
MADA-ETI, ISSN 2220-0673, Vol.1, 2011 www.madarevues.gov.mg
30
Indexation et recherche d’images couleurs dans le domaine des Valeurs Singulières
Ramafiarisona M. H.1, Razafindradina H. B.2, Rakotomiraho S.3
Laboratoire de Télécommunication, d’Automatique, de Signal et d’Images (TASI)
Département Télécommunication – Ecole Supérieure Polytechnique Antananarivo
Université d’Antananarivo BP 1500, Ankatso – Antananarivo 101 - Madagascar
[email protected], [email protected], [email protected]
Résumé :
Cet article représente une des applications de
l’algèbre linéaire appelé : « Décomposition en
valeurs singulières» au traitement d’images
numériques, spécialement un thème a été investi et
testé : c’est la partie indexation et recherche
d’image par le contenu.
La SVD transforme une matrice en un produit de
matrices ���� qui nous permettrait de re-
factoriser l’image en trois matrices. L’utilisation
des valeurs singulières pour chaque décomposition
accéderait à représenter l’image avec de petits
valeurs, pourtant, la reconstruction de l’image
originale. Nous avons traité l’image en rangeant le
maximum d’informations en couleurs R, G, B de
l’image dans les valeurs singulières issues de la
décomposition SVD. Tous les tests et
programmation ont été effectués sous Matlab.
Mots clés: RVB, indexation, SRIC, SVD.
Abstract:
This paper has applied theory of linear algebra
called “Singular Value Decomposition”, to digital
image processing, especially to the one area of that
is investigated and tested, this is the indexing and
retrieval image ; SVD method can transform one
matrix into product ����which allows us to
refactoring a digital image in three matrices: the
using of singular values of such refactoring allows
us to represent the image with smaller values;
witch can preserve useful features of the original
image. To perform indexing image with SVD, we
treated the image by ranging the maximum of their
components in R, G, B into the singular values
after the decomposition. All test and experiments
are carried out by using Matlab as computing
environment and programming language.
Keywords: RGB, indexing, CBIR, SVD.

MADA-ETI, ISSN 2220-0673, Vol.1, 2011 www.madarevues.gov.mg
31
1. Introduction
On décrit ici, une nouvelle méthode d’indexation
d’image couleur dans le domaine des valeurs
singulières (DVS)., nous nous intéresserons
uniquement à l’attribut couleur du fait de son haut
pouvoir discriminant par rapport aux autres
attributs.
Dans les dix dernières années, la reconnaissance de
forme, de motif, l’indexation et la recherche
d’image par le contenu a tiré de larges intentions
des chercheurs après la vision par ordinateur, les
réseaux de neurones. L’application de l’indexation
comprend : reconnaissance des faces, contrôle
d’accès, sécurité d’information, l’interaction
homme-machine…
Le domaine de l’indexation d’image a connu un
essor très rapide ces dernières années sans que l’on
ait pu réellement voir émerger des services
opérationnels. Après une phase très largement
exploratrice ; Swain et Ballard a utilisé
l’algorithme d’histogramme, les histogrammes
peuvent être construits dans plusieurs plages de
couleurs RVB. Un histogramme de couleur est un
produit découpant les couleurs de l’image dans
certains nombres de cases puis en comptant le
nombre de pixels dans chaque case : cela fournit
une vue d’ensemble plus compacte des données
dans une image. C’est un outil intéressant pour la
reconnaissance d’objets ayant une position et une
rotation inconnue par rapport à la scène. [1].
Smith et Chang, utilisent des données statistiques:
moyenne, variance, extraites des sous bandes des
ondelettes afin de présenter les textures. [2]
Swason et Twefik, utilisent les coefficients de
DWT combinée avec une représentation en B-
spline des contours des objets. [2]
Hu identifie sept moments caractérisant l’image.
