Embed Size (px)
Citation preview

029-a NTE SGH – août 2012
Rapport de stage
Mise en place d’une Infrastructure de
Données Spatiales hétérogènes dans le
cadre d’un projet pluridisciplinaire dans
l’objectif de la compréhension de la
biodiversité en République Centrafricaine
Siège social
25bis, rue Jean Dolent
75 014 PARIS
Tél. (+33) 1 45 45 46 61
Fax. (+33) 1 43 31 62 24
SARL au capital de 24 000 € SIRET : 422 598 441 00026
Code APE : 721Z
Aurélie BATANY Master 2 SIG et Gestion de l’Espace
Parcours Professionnel 2011-2012
Sous la direction de :
Rousselin Thierry, maître de stage : Géo212 Guerin Karine, maître de stage : Géo212

Mise en place d’une infrastructure de données
spatiales
Rapport Batany Master 2 SIG et Gestion de l’Espace – août 2012 2/66
Résumé
Ce projet s’inscrit dans le cadre d’un inventaire de la biodiversité dans un parc naturel en
République Centrafricaine. Parmi les contributions géospatiales prévues (GPS, Télédétection,
Géomatique), il est demandé de mettre en place une infrastructure de données spatiales (IDS).
Les travaux réalisés concernent la partie amont : analyse du besoin, modélisation, choix des
outils, développement de la base de données et tests de peuplement avec les multiples types
de données à mutualiser. Le caractère associatif, multipartenaires et international du projet a
orienté vers le développement d’une application webmapping pour la saisie de données en
ligne. Le rapport propose des recommandations pour la phase aval de déploiement de l’IDS,
pour la gestion des attentes variées des partenaires et pour l’utilisation de l’IDS tant pour les
échanges entre scientifiques que pour des besoins de communication et de vulgarisation.
Mots clés : Infrastructure de données spatiales, modèle de données, base de données,
biodiversité, données hétérogènes, interopérabilité, open source, webmapping, SIG, Bassin du
Congo, République Centrafricaine, Sangha.
Abstract
This study is in line with in a biodiversity inventory project in a National Park in Central
African Republic. Among other geospatial activities (through the use of GPS, Remote
Sensing and Geomatics), it is requested to set up a spatial data infrastructure (SDI). This work
deals with the initial steps of the project: gathering and analysis of user requirements,
modeling, software choice, development of the database and tests of data conversion and
integration. Due to the characteristics of the project (non profit, multi-national, …) it was
necessary to access data online through a very simple web base interface allowing all
involved parties to browse, search, analyse and export data. This report also contains technical
and organizational recommendations for the future phases of the project. It will help to gather
additional requirements, manage the project and use it as a platform for scientific exchanges
and communication.
Keywords : spatial data infrastructure, data model, database, biodiversity, heterogeneous data,
interoperability, open source, webmapping, GIS, Congo Basin, Central African Republic,
Sangha.

Mise en place d’une infrastructure de données
spatiales
Rapport Batany Master 2 SIG et Gestion de l’Espace – août 2012 3/66
TTaabbllee ddeess mmaattiièèrreess
1 Introduction ............................................................................. 7
2 Contexte et objectifs ................................................................ 8
2.1 Contexte...................................................................................... 8 2.1.1 Geo212 ............................................................................................ 8 2.1.2 Projet Sangha ................................................................................... 8 2.1.3 La zone d'étude ................................................................................10 2.1.4 Contexte relationnel et organisationnel ...............................................11
2.1.4.1 Impact des caractéristiques du projet ..............................................11 2.1.4.2 Place des travaux Géo212 dans le projet ..........................................12 2.1.4.3 Place des stages dans le projet .......................................................12
2.2 Objectifs .................................................................................... 13 2.2.1 Objectifs initiaux ..............................................................................13 2.2.2 Suivi et recadrage des objectifs ..........................................................15
3 Phase de conception .............................................................. 16
3.1 Définition du besoin .................................................................. 16
3.2 Bibliographie et état de l’art ..................................................... 18 3.2.1 Infrastructure de Données Spatiales ...................................................18 3.2.2 Etat de l’art des IDS existantes dans le domaine de l’environnement ......20
3.3 Objectifs de l’IDS ...................................................................... 22
3.4 Adaptation aux contraintes rencontrées ................................... 23
4 Mise en place de la base de données ...................................... 25
4.1 Méthode de conception ............................................................. 25 4.1.1 Méthode MERISE ..............................................................................25 4.1.2 Concepts retenus..............................................................................27
4.2 Démarche de création de la base de données ............................ 28 4.2.1 Données disponibles .........................................................................28 4.2.2 Démarche suivie ...............................................................................29 4.2.3 Niveaux d’analyse des données ..........................................................30
4.2.3.1 Modèle conceptuel des données ......................................................30 4.2.3.2 Modèle logique des données ...........................................................32 4.2.3.3 Modèle Physique des Données ........................................................36
4.2.4 Règles de création de tables à respecter ..............................................38
4.3 Choix du logiciel ........................................................................ 39 4.3.1 Critères de choix ..............................................................................39
4.3.1.1 Logiciel libre .................................................................................39 4.3.1.2 Lecture d’un grand nombre de format de données spatiales................39 4.3.1.3 Respect des normes et standards de l’OGC .......................................39 4.3.1.4 Logiciel suivi par l’OSGeo ...............................................................40 4.3.1.5 Logiciel connu de l’entreprise ..........................................................40 4.3.1.6 Autres critères ..............................................................................40
4.3.2 Liste des SGBD relationnels ...............................................................41

Mise en place d’une infrastructure de données
spatiales
Rapport Batany Master 2 SIG et Gestion de l’Espace – août 2012 4/66
4.3.3 Logiciel sélectionné : PostgreSQL/PostGIS ...........................................41
4.4 Démarche de peuplement ......................................................... 42 4.4.1 Introduction .....................................................................................42 4.4.2 Méthodes utilisées ............................................................................42 4.4.3 Difficultés rencontrées.......................................................................43 4.4.4 Bilan de peuplement .........................................................................44
4.4.4.1 Travail réalisé ...............................................................................44 4.4.4.2 Tests et contrôle qualité .................................................................44 4.4.4.3 Modifications réalisées ...................................................................45
4.4.5 Recommandations pour la poursuite du projet ......................................45 4.4.5.1 Reprises d’optimisation de la base de données ..................................46
4.4.5.1.1 Choix d’une géométrie unique dans chaque table .................................... 46 4.4.5.1.2 Création d’index spatiaux ..................................................................... 46 4.4.5.1.3 Division de la table classification ........................................................... 46
4.4.5.2 Reprises suite à des erreurs d’intégration .........................................47 4.4.5.3 Reprises suite à des erreurs dans les données sources .......................47 4.4.5.4 Intérêt des informations sur le matériel scientifique de terrain ............47 4.4.5.5 Amélioration des travaux de contrôle et de tests ...............................49 4.4.5.6 Conseil pour la suite de la construction de la base de données ............49
4.5 Conclusion ................................................................................. 49
5 Interface Webmapping ........................................................... 51
5.1 Besoins et objectifs ................................................................... 51
5.2 Qu’est ce que le webmapping ? ................................................. 51
5.3 Démarche et méthode/Choix logiciel ........................................ 53 5.3.1 Road Map du projet d’interface webmapping Sangha ............................53 5.3.2 Critères d’évaluation des solutions ......................................................53
5.3.2.1 Respect des normes de l’OGC .........................................................53 5.3.2.2 Communauté large d’utilisateurs .....................................................54
5.3.3 Etat de l’art .....................................................................................55 5.3.3.1 Les clients légers...........................................................................55 5.3.3.2 Les serveurs cartographiques .........................................................57
5.3.4 Choix des logiciels ............................................................................58
5.4 Développement de l’interface .................................................... 58 5.4.1 Architecture mise en place .................................................................58 5.4.2 Fonctions disponibles ........................................................................60 5.4.3 Difficultés rencontrées.......................................................................61
5.5 Recommandations ..................................................................... 62
6 Conclusion .............................................................................. 63
7 Bibliographie .......................................................................... 65
Mise en place d’une infrastructure de données
spatiales
Rapport Batany Master 2 SIG et Gestion de l’Espace – août 2012 5/66
TTaabbllee ddeess iilllluussttrraattiioonnss
Figure 1 : Situation du Parc Tri National de la Sangha ..................................... 9 Figure 2 : Situation de la zone étudiée ........................................................ 11 Figure 3 : Les grandes étapes du projet définies dans l’OT initial .................... 14 Figure 4 : Exemple d'architecture d'une IDS ................................................ 19 Figure 5 : Les principales fonctions d’un SGBD ............................................. 19 Figure 6 : Architecture du GBIF .................................................................. 21 Figure 7 : Nouvel Organigramme des Tâches prévisionnel ............................. 24 Figure 8 : Représentation en 3D des phases MERISE .................................... 26 Figure 9 : Acteurs de la mise en place du Modèle Conceptuel des Données ...... 30 Figure 10 : Modèle Conceptuel des données du projet SANGHA ...................... 31 Figure 11 : Termes utilisés pour la construction du MLD ................................ 32 Figure 12 : Association entre 2 tables ......................................................... 33 Figure 13 : Zoom sur la partie centrale du modèle logique des données .......... 34 Figure 14 : Exemple de cardinalités possibles .............................................. 35 Figure 15 : Exemple de typologie et de relations .......................................... 37 Figure 16 : La relation de type N:N dans le Modèle Physique des Données....... 38 Figure 17 : Données géométriques avant et après conversion ........................ 43 Figure 18 : Exemple d'inventaire présentant des point-virgules ...................... 44 Figure 19 : Exemples de mauvaises jonctions entre données multisources....... 44 Figure 20 : Exemple de symbole parasite dans les données attributaires ......... 45 Figure 21 : Proposition d’optimisation des tables géométriques ...................... 46 Figure 22 : Proposition d'optimisation de la table de classification des espèces . 48 Figure 23 : Architecture d'un outil de Webmapping ....................................... 52 Figure 24 : Exemple de rendu cartographique avec OpenLayers ..................... 56 Figure 25 : Exemple de rendu cartographique avec GeoExt ........................... 56 Figure 26 : Interface de visualisation de Géobretagne créée avec Mapfish ....... 57 Figure 27 : Architecture de la solution webmapping mise en place .................. 59 Figure 28 : Interface de saisie.................................................................... 60 Figure 29 : Lien vers d’autres pages web .................................................... 60
TTaabbllee ddeess ttaabblleeaauuxx
Tableau 1 : Synthèse de l'analyse des besoins des partenaires contactés ........ 17 Tableau 2 : Les trois niveaux de modèle suivis d'après la méthode MERISE ..... 27 Tableau 3 : Inventaire des données disponibles en juin 2012 ......................... 28 Tableau 4 : Les principaux SGBD analysés................................................... 41 Tableau 5 : Liste des outils de webmapping soutenus par l'OSGeo .................. 54 Tableau 6 : Comparaison des clients légers ................................................. 55 Tableau 7 : Comparaison des serveurs cartographiques ................................ 57 Tableau 8 : Liste des fonctions de l'interface ................................................ 61

Mise en place d’une infrastructure de données
spatiales
Rapport Batany Master 2 SIG et Gestion de l’Espace – août 2012 6/66
Remerciements
Je tiens tout particulièrement à remercier :
Thierry Rousselin mon maître de stage à Géo212, qui m'a permis de réaliser ce stage. Par ces
questionnements et réflexions, il a permis de faire avancer mes travaux dans le bon sens.
Karine Guérin, également mon maître de stage à Géo212, qui a su m'épauler et me conseiller
tout au long du stage.
Nicolas et Sandy, qui par leurs connaissances en modèle de données et base de données, ont
pu m'aiguiller dans mes choix et m’aider à la mise en place des outils.
L’ensemble de l’équipe du projet Sangha pour les échanges constructifs que nous avons pu
avoir. Ma collaboration au sein d’une équipe spécialisée en biodiversité et plus
particulièrement l’entomologie m’a permis de me replonger à nouveau dans le domaine de
l’écologie.
Je tiens également à remercier toute l’équipe de Géo212 : Camille, Gilles, Alexandra,
Jacques, Pierre Noël, ainsi qu’à Bénédicte, pour leurs bonnes idées, leurs très bons conseils, et
leur soutien. Ils ont fait en sorte que ce stage se déroule dans de bonnes conditions.

Mise en place d’une infrastructure de données
spatiales
Rapport Batany Master 2 SIG et Gestion de l’Espace – août 2012 7/66
1 Introduction
La présente étude s’inscrit dans le projet SANGHA, une initiative pluridisciplinaire qui a pour
objectif de découvrir et inventorier la biodiversité dans un Parc National en République
Centrafricaine. Notre travail fait suite à deux missions de terrain de l’équipe de naturalistes du
projet Sangha 2012, l’une s’étant déroulé en 2010, la deuxième s’étant achevée en mars 2012.
Au retour des missions, des milliers d’échantillons, collectes, photographies, mesures
physiques (GPS, température, pression, luminosité), acquises de 2010 à 2012 peuvent être
corrélées avec un série temporelle constituée de dizaines d’images de télédétection de 1979 à
2012 acquises avec des capteurs optiques, radar et infra rouge divers.
Notre travail concerne la mise en place d’une infrastructure de données spatiales (IDS) afin de
satisfaire le besoin de mutualisation des données issues de nombreux domaines d’études.
Les objectifs visent la pérennisation des informations collectées, le soutien à l’analyse
pluridisciplinaire, de la communication tant interne qu’externe (le projet Sangha 2012 inclut
un volet pédagogique avec des interventions dans les écoles en France et en RCA).
Notre travail est présenté dans les chapitres suivants.
Suite à la présentation du contexte et des objectifs de ce stage dans le chapitre 2, le chapitre 3
présente la phase de conception de l’IDS : le recueil du besoin auprès des partenaires et futurs
utilisateurs, une recherche bibliographique et un état de l’art des projets de même type, suivi
de la définition des objectifs de l’IDS.
Le chapitre 4 présente les différentes étapes suivies pour mettre en place un des outils de
l’IDS : la base de données et tester son efficacité via un premier peuplement en données. Le
chapitre 5 traite de la mise en place d’un outil de saisie basé sur le développement d’une
interface de webmapping.
La conclusion (chapitre 6) discute des améliorations et des évolutions qui pourraient être
suivies pour la croissance et la gestion de l’IDS.

Mise en place d’une infrastructure de données
spatiales
Rapport Batany Master 2 SIG et Gestion de l’Espace – août 2012 8/66
2 Contexte et objectifs
Le stage s’inscrit dans le cadre des travaux menés par la société Géo212 pour un projet
naturaliste pluridisciplinaire visant à un inventaire de la biodiversité en forêt centrafricaine : le
projet « Sangha 2012 – Biodiversité en Terre Pygmée ».
2.1 Contexte
Dans ce chapitre sont présentés la société Géo212, le projet SANGHA, la zone d’étude
concernée par le projet, ainsi que les travaux connexes.
2.1.1 Geo212 La société Géo212, créée en 1999, est une SARL prestataire de services, spécialisée dans
l’imagerie satellite et la géomatique, qui travaille principalement comme sous-traitant.
L’équipe de la société est composé de 9 personnes, dont chacune est spécialisée dans un
domaine de compétence qui lui est propre : géographie-cartographie, géologie, agronomie,
spécialistes en SIG et qualité de l'information géographique, architecture en systèmes
d'information et expertise opérationnelle. Géo212 travaille essentiellement avec la défense
française, et a progressivement élargi son domaine d’intervention vers des clients civils
(pétrole, mines, environnement, risques, développement urbain, ...) généralement dans des
pays émergents. Le travail de la société se concentre autour de quatre domaines d’activités :
l’optimisation du choix de sources (images et sources ouvertes glanées sur Internet) appliquée
à la conception de chantiers cartographiques, les services de contrôle qualité (images et base
de données vecteurs), la définition de services thématiques (comme des services de
traficabilité réalisés en partenariat avec le BRGM et le SERTIT), la géomorphologie.
Géo212 s’implique également en recherche et développement par le biais de projets visant des
problématiques variées (système d’alertes sur l’obsolescence de l’information, exploitation de
l’imagerie radar, utilisation des sources ouvertes pour l’aide à la décision, définition du futur
programme géographie – hydrographie – océanographie – météorologie de la défense
française,…).
2.1.2 Projet Sangha Le projet Sangha 2012 s’inscrit dans le cadre d’une recherche pluridisciplinaire dont l’objectif
principal est l’évaluation la plus exhaustive possible de la biodiversité du Parc National de
Dzangha Ndoki en République Centrafricaine. Le terme biodiversité (Fondation pour la
recherche sur la biodiversité, 2008), introduit pour la première fois par Edward O. Wilson en
1988, désigne la dynamique des interactions dans des milieux en changement et se décline en
3 niveaux : la diversité des milieux, la diversité des espèces et la diversité génétique. La zone
forestière de Dzangha Ndoki est principalement connue pour les grands mammifères qui y
vivent, tels que les éléphants, les buffles, les gorilles,…, ainsi que les oiseaux et les arbres qui
s’y trouvent.
La région a fait l’objet de reconnaissances à la fin du 19e siècle (le fleuve Sangha constituait
la voie de passage entre le bassin du Congo et le Tchad) (Robineau, 1967) (Vallat, 1901).

Mise en place d’une infrastructure de données
spatiales
Rapport Batany Master 2 SIG et Gestion de l’Espace – août 2012 9/66
Les multiples missions naturalistes du 20e siècle ont entrainé la création de 3 parcs nationaux
au Cameroun, en République du Congo et en République Centrafricaine, l’ensemble
constituant une aire protégée transfrontalière dont le complexe forestier est géré par un accord
signé entre les pays riverains sous le nom de Tri-National de la Sangha. Sa préservation est
soutenue en premier lieu par les actions du World WildLife Fund (WWF). La zone a été
classée en juin 2012 au Patrimoine Mondial de l’Humanité par l’UNESCO (UNESCO, 2012).
Côté centrafricain, elle est également classée au titre de la convention RAMSAR sur les zones
humides (The Ramsar Convention on Wetlands, 2009).
Figure 1 : Situation du Parc Tri National de la Sangha
(Sources: Wikipedia, image Google Earth)
Pourtant, la faune entomologique est encore assez peu connue, très peu d’études ayant été
réalisées, alors que les insectes peuvent être de bons indicateurs de l’état de la biodiversité.
La toute première expédition entomologique date de 1985, et avait pour objectif d’étudier les
insectes de la zone dans la région de Bayanga (village situé à l’extrémité de la piste de
Bangui). Puis, suite à la création de l’association Insectes du Monde en 1997, les expéditions
ont pris progressivement une plus grande ampleur. Cette association (basée en Ariège) a pour

Mise en place d’une infrastructure de données
spatiales
Rapport Batany Master 2 SIG et Gestion de l’Espace – août 2012 10/66
but principal de sensibiliser le grand public à l’entomologie au travers d’animations,
expositions, préparations naturalistes et production de supports pédagogiques. Elle s’attache à
enrichir les connaissances scientifiques, notamment grâce à des expéditions, des inventaires,
des recherches taxinomiques, la détermination de matériels, ainsi que la publication d’articles
scientifiques. Pour atteindre ses objectifs, Insectes du Monde développe des partenariats avec
des organismes publics et privés, tels que l’Education Nationale, des établissements de
recherche, des musées, des sociétés, mais aussi avec des spécialistes issues de diverses
disciplines (botanique, arachnologie, ornithologie, chiroptérologie…).
Les 7 expéditions conduites jusqu’en 2008 ont progressivement investigué de nouveaux
domaines scientifiques. C’est dans cette logique qu’Insectes du Monde a mis en place le
projet Sangha 2012.
Ce projet prévu sur 3 ans a démarré fin 2009. Il a pour but de promouvoir la recherche et de
développer des actions durables en encourageant et en accompagnant des actions locales. Les
expéditions précédentes, en plus de la mise en place progressive de la pluridisciplinarité
scientifique, ont permis de mieux appréhender la logistique complexe qu’apporte un plus
grand nombre de participants, que ce soit pour le transport, la nourriture ainsi que le matériel.
Le projet Sangha2012 est articulé autour de deux missions de terrain. Il est découpé en 6
phases majeures :
Septembre 2009 – Mars 2010 : Démarrage et conception du projet
Avril 2010 – Octobre 2010 : Préparation de la mission test
Novembre 2010 – Décembre 2010 : Réalisation de la mission test
Janvier 2011 – Décembre 2011 : Exploitation des résultats et préparation de la
mission 2012
Janvier 2012 – Mars 2012 : Réalisation de la mission 2012
Mars 2012 – Décembre 2012 : Exploitation des résultats de la mission 2012
2.1.3 La zone d'étude Le projet est mené en République Centrafricaine, appelée aussi Centrafrique. Enclavé au cœur
de l’Afrique, le pays est constitué de deux grands bassins : le bassin du Tchad qui s’écoule
vers le nord, et le bassin du Congo, formé par les affluents de l’Oubangui qui coulent vers le
sud. Les reliefs les plus importants se situent sur les bordures occidentales et orientales du
plateau, avec au nord ouest les gradins du massif granitique du Yadé compris entre 1000 et
1400 mètres.
La zone d’étude se situe à la pointe sud ouest du pays (Figure 2). Elle est bordée par la
frontière avec le Cameroun à l’ouest, matérialisée par la rivière de la Sangha, et par la
frontière avec la République du Congo au sud et à l’est.

