Embed Size (px)
Citation preview

Variables aléatoires discrètes
4 mars 2017
Table des matières
1 Deux rappels sur la dénombrabilité et la sommabilité 3
2 Espaces probabilisés 42.1 Espaces probabilisables . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42.2 Probabilités, cas général . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62.3 Propriétés, premiers exemples . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
3 Probabilités conditionnelles, indépendance 113.1 Probabilités conditionnelles, trois formules fondamentales . . . . . . . . . . . . 113.2 Indépendance, première approche . . . . . . . . . . . . . . . . . . . . . . . . . 14
4 Variables aléatoires discrètes 164.1 Exemples de variables aléatoires discrètes . . . . . . . . . . . . . . . . . . . . . 174.2 Couples et n-uplets de v. a. discrètes, variables vectorielles . . . . . . . . . . . . 19
5 Moments : espérance, variance et écart-type 225.1 Espérance . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 225.2 Variance, écart-type et covariance . . . . . . . . . . . . . . . . . . . . . . . . . 255.3 Inégalité de Markov et inégalité de Bienaymé-Tchebychev . . . . . . . . . . . . 285.4 Loi faible des grands nombres . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
6 Fonctions génératrices 316.1 Définition, premières propriétés . . . . . . . . . . . . . . . . . . . . . . . . . . 316.2 Sommes de variables indépendantes et entières . . . . . . . . . . . . . . . . . . 34
7 Suites de variables aléatoires 367.1 Marches aléatoires . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 367.2 Chaînes de Markov . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
8 Problèmes et simulations 398.1 Sujet Zéro - Mines - 2015 : Files d’attente M/GI/1 . . . . . . . . . . . . . . . . . 39
9 Annexe : La loi de Poisson est un modèle 42
1

10 Corrigés 47
Vous avez étudié en première année les probabilités sur un en-semble fini. Cela permet de modéliser simplement quelques jeuxet quelques applications réelles comme une partie de la théoriedes sondages par exemple.On a pourtant couramment affaire à des situations simples quifont apparaître des ensembles infinis (et pas toujours dénom-brables).Ce chapitre généralise directement ce qui a été vu en MPSI enpassant des univers finis à certains univers infinis. L’objet cen-tral, comme toujours en probabilité, est la notion de variablealéatoire. Nous nous intéresserons aux variables aléatoires dis-crètes, c’est à dire dont les valeurs forment un ensemble au plusdénombrable.Nous ne revenons donc pas sur les notions de probabilités« continues » que vous avez entrevues en terminale a comme parexemple la loi uniforme qui permet de modéliser la notion d’in-certitude.En d’autres termes, nous ne traitons que la colonne de gauchedans le graphe situé à droite...
a. Sans toutefois justifier de l’existence d’un espace probabilisable !
1
Univers finis
Univers dénombrables
Lois à densité
Mesures de probabilités
2

Lorsqu’on « travaille » sur un espace probabilisé fini (Ω, P ), toute partie de Ω est un événementauquel on sait associer une probabilité :
P (A) =∑
ω∈AP (ω). (0.1)
Tout le travail de ce chapitre consiste à sortir du cadre fini ; on définit pour cela la notion d’espaceprobabilisable dans le cadre le plus général, on revient ensuite en arrière en introduisant la notionde variable aléatoire discrète grâce à laquelle, même avec des univers « compliqués, » on peuts’intéresser à certains événements, typiquement de la forme, (X ∈ A) où X : Ω → E est unevariable discrète (c’est à dire que E est au plus dénombrable), pour lesquels on calculera
P (X ∈ A) =∑
k∈AP (X = k). (0.2)
Les exercices (4) et (5) et leurs successeurs directs ((7), (8), (20)), (21) font partie du cheminementpédagogique de ce cours.
1 Deux rappels sur la dénombrabilité et la sommabilité
• En vue des probabilités discrètes
Définition 1• Un E ensemble est fini s’il est vide ou s’il existe un entier n tel que E soit en bijection avec[[1, n]].• On dit qu’un ensemble est dénombrable s’il est en bijection avec l’ensemble N des entiersnaturels.• On dit qu’un ensemble est au plus dénombrable s’il est en bijection avec une partie de N. Il estdonc fini ou dénombrable par le théorème 1.
Théorème 1• Une partie de N est soit finie soit dénombrable.• Une partie d’un ensemble au plus dénombrable est soit finie soit dénombrable (donc au plusdénombrable).• Une réunion finie d’ensembles dénombrables est dénombrable.• Une réunion dénombrable d’ensembles dénombrables est dénombrable.• Une réunion dénombrable d’ensembles au plus dénombrables est au plus dénombrable.
Exercice 1 0, 1N n’est pas dénombrableOn considère l’ensemble E = 0, 1N des suites formées de 0 et de 1. On veut démontrer parl’absurde que cet ensemble n’est pas dénombrable.On supposera donc qu’il existe une bijection Φ : N→ E.
1. Comprendre les objets, les notations :
3

(a) Soit U = (0, 0, 0, 1, 0, 1, ....) un élément deE.Au vu de cette description partielle quesont U0, U1, ..., U5? Et U6?
(b) Soit U = Φ(p) (p ∈ N quelconque). Que désignent Un, Φ(p)n?
2. On définit une suite V en posant pour n ∈ N :
Vn = 0 si Φ(n)n = 1
Vn = 1 si Φ(n)n = 0
(a) Que vaut Vn si Φ(n) est la suite nulle ? V est elle la suite nulle ?
(b) Que vaut Vn si Φ(n) est la suite formée uniquement de 1 ? V est elle la suite forméeuniquement de 1 ?
(c) Existe-t-il n ∈ N tel que V = Φ(n)?
3. Connaissez vous un ensemble non dénombrable ?
• Un rappel qui nous sera utile pour étudier les propriétés de l’espérance
Théorème 2 sommation par paquets, nombres réelsSi (In)n est une partition de l’ensemble dénombrable I, et si (ai)∈I est une famille sommable denombres réels, alors :
1. Chacune des familles (ai)∈In est sommable.
2. La famille (Tn)n où chaque Tn est défini par
Tn =∑
i∈In
ai
est elle-même sommable.
3. L’égalité qui suit est vérifiée (formule de sommation par paquets) :∑
n∈NTn =
∑
n∈N
∑
i∈In
ai =∑
i∈Iai (1.1)
2 Espaces probabilisés
2.1 Espaces probabilisables
Définition 2 notion de tribuSoit Ω un ensemble quelconque. On note, comme à l’accoutumée, P(Ω) l’ensemble de toutes lesparties de Ω . Une tribu T (on dit aussi σ−algèbre) sur Ω est un sous-ensemble de P(Ω) qui vérifieles axiomes suivants :
1. T est non vide ;
4

2. T est stable par passage au complémentaire :
A ∈ T ⇒ A = ΩA ∈ T ;
3. Pour toute famille dénombrable (An)n∈N, d’éléments de T , ∪n∈N
An ∈ T .
Ces propriétés n’ont rien d’étrange, elles constituent un jeu minimal d’axiomes qui permet d’éta-blir que T vérifie aussi les propriétés suivantes sans lesquelles nous ne pourrions faire de calculayant du sens.
Exercice 2 jouer avec les axiomes, raisonner
1. Démontrer qu’une tribu T sur Ω vérifie aussi :– Pour toute famille dénombrable (An)n∈N, d’éléments de T , ∩
n∈NAn ∈ T ;
– Pour toute famille finie (Ak)0≤k≤n, d’éléments de T , n∪k=0
An ∈ T ;
– Pour toute famille finie (Ak)0≤k≤n, d’éléments de T , n∩k=0
An ∈ T ;
– Ω ∈ T , ∅ ∈ T ;– Si A,B ∈ T , A \B ∈ T .
2. P(Ω) est elle une tribu sur Ω?
3. ∅,Ω est elle une tribu sur Ω?
4. Une intersection de tribus est elle une tribu ?
5. Soit B l’intersection de toutes les tribus sur ]0, 1[ contenant les intervalles ouverts contenusdans ]0, 1[. Contient elle les intervalles fermés ?
Définition 3 vocabulaire de base, extension...– Un espace probabilisable (Ω, T ) est la donnée d’un ensemble Ω et d’une tribu T sur Ω;– Ω est appelé univers des possibles, ses éléments des issues, des réalisations ou des possibles.– Un élément de la tribu T est un événement.– Si T = P(E), les singletons ω où ω ∈ Ω, sont des évènements et on dit alors que ce sont des
événements élémentaires. Ce sera le cas pour Ω au plus dénombrable seulement.– Ω est l’événement certain ; ∅ est l’événement impossible.– Un système complet d’évènements est une famille finie ou dénombrable d’éléments de T ,
deux à deux disjoints et dont la réunion est Ω.– Deux événements disjoints sont dits incompatibles, le complémentaire de A noté A quand on
fait des probabilités est appelé évènement contraire de A.
Exercice 3 Raisonner et démontrerSoit Ω un ensemble quelconque, (E, TE) un espace probabilisable etX : Ω→ E une application.
1. Démontrer que X−1(A)/A ∈ TE est une tribu sur Ω.
2. On suppose que E est un ensemble fini, [[1, n]] par exemple. Pouvez vous construire unetribu finie sur Ω?
Cas concrets : les exercices (4) et (5).
5

Exercice 4 MODéliser
Il était une fois un pays démocratique dans lequel les électeurs étaient appelés à voter par référen-dum sur les questions importantes. Quand le résultat du référendum, était de type A, on revotait.S’il était de type B, le résultat devenait définitif.
Nous voulons donc modéliser l’expérience qui consiste à lancer une pièce et à recommencer tantque « face » n’apparaît pas. Nous ne nous préoccupons que de définir un univers Ω et une tribusur Ω dont les éléments ou événements nous intéressent. Nous parlerons de probabilités plus loin(exercice 7).
1. Faire une proposition pour Ω. Pouvez vous proposer un Ω fini et pertinent ?
2. Pouvez vous proposer un Ω dénombrable ?
3. Faire une proposition pour une tribu sur Ω qui permette de représenter (ou contienne) lesévénements du type « la première « face » apparaît au nieme lancé ». Penser au résultat del’exercice (3).
Exercice 5 MODéliserNous voulons modéliser l’expérience qui consiste à lancer un dé à six faces et à recommencer
tant que 6 n’apparaît pas. Nous ne nous préoccupons que de définir un univers Ω et une tribusur Ω dont les éléments ou événements nous intéressent. Nous parlerons de probabilités plus loin(exercice 8).
1. Faire une proposition pour Ω.
2. ? Pour le choix proposé, Ω est il dénombrable ?
3. F Faire une proposition pour une tribu sur Ω qui permette de représenter (ou contienne) lesévénements du type « Il y a en tout n lancés. » Penser au résultat de l’exercice (3) 1 .
2.2 Probabilités, cas général
Exercice 6 échauffements : familles dénombrables d’événementsOn reprend l’espace probabilisable de l’exercice (4).
1. On note An l’événement : « Les n premiers lancers amènent tous des nombres autres que1 ».Cette suite est elle monotone pour l’inclusion ? Quelle est l’intersection des An?
Réponse attendue : langage courant et langage ensembliste.
2. On note An l’événement : « Les n premiers lancers amènent au moins une fois un ».Cette suite est elle monotone pour l’inclusion ? Quelle est la réunion des An?
Réponse attendue : langage courant et langage ensembliste.
1. Nous avons toujours plusieurs choix pour définir une tribu. La pertinence de chacun d’eux dépend des événementsau sens du langage courant que l’on veut modéliser.
6

