Embed Size (px)
Citation preview

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Programmation dans
Ch. 2. Régression Linéaire & Extensions
M2 CEE
Pr. Philippe Polomé, Université Lumière Lyon 2
2017 – 2018
Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Régressions linéaire
Sommaire
Régressions linéaire
Factors & interactions
Splines
Moindres Carrés Pondérés
Diagnostics de régression
Régression Quantile
Données manquantes (Missing data NA)
Régression automatisée

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Régressions linéaire
Commandes de base de régression dans R
I Le Modèle de Régression Linéaire MRL
yi
= x0i
� + ✏i
avec i = 1...nI En forme matricielle y = X� + ✏I Hyp. typiques en coupe-transversale (cross-section)
I E (✏|X ) = 0 (exogénéité)I Var (✏|X ) = �2I (“sphericité” : homoscédasticité & pas
d’autoc.)I Dans R, les modèles sont usuellement estimés en appelant une
fonctionI Pour le MRL (en coupe) : fm <- lm(formula, data,...)I L’argument ... remplace une séries d’arguments
I de description du modèleI ou de choix de mode de calcul (algorithme)I optionnels

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Régressions linéaire
Commandes de base de régression dans R
I La fonction renvoie un objet
I Ici : le modèle ajusté, stocké sous le nom fmI Peut être imprimé, visualisé (graphe) ou résumé
I On peut calculer sur cet objet :I Prédictions, résidus, tests & divers diagnostics postestimations
I La plupart des commandes d’estimation marchent de la mêmemanière

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Régressions linéaire
SWIRL
I Faites le cours « Regression Models » dans SwirlI Lessons 1-3 & 6
I Les autres : + tard ou optionnelI diapos disponibles en ligne, je pense qu’on peut faire sansI Concentrez-vous sur le code, l’ectrie est connueI Pensez à fermer les fichiers ouverts à la lesson précédente
1. “Introduction”I une phrase à retenir « A coefficient will be within 2 standard
errors of its estimate about 95% of the time »2. “Residuals” est assez difficile (lecture +
programmation+concepts)I Permet d’expliquer les bouclesI Oblige a relire des commandes antérieuresI Attention d’exécuter le program res_eqn.r qd il se montre

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Régressions linéaire
SWIRL
3. “Least Squares Estimation” – RAS4. Introduction to Multivariable Regression
IFaites chez vous
I Installer manipulate au préalableI Je ne suis pas très sûr de la stabilité de cette lessonI Ne pas éditer la fonction myplot qui apparaitI Attention cor(gpa_nor, gch_nor) va être 6= ˆ�, SWIRL attend
=, bug5. “Residual Variation”
IFaites chez vous
I “Gaussian elimination” montre qu’une régression à k variablesI peut être vue comme une succession de k régressions à 1
variableI mais ne pas prendre cela comme une manière de sélectionner
les résultats6. “MultiVar Examples” – RAS

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Factors & interactions
Sommaire
Régressions linéaire
Factors & interactions
Splines
Moindres Carrés Pondérés
Diagnostics de régression
Régression Quantile
Données manquantes (Missing data NA)
Régression automatisée

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Factors & interactions
Régression linéaire multiple avec facteurs
Équation de salaire
I L’objectif de cet exemple est de montrer diverses utilités de RI servant à transformer & combiner les régresseurs
I Jeu de données : cps1988 préchargéI Enquête de pop. mars 1988 du US Census BureauI 28 155 obs. en coupe transv.I hommes de 18-70 ans,I revenu > US$ 50 en 1988I pas auto-employé et ne travaillant pas sans salaire

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Factors & interactions
data("CPS1988")
I summary(CPS1988)I Cardinales
I wage $/semaineI education & experience (=age-education-6) en années
I Catégoriques (factors)I ethnicity vaut caucasian “cauc” & african-american “afam”I smsa résidence en zone urbaineI regionI parttime travail à mi-temps

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Factors & interactions
Équation de salaire
I Modèle :
log (wage) = �1
+�2
exp+�3
exp2
+�4
education+�5
ethnicity+✏
cps_lm<-lm(log(wage)~experience+I(experience^2)+education+ethnicity, data=CPS1988)
I “Insulation function” I( )I permet que ^2 soit compris par R comme le carré de la
variableI sinon, R n’est pas sûr de ce qu’on dit et retire experience^2
I c’est + clair avec une formule y ~ a + (b+c)I Est-ce qu’il y 2 variables à droite : a et (b+c) ou 3 ?I Pour clarifier on écrit y ~ a + I(b+c)
I summary(cps_lm)I Remarquez que le rendement de l’éducation est 8.57%/annéeI Les variables catégoriques sont gérées automatiquement par R
I qui choisit la cat. de référence

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Factors & interactions
ANOVA & Importance relative
I Tables Anova (Analysis of Variance)I anova(modèle lm)
I teste la significativé (avec un F = t2)I à chaque variable :
I associe la fraction du carré des erreurs qu’elle prend encompte par rapport au carré des erreurs total
I Donc, avec le ratio ’Sum Sq’/sum(’Sum Sq’)I on a une idée de l’importance relative de chaque variableI
Pde ces influences = R2 (non-ajusté)
I Le problème est que cette influence dépend de l’ordre desrégresseurs
I Voir PR2017.R

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Factors & interactions
Méthode alternative : Package relaimpo
I “6 metrics for assessing relative importance in linear models”I Les 2 premières sont recommandées : lmg et pmvdI Amène à des chiffres assez 6= d’ANOVA pour exp et exp2
I à cause de leur corrélationI Les métriques lmg et pmvd du package relaimpo
I décomposent R2en contributions non-négativesI qui somment à R2 automatiquement
I Ces métriques s’appuient sur des calculs semblables à ANOVAI Mais se débarrasse de la dépendance à l’ordre en prenant des
moyennes sur tous les ordres possiblesI Moyenne simple pour lmgI Moyenne pondérée pour pmvd