Mise en place d’une infrastructure de données
spatiales
Rapport Batany Master 2 SIG et Gestion de l’Espace – août 2012 11/66
Figure 2 : Situation de la zone étudiée
(Source : image Google Earth)
2.1.4 Contexte relationnel et organisationnel
2.1.4.1 Impact des caractéristiques du projet
Le projet SANGHA étant un projet associatif défini hors du cadre officiel de la recherche
scientifique, les différents intervenants s’impliquent sur des bases de volontariat. Les
membres de l’association Insectes du Monde, même lorsqu’ils sont des scientifiques
reconnus, mènent leurs actions Sangha 2012 en marge ou en complément de leurs activités
professionnelles. Ils disposent donc de peu de temps pour s’y consacrer pleinement. Parmi
eux se côtoient des professionnels en taxinomie qui participent au projet en plus de leur temps
de travail, et des amateurs passionnées, qui présentent donc une méthode de travail moins
méthodique et rigoureuse que les professionnels. Ceci nous laisse supposer que chacun
travaille à sa manière et ne se sont pas concertés pour adopter une méthode de travail
commune. De plus cela signifie qu’au retour d’une mission de terrain lourde (qui a duré pour
certains participants plus de 2 mois) les acteurs n’étaient pas obligatoirement disponibles en
mars et avril pour répondre à nos questions (voir §3.1).
De même les sociétés impliquées dans le projet (pour fournir des prestations ou prêter des
équipements) le font sur une base volontaire et bénévole.

Mise en place d’une infrastructure de données
spatiales
Rapport Batany Master 2 SIG et Gestion de l’Espace – août 2012 12/66
2.1.4.2 Place des travaux Géo212 dans le projet
Le contexte de notre travail est assez particulier puisque la collaboration scientifique fait
intervenir une société spécialisée en imagerie spatiale et géomatique d’une part, et des
spécialistes en entomologie d’autre part, deux acteurs a priori assez « hermétiques ».
Les partenaires du projet SANGHA ont fait appel à Géo212 au départ pour les aider à
préparer les missions de terrain 2010 à l’aide d’images satellites de la zone. Puis
progressivement Géo212 s’est impliquée dans le projet et a proposé à ses partenaires d’utiliser
les possibilités de la géomatique et de la télédétection pour enrichir, étendre et pérenniser les
travaux de terrain menés au cours des expéditions. A l’issue de la première mission et face à
la faible qualité de la géolocalisation des observations, Géo212 a proposé de déployer lors de
la mission 2012 des moyens professionnels de topographie afin de constituer un référentiel
géométrique fiable. Cet acquis, couplé à la transversalité des travaux scientifiques, a induit un
besoin de rassembler les données dans une Infrastructure de Données Spatiales (IDS). Mais si
l’objectif d’ensemble de l’IDS a été validé par l’association, il n’est pas certain que tous les
participants étaient conscients des conséquences et contraintes liées à la mise en place d’une
base de données partagée. Notre travail s’est donc déroulé dans une phase de consolidation de
cette compréhension.
2.1.4.3 Place des stages dans le projet
Notre stage se situe après les 2 grandes missions de terrain, en 2010 (constituée de 40
personnes) et 2012 (70 personnes), et durant l’exploitation des résultats de la mission de 2012.
Lors d’un précédent stage réalisé de mars à août 2011 par Antoine Fivel, un premier travail de
catalogage et d’études sur la qualité des données collectées durant la mission 2010 a été
réalisé. Antoine Fivel a notamment réalisé différents tests de précision sur les données GPS
obtenues à la mission de 2010, ainsi qu’une première classification de la végétation de la zone
à partir des images satellites et des données collectées sur le terrain. Il a mesuré une
imprécision entre les images satellites et les données GPS de l’ordre de 15-20 mètres environ.
Cette conclusion a fait prendre conscience de la nécessité d’envoyer sur le terrain du matériel
GPS professionnel. Cette recommandation a été suivie pendant la mission de 2012, une
géographe de l’équipe de Géo212, Camille Netter, est en effet partie sur le terrain avec du
matériel DGPS pour réaliser plusieurs points d’appuis identifiables sur images satellites à très
haute résolution et plusieurs cheminements GPS permettant de caler les observations au sol
(localisation de capteurs, collecte d’échantillons, photos, mesures diverses).
Au retour de la mission 2012, deux stages ont démarré en parallèle.
Bénédicte Navarro, étudiante en Master 2 Télédétection et Géomatique Appliquées à
l'Environnement de Paris VII, travaille sur les images satellites dont dispose Géo212 sur la
zone, avec notamment deux images satellites acquises début 2012 et recalables précisément
avec les mesures de terrain. Elle constitue un référentiel géométrique commun avec toutes les
images (optiques et radar ; basse ou haute résolution) dont les plus anciennes remontent à
1979. Elle intègre également les mesures des capteurs de terrain laissés sur zone entre les 2
missions (15 mois d’observations en continu). Elle réalise enfin une nouvelle occupation du
sol plus précise que celle réalisée en 2011. Son travail (données et résultats) sera intégré dans

Mise en place d’une infrastructure de données
spatiales
Rapport Batany Master 2 SIG et Gestion de l’Espace – août 2012 13/66
l’infrastructure spatiale de données et influence donc la structure de la base de données. Les
images satellites auront en effet une place importante dans la structure de l'IDS.
2.2 Objectifs
2.2.1 Objectifs initiaux
Le travail demandé dans le cadre du stage est de constituer une infrastructure spatiale de
données hétérogènes pour l’inventaire de la biodiversité en République Centrafricaine dans le
cadre du projet SANGHA à destination de l’ensemble des partenaires.
Les travaux définis dans la fiche descriptive initiale du stage portent sur :
la constitution d’une infrastructure spatiale de données hétérogènes : images satellites,
mesures GPS, relevés de terrain, des photographies géoréferencées, données provenant
de sources ouvertes…,
des analyses diachroniques permettant d’analyser les incertitudes (géométriques,
radiométriques, humaines et temporelles) entre données de télédétection et
observations naturalistes,
l’analyse des interactions entre entomofaune et microhabitats,
la production de cartographies multiéchelles et multi-temporelles permettant de mettre
en avant les évolutions du milieu.
L’objectif final est de participer à la compréhension du biotope actuel et de son évolution sur
les 3 dernières décennies.
Au démarrage du stage, un premier recadrage de ces objectifs a été réalisé en fonction des
retours de la mission de terrain (qui venait de s’achever).
Pour initier notre travail, nous avons écrit un cahier des charges et défini un organigramme
des tâches (OT) macroscopique définissant l'ensemble des grandes étapes du projet sur les 6
mois de stage. (Figure 3).

Mise en place d’une infrastructure de données
spatiales
Rapport Batany Master 2 SIG et Gestion de l’Espace – août 2012 14/66
Figure 3 : Les grandes étapes du projet définies dans l’OT initial
La première grande étape à accomplir est une recherche bibliographique sur les IDS et leurs
composants. Un état de l'art est à réaliser également, afin de déterminer s’il existe des projets
similaires déjà en fonctionnement ou prévus, et ainsi voir si certains éléments de ces projets
permettent d’aiguiller nos choix.
Simultanément, nous devons mener une analyse des besoins des partenaires et futurs
utilisateurs. La diversité des thématiques naturalistes oblige à collecter suffisamment de
besoins utilisateurs pour être sûr que l’IDS pourra satisfaire des besoins multiples. Ce travail
de conception nous permettra de définir le public intéressé par cet outil, et ainsi définir les
objectifs que doit viser l’outil. Ce premier travail permettra également d’apprécier les
compétences humaines nécessaires ainsi que les contraintes d’organisation et de budget.
Pour la mise en place du modèle de données, il nous faudra au préalable définir une méthode
de travail de développement informatique parmi les méthodes existantes. Par le suivi de
cette méthode nous allons alors créer la structure physique de la base de données en fonction
du logiciel de système de gestion de bases de données choisi. Une partie des données sera
par la suite intégrée progressivement dans la base de données.
De part l'hétérogénéité des données (nature et formats de données différents), nous allons
mettre en place une méthode de contrôle des données pour définir les problèmes éventuels
que pourrait contenir la base de données. Si la base de données présente en effet des

Mise en place d’une infrastructure de données
spatiales
Rapport Batany Master 2 SIG et Gestion de l’Espace – août 2012 15/66
problèmes de fonctionnalités, une reprise de données devra être réalisée, sans pour autant
corriger toutes les erreurs. Nous allons pour cela définir les incertitudes possibles.
Après ce travail de mise en place et de gestion de la base de données, il est primordial de
tester la base de données. Nous allons donc définir une thématique d’étude en fonction des
données intégrées, et du temps qui nous est imparti. La thématique ne pourra être déterminée
qu'après implémentation des données, car nous ne travaillerons qu’avec les données intégrées
dans la base de données.
Enfin, si les données intégrées le permettent, nous prévoyons de produire quelques
cartographies illustrant les résultats. Ces cartographies permettront de communiquer sur
l’IDS tant en interne auprès des partenaires pour les convaincre de l’utilité du partage de leurs
données qu’en externe, pour valoriser le projet Sangha 2012.
2.2.2 Suivi et recadrage des objectifs
Au sein de la société, le mode de fonctionnement des stages est celui d’un projet classique.
Dès le début du stage nous avons fixé avec les tuteurs de stage des réunions régulières,
environ 2 fois par mois, afin de voir l’avancement du travail, et de discuter des travaux et des
difficultés éventuelles. Lors de ces réunions étaient également conviées les personnes de
l’équipe impliquées dans le projet de part leur spécialité à l’étape donnée, et Bénédicte
Navarro afin de connaître ses besoins au niveau de l’intégration des données et de les prendre
en compte dans le planning. Ainsi l’ensemble de l’équipe Géo212 a pu suivre l’avancement
du stage.
A titre d’exemple, suite à la réunion n°4 du 27 avril 2012, constatant que seulement 6
scientifiques du projet SANGHA sur les 25 contactés avaient listé leurs besoins, nous avons
pris l’initiative d’organiser un point d’urgence avec les responsables du projet SANGHA en
allant à leur rencontre sur Toulouse. Lors d’une réunion le 16 mai 2012 nous avons pu leur
présenter en détail le projet d’IDS et discuter en direct avec eux de leurs besoins en base de
données (les précédents échanges s’étaient faits la plupart du temps par mail et entretiens
téléphoniques). Cela a permis également d’en apprendre davantage sur les données qu’ils
possédaient et d’obtenir certaines d’entre elles, et ainsi de pouvoir avancer dans nos travaux.
Plus tard dans le projet, nous avons également choisi de modifier l’organigramme des tâches
initialement prévu. En effet, en analysant les difficultés rencontrées dans la collecte des
informations de chaque thématicien au début du stage, nous nous sommes rendus compte
qu’il était plus judicieux pour compléter l’IDS de disposer d’une interface de saisie web
permettant une communication plus simple avec les contributeurs et de leur laisser intégrer
leurs données au rythme de leurs analyses et travaux d’identification. La dernière partie de
l’OT a donc été modifiée en conséquence.
A chaque étape bimensuelle, le planning directeur du stage était présenté et les conséquences
des recadrages étaient analysées avec les tuteurs.
Les trois chapitres suivants se focaliseront sur la phase de conception (§3), sur la mise en
place de la base (§4) et sur l’interface de saisie web (§5).

Mise en place d’une infrastructure de données
spatiales
Rapport Batany Master 2 SIG et Gestion de l’Espace – août 2012 16/66
3 Phase de conception
Dans ce chapitre sera présentée la phase de conception de notre travail. Dans un premier
temps sera présentée l’analyse du besoin, puis la bibliographie et l’état de l’art réalisés, qui
permettront dans un troisième temps de présenter les objectifs à atteindre par l’outil. Nous
terminerons ce chapitre par la présentation des objectifs recadrés.
3.1 Définition du besoin
Il est indispensable dans tout type de projet de bien comprendre les besoins des partenaires et
futurs utilisateurs. Ceci permet de définir les objectifs que la base de données devra remplir.
Nous avons donc pris contact avec les scientifiques qui ont récolté des données lors de la
mission de 2012, et qui seraient susceptibles d’être intéressées par l’intégration de leurs
résultats dans l’infrastructure de données spatiales. 25 personnes ont été contactées par mail et
9 ont répondu à nos questions, lors de rencontres, de contacts téléphoniques ou par mail. Les
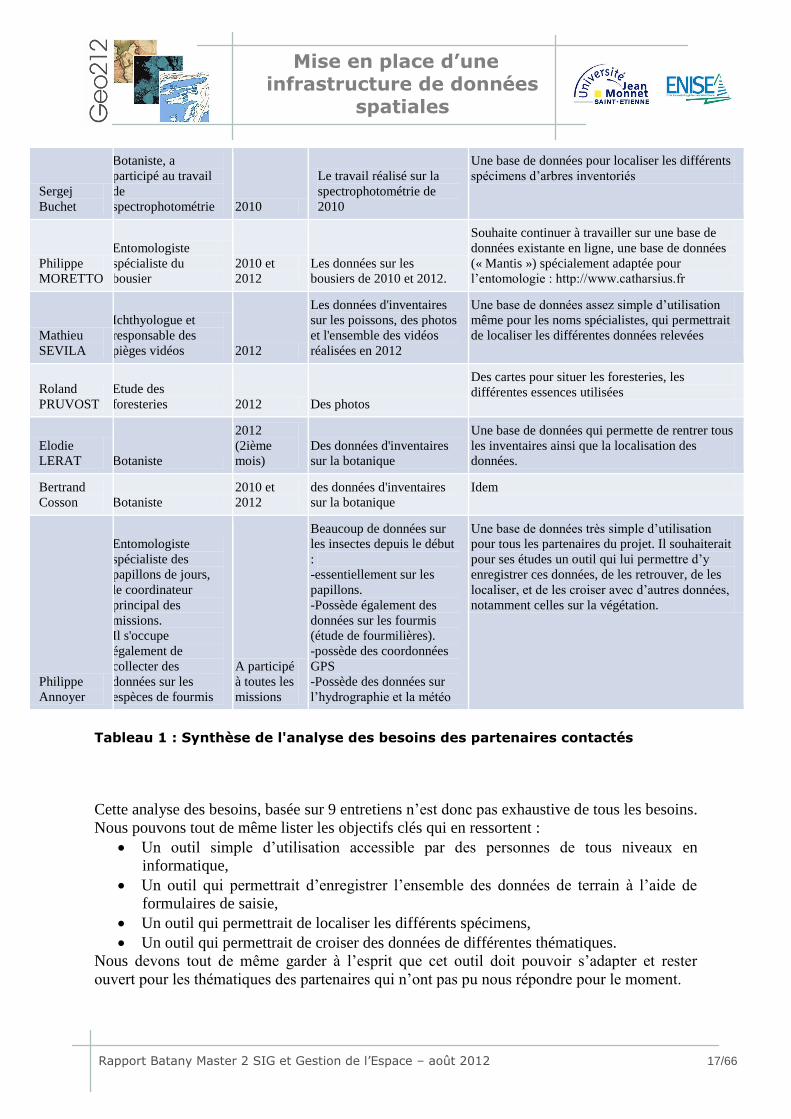
entretiens sont synthétisés dans le Tableau 1. Ces entretiens nous ont permis de mieux
comprendre le projet SANGHA, de bien référencer l'ensemble des données disponibles, de
connaître les informations que les thématiciens souhaitent intégrer dans la base de données.
Par contre, de part le fait qu'ils n'ont pas encore trié et analysé leurs échantillons (à l’issue
d’une mission naturaliste de ce type, le tri et l’analyse des données peut prendre plusieurs
années, cf. §2.1.2), ils ne connaissent pas encore toujours les informations qu’ils pourraient en
ressortir, et donc quels résultats ils souhaiteraient obtenir avec la base de données.
Personne
rencontrée
Fonction dans le
projet
Mission
réalisée Données récoltées
Besoins exprimés
Nicolas
Moulin
Entomologiste
spécialiste des mantes 2010 et 2012 Les mantes depuis 1985
Une base de données en ligne sur internet avec
accès réservé, qui permettrait :
-de réaliser des analyses statistiques
-de réaliser des cartes simples de localisation pour
mettre en évidence ces résultats (poster par
exemple)
-d’analyser ses résultats en les croisant avec celles
du milieu (les lacs)
-d’entrer ses données très facilement (interface
simple)
-éventuellement d’avoir un accès pour le grand
public (beaucoup moins scientifique pour l’aspect
pédagogique et communication)
Samuel
Danflous
Entomologiste
spécialiste des
arachnides, et
coordinateur
scientifique de
l'expédition 2012 2010 et 2012
Les codes des pièges
physiques et des données sur
les insectes et arachnides
Création de formulaires pour que chacun puisse
entrer ses données dans la base de données.
Pouvoir localiser les localités inspectées, mais
également être capable de localiser chaque
échantillon prélevé.
Mise en place d’une infrastructure de données
spatiales
Rapport Batany Master 2 SIG et Gestion de l’Espace – août 2012 17/66
Sergej
Buchet
Botaniste, a
participé au travail
de
spectrophotométrie 2010
Le travail réalisé sur la
spectrophotométrie de
2010
Une base de données pour localiser les différents
spécimens d’arbres inventoriés
Philippe
MORETTO
Entomologiste
spécialiste du
bousier
2010 et
2012
Les données sur les
bousiers de 2010 et 2012.
Souhaite continuer à travailler sur une base de
données existante en ligne, une base de données
(« Mantis ») spécialement adaptée pour
l’entomologie : http://www.catharsius.fr
Mathieu
SEVILA
Ichthyologue et
responsable des
pièges vidéos 2012
Les données d'inventaires
sur les poissons, des photos
et l'ensemble des vidéos
réalisées en 2012
Une base de données assez simple d’utilisation
même pour les noms spécialistes, qui permettrait
de localiser les différentes données relevées
Roland
PRUVOST
Etude des
foresteries 2012 Des photos
Des cartes pour situer les foresteries, les
différentes essences utilisées
Elodie
LERAT Botaniste
2012
(2ième
mois)
Des données d'inventaires
sur la botanique
Une base de données qui permette de rentrer tous
les inventaires ainsi que la localisation des
données.
Bertrand
Cosson Botaniste
2010 et
2012
des données d'inventaires
sur la botanique
Idem
Philippe
Annoyer
Entomologiste
spécialiste des
papillons de jours,
le coordinateur
principal des
missions.
Il s'occupe
également de
collecter des
données sur les
espèces de fourmis
A participé
à toutes les
missions
Beaucoup de données sur
les insectes depuis le début
:
-essentiellement sur les
papillons.
-Possède également des
données sur les fourmis
(étude de fourmilières).
-possède des coordonnées
GPS
-Possède des données sur
l’hydrographie et la météo
Une base de données très simple d’utilisation
pour tous les partenaires du projet. Il souhaiterait
pour ses études un outil qui lui permettre d’y
enregistrer ces données, de les retrouver, de les
localiser, et de les croiser avec d’autres données,
notamment celles sur la végétation.
Tableau 1 : Synthèse de l'analyse des besoins des partenaires contactés
Cette analyse des besoins, basée sur 9 entretiens n’est donc pas exhaustive de tous les besoins.
Nous pouvons tout de même lister les objectifs clés qui en ressortent :
Un outil simple d’utilisation accessible par des personnes de tous niveaux en
informatique,
Un outil qui permettrait d’enregistrer l’ensemble des données de terrain à l’aide de
formulaires de saisie,
Un outil qui permettrait de localiser les différents spécimens,
Un outil qui permettrait de croiser des données de différentes thématiques.
Nous devons tout de même garder à l’esprit que cet outil doit pouvoir s’adapter et rester
ouvert pour les thématiques des partenaires qui n’ont pas pu nous répondre pour le moment.

