Embed Size (px)
Citation preview

Page 1 sur 41
Concours externe Inria 2013
Arrêté du 15 avril 2013
Poste « Ingénieur systèmes et réseaux (H/F) »
Accès au corps des « Ingénieurs d’études »
Epreuve du 9 juillet 2013 Note sur 20 – Coefficient 3 – Durée 3 heures
*******************************************************************************************
La notation prendra en compte la qualité des réponses, mais aussi la rédaction, la présentation, le style et l’orthographe.
Veuillez respecter l’anonymat dans les réponses.
Ne pas omettre de noter votre numéro d’ordre sur les feuilles intercalaires.
L’usage de tout document ainsi que tout matériel électronique est interdit.
Bien que les questions soient rédigées au singulier, les réponses au QCM peuvent être multiples. Vous devez cocher les bonnes réponses Il existe toujours au moins une bonne réponse. Pour chaque question, chaque réponse correcte donne un crédit de 1 point. Toute mauvaise réponse ou oubli d'une bonne réponse coûte 1 point. Toutefois, le total des points d'une question ne peut pas passer en négatif.
*******************************************************************************************
Répartition prévisionnelle des points Partie 1 : 5 points Partie 2 ; 7 points Partie 3 : 8 points

Page 2 sur 41
Partie 1 : QCM (5 points) Q1 : Parmi les chaînes listées ci-dessous, indiquez celles qui seront reconnues par l'expression régulière suivante : ^ab*$ ☐ babb
☐ a
☐ abc
☐ abb
☐ aaaaaab Q2 : Un disque dur SSD : ☐ Permet une plus grande capacité de stockage qu'un disque dur classique
☐ Permet un temps d'accès particulièrement faible
☐ Est un disque dur sécurisé au niveau secret défense
☐ Permet de réduire le poids des ordinateurs portables Q3 : Quel nom donne-t-on au système assurant le fonctionnement d'un jeu de machines virtuelles ? ☐ Hyper virtualiseur
☐ Un système d'exploitation temps réel
☐ Load Balancing (répartition de charge)
☐ Hyperviseur Q4 : La technologie réseau POE désigne : ☐ Le multiplexage de plusieurs connexions sur un seul port de commutateur
☐ L'envoi d'un signal sur chaque port du commutateur au moment d'une coupure d'alimentation (grâce à un condensateur adéquat) ☐ L'obligation de s'authentifier avant d'obtenir l'ouverture définitive d'un port du commutateur
☐ La possibilité pour un commutateur d'envoyer une alimentation électrique sur ses ports Q5 : Parmi ces propositions, citer celle correspondant à un type réel de fibre optique : ☐ Monomode
☐ Dualmode
☐ Multimode
☐ Bimode Q6 : Quelle commande UNIX permet de chercher dans le répertoire /usr tous les fichiers qui ont été modifiés depuis la veille ? ☐ ls -alRtr /usr
☐ find -t file /usr -mtime 1
☐ find /usr –mtime -1 -type f
☐ ls -lRtr /usr Q7 : À quoi sert SNMP ? ☐ À régler l'heure automatiquement sur les équipements réseau
☐ À administrer et surveiller les équipements réseau
☐ À transférer le courrier électronique vers les serveurs de messagerie électronique
☐ À signer électroniquement des documents numériques

Page 3 sur 41
Q8 : Certains équipements réseaux sont configurables via un port série, quelle application peut-on alors utiliser pour s'y connecter ? ☐ FileZilla
☐ Putty
☐ Xmeeting
☐ HyperTerminal Q9 : Quelle est l'utilité du langage CSS ? ☐ Concevoir des pages web dynamiques à contenu scientifique
☐ Mieux séparer le contenu de la présentation
☐ Modifier le contenu d'une page juste avant l'affichage par le navigateur
☐ Ajouter du style aux documents web Q10 : La réglementation sur les marchés publics : ☐ Concerne uniquement certains établissements publics comme les universités
☐ Concerne tous les achats des services de l’état quel qu’en soit le montant
☐ Permet de fixer, lors d’un achat public, les modalités de publicité et de mise en concurrence
☐ Ne concerne pas les dépenses de fonctionnement (consommables, …) Q11 : La métrologie réseau est une discipline chargée : ☐ D'optimiser la consommation de bande passante
☐ D'aiguiller les flux jusqu'à l'équipement destinataire
☐ D'indexer le contenu des sites web pour les moteurs de recherche
☐ De mesurer l'utilisation du réseau à des fins statistiques Q12 : Un CMS (Content Management System, ou Système de Gestion de Contenu) est : ☐ Un ensemble de base de données utilisable en cloud computing
☐ Un système de gestion électronique d’espace de stockage de documents
☐ Une interface permettant de factoriser plusieurs bases de données aux contenus souvent redondants
☐ Un logiciel pour la conception dynamique de sites Web Q13 : Sous Linux, quelle commande affiche la configuration des interfaces réseaux ? ☐ Ipconfig
☐ Netipcfg
☐ Ifconfig
☐ Networkedit Q14 : Quelle est la durée légale de conservation des journaux (logs) ? ☐ 6 mois
☐ 1 an
☐ 2 ans
☐ 5 ans

Page 4 sur 41
Q15 : Cochez les cas où la commande strace est utile : ☐ Permet de tracer l’exécution d’un programme grâce à l’appel système ptrace
☐ Permet de tracer le trajet des paquets en faisant varier le TTL
☐ Permet l’affectation du nom d’une Access Control Entry lorsque l’on modifie les ACL
☐ Permet de supprimer les traces laissées par un processus Q16 : Selon la démarche ITIL, comment doit-on traiter un incident identique qui se représente plusieurs fois ? ☐ Comme un incident récurrent
☐ Comme un problème
☐ Cet incident doit faire l'objet d'une escalade
☐ Comme un incident classique, tant qu'il n'est pas caractérisé autrement par le demandeur Q17 : Selinux fait partie des modules de sécurité de linux qu'apporte-t-il ? ☐Un confinement des applications au moindre privilège
☐ Il permet un audit de codes
☐ Il permet un contrôle d'accès mandataire
☐ Il permet entre autre la gestion du firewall
☐ Il chiffre les données point à point Q18 : Dans quel fichier sont loggées les erreurs selinux ? ☐ /var/log/messages
☐ /var/log/secure
☐ /var/log/audit/audit.log
☐ /var/log/kern.log Q19 : Lors d'un blocage par une politique selinux particulière, comment peut-on résoudre le problème ? ☐ En utilisant la commande setsebool
☐ En utilisant la commande setsecontext
☐ En utilisant la commande audit2allow
☐ En utilisant la commande setenforce Q20 : Parmi les adresses IP suivantes, laquelle est routable ? ☐ 192.168.0.234
☐ 172.16.0.28
☐ 147.210.8.210
☐ 10.0.0.10 Q21 : À quoi correspond le préfixe d’une adresse IP ? ☐ l’adresse de l’hôte
☐ l’adresse du réseau
☐ l’adresse de monodiffusion (unicast)
☐ l’adresse de diffusion (broadcast)

