Embed Size (px)
Citation preview

Input Save Analysis Database
고속 통신 패킷 저장 및 분석을 위한 시계열 데이터베이스의 활용
㈜ 인피니플럭스

전통적인 DBMS 특징 1
패킷 분석에서 DBMS의 한계 2
신개념 시계열 DBMS 3
고속 데이터 처리를 위한 신기술 4
5 패킷 분석 아키텍처
6 성능 비교
7
Table of Contents
발전 방향

1. 전통적인 DBMS 특징

4
데이터 관리 1. 전통적인 DBMS 특징
Transaction
• 모든 데이터 연산에 대해 트랜잭션 • Atomicity, Consistency, Isolation,
Durability • Savepoint, Commit, Rollback
Insert Data
• 초당 5000건 이상 입력하기 매우 힘듦 • 트랜잭션 제공을 하기 위한 로깅 비용이 매우 큼 • 인덱스 갱신 비용이 매우 큼 • 데이터 보다 인덱스 량이 더 커짐에 따라 시스템
성능 저하
Index
• B+ Tree를 기본으로 활용 • Global 인덱스이며, 해당 인덱스에 전체
레코드 정보가 저장 • 트랜잭션 지원을 위한 로깅 및 Recovery
연산 비용 과다 • 이러한 이유로 처리 성능이 수천 건/초
에 불과
Data Management
in a traditional DBMS

5
Concurrency Control
• 기본적으로 Record Level Locking을 제공
• Consistency Read • Non Consistency Read (Record Lock
confliction 발생)
Query Performance
• 전통적인 DBMS는 OLTP에 강점을 가짐 • 데이터의 분포도가 높은 경우 질의 성능이 좋음 • B+ Tree를 기반으로 동작하며, 가장 효율이 좋은
하나의 인덱스를 결정하고 사용함 • 통계 분석을 위한 질의는 매우 느림
Full Text Search
• 데이터베이스에서 텍스트 검색은 지원하지 않음
• LIKE 구문을 활용 • LIKE 사용 시 모든 레코드에 대한 Full
Scan이 발생하여 매우 느림 • 사실상 풀 텍스트 검색 용도로는 사용이
불가능
Query performance
in a traditional DBMS
조회 성능 1. 전통적인 DBMS 특징

6
적용 분야 1. 전통적인 DBMS 특징
트랜잭션을 통해 보관되어야 하는
정보
은행 거래를 위한 금전 정보 및 주요 개인 식별 정보
전통적 데이터베이스에
중요하게 보관되어야 하는 정보
시간의 흐름과 무관하며, 변경되거나 삭제될 수 있는 정보

2. 패킷 분석에서 DBMS의 한계
8
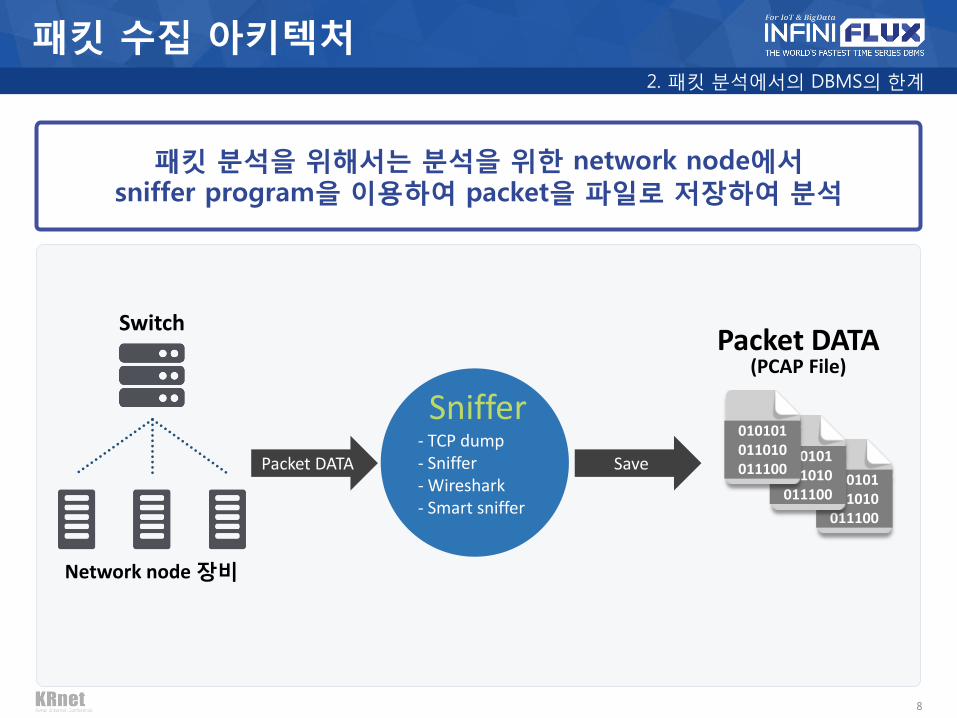
패킷 수집 아키텍처
Packet analysis을 위해서는 분석을 위한 network node에서 sniffer program을 이용하여 packet을 저장하여 분석
Network node 장비
Switch
2. 패킷 분석에서의 DBMS의 한계
패킷 분석을 위해서는 분석을 위한 network node에서 sniffer program을 이용하여 packet을 파일로 저장하여 분석
Packet DATA Save
- TCP dump - Sniffer - Wireshark - Smart sniffer
Sniffer
010101 011010 011100
010101 011010 011100
010101 011010 011100
Packet DATA (PCAP File)

