Embed Size (px)
Citation preview

© Talend 2014 1
Big Data, un nouveau paradigme et de nouveaux challengesSebastiao Correia – 21 Novembre 2014
Séminaire Thématique : Traitement et analyse statistique des données massives, Poitiers.
© Talend 2014 2
Présentation
● Sebastiao Correia
● Talend 2007
● Directeur du développement du produit Data Quality
● Background : thèse en Physique Théorique
● Parcours
● Recherche opérationnelle : Optimisation, planification
● MDM & Business Intelligence
● Qualité des données
© Talend 2014 3
Objectifs du jour
Mettre en évidence quelques changements de paradigmes
Souligner l'importance de la qualité de données
© Talend 2014 4
Agenda
● Présentation de Talend
● Définition du Big Data
● Le framework Hadoop
● L'architecture lambda
● La qualité de données et le Big data
● Applications avec Talend
● Qualité de données
● Apprentissage automatique
© Talend 2014 5
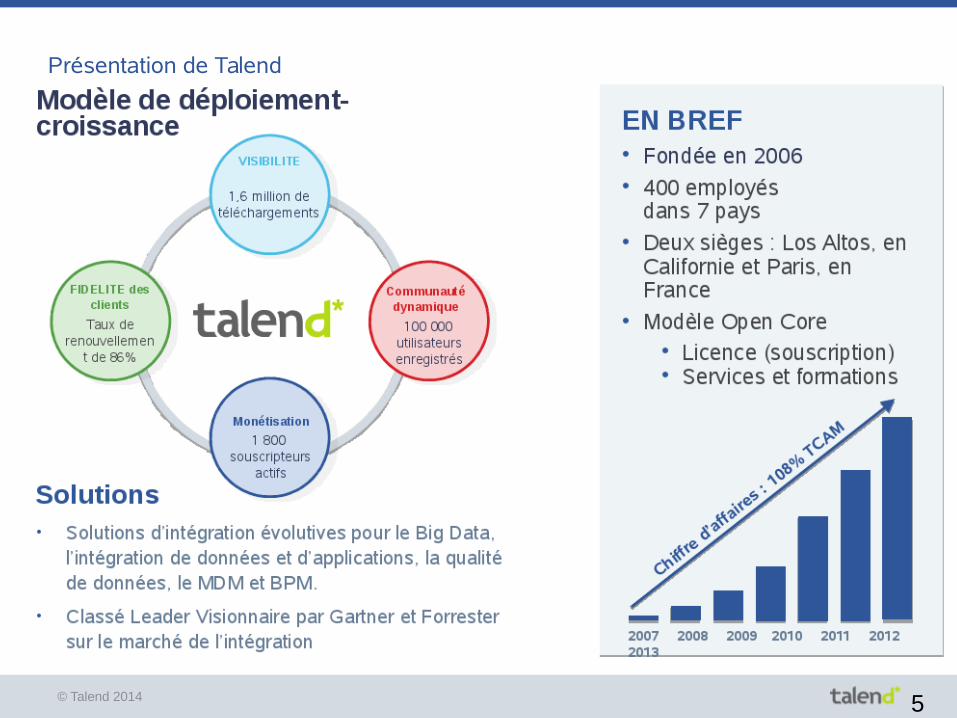
Présentation de Talend
© Talend 2014 6
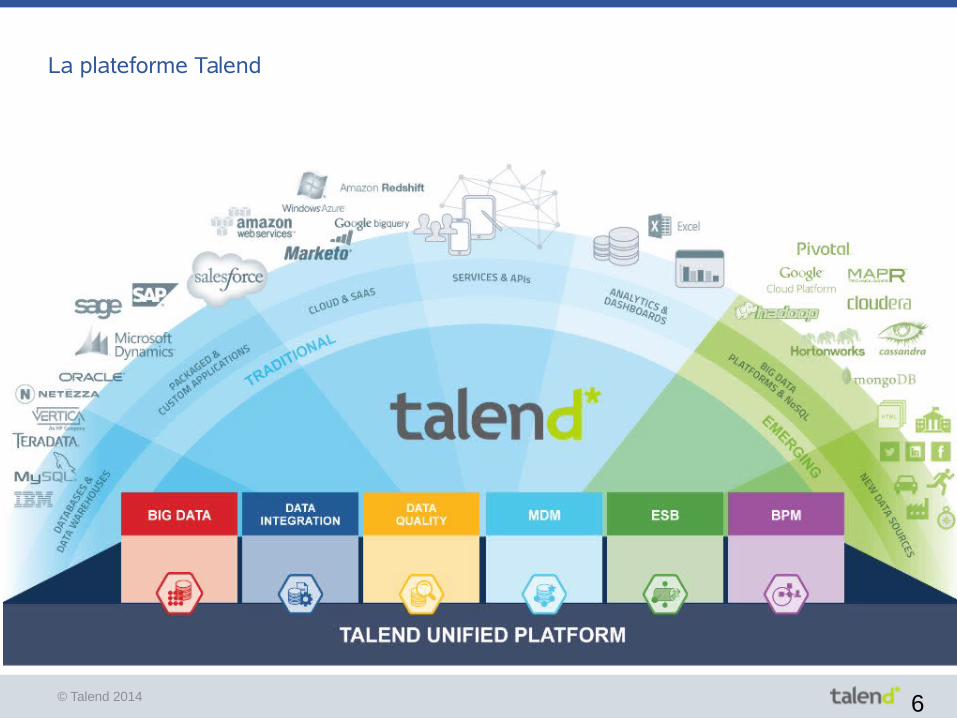
La plateforme Talend
© Talend 2014 7
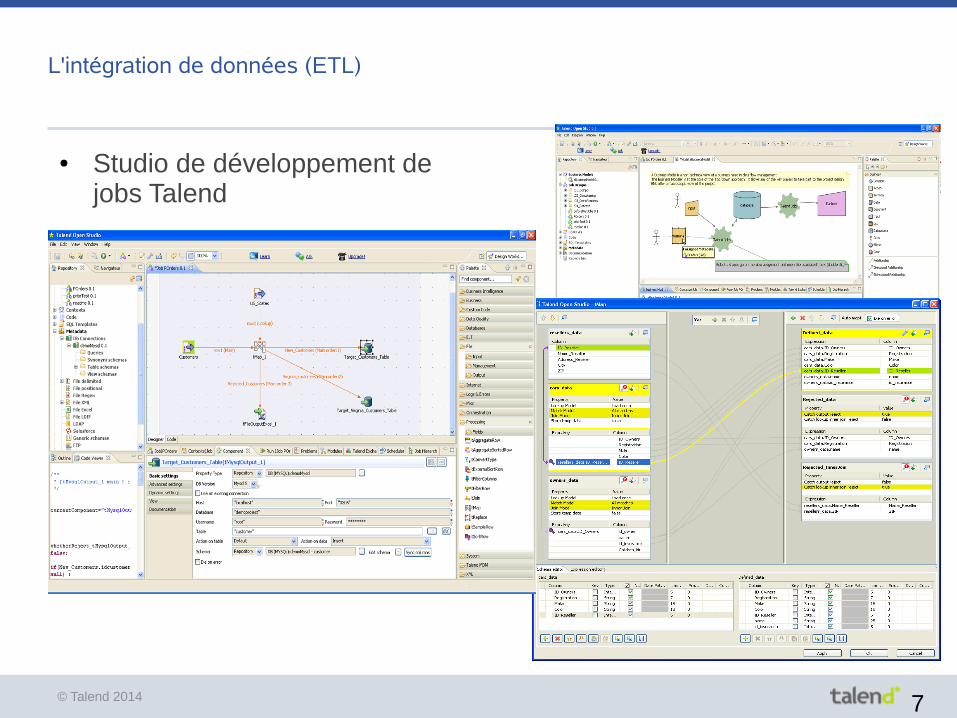
L'intégration de données (ETL)
● Studio de développement de jobs Talend
© Talend 2014 8
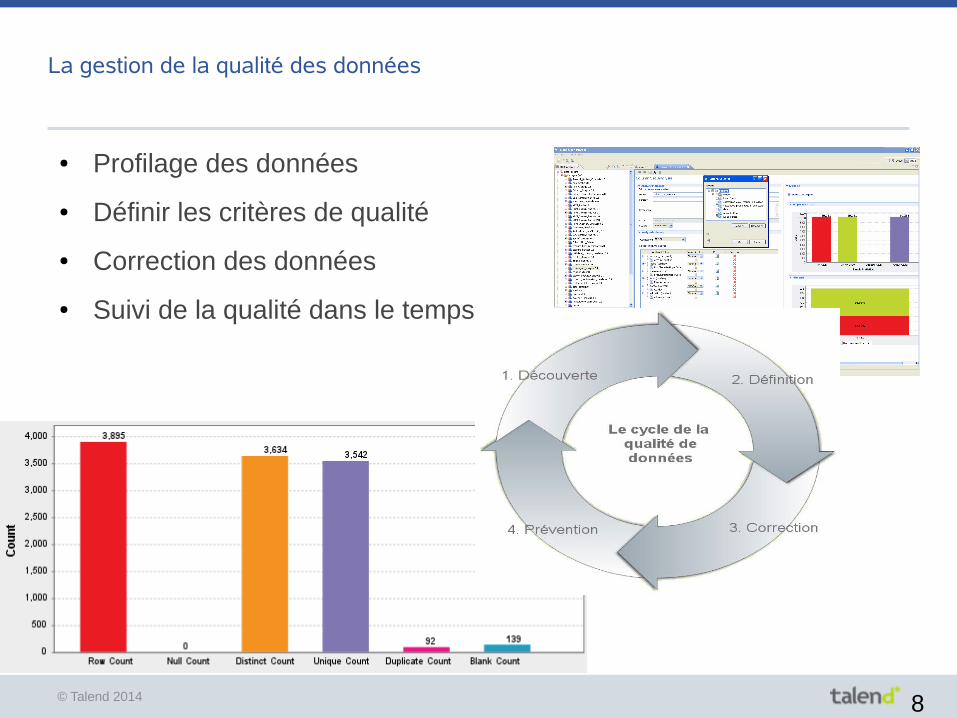
La gestion de la qualité des données
● Profilage des données
● Définir les critères de qualité
● Correction des données
● Suivi de la qualité dans le temps
© Talend 2014 9
Agenda
● Présentation de Talend
● Définition du Big Data
● Le framework Hadoop
● L'architecture lambda
● La qualité de données et le Big data
● Applications avec Talend
● Qualité de données
● Apprentissage automatique
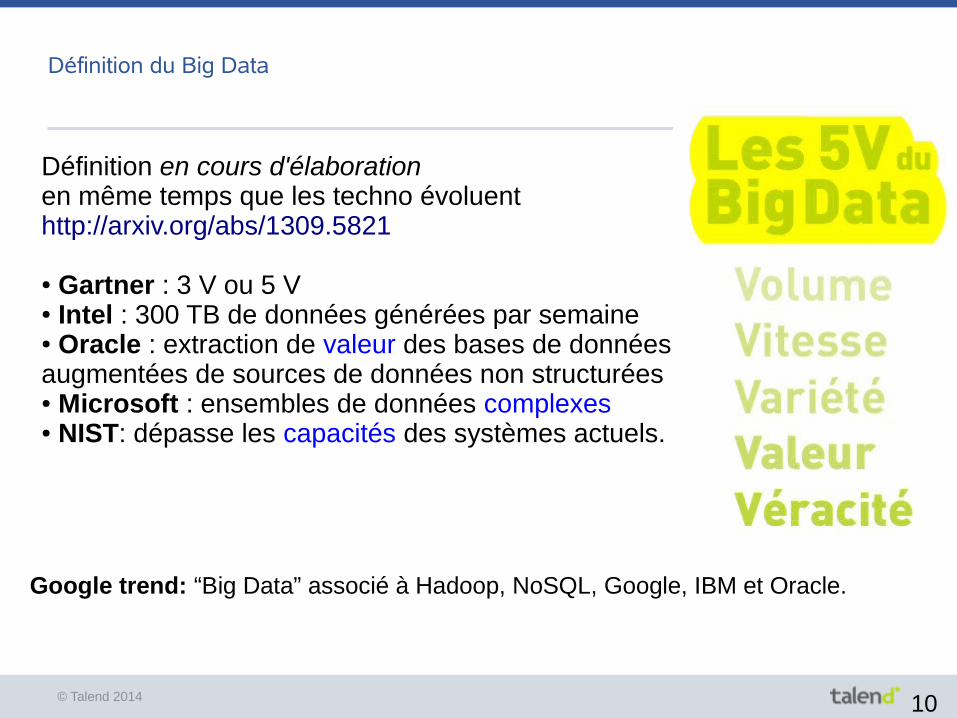
© Talend 2014 10
Définition du Big Data
Définition en cours d'élaborationen même temps que les techno évoluenthttp://arxiv.org/abs/1309.5821
● Gartner : 3 V ou 5 V● Intel : 300 TB de données générées par semaine● Oracle : extraction de valeur des bases de données augmentées de sources de données non structurées● Microsoft : ensembles de données complexes● NIST: dépasse les capacités des systèmes actuels.
Google trend: “Big Data” associé à Hadoop, NoSQL, Google, IBM et Oracle.

© Talend 2014 11
Croissance exponentielle des données
En 2012, 90% des données ont été générées durant les 2 années précédentes.Chaque jour de 2012, 2.5 Exaoctets de données sont créés.http://www.martinhilbert.net/WorldInfoCapacity.html

© Talend 2014 12
Quelques chiffres sur le déluge de données
● Par jour
● 144.8 milliards d'Email.
● 340 millions tweets.
● 684 000 bits de contenu partagé sur Facebook.
