
1
Sommaire:
I. Introduction........................................................................................................................... 4
II. Solvency 2, présentation et contexte actuel....................................................................... 4
III. Approche standard, approche par les modèles internes ................................................ 6
III.1. Présentation ................................................................................................................... 6
III.2. Utilités d’un modèle de risque globale ......................................................................... 6
III.3. Etapes de calcul d’un modèle interne............................................................................ 7
IV. Provision Best Estimate, marge de risque, approche "coût du capital" ...................... 9
IV.1. Présentation................................................................................................................... 9
IV.2. Best estimate ................................................................................................................. 9
IV.3. Marge de risque (MVM), approche de calcul par le coût du capital (Cost of Capital)
.................................................................................................................................................. 10
V. Capital de solvabilité requis (SCR).................................................................................. 13
V.1. Mesures de risque VaR ou TVaR................................................................................. 13
V.2. Horizon temporel.......................................................................................................... 14
V.3. Capital porteur de risque .............................................................................................. 14
V.4. Minimum du capital requis (MCR) .............................................................................. 15
V.5. Capital de solvabilité requis (SCR) .............................................................................. 15
VI. Actif et risques de marché............................................................................................... 19
VI.1. Présentation................................................................................................................. 19
VI.2. Modélisation des actions et des actifs immobiliers..................................................... 19
VI.2.1. Introduction...................................................................................................... 20
VI.2.2. Présentation du modèle .................................................................................... 21
VI.3. Modélisation des obligations, modèle de taux ............................................................ 21
VI.3.1. Présentation...................................................................................................... 22
VI.3.2.Le modèle de COX, INGERSOLL et ROSS .................................................... 23
VI.3.3.Limites de ce modèle ........................................................................................ 23
VI.4. Corrélation et dépendance........................................................................................... 24
VII.4.1. Présentation..................................................................................................... 24
VI.4.2. Les limites de la covariance ............................................................................. 24
VI.4.3. Théorie des copules.......................................................................................... 25
VI.4.3.1. Quelques définitions ............................................................................ 25
VI.4.3.2.Copule archimédienne, copule elliptique.............................................. 27

2
VII. Passif et risque d’assurance non-vie ............................................................................. 30
VII.1. Présentation................................................................................................................ 30
VII.2. Modélisation dynamique des cash-flows futurs ........................................................ 30
VII.3. Calcul de la provision Best Estimate à la date t = 0 (BE (0)) .................................... 32
VII.4. Calcul de la distribution du montant total de sinistres payés de 0 à 1 ....................... 33
VII.5. Calcul du Best Estimate à la date t = 1 (BE(1))......................................................... 33
VIII. Outils mathématiques et statistiques .......................................................................... 34
VIII.1. Processus stochastiques usuelles .............................................................................. 34
VIII.2. Méthodes statistiques pour l’estimation des paramètres .......................................... 35
VIII.2.1. Modèle de régression linéaire, moindres carrées ordinaires (MCO)............. 35
VIII.2.2. Modèle de régression non linéaire, moindres carrées non ordinaire ............. 36
VIII.2.3. Méthode des moments, méthode mu maximum de vraisemblance............... 37
VIII.3. Méthode de simulation Monte-Carlo ....................................................................... 37
VIII.3.1. Présentation ................................................................................................... 38
VIII.3.2. Simulation de distributions discrètes............................................................. 38
VIII.3.2. Simulation de distributions continues ........................................................... 40
IX. Estimation des paramètres et application numérique.................................................. 44
IX.1. Modèles des actifs ....................................................................................................... 44
IX.1.1. Modèle de Merton............................................................................................ 44
IX.1.2. Modèle de taux (CIR) ...................................................................................... 48
IX.1.3. Copule Student ,vt∑ .......................................................................................... 49
IX.2. Modèles des passifs..................................................................................................... 51
IX.2.1. Application du modèle ..................................................................................... 51
IX.2.2. Estimation des paramètres ............................................................................... 52
IX.3. Application numérique................................................................................................ 54
IX.3.1 Modèle de Merton............................................................................................. 54
IX.3.2. Modèle de taux (CIR): ..................................................................................... 55
IX.3.3. Copule Student ,vt∑ .......................................................................................... 55
IX.3.4. Valeur du portefeuille ...................................................................................... 57
IX.3.5. Provision Best Estimate………………..……………………………….…….64
IX.3.6. Résultat du calcul du SCR ............................................................................... 72
X. Provision technique « fair value » (juste valeur ou valeur de marché) ........................ 75

3
X.1. Présentation .................................................................................................................. 75
X.2. Transformation de WANG........................................................................................... 76
XI. Conclusion ........................................................................................................................ 78
XII. Annexes ........................................................................................................................... 79
Bibliographies…...………..……………………………………………………………….…82

4
I. Introduction:
Un des sujets les plus sensibles actuellement dans le monde de l’assurance européen
porte le nom de « Solvency II ». Ce mémoire va se consacrer pleinement à cette
problématique. D’abord, un bref rappel de Solvency II sera présenté avec ses approches de
calculs. Ensuite, je développerai une approche de calcul du capital de solvabilité requis par un
modèle interne appliqué à un assureur non-vie fictif. Pour cela, je considérerai un portefeuille
d’actifs composé d’actions, de titres immobiliers et d’obligations d’état, le passif de l’assureur
sera constitué uniquement des provisions pour les sinistres connus ou non déclarés, mais
survenus, toutes les autres provisions ne seront pas prises en compte. Les modèles
stochastiques seront développés judicieusement, à savoir Merton pour les actions et les titres
immobiliers, Cox-Ingersoll-Ross pour les obligations d’état et le mouvement brownien
géométrique pour les sinistres. Par la suite, je calculerai le capital de solvabilité requis en
projetant le bilan de l’assureur dans 1 an avec l’aide de méthodes de simulation Monte-Carlo.
La marge de risque (MVM) et le minimum du capital requis (MCR) seront évoqués mais ne
seront pas calculés explicitement. Les risques pris en compte sont : risque de taux d’intérêt,
risque d’actions, risque de titre immobilier et le risque d’assurance, tous les autres risques
sont négligés.
II. Solvency 2, présentation et contexte actuel :
La réforme de la réglementation européenne sur les nouvelles normes de solvabilité
est très nettement engagée, dans un cadre global Solvency II, sur les traces de la réforme
bancaire Bâle II. Les réflexions en cours et travaux d’analyses relatifs à cette réforme sont
assurés au sein du Ceiops, comité européen réunissant les autorités de contrôles des vingt-cinq
pays associés.
Dans ce contexte, les assureurs européens ont été interrogés en 2005 sur leurs
provisions techniques et les méthodes d’évaluation harmonisées, comme le Best Estimate ou
l’évaluation par Quantiles qui est présentée notamment dans l’étude d’impacts QIS1
(Quantitative Impact Study). Les études suivantes, le QIS2, lancée en 2006 et le QIS3 en 2007
ont eu pour objectif de mieux cerner les contours d’une formule standard d’évaluation du
capital de solvabilité requis, le SCR (Solvency Capital Requirement), et la méthode de
détermination des besoins en capital minimum, le MCR (Minimum Capital Requirement).

5
Selon l’idée que la marge de solvabilité correspond aux fonds propres, c’est-à-dire la
différence entre les actifs et les engagements de passifs, le principe directeur dans la recherche
des besoins de couverture de la solvabilité des assureurs est la mise en œuvre d’une
probabilité de ruine à moins de 0,05 %.
Un des principes le plus important de Solvency II est basé sur le fait que les actifs (les
placements) et les passifs (les engagements) doivent tous être évalués à leur valeur de marché.
La différence entre la valeur de marché actuelle des passifs, d’une part, et l’estimation non
biaisée de la valeur actualisée (discounted best estimate) de l’espérance mathématique des
flux de paiements afférents, d’autre part, est appelée marge sur la valeur de marché ou
« market value margin » (MVM).
Les risques considérés dans le Solvency II sont les risques de marché, de crédit, de
souscription vie et non vie et le risque opérationnel.

6
III. Approche standard, approche par les modèles internes :
III.1. Présentation:
Le projet de Solvabilité II a pour but d’établir un référentiel harmonisé et cohérent à
l’ensemble des sociétés d’assurance européennes. Deux modes de calcul du besoin en capital
d’une compagnie d’assurance, à priori opposés, sont à l’étude : la formule standard et les
modèles internes.
Dans le premier cas, un ensemble de calculs simplifiés reposant sur des données
comptables et des indicateurs connus, permettent d’établir un besoin minimum de capital,
admis comme relativement arbitraire. Cependant, cette approche s’avère très coûteuse pour
les assureurs, car ses formules sont calibrées pour tous les assureurs et du coup, le capital
requis est généralement supérieur à celui qu’il doit réellement disposer.
Dans le deuxième cas, le CEIOPS prévoit notamment d’inciter les sociétés à mieux
modéliser leurs risques en les autorisant à construire des modèles internes. Cette voie est bien
plus complexe à mettre en œuvre. L’idée de départ est néanmoins simple et pragmatique : la
réalisation de modélisations personnalisées et globales des portefeuilles d’assurance à travers
la prise en compte des passifs, des actifs, et surtout de leurs interactions respectives. Le besoin
en capital pour la solvabilité peut alors s’apprécier directement à la lecture des résultats
générés par le modèle. Ces modèles peuvent être envisagés complètement libres ou structurés
par branche de risques.
Dans quelques années, gageons que les modèles internes mis en place par les
compagnies serviront principalement à leur gestion quotidienne des risques, et accessoirement
aux obligations réglementaires de solvabilité ; ceci est d’ailleurs un des souhaits du projet de
la directive Solvency II.
III.2. Utilités d’un modèle de risque globale :
Cette partie est extraite du livre de FITOUCHI [2005]
a) Les raisons internes à la compagnie :
Le premier objectif est l’identification et la mesure des risques liés à l’activité. En
particulier, l’assureur essaie de quantifier le niveau de capital minimum qui correspond au

7
risque de ruine qu’il estime acceptable. L’optique de l’assureur est de gérer ses risques à un
niveau qu’il juge correct compte tenu de sa structure.
Le deuxième objectif d’un modèle interne est de fournir au groupe d’assurances un
cadre de référence où la rentabilité exigée d’une activité dépend du risque qu’elle fait
supporter à la compagnie. Le modèle permet de déterminer quelles branches sont les plus
risquées et pour quelles rentabilités afin de pouvoir réaliser des arbitrages en ce qui concerne
les stratégies de développement de certaines d’entre elles.
Le modèle permet aussi de disposer d’un outil pour la gestion opérationnelle (politique
de prise ou cession de risque, mesure de performance, allocation d’actif, politique
d’intéressement, de participation aux bénéfices).
b) Les raisons externes à la compagnie
L’objectif principal est la nécessité de pouvoir répondre aux attentes ou aux exigences
d’acteurs externes à l’entreprise (les banques, les agences de notation, les marchés financiers).
Certains groupes anticipent également une évolution des exigences réglementaires.
D’une façon très générale, les modèles de risques globaux essaient :
- de modéliser la distribution de probabilité des fonds propres réels, ou « capital
économique », à un horizon de temps donné ;
- de calculer « un besoin de capital économique », indicateur qui correspond à un
niveau de risque global accepté par l’entreprise ;
- de définir, enfin, sur la base du cadre formulé précédemment, une règle
d’allocation du capital économique aux différentes activités.
III.3. Etapes de calcul d’un modèle interne:
D’après PLANCHET, THEROND, JACQUEMIN [2005], un modèle interne consiste
à simuler les flux futurs de l’entreprise de manière à déterminer une fonction reliant le niveau
des fonds propres au « risque » de l’entreprise. Sa mise en place nécessite donc la
détermination de ce qui caractérise le risque de l’entreprise (la faillite), le choix d’une mesure
de risque (VaR, TVaR) et enfin la modélisation de l’entreprise (actif, passif, actif-passif).
La simulation des flux futurs de l’entreprise va donc nécessiter de modéliser les
éléments qui sont à la source de ces flux : les sinistres et les placements. Généralement, le

8
choix d’un modèle se fonde sur l’hypothèse implicite que la variable modélisée aura dans le
futur le même comportement que par le passé. Ceci se traduit notamment dans le choix des
paramètres qui sont estimés sur des données historiques.
N.B. Pour certaines variables pour lesquelles les données historiques sont trop peu
nombreuses, les modèles devront être déterminés de manière ad hoc (avis d’experts par ex.).
Le modèle doit notamment intégrer, à l’actif :
- évolution des cours et des dividendes/loyers des actifs financiers (actions,
OMPCVM, immobilier, etc.),
- évolution des taux d’intérêt,
- évolution de l’inflation,
- dépendance entre ces différents éléments,
- défaut des émetteurs d’obligations
et au passif :
- survenance et montants de sinistres,
- sinistres catastrophiques,
- défaut des réassureurs,
- dépendance entre les branches.
Dans ce mémoire, par souci de simplicité, certaines des éléments cités ci-dessus ne
seront pas pris en compte.
Voici le schéma de la structure d’un modèle interne :
Figure 1 : Structure d’un modèle interne
Générateur de nombres aléatoires
Estimation des paramètres &
Tests d’adéquation
Modèles
Actif Discrétisation

9
V. Provision Best Estimate, marge de risque, approche par le coût du
capital:
IV.1. Présentation:
Un des principes essentiels de Solvency II est que les actifs (placements) et les passifs
(engagements) doivent être évalués à leur valeur de marché actuelle. Pour de nombreuses
positions financières telles que les actions ou les obligations, la valeur de marché est connue
puisque ces actifs font l’objet d’un négoce. Les passifs techniques ont quant à eux une valeur
de marché que l’on ne peut pas relever et des flux de trésorerie dont l’espérance
mathématique peut seulement être estimée. C’est pourquoi, lorsqu’on veut calculer la valeur
de marché d’une position actuarielle, il faut d’abord modéliser la marge sur la valeur de
marché. Lorsqu’un portefeuille est en liquidation (run-off), l’assuré ne subit aucun dommage si
un tiers prend en charge le risque inhérent au portefeuille en liquidation. Tel est le cas lorsque
l’assureur dispose d’un capital porteur de risque suffisant pour supporter le risque, ou
lorsqu’une instance extérieure (un autre assureur, un investisseur, un bailleur de fonds)
reprend le portefeuille ou injecte du capital dans l’entreprise – ce qui revient au même. Dans
le deuxième cas, l’instance extérieure doit mettre du capital-risque à disposition pour la
liquidation. Elle sera prête à le faire en contrepartie d’une indemnisation.
Le prix d’un passif technique se compose donc d’un montant correspondant à sa
liquidation attendue et d’une indemnisation pour le risque encouru, indemnisation dont la
définition recoupe parfaitement celle de la marge sur la valeur de marché donnée ci-dessus.
Le projet de directive actuel indique que la valeur des provisions techniques sera égale
à la somme du best estimate et d’une marge de risque.
IV.2. Best estimate:
La notion de best estimate est définie par l’extrait suivant : « La meilleure estimation
est égale à la moyenne pondérée par leur probabilité des flux de trésorerie futurs, compte tenu
de la valeur temporelle de l’argent (valeur actuelle probable des flux de trésorerie futurs),
déterminée à partir de la courbe des taux sans risque pertinente. Le calcul de la meilleure

10
estimation est fondé sur des informations actuelles crédibles et des hypothèses réalistes et il
fait appel à des méthodes actuarielles et des techniques statistiques adéquates »
IV.3. Marge de risque (MVM), approche de calcul par le coût du capital (Cost of
Capital):
Comme un passif n'arriverait pas à trouver preneur au prix du 'Best Estimate', une
quantité complémentaire doit être ajoutée au 'Best Estimate' pour pouvoir qualifier l'ensemble
de "valeur de marché" des provisions. Cette quantité supplémentaire qui permettrait alors de
vendre ces passifs, c'est la marge de risque ou 'Market Risk Margin' (MVM).
Il existe encore deux écoles qui s'affrontent en IARD pour pouvoir déterminer cette
'Market Risk Margin', soit le 'Cost of Capital', soit l'approche par les quantiles.
Le 'Cost of Capital' est défini comme le coût du capital qu'un tiers, un réassureur par
exemple, reprenant le stock de provisions', devrait immobiliser pour supporter le risque
jusqu'à extinction complète de ces provisions.
La notion de la marge sur la valeur de marché est valable en tout temps. En règle
générale, on veut connaître la valeur de marché actuelle, soit en t=0. Dans le Swiss Solvency
Test (SST), c’est surtout à la valeur en fin d’année soit t=1 qu’on s’intéresse, je traiterai donc
la marge sur la valeur de marché sous cet angle.
D’après la méthode « coût du capital », sur la base de l’écart de taux d’intérêt (spread)
et du capital risque nécessaire chaque année après t = 1, on peut définir la marge sur la valeur
de marché comme
_31 2(0) (0) (0) 2 (0) 3 (0) _
1 1 2 3 _
(1)(0) ...1 (1 ) (1 ) (1 ) (1 )
run offspread run off
run off
SCRSCRSCR SCRMVMMVM ir r r r r
⎛ ⎞= = + + +⎜ ⎟⎜ ⎟+ + + + +⎝ ⎠
1SCR : inclure les risques de marchés et de crédit.
iSCR (i > 1) : limités aux risques de souscription et risques opérationnels, risques de
crédit/concentration du réassureur.
6%spreadi CoC= = : Coût du capital pour un assureur qui est noté BBB.

11
Remarque : La marge sur la valeur de marché n’appartient pas au bailleur de capital risque
mais à l’assuré.
Il est important de comprendre aussi que la marge sur la valeur de marché doit
indemniser le repreneur pour les risques techniques, mais pas pour tous les risques encourus.
Imaginons un portefeuille qui se compose d’une part de passifs techniques et d’autre part
d’instruments existants (actifs) qui répliquent au mieux les passifs. Pour un portefeuille non-
vie, ce pourraient par exemple être des emprunts souverains générant le flux de trésorerie
attendu par les passifs. La marge sur la valeur de marché ne doit indemniser que les risques de
ce portefeuille. En revanche, elle ne doit pas couvrir les risques de marché du portefeuille
d’actifs existant, dont la composition est généralement différente de ce qu’elle serait dans un
portefeuille de réplication optimale.
Simplification :
Le futur SCR de l’année 1 (SCR1) inclura les risques de marché et de crédit, et les
futurs SCR à partir de l'année 2, seront limités au risque de souscription et au risque
opérationnel et aux risques de crédit/concentration du réassureur. Pour calculer les substituts
des futurs SCR, on estime que l’assureur a calculé le futur SCR à l’année 1(SCR’1) en
incluant uniquement les risques de souscription, opérationnel et de réassurance.
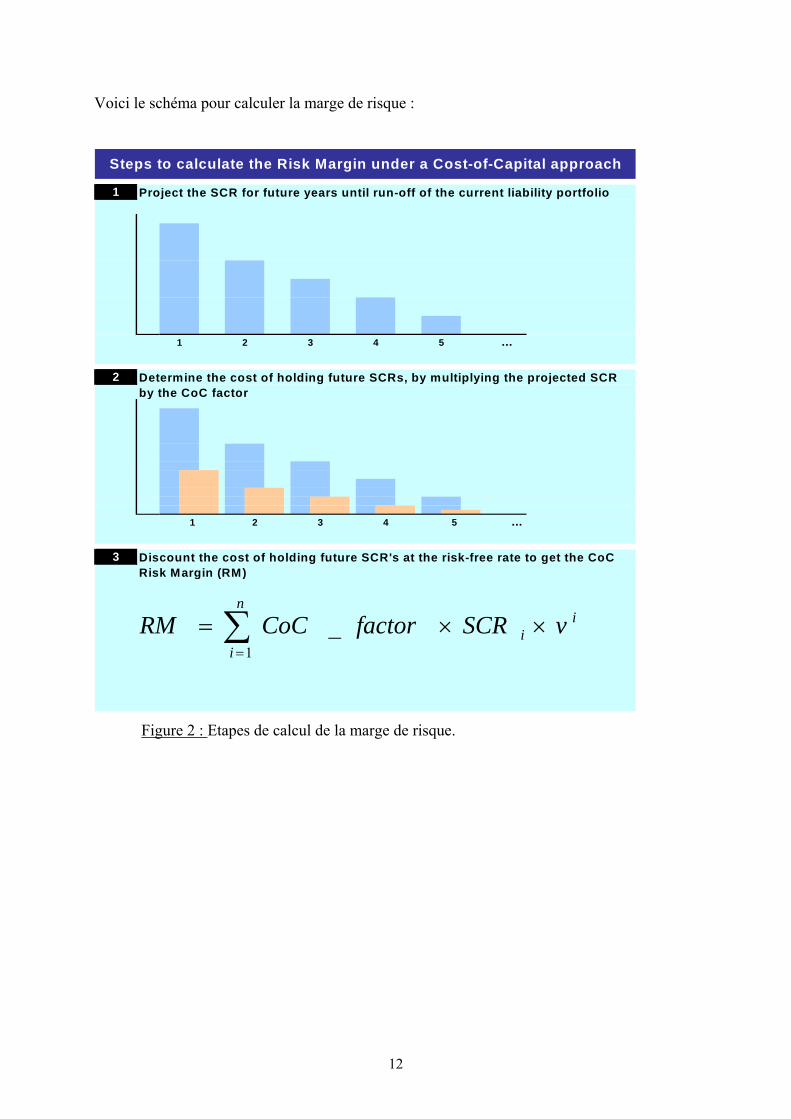
12
Voici le schéma pour calculer la marge de risque :
1
2
3
1 2
Discount the cost of holding future SCR's at the risk-free rate to get the CoC Risk Margin (RM)
3 4 5 ...
Steps to calculate the Risk Margin under a Cost-of-Capital approach
1 2 3 4 5 ...
Project the SCR for future years until run-off of the current liability portfolio
Determine the cost of holding future SCRs, by multiplying the projected SCR by the CoC factor
in
ii vSCRfactorCoCRM ××= ∑
=1_
Figure 2 : Etapes de calcul de la marge de risque.

13
V. Capital de solvabilité requis (SCR):
Notons SCR (Solvency Capital Requirement) le capital de solvabilité requis pour
l’assureur.
Avant de définir le capital requis, il convient d’introduire deux notions de mesure de
risque : la Value at Risk (VaR) et Tail Value At Risk (TVaR).
V.1. Mesures de risque VaR ou TVaR:
Le but de la mesure de risque est généralement de pouvoir représenter par un chiffre
réel une incertitude ou une grandeur dont la valeur est inconnue, à l’aide d’un étalon de
mesure adéquat, de manière à pouvoir exprimer l’exposition au risque de cette grandeur. Dans
ce mémoire, on va utiliser la mesure Value At Risk ou VaR.
a) Définition de la VaR :
La Value-at-Risk (VaR) de la variable aléatoire X au niveau de sécurité 1-α est
définie par
( , ) inf{ | Pr( ) }VaR X x X xα α= ≤ ≥
b) Définition de la TVaR :
La Tail Value at Risk (TVaR) de la variable aléatoire X au niveau de sécurité 1-α est
définie comme l’espérance mathématique conditionnelle E de X, pour X plus petit ou égal à la
VaR au niveau de sécurité 1-α :
[ ]( ) | ( )TVaR X E X X VaR Xα α= ≤
Au même niveau de sécurité, la TVaR est un étalon de mesure de risque plus prudent
que la VaR. Dans la réalité, une distribution des dommages présentera certainement quelques
pertes extrêmement élevées mais dont la probabilité est très faible. Pour ces cas, la TVaR est
plus appropriée que la VaR car elle intègre aussi l’ampleur de ces pertes extrêmes.

