Embed Size (px)
Citation preview

BreizhCamp 2015 #BzhCmp
#MongoDB #bzhcmp
BreizhCamp 2016 #BzhCmp
Tout ce que le getting started MongoDB ne vous dira pas
Bruno BONNIN - @_bruno_b_Pierre-Alban DEWITTE - @padewitte

Bruno BONNIN
Architecte logiciel
https://about.me/brunobonnin

Pierre-Alban DEWITTE
Responsable équipe cloud


Getting started with MongoDB
# Installation de Mongodb > sudo apt-get install mongodb
# Lancement du serveur> sudo service mongod start
# Import de données> mongoimport --db test --collection restaurants --drop --file primer-dataset.json
# Lancement du shell> mongo
// On s’amuse avec quelques commandes CRUD
>>> db.restaurants.insert(...)
>>> db.restaurants.find(...)
>>> db.restaurants.delete(...)

Disclaimer

● Cette présentation est truffée de mauvaise foi
● Ne prenez pas tout, adaptez vous à votre contexte
● Notre but est de vous donner envie d’aller chercher la bonne information

1. Développer efficacement
2. Préparer la production
3. Exploiter
4. Avant de se quitter

Développer efficacement

Schema design

Des documents !
● MongoDB stocke des documents
○ Structure de données hiérarchique
○ Un champ peut être un type de base (entier, string,
booléen), une liste, un objet (on parle de sous-document)
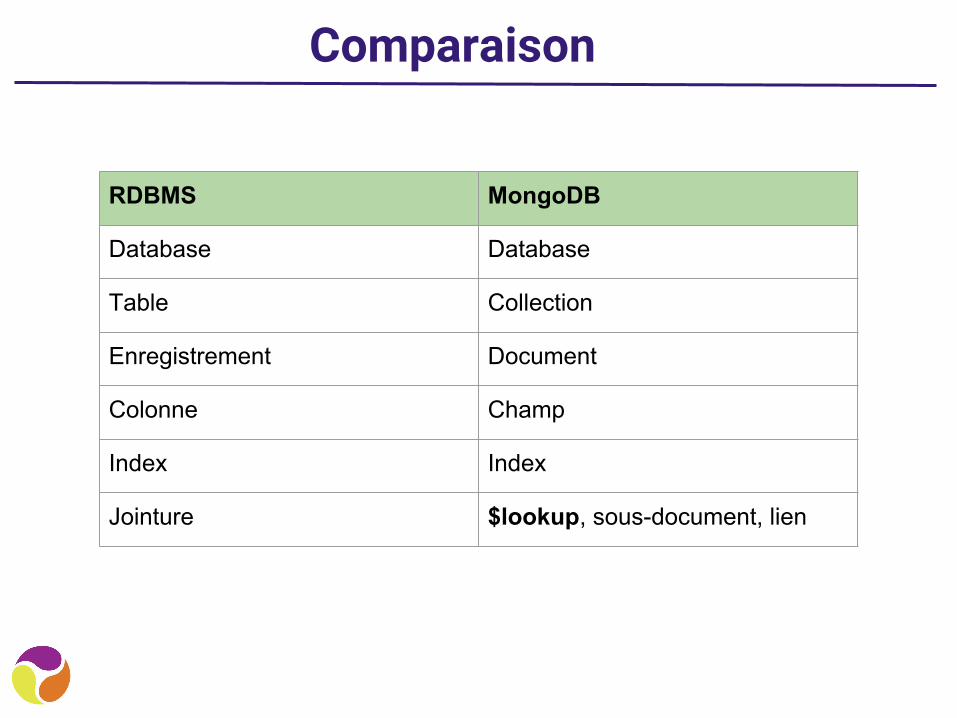
Comparaison
RDBMS MongoDB
Database Database
Table Collection
Enregistrement Document
Colonne Champ
Index Index
Jointure $lookup, sous-document, lien

Modèle relationnel et normalisation
● Data rangées dans les bonnes cases, pas de redondance de l’information
○ C’est beau, c’est carré !
● Mais, attention aux performances lors des recherches sur les disques de l’info dans les différentes tables
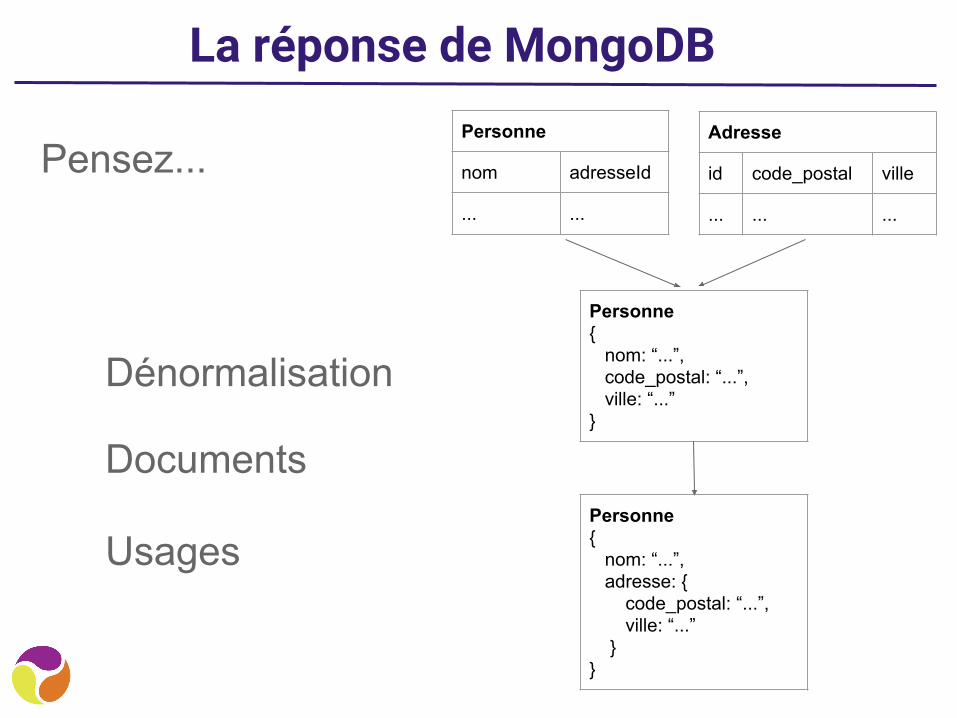
La réponse de MongoDB
Pensez...
Dénormalisation
Documents
Usages
Personne
nom adresseId
... ...
Adresse
id code_postal ville
... ... ...
Personne{ nom: “...”, code_postal: “...”, ville: “...”}
Personne{ nom: “...”, adresse: { code_postal: “...”, ville: “...” }}

Document, sous-document, ...
Pourquoi tout mettre dans un seul doc ?
● locality : stockage de toute l’info au même endroit sur le disque
● consistency : comme il n’y pas de transaction, MongoDB assure que l’update d’un doc est atomique

