Embed Size (px)
Citation preview

les technologies sémantiques
Quel avenir pour l'entreprise ?État des lieux et apports fonctionnels
1re édition – Octobre 2013
liv
re
b
lan
c

2

3
ÉditO« trop d’information tue l’information ». Chacun d’entre nous pourrait illustrer cet adage quotidiennement avec d’innombrables exemples. Grâce aux technologies sémantiques, il tend à tomber en désuétude et nous pourrons, bientôt, définitivement le qualifier d’obsolète. Les technologies sémantiques, dopées initialement par l’explosion du Web, sont devenues indispensables au bon développement des autres technologies de l’information. La fonction première d’un portail collaboratif est de faciliter l’accès à l’information avec des moyens de recherche performants. L’analyse décisionnelle ne se cantonne plus à des modélisations et des synthèses sur des données purement numériques. La richesse des réseaux sociaux est basée sur la capacité à corréler des informations de toute nature. Une application mobile se doit d’isoler la bonne information sur le Web au bon moment et de la présenter de façon optimale… Les exemples ne manquent pas !L’information, structurée et surtout non structurée, qui a foisonné de manière quasi-géométrique en volume, en nature, en variété, au sein du Si, est d’autant plus porteuse pour l’entreprise de valeur et de performance qu’elle interagit, désormais, avec la gigantesque masse de données externes, majoritairement issues du Web. On retrouve bien sûr en corollaire les problématiques de Big
Philippe debard directeur Exécutif Application & technology Services
data, d’Open data, de référencement, de recherche et d’analyse, le besoin d’interagir avec l’information au plus près de sa source en utilisant des terminaux de toute sorte, smartphones, tablettes, qui ont également généralisé les interfaces disruptives, tactiles, voix, gestes.Au travers ce livre blanc, nous avons souhaité vous présenter un état des lieux du domaine des technologies sémantiques, ainsi que leurs cas d’application en entreprise. Nous l’avons conçu comme un outil pragmatique permettant aux décideurs de mieux comprendre les bénéfices de ce type de solutions et de s'orienter vers celle(s) correspondant, le mieux, aux besoins de leur organisation.

4
SOmmAirE
Édito ............................................................................................................................................................................. 3
vous avez dit "sémantique" ?La sémantique, une branche de la linguistique ................................................................................................... 8Linguistique et informatique, le couple gagnant .................................................................................................. 8Le web dit sémantique ou web des données ........................................................................................................ 9tAL et Web sémantique, deux paradigmes disjoints ? ...................................................................................... 10
les technologies sémantiques au service de l'entreprise
Pourquoi les technologies sémantiques ? ............................................................................................................ 14L'information dans l'entreprise .................................................................................................................... 14de la nécessité de gérer l'information non structurée au sein de l'entreprise ..................................... 15La gestion des connaissances ....................................................................................................................... 15
Les apports des technologies sémantiques ......................................................................................................... 16A la recherche d’information ......................................................................................................................... 16A la gestion des données ............................................................................................................................... 19Au content analytics et à l’opinion mining ................................................................................................. 26Cas d’application ............................................................................................................................................. 26

5
panorama du marché sémantique d'entreprise
Solutions actuelles ................................................................................................................................................... 32Cas clients.................................................................................................................................................................. 34
text-mining et analyse de sentiments ........................................................................................................ 34Banque, distribution et vente par correspondance : suivi de l’expérience client grâce au tAL .......... 35traduction automatique ................................................................................................................................ 35CNrS : plate-forme d’UiA grâce aux technologies du Web sémantique ............................................... 40
comment démarrer ?
conclusion
glossaire
bibliographie

6

vous avez dit "sémantique" ?
7

8
La sémantique, une branche de La Linguistique
Avant de nous intéresser à la sémantique proprement dite, il convient tout d'abord de définir la vaste science que représente la linguistique. Ferdinand de Saussure, linguiste suisse considéré comme le père de la linguistique moderne, définit cette dernière comme une « science qui a pour objet la langue envisagée en elle-même et pour elle-même ». Ainsi, la linguistique constitue donc l'analyse scientifique de la langue et ce, indépendamment de tout contexte social, qui souvent, ne fait qu'apporter des jugements de valeur.depuis sa création, la linguistique s'est donc confrontée à différentes questions telles que la structuration de la langue, la production et la perception de la langue par les locuteurs ou encore la transmission de sens entre deux individus grâce au langage... C'est dans ce contexte qu'est née la sémantique, soit l' « étude du langage considéré du point de vue du sens » ou, en d'autre termes, l'étude des signifiés. La sémantique traite donc du sens des mots.
Linguistique et informatique, Le coupLe gagnant
dès les années 1950, linguistique et informatique se rencontrent pour la première fois, grâce aux avancées de l'intelligence Artificielle, notamment, et finiront par donner naissance à ce que l'on appellera plus tard la Linguistique informatique. Celle-ci se subdivise en trois principaux domaines de recherche et d'ingénierie qui sont :
↪ le traitement de la parole qui, comme son nom l'indique, s'intéresse à la parole dans son intégralité, depuis le traitement du signal acoustique à la retranscription textuelle, en passant par la phase de décodage (reconnaissance vocale). La synthèse vocale fait également partie de ce domaine d'étude.
↪ le Traitement Automatique des Langues (tAL), Traitement Automatique du Langage Naturel (tALN) ou encore Ingénierie Linguistique, dont l'objectif est essentiellement de traiter les textes
Contrairement au rire, également
commun à d'autres espèces, le langage
articulé constituerait le propre de
l'Homme. En effet, si certaines espèces
sont bel et bien capables de reproduire
certains sons et donc par là même
certains mots issus d'un langage
humain, ni les grammaires complexes
ni les concepts abstraits utilisés en
permanence par les humains ne se
retrouvent à l'état naturel chez ces
espèces.
il apparaît donc logique que
l'interprétation et la génération de
textes aient constitué les premières
aspirations des pionniers du traitement
Automatique des Langues. Ainsi, l'objectif
initial était d'aboutir à une machine
intelligente capable de comprendre et
d'interpréter le langage naturel humain.
imaginez un monde dans lequel il serait
possible de s'abstraire de tout langage
de programmation et des difficultés
associées pour communiquer avec la
machine ! toutefois, pour interpréter un
énoncé, l’aspect syntaxique seul ne suffit
pas : l’aspect sémantique prend alors
tout son sens !

9
vous avez dit "sémantique" ?
écrits en les analysant, en les résumant ou encore en les traduisant. Les tâches principales sont les suivantes :
� l'annotation de corpus � l'extraction d'entités � le lexique � la traduction automatique � le résumé automatique � la recherche d'information à partir d'un corpus de
documents ↪ le dialogue homme/machine, qui a d'ailleurs motivé les tout premiers travaux de linguistique informatique, en particulier ceux d'Alan turing, qui prédisait cette tâche possible d'ici l'an 2000, 50 ans auparavant. Pourtant, l'échéance est passée et la prédiction n'est toujours pas réalisée, ni réalisable (Audibert, 2010)…
Le problème semble donc plus complexe que prévu. toutefois, certains aspects du domaine de la linguistique informatique trouvent d'ores et déjà des applications dans le monde de l'entreprise et l'on constate l'émergence d'une multitude d'éditeurs spécialisés, notamment dans le tAL qui apparaît comme très prometteur.
Le web dit sémantique ou web des données
En marge de l'ingénierie linguistique qui existe depuis plus de 50 ans s'est développé ce que tim Berners-Lee, le directeur du W3C, a baptisé le Web sémantique. Néanmoins, cette technologie qui a vu le jour en 2001 n'a de sémantique que son nom, si bien que son créateur en a rapidement pris conscience puisque peu de temps plus tard, il proposa le nom de « Web des données ». il s'agit d'un Framework permettant de structurer et de lier l'information présente sur internet à l'aide de métadonnées décrivant des relations ; le sens des données n'est donc pas réellement traité ni interprété. Le principal intérêt réside toutefois dans le fait que les données peuvent alors être « partagées et réutilisées entre plusieurs applications, entreprises et groupes d'utilisateurs ».Afin d'illustrer certains des apports du Web sémantique, prenons l'exemple de Google et de son Knowledge Graph déployé en 2012 (Singhal, 2012). Les rich snippets permettent d'afficher certaines informations complémentaires au site comme la description d'un produit ou d'un article, pour peu que ces informations aient été renseignées en utilisant les formats correspondants. En outre, le Web sémantique permet également à Google de récupérer certaines informations pertinentes à la requête depuis des sites tels que Wikipédia et de les afficher directement dans la page des résultats, ou encore de

10
Enfin, le Web sémantique impose que les connaissances d'un domaine particulier soient gérées et normalisées par des experts issus de ce domaine, afin de maintenir une certaine cohésion en fixant la terminologie métier au sein de l'entreprise.
vous avez dit "sémantique" ?
contextualiser certaines recherches comprenant des mots polysémiques notamment. Ainsi, si l'on effectue la recherche « shetland » sur Google, un volet s'affiche sur la droite de l'écran et permet de ne sélectionner que les résultats en rapport avec les îles, avec le cheval ou avec le chien du même nom :
taL et web sémantique, deux paradigmes disjoints ?
Si le tAL et le Web sémantique constituent a priori deux technologies indépendantes nées dans deux contextes différents, sont-ils par ailleurs incompatibles ? Lorsque l'on s'y intéresse plus en détails, on se rend rapidement compte que ces deux technologies s'avèrent plutôt complémentaires que disjointes. En effet, alors que le tAL offre des structures de désambiguïsation ainsi que la possibilité d'automatiser l'annotation ou la traduction de documents, le Web sémantique, quant à lui, fournit des standards permettant l'interopérabilité et le partage des ressources. de cette façon, le tAL engendre des gains de temps et de productivité considérables en automatisant l'extraction d'entités, la classification de documents ainsi que leur annotation, qui peut alors se faire dans les standards du Web sémantique.
de plus, le Web sémantique met en œuvre une modélisation sous forme de réseau sémantique, une structure imaginée dès 1909 par Charles S. Peirce, puis appliquée à l'informatique en 1956 par richard H. richens (Cambridge Language research Unit) et développée dans les années 1960 par les Anglais Allan Collins, chercheur en sciences cognitives, ross Quillian, linguiste et Elizabeth Loftus, psychologue. La notion fut également formalisée en 1984 par John F. Sowa sous le nom de graphe conceptuel, dont le but est de représenter des connaissances et des raisonnements. Le modèle conceptuel
11
vous avez dit "sémantique" ?
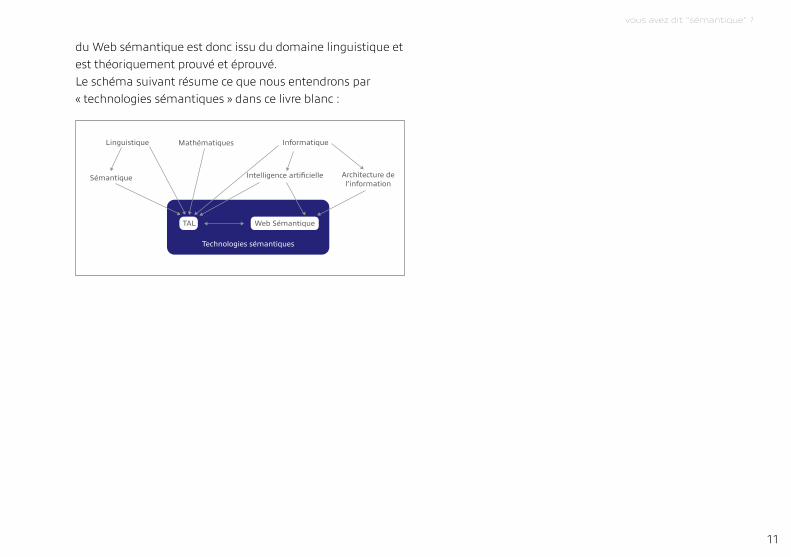
du Web sémantique est donc issu du domaine linguistique et est théoriquement prouvé et éprouvé.Le schéma suivant résume ce que nous entendrons par « technologies sémantiques » dans ce livre blanc :
Linguistique Mathématiques Informatique
Architecture de l’information
Intelligence artificielleSémantique
TAL Web Sémantique
Technologies sémantiques

