Embed Size (px)
DESCRIPTION
MPI. Message-Passing Programming. Le passage de messages. Processus. Le nombre est déterminé au début de l’exécution Demeure constant en cours d’exécution Tous les processus exécutent le même programme Chaque processus possède son propre ID - PowerPoint PPT Presentation
Citation preview

MPI
Message-Passing Programming
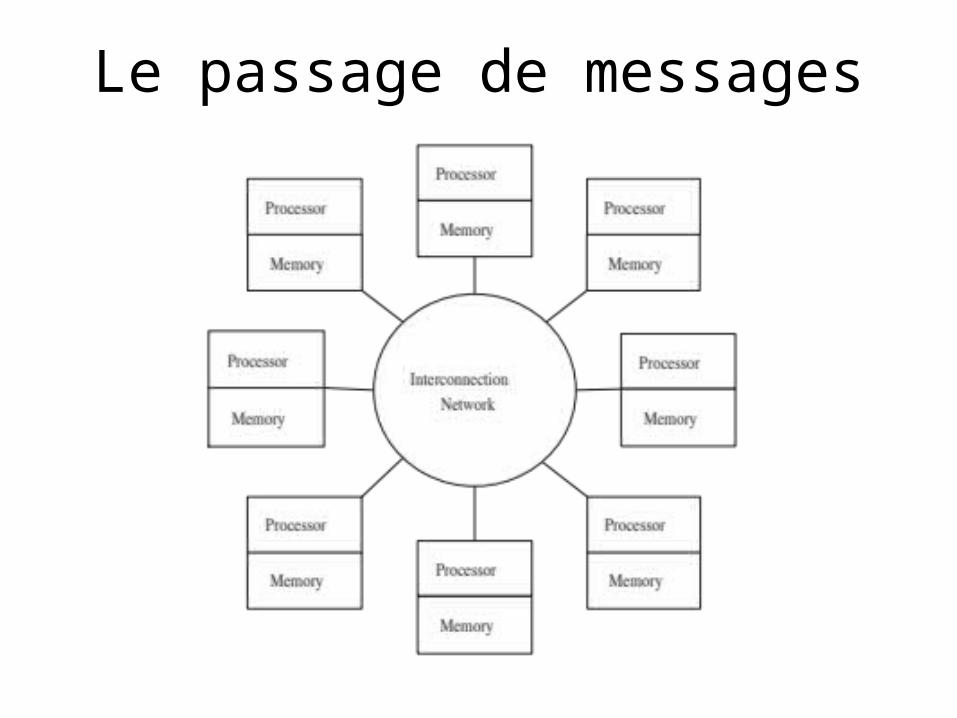
Le passage de messages

Processus
• Le nombre est déterminé au début de l’exécution
• Demeure constant en cours d’exécution
• Tous les processus exécutent le même programme
• Chaque processus possède son propre ID
• Le passage de messages sert à la communication et à
la synchronisation• Même un message vide a une signification

Particularités du modèlepar passage de messages
• Portabilité– Fonctionne aussi bien sur des multi-ordinateurs que sur des
multiprocesseurs
• Facilité de déboguage– Aucune variable partagée
• Sur les multi-ordinateurs le temps de communication est élevé– On doit minimiser la communication– Moins de fautes de cache que sur les multiprocesseurs

Exemple: Satisfaisabilité de circuits
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
Non satisfait
0

Exemple: Satisfaisabilité de circuits
• Le problème de la satisfaction de circuits est NP-
complet
• Aucun algorithme polynomial connu
• Force brute: On regarde toutes les solutions
possibles: Inefficace
• 16 bits en entrée 216 = 65,536 combinaisons à tester

Allocation cyclique des entrées aux processus
• On suppose qu’il y a p processus• On distribue les entrées aux processus de façon
cyclique• Exemple: 5 processus et 12 entrées:
– P0: 0, 5, 10
– P1: 1, 6, 11
– P2: 2, 7
– P3: 3, 8
– P4: 4, 9

Quiz
Supposons qu’il y ait p processus et n entrées possibles et que l’allocation soit cyclique.
1. Quel nombre maximum d’entrées va-t-on allouer à un processus?
2. Quel nombre minimum d’entrées va-t-on allouer à un processus?
3. Combien de processus se voient allouer le nombre maximum d’entrées?

