Embed Size (px)
Citation preview

Interactive Visual Analysis of Lumbar Back PainWhat the Lumbar Spine Tells About Your Life
Paul Klemm1, Sylvia Glaßer1, Kai Lawonn1, Marko Rak1, Henry Volzke2, Katrin Hegenscheid3 andBernhard Preim1
1 Department of Simulation and Graphics, University of Magdeburg, Germany2 Institute for Community Medicine, University of Greifswald, Germany
3 Institute for Diagnostic Radiology and Neuro-Radiology, University of Greifswald, [email protected]
Keywords: Epidemiology, Interactive Visual Analysis, Classification, Multi-Modal Data
Abstract: Epidemiology aims to provide insight into disease causations. Hence, subject groups (cohorts) are analyzedto correlate the subjects’ varying lifestyles, their medical properties and diseases. Recently, these cohortstudies comprise medical image data. We assess potential relations between image-derived variables of thelumbar spine with lower back pain in a cross-sectional study. Therefore, an Interactive Visual Analysis (IVA)framework was created and tested with 2,540 segmented lumbar spine data sets. The segmentation results areevaluated and quantified by employing shape-describing variables, such as spine canal curvature and torsion.We analyze mutual dependencies among shape-describing variables and non-image variables, e.g., pain indi-cators. Therefore, we automatically train a decision tree classifier for each non-image variable. We providean IVA technique to compare classifiers with a decision tree quality plot. As a first result, we conclude thatimage-based variables are only sufficient to describe lifestyle factors within the data. A correlation betweenlumbar spine shape and lower back pain could not be found with the automatically trained classifiers. How-ever, the presented approach is a valuable extension for the IVA of epidemiological data. Hence, relationsbetween non-image variables were successfully detected and described.
1 INTRODUCTION
Epidemiology is the study of dissemination, causesand results of health-related states and events. Largepopulation studies, such as the Study of Health inPomerania (SHIP) (Volzke et al., 2011), gather asmuch information as possible about participants to beassessed towards different diseases. This informationis used to determine risk factors for diseases, informpeople about healthier lifestyles or to support the di-agnosis of widespread diseases. Cohort studies are aninstrument of epidemiological research. We analyzeback pain, one of the most frequent complaints in theWestern civilization. Although the shape and consti-tution of the spine, especially the lumbar spine, playsan important role for back pain, an automatic clas-sification approach for characterization of back painbased on lumbar spine attributes is still missing.
We present an analysis of the image-derived datafrom a cohort study lumbar spine dataset. We extractpossible associations between spine shape and backpain characteristics. For this purpose, we combine
classification algorithms with data visualization tech-niques. Then, Interactive Visual Analysis (IVA) high-lights mutual dependencies between image-deriveddata and back pain-related variables. We focus onhighlighting new correlations and trigger hypothesesgeneration, rather than statistically validate complexepidemiological correlations. Our contributions are:
• An IVA workflow for back pain analysis based onimage-derived variables of 2,240 subjects,
• The identification of lumbar spine shape proper-ties potentially associated with back pain,
• The detection of associations between image-based, socio-demographic and medical variablesfor hypotheses generation,
• The identification of the most important variablesvia classification methods using a novel decisiontree quality plot.

2 EPIDEMIOLOGICALBACKGROUND
Epidemiological reasoning relies on a strictstatistically-driven workflow (Fletcher et al.,2012): (1) physicians formulate hypotheses basedon observations made in their clinical practice; (2)epidemiologists compile a list of variables depicting ahypothesis to prove it; (3) statistical methods, such asregression analysis, assess the correlation of selectedvariables with the investigated condition. Mutuallydependent variables make this analysis challenging.For example, the incidence rate of many diseases,such as different cancer types increases with age(Fletcher et al., 2012).
Challenges of Epidemiological Data Analysis.We focus on epidemiological large scale cohort studydata. The collected data can be analyzed regardingmany diseases and conditions. Epidemiological dataare heterogenous and incomplete. For example, dataabout a disease treatment only affects subjects suf-fering from this condition. Statistical analysis hasto take missing data into account. Epidemiologicaldata acquisition includes a variety of techniques, suchas medical examinations, self-reported questionnairesor genetic examinations. This yields a heterogenousinformation space. Information reduction techniquesare necessary to compare these data. For example,continuous data, such as age, is often discretized intoquantile bins for visualizing age-dependent diseasefrequencies.
Modern cohort studies often comprise medicalimage data. The analysis of these data is challenging.Individual diagnosis or manual segmentation ofeach body structure by radiologists is tedious, costlyand comprises little reproducibility. Segmentationalgorithms are not generally available and need to becarefully adapted for each body structure.
