Embed Size (px)
Citation preview

Méthodes basiques en statistiques
sous R
Master II Modélisation Aléatoire - Paris VII
Enseignant : Mme Picard
Sébastien Le Berre
12 mai 2011

R est un logiciel de calcul largement utilisé par la communauté scientifique mais
également par certaines entreprises car il est à la fois très puissant et gratuit. L’un de ses
principaux atouts est la plateforme de téléchargement de packages (ensemble de fonctions)
qui lui est associée et qui est disponible sur le site cran.r-project.org. Ces packages sont, tout
comme le logiciel lui-même, mis à la disposition de tous si bien que l’utilisateur pourra mettre
à jour l’ensemble des fonctions dont il a besoin au gré des dernières découvertes. En effet,
beaucoup de papiers de recherche ou de thèses sont implémentés en R et les codes sont
souvent rendus publics. En revanche, il conviendra de vérifier le contenu de ces-derniers car il
peut s’agir de codes fonctionnant pour un type de données en particulier où les cas généraux
n’auront pas été pris en compte. Finalement pour le situer dans le paysage des autres éditeurs,
on pourra dire qu’il est plus rapide et beaucoup moins lourd que VBA, moins puissant que
C++ mais il a l’avantage de ne pas demander une gestion de la mémoire aussi laborieuse, et
tout à fait similaire à Matlab mais gratuit d’où l’éventuelle présence d’erreurs dans les
packages contrairement aux librairies commerciales de Matlab.
Le but de cette introduction est de présenter les objets qui sont généralement utilisés dans les
codes de tests statistiques ou de méthodes financières, la façon dont on peut construire un
code fonctionnel, mais aussi l’utilisation de l’interface d’aide et le téléchargement de
nouveaux packages qui permettent d’améliorer les codes et de gagner beaucoup de temps.

Première partie : présentation du codage en R
1. Présentation des objets
Les objets que l’on manipule sous R que ce soit dans les calculs ou dans les fonctions sont
décrits par leur structure et le type de données qu’ils contiennent. On aura par exemple des
vecteurs de chaîne des caractères, des tableaux de valeurs numériques... nous présenterons ici
les objets les plus fonctionnels que sont les vecteurs, les tableaux et les listes.
- Les vecteurs :
Ils peuvent contenir des données de type valeurs numériques, chaîne de caractères ou
indicateur logique (ou encore des nombres complexes mais ils sont surtout utilisés en
physique). Ce ou est exclusif : un vecteur ne peut pas contenir plusieurs type de
données à la fois : s’il y a une valeur numérique, alors il n’y a que ça, les mélanges
chaîne de caractères valeurs numériques sont impossibles.
Les vecteurs contenant des valeurs numériques sont les plus simples à manipuler et
peuvent se construire de la façon suivante :

Les vecteurs de type caractère se construisent également directement ou par
boucle mais ne peuvent évidemment pas faire d’opérations numériques.
Enfin, les vecteurs de type logique, permettent de récupérer les données d’un objet qui
vérifient certaines conditions :

- Les tableaux :
Les tableaux de données généralisent le cas des vecteurs dans la mesure où si le
tableau n’à qu’une dimension il s’agira d’un vecteur avec les mêmes propriétés. Les
tableaux sont donc de dimension n>0 et ne contiennent qu’un unique type de données :
numérique, caractère ou logique.
On les crée de la même manière que les vecteurs puisque s’intéresser à une seule de
ses dimensions (les autres étant fixées) revient à s’intéresser à un vecteur :

Les tableaux de chaines de caractères ou d’indicateur logique sont de la même manière
à considérer comme un assemblage de vecteurs de ce type sur plusieurs dimensions.
- Les listes :
Leur avantage est de pouvoir recenser des valeurs de types différents, utiles pour les
outputs de fonctions ou pour décrire des objets comme des Etats : population (type
numérique), nom des régions (type caractère), membre de l’OTAN (type logical).

