Embed Size (px)
Citation preview

uée
Université Paris IX Dauphine UFR Sciences des Organisations Centre d’Etudes et de Recherche en Informatique Appliq
DISTRIBUEES ET SCALABLES
Présenté et soutenu par
Riad MOKADEM Le 19 septembre 2002
Sous la direction de : Witold LITWIN Professeur Université Paris Dauphine
Devant le jury composé de :
Geneviève JOMIER Professeur Université Paris Dauphine Serge HADDAD Professeur Université Paris Dauphine Alexis TSOUKIAS Professeur Université Paris Dauphine Année Universitaire 2001/2002
DANS LES BASES DE DONNEEES STOCKAGE UTILISANT LES SIGNATURES
Mémoire du DEA 127 (Rapport de Stage) Option : Bases de Données

Mémoire DEA Stockage utilisant les signatures dans les SDDS
Sommaire
2
Introduction…….…………...………………………………………………….… 1- Motivations et Objectif du stage..…………………………………………… 2- Généralités sur les systèmes Distribués
2-1 Les systèmes de stockage …………………………………………….. 2-2 Les systèmes distribués.……………………………………………….
3- Les Structures de Données Scalables et Distribuées
3-1 Généralités sur les SDDS 3-1-1 Les multi-ordinateurs ………………..……………………. 3-1-2 Architecture générale…………………………………….. 3-2 Principes des SDDS………………………………………………….
3-3 Les famille SDDS ….…………………………..………………..…… 3-4 Les SDDS RP* ……...………………………………………………. 3-4-1 Opérations sur les fichiers………………………………….
3-5 Prototype SDDS 2000 3-5-1 Composants du prototype SDDS 2000 ..….………………….. 3-5-2 Organisation d’une case de données……………………….…
3-5-3 Eclatement d’une case……………………………………. 3-6 Protocole de communication 3-6-1 Types de Messages ……………………………………….
3-6-2 Protocoles UDP, TCP…………………………………….. 3-6-3 Techniques de programmation Réseau :…………………..
- Les Sockets, Procédure RPC, Fichiers mappés en mémoire, les Threads. 4- Stockage dans SDDS 2000 4-1 Stockage de Fichier………………………………………………..
4-1-1 Message d’envoi de la requête…..………………………. 4-1-2 Message unicast…………………………………………. 4-1-3 Message de réception…………………………………….
4-2 Envoi de la requête………………………………………………… 4-2-1 Image erronée……………………………………………. 4-2-2 Libération de la mémoire…………………………………
4-3 Réception de la réponse par le client……………………………… 4-4 Traitement de la requête…………………………………………… 4-5 Mise à jour des données stockées……..……………………………
4-6 Remarques………………………………………………………….
Riad MOKADEM - CERIA 2001
5 6 8 10 11 11 11 12 1314 15 17 19 20 2121
25 25 27 27 28 29 29 29 32 32 32
/2002

Mémoire DEA Stockage utilisant les signatures dans les SDDS
5- Signature
3
5-1 Introduction……………………………………………………….
5-2 Signature de fichier………………………………………………. 5-3 Signature de fichier dans les systèmes SDDS 2000………………
5-3-1 Champs de Galois………………………………………. 5-3-2 Calcul de la signature…………………………………… 5-3-3 Signature dans le stockage de données………………….
5-4 Signature numérique SHA 1……………………………………… 5-4-1 Fonction de hachage SHA 1……………………………. 5-4-2 Implémentation………………………………………….
33 33 34 35 36 36 38 39 41 42 43 43 44 45 46 48 49 50 50 53 54 55 55 56 57 58 58
59 59 60 61 61 61 62 63
6- Récupération de Données………………………………….…………….. 6-1 Récupération au niveau du serveur…...……………………….… 6-2 Tolérance aux pannes…………………...………………………. 6-3 Interface de l’application………………...……………………… 7- Mesures de performances 7-1 Environnement expérimental…….……….…………..……….…..
7-2 Stockage de données……………………………………………… 7-3 Récupération de données…………………………………………. 7-4 Signature d’un fichier………………..….…………………….…..
Signature par page……………….………………………... 7-5 Stockage de données en utilisant les signatures………………….. 7-6 Synthèse………………………………………………………….. 7-7 Contrôle de flux………………………………………………...…. 7-8 Stockage du Fichier d’index………………..……………..……….. 7-9 Etude de la scalabilité………………………..……………...……. 7-10Paramètres de Stockage:
- Variation de la taille de pages de données………….…….. - Variation de niveau de signature………………...……….. - Calcul des signatures - Evolution des pages de données…………………………..
7-11 Cas particuliers :
- Signature après éclatement de la case………....…….…… - Utilisation d’un message unicast….……………………….
7-12 Corps de Galois GF(24)…………………………………..……………… 7-13 Signatures cryptographiques ………………………………………………… 7-14 Comparaison avec d’autres travaux………...………………………….. 7-15 Perspectives…...………………………………...……………….……. . 8- Conclusion……………………………………………………………...…… 9- Bibliographie……………………………………………………...……
Riad MOKADEM - CERIA 2001/2002

Mémoire DEA Stockage utilisant les signatures dans les SDDS
Remerciements Je tiens à exprimer vivement ma plus profonde reconnaissance à Monsieur Witold Litwin, Professeur à l’Université Paris Dauphine et Directeur du CERIA (Centre d’Etudes et Recherche en Informatique Appliqué), pour m’avoir proposé le sujet de ce mémoire, conseillé et dirigé tout au long du stage. Sa disponibilité, sa persévérance, son souci du détail ainsi que son encouragement m’ont beaucoup aidé tout le long de ce travail. Mes remerciements vont également à Monsieur Thomas Schwartz, Professeur à l’université de Santa Clara, pour sa collaboration et les discussions tout particulièrement en ce qui concerne les schémas de signatures algébriques. Je remercie Monsieur Aly Wane Diène qui a bien voulu m’aider par ses conseils à chaque fois que j’avais besoin des informations sur le prototype SDDS 2000 qu’il a implémenté en partie lors de sa Thèse en 2001. Je remercie également l’équipe du CERIA, Melle Rym Moussa pour ses conseils judicieux tout au long de mon travail ainsi que Monsieur Brahim Hammadi et Madame Janine Verepla. Je remercie Monsieur Tsangou, Maître Assistant à l’Université de Dakar qui a bien voulu relire attentivement mon mémoire. Je remercie aussi Monsieurs les Professeurs Gérard Lévy, Tore Rich (U. Uppsala), Peter Scheuermann (U. North Western), et Samba Ndiaye (U. Dakar) pour les discussions utiles à propos de mon sujet, durant les visites de ces derniers au CERIA. Enfin, je tiens à remercier également les membres du jury ainsi que l’ensemble des Professeurs du DEA 127.dont j’ai suivi les cours enrichissant mes connaissances variées. Mes remerciements vont notamment à Madame Suzanne Pinson, Responsable du DEA et Madame Geneviève Jomier, Responsable de la direction de Recherche ‘Bases de Données’ pour leur suivi attentif de mes études tout au long de la durée du DEA. Riad MOKADEM
4Riad MOKADEM - CERIA 2001/2002

Mémoire DEA Stockage utilisant les signatures dans les SDDS
Introduction Les dernières décennies ont été marquées par l’évolution rapide des circuits semi-conducteurs. Cela a eu pour conséquence directe, l’augmentation de la capacité de stockage des mémoires. De plus, l’augmentation régulière de la vitesse de la CPU (Central Processor Unit) et l’optimisation des architectures ont permis d’obtenir de remarquables temps d’accès à la RAM(1). Les temps d’accès aux disques durs, par contre, sont restés presque les mêmes, limités par les contraintes de structures mécaniques employées. En revanche, l’augmentation de la densité d’enregistrement a conduit à des augmentations impressionnantes de capacités de stockage à des prix chutant à chaque fois par d’importants ordres de grandeurs. D’un autre coté, les réseaux ont connu d’énormes avancées et l’arrivée des réseaux locaux à haut débit 100-1000 Mb/s a bouleversé l’utilisation de ces ordinateurs au niveau des entreprises, permettant le partage de diverses ressources et une communication plus fiable. De nouveaux concepts architecturaux et de nouvelles terminologies firent alors leur apparition et les Systèmes distribués commencèrent à se développer au dépens des systèmes centralisés. On parle alors de multi-ordinateur Réseau, de réseau de station de travail (NOW), plus récemment, de « Peer to Peer Computing »(2) ou encore de « Grid Computing ». Tous ces concepts visent d’atteindre une puissance de calcul et de stockage, notamment en mémoire vive, bien plus importantes que celle d’un super ordinateur à une fraction de coût de ce dernier en s’appuyant sur des ordinateurs existant interconnectés. Cette solution constitue la réponse prométtante aux exigences des applications modernes. On pourrait citer entre autres, les SGBDs, les systèmes multibases, les systèmes de Data- Mining, les serveurs WEB… nécessitant tous, un grand besoin de volumes de données et de puissances de calcul.
Ces nouvelles architectures impliquent de nouvelles techniques d’organisation de données. Notamment, plusieurs Structures de Données Scalables et Distribuées (SDDSs) ont été proposées dans ce but. En général, ces propositions partent du principe qu’actuellement, il est dix à cent fois plus rapide d’accéder à une page mémoire sur machine distante qu’au disque local. Les données d’une SDDS résident alors dans les mémoires vives des serveurs constituant ce multi-ordinateur. Les fichiers SDDS s’étendent d’un serveur à l’autre et peuvent être répartis sur un nombre indéterminé de serveurs d’une façon complètement transparente par rapport aux applications.
52001/2002Riad MOKADEM - CERIA
(1) RAM : Random Access Memory (2) Peer To Peer : Egal à Egal :Dans cette architecture, tous les ordinateurs sont à la fois serveurs et clients.

Mémoire DEA Stockage utilisant les signatures dans les SDDS
1- Motivations et Objectif du Stage
Le prototype SDDS 2000 disponible en téléchargement sur le site du CERIA [1] a été conçu pour les réseaux de station de travail WINDOWS2000 et WINDOWS NT, il permet de répartir un fichier SDDS à travers la mémoire vive disponible sur l’ensemble des serveurs sur lesquels s’étend ce fichier. Il n’y a pas de limite à priori sur le nombre de clients et de serveurs de SDDS-2000. La taille d’un fichier SDDS en RAM distribuée n’est potentiellement limitée que par le nombre de nœuds serveurs disponibles pour SDDS-2000 sur le réseau. Les expériences ont montré des temps d’accès aux enregistrements de l’ordre de 30 à 100 fois plus rapides qu’au disque local, sur le réseau 100 Mb/s. Ce prototype permet de créer plusieurs fichiers. Ceux-ci peuvent dès lors épuiser la quantité limitée de stockage de la RAM d’un serveur. Il devient utile de sauver les fichiers moins utilisés sur les disques locaux. Puis de les recharger en RAM sur demande. Ces fonctions manquaient au prototype. Leur conception et réalisation a fait l’objet de notre stage.
Pour rendre le stockage le plus rapide, nous avons pris comme principe de ne transférer sur le disque que les parties du fichier qui ont été modifiées depuis la dernière sauvegarde. Pour réaliser ce principe, nous avons expérimenté l’approche par des signatures. Notre choix a porté finalement sur une nouvelle technique de signatures algébriques, opérant sur les corps finis de Galois. Une partie importante de notre travail consistait dans la détermination de la manière optimale d’utilisation de cette approche afin d’atteindre notre but. Le résultat des expériences a servi à l’implémentation du prototype
Démarche suivie et contribution de notre étude
Nous avons étudié la littérature concernant les différents systèmes de stockage, local et distribué, afin de déterminer la stratégie à suivre pour l’implémentation du stockage dans notre système.
Nous avons trouvé plusieurs techniques ou architectures permettant de résoudre nos objectifs indépendamment les uns des autres. Nous avons donc essayé de les combiner tout en respectant l’architecture des SDDS et ainsi, profiter des avantages de chacune en essayant de diminuer leurs inconvénients. A la suite de cette étude préliminaire, notre choix s’est porté sur la conception suivante :
- Stockage à travers la grappe de PC : Les données sont stockées dans les mêmes serveurs contenant ces données. Cela nous permet de garder l’architecture des multi-ordinateurs. Nous verrons par la suite qu’elle procure des capacités de passage à l’échelle (scalabilité).
- Approche logicielle totalement distribué : Cette approche permet de procurer la transparence de la gestion du système de stockage.
- Stratégie de tolérance aux pannes performante : Nous avons essayé d’implémenter une stratégie de tolérance aux pannes tout en ne consommant pas beaucoup de mémoire comme c’est le cas dans la plupart des stratégies de tolérance aux pannes.
6 2001/2002Riad MOKADEM - CERIA

Mémoire DEA Stockage utilisant les signatures dans les SDDS
Plan du mémoire : Dans le chapitre 2, nous donnerons une brève présentation des systèmes distribués. Le chapitre 3 décrit le prototype SDDS 2000. Nous passerons en vue les différentes techniques de programmation utilisées tout au long de notre travail. Par la suite, dans le chapitre 4, on abordera le stockage des données et le protocole proposé. Le chapitre suivant décrit les signatures et l’implémentation de ces derniers dans le module du stockage. Le 6 ème chapitre est consacré au module de chargement des données. Dans le chapitre 7, nous commenterons les mesures de performances des différentes primitives implémentées permettant de confirmer les résultats théoriques obtenus. Le dernier chapitre contient nos conclusions, les perspectives ouvertes par ce travail et les travaux futurs.
7 2001/2002Riad MOKADEM - CERIA

Mémoire DEA Stockage utilisant les signatures dans les SDDS
2- Généralités sur les systèmes Distribués
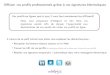
2-1 Systèmes de stockage On distingue deux principales architectures pour le stockage de données sur réseaux[3] : Stockage attaché à un réseau NAS (Network attached Storage) : C’est la solution la plus simple, elle consiste en un ensemble de disques durs vu comme un serveur sollicité par les clients et connecté au réseau Ethernet. Sous réseau local de stockage SAN (Storage Area Network) : Cette solution forme des sous-réseaux à haut débit dédiés au stockage et venant s’intégrer au réseau principal. Les clients doivent envoyer des requêtes de fichiers aux serveurs pour recevoir les données du SAN. Contrairement au système NAS, le SAN est dépourvu d’un système de gestion de fichier.
Figure 2.1 : Architecture NAS Figure 2.2 : Architecture SAN
Client
Serveur
Réseau TCP/IPClient Client
Serveur de stockage
ServeurServeur
CISCOSYSTEMS Passerelle SCSI/Fiber Channe
Serveur de stockage Serveur de stockage
SAN
Client
Serveur
Réseau TCP/IPClient Client
Serveur NAS Serveur
2-1-a Objectifs du stockage de données : Plusieurs objectifs sont à prendre en compte dans la construction d’une solution de stockage. Les plus importants sont : L’intégrité, la sécurité, la transparence et la limitation des coûts associés. Intégrité : L’objectif vital est d’offrir une longue vie, infinie si possible, aux données. Pour cela, il faut garantir que ces données ne seront jamais perdues. En d’autres termes, elles doivent survivre aux incidents matériels, lors d’un passage d’un média à l’autre ou encore lors de transfert d’une machine à l’autre. Performance : L’architecture du stockage de données doit être en rapport avec les performances attendues. Les équipements matériels responsables de la performance sont les
8 2001/2002Riad MOKADEM - CERIA

