Embed Size (px)
Citation preview

THESE DE DOCTORAT DE L’UNIVERSITE PIERRE ET MARIE CURIE
Spécialité : Physique Mention : Electronique
(Ecole doctorale de Sciences Mécaniques, Acoustique et Electronique de Paris)
Présentée par
Hulusi ACIKGOZ
Pour obtenir le grade de
DOCTEUR de l’UNIVERSITÉ PIERRE ET MARIE CURIE
Sujet de la thèse : Technique d’inversion associant la modélisation numérique et les réseaux
de neurones pour la caractérisation microondes de matériaux
soutenue le 5 décembre 2008
devant le jury composé de :
M. Alain Kreisler Professeur Emérite, UPMC-Paris VI Directeur de thèse Mme Valérie Madrangeas Professeur, Université de Limoges Rapporteur Mme Valérie Vigneras Professeur, Université Bordeaux 1 Examinateur M. Marc Hélier Professeur, UPMC-Paris VI Président du jury M. Christian Vollaire Maître de Conférences, Ecole Centrale de Lyon Examinateur M. Yann Le Bihan Maître de Conférences, Université Paris Sud Examinateur M. Olivier Meyer Maître de Conférences, UPMC-Paris VI Invité M. Lionel Pichon Directeur de Recherches, CNRS Invité

Remerciements
Je tiens tout d’abord à remercier Monsieur Alain Kreisler, Professeur Emérite à l’UPMC-Paris 6 et Monsieur Frédéric Bouillaut, Professeur à l’Université Paris Sud, respectivement ancien et actuel Directeur du Laboratoire de Génie Electrique de Paris, pour m’avoir accueilli dans leur laboratoire. Je suis également reconnaissant à Monsieur Alain Kreisler d’avoir accepté de diriger cette thèse.
Mes remerciements vont également à Madame Valérie Madrangeas, Professeur à l’Université de Limoges et à Madame Valérie Vigneras, Professeur à l’Université Bordeaux 1 pour avoir accepté de rapporter sur mes travaux.
J’exprime toute ma gratitude aux autres membres du jury, Monsieur Marc Hélier, Professeur à l’UPMC-Paris 6 et président du jury et Monsieur Christian Vollaire, maître de conférences à l’Ecole Centrale de Lyon, pour avoir accepté d’examiner cette thèse.
Je voudrais plus particulièrement adresser mes remerciements à Messieurs Yann Le Bihan, Maître de Conférences à l’Université Paris Sud, Olivier Meyer, Maître de Conférences à l’UPMC-Paris 6, et Lionel Pichon, Directeur de Recherches au CNRS, pour m’avoir encadré durant ces trois années de thèse. J’exprime ma profonde reconnaissance et estime à Yann Le Bihan (pour la partie modélisation et inversion) et Olivier Meyer (pour la partie expérimentale). Leurs connaissances, méthodologies, et expérience m’ont énormément apportés. De même, je tiens à remercier grandement Lionel Pichon pour sa disponibilité et son implication pendant toute la période de la thèse, ainsi que pour ses conseils avisés.
Je remercie aussi Monsieur Olivier Dubrunfaut, Maître de Conférences à l’UPMC-Paris 6 pour ses conseils et pour tout ce qu’il a pu m’apporter tant sur le plan humain que scientifique.
Mes remerciements vont également à Benjamin Jannier, doctorant CIFRE, avec qui j’ai partagé, mon bureau, pour sa contribution à l’application de la méthodologie d’inversion développée dans cette thèse.
Je ne saurais oublier l’aide très précieuse de Monsieur Laurent Santandréa, Ingénieur d’Etude au CNRS et responsable de la Salle de Calcul. Qu’il soit assuré de mes très sincères remerciements.
Je voudrais également remercier les doctorants du laboratoire avec qui j’ai passé de très bons moments.
Je voudrais surtout ne pas oublier mes proches qui ont su m’épauler aux moments difficiles de mes études supérieures et plus particulièrement pendant ces trois années de thèse. Qu’ils sachent à quel point je leur suis reconnaissant.

SOMMAIRE
INTRODUCTION GENERALE ..........................................................................................................................5 1 GENERALITES ............................................................................................................................................7
1.1 INTERACTION DES MICROONDES AVEC LES MATERIAUX..........................................................................8 1.1.1 Que sont les microondes ?.................................................................................................................8 1.1.2 Loi de comportement diélectrique .....................................................................................................9 1.1.3 Relaxations diélectriques.................................................................................................................11
1.1.3.1. Le modèle de Debye ...................................................................................................................... 11 1.1.3.2. Améliorations apportées au modèle de Debye............................................................................... 14
1.2 CARACTERISATION MICROONDES..........................................................................................................15 1.2.1 Technique de mesure avec contact ..................................................................................................15 1.2.2 Technique de mesure sans contact, en espace libre ........................................................................17 1.2.3 Technique de mesure en cavité résonnante .....................................................................................18
1.3 RESOLUTION DES PROBLEMES DIRECT ET INVERSE................................................................................20 1.3.1 Problème direct ...............................................................................................................................20 1.3.2 Problème inverse .............................................................................................................................22
1.3.2.1 Inversion itérative ................................................................................................................................. 22 1.3.2.2 Inversion directe.................................................................................................................................... 23
2 METHODOLOGIE DEVELOPPEE.........................................................................................................25 2.1 INTRODUCTION .....................................................................................................................................25 2.2 PROBLEME DIRECT - MODELISATION PAR LA METHODE DES ELEMENTS FINIS .......................................26
2.2.1 Rappel des lois de l’électromagnétisme ..........................................................................................26 2.2.2 Méthode des éléments finis (MEF) ..................................................................................................28
2.2.2.1 Principe de la méthode des éléments finis............................................................................................. 29 2.2.2.2 Modélisation par éléments finis sous ANSYS® .................................................................................... 31
2.3 INVERSION PAR RESEAUX DE NEURONES ...............................................................................................33 2.3.1 Neurone formel................................................................................................................................33 2.3.2 Réseaux de neurones .......................................................................................................................35 2.3.3 Apprentissage des réseaux de neurones MLP .................................................................................36
2.3.3.1 Apprentissage supervisé........................................................................................................................ 36 2.3.3.2 Apprentissage non supervisé................................................................................................................. 38
2.3.4 Préparation de l’apprentissage .......................................................................................................38

2
2.3.5 Propriétés des réseaux de neurones MLP .......................................................................................39 2.3.6 Capacité de généralisation..............................................................................................................40
2.3.6.1 La méthode split sample :...................................................................................................................... 41 2.3.6.2 La régularisation bayesienne................................................................................................................. 42
3 APPLICATION DES RESEAUX DE NEURONES A LA CARACTERISATION DIELECTRIQUE LARGE BANDE DE MATERIAUX........................................................................................................................49
3.1 INTRODUCTION .....................................................................................................................................49 3.2 CELLULE DE MESURE : SUPERMIT ........................................................................................................50
3.2.1 Modélisation analytique ..................................................................................................................51 3.2.2 Inversion itérative............................................................................................................................53 3.2.3 Modélisation par la méthode des éléments finis..............................................................................53 3.2.4 Inversion par réseaux de neurones..................................................................................................55
3.2.4.1 Création de bases de données................................................................................................................ 55 3.2.4.2 Mise en œuvre des réseaux de neurones................................................................................................ 57 3.2.4.3 Etude du nombre d’exemples d’apprentissage ...................................................................................... 58 3.2.4.4 Détermination du nombre de neurones cachés ...................................................................................... 60 3.2.4.5 Mesures effectuées sur des matériaux étalons ....................................................................................... 61
3.3 CELLULE A REMPLISSAGE INHOMOGENE : SUPERPOL ...........................................................................64 3.3.1 Modélisation analytique ..................................................................................................................65 3.3.2 Inversion itérative............................................................................................................................65 3.3.3 Modélisation par la méthode des éléments finis..............................................................................66 3.3.4 Inversion par réseaux de neurones..................................................................................................66 3.3.5 Conclusion.......................................................................................................................................70
4 APPLICATION DES RESEAUX DE NEURONES A LA DETERMINATION DES FRACTIONS D’UN FLUIDE PETROLIER...................................................................................................................................73
4.1 CONTEXTE DE L’ETUDE.........................................................................................................................73 4.2 PRINCIPE DU CAPTEUR MO ...................................................................................................................75 4.3 METHODE D’INVERSION SEMI-ANALYTIQUE..........................................................................................76 4.4 METHODE PROPOSEE.............................................................................................................................77
4.4.1 Modélisation du capteur..................................................................................................................78 4.4.2 Réponse du capteur MO ..................................................................................................................80 4.4.3 Inversion : réseaux à 2 entrées........................................................................................................81 4.4.4 Inversion : réseaux à 4 entrées........................................................................................................83 4.4.5 Inversion de données de mesure......................................................................................................85 4.4.6 Conclusion.......................................................................................................................................87
5 OPTIMISATION DE LA BASE D’APPRENTISSAGE..........................................................................89 5.1 INTRODUCTION .....................................................................................................................................89 5.2 BASE REGULIERE ..................................................................................................................................89 5.3 BASE ADAPTATIVE ................................................................................................................................91
5.3.1 Description de la méthode : ............................................................................................................91 5.3.2 Mise en œuvre..................................................................................................................................92

3
5.3.3 Application sur un cas réel : cellule SuperPol ................................................................................94 5.3.3.1 Bases générées à 1 MHz........................................................................................................................ 94 5.3.3.2 Bases générées à 1 GHz ........................................................................................................................ 95 5.3.3.3 Bases générées à 3 GHz ........................................................................................................................ 97 5.3.3.4 Inversion des données simulées bruitées ............................................................................................... 98
5.4 CONCLUSION.......................................................................................................................................101 6 CONCLUSION FINALE ET PERSPECTIVES.....................................................................................103 ANNEXE.............................................................................................................................................................105 BIBLIOGRAPHIE.............................................................................................................................................111 LISTE DES PUBLICATIONS..........................................................................................................................117

4

5
Introduction générale
Ce travail de thèse a été réalisé dans le cadre d’une collaboration entre trois équipes du Laboratoire de Génie Electrique de Paris, MDMI (Matériaux et Dispositifs : des Microondes à l’Infrarouge), COCODI (Conception, Commande et Diagnostic) et ICHAMS (Interactions Champs-Matériaux et Structures). L’étude porte sur l’élaboration d’une procédure d’inversion pour la caractérisation microondes (MO) de matériaux. Celle-ci associe la méthode des éléments finis (MEF) et les réseaux de neurones (RN).
Il existe différentes techniques de caractérisation de matériaux : les ultrasons, les rayons X, les courants de Foucault, les rayons gamma, les microondes (MO) sont parmi les techniques les plus utilisées. Chaque technique a ses avantages et inconvénients et les domaines d’applications diffèrent suivant le type de matériaux et les contraintes mis en œuvre. Parmi les méthodes électromagnétiques, la technique des MO constitue une place importante pour la caractérisation de matériaux diélectriques. En effet, la faculté des MO à pénétrer les matériaux diélectriques et à être sensibles à leur permittivité fait d’eux une méthode à part entière pour ce type de milieu.
Les techniques MO peuvent être divisées en trois grandes catégories : mesure en contact, en espace libre (sans contact) et en cavité. La technique de caractérisation employée dans cette thèse se classe dans la première catégorie : mesure en contact. Elle consiste à utiliser une ligne de transmission en contact direct avec le milieu étudié. Du fait de sa simplicité, c’est une méthode largement utilisée dans la communauté de la caractérisation MO.
Le principe général de la technique des MO est de relier les données d’observation (coefficient de réflexion, de transmission ou admittance) aux propriétés électromagnétiques de la structure étudiée (permittivité, perméabilité) ainsi qu’à sa géométrie. Les paramètres recherchés (propriétés électromagnétiques et/ou géométriques) sont alors déterminés à partir de la mesure MO. Cependant, dans la plupart des cas, le problème inverse permettant de remonter aux paramètres recherchés est difficile à résoudre.
Pour résoudre ce problème inverse, nous proposons dans cette thèse, la combinaison de modélisation par éléments finis (MEF) avec les réseaux de neurones (RN). Le choix des RN réside dans le fait que ce sont des modèles comportementaux intéressants et dont les propriétés en font des approximateurs universels et parcimonieux. Dans cette approche, la modélisation par MEF sert à créer les bases de données nécessaires à l’inversion par RN.

6
Ce manuscrit de thèse est composé de cinq chapitres :
Le premier chapitre présente des généralités sur les MO ainsi que les mécanismes mis en jeu lorsqu’un matériau diélectrique est illuminé par des MO. Dans ce chapitre, nous présentons également quelques techniques de caractérisation MO parmi celles les plus couramment utilisées pour l’étude de matériaux diélectriques. Enfin, les problèmes direct et inverse relatifs à la caractérisation MO sont abordés. Les solutions pouvant être apportées pour résoudre ces problèmes sont présentées.
La méthodologie développée dans cette thèse fait l’objet du deuxième chapitre. Plus précisément, dans une première partie, la résolution du problème direct à l’aide de la MEF est présentée. Ensuite, après avoir décrit ce qu’est un RN ainsi que ses propriétés, nous mettons l’accent sur le problème de généralisation qui peut apparaitre lorsqu’un RN possède trop de paramètres internes. Pour résoudre ce problème, nous présentons deux des méthodes les plus connues : la méthode split sample et la régularisation bayesienne.
Ensuite, le chapitre 3 sera l’occasion d’appliquer l’inversion par RN dans un cas concret, celui de la caractérisation diélectrique large bande de matériaux. Deux types de cellules sont utilisés. Pour la première cellule, la solution analytique du modèle direct existant, celle-ci nous a permis de valider la méthode d’inversion par RN. L’inversion des données d’observations issues de mesures de matériaux étalons est effectuée. Ensuite, nous avons appliqué les RN aux données issues de la deuxième cellule de mesure dont la solution analytique est limitée en fréquence. Ce chapitre permet également de montrer l’efficacité de la régularisation bayesienne comparée à la méthode split sample.
Nous présentons au chapitre 4 une deuxième application des RN pour la résolution d’un problème inverse. L’application concerne la détermination des proportions des constituants d’un fluide pétrolier par des capteurs MO. C’est un sujet qui fait suite à une collaboration entre l’équipe MDMI du LGEP et une société de services pétroliers.
Enfin, une procédure d’optimisation des bases de données pour l’utilisation des RN est présentée au chapitre 5. Nous comparons deux types de bases de données : base régulière dans laquelle les exemples sont distribués de façon uniforme et base adaptative où les exemples sont distribués en prenant en compte le comportement de la sonde. L’efficacité des bases adaptatives est mise en évidence en inversant des données simulées bruitées.

1 Généralités
Au milieu du XXème siècle, les MO était plutôt utilisées pour des applications radar. Mais depuis la découverte, dans les années 50, de l’utilisation des MO pour le chauffage [Cha 88], en collaboration avec des chercheurs du milieu académique, les industriels se sont de plus en plus intéressés à l’utilisation des techniques MO dans de très nombreux domaines. On peut citer comme secteurs applicatifs, l’industrie aéronautique, la micro-électronique, l’industrie agro-alimentaire, etc.
La propagation des MO dépend fortement des propriétés des matériaux. Une des propriétés les plus fondamentales d’un matériau diélectrique est sa permittivité complexe. C’est une mesure de la capacité du diélectrique à absorber et à stocker l’énergie électrique. C’est un paramètre incontournable pour l’étude des matériaux diélectriques. Des chercheurs ont tenté de retrouver théoriquement la permittivité diélectrique en proposant des modèles plus ou moins simplifiés. Parmi ces modèles, le plus connu est celui de Debye [Deb 29]. Depuis, pour s’approcher le plus possible de la réalité, d’autres modèles plus évolués comme ceux de Cole-Cole [Col 41], Cole-Davidson [Dav 51], Havriliak-Negami [Hav 67], ont été proposés.
En parallèle au développement de la théorie concernant l’interaction des MO avec les matériaux diélectriques, diverses techniques de mesure ont été mises au point. L’objectif de ces mesures MO est de retrouver à partir de données de mesure les propriétés qui caractérisent le matériau sous test. Cependant, les problèmes de caractérisation MO sont souvent très complexes et la relation qui lie les données de mesure aux propriétés recherchées n’est pas toujours disponible. Ce genre de problèmes consistant à remonter aux propriétés des matériaux à partir des données de mesures est appelé « problèmes inverses ».
Dans ce chapitre sont présentées, dans un premier temps, des généralités sur les MO ainsi que les mécanismes mis en jeu dans les matériaux diélectriques par l’application d’un champ électrique.
Une deuxième partie expose les principales techniques de caractérisation MO ainsi qu’une bibliographie sur ces méthodes dans le cas de la caractérisation de matériaux diélectriques et du contrôle non destructif.
Enfin, les notions de problèmes direct et inverse ainsi que les solutions qui peuvent y être apportées sont abordées.

8
1.1 Interaction des microondes avec les matériaux
1.1.1 Que sont les microondes ?
Sur le spectre électromagnétique (Figure 1), les MO se situent entre les ondes radar et les infrarouges. La gamme de fréquence correspondante est comprise approximativement entre 300 MHz et 300 GHz. Ces fréquences correspondent à une longueur d’onde dans l’espace libre de 1 mètre à 1 millimètre. Typiquement pour les applications de caractérisation, l’intervalle de fréquence se situe entre quelques dizaines de MHz et quelques dizaines de GHz.
Figure 1 : Le spectre électromagnétique
Les MO sont largement utilisées dans la vie courante. On remarque l’une des premières applications des MO avec les radars. De nos jours, les MO sont de plus en plus utilisées pour le chauffage des aliments. La téléphonie mobile et la télévision utilisent aussi les MO pour transmettre une information.
Les MO sont bien adaptées pour étudier les matériaux diélectriques. En effet, elles peuvent se réfléchir partiellement et se propager à travers les diélectriques tels que les céramiques, les plastiques et les matériaux organiques. Cette interaction peut permettre non seulement d’estimer les dimensions et la forme des matériaux mais également de réaliser une inspection non destructive du milieu pour détecter des anomalies ou des propriétés intrinsèques telle que la permittivité diélectrique et la perméabilité magnétique.
Cependant, les MO sont réfléchies à l’interface d’un conducteur. Les ondes ne pénétrant quasiment pas dans les conducteurs, elles créent à leurs surface des courants de Foucault qui sont à l’origine de la réflexion quasi-totale. C’est pour cette raison que les MO ne peuvent être utilisées dans le cas d’un conducteur que pour étudier sa surface extérieure, notamment pour des mesures de topographie.
Nous présentons dans les lignes qui suivent les mécanismes mis en jeu lors de l’interaction d’une onde électromagnétique avec un milieu diélectrique.

9
1.1.2 Loi de comportement diélectrique
Dans un matériau diélectrique, les électrons sont liés aux noyaux et ne peuvent pas être
libérés par un champ électrique. Le champ électrique ne peut pas déplacer les électrons d’un atome à un autre comme c’est le cas dans un conducteur. A contrario, les électrons de valence d’un conducteur (comme un métal) sont faiblement liés aux noyaux et sont facilement mis en mouvement d’un atome à un autre sous l’influence d’un champ électrique extérieur. Il en résulte que les matériaux diélectriques sont de bons isolants électriques et n’engendrent pas ou très peu de courant de conduction.
Cependant, même s’il n’y a pas de déplacement macroscopique des charges électriques, sous l’application d’un champ électrique, il peut y avoir un phénomène de polarisation. Ceci est illustré sur la Figure 2 dans le cas d’une configuration simple : un atome. Initialement, le centre de gravité des charges négatives (-q) et celui du noyau positif (+q) coïncident. Après application d’un champ électrique extérieur, leurs centres de gravité se séparent et le nuage d’électrons se regroupe dans la direction opposée au champ électrique. Les centres des charges sont maintenant séparés d’une distanceξ . Le moment dipolaire diélectrique induit de la particule (atome) est alors égal à ξμ
rr .q=
+ -
-
-
-
-
-
-
-+-- -- ----
-q +q
ξ
0≠Er
0=Er
+ -
-
-
-
-
-
-
-+-- -- ----
-q +q
ξ
0≠Er
0=Er
+ -
-
-
-
-
-
-
-
+ -
-
-
-
-
-
-
-+-- -- ----
-q +q
ξ
0≠Er
0=Er
Figure 2 : Illustration de l’influence du champ électrique à l’échelle atomique
La polarisation Pr
induite dans le volume du matériau diélectrique est la somme de tous les moments dipolaires induits par atome divisée par le volume.
Sous l’hypothèse de linéarité et pour des matériaux isotropes, Pr
est directement liée au champ électrique E
r appliqué par la relation :
EPrr
χε 0= (1.1)

10
où 0ε et χ sont respectivement la permittivité du vide )/1036
1( 90 mFπ
ε ≅ et la
susceptibilité diélectrique (grandeur sans dimension).
On introduit le déplacement électrique Dr
qui exprime la densité de flux électrique dans le matériau. D
r est exprimée en fonction du champ E
r et de la polarisation P
r induite par la
relation :
PEDrrr
+= 0ε (1.2)
En remplaçant l’expression de Pr
dans Dr
on obtient :
EDrr
0)1( εχ+= (1.3)
où 0)1( εχ+ est la permittivité diélectrique ε du matériau :
0)1( εχε += (1.4)
On remarque que la permittivité du matériau est égale à celle du vide plus une contribution due à la polarisation diélectrique. Les matériaux isotropes ayant leurs vecteurs de polarisation et du champ électrique colinéaire, leur permittivité ε est un scalaire.
La plupart des matériaux diélectriques présentent des pertes, même si elles peuvent être très faibles. Ceci a pour effet que le vecteur de polarisation ne suit pas instantanément les variations du vecteur champ électrique, il y a donc un déphasage entre ces deux derniers. Par conséquent, en passant dans le domaine complexe, le déplacement électrique D
r peut être
relié au champ électrique par :
EjDrr
)'''( εε −= (1.5)
où ε′ est la constante diélectrique qui représente la capacité d’un matériau à être polarisé par un champ électrique externe et ε′′ est le terme d’absorption du matériau qui correspond aux pertes diélectriques dans le matériau, c’est-à-dire classiquement à sa capacité à transformer l’énergie électromagnétique en chaleur. Pour un matériau idéal (sans pertes), la permittivité est réelle.
Lorsque le champ électrique appliqué sur le matériau est supprimé, la polarisation passe d’une certaine valeur (correspondant à une certaine orientation des dipôles) à zéro (l’équilibre) d’une manière non instantanée avec une certaine constante de temps τ. Ce phénomène de dépolarisation du matériau lorsqu’on annule la contrainte externe correspond à la relaxation diélectrique. Ce phénomène est présenté ci-après.

11
1.1.3 Relaxations diélectriques
La permittivité d’un matériau diélectrique peut dépendre fortement de la fréquence du champ électrique appliqué. Différentes relaxations peuvent en effet apparaitre lorsqu’un matériau diélectrique est soumis à un champ électrique harmonique (Figure 3). Chacune de ces relaxations apparaît centrée autour de sa fréquence caractéristique. En partant des fréquences les plus basses, les principales relaxations sont : dipolaires, ioniques et électroniques.
Fréquence (Hz)
Dipolaire
Ionique Electronique
'ε
''ε
103 106 109 1012 1015
Fréquence (Hz)
Dipolaire
Ionique Electronique
'ε
''ε
103 106 109 1012 1015
Figure 3 : Différents phénomènes de relaxation apparaissant sur l’échelle des fréquences
Les paragraphes suivants présentent les différents modèles qui permettent de modéliser la relaxation dipolaire.
1.1.3.1. Le modèle de Debye
Dans ses travaux sur les molécules polaires, Debye présenta une généralisation du comportement des matériaux moléculaire avec polarisation d’orientation dans les zones de relaxation diélectrique, c'est-à-dire dans les situations où la période de l’onde électromagnétique est comparable au temps d’alignement τ de la molécule [Deb 29].
La relation entre la permittivité complexe et la fréquence du champ électrique appliqué que l’on cherche à établir est de la forme :
)()( ωεωε g+= ∞ (1.6)
où )(ωg est une fonction de la pulsation ω ( fπω 2= avec f la fréquence) qui vérifie
∞−=→ εεω sg )0( et 0)( =∞→ωg
Dans (1.6) ∞ε représente la polarisation atomique et électronique quand la fréquence du champ électrique appliqué est très grande devant l’inverse du temps d’alignement moléculaire. A l’inverse, pour des fréquences basses, la permittivité relative se nomme la constante diélectrique relative statique sε (permittivité statique).

12
Supposons qu’un champ électrique soit appliqué pour aligner une molécule et qu’ensuite ce champ soit annulé. Après l’annulation du champ, il est évident que la polarisation et le champ interne à la molécule vont diminuer. Pour évaluer cette diminution de la polarisation P , Debye a supposé que la polarisation décroissait de façon exponentielle avec la constante de temps τ :
)/exp()( 0 τtPtP −=rr
(1.7)
où 0Pr
est la polarisation à l’équilibre.
De plus, dans le modèle de Debye, les processus de relaxation (atomiques, électroniques) qui sont susceptibles d’apparaître pour des fréquences très élevées (au-delà de 1011 Hz) sont négligés et la constante diélectrique correspondante est supposée constante et égale à ∞ε .
Solymar et Walsh [Sol 88] ont montré que les fonctions )(ωg et )(tP sont liées par une transformée de Fourier :
∫∞
+
Κ=Κ=
0
01
)exp()()(
τω
ωωj
PdttjtPg (1.8)
Dans (1.8), K est une constante.
Finalement, en résolvant cette équation et en se servant de la condition ∞−= εε sg )0( , l’expression de la permittivité relative complexe devient [Che 80]:
ωτεε
εωεj
sr +
−+= ∞
∞ 1)( (1.9)
En séparant les parties réelle et imaginaire, on obtient :
221)('
τωεε
εωε+−
+= ∞∞
sr 221
)()(''
τωεεωτ
ωε+
−= ∞s
r (1.10)
Ci-dessous est représentée l’évolution de 'ε et de ''ε en fonction de la fréquence (Figure 4).
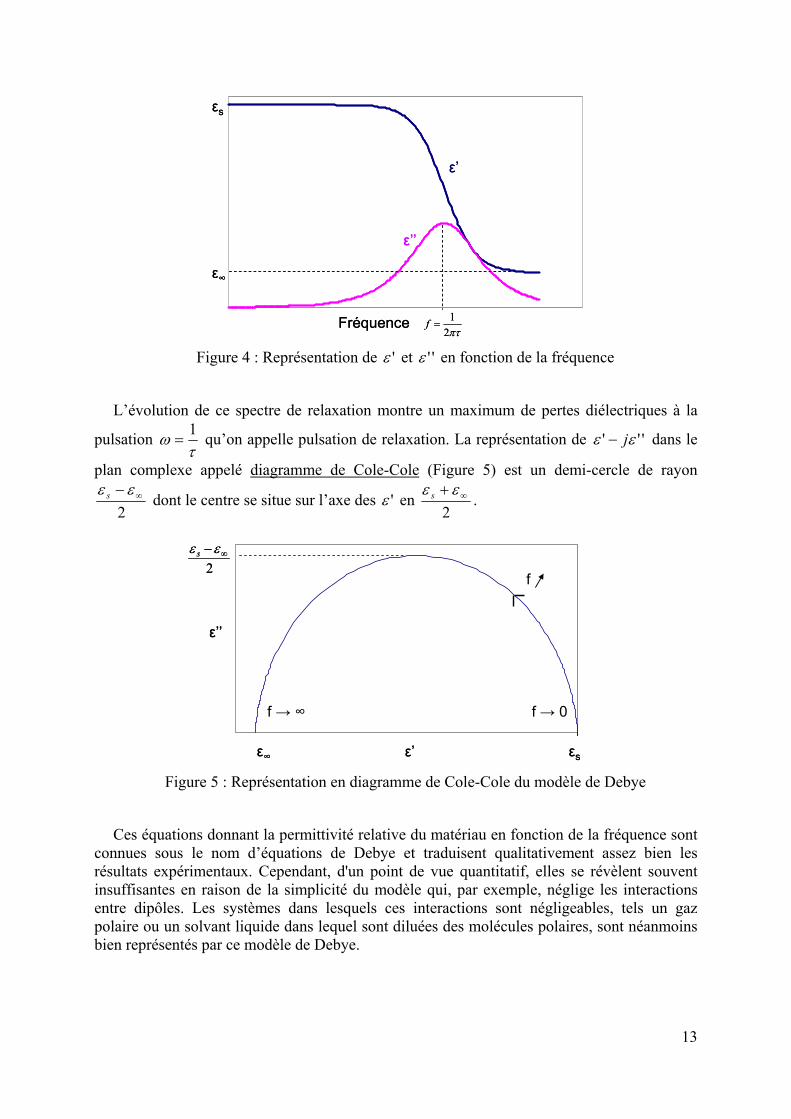
13
εs
ε∞
Fréquence
ε’
ε’’
πτ21
=f
εs
ε∞
Fréquence
ε’
ε’’
πτ21
=f
Figure 4 : Représentation de 'ε et ''ε en fonction de la fréquence
L’évolution de ce spectre de relaxation montre un maximum de pertes diélectriques à la
pulsation τ
ω 1= qu’on appelle pulsation de relaxation. La représentation de ''' εε j− dans le
plan complexe appelé diagramme de Cole-Cole (Figure 5) est un demi-cercle de rayon
2∞− εε s dont le centre se situe sur l’axe des 'ε en
2∞+ εε s .
εsε∞ ε’
ε’’
f → 0f → ∞
2∞−εε s
f
εsε∞ ε’
ε’’
f → 0f → ∞
2∞−εε s
f
Figure 5 : Représentation en diagramme de Cole-Cole du modèle de Debye
Ces équations donnant la permittivité relative du matériau en fonction de la fréquence sont connues sous le nom d’équations de Debye et traduisent qualitativement assez bien les résultats expérimentaux. Cependant, d'un point de vue quantitatif, elles se révèlent souvent insuffisantes en raison de la simplicité du modèle qui, par exemple, néglige les interactions entre dipôles. Les systèmes dans lesquels ces interactions sont négligeables, tels un gaz polaire ou un solvant liquide dans lequel sont diluées des molécules polaires, sont néanmoins bien représentés par ce modèle de Debye.

14
De plus, le modèle de Debye ne prend pas en compte la conductivité électrique statique du milieu. Le modèle de Debye peut cependant être modifié de façon à l’introduire.
01)(
ωεσ
ωτεε
εωε ss jj
−+−
+= ∞∞ (1.11)
où sσ est la conductivité statique du milieu.
1.1.3.2. Améliorations apportées au modèle de Debye
Par ailleurs, différents chercheurs ont tenté d’améliorer le modèle de Debye pour expliquer le comportement diélectrique des systèmes qui ne suivent pas les prédictions faites par le modèle idéal de Debye. Notamment, on peut noter par exemple la prise en compte des interactions entre dipôles qui n’apparaissent pas dans cette loi. Parmi les modèles les plus notables, on rencontre dans la littérature celui de K.S. Cole et R. H. Cole [Col 41] nommé communément modèle de Cole-Cole. Ce modèle introduit la notion de dispersion qui considère la constante de temps non pas comme une valeur fixe mais ayant une distribution gaussienne autour d’une constante de temps moyenne. Le modèle de Debye modifié devient alors :
01)(1
)(ωεσ
ωτεε
εωε αss j
j−
+
−+=
−∞
∞ (1.12)
Dans (1.12) α est un paramètre empirique permettant d’ajuster la largeur de la dispersion. Il caractérise l’écart par rapport au modèle de Debye. Lorsque 0=α , on retrouve le modèle de Debye.
On peut aussi citer d’autres modèles comme ceux de :
- Cole-Davidson :
0)1()(
ωεσ
ωτεε
εωε βss j
j−
+
−+= ∞
∞ (1.13)
oùβ est un paramètre empirique 10 << β
Cette relation qui est due à Davidson et Cole [Dav 51] prend en compte l’asymétrie que peut avoir le spectre diélectrique de certaines substances comme le glycérol. Le diagramme de Cole-Cole correspondant n’est plus symétrique [Che 80].

15
- Havriliak-Negami :
01 ))(1(
)(ωεσ
ωτεε
εωε βαss j
j−
+
−+=
−∞
∞ (1.14)
Cette relation reprend à la fois le modèle de Cole-Cole et de Cole-Davidson lorsque 1=β et 0=α , respectivement. Il a été utilisé pour la première fois pour décrire la relaxation diélectrique dans les polymères [Hav 67]. Il prend en compte l’étalement et l’asymétrie des spectres de relaxation.
Les paramètres intervenant dans ces différents modèles sont à déterminer. En principe, ∞ε et
sε sont obtenus en effectuant des mesures en très basse et très haute fréquences. À ces fréquences extrêmes, ''ε devient nul et 'ε tend vers une valeur limite qui est sε pour les très basses fréquences et ∞ε pour les très hautes fréquences. Cependant, la mesure à ces deux fréquences limites n’est pas toujours simple car d’une part l’instrumentation pour atteindre des fréquences élevées coûte très cher, d’autre part la précision de ces mesures peut être médiocre. Pour réaliser cette détermination, des auteurs ont proposés différentes méthodes plus ou moins précises et complexes [Mir 08] [Bis 00] [Gho 03].
1.2 Caractérisation microondes
L’interaction des MO avec la matière permet de les utiliser à des fins de caractérisation. Dans la suite, nous allons présenter les trois grandes catégories de méthodes de mesure MO existantes : mesure avec contact, mesure en espace libre (sans contact) et mesure dans une cavité résonnante.
1.2.1 Technique de mesure avec contact
C’est sans doute la méthode la plus répandue du fait de sa simplicité de mise en œuvre. Elle peut être divisée en deux catégories : caractérisation en milieu confiné et caractérisation en milieu ouvert (Figure 6). La première méthode impose d’avoir un échantillon de la pièce ou du matériau à étudier. Il faut donc découper la pièce à inspecter et insérer l’échantillon dans une cellule fixée sur le guide d’onde. Ceci est un inconvénient dans certaines applications où la pièce doit pouvoir être réutilisée (contrôle non destructif). Il en découle la nécessité d’avoir recours à une méthode non-destructive, où la pièce est placée directement sous la sonde MO qui permet le guidage de l’onde électromagnétique entre le dispositif de mesure et la pièce. Cette méthode permet de faire l’inspection du matériau sans qu’on ait besoin de le sacrifier. La méthode de mesure en contact présente comme inconvénient majeur que l’on ne maîtrise pas toujours très bien le contact entre le guide d’onde et la pièce, la présence d’un gap d’air pouvant considérablement diminuer la sensibilité du signal de la sonde. Cependant, la métallisation de la surface de contact peut être une solution pour améliorer la qualité de ce dernier. La Figure 6 présente les deux techniques de mesure dans le cas particulier où la sonde est un guide d’onde coaxial.

