Embed Size (px)
Citation preview

Problème de classification
un ensemble de données étiquetées Xa définies dans un domaine D :Xa ⊂ D ;
on suppose que les attributs sont numériques ;
on suppose deux étiquettes : + et -.
Problème de classification : induire un séparateur (= une hypothèse = unclasseur) qui sépare les + des -.
Notons :
Ea l’erreur mesurée sur Xa ;
E : la probabilité de mal classer une donnée quelconque x ∈ D.

.
Problèmes annexes :
les « vraies » données sont bruitées ;
Xa n’est qu’un sous-ensemble de D.

.
Problèmes annexes :
les « vraies » données sont bruitées ;
Xa n’est qu’un sous-ensemble de D.
Donc,
on ne peut pas espérer obtenir une erreur nulle sur Xa ;
ou encore, faut-il vraiment chercher à annuler Ea ?

.
Problèmes annexes :
les « vraies » données sont bruitées ;
Xa n’est qu’un sous-ensemble de D.
Donc,
on ne peut pas espérer obtenir une erreur nulle sur Xa ;
ou encore, faut-il vraiment chercher à annuler Ea ?
quel est le rapport entre cette erreur Ea et l’erreur réelle E ?
minimiser Ea est-il équivalent à minimiser E ?

.
Stratégies classiques :
1. stratégie à la C4.5:
on minimise l’erreur sur le jeu d’exemples classeur brut ;
on simplifie ce classeur (élagage de l’arbre de décision).

.
Stratégies classiques :
1. stratégie à la C4.5:
on minimise l’erreur sur le jeu d’exemples classeur brut ;
on simplifie ce classeur (élagage de l’arbre de décision).
2. stratégie réseau de neurones + arrêt précoce (early stopping) :
on apprend les poids avec un jeu d’exemples ;
en même temps, on mesure l’erreur sur un jeu de validation : Ev ;
on arrête l’apprentissage quand Ev stagne ou augmente.

.
Stratégies classiques :
1. stratégie à la C4.5:
on minimise l’erreur sur le jeu d’exemples classeur brut ;
on simplifie ce classeur (élagage de l’arbre de décision).
2. stratégie réseau de neurones + arrêt précoce (early stopping) :
on apprend les poids avec un jeu d’exemples ;
en même temps, on mesure l’erreur sur un jeu de validation : Ev ;
on arrête l’apprentissage quand Ev stagne ou augmente.
Objectif : éviter le sur-apprentissage et maximiser la capacité de
généralisation du classeur.