Définition 4 notion de probabilitéSoit (Ω, T ) un espace probabilisable. Une probabilité sur (Ω, T ) est une application P : T →[0, 1] qui vérifie les propriétés suivantes :– P (Ω) = 1;– Pour toute suite d’événements deux à deux disjoints de T , (An)n,
P( ∞∪n=0
An
)=∞∑
n=0
P (An) (2.1)
Conséquences immédiates :• P (∅) = 0. Pourquoi ?
• Pour une suite finie, (Ak)0≤k≤n d’événements disjoints,
P (n∪k=0
Ak) =
n∑
k=0
P (Ak)
Il suffit d’appliquer (2.1) à la même suite prolongée par An+p = ∅. Cette définition d’une loi deprobabilité généralise donc celle qui a été donné en première année dans le cadre restreint desunivers finis.
• Une conséquence : pour tout A ∈ T , P (A) = 1− P (A)
• Une deuxième conséquence : une loi de probabilité est croissante pour l’inclusion
si A ⊂ B, alors, P (B) = P (A) + P (B \A) ≥ P (A).
• Cas où Ω est au plus dénombrable et T = P(E) :
Dans ce cas, toute partie A ∈ Ω, est finie ou dénombrable et l’on peut écrire A = ωi; i ∈ I oùI est soit de la forme [[1, n]] soit égal à N. Ainsi A = ∪i∈Iωi et
P (A) =∑
i∈IP (ωi) ≤ 1
En particulier, la famille (P (ω))ω∈Ω est sommable (revoir la définition de la sommabilité) et∑
ω∈Ω
P (ω) = 1 = P (Ω).
2.3 Propriétés, premiers exemples
Théorème 3 propriétés élémentairesSoit (Ω, T , P ) un espace probabilisé.
7

– Continuité croissante : si (An)n∈N, est une suite croissante d’événements, alors
limn→+∞
P (An) = P
(∪n∈N
An
)(2.2)
– Continuité décroissante : si (An)n∈N, est une suite décroissante d’événements, alors
limn→+∞
P (An) = P
(∩n∈N
An
)(2.3)
– Pour toute suite d’événements (An)n∈N, on a
P
(∪n∈N
An
)≤∞∑
n=0
P (An) (2.4)
Démonstrations– Preuve de (2.2) (famille croissante). Faire des dessins !
Observons que∞∪n=0
An = A0 ∪( ∞∪n=0
(An+1 \An)).
De façon analogue pour la famille finie, (Ak)0≤k≤n,
n∪k=0
Ak = A0 ∪(n−1∪k=0
(Ak+1 \Ak)).
On a donc d’après (2.1),
P (∞∪n=0
An) = P (A0) +∞∑
n=0
P (An+1 \n∪k=0
Ak)
P
(n∪k=0
Ak
)= P (A0) +
n−1∑
k=0
P (Ak+1 \k∪j=0
Aj)).
En quoi cela prouve-t-il notre assertion ?
– Preuve de (2.3) : passage au complémentaire.– Preuve de (2.4) : cela découle de
P (∞∪n=0
An) = P (A0) + P
( ∞∑
n=0
(An+1 \An)
)≤ P (A0) +
∞∑
n=0
P (An+1)
8

Exercice 7 MODéliserOn reprend l’expérience abordée dans l’exercice (4) qui consiste à lancer une pièce de monnaie
et à recommencer tant que « face » n’apparaît pas.On choisit ici
Ω = 0N ∪∞⋃
n=1
(0, 0, ..., 0, 1)
et on choisit pour tribu T = P(Ω).
1. Préciser les (0, 0, ..., 0, 1) dans la définition un peu cavalière de Ω.
2. Définir une probabilité sur (Ω, T ) .
3. Une issue est elle négligeable ?
Définition 5
Soit (Ω, T , P ) un espace probabilisé.Un évènement négligeable (ou quasi-impossible) est un événement A ∈ T tel que P (A) = 0.Un évènement presque-sûr (ou quasi-certain) est un événement A ∈ T tel que P (A) = 1.Une propriété Q est presque-sûre lorsque A = ω/Q(ω) est un évènement presque sûr.
Un système quasi-complet d’événements est une famille finie ou dénombrable d’éléments de T ,deux à deux disjoints et dont la réunion est un évènement presque-sûr.
Exercice 8 MODéliserOn reprend l’expérience abordée dans l’exercice (5) qui consiste à lancer un dé à six faces et à
recommencer tant que 6 n’apparaît pas.On choisit ici
Ω = [[1, 5]]N ∪∞⋃
n=1
(a1, a2, ..., an−1, 6)/ai ∈ [1, 5] pour i = 1, ..., n− 1
et on définit la tribu T comme étant la plus petite tribu contenant les événements (a1, a2, ..., an−1, 6)avec ai ∈ [1, 5]...
1. L’ensemble⋃∞n=1 (a1, a2, ..., an−1, 6)/ai ∈ [1, 5] pour i = 1, ..., n− 1 est il dénombrable ?
2. ? Pourquoi Ω n’est il pas dénombrable ?Le cours sur la dénombrabilité et ses prolongements (certains exercices) doivent être bienconnus avant de répondre à cette question.
3. Proposer une probabilité sur (Ω, T ) . Que vaut selon votre définition
P(
[[1, 5]]N)
?
L’événement du langage courant : « Il ne sort que des 1 indéfiniment » est il représenté(est-il un évènement) dans votre tribu ? Sinon, pourquoi cela vous laisse-t-il de marbre ?Êtes-vous satisfait de votre modèle ?
9

Exercice 9 entropie
La théorie de l’information est un modèle mathématique créé par Claude Shannon en 1948, quivise à quantifier mathématiquement la notion d’incertitude. Elle a depuis connu des développe-ments aussi bien en statistique qu’en physique théorique ou en théorie du codage.
On se place dans cette partie dans un espace probabilisé (Ω, T , P ) et on considère un système com-plet d’événements (A1, A2, ..., An) de probabilités respectives (p1, p2, ..., pn) toutes non nulles.On définit l’entropie de ce système par le nombre
H((Ai)i) = −n∑
k=1
pk ln pk.
On veut montrer que l’entropie doit être maximale lorsqu’aucune hypothèse ne peut être privilé-giée.
1. On se place dans le cas n = 4 et on considère une course de quatre chevaux, Ai étantl’événement « le cheval n˚ i remporte la course ».- Calculer l’entropie lorsqu’il y a équiprobabilité entre les événements (Ai).
- Calculer cette entropie lorsque p1 = p2 =1
8et p3 =
1
4.
2. (a) Vérifier que f : x→ x lnx est convexe sur [0, 1].
(b) Conclure.
Exercice 10 divergence de Kullback LeiblerEn théorie de l’information en théorie de l’apprentissage, en statistique en général, on est souventappelé à évaluer l’écart entre deux distributions de probabilités (par exemple une distributionthéorique dont on ne connait pas les paramètres que l’on veut estimer et une série d’observationsempiriques). On utilise souvent la divergence de Kullback-Leibler définie de la façon suivante :
Soient Ω = ω1, ..., ωn un ensemble fini ou dénombrable et P et Q deux lois de probabilités sur(Ω,P(Ω)). En notant pi = P (ωi) et qi = P (ωi) et en supposant que, pour tout i, qi 6= 0 ⇒pi 6= 0,
D(P ||Q) =∑
i/pi 6=0
pi ln
(qipi
). (2.5)
1. On suppose que Ω est fini et que pour tout i, pi > 0.
(a) Démontrer que cette expression est positive.
(b) On pose f(q1, ..., qn) =∑n
i=1 pi ln
(qipi
). Préciser le domaine de définition de cette
fonction et montrer qu’elle atteint son minimum en un seul point. Quel est il ?
(c) On pose f(q1, ..., qn) =∑
i/pi 6=0 pi ln
(qipi
). L’article de Wikipedia énonce : f(q) =
0 ssi (pi = qi) presque sûrement. Qu’est-ce que cela veut dire ? Justifiez l’énoncé unefois que vous l’aurez précisé.
10

3 Probabilités conditionnelles, indépendance
3.1 Probabilités conditionnelles, trois formules fondamentales
Définition 6 probabilités conditionnellesSoit (Ω, T , P ) un espace probabilisé et A un événement de probabilité non nulle. On appelleprobabilité conditionnelle relative à l’élémentA la loi de probabilité (ce qui doit être préalablementvérifié) sur (Ω, T ) définie par
PA(B) =P (A ∩B)
P (A).
On note aussi P (B|A) pour PA(B).
Interprétation en termes de fréquences
Le sens de cette formule est parfaitement clair sur l’exemple suivant, dans lequel on relève lesnombres des événements selon la couleur de la boule, son état d’usure... La probabilité sur Ω(ensemble des boules) étant supposée uniforme,
P (U |R) =P (U ∩R)
P (R)=...
...alors queP (U |B) =
P (U ∩B)
P (B)=...
...
usées non usées totalrouges 45 65 110blanches 48 85 133total 93 150 243
Théorème 4 formule des probabilités composéesPour toute famille (Ai)1≤i≤n d’évènements d’un espace probabilisé (Ω, T , P ) telle queP (∩n−1
i=1 Ai) >0, on a, avec la convention
⋂i∈∅Ai = Ω :
P
(n⋂
i=1
Ai
)=
n∏
k=1
P
(Ak|
k−1⋂
i=1
Ai
)
Démonstration.C’est la définition lorsque n = 2. On procède ensuite par récurrence.
11

On sait lire cette formule sur une structure arbores-cente définie de la façon suivante :– l’arbre A a pour racine l’évènement Ω;– tout nœud de S de hauteur i possède deux fils S ∩Ai et S ∩ Ai.
– à chaque arc (x, y) de l’arbre on associe le poidsP (y|x).
Ceci étant fait, la formule des probabilités compo-sées signifie que pour chaque nœud x de l’arbreP (x), est le produit des valeurs de chaque arc duchemin conduisant de la racine à x.
Théorème 5 formule des probabilités totalesSoit un (Ω, T , P ) espace probabilisé et (Ai)i∈I un système quasi-complet d’évènements (ie :∀(i, j) ∈ I2, Ai ∩Aj = ∅ et P (
⋃i∈I Ai) = 1). Alors, pour tout X ∈ T ,
P (X) =∑
i∈IP (X ∩Ai) =
∑
i∈IP (X|Ai)P (Ai).
Démonstration.
Exercice 11 d’après CCP (sujet 0)Un mobile se déplace aléatoirement dans l’ensemble des sommets d’un triangle ABC de la façonsuivante– si à l’instant n il est sur A, alors à l’instant n+ 1 il est sur B avec une probabilité de 3/4 ou sur
C avec une probabilité de 1/4 ;– si à l’instant n il est sur B, alors à l’instant n+1 il est sur A avec une probabilité de 3/4 ou surC avec une probabilité de 1/4 ;
– si à l’instant n il est sur C alors à l’instant n+ 1 il est sur B.On note An l’évènement « le mobile se trouve en A à l’instant n », Bn l’évènement « le mobile setrouve en B l’instant n » et Cn l’évènement « le mobile se trouve en C à l’instant n »Le mobile commence son trajet en partant du point A.On note, pour tout entier naturel n, an = P (An), bn = P (Bn) et cn = P (Cn)
1. (a) Calculer P (C2).
(b) Déterminer, en les justifiant, des relations de récurrence entre an+1, bn+1, cn+1 etan, bn, cn. On les écrira sous forme matricielle.
2. Soit A =
0 3/4 0
3/4 0 1
1/4 1/4 0
.
(a) Vérifier que tA est une matrice stochastique (ie : à termes positifs, la somme des termesd’une ligne quelconque étant égale à 1).
12