16
Matériau sous testGuide d’onde coaxial
Mur électrique
a)
b)
Matériau sous testGuide d’onde coaxial
Mur électrique
Matériau sous testGuide d’onde coaxial
Mur électrique
a)
b)
Figure 6 : Mesure en contact : a) mesure en milieu ouvert, b) mesure en milieu confiné
Les sondes les plus utilisées sont sans doute d’une part le guide d’onde coaxial [Bou 99] [Bel 86] et d’autre part le guide d’onde rectangulaire [Bak 93]. L’un des avantages d’une mesure en contact utilisant un guide coaxial plutôt qu’un guide rectangulaire est la largeur de bande fréquentielle : le guide coaxial est limité uniquement par une fréquence haute (par exemple 19,6 GHz pour un guide ayant un conducteur externe de diamètre 7 mm) alors que le guide rectangulaire est utilisable sur une bande restreinte (par exemple 8 GHz – 12 GHz pour un guide de 23 mm sur 10 mm). L’utilisation d’une large bande de fréquences permet d’augmenter les informations sur la structure caractérisée. Elle peut par exemple autoriser la caractérisation simultanée de la permittivité et de l’épaisseur d’une couche diélectrique. En effet, en se plaçant à une fréquence où la pénétration de l’onde est faible, la permittivité de la couche peut être évaluée indépendamment de son épaisseur puis, la permittivité étant connue, la mesure d’épaisseur peut se faire à une fréquence où la profondeur d’inspection est plus élevée. De plus, lors de la caractérisation de matériaux en fonction de la fréquence, une caractérisation large bande permet de se rendre compte de la présence éventuelle de plusieurs phénomènes de relaxation de certains matériaux et de comprendre les mécanismes liés à ces relaxations.
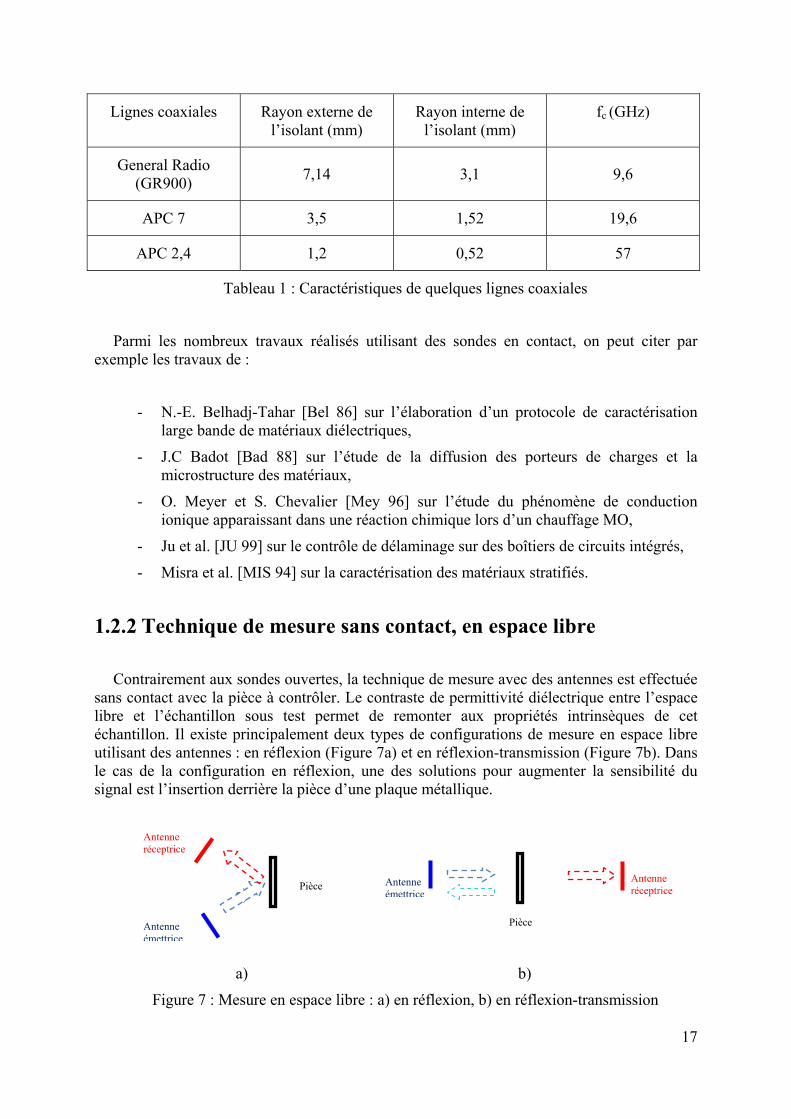
La limite d’utilisation en fréquence de différents standards de guides coaxiaux est donnée dans le Tableau 1. Elle est fixée par la fréquence de coupure fc au-dessous de laquelle seul le mode fondamental TEM (Transverse Electro-Magnétique : les composantes des champs électrique et magnétique parallèles à la direction de propagation sont nulles) se propage dans la ligne. La fréquence de coupure est inversement proportionnelle aux dimensions transversales de la ligne ; plus les dimensions sont petites, plus fc est grande. Les modes d’ordre supérieur apparaissent donc plus loin en fréquence. La sensibilité du dispositif dépend aussi fortement des dimensions transversales. Plus le diamètre augmente, plus la sensibilité augmente mais la résolution spatiale diminue.
17
Lignes coaxiales Rayon externe de l’isolant (mm)
Rayon interne de l’isolant (mm)
fc (GHz)
General Radio (GR900) 7,14 3,1 9,6
APC 7 3,5 1,52 19,6
APC 2,4 1,2 0,52 57
Tableau 1 : Caractéristiques de quelques lignes coaxiales
Parmi les nombreux travaux réalisés utilisant des sondes en contact, on peut citer par exemple les travaux de :
- N.-E. Belhadj-Tahar [Bel 86] sur l’élaboration d’un protocole de caractérisation large bande de matériaux diélectriques,
- J.C Badot [Bad 88] sur l’étude de la diffusion des porteurs de charges et la microstructure des matériaux,
- O. Meyer et S. Chevalier [Mey 96] sur l’étude du phénomène de conduction ionique apparaissant dans une réaction chimique lors d’un chauffage MO,
- Ju et al. [JU 99] sur le contrôle de délaminage sur des boîtiers de circuits intégrés,
- Misra et al. [MIS 94] sur la caractérisation des matériaux stratifiés.
1.2.2 Technique de mesure sans contact, en espace libre
Contrairement aux sondes ouvertes, la technique de mesure avec des antennes est effectuée sans contact avec la pièce à contrôler. Le contraste de permittivité diélectrique entre l’espace libre et l’échantillon sous test permet de remonter aux propriétés intrinsèques de cet échantillon. Il existe principalement deux types de configurations de mesure en espace libre utilisant des antennes : en réflexion (Figure 7a) et en réflexion-transmission (Figure 7b). Dans le cas de la configuration en réflexion, une des solutions pour augmenter la sensibilité du signal est l’insertion derrière la pièce d’une plaque métallique.
a)
a) b)
Figure 7 : Mesure en espace libre : a) en réflexion, b) en réflexion-transmission
Pièce
Antenne réceptrice
Antenne émettrice
Pièce
Antenne émettrice
Antenne réceptrice

18
La Figure 8, montre un banc de mesure en espace libre correspondant au mode réflexion-transmission et utilisant des antennes coniques comme moyen de mesure.
Figure 8 : Banc de mesure en espace libre [HVS Tech.]
La technique en espace libre est particulièrement employée quand le matériau à caractériser est disponible en grandes dimensions. Ces mesures en espace libre sont peu précises du fait des multiples réflexions par les objets environnants, et de la diffraction causée par les bords de l’échantillon. Cependant, ces problèmes peuvent être minimisés en insérant des lentilles dans l’espace libre entre la source de rayonnement et l’échantillon.
Les MO en espace libre ont trouvé différentes applications en contrôle non destructif (CND) (détection de défauts de l’ordre de quelques centimètres dans des pièces de plusieurs mètres [Drea 06], mesure d’épaisseur d’une couche polyéthylène anticorrosion sur un tube d’acier [Skl 06], étude de l’évolution de la conductivité d’un polymère [Rmi 04], délaminage dans des matériaux composites [Wuy 00], détection de défauts dans des panneaux isolants thermiques en mousse [Iva 07] …).
1.2.3 Technique de mesure en cavité résonnante
Une cavité microonde est une enceinte métallique de très haute conductivité (généralement du cuivre très pur). Le plus souvent la cavité est de forme canonique (cylindrique, rectangulaire). Ceci s’explique par la difficulté de calculer la distribution des champs électriques et magnétiques dans des cavités de forme complexe alors que pour des géométries simples, la distribution des champs est très bien connue et calculable. Ci-après est schématisée une cavité cylindrique (Figure 9).
Antennes coniques
Porte échantillon
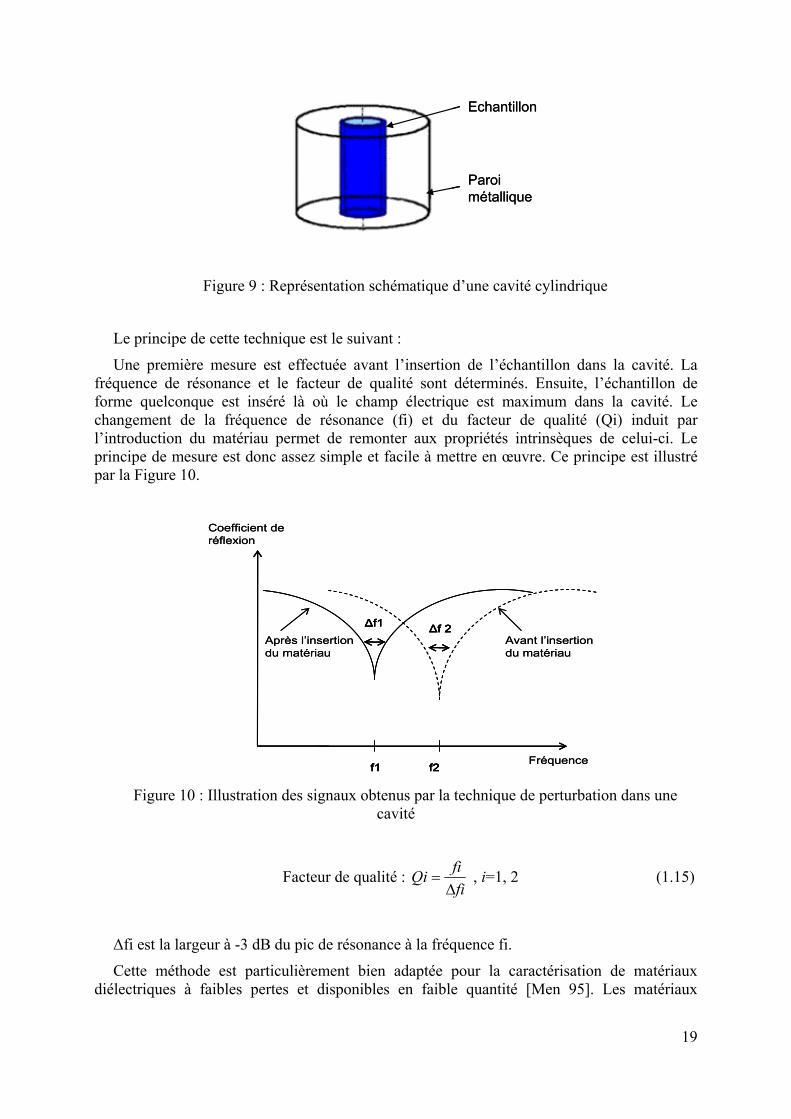
19
Echantillon
Paroi métallique
Echantillon
Paroi métallique
Figure 9 : Représentation schématique d’une cavité cylindrique
Le principe de cette technique est le suivant :
Une première mesure est effectuée avant l’insertion de l’échantillon dans la cavité. La fréquence de résonance et le facteur de qualité sont déterminés. Ensuite, l’échantillon de forme quelconque est inséré là où le champ électrique est maximum dans la cavité. Le changement de la fréquence de résonance (fi) et du facteur de qualité (Qi) induit par l’introduction du matériau permet de remonter aux propriétés intrinsèques de celui-ci. Le principe de mesure est donc assez simple et facile à mettre en œuvre. Ce principe est illustré par la Figure 10.
f1 f2
Δf1 Δf 2Avant l’insertion du matériau
Après l’insertion du matériau
Coefficient de réflexion
Fréquencef1 f2
Δf1 Δf 2
f1 f2
Δf1 Δf 2
f1 f2
Δf1 Δf 2Avant l’insertion du matériau
Après l’insertion du matériau
Coefficient de réflexion
Fréquence
Figure 10 : Illustration des signaux obtenus par la technique de perturbation dans une cavité
Facteur de qualité : fifiQiΔ
= , i=1, 2 (1.15)
Δfi est la largeur à -3 dB du pic de résonance à la fréquence fi.
Cette méthode est particulièrement bien adaptée pour la caractérisation de matériaux diélectriques à faibles pertes et disponibles en faible quantité [Men 95]. Les matériaux

20
caractérisés peuvent être aussi bien isotropes [Les 08] qu’anisotropes [Lin 99]. Les échantillons utilisés peuvent être solides, liquides ou en poudre.
Bien que cette technique de mesure soit très précise, elle n’est malheureusement utilisable que dans une bande de fréquences très étroite. Elle n’est donc inadaptée pour des mesures en large bande.
1.3 Résolution des problèmes direct et inverse
Les techniques MO permettent de caractériser les matériaux diélectriques en les soumettant à une onde électromagnétique. Cette caractérisation est faite en examinant les données d’observation soit issues de la mesure, soit d’un modèle analytique ou numérique. Ces données dépendent des propriétés internes et géométriques de ces matériaux. L’obtention des données d’observation dépendant des caractéristiques du matériau considéré est communément appelée le problème direct (forward problem en anglais). Cependant, dans la plupart des applications, ce qui intéresse un ingénieur ou un scientifique est d’inspecter le matériau ou d’étudier ses propriétés. Les données d’observation doivent permettre de remonter aux paramètres caractéristiques de ces matériaux. Le moyen d’obtention des paramètres caractéristiques du matériau ou de la structure à partir des données d’observation est appelé problème inverse (inverse problem en anglais) (Figure 11).
Problème direct
Problème inverse
Figure 11 : Problème direct / Problème inverse
Nous présentons ci-dessous, les problèmes direct et inverse de mesure MO et décrivons les différentes solutions apportées pour les résoudre. En particulier, nous comparons les différentes techniques d’inversion et détaillons les motivations qui nous ont poussées à utiliser les réseaux de neurones comme méthode d’inversion.
1.3.1 Problème direct
Pour des géométries simples et pour des fréquences relativement basses, on peut établir une formulation analytique du problème étudié. Cette solution analytique donne la relation entre les paramètres physiques et géométriques du matériau à caractériser et les données de mesure. La recherche de cette solution peut cependant être très longue et fastidieuse. De plus, la relation établie peut être très complexe et nécessiter un coût de calcul important.
Paramètres recherchés
Données d’observation

21
Par ailleurs, pour des géométries complexes, la recherche de la solution analytique est rarement triviale voire impossible. Une des solutions pour contourner ce problème est de faire des analogies avec une structure dont on connaît la solution et dont la géométrie est assez proche du problème complexe étudié. Malheureusement, non seulement cette analogie peut ne pas toujours correspondre de façon satisfaisante au cas réel d’un point de vue géométrique, mais aussi la validité de l’analogie peut être très restreinte en fréquence.
La deuxième solution est le recours à une modélisation numérique. L’avantage de cette solution est qu’on peut étudier n’importe quel problème électromagnétique et ceci quelle que soit sa complexité. Aux erreurs de modélisation près, principalement liées au maillage de la structure, le modèle numérique représente généralement assez bien la structure réelle si on prend soin d’appliquer les bonnes conditions aux limites. Un inconvénient de cette méthode est qu’elle peut être très coûteuse en temps de calcul notamment si la géométrie implique des rapports de dimensions élevés.
Nous présentons dans la suite les quelques méthodes de modélisation numérique les plus couramment utilisées :
• Méthode des différences finies [Taf 00]
La méthode des différences finies consiste en une discrétisation directe des équations aux dérivées partielles. Cette méthode s’adapte difficilement aux géométries complexes qui présentent des courbures car elle nécessite un découpage régulier du domaine d’étude. Elle est cependant utilisée pour résoudre des problèmes dans le domaine temporel.
• Méthode des éléments finis [Jin 02]
La méthode des éléments finis (MEF) utilise une formulation variationnelle faible du problème [Sad 92]. Elle vise à obtenir une solution approchée du problème. Grâce à la formulation variationnelle, les solutions du problème vérifient des conditions d’existence plus faibles que celles des solutions du problème de départ. Une discrétisation permet alors de trouver une solution approchée.
Dans la MEF, chaque région du domaine d’étude est découpée en « petits » éléments. Cette opération est nommée le « maillage ». Plus le maillage est fin, plus la solution calculée s’approche de la solution exacte, au détriment du temps de calcul.
Avec la MEF, on peut modéliser des géométrie très variées et complexes (2D, 3D). On peut aussi étudier des phénomènes non-linéaires. Tout ceci peut conduire à des temps de calcul considérables et requiert des ressources importantes. De plus, la MEF nécessite de définir des frontières sur lesquelles seront appliquées les conditions aux limites.
Pour réduire le temps de calcul, on peut limiter le domaine d’étude en considérant les symétries existantes de la structure. Si le problème réel n’a pas

22
de symétrie particulière, on est alors obligé de modéliser la géométrie avec une représentation 3D complète. La MEF peut alors devenir très lourde et fastidieuse.
• Méthode des éléments de frontières [Mil 92]
La méthode des éléments de frontière connue sous l’acronyme anglo-saxon B.E.M (Boundary Element Method), est une technique numérique développée depuis les années 1960 et fondée sur la théorie des équations intégrales de frontière. Elle s’est imposée en alternative à l’autre grande méthode numérique, la MEF, en particulier lorsque le domaine de propagation devient infini. En effet, la méthode des éléments de frontière apparaît plus appropriée en espace infini que la MEF puisque seule la surface de la frontière du domaine doit être discrétisée. Contrairement à la MEF, on n’a pas besoin de mailler tout le domaine de propagation et les éléments de frontière permettent de réduire d’une unité la dimension du problème, le champ électromagnétique en tout point de l’espace étant dû au rayonnement de ces frontières. En outre, contrairement à la MEF, la condition de rayonnement à l’infini est satisfaite automatiquement dans les méthodes d’éléments de frontière par le noyau des formulations intégrales qui répond exactement aux conditions aux limites pour des domaines infinis. La BEM apparaît ainsi plus appropriée au traitement des problèmes de propagation en espace infini [Pre 00]. Le principal inconvénient de la méthode BEM est qu’elle conduit à un système linéaire dont la matrice est pleine. Ceci conduit à un temps de calcul plus important par rapport à MEF dont la matrice du système est creuse.
1.3.2 Problème inverse
Dans ce manuscrit de thèse, on entend par « inversion », la détermination des paramètres utiles de la cible (matériaux sous test) à partir des observations fournies par le système de mesure. Ces paramètres utiles peuvent être la permittivité complexe d’un matériau diélectrique, la concentration d’un mélange de fluides, les dimensions d’une pièce…
Il existe deux grandes catégories d’inversion : l’inversion itérative et l’inversion directe, que nous présentons dans la suite.
1.3.2.1 Inversion itérative
Cette technique d’inversion nécessite l’utilisation du modèle direct. Si la solution du modèle direct ne peut pas être inversée de façon mathématique, ce qui est souvent le cas, elle est insérée dans une boucle itérative. La sortie de la mesure est comparée à celle donnée par le modèle direct (Figure 12). Un algorithme de minimisation d’erreur permet alors de minimiser l’écart (exemple : erreur quadratique moyenne (EQM)) entre le modèle direct et la mesure. Le processus est itératif, et se poursuit jusqu’à ce qu’un critère d’arrêt soit satisfait. Le critère d’arrêt généralement utilisé est lié ou bien au nombre d’itérations maximal ou bien au critère

23
d’erreur qui doit alors être inférieure à un seuil prédéfini. Le schéma du processus d’inversion est donné Figure 12.
+-
Ecart
Données d’observation
mesuréesSystème de mesure
Algorithme de minimisation
d’écart
Modèle direct
Paramètres recherchés
Données d’observation
calculées
Estimation des paramètres recherchés
+-
Ecart
Données d’observation
mesuréesSystème de mesure
Algorithme de minimisation
d’écart
Modèle direct
Paramètres recherchés
Données d’observation
calculées
Estimation des paramètres recherchés
Figure 12 : Schéma du processus itératif d’inversion
À condition d’avoir un modèle peu coûteux en calcul et avec le progrès de la capacité de calcul des ordinateurs, l’inversion itérative peut être rapide et efficace. Cependant, si le modèle analytique n’est pas disponible, la même procédure peut être exécutée en utilisant un modèle numérique comme modèle direct. L’inconvénient de ce type d’inversion à partir d’un modèle numérique est son temps d’exécution. En effet, un modèle numérique peut être coûteux en calcul, et le temps mis pour un calcul dépend fortement de la complexité de la géométrie et de la taille par rapport à la longueur d’onde du système d’étude. Par conséquent, le temps de résolution du problème direct peut-être très élevé. Sachant que la résolution du problème inverse requiert la minimisation de la fonction d’erreur entre les données mesurées et celles calculées par le modèle, le modèle direct est sollicité plusieurs fois avant d’atteindre la précision demandée. De plus, certaines études nécessitent de répéter plusieurs fois la résolution du problème direct pour chaque itération pour différentes configurations (exemple : calcul de permittivité de matériaux à plusieurs fréquences). Par conséquent, la minimisation de la fonction d’erreur doit être répétée pour chaque configuration. Ceci a pour conséquence d’avoir un temps d’inversion qui devient prohibitif.
1.3.2.2 Inversion directe
Dans de rares cas, pour des problèmes dont la solution analytique est très simple, on peut explicitement inverser le modèle direct afin d’évaluer les paramètres recherchés. L’absence d’itération dans ce cas permet d’avoir une inversion plus rapide que celle précédemment citée. L’inversion se présente sous la forme symbolique suivante (Figure 13) :

24
Estimation des
paramètres recherchés
Système de mesure
Inversedu modèle direct
Données d’observation
mesuréesParamètres recherchés Estimation
des paramètres recherchés
Système de mesure
Inversedu modèle direct
Estimation des
paramètres recherchés
Système de mesure
Inversedu modèle direct
Données d’observation
mesuréesParamètres recherchés
Figure 13 : Schéma du processus d’inversion directe utilisant l’inverse du modèle direct
Cependant, pour la plupart des problèmes électromagnétiques, la solution analytique peut être très difficile à obtenir, par conséquent il n’est pas possible de faire de l’inversion directe.
Dans ce cas, on peut cependant utiliser un modèle inverse paramétrique dont on règle les paramètres internes à l’aide d’une base de données obtenue par simulation ou par des moyens expérimentaux. Cette base contient des exemples connus de couples paramètres recherchés –
données d’observation. La procédure est similaire à la précédente mais avec l’inverse du modèle direct remplacé par le modèle inverse paramétrique (
Figure 14).
Estimation des
paramètres recherchés
Système de mesure Modèle inverse
Données d’observation
mesuréesParamètres recherchés Estimation
des paramètres recherchés
Système de mesure Modèle inverse
Estimation des
paramètres recherchés
Système de mesure Modèle inverse
Données d’observation
mesuréesParamètres recherchés
Figure 14 : Schéma du processus d’inversion directe basé sur un modèle d’inverse
Une fois ce modèle inverse établi, l’inversion pour des données issues de la mesure peut être très rapide car ce type d’inversion ne fait pas appel à des itérations successives. Nous récapitulons ces différentes méthodes d’inversion Tableau 2.
Type d’inversion
Modèle sur lequel est basée
l’inversion
Disponibilité du modèle
Durée de la procédure d’inversion
Modèle analytique Rarement Peut être très
rapide Inversion Itérative Modèle
numérique Souvent Peut être très longue
Modèle direct inverse Très rarement Peut être très
rapide Inversion Directe
Modèle inverse Souvent Peut être très rapide
Tableau 2 : Récapitulatif des différentes méthodes d’inversion

25
2 Méthodologie développée
2.1 Introduction
Pour la caractérisation MO de matériaux, nous avons opté pour la technique de mesure avec contact utilisant un guide d’onde coaxial comme sonde de mesure. Les différentes configurations de mesure que nous étudions dans cette thèse seront présentées dans les chapitres 3 et 4. Ces systèmes MO ont généralement des structures complexes dont la solution analytique directe n’existe pas toujours. Quand elle existe, les relations entre les paramètres de la cible et ceux d’observation fournis par la mesure sont souvent complexes et non-linéaires. De ce fait, il n’est pas simple de les inverser mathématiquement. Ainsi, la méthode que nous proposons dans cette thèse est basée sur l’inversion directe des observations à partir d’un modèle inverse paramétrique. Pour réaliser ce modèle inverse, les réseaux de neurones (RN) correspondent bien à nos attentes. Un RN est un modèle qui possède des paramètres internes qu’il faut ajuster de façon qu’il réalise la fonction mathématique souhaitée entre ses entrées et ses sorties. Les entrées correspondent aux données d’observation tandis que les sorties sont les paramètres recherchés de la cible. L’ajustement des paramètres internes est fait à l’aide d’une base de données qui contient des exemples d’entrées et de sorties.
Les RN ont été exploités surtout depuis les années 80 avec la mise en œuvre de l’algorithme de rétro-propagation qui a permis d’étendre leurs applications.
Depuis, on les voit apparaître dans des domaines aussi divers que la reconnaissance de forme [LeC 91], la bio-ingénierie [Dup 98], la mesure d’épaisseur par courant de Foucault [Ben 06], etc.
Dans le domaine des MO, les RN ont également fait leur apparition pour faire de l’imagerie MO [Rek 02] [Maa 06], et pour la caractérisation diélectrique de matériaux [Yak 04] [Bart 99] [Tuc 95].
[Bart 99] et [Tuc 95] ont utilisé dans leurs travaux, comme dans ce travail de thèse, une sonde coaxiale comme moyen de mesure et les RN comme méthode d’inversion. Mais à la différence avec notre approche, leurs bases de données sont construites à partir de données expérimentales. Cette manière de procéder présente certes l’avantage d’utiliser un modèle neuronal assez proche de la réalité mais en même temps il est difficile d’étendre le domaine de validité du modèle en dehors de la gamme d’apprentissage initiale. En effet, la validité d’un RN est limitée par le domaine d’apprentissage qui est défini par les permittivités extrêmes des matériaux utilisés. Si on veut augmenter l’étendue de ce domaine pour caractériser de nouveaux matériaux dont la permittivité est susceptible d’être en dehors de ce domaine, il faudra trouver d’autres types de matériaux qui ont des permittivités qui couvrent celle de ce nouveau matériau. Il est évident que ce travail peut être très coûteux car il n’est pas toujours facile de se procurer tous les types de matériaux dont on a besoin.

26
C’est pourquoi, la méthode que nous proposons dispose uniquement d’une base dont les données sont issues de la modélisation. En se servant de la souplesse d’un modèle numérique, il est possible d’agir à volonté sur les limites du domaine d’apprentissage imposées par la permittivité des matériaux à caractériser. De plus, la modélisation numérique permet de choisir plus facilement les exemples de la base d’apprentissage de façon à augmenter la précision de l’inversion (voir la section 3.1.2). Dans ce travail, nous utilisons la MEF pour générer les bases nécessaires.
Ainsi, la méthode que nous proposons pour résoudre les problèmes de caractérisation MO a deux aspects :
- La résolution du problème direct : elle est faite en utilisant la modélisation numérique basée sur la MEF. Elle permet de résoudre le problème direct quelle que soit la complexité de la géométrie du système d’étude. Par la résolution du problème direct, nous créons les bases de données utilisées pour l’inversion.
- La résolution du problème inverse : en se servant des bases de données créées par le modèle direct numérique, nous procédons à l’inversion par RN de façon à obtenir les paramètres recherchés de la cible.
2.2 Problème direct - Modélisation par la méthode des éléments finis
L’objectif de cette section est de rappeler les notions d’électromagnétisme gouvernant les phénomènes de propagation d’ondes, et de décrire rapidement les différentes étapes de la modélisation numérique par éléments finis.
2.2.1 Rappel des lois de l’électromagnétisme
Tous les phénomènes électromagnétiques, que ce soit en basses ou en hautes fréquences, sont gouvernés par les équations aux dérivées partielles de Maxwell. Elles constituent une forme condensée des lois de l’électromagnétisme. Elles traduisent les relations qui existent, en tout point de l’espace entre le temps (t), le champ électrique (E), le champ de déplacement électrique (D), l’induction magnétique (B), le champ magnétique (H), la densité de charges électriques (ρ) et la densité de courant de conduction (J).
Considérons la propagation d’une onde électromagnétique dans un domaine Ω , borné par des frontières Γ sur lesquelles différentes conditions aux limites peuvent être appliquées (Figure 15).
Figure 15 : Domaine dans lequel une onde électromagnétique est supposée se propager

27
Les équations de Maxwell gouvernant ce milieu sont :
ρ=∇ Dr
. (2.1) Loi de Gauss électrique
0. =∇ Br
(2.2) Loi de Gauss magnétique
tBE∂∂
−=×∇r
r (2.3) Loi de Faraday
JtDH
rr
r+
∂∂
=×∇ (2.4) Loi d’Ampère
où σ est la conductivité du milieu.
On peut introduire les relations constitutives du milieu considéré. Dans notre cas, ces milieux sont linéaires, homogènes et isotropes présentant des pertes (ε et μ complexes) :
EDrr
ε= (2.5)
HBrr
μ= (2.6)
EJrr
σ= (2.7)
En se plaçant dans le domaine complexe, nous pouvons réécrire ces équations en régime harmonique ainsi :
ρ=∇ Dr
. (2.8)
0. =∇ Br
(2.9)
HjErr
ωμ−=×∇ (2.10)
EjHrr
)( εωσ +=×∇ (2.11)
où ω est la pulsation.
Pour un diélectrique parfait ρ et σ sont nuls, par conséquent les équations (2.8) et (2.11) deviennent :
0. =∇ Er
ε (2.12)
EjHrr
εω=×∇ (2.13)

28
A partir de (2.10), on a : Ej
Hrr
×∇−
=ωμ1
Et en remplaçant Hr
dans (2.13), on obtient :
EjEj
rrεω
ωμ=×∇
−×∇ )1( (2.14)
De même, en suivant le même raisonnement on a :
HjHj
rrμω
ωε−=×∇×∇ )1( (2.15)
La solution du problème électromagnétique est calculée en associant ces équations à des conditions aux limites.
- Condition aux limites de type PEC (Perfect Electric Conductor) : nullité de la composante tangentielle du champ électrique sur les parties métalliques (mur électrique), 0
rrr=∧ En ( nr étant le vecteur normal sortant de la surface sur laquelle est
appliquée la condition aux limites)
- Condition aux limites de type PMC (Perfect Magnetic Conductor) : nullité de la composante tangentielle du champ magnétique sur les parties magnétiques (mur magnétique), 0
rrr=∧ Hn
- Source d’excitation, exemple : 0Er
champ électrique appliqué sur la surface
d’excitation, 0EnEnrrrr
∧=∧
En raisonnant en champ électrique, le problème aux limites à résoudre est donc le suivant.
0)1(rrr
=−×∇−
×∇ EjEj
εωωμ
(2.16)
0rrr
=∧ En sur les surfaces métalliques
0EnEnrrrr
∧=∧ sur la surface d’excitation
0rrr
=∧ Hn sur les plans de symétrie
2.2.2 Méthode des éléments finis (MEF)
La méthode des éléments finis qui a été introduite dans les années 70 est une technique de résolution qui a été conçue pour résoudre les problèmes de la mécanique. Actuellement, elle

29
est très répandue et est utilisée dans un grand nombre de domaines industriels ou académiques [Dat 84] [Jin 02] (la mécanique, la thermique, l’électromagnétisme, etc.…).
La méthode des éléments finis permet de résoudre de manière discrète les équations aux dérivées partielles dont on cherche une solution approchée.
2.2.2.1 Principe de la méthode des éléments finis
La première étape de la résolution d’un problème électromagnétique par la MEF est l’obtention de la formulation variationnelle du problème.
La formulation variationnelle est obtenue en faisant le produit scalaire de l’équation (2.16) avec une fonction test V
ret en intégrant dans le domaine d’étude. Ce qui donne :
0)1( =Ω⋅−Ω⋅×∇−×∇∫ ∫Ω Ω
dVEjdVEj
rrrrεω
ωμ (2.17)
En faisant une intégration par partie et en appliquant la relation de Stokes-Green, on obtient :
0)().1()1( =Ω⋅−Γ∧×∇−+Ω×∇−⋅×∇ ∫∫ ∫ΩΩ Γ
dVEjdnVEj
dEj
Vrrrrrrr
εωωμωμ
(2.18)
Le terme de bords s’annule naturellement en présence de conditions aux limites de type PMC. En présence de conditions de type PEC il s’annule en choisissant V
r telle que
0rrr
=∧ nV . Le problème variationnel à résoudre s’annonce alors comme suit :
Trouver Er
tel que :
0)(1=Ω⋅−Ω×∇⋅×∇− ∫∫
ΩΩ
dVEjdVEj
rrrrεω
ωμ (2.19)
La deuxième étape de la résolution consiste en la discrétisation du domaine d’étude Ω en sous domaines. C’est le maillage. Les éléments géométriques de ce maillage sont appelés mailles. Ensuite, il faut choisir la famille de champs locaux, c'est-à-dire à la fois les degrés de liberté (DL) dans les éléments et les fonctions d’interpolations qui définissent le champ local. La maille complétée par ces informations est appelée élément fini.
Par exemple, pour les éléments finis d’arêtes tétraédriques du premier ordre, la fonction d’interpolation relative à l’arête « a » est donnée par :

30
ijjiaW λλλλ ∇−∇=rrr
(2.20)
Dans (2.20) les ji,λ sont les fonctions barycentriques associées aux sommets respectifs i et j de l’arête « a ».
aWr
satisfait la relation suivante :
⎩⎨⎧
≠=
=∫ '0'1
.' aasi
aasildW
aarêtea
rr (2.21)
Le champ électrique est ainsi écrit en termes de fonctions d’interpolation associées aux arêtes des éléments :
∑=
=aN
aaaeWE
1
rr (2.22)
où Na est le nombre total d’arêtes du maillage et ae est la circulation du champ électrique le long de l’arête « a ».
En reportant cette approximation par élément d’arête dans (2.19) et en choisissant comme fonctions de test les fonctions d’interpolation 'a
Wr
]),1['( aNa∈∀ (principe de Galerkin), on obtient :
0)(11
'' =⎥⎦
⎤⎢⎣
⎡Ω⋅−Ω×∇⋅×∇−∑ ∫∫
= ΩΩ
aN
aaaaaa dWWjdWW
je
rrrrεω
ωμ (2.23)
Le problème variationnel est ramené à un problème discret. En effet, la solution approchée est complètement déterminée par les valeurs des DL. Il suffit donc de trouver les valeurs à attribuer aux degrés de liberté DL pour décrire une solution approchée.
Finalement, en prenant en compte les termes d’excitation, on est conduit à un problème discrétisé qui se présente sous forme d’un système matriciel dont une ligne est donnée par :
[ ] '1
'2
' aa
N
aaaaa beSkR
a=+−∑
= (2.24)

31
avec : ∫Ω
Ω×∇⋅×∇= dWWR aaaa ''
rr (2.25)
Ω⋅= ∫Ω
dWWSaaaa )( ''
rrε (2.26)
μεω 22 =k (2.27)
et ba’ est un terme d’excitation sur l’arête a’
La dernière étape est celle du post-traitement consistant à déduire d’autres grandeurs à partir des valeurs aux DL.
2.2.2.2 Modélisation par éléments finis sous ANSYS®
Pour la modélisation numérique de nos structures complexes, nous avons utilisé le logiciel de simulation MEF ANSYS®.
Le module hyperfréquence d’ANSYS® possède deux types d’éléments : les éléments hexaédriques (hf120) et les éléments tétraédriques (hf119). Pour des géométries complexes qui présentent des courbures, il est préférable d’utiliser les éléments tétraédriques. En effet, ceci permet d’avoir une meilleure approximation de la géométrie tout en gardant un nombre d’éléments raisonnable. Avec des éléments hexaédriques, il faudrait mailler finement dans les zones de courbure qui nécessite un grand nombre d’éléments donc un temps de calcul plus long.
ANSYS® dispose d’une formulation par éléments finis d’arêtes. La résolution numérique du problème se fait en découpant le volume d’étude en éléments tétraédriques et le champ électrique est décrit en termes de fonctions d’interpolation associées aux arêtes ou aux facettes de ces éléments.
L’utilisation de ce type d’éléments présente de nombreux avantages [PER 00] par rapport à l’utilisation des éléments nodaux dont les DL sont associés aux nœuds des éléments, mais le plus important est sans doute la prise en compte de la continuité tangentielle des vecteurs de champ à l’interface de deux éléments. En effet, ceci est cohérent avec les caractéristiques physiques de ces vecteurs puisque les lois de l’électromagnétisme imposent la continuité des composantes tangentielles des champs électriques et magnétiques à l’interface entre deux milieux diélectriques.
Nous utilisons des éléments tétraédriques du second ordre dont les DL sont les projections du champ électrique sur les arêtes et les facettes des éléments. Un élément possède deux DL associés à chaque arête et deux autres DL associés à chaque facette. Par conséquent, pour décrire le vecteur champ électrique, un élément tétraédrique du second ordre possède 20 DL dont 12 sur les arêtes et 8 sur les facettes [Jin 02].