14
Contrairement à la VaR, la TVaR quantifie le coût moyen de l’un des 100. %α pires
événements. En pratique, on constate que la TVaR est plus stable que la VaR De plus, elle
présente aussi d’autres propriétés mathématiques intéressantes comme la cohérence.
Malgré tous les avantages de la TVaR par rapport à la VaR, la mesure de risque
utilisée pour déterminer le capital de solvabilité requis dans ce mémoire est la VaR afin de
permettre la comparaison des résultats du calcul de la formule standard.
Un autre objet qui intervient dans le calcul du capital de solvabilité requis est le capital
porteur de risque.
V.2. Horizon temporel:
L’horizon temporel retenu dans ce modèle interne est d’un an. Les calculs doivent
inclure tous les risques provenant de la poursuite du business pendant cet horizon. Toute
l’information reçue durant cet horizon et affectant la position financière de l’assureur doit être
prise en compte pour l’estimation du SCR.
V.3. Capital porteur de risque:
Le capital porteur de risque (CR) est le capital qui peut être utilisé pour compenser les
fluctuations des affaires. Il est défini comme la différence entre la valeur de marché actuelle
des actifs et l’estimation non biaisée de la valeur actualisée de l’espérance mathématique des
passifs.
à la date t = 0 : CR(0) = A(0) – BE(0)
à la date t = 1 : CR(1) = A(1) – BE(1)
Le capital porteur de risque en t = 0 (CR(0)) se détermine à partir des actifs et des
passifs, à l’aide du bilan établi à la valeur de marché actuelle. Il est donc connu. En revanche,
le capital porteur de risque futur (CR(1)) est une inconnue, car l’environnement de
l’entreprise est elle-même inconnue : il s’agit donc d’une valeur aléatoire.
Le montant du capital porteur de risque en fin d’année est indicatif de la valeur de
marché des actifs par rapport à celle des passifs :

15
CR < 0 Actifs < Passifs Best Estimate
0 < CR < MVM Passifs Best Estimate < Actifs < Valeur de marché des passifs
MVM < CR Valeur de marché des passifs < Actifs
Si le capital porteur de risque en fin d’année est supérieur à la marge sur la valeur de
marché, la valeur des actifs est supérieure à la valeur de marché des passifs.
Si CR(1) < MVM(1), le portefeuille en liquidation n’est pas suffisamment capitalisé.
Le risque inhérent à ce portefeuille ne peut donc pas être couvert par le capital porteur de
risque et aucun bailleur de fonds externe ne serait intéressé à l’assumer. Ce risque est donc
supporté entièrement et exclusivement par les assurés.
Tant que le capital porteur de risque reste positif, l’espérance mathématique des
passifs est certes inférieure à la valeur des actifs, mais le risque que les règlements de sinistre
excèdent cette valeur peut cependant être très élevé. Si le capital porteur de risque est négatif,
les actifs ne couvrent même pas l’espérance mathématique des passifs.
V.4. Minimum du capital requis (MCR):
MCR : Niveau de fonds propres en deçà duquel l’entreprise d’assurance présente un
risque inacceptable de ne pas pouvoir faire face à ses engagements.
Le calcul de ce montant ne sera pas abordé dans le cadre de ce mémoire. On peut
prendre simplement MCR = 1/3 SCR.
V.5. Capital de solvabilité requis (SCR):
SCR : niveau de capital qui permet à l’assureur d’absorber des pertes significatives. Il
doit être calibré de telle sorte à jouer un rôle d’alarme. Autrement dit, il est le capital
nécessaire pour couvrir le risque pendant 1 an. Le SCR est donc formulé de façon à ce que la
probabilité de réalisation de l’événement CR(1) < MVM(1) soit la plus faible possible.
Mathématiquement :
[ ](1) | (0) (0) (1)VaR CR CR SCR MVM MVMα = + =

16
Soit (0)1
(1) (0)1CRSCR VaR CR
rα
⎛ ⎞= − −⎜ ⎟+⎝ ⎠
Où CR(t) = A(t) – BE(t) : capital porteur de risque à la date t.
A(t) : valeur du portefeuille d’actif à la date t.
BE(t) : valeur de la provision best estimate à la date t.
t = 0 : date de calcul
t = 1 : l’horizon du calcul
Remarque : Bien que le capital porteur de risque dépend de la marge (MVM), la
variation de ce capital ne l’est pas.
Preuve :
On a :
(0) (0)1 1
(1) (1) (1)(0) (0) (0)1 1CR FP MVMCR FP MVM
r r+
− = − −+ +
Or
(0)1
(1) (0)1
MVM MVMr
=+
Par construction
Donc
(0) (0)1 1
(1) (1)(0) (0)1 1CR FPCR FP
r r− = −
+ + qui est indépendant de la marge.
Avec FP(t) =Actif(t) –Provision technique(t) représentant le niveau du fond propre à la date t.
On peut comprendre ainsi : MVM(1) est l’indemnisation que l’assureur doit payer à
l’acquéreur en plus des montants de sinistres attendus à la date t=1 s’il devait céder ses passifs
à la fin de l’exercice. Pour cela il doit construire une provision pour cette marge à la date t=0
qui est noté MVM(0).
Preuve de la formule de calcul du SCR :
α =0,05%, on cherche le niveau de SCR qu’il faut disposer aujourd’hui pour que l’actif dans
1 an soit inférieur au passif dans 1 an à moins de 0,05%.

17
( )( )( )
(0) (0)1 1
(0)1
(1) (1) | (0) (0)
(1) (1) (1) (1) | (0) (0)
(1) (1) | (0) (0)
(1) (1) | (0) (0)1 1
(1) ((0)1
P Actif Passif CR SCR MVM
P Actif BE Passif BE CR SCR MVM
P CR MVM CR SCR MVM
CR MVMP CR SCR MVMr r
CR MVMP CRr
α
α
α
α
≤ = + ≤
⇔ − ≤ − = + ≤
⇔ ≤ = + ≤
⎛ ⎞⇔ ≤ = + ≤⎜ ⎟+ +⎝ ⎠
⇔ − ≤+ (0)
1
(0) (0)1 1
(0)1
(0)1
1) (0) | (0) (0)1
(1) (1)(0) (0)1 1
(1) (0)1
(1) (0)1
CR CR SCR MVMr
CR MVMP CR MVM SCRr r
CRP CR SCRr
CRSCR VaR CRrα
α
α
α
⎛ ⎞− = + ≤⎜ ⎟+⎝ ⎠
⎛ ⎞⇔ − ≤ − − ≤⎜ ⎟+ +⎝ ⎠
⎛ ⎞⇔ − ≤ − ≤⎜ ⎟+⎝ ⎠
⎛ ⎞⇔ = − −⎜ ⎟+⎝ ⎠
La valeur des actifs dans 1 an est égale à la valeur de marché de nos actions,
immobiliers et obligations dans 1 an plus la valeur des coupons tombés et diminuées des flux
payés pour les sinistres pendant l’année. Toutes ces valeurs sont inconnues à la date t = 0 sauf
les coupons des obligations d’état.
La valeur des passifs Best Estimate dans 1 an est également inconnue en t = 0, elle est
calculée comme l’espérance des montants de sinistres payés en t>1 actualisés
conditionnellement aux aléas de la période 0 à 1.
Ici, j’ai considéré que la composition du portefeuille est inchangée pendant l’année, les
sinistres sont payés en fin d’année et si les coupons ne sont pas suffisants pour payer les
sinistres, il y aura la liquidation de certaines actions ou obligations…
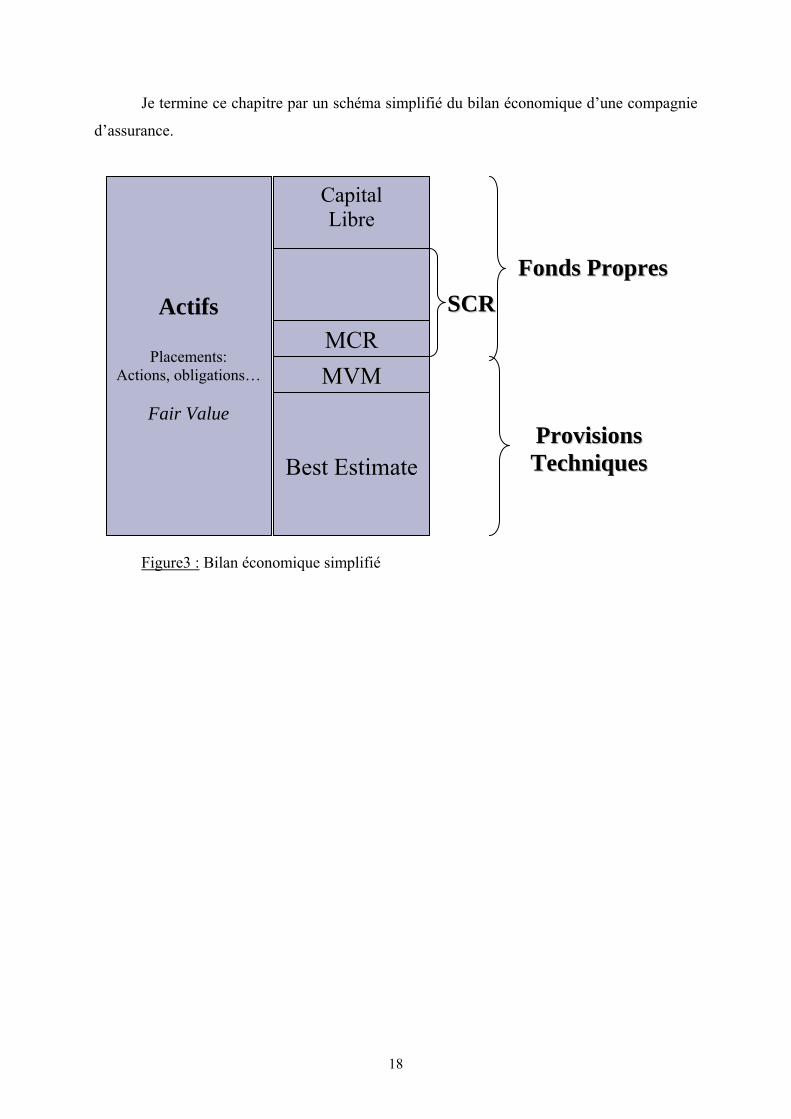
18
Je termine ce chapitre par un schéma simplifié du bilan économique d’une compagnie
d’assurance.
Figure3 : Bilan économique simplifié
Actifs
Placements: Actions, obligations…
Fair Value
Capital Libre
MCRMMVVMM
Best Estimate
FFoonnddss PPrroopprreess SSCCRR
PPrroovviissiioonnss TTeecchhnniiqquueess

19
VI. Actifs et risques de marché :
VI.1. Présentation:
Le risque de marché est le risque de fluctuation du capital porteur de risque sous l’effet
de modifications de la situation conjoncturelle ou de facteurs économiques, désignés ici par
facteurs de risque.
Dans le modèle présenté ici, une allocation d’actifs est fixée initialement (en t=0). Elle
est censée représenter l’allocation optimale reflétant l’équilibre que la compagnie souhaite
maintenir à long terme dans son portefeuille. Cette allocation cible s’exprime en pourcentages
représentant les différentes lignes d’actifs.
Mon portefeuille simplifié se compose de 2 actions, 1 obligation d’état et 1 actif
immobilier.
Les cours des actions et des immobiliers sont modélisés par le processus de Merton
tandis que l’obligation d’état est déduite de la courbe de taux d’intérêt sans risque dont
l’évolution suit le modèle de Cox-Ingersoll-Ross (CIR).
Ensuite, ces actifs n’évoluent pas indépendamment, ils sont corrélés entre eux et avec
les indices des marchés sur lesquels ils sont côtés. Les deux indices choisis sont le CAC 40
pour les actions et l’Euronext CAC Real Estate IX pour les actifs immobiliers. Les structures
de dépendance seront modélisées par la copule de Student qui est choisie pour prendre en
compte la dépendance des valeurs extrêmes.
Enfin, pour connaître la valeur de marché de l’actif en t > 0, les scénarios
économiques doivent projeter des primes de risque d’où la nécessité d’être en « monde réel ».
Exemple : Les actions ne doivent pas évoluer simplement au taux sans risque car il est
primordial de connaître leur vrai rendement pour évaluer correctement les occurrences de
ruine.
Donc, l’espace de travail utilisé dans la modélisation des actifs est celui de probabilité
historique.
VI.2. Modélisation des actions et des actifs immobiliers :
Cette partie s’inspire de l’article « L’impact de la prise en compte des sauts boursiers
dans les problématiques d’assurance », PLANCHET, THEROND [2005].

20
VI.2.1. Introduction:
Pour modéliser l’évolution du prix d’un actif risqué, le modèle de Black & Scholes est
actuellement la référence pour les praticiens de l’assurance. Cependant, confronté à la réalité,
ce modèle n’est pas suffisamment robuste : en effet, il ne tient pas compte de toutes les
données économiques observées sur les marchés financiers. Notamment, ce modèle n’intègre
pas les variations brutales du cours du sous jacent dues à l’arrivée d’information, bonnes ou
mauvaises.
Dans le contexte actuel d’utilisation du modèle de Black et Scholes en assurance,
essentiellement dans le cadre de la détermination d’allocations stratégiques et de l’évaluation
d’options (pour des garanties « plancher » sur des contrats en unités de compte par exemple),
cette relative inadéquation du modèle à la réalité s’avère assez peu pénalisante. En pratique
elle est largement compensée par la facilité de mise en œuvre du modèle.
Toutefois, le projet Solvabilité 2 en cours d’élaboration modifie profondément les
règles de fixation du niveau des fonds propres en assurance en introduisant comme critère
explicite le contrôle du risque global supporté par la société. Ce risque devra notamment être
quantifié au travers de la probabilité de ruine.
Dans ce nouveau contexte, les inconvénients principaux de modélisations de type «
brownien géométrique » et notamment l’insuffisance de l’épaisseur des queues de distribution
(qui conduit à une trop faible représentation des évènements rares) et la non prise en compte
des chocs, à la hausse ou à la baisse, sur les cours (qui conduit à ne pas intégrer au modèle
d’évènements exceptionnels et brutaux) peuvent avoir des conséquences importantes sur
l’appréciation du niveau de capital nécessaire pour contrôler la ruine au niveau fixé. Ce point
est par exemple abordé dans BALLOTTA [2004] pour le cas des options cachées d’un contrat
d’épargne, et dans PLANCHET et THEROND [2005] dans le cadre d’un modèle mono
périodique simplifié en assurance non-vie pour la détermination d’un capital cible et
l’allocation d’actifs.
Compte tenu de la place privilégiée du mouvement brownien géométrique, je
m’intéresse ici aux modèles généralisant cette approche et incluant le mouvement brownien
géométrique comme cas particulier. Le modèle proposé par MERTON [1976] est de ce point
de vue assez naturel; c’est donc le modèle que je retiendrai. Je reprends le modèle proposé par
MERTON [1976] et je m’inspire pour cela de la démarche proposée par RAMEZANI et
ZENG [1998] pour l’estimation des paramètres par la méthode du maximum de
vraisemblance.

21
Pour conclure, les hypothèses de mes modèles me permettront, dans le cadre de
l’approche Solvabilité II, de mieux évaluer l’impact de variations du cours d’une action que
par le modèle classique de Black&Scholes. Si l’adéquation du modèle à nos échantillons n’est
pas acceptée, il est possible que cela provienne de la simplicité des hypothèses. Toutefois, il
est ardu de rajouter des paramètres sans que le modèle proposé devienne trop compliqué à
manipuler.
VI.2.2. Présentation du modèle:
Les actions, les titres immobiliers ainsi que les indices CAC40 et Euronext CAC Real
Estate IX sont modélisés par le modèle de Merton, l’évolution des prix est donnée par
l’équation suivante :
1
²( ) (0)exp ( )2
tN
t kk
S t S t B Uσμ σ=
⎧ ⎫= − + +⎨ ⎬
⎩ ⎭∑
Où :
S(t) : prix de l’actif à l’instant t.
0( )t tB B ≥= : Mouvement brownien.
0( )t tN N ≥= : Processus de Poisson homogène d’intensitéλ .
1( )k kU U ≥= : Suite de variables aléatoires indépendantes identiquement distribuées de
loi Normale (0, )uN σ .
Les processus B, N, U sont mutuellement indépendants.
Les sauts sont ici, dans un souci de simplicité, supposés symétriques et en moyenne nuls.
VI.3. Modélisation des obligations, modèle de taux :
Cette partie est tirée du livre de PLANCHET F., THEROND P et JACQUEMIN J.
[2005], « Modèles financiers en assurance », Editions Economica.

22
VI.3.1. Présentation:
Le prix d’une obligation quelconque de nominal N, de maturité T et de taux facial
ρ s’écrit :
( ) ( )1
1 11 ( , ) ( , ) 1 ( , ) ( , )
T
t i t T ti t
O Nr t i spread t i r t T spread t T
ρ − −= +
⎛ ⎞= × +⎜ ⎟
⎜ ⎟+ + + +⎝ ⎠∑
Où ( , )r t i est le taux sans risque à la date t et de maturité i.
Le spread de taux dépend de la probabilité de défaut de l’émetteur, cette probabilité
pouvant être modélisée à l’aide des copules gaussiennes.
Si l’obligation est sans risque, son prix se déduit des prix des zéros-coupons P(t, T) via
la formule :
1
( , ) ( , )T
ti t
O N P t i P t Tρ= +
⎛ ⎞= × +⎜ ⎟⎝ ⎠∑
Il faut donc pour valoriser ces titres obligataires déterminer le prix des zéros-coupons
ou bien construire une courbe de taux. Il existe 3 approches concernant les modèles de taux :
- Les modèles d’équilibre partiel reposant sur un raisonnement d’arbitrage.
Citons, par exemple, celui de VASICEK [1997] qui comporte une variable d’état et celui
de BRENNAN et SCHWARTZ [1979] qui en comporte deux.
- Les modèles d’équilibre général, tel que le modèle de COX, INGERSOLL et
ROSS [1985] basés sur une description globale de l’économie.
- Les modèles de déformation qui partent de la structure des taux d’intérêt
observés et lui font subir des chocs. Le modèle de HO et LEE [1986] ainsi que sa
généralisation proposée par HEATH, JARROW et MORTON [1987] sont sans aucun
doute les plus connus dans cette catégorie.
Le modèle de VASICEK donne parfois des valeurs négatives, donc on va utiliser le
modèle de COX, INGERSOLL et ROSS (CIR) dans ce mémoire.

23
VI.3.2.Le modèle de COX, INGERSOLL et ROSS [1985] :
Ce modèle, présenté en 1985, introduit un processus en racine carrée qui interdit à un
taux initialement positif de prendre des valeurs négatives, tout en conservant la simplicité du
processus de d’ORNSTEIN-UHLENBECK. Le processus de taux d’écrit sous la forme :
( )t t t tdr a b r dt r dBσ= − +
Où tr est le taux sans risque instantané, tB est un mouvement Brownien en « proba
historique ».
a, b, σ sont des paramètres à estimer
La valeur du zéro-coupon à l’instant t qui paie 1 en T est déterminée, par la formule
suivante :
[ ]( , ) ( , ) exp ( , ) tP t T A t T B t T r= − Où tr est le taux sans risque à la date t
et t < T,
{ }{ }
{ }{ }
22 /
2 2
2 exp ( )( ) / 2( , )
( )(exp ( ) 1) 2
2exp ( ) 1( , )
( )(exp ( ) 1 ) 2
2
aba T t
A t Ta T t
T tB t T
a T t
a
σγ γ
γ γ γ
γγ γ γ
γ σ
⎧ ⎫+ −⎪ ⎪= ⎨ ⎬+ − − +⎪ ⎪⎩ ⎭− −
=+ − − +
= +
VI.3.3.Limites de ce modèle:
Ce modèle présente l’inconvénient de stabiliser la queue de la structure des taux, le
taux à long terme est réduit à une constante indépendante de la forme de la structure. Or, d’un
point de vue purement économique, il n’est pas toujours approprié d’expliquer le marché des
titres obligataires par une seule variable explicative, le taux sans risque instantané. Ces
processus mono-factoriels, ne dépendant que d’une variable d’état, supposent une parfaite
corrélation entre les taux r(t, T), non satisfaite dans la pratique.
Toutes ces limites ont poussé les chercheurs à construire des modèles prenant en
considération plusieurs facteurs (notamment par BRENNAN et SCHWART [1979], [1980] et
LONGSTAFF [1989]).

