Embed Size (px)
Citation preview

.
.
Mesures et tests d’association
Introduction à R pour la recherche biomédicale
http://www.aliquote.org/cours/2012_biomed

.
.
Objectifs
▶ Dans ce cours, on s’intéressera aux tests d’inférence simples visant à
comparer des indices de tendance centrale calculés sur des données
continues, des proportions, des mesures de concordance, estimés à
partir de données observées à la suite d’un procédé
d’échantillonnage.
▶ On considèrera deux échantillons ou plus, indépendants ou non.
▶ L’objectif est de démontrer le principe général de la démarche du test
d’hypothèse à partir de quelques statistiques de test rencontrées
fréquemment en recherche biomédicale.
Ce cours s’appuie en partie sur l’ouvrage de Everitt & Rabe-Hesketh (2001).

.
.
Hypothèse nulle, risque d’erreur en inférence fréquentiste
De manière générale, lorsque l’on s’intéresse à un effet particulier, l’idée est
de postuler l’absence d’effet (hypothèse nulle,H0) et de chercher à vérifier si
les données observées sont compatibles ou non avec cette hypothèse. C’est
le principe même de la démarche hypothético-déductive.
Pour réaliser un tel test, il est nécessaire d’avoir (ou de construire) une
statistique de test, dont la distribution d’échantillonnage est connue (ou
peut être approximée) sous H0, qui nous permettra de répondre à la ques-
tion suivante : en supposant qu’il n’existe pas d’effet dans la population,
quelle est la probabilité d’observer une statistique de test au moins aussi ex-
trême que celle estimée à partir de l’échantillon choisi aléatoirement dans
cette population ? Si cette probabilité se révèle “suffisamment petite”, on
concluera qu’il est vraisemblablement peu probable que le résultat observé
soit dû simplement au hasard de l’échantillonnage.

.
.
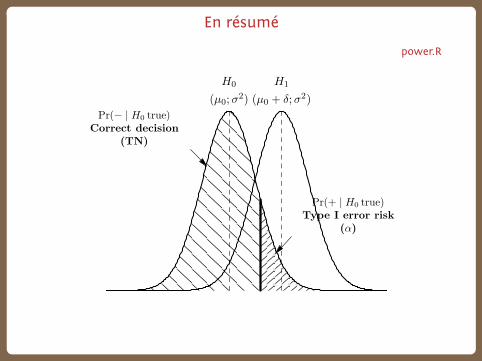
Risque de première et deuxième espèce
Supposons que l’on est à prendre une décision concernant une hypothèse
nulle. Le fameux “risque alpha” (type I) est le risque de conclure à tort à
l’existence d’un effet alors qu’en réalité ce dernier n’existe pas.
À ce risque est typiquement associé, de manière asymétrique, le risque (type
II) de ne pas rejeter H0 lorsque celle-ci est en réalité fausse ; le complémen-
taire de ce risque est appelée la puissance.
Ces risques sont effectivement asymétriques :
▶ dans un essai thérapeutique, si l’on doit décider si on un nouveau
traitement est meilleur que le traitement courant, on cherche à
minimiser le risque d’une mauvaise décision (α = 0.05). ;
▶ si à la fin de l’essai, on ne met en évidence aucune différences
significatives, cela ne signifie pas que les traitements sont équivalents
: il existe un risque β qu’il existe une réelle différence entre les deux.
.
.
En résumé
power.R
H1
(µ0 + !;"2)H0
(µ0;"2)Pr(! | H0 true)
Correct decision(TN)
Pr(+ | H0 true)Type I error risk
(#)

.
.
Comparer deux moyennes
Le test de Student est un test paramétrique permet de tester si deuxmoyennes
de groupe (indépendants ou appariés) peuvent être considérées comme sig-
nificativement différentes en considérant un seuil d’erreur α.
Exemples d’application : comparer un dosage biologique entre deux groupes
de patients, comparer desmesures physiologiques avant et après traitement
chez les mêmes patients.
Conditions d’application : normalité des distributions parentes, homogénéité
des variances, indépendance (dans le cas du test t pour échantillons in-
dépendants).

.
.
En détails
Le test t de Student
La statistique de test est définie comme suit :
tobs =x1 − x2
sc
√1n1
+ 1n2
,
où les xi et ni sont les moyennes et effectifs des deux échantillons, et
sc =[((n1 − 1)s2x1 + (n2 − 1)s2x2
)/(n1 + n2 − 2)
]1/2est la variance commune.
Sous H0, cette statistique de test suit une loi de Student à n1 + n2 − 2 degrés deliberté.Un intervalle de confiance à 100(1− α)% pour la différence x1 − x2 peut êtreconstruit comme suit :
x1 − x2 ± tα,n1+n2−2sc
√1
n1+
1
n2,
avec P(t < tα,n1+n2−2) = 1− α/2.

