Embed Size (px)
Citation preview

Action Concertée Incitative
MASSES DE DONNEES
Descriptif complet du projet
Attention, Toute proposition doit faire l’objet d’un résumé enregistré
avant le 22 mars 2004 directement sur le site web de l’ACI :
http://acimd.liris.cnrs.fr
Chaque dossier doit être
• déposé au plus tard le 29 mars 2004 sur le site web de l’ACI1:
http://acimd.liris.cnrs.fr
• envoyé par voie postale avec les signatures requises en 2 exemplaires
avant le 04 avril 2004 (cachet de la poste faisant foi)
à
Ministère délégué à la Recherche et aux Nouvelles Technologies Direction de la Recherche
Cellule ACI ACI Masses de données
1, rue Descartes 75231 Paris cedex 05
1 En cas de difficulté, une soumission par courrier électronique est possible à l’adresse [email protected]

Action Concertée Incitative
MASSES DE DONNEES
Descriptif complet du projet
I - FICHE D’IDENTITE DU PROJET Nom du Projet : (maximum 20 caractères) DEMI-TON
Titre du Projet : (maximum 3 lignes) Description multimodale pour la structuration automatique des flux de télévision.
Type du Projet2:
Projet de recherche
Projet de recherche multi-thématiques
Projet de recherche avec infrastructure
Projet associé à l’imagerie spatiale
Autre
X
Description courte du Projet : (une demi-page maximum) L'une des difficultés majeures de l'archivage des flux télévisuels est la structuration du flux en segments de différents niveaux entretenant des relations hiérarchiques : découpage du flux en émissions, découpage d'une émission en séquences de plateau et séquences de reportage par exemple. La difficulté de cette tâche est renforcée par le volume souvent très élevé des données à traiter. Par exemple, plus d’une quarantaine de chaînes de télévision qui diffusent pour la plupart 24h/24h sont enregistrées en permanence à l'INA. Le projet a pour objectif d’automatiser la structuration des flux télévisuels. Les outils disponibles actuellement ne portent que sur un seul média, sans fusion entre les différents médias. Nous proposons de développer de nouvelles méthodes basées sur l'utilisation simultanée de toutes les données disponibles : image, son, parole, mais aussi les informations a priori comme par exemple les grilles prévisionnelles de programmes. Cela nécessite d'une part d'établir un formalisme de modélisation qui puisse intégrer ces diverses sources et exprimer les problèmes de structuration que l'on souhaite résoudre, et d'autre part d'adopter une approche descendante afin d'être capable de prendre en compte les informations de haut niveau pour guider les processus d'analyse. Ce problème, apparu lors de collaborations passées davantage tournées vers les applications, nécessite une recherche plus fondamentale qui est l'objet de ce projet. Coordinateur du projet ( Partenaire 1) M. ou Nom du responsable Prénom Laboratoire (sigle éventuel et nom 2 Cocher la case correspondante au type du projet soumis.
Action Concertée Incitative
MASSES DE DONNEES
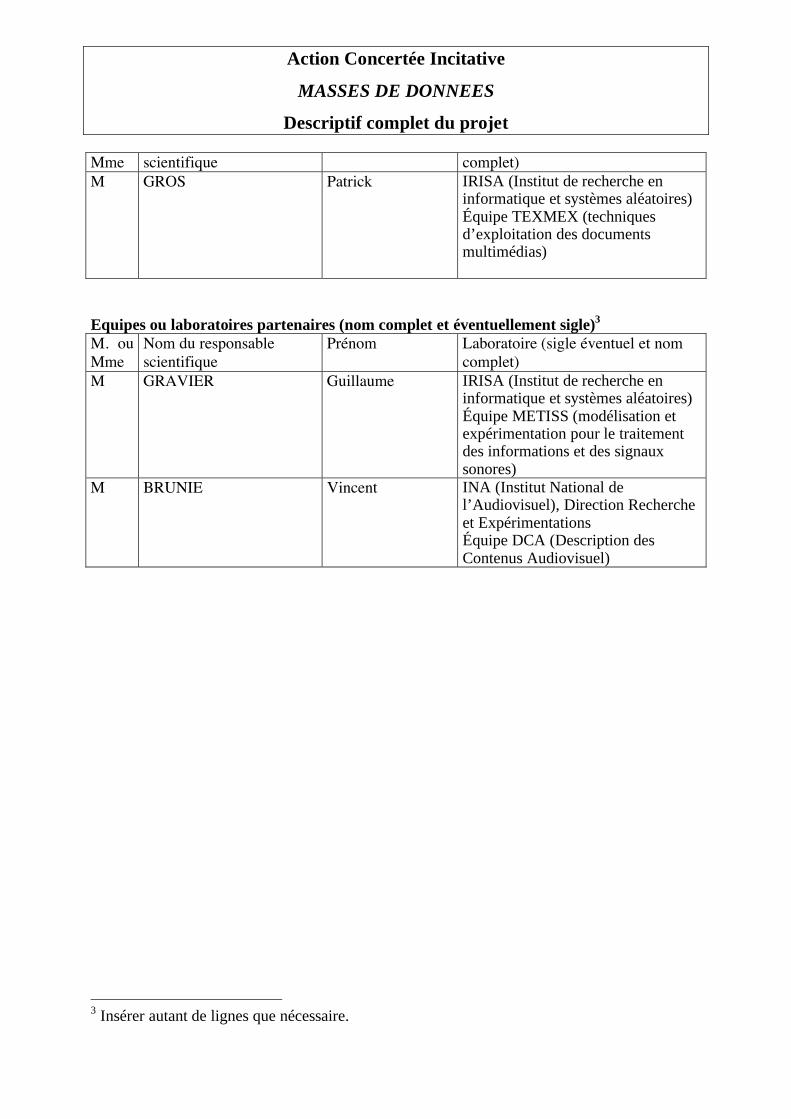
Descriptif complet du projet Mme scientifique complet) M GROS Patrick IRISA (Institut de recherche en
informatique et systèmes aléatoires) Équipe TEXMEX (techniques d’exploitation des documents multimédias)
Equipes ou laboratoires partenaires (nom complet et éventuellement sigle)3 M. ou Mme
Nom du responsable scientifique
Prénom Laboratoire (sigle éventuel et nom complet)
M GRAVIER Guillaume IRISA (Institut de recherche en informatique et systèmes aléatoires) Équipe METISS (modélisation et expérimentation pour le traitement des informations et des signaux sonores)
M BRUNIE Vincent INA (Institut National de l’Audiovisuel), Direction Recherche et Expérimentations Équipe DCA (Description des Contenus Audiovisuel)
3 Insérer autant de lignes que nécessaire.

Action Concertée Incitative
MASSES DE DONNEES
Descriptif complet du projet Informations de cadrage du projet4 : Durée : 36 mois Moyens demandés dans le cadre de l’ACI via le Fonds National de la Science (montants en Euros TTC)5 : Equipement 116 000
Fonctionnement 93 750
Dépenses de personnels (CDD) 191 100
Total 400 850
4 La durée d’un projet ne peut excéder 36 mois. Des demandes de projets d’une durée plus courte (24 mois) devront être particulièrement argumentées. 5 On veillera à ce que les totaux indiqués soient cohérents avec les montants indiqués dans la partie D.a

Action Concertée Incitative
MASSES DE DONNEES
Descriptif complet du projet
II - PRESENTATION DETAILLEE DU PROJET
A- IDENTIFICATION DU COORDINATEUR ET DES AUTRES PARTENAIRES DU PROJET :
A1- Coordinateur du Projet (partenaire 1): Un unique coordinateur doit être désigné par les partenaires. M. ou Mme. Prénom Nom 6 M. Patrick GROS
Fonction 6 Chargé de recherche CNRS – responsable de l’équipe TEXMEX
Laboratoire (Nom complet et sigle le cas échéant) 6
Équipe TEXMEX – IRISA (Institut de recherche en informatique et systèmes aléatoires, UMR 6074)
Adresse 6
IRISA – CNRS Campus de Beaulieu 35042 Rennes cedex
Téléphone 6 02 99 84 74 28
Fax 02 99 84 71 71
Mél 6 [email protected]
Organisme de rattachement financier de l’équipe ou du laboratoire pour le présent projet INRIA – Unité de recherche de Rennes
6 Champ obligatoire
Action Concertée Incitative
MASSES DE DONNEES
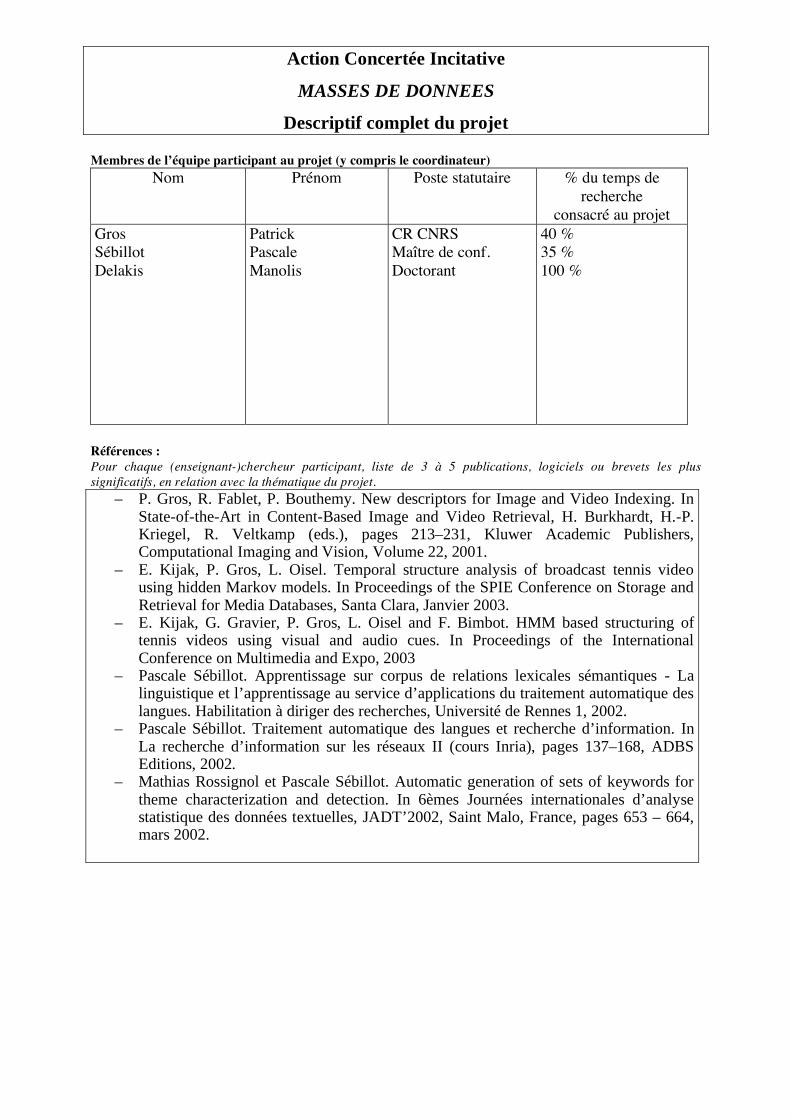
Descriptif complet du projet Membres de l’équipe participant au projet (y compris le coordinateur)
Nom Prénom Poste statutaire % du temps de recherche
consacré au projet Gros Sébillot Delakis
Patrick Pascale Manolis
CR CNRS Maître de conf. Doctorant
40 % 35 % 100 %
Références : Pour chaque (enseignant-)chercheur participant, liste de 3 à 5 publications, logiciels ou brevets les plus significatifs, en relation avec la thématique du projet.
– P. Gros, R. Fablet, P. Bouthemy. New descriptors for Image and Video Indexing. In State-of-the-Art in Content-Based Image and Video Retrieval, H. Burkhardt, H.-P. Kriegel, R. Veltkamp (eds.), pages 213–231, Kluwer Academic Publishers, Computational Imaging and Vision, Volume 22, 2001.
– E. Kijak, P. Gros, L. Oisel. Temporal structure analysis of broadcast tennis video using hidden Markov models. In Proceedings of the SPIE Conference on Storage and Retrieval for Media Databases, Santa Clara, Janvier 2003.
– E. Kijak, G. Gravier, P. Gros, L. Oisel and F. Bimbot. HMM based structuring of tennis videos using visual and audio cues. In Proceedings of the International Conference on Multimedia and Expo, 2003
– Pascale Sébillot. Apprentissage sur corpus de relations lexicales sémantiques - La linguistique et l’apprentissage au service d’applications du traitement automatique des langues. Habilitation à diriger des recherches, Université de Rennes 1, 2002.
– Pascale Sébillot. Traitement automatique des langues et recherche d’information. In La recherche d’information sur les réseaux II (cours Inria), pages 137–168, ADBS Editions, 2002.
– Mathias Rossignol et Pascale Sébillot. Automatic generation of sets of keywords for theme characterization and detection. In 6èmes Journées internationales d’analyse statistique des données textuelles, JADT’2002, Saint Malo, France, pages 653 – 664, mars 2002.

Action Concertée Incitative
MASSES DE DONNEES
Descriptif complet du projet
A2- Equipes ou laboratoires partenaires du Projet 7: Identification de l’équipe ou du laboratoire Equipe ou Laboratoire Équipe METISS – IRISA
Adresse IRISA – CNRS Campus de Beaulieu 35042 Rennes cedex
Organisme de rattachement financier de l’équipe pour le présent projet INRIA – unité de recherche de Rennes
Responsable du projet au sein de l’équipe ou du laboratoire M. ou Mme. Prénom Nom M. Guillaume Gravier
Fonction Chargé de recherche CNRS
Téléphone 02 99 84 72 39
Fax 02 99 84 71 71
Membres de l’équipe participant au projet (y compris le responsable)
Nom Prénom Poste statutaire % du temps de recherche
consacré au projet Gravier Kijak
Guillaume Ewa
CR CNRS ATER U. Rennes 1
40 % 80 %
Références : Pour chaque (enseignant-)chercheur participant, liste de 3 à 5 publications, logiciels ou brevets les plus significatifs, en relation avec la thématique du projet.
– G. Potamianos, C. Neti, G. Gravier, A. Garg and A. Senior. Recent advances in the automatic recognition of audio-visual speech, IEEE Proceedings, 2003.
– E. Kijak, G. Gravier, P. Gros, L. Oisel and F. Bimbot. HMM based structuring of tennis videos using visual and audio cues, Intl. Conf. On Multimedia and Exhibition, 2003
– G. Gravier, F. Yvon, B. Jacob, F. Bimbot. Integrating contextual phonological rules in a large vocabulary decoder, Integration of Phonetic Knowledge In Speech Technology, W. van Dommelen and B. Barry Ed., Kluwer Academic, 2003.
– G. Gravier, F. Yvon, B. Jacob and F. Bimbot. Sirocco - un système ouvert de reconnaissance de la parole., Journées d’Etudes sur la Parole, 2002.
– M. Betser and G. Gravier. Multiple event tracking in soundtracks, Proc. Intl. Conf. On Multimedia and Exhibition, 2004.
– M. Ben, G. Gravier and F. Bimbot. Enhancing the robustness of Bayesian methods for
7 Une fiche doit être remplie pour chaque laboratoire ou équipe partenaire

Action Concertée Incitative
MASSES DE DONNEES
Descriptif complet du projet
text-independent speaker verification, Proc. of Odyssey’04 Speaker and Language Recognition Workshop, 2004.

