Embed Size (px)
Citation preview
p1obs
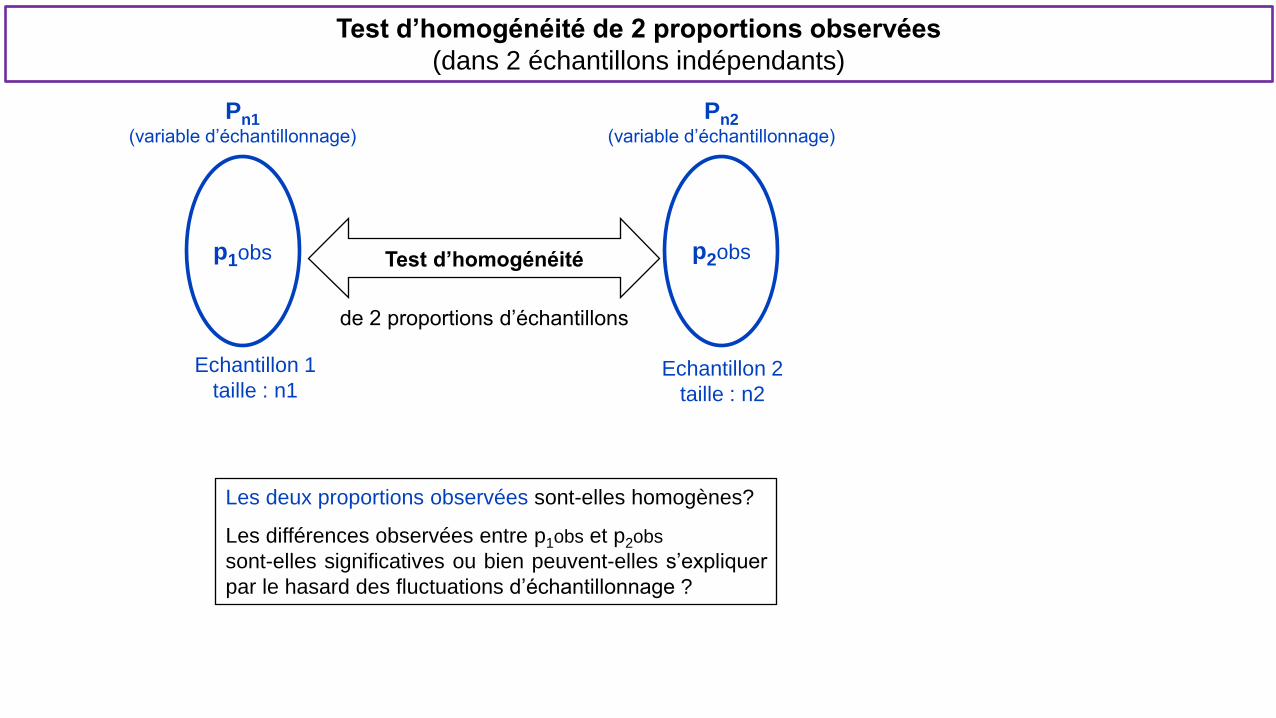
Test d’homogénéité de 2 proportions observées
(dans 2 échantillons indépendants)
Test d’homogénéité
Echantillon 1
taille : n1
Les deux proportions observées sont-elles homogènes?
Les différences observées entre p1obs et p2obs
sont-elles significatives ou bien peuvent-elles s’expliquer
par le hasard des fluctuations d’échantillonnage ?
Pn1 (variable d’échantillonnage)
p2obs
Echantillon 2
taille : n2
Pn2 (variable d’échantillonnage)
de 2 proportions d’échantillons
p1obs
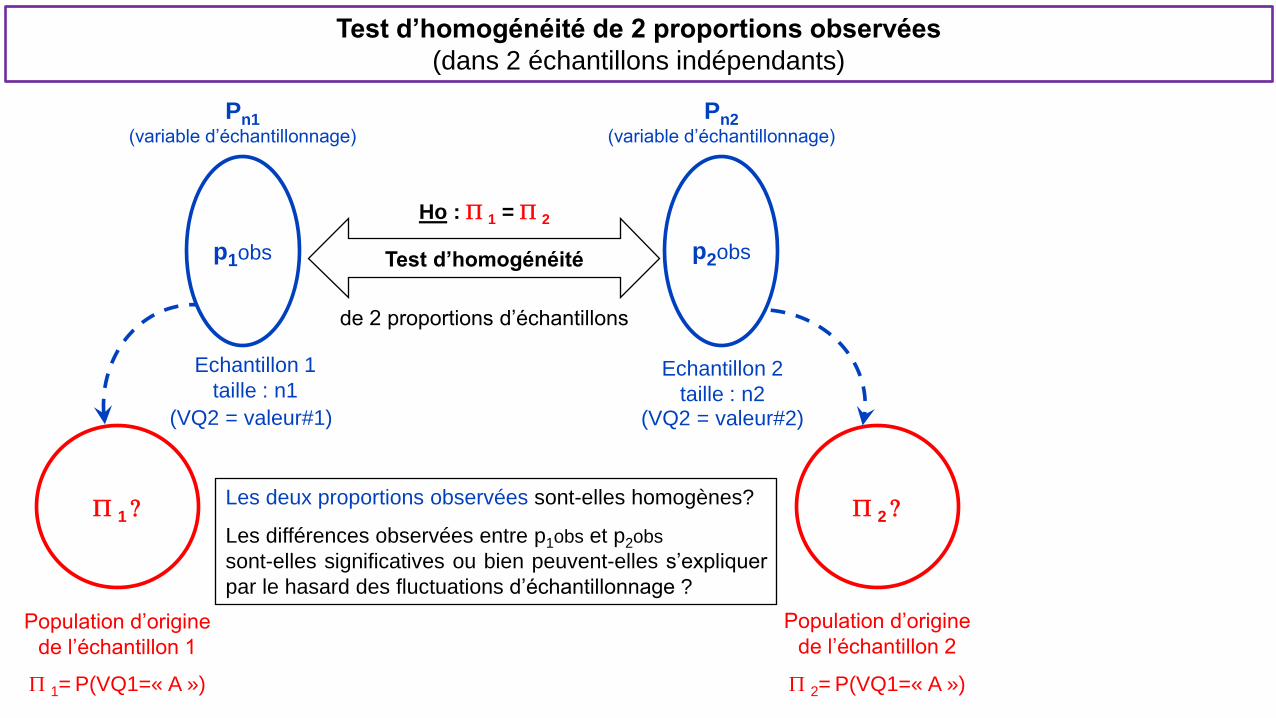
Test d’homogénéité de 2 proportions observées
(dans 2 échantillons indépendants)
Test d’homogénéité
Echantillon 1
taille : n1
Les deux proportions observées sont-elles homogènes?
Les différences observées entre p1obs et p2obs
sont-elles significatives ou bien peuvent-elles s’expliquer
par le hasard des fluctuations d’échantillonnage ?
P 1 ?
Population d’origine
de l’échantillon 1
Pn1 (variable d’échantillonnage)
P 1= P(VQ1=« A »)
p2obs
Echantillon 2
taille : n2
P 2 ?
Population d’origine
de l’échantillon 2
Pn2 (variable d’échantillonnage)
Ho : P 1 = P 2
de 2 proportions d’échantillons
(VQ2 = valeur#1)
P 2= P(VQ1=« A »)
(VQ2 = valeur#2)

p1obs
Test d’homogénéité de 2 proportions observées
(dans 2 échantillons indépendants)
Test d’homogénéité
Echantillon 1
taille : n1