32
Le déroulement d’une simulation avec ANSYS® suit les étapes habituelles suivantes (Figure 16).
Post-processeur • Affichage des résultats
• Calcul des grandeurs désirées à partir des DL
• Création des fichiers de sortie
Figure 16 : Les différentes étapes de la modélisation par ANSYS®
Pré-processeur • Définition des types d’éléments utilisés
• Définition de propriétés physiques des matériaux
• Création de la géométrie
• Attribution des matériaux aux différentes entités géométriques
• Maillage du modèle
Solution • Application des sources électromagnétiques
• Application des conditions aux limites
• Résolution du problème

33
2.3 Inversion par réseaux de neurones
Cette partie concerne la présentation des réseaux de neurones que nous avons mis en œuvre pour résoudre les problèmes inverses rencontrés dans la caractérisation MO. On commence par introduire le neurone formel qui constitue l’élément de base des RN. Ensuite, les réseaux de neurones qui sont l’association de plusieurs neurones formels sont présentés. Plus particulièrement, les RN MLP (Multi-Layer Perceptron) que nous avons utilisés dans ce travail de thèse ainsi que leurs propriétés seront détaillés. Nous verrons ensuite ce qu’est l’apprentissage, comment un RN peut faire de l’apprentissage, et les différents problèmes rencontrés lors du processus d’apprentissage. Enfin, nous mettrons l’accent sur le problème de généralisation qui apparait lorsque le nombre de neurones du RN devient trop important par rapport à la complexité du problème inverse. Plus particulièrement, on comparera deux méthodes permettant de résoudre ce problème : la méthode split-sample et la régularisation bayesienne.
2.3.1 Neurone formel
Un réseau de neurone (RN) est un réseau artificiel basé sur un modèle simplifié du neurone biologique. Les RN dont il est question dans ce travail sont issus d’une tentative de modélisation mathématique du cerveau humain. Les premiers travaux datent de 1943 et sont l’œuvre de Mac Culloch et Pitts [McC 43]. Ils inventèrent le premier neurone formel. Ils supposèrent que l’impulsion nerveuse est le résultat d’un calcul simple effectué par chaque neurone et que la pensée naît grâce à l’effet collectif d’un réseau de neurones interconnectés.
La Figure 17 montre la structure d'un neurone formel [Tou 92]. Chaque neurone formel est un processeur élémentaire. Il reçoit un nombre variable d'entrées en provenance de neurones amonts. A chacune de ces entrées est associé un poids représentatif de la force de la connexion. Chaque processeur élémentaire est doté d'une sortie unique, qui se ramifie ensuite pour alimenter un nombre variable de neurones avals. A chaque connexion est associé un poids.
Figure 17 : Mise en correspondance neurone biologique / neurone formel
34
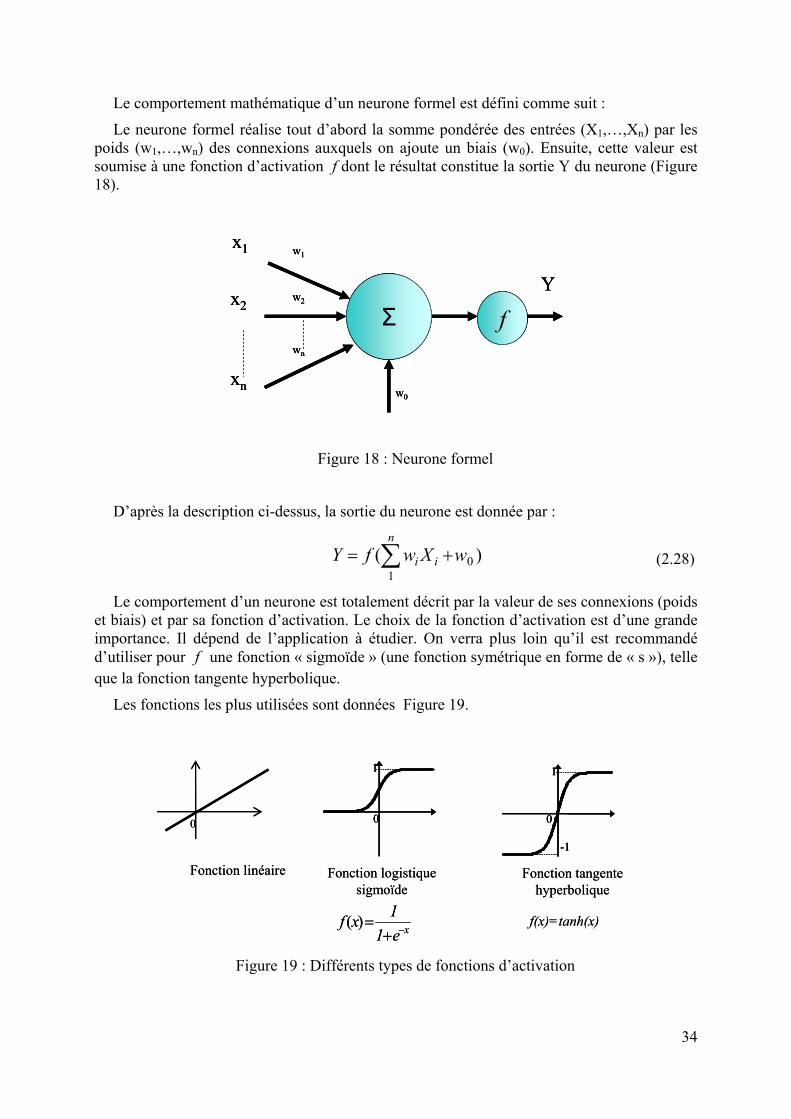
Le comportement mathématique d’un neurone formel est défini comme suit :
Le neurone formel réalise tout d’abord la somme pondérée des entrées (X1,…,Xn) par les poids (w1,…,wn) des connexions auxquels on ajoute un biais (w0). Ensuite, cette valeur est soumise à une fonction d’activation f dont le résultat constitue la sortie Y du neurone (Figure 18).
Σ f
x1
x2
xn
w1
w2
wn
w0
Y
Σ f
x1
x2
xn
w1
w2
wn
w0
Y
Σ f
x1
x2
xn
w1
w2
wn
w0
Y
Figure 18 : Neurone formel
D’après la description ci-dessus, la sortie du neurone est donnée par :
)( 01
wXwfY i
n
i += ∑ (2.28)
Le comportement d’un neurone est totalement décrit par la valeur de ses connexions (poids et biais) et par sa fonction d’activation. Le choix de la fonction d’activation est d’une grande importance. Il dépend de l’application à étudier. On verra plus loin qu’il est recommandé d’utiliser pour f une fonction « sigmoïde » (une fonction symétrique en forme de « s »), telle que la fonction tangente hyperbolique.
Les fonctions les plus utilisées sont données Figure 19.
0
Fonction logistique sigmoïde
1
0
xe11xf −+
=)(
1
-1
0
Fonction tangente hyperbolique
Fonction linéaire
f(x)=tanh(x)
0
Fonction logistique sigmoïde
1
0
1
0
xe11xf −+
=)(
1
-1
0
1
-1
0
Fonction tangente hyperbolique
Fonction linéaire
f(x)=tanh(x)
Figure 19 : Différents types de fonctions d’activation

35
L’objet de la prochaine section est d’introduire la notion de réseaux de neurones et d’énoncer leurs propriétés.
2.3.2 Réseaux de neurones
Tel que nous venons de le voir précédemment, un neurone réalise une fonction non linéaire de ses entrées. Cependant, un seul neurone n’est pas suffisant dans la plupart des applications et il faudra généralement associer plusieurs neurones entre eux. L’association en réseau de plusieurs neurones permet la composition des fonctions non linéaires réalisées par chacun des neurones, ce qui est particulièrement souhaitable pour des systèmes modélisés dont le comportement n’est pas simple.
Il existe principalement deux catégories de RN : les réseaux de neurones non bouclés (aussi appelé feed forward) et les réseaux de neurones bouclés (aussi appelé récurrent). Le feed forward est représenté par un ensemble de neurones connectés entre eux dont l’information circule de l’entrée vers la sortie sans retour vers l’arrière (Figure 20a). La sortie de ce type de réseaux ne dépend pas du temps. Le sens des flèches de la Figure 20 indique le sens de parcours de l’information. Dans les RN récurrents, l’information peut aussi circuler d’un neurone vers celui qui précède (Figure 20b). Ainsi la sortie d’un neurone peut aussi dépendre d’elle-même. Le choix de l’un ou de l’autre des deux types de RN dépend de l’application traitée.
4
52
1
3
Entré
e
Sorti
e
4
52
1
3
Entré
e
Sorti
e
a) b)
Figure 20 : Exemples de RN : a) non bouclé, b) bouclé
Dans ce travail de thèse, nous nous somme intéressés aux RN non bouclés. Les RN bouclés sont généralement utilisés pour effectuer des tâches de modélisation de systèmes dynamiques qui dépendent du temps.
Il existe plusieurs types de réseaux non bouclés, mais dans la pratique, ceux qui sont les plus utilisés sont ceux du type MLP (Multi Layer Perceptron).
Les RN MLP sont des réseaux dont les neurones sont organisés en plusieurs couches successives (Figure 21). Il n'y a pas de connexion entre neurones d'une même couche. Chaque neurone d'une couche est connecté à tous les neurones des couches précédente et suivante. On appelle entrée l'ensemble des paramètres d'entrée, couche de sortie l'ensemble des neurones de sortie. Les couches intermédiaires n'ayant aucun contact avec l'extérieur sont appelées couches cachées. Pour une même couche, les neurones ont la même fonction d’activation. La

36
sortie du RN est obtenue directement après l’application du signal d’entrée, au temps de propagation de l’information près.
Couches cachées Couche de sortie
Entré
e
Sorti
e
Couches cachées Couche de sortie
Entré
e
Sorti
e
Figure 21 : Structure d’un RN MLP
2.3.3 Apprentissage des réseaux de neurones MLP
On distingue deux types d’apprentissages : l’apprentissage supervisé et l’apprentissage non supervisé.
2.3.3.1 Apprentissage supervisé
Ce type d’apprentissage consiste à présenter au RN un ensemble d’entrées et de sorties (i.e. des exemples) qui est obtenu soit à partir d’un modèle direct soit à partir de mesures. Cependant, la génération d’exemples à partir de mesures pour chaque configuration du système d’étude peut être une tâche laborieuse et coûteuse. Par exemple, pour la caractérisation de matériaux, il faut avoir en possession plusieurs matériaux de permittivités différentes et connues. Pour éviter ce problème, la meilleure solution est de passer par une modélisation, qui constitue le modèle direct du système d’étude. Par ce moyen, on peut facilement faire varier la taille du domaine d’étude en modélisant autant de matériaux que nécessaire.
Les exemples, en nombre fini, pour lesquels l’entrée et la sortie désirée sont connues, sont contenus dans une base qu’on appelle base d’apprentissage. La tâche du RN est de minimiser un critère d’erreur sur cette base d’apprentissage. En ce sens du terme, on dit que l’apprentissage est « supervisé », c'est-à-dire qu’on fournit au réseau des exemples de ce qu’il doit faire.

37
Le réglage des poids se fait de manière itérative. Les exemples de la base d’apprentissage sont présentés une première fois au RN. Ensuite la sortie du RN est comparée avec celle contenue dans la base pour tous ces exemples. Le critère d’erreur entre ces deux sorties est par la suite minimisé de façon itérative par un algorithme de minimisation ajustant les paramètres internes du RN. Ce principe d’apprentissage est illustré Figure 22.
Base d’apprentissage
Algorithme itératif de réglage des poids
et des biais
+ -
Entrée
Sortie de la base
Critère d’erreur
Réseau de neurones
Base d’apprentissage
Algorithme itératif de réglage des poids
et des biais
+ -
Entrée
Sortie de la base
Critère d’erreur
Réseau de neurones
Figure 22 : Schéma du principe d’apprentissage d’un RN
L’erreur quadratique moyenne (EQM) est le critère d’erreur le plus souvent choisi dans les problèmes de modélisation. Si on considère les N exemples de la base d’apprentissage, et iY et
iRNY étant respectivement les sorties vectorielles correspondant à l’exemple i de la base et du RN, alors l’EQM est donnée par :
∑=
−=N
iiRN YY
NEQM
i1
21 (2.29)
L’EQM d’un RN MLP doté uniquement de fonctions d’activation dérivables est une fonction différentiable des poids et des biais du réseau. L’apprentissage peut alors être réalisé au moyen d’un des divers algorithmes de rétro-propagation du gradient de l’EQM. Cependant, en pratique, il vaut souvent mieux ne pas utiliser la méthode du gradient simple et ses variantes, dont les temps de convergence sont très supérieurs à ceux des méthodes du second ordre. Ainsi, l’algorithme de minimisation le plus souvent utilisé pour des RN de taille modeste est celui de Levenberg-Marquardt [Dre 02]. Cet algorithme repose, comme tous les algorithmes newtoniens, sur l’inversion sous sa forme approximée de la matrice Hessienne donnée par (2.30).
JJwwCwH T
ji≈
⎪⎭
⎪⎬⎫
⎪⎩
⎪⎨⎧
∂∂∂
=2
)( où C = EQM (2.30)

38
J est la matrice jacobienne de la fonction d’erreur qui correspond aux dérivées premières de l’EQM par rapport aux poids et aux biais. L’ajustement des poids est fait selon la formule itérative suivante :
CwJIwHww Tkkkkk ))(())(( 1
1−
+ +−= μ (2.31)
Dans (2.28) kw est le vecteur des poids et des biais à l’itération k et I est la matrice identité. Le coefficient kμ est un facteur d’amortissement qui est ajusté automatiquement à chaque itération. Si la convergence est rapide, sa valeur devient très faible, ce qui l’approche de l’algorithme de Gauss-Newton qui est plus efficace près du minimum (zone ou l’EQM est quadratique). Si au contraire, la convergence est lente et l’EQM est loin de sa valeur minimale, kμ devient grand et l’algorithme se rapproche cette fois-ci de l’algorithme de descente du gradient qui est plus efficace loin du minimum.
La vitesse de convergence de l’algorithme de Levenberg-Marquardt le rend plus rapide que tous les algorithmes non newtoniens pour des RN de taille modeste [Mat 98]. Pour des RN de plus grande taille, il vaut mieux utiliser la méthode du gradient conjugué (ANNEXE) [Cos 96] [Leb 00].
2.3.3.2 Apprentissage non supervisé
Cette méthode se distingue de l'apprentissage supervisé par le fait qu'il n'y a pas de sortie a priori connue pour l’apprentissage. Dans l'apprentissage non-supervisé, il y a en entrée un ensemble de données collectées qui est traité par le RN comme des variables aléatoires et le réseau construit un modèle de densité pour les regrouper selon des critères de ressemblance qui sont inconnus a priori. Cet apprentissage est surtout utilisé dans un but de visualisation ou d’analyse de données. Ce type d’apprentissage n’est pas utilisé dans ce travail de thèse, puisque ce qu’on désire réaliser est de l’approximation de fonction et non pas de l’analyse ou de l’organisation de données inexploitables telles quelles.
2.3.4 Préparation de l’apprentissage
Pour faire un bon apprentissage avec une erreur la plus faible possible, il est indispensable de procéder à quelques arrangements élémentaires du réseau et des données de la base.
- Il est préférable de procéder au conditionnement des entrées. C'est-à-dire que les entrées doivent être centrées et normalisées. En effet, si des entrées ont des grandeurs très différentes, celles qui sont « petites » n’ont pas d’influence sur l’apprentissage. Il est donc recommandé pour chaque vecteur d’entrée iη d’effectuer le changement de

39
variable iiii σμηη /)(' −= en calculant la moyenne iμ et l’écart-type iσ de ses composantes. Cela permet de faire en sorte que la moyenne de chaque variable soit voisine de zéro, et son écart type de l’ordre de 1 [Dre 02]. De plus, le centrage permet d’accélérer la convergence de l’apprentissage. Ceci évite une perte de temps dans l’adaptation des biais au commencement de l’apprentissage. En effet les fonctions d’activation des neurones non linéaires (logistique sigmoïde ou tangente hyperbolique) doivent fonctionner dans leur zone centrale quasi-linéaire, là où leur dérivée est maximale. Sinon, leur influence sur les variations de l’EQM est faible.
- Il est aussi nécessaire de commencer l’apprentissage en initialisant la valeur des poids et biais. C’est une étape importante car une mauvaise initialisation peut, lors de l’apprentissage, faire converger l’EQM en sortie du réseau, vers un minimum local et laisser de côté la solution optimale. Il existe diverses méthodes qui cherchent à combiner :
• la connaissance que l’on a, de par la base d’apprentissage, de l’allure de la relation entrée/sortie que doit modéliser le RN,
• un caractère aléatoire dans l’attribution des valeurs d’initialisation, afin que deux initialisations successives débouchent sur des valeurs différentes de poids et de biais.
L’intérêt de ce dernier point est que, chaque apprentissage commençant avec des valeurs d’initialisation des poids et des biais différentes, il pourra également aboutir à des solutions différentes de poids et de biais. Il suffira alors, après plusieurs réalisations de la séquence initialisation-apprentissage, de conserver la réalisation donnant le meilleur résultat d’apprentissage (EQM minimale).
Une de ces méthodes est celle proposée par Nguyen et Widrow [NGU 90], destinée à l’initialisation d’un RN MLP à deux couches : une couche cachée à fonctions d’activations tangente hyperbolique et une couche de sortie constituée d’un neurone à fonction d’activation linéaire. Cette méthode repose sur le principe suivant : chaque neurone de la couche cachée va approximer la variation de la fonction de sortie sur une petite portion de son domaine de définition, et sera inactif (saturé à ±1) en dehors. C’est cette méthode que nous avons utilisée.
2.3.5 Propriétés des réseaux de neurones MLP
La sortie d’un RN est une fonction non linéaire de ses entrées et de ses paramètres internes. Cette propriété des RN a une conséquence très importante. En effet, [Bar 93] a montré que l’approximation dépend de la manière dont les paramètres internes sont introduits dans le modèle. Il montre plus précisément que pour un même problème et pour une précision donnée, le modèle dont la sortie est non linéaire par rapport à ses paramètres internes a besoin de moins de paramètres que tout autre modèle dont la sortie est linéaire par rapport à ses paramètres internes. Cette propriété fondamentale des RN à approximer des fonctions non linéaires avec le moins de paramètres possible s’appelle la « parcimonie ». En effet le nombre de paramètres croit exponentiellement avec le nombre de variables dans le cas des approximateurs linéaires par rapport à leurs paramètres, alors qu’il croit de façon linéaire pour les approximateurs non-linéaires par rapport aux paramètres [Bar 93], [Dre 02]. Le choix de la fonction d’activation est donc très important.

40
Pour un nombre d’entrées faible, on peut indifféremment utiliser un modèle linéaire par rapport à ses paramètres internes (polynôme par exemple) ou un modèle non-linéaire par rapport à ses paramètres internes (RN par exemple). Par contre, si le nombre d’entrées est élevé, pour éviter d’avoir trop de paramètres à ajuster, il vaut mieux utiliser un modèle de type réseau de neurones.
Une autre propriété fondamentale des RN MLP est que ce sont des approximateurs universels. C'est-à-dire qu’ils peuvent modéliser le comportement de n’importe qu’elle fonction à condition d’avoir suffisamment de neurones cachés. Cette propriété s’énonce de la façon suivante :
Toute fonction bornée suffisamment régulière peut être approchée uniformément, avec une précision arbitraire donnée (qui est fixée par le critère d’erreur), dans un domaine fini de l’espace de ses variables, par un réseau de neurones comportant une couche de neurones cachés en nombre finis, possédant tous la même fonction d’activation, et un neurone de sortie linéaire [Hor 89].
Pour les problèmes de caractérisation MO que nous considérons dans cette thèse, il suffit donc d’avoir un RN à une couche cachée de N neurones de même fonction d’activation de type sigmoïde avec une couche de sortie de fonction d’activation linéaire. La précision de l’approximation dépendant du nombre N de neurones cachés, nous allons détailler dans la suite les conséquences qui découle du mauvais choix de ce nombre.
2.3.6 Capacité de généralisation
L’apprentissage tend à minimiser l’erreur présentée par le RN vis-à-vis des exemples de la base d’apprentissage. Cependant, l’objectif ultime de l’opération est plutôt de rendre le RN capable d’estimer la sortie du système réel modélisé lorsque celui-ci est soumis à de nouvelles entrées, non comprises dans la base d’apprentissage. Cette aptitude à prédire le comportement du système est nommée capacité de généralisation et dépend de l’architecture du RN (nombre de neurones cachés).
En effet, un nombre de neurones trop faible conduira à un mauvais apprentissage (phénomène de sous-paramétrisation). Pour donner un exemple, on peut considérer l’approximation d’une fonction quadratique par une fonction linéaire. Il est évident que l’approximation d’une fonction complexe par une autre moins complexe d’ordre inférieur va induire des erreurs d’approximation.
En revanche, si le réseau possède un trop grand nombre de neurones cachés donc un grand nombre de paramètres internes, cela va conduire à un phénomène qu’on appelle sur-paramétrisation ou sur-ajustement. La relation entrée-sortie construite par l’apprentissage présente alors souvent, en dehors des exemples appris, de fortes ondulations n’ayant aucun fondement physique. C’est le même phénomène que celui qui apparaît lorsque l’on approxime une fonction par un polynôme d’ordre excessif.
Malgré l’importance de ce problème, il n’existe pas à l’heure actuelle de méthodes fiables pouvant prédire l’architecture d’un RN. L’utilisateur des RN doit donc au préalable déterminer le nombre de neurones de la couche cachée.
Les phénomènes de sous et sur-paramétrisation sont illustrés à la Figure 23. En règle générale, l’EQM calculée sur la base d’apprentissage (erreur d’apprentissage) diminue avec l’augmentation de la taille du RN. En revanche, après une phase initiale de décroissance,
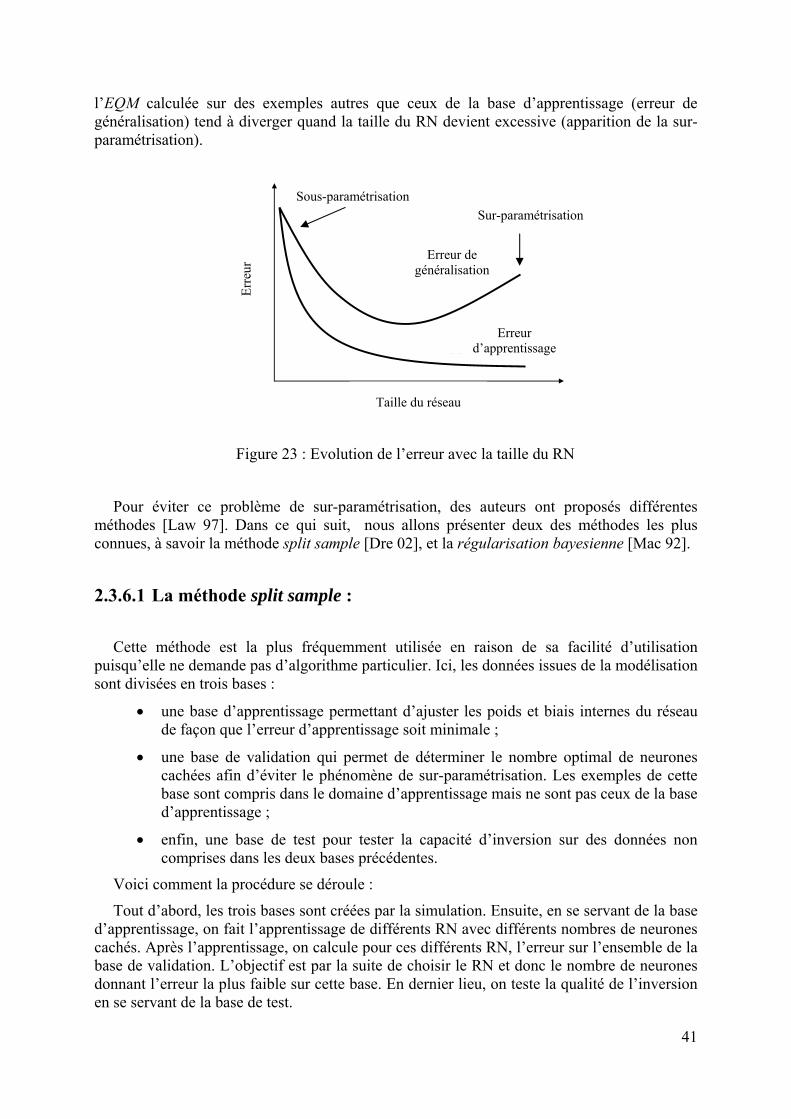
41
l’EQM calculée sur des exemples autres que ceux de la base d’apprentissage (erreur de généralisation) tend à diverger quand la taille du RN devient excessive (apparition de la sur-paramétrisation).
Taille du réseau
Erre
urErreur de généralisation
Erreur d’apprentissage
Figure 23 : Evolution de l’erreur avec la taille du RN
Pour éviter ce problème de sur-paramétrisation, des auteurs ont proposés différentes méthodes [Law 97]. Dans ce qui suit, nous allons présenter deux des méthodes les plus connues, à savoir la méthode split sample [Dre 02], et la régularisation bayesienne [Mac 92].
2.3.6.1 La méthode split sample :
Cette méthode est la plus fréquemment utilisée en raison de sa facilité d’utilisation puisqu’elle ne demande pas d’algorithme particulier. Ici, les données issues de la modélisation sont divisées en trois bases :
• une base d’apprentissage permettant d’ajuster les poids et biais internes du réseau de façon que l’erreur d’apprentissage soit minimale ;
• une base de validation qui permet de déterminer le nombre optimal de neurones cachées afin d’éviter le phénomène de sur-paramétrisation. Les exemples de cette base sont compris dans le domaine d’apprentissage mais ne sont pas ceux de la base d’apprentissage ;
• enfin, une base de test pour tester la capacité d’inversion sur des données non comprises dans les deux bases précédentes.
Voici comment la procédure se déroule :
Tout d’abord, les trois bases sont créées par la simulation. Ensuite, en se servant de la base d’apprentissage, on fait l’apprentissage de différents RN avec différents nombres de neurones cachés. Après l’apprentissage, on calcule pour ces différents RN, l’erreur sur l’ensemble de la base de validation. L’objectif est par la suite de choisir le RN et donc le nombre de neurones donnant l’erreur la plus faible sur cette base. En dernier lieu, on teste la qualité de l’inversion en se servant de la base de test.
Sous-paramétrisation
Erreur de généralisation
Erreur d’apprentissage
Sur-paramétrisation
Taille du réseau
Erre
ur

42
Bien que cette méthode soit très largement utilisée, son temps de mise en œuvre peut être très long : en effet, outre la création d’une base supplémentaire (base de validation) qui est en elle-même une procédure coûteuse en temps de calcul, l’exploration de plusieurs tailles de RN pour trouver le minimum de l’erreur sur la base de validation peut être très longue.
2.3.6.2 La régularisation bayesienne
La régularisation bayesienne appliquée aux RN a été introduite pour la première fois par MacKay en 1992 pour résoudre le problème du sur-ajustement [Mac 92]. Elle est basée sur la maximisation de la densité de probabilité a posteriori des paramètres du réseau de neurones en prenant en compte la base d’apprentissage. Contrairement à la méthode présentée précédemment, cette méthode ne requiert ni l’utilisation d’une base de validation ni l’apprentissage systématique de RN de différentes tailles. Dans ce qui suit, nous présentons la régularisation bayesienne appliquée à l’ajustement des paramètres internes des RN.
• Estimation des poids et des biais
On considère un ensemble de données D correspondant aux exemples de la base d’apprentissage. Un modèle d’approximation n’est généralement pas parfait et le résultat diffère de la solution exacte avec une certaine erreur. La densité de probabilité de cette erreur est supposée gaussienne, blanche, et centrée et donnée par :
)exp()(
1),,/( DD
i EZ
MwDP ββ
β −= (2.32)
w est le vecteur des paramètres internes de iM qui est un modèle neuronal.
2
21∑ −=
D
iN
iRND YYE où iRNY , iY , DN sont respectivement la sortie du RN, la sortie
contenue dans la base d’apprentissage pour le ième exemple et le nombre d’exemples de la
base d’apprentissage. Dσ
β 1= est un paramètre représentatif de l’écart type de l’erreur et
2/)/2( DNDZ βπ= .
Concernant les paramètres internes de iM , on suppose que leur densité de probabilité a priori, c'est-à-dire avant présentation des données de la base d’apprentissage au RN, est aussi gaussienne, blanche et centrée donnée par:
)exp()(
1),/( ww
i EZ
MwP αα
α −= (2.33)

43
où 2/)/2( nwZ απ= , avec
wσα 1= où wσ est l’écart type de la distribution
2
21∑=
nkw wE . n désigne le nombre de paramètres internes kw du RN (poids et biais).
Cette supposition sur la distribution des paramètres internes du réseau est basée sur le fait que les poids et les biais peuvent être soit positifs soit négatifs et que pour obtenir une bonne généralisation en favorisant les variations « douces » de la fonction d’approximation, il est préférable que ces paramètres soient de valeur faible.
La régularisation bayesienne comporte deux étapes. La première est l’estimation des poids et des biais du RN par la théorie de Bayes. La densité de probabilité a posteriori du vecteur de paramètres w est donnée par :
),,/(
),/(),,/(),,,/(
i
iii MDP
MwPMwDPMDwP
βααβ
βα = (2.34)
En substituant (2.32) et (2.33) dans (2.34), on peut écrire :
))(exp(),(
1),,,/( wDF
i EEZ
MDwP αββα
βα +−= (2.35)
où ),,/()()( iDwF MDPZZZ βαβα= (2.36)
Il est à noter que les paramètres internes optimaux sont ceux qui maximisent la densité de probabilité a posteriori ),,,/( iMDwP βα . On remarque dans l’équation (2.35) que la maximisation de cette densité de probabilité a posteriori des paramètres est équivalente à minimiser la fonction objectif régularisée donnée par :
wDT EEE αβ += (2.37)
Le premier terme ED de l’équation (2.37) est proportionnel à l’erreur quadratique moyenne entre la sortie du RN et celle de la base d’apprentissage. C’est la fonction d’erreur habituellement utilisée pour l’apprentissage des RN. Le deuxième terme Ew est un terme de régularisation. Si le terme de régularisation est petit, c'est-à-dire si l’amplitude des paramètres du RN est faible, alors cela conduit à un RN dont la sortie varie de manière douce s’opposant au phénomène de sur-paramétrisation.

44
• Estimation des hyper-paramètres α et β
La deuxième étape de la régularisation bayesienne consiste à ajuster les hyper-paramètres α et β de régularisation de façon à avoir une bonne capacité de généralisation. Si α << β, l’apprentissage sera facilité mais la généralisation risque d’être mauvaise, tandis que α >> β conduit à un réseau dont les paramètres sont très faibles et ne permet pas un bon apprentissage. Il faut donc réaliser un compromis entre les valeurs de α et β. L’approche proposée consiste à les ajuster automatiquement suivant la méthode bayesienne. La densité de probabilité a posteriori de α et β est donnée par :
)/()/,(),,/(
),/,(i
iii MDP
MPMDPMDP
βαβαβα = (2.38)
En supposant la densité de probabilité a priori de α et β )/,( iMP βα uniforme, maximiser ),/,( iMDP βα est équivalent selon (2.36) et (2.38) à maximiser :
)()(),(
),,/(βα
βαβα
DW
Fi ZZ
ZMDP = (2.39)
La seule inconnue ZF de cette égalité est déterminée en faisant un développement limité de ),,,/( iMDwP βα autour de la solution wMP de w au sens du maximum a posteriori obtenue à
la première étape de la régularisation [Mac 92]. Cela conduit à :
))(exp()))det((()2( 2/112/ MPT
MPnF wEZ −= Hπ (2.40)
avec H la matrice Hessienne de la fonction d’erreur régularisée calculée pour wMP.
Les solutions MPα et MPβ de α et β maximisant ),,/( iMDP βα sont obtenues en dérivant le logarithme de ),,/( iMDP βα par rapport à α et β . On obtient :
)(2 MPw
MP
wEγα = ,
)(2 MPD
DMP
wEN γ
β−
= (2.41)
1)(2 −−= MPMPtrn Hαγ est une mesure du nombre de paramètres effectif influents sur la
sortie du RN.

45
L’apprentissage du RN est effectué en ajustant w, α et β à chaque itération de l’algorithme de réglage.
Pour illustrer l’effet du critère d’erreur, nous avons modélisé une fonction 1D non linéaire en utilisant les RN (Figure 24). La fonction non linéaire modélisée est ))sin(exp(xy = sur l’intervalle [0 ; 2].
Nous avons considéré trois cas :
- RN de taille réduite : 1 neurone caché,
- RN de taille moyenne : 3 neurones cachés,
- RN de taille élevée : 25 neurones cachés.
La Figure 24 présente les modèles neuronaux obtenus suivant ces trois cas, avec un apprentissage utilisant l’un ou l’autre des deux critères d’erreur suivant : EQM sur la base d’apprentissage (ED) et critère régularisé (βED + αEw).
Cette figure montre que quel que soit le critère d’erreur, un nombre de neurones insuffisant, donc un nombre de paramètres internes insuffisant conduit à un mauvais apprentissage de la fonction du fait d’une sous paramétrisation. Pour un nombre de neurones et donc de paramètres internes suffisant, les deux critères d’erreur permettent de bien modéliser la fonction considérée et conduisent tous deux à une bonne généralisation. En revanche, pour un nombre excessif de neurones et donc de paramètres internes, le critère d’erreur basé sur EQM conduit à une mauvaise généralisation (sur-ajustement) à cause d’une sur-paramétrisation. A contrario, le critère d’erreur utilisant la régularisation bayesienne permet quant à lui d’avoir encore une bonne généralisation malgré le nombre élevé de neurones.
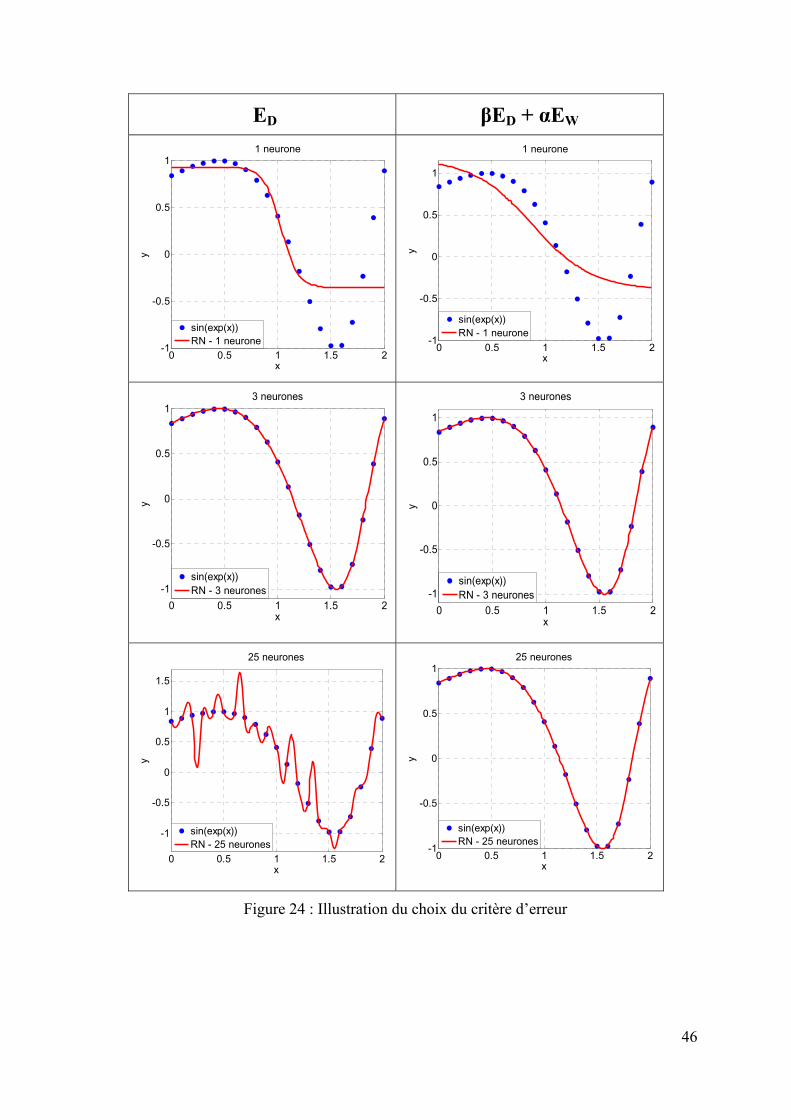
46
ED βED + αEW
0 0.5 1 1.5 2-1
-0.5
0
0.5
1
x
y1 neurone
sin(exp(x))RN - 1 neurone 0 0.5 1 1.5 2
-1
-0.5
0
0.5
1
x
y
1 neurone
sin(exp(x))RN - 1 neurone
0 0.5 1 1.5 2-1
-0.5
0
0.5
1
x
y
3 neurones
sin(exp(x))RN - 3 neurones
0 0.5 1 1.5 2-1
-0.5
0
0.5
1
x
y3 neurones
sin(exp(x))RN - 3 neurones
0 0.5 1 1.5 2
-1
-0.5
0
0.5
1
1.5
x
y
25 neurones
sin(exp(x))RN - 25 neurones
0 0.5 1 1.5 2-1
-0.5
0
0.5
1
x
y
25 neurones
sin(exp(x))RN - 25 neurones
Figure 24 : Illustration du choix du critère d’erreur
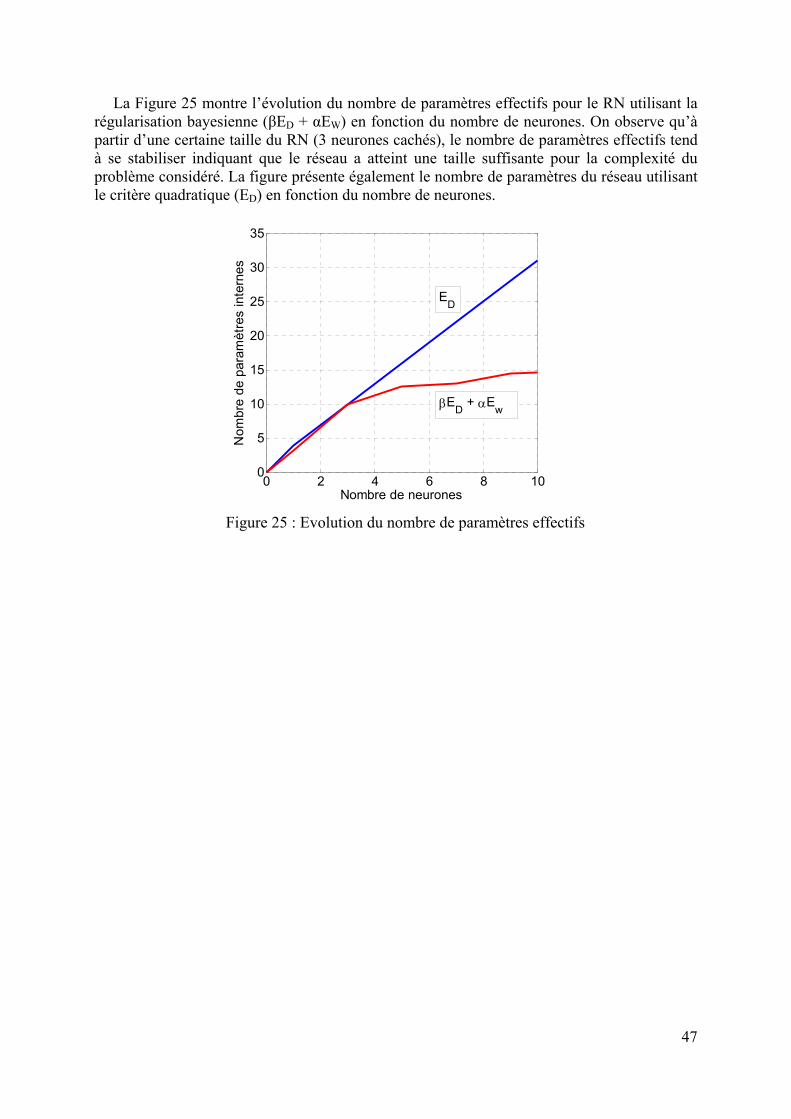
47
La Figure 25 montre l’évolution du nombre de paramètres effectifs pour le RN utilisant la régularisation bayesienne (βED + αEW) en fonction du nombre de neurones. On observe qu’à partir d’une certaine taille du RN (3 neurones cachés), le nombre de paramètres effectifs tend à se stabiliser indiquant que le réseau a atteint une taille suffisante pour la complexité du problème considéré. La figure présente également le nombre de paramètres du réseau utilisant le critère quadratique (ED) en fonction du nombre de neurones.
0 2 4 6 8 100
5
10
15
20
25
30
35
Nombre de neurones
Nom
bre
de p
aram
ètre
s in
tern
es
βED + αEw
ED
Figure 25 : Evolution du nombre de paramètres effectifs

48

49
3 Application des réseaux de neurones à la caractérisation diélectrique large bande
de matériaux
3.1 Introduction
Dans ce chapitre, nous mettons en œuvre l’inversion associant la MEF et les réseaux de neurones sur des cas concrets de caractérisation MO de matériaux diélectriques. Le système de mesure utilisé est l’association d’un guide d’onde coaxial avec un guide cylindrique qui est rempli d’un matériau diélectrique à caractériser. Comme annoncé au chapitre 1, cette méthode pour laquelle le LGEP possède une forte compétence a été choisie comme technique d’investigation.
Les deux cellules de mesure que nous avons utilisées sont les cellules baptisées SuperMit et SuperPol :
- La première cellule (SuperMit, [Bel 86]) qui est utilisée dans l’équipe MDMI depuis les années 80 est constituée d’une jonction abrupte entre un guide coaxial circulaire et un guide circulaire cylindrique terminé par un court-circuit. Le guide d’onde circulaire cylindrique est rempli de façon homogène par le matériau à caractériser. Cette cellule permet de faire des mesures avec une très grande précision sur une très large bande de fréquence (continu – 18 GHz avec le standard APC7).
- La deuxième cellule appelée SuperPol [Mey 96] est aussi l’association d’un guide d’onde coaxial avec un guide d’onde circulaire cylindrique, mais cette fois le matériau à caractériser remplit la cellule de façon inhomogène. Le matériau localisé dans la continuité de l’âme centrale du guide d’onde coaxial et maintenu au centre par une couronne de diélectrique en Teflon. Cette cellule est par exemple utilisée par O. Meyer pour le chauffage MO de liquides biologiques. Contrairement à la cellule précédente, la validité de la solution analytique de celle-ci est très restreinte (fréquence maximale de 10 GHz en standard APC7 et d’environ 2 GHz en standard GR900)
L’intérêt pour nous d’utiliser ces deux cellules est le suivant :
La solution analytique de la cellule SuperMit est entièrement connue. La seule limitation en terme de fréquence est donnée par les dimensions du standard utilisé (apparition des premiers modes d’ordre supérieur dans le guide d’onde coaxial). De ce fait, l’inversion peut se faire directement en introduisant cette solution analytique dans une boucle itérative. L’utilisation des RN n’a alors pas d’intérêt évident. Cependant, la cellule SuperMit sera utilisée pour évaluer la mise en œuvre des RN. Les RN seront par la suite utilisés sur la cellule SuperPol.