Page 5 sur 41
Q22 : Quel est le protocole qui permet d'allouer automatiquement et dynamiquement des adresses IP ? ☐ VRRP
☐ DAIP
☐ DHCP
☐ ADAIP Q23 : Comment s'établit une connexion TCP ? ☐ SYN, SYN/ACK, ACK
☐ Threeway handshake
☐ TCP n'est pas un protocole connecté à l'instar de l'UDP
☐ aucune des réponses précédentes n’est juste Q24 : La commande PING : ☐ permet de tester la bande passante
☐ permet de tester la connectivité http
☐ envoie et reçoit des paquets ICMP
☐ valide ou invalide à coup sûr que la connexion physique est bonne Q25 : La plupart des systèmes d'exploitation offrent une double pile IPv4/IPv6. Nous souhaitons interdire l'utilisation d'IPv6. Quel protocole faut-il désactiver ou filtrer pour cela ? ☐ ISATAP
☐ Teredo
☐ APIPA
☐ 6to4 Q26 : Quel est la bonne commande Linux parmi ces 4 pour indiquer les processus en cours dynamiquement ? ☐ ps –a
☐ ps –aux
☐ top
☐ ps Q27 : Quelle action peut-être faite grâce à puppet ? ☐ installer des paquets sur un ensemble de machines
☐ définir des configurations
☐ déployer des configurations
☐ comparer la configuration présente sur une machine et celle sur le serveur puppet Q28 : Cocher les outils de déploiement d'images : ☐ photorec
☐ puppet
☐ ghost
☐ clonezilla

Page 6 sur 41
Q29 : A quel langage correspond cette ligne ? UPDATE cie_t1 SET Label=CONCAT('<b>',RaisonSociale,'</b><br>',Adresse,'<br>',CP,'-',BureauDist) WHERE CP Like '33%' ☐ bash
☐ perl
☐ mysql ☐ python Q30 : Comment peut-on vérifier que l'option ip forward est activée sur le système ? ☐ cat /proc/sys/net/ipv4/ip_forward
☐ iptables –L
☐ grep -r ip_forward /etc/sysctl*
☐ ipforward -all Q31 : A quel service correspond le fichier de configuration suivant ? [libdefaults] default_realm = ATHENA.MIT.EDU default_tkt_enctypes = des3-hmac-sha1 des-cbc-crc default_tgs_enctypes = des3-hmac-sha1 des-cbc-crc dns_lookup_kdc = true dns_lookup_realm = false [realms] ATHENA.MIT.EDU = { kdc = activedc.mit.edu kdc = activedc-1.mit.edu kdc = activedc-2.mit.edu:750 admin_server = activedc.mit.edu master_kdc = activedc.mit.edu default_domain = mit.edu } EXAMPLE.COM = { kdc = activedc.example.com kdc = activedc-1.example.com admin_server = activedc.example.com } [domain_realm] .mit.edu = ATHENA.MIT.EDU mit.edu = ATHENA.MIT.EDU [capaths] ATHENA.MIT.EDU = { EXAMPLE.COM = . } EXAMPLE.COM = { ATHENA.MIT.EDU = . } [logging] kdc = SYSLOG:INFO admin_server = FILE=/var/kadm5.log ☐ samba
☐ kerberos
☐ active directory
☐ aucun des 3 précédents

Page 7 sur 41
Q32 : A quel service correspond le fichier de configuration suivant ? [global] workgroup = DOCS netbios name = DOCS_SRV passdb backend = ldapsam:ldap://ldap.example.com username map = /etc/samba/smbusers security = user add user script = /usr/sbin/useradd -m %u delete user script = /usr/sbin/userdel -r %u add group script = /usr/sbin/groupadd %g delete group script = /usr/sbin/groupdel %g add user to group script = /usr/sbin/usermod -G %g %u add machine script = \ /usr/sbin/useradd -s /bin/false -d /dev/null \ -g machines %u # The following specifies the default logon script # Per user logon scripts can be specified in the # user account using pdbedit logon script = scripts\logon.bat # This sets the default profile path. # Set per user paths with pdbedit logon path = \\%L\Profiles\%U logon drive = H: logon home = \\%L\%U domain logons = Yes os level = 35 preferred master = Yes domain master = Yes ldap suffix = dc=example,dc=com ldap machine suffix = ou=People ldap user suffix = ou=People ldap group suffix = ou=Group ldap idmap suffix = ou=People ldap admin dn = cn=Manager ldap ssl = no ldap passwd sync = yes idmap uid = 15000-20000 idmap gid = 15000-20000 ... # Other resource shares [homes] comment = Home Directories valid users = %S read only = No browseable = No [public] comment = Data path = /export force user = docsbot force group = users guest ok = Yes [printers] comment = All Printers path = /var/spool/cups/ printer admin = john, ed, @admins create mask = 0600

Page 8 sur 41
guest ok = Yes printable = Yes use client driver = Yes browseable = Yes ☐ samba
☐ ldap
☐ cups
☐ kerberos Q33 : Sous quel format sont stockés les comptes utilisateurs dans le fichier de configuration précédent (de la question Q32) ? ☐ Mysql
☐ NIS
☐ Ldap
☐ Passdb
☐ sam

Page 9 sur 41
Partie 2 : Questions courtes (7 points) C1 : Quels sont les avantages de la virtualisation ? C2 : Dans certaine condition, une machine peut savoir facilement si elle est dans un VLAN. C2a : Précisez ce cas. C2b : Quels autres avantages aurait-on à se placer dans ce cas ? C2c : Quelle serait la solution pour que la machine ne puisse pas savoir si elle est dans un VLAN ? C3 : Proposer des solutions pour limiter les accès à un site web (dans les différents équipements et logiciels entre le client et le serveur) C4 : A l'aide de votre langage de script préféré (shell, perl, python, ...) écrire le code permettant de comparer le condensat du mot de passe de chaque compte stocké dans l’annuaire ldap à une base de donnée de mots passe triviaux. Ces mots de passe sont stockés sous forme d’un condensat par ligne dans un fichier texte. Le script renverra le « uid » du compte qui aura un mot de passe faible. (Les comptes utilisateurs sont de type posixAccount) C5 : Citez 3 inconvénients à NFSv3 : - - - C6 : Faites une comparaison entre nfsv3 vs v4 C7 : Quels seraient les avantages et les inconvénients à utiliser iSCSI en lieu et place de NFS ? C8 : Un serveur NFS peut-il être utilisé dans une architecture de cluster de calcul ? Pourquoi ? C9 : Soit la configuration DNS suivante : acl ournets { 192.168.1.0.0/22; 172.16.1.0/24; }; acl mynets { 10.1.1.53; }; allow-transfer { ournets; mynets; } zone cooking.com { type master; file cooking.zone; allow-transfer { ournets; mynets; }; }; zone barbecue.cooking.com { type master; file barbecue.cooking.zone; allow-transfer { mynets; }; }; zone eating.com { slave; master { 10.1.1.10; }; file eating.zone.cache; allow-transfer { none; }; };
Page 10 sur 41
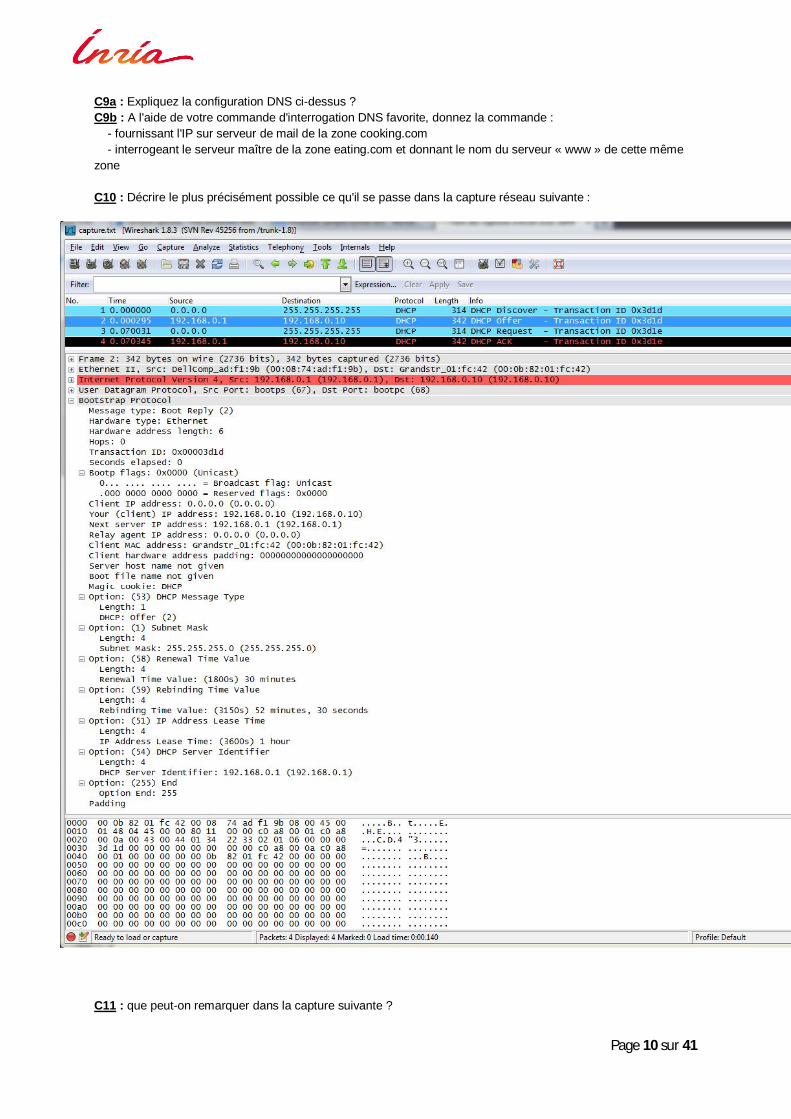
C9a : Expliquez la configuration DNS ci-dessus ? C9b : A l'aide de votre commande d'interrogation DNS favorite, donnez la commande : - fournissant l'IP sur serveur de mail de la zone cooking.com - interrogeant le serveur maître de la zone eating.com et donnant le nom du serveur « www » de cette même zone C10 : Décrire le plus précisément possible ce qu'il se passe dans la capture réseau suivante :
C11 : que peut-on remarquer dans la capture suivante ?