9
패킷 분석 아키텍처
Packet analysis을 위해서는 분석을 위한 network node에서 sniffer program을 이용하여 packet을 저장하여 분석
2. 패킷 분석에서의 DBMS의 한계
패킷 데이터가 파일로 저장될 경우 단순 filter를 이용하여 분석을 수행해야 하며, 대용량 데이터 분석이 불가능
Read data Filter
- TCP dump - Sniffer - Wireshark - Smart sniffer
Sniffer
010101 011010 011100
010101 011010 011100
010101 011010 011100
Packet DATA (PCAP File)
Full Scan 분석 서버
대시보드
리포팅서버

10
패킷 분석에 DBMS 사용 한계
Packet analysis을 위해서는 분석을 위한 network node에서 sniffer program을 이용하여 packet을 저장하여 분석
2. 패킷 분석에서의 DBMS의 한계
전통적인 DBMS를 이용하여 패킷 데이터 분석을 위해서는 실시간 데이터 입력이 불가능하여
저장된 데이터의 일부만 DBMS에 입력하여 분석
010101 011010
010101 011010
010101 011010
분석 서버
대시보드
리포팅서버
DBMS
Network node 장비
Switch
Packet DATA (PCAP File)
SQL쿼리
결과값

3. 신개념 시계열 DBMS

12
InfiniFlux 개요
로그발생
서버
센서
보안
통신장비
분석 서버
관리시스템
대시보드
리포팅서버
결과값
InfiniFlux SQL쿼리
로그/이벤트 저장
3. 신개념 시계열 DBMS
InfiniFlux는 대량으로 발생하는 시계열 머신 로그 데이터를 실시간으로 저장 및 분석하는 혁신적인 기술의 DBMS
기운영체제

13
요구 사항
데이터의 실시간 수집
• 다수의 원시 소스로부터
초당 수만 ~ 수십만 건 저장
데이터 처리 요구사항 3. 신개념 시계열 DBMS
데이터의 실시간 모니터링
• 실시간 인덱싱 및 압축
• 실시간 질의 처리
데이터의 분석
• 수 분 ~ 수 시간의 통계 분석 및 저장
데이터의 백업 및 빠른 복구
• 시계열 기반의 빠른 백업
• 과거 데이터 실시간 확인
데이터의 예측
• 시계열 예측 알고리즘을 통한 위험
방지