Action Concertée Incitative
MASSES DE DONNEES
Descriptif complet du projet A2- Equipes ou laboratoires partenaires du Projet 8: Identification de l’équipe ou du laboratoire Equipe ou Laboratoire Équipe Description des Contenus Audiovisuels (DCA)
Institut National de l’Audiovisuel Adresse Institut national de l’audiovisuel
Direction recherche et expérimentation 4 avenue de l’Europe 94366 Bry sur Marne cedex
Organisme de rattachement financier de l’équipe pour le présent projet Institut national de l’audiovisuel
Responsable du projet au sein de l’équipe ou du laboratoire M. ou Mme. Prénom Nom M. Vincent BRUNIE
Fonction Chercheur – responsable de l’équipe DCA
Téléphone 01 49 83 20 02
Fax 01 49 83 25 82
Membres de l’équipe participant au projet (y compris le responsable)
Nom Prénom Poste statutaire % du temps de recherche
consacré au projet Brunie Vinet Carrive Balin Poli
Vincent Laurent Jean Fabrice Jean-Philippe
Chercheur Chercheur Chercheur Ingénieur Doctorant
30 % 30 % 30 % 30 % 100 %
Références : Pour chaque (enseignant-)chercheur participant, liste de 3 à 5 publications, logiciels ou brevets les plus significatifs, en relation avec la thématique du projet.
– Auffret, G., Carrive, J., Chevet, O., Dechilly, T., Ronfard, R., Bachimont, B. « Audiovisual-based hypermedia authoring : using structured representations for efficient manipulation of AV documents », in proceedings of the ACM conference on Hypertext and Hypermedia 99, february 99, Darmstadt, Germany, February, ACM Press, pp. 169-178.
– Carrive, J., Pachet, F., Ronfard, R., « Clavis : a temporal reasoning system for classification of audiovisual sequences », in proceedings of the Content-Based Multimedia Access (RIAO’2000), Paris, France, 2000, April 12-14, pp. 1400-1415.
– E. Veneau, J. Pepy, L. Vinet, Toward a semantic indexing based on images color features similarity ?, International Conference on Image and Signal Processing,
8 Une fiche doit être remplie pour chaque laboratoire ou équipe partenaire

Action Concertée Incitative
MASSES DE DONNEES
Descriptif complet du projet
(ICISP’2001), Agadir, may 2001. – R. Landais, C. Wolf, L. Vinet, J.M. Jolion. « Utilisation de connaissances a priori
pour le paramètrage d'un algorithme de détection des textes dans les documents audiovisuels. Application à un corpus de journaux télévisés. » 14ème Congrès Francophone AFRIF-AFIA de Reconnaissance des Formes et Intelligence Artificielle. 28-30 janvier 2004 Toulouse.
– J. Carrive, F. Pachet, R. Ronfard (2000), « Logiques de descriptions pour l’analyse structurelle de film », in Ingéniérie des Connaissances, évolutions récentes et nouveaux défis, J. Charlet, M. Zacklad, G. Kassel, D. Bourigault (éd.), Eyrolles, pp. 423-438.
– J. Carrive, P. Roy, F. Pachet, R. Ronfard (2000), « A language for Audiovisual Template Recognition », in proceedings of the Sixth International Conference on Principles and Practice of Constraint Programming, Singapore, September 18-22, 2000.

Action Concertée Incitative
MASSES DE DONNEES
Descriptif complet du projet
B - DESCRIPTION DU PROJET
B1 – Objectifs et contexte : On précisera, en particulier, les verrous scientifiques et technologiques à dépasser, l’état de l’art ainsi que les projets concurrents ou similaires connus dans le contexte national et international, en particulier ceux auxquels
les équipes du projet participent.
1.1 Contexte applicatif et motivation
L’objectif applicatif du projet Demi-Ton est la structuration automatique des flux télévisuels. Cette activité consiste à construire automatiquement une structure de données qui représente l’organisation logique des différents éléments de production et de diffusion présents. Cette structure est alignée sur le flux, c’est-à-dire qu’elle doit comporter les informations temporelles nécessaires pour connaître la position temporelle de chacun de ses éléments.
La structuration de flux télévisuels est actuellement effectuée manuellement par un
nombre important d’acteurs du multimédia ayant à prendre en compte la dimension « flux » des contenus télévisuels et radiophoniques. C’est par exemple le cas des diffuseurs radio et TV, qui doivent être en mesure de produire des informations précises sur ce qui est effectivement passé à l’antenne, des sociétés de pige audiovisuelle, qui réalisent pour le compte de tiers des relevés de diffusion de tels ou tels contenus, des instances publiques de régulation de l’audiovisuel qui doivent être en mesure de vérifier le respect des contraintes légales (par exemple respect de l’équité du temps de parole des personnalités politiques) ou contractuelles (par exemple respect de quotas de diffusion dans le cadre d’un cahier des charges) des diffuseurs. Ce type d’activité peut également trouver sa place dans des applications destinées au grand public, par exemple dans des boîtiers de réception et d’enregistrement TV (Set Top Box, Personnal Video Recorder) qui, du fait de l’augmentation constante de leurs capacités de stockage, devront être capables de permettre à leurs utilisateurs de sélectionner dans le flux les contenus susceptibles de les intéresser et d’organiser ces éléments de flux sur le disque local.
C’est néanmoins dans les centres d’archivage audiovisuel que le problème de la structuration des flux télévisuels se pose de façon la plus aiguë. Ainsi, l'Institut National de l'Audiovisuel (INA), qui a pour mission d'archiver à des fins patrimoniales et commerciales les documents télévisuels et sonores télédiffusés en France, collecte et archive aujourd'hui par une captation permanente au titre du dépôt légal de la télévision 41 chaînes de télévision et 17 chaînes de radio diffusées par voie hertzienne, par le câble et par le satellite.
Le contenu de ces flux doit être documenté de façon adaptée à chaque type documentaire de façon à ce qu'il puisse être exploité au mieux, c'est-à-dire effectivement accessible pour la consultation publique dans le cadre de projets de recherche.
Techniquement, cette documentation se déroule en plusieurs étapes, dont en particulier : captation des flux, segmentation et documentation proprement dite. L'une des activités les plus coûteuses au cours de ce processus est la segmentation qui consiste à « découper » le flux en segments de différents niveaux de façon à ce que chacun de ces segments puisse être documenté séparément : découpage du flux global en émissions, découpage d'une émission en séquences de plateau et séquences de reportage, découpage des séquences de plateau en interviews, découpage des interviews en répliques, par exemple. Cette activité de structuration

Action Concertée Incitative
MASSES DE DONNEES
Descriptif complet du projet est une activité préalable nécessaire à l'activité de documentation à proprement parler puisqu'elle permet à la fois d'isoler des segments homogènes pouvant être documentés individuellement (par exemple : « le reportage où l'on voit les premiers prisonniers de la guerre Iran-Irak ») et de les situer dans le contexte où ils ont été diffusés (par exemple : « ce reportage fait partie d'une rétrospective sur les guerres impliquant l'Irak diffusé le 20 mars 2003 dans une édition spéciale du journal télévisé du 20h de TF1 consacré à la guerre USA-Irak »). Ainsi, par exemple, les documentalistes passent environ 30% de leur temps à isoler les plateaux des reportages dans les émissions de plateau (journaux télévisés et magazines).
Cette activité prend dans un environnement de travail audiovisuel traditionnel une part du temps de travail des documentalistes qui est considérée comme trop importante par rapport à sa valeur ajoutée, en comparaison avec le temps qu'il faut pour rédiger le résumé textuel d'une séquence ou lui attribuer des descripteurs. De plus, dans le contexte de publication automatisée qui ne manquera pas d'apparaître d'ici quelques années (qu’il s’agisse de diffusion en ligne, de cession d’extraits ou encore de publication multimédia), l'activité de structuration se voit également adjoindre la contrainte supplémentaire d'une excellente précision temporelle. En effet, les informations de structuration des flux vont devenir les repères utilisés pour la manipulation de ceux-ci à des fins non seulement de documentation comme c'est le cas dans l'environnement traditionnel, mais également de publication audiovisuelle et multimédia. Cette activité de publication peut impliquer des dispositifs de navigation par petites unités, des découpages et des remontages de segments, des projections de segments isolés, etc. La structuration devient la base d'une activité éditoriale multimédia qui doit reposer sur des repères précis à l'image près afin que les résultats soient conformes aux attentes. Or, la segmentation à des fins de documentation est aujourd'hui effectuée « par excès » afin de gagner du temps puisqu'il n'y a pas d'inconvénient à ce que les segments soient plus grands que ce qu'ils devraient être s'ils ont pour seul objectif de permettre à un opérateur humain de retrouver le contenu associé à une description.
La motivation applicative pour cette recherche consiste donc à tenter d'automatiser l'activité de structuration des flux afin, d'une part, que le travail humain soit concentré sur des activités à plus forte valeur ajoutée et, d'autre part, que le résultat de cette segmentation soit temporellement suffisamment précise pour qu'elle puisse servir de base à toutes les activités de publication multimédia de contenus audiovisuels.
L'importance de toute cette recherche est soulignée par l'augmentation récente des flux à traiter. Le dépôt légal des œuvres télévisuelles a été étendu en 2002 aux chaînes diffusées par câble ou satellite et 22 chaînes supplémentaires ont été ajoutées au processus de captation en septembre 2003. Le simple enregistrement des œuvres captées permet leur mémorisation, mais ne permettra pas d'utiliser un stock qui n'aurait alors plus d'utilité. Les 360 000 heures de télévision qui sont ainsi captées annuellement doivent être rapprochées des 17 000 heures archivées annuellement jusqu'au 1er janvier 2002 et des 513 200 heures que l'INA a en stock et qui représentent les archives de la télévision de l'origine à aujourd'hui (volume évalué au 30 juin 2002). 1.2 Approche globale et objectif du projet
L’approche globale retenue pour résoudre le problème de la structuration automatique des flux télévisuels réside en trois points clés :

Action Concertée Incitative
MASSES DE DONNEES
Descriptif complet du projet
- le traitement multimodal des flux télévisuels afin d’extraire de toutes les modalités disponibles les descripteurs susceptibles de fournir des indices permettant de repérer et d’identifier les éléments de structure présents dans le flux ; les acquis des différentes équipes participant au projet seront mobilisés, et certaines parties seront réorientées pour répondre plus particulièrement aux besoins de la structuration des flux ;
- la mise au point d’un modèle statistique permettant de représenter de façon homogène les différents descripteurs disponibles et de réaliser la fusion des données dans le contexte particulier de la structuration automatique des flux ;
- l’utilisation d’informations a priori, très souvent disponibles en accompagnement des flux, comme par exemple les grilles prévisionnelles de diffusion, qui peuvent également être intégrées dans le modèle ou bien être utilisées pour le contrôle du processus de structuration.
Le projet Demi Ton focalise ses travaux sur la mise au point du modèle statistique et sur
l’utilisation des informations a priori. Il mobilise les technologies existantes dans les équipes partenaires pour l’analyse élémentaire, sauf dans certain cas où il semble possible de faire évoluer des outils existants pour les rendre plus utiles dans ce contexte particulier. 1.3 État de l'art Analyse des pratiques actuelles
Pour permettre l'accès et la manipulation de documents multimédia, des index décrivant le contenu sont nécessaires. À ce jour, la construction des index est généralement prise en charge par les documentalistes qui partitionnent les documents vidéo et leur assignent manuellement un nombre limité de mots clés. Ce travail allie des phases répétitives, longues et à faible valeur ajoutée pour le personnel qui les effectue, comme la structuration des documents, et des phases à forte valeur intellectuelle ajoutée, comme l'annotation et l'indexation fine de certains segments.
Une solution naturelle à ce problème est d'automatiser certaines de ces tâches, en utilisant des techniques de structuration, d'extraction et de classification automatique du contenu du matériel vidéo. Trois aspects principaux sont à prendre en compte dans ce travail. Le premier est relatif au niveau de granularité à considérer et doit répondre à la question « Quoi ? » : que faut-il repérer, le document dans son ensemble, une séquence d'images ou des images isolées ? Le second aspect est relatif aux différentes modalités et à leur analyse et dépend de la réponse à la question « Comment ? » : faut-il indexer en utilisant une classification du signal image ou du signal sonore uniquement, faut-il combiner les différentes modalités ? Le troisième aspect est lié au type d'index à utiliser et doit répondre à la question « Avec quoi ? » : les noms des intervenants dans une émission de télévision, leurs visages, leur voix ou leurs positions relatives ? Outils d’analyse élémentaire
La plupart des solutions proposées pour l'indexation vidéo tentent de répondre à ces questions en reposant sur des approches monomédias : les composantes image, son et texte

Action Concertée Incitative
MASSES DE DONNEES
Descriptif complet du projet sont traitées et utilisées de manière généralement indépendante. Pour chacun de ces médias, de nombreux descripteurs ont été proposés et constituent une boite à outils utilisable. Une bonne compilation de ces approches est présentée dans deux ouvrages de référence [1,2] ainsi que dans des articles de synthèse [3,4].
L'analyse de la composante visuelle bénéficie de résultats obtenus dans le domaine de l'analyse d'images fixes ou de l'analyse du mouvement. De nombreuses contributions ont été proposées pour réaliser la segmentation temporelle des vidéos en plans élémentaires à partir de la détection de transitions visuelles [5], suivie d'un regroupement hiérarchique de ces plans élémentaire en scènes et de leur caractérisation à partir d'un ensemble réduit d'images représentatives (images-clés). Côté description des images, la plupart des descripteurs proposés caractérisent l'ensemble de l'image [6,7] : histogrammes de couleur, descripteurs de texture, descripteurs de forme, descripteurs globaux de mouvement. Ce champ de recherche est encore actif : les histogrammes de couleur se révèlent peu discriminants dans des bases d'images très volumineuses ; les descripteurs de texture sont chacun spécialisés pour certains types de texture et les descripteurs de forme reposent sur une segmentation automatique de l'image, qui est un problème difficile et non résolu dans le cas général. Des approches prometteuses reposant sur l'utilisation d'un ensemble de descripteurs locaux ont été proposées récemment et ouvrent la voie à des techniques dites de reconnaissance partielle : reconnaissance d'objets indépendants du fond de l'image, reconnaissance de portions de scène etc...[8].
De façon à répondre plus directement aux requêtes formulées par l'utilisateur portant plus naturellement sur la sémantique des documents que sur leur contenu élémentaire, des indices visuels de plus haut niveau sémantique peuvent être extraits. La détection et la reconnaissance de visages [9,10], la détection de texte incrusté (sous-titres) [11] ou la détection de logos (imagettes particulières) sont des techniques souvent indispensables pour caractériser des segments vidéo. Beaucoup reste à faire dans ce domaine, la plupart des techniques actuelles s'appliquant dans des conditions contraintes (éclairage contrôlé, fond d'image uniforme, vues frontales, ...) qui ne correspondent qu'à des situations très particulières dans les programmes vidéos.
L'indexation de documents textuels associés aux vidéos (script) bénéficie, contrairement à certains autres médias, d'une longue expérience des archivistes et documentalistes. L'indexation manuelle permet, à l'aide de listes d'autorité (listes de mots-clés) ou de thesaurus, de représenter de manière quasi unifiée, au sein d'un système de recherche d'information, les concepts abordés dans un texte. Cependant, la quantité croissante de documents numériques a laissé place à une indexation automatique « plein texte » (full text) qui, outre le problème du choix des mots contenus dans les textes qui vont les représenter (mots simples ou complexes, mots suffisamment discriminants, mots situés dans une certaine partie du texte,...), pose de nouveaux problèmes liés à une indexation non plus au niveau des concepts mais des mots. Deux de ces problèmes d'ordre sémantique sont fondamentaux : celui de la formulation différente d'une même idée (comment apparier le même concept contenu dans une requête et un texte, mais exprimé différemment) et, problème dual, celui de la désambiguïsation (un même mot - même chaîne graphique - pouvant exprimer des concepts différents). À ces difficultés se combine le fait que le sens d'un mot dans un document portant sur un domaine, et donc les liens sémantiques que ce mot entretient avec d'autres mots, varient en fonction de ce domaine.

