Embed Size (px)
Citation preview

HAMMOUCHE Mahdi EISE 2015/2016
Rapport de stage technique 4ème année du Cycle Ingénieur à Polytech Paris UPMC
30 Mai au 09 Septembre 2016 (interruption du 01 au 28 août 2016)
Tuteur école : Yann DOUZE Mail : [email protected]
Machines virtuelles et haute disponibilité
Société : FR LUMATAdresse : Bâtiment 210, Université Paris-SudOrsay, 91405Tuteur de l'entreprise : Philippe DOS SANTOS Mail : [email protected]


Abstract
This intersphip aims to put in practice FR LUMAT's website high availability. Most of the time,datacenter incidents constitute a point of failure, therefore keeping the website or more generallythe services on line is not an easy task. In order to avoid a similar situation, an application should beindependent of the hardware in which it is executed. The FR LUMAT's IT team aims to providehighly available systems through the use of virtual machines. So, in case of hardware failure, virtualmachines would be automatically migrated to another host. However, this process has a cost. Whenvirtual machines are being migrated, the services are not available during a certain period of time.This is due to storage migration. In order to minimize the cost in time, it is necessary to use adistributed storage system. We will highlight in this report the requirements to set up highlyavailable virtual machines. First we present the work context and look into the problem of FRLUMAT's website high availability. Then, based on this, we have proposed a set of tools and anarchitecture for the virtual machines management. Finaly, we undertook a series of tests in order tovalidate this architecture.


Remerciements
Ce stage aura été une première expérience pour moi au sein d'un laboratoire de recherche. Je tiens àremercier Philippe DOS SANTOS, mon tuteur de stage et Georges RASEEV de m'avoir d'abordaccueilli, mais surtout accompagné durant toute la durée du stage. Leurs soutien, conseils etdisponibilité auront été précieux pour mener à bien mon travail.
Je remercie particulièrement Sébastien DEBEST pour son aide et les échanges informels au sujet dela configuration de la solution Proxmox VE.
Je remercie également Yves BERGOUGNOUX, Olivier DE KERMOYSAN et Jean-YvesBAZZARA pour leur amabilité, leur soutien technique, et les conversations intéressantes que nousavons pu partager.
Je remercie finalement l'ensemble des chercheurs, ingénieurs, techniciens et administratifs de lafédération LUMAT pour leur accueil chaleureux.


Table des matières
Introduction.................................................................................................................1I. Présentation du contexte.........................................................................................2
1. La fédération de recherche LUMAT...............................................................................22. La GMPCS : une grappe de calcul HPC.........................................................................33. Sujet du stage.................................................................................................................4
II. Virtualisation et haute disponibilité......................................................................51. Concepts de base de la virtualisation..............................................................................5
1.1. Virtualisation des systèmes..................................................................................................51.1.1. La virtualisation par isolation.....................................................................................61.1.2. La virtualisation complète...........................................................................................61.1.3. La paravirtualisation...................................................................................................7
1.2. Stockage distribué hautement disponible.............................................................................81.3. Concepts formalisés.............................................................................................................9
2. La virtualisation à travers la solution libre Proxmox VE..............................................102.1. Présentation de Proxmox VE.............................................................................................102.2. Mise en place d'un cluster Proxmox...................................................................................11
2.2.1. Principe de fonctionnement de la Haute Disponibilité avec Proxmox......................12i. Quorum...................................................................................................................................12ii. Fencing...................................................................................................................................13iii. Stockage partagé...................................................................................................................13
2.2.2. Création du cluster Proxmox VE...............................................................................143. Le stockage distribué à travers Proxmox VE pour assurer la Haute Disponibilité........16
3.1. Présentation de Ceph..........................................................................................................163.1.1. Architecture de Ceph..................................................................................................163.1.2. Gestion & réplication des données............................................................................18
i. Les pools.................................................................................................................................18ii. Réplication de données...........................................................................................................19
3.2. Implémentation du système de stockage d'objets CEPH...................................................193.2.1. Configuration du réseau dédié à Ceph......................................................................203.2.2. Installation des paquets Ceph....................................................................................203.2.3. Mise en place des services Ceph................................................................................20
III. Validation de la virtualisation............................................................................221. Tests du cluster Proxmox..............................................................................................22
1.1. Scénario n°1 : maintenance programmée d'une machine...................................................221.2. Scénario n°2 : Arrêt d'urgence d'un nœud..........................................................................231.3. Scénario n°3 critique : Arrêt brutal d'un nœud...................................................................23
2. Tests du stockage distribué...........................................................................................242.1. Scénario n°1 : Arrêt brutal d'un nœud................................................................................242.2. Scénario n°2 : Crash d'un ou de plusieurs disques durs.....................................................242.3. Scénario n°3 : Perte du réseau Ceph sur un ou plusieurs nœuds.......................................25
Conclusion..................................................................................................................26Bibliographie..............................................................................................................28

Introduction
Le stage s'est déroulé au sein de la Fédération de Recherche LUmière MATière (FR LUMAT) duCentre National de la Recherche Scientifique (CNRS) qui regroupe des laboratoires de recherche eta pour mission de favoriser la collaboration scientifique. Elle est située à l'Université Paris-Sud surle campus d'Orsay. J'ai travaillé dans le service informatique pour le calcul haute performance,responsable de la Grappe Massivement Parallèle de Calcul Scientifique (GMPCS). La GMPCS estconstituée de deux branches pour la continuité de service.
Le site web est hébergé sur un ordinateur situé d'une branche de la GMPCS. L'indisponibilité de ceservice peut être due à un arrêt de la machine – à cause d'une panne ou dans le cas d'unemaintenance programmée – ou, à un arrêt de la branche en raison d'un problème d'infrastructure :coupure de courant, panne du système d'air conditionné.
L'objectif du stage est d'assurer un service sans interruption du site web malgré les incidents dansles salles informatiques. Le sujet qui en découle est d'assurer la haute disponibilité du site web. Laproblématique suivante se pose : Comment assurer la disponibilité du site lorsque la machine estindisponible ? Lorsqu'une branche n'est pas disponible ?
La solution proposée utilise les techniques de virtualisation pour permettre la haute disponibilité desservices. Ainsi, le site web sera hébergé dans une machine virtuelle. Lorsque l'hôte est indisponible,la machine virtuelle sera migrée et redémarrée dans une autre machine physique.
Dans un premier temps, je présenterais le contexte dans lequel s'est déroulé mon stage. Puis, jedétaillerais les éléments essentiels autour de la virtualisation et de la haute disponibilité, ainsi queles exigences d'un tel déploiement et les étapes de mon implémentation. Enfin, je présenterais unesérie de tests visant à valider la plate-forme et j'apporterais des recommandations pour lesévolutions possibles de l'infrastructure.
1

I. Présentation du contexte
1. La fédération de recherche LUMAT
La Fédération de Recherche LUmière MATière (FR LUMAT) regroupe quatre laboratoires del'Université Paris-Sud sur le campus d'Orsay, s'articulant autour des thématiques optique, lasers,physique atomique et moléculaire :
• L'Institut des Sciences Moléculaires d'Orsay (ISMO)• Le Laboratoire Aimé Cotton (LAC)• Le Laboratoire Charles Fabry (LCF)• Le Laboratoire des Gaz et des Plasmas (LPGP)
L'objectif de la FR LUMAT est de favoriser la collaboration scientifique à travers des plate-formesmutualisées et le financement de projets scientifiques communs.
Elle est composée d'environ 320 permanents (dont 75 enseignants-chercheurs, 115 chercheurs et130 techniciens, ingénieurs et administratifs) rattachés au Centre National de la RechercheScientifique (CNRS), à l'Université Paris-Sud et à l'Institut d'Optique Graduate School.
Les plate-formes mutualisées mises à disposition des laboratoires sont les suivantes :
• Le Centre Laser de l'Université Paris-Sud (CLUPS)• La Centrale d’Élaboration et de Métrologie des Optiques X-UV (CEMOX)• La plate-forme Détection : Temps, Position, Image (DTPI)• La Grappe Massivement Parallèle de Calcul Scientifique (GMPCS)
L'organigramme de la FR LUMAT s'établit comme suit :
2
Figure 1 : Organigramme de la FR LUMAT