Les deux proportions observées sont-elles homogènes?
Les différences observées entre p1obs et p2obs
sont-elles significatives ou bien peuvent-elles s’expliquer
par le hasard des fluctuations d’échantillonnage ?
P 1 ?
Population d’origine
de l’échantillon 1
Pn1 (variable d’échantillonnage)
P 1= P(VQ1=« A »)
p2obs
Echantillon 2
taille : n2
P 2 ?
Population d’origine
de l’échantillon 2
Pn2 (variable d’échantillonnage)
Ho : P 1 = P 2
de 2 proportions d’échantillons
Test basé sur la loi normale
Ho : P 1 = P 2 P 1 - P 2 = 0
H1 : P 1 ≠ P 2 P 1 - P 2 ≠ 0 ; test bilatéral
H1 : P 1 > P 2 P 1 - P 2 > 0 ; test unilatéral
H1 : P 1 < P 2 P 1 - P 2 < 0 ; test unilatéral
(Peut être également traité par un khi-2)
(VQ2 = valeur#1)
P 2= P(VQ1=« A »)
(VQ2 = valeur#2)
En fait, on teste ici l’existence d’une éventuelle liaison
entre 2 variables qualitatives (VQ1 et VQ2)
chacune à 2 modalités

p1obs
Test d’homogénéité de 2 proportions observées
(dans 2 échantillons indépendants)
Test d’homogénéité
Echantillon 1
taille : n1
Les deux proportions observées sont-elles homogènes?
Les différences observées entre p1obs et p2obs
sont-elles significatives ou bien peuvent-elles s’expliquer
par le hasard des fluctuations d’échantillonnage ?
P 1 ?
Population d’origine
de l’échantillon 1
Pn1 (variable d’échantillonnage)
P 1= P(VQ1=« A »)
p2obs
Echantillon 2
taille : n2
P 2 ?