24
VI.4. Corrélation et dépendance:
VII.4.1. Présentation:
Les actifs n’évoluent pas indépendamment, ils sont corrélés entre eux et avec les
indices des marchés sur lesquels ils sont côtés. Les deux indices choisis ici sont le CAC 40
pour les actions et l’Euronext CAC Real Estate IX pour les actifs immobiliers.
Pour connaître la distribution des valeurs d’un portefeuille, il est nécessaire de pouvoir
anticiper l’évolution conjointe des facteurs de risque. Les facteurs de risque d’un portefeuille
sont les rendements de ses sous-jacents qui sont modélisés à l’aide des Browniens et des
sauts. Ils constituent les composantes aléatoires des prix futurs.
Dans le modèle de Merton, la composante à sauts représente l’information propre au
titre, le brownien associé au marché. Donc négliger la dépendance entre les composantes à
sauts c’est dire que les informations spécifiques à l’entreprise sont indépendantes des
informations d’autres entreprises, ce qui peut se concevoir.
Il s’agit donc d’estimer la distribution conjointe d’une série des browniens. Mais
comme on dispose déjà de la loi marginale de chacun de ces browniens, il reste à déterminer
la manière dont ils évoluent ensemble, c’est-à-dire la structure de dépendance entre ces
browniens.
VI.4.2. Les limites de la covariance:
Une première solution serait d’utiliser la matrice de covariance (décomposition de
Cholesky) pour approximer la dépendance entre les Browniens. Toutefois, la covariance ne
permet pas de décrire correctement la dépendance entre ces derniers et ce pour 2 raisons.
La première est d’ordre théorique. La covariance ne permet de caractériser qu’une
dépendance linéaire entre 2 variables aléatoires. On peut rencontrer des situations où il n’y a
pas de dépendance linéaire entre 2 variables (leur covariance est donc nulle) sans pour autant
qu’elles soient indépendantes. Pratiquement, supposons que, suite à une modélisation
particulière, on obtient une covariance entre 2 taux de rendements de 2 actions appartenant à
un même secteur industriel. Il est évident qu’on ne peut pas conclure l’absence de dépendance
entre ces rendements.
La deuxième raison est d’ordre empirique. Les taux de rendements représentent un
comportement de dépendance extrême qui ne peut être modélisé par la covariance. Tant qu’ils

25
ne prennent pas des valeurs trop grandes, ils varient indépendamment. Mais lorsqu’ils
prennent des valeurs extrêmes, ils les prennent tous en même temps. On parle dans ce cas de
dépendance extrême. C’est typiquement le phénomène que l’on observe lors d’un crash
boursier. Tous les prix chutent très fortement ensemble.
Par conséquent, on ne peut donc se contenter de modéliser la dépendance entre les
rendements ou bien les Browniens par leur matrice de covariance. Il faut chercher à
approximer plus précisément la distribution conjointe des Browniens. La théorie des copules
présente des résultats qui permettent de modéliser une distribution conjointe. Et de parvenir à
une description plus complète de la dépendance entre les variables aléatoires.
VI.4.3. Théorie des copules :
VI.4.3.1. Quelques définitions :
Définition de la copule :
Soit [0,1]1 : ii n u U∀ ≤ ≤ , une copule C est définie comme une fonction de répartition
multivariée :
1 2 1 2:[0,1] [0,1] : ( , ,..., ) ( , ,..., )nn nC u u u C u u u→ →
Dont les marginales sont uniformes sur [0,1].
Théorème de Sklar :
Le théorème suivant fournit un lien entre les distributions multivariée, leurs
marginales, et une copule.
On a 1( ,..., )nX X un vecteur de variable aléatoire dimension n, avec la fonction de
distribution jointe 1,..., nX XF et les distributions marginales
1,...,
nX XF F , i.e. :
1 ,..., 1 1 1( ,..., ) ( ,..., )
nX X n n nF x x P X x X x= ≤ ≤ et ( ) ( )iX i i iF x P X x= ≤ { }1 1,..., n∀ ∈
Alors, il existe une unique copule telle que :
1 1,..., 1 1( ,..., ) ( ( ),..., ( ))
n nX X n X X nF x x C F x F x= [ ]1( ,..., ) , nnx x∀ ∈ −∞ +∞

26
Le théorème de Sklar est central dans la théorie des copules. En gros, il dit qu’on peut
généralement associer une copule à une distribution multivariée. Par conséquent une fonction
de distribution peut être divisée en 2 parties :
+ D’une part, les n fonctions de distributions marginales.
+ D’autre part, une copule reliant ces fonctions.
La copule caractérise entièrement la structure de dépendance stochastique de n
variables aléatoires.
Le théorème dit également que si les lois marginales d’un vecteur aléatoire sont
connues, chaque copule définit une et une seule distribution jointe. Autrement dit, il existe
une et une seule copule qui permet de reconstruire la distribution jointe à partir des
distributions marginales.
Mesure de dépendance de queue :
Une des propriétés des copules qui nous intéresse le plus dans le cadre de Solvency 2
est la dépendance de queue. Soit (X, Y) un couple aléatoire. On définit les coefficients de
queue inférieure et supérieure, respectivement par,
1 1
0lim Pr[ ( ) | ( )]L X Yu
X F u Y F uλ − −
→= ≤ ≤ et 1 1
1lim Pr[ ( ) | ( )]U X Yu
X F u Y F uλ − −
→= > >
Quand les limites existent.
Notons que ces coefficients dépendent uniquement de la copule du couple (X, Y) et
nullement des lois marginales : si (X, Y) admet la copule C, les coefficients de dépendance de
queue sont définis, dès lors que la limite existe, par
0
( , )limL u
C u uu
λ→
= et __
0
( , )lim1U u
C u uu
λ→
=−
où __
C désigne la copule de survie associé à C (c’est-à-dire la fonction de répartition du couple
(1-U, 1-V) si (U, V) admet pour la fonction de répartition C).
Les cas intéressants sont ceux où ces coefficients sont strictement supérieurs à 0
comme ils indiquent la propension des copules pour générer conjointement les évènements

27
extrêmes. Si Lλ > 0 par exemple, il y a une dépendance de queue dans la queue inférieure et si
Lλ = 0, il y a une dépendance asymptotique dans la queue inférieure.
VI.4.3.2.Copule archimédienne, copule elliptique :
En générale il existe 2 familles de copules, les copules archimédiennes et les copules
elliptiques.
a) Les copules archimédiennes :
Définition :
La copule archimédienne de générateur ϕ est définie par
l’égalité ( )11 1( ,..., ) ( ) ... ( )n nC u u u uϕ ϕ ϕ−= + + , dès lors que
1( ) (0)
n
ii
uϕ ϕ=
≤∑
et 1( ,..., ) 0nC u u = , sinon. Le générateur choisi doit être de classe 2C de sorte que (1) 0ϕ = ,
' ( ) 0uϕ ≤ et '' ( ) 0uϕ > .
La notion de la copule archimédienne regroupe un certain nombre de copules comme
CLAYTON, GUMBEL, FRANCK.
Nom Copule
Clayton ( ) 1/( , , ) 1C u v u v
θθ θθ−− −= + −
Franck 1 (exp( ) 1)(exp( ) 1)( , , ) ln 1exp( ) 1u vC u v θ θθ
θ θ⎛ ⎞− − − − −
= +⎜ ⎟− −⎝ ⎠
Gumbel
( ) ( )1/
( , , ) exp ln( ) ln( )C u v u vθθ θθ ⎛ ⎞⎡ ⎤= − − + −⎜ ⎟⎣ ⎦⎝ ⎠
b) Les Copules elliptiques :
Les copules elliptiques sont des copules de distributions elliptiques. Un vecteur
aléatoire X de dimension n suit une distribution elliptique si leurs fonctions caractéristiques
peuvent s’exprimer comme suivant :
1( ) exp( . . ). ( . . . )2
T TX t i t t tϕ μ ϕ= ∑

28
Où
μ est le vecteur colonne des moyennes, et ∑ est la matrice de covariance.
ϕ est la fonction caractéristique.
Parmi les copules elliptiques, les copules Normale et Student ont des propriétés
intéressantes :
-Elles sont symétriques, i.e. si un vecteur 1( ,..., )nU U est distribué selon une de
ces 2 copules, on a 1 1( ,..., ) (1 ,...,1 )n nU U U U− − . Il en résulte que 2 mesures de
dépendance de queues Lλ et Uλ sont égales et sont dénotéesλ .
-Il existe un lien simple entre les composantes de la matrice ∑ et le Tau de
Kendall d’une paire de variables aléatoires. Nelsen(1999) et Embrechts(2001) ont
montré que le Tau de Kendall dépend de la copule et non des distributions marginales.
Il existe 2 copules phares dans la famille des copules elliptiques :
b.1) Copule Normale :
Une copule Normale est une copule de la distribution normale multivariée. Cette
copule a une matrice R comme paramètre. La densité de la copule Normale est de la forme :
11 1/ 2
1 1( ,..., ) .exp '( ).| | 2
NormaleR nc u u S R I S
R−⎛ ⎞= − −⎜ ⎟
⎝ ⎠
où 1( )j jS u−= Φ , 1−Φ est l’inverse de la fonction de répartition de la loi N(0,1) et I est
la matrice d’identité de dimension n.
Cependant la copule Normale ne présente pas la dépendance de queue, i.e. 0Normaleλ = .
b.2) Copule Student :
La copule Student a comme paramètres un nombre réel v et une matrice R de
dimension ( n n× ). La densité de la copule Student s’écrit :
21
1/ 2, 1 2 1
2
1
11 '. .( ) ( )2 2( ,..., ) | | . . .1( ) ( ) (1 )2 2
v nn
StudentR v n vn
j
j
v n v S R Svc u u R v v S
v
+−
−
−+
−
=
⎛ ⎞+ ⎛ ⎞ +Γ Γ ⎜ ⎟⎜ ⎟ ⎝ ⎠= ⎜ ⎟+⎜ ⎟Γ Γ +⎝ ⎠ ∏

29
Où 1( )j v jS T u−= , 1vT − est l’inverse de la fonction de répartition de la loi Student univariée de v
degré de liberté.
b.3) Copule Normale et Copule Student :
Contrairement à la copule Normale, la copule Student montre une dépendance de
queue positive. Cela veut dire qu’il y a moins de valeurs extrêmes générées par la copule
Normale que par la copule Student.
c) Distinction entre les copules elliptiques et les copules archimédienne :
Les copules archimédiennes sont souvent utilisées mais elles ont un
désavantage majeur : elles représentent la structure de dépendance avec peu de paramètres (un
ou deux dans la plupart des cas), qui ne sont pas très cohérents en pratique avec la complexité
des structures observées. Ces copules sont donc irréalistes pour modéliser la dépendance dans
des dimensions supérieures à deux.
Par contre, les copules elliptiques sont particulièrement adaptées à la modélisation des
structures de dépendance en dimension n≥ 2. En effet, l’introduction de la matrice de
corrélation ∑ comme un paramètre multidimensionnel donne une grande flexibilité pour ce
qui est de la forme de la structure et est plus facile à interpréter que les paramètres des copules
archimédiennes.
Donc pour des raisons de facilité de calibration et pour ses qualités dans la prise en
compte des mouvements extrêmes, je vais utiliser la copule Student pour modéliser la
structure de dépendance entre mes titres d’actifs.

30
VII. Passif et risque d’assurance non-vie:
VII.1. Présentation:
Le risque d’assurance, ou risque technique, est le risque de fluctuation du capital
porteur de risque sous l’effet de la réalisation aléatoire des risques assurés d’une part et des
incertitudes propres à l’estimation des paramètres actuariels d’autre part. Il peut être aussi
défini comme le risque que la réserve doit être réévaluée suite à des nouvelles informations.
Ce risque est divisé en risque stochastique et risque de paramètre. Le premier est le risque que
la fluctuation aléatoire des paiements de sinistres rend insuffisants les réserves établies par
l’assureur et le deuxième est le risque concernant l’estimation des paramètres du modèle.
Dans ce mémoire, le passif de l’assureur sera constitué uniquement des provisions
pour les sinistres connus ou non déclarés, mais survenus.
Provisions = IBNR + PSAP
Avec IBNR : provisions pour les sinistres survenus mais pas encore déclarés
PSAP : provisions pour les sinistres survenus dont les coûts n’ont pas été
entièrement réglés.
Ces deux provisions seront estimées à partir d’un triangle de paiement, avec les années
de survenance et les années de développement.
Pour commencer, je vais exposer la méthode de modélisation des paiements de
sinistres.
VII.2. Modélisation dynamique des cash-flows futurs :
Les assureurs doivent de plus en plus raisonner sur la base d’une gestion actif-passif
de leurs risques en donnant toute l’intensité de leurs efforts sur le passif, et non plus se
contenter des modèles historiques ALM, dont l’objectif est principalement lié à une correcte
allocation des actifs. Ce renversement de tendance en direction d’une gestion des risques de
passif constitue une opportunité rare dans l’histoire de l’assurance.
Normalement, les cash-flows futurs (coûts des sinistres…) sont modélisés de manière
statique, i.e. pour quelques dates dans l’avenir, à 1 an, à 2 ans par exemple. On en déduit la
provision technique en actualisant ces cash-flows à la date d’évaluation au taux
correspondant.

31
Dans ce mémoire, j’utilise un modèle dynamique pour représenter les cash-flows
futurs. Cela permet d’être cohérent avec la modélisation des actifs financiers d’où une gestion
actif-passif plus efficace cependant cette idée ne sera pas développé par la suite du mémoire.
En effet, l’actualisation sera effectuée avec les cash-flows aux dates spécifiques (en fin
d’année).
Ce qui suit dans cette partie s’inspire de l’article de HAYER [2001]. Le modèle
développé est une généralisation du modèle « Lognormal age-to-age », HAYNE [1985]. Le
modèle de HAYNE suppose que le facteur de développement suit une loi log-normale.
L’évolution du montant cumulé des sinistres tP se décrit par un processus
stochastique :
( ) ( )t t t tdP t Pdt t PdBμ σ= +
Où tB est un mouvement Brownien, ( )tμ , ( )tσ sont respectivement le taux
d’augmentation marginal et le coefficient proportionnel des montants cumulés.
On en déduit que le facteur de développement suit la loi log-normale :
2 2
2
1 1 1
2 21( ) ( ) , ( )2
t tt
t t t
PLN t t dt t dt
Pμ σ σ
⎛ ⎞⎛ ⎞→ −⎜ ⎟⎜ ⎟⎜ ⎟⎝ ⎠⎝ ⎠∫ ∫ (*)
Ce modèle est appelé le mouvement Brownien géométrique et est fréquemment utilisé
dans le monde financier, l’exemple le plus connu est la formule d’évaluation du prix d’option
de Black-Scholes.
Les éléments que l’on souhaite connaître concernant les passifs sont la provision Best
Estimate à la date 0, la distribution de la provision Best Estimate à la date 1 et la distribution
du montant total de sinistres payés de 0 à 1.
Supposons qu’on a un triangle de paiement suivant avec n années de développements
et la dernière année de survenance est 2006 (rappelons que la date de calcul est 29/12/2006).
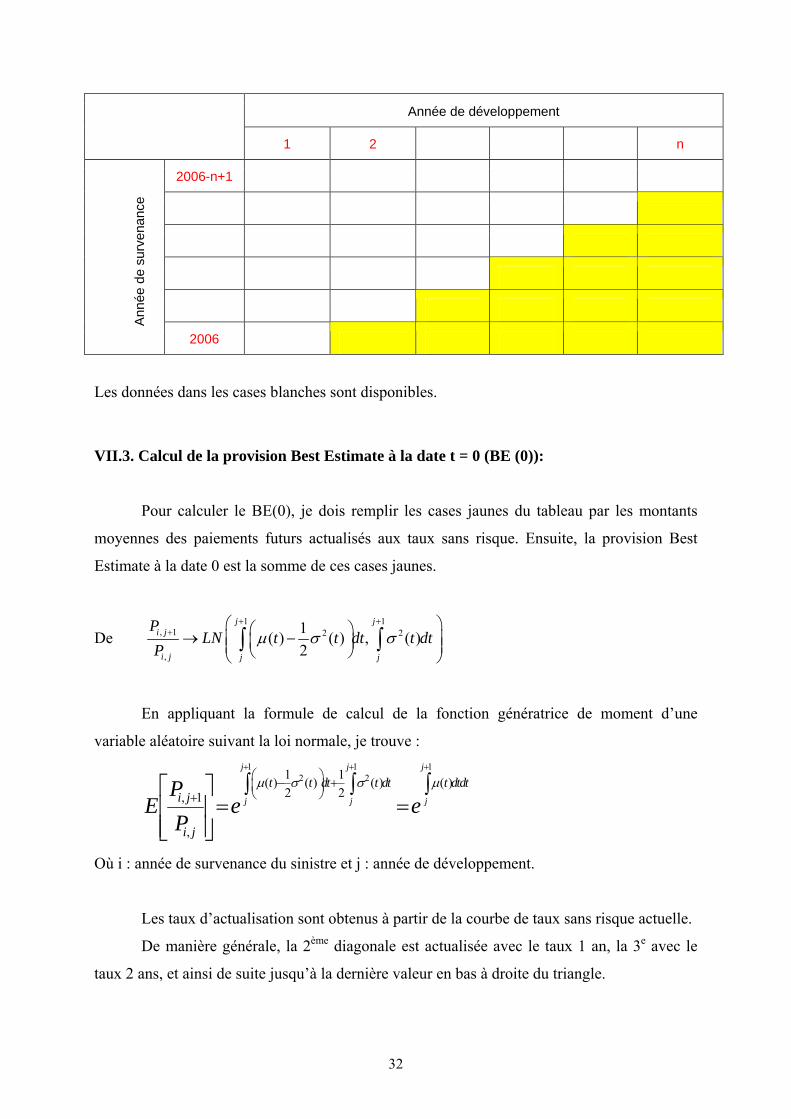
32
Année de développement
1 2 n
2006-n+1
Ann
ée d
e su
rven
ance
2006
Les données dans les cases blanches sont disponibles.
VII.3. Calcul de la provision Best Estimate à la date t = 0 (BE (0)):
Pour calculer le BE(0), je dois remplir les cases jaunes du tableau par les montants
moyennes des paiements futurs actualisés aux taux sans risque. Ensuite, la provision Best
Estimate à la date 0 est la somme de ces cases jaunes.
De 1 1
, 1 2 2
,
1( ) ( ) , ( )2
j ji j
i j j j
PLN t t dt t dt
Pμ σ σ
+ ++
⎛ ⎞⎛ ⎞→ −⎜ ⎟⎜ ⎟⎜ ⎟⎝ ⎠⎝ ⎠∫ ∫
En appliquant la formule de calcul de la fonction génératrice de moment d’une
variable aléatoire suivant la loi normale, je trouve :
1 1 12 21 1( ) ( ) ( ) ( )
2 2, 1
,
j j j
j j j
t t dt t dt t dtdti j
i j
PE e e
P
μ σ σ μ+ + +⎛ ⎞− +⎜ ⎟⎝ ⎠+∫ ∫ ∫⎡ ⎤
= =⎢ ⎥⎢ ⎥⎣ ⎦
Où i : année de survenance du sinistre et j : année de développement.
Les taux d’actualisation sont obtenus à partir de la courbe de taux sans risque actuelle.
De manière générale, la 2ème diagonale est actualisée avec le taux 1 an, la 3e avec le
taux 2 ans, et ainsi de suite jusqu’à la dernière valeur en bas à droite du triangle.

33
VII.4. Calcul de la distribution du montant total de sinistres payés de 0 à 1 :
En utilisant la technique de Monte Carlo, je simule un nombre important de fois la
deuxième diagonale en se basant sur la distribution log-normale des facteurs de
développement. Le montant total de sinistres payés de 0 à 1 est la somme des éléments de
cette diagonale.
VII.5. Calcul du Best Estimate à la date 1 (BE(1)) :
Dans cette partie, je vais utiliser une méthode dite « simulations dans les
simulations ». Pour cela, je simule tous les aléas qui peuvent survenir dans la période 0 à 1
(ici les paiements de sinistres et le taux d’intérêt sans risque), la provision Best Estimate à la
date 1 doit être construite conditionnellement à ces aléas.
En fait, pour chaque 2ème diagonale simulée, en supprimant la première ligne et la
première colonne, j’obtiendrai un nouveau triangle de taille diminuée de 1. Ensuite, je
procède de la même manière que pour le calcul du BE(0) avec les nouvelles données tout en
gardant les mêmes hypothèses sur la distribution des facteurs de développements ainsi que la
forme des fonctions ( )tμ et 2 ( )tσ . Par contre suite aux aléas en 2007, les paramètres de ces
dernières fonctions vont changer.
Un autre paramètre qui va changer aussi est le taux d’actualisation. Avec le modèle
CIR, j’obtiens un échantillon de taux sans risque instantané dans 1 an noté 1r ; les taux
d’actualisations en t = 1 sont obtenus par :
[ ]1(1, ) (1, ) exp (1, )P T A T B T r= −

34
VIII. Outils mathématiques et statistiques:
Avant d’aborder le calibrage des modèles, je voulais présenter brièvement quelques
objets mathématiques importants, et des méthodes d’estimations usuelles qui seront utilisés
dans le cadre de ce mémoire.
VIII.1. Processus stochastiques usuelles :
a) Mouvement brownien :
On rappelle ici les propriétés essentielles de cet objet.
Le mouvement brownien est le plus célèbre des processus de Lévy. C’est un processus
stable, continu (il ne fait aucun saut), ce qui ne l’empêche pas d’être complexe (il est à
variation infinie).
Le mouvement brownien est un processus qui satisfait par construction les trois
propriétés suivantes :
- Accroissements indépendants : les bouts de trajectoires sont indépendants les uns des
autres.
- Accroissements stationnaires.
- Continuité : la continuité est l’absence de saut.
Un processus de Lévy est simplement un processus qui vérifie les deux premières mais
pas forcément la troisième.
b) Processus de Poisson :
Le processus de Poisson est un outil extrêmement utilisé tant pour la modélisation des
sinistres (dans les modèles de type Poisson-composé) que dans les modèles d’actifs dans
lesquels on souhaite introduire des sauts.
On considère des évènements qui se produisent à des dates aléatoires, et on s’intéresse,
pour tout t > 0 au nombre d’évènements qui se sont produits au cours de l’intervalle ]0, ]t , que
l’on note N(t).
Définition et quelques propriétés intéressantes :

35
On définit alors le processus de Poisson d’intensité 0λ > comme le processus N(t)
satisfaisant les conditions suivantes :
- P1 : le processus est à accroissements indépendants, i.e. 1 20 ... nt t t∀ ≤ < < , les
variables aléatoires 1( ) ( ), 1,...,i iN t N t i n−− = sont globalement indépendantes.
- P2 : Le processus est à accroissements stationnaires, i.e. , 0t h∀ > , la loi de
( ) ( )N t h N t+ − ne dépend que de h.
- P3 : ( ( ) ( ) 1) ( )P N t h N t h o hλ+ − ≥ = + et ( ( ) ( ) 2) ( )P N t h N t o h+ − ≥ =
La condition P3 signifie que sur un petit intervalle de temps, on observe 0 ou 1
événement, et que la probabilité d’observer un événement est proportionnelle au temps
écoulé. On peut remarquer que N(0) = 0.
Les trajectoires sont par définition croissantes, continues à droite avec une limite à
gauche. Elles croissent par sauts d’une unité.
On vérifie par ailleurs sans difficulté que si ( )1tN et ( )2
tN sont deux processus de
Poisson indépendants d’intensité respectives 1λ et 2λ , alors 1 2t t tN N N= + est un processus de
Poisson d’intensité 1 2λ λ+ . Pour le vérifier on remarque que tN est un processus à
accroissements indépendants et stationnaire, et qu’il vérifie également P3.
Ce résultat admet la réciproque suivante : si tN est un processus de Poisson et que nT
désigne l’instant du ièmen saut, et si on se donne des variables aléatoires de Bernoulli nX
indépendantes des instants de saut et de paramètre p, on peut construire deux processus en
affectant les sauts de tN à l’un si 1nX = , à l’autre sinon, les 2 processus ainsi obtenus sont
des processus de Poisson indépendants, de paramètre respectifs pλ et (1 )p λ− .
VIII.2. Méthodes statistiques pour l’estimation des paramètres:
VIII.2.1. Modèle de régression linéaire, moindres carrées ordinaires (MCO) :
Soit le modèle suivant Y XB σε= + où 2(0, )Nσε σ→ . Les paramètres à estimer sont
B et σ .

