Embed Size (px)
Citation preview

1 / 38
De l'Interprétation des Données
à la Modélisation Probabiliste,
grâce au Bayésien
Jean-Baptiste Denis (INRA, MIAj, Jouy-en-Josas)
Bucoliques, les Mathématiques ?
Inra-Jouy - 2014_09_19
Il y a eu deux grandes phases de recherche dans ma carrière et la seconde m'a obligé à recourir au Bayésien. Je voudrais donner ici quelques motifs pour que d'autres empruntent ce changement de perspective que représente la statistique B par rapport à la statistique classique.
Mes objectifs :
● Rester au niveau des idées simples,● Tenter une présentation intuitive,● Susciter l'envie de passer bayésien.
Ceci impose
● D'être un peu caricatural,● De solliciter la confiance,● De se baser sur quelques sous-entendus.
2 / 38
PLAN
(1) MotivationsMotivations pour une démarche statistique
(2) Démarche en Statistique Classique
(3) Démarche en Statistique Bayésienne
(4) Comparaison des deux démarches
L'exposé se fera en quatre parties très inégales : deux premières rapides, ce seront des rappels et deux plus développées consacrées au B.
Leurs intitulés insistent sur le parti pris de mise en évidence de la démarche suvie. Un minimum de formules, un exemple ultra-simple, des idées faciles le plus souvent proposées graphiquement.