Population d’origine
de l’échantillon 2
Pn2 (variable d’échantillonnage)
Ho : P 1 = P 2
de 2 proportions d’échantillons La variance de la différence (Pn1 - Pn2)
va être l’élément déterminant pour la
statistique de test. Test basé sur la loi normale
Ho : P 1 = P 2 P 1 - P 2 = 0
H1 : P 1 ≠ P 2 P 1 - P 2 ≠ 0 ; test bilatéral
H1 : P 1 > P 2 P 1 - P 2 > 0 ; test unilatéral
H1 : P 1 < P 2 P 1 - P 2 < 0 ; test unilatéral
(Peut être également traité par un khi-2)
(VQ2 = valeur#1)
P 2= P(VQ1=« A »)
(VQ2 = valeur#2)
En fait, on teste ici l’existence d’une éventuelle liaison
entre 2 variables qualitatives (VQ1 et VQ2)
chacune à 2 modalités
P1obs
0,45
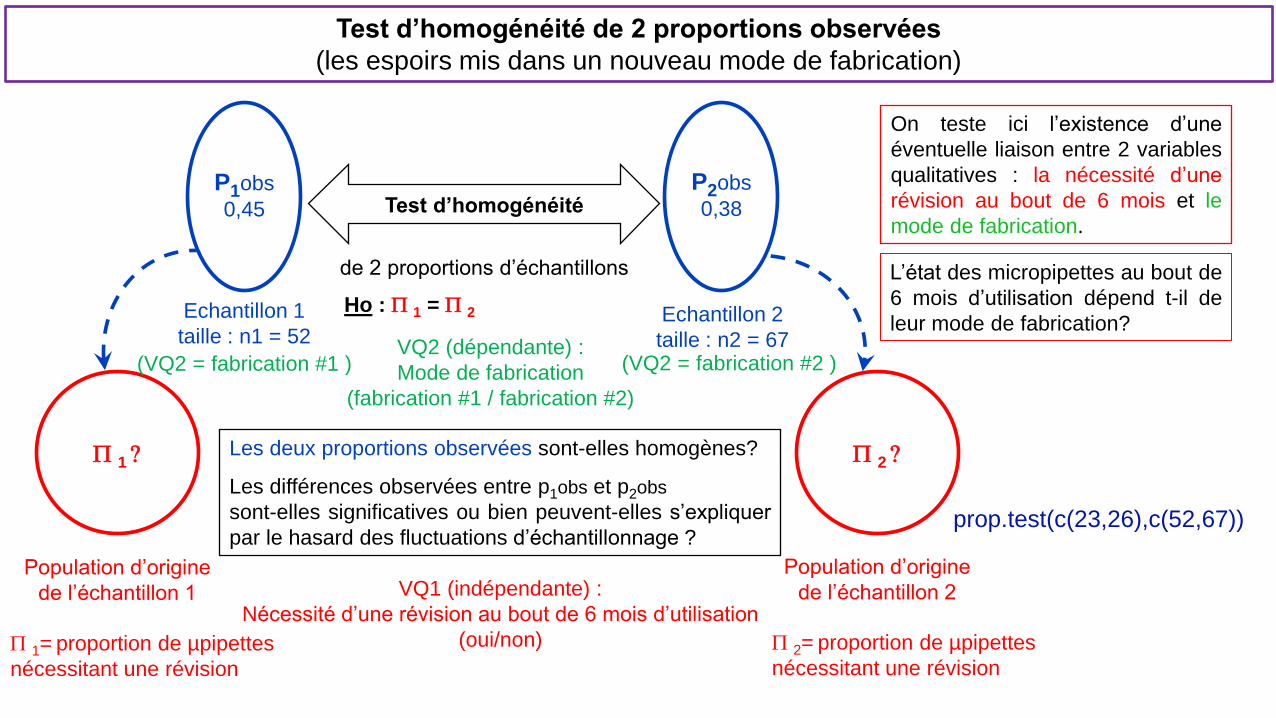
Test d’homogénéité de 2 proportions observées
(les espoirs mis dans un nouveau mode de fabrication)
Echantillon 1
taille : n1 = 52
Les deux proportions observées sont-elles homogènes?
Les différences observées entre p1obs et p2obs
sont-elles significatives ou bien peuvent-elles s’expliquer
par le hasard des fluctuations d’échantillonnage ?
P 1 ?
Population d’origine
de l’échantillon 1
P2obs
0,38
Echantillon 2
taille : n2 = 67
P 2 ?
