Embed Size (px)
Citation preview

Objectifs de la séance
Durant la séance, trois points différents seront abordés :
- L’utilisation des corpus pour travailler en syntaxe et la question de l’établissement des faits
- Les annotations grammaticales comme aide à la recherche de constructions syntaxiques : les possibilités qu’elles offrent, les difficultés, etc.
- Les corpus arborés
1

Quelques rappels (cours d’intro)
Vieux débat sur les données en syntaxe:
Les objectifs de la syntaxe : On s’intéresse aux énoncés possibles du français.
On ne peut pas savoir directement quels sont les énoncés possibles du français. Méthode 1: on regarde les énoncés avérés et on extrapole.
Problème A: taille des corpus
Problème B: capacité à répondre à des questions intéressantes
Méthode 2: on interroge les locuteurs sur leur intuition
Problème A: on ne connaît pas le rapport entre intuition consciente et capacité inconsciente
Problème B: existence de nombreux biais

Quelques rappels (suite)
La linguistique de fauteuil n’a pas bonne presse dans certains cercles de linguistes. Voici une caricature du linguiste de fauteuil. Il est assis dans un fauteuil profond et confortable, les yeux fermés et les bras croisés derrière sa tête. De temps en temps, il ouvre un oeil, se relève brutalement et crie : « Ouah ! Quel super fait ! », attrape son crayon, et écrit quelque chose. Il s’agite alors pendant plusieurs heures dans l’excitation de s’être encore approché d’une compréhension de la véritable nature du langage [. . . ].
La linguistique de corpus n’a pas bonne presse dans certains cercles de linguistes. Voici une caricature du linguiste de corpus . Il a tous les faits dont il a besoin, sous la forme d’environ un zillion de mots, et il conçoit son travail comme celui de dériver des faits secondaires à partir de ces faits primaires. En ce moment il est occupé à déterminer les fréquences relatives des onze parties du discours dans le premier mot d’une phrase et dans le deuxième mot d’une phrase [. . . ].
Ces deux linguistes ne se parlent pas très souvent, mais quand ils le font, le linguiste de corpus dit au linguiste de fauteuil : « Pourquoi devrais-je croire que ce que tu me dis est vrai ? ». Et le linguiste de fauteuil dit au linguiste de corpus : « Pourquoi devrais-je croire que ce que tu me dis est intéressant ? » C. Fillmore (1992) in J. Svartvik, Directions in Corpus Linguistics, Berlin : Mouton De Gruyter.

Point de vue soutenu dans le cours
Historiquement, polarisation du débat entre les partisans de la méthode 1 et ceux de la méthode 2
Du coup, absence d’attention à la qualité méthodologique du travail
Leçon des autres disciplines: toutes les sources de données sont bonnes à prendre Analogie: évidences morphologiques vs. moléculaires pour la classification des
espèces.
La situation est en train de changer (dans certains milieux en tout cas) Utilisation de protocoles expérimentaux contrôlés pour le recueil des intuitions Constitution de corpus de plus en plus gros et de plus en plus utilisables (bien
annotés)

Les jugements de grammaticalité (1) (D’après Carson Schütze (1996) The empirical base of linguistics,U. of Chicago Press.)
Si on se contente de collecter les jugements informellement, on risque d’être biaisé.
Un certain nombre de biais ont été établis par des travaux expérimentaux.
Observation de base: quelle que soit la manière dont on pose la question, on observe des différences individuelles dans les jugements des locuteurs.
Trois sources envisageables pour ces différences: Les grammaires des locuteurs sont différentes La stratégie de réponse des locuteurs est différente
La manière de présenter la tâche est différente

Biais liés au choix des locuteurs (1)
Dépendance au domaine
On sait que les individus sont plus ou moins habiles à différencier les aspects d’un problème cognitif. Ex: différencier une perception visuelle d’une perception sensorielle Ce facteur a une influence sur la capacité des sujets à séparer, par exemple, facteurs syntaxiques et sémantiques.
Age: données pas claires
Sexe: on observe des différences selon le sexe dans les jugements produits.
NB: ces différences ont sans doute une source sociale plutôt que biologique. Cependant cela ne change rien au caractère biaisant des données.
Capacités cognitives générales (mémoire, etc.)

