenkinsen 1976, on utilise ces trois types de processus pour construire un modèle restituant lemieux possible le comportement d’une série temporelle selon une procédure en trois étapes :identification, estimation et diagnostic, qu’il convient de réitérer jusqu’à ce que le résultat
Mémoire de Master de Statistique Appliquée. FOUDA Norbert © ENSP 2010-2012

Fondements théoriques et outils 31
soit jugé satisfaisant.
L’identification
La première étape dans la méthodologie proposée par Box et Jenkins concerne la décom-position retenue de la série chronologique selon les trois types de processus en spécifiant lestrois paramètres p, d et q du modèle ARIMA(p, d, q). On suppose à cet instant que toutecomposante saisonnière a été éliminée de la série chronologique, les modèles avec saisonnalitéimpliquant la spécification d’un autre ensemble de paramètres qui seront abordés ultérieu-rement.
L’identification des processus autorégressifs et de moyennes mobiles susceptibles d’expli-quer le comportement de la série temporelle suppose de vérifier tout d’abord la stationnaritéde la série puisque les processus de base, qu’ils soient autorégressifs ou de moyennes mobiles,sont essentiellement stationnaires en raison des contraintes pesant sur leurs paramètres. Unprocessus est dit faiblement stationnaire si son espérance et sa variance sont constantes etsi sa covariance ne dépend que de l’intervalle de temps.
1. EX2t < +∞, ∀t ∈ Z
2. EXt = µ ∀t ∈ Z
3. cov(Xs, Xs+t) = rt, ∀t, s ∈ Z, où rt =la fonction d’autocovariance de Xt
Si la série n’est pas stationnaire – c’est à dire si la moyenne de la série varie sur le courtterme ou que la variabilité de la série est plus élevée sur certaines périodes que sur d’autres– il convient de transformer la série pour obtenir une série stationnaire. La transformationla plus courante est la différenciation de la série, opération où chaque valeur de la série estremplacée par la différence entre cette valeur et celle qui la précède. Transformation loga-rithmique ou bien racine carrée peuvent être utilisées en situation d’hétéroscédasticité, où lavariance de la série n’est pas constante et dépend des valeurs prises, par exemple avec uneforte volatilité pour des valeurs élevées et une faible volatilité pour des valeurs faibles.Une fois obtenue la stationnarité de la série, l’étape suivante consiste à analyser le graphe dela fonction d’autocorrélation (FAC) et celui de la fonction d’autocorrélation partielle (FAP)afin de déterminer les paramètres (p, d, q) du modèle.Le parametre d est fixé par le nombre de différenciations effectuées pour rendre la série sta-tionnaire, en règle générale une différenciation suffit : ∈ 0, 1, 2.Une fois ce paramètre fixé, il convient de spécifier l’ordre p du processus auto-régressif etq celui de la moyenne mobile. Les corrélogrammes, graphes de la fonction d’autocorrélationet de la fonction d’autocorrélation partielle permettent selon leurs aspects d’identifier cor-rectement les paramètres p et q dont les valeurs n’excèdent pas deux en règle générale :p ∈ 0, 1, 2 et q ∈ 0, 1, 2.
Mémoire de Master de Statistique Appliquée. FOUDA Norbert © ENSP 2010-2012

Fondements théoriques et outils 32
La fonction d’autocorrelation, notée FAC, est constituée par l’ensemble des autocorrélationsρk = corr (Yt, Yt−k) de la série calculées pour des décalages d’ordre k, k ∈ 1, . . . , K. Ledécalage maximum K admissible pour que le coefficient d’autocorrélation ait un sens se situeen général entre n
6≤ K ≤ n
3, où n est le nombre d’observations temporelles. Pour n ≥ 150,
on prendra K = n5.
Le coefficient d’autocorrélation d’ordre k, ρk, peut être estimé par :
rk =∑n
t=k+1(yt−y1)(yt−k−y2)√∑nt=k+1(yt−y1)2
∑nt=k+1(yt−k−y2)
avec y1 = 1n−k
∑nt=k+1 yt et y2 = 1
n−k
∑nt=k+1 yt−1
Sous l’hypothèse H0 : "ρk = 0", la statistique tc = |rk|√1−r2
k
suit une loi de Student à n degrés
de libertés. Si la valeur calculée tc est supérieure au quantile α/2 d’une loi de Student à ndegrés de liberté tc > t
α/2n−2, alors l’hypothèse H0 est rejetée au seuil α (test bilatéral).
La fonction d’autocorrélation partielle, notée FAP, est constituée par l’ensemble des auto-corrélations partielles, le coefficient d’autocorrélation partielle mesurant la corrélation entreles variables Yt et Yt−k, l’influence de la variable Yt−k−1 étant contrôlée pour i < k.
Outre les coefficients de corrélation, les corrélogrammes affichent les intervalles de confianceà 95%, qui permettent de déterminer quels sont les coefficients statistiquement significatifs àprendre en compte. L’interprétation des corrélogrammes pour la spécification des processusAR et MA est généralement gouvernée par les règles suivantes :
– les processus autorégressifs d’ordre p, AR(p), présentent une fonction d’autocorrélationdont les valeurs décroissent exponentiellement avec des alternances possibles de valeurspositives et négatives ; leur fonction d’autocorrélation partielle présente exactement p
pics aux p premières valeurs du corrélogramme d’autocorrélation partielle ;– les processus de moyenne mobile d’ordre q, MA(q), présentent exactement q pics aux
q premières valeurs du corrélogramme de la fonction d’autocorrélation et des valeursexponentiellement décroissantes de la fonction d’autocorrélation partielle ;
– si la fonction d’autocorrélation décroît trop lentement, on conseille de différencier lasérie avant l’identification du modèle ;
– les processus mixtes de type ARMA peuvent présenter des graphes d’autocorrélation etd’autocorrélation partielle plus complexes à interpréter et nécessiter plusieurs itérationsde type identification− estimation− diagnostic.
L’estimation
La procédure auto.arima de la librairie "forecast" permet selon un algorithme rapide d’es-timation du maximum de vraisemblance [Mélard, 1984] d’estimer les coefficients du modèleque vous avez identifié au préalable en fournissant les paramètres p, q.
Mémoire de Master de Statistique Appliquée. FOUDA Norbert © ENSP 2010-2012

Fondements théoriques et outils 33
Le diagnostic
Dans cette étape finale du triptyque identification − estimation − diagnostic de laméthode de Box et Jenkins, les principales vérifications à effectuer portent sur les élémentssuivants :
– les valeurs des fonctions d’autocorrélation et d’autocorrélation partielle de la série desrésidus doivent être toutes nulles ; si les autocorrélations d’ordre 1 ou 2 diffèrent signi-ficativement de 0, alors la spécification (p, d, q) du modèle ARIMA est probablementinadaptée ; cependant, une ou deux autocorrélations d’ordre supérieur peuvent paraléas dépasser les limites de l’intervalle de confiance à 95% ;
– les résidus ne doivent présenter aucune configuration déterministe : leurs caractéris-tiques doivent correspondre à celle d’un bruit blanc. Une statistique couramment uti-lisée pour tester un bruit blanc est le Q’ de Box et Ljung, connue également comme lastatistique de Box et Pierce modifiée. La valeur du Q’ peut être vérifiée sur une basecomprise entre un quart et la moitié des observations et ne doit pas être significativepour que l’hypothèse du bruit blanc puisse être conservée pour la série des résidus.Cette vérification peut facilement être effectuée en utilisant la procédure SPSS Auto-correlation qui donne la statistique de Box et Ljung ainsi que sa significativité à chaquepas du décalage dans le corrélogramme de la fonction d’autocorrélation.
Dans l’approche classique de Box et Jenkins, on examine également l’erreur-type des coeffi-cients du modèle en vérifiant leur significativité statistique. Dans le cas d’un surajustementdes données par un modèle trop complexe, certains coefficients peuvent ne pas être statisti-quement significatifs et doivent donc être abandonnés.
On dit qu’une série Xt suit un processus ARMA d’ordre (p, q) (noté ARMA(p, q)), si onpeut écrire :
Xt− φ1Xt−1 − . . .− φpXt−p = at − θ1at−1 . . .− θqat−q
Φ(B)Xt = Θ(B)at
où la série at est un bruit blanc.
7 Qualité de la prévision
Procédure bootstrap pour calculer le biais, la variance et l’IC de l’estimation dela moyenne et de la médiane de la loi des durées de voyage T
On considère une statistique réelle T (X) fonction des observations de l’échantillon :X1, · · · , Xn. Ici, T (X) représente dans un premier temps l’estimation de la moyenne de laloi des durées de voyage T et dans un deuxième temps l’estimation de la médiane de la loi
Mémoire de Master de Statistique Appliquée. FOUDA Norbert © ENSP 2010-2012