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Factors & interactions
ANOVA Comparaison de modèles anidés (nested)
I Régression + contrainteI cps_noeth<-lm(log(wage)~experience+
I(experience^2)+education, data=CPS1988)I Habituellement, le test porte sur + d’une variable
I anova(cps_noeth,cps_lm)I Plus de 2 modèles peuvent être passés à anova

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Factors & interactions
Interactions
I Effets combinés de régresseursI p.e. en travail, effet combiné d’éducation & ethnicité
I Capturé par des termes multiplicatifs
I Soit a, b, c des factorsI donc chacun avec pls niveaux discrets
I et x, y des variables continues (cardinales)

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Factors & interactions
Différents modèles à interactions
I y~a+x : pas d’interactionI une seule pente mais le factor induit un intercept par niveau
I y~a*x : même modèle que le précédent +I un terme d’interaction pour chaque niveau (variable
dichotomique) de a et de x (différentes pentes)I Dans une notation plus conventionnelle, avec d
ai
= I (a = i) :
[y ⇠ a ⇤ x ] ⌘"
y = �ai
X
i
dai
+ �ai
xX
i
dai
#
I y~(a+b+c)^2I modèle avec toutes les interactions à 2 variables
I mais pas à 3I Donc, autant de dichotomiques que le nombre de
dai�bj
= I (a = i ^ b = j) pour a & bI et pareillement pour a & c et c & b

Interactions éq. de salaire : ethnicité & éducation
I cps_int<-lm(log(wage)~experience+I(experience^2)+education*ethnicity, data=CPS1988)
I Un seul des “+” de cps_lm a été remplacé par *I coeftest(cps_int)
I Une version + compacte de summary( )I La régression donne les effets de education & ethnicity
I appelés “principaux” – main effectsI et le produit de education et d’un indicateur pour le niveau
“afam” de ethnicityI afam a un effet nég. sur l’intercept
I moindre salaire moyen pour les african-americanI et sur la pente de education
I moindre rendement de education pour les african-americanI L’effet est assez peu tranché
I car une significativité à 5% dans un éch. de près de 30 000individus est peu
I Exercice : l’expérience a-t-elle aussi un effet différencié selonl’ethnicité ?

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Factors & interactions
SWIRL Course “Regression Models”
I lesson 7 : “MultiVar Examples2”I BD : Plots pour le BoxPlotI sapply : utilisez help en BD
I Lesson 8 : MultiVar Examples3I Ces 2 lessons sont semblables à ce qu’on a fait
I Utilisez-le comme entrainement

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Splines
Sommaire
Régressions linéaire
Factors & interactions
Splines
Moindres Carrés Pondérés
Diagnostics de régression
Régression Quantile
Données manquantes (Missing data NA)
Régression automatisée

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Splines
Splines : Régressions partiellement linéaires
I Les termes quadratiques sont courants en régressions,I Mais la taille de CPS1988 peut permettre des outils +
flexibles, p.e.
log (wage) = �1+g (experience)+�2education+�3ethnicity+✏
g est une fonction inconnue à estimerI Les splines peuvent servir à cela
I Spline en français “cerce” (wikipedia)

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
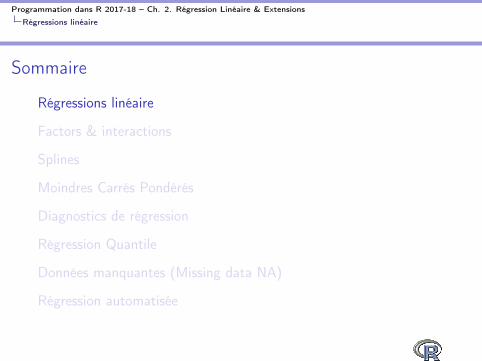
Splines
Spline : polynome continu par morceau
I Entre x et yI Polynome : linéaire, quadratique, cubique...
I Souvent cubiqueI Continu par morceau veut dire
I Les coefficients du polynome peuvent différer dans différentesrégions du plan (x , y)
I Les différents “morceaux” polynome soint joints à des noeuds(knots)
I Donc, en régression, un spline, pour un certain régresseur veutdire que
I L’effet de ce régresseur sur y est modélisé à l’aide d’unpolynome
Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Splines
Splines : représentation graphique

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Splines
Les splines font partie de la distribution de base
I Pas besoin de les installerI mais il faut les charger
I Pls types existent, on a vu les B-splinesI Ils sont pratiques : on choisit le degré du polynomeI Les noeuds sont équidistants
I 2 noeuds =) 3 régionscps_plm <- lm(log(wage)~bs(experience, df=5)+education +ethnicity,data=CPS1988)
I Les coefficients du spline n’ont pas bcp d’interprétation,I mais les autres coef. gardent leur sens
I p.e. rendement de education = 8.82%/année avec cettespécification
I Donc : utiliser les splines pour les régresseurs peu importantsI L’expression bs(experience, df=...) implique par défaut un
polynome de degré 3I df=5 définit implicitement le nombre de noeuds à 5-3=2
I Question : spline sur un factor ? Essayez

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Moindres Carrés Pondérés
Sommaire
Régressions linéaire
Factors & interactions
Splines
Moindres Carrés Pondérés
Diagnostics de régression
Régression Quantile
Données manquantes (Missing data NA)
Régression automatisée

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Moindres Carrés Pondérés
Moindres Carrés Pondérés (Weighted Least Squares)
I MCP est une réponse classique à l’hétéroscédasticitéI Alors que MCO donne un poids 1 à toutes les obs.I MCG équivalent à pondérer chaque obs. par la var. de l’erreur
I Supposons que cette variance dépende d’une variable z
E�
✏2i
|xi
, zi
�
= g⇣
z0i
�⌘
g : une fonction à valeurs positivesI Souvent on suppose E
�
✏2i
|xi
, zi
�
= �2z2
i
I Alors, si le modèle original est yi
= �1 + �2xi + ✏i
I Les variables transformées sont yi
/zi
et xi
/zi
I On passe zi
à R par un argument weight