Biais liés au choix des locuteurs (2)
Education linguistique
Opposition de principe de beaucoup de linguistes: un individu qui a reçu une éducation linguistique est influencé par ses pré-conceptions.
Position extrême inverse: un entraînement est nécessaire à produire des jugements fiables. Pas de moyen expérimental de trancher entre ces deux
Positions. Ce qui est sûr, c’est que les linguistes ne produisent pas les mêmes jugements que les non-linguistes
Education tout court: influence claire, mais est-elle purement de nature sociolinguistique?
Multilinguisme

Biais liés à la tâche (1)
Instructions fournies: les locuteurs peuvent comprendre la tâche de différentes manières
Ordre de présentation: le jugement sur la phrase n+1 est influencé par le jugement sur la phrase n
Répétition: les jugements répétés tendent à diminuer la force des contrastes
Etat mental: en manipulant l’attention des locuteurs, on constate des différences de jugement
Modalité orale ou écrite
Influence évidente des conventions spécifiques de l’écrit Normativité variable Ponctuation et intonation

Biais liés à la tâche (2)
Vitesse de présentation des données
Présentation d’un contexte pragmatique
Naturalité du sens des phrases
Fréquence des mots/constructions utilisés
Transparence morphologique ou sémantique des mots utilisés, etc.
“Les linguistes savent bien que les intuitions sur l’acceptabilité des énoncés tendent à être vagues et inconsistantes, dépendant de ce que vous avez mangé au petit-déjeuner et de ce que prédit votre théorie préférée.”
O. Dahl,

Synthèse
L’existence de biais est clairement établie
NB: ce qu’on observe là est exactement ce qu’on observe dans toutes les sciences expérimentales
La solution est la même que dans toutes les sciences expérimentales:
Evitement des facteurs de biais identifiés
Contrôles statistiques des résultats
Discussion explicite devant les pairs de la procédure expérimentale
Conclusion générale: il n’y a pas de problème à utiliser des jugements de grammaticalité en linguistique — à condition de le faire avec précaution

Le recours aux corpus (1)
L’une des questions qui se pose : les corpus sont-ils assez grands? - > idée de la faiblesse des stimulis (Chomsky)
Evaluation de cette faiblesse à partir d’un exemple empirique… la question de l’inversion du sujet dans les auxiliaires en anglais.
En anglais, règle d’inversion du sujet dans les questions Is Paul talking to my father? Deux formulations possibles:
1. Mettre en tête le premier auxiliaire 2. Mettre en tête l’auxiliaire de la principale
Seul moyen de trancher laquelle de ces formulation est correcte : regarder les phrases dont le sujet contient un auxiliaire The man Paul is talking to is my father 1. Is the man Paul is talking to my father? 2. Is the man Paul talking to is my father?

Le recours au corpus (2)
“Les cas les plus complexes, qui distinguent les hypothèses, se présentent rarement. On peut facilement vivre toute sa vie sans produire un exemple pertinent montrant qu’on utilise une hypothèse plutôt que l’autre.” Chomsky (1980)
Pullum & Scholz (2003) Etude du corpus du Wall Street Journal, qui contient 23000 questions
Plus de 1% des questions ont la structure pertinente Is what I’m doing in the shareholder’s best interest?
D’après ce qu’on sait du discours adressé aux enfants:
ils entendent plus de 750 000 questions avant 3 ans A priori, plus de 7 500 questions devraient avoir la structure
pertinente!

Les corpus assez grands ?
Dans le cas de l’affirmation de Chomsky, on dispose clairement de corpus assez grands pour répondre à la question, ou pour choisir entre deux hypothèses… mais ce n’est pas la taille qui pose problème !
Le cas de l’inversion du sujet en français a. *Paul et moi vivaient dans cette maison. b. Paul et moi vivions dans cette maison. c. Dans cette maison ne vivaient que Paul et moi. d. *Dans cette maison ne vivions que Paul et moi.