Action Concertée Incitative
MASSES DE DONNEES
Descriptif complet du projet L’analyse de la composante son n’a été que peu exploité dans le contexte de la structuration de flux vidéo, à l’exception de la transcription automatique de la parole dans le cadre de l'indexation des journaux télévisés (JT). On trouve néanmoins quelques approches concernant la structuration et la caractérisation de flux sonores. Par exemple, la segmentation d'un flux sonore selon les classes parole/silence/musique ou l'indexation en locuteur sont des tâches largement exploitées, notamment dans le cadre de la transcription du JT ou de conférences. En revanche, la détection de sons clés ou encore la caractérisation de morceaux de musique (rock, classique, etc.) sont des domaines émergeant du traitement avancé du signal sonore qui trouvent leur application dans la structuration vidéo. Ces approches ne sont cependant que marginalement exploitées, à cause du manque de maturité et de fiabilité des techniques utilisées d’une part et, d’autre part, de l’absence de cadre théorique bien défini pour l’intégration. Les techniques présentées jusqu'à présent sont principalement monomédias, alors que les documents vidéo ne peuvent être compris généralement qu'en faisant intervenir tous ces médias. Créer des systèmes basés sur l'utilisation conjointe et simultanée de plusieurs médias demande de trouver un formalisme qui permette de décrire ce couplage. Modèles En matière d’intégration multimodale, de nombreuses approches sont possibles. Elles peuvent être classées en fonction de leurs propriétés respectives par rapport au cycle de traitement, de la prise en compte du contenu et de la méthode de classification. Le cycle de traitement peut être itératif, permettant l'utilisation incrémentale d'informations contextuelles, ou non itératif. La prise en compte du contenu peut être réalisée en utilisant les différentes modalités de manière symétrique (simultanée) ou de manière asymétrique (ad hoc). Finalement, la méthode de classification peut être statistique ou reposer sur un système à base de règles de décision. La plupart des méthodes proposées sont symétriques et non itératives. Certaines suivent une approche à base de règles de décision. En [17], par exemple, les modalités visuelles et sonores sont intégrées de façon à détecter de la parole, du silence, l'identité des locuteurs, des plans contenant ou non des visages, parlants ou non. Les visages parlants sont détectés, en localisant des visages dans les plans vidéos et en mesurant le volume de parole dans ces mêmes plans, puis en utilisant un ensemble de règles de décision. De nombreuses méthodes se basent sur une approche statistique. Un exemple de méthode statistique, symétrique et non itérative est constitué par le système Name-It [18]. Le système associe des visages détectés et des noms, en calculant un facteur de cooccurrence qui combine les résultats des modules de détection et reconnaissance de visages, d'extraction de noms et de reconnaissance de sous-titres. D’autres approches préliminaires utilisant une analyse multimodale sont apparues très récemment [12,13], certaines exploitées commercialement [14]. Dans la plupart, l'intégration des différentes modalités sert de méthode de vérification ou de méthode de compensation des erreurs ou imprécisions de chaque modalité. Un aspect important, indispensable pour l'intégration de données hétérogènes, est la synchronisation et l'alignement de ces différentes modalités, étant donné que ces modalités doivent partager un même référentiel temporel (timeline) et être analysées à un même degré de granularité. L'étude de la littérature dans ce domaine nous montre que les modalités sont généralement converties dans un format conforme à l'expertise principale des équipes de recherche. Ainsi, lorsque l'analyse sonore est la spécialité d'une équipe, les séquences d'images sont converties en (milli)secondes [15]. D'une manière symétrique, les équipes spécialisées en analyse d'image alignent les enregistrements

Action Concertée Incitative
MASSES DE DONNEES
Descriptif complet du projet sonores sur les frames ou les plans détectés. Ces approches supposent un alignement a priori connu et parfait entre les signaux visuels et sonores, ce qui est rarement le cas. Des approches permettant des procédures d'alignement automatique sont à développer. Une première approche proposée en [16], consiste à aligner images et enregistrements sonores en mettant en correspondance les mots résultant d'une transcription sonore et le script d'un journal télévisé. Les modèles de Markov cachés (MMC) s'imposent de plus en plus comme méthode statistique de référence pour l'intégration multimodale [12,15]. Ils offrent l'avantage de pouvoir intégrer des modalités hétérogènes, et sont de plus capables de prendre en compte des données séquentielles. Ils sont en outre particulièrement appropriés pour combiner différents classifieurs monomédias. Notons que, dans ce cas, la plupart des méthodes font l'hypothèse de l'indépendance des médias, qui peut être réductrice. D'autres approches reposent sur l'utilisation de modèles statistiques bayésiens, bien adaptés à la fusion de données [19]. Notons que ces formalismes permettent d'accumuler des évidences issues de médias différents, cela exigeant toutefois que les classificateurs monomédias puissent fournir leurs résultats sous une forme probabiliste. Contrastant avec les méthodes présentées précédemment, certaines approches sont asymétriques, en ce sens que les modalités ne sont pas utilisées simultanément. Par exemple, en [15], un MMC segmente tout d'abord le flux vidéo en trois catégories en se basant sur la modalité audio, puis, dans un second temps, partage plus finement chacun de ces segments en se basant sur la modalité visuelle. Des résultats récents tendent à montrer que l'utilisation de combinaisons de classificateurs statistiques pour l'intégration multimodale est prometteuse. Par contre, les systèmes les employant sont peu nombreux et très spécialisés. En outre, il semblerait que la prise en compte des informations textuelles, riches sémantiquement, est généralement délaissée au profit des modalités visuelles et sonores, alors que la combinaison de ces trois modalités peut permettre de lever de nombreuses ambiguïtés. Il apparaît donc que de multiples applications, plus générales, sont envisageables notamment avec l'extension du formalisme des modèles de Markov cachés et la prise en compte de toutes les ressources disponibles, à des résolutions temporelles différentes. Utilisation d’informations a priori Toutes les méthodes de structuration et de classification de document utilisent une large part d’a priori, notamment sur le contenu du document afin de déclencher les traitements adéquats. Ces connaissances a priori sont souvent liées à une méthode qui ne s’applique qu’à certains types de documents. Par exemple, pour structurer une vidéo de tennis, on peut utiliser efficacement des connaissances a priori sur les règles de production de la télévision ainsi que sur la structure du jeu en terme de match, points et sets [20]. De même, on utilisera des connaissances sur les règles de production pour structurer au mieux un journal télévisé. Dans la grande majorité des cas, les approches de structuration proposées dans la littérature ne s’appliquent qu’à un seul type de document. De ce fait, l’utilisation des connaissances a priori est figée au sein du modèle et ne peut s’adapter de manière dynamique à un contenu. 1.4 Projets passés et projets en cours

Action Concertée Incitative
MASSES DE DONNEES
Descriptif complet du projet De nombreux projets ont adressé la problématique de l'indexation multimodale sans la considérer comme centrale, la plupart avec peu de succès. Parmi ceux auxquels ont participé l'IRISA et/ou l'INA, on peut citer DiVAN (Esprit), Diceman (ACTS) et AGIR (RNRT) qui ont tous eu l'ambition d'extraire des descripteurs multimodaux. Le problème s'est néanmoins révélé plus difficile que prévu, en particulier en ce qui concerne la possibilité d'identifier quels seraient les descripteurs multimodaux utiles pour une activité donnée.
Ces premiers travaux nous ont néanmoins permis de baliser le travail. Au sein du projet RNRT AGIR auquel participaient l'INA, METISS et des personnes de TEXMEX, nous avions exploré une piste syntaxique via l'utilisation des schémas de description MPEG-7. Cela permet une grande puissance d'expression, mais ne résout que le problème... syntaxique. Cela permet de créer des descripteurs aussi complets que souhaités, mais n'assure aucune intégration au niveau des outils d'extraction ou de reconnaissance d'informations. Cela correspond plutôt au modèle de fusion à haut niveau des informations et décisions prises séparément sur chaque média. Ce projet a aussi permis de tester la pertinence des divers outils d'extraction d'informations disponibles sur chaque médias dans le contexte d'applications intéressant l'INA. Les recherches ont progressé et il est maintenant envisageable d'arriver à des résultats satisfaisants en concentrant une activité de recherche sur cette question et sur la façon d'extraire ces descripteurs. Le projet RIAM FERIA auquel participe l'INA et TEXMEX reprend les éléments techniques et architecturaux des projets précédents et a pour but de développer un framework de développement d'applications. Au sein de ce projet sont réunies les compétences nécessaires pour fournir les briques de base, et le projet vise à fournir l'infrastructure logicielle qui permettra de les combiner de manière souple et variée pour des applications différentes. Ce projet est de type précompétitif et il n'est pas le cadre pour résoudre des problèmes théoriques nouveaux. Par contre, les partenaires de Demi-Ton s'appuieront sur l'infrastructure technique fournie par le projet FERIA. Le cadre technologique proposé sera suffisamment unifié pour que la multimodalité et la coopération entre analyse automatique et description manuelle ne rencontre pas d'obstacle technique. On retrouve cette même thématique dans le projet Domus Videum auquel participent l'INA et METISS, dans un contexte et un partenariat un peu différent. Le projet Domus Videum développe quelques approches concernant l’utilisation d’attributs extraits de la bande sons pour le résumé et la structuration de vidéo de sports et de documentaires. Entre autres choses, les travaux menés dans ce cadre sur la structuration audiovisuelle de vidéo de tennis à l’aide de chaînes de Markov cachés ont montré le potentiel de l’approche markovienne pour l’intégration multimodale, tout en mettant en évidence la nécessité d’une approche plus intégrée. La thèse d'Ewa Kijak, dans laquelle TEXMEX et METISS sont impliqués, se termine sur un exemple de modèle d'intégration de quelques informations sonores et visuelles au sein d'un même modèle de Markov caché. Ce travail met en avant les difficultés à résoudre, par exemple celle de la prise en compte au sein d'un même modèle d'informations de granularité temporelle différente : images tous les 24e ou 25e de seconde, informations sonores tous les centièmes de secondes, résultats de segmentation fournissant des intervalles, événements clés ponctuels, décalage entre les divers résultats de segmentation... Les principaux projets connus sur l'indexation multimodale sont : - le projet IST M4 (http://www.dcs.shef.ac.uk/spandh/projects/m4/) qui traite le cas
particulier des réunions de travail filmées ; - le projet RNRT RECIS (http://lisi.insa-lyon.fr/~eegyedzs/Recis/index_en.htm) récemment
terminé qui est orienté vers la recherche de contenus par des outils de navigation construit par analyse séparée des différentes modalités ;

Action Concertée Incitative
MASSES DE DONNEES
Descriptif complet du projet - les projets menés par le consortium suisse IMS (http://www.im2.ch/) sont également
centrés sur la construction d'un cadre d'intégration probablement comparable à celui de FERIA.
Par rapport aux autres projets existants, les points forts de Demi-Ton sont : - la prise en compte des flux télévisuels dans leur ensemble en envisageant leur description
aux niveaux nécessaires ; - la prise en compte de besoins applicatifs désormais clairement identifiés par une
communauté professionnelle ; - le bénéfice d'une architecture technique parfaitement adaptée aux besoins expérimentaux et
garantissant la possibilité de concentrer les efforts du projet sur la recherche qu'il souhaite mettre en œuvre, et non sur le développement de l'infrastructure nécessaire ;
- un environnement expérimental réel ; L’expérience des partenaires de ce projet, acquise à travers la participation aux divers projets mentionnés ci-dessus, est également un point fort pour le succès de Demi-Ton. 1.5 Enjeux scientifiques
L’enjeu scientifique du projet est d’attaquer les points bloquants de l’analyse multimodale des documents multimédias. Le premier enjeu est de mettre en place dans cet objectif une véritable collaboration entre les outils d’analyse propres à chaque modalité. Cet enjeu est abordé depuis maintenant assez longtemps mais les solutions se sont toujours heurtées à deux difficultés. La première est qu'on est encore loin d'avoir épuisé ce qui est faisable sur chaque média et que les spécialistes de chaque média ne manquent pas de travail dans leur propre domaine avant d'envisager d'aller voir ailleurs. La deuxième est plus structurelle : la plupart des équipes de recherche sont monodisciplinaires et ont donc plus de difficultés à traiter des problèmes faisant intervenir plusieurs domaines, d'autant plus que ces domaines ont chacun une grande richesse conceptuelle, théorique et un outillage varié. Le deuxième enjeu est la mise au point d’un modèle de fusion destiné à la reconnaissance des structures des documents audiovisuels dans toute leur complexité, et non plus simplement destiné à la segmentation dans le sens traditionnel du terme. Ceci impose de prendre en compte dans le modèle les informations disponibles sur les relations, hiérarchiques et éventuellement plus complexes, existant entre les segments à identifier. Le troisième enjeu est l’utilisation des informations disponibles a priori. Celles-ci sont complexes et variées et en général d’assez haut niveau. Il s’agit par exemple des grilles de programmes fournies par les diffuseurs qui présentent les horaires prévisionnels de diffusion des programmes. Il peut également s’agir d’images et de sons prototypiques de certains éléments de contenus identifiés comme tels par les documentalistes, comme par exemple des jingles sonores, des habillages, etc. L’objectif est d’être capable d’utiliser ces informations sans lesquelles la structuration automatique ne peut probablement pas être réalisée, d’une part en les incorporant dans le modèle de fusion pour qu’ils soient considérés comme des éléments entrant en jeu dans la reconnaissance à proprement parler, d’autre part en les utilisant pour le pilotage de l’analyse afin par exemple d’éviter des analyses inutiles ou d’adapter les outils (paramétrage ou adaptation de modèle) à ce qui est attendu. Le quatrième enjeu est le passage à une approche descendante. L’approche retenue, notamment par la place importante qu’elle accorde à l’utilisation des informations disponibles a priori de haut niveau, semble remettre en cause le modèle le plus répandu enchaînant

