Embed Size (px)
Citation preview

Théorie des langages et de la compilation
Thierry MassartUniversité Libre de BruxellesDépartement d’Informatique
Septembre 2007

Remerciements
Je tiens à vivement remercierGilles Geeraerts, Sébastien Collette, Camille Constant et Thomas De Schampheleire
pour leur relecture attentive du présent syllabus.
Thierry Massart

Chapitres du cours
1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52 Les langages réguliers et automates finis . . . . . . . . . . . . . . . . . . . . . . . . . . . . 443 L’analyse lexicale (scanning) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1404 Les grammaires . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1635 Les grammaires régulières . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .1876 Les grammaires context free . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1997 Les automates à pile et propriétés des langages context-free . . . . . . . 2358 L’analyse syntaxique (parsing) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2759 Les parseurs LL(k) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29610 Les parseurs LR(k) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36311 L’analyse sémantique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44512 La génération de code . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48113 Les machines de Turing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52614 Eléments de décidabilité . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 560

Références principales
J. E. Hopcroft, R. Motwani, and J. D. Ullman ; Introduction to AutomataTheory, Languages, and Computation, Second Edition, Addison-Wesley,New York, 2001.
Alfred V. Aho, Ravi Sethi, and Jeffrey D. Ullman, Compilers : Principles,Techniques and Tools", Addison-Wesley, 1986
Autres références :
John R. Levine, Tony Mason, Doug Brown, Lex & Yacc, O’Reilly ed,1992.
Reinhard Wilhelm, Dieter Maurer, Compiler Design, Addison-Wesley,1995. (parle des P-machines)
Pierre Wolper, Introduction à la Calculabilité, InterEditions, 1991.

But du coursOrdre des chapitres
Qu’est-ce que la théorie des langages ?Qu’est-ce qu’un compilateur ?
Phases de la compilationQuelques rappels et notations mathématiques
Chapitre 1 : Introduction
1 But du cours
2 Ordre des chapitres
3 Qu’est-ce que la théorie des langages ?
4 Qu’est-ce qu’un compilateur ?
5 Phases de la compilation
6 Quelques rappels et notations mathématiques
5
But du coursOrdre des chapitres
Qu’est-ce que la théorie des langages ?Qu’est-ce qu’un compilateur ?
Phases de la compilationQuelques rappels et notations mathématiques
Plan
1 But du cours
2 Ordre des chapitres
3 Qu’est-ce que la théorie des langages ?
4 Qu’est-ce qu’un compilateur ?
5 Phases de la compilation
6 Quelques rappels et notations mathématiques
6

But du coursOrdre des chapitres
Qu’est-ce que la théorie des langages ?Qu’est-ce qu’un compilateur ?
Phases de la compilationQuelques rappels et notations mathématiques
Que va-t-on apprendre dans ce cours ? (entre autres)
1 Comment définir formellement un modèle pour décrireun langage (de programmation ou autre)un système (informatique)
2 Comment déduire des propriétés sur ce modèle3 Ce qu’est
un compilateurun outil de traitement de données
4 La notion d’outil permettant de construire d’autres outilsExemple : générateur de (partie de) compilateur
5 Comment construire un compilateur ou un outil de traitement dedonnées
en programmanten utilisant ces outils
6 Quelques notions de décidabilité
7

But du coursOrdre des chapitres
Qu’est-ce que la théorie des langages ?Qu’est-ce qu’un compilateur ?
Phases de la compilationQuelques rappels et notations mathématiques
Démarche
Montrer la démarche scientifique et de l’ingénieur qui consiste à1 Comprendre les outils (mathématiques / informatiques) disponibles pour
résoudre le problème2 Apprendre à manipuler ces outils3 Concevoir un système à partir de ces outils4 Implémenter ce système
Les outils ici sont
les formalismes pour définir un langage ou modéliser un système
les générateurs de parties de compilateurs
8

But du coursOrdre des chapitres
Qu’est-ce que la théorie des langages ?Qu’est-ce qu’un compilateur ?
Phases de la compilationQuelques rappels et notations mathématiques
Plan
1 But du cours
2 Ordre des chapitres
3 Qu’est-ce que la théorie des langages ?
4 Qu’est-ce qu’un compilateur ?
5 Phases de la compilation
6 Quelques rappels et notations mathématiques
9

Ordre des chapitres
1. Introduction 2. Langages réguliers et automates finis
3. Les scanners - analyseurs lexicaux
4 Les grammaires
5 Les grammaires régulières
6 Les grammaires context-free
8. Les parsers - analyseurs syntaxiques
9. Les parseurs LL(k)10. Les parseurs LR(k)
11. L'analyse sémantique
12. La génération de code
13. Les machines de Turing
14. Eléments de décidabilité
7. Les automates à pile
marque que A est un prérequis à BA BLégende :
Exemples deséquences de lecture
Pour voirl’ensemble de lamatière : 1-14 enséquence
Pour ne voir que lamatière“compilateur” :1-2-3-4-6-7-8-9-10-11-12
Pour ne voir que lamatière “théoriedes langages” :1-2-4-5-6-7-13-14

But du coursOrdre des chapitres
Qu’est-ce que la théorie des langages ?Qu’est-ce qu’un compilateur ?
Phases de la compilationQuelques rappels et notations mathématiques
Plan
1 But du cours
2 Ordre des chapitres
3 Qu’est-ce que la théorie des langages ?
4 Qu’est-ce qu’un compilateur ?
5 Phases de la compilation
6 Quelques rappels et notations mathématiques
11

But du coursOrdre des chapitres
Qu’est-ce que la théorie des langages ?Qu’est-ce qu’un compilateur ?
Phases de la compilationQuelques rappels et notations mathématiques
Le monde de la théorie des langages
Objectifs de la théorie des langages
Comprendre le fonctionnement des langages (formel), vus comme moyen decommunication, d’un point de vue mathématique.
Définition (Langage - mot)
Un langage est un ensemble de mots.
Un mot (ou lexème ou chaîne de caractères ou string en anglais) est uneséquence de symboles (signes) élémentaires dans un alphabet donné.
12

But du coursOrdre des chapitres
Qu’est-ce que la théorie des langages ?Qu’est-ce qu’un compilateur ?
Phases de la compilationQuelques rappels et notations mathématiques
Alphabets, mots, langages
Exemple (alphabets, mots et langages)
Alphabet Mots LangagesΣ ={0, 1} ε,0,1,00, 01 {00,01, 1, 0, ε }, {ε}, ∅
{a, b, c, . . ., z} bonjour, ca, va {bonjour, ca, va, ε}{“héron”, “petit”, “pas”} “héron” “petit” “pas” {ε, “héron” “petit” “pas”}{α, β, γ, δ, µ, ν, π, σ, τ } ταγαδα {ε,ταγαδα}
{0, 1} ε,01,10 {ε,01,10, 0011, 0101, . . . }
Notations
Nous utiliserons habituellement des notations conventionnelles :
Alphabet : Σ (exemple : Σ = {0, 1})Mots : x , y , z, . . . (exemple : x = 0011)
Langages : L, L1, . . . (exemple : L = {ε, 00, 11})
13

But du coursOrdre des chapitres
Qu’est-ce que la théorie des langages ?Qu’est-ce qu’un compilateur ?
Phases de la compilationQuelques rappels et notations mathématiques
Le monde de la théorie des langages (suite)
Notions générales étudiées ici
La notion de grammaire (formelle) qui définit (la syntaxe d’) un langage,
La notion d’automate permettant de déterminer si un mot fait partie d’unlangage (et donc permettant également de définir un langage(l’ensemble des mots acceptés)),
La notion d’expression régulière qui permet de dénoter un langage.
14

But du coursOrdre des chapitres
Qu’est-ce que la théorie des langages ?Qu’est-ce qu’un compilateur ?
Phases de la compilationQuelques rappels et notations mathématiques
Motivations et applications
Applications pratiques de la théorie des langages
la définition formelle de la syntaxe et sémantique de langages deprogrammation,
la construction de compilateurs,
la modélisation abstraite d’un système informatique, électronique,biologique, ...
Motivations théoriques
Liées aux théories de
la calculabilité (qui détermine en particulier quels problèmes sontsolubles par un ordinateur)
la complexité qui étudie les ressources (principalement temps et espacemémoire) requises pour résoudre un problème donné
15

But du coursOrdre des chapitres
Qu’est-ce que la théorie des langages ?Qu’est-ce qu’un compilateur ?
Phases de la compilationQuelques rappels et notations mathématiques
Plan
1 But du cours
2 Ordre des chapitres
3 Qu’est-ce que la théorie des langages ?
4 Qu’est-ce qu’un compilateur ?
5 Phases de la compilation
6 Quelques rappels et notations mathématiques
16

Définition générale
Définition (Compilateur)
Un compilateur est un programme informatique de traduction CLCLS→LO
avec
1 LC le langage avec lequel est écrit le compilateur2 LS le langage source à compiler3 LO le langage cible ou langage objet
Exemple (pour CLCLS→LO
)
LC LS LO
C Assembleur RISC Assembleur RISCC C Assembleur P7C java CJava LATE X HTMLC XML PDF
Si LC = LS : peut nécessiter un bootstrapping pour compiler CLCLC→LO

But du coursOrdre des chapitres
Qu’est-ce que la théorie des langages ?Qu’est-ce qu’un compilateur ?
Phases de la compilationQuelques rappels et notations mathématiques
Structure générale d’un compilateur
Généralement un langage intermédiaire LI est utilisé.Le compilateur est formé :
d’un front-end LS → LI
d’un back-end LI → LO
Facilite la construction de nouveaux compilateurs
Image
Java Haskell Prolog
P7 C RISC
18

But du coursOrdre des chapitres
Qu’est-ce que la théorie des langages ?Qu’est-ce qu’un compilateur ?
Phases de la compilationQuelques rappels et notations mathématiques
Caractéristiques des compilateurs
Efficacité
Robustesse
Portabilité
Fiabilité
Code debuggable
À une passe
À n passes (70 pour un compilateurPL/I !)
Optimisant
Natif
Cross-compilation
Compilateur vs. Interpréteur
Interpréteur = outil qui analyse, traduit, mais aussi exécute un programmeécrit dans un langage informatique.L’interpréteur se charge donc également de l’exécution au fur et à mesure deson interprétation.
19

But du coursOrdre des chapitres
Qu’est-ce que la théorie des langages ?Qu’est-ce qu’un compilateur ?
Phases de la compilationQuelques rappels et notations mathématiques
Plan
1 But du cours
2 Ordre des chapitres
3 Qu’est-ce que la théorie des langages ?
4 Qu’est-ce qu’un compilateur ?
5 Phases de la compilation
6 Quelques rappels et notations mathématiques
20

But du coursOrdre des chapitres
Qu’est-ce que la théorie des langages ?Qu’est-ce qu’un compilateur ?
Phases de la compilationQuelques rappels et notations mathématiques
Un petit programme à compiler
Exemple (de programme à compiler)
int main() // Conjecture De Syracuse // Hypothèse : N > 0 { long int N; cout << "Entrer Un Nombre : "; cin >> N; while (N != 1) { if (N%2 == 0) N = N/2; else N = 3*N+1; } cout << N << endl; //Imprime 1 }
21

But du coursOrdre des chapitres
Qu’est-ce que la théorie des langages ?Qu’est-ce qu’un compilateur ?
Phases de la compilationQuelques rappels et notations mathématiques
6 phases de compilation : 3 d’analyse - 3 de synthèse
}}
Parsing
Scanning
Analyse sémantique
Optimisation
Génér. du code intermédiaire
Génération du code final
Table des symboles
Gestion des erreurs
Analyse
Synthèse
22

But du coursOrdre des chapitres
Qu’est-ce que la théorie des langages ?Qu’est-ce qu’un compilateur ?
Phases de la compilationQuelques rappels et notations mathématiques
Etapes de la compilation
Compilation découpée en 2 étapes
1 L’analyse décompose et identifie les éléments et relations du programmesource et construit son image (représentation hierachique duprogramme avec ses relations),
2 La synthèse qui construit à partir de l’image un programme en langagecible
Contenu de la table des symboles
Un enregistrement par identificateur du programme à compiler contenant lesvaleurs des attributs pour le décrire.
Remarque
En cas d’erreur, le compilateur peut essayer de se resynchroniser pouréventuellement essayer de reporter d’autres erreurs
23
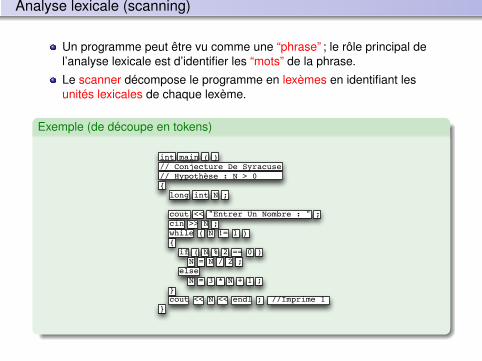
Analyse lexicale (scanning)
Un programme peut être vu comme une “phrase” ; le rôle principal del’analyse lexicale est d’identifier les “mots” de la phrase.
Le scanner décompose le programme en lexèmes en identifiant lesunités lexicales de chaque lexème.
Exemple (de découpe en tokens)
int main ( ) // Conjecture De Syracuse // Hypothèse : N > 0 { long int N ; cout << "Entrer Un Nombre : " ; cin >> N ; while ( N != 1 ) { if ( N % 2 == 0 ) N = N / 2 ; else N = 3 * N + 1 ; } cout << N << endl ; //Imprime 1 }

Analyse lexicale (scanning)
Définition (Unité lexicale (ou token))
Type générique d’éléments lexicaux (correspond à un ensemble de stringsayant une sémantique proche).Exemple : identificateur, opérateur relationnel, mot clé “begin”...
Définition (Lexème (ou string))
Occurrence d’une unité lexicale.Exemple : N est un lexème dont l’unité lexicale est identificateur
Définition (Modèle (pattern))
Règle décrivant une unité lexicaleEn général un modèle est donné sous forme d’expression régulière (voirci-dessous)
Relation entre lexème, unité lexicale et modèle
unité lexicale = { lexème | modèle(lexème) }

But du coursOrdre des chapitres
Qu’est-ce que la théorie des langages ?Qu’est-ce qu’un compilateur ?
Phases de la compilationQuelques rappels et notations mathématiques
Exemples introductifs de la notion d’expression régulière
Opérateurs des expressions régulières :
. : concaténation (généralement omis)
+ : union
* : répétition (0,1,2, ... fois) = (fermeture de Kleene (prononcé Klayni !))
Exemple (Quelques expressions régulières)
chiffre = 0 + 1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9
nat-nb = chiffre chiffre*
operateur = << + != + == + ...
par-ouvrante = (
par-fermante = )
lettre = a + b + ... + z
identificateur = lettre (lettre + chiffre)*26
But du coursOrdre des chapitres
Qu’est-ce que la théorie des langages ?Qu’est-ce qu’un compilateur ?
Phases de la compilationQuelques rappels et notations mathématiques
Résultat du scanning
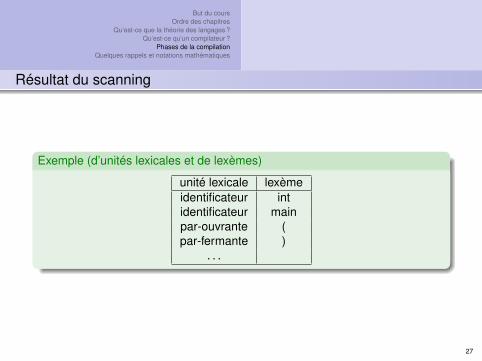
Exemple (d’unités lexicales et de lexèmes)
unité lexicale lexèmeidentificateur intidentificateur mainpar-ouvrante (par-fermante )
. . .
27

But du coursOrdre des chapitres
Qu’est-ce que la théorie des langages ?Qu’est-ce qu’un compilateur ?
Phases de la compilationQuelques rappels et notations mathématiques
Autres buts du scanning
Autres buts du scanning
Met (éventuellement) les identificateurs (non prédéfinis) et littéraux dansla table des symbolesa
Produit le listing / lien avec un éditeur intelligent
Nettoie le programme source (supprime les commentaires, espaces,tabulations, . . .)
apeut se faire lors d’une phase ultérieure d’analyse
28

But du coursOrdre des chapitres
Qu’est-ce que la théorie des langages ?Qu’est-ce qu’un compilateur ?
Phases de la compilationQuelques rappels et notations mathématiques
Analyse syntaxique (parsing)
Le rôle principal de l’analyse syntaxique est de trouver la structure de la“phrase” (le programme) : càd de construire une représentation interneau compilateur et facilement manipulable de la structure syntaxique duprogramme source.
Le parser construit l’arbre syntaxique correspondant au code.
L’ensemble des arbres syntaxiques possibles pour un programme est définigrâce à une grammaire (context-free).
29
But du coursOrdre des chapitres
Qu’est-ce que la théorie des langages ?Qu’est-ce qu’un compilateur ?
Phases de la compilationQuelques rappels et notations mathématiques
Exemple de grammaire
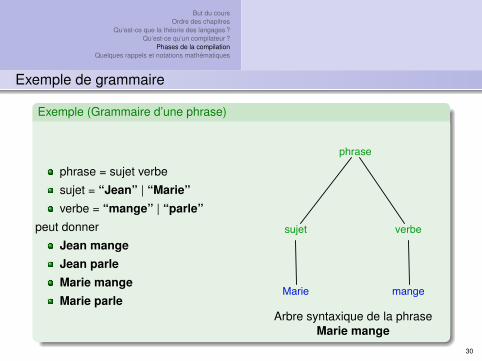
Exemple (Grammaire d’une phrase)
phrase = sujet verbe
sujet = “Jean” | “Marie”verbe = “mange” | “parle”
peut donner
Jean mangeJean parleMarie mangeMarie parle
phrase
sujet verbe
Marie mange
Arbre syntaxique de la phraseMarie mange
30

But du coursOrdre des chapitres
Qu’est-ce que la théorie des langages ?Qu’est-ce qu’un compilateur ?
Phases de la compilationQuelques rappels et notations mathématiques
Exemple de grammaire (2)
Exemple (Grammaire d’une expression)
A = “id” “=” E
E = T | E “+” T
T = F | T “*” F
F = “id” | “cst” | “(” E“)”
peut donner :
id = idid = id + cst * id. . .
E
E T
A
+
F
id
*T
F
cst
F
id
id =
T
Arbre syntaxique de la phraseid = id + cst * id
31

But du coursOrdre des chapitres
Qu’est-ce que la théorie des langages ?Qu’est-ce qu’un compilateur ?
Phases de la compilationQuelques rappels et notations mathématiques
Exemple de grammaire (2 (suite))
Exemple (Grammaire d’une expression)
A = “id” “=” E
E = T | E “+” T
T = F | T “*” F
F = “id” | “cst” | “(” E“)”
peut donner :
id = idid = id + cst * id. . .
=
id +
*id
cst id
d15.15
ci
Table des symboles
Arbre syntaxique abstraitavec références à la table des
symboles de la phrase i = c + 15.15 * d32

But du coursOrdre des chapitres
Qu’est-ce que la théorie des langages ?Qu’est-ce qu’un compilateur ?
Phases de la compilationQuelques rappels et notations mathématiques
Analyse sémantique
Rôle de l’analyse sémantique
Pour un langage impératif, l’analyse sémantique (appelée aussi gestion decontexte) s’occupe des relations non locales ; elle s’occupe ainsi :
1 du contrôle de visibilité et du lien entre les définitions et utilisations desidentificateurs (en utilisant/construisant la table des symboles)
2 du contrôle de type des “objets”, nombre et type des paramètres defonctions
3 du contrôle de flot (vérifie par exemple qu’un goto est licite - voirexemple plus bas)
4 de construire un arbre syntaxique abstrait complété avec desinformations de type et un graphe de contrôle de flot pour préparer lesphases de synthèse.
33

Exemple de résultat de l’analyse sémantique
Exemple (pour l’expression i = c + 15.15 * d)
=
id +
*id
cst
id
d15.15
ci
Table des symboles
varcstvarvar
int->real
scope1
scope2scope1
intrealrealreal
Arbre syntaxique abstrait modifiéavec références à la table des
symboles de la phrase i = c + 15.15 * d

But du coursOrdre des chapitres
Qu’est-ce que la théorie des langages ?Qu’est-ce qu’un compilateur ?
Phases de la compilationQuelques rappels et notations mathématiques
Synthèse
Phases de synthèse
Pour un langage impératif, la synthèse comporte les 3 phases1 Génération de code intermédiaire sous forme de langage universel qui
utilise un adressage symboliqueutilise des opérations standardeffectue l’allocation mémoire (résultat dans des variables temporaires...)
2 Optimisation du codesupprime le code “mort”met certaines instructions hors des bouclessupprime certaines instructions et optimise les accès à la mémoire
3 Production du code finalAllocation de mémoire physiquegestion des registres
35

Exemple de synthèse
Exemple (pour le code i = c + 15.15 * d)
1 Génération de code intermédiaire
temp1 <- 15.15temp2 <- Int2Real(id3)temp2 <- temp1 * temp2temp3 <- id2temp3 <- temp3 + temp2id1 <- temp3
2 Optimisation du code
temp1 <- Int2Real(id3)temp1 <- 15.15 * temp1id1 <- id2 + temp1
3 Production du code final
MOVF id3,R1ITOR R1MULF 15.15,R1,R1ADDF id2,R1,R1STO R1,id1

But du coursOrdre des chapitres
Qu’est-ce que la théorie des langages ?Qu’est-ce qu’un compilateur ?
Phases de la compilationQuelques rappels et notations mathématiques
Plan
1 But du cours
2 Ordre des chapitres
3 Qu’est-ce que la théorie des langages ?
4 Qu’est-ce qu’un compilateur ?
5 Phases de la compilation
6 Quelques rappels et notations mathématiques
37

But du coursOrdre des chapitres
Qu’est-ce que la théorie des langages ?Qu’est-ce qu’un compilateur ?
Phases de la compilationQuelques rappels et notations mathématiques
Notations utilisées
Σ : Alphabet du langage
x , y , z, t , xi (lettre à la fin de l’alphabet) : string de symboles de Σ(exemple x = abba)
ε : mot vide
|x | : longueur du string x (|ε| = 0, |abba| = 4)
ai = aa...a (string formé de i fois le caractère a)
x i = xx ...x (string formé de i fois le string x)
L,L′, Li A, B : langages
38

But du coursOrdre des chapitres
Qu’est-ce que la théorie des langages ?Qu’est-ce qu’un compilateur ?
Phases de la compilationQuelques rappels et notations mathématiques
Opérations sur les strings
concaténation : ex : lent.gage = lentgageεw = w = wε
wR : image miroir de w (ex : abbdR = dbba)préfixe de w . ex : si w=abbc
les préfixes sont : ε, a, ab, abb, abbcles préfixes propres sont ε, a, ab, abb
suffixe de w . ex : si w=abbcles suffixes sont : ε, c, bc, bbc, abbcles suffixes propres sont ε, c, bc, bbc
39

But du coursOrdre des chapitres
Qu’est-ce que la théorie des langages ?Qu’est-ce qu’un compilateur ?
Phases de la compilationQuelques rappels et notations mathématiques
Opérations sur les langages
Définition (Langage sur l’alphabet Σ)
Ensemble de strings sur cet alphabet
Les opérations sur les langages sont donc des opérations ensemblistes
∪,∩, \, A× B, 2A
concaténation ou produit : ex : L1.L2 = {xy |x ∈ L1 ∧ y ∈ L2}L0 =def {ε}Li = Li−1.L
La fermeture de Kleene : L∗ =defS
i∈N Li
La fermeture positive : L+ =defS
i∈N+ Li
le complément :_L = {w |w ∈ Σ∗ ∧ w /∈ L}
40

But du coursOrdre des chapitres
Qu’est-ce que la théorie des langages ?Qu’est-ce qu’un compilateur ?
Phases de la compilationQuelques rappels et notations mathématiques
Relations
Définition (Équivalence)
Relation :
réflexive
symétrique
transitive
Définition (Fermeture de relations)
Soit P un ensemble de propriétés d’une relation R, la P-fermeture de R est laplus petite relation R′ qui inclut R et possède les propriétés P
Exemple (de fermeture réflexo-transitive)
La fermeture transitive R+, la fermeture reflexo-transitive R∗
a b c donne pour R∗ a b c
41

But du coursOrdre des chapitres
Qu’est-ce que la théorie des langages ?Qu’est-ce qu’un compilateur ?
Phases de la compilationQuelques rappels et notations mathématiques
Propriété de fermeture d’une classe de langages
Définition (Fermeture d’une classe de langages)
Une classe de langages C est fermée pour une opération op, si le langagerésultant de cette opération sur n’importe quel(s) langage(s) de C reste danscette même classe de langages C.Exemple : en supposant que op soit binaire
C est fermé pour opssi
∀L1, L2 ∈ C ⇒ L1 op L2 ∈ C
42

But du coursOrdre des chapitres
Qu’est-ce que la théorie des langages ?Qu’est-ce qu’un compilateur ?
Phases de la compilationQuelques rappels et notations mathématiques
Cardinalités
Définition (Même cardinalité)
Deux ensembles ont la même cardinalité s’il existe une bijection entre eux.Notons
ℵ0 la cardinalité des ensembles infinis dénombrables (comme N)
ℵ1 la cardinalité des ensembles infinis continus (comme R)
Nous supposons que les ensembles non dénombrables sont infinis continus.
Cardinalité de Σ∗ et 2Σ∗
Soit un alphabet fini non vide Σ,
Σ∗ : l’ensemble des strings de Σ, est infini dénombrable
P(Σ∗) dénoté aussi 2Σ∗: l’ensemble des langages de Σ, est infini
continu
43

Les langages réguliers et expressions régulièresLes automates finis
Équivalence entre FA et REAutres types d’automates finis
Propriétés des langages réguliersÉquivalence et minimisation d’automates finis
Chapitre 2 : Les langages réguliers et automates finis
1 Les langages réguliers et expressions régulières
2 Les automates finis
3 Équivalence entre FA et RE
4 Autres types d’automates finis
5 Propriétés des langages réguliers
6 Équivalence et minimisation d’automates finis
44

Les langages réguliers et expressions régulièresLes automates finis
Équivalence entre FA et REAutres types d’automates finis
Propriétés des langages réguliersÉquivalence et minimisation d’automates finis
Plan
1 Les langages réguliers et expressions régulières
2 Les automates finis
3 Équivalence entre FA et RE
4 Autres types d’automates finis
5 Propriétés des langages réguliers
6 Équivalence et minimisation d’automates finis
45

Les langages réguliers et expressions régulièresLes automates finis
Équivalence entre FA et REAutres types d’automates finis
Propriétés des langages réguliersÉquivalence et minimisation d’automates finis
Introduction
Motivation
Les expressions régulières permettent aisément de dénoter deslangages (réguliers)
Par exemple, UNIX utilise intensivement les expressions régulièresétendues dans ses shells
Elles sont également utilisées pour définir les unités lexicales d’unlangage de programmation
46

Les langages réguliers et expressions régulièresLes automates finis
Équivalence entre FA et REAutres types d’automates finis
Propriétés des langages réguliersÉquivalence et minimisation d’automates finis
Définition des langages réguliers
Remarque préliminaire
Tout langage fini peut être énuméré (même si cela peut être long).
Pour les langages infinis une énumération exhaustive n’est pas possible
La classe des langages réguliers (définie ci-dessous) comprend tous leslangages finis et certains langages infinis
Définition (classe des langages réguliers)
L’ensemble L des langages réguliers sur un alphabet Σ est le plus petitensemble satisfaisant :
1 ∅ ∈ L2 {ε} ∈ L3 ∀a ∈ Σ, {a} ∈ L4 si A, B ∈ L alors A ∪ B, A.B, A∗ ∈ L
47

Notation des langages réguliers
Définition (ensemble des expressions régulières (RE))
L’ensemble des expressions régulières (RE) sur un alphabet Σ est le pluspetit ensemble contenant :
1 ∅ : dénote l’ensemble vide,2 ε : dénote l’ensemble {ε},3 ∀a ∈ Σ, a : dénote l’ensemble {a},4 ayant r et s qui dénotent resp. R et S :
r + s , rs et r∗ dénotent resp. R ∪ S, R.S et R∗
On suppose ∗ < . < + et on rajoute des () si nécessaire
Exemple (d’expressions régulières)
00(0 + 1)∗
(0 + 1)∗00(0 + 1)∗
04104 notation pour 000010000(01)∗ + (10)∗ + 0(10)∗ + 1(01)∗
(ε + 1)(01)∗(ε + 0)

Propriétés des langages réguliers
Théorème (correpondance expressions et langages réguliers)
Un langage est régulier ssi il est dénoté par une expression régulière.PreuvePar induction structurelle
Propriétés de ε et ∅εw = w = wε
∅w = ∅ = w∅∅+ r = r = r + ∅ε∗ = ε
∅∗ = ε
(ε + r)∗ = r∗
Théorème (cardinalité des langages réguliers)
L’ensemble des langages réguliers est infini dénombrable

Les langages réguliers et expressions régulièresLes automates finis
Équivalence entre FA et REAutres types d’automates finis
Propriétés des langages réguliersÉquivalence et minimisation d’automates finis
Plan
1 Les langages réguliers et expressions régulières
2 Les automates finis
3 Équivalence entre FA et RE
4 Autres types d’automates finis
5 Propriétés des langages réguliers
6 Équivalence et minimisation d’automates finis
50

Les langages réguliers et expressions régulièresLes automates finis
Équivalence entre FA et REAutres types d’automates finis
Propriétés des langages réguliersÉquivalence et minimisation d’automates finis
Automates
Présentation informelle
Un automate M est un modèle mathématique d’un système avec des entréeset des sorties discrètes.Il contient généralement
des états de contrôle (M se trouve dans un de ces états)
un ruban de données contenant des symboles
une tête de lecture
une mémoire
51

Les langages réguliers et expressions régulièresLes automates finis
Équivalence entre FA et REAutres types d’automates finis
Propriétés des langages réguliersÉquivalence et minimisation d’automates finis
Automates
Présentation informelle
b o n j o u r . . .
b
on
...
52
Les langages réguliers et expressions régulièresLes automates finis
Équivalence entre FA et REAutres types d’automates finis
Propriétés des langages réguliersÉquivalence et minimisation d’automates finis
Exemple : un protocole d’e-commerce avec e-money
Exemple (Evénéments possibles :)
1 pay : le client paye le magasin2 cancel : le client stoppe la transaction3 ship : le magasin envoie le bien4 redeem : le magasin demande l’argent à la banque5 transfer : la banque transfert l’argent au magasin
Remarque
L’exemple sera formalisé par un (des) automate(s) fini(s) (voir plus bas)
53

Exemple : un protocole d’e-commerce avec e-money (2)
Exemple (Protocole pour chaque participant)
e-commerce
The protocol for each participant:
1 43
2
transferredeem
cancel
Start
a b
c
d f
e g
Start
(a) Store
(b) Customer (c) Bank
redeem transfer
ship ship
transferredeem
ship
pay
cancel
Start pay
17
e-commerce
The protocol for each participant:
1 43
2
transferredeem
cancel
Start
a b
c
d f
e g
Start
(a) Store
(b) Customer (c) Bank
redeem transfer
ship ship
transferredeem
ship
pay
cancel
Start pay
17
e-commerce
The protocol for each participant:
1 43
2
transferredeem
cancel
Start
a b
c
d f
e g
Start
(a) Store
(b) Customer (c) Bank
redeem transfer
ship ship
transferredeem
ship
pay
cancel
Start pay
17
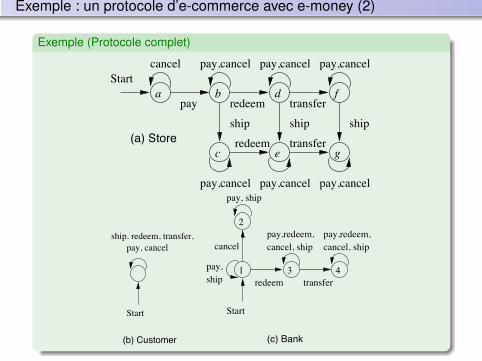
Exemple : un protocole d’e-commerce avec e-money (2)
Exemple (Protocole complet)Completed protocols:
cancel
1 43
2
transferredeem
cancel
Start
a b
c
d f
e g
Start
(a) Store
(b) Customer (c) Bank
ship shipship
redeem transfer
transferredeempay
pay, cancel
ship. redeem, transfer,
pay,
ship
pay, ship
pay,cancel pay,cancel pay,cancel
pay,cancel pay,cancel pay,cancel
cancel, ship cancel, ship
pay,redeem, pay,redeem,
Start
18
Completed protocols:
cancel
1 43
2
transferredeem
cancel
Start
a b
c
d f
e g
Start
(a) Store
(b) Customer (c) Bank
ship shipship
redeem transfer
transferredeempay
pay, cancel
ship. redeem, transfer,
pay,
ship
pay, ship
pay,cancel pay,cancel pay,cancel
pay,cancel pay,cancel pay,cancel
cancel, ship cancel, ship
pay,redeem, pay,redeem,
Start
18
Completed protocols:
cancel
1 43
2
transferredeem
cancel
Start
a b
c
d f
e g
Start
(a) Store
(b) Customer (c) Bank
ship shipship
redeem transfer
transferredeempay
pay, cancel
ship. redeem, transfer,
pay,
ship
pay, ship
pay,cancel pay,cancel pay,cancel
pay,cancel pay,cancel pay,cancel
cancel, ship cancel, ship
pay,redeem, pay,redeem,
Start
18

Exemple : un protocole d’e-commerce avec e-money (2)
Exemple (Système complet)The entire system as an Automaton:
C C C C C C C
P P P P P P
P P P P P P
P,C P,C
P,C P,C P,C P,C P,C P,CC
C
P S SS
P S SS
P SS
P S SS
a b c d e f g
1
2
3
4
Start
P,C
P,C P,CP,C
R
R
S
T
T
R
R
R
R
19

Automates finis (FA)
Mise en garde
Dans ce cours, nous examinerons les automates comme formalismeacceptant un ensemble de strings et donc définissant un langage (tous lesstrings acceptés)
Restriction des automates finis
Un automate fini (FA) :
n’a pas de mémoire
ne peut que lire sur le ruban
la tête de lecture se déplace toujours vers la droite
On distingue
Les automates finis déterministes (DFA)
Les automates finis non déterministes (NFA)
Les automates finis non déterministes avec transitions spontannées(ε-NFA)-> Ajoutons un symbole ε pour décrire ces transitions spontannées

Les langages réguliers et expressions régulièresLes automates finis
Équivalence entre FA et REAutres types d’automates finis
Propriétés des langages réguliersÉquivalence et minimisation d’automates finis
Automate fini : définition formelle
Définition (Automate fini)
M = 〈Q, Σ, δ, q0, F 〉
avec1 Q : ensemble fini des états2 Σ : alphabet (symboles permis à l’entrée)3 δ : fonction de transition4 q0 : état initial5 F ⊆ Q : ensemble des états accepteurs
δ est défini pour
M DFA : δ : Q × Σ→ Q
M NFA : δ : Q × Σ→ 2Q
M ε-NFA : δ : Q × (Σ ∪ {ε})→ 2Q
58

Exemples d’automates finis
Exemple
Un automate déterministe A qui accepte L = {x01y : x , y ∈ {0, 1}∗}
A = 〈{q0, q1, q2}, {0, 1}, δ, q0, {q1}〉
avec δ :
Example: An automaton A that accepts
L = {x01y : x, y ∈ {0,1}∗}
The automaton A = ({q0, q1, q2}, {0,1}, δ, q0, {q1})as a transition table:
0 1→ q0 q2 q0
"q1 q1 q1q2 q2 q1
The automaton as a transition diagram:
1 0
0 1q0
q2
q1 0, 1
Start
21
graphiquement (diagramme de transition) :
Example: An automaton A that accepts
L = {x01y : x, y ∈ {0,1}∗}
The automaton A = ({q0, q1, q2}, {0,1}, δ, q0, {q1})as a transition table:
0 1→ q0 q2 q0
"q1 q1 q1q2 q2 q1
The automaton as a transition diagram:
1 0
0 1q0
q2
q1 0, 1
Start
21String accepté
Un string w = a1a2 . . . an est accepté par le FA s’il existe un chemin dans lediagramme de transition qui débute à l’état initial, se termine dans un étataccepteur et a une séquence de labels a1a2 . . . an

Les langages réguliers et expressions régulièresLes automates finis
Équivalence entre FA et REAutres types d’automates finis
Propriétés des langages réguliersÉquivalence et minimisation d’automates finis
Configuration et langage accepté
Définition (Configuration d’un FA)
Couple 〈q, w〉 ∈ Q × Σ∗
Configuration initiale : 〈q0, w〉 où w est le string à accepter
Configuration finale (qui accepte) : 〈q, ε〉 avec q ∈ F
Définition (Changement de configuration)
〈q, aw〉M〈q′, w〉 si
δ(q, a) = q′ pour un DFA
q′ ∈ δ(q, a) pour un NFA
q′ ∈ δ(q, a) pour un ε-NFA avec a ∈ Σ ∪ {ε}
60

Les langages réguliers et expressions régulièresLes automates finis
Équivalence entre FA et REAutres types d’automates finis
Propriétés des langages réguliersÉquivalence et minimisation d’automates finis
Langage de M : L(M)
Définition (L(M))
L(M) = {w | w ∈ Σ∗ ∧ ∃q ∈ F . 〈q0, w〉∗
M〈q, ε〉}
où∗
Mest la fermeture réflexo-transitive de
M
Définition (Équivalence d’automates)
M et M ′ sont équivalents s’ils définissent le même langage (L(M) = L(M ′))
61

Exemple de DFA
Exemple
Le DFA M accepte l’ensemble des strings sur l’alphabet {0, 1} avec unnombre pair de 0 et de 1.
M = 〈{q0, q1, q2, q3}, {0, 1}, δ, q0, {q0}〉
avec δ et le diagramme de transition :
Example: DFA accepting all and only stringswith an even number of 0’s and an even num-ber of 1’s
q q
q q
0 1
2 3
Start
0
0
1
1
0
0
1
1
Tabular representation of the Automaton
0 1!→ q0 q2 q1
q1 q3 q0q2 q0 q3q3 q1 q2
24
Example: DFA accepting all and only stringswith an even number of 0’s and an even num-ber of 1’s
q q
q q
0 1
2 3
Start
0
0
1
1
0
0
1
1
Tabular representation of the Automaton
0 1!→ q0 q2 q1
q1 q3 q0q2 q0 q3q3 q1 q2
24

Les langages réguliers et expressions régulièresLes automates finis
Équivalence entre FA et REAutres types d’automates finis
Propriétés des langages réguliersÉquivalence et minimisation d’automates finis
Exemple de NFA
Exemple
Le NFA M accepte l’ensemble des strings sur l’alphabet {0, 1} qui seterminent par 01.
M = 〈{q0, q1, q2}, {0, 1}, δ, q0, {q2}〉
avec δ et le diagramme de transition :
Example: The NFA from the previous slide is
({q0, q1, q2}, {0,1}, δ, q0, {q2})
where δ is the transition function
0 1→ q0 {q0, q1} {q0}
q1 ∅ {q2}"q2 ∅ ∅
29
Nondeterministic Finite Automata
A NFA can be in several states at once, or,viewded another way, it can “guess” whichstate to go to next
Example: An automaton that accepts all andonly strings ending in 01.
Start 0 1q0
q q
0, 1
1 2
Here is what happens when the NFA processesthe input 00101
q0
q2
q0
q0
q0
q0
q0
q1
q1
q1
q2
0 0 1 0 1
(stuck)
(stuck)
27
63
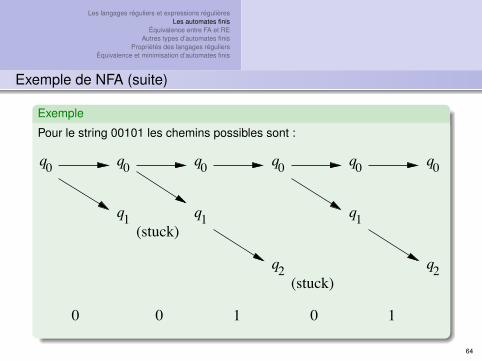
Les langages réguliers et expressions régulièresLes automates finis
Équivalence entre FA et REAutres types d’automates finis
Propriétés des langages réguliersÉquivalence et minimisation d’automates finis
Exemple de NFA (suite)
Exemple
Pour le string 00101 les chemins possibles sont :
Nondeterministic Finite Automata
A NFA can be in several states at once, or,viewded another way, it can “guess” whichstate to go to next
Example: An automaton that accepts all andonly strings ending in 01.
Start 0 1q0
q q
0, 1
1 2
Here is what happens when the NFA processesthe input 00101
q0
q2
q0
q0
q0
q0
q0
q1
q1
q1
q2
0 0 1 0 1
(stuck)
(stuck)
2764
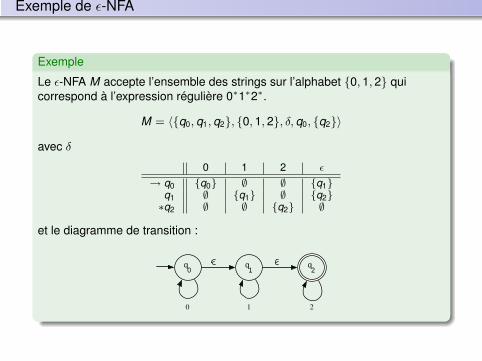
Exemple de ε-NFA
Exemple
Le ε-NFA M accepte l’ensemble des strings sur l’alphabet {0, 1, 2} quicorrespond à l’expression régulière 0∗1∗2∗.
M = 〈{q0, q1, q2}, {0, 1, 2}, δ, q0, {q2}〉
avec δ
0 1 2 ε
→ q0 {q0} ∅ ∅ {q1}q1 ∅ {q1} ∅ {q2}∗q2 ∅ ∅ {q2} ∅
et le diagramme de transition :
0 1 2
q0
q1
q2

Les langages réguliers et expressions régulièresLes automates finis
Équivalence entre FA et REAutres types d’automates finis
Propriétés des langages réguliersÉquivalence et minimisation d’automates finis
Exemple de ε-NFA (suite)
Exemple
Pour le string 022 les chemins possibles sont :
q0
q0
q1
q2
q2
q2
q1
q2
0 2 2ok
bloqué
66

Définition constructive de L(M)
Définition (δ : Extension de la fonction de transition)
Si on définit pour un ensemble d’états S : δ(S, a) =S
p∈Sδ(p, a)
Pour les DFA : δ : Q × Σ∗ → Q
base : δ(q, ε) = q
ind. : δ(q, xa) = δ(δ(q, x), a)
L(M) = {w | δ(q0, w) ∈ F}
Pour les NFA : δ : Q × Σ∗ → 2Q
base : δ(q, ε) = {q}ind. : δ(q, xa) = δ(δ(q, x), a)
L(M) = {w | δ(q0, w) ∩ F 6= ∅}
Pour les ε-NFA : δ : Q × Σ∗ → 2Q
base : δ(q, ε) = eclose(q)
ind. : δ(q, xa) =eclose(δ(δ(q, x), a))
avec eclose(q) =S
i∈Neclosei(q)
eclose0(q) = {q}eclosei+1(q) =δ(eclosei(q), ε)
L(M) = {w | δ(q0, w) ∩ F 6= ∅}

Les langages réguliers et expressions régulièresLes automates finis
Équivalence entre FA et REAutres types d’automates finis
Propriétés des langages réguliersÉquivalence et minimisation d’automates finis
Plan
1 Les langages réguliers et expressions régulières
2 Les automates finis
3 Équivalence entre FA et RE
4 Autres types d’automates finis
5 Propriétés des langages réguliers
6 Équivalence et minimisation d’automates finis
68
Les langages réguliers et expressions régulièresLes automates finis
Équivalence entre FA et REAutres types d’automates finis
Propriétés des langages réguliersÉquivalence et minimisation d’automates finis
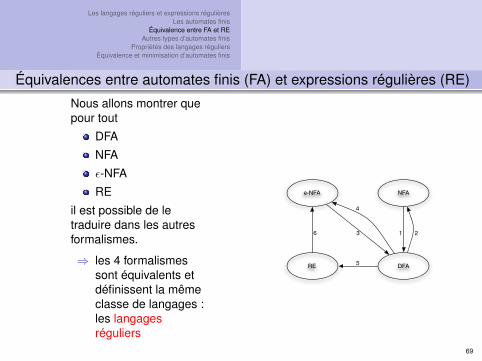
Équivalences entre automates finis (FA) et expressions régulières (RE)
Nous allons montrer quepour tout
DFA
NFA
ε-NFA
RE
il est possible de letraduire dans les autresformalismes.
⇒ les 4 formalismessont équivalents etdéfinissent la mêmeclasse de langages :les langagesréguliers
e-NFA NFA
DFARE
1 23
4
5
6
69

Les langages réguliers et expressions régulièresLes automates finis
Équivalence entre FA et REAutres types d’automates finis
Propriétés des langages réguliersÉquivalence et minimisation d’automates finis
C(NFA) ⊆ C(DFA)
Flèche 1 :
e-NFA NFA
DFARE
1 23
4
5
6
70

Les langages réguliers et expressions régulièresLes automates finis
Équivalence entre FA et REAutres types d’automates finis
Propriétés des langages réguliersÉquivalence et minimisation d’automates finis
Équivalence entre DFA et NFA
Écrire un NFA supprime la contrainte du déterminisme
mais nous montrons que pour tout NFA N on peut construire un DFA Déquivalent (càd L(D) = L(N)) et vice-versa.
on utilise la technique de la construction de sous-ensembles : chaqueétat de D correspond à un ensemble d’états de N
71

C(NFA) ⊆ C(DFA)
Théorème (Pour tout NFA N, il existe un DFA D avec L(N) = L(D))
Preuve :Soit un NFA N :
N = 〈QN , Σ, δN , q0, FN〉
définissons (construisons) le DFA D :
D = 〈QD, Σ, δD, {q0}, FD〉
avec
QD = {S | S ⊆ QN} (càd QD = 2QN )
FD = {S ⊆ QN | S ∩ FN 6= ∅}Pour tout S ⊆ QN et a ∈ Σ,
δD(S, a) = δN(S, a) (=[p∈S
δN(p, a))
Notons que |QD| = 2|QN | (bien qu’en général, beaucoup d’états soient inutilescar inaccessibles)

C(NFA) ⊆ C(DFA) (suite)
Exemple (NFA N et DFA D équivalent)
b
a
q0
q1
qf
a b
5 états sont inaccessibles b
{q }0
a {q ,0
q }1
{q ,0
q }f
a
a
b
{q ,1
q }f
Les langages réguliers et expressions régulièresLes automates finis
Equivalence entre FA et RE
Exemple de ε-NFA
Exemple
Le ε-NFA M accepte l’ensemble des strings sur l’alphabet {0, 1, 2} quicorrespond à l’expression régulière 0∗1∗2∗.
M =< {q0, q1, q2}, {0, 1, 2}, δ, q0, {q2} >
avec δ
0 1 2 ε
→ q0 {q0} ∅ ∅ {q1}q1 ∅ {q1} ∅ {q2}∗q2 ∅ ∅ {q2} {q2}
et le diagramme de transition :
0 1 2
Les langages réguliers et expressions régulièresLes automates finis
Configuration et langage accepté
Définition (Configuration d’un FA)
Couple < q, w > ∈ Q × Σ∗
Configuration initiale : < q0, w > où w est le string à accepterConfiguration finale (qui accepte) : < q, ε > avec q ∈ F
Définition (Changement de configuration)
< q, aw > #M
< q′, w > si
δ(q, a) = q′ pour un DFAq′ ∈ δ(q, a) pour un NFAq′ ∈ δ(q, a) pour un NFAε avec a ∈ Σ ∪ {ε}
∗#M
est la fermeture réflexo-transitive de #M
15 / 20
Les langages réguliers et expressions régulièresLes automates finis
Configuration et langage accepté
Définition (Configuration d’un FA)
Couple < q, w > ∈ Q × Σ∗
Configuration initiale : < q0, w > où w est le string à accepterConfiguration finale (qui accepte) : < q, ε > avec q ∈ F
Définition (Changement de configuration)
< q, aw > #M
< q′, w > si
δ(q, a) = q′ pour un DFAq′ ∈ δ(q, a) pour un NFAq′ ∈ δ(q, a) pour un NFAε avec a ∈ Σ ∪ {ε}
∗#M
est la fermeture réflexo-transitive de #M
15 / 20
q0
q1
q2
20 / 26
a,b
b
q ,1
q }f
{q0
a
b
a
{q }1
{q }f
b
a
a,bb

Les langages réguliers et expressions régulièresLes automates finis
Équivalence entre FA et REAutres types d’automates finis
Propriétés des langages réguliersÉquivalence et minimisation d’automates finis
C(NFA) ⊆ C(DFA) (fin)
Théorème (Pour tout NFA N, il existe un DFA D avec L(N) = L(D))
Preuve (suite) :On va montrer que L(D) = L(N)Il suffit de montrer par induction que :
δD({q0}, w) = δN(q0, w)
Base : (w = ε) : OK par définition des δ
Induction : (w = xa)
δD({q0}, xa)def= δD(δD({q0}, x), a)h.i= δD(δN(q0, x), a)cst= δN(δN(q0, x), a)def= δN(q0, xa)
74

Les langages réguliers et expressions régulièresLes automates finis
Équivalence entre FA et REAutres types d’automates finis
Propriétés des langages réguliersÉquivalence et minimisation d’automates finis
C(NFA) ⊆ C(DFA) (suite)
Exemple (NFA N avec n + 1 états qui a un DFA D équivalent à 2n états)
Exponential Blow-Up
There is an NFA N with n + 1 states that hasno equivalent DFA with fewer than 2n states
Start
0, 1
0, 1 0, 1 0, 1q q qq
0 1 2 n
1 0, 1
L(N) = {x1c2c3 · · · cn : x ∈ {0,1}∗, ci ∈ {0,1}}
Suppose an equivalent DFA D with fewer than2n states exists.
D must remember the last n symbols it hasread.
There are 2n bitsequences a1a2 · · · an
∃ q, a1a2 · · · an, b1b2 · · · bn : q ∈ δN(q0, a1a2 · · · an),q ∈ δN(q0, b1b2 · · · bn),
a1a2 · · · an #= b1b2 · · · bn
41
75
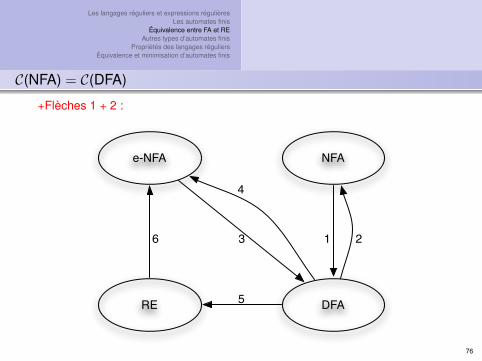
Les langages réguliers et expressions régulièresLes automates finis
Équivalence entre FA et REAutres types d’automates finis
Propriétés des langages réguliersÉquivalence et minimisation d’automates finis
C(NFA) = C(DFA)
+Flèches 1 + 2 :
e-NFA NFA
DFARE
1 23
4
5
6
76

Les langages réguliers et expressions régulièresLes automates finis
Équivalence entre FA et REAutres types d’automates finis
Propriétés des langages réguliersÉquivalence et minimisation d’automates finis
C(NFA) = C(DFA)
Théorème (Un langage L est accepté par un DFA si et seulement si L estaccepté par un NFA)
Preuve :
si⇐ voir théorème précédant
seulement si⇒Il suffit à partir du DFA D de construire un NFA N avec
si δD(q, a) = p alors δN(q, a) = {p}
77

Les langages réguliers et expressions régulièresLes automates finis
Équivalence entre FA et REAutres types d’automates finis
Propriétés des langages réguliersÉquivalence et minimisation d’automates finis
C(ε-NFA) ⊆ C(DFA)
+ Flèche 3 :
e-NFA NFA
DFARE
1 23
4
5
6
78