Document, sous-document, ...
Pourquoi ne pas tout mettre dans un seul doc ?
● On peut récupérer plus d’info qu’on n’en a réellement besoin○ on peut utiliser les projections dans les
queries (ok d’un point de vue réseau),○ mais cela n’empêche le document d’
être entirèrement présent en mémoire avant d’être retourné au client

Références entre docs
Pourquoi séparer dans plusieurs docs ?
● Flexibilité
● Cardinalité forte / gros document:○ Attention à la place mémoire (document
déserialisé en mémoire)○ Taille max des docs: 16Mo

Références entre docs
Pourquoi ne pas séparer dans plusieurs docs ?
● On risque d’avoir à gérer des jointures dans l’application, compliqué !
● Ou utilisation de $lookup : a des contraintes fortes !
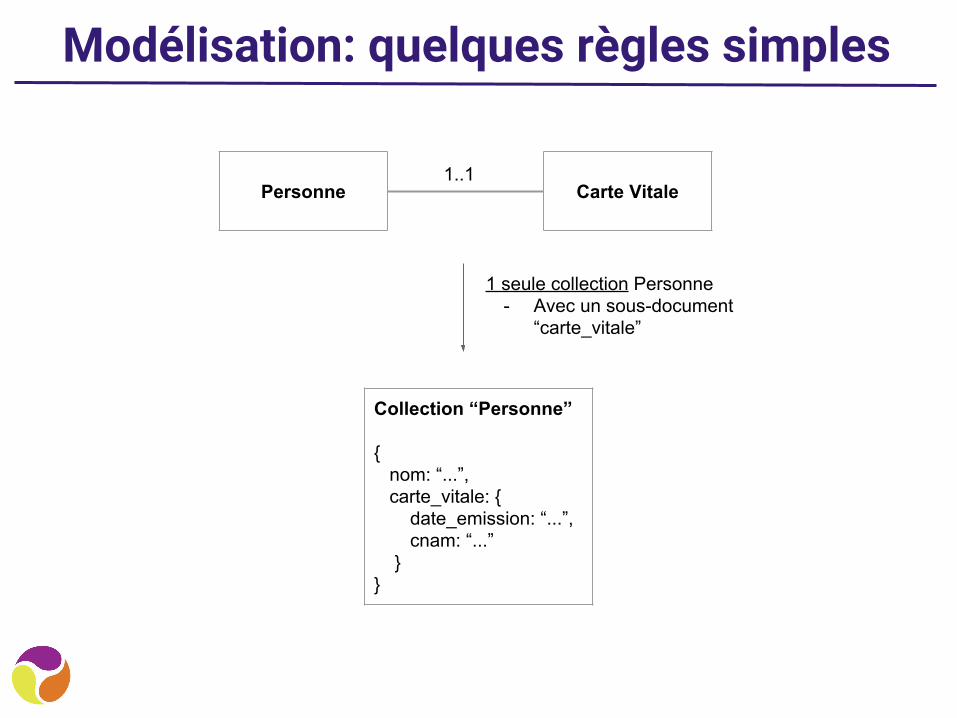
Modélisation: quelques règles simples
1..1
1 seule collection Personne- Avec un sous-document
“carte_vitale”
Collection “Personne”
{ nom: “...”, carte_vitale: { date_emission: “...”, cnam: “...” }}
Personne Carte Vitale
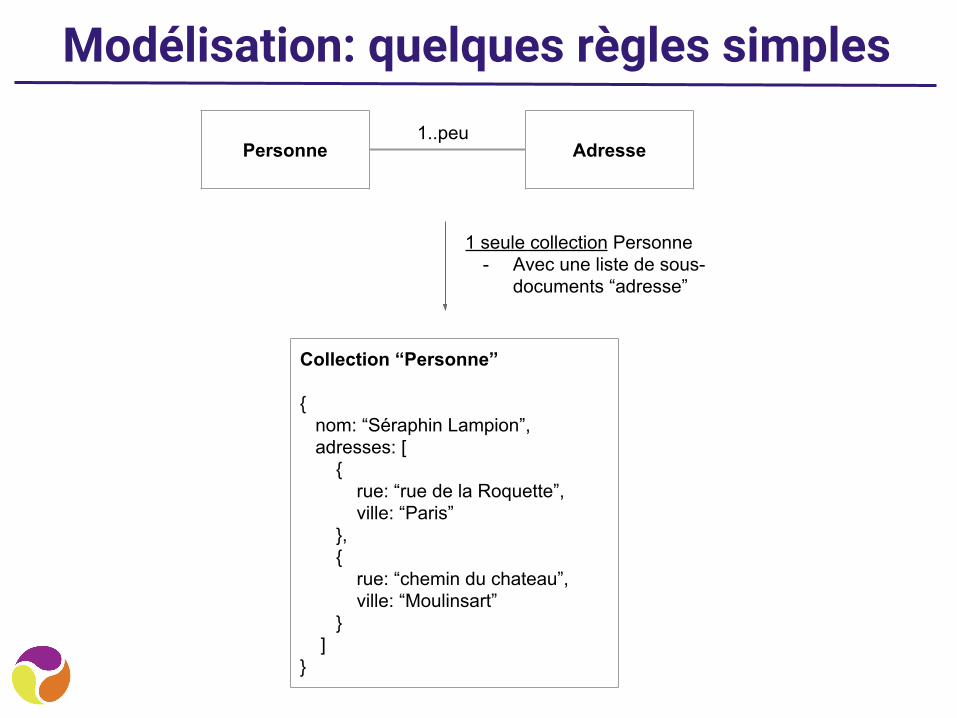
Modélisation: quelques règles simples
1 seule collection Personne- Avec une liste de sous-
documents “adresse”
1..peu
Collection “Personne”
{ nom: “Séraphin Lampion”, adresses: [ { rue: “rue de la Roquette”, ville: “Paris” }, { rue: “chemin du chateau”, ville: “Moulinsart” } ]}
Personne Adresse

Modélisation: quelques règles simples
2 collections Voiture et Composant- C’est Voiture qui référence les composants
1..beaucoup
Collection “Voiture”
{ marque: “...”, modele: “...”, composants: [ “Id_101”, “Id_22”, “Id_345”, … ]}
Voiture Composant
Collection “Composant”
{ id: “...”, type: “...”, prix: ...}

Modélisation: quelques règles simples
2 collections Systeme et Log- C’est Log qui référence le parent !
1..énormément
Collection “Système”
{ id: “...”, host: “...”, ...}
Système Log
Collection “Log”
{ date: “...”, level: “...”, id_systeme: “...”}

Et concernant l’usage...
Ne pas oubliez d’en tenir compte !
● “J’ai besoin de l’ensemble des données à chaque requête”○ Mettez tout dans une seule collection
● “J’ai besoin d’en avoir seulement une partie”○ Faites plusieurs collections et des références ○ Ex: les posts d’un blog et leurs commentaires :
■ 2 besoins : affichage liste des posts + affichage post avec commentaires
■ Modélisation avec 2 collections (posts, comments)

