Embed Size (px)
Citation preview

Comprendre les données visuelles à grande échelle ENSIMAG 2016-2017 Karteek Alahari & Diane Larlus

Au programme
Organisation du cours
Introduction Contexte et applications
Aperçus des problèmes en vision
Evaluation
Représentation des données visuelles Descripteurs locaux et globaux, réseaux de neurones
Application à la fouille de donnée
Problème de la reconnaissance Classification d’images et de vidéos
Séparateurs à vaste marge (SVM)
Pour aller plus loin

Organisation du cours
Séance du jeudi 5 janvier – 8h15 à 11h15
Retour sur les représentation locales
Présentation article 1 + quizz
Troisième cours sur les représentations globales

4
Comprendre
les données
visuelles à
grande
échelle
Complément
du cours 2: Indexation
efficace
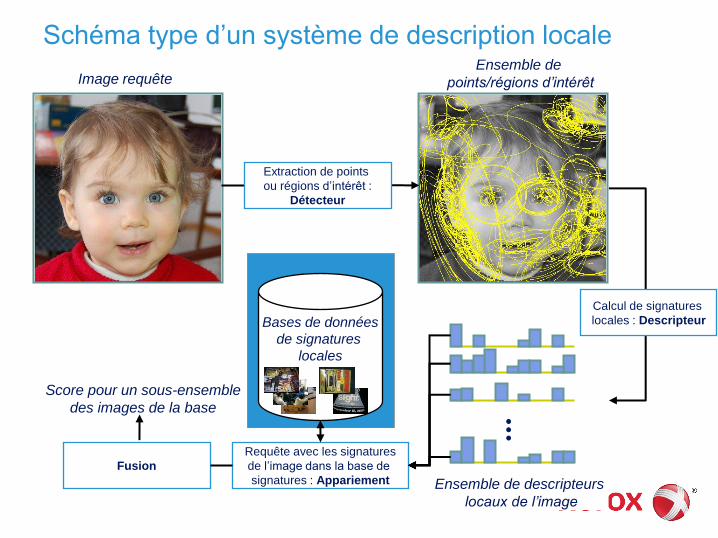
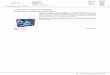
Schéma type d’un système de description locale
Extraction de points
ou régions d’intérêt :
Détecteur
Ensemble de
points/régions d’intérêt Image requête
⋮
Ensemble de descripteurs
locaux de l’image
Calcul de signatures
locales : Descripteur Bases de données
de signatures
locales
Requête avec les signatures
de l’image dans la base de
signatures : Appariement
Fusion
Score pour un sous-ensemble
des images de la base

Indexation
Problème : rechercher efficacement des vecteurs de caractéristique (=descripteurs) proches au sein d’une base de descripteurs → on voudrait éviter de faire une comparaison exhaustive
Opérations supportées : recherche (critique), ajout/suppression (+ ou – critique) selon l’application
Deux types de recherche ► Recherche à ε
► Recherche des k plus proches voisins
objets complexes
⋮
vecteurs de caractéristiques
de grane dimension
extraction de
descripteurs
ajout ou
requête
structure
d’indexation

Plan
Introduction
Indexation mono-dimensionnelle
Indexation multi-dimensionnelle
Perspectives

Notations
base de n vecteurs : Y= { yi ∈ ℝd }i=1..n
vecteur requête : q in ℝd
on note N(q) ⊂ Y les voisins de q → les vecteurs “similaires”
Le voisinage est relatif à une distance (ou une similarité/dissimilarité)
→ on se concentre sur la distance Euclidienne
d(x,y) = ||x-y||2

Qu’est ce qu’un “voisin” ?
un vecteur qui répond à une propriété de proximité absolue ou relative
recherche à ε recherche des k plus proches voisins
Nε(q) = { yi ∈ Y : d(yi,q) < ε } Nk(q) = k-argmini d(yi,q)
k=2

Qu’est ce qu’un “voisin” ?
Remarque : le voisinage au sens des k-plus proches voisins n’est pas symétrique
X= { xi ∈ ℝd }i=1..n
on peut avoir xj ∈ Nk(xi) et xi ∉ Nk(xj)
xi
xj
xk

Algorithme naïf : complexité
Si la base Y n’est pas organisée (=indexée), calculer Nk ou Nε nécessite le calcul de l’ensemble des distances d(q,yi)
► O(n×d)
Pour Nk(q), il faut de plus effectuer l’opération k-argmini d(q,yi)
Exemple: on veut 3-argmin {1,3,9,4,6,2,10,5}
► Méthode naïve 1: trier ces distances → O(n log n)
► Méthode naïve 2: maintenir un tableau des k-plus petits éléments, mis à jour pour chaque nouvelle distance considérée → O(n k)
Intuitivement, on peut faire mieux…
Max-heap
Binary max heap
► structure d’arbre binaire équilibré
► dernier niveau rempli de gauche à droite
► à chaque nœud n on associe une valeur v(n)
► propriété : si ni est un nœud fils de nj, alors v(ni) < v(nj)
Remarque : il admet une représentation linéaire simple: ni a pour père ni/2
10
9 5
6 2 3 1
4
n1
10
n2
9
n3
5
n4
6
n5
2
n6
3
n7
1
n8
4

Plan
Introduction
Indexation mono-dimensionnelle
Indexation multi-dimensionnelle
Perspectives

Indexation mono-dimensionnelle
Application phare : les bases de données (au sens classique du terme)
Différents types d’opérations de recherche
► recherche d’un point/vecteur
► recherche de structures spatiales plus complexes : Ex: recherche d’une valeur dans un intervalle, ou du plus proche voisin d’une valeur
Les structures de références :
► Hashing
► B+ tree

Fichier inversé (inverted file) Cette structure liste des éléments qui ont une valeur donnée
pour un attribut
Bases de données: utilisé pour les clés secondaires (doublons attendus)
Exemple courant d’utilisation : requêtes sur documents textuels (mails, …)
La requête consiste à récupérer la liste des documents contenant le mot
► coût proportionnel au nombre de documents à récupérer
mot 1
mots du dictionnaire (ou clé)
mot 2
mot i doc2 doc3 doc8 doc9
doc1 doc3 doc5

Recherche de documents textuels (1)
Modèle vectoriel
► on définit un dictionnaire de mots de taille d
► un document texte est représenté par un vecteur f = (f1,…,fi,…fd) ∈ ℝd
► chaque dimension i correspond à un mot du dictionnaire
► fi = fréquence du mot dans le document
en pratique, on ne garde que les mots discriminants dans le dictionnaire
“le”, “la”, “est”, “a”, etc, sont supprimés, car peu discriminants
Ces vecteurs sont creux
► dictionnaire grand par rapport au nombre de mots utilisés