Page 11 sur 41

Page 12 sur 41
C12 : Citez des outils permettant la supervision d'un système ? Quels avantages amènent l'utilisation de cet outil ? Quels inconvénients ? C13 : Citez des outils permettant le contrôle d'intégrité d'un système ? Quels avantages amènent l'utilisation de cet outil ? Quels inconvénients ? C14 : Relier les réseaux avec leur explication : A 172.18.125.6/20 1 : 512 adresse par sous-réseau B 192.168.87.212/24 2 : Quatre bits empruntés pour créer les sous-réseaux C 172.27.64.98/23 3 : Le réseau n'est pas scindé en sous-réseaux D 172.31.16.128/19 4 : Six sous-réseaux utilisables C15 : Indiquez ce que fait la commande shell suivante : find /var/www -maxdepth 1 \ \( -name \*.html -o -name \*.php -o -name \*.php3 \) -print0 | \ xargs -0 grep -i "image.jpg" C16 : Expliquez le résultat de la commande suivante : lsof -i -n | grep telnet C17 : Dans le cadre d’une configuration Apache, que signifie cette ligne : AliasMatch ~([a-z]+)/cgi-bin/(.*.html) /htdocs/$1/public_html/$2 C18 : Quelle différence faites-vous entre un cluster de calcul et une grille de calcul ? C19 : Que signifie LVM, à quoi cela sert-il ?

Page 13 sur 41
Partie 3 : Etude de cas (8 points) ANNEXE A http://www.fhgfs.com/cms/ ANNEXE B http://www.fhgfs.com/wiki/wikka.php?wakka=Overview ANNEXE C http://www.fhgfs.com/wiki/wikka.php?wakka=SystemArchitecture ANNEXE D http://www.fhgfs.com/wiki/wikka.php?wakka=DownloadInstallationPackages ANNEXE E http://www.fhgfs.com/wiki/wikka.php?wakka=BuildingKernelModulesOpenTkLibrary ANNEXE F http://www.fhgfs.com/wiki/wikka.php?wakka=NativeInfinibandSupport ANNEXE G http://www.fhgfs.com/wiki/wikka.php?wakka=Striping ANNEXE H http://www.fhgfs.com/wiki/wikka.php?wakka=BasicConfigurationFirstStartup ANNEXE I http://www.fhgfs.com/wiki/wikka.php?wakka=ManualInstallWalkThrough ANNEXE J http://www.fhgfs.com/wiki/wikka.php?wakka=FAQ 1) Le logiciel FhGFS est-il libre et gratuit ? 2) Sous quelle forme le logiciel peut-il être téléchargé et installé et sur quels systèmes d'exploitation fonctionne-t-il ? Que faire si notre système d'exploitation n'est pas un de ceux listés ? 3) Expliquez l'organisation du système de fichiers distribués FhGFS (clients, serveurs et services), comparez-la avec les systèmes plus classiques et expliquez les avantages et inconvénients de FhGFS. 4) Quels réseaux le système FhGFS peut-il utiliser ? Quels sont leurs avantages et inconvénients ? Comment et quand le choisit-on ? Que se passe-t-il si un lien tombe en panne ? 5) Quand la compilation du module noyau client est-elle effectuée et par qui ? Quels peuvent être les paquets additionnels à installer pour qu'elle fonctionne correctement ? Quand ce module sera-t-il chargé en pratique et par qui ? Ces étapes et leur configuration sont-elles centralisées ou répliquées sur différentes machines, et qu'est-ce que cela implique ? 6) Comment les différents objets sont-ils répartis dans le système de stockage ? Quelles sont les options de configuration pour cette répartition ? Quand et combien de fois doit-on les appliquer ? 7) Quels sont les différents moyens de consulter la configuration statique et dynamique du serveur ? Où ces informations sont-elles stockées en pratique ? 8) On imagine disposer de 10 machines physiques destinées à desservir un parc de 300 serveurs de calcul. Comment utilisez-vous ces 10 serveurs pour mettre en place les serveurs FhGFS, un frontal d'accès SSH pour les utilisateurs, et un service de monitoring de l'état de la machine. ? - Expliquer comment vous pouvez optimiser l’utilisation de ces machines pour construire cette infrastructure. - Vous détaillerez aussi les types d’interconnexion entre les différentes machines de l’infrastructure complète. - Enfin vous proposerez un schéma synthétique de cette infrastructure.

Page 14 sur 41
ANNEXE A
FraunhoferFS (FhGFS) is the high-performance parallel file system from the Fraunhofer Competence Center for High Performance Computing. Its distributed metadata architecture has been designed to provide the scalability and flexibility that is required to run today's most demanding HPC applications. FhGFS is provided free of charge. Commercial support is available directly from Fraunhofer or from our international partners.

