Embed Size (px)
Citation preview

RÉSUMÉ EN FRANÇAISDE LA THÈSE DE DOCTORAT
Spécialité
Informatique
École Doctorale Informatique, Télécommunications et Électronique (Paris)
Présentée par
M. Arnaud DESSEIN
Pour obtenir le grade de
DOCTEUR DE L’UNIVERSITÉ PIERRE ET MARIE CURIE
Sujet de la thèse :
Méthodes Computationnelles en Géométrie de l’Informationet Applications Temps Réel au Traitement du Signal AudioComputational Methods of Information Geometry with Real-Time Applications inAudio Signal Processing
soutenue le 13 décembre 2012
devant le jury composé de :M. Gérard Assayag DirecteurM. Arshia Cont EncadrantM. Francis Bach RapporteurM. Frank Nielsen RapporteurM. Roland Badeau ExaminateurM. Silvère Bonnabel ExaminateurM. Jean-Luc Zarader Examinateur

IntroductionCette thèse propose des méthodes computationnelles nouvelles en géométrie de
l’information pour des applications temps réel au traitement du signal audio. Lagéométrie de l’information est un champ des mathématiques qui étudie les statis-tiques par le biais de concepts en géométrie différentielle, comme les variétés diffé-rentiables, et en théorie de l’information, comme les divergences informationnelles.La géométrie de l’information a trouvé de nombreuses applications en apprentissageautomatique et en traitement du signal, du fait que beaucoup d’approches dans cesdomaines reposent sur des modèles statistiques ou des fonctions de distances.Dans ce contexte, nous traitons en parallèle les problèmes applicatifs de la seg-
mentation audio en temps réel, et de la transcription de musique polyphoniqueen temps réel. Nous abordons ces applications par le développement respectif decadres théoriques pour la détection séquentielle de ruptures dans les familles expo-nentielles, et pour la factorisation en matrices non négatives avec des divergencesconvexes-concaves. La thèse est organisée en deux parties principales, contenant res-pectivement trois chapitres théoriques et deux chapitres applicatifs (cf. Figure 0.1).
3. Factorisation en Matrices Non Négatives avec des Divergences Convexes-Concaves
1. Préliminaires enGéométrie de l'Information
2. Détection Séquentielle de Rupturesdans les Familles Exponentielles
5. Transcription de Musique Polyphonique en Temps Réel
4. Segmentation Audioen Temps Réel
I. Méthodes Computationnelles en Géométrie de l'Information
II. Applications Temps Réel au Traitement du Signal Audio
Figure 0.1.: Structure de la thèse. La thèse s’organise en deux parties, présentanten parallèle les deux méthodes computationnelles en géométrie de l’in-formation proposées, d’une part, et leur utilisation respective pour desapplications temps réel au traitement du signal audio, d’autre part.
2

Introduction
Dans le Chapitre 1, nous introduisons les préliminaires théoriques en géométrie del’information nécessaires au développement du Chapitre 2 et du Chapitre 3. Le cha-pitre est divisé en deux sections parallèles correspondant aux outils mathématiquesrequis respectivement dans les deux chapitres indépendants suivants. Nous présen-tons d’abord des résultats importants sur les familles exponentielles de distributionsde probabilité, en relation avec la dualité convexe et la géométrie de l’informationdualement plate. Ces résultats sont utilisés dans le Chapitre 2 pour développer desméthodes computationnelles pour la détection séquentielle de ruptures dans les fa-milles exponentielles. Nous nous concentrons ensuite sur l’introduction de notionspertinentes concernant les divergences informationnelles séparables sur l’espace desmesures discrètes positives, incluant les divergences de Csiszár, les divergences deBregman et leurs généralisations par les divergences de Jeffreys-Bregman et Jensen-Bregman, ainsi que les α-divergences et les β-divergences et leur généralisation parles (α, β, λ)-divergences obliques. Ces notions sont utilisées dans le Chapitre 3 pourélaborer des méthodes computationnelles de factorisation en matrices non négativesavec des divergences convexes-concaves.Dans le Chapitre 2, nous proposons des méthodes computationnelles pour la dé-
tection de ruptures dans les familles exponentielles. À notre connaissance, c’est lapremière fois que le problème bien connu de la détection de ruptures est étudié parl’intermédiaire de la géométrie de l’information. Nous suivons une approche clas-sique où la détection de ruptures est considérée comme un problème statistique dedécision avec des hypothèses multiples, et est résolu à l’aide de statistiques de test derapports de vraisemblance généralisés (GLR). Un inconvénient majeur des travauxantérieurs en détection séquentielle de ruptures, est de considérer des paramètresconnus avant rupture, ou d’approximer les statistiques exactes lorsque ces para-mètres sont inconnus. Nous traitons cet inconvénient en utilisant des statistiquesGLR exactes avec des estimateurs arbitraires, et en les développant explicitementpour les familles exponentielles. Nous montrons des liens forts entre le calcul de cesstatistiques et les estimateurs par maximum de vraisemblance, et obtenons ainsiune procédure générique de détection de ruptures pour des scénarios courants avecdes paramètres connus ou inconnus et des estimateurs arbitraires. Nous interprétonségalement cette procédure dans le cadre de la géométrie de l’information dualementplate des familles exponentielles, apportant ainsi des intuitions à la fois géométriqueset statistiques au problème, et mettant en relation les approches statistiques et lesapproches géométriques reposant sur le calcul de distances pour la segmentation designaux. La procédure est finalement revisitée à l’aide de la dualité convexe, menantà une procédure attractive avec un calcul séquentiel efficace pour les statistiquesGLR exactes, lorsque les paramètres avant et après rupture sont inconnus et sontestimés par maximum de vraisemblance. Nous appliquons cette procédure dans leChapitre 4 pour concevoir un système général de segmentation audio en temps réel.Dans le Chapitre 3, nous développons des méthodes computationnelles pour la fac-
torisation en matrices non négatives (NMF) avec des divergences convexes-concaves.Nous formulons notamment un cadre générique pour la NMF avec des divergencesconvexes-concaves englobant ainsi de nombreuses divergences informationnelles, parexemple, les divergences de Csiszár, certaines divergences de Bregman, et en par-ticulier toutes les α-divergences et β-divergences. Nous introduisons une procédure
3

Introduction
générale d’optimisation à partir de bornes variationnelles par des fonctions auxi-liaires de substitution, pour des divergences convexes-concaves presque arbitraires.Nous obtenons des mises à jour avec décroissance monotone de la fonction coûtpar minimisation de la fonction auxiliaire. Le cadre proposé permet également deconsidérer des divergences symétrisées ou obliques pour la fonction coût. En par-ticulier, les mises à jour génériques sont spécialisées pour fournir des mises à jourpour les divergences de Csiszár, certaines divergences obliques de Jeffreys-Bregman,les divergences obliques de Jensen-Bregman. Cela mène à plusieurs mises à jourmultiplicatives connues, ainsi que des mises à jour multiplicatives nouvelles, pourles α-divergences, β-divergences, et les versions symétrisées ou obliques. Ces résul-tats sont également généralisés en considérant la famille des (α, β, λ)-divergencesobliques. Nous appliquons ces résultats dans le Chapitre 5 pour concevoir un sys-tème temps réel de transcription de musique polyphonique.Dans le Chapitre 4, nous étudions le problème de la segmentation audio. Nous
concevons notamment un cadre générique pour la segmentation audio en temps réel,à partir des méthodes pour la détection séquentielle de ruptures dans les famillesexponentielles développées dans le Chapitre 2. Un problème majeur des travauxantérieurs en segmentation audio est de considérer des signaux et critères d’ho-mogénéité spécifiques, ou de supposer que la distribution des données suit une loinormale. D’autres inconvénients résident dans la complexité computationnelle oudans la non causalité de certaines procédures. Le système proposé adresse ces pro-blèmes en contrôlant le flux d’information audio pour détecter des ruptures en tempsréel. Dans ce cadre, nous mettons également en relation les approches statistiqueset les approches géométriques reposant sur le calcul de distances, grâce à la géomé-trie dualement plate des familles exponentielles. Nous clarifions notamment les liensentre différentes approches standards de segmentation audio, et montrons commentelles peuvent être unifiées et généralisées dans le cadre proposé. Nous présentons dif-férentes applications afin d’illustrer la généralité du cadre, et réalisons notammentune évaluation quantitative pour la détection d’attaques musicales qui démontre quel’approche développée peut améliorer les résultats dans des problèmes complexes.Dans le Chapitre 5, nous étudions le problème de la transcription de musique
polyphonique. Nous proposons notamment un système temps réel pour la transcrip-tion de musique polyphonique, en utilisant les méthodes computationnelles pour laNMF avec des divergences convexes-concaves développées dans le Chapitre 3. Nousconsidérons un cadre supervisé reposant sur la décomposition non négative, où lesignal musical arrive en temps réel au système et est projeté sur un dictionnaire demodèles spectraux de notes appris avant la décomposition. Un inconvénient majeurdes approches existantes dans ce contexte concerne le manque de contrôles sur la dé-composition. Nous abordons ce problème par l’utilisation de la famille paramétriquedes (α, β)-divergences, et par l’interprétation de leur pertinence comme un moyende contrôler le compromis fréquentiel dans la décomposition. Le système proposé estévalué dans une série méthodologique d’expériences, au cours desquelles il s’avèresurpasser deux systèmes de l’état de l’art fonctionnant en différé, tout en conservantdes coûts computationnels faibles et convenables pour des contraintes de temps réel.
4

