Embed Size (px)
Citation preview

1
CRITÈRES D’ÉVALUATION DES FORMATS DECOMPRESSION AUDIOTimothée Baschet, Benoît Navarret

2

3
Ce document a pour objet de recenser les différents critères et méthodes permettant d’évaluerqualitativement un contenu audio. Cette recherche s’inscrit dans le cadre du projet HD3D-IIO ets’articule autour des « codecs » couramment utilisés dans le cadre de la post-production et de ladiffusion audiovisuelles. Il s’agit ici de détailler les caractéristiques des encodeurs/décodeurs qui ontune influence sur la qualité de contenus audio. Nous présenterons ensuite les méthodes permettantd’évaluer qualitativement un contenu audio Evaluer un format de compression suppose unecomparaison du signal dégradé avec un signal de référence. Nous décrirons donc les procédéspermettant d’aboutir à un signal de référence puis les techniques de réduction de débit d’un signalaudionumerique. Une étude de l’existant sous forme de liste comprenant les « codecs » les plusutilisés sera apportée, ainsi que le détail de grands formats standards de compression. Enfin nousdécrirons les différentes méthodes permettant d’évaluer qualitativement un signal audio.
1. La numérisation d’un signal audio
La numérisation d’un signal est une opération qui consiste à convertir un signal « analogique » en unsignal dit « numérique ». Un signal analogique est un signal continu, c’est-à-dire qu’il a en tout tempsune valeur. Au contraire, un signal numérique est discontinu : il est constitué d’une suite de valeursnumériques discrètes.
Un signal audio analogique est un signal électrique. Les valeurs de tension du courant électrique(mesurées en volt) rende compte de l’amplitude du signal audio.
Un signal audio numérique traduit en chiffres les valeurs d’amplitude du signal analogique. Ladiscrétisation du signal analogique est obtenue grâce à ce que l’on nomme « l’échantillonnage »,effectuée par un convertisseur analogique/numérique (en anglais ADC pour Analog/Digital Converter)
1.1. La fréquence d’échantillonnage
Échantillonner un signal audio analogique revient à prélever ses valeurs de tension électrique uncertain nombre de fois par seconde. La fréquence de ces prélèvements est appelée fréquenced’échantillonnage .La fréquence d’échantillonnage est fixée avant l’opération de numérisation et nevarie pas pendant la numérisation.
Les fréquences d’échantillonnage couramment utilisées en audio sont 44100Hz et 48000Hz. Ellessont souvent imposées par des contraintes technologiques. Par exemple, la norme du disque compactaudio (CD audio) impose une fréquence d’échantillonnage de 44100Hz.
4
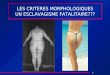
L’échantillonnage est effectué par découpage temporel du signal audio analogique. Ce découpagetemporel permet de reconstruire en données chiffrées la forme d’onde du signal numérisé. Lanumérisation ne repose que sur des séries de 0 et de 1 : il s’agit d’un codage binaire.
Figure 1 : Echantillonnage et numérisation d’un signal audio
1.2. La quantification

5
Alors que l’échantillonnage opère un découpage temporel, l’opération de quantification crée uneéchelle de valeurs discrètes permettant d’attribuer à chaque échantillon une valeur d’amplitude. Laquantification s’exprime en « bit » (un acronyme de binary digit). Les valeurs couramment utilisées enaudio sont 16bit et 24bit.
L’amplitude de chaque échantillon doit impérativement prendre l’une des valeurs définies par l’échellede quantification. Si la valeur d’amplitude de l’échantillon se situe entre deux paliers de l’échelle dequantification, elle est approximée au palier le plus proche. Cette approximation induit une erreur quel’on nomme « erreur de quantification ».
Par suite, plus le nombre de bits est élevé, plus le nombre de paliers est important et l’erreur dequantification faible. Autrement dit, les petites variations d’amplitude du signal échantillonné sontd’autant mieux approximées que la résolution de la quantification est élevée.
La fidélité de la forme d’onde numérisée à la forme d’onde du signal analogique dépend donc de larésolution (exprimée en bit) et de la fréquence d’échantillonnage (exprimée en kHz).
De même que pour la fréquence d’échantillonnage, le choix de la résolution de la quantification estsoumis à des contraintes techniques. Pour le disque compact audio (CD audio), la quantificationrequise est 16bit. Toute autre valeur ne sera pas acceptée.
Avant quantification Après quantification
Figure 2 : Signal échantillonné avant et après quantification
6
1.3. Fréquence d’échantillonnage et repliement spectral
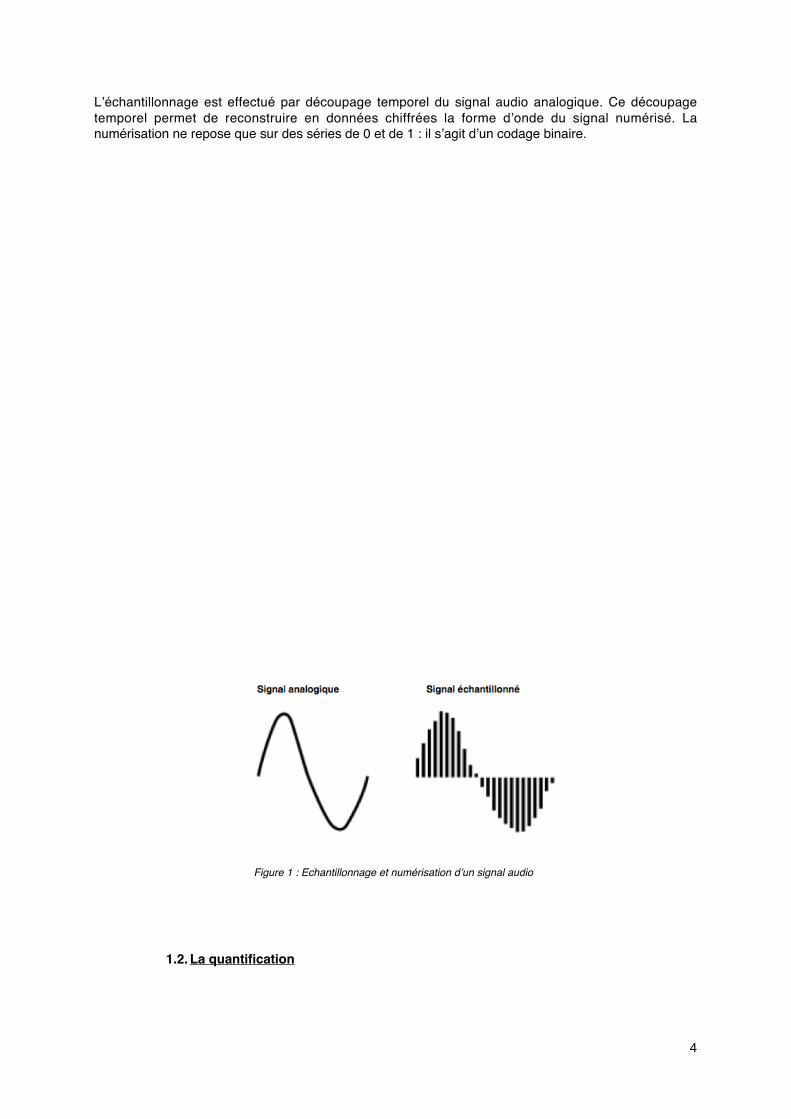
La fréquence d'échantillonnage (Fe) détermine le nombre d’échantillons prélevés par seconde. Elleest importante car elle peut être la cause d’importantes distorsions du signal numérisé. Leschercheurs Shannon et Nyquist ont observé les valeurs limites de Fe à partir desquelles le signalaudio analogique n’est plus reproduit de manière acceptable. De ces travaux est né le fameuxthéorème de Shannon/Nyquist qui suit : « La fréquence d’échantillonnage (Fe) doit être au moinségale au double de la fréquence maximale du signal à échantillonné. »
Dans le cas du CD par exemple, la fréquence d’échantillonnage est de 44100Hz. Cela signifie que lafréquence la plus aiguë pouvant être enregistré sans distorsion est de 44100/2 soit 22050Hz.
Toute fréquence supérieure à 22050Hz produit des artefacts indésirables : le phénomène qui seproduit se nomme alors « repliement spectral » (en anglais aliasing).
Signal A Signal B
AVANTconversion
APRÈSconversion