.
Peut-on faire mieux que cette intuition ?
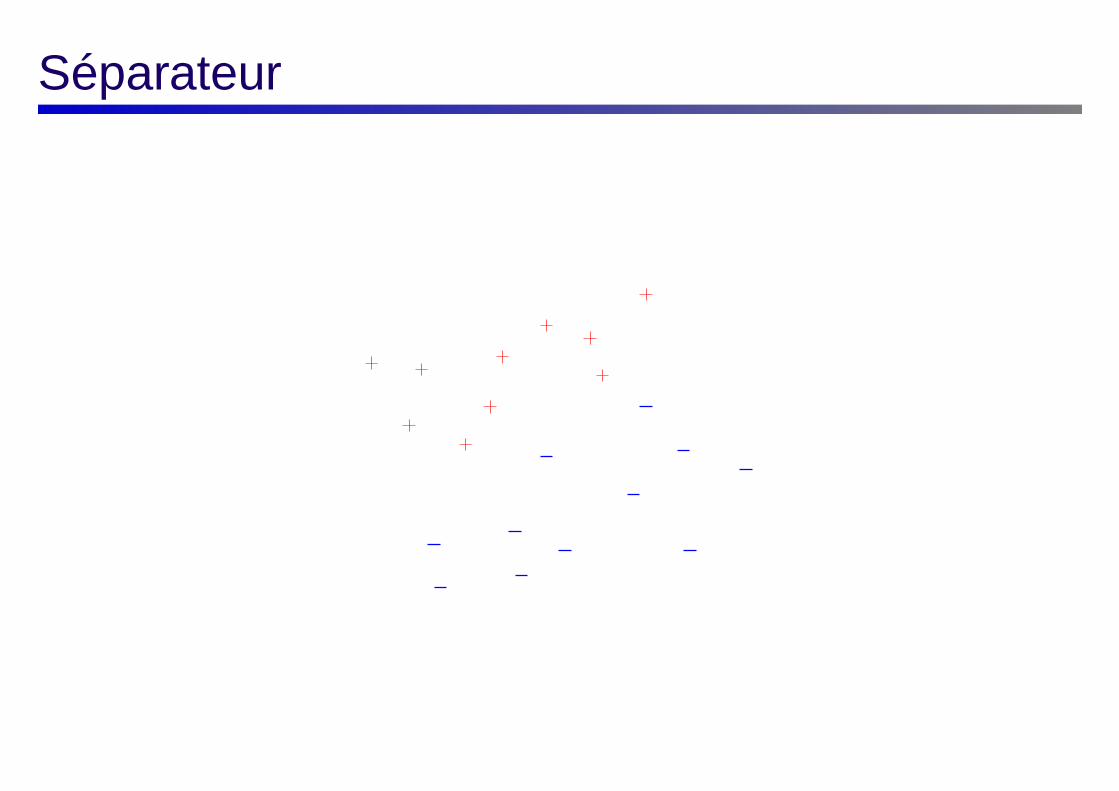
Séparateur
.
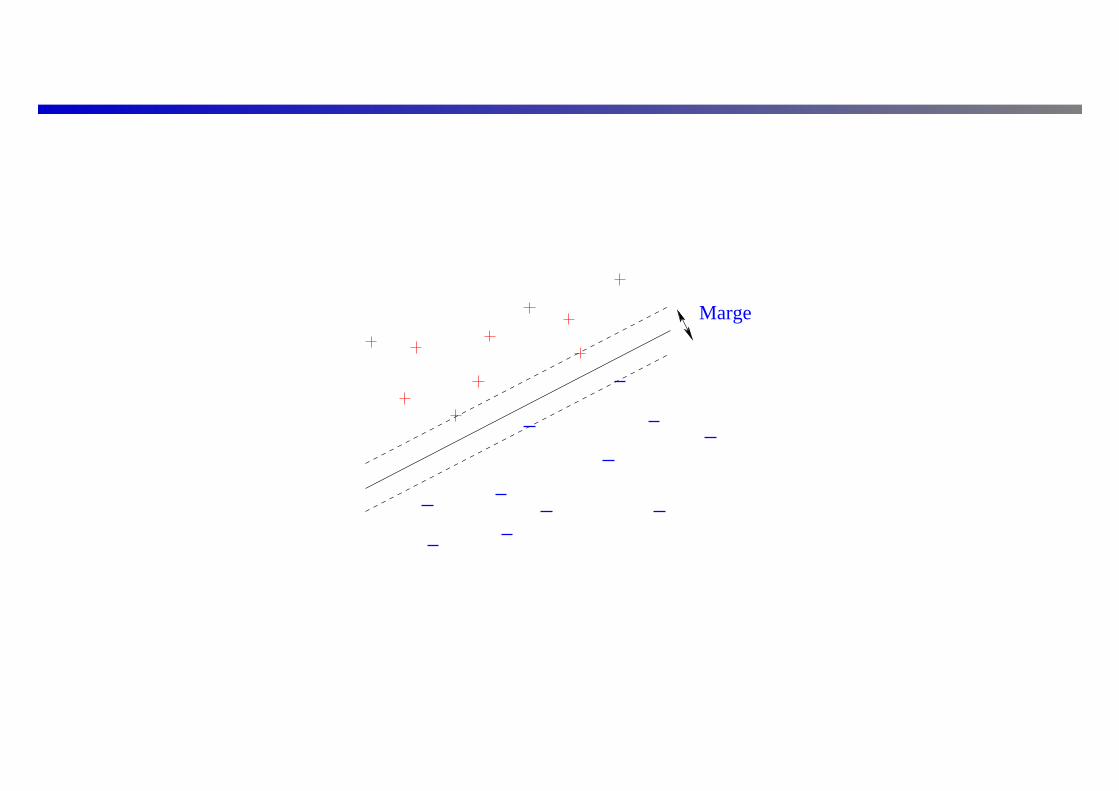
Marge

.
Marge
Trouver le séparateur qui maximise la marge ?