2. La GMPCS : une grappe de calcul HPC
J'ai effectué mon stage dans le service responsable de l'une des plates-formes mutualisées par la FR LUMAT : la Grappe Massivement Parallèle de Calcul Scientifique (GMPCS).
Il s'agit d'un centre de calcul accessible aux laboratoires membres de la fédération, permettant unemutualisation des ressources, dans le but de fournir des moyens pour le Calcul Haute Performance(HPC1). Les impératifs d'une telle structure sont un fonctionnement continu et un maintien desperformances. Ainsi, le travail au sein de ce service se concentre principalement sur la gestion despannes et l'optimisation des performances au travers d'une veille technologique.
Une grappe de calcul regroupe plusieurs machines indépendantes appelées nœuds. Chaque nœud aune fonction précise, la GMPCS dispose de :
• Nœuds de calcul, possédant 2 processeurs multi-coeurs et 128 Go de mémoire en moyenne.• Nœuds de stockage, disposant habituellement de 12 disques de 4 To.• Un nœud frontal, appelé nœud maître, dédié à la gestion de la GMPCS. Il constitue un point
d'accès unique à la grappe.
Les nœuds de la GMPCS sont reliés par un réseau rapide InfiniBand QDR à 40 Gbit/s afin d'assurerdes performances optimales pour les calculs et les Entrées/Sorties. De plus, deux réseaux Ethernetà 1 Gbit/s sont réservés à l'administration.
Afin d'assurer une continuité de service durant le déménagement d'une salle informatique dubâtiment 210, la GMPCS a récemment été distribuée sur un autre bâtiment, le 206. L'architectureactuelle de la grappe est composée de deux branches - disposant chacune de nœuds de calcul,nœuds de stockage et d'un nœud maître – ainsi que d'un nœud de stockage commun situé dans uneautre salle informatique. Ce dernier constitue l'unique lien entre les deux branches. Enfin, les troiséléments constituant la GMPCS possèdent des infrastructures indépendantes - alimentation, systèmede refroidissement – ce qui assure une tolérance aux pannes.
1 High Performance Computing
3
Figure 1: Structure de la GMPC
Figure 2: Structure de la GMPCS

L'accès à la grappe se fait exclusivement de manière sécurisée à travers le protocole SSH2. Afind'assurer une continuité de service, l'utilisateur doit pouvoir se connecter sur la grappe de façontransparente, et ce, même en cas de panne d'un nœud maître ou d'une défaillance réseau. Ceci estassuré par la mise en place d'une adresse IP virtuelle (VIP3) partagée par les nœuds maîtres desbranches 210 et 206 et qui sera le point d'accès unique à la GMPCS.
La connexion à la grappe se fait à travers une connexion SSH sur cette adresse IP virtuelle. De cefait, la robustesse du service est assurée : en cas de panne d'un nœud maître, la grappe resteaccessible à travers le nœud maître de la seconde branche.
3. Sujet du stage
Le service informatique communique au sujet de la GMPCS sur le site webhttp://www.gmpcs.lumat.u-psud.fr qui doit être accessible continuellement. L'objectif est doncd'assurer la haute disponibilité du site.
Le site web est actuellement hébergé dans une machine unique du bâtiment 210. Etant donné lamultitude de raisons menant à l'indisponibilité du serveur : panne, coupure électrique, arrêt duserveur pour maintenance, la problématique qui se pose est la suivante : comment faire en sorted'assurer un fonctionnement continu du site web ?
Afin de répondre à ce besoin, les gestionnaires de la plate-forme, Philippe Dos Santos et GeorgesRaseev se sont tournés vers les techniques de virtualisation pour assurer la haute disponibilité duservice. Ce travail sera effectué sur des machines localisées dans deux salles informatiques, afind'assurer une meilleure robustesse.
La technique consiste à héberger le service web dans une machine virtuelle, qui sera capable demigrer vers un autre hôte physique en cas de défaillance. Cette mise en place nécessite unenvironnement de virtualisation qui sera chargé de gérer les différentes machines virtuellesinstallées sur l'hôte. La solution proposée est Proxmox VE, une distribution GNU/Linux libre baséesur Debian, disposant de l'ensemble des outils nécessaires à la gestion et à la surveillance deserveurs virtuels.
2 Secure SHell3 Virtual IP
4
Figure 3: Accès à la GMPCS

II. Virtualisation et haute disponibilité
La virtualisation est « l'ensemble des technologies matérielles et/ou logicielles qui permettent defaire fonctionner sur une seule machine plusieurs systèmes d'exploitation et/ou plusieursapplications, séparément les uns des autres, comme s'ils fonctionnaient sur des machines physiquesdistinctes »4. Les intérêts d'une telle infrastructure sont multiples : utilisation optimale desressources d'un centre de machines, économie sur le matériel par mutualisation, allocationdynamique des ressources permettant de gérer une montée en charge. Dans notre cas, l'aspectintéressant est une installation, un déploiement et une migration facile des machines virtuelles d'unemachine physique à une autre.
Cependant, en cas de panne d'un serveur hôte, l'ensemble des machines virtuelles hébergées surcelui-ci seront impactées. Dès lors, il est nécessaire de réaliser des redondances lors de la mise enœuvre d'un environnement virtualisé, qui permettra d'assurer la haute disponibilité des machinesvirtuelles. Les impératifs d'un tel déploiement seront détaillés par la suite.
1. Concepts de base de la virtualisation
Cette partie traite des concepts de base de la virtualisation. Il sera tout d'abord question desméthodes/modes de virtualisation desquels s'en dégageront des concepts généraux.
1.1. Virtualisation des systèmes
L'architecture matérielle d'un ordinateur est constituée de telle sorte qu'un unique systèmed'exploitation puisse s’y exécuter à la fois. Afin de permettre à plusieurs systèmes invités d'accéderaux ressources d'une machine simultanément, une couche d'abstraction matérielle est nécessaire.
La virtualisation des systèmes permet à plusieurs instances d'un système d'exploitation (OS) des'exécuter simultanément sur un seul hôte physique. Chaque système d'exploitation s'exécute dansune machine virtuelle (VM) et fonctionne comme s'il était dédié à un ordinateur physique. Il s'agitd'un logiciel intermédiaire interfaçant les machines virtuelles avec le matériel. Cette couchesupplémentaire se présente sous différentes formes selon les techniques de virtualisation, quidivergent en termes de performances.
On distingue tout d'abord la virtualisation par isolation, qui n'est pas une technique devirtualisation. Le système d'exploitation hôte crée des environnements cloisonnés au niveauapplicatif, les processus peuvent donc s’exécuter indépendamment les uns des autres. Lavirtualisation complète s'effectue en émulant entièrement le matériel. Ainsi les systèmesd'exploitation invités ont pour impression d'être les seuls à s’exécuter sur la machine physique.Enfin, la paravirtualisation est une technique de virtualisation complète optimisée, qui présente uneinterface logicielle légère diminuant les coûts d'accès au matériel.
4 http://www.marche-public.fr/Terminologie/Entrees/virtualisation.htm
5

1.1.1. La virtualisation par isolation
Un isolateur est un logiciel permettant de cloisonner l'environnement utilisateur au sein d'unsystème d'exploitation. L’exécution des applications est séparée dans des contextes ou zonesd'exécution. Ainsi, les environnements virtualisés ont tous accès au même système d'exploitation etne sont donc pas complètement isolés. Cette solution est très performante du fait de l'accès directaux ressources par le système d'exploitation. Cependant, on ne peut pas parler de virtualisation desystèmes d'exploitation, étant donné qu'ils sont uniquement liés aux systèmes Linux.
Dans un système UNIX, l'isolation d'un processus dans une sous-arborescence du système de fichierse fait à l'aide de la commande chroot. On l'utilise pour changer d'environnement, c'est à direbasculer vers un autre système Linux. L'utilisation des cgroups permet quant à elle de restreindrel'accès aux ressources (CPU, RAM,etc..)
Parmi les systèmes de virtualisation utilisant l'isolation, on peut citer OpenVZ et LXC.
1.1.2. La virtualisation complète
La virtualisation est dite complète lorsque le système d'exploitation invité n'a pas conscience d'êtrevirtualisé. Ceci est possible grâce à une virtualisation complète du matériel, réalisée par un logicielnommé hyperviseur5. Ce dernier s’exécute à l'intérieur d'un autre système d'exploitation. Ainsi, lessystèmes invités s’exécuteront en troisième niveau au-dessus du matériel.
Nous pouvons citer par exemple les logiciels Oracle VM VirtualBox ou VMware Workstation. Lesperformances de la virtualisation complète peuvent cependant être améliorées grâce à l'assistance
5 Ce type d'hyperviseur est appelé « hyperviseur de type 2 »
6
Figure 4 : Architecture d'un isolateur

