Embed Size (px)
Citation preview
Data Mining
[email protected] ESPRIT©2013-2014
TP n°3 : Règles d’associations
Ben harrath arij 4infini
Note
Ce TP est à rendre en fin de séance.
Objectifs généraux
Dans ce TP, nous allons appliquer la méthode des règles associatives sur des échantillons de données, afin d’extraire
des dépendances entre des profils, des articles, des produits…en se basant sur les critères de pertinence étudiés
dans le cours (support, confidence, lift)
I. Etude des profils de demandes de Crédits
library : arules //voir la description du dataset en pièce jointe (credit-german.doc)
1. Chargement du package :
2. Importation des données :
3. Transformation des données :
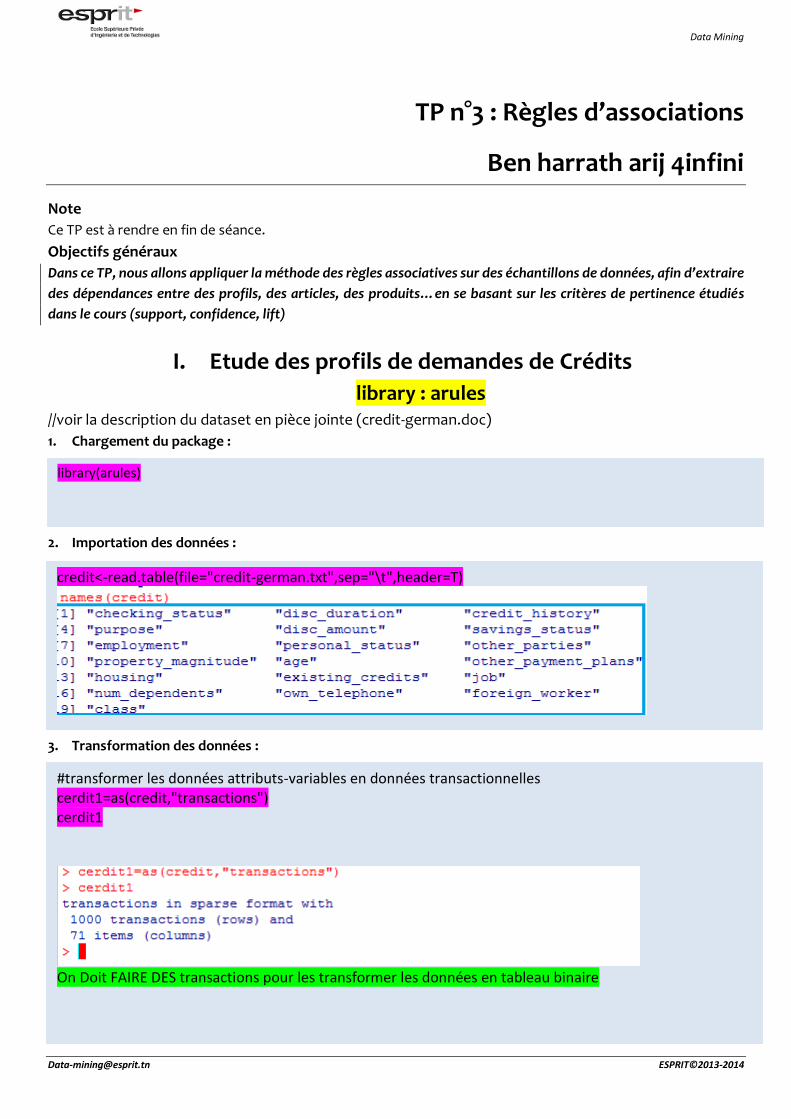
library(arules)
credit<-read.table(file="credit-german.txt",sep="\t",header=T)
#transformer les données attributs-variables en données transactionnelles cerdit1=as(credit,"transactions") cerdit1
On Doit FAIRE DES transactions pour les transformer les données en tableau binaire
Data Mining
[email protected] ESPRIT©2013-2014
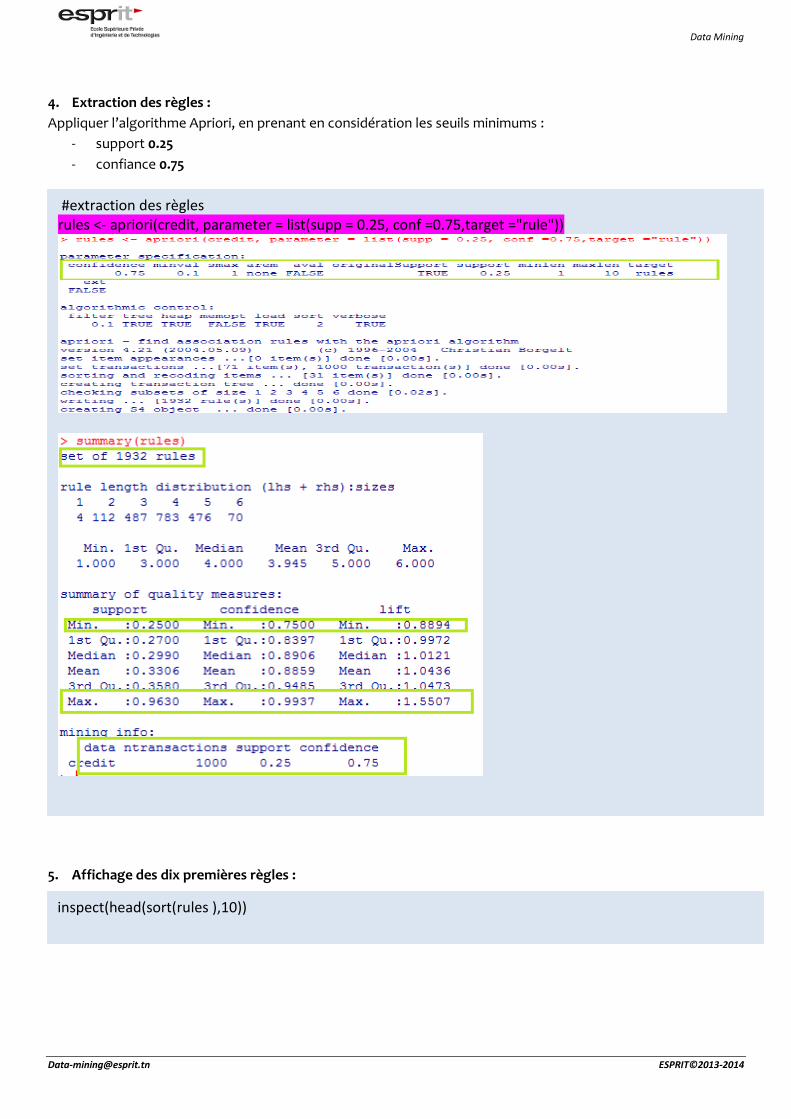
4. Extraction des règles :
Appliquer l’algorithme Apriori, en prenant en considération les seuils minimums :