7
Figure 3 : Phénomène de repliement spectral pour des fréquences supérieures à Fe/2. Les traits continus représentent la formed’onde des signaux analogiques (signaux A et B) ; les points montrent les valeurs du signal analogique qui sontéchantillonnées. La forme d’onde numérisée du signal B est très différente de la forme d’onde analogique.
Pour éviter le phénomène de repliement, les convertisseurs analogique/numérique filtrent le signal enentrée pour éliminer les fréquences supérieures à Fe/2.
Ainsi, si la fréquence d’échantillonnage est de 44100Hz, le filtre appliqué en entrée va supprimer toutefréquence du signal supérieure à 22050Hz. Si Fe est paramétrée à 48000Hz, la nouvelle fréquence decoupure du filtre est 24000Hz. (à vérifier)
Remarque : Les fréquences d'échantillonnage utilisées en audionumérique sont toutes situées au-dessus du double de la fréquence maximale perçue par l'oreille humaine. Ces fréquencesd'échantillonnage assurent donc un codage du signal audio adapté à la bande passante de l’oreille.On peut néanmoins s'interroger sur l'intérêt de coder des fréquences non perceptibles par l'oreillehumaine dans le cas, par exemple, d’une fréquence d’échantillonnage égale à 48kHz ou 96kHz. Destravaux s'intéressent à l'influence de ces fréquences ultrasonores sur certains aspects de notreperception sonore. (référence à citer).
La technique de l’échantillonnage présente donc une limitation importante à connaître pour réaliserdes transferts audio dans de bonnes conditions.
2. La compression du signal audio numérisé
Un signal audio numérisé est stocké sur des disques durs, des disques compacts, des DVD… Lanature de l’information qu’ils contiennent rend ces fichiers relativement volumineux. L’intérêt de lacompression de données audio est de réduire la taille des fichiers audio. La possibilité de réduire ledébit de ces données est généralement appliquée pour des systèmes ayant un débit faible (ex :Internet) ou une capacité de stockage limitée (ex : baladeur mp3).
Les techniques de réduction de débit sont déjà très largement employées dans les domaines ducinéma et de la radio, via le câble, le satellite ou la TNT.
2.1. Les algorithmes de compression
Un algorithme est l’énoncé d’une suite d’opérations permettant de donner la réponse à un problème.Dans le cas de la compression, l’algorithme a pour fonction de réduire la taille d’un fichier selon uncertain nombre de contraintes que le programmeur spécifie. Par exemple, une des contraintes peutêtre de conserver toutes les fréquences inférieures à 20kHz afin de limiter les pertes de qualité sonoredans la zone audible du spectre.
Lors de l’étape de compression et de décompression d’un flux audio ou vidéo, on utilisera desalgorithmes spécifiques rassemblés sous le terme commun de « CoDec ». Un codec est constitué dedeux éléments :

8
• le COdeur contient un algorithme destiné à coder l’information. Dans le cas de lacompression ce sera pour effectuer une réduction du poids des données ;
• le DECodeur contient un algorithme destiné à décoder l’information. Dans le cas de lacompression ce sera pour reconstruire un signal audionumérique.
2.2. Le taux de compression
Compresser revient à réduire le débit du flux audio et/ou vidéo. Les algorithmes sont adaptés enfonction des applications (diffusion internet, télévision, cinéma) pour répondre aux besoins de chacundes médias. La réduction de débit (ou compression) s’exprime généralement sous la forme d’untaux dit « taux de compression ». Le taux de compression peut s’énoncer comme suit :
- soit comme le rapport entre le volume initial des données et le volume après réduction. Si levolume de données est deux fois plus faible après réduction (passant de 10Mo à 5Mo parexemple), on écrira qu’il s’agit d’un taux de 2:1 ;
- soit en pourcentage du volume après réduction par rapport au volume initial. Si le volume dedonnées est deux fois plus faible après réduction, on écrira qu’il s’agit d’un taux de 50%.
Il existe par ailleurs deux types de compressions : la compression « destructive » et la compression« non destructive ».
2.3. Compressions destructive (avec perte) et non destructive (sans perte)
La compression « destructive » supprime définitivement certaines informations pour réduire le débit duflux audio ou vidéo. Cette opération n’est pas réversible : il n’est pas possible de « reconstruire » lesignal original une fois les données compressées.
Ce type d’algorithme repère les données pouvant être détruites sans affecter (selon certainestolérances) la perception que l’on a du son ou de l’image. Parmi les techniques de compression avecperte, une grande majorité des méthodes exploite les résultats issus des recherches enpsychoacoustique1.
La compression « non destructive » permet de préserver les données originales lors de l’étape decompression. Il est ainsi possible de reconstruire les données d’origines dans leur intégralité à l’issuede la décompression. Cependant ce traitement a pour inconvénient de présenter des taux decompression faibles. C’est pourquoi de nombreuses applications utilisent des méthodes decompression avec pertes qui présentent des taux de compression nettement supérieurs.
Les techniques de compression sans perte, non spécifiques au domaine de l’audio, sont utilisées encomplément des techniques avec perte ;c’est le cas du MP3 par exemple.
2.3.1. Méthode appliquée lors d’une compression avec perte
Voici la méthode de compression avec perte couramment utilisée :
• décomposition temporelle du signal non compressé (PCM) en unités de temps élémentaires (les« frames ») ;
1 Pour avoir un complément d’information sur les caractéristiques de l’oreille humaine et les effets demasquage, consulter les annexes 1 et 2.

