Embed Size (px)
Citation preview

Rapport de projet de fin d’étudesValentin Robert12 décembre 2011
Sujet : Conception, mise en œuvre et vérification d’une analyse d’alias pour CompCert, un compilateur Cformellement vérifié
Stagiaire : Valentin Robert
3ème année Informatique, option Génie Logiciel
Maître de stage : Xavier Leroy
Directeur de recherche INRIA
Responsable scientifique de l’équipe-projet INRIA Gallium
01 39 63 55 61
Tuteur : Denis Barthou
Professeur
Membre de l’équipe LaBRI Supports et algorithmes pour les applications numériques hautesperformances
Période de stage : 18 juillet 2011 - 16 décembre 2011
Mots-clés : compilation, analyse statique, analyse d’alias, analyse de pointeurs, preuves formelles
1

Table des matièresRemerciements 5
1 Introduction 6
2 INRIA 72.1 INRIA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72.2 INRIA Paris-Rocquencourt . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72.3 L’équipe-projet Gallium . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
3 Contexte et problématique 83.1 Contexte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83.2 Problématique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 83.3 État de l’art . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 93.4 Cahier des charges . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
4 Spécification et mise en œuvre de l’analyse d’alias 124.1 Description du langage intermédiaire RTL . . . . . . . . . . . . . . . . . . . . . . . . . . 124.2 Principe de l’algorithme de Kildall . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 134.3 Définition du domaine . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 144.4 La fonction de transfert . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 164.5 Implémentation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
4.5.1 Représenter des ensembles infinis . . . . . . . . . . . . . . . . . . . . . . . . . . 204.5.2 Approximer des dictionnaires infinis . . . . . . . . . . . . . . . . . . . . . . . . . 204.5.3 Réduire la complexité de l’implémentation . . . . . . . . . . . . . . . . . . . . . 234.5.4 Améliorer l’approximation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
5 Preuve formelle 285.1 Preuves de programmes, Coq . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 285.2 Principe de la preuve, propriétés attendues . . . . . . . . . . . . . . . . . . . . . . . . . . 295.3 Invariants de preuve . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 315.4 Évolution de l’abstracteur au cours de la preuve . . . . . . . . . . . . . . . . . . . . . . . 36
6 Mesures, tests et résultats 386.1 Données numériques diverses . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 386.2 Étude du résultat d’une analyse . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
7 Limites et améliorations 45
8 Conclusion 46
A Correspondances de notations 47
B Code Coq de la fonction de transfert 48
Glossaire 52
2

Table des figures1 Planning du stage . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 112 Les différentes passes de CompCert C à l’assembleur . . . . . . . . . . . . . . . . . . . . 123 Un graphe de flot de contrôle du langage RTL . . . . . . . . . . . . . . . . . . . . . . . . 134 Exemple de treillis de hauteur finie 3 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 145 Hiérarchie des blocs abstraits et emplacements mémoire abstraits . . . . . . . . . . . . . . 206 Exemples de résultats de la fonction de recherche dans le dictionnaire . . . . . . . . . . . 237 Exemple de résultat de la fonction d’ajout dans le dictionnaire . . . . . . . . . . . . . . . 248 Problème à l’ajout en l’absence de clés du sommet de la hiérarchie . . . . . . . . . . . . . 259 Exemple de dictionnaire hiérarchique . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2610 Principe de la preuve . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3111 Résultat de l’analyse sur l’exemple, représenté de manière incrémentale . . . . . . . . . . 41
Table des tableaux1 Simple évaluation du coût additionnel dû à l’analyse . . . . . . . . . . . . . . . . . . . . 382 Table de correspondance des notations . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
Table des formules1 Fonction de transfert, instructions RTL . . . . . . . . . . . . . . . . . . . . . . . . . . . . 162 Fonction de transfert, opérations arithmétiques . . . . . . . . . . . . . . . . . . . . . . . . 173 Fonction de transfert, fonctions intégrées au compilateur . . . . . . . . . . . . . . . . . . 184 Fonction de transfert, calcul d’adressage . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
Table des fragments de code Coq1 Type des blocs abstraits . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 152 Interface d’un dictionnaire à clés hiérarchiques vers un treillis . . . . . . . . . . . . . . . 213 Propriété forte sur la fonction d’ajout . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 224 Exemple de la syntaxe d’une propriété Coq . . . . . . . . . . . . . . . . . . . . . . . . . 285 Exemple de syntaxe alternative d’une propriété Coq . . . . . . . . . . . . . . . . . . . . . 296 Propriété valsat . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 297 Propriété regsat . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 308 Propriété memsat . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 309 Propriété ok_abs_mem . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3110 Propriété ok_abs_genv . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3211 Propriété ok_stack . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3212 Propriété satisfy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3413 Théorème satisfy_init . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
3

14 Encapsulation de funanalysis en cas d’épuisement du carburant . . . . . . . . . . . . . . . 3515 Théorème satisfy_step . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3616 Fonction de transfert, calcul d’adressage . . . . . . . . . . . . . . . . . . . . . . . . . . . 4817 Fonction de transfert, opérations arithmétiques . . . . . . . . . . . . . . . . . . . . . . . . 4918 Fonction de transfert, fonctions intégrées au compilateur . . . . . . . . . . . . . . . . . . 5019 Fonction de transfert, instructions RTL . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
4

Remerciements
Je souhaite tout d’abord remercier l’ensemble de l’équipe-projet Gallium pour leur accueil chaleureux etleurs conseils avisés qui m’ont permis de m’épanouir et d’apprendre beaucoup de choses durant ce stage,que ce soit dans le cadre de mon projet ou sur des sujets plus vastes.
En particulier, je remercie mon maître de stage Xavier Leroy pour m’avoir offert cette opportunité, encadréau cours de ce stage, et appris certains rouages de Coq. Merci également à Alexandre Pilkiewicz et FrançoisPottier pour leurs précieux conseils en Coq, à Nicolas Pouillard pour nos discussions sur Haskell et Agdaet son support dans mes projets personnels, et à Jonathan Protzenko pour ses conseils en LaTeX et pourm’avoir hébergé quand cela fut nécessaire.
De chaleureux remerciements à mes collègues et enseignants de l’ENSEIRB-MATMECA, notammentChristelle Aroule, Cyril Roelandt et Paul Brauner pour leurs multiples contributions à mon parcours scolaireet extra-scolaire, et à mes collègues et professeurs de l’Université de Californie San Diego, en particulierZachary Tatlock, Ranjit Jhala, Sorin Lerner et Geoffrey M. Voelker.
Plus généralement, merci aux personnes de l’ENSEIRB-MATMECA et d’INRIA qui ont administré cestage.
5

1 Introduction
Lors de ma troisième année en échange à l’Université de Californie San Diego, j’ai grandement appréciéle fait d’être dans une école qui soit à la fois un laboratoire de recherche en informatique, et de pouvoirdiscuter avec des doctorants et des professeurs de leur domaine de recherche, ainsi que de pouvoir assisterà divers séminaires de présentation de leurs travaux, ou de ceux d’invités.
J’ai ainsi décidé de chercher un stage en laboratoire, afin de pouvoir m’immerger dans le milieu de larecherche et pouvoir me faire une idée du travail de recherche au jour le jour et de l’intérêt que je pourraisavoir à effectuer une thèse dans ce domaine. Étant particulièrement interessé par les langages et systèmes deprogrammation, j’ai contacté Xavier Leroy afin de savoir s’il souhaitait me prendre en stage pour travaillersur un des projets de recherche de l’INRIA.
J’ai donc eu la chance de voir cette demande acceptée le 27 mars 2011, et ainsi d’obtenir ce sujet de stagesur la compilation vérifiée. Cela tombait à point nommé puisque je débutais un cours de compilation, pourlequel je devais faire un projet. J’ai ainsi travaillé pendant les mois précédant le stage sous la supervisionde Sorin Lerner et en collaboration avec Zachary Tatlock et Ryan Kanoknukulchai sur un projet de super-optimiseur pour CompCert. Sur cette période, j’ai ainsi appris les bases de Coq de par mon projet, et l’étatde l’art des optimisations dans les compilateurs de par mon cours, ce qui m’a été d’une grande aide audémarrage du stage, bien que Coq ne se maîtrise pas en quelques mois !
Ainsi, ce stage s’est inscrit en continuation de mes cours, et m’a permis d’approfondir mes connaissancesdans ce domaine que j’appréciais particulièrement, et de m’améliorer pour pouvoir ensuite continuer montravail personnel.
6

2 INRIA
2.1 INRIA
Créée en 1967 à Rocquencourt, l’INRIA s’est depuis étendue et dispose à présent de 8 sites en France(Rocquencourt, Rennes, Sophia Antipolis, Nancy, Grenoble, Bordeaux, Lille et Saclay).
Elle emploie plus de 4000 personnes, dont près de 3500 scientifiques regroupés en 171 équipes-projets, etdispose d’un budget annuel de 250 millions d’euros.
2.2 INRIA Paris-Rocquencourt
Le centre de Rocquencourt emploie 620 personnes dont 470 scientifiques, regroupés en 39 équipes derecherche.
Les équipes du centre mènent des recherches dans des domaines aussi diversifiés que les mathématiquesappliquées, l’algorithmique et les langages de programmation, les réseaux et systèmes distribués, la cogni-tique, ainsi que l’application des technologies de l’information aux sciences de la vie et à l’environnement.
2.3 L’équipe-projet Gallium
Créée en 2006 en continuation de l’équipe Cristal, l’équipe-projet Gallium1 effectue sa recherche dans ledomaine de la conception, la formalisation et l’implémentation des langages et systèmes de programmation.
Cette recherche s’appuie notamment sur deux projets célèbres. Premièrement Caml2, langage fonctionneldéveloppé depuis 1985, et notamment sa fameuse implémentation OCaml3. Le second est CompCert4, uncompilateur formellement vérifié (en Coq) pour un grand sous-ensemble du langage C.
Plus généralement, les buts de l’équipe couvrent entre autres ces quelques points :
• concevoir des langages fonctionnels plus expressifs et de plus haut niveau, modulaires, composition-nels et dotés de sémantiques formelles ;
• faire évoluer les systèmes de types (polymorphisme d’ordre supérieur, meilleure inférence) ;
• mieux détecter les erreurs à l’aide de systèmes de types plus riches, et de meilleures analyses sta-tiques ;
• améliorer la compilation, autant sur le plan de l’efficacité que sur celui de la correction ;
• promouvoir les méthodes formelles appliquées à la preuve de programmes, notamment mécanisée.
Mon projet de fin d’études portait sur le compilateur CompCert.
1http ://gallium.inria.fr2http ://caml.inria.fr3http ://caml.inria.fr/ocaml/index.en.html4http ://compcert.inria.fr
7

3 Contexte et problématique
3.1 Contexte
On désigne par le terme de compilateur5 un outil informatique permettant de traduire un code depuis unlangage source vers un langage cible, généralement de plus bas niveau. Une propriété attendue d’un tel outildans le domaine des langages de programmation est qu’il préserve la sémantique du code compilé : le codeexécutable généré à la fin du processus doit se comporter conformément à la sémantique du langage source.
Cependant, on attend également d’un compilateur qu’il produise un code relativement efficace en ressources(temps d’exécution, mémoire consommée, taille de l’exécutable). C’est pourquoi, la plupart des compila-teurs effectuent des optimisations, c’est-à-dire des transformations de programme, supposées sémantique-ment transparentes, mais faisant décroître un ou plusieurs de ces coûts.
Malheureusement, ces optimisations sont souvent complexes, et s’assurer qu’elles ne produisent pas debogues n’est pas trivial dans le flot d’exécution complexe d’un compilateur [YCER11].
Dans le domaine des industries utilisant du logiciel critique (aviation, transports, banques, etc.), la certifi-cation attendue des codes utilisés demande à ce que des vérifications poussées soient effectuées sur le codesource (vérification à base de modèles, de preuves de programme, ou d’analyse statiques par exemple),mais au final, ce code doit être compilé pour produire un exécutable, et la correction du compilateur peutainsi mettre en péril tout ce travail en amont. Bien que des batteries de tests soient par la suite déroulées surle code généré, ceux-ci ne peuvent pas être exhaustifs sur des modèles à taille réelle, de plus ils « ne peuventque démontrer la présence de bogues, pas leur absence »6. Pour ces raisons, il est souhaitable d’avoir uncompilateur formellement vérifié comme CompCert.
Cependant, concevoir et vérifier un tel outil est très complexe, et à moins de n’avoir pu prouver la validitédes optimisations qu’on désire exploiter, on ne peut pas se permettre de les introduire dans le compilateur.Aussi, on souhaite formaliser des mécanismes d’optimisation standard afin de pouvoir en faire bénéficierun compilateur vérifié.
3.2 Problématique
Dans le cadre de mon projet de fin d’études, on m’a chargé de formaliser l’analyse d’alias pour un sous-ensemble formalisé du langage C.
Le principe de cette analyse s’appuie sur le fait que le langage C utilise des références, c’est-à-dire despointeurs vers des emplacements de la mémoire. En leur présence, une analyse naïve des variables duprogramme se doit d’être très prudente. Considérons le code :
5Les mots en gras sont définis dans le glossaire.6Edsger W. Dijkstra
8