36
On considère une variable d’intérêt y appelée variable dépendante et un ensemble de K
variables dites explicatives auquel on adjoint une constante. On dispose de N observations
notés ( )_
1 2, ,..., Ny y y y= de la variable dépendante. On définit de même les vecteurs _ _
1,..., Kx x
et _
x la matrice des variables explicatives à laquelle on adjoint le vecteur constant
'(1,...,1)e = : _ _ _
1, ,..., Kx e x x⎛ ⎞= ⎜ ⎟⎝ ⎠
est donc une matrice de dimension N x (K+1).
Définition :
L’estimateur des moindres carrés ordinaires est défini comme le vecteur b de
dimension K + 1, ( )_ '
0 ,..., Kb b b= , des coefficients de la combinaison linéaire de _ _
1, ,..., Ke x x
réalisant le minimum de la distance de _
y à l’espace vectoriel de NR engendré par
_ _
1, ,..., Ke x x , pour la norme euclidien : 2_ _^
arg minmcob y xb= −
Proposition 1 :
Sous l’hypothèse H1 : les vecteurs _ _
1, ,..., Ke x x sont indépendants,
L’estimateur des moindres carrés existe, est unique et a pour expression
1_ _ _ _^
' 'mcob x x x y−
⎛ ⎞= ⎜ ⎟⎝ ⎠
Et pour les résidus, on a : :
2^
1
( 1)
n
mcoi ii
y b x
n Kσ∧
=
⎛ ⎞−⎜ ⎟⎝ ⎠=− +
∑
VIII.2.2. Modèle de régression non linéaire, moindres carrées non ordinaire:
De même que la régression linéaire, on a le modèle suivant ( )Y X B σε= + où
2(0, )Nσε σ→ . Les paramètres à estimer sont B et σ .
Sauf qu’ici X(B) est une fonction non linéaire, mais le principe d’estimation des
paramètres reste le même.

37
A savoir 2_ _^
arg min ( )mcob y x b= −
VIII.2.3. Méthode des moments, méthode mu maximum de vraisemblance:
Définissons une population par :
( ; ),
( ) ( ; )
m
k kk k
X f x R
E X x f x dx
θ θ
μ μ θ θ
∈
⎡ ⎤ = = =⎣ ⎦
→
∫
Et 1
1
,...,1n
nk
k ii
x x
M xn =
= ∑ statistique observable
a) Méthode des moments :
L’estimateur de moment est obtenu en égalant les moments théoriques et les moments
empiriques.
θ∧
est solution de ( ) 1,...,k kM k mμ θ= = .
En effet, on doit résoudre m équations à m inconnus 1,..., mθ θ
b) Méthode du maximum de vraisemblance :
C’est la plus populaire des méthodes d’estimations.
L’estimateur du maximum de vraisemblance (MLE) de θ est obtenu comme
1 1( ,..., ) arg max ( , ,..., )n nx x l x xθ
θ θ∧
=
Où l est la fonction de vraisemblance qui est définie par : 11
( , ,..., ) ( ; )n
n ii
l x x f xθ θ=
=∏
VIII.3. Méthode de simulation Monte-Carlo :
Le projet Solvency II implique le passage des méthodes déterministes aux méthodes
stochastiques. Le terme « stochastique » amène à l’utilisation de tirages aléatoires respectant

38
des lois de probabilité et permettant d’obtenir une distribution des résultats et ainsi de
représenter le plus fidèlement possible la réalité des risques portés par une compagnie
d’assurance.
Le développement nécessaire de modèles internes en particulier fait donc appel aux
méthodes et outils stochastiques présentés ci-après
VIII.3.1. Présentation:
L’idée sous-jacente est d’approcher le résultat théorique (qui peut être une statistique
associée à une distribution, comme son espérance, sa fonction de répartition, ou, plus
généralement, toute fonctionnelle associée à la distribution étudiée) en effectuant des tirages
dans la loi du phénomène observé.
Pour pouvoir utiliser les modèles de simulations, que ce soit en Assurance Vie, avec
les méthodes de tirages aléatoires, en Assurance Non-Vie, avec les modèles « fréquence-coûts
», ou en finance avec les processus stochastiques il est donc nécessaire de savoir simuler des
réalisations des différentes lois de probabilité.
L’ensemble de ces techniques est généralement regroupé sous le vocable de «
méthodes de Monte-Carlo ». Il en existe de différents types, adaptés à la loi que l’on souhaite
simuler et au contexte. Mais, dans tous les cas, la génération de nombres aléatoires de loi
uniforme est essentielle à toute technique de simulation, du fait de l’utilisation de méthodes
type « inversion de la fonction de répartition ».
VIII.3.2. Simulation de distributions discrètes:
a) Méthode d’inversion :
Le principe est ici de découper l’intervalle [0;1] en sous intervalles dont les bornes
sont les Σ pi croissantes. Ce découpage est dû au fait qu’il n’existe pas obligatoirement de
bijection entre les différentes modalités de la distribution entière et l’intervalle [0;1], puisque
la fonction de répartition d’une distribution entière est en escaliers. L’indice de la borne
supérieure de l’intervalle ainsi créé dans lequel se trouvera le nombre aléatoire de loi
uniforme simulé donnera la valeur simulée de notre distribution.

39
Algorithme :
Si Y a pour loi ( ) ,k kP Y y p k N= = ∈ et si [ ]0,1U Uniforme→
alors, 10
0 0
01
1 1 i n
j jj j
U p ip U pi
y y−
= =
≤ ⎧ ⎫⎪ ⎪< ≤≥ ⎨ ⎬⎪ ⎪⎩ ⎭
+∑ ∑
∑ a même loi que Y.
Exemple : Simuler une réalisation de la loi Poisson(3)
P (X = k) = pk = !
k
ek
λ λ− , k ∈ N, F(k) fonction de répartition/ F(k) = P(X ≤ k)
p0 = 0,049
Simuler une réalisation u de la loi uniforme U(0,1)
+ Si u ≥ p0, on a une réalisation de 0 de la loi simulé
+ Si u < p0, on prend k tel que u > F(k)
Remarque : Il est à noter que cette méthode, très générale, peut être coûteuse en temps de
calcul suivant les cas. Pour chacune des lois entières connues, il existe des méthodes de
simulations particulières, qui s’avèrent beaucoup plus performantes.
b) Méthode de la composition :
Seconde méthode “classique” de simulation pour les distributions entières, ou même
absolument continues, la méthode de la composition a pour objectif de décomposer la densité
de probabilité de la variable aléatoire en mélange de fonctions de densité. Cette
décomposition peut se faire à partir des probabilités conditionnelles.
Méthodologie :
Soit X la variable aléatoire réelle dont nous cherchons une réalisation x.
La méthode de la composition propose de chercher g et Y telles que
( ) ( ) ( )i ii
P X x P Y y g x Y Y= = = =∑
Pour simuler une réalisation de X, il faut simuler un premier nombre aléatoire 1u pour
trouver y réalisations de Y tell que 1( )P Y y u= = puis générer un autre nombre aléatoire 2u
afin d’en déduire 2( )x g u Y y= =

40
Exemple : Une distribution Binomiale Négative BN(r, p) est une distribution Poisson-
Gamma (r, p/q)
Ainsi, il est possible d’utiliser cette propriété pour simuler une distribution Binomiale
Négative, à partir de la méthode de la composition, en deux étapes :
+ Simulation d’une réalisation λ de la loi Gamma (r, p/q),
+ Simulation d’une réalisation de la loi de Poisson de paramètre λ.
On obtient ainsi une réalisation de la loi BN(r, p).
Remarque : Dans cet exemple, et contrairement à la présentation de la méthode, c’est la loi
discrète (loi de Poisson) à laquelle nous appliquons le conditionnement, et non pas la loi
absolument continue, mais il est bien évident que le principe reste le même.
VIII.3.2. Simulation de distributions continues:
a) Méthode de l’inversion de la fonction de répartition :
Classiquement, c’est l’une des méthodes les plus utilisées en simulation, au moins
lorsque la puissance de l’outil informatique permet les calculs, et que l’inversion de la
fonction de répartition est possible, ce qui nécessite le plus souvent une expression analytique
simple de cette fonction.
Proposition : Soit Y une variable aléatoire réelle à valeurs dans R de fonction de répartition
YF . On pose :
1( ) inf{ : ( ) }Y YF u y F y u− = ∈ ≥ , [0,1]u∈
Si 1( )Ydom FU U −→ alors 1( )YF U− et Y ont la même loi.
Ainsi, pour simuler un n-échantillon i.i.d. d’une loi ayant pour fonction de répartition
F, il suffit de simuler n réalisations indépendantes d’une v.a.r. de loi uniforme sur l’intervalle
[0;1], puis d’appliquer l’inverse de la fonction de répartition à chacune de ces valeurs. Ceci
montre tout l’enjeu d’une simulation “optimale” des réalisations d’une loi uniforme, puisque
les seules approximations résident dans cette opération quand l’inversion de la fonction de
répartition est possible de manière analytique.

41
Exemple : Loi Exponentielle ε (q)
Cette loi dépend d’un unique paramètre θ > 0.
La fonction de répartition F de la loi exponentielle est donnée par :
( ) 1 xF x e θ−= −
Grâce à l’expression analytique de cette fonction de répartition, nous pouvons
facilement extraire :
1 1( ) ln(1 )F u uθ
− = − − .
Ainsi, on simule une réalisation u de la loi normale U(0,1), et on obtient une
simulation de X par x = 1( )F u−
Avantage:
+ Facile à comprendre et à implémenter.
+ Cette méthode permet de simuler, notamment, les lois suivantes :
- La loi exponentielle ( )E θ
- La loi de Pareto ( , )P a α
- La loi de Weibull ( , )W τ α
- La loi Normale 2( , )N μ σ
Inconvénient :
+ L’inverse de la fonction de répartition est rarement disponible.
+ Lemme d’inversion ne s’applique qu’en dimension 1.
+ Algorithme résident sur machine seulement pour lois usuelles.
b) Méthode du rejet :
Dans le cas où l’on ne connaît pas la forme exacte de la fonction de répartition, une
solution est de simuler une loi de proposition « plus simple » et d’utiliser un algorithme
d’acceptation-rejet.
Algorithme d’acceptation-rejet :
Soit une loi d’intérêt de densité f et une loi de proposition g telle que ( ) ( )f x Mg x≤
sur le support de f. Alors, on peut simuler suivant f avec l’algorithme suivant

42
Générer x g→ et ([0,1])u U→
Accepter y = x si
( )( )
f xuMg x
≤
Retourner en 1) si rejet
Remarque : Le choix de g et de M doit être fait comme suit :
+ g est une fonction de densité “simple”, que nous savons simuler,
+ M est une constante le plus proche de 1 que possible (ce qui améliore la
qualité du générateur),
+ La probabilité d’acceptation est égale à 1/M, donc la valeur de M règle
l’efficacité (vitesse) de l’algorithme.
Exemple :
On cherche à simuler une loi X qui admet comme densité la fonction
( ) exp( ² / 2)f x x= −
On sait que 2( 1) 1xe− − ≤ soit
2 2 1 1x xe− + − ≤ soit 2
12
x
x
e ee
−
− ≤
Donc, on va prendre 2( ) 2 xg x e−= qui est la densité de la loi d’exponentielle de
paramètre 2 et le constant M = e/2.
Probabilité d’acceptation = 1/M = 2/e = 0,74
Appliquons maintenant l’algorithme de simulation :
Nous simulons un couple (u1, x1) de v.a.r. indépendantes de lois respectives U ([0;1])
et Exponentielle(2).
Si u1 ≤ ( 1)( 1)
f xMg x
, alors nous gardons X = x1
Si u1 > ( 1)( 1)
f xMg x
, alors nous rejetons X = x1, simulons un autre couple (u2, v2)
c) Méthode de la composition :
Utilisée pour les simulations de distributions entières, la méthode de la composition se
généralise aux distributions absolument continues.

43
Méthodologie : Soit X la v.a.r. dont nous cherchons une réalisation x.
Soit Xf la densité de probabilité de X.
La méthode de la composition se propose de chercher g et YF telles que :
( ) ( ) ( ( ))X Yf x g x y d F y= ∫
Pour simuler une réalisation de X, il faut alors simuler un premier nombre aléatoire u1
pour trouver y réalisation de Y telle que F = u1 puis de générer un autre nombre
Aléatoire u2 afin d’en déduire x = g (u2 | Y = y).
Exemple :
Nous voulons simuler une loi qui est un mélange de 2 autres lois continues connues
( )X Exponentielle λ→ et ( , )gamma a bλ →
+ Simulation d’une réalisation λ de la loi Gamma (a, b),
+ Simulation d’une réalisation de la loi d’Exponentielle de paramètre λ.
Nous obtenons ainsi une réalisation de la loi de X.
Avantage :
+ Cette méthode donne une meilleure précision que la méthode de rejet.
Inconvénient :
+ Normalement, il est difficile de décomposer une loi quelconque en 2 lois connues.
d) Conclusion :
Il faut remarquer que certaines lois ne sont pas simulées à partir des trois méthodes
précédentes.
La meilleur méthode (et la plus simple) reste la méthode d’inversion de la fonction de
répartition, viens ensuite la méthode de décomposition, mais il faut savoir décomposer la
densité qui est une tâche difficile. Si ces 2 méthodes ne tiennent pas, on applique la méthode
de rejet.

44
IX. Estimation des paramètres et application numérique:
Normalement, la modélisation d’une variable passe par trois étapes de choix de
modèle, d’estimation des paramètres du modèle sur la base des données historiques et d’étude
de la robustesse du modèle en vue d’accepter ou de rejeter le modèle choisi. Dans ce
mémoire, comme je travaille sur un portefeuille fictif, et par souci de simplicité, je vais passer
la troisième étape. Les logiciels utilisés sont SAS (surtout le proc iml) et R (pour les
graphiques).
IX.1. Modèles des actifs:
IX.1.1. Modèle de Merton:
L’évolution de prix d’un actif financier est donnée par l’équation suivante :
1
²( ) (0)exp ( )2
tN
t kk
S t S t B Uσμ σ=
⎧ ⎫= − + +⎨ ⎬
⎩ ⎭∑ (*)
Où :
S(t) : prix de l’actif à l’instant t.
0( )t tB B ≥= : Mouvement brownien.
0( )t tN N ≥= : Processus de Poisson homogène d’intensitéλ .
1( )k kU U ≥= : Suite de variables aléatoires indépendantes identiquement distribuées de
loi Normale (0, )uN σ .
Les processus B, N, U sont mutuellement indépendants.
Les paramètres à estimer sont ( ), , ,uμ σ σ λ .
La démarche d’estimation de ces paramètres suit celle proposée dans RAMEZANI et
ZENG [1998]. Dans un premier temps des estimateurs sont obtenus par la méthode des
moments. Ils seront ensuite utilisés pour initialiser un algorithme de maximisation de la
vraisemblance qui donne des résultats plus précis avec des propriétés classiques comme :
convergence, efficacité asymptotique, normalité asymptotique.

45
D’après l’équation (*), le rendement de l’actif sur l’intervalle [t, t+h] s’écrit :
1
1
²exp ( )( )2
²exp ( )2
t h
t
N
t h kkt h
r h Nt
t kk
t h B USrS
t B U
σμ σ
σμ σ
+
+=+
+
=
⎧ ⎫− + + +⎨ ⎬
⎩ ⎭=⎧ ⎫
− + +⎨ ⎬⎩ ⎭
∑
∑
ce qui conduit après simplification à l’expression :
²exp ( ) ( )2
t h
t
Nt h
t h t h t kNt
Sr h B B US
σμ σ+
++ +
⎧ ⎫⎪ ⎪= = − + − +⎨ ⎬⎪ ⎪⎩ ⎭
∑
J’en déduis que, si l’on dispose de n observations des cours équi-réparties aux instants
iiTtn
= sur un intervalle [0, T], les variables 1
( )( ) ln( )
ii i
i
S tx x tS t −
= = sont telles que :
( 1) //
1 1
² ( 1)( ) ( ) ( )2
i T niT n NN
i t k kk k
T iT i Tx B B U Un n n
σμ σ−
= =
−⎡ ⎤= − + − + −⎢ ⎥⎣ ⎦∑ ∑
Cela prouve que les variables aléatoires 1,..., nx x sont indépendantes et identiquement
distribuées. En d’autres termes les rendements sur des intervalles disjoints sont indépendants,
et la distribution dépend de la longueur et non pas de la position.
Proposition 1: La densité de r sur une période s’écrit :
2
2 22 20
²( )2( ) exp
2( )2 !
n
rn uu
xef xnn n
λσμλ
σ σπ σ σ
− ∞
=
⎡ ⎤⎡ ⎤⎧ ⎫− +⎢ ⎥⎢ ⎥⎪ ⎪= −⎢ ⎥⎢ ⎥⎨ ⎬++⎢ ⎥⎢ ⎥⎪ ⎪
⎢ ⎥⎢ ⎥⎩ ⎭⎣ ⎦⎣ ⎦
∑
Démonstration : Annexes

46
a) Méthode des moments :
La méthode des moments consiste à égaliser les moments empiriques avec les
moments théoriques. Comme j’ai 4 paramètres à estimer 2 2, , ,uμ σ σ λ , je dois résoudre un
système non linéaire de 4 équations à 4 inconnus.
Compte tenu de la loi du rendement, je m’intéresse aux moments centrés.
Si ²( )2
m E r σμ= = − , je vais donc calculer ( )kkm E r m⎡ ⎤= −⎣ ⎦ , un argument de
symétrie conduit à conclure que 2 1 0km + = . Il suffit donc de déterminer les moments d’ordre
pair.
Je pose alors :
12
2 24
3 46
4 6
( ) ( )( ) ( )( ) ( )( ) ( )
F x E r mF x E r m mF x E r m mF x E r m m
= −⎧⎪ = − −⎪⎨ = − −⎪⎪ = − −⎩
où x = ( 2 2, , ,uμ σ σ λ )
Pour trouver les estimateurs par la méthode de moment, je construits une fonction du
type : 2 2 2 2
1 2 3 4( ) ( ) ( ) ( ) ( )h x F x F x F x F x= + + + . Résoudre le système non linéaire revient à minimiser
la fonction h(x). Pour cela, j’utilise la méthode de « Trust-Region » disponible dans le proc
iml du logiciel SAS, ainsi j’obtiendrai plusieurs solutions dépendant du vecteur
d’initialisation 0x . En effet pour chaque vecteur 0x , on a une solution qui minimise la fonction
h(x) localement. De manière empirique, chaque paramètre varie entre 0 et 1. Par conséquent
pour avoir une solution globale qui minimise le plus la fonction h(x), j’ai simulé 500 vecteurs
0x dont les composantes suivent indépendamment une loi uniforme [0, 1]. Ensuite j’ai retenu
comme solution du système le vecteur solution qui donne le minimum des h(x).
Proposition 2: Le moment centré d’ordre 2k de r s’écrit :
2 2 22
0
(2 )!( ) ( )2 ! !
nk k
k ukn
km E r m e nk n
λ λ σ σ∞
−
=
⎡ ⎤= − = +⎣ ⎦ ∑
Démonstration : Annexe

47
b) Méthode du maximum de vraisemblance :
La méthode des moments a permis d’obtenir un premier jeu d’estimateurs pour les
paramètres du modèle; j’utilise ce jeu comme valeur initiale pour déterminer le maximum
local de la vraisemblance dans son voisinage. Compte tenu de la proposition 1, j’obtiens
l’expression suivante de la vraisemblance :
2
2 21 2 22 2
01
²( )2( ,..., , , , , ) exp
2( )2 !
nn i
n uni uu
xeL x xnn n
λσμλμ σ σ λ
σ σπ σ σ
− ∞
==
⎡ ⎤⎡ ⎤⎧ ⎫− +⎢ ⎥⎢ ⎥⎪ ⎪= −⎢ ⎥⎢ ⎥⎨ ⎬++⎢ ⎥⎢ ⎥⎪ ⎪
⎢ ⎥⎢ ⎥⎩ ⎭⎣ ⎦⎣ ⎦
∑∏
Le but est ici de maximiser la vraisemblance (ou de manière équivalente de minimiser
- 2 2ln ( , , , , )uL x μ σ σ λ ). Concernant les contraintes, il vient de manière évidente que 2 0σ ≥
et 2 0uσ ≥ . Ensuite, je vais étudier les valeurs des estimateurs issues de la méthode des
moments pour encadrer les autres paramètres.
En fait, je dispose des estimateurs obtenus par la méthode des moments. Je considère
que ces estimateurs approchent à plus ou moins 50 % les estimateurs du maximum de
vraisemblance. Par conséquent, je retiens d’imposer quatre contraintes d’inégalité pour
l’optimisation de la log-vraisemblance. Je suis ainsi amené à un classique problème de
maximisation sous contraintes, dont la résolution numérique n’appelle pas de remarque
particulière.
Le système des contraintes se décrit comme suivant :
2 2 2
2 2, ,
0,5 1,50,5 1,5
0,5 1,50,5 1,5
mom mom
mom mom
u mom u mom
mom mom
μ μ μσ σ σσ λ σλ λ λ
≤ ≤⎧⎪ ≤ ≤⎪⎨ ≤ ≤⎪⎪ ≤ ≤⎩
Donc le problème revient à maximiser la vraisemblance sur un compact 4V R∈ .
Comme elle est continue, elle atteint donc son maximum.

48
En résumé, le problème à résoudre est :
4
2 21
2 2 2
2 2, ,
max ( ,..., , , , , )
0,5 1,50,5 1,50,5 1,50,5 1,5
n ur R
mom mom
mom mom
u mom u mom
mom mom
L r r μ σ σ λ
μ μ μσ σ σ
σ λ σ
λ λ λ
∈
⎧⎪⎪ ≤ ≤⎪⎨ ≤ ≤⎪
≤ ≤⎪⎪ ≤ ≤⎩
Remarque :
Par la méthode de l’estimation du maximum de vraisemblance, pour les grands
échantillons et sous certaines hypothèses peu strictes, l’estimateur sera asymptotiquement
sans biais, normal et efficace. On ne sait rien sur l’unicité des solutions de l’équation de
vraisemblance. De plus, cette méthode ne sera valable utilement que pour de grands
échantillons à cause de ses propriétés asymptotiques.
IX.1.2. Modèle de taux (CIR):
Le processus ( )t t t tdr a b r dt r dBσ= − + peut être discrétisé en :
( )t h t t tr r a b r h hr σε+ − = − + avec (0, )Nσε σ→ et h est le pas de discrétisation.
Soit
( )t h t t
t t
t h tt
tt
r r a b r hhr hr
abr r h r harhr
σ
σ
ε
ε
+
+
− −= +
⎛ ⎞⎛ ⎞−⇔ = +⎜ ⎟⎜ ⎟⎜ ⎟ −⎝ ⎠⎝ ⎠
Il s’agit d’un modèle de régression linéaire, alors, par la méthode de moindres carrés
ordinaires (MCO), j’obtiens les valeurs ab et –a, et en résolvant le système de 2 équations à 2
variables, j’obtiendrai les estimateurs de a et de b. La valeur de σ est obtenue directement par
MCO.