Page 15 sur 41
ANNEXE B
Overview FraunhoferFS (short: FhGFS) is the high-performance parallel file system from the Fraunhofer Competence Center for High Performance Computing. The distributed metadata architecture of FhGFS has been designed to provide the scalability and flexibility that is required to run today's most demanding HPC applications. FhGFS is provided free of charge. Commercial support is available directly from Fraunhofer or from our international partners. Key Benefits
Distributed File Contents and Metadata: One of the most fundamental concepts of FhGFS is the strict avoidance of architectural bottle necks. Striping file contents across multiple storage servers is only one part of this concept. Another important aspect is the distribution of file system metadata (e.g. directory information) across multiple metadata servers. Large systems and metadata intensive applications in general can greatly profit from the latter feature.
HPC Technologies: Built on scalable multithreaded core components with native Infiniband support, file system nodes can serve Infiniband and Ethernet (or any other TCP-enabled network) connections at the same time and automatically switch to a redundant connection path in case any of them fails.
Easy to use: FhGFS requires no kernel patches (the client is a patchless kernel module, the server components are userspace daemons), comes with graphical cluster installation tools and allows you to add more clients and servers to the running system whenever you want it.
Client and Servers on any Machine: No specific enterprise Linux distribution or other special environment is required to run FhGFS. FhGFS client and servers can even run on the same machine to enable performance increases for small clusters or networks. FhGFS requires no dedicated file system partition on the servers - It uses existing partitions, formatted with any of the standard Linux file systems, e.g. XFS or ext4. For larger networks, it is also possible to create several distinct FhGFS file system partitions with different configurations.
Increased Coherency (compared to simple remote file systems like NFS): FhGFS provides a coherent mode, in which it is guaranteed that changes to a file or directory by one client are always immediately visible to other clients.

Page 16 sur 41
ANNEXE C
System Architecture
FhGFS combines multiple storage servers to provide a shared network storage resource with striped file contents. This way, the system overcomes the tight performance limitations of single servers, single network interconnects, a limited number of hard drives etc. In such a system, high throughput demands of large numbers of clients can easily be satisfied, but even a single client can profit from the aggregated performance of all the storage nodes in the system. This is made possible by a separation of metadata and file contents. FhGFS clients have direct access to the storage servers and communicate with multiple servers simultaneously, giving your applications truly parallel access to the file data. To keep the metadata access latency (e.g. directory lookups) at a minimum, FhGFS allows you to also distribute the metadata across multiple servers. The following picture shows the system architecture of FhGFS. Note that although all roles in the picture are running on different nodes, it is also possible to run any combination of client and servers on the same machine.
Besides the three basic roles in FhGFS (clients, metadata servers, storage servers) there are two additional system services that are part of FhGFS: The first one is the management daemon, which serves as a central point of system configuration information for clients and servers. The second one is the optional administration and monitoring service (Admon), which provides a graphical frontend for installation and system status monitoring.

Page 17 sur 41
ANNEXE D
Download and Installation of Packages
Note: If you are installing FhGFS for the first time, you should take a look at the Section System Architecture from the User Guide to see what kinds of services you will need to install.
Table of Contents (Page) 1. Package Repositories 2. Package Descriptions 3. Proceed to next Step...
Package Repositories
To start an installation of FhGFS:
1. Download the FhGFS repository file for your Linux distribution from Table 1 to the specified directory.
2. Make the repository available on all nodes, either by storing it in your node boot image or by copying it to all nodes that you want to use with FhGFS.
3. Install the FhGFS services with your distribution's package manager (e.g. "yum install fhgfs-storage" on RedHat). An overview of available packages is provided in the next section.
If you want to download the packages directly instead of using repositories, you can find them here.
Note: FhGFS can be used in heterogeneous environments with different architectures and/or distributions.
Linux Base Distribution Version Package Manager Repository File
(Save to...)
Red Hat Linux (and derivatives, e.g. Fedora)
5.x yum Download (Save to: /etc/yum.repos.d/)
6.x yum Download (Save to: /etc/yum.repos.d/)
Suse Linux (and derivatives, e.g. OpenSuse)
10.x yum Download (Save to: /etc/yum.repos.d/)
11.x zypper Download (Save to: /etc/zypp/repos.d/)

Page 18 sur 41
Debian GNU Linux (and derivatives, e.g. Ubuntu)
5.x (lenny)
apt
Download (Save to: /etc/apt/sources.list.d/)
6.x (squeeze)
apt Download (Save to: /etc/apt/sources.list.d/)
Table 1: FhGFS Repository Files
Note: When using apt, please do not forget to run "apt-get update" after adding the repository.
Repository Signature Keys FhGFS repositories and packages are digitally signed. If you would like to verify the package signatures, you can add the public FhGFS GPG key to your package manager:
For RPM Packages: FhGFS RPM Key For Debian Packages: FhGFS DEB Key
To add the key on RedHat/SuSE, use the following command: rpm --import http://www.fhgfs.com/release/latest-stable/gpg/RPM-GPG-KEY-fhgfs
To add the key on Debian, use the following command:
wget -q http://www.fhgfs.com/release/latest-stable/gpg/DEB-GPG-KEY-fhgfs -O- | apt-key add -
Package Descriptions
Table 2 shows the roles that need to be defined to run FhGFS and the corresponding package for each role. FhGFS has been designed to allow running any combination of services (e.g., metadata and

Page 19 sur 41
ANNEXE D
storage server) on the same node. Additional information about the roles of FhGFS nodes can be found in the User Guide.
Roles Packages
Management Server (one node)
Manages configuration and group membership Hostname or IP address must be known by other nodes at service start time
fhgfs-mgmtd
Metadata Server (at least one node)
Stores directory information and allocates file space on storage servers fhgfs-meta
Storage Server (at least one node)
Stores raw file contents fhgfs-storage
Client
Kernel module to mount the file system Requires userspace helper daemon for logging and hostname resolution
fhgfs-client fhgfs-helperd
Admon - Administration and Monitoring Server (optional)
Continuous monitoring of servers Live statistics
fhgfs-admon
FhGFS utilities for administrators
fhgfs-ctl tool for command-line administration fhgfs-fsck tool for file system checking Several small helper scripts
fhgfs-utils
FhGFS OpenTK library
Depedency library of all FhGFS daemons
fhgfs-opentk-lib
FhGFS Common
Common files for all packages fhgfs-common
Table 2: FhGFS Roles and corresponding Packages

Page 20 sur 41
ANNEXE D
Note: The management server daemon and the optional Admon daemon have only moderate RAM and CPU requirements. As these services are not critical for file system performance, you do not need to run them on a dedicated machine. They are typically running on the cluster master node.
Each FhGFS service (including the client) comes with:
a config file: /etc/fhgfs/fhgfs-X an init script: /etc/init.d/fhgfs-X
After installation, all services will be set to automatic startup at system boot. If you do not want to run FhGFS services automatically during system boot, use chkconfig to disable automatic startup. (Note: chkconfig is also recommended for Debian to disable services, but is a separate package there and not installed by default.) Another way to disable FhGFS services startup would be to set START_SERVICENAME="NO" in the corresponding service config file (/etc/default/fhgfs-X). Note that this would have the side effect of completely disabling init script startup of the service, not only during system boot. Installation does not start any of the services directly, because there are a few configuration options that need to be set before the first startup. These will be described in the following sections.