int *x, *y, z;/* ... */*x = 42;*y = z;z = *x + 1;
En l’absence d’analyse d’alias, on ne peut rien supposer quant à la valeur pointée par x à la dernière ligne.En effet, l’écriture dans la valeur pointée par y à la ligne précédente empêche toute supposition en l’absenced’information sur ce que peut pointer y. Au contraire, si l’on sait avec certitude que x et y ne sont pas desalias, c’est-à-dire qu’ils ne peuvent pas pointer vers le même emplacement mémoire, alors ce code peut êtreoptimisé en :
int *x, *y, z;/* ... */*x = 42;*y = z;z = 43;
Ainsi, au lieu d’un déréférencement, suivi d’une opération arithmétique, le compilateur pourra désormaisaller jusqu’à simplifier la dernière ligne en un chargement d’une valeur dans un registre. L’analyse d’aliasapporte donc une information supplémentaire pouvant être exploitée par les optimisations du compilateurafin de découvrir de nouvelles opportunités, mises en évidence par le calcul d’ensembles pointés disjointsou singletons.
3.3 État de l’art
Les analyses d’alias, aussi appelées analyses de pointeurs se basent généralement sur le principe des analysesde flots de données (utilisant des graphes de flot de contrôle), et peuvent être catégorisées selon diverscritères, dont les suivants :
• Une analyse est dite intra-procédurale si elle examine chaque fonction séparément. Dans le cascontraire, elle est dite inter-procédurale.
• Une analyse est sensible au flot si elle calcule une information pour chaque arête du graphe de flotde contrôle. Ce type d’analyse est plus coûteux (notamment en mémoire) que la version insensible,mais peut fournir des résultats plus précis.
• Une analyse inter-procédurale est sensible au contexte si elle calcule une information différente enfonction du graphe d’appel. Le niveau de sensibilité doit être ajusté afin d’assurer la terminaison pourdes fonctions récursives et mutuellement récursives.
• Une analyse est sensible au chemin d’exécution si elle calcule une information différente en fonctiondu chemin d’exécution. Par exemple, l’étude des différentes branches d’une structure conditionnellesera affinée en fonction de l’information apportée par la condition qu’elles satisfont.
• Une analyse est sensible aux champs si elle stocke une information différente pour les différentschamps des données structurées du langage (enregistrements en Pascal, types struct en C).
9

• Une analyse peut-être de type « may-alias » si son résultat indique ce vers quoi peut pointer unevariable, ou de type « must-alias » si son résultat indique assurément ce qu’une variable pointe. Ladichotomie may/must existe également pour d’autres analyses.
Une analyse de pointeurs entièrement sensible au flot ne passe pas à l’échelle, autant pour des raisons spa-tiales que temporelles, sans avoir au moins appliqué des optimisations préalables. C’est pourquoi l’analysede pointeurs se base généralement sur deux techniques insensibles au flot de données :
• La méthode d’Andersen [And94], dite à base de sous-ensembles, calcule un ensemble de relationsde pointage pour l’ensemble du programme, et met à jour une information de flot unique pour leprogramme entier, de manière faible (c’est-à-dire qu’une information ajoutée n’est jamais retiréepar la suite, ce qui peut être représenté comme le calcul d’un plus petit majorant dans un treillisapproprié).
• La méthode de Steensgaard [Ste96], dite à base d’unification, restreint encore plus l’informationen n’autorisant un pointeur abstrait à ne pointer que vers une unique autre donnée abstraite. Ainsi,lorsqu’un pointeur obtient une deuxième cible, ces deux cibles sont unifiées en une cible abstraite, etleurs cibles respectives sont unifiées récursivement. L’algorithme gagne ainsi à la fois en complexitétemporelle et spatiale (l’unification est plus rapide que la propagation itérative d’Andersen, et legraphe unifié est moins grand), au prix d’une précision diminuée.
Ces analyses se basent sur une étude d’un langage sous-ensemble de C, et bénéficient donc de propriétéssémantiques liées aux opérateurs du langage : l’accès direct ou indirect à un champ d’une structure, l’accèsdans un tableau, le type d’une variable sont syntaxiquement reconnaissables. En pratique, elles présupposentégalement qu’on travaille avec du code C correctement typé, dans la mesure du système de types faible dustandard C, ce que l’on ne souhaite pas axiomatiser. En outre, elles ne se soucient généralement pas de traiterdes fonctionnalités du langage telles que les changements de type (cast) ou l’arithmétique des pointeurs.Puisqu’il existe des codes qu’on souhaite compiler qui bricolent à plus ou moins bon escient aves les types,sans pour autant exhiber des comportements indéfinis du standard, et utilisent des fonctionnalités telles quecelles décrites à l’instant, on ne peut pas entièrement se reposer sur ces travaux.
Au contraire, d’autres approches [G+05], plus rares, essaient de raisonner sur un langage assembleur de basniveau, à la sémantique plus légère : on ne considère que des registres, de la mémoire, et des opérations dechargement et stockage. Cependant, l’état de l’art des analyses non prouvées considère les analyses intra-procédurales comme dépassées, et emploie des algorithmes qui peuvent être difficiles à formaliser dans lecadre de CompCert. Aussi, me suis-je inspiré de ces travaux, et d’autres résultats de recherche rencontrésdurant ma phase d’état de l’art, sans pour autant pouvoir adapter avec précision un algorithme existant.
3.4 Cahier des charges
On souhaite donc :
• une analyse intra-procédurale, ce qui semble dans un premier temps à la fois plus simple à mettreen œuvre et à prouver, et est une étape nécessaire à démontrer la faisabilité du projet d’une analysed’alias formellement vérifiée ;
• une analyse sensible aux champs, ou plutôt, d’un point de vue de plus bas niveau, sensible à la gra-nularité d’une unité mémoire (typiquement, un octet) : on souhaite en effet pouvoir obtenir des in-
10

formations sur les relations de pointage entre les champs de structures C, aussi on ne souhaite pasconsidérer ces structures comme des blocs opaques mais bien comme des ensembles d’emplacementsmémoire ;
• que cette analyse ait lieu à l’étape de compilation durant laquelle les optimisations sont effectuées,afin de ne pas devoir conserver et traduire le résultat de l’analyse de l’instant où elle est effectuéejusqu’à celui où elle est utilisée (voir figure 2 page 12).
.......................... Juil. Août. Sept. Oct. Nov. Déc.
2
.
1
.
2
.
1
.
2
.
1
.
2
.
1
.
2
.
1
.
État de l’art
.
Prototype en OCaml
.
Développement Coq
.
Tests, rapport
Fig. 1 : Planning du stage
11

4 Spécification et mise en œuvre de l’analyse d’alias
4.1 Description du langage intermédiaire RTL
Le processus de compilation de CompCert [Ler09a] fait intervenir de multiples transformations passantpar plusieurs langages intermédiaires (figure 2). Les optimisations sont généralement faites sur un langagenommé RTL (Register Transfer Language), dans lequel les variables du programme ont été remplacées pardes registres ou des accès mémoire, mais dont le code n’est pas encore linéarisé [Ler09b].
Compcert C Clight C#minor
CminorCminorSelRTL
LTL LTLin Linear
MachAsm
side-effects out
of expressions
type elimination
loop simplifications
stack allocation
of variables
instruction
selection
CFG construction
expr. decomp.
register allocation
(Iterated Register Coalescing)
linearization
of the CFG
spilling, reloading
calling conventions
layout of
stack frames
asm code
generation
Optimizations: constant prop., CSE, tail calls, (LCM)
(Instruction scheduling)
Fig. 2 : Les différentes passes de CompCert C à l’assembleur
Ce langage suppose notamment qu’il existe une infinité de registres, qui sont généralement peu réutilisésau sein d’une fonction. Il n’est toutefois pas sous forme SSA puisqu’un même registre peut être utilisé dansdeux branches ou modifié plusieurs fois dans la même branche. Ces registres sont utilisés pour représen-ter les variables du programme source dont l’adresse n’est jamais prise. Au contraire, les variables dontl’adresse est référencée sont placées en mémoire dans la pile.
Le langage est assez réduit, et se compose des opérations suivantes :
Inop est l’opération nulle.
Iop contient l’ensemble des opérations arithmétiques. Elle prend en entrée une liste de registres, et écritle résultat dans un registre.
Iload permet de charger un morceau de mémoire déterminé par sa taille et adressé par zéro à deux re-gistres, et stocke le contenu dans un registre.
Istore stocke la valeur d’un registre dans la mémoire, de manière analogue à Iload.
Icall effectue un appel de fonction, et place la valeur retournée dans un registre.
12

Itailcall effectue un appel de fonction et retourne immédiatement la valeur retournée à l’appelant.
Ibuiltin permet d’appeler une fonction traitée spécialement par le compilateur. Celles-ci contiennentnotamment des fonctions « built-in » dans le compilateur, des opérations sur des variables volatiles,ainsi que malloc, free et memcpy.
Icond effectue un saut conditionnel en fonction d’une condition booléenne.
Ijumptable effectue un branchement multiple, en fonction de la valeur d’un registre.
Ireturn termine la fonction courante et retourne une valeur à la fonction appelante.
Il est également intéressant de considérer les spécificités dumodèlemémoire de CompCert. En effet, celui-cisuppose le code source correct et en déduit des garanties fortes pour l’analyse :
• En supposant l’absence de déréférencement à un indice hors des bornes correctes, on peut donner unrésultat plus précis lorsqu’un accès est effectué à un indice inconnu d’un bloc : en effet, on sait alorsque l’accès s’effectuera uniquement dans ce bloc, et pas arbitrairement dans la mémoire.
• Le modèle fait également une séparation stricte entre les valeurs numériques et les pointeurs : il n’estainsi pas possible de contrefaire un pointeur à partir d’une valeur numérique, tout comme il n’est paspossible d’obtenir un pointeur en contournant les règles de l’arithmétique des pointeurs.
• Le modèle offre également des garanties sur la préservation des pointeurs : il est interdit d’écrire unevaleur à cheval sur la valeur d’un pointeur, puis de déréférencer ce pointeur. Ainsi, un pointeur restevalide et est détruit si une écriture l’altère seulement partiellement.
4.2 Principe de l’algorithme de Kildall
On désigne par graphe de flot de contrôle un graphe orienté dont les nœuds représentent les opérations duprogramme, et les arcs représentent les successions de ces opérations. La représentation intermédiaire enRTL du compilateur CompCert représente chaque fonction sous cette forme.
...
Iop
.
Iload
.
Icond
.Iop. Ireturn......
Fig. 3 : Un graphe de flot de contrôle du langage RTL
L’algorithme de Kildall [Kil73] est un algorithme standard permettant de résoudre un système d’équationsou d’inéquations sur un tel graphe de flot de contrôle. Cette méthode consiste à définir une fonction de trans-
13

fert pour chaque nœud du programme, qui à une information d’entrée (quelconque) associe une informationde sortie.
On dit que le problème est vers l’avant si la fonction de transfert va dans le sens du graphe, et qu’il est enarrière si la fonction de transfert va dans le sens contraire. Selon le problème à résoudre, on choisit l’uneou l’autre approche.
Un exemple d’analyse orientée vers l’arrière est l’analyse de vie des variables du programme : on souhaitedéterminer quelle variable peut encore être utilisée à tout instant du programme. Pour cela, on part de la findu programme, et à chaque utilisation d’une variable, on la note comme vivante.
Pour l’analyse d’alias, on procède vers l’avant, puisqu’à partir de l’information en entrée d’une instruction,on sait calculer l’information en sortie en fonction des effets de l’instruction.
L’algorithme consiste à itérer l’application des fonctions de transfert à partir d’une solution initiale jusqu’àatteindre un point fixe qui est une solution du problème. Il convient cependant de prendre des précautionsafin d’assurer la terminaison d’un tel algorithme : on se place généralement dans un treillis de hauteur finie,c’est-à-dire un ensemble muni d’une relation d’ordre partielle avec une borne supérieure et inférieure, et onutilise des fonctions de transfert monotones, ce qui oblige l’algorithme à terminer en un nombre d’étapesborné par la hauteur du treillis, puisque chaque itération fait progresser le résultat vers le sommet du treillis,jusqu’à ce qu’on atteigne un point fixe.
{a} {b} {c}
{a,b} {a,c} {b,c}
{a,b,c}
∅ ⊥
⊤
Fig. 4 : Exemple de treillis de hauteur finie 3
L’algorithme de Kildall présent dans CompCert est cependant différent car il ne force pas la hauteur dutreillis à être finie. Ainsi, la terminaison est assurée par un carburant, un entier strictement décroissant àchaque itération. L’algorithme peut ainsi échouer si le calcul ne termine pas, en épuisant le carburant. Enpratique, il est donc fixé à une valeur assez importante pour que cela ne se produise pas, dans la mesure oùl’on effectue des analyses de taille raisonnable.
4.3 Définition du domaine
On souhaite catégoriser à l’exécution l’ensemble de ce que peut pointer chaque registre, ainsi que l’ensemblede ce que peut pointer chaque emplacement en mémoire. Dans le cas des registres, l’espace de départ estfini (nombre de registres utilisés par la fonction), mais l’espace d’arrivée est potentiellement infini. Pour
14

les emplacements mémoire, la situation est pire puisque l’espace de départ est également potentiellementinfini.
Ainsi, l’analyse va devoir travailler sur une approximation des ensembles de départ et d’arrivée afin demanipuler des données finies.
On définit donc le type B des blocs abstraits comme :
Inductive B: Type :=| Alloc: node -> B (* bloc alloué au nœud indiqué *)| Allocs: B (* ensemble de tous les blocs alloués *)| Global: ident -> B (* bloc global indicé *)| Globals: B (* ensemble de tous les blocs globaux *)| Other: B (* tous les autres blocs *)| Stack: B (* bloc correspondant à la pile *).
Fragment de code Coq 1 : Type des blocs abstraits
Ce type somme permet de catégoriser tout bloc à l’exécution en un nombre fini de réprésentations : ainsi,tous les blocs concrets alloués en un point d’exécution sont projetés sur le même bloc abstrait, et tous lesblocs obtenus par des appels externes sont projetés sur le bloc abstrait Other. La présence des blocs abstraitsAllocs et Globals permet seulement de faciliter la représentation de l’ensemble des blocs Alloc et Globalrespectivement.
On définit également le type L := (B, int) des emplacements mémoire abstraits comme un type produitd’un bloc abstrait et d’un entier mémoire représentant l’indice de l’emplacement dans le bloc en question.
Ainsi, on peut définir le type S des ensembles d’emplacements mémoire abstraits, puis les types R :=reg → S et M := L → S des résultats de notre analyse de flot de données, c’est-à-dire une fonctionassociant à chaque registre (respectivement, à chaque emplacement mémoire) un ensemble d’emplacementsmémoire vers lesquels ce premier peut pointer.
15