Mise en place d’une infrastructure de données
spatiales
Rapport Batany Master 2 SIG et Gestion de l’Espace – août 2012 18/66
3.2 Bibliographie et état de l’art
Dans ce chapitre nous allons dans un premier temps définir ce qu’est une Infrastructure de
Données Spatiales, puis nous allons présenter les différents outils similaires existants et/ou
auxquels nous pourrions nous inspirer.
3.2.1 Infrastructure de Données Spatiales
Il est souvent difficile d’avoir accès à des données géospatiales pour diverses raisons :
les formats ne sont pas interopérables,
les politiques de distribution sont restrictives,
nous n’avons pas d’information sur les données,
leurs coûts sont souvent élevés.
La mutualisation de l’information géographique par la mise en place d’une infrastructure de
Données Spatiales (IDS) permet de pallier à ces différents problèmes et favorise ainsi l’accès
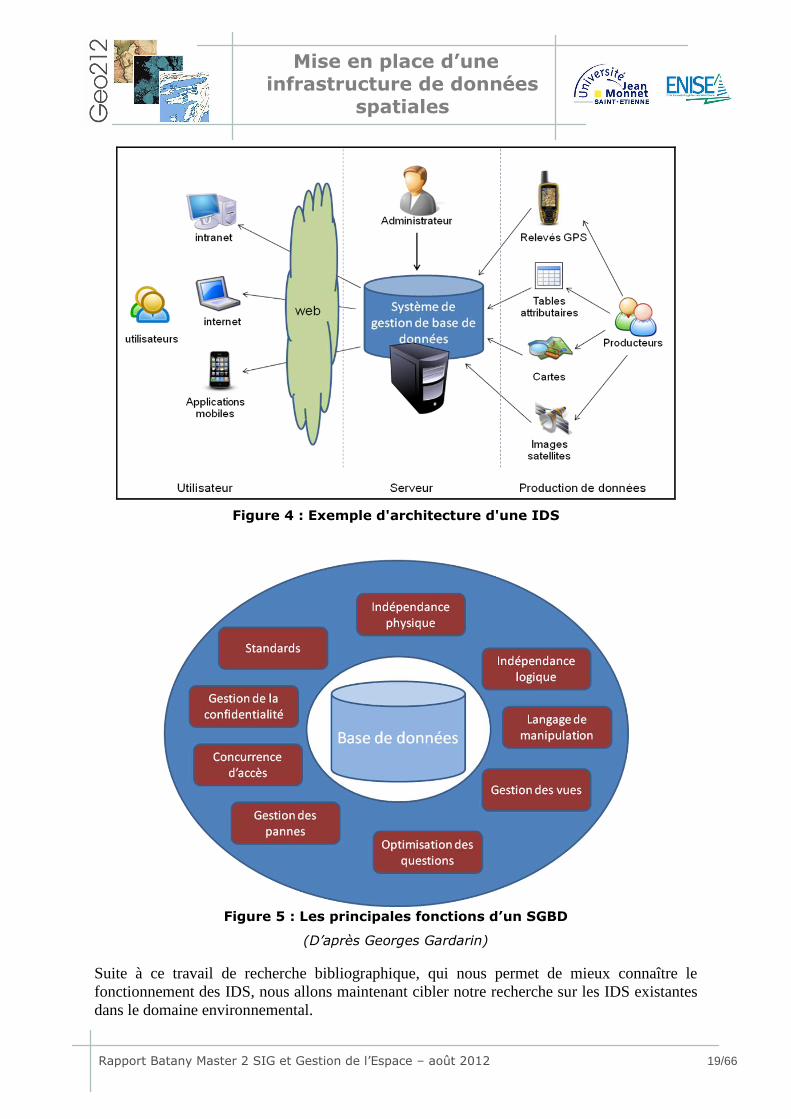
à l’information. Une IDS est un système informatique qui permet de regrouper un ensemble
de services tels que des catalogues de données, des données, des logiciels, des applications,
des serveurs, ….connectés en mode interactif. Elle est utilisée dans la gestion d’informations
localisées telle que des cartes, des relevés de terrain, des images satellites et photos
aériennes… Les IDS sont accessibles généralement sur le web et respectent un ensemble de
conditions d’interopérabilité (telles que des normes, des spécifications...). Cela permet à
l’utilisateur de pouvoir utiliser les services à travers un simple navigateur web ainsi que de
combiner les services proposés par différentes IDS selon ses besoins.
Mais la mise en place d’un tel système nécessite l’accord de tous les partenaires concernés par
le projet (les producteurs, les utilisateurs, l’administrateur…) et doit éventuellement prendre
en compte des IDS existantes dans la région concernée afin de les coordonner. Un exemple
d’architecture d’une IDS est présenté Figure 4, mais toutes les IDS ont leur architecture
propre, adaptée aux besoins des utilisateurs.
Un projet d’IDS est donc plus qu’un simple projet technique et nécessite l’adhésion des
partenaires et la clarification de tous les enjeux liés à la propriété des données et des résultats.
Le cœur d’une IDS est l’ensemble des données qui sont gérées par un Système de Gestion de
Base de Données (SGBD), un logiciel qui permet de stocker, gérer et partager des
informations dans une base de données partagée par plusieurs utilisateurs simultanément. Ce
système gère la qualité des informations, ainsi que leur pérennité et leur confidentialité, sans
que l’utilisateur ne voie la complexité des informations (Figure 5).
Mise en place d’une infrastructure de données
spatiales
Rapport Batany Master 2 SIG et Gestion de l’Espace – août 2012 19/66
Figure 4 : Exemple d'architecture d'une IDS
Figure 5 : Les principales fonctions d’un SGBD
(D’après Georges Gardarin)
Suite à ce travail de recherche bibliographique, qui nous permet de mieux connaître le
fonctionnement des IDS, nous allons maintenant cibler notre recherche sur les IDS existantes
dans le domaine environnemental.

Mise en place d’une infrastructure de données
spatiales
Rapport Batany Master 2 SIG et Gestion de l’Espace – août 2012 20/66
3.2.2 Etat de l’art des IDS existantes dans le domaine de l’environnement
Il existe une association internationale : Global Spatial Data Infrastructure Association
(GSDI1) qui a pour but de promouvoir la coopération internationale et la collaboration dans la
création d’IDS qui permettraient de mieux aborder les problèmes environnementaux et
économiques. Cette organisation est notamment à l’origine du livre « The Spatial Data
Infrastructure Cookbook » qui permet d’aborder les principales étapes de construction d’une
IDS et ses principales fonctions. Depuis 2002, GSDI gère une lettre d’information mensuelle
dédiée à l’Afrique « SDI-Africa » basée au Centre régional pour la Cartographie des
ressources de développement (RCMRD) de Nairobi (Kenya), nœud africain du projet NASA /
GEOSS SERVIR. L’analyse des informations partagées depuis 10 ans nous a permis de
constater que s’il existe un grand nombre d’IDS opérationnelles, nous n’en avons pas trouvé
sur la zone d’étude du projet SANGHA.
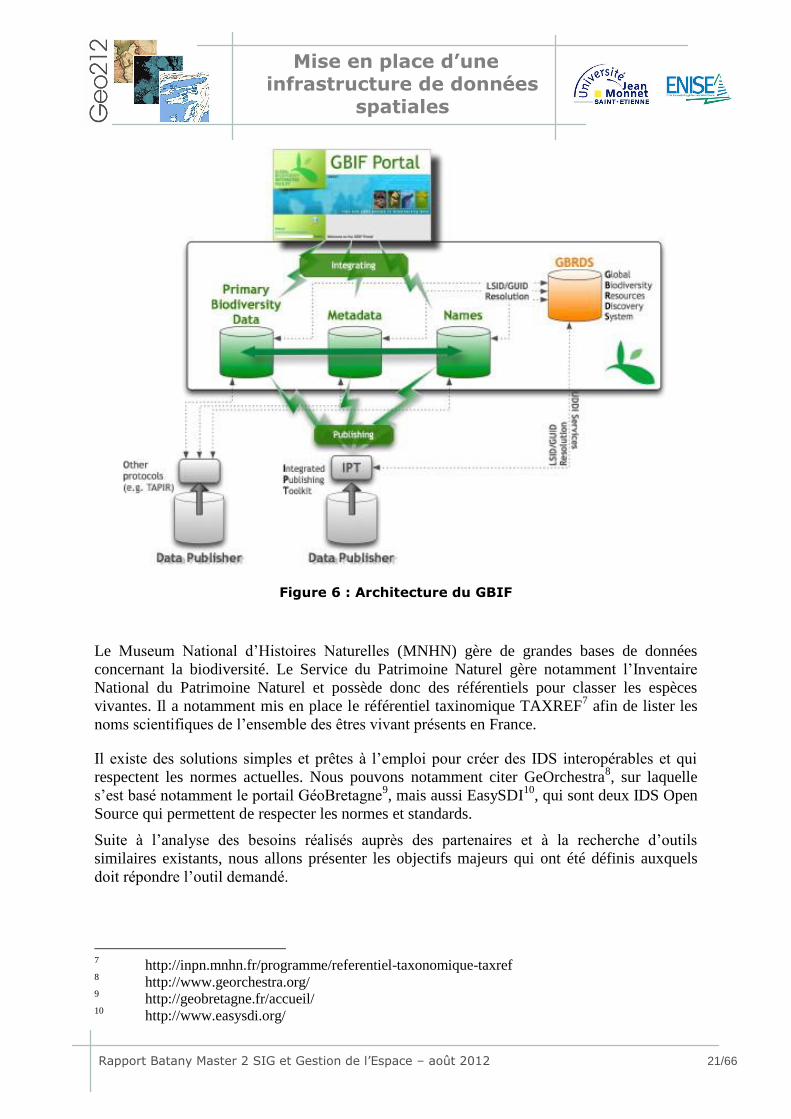
Concernant la biodiversité, un projet international est important, le Système Mondial
d’Information sur la biodiversité (GBIF2), qui référence et rend accessible un grand nombre
de données concernant des collections biologiques et d’observation de la nature. Cet outil
permet de cataloguer l’ensemble des données référencées afin notamment de les rendre
accessible à tout public en garantissant leur interopérabilité, d’estimer les manques
d’expertises, d’aider à la conservation du patrimoine, ou encore d’établir des cartes
thématiques à différentes échelles. Son architecture est rapidement présentée par la Figure 6.
Un certain nombre de structures et associations sont amenées à mettre en place et gérer des
IDS plus restreintes telle que Birdlife International3, une ONG qui gère des banques de
données mondiales sur les oiseaux. En Europe, la directive européenne INSPIRE va permettre
la mise en place progressive d’IDS interopérables dans le domaine de l’environnement. Le
projet PEGASO4 suit ces recommandations pour mettre en place une IDS pour la gestion
intégrée des zones côtières en Mer Méditerranée et en Mer Noire. Au niveau national, en
France, de nombreuses IDS existent, tant au niveau régional que national, (Afigeo, 2010).
Nous pouvons citer dans le domaine environnemental le Système d'Information sur la Nature
et les Paysages (SINP5), une structure basée sur le serveur cartographique du Ministère de
l’écologie, Carmen6, qui permet d’accéder à des données cartographiques.
1 http://www.gsdi.org/
2 http://www.gbif.fr/
3 http://www.birdlife.org/
4 http://www.pegasoproject.eu/
5 http://www.naturefrance.fr/sinp/presentation-du-sinp
6 http://carmen.naturefrance.fr/
Mise en place d’une infrastructure de données
spatiales
Rapport Batany Master 2 SIG et Gestion de l’Espace – août 2012 21/66
Figure 6 : Architecture du GBIF
Le Museum National d’Histoires Naturelles (MNHN) gère de grandes bases de données
concernant la biodiversité. Le Service du Patrimoine Naturel gère notamment l’Inventaire
National du Patrimoine Naturel et possède donc des référentiels pour classer les espèces
vivantes. Il a notamment mis en place le référentiel taxinomique TAXREF7 afin de lister les
noms scientifiques de l’ensemble des êtres vivant présents en France.
Il existe des solutions simples et prêtes à l’emploi pour créer des IDS interopérables et qui
respectent les normes actuelles. Nous pouvons notamment citer GeOrchestra8, sur laquelle
s’est basé notamment le portail GéoBretagne9, mais aussi EasySDI
10, qui sont deux IDS Open
Source qui permettent de respecter les normes et standards.
Suite à l’analyse des besoins réalisés auprès des partenaires et à la recherche d’outils
similaires existants, nous allons présenter les objectifs majeurs qui ont été définis auxquels
doit répondre l’outil demandé.
7 http://inpn.mnhn.fr/programme/referentiel-taxonomique-taxref
8 http://www.georchestra.org/
9 http://geobretagne.fr/accueil/
10 http://www.easysdi.org/
Mise en place d’une infrastructure de données
spatiales
Rapport Batany Master 2 SIG et Gestion de l’Espace – août 2012 22/66
3.3 Objectifs de l’IDS
Sur la base des besoins exprimés par les partenaires, de notre compréhension des IDS et de
leur apport potentiel, et de l’observation d’IDS existantes dans le domaine environnemental,
nous allons définir et prioriser nos propres objectifs. Nos objectifs tiendront compte des
contraintes du projet (voir §2.1.4) et des capacités de Géo212 (environnement technique,
compétences accessibles, …).
Objectif Motivation
1 Aider à la compréhension de la
biodiversité de la zone d’étude, c’est-à-
dire la faune et la flore de l’extrême
sud de la RCA et des pays limitrophes.
Primordial Conforme aux buts de
l’association et du projet Sangha
Facteur d‘adhésion car c’est le
but partagé de tous les
participants
2 Aider à la compréhension du
fonctionnement de l’écosystème.
Important Conforme aux objectifs futurs de
l’association (passer d’un cadre
de missions scientifiques
ponctuelles de collecte
d’échantillons à un observatoire
permanent)
3 Référencer l’ensemble des données
récoltées sur le terrain dans la base de
données, mais aussi les données
obtenues à partir de « sources
ouvertes », mettre en « bibliothèque »
l’ensemble de ces données dans un
référentiel commun.
Primordial Demande exprimée par la
plupart des participants
4 Permettre de localiser les données
échantillonnées sur le terrain.
Primordial Demande exprimée par la
plupart des participants
5 Contribuer à l’analyse croisée de
données, notamment en permettant de
combiner des données d’échelles
spatiales et temporelles différentes.
Important Demande exprimée par un faible
nombre de participants mais
objectif primordial côté Géo212
(et cohérent avec l’objectif n°2)
6 Aider à la préparation des missions
futures, en étant utilisé comme support
logistique.
Important Demande exprimée par les
logisticiens
Pour atteindre ces objectifs de haut niveau, et sur la base de notre état de l’art et des
discussions internes avec l’équipe Géo212, nous fixons en entrée quelques choix
dimensionnant :
Nous allons tenter de nous baser sur le référentiel taxinomique du MNHN et l’adapter
à notre zone d’étude. Ceci nous permettra de rester ouvert et interopérable avec des
outils existants et certifiés, le MNHN travaillant avec de nombreux partenaires
nationaux et internationaux, comme le GBIF, et ainsi de rester concentrés sur notre
objectif principal : la compréhension de la biodiversité.

Mise en place d’une infrastructure de données
spatiales
Rapport Batany Master 2 SIG et Gestion de l’Espace – août 2012 23/66
La localisation des données échantillonnées sur le terrain peut se faire simplement à
l’aide de logiciels SIG. La base de données que nous allons mettre en place doit donc
donner la possibilité de géolocaliser des données géoréférencées.
Elle devra également donner la possibilité de stocker un maximum de données de
divers formats, car nous le rappelons, les données à référencer sont très hétérogènes.
Cette fonctionnalité devrait pouvoir donner la possibilité, à l’aide d’autres outils,
d’autres logiciels, de pouvoir travailler également à la fois sur des données de type
images satellites et des données GPS.
L’outil sera principalement destiné à réaliser des études scientifiques, mais il devra
également pouvoir être utilisé comme support technique, notamment pour tous les
aspects logistiques de préparation des missions, comme par exemple le choix de
zones à étudier, le choix des chemins à suivre pour atteindre ces zones…
Les groupes d'animaux et de végétaux qui seront intégrés dans la base de données
correspondront dans un premier temps aux domaines d'études des personnes qui nous
ont transmis des données et spécifié leur souhait concernant la base de données (voir
Tableau 1). Mais l’outil pourra être capable d’évoluer et d’intégrer les données des
partenaires qui n’ont pas encore pris le temps de répondre.
Les partenaires étant localisés en des lieux multiples (en Europe, au Canada et en
Afrique), l’IDS devra intégrer un outil de visualisation interactif de cartes et des
données, disponible en intranet ou en internet permettant de travailler directement (en
temps réel) sur la base de données.
Les utilisateurs devront pouvoir exploiter les données intégrées dans l’IDS à des fins
de communication sous des formes multiples à définir (cartographies, animations,
visualisations interactives). Ces formes de communication auront des publics variés
(présentation de résultats scientifiques, animations pédagogiques vers les écoles et les
passionnés, partenaires institutionnels et sponsors du projet, …).
Les moyens retenus devront être légers, faciles à administrer et peu coûteux afin de
respecter les caractéristiques organisationnelles et économiques du projet.
3.4 Adaptation aux contraintes rencontrées
La phase de recueil de besoin a pris plus de temps que prévu initialement et n’a abouti que
pour 9 des 25 scientifiques contactés. De plus, notre stage se situant juste au retour de la
mission 2012, certains scientifiques n’étaient pas en mesure de nous transmettre leurs données
(qu’ils n’avaient pas encore exploitées) pour tester leur intégration dans l’IDS. Enfin nous
avons constaté au travers de nos démarches parfois infructueuses et des échanges lors des
entretiens qu’il existait un déficit de communication entre les membres, lié aux contraintes
inhérentes d’un projet bénévole impliquant des acteurs répartis sur 3 continents.
Nous avons donc décidé de mettre en place un outil de saisie des données en ligne qui sera
construit dans un premier temps pour amener les partenaires à s’intéresser au projet de l’IDS
et à comprendre les avantages de la mutualisation et du partage des données. L’objectif est à
la fois pratique (permettre aux partenaires de saisir leurs données et consulter les données
partagées à leur rythme) mais aussi pédagogique (promouvoir les SGBD et SIG au sein du

Mise en place d’une infrastructure de données
spatiales
Rapport Batany Master 2 SIG et Gestion de l’Espace – août 2012 24/66
projet SANGHA, pour que chacun voie progressivement l’intérêt du partage et du croisement
des données et vienne enrichir la base de données).
Les objectifs définis précédemment n’ont pas été modifiés, mais nous avons décidé en mai
2012 de recentrer les travaux initialement prévus sur l’outil de visualisation interactive et de
développer une interface de saisie et de consultation via une application de webmapping.
Nous avons donc modifié l’organigramme des tâches prévisionnel du stage (Figure 7) pour
pouvoir développer cet objectif.
Figure 7 : Nouvel Organigramme des Tâches prévisionnel

Mise en place d’une infrastructure de données
spatiales
Rapport Batany Master 2 SIG et Gestion de l’Espace – août 2012 25/66
4 Mise en place de la base de données
4.1 Méthode de conception
Pour créer un système d’information, il est nécessaire de réfléchir à un ensemble de points
durs : les besoins des utilisateurs, l’organisation que l’on souhaite déployer et l’information
pertinente, etc. Cette complexité suggère donc d’appliquer une méthode de travail rigoureuse
notamment pour mettre en place un modèle sur lequel s’appuyer. La méthode d’analyse
permet de créer un langage commun à l’informatisation et aux acteurs du projet au travers de
différentes étapes allant de concepts/entités décrites en langage naturel, à une implémentation
informatique.
Il existe de nombreuses méthodes d’analyse et de conception de système d’information, la
méthode choisie ici pour le projet est la méthode MERISE. Nous avons choisi de travailler
avec cette méthode car d’une part c’est une méthode française, ce qui facilite la recherche de
documents et d’autre part elle est connue par la société qui possède des ouvrages de référence
de cette méthode. C’est une méthode qui semble être relativement simple à mettre en
application car elle ne demande aucune compétence en modélisation. Les termes utilisés sont
en effet facilement compréhensibles et facilitent les échanges lors de réunions avec les acteurs
du projet.
4.1.1 Méthode MERISE
MERISE est une méthode de développement de projets informatiques de gestion. C’est une
méthode classique adaptée aux bases de données relationnelles.
Pour passer d’une représentation réelle à une représentation virtuelle, le modèle MERISE
présente dans sa démarche d’analyse trois cycles fondamentaux (ou angle de vue) de
l’organisation étudiée :
Le cycle de vie qui décrit les différentes phases du système d’information. Il comprend
le développement du logiciel depuis la décision du développement de l’application,
jusqu’à sa mort.
Le cycle d’abstraction qui représente la démarche de spécification du système
(Organisation étudiée) ; pour passer de la réalité au modèle virtuel de données.
Le cycle de décision qui représente le point de vue des acteurs de l’organisation
étudiée quels que soient leur niveau de décision et d’action.
La démarche d’analyse peut être résumée par le schéma suivant en 3 dimensions (
Figure 8).