12

les technologies sémantiques au service de l'entreprise
13

14
pourquoi Les technoLogies sémantiques ?
L'information dans l'entrepriseLes entreprises l’ont bien compris : les bonnes décisions passent par la bonne gestion de leurs informations et l’on ne présente plus aujourd’hui l’utilité des systèmes d’information. mais les temps changent, et ces mêmes entreprises doivent désormais faire face à un volume toujours plus important d’informations de natures et de formes différentes.
L'information structuréeLes informations structurées se trouvent, par exemple, dans les bases de données ou encore dans les langages informatiques. Ainsi, on les reconnaît au fait qu’elles sont disposées de façon à être traitées automatiquement et efficacement par un logiciel, mais non nécessairement par un humain. d’après Alain Garnier, l’auteur du livre L'information non structurée dans l'entreprise, « une information est structurée lorsqu’elle est répétable, systématique et calculable ». il peut s’agir de formulaires, de factures, de fiches de paie, de libellés…
L'information non structuréePar opposition à la catégorie précédente, les informations non structurées représentent l’ensemble des informations pour lesquelles il est impossible de retrouver une structure prédéfinie. Elles sont toujours destinées à des humains et il s’agit donc essentiellement de documents textes et
multimédias, comme des lettres, des livres, des rapports, des collections d’images ou de vidéos, des brevets, des images satellites, des offres de services, des CV, des appels d’offre… Et la liste est encore longue.
L'information semi-structuréeil est à noter que la frontière entre informations structurées et informations non structurées demeure assez floue et qu’il n’est pas toujours aisé de classer un document dans l’une ou l’autre des catégories. dans ce cas précis, vous avez sans doute affaire à de l’information semi-structurée.Par exemple, un e-mail est structuré de la manière suivante :
les technologies sémantiques au service de l'entreprise
date : mardi, 11 juin 2013 13:14:47 -0400
From : Y
Subject : Sujet
to : X
X-Virus-Status : Clean
X,
Voici les fichiers demandés.
Cordialement,
Y

15
En effet, une partie de cet e-mail s’adressant à une machine, et l’autre à un humain, on trouve une part plus ou moins égale d’informations structurées et non structurées. d’autres exemples sont possibles, comme les pages web (balises structurantes HtmL + textes)…
De la nécessité de gérer l'information non structurée au sein de l'entrepriseici et là, on entend souvent dire que l’information non structurée représente environ 80% de l’information disponible, contre 20% pour l’information structurée (Jeanrond, 2013). Or, d’après Alain Garnier, on aurait désormais atteint un nouveau seuil, et l’information non structurée représenterait donc 99% de l’information disponible dans une entreprise. de plus, les entreprises doivent faire face à un volume de données de plus en plus conséquent, puisque d’après daniel mayer, Vice-Président de la société temis, le volume de données d’une entreprise double tous les deux ans (mayer, 2013). Les données peuvent désormais provenir des réseaux sociaux, des vidéos et photos publiées sur internet, des signaux GPS des smartphones, des indications climatiques captées à travers le monde, des transactions bancaires… Ce phénomène est connu sous le nom de Big data. Si l’on ajoute à ceci l’Open data, qui consiste à rendre publiques ses données, et le Linked data, qui permet d’interconnecter des données de sources différentes, alors les possibilités sont encore plus vastes.
dans un tel contexte, la gestion efficace de l’information s’impose afin de faciliter et d’accélérer la prise de décision. Que ce soit dans le stockage et l’indexation de ces informations ou encore leur recherche et leur restitution, plusieurs solutions théoriques existent et se combinent parfois.
La gestion des connaissancesAu-delà de la simple gestion de l'information, la gestion des connaissances ou knowledge management s'avère nécessaire pour une bonne prise de décision. Alors qu'une information ne constitue qu'une « donnée à laquelle un sens et une interprétation ont été donnés » (itiL France) et ne permettra de prendre qu'une décision locale, les connaissances, quant à elles, découlent de raisonnements et d'analyses sur ces informations tenant compte de l'expérience, des idées et des valeurs des décideurs, ainsi que de leur expertise. de fait, les informations peuvent être confrontées au contexte de l'organisation ou bien à d'autres, afin d'obtenir une interprétation et une meilleure connaissance des phénomènes mis en exergue.C'est dans ce contexte que s'est démocratisée la gestion des connaissances dans le domaine informatique. En effet, une bonne prise de décision requiert une bonne connaissance de son organisation et/ou de son domaine d'expertise... Afin d'obtenir une solution logicielle conforme aux attentes des utilisateurs, pouvant provenir, et c'est souvent le cas, de différents services et métiers, il a fallu développer des méthodes de modélisation des connaissances.
les technologies sémantiques au service de l'entreprise

16
Les apports des technoLogies sémantiques
A la recherche d’information
L'enrichissement sémantiquedans le cadre de la recherche d'information notamment, il importe de pouvoir catégoriser les informations non structurées qui bien souvent sont matérialisées sous la forme de textes (fichiers WOrd ou PdF essentiellement). Or, dans certains cas, les catégories ne sont pas encore connues au moment de l'analyse des documents et il devient alors nécessaire d'exploiter la puissance des solutions de text mining ou d'extracteur d'entités afin d'extraire les différents thèmes et concepts se rapportant au document en cours et d'en déduire le nom de la catégorie à laquelle ce dernier appartient. La multi-classification selon différents critères est également possible.Une fois ces thèmes et concepts déterminés, il faut alors lier ces informations audit document et c'est là tout l'intérêt de l'annotation sémantique qui bien souvent s'effectue sous la forme de métadonnées. il s'agit de données attachées au document et le décrivant.L'utilisation conjointe ou non d'un « annoteur » ainsi que d'un outil de text mining se révèle terriblement efficace dans la classification ou le clustering d'un grand nombre de documents, ce qui permet à la personne qui devait
auparavant s'adonner à cette tâche de gagner un temps précieux qu'elle pourra employer autrement.
La prise en compte du jargon utilisateurConcernant les moteurs de recherche, l'une des applications des technologies sémantiques réside dans l'augmentation de la pertinence de recherche et ce, quels que soient les mots saisis par l'utilisateur. En effet, il existe de nombreux domaines pour lesquels le jargon utilisateur est différent du jargon des décideurs, voire pour lesquels il existe différents jargons métier. C’est notamment le cas pour les domaines juridique et médical. Le moteur de recherche doit alors, idéalement, répondre de la même façon à deux requêtes synonymes.
Prenons par exemple le site musikia :
les technologies sémantiques au service de l'entreprise
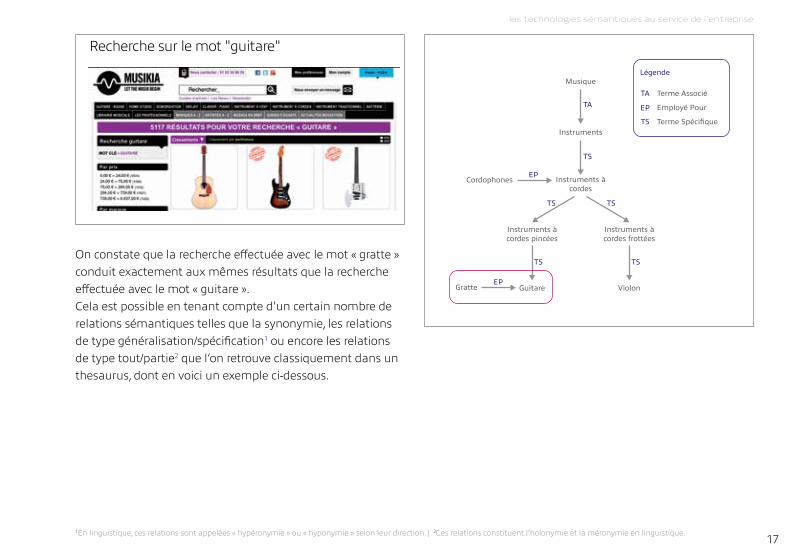
recherche sur le mot "gratte"
17
les technologies sémantiques au service de l'entreprise
On constate que la recherche effectuée avec le mot « gratte » conduit exactement aux mêmes résultats que la recherche effectuée avec le mot « guitare ». Cela est possible en tenant compte d'un certain nombre de relations sémantiques telles que la synonymie, les relations de type généralisation/spécification1 ou encore les relations de type tout/partie2 que l’on retrouve classiquement dans un thesaurus, dont en voici un exemple ci-dessous.
Musique
Instruments
Instruments à cordes
Cordophones
Instruments à cordes pincées
Instruments à cordes frottées
ViolonGuitareGratte
TA
TS
EP
TA
TS
EP
EP
TSTS
TS TS
Terme Associé
Employé Pour
Terme Spécifique
Légende
1En linguistique, ces relations sont appelées « hypéronymie » ou « hyponymie » selon leur direction. | 2Ces relations constituent l’holonymie et la méronymie en linguistique.
recherche sur le mot "guitare"

18
C’est donc grâce à cette structure de données et dans notre cas à l’explicitation de la relation d’équivalence3 « gratte – guitare » que le moteur de recherche trouve des résultats identiques aussi bien pour le mot clef « guitare » que pour le mot clef « gratte ».
La correction orthographiqueLes technologies sémantiques offrent de nouvelles possibilités en termes de correction orthographique en proposant des modes de recherche avancée. Outre la simple faute de frappe, il est en effet possible de détecter des erreurs plus techniques et d'effectuer des recherches purement phonétiques.
L'auto-complétion intelligentedès la saisie des premières lettres, beaucoup d'outils de recherche sémantiques proposent une liste de termes contenant la chaîne entrée.
La désambiguïsation de termesLa liste de termes proposée lors de la saisie est parfois triée selon différentes catégories, voire selon différents contextes du mot, permettant ainsi une désambiguïsation dudit terme en effectuant une recherche sur le terme préférentiel pour le domaine sous-entendu. Les termes sont alors issus d'un thésaurus.
les technologies sémantiques au service de l'entreprise
3relation de synonymie dénotée EP (Employé pour) ou Em (Employer) dans un thésaurus.
La navigation à facettesEn catégorisant les ressources selon différents axes, la classification à facettes met ainsi en œuvre une multi-classification, qui permettra, par exemple, à des services différents mais travaillant sur les mêmes ressources de les rechercher selon leurs propres critères métier. C'est ce que l'on appelle une navigation à facettes ou recherche par facettes : l'utilisateur a le choix entre plusieurs critères ou catégories permettant de filtrer sa recherche, et il peut même les combiner afin de cibler sa recherche. Un exemple valant mieux qu’un long discours, voici la navigation à facettes mise en œuvre sur le site d’Audi :
Exemple de recherche à facettes