par le matériel. Il simplifie la virtualisation logicielle et réduit la dégradation des performances enintégrant des instructions spécifiques à la virtualisation. Cela permet de réduire la charge de travailde l'hyperviseur et permet de consommer moins de ressources. On peut citer l'assistance à lavirtualisation d'Intel : Intel VT (Virtualization Technology).
1.1.3. La paravirtualisation
On parle de paravirtualisation lorsque l'hyperviseur6 et le système d'exploitation invité coopèrent.Dans le cas de la virtualisation complète, les machines virtuelles simulent la présence d'un matérielexistant, pour lequel le système invité a déjà un pilote. En paravirtualisation, l'hyperviseur captureles appels système de l'invité et les transmet au matériel. Ainsi, les machines virtuelles exploitentdirectement le matériel de la machine physique hôte. Dans un environnement de paravirtualisation,les machines virtuelles ont « conscience » qu’elles sont virtualisées. Cette technique nécessite unsystème d'exploitation modifié contenant des drivers chargés de rediriger les appels systèmes versl'hyperviseur. La paravirtualisation offre néanmoins des performances optimales. Parmi lessolutions de paravirtualisation, on peut citer Xen et Proxmox.
6 Ce type d'hyperviseur est appelé « hyperviseur de type 1 »
7
Figure 5 : Architecture de la virtualisation complète

1.2. Stockage distribué hautement disponible
Le stockage distribué se présente comme une couche logicielle qui fédère les volumes physiques enune ressource unique. Un système de stockage distribué permet d'agréger plusieurs disques en unensemble logique. Les données sont donc réparties sur plusieurs disques contenus dans plusieursmachines. Parmi les avantages d'un tel système, on note sa robustesse : les données sontdisponibles même en cas de panne d'un disque, et son élasticité : l'ajout d'un disque au système destockage permet d'augmenter l'espace de stockage.
Afin de mettre en place des systèmes virtualisés hautement disponibles, la problématique de ladisponibilité du stockage se pose face aux pannes des disques. Les systèmes de stockage distribuéspermettent une tolérance aux pannes à travers une réplication des données. Ainsi, un tel systèmepermet d'assurer l'accessibilité aux disques et aux fichiers des systèmes virtualisés de façontransparente, même en cas de défaillances.
Dans le cadre de la virtualisation, l'application d'un stockage réparti s'effectue sur les images dessystèmes d'exploitation des machines virtuelles, leur permettant de démarrer à tout moment, et surles disques de ces systèmes, permettant l'accès aux données des systèmes virtualisés.
8
Figure 6 : Architecture de la paravirtualisation
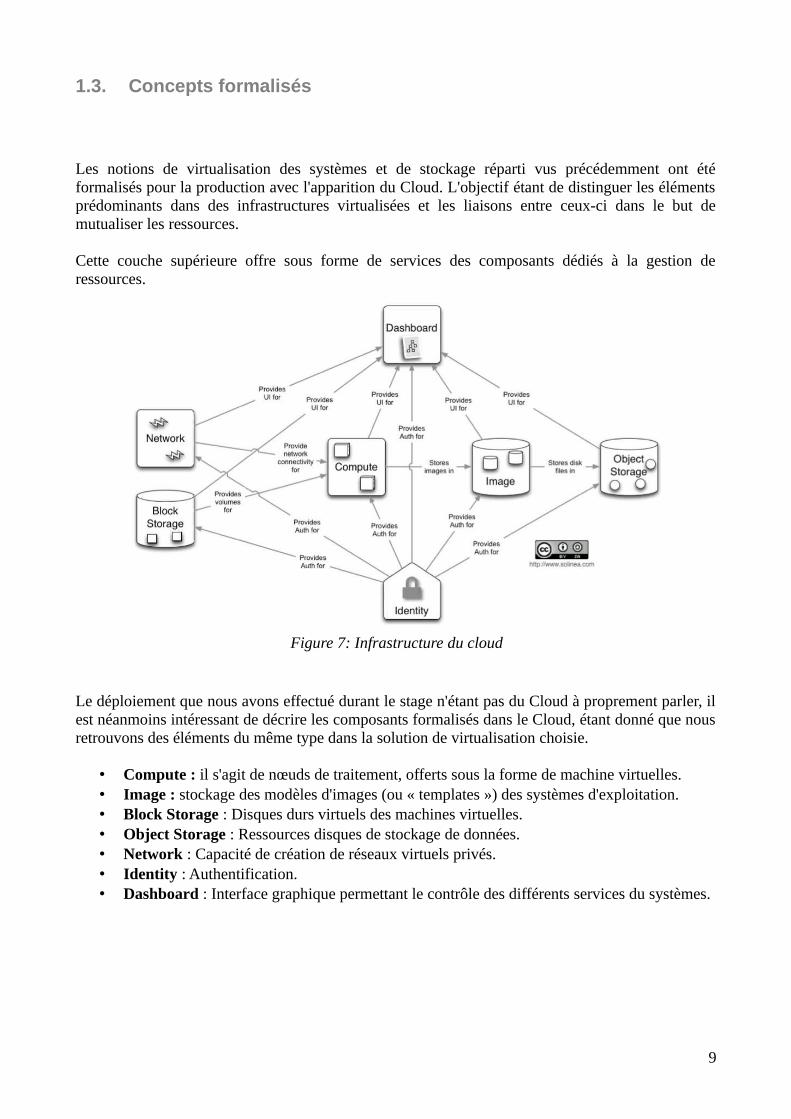
1.3. Concepts formalisés
Les notions de virtualisation des systèmes et de stockage réparti vus précédemment ont étéformalisés pour la production avec l'apparition du Cloud. L'objectif étant de distinguer les élémentsprédominants dans des infrastructures virtualisées et les liaisons entre ceux-ci dans le but demutualiser les ressources.
Cette couche supérieure offre sous forme de services des composants dédiés à la gestion deressources.
Le déploiement que nous avons effectué durant le stage n'étant pas du Cloud à proprement parler, ilest néanmoins intéressant de décrire les composants formalisés dans le Cloud, étant donné que nousretrouvons des éléments du même type dans la solution de virtualisation choisie.
• Compute : il s'agit de nœuds de traitement, offerts sous la forme de machine virtuelles.• Image : stockage des modèles d'images (ou « templates ») des systèmes d'exploitation.• Block Storage : Disques durs virtuels des machines virtuelles.• Object Storage : Ressources disques de stockage de données.• Network : Capacité de création de réseaux virtuels privés.• Identity : Authentification.• Dashboard : Interface graphique permettant le contrôle des différents services du systèmes.
9
Figure 7: Infrastructure du cloud

Dans le cas d'infrastructures à grande échelle, nécessitant un grand nombre de machines virtuelles,un tel déploiement est recommandé. C’est d'ailleurs le cas du CERN7 qui a adopté ce nouveau modede fonctionnement pour la gestion de ses données massives. Cependant, le déploiement restecomplexe et requiert du personnel pour l'administration du système.
Notre infrastructure ne nécessitant que quelques machines virtuelles, nous avons préféré l'utilisationd'une solution de virtualisation, incorporant les mêmes composants que ceux formalisés dans lecloud, mais adaptée à notre besoin : installation plus simple, évolution vers le cloud possible.
2. La virtualisation à travers la solution libre Proxmox VE
Proxmox Virtual Environment est une solution de virtualisation open-source, basée sur unedistribution GNU/Linux de type Debian. Cet environnement permet de déployer et de gérer desmachines virtuelles ainsi que des conteneurs à travers une interface web et en ligne de commande.
L'intérêt de cette solution est son installation simple sur plusieurs nœuds, permettant la mise enplace d'un cluster8. Cette fonction offre des possibilités intéressantes telle que la migration demachines virtuelles d'un serveur physique à un autre. On dit que la migration s'effectue à froidlorsque la machine virtuelle doit être mise hors tension puis redémarrée dans un autre nœud ducluster. Cette stratégie est coûteuse en temps de redémarrage et ne nous permet pas d'assurer unehaute disponibilité du service. L'autre stratégie consiste à migrer à chaud la machine virtuelle, entransférant la machine virtuelle d'un hôte à un autre sans être obligé de l'arrêter. Afin de permettreun transfert de données réduisant au maximum le temps de migration, il est nécessaire d'avoir unstockage partagé entre les nœuds du cluster. L'intégration de plusieurs outils dans l'environnementProxmox, notamment le système de stockage partagé CEPH que nous utiliserons, nous a dirigé versce choix. La large communauté autour de cette solution incluant de nombreux retours d'expérienceet des références institutionnelles ont confirmé notre choix.
2.1. Présentation de Proxmox VE
Proxmox VE est un hyperviseur de Type 1, « bare metal » qui s’exécute directement sur uneplateforme matérielle : cette plateforme est considérée comme un outil de contrôle de systèmed'exploitation. Un OS9 secondaire peut, de ce fait, être exécuté au-dessus du matériel.
L'hyperviseur de type 1 est un noyau hôte allégé et optimisé pour gérer les accès des noyaux d'OSinvités à l'architecture matérielle sous-jacente.
7 Conseil Européen pour la Recherche Nucléaire 8 Grappe de serveurs9 Operating System ou système d'exploitation
10