Milanese et Cherbuliez, utilise la norme de
Transformée de Fourrier Discrète (TFD) comme
attribut ; cette valeur a l’avantage d’être robuste
aux transformations géométriques de l’image
(rotation, symétrie,…). [2]
Pour l’indexation utilisant le critère forme, on s’est
servi des théorèmes de Hough, de Fourrier, de
Laplace ; le filtre de Gabor et les domaines de
transformés pour la texture. [3] [4].
Haralick a disposé l’utilisation de matrices de co-
occurrences. Aussi, plusieurs méthodes
d’indexation dans le domaine des transformés en
ondelettes discrètes (DWT) ont étés déjà présentés.
Il y a aussi une représentation d’image basée sur la
notion de chaînes de symboles, et de nombreux
travaux en indexation d’images ont fait référence à
la notion de points d’intérêt comme base d’une
représentation [5].
Accéder à une information pertinente dans un
contexte distribué et fortement dynamique, par
exemple le web, est un véritable chalenge. Définir
la pertinence selon les critères de l’utilisateur
nécessite la création automatique de profils
dynamiques représentant les centres d’intérêts de
l’utilisateur. Au début, on a indexé les documents
par la SVD, qui a pour but de classifier ces
derniers chacun étant caractérisé par un certain
nombre de concepts ; de mesurer l’apport d’une
décomposition en valeurs singulières par rapport à

MADA-ETI, ISSN 2220-0673, Vol.1, 2011 www.madarevues.gov.mg
32
une analyse robuste en prenant pour cas pratique
une analyse de contenu. [6].
Par Will en 1999, la SVD permet de dégager des
concepts à partir d’éléments primitifs : les mots.
Cette observation est à la base de l’utilisation de la
décomposition SVD dans l’indexation sémantique
des documents [7] dans le but d’identifier les
tendances dans les relations entre les termes et
concepts contenus dans une collection non
structurées du texte. Où �: Représente une matrice
« document- mots » . On suppose cette matrice de
dimension� ∗ . Cette matrice est décomposée
par une SVD en un produit de trois matrices dont
la matrice centrale � est diagonale.
M d ∗ m� = R d ∗ d� ∗ D d ∗ m�∗ U m ∗ m� (01)
Dès lors, la SVD représente une des méthodes de
quantification de l’image couleur, c'est-à-dire
quantifier la couleur par une modélisation/
égalisation de couleur ou encore: appariement ; la
quantification a pour but de réduire le nombre de
pixels dans l’image afin de ne conserver que les
couleurs uniquement dominantes [8].
La SVD, du sens géométrique, est une matrice
carrée qui est une transformation de vecteur. Elle
est employée couramment dans les statistiques et
ici, on la lie avec l’analyse en composante
principale dans le traitement des signaux et
l’identification de modèle ; donc, on pourrait
aisément l’utiliser pour une indexation d’image
dans le but de rechercher une image. Une autre
approche de la SVD traitait un jeu de faces
connues comme vecteurs dans un espace,
s’étendant par de petits groupes de faces. La
reconnaissance est perfectionnée par la projection
d’une nouvelle image dans tous les « espace de
visage » [9].
Il est donc indispensable de posséder des outils
permettant de rechercher les images les plus
pertinentes par leur contenu, comme c'est déjà le
cas pour les systèmes de recherche de texte par
mots clés [2]. Quel modèle mathématique pourrait-
on utiliser afin de rendre efficace le système
d’indexation et aussi pour la phase d’appariement ?
Dans ce travail, on a utilisé l’indexation d’image
par une méthode de la décomposition en valeurs
singulières.
C’est une technique qui est utile pour le traitement
d’image (compression, indexation, classification de
données). Le problème consiste à réduire le
dimensionnement d’un ensemble des données
(échantillon), en trouvant un nouvel ensemble de
variables plus petit que l’ensemble original des
variables, qui néanmoins contient la plupart de
l’information de l’échantillon. Les nouvelles
variables, appelées Valeurs Singulières (VS)
2. Matériels et méthodes
Nous avons effectués la programmation sous
Matlab pour tout le système, tant pour la méthode
d’indexation que pour l’étude de calcul de la
similarité.