19
Motorisation
Hybride V5
Diesel
Essence
Berline
Cabriolet
MonospaceBreak
CoupéCatégorie
V3
V1
V4
V2
Ainsi, en ne sélectionnant que quelques valeurs possibles pour chacune des deux métadonnées, on restreint l'espace de recherche pour ne conserver que l'espace le plus pertinent. Et l’on imagine bien que plus le nombre d'axes sera important, plus il sera possible de réduire sensiblement cet espace et de procéder à une recherche efficace.
Sur la représentation théorique suivante, on remarquera que chaque axe représente une métadonnée ainsi que l'ensemble de ses valeurs possibles.
les technologies sémantiques au service de l'entreprise
A la gestion des données
modèle conceptuelLes technologies sémantiques, et plus particulièrement le Web sémantique, ont révolutionné la manière de penser les données. Alors que jusqu'à présent, il fallait systématiquement penser selon le modèle relationnel et donc, à chaque fois, redéfinir le schéma de données (la structure des tables) propre à la base des données, le modèle que constitue l'ontologie est beaucoup plus universel. En effet, chaque ressource (objet de la vie quotidienne, personne...) est vue comme un nœud relié à d'autres par ce que l'on appellera des relations.
Paris
prédicat objet
sujet
est_situé_enFrance
L'ensemble des ressources constitue un gigantesque graphe conceptuel qui sera sérialisé sous la forme de triplets rdF, c'est-à-dire des relations de type sujet - prédicat - objet.
20
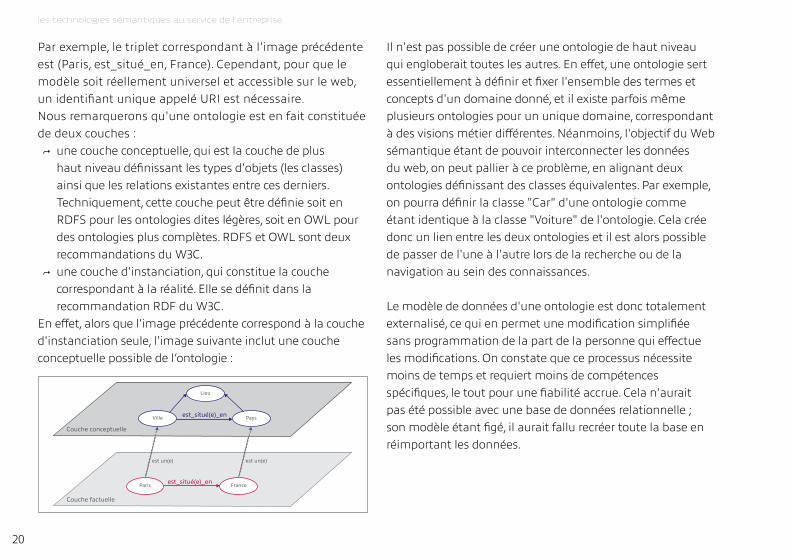
Lieu
Ville Pays
Paris France
est_situé(e)_en
est un(e) est un(e)
est_situé(e)_en
Couche factuelle
Couche conceptuelle
Par exemple, le triplet correspondant à l'image précédente est (Paris, est_situé_en, France). Cependant, pour que le modèle soit réellement universel et accessible sur le web, un identifiant unique appelé Uri est nécessaire.Nous remarquerons qu'une ontologie est en fait constituée de deux couches :
↪ une couche conceptuelle, qui est la couche de plus haut niveau définissant les types d'objets (les classes) ainsi que les relations existantes entre ces derniers. techniquement, cette couche peut être définie soit en rdFS pour les ontologies dites légères, soit en OWL pour des ontologies plus complètes. rdFS et OWL sont deux recommandations du W3C.
↪ une couche d'instanciation, qui constitue la couche correspondant à la réalité. Elle se définit dans la recommandation rdF du W3C.
En effet, alors que l'image précédente correspond à la couche d'instanciation seule, l'image suivante inclut une couche conceptuelle possible de l’ontologie :
les technologies sémantiques au service de l'entreprise
il n'est pas possible de créer une ontologie de haut niveau qui engloberait toutes les autres. En effet, une ontologie sert essentiellement à définir et fixer l'ensemble des termes et concepts d'un domaine donné, et il existe parfois même plusieurs ontologies pour un unique domaine, correspondant à des visions métier différentes. Néanmoins, l'objectif du Web sémantique étant de pouvoir interconnecter les données du web, on peut pallier à ce problème, en alignant deux ontologies définissant des classes équivalentes. Par exemple, on pourra définir la classe "Car" d'une ontologie comme étant identique à la classe "Voiture" de l'ontologie. Cela crée donc un lien entre les deux ontologies et il est alors possible de passer de l'une à l'autre lors de la recherche ou de la navigation au sein des connaissances.
Le modèle de données d'une ontologie est donc totalement externalisé, ce qui en permet une modification simplifiée sans programmation de la part de la personne qui effectue les modifications. On constate que ce processus nécessite moins de temps et requiert moins de compétences spécifiques, le tout pour une fiabilité accrue. Cela n'aurait pas été possible avec une base de données relationnelle ; son modèle étant figé, il aurait fallu recréer toute la base en réimportant les données.

21
les technologies sémantiques au service de l'entreprise
d'après monsieur LiONNE, Président de CYO, l'émergence de ce nouveau paradigme de modélisation des données connaît deux raisons principales :
↪ d'une part, la possibilité de structurer l'information non structurée
↪ d'autre part, la possibilité d'obtenir une vision transverse de plusieurs sources de données différentes.
gestion de référentiels linguistiquesAfin de maintenir le modèle de données, il est nécessaire de lister les termes d’un domaine particulier et de préciser les relations sémantiques qui peuvent exister entre eux. il existe différents modèles plus ou moins riches selon la complexité du domaine à modéliser.
Lorsque le référentiel n’existe pas encore ou qu’il a besoin d’être précisé pour diverses raisons, des outils spécifiques permettent de réaliser cette tâche.
La gestion d’un référentiel linguistique permet une certaine souplesse en autorisant l’utilisateur à effectuer sa recherche dans son propre langage, mais il permet également de définir les terminologies métier dans l’entreprise.

22
stockageAvec l'émergence du Web sémantique et sa modélisation des connaissances sous la forme d'un graphe, il a fallu concevoir de nouvelles façons de stocker les données. C'est ainsi que sont nés les triplestores, des bases de données spécialement conçues pour le stockage et la récupération de triplets rdF. tout comme une base de données relationnelle, un triplestore stocke des données et les récupère via un langage de requête comme SPArQL, qui est celui recommandé par le W3C. mais
contrairement à une base de données relationnelle, un triplestore ne stocke qu'un seul type de données : le triplet, qui représente une relation de type sujet-prédicat-objet. de plus, il est optimisé pour le stockage d'un grand nombre de triplets ainsi que pour leur récupération.
On peut penser que les triplestores se révèlent de facto plus performants que les bases de données relationnelles, puisque la structure unique des triplets ne nécessite a priori plus qu'une seule table pour les stocker :
« ALEXANdEr ESt UN PrOFESSiONNEL
EXPÉrimENtÉ it AVEC UNE EXPErtiSE tANt
dANS LA r&d Et mArKEtiNG. iL A FONdÉ Et
diriGÉ UNE SOCiÉtÉ COGNiUm SYStEmS, QUi
A dÉVELOPPÉ UN GEd à BASE dE XmL POUr
dES CHErCHEUrS AiNSi QU'UN SYStèmE dE
diStriBUtiON dE CONtENU VirAL. ALEXANdEr
A ÉGALEmENt CONSULtÉ dES ENtrEPriSES
dANS LES StrAtÉGiES dE mArKEtiNG SOCiAL.
ALEXANdEr A OBtENU UN dOCtOrAt EN
NEUrOSCiENCES Et UN m.S. EN mAtHÉmAtiQUES
APPLiQUÉES dE L'UNiVErSitÉ dE StANFOrd,
ÉtAtS-UNiS. ALEXANdEr A rEJOiNt mONdECA
EN 2010 POUr CONtriBUEr à LA StrAtÉGiE
mArKEtiNG dE L'ENtrEPriSE Et à LA GEStiON
dE PrOJEtS mArKEtiNG. »
Alexander POLONSKY
directeur marketing
chez mONdECA
Sujet Prédicat Objet:Paris :type :Ville:Berlin :type :Ville:France :type :Pays:Allemagne :type :Pays:Paris :est_situé(e)_en :France:Berlin :est_situé(e)_en :Allemagne
Or il semblerait que ce ne soit pas toujours le cas. En effet, si l'on en croit Alexander POLONSKY, responsable marketing chez mondeca, les bases de
données relationnelles se révèlent plus performantes pour des données simples, les jointures étant relativement coûteuses, alors qu'au contraire, les triplestores

23
seraient plus efficaces pour des données complexes. de plus, l'indexation d'une base de données rdF prend davantage de temps car il faut y rajouter le coût de l'éventuelle inférence. C'est pour cela qu'elle se programme souvent en temps différé, de manière répétée. Par exemple, on peut décider d’indexer les données tous les jours pendant 1 ou 2 heures. Nous noterons également que les triplestores ont des performances bien en deçà de celles des bases de données en termes de temps d’accès. En effet, on comprendra aisément qu’un graphe rdF stocké de la sorte nécessitera un certain temps avant d’être reconstitué, même partiellement.
Enfin, il existe d'autres façons de stocker les triplets rdF que les triplestores. Les triplets rdF peuvent être sérialisés sous d'autres formes telles que le XmL, qui est d’ailleurs l'un des formats recommandés par le W3C, ou encore le JSON.
« requêtage »Le « requêtage » d'un dépôt de données rdF s'effectue, selon les recommandations du W3C, à l'aide de SPArQL, un langage de requête et un protocole permettant, à l'instar de SQL, de rechercher, d’ajouter, de modifier ou de supprimer des données rdF. il existe cependant d'autres langages de requête.La requête ci-contre permet de récupérer l’ensemble des villes ainsi que le pays dans lequel elles sont implantées :
PrEFiX rdf: <http://www.w3.org/1999/02/22-rdf-
syntax-ns#>
PrEFiX Lieux: <http://example.org/Lieux#>
SELECt ?Ville ?Pays
WHErE {
?Pays rdf:type Lieux:Lieu.
?Ville rdf :type Lieux :Ville.
?Ville Lieux :est_situé(e)_en ?Pays
}
les technologies sémantiques au service de l'entreprise
inférenceHérité de l’intelligence Artificielle, le système expert est sans doute l’un des points forts des technologies sémantiques, puisqu’il va en fait raisonner sur le référentiel linguistique en utilisant son moteur d’inférence ainsi que des bases de faits et de règles.
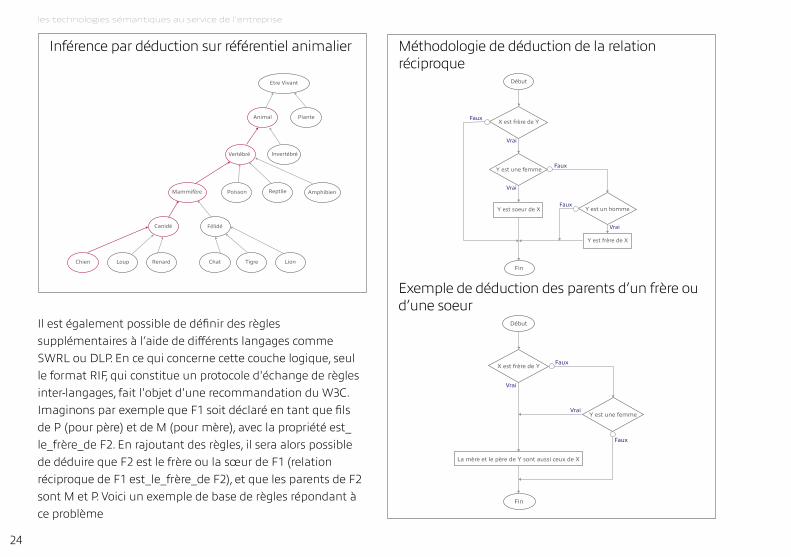
Par exemple, si l’on imagine un référentiel linguistique animalier dans lequel on a précisé qu’un individu de la classe chien fait aussi partie de la classe animal, alors si l’on déclare un nouvel individu comme étant un chien, et que l’on demande l’affichage de tous les animaux, cet individu fera partie des résultats. il s’agit d’une inférence de type généralisation souvent mise en œuvre nativement.
24
il est également possible de définir des règles supplémentaires à l’aide de différents langages comme SWrL ou dLP. En ce qui concerne cette couche logique, seul le format riF, qui constitue un protocole d'échange de règles inter-langages, fait l'objet d'une recommandation du W3C. imaginons par exemple que F1 soit déclaré en tant que fils de P (pour père) et de m (pour mère), avec la propriété est_le_frère_de F2. En rajoutant des règles, il sera alors possible de déduire que F2 est le frère ou la sœur de F1 (relation réciproque de F1 est_le_frère_de F2), et que les parents de F2 sont m et P. Voici un exemple de base de règles répondant à ce problème
Etre Vivant
Animal Plante
Amphibien
Vertébré
ReptilePoisson
Invertébré
Mammifère
Canidé Félidé
LionTigreChatRenardLoupChien
Faux
Vrai
Faux
Faux
Vrai
Vrai
Début
Fin
Y est soeur de X
Y est frère de X
X est frère de Y
Y est une femme
Y est un homme
les technologies sémantiques au service de l'entreprise
méthodologie de déduction de la relation réciproque
inférence par déduction sur référentiel animalier
Faux
Faux
Vrai
Vrai
Début
Fin
La mère et le père de Y sont aussi ceux de X
X est frère de Y
Y est une femme
Exemple de déduction des parents d’un frère ou d’une soeur