9
• calcul d’une transformée pour passer du domaine temporel au domaine fréquentiel, en généralpar MDCT (Modified Discrete Cosine Transform) ;
• série d'analyses permettant de réduire le volume de données à encoder en tenant compte descaractéristiques de l'oreille : les sons susceptibles d'être masqués ne sont pas encodés ;
• quantification spectrale : il s’agit de l'étape de réduction de données ;
• compression de données par codage de Huffman, correspondant à une méthode non destructived'élimination des redondances, pour optimiser la taille des données encodées. On obtient alorsune « frame » de données spectrales compressées.
Cette méthode est ainsi utilisée dans les algorithmes de compression MPEG-1 Layer 3, AdvancedAudio Coding (AAC), Vorbis, Dolby Digital ou ATRAC.
2.3.2. Principales techniques de compression sans perte
2.3.2.1. Codage à longueur variable
Plus connu sous le nom de RLC (Run Length Coding) ou RLE (Run Length Encoding), ce codagedétecte la redondance entre des éléments successifs.
Exemple :
La série de chiffres…
7 1 1 1 1 3 8 8 8 2 2 6
…sera réécrite comme suit :
7 ; 4 x 1 ; 3 ; 3 x 8 ; 2 x 2 ; 6
2.3.2.2. Codage de Huffman (codage entropique)
Le codage de Huffman (inventé en 1952) est une méthode de compression statistique de données.Cet algorithme est souvent utilisé en complément d’autres méthodes de compression (comme leMPEG 1 Layer 3 par exemple).
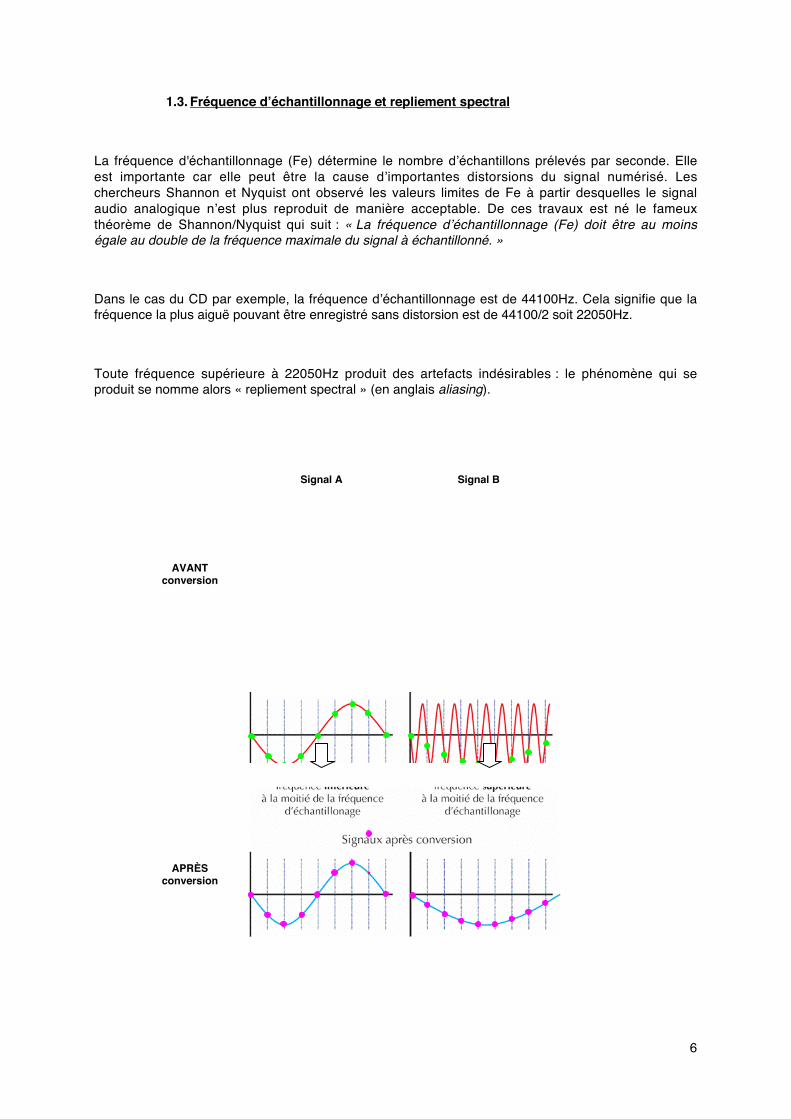
L’algorithme de Huffman comprend plusieurs étapes :
• Calcul statistique de la fréquence d’apparition de chacun des éléments ;
• Classement dans l’ordre décroissant de probabilité d’occurrence ;
• Regroupement des deux éléments ayant la probabilité la plus faible pour constituer unnouvel élément dont la nouvelle probabilité est la somme des deux probabilités des deuxéléments regroupés ;
• Réitération de l’opération. Résultats présentés sous la forme d’une arborescence deséléments suivant l’augmentation de la probabilité d’occurrence (figure 4).
10
Figure 4 : Arborescence d’un codage de Huffman

11
3. Liste des codecs de compression
Voici une liste des algorithmes de compression audionumériques les plus répandus. Des sources pourune étude plus approfondie sont également fournies.2
3.1. Codecs utilisant une compression sans perte
ALAC (Apple Lossless)www.apple.com/itunes
FLAC (Free Lossless Audio Codec)www.flac.sourceforge.net
LA (LosslessAudio)www.lossless-audio.com
LPAC (Lossless Predictive Audio Codec)www.nue.tu-berlin.de/wer/liebchen/lpac.html
MPEG-4 ALS (Audio Lossless Coding)www.nue.tu-berlin.de/forschung/projekte/lossless/mp4als.html
MPEG-4 SLS (Scalable Lossless Coding)www.chiariglione.org/mpeg/technologies/mp04-sls
RAL (Real Audio Lossless)www.realnetworks.com/products/codecs/realaudio.html
WMAL (Windows Media Audio Lossless)www.microsoft.com/windows/windowsmedia/forpros/encoder/default.mspxwww.microsoft.com/windows/windowsmedia/9series/codecs/audio.aspx
MLP (Meridian Lossless Packing)www.meridian-audio.com/p_mlp_in.htm
Adaptative Transform Acoustic Coding (ATRAC Advanced Lossless)www.sony.net/Products/ATRAC3/
3.2. Codecs utilisant une compression avec perte
A A C ( A d v a n c e d A u d i o Coding)www.iso.org/iso/en/CombinedQueryResult.CombinedQueryResult?queryString=AAC
AAC-LD (AAC Low Delay)
HE-AAC (High Efficiency AAC)
2 Les sources internet ont été consultées le 11/10/2007

12
HE-AAC v2 (High Efficiency AAC v2)
AC3www.dolby.com/assets/pdf/tech_library/a_52b.pdf
Adaptative Transform Acoustic Coding (ATRAC1, ATRAC2, ATRAC3, ATRAC3Plus)www.sony.net/Products/ATRAC3
MP1 (MPEG-1 Layer I)www.chiariglione.org/mpeg/standards/mpeg-1/mpeg-1.htm
MP2 (MPEG-1/2 Layer II)www.chiariglione.org/mpeg/standards/mpeg-1/mpeg-1.htmwww.chiariglione.org/mpeg/standards/mpeg-2/mpeg-2.htm
MP3 (MPEG-1 Layer III)www.chiariglione.org/mpeg/standards/mpeg-1/mpeg-1.htm
MPEG-4www.chiariglione.org/mpeg/standards/mpeg-4/mpeg-4.htm
MPEG-7www.chiariglione.org/mpeg/standards/mpeg-7/mpeg-7.htm
MPEG-21www.chiariglione.org/mpeg/standards/mpeg-21/mpeg-21.htm
RealAudiowww.realnetworks.com/products/codecs/realaudio.html
VGFwww.twinvq.org/english/index_en.html
WMA (Windows Media Audio)www.microsoft.com/windows/windowsmedia/forpros/codecs/audio.aspx
AVS (Audio Video Standard)www.avs.org.cn/en/index.asp