.
.
Application
Poids à la naissance : mères fumeur vs. non-fumeur. (Hosmer & Lemeshow,
1989)
data(birthwt , package=MASS)
birthwt$smoke <- factor(birthwt$smoke ,
labels=c("No","Yes"))
t.test(bwt ∼ smoke , data=birthwt , var.equal=TRUE)
data: bwt by smoke t = 2.6529, df = 187, p-value = 0.008667alternative hypothesis: true difference in means is not equal to 0 95 percent confidence interval: 72.75612 494.79735 sample estimates: mean in group No mean in group Yes 3055.696 2771.919
On conclut à l’existence d’une différence entre les poids moyens des enfants
des deux groupes de mère, p < 0.01 (∆ = +284 g [73; 495], en faveur
des non-fumeurs).
.
.
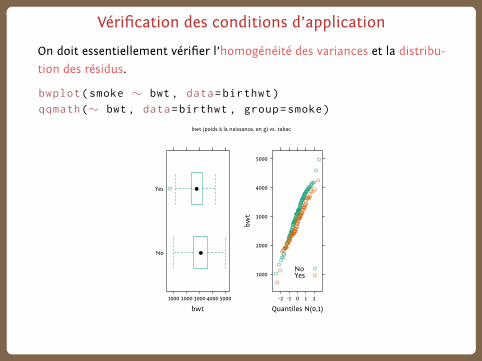
Vérification des conditions d’application
On doit essentiellement vérifier l’homogénéité des variances et la distribu-
tion des résidus.
bwplot(smoke ∼ bwt , data=birthwt)
qqmath(∼ bwt , data=birthwt , group=smoke)
bwt
No
Yes
1000 2000 3000 4000 5000
Quantiles N(0,1)
bwt
1000
2000
3000
4000
5000
-2 -1 0 1 2
NoYes
bwt (poids à la naissance, en g) vs. tabac

.
.
Cas des données non indépendantes
Dans le cas où les échantillons ne sont pas indépendants, p.ex. sujetsmesurés
à deux reprises ou données appariées, le même type de test peut être utilisé,
et la différence de moyennes est comparée à 0.
Le plus souvent ce sont les mêmes unités statistiques qui servent de sup-
port à la comparaison, mais n’importe quelle forme d’appariement, pourvu
qu’elle fasse sens, peut justifier le recours à un test apparié.

.
.
En détails
Le test t de Student pour données appariées
Si l’on note les valeurs observées pour la ième paire x1i et x2i, la différencedi = x1i − x2i est supposée suivre une loi normale. L’hypothèse nulle est µd = 0.La statistique de test est donnée par :
t =di
sd/√n
où di la différence moyenne, et sd est la déviation standard de di. Ici, on peutexploiter la corrélation intra-unité car si X1 et X2 ne sont pas indépendants, alorson sait que V(X1 − X2) = V(X1) + V(X2)− 2Cov(X1, X2).Cette statistique de test suit alors une loi de Student à n− 1 degrés de liberté.Un intervalle de confiance à 100(1− α)% pour la différence di peut êtreconstruit comme suit :
di ± tα,n−1sd/n,
avec P(t < tα,n−1) = 1− α/2.

.
.
Application
Effet de somnifères sur le temps de sommeil. (Student, 1908, p. 20)
t.test(extra ∼ group , data=sleep ,
var.equal=TRUE , paired=TRUE)
data: extra by group t = -4.0621, df = 9, p-value = 0.002833alternative hypothesis: true difference in means is not equal to 0 95 percent confidence interval: -2.4598858 -0.7001142 sample estimates:mean of the differences -1.58
On constate une diminution de la durée de sommeil lorsque le médicament
1 est administré (∆ = −1.6 h [−2.5;−0.7], p < 0.01).
.
.
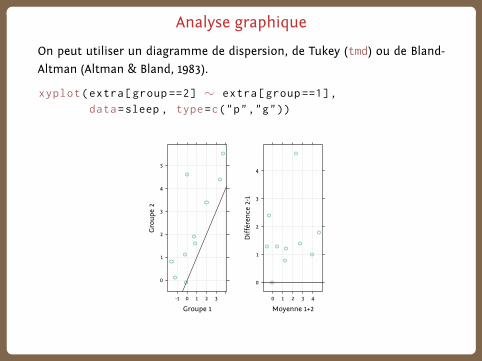
Analyse graphique
On peut utiliser un diagramme de dispersion, de Tukey (tmd) ou de Bland-
Altman (Altman & Bland, 1983).
xyplot(extra[group ==2] ∼ extra[group ==1],
data=sleep , type=c("p","g"))
Groupe 1
Gro
upe
2
0
1
2
3
4
5
-1 0 1 2 3
Moyenne 1+2
Dif
fére
nce
2-1
0
1
2
3
4
0 1 2 3 4

.
.
Alternatives non-paramétriques
Dans le test t, on fait une hypothèse sur la nature de la distribution de la
réponse mesurée dans la population parente. Si l’on relaxe cette hypothèse
et que l’on exige simplement que les échantillons proviennent de popula-
tions ayant des distribution à peu près comparables en terme de forme,
alors on peut utiliser des tests dits non-paramétriques. Dans le cadre de la
comparaison de la tendance centrale de deux échantillons, l’alternative au
test t est le test de Wilcoxon.
Ce type de test est souvent utilisé dans le cas des petits effectifs lorsque les
données disponibles ne permettent pas réellement de vérifier la normalité
des distributions parentes, comme dans le test t. On retiendra toutefois que
le test de Wilcoxon a une puissance relative de 80 % par rapport au test de
Student. Ce type de test présente en outre l’avantage d’être moins sensible
à la présence de valeurs extrêmes.