- support 0.25
- confiance 0.75
5. Affichage des dix premières règles :
#extraction des règles rules <- apriori(credit, parameter = list(supp = 0.25, conf =0.75,target ="rule"))
inspect(head(sort(rules ),10))

Data Mining
[email protected] ESPRIT©2013-2014
6. Affichages des cinq premiers lift :
#afficher les 5 règles avec le lift le + élevé inspect(head(sort(rules,by="lift"),5))
On remarque que tous les valeurs varient si lift=1 donc on peut rien remarquer si lift<1 alors il s’agit d’une coloration négative
Data Mining
[email protected] ESPRIT©2013-2014
II. Etude des relations entre les produits vendus dans une épicerie
library : arules, arulesViz
Groceries est un dataset de format transactions contenant 9835 opérations de ventes agrégées avec
169 catégories de produits, prises durant un mois.
1. Chargement du package :
2. Importation des données :
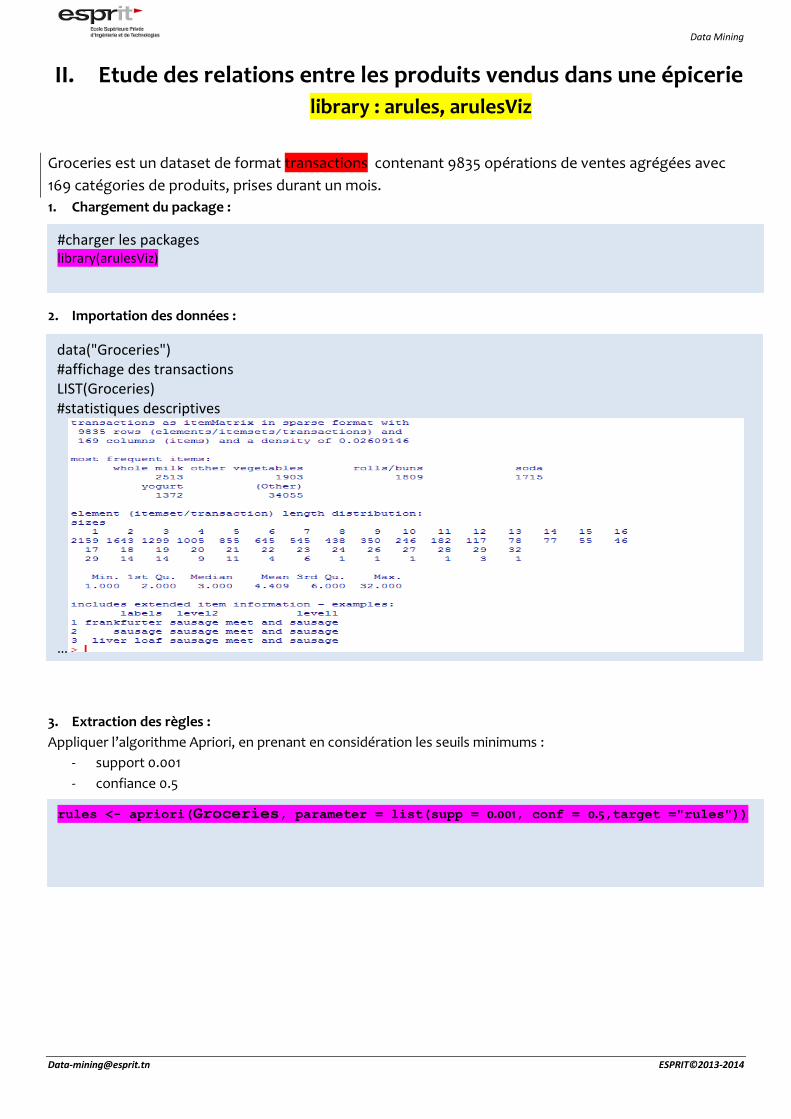
3. Extraction des règles :
Appliquer l’algorithme Apriori, en prenant en considération les seuils minimums :
- support 0.001
- confiance 0.5
#charger les packages library(arulesViz)
data("Groceries") #affichage des transactions LIST(Groceries) #statistiques descriptives
…