25
« titULAirE d’UNE mAîtriSE EN SCiENCES
ÉCONOmiQUES Et SPÉCiALiSÉ dANS LES
tECHNiQUES dE COmmErCiALiSAtiON, iL
A OCCUPÉ PLUSiEUrS POStES AU SEiN dU
GrOUPE CANON, ALLANt dE LA VENtE dE
SOLUtiONS mAtÉriELLES Et LOGiCiELLES
à VALEUr AJOUtÉE, AU SUPPOrt, à LA
FOrmAtiON Et à L’ENCAdrEmENt d’ÉQUiPES
COmmErCiALES. GUiLLAUmE GrOSJEAN A
rEJOiNt ANtidOt EN 2004 POUr APPOrtEr
SON SAVOir-FAirE EN mAtièrE dE VENtE Et
dE StrAtÉGiE dE diStriBUtiON. »
Guillaume GrOSJEAN
responsable Commercial
chez Antidot
navigationLes référentiels linguistiques servant à la modélisation de la connaissance tels que les taxonomies, les thésaurus et les ontologies pour ne citer qu'eux, peuvent s'avérer être de formidables outils de guidage lors d'une recherche. ils peuvent en particulier se manifester à travers la navigation à facettes, dont les concepts proposés proviendront de l'un de ces référentiels et pourront se ramifier si désiré.
agrégationJusqu'à aujourd'hui, lorsqu'une personne souhaitait organiser son voyage grâce à internet, elle recherchait classiquement les horaires et tarifs de transport sur le site de la compagnie de voyage puis se rendait sur le site des hôtels et ainsi de suite... L'une des applications du Web sémantique serait de pouvoir réunir ces informations au sein d'un même et unique site, qui les aurait recherchées et agrégées automatiquement.il existe un exemple très significatif développé par la société Antidot : il s’agit
de l’application monuments Historiques permettant de rechercher des monuments par période, par lieu géographique, par gare la plus proche… et ce à partir de données provenant de 7 sources différentes. Le prototype est disponible à l’adresse http://labs.antidot.net. A noter que l'Open data constitue une source de données très intéressante pour le Web sémantique.
qualité de la donnéeLes exemples précédents nous font prendre conscience du rôle de la qualité des données, puisque l'on comprendra bien qu'une donnée de piètre qualité n'apportera pas grand-chose de nouveau, voire une information erronée... dans le cadre de l'entreprise, il est nécessaire de procéder à l'élaboration d'une cartographie de l'information contenue dans l'entreprise, afin d'en avoir pleinement conscience et de pouvoir la gérer de manière plus efficace. dans l'idéal, il faudrait une personne dédiée à cette tâche : un architecte de l'information dont le rôle serait de définir la typologie

26
et la classification des contenus ainsi que d'optimiser la navigation et la recherche d'information en fonction des objectifs du public visé.dans le cas des technologies du tAL, la qualité du résultat obtenu lors d'une traduction par exemple dépend fortement de la qualité des données utilisées lors de la phase d'apprentissage. il faudra en effet utiliser des textes similaires d'un point de vue thématique et correctement traduits par un traducteur professionnel.
Au content analytics et à l’opinion miningSous l’impulsion du Big data, le Web sémantique tend de plus en plus à s'imposer comme outil de content analytics et l’une des applications les plus évidentes constitue l’analyse de sentiments dans des flux conversationnels sur internet, comme sur les forums, les réseaux sociaux ou encore sur les sites e-commerces avec les avis produits (Polonsky, 2013)… Ainsi, les technologies sémantiques fournissent un moyen d'analyser rapidement les retours et commentaires de la part des clients concernant un produit ou une marque. Cela offrira bien entendu une meilleure réactivité aux équipes des services clients, notamment face à des propos calomnieux.mondeca a ainsi mis au point une chaîne de traitement permettant d'analyser ces flux. En voici les différentes étapes :
↪ Etablissement d'une ontologie en fonction du domaine choisi et de l'objectif
↪ Sa construction se base sur des données telles que les
listes de produits, des documents traitant des produits, des glossaires ou terminologies métier... de la sorte, l'ontologie décrit les sujets, les entités, les produits ainsi que leur contexte d'usage.
↪ Chargement de cette ontologie au sein de la chaîne ↪ introduction des flux de commentaires à l'entrée de la chaîne
↪ Paramètre de la chaîne selon les flux ↪ Analyse des textes afin d'y détecter les termes et concepts du domaine
� traitement propre à l'analyse de sentiments � détection de la tonalité du sentiment : positif ou négatif
↪ détection de l'intensité du sentiment : faible ou fort ↪ Génération des résultats
Cas d’application
La gestion de contenuLes technologies sémantiques, et plus particulièrement les solutions de text mining et d'annotation sémantiques sont une réponse très puissante aux problèmes de gestion de contenu, puisqu’elles permettent généralement :
↪ L’extraction automatique des informations métier dans les informations non structurées
↪ L’enrichissement automatique des métadonnées du document
↪ Une recherche plus efficace à la fois des documents et de leur contenu
les technologies sémantiques au service de l'entreprise

27
de ce fait, elles se marient très bien aux ECm qui, justement, ne permettent qu’un enrichissement manuel des métadonnées, ce qui s’avère inefficace en pratique !
La saisie manuelle des métadonnées soulève quelques problèmes en termes :
↪ d’impartialité du jugementLes métadonnées que je renseigne ne seront pas forcément les mêmes que celles qui auraient été renseignées par mes collègues.
↪ d’évolutivitéQue faire si mon référentiel de mots-clés change ? Dois-je recommencer le tagging de tous les documents existants ?
↪ de pertinence de rechercheSi je tague avec le mot « automobile », que se passe-t-il si j’effectue ultérieurement une recherche à l’aide du mot « voiture » ? Est-ce que je dois renseigner systématiquement tous les synonymes possibles ?
↪ de temps, puisque pour taguer un document on doit : � d’abord le lire � définir un référentiel commun de mots-clefs � parcourir ce référentiel
� dépend évidemment de la taille du référentiel � mais aussi du nombre de documents à taguer !
L’utilisation des technologies sémantiques engendre alors des gains de temps, de productivité et de praticité non négligeables.
Les sites e-commerceL’e-commerce constitue l’une des branches principales d’application des technologies sémantiques. En effet, ces dernières permettent des améliorations à différents niveaux. La première amélioration se fait au niveau du référencement du site, afin d’en accroître le trafic entrant grâce à une réponse plus pertinente du moteur de recherche en ligne. Selon Philippe LiONNE, PdG de CYO, les technologies du Web sémantique permettent d’augmenter le référencement naturel d’environ 15%, ce qui améliore le positionnement des offres sur les moteurs de recherche et permet de proposer des offres inter-enseignes au sein d’un site e-commerce par exemple. dans le cas du site e-commerce BestBuy.com, l’utilisation de ces technologies aurait permis de générer 30% de trafic supplémentaire vers les sites web de la marque (Jay myers, ingénieur en charge du développement du site BestBuy.com, 2010). Si l’on prend l’exemple de Google, son utilisation des annotations rdFa dans son processus de référencement a notamment pour conséquence le fait que « les Snippets (extraits) permettent d’afficher des informations liées aux produits recherchés et augmentent du même coup la visibilité de ceux-ci dans les moteurs de recherche Google et Yahoo » (Alami, 2010). A titre d’information, « les rich snippets sont les informations supplémentaires qui apparaissent sous certains résultats de Google (adresse, carte, avis, note, tarifs etc...) » (Laetitia Chessé, responsable référencement, LiNKEO.COm, 2012).
les technologies sémantiques au service de l'entreprise

28
Le guidage du client sur le site e-commerce constitue le second axe d’amélioration. Une solution interne au site, idéalement constituée, comprend :
↪ un indexeur qui analyse exhaustivement le catalogue de produits pour les indexer dans le moteur de recherche et produit automatiquement toutes les données sémantiques décrivant les produits et offres du site,
↪ un moteur de recherche permettant de retrouver le produit désiré quel que soit le vocabulaire utilisé.
Le but est d’amener l’utilisateur le plus rapidement possible au produit recherché. A cet effet, on retrouve souvent les fonctionnalités habituelles d’auto-complétion et de correction orthographique au cours de la recherche, puis l’implémentation d’une navigation à facettes postérieurement à la recherche, sur la page de résultats, afin de filtrer ces derniers. idéalement, il doit même être possible de préciser directement dans la barre de recherche certains critères que l’on retrouve traditionnellement dans
une navigation à facettes, tels qu’une fourchette de prix par exemple. Le troisième et dernier axe d’amélioration est le fait d’influencer le client afin d’augmenter le montant moyen de son panier. Cela est traditionnellement réalisé en présentant des produits complémentaires à celui qui vient d’être regardé ou acheté. Cette relation pourra donc être plus précise grâce aux technologies du Web sémantique qui permettront de retrouver des produits beaucoup plus proches du besoin ou de l’envie du visiteur et ce, de manière plus efficace qu’avec de simples mots-clefs ou la présentation de ce que d’autres visiteurs ont acheté avec l’objet en question. En outre, les technologies sémantiques peuvent être utilisées pour la recherche et la gestion d’autres collections ( journaux, magazines…). C’est notamment pour cela que beaucoup de médias et éditeurs équipent leur site internet d’un moteur de recherche sémantique.
PHiLiPPE LiONNE A COmmENCÉ PAr
ENSEiGNEr LES mAtHÉmAtiQUES. iL
POSSèdE UN mAStEr dE mAtHÉmAtiQUES,
UN dEUXièmE EN iNFOrmAtiQUE Et
ENFiN UN trOiSièmE EN GEStiON dES
ENtrEPriSES. CrÉAtEUr dE L’ENtrEPriSE
CYO, PHiLiPPE LiONNE ESt UN ACtEUr
rECONNU dES tECHNOLOGiES SÉmANtiQUES
dANS LA rÉGiON dU NOrd-PAS-dE-CALAiS.
Philippe LiONNE
PdG de CYO
29
les technologies sémantiques au service de l'entreprise
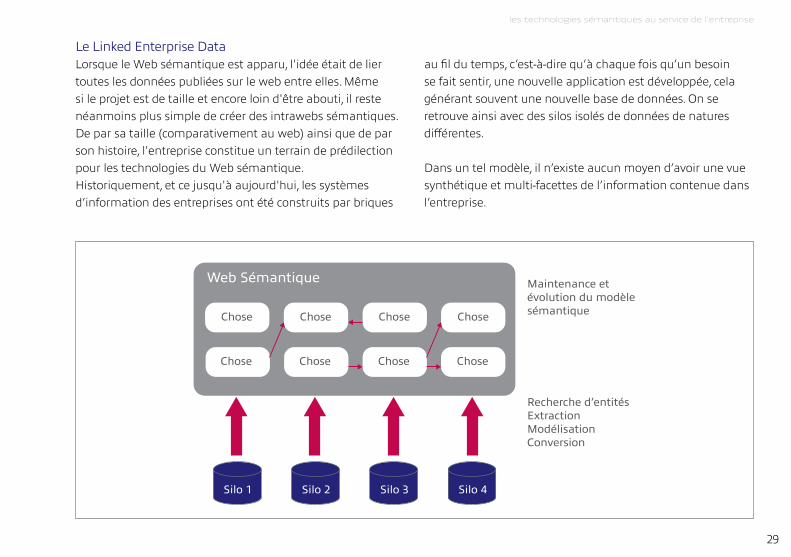
Le Linked enterprise dataLorsque le Web sémantique est apparu, l'idée était de lier toutes les données publiées sur le web entre elles. même si le projet est de taille et encore loin d'être abouti, il reste néanmoins plus simple de créer des intrawebs sémantiques. de par sa taille (comparativement au web) ainsi que de par son histoire, l'entreprise constitue un terrain de prédilection pour les technologies du Web sémantique.Historiquement, et ce jusqu'à aujourd'hui, les systèmes d’information des entreprises ont été construits par briques
au fil du temps, c’est-à-dire qu’à chaque fois qu’un besoin se fait sentir, une nouvelle application est développée, cela générant souvent une nouvelle base de données. On se retrouve ainsi avec des silos isolés de données de natures différentes.
dans un tel modèle, il n’existe aucun moyen d’avoir une vue synthétique et multi-facettes de l’information contenue dans l’entreprise.
Web Sémantique
Chose
Maintenance et évolution du modèle sémantique
Recherche d’entitésExtraction ModélisationConversion
Chose Chose Chose
Chose Chose Chose Chose
Silo 1 Silo 2 Silo 3 Silo 4