Proxmox VE propose deux types de virtualisation définis précédemment en utilisant lestechnologies suivantes :
• Virtualisation complète grâce à l'hyperviseur KVM10 intégré dans le noyau linux, quipermet la virtualisation de tout système d'exploitation sur les processeurs d'architecturex86. Chaque machine virtuelle a un matériel virtuel privé : carte réseau, disque, etc. KVM permet le déploiement de machines virtuelles à partir d'images non modifiées desystèmes Linux ou Windows.
• Virtualisation par isolation grâce aux conteneurs LXC11, qui permettent la créationd'instances de système d'exploitation isolées, Linux uniquement, appelées Serveurs PrivésVirtuels (VPS) ou containers. Cette solution est plus performante qu'une virtualisationmatérielle du fait du peu d'overhead12.
2.2. Mise en place d'un cluster Proxmox
Nous avons donc mis en place la solution Proxmox VE dans une seule salle informatique à titred'essai pertinent, au sein du bâtiment 210. L'objectif est le déploiement dans deux sallesinformatiques distinctes.
10 Kernel-based Virtual Machine11 LinuX Container12 Temps d’exécution du logiciel de virtualisation
11
Figure 8: Comparaison entre les architectures de la virtualisation et de l'isolation

Parmi les fonctionnalités offertes par Proxmox VE, celles qui nous intéressent sont :
• Gestion du cluster à travers l'interface web et en ligne de commande en utilisant une consolenoVNC13. Cette fonction nous indique l'état des nœuds du cluster, permet l'ajout et lasuppression de serveurs. De plus, elle permet une vision de l'état des machines virtuellesavec des graphiques de charge CPU et mémoire.
• Système de fichiers partagé pmxcfs (Proxmox Cluster File System) gérant le stockage desfichiers de configuration. Ceux-ci sont répliqués en temps réel sur tous les nœuds.
• Outil de sauvegarde à chaud, et de restauration permettant la conservation de l'état d'unemachine virtuelle (KVM, conteneur) à un instant donné. La sauvegarde ou « snapshot »intègre le contenu de la mémoire, de la configuration de la machine virtuelle et de l'état desdisques. L'intérêt est de pouvoir rétablir un état stable de la machine virtuelle en casd'installation d'un nouveau logiciel par exemple.
• Outil de Haute Disponibilité Proxmox HA permettant la migration à chaud de machinesvirtuelles KVM et de conteneurs LXC
La haute disponibilité des machines virtuelles assure la continuité de service aux utilisateurs en casde défaillance. Dans un environnement virtualisé, assurer une haute disponibilité impliquel’existence de moyens matériels et/ou logiciels chargés de détecter la défaillance, ainsi que desprocédures permettant une réaction rapide. Dans le cas présent, il s’agit de migrer rapidement etautomatiquement les services indisponibles d’un nœud du cluster Proxmox VE à un autre.
2.2.1. Principe de fonctionnement de la Haute Disponibilité avec Proxmox
Les notions essentielles pour permettre la Haute Disponibilité sont intégrées dans l'environnementProxmox VE à travers différents services. Nous définirons d'abord les problématiques de la mise enplace d'un cluster HA, puis les solutions proposées par Proxmox.
i. Quorum
Le Quorum est généralement un système de vote qui permet de déterminer quel nœud peut avoiraccès aux ressources. Il est utilisé pour éviter le phénomène de « split-brain » qui apparaît lorsqueplusieurs nœuds du cluster essayent de prendre le contrôle de celui-ci. Ceci peut entraîner de laduplication de services, voire de la corruption de données.
Sous Proxmox, ce service est effectué par le programme corosync. Il attribue un seul vote par nœud.Le quorum correspond au nombre minimum de votes nécessaires pour permettre aux nœuds lecontrôle du cluster. Ainsi, il est nécessaire de déployer un cluster contenant au minimum 3 nœudspour obtenir un quorum pertinent dans le cas de la Haute Disponibilité.
13 Client VNC qui permet une connexion via un navigateur web
12