rules <- apriori(Groceries, parameter = list(supp = 0.001, conf = 0.5,target ="rules"))

Data Mining
[email protected] ESPRIT©2013-2014
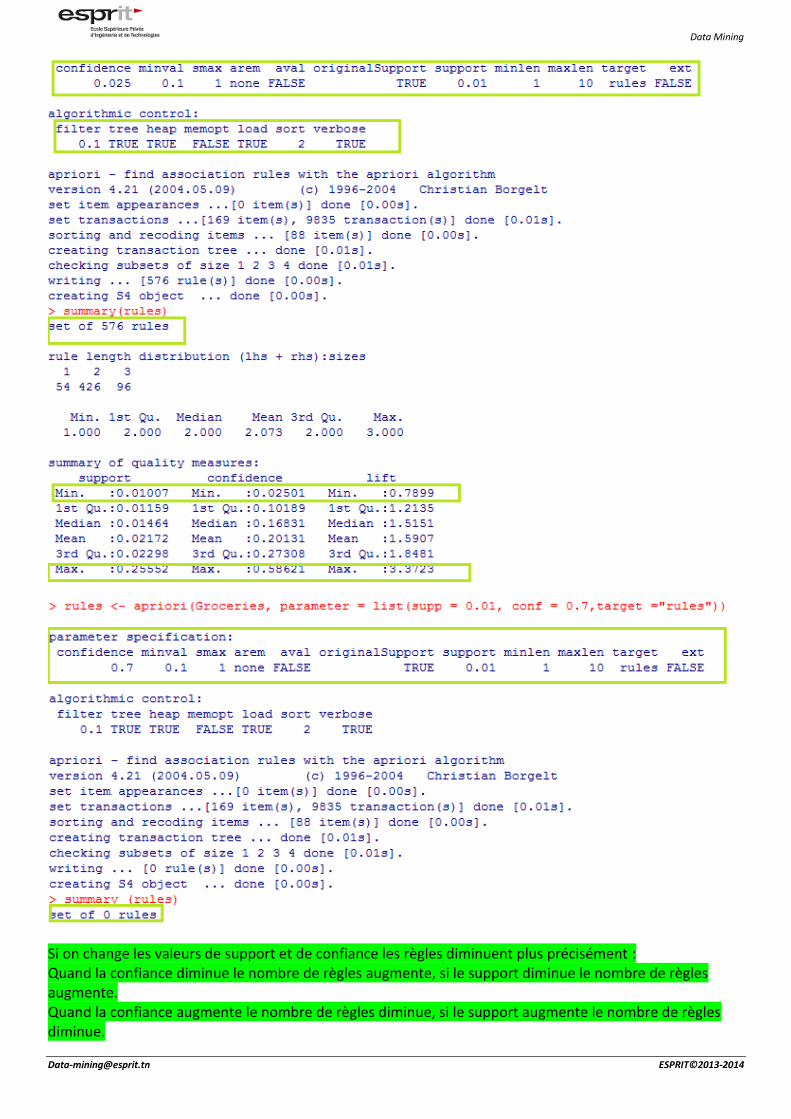
5668 règles :Dont les supports varient de 0.001017 et 0.2267, les confiances de 0.5 à 1, et les valeurs de lift de 1.957 à 18.996 On constate que les valeurs de lift sont tous supérieurs à 1 donc il s’agit d’une corrélation positive
Tester des différentes valeurs de supports et de confiance, ainsi que le paramétrage de la longueur des règles
Interpréter les résultats :
rules <- apriori(Groceries, parameter = list(supp = 0.01, conf = 0.025,target ="rules")) on a changé les valeurs de support et de confiance
Data Mining
[email protected] ESPRIT©2013-2014
Si on change les valeurs de support et de confiance les règles diminuent plus précisément : Quand la confiance diminue le nombre de règles augmente, si le support diminue le nombre de règles augmente. Quand la confiance augmente le nombre de règles diminue, si le support augmente le nombre de règles diminue.
Data Mining
[email protected] ESPRIT©2013-2014
Aussi on a remarqué que le nombre des règles a diminué donc on constate que on changeant l’intervalle le nombre des règles varient .