(b) Donner une interprétation probabiliste de cette observation.
(c) Montrer que A est diagonalisable et déterminer une matrice inversible P telle queP−1AP soit diagonale 2
(d) Déterminer la limite en l’infini des suites (an)n, (bn)n et (cn).
3. F C’est à peu de chose près (l’ordre des questions) un sujet Zéro CCP. Il ne mentionne pasd’espace probabilisé dans lequel ces calculs seraient valides. Pouvez vous corriger cela ?
Calculs en 1 page 47.
Exercice 12 loi de succession de Laplace 3.On considère des urnes (Uk)0≤k≤N . L’urne Uk contient k boules blanches et N − k boules noires.On réalise l’expérience qui consiste à :- choisir une urne au hasard ;- prélever avec remise successivement n boules dans cette urne.On note alors K le numéro de l’urne choisie et Xn le nombre de boules blanches prélevées.
1. Calculer la probabilité de l’événement (Xn = p) (ou la loi de Xn).
2. On se propose de calculer la limite de cette probabilité lorsque N tend vers +∞.(a) Monter que
B(p+ 1, q + 1) =
∫ 1
0tp(1− t)q dt =
p!q!
(p+ q + 1)!
(b) Conclure.
3. Sachant que (Xn = n), quelle est la probabilité que (Xn+1 = n+ 1)?
Théorème 6 formule de BayesSoit un (Ω, T , P ) espace probabilisé et (Ai)i∈I un système quasi-complet d’évènements tel quepour tout i ∈ I, P (Ai) > 0. Alors, pour tout X ∈ T tel que P (X) > 0 et tout j ∈ I,
P (Aj |X) =P (X|Aj)P (Aj)
P (X)=
P (X|Aj)P (Aj)∑i∈I P (X|Ai)P (Ai)
.
DémonstrationRetour à la définition des probabilités conditionnelles et formule des probabilités totales
Exercice 13 banque CCP 2015On dispose de 100 dés dont 25 sont pipés de telle sorte que pour ces dés pipés, la probabilitéd’obtenir le chiffre 6 lors d’un lancer vaut 1/2.
2. Le sujet CCP suggère d’utiliser une calculette. C’est en fait indispensable !3. A associer au problème angoissant : le Soleil se lèvera-t-il encore demain ?
13

1. On choisit un dé au hasard parmi les 100. On le lance et on obtient un 6. Probabilité qu’ilsoit pipé ?
2. On choisit un dé au hasard parmi les 100. On le lance n fois et on obtient n fois 6. Probabilitépn qu’il soit pipé ?
Exercice 14On reprend les dés de l’exercice précédent à ceci près que la probabilité d’obtenir un 6 avec un dépipé est égale à p. On note X le nombre de lancers amenant un 6 sur un total de n lancers.
1. Calculer P (X = k).
2. A partir de quelle valeur de k est il plus probable que le dé soit pipé ?
3.2 Indépendance, première approche
Définition 7 événements indépendantsSoit (Ω, T , P ) un espace probabilisé.On dit que deux événements A et B ∈ T sont indépendants ssi P (A ∩B) = P (A)× P (B).De la même façon, on dit que (Ai)i∈I ∈ T I est une famille d’événements mutuellement indépen-dants (ou indépendants dans leur ensemble) ssi pour toute sous-famille finie, (Aik)1≤k≤n,
P
(n⋂
i=k
Aik
)=
n∏
k=1
Aik .
On observera que la définition de l’indépendance de A et de B revient à dire que, soit l’undes deux événements a une probabilité nulle (et donc également A ∩ B), soit que PA(B) =P (B) et PB(A) = P (A).
Interprétation en termes de fréquencesusées non usées total
rouges 45 65 110blanches 90total
Exercice 15 événements indépendants dans leur ensemble et indépendance deux à deux.Construire, par exemple dans Ω = [[1, 8]], une famille d’événements indépendants deux à deux,non mutuellement indépendants.
Exercice 16
1. Justifier que si A et B sont deux événements indépendants, il en va de même pour A et B,pour A et B.
2. Généralisation ? Formuler et démontrer.
Exercice 17On suppose A et C indépendants de même que B et C. Qu’en est il de A ∪B et C?
14

Exercice 18 indépendance et probabilités conditionnelles.Soit (Ω, T , P ) un espace probabilisé et (Ai)i∈I ∈ T I est une famille de n événements.
1. Monter que si les événements de la famille (Ai)i∈I sont mutuellement indépendants, alors,pour toute sous-famille finie (Aik)1≤k≤n telle que P (∩1≤k≤nAik) > 0 et tout élément Aien dehors de cette famille finie :
P (Ai|Ai1 ∩Ai2 ∩ ... ∩Ain) = P (Ai).
2. On se propose de prouver la réciproque. On suppose donc que pour toute sous-famille finie(Aik)1≤k≤n telle que P (∩1≤k≤nAik) > 0 et tout élément Ai en dehors de cette famillefinie :
P (Ai|Ai1 ∩Ai2 ∩ ... ∩Ain) = P (Ai).
Considérons alors une sous-famille finie (B1, ...., Bm) de (Ai)i∈I .
(a) Montrer lorsque P (B1 ∩B2 ∩ ... ∩Bm) > 0 que
P (B1 ∩B2 ∩ ... ∩Bm) =
m∏
j=1
P (Bj).
Utiliser la formule des probabilités totales.
(b) On se place dans le cas où P (B1 ∩B2 ∩ ...∩Bm) = 0. En raisonnant sur le plus petitindice p ≥ 1 tel que P (B1 ∩B2 ∩ ... ∩Bp) = 0,
Exercice 19 indicatrice d’EulerOn appelle indicatrice d’Euler la fonction φ : N \ 0 → N qui, à n associe le nombre des entiers1 ≤ p ≤ n, premiers avec n.
Soit n ∈ N\0, 1. On considère l’intervalle Ω = [[1, n]] muni de la loi de probabilité uniforme.On note :- n =
∏mi=1 p
αii la décomposition de n en facteurs premiers ;
- Ap l’événement Ap = x ∈ Ω; p|x;- E l’événement E = x ∈ Ω; pgcd(x, n) = 1;Conseil : on dessinera l’intervalle Ω ce qui permettra d’y représenter l’événementApi par exemplesous la forme
1 ... pi ... 2pi ... (ni − 1)− pi ... ni pi
1. Quel rapport entre p(E) et φ(n) défini dans le préambule ?
2. Pour n = 2 × 11 = 22, expliciter A2, A11. Vérifier qu’ils sont indépendants et calculerP (E) ainsi que φ(22) (formule attendue en prévision de généralisations).
3. Retour au cas genéral.
15

(a) Expliciter les événements Apj et ∩j∈JApj pour (pj)j∈J famille de diviseurs premiersdistincts de n.Montrer que les événements Apj mutuellement sont indépendants.
(b) Exprimer E en fonction des Api . En déduire p(E) puis l’expression de φ(n).
Quels théorèmes d’arithmétique interviennent ils ici ?Corrigé en 2 page 48.
4 Variables aléatoires discrètes
Définition 8 variable aléatoire discrèteSoient (Ω, T ) un espace probabilisable. Une variable aléatoire discrète sur Ω est une applicationX : Ω→ E où E est un ensemble au plus dénombrable, telle que, pour tout élément x ∈ E,
X−1(x) ∈ T .
Théorème 7 Si (Ω, T , P ) est un espace probabilisé et X : ω → E une variable aléatoire dis-crète. Alors,– Pour toute partie B ∈ P(E), X−1(B) ∈ T .– On définit une probabilité sur (E,P(E)) en posant :
PX(B) = P (X ∈ B).
Démonstration Le point crucial est la dénombrabilité de E pour le premier point. Pour le secondil y a deux vérifications à faire :--
Vocabulaire et notations :- si X : (Ω, T , P )→ E et Y : (Ω′, T ′, P ′)→ E sont deux variables aléatoires discrètes de mêmeloi, c’est à dire que pour tout x ∈ E (dénombrable), P (X = x) = P ′(Y = x), ou encore siPX = PY , on note X ∼ Y .- On appelle loi de X la loi de probabilité PX . Lorsqu’on donne un nom ou associe un symbole àcette loi, L par exemple, on note encore X ∼ L.
Avec les exercices de modélisation qui précèdent, vous aurez compris que pour construire unmodèle, on a une démarche inversée par rapport à cette définition : on se donne Ω, E et X :Ω → E. On définit alors la tribu T de telle sorte que X devienne une variable aléatoire. Lesprobabilités P et PX sont définies en même temps en posant P (X ∈ A) = PX(A). La distinctionentre P et PX est assez formelle dans cette façon de faire. Elle est cruciale lorsqu’on est amené àétudier plusieurs variables aléatoires sur le même espace probabilisé.
16

Reprenons nos deux exemples prototypes
Exercice 20 MODéliserOn reprend l’expérience abordée dans l’exercice (4) qui consiste à lancer une pièce de monnaie
et à recommencer tant que « face » n’apparaît pas.On choisit ici
Ω = 0N ∪∞⋃
n=1
(0, 0, ..., 0, 1)
et on choisit pour tribu T = P(Ω).
1. Définir un ensemble dénombrable E, une application X : Ω → E et une tribu sur Ω telsque :– X soit une variable aléatoire ;– l’expérience (« face » sort au nieme lancé) soit représentable sous la forme (X ∈ A).
2. Définir une probabilité sur (Ω, T ) et préciser la loi de X.
Exercice 21 MODéliserOn reprend l’expérience abordée dans l’exercice (5) qui consiste à lancer un dé à six faces et à
recommencer tant que 6 n’apparaît pas.On choisit encore
Ω = [[1, 5]]N ∪∞⋃
n=1
(a1, a2, ..., an−1, 6)/ai ∈ [[1, 5]] pour i = 1, ..., n− 1 .
1. Définir un ensemble dénombrable E, une application X : Ω → E et une tribu sur Ω telsque :– X soit une variable aléatoire ;– l’expérience (« 6 » sort au nieme lancé) soit représentable sous la forme (X ∈ A).
2. Définir une probabilité sur (Ω, T ) et préciser la loi de X.
4.1 Exemples de variables aléatoires discrètes
• Loi de Bernoulli. Notation : X ∼ b(p).
On considère une alternative simple : à chaque répétition soit A soit A est réalisé avec pour proba-bilités respectives p et 1− p. On définit une variable aléatoire sur (Ω = A, A,P(Ω)) en posantX(A) = 1, X(A) = 0.La loi de X est alors
P (X = 0) = 1− p, P (X = 1) = p.
• Loi binomiale de paramètres n et p. Notation : X ∼ B(n, p).
On considère ici n répétitions indépendantes
17

– On peut représenter les issues de l’expérience par Ω = 0, 1n, ensemble fini.– On attribue à chaque événement élémentaire la probabilité P (w) = pk(1− p)n−k.– La variable aléatoire X définie sur Ω indiquant le nombre de réalisations de A sur n répétitions
a pour distribution (ou loi de probabilité)
P (X = k) = (nk) pk(1− p)n−k.
• Loi géométrique de paramètre p. Notation : X ∼ G(p).
On considère ici des répétitions indépendantes illimitées de la même expérience de Bernoulli eton considère la variable aléatoire qui renvoie le numéro d’ordre du premier succès (la premièreréalisation de A)
P (X = k) = (1− p)k−1p.
1. Proposer un ensemble probabilisable (Ω, T ). Est il dénombrable ?
2. Proposer une définition de X : Ω →?? ainsi que sa distribution de probabilité (ce quisuppose une probabilité sur (Ω, T )).
Théorème 8 caractérisation de la loi géométrique comme loi sans mémoireX : (Ω, T , P )→ N\0 une variable aléatoire telle pour (n, k) ∈ (N\0)2,
P (X > n+ k|X > n) = P (X > k).
Alors X suit une loi géométrique de paramètre p = P (X = 1).
Interprétation de l’hypothèseOn peut interpréter X comme le n˚ d’ordre ou le temps d’attente de la première réalisation d’unévénement A (succès) au cours d’une suite d’expériences E1, E2, E3, ..., En, ... L’hypothèse sug-gère alors que si le succès n’est pas au rendez-vous après n tentatives, la probabilité qu’il failleattendre encore k essais est la même qu’à partir de la première réalisation. On parle alors de loisans mémoire.
Démonstration1. Faites un dessin pour représenter les événements
(X > n) pour n ≥ 1.Montrer que
P (X > n+m) = P (X > n)P (X > m).
2. On note p = P (X = 1) et αn = P (X > n). Déterminer αn et en déduire P (X = n).Regardez le dessin !
• Loi de Poisson de paramètre λ Notation : X ∼ P(λ).
18