50
Dans les paragraphes suivants, nous détaillons la cellule SuperMit et les résultats obtenus. Ensuite, nous présenterons la cellule SuperPol ainsi que ses résultats d’inversion.
3.2 Cellule de mesure : SuperMit
Le protocole de mesure SuperMit a été mis au point par N.-E. Belhadj-Tahar au LDIM de l’UPMC-Paris6 [Bel 86]. Il s’agit d’une méthode de caractérisation de matériaux sur une très large bande de fréquence. Elle est originale du point de vue utilisation puisqu’une grande gamme de matériaux (liquides, solides, films) peut être caractérisée et la mesure peut être rapide. Cette méthode de mesure s’applique à des diélectriques isotropes et homogènes.
Guide coaxial Support Échantillon(ε = ε’-jε’’)
Court-circuitGuide coaxial Support Échantillon(ε = ε’-jε’’)
Court-circuit
Fig. 26 Vue éclatée de la cellule de mesure SuperMit
L’ensemble (guide d’onde coaxial et la cellule remplie de l’échantillon) est relié à un analyseur de réseaux ou d’impédance pour faire des mesures d’admittance ou de coefficient de réflexion à la discontinuité entre le guide coaxial et la cellule. L’extrémité de la cellule est court-circuitée (Fig. 26 et Fig. 27).
Fig. 27 Vue en coupe de la cellule de mesure SuperMit
Le protocole requiert la propagation d’une onde électromagnétique de mode TEM depuis l’analyseur de réseaux jusqu’au plan de référence (discontinuité) où l’onde est réfléchie et où
Plan de la discontinuité
Échantillon
L’âme centrale du guide d’onde
coaxial
Cout-circuit
2a
2b
d

51
des modes d’ordres supérieurs TMon sont générés. Ces modes peuvent être évanescents ou stationnaires dans le matériau mais sont évanescents dans le guide coaxial. Cependant, la longueur du câble coaxial doit être suffisamment grande pour que ces modes TMon ne se superposent pas à d’autres modes (autres que le TEM) engendrés au début de la ligne par la source.
La principale limitation de cette méthode est donnée par l’apparition du mode TE11. En effet, le premier mode qui est excité et qui risque de se propager en dehors du mode fondamental TEM est le mode TE11. Ce mode d’ordre supérieur est évanescent si la fréquence d’excitation reste en dessous de la fréquence du mode fondamental, au-delà de laquelle il se propage. Cette fréquence de coupure est théoriquement de 19,6 GHz pour le standard APC7 utilisée dans la cellule SuperMit.
Nous avons considéré deux types de matériaux : solide et liquide.
D’un point de vue pratique, la caractérisation de ces deux types de matériaux ne se fait pas avec la même cellule. La cellule SuperMit de base qui permet de caractériser les échantillons solides a été modifiée en introduisant une fenêtre étanche entre le guide coaxial et le matériau (Figure 28). L’introduction de la fenêtre permet d’étudier des échantillons liquides en limitant les problèmes de contacts à l’interface [Bet 04].
Figure 28 : SuperMit pour matériau solide (à gauche), SuperMit avec fenêtre pour matériau liquide (à droite)
Dans notre cas, la fenêtre diélectrique est de type coaxial avec un centre en métal qui permet une continuité de l’âme centrale du guide d’onde coaxial jusqu’à l’échantillon. Contrairement à une fenêtre qui serait pleine, celle-ci permet d’avoir une meilleure transmission du signal de mesure. La fenêtre est constituée d’un diélectrique à très faibles pertes, typiquement du PEEK™ (poly-éther-éther-cétone) (ε’ = 3,2) ou du Plexiglas® (ε’ = 2,7) d’épaisseur de l’ordre du millimètre.
3.2.1 Modélisation analytique
La solution directe de ce protocole a été calculée analytiquement par N-E. Belhadj-Tahar [Bel 86]. La méthode employée n’est basée sur aucune hypothèse simplificatrice et consiste à prendre en compte les modes d’ordres supérieurs engendrés à l’interface entre le guide coaxial et l’échantillon étudié. Grâce à la méthode de raccordement modal, qui prend en compte les conditions aux limites imposées au champ électromagnétique, l’admittance équivalente à la cellule de mesure est exprimée en fonction de la fréquence, de la permittivité complexe du
Guide d’onde Matériau
étudié
Matériau
étudié
Fenêtre

52
matériau contenu dans la cellule et des dimensions de la cellule de mesure. Cette solution analytique est donnée par :
( ) [ ]( )[ ] ( )
( )
⎥⎥⎥⎥⎥
⎦
⎤
⎢⎢⎢⎢⎢
⎣
⎡
−⎟⎟⎠
⎞⎜⎜⎝
⎛⋅
Γ+−⋅
−
−⋅= ∑∑
∞
=
∞
= 12
1
012
120
2
20
2200
0
11
1coth2
ln m
Bn
Am
Amm
n BnBnBn
BnBnd
kk
akZA
Aa
bkbJkkk
dkkakJ
ab
jkYY
ε
εε (3.1)
avec :
a : rayon de l’âme centrale du câble coaxial.
b : rayon du conducteur externe du câble coaxial.
d : épaisseur de l’échantillon.
ε : permittivité relative complexe du matériau.
0k ; constante de propagation dans l’air
kAm : constante de coupure du mode d’ordre supérieur TM0m dans le guide coaxial.
kBn : constante de coupure du mode d’ordre supérieur TM0n dans la cellule.
Y0 : admittance caractéristique de la ligne coaxiale (0,02 S).
Γ : coefficient de réflexion de l’onde TEM sur le plan de la discontinuité.
A0 : amplitude de l’onde TEM incidente.
Am : amplitude du mode d’ordre supérieur TM0m
J0, J1 : fonctions de Bessel de première espèce respectivement d’ordre 0 et 1.
Z1 : combinaison des fonctions de Bessel d’ordre 0 et 1 de première (J0, J1) et de seconde
(N0, N1) espèce :
( ) ( ) ( )( ) ( )⎥
⎦
⎤⎢⎣
⎡−+= akN
akNakJakJakZ Am
Am
AmAmAm 1
0
011 (3.2)
Le calcul de l’admittance normalisée 0/YYd commence par la détermination des quantités
mAk et nBk à partir des équations suivantes :
0)( =akJnBo (3.3)
0)()()()( =− bkNakJakNbkJmmmm AoAoAoAo (3.4)

53
Les sommes dans l’équation finale de l’admittance sont calculées en faisant une troncature sur les indices, c'est-à-dire en limitant le nombre de modes TM présents dans le guide d’onde et la cellule où se trouve le matériau sous test. Le choix du nombre de modes à prendre en compte dépend de la précision qu’on veut avoir sur l’admittance, de la gamme de permittivité et du temps de calcul souhaité. Typiquement, six modes dans l’échantillon et trois dans le guide d’onde suffisent pour avoir une bonne précision et un temps de calcul raisonnable.
3.2.2 Inversion itérative
Cette solution analytique ne peut être inversée directement. Par conséquent, l’inversion est habituellement faite en utilisant la méthode itérative décrite à la section 1.3.2.1. Pour chaque point de fréquence, à partir d’un couple (ε’, ε’’) (ε’ et ε’’ étant respectivement la partie réelle et la partie imaginaire de la permittivité relative complexe) initial choisi arbitrairement, l’admittance théorique correspondante est calculée puis comparée à la valeur mesurée. Le principe du calcul consiste alors à modifier la valeur initiale de ε’ ou/et celle de ε’’ afin de minimiser la différence entre les admittances mesurée et calculée. Après un nombre suffisant d’itérations, les valeurs ε’, ε’’ qui auront permis de minimiser cette différence sont retenues comme étant la permittivité complexe du matériau à la fréquence considérée.
Cette méthode d’inversion est utilisée depuis des années au LGEP pour l’inversion de la solution analytique de la cellule SuperMit et pour tous les calculs de permittivité à partir des cellules dont la solution analytique existe, en donnant pleine satisfaction. Elle est très rapide et efficace. Par conséquent, pour ce genre de cellule, l’utilisation des réseaux de neurones n’est pas nécessaire.
Cependant, pour valider notre méthodologie d’inversion par RN, nous l’avons appliquée à des données issues de cette cellule. Nous avons cherché à déterminer la permittivité complexe de différents matériaux diélectriques. Toujours dans le cadre de la validation de la méthode, nous avons voulu étudier des matériaux « étalons », dont le comportement électromagnétique est a priori connu ou dont la solution peut être trouvée à partir de l’inversion itérative basée sur la solution analytique.
Nous présentons dans ce qui suit la modélisation par la MEF de cette cellule puis la mise en œuvre de l’inversion par RN.
3.2.3 Modélisation par la méthode des éléments finis
Bien qu’une solution analytique existe, la MEF est utilisée pour modéliser la cellule SuperMit afin de créer la base d’apprentissage nécessaire aux RN. Ceci permet de valider la mise en œuvre de la MEF (logiciel ANSYS®) sur un cas où l’on dispose d’une solution de référence. La géométrie de la cellule est axisymétrique, par conséquent pour ne pas alourdir les calculs, nous avons modélisé qu’une portion angulaire de quelques degrés (typiquement 5 degrés). Même si le problème est axisymétrique, nous l’avons étudié en 3D puisque le module hyperfréquence d’ANSYS® ne permet pas une étude en 2D.
Nous avons maillé la structure avec des éléments tétraédriques du second ordre. Dans la modélisation par éléments finis, la taille des éléments a une importance capitale. La précision

54
de la simulation est liée au nombre d’éléments qu’il y a par longueur d’onde. Il faut qu’il y ait au minimum 10 éléments par longueur d’onde. De ce fait, dans toutes les modélisations que nous avons été amenés à faire dans cette thèse, nous nous sommes tenus à satisfaire cette condition. La longueur d’onde étant plus courte dans la cellule d’étude du fait de la présence du matériau qui peut avoir une permittivité élevée, le maillage de la Figure 29 est plus dense dans la cellule que dans le guide d’onde rempli d’air (ε’ = 1). Le nombre d’éléments total dans ce cas précis (SuperMit) est de 1524. Pour une fréquence et pour un matériau, la résolution numérique ne prend environ qu’une dizaine de secondes avec un PC équipé d’un processeur Pentium 4 de 3 GHz et de 1 Go de RAM.
Des conditions aux limites de type PEC sont appliquées sur les surfaces des conducteurs internes et externes du guide d’onde ainsi que sur les parois externes de la cellule. Sur les plans de symétrie, c’est un mur magnétique (PMC) qui est appliqué. C’est la condition aux limites par défaut. À l’entrée du guide d’ondes, une source permettant de générer des ondes TEM est appliquée.
Guide coaxial
(Air)
Échantillon sous test
Murs électriques
Source d’excitation
Guide coaxial
(Air)
Échantillon sous test
Murs électriques
Source d’excitation
Figure 29 : Maillage éléments finis de la cellule SuperMit sans fenêtre
Pour valider notre modèle numérique, nous avons comparé l’admittance obtenue par la modélisation d’un matériau quelconque (ε’ = 55, ε’’ = 5) avec celle calculée par la solution analytique de la cellule SuperMit entre 1 GHz et 12 GHz. Les tracés des parties réelle (G) et imaginaire (B) de cette admittance sont données Figure 30. L’admittance donnée par le modèle numérique concorde très bien avec celle calculée par la solution analytique. Par conséquent, les bases de données peuvent être créées afin de procéder à l’inversion des données de mesure en vue de la caractérisation de matériaux.
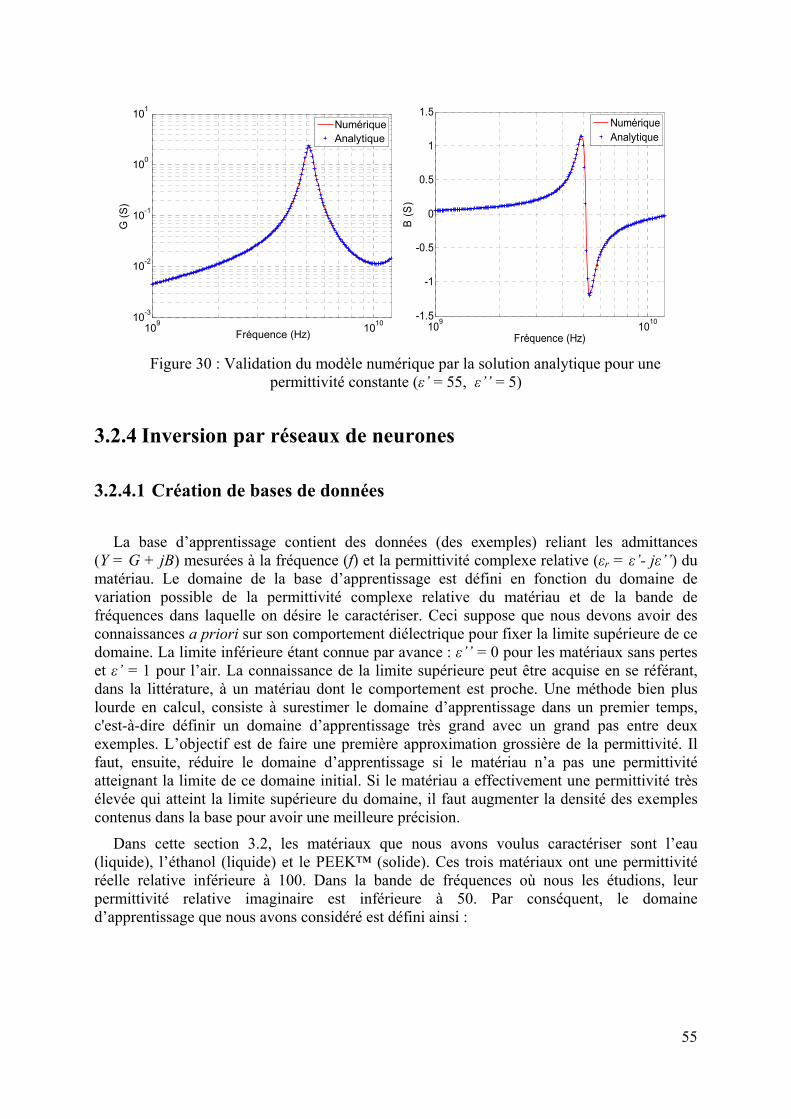
55
109 101010-3
10-2
10-1
100
101
Fréquence (Hz)
G (S
)
NumériqueAnalytique
109 1010-1.5
-1
-0.5
0
0.5
1
1.5
Fréquence (Hz)
B (S
)
NumériqueAnalytique
Figure 30 : Validation du modèle numérique par la solution analytique pour une
permittivité constante (ε’ = 55, ε’’ = 5)
3.2.4 Inversion par réseaux de neurones
3.2.4.1 Création de bases de données
La base d’apprentissage contient des données (des exemples) reliant les admittances (Y = G + jB) mesurées à la fréquence (f) et la permittivité complexe relative (εr = ε’- jε’’) du matériau. Le domaine de la base d’apprentissage est défini en fonction du domaine de variation possible de la permittivité complexe relative du matériau et de la bande de fréquences dans laquelle on désire le caractériser. Ceci suppose que nous devons avoir des connaissances a priori sur son comportement diélectrique pour fixer la limite supérieure de ce domaine. La limite inférieure étant connue par avance : ε’’ = 0 pour les matériaux sans pertes et ε’ = 1 pour l’air. La connaissance de la limite supérieure peut être acquise en se référant, dans la littérature, à un matériau dont le comportement est proche. Une méthode bien plus lourde en calcul, consiste à surestimer le domaine d’apprentissage dans un premier temps, c'est-à-dire définir un domaine d’apprentissage très grand avec un grand pas entre deux exemples. L’objectif est de faire une première approximation grossière de la permittivité. Il faut, ensuite, réduire le domaine d’apprentissage si le matériau n’a pas une permittivité atteignant la limite de ce domaine initial. Si le matériau a effectivement une permittivité très élevée qui atteint la limite supérieure du domaine, il faut augmenter la densité des exemples contenus dans la base pour avoir une meilleure précision.
Dans cette section 3.2, les matériaux que nous avons voulus caractériser sont l’eau (liquide), l’éthanol (liquide) et le PEEK™ (solide). Ces trois matériaux ont une permittivité réelle relative inférieure à 100. Dans la bande de fréquences où nous les étudions, leur permittivité relative imaginaire est inférieure à 50. Par conséquent, le domaine d’apprentissage que nous avons considéré est défini ainsi :

56
1 < ε’ < 100
0 < ε’’ < 50
1 MHz < fréquence < 1,8 GHz
Les données d’entrée de la base d’apprentissage (ε’, ε’’) sont sélectionnées de façon à avoir une distribution uniforme de ces éléments dans le domaine de la base d’apprentissage. Tandis que les points de fréquence sont sélectionnés avec une distribution logarithmique couvrant toute la bande de fréquence d’étude.
Ces données ainsi que celles issues de la simulation sont stockées dans un fichier qui forme la base d’apprentissage. Les paramètres recherchés étant la partie réelle et imaginaire de la permittivité relative du matériau, ceux-ci sont attribués à la sortie des RN. Les autres paramètres, la fréquence f, et les parties réelle (G) et imaginaire (B) de l’admittance (Y) constituent l’entrée.
Cependant, la simulation fournit le coefficient de réflexion Γ calculé en début du guide d’onde, sur le port d’excitation. Pour calculer l’admittance Y obtenue à la discontinuité, il faut ramener Γ sur le plan de la discontinuité entre le guide d’onde et la cellule de mesure où l’étalonnage par l’analyseur de réseaux est fait. Le module de Γ étant le même quel que soit l’endroit sur le guide, seule la phase du coefficient de réflexion en début de ligne ϕ doit être translatée vers le plan de la discontinuité. La relation suivante permet de faire ce changement de plan et ainsi de passer du plan d’excitation au plan d’étalonnage :
λd4πexcitationitédiscontinu +=ϕϕ (3.5)
où d est la longueur du guide d’ondes et λ est la longueur d’onde.
L’admittance Y est obtenue par la relation classique qui la lie à Γ (coefficient de réflexion ramené à la discontinuité):
Γ1Γ1YY 0 +
−= (3.6)
0Y = 0,02 S est l’admittance caractéristique de la ligne coaxiale 50 Ω.
Finalement, G et B sont exprimés en fonction des parties réelle Γ' et imaginaire Γ'' de Γ :
22
220
Γ'')Γ'(1)Γ''Γ'(1Y
G++−−
= et 220
Γ''Γ')(1Γ'2YB++
−= (3.7)

57
Le Tableau 3 présente la forme de la base d’apprentissage où les données issues de la modélisation apparaissent telles qu’elles sont utilisées par les réseaux de neurones.
N° de l’exemple
Fréquence (f)
ε’ ε’’ G B
1 f1 ε’1 ε’’1 G1 B 1
2 f2 ε’2 ε’’2 G2 B 2
… … … … … …
… ... … … … …
n fn ε’n ε’’n G n B n
Tableau 3 : Base d’apprentissage
3.2.4.2 Mise en œuvre des réseaux de neurones
Comme indiqué sur l’organigramme du processus d’inversion de la Figure 31, on a utilisé un RN différent pour chaque paramètre à estimer. En effet, d’une façon générale, il vaut mieux utiliser autant de réseaux que de paramètres à estimer. Ceci rend les réseaux moins complexes avec moins de paramètres internes à ajuster. L’estimation simultanée de ε’ et ε’’ peut paraître superflue. Cependant, elle permet d’avoir des résultats plus généraux qui tiennent compte de phénomènes qui ne sont pas pris en considération dans les modèles de Debye ou Cole-Cole. En effet, même si ces modèles prennent en compte le couplage entre ε’ et ε’’, ce sont des modèles simplistes qui ne sont valables que pour des matériaux dont les interactions entre dipôles sont négligeables. De plus, quand on étudie des liquides, il apparaît généralement un phénomène de conduction en basse fréquence dû aux ions ou aux impuretés présentes dans le liquide. Les modèles de Debye ou celui de Cole-Cole ne permettent pas non plus de prédire ce phénomène (voir la section 1.1.3).

58
RN1
RN2
Modèle numérique
ε’
Propriétés diélectriques du matériau
( f, G, B)
( f, G, B)
Sonde MO
ε’’
RN1
RN2
Modèle numérique
ε’
Propriétés diélectriques du matériau
( f, G, B)
( f, G, B)
Sonde MO
ε’’
Figure 31 : Processus d’inversion par RN
Les RN utilisés sont de type MLP dont l’architecture est donnée au chapitre 2.2. Les neurones de la couche cachée ont tous la même fonction d’activation. Celle qui est utilisée pour nos études est la fonction tangente hyperbolique. La couche de sortie possède un seul neurone de fonction d’activation linéaire. L’apprentissage est effectué au moyen de l’algorithme de Levenberg-Marquardt. Pour éviter les minima locaux de la fonction d’erreur (EQM), l’apprentissage est répété pour plusieurs initialisations différentes.
3.2.4.3 Etude du nombre d’exemples d’apprentissage
Une des précautions à prendre lors de l’inversion par RN est le nombre d’exemples de la base d’apprentissage. En effet, la généralisation dépend fortement de ce dernier. Par exemple, si la fonction à approximer est linéaire, il nous faut au moins deux points pour représenter une droite, et trois points pour représenter un plan. En revanche, si cette fonction est non linéaire, le nombre de points doit être plus conséquent. Les exemples doivent représenter assez bien les zones de forte sensibilité. Plus le nombre d’exemples est élevé, plus la fonction à approximer sera bien représentée et la capacité de généralisation du RN sera élevée. En contrepartie, le nombre d’exemples à apprendre étant plus élevé, le temps d’apprentissage peut être très long. Par conséquent, il faut trouver le bon compromis entre le nombre d’exemples et la capacité de généralisation.
Dans cet objectif, nous avons réalisé plusieurs campagnes d’inversion avec des nombres d’exemples de la base d’apprentissage différents. Nous avons ensuite tracé l’erreur d’estimation sur la même base de test pour des RN construits à partir de ces différentes bases d’apprentissage. La Figure 32 montre l’évolution de l’erreur relative avec le nombre d’exemples d’apprentissage obtenue avec un RN de 25 et 23 neurones cachés respectivement pour ε’ et ε’’. Cette erreur en sortie des RN diminue quel que soit le paramètre ε’ ou ε’’ estimé. Cependant, comme on le constate, au bout d’un certain nombre d’exemples, l’erreur tend à se stabiliser et ne varie que très peu. Il est donc inutile d’avoir un nombre d’exemples trop élevé qui conduira à un temps de création de la base d’apprentissage et de réglage du RN élevés.
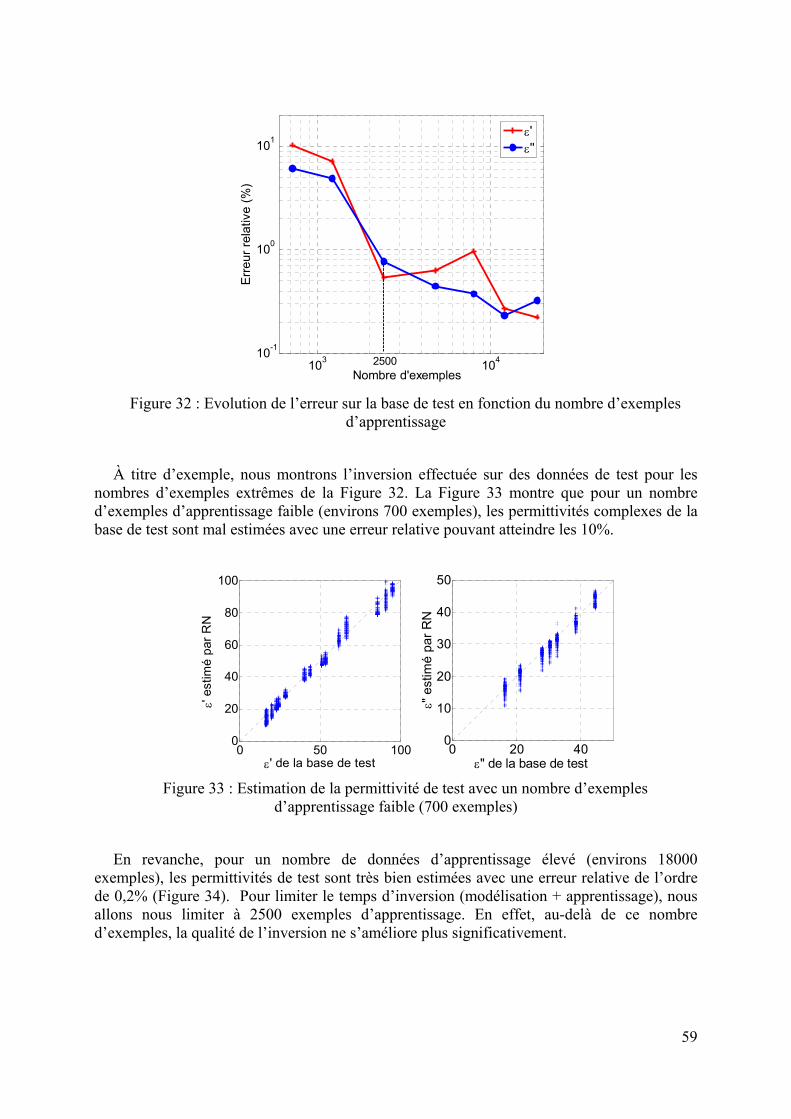
59
103 10410-1
100
101
Nombre d'exemples
Err
eur r
elat
ive
(%)
ε'ε''
2500
Figure 32 : Evolution de l’erreur sur la base de test en fonction du nombre d’exemples
d’apprentissage
À titre d’exemple, nous montrons l’inversion effectuée sur des données de test pour les nombres d’exemples extrêmes de la Figure 32. La Figure 33 montre que pour un nombre d’exemples d’apprentissage faible (environs 700 exemples), les permittivités complexes de la base de test sont mal estimées avec une erreur relative pouvant atteindre les 10%.
0 50 1000
20
40
60
80
100
ε' es
timé
par R
N
ε' de la base de test
0 20 40
0
10
20
30
40
50
ε" e
stim
é pa
r RN
ε" de la base de test
Figure 33 : Estimation de la permittivité de test avec un nombre d’exemples
d’apprentissage faible (700 exemples)
En revanche, pour un nombre de données d’apprentissage élevé (environs 18000 exemples), les permittivités de test sont très bien estimées avec une erreur relative de l’ordre de 0,2% (Figure 34). Pour limiter le temps d’inversion (modélisation + apprentissage), nous allons nous limiter à 2500 exemples d’apprentissage. En effet, au-delà de ce nombre d’exemples, la qualité de l’inversion ne s’améliore plus significativement.
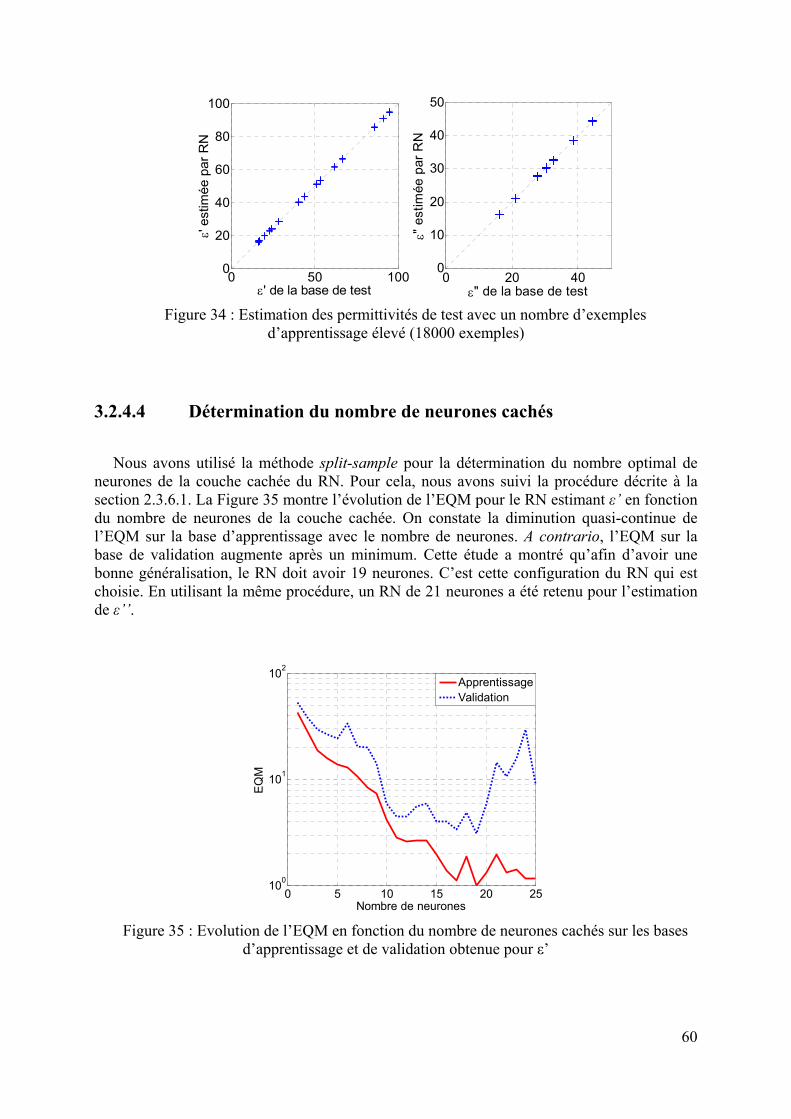
60
0 50 1000
20
40
60
80
100
ε' es
timée
par
RN
ε' de la base de test
0 20 400
10
20
30
40
50
ε" e
stim
ée p
ar R
N
ε" de la base de test
Figure 34 : Estimation des permittivités de test avec un nombre d’exemples
d’apprentissage élevé (18000 exemples)
3.2.4.4 Détermination du nombre de neurones cachés
Nous avons utilisé la méthode split-sample pour la détermination du nombre optimal de neurones de la couche cachée du RN. Pour cela, nous avons suivi la procédure décrite à la section 2.3.6.1. La Figure 35 montre l’évolution de l’EQM pour le RN estimant ε’ en fonction du nombre de neurones de la couche cachée. On constate la diminution quasi-continue de l’EQM sur la base d’apprentissage avec le nombre de neurones. A contrario, l’EQM sur la base de validation augmente après un minimum. Cette étude a montré qu’afin d’avoir une bonne généralisation, le RN doit avoir 19 neurones. C’est cette configuration du RN qui est choisie. En utilisant la même procédure, un RN de 21 neurones a été retenu pour l’estimation de ε’’.
0 5 10 15 20 25100
101
102
Nombre de neurones
EQM
ApprentissageValidation
Figure 35 : Evolution de l’EQM en fonction du nombre de neurones cachés sur les bases
d’apprentissage et de validation obtenue pour ε’
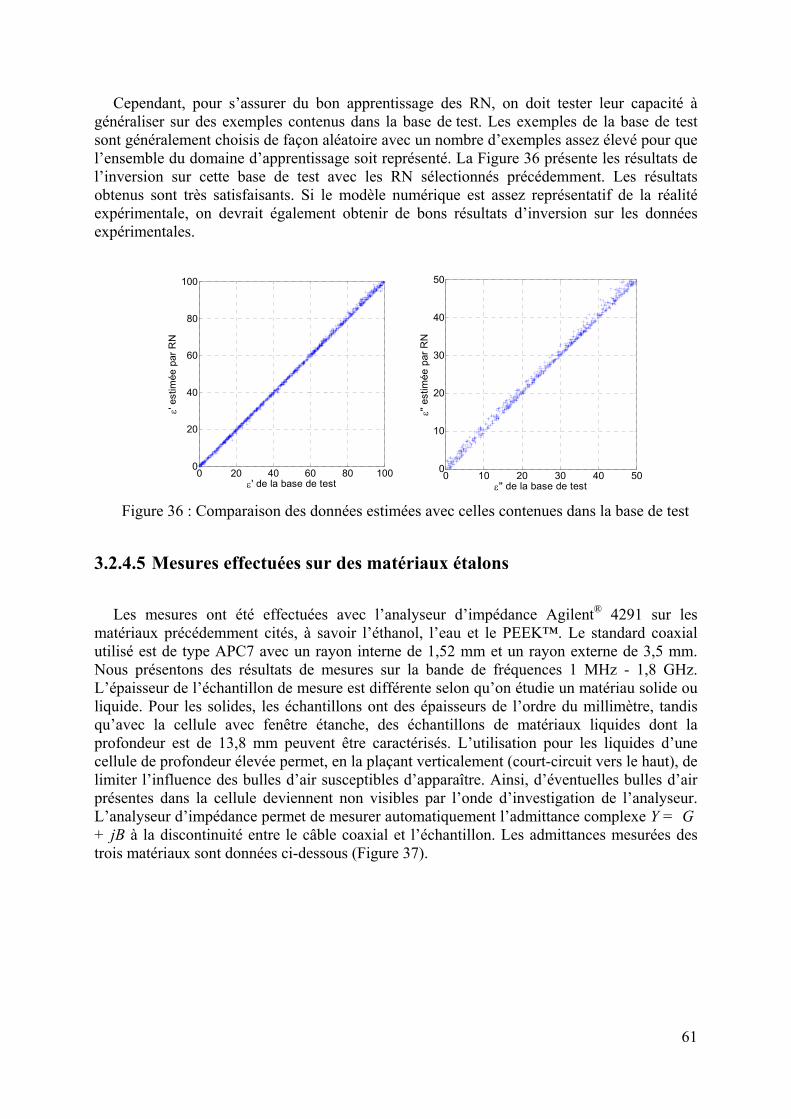
61
Cependant, pour s’assurer du bon apprentissage des RN, on doit tester leur capacité à généraliser sur des exemples contenus dans la base de test. Les exemples de la base de test sont généralement choisis de façon aléatoire avec un nombre d’exemples assez élevé pour que l’ensemble du domaine d’apprentissage soit représenté. La Figure 36 présente les résultats de l’inversion sur cette base de test avec les RN sélectionnés précédemment. Les résultats obtenus sont très satisfaisants. Si le modèle numérique est assez représentatif de la réalité expérimentale, on devrait également obtenir de bons résultats d’inversion sur les données expérimentales.
0 20 40 60 80 1000
20
40
60
80
100
ε' es
timée
par
RN
ε' de la base de test
0 10 20 30 40 50
0
10
20
30
40
50
ε'' e
stim
ée p
ar R
N
ε'' de la base de test
Figure 36 : Comparaison des données estimées avec celles contenues dans la base de test
3.2.4.5 Mesures effectuées sur des matériaux étalons
Les mesures ont été effectuées avec l’analyseur d’impédance Agilent® 4291 sur les matériaux précédemment cités, à savoir l’éthanol, l’eau et le PEEK™. Le standard coaxial utilisé est de type APC7 avec un rayon interne de 1,52 mm et un rayon externe de 3,5 mm. Nous présentons des résultats de mesures sur la bande de fréquences 1 MHz - 1,8 GHz. L’épaisseur de l’échantillon de mesure est différente selon qu’on étudie un matériau solide ou liquide. Pour les solides, les échantillons ont des épaisseurs de l’ordre du millimètre, tandis qu’avec la cellule avec fenêtre étanche, des échantillons de matériaux liquides dont la profondeur est de 13,8 mm peuvent être caractérisés. L’utilisation pour les liquides d’une cellule de profondeur élevée permet, en la plaçant verticalement (court-circuit vers le haut), de limiter l’influence des bulles d’air susceptibles d’apparaître. Ainsi, d’éventuelles bulles d’air présentes dans la cellule deviennent non visibles par l’onde d’investigation de l’analyseur. L’analyseur d’impédance permet de mesurer automatiquement l’admittance complexe Y = G + jB à la discontinuité entre le câble coaxial et l’échantillon. Les admittances mesurées des trois matériaux sont données ci-dessous (Figure 37).
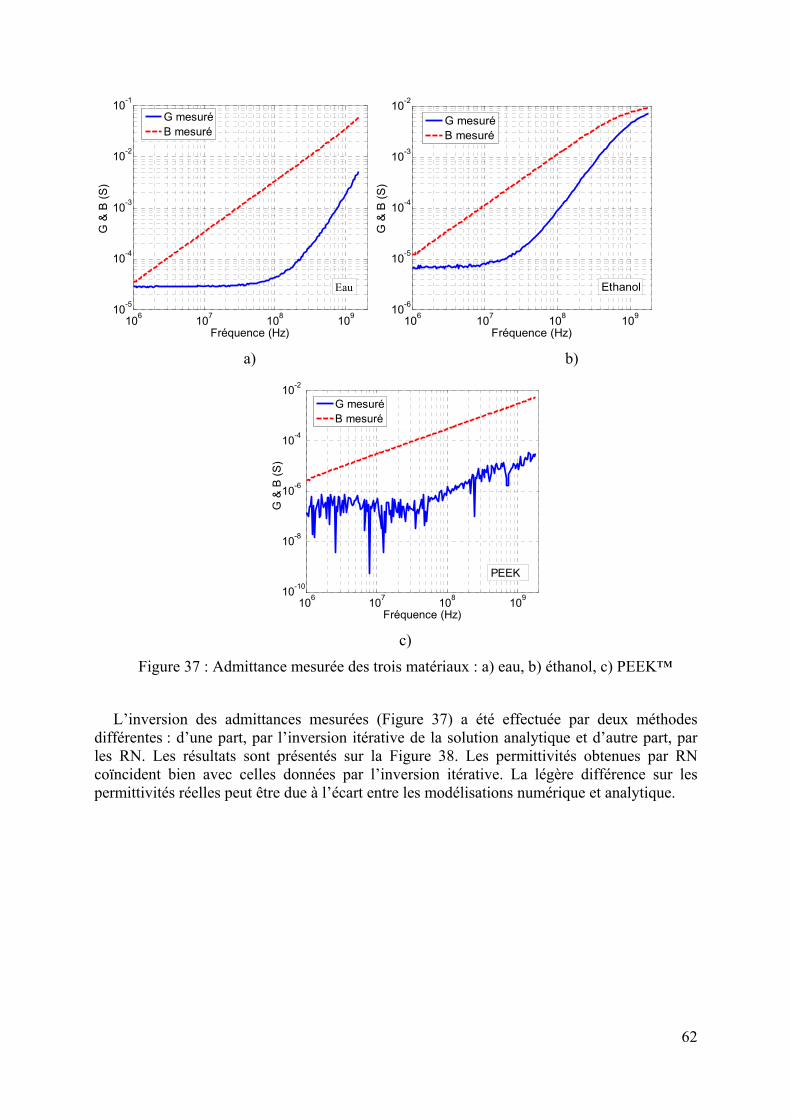
62
106 107 108 10910-5
10-4
10-3
10-2
10-1
Fréquence (Hz)
G &
B (S
)
G mesuréB mesuré
Eau
106 107 108 10910-6
10-5
10-4
10-3
10-2
Fréquence (Hz)
G &
B (S
)
G mesuréB mesuré
Ethanol
a) b)
106 107 108 10910-10
10-8
10-6
10-4
10-2
Fréquence (Hz)
G &
B (S
)
G mesuréB mesuré
PEEK
c)
Figure 37 : Admittance mesurée des trois matériaux : a) eau, b) éthanol, c) PEEK™
L’inversion des admittances mesurées (Figure 37) a été effectuée par deux méthodes différentes : d’une part, par l’inversion itérative de la solution analytique et d’autre part, par les RN. Les résultats sont présentés sur la Figure 38. Les permittivités obtenues par RN coïncident bien avec celles données par l’inversion itérative. La légère différence sur les permittivités réelles peut être due à l’écart entre les modélisations numérique et analytique.
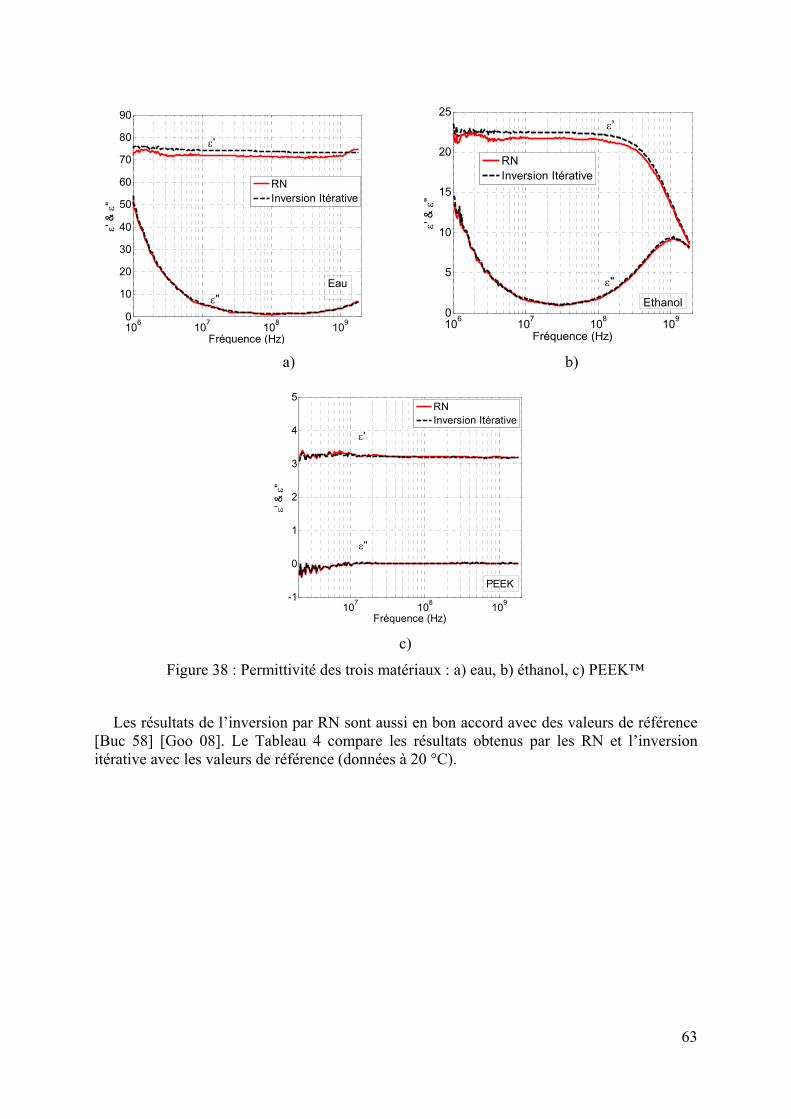
63
106 107 108 1090
10
20
30
40
50
60
70
80
90
Fréquence (Hz)
ε' & ε"
RNInversion Itérative
Eau
ε'
ε"
106 107 108 1090
5
10
15
20
25
Fréquence (Hz)
ε' &
ε"
RNInversion Itérative
Ethanol
ε'
ε"
a) b)
107 108 109-1
0
1
2
3
4
5
Fréquence (Hz)
ε' & ε"
RNInversion Itérative
ε'
ε''
PEEK
c)
Figure 38 : Permittivité des trois matériaux : a) eau, b) éthanol, c) PEEK™
Les résultats de l’inversion par RN sont aussi en bon accord avec des valeurs de référence [Buc 58] [Goo 08]. Le Tableau 4 compare les résultats obtenus par les RN et l’inversion itérative avec les valeurs de référence (données à 20 °C).