Population d’origine
de l’échantillon 2
Ho : P 1 = P 2
de 2 proportions d’échantillons
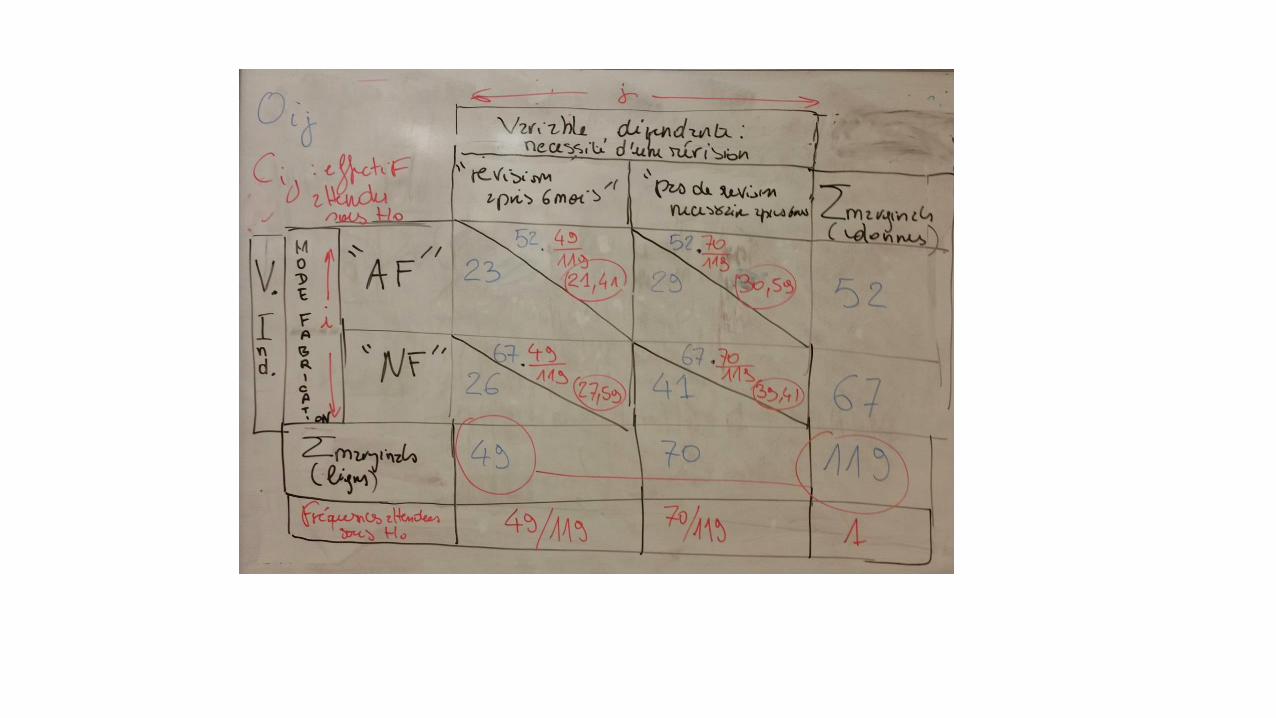
(VQ2 = fabrication #1 )
On teste ici l’existence d’une
éventuelle liaison entre 2 variables
qualitatives : la nécessité d’une
révision au bout de 6 mois et le
mode de fabrication. Test d’homogénéité
L’état des micropipettes au bout de
6 mois d’utilisation dépend t-il de
leur mode de fabrication?
VQ1 (indépendante) : Nécessité d’une révision au bout de 6 mois d’utilisation
(oui/non)
VQ2 (dépendante) : Mode de fabrication
(fabrication #1 / fabrication #2)
(VQ2 = fabrication #2 )
P 2= proportion de µpipettes
nécessitant une révision
P 1= proportion de µpipettes
nécessitant une révision
prop.test(c(23,26),c(52,67))




Sous R ce test se réalise (plus précisément d’ailleurs) de la façon suivante :
> prop.test(c(23,26),c(52,67))
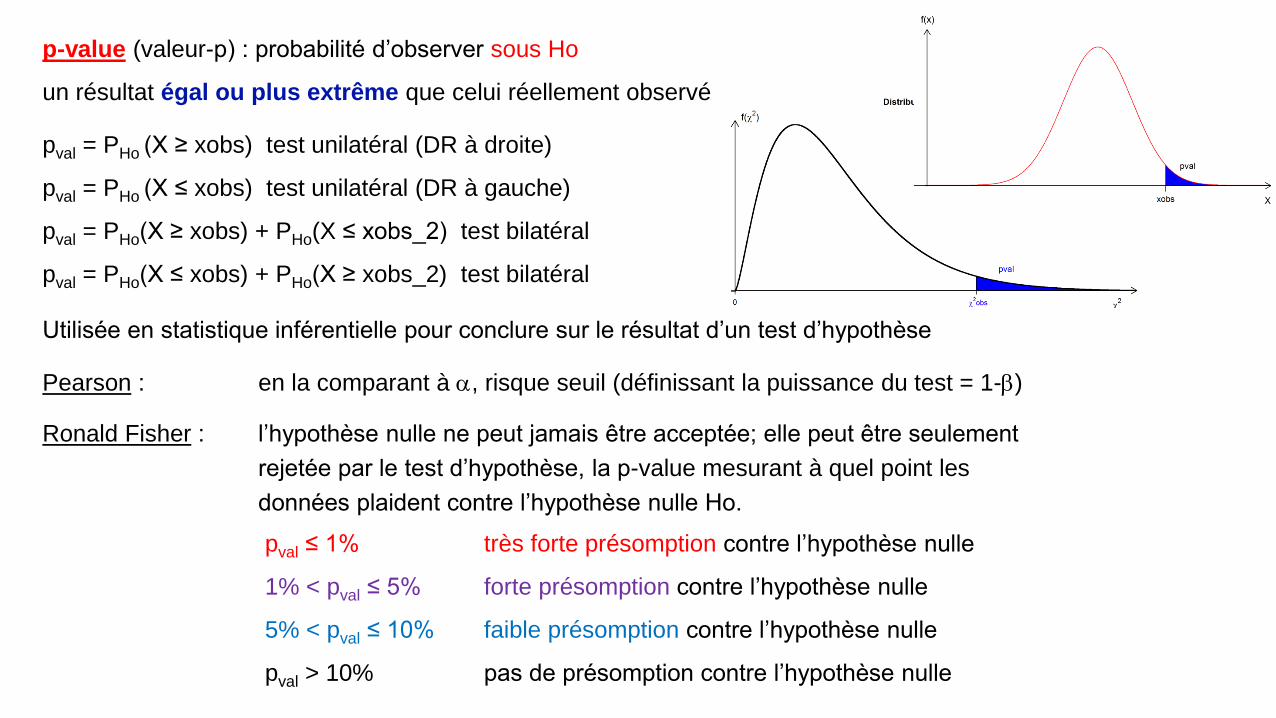
p-value (valeur-p) : probabilité d’observer sous Ho
un résultat égal ou plus extrême que celui réellement observé
pval = PHo (X ≥ xobs) test unilatéral (DR à droite)
pval = PHo (X ≤ xobs) test unilatéral (DR à gauche)
pval = PHo(X ≥ xobs) + PHo(X ≤ xobs_2) test bilatéral
pval = PHo(X ≤ xobs) + PHo(X ≥ xobs_2) test bilatéral