Mémoire DEA Stockage utilisant les signatures dans les SDDS
périphériques de stockage, les ordinateurs hôtes de ces périphériques et surtout le réseau informatique reliant les utilisateurs et les machines de traitement. En particulier, le transport des données de et vers un ordinateur les utilisant ne doit pas constituer un goulot d’étranglement pour le réseau.
Sécurité : L’architecture doit être ouverte dans le sens que de nombreuses machines doivent pouvoir accéder aux données. Les données constituant la plupart du temps une ressource partagée.
Transparence : La notion de transparence signifie que les détails de l’implémentation du stockage doivent être masqués à l’utilisateur. On distingue plusieurs types de transparences : Transparence de concurrence : un utilisateur n’est pas conscient que d’autres utilisateurs
accèdent aux données concurremment. Transparence d’emplacement de données : les utilisateurs sont incapables de savoir à quel ordinateur les données sont rattachées. Transparence d’emplacement des utilisateurs : les utilisateurs stockent les données de la même façon quelle que soit la machine du réseau sur laquelle ils sont connectés. Transparence de nommage : les structures de données tels que les fichiers doivent avoir des noms uniques indépendamment des moyens de stockage utilisés.
Transparence de représentation des données : le format interne des données stockées n’est pas connu des utilisateurs.
Limitation de coûts : L’architecture d’une solution de stockage doit permettre un stockage de grands volumes de données à coûts réduit.
2-1-b Exemples de Systèmes de stockage réparti : 1- Système de stockage distribué et parallèle (Distributed Parallel Storage System DPSS) Cette technique se base sur la technologie de « Grid »(4). Les données se trouvant sur un seul client sont transférées vers de larges tampons (buffers) implémentés dans différents serveurs constituant le réseau (LAN ou WAN). Les différents systèmes de gestions de fichiers s’occuperont alors de stocker ces donnée sur les disques locaux en parallèle. Des algorithmes de partitionement de données sont également utilisées pour une meilleure reconstitution des données notamment la stratégie Round Robin (partitionement en fragments de même taille) en plus de la réplication au niveau des serveurs.
2- Système en Cluster (3) (Cluster File System CFS) Le système de stockage CFS est dédié au flux vidéo et est implémenté sur une grappe de PC connecté par le réseau haut débit Myrinet. Du point de vue stockage, chaque PC appelé aussi nœud possède un ensemble de disques auquel accède localement. L’ensemble de ces disques constituera l’espace de stockage du CFS. Un client s‘adressera à ces sites comme s’il s’agissait d’un seul serveur. Par ailleurs, la gestion de ce système est totalement distribuée entre les nœuds de la grappe. Les données sont distribuées et rapatriées des nœuds suivant la stratégie RAID (5), utilisant des disques de parité et procurant ainsi un système fiable.
9
(3) Cluster : Ensemble de systèmes informatiques indépendants(4) Grid : Technologie en Grille ; chaque ordinateur pouvant communiquer avec un autre se trouvant sur cette grille. (5) RAID ( Redundant Arrays of Indendent Disks) : extra disques contenant des informations redondantes et servant à une récupération
en cas de panne.
2001/2002Riad MOKADEM - CERIA

Mémoire DEA Stockage utilisant les signatures dans les SDDS
3- Architecture à disques partagés : (Shared Disk) Dans cette approche, chaque processeur dispose de sa propre mémoire privée et pourra accéder à n’importe quel disque à travers le réseau d’interconnexion. Il pourra ainsi stocker une page de donnée sur un disque lointain partagé dans son propre cache disque. Par ailleurs, on retrouve d’autres architectures pour le stockage notamment l’architecture NUMA(6) .
2-2 Les systèmes distribués L’interconnexion de plusieurs microprocesseur entre eux permet d’obtenir une puissance de calcul difficilement atteignable sinon non atteignable par les plus grandes machines disponibles actuellement. Un système distribué s’appuie sur un gestionnaire de fichiers physiquement distribué. Le gestionnaire de fichier permet de travailler au niveau logique et est responsable de la liaison avec le niveau physique. Cette distribution de données doit garantir l’équilibre de la répartition de données à travers les nœuds. Elle prend aussi en charge le stockage des données et la gestion des accès distants. Pour cela, on retrouve deux approches : 1- Approche statique : Dans cette approche, un fichier est stocké sur un site alloué initialement. La mise à jour de ces fichiers nécessite alors une re-distribution de ce fichier et la suppression de l’ancienne version. On retrouve plusieurs produits commercialisés tels que NFS(7) et AFS(5). Par ailleurs, quelques méthodes se basent sur un partitionement statique pour répartir un fichier sur plusieurs sites. Round Robin : Cette méthode est utilisée dans les systèmes de stockage RAID permettant de partitionner une relation en fragments de même taille. 2- Approche dynamique : Suivant cette méthode de distribution, le nombre de sites et les critères de partitionnement d’un fichier ne sont pas figés durant la vie de celui ci. Parmi les schémas de partitionnement dynamiques, nous citerons :
DLH(Distributed Linear Hashing) Ce schéma se base sur les architectures de multiprocesseur faiblement couplé et à partage de mémoire. Chaque fichier réside en mémoire centrale et ses paramètres sont stockés en mémoire cache locale de chaque processeur.
SDDS Les structures de données scalables et distribuées ont été proposées pour mettre des fichiers en mémoire distribué dans un environnement multi-ordinateur. Un fichier SDDS n’a pas de répertoire central et peut s’étendre d’un seul site à un nombre indéterminé de sites.
Riad
(6) NUMA : Non-Uniform Memory Access : Ensemble de machines interconnectées et à mémoire partagée.(7) NFS (Network File System) Système de fichiers réparti le plus répandu. (8) AFS (Andrew File System) : Système de fichier distribué dans l’environnement Andrew.
10 2001/2002 MOKADEM - CERIA

Mémoire DEA Stockage utilisant les signatures dans les SDDS
3- Les Structures de Données Scalables et Distribuées 3-1 Généralités :
3-1-1 Multi-Ordinateurs Un Multi-ordinateur est un réseau de station de travail et de PCs faiblement couplés, interconnectés par un réseau d’au moins 10Mb/s(Ethernet, ATM, Fast et Giga Ethernet). Chacune de ces CPU a un accès direct à sa propre mémoire locale[5]. La technologie « Peer To Peer » ou « Egal à Egal » désigne un type de communication pour lequel toutes les machines sont d’une même importance, en d’autres termes, à la fois clients et serveurs. On ne retrouve plus les problèmes de goulot d’étranglement et d’extensibilité existants dans les systèmes précédents et donc, l’ajout de ressources ne nécessite pas de grandes modifications au niveau physique. De plus, une panne au niveau d’une machine n’affectera pas le fonctionnement de la tâche du fait de la distribution de celle-ci sur plusieurs machines. Une entreprise n’aura pas à remplacer une machine (gros ordinateur) par une autre plus puissante mais plutôt à augmenter le nombre de ressources à travers son réseau assurant ainsi une croissance progressive.
Mémoire local
UC
Station de travail Station de travail Station de travail
DonnéesSDDS
Mémoire local
UC
Mémoire local
UC
DonnéesSDDS
DonnéesSDDS
Figure 3.1 : Multi-Ordinateur
3-1-2 Architecture générale de SDDS Les SDDS sont basés sur le modèle Client / Serveur permettant la création de fichiers scalables répartis sur les serveurs de notre système. Ces fichiers sont stockés en mémoire centrale distribuée sous forme de fragments appelés Cases. Il est beaucoup plus rapide d’accéder à des données se trouvant dans la mémoire d’une machine distante que sur un disque local. Le client SDDS est installé sur la même machine que les applications et sera vu comme un service WINDOWS2000/NT. Il est chargé d’intercepter les requêtes de l’application puis de les acheminer vers les serveurs. Il se charge aussi de recevoir les réponses de ces derniers et de les transmettre aux applications respectives.
3-2 Principes des SDDS : L’architecture SDDS permet à un fichier d’être composé d’un nombre illimité d’enregistrements en l’étendant d’un seul site de stockage à un nombre indéterminé de
11 2001/2002Riad MOKADEM - CERIA

Mémoire DEA Stockage utilisant les signatures dans les SDDS
sites(Serveurs). Cela se fait par des éclatements. Dans le cas de SDDS RP, ces enregistrements sont ordonnés à l’intérieur d’un fichier suivant la valeur de leur clé et sont accédés à partir des clients. Par ailleurs, l’une des techniques les plus intéressantes dans les SDDS c’est de pouvoir accéder à un enregistrement donné en un minimum de messages. En effet, cet accès nécessite au maximum deux messages, l’un pour envoyer la requête et l’autre pour recevoir la réponse à cette requête.. Cela est possible du fait de l’existence d’une image approximative de chaque fichier au niveau de chaque client. Cette image peut être erronée car elle est devenue inexacte. Le serveur cible s’occupera alors de rediriger cette requête vers le bon serveur. Celui-ci exécute cette requête puis envoie le résultat accompagné de l’image corrective IAM(Image Adjustment Message) au client. Finalement, le client ajuste son image. En conséquence, il ne fera plus jamais la même erreur. En résumé, les fichiers SDDS présentent les caractéristiques suivantes :
- Un fichier SDDS n’a pas de répertoire central d’accès. Cela permet d’éviter les goulots d’étranglement. - Les serveurs sont responsables du traitement des requêtes et de leur redirection en cas d’image erronée.
La Scalabilité La scalabilité d’un système se résume en sa capacité de supporter une montée en charge concernant les besoins en ressources. En effet, le but de tout système est d’offrir plus de rapidité de calcul sur des opérations de plus en plus complexes. Cela nécessitera des machines spécialisées comportant des ressources non atteignables. La scalabilité constitue cette capacité de supporter cette extensibilité[2]. On étudiera la capacité de notre système à supporter un besoin croissant en espace de stockage en plus de la variation du calcul de la signature pour ces différents espaces de stockage. 3-3 Les Familles SDDSs : Plusieurs SDDS ont été proposés. On constate deux grandes familles.
La famille dite LH* (Linear Hashing) est basée sur la technique du hachage linéaire distribué à travers le réseau. L’adressage d’une case est calculé à partir de la fonction de hachage hi :c c mod 2iN où c représente la clé ; N le nombre initial de cases et i le niveau de fichier(plus grand indice des fonctions de hachage). Un autre schéma appelé DDH développe une version distribuée du hachage dynamique DH.
Lh* lh est une variante de LH* visant les architectures multiprocesseurs à partage de rien. Lh* rs est une autre version de LH* pouvant supporter la haute disponibilité se basant sur des données de parités stockées au niveau de sites de parité. Le calcul de parité se base sur les codes de Reed Solomon. Cette version permet notamment la reconstitution de données en cas de panne d’un ou plusieurs serveurs.
12 2001/2002Riad MOKADEM - CERIA

Mémoire DEA Stockage utilisant les signatures dans les SDDS
La famille RP*(Range Partitionnning) prend en considération l’ordre des éléments. Nous nous s’intéresserons à cette famille tout au long de notre travail. D’autres modèles de SDDS sont disponibles actuellement notamment celles offrant l’accès multi-clé et la haute disponibilité. 3-4 LES SDDS RP* La structure d’un fichier RP est similaire à celle d’un arbre B+ (variante d’arbres B implémenté en mémoire centrale). Chaque fragment d’un fichier correspond à une case pouvant contenir un maximum de b enregistrements. Ces fragments sont stockés au niveau de la mémoire centrale des serveurs. Chacune des cases, lui est associée un intervalle de clés borné par une clé minimale et une clé maximale. Ainsi, un enregistrement de clé c appartiendra à la case d’intervalle [CMin ,CMax ] telle que : CMin <c< CMax .L’ensemble des cases constituera un ensemble de clés ordonnées Initialement, un fichier RP* est composé d’une seule case avec un intervalle initial [ -∞⎯ , +∞⎯ ]. Toutes les insertions se font dans cette case jusqu’à dépassement de la capacité maximale de cette case. Un éclatement est alors provoqué transférant vers un nouveau serveur tous les enregistrements (au nombre de b/2) ayant de clés supérieures à la clé médiane de la case. Les SDDS RP* n, RP*c et RP*s constituent les composants de la famille RP*.
Un client RP*n envoie les requêtes aux serveurs en utilisant uniquement des messages multicast ce qui génère un trafic important de messages. Il n’a pas d’images concernant les fichiers disponibles dans les différents serveurs contrairement au Client RP*c. Chaque client RP*c dispose d’une image des fichiers, lui permettant d’utiliser des messages unicast à chaque fois qu’il s’adresse à un serveur déjà référencé. Des messages multicast sont utilisés dans le cas contraire.
clients
réseau
Serveurs en RAM
IAM
Image du client
Serveurs
Clients
Figure 3.2 : Evolution de l’image de client accédant à un fic
13Riad MOKADEM - CERIA
Re-direction
hier SDDS
2001/2002

Mémoire DEA Stockage utilisant les signatures dans les SDDS
Le serveur recevant une requête vérifie d’abord la disponibilité de la clé dans son intervalle. Dans le cas défavorable, cette requête est ignorée sinon, elle est envoyée à l’ensemble des serveurs par message multicast en joignant l’adresse et intervalle de clés du serveur ayant effectué la re-direction. Une réponse à une requête envoyée sans erreur d’adressage contient un IAM du serveur ayant traité la requête. Cet IAM comporte son adresse et son intervalle de clés. Une réponse à une requête redirigée comporte deux IAM correspondant au serveur ayant fait la redirection et celui ayant traité cette requête. Le client corrige son image afin de ne plus reproduire cette erreur d’adressage. Un client RP*s diffère d’un client RP*c par l’ajout d’un index distribué au niveau des serveurs indexant toutes les cases constituant ainsi des serveurs d’index. Cet index représente l’image globale d’un fichier distribué. Par ailleurs, son but est de remédier à l’utilisation de messages multicast, il n’utilise que des messages unicast mis à part les requêtes parallèles qui nécessitent des messages multicast. Lorsqu’un client fait une erreur d’adressage, le message n’est plus redirigé par multicast vers les autres sites serveurs. Le serveur qui a reçu la requête utilise sa table d’index pour envoyer un message unicast vers le bon serveur.
Comparaison :
3-4-a Opérations sur les fichiers Les clients effectuent diverses opérations sur les fichiers présents dans les mémoires des différents serveurs en envoyant des requêtes aux serveurs concernés. Ces opérations concernent la mise à jour, la suppression et l’insertion de nouveaux enregistrements…etc. On distingue deux types de requêtes :
a- Requête Simple (Key request) Elle correspond à la recherche, à l’insertion, à la suppression ou à la mise à jour d’un enregistrement de clé c ou encore au stockage et chargement des enregistrements constituant une case d’un fichier se trouvant sur différents serveurs. b- Requêtes parallèle Ces requêtes concernent la recherche ou insertion d’un ensemble d’enregistrements appartenant à un intervalle de clés. On appellera cet intervalle l’intervalle de la requête.
14
RP*s : Index sur le serveur RP*c : Index sur le client RP*n : Sans index
Figure 3.3 : Schéma comparatif des protocoles RP*n, RP*c, RP*s
Progression de la complexité de l’implémen-tation
Progression de la charge sur le réseau
2001/2002Riad MOKADEM - CERIA

Mémoire DEA Stockage utilisant les signatures dans les SDDS
Ces requêtes sont envoyées à l’ensemble des serveurs par un message multicast traité ensuite par chaque serveur dont l’intervalle de clés correspond à celui de la requête. Les résultats de ces requêtes sont ensuite envoyés aux clients de façon parallèle.
3-5 Prototype SDDS-2000
Vue globale :
L’architecture de SDDS 2000 se base sur le modèle Client/ Serveur. Ce modèle, apparu au début des années 90, a eu un impact très positif dans le domaine des SGBDs et s’est très vite répandu dans les entreprises. Ce modèle se base sur le fait qu’un processus demandera l’exécution d’une tache à un autre processus (serveur) par l’envoi d’un message qu’on appellera requête. Après exécution de cette opération, une réponse est transmise par le serveur au client.
Sous SDDS 2000, le dialogue client/ serveur est géré par un protocole de communication appelé SDDS-CP (Communication Protocol).
3-5-1 Composants de SDDS-2000 On retrouve quatre composants :
Les Serveurs SDDS : Un serveur SDDS se charge d’exécuter la tâche demandée par le client. Par la suite, une réponse est éventuellement envoyée aux clients.
Les Clients : Un client permet aux applications de formuler leurs requêtes sur les différents fichiers SDDS. Cet accès est fait d’une façon transparente par rapport à l’application.
Le Serveur d’Index : Ce serveur comprend l’index sur les différents fichiers.
Le Serveur de Noms Il s’occupe de l’attribution de noms de fichiers et leur unicité. Il doit être consulté avant chaque création d’un fichier.
Serveurs SDDS Les SDDS 2000 se basent sur des serveurs dits concurrents. Un processus indépendant est créé pour traiter chaque requête d’un client à travers un port qui lui est réservé.
Fonctionnement du Serveur :
Un serveur peut supporter plusieurs cases appartenant à des fichiers différents. La gestion interne des cases est réalisée au niveau du serveur : initialisation d’une case, stockage des données suivant une structure de données, gestion des index, éclatement d’une case qui déborde…etc.
Le serveur se sert de mécanismes assurant le dialogue entre le serveur et les autres composants de SDDS 2000. Ces mécanismes concernent la réception des messages et leur
15 2001/2002Riad MOKADEM - CERIA