Lower Back Pain. Lower back pain is one ofthe most frequent complaints in the Western civiliza-tion (Hoy et al., 2010). The exact causes as well asparticular vulnerable risk groups are unknown. Epi-demiologists want to describe the relation betweenaging and degenerative process of the spine (Szpalskiet al., 2005). They have to analyze the lumbar spineshape as well as lifestyle factors.
3 RELATED WORK
Visual Analysis of Medical Image and Non-ImageData. In a previous work, we proposed an epidemi-
ological IVA workflow, consisting of an iterativesequence of group selection, variable selection andvisualization (Klemm et al., 2014). Hypothesesgeneration was amplified by concurrently analyzingheterogenous variables at once using correlationmeasures. (Turkay et al., 2013) derived descriptivedata metrics from image data. Their proposeddeviation plot shows distribution-specific measuresof a variable, such as skewness or inter-quantilerange, making variables comparable. This approachaimed to trigger hypotheses generation by outliningtendencies between these variables. A survey onimage-centric cohort studies and strategies to analyzethe resulting data is given in (Preim et al., 2015).In a prior work, we analyzed the lumbar spinevariability of 490 subjects (Klemm et al., 2013). Weincorporated hierarchical agglomerative clustering toderive shape groups, yielding average shape groupsand outliers. As opposed to clustering the spineshape, we analyze the discriminative power of theresulting data towards back pain and other non-imagevariables in this work.
Visual Analysis of Heterogenous Non-ImageData. (Zhang et al., 2012) analyzed subject groupsin a web-based linked view system. The resultingdecision rules aim to categorize new subjects asthey are added to the data. They defined a cohortas variable-divided subject group, differing fromthe epidemiological understanding of the term. Thedescribed method lacks details about handling ofmissing data, the definition of similarity or the choiceof the statistical measures. Generalized Pairs Plots(GPLOMs) visualize heterogenous variables in a plotmatrix (Emerson et al., 2013). The plot depends onthe type of variables, which are visualized pairwise.GPLOMs provide an overview, but take up muchscreen space and are therefore only suitable for a fewvariables at once (see example in Fig. 2).
Decision Rule-Driven Analysis of Medical Data.Closest to ours is the work of (Glaßer et al., 2013)and (Niemann et al., 2014). Both used decision treesfor their analyses. Decision trees are easily readableand are frequently used for classifying medical data.(Glaßer et al., 2013) used variables derived fromDCE-MRI data capturing the perfusion in tumoroustissue. To classify breast tumors, they trained adecision-tree classifier, concluding that the extractedkinetic and morphological variables alone are notsufficient for tumor type classification. (Niemannet al., 2014) assessed risk factors for hepatic steatosis(fatty liver disease) using decision trees. Their inter-active data mining tool can analyze association rules
and highlights relations. We combine both ideas byvalidating the significance of image-derived variables.
Unique in our work is the combination of clas-sification techniques with an IVA approach byobserving interesting variable relations in the contextof image-derived variables using multiple decisiontrees for one visualization. We abstract the decisiontree results similar to (Turkay et al., 2013), makingthem comparable in an overview visualization.
4 THE LUMBAR SPINE DATA SET
Our work is based on a data set compiled by Epi-demiologists with a wide range of variables possiblycorrelating with lumbar back pain, comprising non-image and image-derived data for 3,234 subjects.
Non-Image Data. The non-image variablesrange from somatometric variables describing bodymeasures to medical examinations, such as laboratorytests as well as lifestyle factors, e.g., sporting activityor nutrition. The data set comprises 134 variables:
• 21 metric variables, describing somatometric vari-ables and markers retrieved from blood analysis.
• 113 categorical variables divided into 43 dichoto-mous (binary) variables, mostly indicating thepresence of a disease, e.g., pancreatitis or highblood pressure, and 70 variables with more thantwo levels, indicating pain levels, nutrition and so-cial factors, such as marital or retirement status.
All categorical variables are converted into binarydummy variables, indicating the presence or absenceof a categorical variable manifestation. For example,a pain indicator variable ranging from 1 - no pain to4 - large pain is subdivided into four dichotomousvariables to determine, which manifestation can bedescribed best using the image-based variables.