Les corpus assez grands ? (2)
Les corpus ne sont peut-être pas assez grands pour aborder certains points, en revanche, ils peuvent être utiles pour travailler sur certains points (place des adverbes, des adjectifs, etc.).
L’utilisation des corpus nécessite au minimum : Une catégorisation grammaticale pour pouvoir faire des
recherches
Une représentation syntaxique

Approche sur corpus et syntaxe (suite)
Un corpus “brut” est très fastidieux à utiliser pour du travail syntaxique.
Exercice: comment utiliser Google pour travailler sur Le il impersonnel ? La place de l’adjectif et les adverbes ; l’inversion du sujet ;
Annotations syntaxiques: Catégories. Exemple: ELICOP, Frantext catégorisé Structure syntaxique, fonctions. Exemple: corpus arboré de Paris 7

Corpus brut et il impersonnel
Dans quelques fichiers de ACSYNT
Dans quelques fichiers d’ESTER
Voir les problèmes que cela pose
Limitation dans le choix (Pour Ester… pour ACSYNT)
Nombre de données

Corpus brut et autres requêtes (1)
Impossibilité de faire une requête exhaustive, même si on envisage de faire des tris ou des « nettoyages ».
Nécessité d’avoir un corpus annoté
Pour les adjectifs… Quel(s) types d’annotation ?
Quelle requête faire
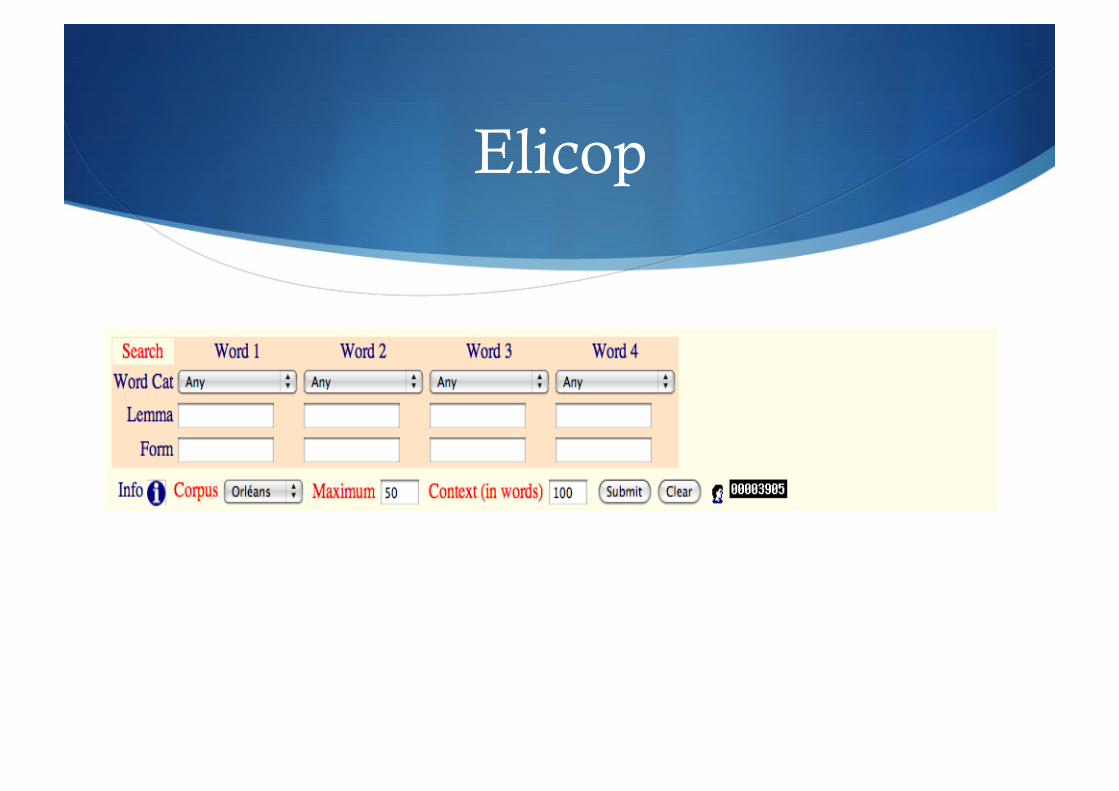
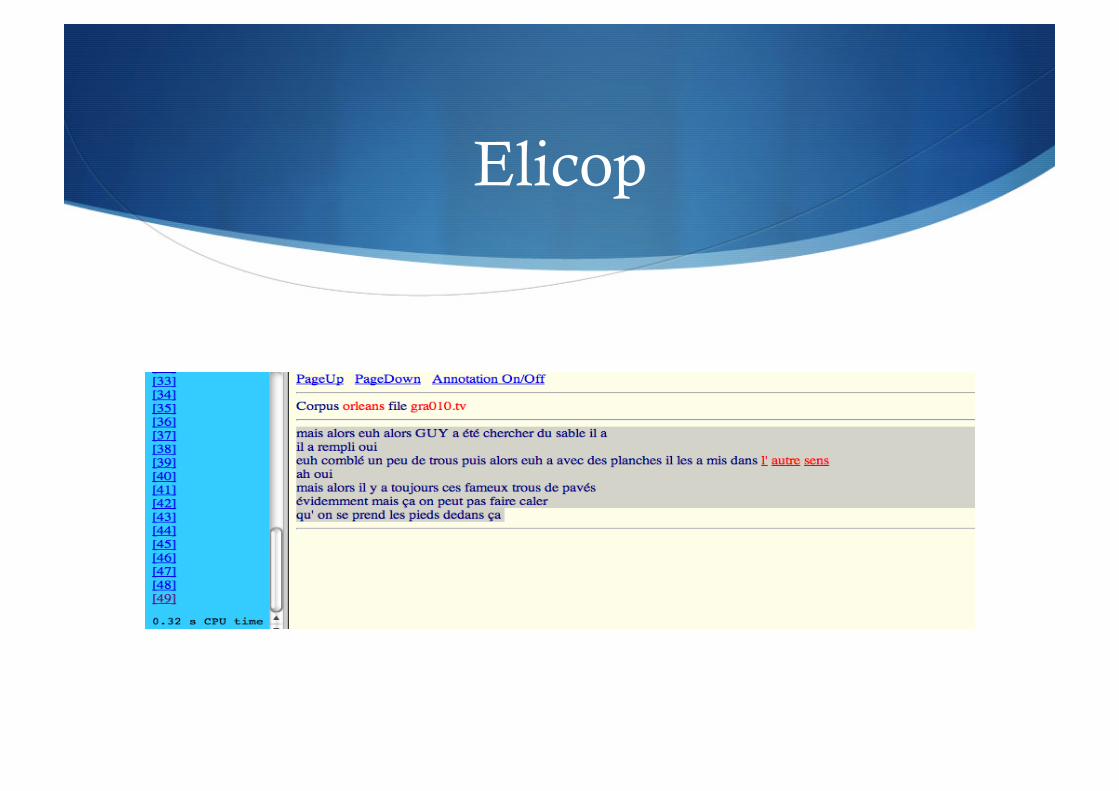
Résultat de ELICOP