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Moindres Carrés Pondérés
Moindres Carrés Pondérés
I Illustration avec données Journals vues + tôt
data("Journals", package = "AER")Journals$citeprice <- Journals$price/Journals$citationsjour_wls1 <- lm(log(subs)~log(citeprice), data=Journals, weights=1/citeprice^2)
jour_wls2 <- lm(log(subs)~log(citeprice), data=Journals, weights=1/citeprice)jour_lm <- lm(log(subs)~log(citeprice), data=Journals)plot(log(subs)~log(citeprice), data=Journals)abline(jour_lm)abline(jour_wls1, lwd=2, lty=2)abline(jour_wls2, lwd=2, lty=3)legend("bottomleft", c("OLS", "WLS1", "WLS2"), lty=1 :3,lwd=2, bty="n")

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Moindres Carrés Pondérés
Moindres Carrés Pondérés
I La plupart du temps, la forme de l’hét. est inconnueI On fait une hyp. linéaire dont on estime les paramètres
I p.e. E�✏2i
|xi
�= exp (�
1
+ �2
log (xi
))
I En pratique1. estimer le modèle original y
i
= �1 + �2xi + ✏i
2. calculer les résidus ✏i
= yi
� ˆ�1 � ˆ�2xi3. régresser ln
�
✏2i
�
= �1 + �2log (xi
) + µi
I appelé “régression auxiliaire”4. 1/
p
exp (�1 + �2log (xi
)) appelé p.e. wi
est passé commel’argument weight
I Exercice : appliquez aux données JournalsI Note : misspécifier Het peut faire pire que bien
I MCO inefficient mais consistantI MCP/MCG efficient si correctement spécifié mais sinon peut
être inconsistant
Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Diagnostics de régression
Sommaire
Régressions linéaire
Factors & interactions
Splines
Moindres Carrés Pondérés
Diagnostics de régression
Régression Quantile
Données manquantes (Missing data NA)
Régression automatisée

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Diagnostics de régression
Diagnostics de régression
I Même en l’absence de collinéarité ou d’autres problèmesévidents de données
I il est utile d’examiner les données pour 2 raisons
1. identifier les outliers (données “aberrantes”)2. identifier les obs. influentes (“leverage points”), s’il en est
I La limite entre aberrant & influent n’est pas netteI Une donnée aberrante n’est pas forcément influente (SWIRL)
I L’identification de ces données peut enclencher une étude +poussée
I La matrice de projection s’utilise pour des diagnosticsI dite aussi matrice chapeau (Hat matrix)
H = X⇣
X0X⌘�1
X0

Diagnostics de régression
I 8y , Hy est le vecteur de valeurs ajustées de la régression MCde y sur X :
Hy = X⇣
X0X⌘�1
X0y = X ˆ� = y
I Prémultiplier le y par la matrice H le change en yI D’où le nom Hat
I Soit hij
l’élément (i , j) de H
yi
= hii
yi
+
X
i 6=j
hij
yj
hii
mesure à quel point yi
est attiré par yi
I Une règle populaireI i est une obs. influente (leverage point) si
hii
> 2 ⇥moyenne (hii
) =
2kn
(k = nbr régresseurs, intercept compris)

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Diagnostics de régression
Diagnostics de régression
I Si on écrit M = I � H , les résidus MC sont
✏ = y�y = (I � H) y = (I � H) (X� + ✏) = X��HX�+(I � H) ✏
donc ✏ = (I � H) ✏
I L’espérance de la matrice de covariance des résidus MC est
E⇣
✏✏0⌘
= E⇣
(I � H) ✏✏0(I � H)
⌘
= �2
(I � H)
I On peut montrer que var (✏i
) = �2
(1 � hii
)
I Donc \var (✏i
) =
c�2(1 � h
ii
) avec c�2= s2
= ✏0✏/ (n � k)

Diagnostics de régression
I Pour identifier les résidus qui sont significativement grandsI Calculer les résidus standardisés
ei
=
✏i
p
s2(1 � h
ii
)
I On peut montrer que
✏i
/ (1 � hii
) = yi
� Xi
b(i)
où b(i) l’estimation MC de � sans l’observation iI En divisant par s2 ou s(i)2, on remet tous les cas à la même
échelleI Règle courante
I Si le résidu standardisé est trop grand p/r aux autres, obs i estaberrante (outlier)
I Plus grand que 2 en valeur absolueI Que 4 pour les grands jeux de données
I Pour autant que le modèle soit correct

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Diagnostics de régression
Diagnostics de régression
I Pour une autre illustrationI data “PublicSchools” du package sandwich préchargé avec
AERI données per capita sur les dépenses pour les écoles publiques
& le revenu (income)I par US states en 1979
I Attention au mode de financement des écoles publiques auxUSA
I Principalement publicI + 1 part subtantielle privéeI Assez bien comme les écoles privées en France

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Diagnostics de régression
Instructions R
data("PublicSchools", package = "sandwich")summary(PublicSchools)ps<-na.omit(PublicSchools)
I omettre les obs avec des na (données manquantes)ps$Income<-ps$Income/10000
I changer l’échelle de revenu pour les plotsplot(Expenditure~Income, data=ps)ps_lm<-lm(Expenditure~Income, data=ps)abline(ps_lm)id<-c(2,24,48)
I crée un petit vecteur d’obs intéressantes

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Diagnostics de régression
Diagnostics de régression
text(ps[id, 2 :1], rownames(ps)[id], pos=1, xpd=TRUE)I Nomme les données du vecteur précédent
I Cette commande n’est pas facile car la position du texteautour du point doit être précisée
I ps[id, 2 :1]I id indique les numéros des obs. qui doivent être nomméesI 2 :1 permet d’inverser l’ordre des colonnes
I pos indique la position du texte autour du pointI Il faut expérimenter
I xpd permet ici de mettre du texte hors de la zone de graphe