.
.
En détails
Le test des rangs de (Mann-Whitney-)Wilcoxon
L’hypothèse nulle est que les deux échantillons comparés proviennent de deuxdistributions ayant les mêmes distributions (paramètre de position, i.e. médiane).La statistique de test est construite comme la plus petite somme des rangs d’undes deux échantillons ; quand n1, n2 > 15 et qu’il n’y a pas d’ex-aequo, on al’approximation suivante pour La statistique de test :
Z =S− n1(n1 + n2 + 1)/2√n1n2(n1 + n2 + 1)/12
∼ N (0; 1),
où S est la statistique de test pour l’échantillon avec n1 observations.Pour deux échantillons appariés, le test des rangs signés est utilisé : on calcule lasomme T+ des rangs des différences zi = x1i − x2i en valeurs absolues positifs ;dans le cadre asymptotique, la statistique de test correspondante est :
Z =T+ − n(n+ 1)/4√n(n+ 1)(2n+ 1)/24
∼ N (0; 1).

.
.
Application
Hamilton depression scale scores. (Hollander & Wolfe, 1999, p. 29)
occ1 <- c(1.83 ,0.50 ,1.62 ,2.48 ,1.68 ,1.88 ,1.55 ,3.06 ,1.30)
occ2 <- c(0.878 ,0.647 ,0.598 ,2.05 ,1.06 ,1.29 ,1.06 ,3.14 ,1.29)
wilcox.test(occ1 , occ2 , paired=TRUE)
Wilcoxon signed rank test
data: occ1 and occ2 V = 40, p-value = 0.03906alternative hypothesis: true location shift is not equal to 0
Le résultat du test suggère une amélioration de l’état (diminution du score
Hamilton de mean(occ2-occ1)=-0.43 points).

.
.
Comparer plus de deux moyennes
L’ANOVA constitue une extension naturelle au cas où plus de deux moyennes
de groupe sont à comparer. Attention, avec k échantillons, l’hypothèse nulle
se lit :
H0 : µ1 = µ2 = . . . = µk,
alors que l’alternative est l’existence d’au moins une paire de moyennes
qui diffèrent (négation logique de H0). Si l’on exprime chaque observation
comme une déviation par rapport à sa propre moyenne de groupe, yij =yi + εij, on voit que la variabilité totale peut se décomposer comme suit :
(yij − y)︸ ︷︷ ︸totale
= (yi − y)︸ ︷︷ ︸groupe
+(yij − yi)︸ ︷︷ ︸résiduelle
.
Conditions d’application : normalité des distributions parentes pour chaque
groupe, homogénéité des variances, indépendance des observations.
.
.
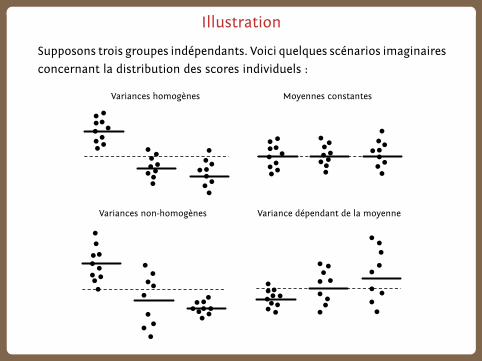
Illustration
Supposons trois groupes indépendants. Voici quelques scénarios imaginaires
concernant la distribution des scores individuels :
Variances homogènes Moyennes constantes
Variances non-homogènes Variance dépendant de la moyenne

.
.
Tableau d’ANOVA
On peut résumer les sources de variations observées au niveau de la variable
réponse comme suit :
Source SC dl CM F
Inter (B)∑k
i=1 ni(yi − y)2 k− 1 SCb/dl (1) (1)/(2)
Intra (W)∑k
i=1
∑nij=1(yij − yi)
2 N− k SCw/dl (2)
Total∑k
i=1
∑nij=1(yij − y)2 N− 1
(SC = somme de carrés, CM = carré moyen)
On rappelle qu’une variance se calcule comme la somme des écarts quadra-
tiques à la moyenne, i.e.∑
j(yj − y)2/(n− 1).La SCb représente la variance des moyennes de groupe (fluctuation autour
de la moyenne générale), et la SCw (“résiduelle”) représente la moyenne des
variances des mesures individuelles autour de la moyenne de groupe (dans
les deux cas, les moyennes sont pondérées).
y1j � y1
y1 � y
yij (j = 1, . . . , ni)
i = 1 i = 2 i = 3

.
.
En détails
Le modèle d’ANOVA à un facteur (effet fixe)
Soit yij la jème observation dans le groupe i. Le modèle d’ANOVA (“effect model”)s’écrit
yij = µ+ αi + εij,
où µ désigne la moyenne générale, αi l’effet du groupe i, et εij ∼ N (0, σ2) un
terme d’erreur aléatoire. On impose généralement que∑k
i=1 αi = 0.L’hypothèse nulle se lit
H0 : α1 = α2 = · · · = αk.
Sous l’hypothèse d’égalité des moyennes de groupe, la variance entre groupe(“between”) et la variance propre à chaque groupe (“within”) permettentd’estimer σ2. D’où le test F d’égalité de ces deux variances.Sous H0, le rapport entre les carrés moyens inter et intra-groupe (qui estiment lesvariances ci-dessus) suit une loi F de Fisher-Snedecor à k− 1 et N− k degrés deliberté.