Recherche de documents textuels (2)
Exemple
► dictionnaire = {“vélo”, “voiture”, “déplace”, “travail”, “école”, “Grenoble”}
► espace de représentation: ℝ6
► “Grenoble est une belle ville. Je me déplace à vélo dans Grenoble”
f=(1/4,0,1/4,0,0,1/2)t
Recherche de document = trouver les vecteurs les plus proches
► au sens d’une mesure de (dis-)similarité, en particulier le produit scalaire
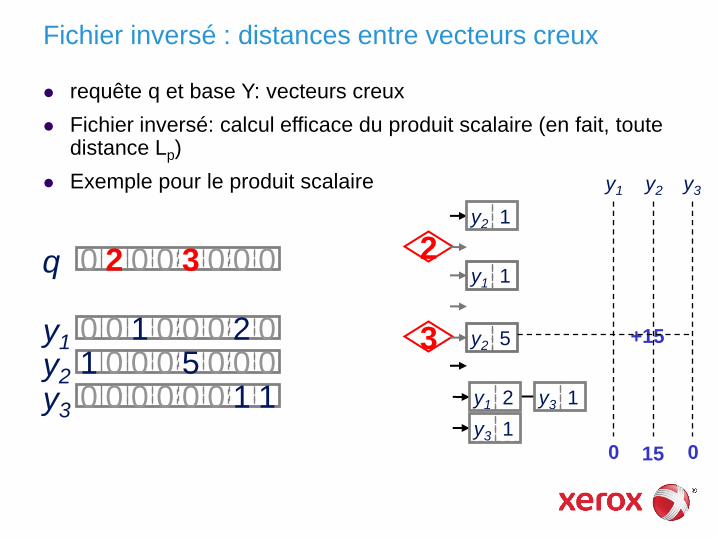
1 0 0 0 5 0 0 0 0 0 1 0 0 0 2 0
0 0 0 0 0 0 1 1
y1
y2
y3
2
3
y2 1
y1 1
y2 5
y1 2
y3 1
y3 1
0 2 0 0 3 0 0 0 q
Fichier inversé : distances entre vecteurs creux
requête q et base Y: vecteurs creux
Fichier inversé: calcul efficace du produit scalaire (en fait, toute distance Lp)
Exemple pour le produit scalaire
y1 y2 y3
+15
15 0 0
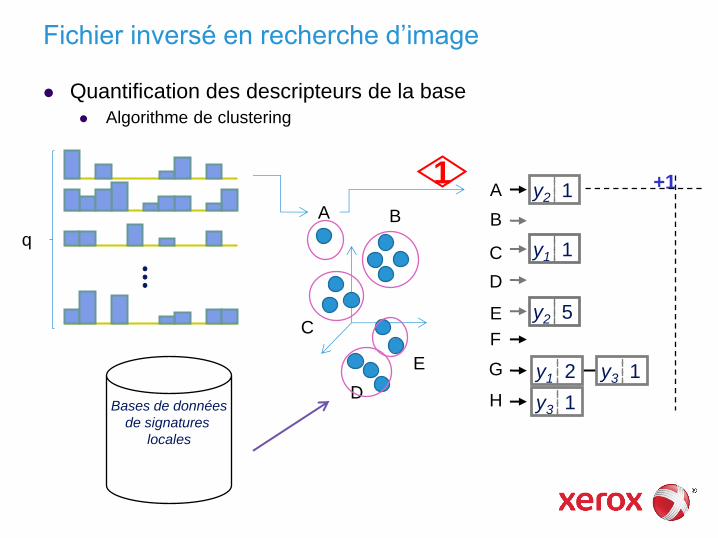
Fichier inversé en recherche d’image
Quantification des descripteurs de la base Algorithme de clustering
y2 1
y1 1
y2 5
y1 2
y3 1
y3 1
⋮
Bases de données
de signatures
locales
A B
C
D
E
A
B
C
D
E
F
G
H
q
1 +1

Plan
Introduction
Indexation mono-dimensionnelle
Indexation multi-dimensionnelle
Perspectives
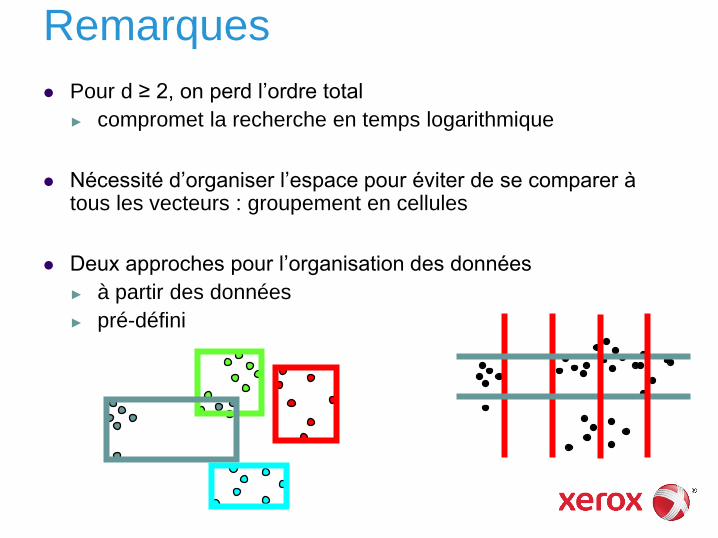
Remarques
Pour d ≥ 2, on perd l’ordre total
► compromet la recherche en temps logarithmique
Nécessité d’organiser l’espace pour éviter de se comparer à tous les vecteurs : groupement en cellules
Deux approches pour l’organisation des données
► à partir des données
► pré-défini

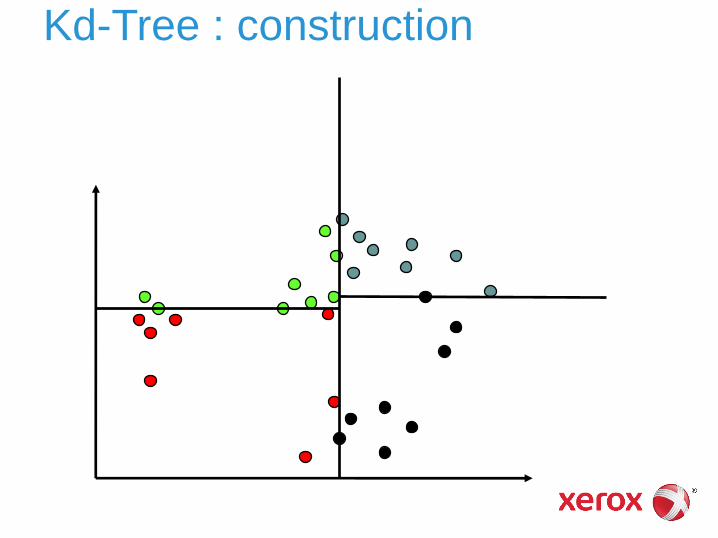
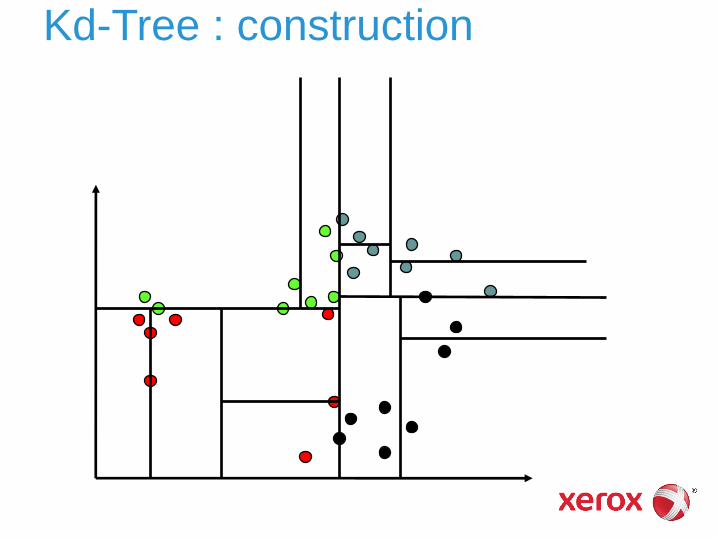
Kd-Tree
Technique (populaire) de partitionnement de l’espace des vecteurs
Espace découpé récursivement en utilisant des hyperplans ► parallèles aux axes (base de représentation initiale du
vecteur)
► point de découpage = valeur médiane sur l’axe considéré
► choix du prochain axe : plus grande variance résiduelle mais plusieurs variantes possibles
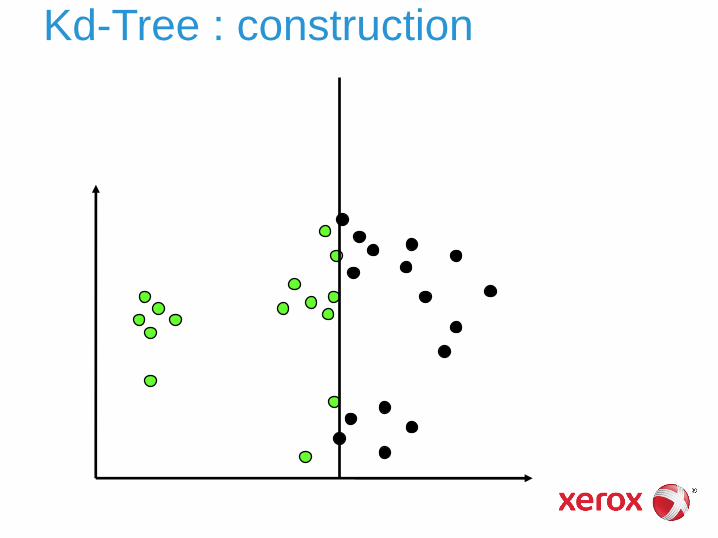
Kd-Tree : construction
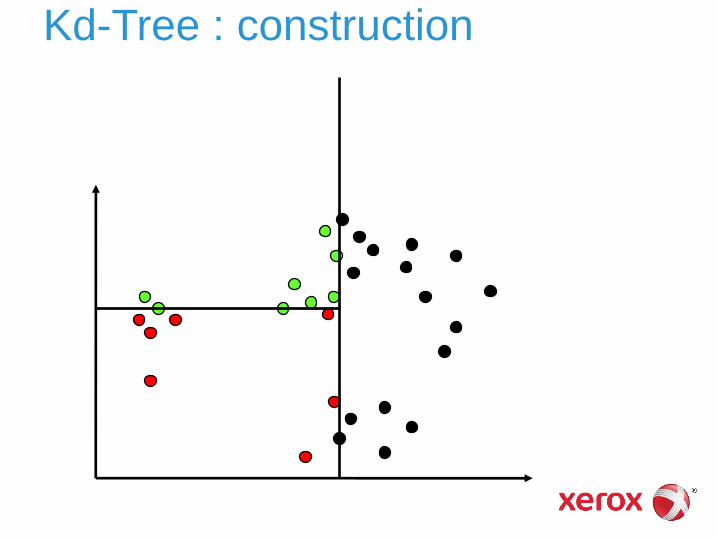
Kd-Tree : construction
Kd-Tree : construction
Kd-Tree : construction