2.1 Théorie de la SVD
La SVD est réputée être un sujet significatif dans
l’algèbre linéaire par de nombreux renommés
mathématiciens. Elle a de nombreuses pratiques et
valeurs techniques, la particularité spéciale de la
SVD est qu’il peut être performant dans beaucoup
de , �� matrices réelles. Soit une matrice avec

MADA-ETI, ISSN 2220-0673, Vol.1, 2011 www.madarevues.gov.mg
33
lignes et � colonnes avec un rang � et � ≤ � ≤
peut être factorisé en trois matrices :
Pour � = 1, 2, … , �;�� sont appelés valeurs
singulières de la matrice .
�! ≥�# ≥ ⋯≥ �% ≥ 0'(�%)! = �%)# = ⋯ =�* = 0 Les ��'(�� sont appelés : droite et gauche
vecteurs singulières de . [10]
2.2 Propriétés de la SVD d’une image
Les valeurs singulières sont les plus importants car
ils sont uniques, ce sont des plus importants
attributs de la matrice image et peut être utilisée
pour la reconnaissance des formes.
�!, �#, … , �* sont uniques, mais �'(� ne les sont
pas.
- Le rang de la matrice est égale au nombre de
leur valeurs singulières non nuls.
- Les V.S représentent l’énergie de l’image, c'est-à-
dire que la SVD range le maximum d’énergie de
l’image dans un minimum de V.S [11]
- Les valeurs singulières d’une image ont une très
bonne stabilité, c’est-à-dire, quand une petite
perturbation est ajoutée à une image, les valeurs
singulières ne change pas significativement.
2.3 Méthode de la nouvelle approche avec SVD
Premièrement, la méthode d’indexation, c'est-à-
dire la phase de l’extraction des informations
essentielles de l’image à présenter est divisée en
deux parties :
• Dissociation de la taille de l’image originale par
trois : Rouge, Vert, Bleu en ne conservant
qu’un seul canal qui range le maximum
d’énergie de l’image dans les valeurs singulières
par ordre décroissant et dans un minimum de
valeurs singulières car chaque image est en
couleur Rouge, Vert, Bleu. Chaque pixel,
chaque site +, ,� contient une information
couleur sur l’intensité du rouge, l’intensité du
vert, l’intensité du bleu.
Figure 01 : Division des composantes couleurs de
l’image
• Décomposition en SVD de chacune des
composantes couleurs de l’image :
= � ∗ � ∗ �� (02)
=
∗ �� ∗ � ∗ �� (� ∗ �� � = -.!, .#, … , .%, .%)!, … , ./0
.� ,� = 1, 2, … , (03)
.��.1 =2�1 = 31 � = 40 � ≠ 46 (04)
� = -�!, �#, … , �%, �%)!, … , �*0 (05)
7!, � = 1, 2, … , � (06)
����1 =2�1 = 31 � = 40 � ≠ 46 (07)
8 = 9�! ⋯ 0⋮ ⋱ ⋮0 ⋯ �*< (08)
��sontappelés�EF'.G8���H.F�èG'8 de A Pour
� = 1, 2, … , �
�! ≥ �# ≥ ⋯ ≥ �% > 0
• Une fois qu’on ait pu extraire les informations
maximales de l’image, et les avoir stockées dans
les minimums de VS ; on peut, à partir d’un
certain rang de la matrice�, reconstituer
R V B Image originale
A
A
A � � ��

MADA-ETI, ISSN 2220-0673, Vol.1, 2011 www.madarevues.gov.mg
34
l’image originale, ici, ce rang nommé � est
égale à la valeur 50. C'est-à-dire abandonner les
� plus basses VS de la matrice �. On capture maintenant un exemple d’image
requête et on recherche la similarité entre l’image
requête et celles se trouvant dans la base.
