Embed Size (px)
Citation preview

1 LESSURPRISES DELAGiNOMlQUE 1
d
.~_. Uncompte ‘apothicai re
* Marseille- G~nopole, Part scientifique de Luminy, case 901, 13288 Marseille cedex 9.
Les ast&isques renvoient au giossaire p. 42
(1) E. Pennisi (2000) Science 288, 1146-1147.
Con&en de g&es dam le g&owe ~u~uin ? On
ne le sait pas encore : entre 30 000 et 120 000.. .
la fourGhe~e est lurge ! Les dernih-es estimations
penchent plutbt pour un chiffre bas, qui red+&
nirait notre vision de la biologic et de l’kvolution :
car la ~o~plexi~~ de l’organis~e Judaic ne se-
rait plus le rksultat d’un nombre trks important
de g&es, mais d’une plus grunde complexite’ dans
1~interaGtiun des g&es entre eux.
a controverse qui est apparue au printemps dernier & propos du
nombre de genes humains (I) doit lais- ser reveurs nombre de nos lecteurs. Comment Z Apres dix ans de pro- grammes Ginome, treize Telethons, des cartes genetiques et physiques an- non&es 2 grand fracas, alors qu’of- ficiellement notre gknome a et6 se- quence a plus de 85 %, non seulement on ne connait pas le nombre exact de genes qui y sont inscrits, mais, de sur- croit, les estimations s’etendent de moins de 30 000 B plus de 120 000 ! L’itonnement provient aussi de la se- rieuse revision & la baisse suggeree par certaines des evaluations les plus re- centes. Alors que I’opinion genitrale semblait tendre vers une valeur proche de 100 000, deux Cquipes au moins annoncent maintenant des nombres inferieurs a 40 000. Pourtant, le se- quencage des genomes, jusqu’ici, a plu- tot mis en evidence des genes qui n’avaient pas CtP prCcCdemment iden- tifies par les techniques gedtiques clas- siques. C’est le cas, par exemple, chez la levure de bike (Saccharomyces ce- revisiue). En realite, la controverse cou- vait depuis plusieurs am&s ; elle prend aujourd’hui un tour aigu en raison de
38 BIOFUTUR 206 l Dkembre 2000
I’obtention d’une stquence quasi com- plete, du fait aussi de I’importance des interets commerciaux en jeu. Si ce debat a lieu, c’est bien sur parce que la definition des genes a partir de la sequence est plus complexe pour le genome humain que pour celui de la levure ou du ver nematode Caenorba~- ditis elegam Chez S. cereuisiae, I’ADN est codant 5 plus de 50 %, la plupart des genes sont dun seul tenant et la prediction des parties codantes a partir de la sequence s’avere rapide et fiable. La quasi-totalite des ORF (open rea- ding frames) *, mis en evidence par l’analyse informatique de la sequence, in s&co, ont ensuite vu leur statut de gene confirme de man&e expkrimenta- le, in viuo. Pour C. elegans, les chases sont un peu plus compliqdes, car les genes sont parfois morcel~s, mais I’in- terpretation reste relativement fiable. Pour I’ADN humain, la dispersion sys- tematique des sequences codantes (qui ne reprisentent en tout que quelques pour cent du gtnomc entier) en une multiplicite d’exons parfois t&s courts et &pares par de longs introns” (~oirkz figwe p. 40) rend leur detection alea- toire. Ce probleme est mis en Cvidence par I’analyse de regions sequencees et
Combien de genes dans nos chromosomes ’ Cents, national de sbquenqage (w,
estimb de 28 000 g&es dans le ghome de
institute for Genomic Research, Rookvilie,
A 120 000.