13
4. Les formats de compression standard : l’exemple du MPEG-1 Audio
Le groupe MPEG (Moving Pictures Experts Group) est issu de deux instances de normalisation : l’ISO(International Standards Organisation) et l’IEC (International Electrotechnical Commission).
Les standards MPEG sont généralement utilisés pour la diffusion( internet, télévision) .Lesalgorithmes MPEG exploitent essentiellement les caractéristiques de l’audition humaine lors de l’étapede compression.
4.1 La norme MPEG1
La norme MPEG-1 (1993) est composée de trois couches (ou modes) optionnelles (Layer 1, 2 ou 3).Chacune de ces couches présente des caractéristiques différentes. De manière générale, chaquenouvelle couche présente par rapport aux précédentes des taux de compression plus élevés (taux decompression maximum).
MPEG-1 / Audio Coding Approximate bit rates Compression factorLayer 1 384 kbit/s 4Layer 2 192 kbit/s 8Layer 3 128 kbit/s 12
Figure 5 : Débits moyens des différentes couches MPEG1 et facteurs de compression.
4.2 Techniques employées
4.2.1 Le modèle psychoacoustique
Les modèles psychoacoustiques essaient de décrire la manière dont une personne perçoit les sons.Ces modèles sont utilisés dans l’algorithme de compression MPEG-1 afin de déterminer avec quellerésolution les différentes données présentes dans le signal audio doivent être codées. Les donnéesperçues avec une grande précision par le système auditif humain seront affectées d’un nombre de bitsplus importants que les données moins perceptibles.
Par exemple, la bande de fréquences 1000-3000Hz correspond à la zone de plus grande sensibilitéde l’oreille. Toute modification du son dans cette zone du spectre peut être préjudiciable car l’auditeury sera très sensible.
Il existe plusieurs modèles psychoacoustiques comme MUSICAM3 ou l’AT&T 4. Ils sont appliquésselon le type de données audio à compresser et le débit en sortie recherché. Par exemple, lescodages d’une voix seule ou d’un orchestre symphonique reposent sur des modèles différents.
4.2.2 Le codage en sous-bandes
Cet algorithme décompose le signal en 32 bandes de fréquences (appelées « sous-bandes ») grâce àdes filtres spécifiques.
3 Musicam est l’ abréviation de Masking pattern adapted Universal Subband Coding And Multiplexing
4 Modèle psychoacoustique développé par la société AT&T

14
L’encodeur fait une analyse fréquentielle par TFTD (Transformée de Fourrier à Temps Discret) dechaque sous-bande et détermine le niveau de bruit tolérable à l’aide d’un modèle psychoacoustique.
Le nombre minimal de bits nécessaires à chaque sous-bande est ensuite attribué par l’encodeur afinque les erreurs de quantification ne soient pas perceptibles. Pour cela, il tient compte des effets demasque. Les informations de quantification de chaque sous-bande sont ensuite transférées avec leséchantillons de la sous-bande codée.
Figure 6 : Division de la bande audiofréquence en 32 sous-bandes
Une dernière étape, le codage entropique, peut être ajoutée à la fin du processus (c’est le cas duMP3). Ce codage sans perte permet la réduction de données en enlevant les redondances desdifférentes données numériques.
Le schéma suivant présente les différentes opérations présentes dans un encodeur perceptuel.
Figure 7 : Principe général d’un encodeur perceptuel

15
Détailler le schéma (flux entrant / flux sortant)
4.3) Caractéristiques des différentes couches
4.3.1) MPEG-1 audio couche 1
Le Mpeg-1 couche 1 est aussi connu sous le nom de « Musicam simplifié ». Son débit peut varier de32 à 448kbit/s pour des fréquences d’échantillonnage classiques de 32, 44,1 et 48kHz.
4.3.2) MPEG-1 audio couche 2
Le Mpeg-1 couche 2 est aussi connu sous le nom de « Musicam ». Son débit peut varier de 32 à192kbit/s pour un signal mono et de 64 à 384kbit/s pour un signal stéréo.
Une des principales différences en ce qui concerne la couche 2 réside dans la précision de l’analysede chaque sous-bande. En effet, une résolution d’analyse plus élevée de ces sous-bandes permet derepérer avec plus de précision les différentes données à encoder.
La figure ci-dessous traite de la difficulté d’évaluer les effets de masque. La largeur des sous-bandesa une influence sur l’appréciation du masquage. Pour un meilleur calcul des phénomènes demasquage, on augmente la résolution de l’analyse fréquentielle de chaque sous-bande en élevant lenombre d’échantillons analysés en entrée. Par exemple, on passe de 128 à 256, 512 ou 1024échantillons.
4.3.3) MPEG-1 audio couche 3
Le Mpeg-1 couche 3, connu sous le nom « MP3 », ajoute une quantification non uniforme ainsi qu’uncodage de Huffman.
Cette couche est la plus complexe des trois et permet des taux de compressions supérieurs auxautres. Chacune des 32 sous-bandes principales est subdivisée en 18 sous-bandes supplémentaires.Son débit peut varier de 8 à 320kbit/s avec des fréquences d’échantillonnage pouvant descendre à 24et 16 kHz.
En résumé, voici un tableau récapitulatif des principales caractéristiques des trois couches audio ducodec MPEG 1.
Complexitédu codeur Plage de débits Caractéristiques
Couche 1 Basse 32 à 448kbpsFiltrage numérique pour les 32 sous-bandesQuantification uniformeSeuil de masquage fréquentiel uniquement
Couche 2 Moyenne 32 à 384kbpsFiltrage numérique pour les 32 sous-bandesQuantification uniformeSeuils de masquage fréquentiel et temporel
Couche 23 Élevée 8 à 320kbpsFiltrage numérique + opération mathématique MDCTQuantification adaptativeSeuils de masquage fréquentiel et temporelCodage de Huffman
16
5. Les critères d’évaluation
5.1. Caractéristiques des encodeurs / Décodeurs
Plusieurs caractéristiques peuvent selon les applications être déterminantes dans le choix d’unencodeur/décodeur.
• Le débit :
Il peut-être exprimé en kbps et peut-être un critère déterminant dans le choix d’un codec. Ainsi, enfonction de l’application et de la bande passante disponible (VOD Internet), le choix du débit proposépar le « codec » peut être primordiale.
• La qualité « audio »
• La Complexité et le temps de retard :
Les encodeurs/décodeurs selon leurs complexité, ont un temps de traitement plus ou moins rapide.Ce temps de traitement se mesure en millions d’instructions par seconde (MIPS) ou en millionsd’opérations par seconde (MOPS). Pour atteindre des taux de compression supérieurs, lesalgorithmes de compression sont en général plus complexes et nécessitent des temps de calcul plusélevés.
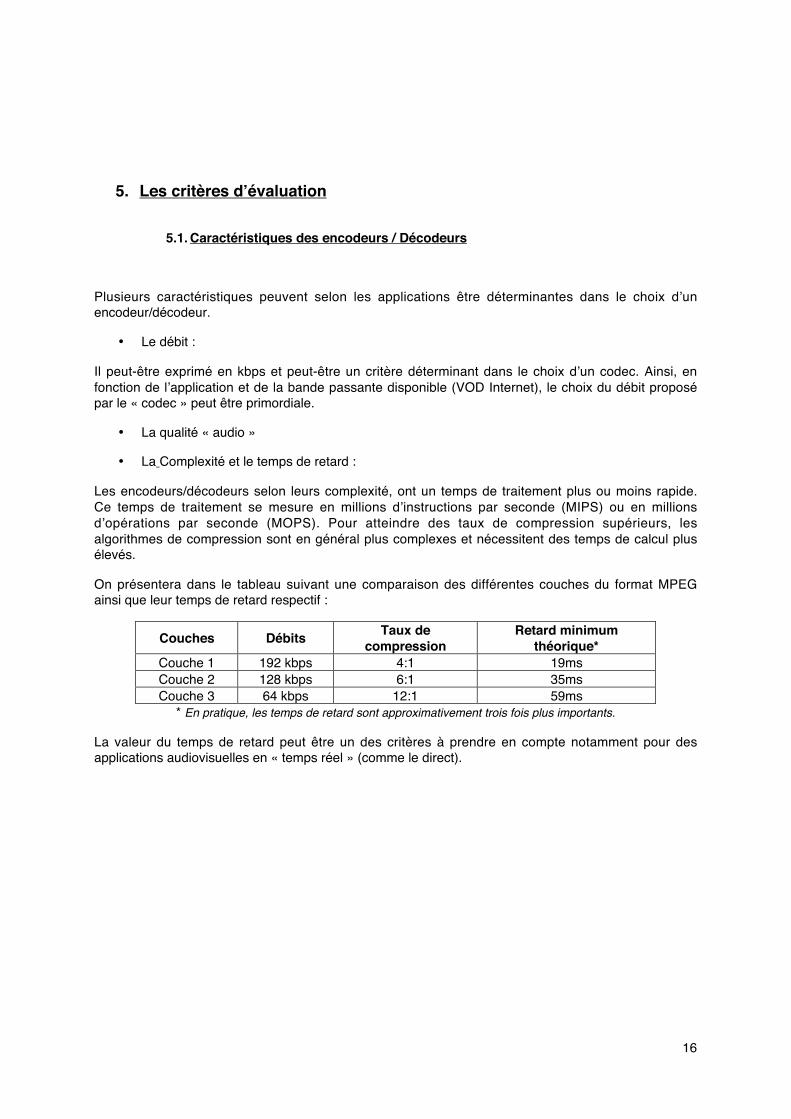
On présentera dans le tableau suivant une comparaison des différentes couches du format MPEGainsi que leur temps de retard respectif :
Couches Débits Taux decompression
Retard minimumthéorique*
Couche 1 192 kbps 4:1 19msCouche 2 128 kbps 6:1 35msCouche 3 64 kbps 12:1 59ms
* En pratique, les temps de retard sont approximativement trois fois plus importants.
La valeur du temps de retard peut être un des critères à prendre en compte notamment pour desapplications audiovisuelles en « temps réel » (comme le direct).