.
On note x une donnée, y sa classe : y = ±1.
Soient :
pour un exemple (−→x , y), le séparateur a pour équation : y =< −→w ,−→x > + b
(une droite en 2D ; un hyperplan en P dimensions) ;
pour un exemple positif (y = +1), < −→w ,−→x > + b ≥ 1 ;
pour un exemple négatif (y = −1), < −→w ,−→x > + b ≤ −1 ;−→w est un vecteur perpendiculaire au séparateur.
Quelle est la largeur de la marge ?

.
1. soit B un point de H+ et A le point le plus proche de B sur H− ;
2. pour tout point O, on a :−−→OB =
−−→OA +
−−→AB ;
3. par définition des points A et B,−−→AB est parallèle à −→w . Donc, il existe λ ∈ R tel que
−−→AB = λ−→w , soit
−−→OB =
−−→OA + λ−→w ;
4. on a :(
B ∈ H+ ⇒ < −→w,−−→OB > + b = 1
A ∈ H− ⇒ < −→w,−−→OA > + b = −1
5. donc, < −→w, (−−→OA + λ−→w ) > + b = 1 ;
6. donc, < −→w,−−→OA > + b
| {z }
−1
+ < −→w, λ−→w >= 1 ;
7. soit, −1 + < −→w, λ−→w >| {z }
λ<−→w ,−→w>
= 1 ;
8. donc, λ = 2
<−→w,−→w>= 2
||−→w||.
9. donc, la marge M = |λ|, soit :
M =2
||−→w||
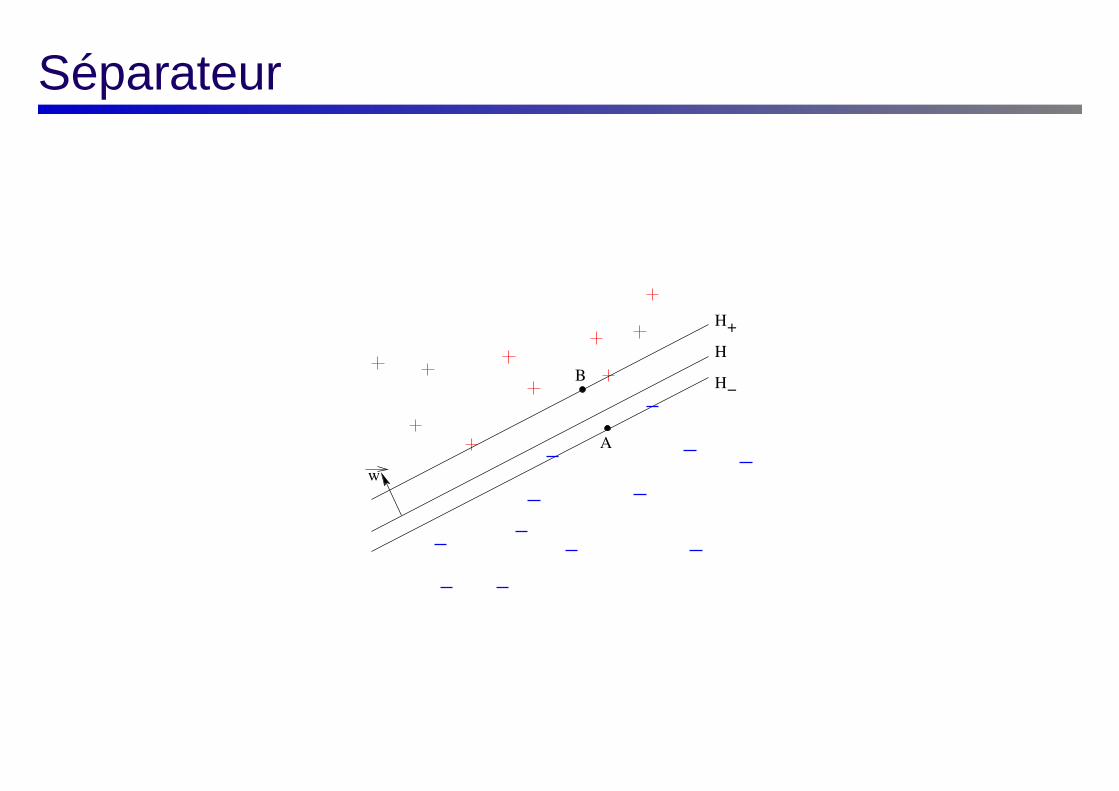
Séparateur
H
H
H−
+
w
B
A

.
Conclusion : on veut maximiser la largeur de la marge, donc maximiser M ,donc minimiser ||−→w||.
||−→w||, ||−→w||2 et 1
2||−→w||2 ont leur minimum pour le même −→w .
Pour ce minimum, on veut respecter : γi = yi(<−→w ,−→xi > + b) − 1 ≥ 0, ∀i.
(i.e., les positifs sont au-dessus du séparateur, les négatifs en dessous).