Kd-Tree
C’est une partition de l’espace ► toutes les cellules sont disjointes (pas de
recouvrement)
► cellules de tailles initialement équilibrées (par construction)
► mais se déséquilibrent si insertion de vecteurs additionnels
peu efficace en grande dimension (ne filtre que peu de cellules)

Kd-Tree : recherche du ppv
arbre de recherche
► descente dans l’arbre (log) pour trouver la cellule ou tombe le point
on cherche le plus proche voisin (ppv) dans la cellule -> donne la meilleure distance r
recherche de l’intersection entre l’hypersphère de rayon r et l’hyperplan séparant la cellule
► si non vide, analyse de l’autre côté de l’hyperplan
► si un point plus proche est trouvé, on met à jour r
on analyse toutes les cellules de l’arbre que l’on ne peut filtrer
► dans le pire des cas, parcours total de l’arbre

Malédiction de la dimension!
ou « fléau de la dimension » (The dimension curse)
Quelques propriétés surprenantes ► vanishing variance
► phénomène de l’espace vide
► proximité des frontières

Vanishing variance
La distance entre paires de points tend à être identique quand d augmente
► le plus proche voisin et le point le plus éloigné sont à des distances qui sont presque identiques
► exemple avec données uniformes (au tableau)
Conséquence
► le plus proche voisin devient très instable
► inégalité triangulaire peu efficace pour filtrer
Les jeux de données uniformes ne peuvent pas être indexés efficacement
► c’est moins vrai pour des données naturelles (ouf !)

Phénomène de l’espace vide
Cas d’école : partition de l’espace selon le signe des composantes
d=100 -> 1.26 1030 cellules >> n
Très peu de cellules sont remplies
► pour une partition pourtant grossière…
Ce phénomène est appelé « phénomène de l’espace vide »
► difficulté pour créer une partition
une bonne répartition des points
avec une bonne compacité
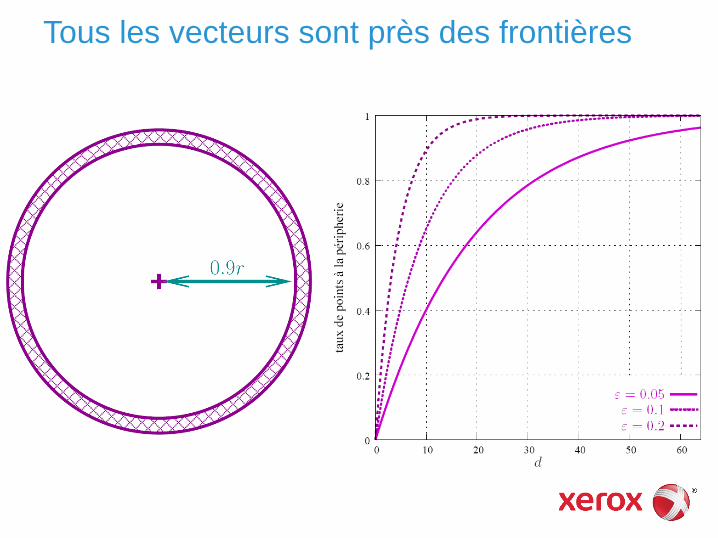
Tous les vecteurs sont près des frontières

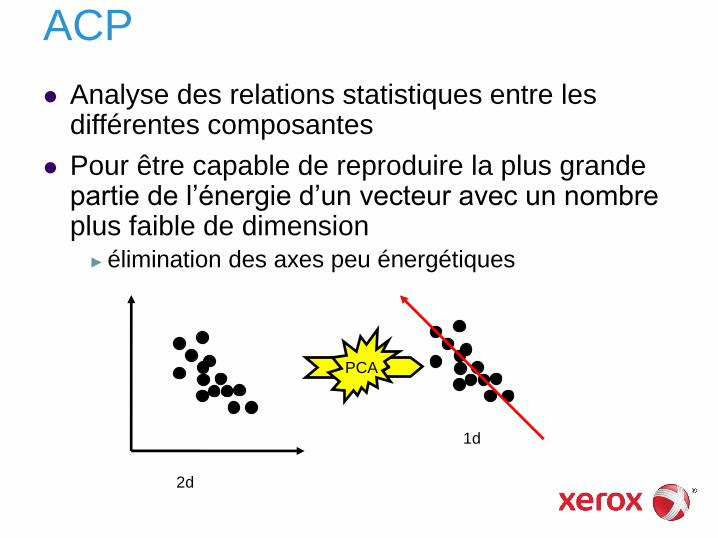
Réduction de la dimensionnalité
Approche la plus courante : analyse en composantes principales (ACP) ► PCA en anglais : Principal Component Analysis
ACP
Analyse des relations statistiques entre les différentes composantes
Pour être capable de reproduire la plus grande partie de l’énergie d’un vecteur avec un nombre plus faible de dimension
► élimination des axes peu énergétiques
2d
1d
PCA

ACP
Il s’agit d’un changement de base ► translation (centrage des données) + rotation
4 étapes (offline) ► centrage des vecteurs
► calcul de la matrice de covariance
► calcul des valeurs propres et vecteurs propres
► choix des d’ composantes les plus énergétiques (+ grandes valeurs propres)
Pour un vecteur, les nouvelles coordonnées sont obtenues par centrage et multiplication du vecteur par la matrice d’ x d des vecteurs propres conservés

ACP
Moins de dimensions, donc meilleur comportement des algorithmes de recherche
Si la réduction préserve la plupart de l’énergie ► les distances sont préservées
► donc le + proche voisin dans l’espace transformé est aussi le plus proche voisin dans l’espace initial
Limitations ► utile seulement si la réduction est suffisamment forte
► lourdeur de mise à jour de la base (choix fixe des vecteurs propres préférable)
► peu adapté à certains types de données