3 / 38
Données
i g Poids 1 A 71 2 A 80 3 A 85 .. . ... 19 B 77 20 B 126 21 B 92 .. . ... 49 C 82 50 C 83 51 C 76 .. . ... 98 C 89
Motivations
C'est l'origine du mot statistique, l'interprétation de données est le premier maillon de la démarche statistique. Pour concrétiser l'exposition, nous nous servirons de la série de 112 mesures de poids de poissons appartenant à trois genres différents. Nos données se présentent donc comme un tableau de trois colonnes (numéro de l'individu, le genre et la masse en gramme).
Il faut toujours représenter de manière exploratoire ses données. Ici les trois histogrammes (aux mêmes échelles) par genre nous donnent une vision synthétique. Les poids se répartissent sur l'intervalle 60 – 120 grammes.
Sans doute d'autres informations seraient très précieuses pour comprendre les variations observées comme :
● L'âge, le sexe et la provenance des différents individus,● La qualité de la balance utilisée,● L'adresse de l'opérateur (voire des opérateurs),● …
4 / 38
Question(s)
Hypothèses d'égalité :
Les poids moyens des trois espèces sont-ils identiques ?
Détermination de valeurs :
Quels sont les poids moyens de chaque espèce ?
Motivations
Mais on ne fait pas de la statistique seulement avec des données, il faut aussi ajouter une (ou des) question(s) à laquelle on veut répondre.
Voici deux questions naturelles associées à notre jeu de données.
Les deux font appel à la notion de 'poids moyen', il faudrait sans doute commencer par la définir. Nous verrons une proposition dans le transparent qui suit. Admettons qu'il s'agisse de la valeur la plus vraisemblable à laquelle on s'attend en observant un poisson choisi 'au hasard'... le hasard demandant lui aussi d'être précisé.
Le néophyte pourrait s'étonner de la proximité des deux questions : si on sait répondre à la seconde, on doit pouvoir répondre à la première... En fait, celle-ci est mal formulée, il aurait mieux valu demander Avec les données observées, est-il vraisemblable de considérer que les trois genres ont mêmes poids moyens ? Mais c'est la formulation classique car plus facile à formaliser.
C'est justement le rôle des modèles paramétriques probabilistes que de formaliser ces questions.
5 / 38
M-P Données
(Notions de Paramètres)
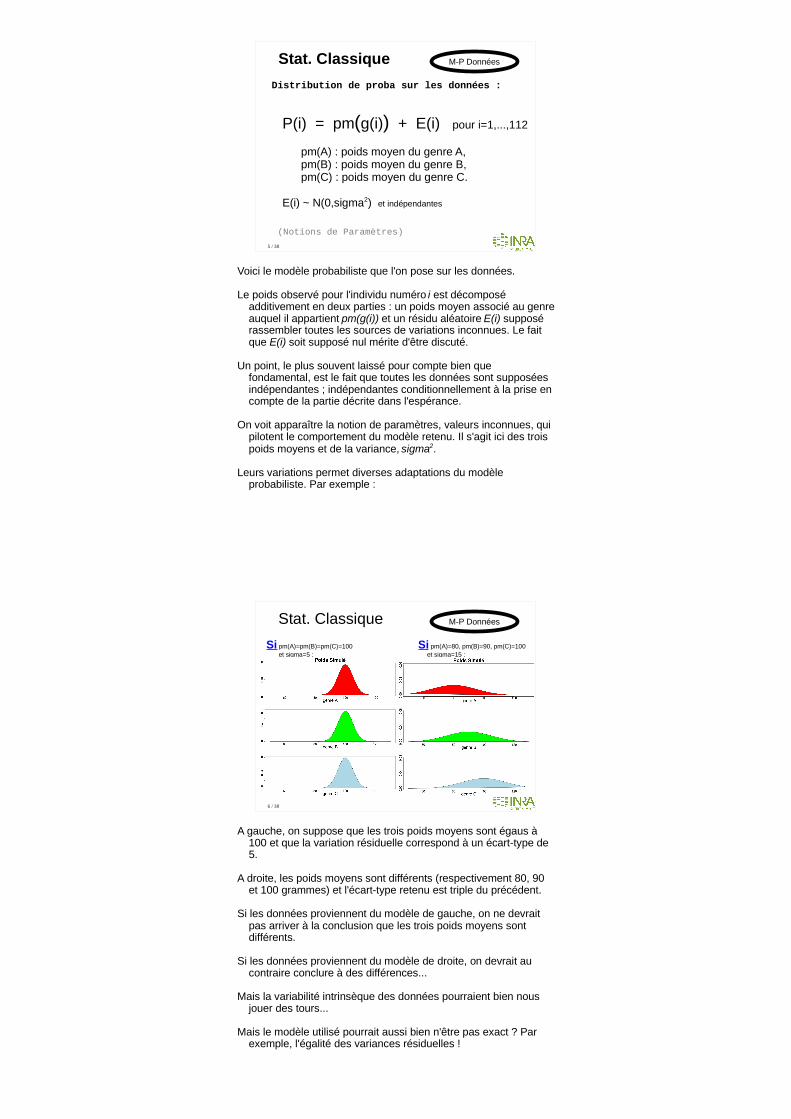
P(i) = pm(g(i)) + E(i) pour i=1,...,112
pm(A) : poids moyen du genre A, pm(B) : poids moyen du genre B, pm(C) : poids moyen du genre C.
E(i) ~ N(0,sigma2) et indépendantes
Stat. Classique
Distribution de proba sur les données :
Voici le modèle probabiliste que l'on pose sur les données.
Le poids observé pour l'individu numéro i est décomposé additivement en deux parties : un poids moyen associé au genre auquel il appartient pm(g(i)) et un résidu aléatoire E(i) supposé rassembler toutes les sources de variations inconnues. Le fait que E(i) soit supposé nul mérite d'être discuté.
Un point, le plus souvent laissé pour compte bien que fondamental, est le fait que toutes les données sont supposées indépendantes ; indépendantes conditionnellement à la prise en compte de la partie décrite dans l'espérance.
On voit apparaître la notion de paramètres, valeurs inconnues, qui pilotent le comportement du modèle retenu. Il s'agit ici des trois poids moyens et de la variance, sigma2.
Leurs variations permet diverses adaptations du modèle probabiliste. Par exemple :
6 / 38
M-P Données
Si pm(A)=pm(B)=pm(C)=100 et sigma=5 :
Si pm(A)=80, pm(B)=90, pm(C)=100 et sigma=15 :
Stat. Classique
A gauche, on suppose que les trois poids moyens sont égaus à 100 et que la variation résiduelle correspond à un écart-type de 5.
A droite, les poids moyens sont différents (respectivement 80, 90 et 100 grammes) et l'écart-type retenu est triple du précédent.
Si les données proviennent du modèle de gauche, on ne devrait pas arriver à la conclusion que les trois poids moyens sont différents.
Si les données proviennent du modèle de droite, on devrait au contraire conclure à des différences...
Mais la variabilité intrinsèque des données pourraient bien nous jouer des tours...
Mais le modèle utilisé pourrait aussi bien n'être pas exact ? Par exemple, l'égalité des variances résiduelles !