En résumé
On veut résoudre le problème d’optimisation suivant :
minimiser 1
2||−→w||2 (= fonction objectif)
en respectant les γi
C’est un problème dit « d’optimisation non linéaire avec contraintes ».
⇒ méthode de Lagrange.

Méthode de Lagrange
Principe : on exprime le lagrangien LP comme somme de la fonction àminimiser (fonction objectif) et de l’opposé de chaque contrainte γi multipliéepar une constante αi ∈ R
+. Les αi constituent les « multiplicateurs deLagrange ».
Autrement dit :
LP =1
2||−→w||2 −
i=N∑
i=1
αiyi(<−→w ,−→xi > + b) +
i=N∑
i=1
αi
LP doit être minimisé par rapport à −→w et b et il faut que les dérivées par
rapport aux αi soient nulles.

Lagrangien dualLe gradient de Lp devant être nul par rapport à −→w et b, on écrit :
{
∂Lp
∂−→w= 0
∂Lp
∂b= 0
d’où l’on tire aisément (en calculant ces dérivées et en les annulant) :
{
−→w =∑i=N
i=1αiyi
−→xi∑i=N
i=1αiyi = 0
De la formulation de LP et de ces deux équations, on tire la formulation dualedu lagrangien en éliminant −→w et qui doit maintenant être maximisé :
LD =i=N∑
i=1
αi −1
2
i=N∑
i=1
j=N∑
j=1
αiαjyiyj < −→xi ,−→xj >

Lagrangien dual
LP et LD ont les mêmes solutions en −→w , b et αi.

Conditions d’existence de solution
Pour que −→w , b et les αi existent, le problème doit vérifier les conditions deKarush-Kuhn-Tucker (KKT) :
∂LP
∂wν= wν −
∑i=Ni=1
αiyixi,ν = 0, ∀ ν = 1, 2, ...P∂LP
∂b= −
∑i=Ni=1
αiyi = 0
yi(<−→w ,−→xi > + b) − 1 ≥ 0, ∀ i = 1, 2, ...N
αi ≥ 0, ∀i = 1, ...N
αi(yi(<−→w ,−→xi > + b) − 1) = 0, ∀ i = 1, ...N
Ces cinq conditions résument ici ce qui a été dit précédemment. Lesconditions KKT sont donc vérifiées et le problème que l’on cherche à résoudrepossède bien une solution.

les vecteurs supports
Les deux dernières lignes indiquent simplement que pour tout exemple −→xi ,soit αi = 0, soit yi(<
−→w ,−→xi > + b) − 1 = 0.
On définit alors :
Définition 1 un vecteur support est un vecteur ( i.e., une donnée) dont lemultiplicateur de Lagrange associé est non nul.

Quelques remarques
1. les multiplicateurs de Lagrange étant positifs dans le problème posé ici,un vecteur support a donc un multiplicateur de Lagrange de valeurstrictement positive ;
2. puisque l’on a αi(yi(<−→w ,−→xi > + b) − 1) = 0 pour tous les points et que
αi 6= 0 pour les vecteurs supports, cela entraîne queyi(<
−→w ,−→xi > + b) − 1 = 0 pour les vecteurs supports ; cela entraîne queces points (les vecteurs supports) sont situés exactement sur leshyperplans H+ et H
−;
3. en fait, seuls les exemples correspondant aux vecteurs supports sontréellement utiles dans l’apprentissage. Si on les connaissait a priori , onpourrait effectuer l’apprentissage sans tenir compte des autres exemples ;
4. les vecteurs supports synthétisent en quelque sorte les aspectsimportants du jeu d’exemples. On peut donc compresser l’ensemble desexemples en ne retenant que les vecteurs supports.