17
5.2 Critères d’évaluation de la « qualité audio »
La plupart des « codecs » audio utilisent des algorithmes de compression avec perte. Le signal estdégradé en fonction du taux de compression adopté. Les algorithmes de compression sans perte,eux, sont utilisés pour la compression de données et / ou en complément des techniques decompression avec perte. Dans ce cas, il n’y a pas de « qualité audio » à déterminer puisque le signaloriginal peut-être reconstruit dans son intégralité après le processus de décompression.
Afin d’évaluer qualitativement les dégradations éventuelles d’un signal audio après codage, réductionde débit et / ou décodage, plusieurs méthodes existent. La plupart de ces méthodes utilisent unsignal-test de référence (le signal original avant codage) pour le comparer ensuite au signal à évaluer(signal après codage et décodage). Le premier type de méthode consiste à effectuer des testsd’écoute (tests subjectifs) avec un panel d’auditeurs novices ou experts. Ces méthodes sontgénéralement considérés comme des références lorsqu’il s’agit d’estimer la qualité audio d’un signal.Néanmoins, ces tests subjectifs sont long et coûteux car ils impliquent le respect de nombreusesconditions comme le choix des auditeurs et du matériel de diffusion sonore, le respect des conditionsd’écoute (acoustique de la salle),les séquences, la chronologies des tests …
Afin de faciliter la mise en œuvre d’une évaluation de la « qualité » d’un signal audio, de nombreusesrecherches ont été menées en psychoacoustique afin de modéliser le système auditif humain. Cesmodèles permettent de prendre en compte différentes caractéristiques de l’audition humaine commeles effets de masquage (décrits en Annexe 1) lors de l’analyse et de l’estimation qualitative du signalaudio. La qualité audio mesurée par ces méthodes est alors appelée « qualité perceptuelleobjective ».
5.2.1 Les critères subjectifs
• La recommandation ITU-R BS 1116
La recommandation UIT-R BS. 11165 définit un cadre et des méthodes pour effectuer des tests dansde bonnes conditions (matériel utilisé, acoustique de la salle, choix des séquences audio, chronologiedes séquences …) afin d’estimer qualitativement un signal audio.
Le protocole consiste en une série d’extraits sonores courts (5 à 10 secondes) diffusés trois fois desuite selon deux possibilités : A B A ou A A B (A étant le signal original et B le signal compressé). Unefois les extraits sonores diffusés, l’auditeur doit identifier la position de B. De plus, l’auditeur doitégalement émettre une opinion sur la « qualité » de B. Cette opinion est exprimée selon un jugementde valeur arbitraire décrit dans le schéma ci-dessous :
5 La recommandation ITU-R BS 1116 se nomme : « Méthodes d'évaluation subjective desdégradations faibles dans les systèmes audio y compris les systèmes sonores multivoies ».

18
Fig. 9 Echelle de dégradation à cinq notes de l’UIT-R BS 1116
Cette recommandation utilise une méthode dite : « à double aveugle, triple stimulus et référencedissimulée ». Cette recommandation est essentiellement utilisée pour détecter et quantifier de faiblesdégradations d’un signal par rapport au signal de référence. En effet, lors de tests concernant dessignaux à faible ou à moyen débit, la plupart des notes se retrouvent en bas de l’échelle ce qui rend ladistinction peu aisée. Selon l’UER6, d’autres méthodes comme MUSHRA7 semblent plus adaptéesaux signaux audio à faible ou moyen débit (notamment ceux utilisés sur internet).
• La recommandation ITU BS.1534-1 (méthode MUSHRA)
Alors que la recommandation précédente (ITU-R BS 1116) utilise une méthode « à double aveugle,triple stimulus et référence dissimulée », MUSHRA8 utilise une méthode « à double aveugle, stimulusmultiples, avec références et repères dissimulés ». Cette méthode sert à évaluer des dégradationsmoyennes et / ou importantes du signal audio. Lors des tests d’écoute, les différents extraits audiosont généralement assez dégradés par rapport à la référence, il est donc aisé de les distinguer decette dernière. Par contre, il est moins facile de pouvoir les évaluer qualitativement entre eux. De cefait, cette méthode au contraire de la recommandation ITU-R BS 1116 permet aux utilisateurs decomparer librement les signaux dégradés de même débit entre eux afin de mieux les évaluerqualitativement. Par exemple, si un test concerne dix systèmes audio, les évaluateurs peuventcommuter entre au moins treize signaux (la référence « connue » + les dix signaux dégradés + uneréférence dissimulée + au moins un repère « dissimulé »). À noter qu’il est possible dans le testd’inclure plusieurs repères.
La notation des stimulus (extraits audio) dans la méthode MUSHRA s’effectue par rapport à uneéchelle de qualité comprenant cinq niveaux et graduée de 0 à 100. Ces différents niveaux sont :
6 UER est l’abréviation de Union Européenne de Radio-Télévision
7 MUSHRA est l’abréviation de : « Multi Stimulus test with Hidden Reference and Anchors »