$lookupDes jointures ! c’est un début…● Left outer join● Uniquement avec des collections non shardées
Collection Conference{ “title”: “Plein de mots-clefs hyper cools...”, “description”: “Refaites votre SI avec tout ça, sinon vous êtes mort!”, “speaker_id”: “techno_maniac”
}
Collection Speaker{ “_id”: “techno_maniac”, “name”: “Jean-Marcel Le Maniac”, “email”: “[email protected]”}
Exemple $lookup
db.Conference.aggregate( [ { “$lookup”: { “from”: “Speaker”, “localField”: “speaker_id”, “foreignField”: “_id”, “as”: “speaker_infos” } } ] )
[ { “title”: “Plein de mots-clefs hyper cools...”, “description”: “Refaites votre SI avec…”, “speaker_id”: “techno_maniac”, “speaker_infos”: [ { “_id”: “techno_maniac”, “name”: “Jean-Marcel Le Maniac”, “email”: “[email protected]” } ]}, … ]

$lookupCollection Conference{ “title”: “Plein de mots-clefs hyper cools...”, “description”: “Refaites votre SI avec ça”, “speaker_ids”: [ “miss_techno”, “techno_maniac” ]}
Exemple $lookup
db.Conference.aggregate( [ { $unwind: “$speaker_ids” }, { $lookup: { from: “Speaker”, localField: “speaker_ids”, foreignField: “_id”, as: “speakers_infos” } }, { $group: { _id: “$_id”, title: { $first: “$title” }, speakers: { $push: “$speakers_infos” } } } ] )
{ “title”: “Plein de mots-clefs hyper cools...”, “speakers”: [{ “_id”: “miss_techno”, “name”: “Jeanne-Irene La Maniac”, “email”: “[email protected]” }, { “_id”: “techno_maniac”, “name”: “Jean-Marcel Le Maniac”, “email”: “[email protected]” } ] }, { ... }, …
Avec des listes, jouez avec $unwind et $group

“C’est un art plus qu’une science!”
Usages !
Usages !Usages !
Usages !
Usages !Usages !

Questions ?

Outillage

● La GUI n’est pas une priorité pour MongoDB● Les meilleurs outils gratuits sont maintenus
par des personnes de MongoDB
Choisir une interface graphique
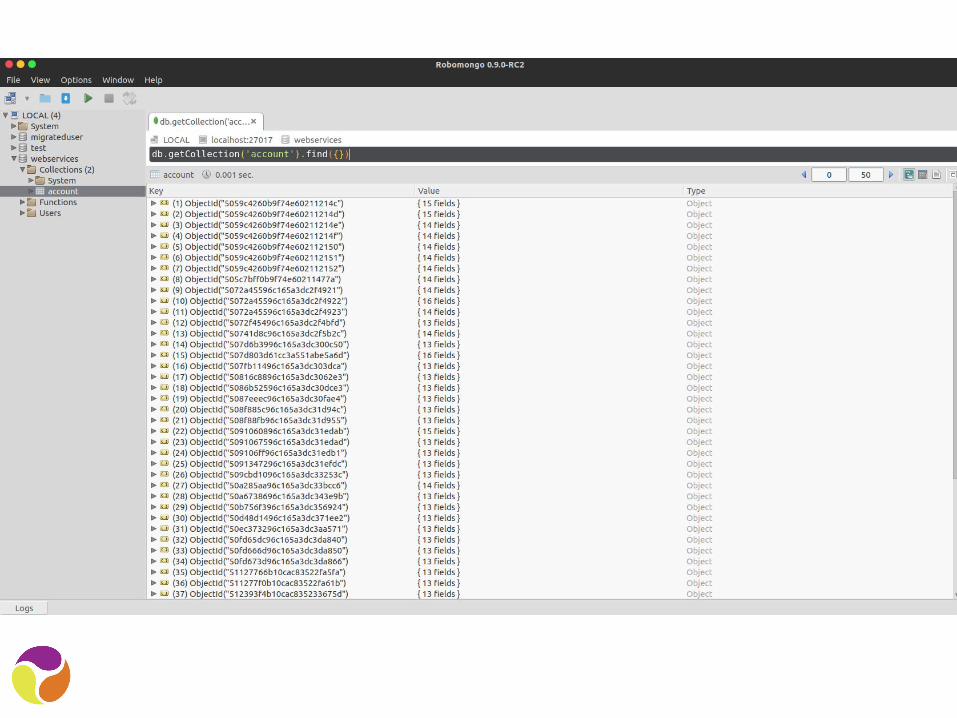

Robot Mongo
● C’est codé avec un vrai langage (C++)
● Est globalement à la traine sur le support de fonctionnalités
● Pensez à utiliser les beta● Plutot complet● Robuste et stable

Mongo Chef
● La seule GUI de niveau professionnel
● A été mis à jours très rapidement les deux dernières années
● Très complet pour du développement comme de l'administration
● Le top coute 149 $ par an
MongoDB Compass

Mongo-hacker
● Le shell MongoDB vitaminé○ Colorisation○ Alias pour compter collections, documents et
indexes○ Alias pour aggrégations gcount, gavg, gsum
● Toujours nécessaire notamment quand la base n’est pas accessible directement
https://github.com/TylerBrock/mongo-hacker

M
● Equivalent pour mongodb de n pour node● Simplification du téléchargement● Changement en une commande de version
mongodb
https://github.com/aheckmann/m

Démo

Frameworks et API

ORM ou plutôt ODM
Avant-propos: eh oui, on est mono-maniaque et on ne développe qu’en Java !
● Driver Java○ Évolue bien, mais bas niveau
● Morphia○ Intéressant
● Spring Data MongoDB○ C’est Spring...
● Hibernate OGM○ Heu...
● Jongo○ Fun !

Driver Java 3.0
Nouvelles classes (les anciennes sont toujours là, hélas…)// A OUBLIER !!!! DB db = mongoClient.getDB("breizhcamp2016");DBCollection dbCollection = db.getCollection("conferences");
Iterator<DBObject> confIter = dbCollection.find().iterator();
// Utilisation d’un mapper pour convertir les DBObjects en objets métier
MongoDatabase db = mongoClient.getDatabase("breizhcamp2016");MongoCollection<Document> dbCollection = db.getCollection("conferences");
// Ou en utilisation directe de la classe métier
MongoCollection<Conference> dbCollection = db.getCollection("conferences", Conference.class);
MongoCursor<Conference> conferences = confCollection.find().iterator();
// Il ne faut pas oublier de déclarer un codec pour la classe Conference

Driver Java 3.0
Codec: permet de gérer finement le codage en BSON (est-ce bien utile ? bof...)
public class ConferenceCodec implements Codec<Conference> {
@Overridepublic void encode(BsonWriter writer, Conference conf,
EncoderContext ctx) { }
@Overridepublic Class<Conference> getEncoderClass() {
return Conference.class;}
@Overridepublic Conference decode(BsonReader reader,
DecoderContext ctx) { }}
public class ConferenceCodecProvider implements CodecProvider {
@Overridepublic <T> Codec<T> get(Class<T> clazz,
CodecRegistry registry) { if (clazz == Conference.class) { return (Codec<T>) new ConferenceCodec(); } return null;
}
}
Utilisation d’un codec générique (projet à suivre!):➔ https://github.com/ylemoigne/mongo-jackson-codec