Mémoire DEA Stockage utilisant les signatures dans les SDDS
décomposition, le formatage des messages suivant la structure attendue par les récepteurs ou encore l’envoi des messages. C’est le niveau d’implantation de SDDS CP.
Un premier processus léger (thread) d’écoute sur un port du réseau, adopte le fonctionnement suivant :
- Attente de l’arrivée d’une requête émise par un client SDDS. - Mise de la requête dans une file d’attente - Signalement de cet évènement. - Retour à la première étape.
Un groupe de processus léger de travail adopte, le fonctionnement suivant :
- Attente de l’évènement signalant l’arrivée d’une requête. - Prélèvement de la requête de la file d’attente. - Analyse de la requête et identification du traitement correspondant. - Traitement ou redirection de la requête vers un autre serveur. - Retour
Client SDDS
Un client SDDS supporte tous les algorithmes de la famille RP*. Il propose à l’application locale un service d’accès aux données des fichiers SDDS et se charge de structurer les requêtes mettant en forme tous les paramètres. Par la suite, ce message est acheminé aux serveurs en utilisant les Win Socket.
Le client dispose de deux modules appelés module d’Envoi et module de Réception. Module d’Envoi C’est le module d’émission des requêtes, il réceptionne les messages venant des applications locales puis les achemine aux serveurs correspondants en se basant sur son image (cas de RP*c et RP*s). Une correspondance est faite entre chaque requête envoyée et l’application correspondante.
Module de Réception Le module de réception reçoit les données et acquittements provenant des serveurs sur les ports correspondants, extrait les données puis les présente à l’application correspondante dans un format convenable. Dans le cas d’une requête simple, la réponse attendue peut être accompagnée d’une image IAM pour la mise à jour de l’image du fichier sur lequel la requête initiale a été appliquée.
Serveur de Noms
Le serveur de noms joue un rôle primordial dans le système SDDS 2000. Il assure l’attribution des noms de fichiers SDDS et assure leur unicité. Il s’occupe de l’attribution des numéros de serveurs pour la gestion de haute disponibilité. Il permet aussi de fournir l’adresse de la prochaine case à un serveur dont la case éclate.
16 2001/2002Riad MOKADEM - CERIA

Mémoire DEA Stockage utilisant les signatures dans les SDDS
Le serveur de noms est lui aussi basé sur le modèle multi-thread avec des threads d’écoute et des threads de travail. Il a une structure semblable à celle d’un serveur de données et est implémenté selon le modèle client/ serveur où les clients et les serveurs de données jouent le rôle de clients soumettant leurs requêtes au serveur de noms.
3-5-2 Organisation d’une case SDDS
Les SDDS permettent un stockage important des données en mémoire centrale. L’accès à ces données est possible à travers l’existence de réseaux performants de transmissions de données. Pour permettre de bonnes performances lors des réponses aux différentes requêtes formulées, ces données sont mises dans des structures appelées cases de données (Buckets).
En-tête
Index SDDS B+-tree
Pages de données
Figure 3.4 : Organisation Interne d’une case SDDS
Une case SDDS est stockée en mémoire centrale grâce à la technique de fichier mappé qu’offre WINDOWS NT et Windows 2000. Toutes les méthodes de communication inter processus fournies par l’API WIN32 reposent sur cette technique.
Noeudsinternes
En-têted'une feuille
...
...... ... ...
...
...
Racine
Feuilles oupages de données
Figure 3.5: Architecture d’une case
17 2001/2002Riad MOKADEM - CERIA

Mémoire DEA Stockage utilisant les signatures dans les SDDS
Deux fichiers mappés en mémoire sont utilisés :
1- Fichier d’index et zone de l’en-tête : L’indexation au sein d’une case SDDS s’appuie sur le modèle d’arbre B +. Ces structures, développées en 1972 par Bayer et McCreight, constituent aujourd’hui le standard d’implémentation d’index dans les systèmes de gestion de fichiers et les SGBD grâce à une grande efficacité dans les accès aux données.
. Le premier niveau de cet arbre est appelé racine, il sert d’index à un second niveau, lui même indexant un troisième niveau qui fait référence aux listes d’enregistrements constituant les feuilles de l’index. Chaque couple (clé, pointeur) constitue la valeur d’index contenu dans les nœuds internes. La racine de l’index contient entre 1 et 2K (K>>1) valeurs d’index. Tout nœud autre que la racine et les feuilles, doit contenir m valeurs d’index telle que K<m<2K. Par ailleurs, chaque feuille peut contenir un nombre n d’enregistrements tel que L<n<2L (L>>1).
Nn Flag Tn Ps C0 P0 C1 P1 CTn-1 PTn-1
En-tête
Valeur d'index
Figure 3.6 : Structure d’un nœud interne
Les nœuds occupent tous la même taille en espace mémoire, allouée à la création. Ils sont composés d’une en-tête suivi d’une zone de stockage de ses valeurs d’index.
Nn : numéro du nœud. Flag : indication qu’un nœud constitue la racine de l’index ou un nœud interne. Tn : nombre courant de valeurs d’index stockées dans le nœud. Ps : pointeur vers le nœud suivant. (Ci, Pi) : valeurs d’index ordonnés. C0 représente la clé minimale et Cn-1 sa clé maximale. Le pointeur Pi pointe vers le nœud fils dont les clés c sont t q C i-1 <c<Ci. 2- Fichier de données:
La zone de données contient les feuilles de l’index avec les données. Chaque feuille est constituée d’une liste d’enregistrements ordonnés suivant les clés (page de données).
CmaxNn Flag Np Pe E0
En-tête
Tf Fp Ps ETf-1
Enregistrement
E1
Figure 3.7: Structure d’une page de données
18 2001/2002Riad MOKADEM - CERIA

Mémoire DEA Stockage utilisant les signatures dans les SDDS
Chaque feuille ou page de données est composée d’un en-tête suivi d’une zone de stockage des enregistrements. Ces enregistrements sont organisés en blocs de taille fixe correspondant aux feuilles de l’index.
On trouve les différents paramètres suivants : Nn, Flag, Ps : même signification que dans l’en-tête d’un nœud interne. Tf : le nombre courant d’enregistrements. Pe : pointeur vers le premier enregistrement possédant la plus petite clé de la page. Cmax : représente la clé maximale de la page. Les Enregistrements Chaque enregistrement est composé d’une en-tête suivi d’une zone de données contenant les enregistrements. Dans cet en-tête, on retrouve des paramètres désignant la longueur de l’enregistrement, le pointeur vers l’enregistrement suivant et la clé de l’enregistrement.
3-5-2 Eclatement d’une case SDDS : Un fichier SDDS peut s’étendre dynamiquement vers un nombre indéfini d’ordinateurs. Cela est possible grâce à l’éclatement des cases de données. Une case est éclatée lorsqu’elle atteint sa capacité maximale définie à la création du fichier. Le choix du serveur qui reçoit la nouvelle case est déterminé par le serveur sur lequel intervient l’éclatement appelé aussi coordinateur . Protocole d’allocation de site :
Une politique des enchères est appliquée, elle consiste à envoyer une demande d’offre à un groupe de sites puis effectuer des évaluations sur les réponses reçues. Cette technique se base sur la taille de la mémoire physique des sites cibles candidats. Ainsi, ce sont les serveurs n’ayant pas encore atteint le nombre maximum des cases autorisées et ne possédant pas encore une case appartenant au fichier correspondant à la case qui débordent. La taille mémoire des serveurs candidats doit être supérieure à la taille de la case Procédure d’éclatement :
Après la détection d’un débordement au niveau d’un serveur, celui ci envoie un message multicast appelé SplitRequest à l’ensemble des serveurs, constamment en écoute sur un port UDP.
L’éclatement de la zone de données consiste à diviser les enregistrements d’une case débordée en 2 groupes, chacun comportant b/2 enregistrements (b : nombre d’enregistrements d’une case débordée). Cette division est réalisée à partir de la clé du milieu de l’éclatement cm. La recherche est effectuée de façon séquentielle dans les feuilles de l’index pour déterminer cette clé du milieu et la zone de données est divisée en deux parties de même taille. Une partie constituée des enregistrements de clé inférieure à cm, l’autre partie comprend les enregistrements de valeur de clé supérieure à cm.
19 2001/2002Riad MOKADEM - CERIA

Mémoire DEA Stockage utilisant les signatures dans les SDDS
Migration des données : La migration consiste à déplacer les enregistrements appartenant à la moitié supérieure de la clé médiane vers le serveur sélectionné pour réaliser l’éclatement. Par ailleurs, durant cette étape, une mise à jour de l’index est nécessaire pour corriger les pointeurs de l’index.
3-6 PROTOCOLE DE COMMUNICATION SDDS 2000 s’appuie sur le protocole TCP/IP. Celui ci assure l’interopérabilité entre une grande variété de plates formes et de technologies réseaux. Ce protocole fait référence à toute une famille de protocoles à l’intérieur de laquelle se retrouvent TCP, UDP. Ces derniers sont les principaux protocoles de la couche de transport. Ils se basent sur le protocole IP ( couche réseau). TCP assure la transmission par flot, fiable et en mode connecté. UDP assure la transmission par message, non fiable et en mode non connecté. Outre sa normalisation et sa standardisation universelle, le protocole TCP/IP est idéal pour l’adressage des éléments d’architectures distribuées. 3-6-1 Types de Messages : Dans un système distribué, toutes les communications se font par des échanges de messages. On distingue deux types de messages échangés entre les différents composants de SDDS-2000 : les messages de données et les messages de service. Les messages de service sont utilisés lors de l’initialisation d’un client, d’un serveur de données, du serveur de données ou encore d’une case de parité. Ils sont aussi utilisés lors de l’allocation d’un site pour l’éclatement d’une case ou lors du contrôle de flux. Les messages de données font référence aux messages utilisés pour l’accès aux données distribuées (requêtes des clients, réponses des serveurs) ou lors du transfert de données lors d’un éclatement d’une case de données.
Client
Serveur d’Index
Serveur de Noms
Serveur de Parité
Serveur de Données
Figure 3.8 : Communication entre composants de SDDS-2000
Chaque type de message est identifié de manière unique. Une procédure de décodage permet au récepteur d’interpréter ce message.
20 2001/2002Riad MOKADEM - CERIA

Mémoire DEA Stockage utilisant les signatures dans les SDDS
SDDS CP constitue le protocole de communication entre les différents composants de cette architecture, il est basé sur UDP pour les messages courts et TCP pour de longs messages dépassant 64 KO. 3-6-2 Le protocole UDP Ce protocole assure l’acheminement de messages, appelés datagrammes UDP, d’une application vers une autre. Ces datagrammes sont d’abord encapsulés dans des paquets IP puis acheminés vers leur destination. La délivrance de ces datagrammes sans perte et d’une manière ordonnée n’est pas garantie. En conséquence, UDP est utilisé pour les transmissions courtes non sécurisé. C’est un protocole plus rapide et plus simple que le protocole TCP. Un message UDP peut être envoyé à un seul destinataire ou à un ensemble d’applications (communication en diffusion)[11].
Un message peut être envoyé en diffusion pour deux raisons : - l’émetteur ne connaît pas l’adresse du destinataire. - le message est destiné à tout un groupe.
On distingue deux sortes de groupes : le Broadcast : Ensemble de sites appartenant au même groupe multicast.
le Multicast : Adresse reconnue par tous les sites du réseau. Le message est adressé à tous les sites.
Remarque Lors de l’envoi du message de service de stockage, les requêtes envoyées aux serveurs
seront structurées sous forme d’un message UDP. Le protocole TCP : Dans le protocole TCP, l’émetteur doit établir une connexion avec le récepteur. Ce protocole s’assure que les paquets transmis sont bien reçus et dans le bon ordre et que les paquets perdus sont retransmis assurant ainsi une grande fiabilité de transfert de données. Les données transmises sont encapsulées dans des datagrammes du protocole IP. Ce dernier décrit la manière dont matériels et logiciels coopèrent selon une architecture en couches permettant une communication entre des applications grâce à la notion de ports. 3-6-3 Communication entre processus : Les communications entre les composantes SDDS 2000 sont basées sur le modèle des Sockets. a- Manipulation des Sockets Les sockets constituent un mécanisme réseau standard dont l’origine remonte à l’Unix de Berkley. L’évolution vers des mécanismes de communication inter-processus dans l’environnement Windows a donné naissance aux Sockets Windows. Un socket est caractérisé par une adresse Internet et un numéro port sur la machine locale. Une paire de sockets, une pour la machine de client, l’autre pour la machine
21 2001/2002Riad MOKADEM - CERIA

Mémoire DEA Stockage utilisant les signatures dans les SDDS
serveur, définit la communication entre le serveur et le client identifiant un processus ou une application de manière unique sur le réseau[6]. Ils offrent un service de communication avec connexion (socket séquence de données) dans le cas d’une communication orientée flux de données. Ils peuvent être aussi utilisés pour une connexion orientée messages (socket data gramme) en utilisant le protocole UDP.
De Données
Echange Machine a
Socket a
@Ip a, N° Port
Machine b
Socket b
@Ip b, N° Port
Figure 3.9 : Communication entre deux machines par sockets
b- Appel de procédure distante RPC (Remote Procedure Call) : Les processus de Windows NT possèdent chacun leur propre espace d’adressage, il n’est pas alors possible d’appeler directement une procédure d’un autre processus. Les moyens de communication entre programmes de machines distantes sont fournis par les RPC. Un programme qui appelle une fonction exécutée par un autre programme sur la même machine utilise un appel LPC (Local Procédure Call). Dans notre système, les appels de procédures locales sont utilisés lors de la communication entre le client et l’application.
c- Les fichiers mappés en mémoire Windows NT se caractérise par une grande protection de la mémoire. Un processus n’a aucun moyen d’accéder aux ressources ou données d’un autre processus d’où la difficulté de partage de données.
Cela se fait dans Win NT à l’aide de fichiers mappés. La technique de fichiers mappés se contente de faire correspondre au fichier une plage d’adresses mémoire dans l’espace d’adressage virtuel de l’application. Une vue du fichier est ensuite créée. L’accès à ce fichier se fera alors à travers un pointeur, les autres threads accèdent à ce pointeur en appelant la fonction OpenFileMapping().
La technique des fichiers mappés permet ainsi aux threads du processus d’accéder simultanément au contenu de cet espace d’adressage.
La différence avec la mémoire virtuelle est que l’allocation de mémoire physique ne se fait qu’après l’appel à la fonction ViewMapOfFile. La fonction CreateFileMapping ne fait que réserver un ensemble d’adresses virtuelles.
Par ailleurs, Win 32 fournit une option permettant de forcer le stockage en mémoire centrale[6][18].
22 2001/2002Riad MOKADEM - CERIA