● Par minute
● 72 heures (259,200 secondes) de video sont partagées sur YouTube.
● 2 millions de recherches sur Google.
● 34 000 “likes” des marques sur Facebook.
● 27 000 nouveaux posts sur Tumblr.
● 3 600 nouvelles photos sur Instagram.
● 571 nouveaux sites web
● 2.5 Petaoctects dans les bases de données Wal-Mart
● 40 To de données générées chaque secondes au LHC
● 25 Po de données stockées et analysées au LHC chaque année.
● 10 To produits par les capteurs des avions lors d'un vol pendant 30 minutes
● 1.25 To ce que peut contenir le cerveau humain
Plus encore sur http://marciaconner.com/blog/data-on-big-data/
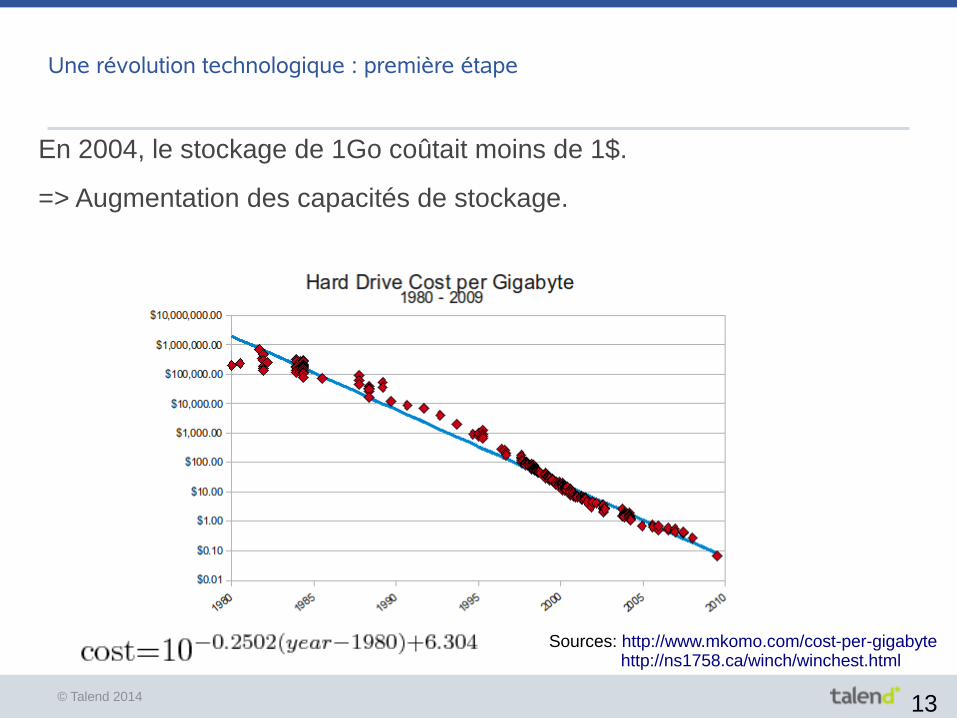
© Talend 2014 13
Une révolution technologique : première étape
En 2004, le stockage de 1Go coûtait moins de 1$.
=> Augmentation des capacités de stockage.
Sources: http://www.mkomo.com/cost-per-gigabyte http://ns1758.ca/winch/winchest.html

© Talend 2014 14
Une révolution technologique : deuxième étape
Développement du Cloud. ● Salesforce 1999● Amazon Web Services 2002● Amazon Elastic Compute Cloud (EC2) 2006● Google Apps 2009
De nouvelles technologies sont apparues dès les années 2000pour gérer la volumétrie et la variétédes données : ● Hadoop HDFS● Map Reduce
© Talend 2014 15
Agenda
● Présentation de Talend
● Définition du Big Data
● Le framework Hadoop
● L'architecture lambda
● La qualité de données et le Big data
● Applications avec Talend
● Qualité de données
● Apprentissage automatique
© Talend 2014 16
La naissance d'Hadoop
● Quelques dates
● 2003 : “The Google File System”, Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung http://research.google.com/archive/gfs.html
● 2004 : “MapReduce: Simplified Data Processing on Large Clusters”, Jeffrey Dean et Sanjay Ghemawat http://research.google.com/archive/mapreduce.html
● 2005 : Naissance d'Hadoop chez Yahoo (HDFS et MapReduce), Doug Cutting et Mike Cafarella http://research.yahoo.com/files/cutting.pdf
● 2006 : “Bigtable: A Distributed Storage System for Structured Data”, Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach, Mike Burrows, Tushar Chandra, Andrew Fikes, and Robert E. Gruber http://research.google.com/archive/bigtable.html
© Talend 2014 17
Le framework Hadoop
● Hadoop
● projet opensource (Fondation Apache) dédié au calcul distribué, fiable et scalable http://hadoop.apache.org/
– Hypothèse de départ : les machines ne sont pas fiables
– Hadoop la haute disponibilité au niveau applicatif (redondance des données entre machines, pertes de connexions, plantages de machines,...)
● Modules
– HDFS : Hadoop Distributed File System (inspiré de GFS)
– MapReduce : système pour le traitement parallèle des gros volumes de données (inspiré de Google MapReduce)
– En version 2 : YARN : système de gestion et planification des ressources du cluster
© Talend 2014 18
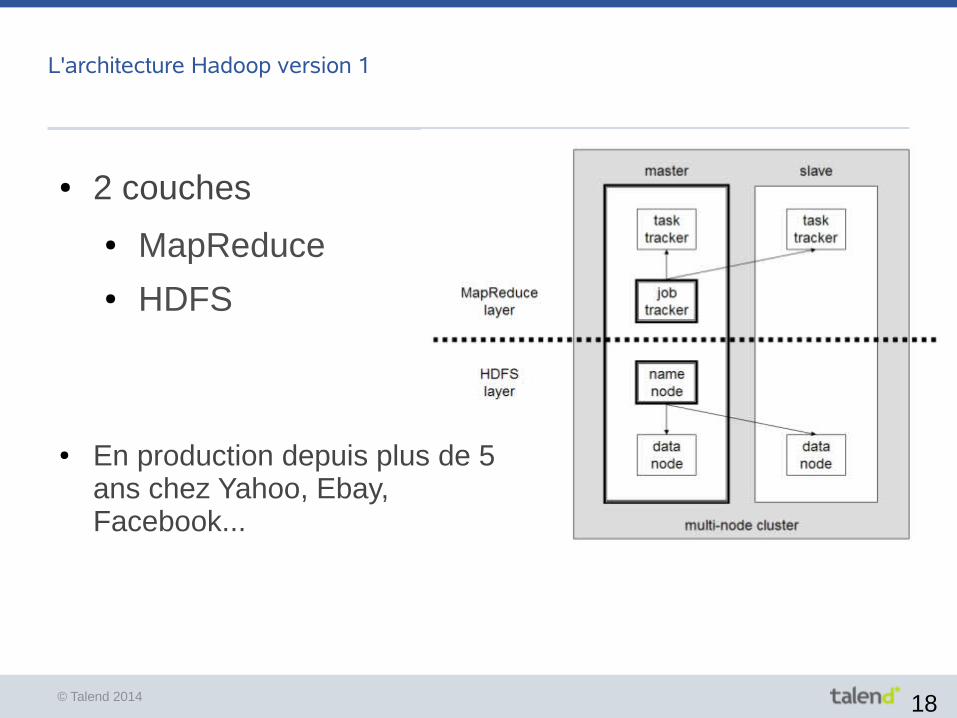
L'architecture Hadoop version 1
● 2 couches
● MapReduce● HDFS
● En production depuis plus de 5 ans chez Yahoo, Ebay, Facebook...
© Talend 2014 19
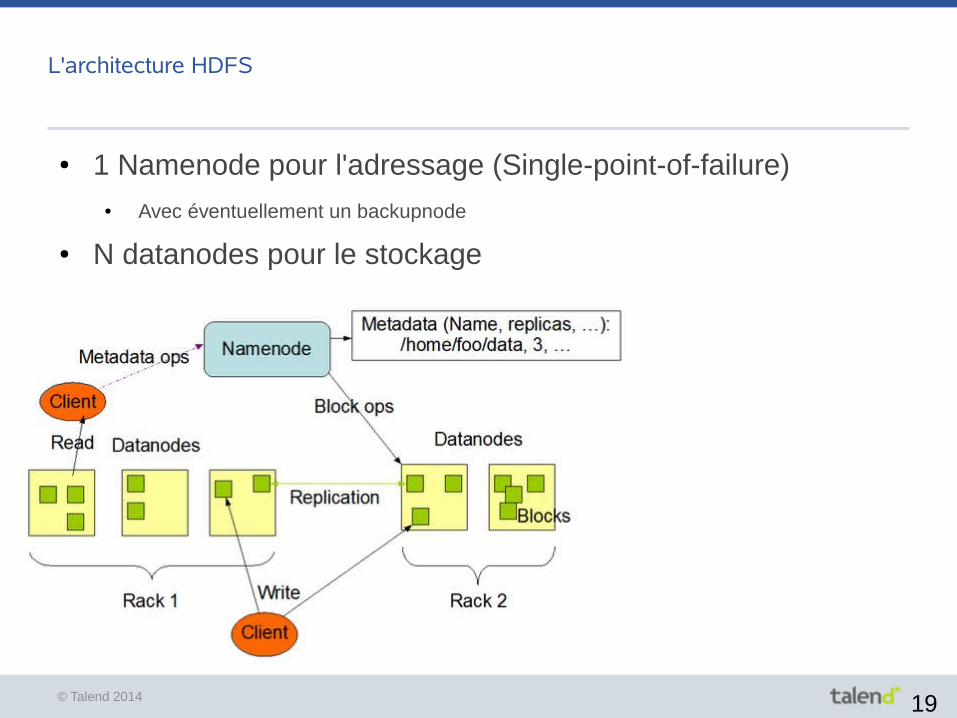
L'architecture HDFS
● 1 Namenode pour l'adressage (Single-point-of-failure)● Avec éventuellement un backupnode
● N datanodes pour le stockage
© Talend 2014 20
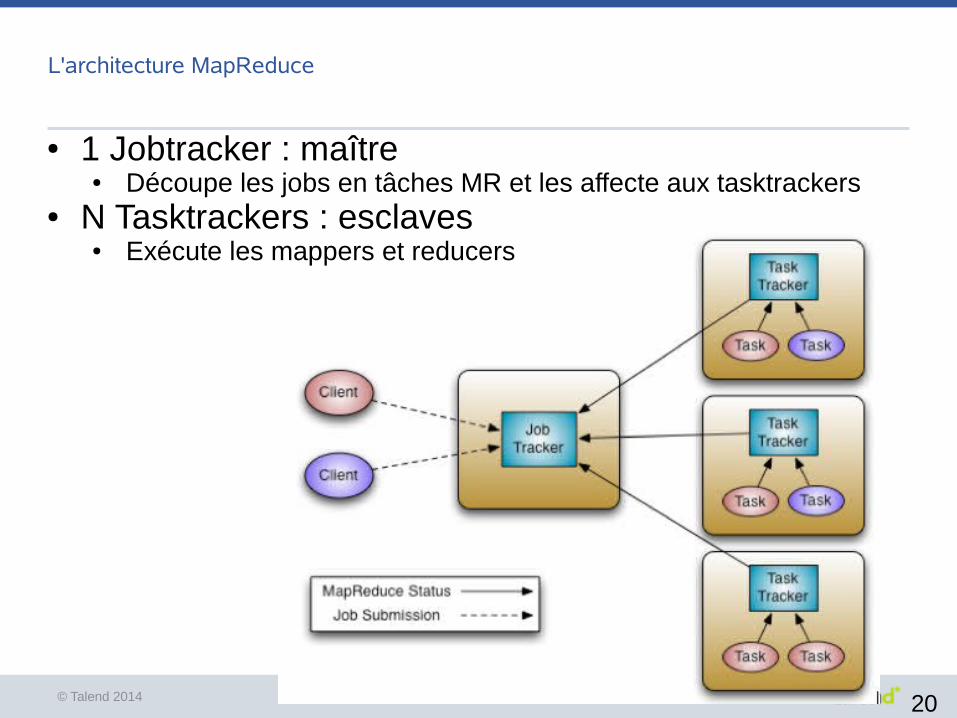
L'architecture MapReduce
● 1 Jobtracker : maître● Découpe les jobs en tâches MR et les affecte aux tasktrackers
● N Tasktrackers : esclaves● Exécute les mappers et reducers
© Talend 2014 21
Hadoop : un premier changement de paradigme
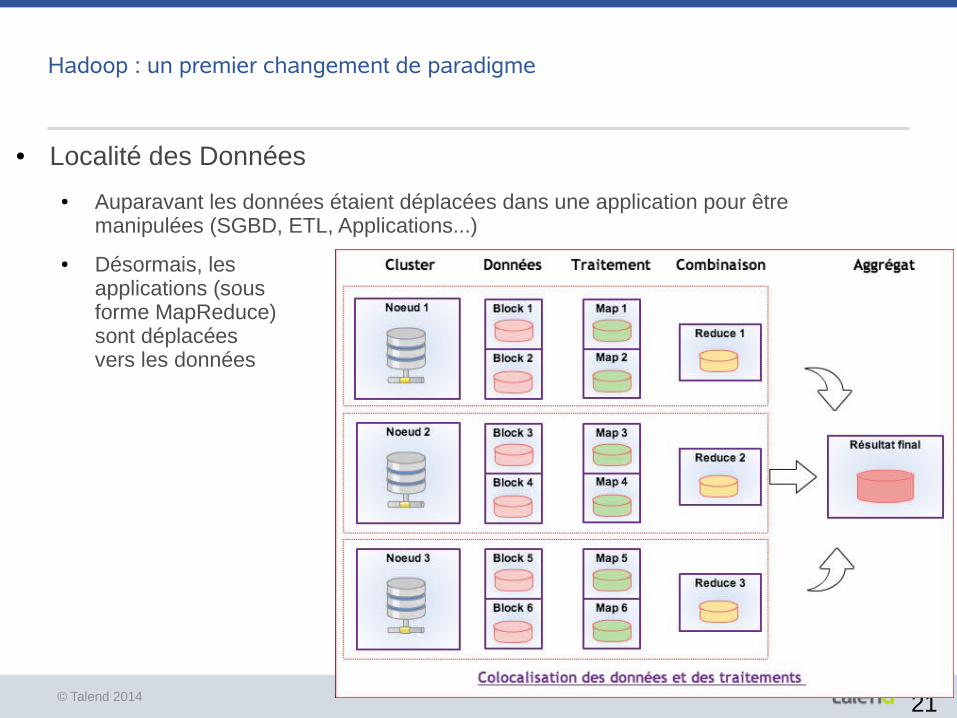
● Localité des Données
● Auparavant les données étaient déplacées dans une application pour être manipulées (SGBD, ETL, Applications...)
