Embed Size (px)
Citation preview

2. COMPARAISON DE
DEUX GROUPES

• Il existe des tests spécifiques pour
• comparer des proportions
• comparer des moyennes
• Données par paires ou non
• Nécessite éventuellement de comparer préalablement les variances
• Des conditions d’applications doivent être respectées pour réaliser les tests

• 2 échantillons aléatoires simples indépendants (pas de correspondances entre les valeurs des 2 groupes)
• Pour chaque groupe d’effectif ni on a xi succès, et donc une proportion pi = xi/ni
• Test de l’hypothèse nulle p1 = p2
• Condition : xi et (ni - xi) ≥ 5
• On peut avoir à calculer les xi à partir de pi et ni
Comparaison de 2 proportions

• Estimation combinée de p1 et p2, notée p ̄
• p ̄= (x1 + x2)/(n1 + n2)
• et q ̄= 1 - p ̄
• Calcul de la statistique test z
• z = (p1 - p2)/√(p.̄q/̄n1 + p.̄q/̄n2)
• Sous H0, z suit une loi Normale (table de Student avec un nombre infini ("grand") de ddl)
• On peut calculer l’intervalle de confiance de p1 - p2

• Quand il ne s’agit pas de proportions :
• 2 groupes d’observations indépendantes : 2 échantillons pouvant être
• Indépendants
• Appariés
• H0 : Les 2 groupes sont issus de la même population,
avec donc la même moyenne
• 2 étapes :
• Comparaison des variances
• Comparaison des moyennes

• Important de tester préalablement l’homogénéité des variances car c’est une condition d’application de certains tests (tests paramétriques)
• Sinon, en cas d’hétéroscédasticité : test simultané de 2 hypothèses nulles
• Problème de Behrens-Fisher
➡Le rejet de H0 peut être due à la différence des
moyennes (la seule hypothèse qu’on veut tester) ou à celle des variances

• Test de Fisher-Snedecor (test F), pour données quantitatives normalement distribuées
• Statistique F : rapport des variances, tenant compte du nombre d’objets par groupes par l’intermédiaire des degrés de liberté
• Si égalité des variances, F doit se situer autour de 1
• La variable F obéit à une loi de distribution de F
Comparaison de 2 variances