19
On présentera ci-après l’interface utilisateur utilisé par l’UER pour ce test.
Figure 10 Interface utilisateur pour les essais MUSHRA utilisé par le groupe
5.2.2 Les critères objectifs
Dans le but de faciliter l’évaluation qualitative d’échantillons audio, de nombreux algorithmes prenanten compte les caractéristiques de l’audition humaine ont été développés. Le but de ces méthodes estde pouvoir anticiper un jugement subjectif de la qualité audio avec des méthodes objectives. Leprincipe général consiste, d’une part, à calculer à l’aide d’un modèle perceptuel d’audition lesdifférences entre le signal original et le signal dégradé9 et, d’autre part, à inclure un modèle cognitifconcernant des connaissances sur le jugement humain de la qualité audio. La validité de cesméthodes s’appuie sur la corrélation entre les données issues de ces tests et les données provenantdes tests subjectifs. Ces méthodes ont d’abord été appliquées aux signaux audio à bande passanteréduite (parole) puis plus tard aux signaux à large bande (musique, ambiances…). En 1996, est
9 On se réfèrera pour une description plus détaillée de ce type de méthode à l’article de John G.BEERENDS et JAN A. STEMERDINK intitulé "A Perceptual Audio Quality Measure Based on aPsychoacoustic Sound Representation", publié dans"Journal of Audio Engineering Society", vol. 12,Décembre 1992, pages 963 à 978.

20
apparu l’algorithme PESQ (Perceptual Evaluation of Speech Quality) normalisé par l’ITU-R permettantd’évaluer la qualité de la voix transmise par un réseau de télécommunication. Plus tard, en 1998,l’algorithme PEAQ (Perceptual Evaluation of Audio Quality) a été normalisé par l’ITU-R afin d’évaluerdes signaux audio à large bande.
• L’algorithme PEAQ10,
L’algorithme PEAQ est une synthèse de six méthodes développées dans les années 90 à savoir :
- L’indice de perturbation DIX (Distortion Index) ; Le rapport bruit à masque (NMR)
- Le rapport bruit à masque (NMR)
- Le système de mesure OASE (Objective Audio Signal Evaluation)
- La mesure perceptuelle de la qualité du son (PAQM)
- Le système PERCEVAL (PERCeptual EVALuation of the quality of audio signal)
- La mesure perceptuelle objective POM (Perceptual Objective Measurement)
- La Toolbox Approach
Cette méthode a pour objectif de fournir « une mesure objective de la qualité du son perçu ». Pourquantifier la qualité du signal compressé par rapport à celle du signal audio original, l’algorithmePEAQ utilise aussi bien des caractéristiques physiques11 que des considérations psychoacoustiques.Un modèle auditif est donc utilisé permettant ainsi de repérer plusieurs phénomènespsychoacoustiques comme les phénomènes de masquage (décrits en annexe 1) ou comme laperception de certaines bandes de fréquence en fonction de leur intensité sonore. Différentesmesures et jugements qualitatifs sont alors déduits après analyse du signal. On présentera ci-dessousle fonctionnement général de l’algorithme PEAQ afin d’en clarifier le procédé :

21
Figure 12 : fonctionnement général de l’algorithme PEAQ
Au vu de la littérature existante12 sur l’évaluation de l’algorithme PEAQ les données issues de cetteméthode semblent être dans la plupart des cas conformes aux résultats des tests subjectifs.Cependant, cette corrélation des données issues de PEAQ avec celles des tests subjectifs (l’IUT-RBS 1387 et ITU-R BS 1116 ) semble moins fiable dans le cas de système audio à faible débit.
5.2.3 Synthèse à propos de la qualité audio
Nous avons présenté plusieurs méthodes permettant de qualifier quantitativement un contenu audiopar rapport à une référence (signal original). Le premier type de méthode regroupe les tests subjectifsconsidérés dans ce domaine comme une référence (d’après les recommandations ITU et UER)lorsqu’il s’agit d’évaluer une certaine qualité audio. Plusieurs recommandations ITU ont donc étéprésentées comme la norme ITU-R BS 1116 et ITU BS 1534-1 destinées à évaluer du contenu audioà différents débits. Toutefois, ces tests sont en pratique très difficilement réalisables à cause desnombreuses conditions à respecter (panels d’auditeurs, matériel utilisé, acoustique de la salle …).Ces procédés sont donc destinés à être appliqués dans des locaux spécifiques et semble être enterme de temps très contraignants. D’autres méthodes objectives ont donc été créées afin de faciliterla mise en œuvre de ce type de test. Ces méthodes reposent sur l’utilisation de modèlespsychoacoustiques et cognitifs destinés à reproduire la manière dont l’être humain perçoit et juge unequalité sonore par rapport à une autre.
L’algorithme PEAQ, normalisé par l’ITU, à donc été succinctement exposé et son processus expliqué.Cependant, ces méthodes objectives restent de bons indicateurs mais semblent, dans certains cas,être peu convainquant au regard des données issues des tests subjectifs notamment pour les faiblesdébits audio. Les tests subjectifs bien que difficile à mettre en œuvre, semblent donc, pour le moment,être le moyen le plus fiable pour évaluer qualitativement un fichier audio.
12 On se réfère ici aux articles concernant l’évaluation de l’algorithme PEAQ à savoir, l’article de C.Schmidmer « Perceptual wideband audio quality assessments using PEAQ »