Améliorer la finesse de la quantification: le quantificateur produit
Problème d'approximation de distances entre requête x et vecteur y de la base
il faut une quantification plus fine que quelques milliers de centroides
► k-means coûteux
► assignement coûteux
► stockage des centroïdes coûteux
Solution: le quantifieur produit (product quantization ou PQ)

Vecteur coupé en m sous-vecteurs:
Sous-vecteurs quantifiés séparément:
chaque qi a un petit vocabulaire
Exemple: y = 128 D en 8 sous-vecteurs de dimension 16
Quantificateur produit pour la recherche des
plus proches voisins
8 bits
16 composantes
⇒ index de 64 bits
y1 y2 y3 y4 y5 y6 y7 y8
q1 q2 q3 q4 q5 q6 q7 q8
q1(y1) q2(y2) q3(y3) q4(y4) q5(y5) q6(y6) q7(y7) q8(y8)
256
centroides

39
Comprendre
les données
visuelles à
grande
échelle
Cours 3: Représentations
globales

Description globale
Une description globale est une représentation de l’image dans son ensemble, sous la forme d’un vecteur de taille fixe
Elle se contente le plus souvent d’exploiter un indice visuel unique
Caractéristiques ► un vecteur de description par objet visuel
► mesure de (dis-)similarité définie sur l’espace de ces descripteurs

Exemple de description globale : histogramme de couleur
Chaque pixel est décrit par un vecteur de couleur
► par exemple un vecteur RGB ∈ R3 , mais le plus souvent on utilise un autre espace de couleur plus approprié
L’ensemble des vecteurs de couleurs forme une distribution
► description de la distribution avec un histogramme
► Nécessite la discrétisation de l’espace + la normalisation
Comparaison de deux histogrammes par une mesure de dissimilarité, par exemple la « distance » du Khi-2 ou earth mover's distance (au tableau)
Color indexing, Swain & Ballard,IJCV 1991
The earth mover's distance, multi-dimensional scaling, and color-based image retrieval Y Rubner, LJ Guibas, C Tomasi - Proceedings of DARPA Image, 1997

Visualisation des distances pour une représentation basée sur la couleur

Apparence globale de l'image : descripteur GIST
Similaire au descripteur SIFT sur une pyramide d'images, avec image = patch.
Peut prendre en compte la couleur si appliqué sur les canaux R, G, B séparément.
[Modeling the shape of the scene: a holistic representation of the spatial enveloppe, Aude
Oliva, Antonio Torralba, IJCV 2001], [Gist of the scene, A. Oliva, Neurobiology of attention, 2005]
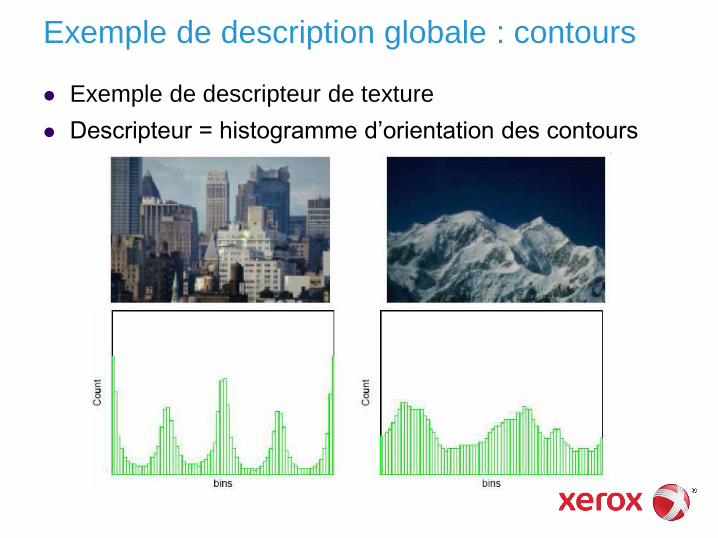
Exemple de description globale : contours
Exemple de descripteur de texture
Descripteur = histogramme d’orientation des contours

Agrégation de descripteurs locaux
Définir un descripteur global à partir de l'ensemble des descripteurs locaux d'une image
► Compact, et plus facile à manipuler
Contraintes
► Des images similaires doivent avoir des représentations similaires
► Des images dissimilaires doivent avoir des représentations dissimilaires
Compromis
► Robustes aux transformations (échelle, occultation, éclairage, etc.)
► Informatifs (bonne description du contenu)
► Efficaces à calculer, à stocker, à manipuler

Agrégation de descripteurs locaux Plan de la suite
• Le modèle Bag-of-Visual-Words
• Le VLAD
• Le Fisher Vector
• Quelques applications
Page 46
Crédit pour la majorité des transparents qui suivent:
F. Perronnin, International Computer Vision Summer School. 2014

Construction d’un descripteur
L’encodage est en général complexe, et contient plusieurs étapes
•On se focalise sur le framework « bag-of-patches »
Pipeline: •Extraction et description de vignettes, ou patches (e.g. SIFT, HOG, LBP, couleur)
X = 𝑥1, … , 𝑥𝑇 • Etape d’encodage: on encode le descripteur local
dans un espace, typiquement de grande dimension (embedding)
𝑥𝑡 → 𝜑 𝑥𝑡
• Etape de pooling: on agrège les embeddings par
vignette, par exemple: sum pooling: 1
𝑇 𝜑 𝑥𝑡𝑇𝑡=1
Page 47

Agrégation de descripteurs locaux : La représentation par sac-de-mots
La base: « bag-of-features », « bag-of-patches »
► bag = on perd l'ordre, la géométrie
Quantification: représentation par sac-de-mots, ou bag-of-words (BoW, aussi appelée bag-of-visual-words ou BoV)
► Un descripteur local -> un entier (par un algorithme de quantification vectorielle)
► histogramme des entiers = descripteur global

Agrégation de descripteurs locaux -- BoW
A B C D E F G
Extraction de descripteurs locaux
Détecteurs de points d’intérêt ou grille dense
Descripteur, par exemple SIFT
Transformation des descripteurs en mots visuels
Histogramme de ces mots visuels