Mise en place d’une infrastructure de données
spatiales
Rapport Batany Master 2 SIG et Gestion de l’Espace – août 2012 26/66
Figure 8 : Représentation en 3D des phases MERISE
(D’après Véronique Sayasenh)
Pour résumer, MERISE est une méthode systémique, qui est caractérisée par :
l’étude séparée des données et des traitements
une analyse de ces éléments décomposée en 3 niveaux : Conceptuel, Logique et
Physique, ce dernier étant le niveau le plus concret.
Pour mettre en place la base de données du projet SANGHA, nous nous sommes basés sur
cette méthode, en adaptant MERISE au projet.
Mise en place d’une infrastructure de données
spatiales
Rapport Batany Master 2 SIG et Gestion de l’Espace – août 2012 27/66
4.1.2 Concepts retenus
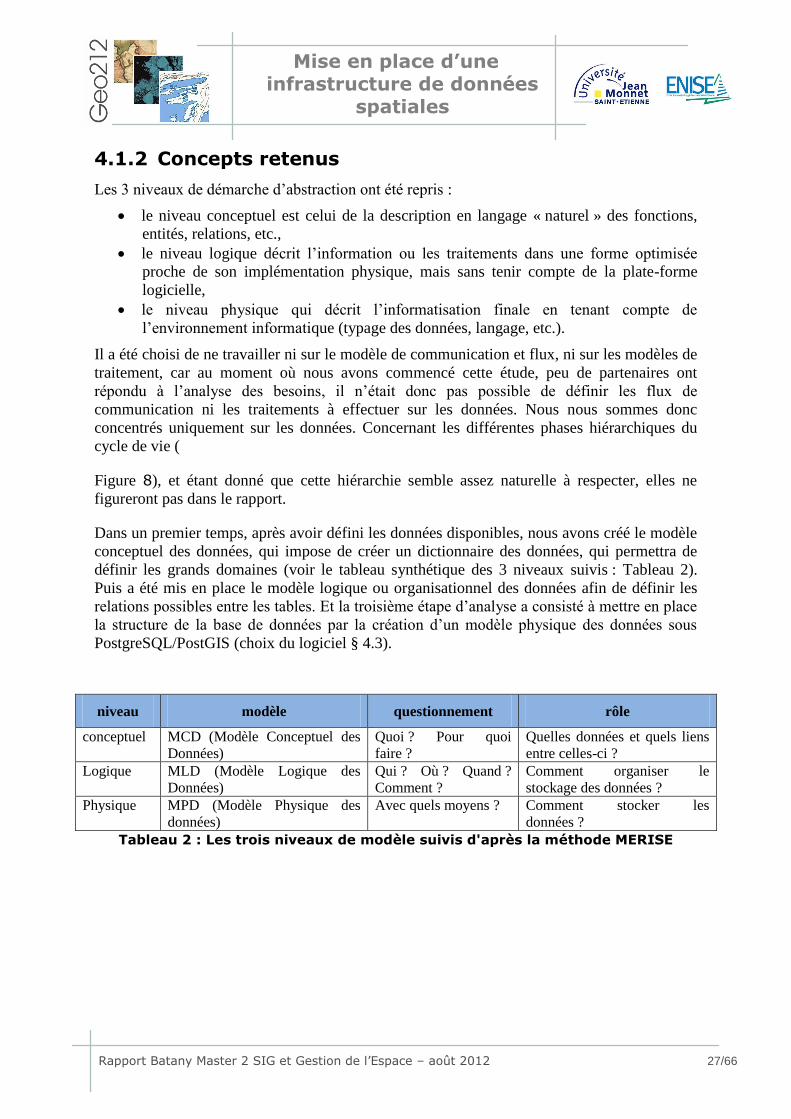
Les 3 niveaux de démarche d’abstraction ont été repris :
le niveau conceptuel est celui de la description en langage « naturel » des fonctions,
entités, relations, etc.,
le niveau logique décrit l’information ou les traitements dans une forme optimisée
proche de son implémentation physique, mais sans tenir compte de la plate-forme
logicielle,
le niveau physique qui décrit l’informatisation finale en tenant compte de
l’environnement informatique (typage des données, langage, etc.).
Il a été choisi de ne travailler ni sur le modèle de communication et flux, ni sur les modèles de
traitement, car au moment où nous avons commencé cette étude, peu de partenaires ont
répondu à l’analyse des besoins, il n’était donc pas possible de définir les flux de
communication ni les traitements à effectuer sur les données. Nous nous sommes donc
concentrés uniquement sur les données. Concernant les différentes phases hiérarchiques du
cycle de vie (
Figure 8), et étant donné que cette hiérarchie semble assez naturelle à respecter, elles ne
figureront pas dans le rapport.
Dans un premier temps, après avoir défini les données disponibles, nous avons créé le modèle
conceptuel des données, qui impose de créer un dictionnaire des données, qui permettra de
définir les grands domaines (voir le tableau synthétique des 3 niveaux suivis : Tableau 2).
Puis a été mis en place le modèle logique ou organisationnel des données afin de définir les
relations possibles entre les tables. Et la troisième étape d’analyse a consisté à mettre en place
la structure de la base de données par la création d’un modèle physique des données sous
PostgreSQL/PostGIS (choix du logiciel § 4.3).
niveau modèle questionnement rôle
conceptuel MCD (Modèle Conceptuel des
Données)
Quoi ? Pour quoi
faire ?
Quelles données et quels liens
entre celles-ci ?
Logique MLD (Modèle Logique des
Données)
Qui ? Où ? Quand ?
Comment ?
Comment organiser le
stockage des données ?
Physique MPD (Modèle Physique des
données)
Avec quels moyens ? Comment stocker les
données ?
Tableau 2 : Les trois niveaux de modèle suivis d'après la méthode MERISE
Mise en place d’une infrastructure de données
spatiales
Rapport Batany Master 2 SIG et Gestion de l’Espace – août 2012 28/66
4.2 Démarche de création de la base de données
4.2.1 Données disponibles Un précédent inventaire des données disponibles avait été réalisé en 2011 par Antoine Fivel
sur la base de la mission 2010. Cet inventaire a été mis à jour avec les données de 2012 et les
données analysées depuis 2011 par les différents partenaires (cf. Tableau 3).
Nature des données Contenu, description objectifs Relevés GPS Position GPS : points et traces Positionner géographiquement les différents relevés et
prélèvements réalisés en missions, et réaliser des prises de
points d’appui.
Positionnement géographique Position enregistrés dans des
fichiers Excel manuellement
Positionner géographiquement les différents relevés et
prélèvements réalisés en missions
Schémas de positionnement Position schématique et imprécise Positionner géographiquement les différents relevés et
prélèvements réalisés en missions
Inventaires entomologiques Données relevées sur les insectes
depuis 1985 jusqu’à 2012
Connaître et évaluer la biodiversité
Inventaires arachnologiques Données relevés sur les
arachnides en 2010 et 2012
Connaître et évaluer la biodiversité
Inventaires botaniques Données relevés en 2010 Connaître et évaluer la biodiversité
photographie Photographie de 2010 et 2012 Préciser la position de points remarquables, identifier et
représenter les espèces échantillonnés
vidéos Vidéos de mammifères relevées
en 2012
Préciser la position de points remarquables, identifier les
espèces animales
Collection d’animaux et
herbiers
Animaux et végétaux prélevés
depuis 1985
Connaître la biodiversité
Relevés météorologiques Relevés réalisés par capteurs
Hobo de 2010 à 2012
Permettre de mieux connaître le climat
Relevés hydrographiques Relevés réalisés par capteurs
Hobo de 2010 à 2012
Permettre de mieux connaître les variations de niveaux d’eau
des lacs
Relevés topographiques Relevés réalisés en 2012 Connaître l’altitude des pourtours des lacs
Images Landsat 15 dates s’étalant sur plus de 30
ans (1979- 2012)
Réaliser des études cartographiques diachroniques à petite
échelle
Images SPOT 23/10/2008, 04/03/2011 Réaliser des études cartographiques détaillées
Images Quickbird 19/01/2005 Réaliser des études cartographiques détaillées
Images Aster 02/08/2008 Réaliser des MNT, informations géostructurales, hydrologie et
hydrographie
Images radar 21/05/2011, 06/06/2011,
21/04/2012, 25/04/2012
Apporter des informations complémentaires aux images
optiques
Données météorologiques
RFE2
Données météorologiques par
décades disponibles depuis 2000
Réaliser des cumuls de précipitations
Tableau 3 : Inventaire des données disponibles en juin 2012
Cet inventaire nous a permis de définir plusieurs grands domaines de données classées par
type de données, car bien que certaines d’entre elles puissent nous transmettre des
informations similaires, elles ne peuvent pas, par la nature de la donnée, être classées dans le
même domaine :
Données brutes obtenues sur le terrain, telles que les relevés GPS, les inventaires, qui
nécessitent d’être inventoriées, analysées (identification, datation, …) et cartographiées ;
Données sources non relevées sur le terrain et susceptibles d’être traitées, telles que des
images satellites, des modèles numériques de terrain, des informations statistiques

Mise en place d’une infrastructure de données
spatiales
Rapport Batany Master 2 SIG et Gestion de l’Espace – août 2012 29/66
climatiques, ou encore des données utilisées comme fond de carte (réseau routier, limites
administratives…);
Données traitées, c’est-à-dire le résultat des analyses et traitements effectués sur les
données brutes et/ou les données sources, que nous ne pouvons pas pour le moment définir
(hormis pour les traitements réalisés au sein de Géo212) du fait du faible nombre de
données disponibles et du manque de réponse des partenaires ;
Un quatrième grand domaine doit être défini pour obtenir des informations
complémentaires sur les données, des données sur les données : ce sont les métadonnées.
Suite à cette réflexion sur les données déjà disponibles, nous avons pris également en
compte :
les données relevées mais non encore disponibles (c’est-à-dire des données non transmises
et les inventaires qui n'ont pas encore été analysés par des spécialistes en taxinomie),
Des métadonnées additionnelles qui nous ont paru intéressantes pour la vie future du
système.
4.2.2 Démarche suivie
Cette réflexion s’inscrit dans la démarche de création du Modèle Conceptuel des Données,
une étape qui conditionne l’ensemble du travail. Nous avons donc consacré beaucoup de
temps à sa création, car les autres étapes dépendent de ce Modèle. Pour le créer, nous avons
entamé un travail de réflexion sur plus d’un mois, de fin mars à fin avril 2012. Plusieurs
versions du modèle ont vu le jour, en organisant régulièrement des réunions avec les
différents acteurs du projet (Figure 9), tant en interne Géo212 qu’auprès des scientifiques
utilisateurs, afin de bien orienter la réflexion.
La difficulté principale a été la recherche d’un consensus face à des contraintes, points de vue,
niveaux de maturité et de compréhension de multiples problèmes.

Mise en place d’une infrastructure de données
spatiales
Rapport Batany Master 2 SIG et Gestion de l’Espace – août 2012 30/66
Figure 9 : Acteurs de la mise en place du Modèle Conceptuel des Données
4.2.3 Niveaux d’analyse des données
4.2.3.1 Modèle conceptuel des données
Le premier niveau défini est le niveau conceptuel des données, où de grands domaines
permettant de distinguer les différentes données existantes, et celles produites prochainement
par l'analyse des données de terrain ont été définis. Nous avons au préalable mis en place le
dictionnaire des données, un document qui référence toutes les données existantes avec leurs
propriétés (une version courte est lisible en annexe 1). Par ce travail de référence, il est plus
facile de créer les grands domaines.
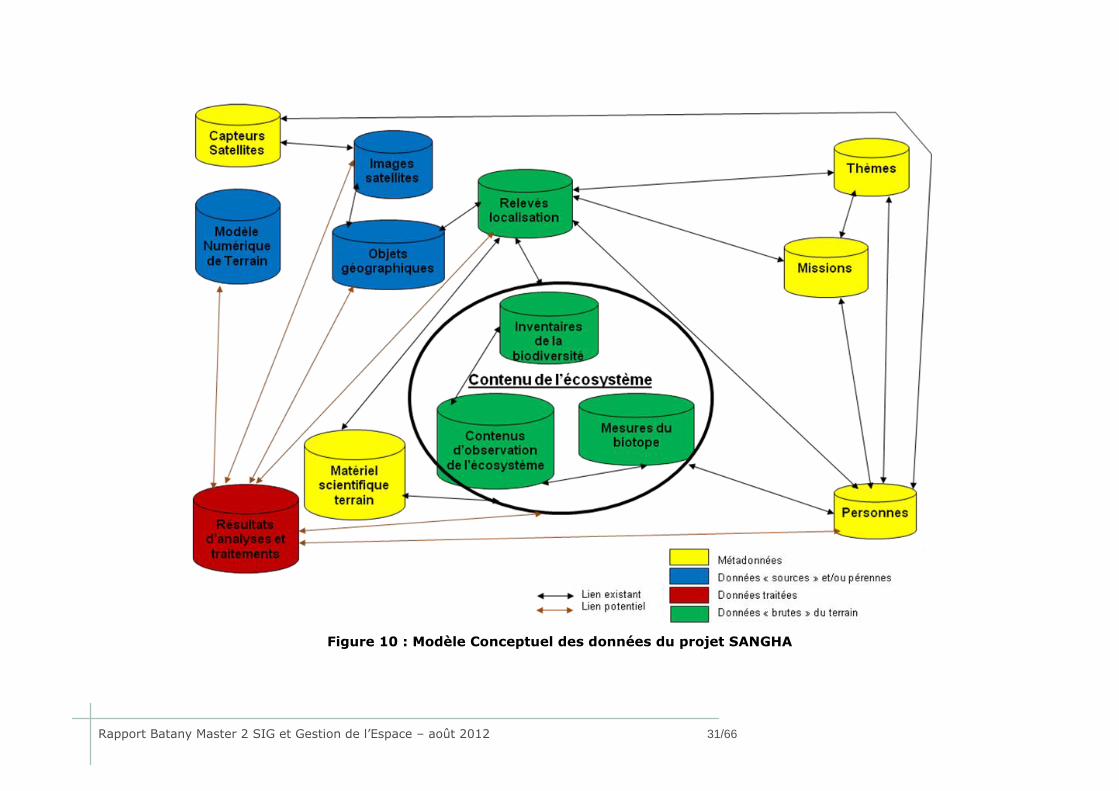
Le schéma suivant présente l'ensemble des grands domaines définis lors de cette réflexion
(Figure 10). La définition des domaines s’appuie à la fois sur les données disponibles et sur
les données prévues mais non encore disponibles, notamment les analyses possibles à réaliser
à partir de ces jeux de données. Les relations qui existent entre les différents domaines ont
également été déterminées par rapport aux différents objectifs définis.
Ce schéma présente bien un grand domaine central : toutes les données qui renseignent sur
l’écosystème. Les domaines biodiversité et biotope sont divisés au sein même de ce grand
domaine de l’écosystème. Les autres domaines « gravitent » tout autour, pour apporter des
informations complémentaires comme la localisation, les objets géographiques, les données
satellitaires, les résultats d’analyse et traitements possibles, et les métadonnées qui sont des
données utiles à connaître pour l'ensemble des missions mais sont uniquement descriptives.
Rapport Batany Master 2 SIG et Gestion de l’Espace – août 2012 31/66
Figure 10 : Modèle Conceptuel des données du projet SANGHA

Mise en place d’une infrastructure de données
spatiales
Rapport Batany Master 2 SIG et Gestion de l’Espace – août 2012 32/66
4.2.3.2 Modèle logique des données
Suite à cette première étape, nous sommes passés au second niveau, le modèle logique des
données, dans lequel les entités sont progressivement définies ainsi que les relations qui
existeraient entre elles, en tenant bien compte des objectifs à atteindre avec l’outil.
Nous avons tout d'abord défini ce qu’est une entité : c’est une « Collection de propriétés, dont
on peut identifier sans ambiguïté chaque occurrence, grâce à une propriété particulière :
l''identifiant' " : à chaque valeur de cet identifiant correspond une seule occurrence »11
(cf.
Figure 11). C’est ce que nous appelons une table. Les domaines ont été divisés en entités, les
tables de la base de données. Les champs des tables ont été également proposés, toujours en
fonction des objectifs visés par la base de données.
Figure 11 : Termes utilisés pour la construction du MLD
Puis les relations (ou associations) entre les différentes tables ont été progressivement
définies. Dans le Modèle Logique des Données nous faisons apparaître des relations (ou
associations) entre les tables (Figure 13). Une association est un objet qui associe au
minimum deux entités, et dont chaque apparition est identifiée par la concaténation des
identifiants des entités concernées. L’association n’a donc pas d’existence propre. Dans
11
D’après Véronique Sayasenh

