Embed Size (px)
Citation preview

République Algérienne Démocratique et Populaire
Ministère de l’Enseignement Supérieur et de la Recherche Scientifique
Université Mentouri Constantine
Faculté Des Sciences de l’Ingénieur
Département d’Informatique
N°: .............................
Série: ..........................
Thèse de Doctorat en Sciences en Informatique
Thème :
Un Cadre Formel pour La Modélisation et
L’analyse Des Agents Mobiles
Présentée par : Mme DEHIMI NARDJESS TISSILIA
Composition du Jury
Pr. MohamedKhirddine Kholladi Université El wed Président
Pr. Chaoui Allaoua Université Constantine2 Rapporteur
Pr. Mohamed Benmohammed
Pr. Hamid Seridi
Pr. Okba Kazar
Université Constantine2
Université de Guelma
Université de Biskra
Examinateur
Examinateur
Examinateur

Dédicaces
À tous ceux que j’aime
et à ceux qui m’aiment.

Remerciements
J‟adresse toute ma gratitude et mes remerciements au Pr Allaoua Chaoui
professeur à l‟université Mentouri Constantine qui a dirigé ce travail avec
compétence et professionnalisme. Je le remercie pour sa patience, sa tolérance
et ses qualités humaines durant ces années de thèse.
Je tiens à remercier chaleureusement, le Pr Kholladi Mohamed
Khireddine de m‟avoir fait l‟honneur d‟accepter de présider mon jury de
thèse.
Je remercie vivement, le Professeur Benmohammed Mohamed, le
Professeur Seridi Hamid et le Professeur Kazar Okba, d‟avoir accepté de juger
mon travail.
Je ne remercierais jamais assez, mon mari Abdelhakim, pour son
abnégation et sa patience, pour son aide et son soutien sur tous les plans.
Un grand merci à toute ma famille grands et petits (mes chères parents
mes beaux-parents, mes adorables quatre enfants, mes frères et sœurs et tous
les autres), pour leurs amour et encouragements.
Sans oublier de remercier tous mes collègues et amis (ies), qui n‟ont pas
manqué de me soutenir durant toutes ses années de thèse, et en particulier ma
chère Fatima Boussela, pour sa présence et son dévouement.

Résumé
L‟émergence des réseaux informatiques à grande échelle a donné naissance à de
nombreuses applications réparties. Ces applications exigent une forte interaction entre
différentes entités distribuées sur le réseau et qui partagent les mêmes ressources et les
mêmes buts. Plusieurs modèles d‟exécution distribués pour ces applications ont été
proposés dans la littérature. Parmi lesquels, le modèle d‟agent mobile trouve bien sa
place en proposant une solution facilitant le développement des applications réparties.
En effet, Un agent mobile est une entité autonome, capable d‟interagir avec son
environnement ainsi que sur soi-même, en se déplaçant d'un site du réseau à un autre
pour atteindre ses objectifs.
Il s‟avère donc que la technologie de la mobilité du code est l'un des domaines de
recherche les plus attrayants. Cependant, le manque de langages de modélisation de la
mobilité du code et les insuffisances formelles des approches existantes, incite à
suggérer de nouveaux formalismes. Dans ce contexte, nous présentons les Réseaux
Reconfigurables étiquetés (Labeled Reconfigurables Nets, LRN). Nous proposons une
approche et un outil de transformation automatique de modèles LRN à leurs
spécifications équivalentes en R-Maude. Cette transformation vise à rendre possible la
vérification des propriétés des systèmes modélisés en utilisant les LRN puisque ce
nouveau formalisme n'a pas d'outils pour l'analyse et la vérification. Notre approche est
basée sur l'utilisation combinée de la méta-modélisation et des grammaires de
graphe. Dans notre travail, le formalisme de diagramme de classe UML de l‟outil
ATOM3 est utilisé pour définir un métamodèle pour les LRN. ATOM3 est aussi utilisé
pour générer un outil de modélisation visuelle pour l‟élaboration de modèles selon le
métamodèle des LRN proposé. Nous avons aussi proposé une grammaire de graphe
pour générer automatiquement, la description R-Maude des modèles LRN
graphiquement spécifiés. Ensuite, la logique de réécriture R-Maude est utilisée pour
effectuer la simulation de la spécification générée.
Mots clés : Agent Mobile, Labeled Reconfigurable Nets, MDA, Grammaires de
Graphe, R-Maude, outil ATOM3.

Abstract
The emergence of large-scale computer networks has given rise to many
distributed applications. These applications require a close interaction between different
entities distributed over the network and share the same resources and the same goals.
Several models for distributed execution of these applications have been proposed in the
literature. Among them, the model of mobile agent offers a solution that facilitates the
development of distributed applications. Indeed, a mobile agent is an autonomous entity
able to react on its environment and on it self, by moving from one network site to
another to reach its objectives.
It appears clearly, that the technology of code mobility is one of the most
attractive areas of research. However, the poorness of modeling languages to deal with
code mobility at requirement phase has incited the researchers to suggest new
formalisms. Among these, we find Labeled Reconfigurable Net (LRN). We propose an
approach and a tool for automatic transformation of LRN models to their equivalent
R-Maude specifications. This transformation aims to make it possible to verify
properties of systems modeled using the LRN, as this new formalism has no tools for
analysis and verification. Our approach is based on the combined use of meta-modeling
and graph grammars. In our work, the formalism of UML class diagram tool ATOM3 is
used to define a meta-model for the LRN. ATOM3 is also used to generate a visual
modeling tool for developing models according to the proposed metamodel of LRN. We
have also proposed a graph grammar to automatically generate the R-Maude description
for the LRN models, graphically specified. Then, the rewriting logic R-Maude is used to
perform the simulation of the generated specification.
Keywords: Mobile Agent, Labeled Reconfigurable Nets, MDA, Graph
Grammars, R-Maude, ATOM3 tool.

ملخص
نظرا لظهور شبكات الحاسوب على نطاق واسع ظهرت العديد من التطبيقات الموزعة.
التطبيقات تتطلب تفاعل وثيق بين مختلف الكيانات الموزعة على الشبكة و التي تتقاسم نفس هذه
. من ماذج لتوزيع تنفيذ هذه التطبيقاتالموارد و تشترك في نفس األهداف. وقد اقترحت عدة ن
المحمول من خالل تقديمه للحلول التي تسهل تطوير التطبيقات الموزعة. العميلبينها، نموذج
المحمول هو كيان مستقل قادر على التفاعل مع بيئته وكذلك مع نفسه، وذلك باالنتقال من العميل
شبكة ألخرى لتحقيق أهدافه.
المحمول تصادفها مشاكل أمنية و توافقية في مختلف قواعد العميللكن تقدم تطبيقات
أدى بالباحثين إلى استكشاف نماذج أخرى لغات النماذج لوصف خاصية التنقل،اإلستقبال ، قلة
أداة للتحول و LRNتطبيقات. نقترح في هذه األطروحة شكلية جديدة هذه الألجل دعم تحقيق
. هذا التحول يهدف الى جعل من الممكن Maude -Rإلى مواصفاتها المعادلة LRNالتلقائي للنماذج
ية جديدة ال يوجد لها األدوات الالزمة ألن هذه الشكل LRNالتحقق من خصائص النظم باستخدام
ستند على االستخدام المشترك للنماذج الفوقية ولقواعد الرسم البياني. في نللتحليل والتحقق. و
. كما يستخدم metamodel -LRNلتحديد ATOM3من أداة UMLعملنا، يتم استخدام مخطط
ATOM3 لتوليد أداة العرض المرئي لوضع نماذج وفقا لmetamodel المقترح لLRN .
LRNالمعادلة للنماذج Maude -Rاقترحنا أيضا قاعدة الرسم البياني للتوليد التلقائي لمواصفات
ألداء المحاكاة للمواصفات المنجزة. Maude -Rالمقترحة. ثم، يتم استخدام منطق إعادة كتابة
، أداة Maude –R، قواعد الرسم البياني، LRN ، MDA: وكيل محمول، الكلمات المفتاحية
ATOM3.

1
Table des matières
Introduction générale ............................................................................................................... 7
Chapitre 1: Agents mobiles et applications réparties…..……………………………….... 11
1.1 Systèmes répartis et Agents mobiles .................................................................................. 11
1.1.1 Structures organisationnelles non mobiles pour les systèmes répartis ..................................... 11
1.1.1.1. Client/serveur ................................................................................................................... 11
1.1.1.2 Événement asynchrone ...................................................................................................... 12
1.1.1.3 Mémoire virtuelle partagée (MVP) ................................................................................... 12
1.1.2. Structures organisationnelles avec mobilité pour les systèmes répartis .................................. 13
1.1.2.1. La mobilité ....................................................................................................................... 13
1.1.2.2. Structures organisationnelles ............................................................................................ 14
1.2. Agents mobiles .................................................................................................................. 15
1.2.1 Définitions ................................................................................................................................ 15
1.2.2 Environnement d'exécution et système d'agents mobiles ......................................................... 16
1.2.3 Services requis pour l'exécution d'agents mobiles.................................................................... 18
1.2.3.1 Structure d'un agent mobile ............................................................................................... 18
1.2.3.2 Création d'agents mobiles .................................................................................................. 18
1.2.3.3 Migration d'un agent .......................................................................................................... 19
1.2.3.4 Service de nommage.......................................................................................................... 20
1.2.3.5 Service de localisation ....................................................................................................... 20
1.2.3.6 Communications entre les agents ...................................................................................... 20
1.2.3.7 Exécution d'un agent ......................................................................................................... 21
1.2.3.8 Sécurité .............................................................................................................................. 22
1.2.3.9 Cycle de vie et contrôle de l'agent ..................................................................................... 23
1.2.4. Domaine d‟application des agents mobiles ............................................................................. 24
1.2.5 Exemples de plateformes existantes ......................................................................................... 25
1.2.6. Avantages et inconvénients du paradigme agents mobiles ..................................................... 26
1.3. Conclusion ......................................................................................................................... 27

2
Chapitre 2: Approche MDA et Transformation de Modèles.…………………………..... 28
2.1 Principe ............................................................................................................................... 28
2.2 Définition des concepts fondamentaux .............................................................................. 29
2.2.1 Modèle ...................................................................................................................................... 29
2.2.2 Métamodèle .............................................................................................................................. 29
2.2.3 Métamétamodèle ...................................................................................................................... 29
2.3 L‟approche MDA ............................................................................................................... 30
2.3.1 Les modèles dans l‟Architecture MDA .................................................................................... 31
2.3.2 Principe de transformation ....................................................................................................... 32
2.3.3 Passage entre modèles .............................................................................................................. 33
2.3.4 Types de transformations de modèles ...................................................................................... 34
2.3.5. Classification des approches de transformation de modèles ................................................... 34
2. 3.5.1 Transformations de type Modèle vers code ...................................................................... 35
2.3.5.2. Transformations de type modèle vers modèle .................................................................. 35
2.4. Transformation de graphes ................................................................................................ 38
2.4.1. Concept de graphe ................................................................................................................... 38
2.4.2. Transformation de graphes ...................................................................................................... 40
2.4.2.1 Grammaires de graphes ..................................................................................................... 41
2.4.2.2. Le principe de règles ........................................................................................................ 41
2.4.2.3. Application des règles ...................................................................................................... 42
2.4.2.4 Système de transformation de graphe ................................................................................ 42
2.4.2.5 Langage engendré ............................................................................................................. 43
2.5. AToM3: Un outil de Modélisation Multi-paradigme ....................................................... 43
2.5.1. Présentation de l‟outil AToM3 ................................................................................................. 43
2.5.2. La Méta-modélisation avec AToM3 ........................................................................................ 44
2.5.3 La Transformation de Modèles. ............................................................................................... 46
2.6. Conclusion ......................................................................................................................... 48
Chapitre 3: Modélisation Formelle et Mobilité…………………………………...………. 49
3.1. But de la modélisation ....................................................................................................... 50
3.2. Différentes Formes de Modélisation ................................................................................ 51
3.3. Techniques d‟analyse ........................................................................................................ 52
3.4. Méthodes Formelles .......................................................................................................... 53
3.4.1. Les langages formels ............................................................................................................... 53

3
3.4.2. Les mythes autour des méthodes formelles ............................................................................. 54
3.4.3. Classification des Méthodes Formelles ................................................................................... 54
3.4.4. Techniques de vérification formelle ........................................................................................ 56
3.4.4.1. Vérification de modèles (Model-Checking) ..................................................................... 56
3.4.4.2. Preuve de théorèmes (Theorem proving) ......................................................................... 56
3.5 Combinaison d‟IDM avec les Méthodes Formelles .......................................................... 56
3.6. Réseaux de Petri ................................................................................................................ 58
3.6.1. Introduction ............................................................................................................................. 58
3.6.2 Concepts de base & définition .................................................................................................. 60
3.6.2.1 Définitions informelles ...................................................................................................... 60
3.6.2.2 Définitions formelles ......................................................................................................... 61
3.6.3 Modélisation des systèmes complexes ..................................................................................... 65
3.6.3.1 Parallélisme ....................................................................................................................... 65
3.6.3.2 Synchronisation ................................................................................................................. 66
3.6.3.3. Partage de ressources ....................................................................................................... 67
3.6.4 Méthodes d'analyse pour les réseaux de Petri .......................................................................... 67
3.6.4.1Analyse par graphes des marquages ................................................................................... 67
3.6.4.2 L‟équation de matrice ........................................................................................................ 68
3.6.4.3 La réduction des RdPs ....................................................................................................... 68
3.6.5 Extensions des réseaux de Petri ................................................................................................ 69
3.6.5.1. Les réseaux de Petri colorés ............................................................................................. 69
3.6.5.2 Les réseaux de Petri synchronisés (RdPS) ....................................................................... 69
3.6.5.3. Les réseaux de Petri temporisés ....................................................................................... 70
3.6.6. Modélisation des systèmes mobiles par les RdPs ................................................................... 70
3.6.6.1. Le paradigme (nets-within-nets) ...................................................................................... 70
3.6.6.2. Le paradigme (Nested Nets) ............................................................................................. 72
3.7. Conclusion ........................................................................................................................ 72
Chapitre 4:Une Plateforme Formelle pour la Modélisation et la Simulation desLRN.. 73
4.1 Réseaux reconfigurables étiquetés (Labeled Reconfigurable Nets LRN) ......................... 74
4.1.1 Définition.................................................................................................................................. 74
4.1.2 Exemples de modélisation des paradigmes de la mobilité avec les LRN ................................ 75
4.1.2.1 L'évaluation à distance ...................................................................................................... 75
4.1.2.2 Code à la demande............................................................................................................. 76

4
4.1.2.3. Mobile Agent ................................................................................................................... 77
4.2 Le système Maude .............................................................................................................. 78
4.2.1 Modules Maude ........................................................................................................................ 79
4.2.2 Syntaxe de Maude .................................................................................................................... 80
4.3 Reconfigurable Maude ...................................................................................................... 82
4.4 Meta-modélisation des LRN (réseaux reconfigurables étiquetés) .................................... 83
4.5 La grammaire de graphe qui génère la spécification R-Maude des modèles LRN…….. 84
4.6 Exemples ........................................................................................................................... 91
4.7 Prototypage R-Maude ....................................................................................................... 95
4.8 Conclusion ......................................................................................................................... 97
Conclusion générale et perspectives ..................................................................................... 98
Références Bibliographiques ............................................................................................... 100

5
Liste des figures
Figure 1.1. Organisation Client/serveur .................................................................................. 12
Figure 1.2. Evaluation à distance ............................................................................................. 14
Figure 1.3. Code à la demande ................................................................................................. 14
Figure 1.4. Agent mobile .......................................................................................................... 15
Figure 1.5. Place et Région ...................................................................................................... 17
Figure 1.6. Migration d‟un agent mobile ................................................................................. 19
Figure 2.1. Pyramide de la modélisation OMG ....................................................................... 30
Figure 2.2. Principe de la construction d‟un système à base de modèles dans le MDA .......... 31
Figure 2.3. Processus de transformation de modèles pilotée par les métamodèles .................. 32
Figure 2.4. Transformations de modèles MDA ........................................................................ 33
Figure 2.5. Exemple typique d‟une transformation de modèle vers modèle ........................... 36
Figure 2.6. Graphe non orienté ................................................................................................. 39
Figure 2.7. Graphe orienté simple ............................................................................................ 39
Figure 2.8. Graphe orienté étiqueté .......................................................................................... 39
Figure 2.9. G‟ est un sous graphe de G .................................................................................... 40
Figure 2.10. Une grammaire déterministe de graphes.............................................................. 41
Figure 2.11. Système de réécriture de graphes ......................................................................... 42
Figure 2.12. Récriture pour la grammaire de la figure 2.10 ..................................................... 43
Figure 2.13. Présentation AToM3 ............................................................................................ 44
Figure 2.14. Méta-Modèle des automates à états finis ............................................................. 45
Figure 2.15. Editeur graphique généré pour les automates à états finis ................................... 46
Figure 2.16. Grammaire de Graphe: élimination de l‟indéterminisme .................................... 47
Figure 2.17. Application de la Grammaire ............................................................................... 48
Figure 3.1. Classification et Utilisation de Langages ou de Méthodes [José] ......................... 51
Figure 3.2. La classification des méthodes formelles .............................................................. 55
Figure 3.3. Les MFs & IDM .................................................................................................... 57
Figure 3.4. Méthode générale de modélisation et d‟analyse basée sur les réseaux de Petri. ... 59
Figure 3.5. Un réseau de Petri comportant 7 places, ................................................................ 60
Figure 3.6. Un réseau de Petri marqué avec un vecteurde marquage ...................................... 61
Figure 3.7. Evolution d‟états d'un réseau de Petri [Claud01] ................................................... 63
Figure 3.8. Un réseau de Petri marqué ..................................................................................... 64
Figure 3.9. Matrice d‟incidence et vecteur de marquage du RdP de la figure 3.8. .................. 65
Figure 3.10. Structure du parallélisme ..................................................................................... 65

6
Figure 3.11. Synchronisation mutuelle .................................................................................... 66
Figure 3.12. Synchronisation par sémaphore ........................................................................... 66
Figure 3.13. Synchronisation par Partage de ressources .......................................................... 67
Figure 3.14. (a) Réseau de Petri (b) Graphe des marquages fini.............................................. 68
Figure 3.15. (a) Réseau de Petri (b) Graphe des marquages infini .......................................... 68
Figure 3.16. RdP (gauche) et RdP coloré (droite) [Scor06] ..................................................... 69
Figure 3.17. Un exemple d'un RdP Nets-within-Nets [Kohler07] .......................................... 71
Figure 3.18. Un exemple d'un RdP Nets-within-Nets après franchissement. .......................... 71
Tableau 3.1. Les types de mobilité. .......................................................................................... 72
Figure 3.19. Nested Nets [Kees06] .......................................................................................... 72
Figure 4.1. Modèle -REV- avant et après le franchissement de rt. .......................................... 76
Figure 4.2. Modèle -COD- avant et après le franchissement de rt. .......................................... 77
Figure 4.3. Modèle -MA- avant et après le franchissement de rt. ............................................ 78
Figure 4.4. Le module fonctionnel PEANO-NAT ................................................................... 80
Figure 4.5. Petri-machine ......................................................................................................... 81
Figure 4.6 Le module système Petri-machine ......................................................................... 81
Figure 4.7 Déclaration d‟une classe sous la forme d‟un module système .............................. 82
Figure 4.8 Méta-Modèle des LRN .......................................................................................... 83
Figure 4.9 barre d‟outils pour l‟environnement de modélisation des LRN ........................... 84
Figure 4.10 Les règles de la grammaire de graphes ................................................................ 85
Figure 4.11 Le modèle LRN de l‟exemple 1 ............................................................................ 91
Figure 4.12 Spécification Maude Générée pour exemple1, .................................................... 92
Figure 4.13 Le modèle LRN de l‟exemple 2 ............................................................................ 93
Figure 4.14 Spécification Maude Générée pour exemple2, .................................................... 94
Figure 4.15 Le modèle LRN de l‟exemple 3 ............................................................................ 94
Figure 4.16 Spécification Maude Générée pour l‟exemple 3 .................................................. 95

7
Introduction générale
L'évolution des réseaux à grande échelle a permis la naissance d'un grand nombre de
nouvelles applications qui se développent autour de ce type de réseau [Arcangeli02] :
commerce électronique, recherche d'information sur le web, plate-forme pour calcul reparti...
Ces applications sont formées d‟entités reparties, la communication et les échanges entre ces
entités est à la base de la bonne fonctionnalité du système en entier.
Le modèle client/serveur est l‟un des modèles les plus utilisé dans de tels systèmes.
Dans ce modèle, seul le client représente une application au sens propre du terme et le rôle du
serveur est de répondre aux demandes des clients. Le serveur construit ses réponses
indépendamment du client, ainsi une partie des données envoyées est inutile, augmentant
ainsi le trafic sur le réseau. De plus ce modèle exige une connexion permanente entre le client
et le serveur, ce qui n'est pas le cas des terminaux mobiles qui sont exposés à la perte de la
connexion. Le concept d'agent mobile apparait dans ce contexte comme une solution
facilitant la mise en œuvre d'applications dynamiquement adaptables, et il offre un cadre
générique pour le développement des applications reparties sur des réseaux de grande taille.
L'envoi du code sur le serveur permet d'adapter les services distants aux exigences du client et
de ne lui envoyer que les informations utiles, ce qui n‟est évidemment pas le cas pour Le
modèle client/serveur.
Un agent mobile [Arcangeli02] est une entité logicielle qui se déplace d'un site à un
autre en cours de l‟exécution pour accéder à des données ou à des ressources distantes. Le
déplacement de l‟agent, se fait avec son code son état d'exécution et ses propres données. En
outre, l'agent lui-même, peut décider d‟une manière autonome de migrer. De ce fait, la
mobilité est contrôlée par l'application et non par le système d'exécution. Le but du
déplacement est généralement d'accéder localement a des données ou à des ressources
initialement distantes, d'effectuer le traitement en local et de ne déplacer que les données
utiles.
Deux grandes normes de standardisation (FIPA [FIPA] et MASIF [MASIF]) et un
nombre important de plates-formes [MASIF], ont apparu pour les agents mobiles, malgré leur
récente introduction. Cependant, le développement des applications des agents mobiles,
rencontre des problèmes liés à l‟interopérabilité et à la sécurité dans les différentes
plateformes d‟accueil. Face aux insuffisances des efforts pour la standardisation de ces

8
plateformes, les chercheurs étaient contraints d‟explorer d‟autres paradigmes, pour une
meilleure prise en charge et mise en œuvre des applications à base d‟agents mobiles.
D'autre part, peu de travaux de recherches portent sur les méthodes et les outils pour l‟analyse
et la conception des systèmes d‟agents mobiles. Les prédominantes approches orientées agent
qui existent jusqu'à maintenant, sont celles qui cherchent à adapter les méthodologies
d'analyse et de conception orientées objets pour le développement des applications d‟agents
mobiles [Bahri09].
Concevoir une approche qui inspire ses notations de l'analyse et de la conception
orientée objet (en particulier du langage UML) et qui pourra être utilisée tout au long du
processus de développement des systèmes d‟agents mobiles, serait très intéressant. UML
possède plusieurs avantages, il est à la fois un support de communication, une norme, un
langage de modélisation objet. Il offre aussi une bonne commodité pour la modélisation et la
compréhension des modèles. Néanmoins, la sémantique semi-formelle d‟UML présente un
inconvénient majeur, vue l‟insuffisance de l‟outil pour la vérification de tels modèles. L‟idée
serait de pouvoir transformer de tels modèles semi-formels, vers des modèles exprimés dans
un langage formel ( tel que les réseaux de Petri) ou carrément vers un code équivalent où la
vérification est possible. Ce point de vue, coïncide avec la philosophie de l‟approche IDM
(Ingénierie dirigée par les Modèles).
L‟ingénierie dirigée par les modèles (IDM ou MDE : Model Driven Engineering) est le
domaine qui met à disposition des outils, concepts et langages pour créer et transformer des
modèles afin de mécaniser le processus que les ingénieurs suivent habituellement à la main.
L‟IDM se concentre sur une préoccupation plus abstraite que la programmation classique (on
y adopte un degré d‟abstraction plus élevé), ce qui permet d‟obtenir plusieurs améliorations
dans le développement de systèmes complexes. Grâce à l‟utilisation importante des modèles
(qui peuvent être exprimés dans des formalismes différents) et des transformations
automatiques entre les modèles, L‟IDM permet un développement souple et itératif, grâce aux
raffinements et enrichissements par transformations successives et automatiques entre les
modèles.
Dans notre étude, nous nous sommes intéressés à l‟utilisation des réseaux de Petri pour
modéliser et vérifier des agents mobiles. Une extension de ces réseaux, où la structure du
réseau peut changer au cours de son exécution a été proposée. Ainsi, dans ce nouveau
formalisme, le Labeled Reconfigurable Nets (LRN) [Kahloul07], les réseaux de Petri ont été
étendus via l‟utilisation des transitions reconfigurables étiquetées. Quand une transition

Introduction générale
9
reconfigurable est tirée, la structure du réseau change. Le changement qui se produit dépend
de certaines informations (destination de la migration, le type de migration, les ressources
requises et leur type pour les processus ou des agents ... etc.). Cette information est présentée
dans une étiquette associée à la transition reconfigurable. Cette idée a été utilisée, pour
montrer comment certains concepts de base définis dans la mobilité peuvent être modélisés, à
savoir: les agents mobiles, l'évaluation à distance, et le code à la demande. Une technique de
modélisation et de simulation d'agents mobiles en utilisant les LRN ainsi qu‟une extension de
Maude ont été également proposées [Kahloul2-08]. Cette extension est appelée reconfigurable
Maude (R-Maude). Dans R-Maude, des règles spécifiques, appelées règles reconfigurables
(RR) sont introduites. Un prototype de R-Maude a été réalisé. L'idée était d'abord modéliser
des systèmes mobiles utilisant les LRN, puis de les traduire dans la spécification R-Maude, et
enfin simuler l'exécution de ces spécifications en utilisant le prototype réalisé.
Dans ce contexte, nous avons en outre proposé une approche totalement automatisée
basée sur la méta-modélisation et les grammaires de graphes pour générer de manière
totalement automatique la spécification R-Maude des modèles réseaux de Petri
reconfigurables proposés en utilisant l‟outil AToM3. En effet, dans notre travail, le
formalisme de diagramme de classe UML de l‟outil ATOM3 est utilisé pour définir un
métamodèle pour les LRN. ATOM3 est aussi utilisé pour générer un outil de modélisation
visuelle pour l‟élaboration de modèles selon le métamodèle des LRN proposé. Nous avons
aussi proposé une grammaire de graphe pour générer automatiquement, la description
R-Maude des modèles LRN graphiquement spécifiés.
Organisation du mémoire
Le reste de ce mémoire est organisé comme suit :
Dans Le premier chapitre de cette thèse, nous avons présenté les différentes
technologies utilisées pour la répartition et la communication entre les différentes entités
d'une application repartie. Nous avons situé la technologie d'agents mobiles par rapport aux
différentes techniques présentées. Nous avons enchainé ensuite avec quelques exemples de
plateformes d'implémentation des applications d'agents mobiles. Avec la multitude de plates-
formes d'exécution, des efforts dans le domaine de la standardisation ont été déployés. Ce
chapitre a été conclu avec des critiques du paradigme.
Dans le deuxième chapitre nous avons commencé par présenter sommairement
l‟Ingénierie Dirigée par les Modèles (IDM), suivie par la présentation de sa variante : Model-

Introduction générale
10
Driven Architecture (MDA). Nous avons insisté plus particulièrement sur la transformation de
modèles, l‟une des techniques prometteuses dans l'approche MDA. Cette approche permet
l'automatisation des processus de modélisation, depuis les phases de développement jusqu‟à
celles de tests, en passant par la génération de code. Nous avons présenté par la suite une
énumération de quelques types de transformation de modèles, suivie d‟une classification de
certaines approches de transformation. Sur un autre plan, nous avons mis l‟accent sur les
transformations de graphes qui représentent une des approches de transformation de modèles
et ce après avoir fait un bref aperçu sur la notion de graphe. Enfin, nous avons présenté
AToM3, l‟outil de transformation utilisé dans notre travail, d‟une façon assez exhaustive, car
nous jugeons importants les éléments présentés dans ce cadre pour la compréhension de notre
contribution.
Le chapitre 3, a été consacré à la présentation des concepts fondamentaux des
techniques formelles, de vérification et validation des systèmes. Nous avons insisté sur les
réseaux de Petri, qui sont un formalisme de modélisation. Ils représentent un cadre formel de
spécification des systèmes grâce à leur sémantique. Un grand avantage de l‟utilisation des
réseaux de Petri est leur force d‟expressivité due à leur aspect graphique. Nous avons abordé
dans un cadre général la modélisation par les réseaux de Petri. Par la suite, nous avons étudié
quelques types de RdPs avec leurs variantes. Nous avons également introduit une brève
présentation des extensions de RdPs pour la mobilité.
Dans le quatrième chapitre, nous avons présenté un nouveau formalisme, basé sur les
réseaux de petri, « les Labeled Reconfigurables Nets (LRN) ». Ce formalisme permet une
modélisation explicite des environnements informatiques et d‟exprimer la mobilité entre eux.
Nous avons décrit par la suite, notre support outillé de manipulation et de simulation des LRN
basé sur la méta-modélisation et les grammaires de graphes. Nous avons enchainé par la
présentation d‟une extension pour Maude: reconfigurable Maude (R-Maude). R-Maude est un
système distribué qui peut être utilisé pour la spécification et la simulation des systèmes à
code mobile. Un prototype de ce système a été réalisé et utilisé pour simuler les spécifications
des modèles LRN. Un exemple des étapes de simulation a été également présenté.
Enfin, une conclusion générale résume notre contribution et présente des perspectives
de notre travail.

11
Chapitre1
Agents mobiles et applications réparties
L‟émergence des réseaux informatiques à grande échelle a donné naissance à de
nombreuses applications réparties. Ces applications exigent une forte interaction entre
différentes entités distribuées dans le réseau, celles-ci partagent les mêmes ressources et
visent à atteindre les mêmes buts. Ces applications réparties adoptent une multitude de
modèles d‟exécution distribués, proposés dans la littérature.
Nous commençons, dans ce chapitre, par présenter brièvement les caractéristiques de
quelques modèles d‟exécution distribuée utilisés pour la mise en œuvre d‟une application
répartie. Nous insisterons sur la description du modèle d‟agent mobile, qui propose une
solution facilitant le développement des applications réparties sur des réseaux à grande
échelle. Cette description permet d‟appréhender la complexité de ce domaine qui est exprimée
par la variété des aspects à considérer dans un tel système.
1.1 Systèmes répartis et Agents mobiles
Dans le développement des applications distribuées, La programmation par agents
mobiles a bien trouvé sa place comme nouveau paradigme. Cependant, pour la construction et
la gestion des systèmes répartis, il existe d‟autres structures organisationnelles, qui peuvent
être classées en deux catégories. L‟une concerne les structures d‟organisation sans mobilité, et
l‟autre comporte les structures d‟organisation avec mobilité.
1.1.1 Structures organisationnelles non mobiles pour les systèmes répartis
Dans la conception d‟une application répartie classique, qui ne nécessite pas la
mobilité, interviennent plusieurs structures organisationnelles dont les plus répandues sont les
suivantes:
1.1.1.1. Client/serveur
Dans le modèle client/serveur, un serveur représente un objet géré sur un site et offrant
des services aux clients. Les fonctionnalités d'une application sont alors encapsulées dans des
services qui sont proposées/exécutées au sein de serveurs. Les serveurs sont ainsi vus comme
des fournisseurs de services. On trouve soit : (i) des serveurs de données, dans lesquels des
clients accèdent à des données localisés sur chaque serveur (SGBD, LDAP, etc...), (ii) soit des
serveurs de calculs, dans lesquels des clients utilisent les ressources de chaque serveur afin
d'exécuter une tache précise.