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Diagnostics de régression
Diagnostics de régression
I Le plot résultant montre qu’il y a une corrélation positive entreIncome et Expenditure
I mais Alaska pourrait être une obs. dominante car elle est loinde la masse des données
I Washington DC & Mississippi pourraient aussi être dominantesI La droite de régression pourrait être influencée par ces points
I Cela pourrait indiquer que ces états suivent des règles 6= debudget
I p.e. on peut imaginer que les coûts de transport en Alaskasont + importants, justifiant d’autres politiques

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Diagnostics de régression
Diagnostics de régression
I Lorsque la fonction plot( ) est appliquée à un objet lmI l’option “which = 1 :6” retourne 6 plots de diagnosticsI plot(ps_lm, which = 1 :6)I par défaut “which” retourne les plots 1, 2, 3, 5
Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Diagnostics de régression
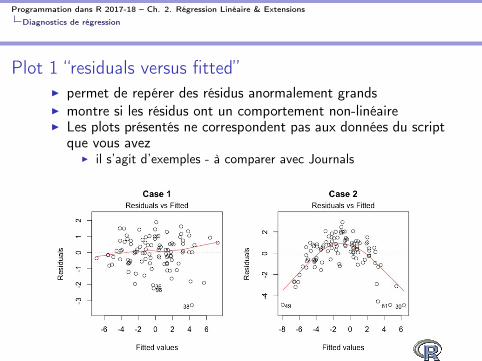
Plot 1 “residuals versus fitted”
I permet de repérer des résidus anormalement grandsI montre si les résidus ont un comportement non-linéaireI Les plots présentés ne correspondent pas aux données du script
que vous avezI il s’agit d’exemples - à comparer avec Journals
Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Diagnostics de régression
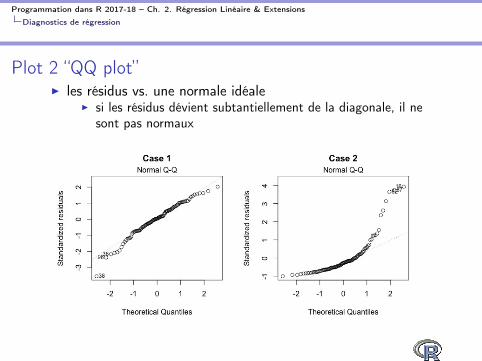
Plot 2 “QQ plot”
I les résidus vs. une normale idéaleI si les résidus dévient subtantiellement de la diagonale, il ne
sont pas normaux
Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Diagnostics de régression
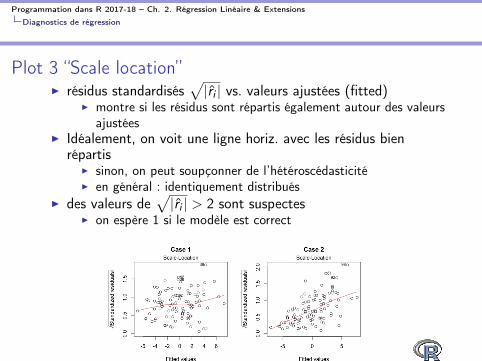
Plot 3 “Scale location”
I résidus standardisésp
|ri
| vs. valeurs ajustées (fitted)I montre si les résidus sont répartis également autour des valeurs
ajustéesI Idéalement, on voit une ligne horiz. avec les résidus bien
répartisI sinon, on peut soupçonner de l’hétéroscédasticitéI en général : identiquement distribués
I des valeurs dep
|ri
| > 2 sont suspectesI on espère 1 si le modèle est correct

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Diagnostics de régression
3 autres plots
I Plot 4 “Cook’s distance”I Plot 6 “Leverage against Cook’s distance”I Plot 5 “Standardized residuals against leverage”
I Le “leverage” d’une obs est hii
I l’élément diagonal de la matrice chapeau H
I Comme var (✏i
|X ) = �2(1 � h
ii
), un grand leverage est associéà une petite variance
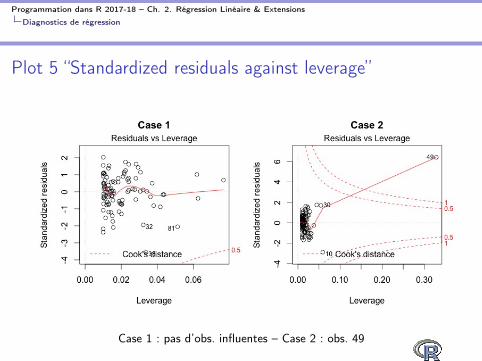
I Plot 5 aide à repérer les obs influentes par opposition à desoutliers
I On cherche les obs qui s’approchent des coins droits du plot,hors des lignes pointillées (distance de Cook)
I Alaska se fait remarquer, mais aussi, dans unemoindre mesure,Nevada et Washington DC
Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Diagnostics de régression
Plot 5 “Standardized residuals against leverage”
Case 1 : pas d’obs. influentes – Case 2 : obs. 49

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Diagnostics de régression
Function R influence.measures( )
I5 diagnostics d’élimination obtenus en retirant une obs. dela régression
I ˆ�(i) est le vecteur de paramètres estimés sans l’obs. iI idem pour �(i) et y(i) = X ˆ�(i)
I DFBETAi
=
ˆ� � ˆ�(i)I DFFIT = y
i
� yi,(i)
I CovRatioi
I déterminant de la mat. de var-cov des ˆ�(i) divisé déterminantde la mat. de var-cov des ˆ�
I D2i
=
(
y�y(i))T
(
y�y(i))
k�2 distance de CookI variance de DFFIT relativement à la variance totale
I Hat InfI + petit élément de la diag de la matrice chapeau HI indique le + grand leverage

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Diagnostics de régression
Diagnostics de régression
influence.measures(ps_lm) # retour au data.frame JournalsI retourne une matrice 6x50
I 1 col par coef + 5 stat, par obs.I marque les obs. influentes
I À ne pas faire avec trop de données

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Diagnostics de régression
Exercice
I Répliquez les diagnostics avec les régression sur JournalsI Swirl
I Cours « Regression Models » dans SwirlI Lesson 9 : “Residuals Diagnostics and Variation”
I Entrainement pour les concepts de la présente section
Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Régression Quantile
Sommaire
Régressions linéaire
Factors & interactions
Splines
Moindres Carrés Pondérés
Diagnostics de régression
Régression Quantile
Données manquantes (Missing data NA)
Régression automatisée