Bag-of-visual-words (BOV)
• Quantification de l’espace des descripteurs, par exemple avec l’algorithme de clustering k-means → vocabulaire visuel
• Chaque patch est associé à son mot le plus proche: 𝜑𝑏𝑜𝑣 𝑥𝑡 = [0,… , 0, 1, 0, … , 0]
• Compter le nombre de descripteurs associés à chaque mot
→ représentation par un histogramme
Page 50
http://www.cs.utexas.edu/~grauman/courses/
fall2009/papers/bag_of_visual_words.pdf
Sivic, Zisserman, “Video Google: A Text Retrieval Approach to Object Matching in Videos”, ICCV’03.
Csurka, Dance, Fan, Willamowski, Bray, “Visual categorization with bag of keypoints”, ECCV SLCV’04.
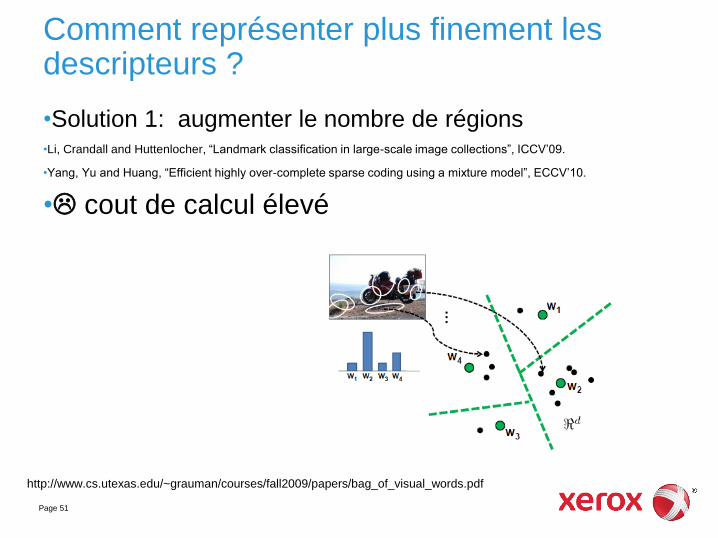
Comment représenter plus finement les descripteurs ?
•Solution 1: augmenter le nombre de régions •Li, Crandall and Huttenlocher, “Landmark classification in large-scale image collections”, ICCV’09.
•Yang, Yu and Huang, “Efficient highly over-complete sparse coding using a mixture model”, ECCV’10.
• cout de calcul élevé
Page 51
http://www.cs.utexas.edu/~grauman/courses/fall2009/papers/bag_of_visual_words.pdf
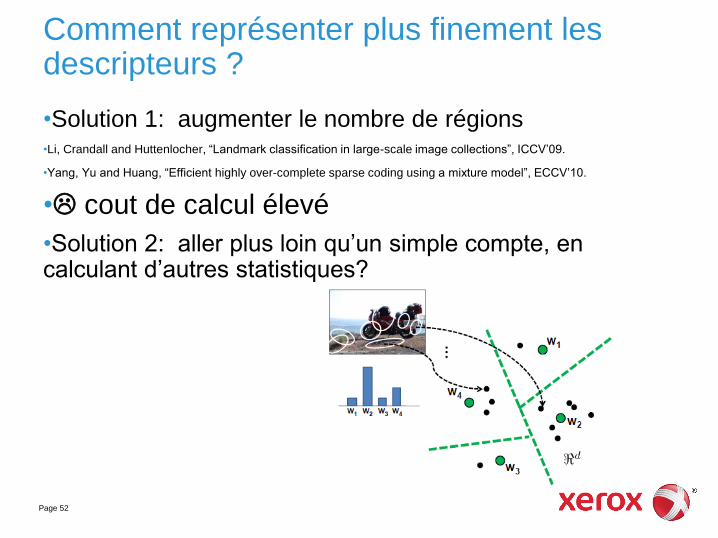
Comment représenter plus finement les descripteurs ?
•Solution 1: augmenter le nombre de régions •Li, Crandall and Huttenlocher, “Landmark classification in large-scale image collections”, ICCV’09.
•Yang, Yu and Huang, “Efficient highly over-complete sparse coding using a mixture model”, ECCV’10.
• cout de calcul élevé
•Solution 2: aller plus loin qu’un simple compte, en calculant d’autres statistiques?
Page 52
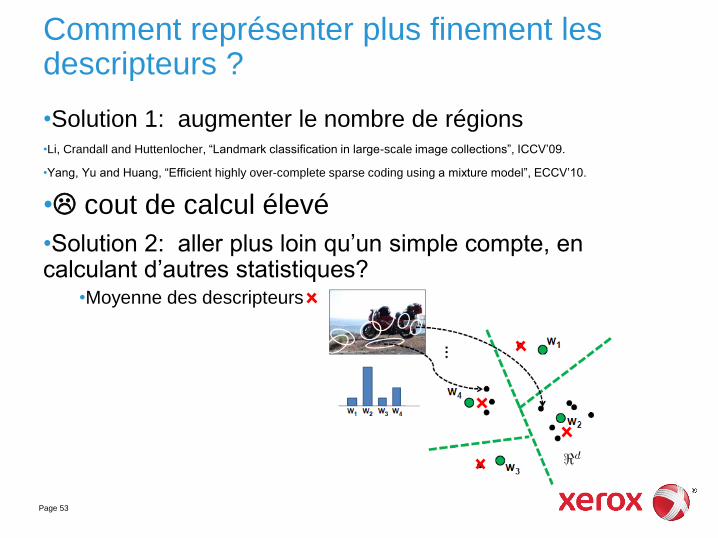
Comment représenter plus finement les descripteurs ?
•Solution 1: augmenter le nombre de régions •Li, Crandall and Huttenlocher, “Landmark classification in large-scale image collections”, ICCV’09.
•Yang, Yu and Huang, “Efficient highly over-complete sparse coding using a mixture model”, ECCV’10.
• cout de calcul élevé
•Solution 2: aller plus loin qu’un simple compte, en calculant d’autres statistiques?
•Moyenne des descripteurs
Page 53

Comment représenter plus finement les descripteurs ?
•Solution 1: augmenter le nombre de régions •Li, Crandall and Huttenlocher, “Landmark classification in large-scale image collections”, ICCV’09.
•Yang, Yu and Huang, “Efficient highly over-complete sparse coding using a mixture model”, ECCV’10.
• cout de calcul élevé
•Solution 2: aller plus loin qu’un simple compte, en calculant d’autres statistiques?
•Moyenne des descripteurs
•(co-) variance des descripteurs locaux
Page 54
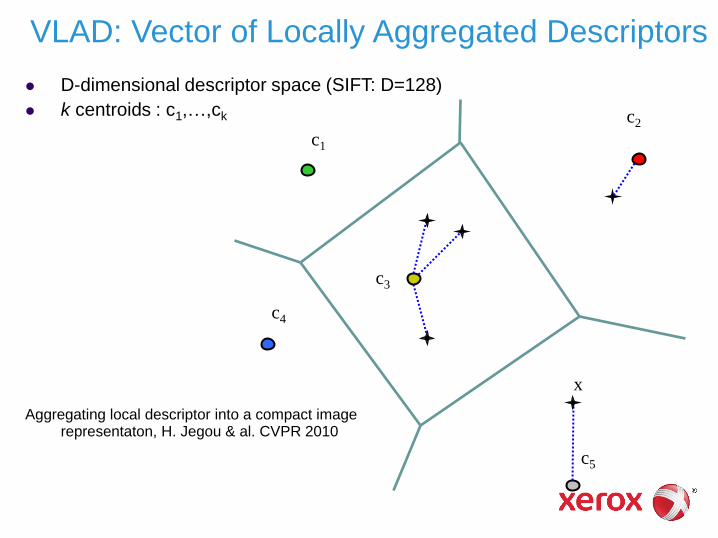
c3
x
c1
c4
c2
c5
D-dimensional descriptor space (SIFT: D=128)
k centroids : c1,…,ck
Aggregating local descriptor into a compact image representaton, H. Jegou & al. CVPR 2010
VLAD: Vector of Locally Aggregated Descriptors

v1 v2 v3 v4
v5
D-dimensional descriptor space (SIFT: D=128)
k centroids : c1,…,ck
Output: v1 ... v
k = descriptor of size k*D
L2-normalized
Typical k = 16 or 64 : descriptor in 2048 or 8192 D
Similarity measure = L2 distance.
VLAD: Vector of Locally Aggregated Descriptors

VLAD: Vector of Locally Aggregated Descriptors
•Offline: learn a codebook {𝜇1, … , 𝜇𝑁}, e.g. with K-means
•Online: given a set of local descriptors X = 𝑥1, … , 𝑥𝑇 :
• assign: 𝑁𝑁 𝑥𝑡 = argmin𝜇𝑖
𝑥𝑡 − 𝜇𝑖
• compute: 𝑣𝑖 = (𝑥𝑡 − 𝜇𝑖)𝑥𝑡:𝑁𝑁 𝑥𝑡 =𝜇𝑖
• concatenate 𝑣𝑖 ’s + ℓ2-normalize
Page 57
Jégou, Douze, Schmid and Pérez, “Aggregating local
descriptors into a compact image representation”,
CVPR’10.
See also: Zhou, Yu, Zhang and Huang, “Image
classification using super-vector coding of local image
descriptors”, ECCV’10.
3
x
v1 v2 v3 v4
v5
1
4
2
5
① assign descriptors
② compute x- i
③ vi=sum x- i for cell i

VLAD: Vector of Locally Aggregated Descriptors
•A graphical representation of 𝑣𝑖 = (𝑥𝑡 − 𝜇𝑖)𝑥𝑡:𝑁𝑁 𝑥𝑡 =𝜇𝑖
•in the case of SIFT descriptors:
Page 58
Jégou, Douze, Schmid and Pérez, “Aggregating local descriptors into a compact image representation”, CVPR’10.