Action Concertée Incitative
MASSES DE DONNEES
Descriptif complet du projet extraction de descripteurs, segmentation et classification pour le remplacer par un modèle où les informations de haut niveau disponibles déterminent le processus d’analyse. De plus, le projet aborde également des enjeux liés à l’apprentissage, à la généralisation et à l’auto-adaptation, sur lesquels il n’effectuera pas de recherches spécifiques mais pourra proposer des pistes intéressantes. Il semble en effet difficile d’envisager, dans le contexte de la structuration automatique, une approche reposant sur un apprentissage supervisé, d’une part de chacun des outils d’analyse, d’autre part du processus global de structuration. Il est nécessaire de prévoir, à terme, des possibilités d’apprentissage par généralisation de façon à ce qu’un outil d’analyse puisse être paramétré par un très faible nombre d’exemples choisis par l’utilisateur, comme par exemple les habillages des séquences de publicité sur telle chaîne. Sur une piste voisine de celles évoquées précédemment, il sera nécessaire d’envisager à terme des moyens d’adaptation automatique des outils d’analyse aux contenus qu’ils traitent en fonction des informations disponibles a priori ou extraites dans une étape précédente de l’analyse. La détection de motifs répétitifs doit aussi permettre aux outils, en utilisant les résultats obtenus lors des premières apparitions d’un motif, d’améliorer sa reconnaissance des apparitions suivantes de celui-ci. B2 – Description du projet : (5 à 10 pages) Entre autres, le caractère innovant du projet (concepts, technologies, expériences …) devra être explicité et la valeur ajoutée des coopérations entre les différentes équipes sera discutée.
Le projet a pour but de proposer un modèle qui permette d'exprimer de manière unifiée toutes les informations issues d'une vidéo, quel que soit le média dont elles sont issues, mais qui permette aussi d'exprimer les besoins d'utilisation de ces données. La fourniture de ce modèle va de pair avec celle des algorithmes d'extraction et de fusion des informations nécessaires et de ceux d'utilisation du modèle obtenu. Le travail effectué sera expérimenté dans le cadre applicatif qui motive ce travail, celui de la structuration automatique de flux de télévision. Pour cela, le modèle sera alimenté par des données générées par des modules d’analyse élémentaire existants dans les équipes du projet. De plus, des possibilités de collaboration entre méthodes d’extraction de descripteurs identifiées comme intéressantes seront étudiées. Cette identification est en partie déjà effectuée, mais de nouvelles pistes pourront être explorées. Les informations disponibles a priori seront utilisées à la fois pour alimenter le modèle et piloter son fonctionnement. 2.1 État des usages Comme il a été dit précédemment, le besoin initial pour la structuration des flux télévisuels est celui lié à l'activité de documentation dans le cadre du dépôt légal de la télévision. Il s'agit donc pour cet usage d'être capable de repérer les unités devant faire l'objet d'une documentation. Le flux capté est une composition de divers éléments : émissions complètes diffusées sans interruption (exemple : l'émission « l'heure de vérité » du xx/xx/xx), émissions diffusées avec des interruptions, publicités, autopromotion, interprogrammes, épisodes d'une série d'émissions, émissions appartenant à une collection, etc. Néanmoins, les segments susceptibles

Action Concertée Incitative
MASSES DE DONNEES
Descriptif complet du projet d'être documentés n'appartiennent pas forcément uniquement à ce niveau. Des segments des niveaux suivants peuvent par exemple également être documentés : - le niveau « saison » caractérisé par la grille de programmes en vigueur sur cette saison ; - le niveau « journée de diffusion » ; - le niveau « tranche horaire » ; - le niveau « programme » qui, comme nous l'avons vu, ne correspond pas nécessairement à
un segment contigu, mais peut avoir été interrompu par divers éléments ; il correspond plutôt en réalité à une unité de production ;
- le niveau « interprogramme » ; - les éléments de structure (souvent appelées « séquences ») des programmes eux-mêmes
dans des émissions composites ou fortement structurées, comme par exemple : les plateaux / reportages / interviews des journaux télévisés ; les interventions des invités dans un grand nombre de programmes à base de
plateaux ; les reportages dans différents types de programmes ; les performances dans les programmes de variétés, etc.
Le besoin supplémentaire pour la structuration des flux télévisuels est celui prescrit par les activités de manipulation de contenus : publication en ligne, vente d’extraits, thématisation, etc. Il s'agit dans ce cas d'offrir la structuration nécessaire aux manipulations des contenus dans des activités de publication de ces contenus. Des niveaux de complexité très différents sont envisageables, il peut s'agir, par exemple : - d'être capable de reconstituer intégralement et « proprement » un programme à partir du
flux de diffusion, sachant qu'il a pu être interrompu par des publicités et subir un début et une fin en fondu enchaîné ;
- d'isoler un reportage au sein d'un journal télévisé ; - de synthétiser toutes les interventions d'un invité dans un talk show comportant plusieurs
invités ; - de naviguer dans un documentaire à base d'interviews par sa table des matières ; - de publier des offres d'extraits thématiques d'une archive généraliste telle que celle de
l'INA. Un des objectifs du projet sera donc de proposer une modélisation des structures des flux sur laquelle pourront s'appuyer les applications de documentation et de navigation. Les modèles génériques (modèles de documents, modèles de média, modèles temporels, modèles structurels) sur lesquels doit s'appuyer cette modélisation sont relativement bien connus et maîtrisés par les équipes présentes dans le projet. Ces aspects ne feront donc pas l'objet de nouvelles recherches. Par contre, les modèles spécifiques dont des exemples viennent d'être donnés devront être développés de façon à répondre aux besoins du projet. Ces modèles seront l'articulation entre la partie « analyse » et la partie « usage » du projet. 2.2 Un modèle général de combinaison Deux stratégies de fusion d'informations sont généralement opposées : intégration précoce d'une part et tardive d'autre part. Dans l'intégration tardive, l'opération de fusion s'appuie sur des décisions partielles prises indépendamment dans chacune des modalités présentes. Bien que l'intégration tardive soit un candidat de choix pour traiter des données hétérogènes, dans la mesure où les décisions partielles sont, par nature, plus homogènes qu'une description bas-niveau de chacun des flux, il nous parait important de baser le processus de structuration sur l'ensemble des informations plutôt que sur un ensemble de décisions

Action Concertée Incitative
MASSES DE DONNEES
Descriptif complet du projet partielles. De plus, ce schéma d’intégration cumule les erreurs des différentes décisions partielles. À l’opposé, l'intégration précoce présente plusieurs inconvénients, notamment celui de la réduction de l'information disponible en essayant d'établir une représentation unique de l'ensemble des flux d'informations dans un espace commun. Il n'est donc pas possible de traiter par cette approche des données de natures trop différentes. Afin de pallier aux problèmes respectifs des deux approches mentionnées, nous proposons de développer un cadre permettant une analyse des flux de données basée sur la modélisation conjointe des différentes sources d'informations. Un tel modèle vise à intégrer au mieux toutes les informations disponibles pour mener la tâche visée à bien. En particulier, un des points importants est la possibilité de prendre en compte au sein du modèle des flux d'informations ayant des résolutions temporelles différentes. Par exemple, cette différence de résolution temporelle apparaît très clairement entre des descripteurs issus d'un flux vidéo à 25 Hz et des descripteurs audio dont la résolution est typiquement 100 Hz. Par ailleurs, notons que cet échantillonnage peut être irrégulier comme c'est le cas, par exemple, pour des flux textuels. Enfin, le modèle doit permettre d’exploiter aisément les informations a priori disponibles comme la grille des programmes. L'approche proposée se base sur une extension du formalisme des modèles de Markov cachés (MMC) en introduisant la notion de trajectoires multiples. Cette approche combine les avantages d'une approche par MMC multi-flux [21] avec ceux d'une approche par modèle de trajectoire ou modèles segmentaux [22]. Ces derniers modèles, introduits en traitement automatique de la parole, associent à un état de la chaîne de Markov non plus une seule observation mais un segment contenant une séquence d’observations. Nous proposons d’étendre ce formalisme afin d'associer un ensemble de segments de longueur et de résolution temporelle différentes à chaque état du MMC. Une telle approche doit non seulement permettre une modélisation conjointe des différentes sources d'information à notre disposition mais permet également d'intégrer des connaissances de haut niveau quant à la tâche à effectuer, notamment au niveau de la structure des MMC. Une première approche du formalisme à base de modèles à trajectoires multiples a été proposée dans le cadre de la thèse de Ewa Kijak (thèse Thomson/IRISA, TEXMEX) et expérimentée sur une tâche de structuration vidéo sur la base des images et du son. Dans ce projet, nous envisageons d'approfondir ce cadre théorique pour prendre en compte de nouvelles sources d'informations (texte, métadonnées, etc.) ainsi que les contraintes et spécificités de la tâche de structuration envisagée. Le travail consiste donc à étayer le formalisme des modèles de trajectoires multiples pour y inclure de nouvelles informations, à étudier comment cette approche se combine avec les tâches de structuration envisagées et à développer les algorithmes appropriés à la structuration. Soulignons que ce travail de modélisation s'accompagne nécessairement de travaux concernant la représentation des flux de données et l'extraction d'information de chacun des flux. 2.3 Les composantes élémentaires Le son En matière de description de la bande sonore, quatre modules seront utilisés, correspondant à quatre fonctions d’analyse sonore élémentaire. Le projet s’appuiera sur les modules développés par l’équipe METISS dans le cadre de précédents travaux. La première fonction consiste à détecter des plages sonores homogènes, permettant ainsi de réaliser une segmentation de la bande sonore qui est un prétraitement indispensable pour certaines applications telles que la transcription. Les techniques mises en œuvre pour cette

Action Concertée Incitative
MASSES DE DONNEES
Descriptif complet du projet tâche sont typiquement des algorithmes de détection de ruptures à l'aide d'un critère d'information bayésien. La deuxième fonction vise à déterminer si un événement sonore donné et connu est présent dans un document ou dans un plage sonore donnée. Dans ce domaine, les méthodes proposées se basent principalement sur l'utilisation de tests binaires d'hypothèses avec une modélisation par mélange de gaussiennes de la distribution des descripteurs audio. La domaine d'application privilégié pour cette tâche est très certainement la vérification vocale d'identité qui consiste à déterminer si un locuteur donné est présent dans un document ou pas La troisième fonction consiste à segmenter et à détecter une ou plusieurs classes de son données dans un document. Deux approches sont possibles pour traiter ce problème. La première consiste à segmenter le document sonore en plages homogènes et à caractériser le contenu de chacune des plages homogènes à l'aide d'une méthode de détection de classe sonore. La seconde approche, très largement utilisée, se base sur l'utilisation d'un modèle de Markov caché dans lequel chaque état correspond à une classe sonore, elle-même modélisée par un mélange de gaussiennes. Enfin, un module de transcription de la parole, basé sur une approche combinant modèles statistiques de langage et modèles de Markov cachés pour la modélisation acoustique, sera utilisé. L'amélioration des systèmes de transcription n'entre pas dans le cadre du projet et l’on se contentera d’adapter le module existant aux données à traiter. À l’inverse, l’interaction entre ce module et les autres médias, en particulier avec les techniques de traitement automatique des langues, sera étudié. La vidéo En matière de description de la vidéo, nous réutiliserons des modules développés dans le cadre de divers autres contrats (PRIAM Médiaworks, RNRT AGIR, RIAM FERIA…) Comme pour le son, le but du présent projet n’est pas de travailler à l’amélioration de ces modules, mais de les placer dans un cadre plus général, et d’étudier leurs interactions. Un premier module, reposant sur l'analyse du mouvement de caméra, aura pour but de détecter les transitions, de segmenter et caractériser les plans. Le découpage en plans est réalisé en analysant les variations du mouvement de la caméra ou les variations de contenu d'une image à l'autre à partir de descripteurs basés « images fixes ». Les paramètres estimés du mouvement de caméra peuvent être utilisés pour typer les segments vidéo ou unités temporelles ainsi déterminés (travelling, changements de plans, zoom). On peut extraire un nombre réduit d'images représentatives (images clés) du flux vidéo, pour représenter au mieux le contenu de chacun de ces segments. Ces dernières permettent de construire des résumés iconiques de la vidéo et d'y définir des points d'entrée. Un second ensemble de fonctionnalités concerne le calcul de descripteurs pour les diverses plages temporelles issues de la segmentation. En matière de vidéo, les éléments les plus intéressants sont la détection et la reconnaissance des visages, la détection et la reconnaissance du texte incrusté (nom des personnes interviewées par exemple) ainsi que la détection d’éléments particuliers comme les logos. L’ensemble de ces fonctionnalités est développé dans le cadre du projet RIAM FERIA et nous les reprendrons donc directement. Le texte L'utilisation de données textuelles se révèle en routine indispensable à la documentation et à l'exploitation des documents audiovisuels. Ces données textuelles sont diverses par leurs contenus et leurs origines. Elles peuvent être professionnelles (thésaurus, conducteurs