2. Syntaxe des boucles et des fonctions
- Les fonctions :
Elles permettent de retourner un résultat que ce soit un simple réel, un tableau ou une
liste en opérant des calculs et des modifications sur les inputs spécifiés. En voici un
exemple :
- Les boucles :
Les boucles itératives ou les conditions logiques de type « if » par exemple sont utiles
pour créer des vecteurs de données ou répéter des estimations (cas des processus
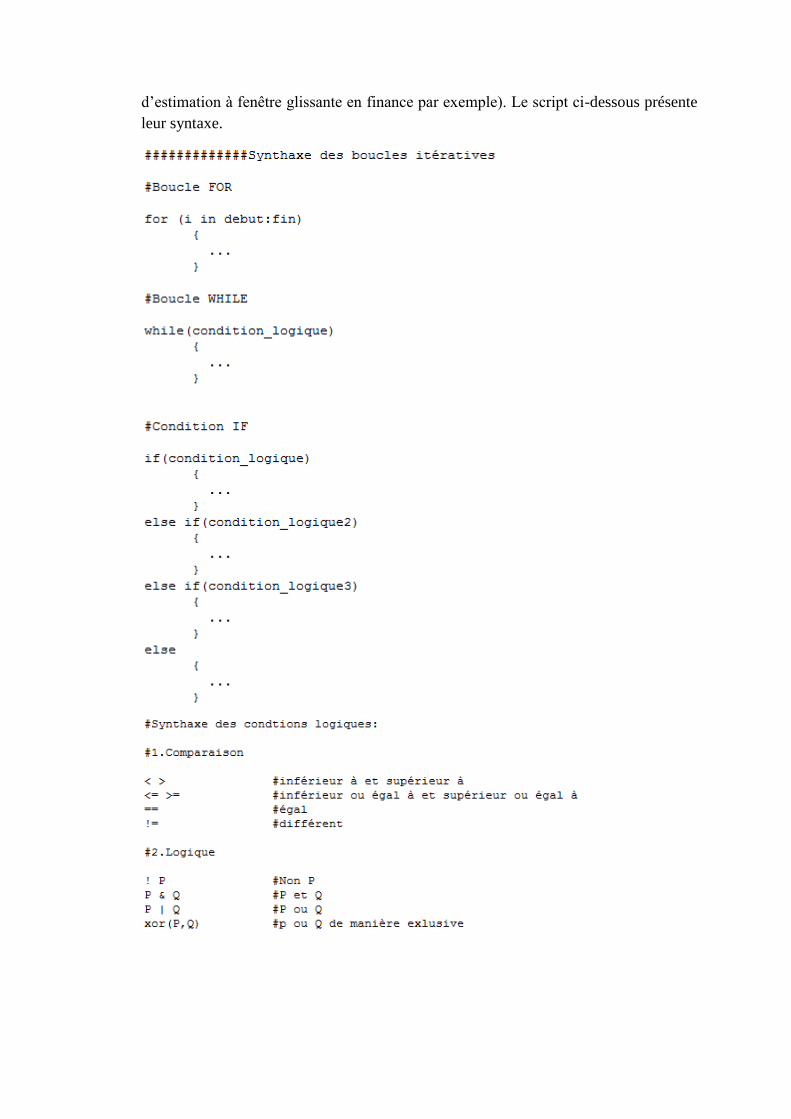
d’estimation à fenêtre glissante en finance par exemple). Le script ci-dessous présente
leur syntaxe.
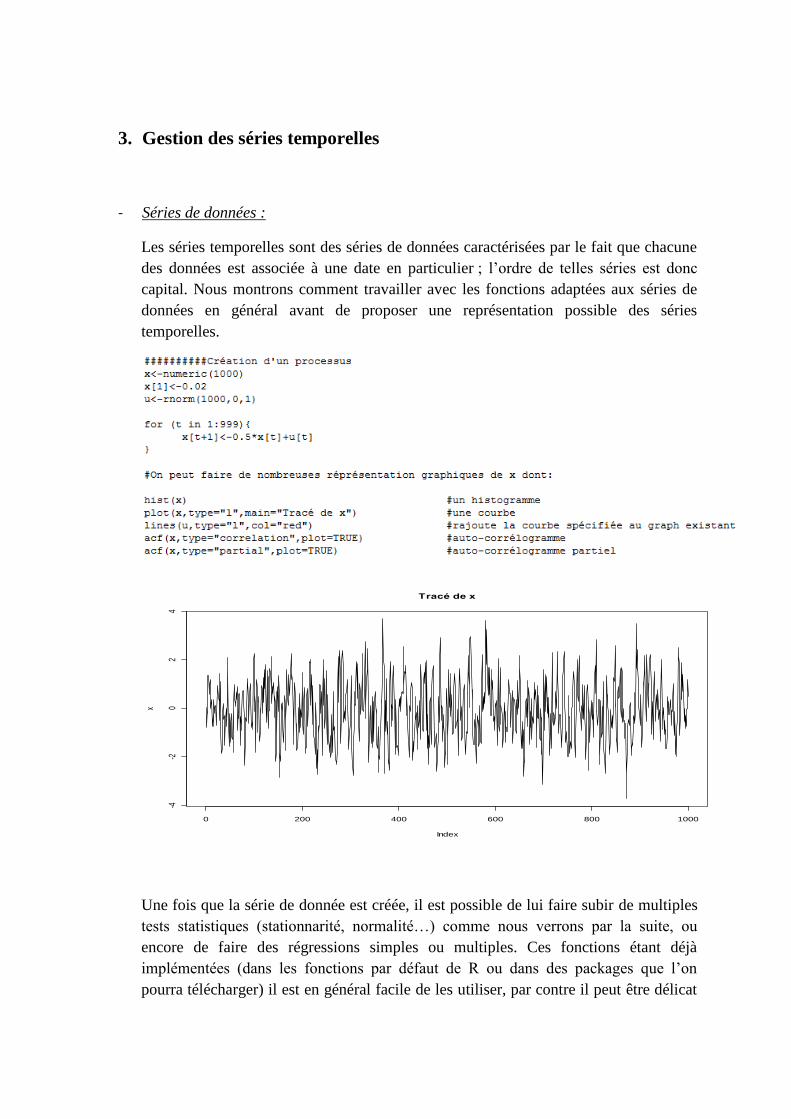
3. Gestion des séries temporelles
- Séries de données :
Les séries temporelles sont des séries de données caractérisées par le fait que chacune
des données est associée à une date en particulier ; l’ordre de telles séries est donc
capital. Nous montrons comment travailler avec les fonctions adaptées aux séries de
données en général avant de proposer une représentation possible des séries
temporelles.
Une fois que la série de donnée est créée, il est possible de lui faire subir de multiples
tests statistiques (stationnarité, normalité…) comme nous verrons par la suite, ou
encore de faire des régressions simples ou multiples. Ces fonctions étant déjà
implémentées (dans les fonctions par défaut de R ou dans des packages que l’on
pourra télécharger) il est en général facile de les utiliser, par contre il peut être délicat
0 200 400 600 800 1000
-4-2
02
4
Tracé de x
Index
x