7 / 38
Estimation,
Test d'Hypothèse
Hypothèse à tester :
pm(A) = pm(B) = pm(C) = pm(A)
Estimation à mener :
pm(A) ?pm(B) ?pm(C) ?
(Utilisation des Paramètres)
Stat. Classique
?
?
? ?
Dans le cadre du modèle paramétrique retenu, nous pouvons formaliser mathématiquement les deux questions que nous nous posions :
Les trois (ou deux des trois?) égalités des couples possible de poids moyens sont-elles vraies ?
Quelles sont les valeurs numériques à attribuer aux trois poids moyens ?
Remarque : Il vaut mieux en effet considérer les trois comparaisons tour à tour car il serait possible qu'on soit capable de détecter une différence significativité entre les poids moyens extrêmes et pas entre le poids moyen intermédiaire et chacun des deux extrêmes.
8 / 38
Estimation,
Test d'HypothèseStat. Classique
Voici la réponse standard de la statistique C ; une estimation accompagnée d'un intervalle de confiance.
Les estimations valent respectivement : 75.9, 82.5 et 85.2.
Il est bien clair que les seules estimations ne suffisent pas, il faut y associer l'ordre de grandeur de leur précision. C'est la fonction des intervalles de confiance.
Si on se base sur les recoupements, on conclut qu'il n'est pas possible de distinguer A de B, ni B de C ; par contre A et C sont déclarés différents. On note la non transitivité des conclusions, conséquence de leur caractère incertain.
Remarque : l'intervalle de confiance se définit en fonction d'un risque de première espèce (probabilité de déclarer différentes des estimations égales), ici pris classiquement à 5 %. La balance entre les deux risques n'est pas aisé car l'hypothèse alternative est composite.

9 / 38
M-P Paramètres
(quasi spécifique au Bayésien)
Distribution de proba sur les paramètres :
pm(g) ~ N( 100, 302) pour g=1,2,3
Sigma ~ U( 2, 100) (et indépendances)
Stat. Bayésienne
La démarche B reprend la démarche C en lui rajoutant une couche. Les paramètres du modèle probabiliste des données ne sont plus considérés comme des valeurs fixes inconnues mais comme des variables aléatoires auxquelles on associe donc une distribution.
Supposons pour notre exemple qui comporte quatre paramètres les distributions ci-dessus.
Remarque : comme on le verra plus tard, ce qu'il faut c'est la distribution jointe des paramètres, ici assurée par les marginales et la supposition d'indépendance. Cette supposition mérite d'être discutée.
10 / 38
M-P Paramètres
(quasi spécifique au Bayésien)
Distribution de proba sur les paramètres :
pm(g) ~ N( 100, 302) pour g=1,2,3
Sigma ~ U( 2, 100) (et indépendances)
Valeur centrale de notre idée initiale
Degré de confiance de notre valeur centrale
Plage envisageable pour la variabilité du poids
Stat. Bayésienne
Lorsqu'on est capable de donner une interprétation aux paramètres, l'établissement d'une telle distribution (qui sera qualifiée de distribution a priori ou priore) n'est pas trop difficile.
On donne en quelque sorte notre idée avant l'utilisation des données de ce que peuvent valoir les paramètres (a priori donc). Ici, on ne pose pas de distinction entre les poids moyens (pm) des trois genres qui sont tous dotés de la même distribution autour d'une valeur centrale de 100, avec un écart-type de 30 ; la normalité n'est pas forcément un détail mais elle peut simplement vouloir dire qu'on pense que les valeurs proches de 100 sont plus beacoup plus probables que des valeurs qui en sont éloignées.
Une autre possibilité, employée ici pour le paramètre Sigma consiste à préciser une plage de variation mais à donner à toute valeur une importance équivalente au travers d'une distribution uniforme. Bien entendu, le paramètre Sigma est aussi facile à interpréter : il caractérise l'ordre de grandeur de la variabilité des poids autour du poids moyen et l'incertitude liée à leurs observations.