Agents mobiles et applications réparties
12
Dans le modèle client/serveur, seul le code initialement installé sur le serveur pourra
être exécuté sur ce dernier, et le rôle de celui-ci est de répondre aux demandes émises par les
processus clients. L‟interaction avec un serveur est établie par le client demandeur d'un
service. Nous pouvons envisager que l'exécution d'une tâche sur un serveur nécessite
l'interaction avec d'autres serveurs (telle que la consultation d'une base de données). Dans ce
cas un même processus peut être à la fois client et serveur. Dans le modèle client/serveur seul
le client représente une application au sens propre du terme. Le serveur a pour fonction de
répondre aux demandes des clients. Les réponses dépendent des requêtes formulées et non pas
des applications clientes qui l'interrogent.
Le client envoie une requête au serveur. Cette requête décrit l'opération à exécuter (le
service demandé) ainsi que ses paramètres. On dit alors que le client invoque une opération
sur le serveur. Le serveur exécute le service demandé par le client et renvoie la réponse. Il
s'agit d'une invocation synchrone, en effet dans ce type de communication le client qui émet
une requête vers le serveur se bloque, en attendant sa réponse (voir figure 1.1).
Figure 1.1. Organisation Client/serveur
1.1.1.2 Événement asynchrone
Ce modèle permet la communication entre plusieurs processus et ceci d'une façon
indirecte. Les différents composants de l'application coopèrent par l'envoi et la réception de
notification. Les processus communiquent entre eux par l'intermédiaire d'une base
représentant un gestionnaire d'abonnement et de distribution d'évènements.
Cette base se charge d‟orienter un évènement vers ses abonnés. Dans ce modèle, il y a
deux types de processus : les émetteurs qui envoient ou publient des évènements dans la base,
et les consommateurs qui s'abonnent à certaines catégories d'évènements. Quand la base reçoit
une notification d'évènement, elle se charge de la distribuer a tous les composants qui ont
déclaré leur intérêt pour recevoir ce message. Ainsi, cet intermédiaire fait un découplage entre
les sources et les consommateurs d'évènements. L'émetteur d'une communication n'est pas
obligé de spécifier la destination de ses messages, de même le destinataire ne connait pas
nécessairement l'origine du message. Ce type d'infrastructure [Leclercq04] qui permet de
communiquer à l'aide de messages est désigné par MOM (Message Oriented Middleware).
1.1.1.3 Mémoire virtuelle partagée (MVP)
Les échanges se font par l'intermédiaire d'une mémoire partagée de grande taille qui
sert d'espace de communication entre des processus sur des ordinateurs qui ne partagent pas
Client Serveur

Agents mobiles et applications réparties
13
physiquement leur mémoire. Son intérêt est de permettre l'utilisation d'un modèle de
programmation qui a des avantages par rapport aux modèles basés sur l'échange de message.
Les processus accèdent à la mémoire partagée par des lectures et des mises à jour sur ce qui
leur semble être de la mémoire ordinaire à l'intérieur de leur espace d'adressage. Le système,
tournant en tâche de fond, assure de manière transparente que les processus s'exécutant sur
différents ordinateurs observent les mises à jour effectuées par d'autres processus.
Le grand avantage de la MVP [Bennett90] est d'épargner au programmeur la gestion
de l'échange de messages quand il écrit une application qui en aurait besoin dans la MVP. On
ne peut toutefois pas éviter complètement l'échange de message dans un système distribue, il
faut bien sûr que le système sous-jacent de la MVP envoie les mises à jours aux différents
processeurs, chacun ayant une copie locale des données partagées [Guyennet97]. Ces données
doivent être mises à jour de façon régulière pour une question de performance mais aussi de
validité des données utilisées.
1.1.2. Structures organisationnelles avec mobilité pour les systèmes répartis
Les applications utilisant les réseaux comme infrastructures, particulièrement Internet,
ont connu une croissance remarquable rapidement. Les structures organisationnelles non
mobiles, tel que l‟approche client/serveur, se heurtent à de grands défis. Vue le caractère
centralisé de ces approches, l‟émergence des nouvelles tendances pour le partage du savoir et
des ressources disponibles sur le réseau planétaire, est énormément ralentit. De ce fait, le
concept de la mobilité est une bonne alternative des approches non mobile.
Dans ce qui suit, nous présentons quelques définitions et concepts de bases de la
mobilité, nous enchainerons avec quelques structures d‟organisation se basant sur la mobilité
pour les systèmes répartis.
1.1.2.1. La mobilité
La mobilité en général est le déplacement physique ou logiciel dans les réseaux de
télécommunication. De ce fait, trois concepts de base sont répandus, on cite: la mobilité
physique (Mobile computing), le code mobile et les agents mobiles.
La mobilité physique se définie comme étant un paradigme dans lequel les utilisateurs du
réseau partagé se connectent via des machines déplaçables [Gardarin93]. La diffusion des
réseaux sans fils, et les réseaux de télécommunication cellulaires, expliquent La motivation
de ce paradigme. Ces réseaux nécessitent de grandes capacités de calcul et de traitement de
l‟information.
La capacité dynamique d‟échange entre les fragments du code à exécuter et les locations
sur lesquels s‟exécutera ce code, définit le code mobile. Un équilibrage de charge entre les
processeurs connectés sur le réseau est assuré par la migration du code (processus, objet,
ou une procédure). Celle-ci permet également d‟améliorer les performances dans la
communication (rassembler les objets qui se communiquent intensivement sur les mêmes
nœuds).
Les agents mobiles sont des entités logicielles qui peuvent se déplacer d'un site du réseau
à un autre pour atteindre leurs objectifs et ce d‟une manière autonome.

Agents mobiles et applications réparties
14
1.1.2.2. Structures organisationnelles
Parmi les structures organisationnelles de la mobilité, nous présentons l‟évaluation à
distance, le code à la demande et le modèle à base d‟Agent Mobile.
1.1.2.2.1 Évaluation distante
Dans une interaction par évaluation distante (voir Figure 1.2), un client envoie un code
à un site distant. Le site récepteur utilise ses ressources pour exécuter le programme envoyé.
Eventuellement, une interaction additionnelle délivre ensuite les résultats au client. Dans ce
schéma, seul le code est transmis au serveur et l'exécution du code se déroule uniquement sur
ce dernier. Le code d'une requête SQL émis vers un serveur de base de données représente un
exemple d'évaluation distante.
Figure 1.2. Evaluation à distance
1.1.2.2.2 Code à la demande
Dans ce schéma, le processus client interagit avec un site distant afin de récupérer un
savoir-faire qui sera exécuté sur la machine cliente. Ainsi, le client télécharge le code
nécessaire à la réalisation d'un service. Le rôle du site distant est de fournir le code du service
qui sera exécuté sur le site client (voir Figure 1.3). Les Applets Java reposent sur cette
technologie de code mobile, il s'agit d'un programme chargé à partir d'une page Web pour être
exécuté sur la machine du client.
Figure 1. 3. Code à la demande

Agents mobiles et applications réparties
15
1.1.2.2.3 Agents mobiles
Par comparaison avec les deux schémas précédents, l'exécution du processus débute
sur le site client. Dans la mesure où le client a besoin d'interagir avec le serveur, ce même
processus (code, état d'exécution et données) se déplace à travers le réseau pour continuer son
exécution et pour interagir localement avec les ressources du serveur (voir Figure 1.4). Après
exécution, l'agent mobile retourne éventuellement vers son client afin de lui fournir les
résultats de son exécution. Dans ce schéma, le savoir-faire appartient au client, l'exécution du
code est initiée côté client et continue sur les différentes machines visitées.
Figure 1.4. Agent mobile
1.2. Agents mobiles
1.2.1 Définitions
Le terme agent est très répandu en informatique. La notion d'agent a donné lieu à de
très nombreuses définitions, notamment dans le domaine de l'intelligence artificielle.
Un agent [Beale94] est une entité logicielle (informatique ou électronique) plongée
dans un environnement dans lequel elle est capable d'agir. Il possède un comportement
autonome relié à ses observations, à sa connaissance et aux interactions qu'il entretient
avec l'environnement et avec les autres agents.
D‟après [Ferber95], un agent est une entité physique ou virtuelle qui est capable d‟agir
dans un environnement et qui peut communiquer directement avec d‟autres agents. Cette
entité est mue par un ensemble de tendances (sous la forme d‟objectifs individuels ou
d‟une fonction de satisfaction, voire de survie, qu‟elle cherche à optimiser). Afin
d‟atteindre ses objectifs, l‟agent tient compte des ressources et des compétences dont il
dispose, ainsi que de sa perception et des représentations qu‟il dispose de son
environnement.
Nous définissons un agent mobile comme étant un agent répondant à cette définition et
capable de se déplacer d'un site a un autre dans un réseau pour accomplir la tâche du client.
De cette définition découlent les points essentiels suivants liés à l‟agent:
Comportement : Un agent est pourvu d'un programme qui lui dicte la tâche à accomplir.
On dit qu'il agit par délégation pour le client. Un agent peut ainsi venir avec une
compétence particulière sur une machine hôte.

Agents mobiles et applications réparties
16
La Mobilité: Un agent mobile est capable de migrer d‟une machine vers une autre pour
atteindre ses objectifs.
La Communication: Les agents peuvent communiquer entre eux ainsi qu‟avec autrui.
Par échanges de messages ou selon un mode de communication établit par l‟architecture
dans laquelle évoluent les agents tels que les SMA (Systèmes Multi Agents).
L’Apprentissage: Un agent est capable d‟augmenter ses capacités par apprentissage en
utilisant ses connaissances.
la Réactivité et La Pro-Activité: un agent réactif est caractérisé par sa réaction aux
événements externes pour l‟exécution de nouvelles tâches. Par contre, un agent Pro-Actif
se caractérise par la capacité d‟anticiper des changements plutôt que de réagir à ces
changements.
Autonomie : Un agent agit indépendamment du client. Il décide lui-même là où il va se
déplacer et ce qu'il doit y faire, en fonction du comportement qui lui a été donné. Ceci
implique que l'on ne peut pas toujours prévoir l'itinéraire des agents.
Environnement : L'environnement dans laquelle l'agent évolue est constitué :
‒ par les machines qui vont accueillir l'agent lors de son exécution; ainsi l'agent utilise
les ressources (unité de calcul, mémoire, etc...) disponibles sur la machine afin
d'accomplir la tâche demandée par le client,
‒ Par les liens réseau que l'agent utilise pour se déplacer entre les différents sites.
‒ Par les autres agents fixes et mobiles avec qui l'agent interagit afin de réaliser son but.
1.2.2 Environnement d'exécution et système d'agents mobiles
Un environnement d'exécution d'agents mobiles fournit une interface de
programmation et un milieu d'exécution offrant des primitives pour créer, lancer et exécuter
un agent mobile. Cet environnement est constitué par un ensemble de programmes statiques,
appelés places, s'exécutant sur les sites du système susceptibles d'accueillir des agents.
Les environnements d'exécution d'agents mobiles offrent plusieurs services de base
permettant l'exécution d'un agent mobile sur un site. Ces services sont: création et migration
d'un agent mobile, communication et échange de messages entre les agents mobiles, accès aux
ressources locales par les agents mobiles et traçage des agents mobiles en cours de
l‟exécution. Viennent s‟ajouter à ces services, fournis par l'environnement d'exécution
d'agents mobiles, des mécanismes mettant en œuvre des notions de qualité de service requise
par les applications, à titre d‟exemple, la sécurité ou la tolérance aux pannes.
Un système d‟agent (appelé aussi serveur d‟agent) est l‟espace de vie des agents. Il est
associé à une autorité qui identifie l‟organisation ou la partie pour laquelle les agents agissent.
La diversité des systèmes ainsi développés, rend les passerelles entre de tels systèmes souvent
impossibles. Afin de permettre l‟interopérabilité entre les systèmes à agents mobiles, l‟OMG
(Object Management Groupe) a montré son intérêt pour cette classe d‟application par la
définition des spécifications de MASIF (Mobile Agent System Interoperability) [MASIF].

Agents mobiles et applications réparties
17
Par ailleurs, la FIPA (Foundation For Intelligent Physical Agents) [FIPA] a lancé un autre
effort pour la spécification de l‟architecture des systèmes d‟agents mobiles.
Cinq concepts jouent un rôle important dans le système d‟agent :
1. La place : Un agent mobile se déplace d‟un environnement d‟exécution à un autre. Cet
environnement est appelé " place ". Une place est un contexte au sein d‟un système
d‟agent, dans lequel un agent s‟exécute. Ce contexte peut fournir un ensemble de services
uniformes sur lesquels l‟agent peut compter indépendamment de sa localisation spécifique.
La place de départ et la place de destination peuvent être situées au sein d‟un même
système d‟agent ou sur des systèmes d‟agents différents. Un système d‟agent peut contenir
une ou plusieurs places (voir figure 1.3).
2. Région : Une région est un ensemble de systèmes d‟agent qui appartiennent à la même
autorité mais qui ne sont pas nécessairement de même type. Le concept de région permet
à une autorité d‟être représentée par plusieurs systèmes d‟agent (voir figure 1.3).
3. Les ressources : Le système d‟agent et la place fournissent un accès contrôlé aux
ressources locales et aux services (base de données, processeurs, mémoire, disques).
4. Le type d’un système d’agent : Le type d‟un système d‟agent permet de définir le
profil d‟un agent. Par exemple, si le type d‟un système d‟agent est " AGLET ", alors le
système d‟agent est implémenté par IBM et supporte Java comme langage de
programmation.
5. Localisation : La localisation est un concept important pour les agents mobiles. On
définit la localisation d‟un agent comme étant la combinaison de la place dans laquelle il
s‟exécute et l‟adresse réseau du système d‟agent où réside la place. Concrètement, elle est
définie par l‟adresse IP et le port d‟écoute du système d‟agent avec le nom de la place
comme attribut.
Figure 1.5. Place et Région

Agents mobiles et applications réparties
18
1.2.3 Services requis pour l'exécution d'agents mobiles
Dans cette section, nous allons décrire les fonctions nécessaires pour construire des
applications reparties à base d‟agents mobiles. Apres une présentation de la structure d'un
agent mobile, nous allons présenter les services suivants :
création d'un agent,
transfert d'un agent,
désignation d'un agent, c'est-à-dire offrir un nom globalement unique a un agent,
localisation d'un agent,
communication entre agents,
exécution d'un agent,
protection d'un agent.
Ces différents services sont détailles dans les paragraphes suivants.
1.2.3.1 Structure d'un agent mobile
Un agent mobile est un programme pouvant se comporter d'une façon autonome au
profit de son client. Chaque agent a son flot d'exécution pour pouvoir prendre l'initiative
d'exécuter des taches. Un agent doit avoir la capacité de migrer d'une machine à une autre sur
le réseau. Pour parler de la migration d'un agent, il est important de connaitre les éléments à
transférer avec l'agent. Une instance d'agent mobile comporte trois parties [Tanenbaum92] :
‒ Un code exécutable qui représente la suite d'instructions définissant le comportement
statique de l'agent mobile,
‒ Un contexte d'exécution qui reflète l'état d'exécution courant de l'agent mobile (valeurs
des registres, pile d'exécution),
‒ Les données ou les ressources utilisées par l'agent mobile ; ces ressources sont divisées
en deux parties [Fuggetta98] :
‒ Les ressources transférables qui sont les valeurs des attributs de l'agent et qui lui
donnent un état global,
‒ Les ressources non transférables qui constituent l'environnement d'exécution fourni
par le système (par exemple les fichiers ouverts, les connexions sockets, les registres,
etc.) et les matériels physiques utilises par l'agent (imprimante, écran, etc.).
Dans le paragraphe §2.3.3, nous allons montrer comment l'agent migre avec son code,
son contexte d'exécution et ses données.
1.2.3.2 Création d'agents mobiles
Dans la mesure où ces agents peuvent se déplacer, on peut se poser la question, lors de
leur création, de l'endroit où l'on souhaite qu'ils démarrent leurs activités. Une fois crée,
l'agent peut être actif, c'est-à-dire que l'exécution de son code est déclenchée. La
création/lancement d'un agent peut prendre plusieurs formes :
‒ Création locale,
‒ Création et exécution à la demande (code on demand),
‒ Création et exécution à distance (remote exécution).

Agents mobiles et applications réparties
19
La création de l'agent n'est pas directement liée à la mobilité, mais a des mécanismes
sur lesquels s'appuie la mobilité. A sa création, un nom globalement unique (cf. §2 .3.4) doit
être attribue à l'agent ce qui va permettre de localiser l'agent et de communiquer avec lui.
1.2.3.3 Migration d'un agent
La migration permet le transfert d'un agent en cours d'exécution d'un site à un autre à
travers le réseau. Nous allons prendre le cas d'un agent qui désire migrer entre deux machines
avec la possibilité de recevoir des messages pendant son déplacement (voir Figure 1.6). Cette
migration comporte les étapes suivantes [Ismail99] :
1. la sérialisation du contexte de l'agent et la production d'un message incluant le contexte
sérialise de l'agent et son code;
2. le processus de l'agent étant suspendu sur sa machine d'origine, toutes les
communications avec d'autres agents sont donc suspendues et l'agent est détruit;
3. l'envoi du contexte et du code de l'agent vers la machine de destination;
4. l'état de l'agent migrant est restaure sur la machine de destination, un nouveau processus
léger est créé pour la poursuite de son exécution;
5. les communications en cours sont redirigées vers la machine de destination, l'agent
n'étant pas encore active, ces messages seront traites après sa réactivation;
6. réactivation de l'agent sur la machine de destination, dès que la partie de son contexte
nécessaire à son exécution est reçue ; la machine de destination s'occupe des liens
dynamiques entre l'agent et son code. A partir de ce moment, la migration prend fin. Le
processus sur la machine d'origine peut être définitivement efface.
Figure 1.6. Migration d‟un agent mobile
Les différentes stratégies de migration d'agents dépendent de la manière dont sont
traitées ces diverses étapes et des données transférées avec l'agent lors de sa migration.
Deux types de migrations ont été proposés dans les plates-formes existantes :

Agents mobiles et applications réparties
20
1. La migration forte permet à un agent de se déplacer quel que soit l'état d'exécution
dans lequel il se trouve. Dans ce type de migration l'agent se déplace avec son code,
son contexte d'exécution et ses données. Dans ce cas, l'agent reprend son exécution
après la migration exactement là où elle était avant son déplacement. La migration forte
nécessite un mécanisme de capture instantanée de l'état d'exécution de l'agent. Elle peut
être proactive ou réactive. Dans la migration proactive, la destination de l'agent est
déterminée par l'agent lui-même. Dans la migration réactive, la migration de l'agent est
dictée par une partie ayant une relation avec l'agent mobile.
2. La migration faible ne fait que transférer avec l'agent son code et ses données. Sur le
site de destination, l'agent redémarre son exécution depuis le début en appelant la
méthode qui représente le point d'entrée de l'exécution de l'agent, et le contexte
d'exécution de l'agent est réinitialisé. Pour que l'agent se branche sur une instruction
particulière de son code après sa migration, le programmeur doit inclure dans l'état de
l'agent des moments privilégies (explicites) dans le code de l'agent (point d'arrêt) pour
pouvoir le relancer. La migration forte, bien que beaucoup plus exigeante à implanter
[Dillenseger02] que la migration faible [Grasshopper98], n'en est pas moins
indispensable pour toutes les applications pour lesquelles les notions de fiabilité et de
tolérance aux pannes sont primordiales.
1.2.3.4 Service de nommage
Dans un système à agents mobiles, les agents ont besoin de communiquer entre eux, ce
qui nécessite de les nommer. Le nom donne à l'agent doit être globalement unique. Dans la
plupart des systèmes à agents mobiles ce nom est construit à partir du nom de la machine (ou
adresse IP) ou l'agent s'exécute, d'un numéro de port et d'un identificateur localement unique.
1.2.3.5 Service de localisation
Afin de communiquer avec un agent mobile, il est nécessaire de le retrouver. La
mobilité de l'agent introduit des contraintes sur les communications qui n'étaient pas présentes
avec les systèmes classiques ou les objets ne pouvaient pas changer de lieu d'exécution. En
particulier, il faut que des entités mobiles puissent communiquer indépendamment de leur
localisation et de leur mobilité [Alouf02]. Le point le plus important concerne la fiabilité, il
faut pouvoir assurer les communications à tout moment avec les objets mobiles. Pour ces
raisons, un système à agents mobiles doit offrir un service de localisation des agents à travers
un serveur de noms. Ce serveur de noms contient la localisation courante de l'agent ou bien
suffisamment d'informations pour le localiser.
1.2.3.6 Communications entre les agents
La communication entre deux entités peut se faire de deux façons, la plus intuitive
consiste à avoir un mécanisme permettant une communication directe entre les objets, ce qui
correspond à la communication synchrone ou asynchrone entre les deux entités.

Agents mobiles et applications réparties
21
Une deuxième manière de la faire est d'avoir des mécanismes de communication indirecte.
Dans ce cas un objet voulant communiquer envoie son message à un objet tiers qui se charge
à son tour de l‟envoyer au destinataire.
Dans un système à agents mobiles, il faut différencier deux types de communication,
selon que la communication intervient entre deux agents ou entre un agent et un groupe
d'agents. Les moyens de communication entre les agents sont multiples, nous pouvons citer la
communication par message, session, tableau blanc, rendez-vous, par évènement distribué ou
local.
1.2.3.7 Exécution d'un agent
Un système à agents mobiles doit offrir la possibilité d'exécuter un agent sur les
machines qui vont accueillir ce dernier, ainsi l'agent utilise les ressources disponibles sur la
machine afin d'accomplir la tache demandée par le client. Sur la machine d'accueil, les agents
mobiles peuvent être amenés à effectuer des entrées/sorties, accéder à l'interface utilisateur, au
système de gestion de fichiers, aux applications externes et à l'interface réseau. Les machines
qui forment notre système d'exécution n'auront pas toutes le même type de système
d'exploitation. Par conséquent, maintenir l'indépendance vis-à-vis du système d'exploitation
d'un environnement d'agents mobiles tout en autorisant en même temps l'accès aux ressources
est un problème important à surmonter dans les environnements d'exécution d'agents mobiles.
C'est pour cette raison que la plupart des environnements d'agents mobiles utilisent le langage
Java comme langage d'implémentation du code mobile [Gomoluch01].
Java est un langage oriente objet développe par Sun et présente officiellement en 1995.
Les applications écrites en Java [Java] sont compilées en bytecode et exécutées sur une
machine virtuelle, la Java Virtuel Machine (JVM). Le succès du langage Java se traduit, entre
autre, par le fait qu'on peut raisonnablement considérer que la machine virtuelle Java constitue
aujourd'hui un environnement d'exécution "universel", car disponible sur toutes les machines
d'un système reparti. Cette propriété en fait une plateforme de développement de choix pour
les applications mobiles ou distribuées car le programmeur n'a pas à gérer différents langages
ou différentes versions d'un programme suivant les systèmes sur lequel il va s'exécuter. En
plus de cette propriété liée a la portabilité, Java propose toute une série de services qui
permettent de construire des applications distribuées mobiles. On trouve notamment :
- la sérialisation/de sérialisation d'un objet afin de le transmettre à travers le réseau.
- la communication entre deux objets situés sur des machines distantes (RMI, socket,
etc...)
- le chargement dynamique de code à partir d'un site distant.
L'utilisation de Java permet de résoudre le problème lie à l'exécution de l'agent sur les
différentes machines du système repartie. Mais avec la diversité des plates-formes
disponibles, nous pouvons nous interroger sur la migration entre les différentes plates-formes.
Chaque plate-forme possède sa propre façon pour définir le comportement des agents, ce
qui pose un problème de compatibilité lors de la migration d'un agent entre les différentes

Agents mobiles et applications réparties
22
plates-formes. Pour surmonter ce problème, des travaux comme dans [Groot04] proposent un
langage générique, pour la description du comportement de l'agent, base sur le langage XML.
Une projection de cette description permet à une plate-forme d'agents mobiles de reconstruire
l'agent avec son propre langage.
L'exécution d'un agent mobile sur une machine hôte pose le problème du piratage des
sites visites. Ce problème, non spécifique aux agents mobiles, est symétrique pour ces
derniers. En effet, un agent mobile est expose au problème du piratage par les logiciels qui
fonctionnent sur les sites qu'il visite. Dans la section suivante, nous allons détailler les
problèmes liés à la sécurité dans un environnement d'agents mobiles.
1.2.3.8 Sécurité
Garantir la sécurité dans les environnements d'agents mobiles est important du fait de
la nature même du modèle d'exécution des agents et du fait des interactions des agents
mobiles avec plusieurs systèmes et ressources. Un système à agents mobiles doit offrir des
mécanismes permettant une exécution sécurisée des agents au sein du système. Trois types de
problèmes de sécurité ont été identifiés pour les environnements d'exécution d'agents mobiles:
‒ La sécurité du site d'accueil contre un agent. Au cours de son exécution, un agent
mobile peut avoir accès aux ressources du site sur lequel il est situé. Un agent malveillant
peut donc profiter des accès aux ressources locales pour propager des virus [Chess97], des
worms ou des chevaux de Troie. Il peut masquer sa véritable identité et lancer une tâche
lourde ce qui va entrainer l‟indisponibilité du service [Bellavista01]. La machine qui va
accueillir l'agent mobile doit être amenée à détecter le mauvais déroulement de l'exécution
de l'agent. Dans [Galtier01], les auteurs présentent une méthode qui permet à l'agent de
définir ses besoins d'une façon indépendante de la machine sur lequel il s'exécute. Le site
d'accueil peut détecter les abus commis par l'agent permettant ainsi de le contrôler. Une
approche classique pour protéger les sites des agents malveillants est de limiter les accès
des agents aux ressources locales du site [Hantz06]. Dans cette approche, le comportement
de l'agent est écrit sous la forme d'un langage interprété. L'agent est exécuté dans un
environnement qui a son tour s'exécute au-dessus du site. Le contrôle de l'agent est ainsi
fait dans l'environnement d'exécution [Carvalho04]. Une seconde approche consiste à ne
laisser s'exécuter que les agents authentifies [Ametller04], une signature est attribuée à
l'agent permettant au site d'accueil de l'authentifier avant son exécution.
‒ La sécurité d'un agent contre le site d'accueil. La protection des agents mobiles contre
des sites hostiles est spécifique au domaine. Les agents sont à protéger à deux niveaux : la
protection du code de l'agent (changement du comportement) et la modification de l'état de
l'agent. Plusieurs approches ont été proposées: l'approche organisationnelle permet,
seulement aux sites dignes de confiance, de gérer des systèmes d'agents mobiles;
l'approche de détection de manipulation offre des mécanismes fondés sur le traçage
permettant de détecter les manipulations de données effectuées sur un agent [Diaz01];
enfin l'approche de protection par boite noire. La cryptographie mobile est une étape vers
l'approche de protection par boite noire. La spécification de l'agent est convertie en code

Agents mobiles et applications réparties
23
exécutable et en un ensemble de données encryptées [Claessens03]. Le cryptage de
données empêche un éventuel attaquant de lire ou de modifier les données. Dans
[Benachenhou05], les auteurs présentent une nouvelle approche qui consiste à exécuter un
agent clone sur un site sur afin de surveiller l'exécution du vrai agent. Cette solution
engendre une augmentation dans le trafic réseau (échange entre l'agent et son clone).
‒ La sécurité d'un agent contre un autre agent. L'agent doit être protégé contre une
éventuelle attaque par un autre agent [Hohlfeld02] situé sur le site hôte ou sur un autre site.
Un agent doit avoir sa propre politique de sécurité qui peut être soit assurée par l'agent lui-
même, soit par le site d'accueil.
1.2.3.9 Cycle de vie et contrôle de l'agent
Un environnement d'exécution pour agents mobiles doit offrir à l'utilisateur la
possibilité de contrôler les activités de l'agent. Depuis sa création jusqu'à sa terminaison, un
agent peut passer par plusieurs étapes (cycle de vie d'un agent). Un langage de programmation
d'agents mobiles doit offrir au programmeur des points d'entrée qui vont lui permettre de
contrôler l'activité de son agent. Un agent passe par une partie ou la totalité des étapes
suivantes :
Création et initialisation. Lors de sa création, l'agent peut être initialise avec des
informations nécessaires à son exécution telles qu'un itinéraire, des préférences de son
utilisateur, etc. Par ailleurs, un agent est initialise par le système avec des informations
nécessaires à son interaction avec son environnement, comme par exemple l'identité de
son utilisateur.
Migration. L'agent se déplace entre les machines du système. Le but de cette migration
est souvent motive par une coopération en local avec des agents fixes ou d'autres agents
mobiles s'exécutant sur le même site. Avant de reprendre ses activités, l'agent aura
besoin des informations sur le nouveau site.
Activation et désactivation. Dans une application basée sur les agents mobiles, un
agent se désactive en suspendant son exécution afin d'être sauvegarde sur un support
non volatile. L'agent mobile est donc gelé. L'activation est l'opération inverse par
laquelle l'agent est restaure afin de continuer son exécution.
Terminaison. Une fois que sa tâche est réalisée, l'agent se termine et son processus
d'exécution est tué. Avant sa terminaison l'agent a besoin de livrer un bilan a son
utilisateur.
Souvent, un environnement d'agent mobile offre aux développeurs des méthodes
relatives au cycle de vie d'un agent. Ces méthodes sont appelées des ≪ call-back ≫. Un agent
doit être informe chaque fois qu'un évènement du cycle de vie commence, réussi ou échoue
(voir Table 1.1). Cela a pour but non seulement de réagir aux évènements en question mais
aussi d'être capable de refuser une création, une migration ou une réinitialisation après un
déplacement.