Utilisée en statistique inférentielle pour conclure sur le résultat d’un test d’hypothèse
Pearson : en la comparant à a, risque seuil (définissant la puissance du test = 1-b)
Ronald Fisher : l’hypothèse nulle ne peut jamais être acceptée; elle peut être seulement
rejetée par le test d’hypothèse, la p-value mesurant à quel point les
données plaident contre l’hypothèse nulle Ho.
pval ≤ 1% très forte présomption contre l’hypothèse nulle
1% < pval ≤ 5% forte présomption contre l’hypothèse nulle
5% < pval ≤ 10% faible présomption contre l’hypothèse nulle
pval > 10% pas de présomption contre l’hypothèse nulle
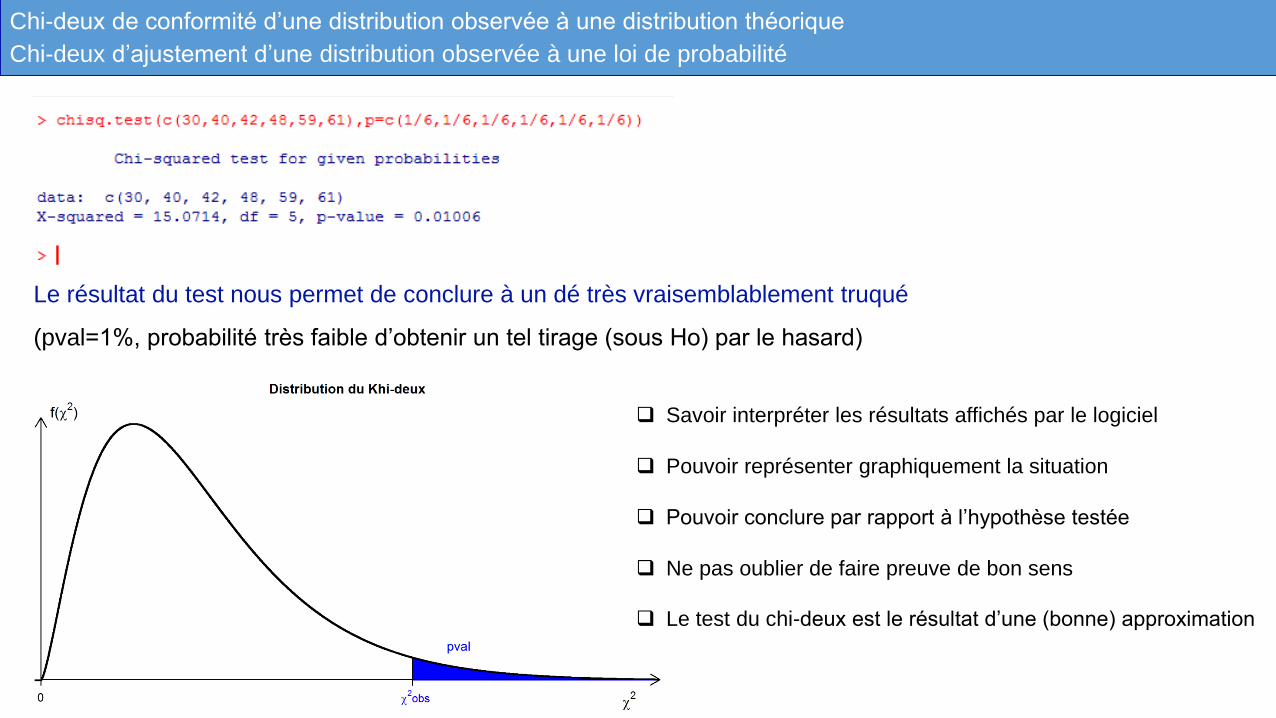
Chi-deux de conformité d’une distribution observée à une distribution théorique
Chi-deux d’ajustement d’une distribution observée à une loi de probabilité
Savoir interpréter les résultats affichés par le logiciel
Pouvoir représenter graphiquement la situation
Pouvoir conclure par rapport à l’hypothèse testée
Ne pas oublier de faire preuve de bon sens
Le test du chi-deux est le résultat d’une (bonne) approximation
Le résultat du test nous permet de conclure à un dé très vraisemblablement truqué
(pval=1%, probabilité très faible d’obtenir un tel tirage (sous Ho) par le hasard)