11 / 38
Stat. Bayésienne
[Données]
M-P Paramètres
Cette distribution a priori sur les paramètres peut et doit être transportée au travers du modèle de probabilité sur les données aux données elles-mêmes.
En voici le résultat. Très logiquement, chaque genre est doté de la même distribution, et on se rend compte en comparant l'étendue qui lui est donnée [-50, 250] que l'a priori proposé n'est pas très informatif !
Remarque : lorsque l'interprétation des paramètres du modèle n'est pas évidente, c'est une bonne technique pour valider une distribution a priori que de la reporter sur des données fictives, en général beaucoup plus tangibles pour un expert du domaine.
12 / 38
M-P Paramètres
Avoir un distribution de proba sur les paramètres donne aux
distributions associées aux données un statut de distributions
conditionnelles :
P(i) | pm,sigma ~ N( pm(g(i)), sigma2)
Stat. Bayésienne
On a alors accès (théorème de Bayes) à
- la distribution conjointe :
[Données,Paramètres] = [Données | paramètres].[Paramètres]
- la distribution conditionnelle inversée :
[Paramètres | Données]
Avoir un distribution de proba sur les paramètres donne aux
distributions associées aux données un statut de distributions
conditionnelles :
D'un point de vue modélisation, les deux modèles probabilistes (sur les paramètres et sur les données) s'articulent parfaitement.
Le modèle probabiliste des données est une distribution conditionnelle par rapport aux paramètres.
Le modèle probabiliste des paramètres est une distribution marginale (qui ne tient pas compte de ce que l'on peut savoir sur les données).
Grâce au théorème de Bayes (des probabilités conditionnelles), une simple multiplication fournit la densité conjointe des paramètres et des données.
Comme nous connaissons les valeurs qu'ont prises les données, il est logique de calculer la distribution des paramètres conditionnelle aux données. Une seconde application du théorème de Bayes nous la procure.
Remarque : on comprend ici la dénomination de statistique bayésienne.

13 / 38
M-P ParamètresStat. Bayésienne
[Paramètres | Données]
Et si on tient compte des données :
Et voici ce que cela donne.
Cette fois-ci, la distribution a posteriori (ou postériore) est bien différente d'un genre à l'autre ! Aussi bien en valeur centrale qu'en dispersion.
14 / 38
M-P Paramètres
Et si on tient compte des données :
Stat. Bayésienne
Et si on la compare à la priore. La différence est criante : les données ont procuré beaucoup d'information.
Attention, les abcisses de gauche et de droite ne sont pas à la même échelle, loin s'en faut ! Les deux segments épais bleus sont en fait égaux.
C'est une pratique capitale que d'opérer des comparaisons entre priore et postériore. Cela donne une idée de l'importance respective de l'information priore et des données ; cela peut permettre de repérer des supports de distribution trop restreints lorsque les postériores s'épaulent aux bornes.

15 / 38
M-P ParamètresStat. Bayésienne
(A-B) + (B-C) + (C-A) = 0
Pour détailler les interprétations ouvertes par la distribution postériore de l'ensemble des paramètres, retenons une représentation graphique qui conserve une parfaite symétrie entre les trois genres.
Les questions posées tournent autour des trois comparaisons qu'expriment les trois différences :
● A-B● B-C● C-A
Mais celles-ci sont liées puisqu'en connaître deux c'est connaître la troisième grâce à l'équation ci-dessus. Si on porte trois axes associés à ces dimensions disposés à 120°, les coordonnées trouvées pour tout point du plan par projection orthogonale sont les trois différences entre les poids moyens.
Du point de vue C, nous cherchons à savoir où se trouve le point associé au vecteur inconnu des poids moyens.
Du point de vue B, nous cherchons à déterminer la distribution de probabilité dans ce plan du vecteur aléatoire des poids moyens.
16 / 38
M-P ParamètresStat. Bayésienne
B < A
Nous pouvons découper le plan en différentes zones d'intérêt.
Par exemple si nous voulons comparer A et B, le demi-plan supérieur à la droite horizontale rouge correspond à tous les points tels que le poids moyen du genre A est plus grand que le poids moyen du genre B.