Agents mobiles et applications réparties
24
1.2.4. Domaine d’application des agents mobiles
Beaucoup de domaines d‟application impliquant les agents mobiles comme nouvelle
technologie ont vu le jour, malgré que les agents mobiles soient introduits récemment. Parmi
ceux-ci nous citons :
Recherche et filtrage d’information : C‟est le plus grand champ d‟application et
d‟expérimentation des agents. Les premiers systèmes commerciaux utilisant des agents
étaient des agents “moniteurs”. C‟étaient des programmes qui alertaient l‟utilisateur quand
une information intéressante apparaît. Alexa est une barre d‟outils d‟aide gratuite à la
navigation. Elle procure des informations statistiques et des liens sur chaque site visité.
Elle aide également au magasinage en ligne en vérifiant l‟identité d‟un site de commerce à
partir des contacts donnés sur la page. Les agents, et spécialement les agents mobiles, sont
adaptés pour agir comme des “bots”, des logiciels qui naviguent continuellement sur la
toile pour trouver de nouvelles informations.
Le Commerce électronique : Les agents sont naturellement adaptés au commerce
électronique, vu que Les principes d‟autonomie et de délégation sont largement employés
dans ce type d‟application. L‟agent agit pour le compte d‟une personne et applique
différentes stratégies pour remplir les services demandés. Pour dialoguer et négocier avec
les services présents sur différents sites et afin de réaliser la meilleure transaction possible,
l‟agent utilise sa mobilité qui lui permet de se déplacer de site en site.
La Compression des documents : Le transfert de documents est très utilisée sur Web. Si
un client veut obtenir une copie d'un document, il doit formuler une demande auprès d‟un
serveur qui lui envoie un flux de données correspondant au contenu du document. Le client
pourra utiliser un outil de compression de données, afin d‟optimiser le transfert de
données. Pour cela, le serveur doit être étendu pour pouvoir assurer cette fonction de
compression. des extensions particulières sont aussi envisagées au niveau des clients pour
que différents client puisse utiliser différents outils de compression.
Services de télécommunication : Dans le domaine des télécommunications, La
fonctionnalité de mobilité trouve toute son utilité. Il est très intéressant de noter Les agents
mobiles peuvent être utilisés pour couvrir les couches de protocoles de communication, de
la maintenance des réseaux jusqu‟aux applications mobiles suivant ainsi l‟usager dans ses

Agents mobiles et applications réparties
25
déplacements. Un “Personal Communicator Agent” (PCA) est un agent mobile chargé de
délivrer un message au destinataire, quel que soit son appareil (téléphone, ordinateur,
portable ou téléphone sans fil). Le PCA d‟un utilisateur doit pouvoir recevoir les messages
et les conduire à l‟utilisateur dans les meilleures conditions. Par exemple, si le seul moyen
de délivrer un message urgent à un utilisateur est via un téléphone sans fil, l‟agent
personnel doit convertir le message textuel en message vocal. Le suivi de l‟utilisateur
même quand il change de machine est assuré par la mobilité de ces agents
Robotique : Le rendement des robots physiques peut être amélioré par les agents. À
l‟aide de capteurs, les robots se basent dans leur comportements sur des agents qui
traduisent l‟information obtenue pour définir les actions à entreprendre (tourner, avancer,
etc.). Exemple : En utilisant une opinion basée sur un comportement réactionnaire, Astérix
est un exemple de robot, qui permet un dépistage de haut niveau.
1.2.5 Exemples de plateformes existantes
Cette partie tente de donner une idée sur les plateformes existantes permettant le
développement et la manipulation des agents mobile. Cette tâche est assez difficile pour
plusieurs raisons:
- Cette technologie est en plein essor bien que la notion d’agent soit relativement
ancienne
- l’évolution très rapide du domaine ne permet pas d’avoir toujours une information
actuelle.
- Il y a plusieurs modèles pour décrire le comportement des agents. Chacun fait l’objet de
recherches et de documents qui ne permettent pas d’avoir une vue globale et homogène.
- La maîtrise technologique des agents est un enjeu économique et stratégique très
important, ce qui explique la difficulté de trouver une normalisation acceptable.
Il existe à l’heure actuelle beaucoup d’implémentations différentes incompatibles entre
elles. Certaines écrites en Java pur, bénéficiant de fait du portage multiplateformes. Citons :
Odyssey [ODYSSEY] (de General Magic), Une des premières plateformes d’agents. Il
est indépendant du protocole de transport utilisé et peut donc s’adapter à RMI (de Sun),
CORBA (de OMG) ou DCOM (de Microsoft).
Aglets [AGLETS] d’IBM, utilisent la notion de référence distante (AgletProxy), le
passage de messages (multicast, broadcast) et le protocole ATP développé par IBM. Il
offre en outre une certaine notion de sécurité en limitant les ressources allouées aux
aglets.
Dima [DIMA] du laboratoire LIP6, est une plateforme pour les systèmes multi agents
permettant le développement de différents types d’agents (réactif, cognitif et hybride).
Cette plateforme ne supporte pas la mobilité. Cette dernière doit être programmée.

Agents mobiles et applications réparties
26
Jade [JADE] du CSELT de l’université de Parma, est un logiciel qui simplifie la mise
en place des systèmes multi-agents par grâce à une interface personnalisée qui répond
aux spécifications de la Fondation pour les Agents Intelligent Physique -FIPA- et grâce
à un ensemble d'outils qui supportent la résolution des bugs. Jade propose en plus des
services de sécurité.
Grasshopper : La plateforme Grasshopper développée par IKV++ (Innovation Know-
how Vision++) en 1997 est un environnement d‟implémentation et d‟exécution pour
agents mobiles. Ce produit développé en Java a été testé sur SUN Solaris 2.5 et 2.6, et
sur Windows (NT et 9x). Pour son fonctionnement, Grasshopper requiert au minimum
la version Java 1.1.4Visibroker 3.1. Grasshopper a la particularité d‟être la première
plate-forme compatible avec le protocole standard MASIF (Mobile Agent System
Interoperability Facility) de l‟OMG (Object Managment Group) et les standards de
FIPA (Foundation For Intelligent Physical Agents).
1.2.6. Avantages et inconvénients du paradigme agents mobiles
Un agent mobile [Arcangeli02] est une entité logicielle qui se déplace d'un site à un
autre en cours d'exécution pour accéder à des données ou à des ressources distantes. Il se
déplace avec son code son état d'exécution et ses données propres. La décision de migration
peut se faire à l'initiative de l'agent lui-même de manière autonome, la mobilité est ainsi
contrôlée par l'application et non par le système d'exécution. Le but du déplacement est
généralement d'accéder localement a des données ou à des ressources initialement distantes,
d'effectuer le traitement en local et de ne déplacer que les données utiles. Malgré leur jeune
apparition, les agents mobiles se sont rapidement imposés en particulier dans le domaine de la
recherche portant sur les applications réparties. Ce paradigme a été aussitôt évalué afin de
vérifier ce qu‟il pouvait apporter comme avantages par rapport aux méthodes de
programmation classiques. Dans la suite de cette section, nous présentons quelques aspects
pour l‟évaluation des agents mobiles:
- La Réduction de la charge Réseau: Il est généralement plus avantageux en terme de
performances, de faire voyager du code plutôt que des données.
- Le Déplacement du Code vers les données: Les serveurs contenant des données
procurent un ensemble fixe d'opérations. Un agent peut étendre cet ensemble pour les
besoins particuliers d'un traitement.
- La Fiabilité: La vie d'un programme classique est liée à la machine où il s'exécute.
Un agent mobile peut se déplacer pour éviter une erreur matérielle ou logicielle ou
tout simplement un arrêt de la machine.
- L'adaptation dynamique du système aux problèmes: Les agents peuvent se répartir
eux-mêmes sur des machines du réseau, afin de mieux tenir compte de l'état du
système au moment où ils doivent exécuter leurs tâches.
- La gestion de la robustesse et de la tolérance aux pannes: Si une machine s'arrête,
l'agent qui s'y trouve peut changer de machine pour terminer sa tâche en cours. En se
déplaçant avec leur code et données propres, les agents mobiles peuvent s‟adapter
facilement aux erreurs systèmes. Ces erreurs peuvent être d‟ordre purement physique

Agents mobiles et applications réparties
27
tel que la disparition d‟un nœud, ou d‟ordre fonctionnel comme l‟arrêt d‟un service. Si
dans un site par exemple un service tombe en panne, l‟agent utilisateur de ce service
pourra alors choisir de se déplacer vers un autre site contenant la fonctionnalité
désirée. Ceci permet une meilleure tolérance aux fautes.
- Indépendance des calculs: Certains services, nécessitant de longues phases de
traitement, ne supportent pas toujours les ruptures de connexion avec les clients. Par
ailleurs, le maintien des liens des communications dans les réseaux à large échelle ou
sans fil, est très difficile. Ceci rend, le modèle d‟évaluation à distance où le client et le
serveur doivent rester connectés tant que le service est en cours d‟exécution, très peu
adéquat. Les agents mobiles offrent aux clients la possibilité de déléguer les
interactions avec le service sans maintenir une connexion de bout en bout.
- La difficulté de développement et l’insuffisance de la standardisation: c‟est
l‟inconvénient majeur des agents mobiles étant donné que ce domaine est encore
relativement jeune. Il se heurte donc, à de fortes contraintes lors des phases de
développement. Comme par exemple le fait qu‟il existe à l‟heure actuelle un trop
grand nombre d‟intergiciels pour agents mobiles dont chacun possède ses propres
défauts et qualités [Cubat05]. La standardisation est donc loin, avec cette diversité
d‟offre.
Les agents ont besoin d‟exprimer les caractéristiques des services qu‟ils recherchent et
surtout d‟obtenir des réponses précises sur leur localisation ainsi que sur la manière de les
utiliser; et comme il n‟existe pas, jusqu‟à présent, de langage standard partagé par toutes les
plateformes de développements des applications d‟agents mobiles pour exprimer ces besoins,
un handicap sérieux se pose pour ce nouveau paradigme. De plus, avec tous les langages
existants, les développeurs sont, encore une fois, face à un large éventail de possibilités.
Heureusement, le domaine des systèmes multi-agents qui cherche à mettre en place des
langages précis en s‟appuyant sur un ensemble d‟ontologies et de protocoles caractérisant les
interactions inter-agents, pourrait apporter une solution à ce problème.
1.3. Conclusion
Dans ce chapitre, nous avons présenté les différentes technologies utilisées pour la
répartition et la communication entre les différentes entités d'une application repartie. Ainsi,
nous avons situé la technologie d'agents mobiles par rapport aux différentes techniques
présentées.
Un agent mobile est une entité autonome qui se déplace d'une machine à l'autre sur le
réseau, sans perdre son code ni son état. C'est l'environnement d'exécution qui se charge
d'assurer cette fonctionnalité. Il permet la création et la migration d'un agent, la
communication et l'échange de messages entre les agents mobiles et il assure la sécurité de
l'agent et de son site d'accueil.
Nous avons enchainé ensuite avec quelques exemples de plateformes
d'implémentation des applications d'agents mobiles. Avec la multitude de plates-formes
d'exécution, des efforts dans le domaine de la standardisation ont été déployés. Ce chapitre a
été conclu avec des critiques de ce paradigme.

28
Chapitre 2
Approche MDA et Transformation de Modèles
L‟ingénierie dirigée par les modèles (IDM ou MDE : Model Driven Engineering) est
le domaine qui met à la disposition de ses utilisateurs, des outils, concepts et langages pour
créer et transformer des modèles afin de mécaniser le processus que les ingénieurs suivent
habituellement à la main. L‟IDM se concentre sur une préoccupation plus abstraite que la
programmation classique ce qui permet d‟obtenir plusieurs améliorations dans le
développement de systèmes complexes. Grâce à l‟utilisation importante des modèles (qui
peuvent être exprimés dans des formalismes différents) et des transformations automatiques
entre les modèles, L‟IDM permet un développement souple et itératif, grâce aux raffinements
et enrichissements par transformations successives et automatiques entre les modèles. Ce que
propose donc, l‟approche de l‟ingénierie des modèles est la mécanisation du processus que les
ingénieurs expérimentés suivent à la main [Kadima05].
Dans cette thèse, notre proposition repose sur la démarche de l‟Ingénierie Dirigée par
les Modèles (IDM). Dans ce chapitre, nous présentons sommairement le principe et les
concepts fondamentaux de cette démarche et nous illustrons sa mise en œuvre à travers
l‟exemple de la variante que l‟Object Management Group (OMG) a définie autour de ses
standards: le Model-Driven Architecture (MDA). Nous donnerons entre autres, une idée sur la
transformation de modèles, sur les grammaires de graphes et un aperçu sur l‟outil utilisé à
savoir: ATOM3.
2.1 Principe
Une définition cohérente d‟un processus de construction d‟un produit nécessite à la
fois une bonne connaissance et une bonne maîtrise du produit à concevoir et de l‟intention du
processus de construction. La bonne connaissance et la bonne maîtrise du produit et de
l‟intention du processus de construction se traduisent par la possibilité d‟obtenir une
description précise et concise du produit, de l‟ensemble des solutions que l‟on souhaite
construire à partir de sa description initiale et de l‟ensemble des préoccupations qui mènent à
l‟ensemble des solutions visées. Dans la démarche de l‟IDM, cette description est exprimée à
travers un ensemble fini de modèles qui peuvent être interprétés ou transformés par une
machine. Pour qu‟une machine puisse interpréter ou transformer un modèle, il faut que le
modèle soit défini dans un langage que la machine comprend. Ce langage est appelé
métamodèle dans la littérature relative à la démarche de l‟IDM. Les métamodèles de
définition des modèles d‟un produit peuvent être différents. Pour gérer cette diversité, l‟IDM
repose sur l‟utilisation d‟un langage commun appelé métamétamodèle pour décrire tous les
métamodèles impliqués dans la description des modèles du produit afin de permettre leur
intégration dans les outils de mise en œuvre du processus de construction.

Approche MDA et Transformation de Modèles
29
Le principe de l‟IDM consiste donc à utiliser des modèles de manière systématique et
intempestive durant le processus de construction d‟un produit. Dans le domaine de
l‟ingénierie des logiciels, le fait d‟utiliser des modèles pour décrire les différents aspects d‟un
produit n‟est pas une idée spécifique à l‟IDM. Il existe d‟autres approches et méthodes de
modélisation telles que Merise ou SSADT, la programmation générative ou encore les usines
logiciels (Software factories) dans lesquelles les modèles sont vus comme étant la base de
toute activité humaine d‟ingénierie [Mokrane04]. La spécificité de l‟IDM repose sur sa
capacité à donner une dimension productive (ou opérationnelle) aux modèles. Dans le monde
de l‟IDM, un modèle est dit productif s‟il est exécutable ou s‟il peut être utilisé pour
construire des artefacts exécutables. Pour pouvoir construire des artefacts exécutables à partir
d‟un modèle, il faut être capable de définir des opérations sur le modèle afin de construire ces
artefacts exécutables. Ces opérations sont appelées des transformations de modèles dans la
démarche de l‟IDM. Tout modèle ou artefact exécutable est défini dans le contexte d‟une
plate-forme [Mireille06].
La démarche de l‟IDM repose donc sur cinq concepts fondamentaux : les modèles, les
métamodèles, les métamétamodèles, les transformations de modèles et les plateformes. Il
n‟existe pas de définitions standards de ces concepts dans le monde l‟IDM. La section
suivante présente les définitions rencontrées et qui semblent être acceptées par la plupart des
utilisateurs de l‟IDM dans la littérature.
2.2 Définition des concepts fondamentaux
2.2.1 Modèle
Un modèle est une abstraction simplifiée d‟un système étudié, construite dans une
intention particulière. Il doit pouvoir être utilisé pour répondre à des questions sur le système
[Jean01]. Un système est une construction théorique que forme l‟esprit sur un sujet (par
exemple, une idée qui est mise en œuvre afin d‟expliquer un phénomène physique qui peut
être représenté par un modèle mathématiques) [Wikipédia08].
2.2.2 Métamodèle
Un métamodèle est un langage qui permet d‟exprimer des modèles. Il définit les
concepts ainsi que les relations entre concepts nécessaires à l‟expression de modèles [Jean01].
Un modèle est une construction possible du métamodèle dans lequel il est défini. Dans la
littérature, un modèle est dit conforme au métamodèle dans lequel il est défini.
2.2.3 Métamétamodèle
Un métamétamodèle est un langage qui permet d‟exprimer des métamodèles. Pour
pouvoir interpréter un méta-modèle il faut disposer d‟une description du langage dans lequel
il est écrit : un méta-modèle pour les méta-modèles. C‟est naturellement que l‟on désigne ce
méta-modèle particulier par le terme de méta-méta-modèle [Marcus04]. Pour limiter le
nombre de niveaux d‟abstraction, le méta-méta-modèle doit avoir la capacité de se décrire lui-
même. Dans le monde de l‟IDM, il existe de nombreux langages tels que Keret [IRISA08],
MOF (pour Meta Object Facility) [OMG06], [OMG03], EMOF (The Essential MOF Model)
[OMG06], Ecore [Merks06] etc. disponibles pour l‟´écriture de métamodèles.
C‟est sur ces principes que se base l‟organisation de la modélisation de l‟OMG
généralement décrite sous une forme pyramidale (figure 2.1). Le monde réel est représenté à
la base de la pyramide (niveau M0). Les modèles représentant cette réalité constituent le

Approche MDA et Transformation de Modèles
30
niveau M1. Les méta-modèles constituent le (niveau M2). Enfin, Le niveau M3 est le niveau
le plus abstrait parmi les quatre niveaux dans cette architecture. Il définit la structure de tous
les méta-modèles du niveau M2 ainsi que lui-même.
Figure 2.1. Pyramide de la modélisation OMG
Dans l‟architecture à quatre niveaux, la validation d‟un modèle se fait via le modèle du
niveau suivant. Ce concept de méta-modèle semble être fondamental. Outre le fait qu‟il aide à
réduire les ambiguïtés et les incohérences de la notation, il constitue aussi un précieux atout
pour les concepteurs, dans le sens où il permet d‟automatiser le processus de développement
logiciel. L‟inconvénient majeur des langages de méta-modélisation dont MOF, c‟est qu‟ils
n‟offrent pas des techniques de validation et des règles de passage d‟un niveau à un autre.
MOF : Meta Object Facility MOF pour (Meta-Object Facility) [OMG00] est un ensemble d‟interfaces permettant
de définir la syntaxe et la sémantique d‟un langage de modélisation. Il a été créé par l‟OMG
afin de définir des méta-modèles et leurs modèles correspondants [Sylvain04]. Il fait partie
des standards définis par l‟OMG. Le MOF spécifie la structure et la syntaxe de tous les méta-
modèles. Ils ont le même formalisme. Il spécifie aussi des mécanismes d‟interopérabilité entre
ces méta-modèles. Il est donc possible de les comparer et de les relier. Grâce à ces
mécanismes d‟échanges, le MOF peut faire cohabiter plusieurs méta-modèles différents
[Sylvain04].
2.3 L’approche MDA
L'approche dirigée par les modèles (Model Driven Approach– MDA) est une variante
de l‟IDM qui a été initiée par l‟OMG en novembre 2000. C‟est un cadre de développement et
de maintenance de produits logiciels basé sur l‟utilisation et la transformation de modèles.
Les outils utilisés dans l'architecture MDA ont pour but de manipuler des modèles
logiciels, de vérifier leur cohérence, de les raffiner, pour terminer avec leurs transformation
automatique en squelettes de code.
MDA peut résoudre les problèmes d'évolutivité, d'interopérabilité, de portabilité, et de
documentation en vue d'augmenter la productivité dans le processus de développement
logiciel.

Approche MDA et Transformation de Modèles
31
2.3.1 Les modèles dans l’Architecture MDA
Dans l‟approche MDA, on perçoit trois points de vue, auquels on associe les modèles
respectifs : CIM, PIM et PSM.
Le modèle CIM : le CIM (Computational Independent Model) Appelé aussi modèle de
domaine ou modèle métier. Il permet de recenser les différents besoins du client
indépendamment de toute implémentation.
Le modèle PIM : le PIM (Platform Independent Model) représente un modèle de
spécification de la partie fonctionnelle du système. Cette spécification doit être conforme
à une analyse informatique cherchant à répondre aux besoins métiers indépendamment de
des détails techniques.
Le PSM : le PSM (Platform Specific Model) correspond au modèle de conception et
d‟implémentation d'une application par rapport à une plateforme spécifique.
Le point de départ de la construction d‟un produit est l‟identification des besoins des
utilisateurs. Dans le MDA, ces besoins sont traduits dans un modèle indépendant de tout
système informatique (CIM pour Computational Independent Model). Le principe du MDA
consiste à séparer ensuite la spécification fonctionnelle (PIM pour Platform Independent
Model) du produit de sa spécification d‟implantation sur une plate-forme technique
particulière (PSM pour Platform Specific Model). Dans l‟idée initiale du MDA, le PSM est
construit à l‟aide d‟un ensemble de transformations automatiques ou semi automatiques de
modèles qui fusionnent les informations spécifiques à la plate-forme choisie (PDM pour
Platform Description Model) et les informations du PIM. Ce PSM peut être raffiné jusqu‟à
l‟obtention du code d‟implantation effective du produit comme l‟indique la figure 2.2.
Figure. 2.2 Principe de la construction d‟un système à base de modèles dans le MDA

Approche MDA et Transformation de Modèles
32
2.3.2 Principe de transformation
La transformation de modèles doit mettre en œuvre des opérations permettant la
création d‟un modèle cible à partir des informations fournies par un modèle source. Elle se
base essentiellement sur les relations entre les modèles. Le passage du modèle source vers le
modèle cible, nécessite la connaissance parfaite des relations existantes entre les deux
modèles.
En MDA la transformation de modèles repose sur l‟utilisation des métamodèles et
comprend deux étapes [Kadima05] successives, qui sont :
La détermination des règles de transformation qui expriment la relation entre les
concepts du métamodèle décrivant le modèle source et ceux du métamodèle décrivant
le modèle cible.
L‟application de ces règles de transformation au modèle source pour générer le modèle
cible.
La figure 2.3 résume les concepts de base et le principe d‟une transformation de
modèles. En somme, une transformation est définie sur la base des métamodèles de sa source
et de sa cible. Les métamodèles et les modèles (source, cible, y compris le modèle de la
transformation) sont enregistrés dans un ensemble de référentiels (repositories). La
transformation est exécutée à l‟aide d‟un moteur de transformation qui est un outil capable de
lire un modèle dans un référentiel donné, d‟appliquer la transformation pour générer une
solution qu‟il décrit dans un référentiel approprié, et ce conformément à la définition de la
transformation.
Figure 2.3. Processus de transformation de modèles pilotée par les métamodèles

Approche MDA et Transformation de Modèles
33
2.3.3 Passage entre modèles
Passer progressivement des PIM aux PSM pour préparer et faciliter la génération de
code vers la plate-forme technique choisie, constitue l‟idée du MDA. Ce passage des PIM aux
PSM est une transformation de modèles [Jean02]. Dans le cycle de vie et de développement
d‟un produit, le MDA identifie différentes catégories de transformations de modèles.
PIM vers PIM (raffinement): Cette transformation constitue un enrichissement et une
spécialisation du modèle, en y apportant des informations indépendantes des spécificités
d'une technologie. La description d'un modèle de répartition, de persistance des données
ou de composants peut être vue comme un raffinement.
PIM vers PSM (projection): C‟est la traduction du modèle générique, vers une
plateforme d'exécution.
PSM vers PSM (réalisation): C'est la mise en œuvre concrète d'un modèle générique
sur une plate-forme d'exécution. Elle consiste en l'ensemble des phases qui mènent à un
logiciel exécutable, telles que la génération de code source, la compilation, le
déploiement, l'instanciation et l'initialisation des composants logiciels.
PSM vers PIM (reverse-engineering): Cette transformation permet l'élaboration du
modèle générique à partir de l'implémentation existante d'un logiciel. En théorie, cette
transformation est censée fournir un modèle générique décrivant l'application à partir
d'une base de code accessible. En pratique, il est très complexe d'automatiser
entièrement ce processus pour tout modèle PSM.
Génération de code: dans la pratique, certains travaux font la distinction entre les PSM
exécutables (ou code) et les PSM non exécutables, mais la génération de code n‟est pas
toujours considérée comme une transformation de modèles. La figure 2.4 montre quand même
qu‟il est possible de passer d‟un PSM non exécutable à du code et inversement. Il est
important de souligner que le passage du code au PSM est une opération de rétro-ingénierie
qui est assez complexe à réaliser. Si le code n‟a pas ´été conçu dans la démarche du MDA, il
faut faire appel aux techniques traditionnelles de rétro-ingénierie pour effectuer de telles
opérations. En somme, il est possible de classer les transformations de modèles possibles dans
le MDA dans quatre catégories comme l‟indique la figure 2.4.
Figure. 2.4 Transformations de modèles MDA

Approche MDA et Transformation de Modèles
34
– les transformations (2) : décrivent le processus de conversion d‟un PIM en un PSM;
– les raffinements (1), (3) et (6) : introduisent ou suppriment des informations dans un modèle ;
– les retro-ingénieries (4) et (7) : convertissent un modèle vers un niveau d‟abstraction plus élevé ;
– la génération de code (5) : transforme un PSM non exécutable en un code exécutable. Nous avons déjà
mentionné que la génération de code n‟est pas toujours considérée comme une transformation de modèles
dans la pratique.
2.3.4 Types de transformations de modèles
D‟un point de vue utilisateur, une transformation prend un ou plusieurs modèles en
entrée et génère un ou plusieurs modèles en sortie [Eric07]. Dans une transformation
interviennent deux composantes: la première est la définition de la transformation, la seconde
est l‟outil de transformation.
Les transformations sont des processus permettant d'une part les manipulations de
modèles, et d'autre part le passage d'un niveau de modèle à un autre [David06]. Pour réaliser
des transformations de modèles, les modèles doivent être exprimés dans un langage de
modélisation défini à l‟aide d‟un méta-modèle. On compte deux types de transformations:
endogènes et exogènes et ce, partant des méta-modèles sources et cibles de la transformation.
Si les modèles utilisés sont issus du même métamodèle, la transformation est dite endogène.
Par contre, si les modèles sources et cibles sont de différents méta-modèles, la transformation
est dite exogène ou translation. Ces deux catégories de transformations peuvent être
subdivisées comme suit :
Transformations endogènes
Optimisation : améliorer les performances tout en maintenant la sémantique,
Restructuration (refactoring) : transformation de la structure pour améliorer certains
aspects de la qualité du logiciel,
Simplification : transformation afin de réduire la complexité syntaxique.
Transformations exogènes
Synthèse : transformation d‟un certain niveau d‟abstraction vers un niveau
d‟abstraction moins élevé.
Rétro ingénierie : inverse de la synthèse.
Migration : transformation d‟un programme écrit dans un langage vers un autre
langage du même niveau d‟abstraction.
Le niveau d‟abstraction constitue un autre facteur important à prendre en considération
dans les transformations. On distingue les transformations horizontales et les transformations
verticales.
Une transformation horizontale est une transformation où les modèles sources et cibles
sont du même niveau d‟abstraction. Alors que, dans une transformation verticale, les modèles
impliqués sont de différents niveaux d‟abstraction.
2.3.5. Classification des approches de transformation de modèles
Selon NPrakash [Prakash06], la classification des approches de transformation de
modèles se base sur plusieurs points de vue, Chacun d‟entre eux permet un type de
classification. D‟après CZarnecki [Czar03] la classification des approches de transformation
de modèles repose sur les techniques de transformation adoptées par ses approches et leurs

Approche MDA et Transformation de Modèles
35
caractéristiques, telles que : la technique des langages de programmation et celle des patrons.
D‟autre part, et s‟intéressant particulièrement au domaine d‟application des modèles et à leur
généricité (capacité de transformer n‟importe quel modèle d‟entrée à n‟importe quel modèle
de sortie), NPrakash [Prakash06] propose une classification selon un point de vue
multidimensionnel.
Selon CZarneki [Czar03], il existe deux types de transformation de modèles :
les transformations de type modèle vers code qui sont aujourd‟hui relativement matures
et les transformations de type modèle vers modèles.
2. 3.5.1 Transformations de type Modèle vers code
La transformation de « modèle vers du code » est utilisée pour générer du code dans
un langage de programmation (Java, C++, XML, HTML, etc.) particulier à partir d‟un modèle
source. On distingue deux approches de transformations de type modèle vers code : les
approches basées sur le principe du visiteur (Visitor-based approach) ou celles basées sur le
principe des patrons (Template-based approach).
Les approches basées sur le principe du visiteur transforment le modèle en entrée
vers un code écrit dans un langage de programmation en sortie. La différence de
sémantique entre le modèle et le langage cible est réduite par l‟ajout de visiteurs au
modèle d‟entrée. Le modèle enrichi par les visiteurs est parcouru pour obtenir Le code
cible et créer ainsi un flux de texte en sortie.
Approches basées sur l‟utilisation de templates. Dans ces approches, un template est
un fragment de texte (du code) cible contenant des bouts de métacodes qui permettent:
(a) d‟accéder aux informations du modèle source
(b) de sélectionner du texte (code)
(c) de réaliser des expansions de manière itérative
2.3.5.2. Transformations de type modèle vers modèle
Les transformations de type modèle vers modèle sont aujourd‟hui plus maîtrisées, en
effet, elles ont beaucoup évolué au cours de ces dernières années, et plus particulièrement
depuis l‟apparition du MDA [OMG04]. Dans la démarche de l‟IDM, la transformation de
« modèle à modèle » est utilisée pour réaliser une activité de génération de modèles qui peut
être automatisée. La conversion d‟une classe UML en une table relationnelle (UML to
RDBMS, figure 2. 5) est un exemple typique de transformation de modèle à modèle souvent
cité dans la littérature à titre illustratif.

Approche MDA et Transformation de Modèles
36
Figure 2.5 Exemple typique d‟une transformation de modèle vers modèle
a- Modélisation de la transformation
Les différences, de la sémantique et de la syntaxe entre les deux modèles, source et cible
tels que : les PMIs et les PSMs, imposent une démarche rigoureuse pour une transformation
de type modèle à modèle qui ne cesse de se développer grâce à la diversité des techniques
MDA. La modélisation de transformation de modèles apparaît alors comme solution à ce
problème. Modéliser une transformation relève de la métamodélisation, qui est désormais, une
technique pilier, dans le cadre de la transformation de modèles.
b- Structure de la transformation
Une transformation de modèle se définit par un ensemble d‟éléments à savoir : des
règles de transformation ainsi que leurs organisations et leurs ordonnancement, une traçabilité
et une orientation doivent être aussi mises sn œuvre. La combinaison de ses éléments permet
de décrire la transformation qui est un modèle en soit même. Cependant, ces règles de
transformation doivent être d‟abord spécifiées afin de pouvoir exprimer les correspondances
entres les concepts des Métamodèles source et cible.
Règles de transformation : une règle de transformation se définit comme une
description de la manière dont une ou plusieurs constructions dans le langage du
modèle source peuvent être transformées en une ou plusieurs constructions dans le
langage du modèle cible [Kadima05]. Des contraintes ou des calculs sur les modèles
sources et cibles de la transformation sont exprimés par une logique de forme
déclarative ou impérative, que doit possède toute règle de transformation.
Spécification des règles de transformation : La correspondance entre les concepts du
métamodèle source et les concepts du métamodèle cible, est exprimée par les règles de

Approche MDA et Transformation de Modèles
37
transformation. La spécification décrit de telles relations indépendamment de toute
exécution. l‟automatisation complète de cette phase est prévue par les techniques MDA.
Certaines approches de transformation fournissent un mécanisme dédié de
spécifications, tel que des pré-conditions et des post-conditions exprimées en OCL. Des
spécifications particulières de transformation peuvent représenter une fonction entre les
modèles source et cible et peuvent être exécutables. Mais généralement, les
spécifications décrivent des relations et elles ne sont pas exécutables.
Pour exprimer les règles de transformation, il n‟existe pas actuellement de standard.
Cependant, Les travaux actuels de l‟OMG sur le standard MOF/QVT (Query Views
Transformation) sont prometteurs. Dans notre these, nous avons utilisé l‟outil ATOM3
[ATOM3].
c- Approches pour la définition de la transformation:
Les différentes caractéristiques présentées dans cette section constituent des points de
variation qui distinguent les différentes approches pour la définition de transformation de type
modèle vers modèle. On peut globalement distinguer cinq types d‟approches :
Manipulations directes
Ces approches se basent sur la représentation interne des modèles source et cible et sur
une collection d‟APIs pour les manipuler. L‟implémentation des règles de
transformation et leur ordonnancement restent à la charge du développeur en langage de
programmation standard comme Java par exemple.
Approches relationnelles
Ces approches utilisent une logique déclarative reposant sur des relations d‟ordre
mathématique pour spécifier les relations entre les éléments des modèles source et cible
par le biais de contraintes. L‟utilisation de la programmation logique est
particulièrement adaptée à ce type d‟approche.
Approches guidées par la structure
Dans ces approches, la transformation se fait en deux étapes. La première consiste à
créer la structure hiérarchique du modèle cible, alors que la deuxième consiste à ajuster
les attributs et les références dans le modèle cible.
Transformations de graphes
Les transformations de graphes, qui sont basées sur les grammaires de graphes
[Gerber02], sont des techniques et des formalismes directement applicables à la
transformation de modèles. Elles sont similaires aux approches relationnelles dans le
sens où elles permettent l‟expression des transformations sous une forme déclarative.
Dans cette approche les modèles source et cible sont représentés sous forme de graphes.
Cette notation visuelle permet aussi d‟exprimer les règles de transformation sous forme
graphique. Cette approche trouve son utilité dans le cas où les formalismes manipulés
possèdent des syntaxes concrètes visuelles. Elle est formelle et bien fondée sur des
bases mathématiques (comme la théorie des graphes et des grammaires formelles) ce
qui permet de vérifier certaines propriétés de la transformation. Cette approche vise à
considérer l‟opération de transformation comme un autre modèle conforme à son propre
méta-modèle (lui-même défini à l‟aide d‟un langage de méta-modélisation).