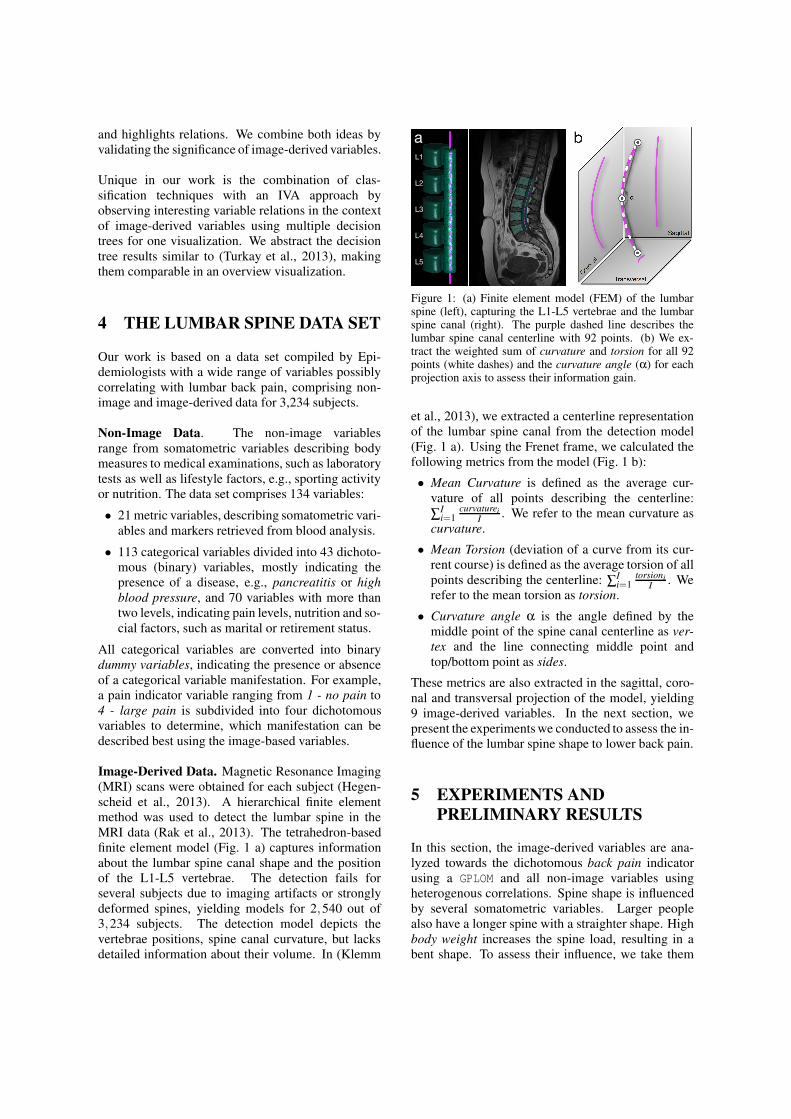
Image-Derived Data. Magnetic Resonance Imaging(MRI) scans were obtained for each subject (Hegen-scheid et al., 2013). A hierarchical finite elementmethod was used to detect the lumbar spine in theMRI data (Rak et al., 2013). The tetrahedron-basedfinite element model (Fig. 1 a) captures informationabout the lumbar spine canal shape and the positionof the L1-L5 vertebrae. The detection fails forseveral subjects due to imaging artifacts or stronglydeformed spines, yielding models for 2,540 out of3,234 subjects. The detection model depicts thevertebrae positions, spine canal curvature, but lacksdetailed information about their volume. In (Klemm
Transversal
Sagittal
Coron
al
a b
α
L1
L2
L3
L4
L5
Figure 1: (a) Finite element model (FEM) of the lumbarspine (left), capturing the L1-L5 vertebrae and the lumbarspine canal (right). The purple dashed line describes thelumbar spine canal centerline with 92 points. (b) We ex-tract the weighted sum of curvature and torsion for all 92points (white dashes) and the curvature angle (α) for eachprojection axis to assess their information gain.
et al., 2013), we extracted a centerline representationof the lumbar spine canal from the detection model(Fig. 1 a). Using the Frenet frame, we calculated thefollowing metrics from the model (Fig. 1 b):• Mean Curvature is defined as the average cur-
vature of all points describing the centerline:∑I
i=1curvaturei
I . We refer to the mean curvature ascurvature.
• Mean Torsion (deviation of a curve from its cur-rent course) is defined as the average torsion of allpoints describing the centerline: ∑I
i=1torsioni
I . Werefer to the mean torsion as torsion.
• Curvature angle α is the angle defined by themiddle point of the spine canal centerline as ver-tex and the line connecting middle point andtop/bottom point as sides.
These metrics are also extracted in the sagittal, coro-nal and transversal projection of the model, yielding9 image-derived variables. In the next section, wepresent the experiments we conducted to assess the in-fluence of the lumbar spine shape to lower back pain.