4.4 La fonction de transfert
Instructions RTL
La fonction de transfert Fop : (R,M) → (R,M) est définie pour chaque opération du graphe de flot decontrôle ainsi :
FInop(succ)(r,m) = (r,m)
FIop(op,args,dst,succ)(r,m) = (Opop,args,dst(r,m),m)
FIload(chunk,addr,args,dst,succ)(r,m) =
(r⊔R[dst 7→⊔
Sx∈@addr(args,r)
m(x)],m) si chunk = Mint32
(r,m) sinon
FIstore(chunk,addr,args,src,succ)(r,m) =
(r,m⊔M(⊔
Mdst∈@addr(args,r)
[dst 7→ r(src)])) si chunk = Mint32
(r,m) sinon
FIcall(sign,fn,args,dst,succ)(r,m) = (r⊔R[dst 7→ ⊤S ],⊤M)
FItailcall(sign,fn,args)(r,m) = (r,⊤M)
FIbuiltin(ef,args,dst,succ)(r,m) = Bief,args,dst(r,m)
FIcond(cond,args,ifso,ifnot)(r,m) = (r,m)
FIjumptable(arg,tbl)(r,m) = (r,m)
FIreturn(res)(r,m) = (r,m)
Formules 1 : Fonction de transfert, instructions RTL
Une opération nulle (Inop) n’affecte pas le résultat.
Une opération arithmétique (Iop) n’affecte pas lamémoire, seulement les registres (voir Formules 2 page 17).
Une lecture mémoire (Iload) n’affecte pas la mémoire, mais seulement le registre destination, et ce uni-quement lorsque l’on charge un mot de 32 bits (taille d’un pointeur). Dans ce cas, le registre destinationpeut pointer vers ce que peut pointer le mot adressé. La fonction @ est également décrite plus bas.
Une écriture mémoire (Istore) n’affecte pas les registres, mais affecte tous les emplacements mémoirepotentiellement adressés. Chacun d’eux peut alors pointer vers ce que pointait le registre source, en plus dece vers quoi il pointait avant.
À la suite d’un appel de fonction (Icall), le registre destination ainsi que l’ensemble de la mémoire peuventpointer vers tout. En effet, dans le cas d’une analyse intra-procédurale, on ne dispose pas de plus d’infor-mations.
Si l’appel est terminal (Itaillcall), il en va de même mais il n’y a pas de registre destination, car la valeurest directement rendue à l’appelant.
16

Bi traite les appels de fonctions externes au programme et est décrite plus bas (Formules 3 page 18).
Pour les autres cas (sauts conditionnels et retour de fonction), rien n’est altéré.
Opérations arithmétiques
OpOlea(addr),args,dst(r,m) = r⊔R[dst 7→ @addr(args, r)]OpOmove,[src],dst(r,m) = r⊔R[dst 7→ r(src)]
OpOsub,[src1,src2],dst(r,m) = r⊔R[dst 7→ unknown_offset(r(src1))]Opop(r,m) = r pour les autres opérations
avec unknown_offset(s) = {(b, i)|∃o (b, o) ∈ s}i∈range(int)
Formules 2 : Fonction de transfert, opérations arithmétiques
L’opération Olea (Load Effective Address) permet de charger dans un registre une adresse obtenue par uncalcul d’adressage. Ainsi, le registre destination peut pointer vers ce qui est adressé.
L’opération Omove permet d’affecter la valeur d’un registre source à un registre destination.
L’opération Osub permet de stocker la différence de deux registres source dans un registre destination. Cetteopération peut produire un pointeur valide par l’arithmétique des pointeurs : le premier opérande doit êtreun pointeur, et le second doit être une valeur numérique. Puisqu’on ne connaît pas la valeur de src2, onconsidère l’ensemble des emplacements du bloc pointé.
Les autres opérations ne produisent que des valeurs numériques ne pouvant pas être des pointeurs.
17

Fonctions intégrées au compilateur
BiEF_external,args,dst(r,m) = (r⊔R[dst 7→ ⊤S ],m)
BiEF_builtin,args,dst(r,m) = (r⊔R[dst 7→ ⊤S ],m)
BiEF_vload,args,dst(r,m) = (r⊔R[dst 7→ ⊤S ],m)
BiEF_vstore,[rdst,rsrc],dst(r,m) = (r,m⊔M(⊔
Mx∈r(rdst)
[x 7→ r(rsrc)]))
BiEF_malloc,args,dst(r,m) = (r⊔R[dst 7→ {(Alloc n, 0)}],m)
BiEF_free,args,dst(r,m) = (r,m)
BiEF_memcpy,[rdst,rsrc],dst,sz,al(r,m) = (r,m⊔M(⊔
Mx∈unknown_offset(r(rdst))
[x 7→ ⊤S ]))
BiEF_annot,args,dst,text,targs(r,m) = (r,m)
BiEF_annot_val,[rval],dst,text,targ(r,m) = (r⊔R[dst 7→ r(rval)],m)
Formules 3 : Fonction de transfert, fonctions intégrées au compilateur
Des appels de fonctions externes au programme (EF_external et EF_builtin) ne changent pas lamémoire,et retournent une valeur inconnue dans le registre destination.
Une lecture volatile (EF_vload) retourne une valeur inconnue dans le registre destination.
Une écriture volatile (EF_vstore) modifie l’emplacement pointé par rdst, lui affectant la valeur contenuedans rsrc. Selon le bloc pointé par ce dernier, il peut s’agir d’une écriture réelle en mémoire.
Une allocation dynamique (EF_malloc) retourne un pointeur vers l’indice zéro du bloc alloué. Ce bloc estabstrait ici en Allocn, où n représente le compteur du programme à l’instruction en question.
La libération d’un bloc (EF_free) n’affecte aucun pointeur.
La copie d’un intervalle de mémoire (EF_memcpy) d’un emplacement source vers un emplacement destina-tion affecte de manière imprévisible le bloc destination.
Une annotation utilisateur qui ne contient pas de valeur (EF_annot) n’altère rien, mais une annotation quien contient une (EF_annot_val) retourne la valeur dans le registre destination.
18

Calcul d’adressage
La fonction @ calcule un ensemble d’emplacements mémoire pouvant être pointés par un adressage donné,en fonction du mode d’adressage et des paramètres. Cette fonction dépend de l’architecture cible, ci dessousun exemple pour x86 32 bits :
@Aindexed(o)([r0], r) = {(b, i+ o)|(b, i) ∈ r(r0)}@Aindexed2(o)([r1, r2], r) = unknown_offset(r(r1))⊔S unknown_offset(r(r2))@Ascaled(sc,ofs)([r0], r) = ⊥S(= ∅S)
@Aindexed2scaled(sc,ofs)([r1, r2], r) = unknown_offset(r(r1))@Aglobal(s,ofs)([], r) = {(Global s, ofs)}
@Abased(s,ofs)([r0], r) = {(Global s, o)|o ∈ range(int)}@Abasedscaled(sc,s,ofs)([r0], r) = {(Global s, o)|o ∈ range(int)}
@Ainstack(ofs)([], r) = {(Stack, ofs)}
Formules 4 : Fonction de transfert, calcul d’adressage
Pour le mode adressé par un registre et un indice (Aindexed), on décale simplement tous les emplacementsvers lesquels peut pointer ce registre.
Pour un adressage utilisant deux registres et un indice (Aindexed2), à l’exécution, l’un des deux registresdevra contenir un pointeur, alors que l’autre devra contenir un entier. Malheureusement, on ne sait pasdéterminer statiquement lequel jouera quel rôle, aussi doit-on prendre en compte les deux cas. Pour chaquecas, on retourne ainsi l’ensemble de tous les indices des blocs pointés par le registre qui joue le rôle depointeur, puisqu’on ne peut pas non plus déterminer statiquement la valeur ou le domaine du registre quijoue le rôle de décalage.
Lemode d’adressage Ascaled est curieux, puisqu’il ne permet pas de calculer une adresse ! Il est notammentexploité à l’aide de l’instruction Olea pour effectuer en une instruction une multiplication suivie d’unesomme (par le calcul d’adresse).
Le mode Aindexed2scaled calcule un pointeur à partir de la valeur de r1.
Les modes d’adressage globaux (Aglobal, Abased et Abasedscaled) calculent une adresse dans un blocglobal qui est statiquement fixé. Pour le premier mode, l’indice est aussi fixé, aussi on retourne l’empla-cement abstrait correspondant. Pour les deux autres modes, l’indice est dynamiquement calculé, aussi onretourne tous les indices du bloc considéré.
Enfin, le dernier mode d’adressage permet de désigner un indice dans la pile, fixé statiquement (c’est-à-dire,un accès à une variable locale dont l’adresse est utilisée dans la fonction), aussi on retourne l’emplacementcorrespondant du bloc abstrait Stack.
19

4.5 Implémentation
4.5.1 Représenter des ensembles infinis
Pour implémenter ces formules, il nous fallait tout d’abord un moyen de représenter efficacement les en-sembles dont il est fait mention dans les formules de la section précédente. Notamment, si l’on considèreun ensemble tel que {(Global s, o)|o ∈ range(int)}, on constate qu’il nous faut représenter ceci sous uneforme symbolique compacte : énumérer les 232 valeurs du type int est hors de question.
En pratique, on ne dispose pas d’une analyse de domaine numérique pour les valeurs du code, aussi onsouhaite seulement deux niveaux de granularité : soit celui d’un indice, soit celui d’un bloc entier. Aussi,nous représenterons ces ensembles sous la forme d’un couple composé d’un ensemble de blocs abstraits(granularité des blocs) qui représente l’ensemble de tous les indices du bloc en question, et d’un ensembled’emplacements mémoire abstraits (granularité des indices).
Il en va de même pour représenter l’ensemble des blocs globaux ou des blocs de sites d’allocation, aussi onpeut définir une hiérarchie des blocs abstraits comme celle décrite en figure 5.
..
All
.
Allocs
.
Stack
.
Other
.
Globals
.
Alloc 1
.
...
.
Alloc a
.
...
.
Global 1
.
...
.
Global g
.
...
. (Stack, 0). .... (Stack, i). (Other, 0). .... (Other, i). (Alloc 1, 0). .... (Alloc 1, i). (Global g, 0). .... (Global g, i)
Fig. 5 : Hiérarchie des blocs abstraits et emplacements mémoire abstraits
Ainsi, pour représenter l’ensemble {(Global s, o)|o ∈ range(int)}, on utilise le couple ({Global s},∅).
4.5.2 Approximer des dictionnaires infinis
Le problème consiste maintenant à représenter un type abstrait de données correspondant à un dictionnaireassociant à chacun des éléments de l’ensemble précédemment décrit une information. Ce dictionnaire estmuni d’opérations get et add préservant les propriétés de l’interface suivante :
20