Approche MDA et Transformation de Modèles
38
Une grammaire de graphe permet ainsi en tant que formalisme de modéliser une
transformation [Vangheluwe02]. Une grande partie des outils récents adoptent cette
approche avec certaines différences tels que : VIATRA, AToM3, AGG et GReAT
[Taentzer05].
Approches hybrides
Les approches hybrides sont une combinaison des différentes techniques. On peut
notamment retrouver des approches utilisant à la fois des règles déclarative et
impérative. ATL (ATLAS Transformation Langage) [Jouault06] est un exemple de cette
approche.
2.4. Transformation de graphes
Dans la modélisation des systèmes, on rencontre le problème de la description de leurs
structures complexes. Les modèles et métamodèles, possèdent le plus souvent une
représentation sous forme de graphe. En effet, la théorie des graphes ouvre un grand champ de
modélisation conduisant à des solutions efficaces pour de nombreux problème. En outre, Les
graphes offrent un support agréable et efficace qui permet la modélisation de systèmes. Par
conséquent, les techniques de transformation et de réécriture des graphes peuvent être
appliquées à la transformation de modèles et exploitées pour spécifier comment évoluent ces
derniers.
Nous allons passer en revue quelques concepts de bases relatifs à la théorie de graphes,
avant d‟aborder les techniques de transformation de graphes et les outils rendant de telles
techniques applicables.
2.4.1. Concept de graphe
On appelle graphe G le couple (S,A) constitué d‟un ensemble S de sommets et d‟un
ensemble A d‟arcs. Chaque arc de A relie deux sommets de S. Un graphe peut être orienté ou
non selon le sens que l‟on donne aux arcs, les deux sommets qu‟ils relient pouvant être
considères comme ordonné ou non. [Yann03].
Principalement, on distingue trois catégories de graphes : les graphes orientés, les
graphes non orientés et les graphes étiquetés (cf. les figures 2.6 et 2.7 et 2.8). Dans la suite de
cette section nous allons présenter quelques définitions relatives aux propriétés et
caractéristiques des graphes :
Graphes non orientés
Un graphe non orienté n‟est qu‟un graphe orienté symétrique: si un arc relie le sommet a au
sommet b, un autre arc relie le sommet b au sommet a; on ne trace alors qu‟un trait entre a et
b que l‟on appelle une « arête ».

Approche MDA et Transformation de Modèles
39
Figure 2.6. Graphe non orienté
Le nombre de sommets présents dans un graphe est appelé ordre du graphe. Le graphe
de la figure 2.6 est d‟ordre 3.
Le degré d'un sommet est le nombre d'arêtes dont ce sommet est une extrémité. Le degré
du sommet B de la figure 2.6 est 3.
Graphes orientés
Un graphe orienté est un graphe dont les arêtes sont orientées: on parle alors de l'origine et de
l'extrémité d'une arête. Dans un graphe orienté une arête est dénommée « arc ».
Figure 2.7. Graphe orienté simple
Graphe étiqueté : Un graphe étiqueté est un graphe orienté, dont les arcs possèdent des
étiquettes. La nécessité de l‟étiquetage découle du fait qu‟un graphe utilisé pour la
représentation d‟un modèle doit être capable de prendre en charge les différentes relations
entre les éléments du modèle représenté. Les graphes orientés ne suffisent pas pour exprimer
les relations entre les éléments du modèle. Un étiquetage des arcs dans les graphes permet de
spécialiser les relations entre les différents sommets dans un graphe.
Figure 2.8. Graphe orienté étiqueté
A
B
C
F
F
S
K

Approche MDA et Transformation de Modèles
40
Le Chemin dans un graphe: le chemin dans un graphe est la succession des arcs parcourus
dans un sens définit dans le graphe, les propriétés et les caractéristiques d‟un chemin sont:
- sa longueur qui est égale au nombre d‟arcs parcourus ;
- le chenin décrit une chaîne si l‟on ne tient pas compte de la direction des arcs ;
- le chemin décrit un circuit s‟il revient à son point de départ ;
- la distance entre deux sommets dans un graphe est la longueur du plus court chemin entre
ces deux sommets, si cette longueur est de 1 les sommets sont dits adjacents.
- le diamètre d‟un graphe est la plus grande distance séparant deux sommets dans ce graphe.
Le sous-graphe : un sous graphe G’(S’,A’) d‟un graphe G(S,A) est un graphe composé
d‟un sous ensemble de sommet S’ S et d‟un sous ensemble d‟arêtes A’A’ tel que A’
représente les arêtes reliant les sommets S’ dans le graphe G (cf. la figure 4.7).
Graphe – G Graphe – G’
Figure 2.9. G’ est un sous graphe de G
2.4.2. Transformation de graphes
Les graphes et les diagrammes sont un moyen très pratique pour la description des
structures complexes et des systèmes ainsi que pour la modélisation des idées de manière
directe et intuitive. Les graphes servent à visualiser les structures complexes des modèles
d‟une façon simple et intuitive, alors que les transformations de graphes, peuvent être
exploitées pour spécifier comment ces modèles peuvent évoluer.
La transformation de graphes est un système de transformation de modèles
[Kadima05], elle se réalise grâce aux règles de transformation [Guerra06]. Les règles
s‟appliquent à un graphe source, en se basant sur le principe du pattern matching, pour
produire un graphe cible. Le principe de base est d‟appliquer les règles de transformation qui
remplacent des sous graphes dans le graphe source par des sous graphes dans le graphe cible
et ce, en utilisant la production préalablement définie dans les règles de transformation.
Les transformations de graphes [Rozenberg99] ont évolué dans la répercussion à
l‟imperfection dans l‟expressivité des approches de réécriture classique comme les
grammaires de Chomsky et la réécriture de termes pour s‟y prendre avec les structures non
linéaires. Une transformation de graphe [Karsai04, Andries99, Rozenberg99] consiste en
l‟application d‟une règle à un graphe et itérer ce processus. Chaque application de règle
A
B
C A
B

Approche MDA et Transformation de Modèles
41
transforme un graphe par le remplacement d‟une de ses parties par un autre graphe. La
transformation de graphe est donc le processus de choisir une règle parmi un ensemble de
règles indiqué, appliquer cette règle à un graphe et réitérer ce processus, jusqu'à
l‟impossibilité d‟application de toute règle.
2.4.2.1 Grammaires de graphes
La transformation de graphe est spécifiée sous forme d‟un modèle de grammaires de
graphes, ces dernières sont une généralisation, pour les graphes, des grammaires de Chomsky.
Elles sont composées de règles dont chacune est composée d‟un graphe de côté gauche (LHS)
et d‟un graphe de côté droit (RHS).
Une grammaire de graphe GG = (P,S,T), est un ensemble P de règles muni d‟un
graphe initial S et d‟un ensemble T de symboles terminaux [Andries99].
Une grammaire de graphes distingue les graphes non terminaux, qui sont les résultats
intermédiaires sur lesquels les règles sont appliquées, des graphes terminaux dont on ne peut
plus appliquer de règles, on dit que ces derniers sont dans le langage engendré par la
grammaire. Pour vérifier si un graphe G est dans les langages engendrés par une grammaire
de graphe, il doit être analysé. Le processus d‟analyse va déterminer une séquence de règles
dérivant G.
Exemple : Une grammaire de graphe à 2 règles.
Figure 2.10. Une grammaire déterministe de graphes
2.4.2.2. Le principe de règles
Une règle de transformation de graphe est définie par : r = (L, R, K, glue, emb, cond)
Elle consiste en:
Deux graphes, L graphe de côté gauche et R graphe de côté droit.
Un sous graphe K de L.
Une occurrence glue de K dans R qui relie le sous graphe avec le graphe de
côté droit.
Une relation d‟enfoncement qui relie les sommets du graphe de côté gauche et
ceux du graphe du côté droit.
Un ensemble cond qui spécifie les conditions d‟application de la règle.

Approche MDA et Transformation de Modèles
42
2.4.2.3. Application des règles
L‟application d‟une règle r= (L, R, K, glue, emb, cond) à un graphe G produit un
graphe résultant H. Le graphe H fourni, peut être obtenu depuis le graphe d‟origine G en
passant par les cinq étapes suivantes :
1. Choisir une occurrence du graphe de côté gauche L dans G.
2. Vérifier les conditions d‟application d‟après cond.
3. Retirer l‟occurrence de L (jusqu‟à K) de G ainsi que les arcs pendillé, c-à-d
tous les arcs qui ont perdu leurs sources et/ou leurs destinations. Ce qui
fournit le graphe de contexte D de L qui a laissé une occurrence de K.
4. Coller le graphe de contexte D et le graphe de côté droit R suivant
l‟occurrence de K dans D et dans R. c‟est la construction de l‟union de
disjonction de D et R et, pour chaque point dans K, identifier le point
correspondant dans D avec le point correspondant dans R.
5. Enfoncer le graphe du côté droit dans le graphe de contexte de L suivant la
relation d‟enfoncement emb :
La dérivation directe depuis G vers H à travers r dénotée par G ⇒ H, est l‟application
de la règle r sur un graphe G pour fournir un graphe H.
2.4.2.4 Système de transformation de graphe
Un système de transformation de graphe se défini comme un système de réécriture de
graphes qui applique les règles de la Grammaire de Graphes sur son graphe initial jusqu'à ce
que plus aucune règle ne soit applicable [Rozenberg99].
Figure 2.11. Système de réécriture de graphes

Approche MDA et Transformation de Modèles
43
Exemple :
Figure 2.12. Récriture pour la grammaire de la figure 2.10
Cette approche de transformations de modèles a plusieurs avantages par rapport aux
autres approches [Rozenberg99]:
Les grammaires de graphes sont un formalisme naturel, visuel, formel et de haut
niveau pour décrire les transformations
Les fondements théoriques des systèmes de la réécriture de graphes permettent
d‟aider à vérifier certaines propriétés des transformations telles que la terminaison ou
la correction.
2.4.2.5 Langage engendré
Soit un ensemble donné P de règles et un graphe G0. Une séquence de transformations
de graphe successive G0 ⇒ G1 ⇒ … ⇒ Gn, est une dérivation à partir de G0 vers Gn par les
règles de P (toutes les règles utilisées appartiennent à P). G0 est le graphe initial et Gn est le
graphe dérivé de la séquence de transformation citée. L‟ensemble des graphes dérivés à partir
d‟un graphe initial S en appliquant les règles de P qui sont étiquetées par les symboles de T
est dit langage engendré par P, S et T, et noté L(P,S,T).
2.5. AToM3: Un outil de Modélisation Multi-paradigme
Actuellement, il existe plusieurs outils de transformation de graphes, entre autres : AGG
[AGG], AToM3 [ATOM3], VIATRA [Viatra], etc. Etant simple et disponinle, ATOM
3 a été
utilisé dans le cadre de cette thèse.
2.5.1. Présentation de l’outil AToM3
AToM3
[ATOM3] « A Tool for Multi-formalism and Meta-Modeling » [De Lara02] est
un outil de modélisation multi-paradigme développé par le laboratoire MSDL
(Modelling,Simulation and Design Lab) à l'université de McGill Montréal, Canada. Comme il

Approche MDA et Transformation de Modèles
44
a été implémenté en Python [Python], il peut être exécuté, sans aucun changement, sur toutes
les plateformes où un interpréteur de Python est disponible (Linux, Windows et MacOS).
AToM3 est un outil visuel qui possède une couche de Méta-modélisation lui permettant
une modélisation graphique des différents formalismes. Il utilise et implémente un ensemble
de concepts tel que : métamodélisation, la modélisation selon plusieurs formalisme et les
grammaires de graphes qu‟il utilise pour la transformation de modèles. Par ailleurs, A partir
de la méta-spécification, AToM3 génère un outil pour la manipulation des différents modèles
décrits dans un formalisme spécifié, ces modèles ont une représentation interne de syntaxe
abstraite, et ils ont une autre représentation externe visuelle sous forme de graphes de syntaxe
concrète. Les règles des grammaires de graphes sont spécifiées par la syntaxe concrète des
modèles.
Dans AToM3, les modèles ainsi que les formalismes ont une description graphique. Les
modèles sont décrits selon des formalismes spécifiés par des méta-modèles, et ce, en utilisant
l‟outil de modélisation généré par AToM3. La transformation de modèles pourra donc
s‟effectuer en utilisant les grammaires de graphes (cf. la figure 2.13).
Figure 2.13. Présentation AToM3
2.5.2. La Méta-modélisation avec AToM3
L‟outil AToM3, utilise le formalisme Entité-Relation (ER) ou le formalisme des
diagrammes de classes d'UML pour définir les formalismes utilisateurs en les décrivant
visuellement par des graphes. Ceci signifie que pour méta-modéliser de nouveaux
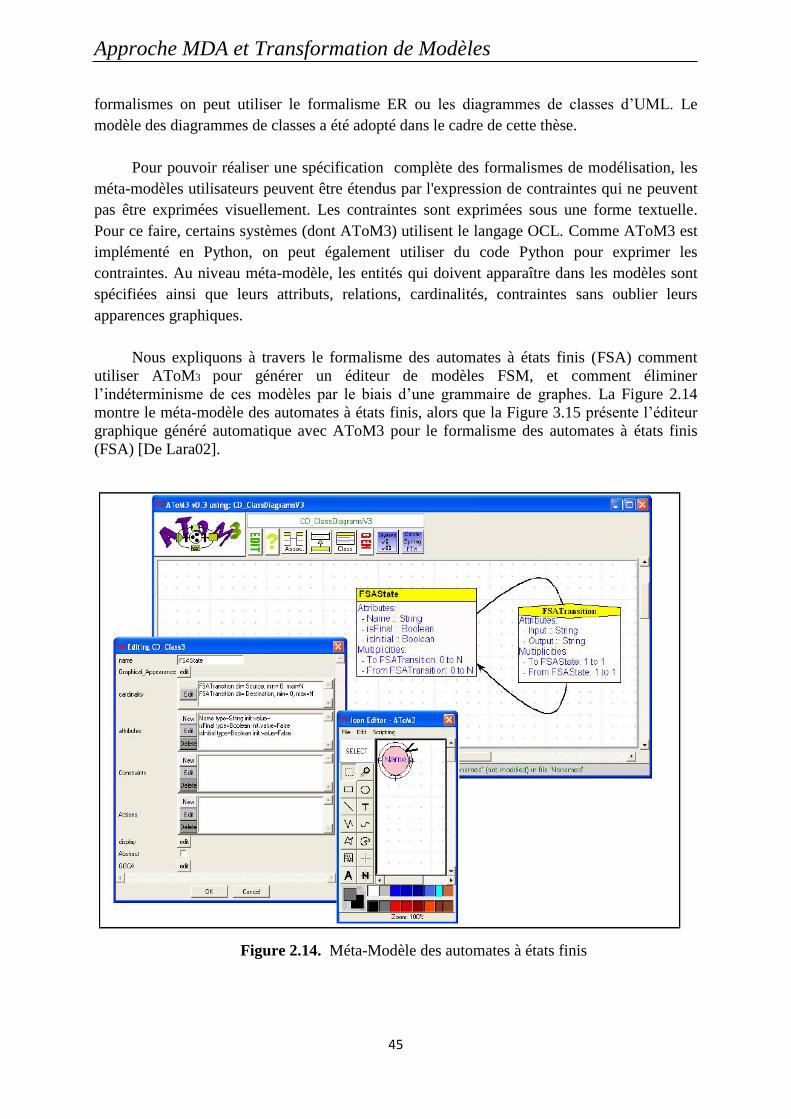
Approche MDA et Transformation de Modèles
45
formalismes on peut utiliser le formalisme ER ou les diagrammes de classes d‟UML. Le
modèle des diagrammes de classes a été adopté dans le cadre de cette thèse.
Pour pouvoir réaliser une spécification complète des formalismes de modélisation, les
méta-modèles utilisateurs peuvent être étendus par l'expression de contraintes qui ne peuvent
pas être exprimées visuellement. Les contraintes sont exprimées sous une forme textuelle.
Pour ce faire, certains systèmes (dont AToM3) utilisent le langage OCL. Comme AToM3 est
implémenté en Python, on peut également utiliser du code Python pour exprimer les
contraintes. Au niveau méta-modèle, les entités qui doivent apparaître dans les modèles sont
spécifiées ainsi que leurs attributs, relations, cardinalités, contraintes sans oublier leurs
apparences graphiques.
Nous expliquons à travers le formalisme des automates à états finis (FSA) comment
utiliser AToM3 pour générer un éditeur de modèles FSM, et comment éliminer
l‟indéterminisme de ces modèles par le biais d‟une grammaire de graphes. La Figure 2.14
montre le méta-modèle des automates à états finis, alors que la Figure 3.15 présente l‟éditeur
graphique généré automatique avec AToM3 pour le formalisme des automates à états finis
(FSA) [De Lara02].
Figure 2.14. Méta-Modèle des automates à états finis

Approche MDA et Transformation de Modèles
46
Figure 2.15. Editeur graphique généré pour les automates à états finis
2.5.3 La Transformation de Modèles.
Dans AToM3 un système de réécriture de graphes qui applique itérativement les règles
d‟une grammaire de graphes pour guider la procédure de transformation, est utilisé pour la
transformation de modèles. Pour diriger le choix de la règle à appliquer l'utilisateur spécifie et
classe ses règles selon des priorités bien étudiées. Selon l‟ordre ascendant de leurs priorités
toutes les règles sont testées, à chaque itération.
Lors de l‟application des règles, les attributs des éléments de la partie LHS doivent
avoir des valeurs qui seront comparées avec les attributs des éléments du modèle pendant le
processus de correspondance (matching). Un attribut peut prendre une valeur spécifique ou
n‟importe quelle valeur (<ANY>). En outre, les liens de traçabilité entre les éléments source
et cibles sont représentés par des étiquettes sous forme de numéros. Si une étiquette d‟un
élément apparaît dans la partie LHS mais pas dans la partie RHS, cet élément sera supprimé
lors de l‟application de la règle. Si au contraire, une étiquette d‟un élément n‟apparaît que
dans la partie RHS, cet élément sera créé suite à l‟application de cette règle. Le nœud sera
maintenu, si son étiquette apparaît à la fois dans la partie LHS et dans la partie RHS de la
règle à appliquer,
Suite à l‟application d‟une règle, les valeurs des attributs des éléments maintenus ou
nouvellement crées par la règle seront définis. On distingue, dans l‟outil AToM3 plusieurs
possibilités de le faire. Si l‟élément est déjà présent dans la partie LHS, les valeurs de ses
attributs peuvent copiées (<COPIED>). On a également la possibilité de leurs donner des
valeurs spécifiques ou de définir un programme Python pour calculer ces valeurs

Approche MDA et Transformation de Modèles
47
(<SPECIFIED>), éventuellement, en utilisant les valeurs des attributs source. A chaque règle
peuvent être attaché, des actions à effectuer et des conditions supplémentaires, liées à son
application.
Outre les règles de transformations, dans la grammaire de graphe, on peut utiliser aussi
une action initiale et une autre finale. L‟action initiale (ou finale) spécifie les actions à
exécuter avant (ou après) l‟application des règles. AToM3 offre à l‟utilisateur la possibilité de
créer, charger, modifier et exécuter une grammaire. Un modèle en sortie est le résultat de
l‟exécution de la grammaire sur le modèle en entrée.
La Figure 3.16 représente la grammaire de graphes qui permet d‟éliminer
l‟indéterminisme dans un modèle des automates à états finis. L‟application de cette
grammaire de graphe sur le modèle de la Figure 3.15 est illustrée par la Figure 3.17.
Figure 2.16. Grammaire de Graphe: élimination de l‟indéterminisme
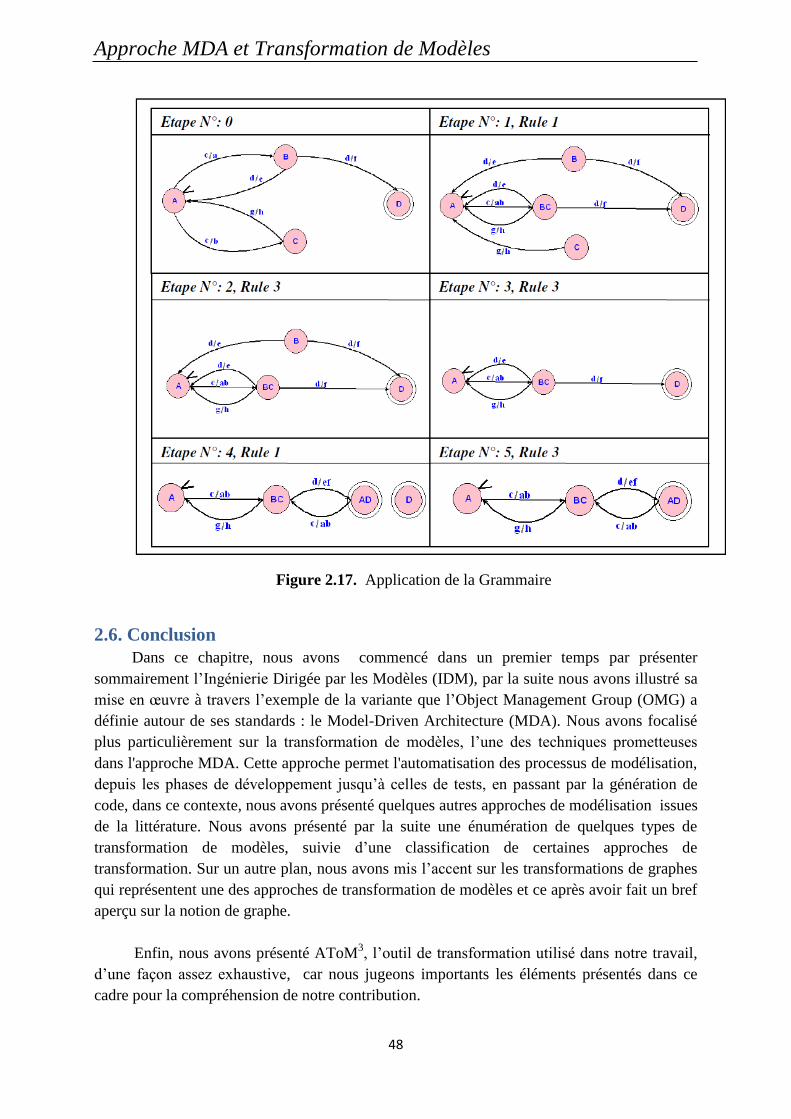
Approche MDA et Transformation de Modèles
48
Figure 2.17. Application de la Grammaire
2.6. Conclusion
Dans ce chapitre, nous avons commencé dans un premier temps par présenter
sommairement l‟Ingénierie Dirigée par les Modèles (IDM), par la suite nous avons illustré sa
mise en œuvre à travers l‟exemple de la variante que l‟Object Management Group (OMG) a
définie autour de ses standards : le Model-Driven Architecture (MDA). Nous avons focalisé
plus particulièrement sur la transformation de modèles, l‟une des techniques prometteuses
dans l'approche MDA. Cette approche permet l'automatisation des processus de modélisation,
depuis les phases de développement jusqu‟à celles de tests, en passant par la génération de
code, dans ce contexte, nous avons présenté quelques autres approches de modélisation issues
de la littérature. Nous avons présenté par la suite une énumération de quelques types de
transformation de modèles, suivie d‟une classification de certaines approches de
transformation. Sur un autre plan, nous avons mis l‟accent sur les transformations de graphes
qui représentent une des approches de transformation de modèles et ce après avoir fait un bref
aperçu sur la notion de graphe.
Enfin, nous avons présenté AToM3, l‟outil de transformation utilisé dans notre travail,
d‟une façon assez exhaustive, car nous jugeons importants les éléments présentés dans ce
cadre pour la compréhension de notre contribution.

49
Chapitre 3
Modélisation Formelle et Mobilité
Définir le processus de construction d‟un produit d‟une façon cohérente, se base sur la
bonne connaissance et la grande maîtrise du produit sans oublier de cerner avec exactitude
l‟intention du processus de construction. La possibilité d‟obtenir une description précise et
concise du produit, ainsi que de l‟ensemble des solutions que l‟on souhaite construire à partir
de la description initiale de celui-ci, traduit justement, la bonne connaissance et la bonne
maîtrise du produit et de l‟intention du processus de construction. Un ensemble fini de
modèles peut exprimer cette description.
Vu la complexité croissante des systèmes complexes et les contraintes de sûreté et de
bon fonctionnement qui leurs sont associées, le développement de ces systèmes sollicite de
plus en plus les activités de modélisation, de vérification et de validation. Définir les
différentes préoccupations qui interviennent dans le cycle de développement, et ce, en
procurant aux développeurs des approches de modélisation pour exprimer exactement les
informations nécessaires à chacune d‟entre elles, relève du rôle de la modélisation. Pour
assurer la fiabilité et la sûreté de fonctionnement du système, en particulier dans les premières
étapes de sa conception, il est nécessaire d‟associer à la modélisation des techniques
d‟analyses pour vérifier les modèles par rapport aux propriétés attendues et valider ceux-ci par
rapport aux exigences du client.
Un agent mobile est une entité logicielle pouvant se déplacer d'un site du réseau à un
autre pour atteindre ses objectifs, et ce d‟une manière autonome. Deux grandes normes de
standardisation (FIPA et MASIF [MASIF]) et un grand nombre de plateformes [MASIF] pour
les agents mobiles sont apparus, malgré leur récente introduction. Cependant, et surtout lors
de la phase de développement, le domaine des agents mobiles se heurte à des contraintes liées
à la modélisation. Les approches orientées-agents existantes dans leur majorité, cherchent à
adapter les méthodologies de modélisation, relatives à l‟analyse et à la conception orientées
objets pour le développement des applications d‟agents mobiles [Bahri09]. Il serait beaucoup
plus intéressant, d'obtenir une approche qui pourra être utilisée tout au long des phases de
développement des systèmes à agents mobiles (propre à eux), et qui inspire ses notations de
l'analyse et de la conception orientée objet (en particulier du langage UML). Néanmoins, un
sérieux problème concernant la relation entre les agents et les objets, se pose.

Modélisation Formelle et Mobilité
50
Il serait avantageux d‟intégrer les méthodes formelles dans les activités de
développement des systèmes, en particulier ceux à base d‟agents mobiles, mais ceci présente
une difficulté réelle liée à la manipulation des concepts théoriques et des méthodes d‟analyse
associées, ainsi que la capacité des développeurs d‟exprimer les propriétés du système de
façon aisée.
Dans ce chapitre, nous présentons une panoplie de méthodes formelles et leur
classification. Ensuite nous abordons l‟utilisation et l‟intégration de ces méthodes formelles à
la méthodologie IDM afin d‟augmenter la fiabilité et de garantir l‟absence d‟erreurs de
conception. Dans ce contexte, les réseaux de Petri représentent une technique formelle
largement utilisée. Un intérêt particulier sera porté sur eux. Nous clôturerons ce chapitre, par
la présentation de quelques extensions de RdPs pour la mobilité.
3.1. But de la modélisation
Modéliser un système avant sa réalisation permet de mieux comprendre le
fonctionnement du système. C‟est également un bon moyen de maîtriser sa complexité et
d‟assurer sa cohérence. La modélisation en informatique peut être vue comme la séparation
des différents besoins fonctionnels et préoccupations extra-fonctionnelle (telles que: la
sécurité, la fiabilité, l‟efficacité, la performance, la ponctualité, la flexibilité, etc.)
[Kadima05]. Un modèle est un langage commun, précis, qui est connu par tous les membres
de l‟équipe et il est donc, à ce titre, un moyen privilégié pour communiquer. Cette
communication est essentielle pour aboutir à une compréhension commune pour les
différentes parties prenantes (notamment entre la maîtrise d‟ouvrage et la maîtrise d‟œuvre
informatique) et précise d‟un problème donné [Aud07].
Dans le domaine de l‟ingénierie du logiciel, le modèle permet de mieux répartir les
tâches et d‟automatiser certaines d‟entre elles. C‟est également un facteur de réduction des
coûts et des délais. Par exemple, les plateformes de modélisation savent maintenant exploiter
les modèles pour faire de la génération de code (au moins au niveau du squelette) voir des
allers retours entre le code et le modèle sans perte d‟information.
La réalisation d‟un système fait intervenir en général, toute une équipe de travail. La
communication entre les différents membres de l‟équipe détermine la réussite du projet à
concevoir. Dans ce contexte, Le modèle se définit comme étant un langage commun aux
membres de l‟équipe, qui facilite la communication et la compréhension entre les différentes
parties concernées par le projet. En effet, dans l‟ingénierie du logiciel le modèle permet une
meilleure répartition des tâches entre les différents intervenants. Ceci a un impact direct sur
la réduction des coûts et des délais de réalisation des projets.
Selon les modèles employés, on distingue plusieurs formes de modélisation.
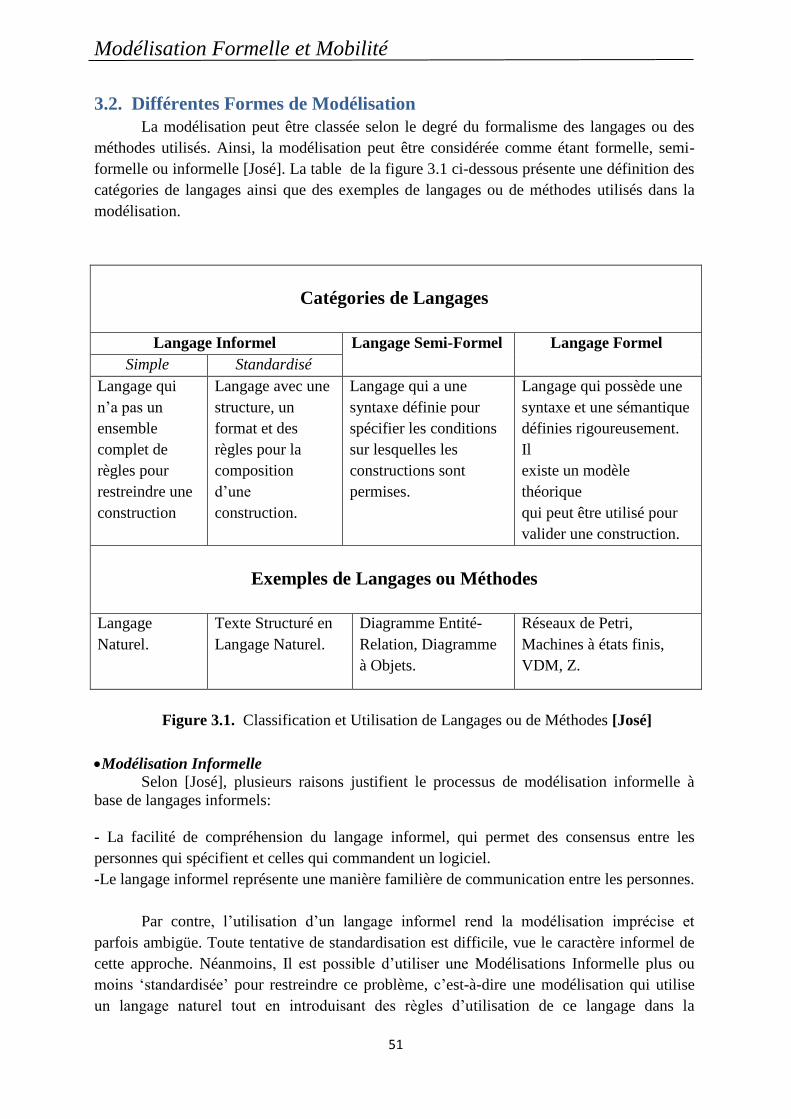
Modélisation Formelle et Mobilité
51
3.2. Différentes Formes de Modélisation
La modélisation peut être classée selon le degré du formalisme des langages ou des
méthodes utilisés. Ainsi, la modélisation peut être considérée comme étant formelle, semi-
formelle ou informelle [José]. La table de la figure 3.1 ci-dessous présente une définition des
catégories de langages ainsi que des exemples de langages ou de méthodes utilisés dans la
modélisation.
Catégories de Langages
Langage Informel Langage Semi-Formel Langage Formel
Simple Standardisé
Langage qui
n‟a pas un
ensemble
complet de
règles pour
restreindre une
construction
Langage avec une
structure, un
format et des
règles pour la
composition
d‟une
construction.
Langage qui a une
syntaxe définie pour
spécifier les conditions
sur lesquelles les
constructions sont
permises.
Langage qui possède une
syntaxe et une sémantique
définies rigoureusement.
Il
existe un modèle
théorique
qui peut être utilisé pour
valider une construction.
Exemples de Langages ou Méthodes
Langage
Naturel.
Texte Structuré en
Langage Naturel.
Diagramme Entité-
Relation, Diagramme
à Objets.
Réseaux de Petri,
Machines à états finis,
VDM, Z.
Figure 3.1. Classification et Utilisation de Langages ou de Méthodes [José]
Modélisation Informelle
Selon [José], plusieurs raisons justifient le processus de modélisation informelle à
base de langages informels:
- La facilité de compréhension du langage informel, qui permet des consensus entre les
personnes qui spécifient et celles qui commandent un logiciel.
-Le langage informel représente une manière familière de communication entre les personnes.
Par contre, l‟utilisation d‟un langage informel rend la modélisation imprécise et
parfois ambigüe. Toute tentative de standardisation est difficile, vue le caractère informel de
cette approche. Néanmoins, Il est possible d‟utiliser une Modélisations Informelle plus ou
moins „standardisée‟ pour restreindre ce problème, c‟est-à-dire une modélisation qui utilise
un langage naturel tout en introduisant des règles d‟utilisation de ce langage dans la