de récupérer leurs outputs : R², T-stat, p-value, coefficients… Voila donc une manière
de procéder pour pouvoir récupérer les outputs des fonctions :
- Séries temporelles :
Comme on l’a vu plus haut lors du tracé de la variable x, les valeurs en abscisse sont
les indices du vecteur (de 1 à 1000) ce qui n’est pas très explicite quand on cherche à
observer le comportement de la série sur une période donnée. On désirerait alors avoir
en abscisse non plus les indices de x, mais les dates et une manière de faire cela est
d’utiliser le package xts.
Il s’agit en premier lieu d’installer ce package dans R. La méthode pour installer
n’importe quel package consiste à le télécharger sur le site cran.r-project.org en format
zip, on click ensuite dans la barre de menu de R sur « Packages » puis sur « Installer le
package depuis le fichier zip ».
Un vecteur de type xts est un vecteur donc chaque valeur est attachée à une date en
index. Voici un script détaillant ce type de vecteurs :
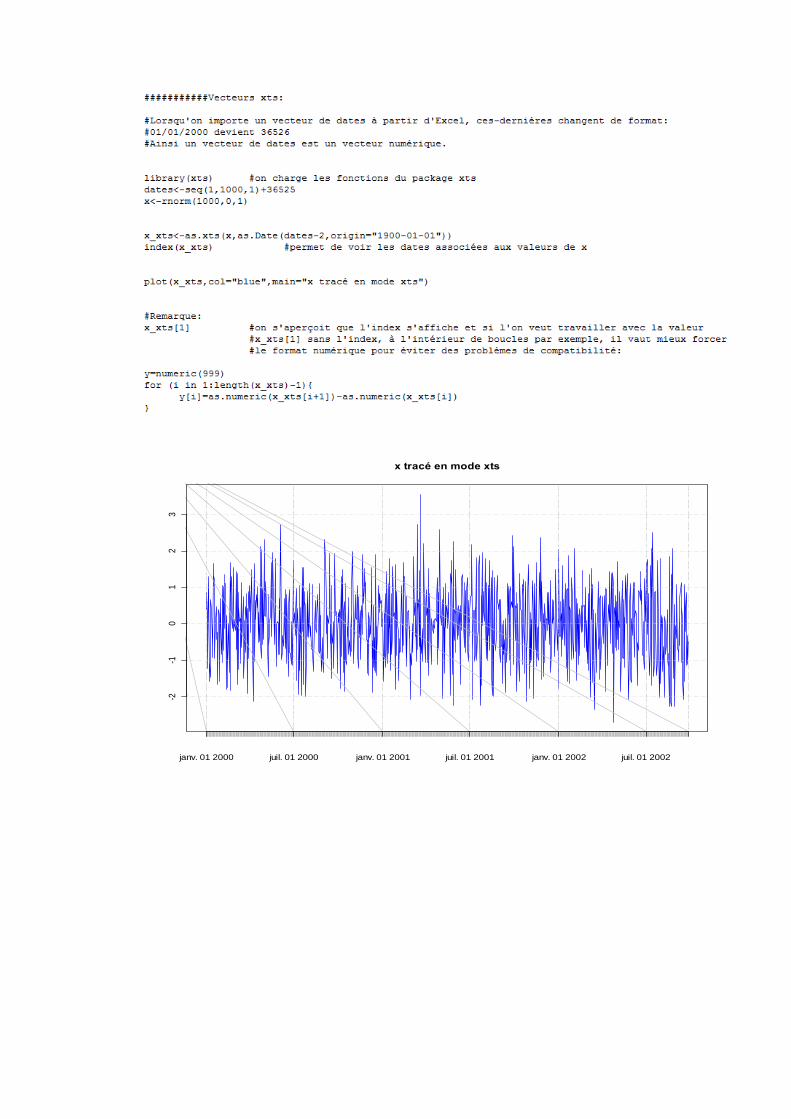
janv. 01 2000 juil. 01 2000 janv. 01 2001 juil. 01 2001 janv. 01 2002 juil. 01 2002
-2-1
01
23
x tracé en mode xts

4. Structure générale d’un script
Pour conclure cette rapide introduction à la programmation sous R, voila un exemple de la
structure qu’aura généralement un script faisant appel à des packages, important des données
et appelant la plupart des objets décrits avant.