VLAD: Vector of Locally Aggregated Descriptors
•An embedding view of the VLAD:
• 𝜑𝑣𝑙𝑎𝑑 𝑥𝑡 = 0,… , 0, (𝑥𝑡−𝜇𝑖), 0, … , 0
•Questions: • can we add other statistics?
• → special case of a more general class of embeddings: Fisher Vector
Page 59
𝐷 non-zero dim
𝑫𝑵-dim embedding

The Fisher vector Score function
•Given a likelihood function 𝑢𝜆 with parameters , the score function of a given sample 𝑥𝑡 is given by:
𝑔𝜆 (𝑥𝑡) = 𝛻𝜆 log𝑢𝜆(𝑥𝑡)
dimensionality depends on # parameters
•Intuition: direction in which the parameters of the model should be modified to better fit the data

The Fisher vector Fisher information matrix
• Fisher information matrix (FIM) or negative Hessian:
𝐹𝜆 = 𝐸𝑥~𝑢𝜆 𝑔𝜆(𝑥)𝑔𝜆(𝑥)𝑇
• Measure similarity between gradient vectors using the Fisher Kernel (FK):
[Jaakkola and Haussler, “Exploiting generative models in discriminative classifiers”, NIPS’98]
𝐾 𝑥, 𝑧 = 𝑔𝜆(𝑥)𝑇𝐹𝜆
−1𝑔𝜆(𝑧)
can be interpreted as a score whitening

The Fisher vector Fisher information matrix
• Fisher information matrix (FIM) or negative Hessian:
𝐹𝜆 = 𝐸𝑥~𝑢𝜆 𝑔𝜆(𝑥)𝑔𝜆(𝑥)𝑇
• Measure similarity between gradient vectors using the Fisher Kernel (FK):
[Jaakkola and Haussler, “Exploiting generative models in discriminative classifiers”, NIPS’98]
𝐾 𝑥, 𝑧 = 𝑔𝜆(𝑥)𝑇𝐹𝜆
−1𝑔𝜆(𝑧)
can be interpreted as a score whitening
•As the FIM, is PSD, we can write: 𝐹𝜆−1 = 𝐿𝜆
𝑇𝐿𝜆
and the FK can be rewritten as a dot product between Fisher Vectors (FV):
𝜑𝜆𝑓𝑣(𝑥𝑡) = 𝐿𝜆 𝑔(𝑥𝑡)
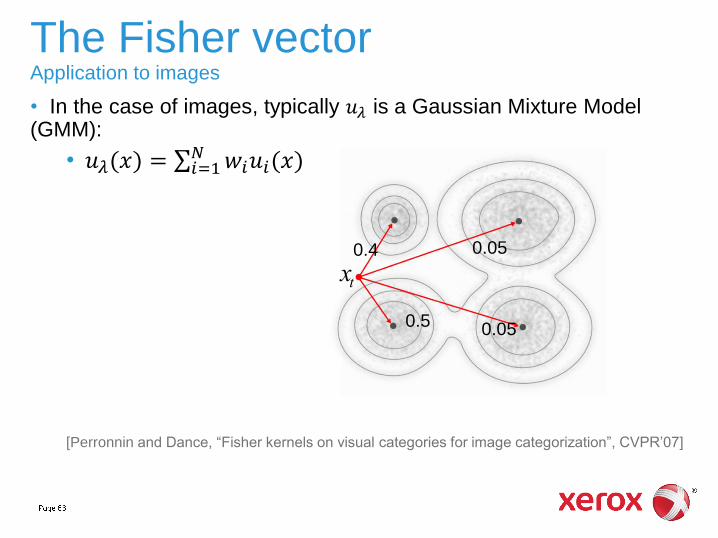
The Fisher vector Application to images
• In the case of images, typically 𝑢𝜆 is a Gaussian Mixture Model (GMM):
• 𝑢𝜆(𝑥) = 𝑤𝑖𝑢𝑖(𝑥)𝑁𝑖=1
[Perronnin and Dance, “Fisher kernels on visual categories for image categorization”, CVPR’07]
0.5
0.4 0.05
0.05

The Fisher vector Application to images
• In the case of images, typically 𝑢𝜆 is a Gaussian Mixture Model (GMM):
• 𝑢𝜆(𝑥) = 𝑤𝑖𝑢𝑖(𝑥)𝑁𝑖=1
• 𝑢𝑖 𝑥 =1
(2𝜋)𝐷/2 Σ𝑖1/2 exp −
1
2(𝑥 − 𝜇𝑖)′Σ𝑖
−1(𝑥 − 𝜇𝑖)
→ visual word
and 𝜆 = 𝑤𝑖 , 𝜇𝑖 , Σ𝑖 , 𝑖 = 1…𝑁
• Typically assume Σ𝑖 = 𝑑𝑖𝑎𝑔(𝜎𝑖2) for computational reasons
→ FV = concatenation of gradients with respect to 𝑤𝑖 , 𝜇𝑖, and 𝜎𝑖
[Perronnin and Dance, “Fisher kernels on visual categories for image categorization”, CVPR’07]

The Fisher vector Formulas
• 𝛾𝑡(𝑖) = soft-assignment of patch 𝑥𝑡 to Gaussian 𝑖
• 𝜑𝑤 𝑥𝑡 =𝛾𝑡(1)
𝑤1, … ,
𝛾𝑡(𝑁)
𝑤𝑁 vs 𝜑𝑏𝑜𝑣 𝑥𝑡 = [0,… , 0, 1, 0, … , 0]
→ extends BOV: soft-assignment + IDF effect
• 𝜑𝜇 𝑥𝑡 = 𝛾𝑡 1
𝜎1 𝑤1𝑥𝑡 − 𝜇1 , … ,
𝛾𝑡 𝑁
𝜎𝑁 𝑤𝑁𝑥𝑡 − 𝜇𝑁 vs
𝜑𝑣𝑙𝑎𝑑 𝑥𝑡 = 0,… , (𝑥𝑡−𝜇𝑖), … , 0
→ extends VLAD: soft-assignment + IDF effect
• 𝜑𝜎 𝑥𝑡 = 𝛾𝑡 1
2𝑤1
𝑥𝑡−𝜇12
𝜎12 − 1 ,… ,
𝛾𝑡 𝑁
2𝑤𝑁
𝑥𝑡−𝜇𝑁2
𝜎𝑁2 − 1 adds 2nd-order stats
→ makes a difference when learning is involved (see next week)
→ in practice consider only the gradients 𝜑𝜇 and 𝜑𝜎 This builds a 𝟐𝑫𝑵-dim embedding
0.5
0.4 0.05
0.05

Linear classification of BOV, VLAD and FV
• 𝜑𝑏𝑜𝑣 𝑥 = [0, … , 0, 1, 0, … , 0]
• A linear classifier 𝑤𝑇𝜑𝑏𝑜𝑣(𝑥) induces in the original space?
1 2 i … i+1
…
Linear classification of BOV, VLAD and FV
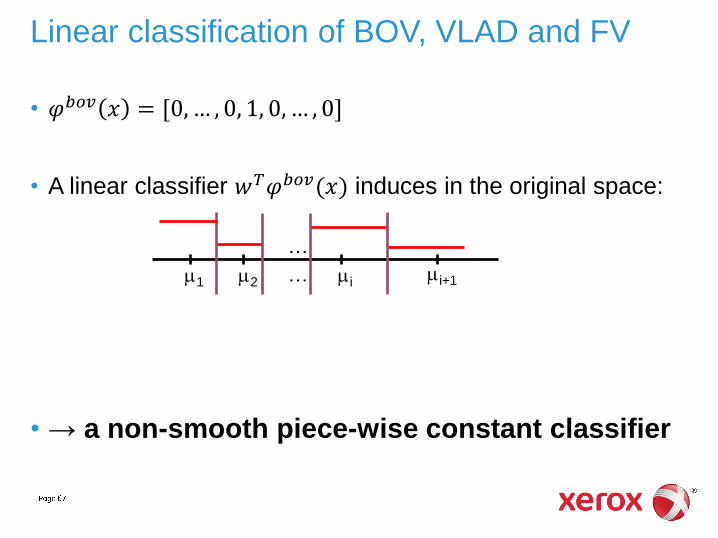
• 𝜑𝑏𝑜𝑣 𝑥 = [0, … , 0, 1, 0, … , 0]
• A linear classifier 𝑤𝑇𝜑𝑏𝑜𝑣(𝑥) induces in the original space:
• → a non-smooth piece-wise constant classifier
1 2 i … i+1
…