ELICOP
Idées de base : les corpus de français parlé ont retenu l'attention des chercheurs que depuis peu. Comme le souligne Claire Blanche-Benveniste (1996, p. 25), les corpus de langue parlée "au travers des ‘fautes’ de performance aident à voir ce qui est central et typique dans une langue". C’est dans cet esprit que les responsables du projet ELICOP, se sont proposé de constituer un grand corpus informatisé de la langue parlée.
Un important travail de constitution de corpus avait été réalisé dans les années 80 (le projet ELILAP) et au début des années 90 (le projet LANCOM). En 1997, les promoteurs du projet ELICOP ont commencé par rassembler systématiquement en les automatisant tous les matériaux disponibles. Par la suite, ils ont établi les principes selon lesquels les corpus seraient formellement uniformisés. Grâce à cette homogénéité formelle, l’ensemble des corpus, accessible sur Internet, peut être consulté pour tout type de recherches et d’applications linguistiques.
Adresse du site : http://bach.arts.kuleuven.be/elicop/
Elicop
Elicop

Frantext et catégories : autre exemple
Exemple de travail avec Frantext catégorisé: recherche sur les adverbes (S. Morand, maîtrise, U. Rennes 2, 2003).
Pour différencier les “adverbes de phrase” des “adverbes de verbe”, il y a un test crucial (Molinier 1996): la possibilité d’utiliser l’adverbe dans le foyer d’une clivée. 1. C’est lentement qu’il est entré. 2. *C’est habituellement qu’il va à Paris.
Bonami, Godard & Kampers-Manhe montrent que ce n’est pas si simple: il y a des emplois métalinguistiques de la clivée qui compliquent les choses. 1. Il va à Paris habituellement. 2. Mais non, ce n’est pas habituellement qu’il va à Paris.
Une étude de corpus devrait nous éclairer.