par ailleurs tres bien connues, notam- ment celle du chromosome 22, le pre- mier chromosome humain g avoir et6 entierement dechiffre (2). De fait, un tiers environ des exons prkdits par les meilleurs programmes d’analyse n’ont pas &existence reeile (faux positifs) et

pr5s d’un tiers des cc vrais )) exons ne sont pas prCdits (faux nCgatifs). Pour- tant, il s’agit li d’Ctudes portant sur des don&es de sCquence cc finie )), de t&s bonne qua& (taux d’erreur infgrieur 5. 0,02 %), g la diff&-ence de la majorit des sCquences aujourd’hui disponibles (2). MZme dans ces conditions opti- males, un gtne qui comporte plusieurs dizaines d’exons, du fait des limites des programmes mentionnkes ci-dessus,
THE: INSTITUTE FOR GENOMIC RESEARCH
gndis que 1’6quipe de Jean Weissenbach, au
Evry) annon@t au pfintemps 2000 un nombre
I’homme, John Quackenbush, au TIGR (The
Maryland, itats-Unis) Bvaluait ce nombre
sera presque toujours incorrectement prkdit. En outre, il sera bien difficile de dCterminer si la trentaine de r&ions codantes dCtect6es dans une region donnCe font partie d’un seul gsne, ou de plusieurs - d’autant que l’on sait tr&s ma1 reconnaitre les promoteurs qui en
indiquent le dCbut, faute d’une sCquen- ce consensus suffisamment nette. L’uti- lisation d’une sequence (s brouillon a), au taux d’erreur important et morcelPe en fragments dont I’ordre et I’orienta- tion ne sont pas toujours assui+s, ne fait que compliquer I’analyse. Les (( signaux H - par exemple, les sCquences CaractPristiques de dPbut et de fin d’exon -, dPji tr6s flous, devien- nent fort difficiles h repPrer lorsque le taux d’erreur atteint 0,l ou mime 1 % : une seule base fausse, OLI sumumCraire, suffit ainsi ?I tronquer ou j dCcaler une phase ouverte de lecture. 11 faut done obligatoirement - du moins dans I’Ctat actuel des connais- sances - utiliser d’autres informations pour repCrer et compter les g&es. La mPthode la plus employee depuis plu- sieurs annPes repose sur I’emploi des sequences partielles d’ADN complC- mentaire (ADNc)“. Ces skquences partielles, nommkes EST (expwsse~ sequence tags) ou ktiquetres de skquence exprimCe, sont accumulCes par millions depuis le dibut des annCes 1990. La comparaison d’un EST avec une sCquence genomique conduit en effet au rep&age de zones homologues qui, normalement, cor- respondent 1 des g&es ewprimbs. La mkthode s’accommode bien de don- &es de type (q brouillon ‘), une simili- tude g 97 ou 98 % &ant en g6niral aussi rPvClatrice qu’i 100 %. La detection des genes dans les sPquences d’ADN humain fait done un usage intensif de ces donnPes, qui ont PrP dkterminantes pour le succ~s de nom- breux travaux ricents en gCnPtique mCdicale. Leur emploi pour evaluer globalement le nombre de nos g&es pose nCanmoins quelques problimes.
> Les clusters d’lJnigene
Nous disposons aujourd’hui dans les bases de don&es publiques (3) de plus de deux millions de sCquences partielles d’ADNc humain. Plusieurs industriels, notamment Human Genome Sciences (Rockville, Mary- land, itats-Unis) et Incyte (Palo Alto, Californie, I&ats-Unis), affir- ment pour leur part en dCtenir un nombre encore plus PlevC. Bien entendu, notre ginome ne comporte pas des millions de g&es : la collec- tion prCsente une forte redondance, due au fait que ces sequences ont it6 obrenues h partir de clones pris au hasard dans de nombreuses banques d’ADNc etablies ?I partir de divers tissus ; par conskquent, plusieurs de ces sequences partielles peuvent correspondre i des parties diff&