Driver Java 3.0
Async API (mêmes noms de classes, pas le même package)
// Async Database et Collection//MongoDatabase db = client.getDatabase("breizhcamp2016");MongoCollection<Conference> collection = db.getCollection("conferences", Conference.class);
Conference conference = new Conference( "Framework TrucMachinChoseJS et Dockerification de mes microservices", "C'est trop cool !", new Speaker("JsAndDockerAndMicroServicesManiac"));
// Insertion d’un élément => il faut fournir une callback//collection.insertOne(conference, (final Void result, final Throwable t) -> { System.out.println("Conference inserée"); });

Morphia
Nécessaire et suffisantMorphia morphia = new Morphia();morphia.map(Conference.class, Speaker.class);
Datastore datastore = morphia.createDatastore(client, "breizhcamp2016");
Conference conf = new Conference("Have fun With MongoDB", "@padewitte", "@_bruno_b_");
datastore.save(conf);
List<Conference> confWithPAD = datastore.find(Conference.class) .filter("speakers", "@padewitte") .field("speakers").sizeEq(1) .asList();
datastore.createAggregation(Conference.class) .unwind("speakers") .project(projection("twitterHandle", "speakers"), projection("title")) .group("twitterHandle", grouping("conferences", addToSet("title"))) .out(Speaker.class);

Pas de transaction, mais...
Ne pas oublier qu’il existe des méthodes findAndXXX permettant d’exécuter des actions de manière atomique
FindOneAndUpdateOptions options = new FindOneAndUpdateOptions().returnDocument(ReturnDocument.AFTER); // UpdatedConf contient les données de la conférence suite à la modifConference updatedConf = confCollection.findOneAndUpdate( new Document(), // Query new Document("$push", new Document("speakerIds", "pad")), // Update options);

Questions ?

Préparer la production

Estimer la volumétrie

Estimer la volumétrie
1. Prototyper et concevoir une première version du schéma
2. Extraire les statistiques de taille de chaque collection pour les datas et les indexa. taille moyenne des datasb. taille moyenne des indexes
3. Pour chaque collection, estimer un nombre de documents
4. Appliquer un coefficient multiplicateur (un conseil, à cacher le dans une formule d’excel)

Extraire les statistiques
> show collections
> count docs
> count index
> db.macollection.count()
> db.macollection.stats(1024*1024)

Le working set
● Portion des données utilisée fréquemment● Attention aux batchs réalisant une lecture
complète d’une collection
● Idéalement la taille du working set doit correspondre à la taille de la RAM
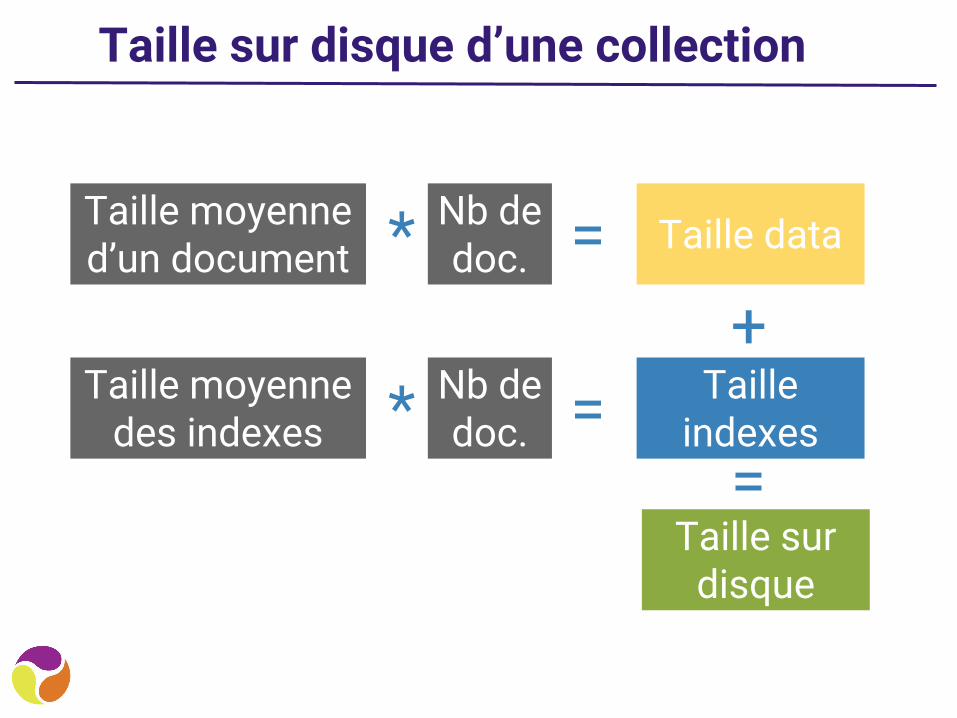
Taille sur disque d’une collection
Taille moyenne d’un document Taille data=* Nb de
doc.
Taille moyenne des indexes
Taille indexes=* Nb de
doc.=
Taille sur disque
+
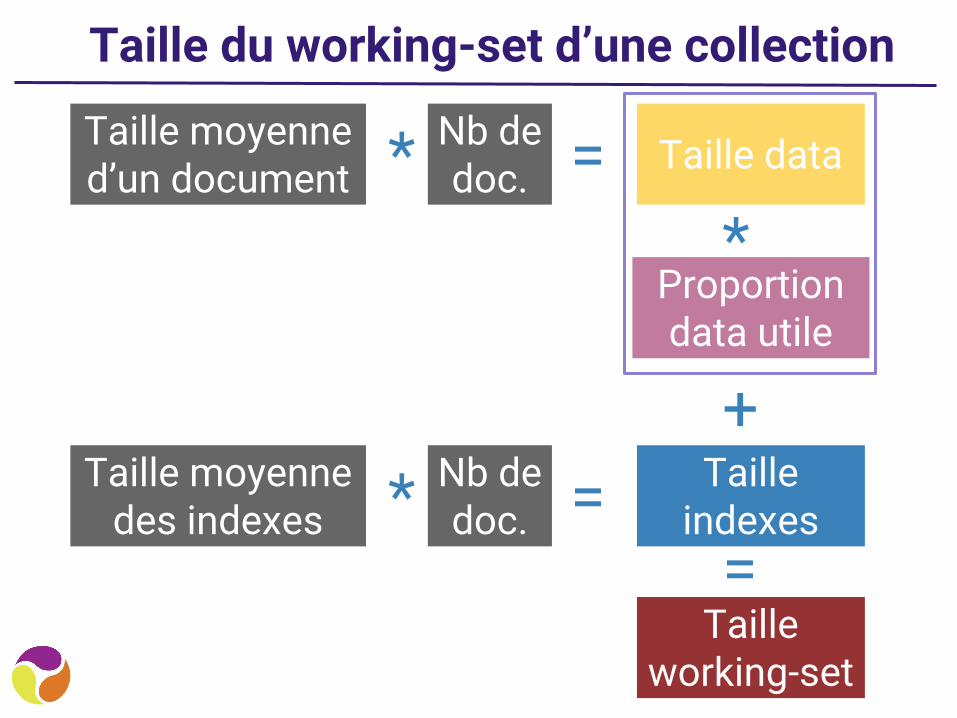
Taille du working-set d’une collection
Taille moyenne d’un document Taille data=* Nb de
doc.
Taille moyenne des indexes
Taille indexes=* Nb de
doc.=
Taille working-set
+
Proportion data utile
*