Frantext et catégories : autre exemple
A partir de FRANTEXT catégorisé, on extrait toutes les séquences “c’est Adv que” (6592 exemples)
Elimination du bruit: 1. C’est plus que du repos, c’est du plaisir. (C.-L. Philippe)
2. Si l'expérience enseigne quelque chose, c'est bien que rien n'est noir ou blanc.(J. Dutourd)
Tri des exemples restants en fonction de l’adverbe utilisé. Analyse de la classe de l’adverbe. Résultats:
Les emplois métalinguistiques semblent (presque) absents Certaines classes attendues rarissimes en clivée

Faire des requêtes à partir de corpus étiquetés
Rechercher les adjectifs préposés
Rechercher les adverbes qui modifient les adjectifs
Rechercher les/des clivés
Travailler à partir du ELICOP

Etiqueter un corpus
Les taggeurs : treetagger…
Aller sur l’un des sites suivants :
http://cental.fltr.ucl.ac.be/treetagger/index.html
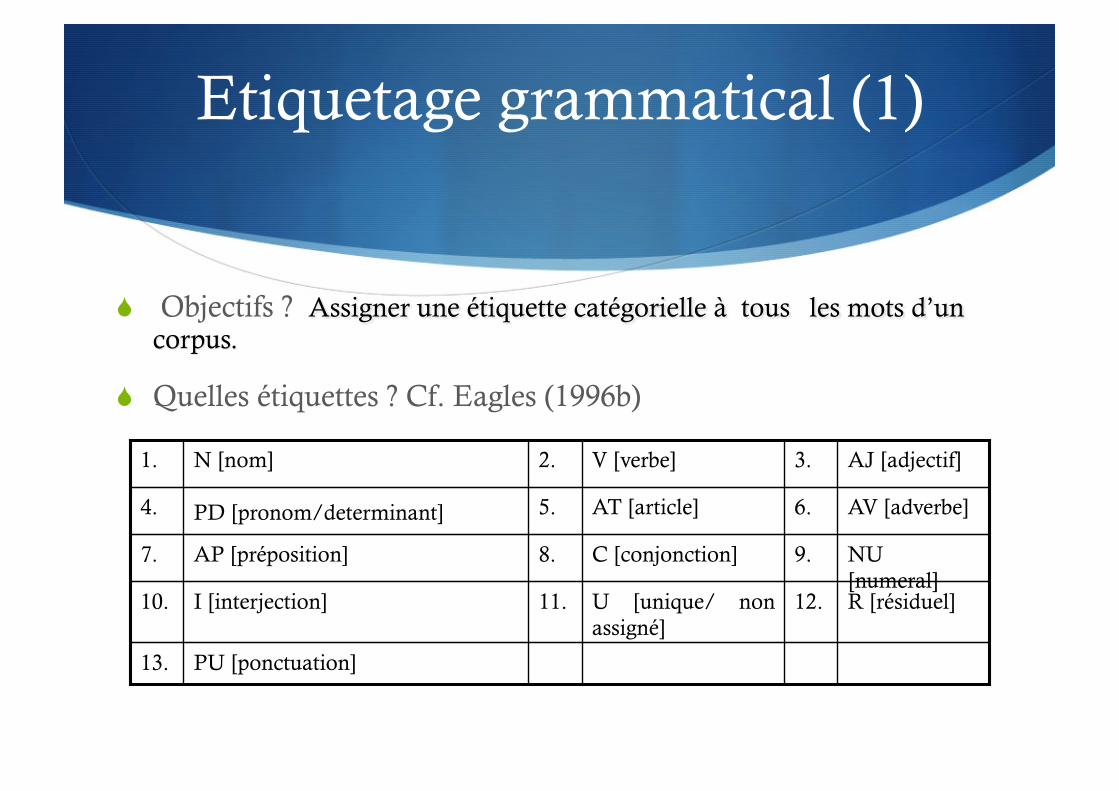
Etiquetage grammatical (1)
PU [ponctuation] 13.
R [résiduel] 12. U [unique/ non assigné]
11. I [interjection] 10.
NU [numeral]
9. C [conjonction] 8. AP [préposition] 7.
AV [adverbe] 6. AT [article] 5. PD [pronom/determinant] 4.
AJ [adjectif] 3. V [verbe] 2. N [nom] 1.

Etiquetage grammatical (2)
La question du dictionnaire : Traitement des locutions ou des interjections; Est-il possible d’ajouter ou de modifier le dictionnaire.
Les outils sur le marché : Cordial; WINBRILL; Tree Tagger.
Quel format d’entrée : Faut-il une ponctuation « standard » ? Format électronique, etc.

Etiquetage grammatical (3)
La granularité : Quelles étiquettes ? La lemmatisation et la catégorisation.
Les étiquettes et les outils : Les réponses aux questions sont dépendantes des
objectifs visés et des outils disponibles.