Les langages réguliers et expressions régulièresLes automates finis
Équivalence entre FA et REAutres types d’automates finis
Propriétés des langages réguliersÉquivalence et minimisation d’automates finis
C(ε-NFA) ⊆ C(DFA)
Théorème (Pour tout ε-NFA E , il existe un DFA D avec L(E) = L(D))
Preuve :Soit un ε-NFA E :
E = 〈QE , Σ, δE , q0, FE〉
définissons (construisons) le DFA D :
D = 〈QD, Σ, δD, qD, FD〉
avec :
QD = {S|S ⊆ QE ∧ S = eclose(S)}qD = eclose(q0)
FD = {S | S ∈ QD ∧ S ∩ FE 6= ∅}Pour tout S ∈ QD et a ∈ Σ,
δD(S, a) = eclose(δE(S, a))
79
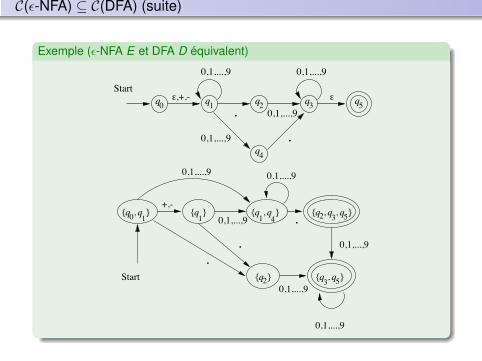
C(ε-NFA) ⊆ C(DFA) (suite)
Exemple (ε-NFA E et DFA D équivalent)Example: ε-NFA E
q q q q q
q
0 1 2 3 5
4
Start
0,1,...,9 0,1,...,9
! !
0,1,...,9
0,1,...,9
,+,-
.
.
DFA D corresponding to E
Start
{ { { {
{ {
q q q q
q q
0 1 1, }q1} , q
4} 2, q3
, q5}
2} 3, q5}
0,1,...,9 0,1,...,9
0,1,...,9
0,1,...,9
0,1,...,9
0,1,...,9
+,-
.
.
.
50
Example: ε-NFA E
q q q q q
q
0 1 2 3 5
4
Start
0,1,...,9 0,1,...,9
! !
0,1,...,9
0,1,...,9
,+,-
.
.
DFA D corresponding to E
Start
{ { { {
{ {
q q q q
q q
0 1 1, }q1} , q
4} 2, q3
, q5}
2} 3, q5}
0,1,...,9 0,1,...,9
0,1,...,9
0,1,...,9
0,1,...,9
0,1,...,9
+,-
.
.
.
50

C(ε-NFA) ⊆ C(DFA)
Théorème (Pour tout ε-NFA E , il existe un DFA D avec L(E) = L(D))
Preuve (suite) :On va montrer que L(D) = L(E). Il suffit de montrer par induction que :
δE({q0}, w) = δD(qD, w)
Base : (w = ε) :
δE({q0}, ε) = eclose(q0) = qD = δ(qD, ε)
Induction : (w = xa)
δE({q0}, xa)def de δE= eclose(δE(δE({q0}, x), a))
h.i.= eclose(δE(δD(qD, x), a))cst= δD(δD(qD, x), a)
def de δD= δD(qD, xa)

Les langages réguliers et expressions régulièresLes automates finis
Équivalence entre FA et REAutres types d’automates finis
Propriétés des langages réguliersÉquivalence et minimisation d’automates finis
C(ε-NFA) = C(DFA)
+Flèches 3 + 4 :
e-NFA NFA
DFARE
1 23
4
5
6
82

Les langages réguliers et expressions régulièresLes automates finis
Équivalence entre FA et REAutres types d’automates finis
Propriétés des langages réguliersÉquivalence et minimisation d’automates finis
C(ε-NFA) = C(DFA)
Théorème (Un langage L est accepté par un DFA si et seulement si L estaccepté par un ε-NFA)
Preuve :
si⇐ voir théorème précédent
seulement si⇒Il suffit à partir du DFA D de construire un ε-NFA E avec
si δD(q, a) = p alors δE(q, a) = {p}
83

Les langages réguliers et expressions régulièresLes automates finis
Équivalence entre FA et REAutres types d’automates finis
Propriétés des langages réguliersÉquivalence et minimisation d’automates finis
C(DFA) ⊆ C(RE)
+ Flèche 5 :
e-NFA NFA
DFARE
1 23
4
5
6
84

C(DFA) ⊆ C(RE)
Théorème (Pour tout DFA D, il existe une RE R avec L(R) = L(D))
Preuve :Soit le DFA D = 〈QD, Σ, δ, q1, F 〉 avec :
QD = {q1, q2, . . . , qn}On définit l’expression régulière Rk
ij décrivant l’ensemble des labelscorrespondants à tous les chemins de D
partant de l’état qi
aboutissant à l’état qj
et ne traversant que des états de l’ensemble {q1, . . . , qk}
Theorem 3.4: For every DFA A = (Q,Σ, δ, q0, F )there is a regex R, s.t. L(R) = L(A).
Proof: Let the states of A be {1,2, . . . , n},with 1 being the start state.
• Let R(k)ij be a regex describing the set of
labels of all paths in A from state i to statej going through intermediate states {1, . . . , k}only.
i
k
j
58

Les langages réguliers et expressions régulièresLes automates finis
Équivalence entre FA et REAutres types d’automates finis
Propriétés des langages réguliersÉquivalence et minimisation d’automates finis
C(DFA) ⊆ C(RE)
Théorème (Pour tout DFA D, il existe une RE R avec L(R) = L(D))
Preuve : (suite)On va définir Rk
ij de façon inductive. Notons que
L“
+qj∈F
Rn1j
”= L(D)
Cas de base :
Cas 1 : i 6= jR0
ij = +{a∈Σ:δ(qi ,a)=qj}
a
Cas 2 : i = jR0
ij = +{a∈Σ | δ(qi ,a)=qi}
a + ε
86

Les langages réguliers et expressions régulièresLes automates finis
Équivalence entre FA et REAutres types d’automates finis
Propriétés des langages réguliersÉquivalence et minimisation d’automates finis
C(DFA) ⊆ C(RE)
Théorème (Pour tout DFA D, il existe une RE R avec L(R) = L(D))
Preuve : (suite 2)Induction :(de la définition de Rk
ij )
Rkij = Rk−1
ij + Rk−1ik (Rk−1
kk )∗Rk−1kj
Induction:
R(k)ij
=
R(k−1)ij
+
R(k−1)ik
(R(k−1)
kk
)∗R(k−1)
kj
Rkj(k-1)
Rkk(k-1)
Rik(k-1)
i k k k k
Zero or more strings inIn In
j
60
string de Rikk-1 string de Rkj
k-10 ou plus de strings de Rkkk-1{{ {
87

Les langages réguliers et expressions régulièresLes automates finis
Équivalence entre FA et REAutres types d’automates finis
Propriétés des langages réguliersÉquivalence et minimisation d’automates finis
C(DFA) ⊆ C(RE)
Exemple (Pour le DFA A, construction de l’RE R avec L(R) = L(A))Example: Let’s find R for A, whereL(A) = {x0y : x ∈ {1}∗ and y ∈ {0,1}∗}
1
0Start 0,1
1 2
R(0)11 ε + 1
R(0)12 0
R(0)21 ∅
R(0)22 ε + 0 + 1
61
88

Les langages réguliers et expressions régulièresLes automates finis
Équivalence entre FA et REAutres types d’automates finis
Propriétés des langages réguliersÉquivalence et minimisation d’automates finis
C(DFA) ⊆ C(RE)
Quelques règles de simplification des RE
(ε + R)∗ = R∗
R + RS∗ = RS∗
∅R = ∅ = R∅∅+ R = R + ∅ = R
89

C(DFA) ⊆ C(RE)
Exemple (Pour le DFA A, construction de l’RE R avec L(R) = L(A))
R(0)11 ε + 1
R(0)12 0
R(0)21 ∅
R(0)22 ε + 0 + 1
R(1)ij = R(0)
ij + R(0)i1
(R(0)
11
)∗R(0)
1j
By direct substitution Simplified
R(1)11 ε + 1 + (ε + 1)(ε + 1)∗(ε + 1) 1∗
R(1)12 0 + (ε + 1)(ε + 1)∗0 1∗0
R(1)21 ∅ + ∅(ε + 1)∗(ε + 1) ∅
R(1)22 ε + 0 + 1 + ∅(ε + 1)∗0 ε + 0 + 1
63
Par substitution directe Simplifié

C(DFA) ⊆ C(RE)
Exemple (Pour le DFA A, construction de l’RE R avec L(R) = L(A))
Simplified
R(1)11 1∗
R(1)12 1∗0
R(1)21 ∅
R(1)22 ε + 0 + 1
R(2)ij = R(1)
ij + R(1)i2
(R(1)
22
)∗R(1)
2j
By direct substitution
R(2)11 1∗ + 1∗0(ε + 0 + 1)∗∅
R(2)12 1∗0 + 1∗0(ε + 0 + 1)∗(ε + 0 + 1)
R(2)21 ∅ + (ε + 0 + 1)(ε + 0 + 1)∗∅
R(2)22 ε + 0 + 1 + (ε + 0 + 1)(ε + 0 + 1)∗(ε + 0 + 1)
64
Simplifié
Par substitution directe

C(DFA) ⊆ C(RE)
Exemple (Pour le DFA A, construction de l’RE R avec L(R) = L(A))
By direct substitution
R(2)11 1∗ + 1∗0(ε + 0 + 1)∗∅
R(2)12 1∗0 + 1∗0(ε + 0 + 1)∗(ε + 0 + 1)
R(2)21 ∅ + (ε + 0 + 1)(ε + 0 + 1)∗∅
R(2)22 ε + 0 + 1 + (ε + 0 + 1)(ε + 0 + 1)∗(ε + 0 + 1)
Simplified
R(2)11 1∗
R(2)12 1∗0(0 + 1)∗
R(2)21 ∅
R(2)22 (0 + 1)∗
The final regex for A is
R(2)12 = 1∗0(0 + 1)∗
65
Par substitution directe
Simplifié
La RE finale pour A est :

Les langages réguliers et expressions régulièresLes automates finis
Équivalence entre FA et REAutres types d’automates finis
Propriétés des langages réguliersÉquivalence et minimisation d’automates finis
C(DFA) ⊆ C(RE) : Observations
La méthode fonctionne aussi avec des NFA ou ε-NFA
Il y a n3 expressions Rkij
Chaque pas inductif quadruple la taille de l’expression
Rnij peut avoir une taille 4n
Pour tout {i, j} ⊆ {1, . . . , n}, Rkij utilise Rk−1
ij
donc on doit écrire n2 fois l’expression Rk−1kk
⇒ Il faut trouver une méthode plus efficace : la technique d’élimination d’états
93
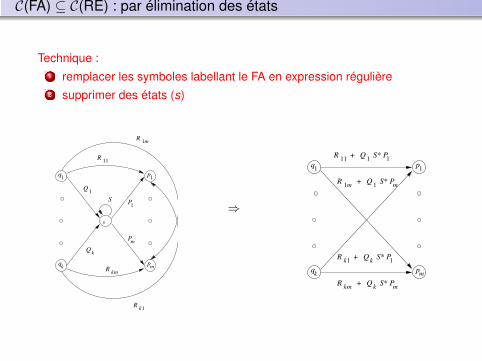
C(FA) ⊆ C(RE) : par élimination des états
Technique :1 remplacer les symboles labellant le FA en expression régulière2 supprimer des états (s)
The state elimination technique
Let’s label the edges with regex’s instead ofsymbols
q
q
p
p
1 1
k m
s
Q
Q
P1
Pm
k
1
11R
R1m
Rkm
Rk1
S
67
⇒
Now, let’s eliminate state s.
11R Q
1P1
R1m
Rk1
Rkm
Q1
Pm
Qk
Qk
P1
Pm
q
q
p
p
1 1
k m
+ S*
+
+
+
S*
S*
S*
For each accepting state q eliminate from theoriginal automaton all states exept q0 and q.
68

C(FA) ⊆ C(RE) : par élimination des états (suite)
Méthode
On construit pour chaque état accepteur q, un automate à 2 états q0 et qen éliminant les autresPour chaque q ∈ F on obtient
soit Aq :
For each q ∈ F we’ll be left with an Aq thatlooks like
Start
R
S
T
U
that corresponds to the regex Eq = (R+SU∗T )∗SU∗
or with Aq looking like
R
Start
corresponding to the regex Eq = R∗
• The final expression is⊕
q∈F
Eq
69
avec la RE correspondante : Eq = (R + SU∗T )∗SU∗soit Aq :
For each q ∈ F we’ll be left with an Aq thatlooks like
Start
R
S
T
U
that corresponds to the regex Eq = (R+SU∗T )∗SU∗
or with Aq looking like
R
Start
corresponding to the regex Eq = R∗
• The final expression is⊕
q∈F
Eq
69
avec la RE correspondante : Eq = R∗
la RE finale est : +q∈F
Eq

Les langages réguliers et expressions régulièresLes automates finis
Équivalence entre FA et REAutres types d’automates finis
Propriétés des langages réguliersÉquivalence et minimisation d’automates finis
C(FA) ⊆ C(RE) : par élimination des états
Exemple (trouvons une RE du NFA A par élimination d’états)
NFA A
Example: A, where L(A) = {W : w = x1b, or w =x1bc, x ∈ {0,1}∗, {b, c} ⊆ {0,1}}
Start
0,1
1 0,1 0,1
A B C D
We turn this into an automaton with regexlabels
0 1+
0 1+ 0 1+Start
A B C D
1
70
Transformation de A en automate labellé par des RE :
Example: A, where L(A) = {W : w = x1b, or w =x1bc, x ∈ {0,1}∗, {b, c} ⊆ {0,1}}
Start
0,1
1 0,1 0,1
A B C D
We turn this into an automaton with regexlabels
0 1+
0 1+ 0 1+Start
A B C D
1
70
96

C(FA) ⊆ C(RE) : par élimination des états
Exemple (suite)
A transformé :0 1+
0 1+ 0 1+Start
A B C D
1
Let’s eliminate state B
0 1+
DC
0 1+( ) 0 1+Start
A
1
Then we eliminate state C and obtain AD
0 1+
D
0 1+( ) 0 1+( )Start
A
1
with regex (0 + 1)∗1(0 + 1)(0 + 1)
71
Élimination de l’état B
0 1+
0 1+ 0 1+Start
A B C D
1
Let’s eliminate state B
0 1+
DC
0 1+( ) 0 1+Start
A
1
Then we eliminate state C and obtain AD
0 1+
D
0 1+( ) 0 1+( )Start
A
1
with regex (0 + 1)∗1(0 + 1)(0 + 1)
71
Élimination de l’état C pour obtenir AD
0 1+
0 1+ 0 1+Start
A B C D
1
Let’s eliminate state B
0 1+
DC
0 1+( ) 0 1+Start
A
1
Then we eliminate state C and obtain AD
0 1+
D
0 1+( ) 0 1+( )Start
A
1
with regex (0 + 1)∗1(0 + 1)(0 + 1)
71
RE correspondante : (0 + 1)∗1(0 + 1)(0 + 1)

C(FA) ⊆ C(RE) : par élimination des états
Exemple (trouvons une RE du FA A par élimination d’états)
A partir de l’automate avec B supprimé :From
0 1+
DC
0 1+( ) 0 1+Start
A
1
we can eliminate D to obtain AC
0 1+
C
0 1+( )Start
A
1
with regex (0 + 1)∗1(0 + 1)
• The final expression is the sum of the previ-ous two regex’s:
(0 + 1)∗1(0 + 1)(0 + 1) + (0 + 1)∗1(0 + 1)
72
Élimination de l’état D pour obtenir AC
From
0 1+
DC
0 1+( ) 0 1+Start
A
1
we can eliminate D to obtain AC
0 1+
C
0 1+( )Start
A
1
with regex (0 + 1)∗1(0 + 1)
• The final expression is the sum of the previ-ous two regex’s:
(0 + 1)∗1(0 + 1)(0 + 1) + (0 + 1)∗1(0 + 1)
72
RE correspondante : (0 + 1)∗1(0 + 1)
RE finale : (0 + 1)∗1(0 + 1)(0 + 1) + (0 + 1)∗1(0 + 1)

Les langages réguliers et expressions régulièresLes automates finis
Équivalence entre FA et REAutres types d’automates finis
Propriétés des langages réguliersÉquivalence et minimisation d’automates finis
C(RE) ⊆ C(ε-NFA) = C(FA)
+ Flèche 6 :
e-NFA NFA
DFARE
1 23
4
5
6
99

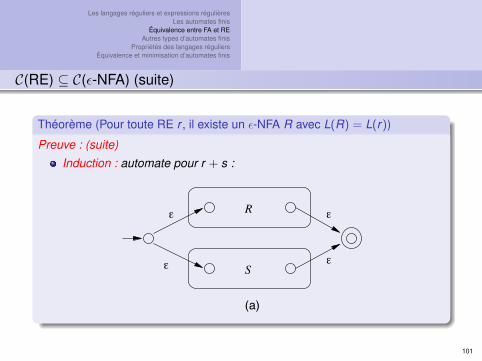
C(RE) ⊆ C(ε-NFA)
Théorème (Pour toute RE r , il existe un ε-NFA R avec L(R) = L(r))
Preuve : par induction.
Cas de base : automates pour ε, ∅ et a :
From regex’s to ε-NFA’s
Theorem 3.7: For every regex R we can con-struct and ε-NFA A, s.t. L(A) = L(R).
Proof: By structural induction:
Basis: Automata for ε, ∅, and a.
!
a
(a)
(b)
(c)
73
Les langages réguliers et expressions régulièresLes automates finis
Équivalence entre FA et REAutres types d’automates finis
Propriétés des langages réguliersÉquivalence et minimisation d’automates finis
C(RE) ⊆ C(ε-NFA) (suite)
Théorème (Pour toute RE r , il existe un ε-NFA R avec L(R) = L(r))
Preuve : (suite)
Induction : automate pour r + s :Induction: Automata for R + S, RS, and R∗
(a)
(b)
(c)
R
S
R S
R
! !
!!
!
!
!
! !
74
101

C(RE) ⊆ C(ε-NFA) (suite)
Théorème (Pour toute RE r , il existe un ε-NFA R avec L(R) = L(r))
Preuve : (suite)
Induction : automates pour rs, et r∗ :
Induction: Automata for R + S, RS, and R∗
(a)
(b)
(c)
R
S
R S
R
! !
!!
!
!
!
! !
74

C(RE) ⊆ C(ε-NFA) (suite)
Exemple (ε-NFA correspondant à (0 + 1)∗1(0 + 1))Example: We convert (0 + 1)∗1(0 + 1)
!
!
!
!
0
1
!
!
!
!
0
1
!
!1
Start
(a)
(b)
(c)
0
1
! !
!
!
! !
!!
!
0
1
! !
!
!
! !
!
75

Les langages réguliers et expressions régulièresLes automates finis
Équivalence entre FA et REAutres types d’automates finis
Propriétés des langages réguliersÉquivalence et minimisation d’automates finis
C(RE) ⊆ C(ε-NFA) (suite)
Exemple (ε-NFA correspondant à (0 + 1)∗1(0 + 1) (suite))
Example: We convert (0 + 1)∗1(0 + 1)
!
!
!
!
0
1
!
!
!
!
0
1
!
!1
Start
(a)
(b)
(c)
0
1
! !
!
!
! !
!!
!
0
1
! !
!
!
! !
!
75
104

C(RE) = C(ε-NFA) = C(NFA) = C(DFA)
e-NFA NFA
DFARE
1 23
4
5
6
En conclusion,
les 4 formalismes sont équivalents et définissent la classe des langagesréguliers
on peut passer de l’un à l’autre par des traductions automatiques

Les langages réguliers et expressions régulièresLes automates finis
Équivalence entre FA et REAutres types d’automates finis
Propriétés des langages réguliersÉquivalence et minimisation d’automates finis
Plan
1 Les langages réguliers et expressions régulières
2 Les automates finis
3 Équivalence entre FA et RE
4 Autres types d’automates finis
5 Propriétés des langages réguliers
6 Équivalence et minimisation d’automates finis
106

Les langages réguliers et expressions régulièresLes automates finis
Équivalence entre FA et REAutres types d’automates finis
Propriétés des langages réguliersÉquivalence et minimisation d’automates finis
Machines avec output (actions)
On a souvent envie de modéliser un système plus “réactif” qui effectue desactions ou produit des outputs lors du traitement.En théorie 2 types standards d’automates finis avec output ont été définis.
les machines de Moore qui ont un output associé à chaque état decontrôle
les machines de Mealy qui ont un output associé à chaque transition
UML a retenu et mélangé tous ces concepts dans ses
diagrammes d’état (statecharts)
diagrammes d’activité
107

Les langages réguliers et expressions régulièresLes automates finis
Équivalence entre FA et REAutres types d’automates finis
Propriétés des langages réguliersÉquivalence et minimisation d’automates finis
Exemple de statechart UML
II.123
State machine
Idle Cooling
tooHot(desTemp) / TurnCoolOn
rightTemp / TurnCoolOff
Event withparameter(s)
tooCold(desTemp) / TurnHeatOn
Heating
rightTemp / TurnHeatOff
Action on
transition
108

Les langages réguliers et expressions régulièresLes automates finis
Équivalence entre FA et REAutres types d’automates finis
Propriétés des langages réguliersÉquivalence et minimisation d’automates finis
Exemple de statechart UML (2)
II.127
State machine
Idle
Self-transition
Call(p) [conAllowed] / add(p)Action
Guard
Event
Connecting
Entry / conMode(on)exit / conMode(off)do / connect(p)Transmit / defer
109

Les langages réguliers et expressions régulièresLes automates finis
Équivalence entre FA et REAutres types d’automates finis
Propriétés des langages réguliersÉquivalence et minimisation d’automates finis
Plan
1 Les langages réguliers et expressions régulières
2 Les automates finis
3 Équivalence entre FA et RE
4 Autres types d’automates finis
5 Propriétés des langages réguliers
6 Équivalence et minimisation d’automates finis
110

Les langages réguliers et expressions régulièresLes automates finis
Équivalence entre FA et REAutres types d’automates finis
Propriétés des langages réguliersÉquivalence et minimisation d’automates finis
Questions qu’on peut se poser sur des langages L, L1, L2
L est-il régulier ?
Pour quels opérateurs les langages réguliers sont-ils fermés ?
w ∈ L ?
L est-il vide, fini, infini ?
L1 ⊆ L2, L1 = L2 ?
111

Les langages réguliers et expressions régulièresLes automates finis
Équivalence entre FA et REAutres types d’automates finis
Propriétés des langages réguliersÉquivalence et minimisation d’automates finis
L est-il régulier ?
Pour montrer que L est régulier
Il faut :
trouver un FA (ou une RE) M etmontrer que L = L(M) càd
que L ⊆ L(M) (tout string de L est accepté par M)que L(M) ⊆ L (tout string accepté par M est dans L)
112

Les langages réguliers et expressions régulièresLes automates finis
Équivalence entre FA et REAutres types d’automates finis
Propriétés des langages réguliersÉquivalence et minimisation d’automates finis
L est-il régulier ?
Exemple
Pour montrer que L est régulier L = {w | w a un nombre pair de 0 et de 1}
On définit par exemple leDFA M et démontre(généralement parinduction) que L = L(M)
Example: DFA accepting all and only stringswith an even number of 0’s and an even num-ber of 1’s
q q
q q
0 1
2 3
Start
0
0
1
1
0
0
1
1
Tabular representation of the Automaton
0 1!→ q0 q2 q1
q1 q3 q0q2 q0 q3q3 q1 q2
24
113

Les langages réguliers et expressions régulièresLes automates finis
Équivalence entre FA et REAutres types d’automates finis
Propriétés des langages réguliersÉquivalence et minimisation d’automates finis
L est-il régulier ?
Pour montrer que L n’est pas régulier
Parfois on peut le montrer grâce au pumping lemma (lemme de pompage)des langages réguliers
Théorème (Pumping lemma des langages réguliers)
Si L est régulieralors∃n ∀w (w ∈ L ∧ |w | ≥ n)⇒ ∃x , y , z
1 w = xyz ∧2 |xy | ≤ n ∧3 y 6= ε ∧4 ∀k ≥ 0⇒ xy k z ∈ L
114

Preuve du pumping lemma pour les langages réguliers
Théorème (Pumping lemma des langages réguliers)
Preuve :
Supposons L régulier
L est reconnu par un DFA M. Soit n le nombre d’états de M
Prenons w = a1a2 . . . am ∈ L avec m ≥ n
Dénotons pi = δ(q0, a1a2 . . . ai) (et p0 = q0)
⇒ ∃i < j : pi = pj ! !(on prend pi = le premier état accédé pour laseconde fois et donc j ≤ n) ! !
Now w = xyz, where
1. x = a1a2 · · · ai
2. y = ai+1ai+2 · · · aj
3. z = aj+1aj+2 . . . am
Startp
ip
0
a1
. . . ai
ai+1
. . . aj
aj+1
. . . am
x = z =
y =
Evidently xykz ∈ L, for any k ≥ 0. Q.E.D.
94
Et donc w = xyz et pour x , y , z on peut facilement vérifier que toutes lespropriétés du pumping lemma sont bien vérifiées.

Comment le pumping lemma permet de dire que L n’est pas régulier
Pumping lemma = condition nécessaire pour que L régulier
L régulier⇒ L satisfait au PLL non régulier⇐ L ne satisfait pas au PL
Négation du pumping lemma
L¬régulier⇐¬∃n ∀w ((w ∈ L ∧ |w | ≥ n)⇒ (∃x , y , z
1 w = xyz ∧2 |xy | ≤ n ∧3 y 6= ε ∧4 ∀k ≥ 0⇒ xy k z ∈ L))
≡ ∀n ∃w ¬((w ∈ L ∧ |w | ≥ n)⇒ (∃x , y , z1 w = xyz ∧2 |xy | ≤ n ∧3 y 6= ε ∧4 ∀k ≥ 0⇒ xy k z ∈ L))

Comment le pumping lemma permet de dire que L n’est pas régulier
Négation du pumping lemma (suite)
≡ ∀n ∃w (w ∈ L ∧ |w | ≥ n) ∧ ¬(∃x , y , z1 w = xyz ∧2 |xy | ≤ n ∧3 y 6= ε ∧4 ∀k ≥ 0⇒ xy k z ∈ L)
≡ ∀n ∃w (w ∈ L ∧ |w | ≥ n) ∧ ∀x , y , z (
1 w 6= xyz ∨2 |xy | > n ∨3 y = ε ∨4 ∃k ≥ 0 ∧ xy k z /∈ L)

Comment le pumping lemma permet de dire que L n’est pas régulier
Négation du pumping lemma (suite)
≡ ∀n ∃w (w ∈ L ∧ |w | ≥ n) ∧ ∀x , y , z1 (w = xyz ∧2 |xy | ≤ n ∧3 y 6= ε)
4 ⇒ (∃k ≥ 0 ∧ xy k z /∈ L)
Exemple (Montrons que L = {0i1i |i ∈ N} n’est pas régulier)
Montrons que L satisfait la négation des conditions du pumping lemma.Pour tout n, pour w = 0n1n ∈ L ∧ |w | ≥ net ∀x , y , z(w = xyz ∧ |xy | ≤ n ∧ y 6= ε : x = 0k , y = 0`(` 6= 0))⇒ xz /∈ L
Example: Let Leq be the language of stringswith equal number of zero’s and one’s.
Suppose Leq is regular. Then w = 0n1n ∈ L.
By the pumping lemma w = xyz, |xy| ≤ n,y #= ε and xykz ∈ Leq
w = 000 · · ·︸ ︷︷ ︸x
· · ·0︸ ︷︷ ︸y
0111 · · ·11︸ ︷︷ ︸z
In particular, xz ∈ Leq, but xz has fewer 0’sthan 1’s.
95

Les langages réguliers et expressions régulièresLes automates finis
Équivalence entre FA et REAutres types d’automates finis
Propriétés des langages réguliersÉquivalence et minimisation d’automates finis
Comment le pumping lemma permet de dire que L n’est pas régulier
Exemple (Montrons que L = {0i2 |i ∈ N} n’est pas régulier)
Montrons que L satisfait la négation des conditions du pumping lemma.Pour tout n, pour w = 0n2
∈ L ∧ |w | ≥ net ∀x , y , z(w = xyz ∧ |xy | ≤ n ∧ y 6= ε)⇒ xy2z /∈ L car n2 < |xy2z| ≤ n2 + n < (n + 1)2
119

Les langages réguliers et expressions régulièresLes automates finis
Équivalence entre FA et REAutres types d’automates finis
Propriétés des langages réguliersÉquivalence et minimisation d’automates finis
Pour quels opérateurs les langages réguliers sont-ils fermés ?
Théorème (Si L et M sont réguliers alors, sont réguliers)
Union : L ∪M
Concaténation : L.M
Fermeture de Kleene : L∗
Complément :_L
Intersection : L ∩M
Difference : L\MImage miroir : LR
120

Les langages réguliers et expressions régulièresLes automates finis
Équivalence entre FA et REAutres types d’automates finis
Propriétés des langages réguliersÉquivalence et minimisation d’automates finis
Pour quels opérateurs les langages réguliers sont-ils fermés ?
Théorème (Si L et M sont réguliers alors, sont réguliers)
Preuve :
Union : L ∪M (Par définition)
Concaténation : L.M (Par définition)
Fermeture de Kleene : L∗ (Par définition)
121

Pour quels opérateurs les langages réguliers sont-ils fermés ?
Théorème (Si L est régulier alors_L est régulier)
Preuve :Si L est reconnu par le DFA A = 〈Q, Σ, δ, q0, F 〉On a
_L = L(B) pour B = 〈Q, Σ, δ, q0, Q\F 〉
Exemple :
Example:
Let L be recognized by the DFA below
Start
{ {q q {q0 0 0
, ,q q1 2}}
0 1
1 0
0
1
}
Then L is recognized by
1 0
Start
{ {q q {q0 0 0
, ,q q1 2}}
0 1}
1
0
Question: What are the regex’s for L and L
99
Example:
Let L be recognized by the DFA below
Start
{ {q q {q0 0 0
, ,q q1 2}}
0 1
1 0
0
1
}
Then L is recognized by
1 0
Start
{ {q q {q0 0 0
, ,q q1 2}}
0 1}
1
0
Question: What are the regex’s for L and L
99

Les langages réguliers et expressions régulièresLes automates finis
Équivalence entre FA et REAutres types d’automates finis
Propriétés des langages réguliersÉquivalence et minimisation d’automates finis
Pour quels opérateurs les langages réguliers sont-ils fermés ?
Théorème (Si L et M sont réguliers alors L ∩M est régulier)
Preuve :
grâce à la loi de De Morgan L ∩M = L ∪M
et le fait que les langages réguliers sont fermés pour l’union et lecomplément
123

Les langages réguliers et expressions régulièresLes automates finis
Équivalence entre FA et REAutres types d’automates finis
Propriétés des langages réguliersÉquivalence et minimisation d’automates finis
Pour quels opérateurs les langages réguliers sont-ils fermés ?
Théorème (Si L et M sont réguliers alors L ∩M est régulier)
Autre preuve : (directe et constructive)
Ayant pour L le DFA AL avec L(AL) = L : AL = 〈QL, Σ, δL, qL, FL〉et pour M le DFA AM avec L(AM) = M : AM = 〈QM , Σ, δM , qM , FM〉on définit le DFA AL∩M
AL∩M = 〈QL ×QM , Σ, δL∩M , (qL, qM), FL × FM〉
avecδL∩M((p, q), a) = (δL(p, a), δM(q, a))
On peut démontrer que AL∩M accepte L ∩M
124
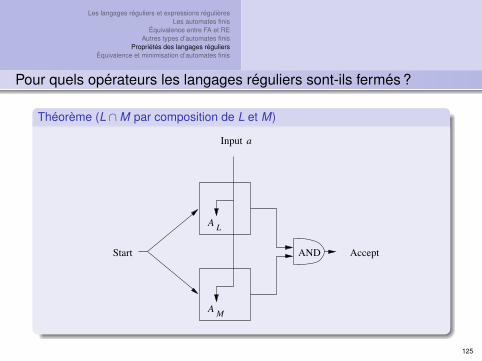
Les langages réguliers et expressions régulièresLes automates finis
Équivalence entre FA et REAutres types d’automates finis
Propriétés des langages réguliersÉquivalence et minimisation d’automates finis
Pour quels opérateurs les langages réguliers sont-ils fermés ?
Théorème (L ∩M par composition de L et M)
If AL goes from state p to state s on reading a,and AM goes from state q to state t on readinga, then AL∩M will go from state (p, q) to state(s, t) on reading a.
Start
Input
AcceptAND
a
L
M
A
A
102
125
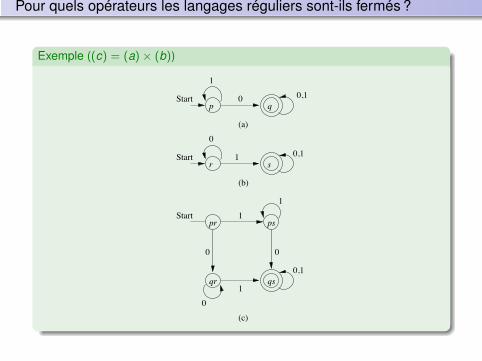
Pour quels opérateurs les langages réguliers sont-ils fermés ?
Exemple ((c) = (a)× (b))Example: (c) = (a)× (b)
Start
Start
1
0 0,1
0,11
0
(a)
(b)
Start
0,1
p q
r s
pr ps
qr qs
0
1
1
0
0
1
(c)
104

Les langages réguliers et expressions régulièresLes automates finis
Équivalence entre FA et REAutres types d’automates finis
Propriétés des langages réguliersÉquivalence et minimisation d’automates finis
Pour quels opérateurs les langages réguliers sont-ils fermés ?
Théorème (Si L et M sont réguliers alors L\M est régulier)
Preuve :L\M = L ∩M
127

Les langages réguliers et expressions régulièresLes automates finis
Équivalence entre FA et REAutres types d’automates finis
Propriétés des langages réguliersÉquivalence et minimisation d’automates finis
Pour quels opérateurs les langages réguliers sont-ils fermés ?
Théorème (Si L est régulier alors LR est régulier)
Preuve : L est reconnu par un FA A = 〈Q, Σ, δ, q0, F 〉À partir de A on peut construire un FA B = 〈Q ∪ {p0}, Σ, δ′, p0, F ′〉 avec
p0 un nouvel état
δ′ est construit à partir de δ en inversant tous les arcs
rajoutant δ(p0, ε) = F
F ′ = {q0}On peut prouver que L(B) = LR
128

Les langages réguliers et expressions régulièresLes automates finis
Équivalence entre FA et REAutres types d’automates finis
Propriétés des langages réguliersÉquivalence et minimisation d’automates finis
w ∈ L, L vide, fini, infini ?, L1 ⊆ L2, L1 = L2
Comment tester que :
w ∈ L ? : voir si un DFA A avec L = L(A) accepte w
L vide ? (L = ∅) : voir si un état accepteur est accessible à partir de l’étatinitial de A
L = Σ∗ ? : voir si l’ensemble des états accepteurs du DFA qui reconnaîtL = l’ensemble des états accessibles.
L infini ? : voir si à partir de l’état initial on peut atteindre un étataccepteur en passant par un état dans un cycle
L1 ⊆ L2 ⇐⇒ L1 ∩ L2 = ∅L1 = L2 ⇐⇒ L1 ⊆ L2 ∧ L2 ⊆ L1
129

Les langages réguliers et expressions régulièresLes automates finis
Équivalence entre FA et REAutres types d’automates finis
Propriétés des langages réguliersÉquivalence et minimisation d’automates finis
Plan
1 Les langages réguliers et expressions régulières
2 Les automates finis
3 Équivalence entre FA et RE
4 Autres types d’automates finis
5 Propriétés des langages réguliers
6 Équivalence et minimisation d’automates finis
130

Les langages réguliers et expressions régulièresLes automates finis
Équivalence entre FA et REAutres types d’automates finis
Propriétés des langages réguliersÉquivalence et minimisation d’automates finis
Équivalence d’états
Soit un DFA A = 〈Q, Σ, δ, q0, F 〉 et {p, q} ⊆ Q.
Définition (p ≡ q (p équivalent à q))
p ≡ q ⇐⇒ (∀w ∈ Σ∗ : δ(p, w) ∈ F ⇐⇒ δ(q, w) ∈ F )
Si p 6≡ q on dit que p et q sont distinguablesOn a p 6≡ q ⇐⇒
∃w : δ(p, w) ∈ F ⇐⇒ δ(q, w) /∈ F ou vice-versa
Intuitivement, on accepte le même langage à partir de p et de q
131

Équivalence d’états
Exemple (Équivalence d’états (pour le DFA M = 〈Q, Σ, δ, A, FM ))Example:
Start
0
0
1
1
0
1
0
1
10
01
0
11
0
A B C D
E F G H
δ(C, ε) ∈ F, δ(G, ε) /∈ F ⇒ C #≡ G
δ(A,01) = C ∈ F, δ(G,01) = E /∈ F ⇒ A #≡ G
119
δ(C, ε) ∈ FM ∧ δ(G, ε) /∈ FM ⇒ C 6≡ G
δ(A, 01) = C ∈ FM ∧ δ(G, 01) = E /∈ FM ⇒ A 6≡ G
on peut, par exemple, voir que A ≡ E

Équivalence d’états
Algorithme de remplissage de table pour calculer les pairs distinctes
Base : p ∈ F ∧ q /∈ F ⇐⇒ DISTINCT [p, q]← VraiInduction : si ∃a ∈ Σ : DISTINCT [δ(p, a), δ(q, a)]
alors DISTINCT [p, q]← VraiExemple : pour le DFA M
We can compute distinguishable pairs with thefollowing inductive table filling algorithm:
Basis: If p ∈ F and q "∈ F , then p "≡ q.
Induction: If ∃a ∈ Σ : δ(p, a) "≡ δ(q, a),then p "≡ q.
Example: Applying the table filling algo to A:
B
C
D
E
F
G
H
A B C D E F G
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x x
121

Les langages réguliers et expressions régulièresLes automates finis
Équivalence entre FA et REAutres types d’automates finis
Propriétés des langages réguliersÉquivalence et minimisation d’automates finis
Équivalence d’états
Théorème (Si p et q ne sont pas distingués par l’algorithme de remplissagede table alors p ≡ q)
Preuve : (par l’absurde)On suppose le contraire : il existe une paire {p, q} telle que :
1 ∃w ∈ Σ∗ : δ(p, w) ∈ F ∧ δ(q, w) /∈ F2 l’algorithme de remplissage de table ne distingue pas p de q
(C) Soit w = a1a2 . . . an le string le plus court qui différentie une paire {p, q}que l’algorithme de remplissage ne distingue pas
w 6= ε sinon l’algorithme distinguerait p de q (donc n ≥ 1)
Prenons r = δ(p, a1) et s = δ(q, a1){r , s} ne sont pas équivalents avec x = a2 . . . an plus court que w et par(C) l’algorithme doit les distinguer.Mais alors l’algorithme doit distinguer {p, q} dans sa partie inductive.Contradiction
134

Les langages réguliers et expressions régulièresLes automates finis
Équivalence entre FA et REAutres types d’automates finis
Propriétés des langages réguliersÉquivalence et minimisation d’automates finis
Équivalence de languages (algorithme direct)
Algorithme pour déterminer si 2 Langages réguliers sont équivalents
Construire des DFAs pour L et pour M (leurs ensembles d’états étantdisjoints)
Regarder le DFA formé de l’union des états de L et de M (l’état initialn’est pas important)
Faire tourner l’algorithme de remplissage de table
Si les 2 états initiaux sont équivalents, L ≡ M
135

Équivalence d’états
Exemple (Les 2 Langages réguliers sont équivalents)Example:
Start
Start
0
0
1
1
0
10
1
1
0
A B
C D
E
We can “see” that both DFA acceptL(ε + (0 + 1)∗0). The result of the TF-algo is
B
C
D
E
A B C D
x
x
x
x
x x
Therefore the two automata are equivalent.125
Example:
Start
Start
0
0
1
1
0
10
1
1
0
A B
C D
E
We can “see” that both DFA acceptL(ε + (0 + 1)∗0). The result of the TF-algo is
B
C
D
E
A B C D
x
x
x
x
x x
Therefore the two automata are equivalent.125
A ≡ C et donc L ≡ M

Les langages réguliers et expressions régulièresLes automates finis
Équivalence entre FA et REAutres types d’automates finis
Propriétés des langages réguliersÉquivalence et minimisation d’automates finis
Minimisation de DFAs
On peut facilement voir que la relation ≡ est une relation d’équivalence.Notons p/≡ la classe d’équivalence de ≡ qui contient l’état pet Q/≡ (resp. F/≡) l’ensemble des classes d’équivalence de Q (resp. F )pour le relation ≡
Algorithme de minimisation d’un DFA A = 〈Q, Σ, δ, q0, F 〉1 Faire fonctionner l’algorithme de remplissage de table2 fusionner les états équivalents : on construit B = 〈Q/≡, Σ, γ, q0/≡, F/≡〉
avecγ(p/≡, a) = δ(p, a)/≡
Pour que B soit bien défini, il faut montrer que
si p ≡ q alors ∀a, δ(p, a) ≡ δ(q, a)
Sinon l’algorithme de remplissage de table aurait conclu que p 6≡ q137

Minimisation de DFAs
Exemple (de minimisation)Example:
Start
0
0
1
1
0
1
0
1
10
01
0
11
0
A B C D
E F G H
δ(C, ε) ∈ F, δ(G, ε) /∈ F ⇒ C #≡ G
δ(A,01) = C ∈ F, δ(G,01) = E /∈ F ⇒ A #≡ G
119
est minimisé en
We can compute distinguishable pairs with thefollowing inductive table filling algorithm:
Basis: If p ∈ F and q "∈ F , then p "≡ q.
Induction: If ∃a ∈ Σ : δ(p, a) "≡ δ(q, a),then p "≡ q.
Example: Applying the table filling algo to A:
B
C
D
E
F
G
H
A B C D E F G
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x
x x
121
Example: We can minimize
Start
0
0
1
1
0
1
0
1
10
01
0
11
0
A B C D
E F G H
to obtain
Start
1
0
0
1
1
0
10
1
0A,E
G D,F
B,H C
129

Les langages réguliers et expressions régulièresLes automates finis
Équivalence entre FA et REAutres types d’automates finis
Propriétés des langages réguliersÉquivalence et minimisation d’automates finis
Pourquoi la minimisation de DFAs ne peut être battue
Prenons B le DFA obtenu grâce à l’algorithme de minimisation à partirde A
On sait que L(A) = L(B)
Supposons C plus petit que B avec L(C) = L(B)
Faisons fonctionner l’algorithme de remplissage de table sur B ∪ C
Comme L(B) = L(C) on doit avoir qB0 ≡ qC
0 et ∀a, δ(qB0 , a) ≡ δ(qC
0 , a)
Étant donné qu’aucun état de B n’est inaccessibleon peut montrer que pour tout état p de B il existe un état q de C tel quep ≡ q
si C plus petit que B il doit exister des états r et s de B, t de C avecr ≡ t ≡ s
Mais alors r ≡ s et l’algorithme aurait dû les fusionner (contradiction)
139

Rôles et place de l’analyse lexicale (scanning)Éléments à traiter
Extension des expressions régulièresConstruction d’un analyseur lexical à la main
Construction d’un analyseur lexical avec (f)lex
Chapitre 3 : L’analyse lexicale (scanning)
1 Rôles et place de l’analyse lexicale (scanning)
2 Éléments à traiter
3 Extension des expressions régulières
4 Construction d’un analyseur lexical à la main
5 Construction d’un analyseur lexical avec (f)lex
140

Rôles et place de l’analyse lexicale (scanning)Éléments à traiter
Extension des expressions régulièresConstruction d’un analyseur lexical à la main
Construction d’un analyseur lexical avec (f)lex
Plan
1 Rôles et place de l’analyse lexicale (scanning)
2 Éléments à traiter
3 Extension des expressions régulières
4 Construction d’un analyseur lexical à la main
5 Construction d’un analyseur lexical avec (f)lex
141

Rôle de l’analyse lexicale (scanning)
1 Identifie les lexèmes et les unités lexicales correspondantes (Rôleprincipal)
2 Met (éventuellement) les identificateurs (non prédéfinis) et littéraux dansla table des symboles1
3 Produit le listing / est lié à un éditeur intelligent4 Nettoie le programme source (supprime les commentaires, espaces,
tabulations, majuscules, . . .) : joue le rôle de filtre
1peut se faire lors de d’une phase ultérieure d’analyse

Rôles et place de l’analyse lexicale (scanning)Éléments à traiter
Extension des expressions régulièresConstruction d’un analyseur lexical à la main
Construction d’un analyseur lexical avec (f)lex
Lexème, unité lexicale, modèle
Définitions
Unité lexicale (ou token) : Type générique d’éléments lexicaux(correspond à un ensemble de strings ayant une sémantique proche).Exemple : identificateur, opérateur relationnel, mot clé “begin”...
Lexème (ou string) : Occurrence d’une unité lexicale.Exemple : N est un lexème dont l’unité lexicale est identificateur
Modèle (pattern) : Règle décrivant une unité lexicaleExemple : identificateur = lettre (lettre + chiffre)*
Relation entre lexème, unité lexicale et modèle
unité lexicale = { lexème | modèle(lexème) }
143
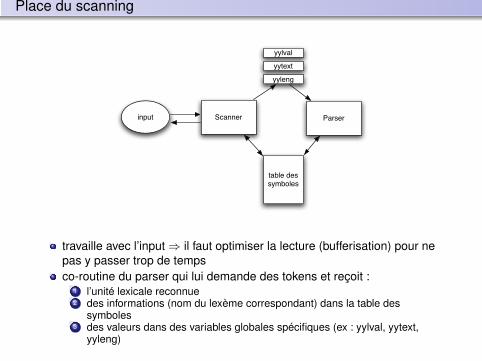
Place du scanning
input Scanner Parser
table des symboles
yyleng
yytext
yylval
travaille avec l’input⇒ il faut optimiser la lecture (bufferisation) pour nepas y passer trop de tempsco-routine du parser qui lui demande des tokens et reçoit :
1 l’unité lexicale reconnue2 des informations (nom du lexème correspondant) dans la table des
symboles3 des valeurs dans des variables globales spécifiques (ex : yylval, yytext,
yyleng)

Rôles et place de l’analyse lexicale (scanning)Éléments à traiter
Extension des expressions régulièresConstruction d’un analyseur lexical à la main
Construction d’un analyseur lexical avec (f)lex
Frontière entre scanning et parsing
La frontière entre scanning et parsing est parfois floueDu point de vue logique :
Au scanning : on reconnaît des lexèmes / unités lexicalesAu parsing : on construit l’arbre syntaxique
Du point de vue technique :Au scanning : on manipule des expressions régulières et l’analyse est localeAu parsing : on manipule des grammaires context free et l’analyse estglobale
Remarques :
Parfois le scanning compte les parenthèses (lien avec un éditeurintelligent)
Exemple compliqué pour le scanning : en FORTRANDO 5 I = 1,3 différent de DO 5 I = 1.3⇒ nécessite une lecture anticipée
145

Rôles et place de l’analyse lexicale (scanning)Éléments à traiter
Extension des expressions régulièresConstruction d’un analyseur lexical à la main
Construction d’un analyseur lexical avec (f)lex
Plan
1 Rôles et place de l’analyse lexicale (scanning)
2 Éléments à traiter
3 Extension des expressions régulières
4 Construction d’un analyseur lexical à la main
5 Construction d’un analyseur lexical avec (f)lex
146

Rôles et place de l’analyse lexicale (scanning)Éléments à traiter
Extension des expressions régulièresConstruction d’un analyseur lexical à la main
Construction d’un analyseur lexical avec (f)lex
Eléments à traiter
1 Les unités lexicales : règles générales :Le scanner reconnaît le lexème le plus long reconnaissable :
Pour <= le scanner ne doit pas s’arrêter à <Pour x36estune variable le scanner ne doit pas s’arrêter à x
Les “mots clés/réservés” (if, then, while) sont dans le modèle “identificateur”⇒ le scanner doit reconnaître en priorité les mots clés (if36x doit bien sûrêtre reconnu comme un identificateur)
2 Les séparateurs : (espaces, tabulation, <CR>), sont soit écartés, soittraités comme tokens vides (reconnus comme tokens par le scannermais non transmis)
3 Les erreurs : le scanner peut essayer de se resynchroniser pourdétecter d’autres erreurs éventuelles (mais aucun code ne sera généré)
147

Rôles et place de l’analyse lexicale (scanning)Éléments à traiter
Extension des expressions régulièresConstruction d’un analyseur lexical à la main
Construction d’un analyseur lexical avec (f)lex
Plan
1 Rôles et place de l’analyse lexicale (scanning)
2 Éléments à traiter
3 Extension des expressions régulières
4 Construction d’un analyseur lexical à la main
5 Construction d’un analyseur lexical avec (f)lex
148
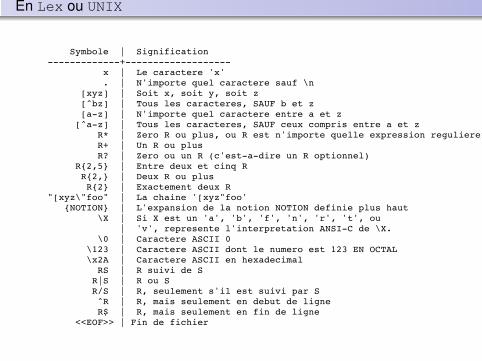
En Lex ou UNIX
269/09/Monday 14h24Mini manuel d'utilisation de Lex et Yacc: Utilisation de Lex dans l'analyse lexicale
Page 2 sur 3http://www.linux-france.org/article/devl/lexyacc/minimanlexyacc-2.html
chiffre10 [0-9] /* base 10 */chiffre16 [0-9A-Fa-f] /* base 16 */
identificateur {lettre}(_|{lettre}|{chiffre10})*entier10 {chiffre10}+
L'exemple en lui-même est clair, mais regardons d'un peu plus près comment sont formées lesexpressions régulières.
2.2 Les expressions régulières
Symbole | Signification-------------+------------------- x | Le caractere 'x' . | N'importe quel caractere sauf \n [xyz] | Soit x, soit y, soit z [^bz] | Tous les caracteres, SAUF b et z [a-z] | N'importe quel caractere entre a et z [^a-z] | Tous les caracteres, SAUF ceux compris entre a et z R* | Zero R ou plus, ou R est n'importe quelle expression reguliere R+ | Un R ou plus R? | Zero ou un R (c'est-a-dire un R optionnel) R{2,5} | Entre deux et cinq R R{2,} | Deux R ou plus R{2} | Exactement deux R"[xyz\"foo" | La chaine '[xyz"foo' {NOTION} | L'expansion de la notion NOTION definie plus haut \X | Si X est un 'a', 'b', 'f', 'n', 'r', 't', ou | 'v', represente l'interpretation ANSI-C de \X. \0 | Caractere ASCII 0 \123 | Caractere ASCII dont le numero est 123 EN OCTAL \x2A | Caractere ASCII en hexadecimal RS | R suivi de S R|S | R ou S R/S | R, seulement s'il est suivi par S ^R | R, mais seulement en debut de ligne R$ | R, mais seulement en fin de ligne <<EOF>> | Fin de fichier
Ainsi, la définition
identificateur {lettre}(_|{lettre}|{chiffre10})*
reconnaitra comme identificateur les mots 'integer', 'une_variable', 'a1', mais pas '_ident' ni '1variable'.Facile, non ?
Enfin, comme dernier exemple, voici la définition d'un réel :
chiffre [0-9]entier {chiffre}+exposant [eE][+-]?{entier}reel {entier}("."{entier})?{exposant}?
2.3 La deuxième partie d'un fichier Lex : les productions
Cette partie sert à indiquer à Lex ce qu'il devra faire lorsqu'il rencontrera telle ou telle notion. Celle-ci

Rôles et place de l’analyse lexicale (scanning)Éléments à traiter
Extension des expressions régulièresConstruction d’un analyseur lexical à la main
Construction d’un analyseur lexical avec (f)lex
Exemple de définition d’unités lexicales
Exemple (d’expressions régulières étendues)
blancs [\t\n ]+lettre [A-Za-z]chiffre [0-9] /* base 10 */chiffre16 [0-9A-Fa-f] /* base 16 */mot-cle-if ifidentificateur {lettre}(_|{lettre}|{chiffre})*entier {chiffre}+exposant [eE][+-]?{entier}reel {entier}("."{entier})?{exposant}?
Toutes ces expressions étendues peuvent être traduites en expressionsrégulières de base (et en FA)
150