Stratégie générale
• Le programme considère les 65,536 entrées possibles
sur 16 bits
• Les entrées sont allouées de façon cyclique
• Chaque processus examine chacune des entrées qui
lui sont allouées
• Chaque entrée satisfaisant le circuit est affichée.

Fichiers à inclure
#include <mpi.h>
#include <stdio.h>

Variables
int main (int argc, char *argv[]) { int i; int id; /* Rang du processus */ int p; /* Nombre de processus */ void check_circuit (int, int);
argc et argv sont nécessaire pour initialiser MPI Chaque processus possède sa propre copie des variables
puisqu’il exécute sa propre copie du programme.

Initialisation de MPI
• Utiliser avant toute autre fonction MPI• Pas nécessairement la première instruction• Permet d’effectuer les réglages nécessaires
à l’utilisation de MPI• Analogie: Constructeur en POO
MPI_Init (&argc, &argv);

Communicators
• Communicator: Groupe de processus– Objet opaque offrant l’environnement nécessaire
au passage de messages entre les processus• MPI_COMM_WORLD
– Communicator par défaut– Contient tous les processus
• Il est possible de créer d’autres communicators
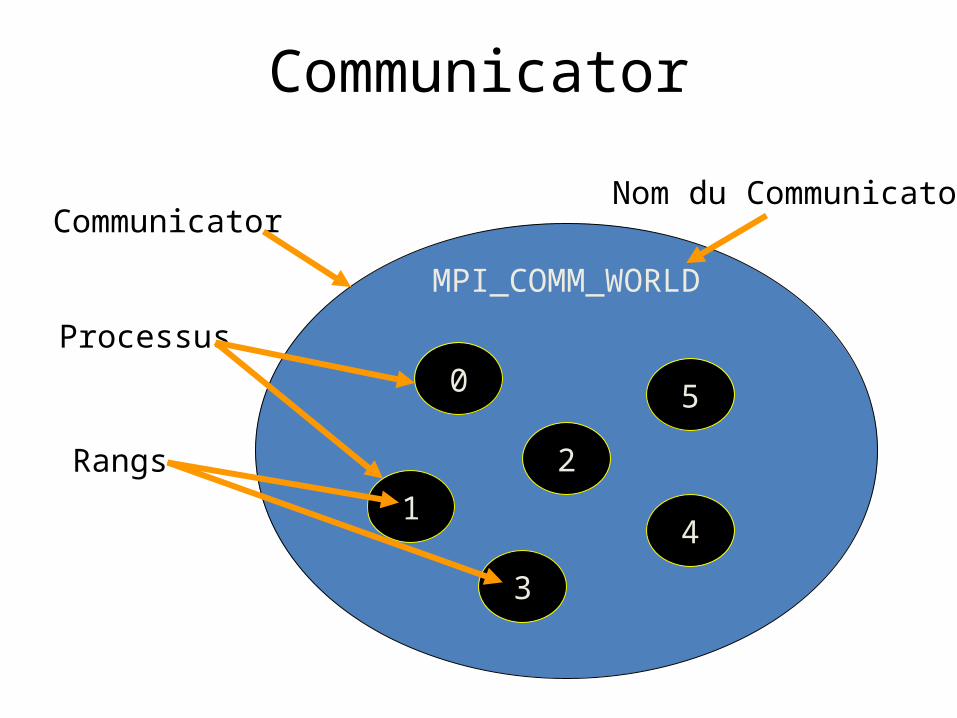
Communicator
MPI_COMM_WORLD
Communicator
0
2
1
3
4
5
Processus
Rangs
Nom du Communicator

Déterminer le nombre de processus
• Premier paramètre: nom du communicator• Valeur de retour: Code d’erreur• Nombre de processus: mis à l’adresse &p
int MPI_Comm_size (MPI_COMM_WORLD, &p);