Fondements théoriques et outils 34
des durées de voyage T.Supposons qu’on souhaite estimer une caractéristique de T (X) en tant que variable aléatoireréelle (v.a.r), par exemple m = E [T (X)]
1. Fixer un entier B « grand »En suite, on va simuler B réalisations indépendantes et identiquement distribués (i.i.d)de la v.a.r T (X∗) avec X∗ = (X∗
1 , · · · , X∗n) où X∗
1 , · · · , X∗n sont i.i.d selon la loi px
(c’est la loi empirique de x qui est l’échantillon empirique de l’estimateur de KM de laloi des durées de voyage pour un corridor arbitraire)
2. On simule successivement
x∗1 = (x∗11, · · · , x∗1n) i.i.dL∼ px
x∗2 = (x∗21, · · · , x∗2n) i.i.dL∼ px
...
x∗B = (x∗B1, · · · , x∗Bn) i.i.dL∼ px
3. On calcule :t∗1 = T (x∗1), · · · , t∗B = T (x∗B) ∈ R, qui sont des réalisations i.i.d de la loi T (X∗)
4. On estime alors m∗ et donc la vraie valeur m = E [T (X)] par :
m∗B =
1
B
B∑k=1
t∗k
5. Estimation de la variance de T (X) :
σB∗ =
1
B − 1
B∑k=1
(t∗k − m∗B)2
Supposons que T (X) est l’estimateur d’un paramètre réel inconnu θ, alors : L’estima-tion concrète de θ est : θ = T (x)
6. Estimation du biais b(T (X)/θ) = E [T (X)]− θ par :
b∗B = m∗B − θ
7. Intervalle de confiance pour θ de niveau 1− α, pour α ∈]0, 12[ :[
t∗B, α2, t∗B,1−α
2
], par défaut α = 0.05
Mémoire de Master de Statistique Appliquée. FOUDA Norbert © ENSP 2010-2012
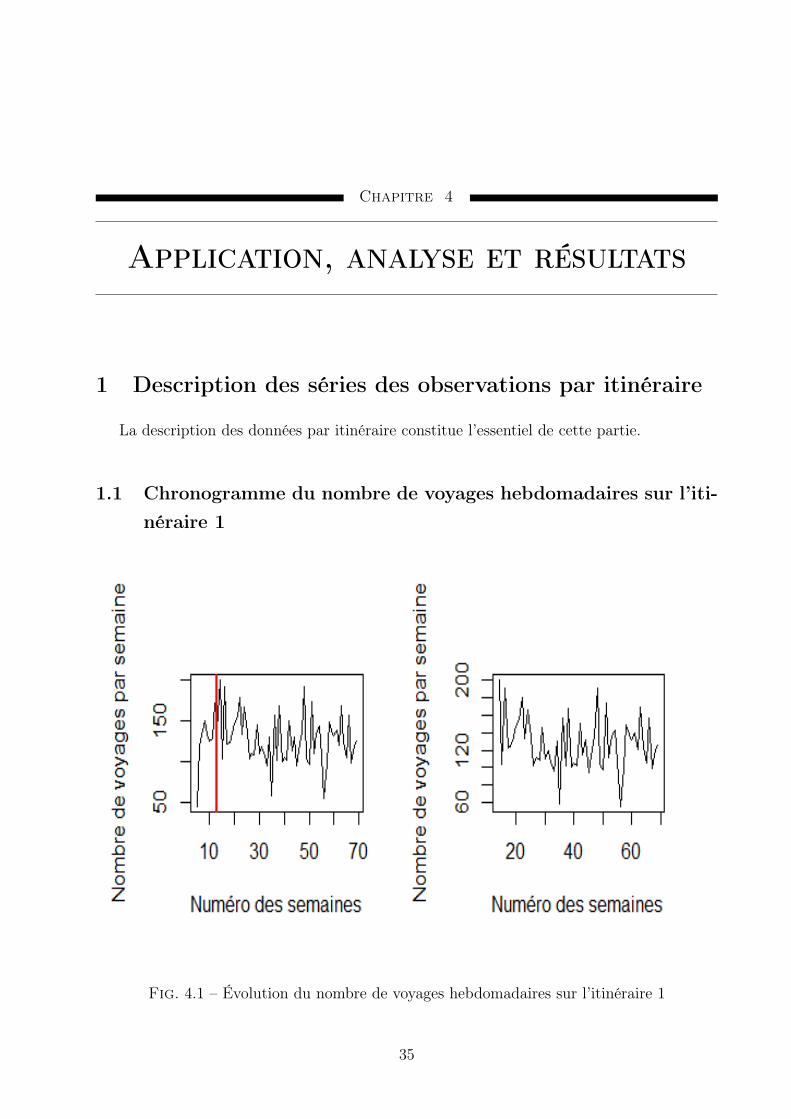
Chapitre 4
Application, analyse et résultats
1 Description des séries des observations par itinéraire
La description des données par itinéraire constitue l’essentiel de cette partie.
1.1 Chronogramme du nombre de voyages hebdomadaires sur l’iti-néraire 1
Fig. 4.1 – Évolution du nombre de voyages hebdomadaires sur l’itinéraire 1
35
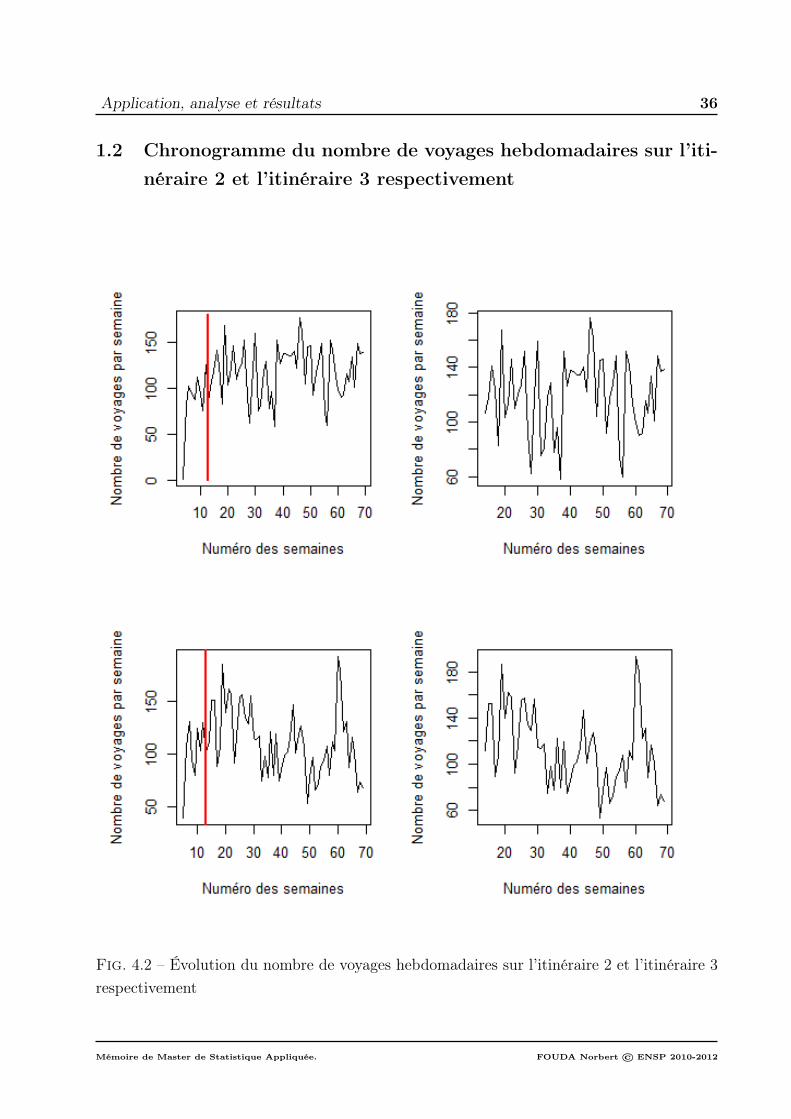
Application, analyse et résultats 36
1.2 Chronogramme du nombre de voyages hebdomadaires sur l’iti-néraire 2 et l’itinéraire 3 respectivement
Fig. 4.2 – Évolution du nombre de voyages hebdomadaires sur l’itinéraire 2 et l’itinéraire 3respectivement
Mémoire de Master de Statistique Appliquée. FOUDA Norbert © ENSP 2010-2012
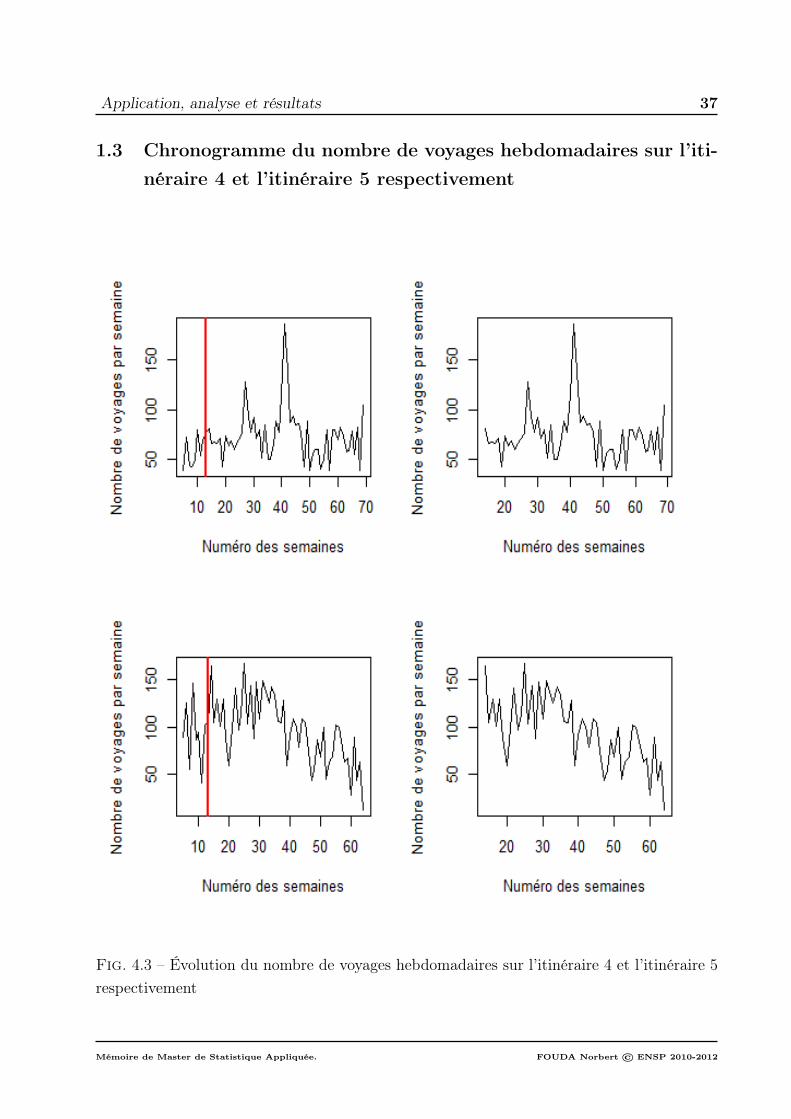
Application, analyse et résultats 37
1.3 Chronogramme du nombre de voyages hebdomadaires sur l’iti-néraire 4 et l’itinéraire 5 respectivement
Fig. 4.3 – Évolution du nombre de voyages hebdomadaires sur l’itinéraire 4 et l’itinéraire 5respectivement
Mémoire de Master de Statistique Appliquée. FOUDA Norbert © ENSP 2010-2012
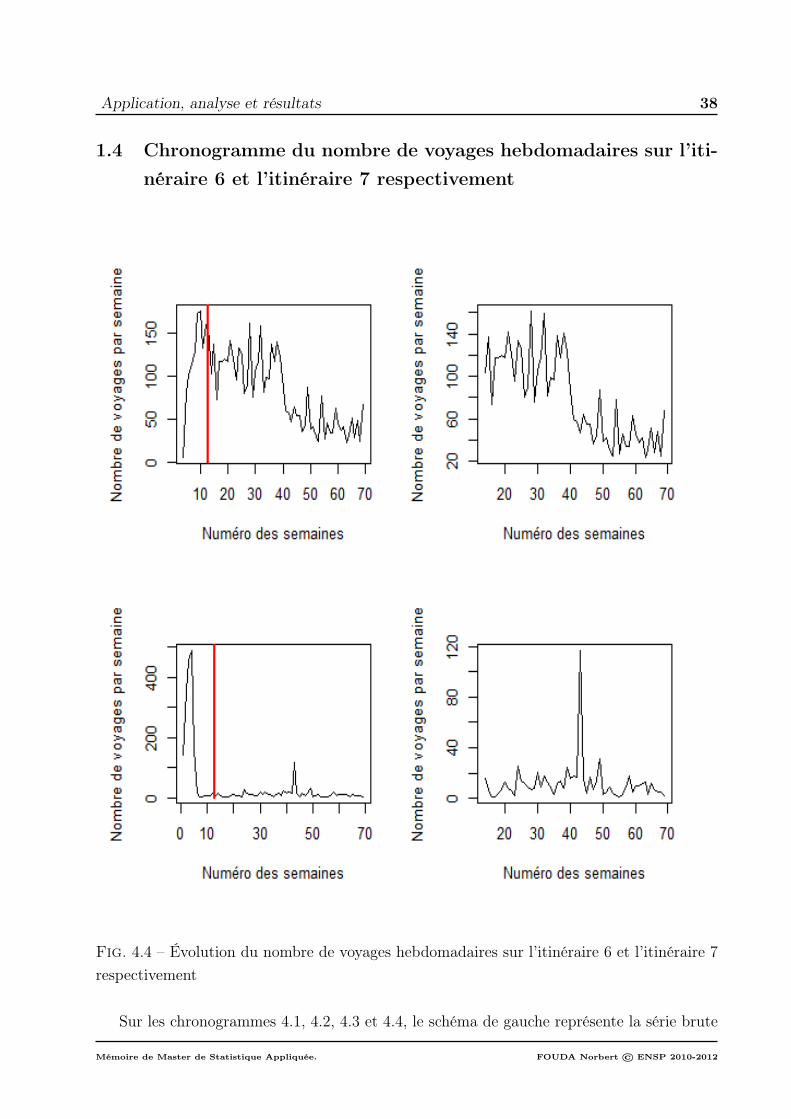
Application, analyse et résultats 38
1.4 Chronogramme du nombre de voyages hebdomadaires sur l’iti-néraire 6 et l’itinéraire 7 respectivement
Fig. 4.4 – Évolution du nombre de voyages hebdomadaires sur l’itinéraire 6 et l’itinéraire 7respectivement
Sur les chronogrammes 4.1, 4.2, 4.3 et 4.4, le schéma de gauche représente la série brute
Mémoire de Master de Statistique Appliquée. FOUDA Norbert © ENSP 2010-2012