.
.
Application
Polymorphisme et gène du récepteur estrogène. (Dupont, 2009)
library(foreign)
polymsm <- read.dta("polymorphism.dta")[,-1]
with(polymsm , tapply(age , genotype , mean))
aov.res <- aov(age ∼ genotype , data=polymsm)
summary(aov.res)
model.tables(aov.res)
plot.design(age ∼ genotype , data=polymsm)
Df Sum Sq Mean Sq F value Pr(>F) genotype 2 2316 1157.9 7.863 0.000978 ***Residuals 56 8246 147.2 ---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Le test F indique que l’on peut rejeter l’hypothèse nulle d’absence de dif-
férence d’âge entre les trois génotypes (Df=3-1=2). Il est possible d’utiliser
le rapport 2316/(2316+8246)=0.219 (η2) pour quantifier la variance expliquée.On pourrait poser la question de savoir quelles paires de moyennes diffèrent
significativement (comparaisons multiples post-hoc).

.
.
Distributions conditionnelles
Ci-dessous un diagramme en forme de boites à moustaches pour les trois
génotypes. Le trait horizontal indique la moyenne globale.
bwplot(age ∼ genotype , data=polymsm)
génotype
age
40
50
60
70
80
1.6/1.6 1.6/0.7 0.7/0.7
.
.
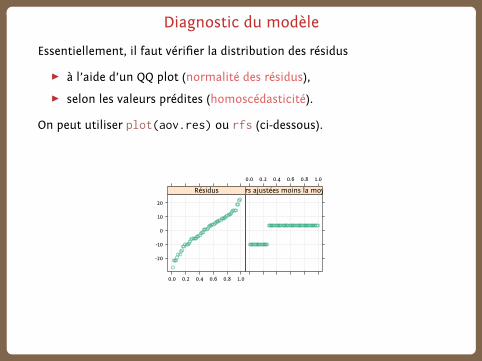
Diagnostic du modèle
Essentiellement, il faut vérifier la distribution des résidus
▶ à l’aide d’un QQ plot (normalité des résidus),
▶ selon les valeurs prédites (homoscédasticité).
On peut utiliser plot(aov.res) ou rfs (ci-dessous).
-20
-10
0
10
20
0.0 0.2 0.4 0.6 0.8 1.0
Résidus
0.0 0.2 0.4 0.6 0.8 1.0
Valeurs ajustées moins la moyenne
.
.
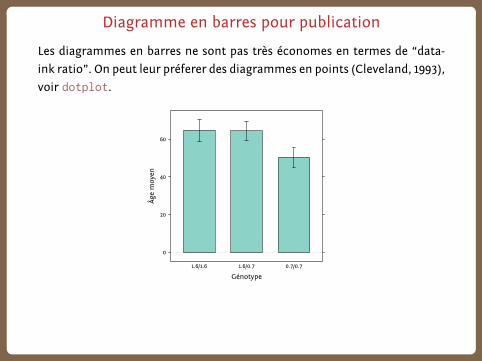
Diagramme en barres pour publication
Les diagrammes en barres ne sont pas très économes en termes de “data-
ink ratio”. On peut leur préferer des diagrammes en points (Cleveland, 1993),
voir dotplot.
Génotype
Âge
moy
en
0
20
40
60
1.6/1.6 1.6/0.7 0.7/0.7

.
.
Quelques remarques
▶ Dans le cas où on compare deux groupes (indépendants), un test t ou
un test F donneront le même résultat (t2 = F) :
summary(aov(bwt ∼ smoke , data=birthwt ))
t.test(bwt ∼ smoke , data=birthwt , var.equal=TRUE)
▶ Pour quoi ne pas faire une simple série de tests t au lieu de l’ANOVA ?
Comparer les m = ∁k(k−1)2 paires de moyennes entraîne une inflation
du risque de première espèce puisque le risque global vaut alors
1− (1− α)m (en supposant les tests indépendants), soit 40 % de
chances de conclure à tort à une différence lorsqu’en réalité il n’y en
a pas (H0 vraie) sur 5 groupes.
▶ On peut voir l’ANOVA comme une simple comparaison de modèles,
i.e. modèle complet (avec prédicteur) vs. modèle nul (résiduelle) :
aov0 <- aov(age ∼ 1, data=polymsm)
aov1 <- aov(age ∼ genotype , data=polymsm)
anova(aov0 , aov1)

.
.
Alternative non-paramétrique
La comparaison de k groupes peut se faire à l’aide d’un test non-paramétrique,
reposant sur des sommes de rangs. L’ANOVA de Kruskal-Wallis, qui est une
extension du test de Wilcoxon-Mann-Whitney, permet de tester si la distri-
bution de la variable réponse peut être considérée comme identique entre
les k groupes. On suppose toujours les groupes indépendants.
kruskal.test(age ∼ genotype , data=polymsm)
Kruskal-Wallis rank sum test
data: age by genotype Kruskal-Wallis chi-squared = 12.0734, df = 2, p-value = 0.002389

.
.
En détails
L’ANOVA de Kruskal-Wallis
Considérant la réponse yij du jème individu du groupe i, et ni le nombre de sujetsdans le groupe i (i = 1, . . . , k, n =
∑i ni), on calcule Ri comme la somme des
rangs du groupe i.En l’absence d’ex-aequo, la statistique de test
H =12
n(n+ 1)
(k∑
i=1
R2ini
)− 3(n+ 1)
suit une loi χ2(k− 1).

.
.
Mesures de corrélation
Le coefficient de corrélation de Bravais-Pearson permet d’évaluer le degré
d’association linéaire entre deux variables continues. Les variables jouent un
rôle symétrique. En pratique, il est calculé à partir de la covariance entre les
deux variables, et normalisé pour prendre des valeurs entre -1 (corrélation
négative parfaite) et +1 (corrélation positive parfaite).
Il est possible de tester si un coefficient de corrélation est nul (H0 : ρ = 0)ou égal à une certaine valeur.