● Désormais, les applications (sous forme MapReduce) sont déplacées vers les données
© Talend 2014 22
Le modèle MapReduce
● Un programme MapReduce est composé de 2 fonctions
● Map() divise les données pour traiter des sous-problèmes
● Reduce() collecte et aggrège les résultats des sous-problèmes
● Fonctionne avec des données sous forme de paires (clé, valeur)
● Map(k1,v1) → list(k2,v2)
● Reduce(k2, list (v2)) → list(v3)
© Talend 2014 23
Le modèle MapReduce
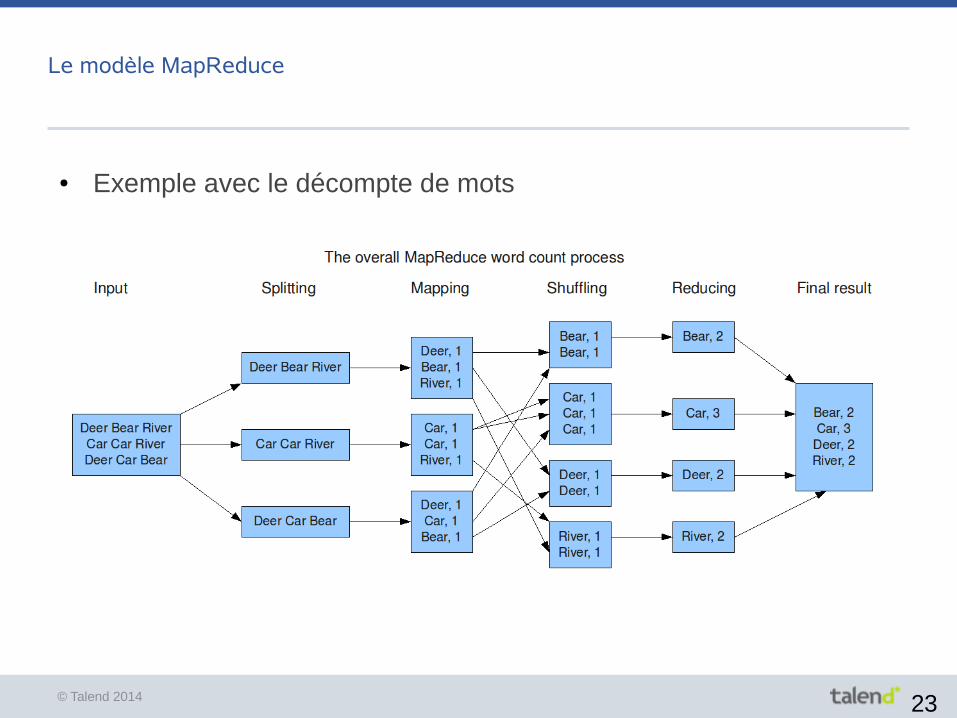
● Exemple avec le décompte de mots
© Talend 2014 24
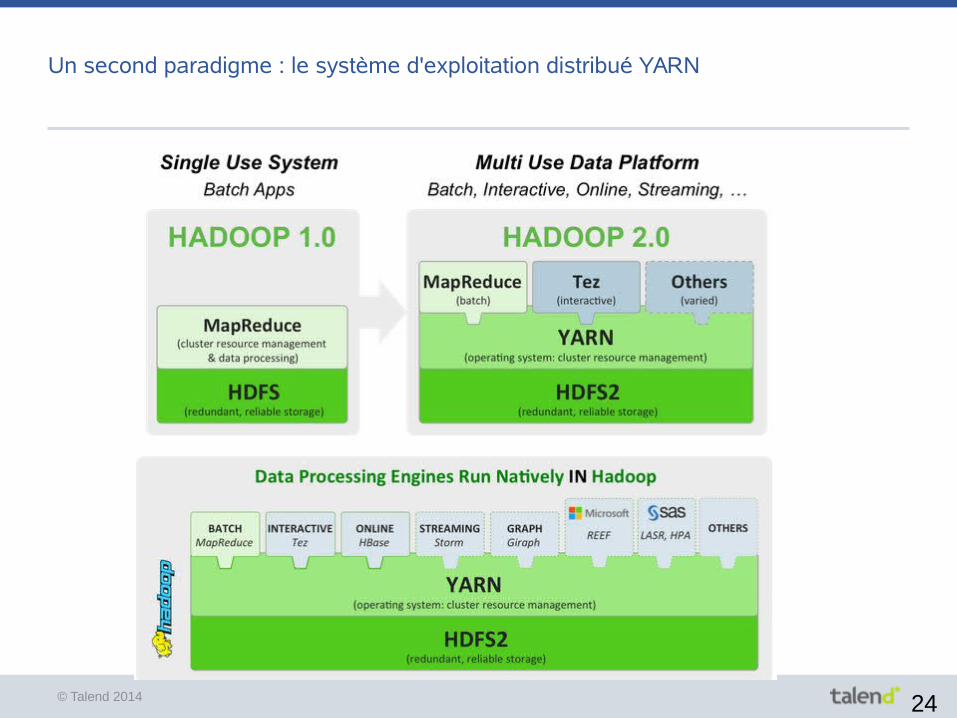
Un second paradigme : le système d'exploitation distribué YARN
© Talend 2014 25
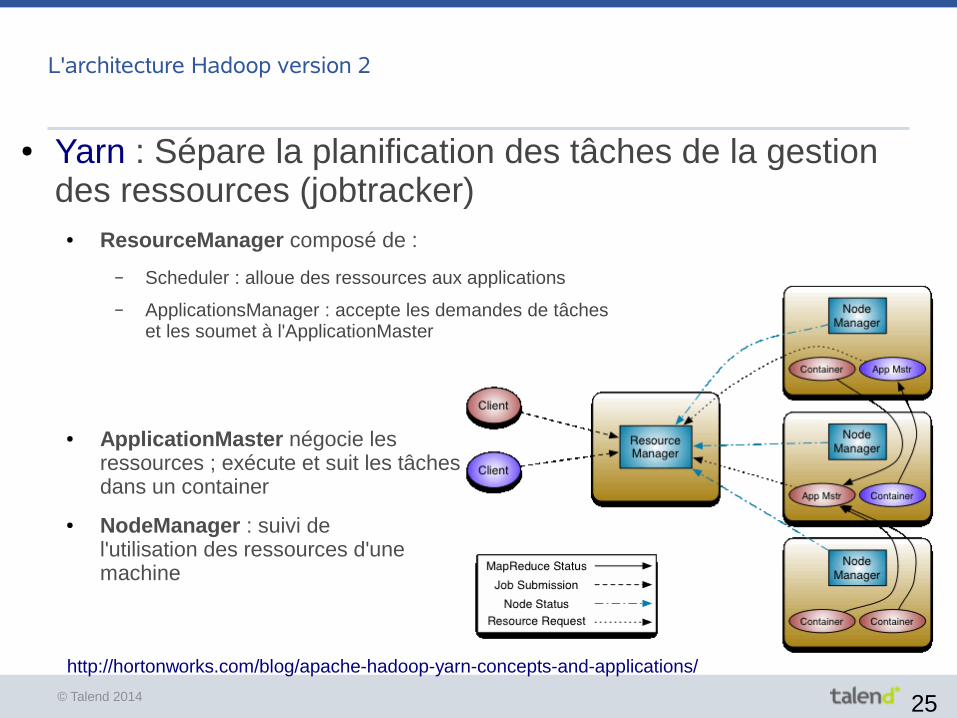
L'architecture Hadoop version 2
● Yarn : Sépare la planification des tâches de la gestion des ressources (jobtracker)
● ResourceManager composé de :
– Scheduler : alloue des ressources aux applications
– ApplicationsManager : accepte les demandes de tâches et les soumet à l'ApplicationMaster
● ApplicationMaster négocie les ressources ; exécute et suit les tâches dans un container
● NodeManager : suivi del'utilisation des ressources d'une machine
http://hortonworks.com/blog/apache-hadoop-yarn-concepts-and-applications/
© Talend 2014 26
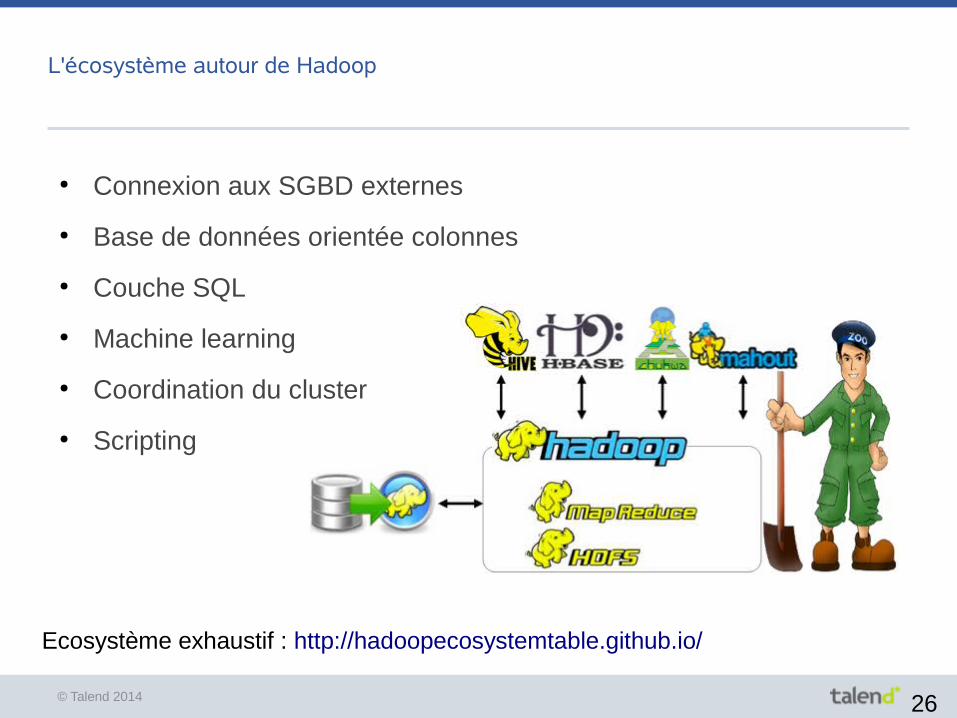
L'écosystème autour de Hadoop
Ecosystème exhaustif : http://hadoopecosystemtable.github.io/
● Connexion aux SGBD externes
● Base de données orientée colonnes
● Couche SQL
● Machine learning
● Coordination du cluster
● Scripting
© Talend 2014 27
Les distributions
● Rôle d'une distribution
● Fournir un ensemble de composants cohérents fonctionnant ensemble
● Assurer la compatibilités et la mise à jour des composants
● Même principe que les distributions Linux
● D'autant plus important que les projets évoluent très rapidement
● De nouveaux composants sont créés
● D'autres sont améliorés...