Prédiction de la classe d’une donnée
Une fois les αi et b obtenus, prédiction de la classe d’une donnée x :
sgn(< −→w ,−→x > + b) =i=N∑
i=1
αiyi < −→xi ,−→x > + b =
j=Ns∑
j=1
αjy(sj) < −→sj ,−→x > + b
où Ns est le nombre de vecteurs supports.

Aspect pratique
une fois le problème posé, comment le résoudre effectivement ?
c’est un problème de « programmation quadratique convexe ».
approches analytiques généralement impossible (sauf si le nombred’exemples est très petit).
Différentes méthodes numériques :
gradient conjugué avec contraintes
méthode de projection
décomposition de Bunch-Kayfman
méthodes de points intérieurs

Cas non linéairement séparable
Idée : à chaque donnée, on associe une variable indiquant si la donnée est du
bon côté du séparateur.

Cas non linéairement séparable
< −→w ,−→x > + b ≥ 1 − ξi si yi = +1
< −→w ,−→x > + b ≤ −1 + ξi si yi = −1
ξi ≥ 0, ∀ i = 1, ...N
une donnée −→xi est bien classée si ξi = 0 ;
si ξi 6= 0, c’est-à-dire si xi est mal classée, alors ξi ≥ 1 ;Ainsi, ξi indique à quel point la donnée xi est du mauvais côté : si xi estdu mauvais côté de la séparatrice, plus xi est loin de la séparatrice, plusξi est grand. Donc,
∑i=Ni=1
ξi est une borne supérieure du nombred’erreurs de classification.

Cas non linéairement séparable
Le problème devient celui de la recherche de l’hyperplan impliquant la margela plus grande et le nombre d’erreurs le plus petit.
Donc, la fonction objectif devient (par exemple) : minimiser :
||−→w||2 + C(i=N∑
i=1
ξi)k (1)
où C est une constante (dénommée « capacité » de la MVS) qui permet de
donner plus ou moins d’importance aux erreurs. Pour que le problème
demeure convexe, on doit prendre k = 1 ou k = 2. Le plus simple est de
prendre k = 1 (ce qui simplifie la forme duale du lagrangien).

Cas non linéairement séparable
On résoud maintenant le problème :
{
minimiser ||−→w||2 + C(∑i=N
i=1ξi)
en respectant les γiξi ≥ 0, ∀i
C’est exactement le même principe que dans le cas linéairement séparable.

Cas non linéairement séparable
Dans le cas non séparable linéairement, nous avons trois types depoints/données :
les données mal classées ;
les données correspondant aux vecteurs supports (bien classées) ;
les données bien classées, qui ne sont pas des vecteurs supports.
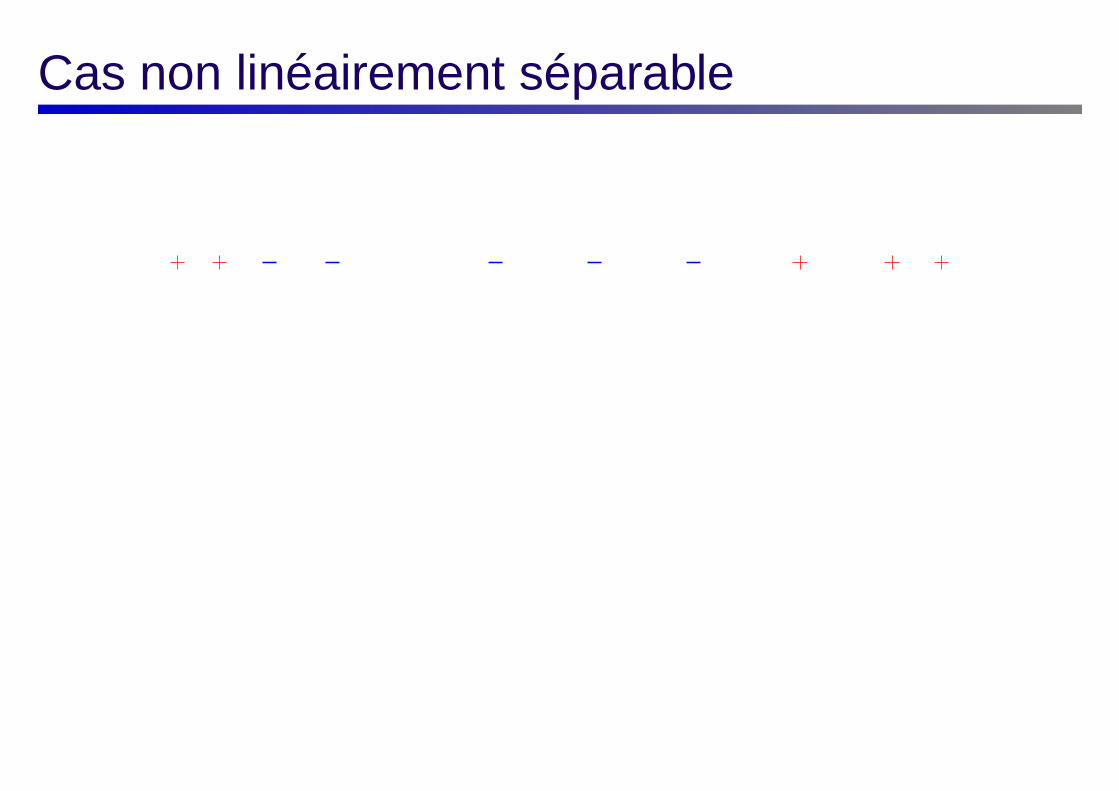
Cas non linéairement séparable