Application, analyse et résultats 39
et celui de droite est la même série, mais prise à partir de la semaine 14. Mais pourquoi lasemaine 14 ? La mise en place du système SYDONIA à la Douane Camerounaise a pris uncertain temps. On le voit sur les graphes 4.1 et 4.2, les séries brutes débutent avec très peud’observations, aussi à l’exception de l’itinéraire 7 qui a enregistré des voyages à la premièresemaine, tous les autres itinéraires ont enregistré leur premier voyage aux alentours de lasemaine 5. En général, l’évolution du nombre de voyages au cours des premières semaines estun peu particulière, c’est ce qui a motivé le choix de la semaine 14 comme début de collectenormale des voyages sur les différents itinéraires.
Après cette correction portée sur les observations, nous supposons que le nouveau systèmemis en place par la Douane Camerounaise fonctionne déjà normalement sur cet itinéraire.Ainsi, les données qui feront l’objet de l’étude ultérieure sont prises à partir de la semaine 14.
L’itinéraire 1 et l’itinéraire 2, graphique 4.1 et graphique 4.2 en haut, ont sensiblementla même allure. Ils sont stable à vu d’oeil, avec des haut et des bas qui s’alternent.
L’itinéraire 3, graphique 4.2 en bas, est caractérisé par de forts pics construits de ma-nière progressive par l’évolution des voyages antérieurs. L’aspect général de cette série tendà décroître au fil du temps.
L’itinéraire 4, graphique 4.3 en haut, présente de forts pics construit de manière brutale,contrairement à l’itinéraire 3. Les semaines, après pics, sont caractérisées par une baisse pro-gressive du nombre de voyages comme à l’itinéraire 3. Dans l’ensemble, la tendance a l’airconstante.
L’itinéraire 5, graphique 4.3 en bas, a un nombre de voyages, bien que variant, sembletourner outour d’une constante jusqu’à la semaine 35. Et après, la tendance décroit mani-festement.
L’itinéraire 6, graphique 4.4 en haut, semble globalement stable, avec des hauts et desbas jusqu’à la semaine 40. Et ensuite décroit brutalement pour se stabiliser à nouveau autourd’une nouvelle valeur à partir de la semaine 50.
L’itinéraire 7, graphique 4.4 en bas, est caractérisé par un faible nombre de voyages,généralement en dessous de 20 voyages par semaine. Cependant, il a subi un choc à lasemaine 43 avec 117 voyages enregistrés.
.
Mémoire de Master de Statistique Appliquée. FOUDA Norbert © ENSP 2010-2012
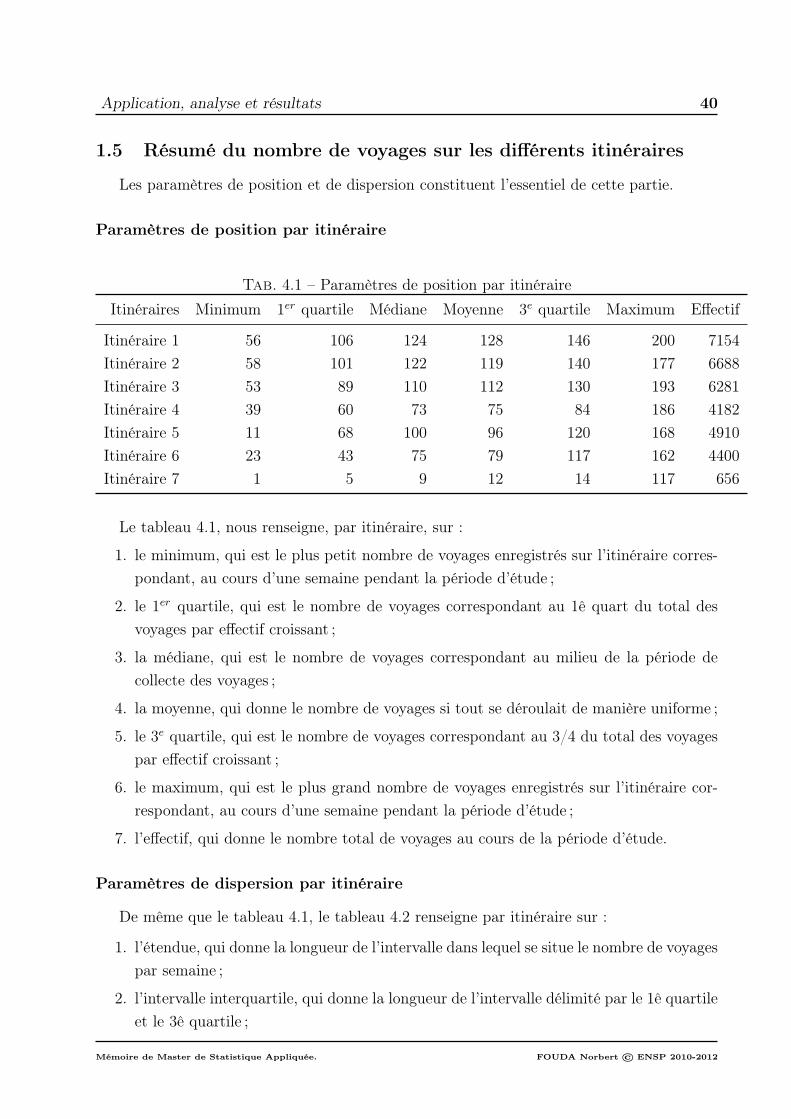
Application, analyse et résultats 40
1.5 Résumé du nombre de voyages sur les différents itinéraires
Les paramètres de position et de dispersion constituent l’essentiel de cette partie.
Paramètres de position par itinéraire
Tab. 4.1 – Paramètres de position par itinéraireItinéraires Minimum 1er quartile Médiane Moyenne 3e quartile Maximum Effectif
Itinéraire 1 56 106 124 128 146 200 7154Itinéraire 2 58 101 122 119 140 177 6688Itinéraire 3 53 89 110 112 130 193 6281Itinéraire 4 39 60 73 75 84 186 4182Itinéraire 5 11 68 100 96 120 168 4910Itinéraire 6 23 43 75 79 117 162 4400Itinéraire 7 1 5 9 12 14 117 656
Le tableau 4.1, nous renseigne, par itinéraire, sur :
1. le minimum, qui est le plus petit nombre de voyages enregistrés sur l’itinéraire corres-pondant, au cours d’une semaine pendant la période d’étude ;
2. le 1er quartile, qui est le nombre de voyages correspondant au 1ê quart du total desvoyages par effectif croissant ;
3. la médiane, qui est le nombre de voyages correspondant au milieu de la période decollecte des voyages ;
4. la moyenne, qui donne le nombre de voyages si tout se déroulait de manière uniforme ;
5. le 3e quartile, qui est le nombre de voyages correspondant au 3/4 du total des voyagespar effectif croissant ;
6. le maximum, qui est le plus grand nombre de voyages enregistrés sur l’itinéraire cor-respondant, au cours d’une semaine pendant la période d’étude ;
7. l’effectif, qui donne le nombre total de voyages au cours de la période d’étude.
Paramètres de dispersion par itinéraire
De même que le tableau 4.1, le tableau 4.2 renseigne par itinéraire sur :
1. l’étendue, qui donne la longueur de l’intervalle dans lequel se situe le nombre de voyagespar semaine ;
2. l’intervalle interquartile, qui donne la longueur de l’intervalle délimité par le 1ê quartileet le 3ê quartile ;
Mémoire de Master de Statistique Appliquée. FOUDA Norbert © ENSP 2010-2012

Application, analyse et résultats 41
Tab. 4.2 – Paramètres de dispersion par itinéraireItinéraires Etendue Intervalle interquartile Ecart-type
Itinéraire 1 154 40 30Itinéraire 2 119 39 28Itinéraire 3 140 41 33Itinéraire 4 147 24 25Itinéraire 5 157 52 35Itinéraire 6 139 74 40Itinéraire 7 116 9 16
3. l’écart-type, qui nous renseigne sur la variabilité du nombre de voyages hebdomadaires.
Nos itinéraires étant ainsi globalement décrites, nous nous appesantirons davantage sur l’iti-néraire 1 et l’itinéaire 5. Nous choisissons l’itinéraire 1 parceque d’une part, il a plus devoyages que les autres, et d’autre part, celui-ci respecte rigoureusement la définition de l’iti-néraire que nous nous sommes donnés dans le cadre de cette étude. L’itinéaire 5 quant à lui,est celui qui renferme le plus de voyages lorsque nous avions procédé au regroupement desvoyages.
2 Estimation des composantes des séries du nombre heb-domadaire de voyages sur l’itinéraire 1 et l’itinéraire 5
Nous appelerons "itiner1" et "itiner5" respectivement, les séries donnant le nombre devoyages hebdomadaires de l’itinéraire 1 et de l’itinéraire 5.
2.1 Estimation de la tendance générale des séries
Nous allons appliquer l’ajustement analytique pour ressortir la tendance générale desséries : itiner1 et itiner5.
Ajustement de la tendance générale
Rappelons la forme générale de la tendance que nous voulons estimer.
yt = a× t + b.
La méthode des moindres carrés appliquée aux séries itiner1 et itiner5 donne :
Mémoire de Master de Statistique Appliquée. FOUDA Norbert © ENSP 2010-2012

Application, analyse et résultats 42
itiner1
Nous avons les tableaux 4.3 qui donne les valeurs des différents coefficients estimés, et 4.4qui donne les valeurs des résidus de cette régression. Il ressort de cette régression (tableau
Tab. 4.3 – Résumé de l’estimation de la tendance générale de la série itiner1Coefficients Estimation Erreur Pr(> |t|)
b 141.0113 10.9937 <2e-16***a -0.3195 0.2468 0.201
4.3) que, seul le coefficient b est significatif. La p-value = 0.201 > 0.05 relative au coefficienta nous pousse à le rejeter au seuil de 5%. D’où l’équation suivante :
(T ) yt = 141.
Or, la moyenne du nombre de voyages par semaine sur l’itinéraire 1 est :
moy_itiner1 = 127.75.
Sachant que le point moyen d’une série bidimensionnelle appartient à la droite de régression,nous considérerons plutôt comme de tendance générale, la droite d’équation :
(T 1) yt = 128, où T 1 désigne la tendance générale de l’itinéraire 1.
Tab. 4.4 – Disposition des résidus de la régression de la série itiner1Minimum 1er quartile Médiane 3e quartile Maximum
-70.827 -21.626 -0.173 17.922 65.327
Le tableau 4.4 montre que les résidus de cette régression ne sont pas symétriques parrapport à l’origine. Ceux-ci semblent étalés vers la gauche.
itiner5
La régression sur l’itinéraire 5, tableau 4.5 montre par contre que tous les coefficients,par rapport à la forme générale de l’équation de la tendance retenue, sont significatifs. D’oùl’équation de la tendance est :
(T 5) yt = −1.54× t + 156.63, où T 5 désigne la tendance générale de l’itinéraire 5.
Le tableau 4.6 comme celui de 4.4 démontre que les résidus de la régression 4.5 ne sontpas symétriques par rapport à l’origine. Tout comme à l’itinéraire 1, ceux-ci semblent étalésvers la gauche.
Mémoire de Master de Statistique Appliquée. FOUDA Norbert © ENSP 2010-2012