La suite de l’aventure : Chi-deux d’indépendance et Chi-deux d’homogénéité
On partira de deux exemples que l’on traitera complètement (l’un en écologie, l’autre en sociologie)
Là encore il faut pouvoir conclure par rapport à l’hypothèse testée
Ne pas oublier de faire preuve de bon sens
On va calculer une distance à l’indépendance donc bien poser l’hypothèse nulle
On utilise la même loi du chi-deux
On est déjà (sans s’en rendre compte) dans la statistique bivariée
L’intérêt se porte sur la relation entre les deux variables, la recherche de corrélation
(ce qui n'implique pas un lien de causalité).


Savoir interpréter les résultats affichés par le logiciel
Pouvoir représenter graphiquement la situation
Pouvoir conclure par rapport à l’hypothèse testée
Ne pas oublier de faire preuve de bon sens
Le test du chi-deux est le résultat d’une (bonne) approximation
La suite de l’aventure : notre premier Chi-deux d’indépendance et Chi-deux d’homogénéité
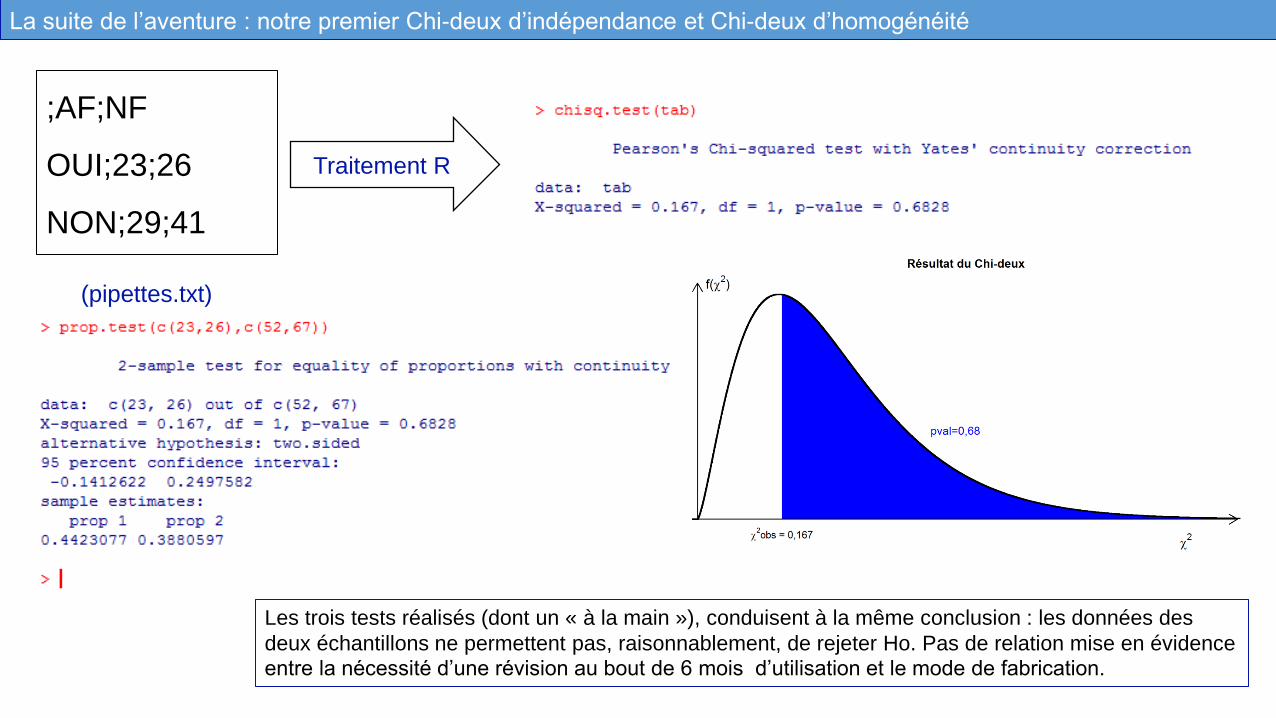
;AF;NF
OUI;23;26
NON;29;41
rm(list=ls(all=TRUE))
tab=read.csv2("pipettes.txt" , sep=";" ,
header=TRUE,na.strings="NA",row.names=1)
chisq.test(tab)
# à comparer avec?
prop.test(c(23,26),c(52,67))
#Votre commentaire….