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Régression Quantile
Motivation : Techniques de régression robustes
I MC peut être assez influencé par peu d’obs.I Si l’échantillon est très grand, cette discussion est - importante
I p.e. en financeI Les diagnostics comme on a vu (“leave-one-out”)
I ne sont pas très bons pour détecter pls outliersI Les graphiques ne marchent bien que si l’on est assez sûr
I des régresseursI de la forme fonctionnelle
I Proposer des estimateurs “robustes” ou “résistants”I qui sont peu ou pas affectés par les outliers

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Régression Quantile
1. Régression Résistante
I Estimateur Least Trimmed Squares (LTS)I MC après retrait des outliers (sous-échantillon)I moindres carrés “élagués” ?
I Les outliers sont définis comme correspondant à un certainquantile des plus grand résidus / leverages
I après une première estimation MCO sur tout l’échantillonI LTS ne fait pas sens sur une série temporelle
I et pas bcp sens dans un groupe homogène, p.e. de paysI Le modèle ne s’applique-t-il que certaines années ou à certains
pays ?

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Régression Quantile
2. Régression Moindres déviations absolues
I Autre régression robuste : Least Absolute Deviation (LAD)estimator :
min
b
n
X
i=1
�
�
�
yi
� X0i
b�
�
�
“Moindres Écarts Absolus” ?I Plusieurs autres noms similaires
I LAD est + vieux que MCOI mais n’a été vraiment appliqué qu’à partir des années 2000
pour des questions de puissance de calculI LAD est un cas particulier de régression quantile
I Prochaine diapo

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Régression Quantile
3. Régression Quantile
I En général, on cherche ˆ�q
t.q.
Pr
n
yi
X0i
�q
o
= q
I Lorsque q = 0.5, c’est la régression médiane
I Trouver ˆ�median
t.q. la moitié des obs. yi
sont + grandes queleur valeur prédite X
i
ˆ�median
I Même chose que LADI Donc, si on choisit 1 obs au hasard (proba 1/n)
I Il y a 50% chance qu’elle soit + grande que sa valeur préditeI On voit que c’est + ordinal que MC
I “+ grand” simplementI de combien n’importe pasI et donc les outliers n’ont pas plus de poids que n’importe
quelle obsI Lorsque q est quelconque, on passe aux quantiles
I prochaine dia

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Régression Quantile
Rappel : Quantiles d’une Population
I Pour une v.a. continue yI Le qeme quantile population est la valeur µ
q
t.q. y µq
avecproba q
I Donc q = Pr [y µq
] = Fy
(µq
)
I Fy
est fonction de distribution (fonction de densité cumulative- cdf) de y
I Pour le modèle de régressionI Le qeme quantile population de y conditionnellement à X
I est la fonction µq
(X ) t.q. y conditionnel à X (l’erreur aufinal) est à µ
q
avec proba q
I la proba est évaluée en utilisant la distribution de yconditionnelle à X

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Régression Quantile
Quantiles de l’échantillon
I Pour une v.a. y , on a un échantillon {y1
, . . . , yn
}I L’estimation du quantile de µ
q
sur base de l’échantillon est labn
q
c eme plus petite valeur de l’échantillonI autrement dit, on ordonne du + petit au + grandI on prend l’observation y
i
qui se trouve en position n ⇥ qI notée µ
q
I où n est la taille de l’échantillonI bn
q
c indique nq
arrondi à l’entier supérieur le + procheI p.e. pour le quartile inférieur µ
1/4, q =
1/4I dans un échantillon de taille n = 97I l’estimateur est la 25eme obs. de l’échantillon
I car 97 ⇥ 1/4 = 24.25 arrondi à l’entier sup. = 25

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Régression Quantile
Quantiles de l’échantillon
I Le qeme quantile de l’échantillon µq
I peut être exprimé comme la solution de la minimisationsuivante p/r �
n
X
i :yi
��
q|yi
� �|+n
X
i :yi
<�
(1 � q)|yi
� �|
I Ce résultat peut être étendu à la régression linéaire :I l’estimateur régression du qeme quantile est le vecteur ˆ�
q
quiminimise sur �
q
n
X
i :yi
�X
0i
�q
q|yi
� X0i
�q
|+n
X
i :yi
<X
0i
�q
(1 � q)|yi
� X0i
�q
|
IInterprétation : l’estimateur partitionne l’échantillon entre
I une part q des prédictions + petites que les obsI et une autre part (1 � q) + grandes

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Régression Quantile
Régression Quantile
I Différents choix de q mènent à différentes estimations de �q
I q = 0.5 mène à la régression médianeI La fonction objectif qu’on vient de voir n’est pas
différentiableI On ne peut pas calculer de dérivéeI Des méthodes de programmation math type Kuhn-Tucker,
optimisation sous contraintes d’inégalité, sont employéesI Donc pas de solution explicite pour ˆ�
q
I Il a été montré queI ˆ�
q
est consistant pour �q
et asymp. normalI sa matrice de var-cov est compliquée
I et peut être estimée par bootstrap (cours np)

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Régression Quantile
Interprétation des résultats d’une régression quantile
I Se rappeler que �q
est t.q. Prn
yi
X0i
�q
o
= q
I Donc : pas la même chose que “� t.q. yi
= X0
i
� + ✏i
”I Cependant, µ
q
= yq
= X0ˆ�q
I Interprétation similaire à MC dans le sens où ˆ�q
reflète unchangement de X sur µ
q
I µq
étant la valeur espérée du quantile q de y
I Puisque �q
est généralement différent pour différents qI l’effet d’un régresseur peut changer selon les niveaux de yI p.e. l’élasticité revenu peut être faible à un bas niveau de
revenus et + forte lorsque ce niveau augmente