.
.
En détails
Le test de corrélation linéaire
Soit x et y deux variables continues, observées sur n individus. On définit lecoefficient de corrélation linéaire comme suit :
r =
∑ni=1(xi − x)(yi − y)√∑n
i=1(xi − x)2√∑n
i=1(yi − y)2.
Rappelons que l’écart-type de x s’écrit sx =√
1n
∑ni=1(xi − x)2.
Sous H0, la statistique de test
t =√n− 2
r√1− r2
suit une loi de Student à n− 2 degrés de liberté.La construction d’un intervalle de confiance pour le coefficient de corrélationestimé passe par une transformation logarithmique particulière (qui permet de seramener à une loi connue, en l’occurence la loi normale).
.
.
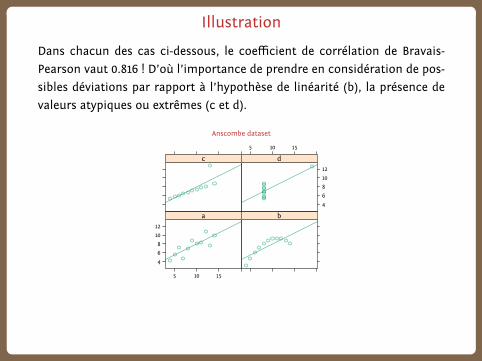
Illustration
Dans chacun des cas ci-dessous, le coefficient de corrélation de Bravais-
Pearson vaut 0.816 ! D’où l’importance de prendre en considération de pos-
sibles déviations par rapport à l’hypothèse de linéarité (b), la présence de
valeurs atypiques ou extrêmes (c et d).
Anscombe dataset
4
6
8
10
12
5 10 15
a b
c
5 10 15
4
6
8
10
12
d

.
.
Application
Health survey of paint sprayers. (Everitt & Rabe-Hesketh, 2001, p. 158)
paint <- read.table("PAINT.DAT" , header=TRUE)
with(paint , cor.test(HAEMO , PCV))
Pearson's product-moment correlation
data: HAEMO and PCV t = 12.4491, df = 101, p-value < 2.2e-16alternative hypothesis: true correlation is not equal to 0 95 percent confidence interval: 0.6882043 0.8444627 sample estimates: cor 0.7780983
On conclut à l’existence d’une corrélation significative entre le taux héma-
tocrite et la concentration en hémoglobine (p < 0.001).
.
.
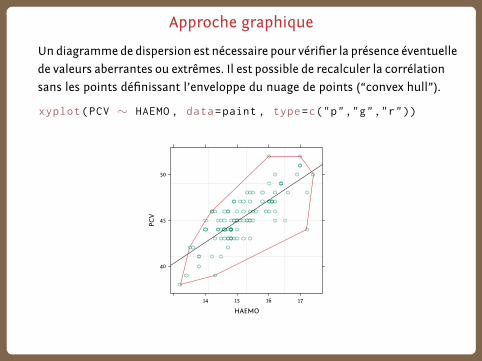
Approche graphique
Undiagramme de dispersion est nécessaire pour vérifier la présence éventuelle
de valeurs aberrantes ou extrêmes. Il est possible de recalculer la corrélation
sans les points définissant l’enveloppe du nuage de points (“convex hull”).
xyplot(PCV ∼ HAEMO , data=paint , type=c("p","g","r"))
HAEMO
PCV
40
45
50
14 15 16 17

.
.
Alternative non-paramétrique
Le coefficient de corrélation de Spearman est calculé à partir des rangs des
observations et par conséquent permet d’estimer une mesure de la mono-
tonicité de la relation entre deux variables continues. Il est évidemment
moins sensible aux valeurs extrêmes. Le calcul de la statistique de test est
comparable au cas de la corrélation linéaire de Pearson, excepté que l’on
remplace les valeurs observées par leurs rangs.
Le coefficient de Spearman peut également être utilisé sur des variables or-
dinales, en particulier lorsque l’on souhaite s’affranchir des hypothèses sur
la distribution continue des réponses mesurées.
library(foreign)
anorex <- read.spss("anorectic.sav" , to.data.frame=TRUE)
with(subset(anorex , time ==1),
cor.test(binge , purge , method="spearman"))

.
.
Test d’association pour tableau à deux entrées
Lorsque les données sont qualitatives, ou catégorielles, un tableau de con-
tingence permet de résumer la distribution des effectifs pour chaque croise-
ment des modalités des variables. On se limitera ici au cas le plus simple
avec deux variables. Notons que l’on a besoin de connaître les marges du
tableau (totaux-lignes et colonnes) donc on a besoin des effectifs, et pas
seulement de données aggrégées comme des proportions.
La question de l’association entre ces deux variables revient le plus sou-
vent à formuler une hypothèse nulle d’indépendence entre les deux variables
étudiées. La notion d’association entre variables catégorielles peut être en-
visagée comme une certaine mesure de corrélation telle que celle discutée
précédemment.
Une discussion approfondie de ces mesures d’association est disponible
dans Bishop, Fienberg, & Holland (2007).