Application, analyse et résultats 43
Tab. 4.5 – Résumé de l’estimation de la tendance générale de la série itiner5Coefficients Estimation Erreur Pr(> |t|)
b 156.631 10.7186 <2e-16***a -1.5476 0.2571 2.19e-07***
Tab. 4.6 – Disposition des résidus de la régression de la série itiner5Minimum 1er quartile Médiane 3e quartile Maximum
-66,679 -20,858 0,226 21,368 50,059
Valeur bootstrap de la tendance générale
En reconstruisant B = 1000 fois nos deux séries : itiner1 et itiner5, de telle sorte que,à partir du fichier de voyages enregistrés journellement de chacun de ces itinéraires, noustirons de manière aléatoire et avec remise, B échantillons de mêmes tailles que le fichier devoyages initial. Sur chacun des B échantillons d’un itinéraire donné, nous reconstruisons lasérie des observations hebdomadaires, et, de là, nous déterminons dans un premier tempsla tendance générale de chacune des B séries des observations hebdomadaires obtenues surchaque itinéraire. Les valeurs bootstrap de la tendance générale sur nos 2 itinéraires sont :
Tendance bootstrap itiner1
Donnée par le tableau 4.7
Tab. 4.7 – Tendance bootstrap et intervalle de confiance de l’itinéraire 1Valeur,boot IC,à,2,5% IC,à,97,5%
Intercept (b) 141,06 133,44 148,48pente (a) -0,32 -0,50 -0,14
Tendance bootstrap itiner5
Donnée par le tableau 4.8Les tendances de nos 2 séries étant ainsi estimées, l’heure est à l’estimation de la saison-
nalité, suivant la méthodologie présentée au chapitre précédent.
Avant d’y arriver, le graphe 4.5 présente l’évolution du nombre de voyages sur l’itinéraire1 avec sa tendance générale déterminée supra, à gauche. A droit, nous avons le graphe del’évolution du nombre de voyages sur l’itinéraire 5 avec sa tendance générale.
Mémoire de Master de Statistique Appliquée. FOUDA Norbert © ENSP 2010-2012
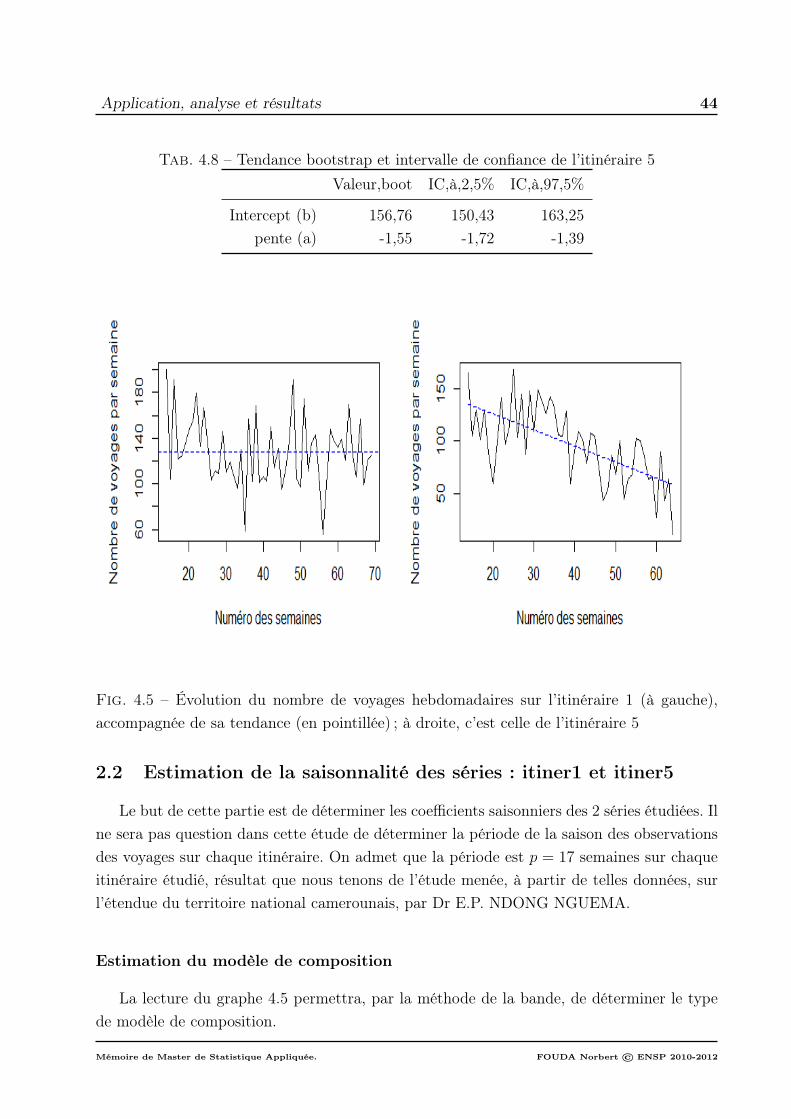
Application, analyse et résultats 44
Tab. 4.8 – Tendance bootstrap et intervalle de confiance de l’itinéraire 5Valeur,boot IC,à,2,5% IC,à,97,5%
Intercept (b) 156,76 150,43 163,25pente (a) -1,55 -1,72 -1,39
Fig. 4.5 – Évolution du nombre de voyages hebdomadaires sur l’itinéraire 1 (à gauche),accompagnée de sa tendance (en pointillée) ; à droite, c’est celle de l’itinéraire 5
2.2 Estimation de la saisonnalité des séries : itiner1 et itiner5
Le but de cette partie est de déterminer les coefficients saisonniers des 2 séries étudiées. Ilne sera pas question dans cette étude de déterminer la période de la saison des observationsdes voyages sur chaque itinéraire. On admet que la période est p = 17 semaines sur chaqueitinéraire étudié, résultat que nous tenons de l’étude menée, à partir de telles données, surl’étendue du territoire national camerounais, par Dr E.P. NDONG NGUEMA.
Estimation du modèle de composition
La lecture du graphe 4.5 permettra, par la méthode de la bande, de déterminer le typede modèle de composition.
Mémoire de Master de Statistique Appliquée. FOUDA Norbert © ENSP 2010-2012