© Talend 2014 28
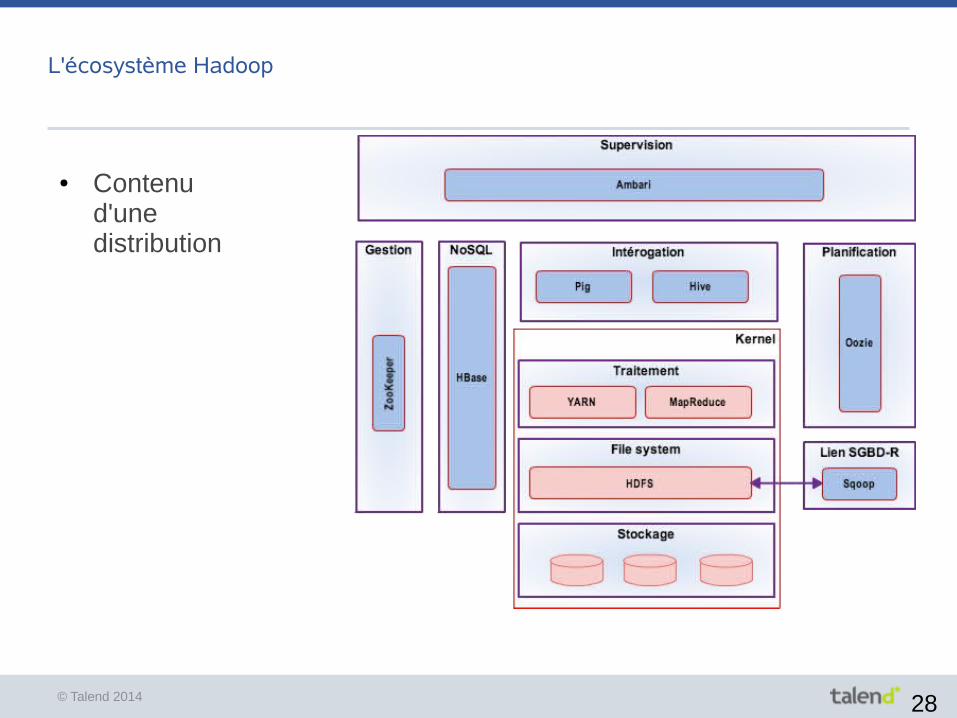
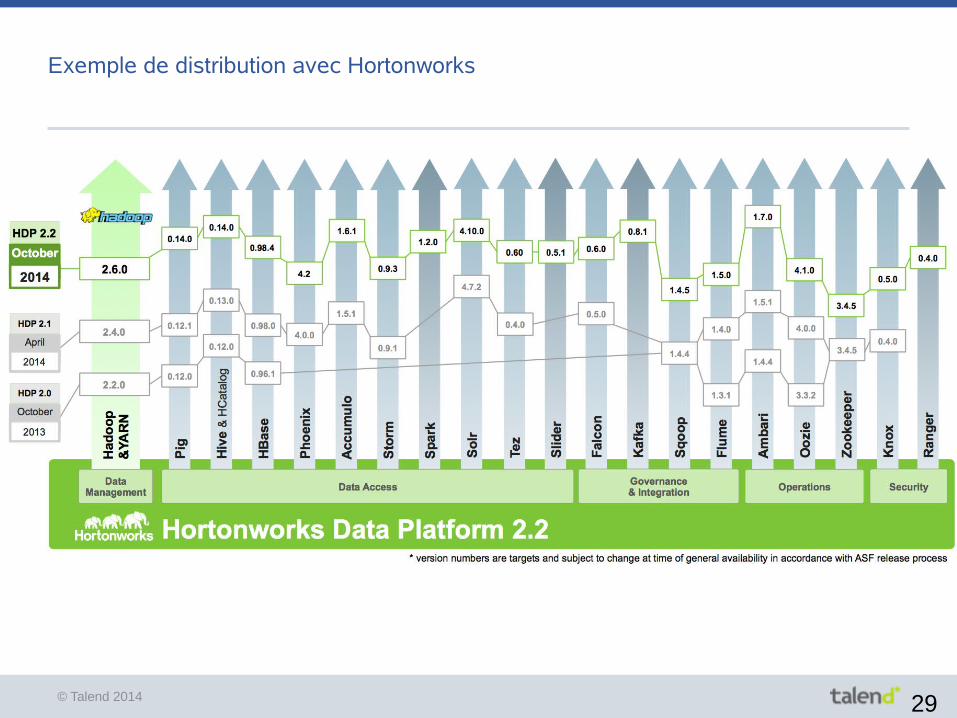
L'écosystème Hadoop
● Contenu d'unedistribution
© Talend 2014 29
Exemple de distribution avec Hortonworks

© Talend 2014 30
Les distributions
● 3 principales distributions :
● Hortonworks
● fidèle à la distribution Apache et donc 100% open source.
● Cloudera
● fidèle en grande partie sauf pour les outils d’administration.
● MapR
● noyau Hadoop mais repackagé et enrichi de solutions propriétaires.
https://www.mapr.com/forrester-wave-hadoop-distribution-comparison-and-benchmark-report
© Talend 2014 31
Agenda
● Présentation de Talend
● Définition du Big Data
● Le framework Hadoop
● L'architecture lambda
● La qualité de données et le Big data
● Applications avec Talend
● Qualité de données
● Apprentissage automatique
© Talend 2014 32
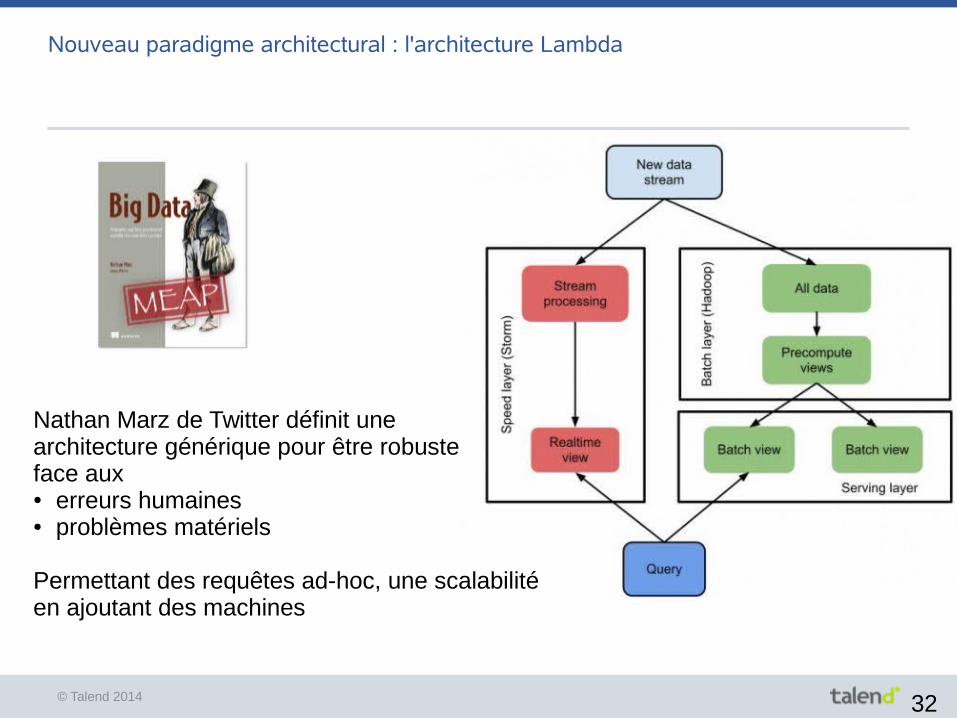
Nouveau paradigme architectural : l'architecture Lambda
Nathan Marz de Twitter définit une architecture générique pour être robusteface aux ● erreurs humaines● problèmes matériels
Permettant des requêtes ad-hoc, une scalabilité en ajoutant des machines
© Talend 2014 33
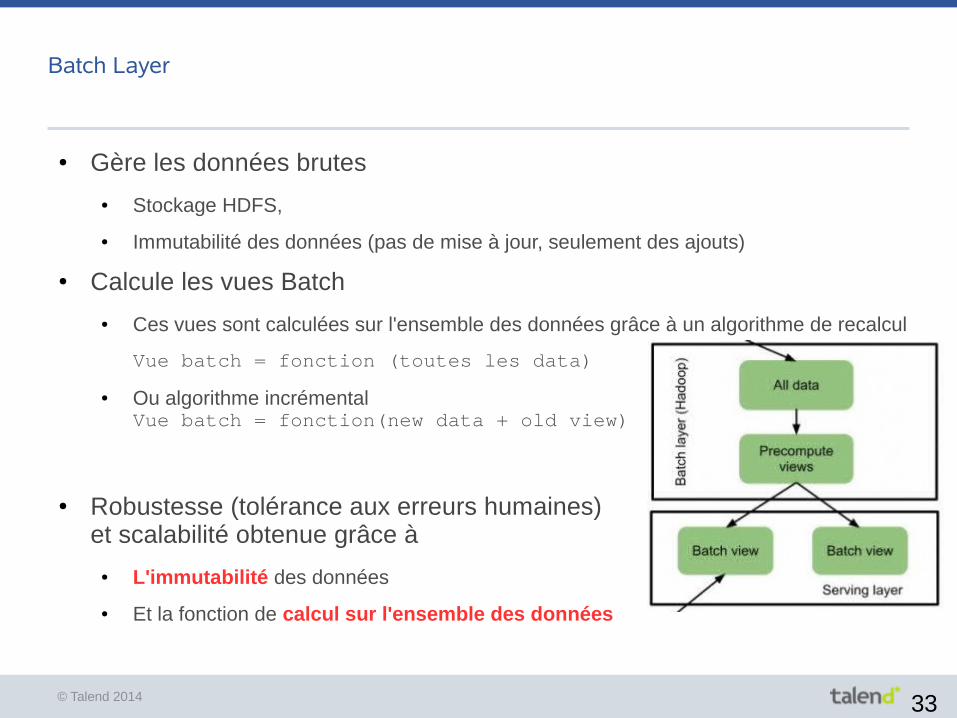
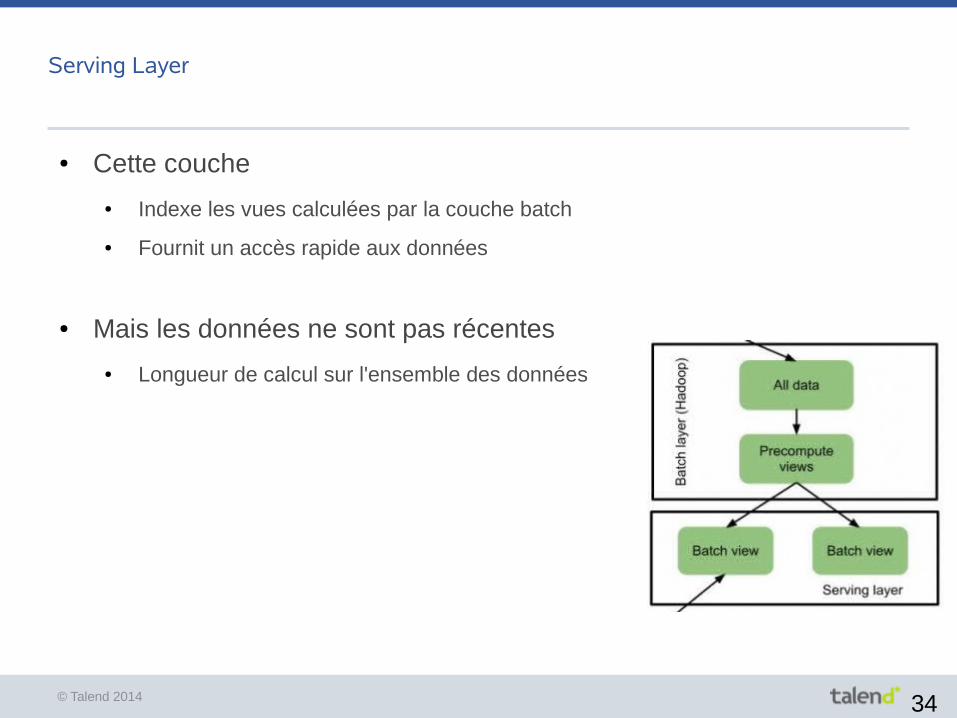
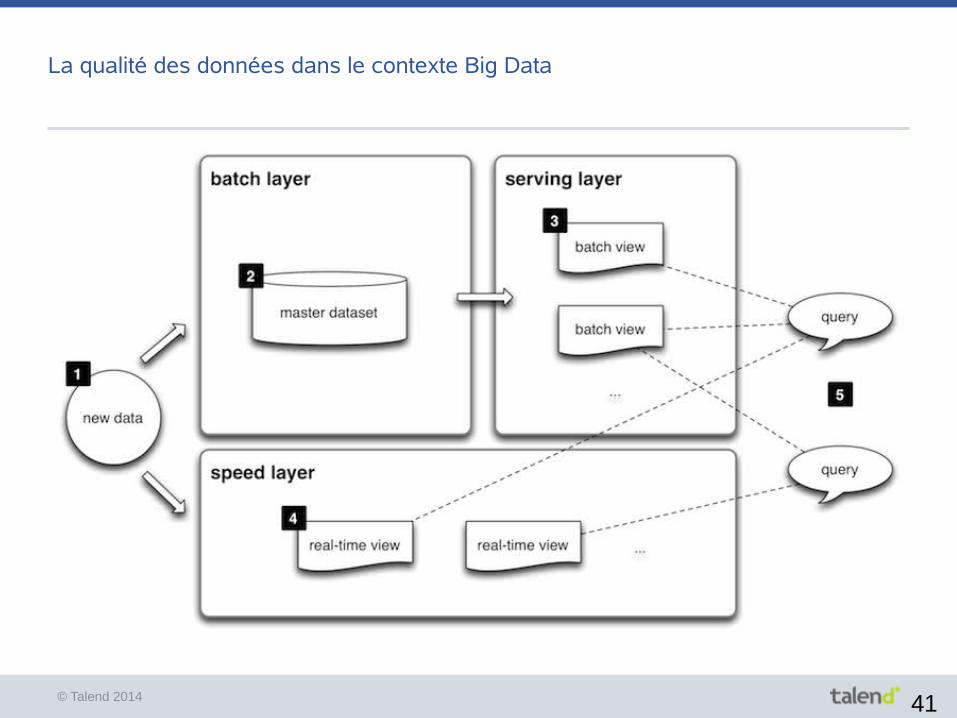
Batch Layer
● Gère les données brutes
● Stockage HDFS,
● Immutabilité des données (pas de mise à jour, seulement des ajouts)
● Calcule les vues Batch
● Ces vues sont calculées sur l'ensemble des données grâce à un algorithme de recalcul
Vue batch = fonction (toutes les data)
● Ou algorithme incrémentalVue batch = fonction(new data + old view)
● Robustesse (tolérance aux erreurs humaines) et scalabilité obtenue grâce à
● L'immutabilité des données
● Et la fonction de calcul sur l'ensemble des données
© Talend 2014 34
Serving Layer
● Cette couche
● Indexe les vues calculées par la couche batch
● Fournit un accès rapide aux données
● Mais les données ne sont pas récentes
● Longueur de calcul sur l'ensemble des données
© Talend 2014 35
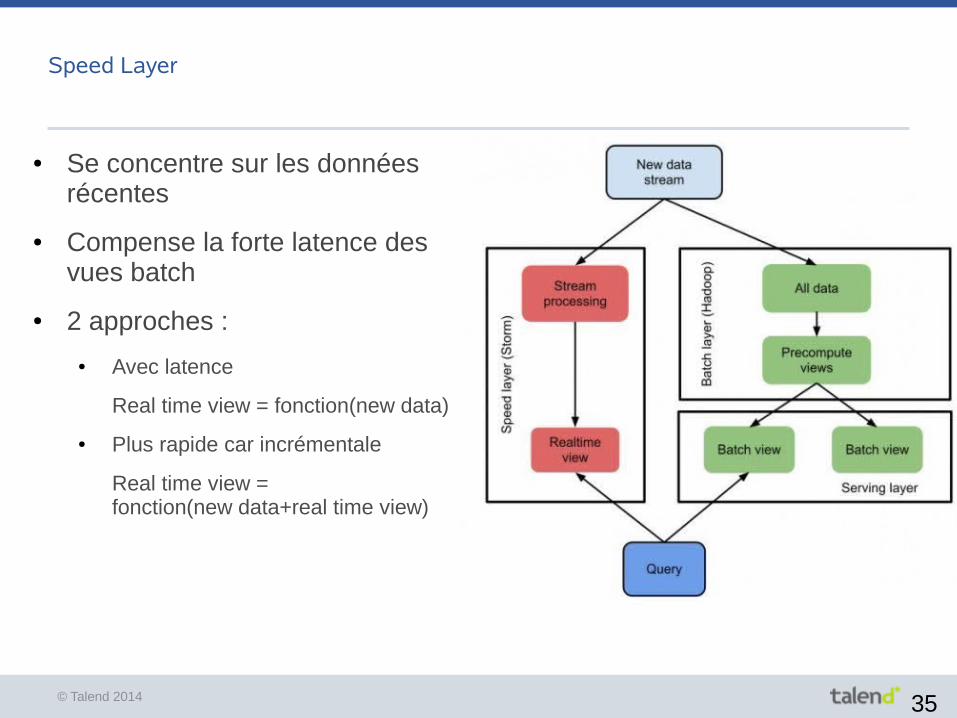
Speed Layer
● Se concentre sur les données récentes
● Compense la forte latence desvues batch
● 2 approches :
● Avec latence
Real time view = fonction(new data)
● Plus rapide car incrémentale
Real time view = fonction(new data+real time view)
© Talend 2014 36
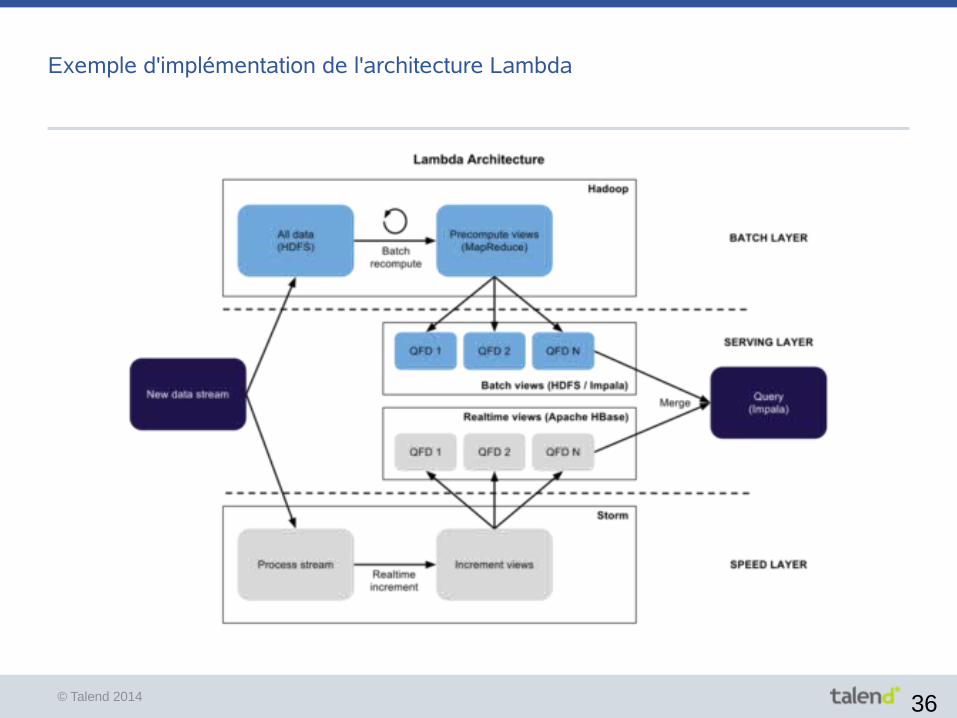
Exemple d'implémentation de l'architecture Lambda
© Talend 2014 37
Insert or Update : un changement de paradigme
● Dans cette architecture, les données sont immutables
● Conséquences :
● Toutes les données doivent avoir un timestamp
● Le suivi de l'évolution des données est plus simple.
● L'utilisation de langages de programmation fonctionnelle est possible
● La programmation fonctionnelle requiert des données immutables
● Le traitement parallèle des données est simplifié grâce aux langages de programmation fonctionnelle
● D'où le succès de Scala avec Spark

© Talend 2014 38
Paradigme du Schéma à la lecture
● Schéma fixe (schema-on-write) : les données doivent se conformer au schéma de base prédéfini
● Evolution de la structure des données difficile
● Schéma à la lecture (schema-on-read) : les schéma sont créés par des vues sur les données
● Pas de contrainte sur la structure des données ingérées par le système
● La structure de sortie est générée par le code