On dit qu’une variable aléatoire X : (Ω, T , P ) → N suit une loi de Poisson de paramètre λ > 0lorsque sa distribution de probabilité est
P (X = k) =λk
k!e−λ.
1. Vérifier qu’il s’agit bien d’une loi de probabilité.
2. Calculer∞∑
k=0
k P (X = k). Comment interpréteriez-vous cette somme ?
Le théorème qui suit est au programme. Il y est parce que c’est un prototype de situation où lasuites des lois d’une suite de variables aléatoires tend vers une autre loi. Il n’est en rien quelquechose de fondamental sur la loi de Poisson qui doit par contre apparaître comme modélisant unesituation bien particulière décrite en Annexe 9.
Théorème 9 approximation d’une loi binomiale par une loi de PoissonOn se donne une suite (pn)n ∈ [0, 1]N\0 et une suite de variables aléatoires (Xn)n telles quepour tout n ∈ N\0, Xn : (Ω, T , P )→ N suit une loi binomiale de paramètres n et pn ∈ [0, 1] :Xn ∼ B(n, pn).On suppose que n pn = λn a pour limite un réel λ. Alors,
limn→+∞
P (Xn = k) =λk
k!e−λ. (4.1)
Démonstration1. Interpréter l’hypothèse n pn = λn ∼ λ.2. Écrire P (Xn = k) et remplacer pn par son expression en fonction de n et de λn.
3. Organiser et conclure.
4.2 Couples et n-uplets de v. a. discrètes, variables vectorielles
Définition 9Soient (Ω, T , P ) un espace probabilisé et X et Y deux variables aléatoires discrètes définies sur
cet espace.• On appelle loi conjointe du couple (X,Y ) la loi de probabilité définie sur X(Ω)× Y (Ω) par
P(X,Y )(A×B) = P ((X ∈ A) ∩ (Y ∈ B))
CommeX(Ω)×Y (Ω) est au plus dénombrable, cette loi est entièrement définie par la donnée desprobabilités
P (X = xi ∩ Y = yj), pour tout (xi, yj) ∈ X(Ω)× Y (Ω).
• Les lois marginales du couple (X,Y ) sont les lois de X et de Y : elles sont données par
P (X = xi) =∑
j
P (X = xi ∩ Y = yj) pour tout xi ∈ Proj1X(Ω)× Y (Ω)
19

P (Y = yj) =∑
j
P (X = xi ∩ Y = yj) pour tout yj ∈ Proj2X(Ω)× Y (Ω)
• Pour x ∈ X(ω) tel que P (X = x) 6= 0 (respectivement P (X > x) 6= 0), la loi conditionnellede Y sachant (X = x) (respectivement (X < x), etc.) est la loi de probabilité sur Y (Ω) définiepar :
P(X=x)(Y = yj) = P (Y = yj |X = x) =P (Y = yj ∩X = x)
P (X = x)
respectivement :
P(X>x)(Y = yj) = P (Y = yj |X > x) =P (Y = yj ∩X > x)
P (X > x)
X\Y y1 . . . yq totalx1 P (X = x1 ∩ Y = y1) . . . P (X = x1 ∩ Y = yq) P (X = x1)...
.... . .
......
xp P (X = xp ∩ Y = y1) . . . P (X = xp ∩ Y = yq) P (X = xp)
total P (Y = y1) . . . P (Y = yq) what else ?
Questions :
1. Pourquoi X(Ω)× Y (Ω) est il au plus dénombrable ?
2. Pourquoi (X,Y ) est elle une variable aléatoire discrète ? En quoi (X ∈ A) ∩ (Y ∈ B) estil un événement ?
3. Montrer que, connaissant les seules lois marginales, on ne peut reconstituer en général, laloi conjointe.
X\Y y1 y2 y3 total
x11
3
x21
3
x31
3
total1
3
1
3
1
31
X\Y y1 y2 y3 total
x11
3
x21
3
x31
3
total1
3
1
3
1
31
Dans ces deux tableaux vous ferez en sorte que les lois conjointes soient distinctes et que les loismarginales soient les mêmes
20

Définition 10 n-uplets de variables aléatoires, variables vectorielles...Soit (Ω, T , P ) un espace probabilisé et Z = (X1, X2, ...., Xn) un n-uplet de v.a définies sur cet
espace (on dit aussi une variable aléatoire vectorielle) :.• On étend les notions précédentes en définissant la loi conjointe du n-uplet :
P (Z = (x1, ..., xn)) = P
(n∩i=1
(X = xi)
)
• ainsi que les lois marginales
P (Xn = ω) =∑
(x1,...,xn−1)
= P (X1 = x1 ∩ ... ∩Xn−1xn−1 ∩Xn = ω)
Définition 11 variables aléatoires indépendantesSoit (Ω, T , P ) un espace probabilisé.• On dit que deux variables aléatoires discrètes X et Y définies sur cet espace sont indépendantesssi pour tous A ⊂ X(Ω), B ∈ Y (Ω),
P ((X ∈ A) ∩ (Y ∈ B)) = P (X ∈ A)× P (Y ∈ B).
• On dit que des variables aléatoires discrètes (Xi)i sont mutuellement indépendantes ssi pourtoute famille finie d’indices (i1, i2, ..., in) et toute famille (Ak)ik avec Aik ∈ Xik(Ω), on a
P
(n⋂
k=1
(Xik ∈ Aik)
)=
n∏
k=1
P (Xik ∈ Aik)
Théorème 10 un résultat fondamentalSoit (X1, X2, ...., Xn) un n-uplet de variables aléatoires discrètes et mutuellement indépen-dantes sur l’espace probabilisé (Ω, T , P ).Alors, pour tout couple (f, g) de fonctions f : X1(Ω)× ...×Xp(Ω) → E = f (
∏pi=1Xi(Ω)) et
g : Xp+1(Ω)× ...×Xn(Ω)→ F = g(∏n
i=p+1Xi(Ω))
(avec 1 ≤ p < n) les variables aléatoiresdiscrètes
Z = f(X1, ..., Xp) et W = g(Xp+1, ..., Xn)
sont indépendantes.
Démonstration on ne la fait pas (hors programme).
Remarque : nous ferons un usage systématique de ce résultat dans les circonstances suivantes :Si (Xn)n est une suite de variables aléatoires indépendantes, alors :
1. Xn+1 et la variable vectorielle Yn = (X1, X2, ..., Xn) sont indépendantes ;
2. Xn+1 et la variable Sn =∑n
k=1Xk sont indépendantes ;
3. X2n+1 et la variable Tn =
∑nk=1X
2k sont indépendantes ;
21

Exercice 22
1. Montrer que des événements sont indépendants ssi leurs variables indicatrices sont desvariables aléatoires indépendantes (la variable indicatrice de A est définie par X(ω) = 1 siω ∈ A, et X(ω) = 0 sinon).
2. Démontrer que si les variables aléatoires discrètes (X1, X2, ...., Xn) sont mutuellement in-dépendantes, alors pour toute famille (φ1, φ2, ...., φn) de fonctions telles que les variablesaléatoires (φ1 X1, φ2 X2, ...., φn Xn) sont définies , celles-ci sont également mutuel-lement indépendantes.
Exercice 23 sup et inf de v.a. indépendantesOn considère des variables aléatoires discrètes (X1, X2, ...., Xn) mutuellement indépendantes àvaleurs dans R..
1. Donner la fonction de répartition de sup(Xi);
2. Donner la fonction de répartition de inf(Xi);
Exercice 24 somme de v.a. première approcheOn considère deux variables aléatoires discrètes (X1, X2) à valeurs dans N.
1. Exprimer la loi de (X1 +X2) en fonction des lois conditionnelles de X2 sachant (X1 = k)pour k ∈ Z.
2. Cas de variables indépendantes ?
3. Peut on généraliser à des variables discrètes à valeurs dans Z,R ou vectorielles ?
Exercice 25Un corps radioactif émet un nombre aléatoire N de particules pendant une durée déterminée. Onsuppose que :– N suit une loi de Poisson de paramètre λ.– Chaque particule est détectée avec une probabilité p ∈]0, 1[.On note X le nombre de particules détectées.
1. Donner la loi de X.
2. Donner la loi de N sachant que X = k.
5 Moments : espérance, variance et écart-type
5.1 Espérance
Définition 12Soit X : (Ω, T , P ) → R une variable aléatoire discrète et à valeurs réelles. On dit que X admetune espérance finie si la famille (au plus dénombrable) (x × P (X = x))x∈X(Ω) est sommable.On pose alors
E(X) =∑
x∈X(Ω)
x× P (X = x)
22

Lorsque X prend des valeurs positives, son espérance est la somme
E(X) =∑
x∈X(Ω)
x× P (X = x) ∈ [0,+∞].
• Exemples de calculs d’espérance :
1. Calculer l’espérance d’une variable aléatoire de loi binomiale de paramètres n et p.
P (X = k) = E(X) =
2. Calculer l’espérance d’une variable aléatoire de loi géométrique de paramètre p (à revoiraprès l’étude des séries entières le cas échéant).
P (X = k) = E(X) =
3. Calculer l’espérance d’une variable aléatoire de loi exponentielle de paramètre λ
P (X = k) = E(X) =
4. Construire une variable aléatoire à valeurs entières, d’espérance infinie.
P (X = k) = E(X) =
Par exemple pour le gain d’un jeu dans lequel le joueur gagne d’autant plus qu’il lancelongtemps un dé, le jeu s’arrêtant lorsqu’il obtient un 1 par exemple.
Théorème 11 comparaison Soient X et Y deux variables aléatoires discrètes sur (Ω, T , P ), àvaleurs réelles. Si |X| ≤ |Y | et si Y admet une espérance finie, alorsX admet aussi une espérancefinie.
Démonstration1. Écrire l’événement (X = x) comme un réunion disjointe (et dénombrable) d’événements
de la forme (X = x) ∩ (Y = y).
2. Majorer les sommes finies de la forme∑xP (X = x).
23

3. Conclure avec le théorème de sommation par paquets (1.1).
Théorème 12 linéarité et positivitéSoient X et Y deux variables aléatoires discrètes sur (Ω, T , P ), à valeurs réelles, qui admettentdes espérances finies. Alors,• X + Y est une va. discrète qui admet pour espérance
E(X + Y ) = E(X) + E(Y ).
• Pour tout λ ∈ R, λX est une va. discrète qui admet pour espérance
E(λX) = λE(X).
• Si X ≤ Y, alors E(X) ≤ E(Y )
Démonstration on fait la preuve pour l’additivité...1. Écrire l’événement (X + Y = z) comme réunion disjointe d’événements définis à partir deX ou de Y.
2. Majorer les sommes finies de la forme∑ |zk|P (X + Y = zk). En déduire que Z est
d’espérance finie.3. Conclure avec le théorème de sommation par paquets (1.1).
Voir détails en 3 .
Théorème 13 formule de transfertSoientX une variable aléatoire discrète sur (Ω, T , P ), à valeurs réelles, d’espérance finie et f uneapplication de X(Ω) dans R.Alors f X : (Ω, T , P ) → R est d’espérance finie ssi la famille (f(x)P (X = x))x∈X(Ω) estsommable. Dans ce cas
E(f(X)) =∑
x∈X(Ω)
f(X)P (X = x) (5.1)
Démonstration non faite
Théorème 14 produit de variables aléatoires indépendantesSoientX et Y deux variables aléatoires discrètes sur (Ω, T , P ), à valeurs réelles, qui admettent desespérances. Si X et Y sont indépendantes, X × Y est une va. discrète qui admet pour espérance
E(X × Y ) = E(X)× E(Y ).
Démonstration
24