Première partie .
Méthodes Computationnelles enGéométrie de l’Information
5

1. Préliminaires en Géométrie del’Information
Nous présentons tout d’abord des préliminaires théoriques sur les familles expo-nentielles, pour la formulation ultérieure de la détection séquentielle de ruptures.Une famille exponentielle est un modèle statistique paramétrique P = {Pθ}θ∈Θ do-miné, et dont les densités de probabilité respectives peuvent s’exprimer selon uneforme canonique relativement générale. Les paramètres θ sont alors appelés para-mètres naturels, et peuvent être étendus à un certain espace convexe N contenant Θpour définir une famille maximale dite complète. L’étude d’une famille exponentiellegénérale peut se réduire après reparamétrisation, choix d’une mesure dominante, etrésumé des observations par une statistique exhaustive, à l’étude d’une famille ex-ponentielle dite standard, qui ne dépend plus que d’une fonction centrale ψ convexedéfinie sur N et appelée log-normalisateur. De plus, cette réduction peut être choisieminimale dans le sens où aucune réduction de dimension de l’espace des paramètresnaturels N , ou du support convexe K des observations, ne soit possible.La classe des familles exponentielles regroupe une grande partie des modèles
employés en statistiques et leurs applications : lois de Bernoulli, Dirichlet, La-place, Pareto, Poisson, Rayleigh, Von Mises-Fisher, Weibull, Wishart, lois normales,log-normales, exponentielles, beta, gamma, géométriques, binomiales, binomiales né-gatives, catégoriques, multinomiales. De plus, la classe des familles exponentiellesest stable sous différentes opérations statistiques courantes : modèles tronqués etcensurés, lois marginales et lois conditionnelles par projections linéaires, distribu-tions jointes de variables indépendantes et modèles d’échantillonnage de variablesindépendantes et identiquement distribuées en particulier. Dans ce contexte, les fa-milles exponentielles permettent non seulement d’unifier et de généraliser les pro-blèmes considérés, mais contribuent aussi souvent à une meilleure compréhension dela structure de ces problèmes.L’étude des familles exponentielles peut également s’enrichir par la théorie de la
dualité convexe. Dans ce contexte, on s’intéresse notamment aux familles raides,pour lesquelles, intuitivement, le gradient ∇ψ du log-normalisateur ne peut pasêtre prolongé en dehors de l’intérieur intN de l’espace des paramètres. Ces fa-milles raides regroupent la grande majorité des familles exponentielles usuelles, etpossèdent des propriétés de convexité extrêmement intéressantes. En particulier,le log-normalisateur ψ est une fonction de type Legendre, conjugué à une fonc-tion duale φ également convexe et de type Legendre, définie par la transformée deLegendre-Fenchel. Cette dualité convexe fournit un système de coordonnées dualdéfini par les paramètres d’espérance η sur l’intérieur intK du support convexe desobservations. Les gradients ∇ψ et ∇φ des potentiels conjugués définissent alors deshoméomorphismes inverses l’un de l’autre, qui permettent de passer d’un système de
6

1. Préliminaires en Géométrie de l’Information
Figure 1.1.: Géométrie dualement plate des familles exponentielles. La divergencecanonique de Kullback-Leibler entre deux distributions de probabilitésur la variété statistique, peut s’exprimer comme une divergence deBregman sur les paramètres naturels ou sur les paramètres d’espérancedans le cadre de la dualité convexe.
coordonnées à l’autre. Cela est notamment pratique pour l’étude de l’estimation parmaximum de vraisemblance, puisque l’estimateur associé peut en général être calculéaisément dans les paramètres d’espérance, comme simple moyenne des statistiquesexhaustives, avant de repasser dans les paramètres naturels par dualité convexe.Ces notions peuvent finalement s’interpréter dans le cadre de la géométrie de l’in-
formation, où une famille exponentielle P = {Pθ}θ∈int N est ue comme une variétéstatistique (cf. Figure 1.1). La métrique d’information de Fisher fournit alors unemétrique riemannienne, et la variété statistique possède deux systèmes de coordon-nées affines duaux donnés par les paramètres naturels θ ∈ intN et les paramètresd’espérance η ∈ intK. Dans la géométrie dualement plate sous-jacente, la fonctionde distance canonique entre deux mesures de probabilité Pθ et Pθ′ est la divergencede Kullback-Leibler DKL. Cette divergence entre mesures peut se calculer de manièreéquivalente comme une divergence de Bregman Bψ entre les paramètres naturels θ′ etθ, ou comme une divergence de Bregman duale Bφ entre les paramètres d’espéranceη et η′. Une telle géométrie généralise donc la géométrie euclidienne auto-duale, avecnotamment deux divergences de Bregman Bψ et Bφ en lieu et place de la distanceeuclidienne auto-duale, mais aussi des géodésiques duales, un théorème de Pythagoregénéralisé et des projections duales.
7

1. Préliminaires en Géométrie de l’Information
Nous introduisons ensuite des préliminaires théoriques concernant les divergencesséparables sur l’espace des mesures discrètes positives. Une divergence, ou parfoisfonction de distance, est une fonction non négative sur le carré cartésien d’un en-semble donné et qui s’annule sur la diagonale. Les divergences permettent donc degénéraliser la notion de distance métrique, en ne requérant ni la propriété de symé-trie, ni l’inégalité triangulaire, communes aux distances métriques. Les divergencessont donc un moyen très général de définir la notion de similarité sur un ensemble,et sont de ce fait omniprésentes dans de nombreux domaines des statistiques, dutraitement du signal, et de l’apprentissage automatique.En considérant des divergences sur un espace euclidien de dimension finie, une
divergence est dite séparable si elle peut se décomposer comme la somme d’unedivergence scalaire donnée sur les différentes coordonnées. Des exemples communsde divergences séparables sont le carré de la distance euclidienne, la divergence deKullback-Leibler, ou encore la divergence d’Itakura-Saito. Nous restreignons ensuitela discussion aux divergences séparables sur l’espace des mesures discrètes positives.Nous introduisons des grandes classes de divergences couramment utilisées. En
particulier, nous définissons les divergences de Csiszár, qui regroupent de nombreusesfonctions de distance comme les divergences de Kullback-Leibler et de Kullback-Leibler duale, la distance en variation totale, la distance de Hellinger, les distancesdu χ2 de Pearson et du χ2 de Neyman. En particulier, la famille paramétrique desα-divergences, omniprésente en statistiques et leurs applications, fait partie de laclasse des divergences de Csiszár.Nous discutons également la classe des divergences de Bregman, qui englobe des
fonctions de distance connues comme le carré de la distance euclidienne, la distancede Mahalanobis, ou encore les divergences de Kullback-Leibler et d’Itakura-Saito. Laclasse des divergences de Bregman contient notamment les α-divergences, ainsi quela famille paramétrique des β-divergences introduite dans le contexte de l’estimationstatistique pour rendre l’estimation par maximum de vraisemblance plus robuste.Contrairement à la classe des divergences de Csiszár, les divergences de Bregman nesont pas stables par échange des deux arguments, et peuvent donc être symétriséesou rendues obliques de plusieurs manières afin de créer de nouvelles divergences.En particulier, deux méthodes standards de symétrisation et leur généralisation paroblicité sont discutées pour introduire les divergences obliques de Jeffreys-Bregman,et les divergences obliques de Jensen-Bregman équivalentes aux divergences obliquesde Burbea-Rao.Nous définissons finalement la famille paramétrique des (α, β)-divergences, récem-
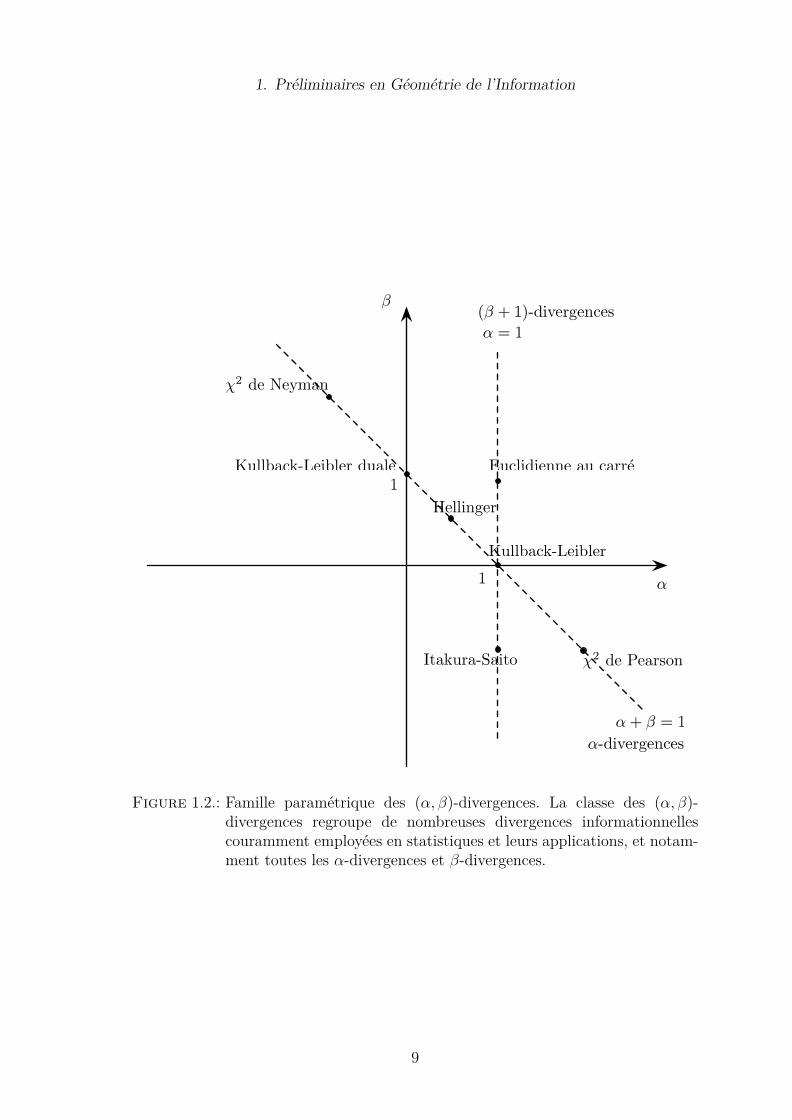
ment introduite dans le contexte de la factorisation en matrices non négatives, et quigénéralise à la fois les α-divergences et les β-divergences (cf. Figure 1.2). Cette fa-mille possède notamment des propriétés intéressantes qui la rendent potentiellementrobuste pour l’estimation en présence de bruit et de données aberrantes. Nous définis-sons également une nouvelle famille paramétrique de (α, β, λ)-divergences obliquespar extension directe des (α, β)-divergences.
8
1. Préliminaires en Géométrie de l’Information
χ2 de Neyman
Euclidienne au carre
χ2 de Pearson
Kullback-Leibler duale
Figure 1.2.: Famille paramétrique des (α, β)-divergences. La classe des (α, β)-divergences regroupe de nombreuses divergences informationnellescouramment employées en statistiques et leurs applications, et notam-ment toutes les α-divergences et β-divergences.
9

2. Détection Séquentielle deRuptures dans les FamillesExponentielles
Considérons une série temporelle x1,x2, . . . constituée d’observations échantillon-nées selon un processus stochastique discret dans le temps et inconnu. En termesgénéraux, le problème de la détection de ruptures consiste à décider si la distri-bution du processus présente des modifications structurelles d’intérêt au cours dutemps (cf. Figure 2.1). Cette décision est souvent associée à l’estimation des mo-ments où des ruptures se produisent dans la distribution. Ces instants sont appeléspoints de rupture, et délimitent des régions temporelles contiguës appelées segments.En plus d’estimer les points de rupture, il est parfois également requis d’estimer lesdistributions sous-jacentes dans les différents segments.Nos contributions au problème de la détection séquentielle de ruptures se résument
de la manière suivante. Nous formulons un cadre générique pour la détection séquen-tielle de ruptures dans les familles exponentielles. Les familles exponentielles formentune classe omniprésente de modèles statistiques paramétriques regroupant de nom-breuses familles de distributions de probabilité usuelles. Le cadre proposé permetdonc la détection séquentielles de ruptures sous diverses hypothèses au niveau dela distribution des données, en généralisant des résultats antérieurs supposant lanormalité des distributions, et en étendant les statistiques approximées dans desmodèles plus généraux en prenant en compte des statistiques exactes par une esti-mation rigoureuse des paramètres inconnus avant rupture.En particulier, nous suivons une approche non bayésienne standard pour la détec-
tion de ruptures dans des modèles statistiques paramétriques P = {Pξ}ξ∈Ξ qui sontdominés, et avec des observations sx = (x1, . . . ,xn) mutuellement indépendantes. La
Figure 2.1.: Vue schématique de la détection de ruptures. Le problème de la dé-tection de ruptures consiste à trouver des variations d’intérêt dans lastructure temporelle d’un processus.
10