22
23
Annexe 1: Rappels de quelques caractéristiques de l’audition humaine
Les méthodes de codage audio étant basées sur différentes caractéristiques de la perception auditivehumaine, nous rappellerons ici quelques principes fondamentaux nécessaires à la compréhension desprincipaux algorithmes de compression.
Des éléments provenant du livrable « Formats audionumériques » ont été réutilisés afin d’assurer unecertaine cohérence générale et de faciliter la compréhension de ce document.
• Bande passante de l’oreille humaine
La bande passante de l’oreille humaine est de 20Hz-20000Hz. Cela signifie que les fréquencesinférieures à 20Hz (les infrasons) ou supérieures à 20kHz (les ultrasons) ne sont pas entenduscomme des hauteurs tonales déterminées.
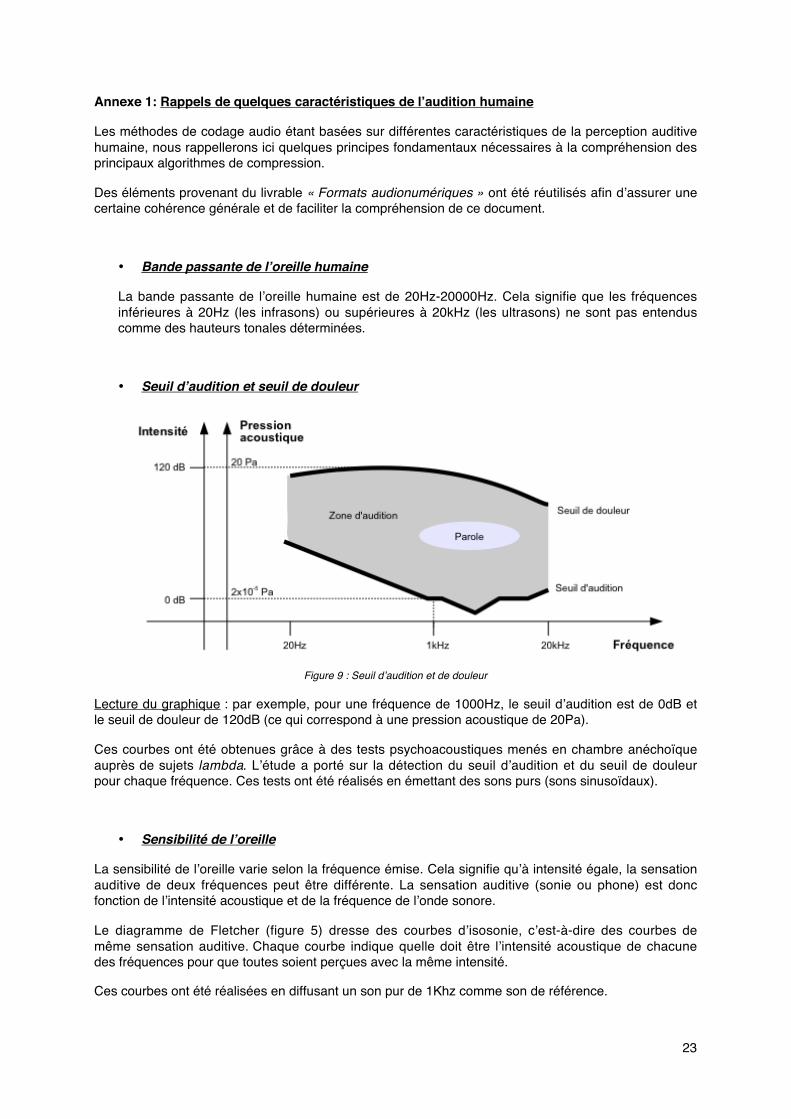
• Seuil d’audition et seuil de douleur
Figure 9 : Seuil d’audition et de douleur
Lecture du graphique : par exemple, pour une fréquence de 1000Hz, le seuil d’audition est de 0dB etle seuil de douleur de 120dB (ce qui correspond à une pression acoustique de 20Pa).
Ces courbes ont été obtenues grâce à des tests psychoacoustiques menés en chambre anéchoïqueauprès de sujets lambda. L’étude a porté sur la détection du seuil d’audition et du seuil de douleurpour chaque fréquence. Ces tests ont été réalisés en émettant des sons purs (sons sinusoïdaux).
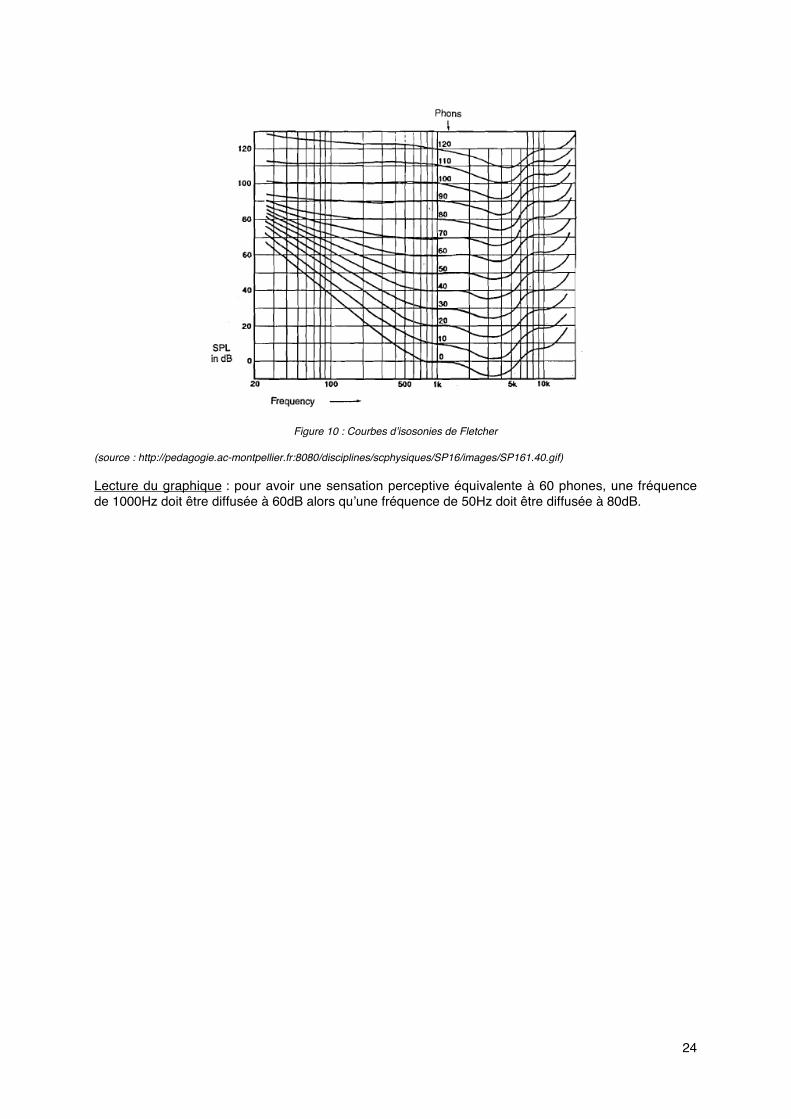
• Sensibilité de l’oreille
La sensibilité de l’oreille varie selon la fréquence émise. Cela signifie qu’à intensité égale, la sensationauditive de deux fréquences peut être différente. La sensation auditive (sonie ou phone) est doncfonction de l’intensité acoustique et de la fréquence de l’onde sonore.
Le diagramme de Fletcher (figure 5) dresse des courbes d’isosonie, c’est-à-dire des courbes demême sensation auditive. Chaque courbe indique quelle doit être l’intensité acoustique de chacunedes fréquences pour que toutes soient perçues avec la même intensité.
Ces courbes ont été réalisées en diffusant un son pur de 1Khz comme son de référence.
24
Figure 10 : Courbes d’isosonies de Fletcher
(source : http://pedagogie.ac-montpellier.fr:8080/disciplines/scphysiques/SP16/images/SP161.40.gif)
Lecture du graphique : pour avoir une sensation perceptive équivalente à 60 phones, une fréquencede 1000Hz doit être diffusée à 60dB alors qu’une fréquence de 50Hz doit être diffusée à 80dB.
25
Annexe 2 : Effet de masque
On parle de « masquage » dès qu’un signal sonore disparaît de l’image sonore à cause de laprésence d’une autre signal sonore. Autrement dit, sur les deux sources sonores en présence, uneseule est vraiment entendue. Cette disparition peut être partielle ou totale.