Migrer ses données

Chemins de migration
Peu d’outillage disponible

mongo-connector
● Ecrit et maintenu par MongoDB en python● Permet de copier depuis MongoDB vers :
○ ElasticSearch○ Solr○ Mongodb○ Postgresql
● Peut permettre de synchroniser une base de préproduction avec la production simplement
● Idéal pour des duplications sans transformation
https://github.com/mongodb-labs/mongo-connector

Apache Camel & Groovydef ds = new OracleDataSource(... )SimpleRegistry registry = new SimpleRegistry();registry.put("myDataSource", ds);def camelContext = new DefaultCamelContext(registry)camelContext.addRoutes(new RouteBuilder() { def void configure() {
from("direct:EXTRACT_SQL") .setHeader("table", constant("CONFERENCES")) .setBody().constant("select * where (CONFERENCES.DATMAJ > sysdate - 2 )") .to("jdbc:myDataSource?outputType=StreamList&useHeadersAsParameters=true") .split(body()).streaming().process(confProcessor) .to("mongodb:myDb?database=mymongo_databse&collection=conferences&operation=save") .end() }})camelContext.start() // send a message to the routeProducerTemplate template = camelContext.createProducerTemplate();template.sendBody("direct:EXTRACT_SQL", "Starting migration");
camelContext.stop()

Questions ?

Exploiter

Replica-set
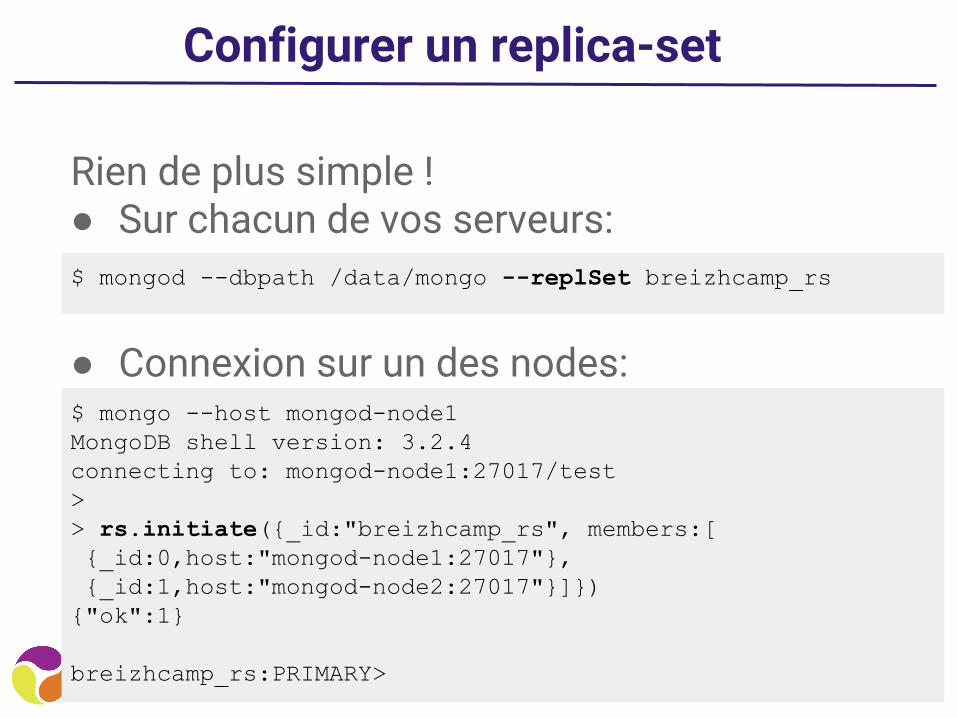
Configurer un replica-set
Rien de plus simple !● Sur chacun de vos serveurs:
● Connexion sur un des nodes:
$ mongod --dbpath /data/mongo --replSet breizhcamp_rs
$ mongo --host mongod-node1MongoDB shell version: 3.2.4connecting to: mongod-node1:27017/test>> rs.initiate({_id:"breizhcamp_rs", members:[ {_id:0,host:"mongod-node1:27017"}, {_id:1,host:"mongod-node2:27017"}]}){"ok":1}
breizhcamp_rs:PRIMARY>

Attention au chainage
https://docs.mongodb.org/manual/reference/replica-configuration/#rsconf.settings.chainingAllowed
PRIMARY
SECONDARY
SECONDARY SECONDARY
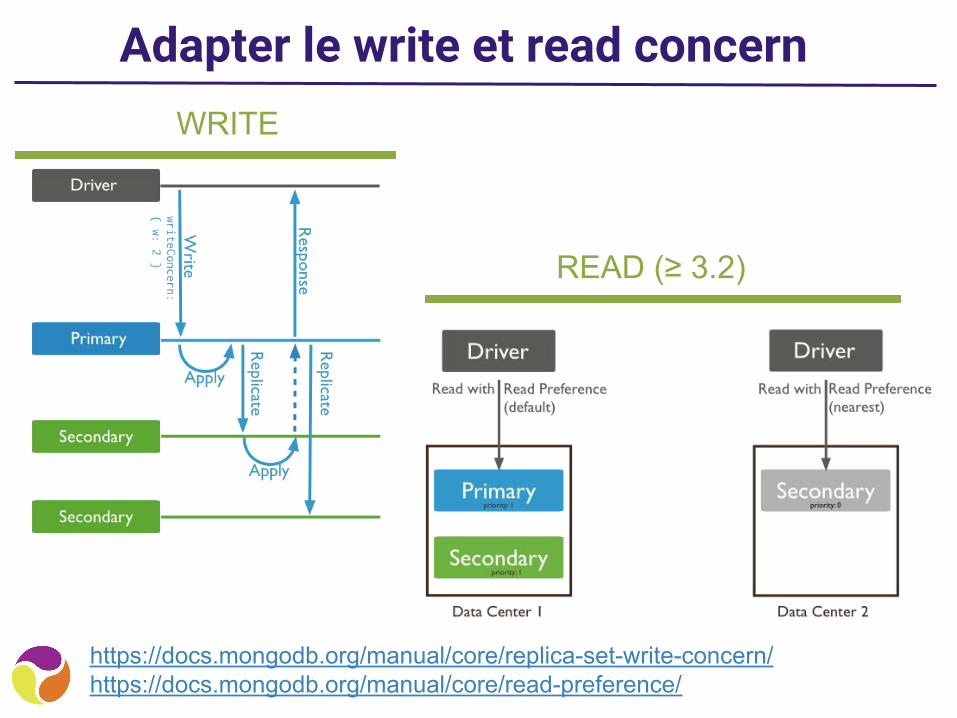
Adapter le write et read concern
https://docs.mongodb.org/manual/core/replica-set-write-concern/https://docs.mongodb.org/manual/core/read-preference/
WRITE
READ (≥ 3.2)

Questions ?