17 / 38
M-P ParamètresStat. Bayésienne
Et si nous faisons cela simultanément pour les trois couples, nous obtenons six secteurs, chacun associés aux six ordres possibles des trois poids moyens.
18 / 38
M-P ParamètresStat. Bayésienne
|A-B| < d & |B-C| < d & |C-A| < d
Mais bien entendu, nous pouvons nous intéresser à n'importe quel région définie par des inégalités définies sur les différences entre poids moyens de tous couples de genre.
A titre d'exemple, si nous ne voulons pas que la valeur absolues de ces difféences excède un seuil donné d, cela revient considérer l'intérieur du petit triangle rouge dont les trois côtés sont perpendiculaires aux trois axes.

19 / 38
M-P ParamètresStat. Bayésienne
(90%)
(1%)
(9%)
Le calcul analytique des distributions postériores est dans la grande majorité des cas impossibles. C'est ce qui a limité le développement pratique de la statistique B.
Mais depuis une vingtaine d'année, ce calcul est devenu progressivement possible numériquement. Plus précisément, on sait réaliser des simulations dans la distribution postériore, qui permettent d'approcher (en théorie aussi bien qu'on le désire si le nombre de tirage n'est pas limité) toute propriété de la distribution.
Dans le cadre de notre exemple, voici 2500 tirages placés dans le plan précédemment défini.
On observe, et c'est cohérent avec les distributions marginales déjà examinées que l'ordre le plus représenté est A < B < C . Mais qu'il existe quand même un certain nombre de points dans d'autres secteurs. De fait pour le million de tirages réellement effectués, des représentants se trouvent pour tous les secteurs.
Un simple dénombrement nous permet d'apprécier la probabilité de chacun des ordres.
20 / 38
M-P Paramètres
Une réponse cohérente et complète :
a priori a posteriori
A < B < C : 0.1667 0.8960
A < C < B : 0.1667 0.0951
B < A < C : 0.1667 0.0088
B < C < A : 0.1667 0.00010
C < A < B : 0.1667 0.00005
C < B < A : 0.1667 0.00002
Stat. Bayésienne
Voici les six ordres, ordonnés par probabilité postériore décroissante. Il y a une certaine logique à cet ordre :
● A est vraiment le plus bas,● lorsque le rang de A est imposé, c'est toujours C qui est plus
haut que B.● Inversement, que C soit le plus bas est le plus improbable,● si le rang de C est imposé, alors B est toujours le plus haut.
Quelle nuance par rapport à un test d'hypothèse qui ne donne comme réponse que « significatif » ou « pas significatif » !
Quelle cohérence par rapport aux diverses propositions de comparaisons multiples ! Ceux qui connaissent les théories statistiques développées à ce propos comprennent !

21 / 38
M-P Paramètres
Une réponse cohérente et complète :
a priori a posteriori
A < B < C : 0.1667 0.8960
A < C < B : 0.1667 0.0951
B < A < C : 0.1667 0.0088
B < C < A : 0.1667 0.00010
C < A < B : 0.1667 0.00005
C < B < A : 0.1667 0.00002
Stat. Bayésienne
→
→→
P(B<C) = 0.905
Bien sûr, on peut très bien simplifier les résultats en s'intéressant à des événements plus simples. La théorie des probabilités nous garantit une complète cohérence.
Par exemple, on peut déduire la probabilité de B < C, simplement en sommant les probabilités de tous les ordres qui sont compatibles avec cette inégalité.
22 / 38
Comparaison : recueil de données
● Planification expérimentale ?● Protocole d'échantillonnage ?● Récoltes successives ?
i g Poids 1 A 68 2 A 83 3 A 91 .. . ... .. . ...
(au passage)
Données Question(s)M-P Paramètres
Données Question(s) C
B
Après avoir décrit les deux approches, abordons maintenant leur comparaison.
En fait, ce transparent n'est pas dans le fil de cet exposé, mais il ne faut jamais manquer une occasion de rappeler que la statistique n'est pas seulement utile pour analyser des données mais d'abord pour aider à leur obtention optimale.
Analyser un tableau de données aussi simple que celui que nous avons considéré jusqu'à présent ne peut correctement se faire que si on connaît (et prend en compte) la manière dont les données ont été collectée : résultats de mesures sur des individus élevés dans des conditions similaire, ou sur des individus qu'on a pêché au hasard de diverses campagnes dans des régions différentes ?
Si on veut comparer C & B, on pourrait dire que c'est avant le recueil des données que la distribution priore doit être élaborée et qu'elle doit contribuer à la définition du protocole qu'on va utiliser, prenant en compte les contraintes financières, techniques, humaines, temporelles...