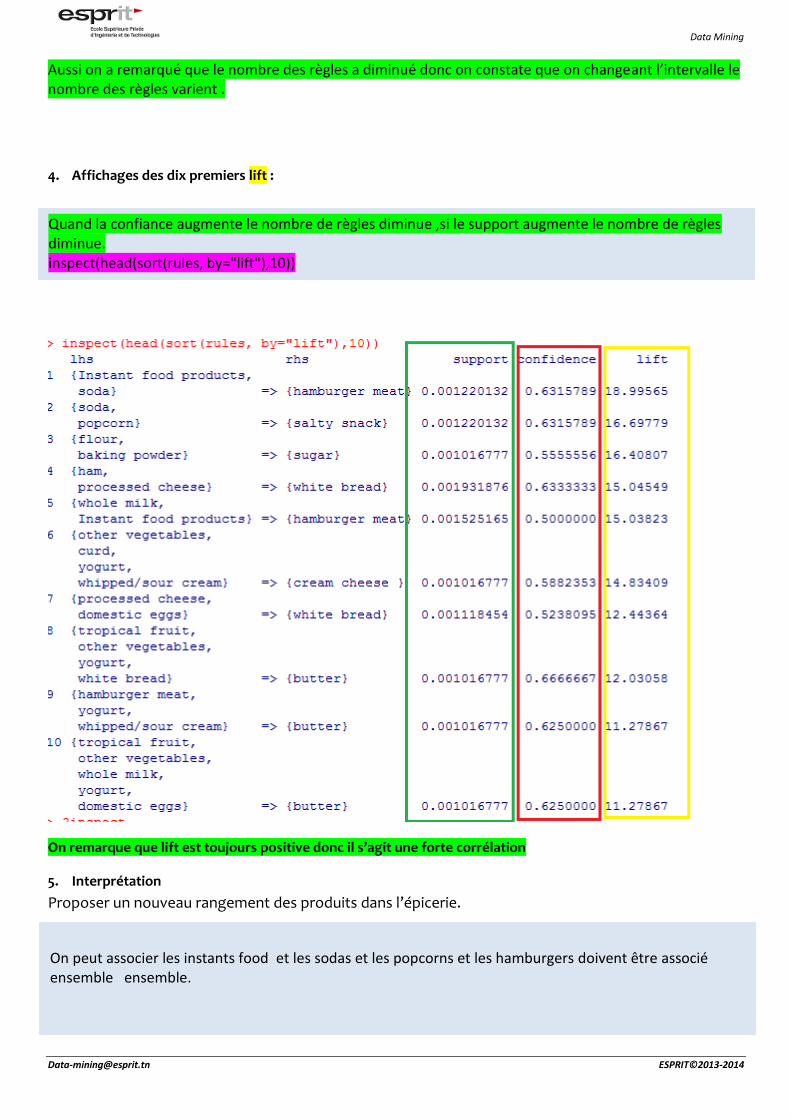
4. Affichages des dix premiers lift :
On remarque que lift est toujours positive donc il s’agit une forte corrélation
5. Interprétation
Proposer un nouveau rangement des produits dans l’épicerie.
Quand la confiance augmente le nombre de règles diminue ,si le support augmente le nombre de règles diminue. inspect(head(sort(rules, by="lift"),10))
On peut associer les instants food et les sodas et les popcorns et les hamburgers doivent être associé ensemble ensemble.
Data Mining
[email protected] ESPRIT©2013-2014
6. Visualisation des Règles d’Association :
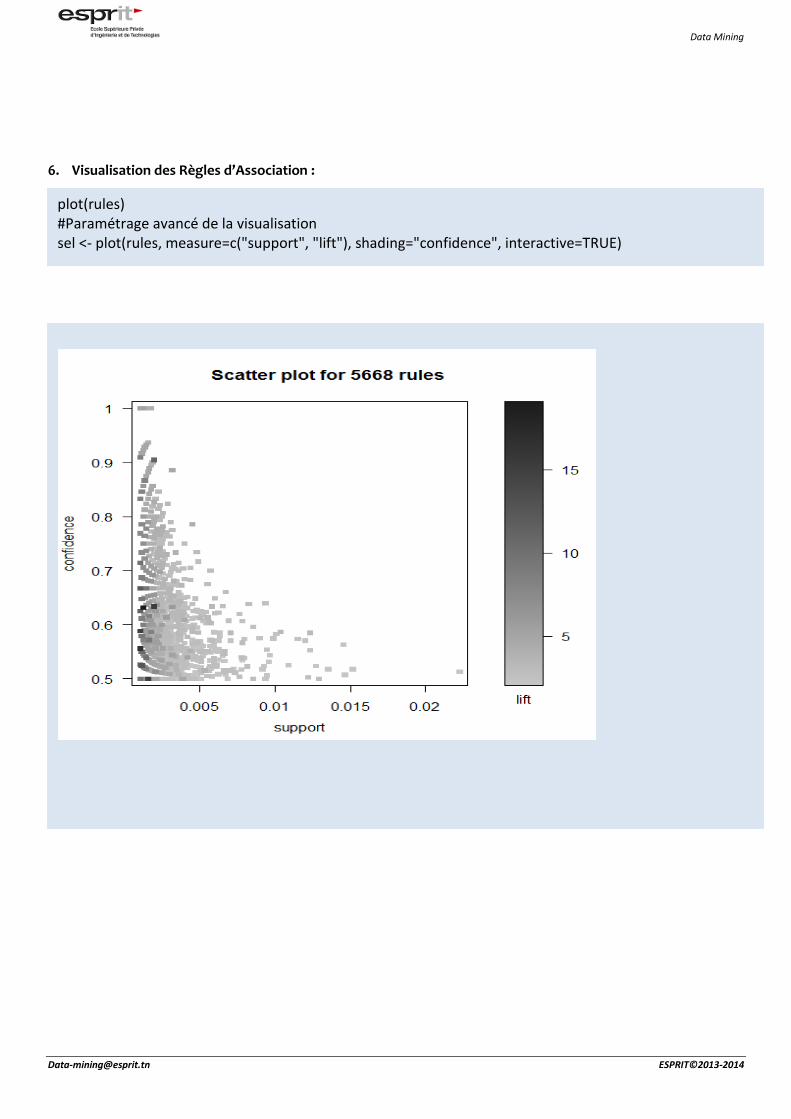
plot(rules) #Paramétrage avancé de la visualisation sel <- plot(rules, measure=c("support", "lift"), shading="confidence", interactive=TRUE)
Data Mining
[email protected] ESPRIT©2013-2014