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Régression Quantile
Interprétation des résultats d’une régression quantile
I MCO est souvent comparé à la régression médianeI car si la distribution de l’erreur est symmétrique, alors médiane
= moyenneI Les régressions quantiles impliquent qu’en se concentrant sur
la seule moyenne contionnelleI MC donne une image incomplète de la distribution de y

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Régression Quantile
Régression quantile : Exemple des déterminants du salaire
I Estimation d’un équation de salaireI Données de Berndt 1991
I Sous-échantillon aléatoire d’une coupe transversale,I Mai 1985 “Current Population Survey”, 533 observations

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Régression Quantile
Régression quantile : les commandes
data("CPS1985", package="AER")cps<-cps1985library(“quantreg”)
I Charge le package régression quantile [CITE]cps_lm<-lm(log(wage)~experience+I(experience^2)+education,data=cps)
I Régression MCOI “Insulation function” comme on a vuI “standard Mincer equation”
cps_rq<-rq(log(wage)~experience+I(experience^2)+education, data=cps,tau=seq(0.2, 0.8, by=0.15))
I Exécute 5 régressions quantiles avec q= 0.2 0.35 0.5 0.65 0.8

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Régression Quantile
Régression quantile : sorties
summary(cps_rq)I Summary fonctionne sur la plupart des objets
I 5 régressions, une est la médianeI Présente les coef + plus un IC
I pas de t ou équivalentI Signale des difficultés de l’optimisation
I “solution may be non-unique”summary(cps_rq, se="boot")
I Calcule des t-stat par bootstrapI Cfr cours npI Va lentement
I Possible de tester via anova( ) si les coefficients sont lesmêmes sur l’ensemble des régressions quantiles
plot(summary(cps_rq))I donne les changements des coefficients des régressions sur les
5 quantilesI avec IC à 90%

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Régression Quantile
Exemple quantile. Prédictions
I Évaluations graphiques des 2 estimateursI On veut calculer les prédictions des 2 estimateurs
I à éducation constanteI D’abord on crée un nouveau dataset :
cps2<-data.frame(education=mean(cps$education), experience=min(cps$experience) :max(cps$experience))
I 2 columnsI la 1º est constante (moyenne de education)I la 2º a toutes les valeurs de experience
I Pour les 2 estimateursI on calcule les prédictions en utilisant predict( )
I format predict(estimateur, nvlle données, options )I et on concatène les résultats dans de nvlles colonnes de cps2
I ensuite on mettra ça dans un plot

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Régression Quantile
Exemple quantile. Prédictions
cps2<-cbind(cps2, predict(cps_lm, newdata=cps2, interval="prediction"))
I Rappel cbind combine des obejts R par colonneI donc on a ajouté les prédictions “fit” du l’estimateur lm aux
nouvelles données cps2,I avec les limites d’intervale à 95% : lwr et upr pour la basses et
la haute respectivementI ceci vient de l’option interval="prediction"
I cps2 a à présent 5 cols :I Moyenne(Educ), experience, prédiction lm, borne inf, borne sup
cps2<-cbind(cps2, predict(cps_rq, newdata=cps2, type=""))I Même chose avec les prédictions de l’estimateur rq
I pas d’intervale de confiance, mais 5 quantilesI type n’est pas vraiment utile ici, mais permettrait de calculer
des IC (par bootstrap)I voir ?predict.rq

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Régression Quantile
Exemple quantile. Évaluations graphiques
I On visualise les résultats des régressions quantiles dans unscatterplot de log(wage) vs. experience
I en ajoutant les lignes de régression pour tous les quantiles(0.2, 0.35, 0.5, 0.65, 0.8)
I à la moyenne de education :
plot(log(wage)~experience, data=cps)for(i in 6 :10) lines(cps2[,i]~experience, data=cps2, col="red")
I On ajoute les cols 6 à 10 de cps2 en lignes rouges dans le plotI On pourrait ajouter les lignes une par uneI Utiliser for permet de garder le code + compact
lines(cps2[,3]~experience, data=cps2, col="blue")I prédiction lm, en blue
for(i in 4 :5) lines(cps2[,i]~experience, data=cps2, col="green")I même chose avec les 2 bornes de l’IC de la prédistion lm, en
green

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Régression Quantile
Exemple quantile. Évaluations graphiques
I Comme il y a 533 observations, bcp sont cachées dans le plotI On ne se rend donc pas compte de la densité des observations
I Ceci peut être résolu en estimant une densité noyau bivariéeI et en faire un plot : la “heatmap”I Une des bases des régressions np
I Peu d’explications sont données ici

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Régression Quantile
Exemple quantile. Évaluations graphiques
I L’estimateur de la densité noyau est (ici) bkde2D( )library("KernSmooth")cps_bkde<-bkde2D(cbind(cps$experience, log(cps$wage)), bandwidth=c(3.5,0.5), gridsize=c(200, 200))
I bkde2D ne fonctionne pas comme lm( ) or rq( )I il faut extraire les cols pertinentes du dataset cpsI et choisir la “bandwidth” et la Gridsize où veut la
représentationI bandwidth : voir cours npI Gridsize : juste les limites du grapheI chacun doit être défini sur les 2 dimensions (experience &
log(wage))image(cps_bkde$x1, cps_bkde$x2, cps_bkde$fhat, col=rev(gray.colors(10,gamma=1)), xlab = "experience", ylab="log(wage)")
I c’est la heatmap

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Régression Quantile
Exemple quantile. Évaluations graphiques
box( )I améliore la présentation
lines(fit~experience, data=cps2)I la ligne de régression
lines(lwr~experience, data=cps2, lty=2)I borne inf de l’IC de la prédiction de la régression lm
lines(upr~experience, data=cps2, lty=2)I borne sup
for(i in 6 :10) lines(cps2[,i]~experience, data=cps2, col="blue")I les prédictions rq