14
문제점
데이터 처리 문제점 3. 신개념 시계열 DBMS
데이터의 실시간 저장
•단순 파일 적재 => 데이터 검색 불가능, 인덱스 필요
•저장 및 인덱스 => 성능 하락
실시간 인덱스 생성
•전통적 DBMS 인덱스(B+Tree) => 매우 느린 성능
• Fractal, Global Bitmap 인덱스 => 10,000 TPS 이상 힘듦
데이터의 분석
•수 천만 ~ 수 억건의 데이터 검색 •다양한 컬럼 조건들 => 단순 검색이 아님
=> 다수 시계열 조건의 질의문 발생 => 대규모 읽기,쓰기 I/O 동시 발생
데이터의 백업 및 빠른 복구
• 특정 시간 영역의 데이터 실시간 보관
• 특정 시간 영역의 실시간 접근, 분석
필요
저장 공간 + I/O bandwidth
• 1K Payload, 100,000 TPS = 8,046 TB/Day(100MB/Sec) • HDD : 100MB/Sec • SSD : 500MB/Sec

15
Real-time data entry
Data freshness x Real-time data entry
X 1000
x 10,000
x 1,000,000
Current (seconds) Old (minutes) Very old (hours)
Text File
HADOOP
Disk DBMS
In-Memory DBMS
Engineered System (ExaData)
Columnar DBMS
Clustered Columnar DBMS
Splunk
InfiniFlux
Batch oriented Big Data Analytics
Conventional Analytics
BI Solutions
Conventional OLTP/OLAP
Real-Time Big Data Analytics
Enhanced HADOOP Solutions
ParStream
x 100,000
Data Freshness
제품 포지셔닝 3. 신개념 시계열 DBMS

16
• 로그 수집기 제공으로 다양한 데이터 원천 소스로부터 데이터 수집 가능
• 데이터 import/export 유틸리티 제공
• 쉽게 데이터 입력 프로그램 구성하도록 라이브러리와 예제 제공
• 초고속 데이터 입력, 초당 100,000 건 이상 데이터 저장 가능
• 실시간 인덱스 생성 저장으로 데이터 입력과 동시에 검색 가능
• 실시간 데이터 압축 저장으로 저장공간 절약
• 표준 SQL 지원 및 익숙한 데이터베이스 관리 환경 지원
• 인터넷 주소 타입 , 무부호 정수형 타입 , LOB(최대 64MB) 타입 등 다양한 데이터 타입 지원
• 시계열 기반 확장 SQL 구문 지원(_arrival_time, duration)
• Dashboard, Graph, Chart 등 사용자 친화적 웹 GUI 제공
• 표준 인터페이스 제공으로 다른 BI 솔루션과 연동 가능
• R, Tableau 등 데이터 분석 툴과 간단하게 연동 가능
• 혁신적인 데이터 백업, 복구, 마운트 기능 제공
• 웹 UI 를 통한 시스템 모니터링, 설정 변경 가능
• 다양한 시스템 운영 및 관리 정보 제공
수집
저장
분석
시각화
관리
주요 기능 3. 신개념 시계열 DBMS

4. 고속 데이터 처리를 위한 신기술

18
• ODBC, CLI, JDBC, RESTful API 지원
• Join, subquery, group by, having, order by
표준 SQL 인터페이스
• 인터넷 주소 타입 지원 : IPv4, IPv6
• 무부호 정수형 타입 : unsigned type (16, 32, 64 bit)
• LOB 지원(최대 64MB) : text, binary
다양한 데이터 타입 지원
표준 SQL 4. 고속 데이터 처리를 위한 신기술