.
.
Illustration
Dans le cas général, un tableau des effectifs (ou des fréquences relatives)
peut être construit comme indiqué ci-dessous. Les ni· (i = 1, . . . , I) et lesn·j (j = 1, . . . , J) sont les distributions marginales des variables A et B,
respectivement.
B
b1 b2 . . . bJ Total
A
a1 n11 n12 . . . n1J n1·a2 n21 n22 . . . n2J n2·...
......
. . ....
...
aI nI1 nI2 . . . nIJ nI·Total n·1 n·2 . . . n·J N
Les modalités de A et B peuvent être nominales et/ou ordinales, les totaux
lignes/colonnes peuvent être fixés ou non, il peut y avoir des cellules vides,
les variables A et B peuvent être liées (pre/post, inter-juges), etc.
.
.
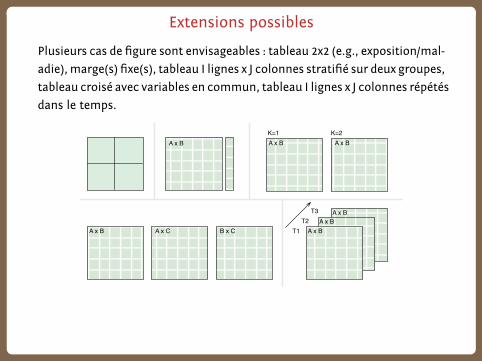
Extensions possibles
Plusieurs cas de figure sont envisageables : tableau 2x2 (e.g., exposition/mal-
adie), marge(s) fixe(s), tableau I lignes x J colonnes stratifié sur deux groupes,
tableau croisé avec variables en commun, tableau I lignes x J colonnes répétés
dans le temps.
A x BA x B
A x B
T1T2
T3
A x B A x C B x C
A x B A x BK=1 K=2
A x B

.
.
Écart à l’indépendance
Rappelons que, dans le cas général d’un tableau I x J, la statistique de Pear-
son consiste à comparer les données observées aux données attendues sous
une hypothèse d’indépendance (“produit desmarges”), soit, à une constante
près, la somme des écarts quadratiques entre les effectifs observée et les ef-
fectifs théoriques (“résidus”), normalisés par ces derniers, soit
Φ2 =I∑
i=1
J∑j=1
(pij − pi·p·j)2
pi·p·j.
Le “chi-deux” de Pearson est simplement NΦ2, et cette statistique de test
suit une loi χ2 à (I− 1)(J− 1) degrés de liberté. Dans le cas 2x2, on a
Φ2 =2∑
i=1
2∑j=1
(pij − pi·p·j)2
pi·p·j=
(p11p22 − p21p12)2
p1·p2·p·1p·2,
ce qui montre bien l’analogie avec une mesure de corrélation sur des vari-
ables dont les modalités ont été transformées en scores numériques.
p11 p12 p1·p21 p22 p2·p·1 p·2

.
.
Approche générale
On peut regrouper les mesures d’association pour les tableaux 2 x 2 en deux
classes, celles qui reposent sur une fonction du produit croisé des cellules
et celles qui se basent sur le coefficient de corrélation de Pearson.
Dans le premier cas, on retrouve l’odds-ratio,
α =p11p22p12p21
,
encore exprimé sous la formeα =p11/p12p21/p22
lorsque l’on considère les totaux-
lignes fixés (e.g., exposition) : p11/p12 est alors la probabilité d’être malade
(vs. non-malade) sachant que l’on a été exposé (vs. non-exposé).
Dans le second cas, si l’on assimile les modalités des variables à deux scores
0/1, alors la corrélation se définit naturellement comme
ρ =p11p22 − p21p12√
p1·p2·p·1p·2=
p22 − p2·p·2√p1·p2·p·1p·2
, d’où r2 = χ2/N.
Ces deuxmesures sont invariantes par permutations des lignes et des colonnes.
p11 p12 p1·p21 p22 p2·p·1 p·2

.
.
Quelques remarques
▶ Il y a de nombreux “tests de chi-deux”. Ne pas confondre la loi que
suit une statistique de test avec l’usage consacré du χ2 pour les
tableaux de contingence !
▶ Les tests du χ2 d’indépendance dans les tableaux I x J permettent de
répondre globalement à la question : y’a-t-il ou non association entre
les variables étudiées ? La nature précise de cette association doit
être étudiée plus en détails (résidus, décomposition du χ2, direction
et taille d’effet, etc.).
▶ Outre le fait qu’ils nécessitent généralement de grands échantillons,
ce type de tests ne reposent que sur les sommes marginales, sans
considération de la nature des variables (nominale, ordinale). Des
tests plus adaptés (et économes en termes de degrés de liberté)
existent dans le cas où l’une des variables ou les deux sont ordonnées.
▶ Bien que l’on ne les présente pas, il existe de nombreuses fonctions
graphiques pour la visualisation des données catégorielles dans les
packages vcd et vcdExtra (Friendly, 2000).