23 / 38
Données Question(s)
M-P Données
Comparaison : classique (modélisation)
Une fois que les données sont disponibles, la première étape en statistique classique consiste définir le modèle probabiliste qu'on va leur associer. Ceci se fait en fonction
● de la manière dont elles ont été obtenues,● des idées que peut avoir l'expert sur le phénomène naturel
auquel elles sont reliées,● et de la question à laquelle on veut apporter une réponse. (le
modèle doit comporter plusieurs alternatives des réponses possibles ; les données doivent être assez informatives pour avoir une chance de les distinguer [identifiabilité]).
24 / 38
Comparaison : bayésien-1 (modélisation)
Données Question(s)
M-P DonnéesM-P Paramètresa priori
Une première interprétation de la démarche B est d'ajouter l'existence de la priore au schéma classique.
La définition du modèle probabiliste sur les données a entraîné la définition de paramètres : pour l'ensemble d'entre eux, on ajouter une distribution probabiliste, définissant ce que nous avons appelé modèle probabiliste sur les paramètres. Ce serait donc juste une information supplémentaire apportée à la démarche classique.

25 / 38
Données Question(s)
M-P Données
Estimation,
Test d'Hypothèse
Comparaison : classique (interprétation)
L'étape finale de la démarche classique, c'est la production de la réponse qui dépend des trois premiers éléments : modèle probabiliste sur les données, questions et données elles-mêmes.
La réponse la plus classique est celle que nous avons vue, estimations et intervalles de confiance associés.
26 / 38
Comparaison : bayésien-1 (interprétation)
M-P Paramètresa posteriori
Données Question(s)
M-P DonnéesM-P Paramètresa priori
Réponse
Probabiliste
Dans la première interprétation du B, c'est quasiment le même schéma qui s'applique :
A partir des éléments précédemment introduits, les mêmes plus la priore, on élabore la réponse.
En fait la réponse se décompose en deux éléments :
● La construction de la postériore qui ne dépend pas de la question mais seulement de la priore, des données et de leur modélisation probabiliste,
● La réponse probabiliste à la question qui en fait ne reprend que la seule postériore, sans recourir directement aux données.

27 / 38
Comparaison : bayésien
Priore accessoire ? oui si beaucoup de données pertinentes !
GEI : beaucoup de données, des questions simples sur une variable.
AQR : des connaissances d'expert plutôt que des données et des questions complexes mettant en jeu des variables très diverses.
La priore prend alors le pas !
GEI : Genotype – Environnment Interactions
QRA : Quantitative Risk Assessment
En fait cette première comparaison tend à instrumentaliser le rôle de la priore, un simple accessoire ajouté à la démarche C.
C'est souvent légitime, mais pas toujours !
J'ai expérimenté cette différence lorsque je suis passé de l'interprétation des interactions génotypes-milieux à la modélisation des risques microbiologiques liés à l'alimentation.
GEI : beaucoup de données, des questions simples sur une variable.
QRA : des connaissances d'expert plutôt que des données et des questions complexes mettant en jeu des variables très diverses.
La priore prend alors le pas !
28 / 38
Comparaison : bayésien-2
QUESTION
M-P DONNÉES
PRIORE
Lorsque les données sont peu nombreuses, quasi inexistantes, la démarche ne peut reposer que sur les connaissance a priori qu'on peut réunir.
Et l'élaboration de la priore passe du statut d'exercice obligé à celui de pierre angulaire sur laquelle repose toute la construction. Elle peut se transformer en outil unique de formalisation quantitatif des connaissances disponibles. Elle peut devenir le générateur de simulateurs numériques de diverses situations – exercice idéal pour l'affiner et la mettre au point.
C'est bien entendu à partir d'elle que la modélisation probabiliste des données sera élaborée comme il est schématisé ci-dessus.