Déterminer le rang d’un processus
• Premier paramètre: Nom du communicator• Le rang (0, 1, …, p-1) est retourné dans le second
paramètre
int MPI_Comm_rank (MPI_COMM_WORLD, &id);
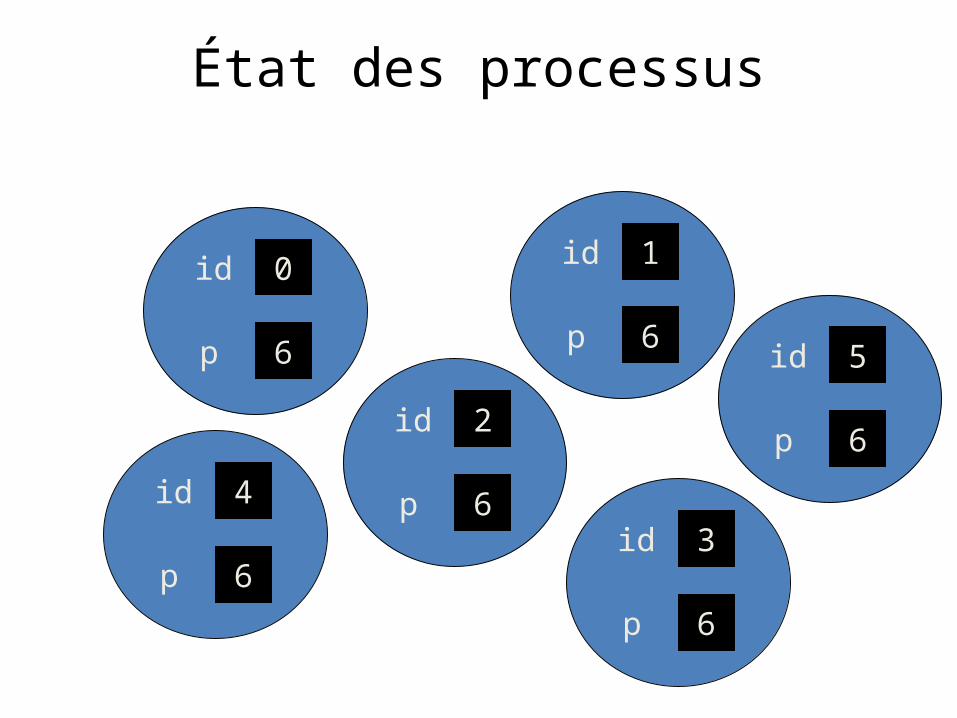
État des processus
0id
6p
4id
6p
2id
6p
1id
6p5id
6p
3id
6p

Allocation cyclique
for (i = id; i < 65536; i += p) check_circuit (id, i);
• Le parallélisme se situe à l’extérieur de la fonction check_circuit
• check_circuit est une fonction séquentielle ordinaire