19
• 데이터 검색할때 시간 범위를 쉽게 지정하기 위해서 제공되는 키워드
• 현재 시각 기준 10분 전까지 데이터의 합계를 구하는 경우
SELECT SUM(traffic) FROM T1 DURATION 10 minute;
• 현재 시점에서 한시간 이전 부터 10분간 데이터의 합계를 구하는 경우
SELECT SUM(traffic) FROM T1 DURATION 10 minute BEFORE 1 hour;
DURATION 키워드 제공
시계열 SQL 4. 고속 데이터 처리를 위한 신기술
• 데이터 입력 순간 숨은 칼럼(_arrival_time)에 nano second 를 자동으로 저장
• 조회시 가장 최근에 입력된 데이터부터 시간의 역순으로 출력
나노 세컨드 단위의 timestamp 자동 저장
20
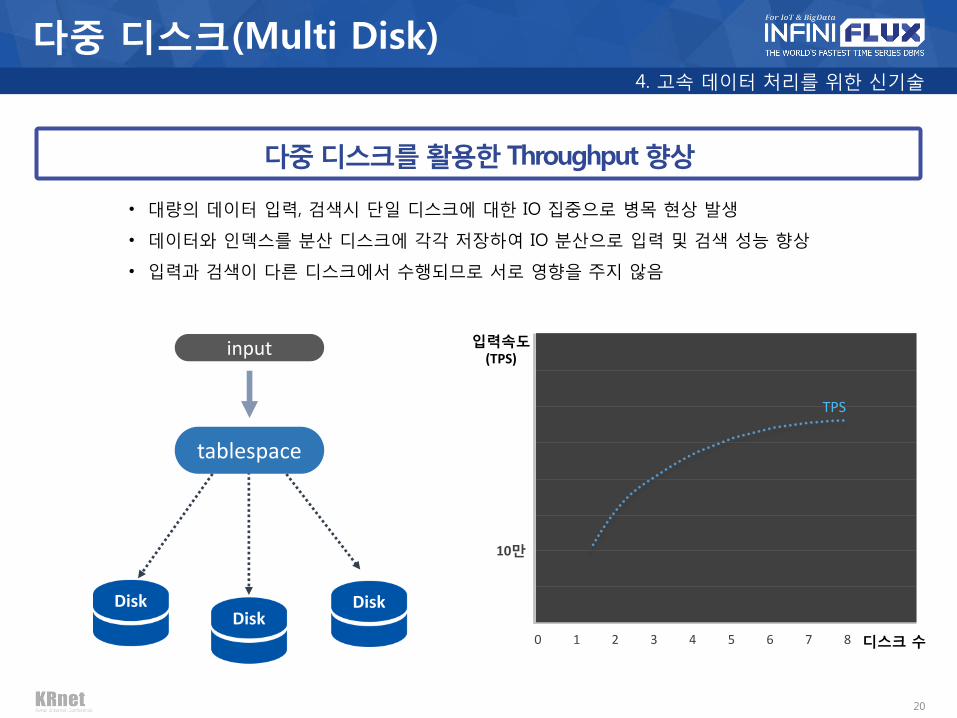
다중 디스크를 활용한 Throughput 향상
• 대량의 데이터 입력, 검색시 단일 디스크에 대한 IO 집중으로 병목 현상 발생
• 데이터와 인덱스를 분산 디스크에 각각 저장하여 IO 분산으로 입력 및 검색 성능 향상
• 입력과 검색이 다른 디스크에서 수행되므로 서로 영향을 주지 않음
0 1 2 3 4 5 6 7 8
TPS
입력속도 (TPS)
디스크 수
10만
Disk Disk
Disk
tablespace
input
다중 디스크(Multi Disk) 4. 고속 데이터 처리를 위한 신기술

21
대용량 데이터 처리에 적합한 인덱스
• 빠른 데이터 증가 환경에서 고속 검색 지원 기술
• 로컬 인덱스와 글로벌 인덱스의 장점을 취해 만든 혁신적인 인덱스 기술
• 일반 서버 환경에서 10억 건 중 1건 검색시간 0.5초
0 1억 10억 100억
LSM 인덱스 적용 후
LSM 인덱스 적용 전
검색시간
데이터 건수
0.5초
1초
LEVEL 0
LEVEL 1
LEVEL 2
1
100만 … 10
100만
1
100만 … 10
100만
1
1000만 … 10
1000만
1
100만
1
1000만
1
1억
LSM(Log Structured Merge) 인덱스 4. 고속 데이터 처리를 위한 신기술