Application, analyse et résultats 45
Méthode de la bande
La distribution du nombre de voyages de l’itinéraire 1, graphe 4.5 gauche, montre claire-ment que celle-ci est contenue dans bande délimitée par 2 droites apparemment parallèles.D’où nous admettons que le modèle de composition de la série itiner1 est additif.Quant à la série itiner5, graphe 4.5 droite, nous admettons que le modèle de compositionest aussi additif. Car, plus précisément, à partir de la semaine 21, toutes les observationsqui suivent sont contenues dans une bande descendante, constituée de 2 droites presqueparallèles.
Expression du modèle attendu
Ainsi, l’équation du modèle des séries itiner1 et itiner5 est de la forme :
Yt = Tt + St + εt.
Où, Tt est la tendance générale du modèle, St la saisonnalité et εt représente le résidu. L’ex-pression du modèle ci-dessus nécessite que nous estimions chaque terme de cette expression.Le terme Tt étant déjà estimé, l’estimation de St est donnée dans le tableau 4.9.
Estimation des coefficients saisonniers centrés
L’estimation des coefficients saisonniers centrés des séries itiner1 et itiner5 est donnéepar le tableau 4.9.
où :
1. Semaine : semaine d’observation correspondant ;
2. Num_coeff : numéro d’ordre du coefficient saisonnier ;
3. coeff_itiner1 : coefficient saisonnier de l’itinéraire 1.
4. coeff_itiner5 : coefficient saisonnier de l’itinéraire 5.
Valeur bootstrap des coefficients saisonniers corrigés
Nous avons les B = 1000 séries des observations hebdomadaires obtenues sur chaqueitinéraire tel que décrit dans le paragraphe intitulé "Valeur bootstrap de la tendance géné-rale". Nous déterminons dans un deuxième temps les coefficients saisonniers de chacune desB séries des observations. Les valeurs bootstrap des coefficients saisonniers sont :
1. Semaine : semaine d’observation correspondant ;
2. Num_coeff : numéro d’ordre du coefficient saisonnier ;
3. coeff.s.c.boot : coefficients saisonniers centrés bootstrap ;
4. ec.typ.boot : écart-type bootstrap des coefficients saisonniers centrés ;
Mémoire de Master de Statistique Appliquée. FOUDA Norbert © ENSP 2010-2012
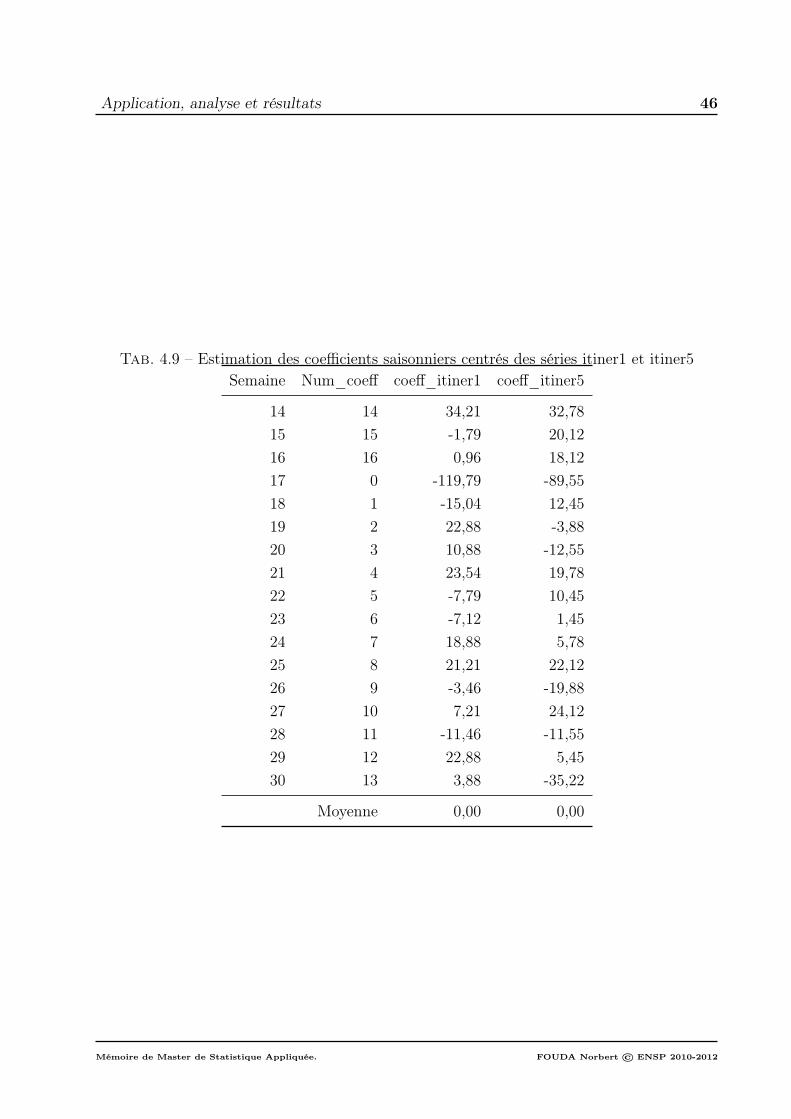
Application, analyse et résultats 46
Tab. 4.9 – Estimation des coefficients saisonniers centrés des séries itiner1 et itiner5Semaine Num_coeff coeff_itiner1 coeff_itiner5
14 14 34,21 32,7815 15 -1,79 20,1216 16 0,96 18,1217 0 -119,79 -89,5518 1 -15,04 12,4519 2 22,88 -3,8820 3 10,88 -12,5521 4 23,54 19,7822 5 -7,79 10,4523 6 -7,12 1,4524 7 18,88 5,7825 8 21,21 22,1226 9 -3,46 -19,8827 10 7,21 24,1228 11 -11,46 -11,5529 12 22,88 5,4530 13 3,88 -35,22
Moyenne 0,00 0,00
Mémoire de Master de Statistique Appliquée. FOUDA Norbert © ENSP 2010-2012
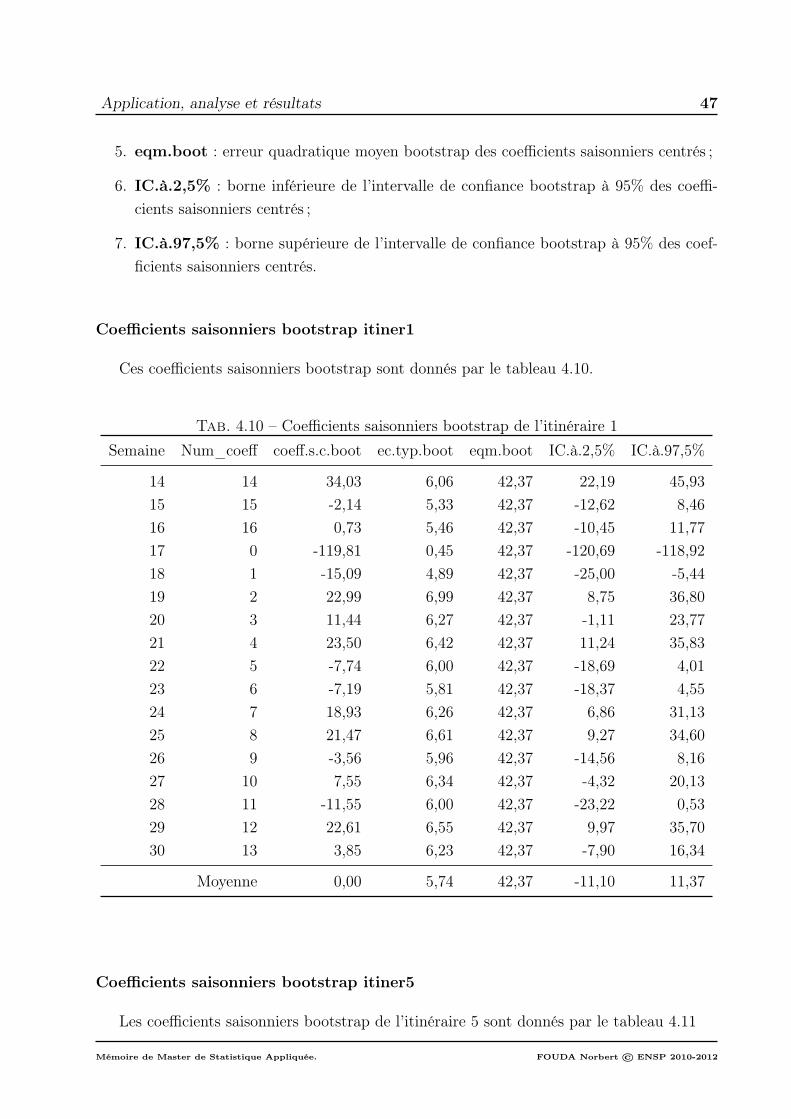
Application, analyse et résultats 47
5. eqm.boot : erreur quadratique moyen bootstrap des coefficients saisonniers centrés ;
6. IC.à.2,5% : borne inférieure de l’intervalle de confiance bootstrap à 95% des coeffi-cients saisonniers centrés ;
7. IC.à.97,5% : borne supérieure de l’intervalle de confiance bootstrap à 95% des coef-ficients saisonniers centrés.
Coefficients saisonniers bootstrap itiner1
Ces coefficients saisonniers bootstrap sont donnés par le tableau 4.10.
Tab. 4.10 – Coefficients saisonniers bootstrap de l’itinéraire 1Semaine Num_coeff coeff.s.c.boot ec.typ.boot eqm.boot IC.à.2,5% IC.à.97,5%
14 14 34,03 6,06 42,37 22,19 45,9315 15 -2,14 5,33 42,37 -12,62 8,4616 16 0,73 5,46 42,37 -10,45 11,7717 0 -119,81 0,45 42,37 -120,69 -118,9218 1 -15,09 4,89 42,37 -25,00 -5,4419 2 22,99 6,99 42,37 8,75 36,8020 3 11,44 6,27 42,37 -1,11 23,7721 4 23,50 6,42 42,37 11,24 35,8322 5 -7,74 6,00 42,37 -18,69 4,0123 6 -7,19 5,81 42,37 -18,37 4,5524 7 18,93 6,26 42,37 6,86 31,1325 8 21,47 6,61 42,37 9,27 34,6026 9 -3,56 5,96 42,37 -14,56 8,1627 10 7,55 6,34 42,37 -4,32 20,1328 11 -11,55 6,00 42,37 -23,22 0,5329 12 22,61 6,55 42,37 9,97 35,7030 13 3,85 6,23 42,37 -7,90 16,34
Moyenne 0,00 5,74 42,37 -11,10 11,37
Coefficients saisonniers bootstrap itiner5
Les coefficients saisonniers bootstrap de l’itinéraire 5 sont donnés par le tableau 4.11
Mémoire de Master de Statistique Appliquée. FOUDA Norbert © ENSP 2010-2012
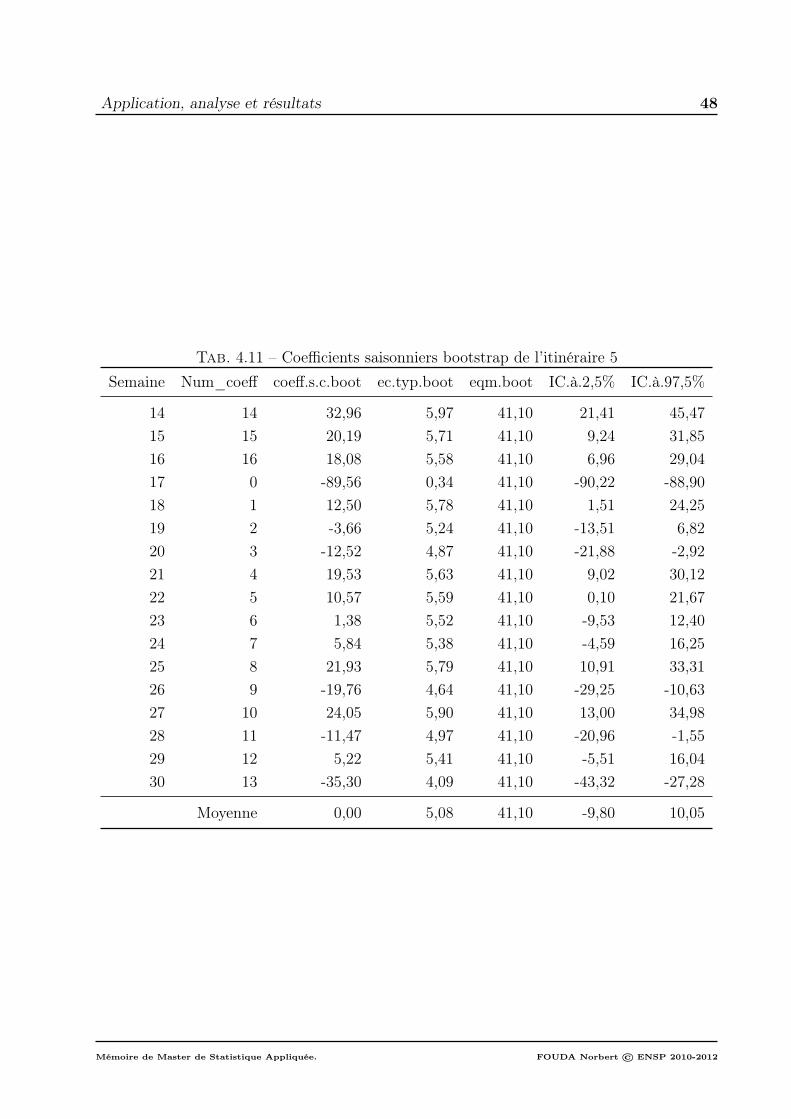
Application, analyse et résultats 48
Tab. 4.11 – Coefficients saisonniers bootstrap de l’itinéraire 5Semaine Num_coeff coeff.s.c.boot ec.typ.boot eqm.boot IC.à.2,5% IC.à.97,5%
14 14 32,96 5,97 41,10 21,41 45,4715 15 20,19 5,71 41,10 9,24 31,8516 16 18,08 5,58 41,10 6,96 29,0417 0 -89,56 0,34 41,10 -90,22 -88,9018 1 12,50 5,78 41,10 1,51 24,2519 2 -3,66 5,24 41,10 -13,51 6,8220 3 -12,52 4,87 41,10 -21,88 -2,9221 4 19,53 5,63 41,10 9,02 30,1222 5 10,57 5,59 41,10 0,10 21,6723 6 1,38 5,52 41,10 -9,53 12,4024 7 5,84 5,38 41,10 -4,59 16,2525 8 21,93 5,79 41,10 10,91 33,3126 9 -19,76 4,64 41,10 -29,25 -10,6327 10 24,05 5,90 41,10 13,00 34,9828 11 -11,47 4,97 41,10 -20,96 -1,5529 12 5,22 5,41 41,10 -5,51 16,0430 13 -35,30 4,09 41,10 -43,32 -27,28
Moyenne 0,00 5,08 41,10 -9,80 10,05
Mémoire de Master de Statistique Appliquée. FOUDA Norbert © ENSP 2010-2012

Application, analyse et résultats 49
3 Modélisation
3.1 Expression du modèle
Dans l’expression du modèle de décomposition retenue plus haut,
Y it = T i
t + Sit + εi
t,
oùi désigne l’itinéraire i.t17 ≡ reste de la division euclidienne de t par 17,
k ≡ ordre du coefficient saisonnier (k ∈
j/j = t17
), voir tableau 4.9
Ik ≡ fonction indicatrice, Ik(x) = 1 si x = k, et 0 sinonak ≡ coefficients saisonniers corrigés de numéro d’ordre k voir tableau 4.9En remplaçant chaque terme par son expression analytique, on obtient :
Yt = 128 +17∑
k=1
a1k × Ik(t
17) + ε1
t ,
pour l’itinéraire 1, et
Yt = −1.54× t + 156.63 +17∑
k=1
a5k × Ik(t
17) + ε5
t ,
pour l’itinéraire 5.
3.2 Prédiction de la partie déterministe
La partie déterministe du modèle est :
Dit = T i
t + Sit
où :
1. T it : valeur de la tendance à la date t de l’itinéraire i ;
2. Sit : désigne le coefficient saisonnier centré de la semaine t de l’itinéraire i.
Partie déterministe du modèle par itinéraire
Elle constitue l’expression analytique de l’équation Dit = T i
t + Sit sur chaque itinéraire.
Série : itiner1
D1t = 128 +
17∑k=1
a1k × Ik(t
17)
Mémoire de Master de Statistique Appliquée. FOUDA Norbert © ENSP 2010-2012

Application, analyse et résultats 50
Série : itiner5
D5t = −1.54× t + 156.63 +
17∑k=1
a5k × Ik(t
17)
Nous effectuons dans la suite les prévisions déterministes sur les 2 prochains mois, desséries bootstrap.Comment effectuerons-nous concrètement une prévision à la semaine t + h (avec h entierpositif) ?
3.3 Méthode de prévision bootstrap
Nous procederons ainsi qu’il suit :
1. On considère le modèle de composition. Ici, on a un modèle additif.
2. On effectue les opérations relatives au modèle de composition (c’est l’addition dans cecas) des observations sur les valeurs des termes du modèle estimés à t + h.
3. On détermine les valeurs des bornes de l’intervalle de confiance bootstrap de la prévisiont + h, dans ce cas :– IC95%(Dt+h) = maxIC95%(Tt+h), IC95%(St+h); ec.typ.boot95%(Dt+h) = ec.typ.boot95%(IC95%(Dt+h))
–– eqm.boot95%(Dt+h) = eqm.boot95%(IC95%(Dt+h))
N.B. L’idée au niveau de la détermination de l’intervalle de confiance du modèle déter-ministe est de trouver l’intervalle susceptible de contenir, à 95%, les combinaisons bootstrapdes termes Tt+h et St+h.
3.4 Valeurs des prévisions déterministes sur les 2 prochains mois
On considère donc h = 8.
Valeurs des prévisions déterministes sur l’itinéraire 1 pour les 2 prochains mois
Valeurs des prévisions déterministes sur l’itinéraire 5 pour les 2 prochains mois
Ajouter le graphe des prévisions
Ajustement
N.B : Il est important pour la bonne marche de la méthode que nous implémentons degarder à l’esprit que, la détermination des valeurs bootstrap (tendance bootstrap, coefficientssaisonniers bootstrap, et résidu bootstrap) se fait successivement sur le même échantillonbootstrap.
Mémoire de Master de Statistique Appliquée. FOUDA Norbert © ENSP 2010-2012