Action Concertée Incitative
MASSES DE DONNEES
Descriptif complet du projet d'émissions, etc.) ou non (ontologies propres à certains domaines, corpus d'articles de journaux), issues du flux audiovisuel (texte incrusté, transcription de la parole) ou externes à celui-ci (programmes électroniques). Nous proposons d’utiliser principalement deux sources de texte : la transcription de la bande sonore sera fournie à un module de thématisation dont le but est de repérer les changements de thèmes dans le texte et de caractériser le thème de chaque segment homogène, information qui pourra être utilisée pour segmenter le flux. Les outils dont nous disposons n’ont pas été conçus dans ce cadre où les textes sont fortement dégradés (textes agrammaticaux, pas de ponctuation ni structure, onomatopées, noms propres non reconnus…). Un important travail est donc à faire pour tester les outils actuels, les adapter et les rendre plus robustes pour pouvoir traiter de telles données, sachant qu’à l’inverse, la segmentation en thèmes peut tirer profit d’indices extraits de la bande son ou vidéo. Ce travail est suffisamment important pour justifier une thèse qui y soit entièrement consacrée. Nous proposons aussi d’étudier une deuxième approche qui part du constat suivant. On dispose dans un certain nombre de cas et plus particulièrement dans celui de l'actualité, d'informations textuelles venant compléter les documents audiovisuels : articles de journaux, dépêches d'agence par exemple. Ces informations peuvent être exploitées pour aider à la structuration d'un ensemble de documents audiovisuels. Des outils de traitement automatique des langues peuvent être mobilisés pour extraire une structuration thématique d'un corpus de textes afférents à un corpus audiovisuel. Cette structuration thématique pourra alors être liée temporellement au corpus audiovisuel par l'intermédiaire d'une analyse textuelle de la transcription de la bande son. Combinaisons entre modules La fusion entre informations issues de modalités différentes est au cœur du projet. Celle-ci sera étudiée selon deux axes de travail. Les modèles stochastiques fournissent un cadre général pour intégrer les informations. Leur utilisation est écrite au paragraphe 2.2. À côté de ce cadre général, des coopérations plus spécifiques entre applications sont intéressantes. Deux cas se présentent. Tout d’abord celui où une fusion des informations de bas niveau issues de deux médias peut permettre une meilleure décision. C’est le cas de la reconnaissance couplée locuteur / visages, la personne dont on entend la voix étant présente à l’écran la plupart du temps. Un cadre bayésien doit permettre d’intégrer de telles informations, en particulier en modifiant les a priori. Notons que dans ce cas, les modules de traitement de chaque média ne sont pas affectés. Il n’y a pour le moment guère de possibilités de modifier un détecteur de visages pour y intégrer une information sonore. Un deuxième cas est celui où les informations issues d’autres médias peuvent être utilisées au sein même d’un module. C’est le cas des modules de segmentation sonores et textuels qui ont besoin de disposer d’une échelle à laquelle ils doivent rechercher des ruptures. La fourniture d’une telle information, issue par exemple de la segmentation de la vidéo en plans pour la segmentation sonore, par la segmentation sonore pour la thématisation, peut permettre un meilleur lissage des résultats et ensuite une fusion plus facile par le modèle stochastique. 2.4 Pilotage du modèle et informations a priori Le problème de la structuration automatique des flux télévisuels sera abordé en adoptant une démarche descendante qui va de la modélisation des flux à analyser aux outils de

Action Concertée Incitative
MASSES DE DONNEES
Descriptif complet du projet traitement de signal à mettre en œuvre. Les différentes étapes de ce processus sont les suivantes :
1) modélisation du flux à structurer. Cela peut par exemple être la grille des émissions prévues, en y incluant des informations connues à l’avance et dont la détection permettra de structurer le flux : exemples de jingles sonores, de visages de présentateurs, échantillons de voix, génériques, etc.
2) modélisation des traitements à effectuer. Il s’agit de piloter intelligemment les outils d’analyse de manière : a) à éviter des calculs inutiles (traitements coûteux sur des plages de publicité qui seront ignorées par la suite, par exemple) et b) à pouvoir fusionner les descripteurs afin d’améliorer les taux de confiance des résultats et d’obtenir des descripteurs plus informatifs.
3) instanciation de ce modèle dans un système effectif. Idéalement, on pourrait imaginer un passage automatique du modèle de flux décrit en 1) au modèle de traitement décrit en 2), ce qui pourra être envisagé ultérieurement et indépendamment. Mais dans un premier temps, il semble plus raisonnable de permettre une description manuelle de ces traitements, telle que : « lancer la transcription de la parole sur les séquences situées entre deux séquences plateau » à l’aide d’un langage déclaratif et contextuel à la description du flux. Un effort important sera fait sur la déclarativité et la souplesse du langage de modélisation (flux et traitement). L’objectif est de permettre de traiter facilement de nouveaux types de grilles, de nouvelles collections de documents, etc… mais aussi de prendre en compte des nouvelles actions (de nouveaux descripteurs) implémentés a posteriori ou définis par l’utilisateur même. Interprétable par la machine, ce langage doit être suffisamment simple pour qu’il puisse être intelligible par des personnes non initiées. Pour le point 3), il est envisagé d’étendre un système existant de raisonnement de manière à pouvoir exécuter les outils d’extraction lorsque nécessaire, en cours de résolution. Plusieurs systèmes sont envisageables et le choix n’a pas encore été effectué : système de résolution de contraintes, systèmes à base de règles, systèmes d’inférence logique, grammaires. Ce système devra permettre aussi de procéder à un ordonnancement des extractions en prenant en compte par exemple la confiance qu’on peut accorder à un extracteur ou celle qu’on peut accorder à une combinaison de ceux-ci. 2.5 Contexte expérimental et évaluation
La structuration automatique des flux télévisuels ne trouve sa pleine mesure que dans un environnement où captation, description, archivage, exploitation et diffusion sont des processus entièrement intégrés. La structuration des flux est une tâche nécessaire à cette intégration et elle ne peut être réellement validée que dans un contexte qui n’existe pas encore. Le contexte expérimental sera celui de l’INA, qui fournira les corpus dans les volumes suffisants. Les expérimentations se feront dans un premier temps dans des conditions « in vitro » mais reconstituant un environnement réaliste des contraintes applicatives rencontrées à l'INA, notamment en termes de volumes et de capacités de traitement. En cas de résultats suffisamment encourageants, ces expérimentations pourront déboucher sur des expérimentations « in vivo » installées sur les lieux de production. Différents types d’évaluations seront menés. En premier lieu, une comparaison qualitative sera effectuée avec le travail des documentalistes actuellement chargées de reconstituer les grilles de diffusion réelles à partir des prévisions des diffuseurs et des flux effectivement enregistrés. Cette évaluation devra évaluer l’intérêt de ce qu’apporte la structuration automatique en plus du simple recalage des grilles effectué actuellement, par

Action Concertée Incitative
MASSES DE DONNEES
Descriptif complet du projet exemple sur la hiérarchisation des éléments, la précision temporelle, le repérage des éléments d’inter programme (publicité, autopromotion, annonces), la systématicité de l’analyse… Une enquête, également qualitative, sera menée sur les possibilités d’intégration des outils de structuration développés dans le « workflow » de l’INA, dont ils pourraient devenir la base sur laquelle le reste s’appuierait. En effet, l’activité de structuration est le préalable nécessaire à toutes les actions ensuite effectuées sur les contenus, qu’il s’agisse de documentation, de recherche, de navigation, de publication, de communication ou de production. L’objectif de cette évaluation est de savoir si le modèle choisi permet de produire toutes les informations nécessaires aux futures activités de l’INA. Enfin, un minimum d’évaluation quantitative semble nécessaire. Le projet tentera de définir ce qu’est une vérité de terrain pour un outil de structuration du flux télévisuel et construira alors des vérités de terrain pour une partie des corpus avec des outils développés pour l’occasion, puis définira leur mode de confrontation avec les résultats des outils. La principale difficulté de cette tâche réside dans le passage d’un mode de repérage purement temporel des éléments (c’est alors de la segmentation) à un mode de représentation structurel, ce qui fait qu’on ne peut pas se contenter d’étudier l’exactitude des bornes temporelles. 2.6 Apport des partenaires Équipe TEXMEX
L'équipe TEXMEX est un projet commun au CNRS, à l'université de Rennes 1 et à l'INRIA. Elle vise à regrouper au sein d'une même équipe des spécialistes de divers domaines concernés par l'exploitation des grandes collections de documents multimédias numériques : traitement des images et des langues, statistiques, bases de données. La présence à l'IRISA d'une équipe spécialisée en son et parole nous a mené à choisir de ne pas traiter ce thème en interne à l'équipe, mais plutôt de vouloir monter une collaboration proche entre les deux équipes. L'équipe s'est fixée trois objectifs. Nous travaillons tout d'abord sur les systèmes d'indexation et de recherche d'images ; nous travaillons tant sur divers composants de ces systèmes, que sur l'interaction entre ces composants et leurs contraintes propres : calcul des descripteurs, algorithmes d'indexation et de recherche, gestion de la mémoire et des caches, supports matériels spécialisés. Un deuxième axe de recherche concerne l'ajout de ressources linguistiques aux moteurs de recherche textuels pour en améliorer les performances. Ce travail oblige à s'intéresser aux ressources linguistiques nécessaires et à leur acquisition, mais aussi à leur utilisation possible au sein des moteurs de recherche, ce qui remet en cause l'utilisation directe du modèle vectoriel de recherche d'information. Le troisième objectif est l'étude du couplage entre médias pour la description des documents multimédias. Les couplages texte – image et vidéo – son sont les premiers sur lesquels nous travaillons. Le présent projet vise à renforcer et développer cet axe. En ce qui concerne ce dernier axe, nous profitons de l’expérience acquise au cours de la thèse de Ewa Kijak sur la structuration des vidéos de tennis, thèse qui s’est déroulée en collaboration avec Thomson et l’équipe METISS. Cette thèse, basée sur l’utilisation de modèles de Markov hiérarchiques, en a montré l’intérêt, a mis aussi les limites et a débouché sur la proposition d’utiliser les modèles de segments. Nous avons repris cette idée, et l'étude théorique des modèles de segments fait l’objet de la thèse de Manolis Delakis qui a débuté à l’automne en collaboration avec l’équipe METISS.

Action Concertée Incitative
MASSES DE DONNEES
Descriptif complet du projet
Nous avons participé à de nombreux projets sur la description de vidéos (PRIAM Médiaworks, RNRT AGIR, RIAM FERIA), projets dans lesquels nous avons plus spécifiquement travaillé sur les modules de traitement de la vidéo (détection et reconnaissance de visages, détection de texte et de logos, reconnaissance d’objets, segmentation au sens du mouvement et calcul d’images clés…). Les compétences de l’équipe concernent donc tant la description des vidéos et le traitement automatique des langues, que l’utilisation conjointe de plusieurs médias. Équipe METISS
L'équipe Modélisation et Expérimentation pour le Traitement des Informations et des Signaux Sonores (METISS) de l'Institut de Recherche en Informatique et Systèmes Aléatoires (IRISA) possède une solide expérience dans les domaines de l’extraction et de la modélisation d’informations sonores. En particulier, l’équipe possède une solide compétence en matière de segmentation de documents sonores, de suivi d’événements sonores et de reconnaissance du locuteur, comme en atteste son implication dans de nombreux projets français (AGIR, DiVAN, Domus Videum, Alize) et européens (CAVE, PICASSO). METISS participe depuis de nombreuses années aux campagnes d’évaluations organisées par le National Institute of Standards and Technolgy (NIST) en reconnaissance du locuteur, ce qui lui permet de disposer d’une connaissance approfondie du domaine. Les récents travaux menés dans le cadre du projet Domus Videum ont permis à METISS de développer une expertise concernant l’extraction d’information dans les bandes sons de vidéos et l’intégration de ces informations dans un processus de structuration. Ce travail d’intégration a été partiellement mené en collaboration avec l’équipe TEXMEX. Enfin, l’expérience des travaux précédents de Guillaume Gravier sur la reconnaissance de parole audiovisuelle sera également un élément déterminant dans la définition d’un modèle pour une approche multimédia intégrée. L’équipe METISS possède également un savoir faire en matière d’indexation d’informations radiodiffusées avec sa participation à la campagne d’évaluation ESTER (Évaluation des Systèmes de Transcription enrichie d’Émissions Radiophoniques) organisée dans le cadre du projet Technolangue EVALDA. Dans le cadre de cette campagne, METISS développe une plate-forme permettant la segmentation du flux radio en tour de parole et en émission d’une part, ainsi que des indexations en locuteurs, en thèmes, en mots, etc. Le module de transcription de la plate-forme s’articule autour du logiciel de reconnaissance de la parole Sirocco, développé conjointement par l’IRISA et Télécom Paris (ENST). Le projet Demi-Ton s’appuiera sur l’ensemble des outils d’analyse du signal développés par l’équipe METISS, notamment concernant la caractérisation du contenu de la bande son, la détection de rupture et la transcription automatique. Équipe DCA
L'équipe de recherche Description des Contenus Audiovisuels (DCA) de l'Institut National de l’Audiovisuel (INA) positionne ses travaux sur les nouveaux moyens d'exploitation des contenus audiovisuels, que ce soit dans le cadre des activités d’exploitation commerciale des archives de l’INA sur la mise en place de nouveaux moyens d'exploitation des fonds et sur la manière de les mettre en œuvre (par exemple catalogue structuré en ligne, thématisation et organisation de l'offre), dans le cadre du dépôt légal audiovisuel, sur l'amélioration qualitative et quantitative du traitement du flux des documents entrant à l'INA (par exemple structuration