2. Détection Séquentielle de Ruptures dans les Familles Exponentielles
. . .
Figure 2.2.: Hypothèses multiples pour un point de rupture. Le problème de la dé-tection de ruptures revient à comparer la plausibilité des hypothèsesrespectives de rupture aux différents instants, avec l’hypothèse qu’au-cun changement ne se produit.
détection de ruptures est alors vue comme un problème de décision avec des hy-pothèses statistiques multiples H0, H
i0, H
i1 (cf. Figure 2.2). Nous employons notam-
ment des statistiques de test GLR pour construire la règle de décision. La plupartdes travaux précédents approximent les statistiques GLR usuelles pour faciliter leurcalcul séquentiel lorsque le paramètre avant rupture est inconnu. Nous considéronsau contraire les statistiques GLR exactes. Nous introduisons également des estima-teurs arbitraires en lieu et place des estimateurs par maximum de vraisemblancehabituellement employés. Outre la généralisation, un intérêt secondaire est de per-mettre le traitement unifié de divers scénarios, traités en général séparément, où lesparamètres avant et après rupture ξ0, ξ
i0, ξ
i1 peuvent être connus ou inconnus.
Ce cadre est ensuite appliqué aux familles exponentielles, et en particulier aux fa-milles standards, raides, minimales, et complètes. Le fait que la famille soit standardet minimale relève uniquement d’un intérêt technique et ne restreint pas l’étude, tan-dis que le fait qu’elle soit complète et raide est théoriquement crucial pour garantirl’existence et la facilité de calcul des estimateurs par maximum de vraisemblancedans une certaine mesure. Dans ce contexte, nous montrons que les statistiques GLRavec des estimateurs arbitraires pξ0,
pξi0,pξi1 sont en fait intrinsèquement liées aux es-timateurs par maximum de vraisemblance pξi0ml,
pξi1ml, et que les estimateurs choisisapportent un terme correctif par rapport au maximum de vraisemblance.Cette relation fournit une procédure générique pour la détection séquentielle de
ruptures dans les familles exponentielles à partir de statistiques GLR avec des es-timateurs arbitraires. Ce paradigme est interprété dans le cadre de la géométriede l’information dualement plate des familles exponentielles, en relation avec la di-vergence de Kullback-Leibler, apportant ainsi des intuitions à la fois statistiques etgéométriques au problème de la détection de ruptures (cf. Figure 2.3). De plus, grâceà la correspondance entre les familles exponentielles et les divergences de Bregmanassociées, cette interprétation donne une vue unifiée de la détection de rupturespour de nombreux modèles statistiques usuels et les fonctions de distance corres-pondantes, rapprochant ainsi les approches statistiques des approches géométriquesreposant sur le calcul de distances pour la segmentation de signaux.
11

2. Détection Séquentielle de Ruptures dans les Familles Exponentielles
Figure 2.3.: Interprétation géométrique de la détection de ruptures. Le problèmede la détection de ruptures dans les familles exponentielles avec desstatistiques de test GLR exactes et des estimateurs arbitraires, peut sevoir comme le calcul de certaines divergences informationnelles entreles distributions estimées et les distributions ayant le maximum devraisemblance dans les différentes hypothèses.
Nous dérivons ensuite des formes spécifiques de la procédure générique pour desscénarios courants, en considérant différentes combinaisons d’estimateurs pour lesparamètres respectifs. En particulier, nous obtenons les statistiques de rapport devraisemblance quand les paramètres avant et après rupture sont tous les deux connus,et des statistiques GLR standards quand le paramètre avant rupture seulement estconnu. Nous comparons les statistiques GLR approximées standards et les statis-tiques GLR exactes quand les deux paramètres sont inconnus. Lorsque cela est per-tinent, nous spécialisons également les résultats pour l’estimation des paramètresinconnus par maximum de vraisemblance. Les expressions obtenues sont systémati-quement interprétables dans la géométrie dualement plate des familles exponentiellespar le biais des divergences informationnelles dans la géométrie sous-jacente.Finalement, nous revisitons le calcul des statistiques GLR par l’intermédiaire de
la dualité convexe pour les familles exponentielles, en reparamétrant le problèmedes paramètres naturels vers les paramètres d’espérance. Cette étude apporte deséléments supplémentaires en faveur du rôle correctif que jouent les estimateurs choisisdans les statistiques GLR par rapport au maximum de vraisemblance. Cela conduità une expression alternative pour les statistiques de test, qui simplifie grandementle calcul des statistiques GLR exactes lorsque les paramètres avant et après rupturesont inconnus. L’expression dérivée est obtenue en formule close en fonction duconjugué du log-normalisateur pour la famille exponentielle. De plus, elle peut êtrecalculée séquentiellement de manière économique, fournissant ainsi une procédureefficace d’un point de vue computationnel pour la détection de ruptures dans lesfamilles exponentielles avec des statistiques GLR exactes, lorsque les paramètresavant et après rupture sont inconnus et sont estimés par maximum de vraisemblance.
12

3. Factorisation en Matrices NonNégatives avec des DivergencesConvexes-Concaves
Considérons un jeu de données {y1, . . . ,yn} de taille n constitué d’observationsnon négatives multivariées de dimension m, et regroupons ces observations dans unematrice non négative Y de taille m× n, dont les lignes et les colonnes représententrespectivement les différentes variables et observations. Le problème de la factorisa-tion en matrices non négatives consiste à trouver une factorisation approchée de Yen une matrice non négative A de taille m × r, et une matrice non négative X detaille r×n, telles que Y ≈ AX, où l’entier r < min(m,n) est le rang de factorisation(cf. Figure 3.1). Dans ce modèle linéaire, chaque observation yj peut alors être ex-primée comme yj ≈ Axj. La matrice A constitue ainsi une base ou un dictionnaire,et les colonnes de X sont la décomposition ou l’encodage des colonnes respectives deY dans cette base. De plus, le rang de la factorisation est généralement choisi telque mr + rn � mn, de sorte que la factorisation peut être considérée comme unecompression ou une réduction des données observées.Nos contributions au problème de la NMF se résument de la manière suivante.
Nous formalisons un cadre générique pour la NMF avec des divergences convexes-
Figure 3.1.: Vue schématique de la NMF. Le problème de la NMF consiste à re-construire des observations non négatives par l’ajout d’un petit nombred’atomes non négatifs avec des poids non négatifs.
13