Mémoire DEA Stockage utilisant les signatures dans les SDDS
Avantages des fichiers mappés en mémoire : Manipulation de données en RAM. En conséquence, les accès aux fichiers sur disque se font très rapidement de la même manière que s’ils étaient en mémoire. Dans un système classique, pour lire ce fichier, un tampon de taille adéquate est alloué, un fichier est ouvert puis appel à une fonction de lecture est effectué pour copier le fichier dans ce tampon. Possibilité de ne mettre en mémoire qu’une portion d’un grand fichier (une vue) ce qui évite le chargement de la totalité du fichier en mémoire.
Fichiers mappés dans les SDDS
Dans les systèmes SDDS, une case du serveur est associée, à l’initialisation, à un pointeur (handle). Celui-ci désignera un fichier mappé créé par le biais de la fonction CreateFileMapping. Lorsqu’un serveur reçoit différentes requêtes provenant des clients, celles-ci sont associées à différents processus qui s’exécutent d’une façon parallèle. L’accès au fichier est établi en utilisant la fonction OpenFileMapping. Chacun des processus peut avoir une vue en utilisant MapViewOfFile. Dans le cas ou plusieurs processus partagent la même vue, ils partagent forcément une partie de la mémoire d’où la nécessité de l’utilisation d’objets de synchronisations pour garantir l’intégrité de cette mémoire partagée.
d- Programmation Concurrente : Dans toute application, le coût d’exécution d’une opération notamment, la réponse à une requête d’un client, doit être minimisé au maximum. Pour cela, la technique de Multithreading est utilisée. Cette technique permet de faire tourner plusieurs threads en même temps dans un même espace d’adressage. En conséquence, des mécanismes de synchronisation sont utilisés notamment les évènements, section critique…etc. Un haut niveau de concurrence est également assuré grâce à des techniques d’ordonnancement tels que les files d’attente et les pools de threads.
Notion de Processus léger : (Thread) Lorsqu’une application WIN32 est activée, un processus est créé. Mais, un processus n’existe jamais tout seul. En même temps, se crée un thread [3] .
Client A Client C Client B
Figure 3.10 : Le Multi-Threading (multi-tâches)
LAN
Thread pour C
Thread pour B
Thread pour A
232001/2002Riad MOKADEM - CERIA

Mémoire DEA Stockage utilisant les signatures dans les SDDS
On retrouve plusieurs définitions d’un thread : « Unité d’exécution ordonnancée dans un processus »[6], « compteur de programme indépendant » ou encore « Partie dynamique d’une application »[5]. Dans WIN NT, un processus peut contenir plusieurs threads qui s’exécutent de manière quasi parallèle comme si c’étais des processus distincts, tout en partageant certaines ressources (variables globales du processus, espace d’adressage virtuel…). En revanche, chacun de ces threads dispose de sa propre pile d’appel, son état du CPU et son espace de stockage local.
Les threads sont essentiels pour les applications réseau et plus spécialement dans les applications serveurs : création de threads d’attente de messages appelés threads d’écoutes et de threads d’exécution de requêtes appelées threads de travail qui permettent la mise en œuvre du multi-tâches dans Windows NT.
Si l’on dispose d’une machine multiprocesseur, les différents threads d’un processus peuvent être exécutés en même temps et c’est ce qu’on appellera multithread. Sur une machine monoprocesseur, cette simultanéité n’est pas parfaite et les threads accèdent tour à tour au processeur qui exécute alternativement les instructions de l’un et de l’autre. Les traitements sont alors concurrents. Cela provoque des problèmes de synchronisation due à des différents accès aux ressources d’où la nécessité d’une bonne création et destruction de ces threads.
Pour synchroniser ces accès et assurer l’exclusion mutuelle, Windows NT, comme Windows 2000 offrent plusieurs primitives : évènements, sémaphores, mutex et sections critiques. La section critique est la plus simple, elle est utilisée à l’intérieur d’un même processus. Elle permet à une ressource globale d’être partagée par plusieurs threads.
Par ailleurs, un objet SWMRG (Single Writer/Multiple Reader Guard) constitue une bonne solution pour les problèmes de synchronisation un écrivain/plusieurs lecteurs. Un objet SWMRG est une structure de données munie de fonctions permettant cela. Il se compose d’objets de synchronisation comme les sémaphores, les mutexes et les évènements. Ainsi, dans notre application, un client ne pourra pas lancer une opération d’écriture et une opération de stockage en même temps.
242001/2002Riad MOKADEM - CERIA

Mémoire DEA Stockage utilisant les signatures dans les SDDS
4- STOCKAGE DE DONNEES
Dans un système SDDS, la mémoire vive des sites serveurs contient les cases des différents fichiers créés suite aux demandes des clients. Cette mémoire doit être réutilisable pour d’autres fichiers. De plus, un fichier dont l’accès n’est pas très fréquent doit pouvoir libérer de la mémoire et être stocké sur le disque du serveur correspondant du fait qu’il occupe de la mémoire inutilement. Aussi, malgré les différents avantages que procure la distribution, la vulnérabilité aux pannes est un problème qui s’accentue avec l’augmentation du nombre de machines sur le réseau. Le stockage de ces données devient alors nécessaire. Par la suite, les clients pourront lancer l’opération du chargement de ce fichier du disque vers la mémoire vive des différents serveurs. 4- 1 Stockage de fichier : Lorsqu’un client veut lancer l’opération de stockage d’un fichier sur l’ensemble des serveurs contenant de cases appartenant à ce même fichier, il s’adresse à l’ensemble des serveurs en envoyant un message multicast. La taille du message correspondant à la requête de stockage ne dépassant pas quelques octets, le protocole UDP est alors utilisé pour l’acheminement des requêtes vers les différents serveurs. De plus, on adoptera un mécanisme d’acquittements individuels par les serveurs aux client. 4-1-1 Structure du message d’envoi de la Requête :
CHAMPS SIGNIFICATION
1 AlgoSDDS RP*c ou RP*n 2 IdApplication Identificateur de l’application 3 AdresSservZéro Adresse du premier serveur de données 4 Position enreg Position de la zone dans le buffer des réponses 5 Flow control Avec ou sans contrôle de flux 6 Code requête Code de la requête : Code de stockage 7 Nom case Nom de la case de données 8 Cléminimale Valeur de clé minimum de la requête 9 Clémaximale Valeur de clé maximum de la requête 10 Ack Avec ou sans acquittement 11 ClasseRequete Classe de la requête (simple, parallèle) 12 Nomfichier Nom du fichier de données 13 Terminaison Déterministe ou probabiliste 14 Tdonnees Taille des données à envoyer 15 Type Stockage Avec ou sans libération de la mémoire.
25Riad MOKADEM - CERIA 2001/2002

Mémoire DEA Stockage utilisant les signatures dans les SDDS
Au moment de l’envoi de la requête, chaque client doit préciser l’algorithme utilisé( RP*c ou RP*n). Cette requête « StorageRequest » est envoyée à l’ensemble des serveurs. Le client utilise alors un message multicast suivant un format particulier dans lequel figurent également le code de la requête (code de stockage), le nom du fichier, la clé minimale, la clé maximale. A la réception de cette requête, les serveurs ne contenant pas de cases appartenant à ce fichier ignorent cette requête. Les autres serveurs stockent le fichier mappé contenant les feuilles de données dans un fichier possédant le même nom créé sur le disque local lors de la première demande de stockage. Ils stockent aussi le fichier mappé correspondant à l’en-tête et l’index de la case de données. Le message contiendra aussi l’option de l’acquittement du serveur. Celui-ci envoiera alors un acquittement ACK au client à la fin du stockage pour préciser la fin de l’opération à son niveau. Cet acquittement est accompagné de l’intervalle de clés de ce fichier appartenant à la case de ce serveur. Dans le cas contraire et au bout d’un certain temps défini dans le module du client, celui ci procédera à la ré-émission de la requête. Cette ré-émission est possible grâce au contrôle de flux que peut assurer le client. En effet, une requête émise par le client peut être perdue à cause du bruit sur le réseau de transmission, la réponse du serveur peut être perdue aussi. En outre, la requête peut bien arriver à sa destination, mais le thread d’écoute peut être indisponible au même moment suite à un engorgement du serveur. De ce fait, beaucoup de protocoles arment un temporisateur à l’envoi d’un message lors de l’attente d’une réponse ou acquittement de réception. Le processus est réitéré alors plusieurs fois selon le nombre de ré-émissions autorisé.
Client Serveur 1
Message StorageRequest
Traitement de la requête
StorageRéponse
Serveur K
Traitement de la requête
Traitement de la requête
Figure 4.1 : Protocole de Stockage d’un fichier
StorageRéponse=Acquittement du stockage + intervalle de clés.
Serveur n
Re émission
Dans le cas où le stockage a été déjà fait sur disque lors des précédentes requêtes, le stockage se fait après comparaison des signatures.
26 2001/2002Riad MOKADEM - CERIA

Mémoire DEA Stockage utilisant les signatures dans les SDDS
4-1-2 Message Unicast0 Dans le cas de l’envoi de la requête de stockage avec un message unicast (Fichier déjà référencé, RP*c), le client précise dans le message de la requête, la valeur de clé maximale et la clé minimale du fichier à stocker(Requête parallèle). Ces deux valeurs de clés sont disponibles dans l’image du fichier au niveau du client et elle peut être fausse suite à des mises à jours du fichier. Avant de stocker la case correspondante à ce fichier, le serveur redirige d’abord cette requête vers le serveur suivant vers lequel une migration de données a été effectuée. Cela est fait pour pouvoir lancer le stockage sur les différents serveurs en parallèle. A la fin du stockage sur chaque serveur, un acquittement accompagné de l’intervalle des clés correspondantes au fichier est envoyé au client, celui-ci profite pour mettre à jour son image erronée du fichier.
Remarque : Dans le cas d’un message multicast, une requête simple est utilisée. En conséquence, le client ne consulte pas son image du fichier (même dans le cas de RP*c). Les paramètres CleMinimale et CleMaximale sont mis à zéro. Ces clients disposent de deux stratégies pour terminer la requête de stockage:
Terminaison déterministe : chaque serveur envoie un message au client. Cette réponse comporte un acquittement du stockage et l’intervalle de clés appartenant au fichier stocké. Le client se chargera alors de faire la somme de tous ces intervalles et comparera l’intervalle obtenu avec l’image de ce fichier à son niveau.
Terminaison probabiliste : chaque serveur envoie un acquittement au client à la fin du stockage. Le client s’attend alors à la réception des acquittements des serveurs concernés sans se soucier de l’intervalle du fichier à stocker.
4-1-3 Structure de la réponse du serveur : A la réception d’un message contenant la requête de stockage du client, les serveurs concernés effectuent l’opération de sauvegarde sur le disque. Ensuite, chacun des serveurs concernés, transmet à travers le réseau un message de réponse. Celui-ci est composé d’une séquence de champs illustrée par le tableau suivant :
CHAMPS SIGNIFICATION 1 Code requete Code de la requete traité par le serveur(stockage) 2 Nombre IAM 1=Cas de re-direction 0= pas de re-direction 3 CléMin Serveur Clé minimale du serveur traitant cette requête 4 CléMax Serveur Clé maximale du serveur traitant cette requête. 5 PortEcouteServ Numéro de port d’écoute du serveur 6 CleMinServ Clé MIN du serveur ayant redirigé la requête (ici 0) 7 CleMaxServ Clé MAX du serveur ayant redirigé la requête (ici 0) 8 AdServ Adresse du serveur ayant redirigé la requête ( ici 0) 9 PortServeur N° de port du serveur ayant redirigé la requête (ici 0) 10 CléReq Clé de la requête envoyée par le client (dans le cas d’une
recherche, non utilisé dans notre cas donc mise à 0) 11 Données Données envoyées par le serveur au client
(Ici 1 : stockage avec succès, 0 : échec )
27 2001/2002Riad MOKADEM - CERIA

Mémoire DEA Stockage utilisant les signatures dans les SDDS
Après la réception des acquittements par le client, celui-ci compare la somme des intervalles reçus avec l’intervalle global qu’il possède au niveau de son image. Si les deux intervalles sont identiques ou si l’intervalle reçu est plus grand, le stockage s’est bien déroulé sinon, le client procède à une mise à jour de son image sinon, il formule une nouvelle requête de stockage.
Remarque : Au niveau de chacun de ces serveurs, un tableau contenant des informations relatives à la case ( nom de fichier, identificateur de fichier, adresse du premier serveur…) est enregistré également sur disque. Cela servira lors de l’opération du chargement de ce fichier à nouveau du disque vers la mémoire vive.
4-2 Envoi de la requête de stockage :
Requête
SendRequest ReSendRequest
Request
Enregistrer la requête dans le buffer CFCM
Set
Attente d’un ACK
Attente des Intervalles de
clés
Envoi
Comparaison d’intervalles
Request
ToSend
Lecture de RequestQueue
Enregistrer IdApp et IdReq
ServServServClient
GetRequest
Attente d’une
Requête
Applicatio
Insertion dans Request Queue
Figure 4.2 : Protocole d’envoi d’une requête
28 2001/2002Riad MOKADEM - CERIA

Mémoire DEA Stockage utilisant les signatures dans les SDDS
La requête de stockage est formulée par l’application. Au niveau du client, un processus léger GetRequest réceptionne cette requête. Il enregistre l’identifiant de chaque requête reçue (IdRequete) ainsi que celui de l’application émettrice (IdApp) dans le journal des requêtes. Cette requête est ensuite insérée dans une file d’attente de type FIFO avant de signaler l’événement « RequestToSend ». Ceci provoque la consultation de cette file d’attente par un autre thread appelé SendRequest qui extrait cette requête puis construit le message à envoyer. Différents paramètres sont assemblés pour la construction du message : Outre l’identifiant de l’application émettrice et le code de la requête (Code stockage), un bit de contrôle de flux est positionné si la requête nécessite un contrôle de flux. Cette requête est alors expédiée au serveur. L’évènement « SetRequest » est signalée au thread ReSendRequest. Celui-ci a la charge de relancer la requete dans le cas du non-acquittement de celle ci à la fin de la temporisation ( TimeOut). 4-2-1 Image Incorrecte : Dans le cas où l’image du fichier au niveau du client serait inexacte au moment de la formulation de la requête, L’envoi de la requête de stockage ne nécessite pas une consultation de l’image du fichier puisqu’elle est envoyée par le biais d’un message multicast. La réception d’un acquittement suivi des intervalles de clés puis la comparaison par rapport à l’intervalle dans l’image du fichier au niveau du client permet à celui-ci de corriger son image. 4-2-2 Libération de la mémoire : Le client précise, lors de la formulation de la requête, le type de stockage :
Stockage sans libération de la mémoire : ce type permet la récupération des données dans le cas d’une panne au niveau de serveurs de données. Stockage avec libération de la mémoire : en plus de la récupération des données, ce type de stockage permet la libération de la mémoire occupé par le fichier à sauvegarder et son utilisation par d’autres fichiers.
4-3 Réception de la réponse par les clients : Un thread appelé ReceiveResponse est responsable de la réception des réponses des serveurs. Il est en attente sur le port UDP du réseau. Il insère chaque réponse reçue dans un tampon avant de signaler l’évènement ArriveRequest. Dans le cas d’une réception d’acquittement du serveur, il signale l’évènement ArriveAck au thread ReSendRequest. Un
29 2001/2002Riad MOKADEM - CERIA

Mémoire DEA Stockage utilisant les signatures dans les SDDS
évènement FinAck est ensuite signalé, le client effectuera la somme de ces intervalles reçus puis effectue une comparaison avec l’intervalle initial.
ReturnReponse
Fin des ACK
ACK
Signaler
ReceiveResponseResendRequest AnalyseRepons
Application
Attente fin de
réception
Lecture d’une réponse d’un
serveur
Comparaison d’intervalles
Attente d’ACK
Attente d’une
Réponse
Attente d’une
Requête
Initialiser horloge
Mettre à jour l’image du client
Insertion de la réponse dans FIFO
Lire FiFO
Déterminer IdApp
Réponse
ServServServClient
Figure 4.3 : Protocole de Réponse à la requête de stockage
Dans le cas où le nouvel intervalle est plus grand, l’image du fichier au niveau du client est mise à jour. A la fin, les données sont transmises à un autre thread qui se charge de les expédier vers l’application à l’origine de la requête indiquant la réussite ou l’échec de l’opération de sauvegarde des données sur les sites serveurs. Lors de la réception des acquittements et intervalles d’enregistrements des serveurs au niveau du client, deux stratégies se présentent :
30 2001/2002Riad MOKADEM - CERIA