Les résultats seront affichés sur une figure
illustrant l’image requête avec la liste des images
trouvées suivant un ordre décroissant selon la
distance entre l’image requête et chacune des
images trouvées. Le nombre souhaité des images à
trouver a été préalablement signalé dans le
programme.
Afin de calculer la similarité entre l’image requête
et les images cibles dans la base d’images (indexée
aussi), plus précisément, on calcule d’abord
l’histogramme des valeurs singulières, une fois ces
dernières trouvées, notons ℎ�8(MNO , ℎ�8(M�O, ℎ�8(MPO ces histogrammes ; ℎ�8(QNO ℎ�8(QNO, ℎ�8(QNO ceux des images dans la base d’image. La
similarité ici retourne la distance euclidienne
calculée entre les histogrammes de toutes les
valeurs singulières concernés, formule (02).
Pendant la phase de la recherche de similarité, on
calcule la distance euclidienne des histogrammes et
les trier par ordre de pertinence suivant le critère
couleur de l’image.
��8( � , �P� == R ℎ�8(QNO − ℎ�8(MNO�# + ℎ�8(Q�O − ℎ�8(M�O�# + ℎ�8(QPO − ℎ�8(MPO�# 1.09�
La signature d’une image par la SVD conserve
un « résumé » de l’information extraite par
l’analyse d’une caractéristique, les valeurs
singulières stockent l’énergie de l’image.
L’indexation a pour but de substituer à une image
qui occupe une place non négligeable en
représentant moins encombrant qui la caractérise le
mieux possible et de ne travailler que sur ce
modèle, lors de la recherche. La difficulté réside et
provient de la définition même du représentant,
c'est-à-dire quelles caractéristiques choisir pour
quel résultat ?
On applique la SVD, ici, comme une technique
d’extraction des informations de l’image, aussi
pour construire les signatures de l’image couleur;
on utilise les informations issues du processus de la
décomposition, c’est ce qu’on appelle l’indexation
par la signature. [11]
La décomposition en valeurs singulières peut donc
être vue comme une technique de réduction de
dimensionnalité.
Afin d’évaluer la méthode choisie, on a essayé
plusieurs types d’image requête suivant différentes
catégories dans la base d’images.
2.4 Architecture du système
Un utilisateur choisit une image requête. On
calcule l’index c'est-à-dire SVD pour l’image
inconnue. Le système mesure la similarité de
l’index inconnu avec les indices de la base. Le
système adresse les meilleures images au sens de la
mesure de similarité, c’est à dire par la distance
euclidienne [12]. Le principe de fonctionnement
est illustré par la figure 02.

MADA-ETI, ISSN 2220-0673, Vol.1, 2011 www.madarevues.gov.mg
35
Figure 02 : Architecture du SRIC utilisant SVD
2.5 Calcul de la similarité
Au sens d’une métrique donnée, on propose ici, par
la distance euclidienne des histogrammes des
vecteurs singulières de l’image requête et les images
de la base, la phase de la recherche d’image. Ce
calcul fournit : les images réponses. C'est-à-dire
classer les images.
La question qui se pose c’est : Quelle est l’image de
la base la plus similaire à la requête ? Le système
adresse les meilleures images au sens de la mesure
de similarité ;
Une distance nulle signifie que les images sont
similaires.
2.6 Choix de la base d’images
Une base de données multimédia est un type de
base de données consacré au stockage et à
l'organisation de données multimédia : documents
sonores, images, vidéos [13]. Les bases de données
images utilisées pour les tests en indexation sont
très diverses et sont, souvent, choisies en fonction
du critère utilisé pour la recherche (par la couleur,
forme, par la texture, etc…). La base utilisée pour
cette étude est une base générique, formée de 1250
images, composée de onze catégories d’images,
chacune composée de 100 images différentes. On
peut y trouver toutes sortes d’images : des images
très colorées et des images texturées. Par exemple :
des imageries en télécommunication, des paysages
enneigés, des images de bâtiments, des animaux,
des voitures, des fleurs, ….