(pipettes.txt)
Traitement : script R
(Chi2_ind1.txt)
La suite de l’aventure : notre premier Chi-deux d’indépendance et Chi-deux d’homogénéité
;AF;NF
OUI;23;26
NON;29;41
(pipettes.txt)
Traitement R
Les trois tests réalisés (dont un « à la main »), conduisent à la même conclusion : les données des
deux échantillons ne permettent pas, raisonnablement, de rejeter Ho. Pas de relation mise en évidence
entre la nécessité d’une révision au bout de 6 mois d’utilisation et le mode de fabrication.
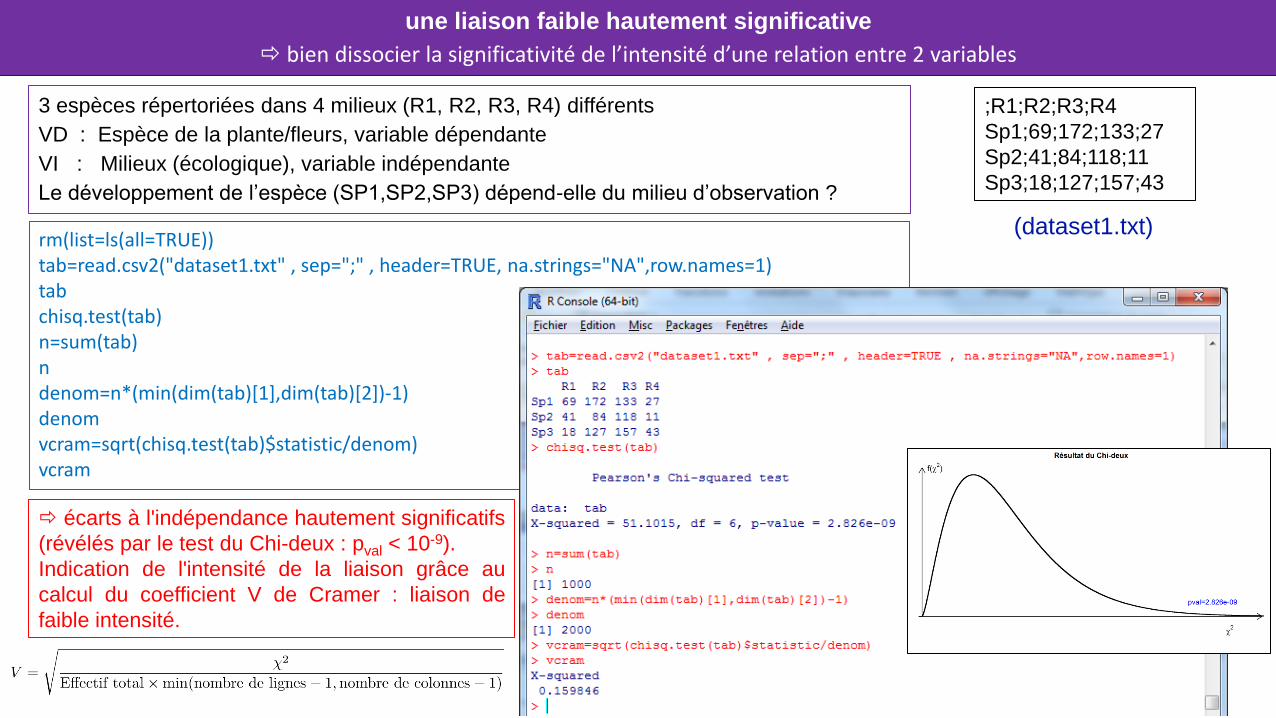
3 espèces répertoriées dans 4 milieux (R1, R2, R3, R4) différents
VD : Espèce de la plante/fleurs, variable dépendante
VI : Milieux (écologique), variable indépendante
Le développement de l’espèce (SP1,SP2,SP3) dépend-elle du milieu d’observation ?
rm(list=ls(all=TRUE)) tab=read.csv2("dataset1.txt" , sep=";" , header=TRUE, na.strings="NA",row.names=1) tab chisq.test(tab) n=sum(tab) n denom=n*(min(dim(tab)[1],dim(tab)[2])-1) denom vcram=sqrt(chisq.test(tab)$statistic/denom) vcram
;R1;R2;R3;R4
Sp1;69;172;133;27
Sp2;41;84;118;11
Sp3;18;127;157;43
(dataset1.txt)
écarts à l'indépendance hautement significatifs
(révélés par le test du Chi-deux : pval < 10-9).