Mémoire DEA Stockage utilisant les signatures dans les SDDS
Ces stratégies ont été implémentées initialement pour les requêtes à intervalles : - le client crée un nouveau thread pour chaque réponse d’un serveur de données (Thread par Réponse). - le client crée un pool de thread pour traiter l’ensemble des réponses (groupe de threads).
Processus léger par réponse :
Chaque thread créé utilise un tampon (buffer) de réception contenant l’intervalle d’enregistrements du serveur de données de provenance. On procédera à la somme de tous les intervalles contenus dans ces buffers puis à la comparaison avec l’intervalle du fichier disponible au niveau de l’image du client. Cette démarche présente l’inconvénient d’une grande consommation de ressources dans le cas d’un grand nombre de serveurs qui acquittent le client.
Groupe de processus légers :
Un groupe de thread est créé à l’initialisation du client et est maintenu à l’état de veille à la fin d’exécution de la requête. Les réponses sont traitées concurremment. Cette démarche induit des gains de performances et est utilisée lors des réponses à une requête parallèle. Cependant, dans le cas où le nombre de serveurs acquittant le client excède le nombre de fils d’exécution, les réponses additionnelles sont mises dans une file d’attente et le client ne peut pas terminer la requête convenablement. 4-4 Traitement de la requête :
Oui
Envoi de la requête par le
client
Réception de la requête par
le serveur
Non
Calcul de signature et lancement du
stockage
Acquittement du client
Figure 4.4 : Organigramme de traitement d’une requête
Formulation de la requête au niveau de l’application
Ignorer cette requête
Case appartenant à ce fichier
Par ailleurs, le stockage concerne trois fichiers essentiels : - Fichiers de données équivalent aux pages de données de la case. - Fichier d’index correspondant à la structure d’arbre B composé de nœuds
internes. - Fichier de paramètres de la case composés des informations relatives à cette
case.
31 2001/2002Riad MOKADEM - CERIA

Mémoire DEA Stockage utilisant les signatures dans les SDDS
4-5 Mise à jour des données stockées : Pouvoir récupérer ultérieurement les données des différentes cases constitue un des buts du module de stockage dans notre système. Dans d’autres systèmes, la réplication constitue une bonne solution. En effet, celle-ci présente l’avantage de conduire à de meilleures performances grâce à la disponibilité locale de copies de ces données Cependant, l’inconvénient majeur de la réplication est :lorsque la case est mise à jour, toutes les copies doivent être aussi mises à jour (propagation des mises à jours). En plus de cet inconvénient, la réplication nécessite plus de mémoire pour pouvoir garder une copie des données. La réplication n’est pas utilisée dans notre système. En revanche, des données de parités sont utilisées (haute disponibilité). Une copie de sauvegarde est créée à la réception de la requête de stockage et la propagation des mises à jour n’est pas assurée automatiquement. C’est une propagation faite à la demande du client. En conséquence, dans le cas d’une panne au niveau d’un ou plusieurs serveurs, le client pourra recharger les données sauvegardées lors de la dernière requête de stockage. 4-6 Remarques : 1- Bien que les requêtes de stockage concernent un groupe d’enregistrements, on ne classera pas ces requêtes envoyées par le client aux différents serveurs comme étant « par intervalle » puisque la précision de cet intervalle n’est pas nécessaire lors de l’envoi de la requête.. 2- Des paramètres de configuration au moment de la création des fichiers mappés permettent de rendre cette propagation de mises à jour automatique. Néanmoins, cela nuira à la rapidité de notre système (objectif de l’utilisation de la mémoire vive). 3- Les requêtes d’entrées/sorties destinées aux disques locaux sont réalisées par un système classique de gestion de fichier local (NTFS dans notre application).
32 2001/2002Riad MOKADEM - CERIA

Mémoire DEA Stockage utilisant les signatures dans les SDDS
5- Signature 5-1 Introduction : Une signature numérique permet d’assurer l’analogue d’une signature manuscrite d’un document sur papier ; il est difficile d’imiter une signature, si bien qu’un fichier accompagné d’une signature numérique est authentifié. Ce concept de signature numérique est surtout utilisé dans les outils de sécurité informatique. Les signatures électroniques servent notamment pour :
- L’authentification du contenu : certifier que des données n’ont pas été modifiées.
- L’authentification de la provenance. Dans notre contexte, nous utiliserons le concept de signature pour authentifier une page de données(groupe d’enregistrements) afin de pouvoir détecter la similarité entre deux pages. 5-2 Signature de Fichier : Les signatures ont été développées initialement pour la comparaison de fichiers traditionnels. Elles se basent sur des algorithmes de calcul de signatures des pages constituant ce fichier. On dira que deux pages de fichiers sont semblables si elles possèdent une même signature. Un fichier est caractérisé par sa signature globale (super signature). Celle-ci est obtenue par le calcul du XOR de la totalité des signatures des pages constituant ce fichier. On dira que deux fichiers sont semblables s’ils possèdent la même signature globale.
Sign(File1)= XOR(Sign1, Sign2,..Sign n) Sign(File2)= XOR(Sign`1, Sign` 2,..Sign` n)
Sign(File1)= Sign(File2) ⇒ File1 = File2
33
Page 1 Page2 Page3
Page n
Page1 Page2 Page3
Page n
Sign 1 Sign 2 Sign 3 Sign n
File 1 File 2
Sign` 1 Sign` 2 Sign`3 Sign` n
Riad MOKADEM - CERIA 2001/2002

Mémoire DEA Stockage utilisant les signatures dans les SDDS
5-3 Signatures dans le système SDDS2000 : Dans le système SDDS 2000, nous n’aurons pas à comparer entre la totalité de deux fichiers puisque ceux-ci distribués sur plusieurs serveurs. Chaque case est divisée en pages. On calculera la signature par rapport à chacune de ces pages (l’ensemble des caractères constituant cette page) et au moment d’une sauvegarde sur disque, seules les pages, dont les signatures ont changées, vont être stockés à nouveau sur disque. Le calcul de la signature est basé sur la structure de corps ou champ de Galois 5-3-1 Corps de Galois :
Un corps de Galois est noté GF(2f ). 2f étant le nombre d’éléments du champ (f >>1). Un champ de Galois présente la particularité d’être fermé sous l’addition, la multiplication, la soustraction ou la division. En d’autres termes, le résultat de l’application de l’une de ces opérations entre deux éléments du champ donne toujours un résultat qui appartient au champ[4]. Par ailleurs, l’addition et la soustraction de deux éléments se réduisent au ou-exclusif (XOR).
L’une des plus importantes propriétés d’un corps de Galois est l’existence d’un polynôme primitif noté α tels que tous les autres éléments du corps non nuls sont une puissance de cet élément primitif. Cette propriété permet de choisir p (élément primitif) puis de déterminer, pour tout élément g du champ, la puissance i telle que pi=g, on écrit alors :
i = logp (g)
Inversement g= Antilogp (i)
Dans notre application, on se basera sur une codification sur 16 bits GF(216 ). En d’autres termes, chaque éléments du corps, appelé symbole, est représenté par un mot de 16 bits. Un symbole est représenté alors sous forme polynomiale dont les coefficients représentent les bits de ce polynôme (par exemple 10010011 correspond au polynôme x7+x4+x+1). La multiplication et la division sont définis en se basant sur la représentation de ces éléments de GF(2f ) en polynômes de degré f. Ainsi, La multiplication de deux éléments du champ est équivalente à la multiplication des polynômes correspondants. Ces opérations sont en général très coûteuses en terme de mémoire et de CPU. Pour faciliter le calcul des opérations de calcul de la multiplication et de division, une table nommée « Antilog » est utilisée.
Le calcul se fera alors suivant la formule suivante : g*b=antilogp (logp(g)+ logp (b) ) g/b=antilogp (logp (g)- logp (b) )
34 2001/2002Riad MOKADEM - CERIA

Mémoire DEA Stockage utilisant les signatures dans les SDDS
Dans notre application, on utilisera la table ‘Antilog’ suivante ;
Nombre Binaire Hexadécimal Logp antilogp
0000 0000 0000 0000 0 - ⎯ 1 0000 0000 0000 0001 1 0 2 0000 0000 0000 0010 2 1 4 0000 0000 0000 0011 3 61481 8 0000 0000 0000 0100 4 2 16 0000 0000 0000 0101 5 57427 32 . . . . .
.
.
.
.
.
. . . . .
1111 1111 1111 1111 FFFF 4725 1
Figure 5.1 : Table AntiLog implémenté en mémoire 5-3-2 Calcul de la signature : Soit une page dont les éléments sont p1,p2,…pi. α étant l’élément primitif du champs de Galois. La signature de cette page s’écrira alors :
Signature (p1,p2,…,pi)=∑ pi αi
La taille de la table des antilogarithmes est déterminée par celle du champ. En conséquence, La table des Antilog aura 2f entrées. Le résultat de tout calcul est réduit modulo 2f –1 pour se positionner à l’intérieur de cette table. Le calcul de la signature d’une case se fait de la manière suivante :
For (i=0; i<=bucket_size; i++) Signature ^ =Antilog [(i+ bucket I )&0xFFFF]; bucket i représente le i ème élément de la case. On procédera à la lecture de cet élément en parcourant le fichier mappé de données. Par ailleurs, une signature sera calculée pour chaque page de la case de données dont la taille est fixée à l’avance (8, 16, 32, 64, ..KO). Considérons page i le i ème élément d’une page de données et page_size la taille fixée de cette page, cette signature par rapport à chaque page s’écrira alors :
For (i=0; i<=page_size; i++) Signature ^ =Antilog [(i+ page i )&0xFFFF];
La probabilité pour que deux pages aient une même signature est de 2-f. Pour réduire cette probabilité, on utilisera une signature portant sur plusieurs symboles. Chaque symbole représente une signature par rapport à αi. Le calcul de cette signature à N symboles réduit alors cette probabilité.
Une signature par rapport à αm s’écrira : Signature αm ^ = antilog [ (m* i + page i) mod (2f –1) ]
35 2001/2002Riad MOKADEM - CERIA
Y^=Z : Y= Y XOR Z

Mémoire DEA Stockage utilisant les signatures dans les SDDS
La signature sur n symboles est représentée par la concaténation des différentes signatures calculées par rapport aux puissances de l’élément primitif. Sign (p1,p2…,pk)= [ signα1 (p1,p2,…,pk), signα2 (p1,p2,…,pk),….,signαn (p1,p2,…,pk) ] signαi étant la signature par rapport à l’élément primitif αi .
Exemple : Signature α1 (page i) =a Signature α2 (page i) =b
Signature (page i)= ab…c
36
Signature αn (page i) =c
On appellera n le nombre de symboles de la signature.
5-3-3 Utilisation de Signatures pour le stockage de données : Pour chacune des pages de la case de données, une signature à n symboles est calculée. Ce calcul concernera les pages de données (en-tête de pages, enregistrements) et les méta-données. Cependant, les signatures des pages représentant les méta données n’est pas déterminant dans le cas d’une mise à jour. L’ensemble de ces signatures est mis dans une structure correspondante à chaque case de fichier au niveau du site serveur.
Struct SIGN { char[25] Nom_file ;
int Signature_page_data[nbre_page_case][Nbre_symbole_signature] ; int Signature_page_méta[nbre_page_index][Nbre_symbole_signature] ; int flag ; } SIGN Signature [NbreMaxBucket] Le nombre de symboles de la signature étant la plus forte puissance de l’élément primitif utilisé lors de la formation de cette signature.(le nombre de signatures concaténés pour obtenir la signature à N symboles). Le paramètre Flag est utilisé pour un stockage direct d’une page lors du premier stockage (sans comparaison avec la signature antérieure).
Exemple : sgn et SGN représentent une structure regroupant les signatures des pages de données constituant la case de données. Page 1 Sign11 Sign12 Sign13 Sign’11 Sign’12 Sign’13
Page 2 Sign21 Sign22 Sign23 Sign’21 Sign’22 Sign’23
….. .. .. .. Page n Sign31 Sign32 Sign33 Sign’31 Sign’32 Sign’33
sgn SGN
Sign KJ : Signature de la page K par rapport à la puissance J de l’élément primitif.
sgn= SGN ⇔ Sign11=Sign’11 et Sign12=Sign’12 et Sign13= Sign’13 On dira que la page 1 n’a pas été mise à jour dans ce cas.
2001/2002Riad MOKADEM - CERIA

Mémoire DEA Stockage utilisant les signatures dans les SDDS
On dira que sgn et SGN sont égaux si toutes les signatures des pages constituant la case de données sont égales.
Réception de la Requête de Stockage
37
Stockage pour la 1ère
fois
Stockage du fichier entier
sur disque
Comparaison avec la signature précédente
SGN
Non
Détermination de la page mise à
jour
Stockage de la page mise à jour sur disque
Oui
Figure 5.2 : Organigramme de traitement d’une requête de stockage avec calcul de signatures
Pas de stockage
SGN=sgn
Calcul de la nouvelle signature
sgn
Non Oui
A chaque requête de stockage, un thread de travail calcule les signatures de l’ensemble des pages constituant une case d’un fichier. Il compare les valeurs obtenues avec les signatures calculées précédemment et stockées en mémoire. Ensuite, à la détection d’une nouvelle signature pour une page de données, le stockage de cette page est effectué. Cela est possible en utilisant la fonction FlushViewOfFile offerte pour les fichiers mappés permettant ainsi, de stocker qu’une portion (vue) de ce fichier sur le disque. Le stockage
2001/2002Riad MOKADEM - CERIA

Mémoire DEA Stockage utilisant les signatures dans les SDDS
peut aussi s’effectuer en utilisant la commande fssek( ) permettant de se positionner dans le fichier et de mettre à jour la page modifiée.. L’utilisation des signatures permettra alors de ne stocker sur disque que les pages mises à jour depuis la dernière sauvegarde. Propriétés des signatures :
- La valeur de la signature change à la moindre mise à jour d’un caractère. - Un échange entre deux caractères affecte la valeur de la signature.
5-4 Signature numérique SHA Cette signature se base sur des théories mathématiques. L’algorithme Secure Hash Standard SHA a été développé pour mettre en œuvre un outil de sécurité permettant une authentification des documents à travers le Web. On suppose que l’on dispose d’une chaîne de caractères m. Une fonction de hachage cryptographique est une fonction qui, pour tout message m de longueur arbitraire, calcule une empreinte numérique représentant une chaîne de longueur fixe. La fonction SHA 1 ( nouvelle version de SHA), déjà implémenté dans Visual studio.net, associe à chaque message une chaîne de longueur 160 bits (soit 40 chiffres hexadécimaux). Ce message est appelé Message Digest, il constitue par la suite une entrée pour une autre fonction appelée Digital Signature. Celle-i permet de vérifier ou de générer la signature finale de la chaîne de caractères. La fonction SHA constitue ainsi une fonction de conversion d’une chaîne de 512 bits en chaîne de 160 bits.
38
Calcul de la signature DSA
Message Digest
SHA 1
Message
Signature Clé Signature Vérificationsignature DS
Message Digest
SHA 1
Message
RFigure5.3 : Signature Numérique
Riad MOKADEM - CERIA
Deux types de clés : symétrique ( mot de passe), asymétrique (publique)
Entrée de la fonction
Clé de A
ésultat de la comparaison
2001/2002

Mémoire DEA Stockage utilisant les signatures dans les SDDS
Dans des applications relatives à la cryptographie et sécurité des données. La fonction SHA 1 permettra le calcul du Message Digest. Celui ci, combiné avec une clé donnera la signature finale du message. Au décryptage de l’information, l’opération inverse est réalisée. La combinaison de la même clé et le Message Digest (obtenu par le biais de SHA 1) est comparée avec la signature sauvegardée. Cela permettra la détection d’un changement au niveau du message initial. Dans notre application, la fonction SHA 1 produit une signature correspondante à chaque page de données. 5-4-1 Fonction de Hachage SHA 1: Afin d’effectuer le hachage(9), on effectue un premier codage d’une chaîne m en une chaîne m’. On note L(m) la longueur (en bits) de m. On représente L(m) sous forme d’une chaîne de 64 bits. On complète m par un bit « 1 », suivi d’un nombre variable de « 0 » puis de L(m), de telle sorte que la chaîne finale soit multiple de 512. On a donc m’=m||pad||L(m) ou pad est constitué d’un bit « 1 » La chaîne m’ est ensuite découpée en n blocs m1,…,mn de 512bits M’=m1||…||mn De même, chaque mi est découpé en 16 blocs mi,1,…..mi,16 de 32 bits donc Mi=mi1||…||mi16 Dans la suite, on effectue des opérations sur des chaînes de 32 bits. Les opérations utilisées sont :
AND : et bit à bit OR : ou bit à bit XOR : ou exclusif bit à bit NOT : complément à 1 bit à bit Sn : rotation circulaire de n bits vers la gauche.
On définit les fonctions suivantes :
ft (B,C,D)=(b AND c) Or (Not b) and d 0<=t<=19 K=5A827999 ft(B,C,D)=b XOR c XOR d 20<=t<=39 K=6ed9ebal ft (B,C,D)=(b AND c) Or (b AND d) OR (c AND d) 40<=t<=59 K=8f1bbcdc ft (B,C,D)=b XOR c XOR d 60<=t<=79 K=ca62c1d6
On effectue alors les étapes suivantes : 1-Initialiser h0=67452301 h1=efcdab89 h2=98badcfe h3=10325476 h4=c3d2e1f0
[9] : Fonction de hachage :Fonction réduisant une liste de données de taille arbitraire en taille fixe et lui associe une valeur numérique
39 2001/2002Riad MOKADEM - CERIA