Action Concertée Incitative
MASSES DE DONNEES
Descriptif complet du projet automatique, assistance à l'indexation par des outils d'analyse automatique du flux audio/vidéo) ou sur la mise en place de nouveaux moyens d'accès aux archives (par exemple outils de navigation dans des collections de documents audiovisuels) et enfin dans le cadre de partenariats avec la communauté des professionnels de l’audiovisuel, par exemple sur l’industrialisation des moyens de production multi-plateformes.. Dans ce cadre d’applications, l’équipe DCA tente de mettre en place des moyens de manipulation des contenus audiovisuels par l'intermédiaire de la manipulation de leurs « descriptions » plutôt que par leur manipulation « directe ». Le programme de recherche de l’équipe est donc centré sur les descriptions des contenus audiovisuels et vise à étudier leur production, leur représentation et leur exploitation. La structuration des flux audiovisuels est une des priorités actuelles de l’équipe qui possède pour cela une solide compétence dans des domaines clés. Sa situation à l’INA lui fournit un accès direct à toute l’information nécessaire pour établir ses connaissances sur les contenus télévisuels, sur les flux et sur les usages, ainsi que la possibilité d’expérimenter dans un environnement réaliste. L’équipe détient une compétence importante sur les langages de description de l’audiovisuel principalement par les travaux de Jean Carrive et la thèse de Gwendal Auffret (2001, UTC / INA) qui ont débouché sur plusieurs versions d’un langage de description nommé AEDI (Audiovisuel Event Description Interface), spécialement adapté aux besoins de description structurée ainsi que sur une influence de l’équipe sur le modèle de lien au média de la norme MPEG-7. De plus, l’équipe mène depuis 1998 des travaux sur diverses techniques d’analyse automatique centrés sur l’extraction de descripteurs de haut niveau et l’adaptation des méthodes aux tâches et aux contenus : thèse d’Emmanuel Veneau (2001, INA / IRISA) sur la macrosegmentation, thèse d’Alexandre Allauzen (2003, INA / LIMSI) sur l’adaptation des modèles de langage de transcription automatique de la parole, thèse de Rémi Landais sur l’extraction de textes incrustés (en cours, LIRIS / INA). Enfin, l’équipe possède également des compétences plus spécifiquement liées à la structuration automatique des flux par la thèse de Jean Carrive (2000, LIP-6 / Sony / INA) traitant de la modélisation de séquences et leur reconnaissance par résolution de contraintes, ainsi que par la thèse venant de débuter de Jean-Philippe Poli (LSIS / INA) centrée sur cette problématique. L’équipe a également participe ou a participé à de nombreux projets européens (DiVAN, Diceman, Echo, Eurodelphes) et nationaux (AGIR, Chaperon, Domus Videum, FERIA) en rapport avec la problématique. 2.7 Apport de la collaboration
Le projet que nous proposons fait face a deux contraintes opposées : nous souhaitons une intégration forte des outils, des modèles, des concepts, et donc une collaboration proche entre équipes, ce qui nécessite un consortium réduit de partenaires fortement impliqués. Mais nous souhaitons aussi que notre travail puisse prendre en compte largement les sources d'informations possibles et donc les médias, de même que les utilisations possibles des descriptions obtenues. D'où la nécessité de compétences très variées. La composition actuelle nous paraît assez optimale, chaque partenaire apportant plusieurs compétences fortes et complémentaires, sans trop de redondance et avec une bonne habitude préalable de la collaboration dans divers projets. Nous souhaitons, à travers ce projet, renforcer cette collaboration. Ce projet se place aussi dans le cadre plus général du rapprochement souhaité entre l’IRISA, les équipes de recherche de la direction de la recherche et de l'expérimentation de l'INA et Thomson. Ce rapprochement, en ce qui concerne le traitement, la structuration et

Action Concertée Incitative
MASSES DE DONNEES
Descriptif complet du projet l’indexation des documents multimédias et audiovisuels, va prendre la forme d’un GIS en cours de montage (GIS ÆTERNAM : analyse et exploitation, recherche et navigation dans les documents audiovisuels et multimédias). Le but de cette collaboration est de confronter, dans une structure permettant une collaboration étroite, les points de vue des utilisateurs de ces technologies, l’INA et la filiale Technicolor de Thomson en sont deux qui possèdent et traitent des quantités très importantes de documents, des industriels fournisseurs de technologie et de matériel, ce qui est la cas de Thomson et de sa filiale Grass Valley, et des scientifiques. Cette collaboration prendra la forme de recherches communes, de participation conjointe à des consortiums, d’échanges d’information, de code, de données, d’informations de veille scientifique ou technologique… Notre participation commune à divers projets sera intégrée à l’activité de ce GIS. La présente proposition constitue l’un des axes de cette collaboration. Elle se situe sur un des thèmes importants de travail pour les trois équipes qui y participent, sans qu’aucune de ces équipes n’ait les moyens propres pour mener ce travail dans ces trois aspects : modules de traitements, modèle stochastique, intégration d’informations a priori. Elle représente donc un bon exemple du type de travaux que nous voudrions instancier au sein du GIS en cours de montage. B3 – Résultats attendus :
Le résultat attendu du projet est un procédé de structuration automatique des flux télévisuels, ainsi que l’expérimentation de ce procédé sur des masses de données importantes.
En rentrant plus dans les détails, le premier résultat du projet sera une analyse des chaînes de traitements documentaires actuelles et des besoins devant être remplis par le résultat de la structuration automatique des flux à l’INA. Dans la mesure du possible, cette analyse sera étendue à des besoins d’autres organismes tels ceux évoqués ci-dessus. Cette analyse comportera également une description précise des données disponibles a priori (grilles prévisionnelles de programmes par exemple) ou de celles qui pourraient l’être de façon réaliste (par exemple, prototypes de jingles ou de séquences annonçant le début d’un programme). Le résultat de cette étude devrait être disponible à environ T0+6. Un autre résultat du projet devra être la mise en place d’une chaîne de traitement spécifique à cette application, fournissant la capacité de stocker les volumes nécessaires sur des serveurs de contenus adaptés à l’analyse automatique, la capacité de traitement suffisante pour effectuer les traitements en un temps raisonnable, mais aussi les outils de visualisation nécessaire à l’appréhension des résultats. La chaîne de traitement devrait être disponible à environ T0 + 12. De plus, des corpus seront constitués pour les expérimentations. Les volumes envisagés sont d’environ 2 à 3 semaines par flux pour environ 2 à 5 chaînes de télévision, soit au maximum 15 semaines de programmes correspondant à plus de 2 500 heures. A titre d’indication, le stockage nécessaire pour l’ensemble est de 1,7 To en MPEG-1 à 1,5 Mb/s et de 9 To en MPEG-2 à 8 Mb/s. Le corpus complet sera constitué au fur et à mesure du projet, mais plusieurs semaines de flux pourront être mise à disposition du projet dès T0 + 3. Une étude sera menée afin d’essayer de savoir comment constituer une vérité de terrain pour une telle recherche et comment les résultats de la structuration automatique peuvent être confrontés à cette vérité de terrain. Le projet développera un outil permettant de

Action Concertée Incitative
MASSES DE DONNEES
Descriptif complet du projet constituer une vérité de terrain et en construira pour un volume qui reste à déterminer. L’ensemble devrait être disponible à T0 + 12. Bien entendu, le modèle général de fusion des informations issues des diverses modalités constitue le principal espoir de résultat de ce projet. Ce modèle sera piloté par un système de pilotage mobilisant des connaissances sur les flux à structurer et sur les traitements à effectuer. Du fait des travaux de thèse déjà engagés à l’IRISA et à l’INA, les premiers résultats tangibles sur ces aspects sont attendus à T0 + 18 et continueront à être développés sur le reste de la durée. De plus, plusieurs études particulières seront menées sur certains outils d’analyse entrant dans la chaîne de façon à ce qu’ils soient adaptés à cette tâche particulière. Enfin, des expérimentations et des évaluations seront effectuées. Celles-ci seront de deux ordres : des expérimentations sur la qualité de la structuration obtenue et des expérimentations sur son utilisabilité dans les contextes applicatifs envisagés. Dans un premier temps, le modèle développé pour la confrontation des structures extraites aux vérités de terrain sera mis en œuvre afin d'évaluer les outils d'extraction. Ces premières évaluations globales devraient pouvoir démarrer à environ T0 + 24. Dans un second temps, vers T0 + 30, des expérimentations d'usage seront menées dont l'objectif sera de confronter les structures extraites aux usages pour lesquels elles ont été prévues. Des interfaces utilisateurs seront développées dans l'objectif de permettre à un utilisateur de vérifier la validité des descripteurs extrait et éventuellement de les corriger, puis de les exploiter pour une tâche de description ou de publication. Le succès du projet mènera à un renouvellement complet du traitement des grands flux de télévision et de vidéos. Il consacrera la nécessité et l'apport d'approches prenant tous les médias en même temps, et élargira le champ d'application des techniques de description automatique de la vidéo, tout en permettant à ces techniques de passer le cap de l'expérimentation sur de petits exemples d'école au traitement des grands volumes de données. Bibliographie [1] B. Furht, S.W. Smoliar, and H-J. Zhang. Video and Image Processing in Multimedia Systems. Kluwer Academic Publishers, Norwell, USA, 2th edition, 1996. [2] A. Hanjalic, G.C. Langelaar, P.M.B. van Roosmalen, J. Biemond, and R.L. Lagendijk. Image and Video Databases: Restoration, Watermarking and Retrieval. Elsevier Science, Amsterdam, The Netherlands, 2000. [3] R.M. Bolle, B.-L. Yeo, and M.M. Yeung. Video query: Research directions. IBM Journal of Research and Development, 42(2):233-252, 1998. [4] R. Brunelli, O. Milch and C.M. Modena. A survey on the automatic indexing of video data. Journal of Visual Communication and Image Representation, 10(2):78-112, 1999. [5] P. Bouthemy, M. Gelcon, F. Ganansia. A Unified Approach to Shot Change Detection and Camera Motion Characterization. IEEE Trans. On Circuits and Video Technology 9, 7, octobre 1999, p. 1030-1044. [6] N. Boujemaa, S. Boughorbel, C. Vertan. Soft Color Signature for Image Retrieval by Content. Eusflat'2001,2, p.394-401, 2001.

Action Concertée Incitative
MASSES DE DONNEES
Descriptif complet du projet [7] R. Fablet. Modélisation statistique non paramétrique et reconnaissance du mouvement dans des séquences d'images : application à l'indexation vidéo. Thèse de doctorat, Université de Rennes 1, juillet 2001. [8] C. Schmid, R. Mohr. Local Grayvalue Invariants for Image Retrieval. IEEE Trans, on Pattern Analysis and Machine Intelligence 19, 5, mai 1997, p. 530-534. [9] C. Garcia, M. Delakis, A Neural Architecture for Fast and Robust Face Detection", Proceedings of the IEEE-IAPR International Conference on Pattern Recognition (ICPR'02), Août 2002, Quebec city, Canada. [10] C. Garcia, G. Zikos, G. Tziritas, Wavelet Packet Analysis for Face Recognition, Image and Vision Computing, 18(4), Février 2000, p.289-297. [11] C. Garcia, X. Apostolidis, Text Detection and Segmentation in Complex Color Images, Proceedings of 2000 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP2000), Juin 2000, Istanbul, Vol. IV, p. 2326-2330. [12] A.A. Alatan, A.N. Akansu, and W. Wolf. Multimodal dialogue scene detection using hidden markov models for content-based multimedia indexing. Multimedia Tools and Applications, 14(2):137-151,2001. [13] N. Babaguchi, Y. Kawai, and T. Kitahashi. Event based indexing of broadcasted video by intermodal collaboration. Graphical models and image processing, 60(1):13-23, 1998. [14] Convera. http://www.convera.com [15] J. Huang, Z. Liu, Y. Wang, Y. Chen, and E.K. Wong. Integration of multimodal features for video scene classification based on HMM. IEEE Workshop on Multimedia Signal Processing, Copenhagen, Denmark, 1999. [16] R. Jain and A.G. Hampapur. Metadata in video databases. ACM SIGMOID, 23(4):27-33, 1994. [17] S. Tsekeridou and I. Pitas. Content-based video parsing and indexing based on audio-visual interaction. IEEE Transactions on Circuits and Systems for Video Technology, 11(4):522-535, 2001. [18] S. Satoh, Y. Nakamura, and T. Kanade. Name-It: Naming and detecting faces in news videos. IEEE Multimedia, 6(1):22-35, 1999. [19] J. Pearl. Probabilistic Reasoning in Intelligent Systems: Networks of Plausible Inference. Morgan Kaufmann, San Mateo, USA, 1998. [20] E. Kijak, G. Gravier, L. Oisel and P. Gros. Audiovisual Integration for Tennis Broadcast Structuring, Intl. Workshop on Content Based Multimedia Indexing, 2003.

Action Concertée Incitative
MASSES DE DONNEES
Descriptif complet du projet [21] H. Bourlard, S. Dupont and C. Ris. Multi-stream speech recognition, Research Report RR 96-07, IDIAP, 1996. [22] Vassilios Digalakis. Segment-based stochastic models of spectral dynamics for continuous speech recognition. Ph. D. Thesis, Boston University, 1992.

Action Concertée Incitative
MASSES DE DONNEES
Descriptif complet du projet
C – MOYENS FINANCIERS ET HUMAINS DEMANDES PAR CHAQUE EQUIPE9
Comme indiqué dans les tableaux ci-dessous, on distinguera
- les financements via le Fonds National pour la Science qui peuvent inclure * du fonctionnement * de l’équipement * des mois de personnel temporaire (CDD) pour un montant ne pouvant excéder 50% du financement total attribué. La durée du ou des contrat(s) prévus, qui ne peuvent excéder 24 mois chacun, sera précisée.
- les moyens demandés aux organismes de recherche qui peuvent inclure * des postes de post-doc * des demandes de délégation ou détachement pour des enseignants-chercheurs * des accueils de chercheurs étrangers
- les demandes d’allocations de recherche
Les diverses possibilités concernant l’attribution de moyens pour recruter ou accueillir des personnels seront globalement très limitées pour l’ensemble des ACI. Leurs demandes devront donc être particulièrement justifiées. Si les bénéficiaires de ces demandes sont connus ou pressentis, les CV correspondants seront joints à la présente demande. On présentera une justification scientifique des moyens demandés pour chacune des équipes impliquées dans
le projet.
9 Une fiche C doit être remplie pour chaque laboratoire ou équipe partenaire
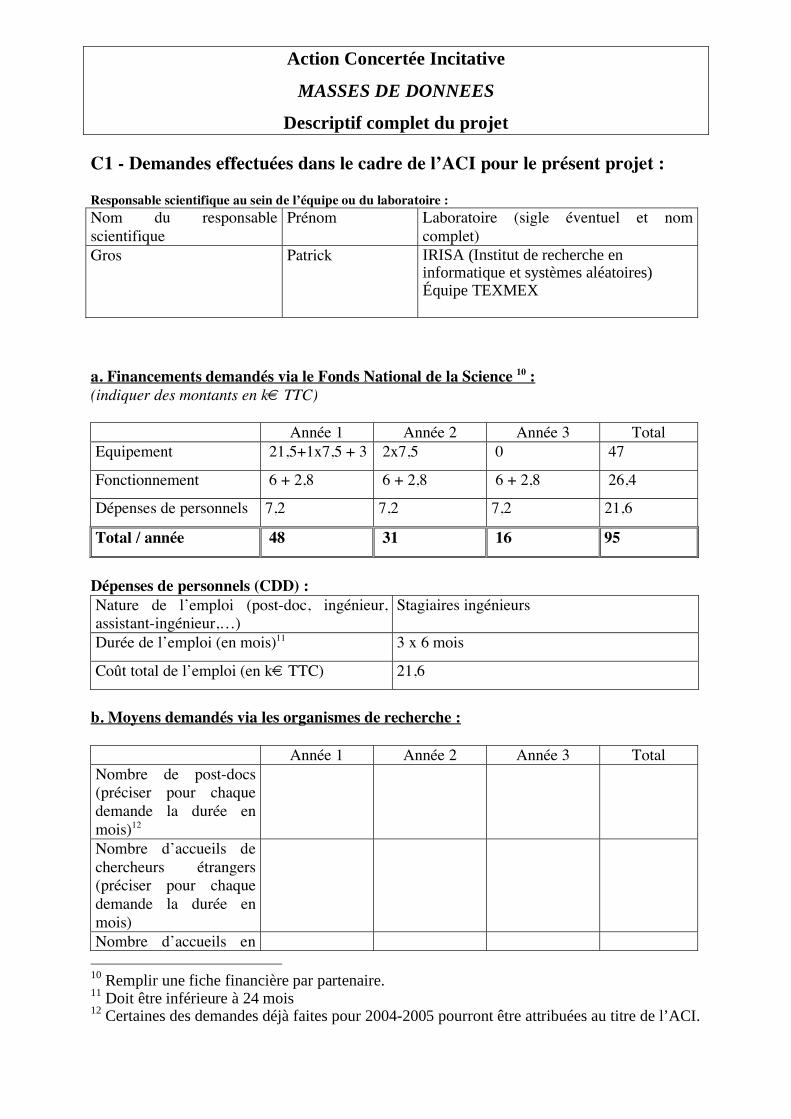
Action Concertée Incitative
MASSES DE DONNEES
Descriptif complet du projet C1 - Demandes effectuées dans le cadre de l’ACI pour le présent projet : Responsable scientifique au sein de l’équipe ou du laboratoire : Nom du responsable scientifique
Prénom Laboratoire (sigle éventuel et nom complet)
Gros Patrick IRISA (Institut de recherche en informatique et systèmes aléatoires) Équipe TEXMEX
a. Financements demandés via le Fonds National de la Science 10 : (indiquer des montants en k TTC) Année 1 Année 2 Année 3 Total Equipement 21,5+1x7,5 + 3 2x7,5 0 47
Fonctionnement 6 + 2,8 6 + 2,8 6 + 2,8 26,4
Dépenses de personnels 7,2 7,2 7,2 21,6
Total / année 48 31 16 95
Dépenses de personnels (CDD) : Nature de l’emploi (post-doc, ingénieur, assistant-ingénieur,…)
Stagiaires ingénieurs
Durée de l’emploi (en mois)11 3 x 6 mois
Coût total de l’emploi (en k TTC) 21,6
b. Moyens demandés via les organismes de recherche : Année 1 Année 2 Année 3 Total Nombre de post-docs (préciser pour chaque demande la durée en mois)12
Nombre d’accueils de chercheurs étrangers (préciser pour chaque demande la durée en mois)
Nombre d’accueils en 10 Remplir une fiche financière par partenaire. 11 Doit être inférieure à 24 mois 12 Certaines des demandes déjà faites pour 2004-2005 pourront être attribuées au titre de l’ACI.