Cas non linéairement séparable
Appliquons une transformation non linéaire : x → x2 :

Cas non linéairement séparable
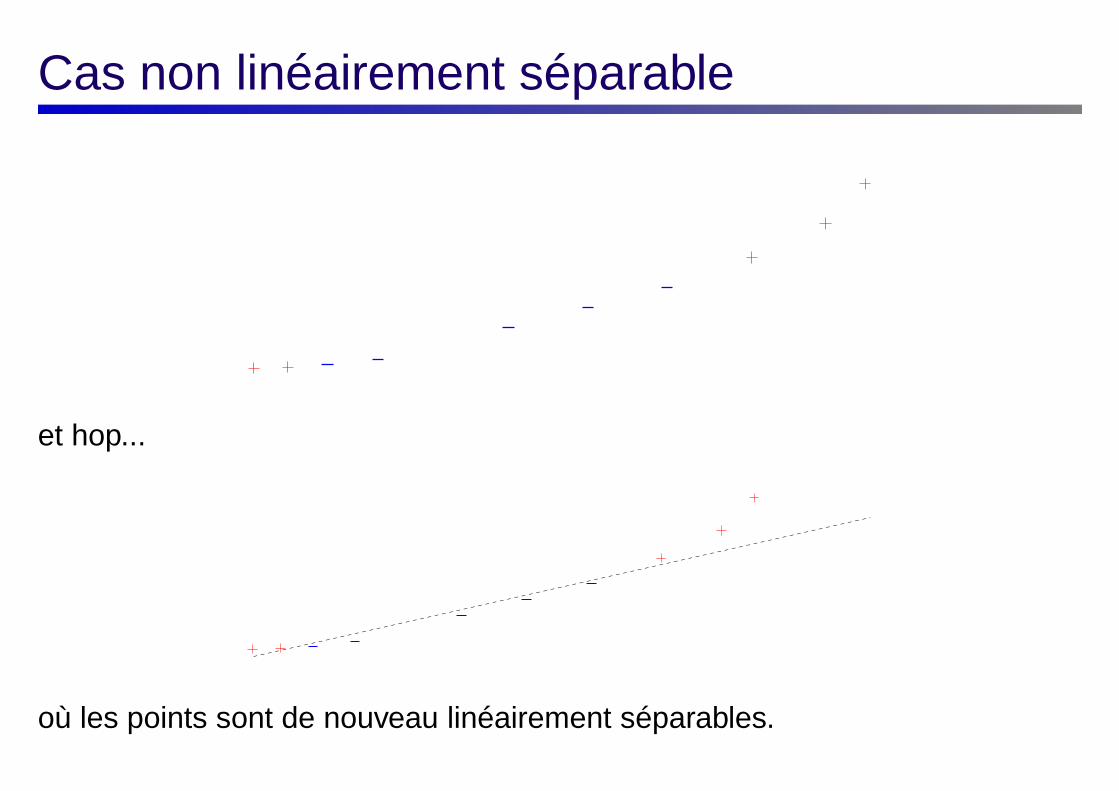
Cas non linéairement séparable
et hop...
où les points sont de nouveau linéairement séparables.