Seconde partie : calculs statistiques
R met à disposition un certain nombre de fonctions permettant de simuler des
distributions suivant des lois aléatoires ou de calculer la fonction de répartition, la densité et la
fonction quantile associée à une variable aléatoire pour un réel donné. Si ces fonctions sont à
la base de tests statistiques elles sont en pratique rarement utilisées pour les réaliser car ces-
derniers sont souvent déjà implémentés dans des packages.
A. Présentation des fonctions associées à la simulation de lois aléatoires
- Génération d’une distribution aléatoire suivant :
Une loi normale : rnorm(taille_echantillon, mean=…, sd=…)
Une loi exponentielle : rexp(taille_echantillon,rate=…)
Une loi gamma : rgamma(taille_echantillon,shape,scale)
Une loi du Chi-2 : rchisq(taille_echantillon,df)
- Calcul de la densité de :
Une loi normale : dnorm(x, mean=…, sd=…)
Une loi exponentielle : dexp(x, rate=…)
Une loi gamma : dgamma(x, shape, scale)
Une loi du Chi-2 : dchisq(x, df)
- Calcul de la fonction de répartition de :
Une loi normale : pnorm(x, mean=…, sd=…)
Une loi exponentielle : pexp(x, rate=…)
Une loi gamma : pgamma(x, shape, scale)