3. Factorisation en Matrices Non Négatives avec des Divergences Convexes-Concaves
Figure 3.2.: Interprétation géométrique de la décomposition non négative. Le pro-blème d’optimisation de la décomposition non négative revient à pro-jeter le vecteur d’observations sur l’intersection de l’enveloppe coniquedes vecteurs de base avec le domaine de la divergence.
concaves. Les divergences convexes-concaves sont des divergences générales qui peu-vent s’exprimer comme la somme d’une partie convexe et d’une partie concave parrapport à l’un des deux arguments. Ces divergences regroupent de nombreuses diver-gences informationnelles usuelles, et notamment les divergences de Csiszár pour lesdeux arguments, toutes les divergences de Bregman à gauche, certaines divergencesde Bregman à droite. En particulier, toutes les α-divergences et β-divergences sonten fait convexes-concaves pour les deux arguments. Ce cadre permet donc de consi-dérer, avec une méthodologie générique, la majorité des fonctions coût proposéesdans la littérature jusqu’à présent, ainsi que de nouvelles fonctions coût.Pour résoudre le problème de la NMF avec des divergences convexes-concaves,
nous considérons des divergences séparables, et réduisons le problème à un cadrecourant de décomposition non négative où les facteurs sont mis à jour à tour de rôlede manière itérative. D’un point de vue géométrique, la décomposition non négativeest alors équivalente à une projection informationnelle py = Apx d’un vecteur d’obser-vations y sur l’intersection Y ′ de l’enveloppe conique des vecteurs de base a1, a2, . . .avec le domaine Y de la divergence (cf. Figure 3.2). Nous proposons une procé-dure d’optimisation générale afin de résoudre cette projection pour des divergencesconvexes-concaves sous de faibles hypothèses de régularité.Cette procédure est inspirée d’une technique d’optimisation par bornes variation-
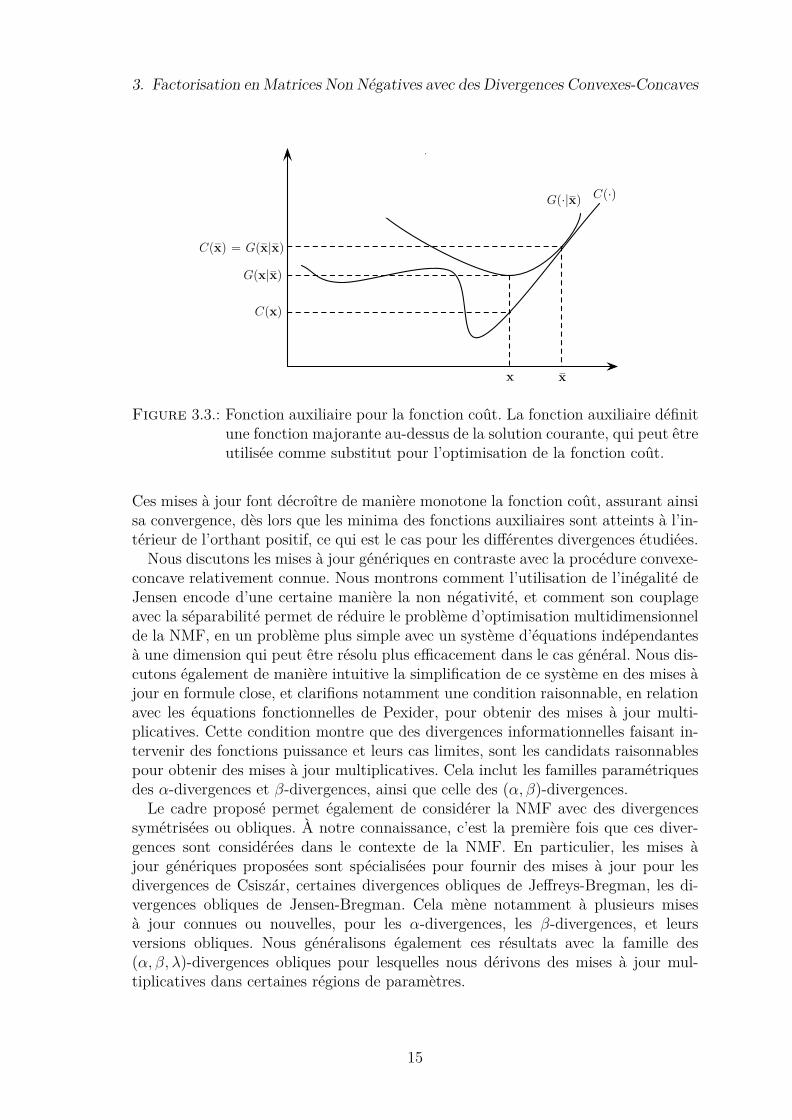
nelles, ou majorisation, où des fonctions auxiliaires majorantes G sont construitesautour des solutions courantes et servent de substituts pour l’optimisation de la fonc-tion coût C (cf. Figure 3.3). Les fonctions auxiliaires construites pour les fonctionscoût convexes-concaves reposent sur l’inégalité de Jensen pour la partie convexe,et sur l’inégalité tangentielle pour la partie concave, et étendent ainsi plusieurs ap-proches fondées sur des fonctions auxiliaires déjà proposées dans la littérature. Nousobtenons des mises à jour génériques du vecteur de décomposition x par minimisa-tion de la fonction auxiliaire autour de la solution précédente sx à chaque itération.
14
3. Factorisation en Matrices Non Négatives avec des Divergences Convexes-Concaves
Figure 3.2.: Auxiliary function for the cost function. The auxiliary function definesa majorizing function above the current solution, which can be used asa surrogate for optimizing the cost.
Lemma 3.1. Let x, sx ! X . If G(x|sx) " G(sx|sx), then C(x) " C(sx).
Proof. Let x, sx ! X . By definition, we have C(x) " G(x|sx) and C(sx) = G(sx|sx).Now if G(x|sx) " G(sx|sx), then we have C(x) " G(x|sx) " G(sx|sx) = C(sx), whichproves the lemma.
Remark 3.8. We also have strict decrease of the cost function as soon as we choosea vector x that makes the auxiliary function strictly decrease as G(x|sx) < G(sx|sx).
Remark 3.9. This justifies the use of an auxiliary function to minimize or at leastmake the original cost function decrease. Indeed, if the current solution is given bysx ! X , then choosing a point x ! X such that G(x|sx) " G(sx|sx) provides a bettersolution. This may be iterated until a termination criterion is met. In general, whenit is possible, the point x is chosen as a minimizer of the auxiliary function at sx, sothat we need to solve the following optimization problem:
minimize G(x, sx) subject to x ! X . (3.5)
The minimization can be done on an arbitrary subset X ! # X as soon as sx ! X !. Itis also possible to equalize the auxiliary function instead, or to choose any point inbetween the minimization and the equalization.
We show in the sequel that we can build auxiliary functions for a wide range ofcommon information divergences presented in Chapter 1. We can therefore op-timize the respective cost functions by variational bounding. We will focus onmaximization-minimization schemes where the auxiliary function is iteratively min-imized to update the solution as discussed above.
48
Figure 3.2.: Auxiliary function for the cost function. The auxiliary function definesa majorizing function above the current solution, which can be used asa surrogate for optimizing the cost.
Lemma 3.1. Let x, sx ! X . If G(x|sx) " G(sx|sx), then C(x) " C(sx).
Proof. Let x, sx ! X . By definition, we have C(x) " G(x|sx) and C(sx) = G(sx|sx).Now if G(x|sx) " G(sx|sx), then we have C(x) " G(x|sx) " G(sx|sx) = C(sx), whichproves the lemma.
Remark 3.8. We also have strict decrease of the cost function as soon as we choosea vector x that makes the auxiliary function strictly decrease as G(x|sx) < G(sx|sx).
Remark 3.9. This justifies the use of an auxiliary function to minimize or at leastmake the original cost function decrease. Indeed, if the current solution is given bysx ! X , then choosing a point x ! X such that G(x|sx) " G(sx|sx) provides a bettersolution. This may be iterated until a termination criterion is met. In general, whenit is possible, the point x is chosen as a minimizer of the auxiliary function at sx, sothat we need to solve the following optimization problem:
minimize G(x, sx) subject to x ! X . (3.5)
The minimization can be done on an arbitrary subset X ! # X as soon as sx ! X !. Itis also possible to equalize the auxiliary function instead, or to choose any point inbetween the minimization and the equalization.
We show in the sequel that we can build auxiliary functions for a wide range ofcommon information divergences presented in Chapter 1. We can therefore op-timize the respective cost functions by variational bounding. We will focus onmaximization-minimization schemes where the auxiliary function is iteratively min-imized to update the solution as discussed above.
48
Figure 3.2.: Auxiliary function for the cost function. The auxiliary function definesa majorizing function above the current solution, which can be used asa surrogate for optimizing the cost.
Lemma 3.1. Let x, sx ! X . If G(x|sx) " G(sx|sx), then C(x) " C(sx).
Proof. Let x, sx ! X . By definition, we have C(x) " G(x|sx) and C(sx) = G(sx|sx).Now if G(x|sx) " G(sx|sx), then we have C(x) " G(x|sx) " G(sx|sx) = C(sx), whichproves the lemma.
Remark 3.8. We also have strict decrease of the cost function as soon as we choosea vector x that makes the auxiliary function strictly decrease as G(x|sx) < G(sx|sx).
Remark 3.9. This justifies the use of an auxiliary function to minimize or at leastmake the original cost function decrease. Indeed, if the current solution is given bysx ! X , then choosing a point x ! X such that G(x|sx) " G(sx|sx) provides a bettersolution. This may be iterated until a termination criterion is met. In general, whenit is possible, the point x is chosen as a minimizer of the auxiliary function at sx, sothat we need to solve the following optimization problem:
minimize G(x, sx) subject to x ! X . (3.5)
The minimization can be done on an arbitrary subset X ! # X as soon as sx ! X !. Itis also possible to equalize the auxiliary function instead, or to choose any point inbetween the minimization and the equalization.
We show in the sequel that we can build auxiliary functions for a wide range ofcommon information divergences presented in Chapter 1. We can therefore op-timize the respective cost functions by variational bounding. We will focus onmaximization-minimization schemes where the auxiliary function is iteratively min-imized to update the solution as discussed above.
48
Figure 3.2.: Auxiliary function for the cost function. The auxiliary function definesa majorizing function above the current solution, which can be used asa surrogate for optimizing the cost.
Lemma 3.1. Let x, sx ! X . If G(x|sx) " G(sx|sx), then C(x) " C(sx).
Proof. Let x, sx ! X . By definition, we have C(x) " G(x|sx) and C(sx) = G(sx|sx).Now if G(x|sx) " G(sx|sx), then we have C(x) " G(x|sx) " G(sx|sx) = C(sx), whichproves the lemma.
Remark 3.8. We also have strict decrease of the cost function as soon as we choosea vector x that makes the auxiliary function strictly decrease as G(x|sx) < G(sx|sx).
Remark 3.9. This justifies the use of an auxiliary function to minimize or at leastmake the original cost function decrease. Indeed, if the current solution is given bysx ! X , then choosing a point x ! X such that G(x|sx) " G(sx|sx) provides a bettersolution. This may be iterated until a termination criterion is met. In general, whenit is possible, the point x is chosen as a minimizer of the auxiliary function at sx, sothat we need to solve the following optimization problem:
minimize G(x, sx) subject to x ! X . (3.5)
The minimization can be done on an arbitrary subset X ! # X as soon as sx ! X !. Itis also possible to equalize the auxiliary function instead, or to choose any point inbetween the minimization and the equalization.
We show in the sequel that we can build auxiliary functions for a wide range ofcommon information divergences presented in Chapter 1. We can therefore op-timize the respective cost functions by variational bounding. We will focus onmaximization-minimization schemes where the auxiliary function is iteratively min-imized to update the solution as discussed above.
48
Figure 3.2.: Auxiliary function for the cost function. The auxiliary function definesa majorizing function above the current solution, which can be used asa surrogate for optimizing the cost.
Lemma 3.1. Let x, sx ! X . If G(x|sx) " G(sx|sx), then C(x) " C(sx).
Proof. Let x, sx ! X . By definition, we have C(x) " G(x|sx) and C(sx) = G(sx|sx).Now if G(x|sx) " G(sx|sx), then we have C(x) " G(x|sx) " G(sx|sx) = C(sx), whichproves the lemma.
Remark 3.8. We also have strict decrease of the cost function as soon as we choosea vector x that makes the auxiliary function strictly decrease as G(x|sx) < G(sx|sx).
Remark 3.9. This justifies the use of an auxiliary function to minimize or at leastmake the original cost function decrease. Indeed, if the current solution is given bysx ! X , then choosing a point x ! X such that G(x|sx) " G(sx|sx) provides a bettersolution. This may be iterated until a termination criterion is met. In general, whenit is possible, the point x is chosen as a minimizer of the auxiliary function at sx, sothat we need to solve the following optimization problem:
minimize G(x, sx) subject to x ! X . (3.5)
The minimization can be done on an arbitrary subset X ! # X as soon as sx ! X !. Itis also possible to equalize the auxiliary function instead, or to choose any point inbetween the minimization and the equalization.
We show in the sequel that we can build auxiliary functions for a wide range ofcommon information divergences presented in Chapter 1. We can therefore op-timize the respective cost functions by variational bounding. We will focus onmaximization-minimization schemes where the auxiliary function is iteratively min-imized to update the solution as discussed above.
48
AbstractC(·)G(·|sx)This thesis proposes novel computational methods of information geometry with
real-time applications in audio signal processing. In this context, we address inparallel the applicative problems of real-time audio segmentation, and of real-timepolyphonic music transcription. This is achieved by developing theoretical frame-works respectively for sequential change detection with exponential families, andfor non-negative matrix factorization with convex-concave divergences. On the onehand, sequential change detection is studied in the light of the dually flat informa-tion geometry of exponential families. We notably develop a generic and unifyingstatistical framework relying on multiple hypothesis testing with decision rules basedon exact generalized likelihood ratios. This is applied to devise a modular systemfor real-time audio segmentation with arbitrary types of signals and of homogeneitycriteria. The proposed system controls the information rate of the audio streamas it unfolds in time to detect changes. On the other hand, non-negative matrixfactorization is investigated by the way of convex-concave divergences on the spaceof discrete positive measures. In particular, we formulate a generic and unifyingoptimization framework for non-negative matrix factorization based on variationalbounding with auxiliary functions. This is employed to design a real-time systemfor polyphonic music transcription with an explicit control on the frequency com-promise during the analysis. The developed system decomposes the music signal asit arrives in time onto a dictionary of note spectral templates. These contributionsprovide interesting insights and directions for future research in the realm of audiosignal processing, and more generally of machine learning and signal processing,in the relatively young but nonetheless prolific field of computational informationgeometry.
Keywords: computational methods, information geometry, real-time applications,audio signal processing, change detection, exponential families, non–negative matrixfactorization, convex-concave divergences, audio segmentation, polyphonic musictranscription.
v
AbstractC(·)G(·|sx)This thesis proposes novel computational methods of information geometry with
real-time applications in audio signal processing. In this context, we address inparallel the applicative problems of real-time audio segmentation, and of real-timepolyphonic music transcription. This is achieved by developing theoretical frame-works respectively for sequential change detection with exponential families, andfor non-negative matrix factorization with convex-concave divergences. On the onehand, sequential change detection is studied in the light of the dually flat informa-tion geometry of exponential families. We notably develop a generic and unifyingstatistical framework relying on multiple hypothesis testing with decision rules basedon exact generalized likelihood ratios. This is applied to devise a modular systemfor real-time audio segmentation with arbitrary types of signals and of homogeneitycriteria. The proposed system controls the information rate of the audio streamas it unfolds in time to detect changes. On the other hand, non-negative matrixfactorization is investigated by the way of convex-concave divergences on the spaceof discrete positive measures. In particular, we formulate a generic and unifyingoptimization framework for non-negative matrix factorization based on variationalbounding with auxiliary functions. This is employed to design a real-time systemfor polyphonic music transcription with an explicit control on the frequency com-promise during the analysis. The developed system decomposes the music signal asit arrives in time onto a dictionary of note spectral templates. These contributionsprovide interesting insights and directions for future research in the realm of audiosignal processing, and more generally of machine learning and signal processing,in the relatively young but nonetheless prolific field of computational informationgeometry.
Keywords: computational methods, information geometry, real-time applications,audio signal processing, change detection, exponential families, non–negative matrixfactorization, convex-concave divergences, audio segmentation, polyphonic musictranscription.
v
Figure 3.3.: Fonction auxiliaire pour la fonction coût. La fonction auxiliaire définitune fonction majorante au-dessus de la solution courante, qui peut êtreutilisée comme substitut pour l’optimisation de la fonction coût.
Ces mises à jour font décroître de manière monotone la fonction coût, assurant ainsisa convergence, dès lors que les minima des fonctions auxiliaires sont atteints à l’in-térieur de l’orthant positif, ce qui est le cas pour les différentes divergences étudiées.Nous discutons les mises à jour génériques en contraste avec la procédure convexe-
concave relativement connue. Nous montrons comment l’utilisation de l’inégalité deJensen encode d’une certaine manière la non négativité, et comment son couplageavec la séparabilité permet de réduire le problème d’optimisation multidimensionnelde la NMF, en un problème plus simple avec un système d’équations indépendantesà une dimension qui peut être résolu plus efficacement dans le cas général. Nous dis-cutons également de manière intuitive la simplification de ce système en des mises àjour en formule close, et clarifions notamment une condition raisonnable, en relationavec les équations fonctionnelles de Pexider, pour obtenir des mises à jour multi-plicatives. Cette condition montre que des divergences informationnelles faisant in-tervenir des fonctions puissance et leurs cas limites, sont les candidats raisonnablespour obtenir des mises à jour multiplicatives. Cela inclut les familles paramétriquesdes α-divergences et β-divergences, ainsi que celle des (α, β)-divergences.Le cadre proposé permet également de considérer la NMF avec des divergences
symétrisées ou obliques. À notre connaissance, c’est la première fois que ces diver-gences sont considérées dans le contexte de la NMF. En particulier, les mises àjour génériques proposées sont spécialisées pour fournir des mises à jour pour lesdivergences de Csiszár, certaines divergences obliques de Jeffreys-Bregman, les di-vergences obliques de Jensen-Bregman. Cela mène notamment à plusieurs misesà jour connues ou nouvelles, pour les α-divergences, les β-divergences, et leursversions obliques. Nous généralisons également ces résultats avec la famille des(α, β, λ)-divergences obliques pour lesquelles nous dérivons des mises à jour mul-tiplicatives dans certaines régions de paramètres.
15