Mise en place d’une infrastructure de données
spatiales
Rapport Batany Master 2 SIG et Gestion de l’Espace – août 2012 33/66
l’exemple ci-dessous (Figure 12), l’association existe, car l’identifiant de la table personne
(id_sangha) se retrouve dans la table inventaires arachnologiques sous le nom de
id_personne.
Figure 12 : Association entre 2 tables
Dans la Figure 13 ne figure qu’une partie du modèle logique des données. En effet seul le
domaine des inventaires de la biodiversité est présenté avec les entités avec lesquelles il serait
directement relié.
Sur cet extrait du Modèle Logique de Données, on peut remarquer que le domaine des
inventaires de la biodiversité a été éclaté en plusieurs entités. D’autres tables figurent
également dans le schéma, car ces tables possèdent une relation avec les tables du domaine
des inventaires de la biodiversité. Cela nous permet de présenter l’ensemble des relations que
nous rencontrons dans le Modèle Logique des Données. Ici un travail de distinction de chaque
entité est nécessaire, c’est-à-dire qu’un travail de définition des données contenu par chacune
des entités a été réalisé, afin de bien nommer chaque entité pour éviter tout synonyme ou
polysème, et ainsi éviter de douter lors du choix de l’entité dans laquelle serait enregistrée
chaque donnée. Par exemple, des données concernant l'hydrographie, récoltées sur le terrain,
sont des données brutes et entrent dans l'entité mesures du biotope du domaine étude de
l'écosystème. Par contre des données hydrographiques obtenues par photo-interprétation
d’images satellites n'entrent pas dans cette entité. Ce sont des données traitées et généralement
stables dans le temps (pas de mise à jour régulière à effectuer), qui sont intégrées dans le
domaine des objets géographiques.
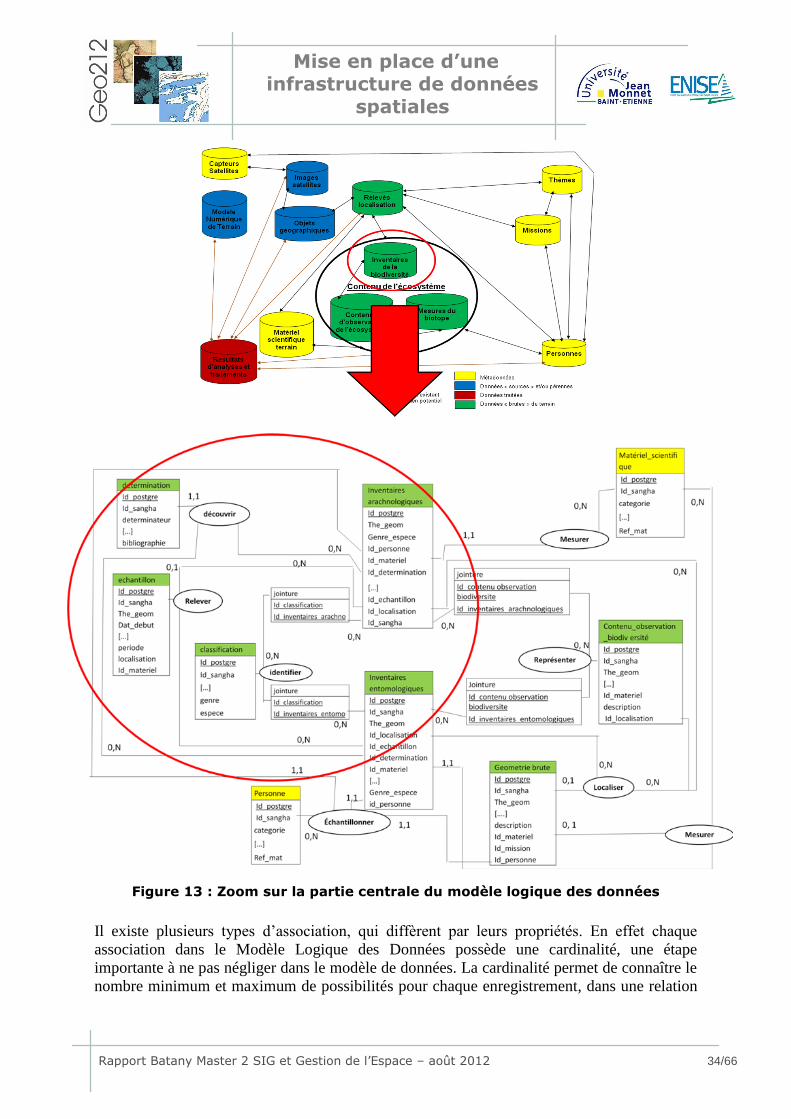
Mise en place d’une infrastructure de données
spatiales
Rapport Batany Master 2 SIG et Gestion de l’Espace – août 2012 34/66
Figure 13 : Zoom sur la partie centrale du modèle logique des données
Il existe plusieurs types d’association, qui diffèrent par leurs propriétés. En effet chaque
association dans le Modèle Logique des Données possède une cardinalité, une étape
importante à ne pas négliger dans le modèle de données. La cardinalité permet de connaître le
nombre minimum et maximum de possibilités pour chaque enregistrement, dans une relation

Mise en place d’une infrastructure de données
spatiales
Rapport Batany Master 2 SIG et Gestion de l’Espace – août 2012 35/66
liant 2 ou plusieurs entités. Le nombre de tables dans la base de données dépend en partie de
ces cardinalités.
La cardinalité minimale peut être de 0 ou 1, et la cardinalité maximale peut être de 1 ou N
(Figure 14).
Une cardinalité minimale à "0" signifie que nous autorisons le cas d'enregistrements de l'entité
considérée qui ne soient pas reliés à l'association (aucune valeur pour ce champ). En prenant
le premier exemple de la Figure 14, une personne peut n’avoir échantillonné aucun inventaire
arachnologique. Par conséquent, une cardinalité minimale à "1" exprime l'obligation de
relier tous les enregistrements de l'entité à l'association (ce qui se matérialisera ultérieurement
par une contrainte). En se basant toujours sur le premier exemple de la Figure 14, un
inventaire arachnologique est échantillonné par une et une seule personne.
Une cardinalité maximale à "n" signifie donc que nous autorisons le cas d'enregistrements de
l'entité considérée qui soient éventuellement reliées, chacun, à plusieurs enregistrements de
l'association. Pour illustrer cette cardinalité, prenons le cas du 3ième
exemple de la Figure 14,
où un enregistrement d’un inventaire peut être classé plusieurs fois ou pas, et inversement, un
enregistrement de classification peut correspondre à plusieurs inventaires ou non. Par
conséquent, une cardinalité maximale à "1" exprimera l'interdiction du "pluriel" comme dans
l’exemple 2 de la Figure 14 où un enregistrement d’inventaire peut correspondre à seulement
une seule géométrie brute ou aucune.
Figure 14 : Exemple de cardinalités possibles

Mise en place d’une infrastructure de données
spatiales
Rapport Batany Master 2 SIG et Gestion de l’Espace – août 2012 36/66
4.2.3.3 Modèle Physique des Données
Ce travail est la dernière étape dans la conception d’un Modèle de Données. Pour pouvoir
mener à bien cette étape, il nous faut définir l’outil que nous utiliserons pour mettre en place
la base de données. Par souci de clarté, nous expliquerons au paragraphe (§ 4.3) notre choix
du logiciel de SGBD et l’utilisation d’un logiciel de création de modèles de données.
Les SGBD structurent différemment une base de données selon leur nature. Actuellement 2
types de gestion de base de données sont couramment utilisés :
Les Systèmes de Gestion de Base de Données Relationnels (SGBDR), fonctionnent
sur une structure centrale composée de tables et de relations, une table étant un tableau
à 2 dimensions où chaque colonne défini un type de données (ou propriété) à stocker
et chaque ligne décrit un enregistrement ou occurrence à stocker.
Les Systèmes de Gestion de Base de Données Orientés Objets (SGBDOO) permettent
de gérer des structures de données complexes. Ils utilisent à la fois la puissance de
modélisation des modèles objets et la puissance de stockage des bases de données
classiques.
Etant donné que le modèle Logique des Données créé nous oriente vers les SGBD de type
relationnels, nous n’avons étudié que ce type de SGBD.
Comme nous l’avons vu dans le chapitre précédent, différents types de relations seront mises
en place dans la future base de données. Nous devons donc redéfinir les relations en fonction
du logiciel choisi ainsi que la typologie de chaque champ, c’est-à-dire la manière de définir
leur nature.
Prenons comme exemple le domaine des objets géographiques qui comprend un grand
nombre d’entités (cf. Figure 15). Nous avons ajouté une table, « source », qui référence toutes
les données utilisées pour créer les données à intégrer dans ce domaine. Cet exemple permet
de mieux comprendre les typologies des champs les plus couramment utilisées:
le type numéric, pour les champs à valeur numérique,
le type bigint, un type numérique de 16 chiffres, utilisés pour l’ensemble des identifiants,
le type serial, un type numérique, utilisé pour les identifiants créés par le logiciel
PostgreSQL,
le type caractère qui permet d’enregistrer du texte, la longueur de celui-ci pouvant être
limité,
le type géométrique qui peut être défini soit en point, linéaire ou surfacique pour
enregistrer les valeurs alphanumériques des données spatiales.
Cette figure présente 2 types de cardinalités :
- les cardinalités reliant les tables des objets à la table source sont de type 1,1 : ce qui
signifie que tout objet géographique provient d’une seule source,
- les cardinalités reliant la table source aux tables des objets sont de type 1,N : c’est-à-dire
que la table source renseigne l’historique d’au moins un ou plusieurs objets.

Mise en place d’une infrastructure de données
spatiales
Rapport Batany Master 2 SIG et Gestion de l’Espace – août 2012 37/66
Figure 15 : Exemple de typologie et de relations
(relations définies pour le domaine des objets géographiques)
Mais les relations de type N : N sont traduites différemment. En effet nous observons
l’apparition d’une table de jointure qui permet de relier les 2 tables (Figure 16). Cette table de
jointure se compose de :
- l’identifiant de la première table (dans l’exemple la table classification : id_classif),
- l’identifiant de la deuxième table (la table inventaires : id_inv).
Ces deux champs constituent la clé primaire de cette table de jointure. En effet le premier
champ correspondant à la classification peut présenter plusieurs fois la même valeur tout
comme le deuxième champ. Mais la combinaison des deux est unique.

Mise en place d’une infrastructure de données
spatiales
Rapport Batany Master 2 SIG et Gestion de l’Espace – août 2012 38/66
Figure 16 : La relation de type N:N dans le Modèle Physique des Données
Lors de la création du Modèle Physique des Données, il nous est paru nécessaire de réfléchir
au problème d’erreurs de saisie des données textuelles, car chaque partenaire sera amené à
saisir dans la base ses propres données. Cette réflexion se trouve en annexe 2.
4.2.4 Règles de création de tables à respecter Pour pouvoir mettre en place ce Modèle de Données, nous nous sommes fixés des règles à
respecter pour la création des différentes tables. En effet, chacune d’entre elle doit respecter
certaines règles qui sont imposées par le logiciel ou définies pour le projet dont voici les
principales (l’ensemble de ces règles sont définies en annexe 3) :
Un champ correspondant à la clé primaire nommé « id_postgre » et de type serial,
l’identifiant à incrémentation automatique du logiciel PostgreSQL.
Un champ permettant d’identifier chaque table de la base de données, de type bigint et
nommé « id_sangha ».
Un champ géométrique nommé « the_geom » pour les tables qui possèdent une géométrie.
Une règle d’intégrité liée aux relations de type 1 : N.

Mise en place d’une infrastructure de données
spatiales
Rapport Batany Master 2 SIG et Gestion de l’Espace – août 2012 39/66
Des règles de codage pour limiter les risques d’orthographes multiples des champs
textuels.
4.3 Choix du logiciel
Avant de créer le modèle physique des données, il nous faut déterminer le logiciel à partir
duquel nous allons créer la base de données.
4.3.1 Critères de choix De l’expression de besoin des utilisateurs, de la compréhension des caractéristiques du projet
(associatif, pauvre, avec des acteurs géographiquement dispersés, …) et de l’analyse de
l’environnement Géo212, des critères de choix ont été établis.
4.3.1.1 Logiciel libre
Le projet SANGHA disposant de peu de moyens financiers, il est indispensable que les
logiciels choisis soient des solutions libres. Mais une autre raison nous amène également à
faire ce choix. En effet les solutions libres sont généralement plus flexibles et interopérables
avec d’autres logiciels.
De part le fait que le code source des applications libres soit disponible, il est alors tout à fait
possible de les modifier afin de répondre spécifiquement aux besoins, bien que leur utilisation
impose généralement de posséder de solides compétences. Les solutions libres étant
également animées par une communauté d’utilisateurs, elles évoluent donc très rapidement et
sont donc relativement fiables dans leur fonctionnement.
4.3.1.2 Lecture d’un grand nombre de format de données spatiales
Un critère important à prendre en compte est la capacité des logiciels à lire un grand nombre
de formats de données dont des données spatialisées, car tous les SGBD ne sont pas capables
de gérer ces données.
De part la multiplicité des partenaires, il est très probable que chacun utilise leurs données
avec leurs propres logiciels. L’outil choisi doit alors permettre une grande interopérabilité
avec le maximum de logiciels. Il doit donc être capable de proposer un grand nombre de
formats de données.
4.3.1.3 Respect des normes et standards de l’OGC
L’Open Geospatial Consortium (OGC) est une organisation à but non lucratif fondée en 1994
pour résoudre les problèmes d’interopérabilité entre les différents outils du domaine de
l’information géographique. Ce consortium international a plusieurs objectifs et notamment
de développer et de promouvoir les standards ouverts de la géomatique et de l’information
géographique, et de favoriser la coopération entre développeurs, fournisseurs et utilisateurs.

Mise en place d’une infrastructure de données
spatiales
Rapport Batany Master 2 SIG et Gestion de l’Espace – août 2012 40/66
Ce consortium regroupe aujourd’hui plus de 250 membres dont les principaux acteurs du
marché, aussi bien dans le domaine public que privé.
Concernant les SGBD spatiaux, ceux-ci doivent respecter deux spécifications internationales
pour les données de type géométrique :
- L’OGC Simple Feature for SQL (OGC SFS),
- La norme ISO SQL/MM.
4.3.1.4 Logiciel suivi par l’OSGeo
Parmi les logiciels libres du domaine de la géomatique, un certain nombre d’entre eux sont
soutenus par l’Open Source Geospatial Foundation (OSGeo), une organisation dont la mission
est d'aider et de promouvoir le développement collaboratif des données et des technologies
géospatiales ouvertes. La fondation fournit une aide financière, organisationnelle et légale à la
communauté géospatiale libre la plus large. De nombreux projets Open-Source sont
actuellement soutenus par l’OSGeo, ce qui signifie pour ces outils qu’une large communauté
s’intéresse à leur développement, et ainsi favorise leur utilisation sur le long terme. Cela
signifie également qu’il est possible d’avoir accès à des formations ou des tutoriels pour
s’approprier le logiciel le plus rapidement possible.
Obtenir le sceau de l'OSGeo donne aux utilisateurs potentiels du projet une confiance accrue
dans la viabilité et la santé de celui-ci, en effet la communauté qui supporte l’outil est
largement augmentée et l’OSGeo assure un suivi à long terme même si la structure initiale
porteuse du projet disparaît.
4.3.1.5 Logiciel connu de l’entreprise
Le dernier critère à ne pas négliger concerne les connaissances et compétences que possède
déjà l’entreprise d’accueil. En effet il est beaucoup plus simple d’apprendre à utiliser un
logiciel qui est déjà utilisé par l’entreprise, plutôt qu’un outil qu’elle ne maîtrise pas.
4.3.1.6 Autres critères
Le logiciel utilisé doit être simple d’utilisation à la fois côté administrateur et utilisateur.
En effet, après la fin du stage, le logiciel sera administré bénévolement par Géo212, qui ne
peut pas y consacrer trop de temps. Au-delà l’administration pourrait être reprise par un autre
partenaire du projet, avec les mêmes contraintes.
Côté utilisateurs, ceux-ci sont multiples et présentent une maîtrise variable des bases de
données (d’expert à béotien absolu). L’outil choisi devra donc proposer une interface pour les
utilisateurs relativement intuitive pour des personnes qui l’utiliseraient occasionnellement.
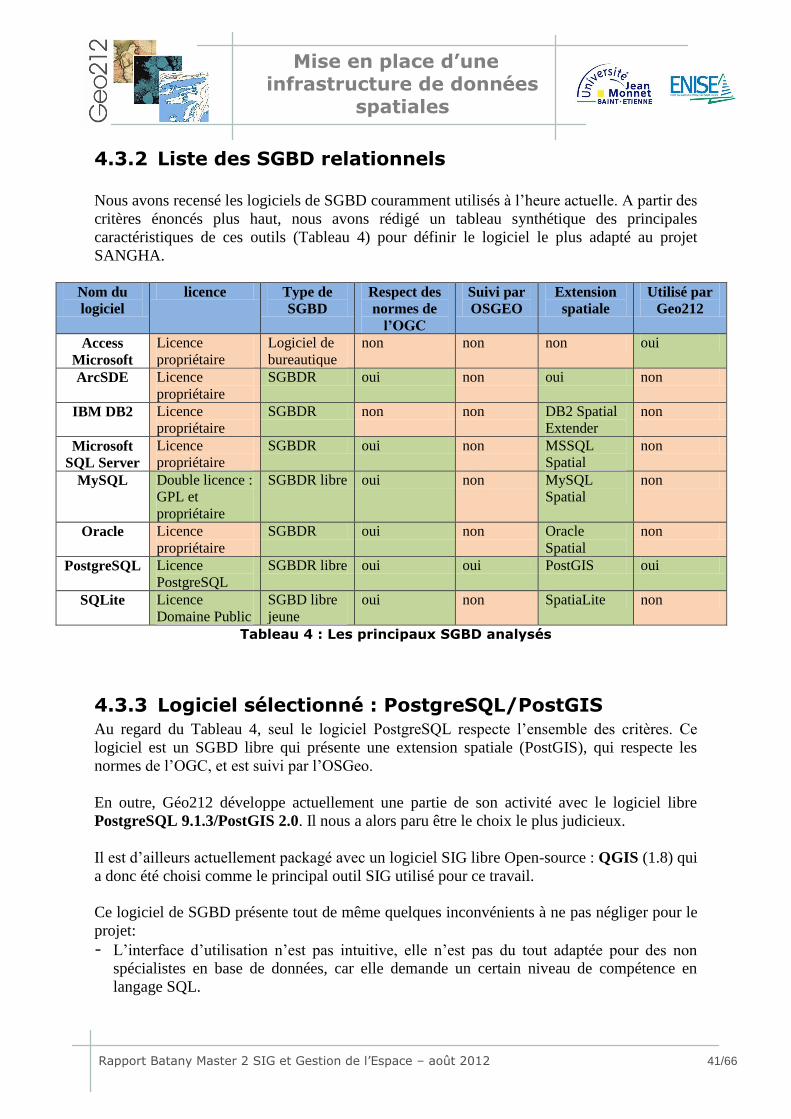
Mise en place d’une infrastructure de données
spatiales
Rapport Batany Master 2 SIG et Gestion de l’Espace – août 2012 41/66
4.3.2 Liste des SGBD relationnels Nous avons recensé les logiciels de SGBD couramment utilisés à l’heure actuelle. A partir des
critères énoncés plus haut, nous avons rédigé un tableau synthétique des principales
caractéristiques de ces outils (Tableau 4) pour définir le logiciel le plus adapté au projet
SANGHA.
Nom du
logiciel
licence Type de
SGBD
Respect des
normes de
l’OGC
Suivi par
OSGEO
Extension
spatiale
Utilisé par
Geo212
Access
Microsoft
Licence
propriétaire
Logiciel de
bureautique
non non non oui
ArcSDE Licence
propriétaire
SGBDR oui non oui non
IBM DB2 Licence
propriétaire
SGBDR non non DB2 Spatial
Extender
non
Microsoft
SQL Server
Licence
propriétaire
SGBDR oui non MSSQL
Spatial
non
MySQL Double licence :
GPL et
propriétaire
SGBDR libre oui non MySQL
Spatial
non
Oracle Licence
propriétaire
SGBDR oui non Oracle
Spatial
non
PostgreSQL Licence
PostgreSQL
SGBDR libre oui oui PostGIS oui
SQLite Licence
Domaine Public
SGBD libre
jeune
oui non SpatiaLite non
Tableau 4 : Les principaux SGBD analysés
4.3.3 Logiciel sélectionné : PostgreSQL/PostGIS Au regard du Tableau 4, seul le logiciel PostgreSQL respecte l’ensemble des critères. Ce
logiciel est un SGBD libre qui présente une extension spatiale (PostGIS), qui respecte les
normes de l’OGC, et est suivi par l’OSGeo.
En outre, Géo212 développe actuellement une partie de son activité avec le logiciel libre
PostgreSQL 9.1.3/PostGIS 2.0. Il nous a alors paru être le choix le plus judicieux.
Il est d’ailleurs actuellement packagé avec un logiciel SIG libre Open-source : QGIS (1.8) qui
a donc été choisi comme le principal outil SIG utilisé pour ce travail.
Ce logiciel de SGBD présente tout de même quelques inconvénients à ne pas négliger pour le
projet:
- L’interface d’utilisation n’est pas intuitive, elle n’est pas du tout adaptée pour des non
spécialistes en base de données, car elle demande un certain niveau de compétence en
langage SQL.