Comme cette base est hétérogène, elle est
généralement destinées au grand public, donc est
accessible via internet ; donc pour une
interprétation subjective. Elle a été élaborée pour
mettre en œuvre une recherche d’image par la
couleur qui va répondre à l’exemple de l’image
requête et dont l’évaluation est qualitative [7].
Calcul des
valeurs
singulières
Indexation
système
appariement
Présentation des
images résultats
Image requête
utilisateur
Image Requête
indexée par SVD
Base
d’image
s
Base
d’images
indexées
Interprétation
et extraction

MADA-ETI, ISSN 2220-0673, Vol.1, 2011 www.madarevues.gov.mg
36
Figure 03 : Quelques extraits d’images dans la base de données
3. Résultats
Etant donné que l’objectif est de sensibiliser au
problème de l'évaluation des résultats de ce
système de recherche d'image et de familiariser
avec les traditionnelles mesures de rappel et de
précision.
C'est-à-dire, dans un premier temps, nous
étudierons les variations de performance de ce
système en fonction des différentes images
requêtes possibles.
3.1 Définitions des mesures de rappel et
précision
La comparaison des réponses d'un système pour
une requête avec les réponses idéales nous permet
d'évaluer les deux métriques suivantes: la
précision et le rappel.
La précision mesure la proportion de réponses
pertinentes retrouvées parmi tous les réponses
retrouvées par le système.
Le rappel mesure la proportion de réponses
pertinentes retrouvées parmi toutes les réponses
pertinentes dans la base.
Précision � ∝
β
Rappel � ∝
δ
Avec :
∝�nombre de réponses pertinentes retrouvées
β �nombre de réponses retrouvées
δ = nombre de réponses pertinentes dans la base
Pour évaluer la précision et le rappel, nous
considérons que les images retrouvées par le
système sont les 10 premières.
Le but est donc de trouver des images pertinentes
à une requête, et donc utiles pour l'utilisateur. La
qualité d'un système doit être mesurée en
comparant les réponses du système avec les
réponses idéales que l'utilisateur espère recevoir.
Plus les réponses du système correspond à celles
que l'utilisateur espère, mieux est le système. Pour
s’y faire, on doit connaître d'abord les réponses
idéales de l'utilisateur. Ainsi, l'évaluation d'un
système s'est faite souvent avec certains corpus de
test. Dans un corpus de test, il y a:
- la liste des images pertinentes pour chaque
image requête.
- un ensemble de base d’images (1100);
- un ensemble de requêtes (pour l’évaluation, on a
pris 30);
Les deux métriques ne sont pas indépendantes. Il
y a une forte relation entre elles: quand l'une
augmente, l'autre diminue. Il ne signifie rien de
parler de la qualité d'un système en utilisant
seulement une des métriques.