Storage

Storage engine
MongoDB s’adapte aux différents use cases en fournissant plusieurs moteurs de stockage
● MMAPv1: présent depuis le début● WiredTiger : depuis la 3.0 et par défaut à partir de la 3.2● In memory (beta)● Autres futurs moteurs
Pour un noeud donné, on ne peut pas changer de type, mais on peut avoir des nodes avec diff. engines

Mettez un tigre dans votre moteur
Super performant en écriture !➔ Lock au niveau du document (et plus au niveau de la
collection)
Gain de place:➔ Support de la compression pour les collections, les
index, les journaux○ Snappy: par défaut pour les docs et les journaux
■ 70% de taux de compression, peu de surcoût en CPU○ Zlib: meilleure compression (mais surcoût de CPU)
Sécurité:➔ Support du chiffrement au niveau du stockage
(uniquement pour MongoDB enterprise)

Les performances
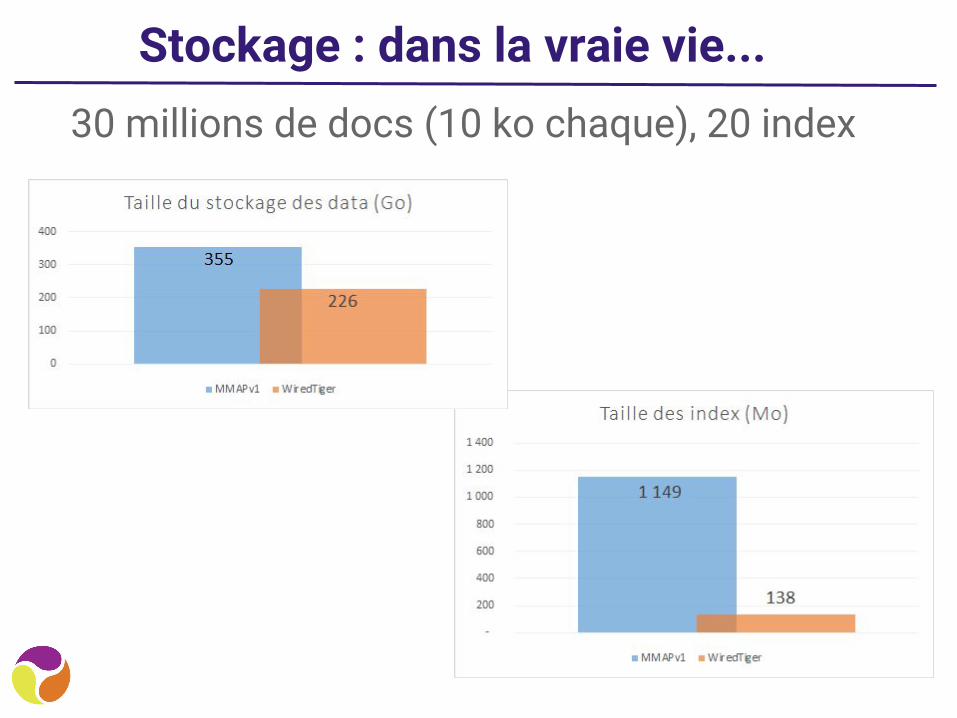
Stockage : dans la vraie vie...30 millions de docs (10 ko chaque), 20 index
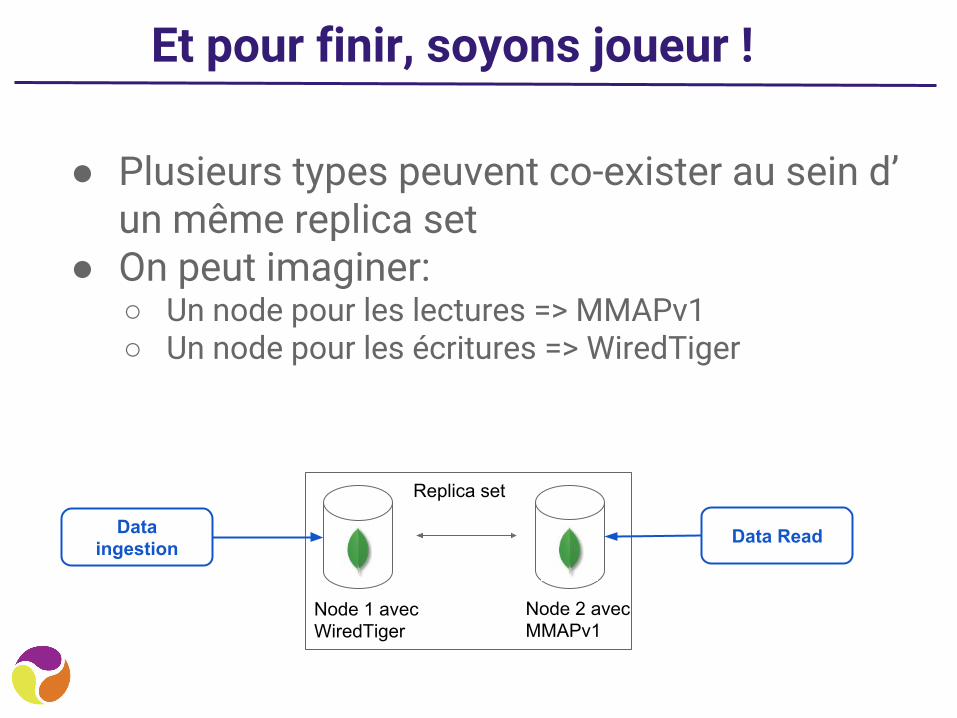
Et pour finir, soyons joueur !
● Plusieurs types peuvent co-exister au sein d’un même replica set
● On peut imaginer:○ Un node pour les lectures => MMAPv1○ Un node pour les écritures => WiredTiger
Node 1 avec WiredTiger
Node 2 avec MMAPv1
Data ingestion Data Read
Replica set

Questions ?