49
IX.1.3. Copule Student ,vt∑ :
Cette partie s’inspire des travaux de KARIM CHEIKH BENANI [2003]
Notons désormais la copule Student par t-copule :
Supposons qu’on désire approximer par une t-copule la structure de dépendance d’un
vecteur aléatoire de distribution jointe inconnue mais dont les lois marginales sont connues et
qu’on dispose d’un échantillon de réalisations { }1,..., nX X X= avec 1( ,..., )ni i iX x x= . On va
chercher à estimer les paramètres ( , )v∑ .
Zeevi et Mashal [2002] sur la base des travaux de Lingskog(2000) ont proposé une
méthode pour estimer ces paramètres.
Cette méthode utilise la fonction de vraisemblance de l’échantillon ( )iG X où,
1( ) ( ( ),..., ( ))ni v i v iG X t x t x= et vt est la fonction de répartition de la Student univariée à v degrés
de liberté. Cette fonction de vraisemblance s’écrit :
1
( , ) ( ( ), , )m
m ii
L v c G X v=
∑ = ∑∏
Où c est la densité de la t-copule. La fonction de log vraisemblance de ( )iG X s’écrit :
1
( , ) log[ ( ( ), , )]m
m ii
l v c G X v=
∑ = ∑∑
Zeevi et Mashal [2002] adoptent une approche différente du maximum de
vraisemblance. Ils ne calculent pas les estimateurs du maximum de vraisemblance de ( , )v∑ .
Dans leur méthode, la fonction de vraisemblance n’est pas simultanément maximisée suivant
∑ et suivant v . Le paramètre ∑ est en premier estimé, puis à partir de cette estimation∧
∑ , ils
cherchent le nombre v qui maximise la fonction de vraisemblance.
a) Estimation de ∑ :
L’estimation de la matrice de corrélation ∑ d’un vecteur aléatoire se ramène à
rechercher le coefficient de corrélation ( , )X Yρ entre chaque couple (X, Y) de composantes.
J’introduis ici 2 mesures de dépendances des variables aléatoires, à savoir le
coefficient de Pearson et le Tau de Kendall.

50
Coefficient de corrélation de Pearson :
Définition : Soit 2 variables aléatoires et soit un échantillon
d’observations{ }( , ) | 1,...,i ix y i m= , la corrélation entre X et Y peut être estimée par
l’estimateur empirique
1
2 2
1 1
( )( )( , )
( ) ( )
m
i ii
pearson m m
i ii i
x x y yX Y
x x y yρ
∧ ∧
∧=
∧ ∧
= =
− −=
− −
∑
∑ ∑
Toutefois, cet estimateur présente un biais important si les variables aléatoires X et Y
possèdent des distributions à queues épaisses. De plus, il présente une variance élevée.
Dans la suite, nous allons présenter un autre estimateur de dépendance entre variables
aléatoires qui correspond bien à la distribution Student multivariée.
Le Tau de Kendall :
Définition : Soit (X, Y) un vecteur aléatoire à valeurs dans 2R . On appelle taux de
Kendall de (X, Y), la constante réelle :
{ } { }( , ) ( )( ) 0 ( )( ) 0i j i j i j i jX Y P X X Y Y P X X Y Yτ = − − > − − − <
Où ( , )i iX Y et ( , )j jX Y sont des réalisations de (X, Y), indépendantes entre elles.
Le tau de Kendall décrit les propriétés de concordance de la relation entre deux
variables aléatoires X et Y.
Cet estimateur de dépendance correspond bien à la distribution Student multivariée.
Matrice de corrélation de ,vt∑ :
LINDSKOG [2001b] a présenté une relation entre le tau de Kendall et la matrice de
corrélation∑ de la variable aléatoire suivant la distribution de Student multivariée.
En effet, si ,vt∑ est une Student multivariée à valeurs dans nR alors :
sin( )2π τ∑ = ou bien ( , ) sin( ( , ))
2i j i jX X X Xπρ τ= avec { }, 1,...,i j n∈
Dans mon problème, je cherche à approximer par une t-copule la structure de
dépendance d’un vecteur aléatoire (des browniens) à valeurs dans R de distribution jointe

51
inconnue (et à priori n’étant plus une Student multivariée) mais dont les distributions
marginales sont connues (normales) et pour lequel je dispose d’un échantillon de réalisations.
b) Estimation de v :
Pour estimer le paramètre v, on recherche la valeur v qui maximise la log
vraisemblance.
1
arg max log[ ( ( ), , )]m
iv V i
v c G X v∧ ∧
∈ =
⎡ ⎤= ∑⎢ ⎥⎣ ⎦∑ où { }3,4,5,...V =
IX.2. Modèles des passifs:
IX.2.1. Application du modèle:
La première étape dans l’application du modèle de marche aléatoire est de vérifier si
les facteurs de développement année par année observés sont indépendants, identiquement
distribués selon la loi Log-Normale. Après il faut identifier des fonctions appropriées pour
( )tμ , ( )tσ et estimer les paramètres pour ces fonctions.
Remarque : une violation sur les hypothèses n’implique pas nécessairement que le calibrage
du modèle est mauvais. Au contraire, elle veut dire que les tests statistiques basés sur les
résultats sont biaisés. L’amplitude de ce biais dépend du degré de la violation.
Sélection de la forme de ( )tμ et ( )tσ :
L’étape suivante dans le processus de modélisation est de choisir la forme appropriée
pour ( )tμ et ( )tσ . Ce n’est pas une tâche triviale : les fonctions polynomiales seront
généralement non-appropriées.
Pour les problèmes de calculs de provisions pour sinistres à payer avec l’hypothèse
que l’assuré n’obtient pas de recours, i.e. il ne peut pas y avoir de paiement négatif, les
fonctions ( )tμ et ( )tσ sont imposées par les mêmes restrictions : elles doivent être positives,
décroissantes, et tendre vers 0 à run-off. Ces types de fonctions sont généralement référés
sous le nom de fonctions de queue.

52
Quelques fonctions pourraient être considérées pour ( )tμ et 2 ( )tσ par exemple :
1
.
1
.
t
e
t
t
γ
β
γ
β
α
α γβ
α γ
⎛ ⎞−⎜ ⎟⎝ ⎠
−
−
⎡ ⎤⎛ ⎞+⎢ ⎥⎜ ⎟
⎝ ⎠⎣ ⎦+
Ici, ces fonctions sont choisies parce qu’elles couvrent une large propriété de queue.
En pratique, plusieurs fonctions de queues peuvent être obtenues en étendant la fonction de
survie des lois de probabilités.
Choisir la fonction la plus appropriée parmi les 3 citées ci-dessus est très compliqué
car on ne peut pas observer directement les valeurs de ( )tμ ou 2 ( )tσ .
IX.2.2. Estimation des paramètres:
Pour chacune des fonctions ( )tμ et 2 ( )tσ , on a 3 paramètres à estimer, à savoir
1 1 1, ,α β γ pour la fonction ( )tμ et 2 2 2, ,α β γ pour la fonction 2 ( )tσ .
Il y a 2 méthodes pour estimer ces paramètres : méthode du maximum de
vraisemblance et celle des moindres carrés. Comme la première a été utilisée pour le calibrage
des modèles des actifs financiers, je vais appliquer la méthode des moindres carrées dans cette
partie.
On a :
2 2
2
1 1 1
2 21( ) ( ) , ( )2
t tt
t t t
PLN t t dt t dt
Pμ σ σ
⎛ ⎞⎛ ⎞→ −⎜ ⎟⎜ ⎟⎜ ⎟⎝ ⎠⎝ ⎠∫ ∫
D’où
2 2
2
1 1 1
2 21ln ( ) ( ) , ( )2
t tt
t t t
PN t t dt t dt
Pμ σ σ
⎛ ⎞⎛ ⎞ ⎛ ⎞→ −⎜ ⎟⎜ ⎟ ⎜ ⎟⎜ ⎟ ⎜ ⎟⎝ ⎠⎝ ⎠ ⎝ ⎠∫ ∫ et
22
1 1
2
2
1 1
2
2
1ln ( ) ( )2
ln ( )
tt
t t
tt
t t
PE t t dt
P
PV t dt
P
μ σ
σ
⎛ ⎞⎛ ⎞ ⎛ ⎞⎜ ⎟ = −⎜ ⎟ ⎜ ⎟⎜ ⎟⎜ ⎟ ⎝ ⎠⎝ ⎠⎝ ⎠⎛ ⎞⎛ ⎞⎜ ⎟ =⎜ ⎟⎜ ⎟⎜ ⎟⎝ ⎠⎝ ⎠
∫
∫

53
La méthode des moindres carrées consiste à minimiser la distance entre les valeurs
théoriques et les valeurs empiriques.
Supposons que les sinistres soient totalement payés au bout de n années.
Pour chaque année de développement i, on calcule la moyenne et la variance des
logarithmes des facteurs de développement notés iμ et 2iσ avec i = {1, 2,…, n-1}, il s’agit ici
des valeurs empiriques.
Les valeurs théoriques sont calculées ainsi :
222
11 1
323
22 2
21
1 1
ln ( )
ln ( )
..............................
ln ( )n
nn
n n
Pg V t dtP
Pg V t dtP
Pg V t dtP
σ
σ
σ−− −
⎛ ⎞⎛ ⎞= =⎜ ⎟⎜ ⎟⎜ ⎟⎝ ⎠⎝ ⎠
⎛ ⎞⎛ ⎞= =⎜ ⎟⎜ ⎟⎜ ⎟⎝ ⎠⎝ ⎠
⎛ ⎞⎛ ⎞= =⎜ ⎟⎜ ⎟⎜ ⎟⎝ ⎠⎝ ⎠
∫
∫
∫
et
222
11 1
323
22 2
21
1 1
1ln ( ) ( )2
1ln ( ) ( )2
..............................
1ln ( ) ( )2
nn
nn n
Pf E t t dtP
Pf E t t dtP
Pf E t t dtP
μ σ
μ σ
μ σ−− −
⎛ ⎞⎛ ⎞ ⎛ ⎞= = −⎜ ⎟⎜ ⎟ ⎜ ⎟⎜ ⎟ ⎝ ⎠⎝ ⎠⎝ ⎠⎛ ⎞⎛ ⎞ ⎛ ⎞= = −⎜ ⎟⎜ ⎟ ⎜ ⎟⎜ ⎟ ⎝ ⎠⎝ ⎠⎝ ⎠
⎛ ⎞⎛ ⎞ ⎛ ⎞= = −⎜ ⎟⎜ ⎟ ⎜ ⎟⎜ ⎟ ⎝ ⎠⎝ ⎠⎝ ⎠
∫
∫
∫
En conséquence, les estimateurs sont obtenus par les programmes suivants :
, ,σ σ σα β γ∧ ∧ ∧
= argmin22g σ− et , ,μ μ μα β γ
∧ ∧ ∧
= argmin 2f μ−
Où { }1 2 1, ,..., nf f f f −= et { }1 2 1, ,..., ng g g g −=
Pour résoudre ces programmes d’optimisations, je commence par estimer les
paramètres , ,σ σ σα β γ∧ ∧ ∧
, puis je les remplace dans le vecteur f, et enfin j’utilise de nouveau la
méthode de moindres carrées pour trouver les valeurs de , ,μ μ μα β γ∧ ∧ ∧
.
Obtention des résultats :
On a :
22
11
11 2 2 1
1 12 1 2 1
( , ) ( ) ( )1
( )1
tt
tt
h t t t dt t t t
t t t t
β β
β β
αα γ γβ
αγβ
− −
− −
⎡ ⎤= + = − + ⎣ ⎦−
⎡ ⎤= − + −⎣ ⎦−
∫

54
Pour chaque couple 1 2( , )t t je trouve 1 2( , )h t t ou 1t
g en fonction de α , β et γ et aussi
sa valeur numérique notée 1
2tσ . Il s’agit ensuite de résoudre le programme d’optimisation
suivant :
( )21
2
0, , 0
1
1
111
n
ii
i iMinα β γ
β β σαγβ
−
≥ ≥ =
− −⎛ ⎞−⎜ ⎟
⎝⎡
⎠⎤+ + −⎣ ⎦−∑
Les contraintes 0γ ≥ et 0α ≥ sont posées pour assurer la positivité de la variance.
Une fois les paramètres de la fonction 2 ( )tσ estimés et notés , ,σ σ σα β γ∧ ∧ ∧
, je vais chercher
ceux de ( )tμ en résolvant le programme d’optimisation suivant :
( ) ( )
2
1
0, , 0 1
1 1 11 11 11 2 1
n
ii
Min i i i iσ σβ β β
α
β
β γ
σσ
σ
ααγ γ μβ β
∧ ∧−
≥ ≥
∧∧−
=
− −−∧
⎡ ⎤⎛ ⎞⎡ ⎤⎢ ⎥⎜ ⎟⎡ ⎤+ + − − + + −⎢ ⎥
⎛ ⎞⎜ ⎟−⎜ ⎟⎜ ⎟⎝ ⎠
⎣ ⎦⎢ ⎥⎜ ⎟− ⎣ ⎦−⎝ ⎠⎣ ⎦∑
Encore une fois, les contraintes 0, 0α γ≥ ≥ assurent la positivité de ( )tμ .
Les solutions obtenues sont notées , ,μ μ μα β γ∧ ∧ ∧
.
La valeur du passif Best Estimate dans 1 an est calculée comme l’espérance des flux
futurs actualisés conditionnellement aux aléas de la période 0 à 1. Ici, on suppose que les
facteurs de développements suivent toujours la loi log-normale mais les paramètres des
fonctions ( )tμ , 2 ( )tσ vont changer.
En t = 0, ( )tμ , 2 ( )tσ prennent la forme de la fonction .t βα γ− + .
En t = 1, ( )tμ , 2 ( )tσ prennent la forme de la fonction 11 1.t βα γ− + .
IX.3. Application numérique:
IX.3.1 Modèle de Merton:
Mon portefeuille se compose de deux actions : Alcatel et Atos, et d’un titre
immobilier : Affine. Les indices choisis sont le CAC40 et l’Euronext CAC Real Estate IX.
Les données historiques des cours sont extraites de Bloomberg. Il s’agit des données
hebdomadaires du 08/01/1999 au 29/12/2006 (date d’évaluation), ce qui donne 417 valeurs
pour chaque titre. La période choisie reflète un cycle complet.
En appliquant les démarches présentées ci-dessus, j’obtiens les résultats suivants :

55
Les estimateurs de la méthode des moments sont :
12121,
1
0,005190,001290,4824
0,0220u
Alcatelμσσλ
= −⎧⎪ =⎪⎨ =⎪⎪ =⎩
2
22
22,
2
0,00080,00550,0389
0,0042u
Atosμσσλ
= −⎧⎪ =⎪⎨ =⎪⎪ =⎩
323
23,
3
400,00080,00040,0006
0,0045u
CACμσσλ
=⎧⎪ =⎪⎨ =⎪⎪ =⎩
42424,
4
_ _0,0030 0,00020,0003
0,0025u
CAC REAL ESTATEμσσλ
=⎧⎪ =⎪⎨ =⎪⎪ =⎩
52424,
4
0,003230,00040,0006
0,0295u
Affineμσσλ
=⎧⎪ =⎪⎨ =⎪⎪ =⎩
Les estimateurs de la méthode du maximum de vraisemblance sont :
12121,
1
0,00260,0020,24
0,033u
Alcatelμσσλ
= −⎧⎪ =⎪⎨ =⎪⎪ =⎩
2
2222,
2
0,000770,0030,0410,05
u
Atosμσσλ
= −⎧⎪ =⎪⎨ =⎪⎪ =⎩
32323,
3
400,00110,00060,00990,027
u
CACμσσλ
=⎧⎪ =⎪⎨ =⎪⎪ =⎩
42424,
4
_ _0,00330,00030,007
0,023u
CAC REAL ESTATEμσσλ
=⎧⎪ =⎪⎨ =⎪⎪ =⎩
5
24
24,
4
0,0020,0005
0,010,027
u
Affineμσσλ
=⎧⎪ =⎪⎨ =⎪⎪ =⎩
IX.3.2. Modèle de taux (CIR):
Les données choisies sont les cours historiques hebdomadaires du taux EONIA (Euro
OverNight Index Average) du 08/01/1999 au 29/12/2006. Cet indice de taux est choisi parce
qu’il est le taux sans risque le plus court disponible à ma connaissance (taux overnight), qui
est indispensable pour le calibrage du modèle de taux instantané.
La méthode MCO donne :
0,0010337
-0,03433
0,000169
ab
a
σ
∧ ∧
∧
∧
⎧ =⎪⎪− =⎨
⎪⎪ =⎩
d’où
0,03433
0,03011
0,000169
a
b
σ
∧
∧
∧
⎧ =⎪⎪
=⎨⎪⎪ =⎩
IX.3.3. Copule Student ,vt∑ :
Les rendements des titres dans le portefeuille et le taux d’intérêt sans risque instantané
sont décrits par les processus suivants :

56
1,
2,
3,
4,
21 1 11, 1 1
1
22 2 22, 2 2
1
23 3 33, 3 3
1
24 4 44, 4 4
1
25 5, 5
: ( )2
: ( )2
40 : ( )2
_ _ : ( )2
: (2
t h
t h
t h
t h
N
t h t kk
N
t h t kk
N
t h t kk
N
t h t kk
t h
A L C A T E L r h h U
A T O S r h h U
C A C r h h U
C A C R E A L E ST A T E r h h U
A F F IN E r
σμ σ ε
σμ σ ε
σμ σ ε
σμ σ ε
σμ
=
=
=
=
= − + +
= − + +
= − + +
= − + +
= −
∑
∑
∑
∑5,
5 55
1
6 6 6 6 6
)
_ : ( )
t hN
t kk
t h t t t t
h h U
IN T E R E ST R A T E r r a b r h hr
σ ε
σ ε=
+
+ +
= + − +
∑
En fait je cherche à simuler le vecteur aléatoire ( )1 2 3 4 5 6, , , , ,t t t t t tε ε ε ε ε ε . Pour cela, j’ai
besoin de connaître sa distribution conjointe dont la structure de dépendance est décrite par la
copule de Student (t-copule).
Les paramètres ( , )vΣ sont estimés à partir des taux de rendements dévolatilisés des
titres financiers et du taux EONIA.
L’estimation du taux de Kendall est :
1 0.3596 0.4662 0.1717 0.0645 -0.04910.3596 1 0.4302 0.1274 0.0069 -0.03440.4662 0.4302 1 0.2909 0.0326 -0.05430.1717 0.1274 0.2909 1 0.0142 -0.0226 0.0645 0.0069 0.0326 0.0142 1 -0.0709-0.0491 -0.0344 -0.0543 -0
.0226 -0
τ∧
=
.0709 1
⎛ ⎞⎜ ⎟⎜ ⎟⎜ ⎟⎜ ⎟⎜ ⎟⎜ ⎟⎜ ⎟⎜ ⎟⎝ ⎠
Et l’estimation de la matrice de corrélation correspondante est :
1 0.1012 -0.07700.5350 1 0.6253 0.1987 0.0109 -0.05400.6683 0.6253 1 0.4410 0.0512 -0.08510.2663 0.1987 0.4410 1 0.0223 -0.0355 0.1012 0.0109 0.0512 0.0223 1 -0.1111-0.07
0.5350
70 -0.0
0.6683 0.2663
540 -0.0851 -0.03 0
55 -
∧
Σ =
.1111 1
⎛ ⎞⎜ ⎟⎜ ⎟⎜ ⎟⎜ ⎟⎜ ⎟⎜ ⎟⎜ ⎟⎜ ⎟⎝ ⎠
57
La fonction de vraisemblance est représentée sur la figure ci-dessous :
Figure 4 : Fonction de vraisemblance
Le v optimal semble être infini. Ceci signifie que la structure de dépendance entre les
rendements des titres dans le portefeuille et le taux d’intérêt sans risque est celle décrite par
une copule gaussienne. Je prends 1100v∧
= . En effet, ZEEVI, MASHAL [2002] a montré qu’à
partir de v=1000, une copule Student est semblable à la copule de même matrice de
corrélation linéaire.
IX.3.4. Valeur du portefeuille:
a) Valeur du portefeuille initiale (t=0) :
Le portefeuille se compose de 7 titres d’ALCATEL, 8 titre d’ATOS, 9 titres
d’AFFINE et 10 obligations d’état de maturité 5 ans, de coupon 5 et de nominal 50.
Les valeurs initiales des actifs financiers sont
10
20
30
10,9€44,93€135€
SSS
⎧ =⎪ =⎨⎪ =⎩
En t=0, les facteurs d’actualisations sont donnés dans le tableau suivant :

58
Facteur d'actualisation
1 an 2 ans 3 ans 4 ans 5 ans
discount 0,9638853 0,9338853 0,8961447 0,8643775 0,8339238
D’où, on en déduit que la valeur de l’obligation en t=0, notée 0O , est égale à 64,13 €.
Finalement la valeur du portefeuille en t=0 est calculée par :
1 2 30 0 0 0 07* 8* 9* 10* 2292,04€A S S S O= + + + =
b) Valeur du portefeuille dans 1 an (t=1) :
Les évolutions des actifs composant le portefeuille étant entièrement définies, leurs
distributions ainsi que celui du portefeuille dans 1 an seront obtenus en utilisant la méthode de
simulation Monte-Carlo.
Rappelons les résultats obtenus des étapes précédents: 1,
2,
3,
21 1 1 11
1 11
22 2 2 22
2 21
23 3 3 33
3 31
4
: exp ( )2
: exp ( )2
40 : exp ( )2
_ _ :
t h
t h
t h
N
t h t t kk
N
t h t t kk
N
t h t t kk
t h
ALCATEL S S h h U
ATOS S S h h U
CAC S S h h U
CAC REAL ESTATATE S S
σμ σ ε
σμ σ ε
σμ σ ε
+=
+=
+=
+
⎧ ⎫⎪ ⎪= − + +⎨ ⎬⎪ ⎪⎩ ⎭
⎧ ⎫⎪ ⎪= − + +⎨ ⎬⎪ ⎪⎩ ⎭⎧ ⎫⎪ ⎪= − + +⎨ ⎬⎪ ⎪⎩ ⎭
=
∑
∑
∑4,
5,
24 4 44
4 41
25 5 5 55
5 51
6 6 6 6 6
exp ( )2
: exp ( )2
_ : ( )
t h
t h
N
t t kk
N
t h t t kk
t h t t t t
h h U
AFFINE S S h h U
INTEREST RATE r r a b r h hr
σμ σ ε
σμ σ ε
σ ε
=
+=
+
⎧ ⎫⎪ ⎪− + +⎨ ⎬⎪ ⎪⎩ ⎭
⎧ ⎫⎪ ⎪= − + +⎨ ⎬⎪ ⎪⎩ ⎭
= + − +
∑
∑
Où ,
2,
6
(0,1)
( )
(0, )
(0,1)
it
it h i
ik u i
t
N
N P h
U N
N
ε
λ
σ
ε
avec i = {1,2,…,5}