rentes, souvent - mais pas toujours - chevauchanres, d’un mime gene exprim6. On peut done comparer toutes ces sequences entre elk3 (et aussi utiliser les dutres informations contenues dans les bases de don&s) afin de regrouper celles qui, il [1~ioif, proviennenr du mtlme g&e. C’est le bur de la construction de repertoires nommts get?” indrses, qui resulrent de I’anatysr des srquenccs par LIII
ensemble de Iogicicls de regroupe- ment. Le plus connu est Unigene (4),
Ic systtmc officiel 22, donr le\ rPsul-
tafs constanimenr tcnus 5 jour sotiT
disponihles sur le ,ite du National (:entcr for Biotechnology Informa- tion (NCBI) (5). La version 172 (sep- tembre 2000) comporte 83 94.5 “ clusters ,“. On pourrait done considtrer que l’ensemble de ces donnees indique I’euistence d’au mains 80 000 +nes dans notre g&o-
me. Reste :1 Pvalucr ce qui manque dans la base de don&es dbEST : bien que ces deuv millions de sbquences aient btb d6termin&s i partir de clone\ issus de trPs nombreuses banques d‘ADNc rPalis6es en utill- sant tous les rissus imaginables (OLI
du moins accessibles), il pcut mw jours esistrr des g&es r&s peu espri- nits, OLI esprim6s uniquement dCins
un tissu bien particulier i LIP instant prC& du d&eloppemenr cmbryon- wire, et q,li t!chapperaienr alnsi :1 cc‘ coniptage. Line maniPre simple d’es- rimer cetre correction consisre :1 considPrer I’ensemble des &es qui ont 6tt idenrifibs dans le cadre de la rechcrche sur Its maladies g&t!-
tiques, et j d&erminer quelle frac- tion de ces derniers est rept&ent& dans dbEST. Cette 6valuation, effec- tu6e par Ir NCBI et consultable sur son site. donnc un chiffre de 90 “0 : elle esr ctitiquable a diffCrenrs Pgards, mais on peut sans doute rerc- nir son ordre de grandeur et considt- rer que la grande majorit de 110s
gines som reprCsentPs dans dbEST. L’on arriw ainsi au chiffre. souvenr cirC, d’en\iron 100 000 genes d,lns
notrc g&omc. C.'e\t :I pnrcir d’une analyse dc ce type que I’equipe de Craig Venter, au TIGR (The Institute for Genomic Research, Rockrille, IMaryland. ctats-Unis) avait proposi en 199.5 une fourchette de 60 000 i 70 000 genes (6) ; diverses estimations du mime ordre ant Pt6 realiskes depuis - la derniere, celle de I’byuipe de John Quackenhush (toujours au
TIGR) aboutissant 5 une valeur de 120 000 g&nes (7). Nous reviendron\ sur cette ttude mute ricente ,~pj-c~\ avoir indiqu6 la nature des probl(.,~l~\
(2)l. Dunham eta/ (1999) Nature 402 (6761).489-495
(3)www ncbl.nlm nlh.gov/dbEST/ dbEST_summary
(4)M.S. Boguski. G.D.Schuler(1995) Nat. Genet. 10. 369-371
(5)www.ncbi.nlm. nih.govi
(6)M.D.Adams et al. (1995) k!afure 377,3-174
(7) F Llang eta/. (2000) mat. Genet 25.239-240
. . .
BIOFLlTLl7 206 l D&xn~bi .YOO 39

1 LESSURPRISES DELAGiNOMlQUE 1
. . . que pose ce genre de calcul et don& une idee du fondement des nouvelles &valuations.