• Pour 2 groupes à n1 et n2 objets
F = s21/s2
2
• Sous H0, F suit une loi à (n1 - 1) et (n2 - 1) ddl
• Conditions
• Indépendance des observations
• Normalité des données
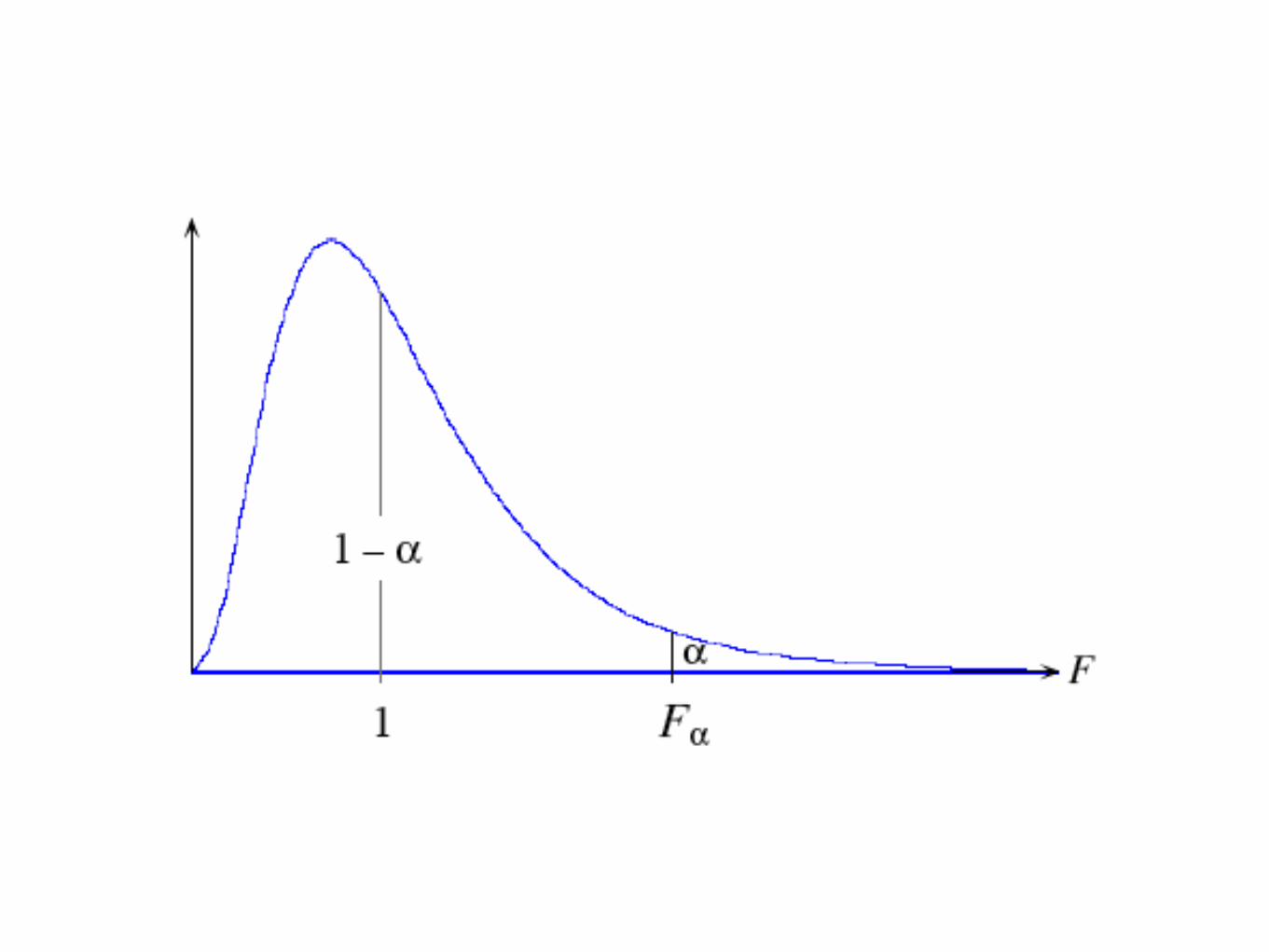

• Souvent, les tables ne donnent que les valeurs critiques de F dans la droite de la distribution
• F = plus grande variance/plus petite variance
• Test unilatéral (souvent) ou bilatéral
• On peut également tester les écarts-types par un test F
• Il existe un test non paramétrique permettant de comparer 2 variances en cas de non normalité : test de Fligner-Killeen

• Test t
• Pour échantillons appariés ou non appariés
• Test statistique
• Paramétrique : référence à la loi Normale
• Comparaison de |t| au seuil dans une table de Student
• Par permutations
• Tests non paramétriques
• Test U de Wilcoxon-Mann-Whitney (échantillons non appariés)
• Test des rangs signés de Wilcoxon (échantillons appariés)
Comparaison de 2 moyennes

• Parfois appelé test Z
• H0 : µ1 = µ2
• Statistique t : différence des moyennes des deux échantillons tenant compte des variances et des n différents
• t suit une loi de distribution de Student à n1+n2-2
degrés de liberté sous H0
Test t pour échantillons indépendants

• Conditions d’utilisation
• Variable quantitative
• Grands échantillons (ni >30)
• Normalité des données (sauf si test par permutations)
• Egalité des variances (homoscédasticité)
• Indépendance des observations

• Quand ni < 30 (et en fait le plus souvent), on
utilise une statistique t corrigée
• Les variances estimées des 2 échantillons sont combinées : meilleure approximation de la variance de la population
• Test t de certains livres/logiciels

• Si les variances sont inégales, il existe également une correction
• Test t modifié selon Welch
• Même calcul de la statistique-test
• Distribution différente : formule pour modifier le nombre de ddl

Test t pour données appariées
• Correspondance 2 à 2 des observations
• Mesures avant-après des mêmes sujets
• Mesures de deux caractères sur les mêmes individus
• Informations supplémentaires
• Pas nécessaire de tester l’homogénéité des variances
• Analyse des différences observées pour chaque paire d’observations
di = xi1 - xi2

• Moyenne des différences = différences des moyennes
µd = µ1 - µ2
• Erreur-type (écart-type de la moyenne)
sd̅ = sd/√n
• Statistique-test
t = d̅/sd̅
• Sous H0 (µd = 0), t obéit à une loi de Student à (n - 1)
ddl, où n est le nombre de paires