Deuxième partie .
Applications Temps Réel auTraitement du Signal Audio
16

4. Segmentation Audio en TempsRéel
La tâche de la segmentation audio consiste à déterminer des instants qui parti-tionnent un signal sonore en des régions temporelles continues et homogènes, desorte que les régions adjacentes présentent des inhomogénéités (cf. Figure 4.1). Cesinstants sont appelés frontières, et les régions continues entre les frontières sont ap-pelées segments. La segmentation audio a été largement étudiée dans la littérature,principalement pour la musique et la voix, et est d’un grand intérêt pour une variétéd’applications en analyse, indexation, et recherche d’informations par le contenu.Nos contributions au problème de la segmentation audio se résument de la manière
suivante. Nous concevons tout d’abord un cadre générique pour la segmentationaudio en temps réel, capable de gérer des signaux et critères d’homogénéité de typesdivers. Ce cadre repose sur les méthodes pour la détection séquentielle de rupturesdans les familles exponentielles développées dans le Chapitre 2. Le système tempsréel proposé détecte des changements en contrôlant le flux d’information audio au furet à mesure qu’il se déroule dans le temps. Le contenu informationnel est quantifié enutilisant des mesures d’information sur des descriptions statistiques du signal. Les
Figure 4.1.: Vue schématique de la tâche de segmentation audio. À partir du signalaudio brut, le but est de déterminer des frontières temporelles tellesque les segments résultant soient intrinsèquement homogènes mais sedistinguent de leurs voisins.
17

4. Segmentation Audio en Temps Réel
Scène sonore
Modélisation statistique
Détection de ruptures
Représentation sonore à court terme
Segmentation audio (temps réel)
Figure 4.2.: Architecture du système temps réel proposé. Le signal audio arriveséquentiellement au système, et est représenté par des descripteurssonores modélisés avec des distributions de probabilité, dont les para-mètres sont ensuite surveillés pour détecter des changements.
unités quantifiées peuvent ensuite être caractérisées par des modèles probabilistesreprésentatifs des différents segments, permettant ainsi le traitement ultérieur duflux audio par ces unités de signal dans des applications avancées.Plus en détails, le système modulaire proposé repose sur le calcul d’une représenta-
tion à court terme du flux audio, et par la modélisation des observations successivesxj issues de cette représentation par une famille paramétrique de distributions deprobabilité (cf. Figure 4.2). La segmentation consiste ensuite à surveiller les para-mètres successifs des distributions Pξj
en temps réel pour détecter la présence dechangements structurels indiquant de nouveaux segments. Le choix des descripteursaudio et du modèle statistique associé est presque arbitraire, et est laissé à l’uti-lisateur en fonction du critère d’homogénéité inhérent à l’application retenue. Enconsidérant des distributions issues d’une famille exponentielle, une large palette defamilles statistiques usuelles peut être utilisée pour modéliser des combinaisons dedescripteurs audio avec des typologies variées, par exemple, des données scalaires oumultidimensionnelles, des données discrètes ou continues.La détection séquentielle de ruptures est réalisée avec les statistiques GLR pour
les familles exponentielles. En plus de leur interprétation statistique initiale, ces
18