64
Les résultats de l’inversion par RN sont aussi en bon accord avec des valeurs de référence [Buc 58] [Goo 08]. Le Tableau 4 compare les résultats obtenus par les RN et l’inversion itérative avec les valeurs de référence (données à 20 °C).
ε’ statique 1ère fréquence de relaxation (GHz)
Valeur de référence
Inversion Itérative RN Valeur de
référence Inversion Itérative RN
Eau 80,4 74,2 72,0 17 … …
Ethanol 25,1 22,4 21 ,8 1,1 1,06 1,06
PEEK™ 3,2 – 3,3 3,19 3,21 Pas de relaxation
Tableau 4 : Permittivité statique et fréquence de relaxation des trois matériaux caractérisés
On constate que les permittivités statiques de l’eau et de l’éthanol obtenus par RN et inversion itérative sont sensiblement inférieures aux valeurs de référence. Ceci provient probablement des erreurs de mesure (contact imparfait entre le guide d’ondes et la cellule de mesure, effet de la température…). De plus, les impuretés présentes dans ces liquides entrainent une modification de leurs propriétés diélectriques.
3.3 Cellule à remplissage inhomogène : SuperPol
Dans le cadre de sa thèse s’intéressant à l’évolution des caractéristiques diélectriques de résines thermodurcissables en cours de traitement thermique MO, O. Meyer s’est attaché à placer l’échantillon à caractériser dans une zone de champ homogène, de manière à minimiser les gradients de température susceptibles d’apparaître en cas d’hétérogénéité de champ [Mey 96]. En effet, dans le cas de la cellule SuperMit, le champ EM est plus intense à proximité de l’âme centrale du guide d’onde. Ceci a pour conséquence, en cas d’utilisation de la cellule pour réaliser un chauffage MO du matériau, d’avoir un chauffage non homogène sur l’ensemble de l’échantillon. Pour pallier ce problème, il a considéré un remplissage inhomogène de la cellule SuperMit qui a conduit à la cellule baptisée SuperPol où le matériau sous test est localisé dans le guide circulaire cylindrique uniquement dans le prolongement de l’âme centrale du guide d’onde coaxial (Figure 39).

65
Figure 39 : Vue en coupe de la cellule de mesure et de chauffage SuperPol
Dans la suite, comme pour la cellule SuperMit, nous présentons la résolution du problème direct par la méthode des éléments finis et l’inversion par RN que nous avons développées.
3.3.1 Modélisation analytique
Contrairement à l’analyse de Kolodziej [Kol 71] complétée par J-C. Badot [Bad 88], O. Meyer a considéré non pas une couronne d’air mais une couronne de diélectrique percée en son centre afin de recevoir le matériau à chauffer et à caractériser. Il a choisi le diélectrique de la couronne de telle façon que sa constante diélectrique et ses pertes soient les plus faibles possible tout en ayant une bonne tenue thermique. Le matériau répondant à ces critères est le Teflon® qui a ε’ = 2,1 et ε’’ = 3.10-4.
Le remplissage de la cellule n’étant pas homogène, la solution analytique obtenue dans le cas de SuperMit n’est plus valable pour la résolution du problème direct de la cellule SuperPol. L’approximation faite par J-C. Badot ne permet d’exploiter cette structure que jusqu’à la fréquence maximale du standard de guide coaxial utilisé : par exemple, en APC 7, la limite supérieure est d’environ 10 GHz et en GR900 de 2 GHz.
3.3.2 Inversion itérative
Le protocole de calcul du problème inverse est identique à celui de SuperMit, jusqu’à la fréquence autorisée par la solution analytique du problème direct. L’admittance mesurée par l’analyseur de réseaux est comparée à celle calculée par le modèle direct. La permittivité du matériau est déterminée en minimisant la différence entre ces deux admittances. Pour aller au-delà de la fréquence limite, jusqu’à la fréquence de coupure du mode TEM, il faut trouver un autre moyen d’inversion comme l’association de la MEF et des RN.
Âme centrale du guide d’onde
coaxial
Échantillon
Plan de la discontinuité
Porte échantillon en Teflon

66
3.3.3 Modélisation par la méthode des éléments finis
La cellule SuperPol est modélisée par le MEF en vue de créer les bases de données. Les conditions aux limites et l’excitation sont appliquées de la même manière que pour la cellule SuperMit. Le maillage d’une portion angulaire est donné à la Figure 40.
Guide coaxial
(Air)
Échantillon sous test
Murs électrique
Source d’excitation
Couronne en Téflon
7,6 mm
2,6 mm
6,2 mm
Guide coaxial
(Air)
Échantillon sous test
Murs électrique
Source d’excitation
Couronne en Téflon
7,6 mm
2,6 mm
6,2 mm
Figure 40 : Maillage par éléments finis de la cellule SuperPol avec couronne en Téflon
La procédure de création des bases est identique à celle de la section 3.2.4.1.
3.3.4 Inversion par réseaux de neurones
Comparaison entre le critère d’erreur quadratique et la régularisation bayesienne
Nous avons d’abord voulu vérifier l’efficacité de la régularisation bayésienne dans un cas
concret qui est la caractérisation de matériaux. Pour cela, nous avons représenté l’évolution de l’EQM sur les bases d’apprentissage et de test pour des RN ayant différents nombres de neurones cachés, en utilisant comme critère d’erreur pour l’apprentissage soit l’EQM soit la régularisation bayesienne. La base d’apprentissage comprend 3000 exemples alors que celle de test contient 500 exemples choisis aléatoirement dans le domaine d’apprentissage. La bande de fréquence d’investigation est toujours 1 MHz - 1,8 GHz. Le domaine de variation de la permittivité est de [1, 30] pour ε’ et [0, 30] pour ε’’. La Figure 41 présente les résultats obtenus en utilisant le critère d’erreur classique EQM sur la base d’apprentissage.
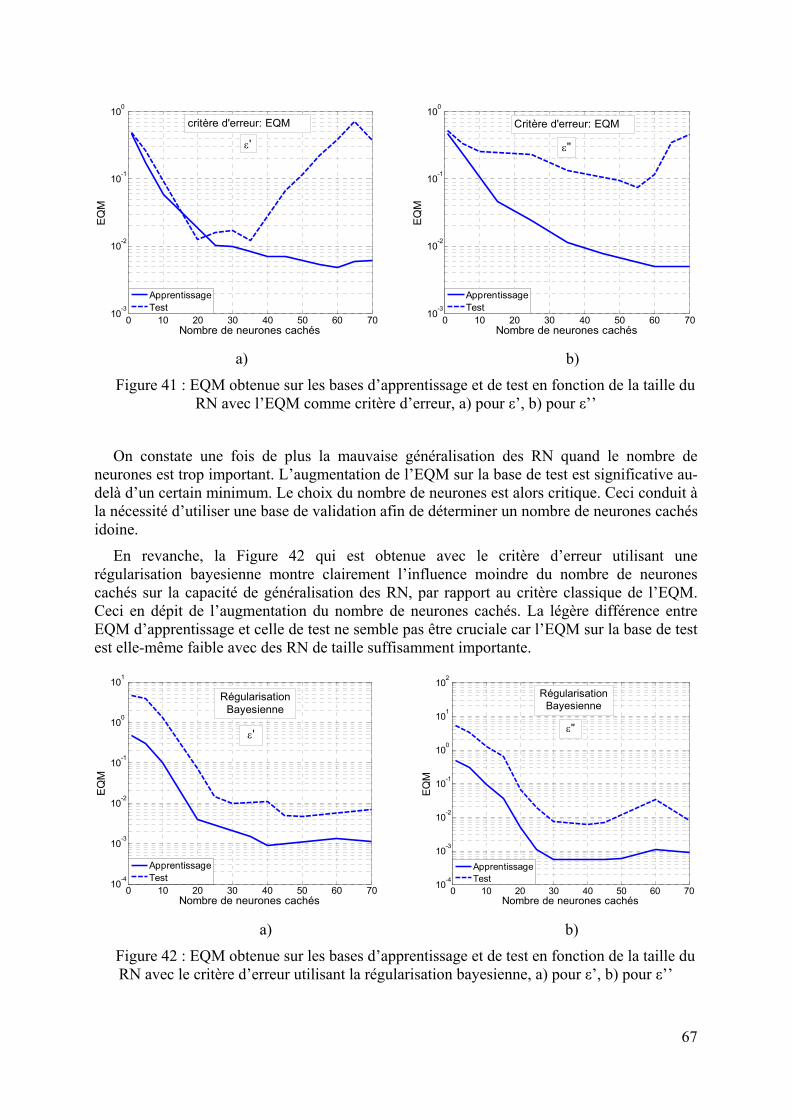
67
0 10 20 30 40 50 60 7010-3
10-2
10-1
100EQ
M
Nombre de neurones cachés
ApprentissageTest
critère d'erreur: EQM
ε'
0 10 20 30 40 50 60 7010-3
10-2
10-1
100
Nombre de neurones cachés
EQM
ApprentissageTest
Critère d'erreur: EQM
ε''
a) b)
Figure 41 : EQM obtenue sur les bases d’apprentissage et de test en fonction de la taille du RN avec l’EQM comme critère d’erreur, a) pour ε’, b) pour ε’’
On constate une fois de plus la mauvaise généralisation des RN quand le nombre de neurones est trop important. L’augmentation de l’EQM sur la base de test est significative au-delà d’un certain minimum. Le choix du nombre de neurones est alors critique. Ceci conduit à la nécessité d’utiliser une base de validation afin de déterminer un nombre de neurones cachés idoine.
En revanche, la Figure 42 qui est obtenue avec le critère d’erreur utilisant une régularisation bayesienne montre clairement l’influence moindre du nombre de neurones cachés sur la capacité de généralisation des RN, par rapport au critère classique de l’EQM. Ceci en dépit de l’augmentation du nombre de neurones cachés. La légère différence entre EQM d’apprentissage et celle de test ne semble pas être cruciale car l’EQM sur la base de test est elle-même faible avec des RN de taille suffisamment importante.
0 10 20 30 40 50 60 7010-4
10-3
10-2
10-1
100
101
Nombre de neurones cachés
EQM
ApprentissageTest
RégularisationBayesienne
ε'
0 10 20 30 40 50 60 7010
-4
10-3
10-2
10-1
100
101
102
EQ
M
Nombre de neurones cachés
ApprentissageTest
RégularisationBayesienne
ε''
a) b)
Figure 42 : EQM obtenue sur les bases d’apprentissage et de test en fonction de la taille du RN avec le critère d’erreur utilisant la régularisation bayesienne, a) pour ε’, b) pour ε’’
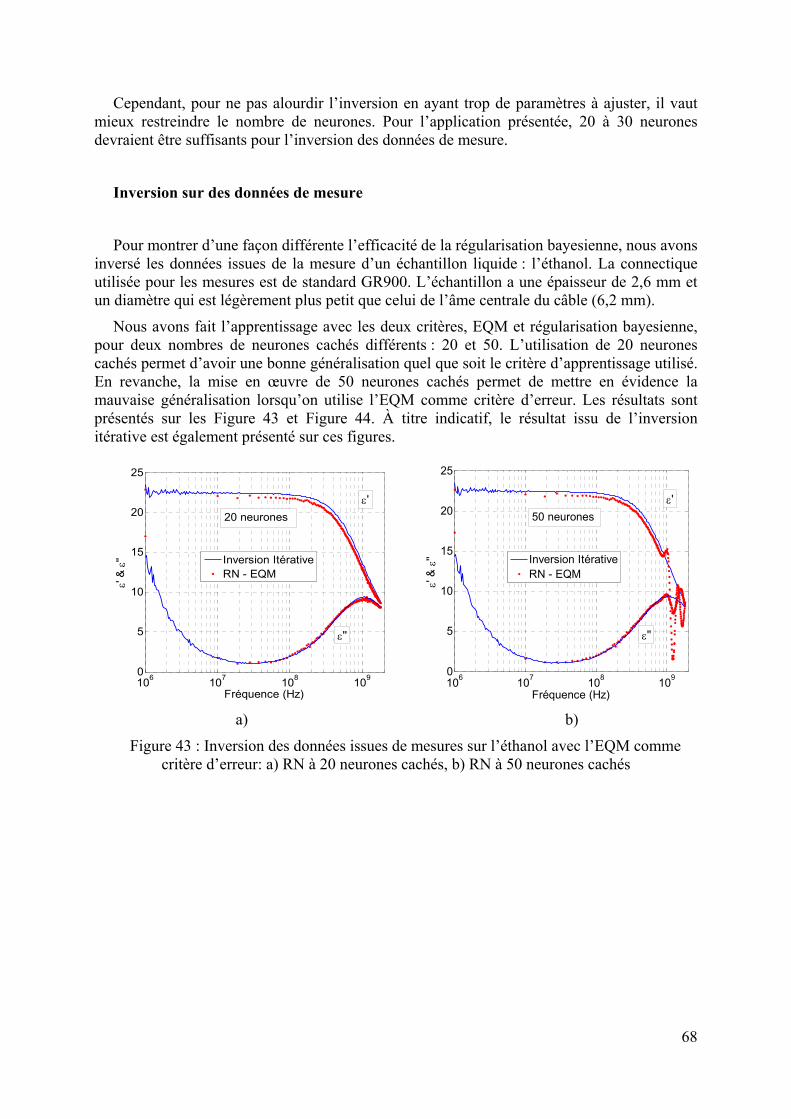
68
Cependant, pour ne pas alourdir l’inversion en ayant trop de paramètres à ajuster, il vaut mieux restreindre le nombre de neurones. Pour l’application présentée, 20 à 30 neurones devraient être suffisants pour l’inversion des données de mesure.
Inversion sur des données de mesure
Pour montrer d’une façon différente l’efficacité de la régularisation bayesienne, nous avons
inversé les données issues de la mesure d’un échantillon liquide : l’éthanol. La connectique utilisée pour les mesures est de standard GR900. L’échantillon a une épaisseur de 2,6 mm et un diamètre qui est légèrement plus petit que celui de l’âme centrale du câble (6,2 mm).
Nous avons fait l’apprentissage avec les deux critères, EQM et régularisation bayesienne, pour deux nombres de neurones cachés différents : 20 et 50. L’utilisation de 20 neurones cachés permet d’avoir une bonne généralisation quel que soit le critère d’apprentissage utilisé. En revanche, la mise en œuvre de 50 neurones cachés permet de mettre en évidence la mauvaise généralisation lorsqu’on utilise l’EQM comme critère d’erreur. Les résultats sont présentés sur les Figure 43 et Figure 44. À titre indicatif, le résultat issu de l’inversion itérative est également présenté sur ces figures.
106 107 108 1090
5
10
15
20
25
Fréquence (Hz)
ε' &
ε''
Inversion ItérativeRN - EQM
ε'
ε''
20 neurones
106 107 108 1090
5
10
15
20
25
ε' &
ε''
Fréquence (Hz)
Inversion ItérativeRN - EQM
ε'
ε''
50 neurones
a) b)
Figure 43 : Inversion des données issues de mesures sur l’éthanol avec l’EQM comme critère d’erreur: a) RN à 20 neurones cachés, b) RN à 50 neurones cachés
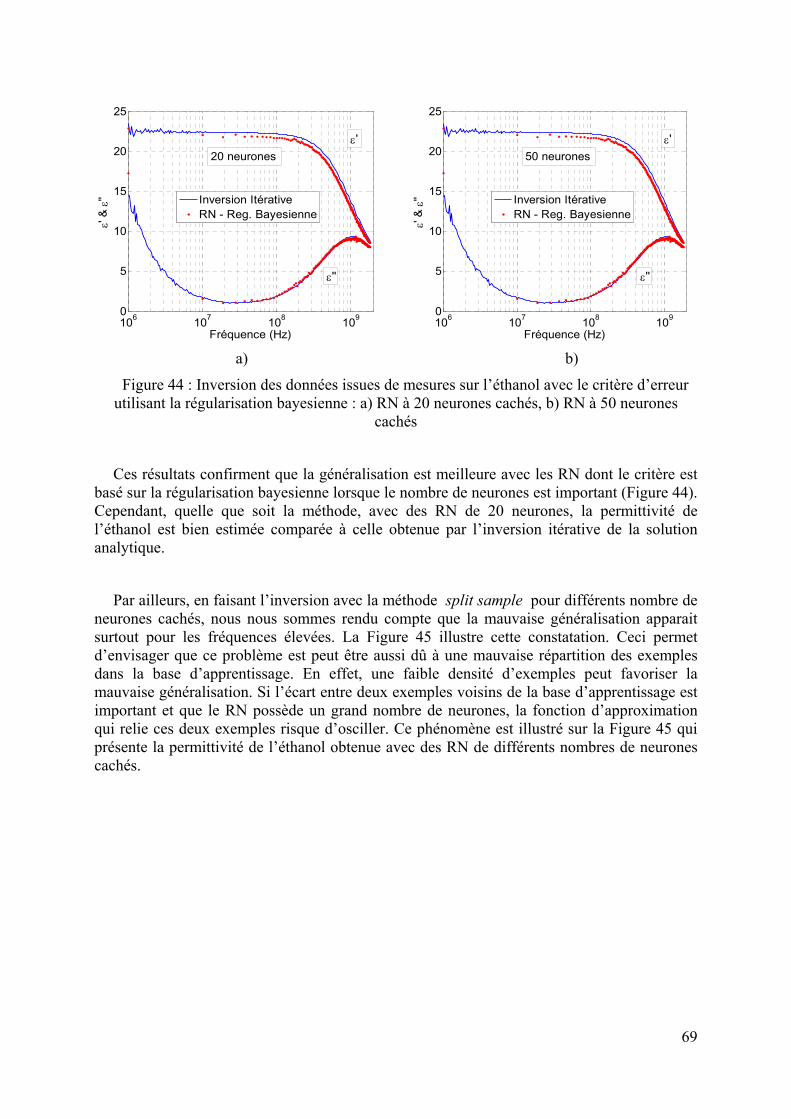
69
106 107 108 1090
5
10
15
20
25ε'
& ε
''
Fréquence (Hz)
Inversion ItérativeRN - Reg. Bayesienne
ε'
ε''
20 neurones
106 107 108 1090
5
10
15
20
25
ε' &
ε''
Fréquence (Hz)
Inversion ItérativeRN - Reg. Bayesienne
ε'
ε''
50 neurones
a) b)
Figure 44 : Inversion des données issues de mesures sur l’éthanol avec le critère d’erreur utilisant la régularisation bayesienne : a) RN à 20 neurones cachés, b) RN à 50 neurones
cachés
Ces résultats confirment que la généralisation est meilleure avec les RN dont le critère est basé sur la régularisation bayesienne lorsque le nombre de neurones est important (Figure 44). Cependant, quelle que soit la méthode, avec des RN de 20 neurones, la permittivité de l’éthanol est bien estimée comparée à celle obtenue par l’inversion itérative de la solution analytique.
Par ailleurs, en faisant l’inversion avec la méthode split sample pour différents nombre de neurones cachés, nous nous sommes rendu compte que la mauvaise généralisation apparait surtout pour les fréquences élevées. La Figure 45 illustre cette constatation. Ceci permet d’envisager que ce problème est peut être aussi dû à une mauvaise répartition des exemples dans la base d’apprentissage. En effet, une faible densité d’exemples peut favoriser la mauvaise généralisation. Si l’écart entre deux exemples voisins de la base d’apprentissage est important et que le RN possède un grand nombre de neurones, la fonction d’approximation qui relie ces deux exemples risque d’osciller. Ce phénomène est illustré sur la Figure 45 qui présente la permittivité de l’éthanol obtenue avec des RN de différents nombres de neurones cachés.
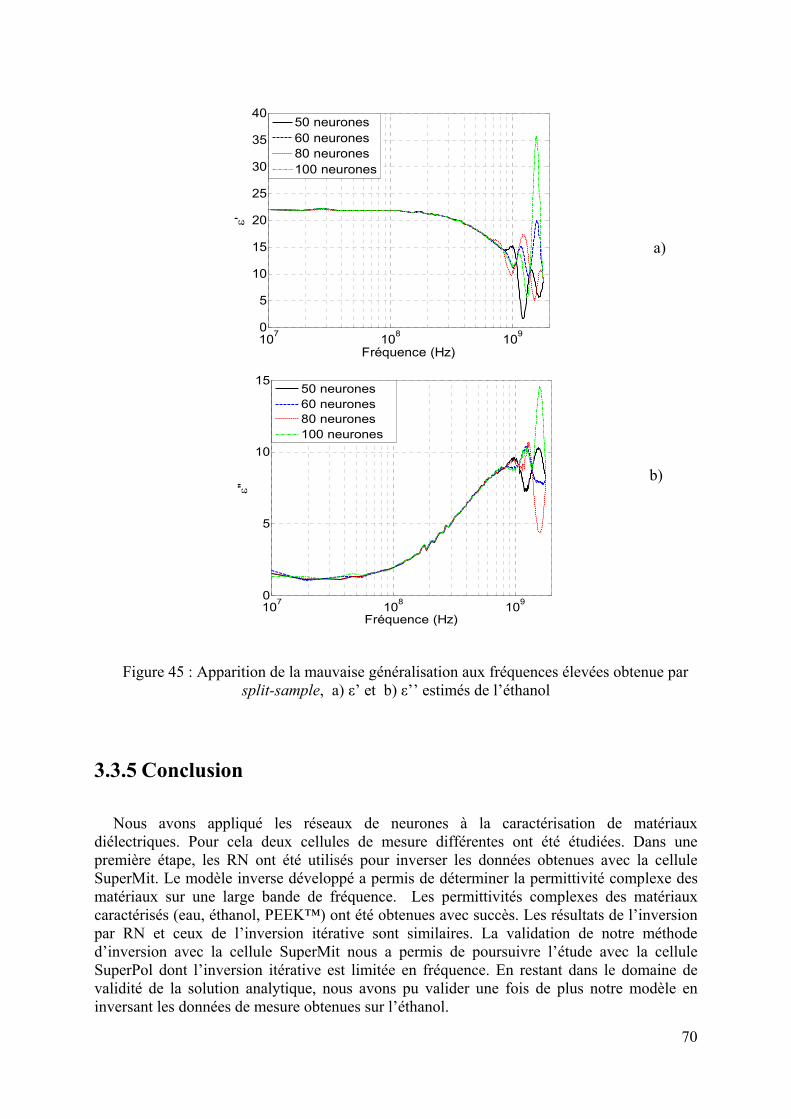
70
107 108 1090
5
10
15
20
25
30
35
40
Fréquence (Hz)
ε'
50 neurones60 neurones80 neurones100 neurones
107 108 1090
5
10
15
Fréquence (Hz)
ε''
50 neurones60 neurones80 neurones100 neurones
Figure 45 : Apparition de la mauvaise généralisation aux fréquences élevées obtenue par split-sample, a) ε’ et b) ε’’ estimés de l’éthanol
3.3.5 Conclusion
Nous avons appliqué les réseaux de neurones à la caractérisation de matériaux diélectriques. Pour cela deux cellules de mesure différentes ont été étudiées. Dans une première étape, les RN ont été utilisés pour inverser les données obtenues avec la cellule SuperMit. Le modèle inverse développé a permis de déterminer la permittivité complexe des matériaux sur une large bande de fréquence. Les permittivités complexes des matériaux caractérisés (eau, éthanol, PEEK™) ont été obtenues avec succès. Les résultats de l’inversion par RN et ceux de l’inversion itérative sont similaires. La validation de notre méthode d’inversion avec la cellule SuperMit nous a permis de poursuivre l’étude avec la cellule SuperPol dont l’inversion itérative est limitée en fréquence. En restant dans le domaine de validité de la solution analytique, nous avons pu valider une fois de plus notre modèle en inversant les données de mesure obtenues sur l’éthanol.
a)
b)

71
Lors d’une deuxième étape, nous avons validé sur des données de test simulées et de mesure la méthode de régularisation bayesienne permettant de contrecarrer le problème de sur-ajustement dû à une sur-paramétrisation. La régularisation bayesienne permet de diminuer considérablement le temps d’inversion. Lors de la détermination de la permittivité de l’éthanol en utilisant la méthode split sample, nous avons constaté que la mauvaise généralisation apparaît surtout aux fréquences élevées quel que soit le nombre élevé de neurones cachés. Nous pensons que pour minimiser ce phénomène, il serait intéressant d’optimiser la base d’apprentissage en choisissant des exemples convenables.
Dans l’avenir, la méthode d’inversion développée sera appliquée à la caractérisation hautes fréquences de matériaux biologiques dans un domaine où la solution analytique n’est plus valable.

72

73
4 Application des réseaux de neurones à la détermination des fractions d’un fluide
pétrolier
Dans ce chapitre, nous appliquons l’inversion par RN à l’extraction des proportions des constituants d’un fluide pétrolier. Ce travail s’intègre dans le cadre de la réalisation d’un capteur MO destiné à être utilisé dans le domaine pétrolier pour la détection des différentes phases existantes dans un pipeline. L’étude de la faisabilité du capteur a été faite par E. Bondet de la Bernardie dans le cadre de sa thèse [Bon 06]. Actuellement, le travail est poursuivi par B. Jannier qui étudie l’application de celui-ci sur site réel. L’objectif de mon travail est d’apporter une réponse au besoin d’inversion des données issues de la mesure par le capteur.
Nous détaillerons dans les sections suivantes le fonctionnement du capteur proposé ainsi que la méthode employée par E. Bondet de la Bernardie pour résoudre le problème inverse. On s’intéressera ensuite à l’inversion des données de mesure par les RN.
4.1 Contexte de l’étude
Dans la plupart des cas, l’exploitation d’un puits de pétrole conduit à l’extraction de fluides composés d’un mélange d’eau et d’huile brute sous forme d’émulsion et de gaz (Figure 46). Ces trois phases remontent à la surface sous forme d’un mélange triphasique qu’il faut décanter. Pour optimiser le processus d’extraction, la mise en place d’une instrumentation évaluant les quantités de ces produits est indispensable. Parmi les différentes techniques déjà existantes sur site, les techniques MO sont parmi les moins contraignantes en termes d’environnement puisque ce sont des méthodes entièrement électromagnétiques qui ne font intervenir aucune source radioactive [Tho 97]. De plus, la méthode employée est non-invasive, c’est-à-dire que les différentes phases sont quantifiées sans faire de prélèvement d’échantillons, ce qui serait une forte contrainte lors de l’extraction.
Une société de services pétroliers qui cherche à développer son expertise dans ce domaine a confié en 2002 le projet de développer une méthode de caractérisation MO à l’équipe MDMI du LGEP. Depuis, une première thèse a été soutenue en 2006 sur la faisabilité du capteur [Bon 06] et une deuxième est en cours sur sa réalisation (B. Jannier).

74
Figure 46 : Schéma de gisement
La méthode retenue est fondée sur la mesure diélectrique utilisant les MO qui est susceptible d’inspecter l’intérieur du pipeline.
Le fluide dans le pipeline peut se trouver sous différentes formes. Le régime d’écoulement dépend fortement des conditions dynamiques ainsi que de la proportion des différents constituants du fluide, l’eau, l’huile et le gaz. La Figure 47 représente les différents régimes d’écoulement possibles. A gauche, l’écoulement où seulement le gaz existe, est représenté. Alors qu’à droite de la figure, est présenté un autre type d’écoulement où seul le mélange de liquide subsiste, la phase gazeuse étant négligeable. Ce dernier type d’écoulement est appelé « écoulement homogène » Entre ces deux régimes limites, on parle d’écoulement triphasique où le mélange de liquides et le gaz coexistent.
Figure 47 : Différents régimes d’écoulement dans le pipeline
Dans ce travail de thèse, nous nous sommes intéressés uniquement à l’écoulement annulaire. Ce type d’écoulement se produit lorsque le débit de gaz est élevé : le liquide s’écoule en émulsion formant une couche liquide sur le pourtour du tuyau et le gaz remonte sous la forme d’une colonne centrée sur l’axe du conduit d’extraction.

75
Les grandeurs recherchées sont les proportions en eau (ou Water in Liquid Ratio) notée Φe et en huile notée Φh dans la phase liquide (Φe + Φh = 1) et la proportion de gaz, Gas Hold-Up (GHU), sur la section du tuyau observée. Le GHU s’exprime simplement comme le rapport de la surface de la section de la colonne de gaz SG sur la surface de la section interne du tuyau ST (Figure 48) :
SG
ST
SG
S
Mélange de liquides
(eau+huile)
Gaz
Pipeline
SG
ST
SG
S
Mélange de liquides
(eau+huile)
Gaz
Pipeline
Figure 48 : Vue en coupe du pipeline
Déterminer le GHU revient donc à estimer le rayon R de la colonne de gaz ou l’épaisseur de la couche liquide.
4.2 Principe du capteur MO
L’originalité du capteur est qu’il est constitué de deux sondes : l’une pour les basses fréquences (BF) (< 1 GHz) et l’autre adaptée pour les très hautes fréquences (HF) (20 – 40 GHz) (Figure 49) [Bon 06]. Chaque sonde est constituée d’un guide d’onde coaxial qui est monté radialement sur le pipeline. Une fenêtre diélectrique placée entre le guide et le fluide en écoulement permet d’assurer l’étanchéité. Les deux sondes ont des rôles différents. La sonde BF pour laquelle la longueur d’onde est grande par rapport à l’épaisseur de la couche de liquide atteint plus facilement la colonne de gaz. Par conséquent, elle est non seulement sensible à la nature du mélange de liquide mais aussi à la variation de la proportion de gaz. Quand à la sonde HF, du fait de la faible longueur d’onde à laquelle elle opère, elle ne peut inspecter que la proximité de la paroi du pipeline, donc uniquement le liquide en question.
Le schéma représentant le principe de mesure des deux sondes dans le cas d’un écoulement annulaire est donné à la Figure 49.
T
G
SSGHU =R

76
Sonde HF
R ?Φe
Sonde BF Sonde HF
R ?Φe
Sonde BF
R ?Φe
Sonde BF
Figure 49 : Principe de mesure sur un écoulement annulaire
4.3 Méthode d’inversion semi-analytique
E. Bondet de la Bernardie a utilisé une méthode semi-analytique pour l’obtention des paramètres recherchés à partir des admittances mesurées avec les deux sondes.
Le déroulement est le suivant :
L’analyseur de réseaux mesure l’admittance en BF et en HF, au niveau de la discontinuité entre la fenêtre et le liquide. La méthode d’inversion est ensuite différente pour chacune des sondes.
- La sonde HF permet de remonter à la composition de la phase liquide par l’intermédiaire d’un calcul numérique. Le comportement de la sonde HF est étudié avec un logiciel de simulation numérique. La fréquence de travail HF est choisie de façon que l’admittance à la discontinuité suive une loi linéaire avec la composition de la phase liquide. La connaissance de Y en fonction de Φe permet de remonter à Φe.
- Pour la résolution du problème électromagnétique en BF, une analogie entre la cellule d’étude nommée SuperTrole et une autre pour laquelle il existe une solution analytique est faite (cellule SuperCuve) [Bon 06] [Bon 08]. Un méplat est introduit dans la cellule SuperTrole dans le but de permettre cette analogie [Figure 50].
a) b)
Figure 50 : Les deux types de cellule : a) SuperCuve, b) SuperTrole
Méplat

77
Pour ce faire, E. Bondet de la Bernardie a tout d’abord comparé la distribution des champs électrique et magnétique dans les deux structures. Il en a conclu qu’il y avait une forte similitude entre les distributions du champ électrique dans les deux cellules et que les champs sont confinés au voisinage de la fenêtre, les intensités au niveau des parois étant très faibles en regard de celles au voisinage de la fenêtre. Ensuite, le domaine de validité de l’analogie a été évalué en calculant l’admittance dans les deux cas pour des remplissages homogènes. Malheureusement, cette analogie n’est faite qu’en BF puisque cette étude a montré qu’elle n’est pas valable au-delà de 900 MHz environ.
Une fois la composition du mélange trouvée par la sonde HF, celle-ci est introduite dans le calcul de la permittivité du mélange en BF pour déduire de l’admittance mesurée avec la sonde BF, le rayon de la colonne de gaz grâce au calcul analytique.
Ces deux étapes d’inversion sont récapitulées sur le schéma de la
Figure 51.
RModèle numérique
Modèle analytique
Mesure BF
Φe +Mesure HF RModèle numérique
Modèle analytique
Mesure BF
Φe +Mesure HF
Figure 51 : Schéma du processus d’inversion semi-analytique
Malheureusement, cette méthode, bien qu’elle soit efficace, se heurte à des contraintes. La première contrainte est le choix de la fréquence HF, telle que l’évolution de l’admittance avec la composition de la phase de liquide soit linéaire ou tout au moins bijective.
La deuxième contrainte est géométrique. C’est celle qui est la plus contraignante puisque, pour faire l’analogie entre les deux cellules SuperCuve et SuperTrole, un méplat a été introduit sur le pipeline. Ce changement apporté sur la forme du conduit d’extraction n’existe pas dans la réalité. Il faut donc faire les études avec une cellule de mesure sans le méplat. Par conséquent, cette méthode d’inversion semi-analytique risque de ne plus être valable.
4.4 Méthode proposée
La méthode que nous proposons est entièrement fondée sur une résolution numérique. De ce fait, nous n’avons aucune restriction ni en terme de géométrie ni en terme de fréquence de travail. Seule la limitation en fréquence due aux connectiques utilisées est à prendre en considération.
Le problème direct est résolu en utilisant le logiciel de simulation numérique qui permet de créer la base d’apprentissage. Une fois les RN créés, les données de mesures (ou de la base de

78
test) sont injectées à l’entrée du RN. Pour simplifier l’architecture du réseau (pour ne pas avoir trop de poids à ajuster), nous avons utilisé, comme pour la caractérisation de matériaux diélectriques, un RN différent pour chaque sortie recherchée. Par contre, en ce qui concerne les entrées, nous avons utilisé différentes configurations possibles qui seront présentées en détail plus loin. Ci-après est représentée la procédure d’inversion pour les deux réseaux (Figure 52).
RN1
RN2
Modèle numérique
Φe
GBF, BBF
GHF, BHF
R
GBF, BBF
GHF, BHF
Capteur
RN1
RN2
Modèle numérique
Φe
GBF, BBF
GHF, BHF
R
GBF, BBF
GHF, BHF
Capteur
Figure 52 : Schéma d’inversion par RN des données du capteur
4.4.1 Modélisation du capteur
Le capteur (sonde + pipeline sans le méplat) a été modélisé en utilisant le logiciel de simulation numérique ANSYS®. Deux sondes MO de dimensions différentes ont été utilisées pour la mesure en BF et en HF. La sonde BF est composée d’un guide d’onde coaxial de standard APC7. La fréquence de coupure donnée par l’apparition du mode TE11 dans le guide d’onde pour le standard APC7 est de 19,6 GHz. Le seul mode propagatif jusqu’à cette fréquence est le mode TEM. La limitation en fréquence ne peut être repoussée au-delà de cette fréquence de coupure qu’en diminuant les dimensions du standard utilisé. C’est pourquoi la sonde utilisée pour les mesures HF est de standard APC2.4, dont le diamètre externe est de 2,4 mm. La fréquence de coupure du mode TEM pour ce standard est 57 GHz.
Le pipeline a un diamètre de 28,7 mm qui est imposé par les contraintes industrielles. La longueur considérée pour le maillage a été fixée à une valeur telle que les extrémités du domaine maillé ne perturbent pas le calcul des champs électromagnétiques à proximité de la sonde.
En tenant compte des symétries, nous n’avons considéré que le quart du modèle. La structure du modèle (sonde + pipeline) ainsi que le maillage correspondant sont donnés à la Figure 53.