Rôles et place de l’analyse lexicale (scanning)Éléments à traiter
Extension des expressions régulièresConstruction d’un analyseur lexical à la main
Construction d’un analyseur lexical avec (f)lex
Plan
1 Rôles et place de l’analyse lexicale (scanning)
2 Éléments à traiter
3 Extension des expressions régulières
4 Construction d’un analyseur lexical à la main
5 Construction d’un analyseur lexical avec (f)lex
151
Rôles et place de l’analyse lexicale (scanning)Éléments à traiter
Extension des expressions régulièresConstruction d’un analyseur lexical à la main
Construction d’un analyseur lexical avec (f)lex
Construction d’un analyseur lexical à la main
Principe de la construction du scanner
On part des descriptions sous forme d’expressions régulières étendues
On “traduit” sous forme d’automate fini “déterministe”
Cet automate est enrichi d’actions (renvoi de résultats) et de retours enarrière éventuels au dernier état accepteur retenu.
152

Exemple
Exemple (scanner qui reconnaît : if, identificateur, entier et réel)
starti
[a-hj-z_]
f
autre
l |c |_
c | [a-eg-z_]
l | c |_
autre
c
c
'.'
autre
c [e | E]
[e | E] [+ |-]
c
c
c
retourne <if,-> ungetc(autre)
retourne <id,valeur> ungetc(autre)
retourne <réel,valeur> ungetc(autre)
retourne <entier,valeur> ungetc(autre)
autre

Rôles et place de l’analyse lexicale (scanning)Éléments à traiter
Extension des expressions régulièresConstruction d’un analyseur lexical à la main
Construction d’un analyseur lexical avec (f)lex
Exemple où il faut retenir la dernière configuration finale
Exemple (scanner pour abc|abcde| . . . )
starta b c d e
reconnaît abcde
Pour le string abcdx , il faut accepter abc et relire dx
154

Rôles et place de l’analyse lexicale (scanning)Éléments à traiter
Extension des expressions régulièresConstruction d’un analyseur lexical à la main
Construction d’un analyseur lexical avec (f)lex
Plan
1 Rôles et place de l’analyse lexicale (scanning)
2 Éléments à traiter
3 Extension des expressions régulières
4 Construction d’un analyseur lexical à la main
5 Construction d’un analyseur lexical avec (f)lex
155

Procédure générale pour l’utilisation de Lex (Flex) et Yacc (Bison)
5
Lex generates C code for a lexical analyzer, or scanner. It uses patterns that match strings in the input and converts the strings to tokens. Tokens are numerical representations of strings, and simplify processing. This is illustrated in Figure 1. As lex finds identifiers in the input stream, it enters them in a symbol table. The symbol table may also contain other information such as data type (integer or real) and location of the variable in memory. All subsequent references to identifiers refer to the appropriate symbol table index. Yacc generates C code for a syntax analyzer, or parser. Yacc uses grammar rules that allow it to analyze tokens from lex and create a syntax tree. A syntax tree imposes a hierarchical structure on tokens. For example, operator precedence and associativity are apparent in the syntax tree. The next step, code generation, does a depth-first walk of the syntax tree to generate code. Some compilers produce machine code, while others, as shown above, output assembly.
lex
yacc
cc
bas.y
bas.l lex.yy.c
y.tab.c
bas.exe
source
compiled output
(yylex)
(yyparse)
y.tab.h
Figure 2: Building a Compiler with Lex/Yacc Figure 2 illustrates the file naming conventions used by lex and yacc. We'll assume our goal is to write a BASIC compiler. First, we need to specify all pattern matching rules for lex (bas.l) and grammar rules for yacc (bas.y). Commands to create our compiler, bas.exe, are listed below:
yacc –d bas.y # create y.tab.h, y.tab.c lex bas.l # create lex.yy.c cc lex.yy.c y.tab.c –obas.exe # compile/link
Yacc reads the grammar descriptions in bas.y and generates a parser, function yyparse, in file y.tab.c. Included in file bas.y are token declarations. The –d option causes yacc to generate definitions for tokens and place them in file y.tab.h. Lex reads the pattern descriptions in bas.l, includes file y.tab.h, and generates a lexical analyzer, function yylex, in file lex.yy.c. Finally, the lexer and parser are compiled and linked together to form the executable, bas.exe. From main, we call yyparse to run the compiler. Function yyparse automatically calls yylex to obtain each token.
Compilation :
yacc -d bas.y # crée y.tab.h et y.tab.clex bas.l # crée lex.yy.ccc lex.yy.c y.tab.c -ll -obas.exe # compile et fait l’édition
# crée bas.exe

Rôles et place de l’analyse lexicale (scanning)Éléments à traiter
Extension des expressions régulièresConstruction d’un analyseur lexical à la main
Construction d’un analyseur lexical avec (f)lex
Spécification Lex
définitions
%%
règles
%%
code additionnel
L’analyseur lexical résultant (yylex()) cherche à reconnaître des lexèmesIl peut utiliser des variables globales :
Nom fonctionchar *yytext pointeur sur le lexème reconnuyyleng longueur du lexèmeyylval valeur de l’unité lexicale
Variables globales prédéfinies
157

Exemple Lex (1)
Exemple (1 d’utilisation de Lex)
%{int yylineno;
%}
%%
^(.*)\n printf("%4d\t%s", ++yylineno, yytext);
%%
int main(int argc, char *argv[]) {yyin = fopen(argv[1], "r");yylex();fclose(yyin);
}
Remarque :
Dans cet exemple, le scanner (yylex()) s’exécute jusqu’à la fin de la lecturecomplète du fichier

Exemple Lex (2)
Exemple (2 d’utilisation de Lex)
digit [0-9]letter [A-Za-z]%{
int count;%}
%%
/* match identifier */{letter}({letter}{digit})* count++;
%%
int main(void) {yylex();printf("number of identifiers = %d\n", count);return 0;
}
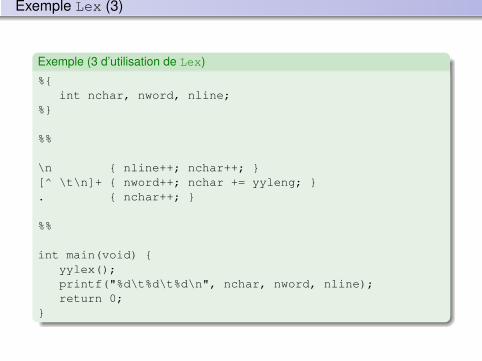
Exemple Lex (3)
Exemple (3 d’utilisation de Lex)
%{int nchar, nword, nline;
%}
%%
\n { nline++; nchar++; }[^ \t\n]+ { nword++; nchar += yyleng; }. { nchar++; }
%%
int main(void) {yylex();printf("%d\t%d\t%d\n", nchar, nword, nline);return 0;
}

Rôles et place de l’analyse lexicale (scanning)Éléments à traiter
Extension des expressions régulièresConstruction d’un analyseur lexical à la main
Construction d’un analyseur lexical avec (f)lex
Exemple Lex (4)
Exemple (4 : scanner et évaluateur d’expressions simples)
/* calculateur avec ’+’ et ’-’ *//* Thierry Massart - 28/09/2005 */%{#define NUMBER 1int yylval;%}
%%
[0-9]+ {yylval = atoi(yytext); return NUMBER;}[ \t] ; /* ignore les espaces et tabulation */\n return 0; /* permet l’arrêt à l’eol */. return yytext[0];
161

Exemple Lex (4 (suite))
Exemple (4 (suite))
%%int main() {int val;int tot=0;int signe=1;
val = yylex();while(val !=0){
if(val==’-’) signe *=-1;else if (val != ’+’) /* nombre */{tot += signe*yylval;signe = 1;
}val=yylex();
}printf("%d\n",tot);return 0;
}

Rôle des grammairesExemples informels de grammaires
Grammaire : définition formelleLa hiérarchie de Chomsky
Chapitre 4 : Les grammaires
1 Rôle des grammaires
2 Exemples informels de grammaires
3 Grammaire : définition formelle
4 La hiérarchie de Chomsky
163

Rôle des grammairesExemples informels de grammaires
Grammaire : définition formelleLa hiérarchie de Chomsky
Plan
1 Rôle des grammaires
2 Exemples informels de grammaires
3 Grammaire : définition formelle
4 La hiérarchie de Chomsky
164

Rôle des grammairesExemples informels de grammaires
Grammaire : définition formelleLa hiérarchie de Chomsky
Pourquoi utilise-t-on des grammaires ?
Pourquoi utilise-t-on des grammaires ?
Beaucoup de langages que l’on désire définir/manipuler ne sont pasréguliers
Les langages “context free” sont utilisés depuis les années 1950 pourdéfinir la syntaxe de langages de programmation
En particulier la syntaxe BNF (Backus Naur Form) est basée sur lanotion de grammaire (context free)
La plupart des langages formels sont définis grâce aux grammaires(exemple : XML).
165

Rôle des grammairesExemples informels de grammaires
Grammaire : définition formelleLa hiérarchie de Chomsky
Plan
1 Rôle des grammaires
2 Exemples informels de grammaires
3 Grammaire : définition formelle
4 La hiérarchie de Chomsky
166

Rôle des grammairesExemples informels de grammaires
Grammaire : définition formelleLa hiérarchie de Chomsky
Exemple de grammaire
Exemple (Grammaire d’une phrase)
phrase = sujet verbe
sujet = “Jean” | “Marie”verbe = “mange” | “parle”
peut donner
Jean mangeJean parleMarie mangeMarie parle
phrase
sujet verbe
Marie mange
Arbre syntaxique de la phraseMarie mange
167

Rôle des grammairesExemples informels de grammaires
Grammaire : définition formelleLa hiérarchie de Chomsky
Exemple de grammaire (2)
Exemple (Grammaire d’une expression)
A = “id” “=” E
E = T | E “+” T
T = F | T “*” F
F = “id” | “cst” | “(” E“)”
peut donner :
id = idid = id + cst * id. . .
E
E T
A
+
F
id
*T
F
cst
F
id
id =
T
Arbre syntaxique de la phraseid = id + cst * id
168

Rôle des grammairesExemples informels de grammaires
Grammaire : définition formelleLa hiérarchie de Chomsky
Autre exemple
Exemple (Le langage des palindrômes)
Soit Lpal = {w ∈ Σ∗|w = wR}Par exemple (en faisant abstraction des majuscules/minuscules et desespaces) :
RessasserHannah
Et la marine va, papa, venir a MalteA Cuba, Anna a bu ça
A Laval elle l’avalaAron, au Togo, tua Nora
SAT ORA REPO TENETO PERARO ... TAS
169

Le dernier exemple est le carré magique (sacré) latin :
ROTAS
N
A
A
A
T T
TO
O
OR
R
R S
E
E
E E
P
P
Traduction littérale possible : Le semeur subreptissement tient l’oeuvre dansla rotation (des temps)Quelques interprétations possibles :
Le laboureur à sa charrue ou en son champ dirige les travaux
Le semeur (christ) à sa charrue (croix) retient son oeuvre (sacrifice)
Dieu dirige la création, le travail de l’homme et le produit de la terre
Rôle des grammairesExemples informels de grammaires
Grammaire : définition formelleLa hiérarchie de Chomsky
Autre exemple de grammaire
Exemple (Le langage des palindrômes)
Limitons nous à Σ = {0, 1}. La grammaire suit le raisonnement inductif :
base : ε, 0 et 1 sont des palindrômes
induction : soit w un palindrôme : 0w0 et 1w1 sont des palindrômes
1 P → ε
2 P → 03 P → 14 P → 0P05 P → 1P1
171

Rôle des grammairesExemples informels de grammaires
Grammaire : définition formelleLa hiérarchie de Chomsky
Autre exemple de grammaire
Terminaux et variables
Dans l’exemple précédent :
0 et 1 sont les terminaux (symboles de l’alphabet terminal)
P est une variable ou non terminal (symbole supplémentaire utilisé pourdéfinir le langage)
P est aussi le symbole de départ (ou l’axiome ou racine)
1-5 sont les règles de production de la grammaire
172

Rôle des grammairesExemples informels de grammaires
Grammaire : définition formelleLa hiérarchie de Chomsky
Plan
1 Rôle des grammaires
2 Exemples informels de grammaires
3 Grammaire : définition formelle
4 La hiérarchie de Chomsky
173

Grammaire : définition formelle
Définition (Grammaire)
Quadruplet :G = 〈V , T , P, S〉
où
V est un ensemble fini de variables
T est un ensemble fini de terminaux
P est un ensemble fini de règles de production de la forme α→ β avec
α ∈ (V ∪ T )∗V (V ∪ T )∗ et β ∈ (V ∪ T )∗
S est une variable (∈ V) appelée symbole de départ
Formellement P est une relation P : (V ∪ T )∗V (V ∪ T )∗ × (V ∪ T )∗
Remarque :
Les exemples précédents utilisent des grammaires context free càd unesous-classe où les règles de production ont la forme A→ β avec A ∈ V

Rôle des grammairesExemples informels de grammaires
Grammaire : définition formelleLa hiérarchie de Chomsky
Définition formelle de l’ensemble des palindrôme sur {0, 1}
Exemple (Le langage des palindrômes)
G = 〈{A}, {0, 1}, P, A〉
avec P = {A→ ε, A→ 0, A→ 1, A→ 0A0, A→ 1A1}
On note les 5 règles de façon compacte en regroupant celles ayant la mêmepartie gauche (ici toutes les règles !) :
A→ ε | 0 | 1 | 0A0 | 1A1
Définition (A-production)
L’ensemble des règles dont la partie gauche est la variable A est appeléel’ensemble des A-productions
175

(Relation de) dérivation
Définition (Dérivation)
Ayant une grammaire G = 〈V , T , P, S〉 Alors
γ ⇒G
δ
ssi
∃α→ β ∈ P
γ ≡ γ1αγ2 pour γ1, γ2 ∈ (V ∪ T )∗
δ ≡ γ1βγ2
Remarques :
Les grammaires sont donc des systèmes de réécriture : la dérivationγ ≡ γ1αγ2 ⇒
Gγ1βγ2 ≡ δ est une réécriture de la partie α en β dans le
string γ qui de dérive en δ
Quand G est clairement identifiée on écrit plus simplement : γ ⇒ δ∗⇒ est la fermeture reflexo-transitive de⇒α
i⇒ β est une notation pour une dérivation de longueur i entre α et β
tout string α dérivable à partir du symbole de départ (S ∗⇒ α) est appeléforme phrasée ou protophrase

Dérivation (suite)
Avec G = 〈{E , T , F}, {i, c, +, ∗, (, )}, P, E〉 et P :
E → T | E + T
T → F | T ∗ F
F → i | c | (E)
On aE ∗⇒ i + c ∗ i
Plusieurs dérivations sont possibles : exemples :1 E ⇒ E + T ⇒ T + T ⇒ F + T ⇒ i + T⇒ i + T ∗ F ⇒ i + F ∗ F ⇒ i + c ∗ F ⇒ i + c ∗ i
2 E ⇒ E + T ⇒ E + T ∗ F ⇒ E + T ∗ i⇒ E + F ∗ i ⇒ E + c ∗ i ⇒ T + c ∗ i ⇒ F + c ∗ i ⇒ i + c ∗ i
3 E ⇒ E + T ⇒ T + T ⇒ T + T ∗ F ⇒ T + F ∗ F⇒ T + c ∗ F ⇒ F + c ∗ F ⇒ F + c ∗ i ⇒ i + c ∗ i
4 . . .

Rôle des grammairesExemples informels de grammaires
Grammaire : définition formelleLa hiérarchie de Chomsky
Langage de G
Définition (Langage d’une grammaire G = 〈V , T , P, S〉)
L(G) = {w ∈ T ∗ | S ∗⇒ w}
Définition (L(A))
Pour une grammaire G = 〈V , T , P, S〉 avec A ∈ V
L(A) = {w ∈ T ∗ | A ∗⇒ w}
178

Rôle des grammairesExemples informels de grammaires
Grammaire : définition formelleLa hiérarchie de Chomsky
Inférence récursive
Inférence récursive
Un autre type de raisonnement bottom-up qui permet de montrer qu’un stringappartient à L(G) est de montrer inductivement :
base : ce qui peut être généré en une dérivation
induction : sachant ce qui peut être généré en au plus i dérivations, devoir ce qui peut l’être en une dérivation supplémentaire
179

Inférence récursive
Exemple (d’inférence récursive)
Avec lesrègles :
1 E →T + E
2 E → T3 T →
F .T4 T → F5 F → F∗
6 F → 07 F → 18 F → (E)
On a par ex. les inférencesrécursives :
Chaînes Prod. Racine utilise(i) 0 6 F −(ii) 1 7 F −(iii) 0∗ 5 F (i)(iv) 1∗ 5 F (ii)(v) 0 4 T (i)(vi) 1 4 T (ii)(vii) 0∗ 4 T (iii)(viii) 1∗ 4 T (iv)(ix) 0.0 3 T (i), (v)(x) 0.1 3 T (i), (vi)(xi) 1.0 3 T (ii), (v)(xii) 1.1 3 T (ii), (vi)(xiii) 0∗.0 3 T (iii), (v)(xiv) 0 2 E (v). . . . . . . . . . . . . . .

Rôle des grammairesExemples informels de grammaires
Grammaire : définition formelleLa hiérarchie de Chomsky
Plan
1 Rôle des grammaires
2 Exemples informels de grammaires
3 Grammaire : définition formelle
4 La hiérarchie de Chomsky
181
Noam Chomsky
Noam Chomsky (www.chomsky.info) (born December 7, 1928) is InstituteProfessor Emeritus of linguistics at the Massachusetts Institute ofTechnology. Chomsky is credited with the creation of the theory of generativegrammar, often considered the most significant contribution to the field oftheoretical linguistics of the 20th century. He also helped spark the cognitiverevolution in psychology through his review of B. F. Skinner’s Verbal Behavior,which challenged the behaviorist approach to the study of mind and languagedominant in the 1950s. His naturalistic approach to the study of language hasalso impacted the philosophy of language and mind (see Harman, Fodor).
He is also credited with the establishment of theso-called Chomsky hiérarchy, a classification offormal languages in terms of their generative power.Chomsky is also widely known for his politicalactivism, and for his criticism of the foreign policy ofthe United States and other governments. Chomskydescribes himself as a libertarian socialist, asympathizer of anarcho-syndicalism.

Rôle des grammairesExemples informels de grammaires
Grammaire : définition formelleLa hiérarchie de Chomsky
La hiérarchie de Chomsky
Définition (La hiérarchie de Chomsky)
Cette hiérarchie définit 4 classes de grammaires (et de langages).
Type 0 : les grammaires non restreintesC’est la définition la plus générale donnée plus haut (sans restriction)
Type 1 : les grammaires context-sensitive (sensibles au contexte)Grammaires où toutes les règles sont de la forme :
S → ε auquel cas S n’apparaît dans aucun membre de droite de règlesα→ β avec |α| ≤ |β|
183

Rôle des grammairesExemples informels de grammaires
Grammaire : définition formelleLa hiérarchie de Chomsky
La hiérarchie de Chomsky
Définition (La hiérarchie de Chomsky (suite))
Type 2 : les grammaires context-free (hors contexte)Grammaires où toutes les règles sont de la forme :
A→ α avec α ∈ (T ∪ V )∗
Type 3 : les grammaires régulièresClasse de grammaires formées des 2 sous-classes suivantes :
1 les grammaires linéaires droites, où toutes les règles sont de la forme :A→ wBA→ w
avec A, B ∈ V ∧ w ∈ T∗
2 les grammaires linéaires gauches, où toutes les règles sont de la forme :A→ BwA→ w
avec A, B ∈ V ∧ w ∈ T∗
184

Rôle des grammairesExemples informels de grammaires
Grammaire : définition formelleLa hiérarchie de Chomsky
La hiérarchie de Chomsky
Remarques - propriétés
Définition équivalente des grammaires context-sensitive : G estcontext-sensitive si ses règles sont de la forme :
αAγ → αβγ avec α, β, γ ∈ (V ∪ T )∗ ∧ A ∈ V
Cette autre définition des grammaires context-sensitive explique le nomde ce type de grammaire (dans le contexte α− γ, la variable A peut seréécrire en β
La grammaire suivante n’est PAS régulière :1 S → ε2 S → A03 A→ 1S
La règle 2 étant linéaire gauche et la règle 3 linéaire droite (mélange des2 types de règles !)
185

Rôle des grammairesExemples informels de grammaires
Grammaire : définition formelleLa hiérarchie de Chomsky
La hiérarchie de Chomsky
Remarques - propriétés (suite)
On dit qu’un langage est de type n s’il existe une grammaire de type nqui le définit.
Nous verrons que type 3 ⊂ type 2 ⊂ type 1 ⊂ type 0
De ce fait si une grammaire est de type n et n + 1, le fait qu’elle soit detype n + 1 est plus précis
186

Rappel (définition)Équivalence entre grammaires régulières et langages réguliers
Chapitre 5 : Les grammaires régulières
1 Rappel (définition)
2 Équivalence entre grammaires régulières et langages réguliers
187

Rappel (définition)Équivalence entre grammaires régulières et langages réguliers
Plan
1 Rappel (définition)
2 Équivalence entre grammaires régulières et langages réguliers
188

Rappel (définition)Équivalence entre grammaires régulières et langages réguliers
Grammaire régulière (définition)
Définition (Grammaire régulière - type 3 dans la hiérarchie de Chomsky)
Classe de grammaires formées des 2 sous-classes suivantes :1 les grammaires linéaires droites, où toutes les règles sont de la forme
A→ wBA→ w
avec A, B ∈ V ∧ w ∈ T ∗
2 les grammaires linéaires gauches, où toutes les règles sont de la formeA→ BwA→ w
avec A, B ∈ V ∧ w ∈ T ∗
189

Rappel (définition)Équivalence entre grammaires régulières et langages réguliers
Plan
1 Rappel (définition)
2 Équivalence entre grammaires régulières et langages réguliers
190

Équivalence entre grammaires régulières et langages réguliers
On peut montrer que1 Tout langage généré par une grammaire linéaire droite est régulier2 Tout langage généré par une grammaire linéaire gauche est régulier3 Tout langage régulier est généré par une grammaire linéaire droite4 Tout langage régulier est généré par une grammaire linéaire gauche
FA
Grammaireslinéaires droites
Grammaireslinéaires gauches
Grammaires régulières
Ce qui implique que la classe des langages générés par une grammairelinéaire droite est la même que celle générée par une grammaire linéairegauche càd la classe des langages réguliers

Rappel (définition)Équivalence entre grammaires régulières et langages réguliers
Équivalence entre grammaires régulières et langages réguliers (suite)
Théorème (Tout langage généré par une grammaire linéaire droite estrégulier)
Principe de la construction / preuve :Ayant une grammaire linéaire droite G = 〈V , T , P, S〉, construire un ε-NFA Méquivalent : M = 〈Q, T , δ, [S], {[ε]}〉 qui simule les dérivations de G
Q = {[α] avec α = S ou α = suffixe(β) où A→ β ∈ P et β ∈ T ∗V ∪ T ∗}δ :
1 δ([A], ε) = {[β] | A→ β ∈ P}2 δ([aα], a) = {[α]} avec a ∈ T ∧ α ∈ (T∗ ∪ T∗V )
192
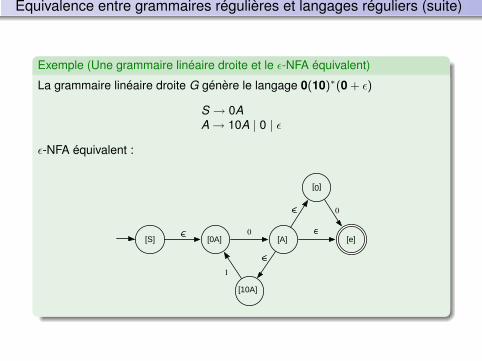
Équivalence entre grammaires régulières et langages réguliers (suite)
Exemple (Une grammaire linéaire droite et le ε-NFA équivalent)
La grammaire linéaire droite G génère le langage 0(10)∗(0 + ε)
S → 0AA→ 10A | 0 | ε
ε-NFA équivalent :
1
0[S] [0A] [A] [e]
[10A]
0
[0]

Rappel (définition)Équivalence entre grammaires régulières et langages réguliers
Équivalence entre grammaires régulières et langages réguliers (suite)
Théorème (Tout langage généré par une grammaire linéaire gauche estrégulier)
Principe de la construction / preuve :Ayant une grammaire linéaire gauche G = 〈V , T , P, S〉,
1 construire la grammaire linéaire droite G′ = 〈V , T , P′, S〉 avecL(G′) = L(G)R .Pour cela il suffit de définir P′ en faisant l’image miroir de toutes lesparties droites de règles :
A→ α ∈ P ⇐⇒ A→ αR ∈ P′
2 construire un ε-NFA M ′ équivalent à G′ : M ′ = 〈Q, T , δ′, [S], {[ε]}〉 quisimule les dérivations de G′
3 construire M avec L(M) = L(M ′)R : inverser toutes les transitions de M ′
et permuter état initial et accepteur : M = 〈Q, T , δ, [ε], {[S]}〉 avec
∀a ∈ T ∪ {ε} : δ(p, a) = q ⇐⇒ δ′(q, a) = p 194

Équivalence entre grammaires régulières et langages réguliers (suite)
Exemple (Une grammaire linéaire gauche et le ε-NFA équivalent)
La grammaire linéaire gauche G génère le langage 0(10)∗
S → S10 | 0
1. Les productions renversées nous donnent :
S → 01S | 0
2. Qui correspond auε-NFA suivant :
0
0[S] [01S] [1S]
[e][0]
1
3. Où on inverse lesflèches et permute l’étatinitial↔ accepteur :
0
0[S] [01S] [1S]
[e][0]
1

Rappel (définition)Équivalence entre grammaires régulières et langages réguliers
Équivalence entre grammaires régulières et langages réguliers (suite)
Théorème (Tout langage régulier est généré par une grammaire linéairedroite)
Principe de la construction / preuve :Soit le DFA M = 〈Q, T , δ, q0, F 〉
si q0 /∈ F : on définit G = 〈Q, T , P, q0〉 équivalent avecp → aq ∈ P ⇐⇒ δ(p, a) = qp → a ∈ P ⇐⇒ δ(p, a) ∈ F
si q0 ∈ F : on fait comme le cas précédant + on rajoute la variable S etS → q0 | ε
196

Équivalence entre grammaires régulières et langages réguliers (suite)
Exemple (Un DFA et la grammaire linéaire droite équivalente)
Soit le DFA pour 0(10)∗ :
1
A B C
D
1
00
0 1
0,1
La grammaire linéairedroite correspondanteest :
A→ 0B | 1D | 0B → 0D | 1CC → 0B | 1D | 0D → 0D | 1D
Après élimination de Dinutile :
A→ 0B | 0B → 1CC → 0B | 0

Rappel (définition)Équivalence entre grammaires régulières et langages réguliers
Équivalence entre grammaires régulières et langages réguliers (suite)
Théorème (Tout langage régulier est généré par une grammaire linéairegauche)
Principe de la construction / preuve :A partir du DFA M,
1 Prenons le DFA M ′ pour LR
2 construisons la grammaire G′ linéaire droite correspondante3 renversons les parties droites des règles de production pour obtenir une
grammaire linéaire gauche G avec L(G) = L(M)
198

Rappels et définitionsArbre de dérivation
Nettoyage et simplification des grammaires context-freeLa forme normale de Chomsky
Chapitre 6 : Les grammaires context free
1 Rappels et définitions
2 Arbre de dérivation
3 Nettoyage et simplification des grammaires context-free
4 La forme normale de Chomsky
199

Rappels et définitionsArbre de dérivation
Nettoyage et simplification des grammaires context-freeLa forme normale de Chomsky
Plan
1 Rappels et définitions
2 Arbre de dérivation
3 Nettoyage et simplification des grammaires context-free
4 La forme normale de Chomsky
200

Rappels et définitionsArbre de dérivation
Nettoyage et simplification des grammaires context-freeLa forme normale de Chomsky
Grammaire context-free (CFG) (définition)
Définition (Grammaire context-free (hors contexte) - type 2 dans la hiérarchiede Chomsky (CFG))
Grammaire où toutes les règles sont de la forme :
A→ α avec α ∈ (T ∪ V )∗ ∧ A ∈ V
Définition (Langage context free (CFL))
L est un CFL si L = L(G) pour une CFG G
201

Rappels et définitionsArbre de dérivation
Nettoyage et simplification des grammaires context-freeLa forme normale de Chomsky
Exemples de grammaire context-free
Exemple (Le langage des palindrômes sur l’alphabet {0, 1})
G = 〈{P}, {0, 1}, A, P〉
avec A = {P → ε | 0 | 1 | 0P0 | 1P1}
Exemple (Langage d’expressions arithmétiques)
G = 〈{E , T , F}, {i, c, +, ∗, (, )}, P, E〉 avec P :
E → T | E + T
T → F | T ∗ F
F → i | c | (E)
202

DérivationsAyant G = 〈{E , T , F}, {i, c, +, ∗, (, )}, P, E〉 et
E → T | E + TT → F | T ∗ FF → i | c | (E)
On aE ∗⇒ i + c ∗ i
Plusieurs dérivations sont possibles : exemples :1 E ⇒ E + T ⇒ T + T ⇒ F + T ⇒ i + T⇒ i + T ∗ F ⇒ i + F ∗ F ⇒ i + c ∗ F ⇒ i + c ∗ i
2 E ⇒ E + T ⇒ E + T ∗ F ⇒ E + T ∗ i⇒ E + F ∗ i ⇒ E + c ∗ i ⇒ T + c ∗ i ⇒ F + c ∗ i ⇒ i + c ∗ i
3 E ⇒ E + T ⇒ T + T ⇒ T + T ∗ F ⇒ T + F ∗ F⇒ T + c ∗ F ⇒ F + c ∗ F ⇒ F + c ∗ i ⇒ i + c ∗ i
4 . . .
Définition (dérivation gauche (resp. droite))
Dérivation de la grammaire G qui réécrit d’abord la variable la plus à gauche(resp. droite) dans la forme phrasée.
la dérivation 1. (de l’exemple) est gauche (on écrit S G∗⇒ α)
la dérivation 2. est droite (on écrit S ∗⇒G α)

Rappels et définitionsArbre de dérivation
Nettoyage et simplification des grammaires context-freeLa forme normale de Chomsky
Plan
1 Rappels et définitions
2 Arbre de dérivation
3 Nettoyage et simplification des grammaires context-free
4 La forme normale de Chomsky
204

Rappels et définitionsArbre de dérivation
Nettoyage et simplification des grammaires context-freeLa forme normale de Chomsky
Arbre de dérivation
Pour une grammaire context-free G, on peut montrer que w ∈ L(G) grâce àun arbre de dérivation.
Exemple (arbre de dérivation)
La grammaire avec lesrègles :
A = “id” “=” E
E = T | E “+” T
T = F | T “*” F
F = “id” | “cst” | “(” E“)”
peut donner :
id = id + cst * id
avec l’arbre de dérivation :
E
E T
A
+
F
id
*T
F
cst
F
id
id =
T
205

Construction d’un arbre de dérivation
Définition (Arbre de dérivation)
Soit une CFG G = 〈V , T , P, S〉. Un arbre de dérivation pour G est tel que :1 chaque noeud intérieur est labellé par une variable2 chaque feuille est labellée par un terminal, une variable ou ε.
Chaque feuille ε est le seul fils de son père3 Si un noeud intérieur est labellé A et ses fils (de gauche à droite) sont
labellés X1, X2, . . . , Xk alors A→ X1X2 . . . Xk ∈ P
Exemple (d’arbre de dérivation)
Pour la grammaire du slide 205
E
E T
A
+
id =
T

Production (yield) d’un arbre de dérivation
Définition (Production de l’arbre de dérivation)
String formé de la concaténation des labels des feuilles dans l’ordre Gauche- Droit. (Correspond à la forme phrasée dérivée)
Exemple (de production d’un arbre de dérivation)
La production de l’arbre de dérivation suivant :
E
E T
A
+
id =
T
estid = T + T

Rappels et définitionsArbre de dérivation
Nettoyage et simplification des grammaires context-freeLa forme normale de Chomsky
Arbre de dérivation complet et A-arbre de dérivation
Définition (Arbre de dérivation complet)
Soit une CFG G = 〈V , T , P, S〉. Un arbre de dérivation complet pour G est unarbre de dérivation tel que :
1 La racine est labellé par le symbole (la variable) de départ2 chaque feuille est labellée par un terminal ou ε (pas une variable).
Exemple (d’arbre complet)
Voir slide 205
Définition (A-arbre de dérivation)
Arbre de dérivation dont la racine est labellée par la variable A
208

Rappels et définitionsArbre de dérivation
Nettoyage et simplification des grammaires context-freeLa forme normale de Chomsky
Pourquoi on appelle ces grammaires context free
Grâce aux arbres de dérivation, on voit clairement pourquoi on parle degrammaire context free.Si A⇒ X1X2 . . . Xk
∗⇒ w l’arbre correspondant à la forme :
X
A
X X1 2 k...
w w w1 2 k...
qui montre que chaque Xi est dérivé indépendamment des autres et doncXi
∗⇒ wi
Les dérivations quelconques mélangent les dérivations des différents Xi . Parcontre, les dérivations gauches ou droites dérivent chaque partieséquentiellement.
209

Rappels et définitionsArbre de dérivation
Nettoyage et simplification des grammaires context-freeLa forme normale de Chomsky
Équivalences : dérivations - arbre de dérivation - inférence récursive
Théorème (Équivalences : dérivations - arbre de dérivation - inférencerécursive)
Soit une CFG G = 〈V , T , P, S〉, et A ∈ V. Les 5 propositions suivantes sontéquivalentes :
1 On peut par induction récursive montrer que w est dans le langage de A2 A ∗⇒ w3 A
G
∗⇒ w
4 A ∗⇒Gw
5 Il existe un A-arbre de dérivation ayant la production w
210

Rappels et définitionsArbre de dérivation
Nettoyage et simplification des grammaires context-freeLa forme normale de Chomsky
Équivalences : dérivations - arbre de dérivation - inférence récursive
Dérivation gauche / droite - arbre de dérivation
Tout arbre de dérivation correspond à1 une dérivation gauche2 une dérivation droite
et vice versa
211

Rappels et définitionsArbre de dérivation
Nettoyage et simplification des grammaires context-freeLa forme normale de Chomsky
Plan
1 Rappels et définitions
2 Arbre de dérivation
3 Nettoyage et simplification des grammaires context-free
4 La forme normale de Chomsky
212

Rappels et définitionsArbre de dérivation
Nettoyage et simplification des grammaires context-freeLa forme normale de Chomsky
Grammaire context-free ambigu
Grammaire context-free ambiguë
Pour une CFG G tout string w de L(G) a au moins un arbre de dérivationpour G.
w ∈ L(G) peut avoir plusieurs arbres de dérivation pour G : dans ce cason dira que la grammaire est ambiguë.
Idéalement, pour permettre le parsing, une grammaire ne doit pas êtreambiguë. En effet, l’arbre de dérivation détermine le code généré par lecompilateur.
On essayera donc de modifier la grammaire pour supprimer sesambiguïtés.
Il n’existe pas d’algorithme pour supprimer les ambiguïtés d’unegrammaire context-free.
Certains langages context-free sont ambigus de façon inhérente.
213

Rappels et définitionsArbre de dérivation
Nettoyage et simplification des grammaires context-freeLa forme normale de Chomsky
Grammaire context-free ambiguë
Exemple (de langage context free ambigu de façon inhérente)
L = {anbncmdm | n ≥ 1, m ≥ 1} ∪ {anbmcmdn | n ≥ 1, m ≥ 1}
Exemple de CFG pour L
S → AB | CA→ aAb | abB → cBd | cdC → aCd | aDdD → bDc | bc
Avec G, pour tout i ≥ 0 aibic id i a 2 arbres de dérivation. On peut démontrerque toute autre CFG pour L est ambiguë
214

Suppression de l’ambiguïté
Priorité et associativité
Lorsque le langage définit des strings composés d’instructions etd’opérations, l’arbre syntaxique (qui va déterminer le code produit par lecompilateur) doit refléter
les priorités et
associativités
Exemple (d’arbres associés à des expressions)
a + b + c
E
E
E
EE
a b
c+
+
a + b ∗ c
E
E
E
a EE
b c
+
*

Suppression de l’ambiguïté
Priorité et associativité
Pour respecterl’associativité àgauche, on n’écritpas
E → E + E | T
Mais
E → E + T | T
Pour respecter les priorités ondéfinit plusieurs niveaux devariables / règles (le symbolede départ ayant le niveau 0) :les opérateurs les moinsprioritaires sont définis à unniveau plus petit (plus prochedu symbole de départ) que lesplus prioritairesOn n’écrit pas
E → T + E | T ∗ E | TT → id | (E)
mais en 2 niveaux :
E → T + E | TT → F ∗ T | FF → id | (E)

Suppression de l’ambiguïté
Exemple (Associativité de l’instruction if)
La grammaire :
instr→ if expr instr | if expr instr else instr | other
est ambiguë
instr
instr
if
instr
other
expr
if expr else instr
other
instr
instr
if
instr
other
expr
if expr
else instr
other
Dans les langages impératifs habituels c’est l’arbre de gauche qu’il fautgénérer

Rappels et définitionsArbre de dérivation
Nettoyage et simplification des grammaires context-freeLa forme normale de Chomsky
Suppression de l’ambiguïté
Exemple (Associativité de l’instruction if)
On peut par exemple transformer la grammaire en :
instr→ open | closeclose→ if expr close else close | otheropen→ if expr instropen→ if expr close else open
218

Suppression des symboles inutiles
Définition (Symboles utiles / inutiles)
Pour une grammaire G = 〈V , T , P, S〉,un symbole X est utile s’il existe une dérivation
S ∗⇒G
αXβ∗⇒G
w
pour des strings α, β et un string de terminaux wSinon X est inutile.
un symbole X produit quelque chose si X ∗⇒G
w pour un string w de
terminaux
un symbole X est accessible si S ∗⇒G
αXβ pour des strings α, β
Théorème (Équivalence symboles utiles - (accessibles + produisent quelquechose))
Dans une CFG,
tous les symboles sont accessibles et produisent quelque chose⇐⇒
tous les symboles sont utiles

Rappels et définitionsArbre de dérivation
Nettoyage et simplification des grammaires context-freeLa forme normale de Chomsky
Suppression des symboles inutiles
Théorème (Suppression des symboles inutiles d’une CFG)
Ayant une CFG G = 〈V , T , P, S〉.Si G′ = 〈V ′, T ′, P′, S〉 est la grammaire obtenue après les 2 étapessuivantes :
1 Eliminer les symboles ne produisant rien et les règles où ilsapparaissent. On obtient GI = 〈VI , TI , PI , S〉
2 Eliminer de GI les symboles non accessibles et les productions où ilsapparaissent.
alors G′ est équivalente à G et n’a plus de symboles inutiles.Preuve :On va montrer que :
1 G′ n’a plus de symboles inaccessibles ou qui ne produisent rien2 L(G′) = L(G)
220

Suppression des symboles inutiles
Théorème (Suppression des symboles inutiles d’une CFG (suite))
Preuve de 1. : on va montrer que G′ n’a plus de symboles inaccessibles ouqui ne produisent rien
∀X ∈ T ′ ∪ V ′
∃α, β : S ∗⇒G′
αXβ (tout symbole de G′ est accessible)
Donc S ∗⇒GI
αXβ (les règles de G′ sont dans GI)
Donc puisque les symboles de αXβ n’ont pas été éliminés dans GI ,αXβ
∗⇒GI
w
Donc X est accessible et produit quelque chose dans GI
Mais tous les symboles utilisés dans αXβ∗⇒GI
w sont aussi accessibles
dans GI (puisque S ∗⇒GI
αXβ) et n’ont donc pas été supprimés (ni leurs
règles) dans G′
Donc X produit aussi quelque chose dans G′
En résumé, X est accessible et produit quelque chose dans G′

Rappels et définitionsArbre de dérivation
Nettoyage et simplification des grammaires context-freeLa forme normale de Chomsky
Suppression des symboles inutiles
Théorème (Suppression des symboles inutiles d’une CFG (suite))
Preuve de 2. : on va montrer que L(G′) = L(G)
Comme P′ ⊆ P, on a L(G′) ⊆ L(G)
Montrons que L(G) ⊆ L(GI) ⊆ L(G′)
∀w ∈ L(G) : S ∗⇒G
w et tous les symboles utilisés dans cette dérivation
génèrent quelque chose
Donc les symboles et règles utilisées sont conservés dans GI et S ∗⇒GI
w
Les symboles utilisés dans S ∗⇒GI
w sont accessibles et donc ils sont
conservés avec leurs règles dans G′ : S ∗⇒G′
w
222

Algorithme pour calculer l’ensemble des symboles qui produisent
Algorithme pour calculer l’ensemble g(G) des symboles qui produisent deG = 〈V , T , P, S〉
Base : g(G)← T
Induction : Si α ∈ (g(G))∗ et X → α ∈ P alors g(G)∪← {X}
Exemple (de calcul de g(G))
Soit G avec les règles S → AB | a, A→ b1 Au départ g(G)← {a, b}2 S → a donc g(G)
∪← {S}3 A→ b donc g(G)
∪← {A}4 Finalement g(G) = {S, A, a, b}
Théorème (A saturation, g(G) contient l’ensemble des symboles quiproduisent quelque chose)

Algorithme pour calculer l’ensemble des symboles accessibles
Algorithme pour calculer l’ensemble r(G) des symboles accessibles deG = 〈V , T , P, S〉
Base : r(G)← {S}Induction : Si A ∈ r(G) et A→ α ∈ P alorsr(G)
∪← {X | ∃α1, α2 : α = α1Xα2}
Exemple (de calcul de r(G))
Soit G avec les règles S → AB | a, A→ b1 Au départ r(G)← {S}2 S → AB donc r(G)
∪← {A, B}3 S → a donc r(G)
∪← {a}4 A→ b donc r(G)
∪← {b}5 Finalement r(G) = {S, A, B, a, b}
Théorème (A saturation, r(G) contient l’ensemble des symboles accessibles)

Rappels et définitionsArbre de dérivation
Nettoyage et simplification des grammaires context-freeLa forme normale de Chomsky
Suppression de la récursivité à gauche
Définition (Récursivité à gauche)
Une CFG G est récursive à gauche s’il existe une dérivation A ∗⇒G
Aα
Note :
Nous verrons, dans les chapitres sur le parsing, que la récursivité à gaucheest un problème pour l’analyse syntaxique descendante. Dans ce cas on laremplace par un autre type de récursivité
225

Rappels et définitionsArbre de dérivation
Nettoyage et simplification des grammaires context-freeLa forme normale de Chomsky
Suppression de la récursivité à gauche
Algorithme pour supprimer la récursivité directe à gauche
AyantA→ Aα1 | · · · | Aαr
l’ensemble des A-productions directement récursives à gauche et
A→ β1 | · · · | βs
les autres A-productions.
Toutes ces productions sont remplacées par :
A→ β1A′ | · · · | βsA′
A′ → α1A′ | · · · | αr A′ | ε
où A′ est une nouvelle variable226

Rappels et définitionsArbre de dérivation
Nettoyage et simplification des grammaires context-freeLa forme normale de Chomsky
Suppression de la récursivité à gauche
Algorithme général pour supprimer la récursivité à gauche
Ayant V = {A1, A2, . . . , An}.
Pour i = 1 jusque n fairePour j = 1 jusque i − 1 faire
Pour chaque production de la forme Ai → Ajα faireSupprimer Ai → Ajα de la grammairePour chaque production de la forme Aj → β faire
Ajouter Ai → βα à la grammaireFpour
FpourFpourEliminer la récursivité gauche directe des Ai -productions
Fpour
227

Suppression de la récursivité à gauche
Exemple (de suppression de la récursivité à gauche)
Soit la G avec lesrègles :
A → Ab | a | CfB → Ac | dC → Bg | Ae | Cc
Traitement de A :
A → aA′ | CfA′
A′ → bA′ | εB → Ac | dC → Bg | Ae | Cc
Traitement de B :
A → aA′ | CfA′
A′ → bA′ | εB → aA′c | CfA′c | dC → Bg | Ae | Cc
Traitement de C :
A → aA′ | CfA′
A′ → bA′ | εB → aA′c | CfA′c | dC → aA′cg | dg | aA′e |
CfA′cg | CfA′e | Cc
Traitement de C (récursivitédirecte) :
A → aA′ | CfA′
A′ → bA′ | εB → aA′c | CfA′c | dC → aA′cgC′ | dgC′ | aA′eC′
C′ → fA′cgC′ | fA′eC′ | cC′ | ε

Factorisation à gauche
Définition (Règles factorisables)
Dans une CFG G, plusieurs A-productions sont factorisables à gauche sielles ont la forme
A→ αβ1 | · · · | αβn
avec un préfixe commun α 6= εRemarque : il peut y avoir d’autres A-productions.
Note :
Pour les analyseurs descendants, on verra qu’il faut factoriser les règlesfactorisables à gauche
Algorithme de factorisation à gauche
Remplacer :A→ αβ1 | · · · | αβn
parA→ αA′
A′ → β1 | · · · | βn

Rappels et définitionsArbre de dérivation
Nettoyage et simplification des grammaires context-freeLa forme normale de Chomsky
Suppression des productions vides
Définition (Production vide)
Un production vide est une production :
A→ ε
Note :
Il existe un algorithme pour supprimer les productions vides.Ceci n’est pas utile pour la construction des analyseurs syntaxiques.Nous ne verrons donc pas cet algorithme.
230

Suppression des productions unitaires
Définition (Production unitaire)
Un production unitaire est une production :
A→ B
avec B ∈ V
Note :
Les productions unitaires sont vues comme des règles qui ne font pas“progresser” la dérivation : il vaut donc mieux les éliminer
Algorithme pour éliminer les productions unitaires
Pour tout A ∗⇒ B en n’utilisant que des productions unitaires, et B → αproduction non unitaireAjouter :
A→ α
A la fin, supprimer toutes les productions unitaires.