.
.
Application 1
Swedish study on aspirin use and myocardial infarction. (Agresti, 2002, p.
72)
aspirin <- matrix(c(28 ,18 ,656 ,658) , nrow =2)
dimnames(aspirin ) <- list(c("Placebo","Aspirin"),
c("Yes","No"))
library(vcd)
asp.or <- oddsratio(aspirin , log=FALSE)
print(list(or=asp.or , conf.int=confint(asp.or )))
summary(oddsratio(aspirin ))
Log Odds Ratio Std. Error z value Pr(>|z|) [1,] 0.44488 0.30362 1.4653 0.07143 .---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
L’estimé du “vrai” OR est plutôt imprécis (l’IC à 95% est large et contient
la valeur 1), et le test sur le log(OR) n’est pas significatif (p = 0.071). Onconcluera que rien ne permet d’affirmer que la probabilité de décès dûe à
un infarctus diffère selon le facteur d’exposition.
.
.
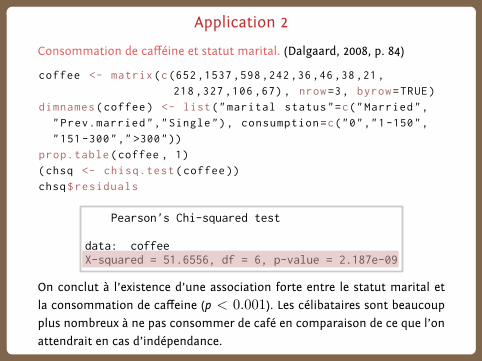
Application 2
Consommation de cafféine et statut marital. (Dalgaard, 2008, p. 84)
coffee <- matrix(c(652 ,1537 ,598 ,242 ,36 ,46 ,38 ,21 ,
218 ,327 ,106 ,67) , nrow=3, byrow=TRUE)
dimnames(coffee ) <- list("marital status"=c("Married",
"Prev.married","Single"), consumption=c("0","1-150",
"151 -300"," >300"))
prop.table(coffee , 1)
(chsq <- chisq.test(coffee ))
chsq$residuals
Pearson's Chi-squared test
data: coffee X-squared = 51.6556, df = 6, p-value = 2.187e-09
On conclut à l’existence d’une association forte entre le statut marital et
la consommation de caffeine (p < 0.001). Les célibataires sont beaucoupplus nombreux à ne pas consommer de café en comparaison de ce que l’on
attendrait en cas d’indépendance.
.
.
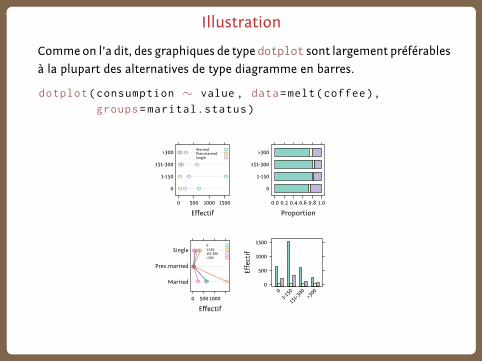
Illustration
Commeon l’a dit, des graphiques de type dotplot sont largement préférables
à la plupart des alternatives de type diagramme en barres.
dotplot(consumption ∼ value , data=melt(coffee),
groups=marital.status)
Effectif
0
1-150
151-300
>300
0 500 1000 1500
MarriedPrev.marriedSingle
Proportion
0
1-150
151-300
>300
0.0 0.2 0.4 0.6 0.8 1.0
Effectif
Married
Prev.married
Single
0 500 1000
01-150151-300>300
Effe
ctif
0
500
1000
1500
01-1
50
151-3
00>3
00

.
.
En détails
Le test de McNemar
Considérons un tableau 2× 2 où les mêmes unités statistiques ont été observéesde manière appariée (mesures pré/post, oeil droit/gauche, etc.). En casd’indépendance, on ne devrait pas observer de différence entre les fréquencesmarginales, soit πx· = π·x, où π désigne une probabilité.Un test d’homogénéité marginale peut être construit à partir de la statistique detest
X2 =(p12 − p21)
2
p12 + p21∼ χ2(1)
lorsque p12 + p21 > 10. Une continuité de correction (−0.5 ou−1, aunumérateur, selon les auteurs) permet d’améliorer l’approximation à la loi χ2(1)dans le cas des effectifs de taille modérée.Lorsque p12 + p21 < 25, on peut avantageusement remplacer ce test par un testbinomial (il s’agit d’un test exact).

.
.
Application 3
Données fictives pré/post traitement.
x <- cbind(c(50,10),c(20 ,40))
dimnames(x) <- list(c("+","-"),
c("+","-"))
margin.table(x, 1)
mcnemar.test(x)
mcnemar.test(x)
binom.test(apply(x, 1, sum), .5)
McNemar's Chi-squared test with continuity correction
data: x McNemar's chi-squared = 2.7, df = 1, p-value = 0.1003
Le résultat non-significatif du test (p = 0.100) suggère que la répartition
entre cas positifs et négatifs n’a pas évolué avec le traitement.

.
.
En détails
Le test exact de Fisher
Le test de Fisher est souvent utilisé en lieu et place du test de Pearson lorsque leseffectifs sont “petits”. Ce n’est pas un cas d’utilisation correcte !Le test de Fisher est un test exact permettant d’évaluer la probabilité d’observerun ceratin arrangement des fréquences des cellules d’un tableau 2× 2 lorsque lesmarges sont fixées et que les deux variables sont indépendantes. On montre quecette probabilité
P =(p11 + p12)!(p11 + p21)!(p21 + p22)!(p12 + p22)!
p11!p12!p21!p22!N!
suit une loi hypergéométrique.Ce test est relativement conservateur, de même que le test du χ2 corrigé pour lacontinuité (correction de Yates), mais l’usage du test de Fisher répond à des testd’hypothèses et un recueil des données particuliers.
Pour plus d’informations, se référer à Campbell (2007).