Une loi du Chi-2 : pchisq(x, df)
- Calcul du quantile de : (0<p<1)
Une loi normale : qnorm(p, mean=…, sd=…)
Une loi exponentielle : qexp(p, rate=…)
Une loi gamma : qgamma(p, shape, scale)
Une loi du Chi-2 : qchisq(p, df)
B. Variables aléatoires gaussiennes
Les théorèmes présentés ci-dessous permettent de caractériser les distributions
résultant de transformations que l’on peut appliquer à des variables aléatoires gaussiennes.
Le théorème de Student permet de connaître les lois suivies par certaines transformations
classiques de variables gaussiennes que l’on pourra retrouver dans le cadre de calcul
d’estimateurs. A titre d’exemple, le premier élément du théorème de Student donne la loi
suivie par un estimateur ( nX ) de la moyenne des variables iX , et nR est, à une constante
multiplicative près, un estimateur de la variance de ces variables.
Le théorème de Cochran s’inscrit également dans la démarche de caractériser les distributions
issues de transformation sur des lois gaussiennes mais il s’applique à des vecteurs aléatoires.
Aussi les conclusions du théorème portent-elles sur les distributions de projections du vecteur
gaussien par des matrices vérifiant certaines conditions.
1. Théorème de Student
Soit nXX ,...,1 , des variables indépendantes identiquement distribuées de loi commune
),( 2m . Alors,
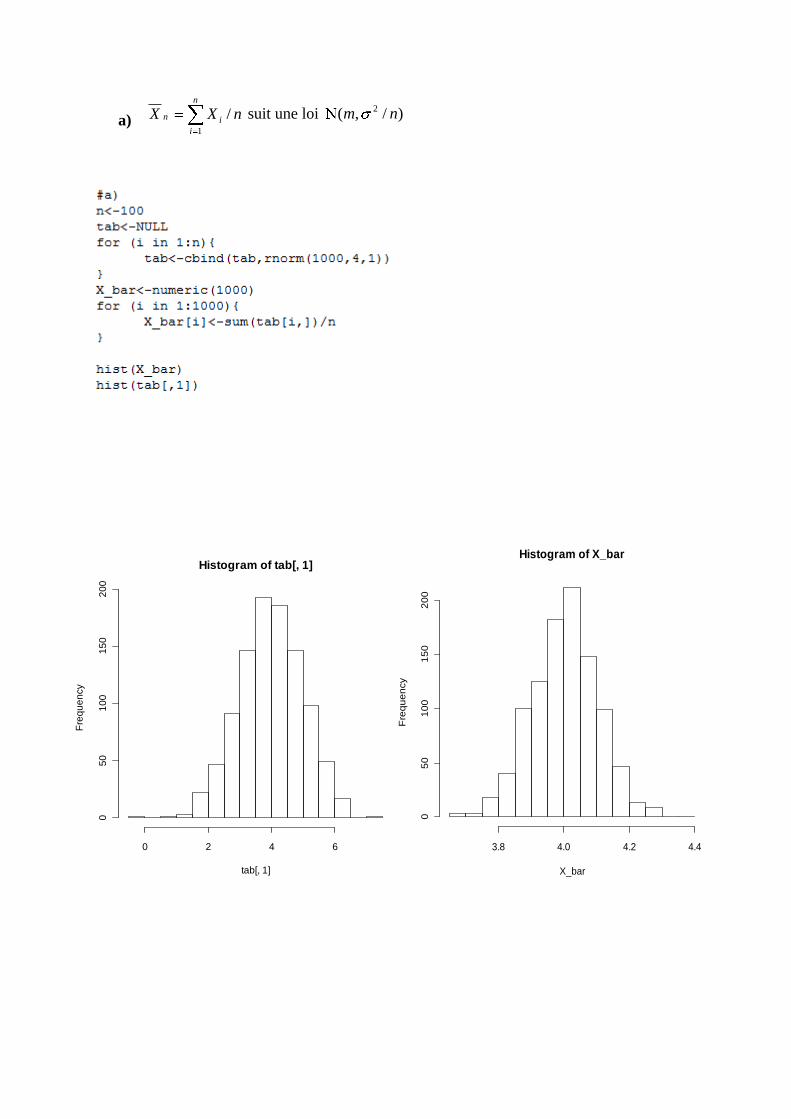
a) n
i
in nXX1
/ suit une loi )/,( 2 nm
Histogram of X_bar
X_bar
Fre
qu
en
cy
3.8 4.0 4.2 4.4
05
01
00
15
02
00
Histogram of tab[, 1]
tab[, 1]
Fre
qu
en
cy
0 2 4 6
05
01
00
15
02
00
On observe un écrasement de la variance lorsque n est grand comme en témoignent les deux
histogrammes avec des valeurs plus proches de la moyenne pour nX . nX est aussi un
estimateur de l’espérance des iX . Finalement, nX converge vers m lorsque n .
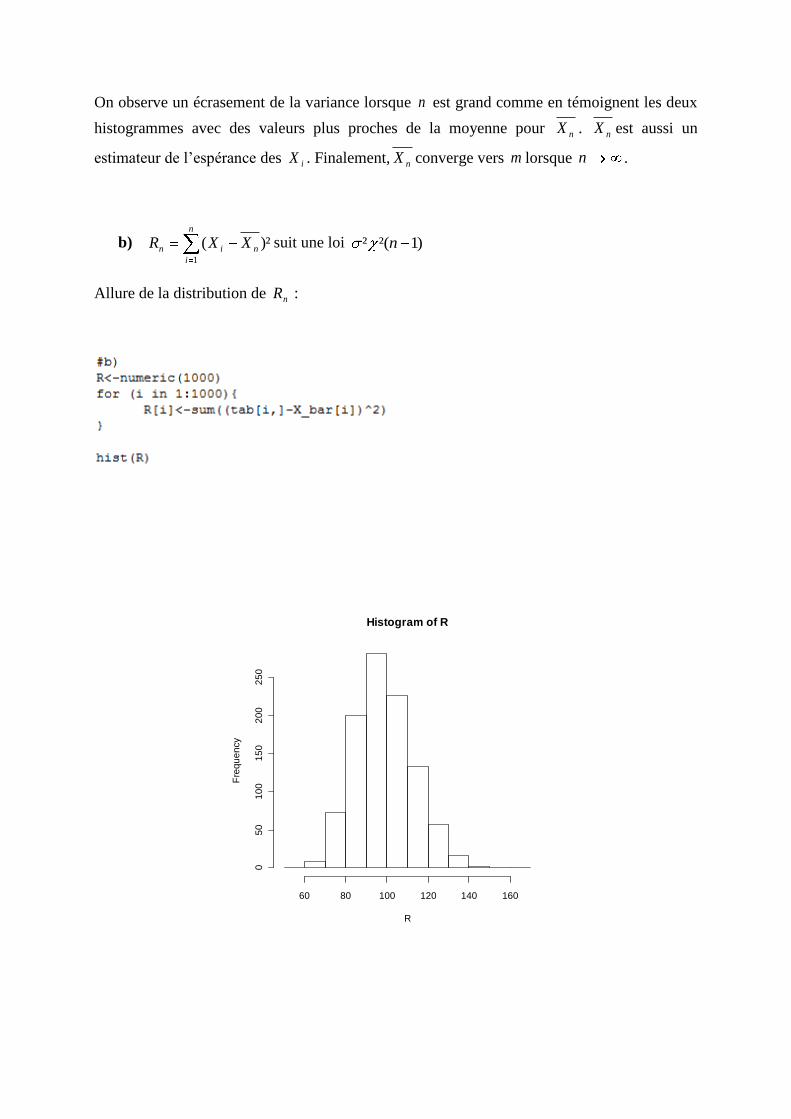
b) n
i
nin XXR1
)²( suit une loi )1²(² n
Allure de la distribution de nR :
Histogram of R
R
Fre
qu
en
cy
60 80 100 120 140 160
05
01
00
15
02
00
25
0
c) nX et nR sont indépendants
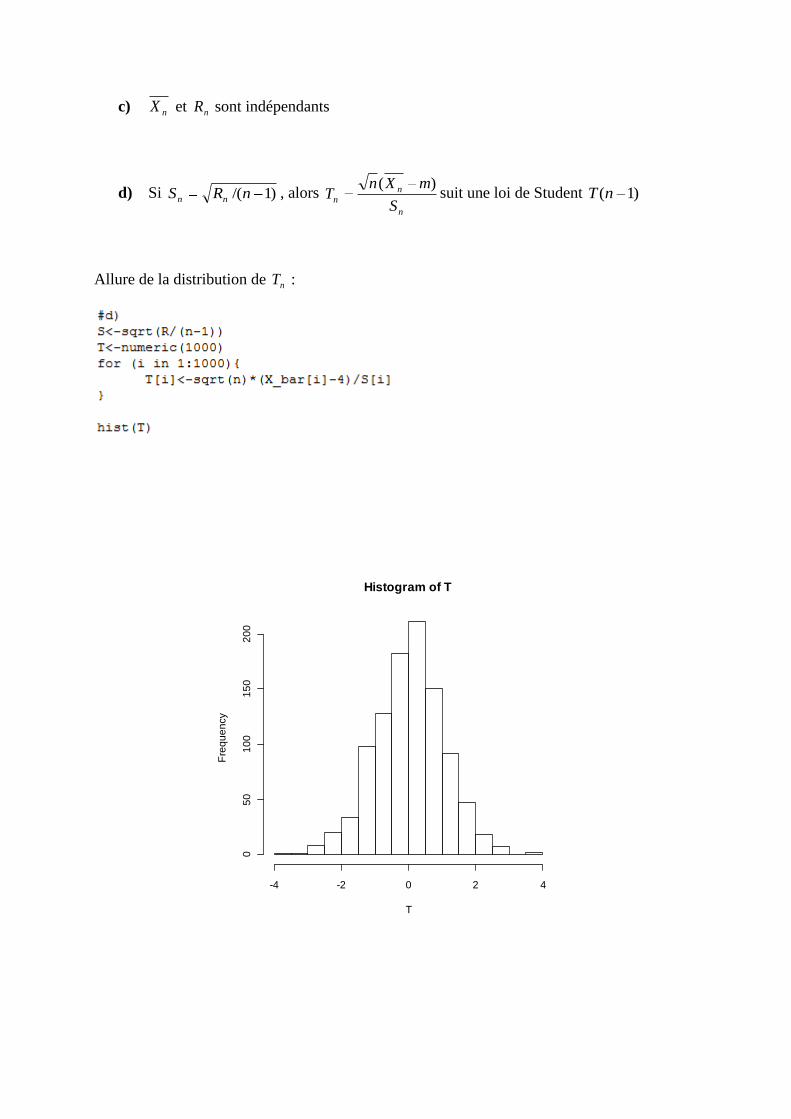
d) Si )1/(nRS nn, alors
n
n
nS
mXnT
)(suit une loi de Student )1(nT
Allure de la distribution de nT :
Histogram of T
T
Fre
qu
en
cy
-4 -2 0 2 4
05
01
00
15
02
00