Modélisation Formelle et Mobilité
52
construction de la modélisation. Un tel type de modélisation garde les avantages de la
modélisation informelle en la rendant moins imprécise et moins ambigüe.
Modélisation Semi-Formelle
Le processus de modélisation semi-formelle est basé sur un langage textuel ou
graphique pour lequel une syntaxe précise est définie [José]. Ce type de modélisation permet
d‟effectuer des contrôles et de réaliser des automatisations pour certaines tâches, bien que La
sémantique des langages Semi-Formels soit souvent assez faible.
Les méthodes de modélisation semi-formelles dans leur majorité, s‟appuient fortement
sur des langages graphiques. Cela, se justifie par l‟expressivité que peut avoir un modèle
graphique bien développé. Le langage textuel est utilisé normalement comme complément
aux modèles graphiques.
Par ailleurs, la modélisation semi-formelle (tels que : UML) utilise fortement les
langages graphiques, ceci permet la production de modèles assez faciles à interpréter.
Néanmoins, les aspects sémantiques impliqués dans cette approche de modélisation souffrent
d‟une remarquable déficience. Afin de pallier aux insuffisances de cette approche,
l‟utilisation de contraintes a été introduite, dans ce contexte, on retrouve à titre d‟exemple les
travaux de S. Cook et J. Daniels [Cook94].
Modélisation Formelle
Les méthodes formelles adoptent un processus de développement rigoureux basé sur
des notations formelles avec une sémantique définie. Les aspects formels se caractérisent par
leurs capacités à exprimer une signification précise, permettant ainsi des vérifications de la
cohérence et de la complétude d‟un système, ceci constitue leur principal avantage. En effet,
et à titre d‟exemple, J. P. Bowen et M. C. Hinchey [Hin95] montrent qu‟avec une traduction
appropriée, les méthodes formelles peuvent aider à la compréhension d‟un système par un
utilisateur. Selon A.Hall [Hall90] les méthodes formelles aident à trouver des erreurs et à
diminuer leur incidence sur la réalisation du projet, à travers une spécification complète qui
peut être appliquée à n‟importe quel type de système, logiciel ou matériel. Elles ne remplacent
cependant pas des méthodes existantes et doivent être utilisées d‟une manière conjointe avec
celles-ci, en effet, si une connaissance mathématique solide est nécessaire pour réaliser des
preuves, elle ne l‟est pas impérativement pour spécifier. L‟utilisation de méthodes formelles
peut provoquer une diminution des coûts et de la durée de réalisation des projets.
Les études pour la création d‟autres outils formels qui couvrent toute la spécification,
outre les outils de preuves déjà existants, montrent l‟intérêt qu‟on porte à ces méthodes. Bien
qu‟elles ne soient pas utilisées dans tous les types de modélisation, L‟application des
méthodes formelles, plus que souhaitable, commence à être imposée par des sociétés dans
certains cas, qui nécessitent plus de rigueur.
3.3. Techniques d’analyse
Les systèmes deviennent de plus en plus complexes, il est donc impératif d‟assurer
certaines performances, et de limiter l‟impact des risques de dysfonctionnement à défaut de
garantir catégoriquement leurs absence. Pour cela, de nombreuses méthodes et techniques ont
été développées pour analyser les systèmes complexes.

Modélisation Formelle et Mobilité
53
Vérification
La vérification répond à la question "Construisons-nous correctement le modèle ?" ("is the
system being built right?"). La vérification est l‟ensemble des inspections, tests, simulations,
preuves automatiques, ou autres techniques appropriées permettant d‟établir et de documenter
la conformité des résultats du développement vis-à-vis des critères préalablement établis, a-t-
on atteint ce qu‟on voulait atteindre ? La vérification est définie comme étant "la confirmation
par examen et apport de preuves tangibles (informations dont la véracité peut être démontrée,
fondée sur des faits obtenus par observation, mesures, essais ou autres moyens) que les
exigences spécifiées ont été satisfaites" [ISO 8402].
Validation
La validation cherche à répondre à la question "Construisons nous le bon modèle?" ("is
the right system being built?"). La validation consiste à évaluer si le système développé est
adéquat quant aux besoins exprimés par ses futurs utilisateurs et ce par rapport à des usages
bien spécifiques. Par définition la validation est la "confirmation, par examen et apport de
preuves tangibles, que les exigences particulières pour un usage spécifique prévu sont
satisfaites. Plusieurs validations peuvent être effectuées s‟il y a différents usages prévus" [ISO
8402].
Qualification
Qualifier un modèle c‟est assurer qu‟il peut servir à la communication claire, sans
ambiguïtés ni interprétation secondaire possible entre les activités du projet et/ou entre les
acteurs d‟un groupe de travail.
Certification
Le modèle est certifié, s‟il respecte une norme et peut donc servir de base à
l‟établissement d‟un référentiel réutilisable et générique à un domaine. L‟implication et la
responsabilité d‟un organisme tiers qui reconnaît la pertinence, la rigueur, l‟intérêt du modèle
et garantit ces qualités lors de sa diffusion, est bien évidement sous-entendue.
3.4. Méthodes Formelles
Les méthodes formelles (MFs) sont des techniques basées sur les mathématiques pour
décrire des propriétés de systèmes. Elles fournissent un cadre très rigoureux pour spécifier,
développer et vérifier les systèmes d'une façon systématique, plutôt que d'une façon ad hoc,
afin de démontrer leur validité par rapport à une certaine spécification [Wing90].
L‟absence des incohérences, des contradictions et des failles dans la conception ainsi
que la détermination de la correction l‟implantation d‟un système, sont tous des éléments très
fortement assurés par ces méthodes. Ces méthodes sont désormais, l‟objet de nombreuses
recherches afin d‟élargir leurs champs d‟application.
3.4.1. Les langages formels
L‟utilisation de langages formels, est à la base des méthodes formelles, et ce pour
donner une spécification du système que l‟on souhaite développer à un niveau de détail désiré.
Un langage formel est en effet un langage doté d‟une sémantique mathématique adéquate
basée sur des règles d‟interprétation et des règles de déduction [Petit99, Benzaken91].
Contrairement aux descriptions en langages informels semi-formels, qui peuvent donner
lieu à différentes interprétations, Les règles d‟interprétation dans les langages formels,

Modélisation Formelle et Mobilité
54
garantissent l‟absence d‟ambiguïté dans les descriptions produites. Alors que les règles de
déduction quant à elles, permettent de raisonner sur les spécifications pour prouver des
propriétés attendues ou éviter les incomplétudes et les inconsistances.
3.4.2. Les mythes autour des méthodes formelles
Bien qu‟il y ait eu une utilisation significative des méthodes formelles dans les
industries critiques [Hinchey95], elles n‟ont pas été très bien accueillies en général par la
communauté de développement de logiciels [Bloomfield99]. Il y a eu beaucoup d‟idées
fausses à propos des méthodes formelles, dans [Hall90], l‟auteur cite sept mythes à leur sujet:
L‟utilisation des méthodes formelles produit un logiciel parfait : faux, une spécification
formelle est un modèle du monde réel et peut donc inclure des erreurs, des malentendus et
des omissions.
Utiliser les méthodes formelles signifie faire de la preuve de programme : La spécification
formelle d‟un système est valable sans vérification formelle des programmes, car une
analyse détaillée est rigoureusement suivie dans le cycle de développement.
Les méthodes formelles ne sont justifiables que pour les systèmes critiques: L‟expérience
industrielle montre que les coûts de développement peuvent être réduits pour tous les
types de systèmes.
Les méthodes formelles sont pour les mathématiciens: faux, les mathématiques employées
par ces méthodes sont élémentaires.
Les méthodes formelles augmentent les coûts de développement : Non prouvé, il y a un
déplacement des coûts vers les premières étapes.
Les clients ne peuvent comprendre les spécifications formelles: un support d‟explication
en langage naturel, ou le prototypage, peuvent être utilisés.
Les méthodes formelles ne sont utilisées que pour les systèmes triviaux : de nombreux
projets industriels relatifs aux systèmes non-triviaux ont été maintenant, mis en œuvre.
3.4.3. Classification des Méthodes Formelles
Dans la littérature, il existe plusieurs classifications des méthodes formelles. Selon J.M. Wing
[Wing90], on peut distinguer les méthodes:
Orientées opérations pour décrire le fonctionnement du système et son comportement par
des axiomes.
Orientées données pour décrire les états du système
Hybrides en combinant les deux orientations.

Modélisation Formelle et Mobilité
55
Figure 3.2. La classification des méthodes formelles
Des trois approches de base, découlent les approches secondaires suivantes :
Basées modèle
Basées logique
Algébriques
Algèbre de processus
Orientées réseaux (graphiques)
a- Approches basées modèle : Dans cette approche. Il n'y a pas de représentation explicite de
la concurrence. Le système est modélisé par la définition explicite des états et des opérations
qui le transforment d'un état vers un autre. Des besoins Non fonctionnels (telles que l'exigence
temporelle) peuvent être exprimée dans certains cas. Exemples de méthodes : Z, VDM, et B.
b- Approches basées logique : Les propriétés du système, y compris les comportements
temporels et probalistiques, peuvent être décrite en utilisant la logique. Le système d‟axiomes
associé à la logique permet de valider ces propriétés. Dans certains cas, un sous-ensemble de
la logique peut être exécuté (par exemple, le système de tempura).La spécification exécutable
est ensuite utilisée pour une simulation et un prototypage rapide. La logique de Hoare,
Dijkstra, logique temporelle… sont quelques exemples de la dite approche.
c- Approches algébriques : On définit ici implicitement des opérations, en reliant leurs
comportement sans définir la signification des états actuels. Similaire à l'approche fondée sur
les modèles, dans le sens ou il n'y a pas de représentation explicite de la concurrence.
Exemples: OBJ, Larch.
d- Algèbre de processus : C‟est dans cette approche, qu‟une représentation explicite des
processus concurrents est autorisée. En effet, les contraintes sur toutes les communications
autorisées et observables entre processus, permettent la représentation du comportement du
système. Exemples: Communicating Sequential Processes (CSP), Lotos, Timed CSP.

Modélisation Formelle et Mobilité
56
e- Approches basées graphes Etant faciles à comprendre et, par conséquent, plus accessibles
aux non-spécialistes, les notations graphiques sont très répandues pour la spécification des
systèmes. Cette approche combine des langages graphiques avec la sémantique formelle, ce
qui permet de puiser des avantages de ces deux axes dans le développement de systèmes.
Exemples: Petri Nets, State Charts.
3.4.4. Techniques de vérification formelle
Habituellement, on distingue deux grandes familles de techniques pour vérifier
formellement la correction d‟un système. La premiere technique est appelée vérification de
modèles, ou model-checking, et consiste à construire un modèle à partir d‟une description
formelle d‟un système. En second lieu, les techniques de preuve (theorem proving) qui sont
des démonstrations mathématiques au sens propre du terme vue que la vérification des
propriétés est effectuée par déduction à partir d‟un ensemble d‟axiomes et de règles
d‟inférences.
3.4.4.1. Vérification de modèles (Model-Checking)
Construire un modèle fini d‟un système et vérifier qu‟une propriété cherchée est vraie
dans ce modèle est à la base de la technique de vérification de modèles. Dans le model-
checking, on peut procéder de deux manières pour la vérification: vérifier qu‟une propriété
exprimée dans une logique temporelle est vraie dans le système, ou comparer (en utilisant une
relation d‟équivalence ou de préordre) le système avec une spécification pour vérifier si le
système correspond à la spécification ou non. Le model-checking est complètement
automatique et rapide, et ce contrairement au theorem proving. Il peut être utilisé pour aider le
débogage en produisant des contre-exemples qui représentent des erreurs subtiles dans la
conception.
3.4.4.2. Preuve de théorèmes (Theorem proving)
Dans cette technique, le système et les propriétés recherchées sont exprimés comme
des formules dans une logique mathématique, qui est décrite par un système formel qui définit
un ensemble d‟axiomes et de règles de déduction. Partant des axiomes du système, la preuve
de théorèmes, constitue le processus de recherche de la preuve d‟une propriété. Des appels
aux axiomes et aux règles, ainsi qu‟aux définitions et lemmes qui ont été possiblement
dérivés, sont fait durant Les étapes de recherche de la preuve. Contrairement au model-
checking, le theorem proving peut s‟utiliser avec des espaces d‟états infinis à l‟aide de
techniques comme l‟induction structurelle. Le processus de vérification, dans cette technique,
peut être lent, sujet à l‟erreur, demande beaucoup de travail et des utilisateurs spécialisés avec
beaucoup d‟expertise, ceci constitue son principal inconvénient.
3.5 Combinaison d’IDM avec les Méthodes Formelles
L'utilisation des méthodes formelles (MFs) s‟avère désormais, essentielle pour le
développement de systèmes complexes, notamment pour les systèmes critiques où les
questions liées à la sûreté/fiabilité sont cruciales. D‟un autre côté, l‟IDM a atteint niveau de
maturité assez important. En effet, elle est devenue une nouvelle démarche en génie logiciel
capable de concevoir, l‟intégralité du cycle de développement en se basant sur la méta-
modélisation et transformation de modèles. On note néanmoins que chacune des deux
approches a des points forts et d‟autres faibles.
Il serait donc intéressant de voir comment ces deux approches peuvent être combinées.
La suite de cette section, montre comment les inconvénients des méthodes formelles peuvent

Modélisation Formelle et Mobilité
57
être surmontés grâce aux apports de l‟IDM et réciproquement. La Figure 3.3, représente
brièvement les avantages et les inconvénients de l‟IDM et des MFs [Gargantini09].
Figure 3.3. Les MFs & IDM
Avantages des MFs. Un modèle abstrait du système peut servir de support pour s‟assurer
que le système en cours de développement répond aux exigences des clients, par
simulation ou tests, et garantir certaines propriétés liées à son comportement par l'analyse
formelle (validation et vérification). Pour cela, l'utilisation des méthodes formelles dans
l'ingénierie des systèmes devient indispensable, surtout dans les phases amont du
développement.
Inconvénients des MFs. Malgré que les applications des méthodes formelles ont envahi
le monde industriel et avec de bons résultats, les développeurs hésitent encore à les
adopter. Outre leur difficulté d‟utilisation et d‟apprentissage, cette réserve est
principalement dû à:
1) Les techniques formelles utilisent des notations complexes par rapport à d'autres
notations intuitives et graphiques utilisées par les langages semi-formels comme le
langage UML.
2) Le manque de l‟assistance aux développeurs dans leurs démarches de
développement de manière transparente à cause de l‟absence de support outillé.
3) Les différentes méthodes formelles ne sont pas intégrées à leurs outils d‟analyses
adjacents.
Avantages de l’IDM. L'automatisation du processus de développement des systèmes est
de plus en plus assurée par l‟approche IDM. Des représentations du système dans cette
approche, se font à un haut niveau d‟abstraction associé aux modèles. Par la suite, le
processus de développement, revient à raffiner, maintenir, et éventuellement transformer
vers d‟autres modèles ou à générer le code exécutable. Il est impératif de noter que ces
différentes activités se font d‟une manière automatique. En outre, et étant le concept clé de
l‟approche IDM, la méta-modélisation, permet de donner à un langage de modélisation
une notation abstraite, ce qui permet de générer automatiquement l‟éditeur qui lui est
associé. Afin de réduire la complexité et d'exprimer efficacement les concepts du
domaine, la métamodélisation de langages, est de plus en plus adoptée pour des domaines
spécifiques.

Modélisation Formelle et Mobilité
58
Inconvénients de l’IDM. La définition de la sémantique d‟un langage par un méta-
modèle reste une question ouverte, cruciale et non maitrisée. alors que la définition d'une
syntaxe abstraite de ces langages est bien maîtrisée et supportée par de nombreux
environnements de métamodélisation. Actuellement, ces environnements, sont en mesure
de faire face à la plupart des problèmes de définition syntaxique, mais ils ne peuvent pas
fournir la sémantique des méta-modèles par manque de supports rigoureux permettant de
le faire. De ce fait, les langages définis par la métamodélisation ne permettent pas
l'analyse formelle des modèles qu‟ils produisent, car leur sémantique est généralement
donnée dans un langage naturel.
Des défis importants se présentent donc aux MFs, on en cite: L'absence de notations
conviviale, le manque d'intégration des différentes techniques formelles et de
l‟interopérabilité de leurs outils. Ceci peut être en partie réglé par l'IDM qui permet, par le
biais des notions de méta-modèle et de transformation de modèles, de concevoir des supports
outillés pour les méthodes formelles et d‟assurer leur interopérabilité. Ceci dit, l‟IDM
n‟apporte pas un plus sur le plan théorique, aux concepts d‟analyse formelle, mais elle peut
permettre de profiter pleinement de leurs avantages en leur assurant une meilleure intégration.
3.6. Réseaux de Petri
3.6.1. Introduction
Les systèmes dynamiques ne peuvent pas être décrits en ne prenant en compte que
leurs états initiaux et finaux. En effet, on doit tenir compte de leur comportement permanent
qui est une séquence d'états, pour qu‟on puisse parler d‟une description bien fondée. Parmi le
grand nombre des techniques formelles qui ont déjà été proposées pour spécifier, analyser et
vérifier ce genre de systèmes, Les réseaux de Petri sont l‟une des plus utilisés.
Carl Adam Petri a introduit le formalisme des réseaux de Petri [Tran05], dans sa thèse
"Communication avec des Automates" à l‟université Darmstadt en Allemagne, en 1962. Un
peu plus tard et au début des années 70s, ce travail a été développé par Anatol W. Holt, F.
Commoner, M. Hack et leurs collègues dans le groupe de recherche de Massachussetts
Institute Of Technology (MIT). En 1975 MIT organise la première conférence sur les réseaux
de Petri et les méthodes relationnels. Par la suite, J. Peterson a publié en 1981, le premier
ouvrage sur les réseaux de Petri .
Le formalisme des réseaux de Petri (RdP) a été proposé comme un outil mathématique
permettant la modélisation des systèmes dynamiques à événements discrets. Les réseaux de
Petri offrent un outil formel avec une bonne représentation graphique permettant de modéliser
et d‟analyser les systèmes discrets, notamment les systèmes concurrents et parallèles.
Grace à leur facette graphique, les réseaux de Petri, aident à comprendre facilement le
système modélisé. En outre, les activités dynamiques et concurrentes des systèmes sont
aisément simulées, par les RDP, vue leur puissance d‟expression mathématique. L‟intérêt
primordial de ces réseaux réside dans leur possibilité d'analyser les systèmes modélisés. En

Modélisation Formelle et Mobilité
59
effet, Ce formalisme bénéficie d‟une multitude de techniques d‟analyse et d‟outils. Des
caractéristiques importantes du système concernant sa structure et son comportement
dynamique sont révélées suite à l‟analyse du réseau de Petri qui le modélise. Les résultats de
cette analyse sont utilisés pour évaluer le système, une évaluation qui permettra ainsi, sa
modification ou son amélioration. La figure 3.4 montre la méthode générale basée sur le
formalisme des réseaux de Petri pour la modélisation et l‟analyse des systèmes.
Figure 3.4. Méthode générale de modélisation et d‟analyse basée sur les réseaux de Petri.
Les réseaux de Petri sont des outils de modélisation utilisés généralement en phase
préliminaire de conception de système afin de réaliser leur spécification fonctionnelle,
modélisation et suivre leur évaluation. Grâce à leur expressivité et à leur souplesse, ils sont
utilisés dans une large variété de domaines Ils permettent notamment :
¤ La modélisation des systèmes informatiques,
¤ L‟évaluation des performances des systèmes discrets, des interfaces homme-machine,
¤ La commande des ateliers de fabrication,
¤ La conception de systèmes temps réel
¤ La modélisation des protocoles de communication,
¤ La modélisation des chaines de production (de fabrication),
¤ ...
En fait, tout système dans lequel circule objets et information peut être modélisé par les RdP,
dont les atouts sont :

Modélisation Formelle et Mobilité
60
¤ Ils permettent de décrire de manière précise mais non formelle la structure d‟un
système,
¤ Ils offrent un support graphique de conception,
¤ Ils permettent de décrire un système étape par étape, en décomposant en éléments plus
simples les éléments constitutifs initiaux du système,
¤ Ils permettent de décrire à l‟aide d‟un même support de base, à la fois la structure et la
dynamique d‟un système,
¤ Ils permettent de passer d‟une description graphique d‟un système à une description
formelle permettant l‟analyse mathématique du système.
3.6.2 Concepts de base & définition
3.6.2.1 Définitions informelles
Intuitivement, un réseau de Petri est un graphe orienté biparti (ayant deux types de
noeuds) : des places représentées par des cercles et des transitions représentées par des
rectangles. Les arcs du graphe ne peuvent relier que des places vers des transitions, ou des
transitions vers des places (pas d‟arcs reliant les places ni d‟arcs entre transitions). Un
exemple de réseau de Petri est illustré par la figure 3.5.
Un réseau de Petri décrit un système dynamique à événements discrets. Les états
possibles du système (qui sont discrets), sont décrits par les places. Les transitions quant à
elles, permettent la description des événements ou des actions qui causent le passage du
système d‟un état vers un autre.
Figure 3.5. Un réseau de Petri comportant
7 places, 8 transitions et 17 arcs orientés
Condition L‟état du système peut être vu comme un ensemble de conditions qui sont de ce fait,
des prédicats ou des descriptions logiques d‟un état du système. Une condition est soit vraie
soit fausse.

Modélisation Formelle et Mobilité
61
Evénement
Les actions se déroulant dans le système définissent Les événements. L‟état du
système conditionne le déclenchement d‟un événement.
Déclenchement, pré-condition, post-condition
Les pré-conditions de l‟événement sont les conditions nécessaires au déclenchement
de celui-ci. Quand un événement se produit, certaines de ses pré-conditions peuvent cesser
d‟être vraies alors que d‟autres conditions (post-conditions de l‟événement), deviennent
vraies.
Le Marquage d’un réseau de Petri
Un réseau de Petri permet de décrire la dynamique du système représenté, étant donné
que c‟est un graphe muni d‟une sémantique opérationnelle, c‟est-à-dire qu‟un comportement
est associé au graphe. Pour cela, on associe un troisième élément: les jetons, aux places. À un
instant donné, une répartition des jetons dans les places est appelée marquage du réseau de
Petri. Grace au marquage d‟un réseau de Petri, l'état du système modélisé par ce réseau est
défini. Le marquage consiste à placer initialement un nombre mi entier (positif ou nul) de
jetons dans chaque place Pi du réseau. Le marquage du réseau sera défini par un vecteur M =
{mi} (cf. la figure 3.6).
Pour un marquage donné, une transition peut être sensibilisée ou non. Si chacune des
places en entrée d‟une transition contient au moins un jeton, elle est sensibilisée. Pour un
marquage donné, L‟ensemble des transitions sensibilisées défini l‟ensemble des changements
d‟états possibles du système depuis l‟état correspondant à ce marquage. C‟est un moyen de
définir l‟ensemble des événements auxquels ce système est réceptif dans cet état.
Figure 3.6. Un réseau de Petri marqué avec un vecteur
de marquage M : M = (1,0,1,0,0,2,0).
3.6.2.2 Définitions formelles
Formellement, un réseau de Petri (R) est un triplé R= (P, T, W) où P est l'ensemble des
places (les places représentent les conditions) et T l'ensemble des transitions (les transitions

Modélisation Formelle et Mobilité
62
représentent les événements ou les actions) tel que P ∩ T =φ et W est la fonction définissant le
poids porté par les arcs où W : ((P ×T) ∪ (T × P)) → N= {0, 1, 2,…}.
Le réseau R est fini si l'ensemble des places et des transitions est fini, c-à-d |P ∪T|∈N.
Un réseau R = (P, T, W) est ordinaire si pour tout (x, y) ∈ ((P ×T) ∪(T × P)):
W(x, y) ≤ 1.
Pour chaque x∈ P ∪T :
*x représente l'ensemble des entrées de x : *x= {y∈P∪T/W (y, x) ≠ 0}
x* représente l'ensemble des sorties de x : x* = {y ∈ P ∪T/W(x, y) ≠ 0}
Remarque
Si *x=φ, x est dite source, si x*=φ, x est dite puits.
Pour exprimer l'état d'un réseau de Petri, les places peuvent contenir des jetons qui ne
sont que de simples marques (points noirs). La structure et l‟état d'un réseau de Petri,
déterminent son comportement.
Notion d’état dans un réseau de Petri
Dans la théorie des réseaux de Petri, l'état d'un réseau est souvent appelé marquage
du réseau. Il est défini par l‟association des jetons aux places. Le marquage d'un réseau de
Petri R= (P, T, W) est défini par la fonction de marquage M : P→ N.
Un réseau de Petri marqué est donné par Σ = (P, T, W, M0) où M0 est le marquage
initial. La règle de franchissement définit le comportement d'un réseau de Petri marqué.
Notion de changement d’état et de règle de franchissement
Le mouvement de jetons des places d‟entrée vers les places de sortie d‟une transition,
traduit le changement d’état du système. Ce mouvement est causé par le franchissement d‟une
transition. Le franchissement représente une occurrence d‟un événement ou d‟une action. La
présence de jetons dans les places d‟entrée de la transition, conditionne son franchissement.
Quand toutes les places en entrée d‟une transition sont suffisamment marquées, la
transition peut être tirée, suite à ce tir ou franchissement, les jetons sont retirés des places en
entrée (ancien état) et ajoutés aux places en sortie (Nouvel état) de la transition franchie.
La relation de transition qui définit le changement d'état dans un réseau marqué lors de
l'exécution d'une action, est appelée règle de franchissement. La formalisation de la possibilité
d‟exécution d‟une action définit la règle de franchissement: on dit qu'une transition t ∈T peut
être franchie à partir d'un marquage M (qui représente l'état du system à un instant donné) si
et seulement si chaque place d'entrée p ∈*t de la transition t contient au moins un nombre de
jetons qui est supérieur ou égale au poids de l'arc reliant cette place d'entrée p à la transition t,
tel que: M (p) ≥W(p, t) ∀ p ∈ P.
Une règle de franchissement est définie par M‟(p) = M (p) - W(p, t) + W (t, p) pour
tout p ∈P, ceci traduit le fait que, lorsque la transition t est franchie à partir d'un marquage

Modélisation Formelle et Mobilité
63
M, il faut retirer W(p, t) jetons à partir de chaque place en entrée à la transition t et ajouter
W(t, p) jetons dans chaque place en sortie de la transition t ce qui permet de produire un
nouveau marquage M'. Le franchissement d'une transition t, dénoté par M [t > M’, est appelé
occurrence de t.
Exécution d'un réseau de Petri : Notion de marquage
L'exécution d'un réseau de Petri est définie par un ensemble de séquences
d'occurrence. Une séquence d'occurrence est une séquence de transitions franchissables
dénotée par σ =M0 t1 M1 t2…tel que Mi -1 [ti > Mi. Une séquence t1 t2… est une séquence
de transitions (commencée par le marquage M) si et seulement si il existe une séquence
d'occurrence M0 t1 M1... avec M=M0. Si la séquence finie t1 t2 …tn conduit à un nouveau
marquage M‟, à partir du marquage M, on écrit M [t1 t2…tn > M‟ ou simplement
M[t1t2…tn> si on ne veut pas spécifier le marquage résultat.
L'ensemble de marquages accessibles d'un réseau marqué (P, T, W, M0) est défini par
[M0 > = {M ∃t1 t2…tn: M0 [t1t2…tn > M}.
Exemple:
Dans le cas des réseaux dits à arcs simples ou de poids égal à 1 (cf. la figure 3.7), Le
franchissement d'une transition consiste à retirer un jeton dans chacune des places d‟entrée de
la transition et à en ajouter un dans chacune de sorties de places de celle-ci.
Figure 3.7. Evolution d‟états d'un réseau de Petri [Claud01]
L'évolution des états d‟un réseau de Petri marqués simple obéit aux règles suivantes :
Quand chacune des places en entrées d‟une transition, possède au moins le nombre de
jetons correspondant au poids de l‟arc la reliant à cette transition, on dit que la
transition est franchissable (sensibilisée ou tirable).
lorsque plusieurs transitons sont validées, le réseau ne peut évoluer que par
franchissement d'une seule transition sélectionnée à la fois.
Le franchissement d'une transition est indivisible et de durée nulle.
On voit donc, que dans l'évolution des réseaux de Petri, ceux-ci peuvent passer par
différents états dont l'apparition est conditionnée par le choix des transitions tirées. D‟où

Modélisation Formelle et Mobilité
64
l‟indéterminisme introduit par ces règles. Ceci cadre bien avec les situations réelles où il n'y a
pas de priorité dans la succession des événements [Claud01].
Représentation matricielle
Les tâches d'analyse et de vérification effectuées sur un modèle RdP peuvent être
simplifiées, grâce à la représentation matricielle d'un RdP. En ffet, manipule une
représentation graphique d'un modèle RdP est une tâche délicate comparée à une
représentation matricielle. Il est également possible, de représenter la fonction W (fonction de
poids) par des matrices.
Définition
Soit Un réseau de Petri R= (P, T, W) avec P= {p1, p2, …, pm} et T= {t1, t2, …, tn}.
On appelle matrice des pré-conditions pré, la matrice m × n à coefficients dans N telle que
pré (i,j)= W(pi, tj) indique le nombre de marques que doit contenir la place pi pour que la
transition tj devienne franchissable. De la même manière on définit la matrice des post-
conditions post, la matrice m × n telle que post (i,j)= W(pi, tj) contient le nombre de marques
déposées dans pi lors du franchissement de la transition tj. La matrice C= post – pré est
appelée matrice d'incidence du réseau (m représente le nombre de places d'un réseau de Petri
et n le nombre de transitions).
Le marquage d'un réseau de Petri est représenté par un vecteur de dimension m à coefficients
dans N. La règle de franchissement d'un réseau de Petri est définie par :
M’ (p) =M (p) + C (p, t).
Exemple
Figure 3.8. Un réseau de Petri marqué avec un vecteur
de marquage M : M = (1,0,0,0).
Pour le réseau ci-dessus (cf. la figure 3.8) , P= {p1, p2, p3, p4} T= {t1, t2, t3}, la
représentation matricielle est donnée ci-dessous (cf. la figure 3.9).