22
마스터 정보 관리용 휘발성 메모리 테이블 제공
• Primary Key 기반 초고속 실시간 입력, 수정, 삭제 가능
• 로그 테이블과의 빠른 조인( join)을 통한 데이터 분석 지원
• 서버 재기동시 테이블 스키마는 유지, 데이터는 재로딩 필요
JOIN
입력, 선택적 삭제
Log table
입력, 수정, 삭제
Volatile table
Memory Disk
syslog Network packet
weblog 코드 정보
메타 정보
상태 정보 JOIN JOIN
iflux 99
USER ID ACTION CODE
After join
iflux login
휘발성 테이블(Volatile Table) 4. 고속 데이터 처리를 위한 신기술

23
빠른 텍스트 키워드 검색 기능 제공
• RDBMS의 LIKE 와 유사한 ‘SEARCH’ 구문 제공
• 키워드 인덱스를 이용하여 빠른 검색 가능
• 영문 뿐만 아니라 UTF-8 형식의 한글, 중국어, 일본어 문자 검색도 가능
SELECT message
FROM textsearch
WHERE message
SEARCH ‘ERROR 500’;
SEARCH
102배 빠름
검색시간 (초)
80
70
60
50
40
30
20
10
0
MySQL LIKE
InfiniFlux LIKE
InfiniFlux SEARCH
1억건 중 200만건 검색
72.7
58.4
0.7
Full Text Search 4. 고속 데이터 처리를 위한 신기술

24
편리한 IP Address Type 지원
• 제품 엔진 레벨에서 IPv4, IPv6 데이터 타입 지원
• Network Mask 형식 지원 및 편리한 연산자와 함수 제공
• 간단하고 빠르게 IP 주소에 대한 저장과 검색 가능
CREATE TABLE
addrtable
(
srcip ipv4,
dstip ipv6
);
INSERT INTO
addrtable
VALUES
(
‘127.0.0.1’,
‘::127.0.0.1’
);
SELECT srcip FROM addrtable
WHERE srcip = ‘192.168.0.*’;
SELECT srcip
FROM addrtable
WHERE srcip
CONTAINED ‘192.168.0.0/16’;
CREATE INSERT SELECT
IP Address Type 4. 고속 데이터 처리를 위한 신기술

25
혁신적인 마운트 기능으로 빠른 백업 데이터 조회
• 마운트 백업된 데이터 정보를 데이터 로딩 없이 즉시 조회할 수 있는 기능
• 데이터베이스 단위 및 테이블 단위 백업, 마운트 지원
• 로컬 디스크, NFS, HDFS 저장공간에 백업, 마운트 가능
과거 현재
2016-02-29 2016-03-01 2016-03-02 2016-03-03 2016-03-04 2016-03-05
2016-02-29 2016-03-01 2016-03-02 2016-03-03
mount backup
2016-03-04 LOCAL NFS HDFS
백업 & 마운트 4. 고속 데이터 처리를 위한 신기술

26
고성능 데이터 압축으로 저장공간 절약
• 논리적, 물리적 2단계 데이터 압축 저장
• 원본 대비 수 배 ~ 수십 배 압축
• 시스템 부하 최소화 및 데이터 입력,검색 성능 향상
13GB 68.5% 압축
4.1GB
데이터 압축 4. 고속 데이터 처리를 위한 신기술

5. 패킷 분석 아키텍처

28
InfiniFlux 활용 아키덱처
분석 서버
대시보드
리포팅서버
InfiniFlux 수집
Switch
5. 패킷 분석 아키텍처
Packet 캡처를 통하여 원시 데이터를 수집한 후 packet header의 내용을 InfiniFlux에 저장
원본 데이터는 PCAP 파일로 별도 저장 후 조회시 활용
meta (header) real time insert
SQL쿼리
결과값
010101 011010
010101 011010
010101 011010
Packet DATA (PCAP File)

29
• 전체 1억 6천만 건의 데이터를 CSV 파일을 통한 DATA Insert 속도 측정
• 전체 데이터에 대한 통계 분석
• 전체 데이터에서 Port Scan 을 찾는 분석을 진행
• 특정 세션 복원을 위한 분석 진행
테스트 환경
데이터의 실시간 저장 하드웨어 사양
- CentOS 6.6
- Intel(R) Core(TM) i7-4790
CPU @3.60GHz(4 core)
- 32GB memory
- SATA DISK
데이터의 실시간 저장 테스트 대상
- InfiniFlux 2.5
- MySQL 5.7 (MyISAM)
테스트 순서
5. 패킷 분석 아키텍처
전통적인 DBMS의 경우 실시간 입력이 불가능 하여 저장된 패킷 헤더 내용을 CSV 파일로 만들어 테스트 진행