Conclusion
a connaissance a priori du volume du trafic de marchandises à venir sur un itinéraire,permettrait à la douane de se prémunir afin de gérer au mieux le transit suivant les nou-velles exigences. La prévision, considérée comme un outil incontournable dans l’élaborationdes stratégies dans ce cadre, se doit d’être fiable afin d’assurer une bonne gestion des af-faires courantes. Pour garantir une bonne fiabilité à la prévision menée dans cette étude,des précautions ont été prises. D’abord sur le plan méthodolgique, l’étude a démarré par laprésentation du paysage du transit. Ensuite, une analyse exploratoire du type de donnéescollectées par le logiciel SYDONIA a été faite. Enfin, la théorie scientifique en matière deprédiction dans le temps a été brièvement présentée suivie de son application sur les donnéesd’étude. Il est important de souligner également que, dans le but d’éviter une quelconquedissociation entre l’application des méthodes choisies et la réalité quotidienne vécue, la pré-sente étude a tenu, quand cela semblait nécessaire, à interpréter les résultats théoriques demanière concrète. Évidemment, ce travail a connu des difficultés. Le mystère reste entiersur la connaissance entre la réalité vécue sur les itinéraires par les transitaires et même laqualité des itinéraires en question. Le fait remarquable qu’il convient d’exhiber est que nousprévoyons 464 voyages pour le mois de janvier 2012 variant dans l’intervalle [273, 671], 537voyages pour le mois de fevrier 2012 avec un intervalle de confiance de [541, 745], et le moisde mars 2012 est annoncé avec 522 voyages compris dans un intervalle de confiance de [326,726]. La mise en place d’un programme, dans un logiciel de statistique libre tel que R, pourgérer uniquement la prévision des voyages, en prenant en compte la réalité de la collectedes données aux problèmes rencontrés par les transitaires, produirait à moindre coût et entemps voulu, des prévisions fiables sur les itinéraires voulus.
51
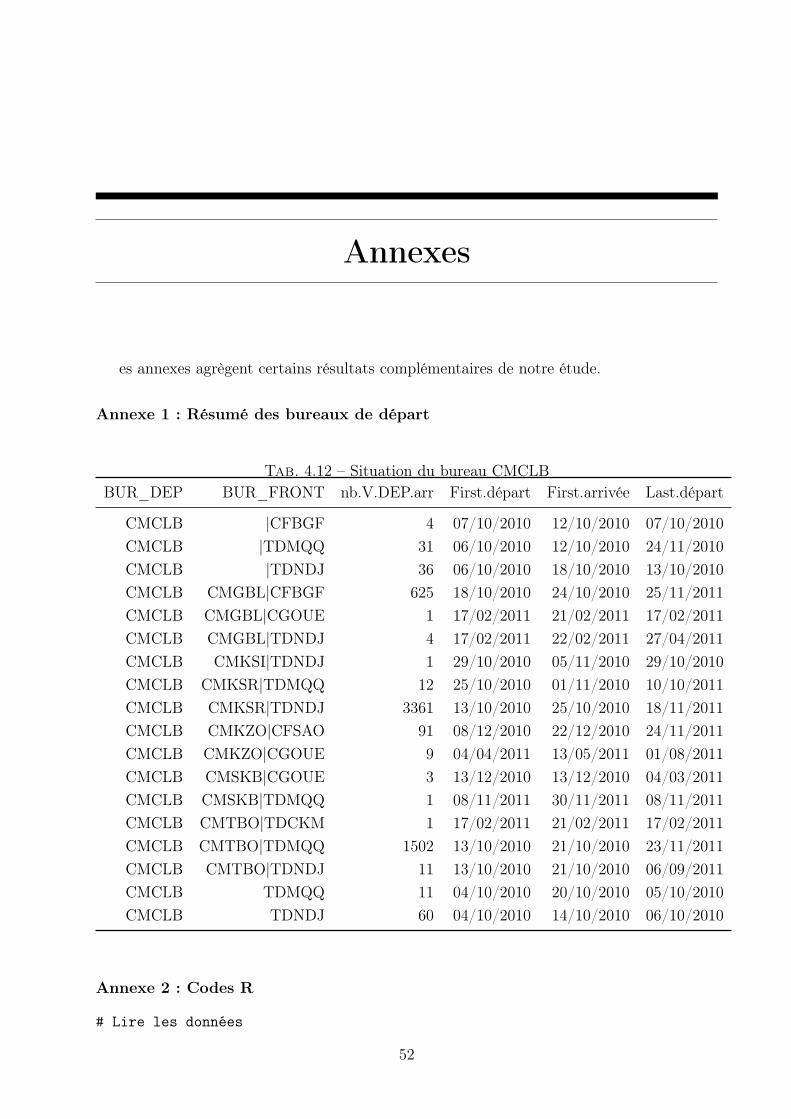
Annexes
es annexes agrègent certains résultats complémentaires de notre étude.
Annexe 1 : Résumé des bureaux de départ
Tab. 4.12 – Situation du bureau CMCLBBUR_DEP BUR_FRONT nb.V.DEP.arr First.départ First.arrivée Last.départ
CMCLB |CFBGF 4 07/10/2010 12/10/2010 07/10/2010CMCLB |TDMQQ 31 06/10/2010 12/10/2010 24/11/2010CMCLB |TDNDJ 36 06/10/2010 18/10/2010 13/10/2010CMCLB CMGBL|CFBGF 625 18/10/2010 24/10/2010 25/11/2011CMCLB CMGBL|CGOUE 1 17/02/2011 21/02/2011 17/02/2011CMCLB CMGBL|TDNDJ 4 17/02/2011 22/02/2011 27/04/2011CMCLB CMKSI|TDNDJ 1 29/10/2010 05/11/2010 29/10/2010CMCLB CMKSR|TDMQQ 12 25/10/2010 01/11/2010 10/10/2011CMCLB CMKSR|TDNDJ 3361 13/10/2010 25/10/2010 18/11/2011CMCLB CMKZO|CFSAO 91 08/12/2010 22/12/2010 24/11/2011CMCLB CMKZO|CGOUE 9 04/04/2011 13/05/2011 01/08/2011CMCLB CMSKB|CGOUE 3 13/12/2010 13/12/2010 04/03/2011CMCLB CMSKB|TDMQQ 1 08/11/2011 30/11/2011 08/11/2011CMCLB CMTBO|TDCKM 1 17/02/2011 21/02/2011 17/02/2011CMCLB CMTBO|TDMQQ 1502 13/10/2010 21/10/2010 23/11/2011CMCLB CMTBO|TDNDJ 11 13/10/2010 21/10/2010 06/09/2011CMCLB TDMQQ 11 04/10/2010 20/10/2010 05/10/2010CMCLB TDNDJ 60 04/10/2010 14/10/2010 06/10/2010
Annexe 2 : Codes R
# Lire les données
52
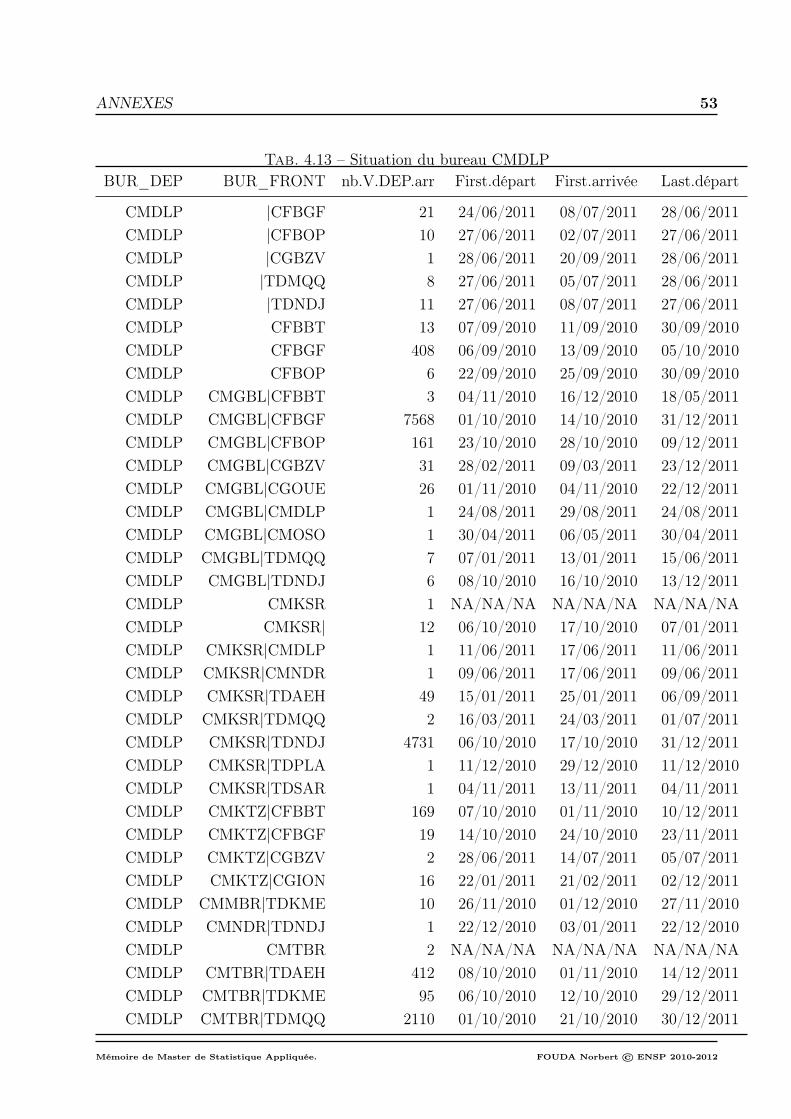
ANNEXES 53
Tab. 4.13 – Situation du bureau CMDLPBUR_DEP BUR_FRONT nb.V.DEP.arr First.départ First.arrivée Last.départ
CMDLP |CFBGF 21 24/06/2011 08/07/2011 28/06/2011CMDLP |CFBOP 10 27/06/2011 02/07/2011 27/06/2011CMDLP |CGBZV 1 28/06/2011 20/09/2011 28/06/2011CMDLP |TDMQQ 8 27/06/2011 05/07/2011 28/06/2011CMDLP |TDNDJ 11 27/06/2011 08/07/2011 27/06/2011CMDLP CFBBT 13 07/09/2010 11/09/2010 30/09/2010CMDLP CFBGF 408 06/09/2010 13/09/2010 05/10/2010CMDLP CFBOP 6 22/09/2010 25/09/2010 30/09/2010CMDLP CMGBL|CFBBT 3 04/11/2010 16/12/2010 18/05/2011CMDLP CMGBL|CFBGF 7568 01/10/2010 14/10/2010 31/12/2011CMDLP CMGBL|CFBOP 161 23/10/2010 28/10/2010 09/12/2011CMDLP CMGBL|CGBZV 31 28/02/2011 09/03/2011 23/12/2011CMDLP CMGBL|CGOUE 26 01/11/2010 04/11/2010 22/12/2011CMDLP CMGBL|CMDLP 1 24/08/2011 29/08/2011 24/08/2011CMDLP CMGBL|CMOSO 1 30/04/2011 06/05/2011 30/04/2011CMDLP CMGBL|TDMQQ 7 07/01/2011 13/01/2011 15/06/2011CMDLP CMGBL|TDNDJ 6 08/10/2010 16/10/2010 13/12/2011CMDLP CMKSR 1 NA/NA/NA NA/NA/NA NA/NA/NACMDLP CMKSR| 12 06/10/2010 17/10/2010 07/01/2011CMDLP CMKSR|CMDLP 1 11/06/2011 17/06/2011 11/06/2011CMDLP CMKSR|CMNDR 1 09/06/2011 17/06/2011 09/06/2011CMDLP CMKSR|TDAEH 49 15/01/2011 25/01/2011 06/09/2011CMDLP CMKSR|TDMQQ 2 16/03/2011 24/03/2011 01/07/2011CMDLP CMKSR|TDNDJ 4731 06/10/2010 17/10/2010 31/12/2011CMDLP CMKSR|TDPLA 1 11/12/2010 29/12/2010 11/12/2010CMDLP CMKSR|TDSAR 1 04/11/2011 13/11/2011 04/11/2011CMDLP CMKTZ|CFBBT 169 07/10/2010 01/11/2010 10/12/2011CMDLP CMKTZ|CFBGF 19 14/10/2010 24/10/2010 23/11/2011CMDLP CMKTZ|CGBZV 2 28/06/2011 14/07/2011 05/07/2011CMDLP CMKTZ|CGION 16 22/01/2011 21/02/2011 02/12/2011CMDLP CMMBR|TDKME 10 26/11/2010 01/12/2010 27/11/2010CMDLP CMNDR|TDNDJ 1 22/12/2010 03/01/2011 22/12/2010CMDLP CMTBR 2 NA/NA/NA NA/NA/NA NA/NA/NACMDLP CMTBR|TDAEH 412 08/10/2010 01/11/2010 14/12/2011CMDLP CMTBR|TDKME 95 06/10/2010 12/10/2010 29/12/2011CMDLP CMTBR|TDMQQ 2110 01/10/2010 21/10/2010 30/12/2011
Mémoire de Master de Statistique Appliquée. FOUDA Norbert © ENSP 2010-2012
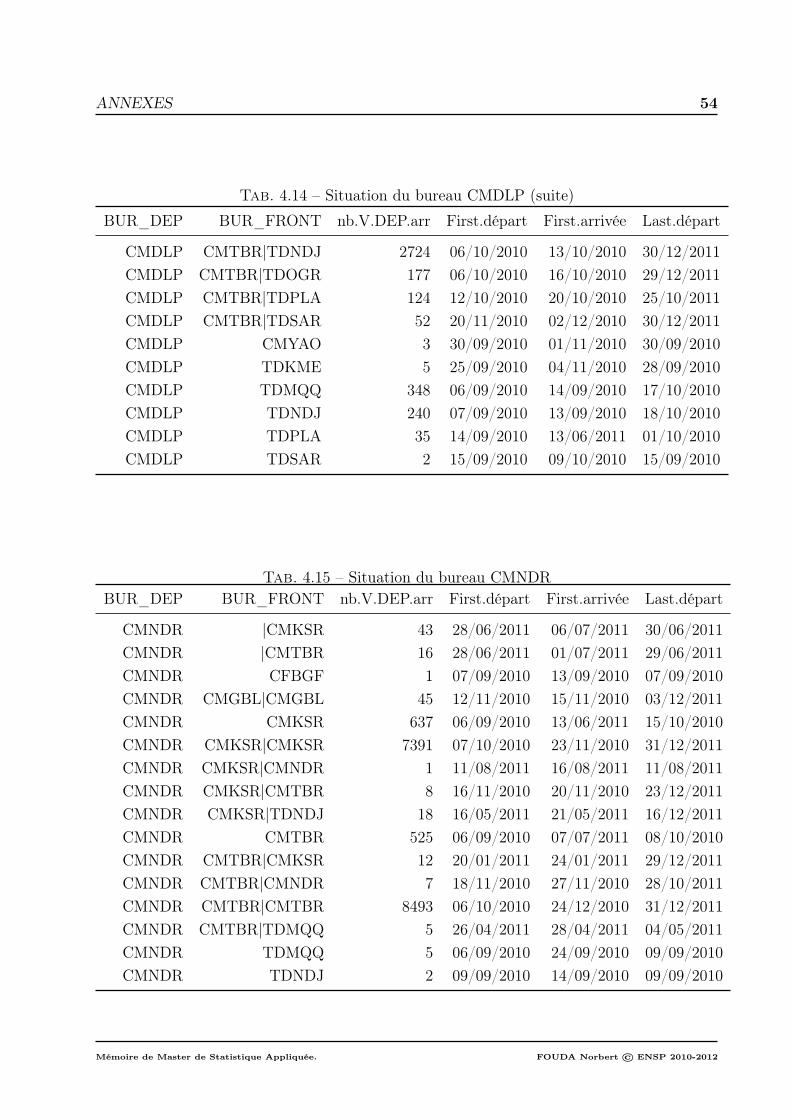
ANNEXES 54
Tab. 4.14 – Situation du bureau CMDLP (suite)
BUR_DEP BUR_FRONT nb.V.DEP.arr First.départ First.arrivée Last.départ
CMDLP CMTBR|TDNDJ 2724 06/10/2010 13/10/2010 30/12/2011CMDLP CMTBR|TDOGR 177 06/10/2010 16/10/2010 29/12/2011CMDLP CMTBR|TDPLA 124 12/10/2010 20/10/2010 25/10/2011CMDLP CMTBR|TDSAR 52 20/11/2010 02/12/2010 30/12/2011CMDLP CMYAO 3 30/09/2010 01/11/2010 30/09/2010CMDLP TDKME 5 25/09/2010 04/11/2010 28/09/2010CMDLP TDMQQ 348 06/09/2010 14/09/2010 17/10/2010CMDLP TDNDJ 240 07/09/2010 13/09/2010 18/10/2010CMDLP TDPLA 35 14/09/2010 13/06/2011 01/10/2010CMDLP TDSAR 2 15/09/2010 09/10/2010 15/09/2010
Tab. 4.15 – Situation du bureau CMNDRBUR_DEP BUR_FRONT nb.V.DEP.arr First.départ First.arrivée Last.départ
CMNDR |CMKSR 43 28/06/2011 06/07/2011 30/06/2011CMNDR |CMTBR 16 28/06/2011 01/07/2011 29/06/2011CMNDR CFBGF 1 07/09/2010 13/09/2010 07/09/2010CMNDR CMGBL|CMGBL 45 12/11/2010 15/11/2010 03/12/2011CMNDR CMKSR 637 06/09/2010 13/06/2011 15/10/2010CMNDR CMKSR|CMKSR 7391 07/10/2010 23/11/2010 31/12/2011CMNDR CMKSR|CMNDR 1 11/08/2011 16/08/2011 11/08/2011CMNDR CMKSR|CMTBR 8 16/11/2010 20/11/2010 23/12/2011CMNDR CMKSR|TDNDJ 18 16/05/2011 21/05/2011 16/12/2011CMNDR CMTBR 525 06/09/2010 07/07/2011 08/10/2010CMNDR CMTBR|CMKSR 12 20/01/2011 24/01/2011 29/12/2011CMNDR CMTBR|CMNDR 7 18/11/2010 27/11/2010 28/10/2011CMNDR CMTBR|CMTBR 8493 06/10/2010 24/12/2010 31/12/2011CMNDR CMTBR|TDMQQ 5 26/04/2011 28/04/2011 04/05/2011CMNDR TDMQQ 5 06/09/2010 24/09/2010 09/09/2010CMNDR TDNDJ 2 09/09/2010 14/09/2010 09/09/2010
Mémoire de Master de Statistique Appliquée. FOUDA Norbert © ENSP 2010-2012