© Talend 2014 39
Agenda
● Présentation de Talend
● Définition du Big Data
● Le framework Hadoop
● L'architecture lambda
● La qualité de données et le Big data
● Applications avec Talend
● Qualité de données
● Apprentissage automatique
© Talend 2014 40
Les dimensions de la qualité de données
● La recherche a conduit à définir des critères concernant les données.
Des Dimensions :
● L'exactitude : dans quelle mesure les données sont-elles correctes ?
● La validité (ou pertinence) : dans quelle mesure les données répondent aux besoins des utilisateurs ?
● La complétude : dans quelle mesure des données sont-elles manquantes ?
● La cohérence : dans quelle mesure les données collectées de diverses manières à différents instants se recoupent-elles ?
● L'actualité : les données sont-elles suffisamment « fraîches » ?
● L'accessibilité (ou facilité d'utilisation) : l'information est-elle facilement accessible, suffisamment claire, documentée ?
● On dénombre plus de 179 dimensions
© Talend 2014 41
La qualité des données dans le contexte Big Data
© Talend 2014 42
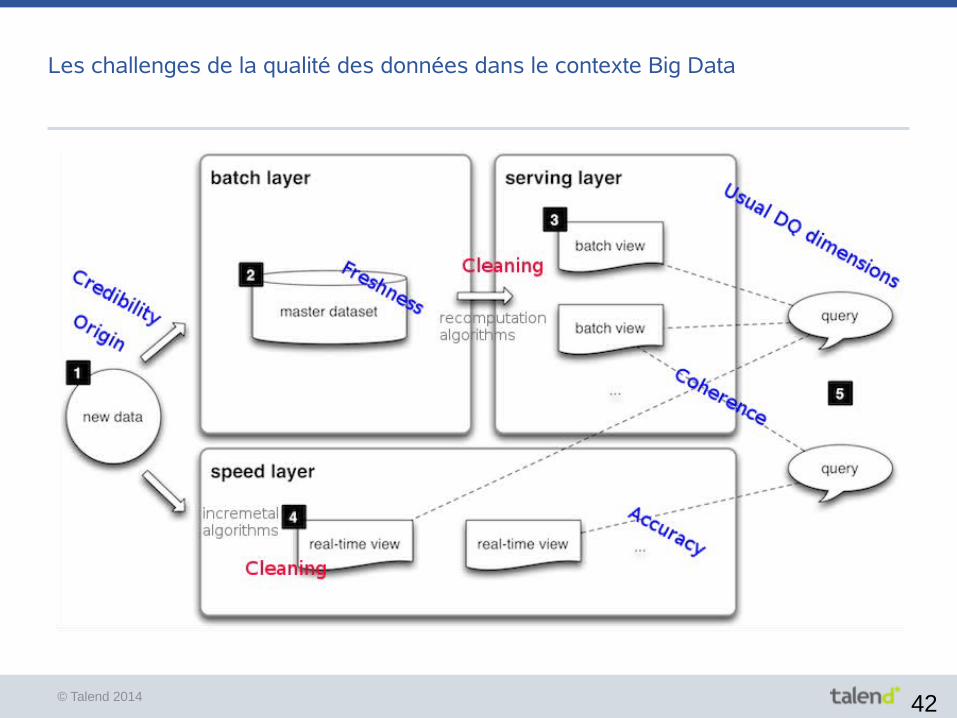
Les challenges de la qualité des données dans le contexte Big Data
© Talend 2014 43
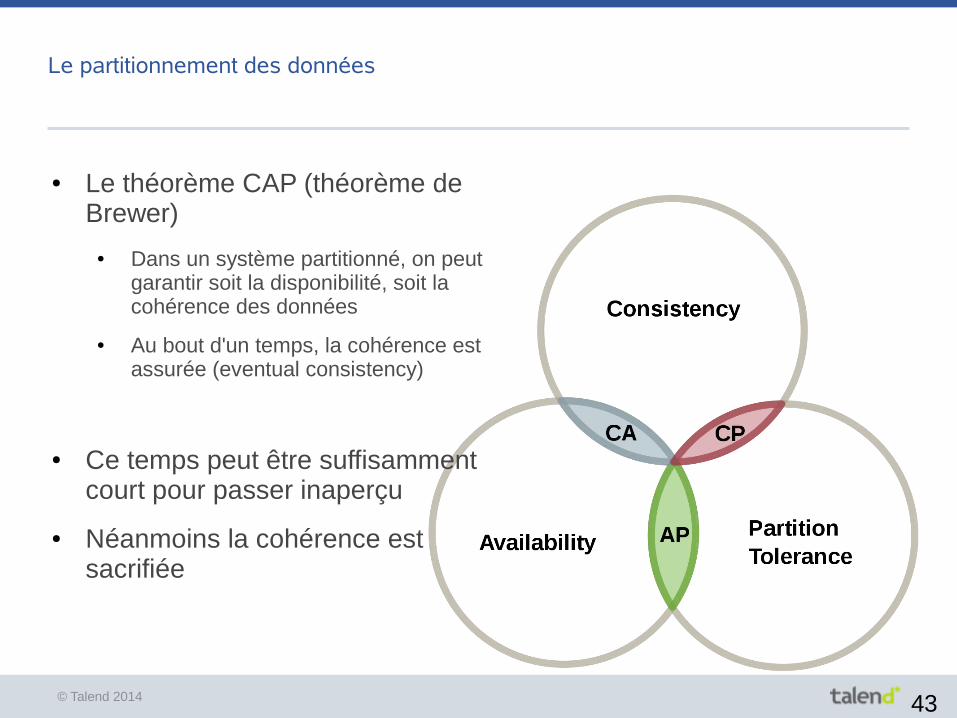
Le partitionnement des données
● Le théorème CAP (théorème de Brewer)
● Dans un système partitionné, on peut garantir soit la disponibilité, soit la cohérence des données
● Au bout d'un temps, la cohérence est assurée (eventual consistency)
● Ce temps peut être suffisamment court pour passer inaperçu
● Néanmoins la cohérence est sacrifiée
© Talend 2014 44
Challenge : assurer la qualité des données
● Les dimensions particulièrement importantes
● La provenance (attention au Data Lake, conserver une traçabilité des données)
● La crédibilité (quelle confiance accorder aux données du web ? )
● La fraîcheur (en partie résolue par l'architecture lambda)
● L'obsolescence (doit-on définir un horizon des événements ? )
● L'unicité (Attention à la duplication d'information à des instants différents)
● La cohérence (théorème CAP)
● L'exactitude (certains algorithmes donnent une réponse probabiliste http://en.wikipedia.org/wiki/HyperLogLog )
● Projet Falcon pour la gouvernance des données (en incubation)
http://falcon.incubator.apache.org/
© Talend 2014 45
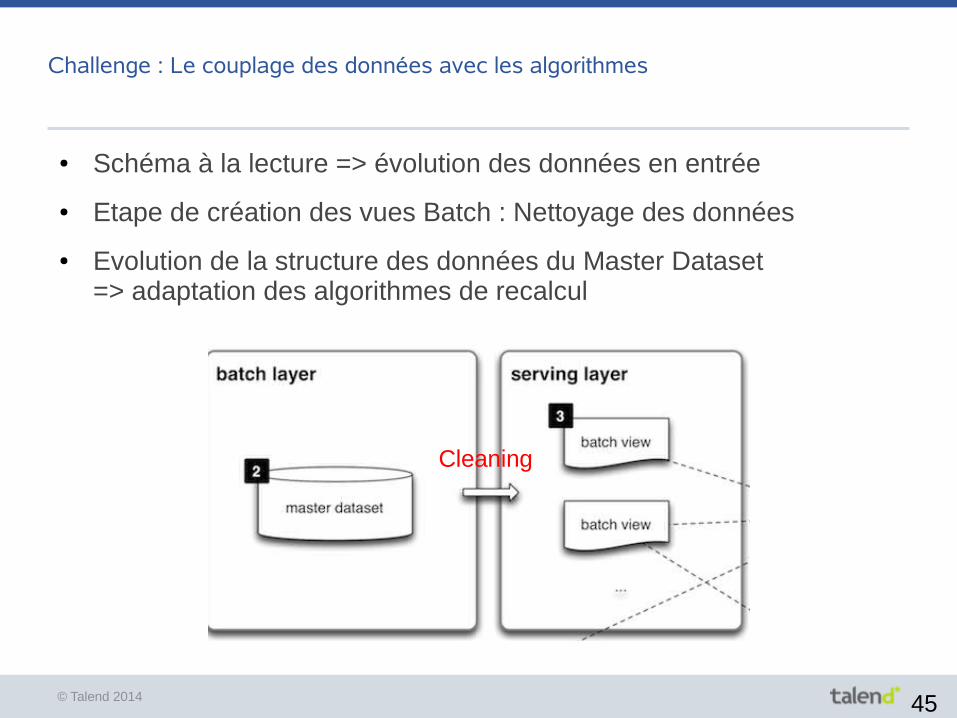
Challenge : Le couplage des données avec les algorithmes
● Schéma à la lecture => évolution des données en entrée
● Etape de création des vues Batch : Nettoyage des données
● Evolution de la structure des données du Master Dataset=> adaptation des algorithmes de recalcul
Cleaning
© Talend 2014 46
Agenda
● Présentation de Talend
● Définition du Big Data
● Le framework Hadoop
● L'architecture lambda
● La qualité de données et le Big data
● Applications avec Talend
● Qualité de données
● Apprentissage automatique
© Talend 2014 47
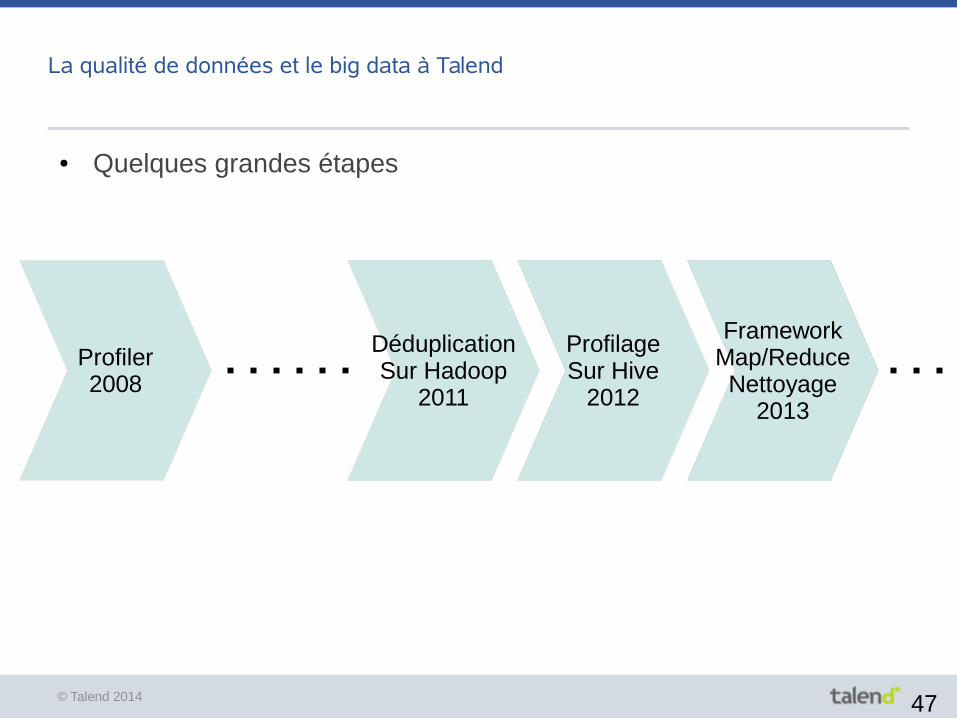
La qualité de données et le big data à Talend
Profiler2008
DéduplicationSur Hadoop
2011
FrameworkMap/Reduce
Nettoyage2013
ProfilageSur Hive
2012
● Quelques grandes étapes
© Talend 2014 48
Profilage in situ avec Talend
● Le profilage est une étape importante de la qualité de données
● Echantillonner les données pour analyser la qualité ? Qualité de l'échantillon ? Représentativité ?