Terminer l’utilisation de MPI
• Dernier appel MPI• Permet au système de libérer les ressources
MPI• Analogie: Destructeur en POO
MPI_Finalize();
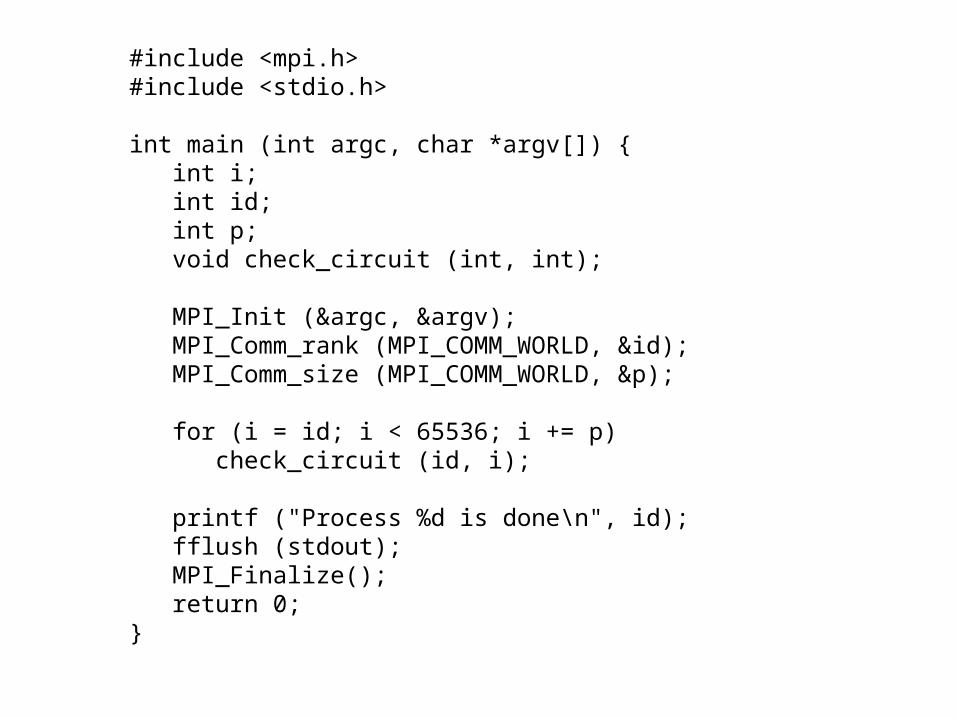
#include <mpi.h>#include <stdio.h>
int main (int argc, char *argv[]) { int i; int id; int p; void check_circuit (int, int);
MPI_Init (&argc, &argv); MPI_Comm_rank (MPI_COMM_WORLD, &id); MPI_Comm_size (MPI_COMM_WORLD, &p);
for (i = id; i < 65536; i += p) check_circuit (id, i);
printf ("Process %d is done\n", id); fflush (stdout); MPI_Finalize(); return 0;}

/* Retourne 1 si le i-ième bit de ‘n’ est 1; 0 sinon */#define EXTRACT_BIT(n,i) ((n&(1<<i))?1:0)
void check_circuit (int id, int z) { int v[16]; /* Each element is a bit of z */ int i;
for (i = 0; i < 16; i++) v[i] = EXTRACT_BIT(z,i);
if ((v[0] || v[1]) && (!v[1] || !v[3]) && (v[2] || v[3]) && (!v[3] || !v[4]) && (v[4] || !v[5]) && (v[5] || !v[6]) && (v[5] || v[6]) && (v[6] || !v[15]) && (v[7] || !v[8]) && (!v[7] || !v[13]) && (v[8] || v[9]) && (v[8] || !v[9]) && (!v[9] || !v[10]) && (v[9] || v[11]) && (v[10] || v[11]) && (v[12] || v[13]) && (v[13] || !v[14]) && (v[14] || v[15])) { printf ("%d) %d%d%d%d%d%d%d%d%d%d%d%d%d%d%d%d\n", id, v[0],v[1],v[2],v[3],v[4],v[5],v[6],v[7],v[8],v[9], v[10],v[11],v[12],v[13],v[14],v[15]); fflush (stdout); }}

Avant de compiler
• ssh –l mpi** linuxmpi1.uqac.ca
• lamboot: À utiliser par chaque usager. Cela sert à démarrer le démon qui gère LAM/MPI.
• lamhalt: Pour arrêter LAM/MPI• lamnodes: Pour connaître les processeurs disponibles• laminfo: Information sur la configuration de LAM/MPI• scp: Pour copier un fichier d’une machine à une autre

Compiler un programme MPI
• mpicc: pour compiler des fichiers C ou C++ utilisant MPI
• Équivalent à:
gcc -I/usr/local/include -pthread -L/usr/local/lib -llammpio -llamf77mpi -lmpi -llam -lutil –ldl
• Faire mpicc –showme pour voir l’équivalence
mpicc –o f f.c

Exécuter un programme MPI
• mpirun –np <N> <exec> [<arg1> …]• mpirun –c <N> <exec> [<arg1> …]
– -np <N> nombre de processus– -c <N> nombre de processus– <exec> exécutable– [<arg1> …] arguments de la ligne de commande