4. Segmentation Audio en Temps Réel
statistiques trouvent des fondations géométriques dans le cadre de la dualité convexeet de la géométrie dualement plate des familles exponentielles. Ce cadre permet alorsde rassembler les approches statistiques et les approches géométriques reposant sur lecalcul de distances pour la segmentation audio, en mettant en évidence des relationsentre les modèles statistiques impliqués et certaines distances associées.Nous clarifions notamment les relations entre différentes approches standards en
segmentation audio, et montrons comment elles peuvent être unifiées et générali-sées dans le cadre proposé. De telles approches incluent les procédures par sommescumulatives avec des statistiques GLR approximées, les méthodes par critère d’in-formation d’Akaike et par critère d’information bayésien en théorie de la sélectionde modèles, ainsi que certaines méthodes à noyaux reposant sur des classificateurscomme les machines à vecteurs de support. De surcroît, les méthodes classiques deflux spectral et de flux cepstral, notamment employées respectivement pour la dé-tection d’attaques et pour la segmentation en locuteurs, peuvent être vues commedes cas spécifiques du cadre modulaire proposé, et plus précisément comme des sim-plifications grossières de statistiques GLR approximées.Ce paradigme est ensuite appliqué à la segmentation de différents types de signaux
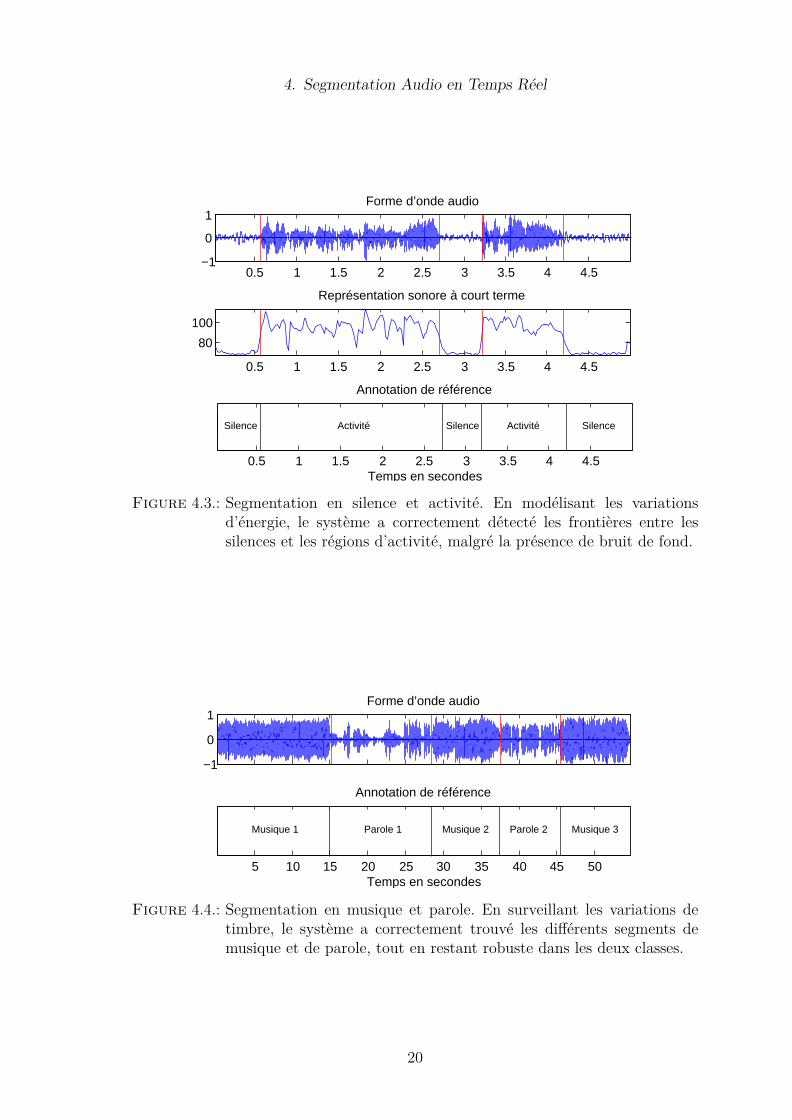
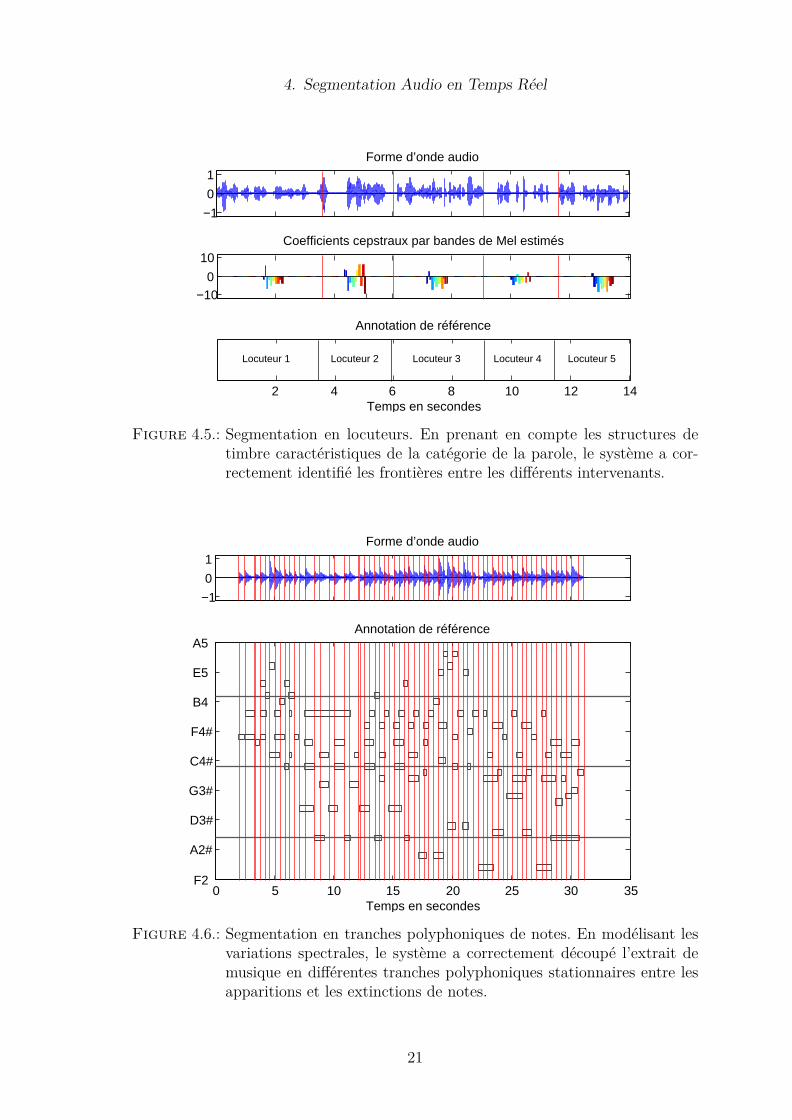
audio, en considérant des typologies de données variées. Par exemple, nous consi-dérons les caractéristiques d’énergie pour une segmentation en régions de silenceet d’activité, en modélisant des observations scalaires d’énergie par des distribu-tions de Rayleigh sur la demi-droite des réels non négatifs (cf. Figure 4.3). Nousnous intéressons également aux caractéristiques timbrales en modélisant des obser-vations cepstrales multidimensionnelles par des distributions normales sphériques,pour la segmentation en musique et parole (cf. Figure 4.4), ou pour la segmentationen locuteurs (cf. Figure 4.5). Enfin, nous analysons des caractéristiques spectralespour la segmentation de musique en tranches polyphoniques de notes, en modéli-sant des histogrammes de fréquences par des distributions multinomiales discrètes(cf. Figure 4.6). Cela illustre la généralité des applications incluses en adaptant lacadre proposé aux critères d’homogénéité considérés sur différents problèmes. Nousréalisons finalement une évaluation quantitative pour la tâche spécifique de la dé-tection d’attaques dans les signaux musicaux (cf. Table 4.1). Nous considérons unebase de données réputée difficile, et montrons que l’approche proposée (GLR) permetd’améliorer les résultats par rapport aux approches standards de flux spectral (SF).
Algorithme λ P R F Fonction de distanceGLR 5.00 60.93 68.55 64.52 Kullback-LeiblerSF 0.06 22.56 33.87 27.08 EuclidienneSF 0.10 34.42 41.26 37.53 Kullback-LeiblerSF 0.17 40.20 42.74 41.43 Différence redressée demi-onde
Table 4.1.: Résultats de l’évaluation pour la détection d’attaques musicales. Les ré-sultats montrent que la méthode proposée fonctionne relativement bienpar rapport aux méthodes de référence de flux spectral, avec une une F -mesure F = 64.52 et des taux de rappel-précisionR = 68.55,P = 60.93,maximaux pour un seuil de détection λ = 5.00.
19
4. Segmentation Audio en Temps Réel
0.5 1 1.5 2 2.5 3 3.5 4 4.5−1
0
1Forme d’onde audio
0.5 1 1.5 2 2.5 3 3.5 4 4.5Temps en secondes
Annotation de référence
0.5 1 1.5 2 2.5 3 3.5 4 4.5
80
100
Représentation sonore à court terme
SilenceSilence SilenceActivité Activité
Figure 4.3.: Segmentation en silence et activité. En modélisant les variationsd’énergie, le système a correctement détecté les frontières entre lessilences et les régions d’activité, malgré la présence de bruit de fond.
−1
0
1Forme d’onde audio
5 10 15 20 25 30 35 40 45 50
Annotation de référence
Temps en secondes
Musique 3Musique 1 Musique 2 Parole 2Parole 1
Figure 4.4.: Segmentation en musique et parole. En surveillant les variations detimbre, le système a correctement trouvé les différents segments demusique et de parole, tout en restant robuste dans les deux classes.
20
4. Segmentation Audio en Temps Réel
−100
10Coefficients cepstraux par bandes de Mel estimés
−1
0
1Forme d’onde audio
2 4 6 8 10 12 14Temps en secondes
Annotation de référence
Locuteur 1 Locuteur 2 Locuteur 3 Locuteur 4 Locuteur 5
Figure 4.5.: Segmentation en locuteurs. En prenant en compte les structures detimbre caractéristiques de la catégorie de la parole, le système a cor-rectement identifié les frontières entre les différents intervenants.
−1
0
1Forme d’onde audio
0 5 10 15 20 25 30 35F2
A2#
D3#
G3#
C4#
F4#
B4
E5
A5
Temps en secondes
Not
e
Annotation de référence
Figure 4.6.: Segmentation en tranches polyphoniques de notes. En modélisant lesvariations spectrales, le système a correctement découpé l’extrait demusique en différentes tranches polyphoniques stationnaires entre lesapparitions et les extinctions de notes.
21

5. Transcription de MusiquePolyphonique en Temps Réel
La tâche de transcription de musique consiste à convertir un signal de musiqueen une représentation symbolique telle qu’une partition (cf. Figure 5.1). Plus pré-cisément, le but de la transcription est d’analyser l’information de bas niveau d’unsignal de musique donné comme une simple forme d’onde sonore, afin d’en extrairedes informations symboliques de haut niveau qui décrivent son contenu musical.Différentes informations musicales peuvent être intéressantes, par exemple, pour latranscription automatique de musique polyphonique, on s’intéresse en général auxhauteurs des notes jouées ainsi qu’à leurs temps d’apparition et d’extinction.
Figure 5.1.: Vue schématique de la tâche de transcription de musique. À partirde l’information de bas niveau d’un signal musical représenté par unesimple forme d’onde, le but est d’extraire des informations de hautniveau qui décrivent son contenu symbolique comme une partition.
22

5. Transcription de Musique Polyphonique en Temps Réel
Échantillons de notes isolées Scène sonore
Factorisation en matrices non négatives Décomposition non négative
Modèles de notes Activations des notes
Représentation sonore à court terme
Représentation sonore à court terme
Apprentissage de modèles de notes (différé) Décomposition du signal musical (temps réel)
Figure 5.2.: Architecture du système temps réel proposé. Le signal audio arrive entemps réel au système, et est décomposé en différentes notes dont lesdescriptions sont fournies sous la forme d’un dictionnaire de modèlesde notes appris avant la décomposition.
Nos contributions au problème de la transcription de musique polyphonique se ré-sument de la manière suivante. Nous développons tout d’abord un système temps réelpour la transcription de musique polyphonique. Ce système repose sur les méthodespour la NMF avec des divergences convexes-concaves exposées dans le Chapitre 3.Les approches par la NMF étant initialement conçues pour du temps différé, nousconsidérons plutôt le cadre supervisé de la décomposition non négative qui permetun traitement séquentiel des données adapté au temps réel.Plus en détails, le système proposé peut se diviser en un module d’apprentissage et
un module de reconnaissance (cf. Figure 5.2). Le module d’apprentissage fonctionneen temps différé et permet de construire un dictionnaire A de modèle spectraux denotes avant la phase de reconnaissance. On suppose que l’utilisateur possède une basede données comprenant un échantillon isolé pour les différentes notes à reconnaître.Un modèle spectral a(k) est alors appris pour chaque note k en factorisant le spec-trogramme Y(k) de l’échantillon correspondant. Le module de reconnaissance, quantà lui, fonctionne en temps réel et réalise la tâche de transcription proprement dite.Le signal de musique polyphonique est d’abord représenté par une transformationfréquentielle à court terme. Les représentations spectrales yj des trames successivessont ensuite projetées par décomposition non négative sur le dictionnaire A pourfournir les activations xj des différentes notes au cours du temps.Dans ce contexte, nous considérons la famille paramétrique des (α, β)-divergences
23