5 EXPERIMENTS ANDPRELIMINARY RESULTS
In this section, the image-derived variables are ana-lyzed towards the dichotomous back pain indicatorusing a GPLOM and all non-image variables usingheterogenous correlations. Spine shape is influencedby several somatometric variables. Larger peoplealso have a longer spine with a straighter shape. Highbody weight increases the spine load, resulting in abent shape. To assess their influence, we take them

Mean Curvature
Mean Torsion
Mean CurvatureCoronal
Mean CurvatureSagittal
Mean CurvatureTransverse
Curvature Angle
Curvature AngleCoronal
Curvature AngleSagittal
Curvature AngleTransverse
Back PainYes
No
Cor: -0.0103Yes: -0.015No: -0.042
Cor: 0.605Yes: 0.607No: 0.603
Cor: 0.99Yes: 0.989No: 0.991
Cor: -0.0379Yes: -0.247No: -0.0733
Cor: -0.0888Yes: -0.887No: -0.889
Cor: -0.311Yes: -0.336No: -0.269
Cor: -0.872Yes: -0.871No: -0.875
Cor: -0.2Yes: -0.205No: -0.194
Cor: 0.0024Yes: 0.0281No: 0.0477
Cor: -0.0129Yes: -0.0113No: -0.0157
Cor: 0.0049Yes: 0.0005No: 0.0145
Cor: 0.0047Yes: 0.0056No: 0.0035
Cor: -0.0151Yes: 0.0211No: -0.069
Cor: 0.0066Yes: 0.0030No: 0.0118
Cor: 0.0216Yes: 0.0294No: 0.0084
Cor: 0.491Yes: 0.489No: 0.495
Cor: -0.0551Yes: -0.0532No: -0.0667
Cor: -0.421Yes: -0.417No: -0.429
Cor: -0.75Yes: -0.751No: -0.747
Cor: -0.358Yes: -0.353No: -0.368
Cor: -0.0592Yes: -0.0724No: -0.0373
Cor: -0.0319Yes: -0.0176No: -0.0689
Cor: -0.901Yes: -0.902No: -0.9
Cor: -0.221Yes: -0.247No: -0.179
Cor: -0.896Yes: -0.896No: -0.896
Cor: -0.21Yes: -0.214No: -0.207
Cor: 0.0215Yes: 0.0071No: 0.0672
Cor: 0.0353Yes: 0.0435No: 0.0225
Cor: 0.0184Yes: 0.00355No: 0.055
Cor: 0.0181Yes: 0.0267No: -0.0058
Cor: 0.217Yes: 0.235No: 0.189
Cor: 0.995Yes: 0.994No: 0.995
Cor: 0.387Yes: 0.383No: 0.397
Cor: 0.134Yes: 0.15No: 0.108
Cor: 0.0439Yes: 0.0607No: 0.0145
Cor: 0.392Yes: 0.386No: 0.405
Figure 2: A GPLOM of all image-derived variables colored by presence (red) or absence (turquoise) of back pain. Pairwisecombinations of image-derived variables are visualized via scatter plots on the left of the matrix diagonal. Their correlationwith back pain is denoted to the right of the matrix diagonal. The box plots (right) and histograms (bottom) display thedistribution of each image variable encoded with back pain. No correlations with back pain can be identified in this plot.
into account when spine curvature and torsion arecorrelated with non-image variables. Discretizingmetric variables using quartiles avoids outlier groups.
GPLOM Analysis. As first experiment we cor-related the shape variable with the dichotomous backpain indicator using a GPLOM (Fig. 2). The metricimage-derived variables are pairwise visualized usingscatter plots on the left side of the matrix diagonal.The combination of the image variables with backpain is visualized as histogram in the last row andas box plot in the last column. The projections tothe transversal planes attract attention as they havemany outliers. We conclude that curvature is not asreliable on the transversal plane as it is on the otherplanes, which was also confirmed through a principalcomponent analysis (see supplementary material ativapp15.dnsalias.com). The GPLOM shows similardistributions of subjects with or without back painwith respect to the shape variables in all sub-plots.
Heterogenous Correlations. We then expanded ourfocus on correlations of image-derived variables withall other non-image variables. Different correlationmetrics depending on the type of the individualvariables are used to derive correlations betweenall variables in the data set. The method uses thePearson product-moment for two continuous vari-ables, polyserial correlation for one continuous andone categorical variable and polychoric correlationsfor two categorical variables. All values are scaledbetween 0 - no correlation and 1 - perfectcorrelation. Some variables are too sparse for
calculating correlations, for example treatment ofdiabetes, or medication against high blood pressureare omitted, since they are not statistically resilient.We display the resulting contingency matrix usinga heat map, encoding correlation values with colorbrightness with white for 0 and dark blue for 1. Wecalculated the contingency matrix for all size groupsand searched for correlations between image- andnon-image variables. The resulting contingency ma-trices show no strong correlation with image variables(see experiments page at ivapp15.dnsalias.com).Only weak correlations could be found for meancurvature with gender (0.42), body size (0.39) andnumber of born children (0.29). One surprising resultwas the small correlation of torsion with Parkinson’sdisease (0.24). Other than that, torsion correlatedwith almost no variables (values between 0 and 0.05).