Module Type OMapInterface (O: OverlapInterface) (L: SEMILATTICE).Parameter t: Type.Parameter get: O.t -> t -> L.t.Parameter add: O.t -> L.t -> t -> t.
Axiom get_add_same: forall k s m, L.ge (get k (add k s m)) s.Axiom get_add: forall x y s m, L.ge (get x (add y s m)) (get x m).Axiom get_add_overlap: forall x y s m,
O.overlap x y ->L.ge (get x (add y s m)) s.
End OMapInterface.
Fragment de code Coq 2 : Interface d’un dictionnaire à clés hiérarchiques vers un treillis
Le module O représente une hiérarchie abstraite, dotée d’une proposition overlap indiquant si deux élé-ments sont en relation hiérarchique (peu importe le sens). Le module L représente l’ensemble d’arrivée,qu’on suppose être un treillis doté d’une opération de calcul du plus petit majorant lub.
Les axiomes indiquent :
• qu’en cherchant une clé après avoir ajouté un ensemble s à cette clé, on doit obtenir un ensemblesupérieur à s (get_add_same).
• qu’en cherchant une clé après avoir ajouté une valeur quelconque à une clé quelconque, on doit obtenirun ensemble supérieur à celui obtenu avant cet ajout (get_add).
• qu’en cherchant une clé après avoir ajouté un ensemble s à une clé qui est en relation hiérarchiqueavec cette première, on obtient un ensemble supérieur à s (get_add_overlap).
Ces propriétés se justifient aisément : supposons qu’on obtienne une information indiquant qu’un indiceinconnu du bloc Alloc a peut désormais pointer vers un ensemble s. On ajoute cette information à notrerésultat. Pour autant, ne sachant pas quel indice particulier a été modifié, on ne peut pas faire fi de l’in-formation s’ déjà présente. On souhaite donc conserver une information qui soit supérieure à s (axiomeget_add_same) et supérieure à s’ (axiome get_add) pour le bloc Alloc a.
Supposons à présent qu’on demande l’information contenue à l’emplacement (Alloc a, 0). Cet empla-cement fait partie du bloc Alloc a, et est donc potentiellement celui qui aurait dû recevoir l’informations si l’analyse avait pu être plus précise, il nous faut donc obtenir une information supérieure à s pour cetteclé, qui est hiérarchiquement inférieure à la clé Alloc. De manière analogue, si on demande l’informationgénérale de tous les blocs alloués grâce à la clé Allocs, on veut obtenir une information supérieure à l’in-formation de chaque bloc Alloc. En particulier, une information supérieure à s. Ainsi, pour tous les blocssitués hiérarchiquement en-dessous ou au-dessus du bloc assigné, on souhaite obtenir un résultat supérieurà l’information assignée.
Il est à noter que l’interface est volontairement relâchée. Par exemple, elle n’oblige pas à ce que l’informa-tion liée à une clé n’ayant aucune relation avec la clé assignée reste constante. Ainsi, une implémentationlégitime de cette interface pourrait dégrader l’information d’autres clés. Ceci a deux avantages. D’abord,cela laisse plus de liberté à une implémentation de l’interface, tout en restant assez fort pour prouver les
21

résultats qu’on souhaite. Ensuite, cela facilite les preuves de conformité d’une implémentation à l’interface,puisque le résultat à prouver est plus faible. Par exemple, dans l’implémentation la plus simple décrite unpeu plus bas, la propriété suivante n’est pas toujours vraie (L.eq dénote l’égalité sur le treillis) :
Definition accurate_add: forall x y s m,~ O.overlap x y -> L.eq (get x (add y s m)) (get x m).
Fragment de code Coq 3 : Propriété forte sur la fonction d’ajout
En revanche, l’interface n’autorise pas le raffinement de l’information liée à une clé. On pourrait vouloirrajouter pour cela une opération set qui effectue ce qu’on appelle une mise à jour forte, dont le résultat surune clé serait inférieur à l’information stockée précédemment pour cette clé. Cela serait en effet utile afinde traiter les cas où l’on sait avec certitude qu’un bloc abstrait correspondant à un bloc concret unique vaêtre écrasé. On sait cela sous les conditions suivantes :
• l’adresse à laquelle s’effectue l’écriture doit être statiquement évaluée à un emplacement mémoireabstrait singleton : en effet, s’il existe deux emplacements mémoire pouvant être la destination del’écriture, on ne peut affirmer qu’un de ces deux emplacements sera écrasé avec certitude.
• le bloc abstrait de cet emplacement doit abstraire exactement un bloc concret à cet instant de l’exécu-tion. C’est le cas des blocs de type Global et Stack, mais pas des blocs de type Alloc et Other, ainsique des blocs plus hauts dans la hiérarchie. En effet, tous ceux-ci abstraient un ensemble de blocsconcrets, et en conséquence un emplacement abstrait singleton tel que {(Alloc1, 0)} ne correspondpas à un unique emplacement concret (on ne pourrait l’affirmer que si le site d’allocation 1 se trouvaitavec certitude hors de toute boucle).
On ne s’intéresse pour l’instant qu’à l’interface présentée plus haut, sans se préoccuper des mises à jourfortes. La manière la plus simple d’implémenter cette interface consiste à implémenter un dictionnaireparesseux sur cet espace de clé dont les opérations se comportent comme suit :
• pour la recherche d’une information associée à une clé, on cherche la clé dans le dictionnaire et onretourne l’ensemble associé. Si la clé n’est pas présente dans le dictionnaire, on cherche son parenthiérarchique, s’il existe, et ainsi de suite (fig. 6).
• l’ajout d’une information pour une clé donnée demande en revanche plus de travail : il faut parcourirl’ensemble des clés, et pour toutes celles qui sont en hiérarchie avec la clé ajoutée, leur associer le pluspetit majorant de l’ensemble qu’elles contiennent et de l’ensemble ajouté. Il faut aussi explicitementajouter la clé si elle n’était pas présente, en initialisant son résultat au plus petit majorant de la valeurobtenue par sa recherche et de l’ensemble ajouté.
Il subsiste une subtilité : que se passe-t-il en l’absence des clés les plus hautes dans la hiérarchie ? On peutenvisager deux alternatives.
• Si l’on suppose que les clés du sommet de la hiérarchie peuvent être absentes, il nous faut préciserdeux choses :
– pour la recherche, si l’on atteint le haut de la hiérarchie sans succès, on retourne le minorant dutreillis ⊥.
22

(* Pseudo-notation : *)
M1 = { Block Allocs -> {A, B, C}Block (Alloc 2) -> {B, C}Loc (Alloc 2, 0) -> {C}Block Stack -> {D} }
(* get (Loc (Alloc 2, 0)) M1 retourne {C}, clé présente *)
M2 = { Block Allocs -> {A, B, C}Block (Alloc 2) -> {B, C}Block Stack -> {D} }
(* get (Loc (Alloc 2, 0)) M2 retourne {B, C}, premier parent trouvé *)
Fig. 6 : Exemples de résultats de la fonction de recherche dans le dictionnaire
– pour l’ajout en revanche, on ne peut pas se permettre de ne rien faire : il nous faut toujourssauvegarder l’information ajoutée dans la clé la plus haute du treillis, faute de quoi on perd del’information, comme explicité dans la figure 8.
• Puisque l’alternative précédente oblige à rajouter les clés du sommet de la hiérarchie dès le premierajout, une autre approche consiste à les placer dans le dictionnaire dès le début, et conserver ce faitcomme un invariant :
– pour la recherche, on est ainsi certain de toujours trouver une valeur en remontant dans la hié-rarchie.
– pour l’ajout, on n’a rien de plus à faire que ce qui était décrit plus haut, et on a désormaisla certitude que l’ajout d’une clé précédemment absente prend bien en compte l’informationaccumulée par son plus proche parent hiérarchique.
4.5.3 Réduire la complexité de l’implémentation
Cette structure partiellement naïve ne s’avère tout de même pas la plus efficace, pour plusieurs raisons :
• d’un point de vue algorithmique, l’opération de recherche s’effectue en une complexité linéaire parrapport à la complexité de recherche dans le dictionnaire sous-jacent, puisqu’on demandera au plus unnombre de clés fixé par la hauteur de la hiérarchie, mais l’opération d’ajout est beaucoup plus coûteusepuisqu’elle doit parcourir l’ensemble des éléments du dictionnaire, et potentiellement effectuer unenouvelle insertion pour chacun d’eux.
• d’un point de vue de la preuve, l’utilisation de plis sur la liste des éléments du dictionnaire rendcompliquées les preuves de conformité à l’interface. En effet, pour toute propriété, après avoir mon-tré qu’une propriété est vraie à un instant, soit au début, soit parce qu’il existe un élément dans ledictionnaire qui ajoute cette propriété, il reste encore à démontrer que le reste du pli préserve cettepropriété.
23

M = {
Block Allocs -> {A, B, C}
Loc (Alloc 1, 0) -> {B}
Loc (Alloc 1, 1) -> {C}
Block (Alloc 2) -> {B, C}
Loc (Alloc 2, 0) -> {C}
Loc (Alloc 2, 1) -> {D}
Block Stack -> {A, E}
}
M = {
Block Allocs -> {A, B, C, Z}
Block (Alloc 1) -> {A, Z}
Loc (Alloc 1, 0) -> {A, B, Z}
Loc (Alloc 1, 1) -> {A, C, Z}
Block (Alloc 2) -> {B, C}
Loc (Alloc 2, 0) -> {C}
Loc (Alloc 2, 1) -> {D}
Block Stack -> {A, E}
}
add (Block (Alloc 1)) {A, Z} M
ancêtre modifié
clé ajoutée
descendant modifié
descendant modifié
Fig. 7 : Exemple de résultat de la fonction d’ajout dans le dictionnaire
En pratique, sur les quelques tests effectués, l’analyse ne s’est pas montrée particulièrement lente : eneffet, tant que les fonctions restent assez courtes, elles manipulent nécessairement peu de valeurs, aussi ilest moins grave de parcourir tous les éléments contenus dans le dictionnaire. Cependant, cela présente desrisques pour passer à l’échelle, notamment sur des fonctions très longues, ce qui peut être le cas par exempleavec du code généré par des outils.
Aussi, on souhaite pouvoir changer cette implémentation que j’ai prouvée par une implémentation plus àmême de nous satisfaire pour les deux points critiques mentionnés ci-dessus. C’est ici que l’interface, queje n’avais pas mise en place auparavant, aide en découplant l’implémentation des dictionnaires des preuveseffectuées en aval.
Une idée de structure plus adaptée serait la suivante : on pourrait calquer une hiérarchie d’enregistrementssur la hiérarchie des clés, chacun de ces enregistrements comportant un ensemble de valeurs vers lequel laclé située à cette hauteur hiérarchique peut pointer, ainsi que deux dictionnaires, l’un sur le domaine desindices indiquant vers quelle valeur peut pointer chaque indice du bloc courant, et l’autre sur le domainedes clés de la strate hiérarchique inférieure, pointant vers les enregistrements suivants (voir figure 9).
Les opérations s’implémenteraient ainsi :
• la recherche s’effectue récursivement depuis le sommet : tant qu’on n’est pas sur la clé, on chercherécursivement dans le dictionnaire des sous-clés, si celui-ci existe. Si cette recherche réussit, on re-tourne le résultat, sinon on retourne le résultat contenu au niveau courant.
• l’ajout d’une information s à une clé procède jusqu’à la clé en modifiant chaque clé parcourue pourlui ajouter l’information s. Pour chaque clé sur le chemin qui n’existait pas, on la crée en prenantl’information contenue dans son parent après ajout de s. La clé cherchée est ensuite créée ou modifiée
24

En l'absence de clés du sommet de la hiérarchie :
M = {}
M' := add (Loc (Alloc 1, 0) S M
M' = { Loc (Alloc 1, 0) -> S}
get (Block Alloc) M'
retourne ∅
FAUX !
En présence de clés du sommet de la hiérarchie :
M = { Block Allocs -> ∅ }
M' := add (Loc (Alloc 1, 0) S M
M' = { Block Allocs -> S,
Loc (Alloc 1, 0) -> S}
get (Block Alloc) M'
retourne S
CORRECT !
Fig. 8 : Problème à l’ajout en l’absence de clés du sommet de la hiérarchie
de la même façon, et si elle existait déjà, on applique ensuite à l’arbre des sous-clés une fonction quiajoute à toutes celles-ci l’information s. Ainsi, toutes les clés en hiérarchie avec la clé à ajouter onteffectivement été modifiées.
4.5.4 Améliorer l’approximation
Il reste encore un souci que l’on pourrait adresser avec une structure de données encore plus ad hoc :lorsqu’une clé était absente et qu’on souhaite l’ajouter avec une valeur s, on doit lui associer le plus petitmajorant de s et de la valeur obtenue par un get sur cette clé avant ajout, qui correspond à la valeur de sonpremier supérieur hiérarchique présent dans le dictionnaire.
Le problème est le suivant : parmi les éléments présents dans ce second ensemble, il en existe qui sontnécessaires à la correction, et qui résultent d’un ajout direct sur le bloc parent en question. Mais l’autrepartie des éléments provient de la propagation vers le haut effectuée par add et ne concerne pas notre clé.Lors de l’ajout de notre clé dans le dictionnaire, ce bruit vient s’ajouter à l’information qu’on y stocke.
De par ce phénomène, plus une clé basse dans la hiérarchie est ajoutée tard, plus elle accumule de bruit liéaux modifications de ses sœurs et nièces. On souhaiterait pouvoir filtrer ce bruit pour améliorer l’approxi-mation, c’est-à-dire satisfaire la propriété accurate_add décrite plus haut. C’est possible en pratique enassociant à toute clé deux ensembles plutôt qu’un :
• Le premier ensemble, que j’appellerai mine, contient les valeurs qui ont été ajoutées directement à laclé en question.
• Le second ensemble, que j’appellerai noise, contient les valeurs qui ont été propagées vers le hautparce qu’elles ont été ajoutées à un descendant de la clé en question.
En faisant cette distinction, il nous est possible de modifier l’implémentation des fonctions get et set de
25