Mise en place d’une infrastructure de données
spatiales
Rapport Batany Master 2 SIG et Gestion de l’Espace – août 2012 42/66
- Les partenaires qui utiliseront les données devront utiliser un autre logiciel (soit en lien
direct avec PostgreSQL, soit après avoir récupéré les données) que celui dont ils disposent
sur leur propre ordinateur.
- L’organisme ou la personne qui dans le futur administrera cette base de données devra
posséder de solides compétences en informatique pour pouvoir utiliser ce logiciel.
Pour mettre en place le modèle physique de données, nous avons utilisé un logiciel de
conception de base de données utilisable en lien avec PostgreSQL. La modélisation de
structure de base de données, la génération et la modification se sont concentrées sur
PostgreSQL : DataBase Designer for PostgreSQL 1.8.2 de chez MicroOLAP. DB Designer
for PostgreSQL est un outil facile d’utilisation, de part son interface graphique intuitive, qui
permet de construire une structure de base de données claire et effective visuellement, de
visualiser le diagramme complet de la base de données, de représenter chaque table, de créer
toutes les relations entre les tables, etc… Cet outil est spécialement conçu pour mettre
directement sur le SGBD l’architecture de la base de données créée à partir de ce logiciel.
4.4 Démarche de peuplement
4.4.1 Introduction
Une étape clé du projet est l’intégration des données dans la base de données. Ce travail est
indispensable pour pouvoir travailler sur les données. Mais comme nous l’avons expliqué
dans le § 3.4, nous ne disposons que de très peu de données pour le moment.
Même si nous n’avons que quelques enregistrements par type de données, nous avons décidé
d’intégrer le plus large panel de types de données dont nous disposons, le plus représentatif de
cette forte hétérogénéité des données. L’objectif est de se confronter au maximum de
problèmes différents, représentatifs de ce qui se passera lorsque toutes les données seront
intégrées. Ce travail nous permettra de réaliser des recommandations pour la suite et de
réfléchir aux solutions qui pourraient exister pour tenter de pallier à ces problèmes.
4.4.2 Méthodes utilisées Pour intégrer les données existantes dans la structure de la base de données créée, 3 méthodes
de peuplement de données dans le SGBD PostgreSQL existent selon le type de données (elles
sont détaillées en annexe 4). Toutes ont été testées et utilisées, chacune ayant ses avantages et
inconvénients :
Données renseignées manuellement directement dans le logiciel PostgreSQL. Cette
technique est intéressante pour de petits jeux de données ne présentant pas de données
géométriques, telles que les métadonnées, des données purement descriptives.
Données intégrées par l’intermédiaire de QGIS. Cette méthode consiste à copier des
données d’un fichier de type .shp ou .dbf vers une table de la base de données. Cette
méthode est rapide pour copier quelques enregistrements (d’une centaine maximum), et
est très pratique pour les données géoréférencées. Dans la table source les champs
doivent se trouver dans l’ordre correspondant à celui de la table.

Mise en place d’une infrastructure de données
spatiales
Rapport Batany Master 2 SIG et Gestion de l’Espace – août 2012 43/66
Données entrées par la ligne de commande sur PostgreSQL. Un fichier entier de type
shapefile peut être intégré directement en ligne de commande par le convertisseur
shp2pgsql. Cette méthode est très utile pour de gros fichiers. Les données doivent être
présentées de la même manière que la table cible.
4.4.3 Difficultés rencontrées Durant le travail d’intégration de données nous avons été confrontés à différents problèmes.
Nous ne listons ici que les problèmes qui nous ont paru être les plus importants (liste
complète en annexe 4) :
Les données concernées par la base de données ont des origines très diverses qui constitue
un problème majeur de lecture : leur format est souvent incompatible avec le logiciel
PostgreSQL. Un long travail de mise en forme des données est nécessaire à l’aide de
nombreux logiciels.
Les coordonnées géométriques ont été généralement enregistrés manuellement dans un
fichier de type Excel, le format n’étant généralement pas lisible sous un SIG (Figure 17).
Figure 17 : Données géométriques avant et après conversion
Les fichiers Excel qui dans une même colonne contiennent plusieurs informations
correspondant à plusieurs attributs d’une même table dans la base de données.
Les données de type date ont été pour la plupart converties en un format lisible par
PostgreSQL.
Le point-virgule rencontré dans les données enregistrées manuellement a compliqué la
tâche de conversion des fichiers en .csv (Figure 18).

Mise en place d’une infrastructure de données
spatiales
Rapport Batany Master 2 SIG et Gestion de l’Espace – août 2012 44/66
Figure 18 : Exemple d'inventaire présentant des point-virgules
4.4.4 Bilan de peuplement
4.4.4.1 Travail réalisé
Un état des lieux des données intégrées a été établi. Un tableau de référencement de toutes les
données à été réalisé ainsi que des cartes permettant notamment de positionner les
échantillonnages (voir annexe 5).
4.4.4.2 Tests et contrôle qualité
Nous avons défini un protocole de test et avons demandé au personnel de la société de servir
d’utilisateurs initiaux de la base de données. Suite aux retours critiques récoltés, des tests ainsi
que des contrôles qualité ont été nécessaire pour vérifier l’intégrité de la base de données.
Ils sont présentés en détail en annexe 6 :
Vérification du système de projection pour l'ensemble des données géométriques.
Vérification de l’affichage des couches dans un SIG à l'affichage. Par exemple les données
concernant l'hydrographie, provenant à la fois de deux sources ouvertes (Hydroshed et
FAO AQUASTAT) et de données créées par l'entreprise, présentent des problèmes de
raccordements des données au niveau des jonctions (Figure 19).
Figure 19 : Exemples de mauvaises jonctions entre données multisources

Mise en place d’une infrastructure de données
spatiales
Rapport Batany Master 2 SIG et Gestion de l’Espace – août 2012 45/66
Vérification des relations entre les tables centrales par la mise en exécution de requêtes sur
les tables du domaine de la biodiversité.
Vérification de la qualité des données attributaires. Nous avons par exemple observé
l’apparition de caractères parasites qui sont apparus pour la plupart en remplacement de
caractères avec accent (Figure 20), une erreur due à l’utilisation de plusieurs logiciels.
Figure 20 : Exemple de symbole parasite dans les données attributaires
4.4.4.3 Modifications réalisées
Par rapport à la modélisation initiale, la modification que nous avons estimée être la plus
importante a concerné la table de classification des noms des spécimens et les tables des
inventaires. Cette table de classification est en relation avec toutes les tables des inventaires
par des tables de jointure.
Nous avions choisi de lier ces tables par des relations de type N : N (cf. Figure 16 du
§4.2.3.3), afin de contourner le problème de rectification possible d’identification des noms
scientifiques des spécimens récoltés. Après avoir récolté les données des partenaires et peuplé
les tables, nous nous sommes aperçus que ces rectifications seraient très rares. Nous avons
donc décidé de modifier ces relations, difficile à mettre en place, par des relations de type 1 :
N. La modification est détaillée en annexe 7.
Des modifications mineures ont également été réalisées (ajouts d’attributs dans les tables
d’inventaires, suppressions de tables de jointure).
4.4.5 Recommandations pour la poursuite du projet
Le peuplement de la base de données et les tests réalisés nous permettent de rédiger un certain
nombre de recommandations utiles pour la suite de la mise en place de la base de données.
Elles portent soit sur des reprises, soit sur des développements complémentaires, soit sur des
recommandations méthodologiques pour l’intégration future de nouvelles données.
Les reprises concernent des points qui n’ont pas été bloquants pour le bon fonctionnement de
la base, du fait du faible volume de données implémenté actuellement. Elles seront
nécessaires pour gérer l’intégration de gros volumes.

Mise en place d’une infrastructure de données
spatiales
Rapport Batany Master 2 SIG et Gestion de l’Espace – août 2012 46/66
4.4.5.1 Reprises d’optimisation de la base de données
4.4.5.1.1 Choix d’une géométrie unique dans chaque table
Un problème observé concerne le stockage des données géométriques. Pour des données de
même nature, il est possible de stocker dans la même table des géométries de type point,
linéaire, et surfacique (par exemple les relevés GPS peuvent représenter des points de
positionnement de pièges physiques, de photographies et de pièges vidéos, et des tracks
linéaires de parcours). Pour des raisons pratiques, l'ensemble des géométries ont été intégrées
dans le même champ.
Mais il s'est avéré que, pour des raisons d'optimisation de la base, cette solution n’est pas
adaptée si la base stocke un grand nombre de données. Un travail de séparation des
géométries, soit dans des champs différents, soit dans des tables différentes, sera à réaliser
(Figure 21).
Figure 21 : Proposition d’optimisation des tables géométriques
4.4.5.1.2 Création d’index spatiaux
La création d'index spatiaux dans une base de données de type PostgreSQL/PostGIS pour les
tables contenant une géométrie, est importante pour des raisons d'optimisation de base de
données volumineuses. Cela permet de réduire le temps de recherche lors de la mise en place
de requêtes lourdes, car un index spatial est une forme d'indexation utilisée pour optimiser les
calculs impliquant des positionnements ou des distances. Ce travail devra également être
réalisé par la suite.
4.4.5.1.3 Division de la table classification
Toujours pour des raisons d'optimisation, il serait intéressant de diviser la table classification
en plusieurs tables. En effet, pour faciliter les recherches des scientifiques parmi les différents
groupes d’animaux observés et échantillonnés sur le terrain, cette table unique pourrait être
remplacée par plusieurs tables (Figure 22), chaque champ correspondant à une table. Cela

Mise en place d’une infrastructure de données
spatiales
Rapport Batany Master 2 SIG et Gestion de l’Espace – août 2012 47/66
permettrait de créer des listes déroulantes de choix, et ainsi imposerait un choix d'écriture lors
de nouveaux enregistrements.
Mais cette transformation de la table classification imposerait de la part de la structure qui
gèrera la base de données d’avoir de solides compétences en gestion de bases de données, car
cette structure de table améliorera les recherches mais compliquera le modèle.
Il serait également intéressant de retrouver dans la même colonne les noms de genre et espèce,
car les espèces sont toujours identifiées par leur nom de genre et espèce.
4.4.5.2 Reprises suite à des erreurs d’intégration
Des erreurs ont été observées, suite à l'intégration des données de différents formats. En effet,
des caractères textuels avec accents dans des fichiers .csv, ne sont pas bien lus en .dbf ou en
.shp (Figure 20), mais cela n'empêche aucunement l'utilisation de la base de données. Ces
problèmes seront à corriger par la suite.
4.4.5.3 Reprises suite à des erreurs dans les données sources
D'autres corrections à apporter ont également été notées, comme la rectification des
coordonnées des photographies réalisées en 2012 sur le terrain (cf.Annexe 6).
Des doublons ont été relevés dans la table classification (deux enregistrements identiques). Il
faudra vérifier dans l’ensemble des tables qu’il n’y ait pas d’enregistrements identiques
surnuméraires.
Dans la table des inventaires, ont été répertoriées des géométries de type ligne (cf. Annexe 6).
Bien qu’il soit effectivement possible de réaliser un inventaire le long d’une route ou d’une
ligne droite, ces données géométriques de type linéaire ne renvoient pas la bonne information
géométrique. Il serait préférable de les supprimer et d’en discuter avec les partenaires s’ils
souhaitent conserver ces informations et comment.
4.4.5.4 Intérêt des informations sur le matériel scientifique de terrain
Un point notable concerne le matériel scientifique de terrain. Même si cette table est purement
informative, nous ne disposons pas des renseignements nécessaires pour savoir, concernant
les pièges physiques et les GPS, qui a utilisé quel matériel, à quel moment, et à quel endroit.
Pour ce faire, il faudra continuer le travail de communication commencé avec les partenaires
pour obtenir ces informations. Ce point sera important si l’IDS est utilisée dans la
planification et l’optimisation des collectes dans les missions futures.
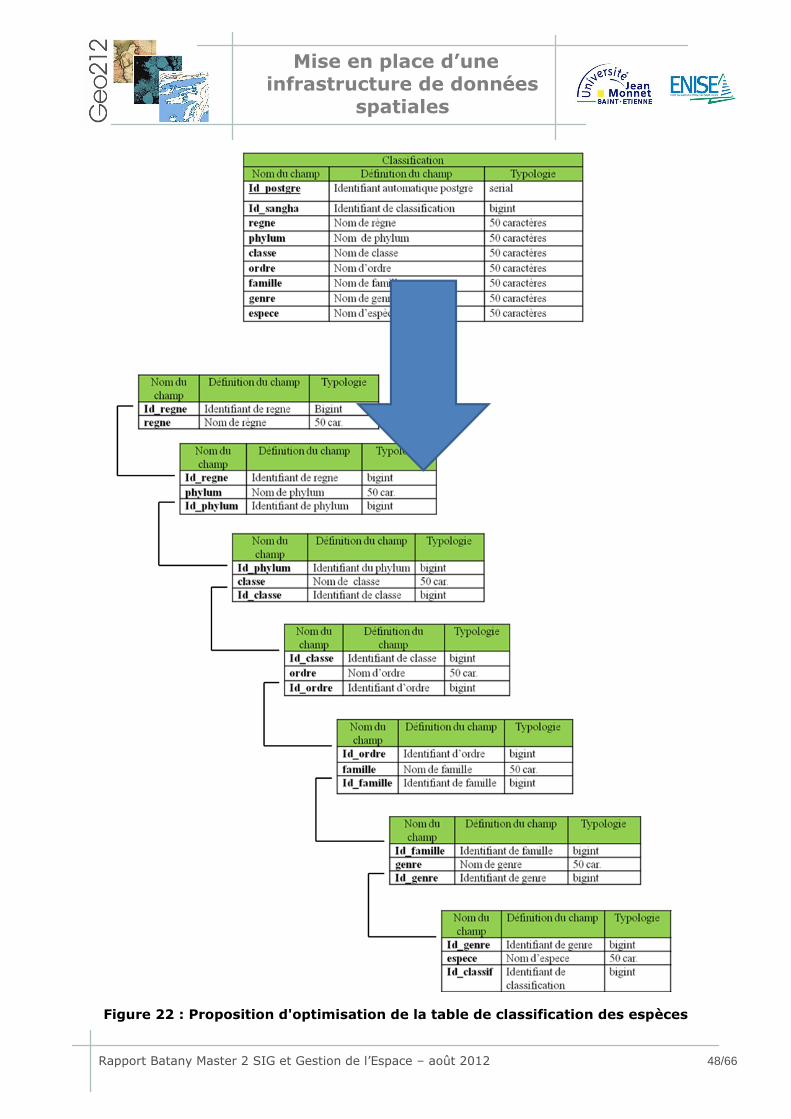
Mise en place d’une infrastructure de données
spatiales
Rapport Batany Master 2 SIG et Gestion de l’Espace – août 2012 48/66
Figure 22 : Proposition d'optimisation de la table de classification des espèces

Mise en place d’une infrastructure de données
spatiales
Rapport Batany Master 2 SIG et Gestion de l’Espace – août 2012 49/66
4.4.5.5 Amélioration des travaux de contrôle et de tests
Il serait intéressant de réaliser un travail de vérification des noms de champs dans chaque
table, afin d’être sûr que chaque champ renvoyant à la même information dans les tables
possède exactement le même nom.
Nous n’avons pas pu tester l’ensemble des fonctionnalités de la base, faute de données
suffisamment importantes en volume. Il faudra réfléchir aux différents tests à réaliser,
notamment pour les tables des domaines des métadonnées, afin de vérifier le bon
fonctionnement de la base de données.
4.4.5.6 Conseil pour la suite de la construction de la base de données
Certains partenaires souhaitent obtenir des données génétiques sur leurs spécimens, et
travaillent généralement avec la base de données boldsystems (http://www.boldsystems.org/).
Certains souhaiteraient intégrer dans les tables d’inventaires un champ permettant de
renseigner le « code barre » correspondant à l’ADN de l’individu (ou de l’espèce), tandis que
d’autres souhaiteraient pouvoir y renseigner le lien vers la page web de l’espèce. De nouveaux
rendez-vous d’analyse des besoins seraient à prévoir avec les partenaires pour intégrer les
informations génétiques dans la base de données.
La base de données doit également permettre de pouvoir travailler avec des données en 3
dimensions. En effet une étude est actuellement en cours sur les fourmilières (cf. Tableau 1) et
les spécialistes souhaiteraient travailler avec des outils qui permettent de les visualiser en 3
dimensions. Cette étude nous amène donc à supposer que d’autres études pourraient être
conduites en 4 dimensions, en prenant en compte également la dimension temporelle. Ces
éléments doivent être gardés en tête, car la base de données doit évoluer au fur et à mesure de
son peuplement.
Un dernier point à ne pas négliger concerne les métadonnées. En effet la base de données
dispose de métadonnées, mais qu’en sera-t-il lorsque le volume de données sera plus
important ? Comment les utilisateurs vont-ils se retrouver parmi toutes les données
disponibles ? Il faut penser à mettre en place un catalogage des métadonnées pour pouvoir
recenser l’ensemble des données disponibles, et ainsi éviter des doublons d’information ou au
contraire un manque.
4.5 Conclusion
Bien qu’actuellement nous ne disposions pas d’un grand nombre de données, un grand
nombre de types de données peuplent maintenant la base.

Mise en place d’une infrastructure de données
spatiales
Rapport Batany Master 2 SIG et Gestion de l’Espace – août 2012 50/66
Ce travail nous a permis d’étudier une grande partie des problèmes que nous serons amenés à
rencontrer dans la suite du peuplement. Nous maîtrisons l’ensemble des problèmes
d’intégration qui pourraient concerner les données et métadonnées du domaine capteurs
satellites, et nous commençons à bien appréhender les données et métadonnées du domaine
naturaliste. Lorsque de nouveaux partenaires viendront collaborer au projet de la base de
données, nous serons en mesure d’appréhender les futurs problèmes à venir de part les
recommandations établies, et part la mise en place d’un outil de saisie pour minimiser les
problèmes d’intégration. En effet, pour faciliter l’intégration des données, que ce soit pour un
administrateur, ou pour les partenaires, il pourrait être proposé des formulaires types de saisie.
Cela a 2 avantages :
- éviter au maximum les pertes de données, lors des transformations possibles ou
nécessaires ;
- limiter les travaux préalables à l’intégration des données.
Ces formulaires peuvent être de différents formats numériques interopérables avec
PostgreSQL, le plus simple pour les données attributaires étant le format .csv.
Nous allons notamment voir dans le chapitre suivant la mise en place d’un formulaire de
saisie pour les données des inventaires.