59
1212
1,
1
0,00260,0020,24
0,033u
Alcatelμσσλ
= −⎧⎪ =⎪⎨ =⎪⎪ =⎩
2
2222,
2
0,000770,0030,0410,05
u
Atosμσσλ
= −⎧⎪ =⎪⎨ =⎪⎪ =⎩
32323,
3
400,00110,00060,00990,027
u
CACμσσλ
=⎧⎪ =⎪⎨ =⎪⎪ =⎩
42424,
4
_ _0,00330,00030,007
0,023u
CAC REAL ESTATEμσσλ
=⎧⎪ =⎪⎨ =⎪⎪ =⎩
5
24
24,
4
0,0020,0005
0,010,027
u
Affineμσσλ
=⎧⎪ =⎪⎨ =⎪⎪ =⎩
La valeur du zéro-coupon est déterminée, par la formule suivante :
[ ]( , ) ( , ) exp ( , ) tP t T A t T B t T r= − où tr est le taux sans risque à la date t
Avec t < T,
{ }{ }
{ }{ }
22 /
2 2
2 exp ( )( ) / 2( , )
( )(exp ( ) 1) 2
2exp ( ) 1( , )
( )(exp ( ) 1 ) 2
2
aba T t
A t Ta T t
T tB t T
a T t
a
σγ γ
γ γ γ
γγ γ γ
γ σ
⎧ ⎫+ −⎪ ⎪= ⎨ ⎬+ − − +⎪ ⎪⎩ ⎭− −
=+ − − +
= +
avec
0,03433
0,03011
0,000169
a
b
σ
∧
∧
∧
⎧ =⎪⎪
=⎨⎪⎪ =⎩
Le vecteur aléatoire ( )'1 2 3 4 5 6,, , , , , Student
t t t t t t vCε ε ε ε ε ε Σ
Avec
1 0.1012 -0.07700.5350 1 0.6253 0.1987 0.0109 -0.05400.6683 0.6253 1 0.4410 0.0512 -0.08510.2663 0.1987 0.4410 1 0.0223 -0.0355 0.1012 0.0109 0.0512 0.0223 1 -0.1111-0.07
0.5350
70 -0.0
0.6683 0.2663
540 -0.0851 -0.03 0
55 -
∧
Σ =
.1111 1
⎛ ⎞⎜ ⎟⎜ ⎟⎜ ⎟⎜ ⎟⎜ ⎟⎜ ⎟⎜ ⎟⎜ ⎟⎝ ⎠
et 1100v∧
=
Les variables itε évoluent indépendamment dans le temps (pour i fixé).
Obtention de résultat :
Commençons à t=0 avec les valeurs initiales des titres et du taux EONIA (0 ,0369).
1) Simuler le vecteur ( )1 2 3 4 5 6, , , , ,t t t t t tε ε ε ε ε ε d’après la t-copule
2) Simuler , ( )it h iN P hλ→ , 2(0, )i
k iU N σ→ , les valeurs des actions et titres immobiliers
sont obtenues par