{s: ptset
m: ptmap
All
{s
m
Allocs
{s
m
Globals
{s
m
Other
{s
m
Stack
{s
m
Alloc 0
{s
m
Alloc 1
{s
{s
(Stack, 0)
{s
(Stack, 1)
(Alloc 1, 0)
{s
(Alloc 1, 1)
...
...
...
Pour modifier les clés en hiérarchie avec Alloc 1 :1) Parcourir et modifier jusqu'à Alloc 1 :All, Allocs, Alloc 12) Appliquer la modification sur tout le sous-arbre m :(Alloc 1, 0), (Alloc 1, 1)
Coût en parcours :- 2 "find" dans des arbres contenant peu d'indices- 1 "map" sur un arbre ne contenant que des valeurs à modifier(Précédemment, 1 "map" sur toutes les clés existantes !)
Fig. 9 : Exemple de dictionnaire hiérarchique
façon à ce que le bruit ne soit pris en compte que là où il est nécessaire :
• pour rechercher une clé donnée dans le dictionnaire, on cherche tout d’abord sa présence. Si elle estprésente, on retourne l’union de mine et noise. Si elle est absente, on retourne en revanche seulementle mine de son parent (qui existera par construction).
• pour ajouter à une clé une information s dans le dictionnaire, il faut absolument modifier (et créer lecas échéant) les clés de ses ancêtres. Pour chacune d’elles :
– si elle existe, on ajoute s à son champ noise.
– sinon, on la crée avec un mine égal à celui de son parent et un noise égal à s.
Une fois tous ses ancêtres créés, on peut s’occuper de la clé elle-même :
– si elle existe, on ajoute s à son champ mine.
26

– sinon, on la crée avec un mine égal au plus petit majorant de s et du mine de son parent.
Il reste encore à mettre à jour toutes les clés descendantes de celle-ci, auxquelles on ajoute s à leurchamp mine. Si le dictionnaire est créé de manière hiérarchique, cela consiste à utiliser une fonctionmap sur ce dernier.
La preuve de conformité de cette implémentation à l’interface mentionnée ci-dessus semble toutefois loind’être triviale, et n’a pas été faite.
27

5 Preuve formelle
5.1 Preuves de programmes, Coq
Afin de pouvoir vérifier mécaniquement des propriétés relatives à notre programme, on utilise l’assistantde preuves Coq. Celui-ci permet, dans une de ses utilisations les plus simples, de définir des programmesdans un langage de programmation proche des ML, puis d’énoncer des propriétés sur ces programmes etde les démontrer en construisant de manière interactive un terme de preuve (les preuves sont en effet destermes du langage).
Le langage utilisé a tout de même quelques spécificités : c’est un langage fonctionnel pur (c’est-à-dire sanseffets de bord), et la terminaison des fonctions doit être assurée. Pour ces raisons, on ne peut pas toujoursécrire le programme qu’on souhaiterait s’il impliquerait des effets ou une récursivité non triviale.
La preuve des propriétés s’effectue de manière interactive : à partir de la propriété que l’on souhaite dé-montrer, Coq nous affiche les hypothèses dont on dispose dans le contexte courant, et les sous-buts que l’ondoit démontrer. On peut alors indiquer, grâce à un langage de tactiques, la façon dont on souhaite procéderdans la preuve. Par exemple, on peut choisir d’appliquer un lemme ou un axiome vers l’avant, pour faireprogresser nos hypothèses en direction de la propriété à prouver, ou vers l’arrière si l’on souhaite prouverun but intermédiaire qui implique notre but.
On peut également indiquer qu’on souhaite raisonner par induction sur une structure inductive, auquelcas Coq s’occupe de construire les cas de base et les cas inductifs à prouver, et de créer les hypothèsesd’induction adéquates.
Par exemple, la preuve ci-dessous démontre qu’une propriété P est vraie pour un terme fold_left f l s(correspondant à la réduction d’une liste par un opérateur associatif à gauche) si la propriété est vraie pourle terme s et est préservée par application de f à gauche :
Lemma fold_left_preserves_prop:forall S F (P: S -> Prop) (f: S -> F -> S) l s,
P s ->(forall x y, P x -> P (f x y)) ->P (fold_left f l s).
Proof.induction l; simpl; auto.Qed.
Fragment de code Coq 4 : Exemple de la syntaxe d’une propriété Coq
Par la suite, j’utiliserai parfois une notation plus fonctionnelle des propriétés, me permettant de nommer leshypothèses afin d’y faire référence plus aisément. Ainsi, l’énoncé ci-dessus est moralement équivalent ausuivant :
28

Lemma fold_left_preserves_prop’:forall S F (P: S -> Prop) (f: S -> F -> S) l s
(INIT: P s)(STEP: forall x y, P x -> P (f x y)),P (fold_left f l s).
Fragment de code Coq 5 : Exemple de syntaxe alternative d’une propriété Coq
Les hypothèses sont ainsi réellement des paramètres dont les types sont dépendants des valeurs d’autresparamètres. Le second style permet de donner un nom à ces paramètres, alors que dans le premier style onpeut seulement les nommer lorsqu’on les introduit dans le cours de la preuve.
5.2 Principe de la preuve, propriétés attendues
On suppose pour l’instant que l’algorithme termine pour toutes les fonctions du programme étudié. Pourchacune de ces fonctions, il retourne une structure associant à chaque point du programme une secondestructure, celle-ci associant à chaque emplacement mémoire abstrait ainsi qu’à chaque registre un ensembled’emplacements mémoire vers lesquels celui-ci peut pointer à cet endroit de l’exécution.
On souhaite qu’une exécution réelle du programme ne sorte pas des limites fixées par cette approximation :il ne doit pas exister de pointeur dont la destination n’est pas incluse dans l’approximation de ce vers quoipointe sa source.
On introduit la notion d’abstracteur d’emplacement mémoire comme une fonction partielle abs : block-> option absblock des blocs concrets vers les blocs abstraits. On voudra évidemment poser des restric-tions sur la façon dont sont abstraits les blocs.
On définit la propriété valsat comme :
Definition valsat (v: val) (abs: abstracter) (s: ptset) :=match v with| Vptr b o =>
match abs b with| Some ab => PTS.In (ab, o) s| None => PTS.eq s PTS.topend
| _ => Trueend.
Fragment de code Coq 6 : Propriété valsat
Cette propriété dénote le fait qu’une valeur concrète (pouvant être un entier, un nombre à virgule flottante, ouun pointeur) pointe dans un ensemble d’emplacements mémoire abstraits, conformément à un abstracteur.
29

Si cette valeur n’est pas un pointeur, cette propriété est trivialement vraie. Sinon, elle pointe vers un bloc b àun indice o, et l’on souhaite alors que l’emplacement abstrait correspond à ce bloc et cet indice soit comprisdans l’ensemble s. Si, pour une raison quelconque, on ne sait pas abstraire le bloc en question, on demandealors à ce que l’ensemble s soit équivalent à ⊤S .
Ainsi, à tout moment de l’exécution, on souhaite que la valeur contenue dans chaque registre satisfasse lapropriété valsat par rapport à l’abstracteur courant et au résultat associé à ce registre par l’analyse :
Definition regsat (r: reg) (rs: regset) (abs: abstracter) (ptm: ptmap) :=valsat rs#r abs (mpt (Reg r) ptm).
Fragment de code Coq 7 : Propriété regsat
L’on souhaite également que pour tout emplacement mémoire concret valide en lecture, la valeur qu’ilcontient satisfasse la même propriété :
Definition memsat (b: block) (o: offset) (m: mem) (abs: abstracter) (ptm: ptmap) :=forall v
(LOAD: Mem.loadv Mint32 m (Vptr b o) = Some v),(match abs b with
| Some ab => valsat v abs (mpt (Loc (ab, o)) ptm)| None => Falseend).
Fragment de code Coq 8 : Propriété memsat
Le cas où on ne sait pas abstraire le bloc est impossible : en effet, on exigera par la suite que tout bloc validesoit correctement abstrait, et par conséquence, tout bloc depuis lequel un chargement réussit l’est aussi.
La preuve consiste alors à montrer qu’à toute étape du programme, il existe un abstracteur φ tel que lespropriétés regsat et memsat soient vérifiées pour le résultat de l’analyse à cette étape. La représentationgraphique en figure 10 représente cette idée : à toutmoment de l’exécution, représentée à gauche, l’ensembledes relations de pointage concrètes, notées par des flèches rouges, doit être surapproximé par l’ensembledes relations de pointage calculées par l’analyse représentées par des flèches bleues. Cette approximationest faite à une projection par abstraction près : pour toute paire d’éléments concrets x et y (x pouvantêtre un registre ou un emplacement, y étant un emplacement), si x pointe vers y lors de l’exécution, alorsl’abstraction de x doit pointer vers l’abstraction de y dans le résultat de l’analyse (l’abstraction d’un registrecorrespondant toujours à ce même registre).
Cependant, il nous faut introduire des propriétés supplémentaires pour mener à bien la preuve : celles-ciconstitueront un invariant qui renforcera nos hypothèses, mais dont il faudra prouver qu’il est maintenu aucours de la preuve.
30

..
Exécution
.
Analyse
.
Abstraction
.
R1
.
R2
.
R3
.
R4
.
R5
.
R6
...............
R1
.
R2
.
R3
.
R4
.
R5
.
R6
.
blocs concrets
.
blocs abstraits
.
Stack
.
Global 1
.
Alloc 3
.
Alloc 3
Fig. 10 : Principe de la preuve
5.3 Invariants de preuve
Le choix des invariants est donc crucial : un invariant trop faible ne permettra pas de mener la preuve à sonterme, alors qu’un invariant trop fort sera dur (voire impossible) à maintenir. Ces invariants ont donc étéraffinés au cours de la preuve pour trouver un bon compromis. La plupart de ces invariants cadrent notreabstracteur afin d’avoir de bonnes propriétés.
Le premier justifie le fait d’avoir choisi une fonction partielle (rendue totale par un type option) pour lesabstracteurs :
Definition ok_abs_mem (abs: abstracter) (m: mem) :=forall b, abs b <> None <-> Mem.valid_block m b.
Fragment de code Coq 9 : Propriété ok_abs_mem
Cette propriété indique que tout bloc abstrait par l’abstracteur est un bloc valide pour la mémoire courante,et réciproquement. Ceci nous permet d’éliminer dans la preuve la possibilité qu’un bloc nouvellement allouépuisse être déjà contenu dans l’abstracteur.
Le deuxième invariant force notre abstracteur à abstraire les blocs globaux de manière appropriée :
31

Definition ok_abs_genv (abs: abstracter) (ge: genv) :=forall i b
(FIND: Genv.find_symbol ge i = Some b),abs b = Some (Global i).
Fragment de code Coq 10 : Propriété ok_abs_genv
Il exprime que le bloc d’identifiant i de l’environnement global ge doit être abstrait par Global i. Ainsi, onsait que le résultat de l’analyse pour le bloc abstrait en question est bien celui utilisé pour valider la valeurdu bloc concret correspondant. Cet invariant est primordial afin de montrer que le résultat de l’analyse estcorrect lorsqu’on est confronté à une opération dont le mode d’adressage est global.
Le troisième invariant permet d’oublier l’abstracteur d’une fonction f lors de l’appel d’une fonction g, puisd’en reconstruire un lorsque g termine tel qu’il satisfasse toujours les propriétés d’invariance :
Inductive ok_stack (ge: genv) (b: block): list stackframe -> Prop :=| ok_stack_nil:ok_stack ge b nil| ok_stack_cons: forall r f bsp osp pc rs stk ptmm abs(STK: ok_stack ge b stk)(MEM: forall b’, abs b’ <> None -> b’ < b)(GENV: ok_abs_genv abs ge)(SP: abs bsp = Some Stack)(RES: funanalysis f = Some ptmm)(RSAT: forall r, regsat r rs abs (ptmm#pc))(RET: PTS.eq (mpt (Reg r) ptmm#pc) PTS.top)(MTOP: mem_at_top ptmm#pc),ok_stack ge b (Stackframe r f (Vptr bsp osp) pc rs :: stk)
Fragment de code Coq 11 : Propriété ok_stack
Cette propriété de la pile prend deux paramètres : l’environnement global du programme, et un bloc. C’estune propriété inductive, trivialement satisfaite pour une pile vide. Dans le cas d’une pile non vide, la pro-priété exprime les faits suivants :
• elle est inductivement vérifiée sur le reste de la pile.
• la tête de pile a la forme Stackframe r f (Vptr bsp osp) pc rs, correspondant au bloc d’ac-tivation de la fonction appelante f. La propriété indique donc notamment que la valeur du pointeurde pile est effectivement un pointeur.
• il existe un abstracteur abs et un résultat d’analyse ptmm tels que :
– l’abstracteur n’est défini que pour des blocs inférieurs à b (le modèle mémoire impliquant quele bloc b’ a été alloué avant le bloc b.
32