> Les problkmes de dbEST et d’lJnigene
(8) www.tigr.org La fiabilitk des gene indexes est en effet discutable, pour des raisons qui tiennent i la fois au contenu de dbEST (ou d’autres bases de don&es similaires) et aux mithodes de regroupement utilisCes. Les courtes skquences qui constituent les EST (300 B 500 nuclkotides en gCnCral) proviennent de I’extrCmitC 5’ ou 3’
de clones d’ADNc pris au hasard dans des banques rtalisCes 5 partir de diffkrents tissus. 11 s’y glisse i I’occa- sion des contaminants : fragments d’ADN genomique, introns non Cpis- sk, ou mime traces d’ADN bactC- rien. Or ces banques ont gCnCrale-
ment et6 igaMes, c’est-g-dire qu’elles ont subi un traitement (i base de dknaturation et de kassocia- tion contrbkes de I’ADNc avant clo- nage) visant h rkduire la fkquence des skquences d’ADNc les plus abon-
dantes, correspondant au petit
nombre des g&nes les plus exprimts. On espkre ainsi augmenter la chance
I’Cgalisation des banques va ramener i une abondance tquivalente le rranscrit majeur et le produit trks rare d’un Cpissage aberrant, pas nkessairement significatif du point de vue biologique. Deux EST obte- nus g partir de ces transcrits peuvent parfaitement ne pas contenir de skquence commune et done appa- raitre comme les produits de deux gPnes diffkrents. Vient ensuite la mkthode utiliske pour regrouper ces siquences partielles en clusters. Afin de tenir compte des pro- bkmes que je viens de mentionner, on effectue une filtration prkalable des skquences, pour Ccarter par exemple celles qui ont une composition en bases par trop anormale pour de I’ADNc humain ; puis on effectue l’assemblage le plus p&is possible. Mais, compte tenu du taux d’erreur des kquences contenues dans dbEST (au moins 1 %, souvent plus), la qualid du regroupe- ment rialise reste problkmatique. En outre, la plupart des artefacts &oquis plus haut tendent g augmenter le nombre de clusters, et done le nombre apparent de g&es. Notons par exemple que, sur les 84 000 clusters d’unigene, plus de 27 000 sont dCfinis par un seul EST... II est assez peu vrai-
purement et simplement ces 30 000 clusters du seul fait qu’ils contiennent une seule siquence. On comprend done que I’analyse et le regroupement des EST en clusters cor- respondant i des gknes prksomptifs pksentent de multiples difficult&. I1 existe d’ailleurs toute une sPrie d’autres gene indexes (par exemple celui de TIGR, consultable sur son site (8)) construits par diffkentes Pquipes essayant de rkoudre les probltmes dont nous avons rCsumC ci-dessus la nature. On confoit aussi que la dCduc- tion du nombre de g&es humains a partir de ces donnCes soit plus com- plexe que l’approche nai’ve &oquCe plus haut. Les rkentes donnkes de skquence obtenues sur le gtnome de I’homme et d’autres espkes offrent- elles une voie alternative ?
> L’apport du skquenqage complet de chromosomes
La kquence compkte du chromoso- me 22 a CtC publike g la fin de l’an-
nCe 1999 par un ensemble de labora- toires oii le Sanger Centre britan- nique apparait comme le principal
producteur de donnees (2). Aprks I’avoir analyske de faGon dCtaillCe
EST 5’ -v--
EST 3’
L’Bpissage alternatif permet de produire des ARN messagers diffbrents, et done des prot&nes diffbrentes,
?I partir d’un meme gene. Ici, I’un des deux exons 2 ou 2’ est dlimin6 en m6me temps que les introns.
Les deux ARN messagers rksultants sont copiBs en ADN compkmentaires (ADNc), et les extr6mitk 5’ et 3’ sont
&quen&es pour produire des Etiquettes de sequence exprimee (EST). Toutefois, I’enzyme qui copie I’ARN en ADN
?I partir de I’extr6mit6 3’ s’arr6te souvent avant d’avoir atteint I’extrkmit6 5’. Du coup, les EST &quen&es du c&B
5’ peuvent tomber dans les exons alternatifs. Ne presentant pas de kgions chevauchantes, elles seront alors
comptabiliskes comme appartenant a des genes diffkents.