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Régression Quantile
Devoir 2
1. Considérer le dataset CigarettesB de Baltagi (2002)I Régresser “real per capita consumption” sur “real price” et “real
per capita income”I Toutes les variables en log
I Obtenir les diagnostics influence.measures(). Quellesobservations sont influentes ? À quels étatscorrespondent-elles ? Ces résultats sont-ils intuitifs ?
2. En discutant les régressions quantiles, on est resté sur lastandard Mincer equation. Cependant les données CPS1985que nous avons utilisées contiennent d’autres régresseurs, entreautres les factors ethnicity, sector, region, et married.Répliquer notre analyse avec ces factors, discuter vos résultats.
3. Adapter les questions 1 et 2 à un autre dataset, que voustrouvez dans R ou ailleurs.
4. SWIRL cours « Regression Models »I Lessons 12 Binary outcomes & 13 Count outcomes

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Données manquantes (Missing data NA)
Sommaire
Régressions linéaire
Factors & interactions
Splines
Moindres Carrés Pondérés
Diagnostics de régression
Régression Quantile
Données manquantes (Missing data NA)
Régression automatisée

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Données manquantes (Missing data NA)
Package & données
I packages VIM & miceI Données sleep sommeil de mammifères de VIM
I length of dreaming sleep (Dream)I nondreaming sleep (NonD)
I their sum (Sleep)I body weight in kg (BodyWgt)I brain weight in grams (BrainWgt)I life span in years (Span)I gestation time in days (Gest)I on 5-point rating scales that ranged from 1 (low) to 5 (high)
I degree to which species are preyed upon (Pred)I degree of their exposure while sleeping (Exp)I overall danger (Danger) faced

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Données manquantes (Missing data NA)
Localiser les données manquantes
I Les symboles RI NA missing value (not available)I NaN valeur impossible (not a number)I Inf & -Inf : 1 et �1, respectivement
I Fonctions d’identificationI renvoient un objet de même taille que leur argument, remplit
de true ou false
x is.na(x) is.nan(x) is.infinite(x)x<-NA true false falsex<-0/0 true true falsex<-1/0 false false true
I Il faut utiliser ces fonctionsI p.e. x==NA ne marche pas

Pourquoi des données manquent
1. Manque n’est corrélé à aucune variable observée ou inobservéeI Pas de vraie inquiétudeI Missing completely at random (MCAR)
2. Manque est corrélé à des variables observéesI mais pas à la valeur inobservée
I p.e. les valeurs faibles auraient tendance à être manquantesI p.e. de plus légers animaux pourraient manquer de données
DreamI Peut-être parce qu’ils sont + difficiles à observerI mais les valeurs de Dream qui manquent ne sont pas corrélées
aux poids qui manquentI C’est-à-dire : Le poids impacte négativement la proba
d’observer Dream, mais pas les valeurs de DreamI Missing at random (MAR)
3. Manque n’est pas du au hasardI p.e. les animaux qui rêvent moins ont + de données
manquantes pour DreamI Estimateurs MC biaisés ! modèles de sélectionI Not missing at random (NMAR)

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Données manquantes (Missing data NA)
Examens graphiques
I Avec complete.cases, on voit 42 complets, 20 avec au moinsune obs manquante
I 12 manquants sur Dream seulI Essayer de comprendre pourquoi des données manquent
I md.pattern(sleep) de mice produit une tableI VIM est fait pour une visualisation des données manquantesI aggr(sleep, prop=FALSE, numbers=TRUE)
I nombre de val. manquantes par variable, seules et encombinaison
I matrixplot(sleep)I données numériques en échelles de gris, clair pour des valeurs
faiblesI NA en rouge
I marginplot(sleep[c("Gest","Dream")], pch=c(20),col=c("darkgray", "red", "blue"))
I Scatter Gest~Dream avec NA en rouge + Boxplots

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Données manquantes (Missing data NA)
Shadow matrix
I remplacer les données par des indicatrices, 1 si NA, 0 sinonI x <- as.data.frame(abs(is.na(sleep)))
I Shadow matrixI y <- x[ , colSums(x) > 0]
I extrait les 5 variables qui ont au moins un NAI cor(y) : corrélations parmi ces indicatrices
I Corrélations assez fortes entre les NA de Dream & deNonD(ream)
I Sans doute liées à la difficulté d’observer les animaux quidorment
I Sleep = Dream+NonD : pas très utileI cor(sleep, y, use="pairwise.complete.obs")
I Corrélations entre les valeurs observées des variables sans NAI et la présence de NA pour les 5 variables de y
I Ne dépassent pas 20% : faiblesI Probablement : MCAR

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Données manquantes (Missing data NA)
Si les NA
I Sont concentrées sur des variables hors régressionI pas d’importance
I Sont MCAR et peu nombreuses (10% ?)I Éliminer les obs qui ont des NA
I newdata <- na.omit(mydata)I Après avoir enlevé les variables qui ne vous intéressaient pas
I Certaines fonction, lm p.e., “passent” les obs avec des NA pourles variables de la régression seulement !
I Voir s’il est possible de combler les manques sur base logiqueI p.e. age manque, mais pas l’année de naissance
I Sont MCAR mais + nombreuses (quel Max ?)I Ou MAR
I Alors méthode d’imputation multipleI NMAR
I Modèles de sélection

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Données manquantes (Missing data NA)
Principe d’imputation multiple
I Multivariate Imputation by Chained Equations (MICE)I La commande reçoit le jeu de données X pertinent
I mice(data, m = 5, method = vector(...), ...)I Une valeur est imputée à chaque NA ! ˜XI Selon une de plusieurs méthodes dites élémentaires indiquée
dans methodI On fait ça le nombre de fois indiqué par m, par défaut 5 :
n
˜X1, ..., ˜X5
o
I with( ) permet d’exécuter une analyse (p.e. lm)I sur tous les jeux de données “complétés” ˜X
i
I Les résultats sur chaque jeu sont stockésI pool( ) aggrège les m résultats en unI Voir script