– l’abstracteur satisfait l’environnement global ge.
– l’abstracteur abstrait le bloc d’activation vers le bloc abstrait Stack.
– ptmm est le résultat de l’analyse d’alias sur la fonction f.
– l’état des registres stocké dans le bloc d’activation satisfait le résultat à l’instruction suivantl’appel dans la fonction f, conformément à abs.
– le registre r, dans lequel sera placé la valeur retournée par la fonction appelée, doit être relié àl’ensemble ⊤S par le résultat de l’analyse à l’instruction suivant l’appel.
– la mémoire doit être reliée à l’ensemble ⊤S dans le résultat de l’analyse à l’instruction suivantl’appel.
On peut noter que ces propriétés ressemblent fortement aux propriétés vraies pour la fonction courante, quiseront décrites ci-après. Sans cette propriété, il nous est très dur de reconstruire un abstracteur en retourde la fonction. Il faudrait pour cela pouvoir discriminer les blocs qui ont été alloués depuis l’appel et lesabstraire en Other, puis retrouver quels blocs étaient alloués à quel endroit et restaurer les abstractionscorrespondantes.
Une autre solution au problème consisterait à empiler les abstracteurs au fur et à mesure des appels dansnotre invariant, conservant ainsi une pile d’abstracteurs en parallèle de la pile d’exécution. Cette solution estcependant bien plus désagréable à maintenir dans la preuve. Puisque ce code n’a pas vocation à être extrait,on choisit d’utiliser la logique classique pour oublier la preuve constructive de l’existence de l’abstracteur,et seulement conserver une propriété d’existence de ce dernier.
On peut à présent décrire la propriété invariante de l’exécution du programme, qui pour un résultat d’analyseet un abstracteur donnés dans un environnement indique que l’état courant d’exécution satisfait ceux-ci :
33

Inductive satisfy (ge: genv) (ptmm: result) (abs: abstracter): state -> Prop :=| satisfy_state: forall cs f bsp pc rs m ptm
(STK: ok_stack ge (Mem.nextblock m) cs)(MEM: ok_abs_mem abs m)(GENV: ok_abs_genv abs ge)(SP: abs bsp = Some Stack)(RES: funanalysis f = Some ptmm)(PTM: ptm = ptmm#pc)(WF: PTM.well_formed ptm)(RSAT: forall r, regsat r rs abs ptm)(MSAT: forall b o, memsat b o m abs ptm),satisfy ge ptmm abs (State cs f (Vptr bsp Int.zero) pc rs m)
| satisfy_callstate: forall cs f args m(MEM: ok_abs_mem abs m)(STK: ok_stack ge (Mem.nextblock m) cs)(GENV: ok_abs_genv abs ge),satisfy ge ptmm abs (Callstate cs f args m)
| satisfy_returnstate: forall cs v m(MEM: ok_abs_mem abs m)(STK: ok_stack ge (Mem.nextblock m) cs)(GENV: ok_abs_genv abs ge),satisfy ge ptmm abs (Returnstate cs v m)
.
Fragment de code Coq 12 : Propriété satisfy
Cette propriété inductive considère les trois étapes différentes d’exécution d’un programme :
• L’état State cs f (Vptr bsp Int.zero) pc rs m est un état en cours d’exécution dans unefonction f. cs constitue la pile, Vptr bsp Int.zero est le pointeur de pile, toujours situé à l’indicezéro du bloc de pile courant, pc est le compteur programme, qui est simplement un indice du graphede flot de contrôle, rs représente l’état des registres, associant à chaque registre une valeur numériqueou un pointeur, et m représente l’état mémoire. Dans ces conditions :
– l’hypothèse RES définit ptmm comme le résultat de l’analyse de la fonction courante.
– les hypothèses RSAT et MSAT spécifient que tout registre et tout emplacement mémoire satisfaitrespectivement regsat et memsat vues plus haut.
– l’hypothèse WF n’est pas liée au déroulement de la preuve directement, elle indique seulementque le résultat de l’analyse doit correspondre à certains critères pour être valide. Cette hypothèseest uniquement placée dans cet invariant parce qu’il est simple de la faire voyager avec lui.
– les autres propriétés ont été décrites plus haut.
34

• L’état Callstate cs f args m correspond à la transition vers un appel de la fonction f. Les infor-mations de l’appelant ont été stockées en tête de cs (notamment l’état des registres), les arguments del’appel sont dans args et la mémoire dans m. Dans cette étape, on n’a seulement besoin des invariantsen rapport avec la mémoire et la pile.
• L’état Returnstate cs v m correspond à un retour d’appel de fonction. L’état sera rétabli à partirde l’élément en tête de la pile cs, et v est la valeur retournée par la fonction (et qui sera placée dansun registre indiqué dans la pile). De même, seules les propriétés liées à la mémoire et à la pile sontnécessaires dans un tel état transitoire.
Enfin, les deux théorèmes qu’on souhaite démontrer sont les suivants :
Theorem satisfy_init:forall p st
(IS: initial_state p st),exists abs, exists ptm, satisfy (Genv.globalenv p) ptm abs st.
Fragment de code Coq 13 : Théorème satisfy_init
Ce premier théorème sert à montrer qu’il existe un abstracteur initial permettant de démarrer la vérificationde l’analyse.
Afin de prouver ce théorème, il nous faut cependant assurer que l’analyse retourne un résultat quelles quesoit les fonctions f du programme p. Ainsi, il faut prendre soin du cas où l’analyse échoue en épuisant lecarburant, auquel cas on renverra un résultat trivialement vrai :
Definition safe_funanalysis f :=match funanalysis f with| Some res => res| None => PTM.topend.
Fragment de code Coq 14 : Encapsulation de funanalysis en cas d’épuisement du carburant
Le second théorème permet de construire incrémentalement, à partir du théorème précédent, l’existenced’un abstracteur à chaque étape de l’exécution :
35

Theorem satisfy_step:forall ge st t st’ ptm abs
(FAOK: forall f, {ff | funanalysis f = Some ff})(STEP: step ge st t st’)(SAT: satisfy ge ptm abs st),exists ptm’, exists abs’, satisfy ge ptm’ abs’ st’.
Fragment de code Coq 15 : Théorème satisfy_step
Ce théorème indique que si l’on connaît un résultat et une abstraction encadrant correctement l’état d’unprogramme dans l’état st, et que ce programme progresse correctement vers un état st’, alors on sait créerun résultat ptm’ et un abstracteur abs’ qui encadrent correctement le nouvel état.
Bien que présentée sous cette forme, la propriété laisse penser qu’on peut utiliser n’importe quel résultatpour ptm, il ne faut pas oublier que la propriété satisfy force l’unification de ce résultat avec celui dela fonction courante via l’hypothèse RES. On a préféré quantifier existentiellement cette valeur ici parceque les états Callstate et Returnstate ne contiennent pas explicitement de fonction, et se contentent durésultat qui précédait dans l’évaluation du programme.
5.4 Évolution de l’abstracteur au cours de la preuve
Il est intéressant de regarder comment évolue l’abstracteur, bien que ce résultat soit peut étonnant.
Ainsi, pour toutes les instructions RTL à l’exception de EF_malloc, l’abstracteur n’est pas modifié. Pource dernier, il est modifié de la sorte :
exists (fun x => if zeq x b then Some (Alloc pc) else abs x).
L’ancien abstracteur est conservé, mais le bloc b qui vient juste d’être alloué est associé à la valeur Allocpc, où pc représente évidemment l’indice de l’instruction courante.
Un second cas où l’on modifie l’abstracteur est lorsqu’on entre dans un appel de fonction. Dans ce cas, onle modifie ainsi :
36

exists (fun b =>if zeq b stk then Some Stack else
match abs b with| Some ab => Some(
match ab with| Global i => Global i| Globals => Globals| _ => Otherend
)| None => Noneend
).
stk est le bloc d’activation qui vient d’être alloué, il est donc abstrait en Stack. Tous les autres blocsprécédemment valides sont envoyés sur le bloc Other, à l’exception des blocs globaux qui sont préservés,conformément à nos invariants.
Enfin, quand on retourne d’un appel de fonction, on jette l’abstracteur courant, et on détruit la propriétéok_stack afin d’obtenir un abstracteur qui vérifie les propriétés qui étaient vraies juste avant l’appel defonction. Il ne nous reste plus qu’à modifier celui-ci pour prendre en compte les blocs qui n’existaient pasencore à cet instant :
exists (fun b =>match abs0 b with| Some _ => abs0 b| None => if (zlt b (Mem.nextblock m0)) then Some Other else Noneend
).
Ici, on conserve toutes les abstractions existantes avant l’appel, et on associe à tous les blocs qui ont étécréés depuis (par construction, ceux qui sont inférieurs au prochain bloc de la mémoire) par Other. Lesautres blocs ne sont pas valides, donc pas abstraits.
37

6 Mesures, tests et résultats
6.1 Données numériques diverses
• 3636 lignes de code Coq
– dont 1397 lignes de spécification
* une moitié définissant l’analyse statique et son implémentation.
* l’autre moitié définissant les propriétés et les énoncés des théorèmes.
– dont 2239 lignes de preuves
* environ 1275 lignes pour les propriétés des structures de données
* environ 964 lignes constituent la preuve principale
• 26 lignes d’OCaml pour instrumenter l’analyse
• 216 lignes d’OCaml pour afficher les résultats de l’analyse
Temps nécessaire pour vérifier mes preuves (Intel Xeon Quad-Core W3565 3.20GHz) :
time make -j4 proof[...]real 2m20.103suser 2m33.466ssys 0m4.516s
Tab. 1 : Simple évaluation du coût additionnel dû à l’analyse
Test (lignes de code) Compilation sans analyse (s) Compilation avec analyse (s)chomp (370) 0.080 0.115aes (1453) 0.160 0.448raytracer (2560) 1.713 2.723compression (4788) 0.985 1.215spass (69073) 16.906 56.693
6.2 Étude du résultat d’une analyse
Cette section présente un code C, sa compilation en code RTL, et le résultat d’une exécution de l’analysesur ce code, suivi des détails expliquant ces résultats.
Pour réaliser ces tests, il a fallu modifier légèrement CompCert afin que les appels à malloc soient correcte-ment remplacés par des appels Ibuiltin EF_malloc, alors que la version actuelle les laisse sous la formed’appels de fonction. Sans cette modification, l’analyse est beaucoup moins précise puisqu’elle ne sait pasreconnaître les opérations d’allocation mémoire. Il serait possible de contourner ce problème autrement, endétectant les malloc pendant l’analyse, mais cela rendrait la preuve plus complexe inutilement.
38

Considérons donc le code C suivant. Celui-ci contient notamment des allocations dynamiques, une structureconditionnelle affectant à la même variable deux valeurs distinctes dans deux branches distinctes, ainsiqu’une boucle sur un tableau :
#include<stdlib.h>
#define SIZE 10
int main(int argc) {int x, y, z, *p1, *p2, *p3, *p4, **t;x = argc;
p1 = &x;p2 = malloc(sizeof(int));if (x < 0) {
p3 = p1;} else {
p3 = malloc(sizeof(int));}t = malloc(SIZE * sizeof(int));for (y = 0; y < SIZE; y++){
t[y] = &z;}p4 = t[0];}
39