Etiquetage grammatical : exemple 1a
Extrait à traiter :
C'est uniquement dans le la fabrication là où ça reste artisanal plus à Papillon que euh dans le r- dans les caves de Société c'est que euh c'est la fabrication de la moisissure en fait qu'on met dans le fromage qui est artisanale encore chez Papillon qui se fait comme autrefois avec du pain que l'on met dans la cave et qu'on laisse moisir <E: d'accord.> et voila

Etiquetage gramatical : exemple 1 d
C' PRO:DEM ce est VER:pres être uniquement ADV uniquement dans PRP dans le DET:ART le la DET:ART le fabrication NOM fabrication plus ADV plus à ADJ <unknown> Papillon NOM papillon c' PRO:DEM ce est NOM est que KON que euh INT euh c' PRO:DEM ce est VER:pres ?tre la DET:ART le fabrication NOM fabrication
de PRP de la DET:ART le moisissure NOM moisissure en PRP en fait NOM fait avec PRP avec du PRP:det du pain NOM pain que PRO:REL que l' PRO:PER la|le on PRO:PER on met VER:pres mettre dans PRP dans la DET:ART le cave NOM cave et KON et qu' PRO:REL que on PRO:PER on laisse VER:pres laisser moisir VER:infi moisir

Etiquetage grammatical : Exemple 2a
Extrait d’un corpus oral d’Acadie transcrit selon les conventions développées par Valibel :
L0 bon / ben pourrais-tu premièrement me dire quel genre de travail tu fais / m'expliquer ça un petit peu
L1 ok je suis euh / ben mon titre comme j'ai indiqué sur ma feuille c'est coordinatrice administrative régionale / ça je m'occupe euh pis c'est en santé publique / ici à Moncton / puis euh je m'occupe: des budgets c'est moi qui fait les gen/ les forcasting pour les budgets / où on est rendu dans les finances / c'est moi qui s'occupe aussi beaucoup des ressources humaines là pour euh / l'embauche des gens pour euh / tous les bénéfices euh (xxx) tous ces choses là hum / puis je suis aussi pour l'informatique là pour la question de des ordinateurs pis tout ça là malgré que je suis pas un experte dans les ordinateurs mais je fais de mon mieux pis j'apprends au fur et à mesure là euh un peu de trouble shooting si tu veux ou des choses euh / techniques là si i-y-a des problèmes au niveau informatique pis même l'achat de l'équipement puis des choses comme ça

Corpus brut et autres requêtes (1)
Pour l’inversion du sujet
De quoi aurait-on besoin ?
Que donnent les corpus arborés ?
Comment annoter syntaxiquement un corpus ?

Annotation syntaxique (1)
Les problèmes sont plus nombreux que pour l’étiquetage grammatical : Tâche plus complexe où les unités sont à définir;
Absence de consensus sur les étiquettes et les unités;
Qu’est-ce que la syntaxe.
Les outils : Surtout développés pour l’écrit;

Annotation syntaxique (2)
Les étiquettes retenues par EAGLES
Phrase Clause
Syntagme Nom. Syntagme verbal Syntagme Adj.
Syntagme Adv Syntagme prép.

Annotation syntaxique (3)
Les étiquettes et principes pour le français (Abeillé et. Al.)
les étiquettes « syntagmatiques » retenues sont données ci-après. AP AdP COORD NP
VN Noyau verbal (verbes avec clitiques, auxiliare, modaux, faire, etc.)
PP
SENT Phrase indépendante (sont aussi notés ainsi tout fragment indépendants isolés par des ponctuations fortes ou des sauts de lignes)

Annotation syntaxique (4)
Vppart Proposition participiale
Vpinf infinitive (qui peut commencer par une préposition)
Srel Ssub (complétive, interrogative indirecte, etc.)
Sint Proposition conjuguée interne (incise, discours direct, etc.)
Principes de découpage retenus : afin de résoudre certaines difficultés syntaxiques, plusieurs choix ont été formulés, parmi lesquels :
l’absence de constituants discontinus ; la possibilité d’avoir des syntagme sans tête (les catégories vides ne sont donc pas utilisées) ; le refus des ambiguïtés résiduelles ; la limitation du nombre de syntagme unaire, c’est à dire composé d’un unique élément.