Modélisation Formelle et Mobilité
65
Figure 3.9. Matrice d‟incidence et vecteur de marquage du RdP de la figure 3.8.
Sémantique du parallélisme et problème de conflits
Quand plusieurs transitions peuvent être franchissables à un moment donné dans un
réseau de Petri, on parle de parallélisme de tir des transitions. Cet aspect pose un problème de
choix pour l‟état futur du réseau qui dépend de la transition sélectionnée parmi toutes celles
offertes. En général, ce conflit est résolu par le choix d‟une sémantique dite du parallélisme
qui définit une stratégie de tir, exemple : tirer une seule transition à la fois.
3.6.3 Modélisation des systèmes complexes
Les RdPs permettent de modéliser un certain nombre de comportements importants
dans les systèmes complexes tels que le parallélisme, la synchronisation, le partage de
ressources, la mémorisation et la lecture d‟information, la limitation d‟une capacité de
stockage, etc.
3.6.3.1 Parallélisme
Le parallélisme représente la possibilité que plusieurs processus évoluent simultanément
au sein du même système. Une transition ayant plusieurs places en sortie, peut provoquer le
départ simultané de l‟évolution plusieurs processus. Le franchissement de la transition T1 met
un jeton dans la place P2 (ce qui marque le déclenchement du processus 1) et un jeton dans la
place P3 (ce qui marque le déclenchement du processus 2).
Figure 3.10. Structure du parallélisme

Modélisation Formelle et Mobilité
66
3.6.3.2 Synchronisation
La synchronisation est modélisée sous deux formes :
Synchronisation mutuelle (Par rendez-vous) : La synchronisation mutuelle ou par
rendez-vous permet de synchroniser les opérations de plusieurs processus qui se
retrouvent au niveau d‟une transition donnée. La Figure 3.11 montre un exemple
de deux processus. Le franchissement de la transition T7 ne peut se faire que si la
place P12 du processus1 et la place P6 du processus 2 contiennent chacune au
moins un jeton. Si ce n‟est pas le cas, par exemple la place P12 ne contient pas de
jetons, le processus 2 est bloqué sur la place P6; il attend que l‟évolution du
processus 1 soit telle qu‟au moins un jeton apparaisse dans la place P12.
Figure 3.11. Synchronisation mutuelle
Synchronisation par signal (sémaphore): Dans ce type de synchronisation,
l‟évolution d‟un processus est conditionnée par celle d‟un autre. Dans l‟exemple
de la figure 3.12, les opérations du processus 2 ne peuvent se poursuivre que si le
processus 1 a atteint un certain niveau dans la suite de ses opérations. Par contre,
L‟avancement des opérations du processus 1 ne dépend pas de l‟avancement des
opérations du processus 2. Si la place "Signal" est marquée et la place "Attente" ne
l‟est pas, cela signifie que le processus 1 a envoyé le signal mais le processus 2 ne
l‟a pas encore reçu. Si, par contre, la place "Signal" n‟est pas marquée et que la
place "Attente" est marquée, cela signifie que le processus 2 est en attente du
signal.
Figure 3.12. Synchronisation par sémaphore

Modélisation Formelle et Mobilité
67
3.6.3.3. Partage de ressources
C‟est un type de modélisation lié à un système au sein duquel plusieurs processus
partagent une même ressource en utilisant le principe de l‟exclusion mutuelle. Dans la Figure
3.13, Le jeton dans la place P0 présente une ressource mise en commun entre le processus 1 et
le processus 2. Le franchissement de la transition T17 lors de l‟évolution du processus 1
entraîne la consommation du jeton présenté dans la place P0. La ressource que constitue ce
jeton n‟est alors plus disponible pour l´évolution du processus 2. Lorsque la transition T18 est
franchie, un jeton est alors est placé dans la place P0 : la ressource devient alors disponible
pour l‟évolution des deux processus.
Figure 3.13. Synchronisation par Partage de ressources
3.6.4 Méthodes d'analyse pour les réseaux de Petri
L‟utilité majeure de la modélisation des systèmes est la possibilité d‟analyser leurs
propriétés. Les réseaux de Petri offrent des techniques d'analyse puissantes pour valider des
modèles de comportement de systèmes à événements discrets. Parmi lesquelles, nous citons le
graphe de marquages, l‟équation de matrice et la réduction des réseaux de Petri.
3.6.4.1Analyse par graphes des marquages
Une idée intuitive pour étudier les propriétés d‟un RdP est de construire le graphe de
tous ses marquages accessibles. Le graphe des marquages accessibles est un graphe dont
chaque sommet correspond à un marquage accessible et dont chaque arc correspond au
franchissement d‟une transition permettant le passage d‟un marquage à l‟autre. On dénote
deux situations :
1. Le graphe est fini. C‟est le cas de figure le plus favorable car dans ce cas toutes les
propriétés peuvent être déduites simplement par inspection de ce graphe.
2. Le graphe est infini. Dans ce cas, et pour déduire certaines propriétés, on est
amenés à construire un autre graphe appelé "graphe de couverture".

Modélisation Formelle et Mobilité
68
Exemple 1
Figure 3.14. (a) Réseau de Petri (b) Graphe des marquages fini
Exemple 2
Figure 3.15. (a) Réseau de Petri (b) Graphe des marquages infini
3.6.4.2 L’équation de matrice
Cette méthode consiste à trouver une représentation matricielle du réseau, les
techniques de l'algèbre linéaire permettent alors d‟obtenir les propriétés structurelles du
réseau.
3.6.4.3 La réduction des RdPs
Pour l‟analyse des propriétés d‟un RdP de taille significative, l‟utilisation du graphe de
marquage ou de l‟équation de matrice s‟avère insuffisante. L‟objectif de la technique par
réduction est de présenter des règles permettant d‟obtenir à partir d‟un RdP marqué, un RdP
marqué équivalent mais plus simple, avec un nombre réduit de places et de transitions. Les méthodes d‟analyse des réseaux de Petri prennent pleine puissance avec leurs
mise en œuvre par le biais d‟un ensemble d‟outils d‟analyse tels que : INA (Integrated
NetAnalyzer) [INA], PEP (Programming Environment based on Petrinets) [Pep], TINA
[Tina],etc …

Modélisation Formelle et Mobilité
69
3.6.5 Extensions des réseaux de Petri
Les systèmes réel impose beaucoup de contraintes, Leur modélisation peut donc
engendrer des réseaux de Petri de taille importante dont la manipulation et l‟analyse est très
difficile. En plus, les RdPs usuels ne permettent pas d‟exprimer certaines propriétés, telle que
la mobilité, rendant ainsi leur analyse assez difficile. Dans ce contexte, plusieurs extensions
de réseaux de Petri ont vu le jour, entre autres on a: les réseaux de Petri colorés [Jensen 97,
Jensen98], Les ECATNets [Bettaz92, Bettaz93], etc. Dans la section suivante, nous
présentons un aperçu de quelques extensions des Rdps.
3.6.5.1. Les réseaux de Petri colorés
Les jetons placés dans les états du réseau seront colorés, ce qui permettra de les
distinguer et augmentera ainsi, l‟expressivité d‟un RdP. Ce procédé de marquage permet de
distinguer les jetons d‟un même état. Cette information permet de distinguer des jetons entre
eux et peut être de type quelconque [Kurt 97]. Ainsi, les arcs ne sont pas seulement étiquetés
par le nombre de jetons mais par leurs couleurs. Le franchissement d‟une transition est alors
conditionné par la présence dans les places en entrée du nombre de jetons nécessaires, qui en
plus satisfont les couleurs qui étiquettent les arcs. Après le franchissement d‟une transition,
les jetons qui étiquettent les arcs d‟entrée sont retirés des places en entrée tandis que ceux qui
étiquettent les arcs de sortie sont ajoutés aux places en sortie de cette transition. Les réseaux
colorés n‟apportent pas de puissance de description supplémentaire par rapport aux réseaux de
Petri, ils permettent juste une condensation de l‟information.
L‟exemple ci-dessous représente un système de production constitué d‟une première
machine avec son stock en sortie limité à 3 produisant la pièce a et d‟une seconde machine
avec son stock en sortie limité à 3 produisant la pièce b. Le passage du RdP (Figure 3.16
gauche) au RdP coloré (Figure 3.16 droite) est appelé pliage et le passage du RdP coloré au
RdP dépliage.
Figure 3.16. RdP (gauche) et RdP coloré (droite) [Scor06]
3.6.5.2 Les réseaux de Petri synchronisés (RdPS)
Dans les modélisations RdPS que nous avons vues précédemment, le fait qu‟une
transition soit franchissable indique que toutes les conditions sont réunies pour qu‟elle soit
effectivement franchie. Le moment où se produira le franchissement n‟est pas connu.

Modélisation Formelle et Mobilité
70
Un RdP synchronisé est un RdP où à chaque transition est associée un événement. La
transition sera alors franchie si elle est validée et en plus, quand l‟événement associé se
produit.
Dans un RdP synchronisé, une transition validée n‟est pas forcement franchissable. La
transition est validée quand la condition sur les marquages est satisfaite. Elle deviendra
franchissable quand l‟événement externe associé à la transition se produit : elle est alors
immédiatement franchie. Si en fonction du marquage de ses places d‟entrée, plusieurs
franchissements sont possibles, un seul se produira effectivement, celui dont l‟événement
associé se produit en premier [Scor06].
3.6.5.3. Les réseaux de Petri temporisés
Dans les réseaux de Petri temporisés introduits par Ramchandani [RAM 74], la durée
d‟une activité est explicitement intégrée. La temporisation peut concerner les places (réseaux
de Petri P-temporisés) aussi bien que les transitions (réseaux de Petri T-temporisés) et ce en
fonction des événements modélisés. Pour les réseaux de Petri P-temporisés. La temporisation
représente alors la durée minimale de tir ou le temps de séjour minimum d‟un jeton dans une
place.
Dans ce qui suit, nous porterons une attention particulière aux réseaux de Petri
étendus pour modéliser la mobilité, vu que dans cette thèse, nous nous intéressons aux
systèmes à base d‟agents mobiles.
3.6.6. Modélisation des systèmes mobiles par les RdPs
La mobilité, a soulevé depuis longtemps de nombreuses questions difficiles
[Kohler02], même La modélisation des systèmes mobiles par les RdPs ordinaires ou étendus
tel que les RdPs colorés est désormais insuffisante, à cause des particularités des applications
mobiles (migration clonage, etc.). Ainsi, l‟introduction de nouvelles extensions aux RdPs,
s‟avère plus que nécessaires pour modéliser les applications mobiles. En effet, tout
récemment, un modèle qui capture la mobilité d'une manière élégante et intuitive, a été
proposé. Un modèle qui est capable d'exprimer les différents types de mobilité des agents et
qui est fondé sur un formalisme dont la sémantique est formelle, autorisant par conséquent, la
vérification de l'exécution de ces systèmes mobiles. un tel modèle, est fondé sur le paradigme
des réseaux dans les réseaux (nets within nets en anglais) qui généralise la notion de jeton
classique à des jetons schématisant des réseaux de Petri.
3.6.6.1. Le paradigme (nets-within-nets)
Le paradigme nets-within-nets [Kohler07] est un formalisme qui fournit une nouvelle
technique de modélisation, en effet l‟idée astucieuse qui donne aux jetons mêmes du réseau
la structure d'un réseau de Petri (Figure 3.17), est innovante. La passivité des jetons dans les
autres types de réseaux de Petri, est levée par les jetons dans les nets-within-nets, qui sont eux
actifs. La notion de jeton dans ce paradigme permet de modéliser les systèmes récursifs et
hiérarchiques de façon simple. En outre, la modélisation des systèmes adaptatifs et mobiles
est tolérée par ce paradigme.
Dans l‟exemple de la Figure 3.17 du réseau de Petri nets-within-nets, nous considérons
la situation où nous avons une hiérarchie à deux niveaux. Un niveau inférieur qui s'appelle
System Nets (le RdP à ce niveau est formé de places contenant des jetons qui sont aussi des

Modélisation Formelle et Mobilité
71
RdPs) et un niveau supérieur qui s'appelle object nets (les places dans le RdP à ce niveau
contiennent des jetons simples). La place P1 de System Nets de la figure 3.17 contient un
Object Nets (Le RdP dont les places sont b1 et b2).
Figure 3.17. Un exemple d'un RdP Nets-within-Nets [Kohler07]
Le franchissement d'une transition dans le niveau inférieur peut être synchronisé par le
franchissement d'une transition dans le niveau supérieur. Dans l‟exemple de la figure 3.4, la
transition t n'est franchissable que lorsque la transition e est franchissable. Cette
synchronisation se fait par des fonctions qui s'appellent down-link et up-link :
Le down-link est la fonction qui mène la transition du niveau inférieur (System
Nets).
Le up-link est la fonction qui mène la transition du niveau supérieur (Object Nets).
Le franchissement de la transition t donne lieu à la situation de la Figure 3.18.
Figure 3.18. Un exemple d'un RdP Nets-within-Nets après franchissement.
L‟interaction entre les Object Nets et les Système Nets induit quatre possibilités pour
contrôler le type de déplacement et par conséquent la mobilité des Object Nets, on distingue
donc, pour un agent donné, quatre possibilités de se déplacer ou de se faire déplacer, tableau
3.1.
L‟Object Net déclenche son propre mouvement dans le Système Nets. dans cette situation
le Système Nets n‟aura aucune influence sur la mobilité des Object Nets (mobilité
subjective).
Le Système Nets force l‟Object Net à se déplacer, dans cette situation l‟Object Net subit
une transportation forcée.
L‟Object Net et le Système Net parviennent à un accord pour la mobilité de l‟Object Net.
L‟Object Net se déplace à l‟intérieur du System Net. Dans cette situation le mouvement de
l‟Object net est non contrôlé (mobilité spontanée).
b1
P1 P2 t
ON : ch()
ON ON
b2
e
: ch(x)
x
P1 P2 t
ON : ch(5)
ON ON
b2
e
: ch(x=5)
5
b1

Modélisation Formelle et Mobilité
72
Tableau 3.1. Les types de mobilité.
3.6.6.2. Le paradigme (Nested Nets)
Ce paradigme est basé sur l‟idée introduite par le paradigme nets-within-nets en se
basant sur l'étude d‟une sémantique autre que la sémantique de référence. En effet, dans ce
paradigme aussi (Nested Nets), chaque jeton peut être un réseau de Petri. Pour modéliser les
systèmes adaptatifs et mobiles [Kees06], les nested nets trouvent bien leur place.
Ce paradigme est une extension des RdPs colorés dont les jetons peuvent changer de
couleur sans le franchissement de transitions [Kees06], (cf. la figure 3.19).
Figure 3.19. Nested Nets [Kees06]
3.7. Conclusion
La modélisation, vérification et validation des systèmes informatiques constituent
aujourd'hui un enjeu crucial. C'est en particulier le cas pour les systèmes critiques dont les
pannes peuvent avoir des conséquences irréversibles et néfastes sur leur environnement
(système mobile par exemple). Dans ce cadre, nous avons présenté dans ce chapitre, les
concepts fondamentaux des techniques formelles de modélisation, vérification et validation
des systèmes. Nous avons insisté sur les réseaux de Petri, qui sont un formalisme de
modélisation. Ils représentent un cadre formel de spécification des systèmes grâce à leur
sémantique. Un grand avantage de l‟utilisation des réseaux de Petri est leur force
d‟expressivité due à leur aspect graphique. Nous avons abordé dans un cadre général la
modélisation par les réseaux de Petri. Par la suite, nous avons étudié quelques types de RdPs
avec leurs variantes. Nous avons également introduit une brève présentation des extensions de
RdPs pour la mobilité.

73
Chapitre 4
Une Plateforme Formelle pour la Modélisation
et la Simulation des LRN
Les outils formels qui ont été utilisées pour modéliser et analyser des systèmes
classiques, ne peuvent supporter les propriétés des systèmes à code mobile [Fuggetta98].
Beaucoup de travaux sur les outils formels tentent d‟étendre les outils classiques afin qu‟ils
puissent traiter la mobilité du code. L‟algèbre de processus basée modèles (π-calcul
[Milner92], join-calcul [Fournet02], HOπ-calcul [Sangiorgi01] par exemple), les PrN
(Predicate/Transition nets) [Xu00] et les modèles de transition basés État (Petri nets par
exemple), sont parmi eux. Afin d‟éviter le développement ad-hoc des systèmes a code
mobile, plusieurs travaux ont proposé des méthodologies et approches ([Duran00],
[Berger05], [Athie03]…) qui visent à résoudre ce problème.
Pour modéliser la mobilité, certains réaux de Petri de haut niveau ont été proposés.
Les plus connus sont les Réseaux Mobiles (variante de réseaux de Petri colorés) [Asperti96].
Beaucoup d'extensions ont été proposées pour adapter les mobiles Petri nets a des systèmes
mobiles spécifiques, tels que : Elementary Object Nets [Valk98], labeled reconfigurable nets
[Kahloul07], Nested Petri Nets [Kees06] [Lomazova02], Hyper Petri Nets [Bednarczyk04]…
Dans [Bahri2-09], les auteurs ont proposé une approche pour transformer diagrammes
mobiles UML Statechart vers des modèles Nested nets et ce dans le but de l'analyse, Elle
produit des modèles graphiques très structurés, et rigoureusement analysables qui facilite la
détection précoce des erreurs comme le blocage, incohérences, etc … Leur approche est basée
sur la transformation de graphe puisque l'entrée et la sortie du processus de transformation
sont des graphes. Ils ont utilisé l‟outil de méta-modélisation ATOM3.
Dans [El Mansouri08], les auteurs ont fourni un environnement graphique pour l'outil
Petri net INA [INA]. Tout d'abord, ils ont proposé un méta-modèle pour les modèles de
réseaux de Petri et l'ont utilisé dans l‟outil de méta-modélisation ATOM3 pour générer
automatiquement un environnement de modélisation visuelle pour définir les modèles à être
analyser par l‟outil INA. Puis, ils ont défini une grammaire de graphes pour traduire les
modèles créés en une description textuelle en langage INA, ensuite, INA est utilisé pour
effectuer l'analyse des spécifications générées.
Dans [Kerkouche08], les auteurs ont présenté un cadre formel et un outil basé sur
l'utilisation combinée de la méta-modélisation et grammaires de graphes pour la spécification
et l'analyse de systèmes logiciels complexes en utilisant le G-Nets formalisme.

Une Plateforme Formelle pour la Modélisation et la Simulation des LRN
74
Leur outil permet au développeur de dessiner un modèle G-Nets et le transformer en son
modèle équivalent PrT-nets automatiquement, afin de l‟analyser en utilisant l‟analyseur
PROD. Dans [Kerkouche09], les auteurs ont proposé une approche pour la transformation des
statechart et des diagrammes de collaboration UML vers des modèles réseaux de Petri
colorés.
Dans ce chapitre, nous proposons une approche et un outil de transformation
automatique de modèles LRN à leurs spécifications équivalentes en Maude pour des fins
d'analyse [Dehimi4-12]. Cette transformation vise à rendre possible la vérification des
propriétés des systèmes modélisés en utilisant les LRN puisque ce nouveau formalisme n'a
pas d'outils pour l'analyse et la vérification. Notre approche est basée sur l'utilisation
combinée de la méta-modélisation et des grammaires de graphe. ATOM3 est l‟outil qu‟on
utilise, il est fondé sur la méta-modélisation et la transformation de modèles.
Dans notre travail, le formalisme de diagramme de classe UML de l‟outil ATOM3 est
utilisé pour définir un méta-modèle pour les LRN. ATOM3 est aussi utilisé pour générer un
outil de modélisation visuelle pour l‟élaboration de modèles selon le méta-modèle des LRN
proposé. Nous avons aussi proposé une grammaire de graphe pour générer automatiquement,
la description R-Maude des modèles LRN graphiquement spécifiés [Dehimi5-12]. Ensuite, la
logique de réécriture R-Maude est utilisée pour effectuer la simulation de la spécification
générée. Notre approche est illustrée par des exemples.
4.1 Réseaux reconfigurables étiquetés (Labeled Reconfigurable Nets LRN)
4.1.1 Définition
Le formalisme «Labeled Reconfigurable Nets (LRN)» [Kahloul07] est conçu pour
modéliser les systèmes à code mobile. Les auteurs dans [Kahloul07], ont tenté de modéliser la
mobilité de façon intuitive et explicite. La mobilité du code (un processus ou un agent) va être
modélisée directement à travers la reconfiguration du réseau. Le formalisme permet l'ajout et
la suppression de places, arcs et transitions au moment de l'exécution.
Officieusement, les réseaux reconfigurables étiquetés (LRN) sont une extension des
réseaux de Petri. Un LRN est un ensemble d'environnements (blocs d'unités). Les connexions
entre ces milieux et leur contenu peuvent être modifié pendant l'exécution. Une unité est un
réseau de Petri spécifique. Une unité peut contenir trois types de transitions (une transition de
départ unique , un ensemble de transitions ordinaires et un ensemble de
reconfigurables transitions ).
Les pré-Conditions et les post-conditions pour franchir une transition, sont les mêmes
que dans les réseaux de Petri. Les Reconfigurables transitions sont étiquetées avec des
étiquettes qui influencent leurs franchissement .Quand une reconfigurable transition est
franchie, un réseau N sera déplacé d‟un environnement E vers un autre environnement E '.
Le réseau N, l'environnement E et E 'sont définies dans l'étiquette associée à la transition.

Une Plateforme Formelle pour la Modélisation et la Simulation des LRN
75
Après avoir franchi la reconfigurable transition, la structure du LRN sera mise à jour
(certaines places, arcs ou transitions seront supprimés ou ajoutés).
4.1.2 Exemples de modélisation des paradigmes de la mobilité avec les LRN
Un système à code mobile est composée d'unités d'exécution (EUs, exécution units),
de ressources et d‟environnements de calcul (CEs, computational environments). EUs seront
modélisés comme unités et les environnements de calcul comme environnements. La
modélisation des ressources nécessite l‟utilisation d‟un ensemble de places.
Les transitions reconfigurables modélisent la mobilité. La clé de la modélisation de la
mobilité consiste à identifier l'étiquette (label) associée à la transition reconfigurable. L'unité à
être déplacé y doit être identifiée, de même que l'environnement cible de calcul et les types de
liaison aux ressources et leur emplacement. Ce label dépend de la nature de la mobilité.
En général, une transition reconfigurable rt est toujours étiqueté <EU, CE, CE‟, , >,
tels que:
EU: l'unité d'exécution qui doit être déplacée.
CE, CE‟: respectivement, les environnements de calcul source cible.
: sera utilisé pour modéliser les ressources transférables et clonées, ψ=ψr∪ψc.(ψr removed
places et ψc cloned places). Donc est vide si le système n'a pas ces ressources.
: modélise les liens après le déplacement.
L'unité d'exécution qui contient la transition reconfigurable rt et l'UE qui représente le
premier argument de l'étiquette associée à rt, seront définies en fonction des trois paradigmes
de conception: l'évaluation distance (REV, remote evaluation), le code à la demande (COD,
code on demand), et l'agent mobile (MA, mobile agent) [Kahloul07].
4.1.2.1 L'évaluation à distance
Dans le paradigme d'évaluation à distance, une unité d'exécution EU1 envoie une autre
unité d'exécution EU2 à partir d'un environnement de calcul CE1 à un autre CE2. La transition
reconfigurable rt est contenue dans l‟unité modélisant EU1 et EU2 sera le premier argument
dans label (étiquette) associé à rt.
Considérons deux environnements de calcul E1 et E2. Tout d'abord, E1 contient deux
unités d'exécution EU1 et EU2, E2 contient une unité d'exécution EU3. Les trois unités
d'exécution d'exécutent des boucles infinies. EU1 exécute des actions {a11, a12}, EU2 exécute
des actions {a21, a22, a23} et EU3 exécute des actions {a31, a32}. a21 nécessite une ressource
transférable TR1 et une ressource non transférable liée par type PNR1 qui est partagé avec a11.
a22 et a12 partagent une ressource transférable liée par valeur VTR1, et a23 nécessite une
ressource non transférable NR1. Dans E2, EU1 nécessite une ressource non transférable lié par
type PNR2 pour exécuter a31. PNR2 ayant le même type de PNR1.

Une Plateforme Formelle pour la Modélisation et la Simulation des LRN
76
Le système sera modélisé par un réseau reconfigurable étiqueté LRN (labeled
reconfigurable net). Ce LRN contient deux environnements E1, E2 qui modélisent les deux
environnements de calcul (CE1 et CE2).les unités EU1 et EU2 vont modéliser les unités
d'exécution UE1 et UE2, respectivement. Dans ce cas, l‟unité UE1 contiendra une transition
reconfigurable rt <EU2,E1,E2,, >, tels que:
1. E1 = (RP1, GP1, U1, A1); RP1 = {TR1, PNR1, VTR1, NR1}. U1 = {EU1, EU2};
2. E2 = (RP2, GP2, U2, A2); RP2 = {PNR2}. GP2 = {PEU1}.
3. r = {TR1}, c = {VTR1};
4. = {(PEU1, str2), (PNR2, a21), (NR1, a23)}.
La figure 4.1 montre le modèle de ce système avant la migration et après la migration.
Figure 4.1. Modèle -REV- avant et après le franchissement de rt.
4.1.2.2 Code à la demande
Dans le paradigme, code à la demande, une unité d'exécution EU1 cherche une autre
unité d'exécution UE2. La transition reconfigurable rt est contenue dans l‟unité qui modélise
EU1 et EU2 sera le premier argument du label de rt. Si l'on reprend l'exemple ci-dessus, l‟unité
EU1 contiendra une transition reconfigurable rt <EU2, E2, E1, , >.
La transition rt <EU2, E2, E1, , > signifie que EU1 demandera à déplacer EU2 de E2 à E1.
Dans ce cas, = {TR1, VTR1}, = {(PEU2, str2), (PNR2, a21), (NR1, a23)}.

Une Plateforme Formelle pour la Modélisation et la Simulation des LRN
77
La figure 4.2 montre le modèle proposé pour modéliser ce système.
Figure 4.2. Modèle -COD- avant et après le franchissement de rt.
4.1.2.3. Mobile Agent
Dans le paradigme des agents mobiles, les unités d'exécution sont des agents
autonomes. L'agent lui-même déclenche la mobilité. Dans ce cas, rt(la transition
reconfigurable) est contenue dans l‟unité qui modélise l'agent et EU (le premier argument) est
également cet agent.
Soit E1 et E2 deux environnements de calcul. E1 contient deux agents, un agent mobile
MA et un agent statique SA1, E2 contient un agent unique statique SA2. Les trois agents
exécutent des boucles infinies. MA exécute des actions {a11, a12, a13}, SA1 exécute des actions
{a21, a22, a23} et SA2 exécute des actions {a31, a32}. Pour être exécutée, a11 a besoin d'une
ressource transférable TR1 et d‟une ressource non transférable liée par type de PNR1 qui est
partagée avec a21. a12 et a22 partagent une ressource transférable liée par valeur, et a13 et a23
partagent une ressource non transférable NR1. Dans E1, SA2 nécessite une ressource non
transférable liée par type PNR2 pour exécuter a32. PNR2 ayant le même type de PNR1.
Le système sera modélisé par un réseau reconfigurable étiqueté LRN (labeled
reconfigurable net). Ce LRN contient deux environnements E1, E2 qui modélisent les deux
environnements de calcul. Dans ce cas, l'unité A qui modélise l'agent mobile A contiendra une
transition reconfigurer rt <A, E1, E2, , >; tels que:
1. E1 = (RP1, GP1, U1, A1); RP1 contenant au moins quatre places qui modélisent les quatre
ressources. Soient TR1, NR1, PNR1 et VTR1 ces places.

Une Plateforme Formelle pour la Modélisation et la Simulation des LRN
78
2. E2 = (RP2, GP2, U2, A2); RP2 = {PNR2}, GP2 = {PA2}.
3. r = {TR1}, c = {VTR1};
4. = {(PA2, str1), (PNR2, a11), (NR1, a13)}.
La figure 4.3 montre le modèle proposé pour modéliser ce système.
Figure 4. 3. Modèle -MA- avant et après le franchissement de rt.
4.2 Le système Maude
Maude est un environnement de programmation destiné à la modélisation de diverses
notions relevant de plusieurs domaines [Eker02, Meseguer03, Clarke03, McCombs03]. Ce
langage, basé sur la logique de réécriture, a été développé en fonction de trois grands
objectifs: la simplicité, l‟expressivité et la performance.
Simplicité : Un programme devrait être le plus simple possible et le plus aisé à
comprendre que possible, et devrait posséder en outre une sémantique très claire.
Expressivité : Il devrait être possible d‟exprimer naturellement une vaste gamme
d‟applications, aussi bien pour un programme déterministe que pour un programme
hautement concurrentiel.

Une Plateforme Formelle pour la Modélisation et la Simulation des LRN
79
Performance : on devrait pouvoir utiliser un langage comme spécification
exécutable d‟un modèle, mais également comme un véritable langage de
programmation compétitif.
La plupart du temps, la simplicité et la performance sont présentes dans n‟importe quel
Langage, ils vont de pair. Par contre, maximiser l‟expressivité du langage est sans aucun
doute l‟un des avantages les plus marquants du langage Maude. Certains diront certainement
qu‟un langage développé spécifiquement pour un domaine donné a l‟avantage de simplifier
les notations pour les initiés. Dans ce contexte, Maude devrait alors être vu comme un
métalangage avec lequel il est très aisé de développer un langage spécifique.
Il est également important de noter que Maude permet de programmer à deux niveaux
différents : Core Maude et Full Maude. On peut différencier les deux niveaux par ce qui suit :
Core Maude: Core Maude est le niveau de base de Maude, programmé directement en
C++. Il implémente toutes les fonctionnalités de base du logiciel, les modules
fonctionnels et les modules systèmes ;
Full Maude: Full Maude est le niveau supérieur. Programmé en Core Maude, Full
Maude est en réalité une extension du premier niveau, avec lequel il est possible de
combiner des modules pour perfectionner le développement. Full Maude offre de
nombreux avantages. Il est notamment utilisé avec le paradigme de programmation
orienté-objet et les modules orientés-objet Maude.
4.2.1 Modules Maude
Le développement Maude se fait par l‟écriture de divers modules décrivant le système
que l‟on écrit. Ainsi, l‟unité de base pour le développement Maude est le module. Il en existe
trois types : les modules fonctionnels, les modules système et les modules orientés-objet.
Module fonctionnel : Les modules fonctionnels sont principalement utilisés pour la
définition de types de données et d‟opérateurs via la théorie des équations.
Module système : Les modules systèmes, quant à eux, sont utilisés pour définir des
théories de réécriture. D‟une certaine façon, tout comme la logique de réécriture est
plus générale que la logique des équations, un module système englobe un module
fonctionnel.
Module orienté-objet : Ce dernier type de module est développé spécifiquement
pour le paradigme de développement orienté-objet qui est aujourd‟hui la norme sur
le marché. Ce type de module est utilisé au niveau de Full Maude.
En plus, Maude a son propre model-checker qui est utilisé pour vérifier les propriétés du
système[Meseguer92].