60
,2
1
exp ( )2
it hN
i i i iit h t i i t k
k
S S h h Uσμ σ ε+=
⎧ ⎫⎪ ⎪= − + +⎨ ⎬⎪ ⎪⎩ ⎭
∑ Avec i = {1,2,…,5}
3) Le taux sans risque instantané est obtenu par 6( )t h t t t tr r a b r h hrσ ε+ = + − +
Comme les paramètres ont été estimés en utilisant les valeurs historiques
hebdomadaires, je vais prendre le pas de simulation h = 1 semaine. Supposons que l’année
financière se divise en 37 semaines, je vais répéter l’algorithme précédent 37 fois, les
dernières valeurs obtenues sont les prix des actifs dans 1 an. En t=1, l’obligation gardera les
mêmes coupons et le même nominal qu’au début mais sa maturité sera réduite à 4 ans, son
prix sera donc déduit du taux sans risque instantané à t=1.
En répétant l’étape précédente 200 fois, j’obtiens les échantillons des titres Alcatel,
Atos, Affine, ainsi que le prix de l’obligation 1 an. Leurs histogrammes sont présentés ci-
dessous :
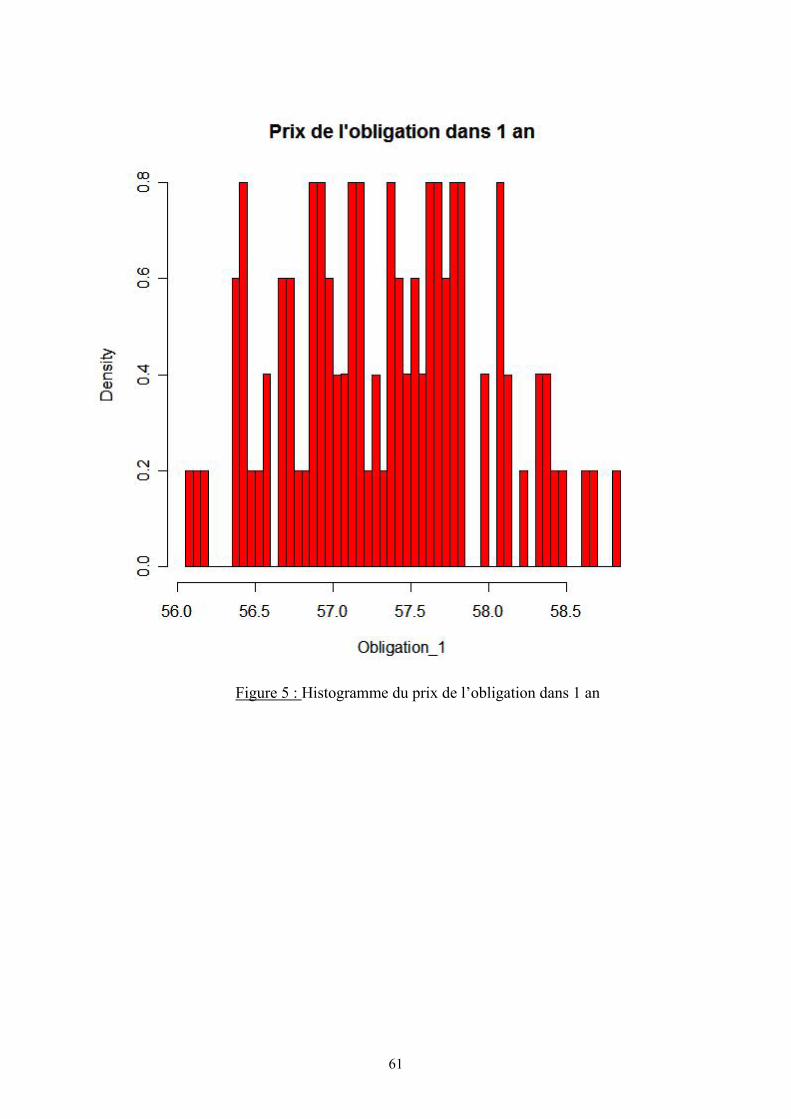
61
Figure 5 : Histogramme du prix de l’obligation dans 1 an
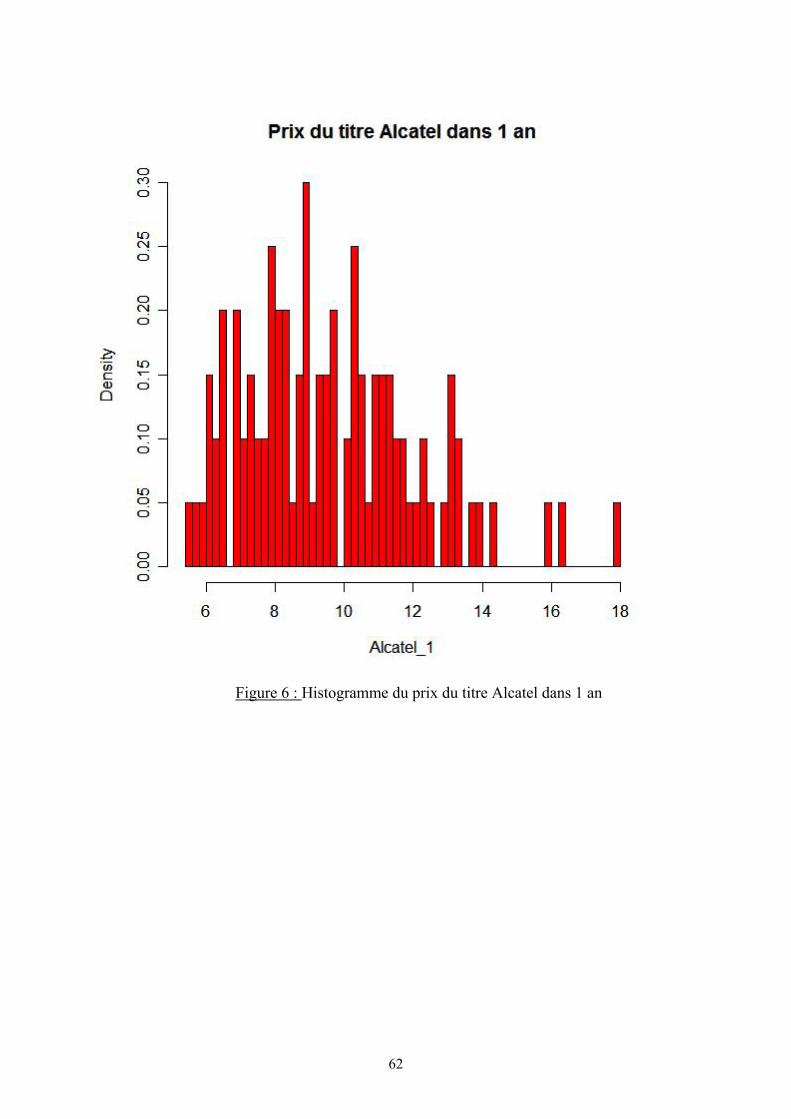
62
Figure 6 : Histogramme du prix du titre Alcatel dans 1 an
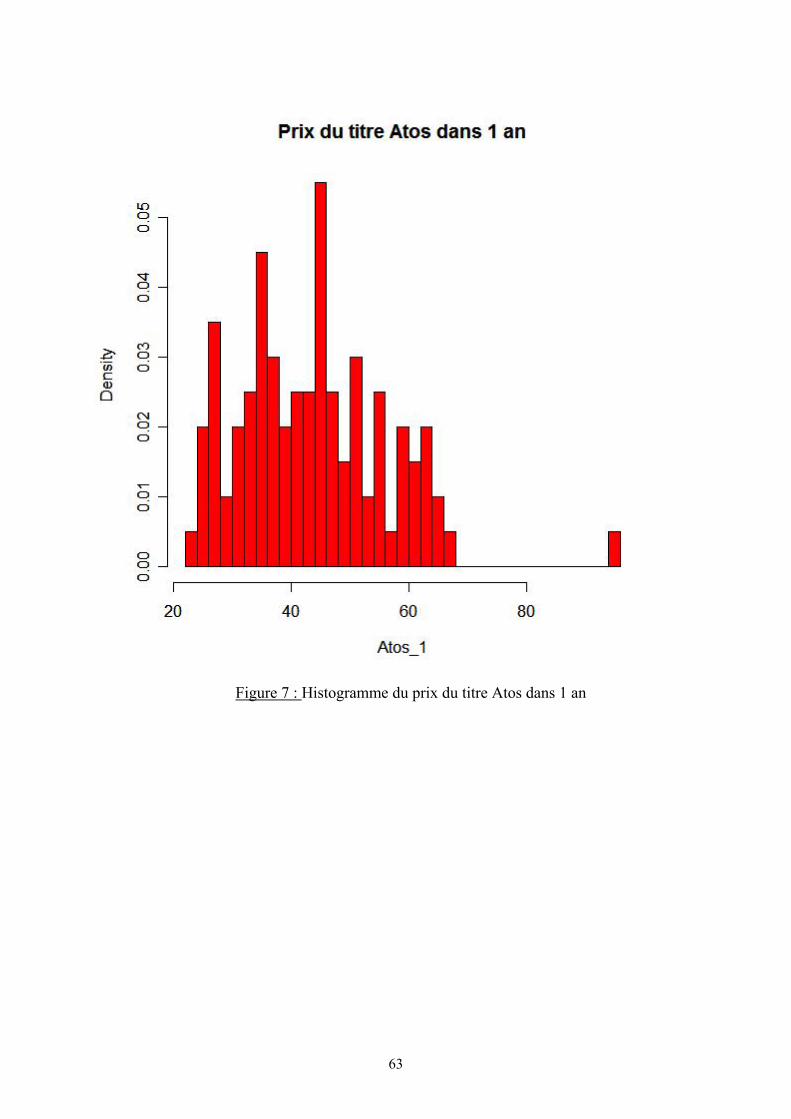
63
Figure 7 : Histogramme du prix du titre Atos dans 1 an
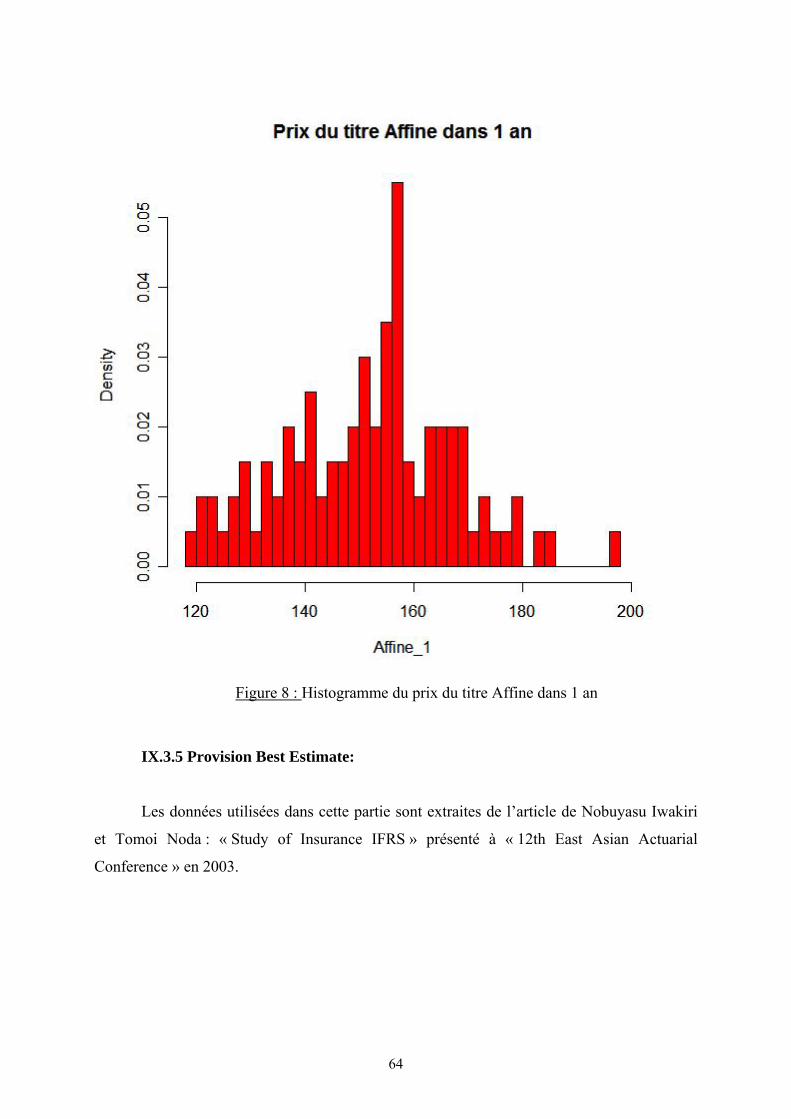
64
Figure 8 : Histogramme du prix du titre Affine dans 1 an
IX.3.5 Provision Best Estimate:
Les données utilisées dans cette partie sont extraites de l’article de Nobuyasu Iwakiri
et Tomoi Noda : « Study of Insurance IFRS » présenté à « 12th East Asian Actuarial
Conference » en 2003.
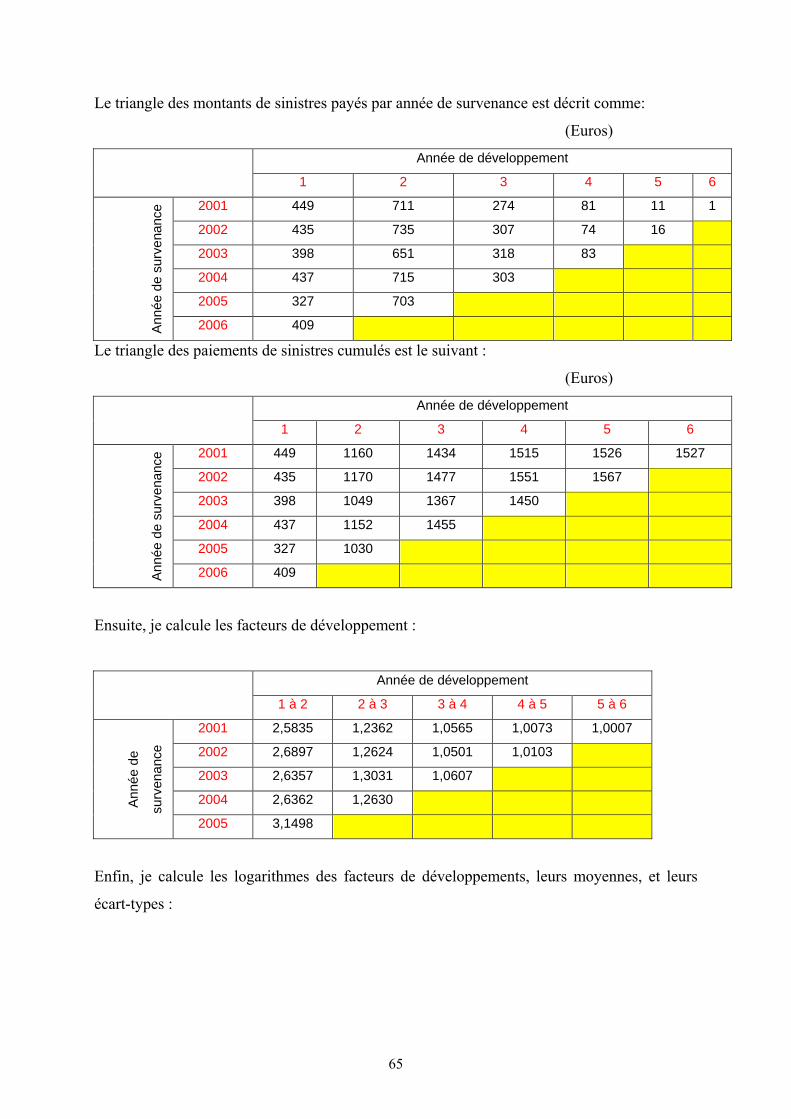
65
Le triangle des montants de sinistres payés par année de survenance est décrit comme:
(Euros)
Année de développement
1 2 3 4 5 6
2001 449 711 274 81 11 1
2002 435 735 307 74 16
2003 398 651 318 83
2004 437 715 303
2005 327 703
Ann
ée d
e su
rven
ance
2006 409
Le triangle des paiements de sinistres cumulés est le suivant :
(Euros)
Année de développement
1 2 3 4 5 6
2001 449 1160 1434 1515 1526 1527
2002 435 1170 1477 1551 1567
2003 398 1049 1367 1450
2004 437 1152 1455
2005 327 1030
Ann
ée d
e su
rven
ance
2006 409
Ensuite, je calcule les facteurs de développement :
Année de développement
1 à 2 2 à 3 3 à 4 4 à 5 5 à 6
2001 2,5835 1,2362 1,0565 1,0073 1,0007
2002 2,6897 1,2624 1,0501 1,0103
2003 2,6357 1,3031 1,0607
2004 2,6362 1,2630 Ann
ée d
e
surv
enan
ce
2005 3,1498
Enfin, je calcule les logarithmes des facteurs de développements, leurs moyennes, et leurs
écart-types :
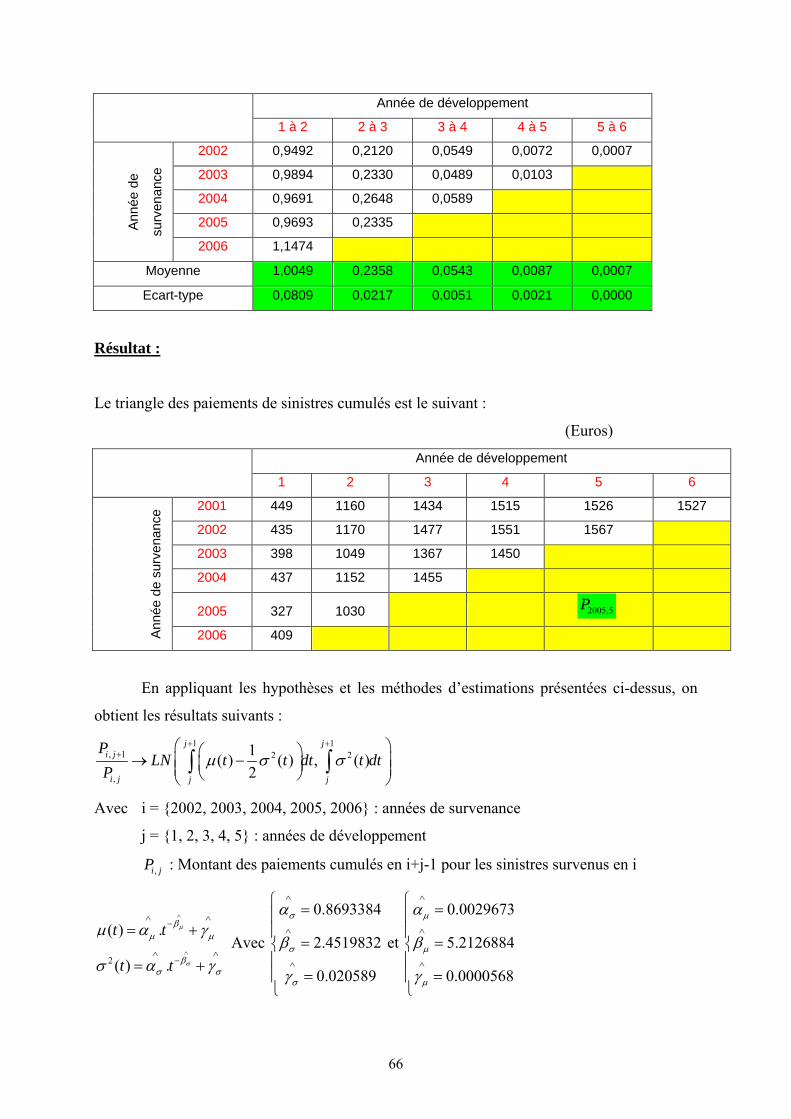
66
Année de développement
1 à 2 2 à 3 3 à 4 4 à 5 5 à 6
2002 0,9492 0,2120 0,0549 0,0072 0,0007
2003 0,9894 0,2330 0,0489 0,0103
2004 0,9691 0,2648 0,0589
2005 0,9693 0,2335 Ann
ée d
e
surv
enan
ce
2006 1,1474
Moyenne 1,0049 0,2358 0,0543 0,0087 0,0007
Ecart-type 0,0809 0,0217 0,0051 0,0021 0,0000
Résultat :
Le triangle des paiements de sinistres cumulés est le suivant :
(Euros)
Année de développement
1 2 3 4 5 6
2001 449 1160 1434 1515 1526 1527
2002 435 1170 1477 1551 1567
2003 398 1049 1367 1450
2004 437 1152 1455
2005 327 1030 2005,5P
Ann
ée d
e su
rven
ance
2006 409
En appliquant les hypothèses et les méthodes d’estimations présentées ci-dessus, on
obtient les résultats suivants : 1 1
, 1 2 2
,
1( ) ( ) , ( )2
j ji j
i j j j
PLN t t dt t dt
Pμ σ σ
+ ++
⎛ ⎞⎛ ⎞→ −⎜ ⎟⎜ ⎟⎜ ⎟⎝ ⎠⎝ ⎠∫ ∫
Avec i = {2002, 2003, 2004, 2005, 2006} : années de survenance
j = {1, 2, 3, 4, 5} : années de développement
,i jP : Montant des paiements cumulés en i+j-1 pour les sinistres survenus en i
2
( ) .
( ) .
t t
t t
μ
σ
βμ μ
βσ σ
μ α γ
σ α γ
∧
∧
∧ ∧−
∧ ∧−
= +
= + Avec
0.8693384
2.4519832
0.020589
σ
σ
σ
α
β
γ
∧
∧
∧
⎧ =⎪⎪
=⎨⎪⎪ =⎩
et
0.0029673
5.2126884
0.0000568
μ
μ
μ
α
β
γ
∧
∧
∧
⎧ =⎪⎪
=⎨⎪⎪ =⎩
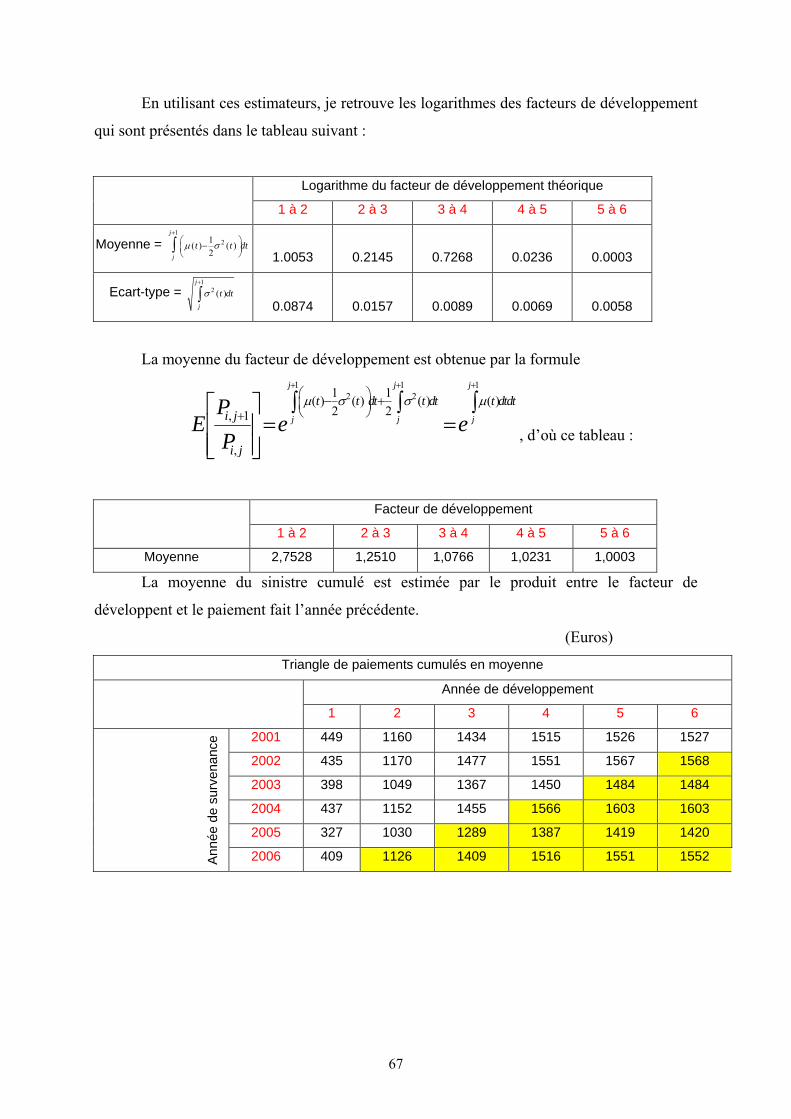
67
En utilisant ces estimateurs, je retrouve les logarithmes des facteurs de développement
qui sont présentés dans le tableau suivant :
Logarithme du facteur de développement théorique
1 à 2 2 à 3 3 à 4 4 à 5 5 à 6
Moyenne = 1
21( ) ( )2
j
jt t dtμ σ
+⎛ ⎞−⎜ ⎟⎝ ⎠
∫ 1.0053 0.2145 0.7268 0.0236 0.0003
Ecart-type = 1
2 ( )j
j
t dtσ+
∫ 0.0874 0.0157 0.0089 0.0069 0.0058
La moyenne du facteur de développement est obtenue par la formule
1 1 12 21 1( ) ( ) ( ) ( )
2 2, 1
,
j j j
j j j
t t dt t dt t dtdti j
i j
PE e e
P
μ σ σ μ+ + +⎛ ⎞− +⎜ ⎟⎝ ⎠+∫ ∫ ∫⎡ ⎤
= =⎢ ⎥⎢ ⎥⎣ ⎦
, d’où ce tableau :
Facteur de développement
1 à 2 2 à 3 3 à 4 4 à 5 5 à 6
Moyenne 2,7528 1,2510 1,0766 1,0231 1,0003
La moyenne du sinistre cumulé est estimée par le produit entre le facteur de
développent et le paiement fait l’année précédente.
(Euros)
Triangle de paiements cumulés en moyenne
Année de développement
1 2 3 4 5 6
2001 449 1160 1434 1515 1526 1527
2002 435 1170 1477 1551 1567 1568
2003 398 1049 1367 1450 1484 1484
2004 437 1152 1455 1566 1603 1603
2005 327 1030 1289 1387 1419 1420
Ann
ée d
e su
rven
ance
2006 409 1126 1409 1516 1551 1552
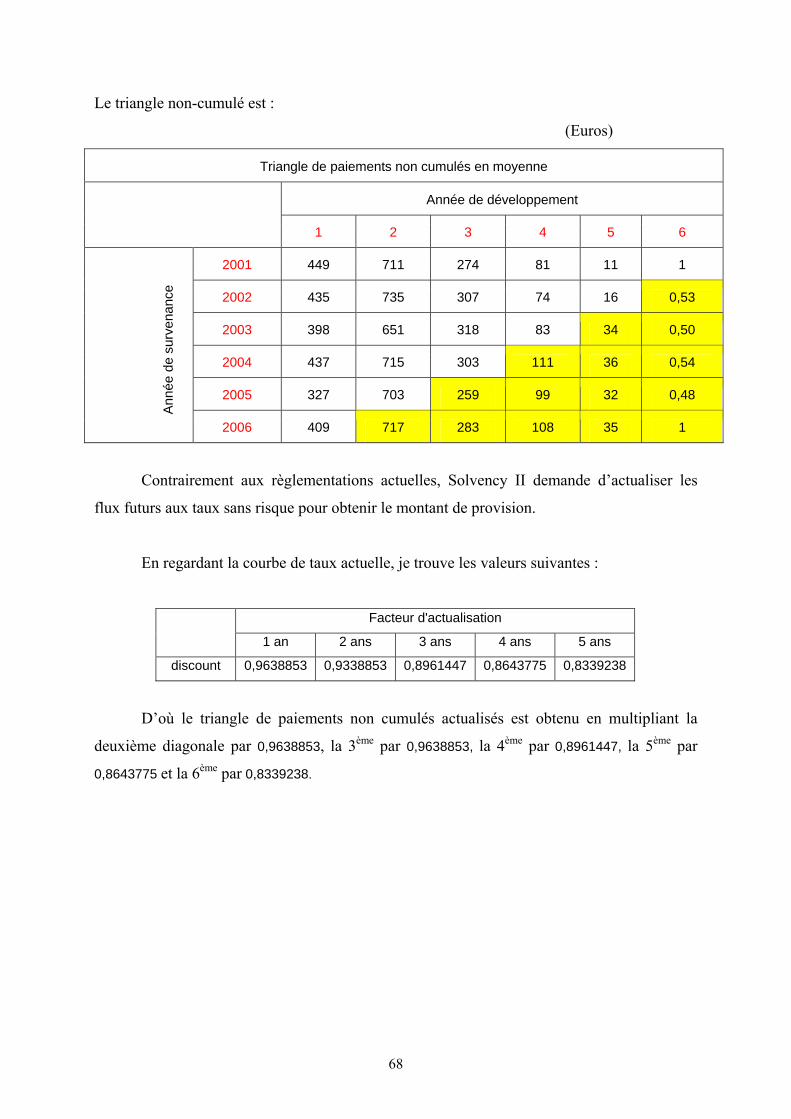
68
Le triangle non-cumulé est :
(Euros)
Triangle de paiements non cumulés en moyenne
Année de développement
1 2 3 4 5 6
2001 449 711 274 81 11 1
2002 435 735 307 74 16 0,53
2003 398 651 318 83 34 0,50
2004 437 715 303 111 36 0,54
2005 327 703 259 99 32 0,48
Ann
ée d
e su
rven
ance
2006 409 717 283 108 35 1
Contrairement aux règlementations actuelles, Solvency II demande d’actualiser les
flux futurs aux taux sans risque pour obtenir le montant de provision.
En regardant la courbe de taux actuelle, je trouve les valeurs suivantes :
Facteur d'actualisation
1 an 2 ans 3 ans 4 ans 5 ans
discount 0,9638853 0,9338853 0,8961447 0,8643775 0,8339238
D’où le triangle de paiements non cumulés actualisés est obtenu en multipliant la
deuxième diagonale par 0,9638853, la 3ème par 0,9638853, la 4ème par 0,8961447, la 5ème par
0,8643775 et la 6ème par 0,8339238.
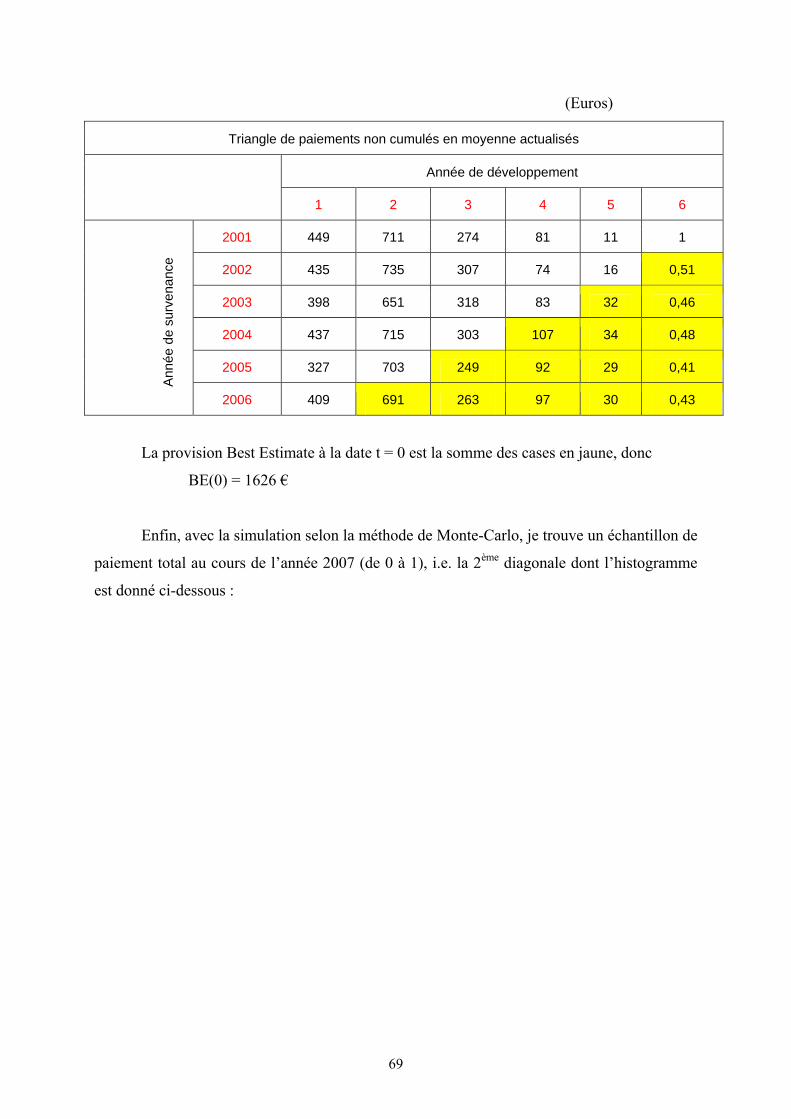
69
(Euros)
Triangle de paiements non cumulés en moyenne actualisés
Année de développement
1 2 3 4 5 6
2001 449 711 274 81 11 1
2002 435 735 307 74 16 0,51
2003 398 651 318 83 32 0,46
2004 437 715 303 107 34 0,48
2005 327 703 249 92 29 0,41
Ann
ée d
e su
rven
ance
2006 409 691 263 97 30 0,43
La provision Best Estimate à la date t = 0 est la somme des cases en jaune, donc
BE(0) = 1626 €
Enfin, avec la simulation selon la méthode de Monte-Carlo, je trouve un échantillon de
paiement total au cours de l’année 2007 (de 0 à 1), i.e. la 2ème diagonale dont l’histogramme
est donné ci-dessous :
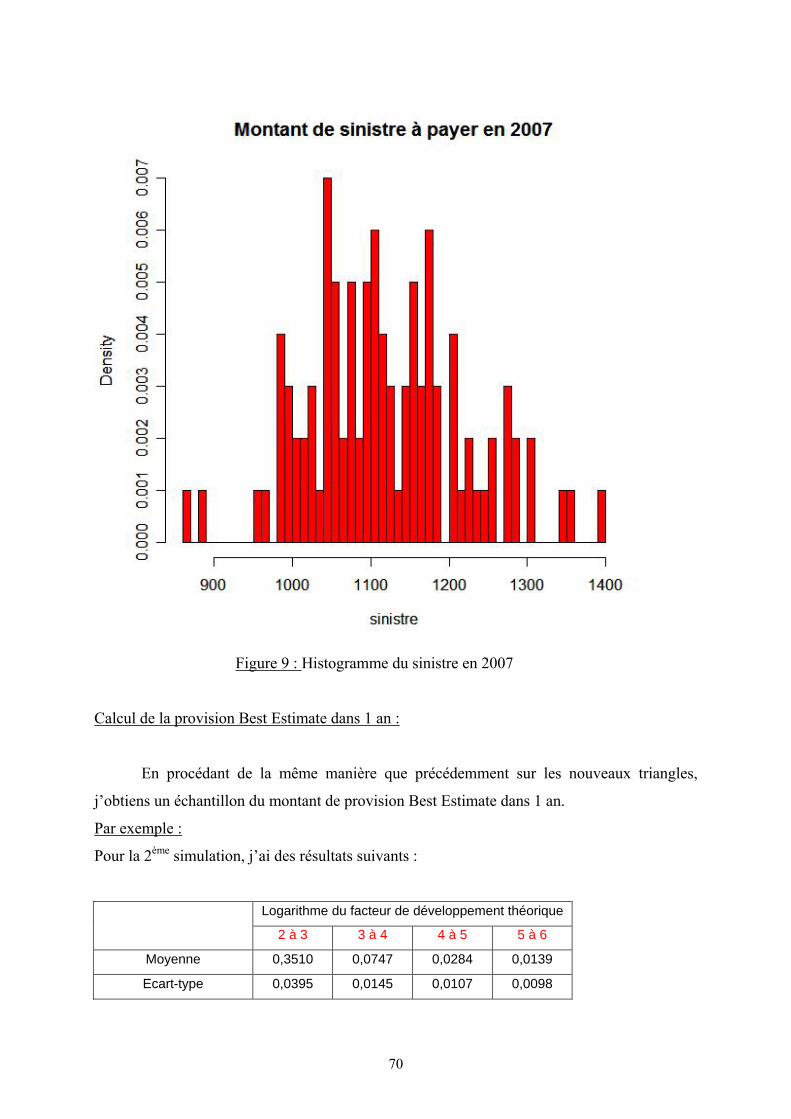
70
Figure 9 : Histogramme du sinistre en 2007
Calcul de la provision Best Estimate dans 1 an :
En procédant de la même manière que précédemment sur les nouveaux triangles,
j’obtiens un échantillon du montant de provision Best Estimate dans 1 an.
Par exemple :
Pour la 2ème simulation, j’ai des résultats suivants :
Logarithme du facteur de développement théorique
2 à 3 3 à 4 4 à 5 5 à 6
Moyenne 0,3510 0,0747 0,0284 0,0139
Ecart-type 0,0395 0,0145 0,0107 0,0098
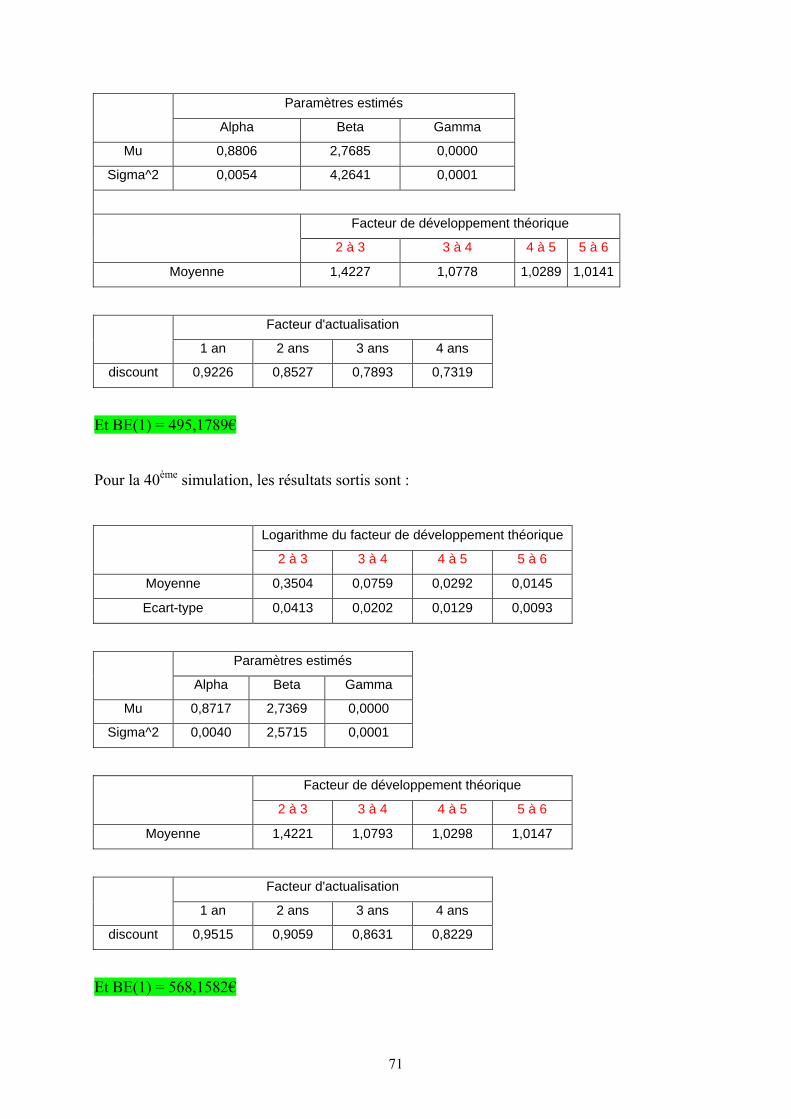
71
Paramètres estimés
Alpha Beta Gamma
Mu 0,8806 2,7685 0,0000
Sigma^2 0,0054 4,2641 0,0001
Facteur de développement théorique
2 à 3 3 à 4 4 à 5 5 à 6
Moyenne 1,4227 1,0778 1,0289 1,0141
Facteur d'actualisation
1 an 2 ans 3 ans 4 ans
discount 0,9226 0,8527 0,7893 0,7319
Et BE(1) = 495,1789€
Pour la 40ème simulation, les résultats sortis sont :
Logarithme du facteur de développement théorique
2 à 3 3 à 4 4 à 5 5 à 6
Moyenne 0,3504 0,0759 0,0292 0,0145
Ecart-type 0,0413 0,0202 0,0129 0,0093
Paramètres estimés
Alpha Beta Gamma
Mu 0,8717 2,7369 0,0000
Sigma^2 0,0040 2,5715 0,0001
Facteur de développement théorique
2 à 3 3 à 4 4 à 5 5 à 6
Moyenne 1,4221 1,0793 1,0298 1,0147
Facteur d'actualisation
1 an 2 ans 3 ans 4 ans
discount 0,9515 0,9059 0,8631 0,8229
Et BE(1) = 568,1582€
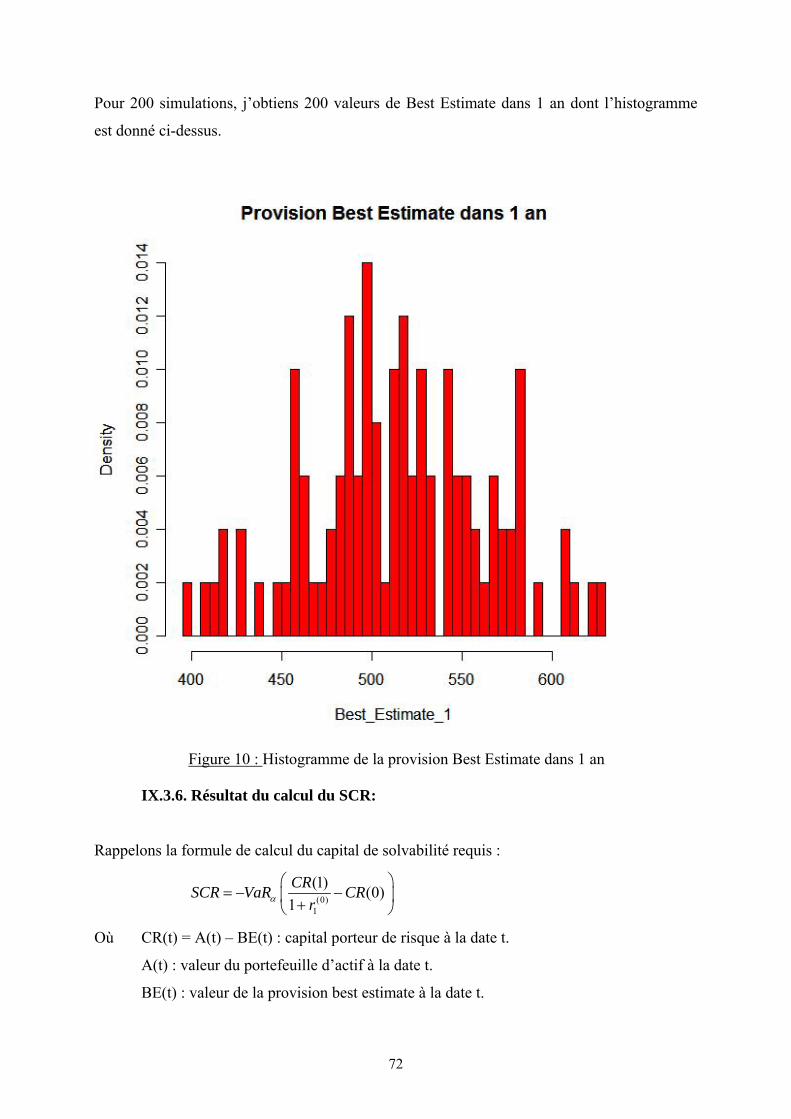
72
Pour 200 simulations, j’obtiens 200 valeurs de Best Estimate dans 1 an dont l’histogramme
est donné ci-dessus.
Figure 10 : Histogramme de la provision Best Estimate dans 1 an
IX.3.6. Résultat du calcul du SCR:
Rappelons la formule de calcul du capital de solvabilité requis :
(0)1
(1) (0)1CRSCR VaR CR
rα
⎛ ⎞= − −⎜ ⎟+⎝ ⎠
Où CR(t) = A(t) – BE(t) : capital porteur de risque à la date t.
A(t) : valeur du portefeuille d’actif à la date t.
BE(t) : valeur de la provision best estimate à la date t.
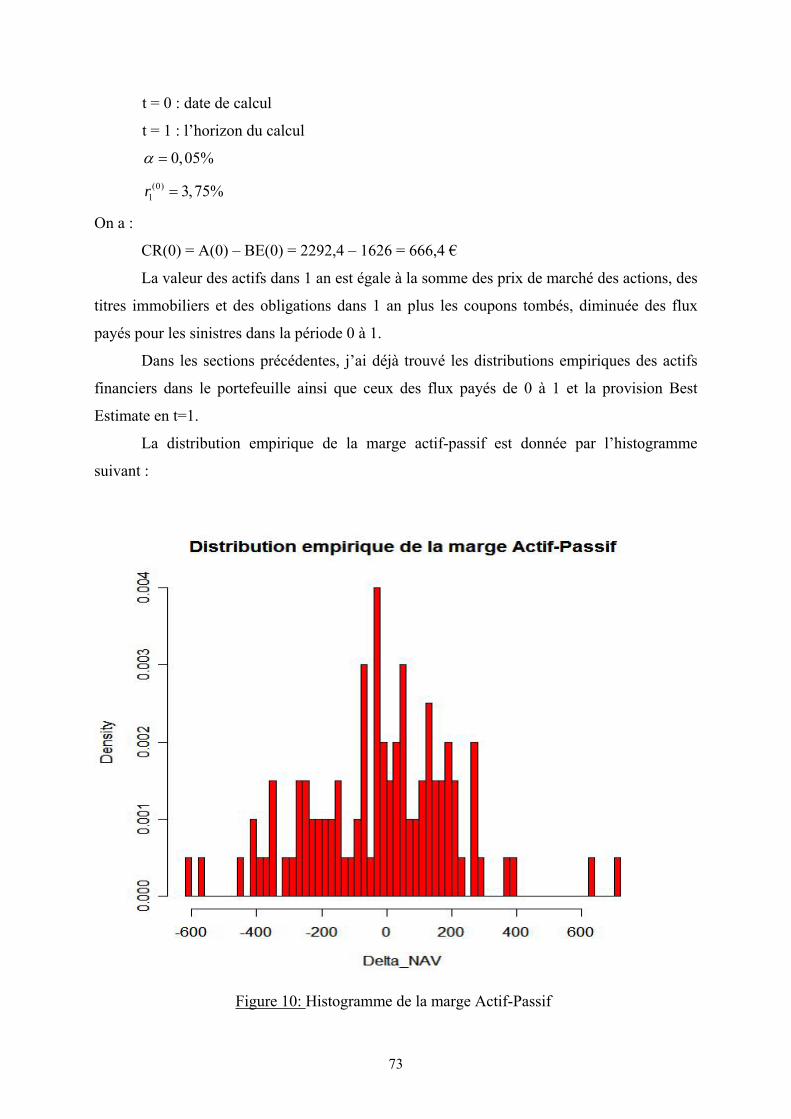
73
t = 0 : date de calcul
t = 1 : l’horizon du calcul
0,05%α = (0)
1 3,75%r =
On a :
CR(0) = A(0) – BE(0) = 2292,4 – 1626 = 666,4 €
La valeur des actifs dans 1 an est égale à la somme des prix de marché des actions, des
titres immobiliers et des obligations dans 1 an plus les coupons tombés, diminuée des flux
payés pour les sinistres dans la période 0 à 1.
Dans les sections précédentes, j’ai déjà trouvé les distributions empiriques des actifs
financiers dans le portefeuille ainsi que ceux des flux payés de 0 à 1 et la provision Best
Estimate en t=1.
La distribution empirique de la marge actif-passif est donnée par l’histogramme
suivant :
Figure 10: Histogramme de la marge Actif-Passif