Mémoire DEA Stockage utilisant les signatures dans les SDDS
2- Pour i= a jusqu’à n :
- Initialiser wt=mi,t+1 pour t=0 ,…,15 - Pour t=16 jusqu’à 79 wt=S1(wt-3 XOR wt-8 XOR wt-14 XOR wt-16) - Initialiser a=h0,b=h1,..e=h4
- Pour t=0 jusqu’à 79 x=S5(a)+ ft(b, c, d)+e+wt+Kt e=d, d=c, c=S30(b), b=a, a=x - h0=h0+a,…,h4=h4+e Le résultat sera alors h(m)=h0||h1||h2||h3||h4. Exemple des Etapes de Calcul de la Signature : Nous allons prendre un exemple. Considérons le message initial comme étant la suite : 01100001 01100010 0100011 01100100 01100101 longueur du message L= 40
a- Ajout de 1 à la fin du message original. 01100001 01100010 0100011 01100100 01100101 1
b- On rajoute des 0 à la fin du message en hexadécimal 61626364 65800000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000
c- On rajoutera 2 mots représentant la valeur L en hexadécimal 40= (28)16. Notre message sera alors
61626364 65800000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000028
d- Par la suite, différentes opérations( OR, XOR, NOT et AND) sont effectuées sur les 16 blocs du message et faisant intervenir les fonctions f1…f79 en plus des différentes constantes K. Cela donne en sortie 5 mots de 32 bits chacun. La signature finale est obtenue en concaténant ces mots. On aura alors la signature finale appelée Message Digest sur 160 bits (20 octets). 5-4-2 Implémentation Une fonction dite de hachage permet d’associer une valeur numérique aux données de taille fixée à l’avance et mises dans un tampon. Cette fonction est disponible au niveau de Visual Studio et procède de la manière suivante : Les données sont d’abord mises dans un buffer de taille dwSize puis un appel à la fonction CryptEncrypt est effectué.
40 2001/2002Riad MOKADEM - CERIA

Mémoire DEA Stockage utilisant les signatures dans les SDDS
pBuffer= new char[dwSize] bResult = CryptEncrypt (hkey, 0, TRUE, 0, pBuffer, &dwSize, dwSize) Apres cet appel, bResult contiendra la valeur numérique associée aux données mises dans le buffer. L’implémentation en C s’effectuera à l’aide de 3 fonctions décrites ci dessus: SHA1Reset : fonction d’initialisation. SHA1Input : préparation du Message Digest. SHA1Result : retourne les 20 octets représentant la signature cryptographique
41 2001/2002Riad MOKADEM - CERIA

Mémoire DEA Stockage utilisant les signatures dans les SDDS
6- Récupération des Données à partir du Disque
Le stockage d’un fichier se fait dans le cas où ce dernier deviendrait peu utilisable en mémoire et donc occupant inutilement de la place mémoire. Si sa présence en mémoire re-devient indisponible, on procédera alors à sa récupération à partir du disque.
Pour faire parvenir la requête de récupération de fichier au serveur, le client procède de la même manière qu’une requête de stockage. Il envoie alors un message à l’ensemble des sites serveurs de données (Message multicast). Les serveurs ne possédant pas de fichier de même nom sur leur disque ignorent cette requête.
42
6-1 Récupération des données au niveau du serveur :
Ré émission
Client Serveur 1
LoadRequest
Traitement de la requête
LoadReponse
Serveur K Serveur n
Traitement de la requête
Traitement de la requête
Figure 6.1 : Protocole de Récupération des données d’une case
Envoi de la requête par le
client
Réception de la requête par
le serveur
Fichiers existants sur
disque
Ignorer cette requête
Chargement de fichiers en mémoire
Mise à jour de l’image du
client
Non
Oui
Figure 6.2 : Organigramme de traitement d’une requête de récupérationAcquittement
du client
Riad MOKADEM - CERIA 2001/2002

Mémoire DEA Stockage utilisant les signatures dans les SDDS
La récupération d’une case de données correspondante au fichier est réalisée en trois étapes : - ouverture du fichier de données sur disque ainsi que le fichier d’index. - création de deux fichiers mappés en mémoire :
- Fichier mappé de données. - Fichier mappé d’index.
- copie du contenu des fichiers sur disque dans les fichiers mappés correspondants. - chargement des paramètres de la case stockés sur disque ( Clé minimum, clé maximum…) . Dans le cas où le stockage a été effectué avec libération de la mémoire, on procéde à la création d’un nouveau fichier mappé sinon une mise à jour est effectuée au niveau du fichier mappé déjà existant. 6-2 Tolérance aux pannes En plus de données de parité permettant de récupérer des données perdues suite à une panne au niveau d’un serveur, une autre méthode consiste en la récupération des données sauvées sur le disque des sites serveurs. Pour détecter une panne au niveau d’un serveur lointain, nous nous baserons sur les accusés de réception envoyés par les serveurs au client après chaque requête. Le client détectera lors une anomalie au niveau des intervalles reçus en comparant ces derniers avec l’image du fichier qu’il dispose à son niveau. Lors d’une panne d’une partie des serveurs de données, l’envoi d’une requête de récupération de données à l’ensemble des serveurs met à jour l’ensemble des cases appartenant à ce fichier. En conséquence, c’est les données enregistrées lors de la dernière requête de stockage qui sont désormais disponibles en mémoire de ces serveurs. Stockage après chargement de données Après une opération de chargement de données suite à une panne serveur, la prochaine requête de stockage conduira à la sauvegarde de ce fichier comme s’il s’agissait du premier stockage en raison de la non disponibilité de la table des signatures perdue lors de la panne et inutile à sauvegarder sur disque. Autres pannes
Le système disque peut être défaillant. De même, le réseau interne peut subir des pannes. Il peut aussi y avoir des pannes logicielles dues à des erreurs internes Panne d’un disque : Une panne sur disque ou son mauvais fonctionnement peut générer des erreurs lors de la récupération ou de l’écriture des données sur ce disque. Dans ces cas, le système de gestion de fichiers renvoie des messages d’erreurs signifiant au client la non possibilité de créer un fichier ou de l’ouvrir sur le disque correspondant.
43 2001/2002Riad MOKADEM - CERIA

Mémoire DEA Stockage utilisant les signatures dans les SDDS
Panne du réseau : Suite à une panne d’une carte réseau ou d’un câble de connexion, le serveur se retrouvera isolé du réseau. La seule solution pour remédier à ce problème, c’est la réplication des données au niveau local. Récupération automatique de données
Nous pourrons supposer qu’une panne est détectée au niveau d’un serveur de données lorsqu’un client relance plusieurs fois une même requête sans pour autant recevoir une réponse ou un quelconque acquittement. Dans ce cas, le client pourra envoyer une requête pour recharger les données en mémoire des serveurs de données défectueux. Interface de l’application
44
Figure 6.3 : Inteface de l’application
Cette figure montre l’interface de l’application montrant les différentes opérations concernant les fichiers SDDS parmi lesquels on retrouve l’opération du stockage et du chargement d’un fichier sur les serveurs de données. Le client intercepte ces opérations puis structure cette requête sous forme de message (requête) destiné aux différents serveurs concernés.
2001/2002Riad MOKADEM - CERIA

Mémoire DEA Stockage utilisant les signatures dans les SDDS
7- Mesures de Performances Ce chapitre décrit les différentes expérimentations établies avec le prototype SDDS 2000. Ces expérimentations concernent notamment le module de stockage et les différentes manières d’effectuer cette tâche.
7-1 Environnement Expérimental :
Le prototype SDDS 2000 a été réalisé dans un environnement Windows 2000 et Windows NT. Il a été implémenté en langage C sous Microsoft Visual C++ 6.0 et différentes fonctionnalités offertes par l’API WIN32 ont été utilisées.
Ces expérimentations ont été réalisées en déployant un réseau local Ethernet 100Mbits/s reliant 5 machines : 3 machines Pentium IV 1.7GHZ et deux machines Pentium III 500MHZ fonctionnant sous Windows 2000. Nous précisons la forte dépendance des résultats de ces expérimentations par rapport à la puissance des machines utilisées (vitesse du processeur, mémoire RAM disponible…etc.) et la nature du réseau. L’emplacement des serveurs et des clients peut aussi affecter nos résultats en raison des coûts de communications entre les composants de SDDS2000. Par ailleurs, on supposera que toutes les machines sont connectées entre elles et sont compatibles au niveau logiciel.
En plus, en raison de la lenteur d’accès à un disque, les micro-ordinateurs récents disposent d’un cache (antémémoire) intermédiaire entre la mémoire et le disque local. Cette lenteur est résolue accumulant les données lues dans une zone tampon. Cependant, pour les fichiers de grandes tailles, le temps de lecture et écriture sur disque demeure assez important.
Le prélèvement de ces résultats pour les analyser par la suite nécessitera aussi des affichages au niveau des serveurs et des clients, pouvant aussi ralentir le fonctionnement global du système.
Nous étudions les temps de stockage dans un système de gestion de fichier traditionnel puis dans les systèmes SDDS2000. Nous comparerons entre ces deux temps en mettant en évidence le comportement de notre système face à une montée en charge d’où l’intérêt de l’implémentation du module de stockage dans les SDDS2000. Nous ferons de même pour la fonction de chargement d’un fichier dans un système distribué.
Nous étudierons ensuite le bénéfice de l’utilisation des signatures lors des opérations de stockage dans le cas de mise à jour de ces fichiers. Une comparaison est effectuée avec des résultats obtenus sans avoir recours à cette technique puis on comparera noss résultats avec d’autres travaux.
Rappelons que le temps de réponse à une requête est réparti en trois composantes : - Le temps d’envoi des paramètres de la requête et l’acheminement des clients
vers les serveurs de données. - Le temps de traitement de la requête. - Le temps d’envoi de la réponse.
45Riad MOKADEM - CERIA 2001/2002

Mémoire DEA Stockage utilisant les signatures dans les SDDS
Durant nos expérimentations, différents paramètres sont pris en considération : Nombre de serveurs 3 à 5. Nombre de clients 1 à 2. Types de requêtes Stockage, Chargement Nature d’envoi des requêtes
+FC (avec Flow Control) : avec contrôle de flux -FC (sans Flow Control) : sans contrôle de flux
Taille des messages - 100 octets pour les paramètres du message - 50 et parfois 80 pour les données.
Paramètres de l’index - Taille d’un nœud interne 80 octets - Taille d’une feuille 100 octets.
Temps En milli-secondes Ms (parfois en secondes S)
Mise à jour dans la case de données (MAJ du fichier)
+WC (With changement) : Mise à jour des enregistrements. ( insertion de moins de 5% d’enregistrements /capacité de la case) -WC (Without Changement) : pas de mise à jour.
Taille des pages de données à l’intérieur d’une case
16 KO (16 à 128 KO dans quelques tests)
Taille d’un Enregistrement 10 KO
Nombre de symboles de la signature
4 octets (2 à 8 dans quelques tests)
Durant ces tests, nous nous servirons de 3 machines Pentium IV 800MHZ utilisé comme des serveurs de données, une machine Pentium III pour simuler un client et une autre pour le serveur de noms puis, par la suite, pour vérifier la scalabilité de nos résultats et pour des raisons d’homogénéité des machines utilisées, nous avons effectué des tests en utilisant 5 machines Pentium III 500MHZ utilisés comme serveurs de données et une machine Pentium IV 1.7GHZ simulant un client SDDS. 7-2 Stockage des Données :
Cette expérience étudie le temps de stockage d’un fichier suivant le nombre de serveurs dans notre système. Nous avons réalisé des stockages de fichiers de différentes tailles pour étudier l’impact de la taille du fichier sur les performances. Nous nous intéresserons particulièrement aux tests de stockage du fichier mappé de données sur disque. Fichier de 100 Enregistrements
462001/2002Riad MOKADEM - CERIA

Mémoire DEA Stockage utilisant les signatures dans les SDDS
Taille de la case (du fichier sur disque) : 1.56 Mo
Nombre de Serveurs Temps de Stockage 1 562 2 532 3 468 4 402
Temps de stockage (Ms)
Fichier de 25000 Enregistrements47
1 2 3 4
600 500 400 300 200 100
Nombre de serveurs
Nombre de Serveurs Temps de Stockage 1 117859 2 112219 3 110004 4 100503
Nombre de serveurs 1 2 3 4
Temps de stockage (Ms)
120000 100000 80000 60000 40000 20000
Taille du fichier : 393 MO
2001/2002Riad MOKADEM - CERIA

Mémoire DEA Stockage utilisant les signatures dans les SDDS
Ces résultats montrent que plus le nombre de serveurs est important, plus le temps de stockage du fichier est réduit. Ainsi, on pourrait s’attendre à de meilleurs résultats à chaque fois que le nombre de serveurs augmente. Le stockage d’un fichier résidant dans un seul serveur est comparable au stockage dans un système de gestion de fichier traditionnel. En augmentant le nombre de serveur, la courbe est décroissante. Cela est dû au traitement parallèle des requêtes de stockage au niveau des serveurs de données, chacun stockant la case correspondante à ce fichier dans son disque local. Le gain en temps de stockage est d’environs 6 à 7% à chaque rajout d’un nouveau serveur. Le gain en temps de stockage sur 4 serveurs par rapport à un seul disque local est de 30%. Pour vérifier ces résultats, nous avons créé un fichier portant sur 25000 enregistrements. Le temps de stockage sur plusieurs serveurs est toujours nettement inférieur au temps de stockage sur un nombre réduit de serveurs. Le gain calculé pour dans ce cas est de 17%. Cer résultats montrent alors la garantie de la scalabilité en ce qui concerne le stockage des données. En dépit de l’extension du fichier, le temps mis pour le stockage dans les différents sites ne dépassera pas le temps mis pour le stockage d’une case sur un seul serveur de données Remarque : Le temps relatif à l’éclatement d’une case ( migration des données vers un nouveau serveur) n’influe pas sur le temps de stockage car cela se passe lors des insertions des enregistrements dans les serveurs de données. De plus, la requête de stockage est envoyée par message multicast à l’ensemble des serveurs. En conséquence, le serveur de données recevant cette requête ne s’occupe que du stockage et de l’envoi de l’intervalle de clés appartenant à ce fichier. 7-3 Chargement des données Après un stockage d’un fichier sur disque dur, un client doit pouvoir lancer le chargement de ce fichier à partir des disques locaux des différents serveurs de données concernés en un temps réduit. Nous effectuerons des expérimentations sur un fichier déjà stocké sur disque. Fichier de 10000 enregistrements : Taille du fichier : 393 Mo
Nombre de Serveurs Temps de Chargement sur disque (Secondes)
1 114.896 2 110.278 3 97.954 4 97.203
48 2001/2002Riad MOKADEM - CERIA

Mémoire DEA Stockage utilisant les signatures dans les SDDS
Nous remarquons que le chargement d’un fichier distribué sur plusieurs serveurs prend moins de temps que son chargement sur un disque local. Cela est possible grâce au parallélisme offert par les systèmes SDDS. En effet, chaque serveur de données charge dans la mémoire locale correspondante la portion de fichier ( Case ou « bucket » de données) structurée sous forme de fichier mappé. Le temps global de chargement étant le temps le plus important de chargement de ce fichier sur les différents serveurs. De même, si nous simulons une panne d’un serveur (Echec d’une case de fichier) ou même plusieurs de ces serveurs, nous pouvons récupérer la totalité des données se trouvant sur ce serveur.
7-4 Signature d’un Fichier :
Chaque chaîne de caractère lui est réservée une valeur dans la table Antilog. On appellera cette valeur la Signature de cette chaîne. Dans notre application, une signature est calculée par rapport aux différents caractères constituant une page de données. Ces pages doivent avoir une taille fixée. La signature à N symboles est obtenue en concaténant les signatures obtenues par rapport aux différentes puissances du polynôme primitif. En conséquence, ces opérations doivent être exécutées de telle façon à minimiser le temps de calcul. Dans nos tests, les signatures portent sur 4 octets (N=2, signature sur 2 symboles) et la probabilité pour que deux pages identiques aient la même signature est de 2-16
Nombre d’enregistrements Temps de calcul de
la signature (Ms) 100 47 1000 453 2000 803 3000 1320 4000 1790 5000 2190
49
Nombre de serveurs 1 2 3 4
12 10 8 6 4 2
2001/2002Riad MOKADEM - CERIA
Temps de Chargement (S)