Une Plateforme Formelle pour la Modélisation et la Simulation des LRN
80
4.2.2 Syntaxe de Maude
Dans ce qui suit, quelques brefs exemples de code Maude seront donnés afin
d‟illustrer le fonctionnement du langage.
Rappel : Logique de réécriture.
La logique de réécriture, dotée d‟une sémantique saine et complète, a été introduite par
Meseguer [Meseguer91]. Elle permet de décrire les systèmes concurrents [Eker02,
Meseguer03, Clavel05]. Cette logique unifie tous les modèles formels qui expriment la
concurrence [Meseguer91]. Dans la logique de réécriture, les formules logiques sont appelées
règles de réécriture. Elles sont de la forme suivante :
La règle R indique que le terme t devient (se transforme en) t‟ si une certaine condition
C est vérifiée. Le terme t représente un état partiel d‟un état global S du système décrit. La
modification de l‟état global S du système vers un autre état S‟ est réalisée par la réécriture
d‟un ou plusieurs termes qui expriment les états partiels.
Modules fonctionnels
Tel que discuté précédemment, il existe trois types de modules en Maude : les
modules fonctionnels, systèmes et orientés-objet. Dans ce qui suit, un très court programme
Maude sera défini à l‟aide d‟un module fonctionnel. La figure 4.4 montre ce court
programme.
Figure 4.4. Le module fonctionnel PEANO-NAT
Ce court programme montre en réalité une façon alternative pour définir les nombres
naturels. On le fait ici à l‟aide de la fonction Successeur. Ainsi, un seul nombre de base existe,
0, et les autres sont définis à l‟aide de la fonction successeur (l‟opérateur s). Deux équations
sont également définies : un nombre naturel additionné à 0 donne ce nombre naturel, et un
nombre naturel additionné au successeur d‟un autre nombre naturel donne le successeur de
l‟addition des deux nombres naturels.
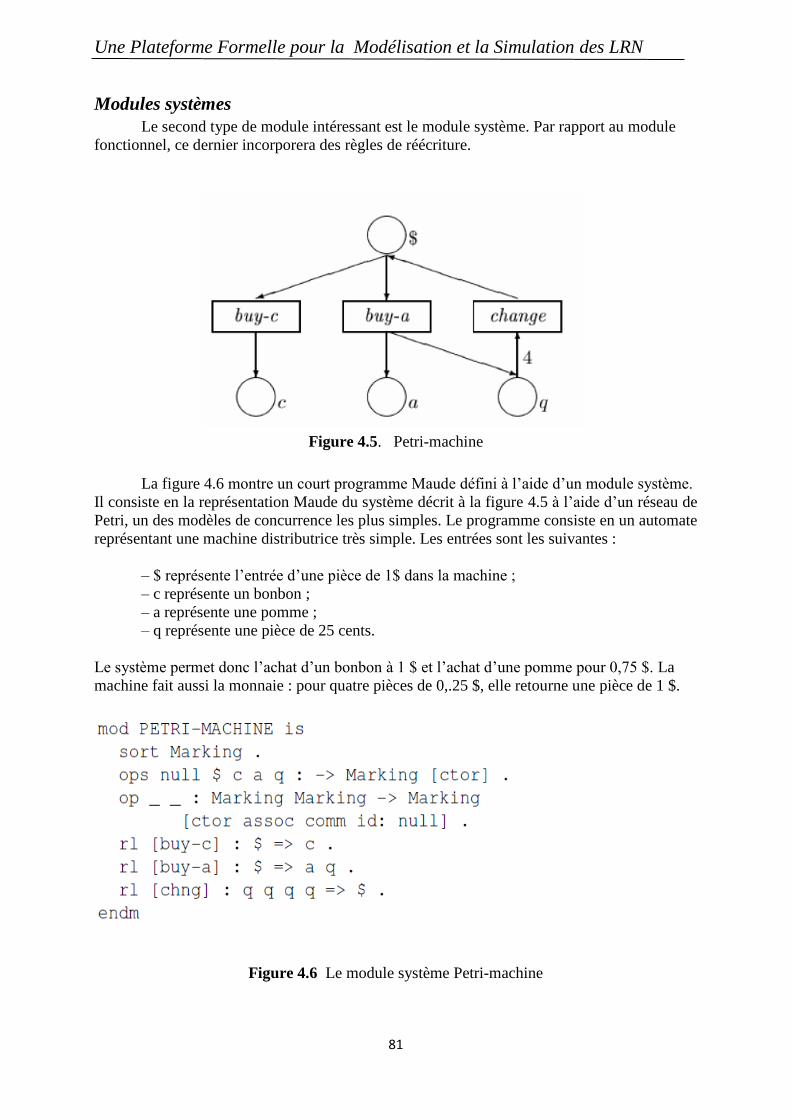
Une Plateforme Formelle pour la Modélisation et la Simulation des LRN
81
Modules systèmes
Le second type de module intéressant est le module système. Par rapport au module
fonctionnel, ce dernier incorporera des règles de réécriture.
Figure 4.5. Petri-machine
La figure 4.6 montre un court programme Maude défini à l‟aide d‟un module système.
Il consiste en la représentation Maude du système décrit à la figure 4.5 à l‟aide d‟un réseau de
Petri, un des modèles de concurrence les plus simples. Le programme consiste en un automate
représentant une machine distributrice très simple. Les entrées sont les suivantes :
– $ représente l‟entrée d‟une pièce de 1$ dans la machine ;
– c représente un bonbon ;
– a représente une pomme ;
– q représente une pièce de 25 cents.
Le système permet donc l‟achat d‟un bonbon à 1 $ et l‟achat d‟une pomme pour 0,75 $. La
machine fait aussi la monnaie : pour quatre pièces de 0,.25 $, elle retourne une pièce de 1 $.
Figure 4.6 Le module système Petri-machine

Une Plateforme Formelle pour la Modélisation et la Simulation des LRN
82
Modules orientés-objet
Les modules orientés-objet sont développés à l‟aide du niveau Full Maude. Ils ont
alors leur propre notation spécifiquement développée pour le paradigme objet. Une classe est
déclarée à l‟aide d‟un module Maude orienté-objet, comme suit :
class ClassName | att1 : attType.
Le principe de réduction d‟un module orienté-objet Maude sous une forme de module système
peut être utilisé. Pour se faire, la notation de la figure 4.7 est utilisée.
Figure 4.7 Déclaration d‟une classe sous la forme d‟un module système
On remarque alors la façon utilisée pour déclarer une classe et ses attributs, à l‟aide
des mots clés Cid, l‟identifiant général de toutes les classes de Maude et Attribute le type de
Maude représentant un attribut d‟une classe.
4.3 Reconfigurable Maude
Maude [Clavel99] est considéré comme un langage de haut niveau et un système de
haute performance supportant des spécifications exécutables et permettant la programmation
déclarative dans la logique de réécriture [Meseguer2-92].
De nombreuses extensions de Maude ont été proposées pour faire face à certains
aspects non pris en compte dans l'ancienne version. Par exemple, Maude [Ölveczky00] est un
système permettant la spécification et l'analyse en temps réel. Maude mobile [Duran00] étend
Maude pour la spécification des systèmes mobiles.
Un codage des Labeled Reconfigurable Net (LRN), dans un langage basé sur Maude a
été proposé, le langage inspiré est appelé «Reconfigurable Maude (R-Maude) » [Kahloul08].
Il bénéficie de la puissance de Maude (comme un méta-langage). Maude a été étendu pour
supporter la traduction des LRN et leur simulation. R-Maude enrichit Maude avec nouveau
type de règles de réécriture. Ces règles sont appelées règles reconfigurables (R-Rules). la
sémantique de ces règles est similaire à celle de la transition reconfigurable des LRN. Quand
une telle règle est exécutée, la spécification R-Maude sera mise à jour de différentes manières
en liaison avec le label (étiquette) associé à cette règle.

Une Plateforme Formelle pour la Modélisation et la Simulation des LRN
83
4.4 Meta-modélisation des LRN (réseaux reconfigurables étiquetés)
Pour construire des modèles du formalisme LRN dans ATOM3, nous devons définir
un méta-modèle pour les LRN. Le méta-formalisme utilisé dans notre travail est les
diagrammes de classes UML et les contraintes sont exprimées en code Python [Dehimi6-12].
Comme le LRN consiste en des places, des transitions et des arcs des places vers les
transitions et des transitions vers les places, nous avons proposé pour la méta-modélisation
des LRN, deux Classes pour décrire les places et les Transitions et deux associations, une
pour les arcs entrants arc-in et l‟autre pour les arcs sortants arc-out, comme illustré par la
Figure 4.8. Nous avons également spécifié la représentation visuelle de chaque classe ou
association. La reconfigurable transition est représentée dans le meta-modèle par une classe
(rectrans), qui hérite de la classe mère (trans) avec l‟attribut label en plus, qui décrit les
informations relatives à la mobilité [Dehimi1-12].
Figure 4.8 Méta-Modèle des LRN
Compte tenu de notre méta-modèle, nous avons utilisé l‟outil ATOM3 pour générer un
environnement de modélisation visuel pour les modèles LRN. La figure 4.9 montre l'outil
LRN généré et une boîte de dialogue pour éditer une transition reconfigurable [Dehimi2-12].

Une Plateforme Formelle pour la Modélisation et la Simulation des LRN
84
Figure 4.9 barre d‟outils pour l‟environnement de modélisation des LRN
4.5 La grammaire de graphe qui génère la spécification R-Maude des
modèles LRN. [Dehimi3-12]
Afin de simuler les modèles LRN, nous les traduisons ici vers leurs représentations
équivalentes dans la syntaxe de R-Maude. Dans cette section, nous montrons comment utiliser
l'environnement de modélisation généré dans la section précédente pour générer la
spécification R-Maude. Nous le faisons en définissant une grammaire de graphes pour
parcourir le modèle LRN et générer le code correspondant R-Maude.
La grammaire de graphe possède une Action initiale qui est utilisé pour créer le fichier
où le code en R-Maude sera généré. Cette action attribue également à tous les éléments
Transition et Place dans le modèle des attributs temporaire utilisées dans les conditions
spécifiées dans les règles. Pour les éléments « Transition », nous utilisons deux attributs :
actuel (current) et visité (visited). L'attribut actuel est utilisé pour identifier la transition dans
le modèle dont le code est à générer, tandis que l'attribut visité est utilisée pour indiquer si le
code pour la transition en cours a été générée ou non. Pour les éléments « Place », deux
attributs sont utilisés : fromVisited et toVisited. L'attribut fromVisited est utilisé pour indiquer
si cette place est traitée comme place d'entrée alors que l'attribut toVisited est utilisé pour
indiquer si cette place est traitée comme place de sortie. Ces attributs sont initialisés à 0.
Dans notre grammaire de graphes, nous avons proposé sept règles (voir figure 4.10)
qui seront appliqués dans l'ordre croissant de leurs priorité, par le système de réécriture
jusqu'à ce qu'aucune règle ne soit applicable. Nous sommes concernés ici par la génération de
code, donc les règles de grammaire ne changeront pas les modèles LRN, d‟où la même
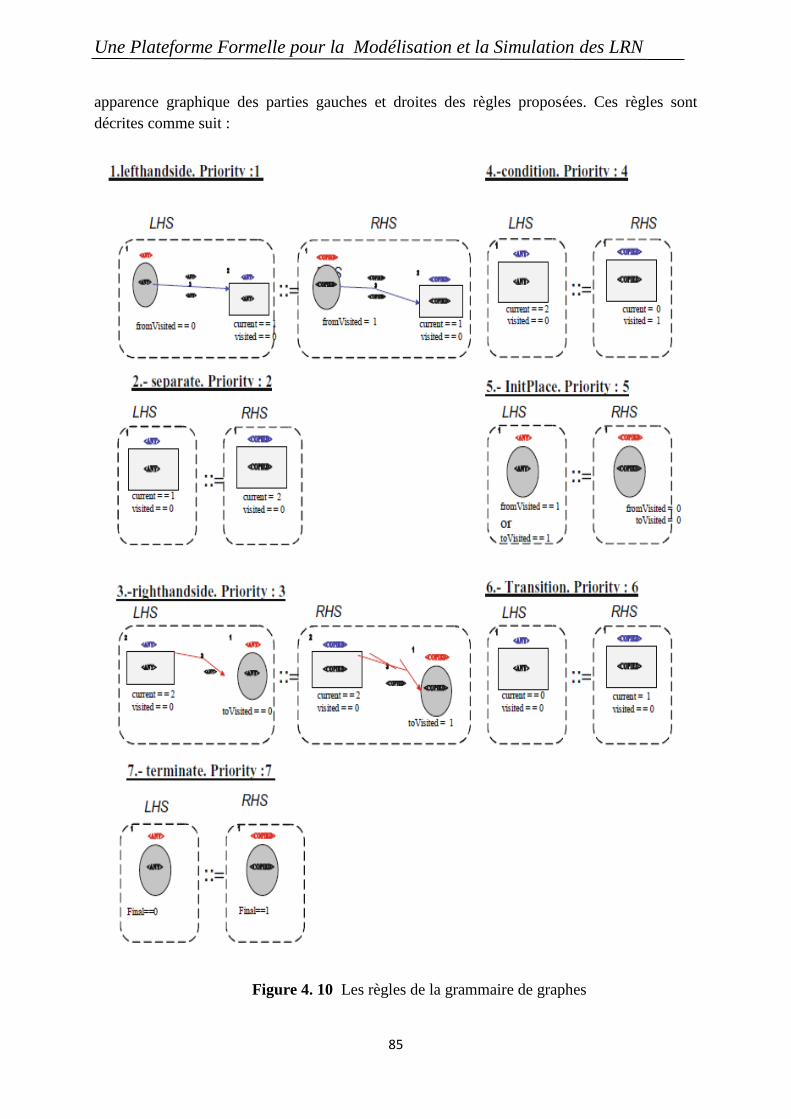
Une Plateforme Formelle pour la Modélisation et la Simulation des LRN
85
apparence graphique des parties gauches et droites des règles proposées. Ces règles sont
décrites comme suit :
Figure 4. 10 Les règles de la grammaire de graphes

Une Plateforme Formelle pour la Modélisation et la Simulation des LRN
86
Règle1 : cotegauche (priorité 1): est appliquée pour localiser une place (qui n'a pas
été traitée, fromvisited = = 0), liée à la transition actuelle avec un arc d'entrée et génère la
spécification R-Maude correspondante. Cette règle de grammaire se charge de la construction
de la partie gauche de la règle de réécriture liée à la transition en cours de traitement
(current= = 1). Une fois exécutée, on marque la place comme traitée (fromvisited = = 1)
Condition liée à la règle1
transition=self.getMatched(graphID, self.LHS.nodeWithLabel(2))
place=self.getMatched(graphID, self.LHS.nodeWithLabel(1))
return place.fromVisited == 0 and transition.visited == 0 and transition.current
== 1
Dans l’Action liée à la règle 1 (la mise à jour de l‟attribut fromVisited )
place=self.getMatched(graphID, self.LHS.nodeWithLabel(1))
place.fromVisited = 1
Règle2: séparer (priorité 2): est appliqué pour générer le code R-Maude qui sépare
LHS(cote gauche) et RHS(cote droit) de la règle de réécriture (RR) équivalente. Ceci ne sera
fait que si toutes les places en entrée de la transition en cours, ont été introduites dans la partie
gauche de la RR liée à cette même transition et dont le code R-Maude est en cours de
génération.

Une Plateforme Formelle pour la Modélisation et la Simulation des LRN
87
Condition liée à la règle2
node=self.getMatched(graphID,self.LHS.nodeWithLabel(1))
return node.visited == 0 and node.current == 1
Dans l’Action liée à la règle2 (la mise à jour de l‟attribut current )
node=self.getMatched(graphID,self.LHS.nodeWithLabel(1))
node.current = 2
Règle3 : cotedroit (priorité 3): est appliqué pour localiser une place (qui n'a pas été
traitée tovisited = = 0) qui est liée à la transition actuelle avec un arc de sortie et de générer
la spécification R-Maude correspondante. Une fois introduite dans la partie droite du code de
la règle à générer, cette place est marquée comme visitée par la mise à un de l‟attribut to
visited qui lui est associé et ce au niveau de l‟action liée à cette règle. Cette règle de
grammaire se charge de la construction de la partie droite de la règle de réécriture liée à la
transition en cours (dont le symbole séparateur => a été déjà introduit par la règle 2 ( current
= = 2) ).

Une Plateforme Formelle pour la Modélisation et la Simulation des LRN
88
Condition liée à la règle3
transition=self.getMatched(graphID, self.LHS.nodeWithLabel(2))
place=self.getMatched(graphID, self.LHS.nodeWithLabel(1))
return place.toVisited== 0 and transition.visited== 0 and transition.current== 2
Dans l’Action liée à la règle3 (la mise à jour de l‟attribut toVisited )
place=self.getMatched(graphID, self.LHS.nodeWithLabel(1))
place.toVisited = 1
Règle4: condition (priorité 4): est appliquée pour terminer la génération du code
R-Maude de la RR (génération du point à la fin de la règle), liée à la transition en cours, à
condition bien sûr d‟avoir introduits toutes les places en sortie dans son côté droit; chose faite
grâce au degré de priorité de cette règle par rapport à la précédente. En fin la transition sera
marquée comme visitée (visited = = 1).
Condition liée à la règle4
node=self.getMatched(graphID, self.LHS.nodeWithLabel(1))
return node.visited == 0 and node.current == 2
Dans l’Action liée à la règle4 (la mise à jour des attributs Visited et current)
node=self.getMatched(graphID,self.LHS.nodeWithLabel(1))
node.visited=1
node.current=0

Une Plateforme Formelle pour la Modélisation et la Simulation des LRN
89
Règle5: InitPlace (priorité 5): s'applique pour localiser et réinitialiser à 0, les attributs
temporaires (fromvisited et tovisited) dans les places, pour le traitement de la prochaine
transition. En effet des places qui ont intervenue dans des transitions déjà traitées, peuvent
intervenir dans d‟autres transitions non encore traitées.
Condition liée à la règle5
place=self.getMatched(graphID,self.LHS.nodeWithLabel(1))
return place.fromVisited!=0 or place.toVisited!=0
Action liée à la règle5
place=self.getMatched(graphID,self.LHS.nodeWithLabel(1))
place.fromVisited=0
place.toVisited=0
Règle6: transition (priorité 6): est appliqué pour sélectionner une transition LRN qui
n'a pas été traitée ( visited = = 0 et current = = 0) et la marque pour commencer son traitement
(current = = 1). Le début de la règle de réécriture R-Maude qui lui est associée est aussi
générée par cette règle (rl [nom] : (pour les transition simples) ou rl [nom] [label] : (pour les
transitons reconfigurables).

Une Plateforme Formelle pour la Modélisation et la Simulation des LRN
90
Condition liée à la règle6
node=self.getMatched(graphID,self.LHS.nodeWithLabel(1))
return node.visited == 0 and node.current == 0
Dans l’Action liée à la règle6 (la mise à jour de l‟attribut current)
node=self.getMatched(graphID,self.LHS.nodeWithLabel(1))
node.current=1
Règle7: terminer (priorité 7):est appliqué pour terminer l'écriture du fichier généré
R-Maude et le ferme, et met à 1 la valeur de l‟attribut « final », initialement mise à 0 (dans
action initiale).
Condition liée à la règle7
return self.graphRewritingSystem.final==0
Dans l’Action liée à la règle7 (la mise à jour de l‟attribut final)
self.graphRewritingSystem.final=1
La grammaire de graphe a également une action finale qui efface les attributs temporaires des
entités.

Une Plateforme Formelle pour la Modélisation et la Simulation des LRN
91
4.6 Exemples
Pour pouvoir concrétiser l‟utilité de la grammaire définie, on a essayé de l‟appliquer
sur divers exemples dont les suivants :
Exemple 1: LRN avec un Agent statique
Le premier exemple concerne un environnement de calcul E1. E1 contient un agent
unique et statique SA1 qui exécute une boucle infinie. SA1 nécessite une ressource non
transférable liée par type PNR2 pour exécuter a32. Le système va être modélisé par un LRN.
La figure 4.11 présente le modèle graphique de cet exemple créé dans notre outil.
Figure 4.11 le modèle LRN de l‟exemple 1
Traduction du modèle LRN vers la Description R-Maude
Cette étape à la représentation graphique d'un modèle LRN comme entrée. Elle consiste
en la traduction de cette représentation graphique vers sa description R-Maude équivalente à
l'aide de la grammaire de graphes définie dans la section précédente. Pour réaliser cette
traduction, l'utilisateur doit exécuter la grammaire de graphe précédemment définie. Le
résultat de la traduction de l‟exemple 1, est donné par la Figure 4.12, c‟est le fichier env2-
system.maude qui contient la description du modèle LRN de la Figure 4.11.

Une Plateforme Formelle pour la Modélisation et la Simulation des LRN
92
Figure 4.12 spécification R-Maude Générée pour exemple1,
env2-system.maude.
Exemple 2: LRN évaluation à distance
Le deuxième exemple concerne l‟environnement de calcul E1 du modèle LRN-REV
(remote evaluation) présenté par la figure 4.1 au début de ce chapitre. E1 contient deux unités
d'exécution EU1 et EU2. Les deux unités d'exécution d'exécutent des boucles infinies. EU1
exécute des actions {a11, a12}, EU2 exécute des actions {a21, a22, a23}. a21 nécessite une
ressource transférable TR1 et une ressource non transférable liée par type PNR1 qui est
partagé avec a11. a22 et a12 partagent une ressource transférable liée par la valeur VTR1, et a23
nécessite une ressource non transférable NR1. La figure 4.13 présente le modèle graphique de
cet environnement créé dans notre outil.
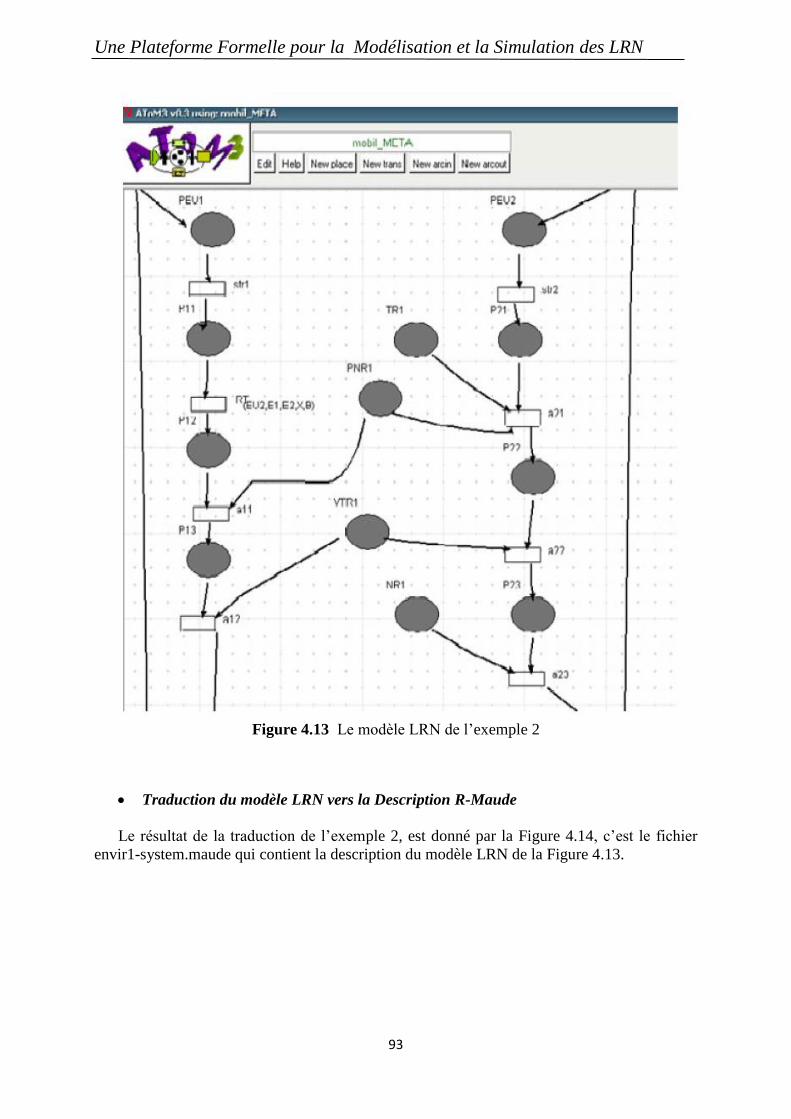
Une Plateforme Formelle pour la Modélisation et la Simulation des LRN
93
Figure 4.13 Le modèle LRN de l‟exemple 2
Traduction du modèle LRN vers la Description R-Maude
Le résultat de la traduction de l‟exemple 2, est donné par la Figure 4.14, c‟est le fichier
envir1-system.maude qui contient la description du modèle LRN de la Figure 4.13.

Une Plateforme Formelle pour la Modélisation et la Simulation des LRN
94
Figure 4.14 spécification R-Maude Générée pour exemple2,
envir1-system.maude.
Exemple 2: LRN avec un Agent Mobile
Le résultat d'une autre spécification R-Maude de l‟exemple 3, est le fichier env1-
system.maude, qui contient la description d'un modèle LRN représenté par la figure 4.15
Nous remarquons que l'environnement LRN dans cet exemple, contient deux agents, un
A1(PA1) mobile qui comprend une transition reconfigurable (RT) et un agent A2(PA2)
statique.
Figure 4.15 le modèle LRN de l‟exemple 3

Une Plateforme Formelle pour la Modélisation et la Simulation des LRN
95
Traduction du modèle LRN vers la Description R-Maude
Le résultat de la traduction de l‟exemple 3, est donné par la Figure 4.16, c‟est le fichier
env1-system.maude qui contient la description du modèle LRN de la Figure 4.15.
Figure 4.16 spécification R-Maude Générée pour l‟exemple 3
4.7 Prototypage R-Maude
Les auteurs dans [Kahloul08], ont prototypé R-Maude. Le prototype est un système
composé d'un éditeur de texte et d‟un interpréteur. L'éditeur est utilisé pour entrer les
spécification et commandes. L‟interpréteur exécute les commandes. Le système a été
expérimenté sur un LAN (Local Area Network), composé d'un petit nombre de machines. Le
système est installé sur toutes les machines hôtes. Les spécifications sont donc édités partout
et au niveau chaque hôte, les commandes peuvent être exécutées. L'exécution des commandes
créera la dynamique du système. Cette dynamique peut être vue comme la migration des
spécifications (ou de leurs parties) à travers le LAN. Les spécifications sont transférées en tant
que messages entre les machines.
L'interpréteur réalisé pour R-Maude peut être utilisé pour interpréter les spécifications
Maude. La différence majeure, c'est que dans ce nouvel interpréteur, l'interprétation des R-
Rules a été ajoutée. Le label de la R-règle précède la règle, et il a la forme [MT |L | IP @ | S].
La sémantique de ces paramètres est la suivante: MT: Type de mobilité (MA, COD, REV),
L: un ensemble d'opérations et de règles à être déplacer, clonés ou retirés de l'hôte local,
@ IP: adresse IP de l'hôte distant, S: ressources à déplacer ou à supprimer de l'hôte local.
Lorsque les spécifications (ou partie d'entre elles) sont déplacés, certaines ressources (R)
nécessaire de tirer quelques règles deviennent distantes (sur un autre hôte). L'adresse IP de
l'hôte distant apparaît avec la ressource concernée sous la forme: R [@ IP].
Pour coder les LRN, la reconfigurable-transition (R-transition) sera traduite en

Une Plateforme Formelle pour la Modélisation et la Simulation des LRN
96
reconfigurable-Règle (R-rule). Ci-après, nous présentons le codage de l‟exemple de l‟agent
mobile représenté par la Figure 4.3, dans R-Maude prototype. Nous considérons que les deux
environnements E1, E2 sont représentés par les deux spécifications sur les deux hôtes (Host1
et Host2). Host1 a l'adresse IP: 192.168.0.1, et Host2 a l'adresse IP: 192.168.0.2.
Sur l'hôte 1, nous avons spécification suivante:
mod E1
sort Place Marking .
subsort Place << Marking .
op _,_ : Marking Marking ->Marking .
ops PA1,P11,P12,P13,P14,PA2,P21,P22,P23,TR1,VTR1,PNR1,NR1:->Place
rl [str1] : PA1=>P11 .
rl [rt][MA|192.186.0.2|{{P11-P14},{str1-a13}}|{TR1,VTR1}] :P11=>P12.
rl [a11] : P12, TR1, PNR1=>P13 .
rl [a12] : P13, VTR1=>P14 .
rl [a13] : P14, NR1=>PA1 .
rl [str2]: PA2=>P21 .
rl [a21] : P21, PNR1=>P22 .
rl [a22] : P22, VTR1=>P23 .
rl [a23] : P23, NR1=>PA2 .
endmod
Sur l'hôte 2, nous avons spécification suivante:
mod E2
sort Place Marking .
subsort Place << Marking .
op _,_ : Marking Marking ->Marking .
ops PA1,PA2,P31,P32,PNR2 : -> Place.
rl [str3] : PA2=>P31 .
rl [a31] : P31=>P32 .
rl [a32] : P32, PNR2=>PA2 .
endmod
Comme exemple de commande, nous avons "rw PA1 " sur l'hôte 1. L'exécution de
cette commande va produire respectivement sur l'hôte 1 et Host2 les deux spécifications:
mod E1
sort Place Marking .
subsort Place << Marking .
op _,_ : Marking Marking ->Marking .
ops PA1,PA2,P21,P22,P23,VTR1,PNR1,NR1:->Place
rl [str2]: PA2=>P21 .
rl [a21] : P21, PNR1=>P22 .
rl [a22] : P22, VTR1=>P23 .
rl [a23] : P23, NR1=>PA2 .
endmod

Une Plateforme Formelle pour la Modélisation et la Simulation des LRN
97
et au niveau de l‟hôte 2. mod E2
sort Place Marking .
subsort Place << Marking .
op _,_ : Marking Marking ->Marking .
ops PA1,PA2,P31,P32,PNR2 : -> Place.
ops VTR1, TR1:-> Place.
ops P11,P12,P13,P14:->Place.
rl [str3] : PA2=>P31 .
rl [a31] : P31=>P32 .
rl [a32] : P32, PNR2=>PA2 .
rl [str1] : PA1=>P11 .
rl [rt][MA|192.186.0.2|{{P11-P14},{str1-a13}}|{TR1,VTR1}] :P11=>P12.
rl [a11] : P12, TR1, PNR2=>P13 .
rl [a12] : P13, VTR1=>P14 .
rl [a13]:P14,NR1[192.168.0.1]=>PA1.
endmod
Enfin, l'état du marquage sera: "P12" sur l'hôte 2. À ce stade, les deux spécifications
poursuivent leur exécution sur les deux hôtes où elles résident.
4.8 Conclusion
Dans ce chapitre, nous avons présenté un nouveau formalisme, basé sur les réseaux de
petri, « les Labeled Reconfigurables Nets (LRN) ». Ce formalisme permet de faire une
modélisation explicite des environnements informatiques et d‟exprimer la mobilité entre eux.
Nous avons présenté la façon dont ce formalisme permet, grâce à une approche simple et
intuitive, la modélisation des paradigmes de la mobilité du code. L'accent a été mis, sur les
liaisons vers les ressources et la façon dont elles seront mises à jour après la mobilité.
Nous avons décrit par la suite, notre support outillé de manipulation et de simulation
des LRN basé sur la méta-modélisation et les grammaires de graphes. Nous avons commencé
par la proposition d'un métamodèle pour les LRN et avons généré par la suite
automatiquement, L‟éditeur approprié qui permet à l‟utilisateur de dessiner un LRN
graphiquement. Nous avons proposé également, une grammaire de graphe pour transformer le
modèle source en un code cible. Notre proposition a été illustrée par des exemples expressifs.
Nous avons enchainé avec la présentation d‟une extension pour Maude: reconfigurable
Maude (R-Maude). R-Maude est un système distribué qui peut être utilisé pour la
spécification et la simulation des systèmes à code mobile. Un prototype de ce système a été
réalisé et utilisé pour simuler les spécifications des modèles LRN. Un exemple des étapes de
simulation a été également présenté.
Notre objectif à travers l‟outil que nous avons développé, est de faciliter l‟utilisation
conjointe des modèles graphiques des LRN et les représentations textuelles dans le langage
R-Maude. Les LRN disposent d‟un côté graphique facilitant le développement d‟un système à
code mobile au cours de sa spécification. D‟autre part la version textuelle en langage
R-Maude permet le développement des outils pour la simulation et l‟analyse des LRN.