5.2 Variance, écart-type et covariance
Définition 13 moment d’ordre 2Soit X une variable aléatoire discrète sur (Ω, T , P ) à valeurs réelles. On dit que X admet un mo-ment d’ordre 2 (ou qu’elle est de carré sommable) ssi E(|X|2) < +∞ (X2 admet une espérancefinie).
Théorème 15 variables de carrés sommablesSoient X et Y deux variables aléatoires discrètes sur (Ω, T , P ) à valeurs réelles ou complexes.
1. Si E(|X|2) < +∞, alors E(|X|) < +∞.2. Si E(|X|2) < +∞, alors E
(|X − E(X)|2
)< +∞. De plus
E((X − E(X))2
)= E(X2)− E2(X) (formule de Huygens)
3. Si E(|X|2) < +∞ et E(|Y |2) < +∞ alors E(|X Y |) < +∞. De plus, pour des variablesréelles,
E (X Y )2 ≤ E(X2)E(Y 2) (inégalité de Cauchy-Schwarz)
4. Si E(|X|2) < +∞ et E(|Y |2) < +∞ alors E((|X|+ |Y |)2) < +∞.L’ensemble des v.a. sur (Ω, T , P ) à valeurs réelles qui admettent un moment d’ordre2, forme un espace vectoriel.
Démonstration
Définition 14 variance, écart-type, covariance
1. Soit X une variable aléatoire discrète à valeurs réelles définie sur (Ω, T , P ), la variance etl’écart-type de X sont définis respectivement par
var(X) = E((X − E(X))2) et σ(X) = var(X)1/2
On note aussi V (X) pour var(X).
2. Soient X et Y deux variables aléatoires discrètes à valeurs réelles définies sur (Ω, T , P ), lacovariance du couple (X,Y ) est définie par :
cov(X,Y ) = E((X − E(X))(Y − E(Y )).
Théorème 16 propriétés de la variance et de la covariance
1. cov est une forme bilinéaire, symétrique, positive sur le sous-espace des v.a. réelles définiessur (Ω, T , P )admettant un moment d’ordre 2.
2. cov(X,Y ) = E(X Y )− E(X)E(Y ).
3. var(X) = cov(XX) = E(X2)− E2(X) (formule de Huygens)
25

4. var(αX + β) = α2var(X) pour tout couple (α, β) ∈ R2.
5. Pour toute famille (X1, ..., Xn) de v.a. réelles définies sur (Ω, T , P ),
var
(n∑
i=1
Xi
)=
n∑
i=1
var(Xi) + 2∑
1≤i<j≤ncov(Xi, Xj).
6. Si X et Y sont des v.a. indépendantes, alors
cov(X,Y ) = 0,
var(X + Y ) = var(X) + var(Y ).
7. Si (X1, ..., Xn) sont mutuellement indépendantes,
var
(n∑
i=1
Xi
)=
n∑
i=1
var(Xi).
DémonstrationTous les calculs sont faciles et vous devez les faire régulièrement (réflexes à acquérir). Pour le casdes variables indépendantes tout repose sur la relation E(XY ) = E(X)E(Y ).
Exercice 26Construire deux variables non indépendantes telles que cov(X,Y ) = 0.
Exercice 27Déterminer l’espérance et la variance de la moyenne empirique de variables réelles et mutuelle-ment indépendantes (X1, ..., Xn).
Rappel : la moyenne empirique est définie par Sn =1
n
∑ni=1Xi.
Définition 15
1. Une v.a. est dite centrée lorsque E(X) = 0 (pour toute v. a. X, X − E(X) est centrée).
2. Une v.a. est dite réduite lorsque V (X) = 1 (pour toute v. a. X, dont la variance n’est pas
nulle,X − E(X)
σ(X)est centrée et réduite).
• Exemples de calculs de variances :
1. Calculer la variance d’une variable aléatoire de loi binomiale de paramètres n et p.
P (X = k) = E(X) = V (X) =
26

2. Calculer la variance d’une variable aléatoire de loi géométrique de paramètre p (à revoiraprès l’étude des séries entières le cas échéant).
P (X = k) = E(X) = V (X) =
3. Calculer la variance d’une variable aléatoire de loi exponentielle de paramètre λ
P (X = k) = E(X) = V (X) =
4. Construire une variable aléatoire à valeurs entières, d’espérance finie et de variance infinie.
P (X = k) = E(X) = V (X) =
27

5.3 Inégalité de Markov et inégalité de Bienaymé-Tchebychev
Théorème 17 inégalité de MarkovSoit X une variable aléatoire à valeurs réelles et positives, d’espérance finie E(X). Pour tout réel
λ > 0, P (X ≥ λ) ≤ E(X)
λ.
DémonstrationNous avons E(X) =
∑
x∈X(Ω)
xP (X = x). Cela se réécrit,
E(X) =∑
x∈X(Ω)
x≥λ
xP (X = x) +∑
x∈X(Ω)
x<λ
xP (X = x).
Comme X est à valeurs positives,
E(X) ≥∑
x∈X(Ω)
x≥λ
xP (X = x) ≥∑
x∈X(Ω)
x≥λ
λP (X = x) = λP (x ≥ λ).
Remarque : On écrit souvent cette inégalité sous la forme P (X ≥ λm) ≤ 1
λavec E(X) = m.
On l’interprète par exemple en terme de dispersion :
– λ = 2, P (X ≥ 2m) ≤ 1
2: pour une variable positive, la probabilité que X soit supérieur à
deux fois l’espérance est inférieure à1
2... ou encore la médiane ne peut être supérieure à deux
fois l’espérance.
– λ = 4, P (X ≥ 4m) ≤ 1
4: pour une variable positive, la probabilité que X soit supérieur à
quatre fois l’espérance est inférieure à1
4...
ou encore le quatrième quartile ne peut être supérieur à quatre fois l’espérance.
Exercice 28Dans un pays A le salaire moyen est m, le salaire médian est µ.
1. Que dire du salaire médian et du salaire moyen ?
2. Que dire de la proportion de la population qui gagne plus de deux fois, plus de cent fois lesalaire moyen ?
3. Que dire des revenus de la population qui se situe dans le dernier décile, dans le derniercentile ?
Données : il y a des best-sellers d’économie scientifique sur la question ( 6= de celle des médias).Ce qui est intéressant, c’est de comparer l’évolution au cours du temps.
28

Théorème 18 inégalité de Bienaymé-TchebychevSoit X une variable aléatoire discrète, à valeurs numériques, définie sur un espace probabilisé
(Ω, T , P ).On suppose queX2 est d’espérance finie et note µ = E(X) et σ2 = E((X−µ)2) = E(X2)−µ2.Alors, pour tout ε > 0,
P (|X − µ| ≥ ε) ≤ σ2
ε2.
Démonstration
Introduisons l’événement A = (|X − µ| ≥ ε) . La variable aléatoire |X − µ|2 se décompose :
|X − µ|2 = |X − µ|2 × 1A + |X − µ|2 × 1A.
Cela donne :
|X − µ|2 = |X − µ|2 × 1A + |X − µ|2 × 1A
V ar(X) = E(|X − µ|2 × 1A
)+ E
(|X − µ|2 × 1A
)
≥ ε2E(1A) + 0
= ε2P (A)
5.4 Loi faible des grands nombres
Théorème 19 loi faible des grands nombresSoit (Xn)n une suite de variables aléatoires indépendantes de même espérance µ et de mêmevariance σ2. Les moyennes empiriques des (Xn)n sont les variables aléatoires définie par
Xn =Snn
=1
n
n∑
k=1
Xk.
1. La moyenne empirique Xn a pour espérance µ et pour varianceσ2
n.
2. Pour tout ε > 0,lim
n→+∞P(|Xn − µ| ≥ ε
)= 0.
3. Plus précisément :
P(|Xn − µ| ≥ ε
)≤ σ2
nε2.
Démonstration
29

1. E(Sn) =n∑
i=1
E(Xi) = nµ et E(Sn) = µ.
2. V ar(Sn) = V ar(n∑
i=1
Xi) = nσ2 (ici l’hypothèse d’indépendance intervient).
3. L’inégalité de Bienaymé-Tchebychev, pour Xn s’exprime :
P (|Xn − µ| ≥ ε) ≤σ2
nε2.
Exercice 29 la plus simple des démonstrations du théorème de WeierstrassOn rappelle que l’on définit les polynômes de Bernstein de degré n en posant
B(n)k (x) = (nk)xk(1− x)n−k
et qu’à toute fonction f continue sur [0, 1] et à toute subdivision (0, 1n ,
2n , ...,
n−1n , 1), on associe
le polynôme
Bn(f)(x) =
n∑
k=0
f
(k
n
)B
(n)k (x).
1. Soit x ∈ [0, 1] et Xn,x une variable aléatoire de loi B(n, x).
Vérifier que E(f
(Xn,x
n
))= Bn(f)(x).
2. Soit ε > 0.
(a) Montrer que pour tout x ∈ [0, 1],
|Bn(f)(x)− f(x)| ≤ E(∣∣∣∣f
(Xn,x
n
)− f(x)
∣∣∣∣).
(b) Justifier qu’il existe αε > 0 tel que
∀(x, y) ∈ [0, 1]2, |x− y| ≤ αε ⇒ |f(x)− f(y)| ≤ ε.
(c) Soit A l’événement défini par A =
(∣∣∣∣X
n− x∣∣∣∣ ≤ αε
).
En écrivant∣∣∣∣f(X
n
)− f(x)
∣∣∣∣ =
∣∣∣∣f(X
n
)− f(x)
∣∣∣∣ 1A +
∣∣∣∣f(X
n
)− f(x)
∣∣∣∣ 1A, mon-
trer qu’il existe un rang à partir duquel
|Bn(f)(x)− f(x)| ≤ 2ε.
(d) Conclusion ?
30