Permettre la connection à distance
• MPI doit pouvoir démarrer des processus sur d’autres processeurs sans fournir de mot de passe
• Chaque processeur dans le groupe doit inclure la liste des autres processeurs dans le fichier .rhosts
• Par exemple sur linuxmpi1.uqac.ca (192.168.237.64):192.168.237.65192.168.237.66192.168.237.67
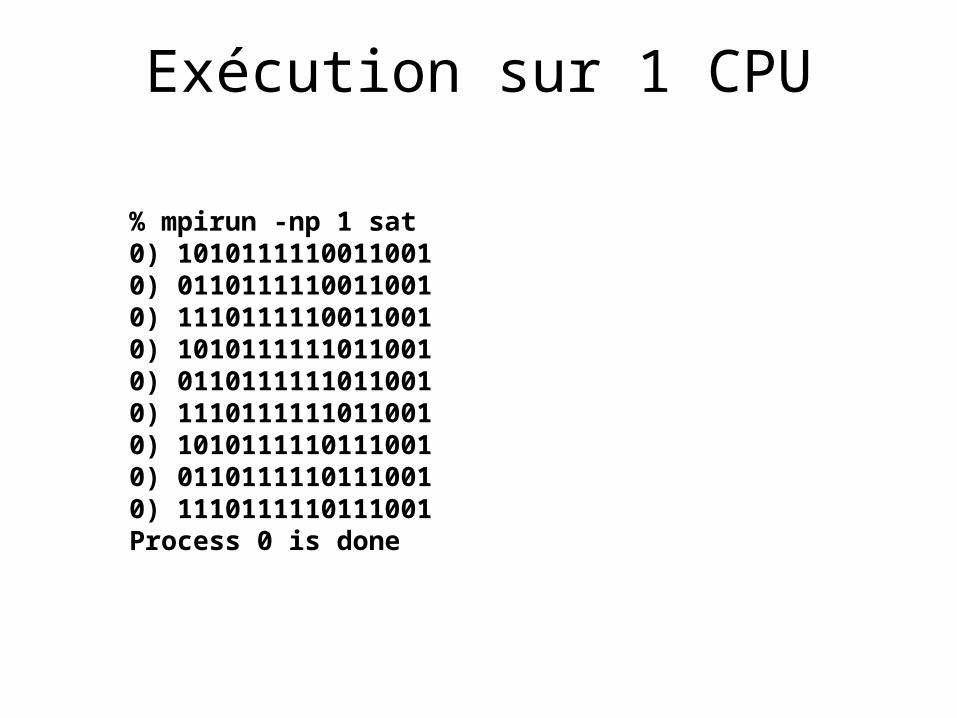
Exécution sur 1 CPU
% mpirun -np 1 sat0) 10101111100110010) 01101111100110010) 11101111100110010) 10101111110110010) 01101111110110010) 11101111110110010) 10101111101110010) 01101111101110010) 1110111110111001Process 0 is done