30
Table name: PACKET_DATA
STIME PROTO
COL SRC_ PORT
DST_ PORT
PACKET_ELN
SRC_IP DST_IP SRC_ MAC
DST_ MAC
FILE_ NAME
FILE_ OFFSET
TCP_ FLAG
Data Type
date Time
short integer integer integer IPv4 IPv4 Varchar
(20) Varchar
(20) Varchar
(512) ulong short
Data Range
발생 시간
Protocol num
Source port
Destination port
길이 Source
IP
Destination
IP
Source MAC
destina
tion MAC
파일 이름
파일 오프셋
TCP Flag
SRC_MAC DST_MAC SRC_IP DST_IP SRC_PORT DST_PORT
00:8c:fa:3a:28:85 ff:ff:ff:ff:ff:ff 192.168.0.131 192.168.0.255 137 137
a0:1d:48:b3:fa:b0 00:26:66:d5:bf:84 192.168.0.151 5.9.12.237 64462 80
00:26:66:d5:bf:84 a0:1d:48:b3:fa:b0 5.9.12.237 192.168.0.151 80 64462
00:26:66:d5:bf:84 a0:1d:48:b3:fa:b0 5.9.12.237 192.168.0.151 80 64462
a0:1d:48:b3:fa:b0 00:26:66:d5:bf:84 192.168.0.151 5.9.12.237 64462 80
성능 비교 Table Schema 5. 패킷 분석 아키텍처
Sample Data

6. 성능 비교

32
성능 비교 6. 성능 비교
InfiniFlux가 데이터 입력과 압축 성능이 월등함
17
7.1
21
51
0
10
20
30
40
50
60
원본 INFINIFLUX MySQL(MyISAM) MySQL(InnoDB)
압축 성능(GB)
• InfiniFlux는 원본 크기보다 58.2%압축됨.(7.1GB/17GB) • 데이터 입력 시간과 검색 시간을 종합하여 계산함

33
1. 저장 된 총 data 건수?
2. 저장 된 data의 시간 범위?
통계 분석
InfiniFlux MySQL
0.001s 0.17s
InfiniFlux MySQL
0.003s 40.42s
Select count(*) from packet_data;
count(*) ----------------------- 163356883 [1] Row Selected. Elapsed Time : 0.001
Select min(stime),max(stime) from packet_data;
min(stime) max(stime) --------------------------------------------------------------- 2008-07-22 10:51:07 2016-02-11 17:52:29 [1] Row Selected. Elapsed Time : 0.003
6. 성능 비교

34
3.특정 network 에서 다른 network 으로의 접속 현황?
통계 분석
MySQL은 IP type 미지원으로 다음 쿼리 사용
SELECT src_ip, count(src_ip)
from packet_data
where src_ip like '192.168.0.%'
and dst_ip not like '192.168.0.%'
group by src_ip
order by 2 desc;
SELECT src_ip, count(src_ip)
from packet_data
where src_ip contained '192.168.0.0/24'
and dst_ip not contained '192.168.0.0/24'
group by src_ip
order by 2 desc;
src_ip count(src_ip) ---------------------------------------- 192.168.0.151 49802 192.168.0.4 312 192.168.0.1 288 ~ 192.168.0.209 2 192.168.0.236 2 192.168.0.28 1 [22] Row Selected. Elapsed Time : 0.001
InfiniFlux MySQL
0.001s 0.43s
6. 성능 비교

35
4. web 접속 현황 top 10
통계 분석
SELECT src_ip, count(dst_port)
From packet_data
where dst_port = 80 or dst_port = 443
group by src_ip,dst_port
order by 2 desc limit 10;
src_ip count(dst_port) ---------------------------------------- 10.128.0.6 90420 192.168.0.151 47209 192.168.15.4 31150 192.168.1.64 5061 172.16.254.128 3665 10.128.0.1 3074 192.168.15.4 1856 192.168.0.151 1751 10.0.1.245 1500 10.0.1.51 1336 [10] Row Selected. Elapsed Time : 0.001
InfiniFlux MySQL
0.001s 0.52s
6. 성능 비교