Ceci se traduit en pseudo-syntaxe RTL ainsi :
f(x1) {23 : int32[stack(0)] = x122 : x9 = stack(0)21 : x18 = 420 : x2 = builtin malloc(x18)19 : x8 = x218 : x17 = int32[stack(0)]17 : if (x17 <s 0) goto 13 else goto 1616 : x16 = 415 : x3 = builtin malloc(x16)14 : x7 = x3
goto 1213 : x7 = x912 : x15 = 4011 : x4 = builtin malloc(x15)10 : x5 = x49 : x11 = 08 : nop7 : if (x11 <s 10) goto 6 else goto 26 : x14 = stack(4)5 : int32[x5 + x11 * 4 + 0] = x144 : x11 = x11 + 13 : goto 72 : x6 = int32[x5 + 0]1 : return x13
}
Les accès mémoire sont dénotés ici par la syntaxe s[o] où s représente la taille de l’accès et o l’indice. Legraphe de flot de contrôle est représenté linéarisé, le flot étant défini par des instructions goto, qui ne fontpas partie du langage RTL, puisque celui-ci est représenté sous la forme d’un graphe.
Le résultat de l’analyse est donné en figure 11, et expliqué pas à pas ci-après.
40
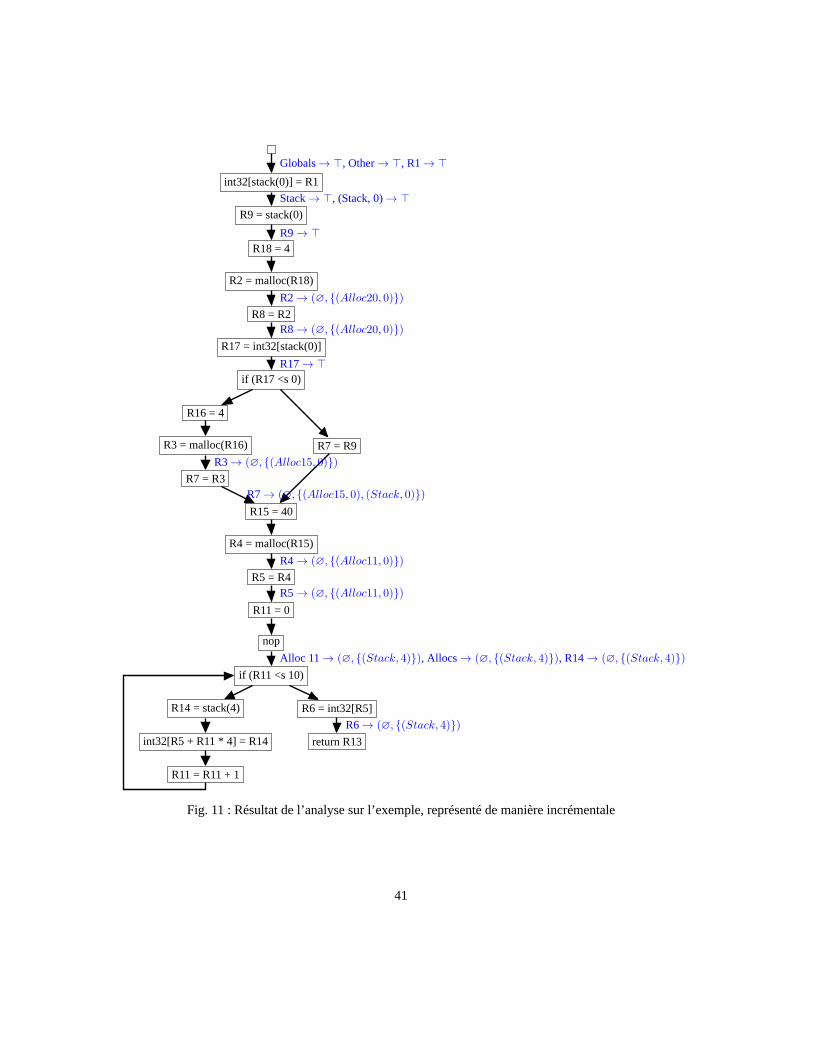
...
int32[stack(0)] = R1
.
R9 = stack(0)
.
R18 = 4
.
R2 = malloc(R18)
.
R8 = R2
.
R17 = int32[stack(0)]
.
if (R17 <s 0)
.
R16 = 4
.
R3 = malloc(R16)
.
R7 = R3
.
R7 = R9
.
R15 = 40
.
R4 = malloc(R15)
.
R5 = R4
.
R11 = 0
.
nop
.
if (R11 <s 10)
.
R14 = stack(4)
.
int32[R5 + R11 * 4] = R14
.R11 = R11 + 1.
R6 = int32[R5]
.
return R13
........................
Globals→ ⊤, Other→ ⊤, R1→ ⊤
.
Stack→ ⊤, (Stack, 0)→ ⊤
.
R9→ ⊤
..
R2→ (∅, {(Alloc20, 0)})
.
R8→ (∅, {(Alloc20, 0)})
.
R17→ ⊤
...
R3→ (∅, {(Alloc15, 0)})
.
R7→ (∅, {(Alloc15, 0), (Stack, 0)})
....
R4→ (∅, {(Alloc11, 0)})
.
R5→ (∅, {(Alloc11, 0)})
..
Alloc 11→ (∅, {(Stack, 4)}), Allocs→ (∅, {(Stack, 4)}), R14→ (∅, {(Stack, 4)})
.....
R6→ (∅, {(Stack, 4)})
Fig. 11 : Résultat de l’analyse sur l’exemple, représenté de manière incrémentale
41

Globals -> ⊤Other -> ⊤R1 -> ⊤
En entrée de fonction, les blocs globaux et autres peuvent potentiellement pointer vers tout (en réalité, ilsne peuvent pas pointer vers la pile, ni vers les blocs qui seront alloués plus tard, mais c’est plus complexeà démontrer). De même, le registre passé en paramètre à la fonction peut éventuellement pointer vers tout.
À présent, je montrerai l’instruction exécutée, d’abord en C, puis en RTL, suivie du résultat différentiel parrapport au résultat du nœud précédent, en évitant de répéter les relations qui n’ont pas changé.
x = argc;
23 : Istore(chunk=Mint32, addr=Ainstack 0, args=[], src=R1, succ=22)Stack -> ⊤(Stack, 0) -> ⊤
En stockant argc dans la variable x, on écrit en pile à l’indice 0 la valeur contenue dans le registre passéen paramètre. Ainsi, cette case mémoire passe à ⊤S , et il en va de même pour le bloc représentant la pileentière, tout indice confondu. Il serait ici intéressant de savoir que l’argument de ligne de commande nepeut pas être un pointeur afin de ne pas perdre cette précision dès le départ.
p1 = &x;
22 : Iop(op=Olea Ainstack 0, args=[], dest=R9, succ=21)R9 -> ({}, {(Stack, 0)})
Il s’agit ici d’un simple référencement.
p2 = malloc(sizeof(int));
21 : Iop(op=Ointconst 4, args=[], dest=R18, succ=20)20 : Ibuiltin(ef=Malloc, args=[R18], dest=R2, succ=19)R2 -> ({}, {(Alloc 20, 0)})19 : Iop(op=Omove, args=[R2], dest=R8, succ=18)R8 -> ({}, {(Alloc 20, 0)})
L’opération 21 n’altère pas le résultat. L’allocation dynamique en 20 crée pour sa part un bloc Alloc 20,vers lequel pointe le registre destination correspondant à la variable p2. L’opération 19 est un artefact sansintérêt dû aux optimisations précédant l’analyse.
if(x < 0)
42

18 : Iload(chunk=Mint32, addr=Ainstack 0, args=[], dest=R17, succ=17)R17 -> ⊤17 : Icond(args=[R17], ifso=13, ifnot=16)
On recharge x et on le compare à 0. Rien de spécial ici, si ce n’est le manque de précision hérité de l’ins-truction 23.
p3 = malloc(sizeof(int));
16 : Iop(op=Ointconst 4, args=[], dest=R16, succ=15)15 : Ibuiltin(ef=Malloc, args=[R16], dest=R3, succ=14)R3 -> ({}, {(Alloc 15, 0)})14 : Iop(op=Omove, args=[R3], dest=R7, succ=12)
Dans la branche de droite, une allocation dynamique similaire à celle étudiée précédemment a lieu. Lerésultat en sortie de 14 n’est pas montré ici puisqu’il sera fusionné avec le résultat en sortie de l’autrebranche pour donner le résultat en entrée de 12.
p3 = p1;
13 : Iop(op=Omove, args=[R9], dest=R7, succ=12)
De même, je ne montre pas ici le résultat après 13 qui sera fusionné avec celui mentionné précédemmenten entrée de 12 :
t = malloc(SIZE * sizeof(int));
R7 -> ({}, {(Alloc 15, 0), (Stack, 0)})12 : Iop(op=Ointconst 40, args=[], dest=R15, succ=11)11 : Ibuiltin(ef=Malloc, args=[R15], dest=R4, succ=10)R4 -> ({}, {(Alloc 11, 0)})10 : Iop(op=Omove, args=[R4], dest=R5, succ=9)R5 -> ({}, {(Alloc 11, 0)})
On remarque ici l’apparition simultanée de deux emplacements mémoire pouvant être pointés par le re-gistre 7 en entrée de l’instruction 12. Ces deux pointeurs correspondent aux deux branches de la structureconditionnelle, conformément à ce qu’on peut attendre. La suite est une autre allocation dynamique.
for (y = 0; y < SIZE; y++)
43

9 : Iop(op=Ointconst 0, args=[], dest=R11, succ=8)8 : Inop(succ=7)Alloc 11 -> ({}, {(Stack, 4)})Allocs -> ({}, {(Stack, 4)})R11 -> ({}, {})R14 -> ({}, {(Stack, 4)})7 : Icond(args=[R11], ifso=6, ifnot=2)
Ces opérations n’altèrent pas le résultat, cependant on remarque beaucoup de changements à partir de l’ins-truction 8. En effet, cette instruction est un point de bouclage pour notre boucle for, et a donc accumulépar point fixe les résultats du corps de la boucle. Nous allons voir plus bas quelles instructions ont ajoutéchacune de ces relations.
t[y] = &z;
6 : Iop(op=Olea Ainstack 4, args=[], dest=R14, succ=5)5 : Istore(chunk=Mint32, addr=Aindexed2scaled (4, 0), args=[R5, R11], src=R14, succ=4)4 : Iop(op=Olea Aindexed 1, args=[R11], dest=R11, succ=3)
L’instruction 6 avait donc rajouté la relation R14 -> ({}, {(Stack, 4)}). L’instruction 5 est intéressante :en l’absence d’information sur la valeur de y, elle a ajouté les relations Alloc 11 -> ({}, {(Stack, 4)})et Allocs -> ({}, {(Stack, 4)}). Ainsi, c’est tout le bloc alloué qui peut pointer vers z. Si l’affectationavait eu la forme t[0] = &z;, le résultat aurait été beaucoup plus précis, de la forme (Alloc 11, 0) ->({}, {(Stack, 4)}).
Enfin, l’instruction 4 correspond à y++, et ajoute une relation R11 -> ({}, {}).
p4 = t[0];
2 : Iload(chunk=Mint32, addr=Aindexed 0, args=[R5], dest=R6, succ=1)R6 -> ({}, {(Stack, 4)})1 : Ireturn(r=Some R13)
Finalement, un chargement à l’adresse 0 depuis un pointeur situé dans le registre 5, qui à cet instant peutpointer vers ({}, {(Alloc 11, 0)}), et sachant que l’intégralité du bloc Alloc 11 peut pointer vers({}, {(Stack, 4)}) résulte en l’ajout de la relation ({}, {(Stack, 4)}).
44

7 Limites et améliorations
À mesure que le stage avançait, j’ai pu observer des limites apparaître dans mon développement, en plusde celles qu’on s’était fixées dans le cahier des charges.
La première limite évidente est le fait que l’analyse soit intra-procédurale : de fait, les résultats sont peuprécis et les approximations conservatrices. Une analyse inter-procédurale serait plus précise, mais pluscoûteuse et plus difficile à prouver, et obligerait probablement à changer le flot de contrôle du compilateur,qui traite pour l’instant les fonctions du programme une par une de bout en bout, séparément.
Une seconde limite, cette fois-ci dûe à mon implémentation, est l’absence de mises à jour fortes : lorsqu’onsait qu’un registre ou un emplacement mémoire ne peut pointer que vers un emplacement singleton, et quele bloc abstrait de cet emplacement abstrait un unique bloc concret, comme ce serait le cas pour les blocsGlobal et Stack, une mise à jour de la valeur pointée est certaine d’écraser celle-ci, et l’on pourrait vouloireffectuer un remplacement plutôt qu’un calcul de borne supérieure dans ce cas. Cependant, la preuve decette amélioration n’est pas faite et demande plus de travail.
Une autre limite est cette fois dûe au modèle de CompCert : il est en effet impossible de séparer strictementles variables contenant des pointeurs des variables contenant des entiers. Ceci implique par exemple quetous les paramètres passés à la fonction qui ont un type entier sont traités conservativement en présumantqu’ils puissent contenir des pointeurs, ce qui explique qu’en entrée de fonction les registres des argumentssont abstraits vers ⊤S . On pourrait imaginer remédier à ce problème en ayant une analyse plus en amontd’inférence de types qui nous indique qu’avec certitude, un registre ne peut pas contenir un pointeur. Cettepropriété est en effet déductible dans certains cas, par exemple si la valeur du registre est utilisée commeopérande d’une multiplication.
Plusieurs améliorations de la preuve existante sont également envisageables. On pourrait tout d’abord sé-parer deux résultats, pour les registres et la mémoire, comme je l’ai fait dans ce rapport. Ceci simplifieraitdes preuves puisque chaque opération ne modifie généralement que l’une de ces deux ptmap.
La preuve pourrait aussi être rendue plus robuste par endroits : certaines preuves sont en effet très répétitives,mais l’effort demandé pour les automatiser n’est pas toujours rentable. Cependant, on paie parfois le prixd’une preuve trop manuelle lors d’une refactorisation.
45