Rappels et définitionsArbre de dérivation
Nettoyage et simplification des grammaires context-freeLa forme normale de Chomsky
Plan
1 Rappels et définitions
2 Arbre de dérivation
3 Nettoyage et simplification des grammaires context-free
4 La forme normale de Chomsky
232

Rappels et définitionsArbre de dérivation
Nettoyage et simplification des grammaires context-freeLa forme normale de Chomsky
Grammaire en forme normale de Chomsky
Théorème (Grammaire en forme normale de Chomsky)
Tout langage context free ne contenant pas ε peut être défini par unegrammaire en forme normale de Chomsky c’est-à-dire une CFG où les règlesde production ont les formes possibles
A→ ABA→ a
Théorème (Grammaire en forme normale de Chomsky)
Tout langage context free contenant ε peut être défini par une grammaireG′ = 〈V ∪ {S′}, T , P′, S′〉 où
P′ = P ∪ {S′ → S | ε}
et G = 〈V , T , P, S〉 est en forme normale de Chomsky.
233

Grammaire en forme normale de Chomsky
Propriété des arbres de dérivation des CFG en forme normale de Chomsky
Soit G une CFG en forme normale de Chomsky, et w ∈ L(G),alors l’arbre (ou les arbres) de dérivation de w dans G est tel que
la hauteur de cet arbre ≥ log2(|w |) + 1
pour un arbre de hauteur k , “génère” un string de taille ≤ 2(k−1)
o
o o
o
o
t t
o
o o
t t
exemple : arbre de taille 3 qui génère un string de longueur 4
Note :
On utilisera cette propriété pour démontrer le lemme de pompage deslangages context-free

Les automates à pile (PDA)Équivalence entre PDA et CFG
Propriétés des langages context free
Chapitre 7 : Les automates à pile et les propriétés deslangages context-free
1 Les automates à pile (PDA)
2 Équivalence entre PDA et CFG
3 Propriétés des langages context free
235

Les automates à pile (PDA)Équivalence entre PDA et CFG
Propriétés des langages context free
Plan
1 Les automates à pile (PDA)
2 Équivalence entre PDA et CFG
3 Propriétés des langages context free
236

Introduction
Présentation informelle
Un automate à pile (PDA) est essentiellement un ε-NFA avec une pile (stack)
Lors d’une transition, le PDA1 Consomme un symbole d’input (ou non si c’est une ε-transition)2 Change d’état de contrôle3 Remplace le symbole T en sommet de la pile par un string (qui peut, en
particulier, être ε (pop), “T” (pas de changement), “AT” (push un A))
b o n j o u r . . .
b
on
...
XYZT

Exemple
Exemple (PDA pour Lwwr = {wwR | w ∈ {0, 1}∗})
correpondant à la “grammaire” P → 0P0 | 1P1 | ε.On peut construire un PDA équivalent à 3 états qui fonctionne comme suit :
En 0 Il peut supposer (guess) lire w : push le symbole sur la pile
En 0 Il peut supposer être au milieu de l’input : va dans l’état 1
En 1 Il compare ce qui est lu et ce qui est sur la pile : s’ils sont identiques, lacomparaison est correcte, il pop le sommet de la pile et continue (sinonbloque)
En 1 S’il retombe sur le symbole initial de la pile, va dans l’état 2 (accepteur).Example: The PDA
1 ,
!, Z 0 Z 0 Z 0 Z 0! , /
1 , 0 / 1 0
0 , 1 / 0 1
0 , 0 / 0 0
Z 0 Z 01 ,
0 , Z 0 Z 0/ 0
!, 0 / 0
!, 1 / 1
0 , 0 / !
q q q0 1 2
1 / 1 1
/
Start
1 , 1 / !
/ 1
is actually the seven-tuple
P = ({q0, q1, q2}, {0,1}, {0,1, Z0}, δ, q0, Z0, {q2}),
where δ is given by the following table (setbrackets missing):
0, Z0 1, Z0 0,0 0,1 1,0 1,1 ε, Z0 ε,0 ε,1
→ q0 q0,0Z0 q0,1Z0 q0,00 q0,01 q0,10 q0,11 q1, Z0 q1,0 q1,1
q1 q1, ε q1, ε q2, Z0
#q2
185

Les automates à pile (PDA)Équivalence entre PDA et CFG
Propriétés des langages context free
PDA : définition formelle
Définition
Un PDA est un 7-tuple :
P = 〈Q, Σ, Γ, δ, q0, Z0, F 〉
où
Q est un ensemble fini d’états
Σ est l’alphabet d’entrée
Γ est l’alphabet de la pile
δ : Q × (Σ ∪ {ε} × Γ)→ 2Q×Γ∗ est la fonction de transition
q0 est l’état initial
Z0 est le symbole initial de la pile
F ⊆ Q est l’ensemble des états accepteurs
239

Exemple de PDA
Exemple (de définition formelle du PDA suivant :)Example: The PDA
1 ,
!, Z 0 Z 0 Z 0 Z 0! , /
1 , 0 / 1 0
0 , 1 / 0 1
0 , 0 / 0 0
Z 0 Z 01 ,
0 , Z 0 Z 0/ 0
!, 0 / 0
!, 1 / 1
0 , 0 / !
q q q0 1 2
1 / 1 1
/
Start
1 , 1 / !
/ 1
is actually the seven-tuple
P = ({q0, q1, q2}, {0,1}, {0,1, Z0}, δ, q0, Z0, {q2}),
where δ is given by the following table (setbrackets missing):
0, Z0 1, Z0 0,0 0,1 1,0 1,1 ε, Z0 ε,0 ε,1
→ q0 q0,0Z0 q0,1Z0 q0,00 q0,01 q0,10 q0,11 q1, Z0 q1,0 q1,1
q1 q1, ε q1, ε q2, Z0
#q2
185
P = 〈{q0, q1, q2}, {0, 1}, {0, 1, Z0}, δ, q0, Z0, {q2}〉
δ (0, Z0) (1, Z0) (0, 0) (0, 1) (1, 0) (1, 1)
→ q0 {(q0, 0Z0)} {(q0, 1Z0)} {(q0, 00)} {(q0, 01)} {(q0, 10)} {(q0, 11)}q1 ∅ ∅ {(q1, ε)} ∅ ∅ {(q1, ε)}∗q2 ∅ ∅ ∅ ∅ ∅ ∅
δ (ε, Z0) (ε, 0) (ε, 1)
→ q0 {(q1, Z0)} {(q1, 0)} {(q1, 1)}q1 {(q2, Z0)} ∅ ∅∗q2 ∅ ∅ ∅

Autre exemple de PDA
Exemple (de définition formelle du PDA P’ suivant :)
1,1 / 11
q0
q1
1,1 /
1,0 / 101,1 /
0,1 / 010,0 / 00
01,Z / 1Z0
00,Z / 0Z0
0,0 / 0,Z /
0,0 /
P = 〈{q0, q1}, {0, 1}, {0, 1, Z0}, δ, q0, Z0, ∅〉
δ (0, Z0) (1, Z0) (0, 0) (0, 1)
→ q0 {(q0, 0Z0)} {(q0, 1Z0)} {(q0, 00), (q1, ε)} {(q0, 01)}q1 ∅ ∅ {(q1, ε)} ∅
δ (1, 0) (1, 1) (ε, Z0)
→ q0 {(q0, 10)} {(q0, 11), (q1, ε)} {(q1, ε)}q1 ∅ {(q1, ε)} {(q1, ε)}

Les automates à pile (PDA)Équivalence entre PDA et CFG
Propriétés des langages context free
Critère d’acceptation
Un string w est accepté :
Par pile vide : le string est totalement lu et la pile est vide.
Par état final : le string est totalement lu et le PDA est dans un étataccepteur.
Remarques :
Pour un PDA P, 2 langages (a priori différents) sont définis :
- N(P) (acceptation par pile vide) et
- L(P) (acceptation par état final)
N(P) n’utilise pas F et n’est donc pas modifié si l’on définit F = ∅
242

Les automates à pile (PDA)Équivalence entre PDA et CFG
Propriétés des langages context free
Configuration et langage accepté
Définition (Configuration d’un PDA P = 〈Q, Σ, Γ, δ, q0, Z0, F 〉)
Triple 〈q, w , γ〉 ∈ Q × Σ∗ × Γ∗
Configuration initiale : 〈q0, w , Z0〉 où w est le string à accepter
Configuration finale avec acceptation par pile vide : 〈q, ε, ε〉 (qquelconque)
Configuration finale avec acceptation par état final : 〈q, ε, γ〉 avec q ∈ F(γ ∈ Γ∗ quelconque)
Définition (Changement de configuration)
〈q, aw , Xβ〉P〈q′, w , αβ〉
ssi〈q′, α〉 ∈ δ(q, a, X )
243

Les automates à pile (PDA)Équivalence entre PDA et CFG
Propriétés des langages context free
Langages de P : L(P) et N(P)
Définition (L(P) et N(P))
L(P) = {w | w ∈ Σ∗ ∧ ∃q ∈ F , γ ∈ Γ∗ : 〈q0, w , Z0〉∗
P〈q, ε, γ〉}
N(P) = {w | w ∈ Σ∗ ∧ ∃q ∈ Q : 〈q0, w , Z0〉∗
P〈q, ε, ε〉}
où∗
Pest la fermeture réflexo-transitive de
P
244

Exemple de séquences d’exécution
Exemple (PDA P avec L(P) = Lwwr = {wwR | w ∈ {0, 1}∗} et exécutionspossibles pour le string 1111)
Example: The PDA
1 ,
!, Z 0 Z 0 Z 0 Z 0! , /
1 , 0 / 1 0
0 , 1 / 0 1
0 , 0 / 0 0
Z 0 Z 01 ,
0 , Z 0 Z 0/ 0
!, 0 / 0
!, 1 / 1
0 , 0 / !
q q q0 1 2
1 / 1 1
/
Start
1 , 1 / !
/ 1
is actually the seven-tuple
P = ({q0, q1, q2}, {0,1}, {0,1, Z0}, δ, q0, Z0, {q2}),
where δ is given by the following table (setbrackets missing):
0, Z0 1, Z0 0,0 0,1 1,0 1,1 ε, Z0 ε,0 ε,1
→ q0 q0,0Z0 q0,1Z0 q0,00 q0,01 q0,10 q0,11 q1, Z0 q1,0 q1,1
q1 q1, ε q1, ε q2, Z0
#q2
185
séquences (slide suivant)

)0Z
)0Z
)0Z
)0Z
)0Z
)0Z
)0Z
)0Z
q2( ,
q2( ,
q2( ,
)0Z
)0Z
)0Z
)0Z
)0Z)0
Z
)0Z
)0Zq
1
q0
q0
q0
q0
q0
q1
q1
q1
q1
q1
q1
q1
q1
1111,0
Z )
111, 1
11, 11
1, 111
! , 1111
1111,
111, 1
11, 11
1, 111
1111,
11,
11,
1, 1
! ! ,, 11
! ,
,(
,(
,(
,(
! , 1111( ,
,(
( ,
( ,
( ,
( ,
( ,
( ,
( ,
( ,
188

Les automates à pile (PDA)Équivalence entre PDA et CFG
Propriétés des langages context free
Exemple de langages acceptés par un PDA
Exemple (Le PDA P du slide 240)
L(P) = {wwR | w ∈ {0, 1}∗} N(P) = ∅
Exemple (PDA P′ du slide 241)
L(P′) = ∅ N(P′) = {wwR | w ∈ {0, 1}∗}
247

PDA déterministe (DPDA)
Définition (PDA déterministe (DPDA))
Un PDA P = 〈Q, Σ, Γ, δ, q0, Z0, F 〉 est déterministe ssi1 δ(q, a, X ) est toujours soit vide soit un singleton (pour a ∈ Σ ∪ {ε})2 Si δ(q, a, X ) est non vide alors δ(q, ε, X ) est vide
Exemple (PDA P déterministe avec L(P) = {wcwR | w ∈ {0, 1}∗})
Deterministic PDA’s
A PDA P = (Q,Σ,Γ, δ, q0, Z0, F ) is determinis-tic iff
1. δ(q, a, X) is always empty or a singleton.
2. If δ(q, a, X) is nonempty, then δ(q, ε, X) mustbe empty.
Example: Let us define
Lwcwr = {wcwR : w ∈ {0,1}∗}
Then Lwcwr is recognized by the following DPDA
1 ,
Z 0 Z 0 Z 0 Z 0! , /
1 , 0 / 1 0
0 , 1 / 0 1
0 , 0 / 0 0
Z 0 Z 01 ,
0 , Z 0 Z 0/ 0
0 , 0 / !
q q q0 1 2
1 / 1 1
/
Start
1 , 1 / !
/ 1
,
0 / 0
1 / 1,
,
c
c
c
220

Les automates à pile (PDA)Équivalence entre PDA et CFG
Propriétés des langages context free
PDA déterministe
Théorème (La classe des langages définis par un PDA déterministe eststrictement incluse dans la classe des langages définis par un PDA (général))
Preuve :On peut montrer que le langage Lwwr défini au slide 240 ne peut être définipar un PDA déterministe
249

Les automates à pile (PDA)Équivalence entre PDA et CFG
Propriétés des langages context free
Plan
1 Les automates à pile (PDA)
2 Équivalence entre PDA et CFG
3 Propriétés des langages context free
250

Les automates à pile (PDA)Équivalence entre PDA et CFG
Propriétés des langages context free
Équivalence PDA - CFG
On va montrer les inclusions suivantes (chaque flèche montrant uneinclusion)
CFG PDA par pile vide
PDA par état final
ce qui prouvera que :
Théorème (Les trois classes de langages suivants sont équivalents)
Les langages définis par une CFG (càd les CFL)
Les langages définis par un PDA avec acceptation par pile vide
Les langages définis par un PDA avec acceptation par état final
251

Équivalence état final - pile vide
Théorème (Pour tout PDA PN = 〈Q, Σ, Γ, δN , q0, Z0, ∅〉 on peut définir un PDAPF avec L(PF ) = N(PN))
construction :
From Empty Stack to Final State
Theorem 6.9: If L = N(PN) for some PDAPN = (Q,Σ,Γ, δN, q0, Z0), then ∃ PDA PF , suchthat L = L(PF ).
Proof: Let
PF = (Q ∪ {p0, pf},Σ,Γ ∪ {X0}, δF , p0, X0, {pf})where δF (p0, ε, X0) = {(q0, Z0X0)}, and for allq ∈ Q, a ∈ Σ∪{ε}, Y ∈ Γ : δF (q, a, Y ) = δN(q, a, Y ),and in addition (pf , ε) ∈ δF (q, ε, X0).
X0
Z0X0
!,
!, X0/ !
!, X0/ !
!, X0/ !
!, X0/ !
q/
PN
Startp0 0
pf
195

Les automates à pile (PDA)Équivalence entre PDA et CFG
Propriétés des langages context free
Équivalence état final - pile vide (2)
Théorème (Pour tout PDA PF = 〈Q, Σ, Γ, δF , q0, Z0, F 〉 on peut définir un PDAPN avec N(PN) = L(PF ))
construction :
From Final State to Empty Stack
Theorem 6.11: Let L = L(PF ), for somePDA PF = (Q,Σ,Γ, δF , q0, Z0, F ). Then ∃ PDAPn, such that L = N(PN).
Proof: Let
PN = (Q ∪ {p0, p},Σ,Γ ∪ {X0}, δN, p0, X0)
where δN(p0, ε, X0) = {(q0, Z0X0)}, δN(p, ε, Y )= {(p, ε)}, for Y ∈ Γ∪{X0}, and for all q ∈ Q,
a ∈ Σ ∪ {ε}, Y ∈ Γ : δN(q, a, Y ) = δF (q, a, Y ),and in addition ∀q ∈ F , and Y ∈ Γ ∪ {X0} :(p, ε) ∈ δN(q, ε, Y ).
!, any/ ! !, any/ !
!, any/ !
X0 Z 0!, / X
0 pPF
Startp q0 0
199
253

Les automates à pile (PDA)Équivalence entre PDA et CFG
Propriétés des langages context free
Équivalence entre PDA et CFG
Théorème (Pour toute CFG G on peut définir un PDA M avec L(G) = N(M))
Principe de la preuve : Ayant G = 〈V , T , P, S〉 une CFG, on construit un PDAM à un seul état qui simule les dérivations gauches de G
P = 〈{q}, T , V ∪ T , δ, q, S, ∅〉 avec∀A→ X1X2 . . . Xk ∈ P : 〈q, X1X2 . . . Xk 〉 ∈ δ(q, ε, A)∀a ∈ T : δ(q, a, a) = {〈q, ε〉}
Au départ le symbole de départ S est sur la pile
Toute variable A au sommet de la pile avec A→ X1X2 . . . Xk ∈ P peutêtre remplacée par sa partie droite X1X2 . . . Xk avec X1 au sommet de lapile
Tout terminal au sommet de la pile qui est égal au prochain symboled’input est matché avec l’input (on lit l’input et pop le symbole)
À la fin, si la pile est vide, le string est accepté254

Les automates à pile (PDA)Équivalence entre PDA et CFG
Propriétés des langages context free
Équivalence entre PDA et CFG
Théorème (Pour tout PDA P on peut définir une CFG G avec L(G) = N(P))
255

Les automates à pile (PDA)Équivalence entre PDA et CFG
Propriétés des langages context free
Plan
1 Les automates à pile (PDA)
2 Équivalence entre PDA et CFG
3 Propriétés des langages context free
256

Les automates à pile (PDA)Équivalence entre PDA et CFG
Propriétés des langages context free
Questions qu’on peut se poser sur des langages L, L1, L2
L est-il context-free ?
Pour quels opérateurs les langages context-free sont-ils fermés ?
w ∈ L ?
L est-il vide, fini, infini ?
L1 ⊆ L2, L1 = L2 ?
257

Les automates à pile (PDA)Équivalence entre PDA et CFG
Propriétés des langages context free
L est-il context-free ?
Pour montrer que L est context-free
Il faut :
trouver une CFG (ou un PDA) G etmontrer que L = L(G) (ou L = N(G) si G est un PDA avec acceptationpar pile vide) càd
que L ⊆ L(M) (tout string de L est accepté par M)que L(M) ⊆ L (tout string accepté par M est dans L)
258

Les automates à pile (PDA)Équivalence entre PDA et CFG
Propriétés des langages context free
L est-il context-free ?
Exemple
Pour montrer que L est context-free L = {0i1i | i ∈ N}
On définit par exemple lePDA P et démontre (parinduction) que L = L(P)
0,0 / 00
q0
q1
, Z /
00,Z / 0Z0
1,0 /
0
q2
1,0 /
259

Les automates à pile (PDA)Équivalence entre PDA et CFG
Propriétés des langages context free
L est-il context-free ?
Pour montrer que L n’est pas context-free
Parfois on peut le montrer grâce au pumping lemma (lemme de pompage)des langages context-free
Théorème (Pumping lemma des langages context-free)
Si L est context-freealors∃n ∀z (z ∈ L ∧ |z| ≥ n)⇒ ∃u, v , w , x , y
1 z = uvwxy ∧2 |vwx | ≤ n ∧3 vx 6= ε ∧4 ∀i ≥ 0 : uv iwx iy ∈ L
260

Preuve du pumping lemma pour les langages context-free
Théorème (Pumping lemma des langages context-free)
Preuve :
Soit L un CFL
L (ou L\{ε}) est reconnu par une CFG en forme normale de Chomsky G(càd avec les règles A→ BC ou A→ a (a ∈ T ∧ A, B, C ∈ V).
Soit k le nombre de variables de G
Prenons n = 2k et |z| ≥ n
Prenons un des plus longs chemins de l’arbre de dérivation de z :plusieurs noeuds du chemin ont le même label (une variable)
Dénotons v1 et v2 2 sommets sur ce chemin labellés par la mêmevariable avec v1 ancêtre de v2 et on choisi v1 “le plus bas possible”a
Découpons z comme indiqué sur la figurea la technique pour trouver v1 et v2 consiste à partir du noeud feuille du chemin choisi et
remonter sur ce chemin jusqu’au moment où l’on retombe sur un sommet déjà rencontré (on leslabelle v1 et v2 (v2 étant sous v1))

Preuve du pumping lemma pour les langages context-free
Théorème (Pumping lemma des langages context-free)
C
B A
A
b
B A
B
B CB C
B A
B A
ab
ab
bab
V1
V2
{ {{ { {u="ba" v="bb" w="a" x="" y="bba"
et donc z = uvwxy

Les automates à pile (PDA)Équivalence entre PDA et CFG
Propriétés des langages context free
Preuve du pumping lemma pour les langages context-free
Théorème (Pumping lemma des langages context-free (suite))
Preuve (suite) :
La hauteur maximale de l’arbre de racine v1 est k + 1 et génère un stringvwx avec |vwx | ≤ 2k = n
De plus comme G est en forme normale de Chomsky, v2 est soit dans lefils droit, soit dans le fils gauche de l’arbre de racine v1
De toute façon, soit v 6= ε soit x 6= ε
On peut enfin voir que uv iwx iy ∈ L(G)Si on remplace le sous arbre de racine v1 par le sous arbre de racine v2, onobtient uwy ∈ LOn peut plutôt remplacer le sous arbre de racine v2 par un nouvelle instancede sous arbre de racine v1, on obtient uv2wx2y ∈ LOn peut répéter l’opération précédente avec l’arbre obtenu et on obtient que∀i : uv i wx i y ∈ L.
263
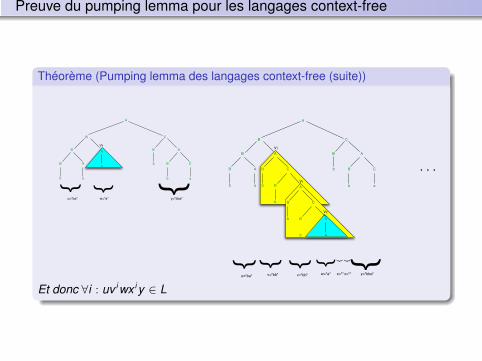
Preuve du pumping lemma pour les langages context-free
Théorème (Pumping lemma des langages context-free (suite))
C
B A
A
b
B A
B
B CB A
abab { {{
u="ba" w="a" y="bba"
V2A
a
C
B A
A
b
B A
B
B CB C
B A
B A
ab
ab
bab
V1
{{{u="ba"
{v="bb"
{
w="a" x="" y="bba"
A
B C
B A
ab
b
V1
V2
{
x=""{
v="bb"
· · ·
Et donc ∀i : uv iwx iy ∈ L

Comment ce pumping lemma permet de dire que L n’est pascontext-free
Pumping lemma des CFL = condition nécessaire pour que L context-free
L context-free⇒ L satisfait au PL des CFLL non context-free⇐ L ne satisfait pas au PL des CFL
Négation du pumping lemma
≡ ∀n ∃z (z ∈ L ∧ |z| ≥ n) ∧ ∀u, v , w , x , y1 (z = uvwxy ∧2 |vwx | ≤ n ∧3 vx 6= ε)
4 ⇒ (∃i ≥ 0 ∧ uv iwx iy /∈ L)
Exemple (Montrons que L = {aibic i |i ∈ N} n’est pas context-free)
Montrons que L satisfait la négation des conditions du pumping lemma desCFL.Pour tout n, pour z = anbncn ∈ L ∧ |z| ≥ net ∀u, v , w , x , y : (z = uvwxy ∧ |vwx | ≤ n ∧ vx 6= ε)⇒uwy /∈ L
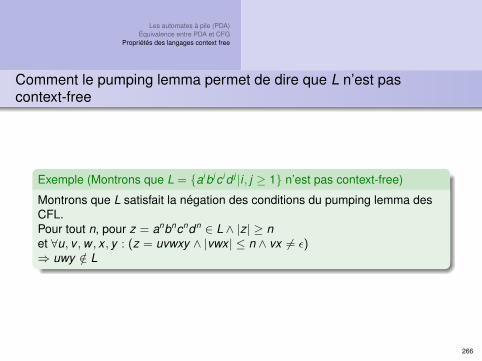
Les automates à pile (PDA)Équivalence entre PDA et CFG
Propriétés des langages context free
Comment le pumping lemma permet de dire que L n’est pascontext-free
Exemple (Montrons que L = {aibjc id j |i, j ≥ 1} n’est pas context-free)
Montrons que L satisfait la négation des conditions du pumping lemma desCFL.Pour tout n, pour z = anbncndn ∈ L ∧ |z| ≥ net ∀u, v , w , x , y : (z = uvwxy ∧ |vwx | ≤ n ∧ vx 6= ε)⇒ uwy /∈ L
266

Pour quels opérateurs les langages context-free sont-ils fermés ?
Théorème (Si L1 et L2 sont context-free alors L1 ∪ L2, L1.L2 et L∗1 sontcontext-free)
Preuve :Soit G1 = 〈V1, T1, P1, S1〉 et G2 = 〈V2, T2, P2, S2〉2 grammaires n’ayant aucune variable en commun et S /∈ V1 ∪ V2 :
Union : Pour G∪ = 〈V1 ∪ V2 ∪ {S}, T1 ∪ T2, P, S〉 avecP = P1 ∪ P2 ∪ {S → S1 | S2}
L(G∪) = L(G1) ∪ L(G2)
Concaténation : L1.L2 : Pour Gconcat = 〈V1 ∪V2 ∪ {S}, T1 ∪ T2, P, S〉 avecP = P1 ∪ P2 ∪ {S → S1S2}
L(Gconcat) = L(G1).L(G2)
Fermeture de Kleene : L∗1 : Pour G∗ = 〈V1 ∪ {S}, T1, P, S〉 avecP = P1 ∪ {S → S1S | ε}
L(G∗) = L(G1)∗

Les automates à pile (PDA)Équivalence entre PDA et CFG
Propriétés des langages context free
Pour quels opérateurs les langages context-free sont-ils fermés ?
Théorème (Si L est context-free alors LR est context-free)
Preuve :L est reconnu par une CFG G = 〈V , T , P, S〉À partir de G on peut construire une CFG GR = 〈V , T , PR , S〉 avec
PR = {A→ αR | A→ α ∈ P}On peut prouver que L(GR) = LR
268

Les automates à pile (PDA)Équivalence entre PDA et CFG
Propriétés des langages context free
Pour quels opérateurs les langages context-free ne sont-ils pasfermés ?
Théorème (Si L et M sont context-free alors L ∩M peut ne pas êtrecontext-free)
Preuve : il suffit de donner un contre exemple !
L1 = {a`b`cm | `, m ∈ N} est un langage context-free (A démontrer !)
L2 = {a`bmcm | `, m ∈ N} est un langage context-free (A démontrer !)
Mais on a vu que L = L1 ∩ L2 n’est pas context-free
269

Les automates à pile (PDA)Équivalence entre PDA et CFG
Propriétés des langages context free
Pour quels opérateurs les langages context-free sont-ils fermés ?
Théorème (Si L est context-free et R est régulier alors L ∩ R est context-free)
Preuve : (directe et constructive)
Ayant le PDA AL avec L(AL) = L : AL = 〈QL, Σ, Γ, δL, qL, Z0, FL〉et le DFA AR avec L(AR) = R : AR = 〈QR , Σ, δR , qR , FR〉on définit le PDA AL∩R
AL∩R = 〈QL ×QR , Σ, Γ, δL∩R , (qL, qR), Z0, FL × FR〉
avec
δL∩R((p, q), a) = {(p′, q′) | p′ ∈ δL(p, a) ∧ q′ = δR(q, a)} (a ∈ Σ ∪ {ε})
On peut démontrer que L(AL∩R) = L ∩ R
270

Pour quels opérateurs les langages context-free ne sont-ils pasfermés ?
Théorème (Si L est context-free alors_L peut ne pas être context-free)
Preuve :Une des lois de De Morgan est :
L1 ∩ L2 = L1 ∪ L2
Donc comme l’intersection n’est pas fermée pour les langages context-freemais que l’union l’est, le complément n’est pas non plus fermé pour les CFL.

Les automates à pile (PDA)Équivalence entre PDA et CFG
Propriétés des langages context free
Pour quels opérateurs les langages context-free ne sont-ils pasfermés ?
Théorème (Si L et M sont context-free alors L\M peut ne pas êtrecontext-free)
Preuve :L = Σ∗\L
et Σ∗ est régulier
272

Les automates à pile (PDA)Équivalence entre PDA et CFG
Propriétés des langages context free
w ∈ L, L vide, fini, infini ?
Comment tester que :
w ∈ L ? : voir si une CFG en forme normale de Chomsky génère wIl existe un algorithme en O(n3) où n est la longueur de w
L vide ? (L = ∅) : voir si dans G avec L(G) = L, le symbole de départproduit quelque chose
L infini ? : voir si une CFG en forme normale de Chomsky qui définit Lest récursive
273

Les automates à pile (PDA)Équivalence entre PDA et CFG
Propriétés des langages context free
problèmes indécidables pour les CFL
Les problèmes suivants sur les CFL sont indécidables (il n’existe pasd’algorithme pour les résoudre de façon générale)
la CFG G est-elle ambiguë ?
le CFL L est-il ambigu de façon inhérente ?
l’intersection de 2 CFL est-elle vide ?
Le CFL L = Σ∗ ?
L1 ⊆ L2 ?
L1 = L2 ?
L(G) est-il un CFL ?
L(G) est-il déterministe ?
L(G) est-il régulier ?
274

Rôles et place de l’analyse syntaxique (parsing)Analyseurs descendants (top-down)Analyseurs ascendants (bottom up)
Chapitre 8 : Le parsing - analyse syntaxique
1 Rôles et place de l’analyse syntaxique (parsing)
2 Analyseurs descendants (top-down)
3 Analyseurs ascendants (bottom up)
275

Rôles et place de l’analyse syntaxique (parsing)Analyseurs descendants (top-down)Analyseurs ascendants (bottom up)
Plan
1 Rôles et place de l’analyse syntaxique (parsing)
2 Analyseurs descendants (top-down)
3 Analyseurs ascendants (bottom up)
276

Rôles et place de l’analyse syntaxique (parsing)Analyseurs descendants (top-down)Analyseurs ascendants (bottom up)
Rôle et place du parser
Rôle principal du parser
Vérifier que la structure de la chaîne de tokens fournie en entrée(typiquement le programme) fait partie du langage (généralement définipar une grammaire context-free)
Construire l’arbre syntaxique correspondant à cette chaîne de tokens
Jouer le rôle de chef d’orchestre (programme principal) du compilateur(on parle de compilateur orienté syntaxe)
Place du parser
Entre l’analyseur lexical et l’analyseur sémantique :
Il appelle le scanner pour lui demander des tokens et
Il appelle l’analyseur sémantique et ensuite le générateur de code pourterminer l’analyse et générer le code correspondant
277

Rôles et place de l’analyse syntaxique (parsing)Analyseurs descendants (top-down)Analyseurs ascendants (bottom up)
Token = terminal
Note :
Dans ce qui suit, nous symbolisons chaque token par un terminal de lagrammaire.
$ en fin de string
Dans la grammaire définissant la syntaxe, on rajoutera systématiquement unnouveau symbole de départ S′, un nouveau terminal $ (symbolisant la fin dustring)a et la règle de production S′ → S$ où S est l’ancien symbole dedépart.
aOn suppose que ni S′ ni $ ne sont utilisés par ailleurs
278

Exemple (Grammaire d’un langage très simple)
Règles Règles de production0 S’ → program $1 program → begin st-list end2 st-list → st st-tail3 st-tail → st st-tail4 st-tail → ε5 st → Id := expression ;6 st → read ( id-list ) ;7 st → write( expr-list ) ;8 id-list → Id id-tail9 id-tail → , Id id-tail10 id-tail → ε11 expr-list → expression expr-tail12 expr-tail → , expression expr-tail13 expr-tail → ε14 expression → prim prim-tail15 prim-tail → add-op prim prim-tail16 prim-tail → ε17 prim → ( expression )18 prim → Id19 prim → Nb
20 | 21 add-op → + | -

Exemple d’arbre syntaxique
Exemple (Arbre syntaxique correspondant à begin Id := Id - Nb ; end $)
$
S'
begin end
program
prim prim-tail
primId add-op prim-tail
-
st-list
st st-tail
Id expression:= ;
Nb

Exemple d’arbre syntaxique et de dérivation gauche / droite
Exemple (Dérivation gauche et droite correspondant à l’arbre syntaxique)
$
S'
begin end
program
prim prim-tail
primId add-op prim-tail
-
st-list
st st-tail
Id expression:= ;
Nb
Dérivation gauche S′G∗⇒ begin Id := Id - Nb ; end $ :
0 1 2 5 14 18 15 21 19 16 4
Dérivation droite S′ ∗⇒G begin Id := Id - Nb ; end $ :
0 1 2 4 5 14 15 16 19 21 18

Rôles et place de l’analyse syntaxique (parsing)Analyseurs descendants (top-down)Analyseurs ascendants (bottom up)
Dérivation gauche
Exemple (Dérivation gauche complète correspondante)
Règle plus grand préfixe ∈ T∗ suite de la protophraseS’ ⇒
0 program $ ⇒1 begin st-list end$ ⇒2 begin st st-tail end$ ⇒5 begin Id := expression ; st-tail end$ ⇒
14 begin Id := prim prim-tail ; st-tail end$ ⇒18 begin Id := Id prim-tail ; st-tail end$ ⇒15 begin Id := Id add-op prim prim-tail ; st-tail end$ ⇒21 begin Id := Id - prim prim-tail ; st-tail end$ ⇒19 begin Id := Id - Nb prim-tail ; st-tail end$ ⇒16 begin Id := Id - Nb ; st-tail end$ ⇒4 begin Id := Id - Nb ; end $
282

Rôles et place de l’analyse syntaxique (parsing)Analyseurs descendants (top-down)Analyseurs ascendants (bottom up)
Dérivation droite
Exemple (Dérivation droite complète correspondante)
Règle protophraseS’ ⇒
0 program $ ⇒1 begin st-list end $ ⇒2 begin st st-tail end $ ⇒4 begin st end $ ⇒5 begin Id := expression ; end $ ⇒
14 begin Id := prim prim-tail ; end $ ⇒15 begin Id := prim add-op prim prim-tail ; end $ ⇒16 begin Id := prim add-op prim ; end $ ⇒19 begin Id := prim add-op Nb ; end $ ⇒21 begin Id := prim - Nb ; end $ ⇒18 begin Id := Id - Nb ; end $
283
Rôles et place de l’analyse syntaxique (parsing)Analyseurs descendants (top-down)Analyseurs ascendants (bottom up)
Structure générale d’un parser
Parser = Algorithme qui reconnaît la structure du programme et construitl’arbre syntaxique correspondant
Comme le langage à reconnaître est context-free, un parser aura lefonctionnement d’un automate à pile (PDA)Nous verrons 2 grandes classes de parsers :
Les analyseurs descendants (top-down)
Les analyseurs ascendants (bottom-up)
284

Rôles et place de l’analyse syntaxique (parsing)Analyseurs descendants (top-down)Analyseurs ascendants (bottom up)
Structure générale d’un parser
Un parser doit, en plus de reconnaître le string, produire un output, qui peutêtre :
l’arbre syntaxique correspondant
des appels aux procédures de l’analyseur sémantique - du générateurde code
. . .
Remarque :
Dans la présentation qui suit, l’output = la séquence des règles de productionutilisées dans la dérivation.Si on sait par ailleurs, que c’est une dérivation gauche (resp.droite), cetteséquence identifie la dérivation et l’arbre correspondant (et permet donc dele construire facilement).
285

Rôles et place de l’analyse syntaxique (parsing)Analyseurs descendants (top-down)Analyseurs ascendants (bottom up)
Plan
1 Rôles et place de l’analyse syntaxique (parsing)
2 Analyseurs descendants (top-down)
3 Analyseurs ascendants (bottom up)
286

Rappel : construction d’un PDA équivalent à une CFG donnée
Au chapitre précédent nous avons vu :
Construction à partir d’une CFG G d’un PDA M avec L(G) = N(M)
Principe de la construction : Ayant G = 〈V , T , P, S〉 une CFG, on construit unPDA M à un seul état qui simule les dérivations gauches de G
P = 〈{q}, T , V ∪ T , δ, q, S, ∅〉 avec∀A→ X1X2 . . . Xk ∈ P : 〈q, X1X2 . . . Xk ) ∈ δ(q, ε, A)∀a ∈ T : δ(q, a, a) = {〈q, ε〉}
Au départ le symbole de départ S est sur la pile
Toute variable A au sommet de la pile avec A→ X1X2 . . . Xk ∈ P peutêtre remplacée par sa partie droite X1X2 . . . Xk avec X1 au sommet de lapile
Tout terminal au sommet de la pile qui est égal au prochain symboled’input est matché avec l’input (on lit l’input et pop le symbole)
A la fin, si la pile est vide, le string est accepté
Dans cette construction, la règle S′ → S$ n’avait pas été rajoutée

Rôles et place de l’analyse syntaxique (parsing)Analyseurs descendants (top-down)Analyseurs ascendants (bottom up)
Ébauche de structure d’un parser descendant
Ébauche de structure d’un parser descendant : PDA à un état et avec output
Au départ S′ est sur la pileLe PDA peut effectuer 4 types d’actions :
Produce : la variable A au sommet de la pile est remplacée par la partiedroite d’une de ses règles (numérotée i) et le numéro i est écrit suroutput
Match : le terminal a au sommet de la pile correspond au terminal eninput ; on pop ce terminal et passe au symbole d’input suivant
Accept : Correspond à un Match du terminal $ : le terminal au sommetde la pile est $ et correspond au terminal en input ; on termine l’analyseavec succès
Erreur : Si aucun match ni produce n’est possible
288

Dérivation gauche
Exemple (Dérivation gauche complète correspondante)Sur la pile Input restant Action Output
S’a begin Id := Id - Nb ; end $ P0 εprogram $a begin Id := Id - Nb ; end $ P1 0
begin st-list end$a begin Id := Id - Nb ; end $ M 0 1st-list end$a Id := Id - Nb ; end $ P2 0 1
st st-tail end$a Id := Id - Nb ; end $ P5 0 1 2Id := expression ; st-tail end$a Id := Id - Nb ; end $ M 0 1 2 5
:= expression ; st-tail end$a := Id - Nb ; end $ M 0 1 2 5expression ; st-tail end$a Id - Nb ; end $ P14 0 1 2 5
prim prim-tail ; st-tail end$a Id - Nb ; end $ P18 0 1 2 5 14Id prim-tail ; st-tail end$a Id - Nb ; end $ M 0 1 2 5 14 18
prim-tail ; st-tail end$a - Nb ; end $ P15 0 1 2 5 14 18add-op prim prim-tail ; st-tail end$a - Nb ; end $ P21 0 1 2 5 14 18 15
- prim prim-tail ; st-tail end$a - Nb ; end $ M 0 1 2 5 14 18 15 21prim prim-tail ; st-tail end$a Nb ; end $ P19 0 1 2 5 14 18 15 21
Nb prim-tail ; st-tail end$a Nb ; end $ M 0 1 2 5 14 18 15 21 19prim-tail ; st-tail end$a ; end $ P16 0 1 2 5 14 18 15 21 19
; st-tail end$a ; end $ M 0 1 2 5 14 18 15 21 19 16st-tail end$a end $ P4 0 1 2 5 14 18 15 21 19 16
end $a end $ M 0 1 2 5 14 18 15 21 19 16 4$a $ A 0 1 2 5 14 18 15 21 19 16 4
où :
Pi : Produce avec la règle i
M : Match
A : Accept (correpond à un Match du symbole $)
E : Erreur (ou blocage qui demande un backtracking) (pas dans l’exemple)
Rôles et place de l’analyse syntaxique (parsing)Analyseurs descendants (top-down)Analyseurs ascendants (bottom up)
Points à améliorer dans l’ébauche de parser descendant
Critique de l’ébauche de parser descendant
Tel quel, ce parser est extrêmement inefficace car il doit effectuer dubacktracking pour explorer toutes les possibilités.
Dans ce type de parser, un choix doit avoir lieu au moment de l’action“Produce”
Si plusieurs choix sont possibles et qu’aucun critère dans la méthode nepermet de choisir, on parlera de conflit Produce/Produce
Sans guide au moment de ce choix, il faudrait éventuellement explorertous les Produce possibles : on aurait donc un parser qui prendrait untemps exponentiel (typiquement dans la longueur de l’input) ce qui estinadmissible !
On présentera des techniques de parsing descendant efficaces auchapitre suivant.
290

Rôles et place de l’analyse syntaxique (parsing)Analyseurs descendants (top-down)Analyseurs ascendants (bottom up)
Plan
1 Rôles et place de l’analyse syntaxique (parsing)
2 Analyseurs descendants (top-down)
3 Analyseurs ascendants (bottom up)
291

Ébauche de structure d’un parser ascendant
Ébauche de structure d’un parser ascendant
PDA à un état et avec output.Il part du string d’input et construit l’arbre de bas en haut. Pour cela, il opèrepar :
1 Mise de symbole d’input sur la pile jusqu’à identification d’une partiedroite α (handle) de règle A→ α
2 “Réduction” : remplacement de la α par A a
Au départ la pile est vide.Le PDA peut effectuer 4 types d’actions :
Shift : lecture d’un symbole d’input et push de ce symbole sur la pile
Reduce : le sommet de la pile α correspond au handle (la partie droited’une règle numéro i : A→ α), est remplacé par A sur la pile et lenuméro de règle utilisée i est écrit sur output
Accept : Correspond à un Reduce de la règle S′ → S$ (qui montre quel’input a été complètement lu et analysé) ; on termine l’analyse avecsuccès
Erreur : Si aucun shift ni reduce n’est possibleaCorrespond formellement à |α| pops suivis d’un push de A

Rôles et place de l’analyse syntaxique (parsing)Analyseurs descendants (top-down)Analyseurs ascendants (bottom up)
Ebauche de structure d’un parser ascendant
Remarque :
On peut remarquer que l’analyse correspond à une analyse droite àl’envers : on part du string et remonte dans les dérivation vers lesymbole de départ. L’analyse est faite à l’envers étant donné qu’on litl’input de gauche à droite.
L’output sera donc construit à l’envers (tout nouvel output se met avantce qui a déjà été produit) pour obtenir cette dérivation droite.
293
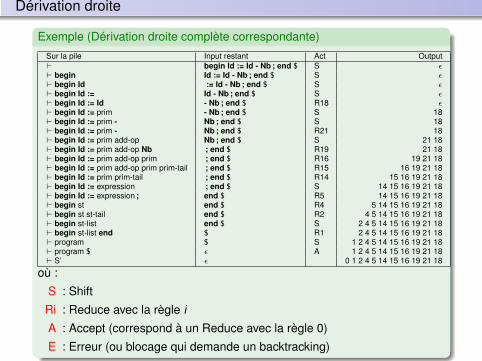
Dérivation droite
Exemple (Dérivation droite complète correspondante)Sur la pile Input restant Act Output` begin Id := Id - Nb ; end $ S ε` begin Id := Id - Nb ; end $ S ε` begin Id := Id - Nb ; end $ S ε` begin Id := Id - Nb ; end $ S ε` begin Id := Id - Nb ; end $ R18 ε` begin Id := prim - Nb ; end $ S 18` begin Id := prim - Nb ; end $ S 18` begin Id := prim - Nb ; end $ R21 18` begin Id := prim add-op Nb ; end $ S 21 18` begin Id := prim add-op Nb ; end $ R19 21 18` begin Id := prim add-op prim ; end $ R16 19 21 18` begin Id := prim add-op prim prim-tail ; end $ R15 16 19 21 18` begin Id := prim prim-tail ; end $ R14 15 16 19 21 18` begin Id := expression ; end $ S 14 15 16 19 21 18` begin Id := expression ; end $ R5 14 15 16 19 21 18` begin st end $ R4 5 14 15 16 19 21 18` begin st st-tail end $ R2 4 5 14 15 16 19 21 18` begin st-list end $ S 2 4 5 14 15 16 19 21 18` begin st-list end $ R1 2 4 5 14 15 16 19 21 18` program $ S 1 2 4 5 14 15 16 19 21 18` program $ ε A 1 2 4 5 14 15 16 19 21 18` S’ ε 0 1 2 4 5 14 15 16 19 21 18
où :
S : Shift
Ri : Reduce avec la règle i
A : Accept (correspond à un Reduce avec la règle 0)
E : Erreur (ou blocage qui demande un backtracking)

Rôles et place de l’analyse syntaxique (parsing)Analyseurs descendants (top-down)Analyseurs ascendants (bottom up)
Points à améliorer dans l’ébauche de parser ascendant
Critique de l’ébauche de parser ascendant
Tel quel, ce parser est extrêmement inefficace car il doit effectuer dubacktracking pour explorer toutes les possibilités.
Dans ce type de parser, un choix doit avoir lieu au moment de l’action“Reduce” et “Shift”
Si plusieurs choix sont possibles et qu’aucun critère dans la méthode nepermet de choisir, on parlera de conflit Shift/Reduce ou Reduce/Reduce
Sans guide au moment de ce choix, il faudrait éventuellement explorertous les Shift et Reduce possibles : on aurait donc un parser quiprendrait un temps exponentiel (typiquement dans la longueur de l’input)ce qui est inadmissible !
On présentera des techniques de parsing ascendant efficaces dans unchapitre ultérieur.
295

Principe du parsing descendantAnalyseurs prédictifs - Firstk - Followk
CFG LL(k)Analyseurs LL(1)
Analyseurs fortement LL(k) (k > 1)Analyseurs LL(k) (k > 1)
Gestion des erreurs et resynchronisationsAnalyseurs LL(k) récursifs
Chapitre 9 : Les parseurs LL(k)
1 Principe du parsing descendant
2 Analyseurs prédictifs - Firstk - Followk
3 CFG LL(k)
4 Analyseurs LL(1)
5 Analyseurs fortement LL(k) (k > 1)
6 Analyseurs LL(k) (k > 1)
7 Gestion des erreurs et resynchronisations
8 Analyseurs LL(k) récursifs
296

Principe du parsing descendantAnalyseurs prédictifs - Firstk - Followk
CFG LL(k)Analyseurs LL(1)
Analyseurs fortement LL(k) (k > 1)Analyseurs LL(k) (k > 1)
Gestion des erreurs et resynchronisationsAnalyseurs LL(k) récursifs
Plan
1 Principe du parsing descendant
2 Analyseurs prédictifs - Firstk - Followk
3 CFG LL(k)
4 Analyseurs LL(1)
5 Analyseurs fortement LL(k) (k > 1)
6 Analyseurs LL(k) (k > 1)
7 Gestion des erreurs et resynchronisations
8 Analyseurs LL(k) récursifs
297

Exemple (CFG d’un langage très simple)
Règles Règles de production0 S’ → program $1 program → begin st-list end2 st-list → st st-tail3 st-tail → st st-tail4 st-tail → ε5 st → Id := expression ;6 st → read ( id-list ) ;7 st → write( expr-list ) ;8 id-list → Id id-tail9 id-tail → , Id id-tail10 id-tail → ε11 expr-list → expression expr-tail12 expr-tail → , expression expr-tail13 expr-tail → ε14 expression → prim prim-tail15 prim-tail → add-op prim prim-tail16 prim-tail → ε17 prim → ( expression )18 prim → Id19 prim → Nb
20 | 21 add-op → + | -

Exemple d’arbre syntaxique et de dérivation gauche
Exemple (Dérivation gauche correspondant à l’arbre syntaxique)
$
S'
begin end
program
prim prim-tail
primId add-op prim-tail
-
st-list
st st-tail
Id expression:= ;
Nb
Dérivation gauche S′G∗⇒ begin Id := Id - Nb ; end $ :
0 1 2 5 14 18 15 21 19 16 4

Principe du parsing descendantAnalyseurs prédictifs - Firstk - Followk
CFG LL(k)Analyseurs LL(1)
Analyseurs fortement LL(k) (k > 1)Analyseurs LL(k) (k > 1)
Gestion des erreurs et resynchronisationsAnalyseurs LL(k) récursifs
Dérivation gauche
Exemple (Dérivation gauche complète correspondante)
Règle plus grand préfixe ∈ T∗ suite de la protophraseS’ ⇒
0 program $ ⇒1 begin st-list end$ ⇒2 begin st st-tail end$ ⇒5 begin Id := expression ; st-tail end$ ⇒
14 begin Id := prim prim-tail ; st-tail end$ ⇒18 begin Id := Id prim-tail ; st-tail end$ ⇒15 begin Id := Id add-op prim prim-tail ; st-tail end$ ⇒21 begin Id := Id - prim prim-tail ; st-tail end$ ⇒19 begin Id := Id - Nb prim-tail ; st-tail end$ ⇒16 begin Id := Id - Nb ; st-tail end$ ⇒4 begin Id := Id - Nb ; end $
300

Principe du parsing descendantAnalyseurs prédictifs - Firstk - Followk
CFG LL(k)Analyseurs LL(1)
Analyseurs fortement LL(k) (k > 1)Analyseurs LL(k) (k > 1)
Gestion des erreurs et resynchronisationsAnalyseurs LL(k) récursifs
Ébauche de structure d’un parser descendant
Ébauche de structure d’un parser descendant : PDA à un état et avec output
Au départ S′ est sur la pileLe PDA peut effectuer 4 types d’actions :
Produce : la variable A au sommet de la pile est remplacée par la partiedroite d’une de ses règles (numérotée i) et le numéro i est écrit suroutput
Match : le terminal a au sommet de la pile correspond au terminal eninput ; on pop ce terminal et passe au symbole d’input suivant
Accept : Correspond à un Match du terminal $ : le terminal au sommetde la pile est $ et correspond au terminal en input ; on termine l’analyseavec succès
Erreur : Si aucun match ni produce n’est possible
301
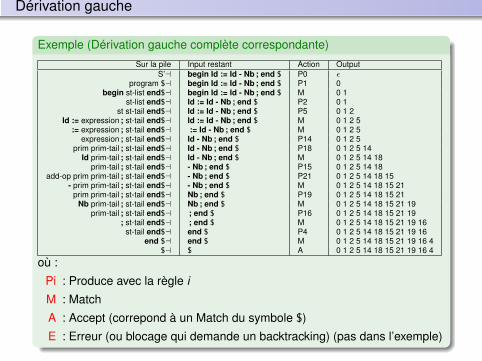
Dérivation gauche
Exemple (Dérivation gauche complète correspondante)Sur la pile Input restant Action Output
S’a begin Id := Id - Nb ; end $ P0 εprogram $a begin Id := Id - Nb ; end $ P1 0
begin st-list end$a begin Id := Id - Nb ; end $ M 0 1st-list end$a Id := Id - Nb ; end $ P2 0 1
st st-tail end$a Id := Id - Nb ; end $ P5 0 1 2Id := expression ; st-tail end$a Id := Id - Nb ; end $ M 0 1 2 5
:= expression ; st-tail end$a := Id - Nb ; end $ M 0 1 2 5expression ; st-tail end$a Id - Nb ; end $ P14 0 1 2 5
prim prim-tail ; st-tail end$a Id - Nb ; end $ P18 0 1 2 5 14Id prim-tail ; st-tail end$a Id - Nb ; end $ M 0 1 2 5 14 18
prim-tail ; st-tail end$a - Nb ; end $ P15 0 1 2 5 14 18add-op prim prim-tail ; st-tail end$a - Nb ; end $ P21 0 1 2 5 14 18 15
- prim prim-tail ; st-tail end$a - Nb ; end $ M 0 1 2 5 14 18 15 21prim prim-tail ; st-tail end$a Nb ; end $ P19 0 1 2 5 14 18 15 21
Nb prim-tail ; st-tail end$a Nb ; end $ M 0 1 2 5 14 18 15 21 19prim-tail ; st-tail end$a ; end $ P16 0 1 2 5 14 18 15 21 19
; st-tail end$a ; end $ M 0 1 2 5 14 18 15 21 19 16st-tail end$a end $ P4 0 1 2 5 14 18 15 21 19 16
end $a end $ M 0 1 2 5 14 18 15 21 19 16 4$a $ A 0 1 2 5 14 18 15 21 19 16 4
où :
Pi : Produce avec la règle i
M : Match
A : Accept (correpond à un Match du symbole $)
E : Erreur (ou blocage qui demande un backtracking) (pas dans l’exemple)

Principe du parsing descendantAnalyseurs prédictifs - Firstk - Followk
CFG LL(k)Analyseurs LL(1)
Analyseurs fortement LL(k) (k > 1)Analyseurs LL(k) (k > 1)
Gestion des erreurs et resynchronisationsAnalyseurs LL(k) récursifs
Points à améliorer dans l’ébauche de parser descendant
Critique de l’ébauche de parser descendant
Tel quel, ce parser est extrêmement inefficace car il doit effectuer dubacktracking pour explorer toutes les possibilités.
Dans ce type de parser, un choix doit avoir lieu au moment de l’action“Produce”
Si plusieurs choix sont possibles et qu’aucun critère dans la méthode nepermet de choisir, on parlera de conflit Produce/Produce
Sans guide au moment de ce choix, il faudrait éventuellement explorertous les Produce possibles : on aurait donc un parser qui prendrait untemps exponentiel (typiquement dans la longueur de l’input) ce qui estinadmissible !
303

Principe du parsing descendantAnalyseurs prédictifs - Firstk - Followk
CFG LL(k)Analyseurs LL(1)
Analyseurs fortement LL(k) (k > 1)Analyseurs LL(k) (k > 1)
Gestion des erreurs et resynchronisationsAnalyseurs LL(k) récursifs
Plan
1 Principe du parsing descendant
2 Analyseurs prédictifs - Firstk - Followk
3 CFG LL(k)
4 Analyseurs LL(1)
5 Analyseurs fortement LL(k) (k > 1)
6 Analyseurs LL(k) (k > 1)
7 Gestion des erreurs et resynchronisations
8 Analyseurs LL(k) récursifs
304

Principe du parsing descendantAnalyseurs prédictifs - Firstk - Followk
CFG LL(k)Analyseurs LL(1)
Analyseurs fortement LL(k) (k > 1)Analyseurs LL(k) (k > 1)
Gestion des erreurs et resynchronisationsAnalyseurs LL(k) récursifs
Introduction des analyseurs prédictifs
Motivation
Lors d’une analyse descendante, les choix que le parser doit effectueront lieu lorsque l’action à réaliser est un Produce et la variableconcernée (au sommet de la pile) a plusieurs règles.
Dans ce cas, l’input qui reste à analyser (non encore Matché) peut servirde “guide”
Dans l’exemple, si on doit faire un produce avec la variable st , selon quel’input restant est Id, read ou write, il est clair que le parser devra faireun Produce 5, 6 ou 7
305

Introduction des analyseurs prédictifs
Analyseur prédictif
Les analyseurs LL(k) sont prédictifs et ont k symboles de prévision (k est unnombre naturel) : lorsqu’une variable est au sommet de la pile, le produceeffectué dépendra,
1 de la variable2 des (au plus) k premiers symboles à l’entrée
Exemple (Table d’action M)
Un analyseur LL(k) aura une table à 2 dimensions M où M[A, u] détermine lenuméro de règle du produce à effectuer quand A est la variable à développer(au sommet de la pile) et u est la prévision.
Pour un analyseur LL(1) la prévision sera un symbole terminal a.
Pour un analyseur LL(k) avec k un entier supérieur à 1, on aura unetable M[A, u] où u sera un string de taille inférieure ou égale à k (limitéau $ final)

Analyseurs prédictifs LL(k)
Exemple (Analyseur prédictif LL(k))
Programme d'analyse prédictive
n j o u r . .
}k- symboles de prévision (lookahead)
S
A
C
...
a b no j ...M
2
4
6
input
bBaA
pile
ouput
S
1
a A
a B
Table d'action M
Remarque : Toute combinaison non prévue dans M donne une erreur lors del’analyse

Analyseurs prédictifs LL(k)
Algorithme général du fonctionnement d’un analyseur prédictif LL(k) pourG = 〈V , T , P, S′〉 et les règles de la forme A→ αi
On suppose que la table M est construite
Parser-LL-k() :=
Initialement : Push(S′)
Tant que (pas Error ni Accept)
X ← Top()
u ← Prévison de l’input
Si (X = A ∈ V et M[A, u] = i) : Produce(i) ;
Sinon si (X = a 6= $ ∈ T ) et u = av (v ∈ T ∗) : Match() ;
Sinon si (X = u = $) : Accept() ;
Sinon : /* rien n’est prévu */ Erreur() ;
FProc
Produce(i) := Pop() ; Push(αi ) ; Fproc
Match() := Pop() ; Avance à l’input suivant ; Fproc
Accept() := Informe du succès de l’analyse ; Fproc
Erreur() := Informe d’une erreur dans l’analyse ; Fproc
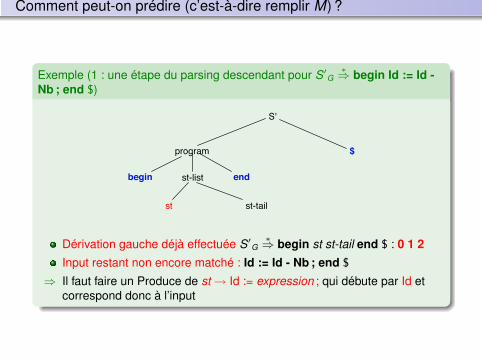
Comment peut-on prédire (c’est-à-dire remplir M) ?
Exemple (1 : une étape du parsing descendant pour S′G∗⇒ begin Id := Id -
Nb ; end $)
$
S'
begin end
program
st-list
st st-tail
Dérivation gauche déjà effectuée S′G∗⇒ begin st st-tail end $ : 0 1 2
Input restant non encore matché : Id := Id - Nb ; end $
⇒ Il faut faire un Produce de st→ Id := expression ; qui débute par Id etcorrespond donc à l’input

Comment peut-on prédire (c’est-à-dire remplir M) ?
Exemple (2 : une étape du parsing descendant pour S′G∗⇒ begin Id := Id -
Nb ; end $)
$
S'
begin end
program
prim prim-tail
primId add-op prim-tail
-
st-list
st st-tail
Id expression:= ;
Nb
Dérivation gauche déjà effectuée S′G∗⇒ begin Id := Id - Nb ; st-tail end
$ : 0 1 2 5 14 18 15 21 19 16Input restant non encore matché : end $
⇒ Il faut faire un Produce de st-tail→ ε car ce qui suit st-tail débute par endqui correspond à l’input

Firstk (X )− Follow(k (X )
Pour un symbole X , on voudra donc connaître :
Firstk (X ) : l’ensemble des strings de terminaux de longueur maximalemais limitée à k caractères qui peuvent débuter un string généré à partirde X
Followk (X ) : l’ensemble des strings de terminaux de longueur maximalemais limitée à k caractères qui peuvent suivre un string généré à partirde X
Dans la figure suivante on a :
y ∈ Firstk (X )
z ∈ Followk (X ) :
X
y zFirst (X)k Follow (X)k
S'

Principe du parsing descendantAnalyseurs prédictifs - Firstk - Followk
CFG LL(k)Analyseurs LL(1)
Analyseurs fortement LL(k) (k > 1)Analyseurs LL(k) (k > 1)
Gestion des erreurs et resynchronisationsAnalyseurs LL(k) récursifs
Firstk - Followk
La construction de la table d’actions M utilise les fonctions Firstk et Followk
définies pour une CFG G = 〈V , T , P, S′〉 donnée :
Définition (Firstk (α). Pour la CFG G, un entier positif k et α ∈ (T ∪ V )∗)
Firstk (α) est l’ensemble des strings de terminaux de longueur maximale maislimitée à k caractères qui peuvent débuter un string généré à partir de α
Mathématiquement :
Firstk (α) =
w ∈ T≤k | ∃x ∈ T ∗ : α
∗⇒ wx ∧ “`|w | = k
´∨`
|w | < k ∧ x = ε´”ff
où : T≤k =Sk
i=0 T i
312