36
1. 목적지 port 번호가 1024 보다 작고 port가 1000번 이상 변경된 IP?
Port Scan
SELECT src_ip
FROM packet_data
WHERE dst_port < 1024
GROUP BY src_ip
HAVING COUNT(DISTINCT dst_port) > 1000;
src_ip ------------------ 192.168.0.151 [1] Row Selected. Elapsed Time : 0.000
InfiniFlux MySQL
0.000s 242.39s
6. 성능 비교

37
2. 1의 결과로 나온 Source IP의 Destination IP 접속 현황 TOP 10
Port Scan
select src_ip, dst_ip, count(dst_ip)
from packet_data
where src_ip ='192.168.0.151'
group by src_ip,dst_ip
order by 3 desc limit 10;
src_ip dst_ip count(dst_ip) --------------------------------------------------------- 192.168.0.151 5.9.12.237 40417 192.168.0.151 192.168.0.11 3076 192.168.0.151 203.133.172.61 1878 192.168.0.151 113.29.189.48 1011 192.168.0.151 203.133.166.61 533 192.168.0.151 203.248.252.2 443 192.168.0.151 217.160.127.1 321 192.168.0.151 192.168.0.41 290 192.168.0.151 211.244.82.174 246 192.168.0.151 203.133.172.21 243 [10] Row Selected. Elapsed Time : 0.178
InfiniFlux MySQL
0.178s 0.13s
6. 성능 비교

38
3. Destination IP 의 port 접속 현황 분석
Port Scan
select src_ip, dst_ip, dst_port, count(dst_port)
from packet_data
where src_ip ='192.168.0.151'
and dst_ip = '192.168.0.11'
group by src_ip, dst_ip, dst_port
order by 4 desc;
src_ip dst_ip dst_port count(dst_port) ---------------------------------------------------------------------- 192.168.0.151 192.168.0.11 137 6 192.168.0.151 192.168.0.11 21 4 192.168.0.151 192.168.0.11 1012 3 192.168.0.151 192.168.0.11 325 3 ~ 192.168.0.151 192.168.0.11 285 3 192.168.0.151 192.168.0.11 348 3 [1024] Row Selected. Elapsed Time : 0.021
InfiniFlux MySQL
0.021s 0.04s
6. 성능 비교

39
4. Port Scan 발생 시간
Port Scan
select min(a.stime) as start_time,
max(a.stime) as stop_time
from (select stime
from packet_data
where src_ip ='192.168.0.151'
and dst_ip = '192.168.0.11') as a;
start_time stop_time ------------------------------------------------------------------- 2016-02-04 10:24:21 2016-02-04 10:41:47 [1] Row Selected. Elapsed Time : 0.016
InfiniFlux MySQL
0.016s 0.05s
6. 성능 비교

40
1. Meta data를 통한 세션 복원
세션 복원
select stime, src_ip, dst_port, file_name, file_offset, tcp_flag
from packet_data
where (src_ip = '192.168.0.151' or src_ip = '106.243.125.195') and
(dst_ip = '192.168.0.151' or dst_ip = '106.243.125.195') and
(src_port = 8888 or src_port = 64945) and
(dst_port = 8888 or dst_port = 64945)
order by 1;
InfiniFlux MySQL
0.013s 0.06s
6. 성능 비교

41
성능 비교표
InfiniFlux MySQL
during time(sec) 871(14M31s) 3054(50m 54s),
Record count 163,356,883(1억 6천만건)
분석
Count(*) 0.001s 0.17s
Min(), Max() 0.003s 40.42s
네트워크 접속 현황 0.001s 0.43s
Web접속 top 10 0.001s 0.52s
Port scan
Port 변경 0.000s 242s(4m 2.39s)
Source IP 의 접속 top 10 0.178s 0.13s
Destination IP 접속 port 0.021s 0.04s
발생 시간 0.016s 0.05s
세션 복원 세션 복원 0.013s 0.06s
총 분석 시간 876.22s 3,338.21s
6. 성능 비교