79
Figure 53 : La structure de la sonde BF + le pipeline (à gauche) et le maillage du quart de la structure (à droite)
La colonne de gaz est modélisée par de l’air. L’onde ne pénétrant que très peu dans celle-ci, son maillage est volontairement relâché, les éléments sont donc plus grands que les autres parties de la cellule. À l’inverse, pour avoir une meilleure précision de modélisation, le maillage est rendu beaucoup plus fin à proximité de la fenêtre.
Nous avons créé les bases de données à 800 MHz et 27 GHz. Ces deux fréquences ont été choisies de façon que la sensibilité du signal à la concentration et au rayon soit la plus forte. Mais ces fréquences sont susceptibles de changer en fonction de la nature et des dimensions des fenêtres. De ce fait, comme nous allons le voir dans la section 4.4.5, les fréquences de mesure utilisées par B. Jannier ne sont pas les mêmes que celles que nous avons utilisées en simulation.
Faire une simulation MO implique de connaitre la permittivité du milieu. La seule connaissance de la concentration du liquide ne permet donc pas de créer la base d’apprentissage. E. Bondet de la Bernardie a étudié différentes lois de mélange pouvant caractériser une émulsion d’eau et d’huile. Ces lois permettent de calculer la permittivité d’un mélange à partir de la concentration et de la permittivité de ses différents constituants. Il en a conclu que la loi de Bruggeman-Hanaï (4.1) est la mieux adaptée quelle que soit la nature et les proportions de l’émulsion [Bon 06]. Celle-ci s’écrit :
dm
c
cd
md φεε
εεεε
−=⎟⎟⎠
⎞⎜⎜⎝
⎛−−
13/1
(4.1)
Colonne de gaz
Phase liquide
Paroi du pipeline
Guide d’onde
Fenêtre étanche
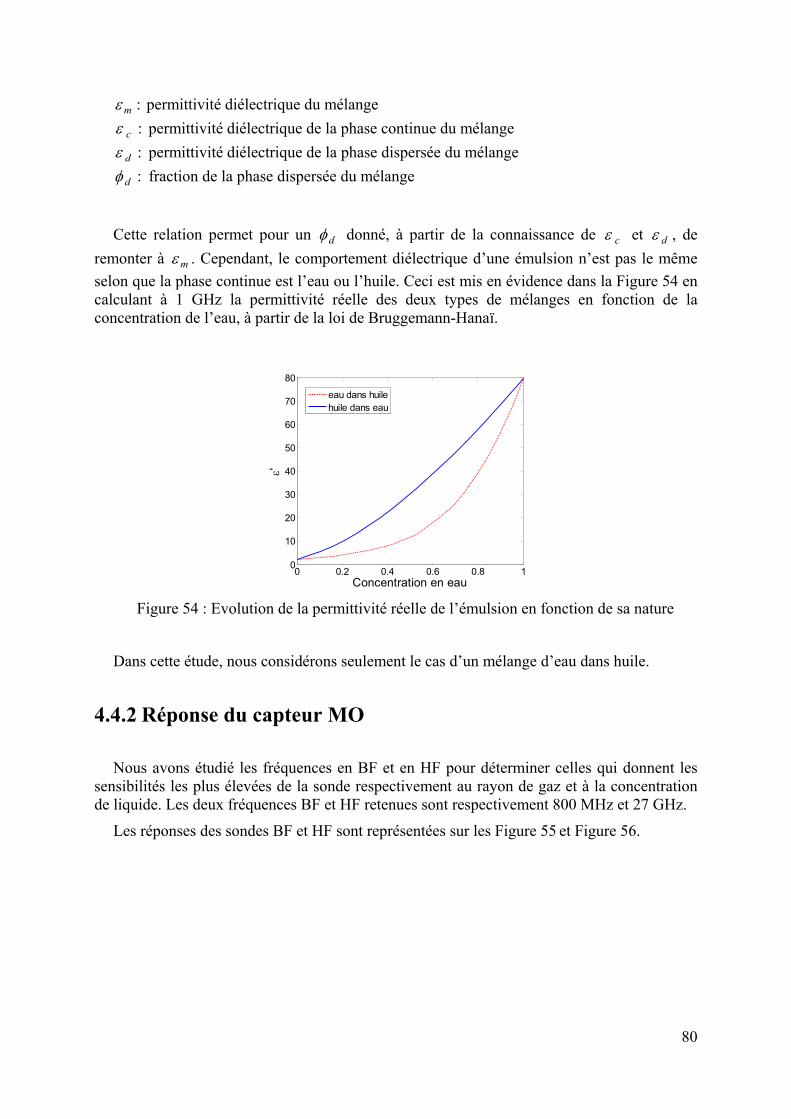
80
:mε permittivité diélectrique du mélange :cε permittivité diélectrique de la phase continue du mélange :dε permittivité diélectrique de la phase dispersée du mélange :dφ fraction de la phase dispersée du mélange
Cette relation permet pour un dφ donné, à partir de la connaissance de cε et dε , de remonter à mε . Cependant, le comportement diélectrique d’une émulsion n’est pas le même selon que la phase continue est l’eau ou l’huile. Ceci est mis en évidence dans la Figure 54 en calculant à 1 GHz la permittivité réelle des deux types de mélanges en fonction de la concentration de l’eau, à partir de la loi de Bruggemann-Hanaï.
0 0.2 0.4 0.6 0.8 10
10
20
30
40
50
60
70
80
Concentration en eau
ε'
eau dans huilehuile dans eau
Figure 54 : Evolution de la permittivité réelle de l’émulsion en fonction de sa nature
Dans cette étude, nous considérons seulement le cas d’un mélange d’eau dans huile.
4.4.2 Réponse du capteur MO
Nous avons étudié les fréquences en BF et en HF pour déterminer celles qui donnent les sensibilités les plus élevées de la sonde respectivement au rayon de gaz et à la concentration de liquide. Les deux fréquences BF et HF retenues sont respectivement 800 MHz et 27 GHz.
Les réponses des sondes BF et HF sont représentées sur les Figure 55 et Figure 56.
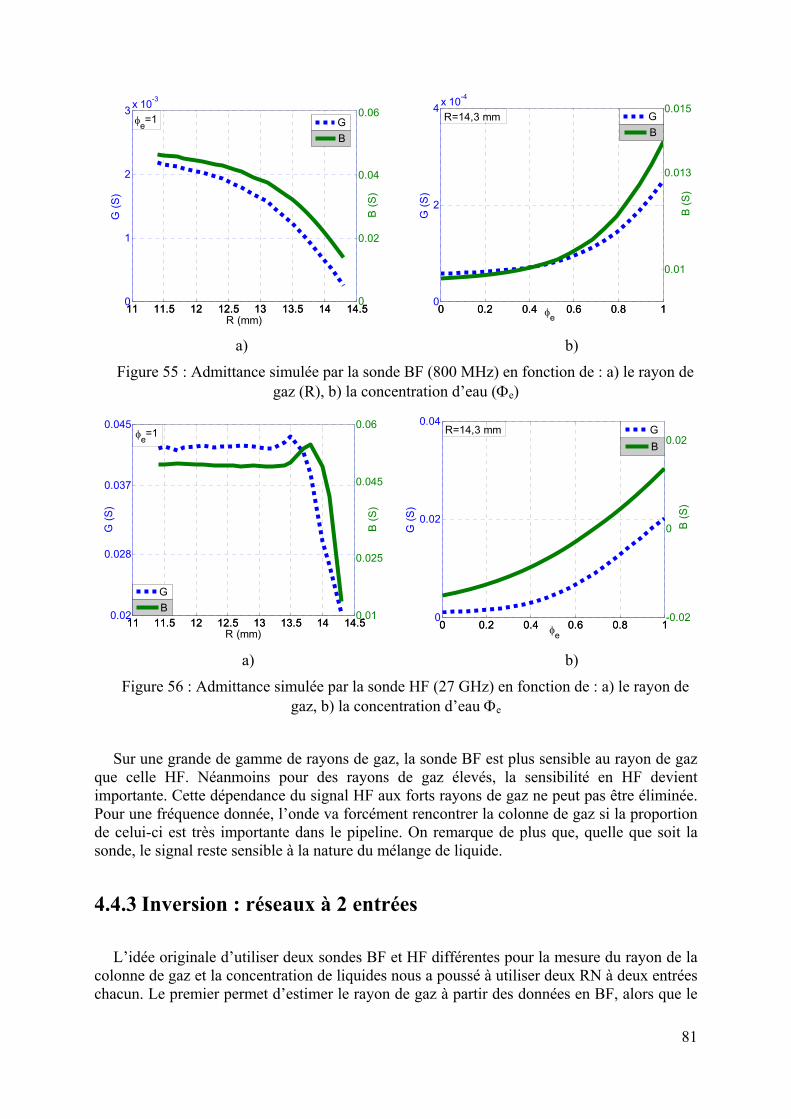
81
11 11.5 12 12.5 13 13.5 14 14.50
1
2
3 x 10-3
G (S
)
R (mm)
11 11.5 12 12.5 13 13.5 14 14.50
0.02
0.04
0.06
B (S
)
BGφe=1
0 0.2 0.4 0.6 0.8 1
0
2
4 x 10-4
G (S
)
0 0.2 0.4 0.6 0.8 1
0.01
0.013
0.015
B (S
)
φe
BGR=14,3 mm
a) b)
Figure 55 : Admittance simulée par la sonde BF (800 MHz) en fonction de : a) le rayon de gaz (R), b) la concentration d’eau (Φe)
11 11.5 12 12.5 13 13.5 14 14.50.02
0.028
0.037
0.045
G (S
)
R (mm)
11 11.5 12 12.5 13 13.5 14 14.50.01
0.025
0.045
0.06
B (S
)
GB
φe=1
0 0.2 0.4 0.6 0.8 1
0
0.02
0.04G
(S)
φe
0 0.2 0.4 0.6 0.8 1-0.02
0
0.02
B (S
)
GB
R=14,3 mm
a) b)
Figure 56 : Admittance simulée par la sonde HF (27 GHz) en fonction de : a) le rayon de gaz, b) la concentration d’eau Φe
Sur une grande de gamme de rayons de gaz, la sonde BF est plus sensible au rayon de gaz que celle HF. Néanmoins pour des rayons de gaz élevés, la sensibilité en HF devient importante. Cette dépendance du signal HF aux forts rayons de gaz ne peut pas être éliminée. Pour une fréquence donnée, l’onde va forcément rencontrer la colonne de gaz si la proportion de celui-ci est très importante dans le pipeline. On remarque de plus que, quelle que soit la sonde, le signal reste sensible à la nature du mélange de liquide.
4.4.3 Inversion : réseaux à 2 entrées
L’idée originale d’utiliser deux sondes BF et HF différentes pour la mesure du rayon de la colonne de gaz et la concentration de liquides nous a poussé à utiliser deux RN à deux entrées chacun. Le premier permet d’estimer le rayon de gaz à partir des données en BF, alors que le
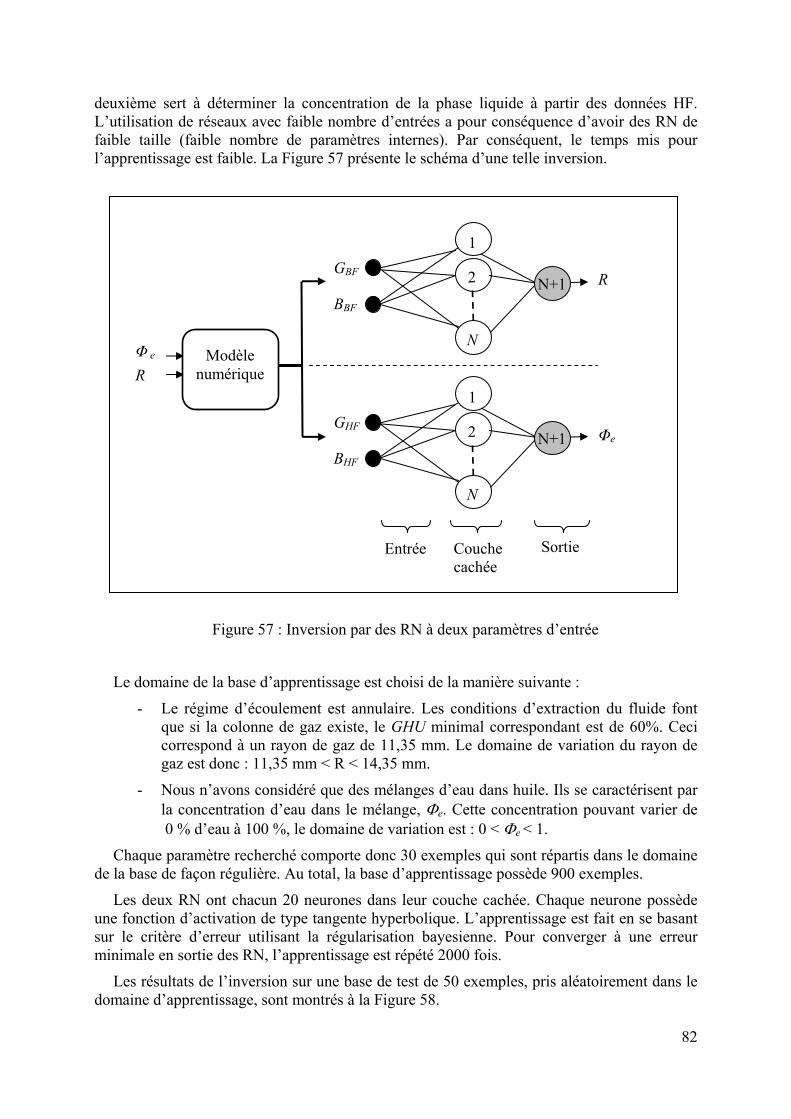
82
deuxième sert à déterminer la concentration de la phase liquide à partir des données HF. L’utilisation de réseaux avec faible nombre d’entrées a pour conséquence d’avoir des RN de faible taille (faible nombre de paramètres internes). Par conséquent, le temps mis pour l’apprentissage est faible. La Figure 57 présente le schéma d’une telle inversion.
Figure 57 : Inversion par des RN à deux paramètres d’entrée
Le domaine de la base d’apprentissage est choisi de la manière suivante :
- Le régime d’écoulement est annulaire. Les conditions d’extraction du fluide font que si la colonne de gaz existe, le GHU minimal correspondant est de 60%. Ceci correspond à un rayon de gaz de 11,35 mm. Le domaine de variation du rayon de gaz est donc : 11,35 mm < R < 14,35 mm.
- Nous n’avons considéré que des mélanges d’eau dans huile. Ils se caractérisent par la concentration d’eau dans le mélange, Φe. Cette concentration pouvant varier de 0 % d’eau à 100 %, le domaine de variation est : 0 < Φe < 1.
Chaque paramètre recherché comporte donc 30 exemples qui sont répartis dans le domaine de la base de façon régulière. Au total, la base d’apprentissage possède 900 exemples.
Les deux RN ont chacun 20 neurones dans leur couche cachée. Chaque neurone possède une fonction d’activation de type tangente hyperbolique. L’apprentissage est fait en se basant sur le critère d’erreur utilisant la régularisation bayesienne. Pour converger à une erreur minimale en sortie des RN, l’apprentissage est répété 2000 fois.
Les résultats de l’inversion sur une base de test de 50 exemples, pris aléatoirement dans le domaine d’apprentissage, sont montrés à la Figure 58.
Sortie
GHF
BHF
2 N+1
1
Entrée Couche cachée
N
Modèle numérique
GBF
BBF
2 N+1
1
NΦ e
R
Φe
R
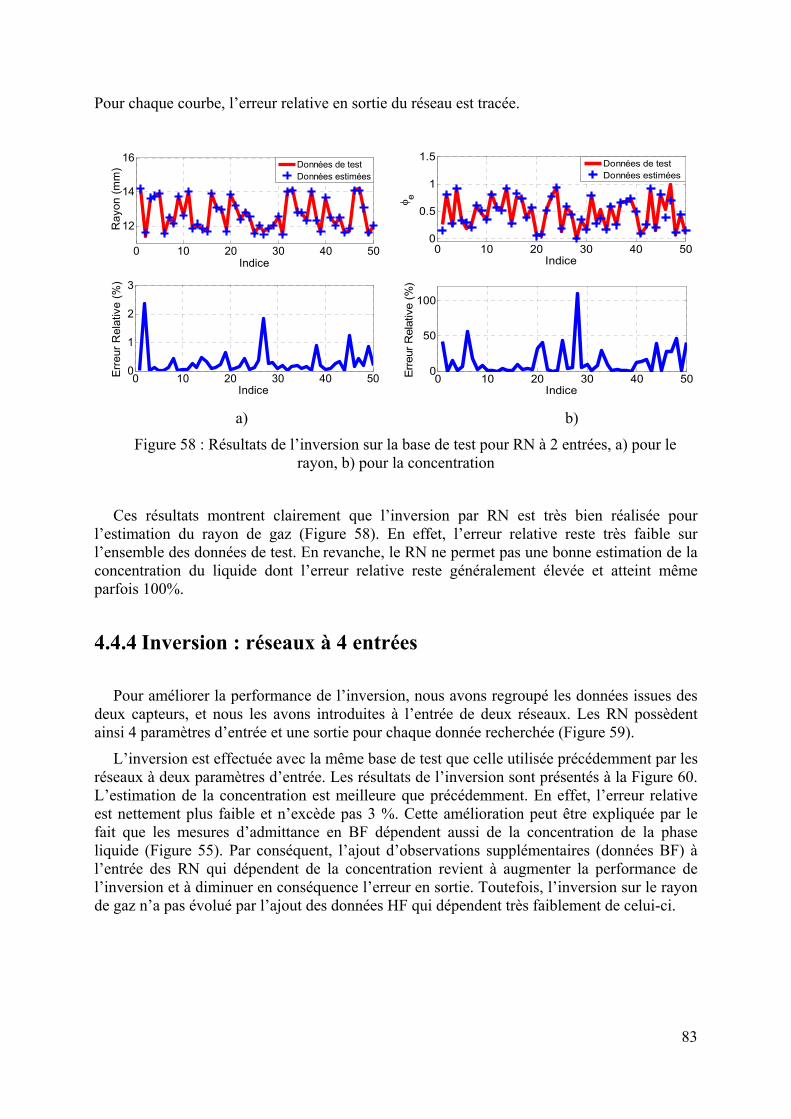
83
Pour chaque courbe, l’erreur relative en sortie du réseau est tracée.
0 10 20 30 40 50
12
14
16
Indice
Ray
on (m
m)
Données de test Données estimées
0 10 20 30 40 500
1
2
3
Indice
Err
eur R
elat
ive
(%)
0 10 20 30 40 500
0.5
1
1.5
Indice
φ e
Données de testDonnées estimées
0 10 20 30 40 500
50
100
IndiceE
rreu
r Rel
ativ
e (%
)
a) b)
Figure 58 : Résultats de l’inversion sur la base de test pour RN à 2 entrées, a) pour le rayon, b) pour la concentration
Ces résultats montrent clairement que l’inversion par RN est très bien réalisée pour l’estimation du rayon de gaz (Figure 58). En effet, l’erreur relative reste très faible sur l’ensemble des données de test. En revanche, le RN ne permet pas une bonne estimation de la concentration du liquide dont l’erreur relative reste généralement élevée et atteint même parfois 100%.
4.4.4 Inversion : réseaux à 4 entrées
Pour améliorer la performance de l’inversion, nous avons regroupé les données issues des deux capteurs, et nous les avons introduites à l’entrée de deux réseaux. Les RN possèdent ainsi 4 paramètres d’entrée et une sortie pour chaque donnée recherchée (Figure 59).
L’inversion est effectuée avec la même base de test que celle utilisée précédemment par les réseaux à deux paramètres d’entrée. Les résultats de l’inversion sont présentés à la Figure 60. L’estimation de la concentration est meilleure que précédemment. En effet, l’erreur relative est nettement plus faible et n’excède pas 3 %. Cette amélioration peut être expliquée par le fait que les mesures d’admittance en BF dépendent aussi de la concentration de la phase liquide (Figure 55). Par conséquent, l’ajout d’observations supplémentaires (données BF) à l’entrée des RN qui dépendent de la concentration revient à augmenter la performance de l’inversion et à diminuer en conséquence l’erreur en sortie. Toutefois, l’inversion sur le rayon de gaz n’a pas évolué par l’ajout des données HF qui dépendent très faiblement de celui-ci.
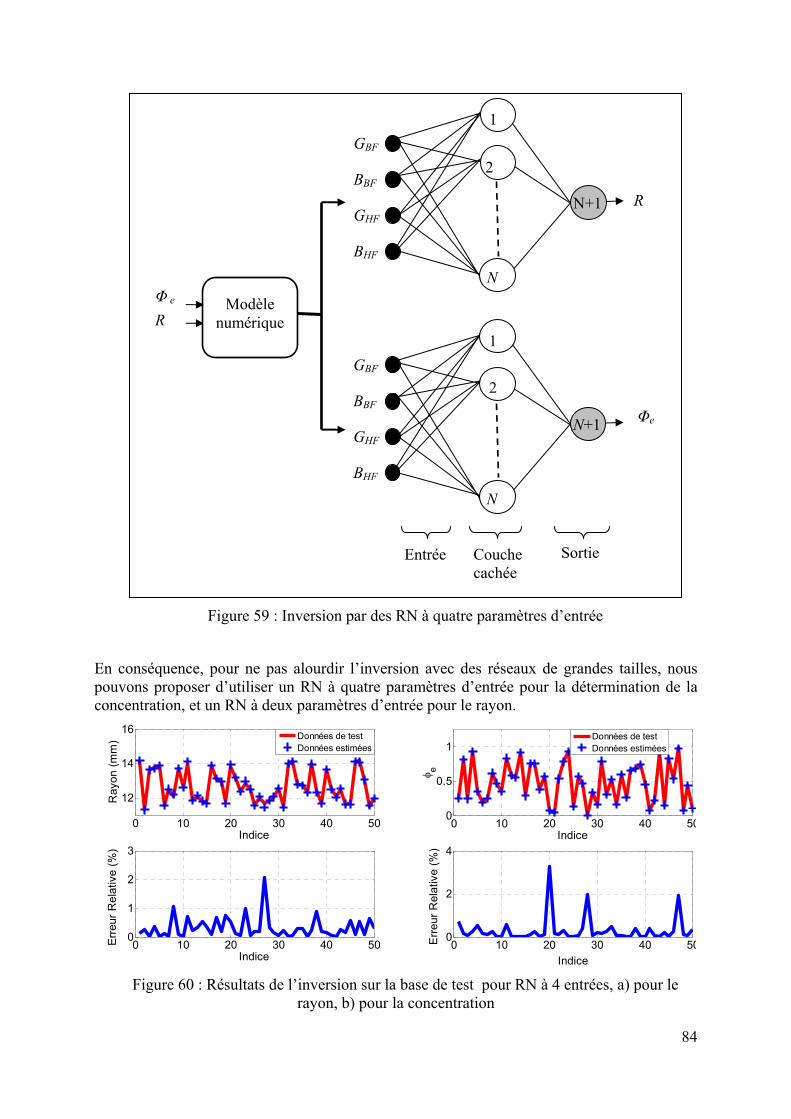
84
Figure 59 : Inversion par des RN à quatre paramètres d’entrée
En conséquence, pour ne pas alourdir l’inversion avec des réseaux de grandes tailles, nous pouvons proposer d’utiliser un RN à quatre paramètres d’entrée pour la détermination de la concentration, et un RN à deux paramètres d’entrée pour le rayon.
0 10 20 30 40 50
12
14
16
Indice
Ray
on (m
m)
Données de testDonnées estimées
0 10 20 30 40 500
1
2
3
Indice
Erre
ur R
elat
ive
(%)
0 10 20 30 40 500
0.5
1
Indice
φ e
Données de testDonnées estimées
0 10 20 30 40 500
2
4
Indice
Err
eur R
elat
ive
(%)
Figure 60 : Résultats de l’inversion sur la base de test pour RN à 4 entrées, a) pour le
rayon, b) pour la concentration
Sortie
GHF
BHF
2
N+1
Entrée Couche cachée
N
Modèle numérique
GBF
BBF
Φ e
R
R
1
GHF
BHF
2
N+1
N
GBF
BBF
1
Φe

85
4.4.5 Inversion de données de mesure
Après avoir validé l’inversion neuronale sur des données simulées, nous avons appliqué les RN sur des données expérimentales. Les mesures ont été réalisées à l’Ecole de Centrale de Lyon par B. Jannier.
Pour s’approcher des conditions réelles, les mesures ont été effectuées en régime dynamique. Le dispositif de mesure est composé d’une boucle d’écoulement diphasique d’eau et d’air. Dans cette partie, on n’inverse donc que les données issues de mesure d’eau et d’air. La concentration du liquide étant connue (Φe =1), l’objectif de l’inversion est alors de déterminer la proportion de la phase gazeuse (GHU) donc le rayon de gaz R. C’est un cas assez simpliste qui ne justifie pas le passage par les RN comme méthode d’inversion. Cependant, ce sont les seules données de mesures qui sont à notre disposition. En attendant d’avoir des données de mesures qui s’approchent plus des conditions réelles d’extraction, l’inversion de ces données constitue une première application des RN dans ce domaine.
Les sondes MO sont intégrées dans la boucle, face à face, au niveau d’un venturi (rétrécissement de la boucle) où sont reproduits les différents régimes d’écoulement pouvant avoir lieu dans un pipeline. Perpendiculairement aux sondes MO, un dispositif de mesure par absorption γ est inséré pour faire des mesures de référence. L’admittance est mesurée à l’aide d’un analyseur de réseaux très large bande Agilent E8364B (10 MHz – 50 GHz). La photo de la Figure 61 montre ces différents dispositifs expérimentaux.
Figure 61 : Banc de mesure en écoulement (École Centrale de Lyon)
Les mesures ont été effectuées respectivement à 600 MHz et à 34,5 GHz pour la sonde BF et celle HF. Pour éliminer la dispersion des points de mesure due aux fluctuations des conditions d’écoulement, un moyennage sur les mesures a été effectué. Les résultats de la Figure 62 représentent l’admittance moyennée mesurée par les sondes BF et HF en fonction du GHU mesuré par le capteur γ.
Analyseur de réseaux Venturi
Capteur γ
Sonde MO
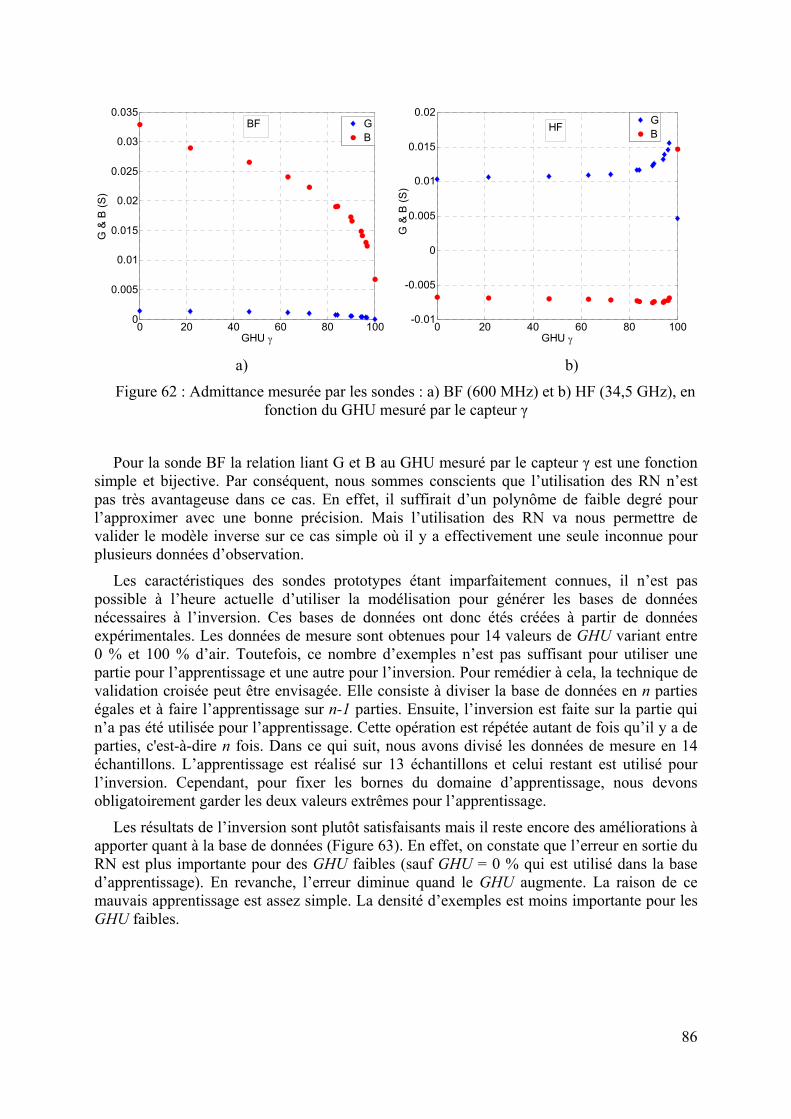
86
0 20 40 60 80 1000
0.005
0.01
0.015
0.02
0.025
0.03
0.035
GHU γ
G &
B (S
)
GB
BF
0 20 40 60 80 100
-0.01
-0.005
0
0.005
0.01
0.015
0.02
GHU γ
G &
B (S
)
GBHF
a) b)
Figure 62 : Admittance mesurée par les sondes : a) BF (600 MHz) et b) HF (34,5 GHz), en fonction du GHU mesuré par le capteur γ
Pour la sonde BF la relation liant G et B au GHU mesuré par le capteur γ est une fonction simple et bijective. Par conséquent, nous sommes conscients que l’utilisation des RN n’est pas très avantageuse dans ce cas. En effet, il suffirait d’un polynôme de faible degré pour l’approximer avec une bonne précision. Mais l’utilisation des RN va nous permettre de valider le modèle inverse sur ce cas simple où il y a effectivement une seule inconnue pour plusieurs données d’observation.
Les caractéristiques des sondes prototypes étant imparfaitement connues, il n’est pas possible à l’heure actuelle d’utiliser la modélisation pour générer les bases de données nécessaires à l’inversion. Ces bases de données ont donc étés créées à partir de données expérimentales. Les données de mesure sont obtenues pour 14 valeurs de GHU variant entre 0 % et 100 % d’air. Toutefois, ce nombre d’exemples n’est pas suffisant pour utiliser une partie pour l’apprentissage et une autre pour l’inversion. Pour remédier à cela, la technique de validation croisée peut être envisagée. Elle consiste à diviser la base de données en n parties égales et à faire l’apprentissage sur n-1 parties. Ensuite, l’inversion est faite sur la partie qui n’a pas été utilisée pour l’apprentissage. Cette opération est répétée autant de fois qu’il y a de parties, c'est-à-dire n fois. Dans ce qui suit, nous avons divisé les données de mesure en 14 échantillons. L’apprentissage est réalisé sur 13 échantillons et celui restant est utilisé pour l’inversion. Cependant, pour fixer les bornes du domaine d’apprentissage, nous devons obligatoirement garder les deux valeurs extrêmes pour l’apprentissage.
Les résultats de l’inversion sont plutôt satisfaisants mais il reste encore des améliorations à apporter quant à la base de données (Figure 63). En effet, on constate que l’erreur en sortie du RN est plus importante pour des GHU faibles (sauf GHU = 0 % qui est utilisé dans la base d’apprentissage). En revanche, l’erreur diminue quand le GHU augmente. La raison de ce mauvais apprentissage est assez simple. La densité d’exemples est moins importante pour les GHU faibles.
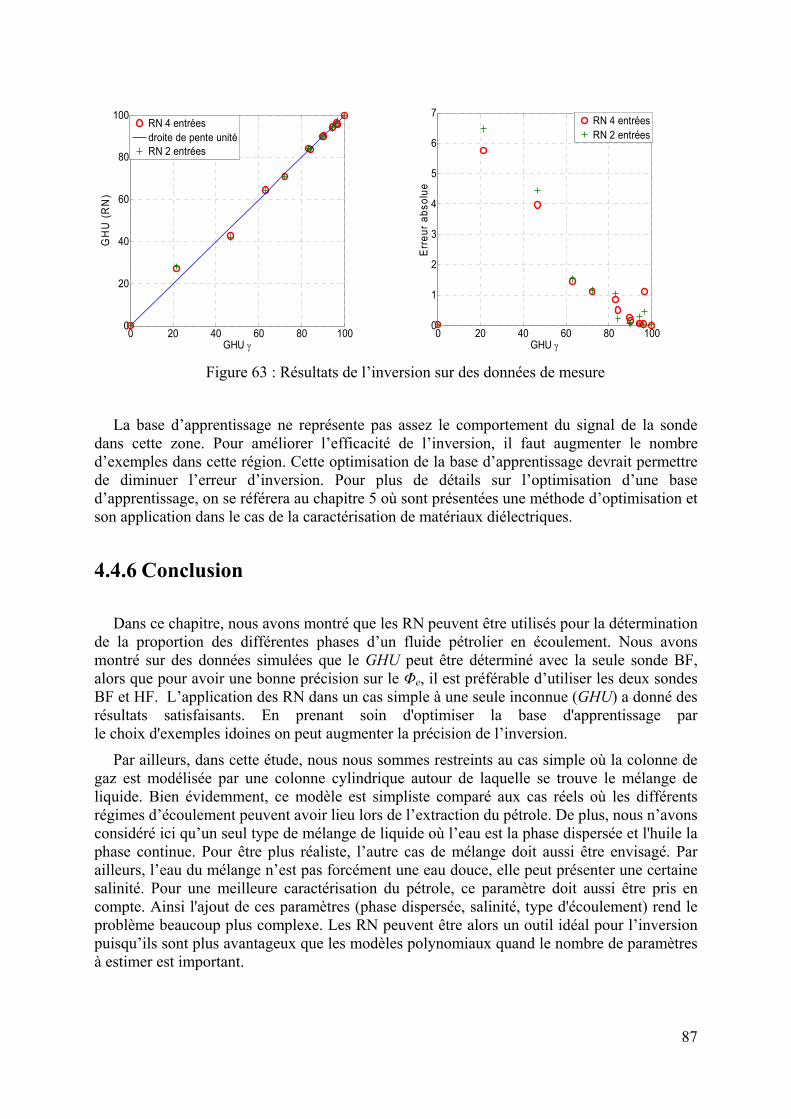
87
0 20 40 60 80 1000
20
40
60
80
100
GHU γ
GH
U (R
N)
RN 4 entréesdroite de pente unitéRN 2 entrées
0 20 40 60 80 100
0
1
2
3
4
5
6
7
GHU γ
Erre
ur a
bsol
ue
RN 4 entréesRN 2 entrées
Figure 63 : Résultats de l’inversion sur des données de mesure
La base d’apprentissage ne représente pas assez le comportement du signal de la sonde dans cette zone. Pour améliorer l’efficacité de l’inversion, il faut augmenter le nombre d’exemples dans cette région. Cette optimisation de la base d’apprentissage devrait permettre de diminuer l’erreur d’inversion. Pour plus de détails sur l’optimisation d’une base d’apprentissage, on se référera au chapitre 5 où sont présentées une méthode d’optimisation et son application dans le cas de la caractérisation de matériaux diélectriques.
4.4.6 Conclusion
Dans ce chapitre, nous avons montré que les RN peuvent être utilisés pour la détermination de la proportion des différentes phases d’un fluide pétrolier en écoulement. Nous avons montré sur des données simulées que le GHU peut être déterminé avec la seule sonde BF, alors que pour avoir une bonne précision sur le Φe, il est préférable d’utiliser les deux sondes BF et HF. L’application des RN dans un cas simple à une seule inconnue (GHU) a donné des résultats satisfaisants. En prenant soin d'optimiser la base d'apprentissage par le choix d'exemples idoines on peut augmenter la précision de l’inversion.
Par ailleurs, dans cette étude, nous nous sommes restreints au cas simple où la colonne de gaz est modélisée par une colonne cylindrique autour de laquelle se trouve le mélange de liquide. Bien évidemment, ce modèle est simpliste comparé aux cas réels où les différents régimes d’écoulement peuvent avoir lieu lors de l’extraction du pétrole. De plus, nous n’avons considéré ici qu’un seul type de mélange de liquide où l’eau est la phase dispersée et l'huile la phase continue. Pour être plus réaliste, l’autre cas de mélange doit aussi être envisagé. Par ailleurs, l’eau du mélange n’est pas forcément une eau douce, elle peut présenter une certaine salinité. Pour une meilleure caractérisation du pétrole, ce paramètre doit aussi être pris en compte. Ainsi l'ajout de ces paramètres (phase dispersée, salinité, type d'écoulement) rend le problème beaucoup plus complexe. Les RN peuvent être alors un outil idéal pour l’inversion puisqu’ils sont plus avantageux que les modèles polynomiaux quand le nombre de paramètres à estimer est important.