Principe du parsing descendantAnalyseurs prédictifs - Firstk - Followk
CFG LL(k)Analyseurs LL(1)
Analyseurs fortement LL(k) (k > 1)Analyseurs LL(k) (k > 1)
Gestion des erreurs et resynchronisationsAnalyseurs LL(k) récursifs
First1(α) (ou First(α))
Définition (First1(α) (ou First(α)))
First1(α), dénoté plus simplement First(α), est l’ensemble des symbolesterminaux qui peuvent commencer un string généré à partir de α, union ε si αpeut générer ε
Mathématiquement :
First(α) =
{a ∈ T | ∃x ∈ T ∗ : α∗⇒ ax}
∪{ε | α ∗⇒ ε}
313

Principe du parsing descendantAnalyseurs prédictifs - Firstk - Followk
CFG LL(k)Analyseurs LL(1)
Analyseurs fortement LL(k) (k > 1)Analyseurs LL(k) (k > 1)
Gestion des erreurs et resynchronisationsAnalyseurs LL(k) récursifs
Calcul de Firstk (α)
Firstk (α) avec α = X1X2 . . . Xn
Firstk (α) = Firstk (X1)⊕k Firstk (X2)⊕k · · · ⊕k Firstk (Xn)
avecL1 ⊕k L2 =
w ∈ T≤k | ∃x ∈ T ∗, y ∈ L1, z ∈ L2 : wx = yz ∧ “`|w | = k
´∨`
|w | < k ∧ x = ε´”ff
314

Calcul de Firstk (X )
Calcul de Firstk (X ) avec X ∈ (T ∪ V )
Algorithme glouton (greedy) : on augmente des ensembles Firstk (X ) jusqu’àstabilisation.
Base :∀a ∈ T : Firstk (a) = {a}∀A ∈ V : Firstk (A) = ∅
Induction : boucle jusqu’à stabilisation :
∀A ∈ V : Firstk (A)∪⇐ {x ∈ T ∗ | A→ Y1Y2 . . . Yn ∧
x ∈ Firstk (Y1)⊕k Firstk (Y2)⊕k · · · ⊕k Firstk (Yn)}
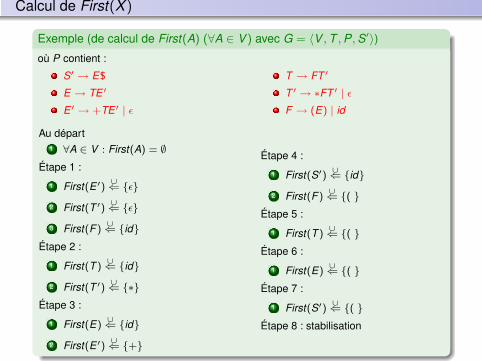
Calcul de First(X )
Exemple (de calcul de First(A) (∀A ∈ V ) avec G = 〈V , T , P, S′〉)où P contient :
S′ → E$
E → TE ′
E ′ → +TE ′ | ε
T → FT ′
T ′ → ∗FT ′ | εF → (E) | id
Au départ1 ∀A ∈ V : First(A) = ∅
Étape 1 :
1 First(E ′) ∪⇐ {ε}
2 First(T ′) ∪⇐ {ε}
3 First(F )∪⇐ {id}
Étape 2 :
1 First(T )∪⇐ {id}
2 First(T ′) ∪⇐ {∗}Étape 3 :
1 First(E)∪⇐ {id}
2 First(E ′) ∪⇐ {+}
Étape 4 :
1 First(S′) ∪⇐ {id}
2 First(F )∪⇐ {( }
Étape 5 :
1 First(T )∪⇐ {( }
Étape 6 :
1 First(E)∪⇐ {( }
Étape 7 :
1 First(S′) ∪⇐ {( }Étape 8 : stabilisation

Calcul de First(X )
Exemple (de calcul de First(A) (∀A ∈ V ) avec G = 〈V , T , P, S′〉)
où P contient :
S′ → E$
E → TE ′
E ′ → +TE ′ | ε
T → FT ′
T ′ → ∗FT ′ | εF → (E) | id
First(S′) = {id , ( }First(E) = {id , ( }First(E ′) = {+, ε}First(T ) = {id , ( }First(T ′) = {∗, ε}First(F ) = {id , ( }

Exemple (de calcul de First2(A) (∀A ∈ V ) avec la même grammaire G)
Au départ1 ∀A ∈ V : First2(A) = ∅
Étape 1 :
1 First2(E ′) ∪⇐ {ε}
2 First2(T ′) ∪⇐ {ε}
3 First2(F )∪⇐ {id}
Étape 2 :
1 First2(T )∪⇐ {id}
2 First2(T ′) ∪⇐ {∗id}Étape 3 :
1 First2(E)∪⇐ {id}
2 First2(E ′) ∪⇐ {+id}
3 First2(T )∪⇐ {id∗}
Étape 4 :
1 First2(S′) ∪⇐ {id$}
2 First2(E)∪⇐ {id+, id∗}
3 First2(F )∪⇐ {(id}
Étape 5 :
1 First2(S′) ∪⇐ {id+, id∗}
2 First2(T )∪⇐ {(id}
3 First2(T ′) ∪⇐ {∗(}Étape 6 :
1 First2(E)∪⇐ {(id}
2 First2(E ′) ∪⇐ {+(}Étape 7 :
1 First2(S′) ∪⇐ {(id}
2 First2(F )∪⇐ {((}
Étape 8 :
1 First2(T )∪⇐ {((}
Étape 9 :
1 First2(E)∪⇐ {((}
Étape 10 :
1 First2(S′) ∪⇐ {((}Étape 11 : stabilisation

Principe du parsing descendantAnalyseurs prédictifs - Firstk - Followk
CFG LL(k)Analyseurs LL(1)
Analyseurs fortement LL(k) (k > 1)Analyseurs LL(k) (k > 1)
Gestion des erreurs et resynchronisationsAnalyseurs LL(k) récursifs
Calcul de First2(X )
Exemple (de calcul de First2(A) (∀A ∈ V ) avec G = 〈V , T , P, S′〉)
dont les règles sont :
S′ → E$
E → TE ′
E ′ → +TE ′ | ε
T → FT ′
T ′ → ∗FT ′ | εF → (E) | id
First2(S′) = {id$, id+, id∗, (id , (( }First2(E) = {id , id+, id∗, (id , ((}First2(E ′) = {ε, +id , +(}First2(T ) = {id , id∗, (id , ((}First2(T ′) = {ε, ∗id , ∗(}First2(F ) = {id , (id , ((}
319

Principe du parsing descendantAnalyseurs prédictifs - Firstk - Followk
CFG LL(k)Analyseurs LL(1)
Analyseurs fortement LL(k) (k > 1)Analyseurs LL(k) (k > 1)
Gestion des erreurs et resynchronisationsAnalyseurs LL(k) récursifs
Followk
Pour déterminer les prévisions
Définition (Followk (β) Pour la CFG G, un entier positif k et β ∈ (T ∪ V )∗)
Followk (β) est l’ensemble des strings de terminaux de longueur maximalemais limitée à k caractères qui peuvent suivre un string généré à partir de β
Mathématiquement :
Followk (β) = {w ∈ T≤k | ∃α, γ ∈ (T ∪ V )∗ : S′ ∗⇒ αβγ ∧ w ∈ Firstk (γ)}
320

Principe du parsing descendantAnalyseurs prédictifs - Firstk - Followk
CFG LL(k)Analyseurs LL(1)
Analyseurs fortement LL(k) (k > 1)Analyseurs LL(k) (k > 1)
Gestion des erreurs et resynchronisationsAnalyseurs LL(k) récursifs
Calcul de Followk (X )
Il ne nous sera nécessaire que de calculer le Follow de variables.
Calcul de Followk (A) avec A ∈ (T ∪ V )
Algorithme glouton : On augmente les ensembles Followk (B) initialementvide, jusqu’à stabilisation.
Base :∀A ∈ V : Followk (A) = ∅
Induction :
∀A ∈ V , A→ αBβ ∈ P (B ∈ V ; α, β ∈ (V ∪ T )∗) :
Followk (B)∪⇐ Firstk (β)⊕k Followk (A)
Jusqu’à stabilisation.
321

Principe du parsing descendantAnalyseurs prédictifs - Firstk - Followk
CFG LL(k)Analyseurs LL(1)
Analyseurs fortement LL(k) (k > 1)Analyseurs LL(k) (k > 1)
Gestion des erreurs et resynchronisationsAnalyseurs LL(k) récursifs
Calcul de Follow(A)
Exemple (de calcul de Follow(A) (∀A ∈ V ) avec G = 〈V , T , P, S′〉)
dont les règles sont :
S′ → E$
E → TE ′
E ′ → +TE ′ | ε
T → FT ′
T ′ → ∗FT ′ | εF → (E) | id
On obtient en appliquant l’algorithme (voir figure) :
Follow(S′) = {ε}Follow(E) = {), $}Follow(E ′) = {), $}Follow(T ) = {), $, +}Follow(T ′) = {), $, +}Follow(F ) = {), $, +, ∗}
322
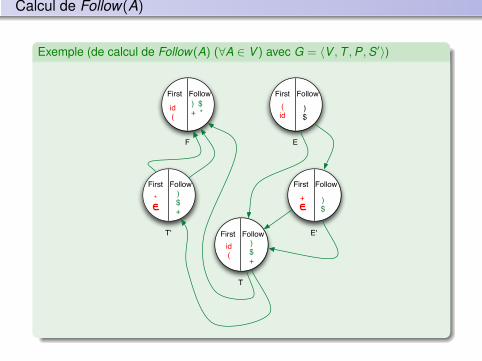
Calcul de Follow(A)
Exemple (de calcul de Follow(A) (∀A ∈ V ) avec G = 〈V , T , P, S′〉)
First Follow
F
First Follow
E
First Follow
E'First Follow
T
First Follow
T'
(id
+
id(
*
id(
)$
)$
)$+
)$+
) $+ *

Principe du parsing descendantAnalyseurs prédictifs - Firstk - Followk
CFG LL(k)Analyseurs LL(1)
Analyseurs fortement LL(k) (k > 1)Analyseurs LL(k) (k > 1)
Gestion des erreurs et resynchronisationsAnalyseurs LL(k) récursifs
Plan
1 Principe du parsing descendant
2 Analyseurs prédictifs - Firstk - Followk
3 CFG LL(k)
4 Analyseurs LL(1)
5 Analyseurs fortement LL(k) (k > 1)
6 Analyseurs LL(k) (k > 1)
7 Gestion des erreurs et resynchronisations
8 Analyseurs LL(k) récursifs
324

CFG LL(k)
CFG LL(k)
LL(k) signifie
Left scanning
Leftmost derivation
k lookahead symbols
Définition (La CFG G = 〈V , T , P, S′〉 est LL(k) (k un nombre naturel fixé) si)
∀w , x1, x2 ∈ T ∗ :
S′ G∗⇒ wAγ G⇒wα1γ G
∗⇒ wx1
S′ G∗⇒ wAγ G⇒wα2γ G
∗⇒ wx2
Firstk (x1) = Firstk (x2)
⇒ α1 = α2
Ce qui implique que pour la forme phrasée wAγ, si on connaît Firstk (x1) (cequi reste à analyser après w), on peut déterminer avec la prévision de ksymboles, la règle A→ αi à appliquer
Problème
En théorie pour déterminer si G (en supposant qu’il génère un langage infini)est LL(k), il faut vérifier une infinité de conditions

Principe du parsing descendantAnalyseurs prédictifs - Firstk - Followk
CFG LL(k)Analyseurs LL(1)
Analyseurs fortement LL(k) (k > 1)Analyseurs LL(k) (k > 1)
Gestion des erreurs et resynchronisationsAnalyseurs LL(k) récursifs
Propriété 1 sur les CFG LL(k)
Théorème (1 sur les CFG LL(k))
Une CFG G est LL(k)⇐⇒
∀A ∈ V : S′ ∗⇒ wAγ, A→ αi ∈ P (i = 1, 2 : α1 6= α2) :
Firstk (α1γ) ∩ Firstk (α2γ) = ∅
Problème
En théorie pour déterminer si la propriété est satisfaite sur G (en supposantqu’il génère un langage infini), il faut vérifier une infinité de conditions : vuque seuls les k premiers symboles nous intéressent, on peut trouver unalgorithme qui fait cela en un temps fini (voir plus loin))
326

Propriété 1 sur les CFG LL(k)
Théorème (1 sur les CFG LL(k))
Une CFG G est LL(k)⇐⇒
∀S′ ∗⇒ wAγ, A→ αi ∈ P (i = 1, 2 : α1 6= α2) :Firstk (α1γ) ∩ Firstk (α2γ) = ∅
Preuve : Par l’absurde
⇒ : On suppose G LL(k) et la propriété non vérifiée.
∃S′ ∗⇒ wAγ, A→ αi ∈ P (i = 1, 2 : α1 6= α2) :Firstk (α1γ) ∩ Firstk (α2γ) 6= ∅Donc ∃x1, x2 :
S′ G∗⇒ wAγ G⇒wα1γ G
∗⇒ wx1
S′ G∗⇒ wAγ G⇒wα2γ G
∗⇒ wx2
Firstk (x1) = Firstk (x2) ∧ α1 6= α2
Ce qui contredit le fait que G soit LL(k)

Propriété 1 sur les CFG LL(k)
Théorème (1 sur les CFG LL(k))
Une CFG G est LL(k)⇐⇒
∀S′ ∗⇒ wAγ, A→ αi ∈ P (i = 1, 2 : α1 6= α2) :Firstk (α1γ) ∩ Firstk (α2γ) = ∅
Preuve (suite) : Par l’absurde
⇐ : On suppose la propriété vérifiée et G pas LL(k)
∀S′ ∗⇒ wAγ, A→ αi ∈ P (i = 1, 2 : α1 6= α2) :Firstk (α1γ) ∩ Firstk (α2γ) = ∅ ∧G n’est pas LL(k)
Donc puisque G n’est pas LL(k) : ∃w , x1, x2 ∈ T ∗ :
S′ G∗⇒ wAγ G⇒wα1γ G
∗⇒ wx1 ∧S′ G
∗⇒ wAγ G⇒wα2γ G∗⇒ wx2 ∧
Firstk (x1) = Firstk (x2) ∧α1 6= α2
Or
Firstk (x1) ∈ Firstk (α1γ)
Firstk (x2) ∈ Firstk (α2γ)
Ce qui contredit la propriété.

Principe du parsing descendantAnalyseurs prédictifs - Firstk - Followk
CFG LL(k)Analyseurs LL(1)
Analyseurs fortement LL(k) (k > 1)Analyseurs LL(k) (k > 1)
Gestion des erreurs et resynchronisationsAnalyseurs LL(k) récursifs
Propriété 2 sur les CFG LL(k)
Théorème (sur les CFG LL(1))
Une CFG G est LL(1)⇐⇒
∀A→ αi ∈ P (i = 1, 2 : α1 6= α2) :First(α1Follow(A)) ∩ First(α2Follow(A)) = ∅
Avantage
Pour déterminer si G est LL(1), il suffit de vérifier un nombre fini de conditions
329

Propriété 3 sur les CFG LL(k)
Théorème (2 sur les CFG LL(k))
Une CFG G est LL(k)⇐
∀A→ αi ∈ P (i = 1, 2 : α1 6= α2) :
Firstk (α1Followk (A)) ∩ Firstk (α2Followk (A)) = ∅
Définition (CFG fortement LL(k))
Une CFG qui satisfait la propriété ci-dessus est fortement LL(k) (strongLL(k))
LL(1) = fortement LL(1)
D’après la propriété sur les langages LL(1) et la définition des langagesfortements LL(k), on déduit que tout langage LL(1) est fortement LL(1)Pour k > 1 on a : strong LL(k)⇒ LL(k)
Avantage
Pour déterminer si G est fortement LL(k), il suffit de vérifier un nombre fini deconditions

A partir de k = 2 : “fortement LL(k)′′ ⊂ LL(k)
Exemple (de CFG G LL(2) mais pas fortement LL(2))
dont les règles sont :
S′ → S$
S → aAa
S → bABa
A→ b
A→ ε
B → b
B → cG est LL(2)
S′ 1⇒ S$ : First2(aAa$) ∩ First2(bABa$) = ∅
S′ 2⇒ aAa$ : First2(ba$) ∩ First2(a$) = ∅
S′ 2⇒ bABa$ : First2(bBa$) ∩ First2(Ba$) = ∅
S′ 3⇒ bbBa$ : First2(ba$) ∩ First2(ca$) = ∅
S′ 3⇒ bBa$ : First2(ba$) ∩ First2(ca$) = ∅G n’est pas fortement LL(2)
Pour S : First2(aAa . . . ) ∩ First2(bABa . . . ) = ∅Pour B : First2(b . . . ) ∩ First2(c . . . ) = ∅Mais pour A: First2(bFollow2(A)) ∩ First2(εFollow2(A)) 6= ∅({ba, bb, bc} ∩ {a$, ba, ca} 6= ∅)

Principe du parsing descendantAnalyseurs prédictifs - Firstk - Followk
CFG LL(k)Analyseurs LL(1)
Analyseurs fortement LL(k) (k > 1)Analyseurs LL(k) (k > 1)
Gestion des erreurs et resynchronisationsAnalyseurs LL(k) récursifs
Grammaires qui ne sont pas LL(k)
Toute CFG G ambiguë n’est pas LL(k) (quelque soit k )
Preuve : évident d’après les définitions de grammaire ambiguë et CFG LL(k)
Toute CFG G (où tous les symboles sont utiles), récursive à gauche n’est pasLL(1)
Preuve :Si G est récursive à gauche, on a pour une certaine variable A (utile parhypothèse) de G,
A→ α | β (donc First(β) ⊆ First(A))
A⇒ α∗⇒ Aγ (donc First(A) ⊆ First(α))
⇒ First(β) ⊆ First(α)
Donc G n’est pas LL(1)
332
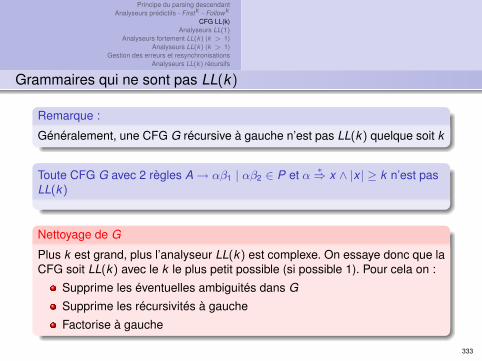
Principe du parsing descendantAnalyseurs prédictifs - Firstk - Followk
CFG LL(k)Analyseurs LL(1)
Analyseurs fortement LL(k) (k > 1)Analyseurs LL(k) (k > 1)
Gestion des erreurs et resynchronisationsAnalyseurs LL(k) récursifs
Grammaires qui ne sont pas LL(k)
Remarque :
Généralement, une CFG G récursive à gauche n’est pas LL(k) quelque soit k
Toute CFG G avec 2 règles A→ αβ1 | αβ2 ∈ P et α∗⇒ x ∧ |x | ≥ k n’est pas
LL(k)
Nettoyage de G
Plus k est grand, plus l’analyseur LL(k) est complexe. On essaye donc que laCFG soit LL(k) avec le k le plus petit possible (si possible 1). Pour cela on :
Supprime les éventuelles ambiguités dans G
Supprime les récursivités à gauche
Factorise à gauche
333

Principe du parsing descendantAnalyseurs prédictifs - Firstk - Followk
CFG LL(k)Analyseurs LL(1)
Analyseurs fortement LL(k) (k > 1)Analyseurs LL(k) (k > 1)
Gestion des erreurs et resynchronisationsAnalyseurs LL(k) récursifs
Plan
1 Principe du parsing descendant
2 Analyseurs prédictifs - Firstk - Followk
3 CFG LL(k)
4 Analyseurs LL(1)
5 Analyseurs fortement LL(k) (k > 1)
6 Analyseurs LL(k) (k > 1)
7 Gestion des erreurs et resynchronisations
8 Analyseurs LL(k) récursifs
334

Principe du parsing descendantAnalyseurs prédictifs - Firstk - Followk
CFG LL(k)Analyseurs LL(1)
Analyseurs fortement LL(k) (k > 1)Analyseurs LL(k) (k > 1)
Gestion des erreurs et resynchronisationsAnalyseurs LL(k) récursifs
Construction d’un analyseur LL(1)
Algorithme de construction de la table des Actions M[A, a]
Initialisation : ∀A, a : M[A, a] = ∅∀A→ α ∈ P (règle numéro i) :
∀a ∈ First(αFollow(A))
M[A, a]∪⇐ i
Note :
La grammaire est LL(1) si et seulement si chaque entrée de la table M aau plus une valeur.
Sinon, cela signifie que des conflits Produce/Produce ne sont pasrésolus
Par exemple pour la CFG G avec les règles (1) et (2) : S → aS | aM[A, a] = {1, 2}
335

Construction de la table d’action d’un analyseur LL(1)
Exemple (Construction de M pour G)
dont les règlessont :
S′ → E$ (0)E → TE ′ (1)E ′ → +TE ′ (2)E ′ → ε (3)T → FT ′ (4)T ′ → ∗FT ′ (5)T ′ → ε (6)F → (E) (7)F → id (8)
First(E$) = {id , ( }First(TE ′) = {id , ( }First(+TE ′) = {+}First(FT ′) = {id , ( }First(∗FT ′) = {∗}First((E)) = {( }First(id) = {id}
Follow(S′) = {ε}Follow(E) = {), $}Follow(E ′) = {), $}Follow(T ) = {), $, +}Follow(T ′) = {), $, +}Follow(F ) = {), $, +, ∗}
M id + ∗ ( ) $
S′ 0 0E 1 1E ′ 2 3 3T 4 4T ′ 6 5 6 6F 8 7

Analyse d’un string avec l’analyseur LL(1)
Exemple (Analyse de a ∗ (b + c)$)
Sur la pile Input restant Action OutputS’a a ∗ (b + c)$ P0 ε
E $a a ∗ (b + c)$ P1 0TE’ $a a ∗ (b + c)$ P4 0 1
FT’E’$a a ∗ (b + c)$ P8 0 1 4idT’E’$a ∗(b + c)$ M 0 1 4 8
T’E’$a ∗(b + c)$ P5 0 1 4 8*FT’E’$a ∗(b + c)$ M 0 1 4 8 5FT’E’$a (b + c)$ P7 0 1 4 8 5
(E)T’E’$a (b + c)$ M 0 1 4 8 5 7E)T’E’$a b + c)$ P1 0 1 4 8 5 7
TE’)T’E’$a b + c)$ P4 0 1 4 8 5 7 1FT’E’)T’E’$a b + c)$ P8 0 1 4 8 5 7 1 4idT’E’)T’E’$a b + c)$ M 0 1 4 8 5 7 1 4 8
T’E’)T’E’$a +c)$ P6 0 1 4 8 5 7 1 4 8E’)T’E’$a +c)$ P2 0 1 4 8 5 7 1 4 8 6
+TE’)T’E’$a +c)$ M 0 1 4 8 5 7 1 4 8 6 2TE’)T’E’$a c)$ P4 0 1 4 8 5 7 1 4 8 6 2
FT’E’)T’E’$a c)$ P8 0 1 4 8 5 7 1 4 8 6 2 4idT’E’)T’E’$a c)$ M 0 1 4 8 5 7 1 4 8 6 2 4 8
T’E’)T’E’$a )$ P6 0 1 4 8 5 7 1 4 8 6 2 4 8E’)T’E’$a )$ P3 0 1 4 8 5 7 1 4 8 6 2 4 8 6
)T’E’$a )$ M 0 1 4 8 5 7 1 4 8 6 2 4 8 6 3T’E’$a $ P6 0 1 4 8 5 7 1 4 8 6 2 4 8 6 3
E’$a $ P3 0 1 4 8 5 7 1 4 8 6 2 4 8 6 3 6$a $ A 0 1 4 8 5 7 1 4 8 6 2 4 8 6 3 6 3

Principe du parsing descendantAnalyseurs prédictifs - Firstk - Followk
CFG LL(k)Analyseurs LL(1)
Analyseurs fortement LL(k) (k > 1)Analyseurs LL(k) (k > 1)
Gestion des erreurs et resynchronisationsAnalyseurs LL(k) récursifs
Plan
1 Principe du parsing descendant
2 Analyseurs prédictifs - Firstk - Followk
3 CFG LL(k)
4 Analyseurs LL(1)
5 Analyseurs fortement LL(k) (k > 1)
6 Analyseurs LL(k) (k > 1)
7 Gestion des erreurs et resynchronisations
8 Analyseurs LL(k) récursifs
338

Principe du parsing descendantAnalyseurs prédictifs - Firstk - Followk
CFG LL(k)Analyseurs LL(1)
Analyseurs fortement LL(k) (k > 1)Analyseurs LL(k) (k > 1)
Gestion des erreurs et resynchronisationsAnalyseurs LL(k) récursifs
Construction d’un analyseur fortement LL(k)
Algorithme de construction de la table des Actions M[A, u](u ∈ T≤k )
Initialisation : ∀A, u : M[A, u] = Error
∀A→ α ∈ P (règle numéro i) :
∀u ∈ Firstk (αFollowk (A))
M[A, u]∪⇐ i
Notes :
La grammaire est fortement LL(k) si et seulement si chaque entrée de latable M a au plus une valeur.Sinon, cela signifie que des conflits Produce/Produce ne sont pasrésolus
En pratique on stocke M de façon compacte
339

Principe du parsing descendantAnalyseurs prédictifs - Firstk - Followk
CFG LL(k)Analyseurs LL(1)
Analyseurs fortement LL(k) (k > 1)Analyseurs LL(k) (k > 1)
Gestion des erreurs et resynchronisationsAnalyseurs LL(k) récursifs
Plan
1 Principe du parsing descendant
2 Analyseurs prédictifs - Firstk - Followk
3 CFG LL(k)
4 Analyseurs LL(1)
5 Analyseurs fortement LL(k) (k > 1)
6 Analyseurs LL(k) (k > 1)
7 Gestion des erreurs et resynchronisations
8 Analyseurs LL(k) récursifs
340

Principe du parsing descendantAnalyseurs prédictifs - Firstk - Followk
CFG LL(k)Analyseurs LL(1)
Analyseurs fortement LL(k) (k > 1)Analyseurs LL(k) (k > 1)
Gestion des erreurs et resynchronisationsAnalyseurs LL(k) récursifs
Analyseurs LL(k) pour les CFG non fortement L(k)
Explication
Cela signifie que pour A→ α1 | α2
Firstk (α1Followk (A)) ∩ Firstk (α2Followk (A)) 6= ∅
Ce qui signifie que :
contrairement au CFG “fortement LL(k)” où les prévisions globalessuffisent
pour les CFG LL(k) non fortement LL(k), il faut utiliser les prévisionslocales
Autrement dit, en pratique, lors de l’analyse, le sommet de la pile et laprévision ne suffisent pas pour déterminer le Produce à effectuer ; il fautaussi “retenir” dans quel contexte local on se trouve.
341

Principe du parsing descendantAnalyseurs prédictifs - Firstk - Followk
CFG LL(k)Analyseurs LL(1)
Analyseurs fortement LL(k) (k > 1)Analyseurs LL(k) (k > 1)
Gestion des erreurs et resynchronisationsAnalyseurs LL(k) récursifs
Déterminons le problème
Reprenons la définition :La CFG G = est LL(k) ⇐⇒ ∀w , x1, x2 ∈ T ∗ :
S′ G∗⇒ wAγ G⇒wα1γ G
∗⇒ wx1
S′ G∗⇒ wAγ G⇒wα2γ G
∗⇒ wx2
Firstk (x1) = Firstk (x2)
⇒ α1 = α2
Ce qui signifie que dans le contexte wAγ, une prévision de k symbolespermet de déterminer de façon unique la prochaine production à utiliser.
342

Principe du parsing descendantAnalyseurs prédictifs - Firstk - Followk
CFG LL(k)Analyseurs LL(1)
Analyseurs fortement LL(k) (k > 1)Analyseurs LL(k) (k > 1)
Gestion des erreurs et resynchronisationsAnalyseurs LL(k) récursifs
Déterminons le problème
Prenons la grammaire LL(2) mais pas fortement LL(2)
de règles :
S′ → S$
S → aAa
S → bABa
A→ b
A→ ε
B → b
B → c
Suivant que l’on a fait S → aAa ou S → bABa, une prévision “ba” signifie quel’on doit faire un produce A→ b ou A→ ε
De façon générale il faut donc calculer le “follow local” de chaque variablepour chaque contexte possible.
343

Principe du parsing descendantAnalyseurs prédictifs - Firstk - Followk
CFG LL(k)Analyseurs LL(1)
Analyseurs fortement LL(k) (k > 1)Analyseurs LL(k) (k > 1)
Gestion des erreurs et resynchronisationsAnalyseurs LL(k) récursifs
Transformation de CFG LL(k) en fortement LL(k)
Etant donné qu’il n’y a qu’un nombre fini de variables et de prévisions delongueur inférieure ou égale à k , on peut expliciter l’ensemble des followlocaux possibles.
On va transformer G en G′ où chaque variable A sera remplacée par uncouple [A, L]
le nom A de la variable dans G
le follow local, c’est-à-dire l’ensemble L des prévisions locales possibles
Pour l’exemple précédent, la variable A se transforme en [A, {a$}] et[A, {ba, ca}]
Propriété
Si G est LL(k) alors G′ est fortement LL(k)
344

Principe du parsing descendantAnalyseurs prédictifs - Firstk - Followk
CFG LL(k)Analyseurs LL(1)
Analyseurs fortement LL(k) (k > 1)Analyseurs LL(k) (k > 1)
Gestion des erreurs et resynchronisationsAnalyseurs LL(k) récursifs
Transformation de CFG LL(k) en fortement LL(k)
Algorithme de transformation de CFG G LL(k) en G′ fortement LL(k)
Ayant G = 〈V , T , P, S′〉 on construit G′ = 〈V ′, T , P′, S′′〉 comme suit :
Initialement :
V ′ ⇐ {[S′, {ε}]}S′′ = [S′, {ε}]P′ = ∅
Répéter jusqu’à ce que toutes les nouvelles variables aient leurs règles :
Ayant[A, L] ∈ V ′ ∧ A→ α ≡ x0B1x1B2 . . . Bmxm ∈ P (xi ∈ T ∗, Bi ∈ V )
P′ ∪⇐ [A, L]→ T (α) avec
T (α) = x0[B1, L1]x1[B2, L2] . . . [Bm, Lm]xm
Li = Firstk (xiBi+1 . . . Bmxm.L)
∀1 ≤ i ≤ m : V ′ ∪⇐ [Bi , Li ]345

Transformation de CFG LL(k) en fortement LL(k)
Exemple (de transformation de G LL(2) en G′ fortement LL(2))
G = 〈V , T , P, S′〉 de règles :
S′ → S$ (0)S → aAa (1)S → bABa (2)
A→ b (3)A→ ε (4)B → b (5)B → c (6)
devient : G′ = 〈V ′, T , P′, S′′〉 avec :
Règle numéro dans G′ numéro dans G[S′, {ε}]→ [S, {$}]$ (0′) (0)[S, {$}]→ a[A, {a$}]a (1′) (1)[S, {$}]→ b[A, {ba, ca}][B, {a$}]a (2′) (2)[A, {a$}]→ b (3′) (3)[A, {a$}]→ ε (4′) (4)[A, {ba, ca}]→ b (5′) (3)[A, {ba, ca}]→ ε (6′) (4)[B, {a$}]→ b (7′) (5)[B, {a$}]→ c (8′) (6)

Transformation de CFG LL(k) en fortement LL(k)
Exemple (de transformation de G LL(2) en G′ fortement LL(2))
G′ = 〈V ′, T , P′, S′′〉 avec :
Règle numéro dans G′ numéro dans G[S′, {ε}]→ [S, {$}]$ (0′) (0)[S, {$}]→ a[A, {a$}]a (1′) (1)[S, {$}]→ b[A, {ba, ca}][B, {a$}]a (2′) (2)[A, {a$}]→ b (3′) (3)[A, {a$}]→ ε (4′) (4)[A, {ba, ca}]→ b (5′) (3)[A, {ba, ca}]→ ε (6′) (4)[B, {a$}]→ b (7′) (5)[B, {a$}]→ c (8′) (6)
M ab aa bb bc ba ca a$
[S′, ε] 0′ 0′ 0′ 0′
[S, {$}] 1′ 1′ 2′ 2′
[A, {a$}] 3′ 4′
[A, {ba, ca}] 5′ 5′ 6′ 6′
[B, {a$}] 7′ 8′

Analyse avec la CFG fortement LL(k) construite
Exemple (Analyse de bba$)
M ab aa bb bc ba ca a$
[S′, ε] 0′ 0′ 0′ 0′
[S, {$}] 1′ 1′ 2′ 2′
[A, {a$}] 3′ 4′
[A, {ba, ca}] 5′ 5′ 6′ 6′
[B, {a$}] 7′ 8′
Lors de l’analyse, on peut faire correspondre l’output aux règles de GSur la pile Input Action Out. de G′ Out. de G
[S′, ε] a bba$ P0’ ε ε[S, $] $ a bba$ P2’ 0’ 0
b [A, {ba, ca}][B, {a$}] a$ a bba$ M 0’ 2’ 0 2[A, {ba, ca}][B, {a$}]a$a ba$ P6’ 0’ 2’ 0 2
[B, {a$}]a$a ba$ P7’ 0’ 2’ 6’ 0 2 4ba$a ba$ M 0’ 2’ 6’ 7’ 0 2 4 5
a$a ba$ M 0’ 2’ 6’ 7’ 0 2 4 5$a ba$ A 0’ 2’ 6’ 7’ 0 2 4 5

Principe du parsing descendantAnalyseurs prédictifs - Firstk - Followk
CFG LL(k)Analyseurs LL(1)
Analyseurs fortement LL(k) (k > 1)Analyseurs LL(k) (k > 1)
Gestion des erreurs et resynchronisationsAnalyseurs LL(k) récursifs
Plan
1 Principe du parsing descendant
2 Analyseurs prédictifs - Firstk - Followk
3 CFG LL(k)
4 Analyseurs LL(1)
5 Analyseurs fortement LL(k) (k > 1)
6 Analyseurs LL(k) (k > 1)
7 Gestion des erreurs et resynchronisations
8 Analyseurs LL(k) récursifs
349

Principe du parsing descendantAnalyseurs prédictifs - Firstk - Followk
CFG LL(k)Analyseurs LL(1)
Analyseurs fortement LL(k) (k > 1)Analyseurs LL(k) (k > 1)
Gestion des erreurs et resynchronisationsAnalyseurs LL(k) récursifs
Récupération sur erreur en analyse prédictive
Lors d’une erreur, l’analyseur peut décider
d’informer de l’erreur et de s’arrêter.
d’essayer de continuer (sans produire de code) pour détecterd’éventuelles erreurs ultérieures (resynchronisation).
On détecte une erreur lorsque
le terminal au sommet de la pile ne correspond pas au prochain symboleà l’entrée
la variable au sommet de la pile ne prévoit pas la prévision à l’entrée
Dans ce cas on peut essayer de se resynchroniser en modifiant
la pile
l’input
350

Exemple : récupération en mode panique
Gestion des erreurs en mode panique
En cas d’erreur :
Popper les terminaux sur la pile jusqu’à la première variable
Sauter les symboles d’input qui ne correspondent pas à une prévisionou un symbole de resynchronisation associé à la variable
Si le symbole rencontré est un symbole de synchronisation, Popper lavariable de la pile
Continuer l’analyse (en espérant que la synchronisation ait eu lieu)

Récupération en mode panique pour un analyseur LL(1)
Symboles de synchronisation
Si l’entrée n’est pas déjà occupée, on ajoute à la table des actions M, pourchaque variable A, les symboles de synchronisation de A ; par exemple :
les symboles de Follow(A)
d’autres symboles bien choisis
Exemple (Table d’action pour l’analyseur LL(1) de G = 〈V , T , P, S′〉)
dont les règles sont :
S′ → E (0)E → TE ′ (1)E ′ → +TE ′ | ε (2) | (3)
T → FT ′ (4)T ′ → ∗FT ′ | ε (5) | (6)F → (E) | id (7) | (8)
M id + ∗ ( ) $
S′ 0 0E 1 1 sync syncE ′ 2 3 3T 4 sync 4 sync syncT ′ 6 5 6 6F 8 sync sync 7 sync sync

Analyse d’un string erroné avec l’analyseur LL(1)
Exemple (Analyse de +a ∗+b$)
Sur la pile Input restant Action OutputS’a +a ∗+b$ Erreur : saute + εS’a a ∗+b$ P0 *
E $a a ∗+b$ P1 * 0TE’ $a a ∗+b$ P4 * 0 1
FT’E’ $a a ∗+b$ P8 * 0 1 4idT’E’ $a a ∗+b$ M * 0 1 4 8
T’E’ $a ∗+ b$ P5 * 0 1 4 8*FT’E’ $a ∗+ b$ M * 0 1 4 8 5FT’E’ $a +b$ Erreur : + est sync : pop F * 0 1 4 8 5
T’E’ $a +b$ P6 * 0 1 4 8 5 *E’ $a +b$ P2 * 0 1 4 8 5 * 6
+TE’ $a +b$ M * 0 1 4 8 5 * 6 2TE’$a b$ P4 * 0 1 4 8 5 * 6 2
FT’E’$a b$ P8 * 0 1 4 8 5 * 6 2 4idT’E’$a b$ M * 0 1 4 8 5 * 6 2 4 8
T’E’$a b$ P6 * 0 1 4 8 5 * 6 2 4 8E’$a $ P3 * 0 1 4 8 5 * 6 2 4 8 6
$a $ A (avec erreurs) * 0 1 4 8 5 * 6 2 4 8 6 3

Principe du parsing descendantAnalyseurs prédictifs - Firstk - Followk
CFG LL(k)Analyseurs LL(1)
Analyseurs fortement LL(k) (k > 1)Analyseurs LL(k) (k > 1)
Gestion des erreurs et resynchronisationsAnalyseurs LL(k) récursifs
Plan
1 Principe du parsing descendant
2 Analyseurs prédictifs - Firstk - Followk
3 CFG LL(k)
4 Analyseurs LL(1)
5 Analyseurs fortement LL(k) (k > 1)
6 Analyseurs LL(k) (k > 1)
7 Gestion des erreurs et resynchronisations
8 Analyseurs LL(k) récursifs
354

Principe du parsing descendantAnalyseurs prédictifs - Firstk - Followk
CFG LL(k)Analyseurs LL(1)
Analyseurs fortement LL(k) (k > 1)Analyseurs LL(k) (k > 1)
Gestion des erreurs et resynchronisationsAnalyseurs LL(k) récursifs
Exemple d’analyseur LL(1) récursif
Un analyseur LL(k) peut facilement être encodé sous forme de programme(récursif) où l’analyse de chaque variable de G est effectuée par uneprocédure récursive.
Le code qui suit donne un analyseur LL(1) récursif pour G dont les règlessont :
E → TE ′ (1)E ′ → +TE ′ | ε (2) | (3)
T → FT ′ (4)T ′ → ∗FT ′ | ε (5) | (6)F → (E) | id (7) | (8)
355

Code récursif d’un analyseur LL(1)
/* main.c *//* E -> TE’; E’ -> +TE’ | e ; T -> FT’ ;
T’ -> *FT’ | e; F -> (E) | id */
#define NOTOK 0#define OK 1char Phrase[100];int CurToken;int Res;
int Match(char t){
if (Phrase[CurToken]==t){
CurToken++;return OK;
}else{
return NOTOK;}
}
void Send_output(int no){
printf("%d ",no);}

Code récursif d’un analyseur LL(1)
int E(void){Send_output(1);if(T()==OK)if(E2()==OK)return(OK);
return(NOTOK);
}

Code récursif d’un analyseur LL(1)
int E2(void){switch (Phrase[CurToken]){case ’+’:Send_output(2);Match(’+’);if(T()==OK)if(E2()==OK)return(OK);
break;case ’$’:case ’)’:Send_output(3);return(OK);
}return(NOTOK);
}

Code récursif d’un analyseur LL(1)
int T(void){Send_output(4);if(F()==OK)if(T2()==OK)return(OK);
return(NOTOK);}

Code récursif d’un analyseur LL(1)
int T2(void){switch (Phrase[CurToken]){case ’*’:Send_output(5);Match(’*’);if(F()==OK)if (T2()==OK)return(OK);
break;case ’+’:case ’$’:case ’)’:Send_output(6);return(OK);
}return(NOTOK);
}

Code récursif d’un analyseur LL(1)
int F(void){switch (Phrase[CurToken]){case ’(’:Send_output(7);Match(’(’);if (E()==OK)if (Match(’)’)==OK)return(OK);
break;case ’n’:Send_output(8);Match(’n’);return (OK);break;
}return(NOTOK);
}

Code récursif d’un analyseur LL(1)
int main(){scanf("%s", Phrase);if (E()!= OK){printf("error1\n");
}else{if (Match(’$’)==OK){printf("\n");
}else{printf("error2\n");
}}
}

Principe de parsing ascendantCFG LR(k)
Parser LR(0)Parser LR(1)
Parser SLR(1)Parser LALR(1)
Classes LL vs LRL’outil Yacc (Bison)
Chapitre 10 : Les parseurs LR(k)
1 Principe de parsing ascendant
2 CFG LR(k)
3 Parser LR(0)
4 Parser LR(1)
5 Parser SLR(1)
6 Parser LALR(1)
7 Classes LL vs LR
8 L’outil Yacc (Bison)
363
Principe de parsing ascendantCFG LR(k)
Parser LR(0)Parser LR(1)
Parser SLR(1)Parser LALR(1)
Classes LL vs LRL’outil Yacc (Bison)
Plan
1 Principe de parsing ascendant
2 CFG LR(k)
3 Parser LR(0)
4 Parser LR(1)
5 Parser SLR(1)
6 Parser LALR(1)
7 Classes LL vs LR
8 L’outil Yacc (Bison)
364
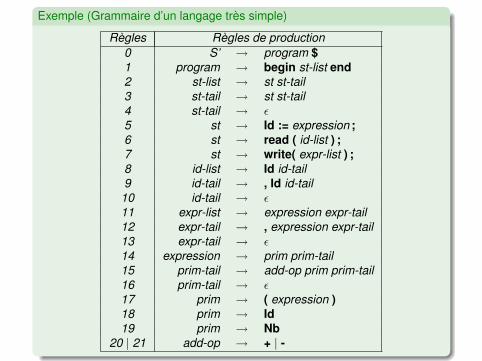
Exemple (Grammaire d’un langage très simple)
Règles Règles de production0 S’ → program $1 program → begin st-list end2 st-list → st st-tail3 st-tail → st st-tail4 st-tail → ε5 st → Id := expression ;6 st → read ( id-list ) ;7 st → write( expr-list ) ;8 id-list → Id id-tail9 id-tail → , Id id-tail10 id-tail → ε11 expr-list → expression expr-tail12 expr-tail → , expression expr-tail13 expr-tail → ε14 expression → prim prim-tail15 prim-tail → add-op prim prim-tail16 prim-tail → ε17 prim → ( expression )18 prim → Id19 prim → Nb
20 | 21 add-op → + | -
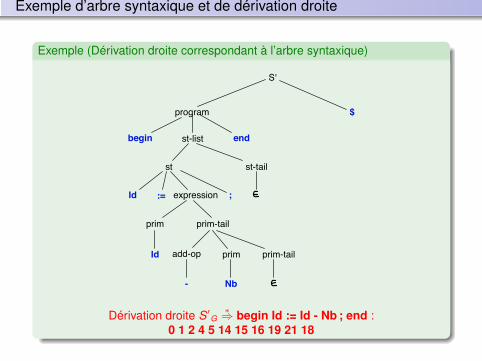
Exemple d’arbre syntaxique et de dérivation droite
Exemple (Dérivation droite correspondant à l’arbre syntaxique)
$
S'
begin end
program
prim prim-tail
primId add-op prim-tail
-
st-list
st st-tail
Id expression:= ;
Nb
Dérivation droite S′G∗⇒ begin Id := Id - Nb ; end :
0 1 2 4 5 14 15 16 19 21 18

Principe de parsing ascendantCFG LR(k)
Parser LR(0)Parser LR(1)
Parser SLR(1)Parser LALR(1)
Classes LL vs LRL’outil Yacc (Bison)
Dérivation droite
Exemple (Dérivation droite complète correspondante)
Règle protophraseS’ ⇒
0 program $ ⇒1 begin st-list end $ ⇒2 begin st st-tail end $ ⇒4 begin st end $ ⇒5 begin Id := expression ; end $ ⇒
14 begin Id := prim prim-tail ; end $ ⇒15 begin Id := prim add-op prim prim-tail ; end $ ⇒16 begin Id := prim add-op prim ; end $ ⇒19 begin Id := prim add-op Nb ; end $ ⇒21 begin Id := prim - Nb ; end $ ⇒18 begin Id := Id - Nb ; end $
367

Ébauche de structure d’un parser ascendant
Ébauche de structure d’un parser ascendant
PDA à un état et avec output. Au départ la pile est vide.Le PDA part du string d’input et construit l’arbre de bas en haut. Pour cela, ilopère par :
1 Mise de symbole d’input sur la pile jusqu’à identification d’une partiedroite α (handle) de règle A→ α
2 “Réduction” : remplacementa de α par A
Donc, le PDA peut effectuer 4 types d’actions :
Shift : lecture d’un symbole d’input et push de ce symbole sur la pile
Reduce : le sommet de la pile α correspond au handle (la partie droited’une règle numéro i : A→ α), est remplacée par A sur la pile et lenuméro de règle utilisée i est écrit sur output
Accept : Correspond à un Reduce de la règle S′ → S$ (qui montre quel’input a été complètement lu et analysé) ; on termine l’analyse avecsuccès
Erreur : Si aucun shift ni reduce n’est possibleaCorrespond formellement à |α| pops suivis d’un push de A

Principe de parsing ascendantCFG LR(k)
Parser LR(0)Parser LR(1)
Parser SLR(1)Parser LALR(1)
Classes LL vs LRL’outil Yacc (Bison)
Ébauche de structure d’un parser ascendant
Remarque :
On peut remarquer que l’analyse correspond à une analyse droite àl’envers : on part du string et remonte dans les dérivations vers lesymbole de départ. L’analyse est faite à l’envers étant donné qu’on litl’input de gauche à droite.
L’output sera donc construit à l’envers (tout nouvel output se met avantce qui a déjà été produit) pour obtenir cette dérivation droite.
Lors d’une analyse correcte, la pile contient toujours un prefixe viablec’est-à-dire un préfixe de forme phrasée “qui ne dépasse pas le handle”c’est à dire formellement que si le handle à trouver est A→ α etcorrespond à la dérivation γAx ⇒G γαx , la pile ne peut contenir qu’unpréfixe de γα.
369

Dérivation droite
Exemple (Dérivation droite complète correspondante)Sur la pile Input restant Act Output` begin Id := Id - Nb ; end $ S ε` begin Id := Id - Nb ; end $ S ε` begin Id := Id - Nb ; end $ S ε` begin Id := Id - Nb ; end $ S ε` begin Id := Id - Nb ; end $ R18 ε` begin Id := prim - Nb ; end $ S 18` begin Id := prim - Nb ; end $ S 18` begin Id := prim - Nb ; end $ R21 18` begin Id := prim add-op Nb ; end $ S 21 18` begin Id := prim add-op Nb ; end $ R19 21 18` begin Id := prim add-op prim ; end $ R16 19 21 18` begin Id := prim add-op prim prim-tail ; end $ R15 16 19 21 18` begin Id := prim prim-tail ; end $ R14 15 16 19 21 18` begin Id := expression ; end $ S 14 15 16 19 21 18` begin Id := expression ; end $ R5 14 15 16 19 21 18` begin st end $ R4 5 14 15 16 19 21 18` begin st st-tail end $ R2 4 5 14 15 16 19 21 18` begin st-list end $ S 2 4 5 14 15 16 19 21 18` begin st-list end $ R1 2 4 5 14 15 16 19 21 18` program $ S 1 2 4 5 14 15 16 19 21 18` program $ ε A 1 2 4 5 14 15 16 19 21 18` S’ ε 0 1 2 4 5 14 15 16 19 21 18
où :
S : Shift
Ri : Reduce avec la règle i
A : Accept (correspond à un Reduce avec la règle 0)
E : Erreur (ou blocage qui demande un backtracking)

Principe de parsing ascendantCFG LR(k)
Parser LR(0)Parser LR(1)
Parser SLR(1)Parser LALR(1)
Classes LL vs LRL’outil Yacc (Bison)
Points à améliorer dans l’ébauche de parser ascendant
Critique de l’ébauche de parser ascendant
Tel quel, ce parser est extrêmement inefficace car il doit effectuer dubacktracking pour explorer toutes les possibilités.
Dans ce type de parser, un choix doit avoir lieu au moment de l’action“Reduce” et “Shift”
Si plusieurs choix sont possibles et qu’aucun critère dans la méthode nepermet de choisir, on parlera de conflit Shift/Reduce ou Reduce/Reduce
Sans guide au moment de ce choix, il faudrait éventuellement explorertous les Shift et Reduce possibles : on aurait donc un parser quiprendrait un temps exponentiel (typiquement dans la longueur de l’input)ce qui est inadmissible !
371

Principe de parsing ascendantCFG LR(k)
Parser LR(0)Parser LR(1)
Parser SLR(1)Parser LALR(1)
Classes LL vs LRL’outil Yacc (Bison)
Plan
1 Principe de parsing ascendant
2 CFG LR(k)
3 Parser LR(0)
4 Parser LR(1)
5 Parser SLR(1)
6 Parser LALR(1)
7 Classes LL vs LR
8 L’outil Yacc (Bison)
372

CFG LR(k)
CFG LR(k)
LR(k) signifie
Left scanning
Rightmost derivation
k lookahead symbols
Définition (La CFG G′ = 〈V , T , P, S′〉 est LR(k) (k un nombre naturel fixé) si)
S′ ∗⇒G γAx ⇒Gγαx
S′ ∗⇒G δBy ⇒Gδβy = γαx ′
Firstk (x) = Firstk (x ′)
⇒
γAx ′ = δBy : c’est-à-direγ = δ,A = B,x ′ = y
Intuitivement cela signifie qu’en examinant Firstk (x) on peut déterminerunivoquement le handle A→ α dans γαx

Principe de parsing ascendantCFG LR(k)
Parser LR(0)Parser LR(1)
Parser SLR(1)Parser LALR(1)
Classes LL vs LRL’outil Yacc (Bison)
Grammaires non LR(k)
Exemple (de grammaire ni LR(0) ni LR(1))
La grammaire G′ suivante n’est pas LR(0) ni LR(1)
S′ → S$S → Sa | a | ε
S′ 2⇒G Sa$⇒Ga$
S′ 2⇒G Sa$⇒Gaa$
First(a$) = First(aa$)
A = S γ = ε α = εx = a$ x ′ = aa$ B = Sδ = ε β = a y = a$
Mais δBy = Sa$ 6= Saa$ = γAx ′
Notons que G′ est aussi ambiguë.
Théorème (Toute CFG G′ ambiguë n’est pas LR(k) quelque soit k )
374

Types d’analyseurs LR(k) étudiés
Type d’analyseurs ascendants étudiés ici
Nous allons voir 3 types d’analyseurs LR(k)
Les analyseurs “LR canoniques” les plus puissants mais coûteux
Les analyseurs “Simple LR” (SLR) : qui sont moins coûteux mais moinspuissants
Les analyseurs “LALR” plus puissants que SLR(1) (un peu moinspuissants que LR(1)) et moins coûteux que les LR canoniques
Fonctionnement d’un analyseur ascendant
Ces 3 types d’analyseurs ascendants utilisent
une pile
une table Action qui en fonction du sommet de la pile et de la prévisiondétermine s’il faut faire un Shift ou un Reduce i où i est le numéro de larègle à utiliser
une table Successeur qui détermine ce qui va être mis sur la pile (voirplus loin)
Principe de parsing ascendantCFG LR(k)
Parser LR(0)Parser LR(1)
Parser SLR(1)Parser LALR(1)
Classes LL vs LRL’outil Yacc (Bison)
Plan
1 Principe de parsing ascendant
2 CFG LR(k)
3 Parser LR(0)
4 Parser LR(1)
5 Parser SLR(1)
6 Parser LALR(1)
7 Classes LL vs LR
8 L’outil Yacc (Bison)
376

Principe de parsing ascendantCFG LR(k)
Parser LR(0)Parser LR(1)
Parser SLR(1)Parser LALR(1)
Classes LL vs LRL’outil Yacc (Bison)
Analyse LR(0)
Principe de la construction de l’analyseur
Le principe d’un analyseur LR est de déterminer un handle et d’effectuerla réduction
On va construire un automate fini déterministe qui reconnaît tous lespréfixes viables et détermine quand on arrive au handle
Notion d’item LR(0)
On utilise dans cette construction la notion de LR(0)-item
Un LR(0)-item est une règle de production avec un • quelque part dansla partie droite de la règlePour la règle A→ α : A→ α1 • α2 avec α = α1α2 signifie qu’il estpossible que l’on soit
en cours d’analyse d’une règle A→ α,après l’analyse de α1 (α1 est sur la pile)avant l’analyse de α2
377

Principe de parsing ascendantCFG LR(k)
Parser LR(0)Parser LR(1)
Parser SLR(1)Parser LALR(1)
Classes LL vs LRL’outil Yacc (Bison)
Analyse LR(0)
Remarque sur A→ α1 • α2
Il s’agit de possibilités qui seront regroupées. On pourra par exemple avoirles 2 possibilités suivantes regroupées :
S → a • AC
S → a • b
2 types de LR(0)-items sont particuliers :
A→ •α qui prédit que l’on peut débuter une analyse utilisant la règleA→ α
A→ α• qui reconnaît que l’on a terminé l’analyse d’une règle A→ α (etdétermine, s’il n’y a pas de conflit, que l’on peut faire le réducecorrespondant)
378

Principe de parsing ascendantCFG LR(k)
Parser LR(0)Parser LR(1)
Parser SLR(1)Parser LALR(1)
Classes LL vs LRL’outil Yacc (Bison)
Construction de l’automate caractéristique LR(0)
Automate caractéristique LR(0)
On va construire un automate fini déterministe qui en fonction descaractères d’input avalés ou des variables déjà acceptées, détermine lesdébuts de handle possibles.
Quand l’automate arrive dans un état “accepteur” càd contenant unLR(0)-item A→ α• (où un handle est complet, A→ α est reconnu, onpeut effectuer la réduction, c’est à dire remplacer α par A
Cet automate reconnaît comme langage l’ensemble des préfixesviables de G′
379

Principe de parsing ascendantCFG LR(k)
Parser LR(0)Parser LR(1)
Parser SLR(1)Parser LALR(1)
Classes LL vs LRL’outil Yacc (Bison)
Construction de l’automate caractéristique LR(0)
Construction de l’automate caractéristique LR(0)
Au départ on marque que l’on doit analyser S′ : S′ → •S$
Un LR(0)-item A→ γ1 • Bγ2 où le • est avant une variable B : signifieque l’on “prédit” que l’on devra analyser B ; en d’autres termes, unepartie droite de règle B → βj : il faut donc rajouter B → •βj , et ce pourtoutes les B-productions B → βj ,
Ajouter, en utilisant le même critère, toutes les LR(0)-items B → •βjusqu’à stabilisation s’appelle l’opération de fermeture
L’opération de fermeture permet d’obtenir l’ensemble des possibilités surl’état de l’analyse de G′ et constitue un état de l’automatecaractéristique LR(0)
Les transitions s X→ s′ de cet automate fini expriment que l’analyse dusymbole (terminal ou variable) X labellant la transition est terminée
380

Principe de parsing ascendantCFG LR(k)
Parser LR(0)Parser LR(1)
Parser SLR(1)Parser LALR(1)
Classes LL vs LRL’outil Yacc (Bison)
Exemple d’automate caractéristique LR(0)
Exemple (De construction d’automate caractéristique LR(0))
Pour G′ qui a les règles suivantes :
S′ → S$ (0)S → aAC (1)S → ab (2)A → c (3)C → d (4)
L’automate caractéristique LR(0) est représenté par la figure suivante :
381

Exemple d’automate caractéristique LR(0)
Exemple (De construction d’automate caractéristique LR(0))
S'SS
S$aACab
S' $
SC
Cd
A cS ab
S S' $S
SSA
ACbc
aa
aA S aAC
C d
S $
a
A C
b c d
0 2 8
1 3 4
7 5 6
noyau
fermeture

Interprétation de l’automate caractéristique LR(0)
État de l’automatecaractéristique : État de l’analyse :
S'SS
S$aACab
0 On est au début de l’analyse (état initial), il fautanalyser S$, ce qui correspond à analyser soitaAC soit ab
SSA
ACbc
aa
1
On a déjà analysé a et il faut encore analyser soitAC soit b. Pour analyser A, on doit analyser c
S aAC
4
On a analysé aAC ; on a donc terminé l’analysed’un S
S' $S
8 On a analysé S$ ; on a donc terminé l’analyse deS′ (il n’y en a qu’un seul puisque S′ → S$ a étérajouté à G) ; l’analyse est donc terminée avecsuccès.