These observations brought us to the decision toincorporate classification techniques to assess the in-fluence of the image-derived variables.
6 INTERACTIVE DECISIONTREE QUALITY PLOT
As described before, correlation coefficients failto infer back pain status based on lumbar spinecanal curvature and torsion. We rely on predic-tive classification to obtain a complex rule set onhow combinations of the image-variables explainnon-image variables. Decision trees are used tocreate predictive models. These models are builtw.r.t. all input variables and capture more complex

relationships than correlation coefficients. Leafsof a decision tree represent class labels, branchesrepresent variable conjunctions leading to the classlabels. Decision trees are easy to understand and toread. Too many branches impose overfitting to thedata (Mitchell, 1997).
Creating Decision Trees. We use the C4.5 al-gorithm, which builds decision trees based oninformation entropy. Categorical attributes withmore levels are biased with more information gainin a decision tree (Deng et al., 2011). Creating adummy variable by converting each manifestation ofa categorical variable into a dichotomous variablebypasses this problem. In the following analysis, westrongly focus on the complexity of decision treesand the classification accuracy.
We have to create a decision tree for everynon-image variable to analyze which one can beexplained by image-derived variables. Since we have134 non-image variables, the calculation yields thesame amount of trees. Further subdivision, e.g., byquantiles of body mass index, increases the numberto 402 trees. We have to abstract the results of theclassification to keep the mental effort of interpretingthe data low.
Decision Tree Quality Plot. We follow the Vi-sual Analytics mantra of analyzing first, show theimportant and analyze further (Keim et al., 2008).A first analysis step was performed by applying theclassification algorithm to the data. The optimalclassification uses a few rules to precisely describethe target variable. Therefore, we are interestedin small trees with a low classification error. Thetwo measures form the axes for a scatter plot of theclassification results. This decision tree quality plotis our central element for the interactive analysis ofdecision trees.
The Error Term. Calculating the mean classificationerror is imprecise for non-uniform distributions. Forexample, if a variable indicating a disease is negativefor 90% of the subjects and the classifier simplyassigns all subjects to not ill, we get a mean error of10%, even though it is very imprecise. Based on thiswe use a summary error based on the weighted mean,which incorporates the discriminative power of eachmanifestation and is denoted as follows:
totalError = 1−M
∑m=1
correctlyClassifiedmM ·Nm
(1)
M represents the set of manifestations of eachvariable. Nm denotes the number of subjects inmanifestation m. The error represents the share of
incorrect classifications and denotes perfect classifi-cation with 0 and always wrong with 1. We displayresults below 0.5 in the visualization, a value below0.25 represents a good classification. It allows forcomparability of error rates between variables withdifferent manifestation count.
Attribute Mapping. The scatter plot axes aredefined by tree size and the previously describederror metric. This allows us to visualize a multitudeof classification results in one plot. Classificationand comparison of variables for subject groups(e.g., male and female subjects) in one plot can beachieved by color coding group affiliation on thedata points. Many variables are sparse, such asmedication of diabetes or reason of early retirement.The classification algorithm may produce higheraccuracy for variables with less subjects due to thesmall sample size, making these results less reliable.Therefore, we provide a way to adjust the minimalnumber of subjects for each variable using a slider.The initial value is empirically set to 100, marking agood tradeoff between sparse variables and statisticalinformative value. Furthermore, we map the numberof subjects associated with a variable to the diameterin the decision tree quality plot. This allows instantreliability assessment of the result. We apply asquare root scale for the tree size axis to highlightdecision trees with few decision rules. Outlier resultswith large decision trees would otherwise distort theresulting plot.
Decision Tree Quality Plot Interaction. Thevisualization provides a good overview of the clas-sification results. Details-on-demand are displayedby clicking on an entry in the visualization, whichthen displays the corresponding decision tree indetail. This allows to sequentially analyze theclassifications. We provide controls for adjusting themaximum classification error and minimum subjectcount for a variable. This gives the user control toabstract or refine the displayed information. Thesubject subdivision is controlled by the selectionof variables, such as gender or employment status.Metric variables, such as body size, are discretizedusing their quantiles. This allows to assess theinfluence of a variable to the classification process.
Implementation. All analyses are available ativapp15.dnsalias.com and are carried out using R,a widely used programming language for statisticalcalculations and visualizations. The interactivevisualizations are realized using the ggvis1 package.
1Developed by RStudio, Inc; ggvis.rstudio.com

The web-based approach allows for quick exchangewith our collaborating epidemiological experts. Theycan use the technique without installing any software.