6 Fonctions génératrices
6.1 Définition, premières propriétés
Définition 16 fonction génératrice d’une variable entièreSoit X une variable aléatoire définie sur un espace probabilisé (Ω, T , P ), à valeurs dans N. Onappelle fonction génératrice de X la série entière définie par
GX(z) =∞∑
k=0
P (X = k)zk = E(zX).
Remarque : On peut généraliser cette notion définir la fonction génératrice d’une suite numérique(an)n en posant
G((an)n)(z) =
∞∑
n=0
anzn,
dans ce cas GX apparaît comme la série génératrice associée à la suite (pn)n (loi de X). Il s’agitlà de l’outil fondamental dans l’étude des dénombrements par exemple.
Théorème 20 propriétés des fonctions génératrices de variables aléatoiresSoit X une variable aléatoire entière (à valeurs dans N) de fonction génératrice GX .
1. La série entière GX converge normalement sur le disque fermé D(0, 1). Elle est en particu-lier continue sur ce disque.
2. GX(1) = 1 et la série entière GX a un rayon de convergence supérieur ou égal à 1.
3. GX caractérise la loi de X : connaissant GX on déduit P (X = k) =G
(k)X (0)
k!.
4. X est d’espérance finie ssi GX est de classe C1 sur [0, 1]. Dans ce cas
G′X(1) = E(X).
5. Si GX est supposée seulement dérivable en 1, alors X est d’espérance finie, GX est declasse C1 sur [−1, 1] et G′(1) = E(X).
6. Xn est d’espérance finie ssi GX est de classe Cn sur [0, 1]. Dans ce cas G(n)X (1) =
E(X(X − 1)...(Xn + 1)).
En particulier, lorsque X2 est d’espérance finie,
V (X) = E((X − E(X))2
)= E
(X2)− E (X)2 = G”
X(1) +G′X(1)−G′2X(1)
Démonstration On prouvera (4)⇒, puis (5) dont on déduira (4)⇐ .
1. Notons un(z) = P (X = n)zn, on a ||un|| ∞[−1,1]
= P (X = n) qui est le tg d’une série
convergente. De la convergence normale sur l’intervalle fermé on déduit la cv uniforme etla continuité de la somme sur [−1, 1].
31

2. GX(1) est défini (convergence simple sur [−1, 1]) et GX(1) =∑∞
n=0 P (X = n) = 1. Ona donc R ≥ 1.
3. Si GX = GY , alors pour tout n ∈ N, P (X = n) =G
(n)X (0)
n!=G
(n)Y (0)
n!= P (Y = n).
Noter que si R = 1, le cours sur les séries entières ne nous apporte que des informationssur l’ouvert ] − 1, 1[. Ce que allons obtenir dans les propositions suivantes fera donc appelà d’autres techniques (en effet, si nous savons que GX est de classe C∞ sur ]−R,R[, nousne savons rien a priori de ce qui se passe sur [−R,R]).
4. (4)⇒ On suppose que∑nP (X = n) converge.
Rappelons le théorème de dérivation terme à terme d’une série sur un intervalle I
(a) Si les fonctions un sont de classe C1 sur I,
(b) s’il existe a ∈ I, tel que∑un(a) converge,
(c) si∑u′n converge uniformément sur tout compact de I,
Alors,∑un converge uniformément sur tout compact de I, la somme est de classe C1 et on
a ( ∞∑
n=0
u′n(x)
)′=
∞∑
n=0
u′n(x)
sur I.Dans le cas présent avec un(x) = P (X = n)xn et u′n(x) = nP (X = n)xn−1, les deuxpremiers points sont clairs et le troisième découle de l’hypothèse car
||u′n|| ∞[−1,1]
= nP (X = n)
est alors le t.g. d’une série convergente.∑u′n converge normalement sur I = [−1, 1].
On a alors sur [−1, 1] :
G′X(x)
( ∞∑
n=0
un(x)
)′=
∞∑
n=1
k P (X = n)xn−1(x)
et, en particulier G′X(1) = 1.
5. On suppose seulement que G′X(1) existe. On écrit le taux de variation
GX(1)−GX(x)
1− x =1
1− x∞∑
n=0
P (X = n)(1− xn)
=1
1− x∞∑
n=0
P (X = n)(1− x)(1 + x+ x2 + ...+ xn−1)
=
∞∑
n=0
P (X = n)(1 + x+ x2 + ...+ xn−1)
32

On voit bien que le terme nP (X)n va apparaître en faisant tendre x vers 1 dans (1 + x +... + xn−1) mais le problème est que nous avons affaire à une somme de série (une limitesur n.) Observons que la fonction
x→∞∑
n=0
P (X = n)(1 + x+ x2 + ...+ xn−1)
est croissante sur [0, 1[ (chaque terme est une fonction croissante) donc inférieure à sa limitequi est ` = G′X(1).
Comme c’est une série à termes positifs sur [0, 1], on a aussi pour tout N :
N∑
n=0
P (X = n)(1 + x+ x2 + ...+ xn−1) ≤∞∑
n=0
P (X = n)(1 + x+ x2 + ...+ xn−1)
≤ ` = G′X(1)
La première somme est finie, on fait tendre x vers 1, cela donne, pour tout N,
N∑
n=0
nP (X = n) ≤ `...
Le reste suit.Cela fait on retourne à la réciproque (4)⇐: si GX est de classe C1 sur [−1, 1], elle estdérivable en 1 et bla bla bla...
6. On se contente de faire les calculs. On mémorise la formule avec l’exercice qui suit.
Fonctions Génératrices de lois usuelles.
Loi paramètre P (X = n) GX E(X) V (X)
de Bernoulli b(p) P (X = k) =
1− p si k = 0
p si k = 11− p+ pz p p(1− p)
binomiale B(n, p) P (X = k) = (nk) pk(1− p)n−k (1− p+ pz)n np np(1− p)
géométrique G(p) P (X = k) = (1− p)k−1ppz
1− (1− p)z1
p
1− pp2
33

de Poisson P(λ) P (X = n) = e−λλn
n!eλ(z−1) λ λ
Exercice 30
Retrouver espérance et variance des lois usuelles à l’aide de leurs série génératrices
6.2 Sommes de variables indépendantes et entières
Théorème 21Si (X1, X2, ..., Xn) sont des variables entières mutuellement indépendantes, alors,
1. La somme S2 = X1 +X2 a pour fonction génératrice le produit des fonctions génératricesde X1 et de X2 : GX1(z)×GX2(z).
2. La loi de X1 +X2 est le produit de convolution (ou produit de Cauchy) des lois de X1 et deX2.
3. La somme Sn = X1 + X2 + ... + Xn a pour fonction génératrice le produit des fonctionsgénératrices
∏nk=1GXk
(z).
4. La loi de Sn = X1 + X2 + ... + Xn est le produit de convolution (ou produit de Cauchy)des lois de X1, X2, ... et Xn.
Démonstration
Exercice 311. Somme de lois de Poisson indépendantes de paramètres λ et µ?
2. Somme de lois binomiales indépendantes de paramètres (n, p) et (m, p)?
3. Somme de lois binomiales indépendantes de paramètres (n, p) et (n, q)?
Exercice 32 ? convergence d’une suite de fonctions génératricesPour faire cet exercice, il faut disposer du théorème de convergence dominée...
1. Soit f(z) =∞∑
k=0
akzk une fonction définie par une série entière de rayon R ≥ 1. On pose,
pour r ∈ [0, 1[ et n0 ∈ N, φr(θ) = e−in0θ f(reiθ
).
(a) Justifier que φr est somme d’une série de fonctions normalement convergente sur Rdont on précisera les termes généraux.
(b) En déduire1
2π
∫ 2π
0φr(t) dt.
34

(c) On suppose que la série entière∑
n anzn converge normalement sur D(0, 1).Que peut
on dire de1
2π
∫ 2π
0φ1(t) dt?
2. On considère une suite de fonctions (fn)n définies par fn(z) =∞∑
k=0
an,kzk. On suppose que
- chacune de ces séries converge normalement sur D(0, 1).
- (fn)n converge simplement vers une fonction f sur D(0, 1).
Que peut on dire de la suite des intégrales1
2π
∫ 2π
0e−in0θfn
(e−it
)dt?
3. Soit (Xn)n une suite de v.a. entières de fonctions génératrices GXn .
(a) On suppose que cette suite de fonctions génératrices converge simplement sur D(0, 1)vers la fonction génératrice g d’une variable entière Y.Montrer que pour tout k ∈ N, limn→+∞ P (Xn = k) = P (Y = k).
(b) Illustration : Soit (Xn)n une suite de variables aléatoires de lois B(n,λnn
)avec
limλn = λ. Montrer que limn→+∞ P (Xn = k) = P (Y = k) ou Y suit une loi dePoisson de paramètre λ.
35

7 Suites de variables aléatoires
7.1 Marches aléatoires
Définition 17 marches aléatoiresSoit (Ω, T , P )un espace probabilisé et (Sn)n∈N une suite de va.a.discrètes
Sn : (Ω, T )→ (E,P(E))
où E est dénombrable et pourvu d’une structure de groupe (E,+). On dit que la suite (Sn)nest une marche aléatoire sur E ssi la famille (Xn)n dans laquelle
X0 = S0
Xn+1 = Sn+ − Sn
est une suite de v.a. (mutuellement) indépendantes et de même loi.
Exercice 33 marches aléatoires. On se propose d’étudier une marche aléatoire sur Z2 c’est àdire le mouvement d’une particule qui se déplace par sauts sur des points de coordonnées entières.
On considère donc une suite de variables aléatoires (Zn)n∈N
(Zn =
[xnyn
]∈ Z2
), définies sur
une espace probabilisé (Ω, T , P ), telle que– pour tout n ∈ N, les deux variables aléatoires xn et yn sont indépendantes ;– les variables aléatoires (les sauts) (Zn+1 − Zn)n sont mutuellement indépendant(e)s ;
– pour tout n ∈ N, Zn+1−Zn suit une loi uniforme sur l’ensemble[
11
],
[−11
],
[−1−1
],
[1−1
]
On suppose que Z0 =
[00
].
1. Représenter les points de Z2 de coordonnées |x| ≤ 3 et |y| ≤ 3 que la particule peutatteindre lors d’une telle marche.
2. Montrer que l’on peut exprimer xn+1 − xn à l’aide d’une de variable suivant une loi deBernoulli de paramètre que l’on précisera.En déduire la loi de xn.
Indication : on observera que xn =
n−1∑
k=0
(xk+1 − xk).
3. Calculer pour (x, y) ∈ Z2 la probabilité P(Zn =
[xy
]).
4. On note On la variable aléatoire égale à 1 si la particule est à l’origine au temps t = n etégale à 0 sinon, et Un la variable égale au nombre de passages à l’origine entre les instants1 et 2n.
(a) Exprimer Un en fonction des Ok.
(b) En déduire l’espérance de Un. On l’exprimera comme somme partielle d’une série∑nj=1 vj .
36

(c) Étudier la convergence de cette série. En déduire un équivalent de E(Un).
Exercice 34 marche aléatoire dans ZOn considère une suite de variables de Bernoulli, (bn)n indépendantes, de même paramètre p et
définies sur (Ω, T , P ). On pose pour n ∈ N, Xn = 2bn − 1 puis S0 = 0, Sn =
n∑
k=1
Xn.
1. Interpréter tout cela en termes de déplacements d’une particule sur un axe. Faire un dessinet préciser S14 lorsque
(Xn)n = (+1,+1,+1,−1,−1,+1,−1,+1,−1,−1,−1,−1,+1,−1, ...).
2. Donner la loi de Sn.
3. Calculer la probabilité de l’événement (Sn = 0). Donner un équivalent de P (S2n = 0).
4. Loi du premier instant d’arrivée au point 1.Soit r ∈ N∗.On note Tr le premier indice n pour lequel Sn = r lorsqu’il existe, sinon Tr = +∞.
(a) Exprimer P (T2 = n + m|T1 = n) en fonction de la loi de T1 (lorsque P (T1 = n) >0).
(b) On note φi la fonction génératrice de Ti. Montrer que φ2(z) = φ1(z)2.
(c) Exprimer P (T1 = n) en fonction de la loi de T2. En déduire une expression de φ1 enfonction de φ2 puis une équation vérifiée par φ1.
(d) Calculer la loi de T1 préciser en particulier T1(∞).
(e) Quelle est la loi de T−1?
5. Loi du premier retour à l’origine.On note T0 le premier indice n ≥ 1 pour lequel Sn = 0 s’il existe, sinon on pose T0 = +∞comme de bien entendu ; T0 est donc le temps d’attente du premier retour à 0.
(a) Déduire des questions précédentes la loi de T0.
(b) Montrer que l’événement (Il existe un temps n fini pour lequel T0 = n) ou encore (laparticule revient à son point de départ en un temps fini) est presque-sûr.
7.2 Chaînes de Markov
Définition 18 chaînes de MarkovUne suite (Xn)n de variables aléatoires définies sur un espace probabilisé (Ω, T , P ) à valeurs
dans E, un ensemble discret, est une chaîne de Markov ssi : pour tous n ∈ N, y, x0, x1, ...., xn ∈E, on a
P (Xn+1 = y|Xn = xn ∩Xn−1 = xn−1 ∩ ... ∩X0 = x0) = P (Xn+1 = y|Xn = xn) (7.1)
dès lors que P (Xn = xnn...,X0 = x0) > 0.E est l’espace des états de la chaîne.
37