29 / 38
Comparaison : bayésien-2
QUESTIONPRIORE
POSTÉRIORE
DONNÉES
L'utilisation des données intervient pour la transformation de la priore en postériore ; l'axe central de la démarche devient ce passage effectué grâce à la disponibilité des données.
Dans ce schéma, le passage de l'ellipse « Modèle-Données » au rectangle « Données » n'est pas anodin. Il signifie que la distribution postériore ne tient pas son caractère aléatoire des données mais de la priore.
En effet, la postériore, c'est la priore conditionnée par l'observation des données. C'est un aléa très différent de celui qui est utilisé pour l'intervalle de confiance en statistique classique où c'est l'aléa des données modélisées qui est utilisé.
30 / 38
Comparaison : bayésien-2
QUESTIONPRIORE
Réponse
Probabiliste
POSTÉRIORE
DONNÉES
La réponse à la question est, comme dans la première interprétation, obtenue à partir de la seule postériore qui représente l'état des connaissance conjuguant la connaissance préalable et l'observation de données.
Cette présentation met en évidence que le noyau central de l'analyse est la modélisation des paramètres. En effet, les données ne servent qu'à modifier notre état de connaissance par une mise à jour.
La réponse au(x) question(s) que l'on se pose se fait directement à partir de la postériore, c'est à dire de notre connaissance la meilleure du phénomène modélisé.
C'est tellement vrai, qu'on peut (et doit pour contrôler la modélisation initiale) regarder la réponse aux questions que propose la seule priore, c'est à dire ne pas tenir compte des données observées.
Cette dernière remarque explicite pourquoi il n'y a pas de problème d'identifiabilité en B : l'existence la priore rend tout paramètre informé avant même la considération de donnéees.

31 / 38
Comparaison : multiples jeux de données
PRIORE
POSTÉRIORE
DONNÉES[1]
DONNÉES[3]
DONNÉES[2]
(méta-analyse statistique)
C'est tellement vrai qu'on peut très facilement imaginer que les données soient des séries de données indépendantes ayant chacune leur logique propre.
Avec les logiciels disponibles actuels cette possibilité est tout à fait à mettre en place. C'est la porte ouverte naturelle à la méta-analyse statistique.
32 / 38
Comparaison : inférence séquentielle
M-P PARAMÈTRES[i-1]
M-P PARAMÈTRES[i]
DONNÉES[i]
i = 1,...,3
PRIORE = M-P PARAMÈTRES[0]POSTÉRIORE = M-P PARAMÈTRES[3]
Et la cohérence de la modélisation probabiliste autorise à ne pas considérer toutes les données en même temps mais à les utiliser séquentiellement au fur et à mesure de leur disponibilité.
Le schéma précédent qui comportait trois jeux de données peut se décliner itérativement comme ci-dessus.
La postériore due à l'utilisation du premier jeu de données peut servir de priore à l'utilisation du second jeu de données et ainsi de suite...

33 / 38
Comparaison : réponse assurée
QUESTIONPRIORE
Réponse
Probabiliste
POSTÉRIORE= PRIORE
PAS de données
(Données Manquantes)
Comme déjà mentionné précédemment, un avantage méconnu mais certain du Bayésien : quelque soit la pauvreté des données, et même s'il n'y a pas de données, l'inférence peut être réalisée.
Le problème souvent difficile de l'identifiabilité en statistique classique ne se pose pas.
En position intermédiaire se trouve la question des données manquantes. Il est intéressant de noter qu'alors qu'en C elles posent souvent des problèmes très ardus, c'est presque le contraire avec les logiciels qui vont être évoqués par après puisque le travail de conditionnement se trouve réduit !
34 / 38
Comparaison : mise en œuvre
Depuis la disponibilité des techniques de simulation MCMC
● Le Bayésien permet d'aborder des modèles très complexes,
● mais ce genre de calcul numérique est délicat !
WinBUGS
JAGS
OpenBUGS
A B C
Il existe maintenant des logiciels très généraux qui permettent de traiter des situations extrêmement complexes, car les modélisations probabilistes (pour les paramètres comme pour les données) sont définis à l'aide de réseaux bayésiens.
Les plus connus sont ceux de la famille BUGS (Bayesian Using Gibbs Sampling), personnellement je recommande JAGS (Just Another Gibbs Sampler). Mais le domaine reste vivant et on assiste à l'émergence de nouvelles apparition comme STAN (en mémoire de Stanislaw Ulam, co-inventeur des méthodes de Monte-Carlo).
L'algorithmique utilisée est celle des MCMC (Markov Chain Monte Carlo), c'est une approche très puissante mais qui n'est pas sans danger (donner un résultat incorrect sans s'en rendre compte).
Mais d'autres techniques apparaissent, comme l'Approximate Bayesian Computation, conséquence des puissances de calculs toujours plus grandes dont nous disposons.