1. Talend offre un profilage in situ de données sur HDFS en utilisant
1. Hive
2. Impala
2. Le profilage peut être fait au niveau des vues Batch ou Real Time
© Talend 2014 49
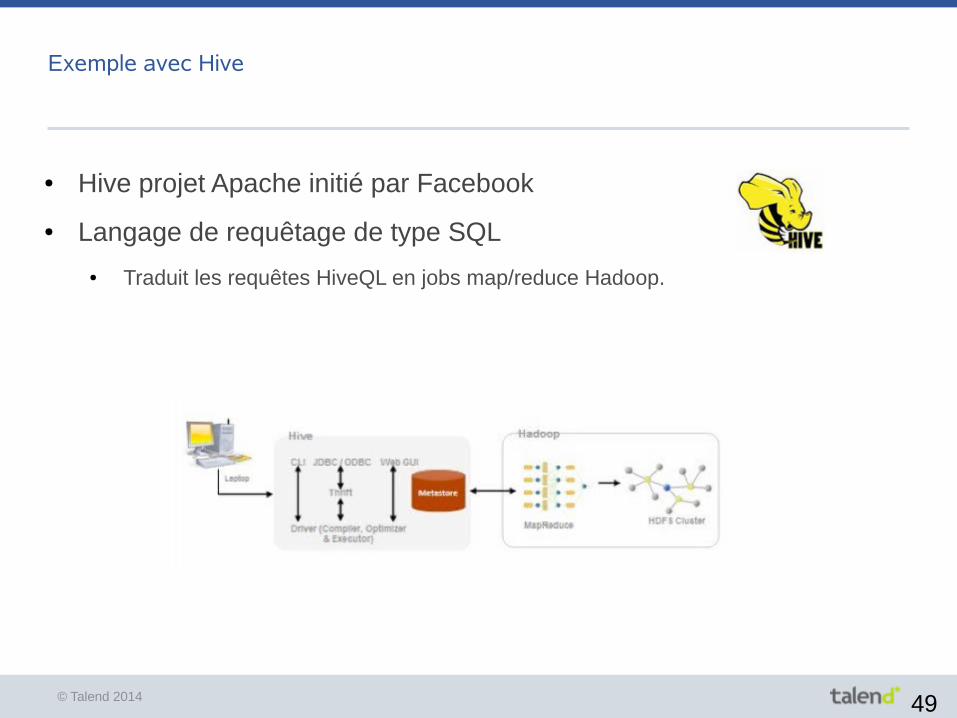
Exemple avec Hive
● Hive projet Apache initié par Facebook
● Langage de requêtage de type SQL
● Traduit les requêtes HiveQL en jobs map/reduce Hadoop.
© Talend 2014 50
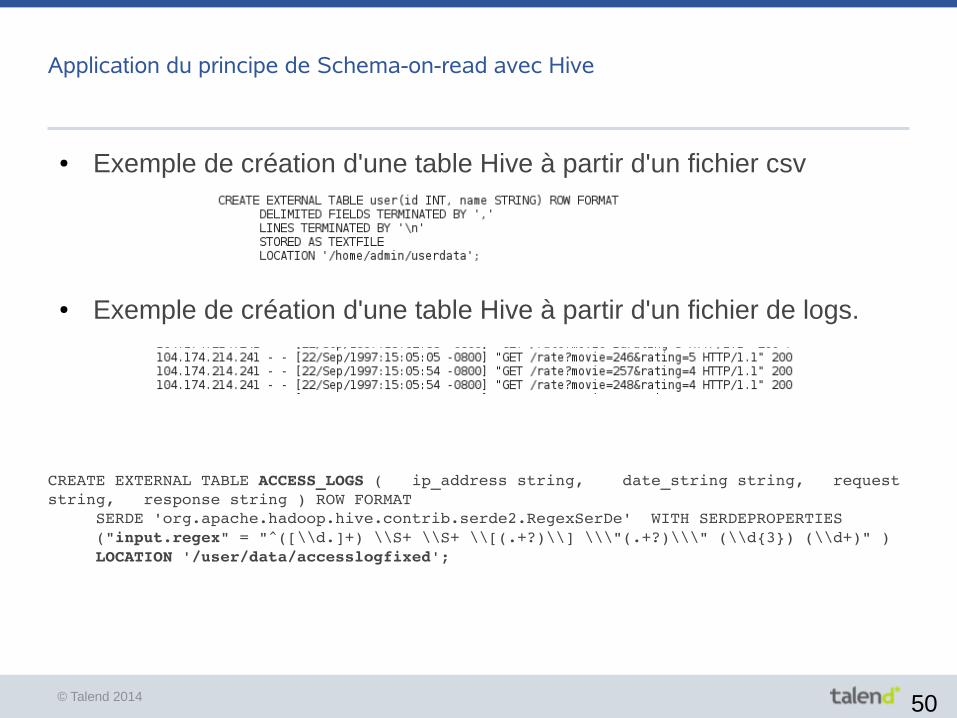
Application du principe de Schema-on-read avec Hive
● Exemple de création d'une table Hive à partir d'un fichier csv
● Exemple de création d'une table Hive à partir d'un fichier de logs.
CREATE EXTERNAL TABLE ACCESS_LOGS ( ip_address string, date_string string, request string, response string ) ROW FORMAT
SERDE 'org.apache.hadoop.hive.contrib.serde2.RegexSerDe' WITH SERDEPROPERTIES ("input.regex" = "^([\\d.]+) \\S+ \\S+ \\[(.+?)\\] \\\"(.+?)\\\" (\\d{3}) (\\d+)" ) LOCATION '/user/data/accesslogfixed';
© Talend 2014 51
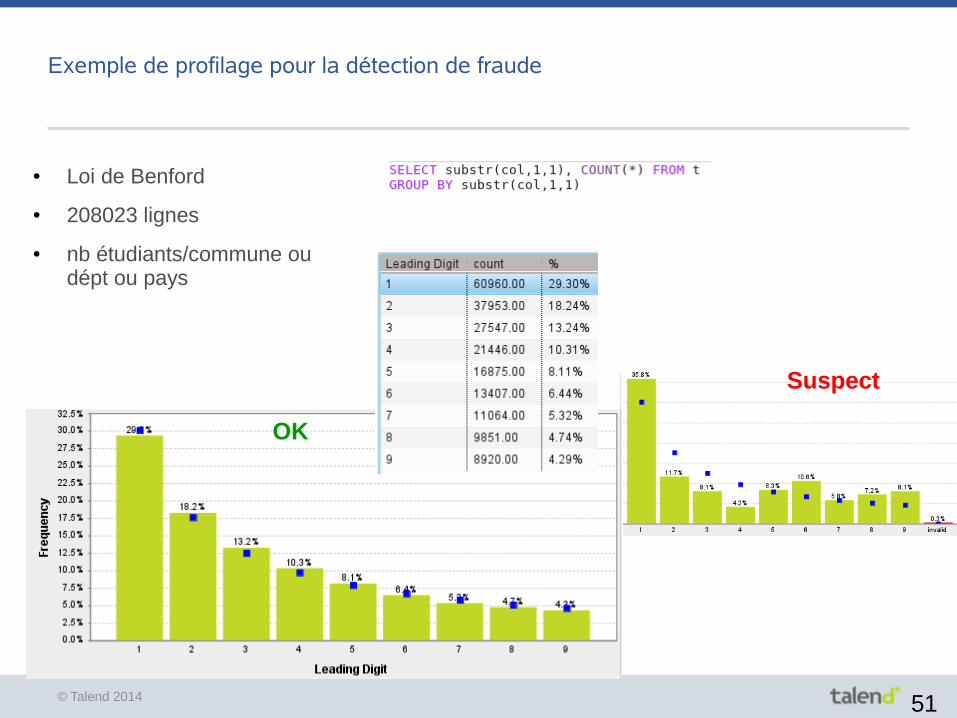
Exemple de profilage pour la détection de fraude
● Loi de Benford
● 208023 lignes
● nb étudiants/commune ou dépt ou pays
OK
Suspect
© Talend 2014 52
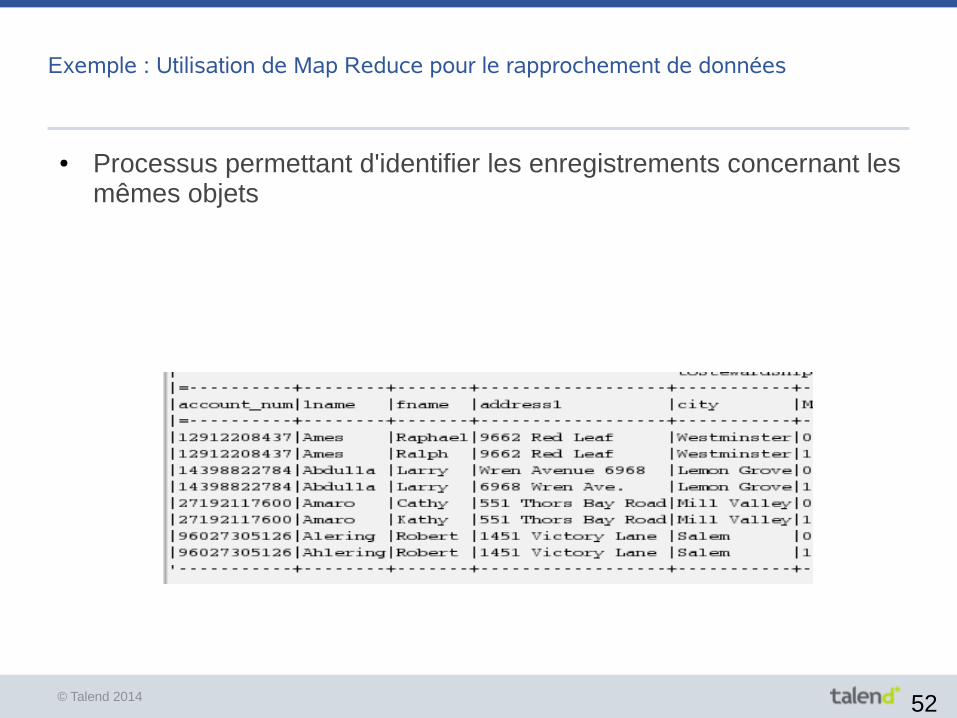
Exemple : Utilisation de Map Reduce pour le rapprochement de données
● Processus permettant d'identifier les enregistrements concernant les mêmes objets

© Talend 2014 53
Le rapprochement de données
● Optimisation en réduisant le nombre de comparaisons
● Stratégie de “blocking”partitionnement des données
● Exemple : 1.000 nouveaux clients à comparer aux 10.000 clients référencés => 10.000.000 de comparaisons !!