8 Problèmes et simulations
8.1 Sujet Zéro - Mines - 2015 : Files d’attente M/GI/1
File d’attente M/GI/1
CCMP
Epreuve 0 de probabilités
On considère la file d’attente à une caisse de supermarché. Il y a un serveuret un nombre de places infini. Les clients sont servis selon la discipline « premierarrivé, premier servi ». On appelle « système », l’ensemble des clients en attenteet du client en service. On considère (An, n ≥ 1) la suite de variables aléatoires àvaleurs dans N où An représente le nombre de clients arrivés pendant le servicedu client n.
On définit la suite (Xn, n ≥ 1) comme suit
X0 = 0 et Xn+1 =
An+1 si Xn = 0,
Xn − 1 +An+1 si Xn > 0.(1)
On suppose que les variables aléatoires (An, n ≥ 1) sont indépendantes et demême loi, de loi commune celle d’une variable aléatoire A.
Hypothèse : On suppose que
– A est à valeurs entières,
– P(A ≥ n) > 0 pour tout entier n,
– A a une espérance finie, on note ρ = E [A].
1 Fonction caractéristiqueDans cette section X représente une variable aléatoire quelconque à valeurs
dans N. On définit sa fonction caractéristique φX par
φX : R −→ C
t 7−→ E[eitX
].
1
38

1. Montrer que φX est continue sur R et périodique.
2. Soit X et Y deux variables aléatoires à valeurs dans N telles que φX = φY .Montrer que X et Y ont même loi.
Indication : on pourra considérer les intégrales
Ik =1
2π
∫ π
−πφX(t)e−ikt dt.
pour tout entier k.
3. Si E [X] < +∞, montrer que φX est dérivable sur R et calculer φ′X(0).
4. Calculer la fonction caractéristique d’une variable aléatoire Z = Y + 1 oùY est de loi géométrique de paramètre p.
2 Remarques préliminaires5. Etablir que Xn représente le nombre de clients dans le système au moment
du départ du client n.
6. Existe-il M > 0 tel que P(Xn ≤M) = 1 pour tout n ≥ 0 ?
7. Montrer que pour tout n ≥ 1, Xn+1 −Xn ≥ −1.
8. Pour tout n ≥ 0, montrer que les variables aléatoires Xn et An+1 sontindépendantes.
3 Convergence9. Etablir l’identité suivant pour X une variable aléatoire à valeurs entières :
E[eitX1X>0
]= φX(t)−P(X = 0)
10. Pour tout entier n, établir la relation suivante :
φXn+1(t) = φA(t)[e−itφXn(t) + (1− e−it)P(Xn = 0)
].
239

On suppose dorénavant que 0 < ρ < 1.On admet qu’alors la suite (P(Xn = 0), n ≥ 1) converge vers une limite,
notée α.On suppose que A n’est pas arithmétique, c’est-à-dire que |φA(t)| < 1 pour
t 6∈ 2kπ, k ∈ Z.
On pose
θ : [−π, π] −→ C
0 7−→ 1
t 7−→ αφA(t)(1− e−it)1− φA(t)e−it
pour t 6= 0.
11. Etablir le développement limité à l’ordre 1, de φA au voisinage de 0.
12. Que doit valoir α pour que θ soit continue en 0 ?
13. On fixe ε > 0. Pour tout t ∈ [−π, π]\0, identifier βt ∈]0, 1[ tel que pourtout entier n suffisamment grand, on ait l’identité suivante :
∣∣φXn+1(t)− θ(t)
∣∣ ≤ βt |φXn(t)− θ(t)|+ ε.
14. Montrer que la suite de fonctions (φXn, n ≥ 1) converge simplement vers θ.
4 ApplicationOn suppose que
φA(t) =1
1 + ρ− ρeit ·
15. Identifier la loi de A.
16. Montrer que φA satisfait les hypothèses requises.
17. Calculer θ et identifier la loi de Y .
340

9 Annexe : La loi de Poisson est un modèle
On propose ici d’introduire la loi de Poisson qui apparaît naturellement dans la modélisation decertains processus de comptage : émission de particules radioactives, appels téléphoniques dans unstandard, arrivées dans une file d’attente... Les débordements au delà du programme sont mineurs(lois continues) mais néanmoins réels.
• On considère donc une expérience aléatoire qui consiste à dénombrer des événements ponctuels(et jamais simultanés) pendant un intervalle de temps de longueur t. On note Xt le nombre d’oc-currences de ces événements au cours de l’intervalle [0, t[ (et on convient de poserX0 = 0).Ainsi,pour tout t > 0, Xt est une variable aléatoire définie sur l’espace probabilisé (Ω, T , P ) à valeursdans N.
• On peut associer à ce processus de comptage la famille (Tn)n où chaque variable aléatoire Tnest le temps d’attente de la nieme observation.
Tn(ω) = inft > 0;Xt(ω) = n (9.1)
Tn est donc une variable aléatoire définie sur l’espace probabilisé (Ω, T , P ) à valeurs dans (R∗+,B).
• On fera sur le processus les trois hypothèses suivantes :
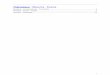
H1 stationnaritéLa probabilité d’observer n occurrences du phénomène entre t1 est t2 ne dépend que de |t2 − t1|.
∀(t1, t2) ∈ R∗+, (Xt1+s −Xt1) et (Xt2+s −Xt2) suivent la meme loi (9.2)
H2 absence de mémoireLes nombres d’observations sur des intervalles disjoints sont indépendants
si t1 < t2 ≤ t3 < t4, alors (Xt2 −Xt1) et (Xt4 −Xt3) sont independantes (9.3)
H3 espacementLa probabilité d’avoir plus d’une observation dans un intervalle de longueur h est négligeabledevant h lorsque h tend vers 0
P (Xt+h −Xt > 1) =h→0
o(h) (9.4)
Théorème 22 lois de Poisson et loi exponentielleSoient (Xt)t∈R∗+ un processus de comptage et (Tn)n la famille des temps d’attente associée parla relation (9.1). On suppose que les hypothèses H1, H2 et H3 sont vérifiées. Alors,– pour tout t > 0, la loi de Xt est la loi de Poisson de paramètre λt, ie :
P (Xt = n) =(λt)n
n!e−λ t;
41

– la loi de T1 (temps d’attente de la première observation) est une loi exponentielle de paramètreλ > 0, ie :
P (T1 ≤ t) = λ
∫ t
0e−λ s ds
– pour tout n ∈ N, la loi de Tn (temps d’attente de la nieme observation) est :
P (Tn ≤ t) =λn
(n− 1)!
∫ t
0sn−1 e−λ s ds
Démonstration• Notons p(n, s) = P (Xs = n) et commençons par évaluer p(0, t). Avec l’hypothèse H1 (9.2),
p(n, s) = P (Xs = 0) = P (Xt+s −Xt = 0)
pour tout t ≥ 0. D’autre part, en observant que (Xt+s = 0) ⊂ (Xt = 0) et avec l’hypothèsed’indépendance (9.3), il vient :
P (Xt+s = 0) = P (Xt+s −Xt = 0 ∩Xt −X0 = 0)
= P (Xs = 0)P (Xt = 0).
Cela nous conduit à l’équation fonctionnelle :
p(0, s+ t) = p(0, t) p(0, s).
Si nous observons que s → p(0, s) est continue à droite et que les seules fonctions continues àdroite, vérifiant l’équation f(x+y) = f(x)f(y) sont les fonctions x→ eax, a ∈ R (démonstrationproposée avec l’exercice 38), nous avons p(0, s) = eas. Comme p(0, s) ≤ 1, il existe λ > 0 telque
p(0, s) = P (Xs = 0) = e−λ s.
• Revenons à p(n, t) = P (Xt = n) :
p(n, t+ s) = P (Xt+s = n ∩Xt = n)
+ P (Xt+s = n ∩Xt = n− 1)
+ P (Xt+s = n ∩Xt < n− 1)
p(n, t+ s) = P (Xt = n)P (Xs = 0)
+ P (Xs = 1)P (Xt = n− 1)
+ P (Xt+s = n ∩Xt < n− 1)
42

p(n, t+ s)− p(n, t)s
= P (Xt = n)P (Xs = 0)− 1
s(9.5)
+P (Xs = 1)
sP (Xt = n− 1) (9.6)
+P (Xt+s = n ∩Xt < n− 1)
s(9.7)
Comme P (Xs = 0) = e−λs et P (Xs > 1) = o(s), on a :
lims→0
P (Xs = 0)− 1
s=
e−λ s − 1
s= −λ (9.8)
lims→0
P (Xt = 1)
s= lim
s→0
1− P (Xt = 0)− P (Xt > 1)
s= λ (9.9)
P (Xt+s = n ∩Xt < n− 1)
s≤ P (Xs > 1)
s= o(1) (9.10)
Ce qui donne :d p(n, t)
dt= −λ p(n, t) + λ p(n− 1, t).
Posons, pour n ∈ N∗, P (t) =
p(0, t)p(1, t)
...p(n, t)
. P (t) est la solution du problème de Cauchy :
dP (t)
dt=
−λ 0 0 . . . 0λ −λ 0 0
0 λ −λ . . ....
.... . . . . . . . .
...0 . . . 0 λ −λ
P (t), P (0) =
10...0
On vérifie que le vecteur de coordonnées Pk(t) =(λ t)n
n!e−λ t est la solution du problème.
• Loi du temps d’attente (lois continues) :On observe que T1 ≤ t ssi Xt 6= 0. Il vient donc
P (T1 ≤ t) = 1− P (Xt = 0) = 1− e−λ t = λ
∫ t
0e−λu du
La loi du temps d’attente de la première observation est donc donnée par la fonction densitéf(t) = H(t)λ e−λ t où H(t) est la fonction de Heaviside. C’est une loi exponentielle de para-mètre λ.
• Loi du temps d’attente de la nieme observation :
43

On observe encore que Tn ≤ t ssi Xt ≥ n. On a donc
P (Tn ≤ t) = 1− e−λ tn−1∑
k=0
(λ t)k
k!.
Dérivons pour déterminer la densité de probabilité :
d
dtP (Tn ≤ t) = 0 si t < 0;
d
dtP (Tn ≤ t) = e−λ t
(λ∑n−1
k=0
(λ t)k
k!− λ∑n−1
k=1
(λ t)k−1
(k − 1)!
)si t > 0;
La densité de Tn est donc H(t)λn
(n− 1)!tn−1e−λ t (loi de Erlang de paramètres λ et n.
Exercice 35 équation fonctionnelle
1. Justifier que sous les hypothèses H1,H2,H3 (ou (9.2), (9.3), (9.4)), la fonction f(t) =P (Xt = 0) est continue à droite.
2. Démontrer que les seules fonctions continues à droite, non nulles, vérifiant l’équation f(x+y) = f(x)f(y) sont les fonctions x→ eax, a ∈ R.Indication : on commencera par montrer que pour r =
p
q∈ Q, f(r) = f(1)p/q.
corrigé en (4)
Exercice 36 générateur aléatoire physique
1. Loi de désintégration radioactiveOn note N(t) le nombre de radionucléides d’une espèce donnée présents dans un échan-tillon radioactif à un instant t. On considère que la probabilité de désintégration d’un deces radionucléides est toujours la même pour l’espèce considérée, quel que soit l’environ-nement. Le nombre total de désintégrations pendant un intervalle de temps donné est alorsproportionnel à N(t) ce que l’on traduit par :
dN(t)
dt= −λN(t) ou N(t) = N(t0)e−λ(t−t0)
44