ii. Fencing
Le « fencing » est un processus majeur dans la mise en place de clusters à Haute Disponibilitéchargé d'isoler un nœud défaillant du cluster . La fonction d'un cluster HA est de gérer des servicesutilisateurs (machines virtuelles) en leur octroyant un état : allumé ou éteint. Cependant, la naturedu service ne lui est pas indiquée et il ne considère ces services que comme des ressources. Or, afind'assurer l'intégrité des donnés, un seul nœud est autorisé à démarrer une VM à un instant donné.Dès lors, chaque nœud doit notifier les changements effectués au niveau des ressources afind'assurer un bon fonctionnement. Cependant, que se passe-t-il lorsque l'on n'arrive pas à détermineravec certitude l'état d'un nœud ou d'une ressource ? C'est à ce moment qu'intervient le processus defencing. Ce dernier agit de sorte que le nœud n’exécute aucune ressource, de façon simple maisbrutale : en réinitialisant le nœud défaillant. Concrètement, cette technique isole un nœud défaillantdu cluster en le réinitialisant ou l'éteignant simplement. Le nœud pourra être redémarré plus tard etrejoindre le cluster. Le processus de fencing nécessite un dispositif qui contrôlera les actionseffectuées sur le nœud à isoler. Typiquement, il s'agit principalement d'un appareil de gestiond'alimentation, permettant de mettre hors tension le nœud défaillant, ou d'une plate forme de gestionde matériel, permettant de contrôler les nœuds à distance.
La dernière version de Proxmox permet une configuration automatique du processus de fencing.Elle utilise un « watchdog fencing » qui agit de façon suivante : si le nœud communique avec lecluster et a le quorum, le watchdog est réinitialisé. Si le quorum est perdu, le nœud n'est pas enmesure de redémarrer le watchdog. Ceci entraîne un redémarrage du nœud au bout de 60 secondes.
iii. Stockage partagé
Dans l'environnement Proxmox, chaque nœud du cluster dispose d'un stockage local et d'unstockage partagé. Les images des machines virtuelles KVM ou les conteneurs LXC sont stockés surle stockage partagé. L'intérêt de ce type de stockage est la possibilité de migrer à chaud lesmachines virtuelles/conteneurs sans temps d'arrêt, étant donné que tous les nœuds du cluster ont unaccès direct aux images des VMs14. Il est alors nécessaire d'utiliser deux réseaux indépendants poursupporter la montée en charge : un réseau pour le trafic des VMs et un second consacré au trafic dustockage. Le service pve-ha-manager gère l'ensemble des services du cluster pour assurer la hautedisponibilité. Les machines virtuelles doivent être gérées grâce à ce service pour éviter un tempsd'arrêt durant leur migration.
14 Machines virtuelles
13
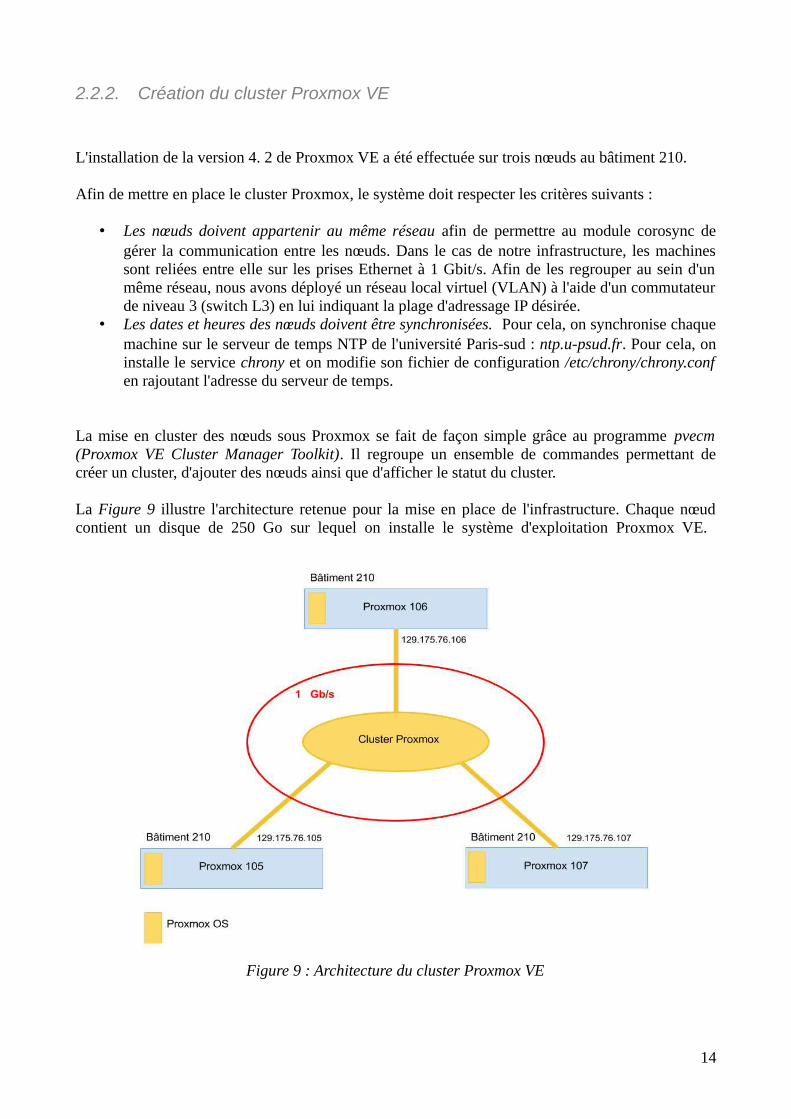
2.2.2. Création du cluster Proxmox VE
L'installation de la version 4. 2 de Proxmox VE a été effectuée sur trois nœuds au bâtiment 210.
Afin de mettre en place le cluster Proxmox, le système doit respecter les critères suivants :
• Les nœuds doivent appartenir au même réseau afin de permettre au module corosync degérer la communication entre les nœuds. Dans le cas de notre infrastructure, les machinessont reliées entre elle sur les prises Ethernet à 1 Gbit/s. Afin de les regrouper au sein d'unmême réseau, nous avons déployé un réseau local virtuel (VLAN) à l'aide d'un commutateurde niveau 3 (switch L3) en lui indiquant la plage d'adressage IP désirée.
• Les dates et heures des nœuds doivent être synchronisées. Pour cela, on synchronise chaquemachine sur le serveur de temps NTP de l'université Paris-sud : ntp.u-psud.fr. Pour cela, oninstalle le service chrony et on modifie son fichier de configuration /etc/chrony/chrony.confen rajoutant l'adresse du serveur de temps.
La mise en cluster des nœuds sous Proxmox se fait de façon simple grâce au programme pvecm(Proxmox VE Cluster Manager Toolkit). Il regroupe un ensemble de commandes permettant decréer un cluster, d'ajouter des nœuds ainsi que d'afficher le statut du cluster.
La Figure 9 illustre l'architecture retenue pour la mise en place de l'infrastructure. Chaque nœudcontient un disque de 250 Go sur lequel on installe le système d'exploitation Proxmox VE.
14
Figure 9 : Architecture du cluster Proxmox VE

Les étapes pour la création du cluster sont les suivantes :
1. Création15 du cluster que l'on nommera proxlumat sur un premier nœud.2. Intégration16 des autres nœuds dans le cluster, en ajoutant l'adresse IP du premier nœud.
La commande suivante sera effectuée sur les autres nœuds.
Le système de fichiers pmxcfs (Proxmox Cluster File System) de Proxmox gère le stockage desfichiers de configuration du cluster dans le répertoire /etc/pve. Ces derniers sont répliqués en tempsréel sur tous les nœuds.
Le répertoire /etc/pve contient les fichiers de configuration suivants :
• corosync.conf : fichier de configuration du cluster.• storage.cfg : répertorie les modes de stockage sur le cluster et leurs caractéristiques.• user.cfg : contrôle les modes d'accès à Proxmox VE (users, groups). • domains.cfg : contient les domaines d'identification gérant les utilisateurs et détermine leur
identité au sein des domaines d'autorisation.• authkey.pub : contient une clé publique utilisée pour crypter les données.
Pour chaque nœud du cluster, il existe un répertoire lui correspondant contenant ses fichiers deconfiguration. Le répertoire /etc/pve/nodes/${NAME} contient les fichiers suivants :
• pve-ssl.pem contenant la clé publique SSL. • /priv/pve-ssl.key contenant la clé privée SSL. • /qemu-server/${VMID}.conf contenant la configuration des machines virtuelles de type
KVM présentes sur ce nœud. • /lxc/${VMID}.conf contenant la configuration des conteneurs LXC présents sur ce nœud.
Les clés SSL publiques et privées sont nécessaires afin d'assurer une communication sécurisée entreles serveurs web et les navigateurs web. Nous pouvons à présent faire un parallèle entre lesélements du système Proxmox et les composants d'une architecture cloud. On retrouve des fichiersde configuration correspondant à l'authentification, au stockage et au monitoring du cluster,correspondant aux briques de la Figure 7.
Une fois les nœuds mis en cluster, le déploiement de machines virtuelles peut être effectué à partirde l'interface graphique de Proxmox (GUI) ou en ligne de commande. Il est à présent possible demigrer les VMs manuellement. Ce processus appelé migration à froid, se déroule en trois étapes :
1. Mise hors tension de la machine virtuelle ou du conteneur.2. Copie de l'état de sa mémoire sur l'hôte cible.3. Démarrage de la machine virtuelle sur l'hôte cible.
15 Commande : pvecm create proxlumat16 Commande : pvecm add 129.175.76.105
15

L'inconvénient de cette méthode est certainement l'indisponibilité des services durant toute la duréede la migration. Cela pose des problèmes majeurs pour des applications nécessitant une hautedisponibilité. Pour palier à ce problème, une autre stratégie est utilisée : la migration à chaud quipermet le transfert d'une machine virtuelle sans temps d'arrêt. Dans ce cas là, les images desmachines virtuelles doivent être stockées dans un volume partagé entre les nœuds. Ainsi, il n'estplus nécessaire de copier l'état des machines d'un volume local à un autre, ce qui réduitconsidérablement le temps de migration.
3. Le stockage distribué à travers Proxmox VE pour assurer la Haute Disponibilité
Un des principaux avantages de Proxmox VE est l'intégration de plusieurs types de stockagespartagés (NFS, GlusterFS, RBD/Ceph) pouvant être utilisés conjointement. Afin de mettre en placeune infrastructure à haute disponibilité, Depuis la version 3.2, Proxmox supporte Ceph entièrement, en tant que client et serveur. La partieserveur s'occupe de la configuration et de la gestion du stockage, et le client assure l'accès austockage pour les machines virtuelles. Cela signifie que la gestion du stockage distribué peuts'effectuer directement à partir de l'interface web Proxmox. On se dirige vers cette solution comptetenu de son excellente performance, sa fiabilité et son élasticité.
3.1. Présentation de Ceph
Ceph est un système de stockage distribué open-source répondant aux besoins de stockagemodernes. Il est flexible jusqu'au niveau exaoctet et son architecture ne contient pas de pointindividuel de défaillance (SPOF17), c'est à dire que le système n'est pas dépendant d'un disque, dont la panne entraînerait l'arrêt complet du système. Cela le rend idéal pour les applicationsnécessitant un stockage flexible hautement disponible.
3.1.1. Architecture de Ceph
L'architecture de Ceph se base sur RADOS, un système de stockage d'objets répartis géré parplusieurs serveurs indépendants appelés nœuds de stockage. Il est équipé d'un logiciel de gestion dustockage qui offre plusieurs fonctionnalités :
• Snapshot ou instantané, permettant la sauvegarde des données à un instant donné.• Optimisation du stockage grâce au « thin provisonning » présentant deux avantages : la
réduction du nombre de disques et l'amélioration des performances. • Réplication des données à travers l'algorithme CRUSH qui fixe les règles de réplication et la
distribution des objets sur les différents nœuds.
17 Single Point Of Failure
16