.
.
Application 4
Fisher’s Tea Drinker. (Agresti, 2002, p. 92)
TeaTasting <- matrix(c(3,1,1,3), nrow=2,
dimnames=list(Guess=c("Milk","Tea"),
Truth=c("Milk","Tea")))
fisher.test(TeaTasting , alternative="greater")
Fisher's Exact Test for Count Data
data: TeaTasting p-value = 0.2429alternative hypothesis: true odds ratio is greater than 1 95 percent confidence interval: 0.3135693 Inf sample estimates:odds ratio 6.408309
Rien ne permet d’établir qu’il existe une association entre l’ordre d’ajout
du thé et du lait et le choix du répondant sur la base de ces résultats (p =0.2429).

.
.
Concordance
Lorsque deux ou plusieurs évaluations catégorielles indépendantes sont ef-
fectuées sur la même unité d’analyse, et que l’on s’intéresse à l’association
ou la corrélation entre les séries d’évaluations, on parle de concordance
(“agreement” dans la littérature anglo-saxonne).
Dans le cas de données numériques, on utiliserait plutôt le coefficient de
corrélation intra-classe (Shrout & Fleiss, 1979).

.
.
En détails
Le coefficient kappa de Cohen
Considérons un tableau à I = J lignes et colonnes. L’idée est de comparer laprobabilité de concordance,
∑j πjj, à celle attendue en cas d’indépendance,
πj·π·j. Avec des variables nominales, le kappa de Cohen se définit comme
κ =
∑j πjj −
∑j πj·π·j
1−∑
j πj·π·j,
et il atteint une valeur de 1 en cas de concordance parfaite. La variance de cetestimateur est assez complexe mais on retiendra que cette statistique de test suitasymptotiquement une loi normale.Lorsque l’évaluation se fait sur une échelle de mesure ordinale, il est possible deconsidérer une version pondérée du kappa :
κw =
∑i
∑j wijπij −
∑i
∑j πi·π·j
1−∑
i
∑j πi·π·j
, 0 ≤ wij ≤ 1.

.
.
Application
Diagnoses of carcinoma. (Agresti, 2002, p. 432)
data(pathologist.dat , package="exactLoglinTest")
patho <- xtabs(y ∼ A + B, data=pathologist.dat)
sum(diag(patho ))/sum(patho)
library(reshape)
patho.expand <- untable(pathologist.dat [,2:3],
pathologist.dat$y)
library(irr)
kappa2(patho.expand)
Cohen's Kappa for 2 Raters (Weights: squared)
Subjects = 118 Raters = 2 Kappa = 0.779
La concordance entre les deuxmédecins apparaît relativement bonne puisque
la différence avec ce que l’on attendrait sous l’hypothèse d’indépendance est
presque de 50 %. On pourrait y associer un IC à 95 % calculé par bootstrap.
.
.
Index
alternative, 46anova, 25aov, 21, 25apply, 44binom.test, 44bwplot, 9, 22byrow, 41c, 8, 13, 16, 32, 40, 41,44, 46cbind, 44chisq.test, 41cor.test, 31, 33data, 8, 9, 12, 13, 21, 22,25, 26, 32, 42, 49diag, 49dimnames, 40, 41, 44, 46
dotplot, 24, 42factor, 8fisher.test, 46groups, 42header, 31kappa2, 49kruskal.test, 26labels, 8library, 21, 33, 40, 49list, 40, 41, 44, 46log, 40margin.table, 44matrix, 40, 41, 46mcnemar.test, 44mean, 16, 21method, 33
model.tables, 21nrow, 40, 41, 46oddsratio, 40package, 8, 49paired, 12, 16plot, 23plot.design, 21print, 40prop.table, 41qqmath, 9read.dta, 21read.spss, 33read.table, 31residuals, 41rfs, 23subset, 33
sum, 44, 49summary, 21, 25, 40t.test, 8, 12, 25tapply, 21time, 33tmd, 13to.data.frame, 33type, 13, 32untable, 49var.equal, 8, 12, 25wilcox.test, 16with, 21, 31, 33xtabs, 49xyplot, 13, 32

.
.
Bibliographie
Agresti, A. (2002). Categorical Data Analysis. John Wiley & Sons.Altman, D. G., & Bland, J. M. (1983). Measurement in medicine: the analysis ofmethod comparison studies. Statistician, 32, 307–317.Bishop, Y. M., Fienberg, S. E., & Holland, P. W. (2007). Discrete Multivariate Analysis.Springer.Campbell, I. (2007). Chi-squared and Fisher-Irwin tests of two-by-two tables withsmall sample recommendations. Statistics in Medicine, 26, 3661–3675.Cleveland, W. S. (1993). Visualizing Data. Hobart Press.Dalgaard, P. D. (2008). Introductory Statistics with R. Springer.Dupont, W. D. (2009). Statistical Modeling for Biomedical Researchers. CambridgeUniversity Press.Everitt, B., & Rabe-Hesketh, S. (2001). Analyzing Medical Data Using S-PLUS. Springer.Friendly, M. (2000). Visualizing Categorical Data. SAS Publishing.Hollander, M., & Wolfe, D. A. (1999). Nonparametric Statistical Methods. Wiley.Hosmer, D., & Lemeshow, S. (1989). Applied Logistic Regression. New York: Wiley.Shrout, P. E., & Fleiss, J. L. (1979). Intraclass correlation: Uses in assessing raterreliability. Psychological Bulletin, 86, 420–428.Student. (1908). The probable error of a mean. Biometrika, 6, 1–25.





