Action Concertée Incitative
MASSES DE DONNEES
Descriptif complet du projet délégations ou détachements11
c. Demande d’une allocation de recherche fléchée: OUI X NON d. Justifications scientifiques de l’ensemble des demandes: Les moyens demandés par l’équipe TEXMEX dans le cadre de cette ACI visent à donner les moyens à l’équipe d’effectuer les recherches et de mener les expériences dans le cadre de la présente proposition. Du coté investissement, les moyens demandés correspondent sont ceux nécessaires pour stocker et traiter les contenus expérimentaux qui seront fournis par l’INA, Soit :
- un serveur vidéo permettant de stocker à des fins expérimentales des volumes de documents audiovisuels suffisamment importants pour chaque phase d’expérimentation. Comme il est envisagé d’expérimenter à chaque fois sur environ deux semaines de flux, le stockage disponible en ligne doit être d’au moins 1 To. Il est également nécessaire de disposer d’une machine suffisamment puissante pour décoder et fournir les échantillons aux processus d’analyse. Le coût estimé d’un tel équipement est de 21500 TTC (14000 pour une baie de stockage SCSI 1 To, 7500 pour un serveur biprocesseur).
- trois serveurs d’analyse biprocesseurs permettant de fournir la puissance de calcul nécessaire, à 7500 chacun.
- une station de travail pour le doctorant à 3000 . Côté fonctionnement, les moyens demandés correspondent à :
- 6000 EUR par an, pour voyage entre les partenaires, des séjours longs de doctorants et post-doc et des séminaires communs chaque année,
- 10% de frais généraux. Enfin, en termes de personnels, les montants correspondent à :
- une allocation de recherche de 3 ans. En sus des travaux déjà entrepris dans le cadre des thèse de M. Delakis à l’IRISA et J.P. Poli à l’INA, un des domaines qui sera la plus nouveau pour nous sera l’utilisation des outils de traitement automatique des langues sur les transcription de bande audio (cf. sujet de thèse : http://www.irisa.fr/formation/sujets2004/metisstexmex1-1.pdf)
- trois stages de fin d’étude d’ingénieur en informatique de 6 mois, un par an, afin d’assister les développements et les expérimentations.

Action Concertée Incitative
MASSES DE DONNEES
Descriptif complet du projet C2 - Autres soutiens financiers apportés au projet : On mentionnera les autres actions relatives au projet dans lesquelles l’équipe ou le laboratoire est engagé (projets européens, autres ACI, RNRT, RNTL, …). Le travail mené au sein de l’équipe TEXMEX sur le sujet de cette proposition s’appuie sur :
- la participation au projet RIAM FERIA. Dans ce projet sont développés plusieurs modules qui seront réutilisés dans le présent contrat, ainsi qu’une plateforme permettant de générer des applications professionnelles ou de tests des modules.
- la thèse de Manolis Delakis est financée par une allocation de recherche du ministère, - le réseau d’excellence européen MUSCLE du sixième programme cadre auquel
participe l’équipe et qui porte sur la compréhension des documents multimédias, avec une emphase particulière sur la collaboration image – son.
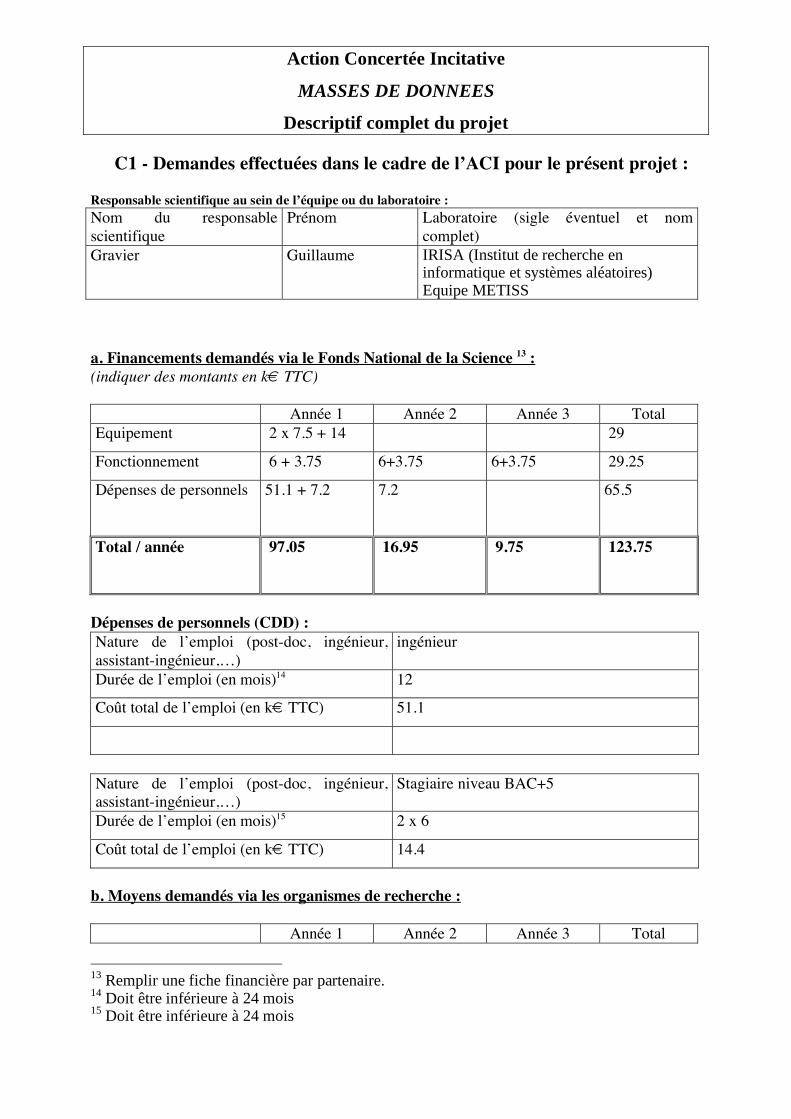
Action Concertée Incitative
MASSES DE DONNEES
Descriptif complet du projet
C1 - Demandes effectuées dans le cadre de l’ACI pour le présent projet : Responsable scientifique au sein de l’équipe ou du laboratoire : Nom du responsable scientifique
Prénom Laboratoire (sigle éventuel et nom complet)
Gravier Guillaume IRISA (Institut de recherche en informatique et systèmes aléatoires) Equipe METISS
a. Financements demandés via le Fonds National de la Science 13 : (indiquer des montants en k TTC) Année 1 Année 2 Année 3 Total Equipement 2 x 7.5 + 14 29
Fonctionnement 6 + 3.75 6+3.75 6+3.75 29.25
Dépenses de personnels 51.1 + 7.2 7.2
65.5
Total / année 97.05 16.95
9.75
123.75
Dépenses de personnels (CDD) : Nature de l’emploi (post-doc, ingénieur, assistant-ingénieur,…)
ingénieur
Durée de l’emploi (en mois)14 12
Coût total de l’emploi (en k TTC) 51.1
Nature de l’emploi (post-doc, ingénieur, assistant-ingénieur,…)
Stagiaire niveau BAC+5
Durée de l’emploi (en mois)15 2 x 6
Coût total de l’emploi (en k TTC) 14.4
b. Moyens demandés via les organismes de recherche : Année 1 Année 2 Année 3 Total
13 Remplir une fiche financière par partenaire. 14 Doit être inférieure à 24 mois 15 Doit être inférieure à 24 mois

Action Concertée Incitative
MASSES DE DONNEES
Descriptif complet du projet Nombre de post-docs (préciser pour chaque demande la durée en mois)16
Nombre d’accueils de chercheurs étrangers (préciser pour chaque demande la durée en mois)
Nombre d’accueils en délégations ou détachements11
c. Demande d’une allocation de recherche fléchée: OUI � NON X d. Justifications scientifiques de l’ensemble des demandes: Les moyens demandés par l’équipe METISS doivent permettre de mener à bien les travaux concernant le traitement de la bande son, notamment concernant la transcription de la parole. Ces moyens doivent couvrir les besoins matériel et humain. Sur le plan matériel, les moyens demandés permettent à l’équipe METISS de renforcer ses moyens de calculs et de stockage afin de pouvoir traiter les volumes de données envisagés dans le cadre de cette proposition. La demande correspond à :
• 2 serveurs de calcul bi-processeurs (2 x 7 500 ) • 1 disque de 1To pour le stockage des données (14 000 )
Sur le plan des moyens humains, la demande correspond à :
• 1 ingénieur pendant la première année du projet pour travailler sur le système de transcription automatique. Le travail envisagé correspond à l’adaptation du système actuel de l’équipe METISS aux flux vidéos (le système actuel opère sur des flux radios qui ont une qualité sonore différente) et sur son amélioration, notamment en terme de vitesse afin de pouvoir transcrire de grands volumes.
• 2 x 6 mois de stage ingénieur ou DEA en informatique, un par an sur les deux premières années du projet, pour assister dans les développements.
Enfin, les moyens demandés couvrent en partie les frais de fonctionnement, soit :
• 6000 par an couvrant les frais de missions, des séjours de doctorants et post-doc et des séminaires communs chaque année,
• 10% de frais généraux.
16 Certaines des demandes déjà faites pour 2004-2005 pourront être attribuées au titre de l’ACI.