de trouver de cc nouveaux 11 g?nes par skquengage au hasard des clones d’ADNc. Toutefois, ce traitement, s’il amkliore en effet la richesse des banques, augmente aussi la propor- tion des skquences provenant d’CvC- nements artefactuels rares, comme ceux que nous venons d’koquer. De plus, beaucoup de genes prkentent des phCnomknes d’Cpissage alternatif produisant plusieurs transcrits i par- tir d’un mCme ensemble d’exons (voir la figure ci-dessus). Lg aussi,
40 BIOFUTUR 206 l Dkembre 2000
semblable qu’un (( vrai )) gke ait CtP par toutes les mkthodes disponibles, CchantillonnC une seule fois en deux les auteurs du sequenlage ont avan&
millions de skquences, et probable que un nombre total de 679 gknes (dont la majorit& de ces EST (et done des 134 pseudogknes). Puisque ce chro-
clusters correspondants, form& d’une mosome reprkente environ 1,l % de
seule skquence) appartiennent 5 la notre ADN, une simple rkgle de trois
catkgorie des artefacts. Toutefois, il est indiquerait environ 61 000 gkes
impossible d’exclure qu’un gkne, expri- pour l’ensemble de notre gtnome. Si
mt par exemple 8 t&s bas niveau dans l’on tient compte d’autres donnkes
l’embryon, ait pu effectivement donner selon lesquelles ce chromosome est
naissance i un seul EST au sein d’une un peu plus riche en genes que la banque construite i partir d’un fcetus moyenne, d’un facteur CvaluC 1 1,38, prkcoce, et il est done dklicat d’kliminer le nombre redescend g 45 000. Ces

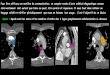
Comparaison du gene de la huntingtine chez I’homme et le fugu, un Poisson cousin de Tetraodon nigroviridis. On constate que I’ordre et
la taille des exons du gene (connect& par les lignes courbes) sont conserves, alors que les introns sont considerablement plus reduits
chez le fugu. Cette compacite s’etend a tout le g&iome du poisson, ce qui en fait un outil precieux pour la genomique fonctionnelle.
(D’apres S. Baxendale et al. [1995] Nat. Genet. 10, 67-76).
chiffres restent eminemment contes-
tables, malgre la qualite de la sequence obtenue (taux d’erreur infe- rieur a 0,02 %). Uestimation a partir d’un Pchantillon representant a peine plus de 1 % de notre gtnome est en effet aleatoire, la precision des fac- teurs utilises pour I’extrapolation est limitee, et le chiffre m@me de 679 genes sera sans doute revise apt& des etudes plus approfondies. La mise en evidence des genes dans la sequence du chromosome 22 a d’ailleurs large- ment fait appel aux don&es de dbEST ; il ne s’agit done pas d’un comptage reellement independant. La sequence suivante, celle du chro- mosome 21, a ete publiee en mai 2000 (91, et indique 225 genes pour une region correspondant a 1 % du genome : ce chiffre, inferieur de moi- tie a celui du chromosome 22, qui est pourtant sensiblement de meme taille que le 21, illustre bien les incerti- tudes de ce type de comptage. Au fur et a mesure que R sortiront )s les sequences completes des differents chromosomes humains, la represen- tativite de I’echantillon va certes s’ameliorer, mais il restera encore un doute sur le nombre de genes annon-
CC pour chacun d’eux et sur les erreurs possibles, par exces ou par defaut, selon les methodes utilisees. Pour vraiment Cvaluer le nombre total de genes contenus dans notre ADN, il faut non seulement disposer d’une fraction reellement significati- ve de la sequence du ginome, mais aussi savoir l’exploiter de maniere purement informatique pour y detecter les genes. On voit que nous sommes loin du compte...
Pchantillon pour detecter des genes dans le genome humain. On peut en effet penser (et les etalonnages preli- minaires rralises sur des genes humains connus le montrent) que les seules regions conservees entre ces deux ADN separes par quatre cents millions d’annees du point de vue de I’ivolution sont les zones codantes : du fait de la pression de selection, celles-ci ont moins diverge, et presen- teraient encore un taux d’homoloaie
> Exofish entre en scene significatif. Diverses mises au point ont abouti a la methode baptisee Exofish, qui definit, a partir de la
(12) H. Roest Crol- lius eta/. (2000) Nat. Genet 25,235-238.