• Pour deux groupes indépendants
• Données quantitatives
• Distribution non normale
• Variances inégales
• Echantillons trop petits pour test t (ex : n = 3)
• Données semi-quantitatives
• Moins puissants que les tests paramétriques
• Efficacité (/test t) = 0,95 : pour obtenir la même puissance, il faut 100 observations au test U contre 95 au test t
• Basé sur les rangs
Test non paramétrique U de Wilcoxon-Mann-Whitney

• On place l’ensemble des valeurs en ordre (les ex-aequos reçoivent un rang médian)
• Plus les groupes sont séparés, moins les valeurs seront entremêlées
• Le test consiste à estimer l’écart à un “entremêlement moyen” des valeurs placées en rang
• La statistique testée, U, mesure le degré de mélange des deux échantillons (H0 : pas de différence)
• Comparaison de la valeur observée par rapport à la valeur critique (Table)
• Convergence vers une loi Normale quand n augmente

• Exemple
Groupe 1 : 0,5 2 2,1 (n1 = 3)
Groupe 2 : 0,7 2,2 3 3,1 (n2 = 4)
Valeurs en ordre 1 2 3 4 5 6 7
Provenance 1 2 1 1 2 2 2
• U1 : nombre de fois qu’un élément du groupe 2 en
précède un du groupe 1 ; U1 = 0 + 1 + 1 = 2
• U2 : l’inverse ; = 1 + 3 + 3 + 3 = 10

• Il y a en tout n1n2 comparaisons : 4 x 3 = 12
U2 = n1n2 - U1
• Si les groupes sont parfaitement séparés
U2 = 0 et U1 = n1n2 , ou l’inverse
• Si les groupes sont parfaitement entremêlés
U1 = U2 = n1n2/2
• Tester H0 revient à mesurer l’écart du plus petit des U
à la valeur n1n2/2 (valeur sous H0)
• Statistique-test = min (U1, U2)

Test non paramétrique de Wilcoxon
• Pour données appariées
• Mêmes conditions que pour le test U
• Efficacité (/test t) = 0,95
• Plus puissant que le test des signes (non développé) : Efficacité (/test t) = 0,63
• Etude des différences entre paires de données
• H0 : pas de différence entre les moyennes des groupes