Sharding
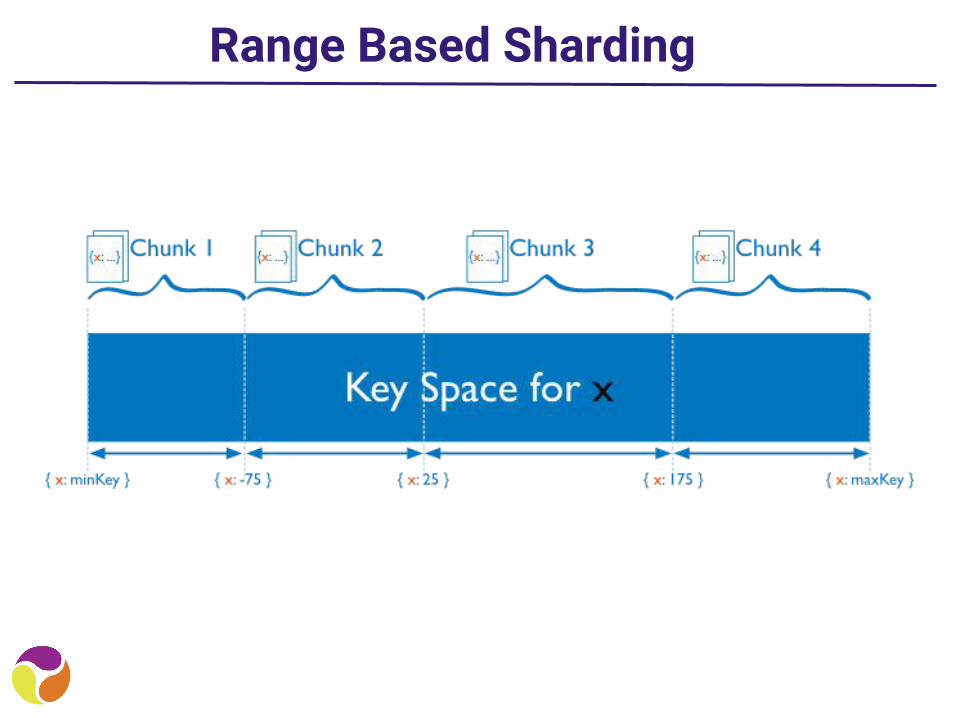
Range Based Sharding
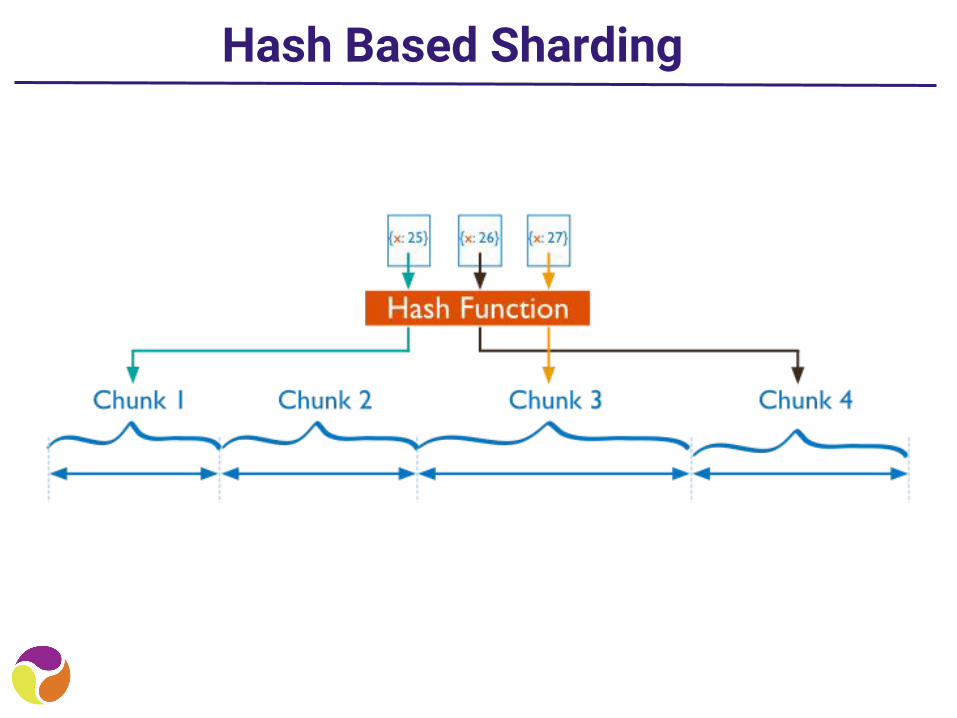
Hash Based Sharding
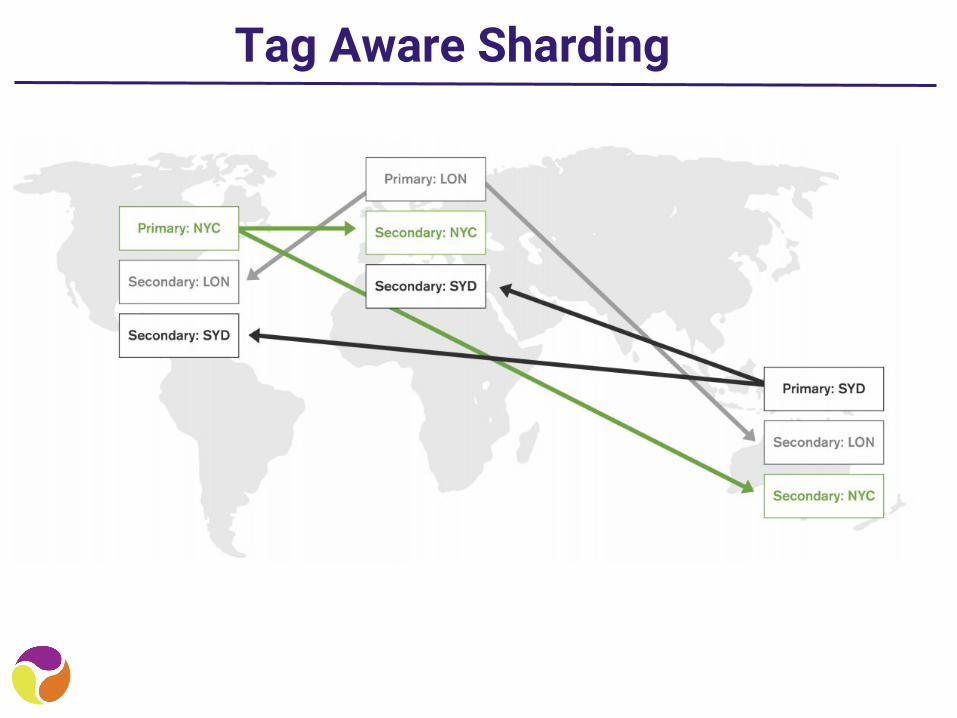
Tag Aware Sharding