Indication de l'intensité de la liaison grâce au
calcul du coefficient V de Cramer : liaison de
faible intensité.
une liaison faible hautement significative
bien dissocier la significativité de l’intensité d’une relation entre 2 variables
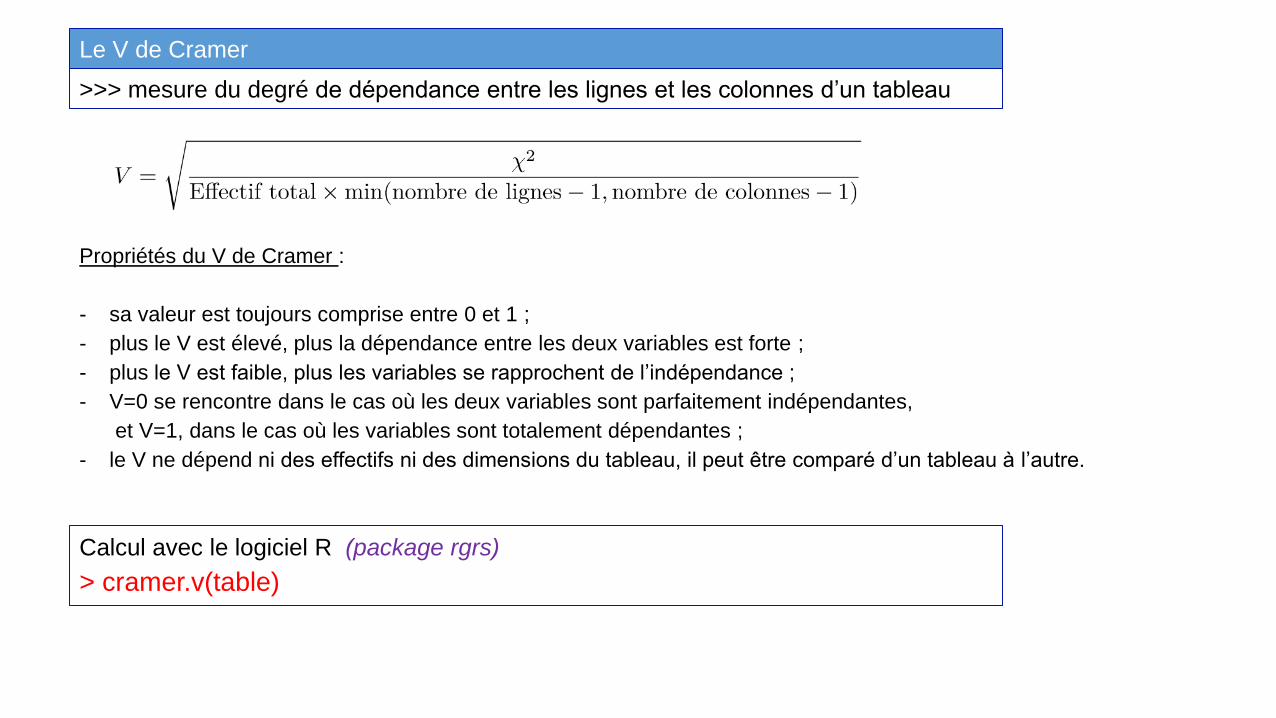
Propriétés du V de Cramer :
- sa valeur est toujours comprise entre 0 et 1 ;
- plus le V est élevé, plus la dépendance entre les deux variables est forte ;
- plus le V est faible, plus les variables se rapprochent de l’indépendance ;
- V=0 se rencontre dans le cas où les deux variables sont parfaitement indépendantes,
et V=1, dans le cas où les variables sont totalement dépendantes ;
- le V ne dépend ni des effectifs ni des dimensions du tableau, il peut être comparé d’un tableau à l’autre.
Le V de Cramer
>>> mesure du degré de dépendance entre les lignes et les colonnes d’un tableau
Calcul avec le logiciel R (package rgrs)
> cramer.v(table)

Et derrière le Chi-deux d’indépendance ?
Si le test du chi-deux permet d’évaluer la significativité de l’écart à l’indépendance,
il nous faut pour être complet étudier l’intensité de la relation mise en évidence
On s’appuyera sur les deux exemples traités (l’un en écologie, l’autre en sociologie)
Ne pas oublier de faire preuve de bon sens
On est au delà du chi-deux : Analyse Factorielle des Correspondances (AFC)
On est déjà (sans s’en rendre compte) dans une statistique de pros!!!
On va utiliser une bibliothèque (pakage) de R : factominer
Méthode basée sur une interprétation graphique
Mais d’abord commençons par le V de Cramer
Vous n’allez plus voir les Stats de la même façon…





