Sous quelles conditions pensez vous que Xt étant le nombre de désintégrations entre lesinstants T et T + t les hypothèses (9.2),(9.3) et (9.4) puissent être considérées commeacceptables. Vont elles d’elles-mêmes ?
2. On suppose que l’on dispose d’un dispositif de comptage du nombre X1 de désintégrationspar seconde et que le paramètre λ t de la loi de Xt est connu.
(a) SoitN ∈ N∗ et Φ : N→ 0, 1, 2, ...N, une fonction croissante. ExprimerP (φ(Xt) =n) en fonction de valeurs P (Xt = k) pertinentes.
(b) On observe que la suite des fréquences cumulées sk =∑k
i=0 P (Xt = i), est stricte-ment croissante de limite 1. Pour chaque entier k ∈ N, on pose
Φ(k) = n si et seulement sin
N≤ sk <
n+ 1
N
i. Montrer que Φ est croissante. Quelles sont les valeurs possibles de φ(k)?
ii. Est on sûr que Φ soit surjective sur [0, N−1]? Donner une CNS portant sur t pourque cela soit le cas.
iii. On suppose dorénavant cette condition remplie. Soit n un entier tel que 0 ≤ n ≤N − 1. On note kn le plus petit entier tel que
n
N≤ skn et k∗n le plus grand entier
tel que sk∗n <n+ 1
N. Exprimer P (Φ(Xt) = n).
iv. Soit ε > 0. Donner une condition sur (on suppose λ fixé) pour que P (φ(Xt) =
n) =1
N± ε.
Corrigé en 5.
45

10 Corrigés
Corrigé n˚ 1 corrigé de l’exercice ??. Une feuille de calcul MAPLE, vous devez savoir faire lamême chose avec votre calculette. Ce sujet Zéro n’était pas gérable sans elle !
(2)(2)
(1)(1)
restart; with LinearAlgebra :
A d Matrix 0, 34
, 0 ,34
, 0, 1 ,14
,14
, 0 ;
Eigenvectors A ; P d % 2 ;
034
0
34
0 1
14
14
0
K14
1
K34
,
K32
127
K1
12
167
1
1 1 0
K32
127
K1
12
167
1
1 1 0
P.DiagonalMatrix K1
4n , 1, K3n
4n .P K1 ;
K3
10 4nC
1235
K5
14
3n
4nK
3
10 4nC
1235
C9
14
3n
4n6
5 4nC
1235
K67
3n
4n
1
10 4nC
1635
C5
14
3n
4n1
10 4nC
1635
K9
14
3n
4nK
2
5 4nC
1635
C67
3n
4n
1
5 4n C15
1
5 4n C15
K4
5 4n C15
46

Corrigé n˚ 2 corrigé de l’exercice 19. On note :- n =
∏mi=1 p
αii la décomposition de n en facteurs premiers ;
- Ap l’événement Ap = x ∈ Ω; p|x;- E l’événement E = x ∈ Ω; pgcd(x, n) = 1;
1. ...
2. • On commence avec deux événements pour y voir clair.
Par le théorème de Gauss x ∈ Api ∩ Apj ssi pi pj |x. En effet, si pi|x alors x = k pi et si
pj |x = k pi, pj |k qui s’écrit pj k′... Donc Api ∩Apj = x ∈ Ω; pi pj |x.
Dessinons Api 1 ... pi ... 2pi ... (n− pi) n
puis Api ∩Apj : 1 ... pipj ... 2pipj ... (n− pipj) n
On a Card(Apj ) =n
pj, Card(Api) =
n
pi, Card(Api ∩Apj ) =
n
pj pid’où l’on tire (équiprobabilité) : p(Api ∩Apj ) = p(Api)× p(Apj )• Généralisons à une famille finie quelconquePar le théorème de Gaussx ∈ ∩jApj ssi
∏j pj |x.
Donc ∩jApj = x ∈ Ω;∏j pj |x.
Comme précédemment, en notant p =∏j pj et nJ =
n
p, il vient
∩jApj = 1, p, 2p, ..., (nJ − 1)p, nJ p = n
On a donc P(∩j∈JApj
)=nJn
=∏j∈J
1
pj=∏j∈J P (Apj ).
3. x ∈ Ω est premier avec n ssi aucun des pi ne divise x.Donc E = ∩mi=1Api et les Api étant indépendants :
p(E) =φ(n)
n=
m∏
i=1
(1− p(Api)) =m∏
i=1
(1− 1
pi
)
De cela on déduit la formule pour φ(n).
Quels théorèmes d’arithmétique interviennent ils ici ? Le théorème fondamental (décompositionunique en facteurs premiers) et le lemme de Gauss. Point.
47

Corrigé n˚ 3 corrigé de la démonstration du théorème 111. On écrira, sous forme de réunion disjointe et dénombrable
(X + Y = z) =⋃
x∈X(Ω)
P (X + Y = z ∩X = x)
=⋃
x∈X(Ω)
P (Y = z − x ∩X = x)
=⋃
(x,y)∈X(Ω)×Y (Ω)x+y=z
P (X = x ∩ Y = y)
2. Cela nous permet de réécrire les sommes au départ finies
n∑
k=1
|zk|P (X + Y = zk) =n∑
k=1
|zk|∑
x∈X(Ω)
P (X = x ∩ Y = zk − x)
=n∑
k=1
|zk|∑
x+y=zk
P (X = x ∩ Y = y)
=n∑
k=1
∑
x+y=zk
|zk|P (X = x ∩ Y = y)
=∑
x+y=zk
|x+ y|P (X = x ∩ Y = y)
≤n∑
k=1
∑
x+y=zk
(|x|+ |y|)P (X = x ∩ Y = y)
Ce dernier terme se réécrit à son tour :
n∑
k=1
∑
x+y=zk
|x|P (X = x ∩ Y = y) +
n∑
k=1
∑
x+y=zk
|y|P (X = x ∩ Y = y (10.1)
Comme (|x|P (X = x) est sommable on a :∑
(x,y)∈X(Ω)×Y (Ω)∃k,x+y=zk
|x|P (X = x ∩ Y = y) =∑
x∈X(Ω)
|x|∑
y∈X(Ω)∃k,x+y=zk
P (X = x ∩ Y = y)
≤∑
x∈X(Ω)
|x|P (X = x) = E(|X|).
Nous avons donc montré que∑n
k=1 |zk|P (X + Y = zk) est sommable et majorée parE(|X|) + E(|Y |).
48

3. Puisque la famille est sommable, nous pouvons réécrire les sommes par paquets :
∑
z
zP (X + Y = z) =∑
z
∑
x+y=z
(x+ y)P (X = x ∩ Y = y)
=∑
z
∑
x+y=z
xP (X = x ∩ Y = y) +∑
z
∑
x+y=z
yP (X = x ∩ Y = y)
=∑
x
x∑
y
P (X = x ∩ Y = y) +∑
y
y∑
x
P (X = x ∩ Y = y)
= E(X) + E(Y )
49

Corrigé n˚ 4 de l’exercice 38
1. Montrons que la fonction f(t) = P (Xt = 0) est continue à droite. En observant que(Xt+s = 0) ⊂ (Xt = 0) et avec l’hypothèse d’indépendance H2-(9.3), il vient :
P (Xt+s = 0) = P (Xt+s = 0 ∩Xt = 0)
= P (Xt+s −Xt = 0|Xt = 0)P (Xt = 0)
= P (Xs = 0)P (Xt = 0).
Avec l’hypothèse H3-(9.4),
f(t+ s)− f(t) = P (Xt+s = 0)− P (Xt = 0)
= P (Xt = 0)(P (Xs = 0)− 1)
= −P (Xt = 0)P (Xs > 0)
=s→0+
o(1)
2. Soit f non nulle et continue à droite vérifiant f(x+ y) = f(x)f(y) pour tout (x, y) ∈ R2.
(a) Commençons par observer que f(0) = 1 : il existe x ∈ R, tel que f(x) 6= 0 etf(x) = f(x+ 0) = f(0)f(x).
(b) Pour tous n ∈ N, t ∈ R f(n.t) = f(t)n. En effet,– cela est vérifié pour n = 0 car f(0) = 1.– si f(n.t) = f(t)n, alors, f((n+ 1)t) = f(n t).f(t) = f(t)n+1...
(c) Pour toutm ∈ Z, f(mt) = f(t)m; en effet, f(x−x) = f(x)f(−x) = f(0) = 1 doncf(x) 6= 0 et f(−x) = f(x)−1. Donc si m ∈ Z−, f(mt) = f(|m| t)−1 = f(t)m.
(d) Montrons enfin que pour tout r =p
q∈ Q, f(r) = f(1)p/q :
– On observe tout d’abord que
f(p) = f
(qp
q
)= f
(p
q
)qsoit f
(p
q
)= f(p)1/q = f(1)p/q
Cela a un sens car la fonction f est positive(f(x) = f
(x2
+x
2
)= f
(x2
)2)
et
ainsi, f(x)1/q est toujours défini si q 6= 0.
(e) On montre enfin que pour x ∈ R, comme f est continue à droite, pour toute suite deréels (rn)n qui converge vers x avec rn > x,
limn→+∞
f(rn) = limr→x+
f(r) = f(x)
limn→+∞
f(rn) = limn→+∞
f(1)rn = f(1)x
En posant f(1) = ea, le tour est joué.
50
Corrigé n˚ 5 corrigé de l’exercice 391. Rappelons nos trois hypothèses :
∀(t1, t2) ∈ R∗+, (Xt1+s −Xt1) et (Xt2+s −Xt2) suivent la meme loi (10.2)
Cela suppose que le nombre moyen de désintégrations ne varie pas au cours du temps. Orla probabilité de désintégration est proportionnelle au nombre de particules. On doit doncconsidérer une durée d’observation au cours de laquelle N(t) = e−λt varie peu.
si t1 < t2 ≤ t3 < t4, alors (Xt2 −Xt1) et (Xt4 −Xt3) sont independantes (10.3)
P (Xt+h −Xt > 1) =h→0
o(h) (10.4)
Pour un tel dispositif dans le commerce voir http ://www.aw-el.com/consultée novembre 2012
2.
51

Indexecart-type, 25
centréevariable, 26
certainévènement, 5
chaînes de Markov, 38comptage
processus, 42conjointe
loi, 19covariance, 25
Erlangloi de, 45
évènement, 5élémentaire, 5certain, 5impossible, 5négligeable, 9presque-sûr, 9quasi-certain , 9quasi-impossible, 9quasi-négligeable, 9
Exponentielleloi, 44
impossibleévènement, 5
information, 10
loiconjointe, 19de Erlang, 45de Poisson, 42Exponentielle, 44
marches aléatoires, 36Markov
chaînes de, 38
n-upletde variables aléatoires, 21
négligeableévènement, 9
Poissonloi, 42
presque-sûrévènement, 9
processusde comptage, 42
quasi-certainévènement, 9
quasi-impossibleévènement, 9
réduitevariable, 26
Shannon, 10système
complet, 5, 9
tempsd’attente, 42
variablecentrée, 26réduite, 26
variable aléatoirevectorielle, 21
variance, 25
52