• On place en rang les valeurs absolues des différences (en excluant les valeurs nulles et en donnant un rang médian en cas d’ex-aequo)
• On attribue à chaque rang le signe de la différence originale
• On somme les rangs positifs (T+) et les rangs négatifs (T-)
• Sous H0, T+ = T- = n(n + 1)/4 (n excluant les
différences nulles)
• Statistique-test = min (T+, T-)
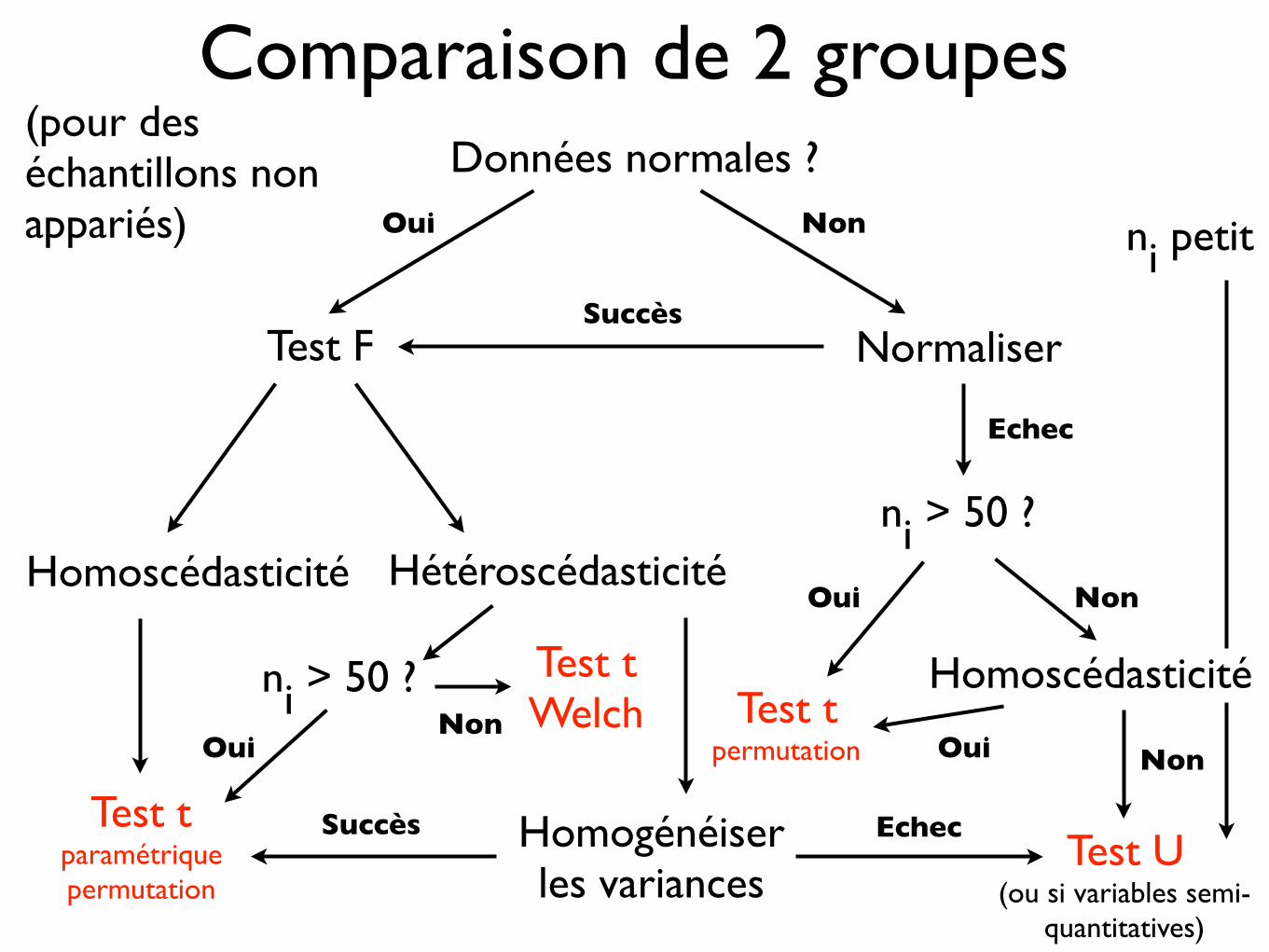
Comparaison de 2 groupesDonnées normales ?
Homoscédasticité
Test tparamétriquepermutation
Hétéroscédasticité
Homogénéiserles variances
Test F
Oui
Normaliser
Non
Succès
Succès
ni > 50 ?
OuiNon
Test tWelch
Echec
ni > 50 ?
Oui
Test tpermutation
Non
Homoscédasticité
Oui Non
Test U(ou si variables semi-
quantitatives)
Echec
ni petit
(pour des échantillons non appariés)