La couche supérieure correspond à une API18 et une librairie librados permet à une applicationd’interagir directement avec le stockage d'objets. Cette librairie est utilisée par Ceph pour fournir àl'utilisateur trois modes d'accès aux objets :
• Une interface directe au stockage d'objet RadosGW, compatible avec lescomposants de stockage du cloud : S3 d'AWS et Swift d'Openstack.
• Une interface de type bloc, RBD, utilisable par un client Linux, une machinevirtuelle dans notre cas.
• Une interface de type système de fichiers distribué,CephFS, utilisable par un clientLinux. Ce système n'est cependant pas encore mature.
L'environnement Proxmox intégrant l'accès au stockage en mode blocs, l'accès à Ceph se fera àtravers le module RBD. Celui-ci autorise les utilisateurs à monter Ceph comme un périphériquebloc.
Lorsqu'une application écrit des données sur le périphérique bloc, Ceph réplique les donnéesautomatiquement à travers le cluster. La partie serveur de CEPH est assurée par 3 types de servicesà déployer :
• OSD (Object Storage Daemon) qui a pour rôle de stocker efficacement les objets. Ilutilise pour cela le disque local du serveur, via un système de fichiers localclassique (XFS, EXT).
• MON (Monitor Daemon) qui permet de suivre l'activité de l'ensemble du cluster. • MDS (MetaData Server Daemon) qui a pour rôle de gérer les métadonnées pour
CephFS. Il n'est pas utilisé car nous utilisons uniquement le module RBD.
Le déploiement de plusieurs démons dans un ensemble de machines constitue un cluster CEPH. Lecaractère redondant de ces services permet de se défaire d'un point unique de défaillance et ainsid'assurer une haute disponibilité du stockage.
18 Application Program Interface
17
Figure 10: Architecture de CEPH
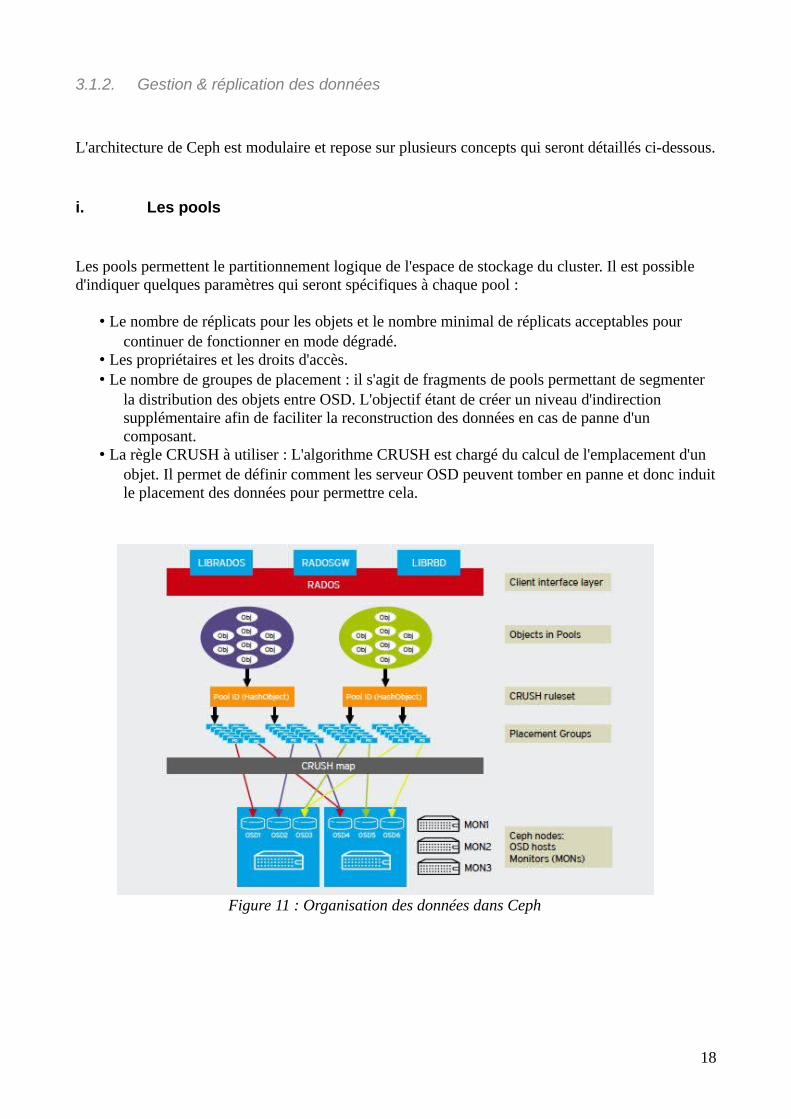
3.1.2. Gestion & réplication des données
L'architecture de Ceph est modulaire et repose sur plusieurs concepts qui seront détaillés ci-dessous.
i. Les pools
Les pools permettent le partitionnement logique de l'espace de stockage du cluster. Il est possible d'indiquer quelques paramètres qui seront spécifiques à chaque pool :
• Le nombre de réplicats pour les objets et le nombre minimal de réplicats acceptables pour continuer de fonctionner en mode dégradé.
• Les propriétaires et les droits d'accès.• Le nombre de groupes de placement : il s'agit de fragments de pools permettant de segmenter
la distribution des objets entre OSD. L'objectif étant de créer un niveau d'indirection supplémentaire afin de faciliter la reconstruction des données en cas de panne d'un composant.
• La règle CRUSH à utiliser : L'algorithme CRUSH est chargé du calcul de l'emplacement d'un objet. Il permet de définir comment les serveur OSD peuvent tomber en panne et donc induitle placement des données pour permettre cela.
18
Figure 11 : Organisation des données dans Ceph

ii. Réplication de données
La réplication des données dans le système Ceph se fait directement sur les pools selon deuxtechniques :
• Clonage : le système stocke autant de copies que spécifié de chaque donnée. L'OSD primairecopie l'objet vers le(s) OSD secondaire(s). Dans ce cas, le coût du stockage augmente avecle nombre de copies spécifié. Ainsi, plus le nombre de copies est important, plus on peut sepermettre de pannes. Par exemple, si le nombre de réplicats spécifié dans le pool est de 3 (1au minimum), et qu'on dispose d'un cluster à 3 nœuds, la perte de 2 nœuds ou une panne de2 disques ne compromet pas nos données.
• Utilisation de code à effacement (erasure coding) : Chaque objet écrit sur le cluster estdécoupé en n segments (avec n = k + m, k correspondant au nombre de segments de donnéeset m le nombre de segments contenant les données de parité). Dans ce cas, lors de laréplication d'un pool, l'OSD primaire découpe l'objet en segments, génère les segmentscontenant les calculs de parité et distribue l'ensemble de ces segments vers les OSDsecondaires en écrivant également un segment en local.
Il est important de noter que le mode bloc RBD utilisé n'est supporté que sur les pools répliqués.
3.2. Implémentation du système de stockage d'objets CEPH
Le déploiement du système de stockage Ceph se fait selon deux politiques selon les besoins enressources et la taille de l'infrastructure. Généralement, les services de stockage Ceph sont installéssur des nœuds de stockage dédiés.
19
Figure 12: Illustration des deux modes de réplication des données