Linear classification of BOV, VLAD and FV
• 𝜑𝑣𝑙𝑎𝑑 𝑥 = 0,… , (𝑥 − 𝜇𝑖), … , 0
• A linear classifier 𝑤𝑇𝜑𝑣𝑙𝑎𝑑(𝑥) induces in the original space?
1 2 i … i+1
…
Linear classification of BOV, VLAD and FV
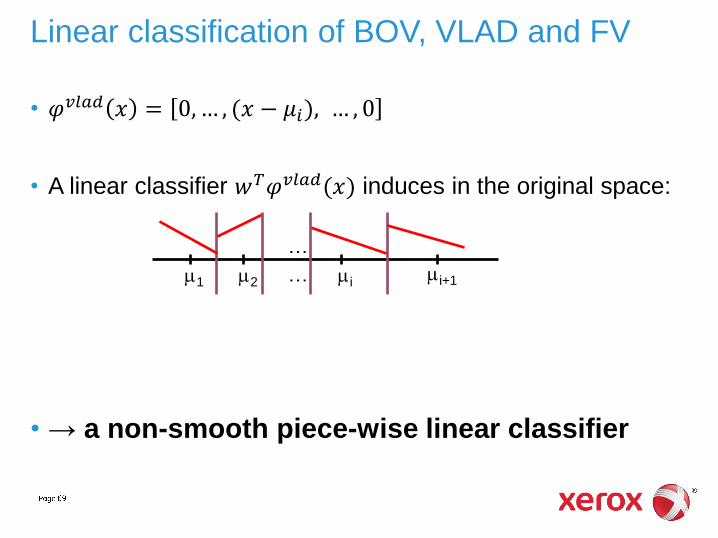
• 𝜑𝑣𝑙𝑎𝑑 𝑥 = 0,… , (𝑥 − 𝜇𝑖), … , 0
• A linear classifier 𝑤𝑇𝜑𝑣𝑙𝑎𝑑(𝑥) induces in the original space:
• → a non-smooth piece-wise linear classifier
1 2 i … i+1
…
Linear classification of BOV, VLAD and FV
• 𝜑𝑓𝑣 𝑥𝑡 = … ,𝛾𝑡 𝑖
𝜎𝑖 𝑤𝑖𝑥𝑡 − 𝜇𝑖 ,
𝛾𝑡 𝑖
2𝑤𝑖
𝑥𝑡−𝜇𝑖2
𝜎𝑖2 − 1 ,…
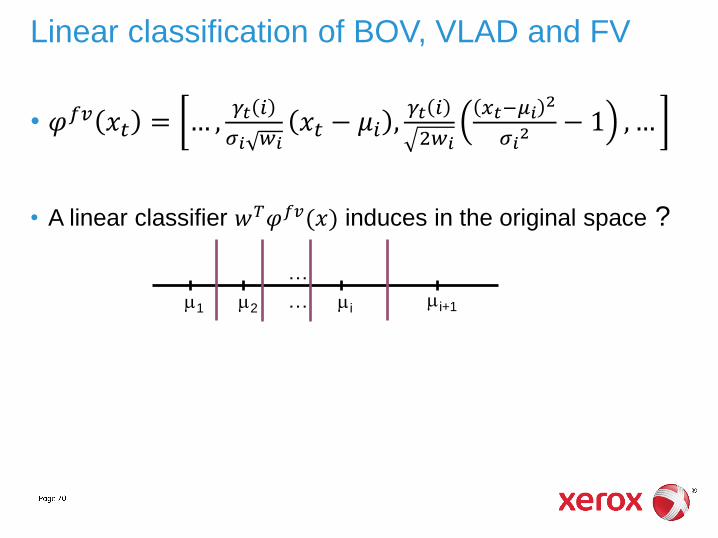
• A linear classifier 𝑤𝑇𝜑𝑓𝑣(𝑥) induces in the original space ?
1 2 i … i+1
…
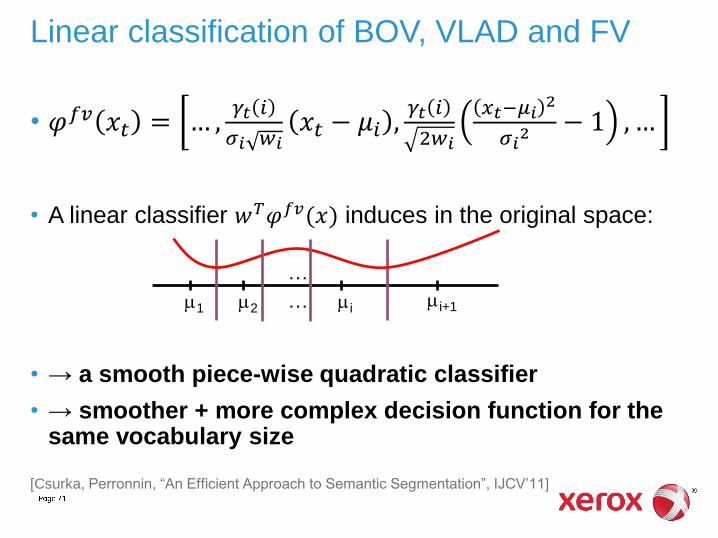
Linear classification of BOV, VLAD and FV
• 𝜑𝑓𝑣 𝑥𝑡 = … ,𝛾𝑡 𝑖
𝜎𝑖 𝑤𝑖𝑥𝑡 − 𝜇𝑖 ,
𝛾𝑡 𝑖
2𝑤𝑖
𝑥𝑡−𝜇𝑖2
𝜎𝑖2 − 1 ,…
• A linear classifier 𝑤𝑇𝜑𝑓𝑣(𝑥) induces in the original space:
• → a smooth piece-wise quadratic classifier
• → smoother + more complex decision function for the same vocabulary size
[Csurka, Perronnin, “An Efficient Approach to Semantic Segmentation”, IJCV’11]
1 2 i … i+1
…

The Fisher vector Practical considerations
• PCA on the local descriptors is necessary: • because of the GMM diagonal approximation
• ℓ2-normalization: • to make the FV more compliant with
the dot-product assumption
• Power-normalization: 𝑧 → 𝑠𝑖𝑔𝑛 𝑧 𝑧 𝛼 with 0 ≤ 𝛼 ≤1 • to correct the patch independence assumption
[Cinbis, Verbeek, Schmid, “Image categorization using Fisher kernels of non-iid image models”, CVPR’12.]
→ when 𝛼 = 1/2, referred-to as signed square-rooting
Page 72
For a detailed analysis see: Sánchez, Perronnin, Mensink, Verbeek,
“Image Classification with the Fisher Vector: Theory and Practice”, IJCV’13.
Results on PASCAL VOC’07:

The Fisher vector Summary
0.5
0.4 0.05
0.05 • Offline: learn a GMM with parameters 𝜆 = 𝑤𝑖 , 𝜇𝑖 , Σ𝑖 , 𝑖 = 1…𝑁
• Online: given a set of (PCA-transformed) descriptors X = 𝑥1, … , 𝑥𝑇
• for each 𝑥𝑡:
• soft-assign to each Gaussian: 𝛾𝑡 𝑖 =𝑤𝑖𝑢𝑖 𝑥𝑡
𝑤𝑘𝑢𝑘 𝑥𝑡𝑁𝑘=1
• accumulate 𝜑𝜇 += … ,𝛾𝑡 𝑖
𝜎𝑖 𝑤𝑖𝑥𝑡 − 𝜇𝑖 , …
and 𝜑𝜎 += … ,𝛾𝑡 𝑖
2𝑤𝑖
𝑥𝑡−𝜇𝑖2
𝜎𝑖2 − 1 ,…
• power- + ℓ2-normalize
•See also:
• INRIA package: http://lear.inrialpes.fr/src/inria_fisher/
• Oxford package: http://www.robots.ox.ac.uk/~vgg/software/enceval_toolkit/