MADA-ETI, ISSN 2220-0673, Vol.1, 2011 www.madarevues.gov.mg
37
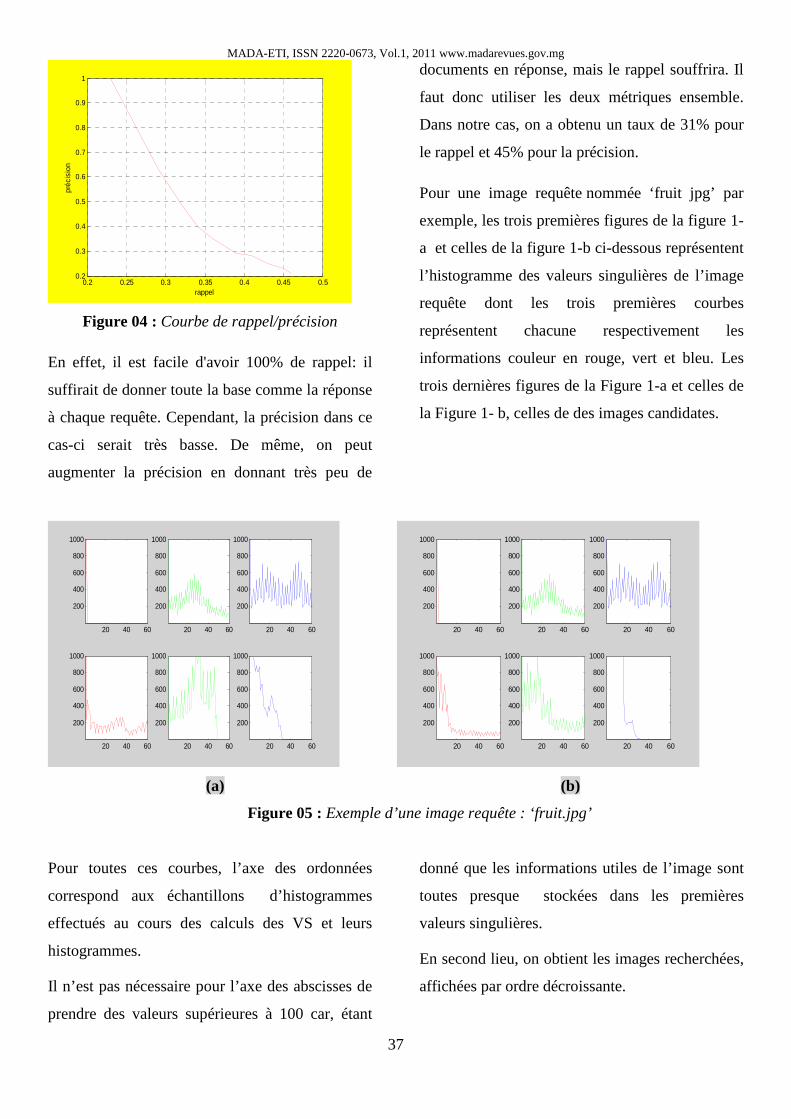
Figure 04 : Courbe de rappel/précision
En effet, il est facile d'avoir 100% de rappel: il
suffirait de donner toute la base comme la réponse
à chaque requête. Cependant, la précision dans ce
cas-ci serait très basse. De même, on peut
augmenter la précision en donnant très peu de
documents en réponse, mais le rappel souffrira. Il
faut donc utiliser les deux métriques ensemble.
Dans notre cas, on a obtenu un taux de 31% pour
le rappel et 45% pour la précision.
Pour une image requête nommée ‘fruit jpg’ par
exemple, les trois premières figures de la figure 1-
a et celles de la figure 1-b ci-dessous représentent
l’histogramme des valeurs singulières de l’image
requête dont les trois premières courbes
représentent chacune respectivement les
informations couleur en rouge, vert et bleu. Les
trois dernières figures de la Figure 1-a et celles de
la Figure 1- b, celles de des images candidates.
(a) (b)
Figure 05 : Exemple d’une image requête : ‘fruit.jpg’
Pour toutes ces courbes, l’axe des ordonnées
correspond aux échantillons d’histogrammes
effectués au cours des calculs des VS et leurs
histogrammes.
Il n’est pas nécessaire pour l’axe des abscisses de
prendre des valeurs supérieures à 100 car, étant
donné que les informations utiles de l’image sont
toutes presque stockées dans les premières
valeurs singulières.
En second lieu, on obtient les images recherchées,
affichées par ordre décroissante.
0.2 0.25 0.3 0.35 0.4 0.45 0.50.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
rappel
préc
isio
n
20 40 60
200
400
600
800
1000
20 40 60
200
400
600
800
1000
20 40 60
200
400
600
800
1000
20 40 60
200
400
600
800
1000
20 40 60
200
400
600
800
1000
20 40 60
200
400
600
800
1000
20 40 60
200
400
600
800
1000
20 40 60
200
400
600
800
1000
20 40 60
200
400
600
800
1000
20 40 60
200
400
600
800
1000
20 40 60
200
400
600
800
1000
20 40 60
200
400
600
800
1000

MADA-ETI, ISSN 2220-0673, Vol.1, 2011 www.madarevues.gov.mg
38
Une fois que le système ait fini de comparer les
histogrammes des VS (Valeurs Singulières) de
l’image requête avec tous les histogrammes de la
base de données d’images en calculant leur
distance euclidienne.