Page 21 sur 41
ANNEXE E
Building Kernel Modules and OpenTk Library Most parts of FhGFS come pre-built and ready to use when you install the packages. However, the client kernel module of FhGFS still needs to be compiled for your specific Linux kernel version. In addition to that, it might be necessary to update the FhGFS open toolkit library (fhgfs-opentk-lib), which contains a part of the FhGFS communication layer.
Table of Contents (Page) 1. FhGFS Client Kernel Modules 2. FhGFS Open Toolkit Library 3. Proceed to next Step...
1 FhGFS Client Kernel Modules
FhGFS client kernel modules are automatically built on startup of the fhgfs-client service (/etc/init.d/fhgfs-client), so no manual build step is required. The init script will also detect client package updates and kernel updates and automatically runs a client module rebuild on next startup. However, Infiniband support is disabled by default. To enable IB support, you need to modify the buildArgs parameter in the build config file /etc/fhgfs/fhgfs-client-autobuild.conf. Default value (without Infiniband support):
buildArgs=-j8 With Infiniband support:
buildArgs=-j8 FHGFS_OPENTK_IBVERBS=1 OFED_INCLUDE_PATH=/usr/src/openib/include
Note: In the buildArgs example above, OFED include files are installed to /usr/src/openib. If you are using the default kernel IB modules (i.e. not the separate OFED modules), then the option OFED_INCLUDE_PATH does not need to be set at all.
To force a rebuild of the client kernel modules, you need to be root on a client node and then call:
[root@fhgfs01 ~]# /etc/init.d/fhgfs-client rebuild

Page 22 sur 41
ANNEXE E
After a successful module build, the fhgfs-client needs to be restarted:
[root@fhgfs01 ~]# /etc/init.d/fhgfs-client restart
2 FhGFS Open Toolkit Library
Note: This section is only relevant if you are using Infiniband hardware. If not, just skip to the next section.
The OpenTk library comes pre-built in two versions: with and without Infiniband suppport. During installation of the packages, the script fhgfs-opentk-lib-update-ib is called, which will automatically enable or disable OpenTk Infiniband support. If you need to enable or disable IB support later on, for example if IB was not properly configured during FhGFS package installation, you may simply call:
[root@fhgfs01 ~]# fhgfs-opentk-lib-update-ib If IB support could not be enabled, the script will tell you why it thinks IB will not work:
[root@fhgfs01 ~]# fhgfs-opentk-lib-update-ib /dev/infiniband/rdma_cm missing, is the rdma_ucm module loaded? Disabling FhGFS infiniband support. Setting symlink in /opt/fhgfs/lib: libfhgfs-opentk.so -> libfhgfs-opentk-disabledIB.so If IB support can be enabled, it will set the symlink to libfhgfs-opentk-enabledIB.so:
[root@fhgfs01 ~]# fhgfs-opentk-lib-update-ib Setting symlink in /opt/fhgfs/lib: libfhgfs-opentk.so -> libfhgfs-opentk-enabledIB.so If you want to force a rebuild of the library (usually not required), you may simply call:
[root@fhgfs01 ~]# fhgfs-opentk-lib-update-ib -r Further options are available if you provide -h as argument.

Page 23 sur 41
ANNEXE F
Native Infiniband Support FhGFS requires OFED API version 1.2 or higher for kernel and userspace Infiniband support.
Clients Native Infiniband support in FhGFS is based on the Open Fabrics Enterprise Distribution ibverbs API (http://www.openfabrics.org). To enable native Infiniband support, the FhGFS Client kernel modules have to be compiled with Infiniband support. Client Infinband support is enabled by setting corresponding the buildArgs option in the client autobuild file (/etc/fhgfs/fhgfs-client-autobuild.conf). This file also contains more details on the values that you need to set to enable Infiniband support.
Servers The FhGFS OpenTk communication library (libfhgfs-opentk.so) for userspace daemons comes pre-built with and without native Infiniband support. You can use the following command to enable the shared library version with native Infiniband support:
$ fhgfs-opentk-lib-update-ib
(Note that the command above is also automatically executed after the FhGFS opentk-lib package installation.)
Verifying Infiniband Connectivity At runtime, you can check whether your IB devices have been discovered by using the FhGFS online configuration tool. The tool mode “LISTNODES” will show a list of all running nodes and their configured network interfaces. The word “RDMA” will be appended to interfaces that are enabled for the native Infiniband protocol. Use the following command to list the storage servers and their available network interfaces:
$ fhgfs-ctl mode=listnodes nodetype=storage print_details $ fhgfs-ctl mode=listnodes nodetype=meta print_details
To check whether the clients are connecting to the servers via RDMA or whether they are falling back to TCP because of configuration problems, use the following command to list active client connections:
$ fhgfs-net
ANNEXE E ANNEXE E
(Note that the command above reads information from /proc/fs/fhgfs/<…>/X_nodes.)

Page 24 sur 41
ANNEXE F
In addition to the commands above, the log files also provide information on established connections and connection failures (if you are using at least logLevel=3). See /var/log/fhgfs-X.log on clients and servers.
General Infiniband Tuning Settings
Client / server side Infiniband RDMA parameters are o connRDMABufSize
The maximum size of a buffer (in bytes) that will be sent over the network. The client must allocate this buffer as physically continuous pages.
Too large values (>64KiB) might cause page allocation failures. o connRDMABufNum
The number of available buffers that can be in flight for a single connection. o Note:
RAM usage per connection is: connRDMABufSize x connRDMABufNum x 2
Keep resulting RAM usage on the server in mind when increasing these values: connRDMABufSize x connRDMABufNum x 2 x connMaxInternodeNum x number_of_clients
connMaxInternodeNum is a general network tuning parameter in the (client) config file
The maximum number of simultaneous connections to the same node.
QLogic/Intel Infiniband Tuning
Increase connRDMABufSize to 64KiB (default are 8KiB) Reduce connRDMABufNum to avoid server side out-of-memory situations The ib_qib module needs to be tuned at least on the server side
o In /etc/modprobe.conf or /etc/modprobe.d/ib_qib.conf options ib_qib singleport=1 krcvqs=4 rcvhdrcnt=4096
Note: The optimal value of krcvqs=<value> depends on the number of CPU cores
This value reserves the number of receive queues for ib-verbs
Please see QLogic OFED releases notes for more details.

Page 25 sur 41
ANNEXE G
Striping Settings
Striping in FhGFS can be configured on a per-directory and per-file basis. Each directory has a specific stripe pattern configuration, which will be derived to new subdirectories and applied to any file created inside a directory. There are currently two parameters that can be configured for the standard RAID-0 stripe pattern: the desired number of storage targets for each file and the chunk size (or block size) for each file stripe. The stripe pattern parameters of FhGFS can be configured with the Admon GUI or the command-line control tool. The command-line tool allows you to view or change the stripe pattern details of each file or directory in the file system at runtime. The following command will show you the current stripe settings of your FhGFS mount root directory (in this case "/mnt/fhgfs"): $ fhgfs-ctl mode=getentryinfo /mnt/fhgfs Use mode=setpattern to apply new striping settings to a directory (in this case "stripe files across 4 storage targets with a chunksize of 1MB"): $ fhgfs-ctl mode=setpattern numtargets=4 chunksize=1m /mnt/fhgfs This is a per-directory setting, so it needs to be applied to already existing subdirectories separately. New subdirectories will derive the settings from their parent directory. Stripe settings will also only be applied to new files, not to existing files in a directory.

Page 26 sur 41
ANNEXE H
Basic Configuration
There are three configuration settings that are mandatory to be set for your specific environment. The following table shows the three settings and the config files, in which you need to apply them:
Setting Configuration File (in /etc/fhgfs)
Storage Paths fhgfs-mgmtd.conf, fhgfs-meta.conf, fhgfs-storage.conf
Management Host
fhgfs-meta.conf, fhgfs-storage.conf, fhgfs-client.conf, fhgfs-admon.conf
Client Mount Directory fhgfs-mounts.conf
Table: Basic settings and corresponding configuration files The info box below contains descriptions of the three options that need to be set before you can run the services:
Storage Paths: Set the value of the “store…Directory” option to configure where the file system should store its internal data. FhGFS stores all data in a subdirectory of an existing partition that has been formatted with any of the standard local Linux file systems (typically XFS for storage servers and ext4 for metadata servers).
Management Host: Set the value of the “sysMgmtdHost” option in the configuration files of the metadata servers, storage servers, clients, and the optional Admon to the IP address or hostname of the management daemon. This will enable automatic server discovery for the clients.
Client Mount Directory: The client mount file consists of two space-separated values. The first value is the directory where you want to mount the file system, the second value is the client configuration file for this mount point. You will typically have a line like this in the fhgfs-mounts.conf file:
/mnt/fhgfs /etc/fhgfs/fhgfs-client.conf
It is also possible to specify multiple mount/config entries in this file (one mount/config pair per line) if you want to mount multiple FhGFS file systems on your client.