7 RESULTS
In this section, we show which non-image variablescan be explained using the 9 image derived variables.We create subject groups to assess the influenceof variables affecting the lumbar spine shape. Thegroups are: all subjects; males and females; and asubdivision by Body Mass Index quantiles (BMI = m
l2where m is the body mass in kilogram and l is thebody size in meter), yielding the groups (17, 24.7](24.7, 27.4] (27.4, 30.5] (30.5, 48]. We plottedeach group twice. The first plot shows all origi-nal variables, the second all categorical variablestransformed into dichotomous dummy variables.The shown mutual dependencies aim to amplifyhypotheses generation. Dedicated statistical analysisof these results solely focussed on epidemiologicalresearch is not the scope of this paper. The resultingplots can be seen in Figure 3.
All Variables. The majority of non-image vari-ables cannot be automatically classified based on theimage-variables. This is reflected in the large amountof variables classified with an error above 0.6.
None of the pain indicators can be reliablydescribed using the image-based variables. The onlyvariable reliably classified in this group is gender,which can be described with an error of 0.31 using 7rules and incorporates only curvature- and curvatureangle-related variables. The distinctness lies in theaverage difference in body size between male andfemale subjects. Medication for high blood pressureis classified for 1,058 subjects with an error of 0.47solely based on coronal mean curvature. A highshare of medicated subjects were correctly classified(796 of 1,058). The majority of non-medicatedsubjects are false-positive classified (262 of 1,058),yielding a poor quality of the classifier w.r.t. epidemi-ological research. The four body size groups couldbe described with an error of 0.48, but the decisiontree comprises 71 rules and imposes overfitting. Thedummy variable analysis yields a result similar to theblood pressure medication. Variables, such as subjectsize 139-164 cm, between 64 and 90 years of age ornutrition-related variables are dominantly populatedby one manifestation. The classifier neglects theother groups and yields an error below 0.5.
Gender Groups. Classifications using groups
divided by gender do not produce satisfying results.Only hypothyroidism could be described for malesubjects with an error of 0.24 for 110 subjects usingthe mean curvature and curvature angle. Sincethere are only 30 male subjects diagnosed withhypothyroidism, the statistical power of the resultis reduced. The dummy variable analysis showedthat female subjects of 139-164 cm body size couldbe discriminated using the mean curvature andcurvature angle, with an error of 0.38.
Body Mass Index Groups. Gender could beclassified for each BMI group using mean curvatureand curvature angle. The error varies between 0.31(BMI of 30.5− 48, 4 decision rules) to 0.39 (BMIof 24.7− 27.4, 5 decision rules). The starting ageof smoking could be described well with an errorbetween 0.25 and 0.32 for all BMI groups exceptfor subjects with a BMI of 30.5− 48. The result isoverfitted to the data due to tree sizes between 14and 16. Some variables, such as body size, can bedescribed with an error of 0.3 to 0.36 using largedecision trees with over 20 rules. Using mostly meancurvature and curvature angle, the leg pain level canbe described using 14 rules with an error of 0.46for obese subjects (BMI higher than 30). This resultalso imposes overfitting. Subjects experiencing painin the last seven days can also be described for thisgroup using the same variables with a tree consistingof 8 rules and an error of 0.35. Obese subjects areprone to back and leg pain due to a more stressedlumbar spine. The stress-induced spine deformationseems to directly influence the pain levels for thesesubjects. The dummy variable analysis shows manyresults using a decision tree with one rule based onmean curvature or curvature angle with an errorbetween 0.35 and 0.47.
8 SUMMARY & CONCLUSION
We provide a method for comparative analysis of de-cision trees independent of the variable manifestationcount using a novel decision tree quality plot. Weapplied the method to gain insight into the predic-tive power of 9 image-derived variables for 134 non-image variables with focus on back pain. The analysiswas performed for subject groups of gender, BMI andbody size to assess their influence on the lumbar spineshape.
The methods presented herein may be applied tocomprehensive epidemiological data sets to inves-tigate mutual dependencies among variables and togenerate hypotheses on potential associations and

aError Rate
Tree Size2√
Error Rate
Tree Size2√��� ��� ��� ��� ��� ��� ��� ��� ��� ��� ���
����
����
����
���
����
����
����
����
���
�� ����������
����������������������
�� ������������������������ ��������� ����������!��� "� ��������#��#�$���!�%� �� �� !�&�����$������������������������!�������$�&'%��������(�
������
�� �� �� �� �� �� ��
���
���
���
��
���
���
���
���
��
�� ���
���������������� �
�����������������������������
����
cError Rate
Tree Size2√
Error Rate
Tree Size2√��� ��� ��� ��� ��� ��� ��� ��� ��� ��� ��� ��� ��
���
����
����
����
����
���
����
����
����
����
���
�� ����������
� �� �� �� �
� �� ����������� �� ��������������
! ������������������� �� �������������
" �!#�������������$�%��!�"��#������ � ��$��#�� � ����% ��&'&���&��&�$$
�����$ !�� � �� ����������� �� �������������
�#���������($ )�����$�*��������&'&����!