FGComp’13: https://sites.google.com/site/fgcomp2013
Algorithme proposé par une collaboration INRIA – Xerox
• Embedding des descripteurs avec Fisher Vector
Exemples d’application La reconnaissance à grains fins
Page 74
aircraft (100) birds (83) cars (196) dogs (120) shoes (70)
#1 rank

Exemples d’application Détection d’objet
Page 75
• ImageNet’13 detection: http://www.image-net.org/challenges/LSVRC/2013/
Algorithme proposé par l’université d’Amsterdam (UVA) :
• Extraction de régions candidates avec selective search
• Embedding des descripteurs avec Fisher Vector
• Fast Local Area Independent Representation (FLAIR)
[Van de Sande, Snoek, Smeulders, “Fisher and VLAD with FLAIR”, CVPR’14]
#1 rank

Exemples d’application Reconnaissance d’actions à grains fins
• THUMOS’13 = reconnaissance d’action: http://crcv.ucf.edu/ICCV13-Action-Workshop/results.html
Algorithme proposé par l’INRIA:
• Trajectoires denses améliorées
• Extraction de plusieurs descripteurs
• Embedding avec un Fisher Vector
[Wang, Schmid, “Action Recognition with Improved Trajectories”, ICCV’13]
Page 76
Soomro, Roshan Zamir, Shah, “UCF101: A dataset of101 human actions classes from videos in the wild”, CRCV-TR-
12-01, 2012.
#1 rank

Pyramide spatiale: préserver la géométrie
Problème: les représentations par « bag-of-patches » ne gardent aucune information sur la géométrie
Solution: calculer des agrégats de descripteurs sur des sous-images
► géométrie rigide
► taille des vecteurs multipliée
Beyond Bags of Features: Spatial Pyramid Matching for Recognizing Natural Scene Categories, S. Lazebnik, C.
Schmid, J. Ponce, CVPR06

Exercice
Calculer la représentation Bag-of-Words
Calculer la représentation VLAD
C1 = (1,1), C2 = (5,2), C3 = (1,4)
X1 = (3,0), X2 = (2,2), x3=(3,4), x4 = (0,4), x5 = (0,1)

Descripteurs denses
Agrégation de descripteurs
► taille du descripteur global indépendant du nombre de descripteurs locaux
► performance croissante avec le nombre de descripteurs
[Sampling strategies for bag-of-features image classification”, Nowak, Jurie, Triggs, ECCV06 ]
détecteur aléatoire marche bien
dense = on se passe de détecteur
important: récupérer une information statistique sur l'image
► ~ texture
[“Dense interest points” T.Tuytelaars, CVPR 2010]

Conclusion Descripteurs globaux
► Souvent version agrégée de descripteurs locaux
► Statistique sur les textures (surtout avec des descripteurs denses)
► Pyramide spatiale multi-échelle = la disposition globale des images apparaît aussi
taille du descripteur = aussi grand que l’on veut / peut (1000 – 1M dimensions) ► Sac-de-mots: représentation éparse
► Fisher / VLAD: représentation dense

81
Comprendre
les données
visuelles à
grande
échelle
La représentation
sac-de-mot
appliquée à la
recherche d’image

LA référence : Josef Sivic and Andrew Zisserman « Video Google: A Text Retrieval Approach to Object Matching in Videos » International Conference on Computer Vision, 2003 (ICCV03) ► peu de vidéo, peu de Google...
► recherche d'une zone sur une image
Idée : calquer le fonctionnement d’un moteur de recherche d’images sur celui d’un moteur de recherche de texte/page web
Video-Google

Description locale : détecteurs + descripteurs
Filtrage spatial et temporel
Bag-of-words
Fichier inversé pour la requête
Re-ranking après vérification de la cohérence spatiale
Étapes

Extracteurs
► MSER
► Hessian-Affine: point d’intérêt + sélection d’échelle + forme elliptique
Descripteurs SIFT (scale-invariant feature transform) [Lowe 04]
Video-Google : description locale

Extracteurs
►
Video-Google : description locale

L’objectif est d’obtenir l’équivalent des “mots” en requête textuelle
Pour cela, quantification vectorielle des descripteurs via un k-means (rappel) ► index de quantification = “mot visuel”
► représentation grossière du vecteur de description locale
► pas d'information géométrique
Video-Google : bag-of-words (début)

Video-Google : bag-of-words (suite)
Exercice : où sont
- MSER
- Harris
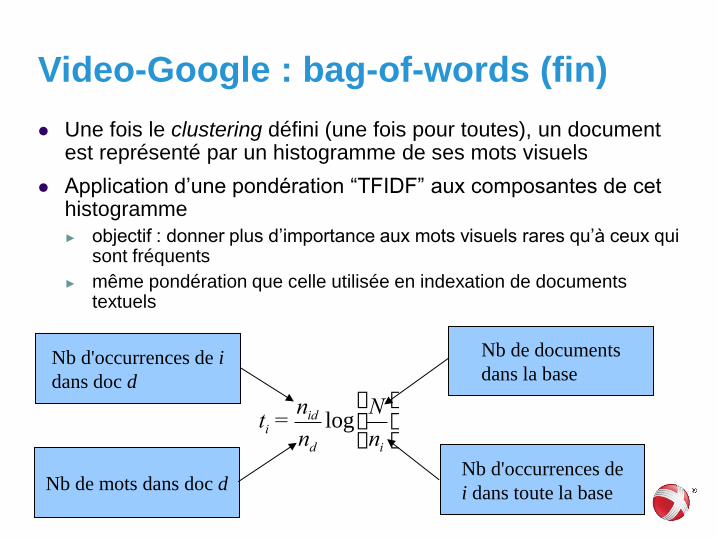
Une fois le clustering défini (une fois pour toutes), un document est représenté par un histogramme de ses mots visuels
Application d’une pondération “TFIDF” aux composantes de cet histogramme
► objectif : donner plus d’importance aux mots visuels rares qu’à ceux qui sont fréquents
► même pondération que celle utilisée en indexation de documents textuels
Video-Google : bag-of-words (fin)
ti =nid
ndlog
N
ni
æ
èç
ö
ø÷
Nb d'occurrences de i
dans doc d
Nb de mots dans doc d
Nb de documents
dans la base
Nb d'occurrences de
i dans toute la base

Utilisé pour comparer les vecteurs de fréquence épars
Mesure de similarité usuellement utilisée : produit scalaire
Analogie avec le texte
► description d’un document
► pondération des mots
Video-Google : fichier inversé

Bag of words ► Principe de base pour l'indexation dans des bases de
taille moyenne (< 10 M d'images)
► Transforme des descripteurs locaux en représentation globale
Nombreuses améliorations possibles ► Meilleurs descripteurs
► Finesse de la représentation
► Géométrie
► Etc.
Conclusion

© 2015 Xerox Corporation. All rights reserved. Xerox®, Xerox and Design® and “Work Can Work Better” are trademarks of Xerox Corporation in
the United States and/or other countries.










![Analyse de la covariance ANCOVA. Exemple Modèle général linéaire de lANCOVA [valeur observée] = grande moyenne + [effet du traitement] + [effet de la](https://img.pdfslide.fr/doc/110x75/551d9db5497959293b8da65e/analyse-de-la-covariance-ancova-exemple-modele-general-lineaire-de-lancova-valeur-observee-grande-moyenne-effet-du-traitement-effet-de-la.jpg)