ANNEXES 55
data <- read.table("GPS_a5_Time_S.txt")#---- Découpage des itinéraires ---------------------
mafonction2 <- function(data)# data = jeu de données déjà lu (i.e. data == read.table(...))
temp2 <- (data[,"BUR_DEP"] == "CMDLP") & (data[,"BUREAU_FRONT"] == "CMGBL|CFBGF")temp4 <- (data[,"BUR_DEP"] == "CMDLP") & (data[,"BUREAU_FRONT"] == "CMKSR|TDNDJ")temp3 <- (data[,"BUR_DEP"] == "CMNDR") & (data[,"BUREAU_FRONT"] == "CMKSR|CMKSR")temp1 <- (data[,"BUR_DEP"] == "CMNDR") & (data[,"BUREAU_FRONT"] == "CMTBR|CMTBR")temp5 <- (data[,"BUR_DEP"] == "CMCLB")temp6 <- (data[,"BUR_DEP"] == "CMDLP") & (substr(data[,"BUREAU_FRONT"],1,5) == "CMTBR")temp7 <- (!temp1) & (!temp2) & (!temp3) & (!temp4) & (!temp5) & (!temp6)corr1 <- data[temp1,]corr2 <- data[temp2,]corr3 <- data[temp3,]corr4 <- data[temp4,]corr5 <- data[temp5,]corr6 <- data[temp6,]corr7 <- data[temp7,]corr <- list(corr1 = corr1 , corr2 = corr2, corr3 = corr3, corr4 = corr4, corr5 = corr5, corr6 = corr6, corr7 = corr7)for (i in 1:7)
write.table(corr[[i]], paste(paste("corr",i, sep = ""), ".txt", sep = ""))return(corr)
#----------------------------------------------------------------------# ETUDE CONJOINTE DES VARIABLES DATE DEPART ET DATE ARRIVEE#----------------------------------------------------------------------#--------------- NUAGE DE POINTS -------------------------
donnees.ens <- read.table("GPS_a5_Time_S.txt")vect.x <- donnees.ens[,10] # extraction de la date de départvect.y <- donnees.ens[,11] # extraction de la date d’arrivée
# Représentation du nuage de points
Mémoire de Master de Statistique Appliquée. FOUDA Norbert © ENSP 2010-2012

ANNEXES 56
plot(vect.y~vect.x, xlab = "Numéro du jour (date) de départ", ylab = "Numéro du jour (date) d’arrivée")model.ens <- lm(vect.y~vect.x)summary(model.ens)abline(model.ens, col="red", lwd=2, main="")
# Etude des résidus de la régressionres <- residuals(model.ens)hist(res, xlab="Valeur du résidu", main="Histogramme des résidus de la liaison arrivée-départ")
#---------------------------------------------------------------# Méthodologie générale de cette étude#---------------------------------------------------------------
#------------ 1ère étape ---------------------------------------# Application au corridor 2#---------------------------------------------------------------
# Lecture des donnéescorr2=read.table("corr2.txt", header=T)
# Taille ou dimension du data.framedim(corr2)
# Extraction de la série à étudierdonnees=table(corr2$periode)donnees
# Transformation en objet tsseri=ts(as.data.frame(donnees)[,2],start=c(2010,9),frequency=1/52)
# Représentation brute de la série (ou chronogramme)t <- as.integer(names(donnees))plot(t,seri,type="l",lty=1,ylab="Nombre de voyages par semaine",xlab="Numéro d’ordre des semaines à partir du 06/09/2010 au 12/09/2010")
# Constat: Au cours des premières semaines, l’allure de la courbe# n’est pas très appréciable. La première observation qui peut être# considérer comme aberrante, probablement à cause de# la mise en place du monitoring, nous suggère de traiter au
Mémoire de Master de Statistique Appliquée. FOUDA Norbert © ENSP 2010-2012

ANNEXES 57
# préalable ces données afin de corriger ces observations.
segments(x0=13,y0=0,x1=13,y1=180,col="red",lwd=2)# ajout d’un segment vertical, c’est à partir de cet instant que nous supposons# que le nouveau système mis en place par la douane fonctionne déjà normalement# sur cet itinéraire.
# Correction de la courbe en considérant le début des observations à la# semaine 13ind <- t > 13t <- t[ind]seri.1 <- seri[ind] # série à partir de la semaine 13plot(t,seri.1,type="l",lty=1,ylab="Nombre de voyages par semaine",xlab="Numéro d’ordre des semaines à parir du 06/09/2010 au 12/09/2010")
#--------------------------------------------------------------------------# Estimation du modèle de composition#--------------------------------------------------------------------------
#------------ Méthode de la bande ----------------------------#-- Equation de la droite passant par les minima, points de coordonnées# (37,58) et (56,60)droite.min <- data.frame(x=c(37,56),y=c(58,60))tab1 <- lm(droite.min$y~droite.min$x)summary(tab)#--- La droite passant par les minima a pour équation: y=0.1053*x+54.1053
#-- Equation de la droite passant par les maxima, points de coordonnées# (19,168) et (46,177)droite.max <- data.frame(x=c(19,46),y=c(168,177))tab2 <- lm(droite.max$y~droite.max$x)summary(tab2)#--- La droite passant par les maxima a pour équation: y=0.3333*x+161.6667
# Représentation de ces droites sur le grphiquecurve(0.1053*x + 54.1053, col="blue", add=T)curve(0.3333*x + 161.6667, col="blue", add=T)
Mémoire de Master de Statistique Appliquée. FOUDA Norbert © ENSP 2010-2012