� ������&'&���&��&�$$�(���������(�! ��&'&+��$�&��&�$*��&���$�
�� ����������,��� � ���$����$���� � �-�#�($� ��������&'&����!� �-�#�($� ��������&'&*�� ��� $�
���-���������(� ������$�����$ *��&'&#���$�
��������������
������������
� �� �� �� �� �� �� �� �� �� �� ������
����
���
����
����
����
����
���
����
����
����
����
���
����
�� ������ ��������� ������ �������
���������� �� ������ �������
������
��������� ��� � ���
���������������� �� ����!���� �������������������� �� ����!����
��"��� #��� ������������
����� ������ � ������$��������� ��� ���
#�����
%&' (&�!����� ����� ����� ��� ����� ������� ) ����
������� ��� � ������� !��
�����������
�����������
���������
�������
BMI
b
Error Rate
Tree Size2√
Error Rate
Tree Size2√
��� ��� ��� ��� ��� ��� ��� ��� ���
����
����
����
����
����
����
����
����
����
����
����
����
����
�� ���������
������� �
������ ����������������� �������
�� �������������� �������������� ��!��"��#����� ��������������
������������
� �� �� �� �� �� �� �� �� ��
����
����
���
����
����
����
����
���
����
����
����
����
���
�� �����������
�� ������ ���������
������������� ���� �� ��������
����� ������
���
����
������
Gender
Figure 3: Decision tree quality plot of all classification results. The x-axis shows the number of decisions of the underlyingmodel, the y-axis the classification error (see Section 6). The upper plot shows the results for all variables, either metricsexpressed via their quantiles, or categorical. The lower plot displays the dummy variables derived from the original variables.Group affiliation of a data point is color coded: no group (a), subdivision into male and female subjects (b) and quartiles ofBody Mass Index (BMI) (c). The number of subjects represented in a variable is denoted using the dot diameter. We onlydisplay variables with an error below 0.5, results above this threshold are dismissed. The interactive plot (see supplementalmaterial) has clickable data points, displaying the corresponding decision tree in a tool tip. Results of high interest are locatedclose to the axis origins.
subgroups. These hypotheses, however, have to besubstantiated by dedicated statistical analyses andreplication in independent cohorts.
Predictive Power of Image-Derived Variables.The presented results indicate that torsion, curvatureand curvature angle of the lumbar spine at the pre-sented precision are not sufficient to describe lumbarback pain in the SHIP data set. Our method allowsto assess their discriminative power, which is largelylimited to separating male and female subjects, nutri-tion variables, as well as different disease indicators.The C4.5 algorithm proved to be an effective tool forevaluating a set of derived metrics regarding theirsuitability to classify non-image variables. Over-fitting to the data indicated by complex decision treeshas to be taken into account as well. The presentedmethod only captures linear relationships betweenvariables. To take more complex associations intoaccount, methods such as regression analysis have tobe incorporated.
Applicability. Methods supporting hypothesesgeneration based on image information are newto the application domain. They are an additionto the standard epidemiological workflow as theyhighlight new and possibly unknown relationships.Classification methods based on decision trees haveproven to be useful for assessing the discriminativepower of a variable set. Their ability to consider vari-able combinations makes them more powerful thancorrelation coefficients calculated for each variable.This advantage comes with a much more complexoutput, the results are more challenging to assess andto abstract. Our method to plot derived metrics andcustom-tailored error measures proved to be effective.Huge result spaces could be navigated fast using ourdecision tree quality plot. Therefore, the method isapplicable not only for deriving information based onimage data, but on all potential target variables.
Future Work. We will focus on more precise

models for extracting measures. Dented vertebraeindicate pathological deformation, and can be cap-tured by segmenting the top and bottom point ofeach vertebra center. Spine canal thickness indicatessigns of herniated disc disease and is also of interest.We aim to include the method into existing visualanalytics methods designed for analyzing shape infor-mation for epidemiological data (Klemm et al., 2014).
Outlook. Combining the power of statisticalanalyses, visual analytics and classification tech-niques is essential for analyzing increasingly complexheterogenous population data. These methods donot aim to replace the traditional epidemiologicalworkflow, but rather complement the weak points ofstandard statistical methods. Our method providesa novel way to gain insight into these complex datasets and amplifies hypotheses generation.