Mémoire DEA Stockage utilisant les signatures dans les SDDS
Le temps de calcul de la signature est presque linéaire par rapport au nombre d’enregistrements sur lequel s’effectue ce calcul. Cependant, une même valeur de données dans les enregistrements (valeur calculée précédemment) ou des valeurs ne dépassant pas 2f, réduisent considérablement le temps de calcul de cette signature (positionnement dans la table Antilog). Ainsi, l’insertion dans la case de données d’enregistrements semblables réduit le temps de calcul de ces signatures puisque le processeur n’aura pas à chaque fois à recalculer la valeur correspondante dans le tableau.
Temps de Calcul de Signatures (Ms)
Nombre d’enregistrements 100 1000 2000 3000 4000 5000
2000 1500 1000 500
Figure 7.4 : Temps de calcul de signature en fonction de la taille de la
7-4-1 Signature par page : Une signature porte sur le nombre de caractère constituant la page sur laquelle la signature est calculée. En conséquente, lors d’une mise à jour d’un enregistrement, le changement concerne la valeur de la signature tandis que le temps nécessaire pour son calcul reste invariant. Les meilleurs résultats obtenus sont de l’ordre de 31Ms pour le calcul des signatures pour une case de données de taille 1.6 MO ce qui approche les 20 Ms/MO. Ce temps est de 0.44Ms pour une page de 16ko ou encore 1.19Ms pour une page de 64KO. 7-5 Stockage des données en utilisant le calcul de signatures : Nous effectuerons des stockages de fichiers de différents volumes sur différents nombres de serveurs puis nous analyserons les résultats obtenus.
50 2001/2002Riad MOKADEM - CERIA

Mémoire DEA Stockage utilisant les signatures dans les SDDS
Stockage de fichier résidant sur un seul serveur : Dans ce cas, nous lancerons une requête de stockage juste après la première sauvegarde et sans avoir mis à jour ni insérer aucun enregistrement. Nous prélevons par la suite le temps mis pour le traitement de cette requête.
Taille sur Disque (MO)
Nombre d’enregistre- ment insérés
Temps calcul signature
Temps du stockage
Temps du stockage -WC
Durée stockage / temps global(%)
1.88 100 46 562 50 8.89 % 2.7 150 78 781 82 10.49 17.6 1000 453 5078 455 8.96 158 10000 4068 46406 4071 8.77 393 25000 11003 117859 11003 9.33
D’après le tableau ci dessus, on voit clairement que le temps nécessaire pour le calcul de la signature est très inférieur au temps nécessaire pour le stockage des même données (les meilleurs résultats obtenus étant de 31Ms pour le calcul de la signature par rapport à une case de données de taille 1.6MO). En effet, dans le cas de la non-mise à jour des données du fichier sur le serveur, l’opération de stockage ne prendra que le temps de calcul de la signature et cela ne prendra en moyenne que 9% du temps nécessaire au stockage.
Taille sur Disque (MO)
Nombre d’enregistre- ment insérés
Temps calcul signature
(Ms)
Temps du stockage
(Ms)
Temps du stockage
+WC
Durée stockage / temps global
(%) 1.88 100 47 562 14 + 47 10.14% 2.7 150 78 781 14 + 80 12.03 17.6 1000 438 5078 15 + 430 8.76 158 10000 4068 46406 15 + 4070 8.80 393 25000 11003 117859 15+11003 9.34
Dans le cas d’une insertion ou d’une mise à jour d’un enregistrement sans pour autant dépasser la taille maximum fixée pour la case de données (cas de l’ éclatement de la case), le calcul des signatures des pages composant cette case est effectué et le stockage ne concerne pas la totalité du fichier.
Suite à ce calcul, la page qui a été mise à jour est détectée et le stockage ne concernera que cette page évitant ainsi de stocker la totalité de la case appartenant à ce fichier. Le temps de stockage additionné au temps de calcul des signatures ne prendra alors que 10% en moyenne du temps global de stockage Par ailleurs, lors d’insertions ou de mise à jours multiples concernant des enregistrements ne se trouvant pas sur une même feuille de données, le stockage concernera les différentes pages mises à jour.
51 2001/2002Riad MOKADEM - CERIA

Mémoire DEA Stockage utilisant les signatures dans les SDDS
Cependant, le stockage de plusieurs pages n’est pas linéaires. En d’autres termes, le stockage de deux pages sur disque n’est pas forcément le double du temps de stockage d’une seule page. Cela est du au positionnement et déplacement de la tête du disque (cas de deux pages situées dans des emplacements distincts). Cela a été confirmé par nos tests. Ainsi, une mise à jour qui modifie deux pages de données conduira au stockage de ces deux pages de données. Le stockage de la deuxième page n’a duré que la moitié du temps de stockage de la première page. Stockage de fichier résidant sur 2 serveurs de données Taille sur
disque (MO)
Nombre d’enregistrement
s insérés
Temps calcul de signature
Temps du stockage
initial
Temps du stockage
-wc
Temps du
stockage +wc
Durée stockage
/ temps
global (%)1.88 100 31 532 27 27 + 15 7.98 2.7 150 46 673 42 42 + 16 8.61 17.6 1000 266 5147 258 258 + 15 5.30 62 5000 1469 23906 1398 1398+ 16 5.91 158 10000 2953 41328 2555 2845+ 16 6.92 393 25000 6564 112219 6564 6564+ 16 5.86
Le temps de calcul de la signature représente le maximum des temps de calcul de signatures sur les deux serveurs de données. Par exemple pour la première ligne du tableau ci dessus, le calcul de la signature dans le 1er serveur durera 16 Ms tandis que dans le 2 ème serveur cela prendra 31 MS (taille de la case 120, une insertion de 150 enregistrements provoquera l’éclatement de la case puis la migration des données vers la nouvelle case : on aura alors 60 enregistrements(120 étant la capacité maximale d’une case de données) au 1 er serveur et 80 dans le deuxième. Apres une opération de stockage initiale, le calcul de la signature lors de la prochaine requête de stockage prendra un peu moins de temps. Cela est dû au calcul des valeurs de signatures déjà effectué précédemment. Lors d’une mise à jour ou d’une insertion concernant quelques enregistrements successifs (sans provoquer d’éclatement), le temps de stockage sera équivalent au temps de calcul de la signature additionné au temps de stockage d’une page de données (16 KO dans notre cas). Rappelons que dans le cas d’une mise à jour, le temps de stockage prélevé dans nos tests sera également équivalent au maximum des temps de stockage sur les différents serveurs.
522001/2002Riad MOKADEM - CERIA

Mémoire DEA Stockage utilisant les signatures dans les SDDS
Stockage de fichier résidant sur 3 serveurs de données Taille sur
disque (MO)
Nombre d’enregistrements
insérés
Temps calcul de signature
Temps du stockage initial
Temps du
stockage
-WC
Temps du
stockage +WC
Durée stockage
/ temps global
2.7 150 Max(32,16,40)40
Max(468,547,582)582
40 40+ 16 9.62%
17.6 1000 301 3700 300
298+ 16 8.48%
158 10000 2913 35050 2798 2798+ 15
8.02%
393 25000 6153 85362 7652 6052 + 16
7.10%
7-6 Synthèse : Cette figure montre l’évolution du temps de stockage sur un, deux et trois serveurs. On constate que : plus le fichier est réparti sur un plus grand nombre de serveurs, la courbe de l’évolution du temps de stockage est moins croissante.
53
Ces expérimentations ont été prises au niveau des serveurs de données. Si l’on veut maintenant s’intéresser au temps de réponse à la requête au niveau du client, on rajoutera le temps de la réception des acquittements Ack venant des différents serveurs concernés
Riad MOKADEM - CERIA 2001/2002
Nombre d’enregistrements
Temps de stockage (Ms)
5000 10000 20000
7000 6000 5000 4000 3000 2000 1000
1 Serveurs
3 Serveurs
2 Serveurs
Un serveur Deux serveurs
Trois serveurs Figure 7.5 : Terminaison de la requête de stockage au niveau du Serveur

Mémoire DEA Stockage utilisant les signatures dans les SDDS
par la requête de stockage en plus du temps nécessaire pour comparer la sommes des intervalles reçus avec l’image du fichier (intervalle de clés du fichier pour chaque serveur) déjà présente au niveau du client. Ce temps est plus ou moins réduit. Lors de ces tests, il faudra aussi prendre en considération le temps mis pour le contrôle de flux (dans le cas d’activation de cette option). 7-7 Contrôle de Flux Le protocole UDP est utilisé pour une transmission rapide de données, il apporte en revanche une perte de fiabilité des communications. Un contrôle de flux peut être mis en place pour surmonter cette limite. En effet, avec la communication UDP, n’importe quel processus client ou serveur peut attendre indéfiniment un datagramme qui s’est perdu. Une méthode simple permet d’éviter cette attente infinie. Elle est basée sur le Time-out destiné à borner le temps d’attente.
Si à l’expiration du Time-out, le client n’a toujours pas reçu d’acquittement, notre méthode consistera à ré émettre le datagramme original et suivant le nombre de ré-émissions fixé, le processus récepteur termine l’attente en générant un code d’erreur. Par ailleurs, ce Time-out doit être fixé de manière dynamique suivant la taille maximum d’une case de données. Quant au problème de la perte de données, il est réglé par l’utilisation des acquittements.
Le contrôle de flux est optionnel, il est demandé par le client au niveau de la requête envoyée au serveur.
54
Cette courbe représente les temps mesurés pour les mêmes expériences mais au niveau du client (temps de réponse ), les résultats sont moins bons pour un grand nombre de serveurs par rapport aux tests effectués précédemment. Néanmoins, cela reste toujours très bénéfique par rapport au temps du stockage sur plusieurs serveurs qui est nettement moins inférieur que le stockage sur un nombre réduit de machines. Par ailleurs, si un seul
Riad MOKADEM - CERIA 2001/2002
5000 10000 20000
Nombre d’enregistrements
Temps de stockage (Ms)
5000 10000 20000
7000 6000 5000 4000 3000 2000 1000
1 Serveurs
2 Serveurs
3 Serveurs
Figure 7.6 : Temps de réponse à une requête de stockage au niveau du client
Un serveur Deux serveurs
Trois serveurs

Mémoire DEA Stockage utilisant les signatures dans les SDDS
serveur concerné par la requête de stockage ne répond pas au client après l’épuisement du Time-out, l’opération est échouée. Les résultats pris dans le cas où le fichier résiderait dans une seule case de données (pas d’éclatement encore) sont presque les mêmes avec les expérimentations au niveau des serveurs. La différence n’est que de quelques 20 à 30 Milli-secondes. Dans le cas de la répartition de fichier sur plusieurs serveurs, les résultats sont moins bons que les précédents. Néanmoins, la courbe représentant le temps de stockage au niveau de plusieurs serveurs est toujours moins croissante à chaque rajout d’un nouveau serveur de données. Cette différence de performance est due essentiellement aux acquittements des différentes machines (d’où la nécessité de machines homogènes pour de meilleurs tests) et au temps nécessaire pour effectuer la somme des intervalles reçus des serveurs au niveau du client. 7-8 Stockage de l’index : L’évolution de la taille du fichier de données par rapport au fichier d’index est représenté par une courbe logarithmique. Par
Par ailleurs, letemps mis pour lecalcul des signaturesdu fichier d’index estde l’ordre de8.15e-5% par rapportau fichier dedonnées(<<<1Ms).
Taille du fichier de données (MO)
5000 10000 20000
1.28 4.37 6.3 8 9
60 50 31.2 15.7 1.57
Figure 7.8 : Evolution de la taille du fichier de données/ fichier d’index
Taille du fichier d’index (Ko)
En plus, la taille du fichier d’index est très réduite par rapport au fichier de données (de 0.05 à 0.1%). L’unité de stockage (la page qu’on stockera sur disque) doit être réduite à moins de 16Ko pouvant être jusqu’à 256 octets ( taille minimum de stockage sur un disque) 7-9 Etude de la scalabilité :
Dans le but d’une meilleure étude de la scalabilité de notre système, nous effectuons cette expérience : On utilise cinq (5) machine Pentium 3 comme étant des serveurs de données, une machine Pentium 4 constitue le client et un autre Pentium 4 pour le serveur
55 2001/2002Riad MOKADEM - CERIA

Mémoire DEA Stockage utilisant les signatures dans les SDDS
de noms. Etant donné que ces serveurs sont moins performants que lors des précédants tests, nous prélèverons sans doute des temps plus important. Cependant, nous pourrons se prononcer avec certitude à propos de la scalabilité de notre système.
Taille d’une case : 17.6MO (insertion de 1000 enregistrements)
Nombre de serveurs Temps de calcul de la signature (Ms)
Temps nécessaire au stockage (Ms)
1 851 12989 2 Max(381,471)=471 8722 3 341 6399 4 271 4710 5 166 3500
Ces Résultats confirment les résultats obtenus avec les 3 serveurs plus puissants. Ils nous permettent d’affirmer que le module de stockage offre des capacités de passage à l’échelle (scalabilité) et on appellera cette propriété le Speed-up(9)[3 ]. La méthode de calcul de la signature offre des propriétés de Scale-up(10) étant donnée que la taille d’une case ne dépassera pas la taille maximum fixé et donc le temps nécessaire pour le calcul de signatures sera toujours borné(temps nécessaires pour le calcul de signatures sur une case de données dont la taille est limitée).
7-10 Paramètres de Stockage :
7-10-a Stockage de données suivant la variation de la taille d’une page :
Nous avons effectué quelques expérimentation en variant la taille d’une page. Les résultats qui suivent montrent le temps de calcul des signatures par rapport à une case de données. Nombre d’enregistrements insérés dans la case : 100
Taille de la page (Ko)
Temps de calcul de signatures de la case (Ms)
Temps moyen de calcul de signature pour une page de données (MS)
8 46 0.44 16 46 0.44 32 42 0.84 64 36 1.19 128 33 2.48
Nombre d’enregistrements insérés : 1500
Taille de la page (Ko) Temps de calcul de signatures de la case (Ms)
8 657 16 656 32 651 64 640 128 637
Ces résultats montrent le temps de calcul des signatures des différentes pages constituant une case de données en variant la taille de ces pages. Ce temps décroît en fonction de la croissance de la taille des pages de données. Cela est logique puisque le processeur aura moins de signatures à calculer. Cependant, pour de pages de données de tailles supérieures et suivant la formule de calcul des signatures, le processeur effectuera à chaque fois
56
(9) Speed-up : On dira que la propriété de speed-up linéaire est vérifiée lorsqu’une augmentation de capacités de la configuration d’une base de données entraîne une diminution du temps de réponse. (10) Scale-up : Les performances restent constantes pour une augmentation proportionnelle de la taille de la base de données.
2001/2002Riad MOKADEM - CERIA