On se souvient du fugu, ce Poisson comparaison des sequences de japonais au genome tres compact l’homme et du poisson, des regions (400 megabases, contre 3 000 chez conservees au tours de I’evolution, I’homme, pour un jeu de genes com- baptisees Ecores (evolutionary
parable au notre) dont Sydney Bren- conserved regions). 11 suffit ensuite ner avait preconise I’ttude au debut de deduire du nombre d’Ecores le des an&es 1990 (10,ll). Le Gcnosco- nombre de genes. Sans rentrer dans pe, pole franfais de sequencage ins- le detail des calculs, decrits dans un talk en I997 a gvry, avait des le article bien documente paru en juin debut choisi de s’inttresser a ce 2000 dans Nature Genetics (vz),
modele, prenant pour objet d’etude disons qu’ils paraissent convain- Tetraodon nigroviridis, un cousin cants : l’application de cette methode non toxique du fugu. Ayant obtenu predit environ 600 genes sur le cho- plus de cent megabases de sequence mosome 22, et les differents tests sur son genome, l’equipe du Geno- effect&s donnent des resultats rai- scope a cherche i employer cet sonnables. Bien entendu, la methode . . .
(9) M. Hattori etal (2000) Nature405, 311-319.
(10) B.R. Jordan (1994) MWSci 10, 1154-1156.
(11) G. Elgar eta/. (1996) Trends Genet. 12, 145-150
BlOFUTUR 206 l DBcembre 2000 41

1 LESSURPRISES DE LAGfNOMIQUE 1
(13) 9. Ewing, P. Green (2000) Nat. Genet. 25, 232-234.
(14) www.ensembl. org
(15) A.A. Mironov er al. (1999) Genome Res. 12, 1288-1293.
(16) D. Bretta eta/. (2000) FEBS Lett 474, 83-86.
(17) www.ensembl. org/genesweep.html
l me n’exige pas que I’on dispose de l’en- semble de la sequence de l’un ou l’autre organisme. Uapplication de cette procedure aux 42 % du genome humain contenus dans les bases de don&es publiques en dtcembre 1999, en majeure partie
entre les deux ensembles Cchantillon- nes seront frequents. En fait, avec des hypotheses raisonnables, on trouve que le nombre total de genes est Cgal a n, x n2 / ml. L’important, naturelle- ment, est de bien choisir les jeux de sequences. Pour le premier jeu 12,, les
aboutissent a un nombre de genes (q confirm& )) de I’ordre de 30 000 (14). Compte tenu des methodes employees, il ne s’agit la que dune valeur minimum, qui peut encore augmenter dans l’avenir, mais elle donne une limite inferieure fiable.
5 g
: 8 , gLj&*dll.~~ I!1 , , , I I II II I
i 20000
,
40000 60000 80000 100000 120000 140000 160000 180000 2000
ttat des paris sur le nombre de genes du g6nome humain, tel qu’il apparaissait le 15 novembre 2000 sur le site
d’ENSEMBL, le programme d’annotation de I’lnstitut europeen de bio-informatique (EBI). Les paris ont ete ouverts
en mai dernier, a la reunion de Cold Spring Harbor sur le genome humain. La moyenne des 228 pans est d’environ
62 600 genes, avec une valeur maximale de 200 000 et une valeur minimale de 27 462.
sous forme d’c( tbauche de travail )) (working dvaft), indique un peu moins de 12 000 genes, soit presque 28 000 pour l’ensemble du genome. En cc tirant s> au maximum les diffe- rents paramttres vers une estimation plus haute, les scientifiques du Geno- scope arrivent a 34 000. En tout etat de cause, ce chiffre est tres bas par
rapport a ce qui Ctait generalement admis. 11 semble pourtant avoir Ctt Ctabli de maniere serieuse... et il est en accord avec une autre analyse rtcente, pourtant fondee, elle, sur l’utilisation des EST.