Compte tenu de la courbe de réponse non linéaire de l’oreille humaine (Annexe 1), l’effet de masquen'est pas linéaire en fréquence.
On distingue le phénomène de masquage simultané, présent pour deux sources simultanées, dumasquage temporel, pour lequel les sons masquant et masqués ne sont pas simultanés.
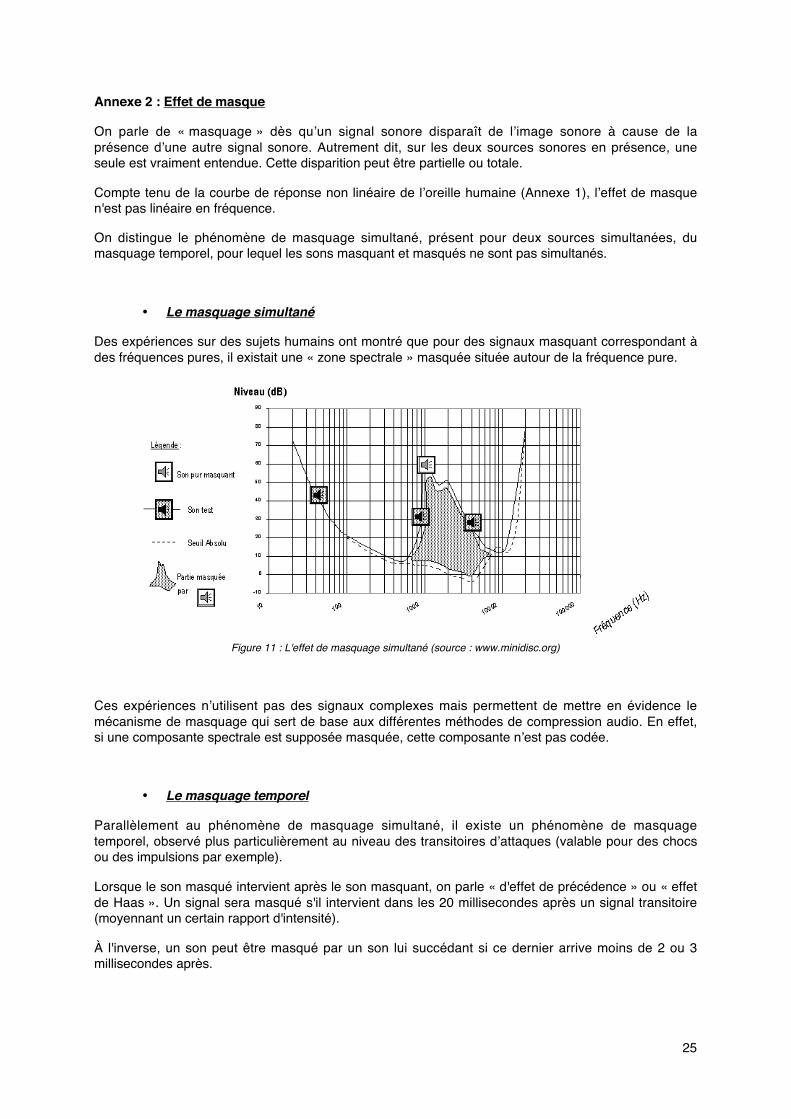
• Le masquage simultané
Des expériences sur des sujets humains ont montré que pour des signaux masquant correspondant àdes fréquences pures, il existait une « zone spectrale » masquée située autour de la fréquence pure.
Figure 11 : L'effet de masquage simultané (source : www.minidisc.org)
Ces expériences n’utilisent pas des signaux complexes mais permettent de mettre en évidence lemécanisme de masquage qui sert de base aux différentes méthodes de compression audio. En effet,si une composante spectrale est supposée masquée, cette composante n’est pas codée.
• Le masquage temporel
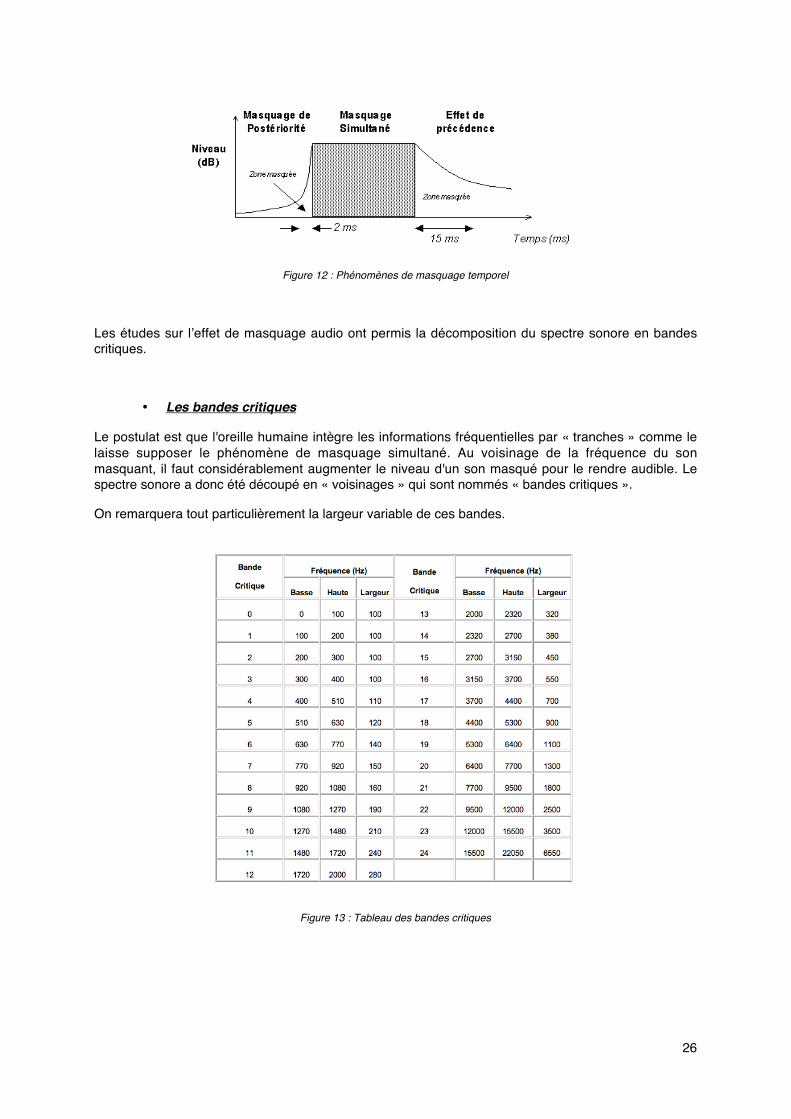
Parallèlement au phénomène de masquage simultané, il existe un phénomène de masquagetemporel, observé plus particulièrement au niveau des transitoires d’attaques (valable pour des chocsou des impulsions par exemple).
Lorsque le son masqué intervient après le son masquant, on parle « d'effet de précédence » ou « effetde Haas ». Un signal sera masqué s'il intervient dans les 20 millisecondes après un signal transitoire(moyennant un certain rapport d'intensité).
À l'inverse, un son peut être masqué par un son lui succédant si ce dernier arrive moins de 2 ou 3millisecondes après.
26
Figure 12 : Phénomènes de masquage temporel
Les études sur l’effet de masquage audio ont permis la décomposition du spectre sonore en bandescritiques.
• Les bandes critiques
Le postulat est que l'oreille humaine intègre les informations fréquentielles par « tranches » comme lelaisse supposer le phénomène de masquage simultané. Au voisinage de la fréquence du sonmasquant, il faut considérablement augmenter le niveau d'un son masqué pour le rendre audible. Lespectre sonore a donc été découpé en « voisinages » qui sont nommés « bandes critiques ».
On remarquera tout particulièrement la largeur variable de ces bandes.
Figure 13 : Tableau des bandes critiques









![REFERENTIEL REGIONAL ONCO-LR Comité Onco-Hématologie · Explorations complémentaires [1] - Biologie : NFS, réticulocytes, électrophorèse des protéines sériques, LDH, ... CRITERES](https://img.pdfslide.fr/doc/110x75/5bed33ea09d3f2f6028b6d0b/referentiel-regional-onco-lr-comite-onco-he-explorations-complementaires.jpg)