Mémoire DEA Stockage utilisant les signatures dans les SDDS
l’opération du « modulo » pour le positionnement dans la table "Antilog" ce qui explique les petites décroissances des temps de calcul (le temps de calcul des signatures décroît de 3.5% pour le passage de pages de données de la taille 8Ko à 64KO). Lors d’une requête de stockage, le calcul de la nouvelle signature permettra de détecter la page dans laquelle les données ont été mises à jour, cette page doit être stockée sur le disque dur local. Le temps de stockage de cette page dépendra alors de la taille de celle ci.
En conséquence, le temps de stockage croit (de façon minime pour les petites pages) suivant la croissance de la taille de la page. Il est alors préférable de travailler avec des pages de tailles réduites. Cela permettra d’avoir des temps plus réduits surtout lorsqu’il s’agit de petites mise à jour(insertion ou modification de quelques enregistrements sans éclatement).
Taille de la page (Ko)
Longueur de la signature (octet) Temps de stockage d’une page (Ms)
8 4 14 16 4 15 32 4 15 64 4 16
7-10-b Stockage de données suivant le nombre de symboles de la signature Nous avons effectué des expérimentations en variant la longueur de la signature.
Ces tests ont été réalisés en calculant les signatures des pages constituant une case de données de taille 2.56 MO puis de taille 17.6 MO.
Taille de la case 1.56MO
Nombre d’enregistrements insérés
Longueur (Nombre de symboles ou octets) de la
signature
Temps de calcul des signature (Ms)
100 4 46 100 6 46 100 8 47 (+3%)
Taille de la case 17.6MO
Nombre d’enregistrements insérés
Longueur (Nombre d’octets) de la signature
Temps de calcul signatures (Ms)
1000 4 438 1000 6 453 (+4%) 1000 8 469 (+4.5%)
Lorsqu’une signature est calculée par rapport à une nouvelle puissance du polynôme primitif, le temps nécessaire pour l’obtention de la signature à plusieurs symboles est plus important.
57 2001/2002Riad MOKADEM - CERIA

Mémoire DEA Stockage utilisant les signatures dans les SDDS
Cette variation est logique puisque le processeur du serveur aura à calculer plus de signature (différentes signatures par rapport à la puissance de l’élément primitif). Cette croissance est d’environ 3 % à chaque rajout de symbole à une signature (1 er fichier) et de 4.5 % dans le 2ème exemple de fichier. Cependant, la différence de temps est constatée au moment de la comparaison entre les valeurs de la nouvelle et l’ancienne signature ( détection de la page mise à jour) lors d’une nouvelle requête de stockage. La probabilité de trouver deux pages identiques avec une même signature décroît en fonction de la croissance de la longueur de la signature à N symbole. En d’autres termes, la probabilité de trouver 2 signatures pour une même page est réduite lorsque la signature à N symboles porte sur un plus grand nombre d’octets. Cependant, pour la raison de comparaison entre les valeurs de super signatures, nous nous limiterons à une longueur de 4 octets largement supérieure aux probabilités d’erreurs d’écritures sur les disques (10-13 pour la mise à jour dans les disques). 7-10-c Calcul des signatures : Deux méthodes se présentent lors du calcul des signatures par rapport aux pages constituant une case de données : Une première méthode consiste à calculer, en premier lieu, la signature par rapport à chaque page en calculant les différentes signatures par rapport aux éléments primitifs α1, α2… αN. Ce calcul permettra d’obtenir la signature pour cette page. On procédera de la même manière pour les signatures d’autres pages. L’autre méthode consiste au calcul des signatures de toutes les pages par rapport à l’élément primitif α1. Par la suite, on calcule les autres signatures pour chaque puissance de l’élément primitif α. La signature finale de chaque page sera constituée de la concaténation des différentes signatures obtenues par rapport à chaque élément primitif. Des mesures ont montré que c’est la deuxième méthode qui est plus efficace. En effet, on constate un gain de temps de 10% par rapport à une case de 1.5Mo et de 17% à 20% pour des cases contenant 25000 enregistrements (393MO). 7-10-d Evolution des pages de données : On se sert des signatures pour détecter le nombre de pages modifiées après une opération de mise à jour ou d’insertion dans ces pages. Tant qu’il n’y a pas de création de nouvelles feuilles de données suite à un éclatement d’un nœud interne, le nombre de pages modifiés, suite à ces mises à jour, est réduit. L’insertion de 5% d’enregistrements (par rapport au maximum de clé que peut contenir la case) provoque le changement de 2% à 3% des signatures. L’insertion de plus de 5% d’enregistrements de clés aléatoires dans la case provoquerait alors la mise à jour de 10% de pages de données. Si ces insertions provoquent un éclatement, une migration de données est effectuée et cela provoquerai la mise à jour d’une grande partie des pages de données.
582001/2002Riad MOKADEM - CERIA

Mémoire DEA Stockage utilisant les signatures dans les SDDS
A la création de la case puis l’insertion d’enregistrements, les moitiés des feuilles de données seront remplies. L’éclatement d’un nœud est provoqué lorsque le nœud est saturé suite à des insertions. C’est alors qu’un nouveau nœud est créé provoquant ainsi une mise à jour des pages de données. Le nombre d’enregistrements à insérer pour produire cet éclatement est d’environs 5% tout en ayant de clés successives (éclatement du nœud).
7-11 Cas Particuliers :
7-11-a Stockage après Calcul de Signature dans le cas d’un éclatement
Dans la section précédente, nous avons vu que la moindre mise à jour ou insertion provoque le changement de la valeur de la signature. En conséquence, un stockage est nécessaire. Cependant, cela ne concernera que les pages ayant été mises à jour ou créées. Néanmoins, un cas particulier se présente, c’est le cas ou des insertions provoquent un éclatement de la case, s’en suit alors une migration des données ainsi que la réorganisation de l’index.
Taille maximum de la case
de données
Nombre d’enregistrements
insérés
Temps de calcul
de signature
Temps de
stockage
Temps de stockage (après Insertion d’un enregistrement
N°199 sans provoquer
d’éclatements)
Temps de stockage (Insertion d’un
enregistrement N° 200
éclatements)
200 198 88 918 16 Max(715,400)=715
Dans ce cas, à la prochaine requête de stockage, les pages de données seront complètement modifiées puisque la moitié des clés ayant migré vers un nouveau serveur Dans le cas le plus défavorable, on stockera alors les cases comme s’il s’agissait du premier stockage mais on bénéficiera toujours de la répartition de ce fichier sur plusieurs cases (réduction du temps de stockage).
7-11-b Stockage de données en utilisant un message unicast :
Dans le cas où la requête de stockage serait envoyée par le client à l’aide d’un message unicast, lorsque le fichier n’existe que sur un seul serveur de données, on constate un même temps de réponse à la requête de stockage au niveau du client. Lorsqu ce fichier est réparti sur plusieurs serveurs de données, les temps nécessaires de réponses au niveau du client sont légèrement en hausse. Cela est dû essentiellement à la re-direction du message de la requête vers les autres serveurs concernés par le stockage de ce fichier. On dira alors que l’utilisation d’un message multicast est plus bénéfique dans le cas des requêtes de stockage contrairement aux autres requêtes (les insertions par exemple) où la consultation de l’image du client permettait un gain de temps utilisant un message unicast dans le cas d’un client RP*c puis la re-direction vers les autres serveurs par message multicast (sauf pour les requêtes parallèles). Ici, cela est plus bénéfique puisque le stockage concernera un groupe de serveurs sans se soucier de l’exactitude de l’image du fichier au niveau du client.
59 2001/2002Riad MOKADEM - CERIA

Mémoire DEA Stockage utilisant les signatures dans les SDDS
7-12 Corps de Galois GF(24) :
Les éléments du champ de Galois GF(16) sont sur 4 bits. Les opérations de multiplication et de division s’effectuerons en utilisant la table suivante (table Antilog) :
Chaîne de
bits Entier Hexadécimal Log
0000 0 0 - 0001 1 1 0 0010 2 2 1 0011 3 3 4 0100 4 4 2 0101 5 5 8 0110 6 6 5 0111 7 7 10 1000 8 8 3 1001 9 9 14 1010 10 A 9 1011 11 B 7 1100 12 C 6 1101 13 D 13 1110 14 E 11 1111 15 F 12
Nous avons effectué des tests de calcul de signature en utilisant la table Antilog à 16 éléments GF(24). Théoriquement, le temps de calcul de signature doit être plus grand en utilisant cette table puisque, lors du calcul des signatures l’utilisation de l’opérateur « Modulo » & est plus fréquente (positionnement dans la table). L’utilisation d’un champ GF (2 16) est bénéfique puisque permettant de codifier les éléments sur un mot de 2 octets. Dans nos tests, pour des cases de données de petites taille, cette variation n’est pas très importante par rapport à la table utilisé dans le champ de Galois GF(2 16). Cependant, une amélioration est constatée lors de calcul de signatures pour des cases de grandes tailles. L’utilisation d’un GF (2 16) nous permet alors une meilleure fiabilité (codification sur un plus grand nombre d’éléments) en plus du gain de temps dans le calcul des signatures. 7-13 Signatures cryptographiques : Nous avons refait les mêmes tests de telle façon à pouvoir comparer entre les signatures cryptographiques et algébriques.
Nombre d’enregistrements
Temps de calcul des Signatures cryptographiques
Temps de calcul des signatures algébriques
100 98 31 150 156 47 1500 2326 650 10000 15230 4068
Une signature cryptographique porte sur 20 octets. En conséquence, le calcul des signatures cryptographiques dure plus de temps.
602001/2002Riad MOKADEM - CERIA

Mémoire DEA Stockage utilisant les signatures dans les SDDS
Avantages et Inconvénients des signatures cryptographiques La méthode SHA 1 est très utilisé dans les applications de cryptographie grâce à l’authentification parfaite des messages. Cependant, la consommation de mémoire (20 octets par signature), l’utilisation de clés inutiles dans notre cas en plus du temps de calcul assez conséquent fait que cette fonction est plutôt bloquante d’autant plus que le but recherché est d’éviter un stockage inutile en tranchant, dans un temps très réduit, sur la similarité des données. 7-14 Comparaison avec d’autres travaux : Notre comparaison concernera aussi des travaux réalisés pour la récupération de
données en générant d’autres données appelées données de parité. Ces données de parité sont utilisées au niveau de ses serveurs pour la récupération d’un enregistrement ou d’une case lors d’une défaillance d’un serveur. Elles se basent sur les codes de Reed-Solomon. Cela va dans le même sens que le chargement des données stockées précédemment pour remédier à un éventuel crash (accident) ou pour libérer de la mémoire. Dans ce contexte, nous avons comparé les temps mis pour récupérer une case en régénérant les données à partir de cases de parité avec le temps mis pour recharger les cases du fichier à partir des disques locaux. Bien que les données de parité soient en mémoire, le temps du chargement d’un fichier est plus ou moins comparable dans le cas d’un grand nombre de serveurs (répartition du fichier) puisque dans ce cas, nous n’aurons pas à reconstituer les données de la case nécessitant des milliers d’itérations. En plus, notre application permettra de récupérer les données sur les disques des serveurs quel que soit le nombre de serveurs en panne ( dépendance du nombre de serveurs de parités dans des travaux similaires[12]). 7-15 Perspectives : Nos expériences ont été réalisées sur un réseau 100Mbits/s avec un nombre de serveurs limité. La disponibilité d’un réseau plus rapide notamment le Giga Ethernet permettra de meilleures performances. La mise des données directement dans le cache permettra aussi un gain de temps considérable notamment en utilisant la routine Prefetch [21]. En outre, l’utilisation d’options de compression de fichiers mappés permet l’allocation d’un moindre espace de mémoire et de disque. Ce travail ouvre de nouvelles possibilités pour l’implémentation de nombreuses applications notamment les SGBD distribués et scalables qui bénéficieront alors de la persistance de données, primordiale dans ces systèmes.
61 2001/2002Riad MOKADEM - CERIA

Mémoire DEA Stockage utilisant les signatures dans les SDDS
CONCLUSION
Le placement statique des données présente plusieurs inconvénients qui limitent les performances d’accès aux données. La répartition dynamique remédie à ces problèmes et fournit un mode de gestion décentralisé et extensible. Nous avons implémenté le stockage réparti à travers des serveurs de données permettant une gestion dynamique de grandes masses de données Nous avons étendu les fonctionnalités du prototype SDDS2000 pour permettre de copier le contenu d’un fichier SDDS réparti sur les disques locaux des sites serveurs. On permet aussi le chargement en mémoire de ces fichiers sur demande. Pour rendre le stockage le plus rapide, nous avons pris comme principe de transférer sur le disque que les parties du fichier qui ont été modifiées depuis la dernière sauvegarde. Pour réaliser ce principe, nous avons expérimenté l’approche par des signatures. Notre choix a porté finalement sur une nouvelle technique de signatures algébriques, opérant sur les corps finis de Galois. Le résultat des expériences a servi à l’implémentation optimale de notre approche.
Notre travail a démontré la validité de l’approche que nous avons adopté. Le calcul de signatures s’est révélé suffisamment rapide pour être utile en pratique. La quantité de mémoires additionnelle nécessaire pour stocker les signatures à 4-symboles employés est négligeable. Enfin, notre analyse a prouvé la scalabilité de notre technique. Notre système est en cours d’être rendu disponible en téléchargement sur le site CERIA. Des expériences devront être faites aussi sur de très grandes cases, de l’ordre de GO permettant de confirmer la scalabilité vérifiée par nos tests. On va analyser aussi les signatures qui utilisent les puissances non-consécutives des éléments primitifs pour diminuer au maximum la probabilité de collisions. Enfin, on devrait continuer l’analyse de l’emploi de signatures cryptographiques, comme SHA1.
Ces dispositifs semblent très prometteurs pour la gestion des données dont la complexité et le volume sont en croissance exponentielle. Notre système devrait alors répondre aux qualités suivantes :
- Scalabilité et extensibilité. - Efficacité. - Couplage avec d’autres systèmes.
62 2001/2002Riad MOKADEM - CERIA

Mémoire DEA Stockage utilisant les signatures dans les SDDS
Bibliographie
[1] [CERIA] http://ceria.dauphine.fr/ [2] [Litwin] Ceria.dauphine.fr/witold.html [3] [Diène AW] Contribution à la gestion de structures de données Distribuées et
Scalables. Université Paris Dauphine 2001. [4] [Litwin W][T. Schwartz] Signatures for Scalable Distributed Data Structures. CERIA Technical Report, 2002-30-8 [5] [Bennour] Un Gestionnaire de Structures Distribuées et Scalables pour les multi-
ordinateurs Windows : fragmentation par hachage, Rapport de thèse, Université Paris Dauphine, 2000.
[6] [Sinha A.K] Network Programming in Windows NT. Addison- Wersley Publishing
Company 1996. [7] [Vingralek & al] Scalable Storage on Network of workstation with balanced load http : //www.bell-labs.com/user/rvingral/publication.html [8][L Xu & J Bruck] Highly Available Distributed Storage System, Proceeding of
workshop on Distributed High Performance Computing. Springer Verlag 1999 [9][Litwin, Neimet & Schneider] RP* : a family of order-preserving Scalable Distibuted
Data Structures, Proceeding of the 20 th VLDB Conference, santiago, Chili, 1994
[10][Brian L, J Hylton & al] A network Aware Distributed Storage Cache for Data
Intensive Environement, Berkley, CA, 94720 [11][Stevens, W. R] TCP/IP règles et protocoles. Editions Addison-Wesley France, SA. 1995.
[12][Moussa R] Implantation partielle & mesures de performances de LH* rs : Une SDDS à haute disponibilité.
[13] [POing] étude et implémentation de SDDS LH* lh dans Windows NT 4.0, 1997. [14] [Fips Pub 180 Federal Information] Secure Hash Standard, 1995 [15] [ J. Richter] Memory-Mapped Files in Windows NT Simplify File Manipulation and
Data Sharing
63 2001/2002Riad MOKADEM - CERIA

Mémoire DEA Stockage utilisant les signatures dans les SDDS
[16] [N Benga] Implémentation d’un client RP* en java. [17] [M Hall, Geoff A & all] Windows Socket (Interface for network programming),
January 1993 [18] [J Richter] Advanced Windows, Memory Mapped Files, Microsoft press 1996 [19] [DIENE A] Organisation interne des SDDS RP*. Mémoire de DEA d’informatique-
Université Cheikh Anta Diop de Dakar 1998 [20] [A. BENHOMME] Conception d’un système de stockage distribué et tolérant aux
pannes, pour un serveur de vidéo à la demande, Ecole Normale Supérieure de LYON. Thèse MathIF, Informatique 2001
[21] [J.Pareira] Algorithme de filtrage efficace pour les systèmes de diffusion d’information à
base de notification. Thèse Doctorat Université de Versailles septembre 2002
64 2001/2002Riad MOKADEM - CERIA