Page 27 sur 41
ANNEXE H
Basic settings description When you have made the changes to the configuration files, it is time to start the FhGFS services.
Start FhGFS Services
You can to start all FhGFS services in arbitrary order by using the corresponding init scripts (/etc/init.d/fhgfs-...). The services will register themselves at the magement server, so clients will automatically know about all available servers.
Note: FhGFS clients have a mount sanity check and cancel a mount operation if servers are unreachable. If you want to mount even with unreachable servers, set sysMountSanityCheckMS=0 in the file fhgfs-client.conf.
Server Tuning
Please make sure to read the chapters about Server Tuning to configure your system for optimal performance.

Page 28 sur 41
ANNEXE I
Installation Commands Walk-Through
This section provides example commands for the manual installation procedure. It is assumed that you did read the previous sections of the chapter Manual Installation to have a basic understanding of the relevant FhGFS services and installation steps.
Table of Contents (Page) Example Setup Step 1: Package Download and Installation Step 2: Client Kernel Module Autobuild Parameters (Infiniband) Step 3: Basic Configuration and Service Startup Step 4: Verify Infiniband RDMA is working Proceed to next Step...
Example Setup
In this example, we use the following hardware and software configuration:
Software: RHEL 6.x or similar on all nodes o Infiniband: OFED 1.2.5 or higher installed to default locations on all nodes
(including kernel-ib and kernel-ib-devel packages from custom OFED setup) Host Services: (*)
o node01: Management Server o node02: Metadata Server o node03: Storage Server o node04: Admon Server o node05: Client
Storage: o Storage servers with RAID-6 data partition formatted with xfs or ext4, mounted to
"/data". o Metadata servers with RAID-1 data partition formatted with ext4, mounted to
"/data".

Page 29 sur 41
ANNEXE I
Note on dedicated nodes: In this example, we are using dedicated hosts for all FhGFS services. This is just to show the different installation steps for each service. FhGFS allows running any combination of services (including client and storage/metadata service) on the same machine. (Especially the management and admon daemons don't require dedicated nodes.)
Step 1: Package Download and Installation
First, the FhGFS package repository file for your distribution needs to be downloaded. Repository files for all distributions are available here. For our RHEL 6 example, we download this repository file and store it in the directory "/etc/yum.repos.d/" on all nodes:
$ ssh root@node0X $ cd /etc/yum.repos.d $ wget http://www.fhgfs.com/release/latest-stable/dists/fhgfs-rhel6.repo Now we can install the packages from the repository. For RHEL 6, the package manager is yum. node01 will become the management server:
$ ssh root@node01 $ yum install fhgfs-mgmtd node02 will become a metadata server:
$ ssh root@node02 $ yum install fhgfs-meta node03 will become a storage server:
$ ssh root@node03 $ yum install fhgfs-storage node04 will become a admon server:
$ ssh root@node04 $ yum install fhgfs-admon

Page 30 sur 41
ANNEXE I
node05 will become a client:
$ ssh root@node05 $ yum install fhgfs-client fhgfs-helperd fhgfs-utils Now that all services are installed, the next step is to configure the client module with Infiniband support. However, this step is only required if you do want to use FhGFS over Infiniband RDMA (ibverbs). If you do not have Infiniband hardware, continue with step 3.
Step 2: Client Kernel Module Autobuild Parameters (Infiniband)
Note: This step is only relevant if you have Infiniband hardware. If you don't have Infiniband, skip this step.
To enable native Infiniband support, the corresponding FhGFS client kernel module build parameters need to be specified. Please feel free to use your favorite text file editor, we will use vim below.
$ ssh node05 $ vim /etc/fhgfs/fhgfs-client-autobuild.conf Find the option "buildArgs" and set it to: buildArgs=-j8 FHGFS_OPENTK_IBVERBS=1 OFED_INCLUDE_PATH=/usr/src/openib/include
Note: Setting OFED_INCLUDE_PATH here is only required if you installed separate Infiniband kernel modules, which we did in our example by installing the OFED kernel-ib package. If you are not sure, check the returned path information of this command: $ modinfo ib_core Separate modules are usually located in the /lib/modules/<kernel_version>/updates/ directory.
Afterwards, force a rebuild of the client kernel module:
$ /etc/init.d/fhgfs-client rebuild

Page 31 sur 41
ANNEXE I
Step 3: Basic Configuration and Service Startup
Basic Configuration Before we can run the services, we need to modify a few options in the configuration files. Please use your favorite text file editor, we will use vim here. The management server needs to know where it can store its data. It will only store some node information like connectivity data, so it will not require much storage space and data access is not performance critical.
$ ssh root@node01 $ vim /etc/fhgfs/fhgfs-mgmtd.conf Find the option "storeMgmtdDirectory" and set it to "storeMgmtdDirectory=/data/fhgfs/fhgfs_mgmtd". The metadata server needs to know where it can store its data and how to reach the management server.
$ ssh root@node02 $ vim /etc/fhgfs/fhgfs-meta.conf 1) Find the option "storeMetaDirectory" and set it to "storeMetaDirectory=/data/fhgfs/fhgfs_meta". 2) Find the option "sysMgmtdHost" and set it to "sysMgmtdHost=node01".
Note on extended attributes: By default, the usage of extended attributes (EAs) is enabled on the metadata server for performance reasons. Those EAs have to be supported by your file system. Please see the chapter Metadata Server Tuning on how to enable EAs for ext3/ext4 file systems.
The storage server needs to know where it can store its data and how to reach the management server.
$ ssh root@node03 $ vim /etc/fhgfs/fhgfs-storage.conf 1) Find the option "storeStorageDirectory" and set it to "storeStorageDirectory=/data/fhgfs/fhgfs_storage". 2) Find the option "sysMgmtdHost" and set it to "sysMgmtdHost=node01".