2. Théorème de Cochran
Soit X de loi ),( nI .
a) Soit kPP ,...,1 k matrices nn auto-adjointes, vérifiant
k
i
in PI1
et k
i
i nPrang1
)(
Alors les matrices iP sont des projecteurs ²)( ii PP et les variables XPi sont des variables
mutuellement indépendantes de loi ),( ii PPN .
b) Soit nQQ ,...,1 k formes quadratiques sur n vérifiant :
,nx k
i
i xQx1
2)( et
k
i
i nQrang1
)(
Alors les variables )(XQi sont mutuellement indépendantes de loi ))(),((2'
ii QrangQ .
C. Méthode de substitution et de contrastes
Les deux méthodes présentées dans ce paragraphe sont des méthodes classiques
d’estimation.
L’avantage de la méthode de substitution est d’être assez simple à comprendre et à mettre en
œuvre, tandis que si la méthode de contrastes est plus compliquée, elle est également plus
précise.

1. La méthode de substitution
La définition d’un estimateur de substitution est la suivante :
Soit rff ,...,1 , r fonctions mesurables de , dans )(, telles que pour tout dans :
rjdPXfXfE jj ,...,1,)())(()(
Soit g fonction continue de r dans E , telle que pour tout dans :
))(),...,(()( 1 XfEXfEgq r
Soit enfin la variable aléatoire :
rf ,...,1 n
i
ijj Xfn
f1
)(1ˆ
On appelle estimateur de substitution de la quantité )(q :
)ˆ,...,ˆ( 1 rn ffgT
Dans le cas où 1r , en prenant pour fonction g l’identité, on voit que 1f̂ est lui-même un
estimateur de substitution de la quantité )(1 XfE .
De plus, si les iX sont des variables aléatoires réelles et si t un point fixé de , les
hypothèses sont vérifiées quel que soit l’ensemble en prenant )(,)(1 utIuf , puisque
1f est bornée. Ainsi, n
i
i tXIn 1
1 est un estimateur de )( tXP .
En voici un exemple :