Méthodes élémentaires d’imputation
I L’option method indique comment imputerI Chaque variable peut avoir une méthode d’imputation
différente, indiquée par vector( )I La méthode par défaut
I diffère par variable selon son typeI Ces méthodes par défaut peuvent être spécifiées
I Par défaut on aI pmm, predictive mean matching pour les données numériques
I Essentiellement une prédiction MCO et choisir aléatoirementparmi les données réelles les + proches
I logreg, logistic regression imputation pour les factors à 2niveaux
I polyreg, une extension à k�2 pour les factors à k catégoriesnon ordonnées
I polr, proportional odds model pour les factors à k catégoriesordonnées
I Aucune imputation pour une variable sans NA
Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Régression automatisée
Sommaire
Régressions linéaire
Factors & interactions
Splines
Moindres Carrés Pondérés
Diagnostics de régression
Régression Quantile
Données manquantes (Missing data NA)
Régression automatisée

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Régression automatisée
Introduction
I Lorsqu’on construit un modèle, 2 forces contradictoiresI Omettre un régresseur pertinent amène à
I hétérogénéité inobservéeI inconsistance des estimateurs MC si le régresseur omis est
corrélé aux régresseurs inclusI Inclure un régresseur non-pertinent qui est corrélé aux
régresseurs pertinentI crée de la multicollinéaritéI et donc les régresseurs pertinents comme non-pertinents
peuvent apparaître non-signif.I Cela peut même arriver entre 2 régresseurs pertinents p.e.
dans une relation de demande, le prix et celui d’un substitut
I Donc, on veut retirer des régresseurs, mais pas les pertinents

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Régression automatisée
Plusieurs manières
I AscendanteI On inclut un régresseur, s’il est significatif on calcule les résidusI On régresse les résidus sur un aute régresseur et ainsi de suiteI Problème : hétérogénéité inobservée dans les premières étapes
I DescendanteI On part d’un ensemble large de régresseursI On élimine progressivement sur base du t-stat ou du F-stat
I ExhaustiveI On utilise la puissance de calcul de la machine pour examiner
toutes les combinaisons de régresseurs

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Régression automatisée
Akaike Information Criterion
I Pour automatiser la recherche, il faut un critèreI R2 ne convient car il ne sert que pour MCOI AIC est général
I AICI k nbr de paramètres estimé du modèleI ˆL la vraisemblance estimée du modèle
I Définie même si le modèle n’est pas estimé par Maximum devraisemblance
I AIC = 2k � 2 ln ˆLI AIC est basé sur la théorie de l’informationI L’intuition est brièvement expliquée à la diapo suivante

Comprendre AIC = 2k � 2 ln LI Soit f le processus inconnu qui a généré les données
I Soit un modèle g1 de fI L’information perdue en utilisant g
1
pour représenter f est ladivergence de Kullback–Leibler D
KL
(f k g1
)
I Que je n’explique pas ici, mais qui est essentiellement le logdu ratio des proba de f aux proba de g
1
, donc toujours < 0I Soit un modèle g2 de f
I Si on connaissait f on pourrait calculer DKL
(f k g1
) etD
KL
(f k g2
) pour choisir le meilleur modèleI AIC permet d’estimer la différence entre les deux D
KL
Iexp ((AIC
min
� AICmax
) /2) est proportionnel à la proba que lemodèle AIC
max
minimise la perte d’informationI p.e. exp ((100 � 102) /2) = .368
I le modèle AICmax
est .368 aussi probable que le modèle AICmin
de minimiser la perte d’infoI p.e. exp ((100 � 110) /2) = .007
I proba .007 que le modèle AICmax
minimise la perte d’info parrapport au modèle AIC
min
I Le nbr de paramètres estimés k pénalise le AIC

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Régression automatisée
Package glmulti
I Trouve les n meilleurs modèlesI parmi l’ensemble candidat spécifié par l’utilisateur
I Les modèles sont ajustés par une fonction spécifiéeI par défaut glm – generalized linear modelI et classé selon un critère spécifié, par défaut AIC ajusté pour la
taille de l’échantillonI La recherche est soit
I exhaustiveI ou utilise un algorithme dit génétique
I lorsque l’ensemble candidat est grand

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Régression automatisée
Package glmulti
I Commande génériqueI glmulti(y, xr, data, level, exclude = c(), method, fitfunction,
...)I y : habituellement la dépendante (“caractère”), mais peut aussi
être un modèleI xr : si y est la dépendante, les régresseurs, sinon inutileI data : le dataframe, obligatoireI level : si 1, seulement les main effects ; si 2, toutes les
interactions à 2 (apparemment pas les carrés ?)I exclude : exclure certain terme (main effect ou interaction)I method : “h” = exhaustive, “g” genetic algorithm, “l”algorithme
“branch & bound” rapideI fitfunction : toute fonction d’ajustement, “glm” par défaut,
“lm”

Programmation dans R 2017-18 – Ch. 2. Régression Linéaire & Extensions
Régression automatisée
Package glmulti : Example
I CPS1985$lwage <- log(wage)I CPS1985$exp2 <- experience^2I cps_multi<-glmulti("lwage",
c("experience","exp2","education","age","ethnicity","gender"),exclude=c("experience :exp2"),data=CPS1985,fitfunction= "lm")
I attention c’est longI Intercept ou non, interactions à 2 ou non, carrés ou non
I 1 régresseur ! 2 (intercept) x 3 (x1 seul, x21 seul, x1 + x2
1 ) = 6modèles
I 2 régresseurs ! 1,x1, x21 , x2, x2
2 ,x1 : x2I combinaisons de ces 6 termes + 1 terme implicite (=ne pas
mettre le terme) = 7 ! modèles = 5040I best models lwage ~ 1 + experience + exp2 + education +
exp2 :experience + gender :experience + gender :exp2I Le traitement des carrés pose un problème










![Multipoint molecular recognition within a calix[6]arene ... · Multipoint molecular recognition within a calix[6]arene funnel complex David Coquie`rea, Aure´lien de la Landeb,c,](https://img.pdfslide.fr/doc/110x75/611e40bdf362c121ca0e7d8a/multipoint-molecular-recognition-within-a-calix6arene-multipoint-molecular.jpg)