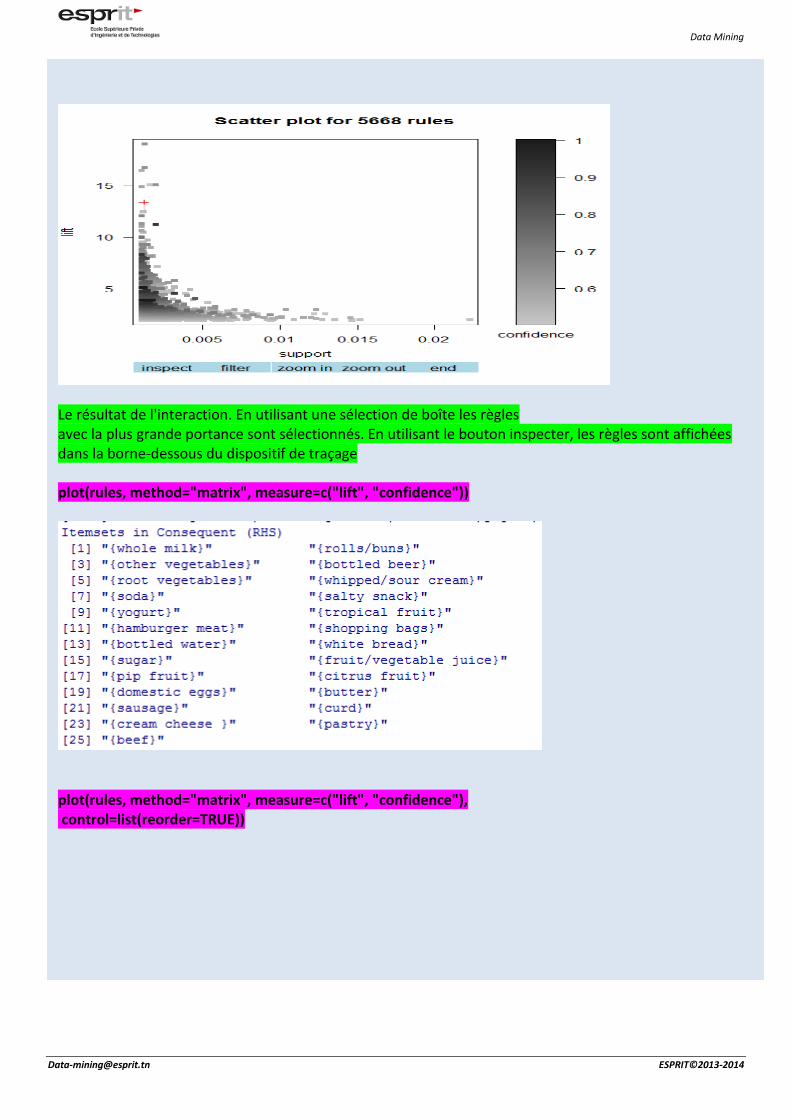
Le résultat de l'interaction. En utilisant une sélection de boîte les règles avec la plus grande portance sont sélectionnés. En utilisant le bouton inspecter, les règles sont affichées dans la borne-dessous du dispositif de traçage plot(rules, method="matrix", measure=c("lift", "confidence"))
plot(rules, method="matrix", measure=c("lift", "confidence"), control=list(reorder=TRUE))
Data Mining
[email protected] ESPRIT©2013-2014
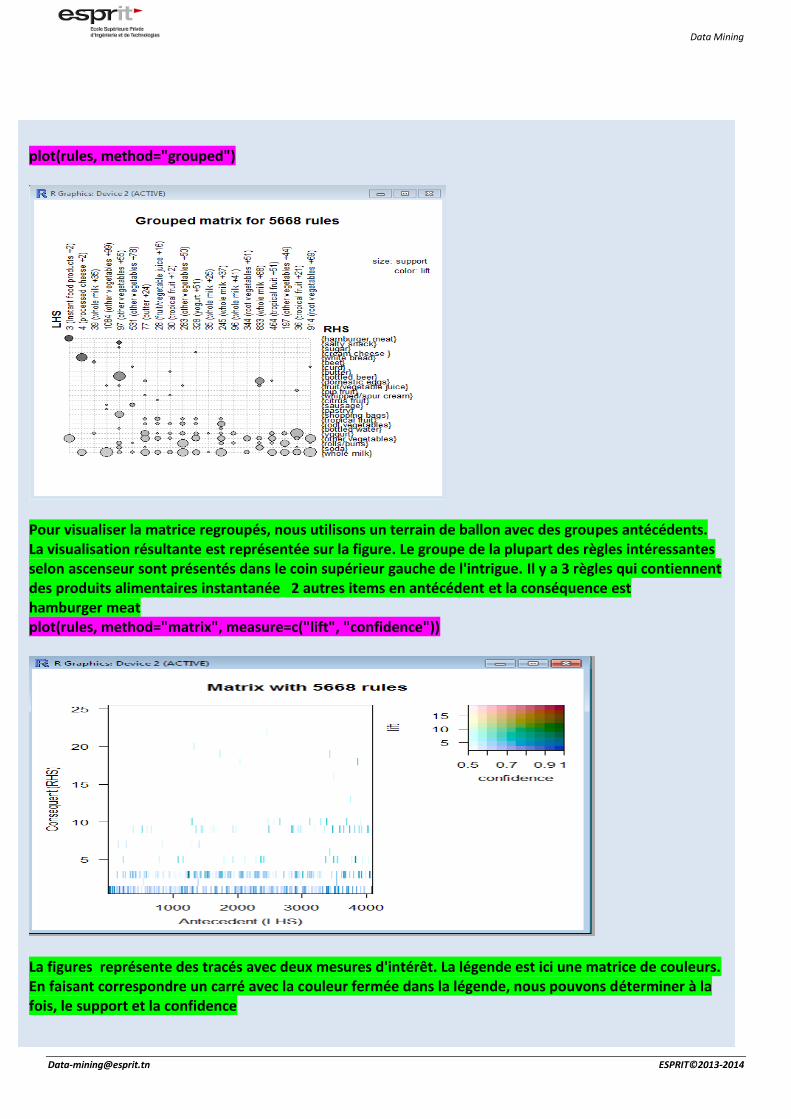
plot(rules, method="grouped")
Pour visualiser la matrice regroupés, nous utilisons un terrain de ballon avec des groupes antécédents. La visualisation résultante est représentée sur la figure. Le groupe de la plupart des règles intéressantes selon ascenseur sont présentés dans le coin supérieur gauche de l'intrigue. Il