En effet, pour deux images similaires, cette
dernière est égale à zéro.
Le système va alors effectuer la recherche et
retourner les résultats par ordre de similarité
décroissante.
Notons pourtant que la SVD reconnait l’image au
sens de la couleur à 75% si on ne se fie qu’au
critère bas niveau de l’image et que si on place
plusieurs images à peu près similaires à l’image
requête dans la base d’image.
Nous avons proposé une méthode d’indexation
qui extrait les informations couleurs dans les
matrices des valeurs singulières. En extrayant les
� − �è' des rangs dans la matrice , nous avons
pu rechercher les images les plus similaires de
l’image requête dans la base.
Image requête
Résultats de la recherche
Im 1 : D = 0 ,00 Im 2 : D = 12,5 Im 3 : D = 12,9 Im 4 : D = 13,4 Im 5: D = 13,9
Im 6 : D = 14,15 Im 7 : D = 14,28 Im 8 : D = 15,06 Im 9 : D = 15,4 Im 10 : D = 15,88
4. Discussions
On remarque bien que certaines images sont loin
de ressembler à l’image requête alors que la
distance entre les deux images se rapproche, et
que dans certains cas, la nuance de couleur entre
l’image cible et celles trouvées est frappante, ceci
est due à l’addition des couleurs rouge, vert, bleu.
Concernant cette méthode d’indexation, l’objectif
est de garder un maximum d’information des

MADA-ETI, ISSN 2220-0673, Vol.1, 2011 www.madarevues.gov.mg
39
données initiales, et voire la possibilité de la
reconstitution de l’image à son état d’origine.
On a pu constater que la perte d’information est
moindre.
Quant aux résultats affichés, les images candidates
de la base sont ordonnées suivant leur score, Les
images de plus grand score étant considérées
comme les plus similaires.
4.1 Avantages de la SVD
-Méthode objective, méthodique et linéaire.
-Optimale dans le terme d’énergie.
-Efficacité élevé avec le niveau de non
homogénéité.
-Ordre de modèle réduit.
4.2 Inconvénients de la SVD
-Difficile extrapolation.
-Taille de données devienne énorme
5. Conclusions et perspectives
On remarque alors que la performance du système
que nous avons utilisé dépend de la nature de la
base de données d’images utilisée.
Si les images présentent une forte couleur, elle est
adéquate. Pour les autres types images elle s’avère
assez inefficace.
D’un autre côté, on a utilisé la décomposition en
valeurs singulières car ils possèdent une propriété
qui permet d’extraire un niveau élevé de l’énergie
de l’image.
Pour effectuer une recherche dans une base
d’images, il faut s’entendre sur ; qu’est ce que
deux images similaires : même forme, même
couleur, même sémantique, etc…. Les résultats
peuvent être complètement différents, pourtant
pouvant être valides, d’après un certain critère.
Une image contient beaucoup d’informations, et
peuvent avoir plusieurs interprétations. Tout ceci
fait que pour rechercher une image : il faut limiter
la recherche à un critère. La difficulté majeure
rencontrée dans le travail réalisé concerne
l’interprétation des résultats. En effet, manipulant
les images, et donc leur attribuant
automatiquement une signification (au sens de la
couleur) pouvant être différente pour chaque
personne, l’aspect qualitatif des résultats obtenus
demeure subjectif.
Les V.S sont les plus importantes puisqu’elles
sont uniques. Cependant, avec l’expérience sur
l’échange de V.S de deux images, le résultat est
très intéressant et montre que les � et � (gauche et
droite) sont tout aussi importants pour la
reconstruction de l’image originale.