Mise en place d’une infrastructure de données
spatiales
Rapport Batany Master 2 SIG et Gestion de l’Espace – août 2012 51/66
5 Interface Webmapping
5.1 Besoins et objectifs
L’interface que nous souhaitons développer doit répondre aux besoins exprimés par les
partenaires (cf. §3.1) et contribuer à simplifier et sécuriser le peuplement des données en
tenant compte des résultats des premiers travaux (cf. §4.4).
C’est un composant de l’IDS qui doit donc être construit dans la continuité de la base de
données comme un moyen d’avoir accès aux données de l’ensemble des partenaires.
La première fonction de cette interface sera de faciliter la saisie et l’intégration des données
des partenaires. L’utilisation de formulaires permettra de pallier aux problèmes de peuplement
de la base de données, il permettra ainsi de limiter les erreurs de saisie.
La deuxième fonction de cette interface sera de partager les données entre partenaires.
L’objectif est de faire en sorte que chaque partenaire ait accès à ses propres données mais
aussi aux données géolocalisées des partenaires. Elle permettra de travailler avec les données
d'autres domaines scientifiques, de pouvoir comparer les analyses, et ainsi augmenter les
capacités d’analyses.
Mais la visualisation des données pourra être également mise au service d’une troisième
fonction de communication et de pédagogie. Beaucoup de partenaires partis sur le terrain
réalisent des expositions et des animations dans des écoles et de multiples établissements
publics. Si la base de données est enrichie en données, l’interface pourrait à long terme
devenir un support de communication vers le grand public, ou encore un support d'aide à la
décision pour les missions futures.
Au-delà de ces trois fonctions, l’interface vise également à pallier au faible nombre de
réponses lors de l’expression de besoin en permettant à tous les partenaires impliqués de
constater l’utilité et la puissance que pourrait avoir l’IDS.
Nous allons voir dans ce chapitre ce qu’est un outil de webmapping, ses composants et la
manière utilisée ici pour le mettre en place.
5.2 Qu’est ce que le webmapping ?
Le terme « webmapping » est vaste car il regroupe des compétences et des techniques
diverses. Ce terme désigne « au sens large, tout ce qui relève de la cartographie en ligne sur
Internet. Sous ce terme générique, on englobe différents types d'applications cartographiques

Mise en place d’une infrastructure de données
spatiales
Rapport Batany Master 2 SIG et Gestion de l’Espace – août 2012 52/66
allant du simple « visualiseur » à l'outil de cartographie thématique, voire au SIG en ligne.
Leur point commun est d'être accessible à travers un simple navigateur Internet. »12
.
Il existe 3 niveaux différents de webmapping, selon les fonctionnalités possibles (Pornon,
2008) :
Le webmapping simple où seule la consultation de données est possible, la visualisation
étant statique ;
Le webmapping « dynamique » signifie que la carte affichée en ligne est interactive. Il est
possible pour un utilisateur d’utiliser des fonctions simples comme le zoom, le choix
d’afficher des couches ou encore d’afficher des info-bulles. Ce niveau permet de dépasser
le téléchargement de cartes statiques et d'accéder à des données géographiques contenues
sur un serveur cartographique, comme par exemple une base de données ou des fichiers
SIG ;
Le webSIG qui permet des fonctions plus avancées comme la réalisation de requêtes
attributaires et spatiales avancées.
L'architecture d’un système de cartographie Web repose principalement sur quatre éléments
fondamentaux (Figure 23):
Les données sont la composante essentielle du système ;
Le logiciel de cartographie Web est un programme côté serveur qui peut produire une
carte dynamique (simple image) à partir des données en fonction de la demande du client ;
Les outils d’interaction de l’application Web: ils permettent à l'utilisateur de manipuler
et d'explorer la carte (zoom avant et arrière, panoramique) ainsi que de récupérer des
informations textuelles ;
Le Navigateur Web: il permet à l’utilisateur (client) d’ouvrir l'application Web et
d’explorer la carte.
Figure 23 : Architecture d'un outil de Webmapping
(D’après Territorial Intelligence)
12
D’après Social Change Online

Mise en place d’une infrastructure de données
spatiales
Rapport Batany Master 2 SIG et Gestion de l’Espace – août 2012 53/66
5.3 Démarche et méthode/Choix logiciel
5.3.1 Road Map du projet d’interface webmapping Sangha
La décision de se lancer dans une telle interface n’ayant été prise qu’en juin 2012 (cf. §2.2.2),
il était clair que le développement complet serait achevé au-delà des limites de notre stage.
Nous avons donc proposé une road map planifiant les travaux à accomplir et détaillant plus
particulièrement les étapes à réaliser entre juin et août 2012 :
1. Etablissement du cahier des charges de l’outil (cf. §5.1)
2. Choix des outils qui permettront de mettre en place cette application.
3. Visualisation des données disponibles dans la base de données. Cette étape correspond à
un webmapping statique.
4. Mise en place des fonctions de zooms, de capture de cartes, de listes déroulantes à choix
multiples. L’outil webmapping devient alors progressivement dynamique.
5. Mise en place de fonctions supplémentaires : en particulier, le téléchargement des
données de la base de données sous différents formats possibles (kml, jpeg par exemple).
6. Capacité de réalisation de requêtes spatiales simples pour les utilisateurs.
7. Capacité de recherche des données par des requêtes spatiales et attributaires. Suite à
cette étape l’outil deviendra un véritable outil webSIG aux fonctionnalités avancées.
Notre travail, présenté ci-après concerne les étapes 2, 3 et 4.
5.3.2 Critères d’évaluation des solutions
Il existe une multitude de logiciels pour créer un outil webmapping. Mais lesquels choisir ?
Nous avons donc défini des critères de choix pour sélectionner les outils les plus appropriés
pour le projet, qui sont les mêmes que pour le choix du SGBD :
Solution peu couteuse s’appuyant sur des logiciels open sources
Interopérabilité avec le SGBD déjà retenu
Respect des normes de l’OGC (détaillé plus bas)
Communauté large d’utilisateurs (détaillé plus bas)
Connaissance des outils par la société Géo212
5.3.2.1 Respect des normes de l’OGC
Parmi ses recommandations, l’OGC s’applique pour les outils webmapping notamment à :
normaliser des formats de données libres afin de favoriser les échanges entre
plateformes. Parmi ceux-ci nous pouvons citer :

Mise en place d’une infrastructure de données
spatiales
Rapport Batany Master 2 SIG et Gestion de l’Espace – août 2012 54/66
o le GML (Geographic Markup Language)
o le KML (Keyhole Markup Language).
normaliser les protocoles qui permettront à deux plateformes de communiquer entre
elles. Il existe plusieurs protocoles :
o Le Web Map Service (WMS) qui permet d’interconnecter des sites
cartographiques par l’échange de fichiers images sous différents formats ;
o Le Web Feature Service (WFS) qui permet d’interconnecter des sites
cartographiques par l’échange de fichiers vecteur grâce au format GML ;
o Le Web Feature Service Transactional (WFS-T, extension du WFS), qui
permet l’ajout, la suppression et la mise à jour d’entités géographiques ;
o Le Web Processing Service (WPS) qui permet de réaliser des traitements de
données à distance (union, intersection...).
Il est donc primordial de choisir un outil qui respecte les normes et les standards de l’OGC
afin de favoriser l’interopérabilité entre l’outil choisi et toute plateforme ou service
respectueux de ces normes.
5.3.2.2 Communauté large d’utilisateurs
Les solutions libres sont généralement suivies par une large communauté d’utilisateurs qui
permet aux outils d’évoluer. Afin de s’assurer que le logiciel est suivi à plus ou moins long
terme et est un projet qui perdure, il est donc préférable de se fier une nouvelle fois à l’OSGeo
(§ 4.3.1.4).
De nombreux projets Open-Source utilisés pour la création d’application de type
webmapping sont actuellement soutenus par l’OSGEO :
Tableau 5 : Liste des outils de webmapping soutenus par l'OSGeo
Certains outils sont actuellement en phase d’incubation auprès de l’OSGeo. Le but de cette
phase est de vérifier l’intégrité du projet candidat.
Passer l'incubation signifie que les éléments suivants sont réunis :
Une communauté ouverte autour du projet,
Un modèle de gouvernance du projet responsable,
Une vérification de la provenance du code,
Une vérification de la licence,
Une bonne gestion générale du projet.
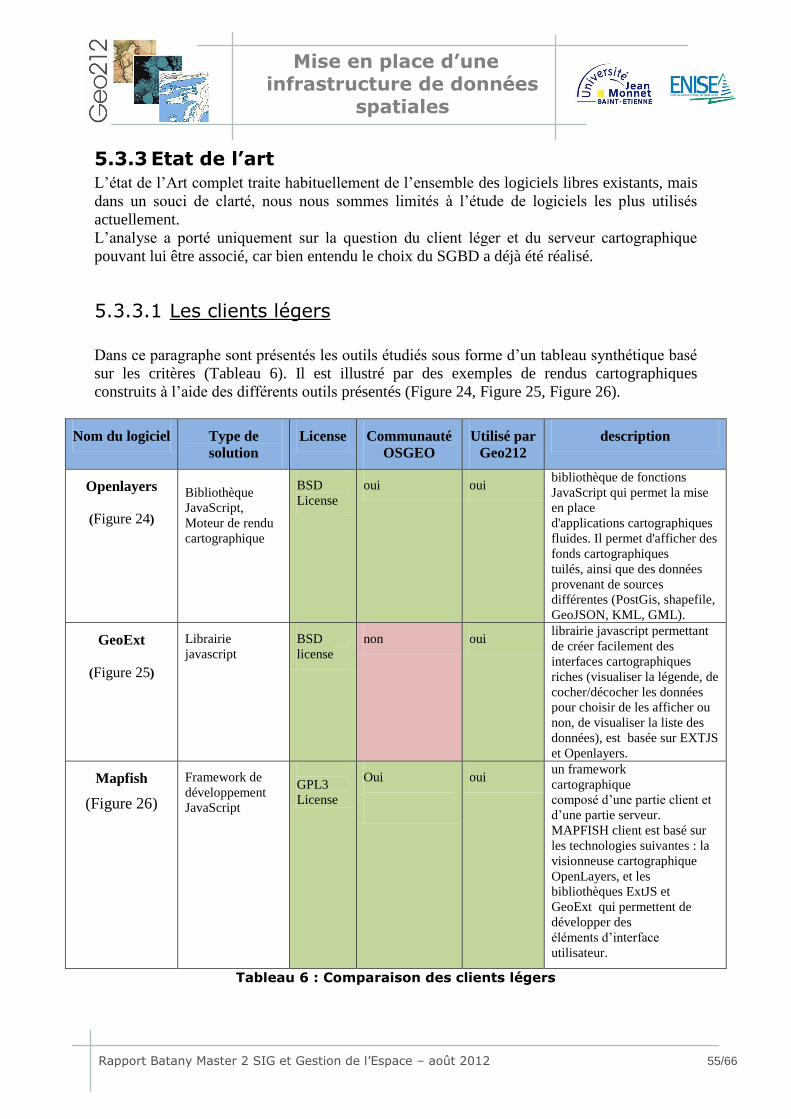
Mise en place d’une infrastructure de données
spatiales
Rapport Batany Master 2 SIG et Gestion de l’Espace – août 2012 55/66
5.3.3 Etat de l’art L’état de l’Art complet traite habituellement de l’ensemble des logiciels libres existants, mais
dans un souci de clarté, nous nous sommes limités à l’étude de logiciels les plus utilisés
actuellement.
L’analyse a porté uniquement sur la question du client léger et du serveur cartographique
pouvant lui être associé, car bien entendu le choix du SGBD a déjà été réalisé.
5.3.3.1 Les clients légers
Dans ce paragraphe sont présentés les outils étudiés sous forme d’un tableau synthétique basé
sur les critères (Tableau 6). Il est illustré par des exemples de rendus cartographiques
construits à l’aide des différents outils présentés (Figure 24, Figure 25, Figure 26).
Nom du logiciel Type de
solution
License Communauté
OSGEO
Utilisé par
Geo212
description
Openlayers
(Figure 24)
Bibliothèque
JavaScript,
Moteur de rendu
cartographique
BSD
License
oui oui bibliothèque de fonctions
JavaScript qui permet la mise
en place
d'applications cartographiques
fluides. Il permet d'afficher des
fonds cartographiques
tuilés, ainsi que des données
provenant de sources
différentes (PostGis, shapefile,
GeoJSON, KML, GML).
GeoExt
(Figure 25)
Librairie
javascript
BSD
license
non oui librairie javascript permettant
de créer facilement des
interfaces cartographiques
riches (visualiser la légende, de
cocher/décocher les données
pour choisir de les afficher ou
non, de visualiser la liste des
données), est basée sur EXTJS
et Openlayers.
Mapfish
(Figure 26)
Framework de
développement
JavaScript
GPL3
License
Oui
oui un framework
cartographique
composé d’une partie client et
d’une partie serveur.
MAPFISH client est basé sur
les technologies suivantes : la
visionneuse cartographique
OpenLayers, et les
bibliothèques ExtJS et
GeoExt qui permettent de
développer des
éléments d’interface
utilisateur.
Tableau 6 : Comparaison des clients légers
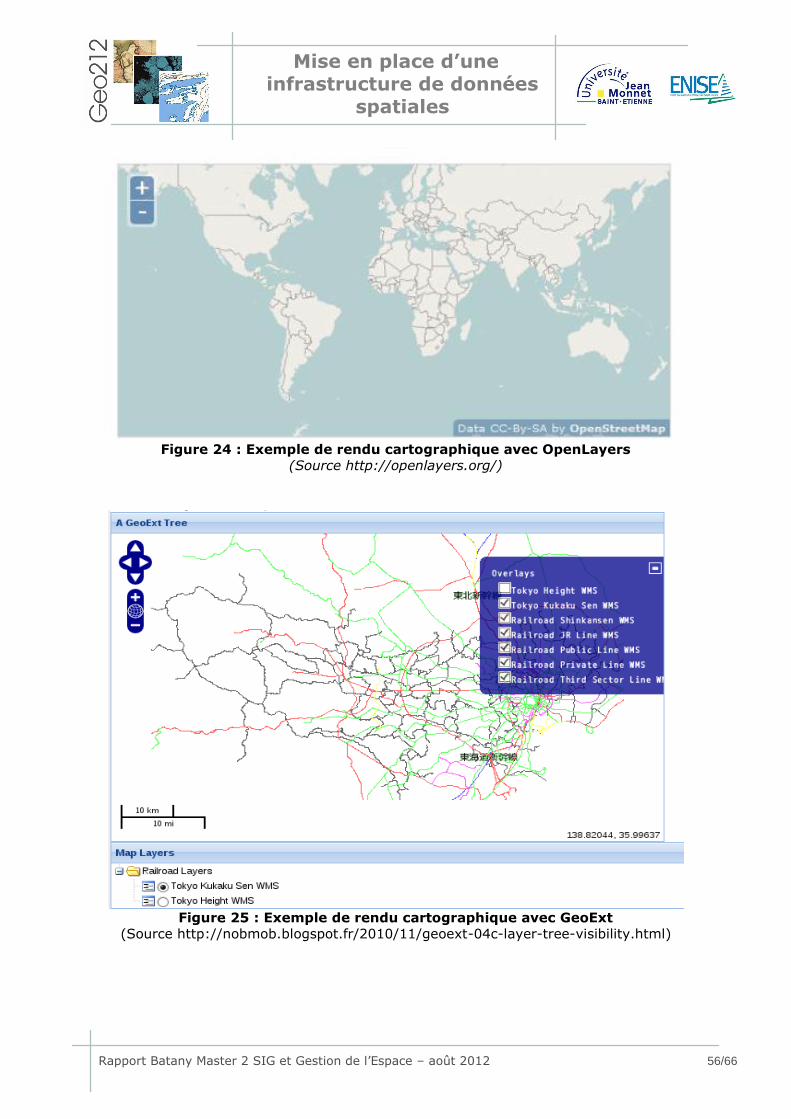
Mise en place d’une infrastructure de données
spatiales
Rapport Batany Master 2 SIG et Gestion de l’Espace – août 2012 56/66
Figure 24 : Exemple de rendu cartographique avec OpenLayers
(Source http://openlayers.org/)
Figure 25 : Exemple de rendu cartographique avec GeoExt
(Source http://nobmob.blogspot.fr/2010/11/geoext-04c-layer-tree-visibility.html)
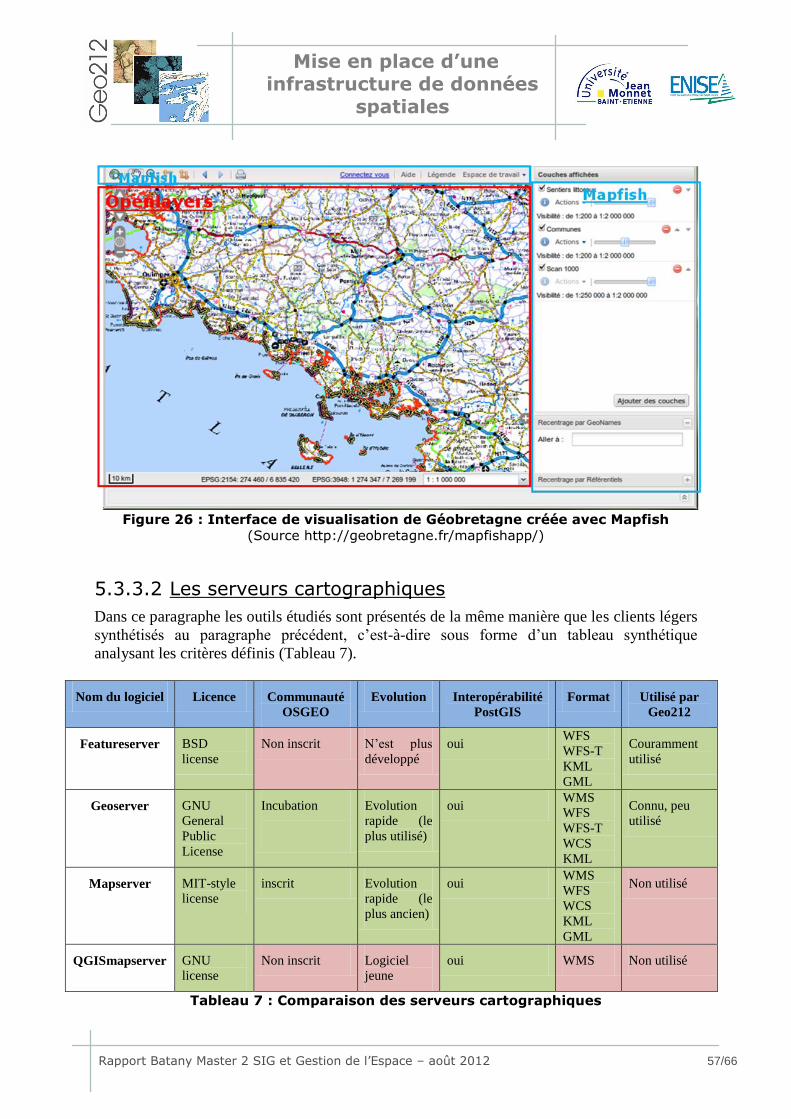
Mise en place d’une infrastructure de données
spatiales
Rapport Batany Master 2 SIG et Gestion de l’Espace – août 2012 57/66
Figure 26 : Interface de visualisation de Géobretagne créée avec Mapfish
(Source http://geobretagne.fr/mapfishapp/)
5.3.3.2 Les serveurs cartographiques
Dans ce paragraphe les outils étudiés sont présentés de la même manière que les clients légers
synthétisés au paragraphe précédent, c’est-à-dire sous forme d’un tableau synthétique
analysant les critères définis (Tableau 7).
Nom du logiciel Licence Communauté
OSGEO
Evolution Interopérabilité
PostGIS
Format Utilisé par
Geo212
Featureserver BSD
license
Non inscrit N’est plus
développé
oui WFS
WFS-T
KML
GML
Couramment
utilisé
Geoserver GNU
General
Public
License
Incubation
Evolution
rapide (le
plus utilisé)
oui WMS
WFS
WFS-T
WCS
KML
Connu, peu
utilisé
Mapserver MIT-style
license
inscrit Evolution
rapide (le
plus ancien)
oui WMS
WFS
WCS
KML
GML
Non utilisé
QGISmapserver GNU
license
Non inscrit Logiciel
jeune
oui WMS Non utilisé
Tableau 7 : Comparaison des serveurs cartographiques