8 Conclusion
Le résultat de mon stage est la démonstration de faisabilité d’une analyse d’alias intra-procédurale, de basniveau, sensible au flot et aux champs, insensible au contexte et aux chemins d’exécution, pour le langageintermédiaire RTL du projet CompCert.
J’ai effectué cette preuve par une méthode dite d’interprétation abstraite, c’est-à-dire en effectuant uneprojection de l’état réel d’exécution sur un état abstrait plus approximatif, et en assurant la validité desrésultats sur cette surapproximation des états possibles du système.
Il reste à présent plusieurs chemins à poursuivre : améliorer la preuve et l’implémentation actuelles, affi-ner les optimisations existantes en tenant compte des résultats de l’analyse, et envisager des analyses plusambitieuses (inter-procédurale par exemple) ou plus efficaces (insensible au flot).
Ce projet de fin d’études était fort intéressant pour plusieurs raisons : tout d’abord, il m’a permis de décou-vrir plus en détail le travail de recherche, et l’ambiance de travail dans un laboratoire. Travailler avec lespersonnes de l’équipe Gallium était particulièrement enrichissant.
Ensuite, le sujet du projet lui-même était très intéressant, et en raccord avec les cours que j’avais suivisprécédemment en France et aux États-Unis, et il était donc agréable de mettre à l’épreuve ces connaissancessur un projet concret. L’apprentissage de Coq était fort enrichissant, notamment par des erreurs de débutantque j’ai commises en cours de développement et qui se sont révélées lorsque la preuve atteignait les recoinsépineux du langage RTL et mettait en exergue la faiblesse de mes invariants.
Si le script de preuve ainsi que l’implémentation méritent encore des retouches, la preuve a désormais étéétablie qu’il est possible de prouver une analyse d’alias non triviale dans un compilateur vérifié, et j’aifourni une implémentation de référence.
À l’issue de ce stage, je candidate à un poste de doctorant afin de pouvoir continuer à travailler dans cedomaine et explorer ce que peuvent apporter les méthodes formelles aux domaines du génie logiciel et de lacompilation. En attendant les décisions quant à ma candidature à l’Université de Californie, San Diego, jecontinuerai de travailler dans l’équipe Gallium, cette fois-ci sur les dernières étapes du processus de com-pilation : l’assembleur et l’éditeur de liens. Je travaillerai à valider le résultat de ces étapes de compilationen OCaml, puisque les opérations effectuées à ce stage manquent d’une sémantique formelle appropriée àla preuve de propriétés. J’ai également reçu de mon maître de stage une proposition de thèse portée sur laformalisation d’un domaine abstrait pour la preuve d’analyses statiques de programmes, sujet qui s’inscritassez bien dans la continuité du travail que j’ai effectué durant ce stage. Ainsi, je devrais pouvoir démarrerune thèse dans une des équipes pour lesquelles je postule à compter de septembre 2012.
46
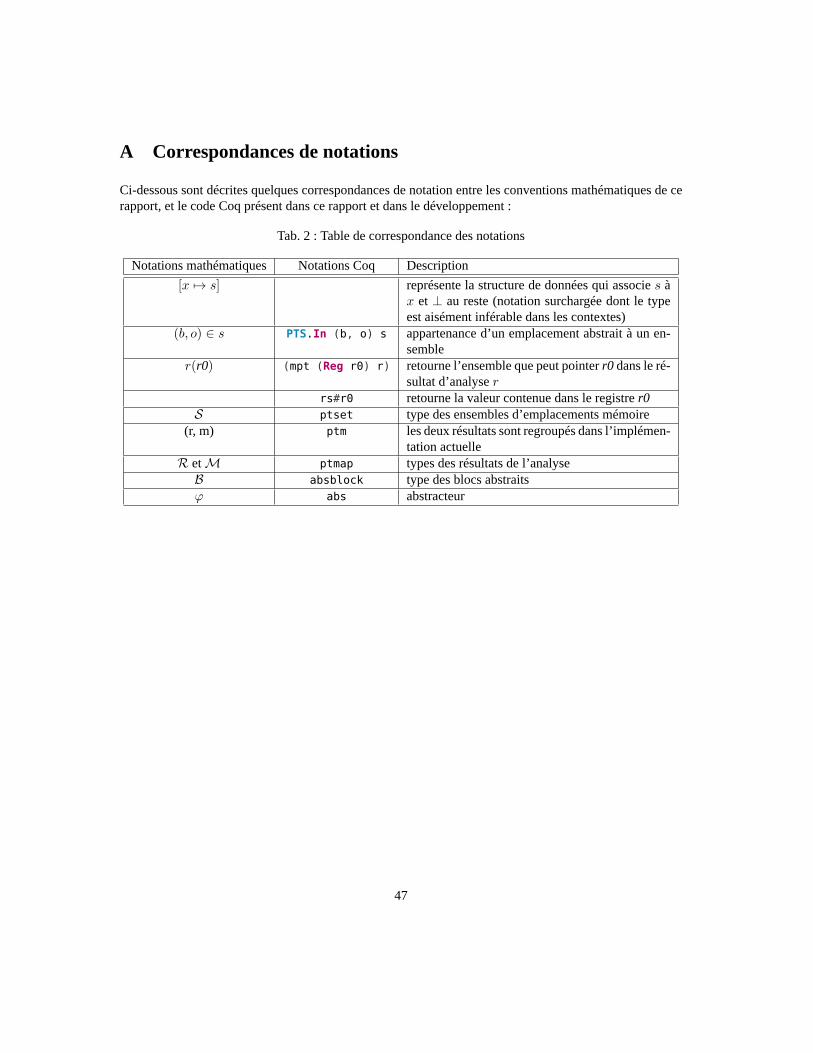
A Correspondances de notations
Ci-dessous sont décrites quelques correspondances de notation entre les conventions mathématiques de cerapport, et le code Coq présent dans ce rapport et dans le développement :
Tab. 2 : Table de correspondance des notations
Notations mathématiques Notations Coq Description[x 7→ s] représente la structure de données qui associe s à
x et ⊥ au reste (notation surchargée dont le typeest aisément inférable dans les contextes)
(b, o) ∈ s PTS.In (b, o) s appartenance d’un emplacement abstrait à un en-semble
r(r0) (mpt (Reg r0) r) retourne l’ensemble que peut pointer r0 dans le ré-sultat d’analyse r
rs#r0 retourne la valeur contenue dans le registre r0S ptset type des ensembles d’emplacements mémoire
(r, m) ptm les deux résultats sont regroupés dans l’implémen-tation actuelle
R etM ptmap types des résultats de l’analyseB absblock type des blocs abstraitsφ abs abstracteur
47

B Code Coq de la fonction de transfert
La fonction de transfert décrite en notations mathématiques dans le rapport est donnée dans sa forme Coqci-dessous.
Tout d’abord, la fonction de calcul d’adressage @ :
Definition mpt_addr addr args m :=match addr, args with
| Aindexed o, r::nil =>Some (shift_ptset (mpt (Reg r) m) o)
| Aindexed2 _, r1::r2::nil =>Some (PTS.lub(unknown_offset (mpt (Reg r1) m))(unknown_offset (mpt (Reg r2) m))
)| Ascaled _ _, _::nil => Some PTS.bot| Aindexed2scaled _ _, r::_::nil =>
Some (unknown_offset (mpt (Reg r) m))| Aglobal i o, nil =>
Some (ABS.empty, ALS.singleton (Global i, o))| Abased i _, _::nil| Abasedscaled _ i _, _::nil =>
Some (ABS.singleton (Global i), ALS.empty)| Ainstack o, nil =>
Some (ABS.empty, ALS.singleton (Stack, o))| _, _ => None
end.
Fragment de code Coq 16 : Fonction de transfert, calcul d’adressage
48

La fonction Op :
Definition transf_op op args dst m :=match op with
| Olea addr =>match mpt_addr addr args m with
| None => m (*!*)| Some s => PTM.add (Reg dst) s m
end| Omove =>match args with
| r::nil => PTM.add (Reg dst) (mpt (Reg r) m) m| _ => m (*!*)
end| Osub =>match args with
| r::_::nil => PTM.add (Reg dst) (unknown_offset (mpt (Reg r) m)) m| _ => m (*!*)
end| _ => m
end.
Fragment de code Coq 17 : Fonction de transfert, opérations arithmétiques
49

La fonction Bi :
Definition transf_builtin ef args dst m :=match ef with| EF_external _ sg => PTM.add (Reg dst) (ABS.singleton Globals, ALS.empty) m| EF_builtin _ sg => PTM.add (Reg dst) (ABS.singleton Globals, ALS.empty) m| EF_vload chunk => PTM.add (Reg dst) PTS.top m| EF_vstore chunk =>
match args with| r1 :: r2 :: nil =>add_set_to_all_elts (mpt (Reg r2) m) (mpt (Reg r1) m) m
| _ => mend
| EF_malloc =>PTM.add (Reg dst) (ABS.empty, ALS.singleton (Alloc n, Int.zero)) m
| EF_free => m| EF_memcpy _ _ =>
match args with| rdst :: rsrc :: nil =>add_set_to_all_elts PTS.top (unknown_offset (mpt (Reg rdst) m)) m
| _ => m (*!*)end
| EF_annot _ _ => m| EF_annot_val _ _ =>
match args with| r1 :: nil => PTM.add (Reg dst) (mpt (Reg r1) m) m| _ => m (*!*)end
end
Fragment de code Coq 18 : Fonction de transfert, fonctions intégrées au compilateur
50

Enfin, la fonction F :
Definition transf c n (m: ptmap) :=match c!n with
| Some instr =>match instr with
| Inop _ => m| Iop op args dst succ => transf_op op args dst m| Iload chunk addr args dst succ =>
if is_mint32_dec chunkthen
match mpt_addr addr args m with| None => m (*!*)| Some s =>
PTM.add (Reg dst) (lub_of_mpt_of_all_elts s m) mend
elsePTM.add (Reg dst) PTS.bot m
| Istore chunk addr args src succ =>if is_mint32_dec chunk
thenmatch mpt_addr addr args m with| None => m (*!*)| Some sdst =>
add_set_to_all_elts (mpt (Reg src) m) sdst mend
elsem
| Icall sign fn args dst succ =>PTM.add (Reg dst) PTS.top (top_mem m)
| Itailcall sign fn args => top_mem m| Ibuiltin ef args dst succ => transf_builtin ef args dst m| Icond cond args ifso ifnot => m| Ijumptable arg tbl => m| Ireturn _ => m
end| None => m
end.
Fragment de code Coq 19 : Fonction de transfert, instructions RTL
51

Glossaire
aliasSe dit de deux variables faisant référence au même objet.
bloc d’activationLe bloc d’activation est un bloc en mémoire créé à chaque appel de fonction non terminal, afin destocker des informations sur la fonction appelante durant le temps de l’exécution de la fonction ap-pelée.
compilationTransformation d’un code depuis un langage source vers un autre langage.
dictionnaireStructure de données permettant d’associer des valeurs à des clés.
déréférencementAction de retrouver l’objet dont l’adresse a été référencée.
graphe de flot de contrôleGraphe orienté représentant un programme, très utilisé comme représentation intermédiaire dans lescompilateurs.
optimisationTransformation d’un code sémantiquement transparente, en vue de réduire un coût.
pointeurUn objet est un pointeur lorsque sa valeur est l’adresse en mémoire d’un autre objet.
registreUn registre est un emplacement mémoire situé dans le processeur. Les registres sont très rapides àaccéder, mais peu nombreux, aussi on souhaite les exploiter au maximum. Cependant, ils n’ont pasd’adresse, aussi il n’existe pas de pointeurs vers un registre.
sémantiqueLa sémantique d’un langage de programmation est la description formelle, mathématique, des pro-priétés attendues de l’exécution d’un code.
SSAReprésentation d’un programme sous forme de graphe de flot de contrôle dans lequel chaque variablen’est assignée qu’une unique fois, facilitant certains raisonnements.
statiqueSe dit de toute chose effectuée avant l’exécution du programme.
52

treillisUn treillis est un ensemble partiellement ordonné tel que tout couple d’éléments admet une borneinférieure et une borne supérieure.
volatileUne variable est dite volatile si elle doit être traitée de manière plus conservatrice par le compilateurqu’une variable habituelle. C’est le cas de variables pouvant changer de valeur ”spontanément”, parexemple par l’action d’un processus concurrent ou parce que la variable est associée à un périphérique.Les opérations liées à ce type de variables sont également dites volatiles.
53

Références
[And94] L. O. Andersen. Program analysis and specialization for the C programming language. PhDthesis, University of Copenhagen, 1994.
[G+05] B. Guo et al. Practical and accurate low-level pointer analysis. In International Symposium onCode Generation and Optimization (CGO’05), 2005.
[Kil73] Gary A. Kildall. A unified approach to global program optimization. In 1st symposium Prin-ciples of Programming Languages, pages 194–206. ACM, 1973.
[Ler09a] Xavier Leroy. Formal verification of a realistic compiler. Communications of the ACM,52(7) :107–115, 2009.
[Ler09b] Xavier Leroy. A formally verified compiler back-end. Journal of Automated Reasoning,43(4) :363–446, 2009.
[Ste96] B. Steensgaard. Points-to analysis in almost linear time. In POPL ’96 Proceedings of the 23rdACM SIGPLAN-SIGACT symposium on Principles of programming languages, 1996.
[YCER11] Xuejun Yang, Yang Chen, Eric Eide, and John Regehr. Finding and understanding bugs in ccompilers. In Proceedings of the 32nd ACM SIGPLAN conference on Programming languagedesign and implementation, PLDI ’11, pages 283–294, New York, NY, USA, 2011. ACM.
54





