● Blocking : 100 x blocs de 10 enregistrements en entrée à comparer à 100 blocs de 100 enregistrements.
● Nb comparaisons : 100 x (10 x 100) = 100 000
● Approche idéale pour Hadoop Map Reduce
© Talend 2014 54
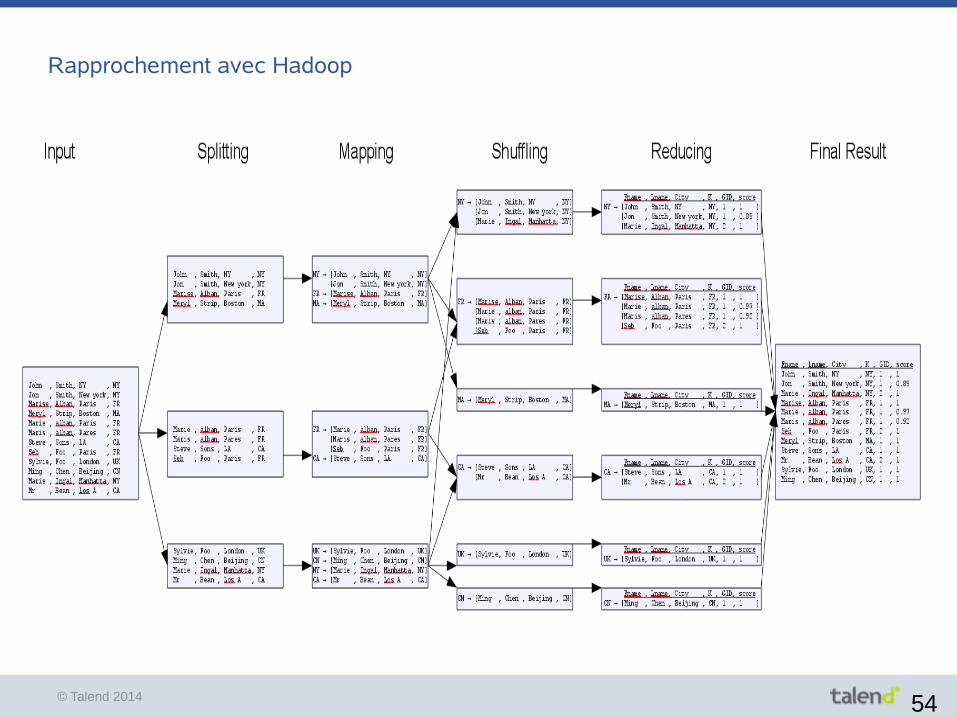
Rapprochement avec Hadoop
© Talend 2014 55
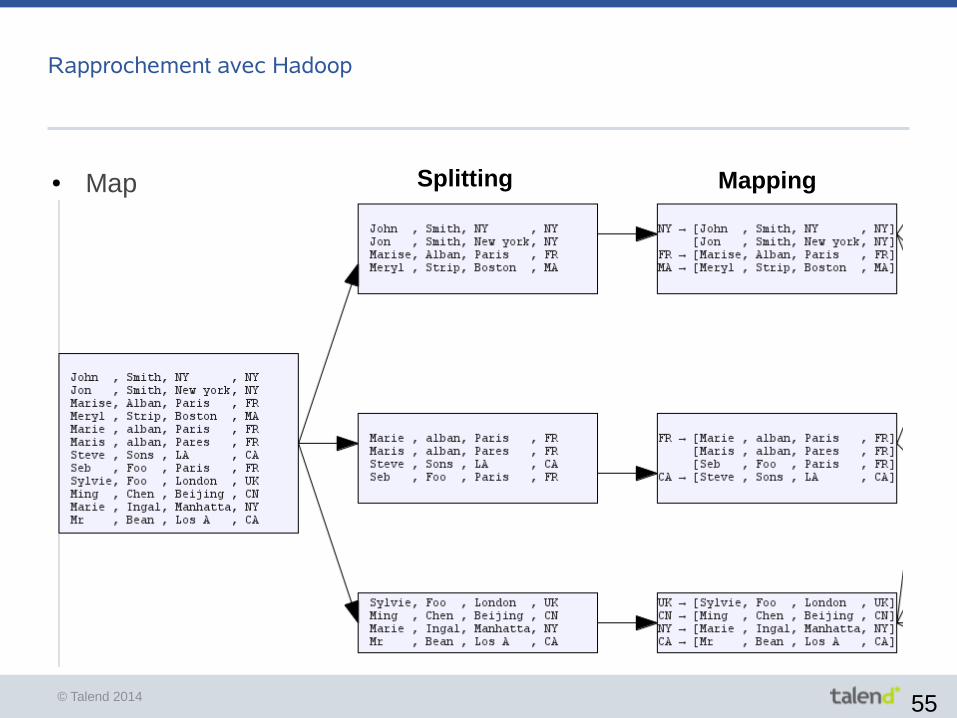
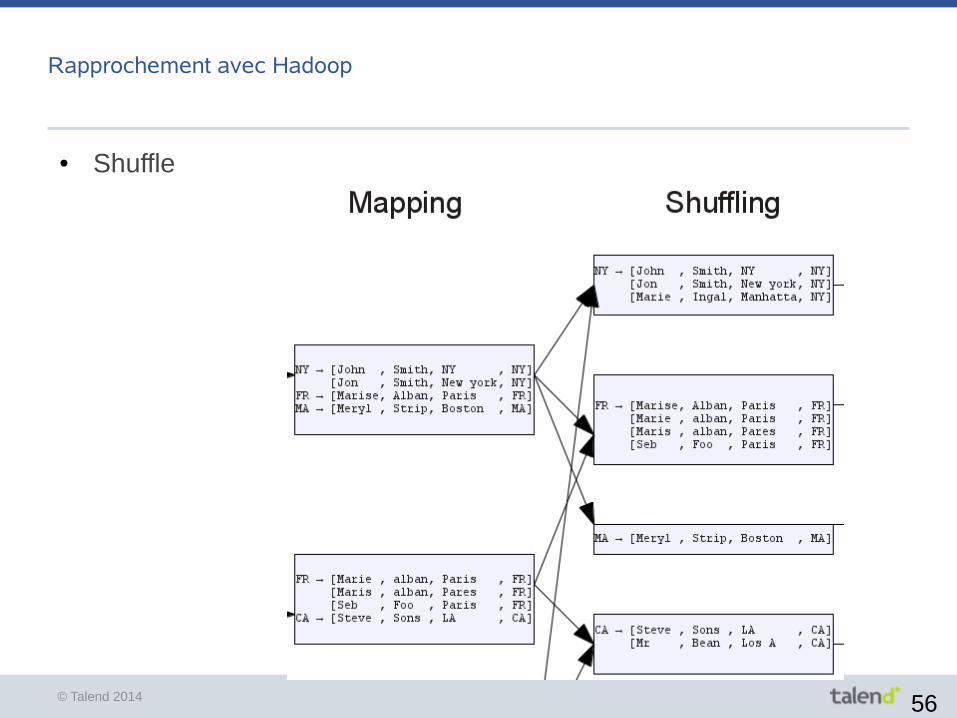
Rapprochement avec Hadoop
● Map Splitting Mapping
© Talend 2014 56
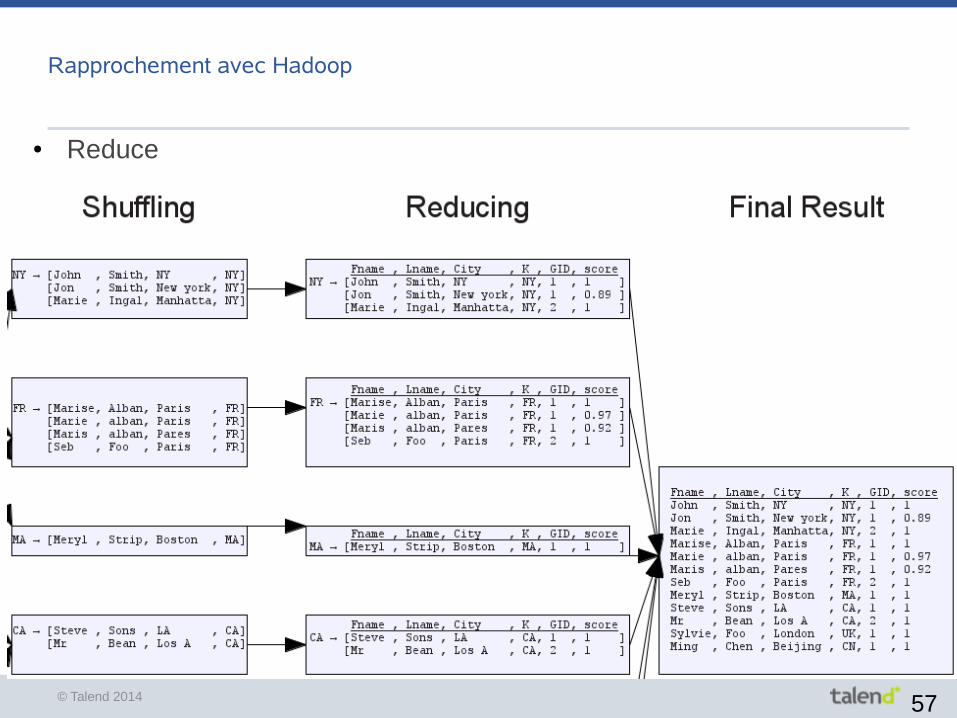
Rapprochement avec Hadoop
● Shuffle
© Talend 2014 57
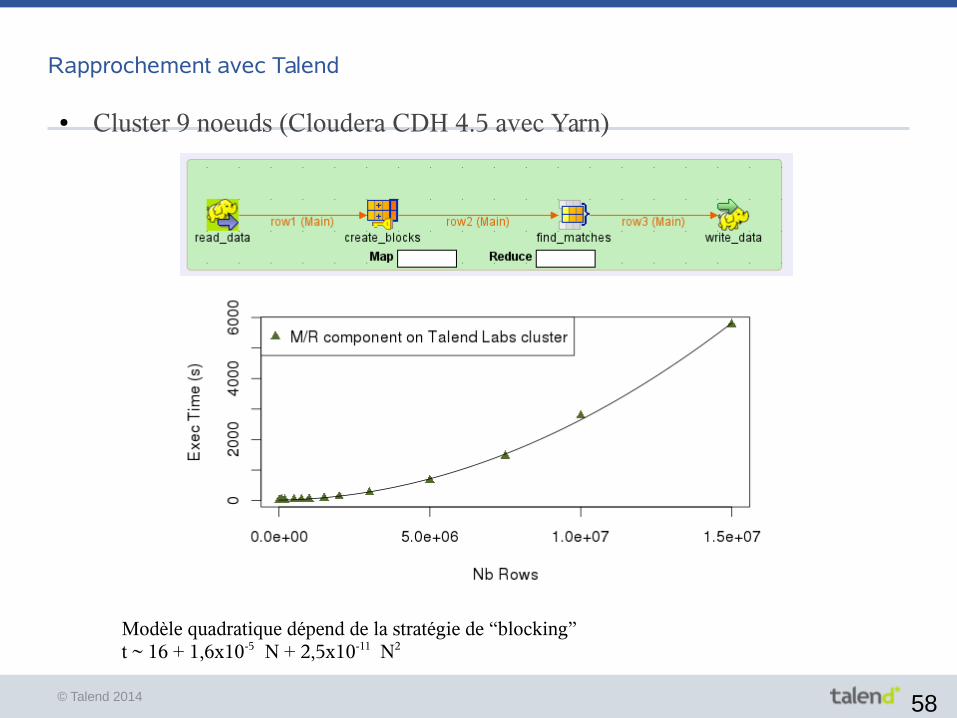
Rapprochement avec Hadoop
● Reduce
© Talend 2014 58
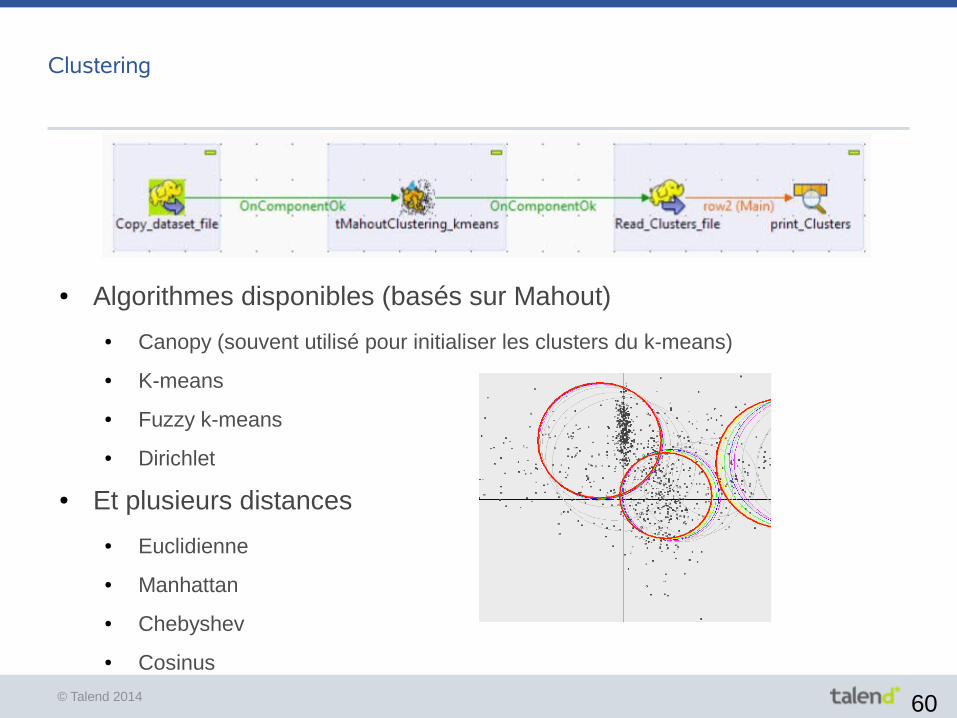
Rapprochement avec Talend
● Cluster 9 noeuds (Cloudera CDH 4.5 avec Yarn)
Modèle quadratique dépend de la stratégie de “blocking”t ~ 16 + 1,6x10-5 N + 2,5x10-11 N2

© Talend 2014 59
Outiller les data scientists
● l'apprentissage automatique
● Composants Mahout pour le clustering
● Composants Spark http://spark.apache.org pour le filtrage collaboratif
● Implémenter son architecture lambda pour l'analytique
● Spark Streaming (micro-batch)
● Framework pour Storm https://storm.apache.org/
– Traiter des millions de tuples par seconde sur chaque noeud.