> Une autre manihe d’employer les EST
Dans le meme numero de Nature Genetics (IS), Brent Ewing et Phil Green - connu notamment pour ses
performants algorithmes d’assemblage de sequence, a l’universid de Washing- ton a Seattle @tats-Unis) - ont applique aux donnees de sequence humaine une methode deja employee pour le ver nematode C. elegans. En bref, il s’agit de mesurer le recouvre- ment entre deux jeux incomplets de sequences de genes (effectifs n,, nz) dont Pun au moins ne doit pas presenter de biais. 11 est aise de comprendre que le nombre rnz de recouvre- ments dependra du nombre total de genes : plus ce dernier est Pleve, moins les recouvrements
auteurs ont pris, soit les 679 genes definis sur le chromosome 22, soit une serie de 7 600 genes obtenus en regroupant les sequences completes d’ARNm (et non plus les douteuses EST) contenues dans Genbank. On peut argumenter que ces deux collec- tions sont assez proches d’un echan- tillonnage au hasard. Le deuxieme jeu n2 est construit a partir de dbEST, en ne retenant (avec des criteres de qualite assez stricts, y compris un reexamen des donnees de sequence brute) que les clusters contenant l’ex- t&mite 3’ de I’ARNm, ce qui Climine deja tous les contaminants qui ne sont pas des ARN messagers : les auteurs en definissent un peu plus de 43 000 a partir d’un million d’EST. Notons qu’ils ne considerent pas que ces 43 000 clusters representent autant de genes : ils savent que ce jeu peut itre redondant et l’utilisent comme un des echantillons de leur methode. 11s determinent alors la fraction de sequences en commun entre le jeu N, de reference et le jeu nz tire de dbEST, et en deduisent une estimation du nombre total de genes. Les calculs men& a partir de I’un ou l’autre des deux jeux de sequences n, retenus aboutissent pratiquement au mime chiffre, soit environ 34 000 genes ! Cette utilisation intelligente de don&es partielles, assortie d’un regard trts critique sur la qualite des sequences contenues dans dbEST, aboutit done a un resultat qui confor- te celui du Genoscope. Notons enfin que les premiers essais d’interpreta- tion de l’ensemble de la sequence humaine, utilisant autant que pos- sible toutes les donnees existantes,
> L’unanimit6 n’est pas atteinte : TIGR contre-attaque
Cette serie d’articles dans Nature Genetics se termine neanmoins sur une estimation haute, celle de l’equipe de John Quackenbush au TIGR (7). I1 s’agit cette fois de la construction d’un gene index tense Ctre de tres haute qualite, et de son emploi pour predire le nombre total de genes contenus dans notre ADN. Les auteurs ont tente de resoudre les differents problemes men- tion&s precedemment. 11s sont partis de 1,6 million d’EST tires de dbEST, en ont elimine p&s de 100 000 suspect& d’etre des contaminants. 11s ont ensuite assemble ces sequences entre elles (en utilisant leurs propres programmes et des criteres stricts) et avec un jeu de 54 000 sequences completes ou incom- pletes de transcrits humains principale- ment obtenues a partir de la base de don&es Genbank. 11s ont elimine tous les clusters contenant un seul EST - il y en avait plus de 300 OOO... soit dix fois plus que dans Unigene, sans doute du fait de criteres d’assemblage plus res- trictifs - pour obtenir un chiffre de 75 000 clusters. 11s ont constate que seulement 55 % des genes connus (annotes dans Genbank) sont contenus dans ces clusters, et en deduisent done que le nombre total de genes est de 75 000 / 0,55, soit 136 000. En intro- duisant une correction pour tenter de tenir compte de l’epissage alternatif, leur estimation descend a 110 000. Les scientifiques du TIGR ont par ailleurs compare leurs 75 000 clusters aux donnees de sequence du chromosome 22, ou ils ont pridit pres de 1 800 genes (au lieu des 679 trouves) ;
42 BlOFlJTUR206 l Dhxmbre2000

I’extrapolation au genome entier
donne cette fois un total de 120 000 genes.