Mise en place d’une infrastructure de données
spatiales
Rapport Batany Master 2 SIG et Gestion de l’Espace – août 2012 58/66
5.3.4 Choix des logiciels
Nous avons choisi d’utiliser, après étude des critères à respecter :
- le serveur cartographique Geoserver car il propose de multiples fonctionnalités et est
relativement simple d’utilisation. Il peut lire de nombreux formats de fichiers
dont PostGIS. Grâce à Geoserver, il est également possible de se connecter à des globes
virtuels comme Google Earth, et aussi à des cartes à base de service web tels que
OpenLayers, Google Maps et Bing Maps ;
- Le client léger Mapfish qui est relativement bien conçu pour créer des interfaces web
riches et se combine facilement avec le serveur Geoserver, étant donné qu’ils sont tous les
2 inscrits à l’OSGeo.
Pour mettre en ligne l’outil nous devrons également utiliser un serveur http, un logiciel qui
respecte le protocole de communication client-serveur HTTP. Nous avons choisi d’utiliser le
serveur Apache, car il est actuellement utilisé par Géo212 et est un logiciel libre.
5.4 Développement de l’interface
L’utilisation de logiciels libres impose une certaine connaissance et compétence en
programmation qui implique d’utiliser quelques logiciels. Nous avons utilisé le logiciel de
déboguage Firebug, une extension du navigateur web Mozilla Firefox qui permet de
déboguer, éditer et modifier le HTML, le CSS et le JavaScript d'une page web. Nous nous
sommes également basés, pour la conception de l’interface de saisie, sur des sites existants
créés avec les outils que nous utilisons (http://sws.irsn.fr/sws/mesure/index et
http://dev4.mapgears.com/bdga-mapfish/). Nous avons en effet repris une partie de leurs
codes sources pour comprendre comment ils ont été construits. C’est un travail relativement
long et compliqué à mettre en œuvre pour toute personne ne disposant pas d’un minimum de
compétence en programmation.
Nous allons présenter l’architecture mise en place, les fonctions que peut réaliser à ce stade
l’interface mise en place et nous terminerons par les différents problèmes rencontrés.
5.4.1 Architecture mise en place
La Figure 27 récapitule l’architecture de l’outil de webmapping mise en place, c’est-à-dire les
différents logiciels qu’utilise cette interface.
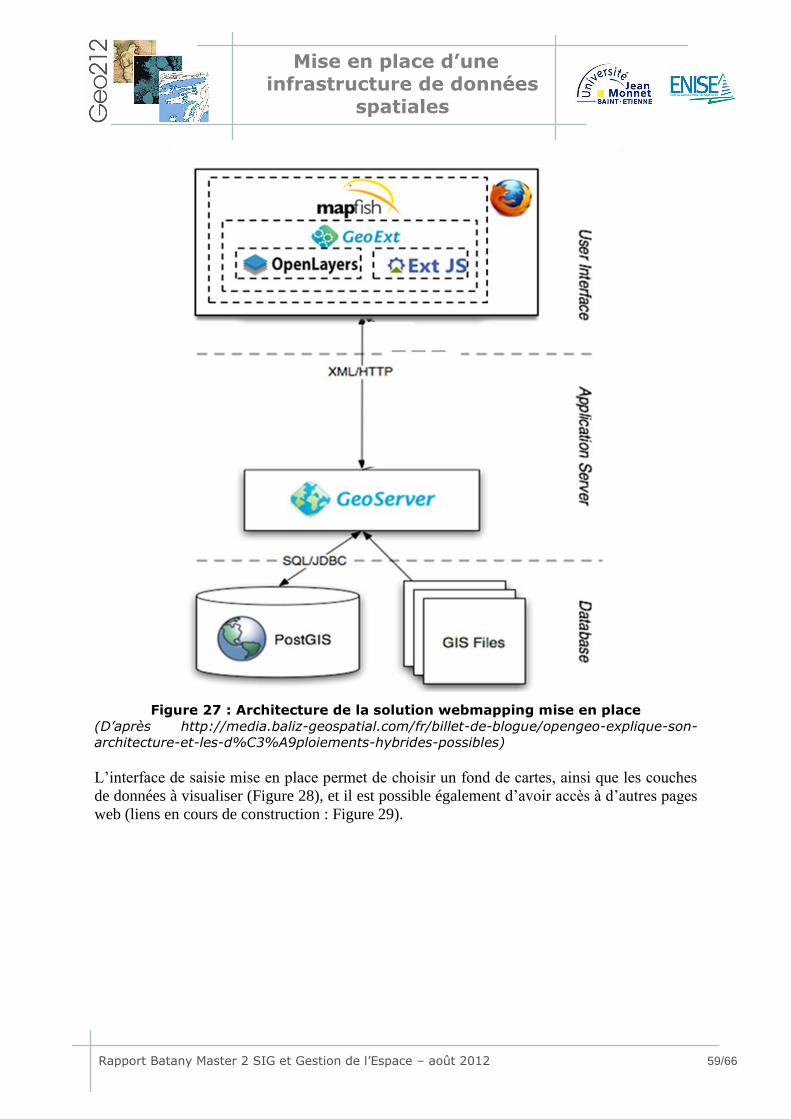
Mise en place d’une infrastructure de données
spatiales
Rapport Batany Master 2 SIG et Gestion de l’Espace – août 2012 59/66
Figure 27 : Architecture de la solution webmapping mise en place
(D’après http://media.baliz-geospatial.com/fr/billet-de-blogue/opengeo-explique-son-
architecture-et-les-d%C3%A9ploiements-hybrides-possibles)
L’interface de saisie mise en place permet de choisir un fond de cartes, ainsi que les couches
de données à visualiser (Figure 28), et il est possible également d’avoir accès à d’autres pages
web (liens en cours de construction : Figure 29).
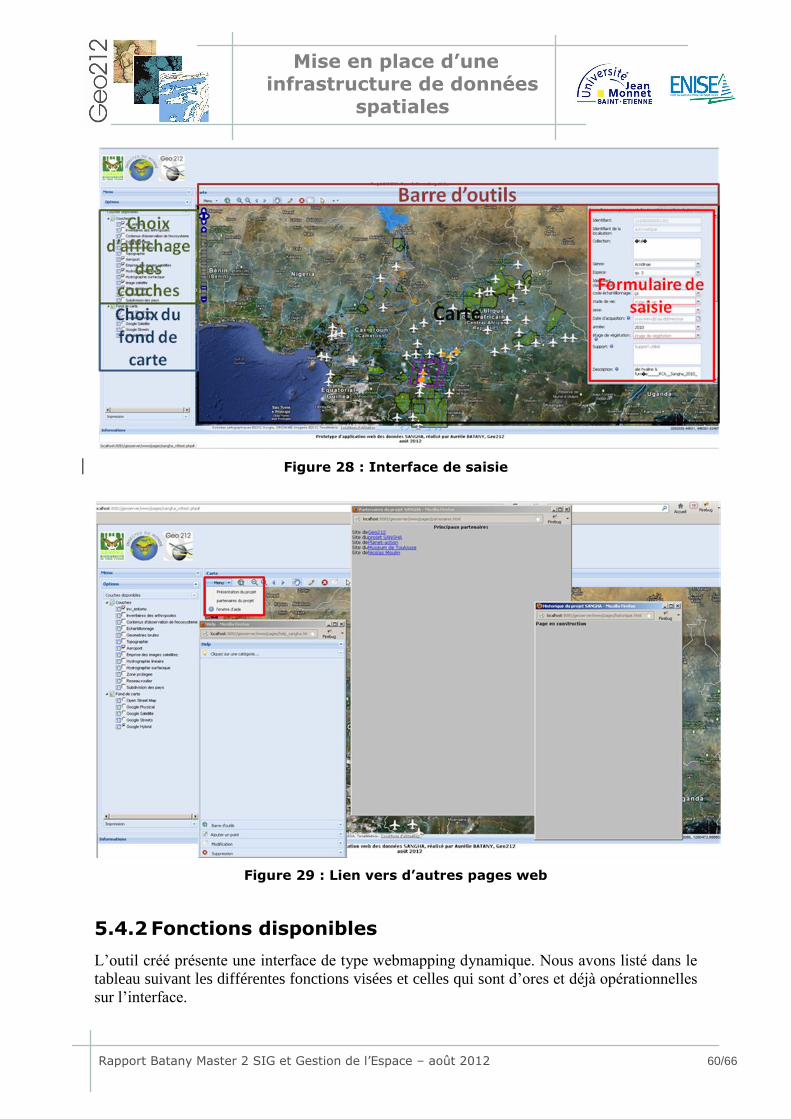
Mise en place d’une infrastructure de données
spatiales
Rapport Batany Master 2 SIG et Gestion de l’Espace – août 2012 60/66
Figure 28 : Interface de saisie
Figure 29 : Lien vers d’autres pages web
5.4.2 Fonctions disponibles
L’outil créé présente une interface de type webmapping dynamique. Nous avons listé dans le
tableau suivant les différentes fonctions visées et celles qui sont d’ores et déjà opérationnelles
sur l’interface.
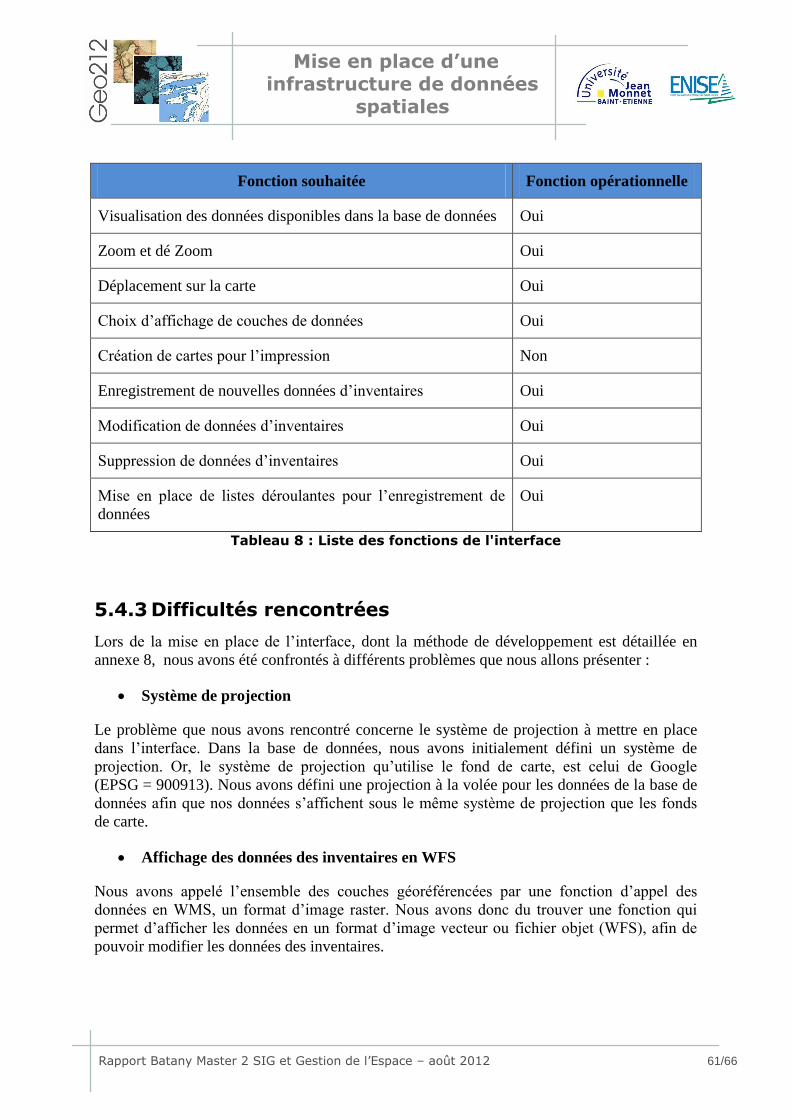
Mise en place d’une infrastructure de données
spatiales
Rapport Batany Master 2 SIG et Gestion de l’Espace – août 2012 61/66
Fonction souhaitée Fonction opérationnelle
Visualisation des données disponibles dans la base de données Oui
Zoom et dé Zoom Oui
Déplacement sur la carte Oui
Choix d’affichage de couches de données Oui
Création de cartes pour l’impression Non
Enregistrement de nouvelles données d’inventaires Oui
Modification de données d’inventaires Oui
Suppression de données d’inventaires Oui
Mise en place de listes déroulantes pour l’enregistrement de
données
Oui
Tableau 8 : Liste des fonctions de l'interface
5.4.3 Difficultés rencontrées
Lors de la mise en place de l’interface, dont la méthode de développement est détaillée en
annexe 8, nous avons été confrontés à différents problèmes que nous allons présenter :
Système de projection
Le problème que nous avons rencontré concerne le système de projection à mettre en place
dans l’interface. Dans la base de données, nous avons initialement défini un système de
projection. Or, le système de projection qu’utilise le fond de carte, est celui de Google
(EPSG = 900913). Nous avons défini une projection à la volée pour les données de la base de
données afin que nos données s’affichent sous le même système de projection que les fonds
de carte.
Affichage des données des inventaires en WFS
Nous avons appelé l’ensemble des couches géoréférencées par une fonction d’appel des
données en WMS, un format d’image raster. Nous avons donc du trouver une fonction qui
permet d’afficher les données en un format d’image vecteur ou fichier objet (WFS), afin de
pouvoir modifier les données des inventaires.

Mise en place d’une infrastructure de données
spatiales
Rapport Batany Master 2 SIG et Gestion de l’Espace – août 2012 62/66
Mise en place de l’interface sur le serveur http Apache
Pour avoir accès à l’ensemble des données de la base de données à partir de l’interface de
saisie, et pouvoir les modifier, il est nécessaire de placer l’interface de saisie sur le serveur
Apache. Au sein de la société géo212, ce type de travaux est réservé à l’équipe de support
informatique, seule habilitée à intervenir sur la configuration des logiciels sur les serveurs. Ce
travail sera réalisé par l’équipe de support dans la suite du projet.
Mise en place du formulaire de saisie
Un formulaire de saisie est assez simple à mettre en place. Pour certaines données, nous
souhaitons que le choix de remplissage soit déjà prédéfini par une liste déroulante. Pour cela
nous avons créé des tables supplémentaires dans la base de données (cf. Annexe 2). Nous
avons besoin de pouvoir afficher dans les listes déroulantes les données qui se trouvent dans
les tables de la base de données. Mais pour cela l’outil doit être interactif : il est en effet
nécessaire que les utilisateurs puissent ajouter de nouvelles valeurs qui s’enregistrent dans la
base de données, et qu’elles soient également visibles dans la liste déroulante. Une des
solutions consiste à appeler les valeurs de ces tables à l’aide d’une fonction php. Mais il ne
nous est pas possible pour le moment d’utiliser des fonctions php, car Geoserver n’est pas un
serveur mais un servlet, il n’est donc pas capable d’interpréter du php.
Nous avons à titre temporaire choisi d’utiliser un autre langage qui permet notamment de
structurer des données issues de tableaux, le JSON, mais cette méthode n’est pas interactive.
En effet, un utilisateur pourra enregistrer de nouvelles données dans la base de données, mais
dans les listes déroulantes de l’interface de saisie, les nouvelles valeurs saisies n’apparaitront
pas. Il faudra réaliser des mises à jour manuelles.
Ce problème devra être corrigé dans la version finale de l’interface avant déploiement.
5.5 Recommandations
Le prototype créé n’est pas totalement opérationnel mais, après avoir été testé en local, il est
prêt pour être installé sur un serveur http afin d’être testé en intranet. Ceci permettra
également de pouvoir travailler directement sur les données disponibles sur PostgreSQL.
Au-delà, la road map prévoit 3 autres étapes à réaliser (voir §5.3.1) mais il sera utile de
réaliser également quelques améliorations:
Créer une page de présentation du projet de mise en place de l’IDS.
Donner la possibilité de réaliser des vues sur certains groupes d’animaux et de pouvoir les
visualiser.
Donner la possibilité de zoomer sur certains points remarquables (par exemple les
campements, les points de rencontres, des arbres remarquables…).
Visualiser les photographies géolocalisées à l’aide de pop-ups.

Mise en place d’une infrastructure de données
spatiales
Rapport Batany Master 2 SIG et Gestion de l’Espace – août 2012 63/66
6 Conclusion
Les objectifs à atteindre par l’infrastructure de données spatiales que nous avons mise en
place, tels que définis au §3.3, ont été en partie atteints. En effet les objectifs primordiaux ont
été réalisés, les objectifs estimés moins importants seront atteints sur un plus long terme, car à
l’heure actuelle l’état d’avancement de l’IDS ne permet pas notamment de « comprendre le
fonctionnement de l’écosystème » de la zone d’étude.
Notre travail a été pénalisé par le fait que la phase d’expression de besoin qui nécessitait
beaucoup d’échanges entre partenaires, se déroulait au moment où les explorateurs rentraient
de 2 mois de terrain et avaient légitimement besoin de souffler. L’IDS a donc été conçue sur
la base des échanges avec une partie des scientifiques mais les choix de conception (très
ouverts et s’appuyant sur les choix des projets internationaux d’inventaire de biodiversité)
devraient permettre d’intégrer à l’avenir les besoins de nouveaux partenaires. Ces problèmes
de communication nous ont fait prendre conscience que pour le développement de l’IDS, un
travail régulier et quotidien de communication entre tous les acteurs est nécessaire pour
développer des échanges d’information et de données. Ce travail est une partie intégrante de
l’infrastructure.
L’IDS mise en place contient notamment une base de données fonctionnelle, contenant les
premières données disponibles, ainsi qu’une interface webmapping qui permet de visualiser
les données intégrées et de saisir de nouvelles données. Il reste à développer un outil de
catalogage, condition impérative d’un fonctionnement optimal de l’IDS.
Nous avons référencé un certain nombre d’IDS existantes, tant au niveau national
qu’international. Ce travail a notamment permis de découvrir le GBIF, le système mondial
d’information sur la biodiversité, qui semble être un acteur important dans ce domaine. Pour
développer notre IDS, il serait intéressant de prendre contact avec cet acteur, afin de recueillir
son expérience, découvrir d’autres institutions qui travailleraient à proximité de la République
Centrafricaine, et ainsi de développer dans de bonnes conditions notre IDS.
Notre travail s’est déroulé en parallèle avec les travaux de télédétection de Bénédicte Navaro.
Les outils mis en place vont permettre à l’équipe de Géo212 d’intégrer l’ensemble des
données capteurs (images, points et track GPS, mesures météorologiques). L’intégration de
ces données permettra de tester la base de données avec de gros volumes d’information et de
proposer aux partenaires et scientifiques un premier jeu de données utilisables pour leurs
analyses via l’interface de saisie mise en place. Cela permettra de voir les améliorations à
apporter à l’interface.
A titre personnel, le travail que nous avons réalisé au cours du stage nous a permis de
développer des connaissances et compétences dans les domaines des bases de données et de la
géomatique. Nous avons en effet découvert comment mettre en place une base de données, et
par l'hétérogénéité des données, nous avons été confrontés à un grand nombre de problèmes
que nous rencontrerons probablement dans notre futur professionnel. Ce projet nous a fait

Mise en place d’une infrastructure de données
spatiales
Rapport Batany Master 2 SIG et Gestion de l’Espace – août 2012 64/66
prendre conscience des difficultés mais aussi de l'importance du rassemblement des acteurs
dans ce type de projet, ce qui nous a permis par la même occasion d'enrichir nos capacités à
travailler en équipe. Ce travail nous a surtout permis de concilier le domaine des SIG que
nous avons découvert il y a peu et l'écologie, domaine dans lequel nous souhaitions
initialement travailler.

Mise en place d’une infrastructure de données
spatiales
Rapport Batany Master 2 SIG et Gestion de l’Espace – août 2012 65/66
7 Bibliographie
Afigeo. (2010). 5èmes rencontres des dynamiques régionales en information géographique.
Catalogue des infrastructures de données géographiques françaises.
Crépin, E. (2004). Qu’est ce que MERISE. Consulté le 24 août 2012:
http://www.ac-nancy-metz.fr/eco-gestion/eric_crepin/analys/chap01/accueil.htm
Fondation pour la recherche sur la biodiversité. (2008). Biodiversité ! (CNRS, Éd.) Consulté
le 20 août 2012, sur Saga Sciences : http://www.cnrs.fr/cw/dossiers/dosbiodiv/index.html
Gardarin, G. Bases de données : Introduction et Objectifs. Consulté le 24 août 2012 :
http://georges.gardarin.free.fr/
GéoTribu. WebMapping : Introduction et définition. Consulté le 13 juillet 2012 :
http://geotribu.net/node/149
Douglas, N. (2004). Developing Spatial Data Infrastructures: The SDI Cookbook v.2.0,
Global Spatial Data Infrastructure (GSDI). Consulté le 24 août 2012 :
http://www.gsdi.org/docs2004/Cookbook/cookbookV2.0.pdf
Pornon, H. (2008). Services Web géographiques : Etat de l’art et perspectives, Géomatique
Expert, 65, 44-50.
Robineau, C. (1967). Contribution à l'histoire du Congo : la domination européenne et
l'exemple de Souanké (1900-1960). Cahiers d'Etudes Africaines , 7 (26), 300-346.
Sayasenh, V. (2007). Merise classique. Consulté le 22 août 2012 :
http://www.compucycles.com/NouveauSite/articles/Merise/Article_07b_gif.htm
Social Change Online. What is Webmapping ? Consulté le 24 août 2012 :
http://webmap.socialchangeonline.com.au/webmapping/overview.html
Spanaki, M. & Lysandros, T. (2003) A holistic approach of map composition utilizing XML.
Consulté le 20 août 2012 :
http://www.svgopen.org/2003/papers/MapCompositionUtilizingXML/index.html#_3
Tardieu, H., Rochfeld, A., Colleti, R. (1987). La méthode MERISE. Tome 1 : Principes et
outils. Les Editions d’Organisation. 318pp.
Territorial Intelligence (2008). CaENTI Interactive Map. Consulté le 22 août 2012 :

Mise en place d’une infrastructure de données
spatiales
Rapport Batany Master 2 SIG et Gestion de l’Espace – août 2012 66/66
http://www.territorial-intelligence.eu/index.php/eng/What-is-new/Editorials/caENTI-
Interactive-Map-%E2%80%93-application-of-the-web-mapping-technology-in-socio-
economic-studies
The Ramsar Convention on Wetlands. (2009). Central African Republic. Consulté le 20 août
2012 : http://www.ramsar.org/cda/ramsar/display/main/main.jsp?zn=ramsar&cp=1-31-
218^16487_4000_1__
UNESCO. (2012). Trinational de la Sangha. Consulté le 20 août 2012, sur Liste du
patrimoine mondial: http://whc.unesco.org/fr/list/1380
Vallat, G. (1901). A la Conquête du continent noir, missions militaires et civiles de 1892 à
1900 inclusivement, d'après des documents officiels. Paris, France: A. Taffin-Lefort (Paris).





