5. Transcription de Musique Polyphonique en Temps Réel
pour la décomposition non négative. En plus de leurs propriétés de robustesseconnues en estimation statistique, nous expliquons de manière intuitive leur perti-nence pour l’analyse audio, en interprétant l’effet des paramètres comme un moyend’apporter un contrôle flexible sur le compromis fréquentiel pendant la décompo-sition. Ce contrôle est en contraste avec les systèmes temps réel antérieurs pour ladécomposition non négative de l’audio, qui ont considéré soit la distance euclidienne,soit la divergence de Kullback-Leibler, sans contrôle adapté sur la décomposition.De plus, c’est la première fois, à notre connaissance, que les (α, β)-divergences ré-cemment introduites sont utilisées dans le cadre de l’analyse de signaux audio.Nous discutons également certaines questions computationnelles de la décomposi-
tion non négative avec les (α, β)-divergences. Nous dérivons notamment des mises àjour multiplicatives adaptées pour le temps réel en prenant avantage du cadre de dé-composition où le dictionnaire de modèles spectraux de notes est fixé. Sous certaineshypothèses peu restrictives, et qui peuvent être obtenues après un prétraitement re-lativement basique des observations, ces mises à jour multiplicatives assurent ladécroissance monotone de la fonction coût et donc également sa convergence. Celagarantit la stabilité du système en ce qui concerne la qualité des activations obtenues.Le système proposé est évalué au cours d’une série méthodologique d’expériences.
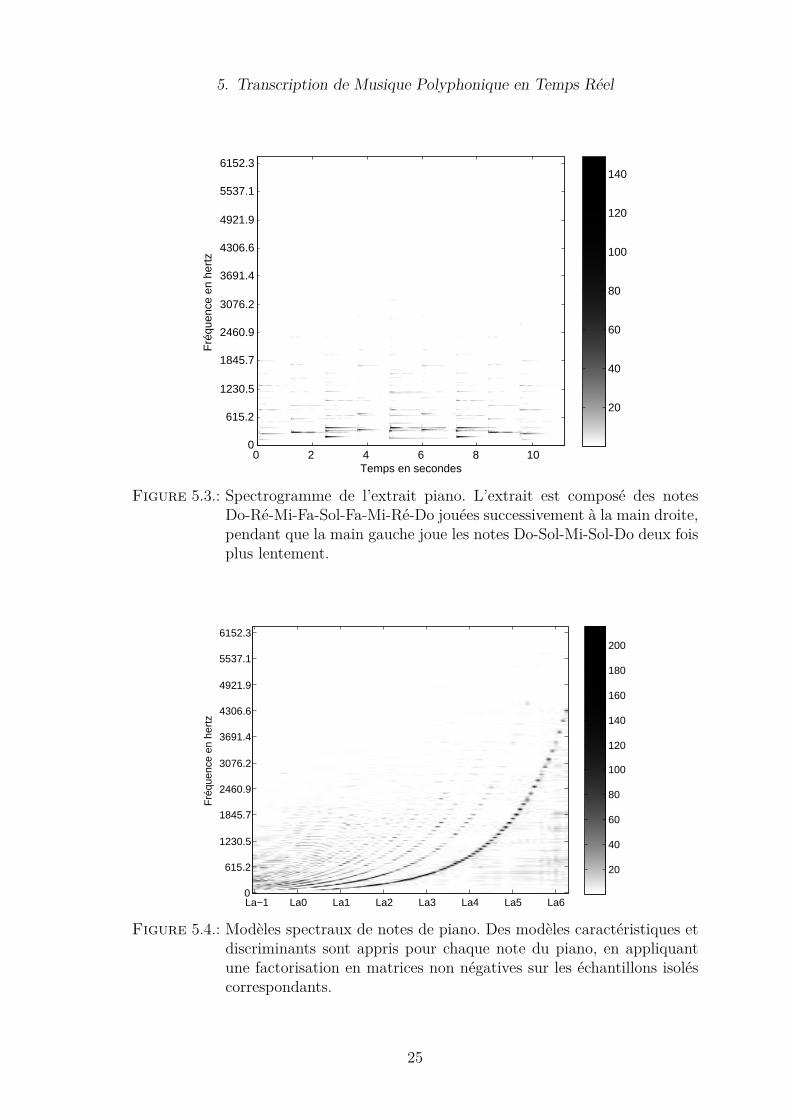
Nous présentons tout d’abord un exemple musical simple de piano pour illustrerla discussion et fournir des perspectives qualitatives sur l’effet des paramètres des(α, β)-divergences (cf. Figures 5.3 et 5.4). Cela met en évidence l’intérêt d’une cer-taine région des paramètres pour la transcription de musique polyphonique, enconcordance avec l’interprétation des paramètres comme un moyen de contrôler lecompromis fréquentiel dans la décomposition (cf. Figure 5.5).Cette région des paramètres est explorée plus en profondeur au cours d’une pre-
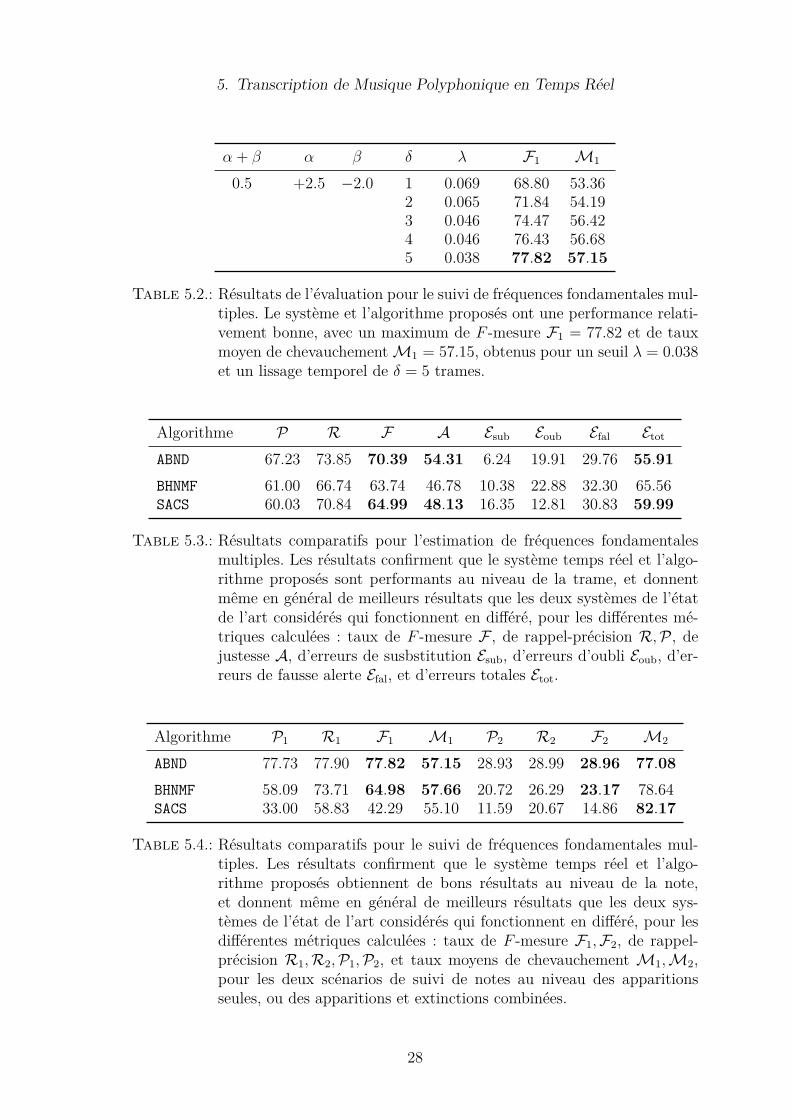
mière évaluation quantitative dans un cadre standard d’évaluation, pour la tâched’estimation de fréquences fondamentales multiples au niveau de la trame (cf. Ta-bleau 5.1). S’ensuit une seconde évaluation concernant le suivi de fréquences fon-damentales multiples au niveau de la note (cf. Tableau 5.2). Dans ces deux tâches,l’approche proposée (ABND) s’avère surpasser deux systèmes de l’état de l’art fonc-tionnant en différé (BHNMF et SACS), tout en maintenant un coût computationnelconvenable pour des contraintes de temps réel (cf. Tableaux 5.3 et 5.4).Pour finir, nous avons également évalué la capacité de généralisation du système
sur de la musique polyphonique plus générale que le piano, et où le dictionnairede notes construit pendant la phase d’apprentissage ne correspond plus exactementaux instruments à transcrire en temps réel. Pour cela, nous avons soumis une ver-sion préliminaire du système à la campagne internationale d’évaluation Music Infor-mation Retrieval Evaluation eXchange 2010, au cours de laquelle le système a étéévalué et comparé à d’autres algorithmes de transcription de musique polyphonique,pour des instruments et styles de musique variés. Bien que le système soumis necontenait que de simples modèles spectraux de notes de piano comme ceux utilisésici, il a pourtant obtenu des résultats comparables aux autres systèmes en com-pétition, qui fonctionnaient par ailleurs tous en différé, et s’est notamment classésecond pour le suivi de notes (cf. http://www.music-ir.org/mirex/wiki/2010:Multiple_Fundamental_Frequency_Estimation_%26_Tracking_Results).
24
5. Transcription de Musique Polyphonique en Temps Réel
Temps en secondes
Fré
quen
ce e
n he
rtz
0 2 4 6 8 100
615.2
1230.5
1845.7
2460.9
3076.2
3691.4
4306.6
4921.9
5537.1
6152.3
20
40
60
80
100
120
140
Figure 5.3.: Spectrogramme de l’extrait piano. L’extrait est composé des notesDo-Ré-Mi-Fa-Sol-Fa-Mi-Ré-Do jouées successivement à la main droite,pendant que la main gauche joue les notes Do-Sol-Mi-Sol-Do deux foisplus lentement.
Fré
quen
ce e
n he
rtz
La−1 La0 La1 La2 La3 La4 La5 La60
615.2
1230.5
1845.7
2460.9
3076.2
3691.4
4306.6
4921.9
5537.1
6152.3
20
40
60
80
100
120
140
160
180
200
Figure 5.4.: Modèles spectraux de notes de piano. Des modèles caractéristiques etdiscriminants sont appris pour chaque note du piano, en appliquantune factorisation en matrices non négatives sur les échantillons isoléscorrespondants.
25

5. Transcription de Musique Polyphonique en Temps Réel
β =
2
α = −1
La−1La0La1La2La3La4La5La6
α = 0 α = 1 α = 2
0
0.5
1
β =
1
La−1La0La1La2La3La4La5La6
0
0.5
1
β =
0
La−1La0La1La2La3La4La5La6
0
0.5
1
Temps en secondes
β =
−1
0 2 4 6 8 10La−1La0La1La2La3La4La5La6
Temps en secondes0 2 4 6 8 10
Temps en secondes0 2 4 6 8 10
Temps en secondes
0 2 4 6 8 100
0.5
1
Figure 5.5.: Activations des modèles spectraux. Les activations sont de meilleurequalité pour 0 ≤ α+β ≤ 1, correspondant à une dépendance d’échelleentre la linéarité et l’invariance, que pour α + β = 2, correspondantà une dépendance quadratique (l’approche exposée ne permettant pasde considérer des valeurs α = 0 dès lors que β 6= 1, les figures corres-pondantes sont laissées vides pour une question de visualisation).
26