30
les technologies sémantiques au service de l'entreprise
Les plates-formes collaborativesLe Web sémantique favorise le partage des connaissances au sein d’une communauté de pratique professionnelle et propose une réponse intéressante en apportant une solution de désambiguïsation lors de la recherche des documents ou encore une navigation à facettes.il permet également de mémoriser des requêtes afin de personnaliser l’environnement pour chaque collaborateur ou d’enrichir la description d’un document en entrant directement un mot-clef non contrôlé.
L'analyse de cVLes technologies sémantiques offrent de nouvelles perspectives dans de nombreux domaines. On peut notamment citer les ressources humaines, domaine pour lequel un analyseur de CV sémantique peut s’avérer extrêmement efficace.
Un moteur d’analyse sémantique de CV permet d’extraire automatiquement du CV analysé des informations telles que le niveau d’études, le nombre d’années d’expérience, le lieu de résidence, les compétences linguistiques, les diplômes obtenus ainsi que les informations personnelles comme l’adresse e-mail, le téléphone, le statut et la situation familiale. C’est dire le temps considérable que ce type d’outils pourrait faire gagner aux chargés de recrutement !

panorama du marché sémantique d'entreprise
31
32
panorama du marché sémantique d'entreprise
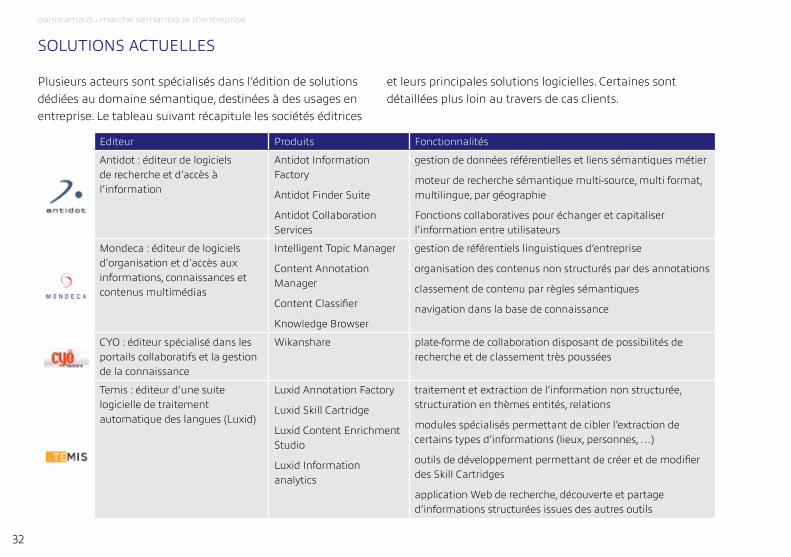
soLutions actueLLes
Plusieurs acteurs sont spécialisés dans l’édition de solutions dédiées au domaine sémantique, destinées à des usages en entreprise. Le tableau suivant récapitule les sociétés éditrices
et leurs principales solutions logicielles. Certaines sont détaillées plus loin au travers de cas clients.
Editeur Produits Fonctionnalités
Antidot : éditeur de logiciels de recherche et d’accès à l’information
Antidot information Factory
Antidot Finder Suite
Antidot Collaboration Services
gestion de données référentielles et liens sémantiques métier
moteur de recherche sémantique multi-source, multi format, multilingue, par géographie
Fonctions collaboratives pour échanger et capitaliser l’information entre utilisateurs
mondeca : éditeur de logiciels d'organisation et d'accès aux informations, connaissances et contenus multimédias
intelligent topic manager
Content Annotation manager
Content Classifier
Knowledge Browser
gestion de référentiels linguistiques d’entreprise
organisation des contenus non structurés par des annotations
classement de contenu par règles sémantiques
navigation dans la base de connaissance
CYO : éditeur spécialisé dans les portails collaboratifs et la gestion de la connaissance
Wikanshare plate-forme de collaboration disposant de possibilités de recherche et de classement très poussées
temis : éditeur d’une suite logicielle de traitement automatique des langues (Luxid)
Luxid Annotation Factory
Luxid Skill Cartridge
Luxid Content Enrichment Studio
Luxid information analytics
traitement et extraction de l’information non structurée, structuration en thèmes entités, relations
modules spécialisés permettant de cibler l’extraction de certains types d’informations (lieux, personnes, …)
outils de développement permettant de créer et de modifier des Skill Cartridges
application Web de recherche, découverte et partage d’informations structurées issues des autres outils
33
panorama du marché sémantique d'entreprise
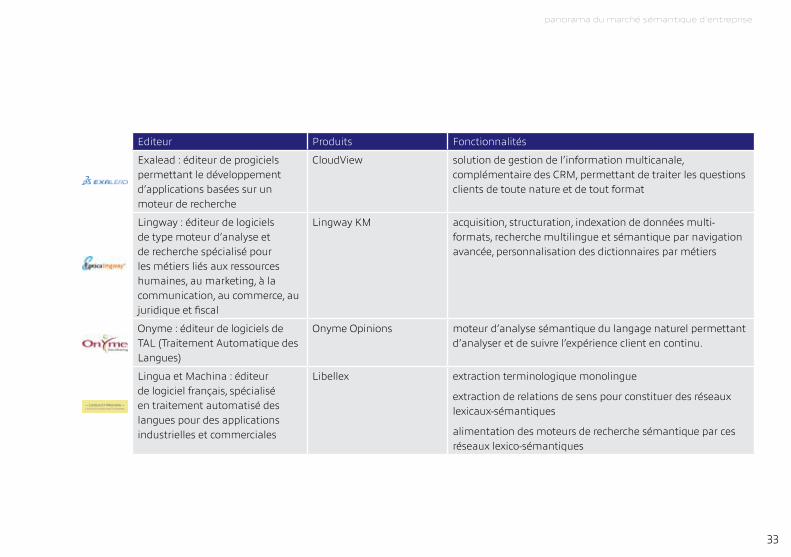
Editeur Produits Fonctionnalités
Exalead : éditeur de progiciels permettant le développement d’applications basées sur un moteur de recherche
CloudView solution de gestion de l’information multicanale, complémentaire des Crm, permettant de traiter les questions clients de toute nature et de tout format
Lingway : éditeur de logiciels de type moteur d’analyse et de recherche spécialisé pour les métiers liés aux ressources humaines, au marketing, à la communication, au commerce, au juridique et fiscal
Lingway Km acquisition, structuration, indexation de données multi-formats, recherche multilingue et sémantique par navigation avancée, personnalisation des dictionnaires par métiers
Onyme : éditeur de logiciels de tAL (traitement Automatique des Langues)
Onyme Opinions moteur d’analyse sémantique du langage naturel permettant d’analyser et de suivre l’expérience client en continu.
Lingua et machina : éditeur de logiciel français, spécialisé en traitement automatisé des langues pour des applications industrielles et commerciales
Libellex extraction terminologique monolingue
extraction de relations de sens pour constituer des réseaux lexicaux-sémantiques
alimentation des moteurs de recherche sémantique par ces réseaux lexico-sémantiques

344Voir « lemmatisation » dans le glossaire pour de plus amples informations.
cas cLients
Aujourd’hui ce sont essentiellement les grandes entreprises qui s’intéressent aux technologies du Web sémantique. Cela n’a rien d’étonnant ! Les technologies sémantiques sont encore en phase d’émergence. Elles ne sont pas encore complètement standardisées ni stabilisées. L’entreprise doit donc être capable de détacher un petit groupe de personnes dédié au travail de veille. Or, cela nécessite des moyens à la fois humains et financiers.
Côté secteurs d'activité, la grande distribution et la vente par correspondance sont les secteurs de prédilection. Pour ces secteurs, les solutions sémantiques permettent une recherche plus pertinente sur les sites Web en tenant compte du vocabulaire de l’utilisateur, en proposant une navigation à facettes… Cela réduit le temps de recherche des clients et augmente la probabilité d’achat. A cela, nous pouvons ajouter l’amélioration du référencement naturel des offres. Les bénéfices deviennent très vite évidents. Les médias ont également une forte tendance à utiliser les technologies du Web sémantique. Le mouvement a d’ailleurs été initié par les médias anglo-saxons qui ont vite compris que ces technologies permettaient un enrichissement de l’information à moindre coût. Ainsi, la BBC a débuté son utilisation des technologies du Web sémantique au moment des Jeux Olympiques de Londres (2012) en complétant la fiche des athlètes à l’aide de données provenant de
Wikipédia (dBpédia). Enfin, l'industrie (pharmaceutique et médicale, notamment) et l'administration sont aussi très demandeuses de solutions sémantiques.
Text-mining et analyse de sentimentsAfin de maintenir leur compétitivité, les centres de contacts d’un géant de l’énergie ont misé sur l’amélioration de relation client (Lemaire, 2011).
A cet effet, le groupe a fait le choix d’utiliser le logiciel de text-mining Luxid de l’éditeur temis qui permet d’extraire les entités sous leur forme lemmatisée, aussi appelée forme canonique4 pour l’étude des verbatims clients. Comme nous l’avons déjà vu plus tôt au cours de ce livre blanc, cela engendre des gains en termes de productivité et d’objectivité lors du classement des commentaires.Une fois sa réclamation traitée, le client reçoit alors une enquête de satisfaction par SmS, auquel il doit répondre par une note de 1 à 10. dans le cas où la note renvoyée serait mauvaise, le centre de contacts concerné confronte manuellement le client à son dossier. dans certains cas, le problème peut nécessiter un rappel du client, soit pour une explication, soit pour une intervention.Enfin, si l’intervention nécessite un rappel, le client reçoit un SmS avec une date prévisionnelle de rappel téléphonique et un numéro de dossier.mondeca propose également une solution de sentiment analysis basée sur les technologies du Web sémantique.
panorama du marché sémantique d'entreprise
35
Banque, distribution et vente par correspondance : suivi de l’expérience client grâce au TALde nombreuses enseignes ont choisi de faire confiance à Onyme Opinions, la solution phare d’Onyme dans le domaine de la mesure, de l’analyse, du suivi de l’expérience client, et ce afin de déterminer leurs forces et faiblesses, que ce soit à l’échelle macroscopique (le réseau, le groupe) ou bien à l’échelle microscopique (l’agence, la région par exemple). L’objectif est donc de fidéliser les clients existants et de véhiculer une image positive de l’enseigne.La solution s’appuie sur un questionnaire de 3 questions, la première fermée et les deux suivantes ouvertes, afin de garantir un taux de réponse le plus élevé possible. Ledit questionnaire peut être diffusé par e-mail, par SmS, voire par d’autres médias et permet d’identifier :
↪ des motifs de satisfaction ou d’insatisfaction qui détermineront les points faibles et les points forts de l’enseigne (première question ouverte)
↪ les attentes exprimées par les clients (seconde question ouverte)
Après avoir défini manuellement la liste des idées contenues dans les verbatims clients, le tAL permettra alors d’associer le retour client à une ou plusieurs (dans la limite de cinq au maximum) idées lors de sa réception. Ensuite, chaque verbatim est traité individuellement afin de garantir la qualité du traitement.Enfin, une synthèse extrêmement lisible car destinée à des responsables métier est produite. Les idées y sont très
facilement identifiables, et les métriques fournies sont directement interprétables par quiconque, sans prérequis en analyse de données. Les propos des clients sont ainsi valorisés et l’on peut même générer des alertes en fonction de la note attribuée afin de rappeler le client concerné par exemple.Onyme Opinions permet d’obtenir un panorama global de la satisfaction client et ainsi de piloter l’enseigne, d’orienter les décisions afin de satisfaire le client. Par exemple, dans une certaine enseigne, l’employé d’un magasin réclamait la climatisation depuis un certain temps déjà, et sa demande n’a jamais abouti. Néanmoins, lorsque la direction s’est aperçue que certains clients abandonnaient littéralement leurs articles dans le magasin, préférant sortir plutôt que de patienter plus longtemps dans la chaleur, le budget nécessaire à l’installation de la climatisation a rapidement été débloqué.
Traduction automatiquePour de nombreuses entreprises, notamment les grands groupes, il devient aujourd’hui indispensable de répondre efficacement au défi multilingue de la mondialisation. Elles doivent permettre à leurs collaborateurs, leurs fournisseurs et leurs clients de communiquer dans de nombreuses langues et ce, malgré la complexité de leurs métiers et leurs terminologies et sans perdre de vue la maîtrise des coûts. il s’agit concrètement pour ces entreprise de :
↪ constituer et tenir à jour à faible coût des ressources
panorama du marché sémantique d'entreprise