Action Concertée Incitative
MASSES DE DONNEES
Descriptif complet du projet C2 - Autres soutiens financiers apportés au projet : On mentionnera les autres actions relatives au projet dans lesquelles l’équipe ou le laboratoire est engagé (projets européens, autres ACI, RNRT, RNTL, …). Le travail mené par l’équipe METISS dans le cadre de ce projet s’appuie sur :
• la participation au projet RNRT Domus Videum sur la structuration et le résumé de vidéos de sport et de documentaires. Notamment, les outils ce projet a permis à l’équipe de développer des outils de bases concernant l’analyse de la bande sonore développés dans le cadre du projet Domus Videum seront réutilisés, après adaptation, pour le présent projet.
• la participation à la campagne d’Évaluation des Systèmes de transcription enrichi d’Émissions Radiophoniques (ESTER), organisée dans le cadre du projet Technolangue EVALDA. Les algorithmes de segmentation, de transcription et de structuration du flux sonore radiophonique développés par METISS dans le cadre de sa participation à la campagne ESTER, serviront de point de départ pour l’analyse du flux sonore dans le présent projet. La participation à la campagne ESTER ne donne lieu à aucun financement.
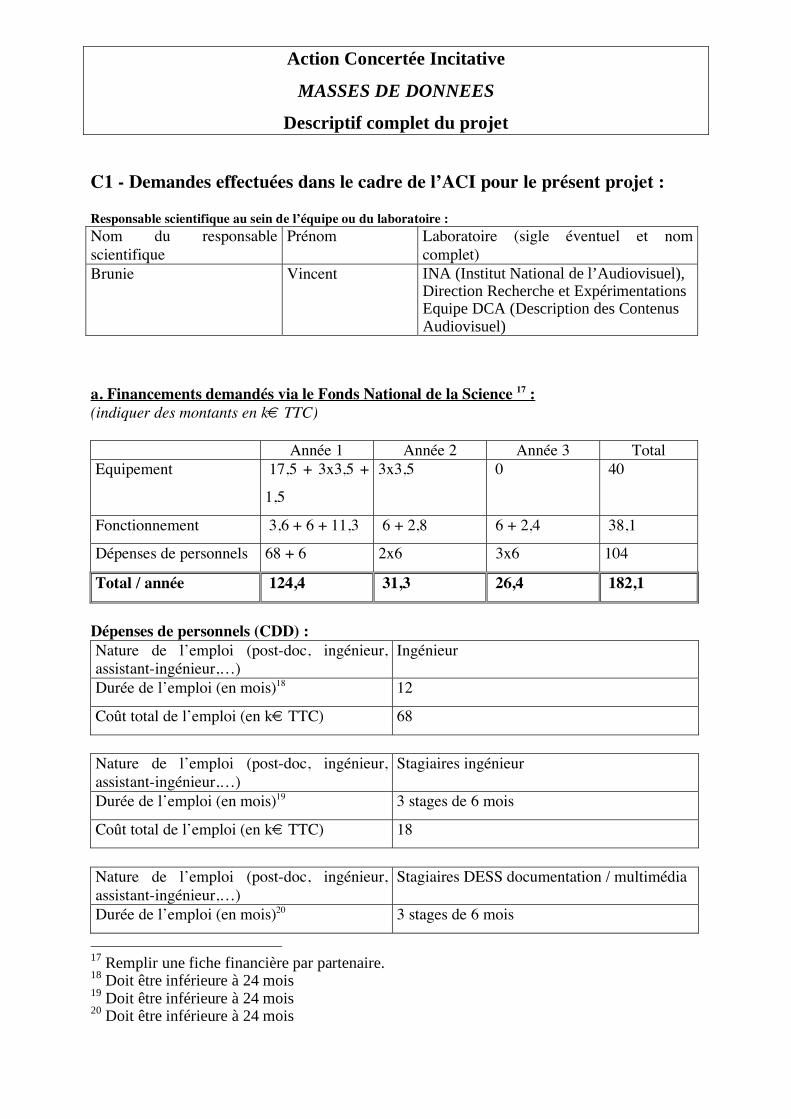
Action Concertée Incitative
MASSES DE DONNEES
Descriptif complet du projet
C1 - Demandes effectuées dans le cadre de l’ACI pour le présent projet : Responsable scientifique au sein de l’équipe ou du laboratoire : Nom du responsable scientifique
Prénom Laboratoire (sigle éventuel et nom complet)
Brunie Vincent INA (Institut National de l’Audiovisuel), Direction Recherche et Expérimentations Equipe DCA (Description des Contenus Audiovisuel)
a. Financements demandés via le Fonds National de la Science 17 : (indiquer des montants en k TTC) Année 1 Année 2 Année 3 Total Equipement 17,5 + 3x3,5 +
1,5
3x3,5 0 40
Fonctionnement 3,6 + 6 + 11,3 6 + 2,8 6 + 2,4 38,1
Dépenses de personnels 68 + 6 2x6 3x6 104
Total / année 124,4 31,3 26,4 182,1
Dépenses de personnels (CDD) : Nature de l’emploi (post-doc, ingénieur, assistant-ingénieur,…)
Ingénieur
Durée de l’emploi (en mois)18 12
Coût total de l’emploi (en k TTC) 68
Nature de l’emploi (post-doc, ingénieur, assistant-ingénieur,…)
Stagiaires ingénieur
Durée de l’emploi (en mois)19 3 stages de 6 mois
Coût total de l’emploi (en k TTC) 18
Nature de l’emploi (post-doc, ingénieur, assistant-ingénieur,…)
Stagiaires DESS documentation / multimédia
Durée de l’emploi (en mois)20 3 stages de 6 mois
17 Remplir une fiche financière par partenaire. 18 Doit être inférieure à 24 mois 19 Doit être inférieure à 24 mois 20 Doit être inférieure à 24 mois
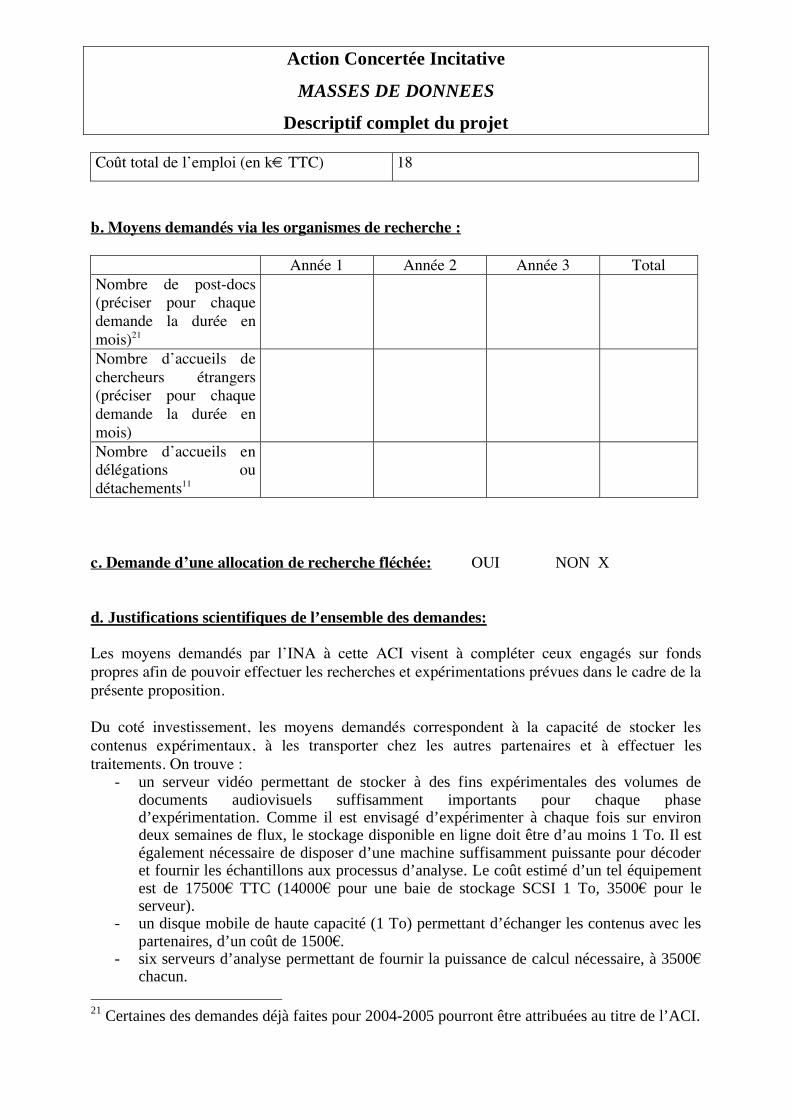
Action Concertée Incitative
MASSES DE DONNEES
Descriptif complet du projet Coût total de l’emploi (en k TTC) 18
b. Moyens demandés via les organismes de recherche : Année 1 Année 2 Année 3 Total Nombre de post-docs (préciser pour chaque demande la durée en mois)21
Nombre d’accueils de chercheurs étrangers (préciser pour chaque demande la durée en mois)
Nombre d’accueils en délégations ou détachements11
c. Demande d’une allocation de recherche fléchée: OUI � NON X d. Justifications scientifiques de l’ensemble des demandes: Les moyens demandés par l’INA à cette ACI visent à compléter ceux engagés sur fonds propres afin de pouvoir effectuer les recherches et expérimentations prévues dans le cadre de la présente proposition. Du coté investissement, les moyens demandés correspondent à la capacité de stocker les contenus expérimentaux, à les transporter chez les autres partenaires et à effectuer les traitements. On trouve :
- un serveur vidéo permettant de stocker à des fins expérimentales des volumes de documents audiovisuels suffisamment importants pour chaque phase d’expérimentation. Comme il est envisagé d’expérimenter à chaque fois sur environ deux semaines de flux, le stockage disponible en ligne doit être d’au moins 1 To. Il est également nécessaire de disposer d’une machine suffisamment puissante pour décoder et fournir les échantillons aux processus d’analyse. Le coût estimé d’un tel équipement est de 17500 TTC (14000 pour une baie de stockage SCSI 1 To, 3500 pour le serveur).
- un disque mobile de haute capacité (1 To) permettant d’échanger les contenus avec les partenaires, d’un coût de 1500 .
- six serveurs d’analyse permettant de fournir la puissance de calcul nécessaire, à 3500 chacun.
21 Certaines des demandes déjà faites pour 2004-2005 pourront être attribuées au titre de l’ACI.

Action Concertée Incitative
MASSES DE DONNEES
Descriptif complet du projet Côté fonctionnement, les moyens demandés correspondent à :
- un ensemble de cartouches S-DLT pour stocker le corpus estimé à 9 To (puisque l’ensemble ne peut être présent sur le serveur), soit 90 cartouches de 100 Go à 70 pièce, soit 3600
- 6000 EUR par an, pour voyage entre les partenaires, des séjours longs de doctorants et post-doc et des séminaires communs chaque année,
- 10% de frais généraux. Enfin, en termes de personnels, les montants correspondent à :
- un CDD d’ingénieur expert d’un an pour la première année du projet pour effectuer les tâches suivantes :
o analyse de la chaîne de traitement et des besoins ; o l’analyse des grilles de programmes ; o développement de l’application de constitution de vérité de terrain ; o ingénierie complète du serveur de contenus, des outils de visualisation et de
l’infrastructure de la chaîne de traitement automatique ; o éventuellement, le montage et les conversions de formats pour les premiers lots
de corpus. - deux stages de 6 mois de documentaliste (DESS), probablement à T0 + 12 et T0 + 24
pour la constitution des vérités de terrain ; - un stage de 6 mois de documentaliste (DESS), à T0 + 30 pour l’analyse des résultats
expérimentaux ; - trois stages de fin d’étude d’ingénieur en informatique de 6 mois, un par an, afin
d’assister les développements. C2 - Autres soutiens financiers apportés au projet : On mentionnera les autres actions relatives au projet dans lesquelles l’équipe ou le laboratoire est engagé (projets européens, autres ACI, RNRT, RNTL, …). L’INA engage des moyens sur le projet en plus de ceux demandés dans la présente proposition. Elle finance la thèse de Jean-Philippe POLI (dans le cadre d’une convention CIFRE) qui a débuté en janvier 2004 dirigée par M. Philippe Jégou, responsable de l’équipe « Inférence, Contraintes et Applications » au LSIS (Marseille, UMR CNRS 6168) qui porte sur principalement sur la mise au point du pilotage du modèle dans ce cadre de la structuration automatique des flux télévisuels. L’INA fournira également l’ensemble des contenus télévisuels expérimentaux nécessaires au projet à ses frais, dans des volumes qui n’ont jamais été atteints pour de tels projets. Une station de captation et d’enregistrement spécifique capable d’enregistrer des flux sans discontinuité a déjà été développée en prévision de ces travaux et sera mobilisée pour toute la durée du projet. De plus, l’INA s’appuiera sur le framework fourni par le projet FERIA (projet précompétitif RIAM), auquel participe également l’équipe TEXMEX, pour effectuer les développements nécessaires pour le serveur de contenu, pour l’infrastructure d’analyse automatique ainsi que pour les outils de visualisation.

Action Concertée Incitative
MASSES DE DONNEES
Descriptif complet du projet
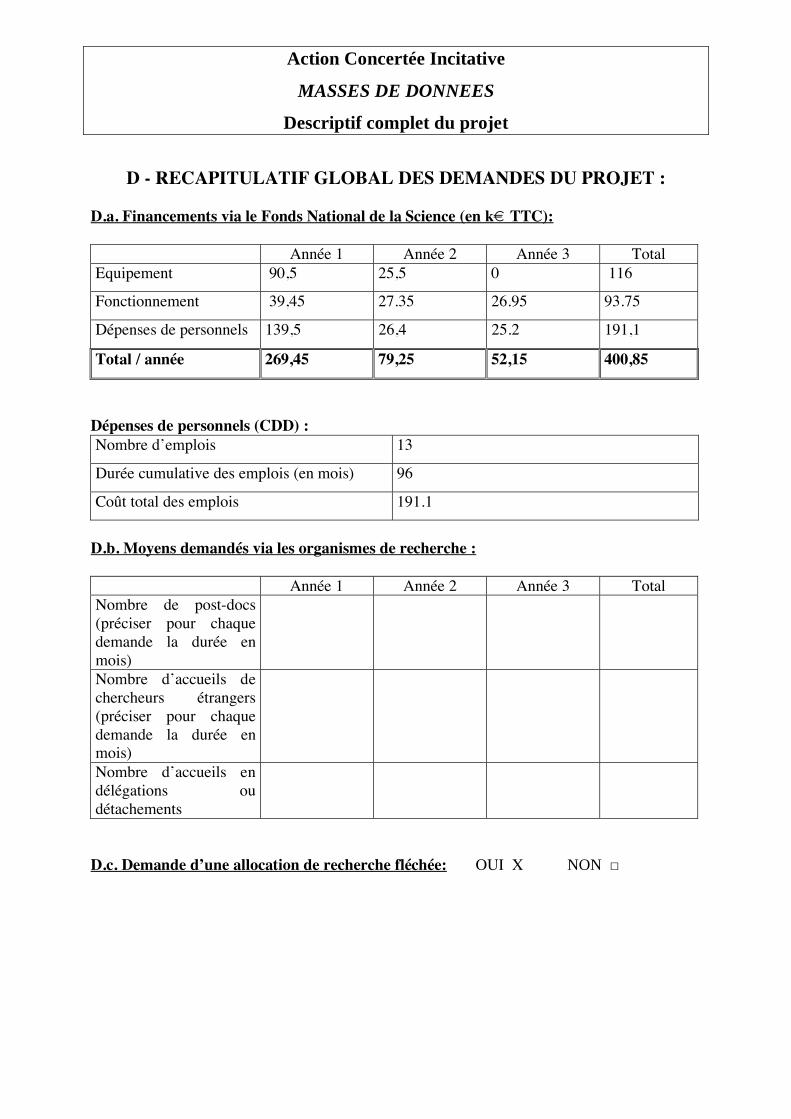
Action Concertée Incitative
MASSES DE DONNEES
Descriptif complet du projet
D - RECAPITULATIF GLOBAL DES DEMANDES DU PROJET : D.a. Financements via le Fonds National de la Science (en k TTC): Année 1 Année 2 Année 3 Total Equipement 90,5 25,5 0 116
Fonctionnement 39,45 27.35 26.95 93.75
Dépenses de personnels 139,5 26,4 25.2 191,1
Total / année 269,45 79,25 52,15 400,85
Dépenses de personnels (CDD) : Nombre d’emplois 13
Durée cumulative des emplois (en mois) 96
Coût total des emplois 191.1
D.b. Moyens demandés via les organismes de recherche : Année 1 Année 2 Année 3 Total Nombre de post-docs (préciser pour chaque demande la durée en mois)
Nombre d’accueils de chercheurs étrangers (préciser pour chaque demande la durée en mois)
Nombre d’accueils en délégations ou détachements
D.c. Demande d’une allocation de recherche fléchée: OUI X NON

Action Concertée Incitative
MASSES DE DONNEES
Descriptif complet du projet
E - ENGAGEMENT DU COORDINATEUR DU PROJET :
La présente page ne sera remplie que dans la version sous forme papier. Je soussigné, Patrick Gros, coordinateur du projet Demi Ton, m’engage dans l’hypothèse où le présent projet serait retenu à :
- fournir un rapport d’évaluation à mi-parcours permettant au Conseil Scientifique d’apprécier l’avancement des travaux et la coopération des équipes participantes.
- un rapport à la fin de l’exécution du projet. Signature du coordinateur du projet : Visa du Directeur du Laboratoire ou de l’Unité de Recherche auquel appartient le coordinateur du projet: Fait à Rennes le 30 mars 2004, Claude Labit





