ACKNOWLEDGEMENTS
SHIP is part of the Community Medicine Research net ofthe University of Greifswald, Germany, which is fundedby the Federal Ministry of Education and Research (grantno. 03ZIK012), the Ministry of Cultural Affairs as well asthe Social Ministry of the Federal State of Mecklenburg-West Pomerania. Whole-body MR imaging was supportedby a joint grant from Siemens Healthcare, Erlangen, Ger-many and the Federal State of Mecklenburg-Vorpommern.The University of Greifswald is a member of the ‘Centre ofKnowledge Interchange’ program of the Siemens AG. Thiswork was supported by the DFG Priority Program 1335:Scalable Visual Analytics. This work was supported by thefederal state of Saxony-Anhalt under grant number ’I 60’within the Forschungscampus STIMULATE.
REFERENCESDeng, H., Runger, G., and Tuv, E. (2011). Bias of im-
portance measures for multi-valued attributes and so-lutions. In Artificial Neural Networks and MachineLearning–ICANN 2011, pages 293–300. Springer.
Emerson, J. W., Green, W. A., Schloerke, B., Crowley, J.,Cook, D., Hofmann, H., and Wickham, H. (2013).The generalized pairs plot. Journal of Computationaland Graphical Statistics, 22(1):79–91.
Fletcher, R. H., Fletcher, S. W., and Fletcher, G. S. (2012).Clinical epidemiology: the essentials. LippincottWilliams & Wilkins.
Glaßer, S., Niemann, U., Preim, B., and Spiliopoulou, M.(2013). Can we Distinguish Between Benign and Ma-lignant Breast Tumors in DCE-MRI by Studying a Tu-mors Most Suspect Region Only? In Proc. of Sympo-
sium on Computer-Based Medical Systems (CBMS),pages 59–64.
Hegenscheid, K., Seipel, R., Schmidt, C. O., Volzke, H.,Kuhn, J.-P., Biffar, R., Kroemer, H. K., Hosten, N.,and Puls, R. (2013). Potentially relevant incidentalfindings on research whole-body MRI in the generaladult population: frequencies and management. Eu-ropean Radiology, 23(3):816–826.
Hoy, D., Brooks, P., Blyth, F., and Buchbinder, R. (2010).The epidemiology of low back pain. Best Practice andResearch Clinical Rheumatology, 24(6):769 – 781.
Keim, D. A., Mansmann, F., Schneidewind, J., Thomas, J.,and Ziegler, H. (2008). Visual analytics: Scope andchallenges. Springer.
Klemm, P., Lawonn, K., Rak, M., Preim, B., Tonnies, K.,Hegenscheid, K., Volzke, H., and Oeltze, S. (2013).Visualization and Analysis of Lumbar Spine CanalVariability in Cohort Study Data. In Proc. of Vision,Modeling, Visualization 2013, pages 121–128.
Klemm, P., Oeltze, S., Lawonn, K., Hegenscheid, K.,Volzke, H., and Preim, B. (2014). Interactive vi-sual analysis of image-centric cohort study data.IEEE Trans. on Visualization and Computer Graph-ics, 20(12):1673–1682.
Mitchell, T. M. (1997). Machine learning. 1997. BurrRidge, IL: McGraw Hill, 45.
Niemann, U., Volzke, H., Kuhn, J.-P., and Spiliopoulou,M. (2014). Learning and inspecting classificationrules from longitudinal epidemiological data to iden-tify predictive features on hepatic steatosis. ExpertSystems with Applications.
Preim, B., Klemm, P., Hauser, H., Hegenscheid, K., Oeltze,S., Toennies, K., and Volzke, H. (2015). Visual Ana-lytics of Image-Centric Cohort Studies in Epidemiol-ogy, chapter Visualization in Medicine and Life Sci-ences III, page in print. Springer.
Rak, M., Engel, K., and Toennies, K. (2013). Closed-formhierarchical finite element models for part-based ob-ject detection. In Proc. of Vision, Modeling, Visual-ization 2013, pages 137–144.
Szpalski, M., Gunzburg, R., Melot, C., and Aebi, M. (2005).The aging of the population: a growing concern forspine care in the twenty-first century. In The AgingSpine, pages 1–3. Springer.
Turkay, C., Lundervold, A., Lundervold, A. J., and Hauser,H. (2013). Hypothesis generation by interactive vi-sual exploration of heterogeneous medical data. InHuman-Computer Interaction and Knowledge Dis-covery in Complex, Unstructured, Big Data, pages 1–12. Springer.
Volzke, H., Alte, D., Schmidt, C., et al. (2011). Cohort Pro-file: The Study of Health in Pomerania. InternationalJournal of Epidemiology, 40(2):294–307.
Zhang, Z., Gotz, D., and Perer, A. (2012). Interactive vi-sual patient cohort analysis. In Proc. of IEEE VisWeekWorkshop on Visual Analytics in Health Care.