– Tolérance à la panne
– Garantit le traitement des données
© Talend 2014 60
Clustering
● Algorithmes disponibles (basés sur Mahout)
● Canopy (souvent utilisé pour initialiser les clusters du k-means)
● K-means
● Fuzzy k-means
● Dirichlet
● Et plusieurs distances
● Euclidienne
● Manhattan
● Chebyshev
● Cosinus
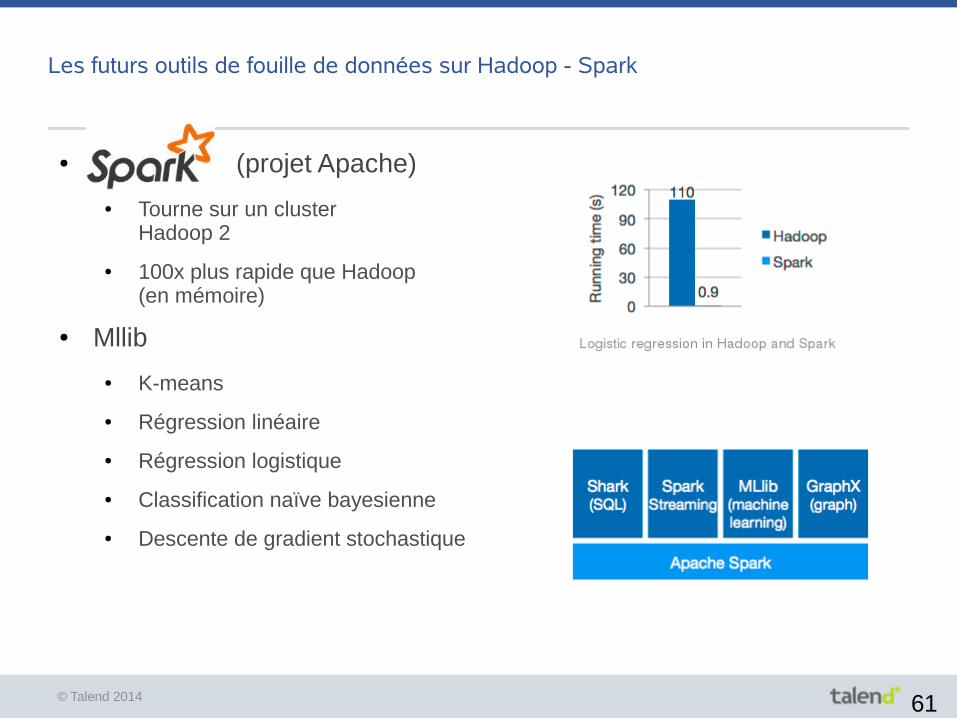
© Talend 2014 61
Les futurs outils de fouille de données sur Hadoop - Spark
● Spark (projet Apache)
● Tourne sur un cluster Hadoop 2
● 100x plus rapide que Hadoop(en mémoire)
● Mllib
● K-means
● Régression linéaire
● Régression logistique
● Classification naïve bayesienne
● Descente de gradient stochastique
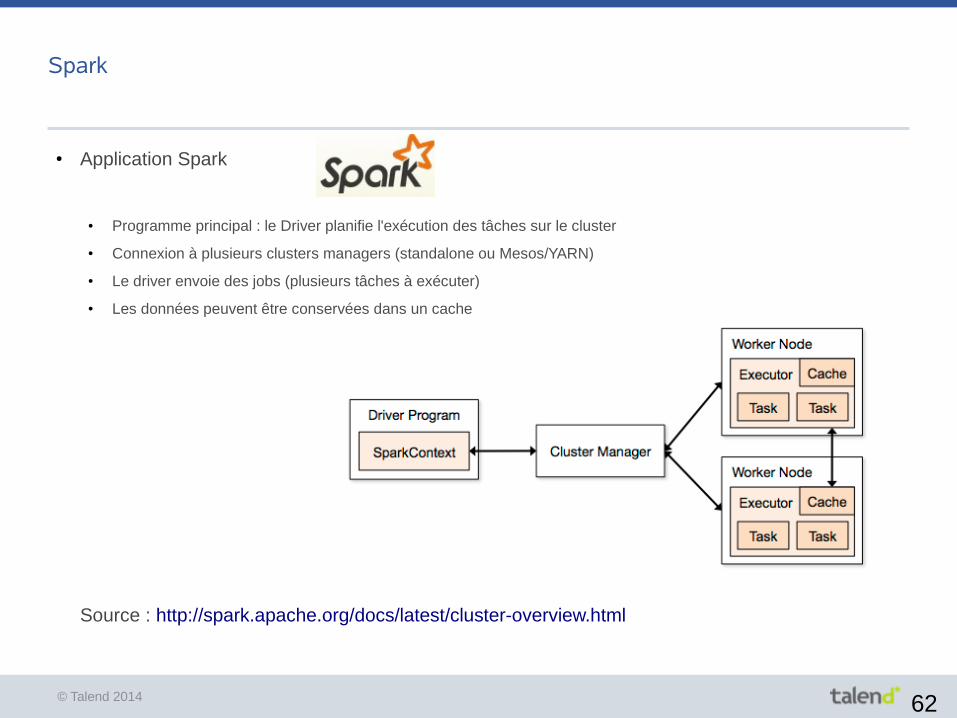
© Talend 2014 62
Spark
● Application Spark
● Programme principal : le Driver planifie l'exécution des tâches sur le cluster
● Connexion à plusieurs clusters managers (standalone ou Mesos/YARN)
● Le driver envoie des jobs (plusieurs tâches à exécuter)
● Les données peuvent être conservées dans un cache
Source : http://spark.apache.org/docs/latest/cluster-overview.html
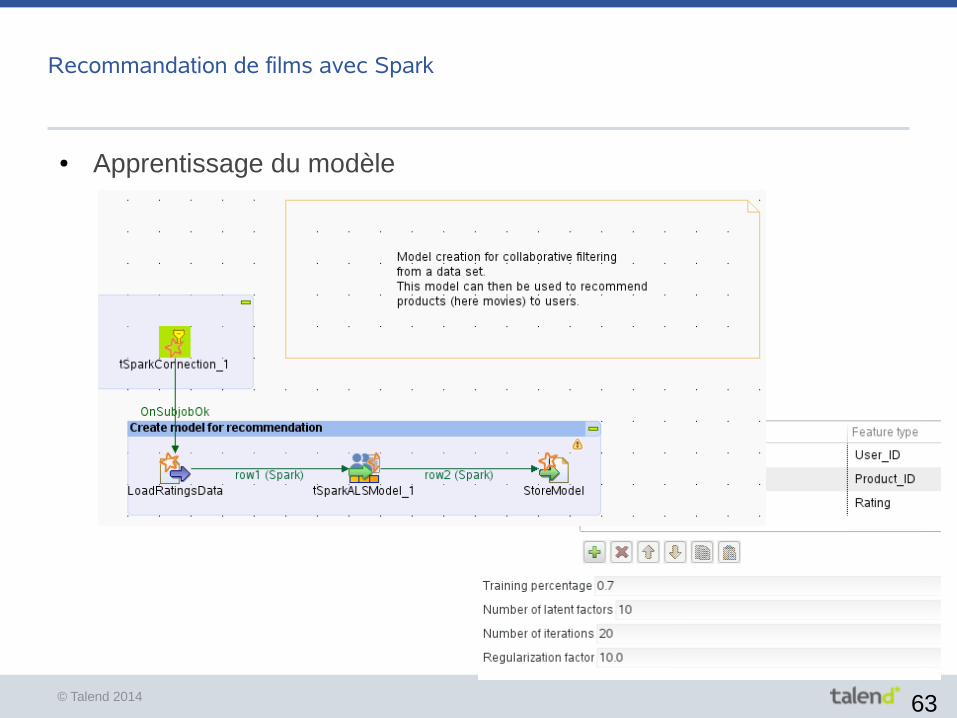
© Talend 2014 63
Recommandation de films avec Spark
● Apprentissage du modèle
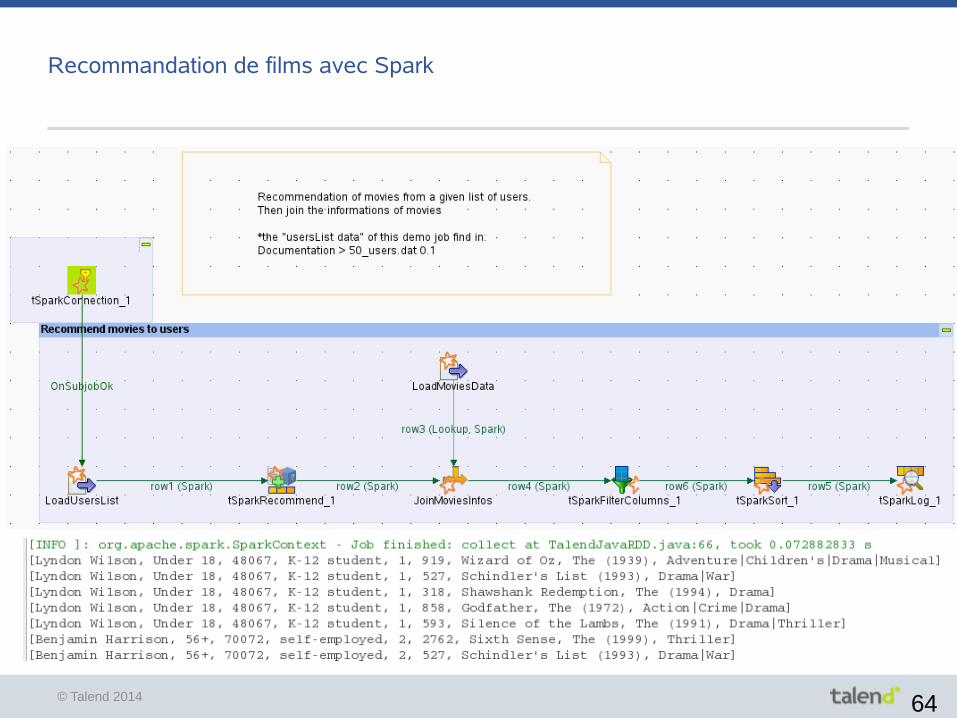
© Talend 2014 64
Recommandation de films avec Spark
© Talend 2014 65
Conclusion
● 2 révolutions technologiques ont conduit à une explosion des données
● Prix du stockage de l'information, le cloud
● De nouveaux paradigmes
● Les algorithmes sont déplacés auprès des données
● Naissance d'un OS distribué autour des données avec Yarn/HDFS
● L'architecture lambda pour la robustesse et la scalabilité
● L'immutabilité des données permet une approche plus mathématique des transformations de donnnées
● Le schéma à la lecture (schema-on-read) relaxe les contraintes imposées sur les données en entrée
© Talend 2014 66
Conclusion
● Les challenges
● La gestion de la qualité des données
● La gestion des algorithmes (complexité)
● Construire les outils pour gérer cette évolution













![Sebastiao-Salgado.pptx [Lecture seule]clubphoto.alcebazat.fr/wp-content/uploads/2017/01/Sebastiao-Salga… · •En2016, Sebastião Salgado se met au service de la liberté de la](https://img.pdfslide.fr/doc/110x75/601e547cd6c89b20d277a36d/sebastiao-lecture-seuleclubphotoalcebazatfrwp-contentuploads201701sebastiao-salga.jpg)

![mémoire CORREIA DA SILVAformatdialogue.intefp.fr/uploads/pdf/files/1548940378/fr/... · 2020. 11. 23. · î z u ] u v -h gpvluh dguhvvhu xq uhphuflhphqw j wrxwhv ohv shuvrqqhv](https://img.pdfslide.fr/doc/110x75/60c967f587076b4ab318c6a5/mfmoire-correia-da-2020-11-23-z-u-u-v-h-gpvluh-dguhvvhu-xq-uhphuflhphqw.jpg)