Cela permet de mettre en place un cluster composé de centaines de nœuds, proposant une capacitéde stockage de l'ordre du pétaoctet. Dans notre cas, au vu de la taille du déploiement et des besoinsmoindres en stockage, il est plus intéressant d'installer les services de Ceph directement sur lesnœuds du cluster Proxmox. L'architecture matérielle des nœuds (composés de plusieurs CPU et deRAM) supporte l’exécution simultanée des services de stockage et des machines virtuelles. Dans cecas, il est primordial de :
• Séparer les réseaux d’administration de Proxmox et la gestion des machines virtuelles duréseau de stockage Ceph.
• Réserver les ressources nécessaires à Ceph : CPU & RAM.
3.2.1. Configuration du réseau dédié à Ceph
Le trafic des données de stockage Ceph nécessite un réseau privé performant. On utilise la priseréseau Ethernet 1 Gbit/s sur les nœuds qu'on relie à un commutateur de niveau 3 (switch L3) auquelon affecte la plage d'adresses 10.10.10.0/24. A partir de l'interface utilisateur de Proxmox onconfigure sur chaque nœud le nouveau réseau simplement en ajoutant un commutateur linux bridgevmbr1 interfaçant la prise eth1 avec l'adresse correspondant au nœud dans le réseau privé. Cetteconfiguration peut se faire en ligne de commande en modifiant le fichier /etc/network/interfaces surchaque nœud.
3.2.2. Installation des paquets Ceph
L'installation des paquets dans l'environnement Proxmox VE se fait grâce à la commande pvecephqui regroupe un ensemble de commandes plus bas niveau. L'intérêt majeur de ce mode d'installationest la gestion des fichiers de configuration de Ceph par le système de fichiers distribué pmxcfs.Ainsi, la configuration du stockage se fait sur un nœud uniquement. L'étape suivante consiste àcréer le fichier de configuration grâce à la commande pveceph init – network 10.10.10.0/24.
3.2.3. Mise en place des services Ceph
Le déploiement du cluster Ceph requiert un certain nombre de serveurs mon et osd pour se trouverdans un état stable. Il est recommandé d'installer un nombre impair de moniteurs afin d'éviter lephénomène de « split brain », cité précédemment dans le cas de Proxmox, afin de pouvoir identifierla panne au sein du cluster Ceph. Un nombre maximal d'osd est souhaitable pour pouvoir recouriraux pannes de disques et assurer un volume de stockage total important.
Dans le cas présent, on décide d'utiliser un service de chaque type par nœud : on dispose donc autotal de 3 mon et 3 osd.
20
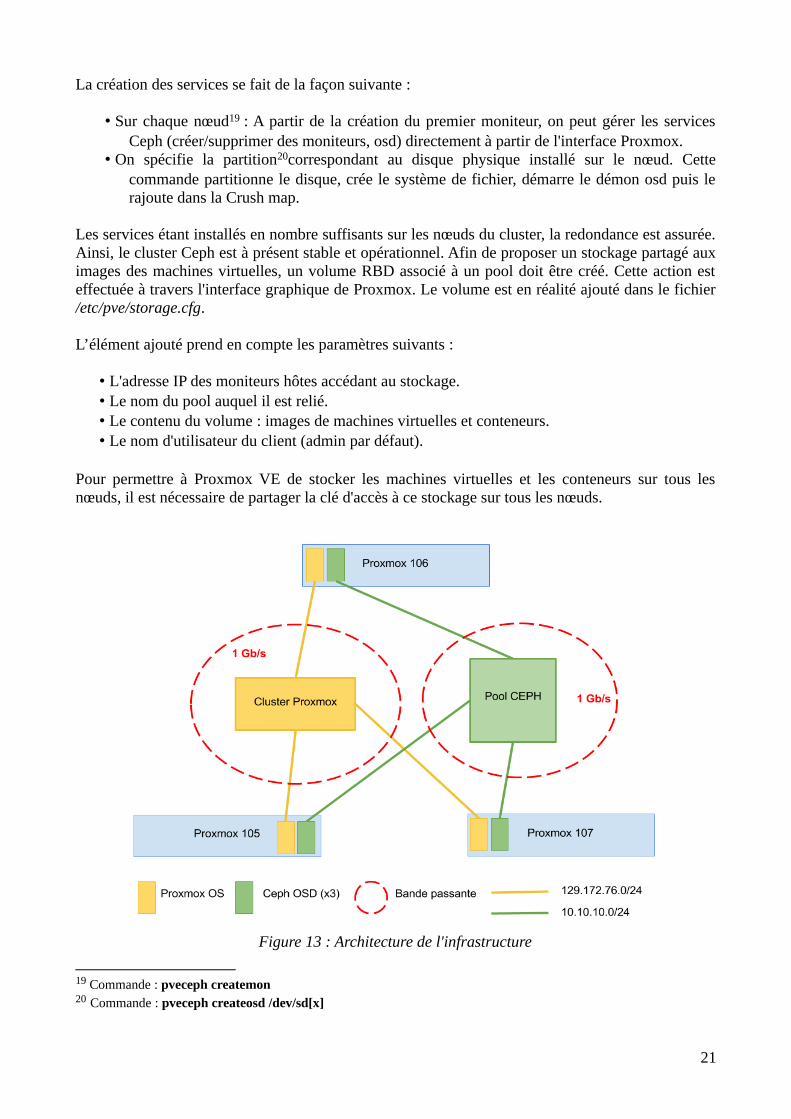
La création des services se fait de la façon suivante :
• Sur chaque nœud19 : A partir de la création du premier moniteur, on peut gérer les servicesCeph (créer/supprimer des moniteurs, osd) directement à partir de l'interface Proxmox.
• On spécifie la partition20correspondant au disque physique installé sur le nœud. Cettecommande partitionne le disque, crée le système de fichier, démarre le démon osd puis lerajoute dans la Crush map.
Les services étant installés en nombre suffisants sur les nœuds du cluster, la redondance est assurée.Ainsi, le cluster Ceph est à présent stable et opérationnel. Afin de proposer un stockage partagé auximages des machines virtuelles, un volume RBD associé à un pool doit être créé. Cette action esteffectuée à travers l'interface graphique de Proxmox. Le volume est en réalité ajouté dans le fichier/etc/pve/storage.cfg.
L’élément ajouté prend en compte les paramètres suivants :
• L'adresse IP des moniteurs hôtes accédant au stockage.• Le nom du pool auquel il est relié.• Le contenu du volume : images de machines virtuelles et conteneurs.• Le nom d'utilisateur du client (admin par défaut).
Pour permettre à Proxmox VE de stocker les machines virtuelles et les conteneurs sur tous lesnœuds, il est nécessaire de partager la clé d'accès à ce stockage sur tous les nœuds.
19 Commande : pveceph createmon20 Commande : pveceph createosd /dev/sd[x]
21
Figure 13 : Architecture de l'infrastructure

III. Validation de la virtualisation
L'objectif du travail effectué durant ce stage a été de mettre en place une infrastructure proposantdes services virtualisés disponibles continuellement. La validation de cette plate-forme se fait selondeux critères :
1. La virtualisation des systèmes2. La haute disponibilité des services
1. Tests du cluster Proxmox
1.1. Scénario n°1 : maintenance programmée d'une machine
Le premier cas de test a pour but de vérifier l'état des services lors d'une maintenance programméesur un nœud ou dans l'une des salles machine. Ce cas apparaît régulièrement, en raison de mises àjour du noyau par exemple. Ainsi, il est nécessaire de migrer les machines virtuelles vers un autrenœud. Deux démarches sont possibles : la migration à froid ou à chaud des machines virtuelles etconteneurs. Étant donné qu'on dispose d'un stockage réparti, et voulant assurer une disponibilitémaximale des services, les machines virtuelles seront migrées sans arrêter leur fonctionnement. Cetest est réalisé très simplement à travers l'interface Proxmox : le seul paramètre à indiquer est lenœud hôte cible.
22
Figure 14: Migration des VMs du nœud proxmox107 au nœud proxmox105