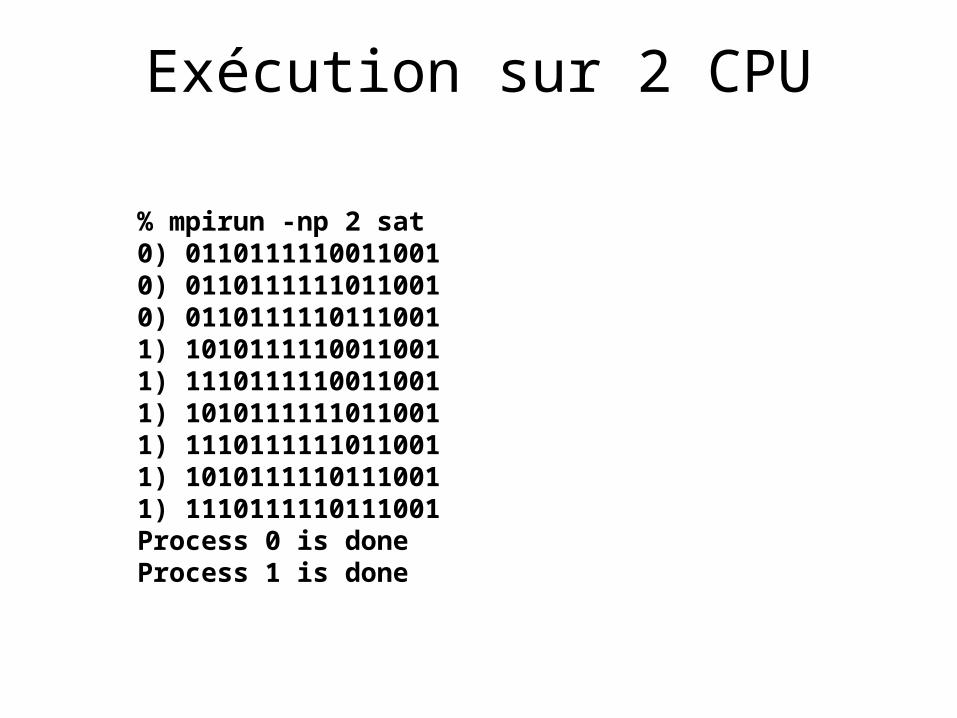
Exécution sur 2 CPU
% mpirun -np 2 sat0) 01101111100110010) 01101111110110010) 01101111101110011) 10101111100110011) 11101111100110011) 10101111110110011) 11101111110110011) 10101111101110011) 1110111110111001Process 0 is doneProcess 1 is done
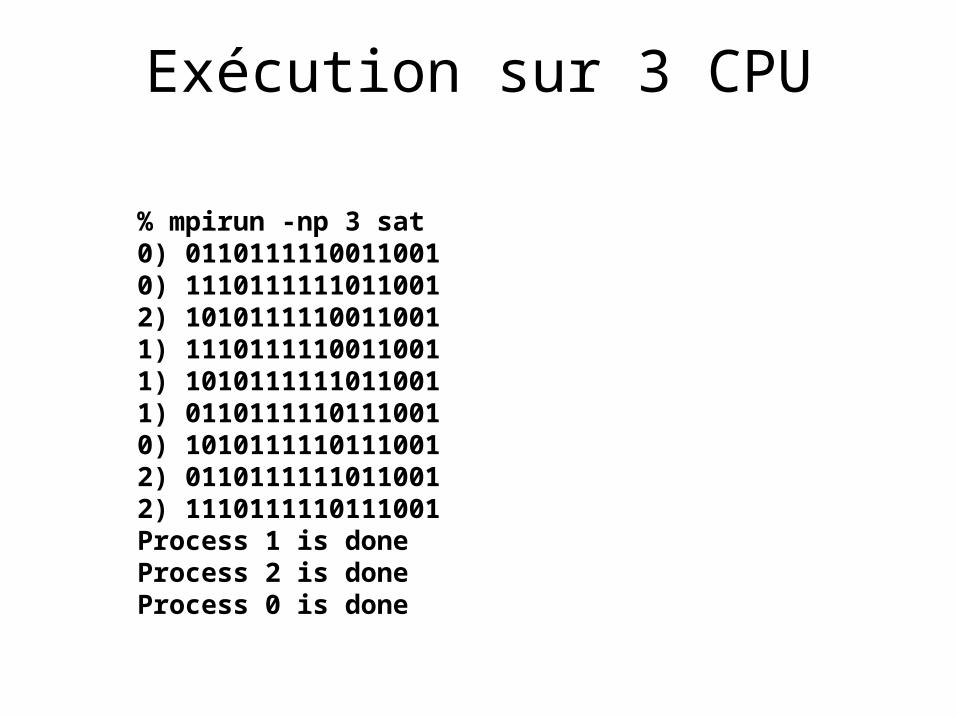
Exécution sur 3 CPU
% mpirun -np 3 sat0) 01101111100110010) 11101111110110012) 10101111100110011) 11101111100110011) 10101111110110011) 01101111101110010) 10101111101110012) 01101111110110012) 1110111110111001Process 1 is doneProcess 2 is doneProcess 0 is done