36
linguistiques spécialisées (lexiques, réseaux lexicaux, mémoires de traduction, glossaires bilingues, etc.)
↪ assurer la cohérence terminologique dans les traductions de documentations techniques de grands projets (nucléaire, aéronautique, automobile)
↪ diminuer les coûts et les délais sur des systèmes de traduction impliquant de dix à quarante langues en grands volumes (publication de catalogues, réseaux sociaux d’entreprise, sites e-commerce)
↪ ou encore assurer la protection des données dans une chaîne de traitement de documents confidentiels.
Si les solutions de traduction automatique existent depuis quelques années, elles sont en perpétuelle phase d’approfondissement par la démocratisation, c’est-à-dire que plus elles permettront d’économiser et seront proposées à un prix abordable, et plus elles se diffuseront vers des entreprises plus modestes.On peut faire un parallèle avec le développement des moteurs de recherche : au début des moteurs de recherche en 1995, seuls étaient disponibles des moteurs de recherche publics comme Alta Vista puis Google. Les moteurs d’entreprise sont arrivés ensuite, notamment en France avec la création de Pertimm en 1997, Antidot en 1999 puis Exalead et Sinequa en 2000. Aujourd’hui, tous les sites d’entreprise, d’information et de commerce en ligne possèdent leur propre moteur de recherche, propriétaire ou open source. Nous pensons que la démocratisation qui s’est appliquée aux
moteurs de recherche s’appliquera également aux moteurs de traduction. Lingua et machina, éditeur de la solution Libellex, constate actuellement les économies suivantes sur les grands projets de traduction industrielle : 30% avec les mémoires de traduction, 50% en y ajoutant la traduction automatique spécialisée, 80% en y ajoutant la post-édition en environnement contrôlé. Libellex est une plateforme de gestion de l’écrit multilingue, hébergée sur un serveur Linux ou Windows et accessible à l’utilisateur par connexion internet ou intranet via un navigateur web.deux axes stratégiques régissent le fonctionnement de Libellex :1. un éventail large et complet de fonctionnalités pour
répondre à tous les besoins de la production et de la gestion de contenu textuel multilingue ;
2. une répartition claire entre les interfaces « professionnelles » qui privilégient la richesse des outils et les informations proposées à l’opérateur spécialiste de l’écrit et les interfaces « bureautiques » qui privilégient la simplicité d’emploi pour tous.
Fonctionnalités associées aux mémoires de traduction ↪ Ajouter des documents au référentiel : l’opérateur injecte deux textes qui sont la traduction l’un de l’autre, en format mS Office, HtmL ou XmL. Libellex « aligne » ces textes, c’est-à-dire qu’il met en correspondance chaque phrase avec sa traduction et stocke ces paires de phrases
panorama du marché sémantique d'entreprise

37
panorama du marché sémantique d'entreprise
dans une « mémoire », qui est un volume en base de données.
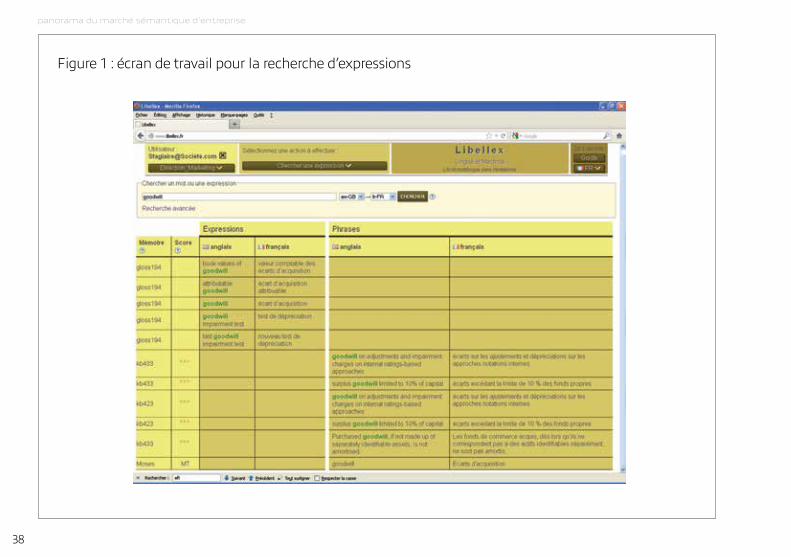
↪ Chercher une expression : l’opérateur saisit une requête, qui peut être un mot, un groupe de mots, une expression ou une phrase. Libellex renvoie toutes les paires de termes et paires de phrases contenant l’intégralité ou une partie de la requête, ainsi qu’une traduction automatique. Voir figure 1.
↪ Faire traduire un document : l’opérateur sélectionne un document à traduire, en format mS Office, HtmL ou XmL. Libellex analyse chaque phrase et va chercher en mémoire la phrase identique ou les phrases similaires avec leurs traductions, ainsi qu’une traduction automatique.
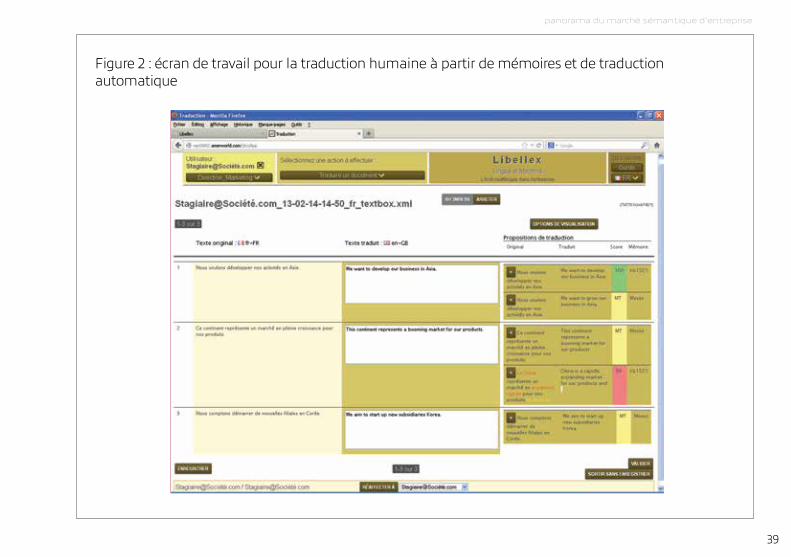
travaux de traduction : le traducteur voit sur son écran le texte à traduire et les paires de phrases récupérées en mémoire, il s’inspire de ces dernières pour effectuer sa traduction. Une analyse tarifaire est également disponible après un comptage des mots dans le document à traduire. des cycles de relecture, de révision et de validation suivent le cycle de traduction. Après validation, le texte traduit est stocké en mémoire. Cette dernière se retrouve donc améliorée après chaque traduction.
38
panorama du marché sémantique d'entreprise
Figure 1 : écran de travail pour la recherche d’expressions
39
Figure 2 : écran de travail pour la traduction humaine à partir de mémoires et de traduction automatique
panorama du marché sémantique d'entreprise

40
« iNGÉNiEUr diPLômÉ dE L’ENSEEiHt
EN iNFOrmAtiQUE, mAtHÉmAtiQUES
APPLiQUÉES Et iNtELLiGENCE ArtiFiCiELLE,
iL A dÉBUtÉ SA CArrièrE CHEz r.i.S
tECHNOLOGiES, ÉditEUr dE PrOGiCiELS
SErVEUrS miNitEL iSSU d'iNFOGrAmES,
AVANt dE dEVENir dUrANt 10 ANS
dirECtEUr mArKEtiNG Et COmmUNiCAtiON
dU GrOUPE JEt mULtimÉdiA. APrèS AVOir
CONtriBUÉ AU dÉVELOPPEmENt dE
StArtUPS LYONNAiSES COmmE UBiCmEdiA,
COGNiKizz Et HiGH CONNEXiON, PiErrE
COL A rEJOiNt ANtidOt EN 2010 : iL Y
ESt EN CHArGE dU mArKEtiNG Et dE LA
COmmUNiCAtiON dE L'ENtrEPriSE. »
Pierre COL
directeur marketing
chez Antidot
CNRS : plate-forme d’UIA grâce aux technologies du Web sémantiquePrésentation gracieusement fournie par Guillaume Grosjean et Pierre Col
isidore est la plateforme d’agrégation et d’enrichissement, le moteur de recherche et de diffusion de toutes les données de la recherche française en Sciences Humaines et Sociales (SHS). toutes les disciplines des SHS sont confrontées à un accroissement accéléré des données numérisées ou nativement numériques. Ces masses de données hétérogènes – sources textuelles, orales, iconographiques, audiovisuelles, images 3d, publications électroniques, séries de calculs – soulèvent de nombreuses questions : accessibilité, interopérabilité, publication, conservation, pérennité. Face à de tels enjeux, le CNrS a mis en œuvre une infrastructure pour la recherche et l’enseignement supérieur afin d’accroître la visibilité des travaux et des résultats de la recherche par une meilleure mise à disposition des données.Le cahier des charges de la plateforme isidore était particulièrement ambitieux,
tant en termes de diversité et de volumétrie des données, qu’en termes de fonctionnalités :
↪ moissonnage ciblé des données scientifiques et des métadonnées structurées selon des protocoles variés. Plus de 2000 sources différentes constituent le corpus SHS.
↪ Normalisation des métadonnées et enrichissement des données en s’appuyant sur des référentiels reconnus dans la communauté.
↪ moteur de recherche sur les données non structurées (texte intégral) et sur les données structurées (métadonnées documentaires existantes ou crées par enrichissement).
↪ mise à disposition des métadonnées enrichies afin de créer une boucle de rétroaction vers les producteurs de données selon les principes et technologies du Web sémantique.
↪ intégration possible du moteur de recherche isidore et des données exposées dans un autre environnement par la mise à disposition d’APi Web.
41
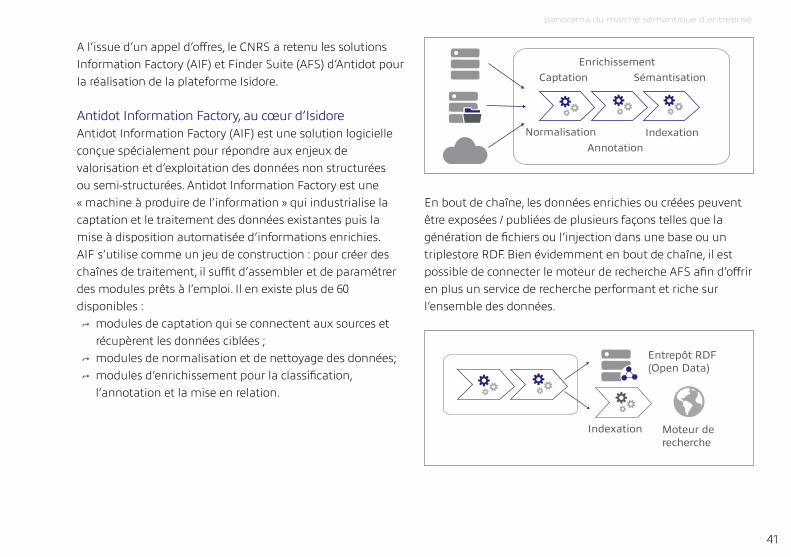
A l’issue d’un appel d’offres, le CNrS a retenu les solutions information Factory (AiF) et Finder Suite (AFS) d’Antidot pour la réalisation de la plateforme isidore.
antidot information factory, au cœur d’isidoreAntidot information Factory (AiF) est une solution logicielle conçue spécialement pour répondre aux enjeux de valorisation et d’exploitation des données non structurées ou semi-structurées. Antidot information Factory est une « machine à produire de l’information » qui industrialise la captation et le traitement des données existantes puis la mise à disposition automatisée d’informations enrichies.AiF s’utilise comme un jeu de construction : pour créer des chaînes de traitement, il suffit d’assembler et de paramétrer des modules prêts à l’emploi. il en existe plus de 60 disponibles :
↪ modules de captation qui se connectent aux sources et récupèrent les données ciblées ;
↪ modules de normalisation et de nettoyage des données; ↪ modules d’enrichissement pour la classification, l’annotation et la mise en relation.
CaptationEnrichissement
Sémantisation
NormalisationAnnotation
Indexation
Indexation Moteur de recherche
Entrepôt RDF(Open Data)
En bout de chaîne, les données enrichies ou créées peuvent être exposées / publiées de plusieurs façons telles que la génération de fichiers ou l’injection dans une base ou un triplestore rdF. Bien évidemment en bout de chaîne, il est possible de connecter le moteur de recherche AFS afin d’offrir en plus un service de recherche performant et riche sur l’ensemble des données.
panorama du marché sémantique d'entreprise