Ces resultats sont done en contradic- tion avec les deux articles discuds pre- cedemment, mais comcident avec les valeurs avanctes par les acteurs indus- triels de ce domaine : depuis longtemps, tant Human Genome Sciences - entre- prise avec laquelle TIGR, au debut de son existence, entretenait des liens tres etroits - que Incyte annoncent des chiffres largement superieurs a 100 000. Des esprits malveillants pour- raient y voir une man&e pour ces entreprises de valoriser leur (c tresor de guerre sb vis-a-vis de leurs clients. Une publicite d’htcyte montre qu’un tel souEon n’est pas totalement absurde. Elle figurait en bonne place dans le numero du 18 mai 2000 de la revue Nuttlre, et annoncait 60 000 genes cc not available anywhere else )). . . en s’appuyant sur une estimation de 120 000 genes humains fondee sur l’analyse de la base de don&es de la firme. gvidemment, si le nombre total
de genes tombe a 30 000 ou 40 000, cet argument de vente devient beaucoup moins seduisant ! Plus serieusement, il n’est pas certain que les scientifiques du TIGR, malgre leurs efforts, aient reelle- ment pu &miner tous les Ccueils de la construction d’un gene index, notam- ment quant a la question de l’epissage altematif. La correction de 20 % envi- ron qu’ils introduisent pour en tenir compte semble bien faible en regard des donnees recentes indiquant que la fre- quence du phenomene est de l’ordre de 35 P 40 % (X,X), d’autant plus que l’egalisation des banques, tout comme la construction des clusters, tendent a majorer sa contribution au nombre apparent de genes.
> Un pari et des conshquences
Cette question du nombre des genes humains suscite un grand indret dans le milieu des genomistes, avec un vif debat lors de la derniere reunion de Cold Spring Harbor en mai 2000. Elle est a l’origine d’un sweepstake
dont les regles sont accessibles sur Internet, tout comme l’etat actuel des paris (17). On voit (figure p. 42) que l’eventail est large, de moins de 30 000 a 200 000 (le petit nombre de parieurs est du au fait qu’il faut etre physiquement present i Cold Spring Harbor pour s’inscrire). Resultat et designation du gagnant a Cold Spring Harbor en 2003... Je n’ai pas encore enregistre mon pari, mais il se situera, on I’a devine, dans la fourchette basse de I’estimation.
Plus serieusement, ce nombre presente
une grande importance pour notre comprehension de la biologie et de I’Cvolution. Si reellement nous n’avions que 30 000 ou 40 000 genes, a peine deux fois plus que le petit ver C. elegans avec ses 959 cellules, sa physiologie et son comportement certes fascinants mais neanmoins fort simples par rap- port aux notres, cela impliquerait que la complexite de I’organisme dicoule essentiellement de la regulation des genes, de leurs interactions et de celles de leurs produits - et non avant tout de leur nombre. Cela nous Ploigne de cer- taines visions simplistes, implicites dans la presentation de I’ADN comme maitre-plan (blueprint) de I’organisme, et montre quelle variete de structures et de fonctions peut decouler d’un nombre d’elements genetiques relative- ment restreint mais dont la combinatoi- re atteint une tres grande complexiti. Sur le plan pratique, cela souligne I’im- portance de toutes les etudes fonction- nelles, de cet apres-genome dont la plu- part des outils restent a developper, sinon a inventer.
D’autres consequences d’une revision a la baisse sont a attendre. En ce qui concerne les mecanismes de l’evolu- tion, il etait assez courant, ces derniers temps, d’evoquer un processus de
double duplication get&ale du geno- me (titraploidisation) menant des 17 000 genes de C. elegans ou de la drosophile aux 80 000 genes humains alors pressentis. Cette siduisante hypo- these d’une double copie des genes, sui- vie de la divergence des sequences per- mettant l’apparition de nouvelles fonc- tions, devient peu vraisemblable. Sans doute sera-t-on aussi conduit a une reevaluation du role biologique de I’tpissage alternatif, dont les vicissi- tudes des gene indexes nous revelent la frequence insou&onnCe. L’incertitude actuelle souligne aussi, naturellement, la ntcessite de progres dans les methodes d’annotation de genomes complexes. II semble que les avandes soient assez lentes dans ce domaine, les performances des logiciels de detection de genes a partir de la sequence d’ADN n’ayant pas beaucoup evolue ces dernieres an&es (voir Particle de
J.L. Risler et A. Louis, p. 44). La dis- ponibilite de grandes quantites de don- nees issues des genomes complexes va certainement stimuler la recherche et, peut-etre, amener a mettre I’accent sur d’autres approches, comme le montre Particle du groupe du Genoscope. Les mathematiciens, de plus en plus nom- breux a s’interesser a I’interpretation du genome, devraient trouver 11 matiere a de fructueux travaux. 0