74
Le capital de solvabilité est déterminé à partir du quantile 0,05% de cette distribution, ce qui
donne :
SCR = 568,9336 €
Ce montant est inférieur au capital porteur de risque en t=0 (666,4) mais on ne peut
rien conclure pour l’instant. En fait tant que le capital porteur de risque reste positif,
l’espérance mathématique des passifs est certes inférieure à la valeur des actifs, mais le risque
que les règlements de sinistres excèdent cette valeur peut cependant être très élevé. Il faut
calculer la marge de risque avant de savoir si l’assureur dispose suffisamment de capital pour
pouvoir assumer tous ses risques.

75
X. Provision technique « fair value » (juste valeur ou valeur de marché :
X.1. Présentation:
Dans cette partie, je vais présenter brièvement une technique qui pourrait être utile
pour la détermination de la provision technique « fair value ».
Le principe de prudence dans les provisions de sinistres ne semble pas devoir être
remis en cause. Toutefois, ce principe s’accommode aujourd’hui de pratiques trop disparates,
qui aboutissent à des niveaux de prudence hétérogènes au sein du marché européen.
La connaissance de la « fair value » des provisions techniques d’assurance est de plus
en plus demandée depuis plusieurs années. Elle est le résultat de changements dans la
réglementation comptable internationale (IFRS 4 phase 2, Solvency II), d’une part, et du
besoin de clarté des provisions pour les actuaires par le biais de cette méthode pour évaluer
les passifs d’assurance, d’autre part.
La « fair value » peut être interprétée comme le montant pour lequel un actif pourrait
être échangé, ou un passif réglé, entre des parties bien informées et consentantes dans le cadre
d’une transaction effectuée dans des conditions de concurrence normale. Elle permet aux
assurés d’évaluer précisément la valeur de l’entreprise d’assurance. Une variété de différentes
techniques d’évaluation était utilisée pour les provisions techniques « fair value ».
En absence des prix de marché observables, il y a théoriquement au moins 3 méthodes
pour estimer la valeur des cash-flows futurs.
1) Actualiser la vraie valeur des cash-flows futurs avec le taux d’actualisation qui est
égal au taux sans risque plus une prime de risque (approche de déflateur).
2) Modifier la probabilité des cash-flows futurs risqués et les actualiser avec le taux
sans risque (approche de la transformation de Wang).
3) Modifier les cash-flows futurs risqués et les actualiser avec le taux sans risque.
La logique économique de la marge de risque est qu’une tierce partie n’accepterait pas
la compensation pour ce transfert si un tel paiement reflète seulement la valeur présente des
cash-flows au taux sans risque. Dès lors, un échange des provisions devrait requérir une prime
ou marge de risque en plus de la valeur présente des engagements actualisés au taux sans
risque.

76
Le QIS3 suggère l’utilisation de la méthode « coût du capital » pour calculer la marge
de risque en plus du best estimate pour avoir la provision technique souhaitée. Cependant,
comme n’importe quel méthode, elle possède un défaut c’est qu’on ne sait pas exactement
quand est le « run-off ». La méthode proposée par WANG [2003] pourrait corriger ce
problème. Elle est basée sur « l’approche des cash-flows » i.e. la probabilité des cash-flows
futurs risqués sera modifiée en appliquant la transformation de Wang et le taux d’actualisation
est le taux sans risque. En gros, cette méthode consiste à transformer la variable aléatoire
initiale en une autre variable pour laquelle on aura juste besoin de calculer l’espérance.
X.2. Transformation de WANG:
On sait qu’on peut calculer l’espérance d’une variable aléatoire (un risque) par sa
fonction de survie.
0 0
( ) ( ) ( )X XE X xf x dx S x dx∞ ∞
= =∫ ∫ où ( ) 1 ( )X XS x F x= −
L’idée de Wang est de changer cette fonction de survie en lui appliquant une fonction
g qui capture tous les risques que peut entraîner la variable X. Autrement dit, on doit chercher
une fonction g qui va créer une autre distribution Y tel que ( ) ( ( ))Y XS t g S t=
Prime de risque ajustée:
'
'
( ) ( ) ( ( )) ( ( )) ( ( ))
( ( )) ( ( )) 1
X X X
X X
H X E Y g S x dx xg S x d F x
g S x d F x
= = =
=
∫ ∫∫ (Intégration par partie)
Comparé à E(X), H(X) peut être interprétée comme une espérance corrigée de X où le
paiement x reçoit un poids ' ( ( ))Xg S x , et la somme de ces poids est égale à 1.
La fonction g possède des caractéristiques qui rendent H(X) > E(X)
77
WANG [2000] propose une fonction g qui a les caractéristiques suivantes :
1( ) [ ( ) ]g u uλ λ−= Φ Φ + où Φ est la fonction de répartition de la loi normale standard.
λ est un paramètre à estimer représentant le « market price of risk »
1) H est une fonction croissante de λ , et préserve « the first and second order stochastic
dominance ».
2) Cette fonction satisfait 4 approches :
+ Le traditionnel principe d’écart-type
+ La théorie du risque économique de Yaari
+ Le modèle CAPM
+ La théorie de pricing des options.
Cas particulier :
Si ( , ²)X N μ σ→ alors ( , ²)Y N μ λσ σ→ +
Si ( , ²)X LN μ σ→ alors ( , ²)Y LN μ λσ σ→ +
La détermination du paramètre λ est l’élément clé de cette méthode. En fait, le « Draf
Statement of Principles (DSOP) suggère que le paramètre λ devrait être déterminé pour
refléter « market’s risk preference ».
Pour la méthode de quantile proposée dans le QIS1 et QIS2, le quantile 75% est
comparable au 1(0,75) 0,67λ −= Φ = .

78
XI. Conclusion:
Dans l’étude que j’ai proposé, l’actif (taux d’intérêt, actions, titre immobiliers) et le passif
(provisions) ont tout deux été modélisés en vue d’obtenir le capital de solvabilité requis. Le
choix de modèle ainsi que son calibrage demande beaucoup de compétences techniques, de
même que les ordinateurs puissants pour l’application numérique avec la méthode de
simulation Monte-Carlo.
Toutefois, il est important de signaler que certains éléments et distinctions (que je n’ai pas
détaillés faute de temps), constituent des facteurs importants du Solvency II, à savoir :
- évolution des cours et des dividendes/loyers des actifs financiers comme OPCVM,
obligations convertibles…
- évolution de l’inflation,
- défaut des émetteurs d’obligations
- modélisation et traitement particulier des sinistres catastrophiques,
- réassurance de tout types (proportionnelle, excédent de sinistre, stop loss...)
- défaut des réassureurs,
- dépendance entre les branches.
- provisions pour primes
- évolution de la souscription
Finalement, la méthode de calcul de provision technique « fair value » par la transformation
de Wang est très intéressant et mérite d’être étudiée plus profondément.

79
XII. Annexes:
Annexe 1 :
Loi du rendement du modèle à sauts :
La densité de r sur une période s’écrit :
2
2 22 20
²( )2( ) exp
2( )2 !
n
rn uu
xef xnn n
λσμλ
σ σπ σ σ
− ∞
=
⎡ ⎤⎡ ⎤⎧ ⎫− +⎢ ⎥⎢ ⎥⎪ ⎪= −⎢ ⎥⎢ ⎥⎨ ⎬++⎢ ⎥⎢ ⎥⎪ ⎪
⎢ ⎥⎢ ⎥⎩ ⎭⎣ ⎦⎣ ⎦
∑
Démonstration :
D’après le théorème des probabilités totales :
( ) ( )( ) | *s sn
P r x P r x N n P N n= = = = =∑
Deux cas se présentent alors :
( ) ( ) ( ) ( )( ) | 0 * 0 | 1 * 1s s s sP r x P r x N P N P r x N P N= = = = = + = ≥ ≥
On note :
( ) ( )| 0 * 0s sA P r x N P N= = = = le cas où il n’y a pas de saut entre t et t+s
( ) ( )| 1 * 1s sB P r x N P N= = ≥ ≥ le cas où il se produit au moins un saut (à la hausse ou à la
baisse) sur la période [t, t+s].
Donc
( ) ( )1
| *s sn
B P r x N n P N n∞
=
= = = =∑
Ainsi, grâce aux densités conditionnelles, on trouve la loi de r(s) :
( ) ( )|0 |1
( ) ( )* 0 ( )*r r s r n sn
f x f x P N f x P N n∞
=
= = + =∑
On va maintenant déterminer les lois conditionnelles du rendement connaissant le
nombre de sauts afin d’en expliciter la loi.

80
Cas 1 : n=0
2 2 20
22
|0 2
1 1( , ) ( ) ,2 2
1 1 1( ) *exp *2 22r
r t t s s Z s N s s
f x x sss
μ σ σ μ σ σ
μ σσσ π
⎛ ⎞⎛ ⎞ ⎛ ⎞+ = − + −⎜ ⎟ ⎜ ⎟⎜ ⎟⎝ ⎠ ⎝ ⎠⎝ ⎠
⎛ ⎞⎡ ⎤⎛ ⎞⎜ ⎟⇒ = − − −⎜ ⎟⎢ ⎥⎜ ⎟⎝ ⎠⎣ ⎦⎝ ⎠
Cas 2 : 1n ≥
( ) ( )
( ) ( )
2
1
2 2
1
2 2 2
22
| 2 22 2
1( , ) ( )2
0, 0,
1( ) ,2
1 1 1( ) *exp *222
n
n ii
n
i u i ui
n u
r nuu
r t t s s Z s U
U N U N n
r s N s s n
f x x ss ns n
μ σ σ
σ σ
μ σ σ σ
μ σσ σπ σ σ
=
=
⎛ ⎞+ = − +⎜ ⎟⎝ ⎠
⇒
⎛ ⎞⎛ ⎞⇒ − +⎜ ⎟⎜ ⎟⎝ ⎠⎝ ⎠
⎛ ⎞⎡ ⎤⎛ ⎞⎜ ⎟= − − −⎜ ⎟⎢ ⎥⎜ ⎟+ ⎝ ⎠⎣+ ⎝ ⎠
→
⎦
→
∑
∑
De plus,
( ) ( )( ) exp!
n
s sN P P N nnλλ λ⇒ = = −→
Finalement, le rendement sur une période s’écrit :
( ) ( )
( )( ) ( )
|0 |1
22
2 22 20
( ) exp * ( ) exp ( )!
1exp 2( ) *exp
2 2! 2
n
r r r nn
n
rn uu
f x f x f xn
x sf x
s nn s n
λλ λ
μ σλ λ
π σ σπ σ σ
∞
=
∞
=
= − + −
⎡ ⎤⎡ ⎤⎛ ⎞⎡ ⎤⎛ ⎞⎢ ⎥⎢ ⎥− −⎜ ⎟⎜ ⎟⎢ ⎥− ⎢ ⎥⎝ ⎠⎢ ⎥⎜ ⎟⎣ ⎦⇒ = −⎢ ⎥⎢ ⎥⎜ ⎟++⎢ ⎥⎢ ⎥⎜ ⎟⎜ ⎟⎢ ⎥⎢ ⎥⎝ ⎠⎣ ⎦⎣ ⎦
∑
∑

81
Annexe 2 :
Le moment centré d’ordre 2k de r s’écrit :
2 2 22
0
(2 )!( ) ( )2 ! !
nk k
k ukn
km E r m e nk n
λ λ σ σ∞
−
=
⎡ ⎤= − = +⎣ ⎦ ∑
Démonstration :
( )( )
( ) ( ) [ ] ( )2 2 2
2 22 20
1 1*exp * exp!22
nk k
n uu
E r m x m x m dxnnn
λλσ σπ σ σ
∞∞
= −∞
⎛ ⎞⎜ ⎟− = − − − −⎜ ⎟++ ⎝ ⎠
∑ ∫
Posons :
( )( )2 2
2 2
1 *( ) u
u
u x m x m u nn
σ σσ σ
= − ⇒ − = ++
D’où
( )2 2
1
u
du dxnσ σ
=+
On a alors :
( ) ( ) ( )
( ) ( )
2 222 2 2
0
2 222 2
0
exp exp! 22
exp exp! 22
n k kku
n
n kk
un
u uE r m n dun
u un dun
λλ σ σπ
λλ σ σπ
∞∞
= −∞
∞∞
= −∞
⎡ ⎤− = − + −⎢ ⎥
⎣ ⎦⎡ ⎤
= − + −⎢ ⎥⎣ ⎦
∑ ∫
∑ ∫
Or 2 2 2 !exp
2 2 !2
k
k
u u kdukπ
∞
−∞
⎡ ⎤− =⎢ ⎥⎣ ⎦
∫ (par intégration par parties)
Donc,
2 2 2
0
(2 )!( ) ( )2 ! !
nk k
ukn
kE r m e nk n
λ λ σ σ∞
−
=
⎡ ⎤− = +⎣ ⎦ ∑

82
Bibliographies:
BAGARRY M. [2006] “Economic capital: a plea for the Student copula”, présenté à l’ICA
2006 à Paris.
BALLOTA L. [2004] « Alternative framework for the valuation of participating life insurance
contracts ». Proceedings of the 14th AFIR Colloquium, 337-367.
BRENNAN M., SCHWARTZ E. [1979] « A continuous time approach to the pricing of
bonds », Journal of Banking and Finance, vol. 3, 133-155.
EMBRECHT P. [2001] Extremes in economics and the economics of extremes, talk at the
SemStat meeting on Extreme Value Theory and Applications in Gothenburg on December 13,
2001.
FITOUCHI D. [2005] « Solvency II : Du projet de réforme à l’approche par les modèles
internes », Editions DEMOS, collection comptabilité et finances.
HO T.S.Y., LEE.S [1986] « Term structure movements and pricing interest rate contingent
claims », Journal of finance, vol.41, 1011-1028
HAYER D. [2001] « A random walk model for the paid loss development » , The casualty
Actuarial Society Forum Fall 2001 Edition, pp 239-254
HAYNE R. [1985], « An Estimate of Statistical Variation in Development Factor Methods»
Proceeding of the Casualty Actuarial Society.
HEATH D., JARROW R., MORTON K. [1990] « Bond pricing and the term structure of
interest rate: a discret time approximations », Journal of financial and quantitative analysis,
vol 25, 419-440.
IWAKIRI N. et NODA T. [2003]: « Study of Insurance IFRS » présenté à « 12th East Asian
Actuarial Conference ».
KARIM CHEIKH BENANI [2003] « Mesures de risques de marché et préférabilité
universelle »
LAMBERTON D., LAPEYRE B. «Introduction au calcul stochastique appliqué à la
finance », Editions Ellipses.
LINDSKOG F., EMBRECHT P., McNEIL A. [2001] « Modelling dependence with copulas
and application to risk management ».
LONGSTAFF F. [1989] « A nonlinear general equilibrium model of the term structure of
interest rate », Journal of financial economics, vol. 23, 195-224.

83
MORGAN E., SLUTZKY M. [2006] “Preparing for Solvency II – Theoretical and pratical
issues in building internal economic capital models using nested stochastic projections”,
présenté à l’ICA 2006 à Paris.
NELSEN R. B. [1998] « An introduction to copulas », Springer Verlag
PLANCHET F., THEROND P-E [2005] « L’impact de la prise en compte des sauts boursiers
dans les problématiques d’assurance ». Proceedings of the 15th AFIR Colloquium
PLANCHET F., THEROND P et JACQUEMIN J.[2005] « Modèles financiers en
assurance », Editions Economica.
RAMEZANI C.A, ZENG Y. [1998] « Maximum likelihood estimation of asymetric jump-
diffusion processes: application to security prices », Working paper.
VASICEK O. [1977] « An equilibrium characterisation of the term structure », Journal of
financial economics, vol 5, 177-188.
WANG S. S. [2000] « A class of distortion operators for pricing financial and insurance risk »
The journal of risk and insurance, 2000, Vol.67, No. 1, pp.15-36.
WANG S.S. [2003] « A universal framework for pricing financial and insurance risk » Astin
Bulletin, Volume 32, No.2, pp 213-234
ZEEVI A., MASHAL R. [2002] « Beyond correlation: Extreme co-movements between
financial assets »
Disponible sur http://www2.gsb.columbia.edu/faculty/azeevi/PAPERS/BeyondCorrelation.pdf
Mémoires d’actuariat :
Mémoire ISFA : Sadek Hami « Modèles DFA : présentation, utilité et application »
Recommended

