42
Le moteur de recherche Antidot Finder Suite permet d’offrir un accès fonctionnellement riche sur l’ensemble des données constituées :
↪ autocomplétion tolérante et structurée lors de la saisie ; ↪ affinage dynamique des réponses grâce aux facettes. Les facettes proposées proviennent pour certaines des métadonnées des documents, alors que d’autres ont été générées par AiF lors de l’enrichissement : catégories issues des étapes de classification, alignement sur des référentiels ;
↪ navigation transversale dans le corpus grâce à des fonctions de rebond et de liens inter documents pour une assistance à la découverte d’information ;
↪ recherche visuelle grâce à des représentations cartographiques ou par le positionnement des documents clefs sur des échelles temporelles.
classification des donnéesParmi les 2055 sources, il en est une, l’archive en ligne HAL-SHS, qui propose près de 30 000 documents déjà tous affectés dans un plan de classement. Cette taxonomie est assez simple et représentative du domaine des SHS, si bien qu’il a été décidé de l’étendre à l’ensemble de sources grâce au module de classification d’AiF. Cela signifie que les millions de documents du corpus isidore doivent être rangés dans ces catégories. Vu les volumes, toute intervention manuelle est bien évidemment exclue.
La première étape consiste à utiliser les 30 000 documents de HAL-SHS déjà catégorisés pour entraîner le module de classification AiF. Celui-ci regarde pour chaque document la ou les catégories dans lesquelles celui-ci est rangé afin d’apprendre. A l’issue de cette phase, ce module génère une base de signatures sémantiques.
Documents déja classifiés Base de signatures
META META META
META
La base de signatures ainsi générée est exploitée lors de la phase de traitement. Lorsqu’un document passe à travers le module de classification, il se voit automatiquement attribuer une ou plusieurs catégories de la taxonomie HAL-SHS. même les documents de HAL-SHS sont retraités et certains qui n’avaient qu’une catégorie s’en voient affecter une seconde. Une des applications de cette classification est de pouvoir offrir, lors de la recherche, une facette (un filtre) qui s’applique à l’ensemble des documents et pas seulement à ceux issus de HAL-SHS.
panorama du marché sémantique d'entreprise

43
Les résultats obtenus ont été évalués et sont d’excellente qualité puisque le score de précision est supérieur à 90%. Ce sont en tout 4 classifications différentes qui sont réalisées dans isidore puisque les éléments du corpus sont analysés et rangés selon d’autres taxonomies comme les sujets et les époques historiques.
gestion des sourcesPour chacune des 2055 sources à capter et enrichir, ce sont plus de 30 modules de traitement qui s’enchaînent. Certains sont propres au type de la source (flux rSS, site, entrepôt OAi …). d’autres sont communs. Chaque module nécessite un ensemble de paramètres de configuration qui spécifient les actions à réaliser. La définition des sources et de leurs caractéristiques est réalisée à travers une application dédiée qui fournit ces paramètres sous forme de fichiers XmL. Une chaîne de traitement AiF a été configurée afin de transformer ces fichiers XmL de définition des sources en fichiers de configuration de la chaîne et des modules AiF. Ainsi la configuration de la captation et de l’enrichissement des 2055 sources est auto-générée et chaque ajout / modification de source depuis l’interface de gestion modifie dynamiquement le comportement de l’ensemble de la solution.
web de donnéesAfin de rendre les documents SHS compatibles avec le Web de données, une Uri (Uniform resource identifier) pérenne leur est attribuée si elles n’en possèdent pas déjà. En effet,
seules quelques sources, comme la BnF, attribuent à leurs données des Uri stables et pérennes. Or l’Uri est l’élément fondamental du Web de données : c’est l’identifiant unique de la ressource par lequel le lien entre données est fait. Ainsi, lorsqu’un document a déjà une Uri, celle-ci est repérée et utilisée. Sinon une Uri pérenne lui est attribuée lors de la phase de normalisation. En bout de chaîne AiF, un sous-ensemble choisi de métadonnées est transformé en rdF selon une ontologie cible, et ces triplets rdF sont injectés dans des entrepôts. Plusieurs triplestores sont constitués, contenant chacun les triplets nécessaires à des usages spécifiques. Ces entrepôts sont rendus accessibles par un point d’accès SPArQL. Les données SHS sont ainsi exposées dans le Web de données dans une perspective d’Open data. respectant les principes de la négociation de contenu en vigueur sur le Web, chaque ressource informationnelle est accessible selon plusieurs formats : HtmL, rdF/XmL, N3.
un succès reconnu par la communauté scientifiqueisidore est reconnu par la communauté comme une réussite indéniable : le CNrS dispose à présent d’une plateforme ouverte dont les services (enrichissement, maillage, recherche, navigation) peuvent être intégrés dans des applications variées dont le portail isidore est le premier représentant.
panorama du marché sémantique d'entreprise

44
témoignage de m. stéphane pouyllau – co-directeur du projet, cnrs« La mission principale du projet, réalisé par le très grand équipement Adonis du CNrS, était de proposer un accès unifié à des données hétérogènes et distribuées. il s’agit de valoriser des données structurées et le texte intégral associé, produits dans les laboratoires et les bibliothèques de recherche. L’unification des données et l’enrichissement offrent la possibilité de naviguer dans un espace documentaire et informationnel étendu permettant d’explorer des questions scientifiques nouvelles mais aussi les frontières scientifiques des disciplines. Les trois modes d’accès (web, api, 3store rdF) sont complémentaires et permettent de développer des outils à géométrie variable suivant les usages. Ainsi, la solution information Factory d’Antidot, qui est au cœur d’isidore, correspond pleinement aux attentes du tGE Adonis car elle permet de traiter à la fois les données structurées, le texte intégral, l’enrichissement, les modes accès dans le respect des standards du Web sémantique ce qui est un réel plus pour nous
panorama du marché sémantique d'entreprise

comment démarrer ?
45

46
comment démarrer ?
caPr ra
du socle
technologique
Déploiement es
La Vision d’osiatisLes technologies du Web sémantique ont fait leur entrée depuis 10 ans dans l’internet et les entreprises, mais elles restent difficilement maîtrisables par la dSi. Ce phénomène entraîne également, nous l’avons vu précédemment, de nombreuses questions sur des sujets très variés, connexes aux problématiques d’architecture, et ancrées sur les métiers.
malgré les particularités propres à ce type de solution, adopter au même titre que d’autres projets d’intégration une démarche structurée et construite est essentiel. L’un des objectifs de la démarche proposée est d’éviter d’amalgamer les différentes facettes de ce type de projet.
il s’agit également d’un projet d’intégration applicative, car les solutions de Web sémantique, comme nous l’avons vu précédemment, s’appuient sur des solutions progicielles très spécialisées. Contrairement aux projets d’intégration progiciels classiques, qui sont des verticaux métiers très périmétrés, le Web sémantique est une solution de nature transverse, en termes de métier et d’architecture.L’intégration doit en effet être envisagée sur ces deux axes :
↪ Sur l’axe technologique, avec des briques techniques diverses, silos de données métier, infrastructure de business intelligence, portails collaboratifs, outils bureautiques, pour n’en citer que quelques-unes,
↪ Sur l’axe métier, avec les applications pour lesquelles le Web sémantique apporte de la valeur dans l’entreprise.
Les référentiels métiers et fonctionnels pouvant être concernés sont nombreux, par exemple, santé, industrie, réglementation, recherche, distribution, ressources humaines…
Ce type de projet implique de ce fait de mobiliser les métiers en amont, et de les impliquer tout au long du projet, en établissant un amont une sorte de « bac à sable », constitué des solutions progicielles choisies, dans lequel les métiers pourront expérimenter progressivement la solution, ajuster l’expression de besoin en fonction des possibilités et limites de la solution, au fur et à mesure de l’intégration de la solution.
Un projet de Web sémantique nécessite donc une démarche particulière, dont l’étude de cadrage va constituer le socle. Le facteur de succès de ce projet est étroitement dépendant des conditions de démarrage. C’est l’étude de cadrage qui détermine les conditions optimales. Elle va se focaliser sur les usages visés, en relation étroite avec les métiers. Elle comprend l’analyse de l’existant, l’identification des enjeux, la définition des objectifs. Elle permet de préciser quelles technologies du Web sémantique seront porteuses de valeur pour les métiers de l’entreprise concernés.
L’étude de cadrageElle comporte trois phases, à l’issue desquelles les conclusions obtenues permettront de disposer du cadre optimal pour réussir le projet.

47
comment démarrer ?
première phaseElle consiste à identifier les enjeux, le périmètre, les orientations stratégiques, les risques et contraintes. il faut pour cela :
↪ Comprendre l’existantCette première étape permet d’analyser l’environnement actuel et de comprendre la « culture » de l’entreprise. Une vision de l’impact des outils du Web sémantique sur la carte des métiers est proposée.
↪ Obtenir les éléments de vision et trajectoireA cette étape, des interviews avec les collaborateurs métiers et it permettent d’échanger avec eux sur l’apport de valeur des technologies du Web sémantique, leur utilisation cible, et leur intégration dans l’environnement informatique de demain. Ces échanges sont l’occasion de démontrer la création de valeur induite par la mise en place d’une politique de Web sémantique.
↪ identifier les besoins, les risques et les contraintesC’est à cette étape que sont identifiés les besoins en termes métier et déclinés sur deux axes :
� Un axe métier, grâce à la synthèse des interviews réalisées lors de l’étape précédente,
� Un axe dSi pour prendre en compte les orientations stratégiques, la vision et l’ambition du projet.
A cette étape sont réalisées l’identification / formalisation des enjeux, les objectifs, le périmètre, les contraintes, les risques et les facteurs clefs de réussite de ce projet.
Cette première phase traitera le sujet au travers différents axes et devra permettre de répondre à de nombreuses questions :
↪ Sommes-nous prêts pour le Web sémantique ? ↪ Quelles utilisations du Web sémantique seront porteuses de valeur pour l’entreprise ?
↪ Quelles solutions de Web sémantique pouvons-nous intégrer ?
↪ Quels services devrons-nous offrir ? ↪ Quelle organisation nous faut-il pour gérer nos applications sémantiques ?
↪ Comment urbaniser le Web sémantique avec les autres briques du système d’information ?
↪ Notre infrastructure est-elle prête pour le Web sémantique ? ↪ Quelle stratégie de déploiement nous faut-il ?
deuxième phaseElle correspond à l’identification d’une trajectoire et d’une cible. Cette phase s’appuie sur la méthodologie Osiatis et sa capitalisation des bonnes pratiques, grâce aux projets similaires déjà traités avec nos partenaires. Elle a pour but de définir une cible et une trajectoire. Elle permet également, en fonction de la trajectoire retenue, l’identification :
↪ des adhérences technologiques, en particulier avec les solutions collaboratives et les portails déjà mis en œuvre
↪ des impacts économiques ↪ du tracé de la trajectoire vers la cible avec les jalons principaux et la matérialisation d’un macro planning.