Interprétation de l’automate caractéristique LR(0)
État et transition dans l’automatecaractéristique : État de l’analyse :
A cS ab
SSA
ACbc
aa
b c
1
7 5
Dans l’état 1 on peut (entreautres) devoir analyser un b ouun c
On va donc faire un Shift
Si l’input shifté est un b on vadans l’état 7
Si l’input shifté est un c on vadans l’état 5
Si l’input est tout autre caractère,c’est une erreur (le string analysén’appartient pas au langage)

Interprétation de l’automate caractéristique LR(0)
État et transition dans l’automatecaractéristique : État de l’analyse :
S'SS
S$aACab
S' $
S ab
S
SSA
ACbc
aa
S
a
b
0 2
1
7
Dans l’état 7 on a terminé uneanalyse de ab ...
ce qui correspond à l’analysed’un S, débutée 2 états avantdans le chemin pris par l’analyse,càd dans l’état 0
donc on termine l’analyse de Sdébutée dans l’état 0
on va donc dans l’état 2
Ceci correspond à un Reduce deS → ab
Note
On voit qu’un Reduce correspond à un Shift d’une variable dont on a terminél’analyse

Principe de parsing ascendantCFG LR(k)
Parser LR(0)Parser LR(1)
Parser SLR(1)Parser LALR(1)
Classes LL vs LRL’outil Yacc (Bison)
Parsing LR
Parsing LR
L’analyse d’un string correspond à la détermination de handles
On va utiliser une pile pour retenir les états du chemin pris dansl’automate caractéristique LR(0)
On part de l’état 0 qui comprend S′ → •S$
Il existe implicitement un état d’erreur ∅ ; toute transition non prévueexplicitement va dans cet état d’erreur
386

Construction des tables Action et Successeur
Les tables Action et Successeur synthétisent les informations à retenir del’automate caractéristique LR(0).
Construction de la table Action
La table Action donne pour chaque état de l’automate caractéristique LR(0),l’action à réaliser parmi
Shift
Reduce i où i est le numéro de règle dans G′ à utiliser pour le reduce
Accept qui correspond au Reduce S′ → S$
Erreur si rien n’est prévu dans cet état
Construction de la table Successeur
La table Successeur représente la fonction de transition de l’automatecaractéristique LR(0). Elle est utilisée pour déterminer
Lorsque l’action est un Shift
Lorsque l’action est un Reduce
dans quel état on va (càd quel état on Push sur la pile, éventuellement (siReduce) après avoir retiré |α| symboles)
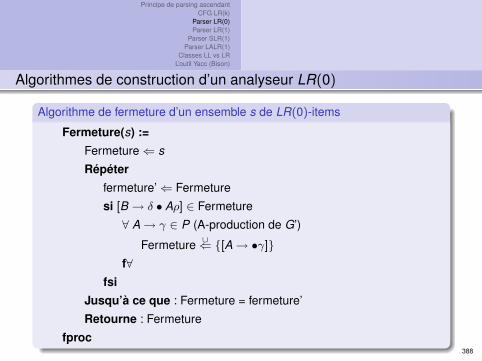
Principe de parsing ascendantCFG LR(k)
Parser LR(0)Parser LR(1)
Parser SLR(1)Parser LALR(1)
Classes LL vs LRL’outil Yacc (Bison)
Algorithmes de construction d’un analyseur LR(0)
Algorithme de fermeture d’un ensemble s de LR(0)-items
Fermeture(s) :=Fermeture⇐ s
Répéterfermeture’⇐ Fermeture
si [B → δ • Aρ] ∈ Fermeture
∀ A→ γ ∈ P (A-production de G’)
Fermeture ∪⇐ {[A→ •γ]}f∀
fsiJusqu’à ce que : Fermeture = fermeture’
Retourne : Fermeture
fproc388

Principe de parsing ascendantCFG LR(k)
Parser LR(0)Parser LR(1)
Parser SLR(1)Parser LALR(1)
Classes LL vs LRL’outil Yacc (Bison)
Algorithmes de construction d’un analyseur LR(0)
Algorithme de calcul de l’état suivant d’un état s pour un symbole X
Transition(s,X ) :=Transition⇐ Fermeture({[B → δX • ρ] | [B → δ • Xρ] ∈ s})Retourne : Transition
fproc
389

Algorithmes de construction d’un analyseur LR(0)
Algorithme de construction de l’ensemble des états C de l’automatecaractéristique LR(0)
Note : Un état de C est un ensemble de LR(0)-items
Construction-automate-LR(0) :=C ⇐ Fermeture({[S′ → •S$]}) ∪ {∅}
/* où ∅ désigne l’état d’erreur */
RépéterSoit s ∈ C non encore traité
∀X ∈ V ∪ T
Successeur [s, X ]⇐Transition(s, X )
C ∪⇐ Successeur [s, X ]
f∀Jusqu’à ce que tous les s soient traités
/* Les entrées de Successeur vide référencient l’état d’erreur ∅ */
fproc
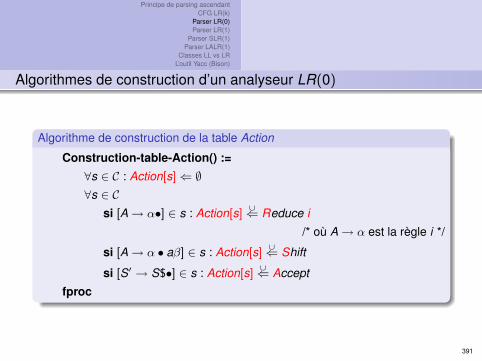
Principe de parsing ascendantCFG LR(k)
Parser LR(0)Parser LR(1)
Parser SLR(1)Parser LALR(1)
Classes LL vs LRL’outil Yacc (Bison)
Algorithmes de construction d’un analyseur LR(0)
Algorithme de construction de la table Action
Construction-table-Action() :=∀s ∈ C : Action[s]⇐ ∅∀s ∈ C
si [A→ α•] ∈ s : Action[s]∪⇐ Reduce i
/* où A→ α est la règle i */
si [A→ α • aβ] ∈ s : Action[s]∪⇐ Shift
si [S′ → S$•] ∈ s : Action[s]∪⇐ Accept
fproc
391

Principe de parsing ascendantCFG LR(k)
Parser LR(0)Parser LR(1)
Parser SLR(1)Parser LALR(1)
Classes LL vs LRL’outil Yacc (Bison)
Langage accepté par l’automate caractéristique LR(0)
Théorème (La CFG G′ est LR(0) si et seulement si la table Action n’a au plusqu’une seule action dans chaque entrée)
Intuitivement, Action[s] résume l’état s
Théorème (Le langage accepté par l’automate caractéristique LR(0) d’uneCFG G′ LR(0), en supposant que tous les états soient accepteurs, estl’ensemble de ses préfixes viables)
Remarque
Les états de l’automate sont généralement renommés par un identificateurentier naturel (0 pour l’état initial)
392

Construction des tables pour G′
Exemple (tables Action et Successeur pour G′ du slide 381)
0
1
2
3
4
5
6
7
8
S
S
S
S
R1
R3
R4
R2
A
1
7 5
6
3
4
2
a b c d A C S
8
$
Action Successeur
Rappel : Implicitement les entrées de la table Successeur non rempliesrenvoient vers un état d’erreur

Principe de parsing ascendantCFG LR(k)
Parser LR(0)Parser LR(1)
Parser SLR(1)Parser LALR(1)
Classes LL vs LRL’outil Yacc (Bison)
Tables d’une CFG LR(0)
Notes
Peu de grammaires sont LR(0) (mais plus que de grammaires LL(0))
Si G′ n’est pas LR(0), on doit considérer une prévision et construire unparser LR(k) avec k ≥ 1.
Évidemment ici aussi, plus k est grand, plus le parser sera compliqué
On essaye de se limiter à k = 1.
394

Principe de parsing ascendantCFG LR(k)
Parser LR(0)Parser LR(1)
Parser SLR(1)Parser LALR(1)
Classes LL vs LRL’outil Yacc (Bison)
Analyseurs prédictifs LR(k)
Remarques sur l’algorithme
On donne ici l’algorithme général de parsing LR(k) pour k ≥ 0
Si k = 0, la table Action est un vecteur
Si k ≥ 1, la table Action a une prévision u de taille ≤ k comme secondparamètre
La construction des tables Action et Successeur pour k > 0 sera donnédans les sections suivantes.
395

Analyseurs prédictifs LR(k)
Algorithme général du fonctionnement d’un analyseur LR(k)
On suppose que les tables Action et Successeur sont construitesParser-LR-k() :=
Initialement : Push(0) /* État initial */
Boucle
s ← Top()
si Action[s, u] = Shift : Shift(s) /* |u| ≤ k et Action est un */
si Action[s, u] = Reduce i : Reduce(i) /* vecteur (pas de paramètre */
si Action[s, u] = ∅ : Erreur() /* u) si le parser est LR(0) */
si Action[s, u] = Accept : Accept()
Fboucle
Fproc
Shift(s) := X ← input suivant ; Push(Successeur [s, X ])a Fproc
Reduce(i) := (la règle i ≡ A→ α) Pour j = 1 à |α| Pop() fpour ;
s ← Top() ; Push(Successeur [s, A]) ; Fproc
Erreur() := Informe d’une erreur dans l’analyse ; Fproc
Accept() := Informe du succès de l’analyse ; Fproc
apeut être l’état d’erreur

Analyse LR(0)
Exemple (Analyse du string acd$ pour G′)
qui a les règles suivantes :
S′ → S$ (0)S → aAC (1)S → ab (2)A → c (3)C → d (4)
Sur la pile Input restant Act Output` 0 acd$ S ε` 01 cd$ S ε` 015 d$ R3 ε` 013 d$ S 3` 0136 $ R4 3` 0134 $ R1 43` 02 $ S 143` 028 ε A 143

Analyse LR(0)
Correspondance entre l’analyse telle que présentée au début du chapitre etl’analyse LR
Bien que cela soit inutile, on peut (pour aider à la compréhension du lecteur)explicitement Pusher sur la pile, les symboles Shiftés (terminaux ou variableslors de Reduce)
Sur la pile Input restant Act Output` 0 acd$ S ε` 0a1 cd$ S ε` 0a1c5 d$ R3 ε` 0a1A3 d$ S 3` 0a1A3d6 $ R4 3` 0a1A3C4 $ R1 43` 0S2 $ S 143` 0S2$8 ε A 143
On a que :
La pile où l’on fait abstraction des numéros d’états, concaténée avecl’input restant est à tout moment une forme phrasée d’une dérivationdroite.
La pile, où l’on fait abstraction des numéros d’état, est toujours unpréfixe viable.

Principe de parsing ascendantCFG LR(k)
Parser LR(0)Parser LR(1)
Parser SLR(1)Parser LALR(1)
Classes LL vs LRL’outil Yacc (Bison)
Exemple 2 d’automate caractéristique LR(0)
Exemple (De construction d’automate caractéristique LR(0))
Pour G′2 qui a les règles suivantes :
S′ → S$ (0)S → aS (1)S → b (2)
L’automate caractéristique LR(0) et les tables Action et Successeursuivants :
399
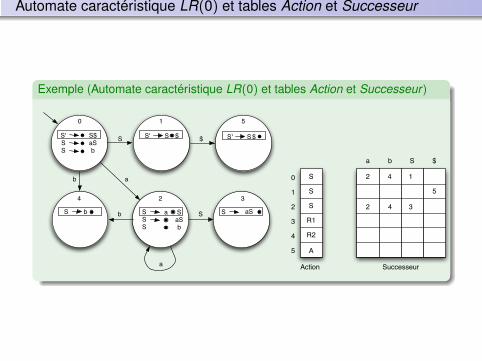
Automate caractéristique LR(0) et tables Action et Successeur
Exemple (Automate caractéristique LR(0) et tables Action et Successeur )
S'SS
S$aSb
S' $
SSS
SaSb
S b
S S' $S
a S aS
S $
b
b S
0 1 5
4 2 3
a
a
0
1
2
3
4
5
S
S
S
R1
R2
A
2
4
a b S $
Action Successeur
4 1
5
2 3

Analyse LR(0)
Exemple (Analyse du string aab$ pour G′2)
qui a les règles suivantes :
S′ → S$ (0)S → aS (1)S → b (2)
Sur la pile Input restant Act Output` 0 aab$ S ε` 02 ab$ S ε` 022 b$ S ε` 0224 $ R2 ε` 0223 $ R1 2` 023 $ R1 12` 01 $ S 112` 015 ε A 112
Note : la règle 0 n’est pas donnée en output

Principe de parsing ascendantCFG LR(k)
Parser LR(0)Parser LR(1)
Parser SLR(1)Parser LALR(1)
Classes LL vs LRL’outil Yacc (Bison)
Exemple 3 d’automate caractéristique LR(0)
Exemple (De construction d’automate caractéristique LR(0))
Pour G′3 qui a les règles suivantes :
S′ → S$ (0)S → SaSb (1)S → ε (2)
L’automate caractéristique LR(0) et les tables Action et Successeursuivants :
402

Automate caractéristique LR(0) et tables Action et Successeur
Exemple (Automate caractéristique LR(0) et tables Action et Successeur )
S'SS
S$SaSb
S' $
SS
baSb
S SaSb
S S' $S
SaSS
S Sa
S $
a
b
S
0 1 5
4 3 2
S aSbS
SbSS
SaSb
a
0
1
2
3
4
5
R2
S
R2
S
R1
A
4
a b S $
Action Successeur
1
52
3
2

Analyse LR(0)
Exemple (Analyse du string aabb$ pour G′3)
qui a les règles suivantes :
S′ → S$ (0)S → SaSb (1)S → ε (2)
Sur la pile Input restant Act Output` 0 aabb$ R2 ε` 01 aabb$ S 2` 012 abb$ R2 2` 0123 abb$ S 22` 01232 bb$ R2 22` 012323 bb$ S 222` 0123234 b$ R1 222` 0123 b$ S 1222` 01234 $ R1 1222` 01 $ S 11222` 015 ε A 11222

Grammaire non LR(0)
Exemple (la grammaire G′4 n’est pas LR(0))
G′4 = 〈{S′, E , T , F}, {+, ∗, id , (, ), $}, P4, S′〉 avec les règles P4 suivantes :
S′ → E$ (0)E → E + T (1)E → T (2)T → T ∗ F (3)T → F (4)F → id (5)F → (E) (6)
n’est pas LR(0) comme le montre la construction de son automatecaractéristique LR(0) où
l’état 7
l’état 11
induisent à la fois une action Shift et Reduce (conflit Shift/Reduce).Nous verrons que G′
4 est une grammaire LR(1).

7E → T •T → T • ∗F
8T → T∗ • FF → • idF → • (E)
9T → T ∗ F •
11E → E + T •T → T • ∗F
12F → (E • )E → E • +T
10F → (E) •
2
7E → T •T → T • ∗F
8T → T∗ • FF → • idF → • (E)
9T → T ∗ F •
11E → E + T •T → T • ∗F
12F → (E • )E → E • +T
10F → (E) •
2
7E → T •T → T • ∗F
8T → T∗ • FF → • idF → • (E)
9T → T ∗ F •
11E → E + T •T → T • ∗F
12F → (E • )E → E • +T
10F → (E) •
2
0S ′ → • E$E → • E + TE → • TT → • T ∗ FT → • FF → • idF → • (E)
1S ′ → E • $E → E • +T
2S ′ → E$ •
3E → E+ • TT → • T ∗ FT → • FF → • idF → • (E)
4T → F •
5F → id •
6F → ( • E)E → • E + TE → • TT → • T ∗ FT → • FF → • idF → • (E)
1
0S ′ → • E$E → • E + TE → • TT → • T ∗ FT → • FF → • idF → • (E)
1S ′ → E • $E → E • +T
2S ′ → E$ •
3E → E+ • TT → • T ∗ FT → • FF → • idF → • (E)
4T → F •
5F → id •
6F → ( • E)E → • E + TE → • TT → • T ∗ FT → • FF → • idF → • (E)
1
0S ′ → • E$E → • E + TE → • TT → • T ∗ FT → • FF → • idF → • (E)
1S ′ → E • $E → E • +T
2S ′ → E$ •
3E → E+ • TT → • T ∗ FT → • FF → • idF → • (E)
4T → F •
5F → id •
6F → ( • E)E → • E + TE → • TT → • T ∗ FT → • FF → • idF → • (E)
1
0S ′ → • E$E → • E + TE → • TT → • T ∗ FT → • FF → • idF → • (E)
1S ′ → E • $E → E • +T
2S ′ → E$ •
3E → E+ • TT → • T ∗ FT → • FF → • idF → • (E)
4T → F •
5F → id •
6F → ( • E)E → • E + TE → • TT → • T ∗ FT → • FF → • idF → • (E)
1
0S ′ → • E$E → • E + TE → • TT → • T ∗ FT → • FF → • idF → • (E)
1S ′ → E • $E → E • +T
2S ′ → E$ •
3E → E+ • TT → • T ∗ FT → • FF → • idF → • (E)
4T → F •
5F → id •
6F → ( • E)E → • E + TE → • TT → • T ∗ FT → • FF → • idF → • (E)
1
0S ′ → • E$E → • E + TE → • TT → • T ∗ FT → • FF → • idF → • (E)
1S ′ → E • $E → E • +T
2S ′ → E$ •
3E → E+ • TT → • T ∗ FT → • FF → • idF → • (E)
4T → F •
5F → id •
6F → ( • E)E → • E + TE → • TT → • T ∗ FT → • FF → • idF → • (E)
1
0S ′ → • E$E → • E + TE → • TT → • T ∗ FT → • FF → • idF → • (E)
1S ′ → E • $E → E • +T
2S ′ → E$ •
3E → E+ • TT → • T ∗ FT → • FF → • idF → • (E)
4T → F •
5F → id •
6F → ( • E)E → • E + TE → • TT → • T ∗ FT → • FF → • idF → • (E)
1
7E → T •T → T • ∗F
8T → T∗ • FF → • idF → • (E)
9T → T ∗ F •
11E → E + T •T → T • ∗F
12F → (E • )E → E • +T
10F → (E) •
2
7E → T •T → T • ∗F
8T → T∗ • FF → • idF → • (E)
9T → T ∗ F •
11E → E + T •T → T • ∗F
12F → (E • )E → E • +T
10F → (E) •
2
7E → T •T → T • ∗F
8T → T∗ • FF → • idF → • (E)
9T → T ∗ F •
11E → E + T •T → T • ∗F
12F → (E • )E → E • +T
10F → (E) •
2
E
F
(T
*
F
id
$
+
E
) T
*
5
id
5id+
F
(
id
(
T
(
F
Principe de parsing ascendantCFG LR(k)
Parser LR(0)Parser LR(1)
Parser SLR(1)Parser LALR(1)
Classes LL vs LRL’outil Yacc (Bison)
Plan
1 Principe de parsing ascendant
2 CFG LR(k)
3 Parser LR(0)
4 Parser LR(1)
5 Parser SLR(1)
6 Parser LALR(1)
7 Classes LL vs LR
8 L’outil Yacc (Bison)
407

Construction de l’automate caractéristique LR(1)
La prévision sera utile quand il est question de faire un Reduce
Dans ce cas, il faut déterminer les prévisions (de longueur jusqu’à k , icik = 1) possibles.
Cela revient à calculer les Follow locaux aux règles (items)
Calcul des LR(1)-items
On aura des LR(1)-items de la forme [A→ α1 • α2, u] où u est un followlocal à A→ α (α = α1α2)
Le LR(1)-item “initial” est [S′ → •S$, ε]
L’opération de fermeture augmente un ensemble s de LR(1)-itemscomme suit :
Ayant [B → δ • Aρ, `] ∈ s
A→ γ ∈ P
)⇒ ∀u ∈ Firstk (ρ`) : s ∪⇐ [A→ •γ, u]
Remarque
Dans ce qui suit nous donnons les algorithmes pour LR(k) même si lesexemples se limitent à k = 1.

Principe de parsing ascendantCFG LR(k)
Parser LR(0)Parser LR(1)
Parser SLR(1)Parser LALR(1)
Classes LL vs LRL’outil Yacc (Bison)
Algorithmes de construction d’un analyseur LR(k)
Algorithme de fermeture d’un ensemble s de LR(k)-items
Fermeture(s) :=Fermeture⇐ s
Répéterfermeture’⇐ Fermeture
si [B → S • Aρ, `] ∈ Fermeture
∀ A→ γ ∈ P (A-production de G’)
∀u ∈ Firstk (ρ`) : Fermeture ∪⇐ [A→ •γ, u]
f∀fsi
Jusqu’à ce que : Fermeture = fermeture’
Retourne : Fermeture
fproc409

Principe de parsing ascendantCFG LR(k)
Parser LR(0)Parser LR(1)
Parser SLR(1)Parser LALR(1)
Classes LL vs LRL’outil Yacc (Bison)
Algorithmes de construction d’un analyseur LR(k)
Algorithme de calcul de l’état suivant d’un état s pour un symbole X
Transition(s,X ) :=Transition⇐ Fermeture({[B → δX • ρ, u] | [B → δ • Xρ, u] ∈ s})Retourne : Transition
fproc
410

Algorithmes de construction d’un analyseur LR(k)
Algorithme de construction de l’ensemble des états C de l’automatecaractéristique LR(k)
Construction-automate-LR(0) :=C ⇐ Fermeture({[S′ → •S$, ε]}) ∪ ∅
/* où ∅ est l’état d’erreur */
RépéterSoit s ∈ C non encore traité
∀X ∈ V ∪ T
Successeur [s, X ]⇐Transition(s, X )
C ∪⇐ Successeur [s, X ]
f∀Jusqu’à ce que tous les s soient traités
/* Les entrées vides de Successeur référencient l’état d’erreur ∅ */
fproc

Principe de parsing ascendantCFG LR(k)
Parser LR(0)Parser LR(1)
Parser SLR(1)Parser LALR(1)
Classes LL vs LRL’outil Yacc (Bison)
Algorithmes de construction d’un analyseur LR(k)
Algorithme de construction de la table Action
Construction-table-Action :=∀s ∈ C, u ∈ T≤k : Action[s, u]⇐ ∅∀s ∈ C
si [A→ α•, u] ∈ s : Action[s, u]∪⇐ Reduce i
/*où A→ α est la règle i */
si [A→ α • aβ, y ] ∈ s ∧ u ∈ Firstk (aβy) : Action[s, u]∪⇐ Shift
si [S′ → S$•, ε] ∈ s : Action[s, ε]∪⇐ Accept
fproc
412
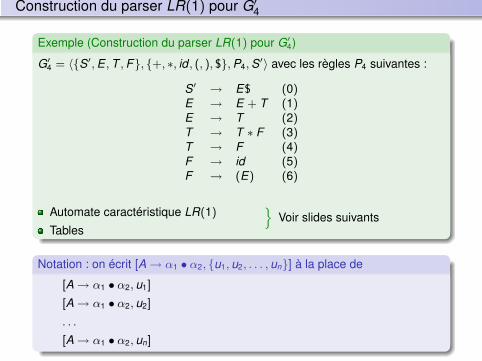
Construction du parser LR(1) pour G′4
Exemple (Construction du parser LR(1) pour G′4)
G′4 = 〈{S′, E , T , F}, {+, ∗, id , (, ), $}, P4, S′〉 avec les règles P4 suivantes :
S′ → E$ (0)E → E + T (1)E → T (2)T → T ∗ F (3)T → F (4)F → id (5)F → (E) (6)
Automate caractéristique LR(1)
Tables
oVoir slides suivants
Notation : on écrit [A→ α1 • α2, {u1, u2, . . . , un}] à la place de
[A→ α1 • α2, u1]
[A→ α1 • α2, u2]
. . .
[A→ α1 • α2, un]
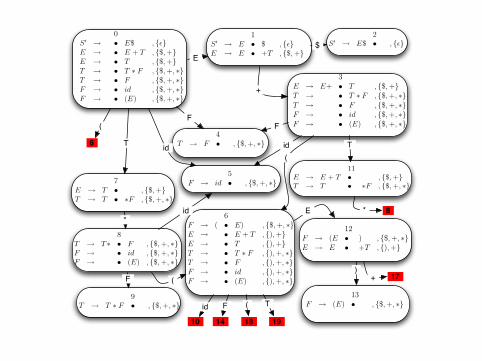
0S ′ → • E$ , {ε}E → • E + T , {$, +}E → • T , {$, +}T → • T ∗ F , {$, +, ∗}T → • F , {$, +, ∗}F → • id , {$, +, ∗}F → • (E) , {$, +, ∗}
1S ′ → E • $ , {ε}E → E • +T , {$, +}
2S ′ → E$ • , {ε}
3E → E+ • T , {$, +}T → • T ∗ F , {$, +, ∗}T → • F , {$, +, ∗}F → • id , {$, +, ∗}F → • (E) , {$, +, ∗}
4T → F • , {$, +, ∗}
5F → id • , {$, +, ∗}
6F → ( • E) , {$, +, ∗}E → • E + T , {), +}E → • T , {), +}T → • T ∗ F , {), +, ∗}T → • F , {), +, ∗}F → • id , {), +, ∗}F → • (E) , {), +, ∗}
1
7E → T • , {$, +}T → T • ∗F , {$, +, ∗}
8T → T∗ • F , {$, +, ∗}F → • id , {$, +, ∗}F → • (E) , {$, +, ∗}
9T → T ∗ F • , {$, +, ∗}
10F → id • , {), +, ∗}
11E → E + T • , {$, +}T → T • ∗F , {$, +, ∗}
12F → (E • ) , {$, +, ∗}E → E • +T , {), +}
13F → (E) • , {$, +, ∗}
14T → F • , {), +, ∗}
15F → (E) • , {), +, ∗}
2
0S ′ → • E$ , {ε}E → • E + T , {$, +}E → • T , {$, +}T → • T ∗ F , {$, +, ∗}T → • F , {$, +, ∗}F → • id , {$, +, ∗}F → • (E) , {$, +, ∗}
1S ′ → E • $ , {ε}E → E • +T , {$, +}
2S ′ → E$ • , {ε}
3E → E+ • T , {$, +}T → • T ∗ F , {$, +, ∗}T → • F , {$, +, ∗}F → • id , {$, +, ∗}F → • (E) , {$, +, ∗}
4T → F • , {$, +, ∗}
5F → id • , {$, +, ∗}
6F → ( • E) , {$, +, ∗}E → • E + T , {), +}E → • T , {), +}T → • T ∗ F , {), +, ∗}T → • F , {), +, ∗}F → • id , {), +, ∗}F → • (E) , {), +, ∗}
1
0S ′ → • E$ , {ε}E → • E + T , {$, +}E → • T , {$, +}T → • T ∗ F , {$, +, ∗}T → • F , {$, +, ∗}F → • id , {$, +, ∗}F → • (E) , {$, +, ∗}
1S ′ → E • $ , {ε}E → E • +T , {$, +}
2S ′ → E$ • , {ε}
3E → E+ • T , {$, +}T → • T ∗ F , {$, +, ∗}T → • F , {$, +, ∗}F → • id , {$, +, ∗}F → • (E) , {$, +, ∗}
4T → F • , {$, +, ∗}
5F → id • , {$, +, ∗}
6F → ( • E) , {$, +, ∗}E → • E + T , {), +}E → • T , {), +}T → • T ∗ F , {), +, ∗}T → • F , {), +, ∗}F → • id , {), +, ∗}F → • (E) , {), +, ∗}
1
0S ′ → • E$ , {ε}E → • E + T , {$, +}E → • T , {$, +}T → • T ∗ F , {$, +, ∗}T → • F , {$, +, ∗}F → • id , {$, +, ∗}F → • (E) , {$, +, ∗}
1S ′ → E • $ , {ε}E → E • +T , {$, +}
2S ′ → E$ • , {ε}
3E → E+ • T , {$, +}T → • T ∗ F , {$, +, ∗}T → • F , {$, +, ∗}F → • id , {$, +, ∗}F → • (E) , {$, +, ∗}
4T → F • , {$, +, ∗}
5F → id • , {$, +, ∗}
6F → ( • E) , {$, +, ∗}E → • E + T , {), +}E → • T , {), +}T → • T ∗ F , {), +, ∗}T → • F , {), +, ∗}F → • id , {), +, ∗}F → • (E) , {), +, ∗}
1
E
0S ′ → • E$ , {ε}E → • E + T , {$, +}E → • T , {$, +}T → • T ∗ F , {$, +, ∗}T → • F , {$, +, ∗}F → • id , {$, +, ∗}F → • (E) , {$, +, ∗}
1S ′ → E • $ , {ε}E → E • +T , {$, +}
2S ′ → E$ • , {ε}
3E → E+ • T , {$, +}T → • T ∗ F , {$, +, ∗}T → • F , {$, +, ∗}F → • id , {$, +, ∗}F → • (E) , {$, +, ∗}
4T → F • , {$, +, ∗}
5F → id • , {$, +, ∗}
6F → ( • E) , {$, +, ∗}E → • E + T , {), +}E → • T , {), +}T → • T ∗ F , {), +, ∗}T → • F , {), +, ∗}F → • id , {), +, ∗}F → • (E) , {), +, ∗}
1
$
0S ′ → • E$ , {ε}E → • E + T , {$, +}E → • T , {$, +}T → • T ∗ F , {$, +, ∗}T → • F , {$, +, ∗}F → • id , {$, +, ∗}F → • (E) , {$, +, ∗}
1S ′ → E • $ , {ε}E → E • +T , {$, +}
2S ′ → E$ • , {ε}
3E → E+ • T , {$, +}T → • T ∗ F , {$, +, ∗}T → • F , {$, +, ∗}F → • id , {$, +, ∗}F → • (E) , {$, +, ∗}
4T → F • , {$, +, ∗}
5F → id • , {$, +, ∗}
6F → ( • E) , {$, +, ∗}E → • E + T , {), +}E → • T , {), +}T → • T ∗ F , {), +, ∗}T → • F , {), +, ∗}F → • id , {), +, ∗}F → • (E) , {), +, ∗}
1
FF
id
0S ′ → • E$ , {ε}E → • E + T , {$, +}E → • T , {$, +}T → • T ∗ F , {$, +, ∗}T → • F , {$, +, ∗}F → • id , {$, +, ∗}F → • (E) , {$, +, ∗}
1S ′ → E • $ , {ε}E → E • +T , {$, +}
2S ′ → E$ • , {ε}
3E → E+ • T , {$, +}T → • T ∗ F , {$, +, ∗}T → • F , {$, +, ∗}F → • id , {$, +, ∗}F → • (E) , {$, +, ∗}
4T → F • , {$, +, ∗}
5F → id • , {$, +, ∗}
6F → ( • E) , {$, +, ∗}E → • E + T , {), +}E → • T , {), +}T → • T ∗ F , {), +, ∗}T → • F , {), +, ∗}F → • id , {), +, ∗}F → • (E) , {), +, ∗}
1
7E → T • , {$, +}T → T • ∗F , {$, +, ∗}
8T → T∗ • F , {$, +, ∗}F → • id , {$, +, ∗}F → • (E) , {$, +, ∗}
9T → T ∗ F • , {$, +, ∗}
10F → id • , {), +, ∗}
11E → E + T • , {$, +}T → T • ∗F , {$, +, ∗}
12F → (E • ) , {$, +, ∗}E → E • +T , {), +}
13F → (E) • , {$, +, ∗}
14T → F • , {), +, ∗}
15F → (E) • , {), +, ∗}
2
T
7E → T • , {$, +}T → T • ∗F , {$, +, ∗}
8T → T∗ • F , {$, +, ∗}F → • id , {$, +, ∗}F → • (E) , {$, +, ∗}
9T → T ∗ F • , {$, +, ∗}
10F → id • , {), +, ∗}
11E → E + T • , {$, +}T → T • ∗F , {$, +, ∗}
12F → (E • ) , {$, +, ∗}E → E • +T , {), +}
13F → (E) • , {$, +, ∗}
14T → F • , {), +, ∗}
15F → (E) • , {), +, ∗}
2
*
7E → T • , {$, +}T → T • ∗F , {$, +, ∗}
8T → T∗ • F , {$, +, ∗}F → • id , {$, +, ∗}F → • (E) , {$, +, ∗}
9T → T ∗ F • , {$, +, ∗}
10F → id • , {), +, ∗}
11E → E + T • , {$, +}T → T • ∗F , {$, +, ∗}
12F → (E • ) , {$, +, ∗}E → E • +T , {), +}
13F → (E) • , {$, +, ∗}
14T → F • , {), +, ∗}
15F → (E) • , {), +, ∗}
2
E
)
+
7E → T • , {$, +}T → T • ∗F , {$, +, ∗}
8T → T∗ • F , {$, +, ∗}F → • id , {$, +, ∗}F → • (E) , {$, +, ∗}
9T → T ∗ F • , {$, +, ∗}
10F → id • , {), +, ∗}
11E → E + T • , {$, +}T → T • ∗F , {$, +, ∗}
12F → (E • ) , {$, +, ∗}E → E • +T , {), +}
13F → (E) • , {$, +, ∗}
14T → F • , {), +, ∗}
15F → (E) • , {), +, ∗}
2
Tid(
7E → T • , {$, +}T → T • ∗F , {$, +, ∗}
8T → T∗ • F , {$, +, ∗}F → • id , {$, +, ∗}F → • (E) , {$, +, ∗}
9T → T ∗ F • , {$, +, ∗}
10F → id • , {), +, ∗}
11E → E + T • , {$, +}T → T • ∗F , {$, +, ∗}
12F → (E • ) , {$, +, ∗}E → E • +T , {), +}
13F → (E) • , {$, +, ∗}
14T → F • , {), +, ∗}
15F → (E) • , {), +, ∗}
2
F
id
10 14 18 19
id F ( T
(
8*
17+
6
(
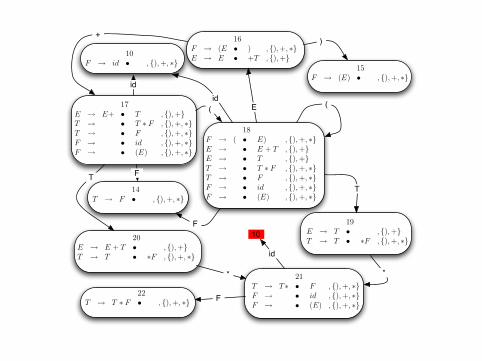
7E → T • , {$, +}T → T • ∗F , {$, +, ∗}
8T → T∗ • F , {$, +, ∗}F → • id , {$, +, ∗}F → • (E) , {$, +, ∗}
9T → T ∗ F • , {$, +, ∗}
10F → id • , {), +, ∗}
11E → E + T • , {$, +}T → T • ∗F , {$, +, ∗}
12F → (E • ) , {$, +, ∗}E → E • +T , {), +}
13F → (E) • , {$, +, ∗}
14T → F • , {), +, ∗}
15F → (E) • , {), +, ∗}
2
16F → (E • ) , {), +, ∗}E → E • +T , {), +}
17E → E+ • T , {), +}T → • T ∗ F , {), +, ∗}T → • F , {), +, ∗}F → • id , {), +, ∗}F → • (E) , {), +, ∗}
18F → ( • E) , {), +, ∗}E → • E + T , {), +}E → • T , {), +}T → • T ∗ F , {), +, ∗}T → • F , {), +, ∗}F → • id , {), +, ∗}F → • (E) , {), +, ∗}
19E → T • , {), +}T → T • ∗F , {), +, ∗}
20E → E + T • , {), +}T → T • ∗F , {), +, ∗}
21T → T∗ • F , {), +, ∗}F → • id , {), +, ∗}F → • (E) , {), +, ∗}
22T → T ∗ F • , {), +, ∗}
3
7E → T • , {$, +}T → T • ∗F , {$, +, ∗}
8T → T∗ • F , {$, +, ∗}F → • id , {$, +, ∗}F → • (E) , {$, +, ∗}
9T → T ∗ F • , {$, +, ∗}
10F → id • , {), +, ∗}
11E → E + T • , {$, +}T → T • ∗F , {$, +, ∗}
12F → (E • ) , {$, +, ∗}E → E • +T , {), +}
13F → (E) • , {$, +, ∗}
14T → F • , {), +, ∗}
15F → (E) • , {), +, ∗}
2
7E → T • , {$, +}T → T • ∗F , {$, +, ∗}
8T → T∗ • F , {$, +, ∗}F → • id , {$, +, ∗}F → • (E) , {$, +, ∗}
9T → T ∗ F • , {$, +, ∗}
10F → id • , {), +, ∗}
11E → E + T • , {$, +}T → T • ∗F , {$, +, ∗}
12F → (E • ) , {$, +, ∗}E → E • +T , {), +}
13F → (E) • , {$, +, ∗}
14T → F • , {), +, ∗}
15F → (E) • , {), +, ∗}
2
id
F
16F → (E • ) , {), +, ∗}E → E • +T , {), +}
17E → E+ • T , {), +}T → • T ∗ F , {), +, ∗}T → • F , {), +, ∗}F → • id , {), +, ∗}F → • (E) , {), +, ∗}
18F → ( • E) , {), +, ∗}E → • E + T , {), +}E → • T , {), +}T → • T ∗ F , {), +, ∗}T → • F , {), +, ∗}F → • id , {), +, ∗}F → • (E) , {), +, ∗}
19E → T • , {), +}T → T • ∗F , {), +, ∗}
20E → E + T • , {), +}T → T • ∗F , {), +, ∗}
21T → T∗ • F , {), +, ∗}F → • id , {), +, ∗}F → • (E) , {), +, ∗}
22T → T ∗ F • , {), +, ∗}
3
16F → (E • ) , {), +, ∗}E → E • +T , {), +}
17E → E+ • T , {), +}T → • T ∗ F , {), +, ∗}T → • F , {), +, ∗}F → • id , {), +, ∗}F → • (E) , {), +, ∗}
18F → ( • E) , {), +, ∗}E → • E + T , {), +}E → • T , {), +}T → • T ∗ F , {), +, ∗}T → • F , {), +, ∗}F → • id , {), +, ∗}F → • (E) , {), +, ∗}
19E → T • , {), +}T → T • ∗F , {), +, ∗}
20E → E + T • , {), +}T → T • ∗F , {), +, ∗}
21T → T∗ • F , {), +, ∗}F → • id , {), +, ∗}F → • (E) , {), +, ∗}
22T → T ∗ F • , {), +, ∗}
3
(
16F → (E • ) , {), +, ∗}E → E • +T , {), +}
17E → E+ • T , {), +}T → • T ∗ F , {), +, ∗}T → • F , {), +, ∗}F → • id , {), +, ∗}F → • (E) , {), +, ∗}
18F → ( • E) , {), +, ∗}E → • E + T , {), +}E → • T , {), +}T → • T ∗ F , {), +, ∗}T → • F , {), +, ∗}F → • id , {), +, ∗}F → • (E) , {), +, ∗}
19E → T • , {), +}T → T • ∗F , {), +, ∗}
20E → E + T • , {), +}T → T • ∗F , {), +, ∗}
21T → T∗ • F , {), +, ∗}F → • id , {), +, ∗}F → • (E) , {), +, ∗}
22T → T ∗ F • , {), +, ∗}
3
E
)
T
id
F
16F → (E • ) , {), +, ∗}E → E • +T , {), +}
17E → E+ • T , {), +}T → • T ∗ F , {), +, ∗}T → • F , {), +, ∗}F → • id , {), +, ∗}F → • (E) , {), +, ∗}
18F → ( • E) , {), +, ∗}E → • E + T , {), +}E → • T , {), +}T → • T ∗ F , {), +, ∗}T → • F , {), +, ∗}F → • id , {), +, ∗}F → • (E) , {), +, ∗}
19E → T • , {), +}T → T • ∗F , {), +, ∗}
20E → E + T • , {), +}T → T • ∗F , {), +, ∗}
21T → T∗ • F , {), +, ∗}F → • id , {), +, ∗}F → • (E) , {), +, ∗}
22T → T ∗ F • , {), +, ∗}
3
T
16F → (E • ) , {), +, ∗}E → E • +T , {), +}
17E → E+ • T , {), +}T → • T ∗ F , {), +, ∗}T → • F , {), +, ∗}F → • id , {), +, ∗}F → • (E) , {), +, ∗}
18F → ( • E) , {), +, ∗}E → • E + T , {), +}E → • T , {), +}T → • T ∗ F , {), +, ∗}T → • F , {), +, ∗}F → • id , {), +, ∗}F → • (E) , {), +, ∗}
19E → T • , {), +}T → T • ∗F , {), +, ∗}
20E → E + T • , {), +}T → T • ∗F , {), +, ∗}
21T → T∗ • F , {), +, ∗}F → • id , {), +, ∗}F → • (E) , {), +, ∗}
22T → T ∗ F • , {), +, ∗}
3
*
16F → (E • ) , {), +, ∗}E → E • +T , {), +}
17E → E+ • T , {), +}T → • T ∗ F , {), +, ∗}T → • F , {), +, ∗}F → • id , {), +, ∗}F → • (E) , {), +, ∗}
18F → ( • E) , {), +, ∗}E → • E + T , {), +}E → • T , {), +}T → • T ∗ F , {), +, ∗}T → • F , {), +, ∗}F → • id , {), +, ∗}F → • (E) , {), +, ∗}
19E → T • , {), +}T → T • ∗F , {), +, ∗}
20E → E + T • , {), +}T → T • ∗F , {), +, ∗}
21T → T∗ • F , {), +, ∗}F → • id , {), +, ∗}F → • (E) , {), +, ∗}
22T → T ∗ F • , {), +, ∗}
3
F
*
10
id
(
+

Tables LR(1)
Action
État + ∗ id ( ) $ ε
0 S S1 S S2 A3 S S4 R4 R4 R45 R5 R5 R56 S S7 R2 S R28 S S9 R3 R3 R310 R5 R5 R511 R1 S R112 S S13 R6 R6 R614 R4 R4 R415 R6 R6 R616 S S17 S S18 S S19 R2 S R220 R1 S R121 S S22 R3 R3 R3
Successeur
État + ∗ id ( ) $ E T F
0 5 6 1 7 41 3 223 5 6 11 4456 10 18 12 19 147 88 5 6 991011 812 17 1313141516 17 1517 10 18 20 1418 10 18 16 19 1419 2120 2121 10 2222

Principe de parsing ascendantCFG LR(k)
Parser LR(0)Parser LR(1)
Parser SLR(1)Parser LALR(1)
Classes LL vs LRL’outil Yacc (Bison)
Critique de LR(1) (LR(k))
Critique de LR(1) (LR(k))
On constate que très vite, l’analyseur (l’automate caractéristique et lestables) devient très gros.
De ce fait, on a essayé de trouver des alternatives, plus puissantes queLR(0) mais plus compactes que LR(1)
⇒ Les parsers SLR(1) (SLR(k)) et LALR(1) (LALR(k))
417

Principe de parsing ascendantCFG LR(k)
Parser LR(0)Parser LR(1)
Parser SLR(1)Parser LALR(1)
Classes LL vs LRL’outil Yacc (Bison)
Plan
1 Principe de parsing ascendant
2 CFG LR(k)
3 Parser LR(0)
4 Parser LR(1)
5 Parser SLR(1)
6 Parser LALR(1)
7 Classes LL vs LR
8 L’outil Yacc (Bison)
418

Principe de la construction des parsers SLR(k)
Principe de la construction des parsers SLR(1)
Le principe est très simple1 On construit l’automate caractéristique LR(0)
2 Pour construire la table Action, on utilise les LR(0)-items et les followglobaux des variables pour déterminer pour quelles prévisions faire desReduce :
Plus précisément
Action[s, a] contiendra l’action Shift si l’état s contient B → δ • aγ pourune certaine variable B et des strings γ et δ,Action[s, a] contiendra l’action Reduce i si
la règle i est A→ αs contient A→ α•a ∈ Follow(A)
Pour SLR(k)
Les mêmes idées sont aisément étendues pour k symboles de prévision : onutilise :
Firstk (aγFollowk (B))
Followk (A).
oVoir slide suivant

Principe de parsing ascendantCFG LR(k)
Parser LR(0)Parser LR(1)
Parser SLR(1)Parser LALR(1)
Classes LL vs LRL’outil Yacc (Bison)
Algorithmes de construction d’un analyseur SLR(k)
Algorithme de construction de la table Action
Construction-table-Action() :=∀s ∈ C, u ∈ T≤k : Action[s, u]⇐ ∅∀s ∈ C
si [A→ α•] ∈ s ∧ u ∈ Followk (A) : Action[s, u]∪⇐ Reduce i
/* où A→ α est la règle i */
si [A→ α • aβ] ∈ s ∧ u ∈ Firstk (aβFollowk (A)) :
Action[s, u]∪⇐ Shift
si [S′ → S$•] ∈ s : Action[s, ε]∪⇐ Accept
fproc
420
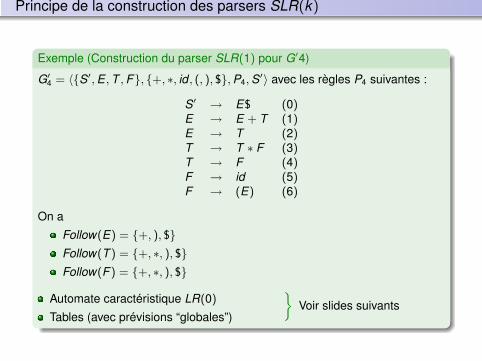
Principe de la construction des parsers SLR(k)
Exemple (Construction du parser SLR(1) pour G′4)
G′4 = 〈{S′, E , T , F}, {+, ∗, id , (, ), $}, P4, S′〉 avec les règles P4 suivantes :
S′ → E$ (0)E → E + T (1)E → T (2)T → T ∗ F (3)T → F (4)F → id (5)F → (E) (6)
On a
Follow(E) = {+, ), $}Follow(T ) = {+, ∗, ), $}Follow(F ) = {+, ∗, ), $}
Automate caractéristique LR(0)
Tables (avec prévisions “globales”)
ffVoir slides suivants

7E → T •T → T • ∗F
8T → T∗ • FF → • idF → • (E)
9T → T ∗ F •
11E → E + T •T → T • ∗F
12F → (E • )E → E • +T
10F → (E) •
2
7E → T •T → T • ∗F
8T → T∗ • FF → • idF → • (E)
9T → T ∗ F •
11E → E + T •T → T • ∗F
12F → (E • )E → E • +T
10F → (E) •
2
7E → T •T → T • ∗F
8T → T∗ • FF → • idF → • (E)
9T → T ∗ F •
11E → E + T •T → T • ∗F
12F → (E • )E → E • +T
10F → (E) •
2
0S ′ → • E$E → • E + TE → • TT → • T ∗ FT → • FF → • idF → • (E)
1S ′ → E • $E → E • +T
2S ′ → E$ •
3E → E+ • TT → • T ∗ FT → • FF → • idF → • (E)
4T → F •
5F → id •
6F → ( • E)E → • E + TE → • TT → • T ∗ FT → • FF → • idF → • (E)
1
0S ′ → • E$E → • E + TE → • TT → • T ∗ FT → • FF → • idF → • (E)
1S ′ → E • $E → E • +T
2S ′ → E$ •
3E → E+ • TT → • T ∗ FT → • FF → • idF → • (E)
4T → F •
5F → id •
6F → ( • E)E → • E + TE → • TT → • T ∗ FT → • FF → • idF → • (E)
1
0S ′ → • E$E → • E + TE → • TT → • T ∗ FT → • FF → • idF → • (E)
1S ′ → E • $E → E • +T
2S ′ → E$ •
3E → E+ • TT → • T ∗ FT → • FF → • idF → • (E)
4T → F •
5F → id •
6F → ( • E)E → • E + TE → • TT → • T ∗ FT → • FF → • idF → • (E)
1
0S ′ → • E$E → • E + TE → • TT → • T ∗ FT → • FF → • idF → • (E)
1S ′ → E • $E → E • +T
2S ′ → E$ •
3E → E+ • TT → • T ∗ FT → • FF → • idF → • (E)
4T → F •
5F → id •
6F → ( • E)E → • E + TE → • TT → • T ∗ FT → • FF → • idF → • (E)
1
0S ′ → • E$E → • E + TE → • TT → • T ∗ FT → • FF → • idF → • (E)
1S ′ → E • $E → E • +T
2S ′ → E$ •
3E → E+ • TT → • T ∗ FT → • FF → • idF → • (E)
4T → F •
5F → id •
6F → ( • E)E → • E + TE → • TT → • T ∗ FT → • FF → • idF → • (E)
1
0S ′ → • E$E → • E + TE → • TT → • T ∗ FT → • FF → • idF → • (E)
1S ′ → E • $E → E • +T
2S ′ → E$ •
3E → E+ • TT → • T ∗ FT → • FF → • idF → • (E)
4T → F •
5F → id •
6F → ( • E)E → • E + TE → • TT → • T ∗ FT → • FF → • idF → • (E)
1
0S ′ → • E$E → • E + TE → • TT → • T ∗ FT → • FF → • idF → • (E)
1S ′ → E • $E → E • +T
2S ′ → E$ •
3E → E+ • TT → • T ∗ FT → • FF → • idF → • (E)
4T → F •
5F → id •
6F → ( • E)E → • E + TE → • TT → • T ∗ FT → • FF → • idF → • (E)
1
7E → T •T → T • ∗F
8T → T∗ • FF → • idF → • (E)
9T → T ∗ F •
11E → E + T •T → T • ∗F
12F → (E • )E → E • +T
10F → (E) •
2
7E → T •T → T • ∗F
8T → T∗ • FF → • idF → • (E)
9T → T ∗ F •
11E → E + T •T → T • ∗F
12F → (E • )E → E • +T
10F → (E) •
2
7E → T •T → T • ∗F
8T → T∗ • FF → • idF → • (E)
9T → T ∗ F •
11E → E + T •T → T • ∗F
12F → (E • )E → E • +T
10F → (E) •
2
E
F
(T
*
F
id
$
+
E
) T
*
5
id
5id+
F
(
id
(
T
(
F