6. 구축 사례

43
사이버 블랙 박스 6. 구축사례
InfiniFlux
Switch
사이버 공격의 증거보존/원인분석을 통한 대규모 침해 사고에 대한 Intelligence 분석
공격 Packet DATA
RBL
침해 공격 원인분석 침해 정보 Intelligence 분석
사이버 블랙박스
010101 011010 011100
010101 011010 011100
악성코드
url C-TAS
보안 위협 정보 공유

7. 발전 방향

45
패킷 데이터 스트림 저장
데이터의 실시간 저장
현재 저장구조
데이터의 실시간 저장
개선 저장구조
• 현재 packet header만 DB에 저장
• 전체 Packet은 pcap 파일로 저장
• 분석 결과를 재생하기 위해서는 offset
칼럼을 이용
• packet 전체를 DB에 저장
• DATA 부분은 binary type으로 저장
• PCAP 파일은 InfiniFlux를 통하여 생성
7. 발전 방향
InfiniFlux
InfiniFlux
패킷 헤더와 동시에 데이터 스트림까지 모두 저장하여 분석 및 세션 재현
Packet DATA (PCAP File)
Header DATA
Packet DATA (PCAP File)
Header DATA
46
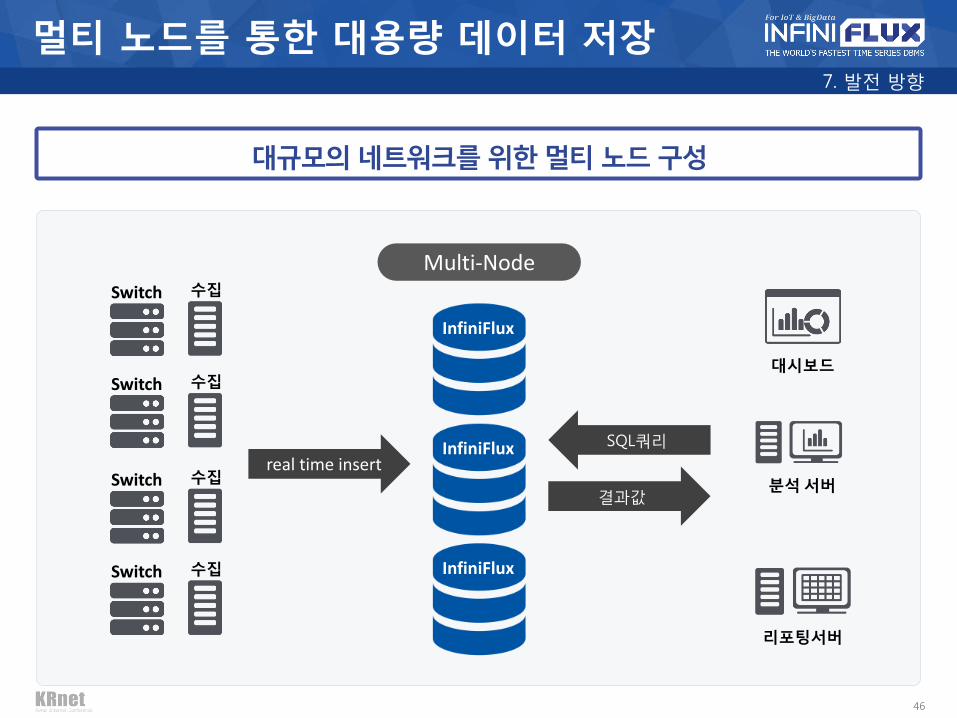
Multi-Node
멀티 노드를 통한 대용량 데이터 저장
분석 서버
대시보드
리포팅서버
수집 Switch
7. 발전 방향
대규모의 네트워크를 위한 멀티 노드 구성
수집 Switch
수집 Switch
수집 Switch InfiniFlux
InfiniFlux
InfiniFlux
real time insert
SQL쿼리
결과값






