ANNEXES 58
# Ajout du texttext (25, 175, "y=0.3333*x+161.6667", col="blue")text (47, 63, "y=0.1053*x+54.1053", col="blue")
# Conclusion: on admet que le modèle est additif.#--------------------------------------------------------------------# Estimation de la tendance par ajustement analytique#--------------------------------------------------------------------
# Ajout de la droite de régression
fm <- lm(seri.1 ~ t)summary(fm)
# Equation de la droite la droite de régession: y=0.07738*x+116.21750
curve(0.07738*x+116.21750, col="gold", add=T)
# Constat: la pente de cette droite n’est pas significative (p-value = 0.745 )# Donc, nous admettons que le nombre de voyages hebdomadaires sur l’itinéraire 2# tourne autour de 119 ( partie entère 119.4286.# Ainsi, la tendance générale a pour équation: y = m
m <- mean(seri.1)abline(h=m, col="red")
# Constat: La série semble présenter une tendance linéaire (à completer)
#---------------------------------------------------------------------------# Estimation de la tendance par ajustement analytique#---------------------------------------------------------------------------
# Calcul de la moyenne de la série (question:est-ce que la moy. appartient tjrs à la droite de régression?)m <- mean(seri.1) # m = 127.75
# Détermination de l’équation de la droite de régression
Mémoire de Master de Statistique Appliquée. FOUDA Norbert © ENSP 2010-2012

ANNEXES 59
fm <- lm(seri.1 ~ t)summary(fm)
# Constat: la pente de cette droite n’est pas significative (p-value = 0.201 )# Donc, nous admettons que le nombre de voyages hebdomadaires sur l’itenéraire 1# tourne autour de 128 ( partie entère(127.75) + 1).# Ainsi, la tendance générale a pour équation: y = m
# Détermination des résidus de la sérieresidu <- seri.1 - mplot(t,residu,type="l",lty=1,ylab="Nombre de voyages détendancialisé par semaine",xlab="Numéro d’ordre des semaines à partir du 06/09/2010 au 12/09/2010")
#---------------------------------------------------------------------------# Estimation des variations saisonnières du nombre de voyages hebdomadaires#---------------------------------------------------------------------------
#--------------------------------------------------------------------# Modèle de décomposition déterministe# - Méthode de la bande: conclusion modèle additif (voir graphe)#--------------------------------------------------------------------
#-------- Calcul de la saison ----------------#
moving.Ave.Odd <- function(time.S,q=3)
n <- nrow(time.S) ; k <- q %/% 2 ;
tS <- rbind(time.S[(k+1):2,],time.S,time.S[(n-k):(n-1),])
m <- k ;for (i in k:1) tS$obs[i] <- mean(tS$obs[(i+1):(i+m)])for (i in (n+1+k):(n+k+k)) tS$obs[i] <- mean(tS$obs[(i-1):(i-m)])
ts.MA <- tS ; ind <- (k+1):(n+k) ;
Mémoire de Master de Statistique Appliquée. FOUDA Norbert © ENSP 2010-2012

ANNEXES 60
for (i in ind) ts.MA$obs[i] <- mean(tS$obs[(i-k):(i+k)])
ts.MA[ind,]
corr2 <- data.frame(time = t, obs = seri.1)moving.Ave.Odd(corr2)
mA.3 <- moving.Ave.Odd(corr2)
lines(mA.3, col = "green",lwd = 2)
mA.17 <- moving.Ave.Odd(corr2, q= 17)
lines(mA.17, col = "red",lwd = 2)
abline(h=m)
#------------- Conclusion ---------------------------# La série admet une saisonnalité de période q=17#-----------------------------------------------------------
#------------------------------------------------------------# Détermination des résidus de la série: e=Y-T-S#------------------------------------------------------------
# Série initiale: Y=seri.1# Tendance: T=m# Coeff.saisonnier: S
Y <- seri.1T <- mobs <- data.frame(time = t, obs = seri.1)ma.17 <- moving.Ave.Odd(obs,q=17)S <- ma.17$obsresidu <- seri.1 - m - S
#-------------------------------------------------------#---- Ajout des droites pour lire la période ---#
Mémoire de Master de Statistique Appliquée. FOUDA Norbert © ENSP 2010-2012

ANNEXES 61
plot(t,seri.1,type="l",lty=1,ylab="Nombre de voyages par semaine",xlab="Numéro d’ordre des semaines à parir du 06/09/2010 au 12/09/2010")curve(0.07738*x+116.21750, col="green4", add=T)
# lines(mA.3, col = "green",lwd = 2)lines(mA.17, col = "red",lwd = 2)abline(h=m)segments(x0=20,y0=60,x1=20,y1=180,col="blue",lwd=2)segments(x0=54,y0=60,x1=54,y1=180,col="blue",lwd=2)segments(x0=20,y0=60,x1=54,y1=60,col="orangered",lwd=2)text (42, 63, "période=34", col="orangered")
#------------ commentaire ------------------# La période graphique vaut: x1-x0 = 54 - 20 = 34. La période de la série# vaut: p = 34/2 = 17; car# période graphique des moyennes mobiles = 2*période série (recherché)
#-------- Courbes de seri.1, tendance et seri.1cvs -------------------corr2=read.table("corr2.txt", header=T)donnees=table(corr2$periode)seri=ts(as.data.frame(donnees)[,2],start=c(2010,9),frequency=1/52)t <- as.integer(names(donnees))ind <- t > 13t <- t[ind]seri.1 <- seri[ind] # série à partir de la semaine 13plot(t,seri.1,type="l",lty=1,ylab="Nombre de voyages par semaine",xlab="Numéro d’ordre des semaines à parir du 06/09/2010 au 12/09/2010")curve(0.07738*x+116.21750, col="gold", add=T) # Tendancetabdes <- read.csv2("table_desaisonnalisé.csv")lines(t,tabdes$seri.1_CVS, col = "blue",lwd = 2)
#--------------- Courbe des résidus ------------------------plot(t,tabdes$Residu,type="l",lty=1,ylab="Résidu du nombre de voyages",xlab="Numéro d’ordre des semaines à partir du 06/09/2010 au 12/09/2010")
#------ Série à modéliser suivant la méthode de Box & Jenkins -------------Z <- data.frame(t,tabdes$Residu)
#------ Graphe des résidusplot(t,residu,type="l",lty=1,ylab="Nombre de voyages détendancialisé et désaisonnalisé",xlab="Numéro d’ordre des semaines à partir du 06/09/2010 au 12/09/2010")abline(h=0)
#-------------------------------------------------------------
Mémoire de Master de Statistique Appliquée. FOUDA Norbert © ENSP 2010-2012

ANNEXES 62
# Série des résidus#-------------------------------------------------------------
Z <- residu
#---------------- Série à étudier : Z -------------------
#-------------------------------------------------------------------------# Etude des residus de la série du nombres de voyages# sur l’itinéraire 2#-------------------------------------------------------------------------
# Lecture du fichierser_res <- read.table("ser_res.txt",header=T,dec=",")
# Extraction de la série des résidusZ <- data.frame(ser_res$t,ser_res$residu)seri_stoch <- ts(Z[,2],start=c(2010,9),frequency=1/52)
# Chronogramme de la sérieplot(date,seri_stoch,type="l",lty=1,ylab="voyages",xlab="semaines")
# Paramètres de la série:# Position
mean(seri_stoch) # 0.8459561# Dispersion: variabilité
var(seri_stoch) # 653.5605# Dispersion: étendu
max(seri_stoch) # 55.2598min(seri_stoch) # -54.54583etendu <- max(seri_stoch) - min(seri_stoch) # 109.8056
# Le résumé démontre que 50% des valeurs de la série sont comprises entre# 1st Qu. = -16.530 ; 3rd Qu. = 16.500
# On note tout la tendance à la symmétrisation d’une part du max(seri_stoch)# par rapport au min(seri_stoch), et d’autre part du 1st Qu. par rapport au# 3rd Qu.
Mémoire de Master de Statistique Appliquée. FOUDA Norbert © ENSP 2010-2012

ANNEXES 63
# Calcul des coefficients d’asymmétrie et d’aplatissementm <- mean(seri_stoch)v <- var(seri_stoch)
n <-length(seri_stoch)# Moment centré d’ordre 3x3 <- (seri_stoch-m)^3mom.ord.3 <- sum(x3)/nsd.3 <- sqrt(v)^3
# Coefficient d’asymétriecoeff.asym <- mom.ord.3/sd.3 # -0.1753134
#--- Constat -----------------# La distribution est un peu plus étalée à gauche
# coefficient d’applatissement: coeff.applatx4 <- (seri_stoch-m)^4mom.ord.4 <- sum(x4)/nsd.4 <- sqrt(v)^4coeff.applat <- mom.ord.4/ sd.4 # 2.369599
#-------- constat ------------# La distribution est un peu plus applatie que la distribution normale# Ces paramètres suggèrent vraisemblablement une particularité à cette série.
# Test de stationnarité de la série.library("forecast")adf.test(seri_stoch) # p-value = 0.5628 > 0.05# On ne rejette pas H0: i.e. la série n’est pas stationnaire au seuil 5%.
# test de stationnarité du bruit differencié:adf.test(diff(seri_stoch)) # p-value = 0.01 < 0.05# On rejette H0: i.e. la série est stationnaire au seuil 5%.
Ici, la série est stationnaire au terme des tests effectués# Donc la série peut être modelisée par un ARMA
# On cherche
Mémoire de Master de Statistique Appliquée. FOUDA Norbert © ENSP 2010-2012

ANNEXES 64
acf(diff(seri_stoch)) # Déterminer le q max = 2pacf(diff(seri_stoch)) # Déterminer le p max = 3
# On détermine le model qui approche le mieux la réalitémodel1=auto.arima(diff(seri_stoch), max.p=3, max.q=2,d=0,trace=FALSE,test="adf",stationary=T)model1summary(model1) # pour voir les résultats
model1.best=auto.arima(diff(seri_stoch), max.p=1, max.q=3,d=0,trace=TRUE,test="adf",stationary=T)
# On choisit le model qui approche le mieux la réalité sur la base du# critère AIC
# On a un ARIMA(0,0,1)
modell1 <- Arima(seri_stoch,c(0,0,1))library("fBasics")res=residuals(modell1)t.test(res,mu=0,conf.level=0.95)Box.test(res,type ="Ljung-Box",lag=50)dagoTest(res)
# On réalise la prédictionforecast(modell1,12)
Mémoire de Master de Statistique Appliquée. FOUDA Norbert © ENSP 2010-2012

Bibliographie
[1] [Thomas Cantens] « La réforme de la douane camerounaise à l’aide d’un logicieldes Nations unies ou l’appropriation d’un outil de finances publiques », /Afriquecontemporaine/ 3/2007 (n° 223-224), p. 289-307. URL : www.cairn.info/revue-afrique-contemporaine-2007-3-page-289.htm
[2] [] Microsoft® Encarta® 2009.
[3] [Yves Aragon] Séries temporelles avec R Méthodes et cas, Springer, 2011.
[4] [Yadolah Dodge] STATISTIQUE Dictionnaire encyclopédique, Springer, 2007.
[5] [NANA YAKAM André] Modèle de prévision du parc des comptes d’une banque : casAfriland First Bank, Mémoire de statistique, 2005.
[6] [Nino Silverio] Séries chronologiques, Notes de cours, 2005.
[7] [Samson Bilangna] La réforme des douanes camerounaises : entre les contraintes localeset internationales, Afrique contemporaine 2/2009 (n° 230), p. 101-113.
[8] [Xavier BRY] Analyse et prévision élémentaires des Séries Temporelles, ENEA/STADE,1998.
[9] [Jean-Luc LEBRUN] Guide pratique de rédaction scientifique, © EDP Sciences 2007.
[10] [Pierre Lafaye de Micheaux, Remy Drouilhet, Benoit Liquet] Le logiciel R Maitriser lelangage Effectuer des analyses statistiques, Springer-Verlag France, 2011.
[11] [Pierre-André Cornillon, Eric Matzner-Løber] Régression avec R, Springer-VerlagFrance, 2011.
65





