35 / 38
Comparaison : Logique de la Démarche
PRIORE
POSTÉRIORE
DONNÉES
Peut-être l'aspect le plus attractif de la démarche B est qu'on arrive au même type d'information que celui de laquelle on est parti !
Si on comprend l'information qu'on entre (priore) on comprend forcément ce qui en sort (postériore).
La démarche statistique Bayésienne peut être présentée comme une démarche d'apprentissage, c'est d'ailleurs par ce biais que les spécialistes de l'intelligence artificielle s'en sont emparés et l'ont développée (cf. les Réseaux Bayésiens).
36 / 38
Comparaison : Fondement Aléatoire Différent
C B
On pourrait se dire que d'un point de vue pratique, Classique et Bayésien ce sont des nuances de puristes car on aboutit aux mêmes résultats. Par exemple, si on compare les intervalles de confiance et les intervalles de crédibilité au même niveau !
C'est vrai ici car l'importance des données par rapport à la priore utilisée est considérable (d'ailleurs mettre une priore plate dégénérée conduit à une postériore égale à la fonction de vraisemblance).
Mais la nature de l'aléa des deux constructions est bien différent !

37 / 38
Comparaison : Fondement Aléatoire Différent
C95 % est la probabilité que l'Intervalle de Confiance à 5 % inclut la vraie valeur inconnue du paramètre lorsque les données varient.
L'aléa est sur le données.
BUn Intervalle de Crédibilité à 95 % est un intervalle de probabilité 95 % selon la distribution postériore.
L'aléa est sur le paramètre.
Dans la démarche C, le point de vue probabiliste est celui du statisticien qui se trompera en moyenne 5 fois sur cent.
Dans la démarche B, le point de vue probabiliste est celui de l'expert du domaine, il met à jour sa 'croyance' probabilisée en fonction de ce qui est observé.
38 / 38
Comparaison : Subjectivement
S. B. Mcgrayne (2012) The Theory that would not Die - How Bayes' Rule Cracked the Enigma Code, Hunted Down Russian Submarines and ...
Pour ceux que je n'aurais pas convaincu que le B c'est vraiment bien, je recommande la lecture de l'ouvrage de Sharon Mcgrayne ; pour les autres aussi d'ailleurs !
Mon initiation au Bayésien date de l'enseignement que nous donnait le Pr. Guy Lefort mais c'est à la fin des années 90 que j'ai replongé d'abord pour synthétiser des résultats de réseaux d'essais variétaux différents (thèse de Vincent Foucteau) et surtout à partir de 2000 lorsque j'ai été confronté au problème difficile de l'appréciation des risques microbiologiques liés à l'alimentation, notamment en collaboration avec Isabelle Albert.
Pour moi, sa plus grande vertu est de fournir un cadre complet et cohérent de raisonnement pour la démarche statistique. Si on y réfléchit un peu, la démarche B est très naturellement appliquée lors de diagnostics : un médecin qui voit arrivé un patient dans son cabinet ne se contente pas de son seul examen, il le replace dans le contexte de sa connaissance du patient et de celui des épidémies en cours...
C'est ce que j'ai tenté de faire comprendre dans cet exposé.
Merci de votre attention.
![p tests d'hypothèse de Neyman et Pearson - fun-mooc.fr · 2 [0:28] Les tests d'hypothèse selon la théorie de Neyman et Pearson reposent sur une formulation assez formelle. De façon](https://img.pdfslide.fr/doc/110x75/5c81a29d09d3f207418cbc6e/p-tests-dhypothese-de-neyman-et-pearson-fun-moocfr-2-028-les-tests-dhypothese.jpg)




