y a 3 règles qui contiennent des produits alimentaires instantanée 2 autres items en antécédent et la conséquence est hamburger meat plot(rules, method="matrix", measure=c("lift", "confidence"))
La figures représente des tracés avec deux mesures d'intérêt. La légende est ici une matrice de couleurs. En faisant correspondre un carré avec la couleur fermée dans la légende, nous pouvons déterminer à la fois, le support et la confidence
Data Mining
[email protected] ESPRIT©2013-2014
III. Market Basket Analyse
Importation des données :
market_basket<- read.transactions(file='market_basket.csv', rm.duplicates=F, format='single', sep=',', cols=c(1,2));
market_basket<-read.table(file="market_basket.txt",sep="\t",header=T) market <- as(as.matrix(market_basket), "transactions")
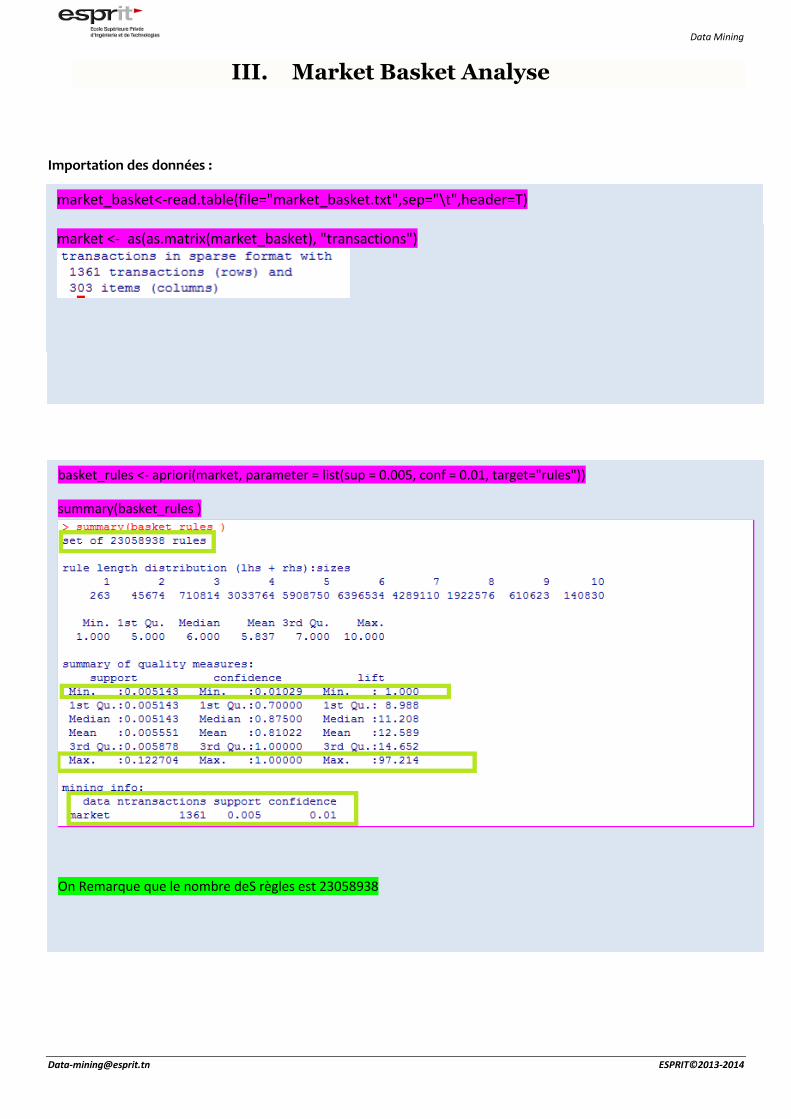