48
Pour compléter et faciliter la « vente » en interne du projet, il peut être également extrêmement intéressant de mener une étude du tCO / rOi.
troisième phaseCette dernière phase de l’étude de cadrage permet de préparer le plan de mise en œuvre, avec :
↪ L’établissement du plan projet (WBS, planning, …) ↪ L’approche matérielle et financière (hardware, plan de charge, investissements, …)
↪ Le plan de mobilisation des différents contributeurs, en particulier les métiers concernés directement par le Web sémantique.
concLusionsA l’issue de cette étude de cadrage, l’entreprise disposera des éléments indispensables au bon démarrage du projet, avec un parfait alignement sur ses enjeux :
↪ Une cible métier (point de départ de la mission) ↪ Une cible technologique répondant aux usages dans un cadre économiquement acceptable
↪ Une roadmap pour la mise en œuvre de la cible ↪ Les impacts économiques de ce projet (mise en œuvre et « run ») ↪ Les impacts sur la dSi, ↪ Une identification des risques, contraintes, adhérences et sous-projets connexes.
↪ Une organisation adaptée au mode projet et aux contraintes propres aux technologies
comment démarrer ?

49

50
CONCLUSiONA travers ce livre blanc, nous avons suivi le parcours des technologies sémantiques qui, bien qu’existant de longue date, demeurent toutefois en pleine évolution. Ainsi, même si le Web sémantique a aujourd’hui plus de 10 ans, on se rend compte que malgré les technologies émergées et désormais bel et bien présentes, la cible d’un Web sémantique tel que défini en 1994 par tim Berners-Lee n’a jamais été atteinte ; le Web n’est pas sémantique par nature ! C’est d’ailleurs l’une des raisons qui fait que l’on préfère parler de Web des données plutôt que de Web sémantique, ce terme étant très ambitieux.
Si l’on s’intéresse cette fois à l’aspect traitement Automatique des Langues, on prend conscience que cette branche a fait d’énormes progrès, notamment grâce au développement de méthodes statistiques. Par exemple, la reconnaissance du langage naturel et la traduction automatique possèdent des résultats bien supérieurs à ceux obtenus initialement. On retrouve ces innovations notamment dans le domaine des Smartphones où la reconnaissance vocale et le langage naturel sont devenus incontournables.
Le Web sémantique et le tAL constituent des technologies très complémentaires. En effet, si le Web sémantique permet
la définition d’ontologies, de thésaurus, etc., ces notions existaient déjà et étaient d’ailleurs utilisées dans le tAL, pour la recherche d’information notamment. Ainsi, le Web sémantique complète le tAL d’une part en proposant un protocole de standardisation des référentiels linguistiques, et le tAL complète le Web sémantique d’autre part, en permettant l’élaboration semi-automatique d’ontologies par exemple.
Les technologies sémantiques ont l’énorme avantage de pouvoir s’intégrer directement dans le système d’information, de par leur nature même. En effet, elles viennent se greffer au Si préexistant et proposent ainsi une vue différente et surtout unifiée de l’information interne, tout en respectant les droits d’accès aux données et/ou documents. de plus, l’enrichissement de la base de connaissances peut se faire de manière incrémentale.
de nos jours, il est possible d’intégrer de telles solutions directement au sein de l’entreprise pour :
↪ Augmenter la productivité des collaborateurs en automatisant certaines tâches rébarbatives et/ou de prendre la meilleure décision le plus rapidement possible, en leur proposant notamment une vision globale de l’information.

51
↪ Optimiser les recherches de l’utilisateur en intégrant son jargon. C’est un avantage concurrentiel majeur dans le cas de l’e-commerce, mais cela s’avère également utile dans la recherche documentaire.
↪ Effectuer de l’analyse d’opinion sur des retours clients ou encore de l’analyse de sentiments sur les réseaux sociaux. Ces applications ont énormément de sens dans le métier du marketing et du e-Commerce.
↪ Patrimonialiser la gestion de référentiels complexes facilitant leur recherche et leur interopérabilité.
↪ démocratiser la gestion et la capitalisation des connaissances formelles et implicites, au travers notamment d’ontologies adaptées au contexte métier. Leur consommation en langage naturel devient dès lors accessible à chacun sans expertise particulière.
En conclusion, si la mise en œuvre de ces nouvelles technologies représente un apport de valeur réel aux entreprises, il est important d’adopter une démarche projet structurée et de garder à l’esprit les adaptations nécessaires, notamment au niveau conceptuel et sémantique de la donnée. Sur ce point, il s’avèrera nécessaire de nommer soit une personne responsable de la cartographie et de la qualité des données, soit un architecte de l’information.

52

glossaire
53
54
glossaire
A
annoteur : Brique logicielle chargée de l'annotation d'un texte à l'aide de métadonnées. 16
auto-complétion : Fonctionnalité informatique permettant à l'utilisateur de limiter la quantité d'informations qu'il saisit avec son clavier, en se voyant proposer un complément qui pourrait convenir à la chaîne de caractères qu'il a commencé à taper. 18 28
C
classification : Action de classer des documents sous des catégories prédéfinies. 10, 16, 18, 41, 42, 43
clustering : dans ce contexte, regroupement de textes selon leurs caractéristiques thématiques communes. 16
corpus : Ensemble fini d'énoncés écrits ou enregistrés, constitué en vue de leur analyse linguistique. 9, 40, 42, 43
correction orthographique : traitement de la langue permettant d'analyser un texte afin de détecter et éventuellement de corriger, les fautes d' orthographe. 18, 28
d
désambiguïsation : Opération consistant à déterminer le sens d’un mot en contexte. 10, 18, 30
DLP : description Logic Programs. 24
E
ECM : Enterprise Content manager ou gestionnaire de contenu d'entreprise. 27
extracteur d'entités : Brique logicielle permettant d'extraire d'un texte toute sorte d'entités nommées telles que des noms de personnes, des noms d'entreprise, etc... ainsi que les relations entre elles. 16
i
indexeur : Outil logiciel associant à un document ses termes les plus significatifs en vue de son traitement par un moteur de recherche. 28
inférence : déduction de conséquences induites par les prédicats. 23
J
JSON : Format générique de données textuelles. 23
L
lemmatisation : Analyse lexicale du contenu d'un texte regroupant les mots d'une même famille. Chacun des mots d'un contenu se trouve ainsi réduit en une entité appelée lemme (forme canonique). La lemmatisation regroupe les différentes formes que peut revêtir un mot. 34
Linked Data : initiative du W3C visant à favoriser la publication de données structurées sur le Web, non pas sous la forme de silos de données isolés les uns des autres, mais en les reliant entre elles pour constituer un réseau global d'informations. 15
O
ontologie : modèle de description des connaissances basé sur des concepts possédant un type, des propriétés et des relations. 19, 20, 26, 50, 51
55
glossaire
Open Data : mouvement visant à rendre accessible à tous via le web les données publiques non nominatives ne relevant ni de la vie privée et ni de la sécurité collectées par les organismes publics. 25, 43
opinion mining : technologies d'analyse automatique des discours (écrits ou parlés) afin d'en extraire des informations subjectives comme des jugements, des évaluations ou des émotions. 26
OWL : Web Ontology Language. 17
r
RDF : resource description Framework. 17, 18, 19
RDFS : rdF Schema. 17
RIF : rule interchange Format. 24, 25
S
SaaS : Software as a Service. 30
SPARQL : SPArQL Protocol and rdF Query Language. 22, 23, 43
SWRL : Semantic Web rule Language. 24
t
TAL : traitement Automatique des Langues. 8, 9, 10, 26, 33, 35, 50
taxonomie : Liste de termes contrôlés organisés de façon hiérarchique. Cela a pour effet de faciliter la recherche de termes basée sur ces relations. 25, 42, 43
text-mining : traitements informatiques consistant à extraire des connaissances selon un critère de nouveauté ou de similarité dans des textes produits par des humains pour des humains. 34
thésaurus : réseau de termes contrôlés, enrichi de relations sémantiques prédéfinies de différentes natures (relations inter-concepts et inter-termes). 18, 25, 50
triplet : Association de type {sujet, prédicat, objet}. 19, 20, 22, 23, 43
U
UIA : Unified information Access ou Accès Unifié à l'information (AUi) en français. 40
V
verbatim : Citation textuelle, mot à mot. 34, 35
W
W3C : World Wide Web Consortium. 9, 20, 22, 23, 24
web des données : initative du W3C visant à favoriser la publication de données structurées sur le Web, en les reliant entre elles pour constituer un véritable réseau d'informations. 9
Web sémantique : Ensemble de technologies développées par le W3C et dont le but est de rendre les ressources du Web interprétables aussi bien par l'Homme que par la machine. On lui préfère l'expression Web des données. 9, 19, 20, 22, 25, 26, 27, 28, 29, 30, 34, 40, 44, 46, 47, 48

56

bibliographie
57
58
bibliographie
Alami, M. (2010, Avril 4). Le Web 3.0, Web sémantique et incidences sur le référencement. récupéré sur marketing internet montréal: http://www.marketing-internet-montreal.com/2010/03/web-3-0-semantique-incidences-referencement/
Antidot. (2011). E-commerce et Web sémantique, la vague va déferler ! . Paris.
Audibert, L. (2010, Novembre 4). traitement Automatique du Langage Naturel (tALN) Outils d’analyse de données textuelles. Paris-Nord, France.
Bourges, Y. (2012, Juin 26). Sémantique en entreprise – illustration par la solution Luxid de temis. récupéré sur Lecko - Le blog des consultants: http://blog.lecko.fr/semantique-en-entreprise-illustration-par-la-solution-luxid-de-temis/
Dr. Jans Aasman. (2011, Avril 18). Will triple Stores replace relational databases? récupéré sur information management: http://www.information-management.com/newsletters/database_metadata_unstructured_data_triple_store-10020158-1.html
Gentre Dozier and Spencer Dille. (s.d.). Will triple Stores replace relational databases? récupéré sur Support de présentation.
Grosjean, G., & COL, P. (2013, Avril). A. Vanègue, intervieweur
Jay Myers, ingénieur en charge du déveleoppement du site BestBuy.com. (2010). Semtech 2010. San Francisco.
Jeanrond, H.-J. (2013). 80% des données d’une entreprise sont non structurées.
Laetitia Chessé, responsable référencement, LiNKEO.COm. (2012, Avril 5). Le Web sémantique, une arme à double tranchant pour le référencement ? récupéré sur Journal du Net : http://www.journaldunet.com/solutions/expert/51287/le-web-semantique--une-arme-a-double-tranchant-pour-le-referencement.shtml
Lemaire, B. (2011, Août 31). EdF analyse ses relations clients pour les améliorer. Consulté le 06 24, 2013, sur cio-online.com: http://www.cio-online.com/actualites/lire-edf-analyse-ses-relations-clients-pour-les-ameliorer-3783.html
Lemire, D. (s.d.). Les informations non structurées. récupéré sur tELUQ : http://benhur.teluq.uqam.ca/SPiP/inf6104/article.php3?id_article=17&id_rubrique=4&sem=2
Lionne, P. (2013, Avril). A. Vanègue, intervieweur
Magnin, M. (2009). Le Web sémantique. récupéré sur technologies: http://www-igm.univ-mlv.fr/~dr/XPOSE2009/Le%20Web%203.0/technologies.html
Mayer, D. (2013). Structurer, gérer, valoriser vos contenus non structurés à l'aide de la sémantique. Paris - La défense.
Polonsky, A. (2013, mai 06). A. Vanègue, intervieweur
Schémas de classification : thésaurus, taxonomie, ontologie…. (s.d.). récupéré sur dialogos - Consulting et architecture interactive: http://www.dia-logos.net/ressources/schemas-de-classification-thesaurus-taxonomie-ontologie
Serniclay, A. (2013, Juin 21). A. Vanègue, intervieweur
Singhal, A. (2012, décembre 5). Lancement en France du Knowledge Graph : des mots aux entités. récupéré sur Le blog officiel de Google France : http://googlefrance.blogspot.fr/2012/12/lancement-en-france-du-knowledge-graph.html
Texier, B. (2007, décembre 1). A ce jour, 99% de l'information est non structurée. récupéré sur Archimag : http://www.archimag.com/article/%C3%A0-ce-jour-99-de-linfo-est-non-structur%C3%A9e

59
contact : [email protected]
équipe web sémantique osiatis
Joëlle Vittone
Alexandre Vanègue
LucArnaud
romaindalle
Grégormaciak
Leader offre

Ce guide vous est proposé par la société Econocom-Osiatis.
Ce document est non contractuel. ©2013 Econocom-Osiatis. tous droits réservés. Conception, rédaction & réalisation : Econocom-Osiatis. Création : indexel.
www.osiatis.comwww.econocom.com





