Tables SLR(1)
Action
État + ∗ id ( ) $ ε
0 S S1 S S2 A3 S S4 R4 R4 R4 R45 R5 R5 R5 R56 S S7 R2 S R2 R28 S S9 R3 R3 R3 R310 R6 R6 R6 R611 R1 S R1 R112 S S
Successeur
État + ∗ id ( ) $ E T F
0 5 6 1 7 41 3 223 5 6 11 4456 5 6 12 7 47 88 5 6 991011 812 3 10
Notons que la table Successeur d’un analyseur SLR(k) est toujours égale àcelle d’un analyseur LR(0)
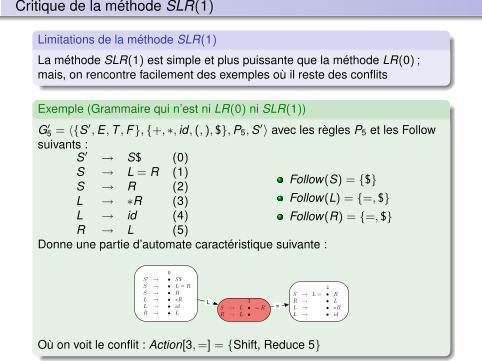
Critique de la méthode SLR(1)
Limitations de la méthode SLR(1)
La méthode SLR(1) est simple et plus puissante que la méthode LR(0) ;mais, on rencontre facilement des exemples où il reste des conflits
Exemple (Grammaire qui n’est ni LR(0) ni SLR(1))
G′5 = 〈{S′, E , T , F}, {+, ∗, id , (, ), $}, P5, S′〉 avec les règles P5 et les Follow
suivants :S′ → S$ (0)S → L = R (1)S → R (2)L → ∗R (3)L → id (4)R → L (5)
Follow(S) = {$}Follow(L) = {=, $}Follow(R) = {=, $}
Donne une partie d’automate caractéristique suivante :
0S ′ → • S$S → • L = RS → • RL → • ∗RL → • idR → • L
1S ′ → S • $
2S ′ → E$ •
3S → L • = RR → L •
1
0S ′ → • S$S → • L = RS → • RL → • ∗RL → • idR → • L
1S ′ → S • $
2S ′ → E$ •
3S → L • = RR → L •
1
L
0S ′ → • S$S → • L = RS → • RL → • ∗RL → • idR → • L
3S → L • = RR → L •
4S → L = • RR → • LL → • ∗RL → • id
1
=
Où on voit le conflit : Action[3, =] = {Shift, Reduce 5}

Principe de parsing ascendantCFG LR(k)
Parser LR(0)Parser LR(1)
Parser SLR(1)Parser LALR(1)
Classes LL vs LRL’outil Yacc (Bison)
Plan
1 Principe de parsing ascendant
2 CFG LR(k)
3 Parser LR(0)
4 Parser LR(1)
5 Parser SLR(1)
6 Parser LALR(1)
7 Classes LL vs LR
8 L’outil Yacc (Bison)
425

Principe de la construction des parsers LALR(k)
Définition (Coeur d’un état d’un automate caractéristique LR(k))
C’est l’ensemble des LR(k)-items de l’état desquels on a supprimé lesprévisions
Exemple (de coeur d’un état s)
7E → T • , {$, +}T → T • ∗F , {$, +, ∗}
8T → T∗ • F , {$, +, ∗}F → • id , {$, +, ∗}F → • (E) , {$, +, ∗}
9T → T ∗ F • , {$, +, ∗}
10F → id • , {), +, ∗}
11E → E + T • , {$, +}T → T • ∗F , {$, +, ∗}
12F → (E • ) , {$, +, ∗}E → E • +T , {), +}
13F → (E) • , {$, +, ∗}
14T → F • , {), +, ∗}
15F → (E) • , {), +, ∗}
2
État
coeur
Principe de la construction des parsers LALR(k)
Le principe est très simple1 On construit l’automate caractéristique LR(k)
2 On fusionne les états ayant le même coeur en prenant l’union de leursLR(k)-items
3 La construction des tables reprend ensuite l’algorithme pour LR(k)

Principe de la construction des parsers LALR(1)
Exemple (Construction du parser LALR(1) pour G′4)
G′4 = 〈{S′, E , T , F}, {+, ∗, id , (, ), $}, P4, S′〉 avec les règles P4 suivantes :
S′ → E$ (0)E → E + T (1)E → T (2)T → T ∗ F (3)T → F (4)F → id (5)F → (E) (6)
Après construction de l’automate caractéristique LR(1) les états suivants ontle même coeur :
3 et 17
4 et 14
5 et 10
6 et 18
7 et 19
8 et 21
9 et 22
11 et 20
12 et 16
13 et 15
Automate caractéristique LALR(1)
Tables
ffVoir slides suivants
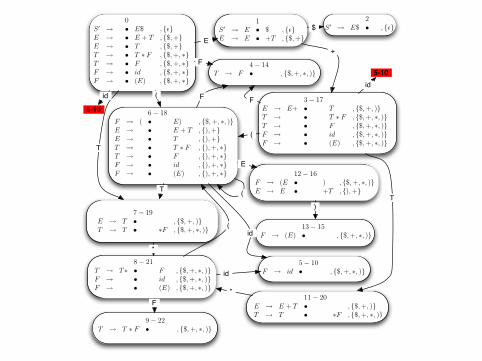
0S ′ → • E$ , {ε}E → • E + T , {$, +}E → • T , {$, +}T → • T ∗ F , {$, +, ∗}T → • F , {$, +, ∗}F → • id , {$, +, ∗}F → • (E) , {$, +, ∗}
1S ′ → E • $ , {ε}E → E • +T , {$, +}
2S ′ → E$ • , {ε}
3− 17E → E+ • T , {$, +, )}T → • T ∗ F , {$, +, ∗, )}T → • F , {$, +, ∗, )}F → • id , {$, +, ∗, )}F → • (E) , {$, +, ∗, )}
4− 14T → F • , {$, +, ∗, )}
5− 10F → id • , {$, +, ∗, )}
6− 18F → ( • E) , {$, +, ∗, )}E → • E + T , {), +}E → • T , {), +}T → • T ∗ F , {), +, ∗}T → • F , {), +, ∗}F → • id , {), +, ∗}F → • (E) , {), +, ∗}
1
0S ′ → • E$ , {ε}E → • E + T , {$, +}E → • T , {$, +}T → • T ∗ F , {$, +, ∗}T → • F , {$, +, ∗}F → • id , {$, +, ∗}F → • (E) , {$, +, ∗}
1S ′ → E • $ , {ε}E → E • +T , {$, +}
2S ′ → E$ • , {ε}
3− 17E → E+ • T , {$, +, )}T → • T ∗ F , {$, +, ∗, )}T → • F , {$, +, ∗, )}F → • id , {$, +, ∗, )}F → • (E) , {$, +, ∗, )}
4− 14T → F • , {$, +, ∗, )}
5− 10F → id • , {$, +, ∗, )}
6− 18F → ( • E) , {$, +, ∗, )}E → • E + T , {), +}E → • T , {), +}T → • T ∗ F , {), +, ∗}T → • F , {), +, ∗}F → • id , {), +, ∗}F → • (E) , {), +, ∗}
1
0S ′ → • E$ , {ε}E → • E + T , {$, +}E → • T , {$, +}T → • T ∗ F , {$, +, ∗}T → • F , {$, +, ∗}F → • id , {$, +, ∗}F → • (E) , {$, +, ∗}
1S ′ → E • $ , {ε}E → E • +T , {$, +}
2S ′ → E$ • , {ε}
3− 17E → E+ • T , {$, +, )}T → • T ∗ F , {$, +, ∗, )}T → • F , {$, +, ∗, )}F → • id , {$, +, ∗, )}F → • (E) , {$, +, ∗, )}
4− 14T → F • , {$, +, ∗, )}
5− 10F → id • , {$, +, ∗, )}
6− 18F → ( • E) , {$, +, ∗, )}E → • E + T , {), +}E → • T , {), +}T → • T ∗ F , {), +, ∗}T → • F , {), +, ∗}F → • id , {), +, ∗}F → • (E) , {), +, ∗}
1
0S ′ → • E$ , {ε}E → • E + T , {$, +}E → • T , {$, +}T → • T ∗ F , {$, +, ∗}T → • F , {$, +, ∗}F → • id , {$, +, ∗}F → • (E) , {$, +, ∗}
1S ′ → E • $ , {ε}E → E • +T , {$, +}
2S ′ → E$ • , {ε}
3− 17E → E+ • T , {$, +, )}T → • T ∗ F , {$, +, ∗, )}T → • F , {$, +, ∗, )}F → • id , {$, +, ∗, )}F → • (E) , {$, +, ∗, )}
4− 14T → F • , {$, +, ∗, )}
5− 10F → id • , {$, +, ∗, )}
6− 18F → ( • E) , {$, +, ∗, )}E → • E + T , {), +}E → • T , {), +}T → • T ∗ F , {), +, ∗}T → • F , {), +, ∗}F → • id , {), +, ∗}F → • (E) , {), +, ∗}
1
0S ′ → • E$ , {ε}E → • E + T , {$, +}E → • T , {$, +}T → • T ∗ F , {$, +, ∗}T → • F , {$, +, ∗}F → • id , {$, +, ∗}F → • (E) , {$, +, ∗}
1S ′ → E • $ , {ε}E → E • +T , {$, +}
2S ′ → E$ • , {ε}
3− 17E → E+ • T , {$, +, )}T → • T ∗ F , {$, +, ∗, )}T → • F , {$, +, ∗, )}F → • id , {$, +, ∗, )}F → • (E) , {$, +, ∗, )}
4− 14T → F • , {$, +, ∗, )}
5− 10F → id • , {$, +, ∗, )}
6− 18F → ( • E) , {$, +, ∗, )}E → • E + T , {), +}E → • T , {), +}T → • T ∗ F , {), +, ∗}T → • F , {), +, ∗}F → • id , {), +, ∗}F → • (E) , {), +, ∗}
1
0S ′ → • E$ , {ε}E → • E + T , {$, +}E → • T , {$, +}T → • T ∗ F , {$, +, ∗}T → • F , {$, +, ∗}F → • id , {$, +, ∗}F → • (E) , {$, +, ∗}
1S ′ → E • $ , {ε}E → E • +T , {$, +}
2S ′ → E$ • , {ε}
3− 17E → E+ • T , {$, +, )}T → • T ∗ F , {$, +, ∗, )}T → • F , {$, +, ∗, )}F → • id , {$, +, ∗, )}F → • (E) , {$, +, ∗, )}
4− 14T → F • , {$, +, ∗, )}
5− 10F → id • , {$, +, ∗, )}
6− 18F → ( • E) , {$, +, ∗, )}E → • E + T , {), +}E → • T , {), +}T → • T ∗ F , {), +, ∗}T → • F , {), +, ∗}F → • id , {), +, ∗}F → • (E) , {), +, ∗}
1
0S ′ → • E$ , {ε}E → • E + T , {$, +}E → • T , {$, +}T → • T ∗ F , {$, +, ∗}T → • F , {$, +, ∗}F → • id , {$, +, ∗}F → • (E) , {$, +, ∗}
1S ′ → E • $ , {ε}E → E • +T , {$, +}
2S ′ → E$ • , {ε}
3− 17E → E+ • T , {$, +, )}T → • T ∗ F , {$, +, ∗, )}T → • F , {$, +, ∗, )}F → • id , {$, +, ∗, )}F → • (E) , {$, +, ∗, )}
4− 14T → F • , {$, +, ∗, )}
5− 10F → id • , {$, +, ∗, )}
6− 18F → ( • E) , {$, +, ∗, )}E → • E + T , {), +}E → • T , {), +}T → • T ∗ F , {), +, ∗}T → • F , {), +, ∗}F → • id , {), +, ∗}F → • (E) , {), +, ∗}
1
7− 19E → T • , {$, +, )}T → T • ∗F , {$, +, ∗, )}
8− 21T → T∗ • F , {$, +, ∗, )}F → • id , {$, +, ∗, )}F → • (E) , {$, +, ∗, )}
9− 22T → T ∗ F • , {$, +, ∗, )}
11− 20E → E + T • , {$, +, )}T → T • ∗F , {$, +, ∗, )}
12− 16F → (E • ) , {$, +, ∗, )}E → E • +T , {), +}
13− 15F → (E) • , {$, +, ∗, )}
2
7− 19E → T • , {$, +, )}T → T • ∗F , {$, +, ∗, )}
8− 21T → T∗ • F , {$, +, ∗, )}F → • id , {$, +, ∗, )}F → • (E) , {$, +, ∗, )}
9− 22T → T ∗ F • , {$, +, ∗, )}
11− 20E → E + T • , {$, +, )}T → T • ∗F , {$, +, ∗, )}
12− 16F → (E • ) , {$, +, ∗, )}E → E • +T , {), +}
13− 15F → (E) • , {$, +, ∗, )}
2
7− 19E → T • , {$, +, )}T → T • ∗F , {$, +, ∗, )}
8− 21T → T∗ • F , {$, +, ∗, )}F → • id , {$, +, ∗, )}F → • (E) , {$, +, ∗, )}
9− 22T → T ∗ F • , {$, +, ∗, )}
11− 20E → E + T • , {$, +, )}T → T • ∗F , {$, +, ∗, )}
12− 16F → (E • ) , {$, +, ∗, )}E → E • +T , {), +}
13− 15F → (E) • , {$, +, ∗, )}
2
7− 19E → T • , {$, +, )}T → T • ∗F , {$, +, ∗, )}
8− 21T → T∗ • F , {$, +, ∗, )}F → • id , {$, +, ∗, )}F → • (E) , {$, +, ∗, )}
9− 22T → T ∗ F • , {$, +, ∗, )}
11− 20E → E + T • , {$, +, )}T → T • ∗F , {$, +, ∗, )}
12− 16F → (E • ) , {$, +, ∗, )}E → E • +T , {), +}
13− 15F → (E) • , {$, +, ∗, )}
2
7− 19E → T • , {$, +, )}T → T • ∗F , {$, +, ∗, )}
8− 21T → T∗ • F , {$, +, ∗, )}F → • id , {$, +, ∗, )}F → • (E) , {$, +, ∗, )}
9− 22T → T ∗ F • , {$, +, ∗, )}
11− 20E → E + T • , {$, +, )}T → T • ∗F , {$, +, ∗, )}
12− 16F → (E • ) , {$, +, ∗, )}E → E • +T , {), +}
13− 15F → (E) • , {$, +, ∗, )}
2
7− 19E → T • , {$, +, )}T → T • ∗F , {$, +, ∗, )}
8− 21T → T∗ • F , {$, +, ∗, )}F → • id , {$, +, ∗, )}F → • (E) , {$, +, ∗, )}
9− 22T → T ∗ F • , {$, +, ∗, )}
11− 20E → E + T • , {$, +, )}T → T • ∗F , {$, +, ∗, )}
12− 16F → (E • ) , {$, +, ∗, )}E → E • +T , {), +}
13− 15F → (E) • , {$, +, ∗, )}
2
*
F
id
E
)
E
F
(
+
T
T
5-10
$
5-10
T (
F F
(
(
*
id
id
id

Principe de parsing ascendantCFG LR(k)
Parser LR(0)Parser LR(1)
Parser SLR(1)Parser LALR(1)
Classes LL vs LRL’outil Yacc (Bison)
Tables LALR(1)
Action
État + ∗ id ( ) $ ε
0 S S1 S S2 A
3− 17 S S4− 14 R4 R4 R4 R45− 10 R5 R5 R5 R56− 18 S S7− 19 R2 S R2 R28− 21 S S9− 22 R3 R3 R3 R313− 15 R6 R6 R6 R611− 20 R1 S R1 R112− 16 S S
429

Principe de parsing ascendantCFG LR(k)
Parser LR(0)Parser LR(1)
Parser SLR(1)Parser LALR(1)
Classes LL vs LRL’outil Yacc (Bison)
Tables LALR(1)
Successeur
État + * id ( ) $ E T F
0 5-10 6-18 1 7-19 4-141 3-17 223-17 5-10 6-18 11-20 4-144-145-106-18 5-10 6-18 12-16 7-19 4-147-19 8-218-21 5-10 6-18 9-229-2213-1511-20 8-2112-16 3-17 13-15
430

Principe de parsing ascendantCFG LR(k)
Parser LR(0)Parser LR(1)
Parser SLR(1)Parser LALR(1)
Classes LL vs LRL’outil Yacc (Bison)
Caractéristiques de la méthode LALR(k)
Théorème (La fusion des états de l’automate caractéristique LR(k) estconsistante)
C’est-à-dire si 2 états s1 et s2 doivent être fusionnés dans l’automateLALR(k) alors ∀X : Transition[s1, X ] et Transition[s2, X ] doivent égalementêtre fusionnés.En effet, Transition(s, X ) ne dépend que des coeurs des LR(k)-items et pasdes prévisions.
431

Caractéristiques de la méthode LALR(k)
Caractéristique de la méthode LALR(k)
Pour toute CFG G′, si on fait abstraction des prévisions, les automatescaractéristiques LR(0) et LALR(k) sont les mêmes.
Il est possible de construire l’automate caractéristique LALR(1)directement à partir de l’automate caractéristique LR(0) sur lequel oncalcule directement les prévisions : cette méthode n’est pas vue dans cecours.
Pour l’exemple précédent, les tables Actions des analyseurs LALR(1) etSLR(1) sont les mêmes (au nom des états près) ; ce n’est généralementpas le cas.
Toute grammaire SLR(k) est LALR(k) mais l’inverse n’est pas toujoursvraie.
Par exemple, la grammaire G′5 du slide 424 n’est pas SLR(1) mais est
LR(1) et LALR(1).

Caractéristiques de la méthode LALR(1)
Il se peut qu’une grammaire LR(1) ne soit pas LALR(1). En effet :
La fusion des états peut rajouter des conflits Reduce / Reduce
Pour la grammaire dont les règles sont :S′ → S$ (0)S → aAd (1)S → bBd (2)S → aBe (3)
S → bAe (4)A → c (5)B → c (6)
les états suivants sont générés dans l’automate caractéristique LR(1)
{[A→ c•, d ], [B → c•, e]}{[A→ c•, e], [B → c•, d ]}
dont la fusion engendre un conflit Reduce 5/ Reduce 6

Caractéristiques de la méthode LALR(1)
La fusion des états ne peut pas rajouter des conflits Shift / Reduce
En effet, si on a dans un même état de l’automate caractéristique LALR(1)
[A→ α•, a] et
[B → β • aγ, b]
alors dans l’état de l’automate caractéristique LR(1) correspondant,contenant [A→ α•, a]
on aurait forcément [B → β • aγ, c] pour un certain c et
le conflit Shift / Reduce existerait déjà au niveau LR(1)

Principe de parsing ascendantCFG LR(k)
Parser LR(0)Parser LR(1)
Parser SLR(1)Parser LALR(1)
Classes LL vs LRL’outil Yacc (Bison)
Plan
1 Principe de parsing ascendant
2 CFG LR(k)
3 Parser LR(0)
4 Parser LR(1)
5 Parser SLR(1)
6 Parser LALR(1)
7 Classes LL vs LR
8 L’outil Yacc (Bison)
435

Inclusion des classes de grammaires
Grammaires ambiguës
Grammaires non ambiguës
LR(k)
LR(1)
LALR(1)
SLR(1)
LR(0)LL(0)
LL(1)
LL(k)
Notes
En pratique, la plupart des grammaires que l’on veut compiler sontLALR(1)
On peut démontrer que les 3 classes des langages LR(k) (càd acceptéspar une grammaire LR(k)), LR(1) et des langages acceptés par unDPDA (automate à pile déterministe) sont les mêmes.
Principe de parsing ascendantCFG LR(k)
Parser LR(0)Parser LR(1)
Parser SLR(1)Parser LALR(1)
Classes LL vs LRL’outil Yacc (Bison)
Plan
1 Principe de parsing ascendant
2 CFG LR(k)
3 Parser LR(0)
4 Parser LR(1)
5 Parser SLR(1)
6 Parser LALR(1)
7 Classes LL vs LR
8 L’outil Yacc (Bison)
437

Principe de parsing ascendantCFG LR(k)
Parser LR(0)Parser LR(1)
Parser SLR(1)Parser LALR(1)
Classes LL vs LRL’outil Yacc (Bison)
Yacc = Yet Another Compiler Compiler (≡ Bison en système GNU)
Que fait Yacc?
Yacc a été conçu comme générateur de parsers LALR(1), et de façonplus générale, de parties de compilateur.
En collaboration avec l’outil Lex, Yacc peut construire une grande partieou même la totalité d’un compilateur.
Yacc est un outil puissant pour créer des programmes traitant deslangages dont la grammaire context-free est donnée.
438

Procédure générale pour l’utilisation de Lex (Flex) et Yacc (Bison)
5
Lex generates C code for a lexical analyzer, or scanner. It uses patterns that match strings in the input and converts the strings to tokens. Tokens are numerical representations of strings, and simplify processing. This is illustrated in Figure 1. As lex finds identifiers in the input stream, it enters them in a symbol table. The symbol table may also contain other information such as data type (integer or real) and location of the variable in memory. All subsequent references to identifiers refer to the appropriate symbol table index. Yacc generates C code for a syntax analyzer, or parser. Yacc uses grammar rules that allow it to analyze tokens from lex and create a syntax tree. A syntax tree imposes a hierarchical structure on tokens. For example, operator precedence and associativity are apparent in the syntax tree. The next step, code generation, does a depth-first walk of the syntax tree to generate code. Some compilers produce machine code, while others, as shown above, output assembly.
lex
yacc
cc
bas.y
bas.l lex.yy.c
y.tab.c
bas.exe
source
compiled output
(yylex)
(yyparse)
y.tab.h
Figure 2: Building a Compiler with Lex/Yacc Figure 2 illustrates the file naming conventions used by lex and yacc. We'll assume our goal is to write a BASIC compiler. First, we need to specify all pattern matching rules for lex (bas.l) and grammar rules for yacc (bas.y). Commands to create our compiler, bas.exe, are listed below:
yacc –d bas.y # create y.tab.h, y.tab.c lex bas.l # create lex.yy.c cc lex.yy.c y.tab.c –obas.exe # compile/link
Yacc reads the grammar descriptions in bas.y and generates a parser, function yyparse, in file y.tab.c. Included in file bas.y are token declarations. The –d option causes yacc to generate definitions for tokens and place them in file y.tab.h. Lex reads the pattern descriptions in bas.l, includes file y.tab.h, and generates a lexical analyzer, function yylex, in file lex.yy.c. Finally, the lexer and parser are compiled and linked together to form the executable, bas.exe. From main, we call yyparse to run the compiler. Function yyparse automatically calls yylex to obtain each token.
Compilation :
yacc -d bas.y # crée y.tab.h et y.tab.clex bas.l # crée lex.yy.ccc lex.yy.c y.tab.c -ll -obas.exe # compile et fait l’édition
# crée bas.exe

Principe de parsing ascendantCFG LR(k)
Parser LR(0)Parser LR(1)
Parser SLR(1)Parser LALR(1)
Classes LL vs LRL’outil Yacc (Bison)
Spécification Yacc
déclarations
%%
productions
%%
code additionnel
Le parser résultant (yyparse()) cherche à reconnaître la phrase compatibleavec la grammaire.Lors de l’analyse d’un parser généré avec Yacc, des actions sémantiquessous forme de code C peuvent être exécutées et des attributs peuvent êtrecalculés (voir exemple et chapitre suivant).
440

Exemple Lex et Yacc : évaluateur d’expressions
Exemple (Partie Lex de l’évaluateur d’expressions)
/* File ex3.l */%{#include "y.tab.h"#define yywrap() 1extern int yylval;%}integer [0-9]+separator [\ \t]nl \n%%{integer} { sscanf(yytext, "%d", &yylval);
return(INTEGER);}
[-+*/()] { return yytext[0]; }quit { return 0; }{nl} { return ’\n’; }{separator} ;. { return yytext[0]; }

Exemple Lex et Yacc : évaluateur d’expressions
Exemple (partie Yacc de l’évaluateur d’expressions (1))
/* File ex3.y */%{#include <stdio.h>%}
%token INTEGER
%%

Exemple Lex et Yacc : évaluateur d’expressions
Exemple (partie Yacc de l’évaluateur d’expressions (2))
lines: /*empty*/| lines line;
line: ’\n’| exp ’\n’
{printf(" = %d\n", $1);}
exp: exp ’+’ term {$$ = $1 + $3;}| exp ’-’ term {$$ = $1 - $3;}| term;
term: term ’*’ fact {$$ = $1 * $3;}term ’/’ fact {$$ = $1 / $3;}fact
;
fact: INTEGER| ’-’ INTEGER {$$ = - $2;}| ’(’exp’)’ {$$ = $2;};
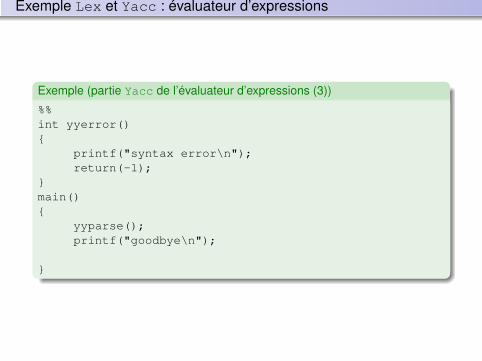
Exemple Lex et Yacc : évaluateur d’expressions
Exemple (partie Yacc de l’évaluateur d’expressions (3))
%%int yyerror(){
printf("syntax error\n");return(-1);
}main(){
yyparse();printf("goodbye\n");
}

Rôle et phases de l’analyse sémantiqueOutils pour effectuer l’analyse sémantique
Construction de l’ASTQuelques exemples d’utilisation de grammaires attribuées
Chapitre 11 : L’analyse sémantique
1 Rôle et phases de l’analyse sémantique
2 Outils pour effectuer l’analyse sémantique
3 Construction de l’AST
4 Quelques exemples d’utilisation de grammaires attribuées
445

Rôle et phases de l’analyse sémantiqueOutils pour effectuer l’analyse sémantique
Construction de l’ASTQuelques exemples d’utilisation de grammaires attribuées
Plan
1 Rôle et phases de l’analyse sémantique
2 Outils pour effectuer l’analyse sémantique
3 Construction de l’AST
4 Quelques exemples d’utilisation de grammaires attribuées
446

Rôle et phases de l’analyse sémantiqueOutils pour effectuer l’analyse sémantique
Construction de l’ASTQuelques exemples d’utilisation de grammaires attribuées
Rôle de l’analyse sémantique
Définition (Rôle de l’analyse sémantique)
Pour un langage impératif, l’analyse sémantique appelée aussi gestion decontexte s’occupe des relations non locales ; elle s’occupe ainsi :
1 du contrôle de visibilité et du lien entre les définitions et utilisations desidentificateurs
2 du contrôle de type des “objets”, nombre et type des paramètres defonctions
3 du contrôle de flot (vérifie par exemple qu’un goto est licite - voirexemple plus bas)
447

Rôle et phases de l’analyse sémantiqueOutils pour effectuer l’analyse sémantique
Construction de l’ASTQuelques exemples d’utilisation de grammaires attribuées
Exemple (de contrôle de flots erronné)
Le code suivant est illicite :
int main (){for(int i=1;i<10;++i)infor: cout << "iteration " << i << endl;
goto infor;}
448

Rôle et phases de l’analyse sémantiqueOutils pour effectuer l’analyse sémantique
Construction de l’ASTQuelques exemples d’utilisation de grammaires attribuées
Première phase de l’analyse sémantiqueConstruction da l’arbre syntaxique abstrait (et du graphe de flux de contrôle)
Définition (AST (Abstract Syntax Tree) Arbre syntaxique abstrait)
Forme résumée de l’arbre syntaxique qui ne conserve que les élémentsutiles pour la suite.
Exemple (de grammaire, d’arbre syntaxique et d’AST)
Soit G avec les règles de production :
exp → exp + term |→ exp − term |→ term
term → term ∗ factor |→ term / factor |→ factor
factor → id | cst | ( exp )
449

Rôle et phases de l’analyse sémantiqueOutils pour effectuer l’analyse sémantique
Construction de l’ASTQuelques exemples d’utilisation de grammaires attribuées
L’expression b*b-4*a*c donnel’arbre syntaxique suivant :
exp
exp '-'
term
term
term '*'
factor
factor
id (b)
id (b)
'*'term factor
id (c)factor'*'term
factor
cst (4)
id (a)
l’arbre abstrait (AST) suivant :
-
* *
id (c)*
cst (4) id (a)
id (b)id (b)
450
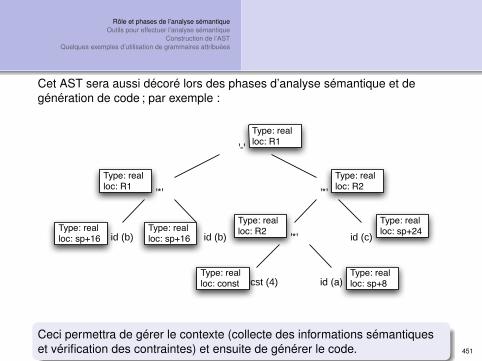
Rôle et phases de l’analyse sémantiqueOutils pour effectuer l’analyse sémantique
Construction de l’ASTQuelques exemples d’utilisation de grammaires attribuées
Cet AST sera aussi décoré lors des phases d’analyse sémantique et degénération de code ; par exemple :
'-'
'*'
id (b)id (b)
'*'
id (c)'*'
cst (4) id (a)
Type: realloc: R1
Type: realloc: R1
Type: realloc: sp+16
Type: realloc: sp+16
Type: realloc: R2
Type: realloc: sp+24
Type: realloc: sp+8
Type: realloc: const
Type: realloc: R2
Ceci permettra de gérer le contexte (collecte des informations sémantiqueset vérification des contraintes) et ensuite de générer le code. 451

Rôle et phases de l’analyse sémantiqueOutils pour effectuer l’analyse sémantique
Construction de l’ASTQuelques exemples d’utilisation de grammaires attribuées
Deuxième phase de l’analyse sémantiqueGestion du contexte (contrôle sémantique)
Rappel sur le rôle de la gestion de contexte
La gestion de contexte des langages impératifs inclut :1 le contrôle de la visibilité et du lien entre les définitions et utilisations des
identificateurs2 le contrôle de type des “objets”, nombre et type des paramètres de
fonctions3 le contrôle de flot (vérifie par exemple qu’un goto est licite)
452

Rôle et phases de l’analyse sémantiqueOutils pour effectuer l’analyse sémantique
Construction de l’ASTQuelques exemples d’utilisation de grammaires attribuées
L’analyseur sémantique manipule /calcule des attributs d’identificateurs
Attributs d’un “identificateur” :
1 sorte (constante, variable, fonction)2 type3 valeur initiale ou fixe4 portée5 propriétés éventuelles de “localisation” (place en mémoire : pour la
génération du code)
453

Rôle et phases de l’analyse sémantiqueOutils pour effectuer l’analyse sémantique
Construction de l’ASTQuelques exemples d’utilisation de grammaires attribuées
Identification de la définition correspondant à une occurrence
Dépend de la portée (chaque langage à ses propres règles de portée)En Pascal / C, peut être déterminée lors de l’analyse grâce à une pile deportée (qui peut être fusionnée avec la table des symboles) : Lors del’analyse
d’un début de bloc : on empile une nouvelle portée
d’une nouvelle définition : on la met dans la portée courante
de l’utilisation d’un élément : on trouve la définition correspondante enregardant dans le stack à partir du sommet
de la sortie d’un bloc : on dépile la portée.
454

Rôle et phases de l’analyse sémantiqueOutils pour effectuer l’analyse sémantique
Construction de l’ASTQuelques exemples d’utilisation de grammaires attribuées
Note
Cette technique permet également de trouver l’adresse d’une variable parexemple :(nombre de frames statiques en dessous de la frame courante, place dans la
frame)
Par exemple avec le code :{int x=3,y=4;if(x==y){int z=8;y=z;
}}
La notion de frame est développée au chapitre \ref{chap12}
y=z pourraitêtre traduit parvar(1,4)←valvar(0,0)
Bas de la pile
x
y
z
frames
455

Rôle et phases de l’analyse sémantiqueOutils pour effectuer l’analyse sémantique
Construction de l’ASTQuelques exemples d’utilisation de grammaires attribuées
Autres problèmes d’identification ou de contrôle :
Surcharge
Plusieurs opérateurs ou fonctions ayant le même nom. Exemple : le ’+’ peutêtre
+ : double x double→ double
+ : int x int→ int
const Matrix operator+(Matrix& m)
. . .
456

Rôle et phases de l’analyse sémantiqueOutils pour effectuer l’analyse sémantique
Construction de l’ASTQuelques exemples d’utilisation de grammaires attribuées
Polymorphisme
Plusieurs fonctions ou méthodes ayant le même nom (ex : methodes demême nom dans différentes classes).
Polymorphisme “pur” : une fonction est polymorphe si elle peuts’appliquer de la même façon à tout type (ex : voir dans les langagesfonctionnels)
Suivant le langage, le contrôle de type et en particulier la résolution dupolymorphisme peut se faire
statiquement c’est-à-dire lors de l’analyse sémantique, à la compilation
dynamiquement c’est-à-dire lors de l’exécution, connaissant le type réelde l’objet.
457

Rôle et phases de l’analyse sémantiqueOutils pour effectuer l’analyse sémantique
Construction de l’ASTQuelques exemples d’utilisation de grammaires attribuées
Note
Dans les langages OO on parled’overloading
nécessite que la signature soit différente pour déterminer quelle méthodeexécuter
d’overridingnécessite que la signature soit la même
de polymorphismesur des objets de classes différentes.
458

Rôle et phases de l’analyse sémantiqueOutils pour effectuer l’analyse sémantique
Construction de l’ASTQuelques exemples d’utilisation de grammaires attribuées
Autres problèmes d’identification ou de contrôle (suite) :
Coercition et casting
Il se peut que dans une opération le type attendu soit T1 et que la valeur soitde type T2.
Soit le langage accepte de faire une coercition càd une conversion detype non explicitement demandée par le programmeur.
Soit la conversion doit être demandée explicitement grâce à unopérateur de casting.
459

Rôle et phases de l’analyse sémantiqueOutils pour effectuer l’analyse sémantique
Construction de l’ASTQuelques exemples d’utilisation de grammaires attribuées
Exemple (de casting et coercition)
{double x=3.14 y=3.14;int i,j;i = x; // coercition: ’int -> double’
// un warning peut être émisx = i; // coercition: ’double -> int’
// un warning peut être émisj = (int) y; // castingy = (double) j; // casting
}
460

Rôle et phases de l’analyse sémantiqueOutils pour effectuer l’analyse sémantique
Construction de l’ASTQuelques exemples d’utilisation de grammaires attribuées
Système de typage
Il faut d’abord1 pouvoir décrire formellement un type2 définir quels types sont équivalents ou compatibles
Définition (Expression de type)
Graphe orienté dont les noeuds peuvent être :
un type de base : bool, int, double,...un constructeur :
arraystructfunctionpointer
un nom de type (défini ailleurs)
une variable de type (représentant apriori n’importe quel type)
Exemple (d’expression detype)
function
struct
intchar
ptr
int
461

Rôle et phases de l’analyse sémantiqueOutils pour effectuer l’analyse sémantique
Construction de l’ASTQuelques exemples d’utilisation de grammaires attribuées
Caractéristiques d’un langage
Il peut être
de typage statique ou dynamique selon que ce typage peut être faitentièrement à la compilation ou doit être fait en partie à l’exécution.
de typage sain si les types de toutes les valeurs utilisées à l’exécutionsont calculées statiquement.
typé si le typage impose des conditions sur les programmes.
fortement typé2
si les informations de typage sont associées aux variables et non pas auxvaleurs, ousi l’ensemble des types utilisés est connu à la compilation et le type desvariables peut être testé à l’exécution.
2Ce terme a plusieurs définitions462

Équivalence de type
Suivant le langage de programmation, l’équivalence de type peut être uneéquivalence de nom ou une équivalence de structure
En Pascal, C, C++
En Pascal, C et C++ on a l’équivalence de nom :
V et W sont de type différent de X et Y
struct {int i; char c;} V,W;struct {int i; char c;} X,Y;
idem
typedef struct {int i; char c;} S;S V,W;struct {int i; char c;} X,Y;
les variables suivantes sont de types équivalents ! : pointeur constantvers un entier
typedef int Veccent[100];Veccent V,W;int X[100],Y[10],Z[1];
Exemple d’équivalence de structure
Dans d’autres langages (Algol68 par exemple), l’équivalence est déterminéepar la structure.
Exemple (Expressions structurellement équivalentes)
function
struct
intptr
ptr
int
struct
intptr
function
struct
intptr
ptr
int
Remarque :
L’algorithme d’unification (voir la résolution en Prolog) permet de vérifier si 2types sont équivalents / compatibles.

Rôle et phases de l’analyse sémantiqueOutils pour effectuer l’analyse sémantique
Construction de l’ASTQuelques exemples d’utilisation de grammaires attribuées
Plan
1 Rôle et phases de l’analyse sémantique
2 Outils pour effectuer l’analyse sémantique
3 Construction de l’AST
4 Quelques exemples d’utilisation de grammaires attribuées
465

Rôle et phases de l’analyse sémantiqueOutils pour effectuer l’analyse sémantique
Construction de l’ASTQuelques exemples d’utilisation de grammaires attribuées
Outils pour effectuer l’analyse sémantique
Même si l’analyse sémantique n’est pas automatisée comme l’est l’analyselexicale ou syntaxique, deux outils existent.
Les actions sémantiques
Les grammaires attribuées
466

Rôle et phases de l’analyse sémantiqueOutils pour effectuer l’analyse sémantique
Construction de l’ASTQuelques exemples d’utilisation de grammaires attribuées
Les actions sémantiques
Définition (Actions sémantiques)
Actions rajoutées dans la grammaire. Lors de l’analyse syntaxique, l’analysede ces actions correspond à effectuer les actions prescrites.
Exemple (d’action sémantique)
Exemple classique : traduction d’expressions en notation algébrique directe(NAD) vers la notation polonaise inversée (NPI) :
E → TE ′
E ′ → +T{printf (′+′)}E ′
E ′ → εT → FT ′
T ′ → ∗F{printf (′∗′)}T ′
T ′ → εF → (E)F → id{printf (val(id))}
467

Rôle et phases de l’analyse sémantiqueOutils pour effectuer l’analyse sémantique
Construction de l’ASTQuelques exemples d’utilisation de grammaires attribuées
Les grammaires attribuées
Définition (Grammaire attribuées)
Il s’agit de traitements spécifiés sur la grammaire context-free décrivant lasyntaxe, qui consistent à évaluer des attributs associés aux noeuds de l’arbresyntaxique
Définition (Attributs hérités et synthétisés)
Il n’existe que deux types d’attributs associés à un noeud :
Hérité : dont la valeur ne peut dépendre que d’attributs de son père oude ses frères,
Synthétisés : dont la valeur ne peut dépendre que d’attributs de ses fils,ou si le noeud est une feuille, est donné par l’analyseur lexical (ousyntaxique).
468

Exemple (de grammaire attribuée)
D → T LT → intT → doubleL → L1 id
L → id
L.typeh := T .typeT .type := intT .type := doubleL1.typeh := L.typehL.tab := AjouterType(L1.tab, id .entree, L.typeh)L.tab := AjouterType(vide, id .entree, L.typeh)
Sur l’arbre, les règlesde calculs des attributsdonne un graphe dedépendances
A 99K B = lavaleur de A estutilisée pourcalculer B
Exemple :double id1 id2 id3Donne :
D
T
double
L
id3L
L id2
id1
type typeh
typeh
typehentree
entree
entree
tab
tab
tab

Rôle et phases de l’analyse sémantiqueOutils pour effectuer l’analyse sémantique
Construction de l’ASTQuelques exemples d’utilisation de grammaires attribuées
Evaluation des attributs
Soit l’ordre est fixé avant la compilation (ordre statique), soit il est déterminélors de la compilation (ordre dynamique).
Evaluation dynamique naïve
tant que les attributs ne sont pas tous évaluésEvalue (Racine)
fonction Evalue(S) (Règle S -> X1 X2 ... Xm) {1 ) propage les attributs présents dans S2 ) pour tout fils Xi (i=1 -> m): Evalue(Xi)3 ) pour tout attribut synthétisé A non encore évalué
si les attributs requis sont évalués alors calcule A}
470

Rôle et phases de l’analyse sémantiqueOutils pour effectuer l’analyse sémantique
Construction de l’ASTQuelques exemples d’utilisation de grammaires attribuées
Autre méthode : Tri topologique
Tout attribut est dans une liste de prédécesseurs.On donne le nombre de prédécesseurs de chacun.On peut évaluer les attributs A sans prédécesseur et diminuer le nombre deprédécesseurs des attributs qui dépendent de A.
Note
Les attributs cycliques posent problème avec ces méthodes
471

Rôle et phases de l’analyse sémantiqueOutils pour effectuer l’analyse sémantique
Construction de l’ASTQuelques exemples d’utilisation de grammaires attribuées
Les types de grammaires attribuées ’classiques’ qui peuvent être évaluéesstatiquement :
Les grammaires S-attribuées : n’ont que des attributs synthétisés (ex :analyseur produits par YACC)
Les grammaires L-attribuées : évaluables lors d’un parcourt LR del’arbre du type parcours en profondeur gauche. Cela signifie qu’unattribut hérité ne dépend que des attributs hérités plus à gauche ou dupère.
Remarques : les évaluations des attributs de ces grammaires peuvent êtreeffectués dans une analyse LL(1) ou LALR(1).
472

Rôle et phases de l’analyse sémantiqueOutils pour effectuer l’analyse sémantique
Construction de l’ASTQuelques exemples d’utilisation de grammaires attribuées
Plan
1 Rôle et phases de l’analyse sémantique
2 Outils pour effectuer l’analyse sémantique
3 Construction de l’AST
4 Quelques exemples d’utilisation de grammaires attribuées
473

Construction d’un AST (ou AS-DAG) pour une expression
Exemple (de construction d’un AST)
E → E1 + T E .noeud := CreerNoeud(′+′, E1.noeud , T .noeud)E → E1 − T E .noeud := CreerNoeud(′−′, E1.noeud , T .noeud)E → T E .noeud := T .noeudT → (E) T .noeud := E .noeudT → id T .noeud := CreerFeuille(id , id .entr ee)T → nb T .noeud := CreerFeuille(nb, nb.entr ee)
CréerFeuille etCréerNoeud
vérifient si le noeudexiste déjà
renvoient un pointeurvers le noeud existantou créé.
a+a*(b-c)+(b-c)*ddonne :
+
+ *
cb
d*
-a
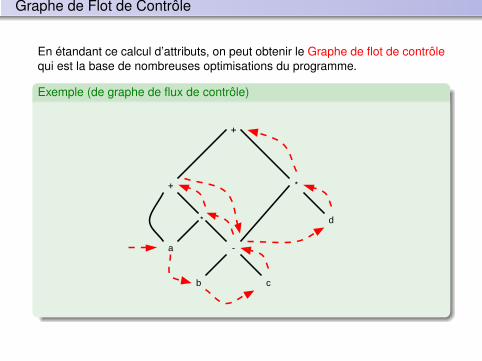
Graphe de Flot de Contrôle
En étandant ce calcul d’attributs, on peut obtenir le Graphe de flot de contrôlequi est la base de nombreuses optimisations du programme.
Exemple (de graphe de flux de contrôle)
+
+ *
cb
d*
-a

Rôle et phases de l’analyse sémantiqueOutils pour effectuer l’analyse sémantique
Construction de l’ASTQuelques exemples d’utilisation de grammaires attribuées
Graphe de Flux de Contrôle
Exemple ((2) de graphe de flux de contrôle)
] Grape de flot pour if B then I1 else I2 endif
if-then-else
B I1
endif
I2 ⇒B
I1
endif
I2
476

Rôle et phases de l’analyse sémantiqueOutils pour effectuer l’analyse sémantique
Construction de l’ASTQuelques exemples d’utilisation de grammaires attribuées
Graphe de flot de contrôle
Definition (Graphe de flot de contrôle)
C’est un organigramme donnant les flux possibles des instructions.
Il est formé de blocs de base.
Un bloc de base est une séquence d’instructions consécutives sansarrêt ni branchement
477

Rôle et phases de l’analyse sémantiqueOutils pour effectuer l’analyse sémantique
Construction de l’ASTQuelques exemples d’utilisation de grammaires attribuées
Plan
1 Rôle et phases de l’analyse sémantique
2 Outils pour effectuer l’analyse sémantique
3 Construction de l’AST
4 Quelques exemples d’utilisation de grammaires attribuées
478

calulatrice en YACC
Exemple (Yacc)S : E ;E : E ’+’ E {$$ = $1+$3}
| T;
T : T ’*’ F {$$ = $1*$3}| F;
F : ’(’E’)’ {$$ = $2}| nb;
Note sur Yacc
Dans cet exemple,
la règle par défaut en YACC est $$ = $1
la pile des attributs se comporte comme une pile d’évaluation postfixée

Rôle et phases de l’analyse sémantiqueOutils pour effectuer l’analyse sémantique
Construction de l’ASTQuelques exemples d’utilisation de grammaires attribuées
évaluation d’une expression en analyse LL(1)
Exemple (de grammaire attribuée)
Avec la grammaire attribuée :E → TE ′ E ′.h := T .val
E .val = E ′.valE ′ → −TE ′
1 E ′1.h = E ′.h − T .val
E ′.val = E ′1.val
E ′ → ε E ′.val = E ′.hT → nb T .val = nb.val
7− 4− 2 sera évalué :
E
T
nb
E'
E'T
nb
h
E'T
nb
val
val
val
val
val
valval
val
val
valh
h
7
7
4
4
7
3
2
2 11
1
1
1
Avec une descente LL(1) récursive, les attributs peuvent être transmis viades paramètres d’entrée ou de sortie.
480

Note préliminaire : langages considérésParticularités des langages impératifs (et organisation mémoire)
Code intermédiaireArchitecture du processeur
Génération du code
Chapitre 12 : La génération de code
1 Note préliminaire : langages considérés
2 Particularités des langages impératifs (et organisation mémoire)
3 Code intermédiaire
4 Architecture du processeur
5 Génération du code
481

Note préliminaire : langages considérésParticularités des langages impératifs (et organisation mémoire)
Code intermédiaireArchitecture du processeur
Génération du code
Plan
1 Note préliminaire : langages considérés
2 Particularités des langages impératifs (et organisation mémoire)
3 Code intermédiaire
4 Architecture du processeur
5 Génération du code
482

Note préliminaire : langages considérés
Restriction
Dans ce cours, nous considérons que le langage source est impératif etprocédural
Types de langages
Array languages
Aspect Oriented ProgrammingLanguages
Assembly languages
Command Line Interface (CLI)languages (batch languages)
Concatenative languages
Concurrent languages
Data-oriented languages
Dataflow languages
Data-structured languages
Fourth-generation languages
Functional languages
Logical languages
Machine languages
Macro languages
Multiparadigm languages
Object-oriented languages
Page description languages
Procedural languages
Rule-based languages
Scripting languages
Specification languages
Syntax handling languages
. . .
Note préliminaire : langages considérésParticularités des langages impératifs (et organisation mémoire)
Code intermédiaireArchitecture du processeur
Génération du code
Plan
1 Note préliminaire : langages considérés
2 Particularités des langages impératifs (et organisation mémoire)
3 Code intermédiaire
4 Architecture du processeur
5 Génération du code
484
Note préliminaire : langages considérésParticularités des langages impératifs (et organisation mémoire)
Code intermédiaireArchitecture du processeur
Génération du code
Questions à se poser
1 Les fonctions peuvent-elles être récursives ?2 Une fonction peut-elle référencer des identificateurs non locaux ?3 Un bloc peut-il référencer des identificateurs non locaux ?4 Quels types de passage de paramètres sont possibles ?5 Des fonctions peuvent-elles être passées en paramètre ?6 Une fonction peut-elle être passée en résultat ?7 Le programme peut-il allouer dynamiquement de la mémoire ?8 L’espace mémoire doit-il être libéré explicitement ?
485

Note préliminaire : langages considérésParticularités des langages impératifs (et organisation mémoire)
Code intermédiaireArchitecture du processeur
Génération du code
Fixons les réponses pour simplifier
1 type(s) de passage de paramètre ? : par valeur et référence2 fonctions récursives ? : oui3 fonction qui fait référence à des id non locaux ? : non4 bloc qui fait référence à des id non locaux ? : oui5 fonctions passées en paramètre ? : non6 fonction passée en résultat ? : non7 allocation dynamique de mémoire ? : oui8 espace mémoire libéré explicitement ? : oui
486

Note préliminaire : langages considérésParticularités des langages impératifs (et organisation mémoire)
Code intermédiaireArchitecture du processeur
Génération du code
Type(s) de passage de paramètre ? : par valeur et référencePrincipaux types de passages de paramètre :
Par valeur : le paramètre formel est une variable locale à la fonction ; savaleur est initialisée avec la valeur du paramètre effectif
Par référence (ou par variable) : l’adresse de la variable passée enparamètre est transmise à la fonction
Par copie (in / out) : le paramètre formel est une variable locale à lafonction ; sa valeur est initialisée avec la valeur de la variable donnée enparamètre effectif ; à la fin de l’exécution de la fonction, la nouvellevaleur est copiée dans le paramètre effectif
Par nom : remplacement textuel du paramètre formel par le paramètreeffectif transmis.
487

Note préliminaire : langages considérésParticularités des langages impératifs (et organisation mémoire)
Code intermédiaireArchitecture du processeur
Génération du code
Fonctions récursives ? : oui
L’exécution d’un programme est schématisé par son arbre d’activation
Exemple (de programme et d’arbre d’activation)void readarray(int a[], int aSize){...}static int partit(int a[], int first, int last) {...}static void QS(int a[], int first, int last) {
if (first < last) {int pivotIndex = partit(a, first, last);QS(a, first, pivotIndex - 1);QS(a, pivotIndex + 1, last);
}}static void quicksort(int a[], int aSize) {
QS(a, 0, aSize - 1);}int main() {
...readarray(a,n);quicksort(a,n);
}488

Exemple d’arbre d’activation pour quicksort
Exemple (de programme et d’arbre d’activation)
main
readarray quicksort(a,8)
partit(a,0,7) QS(a,0,3) QS(a,5,7)
QS(a,0,7)
QS(a,0,2) QS(a,4,3)partit(a,0,3)
QS(a,0,0) QS(a,2,2)partit(a,0,2)
QS(a,5,5) QS(a,7,7)partit(a,5,7)
Exécution = parcours en profondeur de l’arbre d’activation
l’arbre d’activation n’est connu qu’à l’exécution=> pile de contrôle (run-time) pour stocker les contextes et variables localesdes fonctions appelantes