Intuition
En transformant l’espace de description des données de manière non linéaire,elles peuvent devenir linéairement séparables.
peut-on systématiser cette remarque ?
quelle transformation appliquer ?

MVS non linéaire
Remarque technique très importante : dans toutes les équations qui doiventêtre calculées, les points x apparaissent toujours dans des produits scalaires.
Soit
Φ : RP → F
une transformation de l’espace des données (ici, RP ) dans un espace des
caractéristiques F (feature space).
Supposons que l’on dispose d’une fonction K dite de « fonction noyau » :
K(xi, xj) =< Φ(xi), Φ(xj) >

Kernel trick
On peut dès lors effectuer tous les calculs dans le cadre des MVS en utilisantK, sans devoir explicitement transformer les données par la fonction Φ, donc,sans nécessairement connaître cette fonction Φ :
lors de l’optimisation du problème quadratique, on remplace les produitsscalaires < −→xi ,
−→xj > par K(xi, xj) ;
lors de la classification d’une nouvelle donnée −→x , on calculesgn (< −→w ,−→x > + b) =
∑i=Ns
i=1αiy(si)K(si, x) + b.

Fonctions noyau
Peut-on utiliser n’importe quelle fonction comme fonction noyau ?

Fonctions noyau
Peut-on utiliser n’importe quelle fonction comme fonction noyau ?
Les fonctions noyaux acceptables doivent respecter la condition deMercer. Une fonction K(x, y) respecte cette condition si pour toutefonction g(x) telle que
∫
g(x)2dx est finie, on a∫∫
K(x, y)g(x)g(y)dxdy ≥ 0.

Fonctions noyau
Peut-on utiliser n’importe quelle fonction comme fonction noyau ?
Les fonctions noyaux acceptables doivent respecter la condition deMercer. Une fonction K(x, y) respecte cette condition si pour toutefonction g(x) telle que
∫
g(x)2dx est finie, on a∫∫
K(x, y)g(x)g(y)dxdy ≥ 0.
Le respect de la condition de Mercer garantit que le problèmequadratique possède une solution.

Fonctions noyau
noyau polynomial : K(x, y) = (< −→x ,−→y > +c)m, m ∈ N et c > 0 ;
noyau gaussien : K(x, y) = e||−→x −−→y||2
2σ2 ;
noyau neuronal/sigmoïde : K(x, y) = tanh (κ < −→x ,−→y > −δ) où κ > 0 etδ > 0 (stricto senso, cette fonction ne respecte pas la condition de Mercerpour toutes les valeurs des paramètres.
...
En outre, un théorème indique que la combinaison linéaire de fonctionsnoyaux acceptables est une fonction noyau acceptable.

Que penser des MVS ?
très à la mode depuis quelques années ;

Que penser des MVS ?
très à la mode depuis quelques années ;
fournit un optimum global

Que penser des MVS ?
très à la mode depuis quelques années ;
fournit un optimum global mais que signifie vraiment « optimum global » ?

Que penser des MVS ?
très à la mode depuis quelques années ;
fournit un optimum global mais que signifie vraiment « optimum global » ?
liens très forts avec la théorie de l’apprentissage (principe de minimisationdu risque structurel, cf. travaux de Vapnik) ;

Que penser des MVS ?
très à la mode depuis quelques années ;
fournit un optimum global mais que signifie vraiment « optimum global » ?
liens très forts avec la théorie de l’apprentissage (principe de minimisationdu risque structurel, cf. travaux de Vapnik) ;
mise en œuvre effective et logiciels source ouvert disponibles sur le web(cf. SVMTorch par exemple).

![[French] Fiche Technique: Measurement Partner Suite … · •Minimise les risques: licence en fonction du numéro de série du analyseur – pas de risque de perte de licence en](https://img.pdfslide.fr/doc/110x75/5b9d263709d3f2df1f8c534f/french-fiche-technique-measurement-partner-suite-minimise-les-risques.jpg)




















![Data Mining Modèles et Algorithmes - Erick STATTNER · Induction d'un arbre de décision ID3 [Quinlan 1986] a évolué jusqu'aux versions C4.5 et C5.0 principe de base : construire](https://img.pdfslide.fr/doc/110x75/5b9d0eb609d3f2443d8b6432/data-mining-modeles-et-algorithmes-erick-induction-dun-arbre-de-decision.jpg)