5. Transcription de Musique Polyphonique en Temps Réel
α + β α β λ F Fonction de distance0.0 −1.0 +1.0 0.007 55.62
−0.5 +0.5 0.008 60.13∓0.0 ±0.0+0.5 −0.5 0.011 64.00+1.0 −1.0 0.013 64.92 Itakura-Saito+1.5 −1.5 0.015 65.67+2.0 −2.0 0.016 66.19+2.5 −2.5 0.018 66.51+3.0 −3.0 0.019 66.75+3.5 −3.5 0.021 66.86+4.0 −4.0 0.022 66.94+4.5 −4.5 0.023 66.91+5.0 −5.0 0.024 66.87
0.5 −1.0 +1.5 0.009 61.13−0.5 +1.0 0.011 65.52∓0.0 +0.5+0.5 ±0.0 0.015 69.19+1.0 −0.5 0.017 69.92 β-divergence avec β = 0.5+1.5 −1.0 0.018 70.27+2.0 −1.5 0.020 70.37+2.5 −2.0 0.022 70.39+3.0 −2.5 0.023 70.35+3.5 −3.0 0.025 70.27+4.0 −3.5 0.026 70.17+4.5 −4.0 0.027 70.04+5.0 −4.5 0.028 69.92
1.0 −1.0 +2.0 0.013 62.89 χ2 de Neyman−0.5 +1.5 0.016 65.76 α-divergence avec α = −0.5∓0.0 +1.0 0.018 66.92 Kullback-Leibler duale+0.5 +0.5 0.021 67.19 Hellinger+1.0 ±0.0 0.023 67.19 Kullback-Leibler+1.5 −0.5 0.024 67.09 α-divergence avec α = 1.5+2.0 −1.0 0.026 66.94 χ2 de Pearson+2.5 −1.5 0.028 66.78 α-divergence avec α = 2.5+3.0 −2.0 0.028 66.58 α-divergence avec α = 3+3.5 −2.5 0.030 66.37 α-divergence avec α = 3.5+4.0 −3.0 0.031 66.19 α-divergence avec α = 4+4.5 −3.5 0.031 66.00 α-divergence avec α = 4.5+5.0 −4.0 0.032 65.78 α-divergence avec α = 5
Table 5.1.: Résultats de l’évaluation pour l’estimation de fréquences fondamentalesmultiples. Le système et l’algorithme proposés ont une performance re-lativement bonne, avec un maximum de F -mesure F = 70.39, obtenuepour un seuil λ = 0.022, et des paramètres α = 2.5 et β = −2 corres-pondant à une dépendance d’échelle entre la linéarité et l’invariance.
27
5. Transcription de Musique Polyphonique en Temps Réel
α + β α β δ λ F1 M1
0.5 +2.5 −2.0 1 0.069 68.80 53.362 0.065 71.84 54.193 0.046 74.47 56.424 0.046 76.43 56.685 0.038 77.82 57.15
Table 5.2.: Résultats de l’évaluation pour le suivi de fréquences fondamentales mul-tiples. Le système et l’algorithme proposés ont une performance relati-vement bonne, avec un maximum de F -mesure F1 = 77.82 et de tauxmoyen de chevauchementM1 = 57.15, obtenus pour un seuil λ = 0.038et un lissage temporel de δ = 5 trames.
Algorithme P R F A Esub Eoub Efal Etot
ABND 67.23 73.85 70.39 54.31 6.24 19.91 29.76 55.91BHNMF 61.00 66.74 63.74 46.78 10.38 22.88 32.30 65.56SACS 60.03 70.84 64.99 48.13 16.35 12.81 30.83 59.99
Table 5.3.: Résultats comparatifs pour l’estimation de fréquences fondamentalesmultiples. Les résultats confirment que le système temps réel et l’algo-rithme proposés sont performants au niveau de la trame, et donnentmême en général de meilleurs résultats que les deux systèmes de l’étatde l’art considérés qui fonctionnent en différé, pour les différentes mé-triques calculées : taux de F -mesure F , de rappel-précision R,P , dejustesse A, d’erreurs de susbstitution Esub, d’erreurs d’oubli Eoub, d’er-reurs de fausse alerte Efal, et d’erreurs totales Etot.
Algorithme P1 R1 F1 M1 P2 R2 F2 M2
ABND 77.73 77.90 77.82 57.15 28.93 28.99 28.96 77.08BHNMF 58.09 73.71 64.98 57.66 20.72 26.29 23.17 78.64SACS 33.00 58.83 42.29 55.10 11.59 20.67 14.86 82.17
Table 5.4.: Résultats comparatifs pour le suivi de fréquences fondamentales mul-tiples. Les résultats confirment que le système temps réel et l’algo-rithme proposés obtiennent de bons résultats au niveau de la note,et donnent même en général de meilleurs résultats que les deux sys-tèmes de l’état de l’art considérés qui fonctionnent en différé, pour lesdifférentes métriques calculées : taux de F -mesure F1,F2, de rappel-précision R1,R2,P1,P2, et taux moyens de chevauchement M1,M2,pour les deux scénarios de suivi de notes au niveau des apparitionsseules, ou des apparitions et extinctions combinées.
28

ConclusionL’objectif de cette thèse était de proposer des méthodes computationnelles dans
le cadre de la géométrie de l’information, pour des problèmes temps réel en trai-tement du signal audio. Dans ce contexte, nous avons abordé deux problématiquesaudio d’intérêt en proposant des schémas algorithmiques innovants. D’une part, nousavons formulé un cadre générique pour la détection séquentielle de ruptures dans lesfamilles exponentielles, et l’avons appliqué au problème de la segmentation audio entemps réel. D’autre part, nous avons formalisé un cadre générique pour la factori-sation en matrices non négatives avec des divergences convexes-concaves, et l’avonsemployé pour traiter le problème de la transcription de la musique polyphonique entemps réel. Plusieurs perspectives de recherche intéressantes émergent des approchesproposées et pourront être abordées dans des travaux futurs.Pour commencer, nous pourrions élargir le cadre proposé de détection séquentielle
de ruptures dans les familles exponentielles, afin d’améliorer les possibilités de modé-lisation des signaux pour la segmentation audio. Par exemple, il est possible dans unecertaine mesure de considérer des familles qui ne sont pas complètes. Cela permet-trait de prendre en compte avantageusement certaines propriétés sonores pertinentestout en restreignant l’espace des paramètres, par exemple pour la modélisation deprofils spectraux harmoniques en segmentation de musique.Il serait également intéressant d’étendre l’approche proposée pour traiter la dé-
pendance statistique entre les variables aléatoires. Cela fournirait des modèles plusprécis pour certains descripteurs audio qui ont des profils temporels complexes ayantune dépendance claire entre trames successives. Dans ce contexte, les méthodes desélection automatique de descripteurs et de sélection de modèles trouveraient des in-térêts évidents dans l’adaptation de la représentation et du modèle aux observationsen entrée du système.D’autres estimateurs que le maximum de vraisemblance pourraient également
être utilisés, pour inclure par exemple des connaissances a priori sur les signauxpar le biais d’une estimation par maximum a posteriori, ou pour améliorer la ro-bustesse en cas d’erreurs de spécification du modèle à travers des estimateurs dequasi-vraisemblance. Plus généralement, un cadre bayésien serait judicieux dans lessituations où des informations sont a priori connues ou peuvent être apprises à partird’un jeu de données d’entraînement. La robustesse pourrait également être abordéepar des techniques plus élaborées de post-traitement en lien avec des considéra-tions statistiques, par exemple, en élaborant des critères de sélection de modèles quitiennent en compte des échantillons de petite taille, ou en adaptant les heuristiquesde seuillage et de fenêtrage.En ce qui concerne la factorisation en matrices non négatives, des prolongements
directs pourraient être envisagés dans le cadre proposé. Par exemple, un modèleconvexe de factorisation à plusieurs couches permettrait d’utiliser un dictionnaire
29

Conclusion
structuré avec plusieurs atomes par note, voire un modèle hiérarchique complet denotes et d’instruments. Sur un autre plan, un modèle de factorisation tensoriellepermettrait la prise en compte d’une information multi-canal pour aider la trans-cription. L’utilisation de modèles convolutifs permettrait également de modéliserles profils temporels des notes pour surmonter le problème de la stationnarité desmodèles spectraux inhérent à l’approche proposée.En outre, on pourrait employer des fonctions coût plus élaborées afin de fournir
des contrôles alternatifs sur la décomposition audio. À cet égard, l’effet du paramètred’oblicité des divergences mérite d’être étudié de manière approfondie, à la fois despoints de vue théorique et applicatif, afin de comprendre la pertinence ou non deces divergences pour l’analyse audio, et plus généralement pour l’analyse de signauxquelconques. Une approche complémentaire pour améliorer les fonctions coût seraitde considérer des termes de pénalité pour régulariser les solutions, par exemple,en assurant une continuité temporelle, ou en imposant des structures adéquates deparcimonie telles que la parcimonie de groupe.Finalement, on pourrait envisager des schémas d’optimisation alternatifs pour
accélérer la convergence des algorithmes et ainsi réduire les charges de calcul pour letemps réel. Par exemple, la prise en compte de l’égalisation des fonctions auxiliairesau lieu de leur minimisation mérite d’être étudiée. Des mises à jour conditionnellesqui dépendent des observations et des régions de l’espace des solutions sont une autrevoie prometteuse.De manière plus générale, nous avons dans cette thèse, développé des méthodes
computationnelles, en partant soit de modèles statistiques, soit de divergences infor-mationnelles. Pour la détection de ruptures, nous avons réussi à clarifier les relationsentre les modèles statistiques considérés et les divergences canoniques associées, parle biais de la géométrie de l’information dualement plate des familles exponentielles.Cependant, ces relations disparaissent pour la factorisation en matrices non néga-tives dès lors que nous employons des divergences convexes-concaves qui diffèrentdes divergences canoniques associées. Nous l’avons justifié par des considérations derobustesse. Nous perdons néanmoins de ce fait, l’intuition statistique qui permet desavoir si une divergence donnée est adéquate ou non pour analyser des observationsdistribuées selon telle loi de probabilité. Il serait donc intéressant d’avoir des intui-tions nouvelles sur les relations entre modèles statistiques et divergences, en dehorsdes familles exponentielles et des divergences de Kullback-Leibler ou de Bregman.Sur une autre perspective, nous pensons que les deux méthodes computation-
nelles proposées pourraient s’avérer utiles dans d’autres applications et domainesque ceux développés dans cette thèse. Inversement, d’autres méthodes existantesdans le cadre de la géométrie de l’information computationnelle pourraient être uti-lisées avantageusement pour résoudre des problèmes de traitement du signal audio.Les deux paradigmes que nous avons exposés ne sont que des gouttes d’eau dansl’océan. Nous espérons cependant que ces contributions apporteront des pistes deréflexion intéressantes pour le traitement du signal audio, et plus généralement del’apprentissage automatique et traitement du signal, dans le champ émergent maisnéanmoins déjà fécond de la géométrie de l’information computationnelle.
30