Page 32 sur 41
ANNEXE I
Note on multiple storage directories: A storage server can also manage multiple storage target directories. These can just be specified as a comma-separated list, e.g.: storeStorageDirectory=/mnt/raid1,/mnt/raid2,/mnt/raid3
The admon server needs to know how to reach the management server.
$ ssh root@node04 $ vim /etc/fhgfs/fhgfs-admon.conf Find the option "sysMgmtdHost" and set it to "sysMgmtdHost=node01". The client needs to know how to reach the management server and where you want to mount the file system.
$ ssh root@node05 $ vim /etc/fhgfs/fhgfs-client.conf Find the option "sysMgmtdHost" and set it to "sysMgmtdHost=node01". The client mount directory is defined in a separate configuration file. This file will be used by the /etc/init.d/fhgfs-client script. By default, FhGFS will be mounted to /mnt/fhgfs. You need to perform this step only if you want to mount the file system to a different location.
$ ssh root@node05 $ vim /etc/fhgfs/fhgfs-mounts.conf Change the mount directory to your preferred location. You will typically have a line like this in the fhgfs-mounts.conf file above:
/mnt/fhgfs /etc/fhgfs/fhgfs-client.conf (First entry names the mount directory and the second entry refers to the corresponding config file for this mount.)
Service Startup FhGFS services can be started in arbitrary order by using the corresponding init scripts (/etc/init.d/fhgfs-...). All services create log files (/var/log/fhgfs-...).
$ ssh root@node01 /etc/init.d/fhgfs-mgmtd start $ ssh root@node02 /etc/init.d/fhgfs-meta start $ ssh root@node03 /etc/init.d/fhgfs-storage start $ ssh root@node04 /etc/init.d/fhgfs-admon start

Page 33 sur 41
ANNEXE I
$ ssh root@node05 /etc/init.d/fhgfs-helperd start $ ssh root@node05 /etc/init.d/fhgfs-client start
Note on mount cancelling: FhGFS clients have a mount sanity check and cancel a mount operation if servers are unreachable. If you want to mount even with unreachable servers, set sysMountSanityCheckMS=0 in the file fhgfs-client.conf.
Note on SELinux: Some distributions (e.g. RHEL 6) enable SELinux by default. If you are seeing an "Access denied" error when you access the FhGFS mount, read this.
Now that you have your file system up and running, take the time to read some additional notes.
Step 4: Verify Infiniband RDMA is working
Note: This step is only relevant if you have Infiniband hardware. If you don't have Infiniband, skip this step.
First, install the fhgfs-utils package on the client. Afterwards check the connectivity status with the following commands:
$ ssh node05 $ yum install fhgfs-utils $ fhgfs-ctl --listnodes --nodetype=meta --details $ fhgfs-ctl --listnodes --nodetype=storage --details $ fhgfs-net Please check your log files (/var/log/fhgfs-X.log), if you do not see RDMA-enabled interfaces.

Page 34 sur 41
ANNEXE J
Frequently Asked Questions (FAQ)
General Questions
1. Who should use FhGFS? 2. Is FhGFS suitable for production use? 3. What are the minimum system requirements to run FhGFS? 4. Which network types are supported by FhGFS? 5. Can I test-drive FhGFS for free? 6. Do I need a SAN or any kind of shared storage to run FhGFS? 7. Does FhGFS provide high-availability? 8. Can I do everything that can be done with the Admon GUI from the
command-line? 9. Is FhGFS open-source? 10. What does the abbreviation FhGFS mean? 11. How does FhGFS distribute metadata? 12. How to backup metadata?
Installation & Startup
1. Where can I find information about why an Admon-based installation of FhGFS fails?
2. We are not using one of the distributions you are providing packages for, which means we cannot install RPM or DEB packages. What can we do to try FhGFS?
3. Do I need to be ''root'' to run FhGFS? 4. Is it possible to run storage servers and clients on the same machine? 5. Is it possible to run multiple instances of the same daemon on the same
machine? 6. Do I need a special Linux kernel for FhGFS? 7. Does FhGFS need time synchronization between different machines? 8. How to upgrade FhGFS version 2009.08 to 2011.04 or version 2011.04 to
2012.10? 9. Why do I get an 'Access denied' error on the client even with correct
permissions?

Page 35 sur 41
ANNEXE J
Configuration & Tuning
1. How can I remove a node from an existing file system? 2. Is it possible to free up a storage target before removal? 3. I did some testing and want to start over again. Is there an easy way to
delete all residues from the old file system? 4. My hosts have more than one network interface. Is there a way of
configuring FhGFS to use only certain interfaces or certain networks? 5. What needs to be done when a server hostname has changed?
[General Questions]
Who should use FhGFS?
Everyone with an interest in fast, flexible, and easy to manage storage. This is typically the case for HPC clusters, but FhGFS was designed to also work well on smaller deployments like a group of workstations or even heterogeneous systems with different hardware architectures.
Is FhGFS suitable for production use?
Yes, absolutely! FhGFS is not a proof-of-concept or research implementation. FhGFS was designed for production use since the beginning of its development and is fully supported by Fraunhofer and our international partners.
What are the minimum system requirements to run FhGFS?
Currently, native FhGFS client and server components are available for Linux on x86, x86_64 and PowerPC/Cell architectures. In general, all FhGFS components can run on a single machine with only
a single CPU core, a single hard disk and less than 1GB of RAM. But this is probably not what you want to do in practice, so here are some recommendations for your hardware configuration:
Storage Server: o A storage server should have at least 4GB of RAM to have enough memory available
for caching and client connection buffers. 1GB of RAM per attached disk is generally

Page 36 sur 41
a good choice, depending on the actual type of disk and number of file system clients.
o If you are using traditional SATA hard drives (i.e. not SSDs or fast SAS drives), you will typically want to use a RAID with at least 8 drives per server.
o Even though storage server tasks are generally not very CPU-intensive, the Linux buffer caches can produce high CPU load with fast RAID arrays, so it is often good to have a fast CPU here to enable high throughput, especially on high speed networks.
o Keep an eye on the balance between number of disks (in the whole system and per server), network interconnect bandwidth, and number of file system clients. (E.g. depending on your use case, it might not make sense to use more than 12 hard drives per server if the servers are equipped with only a 10Gb interconnect.)
Metadata Server: o If you are working primarily with large files then there is not much work to do for the
metadata server and you might just want to run it on the same machines that are running as storage servers and on the same hard disk partitions.
o On clusters with very different kinds of workloads, you might still want to run the metadata server daemon on the storage server machines (to have a high number of metadata servers without spending the extra money for dedicated machines), but you will probably want to use dedicated disks inside your storage servers for metadata. Since metadata servers are doing a lot of small disk random access (i.e. they are reading and writing a lot of small files) there might be a significant performance impact for storage and metadata access if both are located on the same disks. We also often see in pratice that RAID controllers have (performance) problems when managing different RAID volume types for metadata and storage servers, so you typically also want to have metadata on a separate RAID controller. You might also want to use a dedicated network interface for metadata, since streaming network transfers can have a significant impact on metadata access latency at the network level.
o CPU-usage on metadata servers can be high if you have a high number of clients dealing with many (small) files. So make sure to use a fast CPU and fast drives to guarantee low access latency to metadata.
o The amount of space needed for metadata in comparison to the total storage capacity depends on the actual use case (i.e. the average user file size). For a scratch file system, the reserved space for metadata is typically between 0.5% and 1% of the total storage capacity.
Client: o The patchless client kernel module requires Linux kernel 2.6.16 or higher. No specific
Linux distribution is required for the client and you are free to use even a recent vanilla kernel. Since the client components of FhGFS are designed to be very light-weight, there are no special RAM or CPU requirements.
Management Daemon:

Page 37 sur 41
o The management daemon uses only minimal CPU cycles and memory. Access to the management daemon is not relevant for file system performance. Just run this daemon on any of the storage/metadata servers or on your cluster master.
Admon Daemon: o The admon daemon is frequently storing and querying a lot of values from its
internal database, so it will run some storage transactions and use a moderate amount of RAM and CPU cycles. It is often fine to run it on any of the other storage/metadata server machines, but your cluster master might be a better place for this daemon to make sure that there is no impact on file system performance.
Which network types are supported by FhGFS?
FhGFS supports all TCP/IP based networks and the native Infiniband protocol (based on OFED ibverbs). Servers and clients can handle requests from different networks at the same time (e.g. your servers can be equipped with Infiniband and Ethernet interconnects and some clients connect via native Infiniband while the rest connects via TCP/Ethernet). Clients with multiple connection paths (like Infiniband and Ethernet or multiple Ethernet ports) can also do network failover if the primary connection path fails.
Can I test-drive FhGFS for free?
Yes, FhGFS can be downloaded and used free of charge without any limitations.
Do I need a SAN or any kind of shared storage to run FhGFS?
No, FhGFS is not a storage area network (SAN) file system and it does not rely on shared access to storage. Typical hardware configurations for FhGFS consist of multiple servers with internal (or external non-shared) RAID storage.
Does FhGFS provide high-availability?
Work on high availability support for FhGFS to keep your data accessible in the event of a node failure is already in progress. This feature will not require shared storage. Currently, clients will ignore the fact that a server is down until they need data that is located on the missing host. In this case, they can either wait for the server to come back online or let the IO operation fail after a