basket_rules <- apriori(market, parameter = list(sup = 0.005, conf = 0.01, target="rules"))
summary(basket_rules )
On Remarque que le nombre deS règles est 23058938
Data Mining
[email protected] ESPRIT©2013-2014
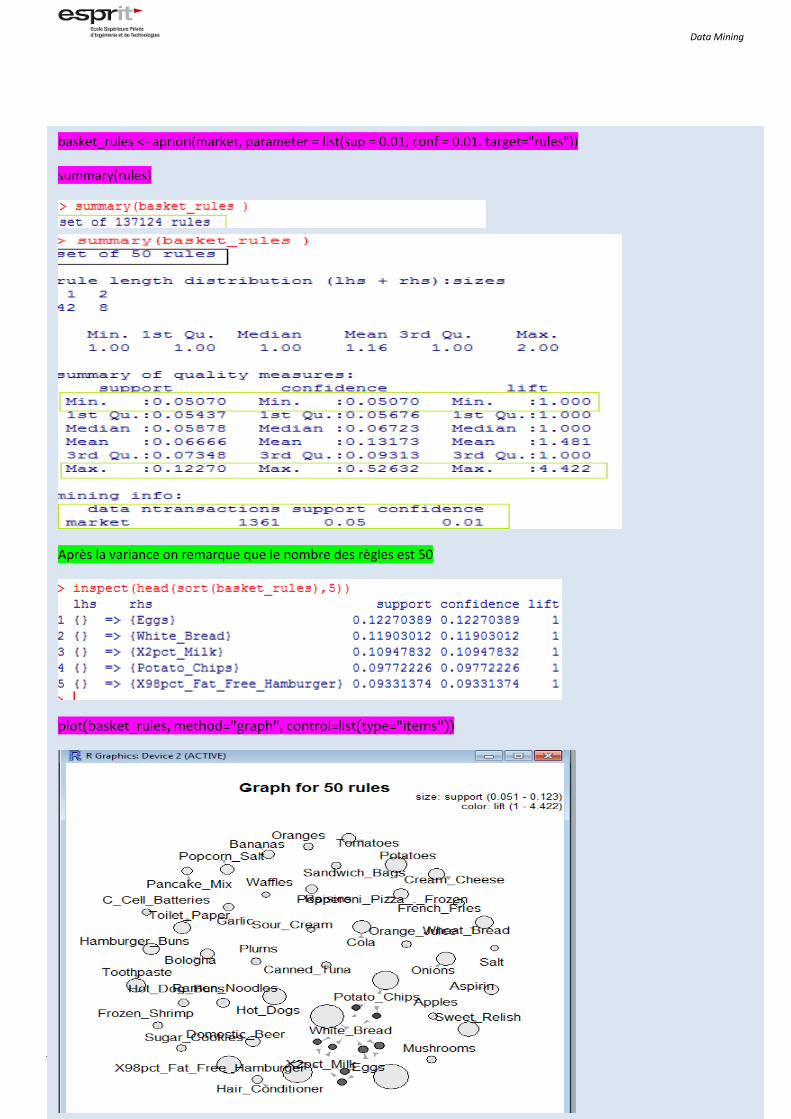
basket_rules <- apriori(market, parameter = list(sup = 0.01, conf = 0.01, target="rules"))
summary(rules)
inspect(head(sort(basket_rules),10))
Les valeurs de lift sont égaux a 1 donc on peut rien remarquer
On va varier les valeurs de confiance et de support
Après la variance on remarque que le nombre des règles est 50
plot(basket_rules, method="graph", control=list(type="items"))
Data Mining
[email protected] ESPRIT©2013-2014
. Cette représentation se concentre sur la façon dont les règles sont composées des éléments individuels et des
spectacles qui partagent les règles.