Améliorer le programme
• On veut trouver le nombre total de solutions• On ajoute une réduction au programme• La réduction est une opération collective qui
implique une communication entre tous les processus

Modifications
• check_circuit– Retourne 1 si le circuit est satisfaisable avec
l’entrée donnée– Retourne 0 sinon
• Chaque processus compte localement le nombre d’entrées satisfaisant le circuit
• La réduction est effectuée sur l’ensemble des résultats.

/* * Circuit Satisfiability, Version 2 * * This enhanced version of the program prints the * total number of solutions. */
#include "mpi.h"#include <stdio.h>
int main (int argc, char *argv[]) { int count; /* Solutions found by this proc */ int global_count; /* Total number of solutions */ int i; int id; /* Process rank */ int p; /* Number of processes */ int check_circuit (int, int);
MPI_Init (&argc, &argv); MPI_Comm_rank (MPI_COMM_WORLD, &id); MPI_Comm_size (MPI_COMM_WORLD, &p);

count = 0; for (i = id; i < 65536; i += p) count += check_circuit (id, i);
MPI_Reduce (&count, &global_count, 1, MPI_INT, MPI_SUM, 0, MPI_COMM_WORLD); printf ("Process %d is done\n", id); fflush (stdout); MPI_Finalize(); if (!id) printf ("There are %d different solutions\n", global_count); return 0;} /* FIN du main */
/* Return 1 if 'i'th bit of 'n' is 1; 0 otherwise */#define EXTRACT_BIT(n,i) ((n&(1<<i))?1:0)

int check_circuit (int id, int z) { int v[16]; /* Each element is a bit of z */ int i;
for (i = 0; i < 16; i++) v[i] = EXTRACT_BIT(z,i); if ((v[0] || v[1]) && (!v[1] || !v[3]) && (v[2] || v[3]) && (!v[3] || !v[4]) && (v[4] || !v[5]) && (v[5] || !v[6]) && (v[5] || v[6]) && (v[6] || !v[15]) && (v[7] || !v[8]) && (!v[7] || !v[13]) && (v[8] || v[9]) && (v[8] || !v[9]) && (!v[9] || !v[10]) && (v[9] || v[11]) && (v[10] || v[11]) && (v[12] || v[13]) && (v[13] || !v[14]) && (v[14] || v[15])) { printf ("%d) %d%d%d%d%d%d%d%d%d%d%d%d%d%d%d%d\n", id, v[0],v[1],v[2],v[3],v[4],v[5],v[6],v[7],v[8],v[9], v[10],v[11],v[12],v[13],v[14],v[15]); fflush (stdout); return 1; } else return 0;}

Prototype de MPI_Reduce()int MPI_Reduce ( void *operand, /* Adresse du tableau d’entrée*/ void *result, /* Adresse du tableau des résultat */ int nbre, /* nombre de réductions à effectuer*/ MPI_Datatype type, /* type des éléments*/ MPI_Op operator, /* Opérateur de réduction*/ int root, /* Rang du processus qui reçoit le résultat*/ MPI_Comm comm /* communicator */
)

MPI_Datatype
• MPI_CHAR• MPI_DOUBLE• MPI_FLOAT• MPI_INT• MPI_LONG• MPI_LONG_DOUBLE• MPI_SHORT• MPI_UNSIGNED_CHAR• MPI_UNSIGNED• MPI_UNSIGNED_LONG• MPI_UNSIGNED_SHORT

MPI_Op
• MPI_BAND• MPI_BOR• MPI_BXOR• MPI_LAND• MPI_LOR• MPI_LXOR• MPI_MAX• MPI_MAXLOC• MPI_MIN• MPI_MINLOC• MPI_PROD• MPI_SUM

Exécution du second programme
% mpirun -np 3 seq20) 01101111100110010) 11101111110110011) 11101111100110011) 10101111110110012) 10101111100110012) 01101111110110012) 11101111101110011) 01101111101110010) 1010111110111001Process 1 is doneProcess 2 is doneProcess 0 is doneThere are 9 different solutions

Analyse de la performance
• MPI_Barrier barrière de synchronization• MPI_Wtick temps en secondes entre 2 tics d’horloge• MPI_Wtime temps en secondes depuis le dernier appel

Code
double elapsed_time;…MPI_Init (&argc, &argv);MPI_Barrier (MPI_COMM_WORLD);elapsed_time = - MPI_Wtime();…MPI_Reduce (…);elapsed_time += MPI_Wtime();