Les désavantages de la SVD c’est qu’il n’est pas
rapide du point de vue machine, le problème sur
lequel [13] son application est puissant, la
puissance conditionnelle de son application est
due aux travaux excessifs associés aux calculs.
Les résultats pour l’indexation et la recherche
d’image donnent une petite erreur de pourcentage
comparée à la reconnaissance utilisant les
dimensions de l’image originale.
Beaucoup d’images sont simples, donc elles ont
seulement besoin de quelques V.S (� = 50� pour
obtenir une approximation, et la partie complexe a
besoin d’utiliser plus de valeur à maintenir leur
qualité.

MADA-ETI, ISSN 2220-0673, Vol.1, 2011 www.madarevues.gov.mg
40
Nous pouvons conclure que l’image n’a pas
besoin d’un même� dans sa totalité.
En générale, l’approche de la SVD est robuste,
simple, facile à implémenter. Il travaille aussi bien
dans des environnements contraignants.
Cela fournit une solution pratique à l’image
compressée et ceux des problèmes de
reconnaissance.
L’optimisation de la recherche sur l’indexation
serait assez nombreuses, ne serait ce que combiner
avec d’autres méthodes autre la couleur, ou encore
passer à la sémantique de l’image. On peut aussi
utiliser la POD (Proper Orthogonal
Decomposition), et comparer ces différentes
méthodes de quantifications d’informations afin
de relever leurs points forts et évaluer les résultats.
6. Références
[1] M. Swain, D. Ballard, « Color indexing
image retrieval », International journal of
computer vision, Octobre 1991.
[2] M. Vissac, J. L. Dugelay, « Un panorama
sur l’indexation d’images fixes », Institut
Eurocom, Department of Multimedia
Communication Rouen, 2009.
[3] Y. Raoui, M. Devy, H. Boyakhof,
« Reconnaissance d’objets : extraction de
points d’intérêts par le détecteur de Harris
Laplace dans des images couleurs »,
Laboratoire d’analyse et d’architecture des
systèmes du CNRS, 2008.
[4] Rui., Huang., Chang., « Image retrieval:
Current techniques, processing direction
and open issues», Journal of visual
Communication and Image Representation,
pp. 1-23, 2009.
[5] M. K. Mandal, F. Idris, S. Panehanathan,
« A criticical evaluation of image and video
indexing technics in the compressed
domain », Image & vision computing
journal, 1999.
[6] A. Favre, « Decomposition en valeurs
singulières et analyse de contenu »,
Visiosoft S.A & L.O : Pochon, IRDP, 2000.
[7] Berry, J. R. Smith, “Latent Semantic
Image”, IEEE International Conference on
Image processing, 2007.
[8] P. Vannoorenberghe, C. Le Compte, P.
Miche, « Histogramme spatiaux couleur
optimisés pour l’indexation d’images par le
contenu », Laboratoire perception et
systèmes d’informations, CNRS, 2005.
[9] A. Matthew, Tuck, P. A. Pentland, « Face
recognition using eigenface method », IEEE
Conference on computer vision and pattern
recognition, pp. 586-591, 1991.
[10] G. Zeng, « Face recognition with singular
value decomposition », CISSE proceeding,
2006.
[11] Razafindradina H.B., Randriamitantsoa
P.A., « Tatouage robuste et aveugle dans le
domaine des valeurs singulières »,
Laboratoire LASM, pp. 5-7, janvier 2010.
[12] Nguyen H. L. T., « Recherche d’image
basée sur le contenu sémantique », Rapport
de TIPE, Institut de la Francophonie pour
l’Informatique, Vietnam, Juillet 2005.
[13] P. Maheswary, N. Srivastava, « Retrieval of
Remote Sensing Images Using Colour &
Texture Attribute », IJCSI, Vol. 4, 2009.

MADA-ETI, ISSN 2220-0673, Vol.1, 2011 www.madarevues.gov.mg
41
Recommended

