88

89
5 Optimisation de la base d’apprentissage
5.1 Introduction
L’utilisateur de RN se trouve confronté à deux principaux problèmes auxquels il doit faire face. Le premier, c’est le choix du nombre de neurones lors de la création du réseau. En utilisant la régularisation bayésienne, on peut diminuer la criticité du nombre de neurones tout en ayant une bonne généralisation. Le deuxième problème est le choix des exemples de la base d’apprentissage. En effet, la qualité de l’inversion dépend fortement du choix des exemples. Les exemples de la base doivent rendre compte de l’évolution de la relation entre les paramètres recherchés et les données de mesure.
De fait, la réponse d’une sonde MO peut être fortement non-linéaire en fonction des paramètres constitutifs des matériaux, de la géométrie du système et de la fréquence de mesure. Cette non-linéarité est d’autant plus importante que l’on monte en fréquence. Lorsqu’on crée une base de données pour l’apprentissage d’un RN, on doit donc prendre en compte cet effet non-linéaire pour qu’il y ait assez de points (exemples) représentatifs du comportement de la sonde.
Dans la suite, nous présentons deux types de base de données ainsi que la comparaison de leurs performances. Le premier qui est souvent employé est obtenu à partir d’exemples distribués de façon uniforme dans l’espace des paramètres recherchés. Nous appellerons ce type de base « base régulière ». Le deuxième type de base que nous proposons est basé sur l’exploration systématique de l’espace des paramètres recherchés permettant d’avoir cette fois une discrétisation uniforme de l’espace des observations. On l’appellera désormais « base adaptative ». Ce travail, a été mené en collaboration avec MM. J. Pávó et S. Gyimóthy de Budapest University of Technology and Economics, dans le cadre d’un Projet d’Action Intégrée franco-hongrois Balaton.
5.2 Base régulière
La première idée qu’on peut avoir lorsque l’on collecte des données pour la base d’apprentissage est de répartir les données de façon régulière dans l’espace des paramètres recherchés, c'est-à-dire avoir la même densité de points quelle que soit la zone de l’espace dans lequel on se trouve. Le comportement de la réponse de la sonde n’intervient pas dans le choix des exemples de cette base.
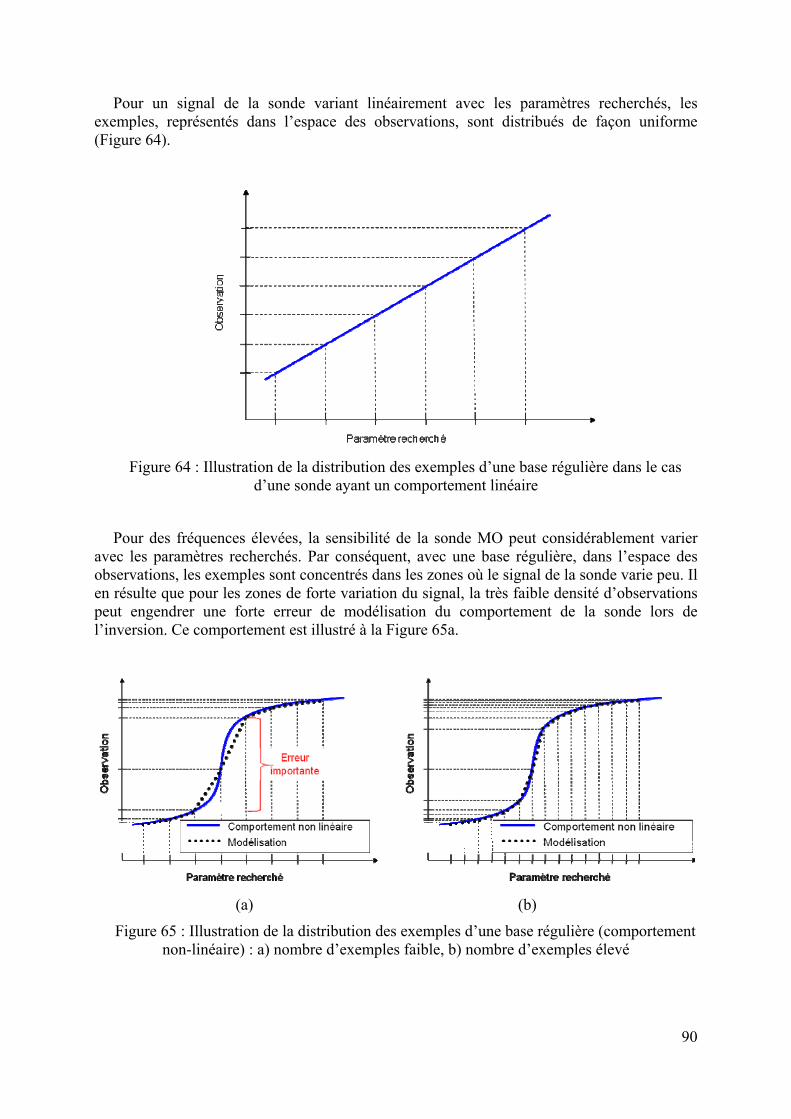
90
Pour un signal de la sonde variant linéairement avec les paramètres recherchés, les exemples, représentés dans l’espace des observations, sont distribués de façon uniforme (Figure 64).
Figure 64 : Illustration de la distribution des exemples d’une base régulière dans le cas
d’une sonde ayant un comportement linéaire
Pour des fréquences élevées, la sensibilité de la sonde MO peut considérablement varier avec les paramètres recherchés. Par conséquent, avec une base régulière, dans l’espace des observations, les exemples sont concentrés dans les zones où le signal de la sonde varie peu. Il en résulte que pour les zones de forte variation du signal, la très faible densité d’observations peut engendrer une forte erreur de modélisation du comportement de la sonde lors de l’inversion. Ce comportement est illustré à la Figure 65a.
(a) (b)
Figure 65 : Illustration de la distribution des exemples d’une base régulière (comportement non-linéaire) : a) nombre d’exemples faible, b) nombre d’exemples élevé

91
Pour pallier ce problème, une première façon de faire est d’ajouter plus d’exemples dans la base (Figure 65b). En effet, ceci permet d’augmenter la densité d’exemples et donc d’avoir une meilleure modélisation de la zone de forte sensibilité avec une erreur de modélisation plus faible. Cependant, dans certains cas, il n’est pas forcément nécessaire d’avoir une même densité de points dans toute la base. Notamment, pour les zones où le signal varie très peu, le fait d’ajouter des points supplémentaires n’améliore pas la qualité de la modélisation. De plus, cela entraîne un temps de mise en œuvre plus important puisque le temps de création d’une base de données dépend principalement du nombre d’exemples.
Une solution pour éviter d’avoir une base de données inadéquate est, comme on va le détailler dans la section suivante, d’avoir une distribution des points de la base qui prend en compte le comportement du signal de la sonde.
5.3 Base adaptative
5.3.1 Description de la méthode :
Soit p le vecteur constitué des n paramètres recherchés et s le vecteur d’observation constitué par les m valeurs du signal de sortie. L’opérateur F du problème direct considéré permet de générer les exemples de la base d’apprentissage en calculant les m points du signal de sortie à partir des p paramètres recherchés :
F(p)s = (5.1)
Dans l’approche présentée, l’espace des paramètres recherchés est maillé avec des éléments simplex (triangle en 2D) dont les sommets (nœuds) sont constitués par les exemples de la base. Ces nœuds ont les valeurs des paramètres recherchés comme coordonnées et les valeurs des observations comme degrés de liberté. La Figure 66 présente un simplex dans le cas d’un problème à 2 paramètres recherchés.
Figure 66 : Eléments simplex 2D de l’espace des paramètres recherchés
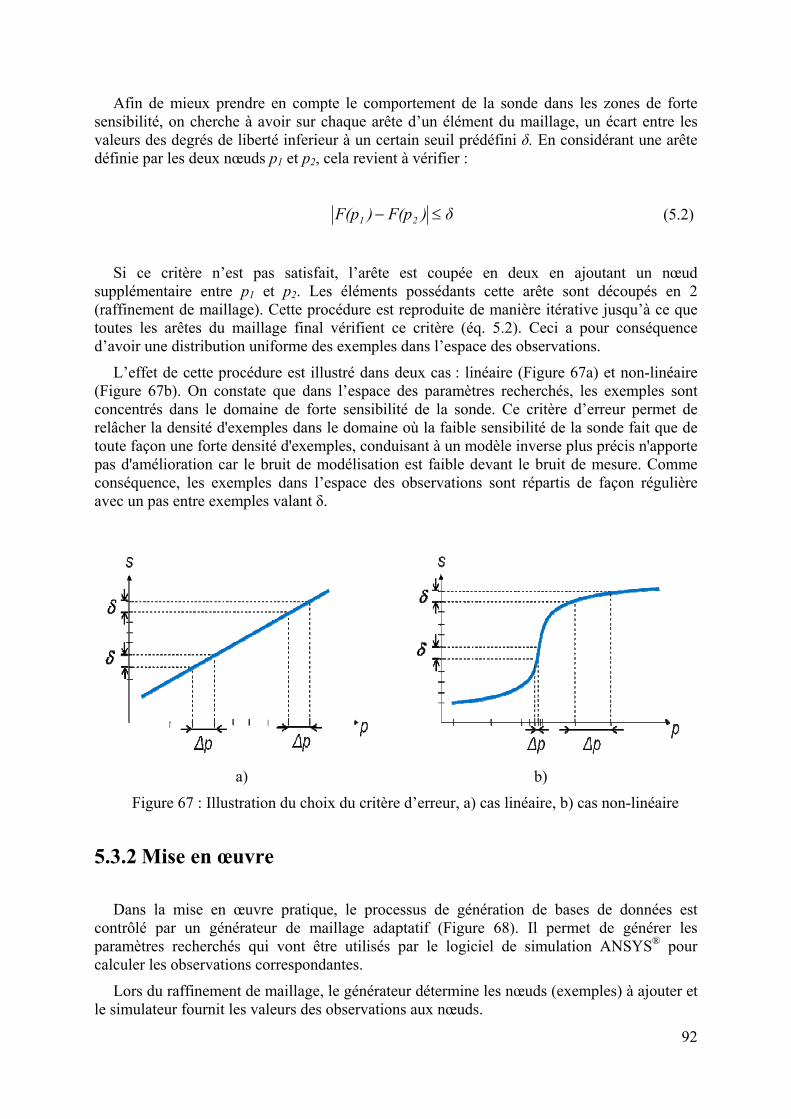
92
Afin de mieux prendre en compte le comportement de la sonde dans les zones de forte sensibilité, on cherche à avoir sur chaque arête d’un élément du maillage, un écart entre les valeurs des degrés de liberté inferieur à un certain seuil prédéfini δ. En considérant une arête définie par les deux nœuds p1 et p2, cela revient à vérifier :
δ)F(p)F(p 21 ≤− (5.2)
Si ce critère n’est pas satisfait, l’arête est coupée en deux en ajoutant un nœud supplémentaire entre p1 et p2. Les éléments possédants cette arête sont découpés en 2 (raffinement de maillage). Cette procédure est reproduite de manière itérative jusqu’à ce que toutes les arêtes du maillage final vérifient ce critère (éq. 5.2). Ceci a pour conséquence d’avoir une distribution uniforme des exemples dans l’espace des observations.
L’effet de cette procédure est illustré dans deux cas : linéaire (Figure 67a) et non-linéaire (Figure 67b). On constate que dans l’espace des paramètres recherchés, les exemples sont concentrés dans le domaine de forte sensibilité de la sonde. Ce critère d’erreur permet de relâcher la densité d'exemples dans le domaine où la faible sensibilité de la sonde fait que de toute façon une forte densité d'exemples, conduisant à un modèle inverse plus précis n'apporte pas d'amélioration car le bruit de modélisation est faible devant le bruit de mesure. Comme conséquence, les exemples dans l’espace des observations sont répartis de façon régulière avec un pas entre exemples valant δ.
a) b)
Figure 67 : Illustration du choix du critère d’erreur, a) cas linéaire, b) cas non-linéaire
5.3.2 Mise en œuvre
Dans la mise en œuvre pratique, le processus de génération de bases de données est contrôlé par un générateur de maillage adaptatif (Figure 68). Il permet de générer les paramètres recherchés qui vont être utilisés par le logiciel de simulation ANSYS® pour calculer les observations correspondantes.
Lors du raffinement de maillage, le générateur détermine les nœuds (exemples) à ajouter et le simulateur fournit les valeurs des observations aux nœuds.
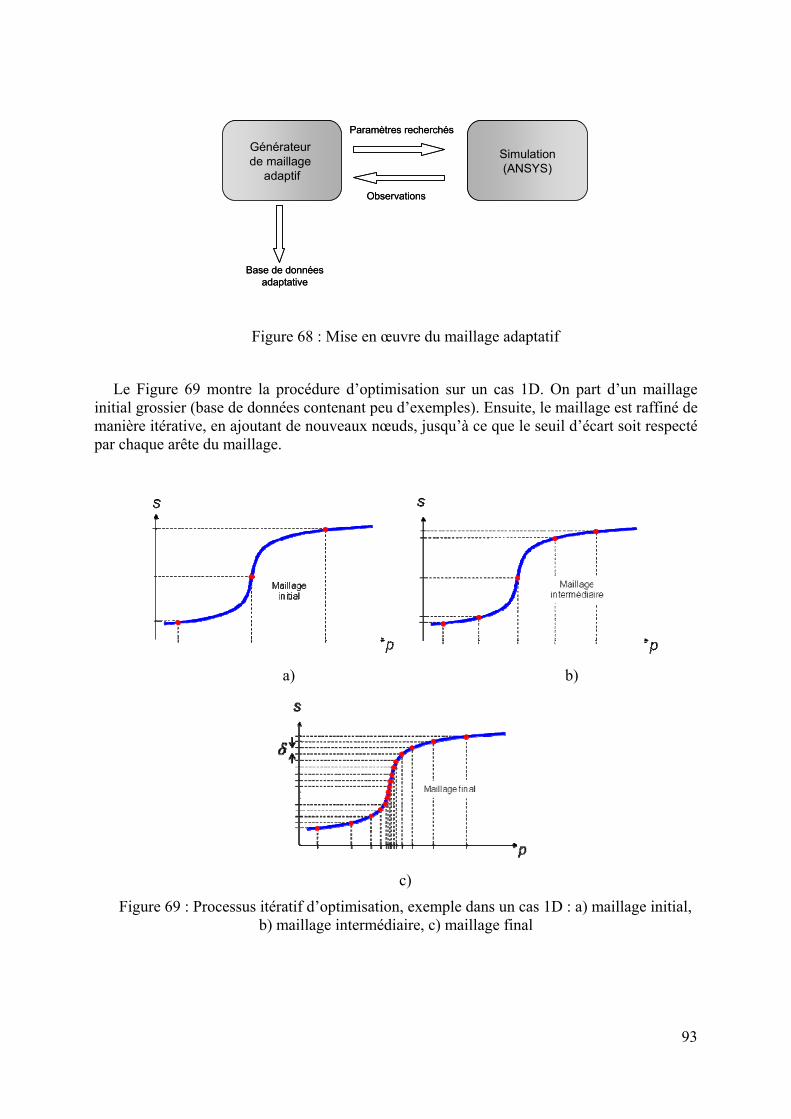
93
Générateur de maillage
adaptif
Simulation(ANSYS)
Paramètres recherchés
Base de données adaptative
Observations
Générateur de maillage
adaptif
Simulation(ANSYS)
Paramètres recherchés
Base de données adaptative
Observations
Figure 68 : Mise en œuvre du maillage adaptatif
Le Figure 69 montre la procédure d’optimisation sur un cas 1D. On part d’un maillage initial grossier (base de données contenant peu d’exemples). Ensuite, le maillage est raffiné de manière itérative, en ajoutant de nouveaux nœuds, jusqu’à ce que le seuil d’écart soit respecté par chaque arête du maillage.
a) b)
c)
Figure 69 : Processus itératif d’optimisation, exemple dans un cas 1D : a) maillage initial, b) maillage intermédiaire, c) maillage final
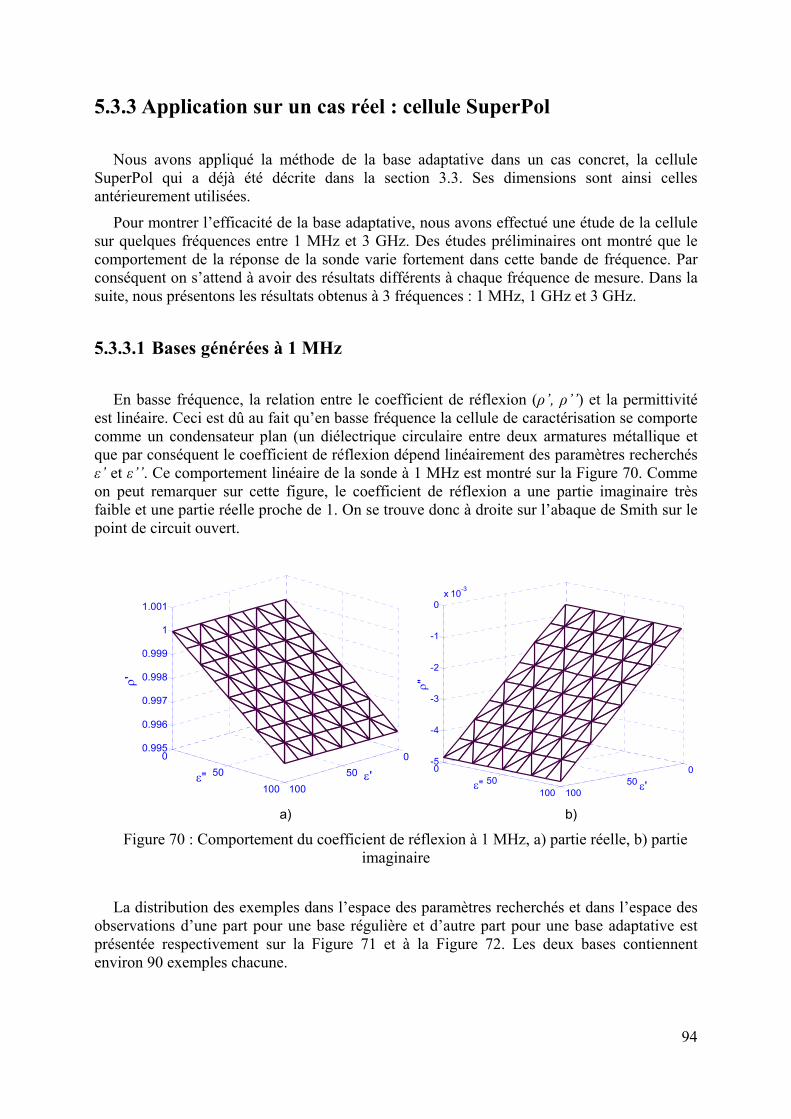
94
5.3.3 Application sur un cas réel : cellule SuperPol
Nous avons appliqué la méthode de la base adaptative dans un cas concret, la cellule SuperPol qui a déjà été décrite dans la section 3.3. Ses dimensions sont ainsi celles antérieurement utilisées.
Pour montrer l’efficacité de la base adaptative, nous avons effectué une étude de la cellule sur quelques fréquences entre 1 MHz et 3 GHz. Des études préliminaires ont montré que le comportement de la réponse de la sonde varie fortement dans cette bande de fréquence. Par conséquent on s’attend à avoir des résultats différents à chaque fréquence de mesure. Dans la suite, nous présentons les résultats obtenus à 3 fréquences : 1 MHz, 1 GHz et 3 GHz.
5.3.3.1 Bases générées à 1 MHz
En basse fréquence, la relation entre le coefficient de réflexion (ρ’, ρ’’) et la permittivité est linéaire. Ceci est dû au fait qu’en basse fréquence la cellule de caractérisation se comporte comme un condensateur plan (un diélectrique circulaire entre deux armatures métallique et que par conséquent le coefficient de réflexion dépend linéairement des paramètres recherchés ε’ et ε’’. Ce comportement linéaire de la sonde à 1 MHz est montré sur la Figure 70. Comme on peut remarquer sur cette figure, le coefficient de réflexion a une partie imaginaire très faible et une partie réelle proche de 1. On se trouve donc à droite sur l’abaque de Smith sur le point de circuit ouvert.
050
100
050
100
0.995
0.996
0.997
0.998
0.999
1
1.001
ε'ε"
ρ'
050
100
050
100
-5
-4
-3
-2
-1
0x 10-3
ε'ε"
ρ"
a) b)
Figure 70 : Comportement du coefficient de réflexion à 1 MHz, a) partie réelle, b) partie imaginaire
La distribution des exemples dans l’espace des paramètres recherchés et dans l’espace des observations d’une part pour une base régulière et d’autre part pour une base adaptative est présentée respectivement sur la Figure 71 et à la Figure 72. Les deux bases contiennent environ 90 exemples chacune.

95
Le comportement linéaire de la sonde conduit à ce que les deux bases présentent une distribution des exemples uniforme à la fois dans l’espace des paramètres recherchés et dans l’espace des observations.
0 20 40 60 80 1000
20
40
60
80
100
ε'
ε"
0.9955 1
-4.5
-3.5
-2
-1x 10-3
ρ'
ρ''
a) b)
Figure 71 : Distribution des exemples de la base adaptative générée à 1 MHz, a) dans l’espace des paramètres recherchés, b) dans l’espace des observations
0 20 40 60 80 1000
20
40
60
80
100
ε'
ε"
0.9955 1
-4.5
-3.5
-2
-1x 10-3
ρ'
ρ''
a) b)
Figure 72 : Distribution des exemples de la base régulière générée à 1 MHz, a) dans l’espace des paramètres recherchés, b) dans l’espace des observations
5.3.3.2 Bases générées à 1 GHz
Quand on monte en fréquence, le comportement de ρ’ et ρ’’ vis-à-vis de ε’ et ε’’ devient sensiblement non-linéaire, et des variations importantes de sensibilité sont observées. Par conséquent, pour prendre en compte la complexité du problème direct, la base de données doit affiner le nombre d’exemples dans les zones de forte sensibilité. La Figure 73 montre qu’effectivement le comportement de ρ’ et ρ’’ en fonction de ε’ et ε’’ n’est plus linéaire.
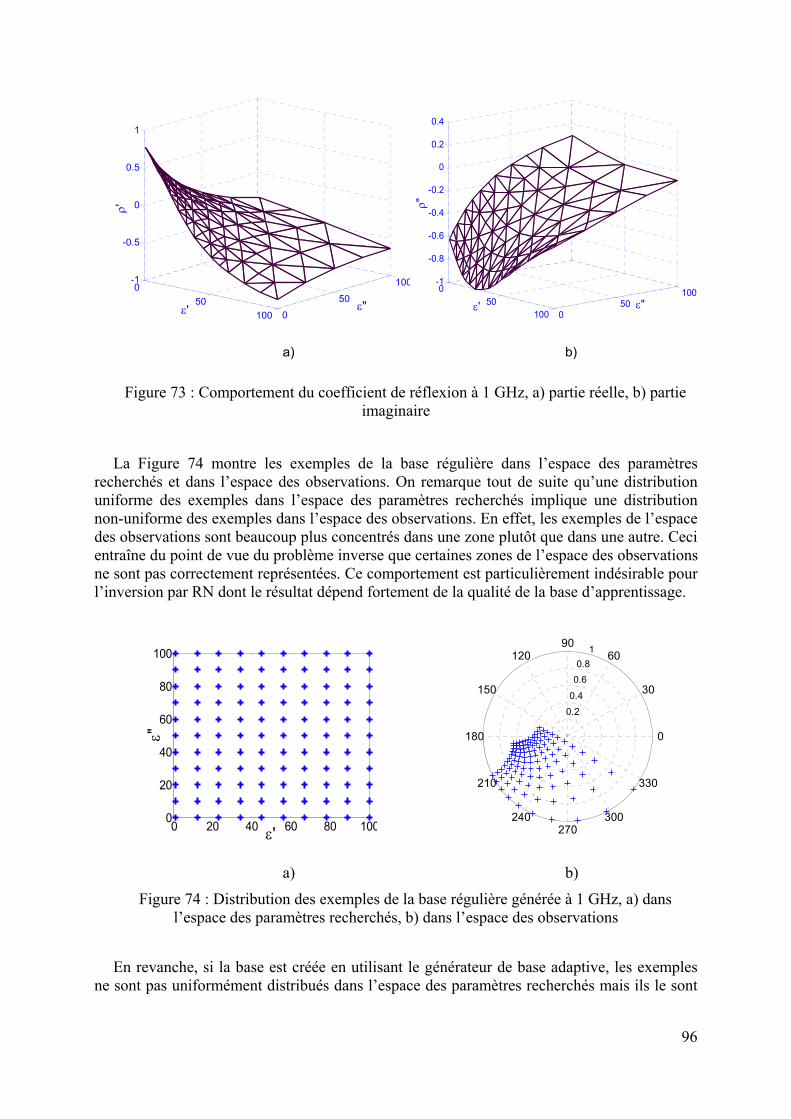
96
050
100 0
50
100-1
-0.5
0
0.5
1
ε"ε'
ρ '
050
100 050
100-1
-0.8
-0.6
-0.4
-0.2
0
0.2
0.4
ε"ε'
ρ"
a) b)
Figure 73 : Comportement du coefficient de réflexion à 1 GHz, a) partie réelle, b) partie imaginaire
La Figure 74 montre les exemples de la base régulière dans l’espace des paramètres recherchés et dans l’espace des observations. On remarque tout de suite qu’une distribution uniforme des exemples dans l’espace des paramètres recherchés implique une distribution non-uniforme des exemples dans l’espace des observations. En effet, les exemples de l’espace des observations sont beaucoup plus concentrés dans une zone plutôt que dans une autre. Ceci entraîne du point de vue du problème inverse que certaines zones de l’espace des observations ne sont pas correctement représentées. Ce comportement est particulièrement indésirable pour l’inversion par RN dont le résultat dépend fortement de la qualité de la base d’apprentissage.
0 20 40 60 80 1000
20
40
60
80
100
ε'
ε"
0.2 0.4
0.6 0.8
1
30
210
60
240
90
270
120
300
150
330
180 0
a) b)
Figure 74 : Distribution des exemples de la base régulière générée à 1 GHz, a) dans l’espace des paramètres recherchés, b) dans l’espace des observations
En revanche, si la base est créée en utilisant le générateur de base adaptive, les exemples ne sont pas uniformément distribués dans l’espace des paramètres recherchés mais ils le sont
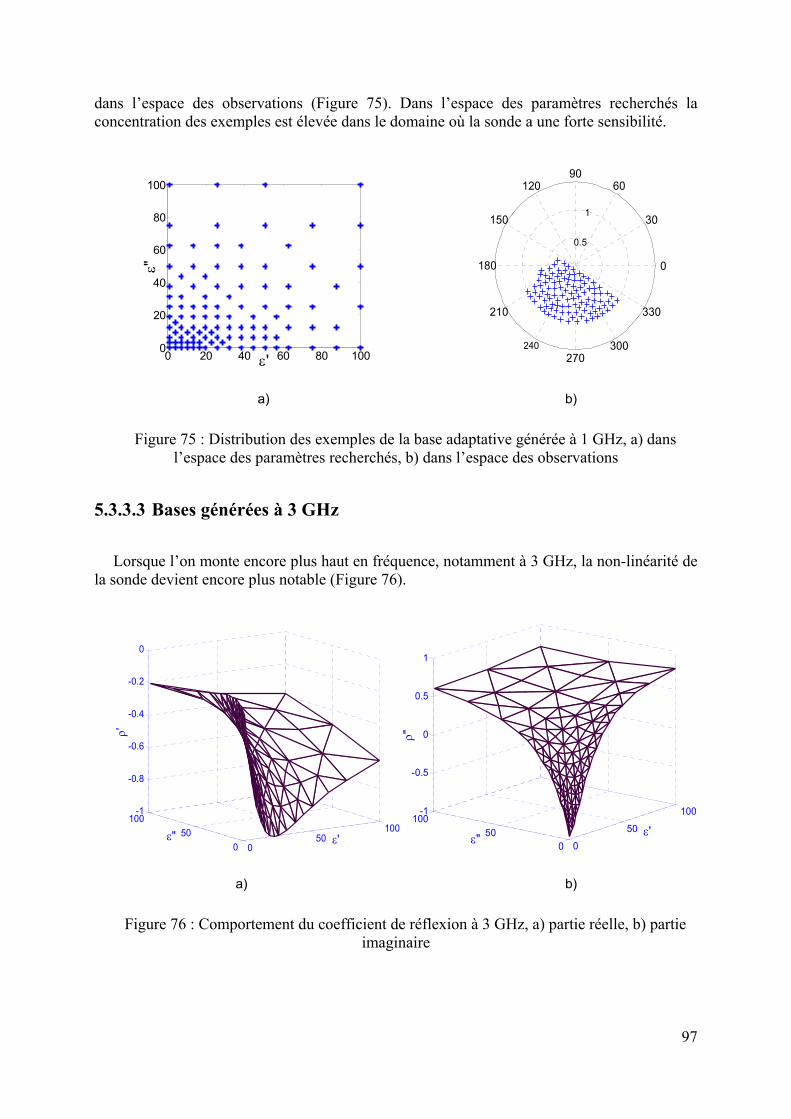
97
dans l’espace des observations (Figure 75). Dans l’espace des paramètres recherchés la concentration des exemples est élevée dans le domaine où la sonde a une forte sensibilité.
0 20 40 60 80 1000
20
40
60
80
100
ε'
ε"
0.5
130
210
60
240
90
270
120
300
150
330
180 0
a) b)
Figure 75 : Distribution des exemples de la base adaptative générée à 1 GHz, a) dans l’espace des paramètres recherchés, b) dans l’espace des observations
5.3.3.3 Bases générées à 3 GHz
Lorsque l’on monte encore plus haut en fréquence, notamment à 3 GHz, la non-linéarité de la sonde devient encore plus notable (Figure 76).
050
100
050
100-1
-0.8
-0.6
-0.4
-0.2
0
ε'ε"
ρ'
0
50
100
050
100-1
-0.5
0
0.5
1
ε'ε"
ρ"
a) b)
Figure 76 : Comportement du coefficient de réflexion à 3 GHz, a) partie réelle, b) partie imaginaire
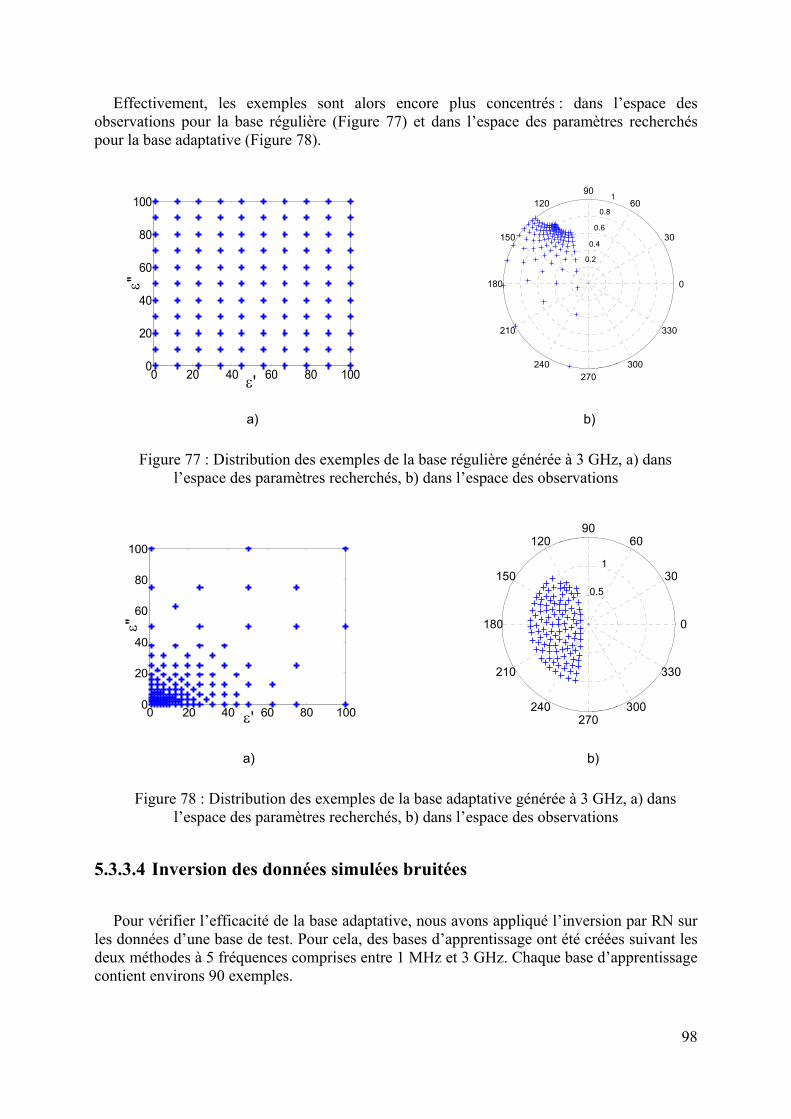
98
Effectivement, les exemples sont alors encore plus concentrés : dans l’espace des observations pour la base régulière (Figure 77) et dans l’espace des paramètres recherchés pour la base adaptative (Figure 78).
0 20 40 60 80 1000
20
40
60
80
100
ε'
ε"
0.2
0.4
0.6
0.8
1
30
210
60
240
90
270
120
300
150
330
180 0
a) b)
Figure 77 : Distribution des exemples de la base régulière générée à 3 GHz, a) dans l’espace des paramètres recherchés, b) dans l’espace des observations
0 20 40 60 80 1000
20
40
60
80
100
ε'
ε"
0.5
130
210
60
240
90
270
120
300
150
330
180 0
a) b)
Figure 78 : Distribution des exemples de la base adaptative générée à 3 GHz, a) dans l’espace des paramètres recherchés, b) dans l’espace des observations
5.3.3.4 Inversion des données simulées bruitées
Pour vérifier l’efficacité de la base adaptative, nous avons appliqué l’inversion par RN sur les données d’une base de test. Pour cela, des bases d’apprentissage ont été créées suivant les deux méthodes à 5 fréquences comprises entre 1 MHz et 3 GHz. Chaque base d’apprentissage contient environs 90 exemples.
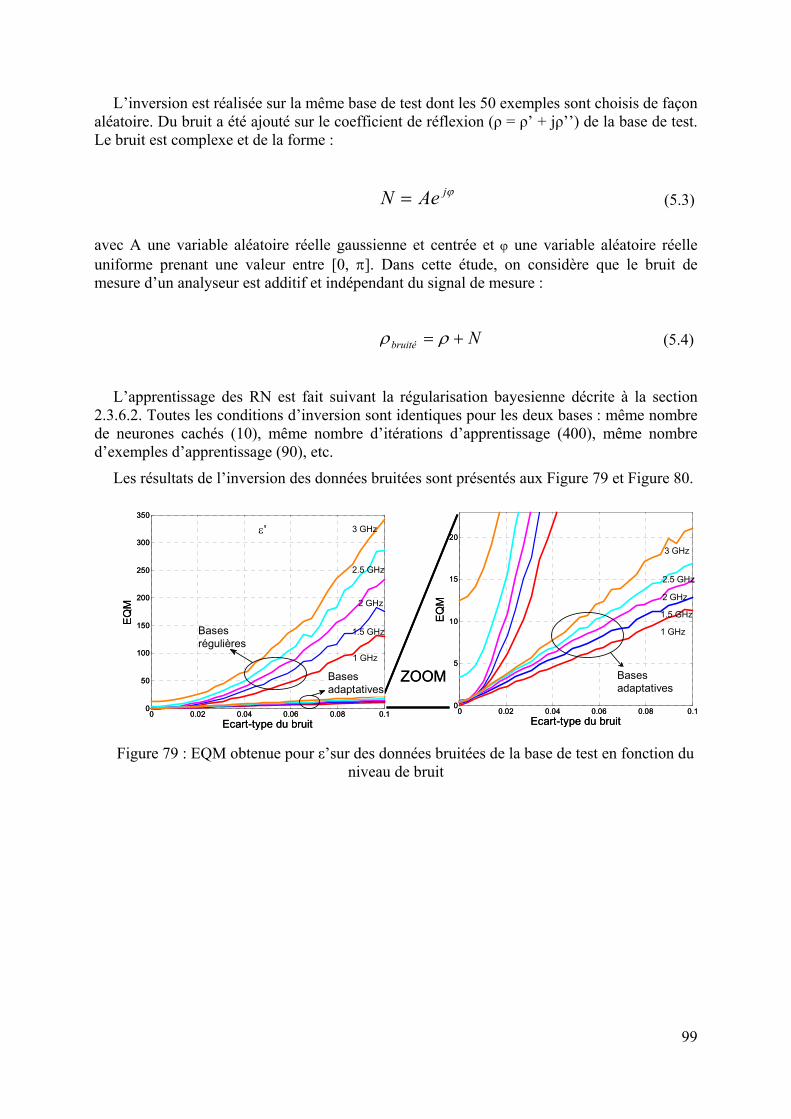
99
L’inversion est réalisée sur la même base de test dont les 50 exemples sont choisis de façon aléatoire. Du bruit a été ajouté sur le coefficient de réflexion (ρ = ρ’ + jρ’’) de la base de test. Le bruit est complexe et de la forme :
ϕjAeN = (5.3)
avec A une variable aléatoire réelle gaussienne et centrée et ϕ une variable aléatoire réelle uniforme prenant une valeur entre [0, π]. Dans cette étude, on considère que le bruit de mesure d’un analyseur est additif et indépendant du signal de mesure :
Nbruité += ρρ (5.4)
L’apprentissage des RN est fait suivant la régularisation bayesienne décrite à la section 2.3.6.2. Toutes les conditions d’inversion sont identiques pour les deux bases : même nombre de neurones cachés (10), même nombre d’itérations d’apprentissage (400), même nombre d’exemples d’apprentissage (90), etc.
Les résultats de l’inversion des données bruitées sont présentés aux Figure 79 et Figure 80.
ZOOM
0 0.02 0.04 0.06 0.08 0.10
50
100
150
200
250
300
350
Ecart-type du bruit
EQ
M
3 GHz
2 GHz
1.5 GHz
1 GHz
2.5 GHz
ε'
Basesrégulières
Basesadaptatives
0 0.02 0.04 0.06 0.08 0.10
5
10
15
20
Ecart-type du bruit
EQ
M 2 GHz
2.5 GHz
3 GHz
1.5 GHz
1 GHz
Basesadaptatives
ZOOM
0 0.02 0.04 0.06 0.08 0.10
50
100
150
200
250
300
350
Ecart-type du bruit
EQ
M
3 GHz
2 GHz
1.5 GHz
1 GHz
2.5 GHz
ε'
Basesrégulières
Basesadaptatives
0 0.02 0.04 0.06 0.08 0.10
5
10
15
20
Ecart-type du bruit
EQ
M 2 GHz
2.5 GHz
3 GHz
1.5 GHz
1 GHz
Basesadaptatives
Figure 79 : EQM obtenue pour ε’sur des données bruitées de la base de test en fonction du
niveau de bruit
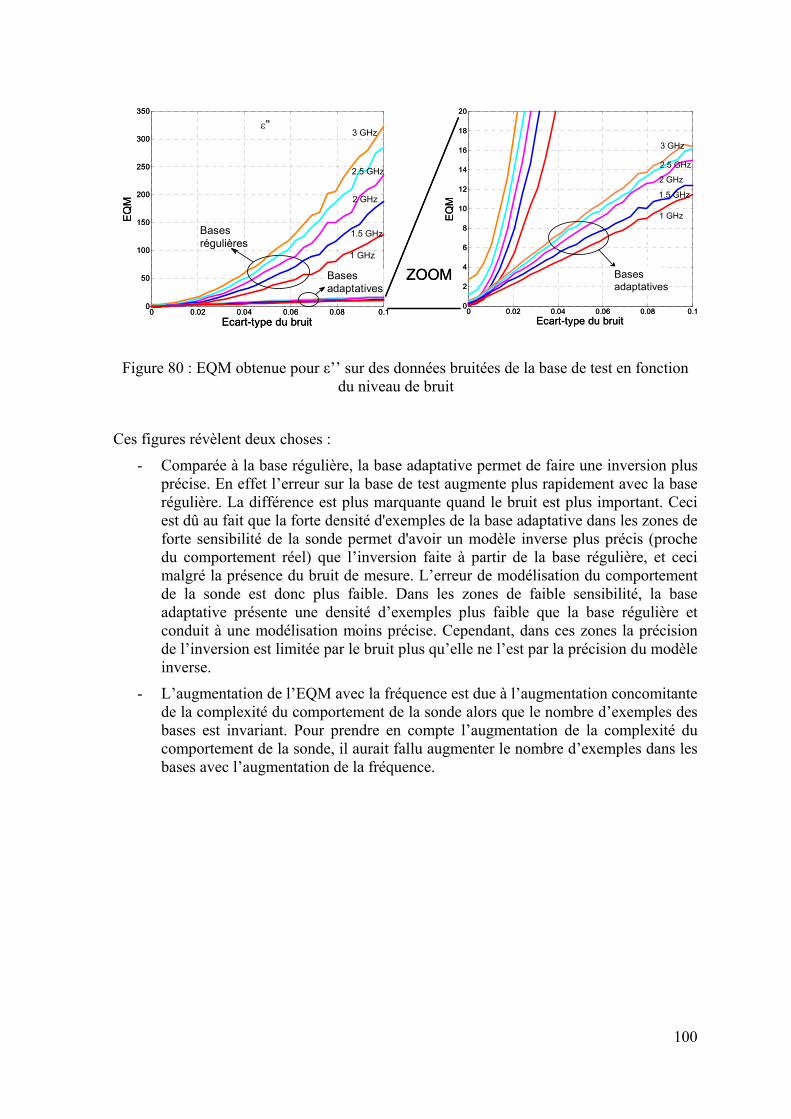
100
ZOOM
0 0.02 0.04 0.06 0.08 0.10
2
4
6
8
10
12
14
16
18
20
Ecart-type du bruit
EQ
M
2.5 GHz
3 GHz
2 GHz
1.5 GHz
1 GHz
Basesadaptatives
0 0.02 0.04 0.06 0.08 0.10
50
100
150
200
250
300
350
Ecart-type du bruit
EQ
M 2 GHz
1.5 GHz
1 GHz
2.5 GHz
3 GHzε''
Basesrégulières
Basesadaptatives
ZOOM
0 0.02 0.04 0.06 0.08 0.10
2
4
6
8
10
12
14
16
18
20
Ecart-type du bruit
EQ
M
2.5 GHz
3 GHz
2 GHz
1.5 GHz
1 GHz
Basesadaptatives
0 0.02 0.04 0.06 0.08 0.10
50
100
150
200
250
300
350
Ecart-type du bruit
EQ
M 2 GHz
1.5 GHz
1 GHz
2.5 GHz
3 GHzε''
Basesrégulières
Basesadaptatives
Figure 80 : EQM obtenue pour ε’’ sur des données bruitées de la base de test en fonction du niveau de bruit
Ces figures révèlent deux choses :
- Comparée à la base régulière, la base adaptative permet de faire une inversion plus précise. En effet l’erreur sur la base de test augmente plus rapidement avec la base régulière. La différence est plus marquante quand le bruit est plus important. Ceci est dû au fait que la forte densité d'exemples de la base adaptative dans les zones de forte sensibilité de la sonde permet d'avoir un modèle inverse plus précis (proche du comportement réel) que l’inversion faite à partir de la base régulière, et ceci malgré la présence du bruit de mesure. L’erreur de modélisation du comportement de la sonde est donc plus faible. Dans les zones de faible sensibilité, la base adaptative présente une densité d’exemples plus faible que la base régulière et conduit à une modélisation moins précise. Cependant, dans ces zones la précision de l’inversion est limitée par le bruit plus qu’elle ne l’est par la précision du modèle inverse.
- L’augmentation de l’EQM avec la fréquence est due à l’augmentation concomitante de la complexité du comportement de la sonde alors que le nombre d’exemples des bases est invariant. Pour prendre en compte l’augmentation de la complexité du comportement de la sonde, il aurait fallu augmenter le nombre d’exemples dans les bases avec l’augmentation de la fréquence.