5782.0p tandis que 5792597.0)2.0(XP où X suit une loi )1,0(N . Cet estimateur de
substitution est donc assez proche de la valeur théorique pour un échantillon de taille
10000n .
2. La méthode de contrastes
Le principe utilisé dans la construction d’estimateurs par la méthode des contrastes est
la minimisation d’une fonction de contraste dont la définition est la suivante :
On appelle fonction de contraste sur toute fonction : telle que pour tout
la fonction ),( admet un unique minimum en .
Cette fonction peut être trouvée par l’intermédiaire d’une différence de processus de contraste
en étudiant sa convergence en probabilité. En effet : pour ),,,,( n
nn
n
n PX une
suite générale d’expériences, on appelle processus de contraste associé à la fonction de
contraste une suite de fonctions aléatoires adaptée à n ),( n
n XU telle que
, on a :
),(),(),(probP
n
n
n
n
n
XUXU
L’idée est alors de remarquer que sous nP , ),(),( n
n
n
n XUXU est proche d’une fonction
de contraste, et qu’il s’agit de minimiser cette expression (et donc de minimiser ),( n
n XU ).
Dans ce contexte, on appelle estimateur de contraste associé l’estimateur nT , quand il
existe, est unique, et qu’il vérifie :
, ),(),( n
n
n
nn XUXTU

L’un des cas particulier de cette méthode est l’estimateur des moindres carrés, il est
très fréquemment utilisé comme technique d’estimation par défaut dans les logiciels de calcul
statistique.
Les moindres carrés ordinaires s’inscrivent dans le modèle linéaire général suivant :
nnpn
p
n
MY
MM
MM
M
Y
Y
Y .,,
...
.
...
,.
1
1
1111
où les i sont des variables indépendantes de même loi g connue, centrées, et qui possèdent
un moment d’ordre 2. On appelle estimateur des moindres carrées l’estimateur p
nˆ qui
vérifie pour n
i
p
j
jijin MYY1 1
)²(),( :
),(),(, YYT nnn
p
Finalement, remarquons que la fonction n
i
iin MYY1
)²)((),( mesure la distance
dans n entre Y et sa prévision par M . On choisit donc comme estimateur de :
p
n Y );,(minargˆ
La méthode d’estimation par moindres carrés est celle qui est utilisée par défaut dans R pour
calculer les coefficients dans le cadre de modèles linéaire ; on fait pour cela appel à la
fonction lm :

D. Tests statistiques
La mise en œuvre des tests statistiques est souvent facilitée par le fait que les fonctions sont
disponibles soit directement dans R soit en téléchargeant un package.
1. Tests de vraisemblance
- test de la moyenne d’une population gaussienne
Soit la moyenne du n-échantillon étudié, il s’agit de tester l’hypothèse nulle : 0
contre l’hypothèse alternative 0 .
On peut procéder en réalisant un test de Student dont le principe est le suivant.
Il s’agit d’abord de calculer un estimateur ˆ de , par la méthode des moindres carrés par
exemple, afin de construire la statistique de test suivante )ˆ(
ˆˆ
sdt qui suit une loi de
Student à 1n degrés de liberté.
On rejette l’hypothèse nulle au niveau de confiance si ct ˆ où c est tel que :
2/)( ctP ( t suivant la même loi que ˆt ).

Le test de Student implémenté ci-dessous permet de comparer ces deux hypothèses.
La p-value est assez élevée, on peut donc accepter l’hypothèse nulle au niveau de confiance
5% selon laquelle la moyenne de l’échantillon est 0, ce qui est cohérent avec les
caractéristiques de notre distribution. On remarquera également que le paramètre de la loi de
Student est bien 1110099 n .
- test d’une sous-hypothèse linéaire
On considère un modèle de la forme suivante :
k
tkttt XXXY ...2
2
1
10
Et l’on désire savoir s’il est possible de réduire le nombre de paramètres de ce modèle en
testant 0: 310H par exemple contre l’hypothèse alternative 0H est fausse. On
appellera alors modèle non restreint le modèle initial et modèle non-restreint le modèle réécrit
en tenant compte de 0H :

k
tkttt XXXY ...4
4
2
20
On procède de la même manière que pour le test de Student en construisant une statistique
de test :
)1/(
/)(
knSSR
qSSRSSRF
edunrestrict
edunrestrictrestricted
où restrictedSSR est la somme des carrés des résidus du modèle restreint, edunrestrictSSR la
somme des carrés du modèle non restreint et q est le nombre de paramètres présents dans
0H , soit 2 dans notre cas.
F suit une loi de Fisher : )1,( knqFisherF
On rejettera l’hypothèse nulle au niveau de confiance si cF où c est tel que
)( cFP

Les outputs de la fonction lm contiennent par défaut les résultats du test de significativité
de tous les paramètres ( 0: 43210H ) et, au vu de la faible p-value, cette
hypothèse nulle peut être rejetée.
Test de 0: 310H :

Finalement cF , on peut donc rejeter 0H ce qui est cohérent avec la manière dont la
série x a été construite : 1 et 3 n’étaient pas nuls.
2. Test d’adéquation non-paramétrique : test du Chi-2
Le test du Chi-2 permet de tester l’hypothèse d’adéquation de la distribution du n-
échantillon étudié à une loi de distribution choisie : 00 : PPH contre 0PP .
On opère d’abord un processus de mise en classe en considérant une partition mesurable de
: kAA ,...,1 telle que jAP j ,0)(0 .
On note ensuite la statistique de comptage de l’ensemble jA :n
i
iAj XNj
1
)(1 et on fabrique
la statistique de test n
i j
j
j
nAP
APn
NnR
1 0
0)(
1))²(( qui converge en loi vers une variable Z
)1²(k .