Risque relatif (RR) et Rapport de cotes (RC)
• Mesures de risque
• Mesure de l'efficacité d'un traitement dans un groupe traité (ou exposé) par rapport à un groupe non traité
• Exemple : rapport entre le nombre de sujets développant une pathologie dans un groupe recevant un médicament et ce nombre dans un groupe contrôle
• Très important en santé humaine et en épidémiologie, dans le cadre d'études prospectives et rétrospectives
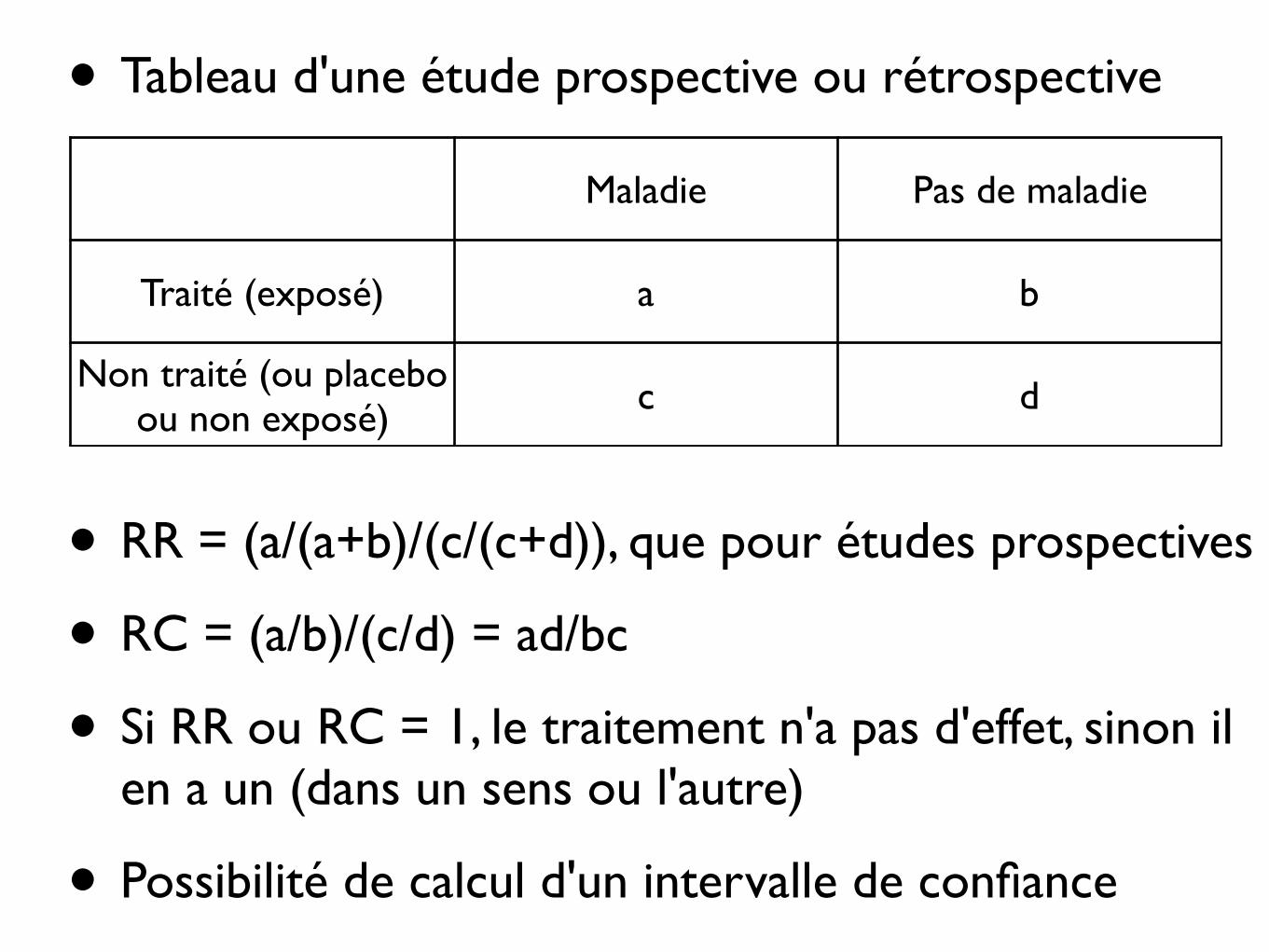
• Tableau d'une étude prospective ou rétrospective
• RR = (a/(a+b)/(c/(c+d)), que pour études prospectives
• RC = (a/b)/(c/d) = ad/bc
• Si RR ou RC = 1, le traitement n'a pas d'effet, sinon il en a un (dans un sens ou l'autre)
• Possibilité de calcul d'un intervalle de confiance
Maladie Pas de maladie
Traité (exposé) a b
Non traité (ou placebo ou non exposé) c d

Risque relatif• RR = relative risk
• Incidence d'un événement dans un groupe/incidence du même événement dans un autre groupe
• Exemple : survenue d'une maladie dans un groupe vacciné et un groupe témoin non vacciné
• RR = chance de tomber malade dans le groupe traité par rapport à cette chance dans le groupe témoin
• Souvent incidence dans groupe témoin pas connue : calcul du RC, qui estime bien le RR

Rapport de cotes
• RC = odds ratio
• Cote = nombre de fois qu'un événement s'est produit dans un groupe/nombre de fois où il ne s'est pas produit. Exemple : 3 contre 1
• En sciences de la santé : comparaison du risque (par exemple de développer une maladie) entre les individus traités et les individus contrôles
• RC = Probabilité pour le groupe traité (ou exposé) / Probabilité pour le groupe contrôle





