Page 38 sur 41
configurable period of time. However, you are free to realize failover based on external tools like Heartbeat and DRBD or external shared storage. If you want to setup failover based on external tools, you will need to run a new instance of the failed daemon on another machine. To make the failover daemon appear like the original daemon, you will need to make sure it uses the same NodeID. (See section "Configuration & Tuning" on this page for information on how to define a NodeID.) Starting with the 2012.10 release series, FhGFS provides optional metadata and file contents mirroring. See here for more information.
Is FhGFS open-source?
We see an increasing demand from the user community for this. Currently, the client source code is already available under the GPL. The source code of the FhGFS server components is not yet publicly available (though we can make special agreements for customers with a support contract). Anyways, you can download and use FhGFS free of charge.
How does FhGFS distribute metadata?
FhGFS distributes metadata on a per-directory basis. This means each directory in your filesystem can be managed by a different metadata server. When a new directory is created, the system automatically picks one of the available metadata servers to be responsible for the files inside this directory. New subdirectories of this directory can be assigned to other metadata servers, so that load is balanced across all available metadata servers.
[Installation and Startup]
Where can I find information about why an Admon-based installation of FhGFS fails?
If you tried to install FhGFS by using the Administration and Monitoring GUI, there are two log facilities that can provide useful information:
The installation log file on the server: You can read it by choosing "Installation and Management" -> "Management Log File" in the GUI
The log file of the Java GUI: This log file is stored in the directory ".fhgfs inside your home directory (fhgfs-admon-gui.log).

Page 39 sur 41
We are not using one of the distributions you are providing packages for, which means we cannot install RPM or DEB packages. What can we do to try FhGFS?
You can try to download the RPM packages for Suse or Red Hat and unpack them with rpm2cpio and cpio (rpm2cpio packname | cpio -i). Afterwards, you might need to change the init scripts to work with your distribution. We cannot guarantee that FhGFS will work with your distribution, but it is worth a try.
Do I need to be ''root'' to run FhGFS?
Yes and no. You do not need root access to start the servers, as these are all userspace processes (of course, you need to change the configuration files to store the file system data and log files at places, where you have write access). The client is a kernel module. To load the module and mount the file system, you normally need to have root privileges. As an alternative, it is also possible to grant permissions to execute the corresponding commands for non-root users via /etc/sudoers.
Is it possible to run storage servers and clients on the same machine?
Yes, it is. You do not need dedicated hosts for any service in FhGFS. For example, it is possible to have one host running a management daemon, a metadata server, a storage server and a client at the same time.
Is it possible to run multiple instances of the same daemon on the same machine?
Yes, it is. To do this, you will need to create a separate configuration file for the other daemon instance, using different network ports, a different storage directory and so on. You might also need to set a different NodeID manually for the other instance, depending on whether it should register at the same management daemon as the first instance. (See "Configuration & Tuning" section on this page for information on how to set the NodeID.) You will also need to modify the startup mechanism of the daemon, as the standard init scripts (/etc/init.d/fhgfs-X) are not prepared to run multiple instances of the same daemon on a machine.
Do I need a special Linux kernel for FhGFS?

Page 40 sur 41
FhGFS client modules require at least kernel version 2.6.16, but apart from that, FhGFS does not need a special kernel: The client kernel modules were designed patchless (so you don't need to apply any kernel patches to run FhGFS) and the server components of FhGFS run as userspace daemons.
Does FhGFS need time synchronization between different machines?
Yes, the time of all FhGFS client and server machines needs to be synchronized for various reasons, e.g. to provide consistent file modification timestamps. Before setting the time manually on a server (e.g. with date or ntpdate), stop all FhGFS services on all machines to prevent inconsistencies.
Why do I get an 'Access denied' error on the client even with correct permissions?
Please check if you have SELinux enabled on the client machine. If it is enabled, disabling it should solve your problem. SELinux can be disabled by setting SELINUX=disabled in the config file /etc/selinux/config. Afterwards, you might need to reboot your client for the new setting to become effective.
[Configuration and Tuning]
How can I remove a node from an existing file system?
Use the FhGFS Control Tool fhgfs-ctl (contained in the fhgfs-utils package) if you need to unregister a server from the file system:
$ fhgfs-ctl --removenode --nodetype=meta <nodeID> (for a metadata node) $ fhgfs-ctl --removenode --nodetype=storage <nodeID> (for a storage node)
Note: If you want to move files from a storage server to the other storage servers before removing, see here: "Is it possible to free up a storage target before removal?"
Is it possible to free up a storage target before removal?
The fhgfs-ctl tool has a mode called "migrate", which allows you to move all files from a certain storage target to other storage targets.
$ fhgfs-ctl --migrate --help

Page 41 sur 41
Note: Migration is directory-based and currently single-threaded, so a single migration instance may perform well below the capabilities of the hardware. It is possible to start multiple non-interfering instances of "fhgfs-ctl --migrate" on the same client (or different clients) for different directory trees, e.g. one instance for /mnt/fhgfs/subdir1 and another instance for /mnt/fhgfs/subdir2.
I did some testing and want to start over again. Is there an easy way to delete all residues from the old file system?
To revert your installation to a completely clean file system, you can follow these steps:
1. Stop all clients and servers (via the Admon GUI or via /etc/init.d/fhgfs-X stop) 2. Delete the data directories of the metadata servers, storage servers and the management
daemon (these are the directories named "store...Directory" in the corresponding /etc/fhgfs/fhgfs-X.conf config files)
3. Start all servers and clients again
My hosts have more than one network interface. Is there a way of configuring FhGFS to use only certain interfaces or certain networks?
Yes, there are two different settings that can be used to achieve this:
In the config file of each service, there is an option called connNetFilterFile. It can be used to activate IP address range based filtering. This setting will allow outgoing connection attempts of a FhGFS service only to the set of specified IP addresses, which is useful if a client (or other service) should not try to connect to certain exported interface IPs of another node, e.g. because some of the interface IPs might not be reachable from the current network or are meant for internal use only.
In the config file of each service, there is an option called connInterfacesFile. By specifying a file with a list of interfaces (one per line) here, you can control which interfaces a FhGFS service registers at the management daemon and in which order they should be tried during connection attempts by other nodes. For instance, if your node has eth0 and eth1, but you only add eth1 to the interfaces file, then the other servers/clients won't know that there is another interface for that server and hence will not try to connect to other interface.
What needs to be done when a server hostname has changed?
Scenario: 'hostname' or '$HOSTNAME' report a different name than during the FhGFS installation and FhGFS servers refuse to start up. Logs tell the nodeID has changed and therefore a startup was refused. Note that by default, node IDs are generated based on the hostname of a server. As IDs are not allowed to change, see here for information on how to manually set your ID back to the previous value: "Is it possible to force a certain node ID or target ID for FhGFS servers?"





