Évolution de la pile run-time lors de l’exécution
Exemple (d’évolution de la pile)
main main
readarray
main
quicksort
main
quicksort
main main main
quicksortquicksort
QS(0,7)
quicksort
QS(0,7) QS(0,7)
QS(0,3)
...
QS(0,7)
partit(0,7) QS(0,3)
partit(0,3)
Note préliminaire : langages considérésParticularités des langages impératifs (et organisation mémoire)
Code intermédiaireArchitecture du processeur
Génération du code
Bloc qui fait référence à des id non locaux ? : oui
Bloc d’activation (Frame)
Chaque zone du stack correspondant à un bloc est nommé bloc d’activation.On utilisera aussi le nom anglais frame.
491

Note préliminaire : langages considérésParticularités des langages impératifs (et organisation mémoire)
Code intermédiaireArchitecture du processeur
Génération du code
Bloc qui fait référence à des id non locaux ? : oui
Les références à des zonesmémoires (variables par exemple)seront codées par des accèsmémoire dont l’adresse est relativeau début de la frame.
Par exemple, l’accès à une variable xdu bloc du grand-père correspond àun accès qui est relatif àl’antépénultième frame du stackrun-time.
Pour cela, chaque frame contientl’adresse du début de la framedirectement en dessous (comme uneliste simplement liée)
Exemple (de lien d’accès)
Si x se trouve dans un bloc“grand-père”, l’accès à x se fait àtravers 2 liens d’accès.
frame active
x
stackpointerlien d'accès
lien d'accès
492

Note préliminaire : langages considérésParticularités des langages impératifs (et organisation mémoire)
Code intermédiaireArchitecture du processeur
Génération du code
Structure d’une frame (bloc d’activation) run-time
Cas le plus complet : bloc correspondant à une fonction
temporaires
données locales
état machine sauvegardée
lien d'accès
paramètres effectifs
valeurs de retour
493

Note préliminaire : langages considérésParticularités des langages impératifs (et organisation mémoire)
Code intermédiaireArchitecture du processeur
Génération du code
Remarque sur l’accès à une composante de tableau
Exemple (d’accès à une composante de tableau)
Si V est un tableau à 3 dimensions n1 × n2 × n3,
en supposant que le langage stocke les éléments “ligne par ligne”
et que la première composante est V [0, 0, 0]
V [i, j, k ] est à l’adresse ∗V + i.n1.n2 + j.n2 + k
que l’on peut également écrire (par Horner) : ∗V + ((i.n1) + j).n2 + k
Remarquons que pour ce calcul, n3 n’est pas requis.
494

Note préliminaire : langages considérésParticularités des langages impératifs (et organisation mémoire)
Code intermédiaireArchitecture du processeur
Génération du code
Allocation dynamique de mémoire ? : oui
Les allocations se font lors des newCela nécessite une zone mémoire supplémentaire : le tas (heap) qui n’a pasde structure (FIFO, LIFO, ...).La zone mémoire contient donc
des zones allouées au programme et
d’autres disponibles (allouables) que les fonctions run-time gèrent
495

Note préliminaire : langages considérésParticularités des langages impératifs (et organisation mémoire)
Code intermédiaireArchitecture du processeur
Génération du code
Espace mémoire libéré explicitement ? : oui (avec delete)
Sinon, un garbage collector est nécessaire pour pouvoir récupérer lesparties du tas qui ne sont plus accessibles par le programme.
Un garbage collector est une fonction run-time qui récupère sur le tas,l’espace mémoire qui n’est plus accessible par le programme.
Cela permet au run-time de satisfaire des demandes ultérieuresd’allocation.
Remarque :
Le garbage collector peut interrompre l’exécution du programme pendant sontravail=> problème pour les systèmes temps réel
496
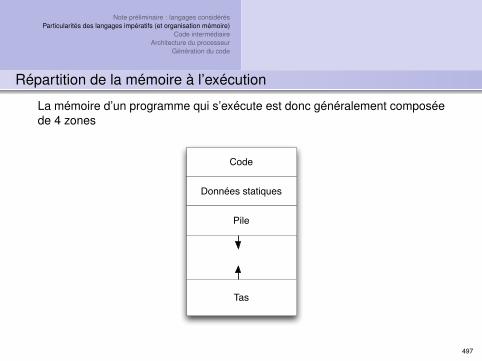
Note préliminaire : langages considérésParticularités des langages impératifs (et organisation mémoire)
Code intermédiaireArchitecture du processeur
Génération du code
Répartition de la mémoire à l’exécution
La mémoire d’un programme qui s’exécute est donc généralement composéede 4 zones
Tas
Données statiques
Pile
Code
497

Un exemple : programme et mémoire associée
Note :
Pour simplifier leschéma, seules lesvariables sontreprésentées sur le tas
int main() //1{ //2int i,j; //3int *p, *q; //4cin >>i; //5p = new int[i]; //6if (i==3) //7{ //8int *r; //9int t=4; //10r=q=new int[i]; //11
} //12delete[] p; //13...
} //14
Code
Après 1 Après 4 Après 6 Après 10
Après 11 Après 12 Après 13
Code Code Code
Code Code Code
qpji
qpji
qpji
qpji
qpji
qpji
[0][1][2]
[0][1][2]
[0][1][2][0][1][2]
[0][1][2]
[0][1][2]
[0][1][2]
tr
tr
tas
pile
}
}bas de la pile
frame 1
frame 2
Note préliminaire : langages considérésParticularités des langages impératifs (et organisation mémoire)
Code intermédiaireArchitecture du processeur
Génération du code
Plan
1 Note préliminaire : langages considérés
2 Particularités des langages impératifs (et organisation mémoire)
3 Code intermédiaire
4 Architecture du processeur
5 Génération du code
499

Note préliminaire : langages considérésParticularités des langages impératifs (et organisation mémoire)
Code intermédiaireArchitecture du processeur
Génération du code
Langages intermédiaires
Deux approches classiques existent :
On utilise un langage intermédiaire avec instructions à 3 adresses deforme générale x := y op z
On utilise le byte-code de machines virtuelles (exemple JVM = JavaVirtual Machine) ce qui peut éventuellement exempter de produire ducode machine.
500

Note préliminaire : langages considérésParticularités des langages impératifs (et organisation mémoire)
Code intermédiaireArchitecture du processeur
Génération du code
Un exemple de machine virtuelle simplifiée : la P-machine
définie dans le livre de Wilhelm et Maurer ; (adaptée au langage Pascal).Une pile d’évaluation et de contexteSP : registre pointeur de sommet de pile (pile : [0..maxstr ])PC : registre pointeur vers l’instruction couranteEP : registre pointeur vers l’emplacement le plus haut nécessaire pourexécuter le block courantMP : registre pointeur vers le début de la frame courante sur la pileNP : registre pointeur vers la dernière zone occupée sur le tascode : [0..codemax ] ; 1 instruction par mot, init : PC = 0types
i : entierr : réelb : booléena : adresse
notationsN signifie numériqueT signifie tout type ou adresse
501

Expressions
Instr Sémantique Cond Resultadd N STORE [SP − 1] = STORE [SP − 1] + STORE [SP]; SP −− (N, N) (N)sub N STORE [SP − 1] = STORE [SP − 1]− STORE [SP]; SP −− (N, N) (N)mul N STORE [SP − 1] = STORE [SP − 1] ∗ STORE [SP]; SP −− (N, N) (N)div N STORE [SP − 1] = STORE [SP − 1] / STORE [SP]; SP −− (N, N) (N)neg N STORE [SP] = −STORE [SP] (N) (N)and N STORE [SP − 1] = STORE [SP − 1] and STORE [SP]; SP −− (b, b) (b)or N STORE [SP − 1] = STORE [SP − 1] or STORE [SP]; SP −− (b, b) (b)not N STORE [SP] = not STORE [SP] (b) (b)equ T STORE [SP − 1] = STORE [SP − 1] == STORE [SP]; SP −− (T , T ) (b)geq T STORE [SP − 1] = STORE [SP − 1] >= STORE [SP]; SP −− (T , T ) (b)leq T STORE [SP − 1] = STORE [SP − 1] <= STORE [SP]; SP −− (T , T ) (b)les T STORE [SP − 1] = STORE [SP − 1] < STORE [SP]; SP −− (T , T ) (b)grt T STORE [SP − 1] = STORE [SP − 1] > STORE [SP]; SP −− (T , T ) (b)neq T STORE [SP − 1] = STORE [SP − 1] ! = STORE [SP]; SP −− (T , T ) (b)
Exemple : add i

Load et store
Instr Sémantique Cond Resultldo T q SP + +; STORE [SP] = STORE [q] q ∈ [0..maxstr ] (T )ldc T q SP + +; STORE [SP] = q Type(q) = T (T )ind T STORE [SP] = STORE [STORE [SP]] (a) (T )sro T q STORE [q] = STORE [SP]; SP −− (T )
q ∈ [0..maxstr ]sto T STORE [STORE [SP − 1]] = STORE [SP]; SP = SP − 2 (a, T )
Utilisation
ldo : met le mot d’adresse q au sommet de la pile
ldc : met la constante q au sommet de la pile
ind : remplace l’adresse au sommet de la pile par le contenu du motcorrespondant
sro : met le sommet de la pile à l’adresse q
sto : met la valeur au sommet de la pile à l’adresse donnée juste endessous sur la pile
Code de x = y ;
Pile← @x ; Pile← y ; sto i

Note préliminaire : langages considérésParticularités des langages impératifs (et organisation mémoire)
Code intermédiaireArchitecture du processeur
Génération du code
Sauts
Instr Sémantique Cond Resultujp q PC = q q ∈ [0..codemax ]fjp q if STORE [SP] == false then PC = q fi (b)
SP −− q ∈ [0..codemax ]ixj q PC = STORE [SP] + q; SP −− (i)
504

Allocation de mémoire et calculs d’adresses (tableaux statiques,dynamiques)
Instr Sémantique Cond Resultixa q STORE [SP − 1] = STORE [SP − 1]+ (a, i) (a)
STORE [SP] ∗ q; SP −−
inc T q STORE [SP] = STORE [SP] + q (T ) and type(q) = i (T )dec T q STORE [SP] = STORE [SP]− q (T ) and type(q) = i (T )chk p q if (STORE [SP] < p) or (STORE [SP] > q) (i, i) (i)
then error(“value out of range′′) fi
dpl T SP + +; STORE [SP] = STORE [SP − 1] (T ) (T , T )ldd q SP + +; (a, T1, T2) (a, T1, T2, i)
STORE [SP] = STORE [STORE [SP − 3] + q]
sli T2 STORE [SP − 1] = STORE [SP]; SP −− (T1, T2) (T2)new if (NP − STORE [SP] ≤ EP) (a, i)
then error(“store overflow′′) fi
else NP = NP − STORE [SP];
STORE [STORE [SP − 1]] = NP;
SP = SP − 2; fi

Gestion de la pile (variables,procédures,...)
Ayant par définitionbase(p, a) ≡ if (p == 0) then a else base(p − 1, STORE [a + 1])
Instr Sémantique Commentaireslod T p q SP + +; STORE [SP] = STORE [base(p, MP) + q] load value
lda p q SP + +; STORE [SP] = base(p, MP) + q load address
str T p q STORE [base(p, MP) + q] = STORE [SP]; SP −− store
mst p STORE [SP + 2] = base(p, MP); static link
STORE [SP + 3] = MP; dynamic link
STORE [SP + 4] = EP; sauve EP
SP = SP + 5
cup p q MP = SP − (p + 4); p est la place pour les paramètres
STORE [MP + 4] = PC; sauve l’adresse de retour
PC = q branchement en q
ssp p SP = MP + p − 1 p = place pour les variables statiques
sep p EP = SP + p; p est la profondeur max de la pile
if EP ≥ NP contrôle la collision
then error(“store overflow′′) fi pile / tas
ent p q SP = MP + q − 1; q zone de données
EP = SP + p; p est la profondeur max de la pile
if EP ≥ NP contrôle la collision
then error(“store overflow′′) fi pile / tas

Note préliminaire : langages considérésParticularités des langages impératifs (et organisation mémoire)
Code intermédiaireArchitecture du processeur
Génération du code
Gestion de la pile (variables,procédures,...)
Utilisation
lod : met sur la pile la valeur d’adresse (p, q) : p liens statiques, qoffset dans la frame
lda : idem mais on met l’adresse du mot sur la pile
str : store
mst : met sur la pile : lien statique, dynamique, EP
cup : branchement avec sauvetage de l’adresse de retour et mise àjour de MP
ssp : allocation sur la pile de p entrées
sep : contrôle si on peut augmenter le stack de p emplacements
ent : exécution en séquence de ssp et sep
Liens statiques et dynamiques : voir référence Wilhelm et Maurer.
507

Note préliminaire : langages considérésParticularités des langages impératifs (et organisation mémoire)
Code intermédiaireArchitecture du processeur
Génération du code
Gestion de la pile (procédures,passages des paramètres,...)
Instr Sémantique Commentairesretf SP = MP; résulat de la fonction sur la pile
PC = STORE [MP + 4]; return
EP = STORE [MP + 3]; restore EP
if EP ≥ NP then
error(“store overflow′′) fi
MP = STORE [MP + 2] restore dynamic link
retp SP = MP − 1; procédure sans résultat
PC = STORE [MP + 4]; return
EP = STORE [MP + 3]; restore EP
if EP ≥ NP then
error(“store overflow′′) fi
MP = STORE [MP + 2] restore dynamic link
508

Note préliminaire : langages considérésParticularités des langages impératifs (et organisation mémoire)
Code intermédiaireArchitecture du processeur
Génération du code
Gestion de la pile (procédures,passages des paramètres,...)
Instr Sémantique Cond Résultatsmovs q for (i = q − 1; i ≥ 0;−− i) (a)
STORE [SP + i] = STORE [STORE [SP] + i];
od
SP = SP + q − 1
movd q for (i = 1; i ≤ STORE [MP + q + 1]; + + i)
STORE [SP + i] = STORE [STORE [MP + q]+
STORE [MP + q + 2] + i − 1];
od
STORE [MP + q] = SP + 1 − STORE [MP + q + 2];
SP = SP + STORE [MP + q + 1];
Utilisation
movs : copie un bloc de taille fixée de données sur la pile
movd : copie un bloc de taille connue à l’exécution
509

Note préliminaire : langages considérésParticularités des langages impératifs (et organisation mémoire)
Code intermédiaireArchitecture du processeur
Génération du code
Gestion de la pile (procédures,passages des paramètres,...)
Ayant base(p, a) = if p = 0 then a elsebase(p − 1, STORE [a + 1])
Instr Sémantique Commentairessmp p MP = SP − (p + 4); set MPcupi p q STORE [MP + 4] = PC; return address
PC = STORE [base(p, STORE [MP + 2] + q]
mstf p q STORE [SP + 2] = STORE [base(p, MP) + q + 1];
STORE [SP + 3] = MP; dynamic linkSTORE [SP + 4] = EP; sauve EPSP = SP + 5
510

Note préliminaire : langages considérésParticularités des langages impératifs (et organisation mémoire)
Code intermédiaireArchitecture du processeur
Génération du code
Label, I/O, et stop
Instr Sémantique Commentairesdefine @i @i = adresse de l’instruction suivanteprin Print(STORE [SP]); SP −− imprime le sommet de la pileread SP + +; STORE [SP] = integer input lecture et mise sur la pile d’un entier; stp fin de programme
511

Note préliminaire : langages considérésParticularités des langages impératifs (et organisation mémoire)
Code intermédiaireArchitecture du processeur
Génération du code
Plan
1 Note préliminaire : langages considérés
2 Particularités des langages impératifs (et organisation mémoire)
3 Code intermédiaire
4 Architecture du processeur
5 Génération du code
512

Note préliminaire : langages considérésParticularités des langages impératifs (et organisation mémoire)
Code intermédiaireArchitecture du processeur
Génération du code
Types de processeurs
En gros, deux grandes classes de processeurs existent :
les machines à registresLes instructions utilisent un ensemble de registres permettant de faireles calculs. Généralement les registres sont spécialisés :
registres générauxregistres pour les calculs flottantsregistres des prédicats (1 bit)pointeur d’instruction courante (PC)pointeur du stack (SP)registres de statuts et contrôlesregistre d’application (rôles spécifiques). . .
Les instructions sont généralement à 1, 2 ou 3 opérandes(du type opcode a1 a2 a3).
513

Note préliminaire : langages considérésParticularités des langages impératifs (et organisation mémoire)
Code intermédiaireArchitecture du processeur
Génération du code
Types de processeurs (suite)
les machines à pileLes instructions utilisent une pile d’évaluation permettant de faire unmaximum d’opérations (calculs, condition de branchement, ...)(Ex : la Java Virtual Machine (JVM))
514

Note préliminaire : langages considérésParticularités des langages impératifs (et organisation mémoire)
Code intermédiaireArchitecture du processeur
Génération du code
Type de processeurs (suite)
On distingue également les processeurs
CISC (Complex Instruction Set Computers) qui ont un grand jeud’instructions avec en général des registres spécialisés (ex :x86,pentium, 680xx)
RISC (Reduced Instruction Set Computers) qui ont un jeu d’instructionstrès limité et en général de nombreux registres universels (SPARC,powerPC, nouvelles architectures, ...)
515

Note préliminaire : langages considérésParticularités des langages impératifs (et organisation mémoire)
Code intermédiaireArchitecture du processeur
Génération du code
Plan
1 Note préliminaire : langages considérés
2 Particularités des langages impératifs (et organisation mémoire)
3 Code intermédiaire
4 Architecture du processeur
5 Génération du code
516

Note préliminaire : langages considérésParticularités des langages impératifs (et organisation mémoire)
Code intermédiaireArchitecture du processeur
Génération du code
Rappels : résultats de l’analyse sémantique
L’output de l’analyseur sémantique comprend :
un arbre syntaxique abstrait décoré (AST)
un (embryon de) graphe de flot de contrôle
une table des symboles structurée permettant de déterminer la portéede chaque identificateur
517

Rappels :AST et graphe de contrôle de flux
Exemple (AST décoré et graphe de flot de l’expressiond + a ∗ (b − c) + (e − f ) ∗ d)
+
+ *
cb
d*
-a
d
fe
-

Rappels :AST et graphe de contrôle de flux
Exemple (AST décoré et graphe de flot d’une instruction if B then I1 else I2endif)
if-then-else
B I1
endif
I2

Note préliminaire : langages considérésParticularités des langages impératifs (et organisation mémoire)
Code intermédiaireArchitecture du processeur
Génération du code
Exemple de graphe de flot de contrôle
Exemple (Graphe de flot correspondant à un simple code)
{int Min=0;for (int i=1; i<n; ++i)if (V[i]<V[Min])Min = i;
return Min;}
i<n
Min=0i=1
V[i]<V[min]
Min=i
return Min
++i
V F
V
F
520

Note préliminaire : langages considérésParticularités des langages impératifs (et organisation mémoire)
Code intermédiaireArchitecture du processeur
Génération du code
Code correspondant à un if
code de eife
then
i1
elsei2
endif
fjp
code du then
code du else
ujp
code de eife
then
i1
endif
fjp
code du then
521

Note préliminaire : langages considérésParticularités des langages impératifs (et organisation mémoire)
Code intermédiaireArchitecture du processeur
Génération du code
Code correspondant à un while
code de ewhilee
do
i1
endwhile
fjp
code du do
ujp
522

Note préliminaire : langages considérésParticularités des langages impératifs (et organisation mémoire)
Code intermédiaireArchitecture du processeur
Génération du code
Représentation d’un bloc de base sous forme de DAG
(DAG = Directed Acyclic Graph) Le DAG contient
un noeud par opérateur et
une feuille par variable / constante utilisée
Exemple (code d’un bloc et DAG associé)
e = a+a*(b-c);f = (b-c)*d;
+ *
cb
d*
-a
e f
523

Note préliminaire : langages considérésParticularités des langages impératifs (et organisation mémoire)
Code intermédiaireArchitecture du processeur
Génération du code
Génération du code correspondant à un bloc de base
Grâce à l’AST (ou AS-DAG),des algorithmes optimisent l’utilisation de registres etl’ordre dans lequel les opérations sont évaluées
Exemple (Pour (a + b)− (c − (d + e)) avec 3 registres)
lw R1 , alw R2 , badd R1 , R1 , R2lw R2 , dlw R3 , eadd R2 , R2 , R3lw R3 , csub R2 , R3 , R2sub R1 , R1 , R2
+b
e
-
-+
d
ca
524

Note préliminaire : langages considérésParticularités des langages impératifs (et organisation mémoire)
Code intermédiaireArchitecture du processeur
Génération du code
Code correspondant à une expression
Exemple (Pour (a + b)− (c − (d + e)) avec 2 registres)
lw R1 , alw R2 , badd R1 , R1 , R2sw R1 , Tlw R1 , dlw R2 , eadd R1 , R1 , R2lw R2 , csub R1 , R2 , R1lw R2 , Tsub R1 , R2 , R1
+b
e
-
-+
d
ca
525

IntroductionLa machine de Turing (TM - 1936)
TM étendues et restreintesClasses des langages RE et R vs classe 0 et classe 1
Propriétés des langages R et RE
Chapitre 13 : Les machines de Turing
1 Introduction
2 La machine de Turing (TM - 1936)
3 TM étendues et restreintes
4 Classes des langages RE et R vs classe 0 et classe 1
5 Propriétés des langages R et RE
526

IntroductionLa machine de Turing (TM - 1936)
TM étendues et restreintesClasses des langages RE et R vs classe 0 et classe 1
Propriétés des langages R et RE
Plan
1 Introduction
2 La machine de Turing (TM - 1936)
3 TM étendues et restreintes
4 Classes des langages RE et R vs classe 0 et classe 1
5 Propriétés des langages R et RE
527

Problèmes que l’on se pose
1 Quel langage est définissable formellement2 Quel problème possède une procédure effective (= procédure
automatisable qui se termine toujours). En d’autres termes quelproblème est-il décidable
3 Quel formalisme utilise t-on pour se poser ces questions (TM = machinede Turing)
Alan Mathison Turing (23 juin 1912 - 7 juin 1954)était un mathématicien britannique et est considéré comme un des pères fondateurs
de l’informatique moderne. Il est à l’origine de la formalisation du concept
d’algorithme et de calculabilité qui ont profondément marqué cette discipline, avec la
machine de Turing. Il a défini la thèse Church-Turing, maintenant largement
partagée, qui postule que tout autre modèle de calcul est définissable par une
machine de Turing (1936) et possède tout ou partie de sa capacité à être
programmée. Durant la Seconde Guerre mondiale, il a dirigé les recherches qui ont
conduit à décrypter le code secret généré par la machine Enigma utilisée par le
camp Nazi. Après la guerre, il a travaillé sur un des tout premiers ordinateurs, puis a
contribué de manière provocatrice au débat déjà houleux à cette période sur la
capacité des machines à penser en établissant le test de Turing.

IntroductionLa machine de Turing (TM - 1936)
TM étendues et restreintesClasses des langages RE et R vs classe 0 et classe 1
Propriétés des langages R et RE
Plan
1 Introduction
2 La machine de Turing (TM - 1936)
3 TM étendues et restreintes
4 Classes des langages RE et R vs classe 0 et classe 1
5 Propriétés des langages R et RE
529

Modèle de la machine de Turing
La machine de Turing est la (une) formalisation admise actuellement pourmodéliser une procédure effective (voir plus bas)
Machine de Turing : description informelle
Automate avec
un contrôle fini
un ruban d’entrée divisé en cellules et infini à gauche et à droite
une tête de lecture / écriture qui examine une cellule à la fois
Contrôle fini
... B B X1 X2 Xi Xn B B ...

IntroductionLa machine de Turing (TM - 1936)
TM étendues et restreintesClasses des langages RE et R vs classe 0 et classe 1
Propriétés des langages R et RE
Modèle de la machine de Turing
Fonctionnement informel de la Machine de Turing
Initialement
les cellules du ruban ont le symbole B (B /∈ Σ)
sauf n cellules contenant l’input (X1..Xn)
la tête de lecture est positionnée sur X1
Un déplacement
change l’état de contrôle
écrit un symbole dans la cellule courante
déplace la tête d’une position à gauche ou à droite
531

IntroductionLa machine de Turing (TM - 1936)
TM étendues et restreintesClasses des langages RE et R vs classe 0 et classe 1
Propriétés des langages R et RE
Définition formelle de la Machine de Turing (TM)
Définition (Machine de Turing (TM))
M = (Q, Σ, Γ, δ, q0, B, F )avec
Q : ensemble fini d’états
Σ : alphabet d’entrée fini
Γ : alphabet fini du ruban avec Σ ⊂ Γ
δ : la fonction de transition δ : Q × Γ→ Q × Γ× D avec δ(p, X ) pastoujours défini et D ∈ {L, R} (Left,Right)
q0 l’état initial
B le symbole blanc avec B ∈ Γ\ΣF l’ensemble des états accepteurs avec F ⊆ Q
532

Description instantanée (ID = état global) d’une TM
... B X1 X2 Xi-1 Xi Xi+1 Xn B ...
p q
r s
{ {α1 α2
Définition (Description instantanée (ID))
ID = (α1, q, α2) ou plus simplement α1qα2 avec
q l’état courant
α1, la chaîne de caractères avant le symbole courant
α2 la chaîne de caractères à partir du symbole courant
Pour pouvoir l’écrire, on oublie dans α1 (resp. α2) les B “initiaux” (“finaux”)

IntroductionLa machine de Turing (TM - 1936)
TM étendues et restreintesClasses des langages RE et R vs classe 0 et classe 1
Propriétés des langages R et RE
Description instantanée (ID = état global) d’une TM
ID particuliers
Si la tête de lecture :
est positionnée k symboles B à gauche du premier symbole 6= BID = qX1X2..Xn avec X1..Xk ces k symboles B
est positionnée k symboles à droite du dernier symbole 6= B,ID = X1..Xn−1qXn avec Xn−k+1..Xn ces k symboles B
534

IntroductionLa machine de Turing (TM - 1936)
TM étendues et restreintesClasses des langages RE et R vs classe 0 et classe 1
Propriétés des langages R et RE
“Mouvement” d’une TM : ID1 `M
ID2 ou ID1 ` ID2
Mouvement d’une TM (ID1M
ID2)
Ayant une TM M = (Q, Σ, Γ, δ, q0, B, F ) avec
δ(q, Xi) = (p, Y , L) : alorsX1X2...Xi−1qXiXi+1...Xn
MX1X2...Xi−2pXi−1YXi+1...Xn
si i = 1 un B est rajouté à gauche dans ID2 (symbole Xi−1)
δ(q, Xi) = (p, Y , R) : alorsX1X2...Xi−1qXiXi+1...Xn
MX1X2...Xi−1YpXi+1...Xn
si i = n un B est rajouté à droite dans ID2 (symbole Xi+1)
535

IntroductionLa machine de Turing (TM - 1936)
TM étendues et restreintesClasses des langages RE et R vs classe 0 et classe 1
Propriétés des langages R et RE
Langage d’une TM
L(M) = {w ∈ Σ∗|q0w∗` αpβ ∧ p ∈ F}
On suppose sans perte de généralité que la TM s’arrête quand elle accepteun mot.Il est possible que pour certains mots non acceptés la TM ne s’arrête jamais
536

Exemple de TM
Exemple
M = ({q0, q1, q2, q3, q4}, {0, 1}, {0, 1, X , Y , B}, δ, q0, B, {q4})
δ SymbolState 0 1 X Y B
q0 (q1, X , R) − − (q3, Y , R) −q1 (q1, 0, R) (q2, Y , L) − (q1, Y , R) −q2 (q2, 0, L) − (q0, X , R) (q2, Y , L) −q3 − − − (q3, Y , R) (q4, B, R)q4 − − − − −
Exemple (Séquence acceptée : 0011)
q00011 ` Xq1011 ` X0q111 ` Xq20Y1 ` q2X0Y1 ` Xq00Y1 ` XXq1Y1 `XXYq11 ` XXq2YY ` Xq2XYY ` XXq0YY ` XXYq3Y ` XXYYq3B `XXYYBq4B
Exemple (Séquence refusée : 0010)
q00011 ` Xq1010 ` X0q110 ` Xq20Y0 ` q2X0Y0 ` Xq00Y0 ` XXq1Y0 `XXYq10 ` XXY0q1B

IntroductionLa machine de Turing (TM - 1936)
TM étendues et restreintesClasses des langages RE et R vs classe 0 et classe 1
Propriétés des langages R et RE
Diagramme de transition d’une TM
Représentation graphique d’une TM
q0 q1 q2
q3 q0q4
start 0/X →
Y/Y →0/0 →
X/X →Y/Y→
B/B→
Y/Y →
Y/Y←0/0←
1/Y←
538

IntroductionLa machine de Turing (TM - 1936)
TM étendues et restreintesClasses des langages RE et R vs classe 0 et classe 1
Propriétés des langages R et RE
Langages récursivement énumérables (RE) et récursifs (R)
Définition (Langage récursivement énumérable (RE))
Langage accepté par une TM, c’est-à-dire langage formé de tous les stringsacceptés par une TM
Définition (Langage récursif (R))
Langage calculé par une TM, c’est-à-dire langage formé de tous les stringsacceptés par une TM qui s’arrête pour tout input.
Note
Un langage récursif peut donc être vu comme un langage tel qu’il existe unalgorithme pour reconnaître ses mots
539

TM pour calculer une fonction entière
La fonction.− est définie comme suit : m
.− n = max(m − n, 0)
Codification :
input : 0m10n
output : les 0 consécutifs donnent la réponse
Exemple
M = ({q0, q1, · · · , q6}, {0, 1}, {0, 1, B}, δ, q0, B)
L’état accepteur est omis car la TM n’est pas utilisée comme accepteur.δ Symbol
State 0 1 Bq0 (q1, B, R) (q5, B, R) −q1 (q1, 0, R) (q2, 1, R) −q2 (q3, 1, L) (q2, 1, R) (q4, B, L)q3 (q3, 0, L) (q3, 1, L) (q0, B, R)q4 (q4, 0, L) (q4, B, L) (q6, 0, R)q5 (q5, B, R) (q5, B, R) (q6, B, R)q6 − − −
TM pour calculer une fonction entière
La fonction.− est définie comme suit : m
.− n = max(m − n, 0)
Exemple
q0 q1 q2
q5 q6
start 0/B →
B/B →
0/0 →
B/B←1/B→
B/B→
0/B→
1/1→
1/1 →
q4B/0→
q30/1 ←
1/B →0/0 ←1/B←
0/0←1/1←

IntroductionLa machine de Turing (TM - 1936)
TM étendues et restreintesClasses des langages RE et R vs classe 0 et classe 1
Propriétés des langages R et RE
Exemple d’exécution pour 4.− 2 (codifié en 0000100)
q0 0 0 0 0 1 0 0q1 0 0 0 1 0 00 q1 0 0 1 0 00 0 q1 0 1 0 00 0 0 q1 1 0 00 0 0 1 q2 0 00 0 0 q3 1 1 00 0 q3 0 1 1 00 q3 0 0 1 1 0q3 0 0 0 1 1 0
q3 B 0 0 0 1 1 0q0 0 0 0 1 1 0
q1 0 0 1 1 00 q1 0 1 1 00 0 q1 1 1 00 0 1 q2 1 00 0 1 1 q2 0
0 0 1 q3 1 10 0 q3 1 1 10 q3 0 1 1 1q3 0 0 1 1 1
q3 B 0 0 1 1 1q0 0 0 1 1 1
q1 0 1 1 10 q1 1 1 10 1 q2 1 10 1 1 q2 10 1 1 1 q2 B0 1 1 q4 10 1 q4 10 q4 1q4 0
q4 B 00 q6 0 542

IntroductionLa machine de Turing (TM - 1936)
TM étendues et restreintesClasses des langages RE et R vs classe 0 et classe 1
Propriétés des langages R et RE
Plan
1 Introduction
2 La machine de Turing (TM - 1936)
3 TM étendues et restreintes
4 Classes des langages RE et R vs classe 0 et classe 1
5 Propriétés des langages R et RE
543

IntroductionLa machine de Turing (TM - 1936)
TM étendues et restreintesClasses des langages RE et R vs classe 0 et classe 1
Propriétés des langages R et RE
Extensions pour les TM
Si l’on restreint une TM à un ruban infini d’un seul côté, on ne diminue pas laclasse de langages acceptés / calculés.Aucune extension proposée n’augmente le pouvoir d’expressivité.
TM avec une mémoire de stockage supplémentaire finie
TM avec un ruban à plusieurs pistes
TM avec sous-routines
TM avec plusieurs rubans
TM non déterministe
544

Traduction TM M1 à k rubans en TM M2 de base
On définit une TM à 2k pistes qui simule M1 :
k pistes pour mettre l’information des k rubans
k pistes pour indiquer la position de la tête
Contrôle fini
B1
x
xA1 A2 AjAi
B2 Bi Bj

IntroductionLa machine de Turing (TM - 1936)
TM étendues et restreintesClasses des langages RE et R vs classe 0 et classe 1
Propriétés des langages R et RE
Traduction TM M1 non déterministe en TM M2 de base
On définit TM2 avec :
une piste contenant les IDi qu’il reste à “exécuter”
un marqueur en plus sur cette piste pour déterminer l’ID suivant
une piste de travail
Contrôle fini
ID1 * xFile d'IDs
Piste de travail
ID2 * ID4 *ID3 * ...
546

IntroductionLa machine de Turing (TM - 1936)
TM étendues et restreintesClasses des langages RE et R vs classe 0 et classe 1
Propriétés des langages R et RE
Qui veut gagner un million de $ ?
Il suffit de répondre à :
La classe des TM qui résolvent un problème en un temps polynomial dans lataille de l’input est-elle égale à la classe des TM non déterministes quirésolvent un problème en un temps polynomial dans la taille de l’input (≡problème dont on peut vérifier une solution en un temps polynomial)
P ?= NP
voir : http://www.claymath.org/millennium/P_vs_NP/
Actuellement on suppute queP 6= NP
547

IntroductionLa machine de Turing (TM - 1936)
TM étendues et restreintesClasses des langages RE et R vs classe 0 et classe 1
Propriétés des langages R et RE
Plan
1 Introduction
2 La machine de Turing (TM - 1936)
3 TM étendues et restreintes
4 Classes des langages RE et R vs classe 0 et classe 1
5 Propriétés des langages R et RE
548

IntroductionLa machine de Turing (TM - 1936)
TM étendues et restreintesClasses des langages RE et R vs classe 0 et classe 1
Propriétés des langages R et RE
Équivalence TM et langage de classe 0
Théorème (Les langages de classe 0 sont RE)
Preuve :Ayant G =< N, Σ, P, S >,on construit une TM M non déterministe a 2 rubans qui accepte le mêmelangage.
le premier ruban contient le string d’input w
le deuxième est utilisé pour contenir la forme phrasée α
549

IntroductionLa machine de Turing (TM - 1936)
TM étendues et restreintesClasses des langages RE et R vs classe 0 et classe 1
Propriétés des langages R et RE
Équivalence TM et langage de classe 0
Théorème ((suite) Les langages de classe 0 sont RE)
Fonctionnement de M :
Init Au départ on met S sur le deuxième ruban, ensuite la TM
1 choisit de façon non déterministe une position i dans α
2 choisit de façon non déterministe une production β → γ de G
3 si β est en position i dans α, remplace β par γ en shiftant ce qui suit (àgauche ou à droite)
4 compare la forme phrasée obtenue avec w sur le ruban 1 :si cela correspond, w est acceptésinon retour au point 1
550

IntroductionLa machine de Turing (TM - 1936)
TM étendues et restreintesClasses des langages RE et R vs classe 0 et classe 1
Propriétés des langages R et RE
Équivalence TM et langage de classe 0
Théorème (La classe RE est incluse dans la classe 0)
Principe de la preuve :Ayant M =< Q, Σ, Γ, δ, q0, B, F >,on construit G =< N, Σ, P, S > avec L(G) = L(M).
551

Inclusion stricte de la classe des langages de type 2 (context-free) dansla classe des langages de type 1 (context sensitive)
Rappels et propriétés
Une grammaire context-sentive a ses règles de la forme α→ β avec|α| ≤ |β|Un langage est context-sensitive s’il est défini par une grammairecontext-sensitive
Les langages context-free sont inclus dans les langagescontext-sensitive
On peut montrer qu’il existe des langages context-sensitive qui ne sontpas context-free (l’inclusion est donc stricte)
Exemple (L02i = {02i| i ≥ 1} est context-sensitive mais pas context-free)
Une grammaire pour L02i :
1 S → DF2 S → DH3 DH → 004 D → DAG
1 GF → AF2 AF → H03 AH → H04 GA→ AAG

IntroductionLa machine de Turing (TM - 1936)
TM étendues et restreintesClasses des langages RE et R vs classe 0 et classe 1
Propriétés des langages R et RE
Langages R versus classe 1 (context sensitive)
R vs context sensitive
On peut montrer que :
Tout langage context sensitive (classe 1) est récursif.Ayant G =< N, Σ, P, S > une grammaire avec les règles α→ β où|β| ≥ |α|, et w ,on peut construire le graphe d’accessibilité à partir de S à toute formephrasée de taille ≤ |w |.et déterminer l’ “accessibilité” S ∗⇒ w
Certains langages récursifs ne sont pas de classe 1 (pas démontré ici)
553

IntroductionLa machine de Turing (TM - 1936)
TM étendues et restreintesClasses des langages RE et R vs classe 0 et classe 1
Propriétés des langages R et RE
Inclusion des classes de langages
En résumé nous avons vu que :
cl 3:réguliers
cl 2:CFLcl 1:CSL
R
cl0 = RE
Non RE
ensemble des langages554

IntroductionLa machine de Turing (TM - 1936)
TM étendues et restreintesClasses des langages RE et R vs classe 0 et classe 1
Propriétés des langages R et RE
Plan
1 Introduction
2 La machine de Turing (TM - 1936)
3 TM étendues et restreintes
4 Classes des langages RE et R vs classe 0 et classe 1
5 Propriétés des langages R et RE
555
IntroductionLa machine de Turing (TM - 1936)
TM étendues et restreintesClasses des langages RE et R vs classe 0 et classe 1
Propriétés des langages R et RE
Théorème (Le complément d’un langage R est R)
Preuve :
Mwoui
nonnon
oui
556

IntroductionLa machine de Turing (TM - 1936)
TM étendues et restreintesClasses des langages RE et R vs classe 0 et classe 1
Propriétés des langages R et RE
Théorème (L’union de 2 langages R est R)
Preuve :
M1w ouioui
M2
nondépart oui
nonnon
557

IntroductionLa machine de Turing (TM - 1936)
TM étendues et restreintesClasses des langages RE et R vs classe 0 et classe 1
Propriétés des langages R et RE
Théorème (L’union de 2 langages RE est RE)
Preuve :
M1w ouioui
M2oui
558

IntroductionLa machine de Turing (TM - 1936)
TM étendues et restreintesClasses des langages RE et R vs classe 0 et classe 1
Propriétés des langages R et RE
Théorème (Si L et_L sont RE alors L (et
_L) sont R)
Preuve :
M1w ouioui
M2 oui non
L et_L sont :
soit tous 2 sont R
soit aucun des 2 n’est RE
soit l’un RE et l’autre non RE
559

Problèmes indécidablesUn exemple de problème indécidable
Technique de réductionCodification (de Gödel) des TM et langages non RE
Langages et propriétés indécidables
Chapitre 14 : Eléments de décidabilité
1 Problèmes indécidables
2 Un exemple de problème indécidable
3 Technique de réduction
4 Codification (de Gödel) des TM et langages non RE
5 Langages et propriétés indécidables
560

Problèmes indécidablesUn exemple de problème indécidable
Technique de réductionCodification (de Gödel) des TM et langages non RE
Langages et propriétés indécidables
Plan
1 Problèmes indécidables
2 Un exemple de problème indécidable
3 Technique de réduction
4 Codification (de Gödel) des TM et langages non RE
5 Langages et propriétés indécidables
561

Problèmes indécidablesUn exemple de problème indécidable
Technique de réductionCodification (de Gödel) des TM et langages non RE
Langages et propriétés indécidables
Problème que les ordinateurs ne savent résoudre
Exemple (Le programme suivant imprime-t-il “hello world” ?)
main(){
printf(‘‘hello world\n’’);}
562
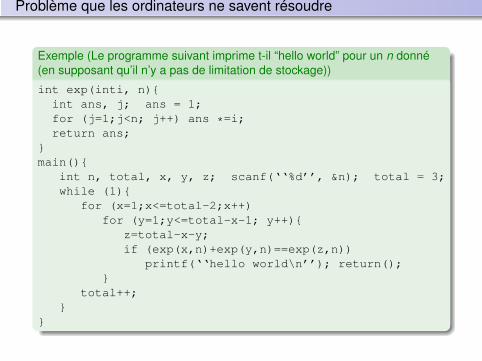
Problème que les ordinateurs ne savent résoudre
Exemple (Le programme suivant imprime t-il “hello world” pour un n donné(en supposant qu’il n’y a pas de limitation de stockage))
int exp(inti, n){int ans, j; ans = 1;for (j=1;j<n; j++) ans *=i;return ans;
}main(){
int n, total, x, y, z; scanf(‘‘%d’’, &n); total = 3;while (1){
for (x=1;x<=total-2;x++)for (y=1;y<=total-x-1; y++){
z=total-x-y;if (exp(x,n)+exp(y,n)==exp(z,n))
printf(‘‘hello world\n’’); return();}
total++;}
}

Problème que les ordinateurs ne savent pas résoudre
Testeur de “hello world”
Peut-on construire un programme H qui
ayant en entrée : un programme P et un input I
détermine si P écrit “hello world” avec I comme entrée ?
H
I
P
oui
non
Le problème : ayant P et I déterminer si P écrit “hello world”, est indécidable
Définition (Problème décidable)
Un problème est décidable s’il existe une procédure effective (unalgorithme) pour le résoudre
sinon le problème est indécidable
Problèmes indécidablesUn exemple de problème indécidable
Technique de réductionCodification (de Gödel) des TM et langages non RE
Langages et propriétés indécidables
Pourquoi les problèmes indécidables doivent exister
Raisonnement
On s’intéresse à des programmes qui répondent “oui” ou “non”,
C’est donc équivalent au problème de l’appartenance d’un string à unlangage,
L’ensemble des langages pour un alphabet fini (d’au moins deuxcaractères) est non dénombrable,
L’ensemble des programmes (étant aussi vu comme une stringd’alphabet fini (typiquement ascii) est dénombrable,
⇒ Un nombre infini continu de problèmes n’ont pas de programme pour lerésoudre
565

Problèmes indécidablesUn exemple de problème indécidable
Technique de réductionCodification (de Gödel) des TM et langages non RE
Langages et propriétés indécidables
Plan
1 Problèmes indécidables
2 Un exemple de problème indécidable
3 Technique de réduction
4 Codification (de Gödel) des TM et langages non RE
5 Langages et propriétés indécidables
566

Problèmes indécidablesUn exemple de problème indécidable
Technique de réductionCodification (de Gödel) des TM et langages non RE
Langages et propriétés indécidables
Le problème du testeur ”hello world” est indécidable
Preuve par contradiction
Hypothèse H existe.Alors on peut construire H1
HI
P
oui
non
oui
hello-worldH1
H1 : reçoit P et I et répond
“oui” si P avec I en entrée écrit “hello world”
“hello world” si P avec I n’écrit pas “hello world”
567

Problèmes indécidablesUn exemple de problème indécidable
Technique de réductionCodification (de Gödel) des TM et langages non RE
Langages et propriétés indécidables
Le problème du testeur ”hello world” est indécidable
Preuve par contradiction
Hypothèse H existe.Alors on peut construire H1 et H2
HP
P
oui
non
oui
hello-worldH1
P
H2
H2 : reçoit P et répond
“oui” si P avec P en entrée écrit “hello world”
“hello world” si P avec P n’écrit pas “hello world”
568

Problèmes indécidablesUn exemple de problème indécidable
Technique de réductionCodification (de Gödel) des TM et langages non RE
Langages et propriétés indécidables
Le problème du testeur “hello world” est indécidable
Que fait H2 avec en entrée H2 ?
H2H2oui
hello world
Répond :
“oui” si H2 avec en entrée H2 répond “hello world”
“hello world” si H2 avec en entrée H2 ne répond pas “hello world”
D’où la contradiction : H ne peut exister
569
Problèmes indécidablesUn exemple de problème indécidable
Technique de réductionCodification (de Gödel) des TM et langages non RE
Langages et propriétés indécidables
Problème décidable
Définition (Problème décidable)
Problème qui a un algorithme pour le résoudre.
Note
Un langage récursif peut donc être vu comme un langage tel qu’il existe unalgorithme pour reconnaître ses mots
Hypothèse de Church ou thèse de Church-Turing
Les fonctions calculables (problèmes décidables) sont les problèmes quipeuvent être calculés par une TM, c’est-à-dire les langages récursifs.
570

Problèmes indécidablesUn exemple de problème indécidable
Technique de réductionCodification (de Gödel) des TM et langages non RE
Langages et propriétés indécidables
Plan
1 Problèmes indécidables
2 Un exemple de problème indécidable
3 Technique de réduction
4 Codification (de Gödel) des TM et langages non RE
5 Langages et propriétés indécidables
571

Problèmes indécidablesUn exemple de problème indécidable
Technique de réductionCodification (de Gödel) des TM et langages non RE
Langages et propriétés indécidables
Réduction d’un problème à un autre
Réduction de P1 à P2
On sait P1 indécidable
On veut prouver que P2 est aussi indécidable
Construitinstance de P1 instance de P2 Décide oui
non
Réduction de P1 en P2
On construit un programme qui transforme toute instance de P1 en uneinstance de P2
Si P2 est décidable, alors P1 aussi
⇒ P2 est indécidable 572
Problèmes indécidablesUn exemple de problème indécidable
Technique de réductionCodification (de Gödel) des TM et langages non RE
Langages et propriétés indécidables
Exemple de réduction
Exemple (Réduction du testeur de “hello world” en testeur de l’appel à unefonction foo)
Transforme une instance de programme pour que s’il écrivait “helloworld”, maintenant, il appelle la fonction foo
Si le testeur d’appel à foo existe, le testeur “hello world” devrait exister
⇒ le testeur d’appel à foo est indécidable
573

Problèmes indécidablesUn exemple de problème indécidable
Technique de réductionCodification (de Gödel) des TM et langages non RE
Langages et propriétés indécidables
Plan
1 Problèmes indécidables
2 Un exemple de problème indécidable
3 Technique de réduction
4 Codification (de Gödel) des TM et langages non RE
5 Langages et propriétés indécidables
574

Codification de TM
Codification de Gödel
On suppose M = (Q, Σ, Γ, δ, q1, B, F ) avec
Q = {q1, q2, . . . , qr}q1 est l’état initial q2 est l’état accepteur (un suffit)
Σ = {0, 1}Γ = {X1, X2, . . . , Xs} avec X1 = 0, X2 = 1 et X3 = B
les directions L = D1 et R = D2
On code
δ(qi , Xj) = (qk , X`, Dm) par C = 0i10j10k 10`10m
M par tous ses codes 111C111C211 . . . 11Cn−111Cn111
Donc
toute TM M correspond à un string binaire < M >.
tout string binaire correspond à une TM (avec la convention que si lestring ne respecte pas la codification, c’est une TM qui ne bouge pas)

Un langage non RE : Ld
Note
La codification de Gödel énumère toutes les TM, et on peut parler de Mi lai eme TM qui correspond à wi le i eme string pour une codification déterminée.
Définition (Ld )
Ld = {wi |wi /∈ L(Mi)}
1 2 3 4
j
1
2
3
4
i
0 1 1 0
1 1 0 0
0 0 1 1
0 1 0 1Diagonale
Mij = 1 ssi wi ∈ L(Mj)

Problèmes indécidablesUn exemple de problème indécidable
Technique de réductionCodification (de Gödel) des TM et langages non RE
Langages et propriétés indécidables
Théorème (Ld n’est pas RE)
Preuve :
∀i : wi ∈ L(Mi) ssi wi /∈ Ld
Donc pour tout i : L(Mi) 6= Ld
Donc aucune TM n’accepte Ld
Théorème (_
Ld est RE (mais pas R))
Preuve :_
Ld n’est pas R sinon Ld le serait aussi_
Ld est RE car on peut construire une TM M (RE) qui simule Mi sur wi
577

Problèmes indécidablesUn exemple de problème indécidable
Technique de réductionCodification (de Gödel) des TM et langages non RE
Langages et propriétés indécidables
Plan
1 Problèmes indécidables
2 Un exemple de problème indécidable
3 Technique de réduction
4 Codification (de Gödel) des TM et langages non RE
5 Langages et propriétés indécidables
578

Lu
Définition (Lu)
Lu = {< M, w > |M accepte w}
Théorème (Lu est RE mais pas R)
Preuve :
Lu est RE : on peut construire une TM Mu qui simule M sur w
Lu n’est pas R : montrons que_
Lu n’est pas R (ce qui implique le résultat)Hypothèse : la TM M_
u “récursive” (càd qui s’arrête toujours) pour_
Lu existe.alors on peut construire M′ “récursive” pour Ld (réduction de Ld vers
_Lu)
M hypothétiquew
ouioui
M'nonnon
Copie <w,w>
⇒ contradiction de l’hypothèse que M_u existe.

Le et Lne
Définition (Le et Lne)
Le = {< M > | L(M) = ∅}Lne = {< M > | L(M) 6= ∅}
Notons que Le et Lne sont des langages complémentaires.
Théorème (Lne est RE)
Preuve :On peut construire une NTM qui accepte Lne
Mi
AccepteMu
Devine w Accepte
Machine pour Lne utilisant la machine universelle Mu

Problèmes indécidablesUn exemple de problème indécidable
Technique de réductionCodification (de Gödel) des TM et langages non RE
Langages et propriétés indécidables
Le et Lne
Théorème (Lne n’est pas R)
Preuve par l’absurde : réduction de Lu à Lne
Hypothèse : Lne est récursif : une TM Mne calcule Lne
Montrons que l’on peut alors construire une TM qui calcule Lu (ce qui estimpossible)On peut construire un algorithme qui à partir de tout < M, w > construitM ′ avec
L(M′) = Σ∗ si M accepte wL(M′) = ∅ si M n’accepte pas w
x
Accepte
M'
Mw Accepte
Machine M’ 581

Problèmes indécidablesUn exemple de problème indécidable
Technique de réductionCodification (de Gödel) des TM et langages non RE
Langages et propriétés indécidables
Théorème (Lne n’est pas R (suite))
la TM pour Lu utilisant Mne est alors :
Mne hypothétique<M,w>
accepteoui
n'accepte pasnonconstruit M' M'
Machine hypothétique pour Lu
⇒ ce qui contredit l’hypothèse
Corollaire (Le n’est pas RE)
Preuve :Lne est RE mais pas R
582

Théorème de Rice sur les langages RE
Note
Le et Lne sont indécidables = cas particulier du théorème de Rice : toutepropriété non triviale sur les langages RE est indécidable càd : il estimpossible de reconnaître les codes de TM dont le langage a la propriété
Définition (Propriété d’un langage RE)
Ensemble de langages RE
Si l’ensemble des langages (ayant cette propriété) est vide ou contienttous les langages, on dit que la propriété est triviale
sinon la propriété est non triviale
Note
Les TM M ont une description finie : L(M) est souvent infini
Pour une propriété P sur les langages RE,LP = {< M > | L(M) a la propriété P}“Décidabilité d’une propriété P” ≡ “décidabilité de LP ”

Théorème de Rice
Théorème (Toute propriété P non triviale des langages RE est indécidable)
Preuve : réduction de Lu à LP
Hypothèse : P est décidable
Supposons que ∅ 6∈ P (sinon on prend la proposition complémentaire)
et qu’un certain langage L ∈ P(L 6= ∅)Une TM ML accepte L
A partir de < M, w > on peut avoir un algorithme qui construit M ′ :
xAccepte
Mw
ML
accepte
départ
L(M ′) = L si M accepte w et L(M ′) = ∅ si M n’accepte pas w.Machine M’ a la propriété ssi M accepte w
On peut ainsi construire une TM qui calcule Lu ce qui est impossible

Problèmes indécidablesUn exemple de problème indécidable
Technique de réductionCodification (de Gödel) des TM et langages non RE
Langages et propriétés indécidables
Conséquences du théorème de Rice
Corollaire (Propriétés indécidables sur les ensembles RE)
Si L est un langage RE les propriétés suivantes sont indécidables :
L est vide
L est fini
L est régulier
L est context free
585

末