98
Conclusion générale et perspectives
Dans cette thèse, nous nous sommes intéressés au paradigme des agents mobiles. Nous
avons essayé de développer cadre formel pour leurs modélisation et analyse. On a commencé
par introduire dans le premier chapitre la notion d‟agent en général, suivie par le paradigme
des agents mobiles. Le constat fait à ce niveau a montré que le développement des
applications des agents mobiles se heurte à des problèmes inhérents à la sécurité et à
l‟interopérabilité dans les différentes plateformes d‟accueil hétérogènes. Les insuffisances des
efforts pour la standardisation de ces plateformes, ont poussé les chercheurs à explorer
d‟autres horizons pour une meilleure prise en charge et mise en œuvre des applications à base
d‟agents mobiles.
D'autre part, très peu de travaux de recherches portent sur les méthodes et les outils pour
l‟analyse et la conception des systèmes d‟agents mobiles. Dans cette optique, une extension
des réseaux de petri vers les Reconfigurables Petri Nets (LRN) a été présentée. En effet, nous
avons proposé une approche totalement automatisée basée sur la méta-modélisation et les
grammaires de graphes pour générer des modèles réseaux de Petri reconfigurables (LRN),
pour la modélisation de la mobilité, en utilisant ATOM3. Nous avons donc décrit, notre
support outillé de manipulation et de simulation des LRN, à commencer par la proposition
d'un méta-modèle pour les LRN pour générer par la suite automatiquement, L‟éditeur
approprié qui permet à l‟utilisateur de dessiner un LRN graphiquement. Nous avons proposé
également, une grammaire de graphe pour transformer le modèle source en un code cible en
R-Maude. R-Maude est un système distribué qui peut être utilisé pour la spécification et la
simulation des systèmes à code mobile. Un prototype de ce système a été réalisé et utilisé
pour simuler les spécifications des modèles LRN. Un exemple des étapes de simulation a été
également présenté.
Nous avons donc, proposé une approche et un outil traitant de la transformation des
modèles LRN vers leur spécification R-Maude équivalente. Cette transformation vise à
permettre de procéder à la vérification des propriétés des systèmes modélisés à l'aide des
LRN, étant donné que ces derniers n'ont pas d'outils pour l'analyse et la vérification. Le coût
de construction d'un outil de modélisation visuelle (LRN par exemple) à partir de zéro est
prohibitif. Nous avons montré dans ce travail que la méta-Approche de modélisation est utile
pour faire face à ce problème car elle permet la modélisation des formalismes eux-mêmes. Par
le biais de la grammaire de graphes, les manipulations de modèles sont exprimées sur une

Conclusion générale et perspectives
99
base formelle et d'une manière graphique très expressive. Notre approche est basée sur
l'utilisation combinée de la méta-modélisation et de la grammaire de graphes. L‟outil ATOM3
est utilisé comme outil de transformation de graphes.
Dans les travaux futurs, nous prévoyons de cacher les étapes de la simulation, L‟objectif
est de décharger l'utilisateur d'avoir à invoquer manuellement R-Maude et de manipuler la
version textuelle du résultat de la simulation. A cet effet, le résultat de la simulation sera
retourné de manière graphique avec la structure du modèle LRN. Nous prévoyons aussi de
mettre l'accent sur la modélisation et l'analyse des aspects. Dans la modélisation aspects, nous
sommes intéressés par le traitement de problèmes tels que la modélisation de la mobilité
multi-sauts, des états des processus durant la migration, ... en ce qui concerne le côté analyse,
nous travaillons sur une sémantique dénotationnelle pour les LRN. Pour R-Maude, le présent
R-Maude ne peut être utilisé que pour simuler les modèles. Les travaux futurs se chargeront
de l'analyse de la spécification, à cet effet, nous prévoyons d‟adapter Maude model-checker à
R-Maude afin d‟effectuer certaines vérification des propriétés des systèmes mobiles. Nous
visons également à faire face aux aspects de sécurité [Armoogum10] [Sarkar11].

Références Bibliographiques
100
Références Bibliographiques
[AGG] AGG Home page: http://tfs.cs.tu-berlin.de/agg/
[AGLETS] AGLETS (IBM Corporation). <URL:http://www.trl.ibm.co.jp/aglets/>.
[Alouf02] Sara Alouf and Fabrice Huet and Philippe Nain, Forwarders vs. Centralized Server:
An Evaluation of Two Approaches for Locating Mobile Agents. Proceedings of the 2002
International Conference on Measurement and Modeling of Computer Systems
(SIGMETRICS-02) pp.278--279, 2002.
[Ametller04] Joan Ametller and Sergi Robles and Jose A.Ortega-Ruiz, Self-Protected Mobile
Agents. AAMAS pp.362-367, 2004.
[Andries99] M. Andries, G. Engels, A. Habel, B. Hoffmann, h.-J. Kreowski, s. Kuske, D.
Pump, A. Schürr et G. Taentzer. Graph transformation for specification and programming.
Science of Computer programming, vol 34, NO°1, pages 1-54, Avril 1999.
[Arcangeli02] Jean-Paul Arcangeli, Abdelkader Hameurlain, Guy Bernard, Jean- Francois
Monin, eds., Agents et code mobiles. Numero thematique de la Revue des sciences et
technologies de l'information, serie Technique et science informatiques (RSTI-TSI), Hermes
Science Publications - Lavoisier, Paris, Vol 21 N°6, 2002.
[Armoogum10] Armoogum, S., Caully, A. Obfuscation Techniques for Mobile Agent code
confidentiality. Journal of E-Technology 1(2), 83–94 (2010)
[Asperti96] Andrea Asperti and Nadia Busi. Mobile Petri Nets. Technical Report UBLCS-
96-10, Department of Computer Science University of Bologna, May 1996.
[Athie03] Athie L. Self and Scott A. DeLoach. Designing and Specifying Mobility within the
Multiagent Systems Engineering methodology. Special Track on Agents, Interactions,
Mobility, and Systems (AIMS) at the 18th ACM Symposium on Applied Computing (SAC
2003). Melbourne, Florida, USA, 2003.
[ATOM3]http://moncs.cs.mcgill.ca/MSDL/research/projects/ATOM3.html.
[Aud07] Laurent Audibert : UML 2.0, Institut Universitaire de Technologie de Villetaneuse,
Département Informatique, Adresse du document:http://www-lipn.univ-paris13.fr/
audibert/pages/enseignement/cours.htm, novembre 2007.
[Bahri09] M.R. Bahri, R. Mokhtari, et A. Chaoui, Modelling of mobile agent-based systems
by UML2.0, Conference international ACIT, Elhamamat, Tunisia 2009.
[Bahri2-09] Mohamed Redha Bahri, Abdelkamel Hettab, Allaoua Chaoui, Elhillali
Kerkouche. Transforming Mobile UML Statecharts Models to Nested Nets Models using
Graph Grammars: An Approach for Modeling and Analysis of Mobile Agent-Based Software
Systems, In Proccedings of IEEE SEEFM2009, the 2009 Fourth

Références Bibliographiques
101
[Bednarczyk04] M.A. Bednarczyk, L. Bernardinello, W. Pawlowski, and L. Pomello.
Modelling Mobility with Petri Hypernets. 17th Int. Conf. on Recent Trends in Algebraic
Development Techniques, WADT‟04. LNCS vol. 3423, Springer-Verlag, 2004.
[Benzaken91] Claude Benzaken. Systèmes Formels: Introduction à la logique et à la théorie
des langages. Editions Masson, 1991.
[Bennett90] John K. Bennett and John B. Carter and Willy Zwaenepoel, Munin: Distributed
Shared Memory Based on Type-Specific Memory Coherence. PPOPP, pp.168--176, 1990.
[Beale94] Russell Beale and Andrew Wood, Agent-Based Interaction. BCS HCI pp.239-245,
1994.
[Bellavista01] Paolo Bellavista and Antonio Corradi and Cesare Stefanelli, How to Monitor
and Control Resource Usage in Mobile Agent Systems , 2001.
[Benachenhou05] Lotfi Benachenhou and Samuel Pierre, A New Protocol for Protecting a
Mobile Agent Using a Reference Clone. MATA, pp.364-373, 2005.
[Berger05] Reinhartz-Berger, I., Dori, D. and Katz, S. (2005). Modelling code mobility and
migration: an OPM/Web approach, Int. J. Web Engineering and Technology, Vol. 2, No. 1,
pp.6–28.
[Bettaz92] M. Bettaz, and M. Maouche. How to specify Non Determinism and True
Concurrency with Algebraic Term Nets. Lecture Notes in Computer Science, N 655, Spring
Verlag, Berlin, p. 11-30, 1992.
[Bettaz93] M. Bettaz, M. Maouche, M. Soualmi, and M. Boukebeche. Protocol Specification
Using ECATNets. Networking and Distributed Computing, pp 7-35. 1993.
[Bloomfield99] R.E. Bloomfield and D. Craigen. Formal methods diffusion: Past lessons and
future prospects. Technical Report D/167/6101/1, Bundesamt fur Sicherheit in der
Informationstechnik, Bonn, Germany, December 1999.
[Carvalho04] Marco M. Carvalho and Thomas B. Cowin and Niranjan Suri and Maggie R.
Breedy and Kenneth Ford, Using mobile agents as roaming security guards to test and
improve security of hosts and networks. SAC pp.87-93, 2004.
[Claessens03] Claessens and Preneel and Vandewalle, (How) Can Mobile Agents Do Secure
Electronic Transactions on Untrusted Hosts? A Survey of the Security Issues and the Current
Solutions. ACMTIT: ACM Transactions on Internet Technology, 2003.
[Clarke03] Clarke, E. M. Model Checking Overview. Presentation Slides, 2003.
[Claud01] C.Kaiser, ANNEXE 2 LES RÉSEAUX DE PETRI, Reproduit avec la permission de
Francis Cottet, ENSMA décembre 2001.
[Clavel05] Clavel, M., Durán, F., Eker, S., Lincoln, P., Martí-Oliet, N., Mesenguer, J. and
Talcott. C. Maude Manual (Version 2.1.1). April 2005.

Références Bibliographiques
102
[Clavel99]. Clavel, M., Durán, F., Eker, S., Lincoln, P., Marti-Oliet, N., Meseguer, J.,
Quesada, J. Maude:specification and programming in rewriting logic. SRI International
(January 1999), http://maude.csl.sri.com
[Chess97] D. Chess and C. Harrison and A. Kershenbaum, Mobile Agents: Are They a Good
Idea?. j-LECT-NOTES-COMP-SCI, pp.25--48, 1997.
[Cook94] Cook (S.) et Daniels (J.). – Designing Object Systems - Object-Oriented Modelling
with Syntropy. – Prentice-Hall, 1994.
[Czar03] K. Czarnecki, S. Helsen, Classification of Model Transformation Approaches,
University of Waterloo, Canada.2003, [email protected], [email protected].
[Cubat05]C. Cubat thèse de doctorat « Agents Mobiles Coopérants pour les Environnements
Dynamiques», Institut National Polytechnique de Toulouse 2005.
[Dehimi4-12] Nardjes Dehimi, Raida Elmansouri, and Allaoua Chaoui. A Formal Framework
and a Tool to Process and Simulate Labeled Reconfigurable Nets Models Based on Graph
Transformation. NDT 2012, Part II, CCIS 294, pp. 404–415. Springer-Verlag 2012.
[Dehimi5-12] Nardjes Dehimi and Allaoua Chaoui. Using Meta-modeling Graph Grammars
and R-Maude to Process and Simulate LRN Models. International Journal of Software
Engineering (IJSE), Volume (3) : Issue (2) : 2012.
[Dehimi3-12] Nardjes Dehimi and Allaoua Chaoui. “Using graph grammars and meta-
modeling to process code mobility in LRN models”. IEEE International Conference on
Information Technology and e-Services 2012. pp.657-662.
[Dehimi6-12] Nardjes Dehimi and Allaoua Chaoui. Processing and Simulating LRN Models
Using Meta-modeling Graph-Grammars and R-Maude. SMTDA 2012Stochastic Modeling
Techniques and Data Analysis International Conference June 2012 Chania, Crete, Greece.
[Dehimi1-12]Nardjes Dehimi and Allaoua Chaoui. A Meta-modelling and Graph Grammar
Based Approach to Process LRN Models. 2nd International Conference on Information
Systems and Technologies 2012.
[Dehimi2-12] Nardjes Dehimi and Allaoua Chaoui. Des Réseaux Reconfigurables Etiquetés à
Maude en Utilisant La Meta-Modélisation et les Grammaires de Graphe. Conférence
internationale sur le traitement de l‟information multimédia Avril 2012, Mascara, Algérie.
[David06] David Durand, Gestion de la Qualité de Service dans les Applications Réparties
sur Bus Middleware Orientés Objet Approche Dirigée par les Modèles, Thèse de Doctorat,
université de Picardie Jules Verne, le 8 novembre 2006.
[DeLara02] J. De Lara and H. Vangheluwe. AToM3: "A Tool for Multi-Formalism
Modelling and Meta-Modelling". Lecture Notes in Computer Science, No 2306, pp. 174-188,
2002.

Références Bibliographiques
103
[Dillenseger02] Bruno Dillenseger and Anne-Marie Tagant and Laurent Hazard,
Programming and Executing Telecommunication Service Logic with Moorea Reactive
Mobile Agents. Mobile Agents for Telecommunication Applications, 4th International
Workshop, MATA 2002 pp.48--57, 2002.
[Diaz01] Jesus Arturo Perez Diaz and Dario Alvarez Gutierrez and Igor Sobrado, A fast data
protection technique for mobile agents against malicious hosts. Electr. Notes Theor. Comput.
Sci, 2001.
[DIMA] DIMA, OASIS, Laboratoire d‟Informatique de Paris 6 (LIP6) <URL :http://wwww-
poleia.lip6.fr/~guessoum/DIMA.html>.
[Duran00] Francisco Duran, Steven Eker, Patrick Lincoln and José Meseguer. Principles of
Mobile Maude. In: Kotz, D., Mattern, F. (eds.) ASA/MA 2000. LNCS, vol. 1882, pp. 73–85.
Springer, Heidelberg(2000).
[Eker02] Eker, S., Meseguer, J. and Sridharanarayanan, A. The Maude LTL Model Checker.
F.Gaducci and U. Montanari, editors, Proc. of the 4th International Workshop on Rewriting
Logic and its Applications (WRLA 2002), 2002.
[El Mansouri08]. El Mansouri, R., Kerkouche, E., Chaoui, A.: A Graphical Environment for
Petri Nets INA Tool Based on Meta-Modelling and Graph Grammars. Proceedings of Word
Academy of Science, Engineering and Technology 34 (October 2008) ISSN 2070-3740
[Eric07] Eric Piel, Ordonnancement de systèmes parallèles temps-réel, de la modélisation à la
mise en oeuvre par l‟ingénierie dirigée par les modèles, Thèse. Lille, le 14 décembre 2007.
[Ferber95] J. Ferber, Les systèmes multi-agents Vers une intelligence collective, Masson,
1995.
[FIPA] Foundation for Intelligent Physical Agents,1998, URL,(www.fipa.org).
[Fournet02] Cédric Fournet Georges Gonthier. The Join Calculus: a Language for
Distributed Mobile Programming. In Applied Semantics. International Summer School,
APPSEM 2000, Caminha, Portugal, September 2000, LNCS 2395, pages 268-- 332, Springer-
Verlag. August 2002.
[Fuggetta98] Alfonso Fuggetta and Gian Pietro Picco and Giovanni Vigna, Understanding
Code Mobility. IEEE Transactions on Software Engineering, pp.342-361, 1998.
[Galtier01] Virginie Galtier and Kevin L. Mills and Yannick Carlinet and Stephen F.Bush
and Amit Kulkarni, Predicting and Controlling Resource Usage in a Heterogeneous Active
Network. Active Middleware Services, pp.35-44, 2001.
[Gardarin93] G. Gardarin O.Gardarin, Le Client-Serveur. Eyrolles, mars 1993.
[Gargantini09] Angelo Gargantini, Elvinia Riccobene and Patrizia Scandurra. Integrating
Formal Methods with Model-driven Engineering . In Proceedings of the Fourth International
Conference on Software Engineering Advances, Porto, Portugal , ISBN: 978-0-7695-3777-1,
2009.

Références Bibliographiques
104
[Gerber02] Anna Gerber, Michael Lawley , Kerry Raymond , Jim Steel and Andrew Wood,
Transformation: The Missing Link of MDA, In : Graph Transformation. Volume 2505 of
Lecture Notes in Computer Science, Springer- Verlag (2002) 90-105 Proc. 1st International
Conference. Graph Transformation, Barcelona, Spain 2002.
[Gomoluch01] J. Gomoluch and M. Schroeder, Information agents on the move: A survey on
loadbalancing with mobile agents, 2001
[Grasshopper98] Grasshopper – A, M. Breugst and I. Busse and S. Covaci and T.Magedanz,
Mobile Agent Platform for IN Based Service Environments. Proceedings of IEEE IN
Workshop, pp.279--290, 1998.
[Groot04] David R. A. De Groot and Frances M. T. Brazier and Benno J. Overeinder, Cross-
Platform Generative Agent Migration, 2004.
[Guerra03] E. Guerra, J. de Lara, A Framework for the Verification of UML Models.
Examples using Petri Nets. Ecole Politechnique Superieur, Ingenieríe de l‟ Informátique,
Université Autónoma de Madrid.Spain 2003
[Guyennet97] H. Guyennet and J-C. Lapayre and M. Trehel, CAliF: une plate-forme de
d'eveloppement de collecticiels utilisant la memoire partagee distribuee. Calculateurs
paralleles, pp.251-271, 1997
[Hall90] A. Hall. Seven myths of formal methods. IEEE Softw., 7(5):11–19, 1990.
[Hantz06] F. Hantz and H. Guyennet, A P2P Platform using sandboxing. HPCS'06,
Workshop on security and high Performance computing systems, In conjunction with ECMS
2006, 20th European Conf. on Modelling and Simulation, Bonn, Germany, pp.736-739, 2006.
[Hin95] Hinchey (M. G.) et Bowen (J. P.). – Seven more myths of formal methods. IEEE
Software, july 1995, pp. 34–41.
[Hinchey95] M. G. Hinchey and J. Bowen, editors. “Applications of Formal Methods”,
Prentice Hall International, 1995. isbn 0-13-366949-1.
[Hohlfeld02] Matthew Hohlfeld and Aditya Ojha and Bennet Yee, Security in the Sanctuary
System, http://historical.ncstrl.org/tr/ps/ucsd_cs/CS2002-0731.ps, 2002.
[INA] INA home page : www2.informatik.hu-berlin.de/~starke/ina.html
[IRISA08] IRISA. Kermeta-breathe life into your metamodels. http ://www.kermeta.org/,
2008.
[Ismail99] L. Ismail and D. Hagimont and J. Mossiere, Evaluation of the Mobile Agents
Technology: Comparison with the Client/Server Paradigm, 1999.
[ISO 8402] ISO 8402 Qualité: Concepts et Terminologie. Partie 1: Termes génériques et
Définitions.

Références Bibliographiques
105
[JADE] JADE: Java Agent Development Framework. <URL: http://www.jade.cselt.it/>.
[Java] Java Sun, http://java.sun.com.
[Jean01] Jean Bézivin and O. Gerbé. Towards a precise definition on the omg/mda
framework. In ASE‟01, november 2001.
[Jean02] Jean Bézivin, Xavier Blanc. MDA : Vers un important changement de paradigme en génie
logiciel. http ://www.sciences.univnantes. fr/info/perso/permanents/vailly/ Enseignement/
Documents/MDA.Partie1. -JBXB.Last.prn.pdf, Juillet 2002.
[Jensen97] Kurt Jensen. A Brief Introduction to Coloured Petri Nets. Lecture Notes in
Computer Science, No 1217, Springer-Verlag, 1997, pp 203-208.
[Jensen98] Kurt Jensen. An Introduction to the Practical Use of Coloured Petri Nets.
Lecture Notes in Computer Science, No 1492, Springer-Verlag, pp 237-292, 1998.
[José] José-Celso Freire Junior_ - Jean-Pierre Giraudin – Agnès Front Atelier MODSI: Un
Outil de Méta-Modélisation et de Multi-Modélisation. Laboratoire Logiciels Systèmes
Réseaux – IMAG B.P. 72 - 38402 – Saint Martin d‟H`eres Cedex – France.
[Jouault06] Frédéric Jouault, Freddy Allilaire, Jean Bézivin, Ivan Kurtev and Patrick
Valduriez. ATL: a QVT like transformation language. In Companion to the 21th Annual
ACM SIGPLAN Conference on Object-Oriented Programming, Systems, Languages, and
Applications, OOPSLA 2006, October 22-26, 2006, Portland, Oregon, USA, pages 719– 720,
2006.
[Kadima05] H. Kadima, MDA une conception orientée objet guide par les modèles.
DUNOD 2005.
[Kahloul07] Laid Kahloul and Allaoua Chaoui, Labeled reconfigurable nets For modeling
code mobility, In proceedings of ACIT 2007. Lattakia, Syria.
[Kahloul08] Kahloul, L., Chaoui, A. LRN/R-Maude Based Approach For Modeling And
Simulation Of Mobile Code Systems. In: Proceedings of ACIT 2008, Tunisia (2008).
[Kahloul2-08]. Kahloul, L. and Chaoui, A. LRN/R-maude based approach for modeling and
simulation of mobile code systems. In Ubiquitous Computing and Communication Journal
(UbiCC journal), Volume 3 Number 6, Volume 3 No. 6, 12/20/2008. http://www.ubicc.org/
search_advanced.aspx.
[Kerkouche08] Kerkouche, E., Chaoui, A.: A Formal Framework and a Tool for the
Specification and Analysis of G-Nets Models Based on Graph Transformation. In: Garg, V.,
Wattenhofer, R., Kothapalli, K. (eds.) ICDCN 2009. LNCS, vol. 5408, pp. 206–211. Springer,
Heidelberg (2008).
[Kerkouche09] Kerkouche, E., Chaoui, A., Khalfaoui, K.: Transforming UML models to
colored Petri nets models using graph grammars. In: Proceedings of IEEE ISCC 2009,
Tunisia, July 5-7, pp.230–236 (2009).

Références Bibliographiques
106
[Karsai04] G. Karsai, A. Agrawal. Graph Transformations in OMG’s Model-Driven
Architecture. Lecture Notes in Computer Science, Vol 3062, 243-259, Springer Berlin /
Heidelberg, juillet 2004.
[Kees06] Kees M. van Hee, Irina A. Lomazova, Olivia Oanea, Alexander Serebrenik, Natalia
Sidorova, Marc Voorhoeve. Nested Nets for Adaptive Systems. 14 EE. ICATPN 2006: 241-
260.
[Kohler02] Köhler M and Rölke H, Mobile object net systems. Concurrency and mobility. in
Proceedings of the International Workshop on Concurrency, Specification, and Programming
(CS&P 2002), Berlin, 2002.
[Kohler07] M. Köhler, R. Langer, R. Lüde, D. Moldt, H. Rölke, R. Valk, Socionic Multi-
Agent Systems Based on Reflexive Petri Nets and Theories of Social Self-Organisation,
Journal of Artificial Societies and Social Simulation vol. 10, no.1, 2007.
http://jasss.soc.surrey.ac.uk/10/1/3.html 31-Jan-2007
[Kurt1 97] Jensen Kurt. Coloured petri nets: Basic concepts, analysis methods and pratical
use, volume 1. Springer, 1997.
[Lomazova02] I.A. Lomazova. Nested Petri Nets. Multilevel and Recursive Systems.
Fundamenta Informaticae vol.47, pp.283-293. IOS Press, 2002.
[Leclercq04] Matthieu Leclercq and Vivien Quema and Jean-Bernard Stefani,DREAM: a
component framework for the construction of resource-aware, reconfigurable MOMs.
Adaptive and Reflective Middleware, pp.250--255, 2004.
[Marcus04] Marcus Alanen and Iven Porres. Coral : A metamodel kernel for transformation
engines. In Second European Workshop on Model Driven Architecture (MDA), Canterbury,
United Kingdom, 2004 september.
[MASIF] MASIF, The OMG Mobile Agent System Interoperability Facility,1997, URL
www.masif.org
[McCombs03] McCombs, T. Maude 2.0 Primer (Version 1.0). August 2003.
[Merks06] Ed Merks Raymond Ellersick Frank Budinsky, David Steinberg and Timothy J.
Grose. Eclipse Modeling Framework. Hermès - Lavoisier, 2006.
[Meseguer03] Meseguer, J. Software Specification and Verification in Rewriting Logic.
2003.
[Meseguer91] Meseguer, J. Rewriting as a Unified Model of Concurrency. In SIGPLAN
OOPS Mess , 2(2) :86–88, 1991.
[Meseguer92] Meseguer J. A Logical Theory of Concurrent Objects and its Realization in
the Maude Language. Agha G., Wegner P. and Yonezawa A., Editors, Research Directions in
Object-Based Concurrency. MIT Press, 1992, pp. 314-390.

Références Bibliographiques
107
[Meseguer2-92] . Meseguer, J.: Conditional rewriting logic as a unified model of
concurrency. Theoretical Computer Science 96(1), 73–155 (1992)
[Milner92] R. Milner, J. Parrow, and D. Walker. A calculus of mobile processes.
Information and Computation, 100:1–77, 1992.
[Mireille06] Mireille Blay-Fornarino Jean-Marie Favre, Jacky Estublier. L‟ingénierie dirigée
par les modèles - Au-delà du MDA. Hermès - Lavoisier, 2006.
[Mokrane04] Mokrane Bouzhegoub Jacky Estublier Jean-Marie Favre Sébastien Gérard
Jean-Marc Jézéquel Jean Bézivin, Mireille Blay. Rapport de synthèse de l‟as cnrs sur le mda
(model driven architecture). http ://www.irisa.fr/triskell/publis/2004/Jezequel04e.pdf.
[ODYSSEY] ODYSSEY (General Magic). <URL:http://www.genmagic.com/technology/
mobile_agent.html>.
[Ölveczky00] Ölveczky, P.C., Meseguer, J.: Real-Time Maude: A tool for simulating and
analyzing realtime and hybrid systems. In: Futatsugi, K. (ed.) Third International Workshop
on Rewriting Logic and its Applications. ENTCS, vol. 36. Elsevier (2000),
http://www.elsevier.nl/ locate.entcs/volume36.html
[OMG00] OMG. Meta object facility (MOF) specification (version 1.3). OMGdocument,
Object Management Group, ftp ://ftp.omg.org/pub/docs/formal/00-04-03.pdf, March 2000.
[OMG03] OMG. Omg‟s metaobject facility. http ://www.omg.org/mof, 2003.
[OMG04] Object Management Group (OMG), Model Driven Architecture (MDA),
http://www.omg.org/mda,2004.
[OMG06] OMG. Meta object facility (MOF) core specification. http ://www.omg.org/docs/
formal/06-01-01.pdf, 2006.
[Pep] PEP home page: http://peptool.sourceforge.net/
[Petit99] Michaël Petit. Formal requirements engineering of manufacturing systems: a
multiformalism and component-based approach . Thèse de doctorat de l'Université de
Namur, Belgique, Octobre 1999.
[Prakash6] N. Prakash, S. Srivastava, S. Sabharwal. The Classification Framework for
Model Transformation, Journal of Computer Science 2 (2): 166-170, 2006.
[Python] Python home page: htpp://www.python.org.
[RAM 74] RAMCHANDANI C., Analysis of asynchronous concurrent systems by timed
Petri nets, PhD thesis, Massachusetts Institute of Technology, Cambridge, MA, 1974, Project
MAC Report MAC-TR-120.
[Rozenberg99] G. Rozenberg. Handbook of Graph Grammars and Computing by Graph
Transformation. Vol.1. World Scientific, 1999.

Références Bibliographiques
108
[Sangiorgi01] D. Sangiorgi and D. Walker. The π-Calculus: A Theory of Mobile Processes.
Cambridge University Press, 2001.
[Sarkar11] Sarkar, A., Debnath, N.: CASE Tool Design for Graph Semantic Based Aspect
Oriented Model. Journal of Intelligent Computing 2(4), 169–182 (2011)
[Scor06] G. Scorletti et G. Binet Réseaux de Petri Maîtres de conférences à l‟Université de
Caen, France 20 juin 2006. Page web: http: //www.greyc.ensicaen. fr/EquipeAuto/Gerard
S/mait_Petri.html.
[Sylvain04] Sylvain Andre. MDA (model driven architecture) principes et ´états de l‟art.
Technical report, CNAM, 05 Novembre 2004.
[Taentzer05] Gabriele Taentzer, Karsten Ehrig, Esther Guerra, Juan de Lara, Laszlo Lengyel,
Tihamer Levendovszky, Ulrike Prange, Gabriele Taentzer, Daniel Varro and Szilvia Varro-
Gyapay. Model Transformation by Graph Transformation : A Comparative Study. Model
Transformations in Practice Workshop at MoDELS, Montego, 2005.
[Tanenbaum92] A. S. Tanenbaum, Modern Operating Systems, Prentice-Hall .1992.
[Tina] Tina Home page : http://www.laas.fr/tina/
[Tran05] V. Tran, V. Moraru, Réseau de Petri, Institut de la Francophonie pourl'Informatique
Promotion 10 15 juillet 2005.
[Valk98] R. Valk. Petri Nets as Token Objects: An Introduction to Elementary Object Nets.
Applications and Theory of Petri Nets 1998, LNCS vol.1420, pp.1-25, Springer-Verlag, 1998.
[Vangheluwe02] Hans Vangheluwe and Juan De Lara. Meta-models are models too. In
Proceedings of the 2002 Winter Simulation Conference, (pp. 597-605), Eds : E. Yücesan, C.-
H. Chen, J. L. Snowdon, and J. M. Charnes, 2002.
[VIATRA] VIATRA, Visual Automated Transformations for Formal Verification and
Validation of UML Models, URL:http://dev.eclipse.org/viewcvs/indextech.cgi/gmt-home/
subprojects/VIATRA2/index.html
[Wikipédia08] Wikipédia. Syst`eme. http ://fr.wikipedia.org/wiki/Acceuil/Syst`eme, 2008.
[Wing90] Jeannette M. Wing. A Specifier's Introduction to Formal Methods. Computer, vol.
23(9):8-23, 1990.
[Xu00] Dianxiang Xu and Yi Deng, Modeling Mobile Agent Systems with High Level Petri
Nets. 0-7803- 6583-6/00/ © 2000 IEEE.
[Yann03] Yann Dantal et Christophe Haug Théorie des graphes Principes et programmation
Soluscience 2003.
