101
5.4 Conclusion
L’approche classique pour générer des bases de données consiste à répartir uniformément les exemples dans l’espace des paramètres recherchés. Mais ceci a un inconvénient, puisqu’en procédant ainsi, le comportement de la sonde n’est pas pris en compte. Pour éviter ce problème, en explorant systématiquement tout le domaine d’apprentissage, nous avons mis en œuvre l’optimisation de la base d’apprentissage en prenant en compte la non-linéarité du signal de sortie. En faisant une étude sur un cas concret d’une cellule de caractérisation MO, nous avons montré que la base adaptative permet effectivement de prendre en compte la complexité du signal tout en ayant un modèle inverse plus précis que dans le cas de la base régulière. En effet, l’erreur sur la base de test obtenue avec la base adaptative est toujours inférieure à celle obtenue avec une base régulière quel que soit le niveau du bruit de mesure ajouté sur le coefficient de réflexion. Les résultats de la base adaptative sont très prometteurs pour des applications réelles de caractérisation MO.
Cependant, l’étude menée concerne des RN à deux paramètres d’entrée, ρ’ et ρ’’. En fait, pour des applications de caractérisation de matériaux diélectriques, et pour des mesures en large bande, il faut créer la base d’apprentissage avec une information en plus, qui est la fréquence de mesure (voir chapitre 3). L’entrée des RN contiendrait donc 3 paramètres. C’est une étude que nous avons commencé à mener.
L’interpolation effectuée par un RN est localement linéaire. Ceci laisse à penser qu’une méthode de génération de bases de données adaptatives basée sur l’erreur d’approximation linéaire entre les nœuds du maillage peut être plus appropriée. Il serait donc intéressant d’étudier l’apport d’une approximation linéaire par rapport à la simple prise en compte de l’écart entre les observations aux nœuds.

102

103
6 Conclusion finale et perspectives
Ce travail de thèse est construit autour de l’application de l’inversion par réseaux de neurones (RN) pour la caractérisation microondes (MO) de matériaux. Nous avons tout d’abord montré l’intérêt d’une inversion directe utilisant un modèle inverse comportemental de type RN. Ce type d’inversion est surtout utile lorsque le modèle direct ne présente pas de solution analytique.
L’originalité de cette thèse réside dans l’utilisation d’une méthode d’inversion purement numérique. En combinant la modélisation par la méthode des éléments finis (MEF) et l’inversion par RN, nous avons montré que les restrictions en termes de fréquence pouvaient être levées. En effet, les cellules (ou capteurs) de mesure pour lesquelles il existe une solution analytique du modèle direct, ont la plupart du temps un domaine de validité limité par des approximations. Ce n’est plus le cas pour la méthode présentée dans ce manuscrit.
Comme première application, nous avons tout d’abord exploité notre méthode d’inversion pour la caractérisation de matériaux diélectriques afin de déterminer leur permittivité. Afin de permettre la validation de la méthode, nous avons appliquée notre méthode avec des données issues d’une cellule de caractérisation pour laquelle il existe une solution analytique. La comparaison entre les RN et l’inversion itérative basée sur la solution analytique montre que les résultats sont très satisfaisants.
Pour éviter les problèmes de généralisation dus à une sur-paramétrisation des RN, nous avons montré l’intérêt d’une régularisation bayesienne. En effet, contrairement à la méthode split-sample, la régularisation bayesienne ne nécessite pas une base supplémentaire pour la validation. La procédure d’inversion devient alors beaucoup plus rapide, puisque d’une part le temps de modélisation est diminué du fait de la moindre quantité de bases à créer et que d’autre part, cette méthode ne requiert pas l’apprentissage systématique de RN de tailles différentes. L’efficacité de cette méthode est mise en évidence par l’inversion de données numériques, mais aussi en caractérisant un matériau diélectrique étalon.
Une deuxième application de notre méthode d’inversion est la détermination des constituants d’un fluide pétrolier en utilisant un capteur MO. Le capteur MO est constitué de deux sondes : l’une basse fréquence (BF) et l’autre haute fréquence (HF). Différents modes d’utilisation des observations BF et HF pour l’inversion ont été mis en œuvre et comparés. L’inversion de données issues de la mesure, dans un cas simple où uniquement un seul paramètre est recherché, est effectuée. Ceci permet d’envisager l’utilisation de notre méthode pour des cas plus réalistes où plusieurs paramètres sont à déterminer.
Une méthode d’optimisation de la structure de la base d’apprentissage a été élaborée et mise en œuvre. L’optimisation de la base d’apprentissage permet de mieux prendre en compte les zones de forte sensibilité de la sonde MO. L’inversion effectuée montre qu’une base adaptative conduit à de meilleurs résultats qu’une base régulière à nombre d’exemples équivalent.

104
Les perspectives portent notamment sur l’application de la procédure développée à des situations plus complexes et réalistes. Ainsi son extension à des gammes de permittivités et de fréquences élevées est à étudier. Les matériaux à prendre en considération sont notamment les liquides biologiques. Cependant, l’augmentation de la non linéarité et l’apparition de résonances peuvent rendre difficile l’apprentissage des exemples de la base d’apprentissage. Ceci pourra impliquer un travail sur l’architecture des RN et sur la structure de la base d’apprentissage. En effet, en tenant compte du type d’approximation réalisé par un RN, différentes méthodes d’optimisation de la base d’apprentissage peuvent être considérées.
Nous devons aussi continuer l’application de la procédure d’inversion pour la détermination des proportions d’un fluide pétrolier dans un contexte expérimental plus réaliste où plusieurs paramètres sont recherchés. Les paramètres à prendre en compte sont la salinité de l’eau du mélange de liquide, la nature de la phase dispersée et le type d’écoulement. Dans ces cas, l’utilisation des RN serait beaucoup plus justifiée.

105
Annexe
Les algorithmes du gradient
Les algorithmes du gradient de l’EQM procèdent à une modification itérative du vecteur w des paramètres du RN selon la règle suivante :
wk+1 = wk + αk dk ( 1)
où dk est la direction de recherche des poids optimaux et αk un coefficient d’adaptation. L’indice k signifie que l’algorithme en est à sa kième itération. Le produit αk dk constitue le pas d’adaptation δwk, vecteur contenant les modifications apportées aux poids et biais du RN dans le but de minimiser l’EQM. Ces algorithmes peuvent se classer en deux grandes catégories, présentées dans ce qui suit.
Méthodes du premier ordre
Ces méthodes reposent sur un développement limité à l’ordre 1 de l’EQM, notée ξ, définie à l’équation (2.26) :
ξ(w+δw) = ξ(w) + (∇ξ(w))t δw + o||δw|| (2)
Pour une valeur suffisamment petite de δw la variation résultante de ξ peut donc s’approximer :
δξ(w) = (∇ξ(w))t δw (3)
L’EQM étant positive ou nulle et devant être minimisée, on cherche à rendre δξ(w) le plus négatif possible. Cela implique que δw soit colinéaire à ∇ξ(w) et de sens opposé, soit :
δw = - p∇ξ(w) (4)

106
où p est un réel positif appelé pas de descente. On obtient alors l’algorithme du gradient déterministe ou algorithme de descente suivant la plus grande pente :
wk+1 = wk – p∇ξ( wk) (5)
La mise en œuvre de cet algorithme nécessite de choisir la valeur du pas de descente. Une valeur très petite de p implique que les poids sont très faiblement modifiés d’une itération à l’autre et conduit à des temps de convergence élevés. A contrario, un pas de descente trop grand risque de rendre l’algorithme instable (oscillations ou divergence).
Une parade à ce problème consiste à utiliser un pas adaptatif. L’adaptation de p s’effectue à chaque itération, en fonction de la valeur prise par l’EQM :
• Si ξk+1 < ξk : l’erreur diminue et on peut accélérer la convergence en augmentant le pas : pk+1 = α pk avec α > 1.
• Si ξk+1 > ξk : l’erreur augmente. Le vecteur des poids de l’itération k+1 est alors recalculé avec un pas plus petit : pk+1 = β pk avec β < 1.
Typiquement, α=1,05 et β=0,95 [Ouk 97].
Une autre possibilité pour augmenter la vitesse de convergence de l’algorithme tout en évitant de le rendre instable est d’introduire un terme proportionnel à la modification des poids effectuée à l’itération précédente. C’est la méthode du momentum, qui rend également l’algorithme moins sensible aux minimums locaux grâce à l’« inertie » qu’elle apporte sur la modification des poids :
wk+1 = wk - (1-m) p ∇.ξ( wk) + m δwk (6)
où m est le momentum (0≤m≤1) et δwk = wk - wk-1, la modification des poids à l’itération précédente.
Les deux précédentes méthodes (pas adaptatif et momentum) peuvent être utilisées simultanément afin d’obtenir un algorithme plus efficace.
Les méthodes du 1er ordre présentent des limitations, même dans le cas simple d’un RN linéaire. Considérons un RN linéaire ayant deux paramètres de réglage w1 et w2. ξ(w1,w2) est alors une fonction quadratique et les courbes isocritères (EQM constante) sont des ellipses

107
(Figure 81). A chaque itération, la direction de recherche, obtenue à partir du gradient de l’EQM, est perpendiculaire aux isocritères. Hormis le cas particulier où les isocritères forment des cercles, les directions de recherche ne passent généralement pas par le minimum de l’EQM (situé dans cette exemple en w1=0 et w2=0). Un grand nombre d’itérations est alors nécessaire pour faire converger l’algorithme.
Figure 81 : Isocritères et directions de recherche successives
Les méthodes du second ordre permettent de s’affranchir de ce problème de convergence. Elles exploitent en effet pleinement la nature quadratique de l’EQM dans le cas où le RN est linéaire, ou localement linéaire.
Méthodes du second ordre
Ces méthodes reposent sur un développement limité à l’ordre 2 de l’EQM :
ξ(w+δw) = ξ(w) + (∇ξ(w))t δw +21 δw t H(w) δw + o||δw||2
(7)
avec H(w)=hi,j1≤ i, j≤ K le Hessien de ξ, matrice carrée de coefficients : hi,j =ww ji∂∂
ξ∂ 2
Si δw est le pas nécessaire pour mener ξ à son minimum, il doit vérifier, en posant δw=δwi1≤i≤K (K étant le nombre de paramètres du RN) :
⎟⎟⎠
⎞
wiδ∂ξ∂
1≤ i ≤ K = 0 (8)
L’application de cette condition sur l’équation (7) implique :
0 = 0 + ∇.ξ(w) + H(w) δw (9)
w
w
Courbes

108
Le pas optimal est donc :
δw = - H(w)-1 ∇ξ(w) (10)
Si le RN est linéaire, le développement limité de ξ à l’ordre 2 correspond à son développement exact en série de Taylor et la convergence se fait en une seule itération. En général ce n’est pas le cas et w est obtenu de manière itérative. Est ainsi défini l’algorithme de Newton :
wk+1 = wk - H(wk)-1 ∇.ξ(wk) (11)
L’inconvénient majeur de l’algorithme de Newton est qu’il nécessite l’inversion d’une matrice, ce qui en restreint l’utilisation à des RN de taille modeste. D’autres méthodes sont dérivées de l’algorithme de Newton, elles sont regroupées sous le terme générique de méthodes newtoniennes :
L’algorithme de Gauss-Newton consiste à négliger dans l’expression du Hessien le terme dépendant des dérivés secondes. Il s’écrit alors [Lê 95] :
H(wk) =2 J(wk)t J(wk) (12)
avec J(wk) la matrice jacobienne de ϕ(wk) (fonction réalisée par le RN).
L’algorithme de Levenberg-Marquardt consiste à remplacer le Hessien de (12) par :
H’(wk)= H(wk) + αk I (13)
avec αk ≥ 0. La récurrence sur les poids est alors :
wk+1= wk - (H(wk) + αk I)-1 ∇.ξ(wk) (14)
Le coefficient αk est destiné à régulariser l’inversion du Hessien (il améliore le conditionnement de la matrice). Il permet de ne pas trop fonder le calcul du pas sur

109
l’hypothèse que l’EQM est quadratique. Quand αk est nul, c’est la méthode de Gauss-Newton qui est utilisée. Quand αk est grand, on retrouve l’algorithme du gradient.
L’algorithme de Levenberg-Marquardt fonctionne comme suit : la méthode de Gauss-Newton étant beaucoup plus rapide dans les zones où l’EQM est quadratique, αk est diminué d’un facteur (usuellement 10) à chaque itération de l’algorithme. Mais, lorsque le calcul du pas d’adaptation débouche sur un accroissement de l’EQM, le pas est recalculé avec αk augmenté de ce même facteur et ce, jusqu’à ce que l’EQM ait décrue par rapport à l’itération précédente.
L’inversion de la matrice H’(wk), d’ordre K (le nombre de paramètres internes du RN), fait que l’algorithme de Levenberg-Marquardt, comme tous les algorithmes newtoniens, est coûteux numériquement. Cependant, sa vitesse de convergence le rend plus rapide que tous les algorithmes non newtoniens pour des RN ne comprenant pas plus de quelques centaines de poids et de biais [MAT 98]. Pour les RN de plus grande taille il existe les méthodes de quasi-Newton qui ne nécessitent pas d’inverser une matrice et, pour les réseaux les plus complexes, la méthode du gradient conjugué [COS 96].

110

111
Bibliographie
[Bad 88] Badot J.C., “Relaxation diélectriques [1kHz-10GHz] dans les conducteurs protoniques et les matériaux hydratés”, Thèse de l’Université Pierre et Marie Curie, Paris, 1988 [Bak 93] Bakhtiari S., Ganchev S.I., Zoughi R., “Open-ended rectangular waveguide for nondestructive thickness measurement and variation detection of lossy dielectric slabs backed by aconducting plate”, IEEE Transaction on Instrumentation and Measurement, vol. 42, no. 1, February, 1993 [Bar 93] Barron A., “Universal approximation bounds for superposition of a sigmoidal function”, IEEE Transactions on Information Theory, vol. 39, pp. 930-945, 1993. [Bart 99] Bartley P.G., McClendon R.W., Nelson S.O., “Permittivity determination by using an artificial neural network”, IEEE Instrum and Meas Tech Conference, pp. 27–30, 1999. [Bel 86] Belhadj-Tahar, N., Fourrier-Lamer, A., “Broad-band analysis of discontinuity used for dielectric measurement,” IEEE MTT, vol. 34, pp. 346–349, 1986. [Ben 06] Bensetti M., Le Bihan Y., Marchand C., Premel D.,, “Non-Destructive Evaluation of Layered Planar Media Using MLP and RBF Neural Networks”, Studies in Applied Electromagnetics and Mechanics, vol. 26 (Electromagnetic Nondestructive Evaluation VII), pp. 81-88, 2006. [Bet 04] Bettaieb L., “Caractérisation de liquides aux hyperfréquences”, stage de M1 d’EEA, UPMC, 2004 [Bis 00] Bishay S.T., “Numerical Methods for the Calculation of the Cole-Cole parameters”, Egypt J. Sol., vol. 23, No. 2, 2000. [Bon 06], Bondet de la Bernardie E., “ Thèse de doctorat de l’univesité Pierre et Marie Curie”, 2006 [Bon 08] Bondet de la Bernardie E., Dubrunfaut O., Badot J.C., Fourrier-Lamer A., Villard E., David P.Y., Jannier B., Grosjean N., Lance M., “Low (10 MHz – 800 MHz) and high (40 GHz) frequencies probes applied to petroleum multiphase flow characterization,” Measurement Science and Technology, Measurement Science and Technology, vol.19, pp. 055602-055610, 2008 [Bou 99] Boughriet A., Wu Z., McCann H. Davis L.E., “The measurement of dielectric properties of liquids at microwave frequencies using open-ended coaxial probes”, 1st World Congress on Industrial Process Tomography, Buxton, Greater Manchester, April 14-17, 1999 [Buc 58] Buckley F., A. Maryott A., “Tables of Dielectric Dispersion Data for Pure Liquids and Dilute Solutions”, National Bureau of Standards, November, 1958.

112
[Cha 88] Chabinsky I.J., “Applications of Microwave Energy Past, Present and Future”, Brave New Worlds, Materials Research Society Symposium Proceedings, vol. 124, Materials Research Society, Pittsburgh, pp. 17–31, , 1988 [Che 80] Chelkowski A, “Dielectric Physics”, Elsevier Scientific Publishing Compagny”, 1980
[Col 41] Cole K. S., Cole R. H., “Dispersion and absorption in dielectrics. I. Alternating current characteristics”, Journal of Chemical Physics, vol. 9, pp. 341-351, 1941. [Cos 96] Costa P., “Contribution à l’utilisation des réseaux de neurones à couches en traitement du signa l. ” Thèse de docteur de l’Ecole Normale Supérieure de Cachan, 20 décembre 1996. [Dat 84] Datt G., Touzot G., “Une présentation de la méthode des éléments finis », Maloine S.A. editeur, 1984. [Dav 51] Davidson D.W., Cole R.H., “Dielectric relaxation in glycerol propylene, and n-propanol”, The Journal of Chemical Physics, vol. 19, pp. 1484-1490, 1951. [Deb 29] Debye P., “Polar molecules”, Edition New York: The chemical catalogue, 1929 [Dre 02] Dreyfus G., Martinez J.-M., Samuelides M., Gordon M.B., Badran F., Thiria S., Hérault L., “Réseaux de neurones, Méthodologie et applications”, editions Eyrolles
[Drea 06] Drean J., Duchesne L., SATIMO, “Non Invasive Electromagnetic Quality Control Système”, ECNDT, Berlin, 2006.
[Dup 98] Duprat A., Huynh T., Greyfus G., “Towards a principled methodology for neural network design and performance evaluation in QSAR; application to the prediction of LogP”, Journal of Chemical Information and Computer Sciences, vol. 38, pp. 586-594, 1998. [Gho 03] Ghodgaonkar D.K., Daud A.B, “Calculation of Debye parameters of single Debye relaxation equation for human skin in vivo”, Proceedings of the 4th National Conference on Telecommunication Technology, pp. 71-74, January 2003. [Goo 08] http://www.goodfellow.com/F/Polyetherethercetone.HTML, consulté en octobre 2008. [Gyi 06] Gyimóthy, Sz. , Pávó, J., Tsuboi, H. ‘Conceptual Evaluation of Inversion Models Used for Layered Structures’, IEEE Transactions on Magnetics, vol. 42, no. 4, April 2006. [Hav 67] Havriliak, S., Negami, S., “A complex plane representation of dielectric and mechanical relaxation processes in some polymers”, Polymer, vol. 8, no. 4, pp. 161, 1967. [Hor 89] Hornik K., Stinchcombe M., White H., “Multilayer feedforward networks are universal Approximators”, Neural Networks, 2, pp. 359-366, 1989

113
[HVS Tech.] HVS Technologies Inc., www.hvstech.com/afspace.html
[Iva 07] Ivashov S.I., Vasiliev I.A., Bechtel T.D., Snapp C., “Comparison between Impulse and Holographic Subsurface Radar for NDT of Space Vehicle Structural Materials”,
PIERS Online, vol. 3, no. 5, pp. 658-661, 2007. [Jin 02] Jin J., “The finite element method for electromagnetics”, 2nd edition, John Wiley and Sons, 2002 [Ju 99] Ju Y., Saka M., Abé H., “Non destructive detection of delamination in IC packages
utilizing open-ended coaxial line sensor”, NDT&E International, vol. 32, pp.259-64, 1999. [Ju 01] Ju Y., Saka M., Abé H., “Non destructive inspection of delamination in IC packages by high-frequency microwaves”, NDT&E International, vol. 34, pp.213-217, 2001. [Kol 71] Kolodziej H., Sobcyk L., “Investigation of dielectric properties of potassium hydrogen maleate”, Acta Physica Polonia, A39, p. 59, 1971. [Law 97] Lawrence S., Giles C. L., Tsoi A. C., “Lessons in neural network training: Ovefitting may be harder than expected”, Proceedings of the Fourteenth National Conference on Artifical Intelligence, AAAI-97, AAAI Press, Menlo Park, California, pp. 540-545, 1997. [Leb 00] Le Bihan Y. “ Conception et caractérisation d’un dispositif à courants de Foucault pour l’évaluation non destructive de l’épaisseur de paroi d’aubes de turbine creuses”, Thèse de doctorat de l’Ecole Normale Supérieure de Cachan, 2000. [LeC 91] LeCun Y., Boser B., Denker J.S., henderson D., Howard R.E., Hubbard W., Jackel L.D., “Backpropagation applied to handwritten zip code recognition”, Neural Computation, vol. 1, pp. 674-693, 1989 [Les 08] www.univ-bret.fr/lest/caracterisation, consulté en octobre 2008. [Lê 95] Lê M.Q., “Conception et modélisation de capteurs électromagnétiques : Application à la mesure simultanée des propriétés physiques et géométriques des objets métalliques”, Thèse de docteur en sciences, Orsay (Paris XI), 3 juillet 1995. [Lin 99] Linfeng C., Ong C.K., Tan B.T.G “Cavity perturbation technique for the
measurement of permittivity tensor of uniaxially anisotropic dielectrics”,IEEE Transaction on Instrumentation and measurement, vol. 48, issue 6, pp. 1023-1030, December 1999.
[Maa 06] Maazi M. Benzaim O., Glay D., Lasri T., “Reconstruction du profil géoétrique d’une fissure enfouie dans un matériau diélectrique par techniques microondes et réseaux et neurones artificiels”, 9ème Journées de Caractérisation Micro-ondes et Matériaux, Saint-Etienne, mars 2006. [Mac 92] MacKay, D. J. C., “Bayesian methods for adaptive models,” Thesis of California Institute of Technology, 1992.

114
[McC 43] McCulloch W.S., Pitts W., “A logical calculus of the ideas immanent in nervous activity”, Bulletin of Mathematical Biophysics, vol. 5, pp. 115-133, 1943.
[Mat 98] Neural Network Toolbox 6.0.1 User’s Guide. The Math Works Inc, 2008.
[Men 95] Meng B., Booske J., and Cooper R., "Extended cavity perturbation technique to determine the complex permittivity of dielectric materials", IEEE Transactions on Microwave Theory and Techniques, vol. 43, no. 11, pp. 2633-2636, November 1995.
[Mey 96] Meyer O. “Instrumentation pour un contrôle de processus de réticulation sous microondes par caractérisation diélectrique large bande. Contribution à la compréhension du couplage du champ électromagnétique aux dipôles moléculaire”, thèse de l’Université Pierre et marie Curie, Paris, 1996. [Mey 02] Meyer O., Chevalier S., Bloquet N., Belhadj-Tahar N., Fourrier-Lamer A., Cellule de caractérisation diélectrique large bande surdimensionnée, 7ème Journées de Caractérisation Micro-onde et Matériaux, Toulouse, mars 2002. [Mil 92] Miller E.K., Medgyesi-Mitschang L., Newman E.H., “Computational Electromagnetics - Frequency-domain method of moments”, IEEE Press, 1992. [Mir 08] Miranda D.A., Lόpez Rivera S.A., “Determination of Cole-Cole parameters using only the real part f electrical impedivity measurements”, Physiological Measurement Journal, vol. 29, pp. 669-683, 2008. [Mis 94] Misra D.K., McKelvey J.A., “Quasistatic method for the characterization of stratified dielectric materials using an open-ended coaxial probe”, Microwave-and-Optical-Technology-Letters. vol. 7, no. 14, 650-3, 1994. [Ngu 90] Nguyen D., Widrow B.. “Improving the Learning Speed of 2-Layer Neural Networks by Choosing Initial Values of the Adaptative weights”, International Joint Conference on Neural Networks, San Diego, USA, June 1990. [Ouk 97] Oukhellou L. “Paramétrisation et classification de signaux en contrôle non destructif. Application à la reconnaissance des défauts de rails par courants de Foucault”, Thèse de docteur en sciences, Orsay (Paris XI), 4 juillet 1997.
[Pav 07] Pávó, J., Gyimóthy, Sz., ‘Adaptive inversion database for electromagnetic nondestructive evaluation’, NDT&E International , vol. 40, no. 3, pp. 192-202, 2007. [Per 00] Pereira Carpes Junior W., “Modélisation tridimensionnelle par elements finis destinée aux analyses de propagation d’ondes et de compatibilité électromagnétique”, Thèse de doctorat de l’université Paris XI, 2000. [Pre 00] Premat E., “ Prise en compte d’effets météorologiques dans une méthode d’éléments finis de frontière”, Thèse de doctorat de l’Institut National des Sciences Appliquées de Lyon, 2000.

115
[Rek 02] Rekanos, I. T., “Neural network based inverse scattering technique for online microwave imaging”, IEEE Transactions on Magnetics, vol. 38, no. 2, March 2002. [Rmi 04] Rmili H., Oyhenart L., Miane J.L., Vigneras V., Olinga T., Zangar H., Parneix J.P., “Etude de l’évolution de la conductivité microonde de la polyaniline au cours de la formation d’un film”, 8ème Journées de la Caractérisation Microondes et Matériaux, La Rochelle, du 31 mars au 2 avril 2004. [Sad 92] Sadiku M.N.O., “Numerical techniques in electromagnetic”, CRC Press, 1992 [Sol 88] Solymar L., Walsh D., “Electrical Properties of Materials”, Oxford University Press, 1988.
[Skl 06] Sklarczyk C., Pinchuk R., Melev V., “ Nondestructive and Contactless Materials Characterization with the Help of Microwave Sensors”, ECNDT, Berlin, 2006.
[Taf 00] Taflove A., Hagness S.C., “Computational Electrodynamics - The finite-difference time-domain method”, Artech House, 2000 [Tho 97] Thorn R., “Recent developments in three-phase flow measurement”, Measurement Science and Technology, vol. 8, pp. 691-701, 1997 [Tou 92] TOUZET C., Les réseaux de neurones artificiels : introduction au connexionnisme, 150 pages, Préface de Jeanny Hérault, EC2 éd., Paris, 1992. [Tuc 95] Tuck D., Coad S., “Neurocomputed model of open-circuited coaxial probes”, IEEE Microwave Guided Letters, vol. 5, pp. 105–107, 1995. [Wuy 00] Wuyun-Bao B.; Yunliu Y.; Tongyi A., “Pyramid horn-a near field sensor for
NDT”, 2nd International Conference on ICMMT, pp. 557–560, Pékin, 2000.

116

117
Liste des publications
Publications dans des revues internationales à comité de lecture
[1] H. Acikgoz, Y. Le Bihan, O. Meyer, L. Pichon, “Neural networks for broad-band evaluation of complex permittivity using a coaxial discontinuity”, Eur. Phy. J. Appl. Phys. vol. 39,197-201, 2007
[2] H. Acikgoz, Y. Le Bihan, O. Meyer, L. Pichon, “Microwave Characterization of Dielectric Materials using Bayesian Neural Networks”, Progress In Electromagnetics Research C, vol. 3, 169-182, 2008
[3] H. Acikgoz, L. Santandrea, Y. Le Bihan, S. Gyimothy, J. Pavo, O. Meyer, L. Pichon, “Generation and use of optimized databases in microwave characterization”, IET Science, Measurement & Technology, acceptée, à paraître fin 2008
[4] H. Acikgoz, B. Jannier, Y. Le Bihan, O. Dubrunfaut, O. Meyer, L. Pichon, “Direct and Inverse Modeling of a microwave sensor determining the proportion of fluids in a pipeline”, IEEE Transactions on Magnetics, acceptée, à paraître en 2009.
Conférences internationales avec comité de lecture et actes
[5] H. Acikgoz, Y. Le Bihan, O. Meyer, L. Pichon, “Neural networks for broad-band evaluation of complex permittivity using a coaxial discontinuity”, NUMELEC’06, Lille, France, 29-30 Novembre and 1er Décembre ,2006
[6] H. Acikgoz, Y. Le Bihan, O. Meyer, L. Pichon, “ Microwave Characterization of Dielectrics Materials Using the Combination of a Finite Element Technique and Neural Networks”, Compumag, Aachen, 24-28 Juin, 2007
[7] H. Acikgoz, L. Santandrea, Y. Le Bihan, S. Gyimothy, J. Pavo, O. Meyer, L. Pichon, “Generation and use of optimized databases in microwave characterization”, IET Computation on Electromagnetic, Brighton, UK, 7 – 10 Avril, 2008
[8] H. Acikgoz, B. Jannier, Y. Le Bihan, O. Dubrunfaut, O. Meyer, L. Pichon, “Direct and Inverse Modeling of a microwave sensor determining the proportion of fluids in a pipeline”, 13th Biennial IEEE Conference on Electromagnetic Field Computation (CEFC), Athens, Greece, 11 – 15 May, 2008

118
Conférences nationales avec comité de lecture et actes [9] H. Acikgoz, Y. Le Bihan, O. Meyer, L. Pichon, “Technique d’Inversion par
Réseaux de Neurones Appliquée à la Caractérisation Large Bande de Matériaux Diélectriques”, Journées Nationales Micro-Ondes, Toulouse, 23-24-25 mai 2007
[10] H. Acikgoz, B. Jannier, Y. Le Bihan, O. Dubrunfaut, O. Meyer, “Modélisation
numérique d’un capteur pour la mesure des concentrations des phases d’un fluide en écoulement et inversion par réseau de neurones”, 10èmes Journées de Caractérisation Microondes et Matériaux, Limoges, 2 au 4 avril 2008
[11] H. Acikgoz, Y. Le Bihan, O. Meyer, L. Pichon, “Caractérisation micro-ondes
de matériaux diélectriques par réseaux de neurones avec régularisation bayesienne”, 10èmes Journées de Caractérisation Microondes et Matériaux, Limoges, 2 au 4 avril 2008
Séminaire
[12] H. Acikgoz, Y. Le Bihan, O. Meyer, L. Pichon, “Caractérisation micro-ondes
de matériaux diélectriques par combinaison de la méthode des éléments finis et des réseaux de neurones”, Journée des Doctorants, Réseau Micro-Ondes Ile-de-France (AREMIF), Paris, 8 mars 2007





