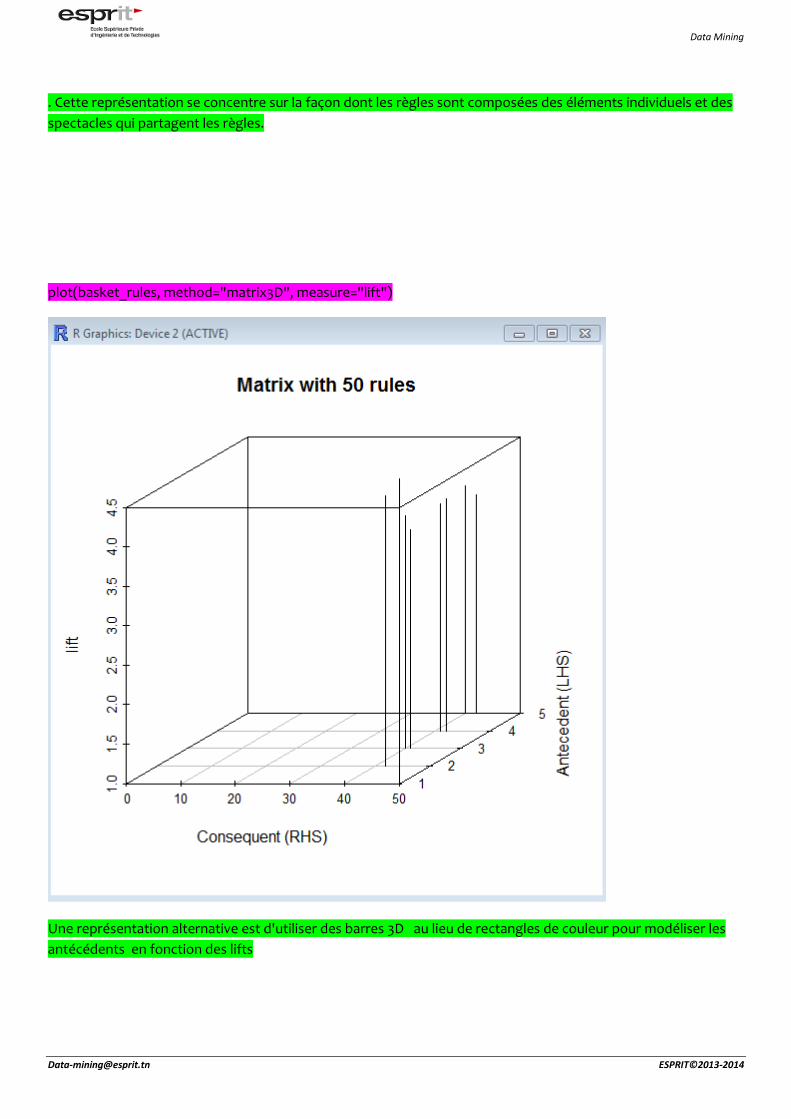
plot(basket_rules, method="matrix3D", measure="lift")
Une représentation alternative est d'utiliser des barres 3D au lieu de rectangles de couleur pour modéliser les
antécédents en fonction des lifts
Data Mining
[email protected] ESPRIT©2013-2014
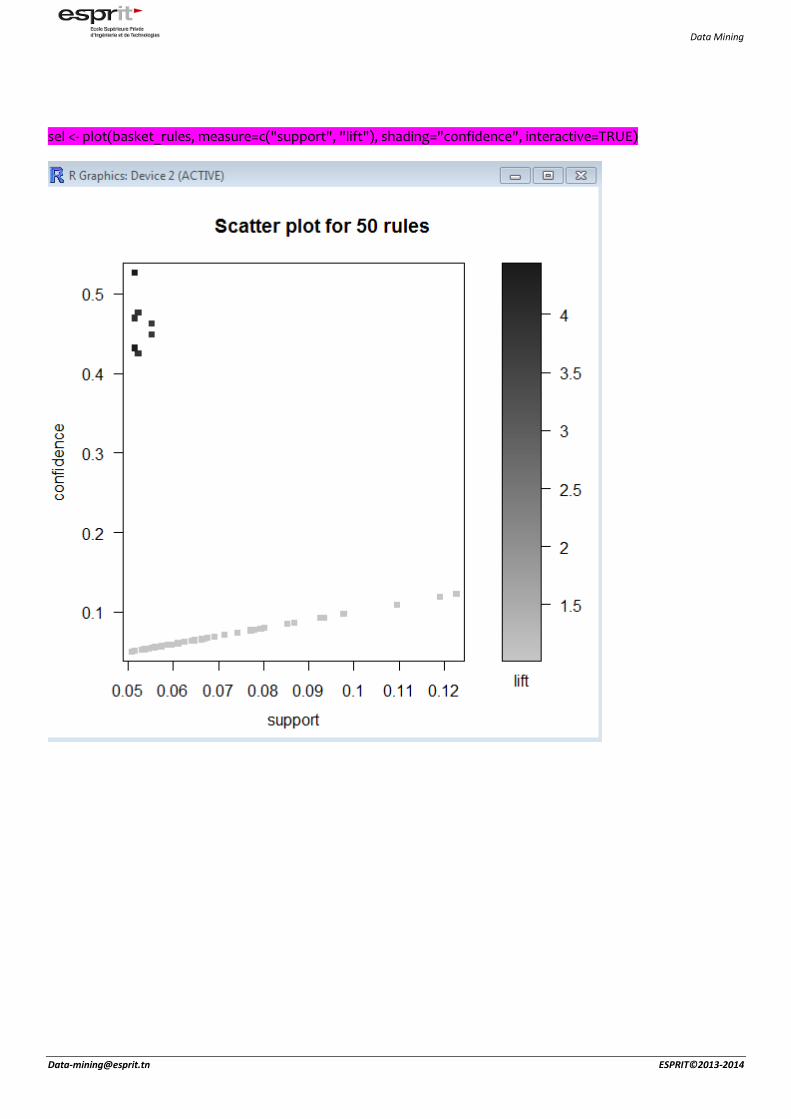
sel <- plot(basket_rules, measure=c("support", "lift"), shading="confidence", interactive=TRUE)





