1.2. Scénario n°2 : Arrêt d'urgence d'un nœud
L'objectif de ce test est de vérifier la migration automatique des machines virtuelles. On peutsimuler un tel scénario en étudiant le comportement de la machine lors de l'arrêt brutal (shutdown-h now) ou le redémarrage du nœud. Les machines virtuelles sont gérées par le service pve-ha-manager. Il utilise le principe de fencing pour évaluer la panne d'un nœud du cluster. Lorsqu'onredémarre un nœud, celui-ci perd son quorum, et son état devient inconnu. Si la machine reste horstension pendant environ deux minutes, le gestionnaire de ressources du cluster (pve-ha-crm) secharge d' « extraire » les services s’exécutant sur l'hôte et de les redémarrer dans un autre nœud.
1.3. Scénario n°3 critique : Arrêt brutal d'un nœud
Une coupure électrique brutale peut subvenir en salle machine. Dans ce cas, le problème qui se poseest l'indisponibilité du dispositif de fencing : l'IPMI. Dans les versions précédentes de Proxmox VE,ce scénario était critique : aucune décision n'était prise au niveau du cluster, d'où l'arrêt complet desmachines virtuelles qui s’exécutaient sur le nœud. La disponibilité des services ne pouvait pas êtreassurée et le seul moyen de redémarrer les services nécessitait une intervention humaine.
Le processus de fencing dans la version 4.2 est géré par Proxmox et ne demande aucuneconfiguration. Il est géré de façon matérielle à travers l'IPMI par exemple, ou logicielle, à travers undriver, le softdog Linux. Dès lors, lorsque l'IPMI est hors-tension, le processus de fencing se fait demanière logicielle. Le comportement des machines virtuelles lors de ce test est donc identique auscénario précédent.
23
Figure 15: Comportement des machines virtuelles lors du redémarrage du nœud proxmox107

2. Tests du stockage distribué
Il est question à présent d'observer l'état des données lors des scénarios détaillés précédemment.
2.1. Scénario n°1 : Arrêt brutal d'un nœud
Le système de stockage mis en place supporte deux pannes de nœuds. En effet, le pool créé pour lestockage des conteneurs et des images des machines virtuelles réplique les données sur 3 disques etfonctionne avec un minimum d'1 disque, dans un état dégradé. Nous souhaitons vérifier l'impact surl'état du stockage de l'arrêt brutal d'un nœud. L'observation du fichier journal Ceph nous donne desindications sur l'état des services (dernière ligne de la figure 16).
Un tiers des disques sont absents et certains groupes de placements se retrouvent amputés de l'osdqui leur est associé. Il en résulte le passage d'un tiers des objets dans un état dégradé. Si l'osd n'estpas réapparu au-delà d'une courte période (5 minutes environ), les moniteurs du clusterreconstruisent la CRUSH map avec les disques toujours présents. Cela consiste à dupliquer denouveau les données impactées sur des osd de substitution pour retrouver un état stable. Au niveaudu fonctionnement des machines virtuelles, on ne constate aucun désagrément, compte tenu del'espace de stockage important comparé au volume des images des machines virtuelles.
2.2. Scénario n°2 : Crash d'un ou de plusieurs disques durs
Les pannes de disques sont un phénomène courant dans les salles machines. Lorsqu'un serveur dedonnées osd tombe en panne, les groupes de placements apparaissent dans un état dégradé. Il estnécessaire de le remplacer.
24
Figure 16: Historique de l'état du cluster Ceph lors de l'arrêt brutal d'un nœud

Le processus se fait en 2 étapes :
1. Création 21du nouvel OSD.2. Suppression de l'OSD correspondant au disque hors service :
◦ Suppression22 de l'osd défaillant de la Crush map.◦ Suppression23 de la clé d'authentification de l'osd.◦ Suppression24 de l'osd.
Une fois installé, le cluster intègre le nouvel osd et commence la récupération des données. L'étatdu cluster ceph repasse à un état normal et l'ensemble des objets est à nouveau accessible.
2.3. Scénario n°3 : Perte du réseau Ceph sur un ou plusieurs nœuds
Le dernier test concernant les données est effectué au niveau du réseau. La communication avec lereste du cluster ceph est coupée sur un des nœuds en retirant le câble réseau. On observe uncomportement similaire au cas d'un arrêt brutal du nœud. De plus, ce scénario n'a pas d'impact surle fonctionnement des machines virtuelles.
21 Commande : pveceph createosd22 Commande : ceph osd crush remove osd.xx23 Commande : ceph auth del osd.xx24 Commande : ceph osd rm xx
25

Conclusion
Ce stage avait pour objectif de trouver une solution pour permettre la haute disponibilité desservices. Les techniques de virtualisation répondent à ce problème, car elles permettent de migrerun service d'un ordinateur à un autre en cas de dysfonctionnement. Mon rôle a été tout d'abord dem'informer sur les caractéristiques de la virtualisation pour en déduire l'état de l'art actuel. J'ai identifié les deux éléments essentiels pour la mise en place de la solution :
1. Un environnement de virtualisation pour créer et migrer les machines virtuelles. 2. Un stockage partagé pour permettre la migration des machines virtuelles sans temps d'arrêt.
La solution choisie Proxmox VE est un environnement de virtualisation intégrant le système destockage partagé CEPH. La dernière étape consista à rédiger un cahier de recette et effectuer lestests associés afin de valider le déploiement.
Afin de réaliser ce travail, j'avais à ma disposition 3 ordinateurs situés dans une même salleinformatique. Cette réalisation est convenable dans un contexte de tests mais complètementinadaptée pour la production car il n'y a pas assez de redondance : une coupure de courant entraînel'indisponibilité totale des services. Cela constitue un unique point de défaillance, incompatible avecla haute disponibilité. Un déploiement idéal se ferait sur 3 nœuds localisés dans 3 sallesinformatiques différentes. Ainsi, les infrastructures – électricité, climatisation, réseau – étantindépendantes, les causes de pannes sont réduites. La prochaine étape pour la fédération LUMATsera d'étendre ce déploiement sur un autre bâtiment.
La validation pratique du travail réalisé lors de mon stage consiste à assurer la haute disponibilitédu site web. La solution choisie est surdimensionnée pour un site web, mais il s'agit de la premièreétape pour l'évaluer. L'utilité future est la mise en place de cette infrastructure à disposition del'ISMO pour héberger ses services d'administration – serveur DHCP, serveur de base de données.
L'étude des techniques de virtualisation m'a permis d'avoir une vision globale sur lesproblématiques de haute disponibilité dans l'industrie. Une solution telle que Proxmox est adaptéeaux infrastructures de taille moyenne25 mais le passage à l'échelle se fait en migrant vers le cloudqui a pour avantage l'utilisation de composants dédiés à une seule tâche.
Ce stage permet également un début de réflexion dans le cas du calcul HPC. Les évolutionsmatérielles et logicielles des grappes de calculs impliquent un besoin d’adaptation des applicationsau nouvel environnement de programmation. Les questions de pérennité et de portabilité desapplications se posent. Une solution éventuelle serait la virtualisation pour le HPC. Son principalavantage est l'indépendance de l'environnement de programmation vis à vis de la machine physique.Elle n'est cependant pas sans coût : cette couche d'abstraction supplémentaire entraîne une perte deperformances qui peut être considérable dans ce domaine. Pour cela, la solution de virtualisationpréconisée utilise des conteneurs pour limiter les pertes de performances26.
25 De l'ordre de quelques dizaines de nœuds. Proxmox est limité par une taille maximale de 32 nœuds et peut hébergerune centaine de machines virtuelles en raison de son environnement integré.
26 De l'ordre de 5 %
26

27

Bibliographie
GEIGER, Sébastien. Retour d'expérience de la plateforme de virtualisation sous Proxmox VE à l'IPHC. Journée SysAdmin, 04 décembre 2014 à Toulouse,www.iphc.cnrs.fr/IMG/pdf/2014. proxmox.inra .pdf
FERRE, Richard et Romain PACÉ. Retour d'expérience sur PROXMOX et HA. Une solution de virtualisation et de disponibilité de services. Journées Mathrice, 8 au 10 avril 2014 à Grenoble,https://indico.math.cnrs.fr/event/208/session/3/contribution/9/material/slides/0.pdf
DELHOMME, Olivier. « Présentation et installation du système de stockage réparti CEPH », GNU/Linux Magazine France. N°179 (Février 2015), p. 32-38.
DELHOMME, Olivier. « Mise en œuvre de CEPH », GNU/Linux Magazine France. N°180 (Mars 2015), p. 30-39.
BALLANS, Hervé. Système de stockage Ceph pour une infrastructure de virtualisation à haute disponibilité. Journées Mathrice, 14 octobre 2015 à Orsay,https://indico.math.cnrs.fr/event/800/session/2/contribution/15/material/slides/0.pdf
DUPONT, Yann. Stockage distribué : retour d'expérience avec CEPH. Journées Réseaux, 2013 à Montpellier,https://2013.jres.org/archives/48/paper48_article.pdf
28