Tag Aware Sharding
Il existe certainement d’autres bases de données adaptées à de tels besoins
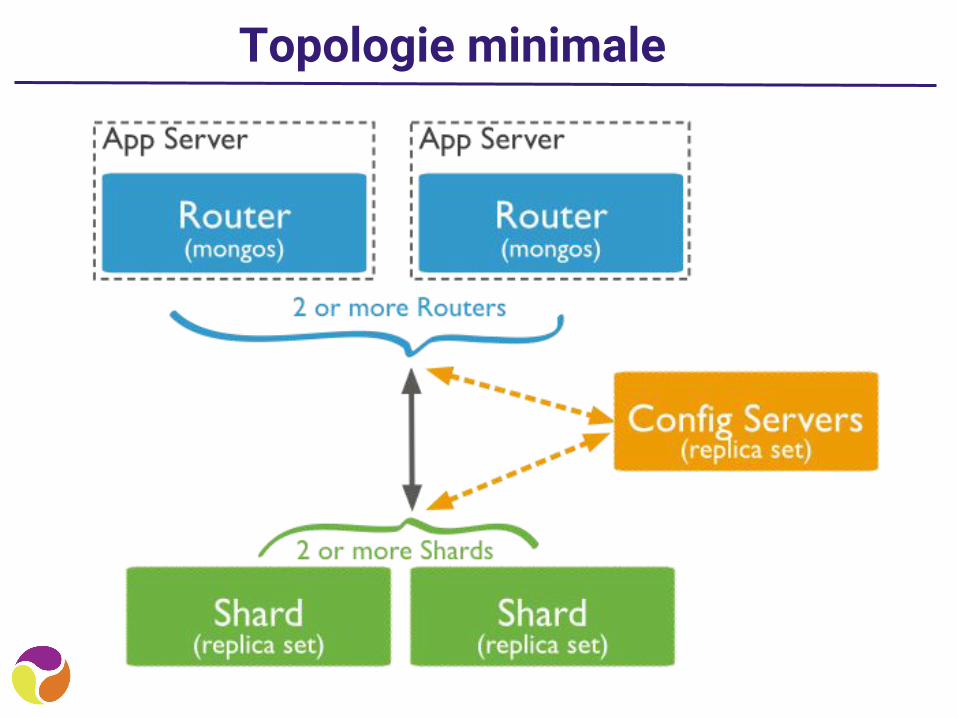
Topologie minimale

Testez en environnement cible
● Update et remove doivent inclure la clé de sharding
● La lecture sur les secondaires est à éviter tant que possible (orphans)
● Limites sur l’aggrégation ○ pas de join depuis une collection shardée○ optimisation largement dépendante des données

Si jamais vous êtes encore motivés
● Sans réseau correct point de salut● Colocaliser les MongoS avec vos
applications● N’oubliez pas de sauvegarder les MongoS
(pas de reconstruction possible simplement)
● Faites vérifier votre architecture par un ami
Quand sharder ?
● Quand ce n’est pas votre premier projet MongoDB en production
● Quand vous pouvez acheter quelques machines de plus (à minima triplement du nombre de machine)
● Quand il n’est pas possible de faire autrement ○ Envisager d’abord la scalabilité verticale ○ Monitorer la taille de votre working set pour
anticiper le plus possible cette opération

Les points d’attention
● Privilegier autant que possible le sharding haché
● Surveiller les plages de lancement du balancer
● Nettoyer régulièrement les orphans● Ne jamais lire sur un secondary si l’
exactitude de la donnée est critique
https://docs.mongodb.org/manual/reference/command/cleanupOrphaned/

Questions ?

Analyser les performances

Mongo tools
● Log avec requêtes lentes et cursor.explain()
● mongotop : stats (temps) lecture/ecriture par collection
● mongostat : stats système de l’instance○ insert, query, update, delete (nombre de requêtes/s)○ getmore command flushes ○ mapped (MMAPv1), vsize, res○ faults (MMAPv1)○ qr|qw (queue)○ ar|aw (active clients)

Mtools
● La boite à outils indispensable pour analyser les logs
https://github.com/rueckstiess/mtools

Supervision et métrologie

Les points de supervision système
● Espace libre● Nombre de connexions réseau● Nombre de fichiers ouverts● Mémoire utilisée
Dans le cas d’un replica-set :● Statut dans le replica-set● Présence de fichiers dans le répertoire
rollbacks
https://docs.mongodb.org/manual/core/replica-set-rollbacks/

Les solutions
Pas de plugin permettant la découverte automatique● Zabbix
○ Set de graph et d’alarmes préconfigurées○ Il faudra mettre les mains dans PHP
● Nagios○ Nombreux check à ajouter○ Accompagné du plugin CACTI il est aisé de se
construire une métrologie○ Il faudra mettre les mains dans Python
● Votre script dans votre langage de prédiletion
https://github.com/nightw/mikoomi-zabbix-mongodb-monitoringhttps://github.com/mzupan/nagios-plugin-mongodb

Métrologie
● Définir des alertes sur événements ou seuil est important
● En cas de problème de performance complexe avoir grapher les métriques clefs auparavant est encore plus important

Backup

MongoDump / MongoRestore
● Tool de Mongo permettant la sauvegarde● Dans le cas d’un replica set utiliser l’option --
oplog à la sauvegarde et la restauration pour backuper un maximum d’enregistrement
● Il est nécessaire d’avoir la place disponible et peut prendre beaucoup de temps

Copie des fichiers
● Il est possible de backuper par copie des fichiers
● Dans le cas de NMAP il est indispensable d’activer le journal et que celui ci soit présent sur le même volume que les données
● Dans le cas d’un replica set préférer la sauvegarde sur le primary ou alors s’assurer que le secondary source de la sauvegarde n’est pas en retard
● Si vous pouvez vous le permettre préférer stopper l’instance

Faire son propre “Point in time …”
● Si jamais vous avez un oplog couvrant l'intervalle de temps entre une sauvegarde et le moment auquel vous pouvez restaurer il est possible de ne pas perdre de données
● Commencer par isoler un membre puis sauvegarder l’oplog
● http://www.codepimp.org/2014/08/replay-the-oplog-in-mongodb/
● A tester absolument dans un environnement non cible la première fois

MongoDB Cloud Manager Backup
● De loin la solution la plus simple mais nécessite une souscription
● Fonctionne par lecture de l’oplog en continue
● Permet le point in time recovery● Disponible dans le cloud ou dans votre
réseau● Si auo-herbergé la machine de backup doit
être aussi puissante avec encore plus de stockage que vos autres machines

Solution idéale
● Un backup idéal est un backup testé
● Pour des petits volumes MongoDump est suffisant
● Les outils de MongoDB corp sont clairement plus simple à utiliser

Questions ?

Avant de se quitter

Gestion de projet
Gérer son projet
Concevoir Développer
QualifierEvaluer les performances

● Un bon schéma doit répondre :○ Aux besoins métier○ Aux exigences de performance
● Pour bien connaitre le besoin, il faut le développer et le tester
● Pour savoir si l’application répond aux exigences de performance, il faut la tester
● Les tests doivent commencer avec le développement
● Pour tester rapidement, il faut déployer rapidement
En résumé

Agilité
Continuous testing
DevOps
Ingénierie des exigences

Pour continuer

Les liens à connaitre
https://docs.mongodb.org/manual/administration/production-checklist/
https://docs.mongodb.org/manual/faq/diagnostics/

Se former
https://university.mongodb.com/

Se tenir informer
https://www.mongodb.com/presentations/all
https://www.mongodb.com/community

#mongodb #bzhcmp
@_bruno_b_@padewitte

Pour compléter
http://dba.stackexchange.com/questions/121160/mongodb-mmapv1-vs-wiredtiger-storage-engines
https://objectrocket.com/blog/company/mongodb-wiredtiger
http://zanon.io/posts/mongodb-storage-engine-mmap-or-wiredtiger






















![[Breizhcamp 2015] MongoDB et Elastic, meilleurs ennemis ?](https://img.pdfslide.fr/doc/110x75/55b8e65abb61eb97088b4702/breizhcamp-2015-mongodb-et-elastic-meilleurs-ennemis-.jpg)