On définit alors )1(k tel que ))1(( kZP et on peut utiliser la suite de tests
)1(1 1),...,( kRnn nxx qui est asymptotiquement de niveau pour tester 00 : PPH
Il est possible de trouver ce test sous R, mais il est nécessaire de calculer soi-même la
proportion de l’effectif associée à chacune des classes de l’intervalle des valeurs de la
distribution. En voici un exemple.
Test d’adéquation à une loi uniforme :
On accepte donc l’hypothèse nulle d’adéquation de l’échantillon à une loi uniforme en raison
de la p-value assez élevée du test.
Test d’adéquation à une loi normale :

On accepte donc l’hypothèse nulle d’adéquation de l’échantillon à une loi normale au vu de la
p-value élevée du test.
E. Test de sphéricité et ACP
1. Test de sphéricité
Les tests de sphéricité permettent de déterminer si les composantes d’une matrice qui
ne sont pas sur la diagonale sont nulles, c'est-à-dire s’il y a des interactions entre les variables.
On teste alors l’hypothèse nulle : :0H la matrice est proche de la matrice identité à une
constante multiplicative près.
Cependant il serait pratique de pouvoir tester la présence de telles interactions entre plusieurs
échantillons, c'est-à-dire sur une matrice 1000x3 par exemple et donc pas sur une matrice
carrée. La fonction présentée après permet de faire ceci en standardisant la matrice des
échantillons à une taille adéquate avant le test.

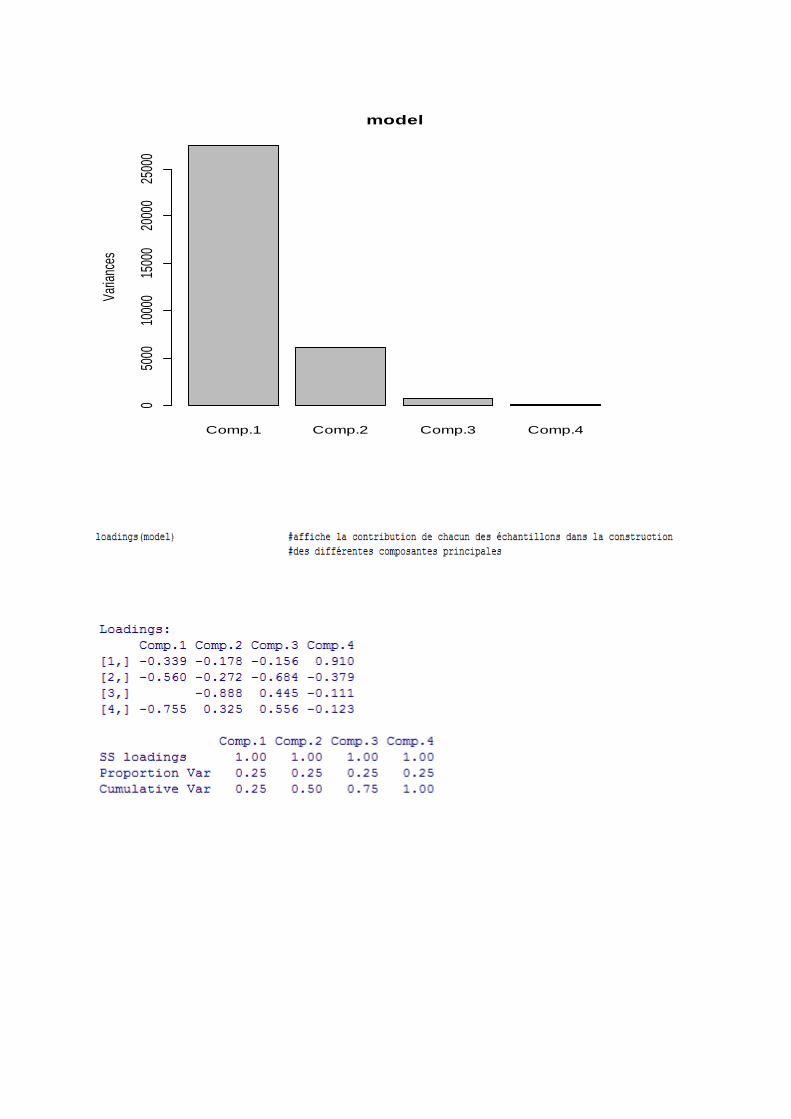
2. Analyse en composantes principales
Si le test de sphéricité a permis de rejeter l’hypothèse nulle, il est possible de mener
une analyse en composante principales sur les échantillons considérés. Celle-ci-permettra
d’identifier les composantes principales et la participation de chacun des échantillons dans la
construction de ces-dernières.
Comp.1 Comp.2 Comp.3 Comp.4
modelVa
rianc
es
050
0010
000
1500
020
000
2500
0





