Annotation syntaxique et tree-bank du français
Corpus de Paris 7 (http://www.llf.cnrs.fr/Gens/Abeille/ French-Treebank-fr.php)
Tirage au hasard de phrases dans Le Monde de 1989 à 1993, pour un total de 1 000 000 de mots
Annotation (en XML) pour: Lexique: identification du lexème, de sa catégorie, de ses traits morphosyntaxiques Syntaxe: annotation pour la structure en constituants et les fonctions syntaxiques.
Procédure: D’abord, création d’annotations préliminaires par des outils automatiques Ensuite, vérification à la main de la qualité des résultats

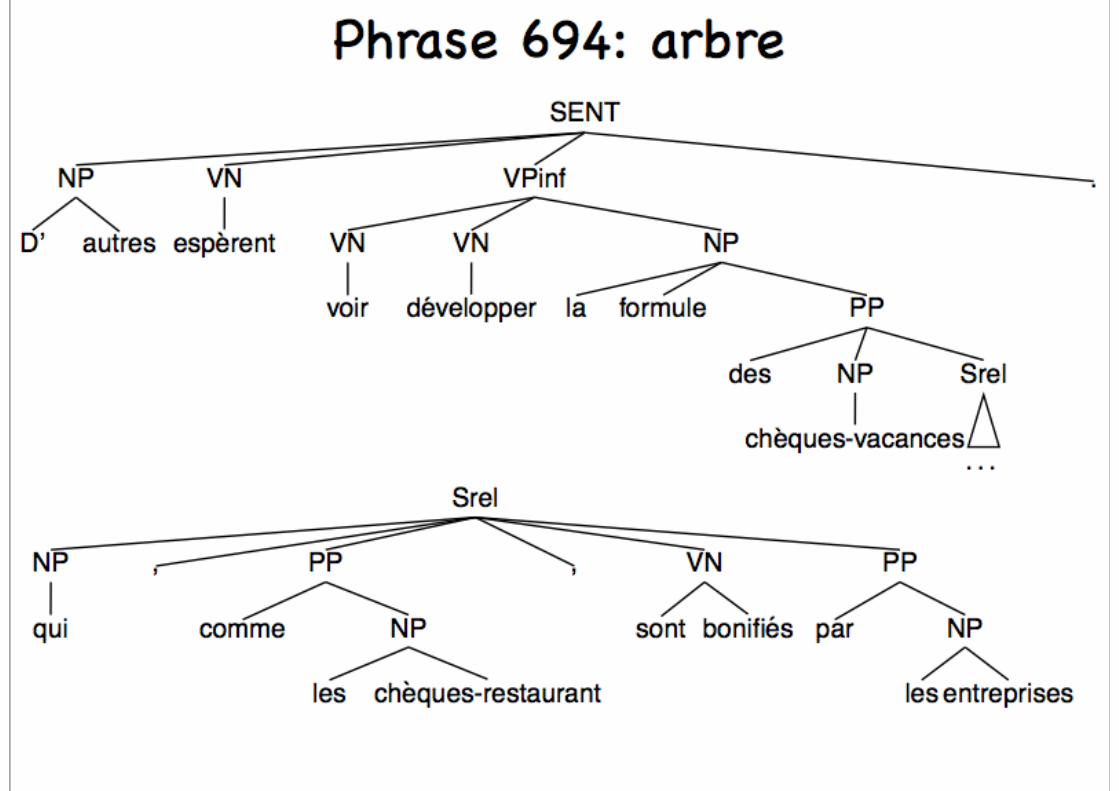
Un exemple de corpus arboré
<SENT nb="1">
<w lemma="le" cat="D" subcat="def" mph="fs">L’
</w> <w compound="yes" lemma="Association des industriels japonais » cat="N" subcat="P" mph="fs »> <w catint="N">Association</w><w catint="P">des</w>
<w catint="D"/> <w catint="N">industriels</w>
<w catint="A">japonais</w></w>
<w lemma="prévoir" cat="V" subcat="" mph="P3s">prévoit</w><w lemma="un" cat="D" subcat="ind" mph="fs">une</w>
<w lemma="léger" cat="A" subcat="qual" mph="fs">légère</w>
<w lemma="reprise" cat="N" subcat="C" mph="fs">reprise</w>
<w lemma="en" cat="P">en</w> <w lemma="1993" cat="N" subcat="card" mph="fs">1993</w> <w lemma="." cat="PONCT" subcat="S">.</w>
</SENT>